

Introduction
The COVID-19 pandemic began in Wuhan, China, in December 2019 and has seriously threatened the health and lives of people worldwide in a short period, and it continues to this day1. Doctors, researchers, and healthcare policymakers around the globe have been challenged to provide effective prevention and treatment methods to combat the pandemic. Unfortunately, a definitive treatment has not yet been discovered, and currently, prevention through adherence to health protocols alongside vaccination are recognized as the only agreed-upon and effective solutions. Although the rapid development of a vaccine against COVID-19 is an extraordinary achievement, successful vaccination for the global population presents numerous challenges, from production to distribution, deployment, and, most importantly, acceptance. In fact, trust in vaccines is vital and fundamentally depends on the ability of governments to communicate the benefits of vaccination and to provide vaccines that are safe and effective2. The specific circumstances have led to many vaccines being used for public administration solely with emergency authorization and without completing all phases of clinical trials, with safety data being published as interim reports or clinical trial reports3,4,5,6. It is worth noting that the drug approval process, including that of the COVID-19 vaccine, involves studies and clinical trials on consumers to record and analyze related symptoms and side effects. Therefore, the public and private sectors have united to test vaccines that are effective and safe.
In this regard, the Case Report Form (CRF) is recommended as it is a specialized document in clinical research that can impact the success of the study7 and must be appropriate in content based on the study protocol, including the necessary information for collecting specific study data. CRF systems are of two types: paper-based systems and electronic data-based systems8. Suitable methods and tools for managing clinical data (including data collection, electronic information recording, printing the Case Report Form (CRF), maintaining the CRF, data storage, validation, privacy protection, and more) have been provided, and the use of electronic systems has become widespread in this field due to advantages such as improved data quality, online dispute management, rapid database locking, cost reduction, increased efficiency, and so on9,10,11. This underscores the need to utilize an eCRF system, considering the benefits of this approach to data collection in clinical trials during pandemic conditions.
Given the importance of conducting these studies for unknown drug and vaccine side effects, this research will focus on the design and evaluation of an eCRF system for studying the side effects of COVID-19 vaccination. In designing this eCRF, considering the complexity of these studies for the COVID-19 vaccine (including the large volume of data, the diversity of data due to various factors such as the diversity of strains, symptoms, and clinical manifestations, etc.), and on the other hand, the form-based and record-based nature of the eCRF system, the data model of this system will utilize a modern NoSQL document-based data model instead of the traditional relational data model. This approach seems to be more suitable for the nature and characteristics of eCRF and the specific features of the viruses and the vaccines designed for them.
The rest of the paper is organized as follow: the proposed NoSQL document-based eCRF system for study of vaccines with variable adverse events (regarding the COVID-19 vaccines as the case study) is presented in Sect. 2. The needed steps and phases (w.r.t. software development process) are described in details. The proposed eCRF is analyzed and evaluated in terms of different aspects and quality metrics in Sect. 3 and discussed in Sect. 4. Finally, the paper in concluded in Sect. 5.
The proposed NoSQL document-based eCRF system
The current research is of an applied-descriptive type and consists of three main phases. Its aim is to create a case reporting system for collecting a minimum dataset related to the adverse outcomes of COVID-19 vaccine side effects, based on a NoSQL data model with a document-based storage approach, conducted in the year 2024.
To achieve a web-based case reporting system that provides a set of minimum essential data on adverse effects resulting from medication or vaccination, we first needed to determine and define the minimum data set and the expected capabilities of the reporting system. One of the core requirements of the case report form served as a basis for designing a suitable database, considering the variable nature of the virus and the potential rare allergic reactions resulting from vaccine administration. Therefore, in the next step, we specified which data model we wanted to use based on the system’s intended purpose. The model selection should be such that it can adapt over time to changes in future research or updates to the existing system for other virus strains, thereby reducing associated costs. Following that, the third phase was the design of the reporting system, which included modules to meet the proposed requirements.
Phase I: needs assessment and planning
Initially, we conducted a survey to determine what features and functionalities are required for a reporting system to collect information on the adverse effects of COVID-19 vaccination12. For this purpose, in the requirements engineering phase, which lasted for six months, the necessary information was gathered using methods such as observation, brainstorming, questionnaires, and literature review from internet searches in scientific databases like Scopus, Web of Science, and Google Scholar, as well as examining similar studies. The study population included library resources and a group of patients, health caregivers, disease experts, and health managers who were selected to complete the questionnaires. All procedures were conducted in accordance with relevant ethical guidelines and regulations. The study protocol was approved by the Ethics Committee of Tarbiat Modares University (Approval Code: IR.MODARES.REC.1400.333). Informed written consent was obtained from all participants, and from legal guardians where applicable. Additionally, the research environment was the health center of Sari County from Mazandaran University of Medical Sciences, which facilitated access to stakeholders and the conduct of field studies. The requirements and design specifications for the system were extracted in the form of an SRS standard and reviewed in subsequent phases12. Therefore, by examining existing vaccine adverse event reporting systems in the country and obtaining feedback from specialists, the main features were identified. Subsequently, the necessary capabilities were reviewed by a group of experts consisting of two physicians, one faculty member in medical informatics, one faculty member in virology, and two faculty members in biostatistics, thus confirming the content validity of the designed questionnaire qualitatively. In this study, the data obtained from the completed questionnaires by the designated groups were analyzed using SPSS software, version 26. Consequently, absolute frequency values for each of the questionnaire items were calculated from the perspective of each respondent group and, in general, from the perspective of all respondents. The focus then shifted to the core elements for developing the reporting system, considering the conducted studies and the minimum required dataset12. In the next phase, to present a model based on expectations and required capabilities, the requirements and modules were determined, resulting in the necessary modeling to advance the project objectives.
Phase II: design and implementation
Architecture and system model
To develop the case reporting system, it is essential to utilize the software development life cycle, which includes the stages of requirements determination, design, implementation, evaluation, deployment, and maintenance. These stages are designed based on recognized software engineering standards, such as the IEEE/EIA 12,207 standard, to ensure that the software development process is carried out in the best possible manner and that user requirements are accurately met13. In this context, a three-layer model is used as the conceptual model of the system. At the highest level, the logical layer presents the main functions of the program. This layer is responsible for processing data and providing it to the display layer. The data layer provides an interface for the logical layer and performs necessary operations, including storing, editing, deleting, and retrieving data, without getting involved in the complexities of the database. In this layer, the database is designed and utilized. In the display layer, the case reporting system is web-based.
The architecture of the vaccine adverse event reporting system, as shown in Fig. 1, will consist of four sections. The first section addresses the stakeholders of the system, including managers, patients, health caregivers, experts, and other relevant individuals. These users can interact with the system through common web browsers such as Edge, Chrome, Firefox, and others to access the services and information they need. The second section pertains to the web server, which receives requests and inquiries sent by users and responds to them with the aim of delivering web pages, necessary site files, executing applications, and providing various services such as databases, ultimately presenting results to users.
The third section is the user interface, which enables users to interact with the system through web pages, forms, menus, and buttons. This interface provides the necessary tools for users such as managers, patients, and caregivers to access features, submit reports, and navigate the system efficiently. The fourth section is the core program, responsible for processing data and executing the main logic of the system. It collects and validates information submitted by users, such as adverse event reports, and generates meaningful outputs like statistics, analyses, and reports for further use or display.
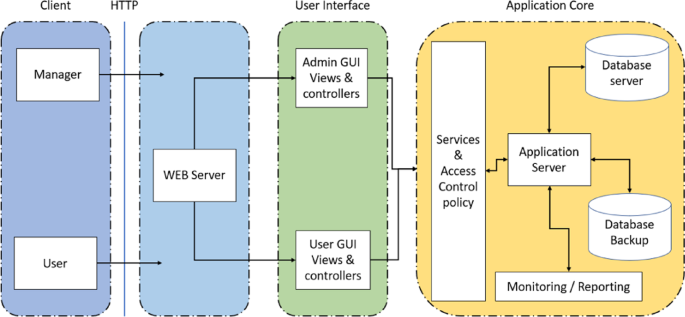
Presented architectural framework of the case reporting system.
We aimed to collect a minimum expected dataset for clinical trial studies within the conceptual model architecture, focusing on the core of the localized eCRF system to gather data on COVID-19 vaccine side effects based on a NoSQL document-based database, as shown in Fig. 2. To achieve this, we reviewed the study by Psotka and colleagues, which included specific components such as demographics, vital signs, physical examinations, patient-reported outcomes, medical history, laboratory tests, concomitant medications, and device treatments14. This conceptual model consists of three sections: components, modules, and the main objectives of the eCRF core. The main components and modules have been modified to align with the reporting system’s goals. Details of this step have been reported elsewhere12.
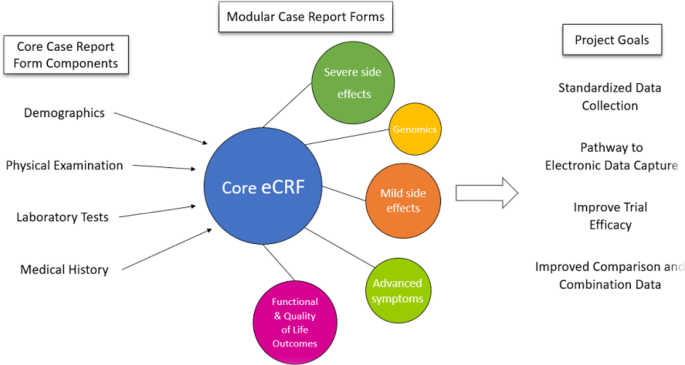
Conceptual model of the eCRF core for collecting data on COVID-19 vaccine side effects.
System modules
System modeling approach
Before creating a system, it is necessary to provide a structure for each module to clarify its functionality and the relationships between these modules. The models were designed using UML language and with the help of Visual Paradigm software as the tools used in the research environment, including class diagrams, use case diagrams, Entity-relationship diagram, and activity diagrams. The created diagrams were used to display the system structure, the relationships among data elements, and each of the existing sections in the system, as well as to generate a scenario for examining the work process. The actors in the system design include two groups: administrators and users, who in this research are referred to as disease specialists, health caregivers, or patients.After extracting the requirements, modeling was carried out at three levels: data modeling, functional modeling, and workflow modeling, each of which is presented below:
-
Structural view of classes and objects:
In the case reporting system, the class diagram accurately and comprehensively displays entities such as “care providers” (employee), “patient,” “case report form,” and the relationships among them (see Appendix A Fig. 16). This diagram shows that the class “care providers” serves as a base class, which includes subclasses such as manager, specialist, and health caregiver that inherit from it. Additionally, the relationship between “health caregiver” and “case report form” is defined such that each health caregiver can create an unlimited number of case report forms, while each form is registered by only one health caregiver.
-
Dynamic view of users’ interactions:
In Appendix A Fig. 17, the users of the case reporting system include system owners, healthcare providers, and patients, and the use cases are depicted based on the extracted requirements, such as patient registration and report generation. Relationships such as “includes” and “extends” are used to illustrate the division of responsibilities and enhance the system’s capabilities, such as “access level determination,” which is an extended use case of “report generation.” These relationships cover the diverse needs of the project through the reuse of use cases and the development of tasks.
-
Dynamic view of activity flows:
In activity diagrams, the start of a process is represented by a filled circle, the end by a cross mark in an empty circle, and each activity is shown with a rectangle. The workflow is indicated by arrows, and decisions are represented by diamond shapes. Appendix A Fig. 18 provides an example of the activity diagram for the case reporting system, illustrating how vaccine side effects are reviewed and recorded for a patient either through self-reporting or by a healthcare provider.
-
Structural view of Entity Relationship.
To facilitate a clear understanding of the data structure for developers and contributors, a UML Class Diagram (besides the Entity Relationship Diagram (ERD)) were designed to visually represent the relationships between entities and the stored data (Appendix A Fig. 16). These diagrams are included in the project documentation and serve as a quick reference guide to the underlying data architecture.Prototype Design.
Based on the modeling conducted, a prototype of the vaccine side effects reporting system was created as a model template using the web service Figma, which was one of the other tools utilized in the research. This was done to evaluate, assess, and revise the completed models by creating a visual representation to reduce product development costs, ultimately accelerating the determination of relationships between the system entities and the implementation of the graphical user interface. In the software development approach of this research, the agile development thinking method was employed with the Scrum framework, which is a repeatable and incremental framework for project control and an alternative to the waterfall model of software development. Scrum allows teams to break the project into smaller parts and continuously deliver them to customers through short iterations (usually 2 to 4 weeks) known as sprints.
Phase III: Software development
Data models in clinical data collection systems, particularly in electronic case report forms (eCRFs), play a vital role in recording and managing information. Some diseases and side effects of medications or vaccines have variable natures and can encompass a wide range of symptoms. In such cases, structured relational data models may have limitations and may not effectively manage this diversity. Therefore, the use of unstructured data models such as NoSQL, especially document-oriented models, can provide a suitable solution. This is because these forms are designed as electronic documents with a flexible structure. In document-oriented models, each document can store data specific to a patient, study, or particular sample in a single format, without the need for the rigid schema constraints of relational models. NoSQL databases are not entirely schemeless; instead, they often adopt an implicit schema that emerges from the structure of inserted data over time. While relational databases enforce an explicit schema at the table and field level, systems like MongoDB allow flexible data modeling without predefined structures. In practice, developers typically follow an internal or code-level data model, even if it is not enforced by the database15. Thus, the difference in schema handling between relational and NoSQL databases lies on a spectrum of flexibility rather than a strict dichotomy. Consequently, the use of NoSQL databases, particularly document-oriented models, serves as a data storage approach for eCRFs, storing data in the form of documents (such as JSON or XML) that offer high flexibility in managing complex and variable data. A related study demonstrated PostgreSQL’s ability to support complex data environments through tools like ZomboDB, i2b2, and React-Admin. However, this architecture, while powerful, requires advanced technical skills and custom development. Additionally, the PostgREST Data Provider is tightly coupled with PostgREST due to its specific filters and features16,17. Thus, while PostgreSQL can replicate many NoSQL capabilities, choosing between it and document-based systems like MongoDB should be based on project requirements, performance expectations, development ease, and operational costs.
Traditional relational database management systems (RDBMS) have historically faced challenges in managing diverse and evolving data structures, particularly in scenarios requiring high flexibility, such as electronic case report forms (eCRFs) used in vaccine adverse event studies. This is because relational databases enforce rigid schemas that necessitate predefined structures, making it difficult to accommodate dynamically changing attributes and unstructured data. However, modern relational DBMSs, particularly PostgreSQL, have addressed some of these limitations through JSONB support, which enables semi-structured data storage and querying, allowing for more schema flexibility. Additionally, PostgreSQL offers advanced indexing and optimization techniques that enhance query performance. Furthermore, modular extensions like ZomboDB integrate PostgreSQL with Elasticsearch, providing full-text search capabilities that improve data retrieval efficiency16,18. These advancements demonstrate that relational databases have evolved to support more flexible data models.
A key difference between relational and document-based NoSQL databases is their approach to data structure enforcement. Relational databases require explicit, predefined schemas, meaning that any structural changes necessitate schema modifications, which can be complex and time-consuming. NoSQL databases, such as MongoDB, offer a more flexible approach by allowing documents with varying structures to coexist within the same collection. However, this does not mean NoSQL databases are entirely “schema-free.” Instead, they follow a “flexible schema” model, where structure is not strictly enforced by the database but is often maintained through application-level conventions19. MongoDB, for instance, acknowledges the presence of “implicit schemas”, where documents generally follow a predictable format to ensure data consistency across an application19.
While this flexibility makes NoSQL databases well-suited for applications with evolving data models—such as electronic case report forms (eCRFs) in vaccine studies—best practices in NoSQL schema design often encourage some level of structural consistency to facilitate querying and indexing. Thus, rather than a binary distinction between “strict” and “schema-less” databases, it is more accurate to view schema enforcement as a spectrum, where relational databases offer rigid enforcement, NoSQL databases allow flexible structures, and real-world implementations often balance structure with adaptability.
Despite these improvements, NoSQL document-based databases remain particularly advantageous for use cases like eCRFs, where data structures frequently change, and strict schemas can hinder adaptability. Unlike relational databases that still require schema updates for structural modifications, document-based NoSQL systems such as MongoDB inherently support schema evolution, allowing attributes to be added or modified without affecting existing records. Additionally, NoSQL databases optimize storage for hierarchical and nested data, reducing the need for complex joins and improving query efficiency. Given the unpredictable nature of vaccine adverse effects and the necessity for a scalable, adaptable reporting system, a document-oriented NoSQL model provides a more natural fit for the eCRF system developed in this study.
Regarding this fact that adverse effects of vaccines may change over time, the presented NoSQL document-based eCRF aims to resolve the defect of conventional eCRFs that are based on the structured (i.e., the Relational) data model and provide a better support of schema evolution. Unlike traditional relational databases that enforce strict schemas, NoSQL databases such as MongoDB supports schema evolution through flexible document structures. Each document within a collection can have a different structure, allowing new attributes to be introduced without requiring schema migrations, without affecting existing records or downtime.
Data storage structure
The next step will focus on developing the system based on the first three steps of the architecture. Initially, the structure of the repository was implemented by examining each of the entities and their required data, utilizing a storage approach in the form of JSON documents. Although JSON originated from JavaScript, Node.js was not specifically built for storing data in JSON format. However, its JavaScript foundation makes it particularly efficient in handling JSON, similar to other languages like Python, which also manage JSON data effectively. IN this data model, the relationship between entities is established through references to information within the documents. In other words, each entity can establish its connections with other entities by specifying identifiers or shared data within the documents. This approach provides flexible connections and allows us to easily relate relevant information without the need to define complex relationships and intermediary tables. For example, in Fig. 3, the entity “User” is related to the entity “Access Levels,” such that each user can belong to one or more access levels (such as admin, disease specialist, etc.). In this case, a field like “accessibility” is created in the “User” document to store the identifiers of the access levels related to each user. Similarly, the entity “Health History” is related to the entity “Patient,” so that each health history belongs to a patient. In this case, we can create a field like “healthHistory” in the “Patient” document that refers to the identifier of the related health history. With this approach, the relationships between entities are established in a simple and understandable manner, allowing us to easily access related information from one entity to another.

Example of how to store user entity information in a document.
According to the sample document provided in Fig. 4, a unique identifier was created for each patient, which serves as the primary key in the database. This identifier allows us to store all patient information in a dedicated document and ensures that the patient’s information can be retrieved separately and accurately. Since the data is stored in a document-oriented manner, each document can include all relevant information about the patient, including medical history, demographic information, vaccination status, and side effects, without the need for complex and multi-table structures. Additionally, where necessary, we utilized MongoDB’s built-in validation capabilities based on JSON Schema to programmatically enforce and ensure the integrity of data structures.

Sample document for patient case report.
To enhance accuracy and improve communication, a unique user identifier (patient) is added to each document. This bidirectional connection allows us to retrieve patient information based on their identifier and manage the general information of system users. In the next section, the demographic information of the patient, including date of birth, gender, education level, employment status, economic status, place of residence, and contact information, is stored in the system. This information helps us identify the social and individual status of the patient. Additionally, information related to the patient’s health history, including chronic diseases, results of various tests (such as PCR tests), and allergies, has been recorded.
Vaccination and side effects data
The most important part of this model is the information related to vaccination and side effects. For each vaccine, details such as the name of the vaccine, the date of vaccination, the date of onset of side effects, the vaccine dose, the type of side effect, and the age of the patient at the time of vaccination are recorded. In addition, the patient’s health indicators, such as weight, height, body mass index (BMI), and specific conditions such as smoking status and pregnancy/menstrual status (for women) are also considered for a more thorough examination of reactions to vaccines.
The reason for collecting this information in a document-oriented data model is to enable us to systematically and accurately record and track all aspects of health and side effects related to each patient. By using this model, the data is stored in a completely disaggregated and interrelated manner, allowing us to thoroughly evaluate and analyze the vaccination process and its side effects. This approach not only facilitates the examination of individual reactions to vaccines but can also assist in identifying general patterns and side effects based on specific individual characteristics. This information will be highly beneficial for researchers, physicians, and health decision-makers, leading to improved quality of healthcare and vaccination at the community level.
Data access restrictions
In the implemented system,patients—whether self-registered or registered by authorized healthcare providers—are granted highly restricted access by default. Their permissions are limited primarily to submitting personal health-related reports or forms. For other user categories, such as healthcare providers with different roles, access levels are predefined based on the minimum necessary access principle. These restrictions are role-based and fixed, ensuring that each user can only access the information relevant to their responsibilities. Any modification to these access levels can only be carried out by the system administrator, ensuring that any changes are controlled, auditable, and aligned with security policies. This approach minimizes potential security risks by avoiding unnecessary access grants and maintaining strict role-based access control (RBAC) policies.
Develop system
After determining the storage approach and with the help of the initial design created using the Figma web application, the implementation of the user interface proceeded with the creation of pages and functionalities. In this context, the pages for user account creation, patient registration, and login were implemented as shown in (Appendix A Figs. 6, 7 and 8).
A login page was designed for both groups: healthcare providers and patients (Appendix A Fig. 6). If a patient has not previously registered, they or their companion can initiate the initial registration for self-reporting the incident and then enter the other required information. Otherwise, the patient can visit healthcare service centers and provide information to the healthcare provider to register and complete the incident reporting process (Appendix A Fig. 7). For healthcare providers, in addition to the registration process, the site administrator is responsible for enforcing access restrictions for each user based on their respective roles (Appendix A Fig. 8). Furthermore, by applying restrictions on data entry in each of the designed fields, such as the character length of the national ID, allowed characters, and verification of entered numbers, we aimed to prevent the entry of incorrect data by issuing warnings with appropriate messages.
Then, the main page was implemented for all users to manage the system and access the features designated for each role, as shown in (Appendix A Fig. 9). In addition, capabilities for providing quick statistical reports have been created for all service providers.
(Appendix A Fig. 10) is a page where users will encounter a list of registered patients within their area of activity. They will have access to a search filter for quick patient searches using national ID numbers, first names, and last names. If a patient’s registration has been left incomplete, it will be clearly marked as “incomplete” in the list. For each patient in the list, a button will be displayed to continue the patient’s registration. To enhance the speed of the workflow, features such as deleting a patient, editing demographic information, recording vaccine side effects, and registering/editing the patient’s history have been included, taking into account the limitations of each role.
When the user proceeds to enter the patient’s additional information and subsequently the individual’s health history, a new vaccine side effects report page is generated with a unique global identifier. By directing the user to this page, relevant information regarding vaccine side effects can be recorded (Appendix A Fig. 11). Additionally, to prevent the entry of incorrect data for the vaccination date and the date of the side effect, these dates will be reviewed to ensure that the vaccination date is not after the date of the side effect. Furthermore, vaccine doses will be limited and checked to avoid the entry of incorrect or duplicate doses. The Body Mass Index (BMI) will be calculated based on specified height and weight values, which have defined ranges. If a side effect is being recorded for the second time, these values will be automatically retrieved from the previous report form. Finally, the options for pregnancy status and menstrual cycle status for women will not be displayed to men.
Reporting module and access filtering
One of the important components of the reporting system is the ability to generate reports from the entered data in a completely flexible manner for customization with the created filters for reporting to stakeholders. These reports are generated based on the complex command capabilities provided by the key features of document-based databases. (Appendix A Fig. 12) displays various sections of the created filters that users can apply to generate their reports. However, by default, additional filters will be applied to maintain the confidentiality of patient records and control user access based on their roles compared to their colleagues, which will result in reports being generated by the name of the village, health center, county, and province.
The final output will be a PDF file corresponding to (Appendix A Fig. 13), generated with the applied filters for the report. These reports will be archived as a list and will be accessible separately for each healthcare provider on the user’s dashboard.
Development tools and framework
The system was developed entirely using Visual Studio Code version 1.85.0 and the Node.js programming language version 18.15.0, which is a compatible, comprehensive, and efficient language aimed at storing data in JSON format. Additionally, to store diverse data related to the variant strains of the virus concerning vaccine side effect reports, a document-based data model provided by the MongoDB database management system was utilized. In order to establish connections and send the received data to the repository and perform related operations, we employed the mongoose module version 6.6.2 in the system design. This research utilized various modules such as axios, bcryptjs, express-session, and other tools for system development. The use of these tools was aimed at ensuring security, managing complex data, processing forms, displaying statistics, generating reports, and performing necessary operations.
Analysis and evaluation of the proposed eCRF system
Essentially, evaluation of a software is the third step on the software development process in Software engineering methodology after the steps requirement engineering, and development (i.e., design and implementation), In this section, as the next step, a comprehensive evaluation and analysis in terms of different important quality attributes (i.e., non-functional requirements) of the proposed eCRF system as a software system is presented.
phase IV: Evaluation
Evaluation of a software system is known as a Verification and Validation (a.k.a. V&V) process. Evaluation of the proposed eCRF system as a software system is also performed both as the verification (i.e., w.r.t. the system’s requirements) and validation (i.e., users’ experience evaluation) as reported and discussed here.
User experience evaluation using the UEQ
The evaluation of the software is conducted using usability testing methods, based on standards and criteria from the User Experience Questionnaire (UEQ), which is utilized in this study to collect empirical data regarding participants’ perceptions and to compare their experiences in order to examine aspects of classical usability and user experience in the reporting system. Participants were experts in medical Informatics and related disciplines (they were not patients; so no patient information gathering happened during this study). The UEQ measures six dimensions of user experience, which include: attractiveness, clarity, efficiency, reliability, stimulation, and novelty20. The total number of attributes present in each of these dimensions in the UEQ reaches 26 pairs of opposing attributes designed to capture various aspects of user experience. These dimensions are assessed using bipolar adjectives, such as “attractive” versus “unattractive” or “stimulating” versus “boring,” on a scale from 1 (completely disagree) to 7 (completely agree). The tool was prepared in Google Forms, converted, and distributed among a group of users who have utilized the reporting system. Participants in this research completed the questionnaire based on a seven-point Likert scale. The scores for each of the six scales were averaged and compared using a standard metric, and charts were created to visualize the results. The sample for the study was recruited through purposive sampling, freely and easily accessible at Mazandaran University of Medical Sciences (Sari County Health Center), to evaluate the usability from the participants’ perspective. The data obtained from the UEQ were then analyzed to determine the average evaluations for each scale. The averages presented for each scale reflect the degree of users’ evaluations in that specific domain. The findings were obtained through the completion of questionnaires, in which each scale of user experience was assigned a weight. This weighting was based on a scale from − 3 (very bad) to + 3 (excellent), indicating the acceptance and popularity of each user experience scale with the reporting system in question.
Performance comparison between relational and non-relational data models
In the subsequent evaluation, the performance of two data models, SQL and NoSQL, was compared using the document-based data model provided by the MongoDB database management system and the relational data model provided by SQL Server 2019 (v15.0.2000.5). To evaluate changes in system performance, insertion operations were repeatedly executed with different batch sizes of 100, 1,000, 10,000, and 25,000 record. These datasets were inserted into each database to measure the insertion speed and the response time to the generated queries. Additionally, resets were performed between tests to clear caches, as recommended in22, ensuring accurate and consistent benchmarking result. Direct SQL queries were used to access the SQL Server database. Initially, data were read from a CSV file using the BULK INSERT command, and then inserted directly into the SQL Server database through SQL statements. This approach relies on raw SQL queries for data operations rather than using an Object-Relational Mapping (ORM) tool such as SQLAlchemy or Django ORM. While using an ORM simplifies database management by abstracting much of the underlying complexity, it’s crucial to monitor performance and apply direct optimizations, when necessary, as this abstraction can sometimes result in inefficiencies without fine-tuning. To generate the necessary data, considering the existing limitations and the lack of connection to electronic health records, and consequently the unavailability of data related to individuals’ identities, health histories, and their allergic reactions post-vaccination, data was produced with the help of the site mockaroo.com.
Benchmark environment configurations and results
Benchmarking was performed on a machine running Microsoft Windows 10 Enterprise, Version 22H2 (OS Build 19045.5487). Both the benchmarking client and the database server were installed and executed on the same machine, with no external client involved. The execution was done sequentially, without multi-client parallel execution. This configuration ensured that any performance differences were a result of the data models themselves and not influenced by external factors such as network latency or client-side processing.
This research examines a system for reporting vaccine side effects based on the data model of the sender. The main goal of designing the system is to accurately collect data related to vaccine side effects, reduce data entry errors, and enable rapid adaptation to informational changes resulting from virus mutations. The proposed system includes the following modules:
-
Information and Side Effects Collection: The ability for users to register identity information, health history, and vaccine side effects.
-
Document Management: Utilizing the JSON format for data storage and management to provide flexibility and reduce storage complexities.
-
Report Generation: The ability to extract data for research analysis and a more detailed examination of vaccine side effects.
Analysis of needs assessment and planning
Details of the methods and results of the literature review, as well as the process of selecting and validating features, had been previously published12. This research collected system requirements using three methods: observation, reflection, and questionnaires. During this phase, similar systems such as the Integrated Health System (Sib), Electronic Record of Health Events and Referrals(Parsa), Health Information Software (Nab), and the Research System on COVID-19 Vaccine Adverse Effects in Kermanshah were examined and studied. Functional and non-functional requirements were categorized in standard SRS tables. Using eCRF standards and background studies, the minimum necessary dataset was identified, including demographic information, health history, and details of vaccine adverse effects.
Identification and validation of functional system features
Based on expert opinions, 36 relevant features out of 48 were approved. These features include: vaccine name, injection date, date of adverse effect occurrence, type of adverse effect, dose, history of vaccine reaction, smoking history, chronic disease history, history of COVID-19 infection, pregnancy status, menstrual status, employment status, emergency contact number, mobile phone number, telephone number, national ID, age, weight, height, BMI, gender, and date of birth. Management of staff accounts, management of patient accounts, management of service provider centers, management of case report forms, management of vaccines, management of health history, access restrictions, search functions, numerical and graphical indicators, report generation with applied filters, alerts, information retrieval, and setting target ranges.
Comparison of similar platforms and their reporting limitations
The systems SIB, Parsa, and NAB were created as web-based platforms, but the research system in Kermanshah was used with a desktop application designed for offline use. As a result, the identity information of individuals was not verified. Additionally, there was no self-reporting capability for patients or a registration feature for health caregivers, who were directly involved and received the most reports of vaccine side effects. There were also limitations in access for experts to the entered data and in generating reports. Users were unable to correct the entered data, and this capability was only available to managers in higher domains. However, the ability to enter identity information, medical history, and vaccine side effects was granted to users. In the Parsa and SIB systems, health caregivers (Behvarz) were able to report vaccine side effects like disease experts. However, they were not given the ability to access, generate reports, edit, or delete recorded side effects within their covered population; these actions could only be performed by higher-level experts from health treatment centers. Nevertheless, they were not granted the ability to delete or edit, and only an individual at the county level had access to these capabilities.
System services, stakeholders, and design assumptions
In describing the case reporting system, the services and stakeholders of the system, as well as the identified limitations and assumptions, are initially outlined. The services of the system are categorized into six groups: creating user accounts, registering patients, creating case report forms, reporting, managing users, and recording vaccine side effects. The stakeholders of the system include patients, health caregivers (such as health workers and disease specialists), executive managers, EHR systems, laboratory research, and pharmaceutical companies. The existing limitations in the design of the system include the lack of access to electronic health records, electronic medical records, the civil registration system, and mobile operator systems for retrieving patient information and verifying their identities. It is assumed that if the case reporting system is developed, these accesses will be provided.
Discrepancies
One of the important aspects of the system that was considered by the design team during the needs assessment was the focus on error detection and improving the quality of input data. To this end, a system was designed that included forms with defined fields and precise validation. For example:
-
The fields for height, weight, age, BMI, and number of vaccine injections had data entry restrictions to ensure that only logical and valid values were accepted.
-
The vaccination date cannot be recorded after the date of the adverse event.
-
Options related to pregnancy status and menstrual cycle status were designed to be displayed only for the female gender, while these fields were disabled for males.
-
The fields for contact number and national ID had character length restrictions and character type restrictions (numeric only), and entering this information was essential for completing the form.
-
The fields for first name and last name accepted only permitted characters and prevented the entry of unauthorized characters.
These measures not only helped reduce errors caused by incorrect data entry but also increased the assurance of data accuracy throughout the system. Additionally, this design aimed to simplify data entry for users and prevent mistakes in later stages of data development and analysis.
Moreover, “Vaccine Adverse Events” section which includes a list of common and predictable adverse events is addressed. Users can select one or more of these adverse events through dedicated checkboxes. However, if an adverse event occurs outside the list of anticipated adverse events, the user can access a text field specifically for recording uncommon adverse events by selecting the “Other” option. Also, to facilitate the recording of multiple unforeseen adverse events, this field has been designed so that the user can enter each adverse event and record it as an independent tag by pressing the Tab key. This feature allows for accurate and systematic separation of uncommon adverse events and helps increase flexibility in collecting diverse and unstructured data.
Usability evaluation
During the research evaluation phase, a test scenario was implemented in the reporting system. Valuable feedback and suggestions for system improvement were provided by users in a brainstorming session. Among the suggestions were the removal or insensitivity to the completion of proxy fields, postal codes, and patients’ heights. Subsequently, the electronic reporting system was tested in a usability evaluation by healthcare providers and individuals experiencing vaccine-related complications. Out of 19 participants (Table 1.) who worked with the system for 10 days during this evaluation, 12 were female and 7 were male. Additionally, among all participants, 2 were aged between 18 and 25 years (2/19, 10.5%) and 17 were over 25 years old (17/19, 89.5%).
Results of user experience evaluation
The analysis of the responses showed that the average score for all scales ranged from 1.5 to 3 (Table 2). Specifically, the average scores were 2.2 for attractiveness, 2.6 for clarity, 2.4 for efficiency, 2.5 for reliability, 2.3 for motivation, and 1.9 for innovation.
Table 2 categorizes the interests of users of the case reporting system based on pragmatic quality (transparency, efficiency, reliability) and hedonic quality (motivation and innovation), showing that the highest median relates to transparency (2.56) and the lowest to innovation (1.94). Respondents’ answers regarding reliability indicate that the case reporting system is simple and trustworthy. It also provides guaranteed results and is very useful for real-time sharing. Despite the transparency rating (2.56), after using the case reporting system, users felt that the concept of the requested data was clear during use, and after one training session on how to operate the system, there was no further need for training or guidance. This indicates that a user can easily perform the necessary operations after a break in using the system by simply restarting their work with it. This is because, during the design of this system, efforts were made to ensure that features and modules were arranged simply and clearly, with many explanations provided in alerts, especially when entering incorrect or out-of-range data.
In contrast, the lowest median related to innovation is due to the study’s objective, which was to utilize the document-based data model and replace it with older data models that seemingly did not differ much from similar systems in this field. As a result, the advantages of using this model were not tangible for users. Meanwhile, other capabilities, such as generating reports with appropriate filters, producing report outputs in PDF format, and self-reporting for patients, appeared to be the most prominent features from the participants’ perspective in this scale.
The results obtained from the evaluation of the reporting system were compared with a reference dataset from previous studies (Fig. 5). This reference dataset includes information collected from approximately 21,000 individuals across 468 different studies on various products. This comparison allowed for conclusions to be drawn regarding the relative quality of the evaluated reporting system in comparison to other products. Scores for each scale were provided for awareness, as we aimed for this system to offer transparency and clarity to users as much as possible. Our goal was to design it to be user-friendly by reducing complexity and using appropriate colors, so that, while being simple, the time spent on processes would be minimized. Additionally, many explanations were provided, along with alerts for incorrect and out-of-range data entries. One of the reasons for the high reliability assessment for healthcare providers could be the ability to view and access data online and instantly, with access restrictions and hidden views based on each individual’s role and job category. This allowed them to track vaccination follow-ups in the event of serious adverse occurrences by reviewing and analyzing the obtained data and to immediately implement their intervention policies. Typically, only senior management had the capability to view the reports.
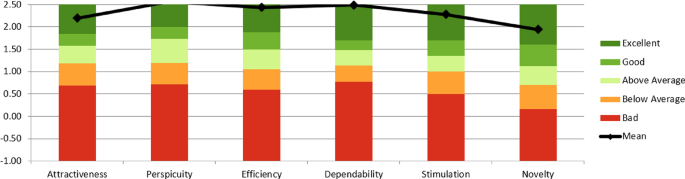
Comparison of reporting system measurements with previous studies.
Security assessment
In order to evaluate the risk level of the vulnerability of the reporting system, a checklist for the security of the reporting system was provided to a developer with 18 years of experience in web system development(see Appendix B Table 5). They were asked to assess the components by reviewing the system’s code and working with the system. Based on the review conducted using the checklist in accordance with the ASVS standard, it is determined that the created system is generally compliant with the required security standards. This system meets the needs of the ASVS standard not only in terms of stability and optimal performance but also in terms of protecting information and privacy. Therefore, it can be concluded that the system operates at an acceptable level of security and can serve as a standard foundation for future projects.
Security assessment of the system using the asvs standard
In order to assess the risk level of the vulnerability of the reporting system, the Application Security Verification Standard (ASVS) has been utilized, which serves as the basis for the initial plan to create a secure coding checklist specific to the system. This open-source standard was first introduced21 and has since been developed and made available to the public with the collaboration of contributors for updated versions. Therefore, aligning ASVS with the product enhances the focus on the security requirements that are important for the reporting system21.
Evaluating the efficiency of the document-based data model
In this study, the performance of the MongoDB database system was evaluated in comparison to SQL Server by performing two main operations, insertion and search, with a large number of records. The specified operations were carried out in both databases, and the results were displayed through charts based on the data obtained from insertion and search.
-
Insertion operation: In analyzing the results obtained from the insertion operation, it was clearly evident that for data with identical fields and simple insertion operations, SQL Server required more time compared to MongoDB. As shown in (Appendix A Fig. 14), this cost becomes significantly more pronounced with an increase in the number of records. This cost in SQL Server is due to its relational structure and database transactions, which typically introduce the most complexity during insertion operations. In contrast, while the insertion time in MongoDB increases with the number of records, the pattern of this increase is much more proportional to the number of records, indicating potential performance improvement.
-
Search operations: In search operations, both SQL Server and MongoDB behave similarly, with the execution time of search operations increasing as the number of records grows. This indicates that both databases face challenges with increasing data volumes, leading to longer execution times for operations. However, despite this similarity, there are also differences in the speed of search operations between these two databases, as shown in the chart in (Appendix A Fig. 15). In MongoDB, due to its NoSQL structure and the use of indexes, search operations can be optimized on a larger scale and may perform better than in SQL Server. These results and differences are crucial for selecting the most suitable database for any specific project or scenario.
We therefore emphasize that both SQL and NoSQL DBMS were evaluated using default settings without specific hardware optimizations. No explicit caching mechanisms beyond the DBMS’s native caching behavior were employed. The use of optimizers could have influenced the final outcome of the database performance evaluation process. However, implementing such enhancements requires additional research processes, which have been extensively addressed in other studies. Therefore, in this study, we utilized only a primary key for both databases, aiming to assess insertion and query speed under equal conditions and without performance-enhancing mechanisms. Although indexing could potentially improve query response times in relational DBMSs, it would, on the other hand, reduce insertion speed due to the overhead of updating indexes with each insertion. Searches were performed using the standard query capabilities of both MongoDB and SQL, without employing advanced full-text search features like n-grams or Okapi BM25. Future evaluations may include these algorithms to further optimize search performance.
Supporting quality attributes of the presented eCRF
Each software system should provide the application-dependent functionalities and services, and a proper level of quality attributes (e.g., performance, scalability, usability, availability, security, maintainability, etc.). Some of such quality attributes which seems to be more important for the presented system to be applicable, are addressed here.
Performance
Longitudinal studies where patient records evolve (such as the Cohort studies) is important for scientists, pharmaceutical companies and governmental bodies. The NoSQL document-based model inherently and effectively supports longitudinal studies as documents can be updated dynamically to accommodate evolving patient records without rigid schema constraints as well as data tracking support by allowing nested documents and array structures for storing patient follow-ups. Also, version control mechanisms in eCRF software ensure that changes in patient data over time are retained without overwriting historical records. The system utilizes timestamps and metadata tagging to facilitate temporal queries and trend analysis across different time points.
Case study example: Consider a study tracking COVID-19 vaccine adverse effects over two years. A patient may receive multiple vaccine doses, each potentially leading to different side effects over time. Using a document-based model: Each patient record is stored as a single document, where adverse event data can be added dynamically under a “sideEffects” array. Time-stamped updates allow retrieval of patient history at different points in time.
Instead of requiring multiple relational tables and complex JOIN queries, a single query can fetch the patient’s full vaccination history and side effects. This structure allows researchers to track long-term effects, analyze trends, and perform predictive modeling based on evolving data. Version control mechanisms ensure that changes in patient data over time are retained without overwriting historical records. The system utilizes timestamps and metadata tagging to facilitate temporal queries and trend analysis across different time points.
Performance is definitely an important issue especially in studies with huge amount of data (e.g., longitudinal studies throughout a country or continent). In our implementation, the SQL database was accessed using direct SQL queries rather than an Object-Relational Mapping (ORM) framework. This decision was made to optimize performance and maintain precise control over query execution, particularly for complex queries involving multiple joins and indexing strategies. Given the document-based NoSQL model used in the presented eCRF (MongoDB as the database engine or datastore), indexing and retrieval speed have been addressed through the following mechanisms:
-
Use of the compound and dynamic indexing: The system employs compound indexes on frequently queried fields such as patient ID, vaccine type, date of report, and adverse event category. In addition, dynamic indexing is applied based on user queries to optimize search performance.
-
Schema-less flexibility with optimized access paths: Since the data model is document-based (e.g., JSON/BSON documents), the system can efficiently retrieve nested or unstructured data without requiring costly joins or schema validations, which improves speed especially for heterogeneous case report forms.
-
Sharding for scalability.
Scalability
To handle the huge amount of data (e.g., millions of case reports) and scale the system in size, horizontal Scalability (i.e., scaling out) via Sharding (built-in mechanism in MongoDB) could be used in deployment of the presented eCRF. Sharding allows data to be distributed across multiple servers, enabling parallel read and write operations that significantly reduce latency in large-scale datasets. Also, load balancing strategies such as read and write separation (e.g., directing read queries to secondary nodes) are employed to optimize system performance.
A shard key is chosen to evenly distribute data (e.g., patient ID, timestamp). Shard clusters consist of multiple nodes, each responsible for a subset of the data. The Mongos query router directs queries to the appropriate shard, ensuring optimal retrieval performance. Automatic balancing mechanisms redistribute data as new nodes are added, preventing bottlenecks.
Moreover, replication is used to ensure high Availability and disaster recovery.
Security analysis
Security is critical, especially for clinical data management. While ensuring full compliance with HIPAA, GDPR, and other clinical data protection regulations was not the primary focus in the prototype development phase, we have incorporated several privacy and security measures. However, we acknowledge that certain areas require enhancement, particularly in data encryption at rest and multi-factor authentication. The following table provides an illustrative overview of the system’s current security features and areas for improvement (Table 3).
Discussion and principal findings
The software introduced in this study is web-based and utilizes a document-based data model for data storage. This web application, in addition to leveraging the advantages of document-based data models such as high search and insertion speeds, and consequently faster response times to user requests compared to relational data models, can facilitate patient registration, manage data access for users, reduce the entry of erroneous data such as height, weight, and permissible age range, and prevent the use of invalid characters during registration. It also allows for patient self-reporting for registration and reporting vaccine side effects, user management, management of case report forms, automatic calculation of body mass index, identification and prevention of duplicate dose entries, recognition of non-compliance with injection dates relative to the date of vaccine reaction, generation of customized reports with access restrictions defined for each role, and reduction of costs associated with system updates considering potential unforeseen vaccine side effects and its practical adaptation for conducting other pharmaceutical studies.
Unlike other vaccine adverse event reporting systems in Iran, this system has been designed and implemented using case report forms and a document-based data model to reduce the costs of system updates and to adapt it for conducting drug adverse event research.
Trust in vaccines is vital and fundamentally depends on the ability of governments to communicate the benefits of vaccination and to provide vaccines that are safe and effective23. Therefore, in order to inform and classify these events, individuals are asked to report any adverse effects they experience after vaccination in a system or through CRF forms24. The case reporting system has been implemented in such a way that stakeholders in government organizations can easily track the safety of vaccines used nationwide, with accessible registration for everyone and ease of reporting even mild adverse events, allowing for self-registration and self-reporting by the general public. In the research by Rouri and colleagues, the need for examining and designing electronic case report forms (eCRF) and collecting electronic data, particularly in pharmaceuticals and clinical research, has been addressed25. Their findings highlight the importance of tailored eCRF design to ensure data quality and emphasize the challenges of integrating such systems into existing research infrastructures.
In designing the electronic case report form, attention must be paid to the importance of data integrity and responsiveness to all user needs. These users may include researchers, site coordinators, study monitors, data entry personnel, medical coders, and standard statisticians26. Therefore, data should be organized in a format that facilitates easy and straightforward data analysis26. The capability for data integration in this research is provided through the use of a document-based data model, focusing on storing all input data of an individual in a document with a unique identifier. In the research by Youn and colleagues, the need for a medical research framework based on a NoSQL DBMS was proposed27. Consequently, the use of the document-based data model was employed in the final product of this research, following an examination and comparison of various approaches in NoSQL data models and the observed advantages of the document-based model, aligning it with the nature of case report forms and considering the potential unknown side effects of vaccines.
In the study by N-Lordache, it was noted that by utilizing the electronic case report form, more accurate data could be collected while ensuring the privacy of patients. This approach is also expected to lead to reduced costs, increased efficiency and accuracy in data collection, and further support the protection of patient privacy9. The findings of these researchers confirm similar capabilities that have been designed and implemented in the case reporting system developed from this research.
In the implemented system, patients (whether self-registered or registered by authorized healthcare providers) are granted highly restricted access by default. Their permissions are limited primarily to submitting personal health-related reports or forms.
In contrast, access levels for other user categories (i.e., healthcare providers with different roles) are predefined based on the minimum necessary access principle. These restrictions are role-based and fixed, ensuring that users can only access the information relevant to their responsibilities.
Any modification to these access levels can only be carried out by the system administrator, ensuring controlled and auditable changes in user privileges. This approach mitigates potential security risks by avoiding unnecessary access grants and maintaining strict role-based access control (RBAC) policies.
To have a more thorough comparison of the presented eCRF with existing structured, and hybrid eCRF systems, HL7 or FHIR28-based solutions, some major aspect and features should be addressed (Table 4).
NoSQL approaches provide flexibility in data management compared to the conventional structured data model; whilst FHIR-based solutions offer interoperability benefits but introduce complexity in implementation and require predefined schemas, which are less suited for highly variable datasets like vaccine adverse event reporting.
According to the table, it can be summarized that:
-
Structured SQL-Based eCRFs: Best for traditional, well-structured clinical trials but struggles with flexibility and schema evolution.
-
Hybrid SQL + NoSQL eCRFs: Offers a balance between structure and flexibility but increases complexity.
-
Proposed NoSQL eCRF: Excels in handling unstructured and variable data, making it ideal for adverse event tracking and evolving clinical research.
-
FHIR-Based eCRF: Optimized for modern interoperability but requires learning the FHIR standard.
-
HL7-Based eCRF: Works well for legacy healthcare integration but lacks flexibility and real-time capabilities.
The limitations of this research include the lack of access to electronic health records, hospital electronic records, and laboratory electronic systems for retrieving the health history of individuals in the community. Additionally, the absence of a requirement for the initial registration of individuals who have prior health, medical, or laboratory information in existing electronic records is noted as one of the primary interactive limitations with other available systems. Furthermore, the lack of access to SMS service provider systems and the civil registration system to ensure the safety and verification of patients’ identity information during self-reporting is another interactive limitation that has been excluded from the implementation in the prototype product due to its financial burden. The inability to utilize the case reporting system to create user profiles and input necessary information for those individuals in the community who have minimal literacy with computer systems and the internet is also considered a limitation of the system.
One of the key advantages of the presented NoSQL eCRF system is its schema flexibility, allowing seamless adaptation to evolving clinical trial requirements. However, we recognize that a lack of predefined schema may present onboarding challenges for new developers.
The most significant strength of this research lies in the design and implementation of an efficient reporting system accessible to everyone, anytime and anywhere, for recording vaccine side effects and generating reports for stakeholders. This aims to assess the safety of vaccines used in the country and assist in reducing the costs associated with changes in the system, while considering the potential for reuse in other clinical studies related to drug side effects and the possible need for system updates in light of emerging unknown vaccine side effects in new strains of the disease.
The flexibility to generalize the presented system to other vaccine studies or drug trials may be another concern. The presented system is designed with flexibility in mind, allowing it to be applied to other vaccine studies and drug trials. For example, the modular system architecture ensures that new variables, entities, and workflows can be incorporated with minimal disruption and effort. Moreover, NoSQL data model claim to be schema-free and they will easily support changes in needs; so, the NoSQL document-oriented database structure allows the storage of heterogeneous data types without predefined schemas and allows flexibility in capturing diverse data points, accommodating different study requirements without major redesigns. Therefore, by modifying the data collection and validation layers, the presented eCRF system can be easily generalized to accommodate other vaccine or pharmaceutical trials and studies. One of the use-cases and applications of eCRF systems, besides the approval of the drug or vaccine throughout the corresponding studies, is research in medical or public health fields by researcher and scientist. Emerging methods, techniques and tools in AI (e.g., ML/DL) has added up the need for such data gathering platforms. There is some references of such studies29,30,31,32,33,34,35.
Conclusion and future directions
In this research, the design and evaluation of a web-based adverse event reporting system was conducted to collect the minimum required dataset of vaccine-related adverse events for stakeholders. This system, like other similar systems, is not solely focused on the collection of vaccine adverse events; rather, it employs a document-based data model aimed at enhancing efficiency and response speed to user requests while reducing costs associated with reuse in similar clinical research for drug safety assessments. For the primary stakeholders of the system, it can effectively reduce data entry errors and generate reports with diverse filters. With the help of this practical system, users can register relevant adverse event information in the database without needing to visit in person. The level of satisfaction and usability of the designed reporting system in this research was evaluated as excellent. Although positive evaluation criteria were observed, the limited sample size does not allow for definitive conclusions to be drawn from the findings of this study. Therefore, to inform the design of clinical trials in this area, a deeper exploratory analysis of usability issues is required. It is also expected that, with an innovative approach to the document-based reporting system, a solution will emerge to reduce the costs of system reuse and increase the security and response speed for users identifying drug safety, leading to sustainable effects. Based on the findings of the present research, it is recommended that, considering the system’s need for patient identity information, capabilities for integration with electronic health record systems, electronic medical records, SMS services, mobile operators, and inquiries from the Civil Registration Organization be added to the reporting system in future studies.
The document-based data model in this system acts as an agile and flexible tool for collecting information from multiple sources. By utilizing this model, updated information is made continuously and readily available in real-time. Additionally, this system, when developed, facilitates the establishment of direct and two-way communications between data sources, enhancing responsiveness to changes and sudden events related to vaccine side effects.