Month: September 2024
Networking Cost Estimations and Analysis with Open-Source AWS Networking Cost Calculator

MMS • Steef-Jan Wiggers
AWS recently released an open source project called AWS Networking Costs Calculator, which allows users to run an AWS networking-focused calculator to estimate and visualize the various charges for a given network architecture.
Users can use the calculator to select their AWS region and the networking services in their architecture, along with other relevant inputs such as the number of endpoints used and the amount of data transferred or processed. This will generate a sample diagram that helps visualize traffic’s connectivity and flow.
In a Networking and Content Delivery blog post, the company explains that the calculator has two main components:
- A serverless backend part that uses the AWS Price List Query APIs to get the updated prices for the different networking services. This process runs daily inside an AWS Lambda function, with prices cached in Amazon DynamoDB.
- A ReactJS front-end web application (hosted on Amazon Simple Storage Service (Amazon S3) and fronted with an Amazon CloudFront distribution), which is the calculator user interface.
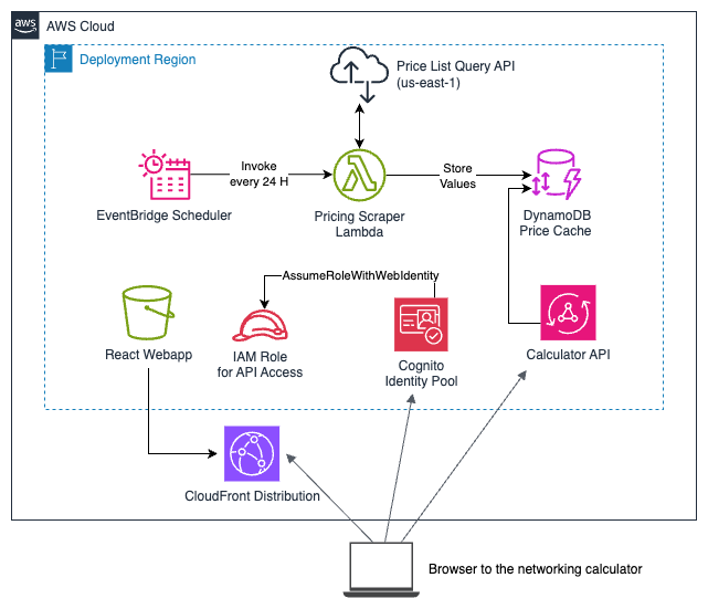
AWS Networking Costs Calculator high-level architecture (Source: AWS Networking and Content Delivery blog post)
Before deploying the tool in an AWS account, users must ensure that they have a Linux-based OS, NodeJS (version 18 or later) and NPM, AWS Cloud Development Kit (AWS CDK), and an AWS account with AWS CLI (v2) installed and configured. After verifying the prerequisites, they can run the deployment script from the project’s root directory using the $ ./deploy.sh command. The deployment will take 5–10 minutes. Once completed, users will receive a CloudFront front-end URL to access the tool.
In a LinkedIn post, AWS principal solutions architect Hrushik Gangur writes:
No more guessing, using Excel sheets, or interpreting AWS documentation to figure out data transfer/processing costs, specifically when your workload uses multiple networking services. Install this tool locally on your laptop, drag and drop, and connect networking service, and get total end-to-end networking cost!
However, the company also states that the pricing users see in the tool for their network architecture is an estimate. The actual costs may vary depending on factors such as other AWS services or third-party products in use. In addition, not all AWS networking services are available for cost estimates in the tool.
Taranvir Singh, an IDC Analyst for Worldwide Cloud Networking Research, wrote in another LinkedIn post:
Unpredictable costs are a significant concern for clients using cloud services. While cloud pricing calculators are available, they primarily focus on compute and storage, leaving a gap in networking costs, which can significantly impact overall IT budgets. I’m not a fan of the self-hosted aspect and any cost that customers will incur for this tool, but I feel this is temporary, and the AWS team is working on it.
Lastly, other means of estimating and analyzing costs exist, such as the AWS Cost CLI, the AWS Pricing Calculator, and third-party products.
Grafana K6 Releases: Enhancements in Typescript, Ecmascript, Browser Testing, and More
MMS • Claudio Masolo

The Grafana k6 team releases a new version of its open-source load testing tool approximately every two months, bringing new features and improving user experience. Several recent updates have introduced key improvements, notably related to TypeScript support, ECMAScript compatibility, and enhancements to browser testing, gRPC, memory management, cryptography, and test result storage.
One of the major updates introduced in the k6 version 0.52 release is allowing native support for TypeScript. Previously, developers using TypeScript with k6 were required to bundle their scripts using tools like Webpack or Rollup before running them. With this update, TypeScript tests can now be run directly from the k6 command-line interface (CLI) by using a special compatibility mode option. This new feature significantly simplifies the testing process for developers who prefer TypeScript, making it easier to work with k6, especially when reusing existing TypeScript libraries.
In addition to TypeScript, the v0.52 release also introduced support for a range of ECMAScript 6 (ES6) and newer features that had previously been unavailable in k6. These include features like optional chaining, object spread, and private class fields. By incorporating these ECMAScript (ES+) features, k6 has become more compliant with the modern JavaScript ecosystem, allowing developers to utilize contemporary JavaScript syntax without the need for workarounds. As of the k6 v0.53 release, these ES6+ features are now available in the default compatibility mode, making it even easier for developers to use them without any special configuration.
Another area of focus in recent k6 updates has been the browser testing module. Initially introduced in 2021, the browser module did not support asynchronous operations or the JavaScript async and await keywords. This changed with the k6 v0.52 release, where browser APIs were made fully asynchronous, aligning with the broader JavaScript ecosystem and ensuring compatibility with tools like Playwright. This update has made the browser testing experience more user-friendly and intuitive, although it did introduce breaking changes to existing browser scripts. To help users adapt to these changes, the k6 team provided a migration guide detailing the affected APIs and how to modify existing scripts to ensure compatibility. The browser module has now officially graduated from experimental status to a core module, making it stable and available under k6/browser instead of k6/experimental/browser.
Alongside the browser module, the gRPC streaming functionality also underwent significant changes. In the k6 v0.51 release, the grpc. Stream feature, which supports bi-directional gRPC streaming, was fully integrated into the stable k6/net/grpc module. This graduation ensures that no further breaking changes will occur, allowing developers to confidently use the gRPC APIs in their tests and upgrade to future versions without concern. In addition, the gRPC module now supports non-blocking asynchronous operations with the client.asyncInvoke method, which returns a Promise and provides more efficient performance.
The k6 v0.51 release also addressed the challenge of running load tests with large files, which previously led to Out of Memory (OOM) errors. While the SharedArray object had provided some relief, it still loaded all file content into memory. To tackle this, the k6 team introduced the Stream module, which allows developers to read large files in small chunks, reducing memory consumption and significantly improving efficiency. The new Stream API enables k6 to handle large datasets by loading them piece by piece, preventing OOM issues during testing.
Additionally, the k6 v0.51 release made common JavaScript timer methods like setTimeout, clearTimeout, setInterval, and clearInterval globally available. Previously, these methods had to be imported from the k6/timers or k6/experimental/timers modules. By making these methods globally accessible, k6 now aligns more closely with the behaviour of other JavaScript environments and simplifies the process of managing asynchronous operations within tests.
Cryptographic operations have also seen improvements in recent k6 releases. The tool now supports additional Web Crypto methods, including new asymmetric cryptography algorithms such as ECDH and ECDSA, along with support for pkcs8 and spki formats. It also supports the import and export of keys in JSON Web Key (JWK) format, further enhancing k6’s ability to test secure applications that use cryptography. While the webcrypto module remains a work in progress, these updates are a step forward in making cryptographic testing more robust within k6.
Finally, the integration of OpenTelemetry (OTEL) into k6’s core functionality was another important update introduced in the k6 v0.53 release. OTEL has become a standard for telemetry and observability, and its inclusion in k6 allows users to send test results directly to OpenTelemetry backends. This addition enables k6 users to map k6 metrics and tags to OTEL equivalents and output test results to default OTEL exporters without needing additional configurations. This further expands k6’s flexibility in how test results are stored and analyzed, integrating it with industry-standard telemetry tools.
In addition to k6, other noteworthy load testing tools include Autocannon and Locust. Autocannon, written in Node.js, is a fast HTTP benchmarking tool designed for testing web server performance under heavy traffic. It provides key metrics like throughput and latency. Meanwhile, Locust is an open-source load testing tool that uses Python scripts to define custom user behaviour. It can simulate millions of concurrent users, making it ideal for large-scale performance testing.
MMS • Dustin Thostenson
Subscribe on:
Transcript
Shane Hastie: Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today, I’m sitting down with Dustin Thostenson. Dustin is East Coast USA, Dustin?
Dustin Thostenson: Central. We’re in the flyover country, Iowa.
Shane Hastie: I’m as normal, coming to you from New Zealand. My normal starting point is who’s Dustin?
Introductions [01:04]
Dustin Thostenson: Thanks for allowing me to be on here. Who’s Dustin is a great question. I have been in technology for 25 years now, but I owe all of my gray hair to my kids. I didn’t have gray when the kids came around, so I don’t think it was the tech. Been in the field for 25 years and I’ve had a lot of different experiences, a lot of software development. I’ve been able to teach at a university or a community college. I’m not going to try to inflate it. Did that for a decade, for nights and evenings. I’ve done different types of coaching roles, a lot of consulting, and I’ve been an independent consultant for 15 years. My focus really has been on being able to do the work and to deliver high-quality software. I’ve also found my greatest joy is being able to help others not only improve their skill set, and also improve the teams that they work on. I want to make sure that other people have the chance to be on some really high-performing teams, enjoy their work and delight their customers. I think they deserve that.
Shane Hastie: Dustin, we have bumped into each other over the years at various events, but the thing that I wanted to talk to you about today is you’ve been talking recently about techniques to tackle technical debt. What are some of these techniques?
Common patterns of technical debt [02:20]
Dustin Thostenson: For all the teams that I’ve worked on, I’ve found a common theme, and it seems like most people are struggling with tech debt. When I talk about tech debt, what I really just mean is that ability to have flow. Your team’s ability to deliver. All those little things that slow somebody down, complex code, flaky builds, slow pipelines. I view those as all things that can be improved and things that we’ve seen improved with other people. That’s my more general view of tech debt. A lot of times I’ve seen people try to look a purely technical approach or a tool approach to solve that thinking if we just implement this tool or change these practices or get better PRs, we’ll solve the problem.
Or maybe if we just get time, just quit developing for new features for a month and we’ll just fix all these problems. What I’ve actually seen is there’s a lot of different things that can be done to help this problem that sometimes people don’t really think about. I’ve been collecting some of my experiences and the experiences of other people and I’ve really found that there are technical and interpersonal things that people can do at different scales, things that somebody can do for themselves, for their team, and also for their stakeholders or the greater company that they work in. I don’t have one simple answer though that just buy my product and it’s all fixed, unfortunately.
Shane Hastie: There is no tech debt magic wand. Who would’ve thought?
Dustin Thostenson: Not yet. If I could box it though.
Shane Hastie: Self, team, and stakeholders. Let’s dig a little bit into self. Individually, what are some things that the individual contributor, developer, architects, on a team can do to help reduce technical debt at their level?
Things an individual contributor can do [04:20]
Dustin Thostenson: I think when it comes to any type of problem, the first step is usually acknowledgement and identification. A lot of times we’ve got people who are rushing to get things done and they might not see how the decisions they make today are going to impact tomorrow. Sometimes they might not recognize that the way that they’re coding a solution has a formal code smell name to it and they might not recognize that they’re creating a temporal coupling smell. It makes sense to include this logic right here because the spec says it does this and then it does that and then it does that and then it does that. People might just put those things right at that level instead of recognizing we’ve got PDF exports over here and CSV exports and recognizing that there are different responsibilities that could be separated that could help make things a little bit easier, and that goes with the code or the pipeline. It’s really agnostic to technology. I think recognizing that a decision being made now could have an impact. Sometimes that just comes with experience, but there are ways to get it.
Shane Hastie: If I don’t have the experience yet, where do I find it?
Useful resources [05:38]
Dustin Thostenson: There are some books out there. Josh Kerievsky has a book called Refactoring to Patterns, and that bridges with Martin Fowler’s book on design patterns. It bridges nicely with Michael Feathers’ book on Working Effectively with Legacy Code. There are some publications out there where you could just read it and then start learning the names for the different things that you’re seeing and then possibly learning some of the different refactoring techniques which could allow you to take steps to get over to there. That helps with the acknowledgement of it and the identification to have that trigger to say, wait a second, something’s not right here.
Then Emily Bache has got a great GitHub repo with a bunch of code katas, and that’s the thing that I’ve done for myself a lot. It’s something I’ve done with teams. Just being able to grab some different code katas and practice cloning the code, making a bunch of changes and seeing if you can go through all those steps. That can make a huge difference because now when you see the problem and then you’ve been practicing the muscle memory to hit the keyboard shortcut, to extract the method or to rename something, it becomes a lot easier. It doesn’t have to be a dedicated effort. You can just do it as you see it and then it just happens.
Shane Hastie: There are good solid resources people can dig into to identify those patterns. Personal opinion, I see far too little recognition of the importance of patterns in developer education today. Am I being harsh?
Recognising patterns [07:21]
Dustin Thostenson: I don’t think you are, and I’m assuming that sometimes when you would bring that up, people will bring up the edge case scenario of the ivory tower architects who try to implement every pattern, and there’s definitely a pendulum that goes back and forth. If you find yourself doing the same thing and it’s causing a problem, maybe introduce a factory. That’s been a solved way to do it. Or if you’re having to kick out reports and you recognize there seems to be a pattern here, maybe you could add a strategy pattern and maybe just seeing what that pattern is allows you to see a new way that the code could look.
I don’t think that you have to come up with all the patterns and have everything designed perfect, but when you see that something isn’t working, sometimes it’s good to have that in your toolbox, so you say, “What if I try this?” If you know the name of it, then you can communicate with your teammates more quickly. Sometimes you might just stumble upon something that makes sense and find out later on, “Oh, that was a chain of command pattern. It made sense, and I guess it has a name”.
Shane Hastie: Those are some things that individually I can do and digging into my own learning about patterns and starting to recognize patterns and use them. What about at the team level?
Things we can do at the team level [08:35]
Dustin Thostenson: Sometimes people will try to inflict help on others, and that doesn’t usually work so well. I’ve come to the realization that the only person I can control in my life is myself, and I struggle to do that. I would be in much better shape and probably running a 5K tonight instead of sitting down and playing on my computer. I think it’s a good acknowledgement to say I can only control myself. Once somebody does that, and once somebody does start to practice those behaviors, it does become easier for other people to emulate. Sometimes people might see what you’re doing and they might want to do that because it looks more enjoyable. If you have people who are willing to go with you, that’s when you start leading that influence. You make it easy for people to join.
I’ve seen teams have team katas as a team agreement. They say, “After stand-up every day, we’re going to spend 15 minutes and we’re just going to have fun. We’re going to work on a kata. Yes, I know that we write code all day, but we’re not going to be focusing on the business problem that we’re trying to solve. We’re going to focus on the pattern or the muscle memory of it. We’re going to focus on mobbing so we know how to talk to each other and we know how to communicate what we’re thinking better”. Sometimes just those little things where you practice the dribbling and the shooting, and when you practice those little things, then when it’s game time, it all comes together easier without the pressure of we have to get this story done by the end of the day because the sprint is over.
Shane Hastie: What if I’m not in a position to lead this team? How do I bring others on this journey with me?
Leading through influence [10:15]
Dustin Thostenson: A lot of the best influence doesn’t come from positional hierarchy. You can be an influencer without having that formal title. One of my favorite quotes is from Jerry Weinberg where he says, “Consulting is the art of influencing people at their request”. That makes a lot of sense to me because if I’m doing work on a team and I don’t have a tech lead or any formal title, if the team is open to pairing, then I want to make sure when people are pairing with me that they’re having a good experience, that we’re getting stuff done, we’re delivering a quality product, and maybe they learn some things.
Maybe they see a keyboard shortcut that they didn’t know before. Maybe they recognize a different way to write tests quicker and faster where it’s actually preferable to create a test and reproduce the problem. It doesn’t even matter at the company or even internationally, nobody cares what conferences I’ve spoke at. Nobody cares if I was an author or anything. What they care about is what they see and what their experience is. If they’re enjoying your time, they might want to try that too, and if they don’t, that’s their choice.
Shane Hastie: Stepping out into the wider community, you said it beautifully earlier, the gray area, the mass community around us who have high expectations and are often frustrated, things aren’t going exactly like we would hope.
Dustin Thostenson: We’re spending a lot of money on it.
Shane Hastie: We’re spending a lot of money. It’s taking a lot of time. We need these products to help the organization achieve some great goals, and it’s just not happening. How do we as technologists bring those people along with us?
Communicating the value of reducing technical debt to non-technologists [12:07]
Dustin Thostenson: I think a lot of us in technology have learned technology. We went to school to study technology. We listen to podcasts and read books and watch YouTube videos on technology. We search Stack Overflow to understand technology. What we don’t do is we don’t always focus on the people and what makes sense for us doesn’t always make sense for them. I think that there’s a couple of steps that you can take to help bridge that. Again, going back to that concept of acknowledgement, acknowledge that they have motivations. They have customers they’re trying to make happy. They have a board of directors that’s expecting ROI. They’ve got marketing which has timelines. I think it helps to just understand this person has pressure on them as well too, and they have a different type of responsibility, so what is it that they care about and what is it that they really need?
Oftentimes, if you listen, and you can now also parrot it back to them to say, “Oh, so all these quality issues are causing a problem with you because the customers aren’t happy, and now we’re having to create all these defect bugs, which is pushing off additional work that we can do today. If we didn’t have all these defects, then we could probably make marketing happy because we can hit the conference that they were going to announce all the new features at”. If you can understand it from their point of view and reflect it back to them, when they hear you say it, they know that you understand. The other thing is, I’m going to laugh about this a little bit, I originally was telling people you need to be clear and concise in that messaging. You need to figure out what details do you really need to share and only give the deeper details if they ask questions.
The reason this tickles me is because the first time I talked about being clear and concise, a friend in the front row said, “I think you mean succinct”. There’s a diagram that I’ve seen that has different pictures of data, information, knowledge, insight, and wisdom, and it talks about the granularity of the data and being able to add meaning to the data and have relationships with the data. Then when you get an insight, to be able to recognize this thing over here eventually connects to this other part over here, whether it’s an opportunity, an outcome, problem, solution, but there’s a relationship through that. That to me is what I try understand so when I talk to somebody, I can get to that point quickly. Then when they say, “But how do you go from point A to point B?” Then I need to make sure that I can tell that story quickly using the words that they understand.
Not talking down to them, but addressing it for their needs. Then when they want more information, you start getting into the relationships and maybe schedule an offline meeting, but just be able to communicate with them so you can keep their attention and not force a memory overload error or make them feel dumb. Just treating people with respect, understanding that they have a different background, and that’s fine. They could do the same thing to you. I found some of those things in my long-winded answer about being succinct have been very helpful in bridging that relationship and making sure that we’re all working towards the same goals.
Shane Hastie: These are not skills that one stereotypically technology folks are known for, and also, they tend not to be skills that we are trained in. How do we build those skills? How do we build that muscle?
Building communication skills and taking responsibility [15:44]
Dustin Thostenson: I agree with you. For me, I think part of it was recognizing when things weren’t going well for me to stop blaming others. That guy is Peter Principled, and that person is just dumb. They don’t get it. I realized, again, I can’t control them. If I had to go in a time machine, is there something I could have done differently? I used to think about that when I would drive home from work. I’d reflect on my day and go, “If I had that meeting again, what would I do differently?” That reflection, I think helped me acknowledge that some things weren’t going perfect and that maybe if I tried something different, there’d be an opportunity. That was the first real awakening for me. Then I’ve had some different consulting opportunities where all the coaches were hanging out in the same spot and we would complain to each other at the night and then they said, “Yes, you’re right. This client, they’re screwed up. Yes, they should do something about it”.
Well, guess what? They did, they hired us, so what are we going to do? Sometimes they would be preaching to the choir, “Oh, they need to do this, this, and this”. Then they would stop themselves and say, “Oh, I’m just preaching to the choir”. I said, ‘No, you’re practicing. You’re taking all these ideas that you have in your head and going through them, so the next time you do that, you’re going to give a quick answer”. Sometimes having targets, I’m mentoring a kid who just graduated college and he was going to have a meeting with a vendor in the university for his product, and I said, “Well, the first thing is you have to make sure that you’re all in alignment, so don’t talk about how you’re going to do something. Talk about what you want to do and how that aligns”.
He did. He goes, “Well, that worked really good”. I mentioned, “Now you want to listen to what they have to say because if they’re going to give you access to an API, they’re going to have some real concerns, so you need to hear that and you need to acknowledge it. Then you need to make sure that you’re going to do something about it and keep telling them about it”. It was some simple checklist, but it was something that was at the top of his head that he was at least looking for. I think the big thing for me is this all really came down to, I had learned about the responsibility process eight or 10 years ago, and I had studied with Dr. Christopher Avery for a bit. That really helped change my life because I realized that when these things happen, we’re going to go through some different stages. Our first stage is were going to deny that there’s a problem.
Yes, well, I don’t see a problem at all hitting that production delivery date. Then when something happens, we start telling ourselves stories about blame, and you look at everybody else as they’re the reason for it, but you’re giving up all of your ownership. You’re giving away all of your power to do anything about it. After that, you get into justification where you start telling yourself, Yes, but we always miss production dates and we never do anything right here. Again, you’re telling yourself stories about why it’s okay for this bad thing to happen. For myself and others, I see people get into shame a lot where you’re basically blaming yourself. At least you’re taking a little bit of ownership for it, but it’s not healthy.
Sometimes you might work nights and weekends because you feel like you’re obligated to the team that if you were better, they wouldn’t have to do it, and you’re going to work as hard as you can, but eventually get into that responsibility mode where you get to look at the problem objectively and you get to decide, how would I like to see this come out? You get to make a choice, and it’s not responsibility as in accountability, but it’s about your ability to respond. I think that with individuals and the way that they work with the teams and the way that they work with their stakeholders, you get to analyze what’s going on and make that choice, how can I best respond to this in order to have the best possible outcome for me and all the people I care about?
Shane Hastie: It’s a hard ladder to climb, the responsibility process, isn’t it?
Dustin Thostenson: It is much easier when you spend months or years looking at other people and being able to frame it. It’s much easier when you see somebody denying a problem right off the bat or when you hear them talking about a problem and using blame. When you start to have that framing and you see the pattern that other people go through, then eventually you start wondering, well, maybe I’m like everybody else. Maybe I’m just as human as everybody else. Then just like seeing the bad code and recognizing this is a trigger, this is a code smell, this code smell has a name, you can start to recognize that own trigger in yourself and go, “Ooh, trigger happened. Now do I react out of habit or do I take a moment and add a little bit of space to decide what am I going to do with this trigger?” It’s a lifelong journey for me, I’m sure, but it’s one that I like.
Shane Hastie: You quoted Jerry Weinberg, and I want to go back to one of his sayings, “No matter what you think the problem is, it’s a people problem”.
Dustin Thostenson: It’s always a people problem. Absolutely.
Shane Hastie: If you don’t think it’s a people problem, it’s a people problem. As technologists, how do we get better at working with people?
No matter what you think the problem is, it’s always a people problem [20:57]
Dustin Thostenson: I think that the acknowledgement of that quote, Jerry’s stuff is so amazing because it’s so easy to read quickly and gloss over it. I think just acknowledging that, that is the case, changes what we see in the world. It changes what we’re looking at. If we think that it’s a problem with the old framework or an old tool or bad code, that’s all that we’re going to look at. Jerry also said things are the way they are because they got that way. If you’re looking at the code and you come in and this is crap, and this is crap and junk, junk, junk, junk, junk, the people who wrote that might be in the room and they might have done the best that they could at the time.
It’s very possible that they were new and they didn’t know a better way or they were covering for somebody who was on maternity leave and they had twice the workload and half the timeline. There’s a lot of reasons why things get to be the way they are. It’s never mal-intent. Usually, it’s not mal-intent. I think recognizing that and understanding what would have to happen in this environment for these things to come true gives you a little empathy. Then if you start looking at that and saying, “Okay, well, this is what we have today. What are people willing to do? How are we willing to try some different things?” Now you start looking at the way a company is organized.
Are they functionally organized where you have a UI team and a backend team and a database team and a security team? Recognize, well, if we were to make a change, what would have to happen? Who would have something to be lost if we did this? Who’s losing their team of 20 or 200 people? What does that do for them? Who’s losing their pride because they were the master of the system and they’ve always been that person, and now they might not have that credibility or the ego anymore. When you start looking at some of those hidden motivations or at least asking questions, you’re going to find out what is possible and what might not be possible yet, and then you can start figuring out how do we apply the tech to work within these constraints instead of just applying a template that just throw Kubernetes on everything and it’ll work.
Shane Hastie: That’s been some really useful resources there. Some great pointers. If people want to continue the conversation, where do they find you?
Dustin Thostenson: They used to be able to find me on Twitter, but now I guess it’s called X. You can find me there as Dustinson. I love connecting with people there. You can also catch me on LinkedIn, and I have been trying to build up my own website a little bit more, trying to put some more content in some of the recordings of the talks I’ve given. I love going to conferences and still meeting people in the old analog way.
Shane Hastie: Dustin, thanks so much for taking the time to talk to us today.
Dustin Thostenson: It’s been an absolute pleasure. Thank you for all the work that you’re doing to bring this out to the community and make a more positive impact. Appreciate that you’re doing these things. Thank you.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Ben Linders

Copying and pasting code from one Windows folder to another as a deployment method can cause downtime. Jemma Hussein Allen presented how they automated their deployments and the benefits that they got from it at QCon London.
The main challenges with manual deployments of application and infrastructure code were due to environmental inconsistencies that happened due to a range of factors, of which the main one was aligning code deployment with deployments of dependent resources such as databases, Hussein Allen said. Before options such as blue/green deployment became available, changes that were not backward compatible meant brief periods where the database schema and code were out of sync and caused failed requests during deployments, she added.
Hussein Allen mentioned that general human error also plays its part, where certain file updates are missed, or incorrect versions are copied to the new environment. Human error can also be a big factor in testing if there are no mandated safety checks and local testing is the responsibility of individual developers:
Process automation helps to remove the human error component, and with intelligent deployment mechanisms, checks such as file share latency can be checked before deployments to ensure downtime isn’t an issue.
Manual deployment involving file shares can also be a big issue if the timing of file copies is out of sync, as it can result in incomplete deployments, Hussein Allen said. Updates to dependent resources can also be codified and synchronised to ensure changes are deployed in the correct order, she suggested:
These days, with deployment automation and blue/green deployments, new versions can be deployed and tested in a production environment before being made available to end users.
The first stage for automation was to document each deployment step, no matter how small, Hussein Allen said. Some key considerations were whether the step was manual or already automated, any downstream or upstream dependencies on other resources, and any access configuration, permissions, or secrets needed to carry out the step. This gave them a good overview of the current deployment method and highlighted any steps that would take a large amount of work to automate, she mentioned.
After they had a good understanding of the process, they looked into existing available tools to assess their suitability. They also looked at the existing deployment tools in use in the organisation to determine if these would be suitable, as people who were already experienced with the tool are really valuable:
Unfortunately, none of the existing tools were suitable for this type of workload, so we carried out a wider search to assess the suitability of other tools, taking into account support for the workload type and how they integrated with the existing company tooling.
Once the assessment stage was complete, they started to implement a proof of concept in the development environment.
We started with a small part of the application, and once we had successfully set things up in development for a specific application segment, we moved that deployment process to the staging environment.
As staging had slightly more policy constraints than development, testing in this environment was important, Hussein Allen mentioned.
After the proof of concept had been implemented, they then assessed how the solution could be rolled out to other application segments and environments with minimal disruption.
The main benefit from automating deployments is a quicker and cleaner release process, especially when working collaboratively in a team, Hussein Allen said. Centralised change logs and deployment trackers also provide much better deployment visibility across teams, she added.
Hussein Allen mentioned that standardisation of deployment steps can improve familiarity and understanding of a paved road and the components needed to test and deploy quality applications. The CNCF defines a “golden path” as the “Templated compositions of well-integrated code and capabilities for rapid project development“. The paved road / paved path / golden path approach has become more popular with larger organisations as it is a proven method to speed up developer adoption of standardised company processes and tooling, as Hussein Allen explained:
I have seen the adoption of well-crafted templates by development teams majorly increase the speed of utilising company-specific tooling and logic in applications.
Automation will almost always save time and effort in the long run, even if it takes slightly more effort initially, Hussein Allen concluded.
Microsoft’s Customer Managed Planned Failover Type for Azure Storage Available in Public Preview
MMS • Steef-Jan Wiggers
Microsoft recently announced the public preview of a new failover type for Azure Storage with customer managed planned failover. This new failover type allows a storage account to failover while maintaining geo-redundancy, with no data loss or additional cost.
Earlier, the company provided unplanned customer managed failover as a disaster recovery solution for geo-redundant storage accounts. This has allowed their customers to fulfill their business needs for disaster recovery testing and compliance. Furthermore, another available failover type planned (Microsoft managed) is available. With the new customer managed planned failover type, users are no longer required to reconfigure geo-redundant storage (GRS) after their planned failover operation.
In a question on Stack Overflow, if Azure Storage failover and failback need two replications, the company replied hinting at the new failover type:
Yes, two replications would be required, and the process would work as documented. We currently have Planned Failover in private preview, allowing customers to test the Failover workflow while keeping geo-redundancy. As a result, there is no need to re-enable geo-redundancy after each failover and failback operation. This table highlights the key differences between Customer Managed Failover (currently GA) and Planned Failover (currently in the planned state).

If the storage service endpoints for the primary region become unavailable, users can fail over their entire geo-redundant storage account to the secondary region. During failover, the original secondary region becomes the new primary region, and all storage service endpoints are then redirected to the new primary region. After the storage service endpoint outage is resolved, users can perform another failover operation to fail back to the original primary region.
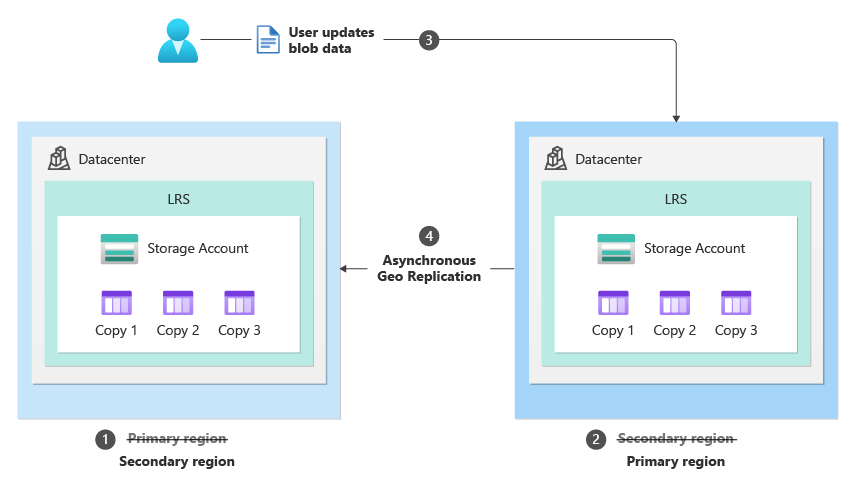
(Source: Microsoft Learn)
There are various scenarios where Planned Failover can be used according to the company:
- Planned disaster recovery testing drills to validate business continuity and disaster recovery.
- Recovering from a partial outage in the primary region where storage is unaffected. For example, suppose storage service endpoints are healthy in both regions, but another Microsoft or 3rd party service faces an outage in the primary region. In that case, users can fail over their storage services. In this scenario, once users fail over the storage account and all other services, their workload can continue to work.
- A proactive solution in preparation for large-scale disasters that may impact a region. To prepare for a disaster such as a hurricane, users can leverage Planned Failover to fail over to their secondary region and then fail back once things are resolved.
AWS and Google Cloud’s competitive storage offerings offer similar disaster recovery options, such as multiple active regions (AWS) and dual/multiple buckets (GCP).
In a recent tweet emphasizing that backups are essential, Fletus Poston tweeted:
You likely know having a backup is essential—but it’s not enough. A backup that hasn’t been validated could leave your business vulnerable when disaster strikes. Whether it’s a ransomware attack, hardware failure, or accidental deletion, relying on untested backups can lead to incomplete or corrupted data recovery.
The new failover type is available in Southeast Asia, East Asia, France Central, France South, India Central, and India West Azure regions.
.NET 9 Release Candidate 1: Approaching Final Release with Updates Across the Framework
MMS • Almir Vuk

Last week, Microsoft released the first release candidate for the upcoming .NET 9 framework, which includes a range of updates across its core components, such as the .NET Runtime, SDK, libraries, C#, and frameworks like ASP.NET Core and .NET MAUI.
Regarding the .NET libraries, new APIs were added to ClientWebSocketOptions and WebSocketCreationOptions, enabling developers to configure WebSocket pings and automatically terminate connections if no response is received within a specified timeframe.
Additionally, new types—ZLibCompressionOptions and BrotliCompressionOptions—have been introduced, providing more detailed control over compression levels and strategies. These additions offer greater flexibility compared to the previous CompressionLevel option.
For users working with TAR archives, the public property DataOffset has been introduced in System.Formats.Tar.TarEntry allows access to the position of data in the enclosing stream. This provides the location of the entry’s first data byte in the archive stream, making it easier to manage large TAR files, including concurrent access features.
From this version, LogLevel.Trace events generated by HttpClientFactory will now exclude header values by default. However, developers can log specific header values using the RedactLoggedHeaders helper method, enhancing privacy and security.
Furthermore, the new command dotnet workload history has been introduced. As explained, this command tracks the history of workload installations or modifications within a .NET SDK installation, offering insights into workload version changes over time. It is intended to assist users in managing workload versions more efficiently, as stated similar to Git’s reflog functionality.
The release candidate also introduces updates to ASP.NET Core, such as a keep-alive timeout for WebSockets, support for Keyed DI services in middleware, and improvements to SignalR distributed tracing, aiming to improve performance and simplify development workflows.
Interested readers can read more about ASP.NET Core RC1 updates in the latest and detailed InfoQ news article.
Regarding .NET MAUI the release focuses on addressing issues and stabilizing the platform in preparation for the general availability (GA) release. Among the new features is HorizontalTextAlignment.Justify, which provides additional text alignment options for Labels. Also, updates to HybridWebView are included, with a guide for developers upgrading from .NET 9 Preview 7 to RC1, especially about Invoking JavaScript methods from C#.
With a note that .NET for Android and iOS in this release, are primarily focused on quality improvements, as reported this release requires Xcode 15.4 for building applications.
Lastly, looking into the community discussion for this release, an interesting conversation clarified that the Out-of-proc Meter wildcard listening feature is a new feature not previously available in either in-process or out-of-process scenarios.
Tarek Mahmoud Sayed, collaborator on .NET project, wrote the following:
The wildcard support is the new feature that was not supported in proc or out of proc. The sample showing the in-proc just for simplicity to show using the wildcard. You can still listen out-of-proc too and leverage the wildcard feature. We are working to make diagnostics tools like dotnet monitor to leverage the feature too. Let me know if there still anything unclear and I’ll be happy to clarify more.
Interested readers can find more information about this version in the official release notes. Lastly, the .NET 9 Release Candidate 1 download is available for Linux, macOS, and Windows.
MMS • Danilo Sato

Transcript
Sato: The track is about the architectures you’ve always wondered about, and I work in consulting, and sometimes, not always, I have lots of stories about architectures you probably don’t want to know about. I’ll try to pick the things that are interesting. One of the benefits of working in consulting is I see lots of things, and what I try to do with these topics is less about zeroing in on a specific solution or a specific way of doing things, but we like to look at things more like, what are the patterns, what are the different ways that people can do it maybe using different types of technology stacks?
What is this Organization’s Business?
To start with, because we’re talking about data architectures, I want to start with a question. I’ll show you a data architecture, and I’ll ask you like, help me find what is this organization’s business? This organization has a bunch of data sources, so they’ve got ERP systems, CRM system. They do their finance. They get external data. Then they ingest their data through a data lake or a storage. They do that through streaming. They do that through batch. They do a lot of processing of the data to cleanse it, to harmonize the data, to make it usable for people. Then they do serving of the data. They might put it in a data warehouse, on a data mart where lots of consumers can use that data. They put it on a dashboard to write reports, to train machine learning models, or to do exploratory data analysis.
Which company is that? Has anyone seen anything like this before? I call this the left to right data architecture. Probably most people will have something like this, or a variation of this. What I like about using data products, and some of the ideas in data mesh, is that we can talk about data architectures slightly like this. I’ll describe a different one now, and I’ll use these hexagons to represent data products, and then some square or rectangles for systems. This company has data about content. They call it supply chain, because they have to produce the content. They add metadata to the content.
Then they make that content available for viewers to watch that content. When they watch that content, they capture viewing activities. What are people actually watching? What are they not watching? When do they stop watching? When do they start watching? Then they do marketing about that to get people to go watch more of their content. They have this, they call them audiences. When we’re looking around different types of audiences, one of the things that marketing people like to do is to segment the audience so that we can target the message to reach people that might actually be more interested in a specific type of content than another one.
Which company is this? There’s still a few of them, but at least the industry should be much easier to understand now, because we’re talking about the domain. In this case, this was a project that we’ve done with ITV, which is here in the UK. I don’t think I need to introduce but it’s a broadcaster. They produce content. They distribute that content. They actually have a studios’ business as well. There’s way more of that, but this was a thin slice of the first version of when we started working with them to build the data mesh. The first use case was in marketing. What we were trying to do is bring some of that data they already had into this square here.
I didn’t put the label, but it was the CDP, the customer data platform, where they would do the audience segmentation, and then they could run their marketing campaigns. The interesting thing is, once you do segments, then the segments themselves is useful data for all the parts of the business as well to know about. We can describe architecture in a more domain specific way. These are the things that hopefully will be more meaningful than the things underneath. Because if we zoom in into one of these data products, you’ll see that it actually has a lot of the familiar things.
We’ll have ingestion of data coming in. It might come in batches. We might do it in streaming. We might have to store that data somewhere. We still do pipelines. We still process the data. We have to harmonize and clean it up. We will need to serve that data for different uses. That can be tied in to dashboards or reports, or more likely, it could also be useful for all the downstream data products to do what they need. When we look inside of the data product, it will look familiar with the technology stacks and maybe architectures that we’ve seen before, but data products gives us this new vocabulary or this new tool, how we describe the architecture that’s less about the technology and more about the domain.
Background
In this talk, I was looking at, where should I talk about? Because those two, to me, is very related. It’s like we could look inside and how we architect for this data product. The other thing that I’m quite excited about is that you can actually architect with data products, which is more about that bigger picture, looking at the bigger space. This is what I’ll try to do. I am the Global Head of Technology at Thoughtworks. I’ve been here for over 16 years, but you see, my background is actually in engineering. I joined as a developer, and I fell into this data and AI space while here at Thoughtworks.
I was here when Zhamak wrote the seminal article to define data mesh principles and early reviewer of the book, and we’ve been trying to apply some of these ideas. The reason why I picked the topic to be data products and not data mesh, is because what we found is, it’s a much easier concept for people to grasp. You have hints if you’ve read the data mesh book or the article. There’s lots of things that you see there that comes from that. Data product is one way that’s easy for people to engage with that content.
Shift in Data Landscape
To tell you a little bit about the history, like why we got to where we are, why is it hard to architect or to design data architectures these days. There’s been a shift. Way back, we would be able to categorize things about like, we’ve got things that happen in the operational world. We’ve got data that we need to run the business, that have operational characteristics, and then we have this big ETL to move data into the analytical space where we’ll do our reporting or our business intelligence. That’s where a lot of those left to right architectures came about. We can use different ways to do those things, but in terms of how we model things, like databases, when I came into the industry, there weren’t many options.
Maybe the option is like, which relational database am I going to use? It was always like, tables. Maybe we design tables in a specific way if we’re doing transactional workloads versus if we’re doing analytical workloads. That was the question. Like, is it analytical workloads? Is it transactional workload? Which relational database do we use? Early in the 2000s there were maybe a few new things coming up there, probably not as popular these days, but some people try and build object database or XML databases. Things have evolved, and these days, this is what the landscape looks like. This got published. Matt Turck does this every year. This started off as the big data landscape, I think 2006 or something like that.
Then it’s been evolving. Now it includes machine learning, AI, and data landscape, which he conveniently calls it the MAD Landscape. It is too much for anyone to use to understand all of these things.
The other thing that happened is that we see those worlds getting closer together. Whereas before we could think about what we do operationally and what we do for analytics purposes as separate concerns, they are getting closer together, especially if you’re trying to train more like predictive, prescriptive analytics. You train machine learning models, ideally you want the model to be used, backed by an operational system to do things like product recommendation or to optimize some part of your business. That distinction is getting more blurry, and there are needs for getting outputs of analytics back into the operational world, and the other way around.
A lot of these analytics needs good quality data to be able to train those models or get good results. These things are coming together. These were some of the trends where the original idea from data mesh came from. We were seeing lessons we learned for how to scale usage of software. A lot of the principles of data mesh came from how we learn to scale engineering organizations. Two in particular that I call out, they are principles there in the book as well, but one is the principle of data as a product. The principle means, let’s treat data as a product, meaning, who are the people that are going to use this data? How can we make this data useful for people?
How can we put the data in the right shape that makes it easy for people to use it? Not just something that got passed around from one team to another, and then you lose context of what the data means, which leads to a lot of the usual data quality problems that we see. In data mesh, at least, data product side is the building block for how we draw the architecture, like the ITV example I showed earlier on. The other thing around that is that if we’re treating as a product, we bring the product thinking as well.
In software these days we talk about product teams that own a piece of software for the long run, there’s less about those build and throw over the wall for other people to maintain. The data products will have similar like long-term ownership, and if we can help drive alignment between how we treat data, how we treat technology, and how we align that through the business.
The other big concepts that influenced a lot of data mesh was from domain-driven design. The principle talks about decentralizing ownership of data around domains. What Zhamak means with domains in that context is from Eric Evans’ book on domain-driven design, which originally was written about tackling complexity in software. A lot of those core ideas for how we think about the core domain, how do we model things? How do we drive ubiquitous language? Do we use the right terminology that reflects all the way from how people talk in the corridors all the way to the code that we write? How do we build explicit bounded contexts to deal with problems where people use the same name, but they mean different things in different parts of the organization? A lot of that, it’s coming from that, applied to data.
Modeling is Hard
The thing is, still today, modeling is hard. I like this quote from George Box, he says, “Every model is wrong, but some of them are useful.” To decide which one is useful, there’s no blanket criteria that we can use. It will depend on the type of problem that you’re trying to solve. We’ve seen on this track, I think most people said, with architecture, it’s always a tradeoff. With data architecture, it’s the same. The way that we model data as well, there’s multiple ways of doing things. This is a dumb example, just to make an illustration.
I remember when I started talking about these things, there were people saying, when we model software or when we model data, we should just try to model the real world. Like, this thing exists, let’s create a canonical representation of the thing. The problem is, let’s say, in this domain, we’ve got shapes with different colors. I could create a model that organizes them by shape. I’ve got triangles, squares, and circles, but I could just as easily organize things by color. You can’t tell me one is right, the other one is wrong, if you don’t know how I’m planning to use this. One might be more useful than the other depending on the context. These are both two valid models of this “real world”. Modeling is always this tradeoff.
How Do We Navigate?
We’ve got trends from software coming into data. We’ve got the landscape getting more complex. We’ve got some new, maybe thinking principles from data mesh. How can we navigate that world? The analogy that I like to use here is actually from Gregor Hohpe. He talks about the architect elevator, architect lift, if you’re here in the UK, would be the right terminology. In his description, he wrote a book about it, but he talks about how an architect needs to be able to navigate up and down. If you imagine this tall building as representing the organization, you might have the C-suite at the top, you might have the upper management, you might have the middle management, the lower management, and then you might have people doing the work at the basement somewhere.
As an architect, you need to be able to operate at these multiple levels, and sometimes your role is to bring a message from one level to the other, to either raise concerns when there’s something that’s not feasible to be done, or to bring a vision down from the top to the workers. I like to apply a similar metaphor to think about architecture concerns. I’m going to go from the bottom up. We can think about data architecture within a system. If we are thinking about how to store data or access data within an application, a service, or in this talk, more about within the data product, and then we’ve got data that flows between these systems. Now it’s about exposing data, consuming that data by other parts of the organization.
Then you’ve got enterprise level concerns about the data architecture, which might be, how do we align the organizational structure? How do we think about governance? In some cases, your data gets used outside of the organization, some big clients of ours, they actually have companies within companies, so even sharing data within their own companies might be different challenges.
Data Architecture Within a System
I’ll go from the bottom to the up to talk about a few things to think about. Start, like I said, from the bottom, and the first thing, it’s within a system, but which system are we talking about? Because if we talk about in the operational world, if we’re serving transactional workloads where there’s lots of read/writes and lots of low latency requirements, that choice there is not as much about data product, but it’s, which operational database am I going to use to solve that problem? When we talk about data product in data mesh, you will see, like in the book, the definition is about a socio-technical approach to manage and share analytical data at scale.
We’ve always been focusing data products on those analytical needs. It’s less about the read/write choices, but it’s more about using data for analytical needs. The interesting thing is that some folks that work in the analytics, we’re quite used about breaking encapsulation. I don’t know if you’ve got those folks in your organization, but they’re like, just give me access to your database, or just give me a feed to your data, and then we’ll sort out things. We don’t do that when we design our operational systems. We like to encapsulate and put APIs or services around how people use our things.
In analytics, at least historically, it’s been an accepted way of operation where we just let the data team come and suck the data out of our systems, and they will deal with it. You end up with that disparate thing, and when we break encapsulation, the side effect is that the knowledge gets lost. This is where we see a lot of data quality problems creep in, because the analytics team is going to have to try to rebuild that knowledge somehow with data that they don’t own, and the operational teams will keep evolving so they might change the schema. We create a lot of conflict. The data team doesn’t like the engineering teams, and vice versa.
In the operational database side, like any other architecture choice, it’s understanding what are the data characteristics that you need, or the way to think about the cross-functional requirements. From data, it might be like, how much volume are you expected to handle? How quickly is that data going to change? Aspects around consistency and availability, which we know it’s a tradeoff on its own, different access patterns. There will be lots of choices. If you think about all the different types of databases that you could choose, I would just quickly go through them. You’ve got the traditional relational database, which is still very widely used, where we organize data in tables.
We use SQL to query that data. You’ve got document databases where maybe the data is stored as a whole document that we can index and then retrieve the whole document all at once. We’ve got those key-value stores where, maybe, like some of the caching systems that we built, we just put some data in with a key value that we can retrieve fast. We’ve got some database there, those wide column style databases like Cassandra or HBase, where we model column families, and then you index the data in a different way depending on the types of the queries that you’re going to make. We’ve got graph databases where we can represent the data as graphs or relationships between nodes and entities, and infer or maybe navigate the graph with a different type of query.
Some people say like search database, like Elasticsearch, or things like that. We’re trying to index text to make it easier to search. We’ve got time-series databases, so maybe you’ve got high throughput temporal data that we might need to aggregate by different periods of time because we’re trying to do statistics or understand trends. We’ve got columnar databases, which is popular with analytical workloads, where maybe the way that we structure the data and the way that it’s stored, it’s more organized around column so it’s easier to run analytical queries against that. This thing keeps evolving. I was just revisiting these slides, and actually now, with all the new things around AI and new types of analytics, there’s even like new types of databases that are coming up.
Vector database is quite popular now, where if you’re trying to train an LLM or do reg on the LLM, you might want to pull context from somewhere, or whether we store our embeddings will be in a vector database. Machine learning data scientists, they use feature stores where they can try to encapsulate how they calculate a feature that’s used for training their models, but they want that computation to be reused by other data scientists, and maybe even be reused when they’re training the model, and also at inference time, where they will have much more strict latency requirements on it.
There are some metrics databases coming up, like, how do we compute KPIs for our organization? People are talking about modeling that. Even relations, like, how can we store relations between concepts? How can we build like semantic layer around our data so it’s easier to navigate? This landscape keeps evolving, even if I take all the logos from who are the vendors that are actually doing this.
There’s more things. We could argue after, it’s like, actually, Elasticsearch claims they’re actually a document database as well, they’re not just a search database. I can query the SQL in a graph database as well, because there’s a dialect that’s compatible with that. There’s lots of nuances around that. There are some databases that claim to be multimodal. Like, it doesn’t matter how it’s going to get stored, you can use a product and it will give you the right shape that you need.
You have to choose whether you’re going to use the cloud services that are offered, whether you’re going to go open source, or whether you’re going to get a vendor. The interesting one like, sometimes you don’t even need a full database system running. When we talk about data, sometimes it’s like, I just want a snapshot of that data to be stored somewhere in the lake. It might be like a file. It might be a parquet file. It’s just sitting on a storage bucket somewhere.
Data Product
Now I’ll shift more to the data product, which is more on the analytical side. One of the questions I get a lot from clients is to understand like, but what is a data product? Or, is this thing that I’m doing a data product? The way that I like to think about it, I’ll ask you some questions here. If you’ve got a table, you’ve got a spreadsheet, do you think that’s a data product? The answer is probably not, but there’s other ways that we can have data. Maybe it’s an event stream or an API, or I’m plugging a dashboard into this, does this become a data product now? Who thinks that? It doesn’t stop there, because if we’re going to make it a data product, we need the data to be discoverable and the data to be described.
There will be schema associated with the data, how that data gets exposed, especially on the output sign, and we want to capture metadata as well. That makes it more robust. Now, is that a data product? It doesn’t end there. We want the metadata and the data product to be discoverable somewhere. We’re probably going to have a data catalog somewhere that aggregates these things so people can find it. We also, like I said before, in the zoomed in version, there will be code that we write for how to transform, how to ingest data, how to serve data for this product. We need to manage that code. We need to choose what kind of storage for this data product we’re going to use, if we’re doing those intermediary steps. As we do transformation, we probably want to capture lineage of data, so that’s going to have to fit somewhere as well.
More than that, we also want to put controls around quality checks. Like, is this data good? Is it not good? What is the access policy? Who is going to be able to access this data? Even we’re talking about data observability these days, so we can monitor. If we define service level objectives or even agreements for our data, are we actually meeting them? Do we have data incidents that needs to be managed? This makes a little bit more of the complete picture. We want the data product to encapsulate the code, the data, the metadata that’s used to describe them. We use this language, we talk about input ports, output ports, and control ports. Then the input ports and outputs is how the data comes in and how the data gets exposed. It could be multiple formats. It might be a database-like table, maybe, as an output port. It might be a file in a storage somewhere. We might use event streams as an input or output. It could be an API as well.
Some people talk about data virtualization. We don’t want to move the physical data, but we want to allow people to connect to data from other places. There are different modes of how the data could be exposed. Then the control ports are the ones that connect to the platform, to either gather information about what’s happening inside the data product, to monitor it, or maybe to configure it.
The thing about that is, because it gets complex, what we see is, when we’re trying to build data products, a key piece of information that comes into play is the data product specification. We want to try to create a versionable way to describe what that product is, what is its inputs, what is its outputs? What’s the metadata? What’s the quality checks? What are the access controls that we can describe to the platform, how to manage, how to provision this data product. The other term that we use a lot when we talk about data products is the DATSIS principles.
Like, if we want to do a check mark, is this a data product or not? The D means discoverable. Can I find that data product in a catalog somewhere? Because if you build it, no one can find it, and it’s not discoverable. If I find it, is it addressable? If I need to actually use it, can I access it and consume it through some of these interfaces that it publishes? The T is for trustworthy. If it advertises this quality check, so the SLO or the lineage, it makes it easier for me, if I don’t know where the data is coming from, to understand, should I trust this data or not? Self-describing, so all that metadata about, where does it fit in the landscape? Who’s the owner of that data product? The specification, it’s part of the data product. It needs to be interoperable.
This gets a little bit more towards the next part of the presentation. When we talk about sharing data in other parts of the organization, do we use a formal language or knowledge representation for how we can allow people to connect to the data. Do we define standard schemas or protocols for how it’s going to happen? Then S is for secure, so it needs to have the security and access controls as part of that.
Data Modeling for (Descriptive/Diagnostics) Analytical Purposes
Quickly dive into when we talk about analytics, one of the modeling approaches. I put here in smaller caps, like this is maybe for more descriptive, diagnostics types of analytics. It’s not anything machine learning related. We usually see about this like, there’s different ways to do modeling for analytics. We can keep that raw data. We can use dimensional modeling. We can do data vault. We can do wide tables. Which one do we choose? Dimensional model is probably one of the most popular ones. We structure the data either in a star schema or a snowflake schema, where we describe facts with different dimensions. Data vault is interesting. It is more flexible. You’ve got this concept of hubs that define business keys for key entities that can be linked to each other.
Then both hubs and links can have these satellite tables that is actually where you store the descriptive data. It’s easier to extend, but it might be harder to work with, for the learning curve is a little bit higher. Then we’ve got the wide table, like one big table, just denormalize everything, because then you’ve got all the data that we need in one place. It’s easy to query. That’s another valid model for analytics. This is my personal view. You might disagree with this. If we think about some of the criteria around performance of querying, how easy it is to use, how flexible the model is, and how easy to understand? I put raw data as kind of like the low bar there, where, if you just got the raw data, it’s harder to work with because it’s not in the right shape.
Performance for querying is not good. It’s not super flexible, and it might be hard to understand. I think data vault improves on that, a lot of them especially on model flexibility. Because it’s easy to extend their model, but maybe not as easy to use as a dimensional model. The dimensional model might be less flexible, but maybe it’s easy to use and to understand. Many people are used to this. Performance might be better because you’re not doing too many joins when you’re trying to get information out of it. Then, wide tables, it’s probably like the best performance. Because everything is in a column somewhere, so it’s very quick to use and very easy, but maybe not super flexible. Because if we need to extend that, then we have to add more things and rethink about how that data is being used.
Data Architecture Between Systems
I’ll move up one level now to talk about data architecture between systems. There are two sides of this. I think the left one is probably the more important one. Once we talk about using data across systems, now, decisions that we make have a wider impact. If it was within my system, it’s well encapsulated. I could even choose to replace the database or come up with a way to migrate to a different database, but once the data gets exposed and used by other parts of the organization, now I’ve made a contract that I need to maintain with people.
Talking about, “What’s the API for your data product?” The same way that we manage APIs more seriously about, let’s not try to make breaking changes. Let’s treat versioning more as a first-class concern. That becomes important here. Then the other thing is how the data flows between the systems. Because there’s basically two different paradigms for handling the data in motion. Thinking about the data product API, because it needs more rigor, one of the key terms that are coming up now, people are talking about this, is data contracts.
We’re trying to formalize a little bit more, what are the aspects of this data that is in a contract now? We are making a commitment that I’m going to maintain this contract now. It’s not going to break as easily. Some of the elements of the contract, the format of the data, so, is my data product going to support one type or maybe multiple formats? Is there a standard across the organization? Examples may be Avro, Parquet, maybe JSON or XML, Protobuf, like that. There are different ways that you could choose. The other key element is the schema for the data, so that helps people understand the data that you’re exposing.
Then, how do we evolve that schema? Because if we don’t want to make breaking changes, we need to manage how the schema evolves in a more robust way as well. Depending which format you chose, then there’s different schema description languages or different tools that you could use to manage that evolution of the schema. The metadata is important, because it’s how it hooks into the platform for discoverability, to interop with the other products. Then, discoverability, how can other people find it? I mentioned before having something like a data catalog that makes it easy for people to find. They will learn about what the data is, how they can be used, and then decide to connect to the API.
When we talk about data in motion, like I said, there’s basically two main paradigms, and they’re both equally valid. The very common one is batch, which usually is when we’re processing a bounded dataset over a time period. We’ve got the data for that time period, and we just run a batch job to process that data. When we’re doing batch, usually going to have some workflow orchestrator for your jobs or for your pipelines, because oftentimes it’s not just one job, you might have to do preprocessing, processing, joining, and things like that. You might have to design multiple pipelines to do your batch job. Then the other one that’s popular now is streaming.
We’re trying to process an infinite dataset that keeps arriving. There are streaming engines for writing code to do that kind of processing. You have to think about more things when you’re writing these things. The data might arrive late, so you have to put controls around that. If the streaming job fails, how do you snapshot so that you can recover when things come back? It’s almost like you’ve got a streaming processing job that’s always on, and it’s receiving data continuously. There’s even, for instance, Apache Beam, they try to unify the model so you can write the code that could either be used for batch processing or stream processing as well.
Flavors of Data Products
The other thing, thinking about between systems, I was trying to catalog, because there are different flavors of the data products that will end up showing up in the architecture. When we read the book and when we read the first article from Zhamak, she talks about three types of data products. For example, we’ve got source-aligned data products. Those are data products that are very close to, let’s say, the operational system that generates that data. It makes that data usable for other parts of the organization. Then we may have aggregate data products. In this example here, I’m trying to use some of the modeling that I’ve talked about before.
Maybe we use a data vault type of modeling to aggregate some of these things into a data vault model as an aggregate. The dimensional model, in a way, is aggregating things as well. This is where it gets blurry, the dimensional model might also act as a consumer-aligned data product, because I might want to plug my BI visualization tool into my dimensional model for reporting or analytics. I might transform, maybe from data vaults into a dimensional model to make it easier for people to use, or maybe as a wide table format. Then the other one I added here, which is more, let’s say we’re trying to do machine learning now, I need to consume probably more raw data, but now the output of that trained model might be something that I need to consume back in the operational system.
We’ve got these three broad categories of flavors of data products. What I’ve done here, there are more examples of those types of products, so I was trying to catalog a few based on what we’ve seen. In the source-aligned, we’ve got the obvious ones, the ones that are linked to the operational system or applications. Sometimes what we see is like a connector to a commercial off-the-shelf system. The data is actually in your ERP that’s provided by vendor X. What we need is connectors to hook into that data to make it accessible for other things. The other one I put here, CDC anti-corruption layer. CDC stands for Change Data Capture, which is one way to do that, pull the rug of the data from the database from somewhere.
This is a way to try to avoid the leakage, where we can try to at least keep the encapsulation within that domain. We could say, we’ll use CDC because the data is in a vendor system that we don’t have access, but we’ll build a data product that acts as the anti-corruption layer for the data, for everyone else in the organization. Not everyone needs to solve that problem of understanding the CDC level event. Or, external data, if I bought data from outside or I’m consuming external feeds of data, maybe they might show up as a source-aligned in my mesh. The next one aggregate.
Aggregate, I keep arguing about with my teams as well, because lots of things are actually aggregates when we’re trying to do analytics. In a way, it’s like, is it really valid or not? We see just as an example like this, sometimes aggregates are closer to the producer. The example I have is, we’re working with the insurance company, and you can make claims on the website, so I can call on the phone. What happens behind the scenes is there’s different systems that manage the website and the phone. You’ve got claims data from two different sources, but for the rest of the organization, maybe it doesn’t matter where the claim comes from, so I might have a producer owned aggregate that combines and makes it easy for people downstream to use that. We might have this especially analytical models that are more like aggregates across domains.
When we’re trying to do KPIs, usually, business people ask about everything. You need to have somehow access to data that comes from everywhere. The common one is consumer owned. When we’re trying to do, maybe, like a data warehouse model, or something like that, you aggregate for that purpose. Then the other one, like a registry style. This one comes up when we’re trying to do, for instance, master data management in this world, where, let’s say we’ve got our entity resolution piece in the architecture, where we’ve got customer data everywhere. I aggregate into this registry to try to do the entity resolution, and then the output is like, how did I cluster those entities, that can be used either by other operational systems or for downstream analytics?
Then in consumer-aligned, there’s many of them. Data warehouse is a typical one. I put operational systems here as well because people talk about reverse ETL, where we take the output from analytics, put it back into the operational system. To me, that’s just an example. I’m using output from another product to feed back into the operational system. This was the example from the ITV one in the beginning, where we’re trying to feed that audience data into the CDP. It’s actually aggregating things and putting in the consumer for marketing.
I think metric store, feature store, building machine learning models, examples of things that are more on the consumer side. Or if we’re trying to build like an optimization type of product, maybe, that might need data from other places, and then the outputs might be the optimization. The interesting thing, if you think about this now, is that data products were born with the purpose of being analytical data products, but now we’re starting to feed things back into the operational world, which means the output ports can actually be subject to operational SLAs as well. This is a question that I get a lot.
It’s like, if I’m only using data products for analytics, how does it feed back into the operational world? In my view, I think that’s a valid pattern. Like the output port can be something that you need to maintain just as another operational endpoint that gives you, let’s say, model inference at the speed that the operational system needs.
Data Architecture at Enterprise Level
That leads me to the last level, at the enterprise level. Here we start getting more into organizational design. How is the business organized? How do we find those domains? A lot of that strategic design from DDD comes into play here, because we need to find, where are the seams between the different domains? Who’s going to own these different domains? One question that comes up a lot when we talk about data mesh specifically, is, data mesh is very opinionated about if you need to scale, if you got a lot of data, a lot of use cases, the centralized model will become a bottleneck at some point.
If you haven’t got to that point, maybe that’s a good way to start. If you’re trying to solve the problem of, my data teams are a bottleneck, then the data mesh answer is, look at a decentralized ownership model for data. A lot of that domain thinking data as a product is what enables you to decentralize ownership. This is a decision you can make. When we start mapping that to different domains or different teams, you’ve got, data products usually sit in a domain. Domain will have multiple data products.
The data products can be used both within that domain or across different domains. We will draw different team boundaries around that. The team could own one or multiple data products, which is another question I get a lot, like, if I’m going to do all this, do I need one team for each data product? Probably not. The team might be able to own multiple of them. Sometimes they can own all of the data products for a domain, if it’s something that fits in the team’s head. The key thing is they have that longer term ownership for those data products.
Then, this is another principle from data mesh to enable this. If you’re trying to decentralize, if you’re trying to treat data as a product, how do I avoid different teams building data in a different way, or building things that don’t connect to each other? The answer is, we need a self-serve platform that helps you build those in a more consistent way, and also to drive speed, because then you don’t need every team solving the same problem over again. The platform needs to think about, how does it support these different workloads, whether it’s batch or streaming? Is it analytical, or AI, operational things? The platform also enables effective data governance, so when we start tracking those things I was talking before about quality, lineage, access control. If the platform enables that, then it gives you a better means to implement your data governance policies.
It delivers more of this seamless experience, how data gets shared and used across the organization for both producers, consumers of data. It might be engineering teams, and eventually even business users. If you try to drive those democratizing of analytics, and we’ve got business people trained to use things, they could also be users in this world. How does the platform support these multiple workloads? Going back to the example I had before, I had the self-service BI here as an example of a platform capability, maybe. There’s actually more. In this case, I’ve picked a few examples.
I might have to pick different types of databases on the operational side. Maybe event stream platform to support how the events flow between the systems. Some kind of data warehouse technology here. I need a lot of the MLOps stack for how do I deploy the machine learning models? How do I manage all of that?
Another way to talk about, if you read the Data Mesh book, Zhamak talks about, data platform is actually multiplane. Oftentimes, when I go to clients, especially if they’re not doing data products or data mesh, they will already have something in place. They will have the analytics consumption plane and the infrastructure plane. Analytics is where they’re doing those visualizations or business reporting, or even, like I put data science, machine learning as a use case of data here that’s built on some infrastructure that they’ve been building, could be cloud, could be on-prem. Infrastructure will be the building blocks to actually store the data, process the data, put some controls around that data.
The thing that we also need, I think, in the book, she talks about the data mesh experience plane. If we’re abstracting away from data mesh, what that is, is really like a supervision plane. I’m trying to get a view of what’s across the entire landscape of data. The missing bit there is the data product experience plane. This is something that usually we don’t find because that is where we put capabilities around, how do I define the specification for the data product, the types of inputs and output ports that I will support? How do I support the onboarding and the lifecycle of managing these data products, metadata management? There’s a lot of things, even like, I think we’ve got data product blueprints.
When I was talking about the different flavors, if the organization has data products that are similarly flavored, one thing you can do is extract those as blueprints. When you need another one that’s very similar to that, then it’s even easier for the teams to create a new one. In the supervision plane, especially in data mesh, like we talk about computational governance, that’s the term that we use in the book. The idea is, actually we’re informing that, connecting to the infrastructure plane, and building that into the data product onboarding and the lifecycle management so that we can actually extract those things around data lineage, data quality, auditing.
If you need access audits for who’s doing what. This is a capability view, so I didn’t put any product or vendor here, but it’s a good way to think about that platform. You can see how it can quickly become very big. There’s lots of things that fall under this space. Usually, we will have one or multiple teams that are actually managing that platform as well, and they build and operate the infrastructure. The key thing is self-serve platform. If it’s not self-serve, then it means the teams that need things will have to ask the teams to build it. Here, self-service enables you to remove that bottleneck, so when they need it, they can get it.
One way that I really like to think about how to structure the teams and how to split the ownership is using team topologies. If you haven’t read this highly recommended book, it’s not just for data, it actually talks about software teams and infrastructure teams. The way that I really like is they use the idea of cognitive load as a way to identify like, is it too much for the team to understand? Maybe we can split things, split teams. How does value flow between these different teams? What’s the interaction modes between them? Just a quick, is a hypothetical example here, but using the team topology terminology, if you’re used to it.
Maybe the self-serve data platform team offers the platform as a service, so that’s the interaction mode, and the data product teams are the stream-aligned teams from team topology terminology. Then we might have, let’s say, governance as an enabling team that can facilitate things within the product, and they might collaborate with the platform team to implement those computational aspects of governance into the platform itself.
The last bit I’ll talk about is governance, because when we talk about enterprise data usage, governance becomes important. How does the company deal with ownership, accessibility, security, quality of data? Governance goes beyond just the technology. This gets into the people and the processes around it. An example here, tying back to the data product space. Computational governance could be, we build a supervision dashboard like that, where we can see across the different domains, these are the data products that exist. I could see, do they meet the DATSIS principles or not? I even have some fitness function or tests to run against to see if the data product actually meets them or not.
Summary
Thinking about data, there’s a lot of things. I talked about, data within the system, between systems at the enterprise level.
Questions and Answers
Participant: You mentioned the data platform, this self-service one, but that’s not something that you just get completely out of the blue one day. It needs to be built. It needs to be maintained. How do you get to that point? Especially considering like your data source is mostly operational data, do you use your operational data teams to be building that, or do you bring in data product teams, or a bit of mix and match? Because there are pros and cons, both of them.
Sato: I think if you’ve got ambition to have lots of data products then the platform becomes more important. When we’re starting projects, usually what we say is, even if you don’t start with all the teams that you envision to have, you should start thinking about the platform parts of it almost separate. We might build that together with the same team to start with, but very quickly, the platform team will have its own roadmap of things that they will need to evolve, and you will want to scale more data product teams that use it. Again, this is assuming you’ve got the scale and you’ve got the desire to do more with data. That’s the caveat on that. I think it’s fine to start with one team, but always keep in mind that those will diverge over time.
See more presentations with transcripts
MMS • Daniel Dominguez

Stability AI has introduced three new text-to-image models to Amazon Bedrock: Stable Image Ultra, Stable Diffusion 3 Large, and Stable Image Core. These models focus on improving performance in multi-subject prompts, image quality, and typography. They are designed to generate high-quality visuals for various use cases in marketing, advertising, media, entertainment, retail, and more.
The new models offer a range of features: Stable Image Ultra delivers high-quality, photorealistic outputs, making it ideal for professional print media and large-format applications; Stable Diffusion 3 Large balances generation speed and output quality, suited for producing high-volume, high-quality digital assets such as websites, newsletters, and marketing materials; and Stable Image Core is optimized for fast, affordable image generation, perfect for rapidly iterating on concepts during the ideation phase.
These models address common challenges like rendering realistic hands and faces and offer advanced prompt understanding for spatial reasoning, composition, and style.
Stability AI Diffusion models, can be used for inference calls using the InvokeModel and InvokeModelWithResponseStream operations. These models support various input and output modalities, which can be found in the Stability AI Diffusion prompt engineering guide.
To use a Stability AI Diffusion model, the model ID is required, which can be found in the Amazon Bedrock model IDs. Some models also work with the Converse API, which can be checked in the Supported models and model features.
It is important to note that the Stability AI Diffusion models support different features and are available in specific AWS Regions, which can be found in Model support by feature and Model support by AWS Region respectively.
Stuart Clark, senior developer advocate at AWS, shared on his X profile:
Imagine creating stunning visuals with just text prompts, now you can!
User AI Master Tools commented:
AI in Creative Fields: Stability AI’s launch of a new model to Amazon BedRock and the debut of Luma AI’s Dream Machine 1.6 highlight the ongoing integration of AI into creative processes, from art to content generation.
The community’s response to Stability AI’s integration of its top three text-to-image models into Amazon Bedrock has been diverse, reflecting a mix of excitement, strategic insight, and critical perspectives. Enthusiasts are eager to see how this development will transform content creation across industries, while others are focused on the technical advantages and increased accessibility this integration provides. However, concerns about centralization, data privacy, and the impact on open-source AI remain part of the conversation.
MMS • Aditya Kulkarni

The Kubernetes project has recently announced the release of version 1.31, codenamed “Elli”. This version incorporates 45 enhancements, with 11 features reaching Stable status, 22 moving to Beta, and 12 new Alpha features introduced. Key features in this release include enhanced container security with AppArmor, improved reliability for load balancers, insights into PersistentVolume phase transitions, and support for OCI image volumes.
Matteo Bianchi, Edith (Edi) Puclla, Rashan Smith and Yiğit Demirbaş from the Kubernetes Release Communications team covered this announcement in a blog post. Kubernetes v1.31 marks the first release following the project’s 10th anniversary.
Among the stable features in this release, Kubernetes now fully supports AppArmor for enhanced container security. Engineers can use the appArmorProfile.type field in the container’s securityContext for configuration. It is recommended to migrate from annotations (used before v1.30) to this new field.
Kubernetes v1.31 now also offers stable improved ingress connectivity reliability for load balancers, minimizing traffic drops during node terminations. This feature requires kube-proxy as the default service proxy and a load balancer supporting connection draining. No additional configuration is needed as it’s been enabled by default since v1.30.
The latest release introduces a new feature to track the timing of PersistentVolume phase transitions. This is achieved through the addition of a lastTransitionTime field in the PersistentVolumeStatus, which records the timestamp whenever a PersistentVolume changes its phase (e.g., from Pending to Bound).
This information is valuable for measuring the duration it takes for a PersistentVolume to become available for use, thus aiding in monitoring and improving provisioning speed.
Furthermore, this feature provides valuable data that can be utilized to set up metrics and service level objectives (SLOs) related to storage provisioning in Kubernetes.
One of the features in the release, which is now in Alpha, is support for Open Container Initiative (OCI) compatible image volumes. Kubernetes v1.31 introduces an experimental feature that allows the direct use of OCI images as volumes within pods. This helps AI/ML workflows by enabling easier access to containerized data and models.
The cloud native technology community showed particular excitement about this feature. Users of the Kubernetes subreddit took notice of the announcement post. One of the Reddit users expressed that this is a “very cool” feature, and in the same thread explained the benefits of having the model as an image.
AI & Kubernetes experts at Defense Unicors (a Medium Publication) also welcomed the use of OCI images to manage and share the AI models, making the process smoother and more integrated with other tools.
The features that graduated to Beta include nftables API, the successor to the iptables API, that delivers improved performance and scalability. Notably, the nftables proxy mode processes service endpoint changes and packets more efficiently than iptables, particularly benefiting clusters with extensive service counts.
For further engagement, users can join the Kubernetes community on Slack or Discord, or post questions on Stack Overflow. Kubernetes v1.31 is available for download from the official website or GitHub.
MMS • Sergio De Simone

To efficiently and effectively investigate multi-tenant system performance, Netflix has been experimenting with eBPF to instrument the Linux kernel to gather continuous, deeper insights into how processes are scheduled and detect “noisy neighbors”.
Using eBPF, the Compute and Performance Engineering teams at Netflix aimed at circumventing a few issues that usually make noisy neighbors detection hard. Those include the overhead introduced by analysis tools like perf, which also implies they are usually deployed only after the problem has already occurred, and the level of engineer expertise required. What eBPF makes possible, according to Netflix engineers, is observing compute infrastructure with low impact on performance to achieve continuous instrumentation of the Linux scheduler.
The key metric identified by Netflix engineers as an indicator of possible performance issues caused by noisy neighbors is process latency:
To ensure the reliability of our workloads that depend on low latency responses, we instrumented the run queue latency for each container, which measures the time processes spend in the scheduling queue before being dispatched to the CPU.
To this aim, they used three eBPF hooks: sched_wakeup, sched_wakeup_new, and sched_switch. The first two of them are invoked when a process goes from ‘sleeping’ to ‘runnable’, i.e., when it is ready to run and waiting for some CPU time. The sched_switch hook is triggered when the CPU is assigned to a different process. Process latency is thus calculated by subtracting the timestamp at the moment the CPU is assigned to the process and the moment when it first becomes ready to run.
Finally, the events collected by instrumenting the kernel are processed in a Go program to emit metrics to Atlas, Netflix metrics backend. To pass collected data to the userspace Go program, Netflix engineers decided to use eBPF ring buffers, which provide an efficient, high-performing, and user-friendly mechanism that does not require extra memory copying or syscalls.
Along with the timing information, eBPF also makes it possible to collect additional information about the process, including the process’s cgroup ID which associates it to a container, which is key to correctly interpret preemption. Indeed, detecting noisy neighbors is not just a matter of measuring latency, since it also requires tracking how often a process is preempted and which process caused the preemption, whether it runs in the same container or not.
For example, if a container is at or over its cgroup CPU limit, the scheduler will throttle it, resulting in an apparent spike in run queue latency due to delays in the queue. If we were only to consider this metric, we might incorrectly attribute the performance degradation to noisy neighbors when it’s actually because the container is hitting its CPU quota.
To make sure their approach did not hamper the performance of the monitored system, Netflix engineers also created a tool to measure eBPF code overhead, bpftop. Using this tool, they could identify several optimizations to reduce even more the overhead they initially had, keeping it below the 600 nanoseconds threshold for each sched_* hook. This makes it reasonable to constantly run the hooks without fearing they will have an impact on system performance.
If you are interested in this approach to system performance monitoring or understanding better how eBPF works internally, the original article provides much more detail than can be covered here, including useful sample code.