Category: Uncategorized

MMS • RSS
Principal Financial Group Inc. cut its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 20.0% during the 1st quarter, according to its most recent 13F filing with the Securities and Exchange Commission (SEC). The institutional investor owned 4,798 shares of the company’s stock after selling 1,201 shares during the quarter. Principal Financial Group Inc.’s holdings in MongoDB were worth $842,000 at the end of the most recent reporting period.
Other institutional investors and hedge funds have also recently added to or reduced their stakes in the company. Vanguard Group Inc. raised its holdings in shares of MongoDB by 0.3% in the 4th quarter. Vanguard Group Inc. now owns 7,328,745 shares of the company’s stock valued at $1,706,205,000 after purchasing an additional 23,942 shares during the period. Franklin Resources Inc. raised its holdings in shares of MongoDB by 9.7% in the 4th quarter. Franklin Resources Inc. now owns 2,054,888 shares of the company’s stock valued at $478,398,000 after purchasing an additional 181,962 shares during the period. Geode Capital Management LLC raised its holdings in shares of MongoDB by 1.8% in the 4th quarter. Geode Capital Management LLC now owns 1,252,142 shares of the company’s stock valued at $290,987,000 after purchasing an additional 22,106 shares during the period. First Trust Advisors LP raised its holdings in shares of MongoDB by 12.6% in the 4th quarter. First Trust Advisors LP now owns 854,906 shares of the company’s stock valued at $199,031,000 after purchasing an additional 95,893 shares during the period. Finally, Norges Bank bought a new stake in shares of MongoDB in the 4th quarter valued at about $189,584,000. 89.29% of the stock is owned by institutional investors.
Insider Activity at MongoDB
In related news, Director Dwight A. Merriman sold 820 shares of the company’s stock in a transaction that occurred on Wednesday, June 25th. The shares were sold at an average price of $210.84, for a total transaction of $172,888.80. Following the sale, the director owned 1,106,186 shares of the company’s stock, valued at approximately $233,228,256.24. This represents a 0.07% decrease in their position. The transaction was disclosed in a legal filing with the SEC, which is accessible through this hyperlink. Also, Director Hope F. Cochran sold 1,174 shares of the company’s stock in a transaction that occurred on Tuesday, June 17th. The stock was sold at an average price of $201.08, for a total transaction of $236,067.92. Following the sale, the director directly owned 21,096 shares in the company, valued at $4,241,983.68. This trade represents a 5.27% decrease in their position. The disclosure for this sale can be found here. In the last ninety days, insiders have sold 32,746 shares of company stock worth $7,500,196. 3.10% of the stock is owned by corporate insiders.
Analyst Ratings Changes
MDB has been the topic of a number of research reports. Needham & Company LLC reiterated a “buy” rating and issued a $270.00 price target on shares of MongoDB in a research note on Thursday, June 5th. Loop Capital lowered shares of MongoDB from a “buy” rating to a “hold” rating and decreased their target price for the stock from $350.00 to $190.00 in a research report on Tuesday, May 20th. JMP Securities restated a “market outperform” rating and set a $345.00 target price on shares of MongoDB in a research report on Thursday, June 5th. Wedbush restated an “outperform” rating and set a $300.00 target price on shares of MongoDB in a research report on Thursday, June 5th. Finally, Truist Financial decreased their target price on shares of MongoDB from $300.00 to $275.00 and set a “buy” rating on the stock in a research report on Monday, March 31st. Nine research analysts have rated the stock with a hold rating, twenty-six have assigned a buy rating and one has assigned a strong buy rating to the stock. Based on data from MarketBeat, the stock presently has an average rating of “Moderate Buy” and a consensus price target of $281.35.
Get Our Latest Stock Analysis on MDB
MongoDB Price Performance
Shares of NASDAQ MDB opened at $221.21 on Friday. The stock has a market capitalization of $18.08 billion, a P/E ratio of -194.04 and a beta of 1.41. The company has a 50-day moving average price of $202.71 and a 200-day moving average price of $213.05. MongoDB, Inc. has a 1 year low of $140.78 and a 1 year high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 earnings per share (EPS) for the quarter, beating analysts’ consensus estimates of $0.65 by $0.35. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. The firm had revenue of $549.01 million during the quarter, compared to analysts’ expectations of $527.49 million. During the same period last year, the company earned $0.51 earnings per share. The business’s revenue was up 21.8% on a year-over-year basis. As a group, equities research analysts anticipate that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Just getting into the stock market? These 10 simple stocks can help beginning investors build long-term wealth without knowing options, technicals, or other advanced strategies.
MMS • RSS
![]() Stock analysts at Stephens started coverage on shares of MongoDB (NASDAQ:MDB – Get Free Report) in a report issued on Friday, MarketBeat reports. The brokerage set an “equal weight” rating and a $247.00 price target on the stock. Stephens’ price target indicates a potential upside of 11.66% from the company’s current price.
Stock analysts at Stephens started coverage on shares of MongoDB (NASDAQ:MDB – Get Free Report) in a report issued on Friday, MarketBeat reports. The brokerage set an “equal weight” rating and a $247.00 price target on the stock. Stephens’ price target indicates a potential upside of 11.66% from the company’s current price.
A number of other research analysts have also commented on MDB. Needham & Company LLC reaffirmed a “buy” rating and set a $270.00 price objective on shares of MongoDB in a research report on Thursday, June 5th. Loop Capital cut shares of MongoDB from a “buy” rating to a “hold” rating and cut their price target for the stock from $350.00 to $190.00 in a research note on Tuesday, May 20th. Truist Financial cut their price target on shares of MongoDB from $300.00 to $275.00 and set a “buy” rating for the company in a research note on Monday, March 31st. Scotiabank raised their price target on shares of MongoDB from $160.00 to $230.00 and gave the stock a “sector perform” rating in a research note on Thursday, June 5th. Finally, Macquarie restated a “neutral” rating and set a $230.00 price target (up previously from $215.00) on shares of MongoDB in a research note on Friday, June 6th. Nine investment analysts have rated the stock with a hold rating, twenty-six have issued a buy rating and one has assigned a strong buy rating to the company. According to MarketBeat, MongoDB has an average rating of “Moderate Buy” and an average price target of $281.35.
View Our Latest Research Report on MDB
MongoDB Trading Up 1.2%
<!—->
Shares of NASDAQ:MDB opened at $221.21 on Friday. The stock has a market capitalization of $18.08 billion, a PE ratio of -194.04 and a beta of 1.41. MongoDB has a 1 year low of $140.78 and a 1 year high of $370.00. The firm has a fifty day moving average price of $202.71 and a 200 day moving average price of $213.05.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share for the quarter, topping analysts’ consensus estimates of $0.65 by $0.35. The firm had revenue of $549.01 million during the quarter, compared to analyst estimates of $527.49 million. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. The business’s revenue was up 21.8% on a year-over-year basis. During the same quarter in the previous year, the business earned $0.51 EPS. On average, sell-side analysts forecast that MongoDB will post -1.78 earnings per share for the current fiscal year.
Insider Buying and Selling
In related news, CEO Dev Ittycheria sold 3,747 shares of the firm’s stock in a transaction on Wednesday, July 2nd. The shares were sold at an average price of $206.05, for a total transaction of $772,069.35. Following the sale, the chief executive officer directly owned 253,227 shares in the company, valued at $52,177,423.35. This trade represents a 1.46% decrease in their ownership of the stock. The sale was disclosed in a legal filing with the SEC, which is available at this hyperlink. Also, Director Dwight A. Merriman sold 820 shares of the firm’s stock in a transaction on Wednesday, June 25th. The shares were sold at an average price of $210.84, for a total transaction of $172,888.80. Following the completion of the transaction, the director directly owned 1,106,186 shares of the company’s stock, valued at approximately $233,228,256.24. This trade represents a 0.07% decrease in their position. The disclosure for this sale can be found here. Insiders have sold a total of 32,746 shares of company stock worth $7,500,196 over the last ninety days. Company insiders own 3.10% of the company’s stock.
Institutional Inflows and Outflows
Hedge funds and other institutional investors have recently modified their holdings of the company. 111 Capital bought a new stake in shares of MongoDB during the 4th quarter worth about $390,000. Park Avenue Securities LLC boosted its holdings in shares of MongoDB by 52.6% during the 1st quarter. Park Avenue Securities LLC now owns 2,630 shares of the company’s stock worth $461,000 after buying an additional 907 shares during the period. Cambridge Investment Research Advisors Inc. boosted its holdings in shares of MongoDB by 4.0% during the 1st quarter. Cambridge Investment Research Advisors Inc. now owns 7,748 shares of the company’s stock worth $1,359,000 after buying an additional 298 shares during the period. Sowell Financial Services LLC bought a new stake in shares of MongoDB during the 1st quarter worth about $263,000. Finally, Farther Finance Advisors LLC boosted its holdings in shares of MongoDB by 57.2% during the 1st quarter. Farther Finance Advisors LLC now owns 1,242 shares of the company’s stock worth $219,000 after buying an additional 452 shares during the period. Institutional investors own 89.29% of the company’s stock.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
MongoDB (NASDAQ:MDB – Get Free Report) was upgraded by analysts at Stephens to a “hold” rating in a report released on Thursday,Zacks.com reports.
Several other analysts also recently commented on the stock. Mizuho reduced their target price on shares of MongoDB from $250.00 to $190.00 and set a “neutral” rating for the company in a report on Tuesday, April 15th. Needham & Company LLC reaffirmed a “buy” rating and set a $270.00 target price on shares of MongoDB in a report on Thursday, June 5th. Monness Crespi & Hardt raised shares of MongoDB from a “neutral” rating to a “buy” rating and set a $295.00 target price for the company in a report on Thursday, June 5th. Stifel Nicolaus reduced their target price on shares of MongoDB from $340.00 to $275.00 and set a “buy” rating for the company in a report on Friday, April 11th. Finally, Wedbush reaffirmed an “outperform” rating and set a $300.00 target price on shares of MongoDB in a report on Thursday, June 5th. Nine analysts have rated the stock with a hold rating, twenty-six have assigned a buy rating and one has issued a strong buy rating to the company. According to MarketBeat.com, the stock currently has an average rating of “Moderate Buy” and an average price target of $281.35.
View Our Latest Stock Report on MongoDB
MongoDB Stock Up 1.2%
Shares of NASDAQ:MDB opened at $221.21 on Thursday. The firm has a market cap of $18.08 billion, a price-to-earnings ratio of -194.04 and a beta of 1.41. MongoDB has a 12 month low of $140.78 and a 12 month high of $370.00. The company’s fifty day simple moving average is $202.71 and its 200 day simple moving average is $213.18.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share for the quarter, beating analysts’ consensus estimates of $0.65 by $0.35. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. The business had revenue of $549.01 million during the quarter, compared to the consensus estimate of $527.49 million. During the same quarter last year, the firm earned $0.51 earnings per share. The firm’s revenue for the quarter was up 21.8% compared to the same quarter last year. Research analysts expect that MongoDB will post -1.78 earnings per share for the current fiscal year.
Insider Activity
In other news, Director Dwight A. Merriman sold 820 shares of the company’s stock in a transaction on Wednesday, June 25th. The shares were sold at an average price of $210.84, for a total value of $172,888.80. Following the sale, the director directly owned 1,106,186 shares of the company’s stock, valued at approximately $233,228,256.24. This represents a 0.07% decrease in their position. The transaction was disclosed in a document filed with the SEC, which is available through the SEC website. Also, Director Hope F. Cochran sold 1,174 shares of the company’s stock in a transaction on Tuesday, June 17th. The shares were sold at an average price of $201.08, for a total transaction of $236,067.92. Following the completion of the sale, the director directly owned 21,096 shares in the company, valued at approximately $4,241,983.68. This represents a 5.27% decrease in their ownership of the stock. The disclosure for this sale can be found here. In the last three months, insiders have sold 32,746 shares of company stock valued at $7,500,196. 3.10% of the stock is currently owned by insiders.
Institutional Inflows and Outflows
A number of institutional investors have recently modified their holdings of the stock. 111 Capital acquired a new position in MongoDB during the fourth quarter worth $390,000. Park Avenue Securities LLC raised its holdings in MongoDB by 52.6% during the first quarter. Park Avenue Securities LLC now owns 2,630 shares of the company’s stock worth $461,000 after buying an additional 907 shares during the last quarter. Cambridge Investment Research Advisors Inc. raised its holdings in MongoDB by 4.0% during the first quarter. Cambridge Investment Research Advisors Inc. now owns 7,748 shares of the company’s stock worth $1,359,000 after buying an additional 298 shares during the last quarter. Sowell Financial Services LLC acquired a new position in MongoDB during the first quarter worth $263,000. Finally, Farther Finance Advisors LLC raised its holdings in MongoDB by 57.2% during the first quarter. Farther Finance Advisors LLC now owns 1,242 shares of the company’s stock worth $219,000 after buying an additional 452 shares during the last quarter. Institutional investors and hedge funds own 89.29% of the company’s stock.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Discover the 10 Best High-Yield Dividend Stocks for 2025 and secure reliable income in uncertain markets. Download the report now to identify top dividend payers and avoid common yield traps.
MMS • Steef-Jan Wiggers

Google Cloud has recently introduced a new feature, Cloud Storage bucket relocation, designed to simplify the process of moving data buckets to different geographical locations without disrupting applications significantly.
The way this feature works is that the name of the bucket and all associated object metadata will remain unchanged during the relocation process. This means there will be no alterations to paths, ensuring that applications experience minimal downtime while the storage is being moved. Additionally, the objects will retain their original storage class (such as Standard, Nearline, Coldline, or Archive) and will keep their time-in-class in the new location. This meticulous preservation is crucial for maintaining established data governance, ensuring the continued operation of object lifecycle management rules, and simplifying application integration, as no changes to access paths or configurations are required after migration.
The new bucket relocation capability is integrated within Google Cloud’s Storage Intelligence suite, working alongside tools like Storage Insights, which offer deep visibility into storage landscapes and identify optimization opportunities. Vaibhav Khunger, a senior product manager, Google Cloud, explains the synergy:
Bucket relocation then lets you act on these insights, and move your data between diverse Cloud Storage locations — regional locations for low latency, dual-regions for high availability and disaster recovery, or multi-regions for global accessibility.
Bucket relocation employs two key techniques: asynchronous data copy and metadata preservation. The asynchronous data copy enables data transfer in the background, minimizing disruptions to ongoing operations such as writing, reading, and updating. On the other hand, Metadata preservation ensures that all associated information, including storage class, bucket, and object names, timestamps, access control permissions, and custom metadata, is seamlessly transferred without alteration. This approach reduces risks and overhead typically involved in manual migrations, allowing applications to function without modifications, as the bucket name remains unchanged throughout the process.
Abdel Shiouar, a Google senior cloud developer advocate, comments on LinkedIn:
While Google Cloud Storage had a transfer service for a while, it did not help moving and preserving some metadata (lifecycle for example). The relocation feature is an industry unique non-disruptive bucket migrations tool that syncs up the source and destination and help move metadata including any custom ones.
While the non-disruptive nature of bucket relocation offers significant advantages, some early community discussions have highlighted potential considerations regarding its pricing model and administrative overhead for certain organizational structures. A Reddit user commented:
Definitely neat, but the list of billed items is unfortunate (per GiB for the relocation, per GiB for egress, per GiB for replication, class A operation per object, Management hub subscription per million objects). Granted, the delta between do-it-yourself and this is the per GiB for relocation and the Management hub subscription, but that per GiB for relocation will add up quickly and management hub being a per org subscription could trip things up bureaucratically – e.g., if I’m in a product team I’ll need to hunt down the org admin to turn on management hub and then ensure they set it up to only include my bucket so we don’t get hit with a potentially huge bill and only then can I relocate my bucket… It’s just unfortunate.
Lastly, users can learn more through the bucket relocation documentation and the Storage Intelligence overview.
MMS • RSS
In a bold outlook, Dan Ives, the global technology head at Wedbush Securities, suggests that Microsoft and Nvidia are poised for remarkable growth due to advancements in artificial intelligence (AI). Ives foresees that these technological giants could achieve a combined market value of $5 trillion by next year, driven by their innovative strides in AI.
A surge in AI applications heralds a transformative period for key technology firms. Microsoft is at the forefront of this innovation under the guidance of CEO Satya Nadella, while Nvidia continues to align with AI trends. These developments signal a potential leap in market value for both companies.
Ives highlights other promising firms within the software sector poised to benefit from AI gains. Palantir, MongoDB, Snowflake, and IBM are seen as key players likely to see significant growth due to their focus on generating revenue through AI and data technologies.
In recent years, technological advances have not fully translated into stock performance, but the rise in AI usage is expected to shift this trend. The increased demand for cybersecurity and data-concentrated solutions hints at a promising horizon for companies heavily invested in these areas, potentially leading to elevated market valuations and long-term profitability if current conditions sustain.
These projections also impact the cryptocurrency market. Seen parallel to tech stocks, cryptocurrencies might witness increased interest as companies like Nvidia and Microsoft show significant valuation growth. AI-related cryptocurrencies could benefit from this positive shift, marking them as crucial players in the evolving financial landscape.
The influence of AI and rapid technological progression sets the stage for potential growth in market value among established tech leaders. Investors are keenly observing both giants and software-specialized entities. As new technologies are integrated, the consequential effects across various economic indicators suggest a promising future for strategically driven tech firms.
In the first half of 2025, the technology sector witnessed significant shifts, with Nvidia and Microsoft emerging as standout performers. The year began with a series of events that initially rattled the market, including the release of the ‘DeepSeek’ chatbot by a company, which sparked concerns about potential dominance in artificial intelligence. This development led to swift losses for AI leaders such as Nvidia, Alphabet, Arm Holdings, and Advanced Micro Devices. However, the market’s resilience became evident as it quickly recovered from these shocks.
One of the key drivers of Nvidia’s surge was its strong performance in the AI sector, particularly in data centers and enterprise solutions. The company’s stock price jumped by over 80% in less than four months, briefly reclaiming its position as the world’s most valuable company. This remarkable growth was fueled by investor optimism surrounding the AI outlook and the easing of trade policies. Nvidia’s market capitalization reached $4 trillion, surpassing Microsoft, which had a market cap of $19.4 billion with a trailing price-earnings ratio of 27.38x. Microsoft’s revenue was projected to grow by 5% this year and an additional 6.08% the following year.
The valuation race between Nvidia and Microsoft intensified as Nvidia’s shares rose by 17% in June, outpacing Microsoft in market capitalization. This surge was partly attributed to a meeting between Nvidia’s CEO, Jensen Huang, and the Commerce Chief, which signaled a potential easing of trade tensions and bolstered investor confidence. Analysts weighed the prospects of Nvidia’s continued dominance in the AI sector, with some predicting that the company could maintain its top spot for the near future. However, there were also warnings that Nvidia’s stock might be ‘overheating,’ given its rapid ascent.
Despite these concerns, the overall sentiment remained bullish. Nvidia’s upcoming earnings report, expected on August 27, 2025, was anticipated to show an EPS of $0.99, marking a 45.59% rise compared to the same quarter of the previous year. This positive outlook, coupled with the company’s strong performance in data center sales and its leadership in AI technology, positioned Nvidia as a formidable player in the tech industry. The market’s resilience and the easing of trade policies provided a favorable environment for both Nvidia and Microsoft to continue their upward trajectory, solidifying their positions as leaders in the technology sector.

Mdb Capital Holdings, Llc shares fall 2.22% intraday after Stephens initiates MongoDB at …
MMS • RSS
Disclaimer: The news articles available on this platform are generated in whole or in part by artificial intelligence and may not have been reviewed or fact checked by human editors. While we make reasonable efforts to ensure the quality and accuracy of the content, we make no representations or warranties, express or implied, as to the truthfulness, reliability, completeness, or timeliness of any information provided. It is your sole responsibility to independently verify any facts, statements, or claims prior to acting upon them. Ainvest Fintech Inc expressly disclaims all liability for any loss, damage, or harm arising from the use of or reliance on AI-generated content, including but not limited to direct, indirect, incidental, or consequential damages.
MMS • RSS
Bridgewater Advisors Inc. acquired a new stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) during the 1st quarter, according to its most recent disclosure with the Securities and Exchange Commission. The fund acquired 1,158 shares of the company’s stock, valued at approximately $202,000.
A number of other institutional investors have also modified their holdings of the company. Wealthfront Advisers LLC lifted its holdings in shares of MongoDB by 4.1% during the 1st quarter. Wealthfront Advisers LLC now owns 4,511 shares of the company’s stock valued at $791,000 after acquiring an additional 179 shares in the last quarter. Massachusetts Financial Services Co. MA purchased a new position in MongoDB in the first quarter valued at about $14,376,000. OVERSEA CHINESE BANKING Corp Ltd lifted its stake in shares of MongoDB by 14.1% during the first quarter. OVERSEA CHINESE BANKING Corp Ltd now owns 19,206 shares of the company’s stock worth $3,369,000 after purchasing an additional 2,371 shares in the last quarter. Signaturefd LLC grew its stake in shares of MongoDB by 24.1% in the first quarter. Signaturefd LLC now owns 1,754 shares of the company’s stock valued at $308,000 after buying an additional 341 shares in the last quarter. Finally, UNICOM Systems Inc. raised its holdings in shares of MongoDB by 116.7% during the 1st quarter. UNICOM Systems Inc. now owns 45,500 shares of the company’s stock valued at $7,981,000 after buying an additional 24,500 shares during the period. Hedge funds and other institutional investors own 89.29% of the company’s stock.
Wall Street Analyst Weigh In
A number of equities analysts have weighed in on MDB shares. Needham & Company LLC restated a “buy” rating and issued a $270.00 price target on shares of MongoDB in a report on Thursday, June 5th. Royal Bank Of Canada reaffirmed an “outperform” rating and set a $320.00 price target on shares of MongoDB in a report on Thursday, June 5th. Piper Sandler lifted their price target on shares of MongoDB from $200.00 to $275.00 and gave the stock an “overweight” rating in a research note on Thursday, June 5th. Stephens started coverage on shares of MongoDB in a report on Friday. They issued an “equal weight” rating and a $247.00 price objective on the stock. Finally, Truist Financial lowered their target price on MongoDB from $300.00 to $275.00 and set a “buy” rating for the company in a research note on Monday, March 31st. Nine analysts have rated the stock with a hold rating, twenty-six have issued a buy rating and one has assigned a strong buy rating to the stock. According to MarketBeat, the company presently has an average rating of “Moderate Buy” and a consensus target price of $281.35.
Get Our Latest Research Report on MongoDB
MongoDB Trading Up 1.2%
NASDAQ:MDB traded up $2.68 during midday trading on Friday, reaching $221.21. 1,822,164 shares of the company traded hands, compared to its average volume of 1,984,265. The company has a fifty day moving average price of $202.71 and a 200 day moving average price of $213.18. MongoDB, Inc. has a twelve month low of $140.78 and a twelve month high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share (EPS) for the quarter, beating the consensus estimate of $0.65 by $0.35. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. The company had revenue of $549.01 million during the quarter, compared to the consensus estimate of $527.49 million. During the same quarter in the previous year, the company posted $0.51 earnings per share. The company’s revenue for the quarter was up 21.8% compared to the same quarter last year. Equities research analysts predict that MongoDB, Inc. will post -1.78 EPS for the current year.
Insider Buying and Selling at MongoDB
In other news, Director Hope F. Cochran sold 1,174 shares of the business’s stock in a transaction that occurred on Tuesday, June 17th. The stock was sold at an average price of $201.08, for a total transaction of $236,067.92. Following the completion of the transaction, the director directly owned 21,096 shares in the company, valued at approximately $4,241,983.68. The trade was a 5.27% decrease in their ownership of the stock. The sale was disclosed in a filing with the SEC, which is accessible through the SEC website. Also, CEO Dev Ittycheria sold 3,747 shares of the stock in a transaction that occurred on Wednesday, July 2nd. The stock was sold at an average price of $206.05, for a total value of $772,069.35. Following the completion of the transaction, the chief executive officer directly owned 253,227 shares of the company’s stock, valued at $52,177,423.35. This trade represents a 1.46% decrease in their ownership of the stock. The disclosure for this sale can be found here. Over the last 90 days, insiders have sold 32,746 shares of company stock worth $7,500,196. 3.10% of the stock is owned by company insiders.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Explore Elon Musk’s boldest ventures yet—from AI and autonomy to space colonization—and find out how investors can ride the next wave of innovation.
MMS • RSS
Stephens initiated coverage on shares of MongoDB (NASDAQ:MDB – Get Free Report) in a research report issued to clients and investors on Friday, Marketbeat.com reports. The firm set an “equal weight” rating and a $247.00 price target on the stock. Stephens’ target price indicates a potential upside of 12.08% from the stock’s previous close.
Several other brokerages also recently weighed in on MDB. Royal Bank Of Canada reissued an “outperform” rating and set a $320.00 price target on shares of MongoDB in a research report on Thursday, June 5th. Guggenheim raised their price target on shares of MongoDB from $235.00 to $260.00 and gave the company a “buy” rating in a research report on Thursday, June 5th. Wedbush reaffirmed an “outperform” rating and issued a $300.00 target price on shares of MongoDB in a report on Thursday, June 5th. Monness Crespi & Hardt raised MongoDB from a “neutral” rating to a “buy” rating and set a $295.00 target price on the stock in a report on Thursday, June 5th. Finally, William Blair reaffirmed an “outperform” rating on shares of MongoDB in a report on Thursday, June 26th. Nine research analysts have rated the stock with a hold rating, twenty-six have given a buy rating and one has issued a strong buy rating to the company. According to MarketBeat, the stock has an average rating of “Moderate Buy” and a consensus target price of $281.35.
Check Out Our Latest Analysis on MDB
MongoDB Trading Up 5.1%
MongoDB stock opened at $220.38 on Friday. MongoDB has a 12 month low of $140.78 and a 12 month high of $370.00. The business’s 50 day simple moving average is $201.86 and its 200 day simple moving average is $213.26. The company has a market cap of $18.01 billion, a price-to-earnings ratio of -193.32 and a beta of 1.41.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 EPS for the quarter, topping the consensus estimate of $0.65 by $0.35. MongoDB had a negative net margin of 4.09% and a negative return on equity of 3.16%. The business had revenue of $549.01 million during the quarter, compared to analyst estimates of $527.49 million. During the same period last year, the business posted $0.51 earnings per share. MongoDB’s quarterly revenue was up 21.8% compared to the same quarter last year. As a group, equities research analysts forecast that MongoDB will post -1.78 earnings per share for the current fiscal year.
Insider Buying and Selling
In related news, CEO Dev Ittycheria sold 3,747 shares of the company’s stock in a transaction that occurred on Wednesday, July 2nd. The shares were sold at an average price of $206.05, for a total transaction of $772,069.35. Following the sale, the chief executive officer directly owned 253,227 shares of the company’s stock, valued at $52,177,423.35. This represents a 1.46% decrease in their position. The sale was disclosed in a filing with the Securities & Exchange Commission, which is accessible through this hyperlink. Also, Director Hope F. Cochran sold 1,174 shares of the company’s stock in a transaction that occurred on Tuesday, June 17th. The stock was sold at an average price of $201.08, for a total transaction of $236,067.92. Following the sale, the director directly owned 21,096 shares in the company, valued at approximately $4,241,983.68. The trade was a 5.27% decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold a total of 32,746 shares of company stock valued at $7,500,196 in the last ninety days. Company insiders own 3.10% of the company’s stock.
Institutional Inflows and Outflows
Several large investors have recently modified their holdings of MDB. OneDigital Investment Advisors LLC boosted its stake in MongoDB by 3.9% during the 4th quarter. OneDigital Investment Advisors LLC now owns 1,044 shares of the company’s stock worth $243,000 after purchasing an additional 39 shares during the period. Handelsbanken Fonder AB increased its holdings in shares of MongoDB by 0.4% in the 1st quarter. Handelsbanken Fonder AB now owns 14,816 shares of the company’s stock valued at $2,599,000 after purchasing an additional 65 shares in the last quarter. O Shaughnessy Asset Management LLC increased its holdings in shares of MongoDB by 4.8% in the 4th quarter. O Shaughnessy Asset Management LLC now owns 1,647 shares of the company’s stock valued at $383,000 after purchasing an additional 75 shares in the last quarter. Wedbush Securities Inc. increased its holdings in shares of MongoDB by 2.6% in the 1st quarter. Wedbush Securities Inc. now owns 3,022 shares of the company’s stock valued at $530,000 after purchasing an additional 77 shares in the last quarter. Finally, Fifth Third Bancorp increased its holdings in shares of MongoDB by 15.9% in the 1st quarter. Fifth Third Bancorp now owns 569 shares of the company’s stock valued at $100,000 after purchasing an additional 78 shares in the last quarter. Institutional investors and hedge funds own 89.29% of the company’s stock.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Thinking about investing in Meta, Roblox, or Unity? Enter your email to learn what streetwise investors need to know about the metaverse and public markets before making an investment.
MMS • RSS
![]() Nisa Investment Advisors LLC cut its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 86.1% during the first quarter, according to the company in its most recent filing with the Securities & Exchange Commission. The institutional investor owned 800 shares of the company’s stock after selling 4,955 shares during the quarter. Nisa Investment Advisors LLC’s holdings in MongoDB were worth $140,000 as of its most recent SEC filing.
Nisa Investment Advisors LLC cut its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 86.1% during the first quarter, according to the company in its most recent filing with the Securities & Exchange Commission. The institutional investor owned 800 shares of the company’s stock after selling 4,955 shares during the quarter. Nisa Investment Advisors LLC’s holdings in MongoDB were worth $140,000 as of its most recent SEC filing.
A number of other hedge funds and other institutional investors have also modified their holdings of the company. HighTower Advisors LLC grew its position in MongoDB by 2.0% during the 4th quarter. HighTower Advisors LLC now owns 18,773 shares of the company’s stock worth $4,371,000 after purchasing an additional 372 shares during the last quarter. 111 Capital acquired a new stake in shares of MongoDB in the fourth quarter valued at about $390,000. Park Avenue Securities LLC raised its position in MongoDB by 52.6% during the first quarter. Park Avenue Securities LLC now owns 2,630 shares of the company’s stock worth $461,000 after acquiring an additional 907 shares during the last quarter. Cambridge Investment Research Advisors Inc. raised its position in MongoDB by 4.0% during the first quarter. Cambridge Investment Research Advisors Inc. now owns 7,748 shares of the company’s stock worth $1,359,000 after acquiring an additional 298 shares during the last quarter. Finally, Sowell Financial Services LLC acquired a new position in shares of MongoDB in the first quarter valued at approximately $263,000. 89.29% of the stock is currently owned by institutional investors and hedge funds.
Insider Buying and Selling at MongoDB
In other MongoDB news, CEO Dev Ittycheria sold 3,747 shares of the stock in a transaction on Wednesday, July 2nd. The stock was sold at an average price of $206.05, for a total transaction of $772,069.35. Following the sale, the chief executive officer owned 253,227 shares of the company’s stock, valued at approximately $52,177,423.35. This trade represents a 1.46% decrease in their position. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which can be accessed through this hyperlink. Also, Director Hope F. Cochran sold 1,174 shares of MongoDB stock in a transaction dated Tuesday, June 17th. The stock was sold at an average price of $201.08, for a total value of $236,067.92. Following the sale, the director directly owned 21,096 shares of the company’s stock, valued at approximately $4,241,983.68. This represents a 5.27% decrease in their position. The disclosure for this sale can be found here. Over the last quarter, insiders sold 32,746 shares of company stock valued at $7,500,196. Company insiders own 3.10% of the company’s stock.
MongoDB Stock Up 4.2%
<!—->
NASDAQ:MDB opened at $218.53 on Friday. The stock has a market cap of $17.86 billion, a P/E ratio of -191.69 and a beta of 1.41. The business’s 50-day moving average price is $201.86 and its two-hundred day moving average price is $213.26. MongoDB, Inc. has a twelve month low of $140.78 and a twelve month high of $370.00.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Wednesday, June 4th. The company reported $1.00 EPS for the quarter, beating analysts’ consensus estimates of $0.65 by $0.35. The company had revenue of $549.01 million during the quarter, compared to analysts’ expectations of $527.49 million. MongoDB had a negative return on equity of 3.16% and a negative net margin of 4.09%. The firm’s revenue for the quarter was up 21.8% compared to the same quarter last year. During the same quarter last year, the business posted $0.51 EPS. On average, equities research analysts expect that MongoDB, Inc. will post -1.78 EPS for the current fiscal year.
Wall Street Analyst Weigh In
Several equities analysts recently commented on the stock. UBS Group upped their price target on shares of MongoDB from $213.00 to $240.00 and gave the stock a “neutral” rating in a research report on Thursday, June 5th. Barclays upped their price target on shares of MongoDB from $252.00 to $270.00 and gave the company an “overweight” rating in a report on Thursday, June 5th. Stifel Nicolaus dropped their target price on shares of MongoDB from $340.00 to $275.00 and set a “buy” rating on the stock in a report on Friday, April 11th. Redburn Atlantic raised shares of MongoDB from a “sell” rating to a “neutral” rating and set a $170.00 price objective on the stock in a report on Thursday, April 17th. Finally, Monness Crespi & Hardt upgraded shares of MongoDB from a “neutral” rating to a “buy” rating and set a $295.00 target price for the company in a research report on Thursday, June 5th. Eight research analysts have rated the stock with a hold rating, twenty-six have issued a buy rating and one has issued a strong buy rating to the company’s stock. According to MarketBeat, the stock currently has an average rating of “Moderate Buy” and an average price target of $282.39.
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
On July 18, 2025, MongoDB (MDB, Financial) was the subject of a new coverage initiation by the analyst Brett Huff from Stephens & Co. The firm has announced a price target for MongoDB at USD 247.00, marking the first time this specific target has been set.
The rating assigned to MongoDB (MDB, Financial) by Stephens & Co. is “Equal-Weight.” This rating suggests that the analyst sees the stock’s performance aligning with the average returns expected from the market.
This move comes as Stephens & Co. begins its formal analysis of MongoDB (MDB, Financial), providing investors and market watchers with a fresh perspective on the company’s valuation and market position.
Wall Street Analysts Forecast
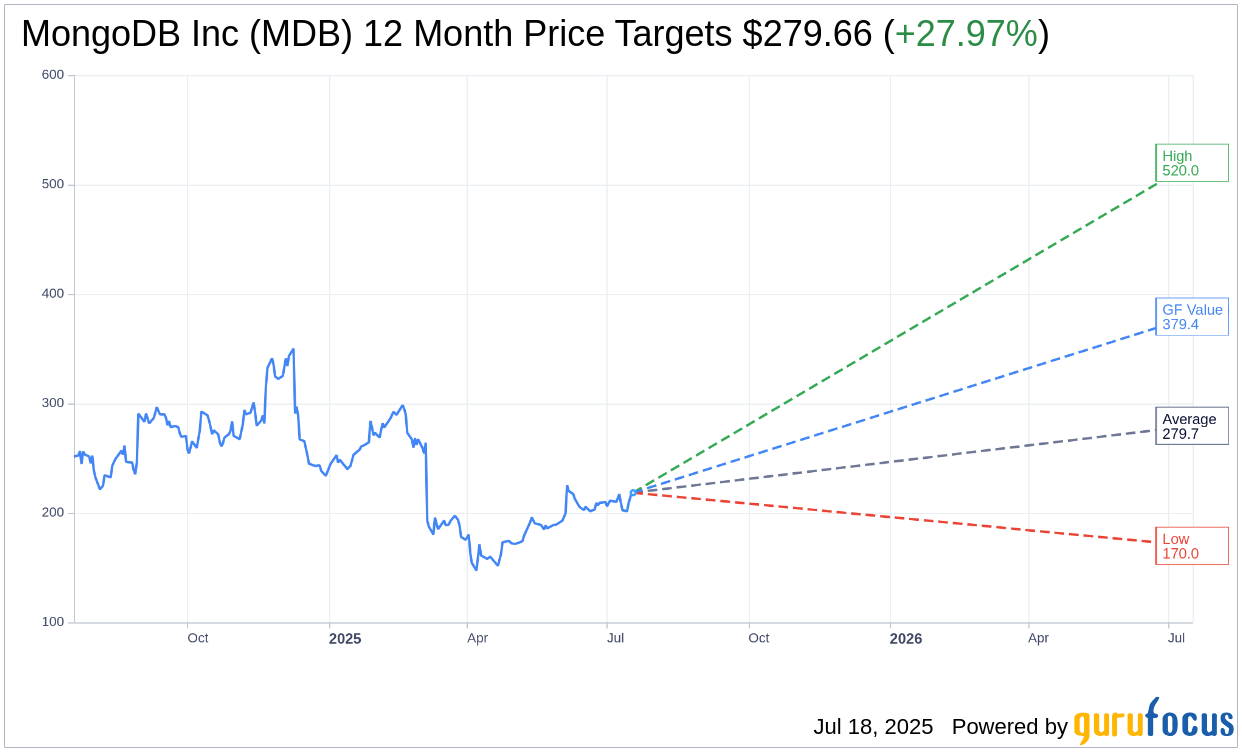
Based on the one-year price targets offered by 36 analysts, the average target price for MongoDB Inc (MDB, Financial) is $279.66 with a high estimate of $520.00 and a low estimate of $170.00. The average target implies an
upside of 27.97%
from the current price of $218.53. More detailed estimate data can be found on the MongoDB Inc (MDB) Forecast page.
Based on the consensus recommendation from 37 brokerage firms, MongoDB Inc’s (MDB, Financial) average brokerage recommendation is currently 1.9, indicating “Outperform” status. The rating scale ranges from 1 to 5, where 1 signifies Strong Buy, and 5 denotes Sell.
Based on GuruFocus estimates, the estimated GF Value for MongoDB Inc (MDB, Financial) in one year is $379.42, suggesting a
upside
of 73.62% from the current price of $218.53. GF Value is GuruFocus’ estimate of the fair value that the stock should be traded at. It is calculated based on the historical multiples the stock has traded at previously, as well as past business growth and the future estimates of the business’ performance. More detailed data can be found on the MongoDB Inc (MDB) Summary page.
Comments
Add a public comment…
No comments yet