Month: December 2024

MMS • Ben Linders

As customers take on a more active role in national language adaptation, the process should be simple, using tools they are familiar with, Daniela Engert stated in her talk at NDC TechTown. They decided to use GetText in C++ where they provide tools and procedures for their customers to provide translations.
Engert mentioned that they want their customers to be a bigger part of the whole development process. With the opportunity of their – at least optional – ultimate decision about the “language” (national or regional language, jargon, terms, script) the application communicates with them, they are increasingly less passive consumers:
We need to be aware of the needs of our customers to take part in this process, and learn to abandon some control over what we thought to be our private playground, bound only by our company culture and upbringing in our wider environment.
If we expect customers to work with us on a product that satisfies their needs and meets their expectations, we should make the whole process as simple as possible to people outside of our inner circle, Engert said. What we may perceive as “simple” and “easy” might just reflect a very particular world view, she explained:
For example, we might see an XML file with all the necessary information for the language translation process as “perfect”, albeit wordy. But customers and all the people involved at their site like end users, professional translators, or the like, will most likely perceive this as gobbledygook with arcane and obscure rules, possibly outright frightening.
There is no “blessed way” of doing it, there are rightfully no related functions in the C++ standard library, and there is no “standard” library that fulfills the needs. Instead, we have the choice of multiple libraries from both C++ and C, Engert said, so we then need to figure out which one suits us best.
There are solutions available that come with a rich enough ecosystem of tools and information sources that can guide us. Some of them are pretty specific to a subset of programming languages or communities. These are great because their gravitational pull helps defend their selection, Engert said.
Some tools are more geared to a wider audience, Engert mentioned. This is part of the landscape where you might find a solution that fits possibly all applications (and their dependencies) that you might intend to adapt to more languages than just one:
Such solutions tend to be more open to inputs from communities outside the programmers’ guild. They often have a richer tooling ecosystem and more sources for information at different levels of understanding the problems. That’s good for our customers, too.
They chose to use the GetText tools in their company, Engert said, to develop a feature in e.g. C++ with little to no translation in mind, in a language they preferred. Tools that come with GetText then extract all those strings that require translation and put them into a container text file with all the already existing translations.
Engert mentioned that they let their customers come up with translations of their own taste, using their preferred procedures and tools. Or they do it themselves if the customer chooses so. Tools build the artifacts that they incorporate into the application and deploy to the machines at the customer site (they are a company that builds machines). People can then select one more UI language when working with the machine, Engert said.
The GetText facilities became standardised this year, after a decades-long history and widespread use in the industry, Engert mentioned. They take advantage of other standards like Unicode and the information available there about how to handle languages and their peculiarities like language forms dependent on quantities, she concluded.
InfoQ interviewed Daniela Engert about doing natural language adaptation.
InfoQ: How can we involve customers in national language adaptation?
Daniela Engert: Timely involvement and short development cycles are more likely with the least possible entry barriers for people that are much less affine to the world of IT than we implicitly are. Rather choose something as simple as a text file with the least possible amount of rules to follow.
Ideally, a customer can modify such a file with any text editor at hand, with a small chance of introducing errors. And if they do, like using e.g. MS Word as their preferred tool, we can quickly undo it without loss of information. Ideally, we can give them tools that feel like all the other tools they are already familiar with.
InfoQ: What will the future bring when it comes to national language adaptation in C++?
Engert: I can see no appetite in the committee to incorporate something like that into the C++ standard library. Besides alluding to language translation in some proposals, I am not aware of any substantial efforts or even proposals to widen the target area of C++.
Many of the committee members – like myself – are volunteers with little to no support from their employers. Our resources and our energy are limited. That’s the reality of most ISO languages with no company backing. C++ was always meant to be a tool for implementing libraries, tailored to certain applications and particular needs. Let’s keep it this way. The language itself is expressive enough, powerful enough, and dynamic enough to fulfill current and future requirements.
MMS • Christopher Luu

Transcript
Luu: My name is Christopher Luu. I do work at Netflix. I work on the growth engineering team. What that means is that we work on the customer lifecycle, anything that happens for Netflix before the user is a member, while the user is a member, if they subsequently cancel and become a non-member, and everything in between. This talk is about how we decided to approach server-driven UI, not just for mobile, but for all of our platforms. The problems that we were encountering that caused us to even go down this path. A little bit about what are the problems that we encountered, what are the challenges that we faced? All that kind of stuff, typical stuff.
What is Server-Driven UI (SDUI)?
What is server-driven UI, SDUI? It is a UI driven by the server. We’re going to talk about the spectrum of SDUI. What exactly does it mean to be on the spectrum here of server-driven UI? All the way on one side, we got something that’s really not very server-driven, like a completely offline app might be. You could think like a calculator app or something like that. It doesn’t ever need to talk to the server unless it’s stealing your data, which they probably are. All the way to the other side, you can have something that is extremely server-driven like a WebView. Something that is driven entirely by a server, where it’s sending HTML and JavaScript and CSS, and it renders it. That’s the other side of it.
Then everything in between in the spectrum. You’ve got the RESTful API. You’ve got GraphQL APIs. You even got SOAP APIs, for some reason. I think pretty much all of us probably do some form of server-driven UI. That’s the point. Even at Netflix, before we embarked on this journey, we were doing server-driven UI. We had all sorts of different protocols. You may have heard of Moneyball, or Falcor, or some of our GraphQL experimentation. All of these are server-driven UI, because the server is telling each of the clients to drive the UI to do something, to show something. For this particular case, we wanted to get a little bit closer to all the way on the other side of that, which is right there. Maybe not right there, I just put it there. We wanted to be server-driven for this particular problem.
Pros and Cons of Server-Driven
What are some of the pros of being more server-driven UI, in my opinion? One of the big pros here is this first bullet, the updating of the UI without a client update, because the server itself is what is driving the UI. What is so key about that, especially for our mobile applications, is that we can update the UI without needing to submit it to Apple or to Google, or for our TV, they can just refresh and get the latest version. That’s pretty cool for us, especially as we’re trying to do a lot of experimentation. We’re also able to share a little bit more code and logic across all the different platforms that we’re dealing with. Netflix is on a lot of different devices. With all of these different platforms, we’re really interested in being able to share some of that logic so not every single client has to reimplement the same networking code and the same parsing logic and all that stuff.
Netflix is a very A/B heavy company, and so being able to iterate fast on different A/B tests is a great benefit for us. That’s one of the big pros that we’re looking for here. This other point is interesting to us, where developers can work on other platforms as well. What that means is that even if I have no idea what mobile development is like, I’ve never touched Xcode or Android Studio or anything like that, I may actually still be able to create a UI from the server and have it render with native UI elements. That’s a pretty cool prospect for us, especially as we’re trying to juggle all of the different developers that we have and try to figure out which projects they could be assigned to.
Of course, there are cons. What are some of these cons that we have to consider here? We’ve got the higher upfront cost to architect. We’re dealing with not just a simple RESTful API anymore, but we have a little bit more to deal with in order to, upfront, be able to architect exactly what we’re going to be able to drive from the server. There’s this complicated backwards compatibility concern. We’ve got an app that’s out in the App Store, maybe the user doesn’t update it for a while. How do we deal with that? There’s this non-native UI development.
What that means is that all of us engineers, we pick the particular platform that we’re developing for, probably because it’s delightful to us. We like SwiftUI development. We like Jetpack Compose. We like Angular and React. We like these particular ones. If we’re changing it so that now we’re having to do the development of a UI from the server, that’s not necessarily the best thing. It’s also harder to support offline apps. If, by necessity, the UI of an application needs to be driven by the server, if it can’t connect to the server, then what are we going to do? These are problems that we have to deal with. It’s also harder to debug. You’ve got more layers of abstraction in between the client, all the way up to where the UI is being driven.
What Were We Trying to Solve?
What were we as Netflix on the growth team trying to solve here? I’m going to tell you a little bit of a story. It’s a story that got us to this point. We’re going to be talking about UMA. Of course, at Netflix, and I’m sure at a lot of other companies, we have a lot of different acronyms. UMA is the Universal Messaging Alert. This is a generic UI that we were trying to drive across all of our platforms in order to notify the user of something. They may have a payment failure, and we want to be able to rectify that so that they can go on streaming our lovely service. There may be a promotional aspect where we want to drive the user to certain parts of the app. Maybe there’s a new feature that we want to exploit for them, something like that. There are all these different kinds of alerts.
Our messaging partners have created this lovely template of different kinds of alerts that we can display to the user. Here, just as a very simple alert, it’s got a title, a body, some CTAs. You might imagine a JSON payload driving that being something on the left there, with the title, body, the CTAs, and it tells it to do something. It’s really cute and cuddly. It’s not that complicated. All of our platforms can implement it pretty easily. I might call that UMA-kun. It’s nothing to be concerned about. Let’s pretend we were actually trying to iterate on this a bit. If we were trying to actually create an API for this, you might have a title, it’s a string, easy enough. We’ve got a body. It’s a formatted string because we know copywriters, they want to put some bold, or they might want to link to a privacy policy or something like that, so we got to make it formatted. Big deal. We got the CTAs.
We do need to have the ability to block the user in case it’s something really legal specific. They need to accept some new terms of use, or something like that. We need the ability to say whether they can close it without using one of the CTAs. The design team came and say, “Actually, we want to try something like this. This is going to be really awesome”. That means, now there’s some eyebrow text. That’s the text that goes above the title. Sure, we can add that. Now it looks like you center aligned the content instead of what it was before, which is left aligned, so now we got to add some text alignment. Background color, it’s not the same color as before. There’s a header image now, this banner image.
Sometimes they might want an icon instead of an image. Maybe like a warning sign or something like that. Then there might be a footer, if it’s really legal. They need to add some copy beneath the CTAs. Maybe there needs to be another background image in case they don’t just want to use a color, they got to use some gradients or something beautiful in the background. Maybe there needs to be text color that changes, depending on the brand and what is displayed in the background, could even need some secondary CTAs. You all get the picture.
UMA-kun rapidly turned into UMA-sama. This got to the point where we were trying to deal with all of these different requirements, and not only were there different requirements where this particular once simple API shifted and became more complicated. We also have different platforms that we have to deal with. The four main innovation platforms currently on Netflix are TV, web, iOS, and Android. TV, we do have a special platform that means that we don’t have to do a very specific UI for every single TV brand out there. We have our own platform that allows us to evolve those relatively quickly. For iOS and Android, specifically, we have this long tail version issue.
This means that, because of how quickly we release app versions, there are likely going to be a good number of users who don’t necessarily always update to the latest version. Not only that, iOS might drop support for a certain device, like the latest iPad, or iPads four years ago may not run necessarily the latest version of iOS. Someone gets an iPad from their parents or something like that, and all of a sudden it just stops working with Netflix. That wouldn’t be great. We can’t drop support for those. We have to consider all of these different things.
Let’s say, if we’re going back to UMA-sama, and we’re like, now iOS happened to introduce the footer field in version XYZ, but TV didn’t implement it until this certain date. Web is ok. Web’s generally ephemeral. You refresh the page, you get the latest version. Maybe that’s not as big of a deal. Android, they’re slackers. They haven’t implemented it yet, whatever. The point is, the backend now has to figure out, can I even send this message that has this particular field in it? How does it deal with that? This is one of the key problems that we were trying to solve as we just explored server-driven UI. It’s worth mentioning that this also does exist on the TV side as well, like our older TVs, something that was sold many years ago may not be able to support the latest version of our platform, so we also had to deal with this problem there as well.
Not only that, many of our interstitials and things are multi-step. We’ve got this first message that appears, maybe it’s bugging the user to enter their phone number, but then we also have to verify their phone number and then show them some toast that lets them know that they were able to enter it properly. We deal with a lot of microservices at Netflix, which means that likely the first screen might be driven by one server, and then the client has to do completely other integration with some very other service in order to populate the next couple screens and be able to submit them.
Possible Solutions
What are some possible solutions? We could do a WebView. That was all the way on one side of this server-driven spectrum. If you remember, the design of UMA-kun was an interstitial, it’s something that pops up. I personally have never seen a WebView that looks very good, especially in the context of presenting an interstitial. We might have to take over the user screen or something like that. That’s just not great. What if we just evolved the template? Now that we know all of the properties that UMA-sama has, can we just learn from that? That is our new API, and then just set it from day one, and then now we’ll never evolve it again. Yes, no one believes that.
We, of course, looked at server-driven UI, and we looked at something that we call CLCS, we call it CLCS for short. It does not stand for Christopher Luu’s Component System. It stands for the Customer Lifecycle Component System. It’s designed to be able to drive all of these different kinds of interstitials relevant to dealing with everything from the customer lifecycle.
CLCS (Customer Lifecycle Component System)
CLCS in general, is a wrapper around our design system. This is really important for us, because I am a lazy engineer, I do not want to have to go and implement all of the UI components necessary to build a server-driven UI. I, as a lazy engineer, am going to be able to utilize all of the lovely work being done on all of our platforms to adopt our new design system. This allowed us to move much more rapidly, because we already had all these kinds of buttons and components and things that we could use. It supports multi-step interstitials because it completely abstracts away all of the backend logic away from the client.
Now the client deals with one little middleware layer that then reaches out to all of the other microservices and figures out, I’ve got a message. Here’s the message. It’s displayed in some template, something like that. I’m going to turn it into this server-driven UI payload, give it to the client. The client sees, great, I’m going to render it. I’m going to collect some user input. Maybe it’s a form, or like that collecting phone number interstitial I showed you before. Collect all that data, send it back to the server. Server says, this means that you want to render the next screen. Here’s the next screen, and on it goes.
That design system at Netflix is called Hawkins. Basically, Hawkins consumer design system is how we try to establish a branding guideline across all of our applications, across all of our platforms, into a set of typography tokens, components like the button, or checkbox, or inputs, any of the various kinds of components that you might want to build, UIs. Also, colors, like surface colors, foreground colors, borders, all that stuff. Because this Hawkins design system was very much in progress when we started the server-driven UI, we were able to leverage all of that and essentially just wrap it up in a nice little server-driven UI bundle and deliver that to the client. Then the client could basically utilize all of these 100% native components built in what other UI frameworks are native to that platform.
On iOS, that might be SwiftUI. On Android that might be Jetpack Compose, or it could be the legacy XML, it could be Flutter, it could be React native. We don’t really care. All we care about is that now all of these design system components are being implemented on each platform, and we’re able to utilize these. Not only that, they already established the certain levers, because one of the key pieces about going down this route that we wanted to do was to not reinvent a browser. We did not want to just reinvent HTML because otherwise why not just send the WebView? It was very important to us to pick specific things about each of the components that we wanted to be able to drive from the server.
On the left side, you might see all the different kinds of buttons there. Those are the exact levers that we provide through the server-driven UI to customize the way that a button looks. We don’t let you specify a height or an arbitrary width or anything like that. We utilize the particular levers that the Hawkins design system was able to provide for us. Similarly, we don’t allow you to just change the foreground color, because that’s where it starts to eke into being more like a browser, which we just did not want to do.
CLCS at a whole is basically components, fields, and effects. The components are all of those building blocks, buttons, inputs, checkboxes, all that stuff. Then, we basically glue all those things together with stacks, essentially vertical stacks, horizontal stacks, or because of web, more responsive stacks. Stacks that might want to be horizontal if I’ve got enough room there, or might want to be vertical if I don’t have enough room. We’ve got fields, this is how we actually collect user input. This is maybe a string, a Boolean number, depending on the kind of data that we want to collect for a user. Then the effects.
These are what actually happens when the user interacts with the particular component, so when the user taps on a button, it might dismiss the interstitial, or submit for the next screen, or log something, something like that. This is what it actually can look like. Here I was trying to fit every single possible UI platform that Netflix supports, which is the web, TV, iOS, and Android on one screen. It honestly didn’t fit. I had to try to jam it as much as possible. You see, there’s an iPhone, there’s an Android phone, there’s an Android tablet, there’s an iPad, there’s a web screen jammed in the corner there. There’s a TV emulator on the bottom right. They’re all displaying the exact same payload here, which is a complicated one. It’s got three cards here.
Each one has a banner image and the title and body. For smaller screens, they get laid out vertically. For larger screens, they get laid out in a nice little horizontal stack. This is all being driven by a single payload across all the four major platforms.
Let’s take a little bit of a closer look at a CLCS screen. Here we’ve got one of the more typical UMA-kuns. We’ve got an image at the top. It’s an icon in this particular case. We got some title. We got a body. We got some CTAs. We’ve got the footer. Essentially, we were able to break that down as essentially one modal that contains a vertical stack. You can see that, it’s pretty vertically oriented there. The first element of that vertical stack might be a horizontal stack that includes a single child that is center aligned. The next one is just the title text. The next one is just the body text. Those are text elements that have specific typography tokens that tell them to render with a specific font and weight. Then we’ve got the CTAs. The CTAs is actually going to be in one of those responsive stacks that I mentioned, which means that on a larger screen, those might want to be displayed next to each other, whereas on a smaller screen, vertically.
Finally, the footer text at the bottom. What could that actually look like in the CLCS code that we generate? It could look like this. It does look like this. Basically, because a lot of our engineers at Netflix, and especially on the growth team, are web engineers or TV engineers, they’re very familiar with React programming. We utilize JSX and TSX to essentially allow us to author the UI like this from the server. You can see, it’s all of those elements that I mentioned before. It’s got that modal. It’s got that vertical stack, the horizontal stack with the content justification as center. Because of this, we’re able to actually generate this UI. It turns it into the payload that each of the clients expect, and then those clients take it off to the races, and they’re actually able to render it as you saw on the other screen before.
Backwards Compatibility
Mr. Netflix man, you were talking about backwards compatibility. This is a key problem that we have to deal with. Because there’s all those folks that might not have updated to the latest version. What if you create some new components that cannot be rendered in the old version that someone might be running, what do we do there? Or, how do you make sure that you’re not sending something that would just completely make the app crash, or something like that. We actually rely a lot on GraphQL. This is part of our transition to GraphQL at Netflix. We do a lot with the built-in safety features of GraphQL that allows us to ensure that there are no breaking schema changes. It allows us to also fall back on components using what we call request introspection.
Then we can also basically know that they are a set of baseline components that are implemented on all the different platforms, at a minimum, if they support the CLCS spec. What do I mean by GraphQL features? The way that GraphQL works is that it’s essentially when you are trying to query for something, you might create a fragment. Here’s an example of a fragment on a button component. Here, with GraphQL, you have to specify every single property that you want to get, and maybe expand on that with another fragment, something like that. Here we might be getting the accessibility identifier, the label, the button size, type, icon, onPress. Because of the way that GraphQL works, if we were to remove the label property altogether, all of our deployment scripts, our CI/CD, everything, would yell at us and say, “You can’t do that. That’s a breaking schema change”.
We also have a lot of observability so that we can see exactly how often this particular property is being utilized. Maybe in the future, if we do decide to deprecate something, we could take a look at that and safely remove it. It makes it very hard. You have to force it to actually remove something like that. That’s one of the nice things. We don’t have to worry about it accidentally removing something that hundreds of clients are still being used.
The component fallback thing is an interesting one, though. Let’s pretend we have this overarching fragment called ComponentFragment, it spreads over the entire interface for CLCS component. Every component that exists belongs in this one huge switch statement. Eventually, I don’t show it here, but you might assume that there’s the button fragment referenced here, or the text fragment, or the checkbox fragment, all that stuff. Let’s pretend there’s this fancy new label that we want to introduce for some reason.
The FancyLabel is now added to this ComponentFragment, and there’s a fragment for it. That’s all well and good. When we actually define how this particular component is rendered or is put together, we define a component in our CLCS backend that essentially is able to take in a fallback. What that fallback does is it essentially takes all the properties that belong to that FancyLabel. Let’s pretend it’s these key, label, color, typography, all that stuff, and it’s able to then say, what are you going to do if this particular component just does not exist? If the user did not request it. The user’s not spreading on it. It has no reference to this, because of the way that GraphQL works, and every request has to basically reference all of the things that a particular client supports, that is our tell. It says, “They didn’t request the FancyLabel component, so I need to fall back in this case”.
In this case, we could fall back to a less fancy label, just give them a text, great, whatever. They’re using an old version, maybe they don’t need to see the latest stuff. We could also potentially do other things. We could send them a button that says, “Sorry, you got to update to the latest version. Here’s a way to get to the app store”, something like that. It’s completely arbitrary, made up, but there are options here. This is a way that we can actually fall back, which is key, because we do want to continue to evolve CLCS. We don’t want to just stay at the set of baseline components.
How does UI development actually look like in CLCS? We’re going to explore something that I call templating and demoing. Essentially, you might assume that we have this function that says, MyLovelyScreen template. It takes in these options, let’s say a title and a date, and it’s able to render it. This is a very pared down version of what this payload might look like. You might assume it’s got this modal with a stack of these two text elements, or something like that. This is our template function. When I actually want to render this, let’s say there’s a backend that I want to integrate with, you might have the MyLovelyScreen function, which promises to return a screen. In that case, it reaches out to the backend, it fetches the data, it’s able to get that.
Then it calls that MyLovelyScreen template, so that it can actually render it in the way that it’s supposed to. At the same time, we can also create a completely mocked version of this, like a demo. In this case, it’s passing in a title and a date that’s completely arbitrary. It’s made up. It’s basically utilizing the exact same rendering path. It’s going to be rendering that same screen here. Because it’s utilizing the exact same thing, we can use this for a lot of things, actually, these demos. We can use this for our automated testing strategy. These demos, because they render in the exact same way that the more server, actual backend driven version looks like, that means that we’re able to run all sorts of different kinds of screenshot tests against them. The client is now essentially forced into basically just being a rendering engine and a user input collection engine.
Now, if we were wanting to set up these tests where the client is getting this demo payload. For all intents and purposes, it looks exactly like the real payload. We’re able to take screenshot tests there and ensure that there are no regressions introduced if something changes in the client renderer, or something changes in the backend, or something like that. That’s pretty cool, because in the past, we have been pretty reliant on end-to-end tests at Netflix, which means that we have to set up a user. We have to create this fake user. We have to set it up in this particular state to get this particular message, get to this particular screen to actually render this particular screen. It was a pain. It’s faulty. There are so many points of failure.
Now, because we’re able to go and get just this demo and say, “Backend, give me a demo of this particular screen”. We’re able to bypass all that, and just get the logic that we want and show the particular payload. Not only that, it’s super helpful for localization quality control. We support a lot of different languages in our app, and in order to support our localization teams, we take screenshots of everything and say, does this screen look ok in your language?
In the past, with those end-to-end tests, they were a massive pain to try and get the user in all these different states and ensure that they work, whereas now all it has to do is make a single call, get a demo, come back and render it with that particular language. We’re able to do these client integration tests, so we had build up that much more confidence about how CLCS is implemented. These are tests that maybe challenge how the effects are implemented. Or, they’re hyper-focused on each particular effect, so that we can ensure that when we ask it to do something, it’s doing the right thing. We’re also, from the backend side, able to take a lot of snapshot tests with our templates.
I mentioned the template before with the MyLovelyScreen, we’re now able to take actual snapshots of the output, and when that changes, then we know, “We know that you updated this template to add some new field or something like that”. Since we have a snapshot, it says, this change, is that right? Is that what we’re expecting? Allowing us to have much more granular confidence in the actual templates that we’ve created. What about this end-to-end test? Those are still important for us to ensure that, at the end of the day, it’s great that the client does what it’s expecting to do, but what if something in the backend does actually happen?
For this, we actually created a pretty cool system that allows us to create a completely headless version, a completely headless client that implements CLCS. What that means is that it can take a CLCS payload and then interpret it, be able to traverse its DOM to determine if elements are existing when they’re supposed to be, and even click on buttons for us. The really nice thing about this is that we have one centralized place for all of our platforms. In the past, we had every single platform, Android, iOS, TV, web, they had to create their own end-to-end tests, set up all of this stuff to get to the right state to do it. Now it’s all happening just in one place, in the backend. If something happens downstream from us, we can point at the right place, and they’ll hopefully fix it for us.
What’s Next for CLCS?
We’re getting to the point now where we can talk about what’s actually next for CLCS. We’re going to continue to migrate our old messages. There’s a lot of those old UMA-kuns that are out there that we’re looking to transition to the new interstitial system. We’re going to experiment usage across other multi-step forms that are particularly pertinent in the customer life cycle stuff that I mentioned before. We’re going to try to replace some of our old WebView-based flows. Not only are WebViews more less elegant for our users to use, but they’re complicated for us to maintain. That means a whole nother canvas that web engineers have to go and test on.
If we’re able to eliminate those and just replace it with CLCS flows, that’d be pretty cool. We’re going to take over the entire app. No, that’s not our purpose. There’s a lot of other parts of our app that will not necessarily work well with CLCS. We’ve got our huge screen where you’re scrolling through all your different movies and TV shows and things like that that you want. There’s no way we’re going to want to render that in CLCS. That doesn’t necessarily make sense. The goal is to be hyper-specific about this particular flavor of server-driven UI. What is it really good at? Use that. Don’t try to leak it into everywhere because server-driven UI is cool.
If I Could Turn Back Time
If I were able to turn back time and go back to where we were when CLCS was first created, I’d probably try to do a few of these things. This might be helpful for you, if you’re trying to implement your own server-driven UI. I’d probably try to establish that baseline a lot earlier. It’s hard. It’s kind of a chicken and the egg, because once you start building the experiences, that’s when you realize, we actually need this other component. That’s going to push back the baseline further as you continue to explore these. If we could really sit down and try to establish what those things really are, I think that would help us a lot more in the long run, and give us a lot more runway to run with.
Also, try to formalize that testing strategy earlier. We’re at a pretty good place with our testing strategy, but it took us a while to get there. I’d probably try to work with some of our testing partners and try to figure out, how can we actually speed up this formalization so that we just build up that much more confidence in this brand-new system. Also, try to have better alignment with our design system partners. When this started, we were parallel tracked with the design system. We were basically just trying to exploit all of the wonderful work that they were doing. Now that we are much more aligned, that means that we can have much closer roadmaps together and try to evolve together, rather than each independently working separately.
We also would have been more helpful to align all of the platforms on the templates earlier. I showed you that big screen that showed all of the different platforms displaying the same UI with the same payload. It took us a while to get to that point. Before, we had a lot of if statements. We had an, “If I’m on TV, then do this one thing. If I’m on mobile, do this other thing. If I’m on a tablet, do this other thing”. Being able to align the platforms and the templates, means that we’re able to evolve those templates much more quickly and much more confidently.
Should I Adopt SDUI?
Should I adopt UI? Should any of you adopt SDUI? SDUI is super personal. It’s super specific to what you’re trying to solve. On that big spectrum of SDUI, there might be certain elements that you want to garner from it. You might not need all of the flexibility that we have on the Netflix side, so maybe you’ll go closer to the other side. You probably are using some form of SDUI, so maybe the answer is yes.
Questions and Answers
Participant 1: You have design components for SDUI. You have a separate set of design components for your native drawing, for the other non-SDUI driven, or do you reuse the same design components?
Luu: Do we use a different set of design components for SDUI versus just the regular native development?
No, we utilize the exact same components across both. The whole point of the design system was to ensure that all of our UIs, they’re adopting the Netflix branding guidelines. The whole point, it would be pretty weird if you all of a sudden got this popup and it had a completely different design element with different typography, different colors, different components altogether. We utilize the exact same components that they have.
Participant 2: From the app perspective, the CLCS makes the app more complicated in one sense, because there’s two different rendering mechanisms. There’s the native stuff, and then there’s the CLCS stuff on top. From the apps’ perspective, is it worth it? Because dealing with these popups and the flows was a pain, so they rather render stuff than trying to do five different screens in a row and all the different permutations in native code, or do the apps don’t really have a say in that, because you say, you use CLCS, and that’s it.
Luu: Is it a pain? No. We have found that it actually worked quite well for us, because a lot of the kinds of flows that we’re driving through the CLCS flows, are some of the more annoying kinds of UIs you want to develop. All of the developers that were traditionally developing those in the past were more than happy to hand that over to this new system. It’s completely outside of their interest. They want to do something that has really fun animations, that shows this thing over here and all that stuff. The developers that develop the CLCS frameworks, for them, it’s interesting because they’re building this whole new system inside of the app code base. That piece is interesting. I think everyone’s pretty happy, actually.
Participant 2: The applications that were built or finished, or the versions of the application that were finished before CLCS were implemented, they still do the old alarms. It’s only the new versions that get to use CLCS. You have to support both, the old native alarms plus CLCS on top for the new versions.
Luu: That is 100% true. We still have a lot of versions of the applications for all of our platforms, except for web, that have no semblance of any idea of what CLCS is. We still have to support those in some fashion or another. In this particular case we showed you UMA. UMA does still exist. That is a kind of payload that is still being sent by our backends as needed. It’s not being used for new messages. We have other fallbacks. There are other ways to send more simpler alerts. Not necessarily something that looks as nice as an UMA, but it’s still just a functional maybe like a JavaScript alert, or UI alert dialog, or something like that in iOS. We still have the ability to fall back on those older versions if we need to. The true story is that there’s still going to be that subset that’s always going to be a problem that we have to deal with until we can somehow completely deprecate those old versions.
Participant 3: How do you manage the navigation stack with these kinds of systems, because if I want to go back or forward or navigate through the application, how do you do that?
Luu: How do you deal with navigation stacks with this system?
We cheated because we already have a system in place for growth that is essentially a very big state machine for a user. Our UI development in the past has depended on this essential service that tells us the state of a user. If I’m in this particular state, show this kind of screen. We’re utilizing that already. Essentially, if I’m on screen five, and then the user hits back, we say, state machine, what state do I go to the user? Because the user asked to go back, and that tells you to go to state three or something like that. That, at its core, is how we deal with it. We also do have a semblance of a navigation stack in the CLCS backend itself, so we’re able to store the state of a particular user and know where they are in a particular flow. Even if that state machine wasn’t part of the process, we’re still able to figure out some semblance of where they should go. It is complicated.
Participant 3: How do you handle offline requirements?
Luu: How do you handle offline? We’re lucky in that most of these particular screens are happening in a world where the user has to be online. We’re basically asking our messaging service, do you have a message to display to this user? In this particular case, the user has to be online to get that message. If not, it’s not the end of the world. They can continue to operate offline. However, there are use cases that we’re exploring where we’re trying to figure that out, like, is there a way that we can deal with an offline connectivity state?
The true answer is that, yes, absolutely, because at the end of the day, the payload that we’re getting back to render as CLCS as a screen is just a GraphQL output, which happens to be a JSON payload. There’s no reason that we couldn’t necessarily bundle that JSON payload with the application in order to render in the fallback case where the user doesn’t have connectivity. It’s not the best case, because we’re not able to update that payload, but it still allows the user to be unblocked if it’s a particularly critical flow.
Participant 4: How do you do caching?
Luu: How do we do caching? We actually rely mostly on the different frameworks that we’re using. On our mobile clients, we’re heavily invested in using Apollo clients. The Apollo mechanism has caching part of it. A lot of our network engineers on the client side have already built our own caching mechanisms on top of them, so we’re able to utilize that caching. There are all sorts of other caches too. There’s a cache at the DGS level, or at the backend level, which is able to not necessarily always have to go back to messaging if the message was requested X amount of time ago. In general, we basically utilize most of the existing caches that we already have implemented because we already had networking implementations on all of the different platforms.
Participant 5: Have you ever encountered the issue, for example, some interfaces being so complicated, which you cannot have it. For example, you can have it in web, and you can’t have it on TV, and probably you’re going for the fallback, but there is another fallback required because some other version in some, for example, Android, doesn’t have. That you want a message to tell the user that, you need to update so you have multiple fallbacks, or how did you deal with this situation?
Luu: How do you deal with recursive fallbacks?
In general, the fallback logic that we have in place is already able to do that. If you fall back to another component that’s not necessarily baseline, it’s already going to be able to fall back on its fallback and continue recursively. That’s not particularly a problem. I do want to touch on one piece that you mentioned, though, which is, what do you do about some component that is actually more difficult to render in general, for a particular platform. There’s an interesting strategy that we’ve started to adopt now where our components don’t necessarily need to be specific Lego blocks that are Hawkins components in our design system.
They can actually be larger components that could encapsulate more interesting behavior. Something that adopts animations, or maybe is a much more complicated responsive thing that we need to render specifically for web. We wholeheartedly support those with the caveat that we know that the further that we get away from these building blocks, it means the more complicated it’s going to make maintaining those particular components that we’ve introduced or adopting them across all the different platforms.
Participant 6: Can you describe, like I’m telling a 5-year-old, how does the client ask the server for the building blocks that he wants to display? For example, does it send a request to the server saying, this is the platform name, for example, iPhone 15 Pro Max, and this is the dialog I want to display. Then the server will return what will be displayed.
Luu: How do we start this whole process, and what kind of data are we able to pass back to the server so that it knows exactly what to tell it to render?
We cheated. We utilize all of the existing stuff that was already in place for our networking backend. That includes a bunch of headers that we send for every single request that informs a lot of like, which particular device I’m on, or not necessarily which device, but which client I’m running on in my iOS or Android, what version of that I’m running, like my screen size, something like that. We already have a lot of these headers that it’s able to inform what we do on the backend side.
Because these are GraphQL endpoints, they’re just queries and mutations that we’re utilizing, we’re also able to add additional properties at any point. If there’s something specific to one particular entry point that we want to drive, some specific thing about what the user is doing at that time, maybe if they have a lower connection because they’re on cellular or something like that, we’re able to add that data as well anytime we want, for any particular entry point. We’re just able to leverage a lot of the flexibility that being GraphQL allows us.
Participant 7: If the device is in portrait and landscape, does the server send back and say the dialog box should be wider then narrower, or does the device automatically know that, and does that layout work?
Luu: Our goal was to not have to go back to the server for that, because that’s a whole nother round trip. As part of our payload, we added that responsive stack. Basically, it has children, and it does something with those children based on the amount of space available to it. In that particular case, the responsive stack might say, because I’m in landscape mode, I’m going to be able to lay this out in all sorts of manners. It’s actually a very complicated component, but that’s how we leverage it, and we’re able to use that for web as well. Because on web, if you’re resizing the window, it’s going to really suck if you’re going to have to do another request every single time that the breakpoint changes. That’s how we decided to leverage it on our end.
See more presentations with transcripts
MMS • Sergio De Simone

Android XR is Google’s new operating system aimed at powering devices like headsets and glasses and making possible new experiences, a.k.a. apps, running on them. Android XR will integrate Gemini, Google’s AI assistant, to enable understanding user intent, defining a plan, guiding through tasks, and more.
Android XR is build on top of the Android OS, leveraging key components like ARCore, Android Studio, Jetpack Compose, Unity, and OpenXR to provide solid foundations for the new platform. Android XR apps will make it possible for a virtual environment to coexist with the real world. For example, says Google, they are working to allows users to watch YouTube videos on a virtual big screen, display photos in 3D, and so on.
We’ll soon begin real-world testing of prototype glasses running Android XR with a small group of users. This will help us create helpful products and ensure we’re building in a way that respects privacy for you and those around you.
Android XR apps will exist inside virtual spaces and include 3D elements, spatial panels, and spatial audio to create a sense of depth, scale, and realism. They will also leverage multimodal interaction capabilities using hands and eyes.
To make it easier for developers to create Android XR apps, Google has also announced the Android XR SDK.
You’ll have endless opportunities to create and develop experiences that blend digital and physical worlds, using familiar Android APIs, tools and open standards created for XR.
A key component of the Android XR SDK is Jetpack XR, which includes new XR-specific libraries, such as Jetpack Compose for XR, Material Design for XR, Jetpack SceneCore, and ARCore for Jetpack XR.
Besides Jetpack Compose XR, the Android XR SDK also supports creating apps based on Unity or WebXR.
You can use the Android XR SDK with Android Studio Meerkat, which also includes the new Android XR Emulator. This will make it possible to use a virtualized XR device to deploy and test apps built with the Jetpack XR SDK. The emulator will rely on keyboard and mouse to enable navigation in the virtual 3D space using a palette of tools to rotate the scene, zoom in and out, and so on.
Android XR will have its own Play Store, where you will find apps created specifically for Android XR as well as compatible Android apps, which will be automatically spatialized with no developer effort.
First and foremost, Android XR’s preview aims at providing device makers and creators the opportunity to start creating a whole new ecosystem of devices and apps. According to Google, the first Android XR device will be released by Samsung in 2025.
Android XR and the Android XR SDK are currently available in preview only. If you are interested in getting access to the new platform, you can apply here.
MMS • RSS

A powerful rally in the U.S. stock market in 2024 has set the stage for even greater momentum in 2025. The S&P 500 index reached a record-breaking closing value of 6,090.27 in December, and experts anticipate more gains as a new rate cut cycle takes effect.
Drawing insights from historical data, Charles Schwab highlights that 86% of the time, the S&P 500 posted positive returns within a year after the commencement of rate cuts since 1929. While downturns occurred in 2001 and 2007 due to recessions, the present environment seems different. The Federal Reserve’s rate reduction in September 2024 provides optimism for continued growth. Analysts from UBS predict the S&P 500 will climb to 6,400, while John Stoltzfus from Oppenheimer Asset Management forecasts a rise to 7,100 in 2025.
Amidst these promising projections, certain stocks stand out for their potential to ride the upward trend, particularly Oracle and MongoDB.
Oracle has carved a niche in cloud services and AI infrastructure. Despite narrowly missing analysts’ estimates in the recent fiscal quarter, Oracle’s dominance in AI data centers, partnering with giants like Nvidia and OpenAI, sets it apart. Its innovative cloud infrastructure design, widespread geographical presence, and cost-efficient scalability are catalysts for its growth.
On the other hand, MongoDB is gaining traction with its flexible database solutions. Although shares dipped following leadership changes, MongoDB’s impressive expansion, with over 52,600 customers, underscores its resilient performance. The company’s focus on AI-powered applications and modernization of legacy systems positions it for sustained success.
These attributes make Oracle and MongoDB potential winners as investors seek to capitalize on the stock market’s anticipated 2025 upswing.
Stocks to Watch: Oracle and MongoDB Poised for Growth in 2025
In the landscape of financial market predictions for 2025, Oracle and MongoDB surface as noteworthy contenders, driven by their strategic innovations and market adaptability. As the S&P 500 continues its upward momentum, bolstered by historical trends and recent rate cuts, these companies are well-positioned to benefit from the evolving market dynamics.
Oracle’s Strategic Expansion in AI and Cloud
Oracle’s strategic investments in cloud services and artificial intelligence (AI) infrastructure have fortified its position in the tech industry. Despite minor setbacks with analyst expectations, Oracle’s partnerships with industry giants such as Nvidia and OpenAI highlight its robust presence in AI data centers. The company’s innovative cloud infrastructure, coupled with its extensive geographical reach and scalable cost efficiencies, are significant growth accelerators. As businesses increasingly shift towards AI-driven solutions, Oracle’s offerings provide a compelling proposition for sustained expansion.
MongoDB’s Resilient Growth in Database Solutions
MongoDB continues to make its mark with flexible database solutions that cater to modern enterprise needs. Despite recent leadership changes, the company’s expansion to over 52,600 customers signals strong market performance and resilience. MongoDB’s focus on AI-powered applications and its initiatives to modernize legacy systems underscore its commitment to staying at the forefront of technological advancements. These factors contribute significantly to MongoDB’s potential success in an upward-trending stock market.
Market Predictions and Trends for 2025
Financial experts suggest a promising trajectory for the stock market, with predictions of the S&P 500 reaching values as high as 7,100 by 2025. This optimism is largely fueled by the Federal Reserve’s recent rate cuts and historical patterns that favor market upturns following such financial measures. With the S&P 500 anticipated to maintain its growth, stocks like Oracle and MongoDB are likely to attract investors aiming to leverage market opportunities.
Potential Challenges and Considerations
While the outlook appears bright, potential challenges should not be overlooked. Both companies must navigate the fast-paced technological landscape, addressing competitive pressures and the ever-evolving consumer demands. Additionally, macroeconomic factors and geopolitical uncertainties could pose risks to their growth trajectories.
For investors looking to capitalize on these trends, keeping a close watch on Oracle’s and MongoDB’s strategic implementations and market movements will be essential. As the financial environment continues to evolve, these tech giants are well-poised to be front-runners in the anticipated 2025 market upswing.
For further insights on market trends and investment strategies, visit the main domain sites of Oracle and MongoDB.
MMS • RSS

These high-quality stocks are well positioned to surge in 2025.
The U.S. stock market posted a stellar performance in 2024, with the benchmark S&P 500 index reaching an all-time high closing value of 6,090.27 on Dec. 6.
But things may turn even better in 2025. According to Charles Schwab, based on 14 interest rate cycles since 1929, the S&P 500 index has posted positive returns 12 months from the first rate cut in the cycle 86% of the time. The benchmark index posted negative returns after rate cuts in 2001 and 2007, attributed mainly to the recessionary environment.
In September 2024, the Federal Reserve commenced the ongoing rate cut cycle by reducing benchmark interest rates by 50 basis points. Subsequently, since the current economic environment does not appear recessionary, it may be prudent to expect the index to continue growing till September 2025. Many analysts seem to agree with this projection. UBS expects the S&P 500 to reach 6,400, while Oppenheimer Asset Management’s chief investment strategist, John Stoltzfus, expects the index to reach 7,100 in 2025.
Against this backdrop, it makes sense for retail investors to pick up small positions in high-quality stock riding secular tailwinds. Here’s why these two companies picks fit the bill.
1. Oracle
When investing in database software and cloud services stocks, Oracle (ORCL -1.10%) is an obvious choice. The company’s second-quarter fiscal 2025 top- and bottom-line performance missed consensus estimates by a slight margin (for the period ended Nov. 30). Despite this, the company’s prominent role in the ongoing AI revolution and its strength in traditional databases make it a worthwhile pick in December 2024.
Oracle’s cloud services and licensing support revenue accounts for almost 77% of the company’s total revenue. The cloud business is expected to rake in $25 billion in revenue in fiscal 2025. Oracle’s prominence in providing artificial intelligence (AI)-optimized data center infrastructure is the main factor fueling the growth of its cloud business. The company’s Oracle cloud infrastructure is used by major AI companies such as Nvidia, Meta Platforms, xAI, OpenAI, and Cohere to train their most important generative AI models.
Oracle is also focused on further improving the performance of its cloud infrastructure and recently released the largest and fastest supercomputer in the world, which uses up to 65,000 Nvidia H200 GPUs. This performance advantage has made Oracle cloud infrastructure faster and cheaper than many competing infrastructure clouds, helping it win large AI training workloads. The company’s GPU usage also jumped by a stunning 336% year over year in the second quarter.
Oracle differentiates itself from many other cloud infrastructure players with its unique cloud architecture. The company has opted for a modular design approach where only six standardized data racks are needed to build a cloud region that provides all services to clients. The company can easily scale the data center infrastructure from 50 kilowatts to 1.6 gigawatts in line with the demand cheaply and efficiently. The standardization in racks and services has also helped Oracle effectively deploy automation tools in its cloud infrastructure.
Oracle has also established a broad geographical footprint with 98 cloud regions. The company has entered into multi-cloud agreements with Microsoft‘s Azure, Alphabet‘s Google Cloud, and Amazon‘s AWS, which further allows customers high flexibility to deploy their systems in the cloud.
Admittedly, Oracle does not seem to be the hottest stock on Wall Street. However, the company recently was trading at just 8.43 times trailing-12-month sales — better than the software industry median price-to-sales (P/S) ratio of 10.4. As multiples expand in line with robust growth, Oracle may see significant share price gains in the coming months.
2. MongoDB
The second database specialist worth investing in is MongoDB (MDB -7.42%). Although the company managed to handily beat consensus revenue and earnings estimates in the third quarter of fiscal 2025, shares have tanked on unexpected news of longtime CFO and Chief Operating Officer Michael Gordon leaving at the end of January 2025. The subsequent price correction has presented an excellent entry opportunity for retail investors.
MongoDB added nearly 1,900 new customers sequentially and ended the third quarter (ended Oct. 31) with a total customer count of more than 52,600. Furthermore, the company catered to 2,314 high-value customers (those generating at least $100,000 in annual recurring revenue) in the third quarter, up from 1,972 customers in the same quarter of the prior year.
Atlas, a cloud-native and integrated suite of database tools and services, accounts for nearly 68% of MongoDB’s total revenue. The cloud platform’s revenue grew 26% year over year in the third quarter, driven by robust adoption by enterprises for running mission-critical projects. Atlas catered to more than 51,100 customers at the end of the third quarter, up from over 44,900 in the same quarter of the prior year.
MongoDB is focusing on reallocating some of its go-to-market resources from mid-market to large enterprise channels. While the funds’ reallocation from the mid-market segment to the enterprise channel is expected to reduce the pace of direct sales customer growth in the short run, it should drive higher revenue growth in the long run.
MongoDB uses AI tools and professional services to modernize customers’ legacy applications. Since many of these applications are based on relational databases, the company also deploys a relational migrator to migrate them to MongoDB’s platform (suitable for documents and other complex data structures). This modernization reduces cost, time, and risk of data loss or corruption. Hence, MongoDB sees a solid long-term growth opportunity in the legacy application modernization market.
Finally, MongoDB is also poised to benefit from enterprises increasingly focusing on AI-powered applications, which mostly require querying complex and rich datasets. The company says its unified platform approach (combining source data, metadata, operational data, and vector data) is superior to using multiple complex databases.
Considering its several growth tailwinds and strong financials, MongoDB seems a compelling buy now.
John Mackey, former CEO of Whole Foods Market, an Amazon subsidiary, is a member of The Motley Fool’s board of directors. Suzanne Frey, an executive at Alphabet, is a member of The Motley Fool’s board of directors. Randi Zuckerberg, a former director of market development and spokeswoman for Facebook and sister to Meta Platforms CEO Mark Zuckerberg, is a member of The Motley Fool’s board of directors. Manali Pradhan has no position in any of the stocks mentioned. The Motley Fool has positions in and recommends Alphabet, Amazon, Meta Platforms, Microsoft, MongoDB, Nvidia, and Oracle. The Motley Fool recommends the following options: long January 2026 $395 calls on Microsoft and short January 2026 $405 calls on Microsoft. The Motley Fool has a disclosure policy.
1 No-Brainer Electric Vehicle (EV) Stock to Buy With $500 Right Now – The Globe and Mail
MMS • RSS
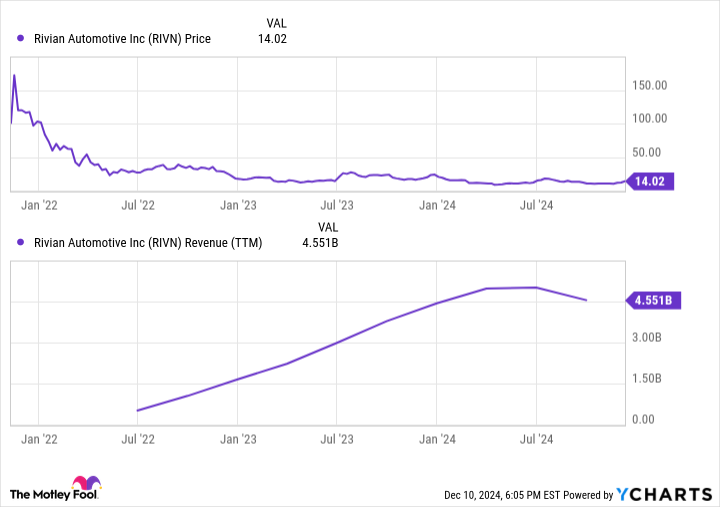
This year, the valuations of many electric car stocks slumped. One that struggled mightily at times was Rivian(NASDAQ: RIVN). At the start of 2024, shares were priced above $20. Last month, they fell below the $10 mark.
Then something extraordinary happened. In recent weeks, Rivian shares have surged by more than 40%. It seems as if market sentiment for this struggling EV stock has finally turned around. But if you think the upside potential has already been realized, think again. This is a business that could grow significantly in the years to come, and there’s one event in particular that should have growth investors excited.
Pay attention to this major upcoming milestone
Even after the recent run-up, Rivian’s share price is still more than 40% below where it began this year. The downtrend is nothing new for the EV maker. Since its IPO in 2021, its shares have lost more than 80% of their value. When it first went public, the company had a market cap of roughly $100 billion. Today, its market cap has shrunk to just $14 billion. For comparison, leading EV maker Tesla is valued at nearly $1.3 trillion.
What’s strange is that Rivian’s sales base was actually exploding over those years, growing from nearly nothing to more than $4 billion annually. At its height, the company was bringing in more than $5 billion in sales every year, yet its share price remained in the dumps. There are several reasons for this, but the biggest is quite simple: The market steeply overvalued Rivian when it went public. In 2021, it was one of several EV companies to do so, and it was a time when the valuations of many cleaner-energy-related businesses were shooting through the roof. Rivian has done a terrific job creating quality vehicles that consumers love, which has driven its sales higher and higher (at least, until their recent slump). Yet the company’s business results still weren’t outstanding enough to justify its extreme valuation. The result was perhaps inevitable — a drastic reduction in Rivian’s valuation.
But just as markets can overvalue a stock significantly, so too can they undervalue a stock. That’s seemingly the case for Rivian today, as shares trade at just 3.1 times sales. Tesla, a more mature competitor with a more diversified business model, trades at nearly 14 times sales. Lucid Group, another EV upstart in a similar position to Rivian, trades at nearly 10 times sales.
Of course, a cheap valuation isn’t any good for would-be investors unless the company can outpace the market’s low expectations for it. You may look at Rivian’s recent revenue decline and think its best days are behind it — but think again. In 2026, the company expects to launch three new mass-market models, all with starting prices below $50,000. The two models it currently has in production have base prices of about $70,000 and $76,000, with high-end versions priced at $100,000 or more. Getting its new models to market should allow it to compete for tens of millions of additional customers whose budgets for a new vehicle are tighter. When Tesla released its mass-market vehicles — the Model 3 and Model Y — its revenue base multiplied by several times in value in the years that followed. The same could be true for Rivian if it can survive until then.
But if you’re still hesitant about buying the stock after its recent run-up, you should know that there’s an event coming in the near term that could provide you with another buying opportunity.
This could be your next big buying opportunity
Rivian will deliver its next quarterly report on Feb. 18. If you believe the predictions of the company’s management team, it should shift to producing positive gross margins — a huge potential win for a company that thus far has been losing tens of thousands of dollars on every vehicle it sells.
In short, every time Rivian made a sale, its net loss widened. In the fourth quarter, all of that could change.
If Rivian achieves positive gross margins, expect the market to react favorably. It would represent a huge achievement for a company operating in an industry that has had plenty of financial failures. But if Rivian fails to meet that target, the stock could pull back again, creating an opportunity for investors to buy shares at a discount.
Still, betting on quarterly results is an inferior strategy compared to taking a long-term approach. If you like Rivian as a business — particularly while it’s still trading at a historically cheap valuation — don’t be afraid to jump in at today’s prices. You could still add more to your position in a couple of months if the company fails to achieve gross profitability this quarter.
Don’t miss this second chance at a potentially lucrative opportunity
Ever feel like you missed the boat in buying the most successful stocks? Then you’ll want to hear this.
On rare occasions, our expert team of analysts issues a “Double Down” stock recommendation for companies that they think are about to pop. If you’re worried you’ve already missed your chance to invest, now is the best time to buy before it’s too late. And the numbers speak for themselves:
- Nvidia:if you invested $1,000 when we doubled down in 2009,you’d have $348,112!*
- Apple: if you invested $1,000 when we doubled down in 2008, you’d have $46,992!*
- Netflix: if you invested $1,000 when we doubled down in 2004, you’d have $495,539!*
Right now, we’re issuing “Double Down” alerts for three incredible companies, and there may not be another chance like this anytime soon.
*Stock Advisor returns as of December 9, 2024
Ryan Vanzo has no position in any of the stocks mentioned. The Motley Fool has positions in and recommends Tesla. The Motley Fool has a disclosure policy.
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report)’s stock price was down 5.6% during mid-day trading on Friday . The stock traded as low as $271.50 and last traded at $272.35. Approximately 2,358,962 shares were traded during mid-day trading, an increase of 55% from the average daily volume of 1,522,469 shares. The stock had previously closed at $288.61.
Analysts Set New Price Targets
Several equities research analysts have recently commented on the company. Canaccord Genuity Group boosted their price objective on MongoDB from $325.00 to $385.00 and gave the company a “buy” rating in a report on Wednesday. Oppenheimer boosted their price target on shares of MongoDB from $350.00 to $400.00 and gave the company an “outperform” rating in a research note on Tuesday. Royal Bank of Canada raised their price objective on shares of MongoDB from $350.00 to $400.00 and gave the company an “outperform” rating in a research note on Tuesday. Mizuho lifted their price objective on shares of MongoDB from $275.00 to $320.00 and gave the company a “neutral” rating in a report on Tuesday. Finally, Needham & Company LLC upped their target price on shares of MongoDB from $335.00 to $415.00 and gave the stock a “buy” rating in a report on Tuesday. One equities research analyst has rated the stock with a sell rating, six have given a hold rating, twenty have given a buy rating and one has given a strong buy rating to the company’s stock. According to MarketBeat.com, MongoDB currently has an average rating of “Moderate Buy” and a consensus price target of $370.08.
Check Out Our Latest Stock Report on MongoDB
MongoDB Stock Down 7.4 %
The firm has a 50 day moving average of $293.17 and a 200 day moving average of $268.08. The firm has a market cap of $19.74 billion, a PE ratio of -97.51 and a beta of 1.17.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings results on Monday, December 9th. The company reported $1.16 EPS for the quarter, beating analysts’ consensus estimates of $0.68 by $0.48. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The firm had revenue of $529.40 million for the quarter, compared to analysts’ expectations of $497.39 million. During the same quarter in the prior year, the firm earned $0.96 EPS. The business’s revenue for the quarter was up 22.3% compared to the same quarter last year. On average, research analysts anticipate that MongoDB, Inc. will post -2.29 EPS for the current year.
Insider Transactions at MongoDB
In other news, CRO Cedric Pech sold 302 shares of the stock in a transaction dated Wednesday, October 2nd. The shares were sold at an average price of $256.25, for a total value of $77,387.50. Following the sale, the executive now directly owns 33,440 shares of the company’s stock, valued at approximately $8,569,000. This represents a 0.90 % decrease in their ownership of the stock. The sale was disclosed in a filing with the SEC, which can be accessed through the SEC website. Also, CAO Thomas Bull sold 1,000 shares of the firm’s stock in a transaction that occurred on Monday, December 9th. The shares were sold at an average price of $355.92, for a total transaction of $355,920.00. Following the completion of the transaction, the chief accounting officer now owns 15,068 shares of the company’s stock, valued at $5,363,002.56. This trade represents a 6.22 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders sold 26,600 shares of company stock worth $7,611,849 over the last quarter. Corporate insiders own 3.60% of the company’s stock.
Hedge Funds Weigh In On MongoDB
A number of institutional investors have recently added to or reduced their stakes in the business. MFA Wealth Advisors LLC bought a new stake in shares of MongoDB during the 2nd quarter worth $25,000. Quarry LP lifted its stake in MongoDB by 2,580.0% during the second quarter. Quarry LP now owns 134 shares of the company’s stock worth $33,000 after purchasing an additional 129 shares during the last quarter. Brooklyn Investment Group bought a new stake in MongoDB during the third quarter worth about $36,000. Continuum Advisory LLC boosted its holdings in shares of MongoDB by 621.1% in the 3rd quarter. Continuum Advisory LLC now owns 137 shares of the company’s stock worth $40,000 after purchasing an additional 118 shares in the last quarter. Finally, Hantz Financial Services Inc. bought a new position in shares of MongoDB during the 2nd quarter valued at about $35,000. 89.29% of the stock is currently owned by institutional investors.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Thinking about investing in Meta, Roblox, or Unity? Click the link to learn what streetwise investors need to know about the metaverse and public markets before making an investment.
MMS • RSS
Geode Capital Management LLC lifted its position in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 2.9% in the 3rd quarter, according to the company in its most recent disclosure with the Securities & Exchange Commission. The fund owned 1,230,036 shares of the company’s stock after purchasing an additional 34,814 shares during the quarter. Geode Capital Management LLC owned about 1.67% of MongoDB worth $331,776,000 as of its most recent SEC filing.
A number of other institutional investors and hedge funds have also recently modified their holdings of MDB. Blue Trust Inc. lifted its position in MongoDB by 26.6% during the second quarter. Blue Trust Inc. now owns 538 shares of the company’s stock valued at $134,000 after purchasing an additional 113 shares during the period. OFI Invest Asset Management boosted its stake in shares of MongoDB by 420.4% in the second quarter. OFI Invest Asset Management now owns 510 shares of the company’s stock worth $119,000 after buying an additional 412 shares during the last quarter. Fifth Third Bancorp boosted its stake in shares of MongoDB by 7.6% in the second quarter. Fifth Third Bancorp now owns 620 shares of the company’s stock worth $155,000 after buying an additional 44 shares during the last quarter. MFA Wealth Advisors LLC acquired a new stake in MongoDB during the second quarter worth about $25,000. Finally, MN Wealth Advisors LLC purchased a new position in MongoDB during the second quarter valued at approximately $576,000. Institutional investors and hedge funds own 89.29% of the company’s stock.
Analysts Set New Price Targets
MDB has been the subject of a number of recent analyst reports. Royal Bank of Canada lifted their price objective on shares of MongoDB from $350.00 to $400.00 and gave the company an “outperform” rating in a report on Tuesday. Mizuho lifted their price target on MongoDB from $275.00 to $320.00 and gave the company a “neutral” rating in a research note on Tuesday. The Goldman Sachs Group increased their price target on MongoDB from $340.00 to $390.00 and gave the stock a “buy” rating in a research report on Tuesday. Scotiabank boosted their price objective on MongoDB from $295.00 to $350.00 and gave the company a “sector perform” rating in a research report on Tuesday. Finally, Oppenheimer upped their target price on MongoDB from $350.00 to $400.00 and gave the stock an “outperform” rating in a research note on Tuesday. One equities research analyst has rated the stock with a sell rating, six have assigned a hold rating, twenty have given a buy rating and one has issued a strong buy rating to the company. According to MarketBeat, MongoDB presently has a consensus rating of “Moderate Buy” and an average target price of $370.08.
Get Our Latest Analysis on MongoDB
Insiders Place Their Bets
In other news, CRO Cedric Pech sold 302 shares of MongoDB stock in a transaction on Wednesday, October 2nd. The shares were sold at an average price of $256.25, for a total transaction of $77,387.50. Following the completion of the sale, the executive now directly owns 33,440 shares of the company’s stock, valued at approximately $8,569,000. The trade was a 0.90 % decrease in their position. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is accessible through the SEC website. Also, CAO Thomas Bull sold 154 shares of the firm’s stock in a transaction on Wednesday, October 2nd. The shares were sold at an average price of $256.25, for a total value of $39,462.50. Following the completion of the sale, the chief accounting officer now owns 16,068 shares in the company, valued at approximately $4,117,425. This represents a 0.95 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold a total of 26,600 shares of company stock worth $7,611,849 in the last quarter. 3.60% of the stock is owned by company insiders.
MongoDB Stock Down 7.4 %
NASDAQ:MDB traded down $21.42 during trading hours on Friday, reaching $267.19. 5,086,127 shares of the stock were exchanged, compared to its average volume of 1,534,332. MongoDB, Inc. has a twelve month low of $212.74 and a twelve month high of $509.62. The business has a 50-day moving average of $293.17 and a two-hundred day moving average of $268.08. The company has a market capitalization of $19.74 billion, a price-to-earnings ratio of -97.51 and a beta of 1.17.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings results on Monday, December 9th. The company reported $1.16 earnings per share (EPS) for the quarter, topping the consensus estimate of $0.68 by $0.48. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The business had revenue of $529.40 million for the quarter, compared to analysts’ expectations of $497.39 million. The business’s quarterly revenue was up 22.3% on a year-over-year basis. During the same quarter in the prior year, the company earned $0.96 earnings per share. On average, research analysts forecast that MongoDB, Inc. will post -2.29 EPS for the current fiscal year.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Wondering where to start (or end) with AI stocks? These 10 simple stocks can help investors build long-term wealth as artificial intelligence continues to grow into the future.