Month: April 2025

MMS • RSS
Gilder Gagnon Howe & Co. LLC lessened its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 1.3% during the 4th quarter, according to its most recent disclosure with the SEC. The institutional investor owned 364,573 shares of the company’s stock after selling 4,810 shares during the quarter. Gilder Gagnon Howe & Co. LLC owned about 0.49% of MongoDB worth $84,876,000 as of its most recent filing with the SEC.
Other hedge funds and other institutional investors have also made changes to their positions in the company. Strategic Investment Solutions Inc. IL acquired a new stake in MongoDB in the 4th quarter valued at about $29,000. Hilltop National Bank increased its stake in shares of MongoDB by 47.2% during the fourth quarter. Hilltop National Bank now owns 131 shares of the company’s stock worth $30,000 after buying an additional 42 shares during the period. NCP Inc. purchased a new position in MongoDB in the fourth quarter worth approximately $35,000. Versant Capital Management Inc lifted its stake in MongoDB by 1,100.0% in the fourth quarter. Versant Capital Management Inc now owns 180 shares of the company’s stock worth $42,000 after acquiring an additional 165 shares during the last quarter. Finally, Wilmington Savings Fund Society FSB acquired a new position in MongoDB during the 3rd quarter worth approximately $44,000. Hedge funds and other institutional investors own 89.29% of the company’s stock.
Insider Buying and Selling
In other news, CEO Dev Ittycheria sold 18,512 shares of the stock in a transaction that occurred on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $3,207,389.12. Following the sale, the chief executive officer now directly owns 268,948 shares in the company, valued at $46,597,930.48. This represents a 6.44 % decrease in their ownership of the stock. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is available through the SEC website. Also, CAO Thomas Bull sold 301 shares of MongoDB stock in a transaction that occurred on Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total value of $52,148.25. Following the transaction, the chief accounting officer now owns 14,598 shares of the company’s stock, valued at $2,529,103.50. This represents a 2.02 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold a total of 47,680 shares of company stock worth $10,819,027 in the last quarter. Company insiders own 3.60% of the company’s stock.
Analyst Ratings Changes
Several equities research analysts have recently issued reports on the stock. Robert W. Baird lowered their target price on shares of MongoDB from $390.00 to $300.00 and set an “outperform” rating for the company in a research note on Thursday, March 6th. Wells Fargo & Company downgraded MongoDB from an “overweight” rating to an “equal weight” rating and dropped their price objective for the company from $365.00 to $225.00 in a report on Thursday, March 6th. Oppenheimer decreased their target price on MongoDB from $400.00 to $330.00 and set an “outperform” rating for the company in a research note on Thursday, March 6th. Wedbush dropped their price target on shares of MongoDB from $360.00 to $300.00 and set an “outperform” rating on the stock in a research note on Thursday, March 6th. Finally, Rosenblatt Securities reissued a “buy” rating and set a $350.00 price objective on shares of MongoDB in a report on Tuesday, March 4th. Eight analysts have rated the stock with a hold rating, twenty-four have issued a buy rating and one has assigned a strong buy rating to the company. Based on data from MarketBeat.com, MongoDB has an average rating of “Moderate Buy” and a consensus target price of $294.78.
Check Out Our Latest Analysis on MDB
MongoDB Trading Up 0.2 %
Shares of MDB stock opened at $173.50 on Friday. MongoDB, Inc. has a 12-month low of $140.78 and a 12-month high of $387.19. The company has a market cap of $14.09 billion, a price-to-earnings ratio of -63.32 and a beta of 1.49. The stock has a 50 day simple moving average of $195.15 and a 200-day simple moving average of $249.13.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its earnings results on Wednesday, March 5th. The company reported $0.19 EPS for the quarter, missing the consensus estimate of $0.64 by ($0.45). MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The company had revenue of $548.40 million for the quarter, compared to analysts’ expectations of $519.65 million. During the same quarter in the previous year, the firm posted $0.86 earnings per share. On average, equities analysts forecast that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Explore Elon Musk’s boldest ventures yet—from AI and autonomy to space colonization—and find out how investors can ride the next wave of innovation.
MMS • RSS

#inform-video-player-1 .inform-embed { margin-top: 10px; margin-bottom: 20px; }
#inform-video-player-2 .inform-embed { margin-top: 10px; margin-bottom: 20px; }
Berry joins MongoDB with more than three decades of expertise in software and cloud businesses
NEW YORK, April 28, 2025 /PRNewswire/ — MongoDB, Inc. (NASDAQ: MDB) today announced the appointment of Mike Berry as Chief Financial Officer, effective May 27, 2025. Berry will lead MongoDB’s accounting, FP&A, treasury and investor relations efforts and partner with other senior leaders to set and deliver on the company’s long-term strategic and financial objectives.
#inform-video-player-3 .inform-embed { margin-top: 10px; margin-bottom: 20px; }
MMS • RSS

- MongoDB (MDB, Financial) appoints Mike Berry as the new Chief Financial Officer, effective May 27, 2025.
- Berry brings over 30 years of experience in the technology and software industry, previously serving as CFO at major firms such as NetApp and McAfee.
- MongoDB to report Q1 FY2026 financial results on June 4, 2025, after the markets close.
MongoDB, Inc. (MDB) has announced the appointment of Mike Berry as its Chief Financial Officer, effective May 27, 2025. Berry joins MongoDB from NetApp, where he served as CFO for the past five years. With a rich career spanning over three decades, Berry has held CFO roles at technology firms including McAfee, FireEye, Informatica, IO, SolarWinds, and i2 Technologies.
In his new role at MongoDB, Berry will oversee accounting, financial planning and analysis (FP&A), treasury, and investor relations. He is also expected to work closely with senior leadership to set and achieve the company’s strategic and financial goals. Berry’s experience with consumption models and scaling businesses to over $5 billion in revenue is particularly valuable as MongoDB focuses on growth in the GenAI space and legacy workload modernization.
MongoDB’s CEO, Dev Ittycheria, expressed confidence in Berry’s ability to contribute to the company’s long-term vision, noting that his expertise aligns perfectly with MongoDB’s objectives in tapping into new opportunities with GenAI applications.
In addition to this leadership announcement, MongoDB is scheduled to release its financial results for the first quarter of fiscal year 2026 on June 4, 2025. Following the release, the company will hold a conference call at 5:00 p.m. Eastern Time to discuss the results and business outlook.
MMS • RSS
MongoDB (MDB, Financial) has announced the appointment of Mike Berry as its new Chief Financial Officer, starting on May 27. Berry will be responsible for overseeing the company’s accounting, financial planning and analysis, treasury, and investor relations departments. Additionally, he will collaborate with MongoDB’s senior leadership to establish and implement long-term strategic and financial goals.
Berry transitions to MongoDB from NetApp, where he held the CFO position for the past five years. His extensive experience in financial leadership is expected to support MongoDB’s growth and strategic initiatives.
Wall Street Analysts Forecast
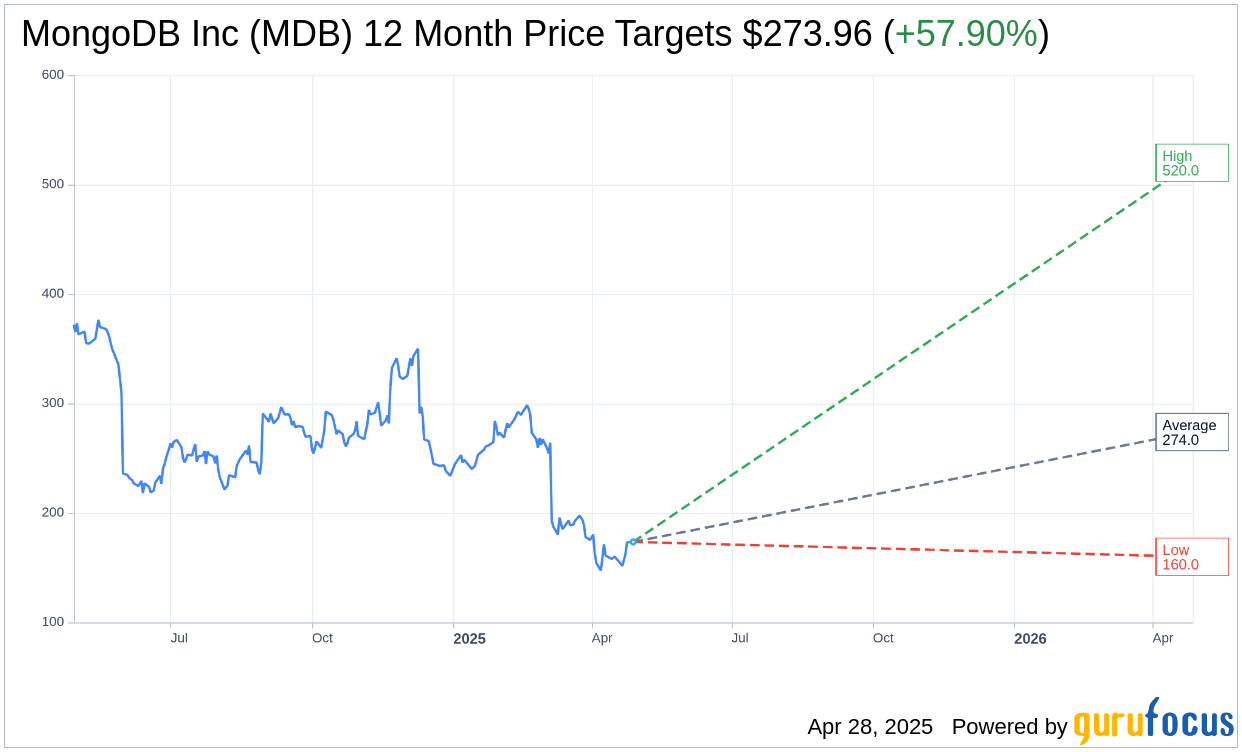
Based on the one-year price targets offered by 34 analysts, the average target price for MongoDB Inc (MDB, Financial) is $273.96 with a high estimate of $520.00 and a low estimate of $160.00. The average target implies an
upside of 57.90%
from the current price of $173.50. More detailed estimate data can be found on the MongoDB Inc (MDB) Forecast page.
Based on the consensus recommendation from 38 brokerage firms, MongoDB Inc’s (MDB, Financial) average brokerage recommendation is currently 2.0, indicating “Outperform” status. The rating scale ranges from 1 to 5, where 1 signifies Strong Buy, and 5 denotes Sell.
Based on GuruFocus estimates, the estimated GF Value for MongoDB Inc (MDB, Financial) in one year is $432.68, suggesting a
upside
of 149.38% from the current price of $173.5. GF Value is GuruFocus’ estimate of the fair value that the stock should be traded at. It is calculated based on the historical multiples the stock has traded at previously, as well as past business growth and the future estimates of the business’ performance. More detailed data can be found on the MongoDB Inc (MDB) Summary page.
MDB Key Business Developments
Release Date: March 05, 2025
- Total Revenue: $548.4 million, a 20% year-over-year increase.
- Atlas Revenue: Grew 24% year-over-year, representing 71% of total revenue.
- Non-GAAP Operating Income: $112.5 million, with a 21% operating margin.
- Net Income: $108.4 million or $1.28 per share.
- Customer Count: Over 54,500 customers, with over 7,500 direct sales customers.
- Gross Margin: 75%, down from 77% in the previous year.
- Free Cash Flow: $22.9 million for the quarter.
- Cash and Cash Equivalents: $2.3 billion, with a debt-free balance sheet.
- Fiscal Year 2026 Revenue Guidance: $2.24 billion to $2.28 billion.
- Fiscal Year 2026 Non-GAAP Operating Income Guidance: $210 million to $230 million.
- Fiscal Year 2026 Non-GAAP Net Income Per Share Guidance: $2.44 to $2.62.
For the complete transcript of the earnings call, please refer to the full earnings call transcript.
Positive Points
- MongoDB Inc (MDB, Financial) reported a 20% year-over-year revenue increase, surpassing the high end of their guidance.
- Atlas revenue grew 24% year over year, now representing 71% of total revenue.
- The company achieved a non-GAAP operating income of $112.5 million, resulting in a 21% non-GAAP operating margin.
- MongoDB Inc (MDB) ended the quarter with over 54,500 customers, indicating strong customer growth.
- The company is optimistic about the long-term opportunity in AI, particularly with the acquisition of Voyage AI to enhance AI application trustworthiness.
Negative Points
- Non-Atlas business is expected to be a headwind in fiscal ’26 due to fewer multi-year deals and a shift of workloads to Atlas.
- Operating margin guidance for fiscal ’26 is lower at 10%, down from 15% in fiscal ’25, due to reduced multi-year license revenue and increased R&D investments.
- The company anticipates a high-single-digit decline in non-Atlas subscription revenue for the year.
- MongoDB Inc (MDB) expects only modest incremental revenue growth from AI in fiscal ’26 as enterprises are still developing AI skills.
- The company faces challenges in modernizing legacy applications, which is a complex and resource-intensive process.
- CEO Buys, CFO Buys: Stocks that are bought by their CEO/CFOs.
- Insider Cluster Buys: Stocks that multiple company officers and directors have bought.
- Double Buys: Companies that both Gurus and Insiders are buying
- Triple Buys: Companies that both Gurus and Insiders are buying, and Company is buying back.
MMS • RSS
Berry joins MongoDB with more than three decades of expertise in software and cloud businesses
NEW YORK
, April 28, 2025 /PRNewswire/ — MongoDB, Inc. (NASDAQ: MDB) today announced the appointment of Mike Berry as Chief Financial Officer, effective May 27, 2025. Berry will lead MongoDB’s accounting, FP&A, treasury and investor relations efforts and partner with other senior leaders to set and deliver on the company’s long-term strategic and financial objectives.
![]()
Berry joins MongoDB from NetApp, where he served as CFO for the past five years. A seven-time CFO, Berry previously held that role at McAfee, FireEye, Informatica, IO, Solarwinds, and i2 Technologies. Berry brings to MongoDB over 30 years of experience, a wealth of experience in the technology and software industry, and a proven track record of driving profitable growth.
“Mike’s unique combination of strategic, operational, and financial expertise makes him a key addition to the MongoDB leadership team,” said Dev Ittycheria, President and CEO of MongoDB. “His industry expertise and proven ability to drive efficient growth aligns perfectly with our vision for the future. This is an incredibly exciting time for MongoDB as customers are in the very early stages of harnessing GenAI to build new applications and modernize their vast installed base of legacy workloads. Mike’s experience with consumption models and history of successfully scaling businesses to $5 billion in revenue and beyond make him the ideal choice to serve as MongoDB’s next CFO.”
“I’m thrilled to join MongoDB at such an exciting moment in its growth journey,” said Berry. “The company’s incredible track record of product innovation and established leadership position in one of the largest, most strategic markets in software provides significant growth drivers that we expect to benefit our business for years to come. While it was not my intention to pursue another CFO role when we announced my retirement from NetApp, the opportunity to join a company the caliber of MongoDB was incredibly compelling. I can’t wait to get started in late May and I look forward to working with the team to create long-term value for our customers, shareholders, and employees.”
F1Q Earnings Date Announcement
The Company will report its first quarter fiscal year 2026 financial results for the three months ended April 30, 2025, after the U.S. financial markets close on June 4, 2025.
In conjunction with this announcement, MongoDB will host a conference call on Wednesday, June 4, 2025, at 5:00 p.m. (Eastern Time) to discuss the Company’s financial results and business outlook. A live webcast of the call will be available on the “Investor Relations” page of the Company’s website at http://investors.mongodb.com. To access the call by phone, please go to this link (registration link), and you will be provided with dial in details. To avoid delays, we encourage participants to dial into the conference call fifteen minutes ahead of the scheduled start time. A replay of the webcast will also be available for a limited time at http://investors.mongodb.com.
About MongoDB
Headquartered in New York, MongoDB’s mission is to empower innovators to create, transform, and disrupt industries with software. MongoDB’s unified database platform was built to power the next generation of applications, and MongoDB is the most widely available, globally distributed database on the market. With integrated capabilities for operational data, search, real-time analytics, and AI-powered data retrieval, MongoDB helps organizations everywhere move faster, innovate more efficiently, and simplify complex architectures. Millions of developers and more than 50,000 customers across almost every industry—including 70% of the Fortune 100—rely on MongoDB for their most important applications. To learn more, visit mongodb.com.
Forward-Looking Statements
This press release includes certain “forward-looking statements” within the meaning of Section 27A of the Securities Act of 1933, as amended, or the Securities Act, and Section 21E of the Securities Exchange Act of 1934, as amended, including statements concerning the Company’s expectations regarding the performance of the new chief financial officer. These forward-looking statements include, but are not limited to, plans, objectives, expectations and intentions and other statements contained in this press release that are not historical facts and statements identified by words such as “anticipate,” “believe,” “continue,” “could,” “estimate,” “expect,” “intend,” “may,” “plan,” “project,” “will,” “would” or the negative or plural of these words or similar expressions or variations. These forward-looking statements reflect our current views about our plans, intentions, expectations, strategies and prospects, which are based on the information currently available to us and on assumptions we have made. Although we believe that our plans, intentions, expectations, strategies and prospects as reflected in or suggested by those forward-looking statements are reasonable, we can give no assurance that the plans, intentions, expectations or strategies will be attained or achieved. Furthermore, actual results may differ materially from those described in the forward-looking statements and are subject to a variety of assumptions, uncertainties, risks and factors that are beyond our control including, without limitation: our customers renewing their subscriptions with us and expanding their usage of software and related services; the effects of the ongoing military conflicts between Russia and Ukraine and Israel and Hamas on our business and future operating results; economic downturns and/or the effects of rising interest rates, inflation and volatility in the global economy and financial markets on our business and future operating results; our potential failure to meet publicly announced guidance or other expectations about our business and future operating results; our limited operating history; our history of losses; failure of our platform to satisfy customer demands; the effects of increased competition; our investments in new products and our ability to introduce new features, services or enhancements; our ability to effectively expand our sales and marketing organization; our ability to continue to build and maintain credibility with the developer community; our ability to add new customers or increase sales to our existing customers; our ability to maintain, protect, enforce and enhance our intellectual property; the effects of social, ethical and regulatory issues relating to the use of new and evolving technologies, such as artificial intelligence, in our offerings or partnerships; the growth and expansion of the market for database products and our ability to penetrate that market; our ability to integrate acquired businesses and technologies successfully or achieve the expected benefits of such acquisitions; our ability to maintain the security of our software and adequately address privacy concerns; our ability to manage our growth effectively and successfully recruit and retain additional highly-qualified personnel; and the price volatility of our common stock. These and other risks and uncertainties are more fully described in our filings with the Securities and Exchange Commission (“SEC”), including under the caption “Risk Factors” in our Annual Report on Form 10-K for the fiscal year ended January 31, 2025, filed with the SEC on March 21, 2025 and other filings and reports that we may file from time to time with the SEC. Except as required by law, we undertake no duty or obligation to update any forward-looking statements contained in this release as a result of new information, future events, changes in expectations or otherwise.
Investor Relations
Brian Denyeau
ICR for MongoDB
646-277-1251
Media Relations
MongoDB PR
![]() View original content to download multimedia:https://www.prnewswire.com/news-releases/mongodb-inc-announces-mike-berry-as-chief-financial-officer-302439668.html
View original content to download multimedia:https://www.prnewswire.com/news-releases/mongodb-inc-announces-mike-berry-as-chief-financial-officer-302439668.html
SOURCE MongoDB, Inc.
Docker Desktop 4.40 Introduces Model Runner to Run LLMs Locally Expanding its AI Capabilities
MMS • Craig Risi
Docker Desktop 4.40, released on March 31, 2025, introduces a suite of features aimed at enhancing AI development workflows and strengthening enterprise compliance capabilities.
A notable addition is the Docker Model Runner, currently in beta for macOS with Apple Silicon. This feature allows developers to pull, run, and manage AI models directly from Docker Hub within Docker Desktop, streamlining the process of integrating AI models into containerized applications.
Traditionally, integrating AI models into applications has required manual setup, environment configuration, and often the use of external platforms or tools to run and test models. The Model Runner changes this by allowing developers to pull, run, and manage AI models as easily as they would run containers — directly from Docker Hub, using familiar Docker workflows.
This functionality is important because it bridges the gap between model development and application deployment. Developers can now test models in a controlled environment without needing to rely on cloud-based inference APIs or heavy local setups. This encourages more experimentation and tighter integration of AI into everyday development workflows, particularly useful for building AI-enhanced applications where models need to be embedded or fine-tuned locally.
The Model Runner supports popular model formats and can execute models with standard inputs, making it a general-purpose tool for running inference tasks. Whether it’s image recognition, text generation, or other predictive capabilities, developers can now treat models as first-class citizens in their toolchain. Over time, this could lead to more seamless AI integration across DevOps practices, from prototyping to deployment.
As part of the release, the Docker AI Agent has been upgraded to support the Model Context Protocol (MCP), enabling it to function both as a client and a server. This integration allows the AI Agent to interact seamlessly with external tools and data sources, enhancing its utility in various development scenarios. Developers can now perform tasks such as running shell commands, managing local files, and conducting Git operations directly through the AI Agent.
Complementing the AI Agent’s capabilities, the new AI Tool Catalog extension in Docker Desktop provides a centralized platform for discovering and connecting to various MCP servers. This extension simplifies the process of integrating additional AI tools and models into the Docker ecosystem, promoting a more modular and customizable development environment.
For enterprise users, Docker Desktop 4.40 introduces Settings Reporting, a feature that offers administrators comprehensive visibility into user compliance with assigned settings policies. This enhancement builds upon the Desktop Settings Management capabilities introduced in version 4.36, providing organizations with improved tools for enforcing compliance and security standards across development teams.
Overall, Docker Desktop 4.40 represents a step forward in integrating AI development tools into the Docker ecosystem while also addressing the compliance needs of enterprise users.
MMS • RSS
Pinebridge Investments L.P. boosted its stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 47.1% during the 4th quarter, according to its most recent 13F filing with the SEC. The firm owned 26,879 shares of the company’s stock after buying an additional 8,611 shares during the period. Pinebridge Investments L.P.’s holdings in MongoDB were worth $6,258,000 at the end of the most recent quarter.
Other institutional investors also recently bought and sold shares of the company. Strategic Investment Solutions Inc. IL purchased a new stake in shares of MongoDB in the fourth quarter worth approximately $29,000. Hilltop National Bank lifted its position in shares of MongoDB by 47.2% during the fourth quarter. Hilltop National Bank now owns 131 shares of the company’s stock worth $30,000 after purchasing an additional 42 shares during the last quarter. NCP Inc. purchased a new stake in shares of MongoDB during the fourth quarter valued at $35,000. Versant Capital Management Inc grew its holdings in shares of MongoDB by 1,100.0% in the fourth quarter. Versant Capital Management Inc now owns 180 shares of the company’s stock worth $42,000 after purchasing an additional 165 shares during the last quarter. Finally, Wilmington Savings Fund Society FSB bought a new position in shares of MongoDB in the third quarter worth about $44,000. 89.29% of the stock is currently owned by institutional investors.
Insider Buying and Selling at MongoDB
In other news, Director Dwight A. Merriman sold 3,000 shares of the business’s stock in a transaction dated Monday, February 3rd. The shares were sold at an average price of $266.00, for a total transaction of $798,000.00. Following the completion of the sale, the director now owns 1,113,006 shares of the company’s stock, valued at $296,059,596. The trade was a 0.27 % decrease in their ownership of the stock. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is available at this link. Also, insider Cedric Pech sold 1,690 shares of the company’s stock in a transaction dated Wednesday, April 2nd. The stock was sold at an average price of $173.26, for a total transaction of $292,809.40. Following the transaction, the insider now owns 57,634 shares of the company’s stock, valued at approximately $9,985,666.84. This trade represents a 2.85 % decrease in their position. The disclosure for this sale can be found here. Over the last quarter, insiders sold 47,680 shares of company stock valued at $10,819,027. Corporate insiders own 3.60% of the company’s stock.
MongoDB Trading Up 0.2 %
Shares of MDB stock traded up $0.29 during trading hours on Friday, hitting $173.50. The company’s stock had a trading volume of 2,105,392 shares, compared to its average volume of 1,841,392. The stock has a market cap of $14.09 billion, a PE ratio of -63.32 and a beta of 1.49. The company has a 50 day moving average of $195.15 and a 200 day moving average of $248.95. MongoDB, Inc. has a 12-month low of $140.78 and a 12-month high of $387.19.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its earnings results on Wednesday, March 5th. The company reported $0.19 EPS for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). The company had revenue of $548.40 million during the quarter, compared to analysts’ expectations of $519.65 million. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. During the same quarter in the previous year, the company earned $0.86 EPS. As a group, analysts anticipate that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
Wall Street Analysts Forecast Growth
Several equities research analysts have issued reports on the stock. Daiwa America raised shares of MongoDB to a “strong-buy” rating in a research report on Tuesday, April 1st. Citigroup dropped their price objective on MongoDB from $430.00 to $330.00 and set a “buy” rating on the stock in a research note on Tuesday, April 1st. Canaccord Genuity Group reduced their price objective on MongoDB from $385.00 to $320.00 and set a “buy” rating on the stock in a report on Thursday, March 6th. Wells Fargo & Company cut MongoDB from an “overweight” rating to an “equal weight” rating and lowered their target price for the stock from $365.00 to $225.00 in a report on Thursday, March 6th. Finally, Piper Sandler cut their price target on MongoDB from $280.00 to $200.00 and set an “overweight” rating on the stock in a research note on Wednesday. Eight investment analysts have rated the stock with a hold rating, twenty-four have assigned a buy rating and one has given a strong buy rating to the company. According to MarketBeat, the stock has an average rating of “Moderate Buy” and an average price target of $294.78.
Read Our Latest Analysis on MDB
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Wondering where to start (or end) with AI stocks? These 10 simple stocks can help investors build long-term wealth as artificial intelligence continues to grow into the future.
Is There An Opportunity With MongoDB, Inc.’s (NASDAQ:MDB) 27% Undervaluation? – Simply Wall St
MMS • RSS
Key Insights
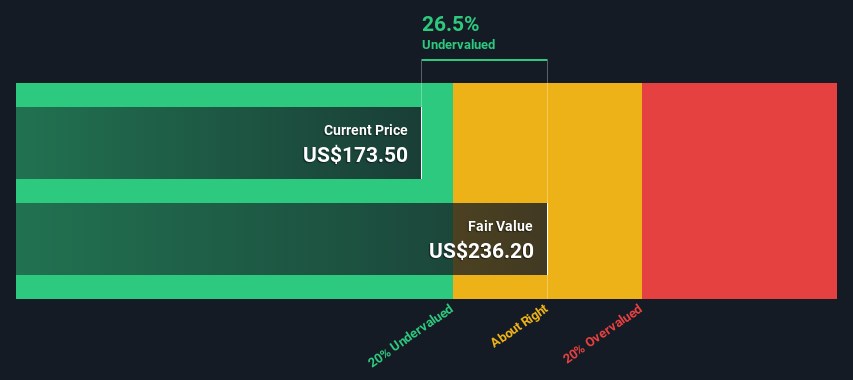
- The projected fair value for MongoDB is US$236 based on 2 Stage Free Cash Flow to Equity
- MongoDB’s US$174 share price signals that it might be 27% undervalued
- Our fair value estimate is 12% lower than MongoDB’s analyst price target of US$268
In this article we are going to estimate the intrinsic value of MongoDB, Inc. (NASDAQ:MDB) by taking the expected future cash flows and discounting them to their present value. Our analysis will employ the Discounted Cash Flow (DCF) model. Models like these may appear beyond the comprehension of a lay person, but they’re fairly easy to follow.
We generally believe that a company’s value is the present value of all of the cash it will generate in the future. However, a DCF is just one valuation metric among many, and it is not without flaws. If you want to learn more about discounted cash flow, the rationale behind this calculation can be read in detail in the Simply Wall St analysis model.
We’ve discovered 3 warning signs about MongoDB. View them for free.
Is MongoDB Fairly Valued?
We’re using the 2-stage growth model, which simply means we take in account two stages of company’s growth. In the initial period the company may have a higher growth rate and the second stage is usually assumed to have a stable growth rate. To start off with, we need to estimate the next ten years of cash flows. Where possible we use analyst estimates, but when these aren’t available we extrapolate the previous free cash flow (FCF) from the last estimate or reported value. We assume companies with shrinking free cash flow will slow their rate of shrinkage, and that companies with growing free cash flow will see their growth rate slow, over this period. We do this to reflect that growth tends to slow more in the early years than it does in later years.
Generally we assume that a dollar today is more valuable than a dollar in the future, so we discount the value of these future cash flows to their estimated value in today’s dollars:
10-year free cash flow (FCF) forecast
| 2025 | 2026 | 2027 | 2028 | 2029 | 2030 | 2031 | 2032 | 2033 | 2034 | |
| Levered FCF ($, Millions) | US$125.4m | US$144.3m | US$228.1m | US$349.3m | US$575.6m | US$843.9m | US$1.06b | US$1.25b | US$1.42b | US$1.57b |
| Growth Rate Estimate Source | Analyst x14 | Analyst x17 | Analyst x14 | Analyst x6 | Analyst x3 | Analyst x3 | Est @ 25.19% | Est @ 18.45% | Est @ 13.74% | Est @ 10.45% |
| Present Value ($, Millions) Discounted @ 7.9% | US$116 | US$124 | US$182 | US$258 | US$394 | US$536 | US$622 | US$683 | US$720 | US$737 |
(“Est” = FCF growth rate estimated by Simply Wall St)
Present Value of 10-year Cash Flow (PVCF) = US$4.4b
After calculating the present value of future cash flows in the initial 10-year period, we need to calculate the Terminal Value, which accounts for all future cash flows beyond the first stage. The Gordon Growth formula is used to calculate Terminal Value at a future annual growth rate equal to the 5-year average of the 10-year government bond yield of 2.8%. We discount the terminal cash flows to today’s value at a cost of equity of 7.9%.
Terminal Value (TV)= FCF2034 × (1 + g) ÷ (r – g) = US$1.6b× (1 + 2.8%) ÷ (7.9%– 2.8%) = US$32b
Present Value of Terminal Value (PVTV)= TV / (1 + r)10= US$32b÷ ( 1 + 7.9%)10= US$15b
The total value is the sum of cash flows for the next ten years plus the discounted terminal value, which results in the Total Equity Value, which in this case is US$19b. In the final step we divide the equity value by the number of shares outstanding. Compared to the current share price of US$174, the company appears a touch undervalued at a 27% discount to where the stock price trades currently. The assumptions in any calculation have a big impact on the valuation, so it is better to view this as a rough estimate, not precise down to the last cent.
Important Assumptions
Now the most important inputs to a discounted cash flow are the discount rate, and of course, the actual cash flows. Part of investing is coming up with your own evaluation of a company’s future performance, so try the calculation yourself and check your own assumptions. The DCF also does not consider the possible cyclicality of an industry, or a company’s future capital requirements, so it does not give a full picture of a company’s potential performance. Given that we are looking at MongoDB as potential shareholders, the cost of equity is used as the discount rate, rather than the cost of capital (or weighted average cost of capital, WACC) which accounts for debt. In this calculation we’ve used 7.9%, which is based on a levered beta of 1.182. Beta is a measure of a stock’s volatility, compared to the market as a whole. We get our beta from the industry average beta of globally comparable companies, with an imposed limit between 0.8 and 2.0, which is a reasonable range for a stable business.
View our latest analysis for MongoDB
SWOT Analysis for MongoDB
Strength
- Currently debt free.
Weakness
- No major weaknesses identified for MDB.
Opportunity
- Has sufficient cash runway for more than 3 years based on current free cash flows.
- Good value based on P/S ratio and estimated fair value.
Threat
- Not expected to become profitable over the next 3 years.
Moving On:
Whilst important, the DCF calculation is only one of many factors that you need to assess for a company. DCF models are not the be-all and end-all of investment valuation. Instead the best use for a DCF model is to test certain assumptions and theories to see if they would lead to the company being undervalued or overvalued. For instance, if the terminal value growth rate is adjusted slightly, it can dramatically alter the overall result. Can we work out why the company is trading at a discount to intrinsic value? For MongoDB, we’ve put together three relevant items you should assess:
- Risks: You should be aware of the 3 warning signs for MongoDB we’ve uncovered before considering an investment in the company.
- Future Earnings: How does MDB’s growth rate compare to its peers and the wider market? Dig deeper into the analyst consensus number for the upcoming years by interacting with our free analyst growth expectation chart.
- Other High Quality Alternatives: Do you like a good all-rounder? Explore our interactive list of high quality stocks to get an idea of what else is out there you may be missing!
PS. The Simply Wall St app conducts a discounted cash flow valuation for every stock on the NASDAQGM every day. If you want to find the calculation for other stocks just search here.
If you’re looking to trade MongoDB, open an account with the lowest-cost platform trusted by professionals, Interactive Brokers.
With clients in over 200 countries and territories, and access to 160 markets, IBKR lets you trade stocks, options, futures, forex, bonds and funds from a single integrated account.
Enjoy no hidden fees, no account minimums, and FX conversion rates as low as 0.03%, far better than what most brokers offer.
Sponsored Content
New: Manage All Your Stock Portfolios in One Place
We’ve created the ultimate portfolio companion for stock investors, and it’s free.
• Connect an unlimited number of Portfolios and see your total in one currency
• Be alerted to new Warning Signs or Risks via email or mobile
• Track the Fair Value of your stocks
Have feedback on this article? Concerned about the content? Get in touch with us directly. Alternatively, email editorial-team (at) simplywallst.com.
This article by Simply Wall St is general in nature. We provide commentary based on historical data and analyst forecasts only using an unbiased methodology and our articles are not intended to be financial advice. It does not constitute a recommendation to buy or sell any stock, and does not take account of your objectives, or your financial situation. We aim to bring you long-term focused analysis driven by fundamental data. Note that our analysis may not factor in the latest price-sensitive company announcements or qualitative material. Simply Wall St has no position in any stocks mentioned.
MMS • Ben Linders

High performance and sustainability correlate; making software go faster by improving the efficiency of algorithms can reduce energy requirements, Holly Cummins said at QCon London. She suggested switching systems off when not in use to reduce the environmental footprint. Developers can achieve more by doing less, improving productivity, she said.
A high performance sustainable system should have a low memory footprint, high throughput, avoid excessive networking, and support elastic scaling. These are characteristics we already want for our software, Cummins said.
Building hardware has an environmental impact, both in terms of raw materials, and embodied carbon from the energy required, Cummins said. When the hardware reaches the end of its life, it ends up in landfills. E-waste, or electronic waste, takes up space, and puts non-renewable resources like copper, platinum, and cobalt out of circulation.
E-waste can pose health hazards to the people doing the recycling, so the best way to solve the problem is to just generate less of it, Cummins suggested.
Often, software has obsolete assumptions baked into its design. If we can identify those assumptions and update the design, we can improve performance, reduce latency, reduce costs, and save energy, Cummins explained:
Many Java frameworks make heavy use of reflection, which allows the behaviour to be updated dynamically. But for modern applications, that dynamism requirement isn’t there anymore. We don’t swap out application components at deploy-time or run-time. Applications are often deployed in containers, or the complete deployment package is generated by a CI/CD run.
To reduce the environmental footprint, Cummins suggested switching systems off when they’re not in use. Many organisations will run a batch job at the weekends, but keep the system doing the job up all week. Or they’ll keep staging systems running overnight, when no one is using them:
People are nervous about doing this because we’ve been burned in the past by systems that never behaved correctly again after being turned off. This fear of turning things off is kind of unique to computer systems. Nobody goes out of a room leaving the light on because it’s too risky and complicated to turn the light back on.
Boilerplate code- code that’s pretty much the same in every application- is a sign that the API design, or maybe even the language design, isn’t quite right. It’s a waste of time for developers to write code that isn’t really adding differentiated meaning, Cummins explained:
The solution to boilerplate is not to get AI to write the boilerplate; the solution is to design more expressive APIs.
Cummins mentioned that there’s evidence that we can achieve more per working hour if we work less, and achieve more overall:
Henry Ford moved his factories from a 48-hour, six-day working week to a 40-hour, five-day working week, after his research showed that the longer hours did not result in more output. More recently, a study found that companies experimenting with four-day weeks report 42% less attrition, which makes sense, and a 36% increase in revenue, which is perhaps more surprising.
At an individual level, studies find that switching off can improve productivity, Cummins said. One mechanism for this is the default mode network, an area of the brain that becomes more active when we’re not doing anything. The default mode network is involved in problem solving and creativity, which is why so many of us have great ideas in the shower, she said.
Cummins mentioned Jevon’s paradox, which says that increasing capacity increases demand. This is why widening highways doesn’t reduce travel times – more cars use the new, wider, road, and so traffic jams still happen. We can take advantage by leveraging an inverse Jevon’s manoeuvre. If we work shorter hours, the demands on our time become lower, and we can still achieve important things, she concluded.
InfoQ interviewed Holly Cummins about eliminating software waste and reducing the environmental footprint.
InfoQ: How can we eliminate software waste?
Holly Cummins: Dynamism has a cost; many Java applications are paying the dynamism tax, without getting a benefit. Quarkus fixes this by providing a framework which allows libraries to do more up-front, at build time. That shift to build time gives applications which have a smaller memory footprint, and run much faster.
Also, smaller, fine-tuned, generative AI models can sometimes give better results than big models, for a lower cost, and with lower latency. Or for more complex problems, linking a few smaller models together with an orchestration model can work great. It’s challenging the assumption that bigger is always better.
InfoQ: How can we build systems with a smaller environmental footprint?
Cummins: We should design systems to have a light-switch-like ease of turning them on and off. That means idempotency, resiliency, and infrastructure as code. That’s more or less what you need anyway if you’re designing cloud native systems. Once the systems support it, we can automate turning systems off when they’re not needed. I call the two of these together LightSwitchOps.
Just turning things off can generate pretty huge savings. For example, a Belgian school saved €12,000 a year with a script to shut computers off overnight, and a US company reduced their AWS bill by 30% by stopping instances out of working hours. Scripts don’t need to be home-rolled, either. For a more interactive solution, Daily Clean gives a nice UI for setting power schedules.
MMS • Eran Stiller Daniel Bryant Sarah Wells Thomas Betts

Transcript
Thomas Betts: Hello and welcome to the InfoQ podcast. I’m Thomas Betts, and today we will be discussing the current trends in software architecture and design for 2025. One of the regular features on InfoQ are the trends reports, and each one focuses on a different aspect of software development. These reports provide InfoQ readers with a high-level overview of the topics you want to pay attention to. We look at the innovator and early adopter trends to see what they’re doing and maybe it might be appropriate for you to adopt in the next year or so.
Now this conversation today is just one half of the trends report. On infoq.com, you can find the trends graph and the written report, which has a lot more information about topics we might not be able to go into detail today in this conversation. Joining me today are a panel of InfoQ editors and QCon program committee members, including Eran Stiller, Daniel Bryant and Sarah Wells. So let’s go around and do quick introductions, starting with Eran.
Eran Stiller: Hi everyone. My name is Eran Stiller. I’m a chief architect at Cartesian, which is a small startup, six people startup, which is always exciting. I’m also an InfoQ editor for the past, I don’t know how many years. And I think as every year, I always wait for this trends report. I think it’s one of the fun things they do every year. So yes, can’t wait to start.
Thomas Betts: Daniel?
Daniel Bryant: Hi everyone, Daniel Bryant. I work at Syntasso on platform engineering. Long career in development and architecture as well. And again, I’m very lucky these days I get to work with a lot of architects in my day job. Super excited to be writing for InfoQ as well, doing news management and helping out at QCon whenever I can as well.
Thomas Betts: And finally, Sarah.
Sarah Wells: Hi. Yes, I’m Sarah. I am chairing the QCon London program committee this year. I am an independent consultant, an author with O’Reilly, and my background is as a tech director and principal engineer in content API, microservices, DevOps, platform engineering, a whole bunch of areas.
Thomas Betts: A little bit of everything.
Sarah Wells: Yes.
Thomas Betts: And myself, like I said, I’m Thomas Betts. My day job, I’m a solution architect for Blackbaud, which is a software provider for Social Good. I’ve been doing this software development thing for longer than I care to admit and been an InfoQ editor for almost a decade. So like Eran said, this is one of my highlights of the year to be able to talk about these things and write up the report.
AI for software architects – LLMs, RAG, and agentic AI [02:43]
Thomas Betts: So I think to get started, it’s 2025. I think we have to call out the 800 pound artificial gorilla in the room, AI. Now there’s a separate trends report on InfoQ that’s dedicated to AI, ML and data engineering. I highly recommend it. It’s great for getting into those details of what’s underneath that AI umbrella, but this is the architecture and design trends discussion.
So I want to focus on things that architects care about and we can’t ignore AI anymore. So what are the big concepts that are bubbling up and we have to integrate into our systems? What are the trade-offs that architects need to consider regarding solutions? I know a year ago the trends report, we called out LLMs, were just brand new, but within a year they were already early adopter technology, but a lot of those cases were glorified chat bots. So Eran, I’m going to start with you. What’s changed in the past year? What are we seeing, the innovation that architects had to respond to?
Eran Stiller: Yes, I think that the landscape is just exploding. Like, in terms of architects, the amount of things that we need to know now that we didn’t need to know, I don’t know, two years ago, it’s just mind-blowing. For example, whenever I look for articles for InfoQ, like to cover in InfoQ, the amount of AI topics that I go through that are directly architecture related is amazing. You mentioned LLMs, which is the big elephant in the room. We’ve all been using it, but now it has all kinds of these satellite technologies around it that we also need to be aware of. And sometimes we use them as a service, we don’t care how it’s built, we just have an API, we just use it and that’s it. And that’s great. As an architect, you don’t need to know everything, but you need to know it exists. And sometimes you need to implement it yourself.
So some examples include RAG, retrieval-augmented generation. So basically, which is a simple way to enrich the context for an LLM. We want to use an LLM, you don’t want to train the model yourself, but you want to fine tune it to your own needs. For example, you’re in organization, you have a bunch of documents, or maybe you’re an architect, you have a bunch of ADRs, you want to ask questions about them, and you want to know why was something done two years ago, three years ago and who did it. So you can use RAG to enrich that content. Again, as I said, we’re not going to go into detail of how it’s done, but when I look at various articles that big companies, their authors write, they often use it to do various things to achieve in their systems. So RAG is one.
We’ve also recently started seeing growth in systems that are called Agentic AI. Before that it was called AI Agents. I think they changed the name to Agentic AI. Again, in a nutshell, basically what it means is you give AI a bunch of tools that it can use. So for example, it can go search the web, it can go and call some API call. And you give them, the AI, some description of these tools, what they can do, how to use them. There’s a protocol around it which Anthropic introduced. It’s called MCP, like a model context protocol, if I remember. I hope I’m not wrong in the acronym. And basically, it makes things more interoperable. It can use more stuff around it. So again, a lot of acronyms, a lot of things you need to know. As an architect, you don’t necessarily need to know the nitty-gritty of all of it, but you definitely need to know what you’re doing and you don’t want to be caught off guard.
Thomas Betts: Yes, what is the shape of the box on my diagram? Like, “Oh, here’s an LLM. Well, what is it used for? When would I use it?” And I’ve seen a lot of people thinking you can use an LLM for everything, I can put AI in anywhere. And they don’t realize, just like any software tool, there are trade-offs, right? These are non-deterministic software. If you wanted to have the ability to calculate numbers exactly, it’s not good at that. It’s great at predicting the next word, but it’s not great at doing simple math, so don’t ask it to do that. Don’t think you can replace all of your software with a bunch of AI boxes. I think the Agentic is one of those things where it goes one level higher, and this is where architects have to start thinking about, “Okay, so do I have different components in my system that I can have parts of AI operating together?” Daniel, have you seen stuff like that too?
Daniel Bryant: Yes, I mean I think the interesting thing that, to me, what you were saying there, Eran, is the MCP stuff. Because my previous space was very much focused on API’s. I think the angle I’d look at it, what I’m most interested in, is as an architect thinking about my responsibilities in relation to the API. So, I mean, it applies for whatever you’re sending over the wire to any third-party AI, but to your point, people are almost putting everything into LLMs. Before you know it you’ve got like PII, personally identifiable information, private information, stuff that shouldn’t be going over the wire.
Now we as architects need to have a handle on that, right? What’s being sent, how’s it being processed? Like in the UK and EU we have GDPR, but there’s many of the laws across all the lands around the world. But I think that’s what I’m most interested in at the moment is, as we’ve all said, they’ve taken the world by storm and we are, as architects, almost not getting time to catch up on some of the impacts and choices we are making around the security, the observability, the extensibility, the maintainability. All the other things we love as architects are kind of being thrown a little bit out of the window. So I’m encouraging folks to think good design principles, think good data hygiene, think good API design. That is really important, regardless of what you’re calling into, but very much with LLMs and this AI services.
Sarah Wells: I think that’s a really interesting challenge for architects, because every business wants to tell a story about using AI. So there’s a lot of pressure to get something out there really quickly. So you want to put in all of the -ilities, but how do you push back on someone saying, “Well, no, but I need to have it. I need to be able to tell this story next week”. So I think it’s always true that you’re balancing those as an architect, but there’s a lot of pressure on it right now.
I was talking to Hannah Foxwell earlier today. She’s going to give a talk about Agentic AI at QCon London, the closing keynote. And she mentioned just in passing about thinking of the agents like they’re microservices, because when you’ve got different agents that have different skills, so they have different things they can do, you’re composing them together to deliver some level of functionality. And I think that seems to me a really useful way for architects to think about this. How are you going to put multiple boxes together and the things around that to check whether you are actually just passing rubbish information on between agents.
Thomas Betts: Right, right. And then it goes back to some of the things Daniel was mentioning. You talked about the security aspect of it. You don’t want to send the LLM all of your personal PII data and all your customer data. How do you scrub that down so you send enough information that’s useful? And when you think about it, like microservices, I like that analogy because a well-designed microservice architecture, you have very clearly defined context boundaries, right? Like here’s the contract of how you talk to me, and here’s what I share with you. I may have a lot of private information stored in my database that I’m not going to share with you, but here’s what is in that public contract. So the thing about the agents, in that same way, really seems to mesh with my idea of how to design a system into reusable elements.
Eran Stiller: Or as an architect you can decide, “Well, I really do need to send that private information”. And then you can think, “Okay, maybe I’ll run that LLM locally”. And then you get into the big, entire world of open source LLMs and how do you run them? It goes also into the platform architecture. How do we scale them? How much would it cost to run all these LLMs? Maybe something about, “Okay, maybe..”. We haven’t mentioned, there’s also something that’s called small language models. “Maybe I’ll run this fine-tuned small thing that can do what I want”, but you really need to understand all these things in order to make these decisions.
Thomas Betts: We have a trend, I think it’s on the early adopters, the edge computing. Architects are thinking about how much more code can I put closer to the user, because then there’s no latency going over the wire. And if I can put the large language model, well that’s too big, but I can put a small language model and it can do enough, or I can make it specially trained for that use case, that’s going to run in that environment. This gets back to, we now label everything with AI and a lot of times it means LLMs, but some of this is just core machine learning. And like I said, we’re not going to go into the details, but this is… Create a small model. Maybe it’s a language model, maybe it’s some other thing. So those ideas have been around for a while. We’ve been able to distribute smaller models before, it was just when the large language models became big a few years ago that they became enormous, right?
This wasn’t saying you could run on your machine. So how do we get to the other side of the teeter totter and move the scales? So the last thing I wanted to talk about with AI was the role of the architect in an AI assisted world. Because we’ve had this topic on the trends report for… In a various form for the last, I don’t know, five, six, seven years at least. Architect is a technical leader. Socio-technical considerations, architects need to worry about. I’m not saying I need to bring the AI into my socio-technical aspect, but maybe I do. Are there things that I can design with Conway’s law around a team? And then well, is it a team that’s made up of AI programmers or software engineers who are augmented by more AI? Can I make my architecture decisions better because I’m using the AI to search my previous ADRs? Or I can ask it to review an ADR before I go and present it to someone else? Has anyone else run into people doing their job differently because this is just a new tool they have at their disposal?
Eran Stiller: I think I’ve started doing my job differently as an architect because of these tools. For example, as an architect, one of the things you’re naturally expected to do other than architecting the system is mentoring team members, deciding on coding standards, coding guidelines, code quality, and how do we do code reviews, stuff like that. And now when I have all these tools, I can actually use them as part of my job to do all these things. So for example, we have various code assisted tools like GitHub, Copilot, Cursor, whatever. There are many of them, and I know at least some of them, I don’t know all of them, but at least some of them have this mechanism where you can fine tune them, you can provide rules on how to help your developers. So for example, specifically in my company, we’re using Cursor and it has a mechanism that’s called Cursor Rules.
And what that means, you can provide the… You can tell it, “Okay, these folders are React apps and these are the best practices we implement when we write React, and these folders do that and these folders do that”. And you can provide as an architect all your guidelines there. And then when your developers use the tool to write code, because I hope they do it because it makes them much faster developers, more efficient developers, then they get all of these code guidelines already built into what they’re writing, which makes my work easier as an architect. So I think definitely there’s lots of places we can use them, we can extend it to how do we do code reviews and so on, but that’s my 2 cents.
Thomas Betts: Yes, I think we’ve had things like linters and an editor config file that says, “Oh, you need to put your curly braces at the end of the line. No, on the next line and two space tabs”, and whatever.
Eran Stiller: It’s the high level.
Thomas Betts: You can define those things, but they’re very much at the syntax level. I think what architects… Some companies have been able to introduce fitness functions and say, “Okay, this can tell that this module is adhering to our architecture guidelines”, but those are often more squishy. And so I think there’s going to be a place where we might be able to see some AI based tools be able to just analyze the code, not straight from a static analysis like, “Oh, you’re using an out-of-date library”, or “You didn’t follow this”, but does it smell right? Did you do the thing correctly? Did you follow what we’re trying to do? Help me with my pull requests before the person has 10 years of experience again, weigh in and say, “You know that’s not how we write things. You should pull this out into a separate method”, that type of stuff.
Cell-based architecture for resilience [15:31]
Thomas Betts: So last year we added cell-based architecture as an innovator trend and we’ve seen a lot more companies adopting this as a strategy to improve resiliency, but it also has potentially good cost and performance benefits. Daniel, you want to give us a quick refresher on what’s the idea behind cell-based architecture and when is that pattern appropriate?
Daniel Bryant: Yes, sure thing, Thomas. I mean, it definitely dovetails on microservices, which I’ll doff my cap to Sarah. Here you’re the expert in the room on microservices, so we definitely hear from you in a second. But Rafal Gancarz did a fantastic eMAG for us in InfoQ talking about the cell-based architecture.
For me it is an extension to microservices, and you focus a lot more on the cell as the unit of work here, and you are isolating… It’s almost like a bounded context plus plus. It’s a cell of work and you’ve got very strict guidelines around bulkheads and failure. A lot of companies… We saw great talk, I think it was QCon San Francisco by Slack who used a cell-based architecture and they’d architected these cells, so if one cell breaks, falls over, gets compromised or whatever, it doesn’t take out the whole system. So it’s microservices, but with a much stricter boundary in my mind, and the way you operationally run them is interesting from an architecture standpoint, because they have got to be isolated. But I know Thomas, you’ve done a fair bit, I think, of work with cell-based architecture as well, right?
Thomas Betts: Yes, I mean I haven’t personally implemented them, but the coverage on InfoQ definitely exposed me and we’ve seen a lot more companies writing on their own blogs of, “Here’s how we did our cell-based architecture”. So that’s how we can tell it’s being adopted more. I like that it was, “Okay, we’re going to build all these microservices”, and then things like a service mesh, because I need to do service discovery. We had all these other tools come in, but you can get to the point where if one goes down, then I don’t know how to contain the blast radius and how do you impose logical boundaries around those things? So it’s a little bit of, “I want to be deployed into multiple availability zones, but thinking about that a little bit more and sometimes bringing in the business context, not just the technology side”.
So it’s like, “I want to make sure that customers in the East Coast or Europe or wherever they are are served the closest traffic”. We’ve had those patterns for a while, but when something fails, how do we make sure that that doesn’t blow up the rest of the region or take them down entirely and they’re still able to do their work? I mentioned the cost and performance benefits. Sometimes because you start restricting the boundaries and say “You can only call somebody else in the cell”. You’re not sending that traffic over the wire, over the ocean maybe. So you’re making a lot more closer calls. So sometimes things just get faster because you’ve put these constraints around it. But Sarah, I’d love to hear your ideas, because I think this is core to things that are in your book.
Sarah Wells: So it’s really interesting because I think I was thinking about these things without knowing cell-based architecture as a term. Certainly when we were doing microservices at the FT, we had a lot of cases where we thought, “Well, how can we simplify what we’re trying to do to make it easy for us to reason about what might happen when things fail?” So for example, we had parts of our architecture where we decided we didn’t want to try… We basically were going to have databases in different regions that didn’t know anything about each other. So that in theory, the same data in both, but we’re not even attempting to double-check other than occasionally counting records, just to simplify what we’re trying to do.
We did the same thing with calls between instances. Well, do we want to call to a different availability zone to a different region? We’re not going to go across regions. So I think providing the context for how you decide the terminology for making those decisions, because people often talk about things like bulkheads, but it’s quite far down the list of things you do in a microservices architecture, because it’s confusing. Everything that you have to consider is confusing. So you’re like, until you have a massive incident, it’s normally not the top of your list. But if you can start off by thinking in terms of, “Well, which of these services hang together? How could we split them up? Where are we separating our data?” I love the idea that you can save money by deciding that you don’t make calls across availability zones. I just think, well, that seems like a really sensible idea.
Monzo Bank’s unorthodox backup strategy [19:47]
Thomas Betts: And I think there’s a parallel discussion here. Eran, you wrote the article about Monzo and their backup strategy, which is sort of related. That was their thinking of, “If something goes down, how do we have a backup?” Because an online bank, “How do we have a backup bank?” But it wasn’t as simple as like, “Oh, we have two cells that are identical”. Can you go into the details of how they thought through that problem? I think it’s an interesting one.
Eran Stiller: An interesting one, and I saw some interesting discussions about this item online after I posted it, where in that case… I think we should probably have a link to the article somewhere. Basically what they’ve done is instead of having an identical replica, which is what we usually do, we have this standby or active-active or whatever it is that we do, they follow, “Okay, in case of an outage, what from a business perspective, what are the most important things that we want to keep alive? What brings us money?” In their case, it was transactions. We want people to be able to use their credit cards and buy things, because if they can’t, it’s going to be bad for the bank obviously. And once they had that list, they architected their, how do you call it, the secondary zone or their backup deployment to only implement those things.
And that means that the environments are not identical. And that means they brought business insights into the way they implemented the backup strategy. And so what they said, “We have this main environment, it does everything, but we have this small thing here on the side that’s isolated, and that’s very much aligned to the cell-based architecture concept”, even though it’s not a cell-based architecture. But the concepts are the same. “We want to have this isolated, we want to have separate, we don’t want to have common points of failure”. So one of the things they’ve done, for example, is they didn’t take a subset of the services and just deploy it to the secondary environment. They wrote a new set of services, it’s a different code base. And I remember reading it, even when I was reading it first, I said, “But why? It’s such a waste. You’re writing all this code and how are you going to test it? It’s on backup. How do you know it’s even going to work?”
And I actually chatted dollars, I asked them a bunch of questions about it and I actually came to learn and appreciate this approach where it’s a separate call base. So if you have a bug in the main environment, that bug is not going to overflow to the secondary environment. It’s still going to be there. And then in regards to how do you test it, where you test it in production, every day, it takes some percentage of the traffic and you route it there and you see it works and you compare it at the end. So it’s not only when there’s an outage, you run it all the time just on a small subset of users who get the emergency experience. Fits well with the cell-based architecture theme of, “We want this stuff”.
Thomas Betts: And it goes back to what are the -ilities that the architects care about? In this case resiliency, the ability to survive an outage, whether that’s code that didn’t run or the availability zone goes down. Like, “We need to be able to still run the business. How do we solve that?” And it’s clearly a case of one size does not fit all. Even the cell-based architecture is not a, “I can just press this button and boom, I have a cell-based architecture”. You have to think about it. In Monzo’s case, they made a lot of decisions to implement things differently. Like you said, a different code base that seems like a waste actually provides extra reliability.
Privacy engineering and sustainability [23:20]
Thomas Betts: So those types of trade-offs show up everywhere. And I think it’s just one of those things as an architect you have to consider, “Is there some different way we want to solve this?” And that’s what I love hearing about these innovative stories. I would not have built a separate smaller backup bank, but I can definitely see the benefit of it. I think the other thing we’ve seen about, not just thinking about reliability, but some of the new trends we had were privacy engineering, and sustainability and green software came onto the list last year. Sarah, you made an interesting comment before we started recording, that we need to have a shift left mindset around these things, about the adoption. Can you tell us more about what you were thinking of when you said that?
Sarah Wells: Well, I just thought that this is the architecture equivalent of all the shift left things that were happening in software engineering where people were involving testing earlier, involving security earlier. It feels like it’s the same pattern of, “If you consider this early, it’s less costly to do it. You can build it in from the beginning”. So if you think about you’re building your architecture so that you are considering privacy, so you’re thinking carefully about where you’re putting that data. And I think there are lots of places where people suddenly go, “I have no idea where I’m exposed and where private data may be stored”. And I think with sustainability and making sure you’re not incurring too many costs, often you only look at that after you realize your bill is really high. But if you think about it early, it’s great. But I think you might face some of the same challenges, because you have to convince people that you should spend more time investing in the thing that the moment isn’t critical.
So if you’re starting to think about how do I build this so it won’t cost a lot at the point where it isn’t costing a lot, because you haven’t built that much of the system, but it’s kind of tough in the same way that it can be hard to persuade people to invest a lot of time in thinking about security when they haven’t yet built a thing that they know they can sell. So I thought that was just an interesting pattern, and I wondered what else might move earlier in the architectural thinking, other things, because obviously with shift-left in engineering, everything gradually just moved left.
Thomas Betts: The left keeps moving, right? The goalposts keep going. You just have to keep going more and more left, because who’s doing this. Daniel, you were nodding along. I know this is some of the platform thinking. I think that we’re going to get to that a little bit more, but how am I going to deploy it? How do I secure it? How do I make it sustainable or use less energy or less carbon? All those things come into play at some point. Are you seeing in your day job, or in stuff on InfoQ, people talking about these trends earlier than they were before?
Daniel Bryant: Yes, for sure. And to Sarah’s point, I definitely see a split, because I’m very lucky, I get to work with startups and then big banks and other enterprises as we call them as well. And the startups is fundamentally like, “Can I get product market fit?” So they are not even threat modeling sometimes, they’re literally just like, “Hey, I’m going to put this thing out there, if I get some customers, we’ll get some funding and then we’ll think about doing this stuff”. And more power to you if you are a startup, that’s how I like to work. Sounds like, Eran, you’re in that space too.
I like the startup vibe, but you’ve got to respect it’s a slight hustle until you get product market fit. But the big banks and so forth, they are doing what is akin to threat modeling, but more green modeling, if I’m making up the term, I’m not sure if that is a term, but you know what I mean, right? They’re doing more analysis. They realize that running things green, not only is it good for the mission, but often it’s cheaper, more cost-effective should I say. So they are spending time now. I think the shift left message has landed with a lot of architects, particularly in enterprise space.
Eran Stiller: And they even showed on the UI, they show, “Hey, you’re in this mode right now because we’re testing and they can opt out if you want”. So that’s like an innovative approach. Also, as I said-
Daniel Bryant: They have a clear line to justify it, but if we threat model now we spend a week doing this, it’s going to save us maybe six months of battle testing at the end. If we bake it in now, it’s going to cost less. Same thing with even the green modeling or thinking about your carbon footprint. It’s so much harder to get rid of that cost at the end of process than it is at the beginning.
So I’m definitely seeing folks doing that. Softly, softly. And I do think to the points we’ve made at several point in this podcast, the tools really need to help you do this, whether it’s AI powered or not, but something I talk about a lot on my team is there’s always a certain amount of cognitive load. And the danger is if you’re shifting stuff left, you often shift that load left onto other people. So it used to be the security folks, the cost, and us folks at the end of the pipeline, now it’s being shifted onto us as developers, us as architects, and without the tools, you just get cognitive overload. You just get overly burdened.
Commoditization of platform engineering [28:00]
Sarah Wells: Isn’t this an opportunity for platform architecture, for building the stuff into that platform so that people don’t have to take on that cognitive load? It’s already there in whatever you’re deploying, the tools that you’re using, everything that’s there is your foundation?
Daniel Bryant: A hundred percent agree, Sarah. This is what definitely I’m seeing in my day job. Folks are trying to feel platforms, even more so the context I’m working in with compliance in mind, “Making it easy to do the right thing”, is a phrase I find myself saying a lot. And again, I’m quoting other people standing on the shoulders of giants here, but yes, a hundred percent Sarah, to Eran’s point, they’re baking in certain rules and checks along the way, but even some guidelines and so forth in the tools early on in the process to make it easy to do the right thing.
Thomas Betts: Yes, and that’s where the architecture… And this is where platform architecture I think is the term, is the thinking about how do we make a platform that takes some of that cognitive load off the people who are going to be actually driving the carbon usage, the privacy concerns, the security concerns. If I have to have 10 teams and they all have to think about, “How do I make my data secure”, and “How do I make this call”, or whatever it is, if they all have to think about that, that’s distributing the energy and the cognitive load around versus, “Okay, we have taken the time to figure this out, solve it in the best practice way. And if you get on our paved road platform solution, maybe you could do a little better, but you’re going to do pretty good for everybody”.
And I think that’s the good enough approach that architects need to try and get to, not the, “Perfect as the enemy of good enough”, that we want to have the solution that applies to enough people. Because if you wait until the end and then you get some, “Oh, here’s a GDPR”, and pretty soon the only solution is, “Let’s just secure everything because we don’t know how to secure in just the little bits that we need to do”.
Sarah Wells: I always think that you don’t want people to have to go and read something that explains to them what they’re expected to do. You want to just make it so they can’t do it wrong. That’s an architectural thing. Make it so that people can’t shoot themselves in the foot.
Daniel Bryant: Yes, well said, Sarah.
Thomas Betts: The last thing I wanted to talk about for platforms, my sense Daniel, is in the last, say five or 10 years ago, this was much… You’d have your DevOps experts on staff and they would have to be building your paved road, your engineering system, whatever it is. A lot more of that custom code has just become commodities off the shelf software. And first two questions. One, am I correct in that assumption? And second, how do architects respond to that when we’re shifting from a build versus buy mentality for the platform?
Daniel Bryant: Yes, I’m seeing tools that a lot of the platform architecture and the software architecture is symbiotic. I’ve done a talk actually at KubeCon last year about… It was platform engineering for software architects, was my pitch, because I’m bumping into a lot of folks. I think I’m going to KubeCon soon, and the largest chunk of the audience are actually application architects going to KubeCon, which has historically been a very much Kubernetes platform shaped conference, which again, I grew up in, I know and love, but when architects started rolling in now I was like, “Oh, these conversations I’m having with folks are very different”.
But there, to Sarah’s point earlier, they’re being told that you’ve got to go Kubernetes, because some vendors are actually packaging their software as Kubernetes packages there. “If you are not running Kubernetes, you don’t get access to the latest version of the certain checking software or verification software”.
I’ve literally heard that in banks where they’re buying off the shelf components, and it’s now being packaged as Kubernetes components. And if they don’t have Kubernetes, that’s a problem. So I think the application architects are having to be much more aware of what platforms… How to define them, what they offer, these things. Now, I talk a lot about platform as a product. You have to have a platform that makes it easy to do the right thing from getting your ideas, your code tested, verified, secured, all the way through to adding value to users in production.
And as we’ve said a few times in this podcast, make that process as pain-free as possible. But as an architect, you’ve got to know all these things. It is another thing, another group of things to learn about Kubernetes, Serverless. There’s all those various vendors that Heroku and Vassal offer different forms of platform as a service and you often get them popping up a shadow IT in big enterprises. So you have to be aware of these things and offer guidance as to what is the way to do things in this company. “We lean towards this approach. We don’t go here because here’s the trade-offs and we don’t like these trade-offs”.
Thomas Betts: Yes. Yes, I made a comment, I met with some of my coworkers last week and the product manager for our platform that we build, our engineering system, I told him, “I don’t speak Kubernetes, and thank you for that”, because that’s a huge win for me when I’m doing the architecture. I know that the pods are going to get created and I can say, “Oh, I need four, I need two”. Now, there’s times when I need to know what that means underneath the covers, but most of my day I don’t need to. So it’s like when I need to dive deep, and this is the T-shaped architect, I need to be broad in a lot of topics and then be able to dive down and the things that I don’t know about, I want to know who are the experts that know that.
And so that goes back to the same ideas of compartmentalization. Put the microservices together, have these little pods, whether it’s people or servers of where’s the specialty? How do I do that? Is it an Agentic AI that I’m calling to do that, or is it the platform team or is it this very specific stream aligned development team? So being able to think in those pieces helps reduce the cognitive load on the architect, because now you don’t have to know about all the details all the time.
Eran Stiller: But I think it’s very similar to what you mentioned about the AI, that you don’t necessarily need to know the nitty-gritty, how it works and how to implement it, but you need to know it’s there and what it gives you and how you can use it to your benefit, and what are the pros and cons of each, again, at a high level. Because if you do know these things, it’ll make your job as an architect much easier, and you’ll probably be able to do a much better job with it. And that’s where I think also QCon fits in and all the other conferences that you go and learn this stuff.
Closing thoughts [34:15]
Thomas Betts: I’m going to leave it there. That was a fantastic wrap up, Eran, saying that we need to know the high level aspects of what are these things, and then if I need to dive deep, just go read Qcon.
Eran Stiller: I love that.
Thomas Betts: Go to attend Qcon. So I want to thank everyone again for attending today, Eran, Daniel and Sarah, thank you for being here.
Eran Stiller: Thanks.
Sarah Wells: Thank you.
Daniel Bryant: Thank you very much.
Thomas Betts: And we hope you’ll join us again for another episode of the InfoQ podcast.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.