Month: May 2025

MMS • RSS

A prominent NoSQL database, MongoDB supports today’s applications with its extensible, scalable schema. For starters, willing to learn MongoDB in 2025, YouTube provides free top-class tutorials explaining even the most intricate concepts in a step-by-step manner. FreeCodeCamp, The Net Ninja, and Traversy Media are some channels providing easy-to-grasp tutorials on CRUD operations, schemas, and MongoDB Atlas, so that anyone can learn database skills easily.
Here, the best YouTube channels to learn MongoDB from scratch are listed with highlight on their hands-on lessons, beginner-friendly step-by-step guides, and real-world projects for future developers.
MMS • RSS
![]() Captrust Financial Advisors reduced its position in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 31.1% during the 4th quarter, according to the company in its most recent 13F filing with the Securities & Exchange Commission. The firm owned 995 shares of the company’s stock after selling 450 shares during the quarter. Captrust Financial Advisors’ holdings in MongoDB were worth $232,000 at the end of the most recent quarter.
Captrust Financial Advisors reduced its position in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 31.1% during the 4th quarter, according to the company in its most recent 13F filing with the Securities & Exchange Commission. The firm owned 995 shares of the company’s stock after selling 450 shares during the quarter. Captrust Financial Advisors’ holdings in MongoDB were worth $232,000 at the end of the most recent quarter.
Several other hedge funds have also recently bought and sold shares of MDB. Norges Bank bought a new position in MongoDB in the 4th quarter valued at about $189,584,000. Marshall Wace LLP bought a new stake in shares of MongoDB during the 4th quarter valued at approximately $110,356,000. Raymond James Financial Inc. bought a new stake in shares of MongoDB during the 4th quarter valued at approximately $90,478,000. D1 Capital Partners L.P. bought a new stake in shares of MongoDB during the 4th quarter valued at approximately $76,129,000. Finally, Amundi grew its holdings in shares of MongoDB by 86.2% during the 4th quarter. Amundi now owns 693,740 shares of the company’s stock valued at $172,519,000 after purchasing an additional 321,186 shares during the last quarter. 89.29% of the stock is owned by institutional investors.
Insider Activity at MongoDB
In other MongoDB news, Director Dwight A. Merriman sold 3,000 shares of the business’s stock in a transaction on Monday, March 3rd. The shares were sold at an average price of $270.63, for a total transaction of $811,890.00. Following the completion of the sale, the director now owns 1,109,006 shares in the company, valued at approximately $300,130,293.78. The trade was a 0.27% decrease in their position. The sale was disclosed in a document filed with the SEC, which can be accessed through the SEC website. Also, CAO Thomas Bull sold 301 shares of the business’s stock in a transaction on Wednesday, April 2nd. The shares were sold at an average price of $173.25, for a total transaction of $52,148.25. Following the sale, the chief accounting officer now owns 14,598 shares of the company’s stock, valued at $2,529,103.50. This trade represents a 2.02% decrease in their position. The disclosure for this sale can be found here. Insiders have sold 33,538 shares of company stock worth $6,889,905 in the last quarter. Company insiders own 3.60% of the company’s stock.
MongoDB Stock Down 2.1%
<!—->
MongoDB stock opened at $185.01 on Thursday. MongoDB, Inc. has a 12-month low of $140.78 and a 12-month high of $379.06. The firm’s fifty day moving average is $174.84 and its 200 day moving average is $237.45. The company has a market capitalization of $15.02 billion, a PE ratio of -67.52 and a beta of 1.49.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The company had revenue of $548.40 million for the quarter, compared to analyst estimates of $519.65 million. During the same quarter in the previous year, the firm earned $0.86 EPS. Sell-side analysts expect that MongoDB, Inc. will post -1.78 EPS for the current fiscal year.
Analysts Set New Price Targets
Several equities research analysts recently issued reports on MDB shares. Piper Sandler decreased their price target on shares of MongoDB from $280.00 to $200.00 and set an “overweight” rating on the stock in a report on Wednesday, April 23rd. Monness Crespi & Hardt raised shares of MongoDB from a “sell” rating to a “neutral” rating in a report on Monday, March 3rd. KeyCorp lowered shares of MongoDB from a “strong-buy” rating to a “hold” rating in a report on Wednesday, March 5th. Daiwa America raised shares of MongoDB to a “strong-buy” rating in a report on Tuesday, April 1st. Finally, Redburn Atlantic raised shares of MongoDB from a “sell” rating to a “neutral” rating and set a $170.00 price target on the stock in a report on Thursday, April 17th. Nine equities research analysts have rated the stock with a hold rating, twenty-three have issued a buy rating and one has assigned a strong buy rating to the company. According to data from MarketBeat.com, the company presently has a consensus rating of “Moderate Buy” and a consensus price target of $288.91.
Get Our Latest Stock Report on MDB
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • Dan Chao

Transcript
Chao: I want to introduce Pkl, and introduce it in high level terms. I want to spend most of the time in the editor and showing you what it’s like to use Pkl.
I’m one of the core maintainers of Pkl at Apple. It’s a pretty small team. There’s three of us maintaining Pkl, but it’s a great group. I think we’ve done some pretty awesome things throughout the years. I am an ex-musician. I went into tech by meandering through the musician lifestyle and getting a degree in music performance, and then suddenly realizing, I really like programming.
Then I got really obsessed with it and been doing it ever since. As far as tech, I’ve been all over the place. I’ve spent a bunch of my time doing services. I’ve also done apps. I’ve done iOS and Android. I’ve been a DevOps engineer. I’ve worn every single hat that you can wear, including being a designer for some reason. One of the things that I’ve done in the past that was also language related is I used to design children-oriented programming languages, which is not object-oriented. It’s not functional. It’s this stuff. It’s something meant for a kid between 5 to 8 years old to 13 years old to learn how to program.
Evolution of Static Config
This is the Google Trends result for the search term, infrastructure as code. On the vertical axis, what you’ll see is plotting the frequency of the search term, where higher on the plot is more frequent. Then, on the horizontal axis is the search term over time. What this is telling us is infrastructure as code is how the industry as a whole is coalescing for how to manage infrastructure. Infrastructure as code generally looks something like this.
Usually, the code is YAML. You write a bunch of YAML, and then you check it in into GitHub or some other source code repositories, SVN system. You check that in, and then you provide that. You apply it to some engine somewhere that takes this, and then takes what you’re declaring, and then, you get infrastructure. This is a made-up example. I think if you’re familiar with infrastructure as code, this might look similar to the things out there. Here, we’re declaring, I want two machines. I want a machine in the us-west region. I want a machine in the us-east region, and here’s all the properties about the machine that I want. Here’s the environment variables that I want. I want this many CPUs, this much memory. Here’s how to configure the healthcheck.
This has been amazing. This is something that has allowed us to really improve the velocity of changing infrastructure over time. It’s simplified deployments quite a lot. One of the things that comes with this is, eventually, your configuration will grow in complexity. It can grow in complexity in two ways. It can scale in complexity of logic. It also can grow in complexity of how much configuration that you’re describing. We’ve already started down this path. We have this format, it’s YAML. We have this problem that we need to somehow scale our system.
Often, what you see is something that looks like this. We have our engine. How do we solve this? We have YAML. Let’s go ahead and go with YAML. Let’s come up with a new property called $$imports, and this accepts some relative path, env/prod.yml. We’ll just look for that file with that path, and we’ll load it in, and then we’ll have our custom rule for how to merge that into our config. Then we can follow this line of thinking.
As more requirements come up, we can add more to our system. Maybe we need to create some parameters for our system. We’ll have $$params. Then this also accepts some relative path, and this is how you create different machines based off of different things. Then maybe we need to differentiate the number of CPUs, depending on whether we’re deploying to production or some other environment. We could keep following this path and create more rules entirely within YAML. The thing about this is, if you take a step back, you start to realize this is actually a programming language. We’ve just invented a new language for our system. It just happens to be one that’s hard to understand, hard to write, and it’s bespoke to this one system.
I want to propose that this is driving in the wrong direction. As you evolve down this path, you create things that are ad hoc. My product describes complexity this way, but another competitor might come out with their own way to manage complexity. As a team that uses both products, they’ll need to context switch between one thing and another. This causes a lot of mistakes to be made easily. For example, as far as the language is concerned, you’ve invented a new language, but the core underlying language is still YAML, and YAML doesn’t know anything about what you’re doing here.
One of my examples is, there was this interpolation syntax with these brackets. As far as the editor is concerned, if you’re in VS Code, you’re in IntelliJ, it’s just a string. It’s also hard because I need to context switch how I manage the complexity from one thing to another. Another thing that’s hard is, as I describe my configuration, I want that to be valid. Because we’re describing data, that data needs to be valid. If I say that the CPUs that I’m deploying is 10 million, then we have a problem.
What Is Pkl?
There’s a great quote from Brian Goetz, who is one of the Java architects over at Oracle. He tweeted this saying, every declarative language eventually becomes a terrible programming language, just without the aid of actual language design.
Just to clarify, this is talking about static declarative languages. We want to flip this around. What if instead of starting with YAML, or JSON, or some ad hoc format, what if we start with a language? What if we build this language with solid principles that let you catch errors, that lets you build abstractions easily, and then you use that same language to describe the data? We found that this works really well. That’s what Pkl is. Pkl is two things. It’s both a programming language and a configuration language. You’ll see what I mean later when I go into my demo. It’s a programming language in that you have all the same facilities that you have in a typical language. You have functions, type annotations, you have imports. It’s a configuration language because that’s what it’s meant to do. It doesn’t have things that are scoped beyond configuration. For example, it doesn’t have an event loop, so you can’t have async/await APIs, or something like that. That’s the overview of Pkl.
Demo
Then, I think the best way to learn about a new language is to see somebody writing it. That’s what I’m going to do. This is going to be a live demo. I’m switching over to IntelliJ. Here, I have an empty file. Before I get into this, we have IntelliJ, but we also have an LSP. We also have plugins for VS Code, for Neovim. Then, if you have some other editor that you like, if it supports the LSP, then you can get Pkl support in there as well. Going back to this. This is an empty Pkl file. This is tour.pkl. I have the Pkl plugin installed, and this is an empty object. You can think of Pkl files, if you use the JSON analogy, as an object that has an implicit open curly brace, an implicit closing curly brace, and then you declare properties inside.
For example, I can say foo = 1. Then, I have my shell open right here, and I can go ahead and eval tour.pkl, and I’m going to produce this in JSON. Pkl is a language that evals into a static format. That’s just one of the things, but it does more than that, but I’ll get to that. I can have this output in XML. I can have this produce YAML and plists. Then you can also extend Pkl to produce other formats too. We have foo = 1. I can say bar = foo. Foo is not just a property. It’s also something that could be referenced. Foo is 1, bar is foo. Let’s go back to JSON. Now we have foo and bar that are both the same thing.
Then, you can have nested objects. Here’s a nested thing, prop = 1, and now we have a nested thing. One of the concepts that drives how we think about Pkl and how we want to design Pkl is to have it closely model the target configuration so that when you read a Pkl file, it looks like the thing that you’re targeting. If you’re describing Kubernetes, for example, you don’t have to guess what that means.
Now I want to jump into what it’s like to use Pkl. Earlier in my slides, we had this. We had my made-up infrastructure as code system, and I want to show you what it looks like when you use Pkl to describe this rather than YAML. One of the concepts of Pkl is you want to describe the schema of the system. Then, once you have the schema, then you can provide the data. Let’s go ahead and do that. I’m calling this FooBarSystem.
Then, let’s take the YAML and let’s figure out what it looks like as Pkl. We have machines, so that’s a property, and we can go ahead and declare a property. In this case, instead of providing a value, because I’m describing the schema, I’m just going to provide a type annotation. Machines happens to accept a YAML sequence of objects, and in Pkl, the way that you describe that is to say this is a listing. This is a listing of something, in this case, let’s call it Machine.
Now that we’ve described this top-level machines thing, the editor has told us, I don’t know what machine is, and then we get some editor hints in here. Let’s go ahead and fill it out. Machines is also an object, so we’ll call that a class, and the region is a String. We can actually do a little better than that. Here, let’s assume that region is a closed set of strings. We only have so many regions. We don’t have us-west-3. We don’t have us-south or us-north.
In this case, we can just say this is us-west or us-east. This might look familiar if you come from TypeScript, or maybe Scala 3, or other languages that have union types. Then we have environment, and these are environment variables. This is an arbitrary map of string to string. In Pkl, we’ll say this is a mapping of string to string. Next, we have CPUs, which is an Int. Earlier I said, maybe it’s not valid if we want to create a machine with 10 million CPUs. We can actually say this is an int, or this is less than 64. What I’m doing here is I’m creating a type that has a constraint on it, and this constrains the set of possible values that you can provide to CPUs. Also say this is a UInt, because maybe negative CPUs doesn’t make sense either.
One more example. The next thing is memory. Memory, over here, is a string. In Pkl, we can do a little better than that. We can say memory is a data size, and data size is a primitive that’s built right into Pkl. What this means is you don’t need to guess how that system represents 4 gigabits, because you don’t write a string, you use the primitive that’s built into Pkl.
I’m going to skip ahead, and I’m going to show you what it might look like in an actual code base. Typically, you would take a little bit of time and make this somewhat polished so that when you later use this, it’s clear to your developers what all of these things mean. I’m going to go ahead and copy and paste that to here. Then I’m going to blast through the rest of this real quick. We have CPUs. Here, I said it’s a UInt8. Then we have healthchecks. Healthchecks has a port, that’s a UInt16. The type, again, it’s a string literal union. Then the interval, on the YAML side, we have 5. What is 5? What does that mean? In Pkl, we can say this is a duration. Again, that’s a primitive type within Pkl. Then, finally, we’re going to say the output of this module is YAML.
Then when you encounter a data size, this is how you should turn that into YAML. When you encounter a duration, this is how you should turn this into YAML. In this case, a data size is turning into a string. Duration is turning into an int. One of the analogies that you can use to think about Pkl is when we defined this, we’ve just defined a form. Then when we define the data, we’re filling out that form. Let’s go ahead and do that. Here’s another Pkl file, myConfig. It starts with amends FooBarSystem. Amends is the secret sauce for a lot of how Pkl works. Amending says, I am an object that is like this other thing except with more things. In this case, the other object is FooBarSystem. Let’s go ahead and fill out the form that we just defined. This has a top-level property called machines. As I fill this in, I know what everything means. I want to declare two machines. The first one, the region is us-west. The environment has HTTP proxy. I’ll go ahead and copy and paste. Then we have CPUs, which is 4. If we said -4, then we get an error.
Constraint violation, I expected this thing, but you provided -4 in this. This blows up on you. One of the great things about doing it this way is you get immediate feedback. Not just for this is an int and it’s supposed to be a string, but this is supposed to be in between 0 and 64, or 0 and whatever. You get refined validation errors built right into the language. Then the memory is 4 gigabits. The healthchecks, I want one healthcheck where the port is 4050, type is TCP, the interval is 5, except 5 doesn’t make sense in this case. We’ll say healthcheck every 5 minutes, which is actually a crazy healthcheck number, but we’ll go with it.
Then, now that we have this, I can use the Pkl CLI and I can eval this, and I end up with almost exactly the same YAML. I have one more machine to go. This other machine is almost the same. I’m just going to go ahead and copy and paste it. The only difference is the region is us-east. Then the environment variable is also calculated in terms of the region, in this case. We’ll eval this again. Now we get the same input. These two YAML files are structurally the same. This is what it looks like to write it in Pkl.
We can actually do a little bit better than this. Like I said, both the us-west region and us-east are almost the same thing. Again, we can use amends as a way to simplify and help ourselves a little bit. Because when you amend, you say, I’m like the parent object except with these things. In this case, I’m going to go ahead and create a new property. Here I’m saying it’s local. Creating a new local property of type machine. I don’t want the region here because it differs from my two downstream things.
Then, the environment variable is also different. In this case, we can actually already use it. Later when we amend it, we render in terms of what we’re amending. Go ahead and do that now. The syntax says amends, but this is an amends expression. When you have baseMachine wrapped with parentheses and then an object block, you’re saying this object is just like this guy except the region is us-west. We can do the same thing here. This object is like the same guy, except the region is us-east. We’ll go ahead and eval and we get the same error. I want to show what it looks like to make an error. I’m going to make an error here. If I make an error, then I get some helpful message saying, this didn’t make sense and here’s where the error is. That’s part one.
We’re going to move into a real-world scenario. In this case, I’m going to show what it might look like to use Pkl to configure something with Kubernetes. Here’s part two. Within part two, I have a file called pkl:Project. I’ve declared two dependencies. These dependencies are packages that are published to pkg.pkl-lang.org. You can create your own packages and publish them at will and that works super easily. I have a pkl:Project with two dependencies, Kubernetes and Prometheus. Then here, again, I’ve defined the schema for my configuration.
In this case, the schema has Prometheus as a property to fill in. We’ve defined some things that are defined in terms of Prometheus. For example, we have a configMap and we have deployment. Prometheus is a bunch of things, but one of the things it does is it’s a scraper that you can deploy somewhere and it can scrape metrics and send it off to some server. One of the ways that you can deploy a scraper is you create a deployment and then you create a prometheus.conf that configures the scraper.
Then you deploy it, apply it to Kubernetes, and then you have your scraper running. That’s what we’re doing here. We’re creating a configMap and a deployment. We’re defining the configMap in terms of Prometheus. The configMap’s data has prometheus.conf, and the value is the textual output of Prometheus. Think about what you would do if you were defining YAML. If I were to do the same thing in YAML, I would again create a configMap with a prometheus.conf. Then, in YAML, I just have a string. Then within the string, the editor just says, this is a YAML string. You lose context there, you don’t know that this is a prometheus.conf. In Pkl, we can go the other way around. We can define an abstraction that says, if you want to deploy Prometheus, this is what you define, you define the Prometheus configuration and then I’ll take care of everything else for you.
We’ve defined the form, and now we can fill out the form. Here’s, again, another file. It amends Prometheus deployment, just like we did earlier. Then we can start filling in the form. In this case, we are creating a Prometheus scraper. This needs some scrape_configs, and we’ll go with Kubernetes scrape_configs. This is of type Listing of KubernetesSdConfig. It’s a listing, and so I need to put things inside. Here’s the thing I’m putting. Let’s continue filling this out. What is namespaces? Namespaces is a namespace spec that takes names. It takes names. We’ll go ahead and scrape foo. This is not important. I just wanted to show what it’s like to use Pkl. Compare this to what it would be if you were writing something like YAML or JSON. That would probably look like you having a browser window open and then looking up documentation.
The cool thing is because it’s part of the language, it’s part of the API of this config object, and it could just look it up just like I would if I were writing Java or Swift or something. Now we’ll go ahead and pkl eval this, and we have an error. I didn’t expect this, but I like that this is happening. There is something about my config that’s invalid. What’s invalid about it? The first scrape_configs needs a job name. This needs a job name, and again, this is called foo. Now it works. Like I said earlier, what we’re doing is we’re actually deploying two Kubernetes resources, but as a user filling in this form, I didn’t have to care about that. All I care about is what the Prometheus scraper looks like.
Then, I want to take this concept and go even further. Part three. Now we have this concept of, we create these abstractions, and we use that to deploy to the external system. Let’s keep going here. I’m going to show you what it might look like to use Pkl to deploy. We’ll stick with the Kubernetes theme, and we’ll stick with Prometheus. How you might use Pkl to manage a large-scale Kubernetes deployment. With Kubernetes, often what you do is you don’t just deploy to a single cluster. You deploy to different clusters all over the world.
Part three, imagine that that’s the root of a repo, and within part three, I have top-level directories called production and staging. Within production and within staging, you have us-east and us-west, and what we’re doing here is we’re using the directory structure to manage the complexity of our config. Here’s the same abstraction. Again, it’s a Prometheus that you fill in, I’ve added a little bit more things here. I’ve added resource requirements and the version of Prometheus that we’re deploying, and then we end up deploying exactly the same thing. This is how you might use this template, this form that I just defined. I do exactly the same thing. I create a file that amends it, and then I can fill it out. In this example, this is a Prometheus that’s deploying, but the difference is it’s deploying version 10.
Then I can also say, in us-east specifically, we want to change Prometheus in this way. Because we’re using the directory structure in multiple files, we could put the things that have to do with production in us-east in this file specifically, and we could put things that have to do with us-west in us-west specifically. Imagine you’re a team, you’re doing red-blue deployments or something, and you want to deploy version 10, deploy that and have that go up for a little bit of time, then you just come here and you say version 10, and then you apply it.
Notice, this file starts with amends “…”. Amends, again, is the thing where it means, I am an object like this guy except with these qualities. In that case, this guy, what “…” means is the first file with the same name in the directory ancestry tree, so it just goes up until it finds another file with the same name. You will go ahead and follow that, and that comes here. This is another file that also amends “…” and this says the resource requirements for all of production should have 10 CPU requests and 8 gigabits for memory.
Then, if I wanted to change something that affects all of production, then I just add that here. As you separate things into multiple files, then it becomes really easy for you to figure out, where is that complexity managed? Does it have to do with production? Then I just go into production and / whatever. In this layout, I have Prometheus that extends component, and component, in this case, is a building block to build a logical set of Kubernetes resources, so another component could be deploying Redis, for example. It could be deploying your bespoke application. This model lets you come in here, create something that extends component, and just define the knobs that you care about for that thing. Then, again, we’ll go ahead and eval that, and we get the same thing. We once again get YAML. If I wanted everything that had to do with production, then I can shell glob that, and I get all the production stuff. That’s part three.
So far, what I’ve talked about is how you can use Pkl to target external configuration, and that’s just one of the ways that you can use Pkl. If your external system doesn’t know how to speak Pkl, then you can use Pkl to render a format that that thing speaks. For example, Kubernetes doesn’t know anything about Pkl, but that’s ok, because we could just render that into YAML, which Kubernetes does understand. However, we also provide libraries for languages. If you’re creating an application, you can think of Pkl as just a library. We maintain libraries for Swift, for Go, for Java, and for Kotlin. Then we have an extension point, and we have an amazing community that’s provided a bunch of bindings for a bunch of different languages out there. I’m going to go ahead and clear that. I want to show what it might look like, I’m going to pick on Java in this case. If you’re a Java developer, this might look familiar. I have a build.gradle. Then, within the build.gradle, I have the Pkl plugin.
Then, I’m using the Pkl plugin right here. javaCodeGenerators, this is interesting. Within this application, I have source main resources and source main Java. If we go into source main resources, I have yet another template, but in this case, this describes the config of my application. Here we have defined the host, the port, the databases, and that’s a listing of database connection. Then, I’ve defined a Java code generator, and I’m going to go ahead and run that. I’m going to call gradlew config Classes. I’m running a task that takes the Pkl source code, and it turns it into Java. Now that I’ve run that, I now have Java available. This is the same thing that we’ve just described in Pkl, except it’s Java.
Now, in the actual application, I’m using the Pkl library to evaluate that file as an instance of a Java class, and that’s here, so that looks like this. It uses the ConfigEvaluator, calls the evaluate method, and then it converts the result into an AppConfig. Down here, we’re loading the AppConfig in my main function, and then I’m just printing. This is a demo anyway, so it doesn’t actually do anything except for printing the line, but let’s go ahead and run it. Here we go. This is the result, indeed, it is listening on localhost 10105, except it’s not. What this means is, in Java, you also get type safe config. You don’t need to worry about what the properties are. You don’t need to call .getProperty and cast it to a string, and hopefully it works, and hopefully somebody didn’t misconfigure it, because in Pkl, that’s type checked. If this evals successfully, you get valid data. Then, in Java, you get type-safe accessors, so you have .host and .port, and then if you call wrong property, then you get a compile error.
Participant 1: You end up with an instance of a Java class that contains the actual configuration?
Chao: Yes, that’s just a Java POJO.
Summary
Pkl’s power is it can meet you with your needs as first-party config and as third-party config. Pkl is just one logical application. It’s one program. For example, what this lets you do is you can manage your infrastructure in Pkl, and you can eval the same stuff directly in Java, so you can make sure those two things don’t go out of sync with each other. Because it’s one language that you have to learn, you can manage all the complexity of configuration directly in Pkl rather than spread it out in different places, and that’s what we hope Pkl becomes. We really like it, and I hope you like it too. We’re just getting started.
Resources
If you want to get involved and learn more about Pkl, here are some things for you. Our website is pkl-lang.org, and on there you can learn all about the language. There’s a tutorial that you can go through. There’s a language reference. There’s links to all the libraries and all the things that we do. If you want to get involved in development of Pkl, please do. We love pull requests. We love our contributors. It’s at github.com/apple/pkl. Then, we also have an awesome community of users already. You can go to pkl.community. This is not managed by us, by Apple. This is maintained by other people. On there, you can find a Discord, and some of the maintainers hang out on there too.
Questions and Answers
Participant 2: These Pkls are really well-suited, I think, for distribution throughout an organization, is there any mechanism that is supporting that? For instance, you don’t want to copy files, but you want to make maybe reference to a library that contains any Pkl files.
Chao: Earlier I showed a pkl:Project file with dependencies. Those dependencies are called packages, and you can create your own packages and publish them anywhere you want.
Participant 2: There is no particular format?
Chao: There’s a format. You’d use the CLI to create packages.
Participant 3: I’m just curious if you could talk about some design goals of this compared to CDK and the AWS Constructs library, because it feels like there’s a lot of similar goals, but I’m sure that you have some different ones in mind as well.
Chao: CDK is focused on a particular use case. CDK is meant for describing infra. That’s AWS?
Participant 3: CDK is built on a library called Constructs that’s more general purpose.
Chao: Maybe the bigger question is, I’ve described these things where you can use a programming language for config, but there’s also libraries that use Go, or Python, or TypeScript as a DSL for config, why would you use Pkl instead? I think one of the reasons that you would use something like Pkl is because if you have a polyglot organization where you have developers that use Java, that use other things, and you try to convince them, to configure Java, why don’t you use the CDK in Go? That’s going to be a hard sell. I think another thing is, unlike Python and TypeScript and other languages, Pkl’s designed for config, and so it has a lot of things that are lacking in those languages. It’s purposefully lacking things that are available in those other languages. For example, I showed type constraints. This is a port that should be between 10 and 63. You could describe that in Pkl, and the type system understands that, whereas TypeScript doesn’t.
Participant 4: I think you talked about publishing packages and having a repository. Are there well-known packages to define things? I know I’ve had to deal with Envoy config, for example. Is there something that predefines all the types that I can just reference and then navigate through and understand how to configure it?
Chao: We maintain packages, and we have a doc site that you can go through to look at all the packages that we maintain. Then, we also have code generators that take, for example, JSON schema. If you have schema already written in JSON schema, you could just generate Pkl from that.
Participant 5: I’m just curious if you can talk a little bit more about something like Pulumi, and what are some reasons why someone would use Pkl over that?
Chao: I think that relates to the first question, which is, why would you use Pkl over Python or TypeScript? Which is, Pkl is a language designed for config, and it has a lot of features that don’t exist. Then, it’s also a lot more portable. If you’re a Java developer, you’re probably not going to want to use Pulumi to configure your Java app. Pulumi is also multiple things. It’s like SDKs plus the Pulumi engine. It’s apples to oranges. You can use Pkl to configure Pulumi too, because they have a YAML spec.
See more presentations with transcripts
MMS • RSS
MongoDB (NASDAQ:MDB – Get Free Report) was downgraded by research analysts at Loop Capital from a “buy” rating to a “hold” rating in a research report issued to clients and investors on Tuesday, MarketBeat reports. They presently have a $190.00 price target on the stock, down from their prior price target of $350.00. Loop Capital’s target price would suggest a potential upside of 0.52% from the stock’s previous close.
A number of other brokerages have also commented on MDB. Macquarie decreased their price target on shares of MongoDB from $300.00 to $215.00 and set a “neutral” rating on the stock in a report on Friday, March 7th. China Renaissance assumed coverage on MongoDB in a research report on Tuesday, January 21st. They set a “buy” rating and a $351.00 price target on the stock. Truist Financial cut their price objective on MongoDB from $300.00 to $275.00 and set a “buy” rating for the company in a report on Monday, March 31st. Stifel Nicolaus decreased their price objective on MongoDB from $340.00 to $275.00 and set a “buy” rating on the stock in a report on Friday, April 11th. Finally, Wells Fargo & Company lowered MongoDB from an “overweight” rating to an “equal weight” rating and cut their target price for the stock from $365.00 to $225.00 in a research note on Thursday, March 6th. Nine equities research analysts have rated the stock with a hold rating, twenty-three have given a buy rating and one has issued a strong buy rating to the company’s stock. Based on data from MarketBeat, the company currently has an average rating of “Moderate Buy” and a consensus target price of $288.91.
Check Out Our Latest Research Report on MDB
MongoDB Trading Down 1.2%
MongoDB stock opened at $189.01 on Tuesday. MongoDB has a 1-year low of $140.78 and a 1-year high of $379.06. The firm has a market capitalization of $15.35 billion, a PE ratio of -68.98 and a beta of 1.49. The firm’s 50 day simple moving average is $174.77 and its 200 day simple moving average is $238.15.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings data on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing the consensus estimate of $0.64 by ($0.45). MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The business had revenue of $548.40 million for the quarter, compared to the consensus estimate of $519.65 million. During the same period in the prior year, the business posted $0.86 EPS. Research analysts forecast that MongoDB will post -1.78 earnings per share for the current year.
Insider Buying and Selling
In related news, CFO Srdjan Tanjga sold 525 shares of the stock in a transaction dated Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $90,961.50. Following the completion of the transaction, the chief financial officer now directly owns 6,406 shares in the company, valued at $1,109,903.56. This trade represents a 7.57% decrease in their position. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which is available through this hyperlink. Also, insider Cedric Pech sold 1,690 shares of the company’s stock in a transaction dated Wednesday, April 2nd. The stock was sold at an average price of $173.26, for a total transaction of $292,809.40. Following the completion of the sale, the insider now owns 57,634 shares in the company, valued at approximately $9,985,666.84. This trade represents a 2.85% decrease in their position. The disclosure for this sale can be found here. Insiders sold a total of 33,538 shares of company stock valued at $6,889,905 over the last three months. Corporate insiders own 3.60% of the company’s stock.
Institutional Inflows and Outflows
A number of large investors have recently added to or reduced their stakes in MDB. Strategic Investment Solutions Inc. IL purchased a new position in shares of MongoDB in the 4th quarter worth about $29,000. Cloud Capital Management LLC purchased a new position in MongoDB in the first quarter worth about $25,000. NCP Inc. bought a new position in shares of MongoDB in the fourth quarter worth approximately $35,000. Hollencrest Capital Management purchased a new stake in shares of MongoDB during the first quarter valued at approximately $26,000. Finally, Cullen Frost Bankers Inc. lifted its position in MongoDB by 315.8% in the 1st quarter. Cullen Frost Bankers Inc. now owns 158 shares of the company’s stock valued at $28,000 after acquiring an additional 120 shares in the last quarter. Hedge funds and other institutional investors own 89.29% of the company’s stock.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Discover the top 7 AI stocks to invest in right now. This exclusive report highlights the companies leading the AI revolution and shaping the future of technology in 2025.
MMS • Ben Linders

Web accessibility ensures content is usable by people with disabilities. According to Joanna Falkowska it can give a competitive edge, improve SEO, and support basic human rights. She emphasizes using WCAG standard and making accessibility a shared team responsibility from the start of development, to prevent costly fixes later in the process.
Joanna Falkowska spoke about creating accessible websites at DEV: Challenge Accepted.
Web accessibility is about making web content available to users with disabilities. Falkowska suggested using the Web Content Accessibility Guidelines to improve accessibility and create an inclusive website.
Web accessibility should be considered a basic human right, said Falkowska. We should care about website accessibility because most of us either are affected by disability directly or have family members, friends or colleagues who have it, she added. Product accessibility can give you a competitive edge over other businesses.
Some companies consider accessibility as a natural consequence of their DEI policy and a basic human right. There are also those who care about accessibility primarily due to SEO results, as search engines prioritise accessible sites in their search results, Falkowska said.
Accessibility may be important for companies due to legislation. Many countries and institutions implement dedicated digital accessibility laws that concern specific institutions and/or businesses, Falkowska mentioned:
One of the most recent ones is the European Accessibility Act. It is an EU directive that will come into force in July 2025, addressing a wide range of services, among others: e-commerce, banking and transport.
The Web Content Accessibility Guidelines is a standard that is recognized worldwide. Any legal act that requires conformance with accessibility rules quotes WCAG as its reference point, Falkowska said. It is available on-line and completely free. There is also a thorough list of international accessibility policies available. Falkowska invited people to read it and adapt their web content according to its success criteria.
Falkowska suggested that team members should be fluent in accessibility standard, at least in relation to the success criteria that refer to their role:
For example, it is the role of the designer to address all of the colour contrast issues there may be but also, if the authoring team has some flexibility, they should be aware of the colour contrast rules they need to follow in order for the final content to be accessible.
Accessibility issues, just as any other type of bugs, tend to be more expensive to fix in the later stages of development, Falkowska said. Therefore, development teams who want to achieve and maintain an accessibility standard, need to make accessibility part of the earliest stages of development.
Falkowska suggested making it part of the process to discuss and add precise accessibility acceptance criteria to the ticket description while grooming new stories:
Many teams do not do it, and as a result, accessibility gets added either after the ticket is rejected in the testing phase or even later – when the accessibility audit is completed.
Accessibility is undeniably a team sport. If we want to integrate it with the development process, we need to address it at all of its steps, Falkowska concluded.
InfoQ interviewed Joanna Falkowska about developing accessible websites.
InfoQ: What’s your advice to developers who want to start with accessibility?
Joanna Falkowska: If you are new to the subject of accessibility, I would recommend taking the time to read and understand all of the success criteria WCAG provides. It may look overwhelming at first but you can learn them in chunks, according to subsequent sections (guidelines) or based on conformance levels (from A up to AAA).
The second thing would be learning how to use assistive technology, especially screen readers, but also simple things like navigating with a keyboard instead of a mouse.
Finally, once you learn all of that, the first thing to do is… make friends with and, if needed, educate the design team. Many accessibility issues would not pop up at the development stage if the designs were following WCAG standards right from the start.
InfoQ: What can be done to make accessibility an integral part of your development process?
Falkowska: Make sure that accessibility is not simply “outsourced” to an accessibility team from a different department or an external auditing company.
The accessibility team should be there to support you only in the issues that go beyond the basic scope, e.g. you are struggling to decide what order to implement for keyboard navigation and need someone to share the most convenient solution.
The auditing company should come only in the last stage of the development. They are there to certify your accessibility level rather than teaching you what should have been done at the beginning of the development. We all know that changing the designs while the app is running costs much more than designing the wireframes with accessibility in mind.
Suppose we want to integrate accessibility into the development process. In that case, the product owner should raise the topic of accessibility repeatedly: right at the design stage, before the development starts, and up until the testing phase.
If your team members do not know what to consider while developing an accessible solution, you may want to request an accessibility specialist to join your team and help you draft requirements with WCAG in mind, teaching everyone what to consider during grooming sessions.
Developing accessible solutions might bring more clients to your website. Adding accessibility skills to your personal portfolio will make you a more competitive employee on the IT market. Companies that are legally obliged to deliver accessible solutions will quickly learn that it is more cost-effective to employ team members that know what role they play in delivering accessible apps.
MMS • RSS
![]() MongoDB (NASDAQ:MDB – Get Free Report)‘s stock had its “outperform” rating restated by equities research analysts at Royal Bank of Canada in a report released on Tuesday,Benzinga reports. They presently have a $320.00 target price on the stock. Royal Bank of Canada’s target price indicates a potential upside of 72.96% from the company’s current price.
MongoDB (NASDAQ:MDB – Get Free Report)‘s stock had its “outperform” rating restated by equities research analysts at Royal Bank of Canada in a report released on Tuesday,Benzinga reports. They presently have a $320.00 target price on the stock. Royal Bank of Canada’s target price indicates a potential upside of 72.96% from the company’s current price.
Several other equities research analysts have also recently commented on MDB. Barclays dropped their target price on shares of MongoDB from $280.00 to $252.00 and set an “overweight” rating for the company in a research report on Friday, May 16th. Needham & Company LLC lowered their price target on MongoDB from $415.00 to $270.00 and set a “buy” rating for the company in a research report on Thursday, March 6th. Stifel Nicolaus decreased their price target on MongoDB from $340.00 to $275.00 and set a “buy” rating for the company in a research note on Friday, April 11th. Monness Crespi & Hardt upgraded MongoDB from a “sell” rating to a “neutral” rating in a research note on Monday, March 3rd. Finally, Cantor Fitzgerald assumed coverage on MongoDB in a report on Wednesday, March 5th. They issued an “overweight” rating and a $344.00 target price on the stock. Nine analysts have rated the stock with a hold rating, twenty-three have issued a buy rating and one has given a strong buy rating to the stock. According to data from MarketBeat.com, MongoDB presently has an average rating of “Moderate Buy” and a consensus price target of $288.91.
Check Out Our Latest Analysis on MDB
MongoDB Trading Down 2.1%
<!—->
MDB opened at $185.01 on Tuesday. MongoDB has a 12 month low of $140.78 and a 12 month high of $379.06. The business’s 50-day moving average price is $174.84 and its 200-day moving average price is $237.45. The company has a market cap of $15.02 billion, a P/E ratio of -67.52 and a beta of 1.49.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing the consensus estimate of $0.64 by ($0.45). MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The company had revenue of $548.40 million for the quarter, compared to the consensus estimate of $519.65 million. During the same quarter in the previous year, the business earned $0.86 earnings per share. Equities research analysts forecast that MongoDB will post -1.78 earnings per share for the current fiscal year.
Insider Activity at MongoDB
In other news, CEO Dev Ittycheria sold 8,335 shares of the company’s stock in a transaction that occurred on Wednesday, February 26th. The shares were sold at an average price of $267.48, for a total value of $2,229,445.80. Following the completion of the sale, the chief executive officer now owns 217,294 shares of the company’s stock, valued at approximately $58,121,799.12. This represents a 3.69% decrease in their position. The sale was disclosed in a document filed with the Securities & Exchange Commission, which is accessible through this link. Also, CAO Thomas Bull sold 301 shares of the business’s stock in a transaction dated Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total transaction of $52,148.25. Following the completion of the transaction, the chief accounting officer now owns 14,598 shares of the company’s stock, valued at $2,529,103.50. This represents a 2.02% decrease in their ownership of the stock. The disclosure for this sale can be found here. In the last ninety days, insiders have sold 33,538 shares of company stock worth $6,889,905. Insiders own 3.60% of the company’s stock.
Institutional Investors Weigh In On MongoDB
A number of large investors have recently made changes to their positions in MDB. Cloud Capital Management LLC acquired a new stake in MongoDB during the 1st quarter valued at approximately $25,000. Hollencrest Capital Management acquired a new stake in shares of MongoDB in the first quarter valued at about $26,000. Cullen Frost Bankers Inc. increased its stake in MongoDB by 315.8% during the 1st quarter. Cullen Frost Bankers Inc. now owns 158 shares of the company’s stock worth $28,000 after buying an additional 120 shares in the last quarter. Strategic Investment Solutions Inc. IL purchased a new stake in shares of MongoDB during the fourth quarter worth $29,000. Finally, NCP Inc. acquired a new stake in shares of MongoDB in the fourth quarter valued at approximately $35,000. 89.29% of the stock is owned by hedge funds and other institutional investors.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
![]() MongoDB (NASDAQ:MDB – Get Free Report) is expected to be issuing its Q1 2026 quarterly earnings data before the market opens on Thursday, May 29th. Analysts expect the company to announce earnings of $0.65 per share and revenue of $527.49 million for the quarter. MongoDB has set its Q1 2026 guidance at 0.630-0.670 EPS and its FY 2026 guidance at 2.440-2.620 EPS.
MongoDB (NASDAQ:MDB – Get Free Report) is expected to be issuing its Q1 2026 quarterly earnings data before the market opens on Thursday, May 29th. Analysts expect the company to announce earnings of $0.65 per share and revenue of $527.49 million for the quarter. MongoDB has set its Q1 2026 guidance at 0.630-0.670 EPS and its FY 2026 guidance at 2.440-2.620 EPS.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share for the quarter, missing the consensus estimate of $0.64 by ($0.45). The company had revenue of $548.40 million for the quarter, compared to analysts’ expectations of $519.65 million. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. During the same quarter last year, the firm posted $0.86 earnings per share. On average, analysts expect MongoDB to post $-2 EPS for the current fiscal year and $-2 EPS for the next fiscal year.
MongoDB Stock Performance
NASDAQ MDB opened at $185.01 on Thursday. The business’s fifty day moving average is $174.84 and its 200 day moving average is $237.45. The company has a market capitalization of $15.02 billion, a PE ratio of -67.52 and a beta of 1.49. MongoDB has a fifty-two week low of $140.78 and a fifty-two week high of $379.06.
Analyst Upgrades and Downgrades
<!—->
Several brokerages have recently issued reports on MDB. Scotiabank reaffirmed a “sector perform” rating and issued a $160.00 target price (down from $240.00) on shares of MongoDB in a report on Friday, April 25th. Morgan Stanley reduced their price objective on MongoDB from $315.00 to $235.00 and set an “overweight” rating on the stock in a research note on Wednesday, April 16th. Wedbush reduced their price objective on MongoDB from $360.00 to $300.00 and set an “outperform” rating on the stock in a research note on Thursday, March 6th. Canaccord Genuity Group cut their target price on MongoDB from $385.00 to $320.00 and set a “buy” rating on the stock in a research note on Thursday, March 6th. Finally, Daiwa Capital Markets started coverage on MongoDB in a research note on Tuesday, April 1st. They set an “outperform” rating and a $202.00 target price on the stock. Nine research analysts have rated the stock with a hold rating, twenty-three have assigned a buy rating and one has issued a strong buy rating to the company. Based on data from MarketBeat, the stock has an average rating of “Moderate Buy” and an average target price of $288.91.
Get Our Latest Report on MongoDB
Insiders Place Their Bets
In other news, Director Dwight A. Merriman sold 3,000 shares of the company’s stock in a transaction that occurred on Monday, March 3rd. The shares were sold at an average price of $270.63, for a total value of $811,890.00. Following the completion of the sale, the director now directly owns 1,109,006 shares of the company’s stock, valued at approximately $300,130,293.78. This represents a 0.27% decrease in their position. The sale was disclosed in a legal filing with the SEC, which is accessible through this link. Also, CAO Thomas Bull sold 301 shares of the stock in a transaction that occurred on Wednesday, April 2nd. The shares were sold at an average price of $173.25, for a total transaction of $52,148.25. Following the sale, the chief accounting officer now directly owns 14,598 shares of the company’s stock, valued at approximately $2,529,103.50. This represents a 2.02% decrease in their ownership of the stock. The disclosure for this sale can be found here. In the last 90 days, insiders sold 33,538 shares of company stock worth $6,889,905. Insiders own 3.60% of the company’s stock.
Institutional Inflows and Outflows
A hedge fund recently raised its stake in MongoDB stock. Integrated Wealth Concepts LLC increased its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 31.6% in the 1st quarter, according to the company in its most recent filing with the Securities and Exchange Commission. The firm owned 1,363 shares of the company’s stock after buying an additional 327 shares during the period. Integrated Wealth Concepts LLC’s holdings in MongoDB were worth $239,000 at the end of the most recent reporting period. Institutional investors own 89.29% of the company’s stock.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
Azure Logic Apps Introduces ‘Agent Loop’ for Building AI Agents in Enterprise Workflows
MMS • Steef-Jan Wiggers
At the annual Build conference, Microsoft announced agent loop, a new capability within Azure Logic Apps that allows developers to build AI agents directly into their enterprise workflows.
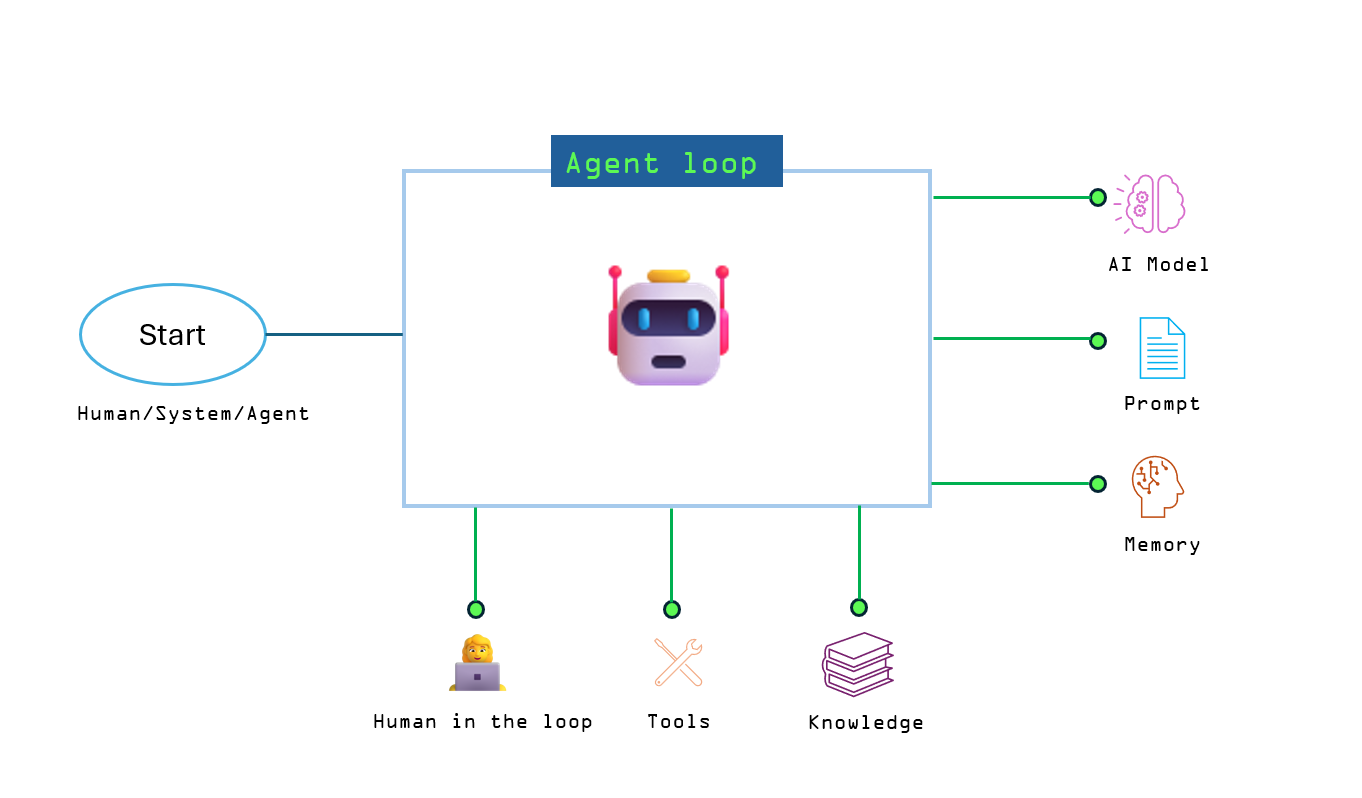
Agent loop is a central component for AI Agent development within Logic Apps. It is a new action type integrating a chosen AI model (like Azure OpenAI), domain-specific tools (via Logic Apps connectors), and enterprise knowledge sources. With the component, developers can create various types of AI agents, including autonomous agents for tasks like loan approvals, conversational agents for customer support, and multi-agent systems for coordinated activities such as sales report generation.
(Source: Microsoft Tech community blog post)
Built upon the kernel object in the Semantic Kernel, the agent loop leverages an LLM to determine the necessary steps. At the same time, the Azure Logic Apps runtime handles the execution of these plans. This approach offers significant flexibility, allowing for the creation of both conversational and fully autonomous agents that can respond to real-time events via Logic Apps’ extensive library of connectors.
Divya Swarnkar, a program manager at Microsoft, told InfoQ :
With over 1,400 connectors, Logic Apps is uniquely positioned to power AI Agents with rich context and seamless access to enterprise systems and APIs, enabling them to reason and act reliably.
Agent loop operates through an iterative “Think, Act, and Learn cycle.” The AI agent reasons about its goal and context, takes action by invoking connectors, and then reflects on the results to adjust its plan if needed. Azure Logic Apps manages this cycle automatically.
Microsoft highlights several potential use cases for AI Agents built with agent loop, including:
- Product Return Agent: Verifying order details, return eligibility, and processing refunds or requesting further information.
- Loan Approval Agent: Evaluating credit scores, income, and risk profiles to auto-approve or route applications.
- Recruiting Agent: Screening resumes, summarizing qualifications, and drafting personalized outreach.
- Sales Report Generation Workflow: Utilizing multiple agents for drafting, reviewing, and publishing reports.
- IT Operations Agent: Triaging alerts, checking changes, and resolving common issues or escalating when necessary.
- Multi-Agent Retail Supply Chain Solution: Coordinating inventory and logistics agents for timely restocks and optimized fulfillment.
Furthermore, the key benefits of building AI Agents in Logic Apps with agent loop include declarative orchestration, code extensibility, access to a vast library of integrated tools, observability with full traceability of agent decisions, enterprise-grade governance inheriting the security and compliance of Azure Logic Apps, straightforward human-in-the-loop and multi-agent coordination, and faster time to value by abstracting away the boilerplate of agent architecture.
Kent Weare, a Principal Program Manager for Logic Apps at Microsoft, states:
Building agents or workflows isn’t a binary choice. The most effective solutions often combine both — and that’s where Logic Apps excels. With Agent Loop, customers have full control to dial up the level of agentic automation that fits their needs. Logic Apps is where traditional workflows and AI agents come together, combining forces to solve complex business problems — all within a trusted, enterprise-grade platform. I don’t think any other platform offers this!
In addition, further emphasizing the potential, Cameron McKay, an Azure Application Architect, concluded in a LinkedIn blog post about the agent loop feature in Logic Apps:
This functionality has a lot of potential, and the number of use cases is up to the business and implementer; a few use cases include responding to error events and performing processes based on conversations with humans. I’m excited to see how the use cases for this functionality evolve; without a doubt, this is a highly transformative and useful piece of functionality being added to the Azure Logic Apps toolkit.
Agent loop is available in Azure Logic Apps Standard, and the company has provided documentation and demos to help developers get started. It has also outlined future plans for multi-agent hand-off support, A2A (Agent-to-Agent) protocol support, and OBO Auth for Logic Apps Agents.
MMS • Matt Foster
HashiCorp has released the Terraform MCP Server, an open-source implementation of the Model Context Protocol designed to improve how large language models interact with infrastructure as code. By exposing real-time Terraform Registry data—such as module metadata, provider schemas, and resource definitions—in a structured format, the server enables AI systems to ground their suggestions in current, validated configuration patterns. This allows tools like Claude, Co-Pilot and ChatGPT to generate more accurate, context-aware Terraform code by prioritizing canonical sources over outdated or hallucinated examples from training data.
The Model Context Protocol (MCP) is a standard designed to help large language models retrieve structured, machine-readable data from external systems in real time. Rather than relying solely on static training data, AI tools can use MCP to query live sources via JSON-over-gRPC, enabling grounded, context-aware responses. In the Terraform MCP Server implementation, the protocol serves as a bridge between AI systems and the Terraform Registry, exposing data about modules, providers, resources, and their schemas.
This setup allows an AI model to retrieve up-to-date configuration details—such as input arguments for a provider, usage patterns for a popular module, or the latest available version—by issuing standardized queries to an MCP endpoint.
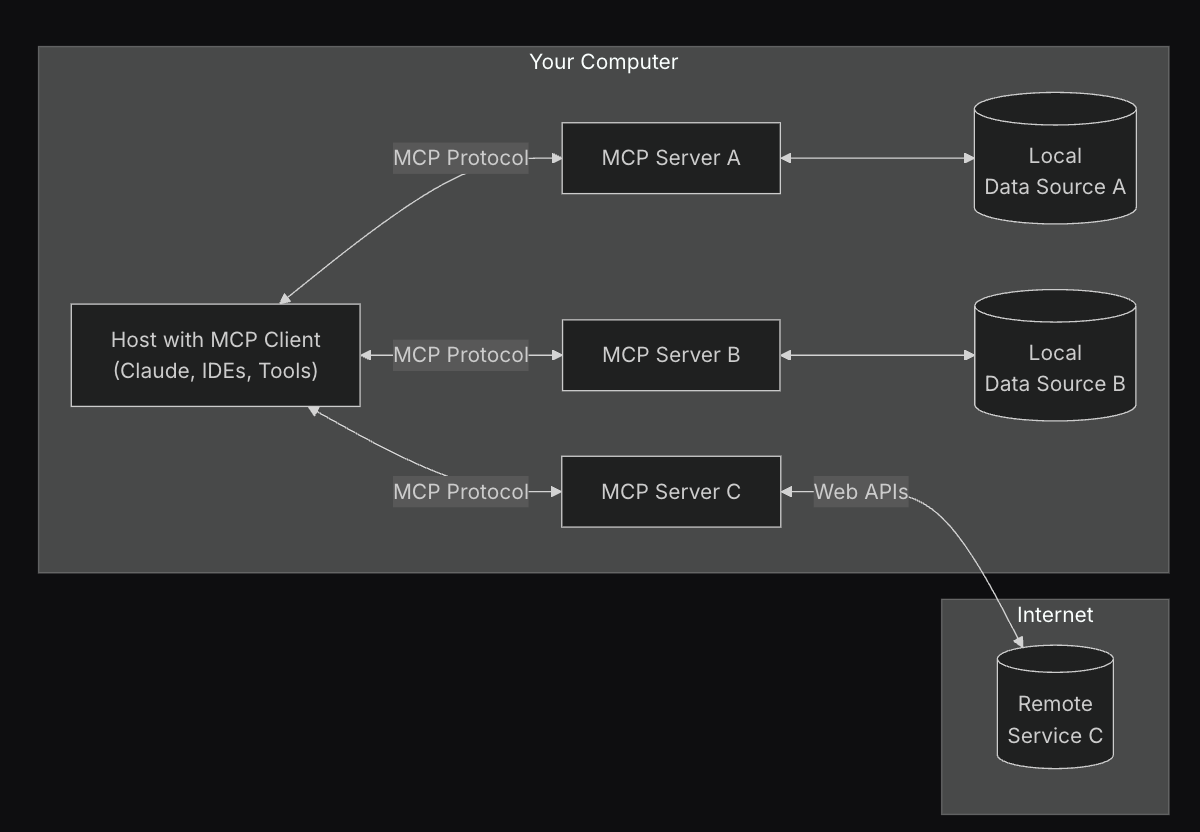
Source Hashicorp
Surfacing this data in a structured format, the server allows AI-assisted tools to align more closely with the latest Terraform standards and configurations. While HashiCorp does not claim specific accuracy improvements yet, it is fair to infer that this approach may help mitigate issues that arise when models rely on outdated or hardcoded infrastructure knowledge (hallucinations).
Although the Terraform MCP Server itself is still in early development, HashiCorp has already demonstrated its integration with GitHub Copilot at Microsoft Build 2025, allowing developers to retrieve context-aware Terraform recommendations grounded in live registry data directly from their IDEs.
Independent projects are also experimenting with the MCP protocol for Terraform: terraform-docs-mcp implements a Node.js-based MCP server to surface module metadata for AI assistants, offering a lightweight alternative for exposing registry data outside the Terraform ecosystem. Meanwhile, tfmcp explores a CLI-driven approach to managing Terraform workflows via LLMs like Claude, enabling tasks such as reading configuration files and analyzing plans through structured prompts. While these community efforts don’t rely on HashiCorp’s implementation, they signal growing interest in the MCP ecosystem as a machine-readable interface to infrastructure knowledge.
Together with other emerging efforts, Terraform MCP Server is another example of a broader pattern in AI-assisted tooling to unify developer workflows. While HashiCorp has not explicitly stated strategic intentions behind MCP, the adoption of such protocols suggests a shift from product-specific AI integrations toward interoperable interfaces designed to support a diverse ecosystem of assistants, clients, and automation workflows.
MMS • RSS
Quantinno Capital Management LP raised its stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 100.2% during the fourth quarter, according to the company in its most recent Form 13F filing with the Securities and Exchange Commission. The fund owned 14,262 shares of the company’s stock after acquiring an additional 7,137 shares during the period. Quantinno Capital Management LP’s holdings in MongoDB were worth $3,321,000 as of its most recent SEC filing.
A number of other institutional investors have also recently modified their holdings of MDB. Strategic Investment Solutions Inc. IL purchased a new stake in shares of MongoDB in the fourth quarter worth $29,000. NCP Inc. purchased a new stake in shares of MongoDB in the fourth quarter worth $35,000. Coppell Advisory Solutions LLC grew its stake in shares of MongoDB by 364.0% in the fourth quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock worth $54,000 after acquiring an additional 182 shares during the last quarter. Smartleaf Asset Management LLC boosted its position in shares of MongoDB by 56.8% during the fourth quarter. Smartleaf Asset Management LLC now owns 370 shares of the company’s stock valued at $87,000 after buying an additional 134 shares during the last quarter. Finally, Manchester Capital Management LLC boosted its position in shares of MongoDB by 57.4% during the fourth quarter. Manchester Capital Management LLC now owns 384 shares of the company’s stock valued at $89,000 after buying an additional 140 shares during the last quarter. 89.29% of the stock is owned by hedge funds and other institutional investors.
Wall Street Analyst Weigh In
MDB has been the topic of several recent analyst reports. Monness Crespi & Hardt raised MongoDB from a “sell” rating to a “neutral” rating in a research report on Monday, March 3rd. Citigroup dropped their price objective on MongoDB from $430.00 to $330.00 and set a “buy” rating on the stock in a research report on Tuesday, April 1st. Rosenblatt Securities reaffirmed a “buy” rating and set a $350.00 price objective on shares of MongoDB in a research report on Tuesday, March 4th. Scotiabank reaffirmed a “sector perform” rating and set a $160.00 price objective (down from $240.00) on shares of MongoDB in a research report on Friday, April 25th. Finally, Oppenheimer dropped their price objective on MongoDB from $400.00 to $330.00 and set an “outperform” rating on the stock in a research report on Thursday, March 6th. Eight analysts have rated the stock with a hold rating, twenty-four have issued a buy rating and one has given a strong buy rating to the stock. Based on data from MarketBeat.com, the company presently has an average rating of “Moderate Buy” and an average price target of $293.91.
Read Our Latest Stock Report on MDB
MongoDB Trading Down 1.2%
NASDAQ:MDB opened at $189.01 on Tuesday. MongoDB, Inc. has a 12-month low of $140.78 and a 12-month high of $379.06. The stock has a 50-day moving average price of $174.77 and a 200 day moving average price of $238.15. The stock has a market capitalization of $15.35 billion, a P/E ratio of -68.98 and a beta of 1.49.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing the consensus estimate of $0.64 by ($0.45). MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The business had revenue of $548.40 million for the quarter, compared to analysts’ expectations of $519.65 million. During the same quarter in the prior year, the business posted $0.86 EPS. On average, research analysts predict that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
Insider Buying and Selling
In other MongoDB news, insider Cedric Pech sold 1,690 shares of the firm’s stock in a transaction that occurred on Wednesday, April 2nd. The stock was sold at an average price of $173.26, for a total transaction of $292,809.40. Following the completion of the transaction, the insider now owns 57,634 shares in the company, valued at $9,985,666.84. This trade represents a 2.85% decrease in their position. The transaction was disclosed in a filing with the SEC, which is available through this link. Also, CFO Srdjan Tanjga sold 525 shares of the firm’s stock in a transaction that occurred on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $90,961.50. Following the transaction, the chief financial officer now owns 6,406 shares of the company’s stock, valued at $1,109,903.56. This represents a 7.57% decrease in their position. The disclosure for this sale can be found here. Over the last 90 days, insiders sold 33,538 shares of company stock worth $6,889,905. 3.60% of the stock is owned by corporate insiders.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Learn the basics of options trading and how to use them to boost returns and manage risk with this free report from MarketBeat. Click the link below to get your free copy.