Category: Uncategorized

MMS • Craig Risi

Zendesk has unveiled its new Foundation Interface, a unified platform designed to transform infrastructure provisioning into a fully self-service experience. This platform enables engineers to request infrastructure components, such as databases, object storage, compute resources, and secrets, by simply defining requirements in a declarative YAML file. These requests are then automatically validated, provisioned, and monitored through a seamless workflow integrated with Spinnaker and Kubernetes. The result is a major reduction in the time, friction, and uncertainty that previously accompanied infrastructure requests.
At the heart of this transformation lies a robust internal architecture that Zendesk engineers describe as a “genie and helpers” model. The Gatekeeper acts as the initial validator of requests, ensuring correct syntax, resource definitions, and permission scopes. Once approved, requests are routed to the Orchestrator, which breaks them down into Kubernetes-native constructs, specifically, Custom Resources (CRs). These CRs are then handled by domain-specific Kubernetes operators. The Watchdog component continuously monitors the state of these Custom Resources, ensuring all provisioning tasks succeed and signaling Spinnaker when it is safe to proceed with application deployments.
Kubernetes operators are central to this process. An operator is a software extension that uses Kubernetes APIs and the controller pattern to manage complex, stateful applications or infrastructure services.
Operators are typically implemented using controller frameworks such as the Operator SDK, Kubebuilder, or Metacontroller. These frameworks enable teams to define Custom Resource Definitions (CRDs) that extend the Kubernetes API to include new object types, for example, an Aurora Database or a Redis instance. Paired with each CRD is a controller loop that watches for changes to these resources and reconciles the desired state with the actual cluster state.
In practice, this means that when an engineer requests a database through the Foundation Interface, the corresponding operator provisions that database by interfacing with cloud provider APIs, applies configuration, and monitors for success or failure, all without human intervention.
This model ensures that each infrastructure component, be it S3 buckets, RDS instances, or more bespoke services, has a dedicated operator that knows how to provision, configure, and manage its lifecycle. Operators are designed to be idempotent, meaning they can safely reapply the desired state if conditions change, and they can handle edge cases or error recovery without manual intervention. The use of Kubernetes-native tools also means that Zendesk benefits from observability, auditability, and consistency across all provisioned resources.
By integrating this architecture with Spinnaker pipelines, Zendesk engineers can now deploy applications alongside their supporting infrastructure in a single, repeatable flow. The Foundation Interface ensures that infrastructure is provisioned securely and consistently, with automated checks and centralized tracking. Developers are no longer required to submit tickets or wait for manual approvals; they simply write a YAML file and trigger a deployment. The system handles everything else, from validation and resource creation to health checks and status reporting.
Darragh Kennedy, Director of Software Engineering at Zendesk, shared on LinkedIn that the journey toward a self-service infrastructure began years ago with the creation of the Foundation group. He highlighted how the team “built this from the ground up and iterated on it over the years to create a flexible and robust entry point”, underscoring the carefully engineered foundation behind the platform.
His post illustrates the long-term commitment and internal evolution leading to the current system:
“It seems like an age ago that we created the Zendesk Foundation group… we built this from the ground up and iterated on it over the years to create a flexible and robust entry point.”
This commentary reflects a deeper understanding of the engineering effort behind the Foundation Interface, emphasizing that it’s not a quick fix but a mature, iterative platform designed to scale with Zendesk’s engineering needs.
However, functionality like this is not unique to Zendesk. A recent example is Pulumi IDP, launched in May 2025. It offers a “golden path” through standardized infrastructure components and a private registry. This allows developers to consume reusable, policy‑approved configurations (in YAML) for provisioning infrastructure safely and efficiently. Unlike portal‑centric platforms, Pulumi IDP focuses tightly on infrastructure delivery patterns shaped and consumed via platform engineering practices.
The broader industry trend toward Internal Developer Platforms (IDPs) built on Kubernetes is gaining momentum. These platforms abstract Kubernetes complexity behind declarative interfaces and pre‑packaged workflows, enabling teams to self‑serve environments, deploy apps, and manage resources without needing to learn Kubernetes internals. Analysts highlight that success depends not only on technology but also on clear documentation, developer education, and strong platform governance Platform Engineering.
These parallels demonstrate that Zendesk’s choice to define infrastructure through YAML, validated via Kubernetes CustomResources and orchestrated through operators and pipelines, aligns closely with a growing movement. Organizations across sectors are adopting Kubernetes‑based self‑service platforms that abstract complexity, enforce policy, and promote developer productivity, just as Zendesk’s Foundation Interface aims to do.
Java News Roundup: JDK 25 in RDP2, Spring Framework, Payara Platform, Open Liberty, Eclipse DataGrid
MMS • Michael Redlich

This week’s Java roundup for July 14th, 2025, features news highlighting: JDK 25 in rampdown phase 2; the seventh milestone release of Spring Framework 7.0; the July 2025 editions of the Payara Platform, Open Liberty and Oracle Critical Patch Update; and Eclipse DataGrid is open-sourced.
OpenJDK
After its review had concluded, JEP 504, Remove the Applet API, was elevated from Proposed to Target to Targeted for JDK 26. This JEP proposes to remove the Applet API, deprecated in JDK 17, due its continued obsolescence since applets are no longer supported in web browsers.
Oracle has released versions 24.0.2, 21.0.8, 17.0.16, 11.0.28, and 8u462 of the JDK as part of the quarterly Critical Patch Update Advisory for July 2025. More details on this release may be found in the release notes for version 24.0.2, version 21.0.8, version 17.0.16, version 11.0.28 and version 8u461.
JDK 25
Build 32 of the JDK 25 early-access builds was made available this past week featuring updates from Build 31 that include fixes for various issues. Further details on this release may be found in the release notes.
As per the JDK 25 release schedule, Mark Reinhold, chief architect, Java Platform Group at Oracle, formally declared that JDK 25 has entered Rampdown Phase Two. This means that: no additional JEPs will be added for JDK 25; and there will be a focus on the P1 and P2 bugs which can be fixed via the Fix-Request Process. Late enhancements are still possible, with the Late-Enhancement Request Process, but Reinhold states that “the bar is now extraordinarily high.” The final set of 18 features for the GA release in March 2025 will include:
JDK 25 is designated to be the next long-term support (LTS) release following JDK 21, JDK 17, JDK 11 and JDK 8.
JDK 26
Build 7 of the JDK 26 early-access builds was also made available this past week featuring updates from Build 6 that include fixes for various issues. More details on this release may be found in the release notes.
GraalVM
The release of GraalVM for JDK 24 Community 24.0.2 features fixes based on the Oracle Critical Patch Update for July 2025. These include: use of the DWORD type for comparing search values in the AMD64ArrayIndexOfOp class; and a resolution to a Java UnsatisfiedLinkError, an error thrown if the JVM cannot find an appropriate native-language definition of a method declared as native, when using the JDK Flight Recorder. Further details on this release may be found in the release notes.
BellSoft
Concurrent with Oracle’s Critical Patch Update (CPU) for July 2025, BellSoft has released CPU patches for versions 21.0.7.0.1, 17.0.15.0.1, 11.0.27.0.1, 8u461, 7u471 and 6u471 of Liberica JDK, their downstream distribution of OpenJDK, to address this list of CVEs. In addition, Patch Set Update (PSU) versions 24.0.2, 21.0.8, 17.0.16, 11.0.28 and 8u461, containing CPU and non-critical fixes, have also been released.
Spring Framework
The seventh milestone release of Spring Framework 7.0.0 delivers bug fixes, improvements in documentation, dependency upgrades and new features such as: new dedicated @Retryable, @ConcurrencyLimit and @EnableResilientMethods annotations as part of the new Resiliency Features; a new JmsClient interface to provide common send and receive operations against a JMS destination; and a new HttpMessageConverters interface to build and configure an immutable collection of HttpMessageConverter instances for client or server usage. More details on this release may be found in the release notes.
Payara Platform
Payara has released their July 2025 edition of the Payara Platform that includes Community Edition 6.2025.7, Enterprise Edition 6.28.0 and Enterprise Edition 5.77.0. All three editions deliver: critical bug fixes, component upgrades and new features: improved Trino SQL query engine support for handling JDBC connections; and removal of the CDI Deve Mode that streamlines implementation of the Jakarta Context and Dependency Injection 4.1 specification resulting in reduced complexity and improved performance.
This edition also delivers Payara 7.2025.1.Alpha3 that advances support for Jakarta EE 11 with new features: removal of the X-Powered-By header for improved security; and a new bundle that supports all the Jakarta EE 11 XML Schemas.
Further details on these releases may be found in the release notes for Community Edition 6.2025.7 and Enterprise Edition 6.28.0 and Enterprise Edition 5.77.0.
Open Liberty
The release of Open Liberty 25.0.0.7 features extending the scope of the maxFiles parameter in Open Liberty’s access logging configuration that improves “log file cleanup and helps ensure that all matching log files in the output directory are considered, not just those generated by the current process.“
Helidon
The release of Helidon 4.2.4 delivers bug fixes, dependency upgrades and notable changes such as: migrate use of the deprecated GlobalConfig class and the overloaded global() method, defined in the Config interface, to the get() method defined in the Services class; and support for Gson to complement their existing media support for Jackson, Jakarta JSON Processing and Jakarta JSON Binding. More details on this release may be found in the release notes.
Eclipse Foundation
Microstream has announced that Eclipse DataGrid, a new project introduced at JCON Europe 2025, is now available as open-source. DataGrid is a merger of EclipseStore and the MicroStream Cluster that enables in-memory searching and complex in-memory data manipulation. Developers who would like to learn more can attend the Eclipse Data Grid Introduction: In-Memory Data Processing free virtual event on Tuesday, July 22, 2025.
Micrometer
The first milestone release of Micrometer Metrics 1.16.0 delivers bug fixes, improvements in documentation, dependency upgrades and new features such as: a new withNoneValue() method, defined in the KeyName interface, to create an instance of the KeyValue interface with no value; and the addition of new classes to support observability using Jakarta Mail that complements the existing functionality with Jakarta Messaging. Further details on this release may be found in the release notes.
The first milestone release of Micrometer Tracing 1.6.0 delivers dependency upgrades and new features such as: a migration of their nullability annotations to JSpecify; and support for extracting multiple values for a single key in the Propagator interface for compliance with the W3C baggage specifications. More details on this release may be found in the release notes.
Project Reactor
The fifth milestone release of Project Reactor 2025.0.0 provides dependency upgrades to reactor-core 3.8.0-M5, reactor-netty 1.3.0-M5, reactor-pool 1.2.0-M5, reactor-addons 3.6.0-RC3 and reactor-kotlin-extensions 1.3.0-RC2. Further details on this release may be found in the release notes.
Similarly, Project Reactor 2024.0.8, the eighth maintenance release, provides dependency upgrades to reactor-core 3.7.8 and reactor-netty 1.2.8. There was also a realignment to version 2024.0.8 with the reactor-pool 1.1.3, reactor-addons 3.5.2, reactor-kotlin-extensions 1.2.3 and reactor-kafka 1.3.23 artifacts that remain unchanged. Further details on this release may be found in the release notes.
MMS • Teena Idnani

Transcript
Olimpiu Pop: Hello, everybody. I’m Olimpiu Pop. And I’m an InfoQ editor. And today I have in front of me Teena Idnani, the first keynote speaker from Dev Summit Munich and one of the speakers from this year’s QCon. She accomplished many amazing things. But without further ado, I’ll have to ask Teena to introduce herself. Teena, please.
Teena Idnani: Yes. Hi, Olimpiu. Thank you for having me. I am delighted to be here. And as an introduction, I’m a senior solution architect at Microsoft. I help organizations with their digital transformation journey, helping them design scalable cloud-native architectures. Before joining Microsoft, I worked at JP Morgan Chase, where I assisted the bank with setting up its Azure platform as part of its multi-cloud strategy.
Beyond my day-to-day work, I’m passionate about quantum computing and its potential applications, particularly in finance. I also actively mentor aspiring technologists, with a focus on supporting women in the tech industry. And, as you mentioned, I recently had the fantastic opportunity to share some insights into multi-cloud event-driven architecture at QCon 2025, which took place in April. I’m very excited to discuss the topic further with you here. But before we dive in, I want to mention that all thoughts and opinions that I’ll be sharing today are my own and don’t represent my employer’s views.
The Benefits of Event-Driven Architecture [01:54]
Olimpiu Pop: Okay, great. Thank you, Teena. So I was thinking about your presentation at QCon, and you had that scary diagram, those boxes, and it was unbelievable. And then it’s fascinating that, these days, we are discussing, even in the banking ecosystem, which was traditionally more conservative, the concept of multi-cloud and various layers of services that you’ll have, and probably on-premises as well. The important stuff that you don’t want to go out and then you have on different types of clouds, various services. And what are the key points that people should have in mind when looking into this kind of transformation, when you’re discussing multi-cloud in an ecosystem as complicated as the banking ecosystem?
Teena Idnani: Let’s discuss event-driven architecture, and then we’ll incorporate the multi-cloud aspect. At its core, event-driven architecture is a design paradigm that involves the production, detection, consumption, and even reaction to events. That’s what drives the system. And I remember the scary complex diagram, which I showed, in which there were hundreds of interconnected components which were distributed, and we are talking about that complexity. Event-driven programming is all about making these distributed components loosely coupled and enabling them to react to events. And that’s driving the system. For example, if you use an e-commerce platform, when a customer places an order, it generates an order-created event. That event contains all the necessary information, and the metadata may include the customer ID, product details, shipping address, and payment information.
But here is where it gets interesting: that single action that the customer did to place the order basically triggers a cascade of other events. For example, the payment system generates a payment process event, the inventory system creates an inventory reserved event, and the shipping system might generate, maybe, a shipping label created event. Now, each of these systems does not directly know the other. They’re just reacting to events that they care about, which means that you can have hundreds and thousands of interconnected components. Still, you don’t have to worry about them when you’re talking about event-driven, because the individual systems do not need to know about others directly. They’re just reacting to the events that they care about. So that’s what simplifies it. And what makes these event-driven architectures powerful is how they enable these loosely coupled systems.
Unlike when you talk about traditional request-response patterns, where services directly call each other. In an event-driven model, these components communicate by publishing and subscribing to events. This event-driven approach offers numerous advantages. And yes, there are a lot of considerations as well that you need to take care of. First, if I discuss the benefits, it provides exceptional scalability because your components can be scaled independently.
Event-Driven in Multi-Cloud [05:11]
Additionally, it enhances resilience. So, for example, if one component fails, others can continue operating. And most importantly, it enables that real-time responsiveness because your events are processed as they occur. Now, if you bring the multi-cloud flavor to it, what happens is that in a multi-cloud, you are not just talking about different services which are there in a particular system, but now you are also talking about extending those services to various cloud providers.
And that’s when it becomes essential to have some strategic considerations when companies are doing these multi-cloud transformations. For example, if you’re talking about the architecture and design, then you need to design for portability from the start. Use containerization, use microservices. When you’re building your APIs, you must be building cloud-agnostic APIs so that you avoid a deep vendor lock-in. Data is imperative when it crosses event boundaries. So you need to plan for data synchronization and consistency across clouds. And then the foundation of multi-cloud, right? The network. You also need to consider your hybrid connectivity patterns and network architecture across all areas.
Olimpiu Pop: Let me see if I got it right. So, an event-driven architecture is a domino system. You have the part that just gets started, you have an input, and then that cascades into multiple events, and they just go up to the point where they can. And then if something happens with a given system, you have that resilience that lets say the request is kept, and then when the system goes online, it’ll just start processing as well. If that’s the case in some situations, we can defer doing that. And then, because I got ahead of myself and added multi-cloud to the conversation in that particular case, you have to be careful about how you weave those into making pretty easy things. So, you’ll probably have IDs that are represented and make sense from one side to another, even though they are not the IDs you usually have in a database, where you simply link them. However, it’ll be the correct part.
Handling Data Residency and Regulation in Multi-Cloud [07:46]
Great, thank you. Still, it is funny for me. I was just thinking while we were discussing topics the previous weeks, now we are talking that much about sovereign cloud, and then we are debating now about how those things get represented in this new ecosystem with multi-cloud, but also sovereign cloud, because that adds an extra level of complexity. The banking sector is one of the most regulated ones. How do you anticipate this extra headache will look? So you have multi-cloud, and then you have the regulations, and then you have the new drive towards having your data contained in a place where you want to do it. Would it affect it or not?
Teena Idnani: Yes, it’ll affect it, and very rightly said, in financial organizations it becomes imperative to take care of these data residency requirements as well because of the strict compliance regulations that these financial organizations need to meet. But that’s where multi-cloud is also an advantage, because earlier, when you were imagining you were just in one particular cloud or maybe in one specific on-premise system, you were relying on the capabilities that that provider was giving to you. And sometimes, because of these data residency requirements, you really cannot access all the services that you ideally want to access. But this multi-cloud has expanded that service set for you. Each cloud provider offers a vast suite of services available in different regions. Now, if you don’t have a real vendor lock-in with a particular multi-cloud provider, then you can choose the best service that you feel would suit your specific scenario.
And of course, meeting the data residency requirements and the sovereign requirements of your regulator that you’re bound to. But it makes it easier to deal with. A lot of these regulatory organizations question a lot about the concentration risk. For example, if you are a large fintech bank and all your workloads are concentrated in a single cloud provider, such as AWS, then it becomes a concentration risk, given what happens if that cloud provider goes down. In those cases, it becomes essential for these fintech banks to explore the multi-cloud services to also look at these concentration risks that might get mitigated when you have multiple multi-cloud providers. So there are considerations when you are dealing with multi-cloud providers, specifically when it comes to these regulations, but there are also a lot of advantages around it.
Olimpiu Pop: Well, where there is an advantage, there is also a disadvantage. And then we have the chance, as technologists, to say it depends and make everybody smile hopefully. Did you say that you’re probably looking for solutions that are, let’s say, cloud-native, because that will help you, or maybe not go there to make things agnostic? Not relying on services tailor-made for one of the cloud providers will allow you to be sure that you have what it takes. Therefore, it’s better to use the cloud as infrastructure, simply, and then that’s it. So, you have a container, and then the cloud is simply a place where it resides; you just ensure that the infrastructure is not under your desk, but in the cloud. So, more or less, that should be the case.
Teena Idnani: Yes, that’s one way to look at it.
Olimpiu Pop: Okay.
Vendor Specific or Cloud-Native Services: What to Choose For Your Need? [11:31]
Teena Idnani: Yes, so it depends. In this case, yes, you are correct; we can utilise containers and then leverage your cloud providers as our infrastructure setup. But if you want to take advantage of the services that these cloud providers provide, then it also becomes essential to look at the past offerings of these cloud providers. So, it depends on a use-case-to-use-case basis whether you want to go for containerization and then use your cloud provider as an infrastructure provider, or you want to use the different platform-as-a-service offerings that these cloud providers have to offer, given their past services. For example, if I were to focus solely on Azure, we have Azure Functions. Now, with Azure functions, if you can configure them correctly, or with AWS Lambda functions, you can configure them to provide scalability options.
They can give you different security configurations like identity management, authentication, authorization. So those are the kind of things that you automatically get, the redundancy options. So there are advantages. The interoperability will be difficult, but that is the trade-off, right? Do you want to reap the full benefits that these cloud providers can provide you by using their platform services? However, to ensure this, you will require interoperability between the different services and systems hosted by various cloud providers. Or you want to go with, let’s say, each microservice that you have, you containerize it, and then you host it on a particular cloud provider, and that’s how you start using it. It depends on the use case that you’re dealing with.
Olimpiu Pop: Okay, but that begs the question. Okay, this is very complex, that’s for sure. How do you stay on top of that? Because banks also have a very high Service Level Agreement (SLA), usually in terms of operational efficiency. That’s the main question. How do you stay on top of that? Numerous solutions are emerging in the cloud-native ecosystem that are now taking centre stage.
Teena Idnani: Therefore, I suggest that you first upgrade yourself and stay current, especially with the new services being released by cloud providers on a daily basis. It’s not easy, but I want the organizations to invest in your team skills. And very rightly said this: multi-cloud systems, specifically event-driven architectures, require a different way of thinking. Your developers need to understand, first of all, the concepts like “What is eventual consistency? What is that idempotency? Distributed tracing?”
Additionally, your operations team needs to be comfortable with multiple cloud platforms. So this is not just a technology transformation that we are talking about; it’s also a skill transformation. So the teams must stay upskilled on the latest cloud providers. It’s also a massive mindset transformation to reap the benefits of cloud and see how you can use which service of which cloud provider, which will work well in the specific use case that you’re in. And then, how do you build these well-architected systems, applications, and architectures? Yes, not an easy job for sure, but that’s what keeps us on our toes, right?
Observability in Multi-Cloud Environments [15:05]
Olimpiu Pop: Yes, that’s true. So I was at KubeCon, and a lot of the folks there were talking about OpenTelemetry and open observability and all the other stuff. As an architect, what are you recommending? What did you try, and what was working in terms of observability?
Teena Idnani: Yes, I recommend OpenTelemetry. So, basically what I usually advocate is that observability is where many multi-cloud initiatives succeed or fail. Observability is critical, but at the same time, it’s very challenging in multi-cloud environments because when your events cross multi-cloud boundaries, traditional monitoring approaches break down, resulting in lost end-to-end visibility. So to solve that, what I recommend is, first of all, standardizing on an observability data model across all clouds, which means agreeing to standard formats for tracing, for metrics, for logs, regardless of which cloud they originate from.
And then yes, I do recommend OpenTelemetry as a foundation for this standardization because OpenTelemetry basically provides vendor-neutral APIs. That’s a crucial aspect here, as it allows for the instrumentation to collect your telemetry data. This means that your application code instruments all the different events the same way, regardless of which cloud provider you’re running it on. You’re running it in AWS, you’re running it in Azure, or you’re running it in GCP, and then that’s one platform that you need to use.
However, for tracing specifically, I have seen teams that work together implement these correlation IDs that persist across different cloud boundaries. Each event will carry its unique ID, but it’ll also contain the complete causality chain, allowing them to reconstruct the entire event journey, even if it spans multiple services across different clouds.
Olimpiu Pop: Okay.
Teena Idnani: And then you have dashboards at any given point in time; you do require visualization tools and the dashboards because it’s essential to create a unified observability platform that aggregates data from all cloud providers. In such cases, I prefer a cloud-agnostic solution because you’re dealing with a multi-cloud environment. So, using a cloud-agnostic solution, like Grafana or Elasticsearch, or you could leverage one particular cloud’s monitoring capabilities as a central aggregation point and get the rest of the cloud providers to send all the traces and logs to that central aggregation point. However, I believe observability, when it arrives, is crucial to ensure that we get it right, especially in multi-cloud scenarios.
Olimpiu Pop: So, regardless of whether we are working in a single cloud environment where we have multiple services or we are working in a multi-cloud environment, the secret sauce is to remain consistent and harmonize the way we are using it. For instance, in the case of logs, always use the same standard so that it makes sense and they look the same regardless of where the information is coming from, whether it’s cloud A, cloud B, or our infrastructure under the desk. And then, when you’re discussing tracing, given that you would like to have it properly organized and you have the complete picture of everything, just make sure that the ID is moving from one call to another, regardless of the cloud boundary, to just allow the telemetry magic to show itself.
Teena Idnani: Yes, yes, exactly. I think you just nailed it. Absolutely. This is one of the most common mistakes that I often see: the need for that semantic consistency in your data. By that, I don’t just mean that your data format matches and matches. No, actually, the meaning behind those metrics, those error codes, should be consistent as well. So absolutely, consistency is the key there.
Olimpiu Pop: Okay. And then the visualization is just the aggregator. If you completed the first two correctly, the rest should be a breeze because OpenTelemetry is a standard, and everything has been built on top of it, allowing us to take advantage of the benefits of consistency.
Teena Idnani: Right. And additionally, I think what is beneficial is rather than just having technical dashboards, instead of just showing your CPU utilization across different clouds, if you have these business process dashboards wherein you are showing things like how many orders got processed per minute or maybe your average order processing time, or if you want to show maybe your orders which are stuck in processing. That will be an excellent use of the dashboards and the visualization because it’ll give your business stakeholders visibility into what’s happening without really needing to understand the underlying technical complexity.
Olimpiu Pop: I like this because I see more people who are talking about user experience and the benefits that the end user sees, so the business side of the organization. So I liked that you touched on that because it’s a notch closer to the ideal situation where you’re just delivering a service, and then you don’t care about the underlying technology. So, that is the advice that we need to keep in mind: a domain boundary, let’s say, when we are moving from one side to another, and then think from the point of view of the domain. So, rather than just saying that we want, I don’t know, five orders per minute, the satisfaction of filling in that order is 20%.
When to Consider Event-Driven Architecture for Your System [20:57]
It’s Friday, so it’s hard to come up with proper numbers. Nevertheless, event-driven architecture is not for the faint of heart. So it’s not something that you’ll start off the bat because, as you said, it’s not a classical architecture server-side that’s quite simple to understand. Event-driven requires a level of understanding of everything before you get started, and to make things right. When shouldn’t you use event-driven architecture, or what’s the scale of your system or the amount of events? I don’t know. What is a proper heuristic to make sure that you understand when you should look into event-driven architectures rather than overcomplicating your life?
Teena Idnani: Yes, very, very well said. The first suggestion from my side would be to consider whether it’s a straightforward scenario that your application is dealing with. There’s no need to over-engineer, as event-driven systems require a mindset shift when building them. Because right from the start of when you need to be brainstorming the events, you need to start thinking from a domain-driven model, those kinds of things, and then you need to make your way out. It is complex, and it is not easy.
So, in case your application is something that can be handled alongside the rest of the communication, such as a simple linear workflow. It has straightforward crowd operations, without much unpredictability; they’re all very predictable. Then I won’t say you need to go for an event-driven approach. If you have a simple request-response pattern where direct calls are sufficient, I recommend sticking to the direct request-response pattern rather than building an event-driven system on top of it.
If your application is a small-sized application with minimal integration requirements, you have few integration boundaries, you’re not interacting with multiple different systems, and you don’t require loose coupling between the systems, then I would say don’t opt for an event-driven approach. Or sometimes we have tasks that need batch processing. So, event-driven is more for real-time things. So, if you have to do something, a batch overnight job has to run. I don’t see a reason why you need to be using an event-driven approach for those kinds of things. Other places where you should be thoughtful before using event-driven are, “What if your application has strong consistency requirements?” As you may have heard, I mentioned at the QCon conference that you should be aware of your consistency. Is your application okay with eventual consistency? And consistency is not binary; it’s a spectrum.
You need to determine the consistency level your application can use. If it requires strong consistency, I recommend that, for example, if a financial transaction requires your asset properties across multiple operations, then an event-driven approach may not be the best use case. Another example is your real-time inventory management, where stock levels should be accurate; otherwise, you are sending an order for a product that doesn’t exist.
So those kinds of things become more challenging when you’re doing it in an event-driven way. It’s not possible to do event-driven in those scenarios, but the debugging will become a little bit more challenging for such simple scenarios. You will see those observability challenges. You will experience performance and latency-related issues. And then we talked about the skill set of the people. So you will have those team constraints, the organization constraints. You may also sometimes encounter data limitations. So, if you have highly sensitive data, then you cannot save it in your queues. Those kinds of things sometimes become a reason for you not to use the decoupling method of event-driven programming, and instead opt for straight, direct request-response mechanisms.
Olimpiu Pop: Okay, that’s fair. In a lot of situations, as mentioned, I was discussing with Sam Newman the other day, and he was saying the following: “If you want… So, pretty much, that’s why it jumped into my mind. It’s pretty much as you are saying, “If you have other options, don’t go to event-driven”. And he was saying the same thing. “If you have other options, don’t go to microservices; start with the monolith and then break down pieces and go there”. Can we apply the same heuristic here?
Teena Idnani: If you have other options, then don’t go for event-driven. There are some antipatterns that you should avoid for event-driven. So, for example, do not use events for synchronous request-response; otherwise, you end up over-engineering simple problems with unnecessary event complexity. So, those are the kinds of things you need to avoid. Microservices are a good pattern to go with. It’s again a trade-off, right? Monolith versus microservices: both have their trade-offs. With a monolith, you are too tightly coupled; then you’re not doing that loose coupling. I would say it is required to use, but then you just need to be careful about certain antipatterns where you should avoid using an event-driven approach.
At Event-Storming, Bring Together the Technical People with the Business Domain People [26:36]
Olimpiu Pop: Fair enough. Thank you. I was just thinking, as you’re discussing, you have the event storming, and you’re just thinking about your events, and then you have to consider them to be in a given domain. Would you believe it would be helpful to have more complex teams? You were just saying that you need to have people who understand the business domain, where you have a horizontal cut through your company. As you mentioned earlier, we should also consider everything from a business perspective. However, techies are usually not as keen on this approach, as they care about zeros and ones. Well, we’ll not discuss qubits these days because it’s another conversation, but they don’t care about these things. How do you make sure that those points are tackled properly in these kinds of systems?
Teena Idnani: For event storming, right, it’s essential that you’re not just doing event storming with your technical people in the room. No, you must be doing event storming with the business analysts and the product owners, who have complete knowledge about it. And then yes, you should have tech in the same room as well because tech should hear about it. Gone are the days when tech would just take the requirement and then implement the requirement. It’s essential to know the big picture.
“Why are we doing it? What business problem are we trying to solve by using technology?” Therefore, it’s essential that business and technology meet each other’s needs; technology needs to support business, and vice versa. When you are discussing these domain-driven designs, when you’re talking about event storming, you are basically building what the user journey looks like. How will the customer, let’s say, place an order? What events will be generated in that case? How will those events then be consumed by the different application systems and the different components? You need to start doing that from a business point of view and then see how technology can help in achieving that outcome, the business outcome that we want.
Olimpiu Pop: Okay. In your experience up to now, in designing systems, let’s say event-driven systems, what are usually the customers looking for? I mean, as we discussed, you’re discussing with business leaders or whatever, whoever are the business stakeholders. I bet that they’re not coming to you and saying, “Hey Teena, I would like an event-driven system that does that for me”. What are they actually looking for?
Teena Idnani: Yes, they’re looking for solutions to their problems. Let me give you an example from one of my previous organisations’s example. One of the organizations I was working with, they were undergoing this digital transformation journey, and they had this requirement that one of the systems that they were using was really not giving them the business value. The transactions which were being processed on that system were really not very scalable. It was not giving them that right value add, and they were thinking of different options. What to do with it? One way would be to deprecate that capability altogether. Do not use that, and do not offer that to your customers again.
The other would be, let’s take a third-party service, which would do that for us. And then the last one would be, let us develop something internally, which then we can build from scratch, use the latest cloud-native services so that we are taking care of those requirements, not just the functional requirements, but also ensuring that we are building them, the applications, as scalable, as performance oriented, and then they have the right resiliency and redundancy and different kind of options.
So that’s the problem they come to us with. “That is the challenge that we are seeing. How do you think you can help us, or what is the best way to move forward?” And then in the example that I’m giving, we actually went with the third option. We decided that we would build a modern, digitally transformed application, API-driven, but we built it in Azure. And then it was also having a lot of integration points with the other components, which were already legacy and existing. And that’s when then the whole strategy comes into picture, that you need to look at all the integration data points, how your new service is going to integrate with the others, which cloud provider is it going to be hosted on, and then what are the different data residency requirements and everything that comes with it. But to start with, it all starts with a business problem. And then moving forward. How do you solve that business problem using the tech that we have?
How to Secure Your Systems’ Data [31:31]
Olimpiu Pop: Okay, it seems like problems taken from a manual, and that’s quite nice. So we are discussing about scalability or discussing about resilience and also redundancy because a lot, not the banks, stuck in my mind. The banks still have old systems, decade-old systems at some point. But those systems are working as expected. But again, they need to have some boundaries. Then, you need to integrate them with modern technology, as we would like to have banking capabilities on our phones. We want to have very fast banking wherever we are. So then this is the opportunity to do that. You just create, probably, a wrapper around the old systems. You create those boundaries; you just ensure that they react in the proper way, and then you push all those pieces together to just ensure that we are taking care also about the non-functional requirements, so the legal requirements at some point.
But as we are discussing about non-functional and discussing about data. Data is very expensive these days, especially if it gets outside the boundaries of the companies. How should you treat, from the security point of view, event-driven architectures? How do they differ from the classical architectures, or if they differ in any way?
Teena Idnani: It would be different when you are talking with varying systems of cloud.
Olimpiu Pop: Okay.
Teena Idnani: So security would be like, “You need to think about your data in transit”. So how do you secure your data when it is in transit, right? So, for example, you would want to encrypt all your event messages, which are crossing the different boundaries using your TLS or SSL, and you would use your mutual TLS; you would apply the digital signatures. So I think yes, you would want to do similar things that you would do for your on-premise system as well, similar to your multi-cloud systems. Ultimately you need to keep your data secure, and not just in transit, but also at rest. And I think that is where a lot of these database services, so if you’re talking about the PaaS services, which these cloud provider, provide, they provide you those encryption capabilities, whether it is at risk, whether it is in transit as well.
And then it’s very important for you to implement your key rotations. If you are having your storage account and then you have your access keys, then you need to ensure that you are doing those regular key rotations to ensure that we are keeping the data which is in these storage accounts kind of secure. So I would say that the considerations… Data is important; you need to keep it secure, whether it is in your on-premise system, whether it is in your cloud systems. With cloud providers, like I mentioned, these providers, they do provide you with those services that can help you keep your data secure, but configuration is your responsibility. So security is like a shared responsibility between your cloud providers and between you. You can’t just say that, “Hey, because I’ve hosted my data on a particular cloud provider, it is implicitly secure”. No, it is your responsibility. Like, the cloud providers will give you the right tools to make your data secure, but then the configuration responsibility lies with you.
Olimpiu Pop: But it just jumps in my mind now. It’s pretty much like your house. You have your house, but you have to take care of your windows and doors to be locked so that you’re safe. But then whenever somebody is leaving your house, you’re just making sure that you explain to them, “Be sure that you cross the road carefully and that you’re secure also in traffic”. So yes, fair enough. Thank you.
Teena Idnani: Yes, wonderful example. Exactly. And I think it’s also very important to have that network security. You gave me the example of house, and that’s exactly when I remembered the network parameter. So you need to ensure that you’re using the right private endpoints; you are avoiding that public internet exposure to your data. So absolutely, I think all of these things are very important when it comes to the security of your data.
Olimpiu Pop: Okay, cool. This was really insightful. So was there anything else that I should have asked you about event-driven and multi-cloud that I didn’t, but I should have?
Teena Idnani: No, I think you’ve pretty much covered it all. I think the considerations when you’re dealing with event-driven, specifically in the case of multi-cloud. And then I think observability was one part that I was not really able to touch very well on my QCon presentation, as you have the time limitations, and I still think I had so much to cover. So yes, I think you pretty much covered it all.
Olimpiu Pop: Okay, thank you. Thank you, Teena, for your time and for all the insights.
Teena Idnani: Thank you. It was a pleasure.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS
![]() Cerity Partners LLC reduced its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 1.6% in the first quarter, according to the company in its most recent disclosure with the Securities and Exchange Commission. The firm owned 9,518 shares of the company’s stock after selling 156 shares during the period. Cerity Partners LLC’s holdings in MongoDB were worth $1,669,000 as of its most recent SEC filing.
Cerity Partners LLC reduced its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 1.6% in the first quarter, according to the company in its most recent disclosure with the Securities and Exchange Commission. The firm owned 9,518 shares of the company’s stock after selling 156 shares during the period. Cerity Partners LLC’s holdings in MongoDB were worth $1,669,000 as of its most recent SEC filing.
A number of other institutional investors also recently modified their holdings of MDB. Alps Advisors Inc. raised its stake in MongoDB by 42.5% in the first quarter. Alps Advisors Inc. now owns 8,047 shares of the company’s stock worth $1,411,000 after buying an additional 2,400 shares in the last quarter. DekaBank Deutsche Girozentrale raised its stake in MongoDB by 2.0% in the first quarter. DekaBank Deutsche Girozentrale now owns 45,196 shares of the company’s stock worth $7,956,000 after buying an additional 870 shares in the last quarter. Brown Advisory Inc. raised its stake in MongoDB by 671.1% in the first quarter. Brown Advisory Inc. now owns 24,258 shares of the company’s stock worth $4,255,000 after buying an additional 21,112 shares in the last quarter. China Universal Asset Management Co. Ltd. increased its stake in shares of MongoDB by 53.0% during the first quarter. China Universal Asset Management Co. Ltd. now owns 1,839 shares of the company’s stock valued at $323,000 after purchasing an additional 637 shares in the last quarter. Finally, Envestnet Asset Management Inc. increased its stake in shares of MongoDB by 44.6% during the first quarter. Envestnet Asset Management Inc. now owns 127,425 shares of the company’s stock valued at $22,350,000 after purchasing an additional 39,311 shares in the last quarter. 89.29% of the stock is currently owned by hedge funds and other institutional investors.
Insider Buying and Selling
In other news, Director Dwight A. Merriman sold 820 shares of the firm’s stock in a transaction that occurred on Wednesday, June 25th. The shares were sold at an average price of $210.84, for a total transaction of $172,888.80. Following the completion of the sale, the director owned 1,106,186 shares of the company’s stock, valued at approximately $233,228,256.24. This trade represents a 0.07% decrease in their ownership of the stock. The transaction was disclosed in a filing with the Securities & Exchange Commission, which can be accessed through this hyperlink. Also, Director Hope F. Cochran sold 1,174 shares of MongoDB stock in a transaction on Tuesday, June 17th. The stock was sold at an average price of $201.08, for a total transaction of $236,067.92. Following the completion of the transaction, the director directly owned 21,096 shares of the company’s stock, valued at approximately $4,241,983.68. This represents a 5.27% decrease in their position. The disclosure for this sale can be found here. Over the last three months, insiders have sold 32,746 shares of company stock valued at $7,500,196. Insiders own 3.10% of the company’s stock.
Analyst Ratings Changes
<!—->
A number of brokerages have weighed in on MDB. Morgan Stanley decreased their target price on shares of MongoDB from $315.00 to $235.00 and set an “overweight” rating for the company in a research note on Wednesday, April 16th. Monness Crespi & Hardt raised shares of MongoDB from a “neutral” rating to a “buy” rating and set a $295.00 target price for the company in a research note on Thursday, June 5th. Bank of America raised their price target on shares of MongoDB from $215.00 to $275.00 and gave the company a “buy” rating in a research report on Thursday, June 5th. Stifel Nicolaus reduced their price target on shares of MongoDB from $340.00 to $275.00 and set a “buy” rating for the company in a research report on Friday, April 11th. Finally, William Blair reissued an “outperform” rating on shares of MongoDB in a research report on Thursday, June 26th. Nine equities research analysts have rated the stock with a hold rating, twenty-six have issued a buy rating and one has given a strong buy rating to the stock. Based on data from MarketBeat.com, MongoDB currently has an average rating of “Moderate Buy” and an average price target of $281.35.
Get Our Latest Analysis on MDB
MongoDB Trading Up 1.2%
Shares of MongoDB stock opened at $221.21 on Monday. The company has a fifty day simple moving average of $202.71 and a 200-day simple moving average of $212.83. MongoDB, Inc. has a 12-month low of $140.78 and a 12-month high of $370.00. The stock has a market cap of $18.08 billion, a price-to-earnings ratio of -194.04 and a beta of 1.41.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share for the quarter, topping analysts’ consensus estimates of $0.65 by $0.35. The business had revenue of $549.01 million for the quarter, compared to analysts’ expectations of $527.49 million. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. The business’s revenue for the quarter was up 21.8% on a year-over-year basis. During the same period in the prior year, the company posted $0.51 EPS. On average, analysts forecast that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • Matt Foster
A recent study challenges the widespread belief that AI tools accelerate software development. Researchers at METR conducted a randomized controlled trial of experienced open-source developers using AI-enhanced development tools like Claude 3.5 and Cursor Pro. Contrary to expectations, they found that AI-assisted programming led to a 19% increase in task completion time—even as developers believed they were working faster. The findings reveal a potential gap between AI’s perceived promise and its real-world impact.
To evaluate AI’s influence under realistic conditions, the researchers designed a randomized controlled trial (RCT) rooted in production-grade environments. Rather than using synthetic benchmarks, they recruited experienced contributors to complete real tasks across mature open-source repositories.
Participants were 16 professional developers with an average of five years of experience on the projects they were assigned. The repositories included realistic, ‘in-anger’ issues drawn from their own codebases: very large (> 1.1m lines of code), well established open source projects.
Across 246 tasks, each developer was randomly assigned to a maximum of two-hour sessions either with or without access to AI assistance. Those with access used Cursor Pro, a code editor with integrated support for Claude 3.5/3.7 Sonnet. The control group was explicitly blocked from using AI tools.
The study collected both objective and subjective metrics, including task duration, code quality, and developer perception. Before and after each task, developers and external experts predicted the likely effect of AI on productivity.
The central result was both striking and unexpected: AI-assisted developers took 19% longer to complete tasks than those without AI. This contradicted pre-task expectations from both participants and experts, who had predicted an average speedup of ~40%.
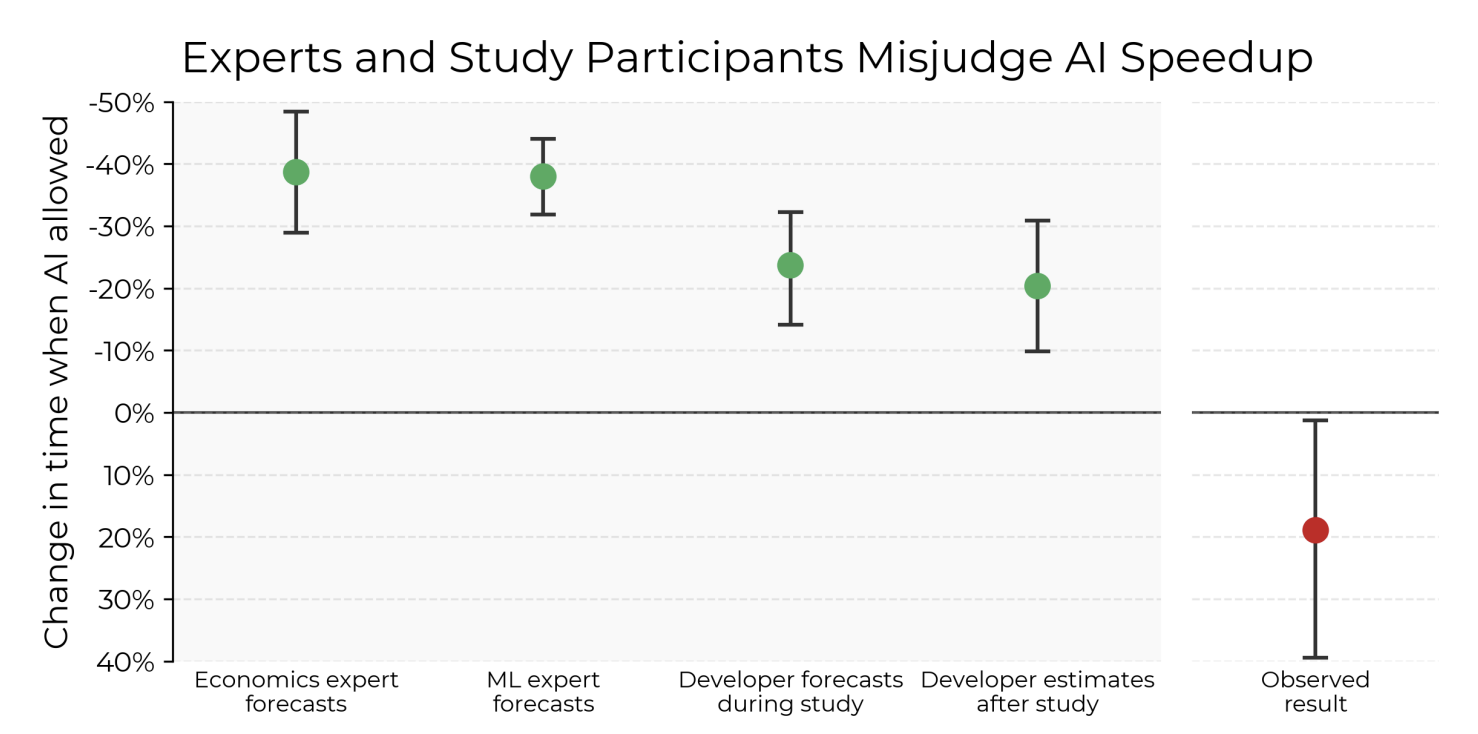
The authors attributed the slowdown to a variety of contributing factors, including time spent prompting, reviewing AI-generated suggestions, and integrating outputs with complex codebases. Through 140+ hours of screen recordings, they identified five key contributors to the slowdown. These frictions likely offset any up-front gains from code generation, revealing a significant disconnect between perceived and actual productivity.
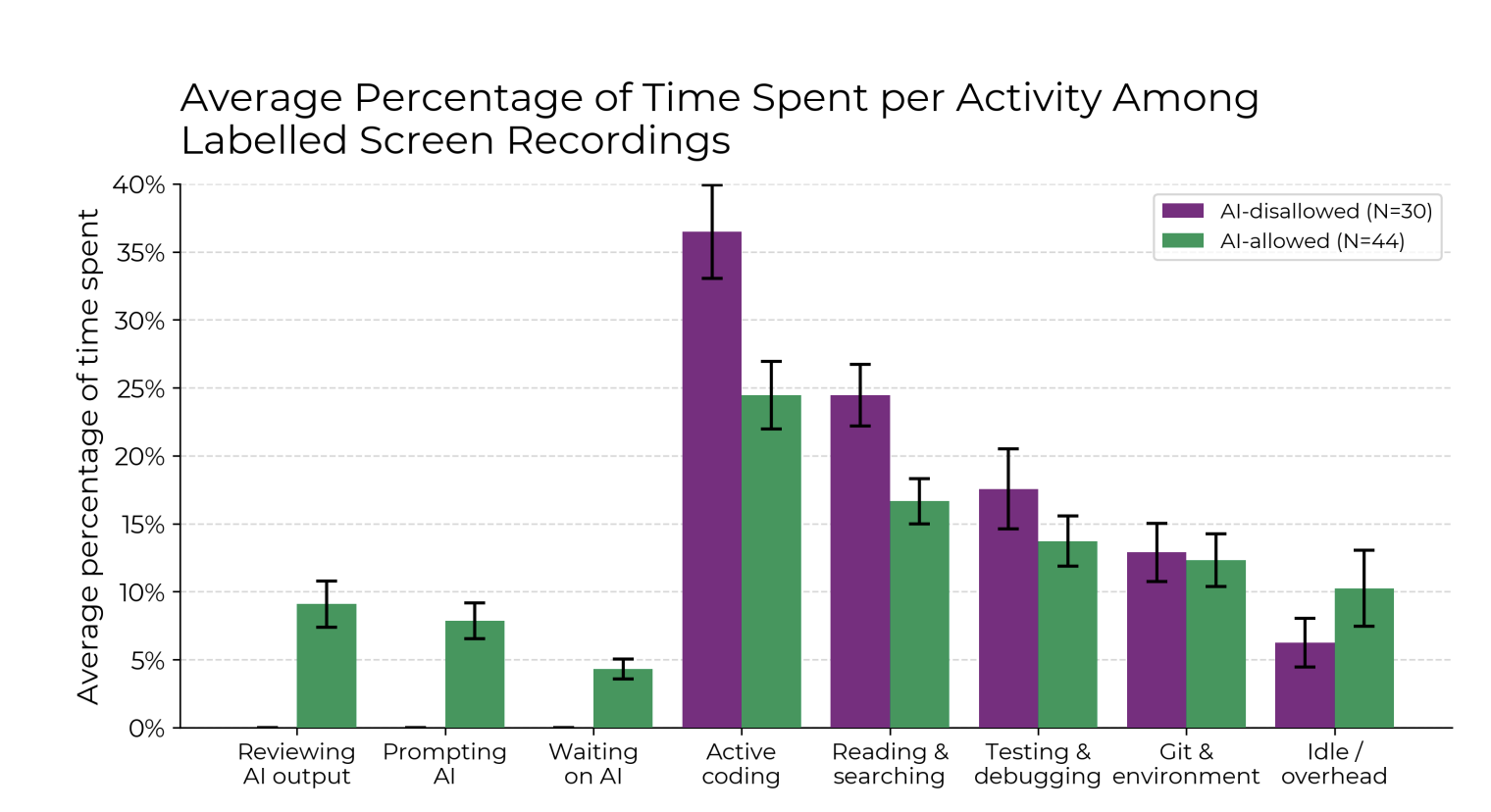
The researchers highlight this phenomenon as a ‘perception gap’—where friction introduced by AI tooling is subtle enough to go unnoticed in the moment but cumulatively slows real-world output. The contrast between perception and outcome underscores the study’s importance of grounding AI tool evaluation not just in user sentiment, but in rigorous measurement.
The authors caution against overgeneralizing their findings. While the study shows a measurable slowdown with AI tooling in this particular setting, they stress that many of the contributing factors are specific to their design. The developers were working in large, mature open-source codebases—projects with strict review standards and unfamiliar internal logic. The tasks were constrained to two-hour blocks, limiting exploration, and all AI interactions were funneled through a single toolchain
Importantly, the authors emphasize that future systems may overcome the challenges observed here. Improvements in prompting techniques, agent scaffolding, or domain-specific fine tuning could unlock real productivity gains even in the settings tested.
As AI capabilities continue to progress rapidly, the authors frame their findings not as a verdict on the usefulness of AI tools—but as a data point in a fast-evolving landscape that still requires rigorous, real-world evaluation.
MMS • RSS
Teams are increasingly moving away from DynamoDB, a widely used NoSQL database service provided by Amazon Web Services (AWS), in favor of alternative solutions. The shift is driven by several key factors, including lower latency, reduced costs, multi-cloud flexibility, and better performance at scale. ScyllaDB, a high-performance NoSQL database, has emerged as a popular alternative, offering these advantages and more.
One of the primary reasons teams are ditching DynamoDB is the need for lower latency. In high-performance applications, even milliseconds of delay can significantly impact user experience and system efficiency. ScyllaDB, designed to handle high-throughput workloads with minimal latency, provides a more responsive solution.
Cost reduction is another critical factor. While DynamoDB offers a pay-as-you-go pricing model, the costs can quickly escalate with increased usage and data storage requirements. ScyllaDB, on the other hand, provides a more cost-effective solution by optimizing resource utilization and reducing operational expenses.
Multi-cloud flexibility is also a significant consideration. Many organizations are adopting multi-cloud strategies to avoid vendor lock-in and enhance disaster recovery capabilities. ScyllaDB supports deployment across multiple cloud providers, offering greater flexibility and resilience compared to DynamoDB, which is tightly integrated with the AWS ecosystem.
Performance at scale is another area where ScyllaDB excels. As applications grow and data volumes increase, maintaining high performance becomes challenging. ScyllaDB is engineered to handle large-scale workloads efficiently, ensuring consistent performance even as data and user demands grow.
In summary, the migration from DynamoDB to ScyllaDB is driven by the need for lower latency, reduced costs, multi-cloud flexibility, and better performance at scale. As organizations continue to seek more efficient and cost-effective database solutions, ScyllaDB is poised to become a leading choice in the NoSQL database market.

MMS • RSS
![]() Principal Financial Group Inc. cut its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 20.0% during the 1st quarter, according to its most recent 13F filing with the Securities and Exchange Commission (SEC). The institutional investor owned 4,798 shares of the company’s stock after selling 1,201 shares during the quarter. Principal Financial Group Inc.’s holdings in MongoDB were worth $842,000 at the end of the most recent reporting period.
Principal Financial Group Inc. cut its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 20.0% during the 1st quarter, according to its most recent 13F filing with the Securities and Exchange Commission (SEC). The institutional investor owned 4,798 shares of the company’s stock after selling 1,201 shares during the quarter. Principal Financial Group Inc.’s holdings in MongoDB were worth $842,000 at the end of the most recent reporting period.
Other institutional investors and hedge funds have also recently added to or reduced their stakes in the company. Vanguard Group Inc. raised its holdings in shares of MongoDB by 0.3% in the 4th quarter. Vanguard Group Inc. now owns 7,328,745 shares of the company’s stock valued at $1,706,205,000 after purchasing an additional 23,942 shares during the period. Franklin Resources Inc. raised its holdings in shares of MongoDB by 9.7% in the 4th quarter. Franklin Resources Inc. now owns 2,054,888 shares of the company’s stock valued at $478,398,000 after purchasing an additional 181,962 shares during the period. Geode Capital Management LLC raised its holdings in shares of MongoDB by 1.8% in the 4th quarter. Geode Capital Management LLC now owns 1,252,142 shares of the company’s stock valued at $290,987,000 after purchasing an additional 22,106 shares during the period. First Trust Advisors LP raised its holdings in shares of MongoDB by 12.6% in the 4th quarter. First Trust Advisors LP now owns 854,906 shares of the company’s stock valued at $199,031,000 after purchasing an additional 95,893 shares during the period. Finally, Norges Bank bought a new stake in shares of MongoDB in the 4th quarter valued at about $189,584,000. 89.29% of the stock is owned by institutional investors.
Insider Activity at MongoDB
In related news, Director Dwight A. Merriman sold 820 shares of the company’s stock in a transaction that occurred on Wednesday, June 25th. The shares were sold at an average price of $210.84, for a total transaction of $172,888.80. Following the sale, the director owned 1,106,186 shares of the company’s stock, valued at approximately $233,228,256.24. This represents a 0.07% decrease in their position. The transaction was disclosed in a legal filing with the SEC, which is accessible through this hyperlink. Also, Director Hope F. Cochran sold 1,174 shares of the company’s stock in a transaction that occurred on Tuesday, June 17th. The stock was sold at an average price of $201.08, for a total transaction of $236,067.92. Following the sale, the director directly owned 21,096 shares in the company, valued at $4,241,983.68. This trade represents a 5.27% decrease in their position. The disclosure for this sale can be found here. In the last ninety days, insiders have sold 32,746 shares of company stock worth $7,500,196. 3.10% of the stock is owned by corporate insiders.
Analyst Ratings Changes
<!—->
MDB has been the topic of a number of research reports. Needham & Company LLC reiterated a “buy” rating and issued a $270.00 price target on shares of MongoDB in a research note on Thursday, June 5th. Loop Capital lowered shares of MongoDB from a “buy” rating to a “hold” rating and decreased their target price for the stock from $350.00 to $190.00 in a research report on Tuesday, May 20th. JMP Securities restated a “market outperform” rating and set a $345.00 target price on shares of MongoDB in a research report on Thursday, June 5th. Wedbush restated an “outperform” rating and set a $300.00 target price on shares of MongoDB in a research report on Thursday, June 5th. Finally, Truist Financial decreased their target price on shares of MongoDB from $300.00 to $275.00 and set a “buy” rating on the stock in a research report on Monday, March 31st. Nine research analysts have rated the stock with a hold rating, twenty-six have assigned a buy rating and one has assigned a strong buy rating to the stock. Based on data from MarketBeat, the stock presently has an average rating of “Moderate Buy” and a consensus price target of $281.35.
Get Our Latest Stock Analysis on MDB
MongoDB Price Performance
Shares of NASDAQ MDB opened at $221.21 on Friday. The stock has a market capitalization of $18.08 billion, a P/E ratio of -194.04 and a beta of 1.41. The company has a 50-day moving average price of $202.71 and a 200-day moving average price of $213.05. MongoDB, Inc. has a 1 year low of $140.78 and a 1 year high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 earnings per share (EPS) for the quarter, beating analysts’ consensus estimates of $0.65 by $0.35. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. The firm had revenue of $549.01 million during the quarter, compared to analysts’ expectations of $527.49 million. During the same period last year, the company earned $0.51 earnings per share. The business’s revenue was up 21.8% on a year-over-year basis. As a group, equities research analysts anticipate that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • Mark Silvester

Pulumi now allows developers to use Terraform modules directly, without converting them first. This preview feature allows Pulumi programs written in TypeScript, Python, Go, C# or Java to consume Terraform modules as-is, removing one of the key barriers to adoption.
Writing in the announcement post, Pulumi engineer Anton Tayanovskyy said the feature “addresses one of the most significant challenges our users face when migrating from Terraform to Pulumi” particularly for teams with deep investments in Terraform modules. He explained that it “gives you the best of both worlds: the ability to start new projects in Pulumi immediately while preserving your existing Terraform modules until you’re ready to migrate them”.
Support is provided through the pulumi package add terraform-module command, available from CLI version 3.178.0. Under the hood, Pulumi wraps Terraform’s execution engine using the terraform-module provider. This allows infrastructure defined in .tf modules to behave like native Pulumi components, while still integrating with Pulumi’s state backend, secrets management and automation workflows.
Enterprise accounts lead Dipali Patel described the announcement as a turning point, writing on LinkedIn that “Pulumi just made your Terraform life way easier,” and calling it “the ultimate ‘no excuses’ moment to start modernising your Infra as Code, without the pain of a full rewrite.” Her comments highlight a recognition among teams of the value in tooling that supports gradual transitions over all-or-nothing migrations.
The official Pulumi LinkedIn account echoed that message, stating the new functionality solves “one of the biggest challenges in migrating complex infrastructure.” Pulumi has positioned itself as a platform that allows developers to work in general-purpose languages without giving up compatibility with existing tools and ecosystems.
The feature remains in preview, and Pulumi has been clear about its limitations. The GitHub documentation notes that “Terraform modules have insufficient metadata to precisely identify the type of every module output,” and recommends overriding inferred types manually where needed. Feedback is actively encouraged as the company works to improve compatibility and stability.
Pulumi’s support for Terraform modules mirrors similar features in other widely used tools. CDK for Terraform allows infrastructure to be defined in TypeScript, Python, Java, C# or Go while using existing Terraform modules from the Terraform Registry. Terragrunt also supports referencing remote Terraform modules, helping teams manage shared infrastructure configurations more easily. By enabling direct module support, Pulumi aligns with this broader trend of integrating with Terraform ecosystems rather than replacing them.
The feature allows Pulumi to interoperate more easily with existing Terraform code, offering teams a way to incorporate familiar modules while exploring Pulumi’s language-based approach. It is intended to support gradual adoption without requiring full migration up front.
Massachusetts Financial Services Co. MA Acquires New Position in MongoDB, Inc. (NASDAQ:MDB)
MMS • RSS
Massachusetts Financial Services Co. MA acquired a new position in MongoDB, Inc. (NASDAQ:MDB – Free Report) in the first quarter, according to its most recent Form 13F filing with the Securities & Exchange Commission. The institutional investor acquired 81,961 shares of the company’s stock, valued at approximately $14,376,000. Massachusetts Financial Services Co. MA owned approximately 0.10% of MongoDB at the end of the most recent reporting period.
Other institutional investors and hedge funds have also bought and sold shares of the company. Cloud Capital Management LLC purchased a new stake in MongoDB in the 1st quarter worth $25,000. Strategic Investment Solutions Inc. IL purchased a new stake in shares of MongoDB in the fourth quarter worth about $29,000. Coppell Advisory Solutions LLC boosted its stake in MongoDB by 364.0% during the fourth quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock valued at $54,000 after buying an additional 182 shares during the last quarter. Aster Capital Management DIFC Ltd purchased a new position in shares of MongoDB in the fourth quarter valued at $97,000. Finally, Fifth Third Bancorp increased its position in MongoDB by 15.9% in the first quarter. Fifth Third Bancorp now owns 569 shares of the company’s stock worth $100,000 after purchasing an additional 78 shares during the last quarter. 89.29% of the stock is owned by institutional investors.
Insider Buying and Selling at MongoDB
In other MongoDB news, CEO Dev Ittycheria sold 25,005 shares of the stock in a transaction that occurred on Thursday, June 5th. The stock was sold at an average price of $234.00, for a total transaction of $5,851,170.00. Following the transaction, the chief executive officer owned 256,974 shares in the company, valued at approximately $60,131,916. This represents a 8.87% decrease in their ownership of the stock. The sale was disclosed in a document filed with the SEC, which can be accessed through this hyperlink. Also, Director Dwight A. Merriman sold 2,000 shares of the stock in a transaction that occurred on Thursday, June 5th. The shares were sold at an average price of $234.00, for a total value of $468,000.00. Following the transaction, the director owned 1,107,006 shares in the company, valued at $259,039,404. This trade represents a 0.18% decrease in their position. The disclosure for this sale can be found here. Over the last quarter, insiders sold 32,746 shares of company stock valued at $7,500,196. Corporate insiders own 3.10% of the company’s stock.
Wall Street Analysts Forecast Growth
Several research firms have recently issued reports on MDB. Guggenheim raised their price objective on MongoDB from $235.00 to $260.00 and gave the company a “buy” rating in a research note on Thursday, June 5th. William Blair reissued an “outperform” rating on shares of MongoDB in a research note on Thursday, June 26th. UBS Group raised their target price on shares of MongoDB from $213.00 to $240.00 and gave the stock a “neutral” rating in a report on Thursday, June 5th. Mizuho cut their price target on shares of MongoDB from $250.00 to $190.00 and set a “neutral” rating on the stock in a report on Tuesday, April 15th. Finally, Royal Bank Of Canada reissued an “outperform” rating and issued a $320.00 price objective on shares of MongoDB in a research report on Thursday, June 5th. Nine equities research analysts have rated the stock with a hold rating, twenty-six have assigned a buy rating and one has assigned a strong buy rating to the stock. According to MarketBeat, the stock currently has a consensus rating of “Moderate Buy” and a consensus target price of $281.35.
Get Our Latest Research Report on MDB
MongoDB Trading Up 1.2%
NASDAQ MDB opened at $221.21 on Friday. MongoDB, Inc. has a 12-month low of $140.78 and a 12-month high of $370.00. The company has a fifty day simple moving average of $202.71 and a two-hundred day simple moving average of $213.05. The stock has a market cap of $18.08 billion, a P/E ratio of -194.04 and a beta of 1.41.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share (EPS) for the quarter, topping analysts’ consensus estimates of $0.65 by $0.35. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. The company had revenue of $549.01 million during the quarter, compared to analyst estimates of $527.49 million. During the same period last year, the firm posted $0.51 EPS. MongoDB’s revenue for the quarter was up 21.8% compared to the same quarter last year. As a group, sell-side analysts forecast that MongoDB, Inc. will post -1.78 earnings per share for the current year.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Nuclear energy stocks are roaring. It’s the hottest energy sector of the year. Cameco Corp, Paladin Energy, and BWX Technologies were all up more than 40% in 2024. The biggest market moves could still be ahead of us, and there are seven nuclear energy stocks that could rise much higher in the next several months. To unlock these tickers, enter your email address below.
MMS • Matt Saunders

Cloud-based web development service Wix has written about a new approach to integrating artificial intelligence into continuous integration and continuous deployment (CI/CD) systems. In a blog post, Wix demonstrates how probabilistic AI can coexist with deterministic development processes, adding chaos without compromising reliability.
In the post, Wix’s Mobile Release Engineering team explains how they successfully implemented AI tools within their CI/CD infrastructure to use AI’s learning capabilities without undermining the predictability that CI/CD systems require. They make it clear that their use of AI is to augment human decision-making rather than replace automated processes.
Itai Schuftan, who leads the Mobile Release Engineering team, explains that the key insight was recognising that not every aspect of CI/CD needs to be deterministic. Whilst builds and deployments must remain bulletproof, tasks such as interpreting logs, triaging errors, and recommending fixes operate in grey areas where AI’s pattern recognition excels.
When it came to CI/CD, almost no one was going near it. Maybe for good reason — it’s a hard, unforgiving space where the margin for error is tiny. But my manager truly believed this was worth exploring. That there had to be a way to combine AI’s growing capabilities with the world of build pipelines and mobile tooling.
Wix was careful to ensure that boundaries were not overstepped, and AI is not used to trigger deployments or make critical infrastructure decisions. Instead, it guides the humans who do, making them more efficient and reducing the cognitive load of managing complex build systems.
One of Wix’s most successful AI implementations addresses analysing build logs, a persistent pain point for DevOps teams. Traditional build logs are lengthy, noisy, and inconsistent across platforms, often burying critical error information amongst dependency warnings and cryptic stack traces.
Wix deployed their internal AI assistant to parse these logs systematically, identifying actual errors rather than simply flagging the first problematic line. The system highlights key issues, attempts to explain them in plain language, and suggests potential solutions. This has reportedly saved hours of back-and-forth communication each week between developers and infrastructure teams.
This has also allowed developers to work more autonomously, as previously, many build failures required developers to contact DevOps engineers for help, creating a bottleneck and interrupting their work. The AI-powered log analysis frequently lets developers understand and resolve issues independently.
Similar approaches are being adopted across the industry. For example, Datadog’s AI-driven monitoring capabilities interpret logs in real time, highlighting errors and diagnosing root causes with plain-language explanations. Their system also has predictive failure analysis and can automatically restart failed services or roll back to stable versions, minimising downtime in production environments.
Wix has implemented Model Context Protocol (MCP), a specification that provides structured context to large language models before processing queries. The MCP server gives context to the AI by supplying build logs, module metadata, and relevant documentation. Connecting the AI to the MCP server lets the system narrow down faults, find where they occurred, and often correctly identify the affected module. The benefits are more accurate summaries, better root cause detection and actionable next steps.
Levelling up the AI by adding aid from MCP to understand domain context has allowed Wix to reduce the verbosity needed to prompt the AI and the hand-holding required in a more generic AI approach.
MCP shifted us from ‘AI assistant’ to ‘AI teammate.’ It no longer needs hand-holding or verbose prompts — it just gets it.
Wix has also developed an automated migration system that addresses code degradation across its mobile applications, which can be very complex and consist of dozens of subprojects. The migration system uses static analysis, heuristics, and LLM capabilities to identify and update relevant module code while suggesting tailored fixes. The migration framework understands specific module contexts, including dependencies, code style, and project settings, and avoids applying generic updates. It generates pull requests with proposed migrations and explanations of changes, allowing migration owners to approve, modify, or reject suggestions.
This system has dramatically improved migration timelines. Wix reports that migrations previously requiring up to three months can now be completed across 100 modules within 24-48 hours, whilst maintaining code quality through human oversight.
The success reflects broader industry adoption of AI-powered migration tools. Sourcegraph’s AI code intelligence drives automated migrations for organisations including Reddit and FactSet, reportedly improving migration speed and reducing bugs by up to 60%. Google uses similar strategies in its generative AI-powered workflows for automated code migrations. It allows AI to autonomously produce verified code changes that pass unit tests, with human engineers retaining approval controls. Google’s implementation has reportedly accelerated migration workflows and cut overall migration time by up to 50% while maintaining code stability and auditability through human oversight.
Carefully and thoughtfully adding AI to their CI/CD pipelines has produced measurable improvements in system stability and developer experience at Wix. By introducing controlled non-determinism in appropriate areas, the CI/CD process has become more stable, predictable, and user-friendly. Wix attributes this success to clearly defining boundaries and keeping human oversight where it’s needed. This methodology is gaining traction across the technology industry. Healthcare platforms like Epic and Meditech use deterministic AI agents embedded in CI/CD pipelines for secure, explainable validation and deployment workflows, prioritising reproducibility and compliance requirements.
Schuftan closes out the blog piece by pointing out that they are still iteratively improving when they use the new AI-enabled tools, using them to find and fix bottlenecks and repetitive tasks.
The irony is: by introducing a bit of non-determinism in the right places, we’ve made our CI/CD process feel more stable, more predictable, and way more human-friendly.