Month: May 2025

MMS • RSS
![]() MongoDB (NASDAQ:MDB – Get Free Report) was downgraded by research analysts at Loop Capital from a “buy” rating to a “hold” rating in a research report issued on Tuesday, Marketbeat Ratings reports. They presently have a $190.00 target price on the stock, down from their previous target price of $350.00. Loop Capital’s price target indicates a potential upside of 2.70% from the stock’s current price.
MongoDB (NASDAQ:MDB – Get Free Report) was downgraded by research analysts at Loop Capital from a “buy” rating to a “hold” rating in a research report issued on Tuesday, Marketbeat Ratings reports. They presently have a $190.00 target price on the stock, down from their previous target price of $350.00. Loop Capital’s price target indicates a potential upside of 2.70% from the stock’s current price.
A number of other analysts also recently issued reports on MDB. UBS Group set a $350.00 price objective on shares of MongoDB in a report on Tuesday, March 4th. Royal Bank of Canada reduced their price target on MongoDB from $400.00 to $320.00 and set an “outperform” rating on the stock in a research report on Thursday, March 6th. Scotiabank reaffirmed a “sector perform” rating and issued a $160.00 price objective (down from $240.00) on shares of MongoDB in a report on Friday, April 25th. Monness Crespi & Hardt upgraded MongoDB from a “sell” rating to a “neutral” rating in a research report on Monday, March 3rd. Finally, Mizuho decreased their price target on MongoDB from $250.00 to $190.00 and set a “neutral” rating on the stock in a research report on Tuesday, April 15th. Nine equities research analysts have rated the stock with a hold rating, twenty-three have assigned a buy rating and one has issued a strong buy rating to the stock. According to data from MarketBeat.com, the stock presently has a consensus rating of “Moderate Buy” and an average target price of $288.91.
Check Out Our Latest Analysis on MongoDB
MongoDB Stock Performance
<!—->
Shares of MDB stock opened at $185.01 on Tuesday. MongoDB has a 52 week low of $140.78 and a 52 week high of $379.06. The company has a market capitalization of $15.02 billion, a price-to-earnings ratio of -67.52 and a beta of 1.49. The company has a 50-day simple moving average of $174.84 and a 200 day simple moving average of $237.45.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share for the quarter, missing the consensus estimate of $0.64 by ($0.45). The firm had revenue of $548.40 million for the quarter, compared to analyst estimates of $519.65 million. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. During the same period in the previous year, the business posted $0.86 earnings per share. Sell-side analysts forecast that MongoDB will post -1.78 EPS for the current year.
Insider Buying and Selling
In related news, CAO Thomas Bull sold 301 shares of MongoDB stock in a transaction that occurred on Wednesday, April 2nd. The shares were sold at an average price of $173.25, for a total value of $52,148.25. Following the completion of the transaction, the chief accounting officer now directly owns 14,598 shares in the company, valued at approximately $2,529,103.50. The trade was a 2.02% decrease in their position. The transaction was disclosed in a filing with the Securities & Exchange Commission, which is accessible through this hyperlink. Also, CFO Srdjan Tanjga sold 525 shares of the stock in a transaction on Wednesday, April 2nd. The stock was sold at an average price of $173.26, for a total value of $90,961.50. Following the sale, the chief financial officer now owns 6,406 shares in the company, valued at approximately $1,109,903.56. This represents a 7.57% decrease in their position. The disclosure for this sale can be found here. Over the last ninety days, insiders have sold 33,538 shares of company stock worth $6,889,905. 3.60% of the stock is owned by insiders.
Institutional Inflows and Outflows
Large investors have recently bought and sold shares of the company. Acadian Asset Management LLC raised its position in MongoDB by 181.8% during the first quarter. Acadian Asset Management LLC now owns 562,190 shares of the company’s stock valued at $98,586,000 after purchasing an additional 362,705 shares in the last quarter. IFM Investors Pty Ltd boosted its stake in MongoDB by 4.3% in the first quarter. IFM Investors Pty Ltd now owns 13,796 shares of the company’s stock worth $2,420,000 after buying an additional 569 shares in the last quarter. UBS AM A Distinct Business Unit of UBS Asset Management Americas LLC boosted its stake in MongoDB by 11.3% in the first quarter. UBS AM A Distinct Business Unit of UBS Asset Management Americas LLC now owns 1,271,444 shares of the company’s stock worth $223,011,000 after buying an additional 129,451 shares in the last quarter. Woodline Partners LP grew its position in MongoDB by 30,297.0% during the first quarter. Woodline Partners LP now owns 322,208 shares of the company’s stock valued at $56,515,000 after acquiring an additional 321,148 shares during the last quarter. Finally, Meiji Yasuda Life Insurance Co raised its stake in shares of MongoDB by 36.1% during the first quarter. Meiji Yasuda Life Insurance Co now owns 3,997 shares of the company’s stock worth $701,000 after acquiring an additional 1,060 shares in the last quarter. 89.29% of the stock is owned by institutional investors.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
Prime Intellect Releases INTELLECT-2: A 32B Parameter Model Trained via Decentralized Reinforcement
MMS • Robert Krzaczynski
Prime Intellect has released INTELLECT-2, a 32 billion parameter language model trained using fully asynchronous reinforcement learning across a decentralized network of compute contributors. Unlike traditional centralized model training, INTELLECT-2 is developed on a permissionless infrastructure where rollout generation, policy updates, and training are distributed and loosely coupled.
The system is built around PRIME-RL, a new training framework designed for asynchronous RL in untrusted environments. It separates the tasks of generating rollouts, updating models, and broadcasting weights. Policy updates are handled by SHARDCAST, a component that distributes model weights using a tree-based HTTP network. Inference rollouts submitted by workers are verified through TOPLOC, a locality-sensitive hashing mechanism that detects tampering or numerical discrepancies before allowing the results to influence training.
Source: https://arxiv.org/html/2505.07291v1
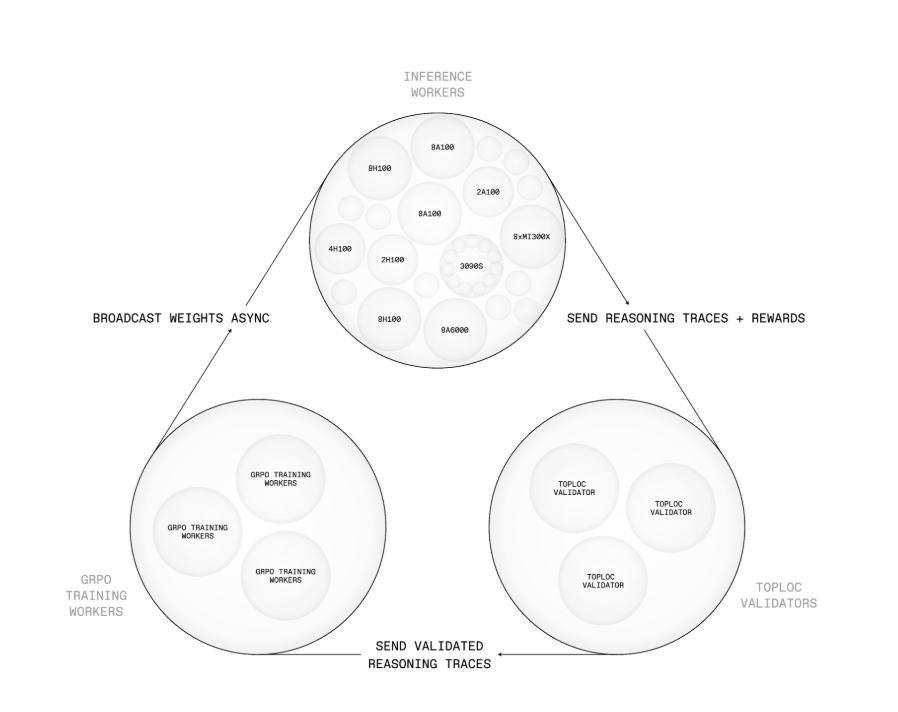
INTELLECT-2 was trained on 285,000 math and coding tasks sourced from datasets such as NuminaMath-1.5 or SYNTHETIC-1. The reward signal combines binary task success with token-length penalties or bonuses, allowing fine-grained control over inference-time compute budgets. Training stability was supported by techniques such as two-sided GRPO clipping, gradient norm management, and both offline and online filtering of high-value tasks.
The asynchronous training process overlaps inference, communication, and model updates, avoiding typical bottlenecks found in centralized RL systems. A Rust-based orchestrator running on a testnet coordinates the global pool of contributors, handling hardware checks, heartbeats, task assignments, and contribution tracking—operating similarly to peer-to-peer or blockchain-based systems.
Performance evaluations showed improvements on targeted math and programming tasks, particularly over QwQ-32B, a previous RL-trained model. Broader benchmark improvements were more modest, suggesting gains were mostly confined to training data domains. Prime Intellect noted that improvements might be more significant using stronger base models, such as Qwen3, or by integrating more complex environments and reasoning tools.
One Reddit user remarked on the broader implications:
Distributed training and distributed inference seem like the way to go. Maybe something similar to P2P or blockchain with some kind of rewards for computational contributions/transactions. Not necessarily yet another cryptocurrency, but maybe credits that can be used for free computing on the network.
Future work includes increasing the inference-to-training compute ratio, enabling multi-turn reasoning with integrated tools like web search or Python, crowdsourcing RL tasks, and experimenting with decentralized model merging methods such as DiLoCo.
The model, code, training framework, and documentation are publicly available on the Prime Intellect website. Additional tools and interfaces, including a Hugging Face release and a chat demo, are also publicly accessible.
MMS • RSS
Spyglass Capital Management LLC increased its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 5.8% during the fourth quarter, according to its most recent filing with the Securities and Exchange Commission. The firm owned 249,683 shares of the company’s stock after acquiring an additional 13,712 shares during the period. MongoDB makes up about 3.3% of Spyglass Capital Management LLC’s holdings, making the stock its 19th biggest position. Spyglass Capital Management LLC owned 0.34% of MongoDB worth $58,129,000 at the end of the most recent reporting period.
Other hedge funds and other institutional investors have also bought and sold shares of the company. B.O.S.S. Retirement Advisors LLC bought a new stake in MongoDB during the 4th quarter worth approximately $606,000. Union Bancaire Privee UBP SA bought a new stake in MongoDB during the 4th quarter worth approximately $3,515,000. HighTower Advisors LLC increased its holdings in MongoDB by 2.0% during the 4th quarter. HighTower Advisors LLC now owns 18,773 shares of the company’s stock worth $4,371,000 after acquiring an additional 372 shares during the period. Nisa Investment Advisors LLC increased its holdings in MongoDB by 428.0% during the 4th quarter. Nisa Investment Advisors LLC now owns 5,755 shares of the company’s stock worth $1,340,000 after acquiring an additional 4,665 shares during the period. Finally, Jones Financial Companies Lllp increased its holdings in MongoDB by 68.0% during the 4th quarter. Jones Financial Companies Lllp now owns 1,020 shares of the company’s stock worth $237,000 after acquiring an additional 413 shares during the period. Institutional investors own 89.29% of the company’s stock.
Insider Activity
In related news, Director Dwight A. Merriman sold 3,000 shares of the business’s stock in a transaction dated Monday, March 3rd. The shares were sold at an average price of $270.63, for a total transaction of $811,890.00. Following the sale, the director now owns 1,109,006 shares of the company’s stock, valued at $300,130,293.78. The trade was a 0.27% decrease in their ownership of the stock. The transaction was disclosed in a legal filing with the SEC, which is available at this link. Also, CEO Dev Ittycheria sold 8,335 shares of the business’s stock in a transaction dated Wednesday, February 26th. The stock was sold at an average price of $267.48, for a total transaction of $2,229,445.80. Following the sale, the chief executive officer now directly owns 217,294 shares in the company, valued at $58,121,799.12. The trade was a 3.69% decrease in their position. The disclosure for this sale can be found here. In the last 90 days, insiders have sold 33,538 shares of company stock valued at $6,889,905. Corporate insiders own 3.60% of the company’s stock.
MongoDB Price Performance
MongoDB stock traded down $3.93 during trading hours on Wednesday, reaching $185.01. The stock had a trading volume of 2,005,037 shares, compared to its average volume of 1,926,229. The stock has a market cap of $15.02 billion, a PE ratio of -67.52 and a beta of 1.49. MongoDB, Inc. has a 52 week low of $140.78 and a 52 week high of $379.06. The company has a fifty day simple moving average of $174.84 and a 200-day simple moving average of $237.45.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). The firm had revenue of $548.40 million during the quarter, compared to the consensus estimate of $519.65 million. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. During the same period last year, the business earned $0.86 EPS. Research analysts predict that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
Analyst Upgrades and Downgrades
A number of analysts recently weighed in on the stock. Wells Fargo & Company lowered shares of MongoDB from an “overweight” rating to an “equal weight” rating and decreased their target price for the stock from $365.00 to $225.00 in a report on Thursday, March 6th. China Renaissance initiated coverage on shares of MongoDB in a research note on Tuesday, January 21st. They issued a “buy” rating and a $351.00 price target for the company. Stifel Nicolaus cut their price target on shares of MongoDB from $340.00 to $275.00 and set a “buy” rating for the company in a research note on Friday, April 11th. UBS Group set a $350.00 price target on shares of MongoDB in a research note on Tuesday, March 4th. Finally, Wedbush cut their price target on shares of MongoDB from $360.00 to $300.00 and set an “outperform” rating for the company in a research note on Thursday, March 6th. Nine analysts have rated the stock with a hold rating, twenty-three have issued a buy rating and one has assigned a strong buy rating to the company. According to MarketBeat.com, the stock has an average rating of “Moderate Buy” and a consensus price target of $288.91.
View Our Latest Analysis on MongoDB
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Enter your email address and we’ll send you MarketBeat’s guide to investing in 5G and which 5G stocks show the most promise.
MMS • Craig Risi

HashiCorp has announced the general availability (GA) of HCP Vault Radar, a tool designed to help organizations detect and remediate unmanaged and leaked secrets across their environments. With the GA release, HCP Vault Radar introduces a new feature that allows users to import discovered secrets directly into HashiCorp Vault, streamlining the process of securing sensitive information.
HCP Vault Radar scans various data sources, including Git repositories, CI/CD platforms, collaboration tools like Confluence and JIRA, cloud storage services such as Amazon S3, and infrastructure as code tools like Terraform. By analyzing these sources, the tool identifies secrets like API keys, passwords, and tokens that may have been inadvertently exposed or hardcoded. The findings are then presented in a centralized dashboard, enabling security teams to prioritize and address potential vulnerabilities effectively.
One of the key enhancements in this GA release is the ability to import detected secrets into HashiCorp Vault. This integration facilitates the transition from identifying exposed secrets to securing them within a managed secrets store, allowing for actions such as rotation and revocation. By consolidating secret management, organizations can reduce the risk associated with secret sprawl and improve their overall security posture.
Since its initial Beta release, HCP Vault Radar has enhanced its features to minimize false positives and assist in risk assessment. It evaluates factors such as whether a secret was previously stored in Vault, its version history, and whether it is still active. These insights help security teams determine the severity of each finding and prioritize remediation efforts accordingly.
To support remediation workflows, HCP Vault Radar provides contextual guidance based on the type of secret detected. It also integrates with incident management tools like Slack, PagerDuty, Splunk, JIRA, and ServiceNow, enabling seamless communication and tracking of remediation tasks.
In a blog post on Medium, there is appreciation for Vault Radar’s capabilities in detecting and managing secrets. One user noted, “Vault Radar is a powerful tool for detecting and managing secrets sprawl in your organization,” emphasizing its role in enhancing security practices.
However, some professionals have raised concerns about the complexity and cost associated with implementing such tools. In a Reddit discussion, a user commented on the challenges of navigating HashiCorp’s offerings, stating, “It’s been really confusing to say the least,” and highlighting concerns about the expense of certain features.
Despite these concerns, there is industry recognition for the importance of tools like HCP Vault Radar in proactively managing secrets and reducing the risk of breaches. As organizations continue to prioritize security, the adoption of comprehensive secrets management solutions is likely to grow.
MMS • Sergio De Simone

Docker has launched Docker Hardened Images, a catalog of enterprise-grade, security-hardened container images designed to protect against software supply chain threats. By relieving DevOps teams from the chore of securing their containers on their own, hardened images provide an easier way to meet enterprise-grade security and compliance standards, Docker says.
Hardened Images aim to increase teams’ confidence that image components have not been tampered with and do not include malicious code. Additionally, it is common for developers to begin with a base image and add packages incrementally, which often expands the attack surface introducing unnecessary or outdated dependencies.
Docker Hardened Images are built with security in mind and are not just “trimmed-down versions of existing containers”:
These images go far beyond being just slim or minimal. Docker Hardened Images start with a dramatically reduced attack surface, up to 95% smaller, to limit exposure from the outset.
To this end, Docker explains, Docker Hardened Images strip away unnecessary components like shells, package managers, and debugging tools that are useful during development but expand the attack surface in production. Developers still have the option to customize these images by adding certificates, packages, scripts, and configuration files using the Docker UI.
As an example, the Node hardened image reduces the overall package count by 98% in comparison with the stock Node image.
Reducing the number of packages also lowers the effort required to comply with a “zero vulnerability” policy. According to Sysdig in its 2023 Cloud-Native Security and Usage Report, only 15% of reported unpatched critical and high-severity vulnerabilities affect packages used at runtime. Yet, unused vulnerable packages still count toward overall vulnerability tallies, leading to a staggering 87% of container images including critical or high-severity vulnerabilities. As noted by Hacker News user koblas, this inflates the number of images that must be patched) compared to a scenario where images only include strictly required packages
The classic UNIX problem was that the LPT printer daemon has an issue (it had lots and lots). But, none of your systems were running LPT, but you still had to patch 1000+s of systems just to maintain a security policy.
What’s different between full on UNIX systems and Docker, the possibility of deploying code based on scratch images. Imagine a system which only had the pieces necessary to run in production, your security exception reports would go to zero.
Moreover, Docker promises to rebuild hardened images whenever updates are released or new CVEs are published for dependencies. All new builds get fresh attestations in compliance with Docker’s SLSA Build Level 3–compliant build system.
We patch Critical and High-severity CVEs within 7 days—faster than typical industry response times—and back it all with an enterprise-grade SLA for added peace of mind.
Docker claims that, for most developers, migrating to Hardened Images is as simple as changing the FROM clause in their Dockerfiles. Developers already using Debian- or Alpine-based images will feel at home, as Hardened Images support both.
Docker is not the only provider of hardened images. Security solution provider Chainguard is also offering a catalog of over 1300 hardened images.
Using a hardened base image is only part of the story when it comes to securing your containers. You may also want to explore key best practices for hardening containers more comprehensively.
MMS • RSS
Firestore developers can now take advantage of MongoDB’s API portability along with Firestore’s differentiated serverless service, to enjoy multi-region replication with strong consistency, virtually unlimited scalability, industry-leading high availability of up to 99.999% SLA, and single-digit milliseconds read performance.
See live demos of how to:
- Use Firestore with MongoDB compatibility, along with the upcoming data interoperability features to leverage Firestore’s real-time and offline SDKs side-by-side
- Use Firestore migration tooling to connect to your existing document databases and perform streaming migrations to Firestore
- How Firestore’s customer-friendly serverless pricing enables you to save on total cost of operations (TCO)
Register Now to attend the webinar Hands On: Firestore With MongoDB Compatibility in Action.
Don’t miss this live event on Tuesday, June 10th, 11 AM PT / 2 PM ET.
| SPEAKERS | MODERATOR | |||
 |
 |
 |
||
| Minh Nguyen Senior Product Manager Google Cloud |
Patrick Costello Engineering Manager Google Cloud |
Stephen Faig Research Director Unisphere Research and DBTA |
MMS • RSS
Interested in diving into our Django MongoDB Backend integration? Follow along with this quickstart to create a Django application, connect that application to a MongoDB deployment, ensure your deployment is hosted on MongoDB Atlas, and interact with the data stored in your database using simple CRUD operations.
What is Django?
Let’s first go over what Django is. Django is a high-speed model-view-controller framework for building web applications. There are a ton of key benefits of utilizing Django in projects, such as rapid development, a variety of services to choose from, great security, and impressive scalability. Django prides itself on being the best framework for producing flawless work efficiently. As we’ll see throughout this quickstart, it’s incredibly simple to get up and running with our Django MongoDB Backend integration.
Pre-requisites
To be successful with this quickstart, you’ll need a handful of resources:
- An IDE. This tutorial uses Visual Studio Code.
- Python 3.10 or later. We recommend using 3.12 in the environment.
- A MongoDB Atlas cluster.
Create Your MongoDB Cluster
Please follow the steps to create a MongoDB cluster on our free tier cluster, which is free forever. Please make sure that the “Network Settings” are correctly set up for easy connection to the cluster, and that a secure username and password have been chosen. Once the cluster is configured, please make sure the connection string is in a safe place for later use.
Load the sample data into the cluster, and in the connection string, specify a connection to the sample database we are using, sample_mflix. Do this by adding the name of the database after the hostname, as shown in the code snippet below:
mongodb+srv://:@samplecluster.jkiff1s.mongodb.net/?retryWrites=true&w=majority&appName=SampleCluster
Now that our cluster is ready, we can create our virtual environment!
Create Your Virtual Environment
Our first step is to create our Python virtual environment. Virtual environments allow us to keep the necessary packages and libraries for a specific project in the correct environment without having to make changes globally that could impact other projects.
To do this, run:
python3.12 -m venv venv
Then, run:
source venv/bin/activate
Once the (venv) is next to the directory name in the terminal, the virtual environment is correctly configured. Make sure that the Python version is correct (3.10 and above) by double-checking with:
python —version
Once the virtual environment is set up, we can install our Django integration!
Installing Django MongoDB Backend
To install the Django integration, please run the following command from the terminal:
pip install django-mongodb-backend
If both PyMongo and Django are installed in the environment, please ensure that the PyMongo version is between 4.6 and 5.0, and that the Django version is between 5.0 and 5.1.
When correctly run, this is what we’ll see in our terminal:

Once this step is complete, our integration is correctly downloaded along with the dependencies that include Django and PyMongo required for success.
Create Your Django Project!
We’re all set up to create our Django project. This django-mongodb-project template is about the same as the default Django project template, with a couple of important changes. It includes MongoDB-specific migrations, and the settings.py file has been modified to make sure Django uses an ObjectId value for each model’s primary key. It also includes MongoDB-specific app configurations for Django apps that have default_auto_field set. This library allows us to create our own apps so we can set django_mongodb_backend.fields.ObjectIdAutoField.
Run this command to create a new Django project called quickstart:
django-admin startproject quickstart --template https://github.com/mongodb-labs/django-mongodb-project/archive/refs/heads/5.0.x.zip
Once this command is run, it will show up on the left-hand side of the project file:
Once you can see the quickstart project, it’s time to update our database settings. To do this, go to the settings.py file under the quickstart folder and head over to the DATABASES setting. Replace the ”” with the specific cluster URI, including the name of the sample database:
DATABASES = {
"default": django_mongodb_backend.parse_uri(""),
}
Now, we can make sure that we have correctly installed the Django MongoDB Backend and our project is properly set up. Make sure to be in the quickstart folder and run this command:
python manage.py runserver
Click on the link or visit http://127.0.0.1:8000/. On this page, there will be a “Congratulations!” and a picture of a rocket:
Now that we know our setup has been successful, we can go ahead and create an actual application where we can interact with the sample data we previously downloaded! Let’s dive in.
Creating an Application for Our “sample_mflix” Data
We are first going to create our sample_mflix application. Head into the root directory of your project and run this command to create an application based on our custom template:
python manage.py startapp sample_mflix --template https://github.com/mongodb-labs/django-mongodb-app/archive/refs/heads/5.0.x.zip
The django-mongodb-app template makes sure that your apps.py file includes the line: “default_auto_field = ‘django_mongodb.fields.ObjectIdAutoField’”. This ensures that instead of using the original Django BigAutoField for IDs, we are using MongoDB’s specific ObjectId feature.
Once you create your project, we are going to create models for our movie, viewer, and award data.
Create Models for Our Movie, Viewer, and Award Data
To create data models, all we have to do is open up our models.py file inside of our newly created sample_mflix directory and replace the entire file with the following code.
from django.db import models
from django.conf import settings
from django_mongodb_backend.fields import EmbeddedModelField, ArrayField
from django_mongodb_backend.models import EmbeddedModel
class Award(EmbeddedModel):
wins = models.IntegerField(default=0)
nominations = models.IntegerField(default=0)
text = models.CharField(max_length=100)
class Movie(models.Model):
title = models.CharField(max_length=200)
plot = models.TextField(blank=True)
runtime = models.IntegerField(default=0)
released = models.DateTimeField("release date", null=True, blank=True)
awards = EmbeddedModelField(Award, null=True, blank=True)
genres = ArrayField(models.CharField(max_length=100), null=True, blank=True)
class Meta:
db_table = "movies"
managed = False
def __str__(self):
return self.title
class Viewer(models.Model):
name = models.CharField(max_length=100)
email = models.CharField(max_length=200)
class Meta:
db_table = "users"
managed = False
def __str__(self):
return self.name
The Movie model here represents our sample_mflix.movies collection and stores information about various movies! The Viewer model, on the other hand, represents the sample_mflix.users collection and stores important user details for a movie streaming platform. The Award model represents the embedded document values that are stored in the Movie model.
Once this is done and the models.py file is saved, let’s create views to display our data.
Create Views to Display Our Data
To display data from the sample_mflix database, we’ll add views to the views.pyfile. Open it up from your sample_mflix directory and replace the contents with the code below.
Here, we are displaying a landing page message and information about the Movieand Viewer models we configured above:
from django.http import HttpResponse
from django.shortcuts import render
from .models import Movie, Viewer
def index(request):
return HttpResponse("Hello, world. You're at the application index.")
def recent_movies(request):
movies = Movie.objects.order_by("-released")[:5]
return render(request, "recent_movies.html", {"movies": movies})
def viewers_list(request):
viewers = Viewer.objects.order_by("name")[:10]
return render(request, "viewers_list.html", {"viewers": viewers})
Once we have finished this section, we are ready to move on and configure URLs for our views.
Configure URLs for Our Views
To be successful in this section, we need to create a new file called urls.py inside of our sample_mflix directory. This file maps the views we defined in the previous step to dedicated URLs.
Copy the code below into this new file:
from django.urls import path
from . import views
urlpatterns = [
path("recent_movies/", views.recent_movies, name="recent_movies"),
path("viewers_list/", views.viewers_list, name="viewers_list"),
path("", views.index, name="index")
]
Once that has been copied in, we can go ahead to our quickstart/urls.py file and replace the file’s content with the code below:
from django.contrib import admin
from django.urls import include, path
urlpatterns = [
path("admin/", admin.site.urls),
path("", include("sample_mflix.urls")),
]
Once we’ve finished replacing the file’s content, we can create templates to properly format our data.
Create Templates to Format Your Data
First, create a templates subdirectory inside of the sample_mflix directory. Once this subdirectory is created, create a recent_movies.html file inside it. We are going to copy the following code to format the movie data requested by the recent_movies view:
Recent Movies
Five Most Recent Movies
{% for movie in movies %}
-
{{ movie.title }} (Released: {{ movie.released }})
{% empty %}
- No movies found.
{% endfor %}
Create another file in this same templates subdirectory and call it viewers_list.html. This template formats the user data that is requested by our viewers_list view. Copy the following code:
Viewers List
Alphabetical Viewers List
Name
Email
{% for viewer in viewers %}
{{ viewer.name }}
{{ viewer.email }}
{% empty %}
No viewer found.
{% endfor %}
Now that your templates are in place, we can include our application inside our project!
Including Our Application Inside Our Project
To do this, head over to the settings.py file nested in the quickstart directory and edit the INSTALLED_APPS section to look like this:
INSTALLED_APPS = [
'sample_mflix.apps.SampleMflixConfig',
'quickstart.apps.MongoAdminConfig',
'quickstart.apps.MongoAuthConfig',
'quickstart.apps.MongoContentTypesConfig',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]
Once that has been done, we can create migrations for our new models.
Create Migrations for Your New Models
We want to create migrations for our Movie, Award, and Viewer models and apply all these changes to the database. Head back to the root of your project and run the following commands:
python manage.py makemigrations sample_mflix
python manage.py migrate
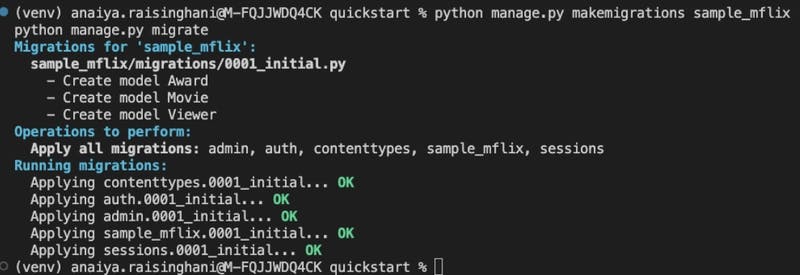
Once the migrations are created, we have a basic Django MongoDB backend application! We can use this simple application to interact with our sample_mflixdatabase. This means running basic CRUD operations on the data.
So, let’s go over how to do that.
Write Data
We are going to be working with a Python shell, so head back into the project’s root directory and bring up the shell with this command:
python manage.py shell
Once you’re in your shell, we can import the necessary classes and modules for creating a datetime object. Do this by running the code below:
from sample_mflix.models import Movie, Award, Viewer
from django.utils import timezone
from datetime import datetime
Now, we’re ready to insert a movie into our database! We can do this by running the code below to create a Movie object that stores data about a movie named “Minari”, including its awards:
movie_awards = Award(wins=122, nominations=245, text="Won 1 Oscar")
movie = Movie.objects.create(
title="Minari",
plot="A Korean-American family moves to an Arkansas farm in search of their own American Dream",
runtime=217,
released=timezone.make_aware(datetime(2020, 1, 26)),
awards=movie_awards,
genres=["Drama", "Comedy"]
)
This Movie object actually stores incorrect data about the movie: the runtime value is listed as 217, but the correct value is 117.
Let’s fix this by running the code below:
movie.runtime = 117
movie.save()
Now, let’s insert a viewer into our database as well. We can do this by creating a Viewer object that stores data about a viewer named “Abigail Carter”. Run the following code to do so:
viewer = Viewer.objects.create(
name="Abigail Carter",
email="[email protected]"
)
Let’s delete a Viewer object. A movie viewer by the name of “Alliser Thorne” is no longer a member of the movie streaming service. To remove this viewer, run the code below:
old_viewer = Viewer.objects.filter(name="Alliser Thorne").first()
old_viewer.delete()
Once that’s done, exit your shell using this command:
exit()
Ensure we are in the quickstart directory, and start the server using this command:
python manage.py runserver
Great! We can now go and make sure our Movies model was correctly inserted into the database. Do this by accessing the link: http://127.0.0.1:8000/recent_movies/
This is what you’ll see, with our latest movie right on top:
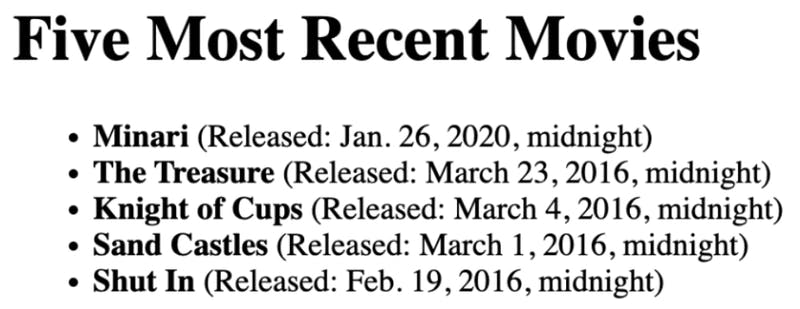
Let’s check our Viewer model, as well. Visit the link: http://127.0.0.1:8000/viewers_list/.
There will be a list of 10 viewer names in our database. “Abigail Carter” will be at the top, and the viewer “Alliser Thorne” will have been deleted:

Once these steps have been completed, documents in the sample_mflix sample database will have been inserted and edited.
Now, we can query the data inside our database.
Reading Back Our Data
Open up your Python shell again, and please make sure that you have imported the necessary modules from when you first created the Python shell back under the step, “Write Data.”
from sample_mflix.models import Movie, Award, Viewer
from django.utils import timezone
from datetime import datetime
Once your shell is ready to go, we can query our users collection for a specific email.
We want to query our sample_mflix.users collection for a user with the email ”[email protected]”. Do this by running the following:
from sample_mflix.models import Movie, Viewer
Viewer.objects.filter(email="[email protected]").first()
This will return the name of our user:
Now, let’s query our movie collection for runtime values.
In the same shell, run the following code to find movies that have a runtime value that is less than 10:
Movie.objects.filter(runtime__lt=10)
This will return a list of matching movies, as seen in the screenshot below:

Once this step is finished, feel free to run queries on any data stored inside the MongoDB cluster!
Let’s Create an Admin Site
It’s possible to create a Django admin site so that users can edit their data straight from a web interface.
Let’s first create an admin user. From the root directory, run the following code:
python manage.py createsuperuser
The terminal will ask for a username, email address, and password. Enter the following information below to create a user with specified credentials:
Username: admin
Email address: [email protected]
Password:
Password (again):
To enter the admin site, run the following code:
python manage.py runserver
Access the site by visiting http://127.0.0.1:8000/admin/. A login screen will appear:
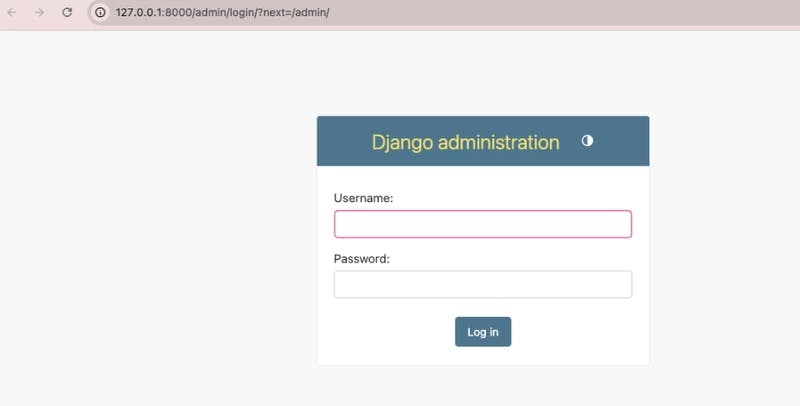
Enter the name and password that were created previously to log on.
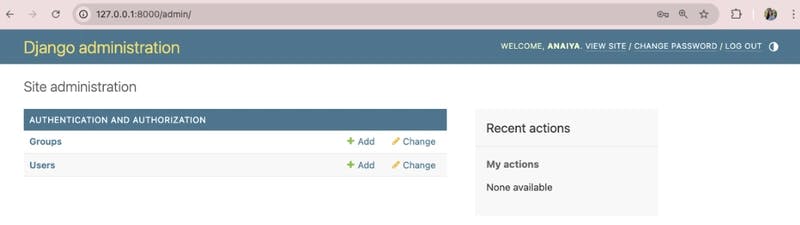
Here, the following information is presented, and users can edit their project authentication configuration through a selection of the Groups or Users rows in the Authentication and Authorization table.
Let’s edit the data in our users sample collection. Remember that this is represented by the Viewer model, which is not associated with the Users row as shown in the admin panel.
Head to the sample_mflix/admin.py file and paste in the code below:
from django.contrib import admin
from .models import Viewer
admin.site.register(Viewer)
Refresh the Django administration site, and it will be updated:
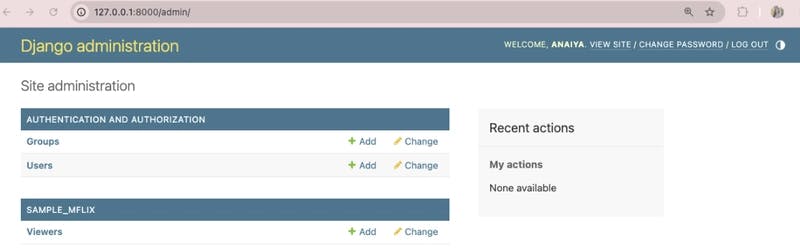
Now, we are able to select a viewer object. Do this by clicking on the Viewers row of the SAMPLE_MFLIX table to see the list of viewers, as seen below:
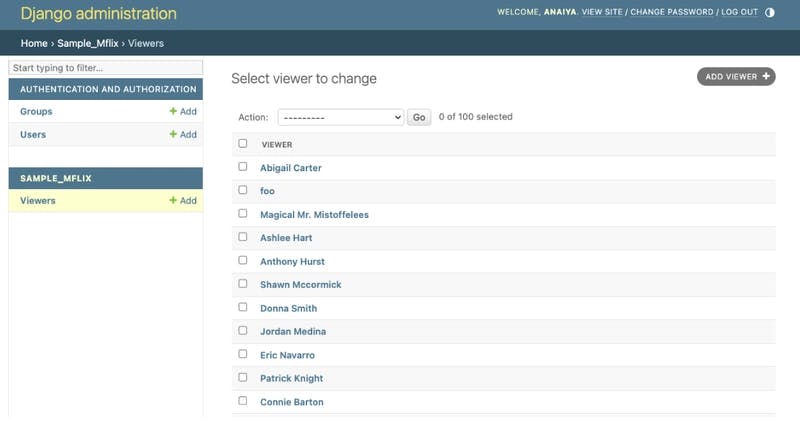
At the top of the list, click on Abigail Carter. From here, we will be able to see the Name and Email.
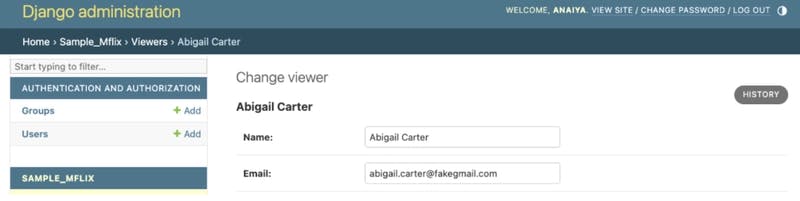
Here, we are able to edit the information, if chosen. Users are able to edit any field and hit the SAVE button to save any changes.
Great job, you have just completed the Django MongoDB Backend Quickstart! In this quickstart, you:
- Created a Django application.
- Connected your Django application to a MongoDB deployment.
- Ensured your deployment is hosted on MongoDB Atlas.
- Interacted with the data that is stored inside your cluster.
- Created a Django admin page.
To learn more about Django MongoDB Backend, please visit the docs and our repository on GitHub.
This article is written by Anaiya Raisinghani (Developer Advocate @ MongoDB) and Nora Reidy (Technical Writer @ MongoDB).
CloudBees Unify, YugabyteDB adds support for DocumentDB, and more — SD Times Daily Digest
MMS • RSS

CloudBees has announced it has brought its multiple standalone products together under a single platform called CloudBees Unify.
According to the company, CloudBees unifies acts like a layer on top of existing toolchains, and it uses an open and modular architecture to connect to other tools like GitHub Actions and Jenkins.
Key features include a unified control plane, progressive adoption model, continuous security scanning, AI-driven testing, and artifact traceability and unified releases.
“Since our founding, we’ve been partnering with the world’s most complex organizations to help them deliver software with speed, safety, and choice,” said Anuj Kapur, CEO of CloudBees. “CloudBees Unify builds on that foundation of trust and openness, giving enterprises the flexibility to integrate what works, govern at scale, and modernize on their own terms, without the need to rip and replace. We’re meeting them where they are and helping them move forward with confidence.”
YugabyteDB adds support for Postgres extension DocumentDB
DocumentDB is an open source NoSQL database created by Microsoft to offer a Postgres-based standard for BSON data types.
According to Yugabyte, adding NoSQL workloads into YugabyteDB provides developers with more database flexibility and cuts down on database sprawl.
“Although developers use MongoDB for NoSQL document database needs, it is not open source and presents many users with vendor lock-in issues,” said Karthik Ranganathan, co-founder and CEO of Yugabyte. “Enterprises are looking for a single multi-cloud, vendor-agnostic solution, based on open standards, that can meet their SQL and NoSQL requirements. The icing on the cake is that it is based on Postgres, the fastest growing database in terms of adoption. That’s what we’re providing with the Postgres extension to support document data and operations.”
Azul and JetBrains announce partnership to improve Kotlin runtime performance
Together the companies hope to find ways to improve runtime performance, combining Azul’s JVM expertise with Kotlin’s ability to control bytecode generation.
“On the Kotlin team, we pay close attention to performance, offering language features such as inline functions and classes, optimizations in the standard library, thoughtful bytecode generation, and the Kotlin coroutines library, among other initiatives. A significant contribution to runtime performance comes from the JDK. We believe that viewing these components as an integrated system can bring even greater performance benefits,” JetBrains wrote in a blog post.
MMS • RSS

MongoDB (MDB) ended the recent trading session at $188.94, demonstrating a -0.04% swing from the preceding day’s closing price. This change was narrower than the S&P 500’s daily loss of 0.39%. At the same time, the Dow lost 0.27%, and the tech-heavy Nasdaq lost 0.38%.
Heading into today, shares of the database platform had gained 24.62% over the past month, outpacing the Computer and Technology sector’s gain of 19.26% and the S&P 500’s gain of 13.07% in that time.
The upcoming earnings release of MongoDB will be of great interest to investors. In that report, analysts expect MongoDB to post earnings of $0.65 per share. This would mark year-over-year growth of 27.45%. Meanwhile, our latest consensus estimate is calling for revenue of $526.72 million, up 16.9% from the prior-year quarter.
MDB’s full-year Zacks Consensus Estimates are calling for earnings of $2.56 per share and revenue of $2.26 billion. These results would represent year-over-year changes of -30.05% and +12.48%, respectively.
It is also important to note the recent changes to analyst estimates for MongoDB. Recent revisions tend to reflect the latest near-term business trends. Hence, positive alterations in estimates signify analyst optimism regarding the company’s business and profitability.
Based on our research, we believe these estimate revisions are directly related to near-team stock moves. To exploit this, we’ve formed the Zacks Rank, a quantitative model that includes these estimate changes and presents a viable rating system.
Ranging from #1 (Strong Buy) to #5 (Strong Sell), the Zacks Rank system has a proven, outside-audited track record of outperformance, with #1 stocks returning an average of +25% annually since 1988. The Zacks Consensus EPS estimate has moved 0.18% lower within the past month. As of now, MongoDB holds a Zacks Rank of #3 (Hold).
In terms of valuation, MongoDB is currently trading at a Forward P/E ratio of 73.98. This indicates a premium in contrast to its industry’s Forward P/E of 28.98.
It is also worth noting that MDB currently has a PEG ratio of 11.72. The PEG ratio is similar to the widely-used P/E ratio, but this metric also takes the company’s expected earnings growth rate into account. The Internet – Software industry had an average PEG ratio of 2.22 as trading concluded yesterday.
The Internet – Software industry is part of the Computer and Technology sector. This industry, currently bearing a Zacks Industry Rank of 73, finds itself in the top 30% echelons of all 250+ industries.
The Zacks Industry Rank gauges the strength of our individual industry groups by measuring the average Zacks Rank of the individual stocks within the groups. Our research shows that the top 50% rated industries outperform the bottom half by a factor of 2 to 1.
Gemma 3 Supports Vision-Language Understanding, Long Context Handling, and Improved Multilinguality
MMS • Srini Penchikala

Google’s open-source generative artificial intelligence (AI) model Gemma 3 supports vision-language understanding, long context handling, and improved multi-linguality. In a recent blog post, Google DeepMind and AI Studio teams discussed the new features in Gemma 3. The model also highlights KV-cache memory reduction, a new tokenizer and offers better performance and higher resolution vision encoders.
Gemma 3 Technical Report summarizes these new features and capabilities. The new vision-language understanding capability includes the models (4B, 12B and 27B parameters) using a custom Sigmoid loss for Language-Image Pre-training (SigLIP) vision encoder, which enables the models to interpret visual input. The encoder operates on fixed 896×896 square images and to handle the images with different aspect ratios or high resolutions, a “Pan & Scan” algorithm is employed. This involves adaptively cropping the image, resizing each crop to 896×896, and then encoding it. The Pan & Scan method further improves performance on tasks involving non-square aspect ratios, high-resolution images, and text reading in images. The new model also treats images as a sequence of compact “soft tokens” produced by MultiModalProjector. This technique cuts down on the inference resources needed for image processing by representing visual data with a fixed number of 256 vectors.
The vision encoder processing in Gemma 3 uses bi-directional attention with image inputs. Bidirectional attention is a good approach for understanding tasks (as opposed to prediction tasks) where we have the entire text and need to deeply understand it (like in models such as BERT).
Architectural changes for memory efficiency include modifications to reduce KV-cache memory usage, which tends to increase with long context. These changes reduce the memory overhead during inference with long context compared to global-only attention mechanisms used in Gemma 1 and the 1:1 local/global ratio used in Gemma 2. This allows for the analysis of longer documents and conversations without losing context. Specifically, it can handle 32k tokens for the 1B model and 128k tokens for larger models.
Gemma 3 also introduces an improved tokenizer. The vocabulary size has been changed to 262k, but uses the same SentencePiece tokenizer. To avoid errors, they recomend to use the new tokenizer with Gemma 3. This is the same tokenizer as Gemini which is more balanced for non-English languages. Gemma 3 has improved multilingual capabilities due to a revisited data mixture with an increased amount of multilingual data (both monolingual and parallel). The team also revised the pre-training data mixture and post-training process to enhance its multilingual capabilities.
Gemma 3 models showed better performance compared to Gemma 2 on both pre-trained instruction-tuned versions across various benchmarks. It is a better model that fits in a single consumer GPU or TPU host. The Gemma 27B IT model ranks among the top 10 models in LM Arena as of Apr 12, 2025, outperforming much larger open models and showing a significantly higher Elo score than Gemma 2.
Gemma 3 models’ longer context handling can generalize to 128k context length after Rotary Position Embedding (RoPE) rescaling during pre-training. They increased RoPE base frequency from 10k to 1M on global self-attention layers, and kept the frequency of local layers at 10k.
For more information on Gemma 3 model, check out the developer guide, model card, meme generator, and Gemmaverse to explore Gemma models developed by the community.