Month: May 2025

MMS • Ben Linders

After being on an agile journey where practices have primarily been centered on IT, a company is now exploring ways to extend them beyond IT and scale their approach. At Agile Tampere, Ramya Sriram presented how they focus on continuous improvement through agile practices, feedback, and customized maturity assessments. Emphasizing flow metrics with a strong learning culture, they aim for efficiency and sustainable growth.
Sriram mentioned that their company has reached a strong position in its agile journey, and is reflecting on how they want to evolve and transform further:
This marks the beginning of what we’re calling Agile 2.0, where we are focusing on scaling and broadening our impact. Teams outside IT are also learning more about agile practices and we are also studying agile hardware to understand its full usage.
We’re proud of our current maturity level, but as part of our commitment to continuous improvement, we are always learning and adapting, Sriram said. Their next steps are guided by insights drawn from maturity assessments, interviews, and feedback, focusing on areas such as teamwork, agile practices, value delivery, learning and improvement, quality practices, customer satisfaction, organizational alignment, and delivery execution. Each of these areas presents both strengths and opportunities, which require ongoing evaluation and action, Sriram mentioned.
To support this evolution, Sriram mentioned that her company has initiated efforts to expand agile training and coaching, providing teams with the tools and knowledge they need to grow. They have also conducted bootcamps to collaboratively identify challenges, share best practices, and tackle impediments together. This collaborative approach is laying the foundation for a more integrated and impactful agile journey, Sriram said.
Sriram mentioned that they have been using flow metrics and maturity assessment tools to level up their agile practices. These tools have been game-changers for planning outcomes, boosting efficiency, and delivering products with more predictability and agility, she explained:
We started with the SAFe toolset, specifically the Facilitating SAFe Assessments framework, for our maturity assessments. But instead of a one-size-fits-all approach, we customize the templates to fit our unique needs. This helped us focus on what really mattered to our teams and stakeholders.
Their teams keep a close eye on their flow metrics. Sriram mentioned that they have been inspired by measure and grow from the Scaled Agile Framework. These metrics aren’t just numbers—they reveal bottlenecks, highlight challenges, and guide us toward better planning and smoother workflows, Sriram explained:
It’s all about finding balance. If teams only focus on technically completing requirements without considering real stakeholder needs, people aren’t happy. On the flip side, if teams take on too little work, stakeholders might feel like their priorities are constantly being pushed to the next quarter.
The sweet spot lies in balancing work intake with capacity while staying flexible enough to adapt to changing requirements—that’s what agility is all about, Sriram said.
In today’s era of digital transformation, with advancements like Artificial Intelligence, Machine Learning, and Generative AI, the question often arises—are these a boom or a bane? Regardless of the innovations, the cornerstone remains the same: continuous improvement and learning, Sriram said. These drive innovation and pave the way for sustainable progress, she concluded.
InfoQ interviewed Ramya Sriram about continuous improvement.
InfoQ: How do you use feedback from customers for improvement?
Ramya Sriram: Customer feedback plays a big role. Through surveys, retrospectives, and demos, we gather insights that help us continuously improve. Sometimes, it’s a big change, like tweaking release cycles. Other times, it’s small but impactful—like improving communication during a tribe demo, scheduling testers more effectively for UAT, or enhancing end-user documentation.
This continuous feedback loop keeps us aligned with what truly matters, helping us deliver better results while staying adaptable and grounded.
InfoQ: What’s your advice for sustainable improvement in software organizations?
Sriram: For me, the focus is on prioritizing quality over quantity while fostering strong feedback loops to continuously evolve, learn, and refine how we work. It’s crucial to nurture and even deepen our commitment to a culture of continuous learning and innovation. Breaking down silos and promoting cross-team collaboration is essential to this effort.
We must also keep a close eye on measuring and optimizing workflow by addressing bottlenecks and enhancing efficiency, all while emphasizing the importance of people and ensuring a culture of psychological safety.
MMS • Rashmi Venugopal

Transcript
Venugopal: These are some typical growth trajectories of successful companies. The hockey stick being the most sought after and popular one. The software systems that worked well during the initial phases of a company, phase A, will not be sufficient as you prepare to scale your business in phase B. The exponential growth phase, phase C, requires drastically different software capabilities than A or B. Successful companies, like the ones that live to see exponential growth, outgrow their software systems one way or the other. I’m making the case that legacy systems are a byproduct of success. Despite being a byproduct of success, legacy systems have a bad rep. Just the word legacy evokes strong emotions, and for good reason. We associate legacy with technical debt, painful migrations, high maintenance costs, and poor developer experience.
For the long-term success of your company, build the muscle to renovate legacy systems. While legacy systems are a byproduct of success in the past, success in the future depends on your ability to not let legacy systems get in the way of the growth for your company. That brings me to my first takeaway, that legacy systems are inevitable. Don’t let them weigh you down. Make them work for you instead. In fact, this takeaway is the inspiration for my talk.
Background
Welcome to Renovate to Innovate: The Fundamentals of Transforming Legacy Architecture. I’m Rashmi Venugopal, a staff engineer at Netflix. I spent the last decade building and operating reliable distributed systems at scale. During that time, I’ve been fortunate to work with, learn from, and grow amongst some of the brightest minds at Microsoft, CMU, Uber, and most recently at Netflix. First, we’ll unpack what legacy systems are and why they exist. The focus of this talk is technical renovation. We’ll cover what it means, when a technical renovation is applicable, and discuss strategies for effective renovation.
Legacy Systems – What?
What is the first thing that comes to mind when you think of the word legacy? Old, unsupported, unchangeable, and no tech. Let’s see how you all match up with OpenAI’s word cloud for the term legacy. I see a few in here, not bad. As you can tell, the term legacy is quite overloaded. Let’s spend a couple minutes to get on the same page about what legacy means in the context of this talk. I define a system as legacy if it is incapable of keeping up with business requirements. After all, your software systems exist to serve your business goals. Let’s make this more concrete and talk through some symptoms of legacy systems. There are numerous dimensions of complexity in software engineering. Legacy systems usually have substantial complexity in one or more of these dimensions. Working across a large number of teams and people slows engineers down. This is because of coordination tasks. That is organizational complexity.
Operational complexity is when there’s insufficient automation, testing, monitoring, observability leading to high operational costs. Cognitive complexity is when institutional knowledge builds up. Documentation becomes outdated or people turn over. Why is complexity such a bad thing after all? As complexity goes up, innovation velocity goes down. There’s a direct correlation between complexity and innovation velocity. Product and project managers expect productivity to scale linearly with complexity. Engineers, we know better. Our past experience has primed us to be more pragmatic. It is a sign of a legacy system when the reality of how long it takes far exceeds expectations in a bad way.
Another sign of legacy system is degraded quality of experience. Quality of experience measures the overall satisfaction of end users when they interact with a system. I’m sure we’ve all experienced the very real frustration of waiting many seconds for a page to load. Amazon has an infamous study where they quantify the impact of latency on their business. They find that every 100-millisecond increase in latency impacts their sales by 1%. A dip in the quality of experience despite your best efforts to tune them is a symptom of a legacy system. To recap, I consider a system to be legacy if it is incapable of keeping up with business requirements.
Legacy Systems – Why?
Now that we’ve covered what legacy systems are, let’s talk about why software systems become legacy in the first place. The most obvious reason is the rapid pace at which technology advances today. Who here has used two or more of these devices? Systems that were once considered cutting edge struggle to keep up with modern industry standards just a few years down the line. Technology choices become outdated. In addition to this obvious reason, there are two schools of thought that explain software degradation. The first school of thought is the bit rot theory. It states that software gradually degrades over time due to incremental changes to itself or its surroundings. An unused code path is an example of bit rot, so is code duplication. A lack of documentation or a loss of knowledge is yet another example. In theory, bit rot can be kept in check with good software engineering practices.
In reality, bit rot accumulates over time. The second school of thought is the Law of Architectural Entropy. It states that software systems lose their integrity when features are added without much consideration of the original architecture. The primary driving factor for architectural entropy is the real and unintentional tradeoffs that engineers have to make in order to deliver results faster or meet deadlines. Imagine the growth of a successful e-commerce company. In the early stages, they’re focused on establishing a thriving business. Evolving their architecture to be perfect is just not a priority. In fact, changes to the architecture is driven by business needs.
In this example, every new feature is added to the existing monolith, steadily increasing the architectural entropy. In the real world, software systems are affected by all of these phenomena. This explains why outdated and legacy systems are more commonplace than we’d like them to be. Now that we’ve agreed that legacy systems are commonplace, let’s ask ourselves, do we always proactively renovate legacy systems? I wish we did. The inevitability of software degradation on one hand, combined with the lack of renovation of legacy systems on the other, leaves us with systems that are difficult to maintain, understand, and extend. These are the systems that are very likely to get in the way of growth and success for your organization’s future.
Technical Renovation – What?
That brings us to technical renovation. What does technical renovation actually mean? I define technical renovation as the act of upgrading or replacing outdated systems and technology to improve the software’s state of affairs. Every time I bring up technical renovation, I get asked, how does refactoring fit in? Why is technical renovation different from refactoring? I’d like to address the elephant in the room with a closet analogy. Refactoring is like organizing your closet. Organizing involves moving things around. You make it easy to access all pieces of your clothing. You might even get rid of some stuff to make room for more things.
This whole process has a side effect of reminding you what you already have and it potentially influences your future wardrobe investments. Renovation is when you break down the walls of your closet to replace a regular one with a walk-in one. Renovation goes beyond just moving things around. Renovation is when you make a drastic change to shake things up and the end result gives you capabilities that you did not have before. Renovation is usually a much larger undertaking and therefore occurs less frequently than refactoring. While this talk is about technical renovation, I just wanted to pause to say that refactoring is valuable. It is a valid strategy to maintain a healthy codebase and there’s many benefits to maintaining a healthy codebase.
Technical Renovation – When?
Now that we’ve discussed what technical renovation is and how it’s different from refactoring, let’s review some scenarios for which technical renovation is applicable. In other words, if technical renovation were a hammer, what do the nails look like? As your business needs evolve, attempting to reuse existing systems to solve for something drastically different doesn’t typically end very well. Here’s an example of a business-driven renovation. Netflix evolved from a DVD distribution company to a streaming service. The capabilities required to deliver DVDs is drastically different from the capabilities required to stream video on-demand. The systems that served Netflix well in the DVD era isn’t going to be sufficient to run a successful streaming service.
The point being, drastic changes in business needs eventually call for a renovation. Technical renovation is also a valid strategy for an ecosystem-driven change. When the ecosystem changes, the underlying assumptions built into the existing systems are challenged. If you’re going from hosting REST APIs to now serving data behind a GraphQL gateway, a renovation is in order. Technical debt occurs when you borrow from the future to make a tradeoff for the present. Even with the most well-intentioned engineers, there are scenarios when technical debt accumulates, and accumulates to a point of no return. Unexpected longevity is one such example.
Sometimes software systems turn out to be more successful than anyone imagined they would be. While that specifically is a good problem to have, the unexpected longevity accumulates significant technical debt. That makes technical renovation a viable option to improve the state of affairs. These are some nails for the hammer that is technical renovation. Time for our next takeaway. Use the right tool for the right problem. Leverage renovation for the scenarios similar to the ones we just discussed. Refactor your code as often as it makes sense to do so.
Technical Renovation – Strategies
Let’s talk about how to approach a technical renovation next. I’d like to share four strategies to consider as you embark on your renovation journey. I found these strategies useful to do renovation right. My first strategy is evolutionary architecture. Historically, architecture is viewed as something that has to be developed ahead of time, even before a single line of code gets written. It’s also perceived as something that’s set in stone, never to change. In the world of modern technology, this pre-planned approach to architecture doesn’t keep up with the evolving needs of your business. Here’s an alternate approach to consider for your renovation initiative. Evolutionary architecture emphasizes incremental changes because complex systems cannot be fully designed upfront. It advocates for evolvability. When your priority changes, your tools should change with it. How do we make evolvable architecture a reality?
Step one, identify a set of fitness functions that represent the desired qualities of your end state, such as performance, scalability, security. Once you’ve picked the quality that matters the most for your business, use that to inform engineering decisions. In that process, ask yourself some hard questions. Does performance really matter? If yes, by how much? Will users actually notice the difference between a 1-second page load and an 800-millisecond page load? The point is, don’t optimize prematurely. As a rule of thumb, if you don’t regret any of your early decisions, chances are you overengineered. Excessive abstractions or overly generic solutions and premature scalability are some common pitfalls to watch out for.
Step two, invest in continuous delivery. Create an infrastructure that you can use to execute fast. Automate the steps between developing, testing, and releasing a feature. Step three, make small and incremental changes. Making changes in the Big Bang fashion is difficult to get right. Incremental changes makes it easy to course correct as you go. The crux of evolutionary architecture is to make small changes, release them often, and use feedback loops to see how well you’re doing against your fitness functions. As the business requirements evolve, your fitness functions are going to change. Lean into continuous delivery and incremental changes to keep up with your evolving needs.
Speaking of incremental changes, my next strategy breaks down an incremental approach to renovation: make it work, make it right, make it fast. I’m sure most of us have heard of this quote from Kent Beck, we apply to writing code. I’m making the case that this applies more broadly to software engineering, including your renovation initiatives. The first part, make it work, is all about getting the assurance that your problem can be solved one way or the other. From a coding perspective, make it work is all about giving yourself the permission to write ugly, unreadable code. Even if it means you have to hardcode inputs along the way, that’s fine.
In the case of your renovation, use this time to validate your technology choices, handle the common use cases, and eliminate some bad solutions along the way. If your integration is just barely held together by duct tapes, so be it. Now is not the time for perfection. I consider a proof of concept as a good outcome of the make it work phase. It’s time to make it right once you’ve established the validity of your solution. From a coding perspective, you would prioritize readability, adding tests, or even refactoring. For your renovation initiative, make sure your edge cases are accounted for, your fitness functions are being met, and even test against some real-world users to see how your solution holds up. I view a minimum viable product as a good outcome of this phase. A working solution that’s a natural extension of your proof of concept. That brings us to make it fast.
From a coding perspective, make it fast feels like a performance thing. It gets interpreted very literally. How do I make this piece of code run faster? For your renovation initiative, however, make it fast is so much more than just performance. It’s adding documentation. It’s integrating with continuous delivery. It’s setting up observability and monitoring. All this speeds up your development process and is very much in the realm of make it fast. The output of this phase is production grade software that’s ready for prime time. This structured approach to tackling the different aspects of a technical renovation helps break down a daunting endeavor into trackable and manageable milestones. You’re set up to overcome analysis paralysis because you’ve given yourself the permission to just focus on making it work.
Then you iterate to make it right and ensure that your fitness functions are met. If you care about performance, and performance is one of your fitness functions, now is the time to get it right. Lastly, optimize for speed of execution. This structured approach also gives me the clarity I need to move fast without breaking things. My third takeaway is a combination of the two strategies that we just discussed. As you renovate your systems, build incremental and evolvable software that is capable of aligning with changing business needs.
On to the third strategy. Deprecation driven development focuses on what we gain from deprecating as opposed to what we lose. I’m making the case that removing code is as important as adding code. Systematically removing obsolete technology is a prerequisite for healthy software systems. Weigh the tradeoffs before you renovate a feature. Be honest about the return on investments especially when it doesn’t justify the effort required to migrate them, because not all features are equally important. When you encounter a feature that is not critical to the success or the growth of your organization, consider leaving them in the legacy system.
Better yet, deprecate them because the cost of maintaining is often higher than the cost of building them in the first place. Netflix winding down DVD.com is a good example of a product deprecation that was driven by a similar tradeoff, the tradeoff that’s between the cost to maintain and the benefits to business. As the number of DVD members continued to shrink, it became increasingly difficult to justify the cost of providing the best-in-class experience for DVD users. Once the decision to deprecate was made, this clarified engineering priorities. We didn’t invest in DVD related technology the year leading up to the deprecation. No points for guessing what my fourth takeaway is. Removing features is as important as adding new features. Be ruthless about deprecating features that don’t serve your business, because they either weigh you down with high maintenance cost or make your renovation journey endless and expensive.
My fourth strategy is intentional organization design. As your company grows from phase A to B to C, renovating your organization is just as important as renovating your software. Intentional organization design is all about identifying the optimal collaboration model to drive the best business outcomes. The goal is to make it easy for ideas to flow through the organization. In addition to the flow of ideas, organization design also has an impact on architecture. Conway’s Law explains the synergy between the two. It suggests that the way teams are organized influences the architecture of the systems they create.
For any organization that’s undertaking a technical renovation initiative, it’s a good idea to first take a step back, assess the org structure, identify any changes that might be worth making. It could be to streamline communication or minimize cross-team collaboration. Let’s look at an example of organizing teams to make this more concrete. Design A involves grouping engineers based on their function, like frontend, middle-tier, backend. Design B groups engineers based on a common product deliverable, but as full-stack teams. Each design has its pros and cons. A optimizes for engineers to ramp up quickly and provides space for them to become experts at their craft.
If every new feature requires making changes to all three parts of the stack, they will need somebody outside to coordinate and assign tasks and manage dependencies. If you happen to be optimizing for minimum cross-team collaboration, Design B might be more efficient for you. In summary, you have to choose to strengthen the communication paths that are most important for your organization, because every communication path can’t be the strongest.
The Growth Mindset
While this brings us to the end of the renovation strategies that are important to consider as you work to transform your legacy systems, I’d like to talk about an important piece of the puzzle that’s required to bring all the work for a technical renovation to actually come together, the growth mindset. The strategies I shared may seem ambitious. They’re intentionally aspirational in the spirit of shooting for the stars and landing on the moon. Also, because there are no silver bullets for technical renovation. The ideal approach is highly context dependent. Your strategy and decisions should be debated on a case-by-case basis and accounted for the unique circumstances and goals for your organization.
Recap
Start with the right perspective, the perspective that legacy systems are inevitable in successful companies because they are a byproduct of success. For continued success, don’t let them weigh you down. Invest in building the muscle to renovate legacy systems. Use the right tool for the right problem. Refactoring solves some problems, but not all. Invest in technical renovation when it makes sense to do so. When you do invest in renovating your systems, approach that with a focus on building incremental and evolvable systems that keep up with your business. Removing lines of code is as important as adding lines of code. Regardless of what the growth trajectory of your company looks like, you can rest assured that the path to successfully transforming legacy systems will be bumpy. Embrace the growth mindset, seek feedback, learn from your mistakes, and enjoy your renovation journey.
See more presentations with transcripts
MMS • Robert Krzaczynski
Researchers at Carnegie Mellon University have introduced LegoGPT, a system that generates physically stable and buildable LEGO structures from natural language descriptions. The project combines large language models with engineering constraints to produce designs that can be assembled manually or by robotic systems.
LegoGPT is trained on a new dataset called StableText2Lego, which includes over 47,000 LEGO models of more than 28,000 unique 3D objects, each paired with detailed captions. The models are derived by converting 3D meshes into voxelized LEGO representations, applying random brick layouts, and filtering unstable designs using physics simulations. Captions are generated using GPT-4o based on renderings from multiple viewpoints.
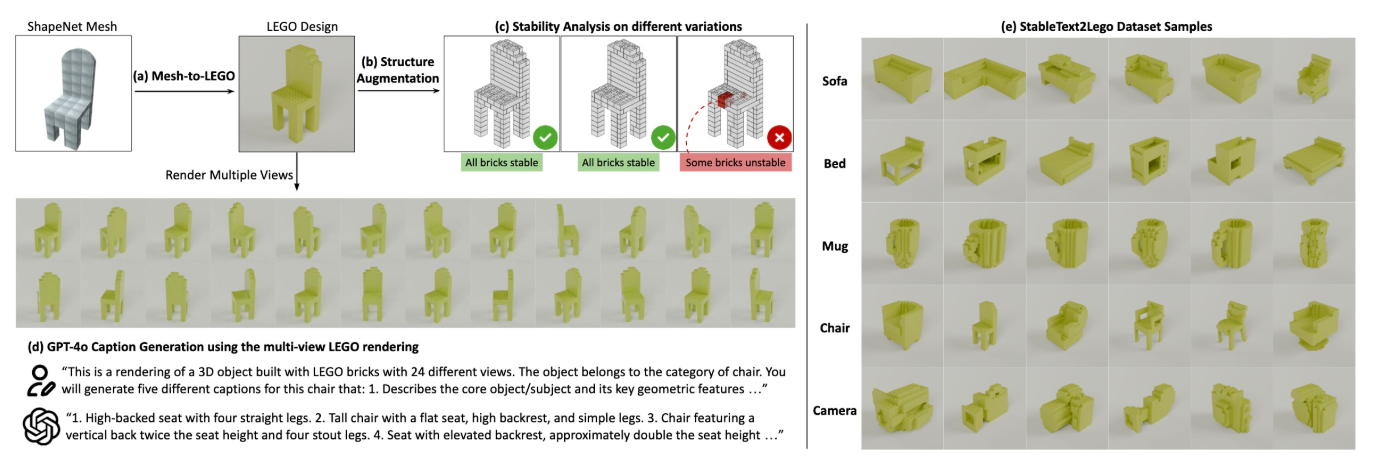
Source: https://avalovelace1.github.io/LegoGPT/
The model architecture is based on Meta’s LLaMA-3.2-1B-Instruct and fine-tuned using an instructional format that pairs LEGO brick sequences with descriptive text. At inference time, the system predicts one brick at a time in a bottom-to-top raster-scan order, applying several validation checks to ensure that each brick placement adheres to known constraints such as part existence, collision avoidance, and structural feasibility.
To handle instability during generation, LegoGPT includes a rollback mechanism. If a newly added brick leads to a physically unstable structure, the system reverts to the last stable state and continues to generate from that point. This approach is intended to produce final structures that are both prompt-aligned and mechanically sound.
Reactions from the community have been mixed. One user on Hacker News noted:
This does not seem like a very impressive result. It is using such a small set of bricks, and the results do not really look much like the intended thing. It feels like a hand-crafted algorithm would get a much better result.
In contrast, another response emphasized the methodological contribution:
But I think the cool part here is not photorealism, it is the combo of language understanding and physical buildability.
The system includes tooling for visualization and texturing using external packages like ImportLDraw and FlashTex. The team also provides scripts for fine-tuning on custom datasets and supports interactive inference through a command-line interface.
LegoGPT, along with its dataset and associated tools, is released under the MIT License. Submodules used for rendering and texturing have separate licenses. Access to some components, such as the base language model and Gurobi solver for stability analysis, may require separate agreements.
The work aims to support future research in grounded text-to-3D generation, physical reasoning, and robotics, offering a reproducible benchmark for evaluating structural soundness and prompt alignment in generative models.
MMS • Markus Kett

Transcript
Kett: This talk is all about ultra-fast in-memory database processing with Java. Who of you is a Java developer? Who of you is a database developer? Who develops database applications or works on database stuff in general? Who has performance issues? This is a question for the database vendors. In this session, I will show you how you can build the fastest database applications on the planet. This depends on you, what you’re doing, which solution you choose. This is an approach that is not new. It’s used by gaming companies, online banking companies already for 20 years. Now we have a framework.
This talk is about how you can use this approach. Here we can see a lot of fancy new applications, applications of the future, so virtual reality, AI, everything is about AI these days, blockchain, and so on. For all of these modern applications, there are some factors, super important and critical. Everybody wants high performance, of course. Of course, we want low data storage costs in a cloud. Simplicity is very important for developers. Sustainability is very important for managers and organizations. Today, the reality is different. I will show you why.
My name is Markus. I’ve worked on Java for more than 20 years now. With my team, I work on several open-source projects. I’m also an organizer of a conference, try to give something back to the Java community. This is always a lot of fun. With my company, we are very active in the community. We are a member of the Eclipse Foundation. Most people know about Eclipse Foundation because of the Eclipse development environment, but it’s much more. We run more than 100 open-source projects under the roof of the Eclipse Foundation. Java Enterprise is now part of the Eclipse Foundation, it’s now called Jakarta EE. We are also a member of the Micronaut Foundation. Who of you knows Micronaut or uses Micronaut? This is a microservice framework. We are also contributing to the Helidon project. Who of you knows what Helidon is? Helidon is also a microservice framework and runtime for building microservices in Java. It’s driven by Oracle, but it’s open source.
Data Processing, Today
Let me talk about database development of today. The situation is a little bit different. In my previous project, we’ve worked on a development environment, based on Eclipse. It should become a Visual Basic for Java. We developed a GUI builder. Everything went fine. We developed a Swing GUI builder, then a JavaFX GUI builder, then a WADing GUI builder for creating HTML user interfaces. The problem we had, as soon as we want to show data on a screen, then everything went bad, slow, complex, so we tried to improve this. We’ve worked on the JBoss Hibernate tools for Eclipse for almost 10 years now. We tried to simplify the Hibernate tools to accelerate speed, and we were not successful. Why? It’s because there are so many technical problems. This is my background.
When I talk about database programming, please keep this in mind. I worked on database stuff, traditional databases, for more than 10 years. It’s great. What we have in Java is great. We have a lot of challenges with this technology. Here’s why. Today, database programming is mostly too slow. Performance is too slow. This is why you were laughing when we talked about performance issues. Database costs in the cloud are mostly too high. All managers talk about the cloud costs are skyrocketing, and the complexity is way too high, and the systems are mostly not sustainable. Now I want to show you why.
Let’s have a look at how the database server concept works, actually. We have an application. Here we have a JVM, and we have memory. We have an application or a microservice, and we have a relational database. Let’s have a look inside the relational database, because mostly it seems like a black box. We send an SQL to a database, and we get the result. Great. When we have a look inside the database, then we can see there is a lot of memory. We have a server, of course. Then we have storage. We have a database management system, and probably there is also business logic running inside a database, stored procedures, stored functions.
Please keep these components in mind. Storage, computing, a lot of memory, and maybe business logic. What’s the problem here? When I came to Java more than 20 years ago, I was stupid enough to ask one question, what’s the difference between Java and JavaScript? The Java developers, they told me, “Markus, you cannot compare Java with JavaScript, because Java is object-oriented. It’s type safe”. That’s great. That is super important. That is what we love. Now I got it. This is important for database programming. Everything is great when we do it in Java. Everything is object-oriented, type safe.
Clean code is super important. As soon as we want to store data in a database, then the horror begins, because all database systems on the market are incompatible with the programming language. It’s the same in .NET. It’s the same with object-oriented programming languages, incompatible. It’s because you cannot store native Java objects seamlessly in a relational database. This is impossible. We have some impedance mismatches here. Granularity mismatch subtypes, so inheritance is not supported by the relational model. Then we have different data types. In Java, we have some primitive data types. In PostgreSQL, we have around 40 or even more data types supported by the database. This is always a challenge.
The question is, what about the NoSQL databases? Who of you uses NoSQL databases today? Are they better? The fact is they are very different. What’s the difference? The NoSQL databases now, they introduce new data types, new data structure. This is the biggest difference. The functional principle is pretty much the same. They are also server databases, mostly. Now they introduce key-value. They introduce documents like JSON, XML, or a column store, or graph database like Neo4j. We have the object-oriented databases in the 1990s, because, initially, we want to store objects in a database, so it was obvious to invent object-oriented databases.
Obviously, it didn’t work well. We have time series databases. Now with AI, we have the vector databases. What database should we choose? They are all also incompatible with the native object model of Java. That’s a fact. They are also incompatible, and that’s a challenge. In Java, we can do everything. We can handle all types. We can store and process all data structure and data types. We can deal with everything. That’s great. This is different with databases. They are limited in terms of the use case. This leads to big challenges. You can read more about this in the internet, or even on Wikipedia, we can find an article about object-relational mapping or impedance mismatches.
This is how it works. In our application, we need something additional to store data in a database. We use object-relational mapping. This is a well-known concept, and it’s worked great for decades. Who of you uses Hibernate, EclipseLink? Object-relational mapping is very common to store data in a database, or Java object in a relational database. There are drawbacks. This is super expensive because object-relational mapping is very time-consuming and it leads to high latencies. Suddenly, your queries become really slow. This is what we found out. Is this true? Yes, we agree. Not always? Mostly? Sometimes? We can fix this problem, of course. Let’s add a cache. This is what we did in our development environment. We introduced Hibernate. Then it was too slow. Then we added a cache. Then we have additional complexity.
Now we have to deal with cache configurations and so on. Now the results are stored in memory. This will be way faster. We were not satisfied with the performance, actually. Why? Have you ever measured how long it takes to read data from a cache? I grew up with assembly programming. In the keynote, we heard about assembly will become, hopefully, more popular in the future when we deal with quantum computing. When I had a Commodore 64, then I was able to process data in memory in microseconds. When I read data from a local cache with Hibernate, then it takes milliseconds. I was like, what’s the problem here? Why does it take milliseconds when I fetch data from a local cache? The problem is object-relational mapping. Obviously, this is super expensive.
Then we talked about single-node applications. Who of you develops distributed applications? That’s a little bit more complex. Now, here we have an application that runs on multiple machines. What’s happening when you change data on one machine? Then the machine will be synchronized with the database. Everything is fine. The problem is all other nodes are not in sync with the database. This can be a problem. We are developers. We can solve this problem. There is another cache strategy. Let’s put the cache in between the database and the application layer. Because we are in the cloud, so we want to avoid a single point of failure, so we use a distributed cache. We use a cache that is executed on multiple machines. Who uses a distributed cache like Redis? Very common.
Then we have such an architecture. You can see the machines growing more and more. Does it make sense to run a cache without memory? No, it’s nonsense. Of course, we need a lot of memory. We use memory, and we need memory. What about the database? Do we run a database application on a single database node? Probably, yes. If the application is mission critical, maybe you will run a database cluster to share the load, data redundancy, and so on. We have a database running on multiple nodes means there are more machines running. Does it make sense to run a database without memory or low memory? It can do that, but it will be slow. You need a lot of memory in a database server as well.
Now, we talk about an application that runs on multiple machines. Now we deal with microservices. We split the application in multiple services, and it looks like that. We have a lot of machines running to maintain. This is very common. Then we have a great database, and databases are so fast today. Who of you uses Elasticsearch? Why? The database is fast enough. Obviously, sometimes it’s not fast enough, so you add another solution, and now you can explain to your managers why cloud computing is so expensive. This is really true. This is not the case in all applications. Sometimes you have only one solution or two or three solutions.
On top of that, we talked about data structure, data types. Let’s say you have your Oracle database, and then you need some sensor data, you will have a time series database, probably. Then you deal with vector. Then we have a vector database for AI, so you have, on top of that, multiple database systems running. This is the reason why database development is super effortful, expensive in the cloud, slow. It’s not sustainable, actually. It will produce a lot of CO2 emission and consume energy. Let’s wait for quantum computing. See you next year.
Alternative Java-Native Approach
What’s the alternative? Is there an alternative, actually? Yes, it is already. You don’t have to wait for quantum computing, if you change the software stack. This is not magic, it’s actually obvious. Let’s have a look at how it works. Here is a solution for cheap data storage. When we use a PostgreSQL database, for instance, it’s a server database, and this is an example based on AWS. You use PostgreSQL as a service, just with 2 CPUs, 8 gigabyte memory, and 1 terabyte memory. Run it on one node. It will cost you around $4,000 per year. If you need multiple instances, of course, your price will double, triple, and so on.
If you need more nodes, six nodes will cost you around $30,000 per year. The cloud providers, they provide us Blob storage, or binary data storage like AWS S3. The cool thing here is it costs almost nothing. 1 terabyte S3 costs only $300 per year. That’s great. You can have the same on Azure or Google Cloud. There is a solution where we can save a lot of cost in the cloud, and look at the CO2 emission. It’s almost nothing. The energy consumption is 99% lower. You don’t have to maintain it, it’s managed by the cloud provider.
Here are some facts about Java. Because on all conferences, we talk about, we love Java. If you attend a Java conference, you will hear this phrase, we love Java. Now let’s have a look on why we love Java. It’s so fast. Everything that’s executed in memory in Java is executed in microseconds. This is similar to my Commodore 64. Sometimes it’s even faster, even nanoseconds, because of our great JIT compiler. We have the best data model on the planet, objects, object graphs. We can deal with all data types. We can deal with all data structure, vectors, JSON, XML, relations, graph, like graph database. Everything is possible. This is a multi-model data structure from the beginning. No limitations in terms of the use case. What about searching and filtering? We have Streams API. With Java Streams, you can search and filter in memory in microseconds. You can compare this with a JPA or a SQL query. Mostly 1,000x faster than a comparable JPA query.
Now I will show you a brief demo. Here we have two applications running in parallel. One is built with the JPA stack, so with Hibernate. We have a PostgreSQL database, 250 gigabytes. This is a bookstore application. We use Ehcache. It’s a hot Ehcache. This is in memory, so we fetch data directly from memory. On the right, you can see the query code. Here we use Spring Data as a framework. The second application is built with EclipseStore. We use a Blob store, like S3, and it is S3. We use Java Streams to search and filter. All queries are executed, sometimes 10 times faster, sometimes 100 times faster, sometimes more than 1,000 times faster than the comparable JPA query. Keep in mind, we fetch data directly from a cache. With Java Streams, we are up to 1,000x faster than Hibernate Cache. This is the performance of Java. You can improve it even by changing the JVM, for instance. JVM, you can accelerate in-memory processing by, for instance, the OpenJ9 JVM. It’s also an Eclipse project. It can be 20% more efficient and faster than HotSpot. You can play around with the different JVMs. It’s incredibly fast.
EclipseStore
What’s the problem? The only thing missing in Java was persistence. How can we now store data on disk? This is what we have developed at the Eclipse Foundation. This project is not a prototype or just an idea. We have been developing this for more than 10 years. It’s production-ready. It’s in use. It’s in production use by companies like Allianz, Fraport, here in Germany. More companies are using this framework. It’s under Eclipse public license, which means you can use it for commercial purposes free of charge. There are four benefits. 1,000x faster data processing in memory. You save more than 90% cloud database costs, and we do not talk about license fees. It’s Java-Native, which means simple to use. It’s fully object-oriented. It’s type safe. It feels like a part of Java. This is very important. Because we don’t need a database server anymore, just storage, we save 99% energy and CO2 emissions, and you develop the fastest application on the planet, and at the same time, you save the planet. How great is this? How does it work? What actually is EclipseStore?
It is a micro-persistence engine, so it is a persistence similar to Hibernate, to store native objects. This is the difference to Hibernate, to store your native Java objects seamlessly to disk, and to restore it when needed. That’s the functional principle of the framework, without object-relational mapping, without any mappings, without any data conversion, there’s no more JSON conversion behind the scenes or something like that. It’s the biggest difference, very important to all databases on the market, no mappings, no data conversion, the original Java model is used. Use the original Java object model, and you can persist your POJOs seamlessly into any data storage.
It’s just a Maven dependency. It’s very easy to use. The whole framework has only one dependency to the Eclipse Serializer that’s used behind the scenes. The only thing you need is an EclipseStore Instance. This is how it works through runtime. You need an instance of your data storage in memory, and in memory it works like a tree. Who of you was a Swing developer? What about JavaFX? It’s the same here with EclipseStore, you need a node, an instance, a root object, and then you add objects, and all objects that are reachable from this root object can be persisted and stored on disk. This is the functional principle. I create a root object, add some objects. You can use all Java types. Only Java types that can be recreated can be used and stored. You cannot store a thread, obviously, but all other Java objects can be used.
Then you call a store method, and then a binary representation of your object will be created and stored on disk. The information is stored in a binary form, and we use the Eclipse Serializer for creating the binary, and store it on disk. This operation is transaction safe. We get a commit from the engine, and then it’s guaranteed that the object is really stored on disk. Let’s add some more objects. We call a store method, and another binary file is created. This is how it works. In each store method, each store operation creates a new binary file in the storage. It’s different to the relational model. It’s an append log strategy. The method call is very simple, just one method to call, and then you can store your objects. This is a blocking, transaction safe, all or nothing atomic operation. Vice versa, when you start the application, what’s happening? When you start an application, then the framework will load your object graph into the memory.
Handling Concurrency in Java
Kett: How does it work with multiple threads? You can use all Java concepts to handle concurrency, but you have to care for concurrency. We have to handle this in Java, or we can handle this in Java. Then you have full control on which objects and which threads store the object transaction, save to disk. You will get a commit from the library.
EclipseStore
Kett: When we start an application, then the engine will load the whole object graph into memory. Now this is, at this point, very important to mention. The object graph information is all loaded. Only the object graph information, which means only object IDs are loaded into the memory. We will not load the whole database into the memory. Only the object IDs are loaded, so you’ve got an indexed object graph in memory. Then you can define which object references should be preloaded in memory or should be loaded on demand by using lazy loading. You can have a terabyte, tons of object in your storage, you have only 2 gigabyte memory, it will work. It’s super easy to define your classes as lazy or eager, this is just a wrapper class. Then the engine will either preload object references in memory or load it when you call the object with a GET method. This is how it basically works.
Queries are simple, because we use Java Stream’s API for searching and filtering. This is very fast. You can check this out, each query will take only microseconds, mostly because of the speed of the Java Stream’s API memory. The storage will grow more, and so this is the reason why there is also a garbage collector for your file storage. If you have older objects in the memory, and we change the data model, then we have lazy objects in the memory or corrupt objects, and a garbage collector process will clean up the file storage constantly and will keep your storage small. This is the functional principle.
The Eclipse Serializer is the heart of this framework. On top of that, we provide an implementation for the JVM. Eclipse storage is built for the JVM, but there is also an implementation for Android. Who of you is a mobile developer or develops mobile applications as well? What happens if your classes change? This can be challenging, but it’s not with EclipseStore, because we have a concept that’s called the legacy-type mapping, and the framework cares for all of your changes automatically, or you can also, for complex cases, define a so-called legacy-type mapping.
Then the storage or the legacy objects will be updated through runtime, so you never have to stop your application and refactor the whole storage. This is not how it works. We have a file system garbage collector, as mentioned, a file system abstraction, which means you can store your data in a Blob store, but you can also store your data locally, just on disk. You can store your data almost everywhere, so in any binary data storage. This is confusing because a relational database can deal with binaries. You can even store your binaries in a relational database, but keep in mind, there is no object-relational mapping anymore. We just store binary data. There are database connectors that you can use on Oracle database, you can use PostgreSQL.
Actually, it makes no sense, but in some business cases, it can make sense. We had a customer. They used Oracle. They told us, that’s a great approach, but we have to use Oracle. Now we store EclipseStore binaries in an Oracle database. It’s possible. The Oracle guys do pretty much the same with their graph layer, so they provide a graph database, but it’s not the graph database, it is actually a graph API layer on top of the relational database. They store graph information as a binary in a relational database.
Then we have a storage browser, where you can browse through your storage data, and a REST interface, so you can get access to your storage and search and query your storage directly via REST. There are backup functions and converter to CSV, for instance, that you can migrate easily to EclipseStore or from EclipseStore to any other database, if you like. It runs with JVM from Java version 11. It runs with any JVM languages on Android. It runs in containers. It runs in Docker containers on Kubernetes, even with GraalVM Native Images.
We talked about single-node applications, and this functional principle works also in distributed systems. For this scenario, MicroStream provides you a PaaS platform for deploying and running distributed EclipseStore applications. We also provide an additional version for even more performance, with indexing, for instance. You get out the most speed that’s possible. How does it work? Now we can execute an Eclipse application on multiple machines, and the MicroStream cluster provides you data replication, data redundancy. The service is fully managed or available on-prem. There is eventual consistency approach. This is how it looks like in a distributed environment.
Back to our previous architecture, we have a Hibernate application running on multiple machines, a distributed cache, we have a database system. Now we replace the Hibernate applications with the EclipseStore applications. As we keep and query all data in memory, it is already working like a distributed cache. We store data in a Blob store, AWS, for instance, so we can skip the database cluster completely. As mentioned, we keep data in memory, we replicate data in memory through multiple JVMs. We don’t need a distributed cache anymore, so we can also skip the local cache. Then you can still use Elasticsearch if you like, but you can also use Lucene, and you don’t need a search cluster anymore. It depends on you. Then, the end result is a really small cluster architecture, low cost, super-fast, easy to implement and maintain because everything is Core Java. It feels like a part of the JVM, it feels like a part of the JDK.
Importing an EclipseStore Binary File into Lucene
Participant 2: You mentioned Lucene, so can you import an EclipseStore binary file into Lucene and then it will just work?
Kett: No, this is not how it works. You can use and combine Lucene with EclipseStore as you can use all Java libraries and combine it, that are available in the Java ecosystem. Lucene cannot parse the binaries. You include Lucene and you will search and filter in memory. The binary files are only used for storing the object persistently on disk. You never touch the binary file. It’s the same with your database server. Your database system will store the data in an internal format on disk. You never touch it, actually. It’s the same here.
Rules and Challenges (EclipseStore)
There are also some rules and challenges with EclipseStore because every technology has pros and cons. There’s a comparison. Here’s, again, the traditional database server paradigm. We have an application and we have a database server. Queries are executed on the database server. The persistent data are stored in the database server, obviously. With EclipseStore, it changes. Now, your database is in memory. You don’t have to load the whole database in memory, but it works like the same. It feels like the whole database is in memory, but it’s not. It’s managed by lazy loading by the engine.
Keep in mind, your database is in memory. We search and filter in memory in the application node. Only the storage data are stored in a S3 bucket or something like that. That’s the main difference. You have to think a little bit different. There are no more classic select, you send to a server. You don’t use SQL, you use Java Streams. There is no database server. We have a graphical user interface where you have to create a database model. You just have to create classes. That’s it. There is no more database model anymore.
Again, in-memory means everything is executed in memory, so you actually need a lot of memory. If you have a lot of memory, I showed you how you can save a lot of memory, because we don’t need a database cluster. We don’t need a distributed cache cluster. We have a little bit more money left for buying a little bit more memory. If you don’t have enough memory, you have small memory machines, it will work. This is very important. The more memory you have, the faster your system will be. This is not standard, but I like to mention it, if you need a way faster approach for really blocking operations, transaction safe operations, with the speed of an asynchronous approach, with really high write performance, then you can use, for instance, persistent memory. This is super interesting. You just have to add persistent memory to your server.
Then, all write operations are not directly stored to disk, it’s stored in a persistent memory area. It’s transaction safe. It takes microseconds to store it and not milliseconds because of disk I/O operation stuff. You can store it in a high-performance way. It’s like you copied from one memory area to another memory area, but this area is persistent, and it provides you persistence. It’s called persistent memory. Then, behind the scenes, you can synchronize the persistent memory with your disk asynchronously. This is extremely fast.
Challenges with EclipseStore. The biggest challenges are, you have to think like a Java developer. Java developers mostly don’t think like Java developers in terms of database programming. In terms of database programming, our brain works like a relational database. If I tell you, “Please create a database application, I need a shop system. I have customers. I have articles”.
Then, your brain will create a relational model in microseconds, sometimes milliseconds, because we are used to using a relational model sometimes 10 years, 20 years, or 30 years even. You have to stop with relational modeling. Create an object model that fits for Java. Forget what you have ever heard about a relational model. Forget what you have ever heard about a relational database system, how it works. Focus on how Java works, how you would implement it in Java. Trust the framework will be able to store it. That’s it. That’s the biggest challenge, to create a proper object model. It’s built for Java developers. We have no surprises for DevOps and for database admins.
This is the reason why, if you have colleagues, they are database admins, probably they will not like it. This is not a drop-in replacement. Please stop dreaming about, there is a magic button. I can now replace my Hibernate stack and my relational database with EclipseStore and it will work seamlessly. This is not going to happen. There is a migration effort and path, but it’s doable. It’s not complicated, but there is an effort. Keep this in mind. No SQL support, but the application can be queried by external services and applications by using GraphQL, REST. This is possible, but no native SQL support, obviously.
Conclusion
Traditional database applications. This approach provides you simplicity. It’s because you can deal with all Java types. There is no more mapping, no more data conversion behind the scenes. It’s Core Java. There are no dependencies. You can use POJOs, and everything can be stored. It can be replicated. You can build distributed applications very easily. You will have high performance. Because of the speed of Java, all operations are executed in-memory with Java Streams in microseconds or even faster. It’s suited for low latency, real-time data processing. You have really awesome throughput. It will save a lot of cloud costs because there is no database server anymore. There is just storage. Just storage is more than 90% cheaper than any database server in the cloud. That’s great. Because there is no more server required, and these numbers are from Amazon, you will save more than 99% of CPU power, energy, and CO2 emission. Here is a comparison of what could be saved if we replaced all database servers with object storage. This would be amazing. This is not going to happen. This is only in theory. Between 20% to 30% or probably even more servers on the planet are database servers. These numbers are growing because of AI. More vector databases are required. We could save a lot of energy and CO2 emission.
Resources
If you are interested in learning this approach, I have a free course for you. You can enroll for EclipseStore course for free. We provide advanced training and even fundamental training for free. If you’re interested, check it out, www.javapro.io/training. Build the fastest applications on the planet by using Java.
Questions and Answers
Losio: You say, I never have to access directly the storage layer, so S3. I don’t care about how you store the data in S3. If you have 1 million records in your table, do you store 1 million binaries? It’s one file? How is structure there?
Kett: Behind the scenes, the engine will reconfigure the storage constantly, and reorganize the storage constantly. You don’t have to care about, how does the structure look like in my storage. That’s done automatically by the engine. We have a garbage collector process which deletes the legacy objects. You can configure that. This is how it works.
Participant 3: As far as I understood, you position the solution as a drop-in replacement, for DBMSs, or for enterprise applications, or just different, or just for embedded applications.
Kett: It is a persistence framework for storing Java objects, this is what we had in mind, to replace Hibernate. You use Hibernate to store your objects in a database. You use it for almost all use cases. You can build complex enterprise applications, or you just store your tests, or anything that can be stored. You can use it for almost any purpose. It is great for low-latency applications, where you need real-time speed, where you really need high speed. That’s great to use it for that purpose.
Participant 3: I’m not a DBA, but I would like to protect the DBMSs. There’s five points on the slide regarding the implementation that you will have to do. On your application side, it’s not fair for me to mention something on top of your business logic.
Basically, all the stuff, if you know about the Postgres and MVCC, Multi-Version Concurrency Control, a very complicated thing that allows you access to the data storage from multiple applications. Also, regarding the tools, so good luck with doing the updates of these Java applications, as soon as your enterprise application requirements change. You have DML, DDL, and all these high-level abstractions. I’m talking about SQL like things, that allows you to do very complicated things, just with a few lines of code, instead of implementing very challenging code on the Java side. Do I understand right, that this very complicated layer, like concurrency thing, that is not comparable to this enterprise-y thing that we just do. It’s very complicated. Does it mean that the enterprise application developers have to deal with that as well?
Kett: Obviously, the database cares for concurrency and everything. You don’t have to care for anything. In practice, we see that we have to care for concurrency. We do it anyway, in Java, very often. With microservices, it changes completely, transaction safety and so on. With Java, we have great solutions for that. In our perspective, this is not more effort. It is pretty much the same effort, because mostly you have to do it anyway. You need experience with concurrency handling in Java. Actually, it’s Core Java stuff. There are no new things to learn. This is not like a SQL database, you have to learn a new data model, new query language. It’s Core Java stuff.
See more presentations with transcripts
MMS • RSS

Begin exploring Smartkarma’s AI-augmented investing intelligence platform with a complimentary Preview Pass to:
- Unlock research summaries
- Follow top, independent analysts
- Receive personalised alerts
- Access Analytics, Events and more
Join 55,000+ investors, including top global asset managers overseeing $13+ trillion.
Upgrade later to our paid plans for full-access.
MMS • RSS

Context-aware vibe coding via MCP clients
Another advantage of MongoDB integrating MCP with its databases is to help developers code faster, Flast said, adding that the integration will help in context-aware code generation via natural language in MCP supported coding assistants, such as Windsurf, Cursor, and Claude Desktop.
“Providing context, such as schemas and data structures, enables more accurate code generation, reducing hallucinations and enhancing agent capabilities,” MongoDB explained in the blog, adding that developers can describe the data they need and the coding assistant can generate the MongoDB query along with application code that is needed to interact with it.
MongoDB’s efforts to introduce context-aware vibe coding via MCP clients, according to Andersen, will help enterprises reduce costs, both financial and technical debt, and sustain integrations with AI infrastructure.
MMS • RSS
Schonfeld Strategic Advisors LLC reduced its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 19.1% in the 4th quarter, according to its most recent 13F filing with the Securities and Exchange Commission. The institutional investor owned 25,556 shares of the company’s stock after selling 6,018 shares during the quarter. Schonfeld Strategic Advisors LLC’s holdings in MongoDB were worth $5,950,000 as of its most recent filing with the Securities and Exchange Commission.
A number of other hedge funds and other institutional investors also recently added to or reduced their stakes in the business. Vanguard Group Inc. increased its position in MongoDB by 0.3% during the 4th quarter. Vanguard Group Inc. now owns 7,328,745 shares of the company’s stock worth $1,706,205,000 after purchasing an additional 23,942 shares in the last quarter. Franklin Resources Inc. grew its holdings in shares of MongoDB by 9.7% during the fourth quarter. Franklin Resources Inc. now owns 2,054,888 shares of the company’s stock worth $478,398,000 after buying an additional 181,962 shares in the last quarter. Geode Capital Management LLC raised its position in shares of MongoDB by 1.8% in the fourth quarter. Geode Capital Management LLC now owns 1,252,142 shares of the company’s stock valued at $290,987,000 after buying an additional 22,106 shares during the last quarter. First Trust Advisors LP lifted its stake in shares of MongoDB by 12.6% during the fourth quarter. First Trust Advisors LP now owns 854,906 shares of the company’s stock valued at $199,031,000 after buying an additional 95,893 shares during the period. Finally, Norges Bank acquired a new stake in MongoDB during the fourth quarter worth approximately $189,584,000. Institutional investors and hedge funds own 89.29% of the company’s stock.
Insider Transactions at MongoDB
In related news, CFO Srdjan Tanjga sold 525 shares of the company’s stock in a transaction that occurred on Wednesday, April 2nd. The stock was sold at an average price of $173.26, for a total transaction of $90,961.50. Following the sale, the chief financial officer now directly owns 6,406 shares of the company’s stock, valued at approximately $1,109,903.56. This represents a 7.57 % decrease in their position. The transaction was disclosed in a legal filing with the SEC, which is accessible through this hyperlink. Also, CAO Thomas Bull sold 301 shares of the firm’s stock in a transaction on Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total value of $52,148.25. Following the transaction, the chief accounting officer now owns 14,598 shares in the company, valued at $2,529,103.50. This trade represents a 2.02 % decrease in their ownership of the stock. The disclosure for this sale can be found here. In the last 90 days, insiders sold 36,345 shares of company stock valued at $7,687,310. Insiders own 3.60% of the company’s stock.
Wall Street Analyst Weigh In
MDB has been the topic of a number of recent analyst reports. Barclays reduced their price target on MongoDB from $330.00 to $280.00 and set an “overweight” rating on the stock in a research note on Thursday, March 6th. Stifel Nicolaus reduced their target price on MongoDB from $340.00 to $275.00 and set a “buy” rating on the stock in a research report on Friday, April 11th. Cantor Fitzgerald initiated coverage on MongoDB in a research note on Wednesday, March 5th. They issued an “overweight” rating and a $344.00 price target on the stock. Rosenblatt Securities reaffirmed a “buy” rating and set a $350.00 price objective on shares of MongoDB in a research note on Tuesday, March 4th. Finally, Daiwa America raised shares of MongoDB to a “strong-buy” rating in a research report on Tuesday, April 1st. Eight research analysts have rated the stock with a hold rating, twenty-four have issued a buy rating and one has issued a strong buy rating to the company. Based on data from MarketBeat, the stock currently has an average rating of “Moderate Buy” and an average price target of $294.78.
Read Our Latest Research Report on MDB
MongoDB Stock Performance
Shares of NASDAQ MDB traded up $1.32 during midday trading on Monday, reaching $172.96. 1,254,868 shares of the company’s stock were exchanged, compared to its average volume of 1,851,850. MongoDB, Inc. has a 52-week low of $140.78 and a 52-week high of $379.06. The business’s fifty day moving average price is $184.75 and its two-hundred day moving average price is $244.79. The stock has a market capitalization of $14.04 billion, a PE ratio of -63.12 and a beta of 1.49.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings data on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing the consensus estimate of $0.64 by ($0.45). MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The business had revenue of $548.40 million for the quarter, compared to analysts’ expectations of $519.65 million. During the same quarter in the prior year, the firm earned $0.86 earnings per share. Analysts predict that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

With the proliferation of data centers and electric vehicles, the electric grid will only get more strained. Download this report to learn how energy stocks can play a role in your portfolio as the global demand for energy continues to grow.
MMS • Cooper Bethea

Transcript
Bethea: My name is Cooper Bethea. I’ve been an infrastructure engineer, an SRE, a production engineer. I worked at Slack and Google. I worked at a couple smaller places too. I worked at Foursquare, and Sift, formerly Sift Science. I’m a software engineer, but I’m bad at math. I like people. I’m better at people than I am at math. I ended up in this place where I’m doing a lot of work on site reliability and uptime, mostly because I was willing to hold a pager.
It turns out, in the end, this all adds up to me enjoying leading large infrastructure projects where the users don’t really notice anything, except at the end, everything works better. This talk is about one of these projects. I was an engineer at Slack, and I led a project to convert all of our user-facing production services from a monolithic to a cellular topology. How many of you use Slack at work? Clearly, this project needs some justification, and that’s what my VP thought too. I’m going to start by describing how we came to start this project.
Then I’ll give you an overview of how our production environment looked before, and then how it looked after, and these will look similar. You will wonder why this was so hard that I got to do a talk, because we didn’t even invent an algorithm or anything. This project was hard. I think projects like these are hard. We tried to do this at Slack once before, and it never really got off the ground. Part of what I’m going to talk about is how and why our rendition of this project actually succeeded.
One thing I would ask you to consider as you’re listening to this talk is these large migration projects often fail or run aground, even when you thought they would be simple, just changing one system to another system. We’re not even writing new software. A lot of the time, it’s just these reconfigurations of software. Why is this hard? This is some good old AI-generated slop that I made about a ship voyage, because a lot of these pictures are copyrighted. Similarly, we can ask, why did it used to be hard to sail a ship across the ocean? You know where you’re starting from, you know where you want to end up, but it was still hard. I think that big projects like these are similar, like these exploratory voyages that we used to do, where you know where you’re going, but you don’t know exactly how you’ll get there. I think that’s very confusing. It can be hard for organizations. Like all the best projects, this project was born from fear, anger, lost revenue, and a bad graph.
One day, we’re just slacking along, doing our projects, running the site or whatever, and this happens. This is a graph of TCP transmits split by availability zone in Amazon U.S.-east-1. For us, TCP transmits have always been a pretty clear sign that something is going wrong. Packets are getting dropped somewhere, whether it’s on one of the endpoint nodes, there’s a network and hardware in between, something is not good, and we need to take a look at that. If you look at the monitoring and do a little mental math, you can see that we have more of these dropped packets in one AZ than the others. You can see that the one sums to the same as the second two. We got the idea that this was about packets being lost traveling from that AZ into the other two AZs. We were like, that’s bad.
We basically called AWS, we did the thing where you filed your support ticket, and they were like, we were looking at it, and then we’re all sitting on Zoom. Then they found the network link and they fixed it, and all our errors went away. Then a few hours later, there was an automated system that put the link back in service, and it went down again. We called AWS again, and they processed the ticket, and they fixed it again. We were tired. We were just like, why do we have to go through this? Why do our users have to endure this? We built this distributed system, and it really ought to be able to deal with a single AZ being entirely unavailable. Why do we service errors? Why didn’t we just steer around the bad availability zone? It’s in the name, availability zone. You’re supposed to be able to build availability out of these things, multiples of them. We do a lot of trying to detect errors in distributed systems like, why didn’t that save us here either?
Slack’s Architecture
First, let’s take a look at the architecture of Slack. It’s a little different from what you’ll see at other sites, but not that weird. What we do is we have these edge regions where we terminate SSL close to users. We’ll get you a WebSocket out there. We’ll serve files, stuff like that that makes sense to push close to the users. Then the most important work on the site all actually happens inside U.S.-east-1. That’s where we retrieve channel histories.
If you post a message, that’s where the fanout starts. All that happens in one region, U.S.-east-1. What we do is we forward the traffic into this internal load balancing layer that you can see here that fronts each availability zone, and then these internal load balancers direct the traffic into a webapp, which is what you’re thinking, it’s based in Hack. It processes HTTP requests for users with the help of backend services and datastores. You would look at this and be like, we could just stop sending traffic to that AZ, and this would just work. We should just have done that when we had the outage. That didn’t work because this slide is a lie, because this is actually what everything looks like behind the webapp servers. You can see what’s going on here. This is spiritually descended from these three-tier architectures that we know. You’ve got a reverse proxy.
Then you’ve got an app server that terminates HTTP. Then you’ve got some databases behind it that it gets data from to answer these questions. We’ve just got this extra layer of reverse proxies because we’re crossing a regional boundary. We’ve got a whole bunch of different services on top of the database, including Memcache. There’s a Pub/Sub system that does fanout. There’s a search tree, stuff that is useful to the webapp in answering these queries. You’ll notice that most of these services are actually being accessed cross-AZ, because that was how we built them out, basically. We were counting on failover happening. We weren’t paying attention when we set up this part of the stack.
It turns out we got even more problems than that. Our main datastore is Vitess, which is a coordination layer, a sharding layer on top of MySQL in the end, and it’s strongly consistent. It needs a single write point for any given piece of data. You have to manage failover within the system. You can’t just stop sending Vitess traffic in one zone. If that zone contains the primary for a shard, you actually need to do an operation in Vitess to failover primariness, mastership of that shard to a different availability zone. We’ve got our work cut out for us at this point. We couldn’t pop the AZ out of frontend load balancing, but maybe we could do this automated thing I was talking about. Like just have the computers figure it out themselves and be like, that’s not really good anymore. We can just have the app service manager in our backends and fail away from the impacted AZ. This is a simplified waterfall. There’s a chunk of a waterfall graph between the webapp and its backends.
Once an API request from a user gets in there, there’s actually a lot of fanout. It’s not just these five RPCs, it’s maybe 100 RPCs. I’m like, wave our hands, like if you need to do 100 RPCs to your backends and you’re living with a 1% error rate, you’re probably not going to ever assemble a whole HTTP request, without a bunch of retries, things getting slow and messy. Then, conversely, once the app server is trying to handle things, the only reasonable response to like, I’m serving a lot of errors, I’m missing a lot of my backends, is for it to just lame duck itself to the load balancer and get taken out. This is viscerally unnerving to me, because we are forced to face this idea that if these webapp servers all have the same backend dependencies and they’re starting to lame duck themselves because one of these backends that they’re fanning in on is failing, we’d have a big possibility for cascading failure across the site.
Another consideration is like, in Memcache, you mostly shard your data via clients hashing over backend, use consistent hashing. Clients in the affected AZ had a different view of their backends in the Memcache ring, so we would get cache items duplicated in the Memcache ring. There’s some little consistency issues in there, and they can be found missing when they actually exist. That’s a recipe for database pressure, which again, fanning in, overloading the site in a bad way.
We thought about all this and we were like, it’s actually hard for the computers to do the right thing here. We want, perfectly, all the webapps in that one AZ to lame duck themselves and none of the webapps anywhere else to lame duck themselves. Then we got to do some stuff with Vitess, we’ll talk about later. It just felt bad. We were humans and we could see the graphs. We were sitting on the Zoom call being like, maybe we should drain this availability zone. If we could have smashed the button, we would have smashed the button, and we would have done it. We were also worried that if we remove traffic entirely from one AZ, it would maybe overload the other two AZs and send the site in cascading failure. We’re limping along at this point.
Originally, we’re serving like 1% errors. We are not in our SLO. It’s not as bad as it could be. We were afraid that we could send it into cascading failure and make it worse. We had some ideas, but we didn’t really trust it. It’s really scary to do things for the first time in an incident. What actually happened is we just sat on Zoom and talked about it for a while, and then AWS fixed it while we were talking about it. Then we felt bad. I felt bad enough that I wrote a post in Slack because that’s what we did there. It was called, we should be able to drain an AZ. Everybody was like, yes, we should. Then we’d made a plan.
Cellular Design
I’m going to start by talking about cells. In our implementation, a cell is an AZ. A cell is a set of services in an AZ. That set may be drained or removed from service as a unit. This is what we ended up looking like. Here’s the goals that we needed to satisfy. We took this backwards. We arrived at the cellular design by considering this actual use case that we had, which is, we wanted to be able to drain an AZ as much as possible.
Our goals are, remove as much traffic as possible from an AZ within five minutes. This is just table stakes when you’re in like four or five nines and higher territory, you need tools that work fast because you only get to have a little bit of downtime. Drains must not result in user visible errors. One of the things about being able to drain a data center in AZ is it’s a generic mitigation. As long as a failure is contained within a single AZ, you can just be like, something is weird in this AZ, I’m going to drain it. You can do that without understanding the root cause. It offers you a chance to make things better for your users while you’re still working on understanding what went wrong. If we add errors by draining, we’re probably not going to want to do that because it will make our SLOs worse. Drains and undrains must be incremental.
By the same token, what we want is we want to be able to pull an AZ, fix whatever we think broke inside that AZ, and then leak a little bit of traffic back in there, just like 1% or something, and be like, are we still getting errors? Did we fix the thing? It’s much better than just dumping all the traffic back in there. We wanted to be very incremental to a 1%-ish layer. Finally, the drain mechanism must not rely on the impacted AZ. Sometimes, especially when we have these big network outages, you’ll see some of the first things that we did when we were trying to make this work is we would SSH around the servers and make them lame duck themselves. We just did not want to be in a place where we were trying to do that on the end of a bad network link in a real big incident.
How Things Were Done, and Choices Made
Now I’m going to talk about the ways that we did it and back into how we choose to do those things. The first one, this is pretty straightforward and it’s the thing that you’re probably already thinking about, siloing. We have servers in one AZ and they just talk to upstream servers in that same AZ. It’s pretty simple, and for services that it works for, it works great. This is mostly a matter of configuration for services that are ok with this. We did some help in the service discovery layer and our internal service mesh to support this, but you don’t really need to do all that stuff.
Other services on the other end, difficulty, we have Vitess, where, as I mentioned, we have to internally manage the draining. Anything that’s strongly consistent in your architecture is probably going to need to have writes processed through a single primary point. You’ll have to do some failover. In our case, we’re actually able to do this faster than it seems in Vitess because each of these shards is independent. As long as there’s not too much pressure on the database overall, you can start flipping the shards in parallel and actually go quite quickly. We ended up building features into some autohealing machinery that we have for Vitess that would let us do this really quickly.
Then we started thinking like, what do we choose for each service and why? I’ve mentioned some things about state and strong consistency. It would be nice to have something a little more principled to think about here. Like I said, we like the siloing the best we can do it. Service centers don’t have to manage drains for themselves. They get to have three or four isolated instances of their service, so the blast radius of failures is better. In practice, they can’t all do that. Services that can do this and can’t do that, sort of break down by this idea of stateful or stateless. Like, is the service a system of record for some piece of data? If so, it will probably be harder to just silo.
Further than that, we can look at the CAP theorem a little bit to get an idea. We know the CAP theorem tells us that a system can be available during a network partition, or it can be consistent during a network partition, but not both. Actually, in practice, this ends up being a little more of a continuum. There are different pieces of storage software that satisfy this differently with different properties. When you look here, we’ve got the webapp, which is our canonical stateless thing. It’s just processing based on stuff it gets from datastores. Then we’ve got Vitess on the other end, and that’s strongly consistent.
In the middle, we actually have stuff like our Pub/Sub layer or the Memcache. It turned out that we were using Memcache as a strongly consistent datastore, which is the default thing that you do because you’re just always writing to one Memcache node and then reading out of that Memcache node again. This didn’t really work out great for us, but we found that there were many places in our application where we had trusted that we would have strongly consistent semantics. One of the things that we ended up doing for Memcache, and this is me trying to give you a little bit of flavor around the decision-making process, is we set up a series of per-cell Memcaches. Then we maintained a global Memcache layer, and we slowly, call site by call site, migrated from the old system to the new system.
Let’s look at one other thing here. We’ve got this other idea of services that need to be global, but they’re built on these strongly consistent datastores. For example, we used Consul for service discovery. Consul, underneath it all has a consensus database that is strongly consistent. A Consul cluster tends to fail as a unit and totally. What we used to do is we had many of these Consul clusters, they were striped across all the availability zones.
Eventually, we were able to bring down the number of Consul clusters in each availability zone into a high and low priority. Then we use our xDS Control Plane. xDS is the Envoy API for dynamic configuration. We were also able to use that for service discovery information, since that’s just a subset of what it’s already doing. We have this eventually consistent read layer where you see the Global xDS Control Plane over at the top, and it sits on top of these pre-AZ Consul clusters and assembles the information and presents it to them. By maintaining this as an eventually consistent service, if you have to run global services, I really recommend that they be eventually consistent as much as possible. It’s just the data model makes sharding and scaling much simpler. It’s a pretty safe choice for you. You can also see that we’ve brought down the number of Consul clusters. I’ll talk about that later. There’s a way in doing this project that we were able to do some things that we’ve been putting off, some housekeeping.
Finally, there’s the drain mechanism itself. We have traffic control via the Envoys and the xDS to get to the drains. As mentioned, the first implementation, we would use service to health check down. That’s why you see a duck emoji. We decided that that wasn’t incremental or nice enough for the data. There’s a very nice feature in the Envoy configuration called traffic weighting. We can just say, by default, everybody gets 33%. Then when we drain, we will set the cell to 0%. It just works.
Now I’ll back out. Here’s our original diagram. This is where we started. Again, here’s where we ended up. I’m going to flip back and forth a couple times. You can see we have less lines now. Things are nice and orderly. I’m glad that the slide is laid out this way. We’ve controlled the cross-AZ traffic in some pretty nice ways. We just have a few services that are talking cross-AZ now, and we’re being choosy about them. We can treat these services with more care, because we’re letting them break some cellular boundary, and there’s some potential for bad data poisoning, like for them to put load on other cells.
Fortunately, these are already our databases and our systems that are the system of record for data. We’re already being careful about them. Everybody who runs databases says it’s hard. I’ve always avoided it. This also gives us a model for bringing up a new availability zone if we want to, because we can just build one of these things out, build the data storage systems, start the replication underneath, and then build the other layers up from the bottom, and eventually enable them in load balancing. If we want to move around, do more or less AZs, stuff like that in the future, it becomes more like doing one at the end.
The Success Drivers
I did say we tried and failed to do this before. This looks pretty simple, and I’ve explained it to you in a nice way. Why did we succeed this time? This is the part of the talk where things get messy, and we’re going to talk about people’s feelings and why doing stuff is hard. The first time we talked about doing this, we were going to make these empty isolated cells and build all the infrastructure into them, and at some point, go lights on and cut over. Among other things, there were going to be solid network boundaries between these cells. There’s going to be a bunch of data repartitioning. It gave us a lot of nice properties. In the end, it was too hard to do. The reason for that is because we couldn’t stop working on features. Customers do not care that you’re doing this. None of your customers care that you are rebuilding your production environment, I promise.
At the same time, we’re talking about building this very beautiful system here. This is a lot different from the old system. The whole time we’re like building these, we’re maintaining two very separate environments and production topologies. This is a big drag on productivity because you have to make everything work twice and then keep it working. The environment that you’re not using is going to decay over time and stuff. Not everything is going to be covered perfectly by integration tests. Weird things will fail. God help your monitoring. There’s a lot of divergence that is happening when you’re working in this mode. The mental overhead is really high. We were like, we couldn’t even do this in a quarter. You can’t take a quarter off work for your whole infrastructure organization to do stuff. There’s no way we flip it out really quick. The resource cost is also an issue.
If we’re paying double for the site the whole time, we’re going to get broke. In the end, we abandoned this design, not because the end state was flawed, but because we couldn’t really find good answers to the concerns about how we actually develop and roll it out. The core property this solution is lacking is incrementality. We can’t really move smoothly back and forth from the old regime of things to the new regime. We can’t keep working on other stuff at the same time without doubling effort.
Conversely, we don’t realize any value from this project until we cut everything over to the new system. There’s a very real risk that it’ll get canceled along the way. We’ll start trying to cut over to the new systems and realize that we are worse off than before. Then we’ve just made a big mess and everybody is mad at us. None of these problems are really, again, entwined with the beginning or end states. In these large projects, it’s the messy middle where all the complexity and risk is lying. You have to respect the migration process. It’s the most important and the most fraught part of any big project like this.
At this point, we went to the literature, actually. This is called the slime mold deck, a lot of people do. This guy, Alex Komoroske at Google wrote it. You can see the URL here, https://komoroske.com/slime-mold/, but also if you just Google, slime mold deck, it’s the first thing. Then a bunch of Reddit stuff for slime and decks. It’s actually about how these coordination headwinds can slow progress on projects in large organizations. As Alex states the problem, is that coordination costs go up as the organizations grow larger. That’s what actually this is all about, coordination costs. Our original plan required us to tightly coordinate across every service at the company to build these empty cells all the way up before you turn them on. We can’t really set things up so that engineering teams can take bites out of the problem for themselves quarter over quarter.
Every team is going to support two separate environments until everybody is done. What do we do instead? We embrace this approach where we’re doing bottom-up development. When we went service by service and really figured out what made sense for that service, you remember there was that rubric with like AP and CP, I told you about. The people working on the core project team, we just sat down with each service and worked on developing a one-pager, like, maybe you can’t just be siloed or maybe you can’t just fail over now, but can we get to that place? What do we need to do to do that? Then also, one of our tactics is that we really embraced good enough. One service not being compliant with this does not risk the whole project. We can’t like not turn the thing on because one service got delayed a quarter. People have outages. Priorities change. We need to not coordinate so tightly. We need to make it so that things converge.
The concept laid out in the slime mold deck is this idea that instead of doing a moonshot, a straight shot for a very ambitious project, you should do a series of roofshots where you’re not necessarily going the most direct route, but you’re locking in value at each step of the way. Each service in my example here, that becomes compliant, locks in value for the project and reduces our execution risk. We don’t go straight to the goal, we use it site by. Another way to look at this is we’re willing to sacrifice some efficiency in return for a reduced risk of failure overall. We operated at Slack in this way where the infrastructure teams were in the same organization, but were largely independent. I think this is pretty common at large organizations now. I believe that most services operate at a local maximum of efficiency.
Some people show up and are like, “This service is terrible. That must be awful. You must’ve designed it in a dumb way”. I don’t think that’s true. All the people that you’re working with are actually smart just like you are. They have just been operating under different constraints. Services evolve over time. Every service owner in particular has a laundry list of technical debt that they want to clean up and they never have time to. That is because tech debt is the price of progress. It is not some engineering sin. Some of these things that service owners want to do and never get the time to do will make cellularizing things easier. In our big project, we can give these teams air cover to reduce some complexity before they add it back.
For example, in the service discovery system, returning to this example, we used to operate all these functionally sharded Consul clusters, and they spanned AZs. The idea here was that we would separate these internal Slack servers from stepping on each other’s Consul clusters. That wasn’t actually the greatest idea because it turns out, once again, customers don’t care. Any of these critical services being down basically meant that Slack was down for everybody. We just knew which service to point the finger at when we had these outages. In the spirit of reducing complexity, as part of doing the work, we just moved to these high and low SLO clusters, each within an AZ. Then we assembled the service discovery information over the top using the xDS layer that I talked about before. We were able to collapse all these functional clusters into high and lower priority clusters.
The high priority clusters aren’t better and we don’t run them better. We just expect more from the customers of the high priority clusters. If you’re a critical service, you need to be attached to a high priority cluster. Then you need to be careful about how you use that shared resource. Again, this is one of these things like selecting the datastores where we’re able to zero in on these extremely critical services and expect a little more from them. As it turns out, teams love this. Even if the team that you’re working with isn’t really sold on cellularization as a project, they almost certainly think that their team has a lot better work to do, and they’re right. They can get some value to themselves just from cleaning up the tech debt. You can see how this leads to a place where the teams have both the flexibility and enthusiasm to work on this larger product.
Project Cadence
I’m going to talk about the cadence that we used in this project. I started with this one-pager, which is, we should be able to drain an AZ. I circulated it to a bunch of engineers from different teams that I knew and trusted. The goal here is really to identify anything that just obviously won’t work. You don’t need to plan this project all the way to the end from the beginning. Most of the time, you’re looking for reasons to stop. You can bring this to institutional design review processes, just circulate it to people and listen to everybody’s opposition to why it won’t work. At this point, you haven’t really spent a lot of effort. We haven’t spent a lot of effort organizationally on making this project work. If it doesn’t work, that’s fine. We didn’t waste too much effort here. At the end of this phase, in return, you should have enough confidence that you can go to the engineering management, go through whatever processes you need and get agreement to run a pilot for a quarter or two. There’s a theme here where we’re gradually committing more as we gain confidence.
At that point, you want to start with several high-value services and engage deeply to make progress. It’s important that they are high value and critical services because those services are probably the most complex and because they will pay off faster in terms of like when we get them cellularized. There we go, a big chunk of value from doing that service. We also know the complexity of the problem is tractable, and we get some ideas about the common infrastructure that we’ll build to help.
At the end of this phase, we’ll attain organizational buy-in again through the management chain to expand all critical services. This is going to be the longest phase of the project. You can imagine there’s like a graph of engineers over time, and this is definitely the fattest part of the graph. Then we’ll start tailing off later. At the end of this phase, what we really want to do is all services have items in their roadmap or we’ve decided they’re just not worth doing. We start tracking our progress really heavily during this phase. One thing that we do is we regularly would do drains of the AZ to see how much we can get. Then, week over week, we can make a graph that’s like, we removed more bandwidth, and it goes up, hopefully. Then we can also build the infrastructure. I mentioned we can do some things to help people in the service mesh, but there’s also deployment tooling, job control. This is the part where your shared infrastructure tooling and systems will need to start changing to accommodate.
Finally, in the last phase of this project, we’re going to wind down, where we set things up, so like the happy path for new services is going to be siloed by AZ. You have to go outside some guardrails in the configuration to make a global service. We make sure that our long-term work for non-compliant services is tracked in roadmaps and OKRs. Then any work that doesn’t make the cut, we have incident review processes. As long as we’re tracking these things that we decided not to do, we can always bring them back up in response to a need.
When is Good Enough, Good Enough?
Now I’m going to go and talk about what I mean by doing things just good enough. At some point, the juice isn’t worth the squeeze. We had data warehousing systems at Slack that were basically just used by data analysts. Maybe there’s some batch processes that run, but user queries basically never touched those data warehouses. We don’t really care if they become cellular or not. That’s fine. If we decide it’s really important at some point, sure, but we’re here on behalf of the customers. It’s probably fine to stop before we get to those. Again, as with the rubric before, we want some structured way to think about this. Our two concerns are really, how do we figure out where to stop, and how do we keep what we’ve gained despite not doing literally everything in our environment? We figured out where to stop by working with each service to figure out the criticality of that service. chat.postMessage, for example, is the name of the API method that you use to post a message into Slack.
If chat.postMessage needs to touch your service before it can return, you are very critical. You’re really important for us to convert. Then, side by side, we want to have some idea about difficulty. That’s where the getting together with each service team and writing this one-pager about like, what it would mean, what we think the best solution for that team is, and how much effort it will take us to get there. You can use this to gauge difficulty. Then this tuple of criticality, importance, and difficulty. Criticality and difficulty is a good way that you can interface with engineering management about this project. You can be like, this is important and hard. This is important and easy. This is not important and easy. This is not important and hard, and do this Eisenhower decision matrix thing. We did a lot of these in phase one and two. Then when we got to phase three, which is the very wide phase, everyone was used to looking at and talking about these things. There wasn’t a lot of back and forth about whether we were doing this the right way or not.
Again, incrementality is most important. You should expect some of these services will need to take maybe a year, or more than a year to really get everything done because sometimes your most critical services are the most backlogged services, and the most difficult to maintain. We need to maintain an awareness of where the moon is as we roofshot along quarter to quarter. We made it so that each team’s engineering roadmap actually had compliance with this program as a goal. Quick sidebar is that, I believe that engineering roadmaps are just completely crucial for teams in infrastructure, in larger companies. If you just have a short document that says like, “This is what our service is like now. This is what we think our service will be like in a year, and here are some ways that we are getting there”. It’s just a very powerful tool to communicate both outside your organization into the rest of the engineering organization. It’s a good way for team members to understand the value and importance of their own work. I love a roadmap.
Finally, we measured our progress with weekly drains. If you’ll remember, we were worried about the capacity implications of it. We were like, every Friday for a while, around noon Pacific, we would drain the AZ and see how far we got. Then we watched the number go up and up over time. We’d do like 10%, and then we’d be like, can we do 20%? Then keep pulling traffic until we got scared. I think we only broke stuff one time. It was really good because it was a great signal for us to give to the company that we were getting something done. It’s meaningful. It’s the amount of bandwidth that’s left. It is a reasonable stand-in for user requests going through there. We were able to make it move. When it stopped moving, we could have conversations about that, and when we could expect it to move again.
Where Does That Leave Us?
This is where we actually ended up. Siloed services are drainable in 60 seconds via the load balancing layer. The Vitess automation reparents the nodes away from the fast AZ, as fast as the replication permits. We didn’t get all the critical services there 100%, but they’ve all got their roadmaps. One thing that you can use if you feel like things are getting deprioritized for too long is like, is it that important if they’re not having outages? Maybe it’s not. Conversely, if they have outages, maybe cellularizing would help. This is a really good thing to include in your incident review process. We’ve built into all our relevant infrastructure systems this default happy path, which is siloed per AZ configurations. We’re doing regular drains. At some point, we were like, we’re just doing these enough now that we don’t need to do them every Friday. Once you’re in the cycle, then you start having a good feeling about your capacity planning and you’re able to do it, and this is something that you can do if there’s an outage. Finally, we got a little bit of a savings because we reduced cross-AZ data transfer costs. That was nice.
Do We Actually Use This Thing?
The question that people always ask is like, do you really drain? Yes, we do. You get to use it more over time. You can use it for these single AZ AWS outages, but then you can also use it to help you do deploys. The same database that we power the frontend drains from, we just open the same one up to internal service mesh customers. Then they can roll forward, roll back their services. It actually opens up this new blue-greenish deploy method, where instead of just having like blue-green, you have like AZ 1, 2, 3, 4.
Then if you want to deploy some software, you just drain one of those AZs, pop the new software on it, undrain to 1%, 10%, 20%, whatever, and step it up that way. You can do that. It can give you a cleaner rollback experience than just popping binaries, like some people do. Siloing is helpful in other ways too. Sometimes you can have a poisonous deploy of a service, where the service itself is ok, but it’s causing another service to crash somehow. The siloing just helps naturally because of that. You can only endanger your upstream services in your own AZ. In general, we got to a place where if something looks wrong and it’s bounded by an AZ, generic mitigation. Like, let’s just try a drain and see if it gets better. Drains are fast. Drains are easy to undo. We don’t have to root cause our problems anymore.
Lessons Learned
Finally, what do we learn about running infrastructure projects in a decentralized environment? You really have to listen to people and you really have to move gradually and incrementally. You have to remember that every service is operating at a local maximum. The way things are is not because people are foolish, it’s because of the evolutionary pressures that shape the development of your system. Projects like this can actually provide potential energy to help these services escape from their local maximum to something better.
Questions and Answers
Brush: Have you had someone have an outage that this would have helped and they hadn’t completed their roadmap yet? Has that happened yet?
Bethea: Yes. That actually was very satisfying while we were in progress. People would be like, we had this outage, and we’d be like, siloing would help you, actually. Have you considered doing our program?
Participant 1: At my company, we do something very similar to this every week, where we’re draining, it’s not in AWS right now, but we often run into challenges convincing leaders that this is a smart thing to do because sometimes putting strain on the system will have some impact. Did you all have that and how did you all overcome it, or address it?
Bethea: Especially when you first start doing this, people will get anxious. You are removing capacity from a system. You can either do it like the inductive or the deductive way, where you either pencil it out and be like, we should be able to do this. Or you can do what we actually ended up doing where we would do these drains and walk them up slowly, and then like, if things got hot. Also, there is, I think, a compelling argument to be made that if you can’t do it when things are pretty normal, then you really shouldn’t be doing it when things are really bad.
Bethea: Did going to silos impact our continuous deployment? Tremendously, actually, because we ended up redoing the way that we did deploys entirely. We used to have a deployment system that did a lot of stuff, but in the end, it went from maybe 10% to 100%, spread across all AZs. We actually reworked it to fill up an AZ first and then spread across the other AZs on the idea that we could just simply revert that AZ by draining.
Participant 2: Then, as it came up, you would ship the traffic to a new AZ, 1%, and then bring the others up, or you would have old version and new version of this traffic at the same time?
Bethea: I think we were doing a little bit of a hybrid version just for historical reasons where we would roll that AZ forward by popping the binaries, by just flipping the binaries. If we needed to revert during the process, we would just pull traffic.
See more presentations with transcripts
MMS • RSS
JAT Capital Mgmt LP lessened its stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 84.3% in the 4th quarter, according to the company in its most recent 13F filing with the SEC. The institutional investor owned 13,575 shares of the company’s stock after selling 72,745 shares during the quarter. MongoDB comprises approximately 0.5% of JAT Capital Mgmt LP’s holdings, making the stock its 27th largest position. JAT Capital Mgmt LP’s holdings in MongoDB were worth $3,160,000 as of its most recent SEC filing.
Several other large investors also recently made changes to their positions in MDB. Strategic Investment Solutions Inc. IL bought a new stake in shares of MongoDB in the fourth quarter valued at approximately $29,000. Hilltop National Bank increased its position in MongoDB by 47.2% during the fourth quarter. Hilltop National Bank now owns 131 shares of the company’s stock worth $30,000 after acquiring an additional 42 shares during the period. NCP Inc. bought a new position in MongoDB during the fourth quarter worth $35,000. Versant Capital Management Inc increased its position in MongoDB by 1,100.0% during the fourth quarter. Versant Capital Management Inc now owns 180 shares of the company’s stock worth $42,000 after acquiring an additional 165 shares during the period. Finally, Wilmington Savings Fund Society FSB bought a new position in MongoDB during the third quarter worth $44,000. Institutional investors own 89.29% of the company’s stock.
Analyst Ratings Changes
MDB has been the topic of a number of research reports. Daiwa Capital Markets initiated coverage on shares of MongoDB in a research report on Tuesday, April 1st. They set an “outperform” rating and a $202.00 target price on the stock. Scotiabank reaffirmed a “sector perform” rating and set a $160.00 target price (down previously from $240.00) on shares of MongoDB in a research report on Friday. Loop Capital dropped their target price on shares of MongoDB from $400.00 to $350.00 and set a “buy” rating on the stock in a research report on Monday, March 3rd. Truist Financial lowered their price target on shares of MongoDB from $300.00 to $275.00 and set a “buy” rating on the stock in a report on Monday, March 31st. Finally, Stifel Nicolaus dropped their price objective on shares of MongoDB from $340.00 to $275.00 and set a “buy” rating for the company in a research note on Friday, April 11th. Eight research analysts have rated the stock with a hold rating, twenty-four have issued a buy rating and one has given a strong buy rating to the company’s stock. Based on data from MarketBeat, the company currently has a consensus rating of “Moderate Buy” and a consensus price target of $294.78.
Get Our Latest Stock Analysis on MDB
Insider Activity at MongoDB
In related news, CEO Dev Ittycheria sold 18,512 shares of the business’s stock in a transaction on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $3,207,389.12. Following the sale, the chief executive officer now directly owns 268,948 shares of the company’s stock, valued at approximately $46,597,930.48. The trade was a 6.44 % decrease in their position. The transaction was disclosed in a legal filing with the SEC, which can be accessed through this hyperlink. Also, insider Cedric Pech sold 1,690 shares of the business’s stock in a transaction on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total transaction of $292,809.40. Following the completion of the sale, the insider now directly owns 57,634 shares in the company, valued at $9,985,666.84. This represents a 2.85 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold 39,345 shares of company stock worth $8,485,310 in the last ninety days. Company insiders own 3.60% of the company’s stock.
MongoDB Trading Up 0.1 %
Shares of NASDAQ MDB opened at $174.69 on Wednesday. The firm has a market capitalization of $14.18 billion, a PE ratio of -63.76 and a beta of 1.49. MongoDB, Inc. has a 1 year low of $140.78 and a 1 year high of $387.19. The firm’s 50-day moving average is $190.43 and its 200-day moving average is $247.31.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing the consensus estimate of $0.64 by ($0.45). The business had revenue of $548.40 million during the quarter, compared to the consensus estimate of $519.65 million. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. During the same period last year, the business posted $0.86 EPS. As a group, equities research analysts anticipate that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Enter your email address and we’ll send you MarketBeat’s guide to investing in 5G and which 5G stocks show the most promise.
MMS • Steef-Jan Wiggers
Google has unveiled its seventh-generation Tensor Processing Unit (TPU), Ironwood, at Google Cloud Next 25. Ironwood is Google’s most performant and scalable custom AI accelerator to date and the first TPU designed specifically for inference workloads.
Google emphasizes that Ironwood is designed to power what they call the “age of inference,” marking a shift from responsive AI models to proactive models that generate insights and interpretations. The company states that AI agents will use Ironwood to retrieve and generate data, delivering insights and answers.
A respondent in a Reddit thread on the announcement said:
Google has a huge advantage over OpenAI because it already has the infrastructure to do things like making its own chips. Currently, it looks like Google is running away with the game.
Ironwood scales up to 9,216 liquid-cooled chips, connected with Inter-Chip Interconnect (ICI) networking, and is a key component of Google Cloud’s AI Hypercomputer architecture. Developers can leverage Google’s own Pathways software stack to utilize the combined computing power of tens of thousands of Ironwood TPUs.
The company states, “Ironwood is our most powerful, capable, and energy-efficient TPU yet. And it’s purpose-built to power thinking, inferential AI models at scale.”
Furthermore, the company highlights that Ironwood is designed to manage the computation and communication demands of large language models (LLMs), mixture of experts (MoEs), and advanced reasoning tasks. Ironwood minimizes data movement and latency on-chip and uses a low-latency, high-bandwidth ICI network for coordinated communication at scale.
Ironwood will be available for Google Cloud customers in 256-chip and 9,216-chip configurations. The company claims that a 9,216-chip Ironwood pod delivers more than 24x the compute power of the El Capitan supercomputer, with 42.5 Exaflops compared to El Capitan’s 1.7 Exaflops per pod. Each Ironwood chip boasts a peak compute of 4,614 TFLOPS.
Ironwood also features an enhanced SparseCore, a specialized accelerator for processing ultra-large embeddings, expanding its applicability beyond traditional AI domains to finance and science.
Other key features of Ironwood include:
- 2x improvement in power efficiency compared to the previous generation, Trillium.
- 192 GB of high-bandwidth memory (HBM) per chip, 6x that of Trillium.
- 1.2 TBps bidirectional ICI bandwidth, 1.5x that of Trillium.
- 7.37 TB/s of HBM bandwidth per chip, 4.5x that of Trillium.
(Source: Google blog post)
Regarding the last feature, a respondent on another Reddit thread commented:
Tera? Terabytes? 7.4 Terabytes? And I’m over here praying that AMD gives us a Strix variant with at least 500GB of bandwidth in the next year or two…
While NVIDIA remains a dominant player in the AI accelerator market, a respondent in another Reddit thread commented:
I don’t think it will affect Nvidia much, but Google is going to be able to serve their AI at much lower cost than the competition because they are more vertically integrated, and that is pretty much already happening.
In addition, in yet another Reddit thread, a correspondent commented:
The specs are pretty absurd. Shame Google won’t sell these chips, a lot of large companies need their own hardware, but Google only offers cloud services with the hardware. Feels like this is the future, though, when somebody starts cranking out these kinds of chips for sale.
And finally, Davit tweeted:
Google just revealed Ironwood TPU v7 at Cloud Next, and nobody’s talking about the massive potential here: If Google wanted, they could spin out TPUs as a separate business and become NVIDIA’s biggest competitor overnight.
These chips are that good. The arms race in AI silicon is intensifying, but few recognize how powerful Google’s position actually is. While everyone focuses on NVIDIA’s dominance, Google has quietly built chip infrastructure that could reshape the entire AI hardware market if it decides to go all-in.
Google states that Ironwood provides increased computation power, memory capacity, ICI networking advancements, and reliability. These advancements, combined with improved power efficiency, will enable customers to handle demanding training and serving workloads with high performance and low latency. Google also notes that leading models like Gemini 2.5 and AlphaFold run on TPUs.
The announcement also highlighted that Google DeepMind has been using AI to aid in the design process for TPUs. An AI method called AlphaChip been used to accelerate and optimize chip design, resulting in what Google describes as “superhuman chip layouts” used in the last three generations of Google’s TPUs.
Earlier, Google reported that AlphaChip had also been used to design other chips across Alphabet, such as Google Axion Processors, and had been adopted by companies like MediaTek to accelerate their chip development. Google believes that AlphaChip has the potential to optimize every stage of the chip design cycle and transform chip design for custom hardware.