Category: Uncategorized

MMS • RSS
Wolfe Research has initiated coverage on MongoDB (MDB, Financial) with an Outperform rating and set a target price of $280. Analyst Alex Zukin highlights that the company’s shares have fallen 10% year-to-date, presenting a potential opportunity for investors. According to the research note, MongoDB is positioned favorably due to conservative estimates and enhanced execution strategies.
Wolfe Research underscores that MongoDB stands at the forefront of two key industry trends: the modernization of enterprise data and the burgeoning adoption of artificial intelligence. These factors combine to place MongoDB in a promising position for future growth and market performance. The firm anticipates that improving profit margins will contribute positively to the company’s overall narrative and investor appeal.
Wall Street Analysts Forecast
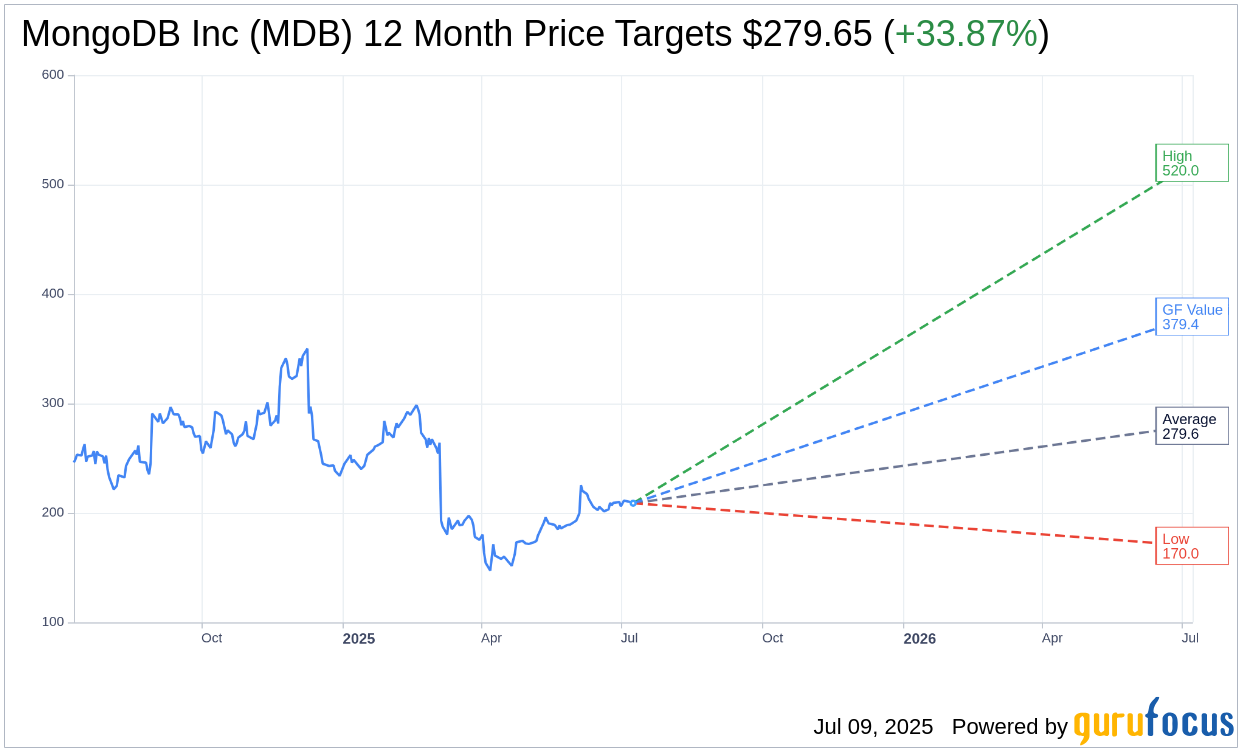
Based on the one-year price targets offered by 35 analysts, the average target price for MongoDB Inc (MDB, Financial) is $279.65 with a high estimate of $520.00 and a low estimate of $170.00. The average target implies an
upside of 33.87%
from the current price of $208.90. More detailed estimate data can be found on the MongoDB Inc (MDB) Forecast page.
Based on the consensus recommendation from 37 brokerage firms, MongoDB Inc’s (MDB, Financial) average brokerage recommendation is currently 1.9, indicating “Outperform” status. The rating scale ranges from 1 to 5, where 1 signifies Strong Buy, and 5 denotes Sell.
Based on GuruFocus estimates, the estimated GF Value for MongoDB Inc (MDB, Financial) in one year is $379.42, suggesting a
upside
of 81.63% from the current price of $208.9. GF Value is GuruFocus’ estimate of the fair value that the stock should be traded at. It is calculated based on the historical multiples the stock has traded at previously, as well as past business growth and the future estimates of the business’ performance. More detailed data can be found on the MongoDB Inc (MDB) Summary page.
MDB Key Business Developments
Release Date: June 04, 2025
- Revenue: $549 million, a 22% year-over-year increase.
- Atlas Revenue: Grew 26% year over year, representing 72% of total revenue.
- Non-GAAP Operating Income: $87 million, with a 16% non-GAAP operating margin.
- Customer Count: Over 57,100 customers, with approximately 2,600 added sequentially.
- Net ARR Expansion Rate: Approximately 119%.
- Gross Margin: 74%, down from 75% in the year-ago period.
- Net Income: $86 million or $1 per share.
- Operating Cash Flow: $110 million.
- Free Cash Flow: $106 million.
- Cash and Equivalents: $2.5 billion.
- Share Repurchase Program: Increased by $800 million, totaling $1 billion.
- Q2 Revenue Guidance: $548 million to $553 million.
- Fiscal Year ’26 Revenue Guidance: $2.25 billion to $2.29 billion.
- Fiscal Year ’26 Non-GAAP Income from Operations Guidance: $267 million to $287 million.
For the complete transcript of the earnings call, please refer to the full earnings call transcript.
Positive Points
- MongoDB Inc (MDB, Financial) reported a 22% year-over-year increase in revenue, reaching $549 million, surpassing the high end of their guidance.
- Atlas revenue grew 26% year over year, now representing 72% of total revenue, indicating strong adoption of their cloud-based platform.
- The company achieved a non-GAAP operating income of $87 million, resulting in a 16% non-GAAP operating margin, which is an improvement from the previous year.
- MongoDB Inc (MDB) added approximately 2,600 new customers in the quarter, bringing the total customer count to over 57,100, the highest net additions in over six years.
- The company announced a significant expansion of their share repurchase program, authorizing up to an additional $800 million, reflecting confidence in their long-term potential.
Negative Points
- Despite strong results, MongoDB Inc (MDB) noted some softness in Atlas consumption in April due to macroeconomic volatility, although it rebounded in May.
- The non-Atlas business is expected to decline in the high single digits for the year, with a $50 million headwind from multiyear license revenue anticipated in the second half.
- Gross margin slightly declined to 74% from 75% in the previous year, primarily due to Atlas growing as a percentage of the overall business and the impact of the Voyage acquisition.
- The company experienced slower than planned headcount additions, which could impact future growth and operational capacity.
- MongoDB Inc (MDB) remains cautious about the uncertain macroeconomic environment, which could affect future consumption trends and overall business performance.
MMS • RSS
MongoDB, Inc. (MDB, Financial) has received a fresh ‘Outperform’ rating from Wolfe Research. The coverage was initiated by analyst Alex Zukin on July 9, 2025. Along with the new rating, the firm announced a price target of $280.00 USD for MongoDB.
The new rating and price target reflect Wolfe Research’s positive outlook on MongoDB. The ‘Outperform’ rating suggests that the stock is expected to perform better than the overall market within the foreseeable future.
This new coverage and rating highlight MongoDB’s potential for growth, as seen by Wolfe Research’s financial analysts. Investors and market participants will be watching closely to see how MongoDB’s market performance aligns with the newly set price target.
Wall Street Analysts Forecast
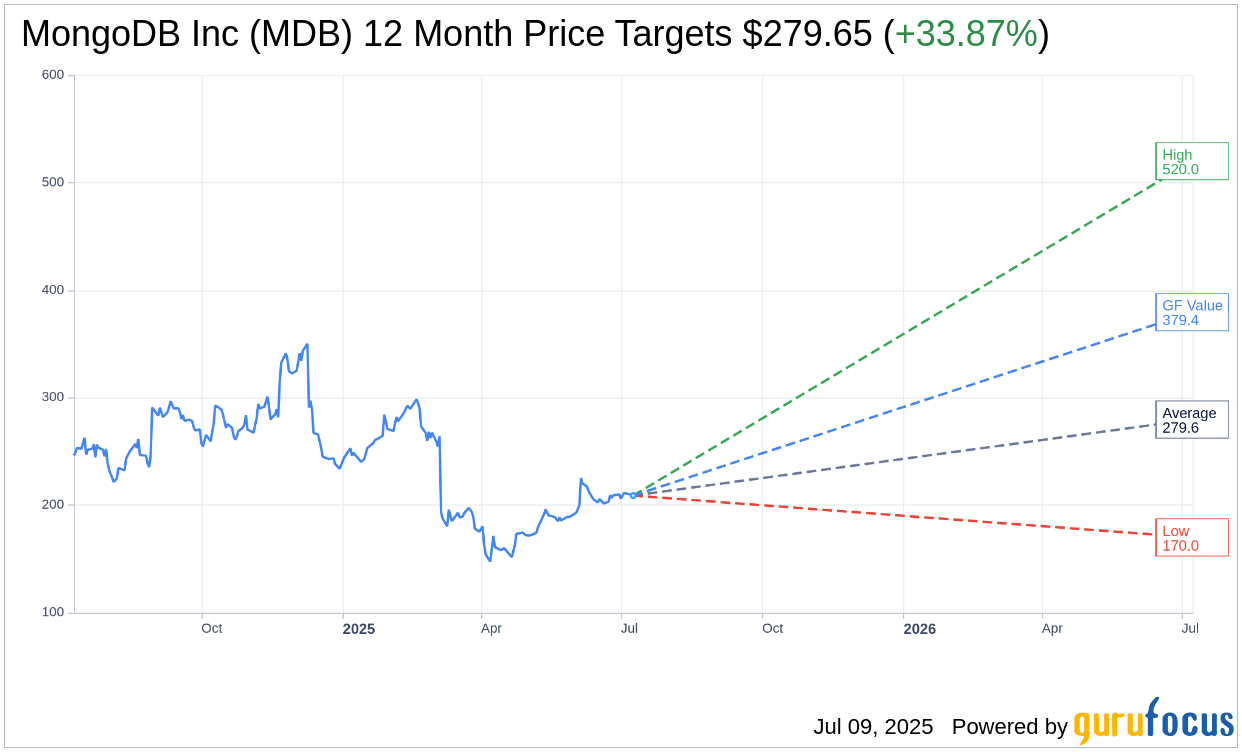
Based on the one-year price targets offered by 35 analysts, the average target price for MongoDB Inc (MDB, Financial) is $279.65 with a high estimate of $520.00 and a low estimate of $170.00. The average target implies an
upside of 33.87%
from the current price of $208.90. More detailed estimate data can be found on the MongoDB Inc (MDB) Forecast page.
Based on the consensus recommendation from 37 brokerage firms, MongoDB Inc’s (MDB, Financial) average brokerage recommendation is currently 1.9, indicating “Outperform” status. The rating scale ranges from 1 to 5, where 1 signifies Strong Buy, and 5 denotes Sell.
Based on GuruFocus estimates, the estimated GF Value for MongoDB Inc (MDB, Financial) in one year is $379.42, suggesting a
upside
of 81.63% from the current price of $208.9. GF Value is GuruFocus’ estimate of the fair value that the stock should be traded at. It is calculated based on the historical multiples the stock has traded at previously, as well as past business growth and the future estimates of the business’ performance. More detailed data can be found on the MongoDB Inc (MDB) Summary page.
MMS • RSS
![]() Amalgamated Bank grew its stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 10.3% during the first quarter, according to the company in its most recent disclosure with the Securities and Exchange Commission. The firm owned 5,197 shares of the company’s stock after purchasing an additional 484 shares during the period. Amalgamated Bank’s holdings in MongoDB were worth $912,000 at the end of the most recent reporting period.
Amalgamated Bank grew its stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 10.3% during the first quarter, according to the company in its most recent disclosure with the Securities and Exchange Commission. The firm owned 5,197 shares of the company’s stock after purchasing an additional 484 shares during the period. Amalgamated Bank’s holdings in MongoDB were worth $912,000 at the end of the most recent reporting period.
Other institutional investors have also modified their holdings of the company. Norges Bank acquired a new position in MongoDB during the fourth quarter worth $189,584,000. Marshall Wace LLP acquired a new position in shares of MongoDB during the 4th quarter worth $110,356,000. D1 Capital Partners L.P. purchased a new position in shares of MongoDB in the 4th quarter valued at about $76,129,000. Franklin Resources Inc. boosted its holdings in MongoDB by 9.7% during the fourth quarter. Franklin Resources Inc. now owns 2,054,888 shares of the company’s stock worth $478,398,000 after buying an additional 181,962 shares in the last quarter. Finally, Pictet Asset Management Holding SA boosted its holdings in MongoDB by 69.1% during the fourth quarter. Pictet Asset Management Holding SA now owns 356,964 shares of the company’s stock worth $83,105,000 after buying an additional 145,854 shares in the last quarter. Institutional investors and hedge funds own 89.29% of the company’s stock.
Analyst Ratings Changes
A number of equities research analysts have recently issued reports on the stock. Monness Crespi & Hardt upgraded shares of MongoDB from a “neutral” rating to a “buy” rating and set a $295.00 price target for the company in a research report on Thursday, June 5th. Daiwa Capital Markets assumed coverage on MongoDB in a research report on Tuesday, April 1st. They set an “outperform” rating and a $202.00 target price on the stock. Guggenheim raised their price target on MongoDB from $235.00 to $260.00 and gave the company a “buy” rating in a research report on Thursday, June 5th. JMP Securities reiterated a “market outperform” rating and issued a $345.00 price objective on shares of MongoDB in a research report on Thursday, June 5th. Finally, DA Davidson restated a “buy” rating and set a $275.00 target price on shares of MongoDB in a report on Thursday, June 5th. Eight equities research analysts have rated the stock with a hold rating, twenty-five have given a buy rating and one has assigned a strong buy rating to the company. According to MarketBeat.com, MongoDB presently has a consensus rating of “Moderate Buy” and an average target price of $282.47.
<!—->
View Our Latest Research Report on MongoDB
MongoDB Stock Down 0.5%
MDB stock opened at $208.90 on Wednesday. MongoDB, Inc. has a 12-month low of $140.78 and a 12-month high of $370.00. The company has a 50 day moving average of $196.81 and a two-hundred day moving average of $214.59. The company has a market cap of $17.07 billion, a price-to-earnings ratio of -183.25 and a beta of 1.41.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 earnings per share (EPS) for the quarter, beating the consensus estimate of $0.65 by $0.35. The business had revenue of $549.01 million during the quarter, compared to analyst estimates of $527.49 million. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. MongoDB’s quarterly revenue was up 21.8% compared to the same quarter last year. During the same quarter in the previous year, the business earned $0.51 EPS. On average, research analysts anticipate that MongoDB, Inc. will post -1.78 EPS for the current year.
Insiders Place Their Bets
In other news, Director Dwight A. Merriman sold 2,000 shares of MongoDB stock in a transaction dated Thursday, June 5th. The stock was sold at an average price of $234.00, for a total value of $468,000.00. Following the transaction, the director directly owned 1,107,006 shares in the company, valued at approximately $259,039,404. The trade was a 0.18% decrease in their ownership of the stock. The transaction was disclosed in a document filed with the SEC, which is accessible through this hyperlink. Also, CEO Dev Ittycheria sold 25,005 shares of the firm’s stock in a transaction that occurred on Thursday, June 5th. The shares were sold at an average price of $234.00, for a total value of $5,851,170.00. Following the completion of the sale, the chief executive officer directly owned 256,974 shares in the company, valued at $60,131,916. This trade represents a 8.87% decrease in their position. The disclosure for this sale can be found here. Insiders sold a total of 32,746 shares of company stock valued at $7,500,196 in the last quarter. Insiders own 3.10% of the company’s stock.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • Steef-Jan Wiggers
Figma recently revealed its cloud computing costs in its initial public offering (IPO) filing, revealing a daily expenditure of around $300,000 on Amazon Web Services (AWS). As a result, the company allocates approximately $100 million each year, which accounts for about 12% of its reported revenue of $821 million.
Figma, a widely used interface design tool, relies entirely on AWS for its “computing, storage capabilities, bandwidth, and other services.” The S-1 filing further details a renewed hosting agreement with AWS, signed on May 31, 2025, which commits Figma to a minimum spend of $545 million in cloud hosting services over the next five years. However, the filing doesn’t break down how these costs are allocated across specific services, such as storage, compute, or bandwidth.
In addition to a substantial financial investment, Figma’s filing emphasizes the risks associated with extensive cloud integration. The company acknowledges its complete reliance on AWS’s performance, which makes it vulnerable to potential outages. Furthermore, AWS has the authority to change and interpret its terms of service and other policies, including during contract renewals, which could negatively affect Figma’s business operations. If AWS were to cancel the contract entirely, it would create significant challenges for Figma, as its cloud service infrastructure is specifically designed to operate within the AWS ecosystem.
Per Borgen, a CEO at Scrimba, posted on LinkedIn:
For comparison, at Scrimba, we spend far less than 1% of our revenue on infrastructure. This is because we skipped the cloud and run on dedicated servers instead. But it’s not just about cost. Figma’s infra is tightly coupled to AWS. If Amazon changes terms or pulls the plug, they’re in trouble. And it’s all by their own admission. So the question isn’t just “Is it expensive?” It’s also “How much control are you giving up?”
The deep entanglement of Figma with a cloud provider goes far beyond simply using virtual machines. As one insightful commenter on Hacker News, nevon, explained:
A common misconception about moving off the cloud is viewing it solely as a VM provider. In reality, the cloud integrates deeply into your systems. Your permissions rely on cloud identities, firewalls use security group references, and cross-region connectivity depends on cloud networking. You manage secrets with cloud tools, monitor metrics through cloud observability, and often utilize whitelisted IP ranges provided by the provider. Additionally, database upgrades, VM images, and auditing are tied to the cloud services. Even your applications may depend on cloud-managed containers and event buses, while disaster recovery plans hinge on the provider’s backup and failover capabilities.
The explanation of nevon clarifies why migrating from a cloud platform, even for a large company like Figma, is not a quick or simple task.
Figma’s revelation adds to the ongoing industry discussion about the escalating costs of cloud computing as companies scale. This has led some organizations exploring the repatriation of specific workloads or data from the public cloud to on-premises or co-located infrastructure. A prominent example is 37signals, whose CTO, David Heinemeier Hansson, has been a vocal advocate for exiting the cloud. They initiated their repatriation efforts in 2022, when their annual cloud bill exceeded $3.2 million. By October 2024, 37signals estimated a $2 million savings that year by moving away from cloud services. Their latest phase involves exiting AWS’s S3 storage service, which Heinemeier Hansson anticipates will save the company around $1.3 million annually.
Ultimately, Figma’s substantial cloud bill serves as a stark reminder of the core dilemma facing modern tech companies: the trade-off between the agility and convenience offered by hyperscale cloud providers versus the escalating costs and the inherent risks of deep vendor lock-in.
MMS • RSS
MongoDB’s stock (MDB) has underperformed since the start of this year, dropping 14.6% YTD as the broader Nasdaq Composite index has gained 5.9%.
The company, a leading modern, general purpose database platform, finds itself battling with mixed narratives; a company with undeniable growth potential with analyst support, yet navigating a market still recalibrating after the tech sector pullback of recent years.
Wolfe Research’s initiation of coverage with a $280 price target and Outperform rating provides a much-needed vote of confidence. This bullish outlook hinges on the firm’s belief in MongoDB’s strong growth prospects and its strategic positioning within the evolving database landscape.
This positive assessment aligns with MongoDB’s recently reported robust first-quarter results for fiscal year 2026. Revenue surged by 21.9% year-over-year to $549 million, exceeding analyst expectations. The company’s cloud-based Atlas service, a key growth driver, witnessed a 26% expansion, now contributing a substantial 72% to total revenue.
Further fueling optimism, MongoDB has raised its full-year revenue guidance, signalling sustained momentum.
Adding another layer of financial engineering, MongoDB has accelerated its share repurchase program, reducing its share count by 4.35% sequentially in Q1 and bolstering the remaining allotment by $800 million.
Beyond the financials, MongoDB is actively enhancing its technological capabilities. The company’s focus on AI is evident in its strategic acquisition of Voyage AI, a startup specializing in AI-powered search and retrieval models. The partnership with Swiss private bank Lombard Odier to modernize its core banking technology using generative AI further illustrates the company’s prowess in this domain, demonstrating its effectiveness in large-scale, mission-critical environments.
Recent analyst reactions following the strong Q1 results have been largely positive. Macquarie raised its price target to $230 from $215, maintaining a “Neutral” rating, citing the company’s strong performance easing previous concerns. Wedbush upgraded MongoDB to “Buy” from “Hold,” highlighting the company’s potential in the AI revolution and the early stages of Atlas monetization.
Searching for the Perfect Broker?
Discover our top-recommended brokers for trading or investing in financial markets. Dive in and test their capabilities with complimentary demo accounts today!
YOUR CAPITAL IS AT RISK. 76% OF RETAIL CFD ACCOUNTS LOSE MONEY
MMS • RSS
Wolfe Research has started coverage on MongoDB (MDB, Financial), giving the stock an Outperform rating. The firm has set a price target of $280 for the company’s shares, indicating a positive outlook on its future performance.
Wall Street Analysts Forecast
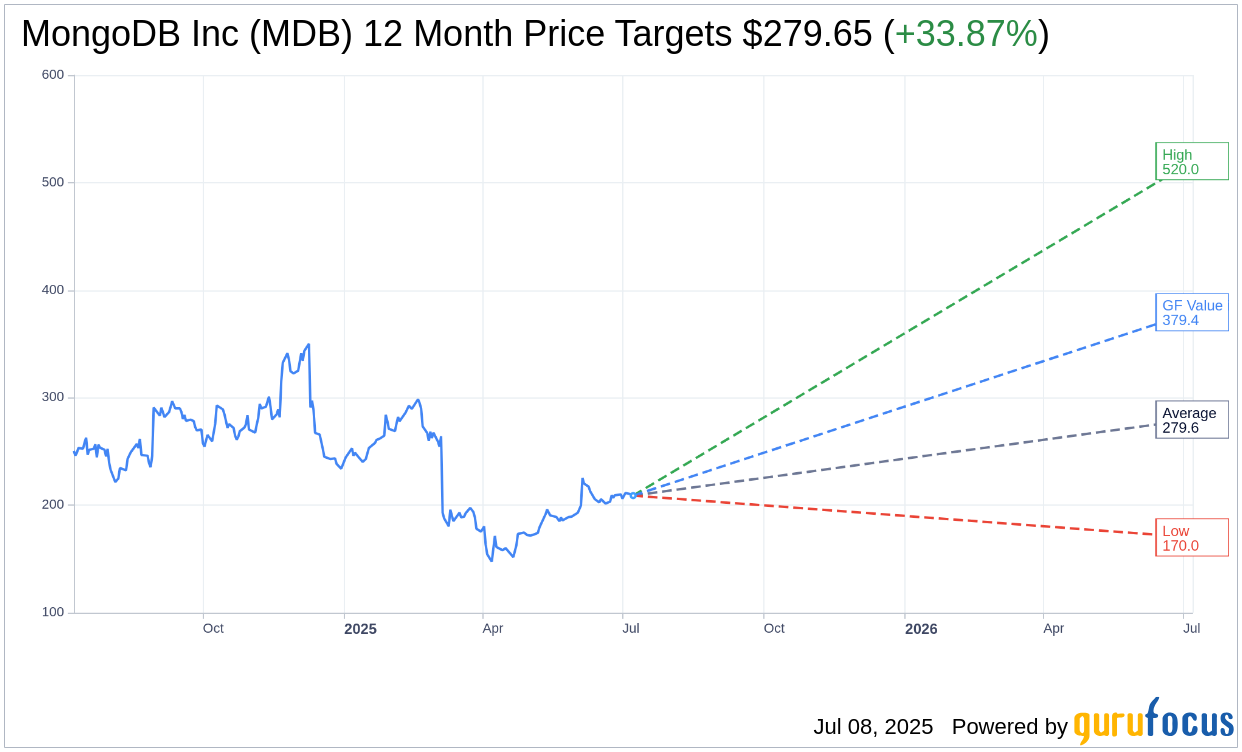
Based on the one-year price targets offered by 35 analysts, the average target price for MongoDB Inc (MDB, Financial) is $279.65 with a high estimate of $520.00 and a low estimate of $170.00. The average target implies an
upside of 33.87%
from the current price of $208.90. More detailed estimate data can be found on the MongoDB Inc (MDB) Forecast page.
Based on the consensus recommendation from 37 brokerage firms, MongoDB Inc’s (MDB, Financial) average brokerage recommendation is currently 1.9, indicating “Outperform” status. The rating scale ranges from 1 to 5, where 1 signifies Strong Buy, and 5 denotes Sell.
Based on GuruFocus estimates, the estimated GF Value for MongoDB Inc (MDB, Financial) in one year is $379.42, suggesting a
upside
of 81.63% from the current price of $208.9. GF Value is GuruFocus’ estimate of the fair value that the stock should be traded at. It is calculated based on the historical multiples the stock has traded at previously, as well as past business growth and the future estimates of the business’ performance. More detailed data can be found on the MongoDB Inc (MDB) Summary page.
MDB Key Business Developments
Release Date: June 04, 2025
- Revenue: $549 million, a 22% year-over-year increase.
- Atlas Revenue: Grew 26% year over year, representing 72% of total revenue.
- Non-GAAP Operating Income: $87 million, with a 16% non-GAAP operating margin.
- Customer Count: Over 57,100 customers, with approximately 2,600 added sequentially.
- Net ARR Expansion Rate: Approximately 119%.
- Gross Margin: 74%, down from 75% in the year-ago period.
- Net Income: $86 million or $1 per share.
- Operating Cash Flow: $110 million.
- Free Cash Flow: $106 million.
- Cash and Equivalents: $2.5 billion.
- Share Repurchase Program: Increased by $800 million, totaling $1 billion.
- Q2 Revenue Guidance: $548 million to $553 million.
- Fiscal Year ’26 Revenue Guidance: $2.25 billion to $2.29 billion.
- Fiscal Year ’26 Non-GAAP Income from Operations Guidance: $267 million to $287 million.
For the complete transcript of the earnings call, please refer to the full earnings call transcript.
Positive Points
- MongoDB Inc (MDB, Financial) reported a 22% year-over-year increase in revenue, reaching $549 million, surpassing the high end of their guidance.
- Atlas revenue grew 26% year over year, now representing 72% of total revenue, indicating strong adoption of their cloud-based platform.
- The company achieved a non-GAAP operating income of $87 million, resulting in a 16% non-GAAP operating margin, which is an improvement from the previous year.
- MongoDB Inc (MDB) added approximately 2,600 new customers in the quarter, bringing the total customer count to over 57,100, the highest net additions in over six years.
- The company announced a significant expansion of their share repurchase program, authorizing up to an additional $800 million, reflecting confidence in their long-term potential.
Negative Points
- Despite strong results, MongoDB Inc (MDB) noted some softness in Atlas consumption in April due to macroeconomic volatility, although it rebounded in May.
- The non-Atlas business is expected to decline in the high single digits for the year, with a $50 million headwind from multiyear license revenue anticipated in the second half.
- Gross margin slightly declined to 74% from 75% in the previous year, primarily due to Atlas growing as a percentage of the overall business and the impact of the Voyage acquisition.
- The company experienced slower than planned headcount additions, which could impact future growth and operational capacity.
- MongoDB Inc (MDB) remains cautious about the uncertain macroeconomic environment, which could affect future consumption trends and overall business performance.
MMS • Carlos Arguelles

Transcript
Arguelles: My name is Carlos Arguelles. I’m a Senior Principal Engineer in Amazon Worldwide Stores. I’m here to talk about inflection points that I got to see throughout my time at Amazon. It was an interesting time because the company grew by about 3000% while I was there. Lots of interesting little turns and so forth. First, I’m going to talk about Thanksgiving. There are three things that we do. First, we eat massive amounts of turkey and really unhealthy food with our family. Second, we pass out in a food-induced coma after eating all that crap. Then when we wake up, we do Christmas shopping. Welcome to Black Friday. It is one of the busiest shopping days of the year for Amazon, as is Cyber Monday and Prime Day. If you are in the Amazon Worldwide Stores, these are really big deals: Black Friday, Cyber Monday, Prime Day, and so forth.
A Lesson from Amazon (Never Waste a Great Crisis)
I’m going to take you back in time to 2011. I was a youthful SDE-II, I had hair. I’d been at Amazon for a couple years. I started in 2009. By 2011, I was feeling comfortable with my role and I was feeling good. I was beginning to pursue a senior engineer promotion. I own a service like this, just at a very high level. There’s the Amazon retail site, and it was sending a bunch of information to my service. We were putting that in S3, and we were processing petabytes of data on, at the time, it was a bunch of MapReduce jobs. The data from all that was going back and feeding a bunch of critical services in the Amazon store. Really fun thing. As Black Friday was coming, I made a list of everything that I needed to be testing or that people around me needed to be testing. Big long list of like, here’s the things that we should be testing.
Then I costed everything and I figured out, here’s the things that we can get done and here’s the things that are definitely not getting done. I drew that line. Load and performance testing was below the line. It was the thing that was immediately below the line. I had one more pitch. I went to my director and I said, this is Amazon. I think we’re going to get a lot of customers on Black Friday. We should be doing this. He said, how long is it going to take to do this? Probably two months to do it right. He said, no, we don’t have time for this. There are a thousand things that we need to be doing, and it doesn’t look like it’s very risky for this particular architecture. Let’s go for it.
Sure enough, Black Friday comes along. The first thing that we noticed was our service was underscaled, which is not a big deal, but all these alarms are going off and all these pagers are going off. This is before the days of EC2 and being able to autoscale, so we’re frantically running around the building and getting hardware, and we added hardware. Good crisis averted? No, not quite, because all we did is we just pushed that load further into the stack and all these additional hosts were writing additional pieces of metadata to a database.
This was before the days of DynamoDB and so forth. This was a good old-fashioned Oracle database running on a good old-fashioned piece of metal. It failed miserably. When it did, the whole thing started failing because my service couldn’t write to this piece of metadata. It started rejecting requests. It stopped answering requests. The retail site flew blind for eight hours during the busy shopping day of the year in 2012. It was my fault.
The next morning, a one-on-one shows up with my director, and I’m thinking, this is the day I get fired, because I just cost the company multiple millions of dollars in an operational issue. For the first 10 minutes, he’s asking me all kinds of questions, trying to understand how did this happen, what things we could have done to prevent it, and so forth. After about 50 minutes of a lot of really hard questions and me sweating, he just sat back and he said, how are you going to prevent this from ever happening again? I thought, I’m not getting fired. That’s good news.
Then I thought, this is actually hard work. I have to go build all this infrastructure to do proper load and performance testing against my service. I went ahead and did that. The thing is, this was an inflection point because before that day, I had gone to my director and I had said, we need to be building all this infrastructure. He had said, no, we don’t have time for this. After a multimillion-dollar operational problem, we sure had time for that. That’s what I mean by an inflection point. My first piece of advice is, don’t ever waste a great crisis. That was a turning point for me, for my career, and also for a lot of infrastructure at Amazon.
Career Journey
Now that I’ve told you that little story, what I’ve done. I started at Microsoft back in ’97. I was in various parts of engineering productivity, in Microsoft Office, in Microsoft Windows. I was there for 11 years and 3 months. Then in 2009, I joined a little company called Amazon. I also spent 11 years and 3 months at Amazon, until 2020. In 2014, I became the principal engineer responsible for Builder Tools. Builder Tools is all the tooling that Amazon engineers use internally to do source control, building, deploying, testing, all of those things. We have all kinds of internal tools for doing that. I worked in that team for about six years. I was the lead for company-wide infrastructure for integration testing. Then I went over to Google. There, I also was a technical lead for company-wide infrastructure for integration testing.
The infrastructure that tens of thousands of Googlers use to create test environments, run integration tests, and so forth. Same role, very different companies and very different technologies. I’ll talk a little bit about that. About six months ago, I decided, Google has been fun, but Amazon is my home, and that’s where I want to come back to. I came back about six months ago. That’s been my journey.
I want to talk mostly about this period, because the last couple years have been in flat headcount for the vast majority of the tech industry. 2009 to 2020 was kind of a crazy time. How crazy, might you ask? In terms of engineers, when I started, we were less than 3,000 engineers, which felt like a big company. When I left, we were 80,000. That’s about a 3,000% growth in just engineers. By all accounts, market cap back then was $32 billion, which seemed like a lot of money. It’s $2.2 trillion today. It was good times. I get to grow with the company. I started as an SDE-II. Three years later, I got promoted to senior engineer. Three years later, I got promoted to principal engineer. When I got rehired, I got rehired as a senior principal. It’s been fun to grow up with a company as the company was also growing up. 2009, Amazon is more like an adolescent Amazon. 2024, Amazon is more like a more grown-up Amazon.
Inflection Point – Number of Engineers
The main thing that I want you to take away from this is that, there’s inflection points where investments in engineering productivity become feasible, when before that point, they weren’t. I want you to be able to recognize some of the patterns. I want to encourage you to seize the day and actually push for those things. The most obvious inflection point is number of engineers. That’s a very clear one. You can see the company growing from 3,000 to 6,000 to 20,000 to 50,000, and so forth.
At any one of these points, things that didn’t really matter before, now they actually matter a whole bunch. That’s what I mean by that, is 3,000, may be some amount of toil, we just ignore it. Little bits of toil really add up at 50,000, 80,000. Google was 120,000 engineers. It’s mind boggling how much this little bit of toil really adds up. That’s the thing that empowers us to build a lot of the things that we build for engineering productivity. The framework that I use is usually this when I’m thinking about, should we make this kind of investment in engineering productivity? How much toil are we talking about? How often does it happen? How many people does it affect? I’ll give you an example of that.
A couple months ago, somebody came to me and they were annoyed because there was something that took about 10 seconds to do. It was just this annoying manual thing and it took 10 seconds to do. We sat down and we went through my little back of the napkin calculator to figure out, how much money are we wasting? What kind of productivity are we talking about here that is affected by these 10 seconds? How often do you see this happen? Maybe five times a week. How many people do we think it affects? Probably about 100,000, so engineers, TPMs, and so forth. How many SDE years do you think we are wasting with these 10 seconds? At Amazon scale, a 10-second silly little thing that you have to do every single day amounts to 35 SDE years of productivity on the table. It’s not just the amount of money that we’re wasting, but actually those engineers could be doing something more interesting and more valuable for the company. That’s the really cool thing that comes with scale.
This engineer and I were talking and my next question was, how long is it going to take you to automate this away? He said two months. All of us engineers are overly optimistic about our ability to meet deadlines. I said, two months, cool, that’s going to take you four months.
Then, once you put a piece of code in production, you have to operate it. Over the course of five years, there’ll be operations, and PagerDuty, and software upgrades, and all kinds of things, so let’s throw in another two months for operations over the longer term. That’s probably going to take about half an SDE year to do this thing. If it can save 35 years of productivity, that’s a pretty good investment. Let’s go ahead and do it. The story is even better because I just talked about the year one, but you have to remember that this compounds over time. If you remove some ridiculous toil that everybody had, over the course of 5 years with flat headcount, that’s 174 SDE years, because it’s just 35 times 5. If you’re in hypergrowth, if the company is doubling in size every year, first year is 35, second year is 70, third year is 140, that really adds up. A lot of the investments we’re able to make at Amazon were based on that kind of growth that made some things more reasonable to do.
I know that measuring engineering productivity is pretty intangible. I think a lot of us feel hopeless. I recommend this book to you. I think it’s great. It’s called, “How to Measure Anything”. It helped me think about how to measure a lot of things in engineering productivity that feel intangible. How much time is somebody wasting on something? How much time is the whole company wasting on something? This is a great book to start thinking about that because I think we often give up too early and we could at least have a sense of, maybe that 35 years is not 100% correct, maybe it’s 20 years, maybe it’s 50 years, but it’s a lot more than half a year. That gives me a ballpark so that I know, is this a sensible investment?
Inflection Point – A Crisis
That’s one inflection point, but that’s not the only inflection point that you can have. Another one is a crisis, of course. I talked a little bit about that at the beginning with my horror story. Anybody know who this is? That’s Taylor Swift. This is the 2018, I think, world premiere of, “You Need To Calm Down”. The reason this was important to me is because she chose Amazon Prime Video to livestream that world premiere. I was pretty nervous because she happens to have a few fans. This is a pretty high-stakes event. We were expecting tens of millions of people to all livestream at the same time. They used my little technology that I had written because of that horrible operational issue in 2011 to validate that they could handle tens of millions of users livestreaming. That was a pretty cool journey from there, from this operational issue, to being responsible for making sure that we can livestream to 40 million people.
The way it happened was I wrote a bunch of infrastructure for my team because I needed it, because I wanted to redeem myself, and I was able to prevent and mitigate a bunch of issues in 2012. Then I thought, maybe other people should be doing this sort of thing, and I started sharing that infrastructure that I built, all the tools. Then 2 teams started using it, and then 10, and 100. It was still my pet project and weekend project, and eventually 1,000 different services were using it, and then it became my day job. Then 10,000 services were using it, and it became the day job of many other engineers around me. At some point it became the Amazon-wide load and performance testing infrastructure that we use for things like Taylor Swift and launching AWS services, and so forth. That all started with a crisis: with a personal crisis and with a work crisis. Never underestimate a good crisis as an inflection point for engineering productivity.
Inflection Point – Maturity
Sometimes the inflection point is maturity. Let me give an example of what I mean by that. All these big companies, Amazon, Microsoft, Google, Meta, they’ll have a tremendous amount of duplication in engineering productivity tools. It’s the bane of my existence because I’m strongly opposed to duplication. It happens. Big companies do that. I think there’s two valid reasons for doing that. The first one is, if you are in a period of hypergrowth, you have to move fast, and you have to move independently of everybody else. I think under those circumstances, each organization will optimize for what they need to get to market. I think that makes sense, even though it personally pains me to see duplication.
The other one is that there are times in life where there’s a huge amount of ambiguity. We are in one today with GenAI. I don’t know how GenAI is going to shape engineering productivity. If anybody tells you they know, they’re lying. I know that it will. I know that it will significantly change the way that you write code, that you test code and so forth, but we don’t know. We have dozens of efforts within the company to try to figure out what are the places where GenAI can really make a difference for us. I think that makes sense. When there’s ambiguity in a space, sure, let a thousand flowers bloom and see what happens. There’s also a time and a place for converging on some of those infrastructures. That’s another thing that I want to drive is that sometimes the inflection point is converging, not expanding. It’s deprecating things. It’s removing code, which makes me very happy.
When I rejoined Amazon, I was part of the Amazon Worldwide Stores. One of the things that was interesting to me is that more of our customers are using us on mobile than ever before. You can read the trends here that mobile is going to become a lot more important than web. We are no longer a website. We are a store. Most of our customers are using us on mobile. We have to really revamp and rethink the way that we test for Amazon store. As we were thinking about a bunch of infrastructure that we want to build for engineering productivity, so that you can provision devices, run tests against those devices, and then return devices back to the pools. You can do that with physical devices through AWS Device Farm. You can do that with virtual devices through emulators and simulators. We were brainstorming on a bunch of infrastructure that we wanted to build. Before we started to actually build it, I thought, this is Amazon.
There’s a lot of other teams within Amazon that are shipping mobile apps. I should talk to them and see what they did. Sure enough, I got in contact with a bunch of great people in Amazon Prime Video, and they’ve been doing this for a very long time. They have massive amounts of investments and maturity in their infrastructure that does what we want. I connected with people in Amazon Music. Also, they built a bunch of really cool infrastructure. Of course, teams that are dealing with devices like Alexa and Kindle also have massive amounts of infrastructure. A lot of this is duplicate. It made sense at the time because all these organizations are moving super-fast in getting to market and trying to establish their market. This is probably a time where it makes more sense for us to learn from each other and converge and so forth. That’s what I’ve been doing for the last few months is working across all these different organizations and driving convergence towards a more shared model.
That’s a beautiful thing about Amazon too, because as a senior principal, I don’t actually care about my specific organization. I act on behalf of Amazon, the company. All these different organizations may have their priorities, but my priority is Amazon and what’s best for the company. That’s really cool to be able to have a healthy disregard for organizational boundaries. Point is, not all the inflection points are to expand, sometimes it’s to converge. At Google, when I was technical lead for infrastructure for integration testing, it was the same thing. There was four different infrastructures that grew at Google completely independently of each other for integration testing. It didn’t make any sense. They were completely incompatible with each other. We started converging that effort too. That was my life at Google for a few years.
Inflection Point – Operational or Engineering Excellency
Sometimes the inflection point is operational or engineering excellency. What do I mean by that? Here’s some examples. Back in 2009, I could actually SSH to a production box. It was cool. There was no restrictions on that. I can guarantee you, in 2024, you do not want your intern SSH into your EC2 or S3 production environment. We blocked SSH to hosts. Didn’t at the time. We were smaller. We’re moving faster. We didn’t have gates like that. At some point of your engineering or operational excellency maturity, you have to start putting some gates. I think that’s a thing that you see as your company grows, as the number of engineers grows, there’s a lot more things that can go wrong and you have to start putting some gates in place. Can you submit code directly? Back in 2009, you could. I didn’t actually need a code review. I should get a code review. I was told to get a code review, but there was nothing in the repository that was preventing me from just submitting and merging code. We put a blocker on that.
Now if you want to submit a piece of code, you have to go through the code review process. The code review process itself makes sure that you get two shipments from your two closest friends. Then and only then does the code review tool submit the code and merges the code. Google does the same thing. Maturity thing. All these gates, to some degree, they slow you down. They’re obnoxious, but they’re necessary and they become super necessary at scale. Should every AWS service have a canary? Absolutely. We run four nines and more for SLAs for all of AWS. In 2018, 2019, I led an effort to get canaries for every single AWS service. You cannot launch an AWS service without a canary because our customers really matter, our availability is super important. You don’t have an option. Should we gate on code coverage? Yes, you should.
You can decide within your team what code coverage target you want, but I want you to make a deliberate decision as to how much code you want to let go to production that is untested. Again, these are all gates. They’re obnoxious. If you’re in a smaller company, you can get away with a lot of these, but as your company grows, you have to put more gates in place. I can tie a production problem, an operational issue to each one of these. That’s how we started putting these gates because we learned from operational issues and we thought, yes, it’s probably not a good idea for Joe intern to SSH to a production host. We should block that.
Inflection Point – A New Market
Sometimes the inflection point is a new market. For us, being in Builder Tools, my bread and butter was creating engineering productivity for web services. Why wouldn’t you want a web service? Everything that Amazon did was web services. Not really. We started creating devices. We have software that has to go on those devices, but most of our CI/CD tooling was very tailored towards web services. We had to change a lot of the big 10 assumptions so we can accommodate things like mobile phones and Alexas and Kindles. Anybody know what this last thing is? It’s a turnstile.
If you use an Amazon Go store, it’s one of those stores where you can walk in, you scan your credit card, and then you buy whatever you want and you just walk out. There’s no checkout process. We have turnstiles. Those turnstiles run software, and we have to test that software. Did I imagine in 2009 that I would be changing our CI/CD infrastructure so that we could test turnstiles? No, I had no idea. My focus was web services, but as your company expands and it gets into other markets, a lot of the assumptions that you’ve baked into your tooling become invalid and you have to figure how to widen your horizon a little bit.
Foundational Decisions
Lastly, some decisions are really foundational. I’m going to do a case study on this one for quite a while here. They will have ramifications on the way that many other tools around it will shape for generations of engineers. I’ve known Amazon for 15 years. I’ve seen many generations of engineers. It’s interesting to see how some of these tools shape up. Here’s 2009. We’re about 3,000 engineers. AWS was in its infancy. There was foundational services like EC2 and S3, but not much more than that. The Amazon store was slowly moving away from a monolith. I think we started the move away in 2007. Back in the days, Amazon was a single binary, very large monolith called Obidos.
Then at some point, it became too hard to compile, too hard to copy to production, too hard to load into memory, too hard to collaborate between engineers because everything was very tightly coupled. We said, let’s break it up into microservices. This is super obvious today, but in 2007, it wasn’t that obvious. We started our long breakup of the Amazon monolith into hundreds and thousands of services. For example, and this is just 2010, that when you go to an Amazon product detail page, there’s between 200 and 300 services that are being called just to construct your page. This is 2010. I can tell you there’s a few more than 300 today just involved in constructing just your Amazon product page, which is super crazy. The thing that we really wanted to do in 2009 as we started breaking up the monoliths with was creating a foundational break and wall between different teams so they couldn’t depend on each other’s code. That’s the whole point of breaking up a monolith.
The first thing that we did is we created this concept of a two-pizza team, which is a peculiar, weird Amazon term that you’ll hear a lot. A two-pizza team is essentially the number of engineers that you can feed with two pizzas. Hopefully they don’t eat a lot. It’s less than 10. If you got more than 10 engineers, they’re going to be pretty hungry with two pizzas. I think somebody in the S-team, Jeff or somebody came up with this term of two-pizza team, and it was just like this cute term, so it really stuck. You’ll hear this term two-pizza team when talking to Amazonians all the time. It’s just a 6 to 10-person team. The idea was, we’re going to break up this monolith into microservices. They have a single purpose in life to do something. There’s a two-pizza team that single-handedly owns this service. They need to be able to operate independently from each other.
The only communication between these two is going to be through the network, RPC, HTTP, so forth. There’s no code shared whatsoever. How are we going to discourage code from being shared? We’re going to have microrepos. Team 1 is going to have its own repo. Team 2 is going to have its own repo. Never shall those two repos meet. You want to talk to me? Do it through the network. This is where we’re doing this, monorepo versus multi-repo. Who’s monorepo team here? Who’s a fan of monorepo? Anybody a fan of multi-repo? I did not expect that. We have more fans of multi-repo than monorepo.
Amazon is a multi-repo shop from day one. Because of that fundamental decision in 2007 to start breaking up the monolith and to create these walls, we’re very much a multi-repo world. Asking whether you love the monorepo or you love the multi-repo, it’s like asking a soccer fan, do you love Argentina or do you love Brazil? How many soccer fans here? I’m Argentinian. I was born and raised in Argentina. You ask me, of course, Messi is the GOAT. If you ask somebody from Brazil, they’re going to have a very different opinion on that. The whole monorepo versus multi-repo is a pointless debate. What I’ve learned working four years at Google, which is a monorepo world, and my time working at Amazon, which is a multi-repo world, is that you’re going to have to face and solve complexity. You’re just going to have to do it in different places. It’s not that one is going to be better than others, it’s just different complexity.
Software Development Life Cycle
Let’s go into the software development cycle. You’ve got some local dev changes. You have a code review. You submit a merge. You deploy some test stage. Then you deploy to production. That’s your standard flow. Hopefully, you’re going to test, integration tests in each one of these steps. You have some local dev changes, you’re going to run integration tests to make sure you’re happy. You’re going to put it up for code review.
Generally, a code review tool is going to run a bunch of tests. Then you submit it, merge it, so forth. Multi-repo is like a house with all these different rooms. You can break one of those repos, and the beautiful thing is that it doesn’t break anybody else. You’re going to piss off your two-pizza team, because you’re going to break up your tiny little repo, but you’re not going to anger the other 80,000 engineers. Whereas, think of a monorepo world as like a studio apartment. You break it, you really break it. Google had 120,000 engineers working on a monorepo, and not only that, but they were pretty gutsy because there were no branches. Everybody’s working on head. They made it work. It’s pretty amazing.
To Google’s credit, there’s a lot of really smart people that spent a lot of time and massive amounts of infrastructure to make a monorepo with no branches work for 100,000 engineers. It works, except when it doesn’t. There was a couple times where I couldn’t check in a piece of code because some random person had checked in another piece of code that made no sense to me. I was like, why am I failing because of this person that I’ve never met? For the most part, it worked.
The point is, multi-repos provide this natural, lovely blast radius reduction. That changes a lot of the equation in terms of engineering productivity, because that’s a pre-submit world and a post-submit world. In a place that has a monorepo, the pre-submit world is super important, because if you check in, you break the world. Google and other monorepo shops invested massive amounts to make the pre-submit story really work. Lots of investments in integration testing pre-submit: integration testing against local dev changes, integration testing against code reviews. That is where we put most of our time and energy at Google.
Whereas at Amazon, it’s not that we didn’t want to do that. Of course, we want to shift left and catch bugs as early as possible. Having the blast radius reduction in the walls of the repos give us a little bit of breathing room, so we spent a lot more time focusing on things like the kinds of tests that we were going to do post-submit. The irony is that Google is amazing pre-submit and fairly mediocre post-submit. Amazon is fairly mediocre pre-submit and amazing post-submit. You can see the story play out. It all started with one thing and it led to another and another. It really influenced the way that we thought about developer tools and so forth.
There’s something else that happens. Normally, if you own a microservice, your end state is you deploy to production and you’re done, but not every single repo is tied to a service. Sometimes a repo, the end stage of a repo is to push to another repo. Why might you do that? At the end of the day, sometimes you have to build a monolith, whether you like it or not. Mobile apps are monoliths. You have to compile them. You have to put them in a play store. It’s a single binary, whether you like it or not. You have to build some monoliths at some point. You have to assemble large products. The way that you do it in the multi-repo world is you have small repos flowing into bigger repos flowing into bigger repos and cascading like that.
If you break one of the smaller repos and you didn’t have gates in place to prevent that piece of code from being pushed to the next repo, it breaks it, and it breaks it, and it breaks the world. It is possible to break the world, it’s just a lot more difficult. The kinds of testing that you do before either you deploy to production or before you push to another repo, that’s super critical because that’s your last line of defense before something breaks the world. That’s why at Amazon that was super important. We could be slightly more relaxed about the pre-submit story because it wasn’t a break the world situation.
Then deploying to production was a big deal too. What kinds of things might you worry the most if you’re in a pre-submit monorepo world? Test selection. Because out of the billions of tests that exist in Google, what tests should I be running for this specific code change? That’s a non-trivial problem. Ephemeral test environment, so I have to be able to spin off a test environment, run my tests, and then shut it down. Google does this extremely well. Hermetic test environments to reduce a lot of the test flakiness. These ephemeral test environments that I’m spinning on demand, I want to be able to sandbox them so that I don’t have flakiness because of the network or because of dependencies that are flaky and so forth. This is the kind of thing that we invested very heavily in a monorepo world. I wrote a lot about this. Here’s a couple links if you want to read. I wrote a couple articles on that.
On the other hand, if you’re in a multi-repo world, here’s the things that we cared about. We wanted to have long-lived static test environments with super high fidelity, so we invested in that. Canaries, telemetry, rollback, alarming in production, those are the things that we’re investing on the most, not because we didn’t care about hermetic ephemeral test environments, but they’re massively expensive to do. Google has spent hundreds of engineers for a decade to do this sort of thing. It’s not just testing, so things like vending libraries is really a little bit challenging. We had to build mechanisms for you to vend a library. Because the way you vend a library is you put it from your repo, you promote it to other repos. You can imagine a situation where one repo is pushing to tens of thousands of repos. That’s a big blast radius. Finding versions.
In a monorepo world, it’s much easier to reason about the world, because everybody’s got the same version. In a multi-repo world, it’s free for all. If you have a security problem, you have to find out who’s using version XYZ of Foobar. Then we had to build tooling around that to keep track of what repos have what versions of what so that we can go fix that. I wrote about that too. Lots to say about different ways of viewing CI/CD. There’s another link for you. There’s a bunch of links too about just the way that Amazon thinks about CI/CD. There’s a couple of articles that my peers wrote about the CI/CD process at Amazon, so I’ll point you to that.
Proprietary Tooling vs. Third-Party/Open-Source Tools
My last thought is, be deliberate about the kind of proprietary tooling that you end up building for your company versus when you use third-party tools. I think there’s a couple of reasons why it makes sense to write proprietary bespoke tools. The first one is, you’re trying to do something and the third-party open-source tools just don’t scale.
I built the Amazon load and performance testing infra because in 2012, I couldn’t find any open source that could generate hundreds of millions of transactions per second. I needed to do it, so I built it for my company. Sometimes optimizations matter. Google has their own IDE. They don’t sell it. It’s an internal tool. Does it make sense for Google to invest hundreds of engineers in their own IDE? It does. Because if you’ve got 120,000 engineers, $400,000 each, and that’s just your average SDE-II, that’s $50 billion a year that Google’s spending paying their engineers. I think that, yes, investing in an IDE that’s going to make your $50 billion a year move a little faster, that’s a great use of engineering productivity resources. I’m a huge fan of the Google IDE.
The last one is that there’s an ecosystem effect that compounds. If you get tools that are working with each other in an ecosystem, that’s super powerful versus you’re bringing a bunch of third-party tools and they don’t really work with each other. You have to build all the glue for all these tools to talk to each other. That’s very difficult. If you build an ecosystem where everything integrates together, that’s really powerful. That’s why companies like Amazon, and Microsoft, and Google, they have massive investments in engineering productivity and internal tools for everything that you could possibly want.
My warning is that when we go down this road, there’s always the danger of falling into the bubble, the Amazon bubble, the Google bubble. You always have to be aware of what else is going on in the industry. The minute you’ve created bespoke tools, you’re in the hook for advancing those tools along the industry. I often see that’s not the case. Maybe 10 years ago, the industry wasn’t there. We built something, but we didn’t evolve it, and the industry moved, and now we have subpar tools. That’s my warning about proprietary tools. I have a love-hate relationship. I’ve spent 27 years building proprietary tools for Microsoft, Amazon, Google, but I have this love-hate relationship with them.
Conclusion
There’s inflection points when these engineering productivity investments make sense. There’s a number of them that I gave you. Now you know how to recognize them. Go seize the day and go do the right thing for wherever it is that you’re working.
See more presentations with transcripts
MMS • RSS
Amazon DynamoDB is a serverless, NoSQL, fully managed database service that delivers single-digit millisecond latency at any scale.
In provisioned mode of DynamoDB, you pay for the capacity you provision, regardless of actual usage. The percentage of consumed capacity relative to provisioned capacity is known as throughput utilization.
In this post, we demonstrate how to evaluate throughput utilization for DynamoDB tables in provisioned mode. Understanding this metrics helps you determine whether switching to on-demand mode is the right choice. Moving to on-demand mode, where you pay-per-request for throughput, can optimize costs, eliminate capacity planning, minimize operational overhead, and enhance overall user experience for your applications.
Overview
DynamoDB supports two throughput modes: on-demand and provisioned.
- On-demand mode charges per request, automatically scaling without requiring capacity planning or auto scaling management.
- Provisioned mode lets you specify the required read and write capacity per second for your application.
In November 2024, we announced a 50% price reduction on DynamoDB on-demand throughput and up to 67% off global table throughput. With this announcement, you can now enjoy the power and flexibility of DynamoDB while being more cost-effective, scaling down to zero, and focusing more resources on driving innovation and growth.
If you were already using on-demand mode, you may have a noticed a drop in your DynamoDB costs overnight when the billing changes were applied around November 1, 2024. One of the key advantages of DynamoDB is that new features and improvements can automatically benefit your applications as they’re released, without requiring manual database version upgrades. However, if you’re using provisioned mode, it’s important to analyze your read and write throughput consumption to determine if switching to on-demand mode is now more cost-effective. This post explains how to evaluate throughput utilization.
Throughput utilization
Throughput utilization is high when your consumed throughput is close to provisioned capacity. If you provision significantly more read or write capacity than actual usage, your throughput utilization is low, leading to unnecessary costs.
Tables with low throughput utilization can benefit from switching to on-demand mode, which offers automatic scaling and potential cost savings.
However, throughput utilization alone does not reflect operational overhead, such as capacity planning, auto scaling management, and regular configuration tuning in provisioned mode. When deciding whether to switch to on-demand mode, consider both throughput utilization and operational costs to make an informed decision.
Plotting throughput utilization
To plot throughput utilization, you can use Amazon CloudWatch metrics for each table or global secondary index (GSI). To plot throughput utilization, use the following instructions.
To access CloudWatch metrics, follow the steps:
- On the CloudWatch console, in the navigation pane, select All metrics.
- Search for your table name, for example, couponstore. Choose DynamoDB and Table metrics.
- From the available list of metrics, select both the
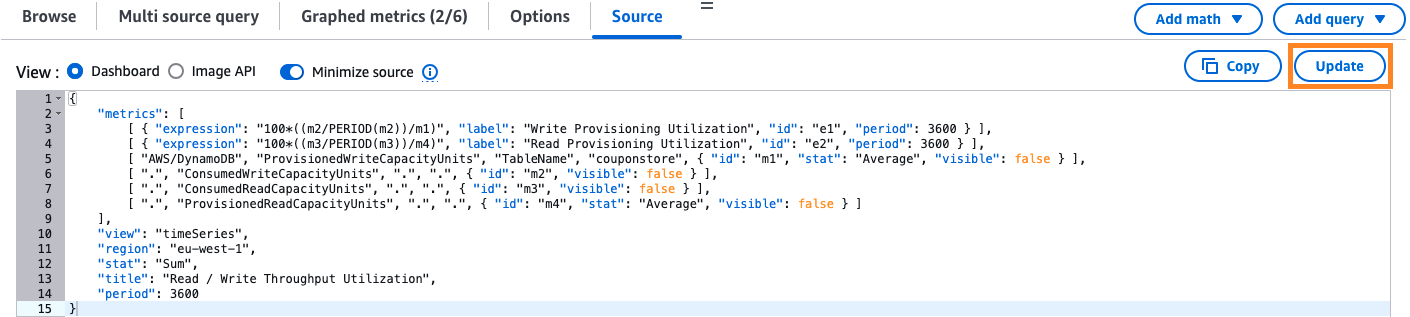
Consumed*andProvisioned*metrics for Read and Write capacity. For example, selectProvisionedReadCapacityUnitsandConsumedReadCapacityUnitsfor Reads.
The following screenshot shows the selected read and write metrics for our sample table, couponstore.
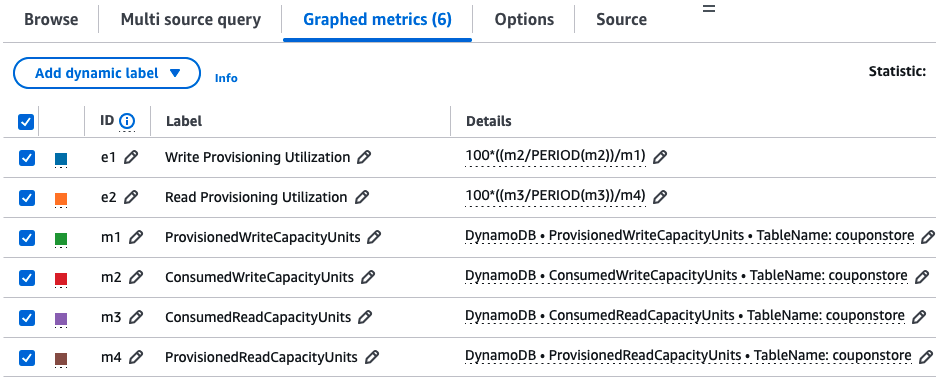
To add math expressions, follow these steps:
- In the Graphed metrics tab, choose Add math and Empty expression.
- Identify the ID of the
ConsumedWriteCapacityUnitsandProvisionedWriteCapacityUnitsmetrics (for example,m2andm1). - Add the following math expression for write throughput utilization:
- Repeat for read throughput. If the metrics are
m3andm4, the expression is:
The following screenshot shows the Graphed metrics screen with the math expressions:
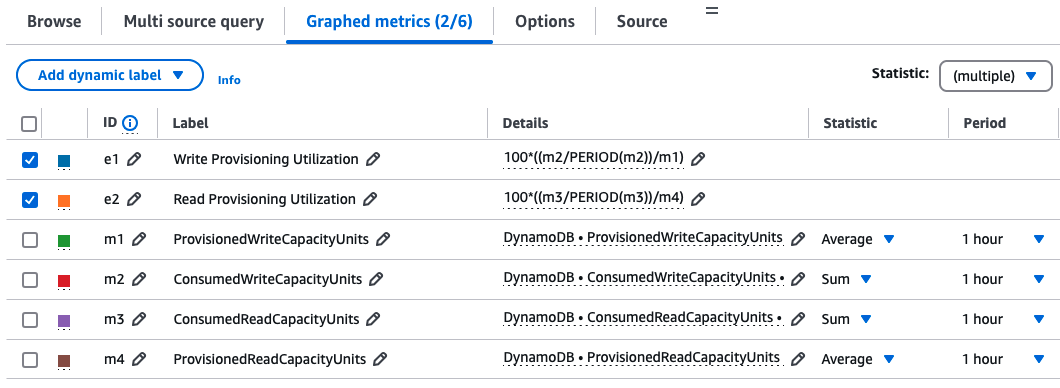
To configure graph settings, follow these steps:
- On the top of the screen, set the time window to at least one month.
- On the Graphed metrics tab under Statistic, use the Sum statistic for
consumed*metrics and Average forprovisioned*metrics. - Adjust the Period to at least 1 hour. If analyzing historical data, use higher granularity if necessary.
- Disable (but don’t delete) the consumed and provisioned metrics to focus on the math metrics. These will represent your throughput utilization.
The following screenshot shows these settings.
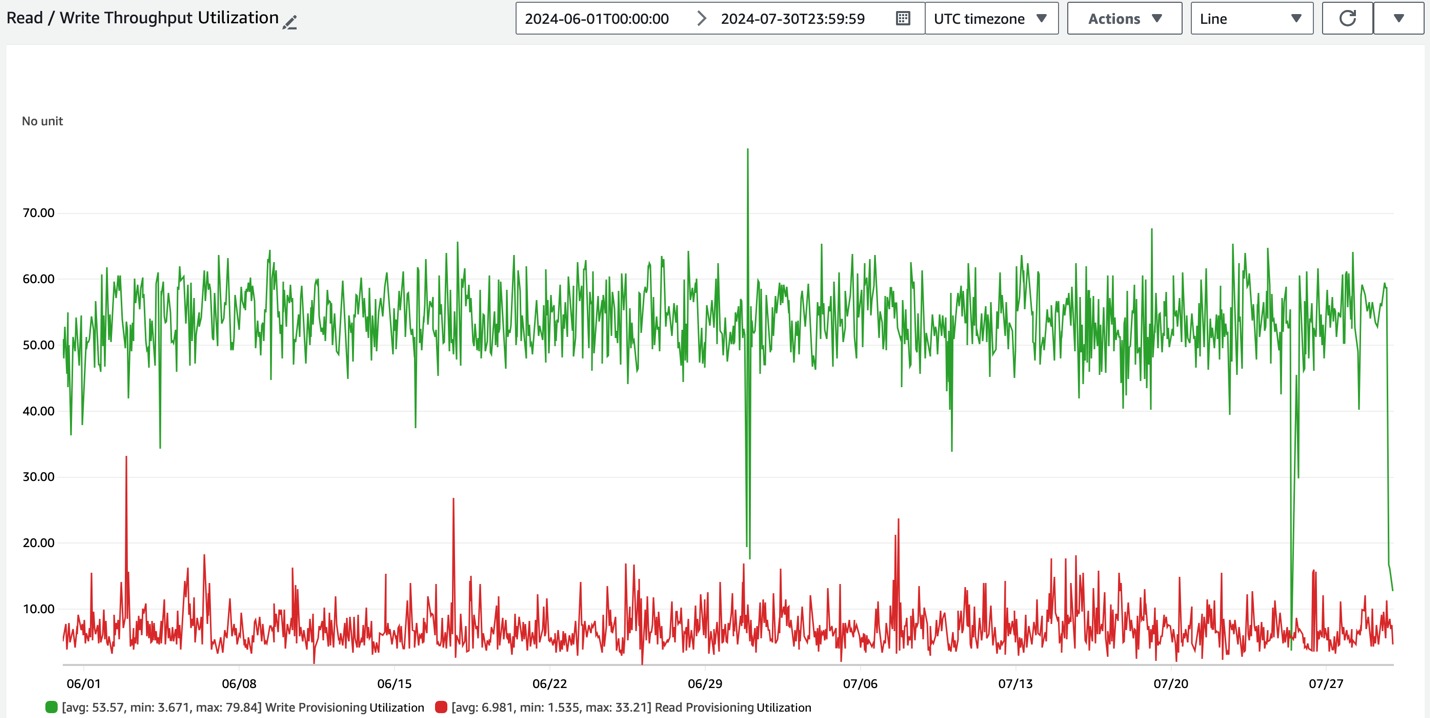
Interpreting throughput utilization
Throughput utilization is expressed as a percentage, ranging from 0% to 100%. For example, if the graph shows utilization ranging around 30%, it indicates that the table is generally over-provisioned by about 70%. Alternatively, if the utilization is around 60%, your workload has a 40% buffer.
When to switch to on-demand
To understand how to decide when to switch to on-demand, consider the following points:
Below 30% utilization:
- If the throughput utilization averages below 30% over a month (or consecutive months), switching to on-demand capacity mode is highly recommended. This change optimizes cost, reduces operational overhead, and improves scaling.
Between 30% and 45% utilization:
- If the average utilization is between 30% and 45%, switching to on-demand can still be beneficial, particularly from a total cost of ownership (TCO) perspective.
- This switch can reduce or eliminate throttling that could occur in provisioned mode.
- You’re no longer continually reviewing and managing auto scaling configurations. This gives you less operational overhead so you can focus more on building new functionality.
If utilization exceeds 45%, provisioned mode may be a suitable choice for the table, excluding total cost of ownership factors.
CloudWatch metric source code
You can also use the following CloudWatch metrics console configuration to calculate throughput utilization for your table or GSI.Use the following code for tables. Replace
with your table’s name.
Add the desired source code into the CloudWatch Metrics console. After replacing the table and GSI placeholders, choose Update to graph throughput utilization, as shown in the following screenshot.
Cleanup
Consider this a reminder to delete any temporary resources created while following this post. This includes DynamoDB tables, custom CloudWatch metrics, and CloudWatch dashboards.
Considerations
This analysis focuses on throughput utilization and doesn’t account for the total cost of ownership (TCO), such as personnel to manage resources and tune auto scaling configurations. It’s important to understand your TCO and evaluate whether switching to on-demand helps you optimize on the bottom line. Use these utilization graphs as a starting point for evaluating a switch to on-demand capacity mode.
We recommend plotting throughput utilization for 1 or more months in the past to get a trend view. Also, a CloudWatch metrics period of 1 hour or more can often smooth out any short bursts in provisioning and utilization. Consider changing the period of the metrics to higher granularity such as 1 minute, 5 minutes, or 15 minutes and observe the bursts the occur. On-demand capacity mode will certainly be beneficial for these spikes by design.
Conclusion
In this post, we demonstrated how to measure throughput utilization for your provisioned mode DynamoDB tables and GSIs. Evaluating your table’s utilization helps you make informed decisions about switching to on-demand mode optimizing costs, and reducing operational overhead.
If you’re looking for an automated way to analyze utilization across multiple tables, check out the metrics-collector tool open-sourced by my team.
To deepen your understanding of DynamoDB’s on-demand capacity mode and its potential benefits, read Demystifying Amazon DynamoDB on-demand capacity mode.
Did this post help you evaluate the appropriate capacity mode for your tables? Share your feedback in the comments!
About the Author
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) CEO Dev Ittycheria sold 3,747 shares of the firm’s stock in a transaction on Wednesday, July 2nd. The shares were sold at an average price of $206.05, for a total value of $772,069.35. Following the transaction, the chief executive officer directly owned 253,227 shares in the company, valued at $52,177,423.35. This trade represents a 1.46% decrease in their ownership of the stock. The sale was disclosed in a document filed with the SEC, which is available at this link.
Dev Ittycheria also recently made the following trade(s):
- On Thursday, June 5th, Dev Ittycheria sold 25,005 shares of MongoDB stock. The shares were sold at an average price of $234.00, for a total transaction of $5,851,170.00.
MongoDB Stock Down 0.6%
Shares of MDB traded down $1.33 during mid-day trading on Monday, reaching $210.01. The company’s stock had a trading volume of 1,575,533 shares, compared to its average volume of 1,963,278. The company has a market cap of $17.16 billion, a price-to-earnings ratio of -184.22 and a beta of 1.41. The business has a fifty day moving average of $195.41 and a 200 day moving average of $215.08. MongoDB, Inc. has a 1 year low of $140.78 and a 1 year high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share for the quarter, beating the consensus estimate of $0.65 by $0.35. The firm had revenue of $549.01 million for the quarter, compared to analyst estimates of $527.49 million. MongoDB had a negative return on equity of 3.16% and a negative net margin of 4.09%. MongoDB’s quarterly revenue was up 21.8% on a year-over-year basis. During the same period in the previous year, the firm earned $0.51 earnings per share. On average, analysts predict that MongoDB, Inc. will post -1.78 earnings per share for the current year.
Hedge Funds Weigh In On MongoDB
A number of large investors have recently made changes to their positions in MDB. Jericho Capital Asset Management L.P. acquired a new stake in shares of MongoDB during the first quarter worth approximately $161,543,000. Norges Bank purchased a new stake in MongoDB in the 4th quarter worth approximately $189,584,000. Primecap Management Co. CA boosted its stake in shares of MongoDB by 863.5% during the 1st quarter. Primecap Management Co. CA now owns 870,550 shares of the company’s stock valued at $152,694,000 after buying an additional 780,200 shares during the period. Westfield Capital Management Co. LP acquired a new stake in shares of MongoDB during the 1st quarter valued at $128,706,000. Finally, Vanguard Group Inc. grew its holdings in shares of MongoDB by 6.6% during the 1st quarter. Vanguard Group Inc. now owns 7,809,768 shares of the company’s stock valued at $1,369,833,000 after acquiring an additional 481,023 shares in the last quarter. Institutional investors and hedge funds own 89.29% of the company’s stock.
Analyst Ratings Changes
A number of analysts have commented on MDB shares. UBS Group boosted their price target on shares of MongoDB from $213.00 to $240.00 and gave the stock a “neutral” rating in a research report on Thursday, June 5th. Scotiabank raised their price objective on shares of MongoDB from $160.00 to $230.00 and gave the company a “sector perform” rating in a research note on Thursday, June 5th. Guggenheim upped their target price on MongoDB from $235.00 to $260.00 and gave the stock a “buy” rating in a research report on Thursday, June 5th. Citigroup lowered their price target on MongoDB from $430.00 to $330.00 and set a “buy” rating on the stock in a research report on Tuesday, April 1st. Finally, Needham & Company LLC restated a “buy” rating and issued a $270.00 price objective on shares of MongoDB in a report on Thursday, June 5th. Eight analysts have rated the stock with a hold rating, twenty-five have issued a buy rating and one has issued a strong buy rating to the stock. Based on data from MarketBeat.com, MongoDB presently has an average rating of “Moderate Buy” and an average target price of $282.47.
Read Our Latest Stock Analysis on MDB
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

MarketBeat just released its list of 10 cheap stocks that have been overlooked by the market and may be seriously undervalued. Enter your email address and below to see which companies made the list.
MMS • RSS

| Reporter Name | Relationship | Type | Amount | SEC Filing |
|---|---|---|---|---|
| Merriman Dwight A | Director | Sell | $206,050 | Form 4 |
| Pech Cedric | President, Field Operations | Sell | $72,941 | Form 4 |
| Ittycheria Dev | President & CEO | Sell | $772,069 | Form 4 |
Several MongoDB executives have recently conducted transactions involving the company’s Class A Common Stock, as reported in SEC Form 4 filings.
Dwight A. Merriman, a Director at MongoDB, sold 1,000 shares on July 2, 2025, at a price of $206.05 per share, resulting in a total sale amount of $206,050. Following this transaction, Merriman’s direct ownership stands at 1,106,316 shares, with an additional 604,741 shares held indirectly through the Dwight A. Merriman Charitable Foundation and a trust for his children’s benefit. This sale was executed under a Rule 10b5-1 trading plan.
Cedric Pech, the President of Field Operations, sold 354 shares on the same date at $206.05 per share, totaling $72,941. This sale was to cover tax obligations related to the vesting of restricted stock units, leaving Pech with a direct ownership of 57,280 shares.
MongoDB’s President & CEO, Ittycheria Dev, also sold shares to cover tax obligations related to the vesting of restricted stock units, disposing of 3,747 shares at $206.05 each for a total of $772,069. After the transaction, Ittycheria Dev directly owns 253,227 shares.