Category: Uncategorized

MMS • Ben Linders

Security can clash with development efficiency. Focusing on minimizing breach impact can be more effective than prevention. Dorota Parad argues for flexibility in compliance and collaborating with security teams to define practical protections. Limiting blast radius and using automation can boost security with minimal productivity loss.
At QCon San Francisco, Dorota Parad presented how to build secure software without sacrificing productivity.
Security can be at odds with a fast and efficient development process. Focusing on minimizing the impact of breaches can be more effective than trying to prevent the breach in the first place. In Ensuring Security without Harming Software Development Productivity, Dorota Parad explored creating a foundation for security without negatively impacting engineering productivity.
Parad suggested pushing back on security mandates, as they can hinder productivity. This starts with understanding where those mandates are coming from:
The job of a CISO and your security team is very rarely about security; they are there to ensure compliance. Contrary to popular opinion, compliance doesn’t just mean mindlessly ticking checkboxes, the checkboxes are just (one) means to an end.
It all boils down to crafting a narrative that will convince third-party stakeholders – auditors, regulators, insurance companies – that your company does a good enough job minimizing security risks, Parad said.
None of the security certifications or regulations are prescriptive; it is up to your company to define the scope, means, and implementation, Parad said. It can be a daunting task, so it may be tempting to optimize for the ease of audits and do something like force invasive MDM (mobile device management) software without considering how it will affect engineers’ productivity, she added.
If you want to get rid of some of the more annoying mandates, you need to start a dialog with your security team and help them craft that convincing narrative they’re after, Parad suggested. This means documenting how you think about risks in your area, what you’re doing to reduce the blast radius of breaches, what levels of protection you have in place, and how you’re minimizing the impact of incidents.
Parad explored what can be done to minimize the impact of security breaches. She gave the example of a common threat: a malicious actor getting their hands on one of our engineer’s cloud account credentials:
What’s the worst that can happen here? If we applied the principle of bulkheads, then those credentials are limited in scope to a single cloud account, which may or may not host our production environment.
Parad mentioned that if we utilize modern software development practices, the access would be limited to read-only and innocuous configuration changes, since resource creation and deletion would be automated and only permitted as part of CI/CD pipeline.
If that account includes access to a database containing user data, and if we applied proper encryption, the data is effectively useless to the attacker, Parad added.
Trying to prevent the incident would be a prohibitively costly endeavor, involving multiple remediations to account for all the different attack vectors, Parad said. Limiting the impact is a holistic solution that doesn’t take as much effort or cost, and often comes with additional benefits of increased robustness, she concluded.
InfoQ interviewed Dorota Parad about how security and engineering productivity can go together.
InfoQ: What’s your approach to pushing back on security mandates that hinder productivity?
Dorota Parad: You can only push back on mandates if you have an alternative way to minimize security risks. This is where the BLISS framework (bulkheads, levels, impact, simplicity, and pit of success) helps, by offering an alternative that doesn’t get in your engineers’ way. With Bliss, you can make your security strategy almost invisible to the engineers while embedding it deep into the culture at the same time, Parad said
InfoQ: Can a CI/CD pipeline be considered a security practice?
Parad: This sometimes raises eyebrows among security folks, but yes, I consider a CI/CD pipeline a security tool. Implemented properly, it severely reduces the risk of malicious code ending up in your production.
A typical build/deployment pipeline involves increasingly strict levels of protection the closer to production the code gets – we start with git access controls to make a commit, then developer credentials to create a pull request, we have automated testing that may catch some issues, and finally a second set of credentials and a human review to merge. That’s a very powerful way to minimize security risks.
InfoQ: How can we increase security with a CI/CD pipeline?
Parad: Every single piece of code needs to go through that pipeline in order to reach production, no exceptions. No manual tinkering to push the build through, no bypassing of steps, no logging onto the servers to copy files or run some scripts.
The only way to achieve that in practice is by keeping your CI/CD pipelines healthy and robust, so that they only fail when something is truly wrong. Flaky pipelines are the enemy of both security and productivity.
MMS • RSS
Welch & Forbes LLC boosted its holdings in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 27.3% during the 1st quarter, according to the company in its most recent disclosure with the Securities and Exchange Commission. The institutional investor owned 30,948 shares of the company’s stock after acquiring an additional 6,630 shares during the quarter. Welch & Forbes LLC’s holdings in MongoDB were worth $5,428,000 as of its most recent SEC filing.
Other institutional investors and hedge funds have also recently bought and sold shares of the company. Cloud Capital Management LLC acquired a new stake in MongoDB during the 1st quarter worth about $25,000. Cullen Frost Bankers Inc. grew its stake in MongoDB by 315.8% during the 1st quarter. Cullen Frost Bankers Inc. now owns 158 shares of the company’s stock valued at $28,000 after acquiring an additional 120 shares in the last quarter. Strategic Investment Solutions Inc. IL purchased a new position in MongoDB during the 4th quarter valued at about $29,000. Coppell Advisory Solutions LLC grew its stake in MongoDB by 364.0% during the 4th quarter. Coppell Advisory Solutions LLC now owns 232 shares of the company’s stock valued at $54,000 after acquiring an additional 182 shares in the last quarter. Finally, Aster Capital Management DIFC Ltd purchased a new position in MongoDB during the 4th quarter valued at about $97,000. Institutional investors and hedge funds own 89.29% of the company’s stock.
MongoDB Trading Up 4.2%
Shares of NASDAQ:MDB traded up $8.89 during trading on Thursday, hitting $218.53. 2,240,733 shares of the company’s stock traded hands, compared to its average volume of 1,983,121. MongoDB, Inc. has a 52 week low of $140.78 and a 52 week high of $370.00. The company has a market cap of $17.86 billion, a price-to-earnings ratio of -191.69 and a beta of 1.41. The company has a 50-day moving average price of $201.86 and a 200-day moving average price of $213.26.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 earnings per share for the quarter, beating the consensus estimate of $0.65 by $0.35. MongoDB had a negative return on equity of 3.16% and a negative net margin of 4.09%. The business had revenue of $549.01 million for the quarter, compared to analysts’ expectations of $527.49 million. During the same quarter in the previous year, the business posted $0.51 EPS. MongoDB’s revenue for the quarter was up 21.8% on a year-over-year basis. On average, analysts predict that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
Analyst Upgrades and Downgrades
Several equities analysts have weighed in on MDB shares. Truist Financial lowered their target price on MongoDB from $300.00 to $275.00 and set a “buy” rating on the stock in a research note on Monday, March 31st. UBS Group lifted their target price on MongoDB from $213.00 to $240.00 and gave the company a “neutral” rating in a research note on Thursday, June 5th. Bank of America boosted their price target on MongoDB from $215.00 to $275.00 and gave the company a “buy” rating in a research note on Thursday, June 5th. Royal Bank Of Canada reaffirmed an “outperform” rating and set a $320.00 target price on shares of MongoDB in a research report on Thursday, June 5th. Finally, Wolfe Research began coverage on MongoDB in a research report on Wednesday, July 9th. They set an “outperform” rating and a $280.00 target price for the company. Eight investment analysts have rated the stock with a hold rating, twenty-six have given a buy rating and one has issued a strong buy rating to the company’s stock. According to data from MarketBeat, the company has an average rating of “Moderate Buy” and an average target price of $282.39.
Check Out Our Latest Stock Report on MDB
Insider Buying and Selling at MongoDB
In other MongoDB news, Director Hope F. Cochran sold 1,174 shares of the business’s stock in a transaction that occurred on Tuesday, June 17th. The stock was sold at an average price of $201.08, for a total transaction of $236,067.92. Following the transaction, the director owned 21,096 shares of the company’s stock, valued at $4,241,983.68. The trade was a 5.27% decrease in their position. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is available through this link. Also, Director Dwight A. Merriman sold 820 shares of the business’s stock in a transaction that occurred on Wednesday, June 25th. The stock was sold at an average price of $210.84, for a total value of $172,888.80. Following the transaction, the director directly owned 1,106,186 shares in the company, valued at $233,228,256.24. The trade was a 0.07% decrease in their ownership of the stock. The disclosure for this sale can be found here. In the last quarter, insiders have sold 32,746 shares of company stock worth $7,500,196. Corporate insiders own 3.10% of the company’s stock.
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Learn the basics of options trading and how to use them to boost returns and manage risk with this free report from MarketBeat. Click the link below to get your free copy.
MMS • RSS

On July 16, 2025, MongoDB’s trading volume reached $331 million, marking a 33.62% decrease from the previous day. The stock ranked 318th in terms of trading volume for the day. MongoDB (MDB) rose by 0.47%, marking its second consecutive day of gains, with a total increase of 4.02% over the past two days.
On July 15, 2025, MongoDB Inc (MDB) experienced a significant surge in its stock price, reaching an intraday high of $210.78 before closing at $210.25, up from its previous close of $210.25. This price movement places MDB 43.18% below its 52-week high of $370.00 and 49.35% above its 52-week low of $140.78. The trading volume for the day was 878,370 shares, which is 33.1% of the average daily volume of 2,653,057 shares.
Analysts have provided one-year price targets for MongoDB Inc, with an average target price of $279.66. This target implies a potential upside of 33.01% from the current price of $210.25. The high estimate for the target price is $520.00, while the low estimate is $170.00. Additionally, based on the consensus recommendation from 38 brokerage firms, MongoDB Inc’s average brokerage recommendation is currently 1.9, indicating an “Outperform” status. The rating scale ranges from 1 to 5, where 1 signifies a Strong Buy and 5 denotes a Sell.
GuruFocus estimates the GF Value for MongoDB Inc in one year to be $379.42, suggesting an upside of 80.46% from the current price of $210.25. The GF Value is an estimate of the fair value at which the stock should be traded, calculated based on historical trading multiples, past business growth, and future performance estimates.
MMS • RSS

Table of Contents
Oracle released its second quarterly edition of this year’s Critical Patch Update. The update received patches for 309 security vulnerabilities. Some of the vulnerabilities addressed in this update impact more than one product. These patches address vulnerabilities in various product families, including third-party components in Oracle products.
In this quarterly Oracle Critical Patch Update, Oracle Communications received the highest number of patches, 84, constituting about 27% of the total patches released. Oracle MySQL and Oracle Fusion Middleware followed, with 40 and 36 security patches.
228 of the 309 security patches provided by the April Critical Patch Update (about 74%) are for non-Oracle CVEs, such as open-source components included and exploitable in the context of their Oracle product distributions.
This batch of security patches received 15 updates for Oracle Database products. The following is the product-wise distribution:
- Six new security updates for Oracle Database Server with a maximum reported CVSS Base Score of 8.8.
- One of these updates applies to client-only deployments of the Oracle Database.
- One new security update for Oracle Application Express with a maximum reported CVSS Base Score of 9.0.
- One new security update for Oracle Blockchain Platform with a maximum reported CVSS Base Score of 6.5.
- Five new security updates for Oracle GoldenGate with a maximum reported CVSS Base Score of 7.5.
- One new security update for Oracle NoSQL Database with a maximum reported CVSS Base Score of 3.7.
- One new security update for Oracle REST Data Services with a maximum reported CVSS Base Score of 6.1.
In these security updates, Oracle has covered product families, including Oracle Database Server, Oracle Application Express, Oracle Blockchain Platform, Oracle GoldenGate, Oracle NoSQL Database, Oracle REST Data Services, Oracle Commerce, Oracle Communications Applications, Oracle Communications, Oracle Construction and Engineering, Oracle E-Business Suite, Oracle Enterprise Manager, Oracle Financial Services Applications, Oracle Fusion Middleware, Oracle Analytics, Oracle HealthCare Applications, Oracle Hospitality Applications, Oracle Hyperion, Oracle Insurance Applications, Oracle Java SE, Oracle JD Edwards, Oracle MySQL, Oracle PeopleSoft, Oracle Retail Applications, Oracle Siebel CRM, Oracle Supply Chain, Oracle Utilities Applications, Oracle Virtualization.
Qualys QID Coverage
Qualys has released the following QIDS mentioned in the table:
| QIDs | Title |
| 20487 | Oracle Database 21c Critical Patch Update – July 2025 |
| 20488 | Oracle Database 19c Critical Patch Update – July 2025 |
| 20490 | Oracle MySQL Server July 2025 Critical Patch Update (CPUJUL2025) |
| 383578 | Oracle Java Standard Edition (SE) Critical Patch Update – July 2025 (CPUJUL2025) |
| 383580 | Oracle Coherence July 2025 Security Patch Update (CPUJUL2025) |
| 383586 | Oracle Managed Virtualization (VM) VirtualBox Multiple Security Vulnerabilities (CPUJUL2025) |
| 296127 | Oracle Solaris 11.4 Support Repository Update (SRU) 83.195.1 Missing (CPUJUL2025) |
| 87583 | Oracle WebLogic Server Multiple Vulnerabilities (CPUJUL2025) |
Note: The table will be updated with additional QIDs once released.
Notable Oracle Vulnerabilities Patched
Oracle Communications
This Critical Patch Update for Oracle Communications received 84 security patches. Out of these, 50 vulnerabilities can be exploited over a network without user credentials.
CVE-2024-25638, CVE-2025-48734, CVE-2024-47606, CVE-2024-1135, CVE-2025-23016, CVE-2025-27363, and CVE-2023-27349 in different Oracle Communications products have high severity ratings.
Oracle MySQL
This Critical Patch Update for Oracle MySQL received 40 security patches. Out of these, three vulnerabilities can be exploited over a network without user credentials.
CVE-2024-9287 and CVE-2025-32415 in MySQL Workbench have high severity ratings. An attacker may exploit these vulnerabilities without privileges in a low-complexity network attack.
Oracle Fusion Middleware
This Critical Patch Update for Oracle Fusion Middleware received 36 security patches. Out of these, 22 vulnerabilities can be exploited over a network without user credentials.
CVE-2025-31651 and CVE-2024-52046 in different Oracle Fusion Middleware products have critical severity ratings with a CVSS score of 9.8. A remote attacker may exploit these vulnerabilities without privileges in a low-complexity network attack.
Oracle Communications Applications
This Critical Patch Update for Oracle Communications Applications received 29 security patches. One of the vulnerabilities can be exploited over a network without user credentials.
CVE-2025-48734 and CVE-2024-56406 in different Oracle Communications Applications products have high severity ratings with a CVSS score of 8.8 and 8.6. A remote attacker may exploit these vulnerabilities without privileges in a low-complexity network attack.
Oracle Financial Services Applications
This Critical Patch Update for Oracle Financial Services Applications received 18 security patches. Out of these, 13 vulnerabilities can be exploited over a network without user credentials.
CVE-2025-48734 impacting different Oracle Financial Services Applications products has high severity ratings with a CVSS score of 8.8. A remote attacker may exploit these vulnerabilities without privileges in a low-complexity network attack.
MMS • Nivedita Murthy Zsolt Nemeth Katie Paxton-Fear Ben Bridts Re

Transcript
Renato Losio: In this session, we’ll chat about designing for defense and architecting APIs with Zero Trust principles.
I would like just to give a couple of words about this panel and about myself, and clarify what we mean by designing for defense and what’s the topic today. API security has moved in the last decade from being, I wouldn’t say optional, but not that important. I’m old enough that when I started playing with APIs it was not on top of our mind, to be now essential, and is now a primary front in our system defense. Traditional security models are not enough anymore and that’s where Zero Trust security comes in.
My name is Renato Losio. I’m a cloud architect. Also, I’m an editor here at InfoQ. I’m not the expert here, the experts are our four experts coming from different companies, different sectors, and different backgrounds. I’d like to give them the chance to discuss the topic. Just a couple of more words about what we are going to discuss. We’re going to explore why APIs are the center of today’s security threats and how we are going to apply Zero Trust principles to protect them. I would like to give a chance to each one of our four panelists to introduce themselves, and share their professional journey in designing for defense and why they’re here today.
Ben Bridts: My name is Ben. I’ve been working as a Cloud Engineer, Cloud Architect for a little over 10 years. Specialized in AWS, so I’m also an AWS Community Hero. My background is in operations, which means that the longer I do this, the more security things I have to do, the more learnings on architecture, the more compliance, sovereignty becomes important.
Katie Paxton-Fear: I’m Dr. Katie Paxton-Fear. I am a Principal Security Researcher at Harness. My career journey I often say is that I used to make APIs and now I break them. I’m an API hacker. I find vulnerabilities in APIs before the bad guys can. I show companies how you can secure your APIs, be more effective. I write that a lot as technical content, webinars, blogs, white papers, all to really improve API security for everyone.
Nivedita Murthy: My name is Nivedita Murthy. I’m a Senior Staff Consultant here at Black Duck. I’ve been in this industry for 16 years now working in all areas of AppSec. Currently helping our clients improve their application security program by providing consultation on strategic initiatives out here.
Zsolt Németh: My name is Zsolt. I’ve been in cybersecurity for 16, 17 years. Started out as a developer of algorithms or symmetric ciphers, mainly. I got into the cloud space about 10 years ago. What we are doing now is actually using moving target defense for strengthening security postures, or hiding the attack surface against the attackers.
What Is Zero Trust Security?
Renato Losio: I’d like to basically start with the most basic probably question, but just to really set ourself on the same page and as well give a feeling of really what we are talking about. What is Zero Trust security? What is so important for APIs?
Katie Paxton-Fear: Zero Trust started out really as a methodology for securing networks and infrastructure, but it’s become a lot more than that. It’s become a general ethos around how we should think about security. It’s quite straightforward. Zero Trust is about assume breach, assume you’ve already been compromised and secure your assets accordingly. If you’ve got something like APIs, obviously they’re highly connected.
If one API is breached, how do you protect every other API, for example? It’s very much thinking about like principles of least privilege. Making sure that nobody or no API or no API user has more privileges than they should. It’s about making sure that any PII you have is protected appropriately with whatever precautions you want to put in place, like encryption, for example. Really, what we’ve really seen in the past few years is it’s becoming the way folks think about security and the way folks start to pull the pieces together around security and what good security looks like.
Renato Losio: I don’t know if you want to add anything else to the topic or maybe clarify what you think is important for APIs.
Zsolt Németh: The short version is, assume compromise always. That’s it. APIs, 10 years ago, it was like a vent on a house. Right now, this is the front door, and that’s why it’s important, because the side window or the garage, whatever, you can get in easily. Right now, it’s actually much worse because this is basically the front door the attackers are usually getting in. That’s why you need to basically defend it. Again, before that in the architectures, there were something like safe zones or whatnot, but that’s not true anymore.
Challenges of Applying Zero Trust, with no Background in Security
Renato Losio: I have a question as a practitioner myself, that is not coming from a security background. I’m old enough that every few years, I hear that things are getting worse and it’s getting harder and it’s getting more important. I find it as a developer always a bit scary as I don’t feel really enough. What are the main challenges for a software architect, software developer to applying those principles to get to the front, to protect that front or make it so essential in the technical journey? What are the challenges you see?
Ben Bridts: Like everything with software, there are so many options. There are so many things to get right, that it can be challenging to know where to start. It can be challenging to know what exactly you need. There’s a challenge in some way, like the thing that Katie said of like assume compromise, helps with that as well. You have to assume that it’s untrusted.
I think the main challenge is like, I have this API, like I’m used to this specific framework that I’ve been using for so long, like what’s my first step to start securing my APIs? Am I going to focus on more general approaches? This is an example. It’s not what I recommend. Like, am I looking at firewalls and stuff like that, or am I looking at authentication, authorization, like complete new policy languages? There’s a whole spectrum of things that all fall within the same thing, that knowing where to take your first step to start securing your APIs and to build something that you can comfortably say, this is where I trust, or I know that even though I don’t trust anyone, this is a valid request that I can actually act on.
Renato Losio: What do you see as the main challenge for someone like myself or a software architect that is not coming from a security background?
Nivedita Murthy: I think it’s the not complexity that you add when you start thinking from a security side. Let’s take, for example, a SELECT * from a table. It’s easy to write that query. There’s no filter. It gives me all the information. It’s easy to send it out. It’s easy for the developer to write it. When we start telling them, you cannot send the entire table. You need to put in filters. You need to put in checks. They need to add some filters out there. Adding that, especially in terms of an API, gets a little bit tricky, gets a bit more difficult. That’s where engineers say, security is making my work difficult here.
It’s just adding more time, more complexity to the problem out here. I just want to give my API out and make this functionality available to everyone. When security comes in and says, no, you cannot just make all the data available immediately to everyone, you have to put in certain checks. That same data has to be split into four different APIs, or maybe verify that the request is coming from the right place, or add in limits to the number of records coming in. That’s where the developer thinks it’s getting a bit more trickier, a bit more complex, a bit more difficult for me to just send out this functionality in the next two, three days that they have been given to set up the new API.
Incentivizing Devs to Apply Zero Trust Principles, Upfront
Renato Losio: I see that when you mention the extra effort is something that everyone was nodding. That’s actually the feeling I have sometimes as a developer, that always that concern, instead of saying, that’s one of the key aspects that I cannot get the API wrong. I cannot break security. Day one is like, I see that as a burden. I’m thinking as well, when I build something simple, like I’m using even a manual service, like an API gateway or whatever else, and I feel like, I can’t just do it. I can’t just put it out there. How do you interact with a developer that feels that applying those principles upfront is going to slow down development, or I’m just doing my first MVP, so it doesn’t really matter, but be sure I will take care of that later on. Why is that wrong? How should they adapt that?
Katie Paxton-Fear: I think it’s really challenging, especially for APIs in particular, and I’ll explain why. APIs as a product are very developer-driven. Unlike other products where we might have something like user requirements, and we’re thinking about customers. When it comes to APIs, our customers are developers, they’re us. They might literally be us, as in, we might be developing the next application that connects to that API.
One of the problems and the challenges there is that when developers are in a position where they’re being told to add security, if they’re being told by the security team, it’s like interfering with their child. This is something that they’ve designed from the ground up that meets their requirements, that they’re in complete control of, and the first thing we do as a security team is take it away from them. I can see how any developer would get really annoyed about it. It’s normal for people to get annoyed. I think for us as security teams, we don’t really consider the developer perspective that often. We’re so much thinking about security. We are in a world of security vulnerabilities. We’re reading the news about security breaches. Developers aren’t in that world. It’s up to us to be a resource for them. Not to be the person going, “No, you can’t do that. You can’t do that. Stop what you’re doing”.
Instead be, “You want to do that? Let me help you. I will do this. I will take on the cognitive load of figuring out the security side of this so you can focus on what you’re doing and what you’re best at”. I think really one of the main challenges I see in a lot of teams is that when APIs, particularly if they’re developed to be initially internal only, they do not have the same stringent security because it’s internal only. Who cares? For something like implementing Zero Trust, that’s so key. If your developers are in a position where they’re going, “It’s internal only, so it doesn’t matter. It’s for me and me alone, so it doesn’t matter. Stop telling me how to do my job. I’ve worked in this industry for 15 years. I know what I’m doing”. You have this recipe for a real breakdown in communications.
My first advice for any team is to go buy your developers donuts. Give them something. Give them a reason to want to speak to you. Stop telling them no. Start saying yes. Develop that friendship because that is where things will go wrong, that relationship between developer and security team.
Ben Bridts: For developers listening to this, it’s a two-way street as well. Security is not there to block you. We want everything that Nive said of rate limiting and stuff like that. Good security is good design. You want it in your API. Problems arise if you’re like, build everything first, and then go to security, trying to push it through in one day and now we need approval. If you come to security on day one, say, I’m going to build an API. Maybe you haven’t thought about this is going to be internal or external or things like Zero Trust. Maybe there’s a way to build that in from the start and not have that at the end.
Katie Paxton-Fear: As a security team, that’s where you should be. You need to be in the design phase. You need to be there. You need to be that resource, so they don’t have to think about there.
Zsolt Németh: However, the problem is like, we’re talking to a lot of CISOs, a lot of security teams, and they usually just tell the developers that, I’ve got this dashboard. It’s pretty easy to use. Why don’t you just do it? It’s super easy. There are three big problems. One is, developers are definitely not security guys. You need to figure out, not just how to talk to them. You have different priorities than us. Ours is security. We kept trying to get rid of that, like shift left and whatever. Like whatever happens down there, that’s the developer’s problem, or the head of DevOps, or DevSecOps, or you name it. It didn’t work.
The other problem is you have different priorities. The first thing, when I talk to a developer, the application has to work. Then, load testing, then resilience, then UX, and maybe then comes security. By that time, that’s just too much of a burden. As Katie said, security guys should help or could help, not just by buying donuts, but obviously going further and just start a conversation. That conversation is not really happening, according to our experience. That’s the biggest problem because you are there, they expect you to solve something which you don’t even have an idea about, and that causes bad luck.
Nivedita Murthy: I think Zsolt and Katie, all of you have mentioned about providing incentive in a way to the developer. What we do over here also is that when we provide them a security report, a penetration test report, for example, we always highlight first what are the good things that we found in their application, because you don’t want to go straight away for the bad points. You want to actually say to the developers what good did they do. They’ve actually, inadvertently, without them actually thinking maybe, they have secured their application. You want to point that out first that these are the good things in your application. You’re protected against authentication attacks, or authorization attacks, or maybe some validation attacks out there. You’ve done that and that’s great, but let’s also focus on these areas in your code which may need some improvement, may need some curing.
One of you mentioned over there that it should not be on the developer to think so much about security. It is the security team’s responsibility. That’s why this question should come at the design phase itself that, how do you design this application, so that it’s easier for them to just push out those APIs which are inherently secure, and does not give out the information that it’s not supposed to give in the first place. Pushing this requirement in the design phase itself helps in the long run. It reduces the effort involved in developing these APIs as well.
Internal APIs vs. External APIs: What’s the Difference?
Renato Losio: When you mentioned about internal versus external APIs, the high-level concept is very clear to me. As well, I can say, I have many different microservices all talking with their own API and different teams talking together. Sometime I ended up in a discussion that there was a bit of a mismatch what we meant. The other person meant internal means only private IP. There’s no public IP there. Some other really much more extended concept like, by internal I meant the specification was just for some internal product. How do you see that? When you meant internal, you meant just nothing in the public space, or what’s usually the definition of an internal API?
Katie Paxton-Fear: I meant both of them, because there is no really clear definition of what internal means. Obviously, with the kind of infrastructure we have at the moment, especially around mobile apps. Mobile apps are essentially just APIs at the end of the day, they all connect via APIs. For an organization to have a mobile app, you also need the API, that can’t be just restricted to your network. It has to be online. You don’t have to provide documentation. You don’t intend anybody else to use it, but your mobile app, the API still needs to be there. Often, people refer to that as the idea of an internal API, because as you say, only developers have access to the API docs. Then you have APIs that are really designed to be internal only, so they are going to be restricted. I will say, as an API hacker, that is rarely true. I have found many internal APIs that are publicly available on the internet.
Renato Losio: Through a proxy or whatever else, yes.
Katie Paxton-Fear: A proxy or you can usually pivot as well. Like you just need access to one API, then that will make requests on your behalf. Or just people are like, it’s not on a domain name, if it’s on an IP address, for example, but it’s still available. Or they’ve got references to it in the code, like in JavaScript, even if they’re not making API calls directly. That’s also another fun way to find internal only APIs. This goes back to why Zero Trust. Like, assume those APIs are compromised. Assume I can already see them. How does your security strategy for those APIs shift when that is the case?
Ben Bridts: I fully agree with that. I think the distinction of like internal versus external is an access level, not just for APIs, but for everything, is very risky. In terms of APIs, talking about like, this is a user API versus an administrative API, whether that’s callable from inside or outside, like own apps or different apps, it doesn’t matter. It has certain things it can do. That’s the important part. That will drive, how are we going to protect it? What are the policies we’re going to apply to certain endpoints?
Admin APIs vs. User APIs
Nivedita Murthy: You mentioned about admin API versus user API. APIs were introduced to just make it simple and easier for applications to interact or developers to get information from applications, just interfaces. Do we really need an admin API for that matter on an API level, is that necessary in the first place?
Ben Bridts: No, I think this is more of me putting on my developer hat and how I think about data models in the sense that both are accessed by principles that are going to be doing something. In some cases it’s going to be very clear, this principle is my end user, my customer that’s going to be acting on their data and need their permission model. That’s what I call the user API. It’s end user facing API. Whether that’s internal, external, where it is coming from, it’s doing something for the end user directly.
Then it’s like, I need reporting on that. Maybe I need a support team. Not even how I design my microservices, but like project concept. That’s more of like admin level stuff. That’s going to be acting on multiple users possibly, or impersonating a user, or all that kind of more risky stuff, more traditionally what you call like an internal API. It will still need to be authenticated to a certain user. It’s not like admin that can do everything. A certain support person can do certain support things.
Katie Paxton-Fear: Do we need an API to do that, because we’re talking about Zero Trust. You want to limit access. We want to also limit in terms of how the application can be accessed with elevated privileges. Would it make sense to have at an API level or just give an interface an actual web application, so it doesn’t go through an API. That’s from a design perspective.
Ben Bridts: For me, everything is an API. If that’s a PHP app that’s rendering web pages or that’s like a fat client, it’s an API. It’s doing something somewhere.
Where Should a Developer Prioritize?
Renato Losio: One of the challenging parts as an architect, as a software developer in general is, we say security should be part of implementing and designing robust and proper APIs, at least in theory. Things about rate limiting or whatever else I’m thinking about, or zero security, whatever else I want to implement. Somehow when I implement my API, I’m thinking about my problem. I think it’s not against the security team or against someone else. It’s just, I want to implement my feature A, that is, add a contact to the user, post something somewhere, and I feel like reinventing the wheel if I have to do at my layer, at my level. Either I’m using something that is out of the box, a tool or something that is doing it for me and someone else is managing that, possibly. Where should I worry? As a developer, should I think about rate limiting or is it something that comes later? Day one, where should I start from? Because if I have to implement it myself, probably it’s more complex than my API somehow. I feel like I’ve reinvented the wheel.
Katie Paxton-Fear: I can tell you about my very first vulnerability I ever found. It was on Uber, and I found this vulnerability. It was in a major Uber product. It’s long since resolved now. I’ve spoken about many times. It’s not sensitive. The way I found that is because I saw a RESTful API that was implemented correctly. As a developer, I knew that RESTful APIs are supposed to use PUT and DELETE. They’re supposed to use the different HTTP verbs. Have I ever developed an application that ever uses those? No, everything is POST and GET. By seeing that in the wild and seeing it on this application, I’m like, this is done correctly. There is no way a human wrote this. Surprise, the human didn’t write it. It was an automated tool, which then didn’t add the required authorization checks and actually authentication as well, because it was essentially just a generated API.
I see that all the time now of people trying to take a shortcut, especially nowadays you’ve got AI and vibe coding. I think tools are great. They are really great for allowing you to do things more effectively and more efficiently. I think you got to know some of the principles yourself as well. It’s not enough to just rely on them and just assume, the tool will handle everything so I don’t need to think about it, because the tool is dumb and you’re the smart one in the room.
Renato Losio: All my assumption of just putting some managed services and lead the security for that in front of my simply developed API is already gone.
Zsolt Németh: What I wanted to add just briefly about rate limiting. Obviously, it’s a heaven for attackers, so like DDoS, brute force, whatever, we call it the architectural sins. You need to be aware of that. As a developer, rate limiting isn’t easy stuff, like how you separate the data planes and the control planes. What we see at most of the customers, like they log everything without protecting the logs. You can basically just get there and mine your information out, or use AI to mine your information out. It all gets back to a bigger problem from the developer perspective, whether the API is ready or you need to write it from the ground up, because if it’s ready, you need to put the work in to redesign the whole thing. That’s a lot of overhead, which most of the CISOs or CIOs don’t like, because that’s additional money to be spent.
The Most Common API Vulnerabilities
Renato Losio: I’d like actually to go back to what Katie mentioned before, the case of Uber. I don’t want to go too much into detail of a specific case. I’d like to scare our developers a bit. Without necessarily naming a specific company, but share common API vulnerabilities, what are common things that usually developers don’t think about, apart from authentication, of course, that is the first, probably the only thing that we think about, or which method we use. One guilty one usually is POST, whatever it is, for GETs. That’s it. I don’t know if you have any story, anything you want to share that could tell us how to go to the next level and how to think a bit more about what we do. I had the feeling before you mentioned as well, don’t expose anything that you don’t need, like an admin, but if you have anything you want to share.
Nivedita Murthy: The one commonality that I saw in all the breaches that have happened so far, they’ve all collected information about people in the database, and sensitive information specifically. Today data is valuable. It is money, more than actual money. Sometimes data is money. It can be used for nefarious purposes, going from phishing, scamming, or whatever, but you can sell data to someone else for whom that information is valuable. I also have used APIs a lot to write my own scripts to automate stuff.
One of the easiest things to do is just call an API, get information about a certain thing and just push it into an Excel sheet, just export it out. This is basically data scraping. That is one thing that happens regularly with APIs. You’re just pulling information, pushing it into a file or into a database. You do that continuously. When you are an engineer developing an API, you need to think about this. What are the different ways a malicious user would basically get information out of my application and push it out somewhere else? Does that information need to be out there in the first place? From the U.S. side, does the SSN number have to be on an API? Does the address have to be on an API? Is that information necessary for the API to process? Those are the things that you need to think about.
Katie Paxton-Fear: I 100% agree. I think what separates out a lot of API attacks from other attacks that we see in the media is how targeted they are. If you look at something like ransomware, it is targeted. Criminal gangs will go after specific industries and they’ll go after the entire gamut of those industries, a bunch of different companies in that industry. However, the difference between that is that it’s often very opportunistic. There’s a vulnerability or there’s a known flaw that they can exploit and get the ransomware on the computer, or they’re just sending a bunch of phishing emails and then whichever company clicks it and runs the malware, that’s how they get infected.
One difference we see in API attacks is that the kind of attackers that go after APIs, they know what they’re doing. They often know about things like what the API does. They know that wider context. They know it’s got a social security number. They know it’s maybe got credit card information in there. They know that. They understand the API. They’re understanding the attack surface. Often, they can actually understand your API attack surface better than you do. What’s important to know is that most API security vulnerabilities are not ever going to be massive vulnerabilities. We’re never going to see the API security vulnerabilities on pure technical merit alone. It’s not like the hardware security people. Most API security mistakes are that little mistake, small mistakes.
In the entire library of an entire API where you have hundreds of endpoints, you have thousands of users, you have millions of requests every day, you just cannot spot the malicious stuff among all the noise. It might be the difference between one line of code and two lines of code. Where I see the most as a hacker is often silly little mistakes made in things like authorization. There’s no if statement to check if a user owns that object before they start to edit it. There’s no check to make sure the user’s logged in. Those are, again, silly little mistakes. They’re not massive, huge fundamental shifts in the way we think about technology. They’re, “I just didn’t write that”, kinds of mistakes.
API Monitoring
Renato Losio: I was thinking, as Katie just mentioned, sometimes there’s little mistakes or little things. In a large number of APIs, I might have an entire SDK, hundreds of APIs, whatever it is. How do I monitor? Do I monitor my API for that? I’ve built my nice app. Let’s go back to the example we had at the beginning of an app. Maybe I haven’t even published my APIs, but still, there’s something there. What should I do? Should I do something?
Zsolt Németh: It depends what you want to do. There are lots of open-source tools, but Harness is one of them, and so on, what you could use. From my perspective or our customer’s perspective, yes, we can put Falco in it for runtime container security, but more basic stuff. I think it’s mandatory now everywhere to sign your container, so that you use Cosign, or something like that.
Renato Losio: The way I see it, as a developer myself, either I’m using some managed tool, whatever, it’s from a cloud provider or something else, where I have some API, build my API, I build just my logic. Then the only real monitoring that I’m doing sometimes is just on a number of requests, error rates, or whatever. That as well doesn’t tell the full story, because as Katie mentioned, it can be a single mistake that opened up. Not necessarily I’m going to see a huge spike of errors or whatever, and my data might be out there. I was just wondering what I should do as a first step.
The Danger of a Malicious API Structure
How dangerous can an API malicious structure be for a company?
I assume it can be as malicious as not having the company anymore.
Nivedita Murthy: Think about traversal. We have something called as, you jump from one box to the other, the same thing can happen with an API as well. I think Katie mentioned an example where she was able to pick up an internal API from an API that was external. How we look at the structure is, is it sending information about an internal API that is not supposed to be available to other users, or, are you able to jump from one API to the other without verification? Maybe you need elevated privileges to use a certain API, but if you jump using one API to the next one, does it allow you to go over there? You have to think about, in that sense as well, as to, is the entire API design a faulty way by allowing to go places where you’re not supposed to go in the first place.
Katie Paxton-Fear: There’s two things to think about. I’m going to answer both of them because I’m selfish. If you’re wondering, do I have a rogue, malicious API? Has an attacker deployed an API on my systems for their own usage? That is bad-bad. The second attackers can deploy anything on your systems, the entire system is compromised, like full stop. If that is happening, you need to turn it off at the wall, like switch it off, do a full recovery, because you just don’t know how deep they managed to get into your infrastructure. If the question is not necessarily, is the API malicious, but are malicious users using an API, how bad can it be? It’s like saying, how long is a piece of string? It really depends on what that API is doing, what sensitive data it’s handling, what sensitive processes it’s handling, because it’s not always about data. Sometimes it’s about processes as well.
Somebody asked me once, they were like, is API security a million-dollar problem? I’m like, it depends on how many APIs you have and how valuable they are to your business. APIs now often are such big drivers for organizations to grow in terms of customers, to provide them as a product, just to enable people to deeply connect to them. Look at the backlash when Twitter removed its API from being able to be public and people had to pay for it. That caused massive backlash. APIs now often become the crown jewels of how a business functions. If you’re wondering, how bad can API security be, what industry are you in? If you’re in finance, maybe it’s financial losses, maybe it’s loss of customer trust, maybe it’s a further breach where they use APIs as an initial access point and then pivot into other systems.
Really, APIs are so dependent on the context in which they run, and that really makes them unusual when compared to other web applications as well. I can’t tell you how bad it is unless you tell me the company you work for, and then I’ll tell you as a hacker, here’s what I would do and here’s how I would target it and here’s what I would go after, because this is what I would see as valuable.
Open-Source Security and Monitoring Tools, for Devs
Renato Losio: Zsolt before mentioned some open-source tools, I would like to go a bit deeper in that sense. If there’s any tool that you think, not as a security expert, but a developer should be aware of, or should be familiar with, or should use to protect or even just to monitor, whatever. I don’t know if you have any recommendation.
Ben Bridts: It’s a hard question because there’s flaws with a lot of them. I think knowing about JWTs and how they work and what the pitfalls are there is probably the one that’s going to give you the most value. Wherever you’re working in the industry, you’re probably going to have to deal with that at some point.
On the other hand, if you want to look at what would be good authorization design or a good way to secure your API, I’m not the biggest fan of them necessarily. Very specifically, but I assume this exists in other clouds as well, for AWS, looking at how their Signature Version 4 signing works, for example, and how other people use that to imitate S3 in some cases. This is cool to have in your back pocket of how you can design APIs to only trust a request one time. I think it’s very useful and very good to know. I’m not sure if that is something that I would be able to implement at my day job as a developer, to come up with, now we’re going to full sign every request and have nulls on there, like you can only do it once. It’s going to be valid for a minute and then we throw it away. I would start with JWTs.
I also would really recommend looking at using a library for that. I think Google has a good one in Tink for that, that turns off all the things you don’t need. Turn everything off. There are so many things in there that you don’t need, just turn it off. Only use the specific thing you need.
Modern Programmatic Techniques of Securing APIs
Renato Losio: What is the best modern programmatic technique of securing an API? Does it depend on the type of API? What about two or something else?
Zsolt Németh: At a high level, I can start with that. How I would do it or how our guys are doing it here is that they’re not kind of collecting tools. We have OVAL. We have Kyverno. We have Oathkeeper. Basically, they focus on the weakest spots of the architecture, which either they find or we tell them that this is going to be a problem, have a look at it, and solve that specific problem first. Obviously, you can pre-scan your API pre-deployment. You have tons of tools for that, and so on. Basically, I think you should solve the problems first and not finding the problems, and trust the security guys or trust the security team to actually point out these problems first.
How to Identify a Compromised API
Renato Losio: Do you want to answer the one-million-dollar question of how to identify that your API was already compromised?
Katie Paxton-Fear: It’s weird because as an API hacker, I don’t often see that. I often am on the outside looking in at APIs. Some things to be aware of is, one, large amounts of data being transferred out of your organization. That’s the standard one. You’ll see it a lot mentioned because nowadays, we are seeing really large data breaches, as Nivedita said earlier. We are seeing people going after PII especially, usually to use in other kinds of attacks.
Other things to keep in mind, though, if you’re working in an industry, knowing what’s happening. In fact, the biggest recommendation I have to any developer ever about how to learn about API security or just security in general, go to a security conference. Go to your local BSides, go to DEF CON, go somewhere like that, become immersed in that world, and you will probably know what to look for. You’ll be able to see how that interacts with the system you have because you’re an expert in that, way more about than anyone else is in terms of how your organization is laid out. Actually listening, these are the kinds of attacks we’re seeing.
These are some of the IOCs, Indicators of Compromise that we’re seeing, like check these out. I think the number one mistake any organization makes is just doing nothing. When it comes to API security, it’s often left as a nice to have. People aren’t actively investing in it, so there’s not an awful lot of tools that can give you that information. There’s not in-depth monitoring and logging for APIs that you can easily get that’s free and open source. It’s a very specialist solution. With that, it makes it challenging, because any indicators that I could give you, you would have to have the right setup to look for them, so looking for them in the first place, having a process that you could go through those logs, review them, see what they say, go through that, how would I investigate this kind of attack? Creating those runbooks can often be far more valuable than any kind of individual indicator that I could give you, for example.
Renato Losio: If I understand, I need to have the logs. I need at least to keep an eye on my networking activity.
Nivedita Murthy: As a developer, especially someone who’s working on APIs, you definitely have access to Postman. Start off with, just try and manipulate the values that you’re sending to see how it reacts. Don’t do it like normal user functionality, I think, as a malicious user, maybe. Add an extra character, add too many numbers, for example, or just remove a filter and see how your own API reacts to that scenario. That’s your first step to testing out, is your API vulnerable to malicious attacks? Like Katie mentioned, this is a specialist scene on how to monitor whether it’s being vulnerable to, let’s say, multiple attacks out here.
One thing I could provide is, there is a page on the OWASP website. When I say OWASP, it is Open Worldwide Application Security Project, which gives a lot of free resources and open-source resources for securing your application, and also guidance on how to do that. There’s an entire page which lists out both commercial as well as open-source projects that’s dedicated to API security. You can pick out one of them, and see how it works, try and use it, and see whether your API is secure or not in certain manners. There are limitations to each tool for sure, but you can start off over there and learn how good is your API in terms of security versus how bad is it.
Resources for API Security
Renato Losio: What is a tool, what is even a paper, podcast, book, or even a conference, as Katie mentioned, that you recommend every developer should not miss? I don’t know if you want to give an advice, an idea for, go out of this roundtable, listen to this podcast or go join this conference, or something.
Ben Bridts: I help organize fwd:cloudsec in Europe, so I’m just going to mention that. I really like that one. Look for security-specific conferences. I think the OWASP thing is also a good thing to look at. I think we maybe should pivot back to APIs and Zero Trust, but the base vulnerabilities of sanitize your inputs and know what you’re getting. Especially in this time, don’t trust your client. Anybody can open your app and see what’s in there. Those things are also still going to be out there. That’s not new. We should just keep talking about it until more people fix them.
Zsolt Németh: I would go to the conferences as well, or if you’re here in the Bay Area, so a lot of meetups, but probably that’s happening everywhere as well. I know in the Netherlands, it’s a lot of activity going on in terms of security, not specifically an API, but more like Zero Trust, I’m sure.
Understanding Zero Trust in API Design
Renato Losio: As I understand it, Zero Trust in API design is primarily a concept with tools supporting each aspect, like assume breach maps to short-lived token, or never trust, always verify, map to OAuth on every API call. Do you have any comment about it?
Katie Paxton-Fear: When it comes to Zero Trust, it used to be far more prescriptive of how to meet these. It’s become much more a lesser methodology and more a philosophy around how you do security. With that, the way you implement Zero Trust in your APIs as you’re creating them can look really different. If you go with assume breach, that can mean short-lived token. It can also mean, what other APIs does this API have access to? What other data does this API have access to? Ensuring that you have things in place to not just have short-lived tokens, but also to recognize a compromised API to do something like rotate secrets, or something like that. When we talk about the idea of never trust, always verify, again, you can do that in multiple different ways. It really does depend on that API. I would say for Zero Trust, like practically how I would implement Zero Trust in an API, would be, follow the advice of assume breach.
Go through every single API and ask yourselves, if this was breached, what would happen? What would they do next? Even better like, I think Nivedita is absolutely correct, learn how to hack. Have a go at hacking. Have a go at API hacking and have a look into what attackers can actually do to help give your team ideas. Also, it’s just fun.
For a lot of developers, you don’t often get to do something just for fun. I’ve actually had quite a lot of good experiences with developers of teaching them how to hack to get them more engaged in security, but also have them thinking about security and what an attacker could do. It’s really about getting in that mindset of an attacker. There are some good easy wins there. OAuth, easy win. Tokens, easy win. Having expired, like all of them are easy wins. Fundamentally, they are easy wins. They are first steps. They are baby steps. There is a lot more that you can do to really inhabit the philosophy of assume breach.
Resources for API Sec, and Security in General
Nivedita Murthy: To the previous question, yes, security conference. The other thing, listen to some podcasts which is outside of application security. I like to listen to something outside of my domain just to get some ideas as to how attackers try to do things outside of it, and maybe apply in my application. How can I do that same thing? Can I replicate that in a way in my application, or use the same method? The one which I enjoy is by Jack Rhysider. He talks to various people and their experiences, what they have encountered, how did they open up an application.
There was one where someone made free video game money out of the video games by just changing a value or something. That was fun to listen. Those same principles can be applied in API. I would definitely recommend just listening to some stories. You can listen to that on podcast. You can listen to over here, like this webinar, or going to conferences or even local meetups, and just talking to people within the industry about their experience and what have they been doing out there.
Ideal Starting Point in API Security
Renato Losio: Until now, I got super excited thinking about being always in a brand-new API, start from scratch, zero principle, all great. Now, I’m in my reality, day-to-day programming job, and suddenly I have my 200 APIs already there written in Java, .NET, whatever you want, with some database behind, some authentication already in place. I want to do something in the right direction. How do I tackle it? Just ignore it, start from scratch? What are the baby steps in this case when I have already something in place? Where should I start?
Zsolt Németh: I think I’ll just reiterate what I said a bit earlier. Start with the weaknesses that you already have, and fix them one by one. We won’t get to zero weakness anytime soon, but your security posture is going to be much more solid.
Ben Bridts: My first reaction is you probably know in the sense that like it’s your APIs, it’s like your bunch of things. The question is like, what are the things that you feel like this is important data that’s behind it, or this is something that’s going to be a problem if somebody does something wrong with it. Or the other side of it, like what’s the thing you haven’t touched in 10 years? You know where the bodies you’re hiding is in your closet. Start with that one.
Low-Hanging Action Items and Key Learnings
Renato Losio: What’s an action item for our audience? Give an advice of what you can do tomorrow as a first step to take the advice from today and do something tomorrow. It doesn’t have to be, change the code, can be even just read a book, can be, see a podcast.
Katie Paxton-Fear: Literally anything. You’re doing better than 10% of organizations if you do literally anything about API security. Most folks have their head buried way in the sand. Simply listening to this, you’ve already taken your first few steps. Now it’s just time to keep on walking.
Nivedita Murthy: This is the regular advice I give all my clients in general. Have an inventory of what you have. You will then realize that there’s something out there that you created 12 or 15 years ago, but never used it, but it still exists as of today. You might want to just do a cleanup of your inventory or your APIs. Just whittle it down to a manageable number of APIs that you can think of, and which one’s important versus not so important. Just create an inventory, have that list ready. I love lists, create your list of APIs here.
Zsolt Németh: I would do actually much simpler. Go to ChatGPT and ask for a detailed plan. No, I wouldn’t. On a serious note, I would start with reading because I’m old school and I like reading. I would basically read, even just horror stories of what happened with unintended APIs, or when people figured out that, there was a behavioral drift in our API, and they figured out nine months too late. There is no too late. I’ve seen a couple of CISOs being fired because they noticed something way too late, and the attacker dwell time was usually like 5 years plus, not to mention one. Basically, I just want to rephrase what Katie said, yes, anything. I would personally start with reading short and sweet stuff.
Ben Bridts: I have two things. The first thing is like, go have fun and poke around your stuff. I’m not a serious hacker at all, but what I do is every time there’s an internal app, like we have to reserve parking for somewhere, or there’s like, this is how you book a meeting room, and you get a mobile app for that. See how that works. You’re a developer. You can do things that they don’t want you to do. Reserve that meeting room that’s only for the director, or stuff like that. It’s a very fun way to learn how those things work and to see what’s available to someone who is not trusted with the thing. You get the device, like they don’t trust you, but you can do all those things. Secondly, go get those donuts from the security team. Just talk to each other. It’s really helpful for both sides.
See more presentations with transcripts
MMS • RSS

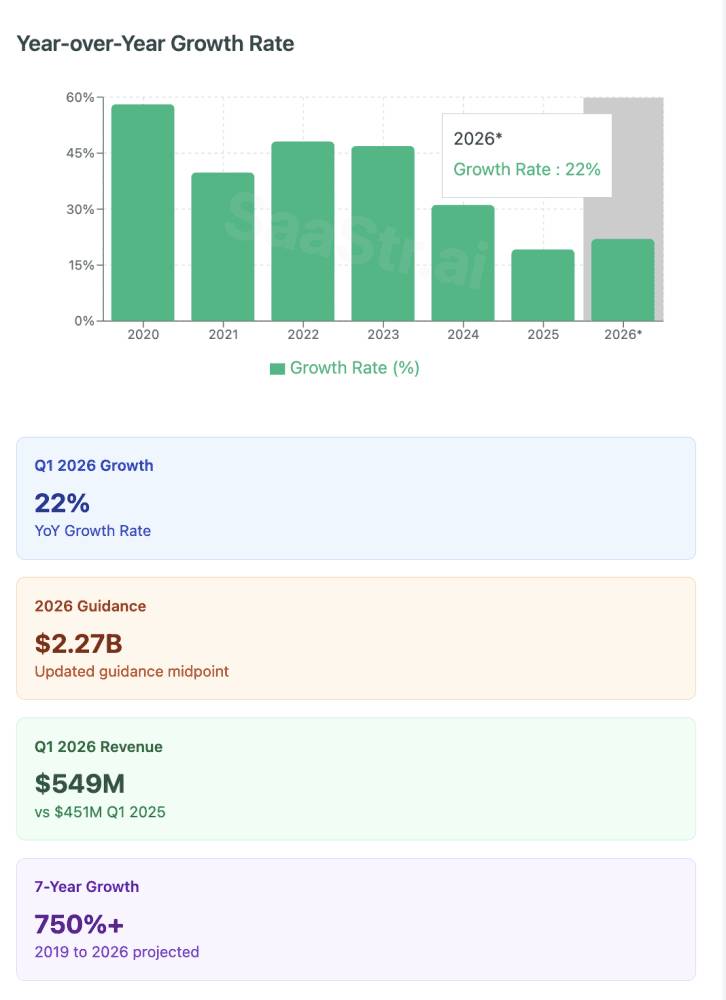
MongoDB recently dropped its Q1 2026 results, and well … Mongo is back.
At $549M quarterly revenue (22% YoY growth), they’re proving something important: you CAN still grow 20%+ at massive scale.
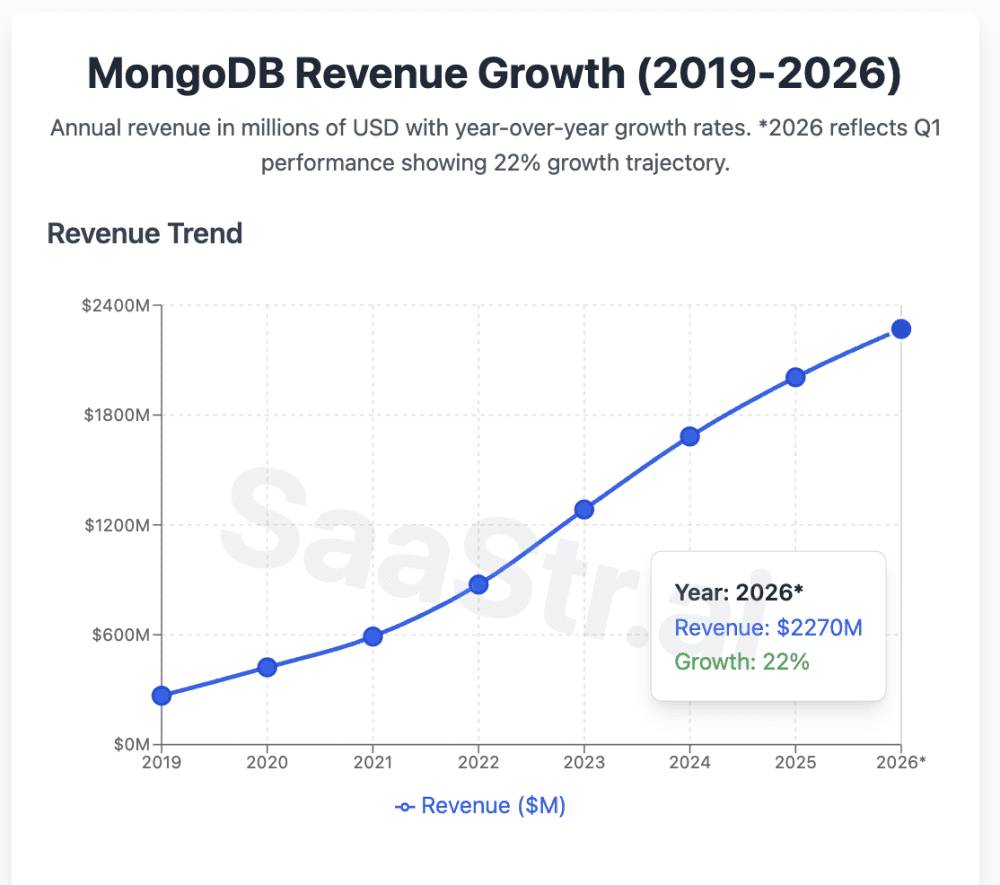
Here are 5 top takeaways every B2B leader should internalize:
1. The “Growth Re-Acceleration” Playbook at $2B+ Scale
The Numbers: After moderating to 19% growth in FY2025, MongoDB bounced back to 22% in Q1 2026.
Why This Matters: Most companies see linear deceleration as they scale. MongoDB proved you can actually re-accelerate growth even at $2B+ ARR through:
- Product expansion (Atlas now 72% of revenue, up from 71% last quarter)
- Customer base expansion (2,600 net new customers – highest in 6 years!)
- Market category expansion (AI workloads driving new use cases)
The SaaStr Takeaway: Don’t accept linear growth deceleration as inevitable. Product innovation can reignite growth engines even at massive scale.
2. The Atlas Flywheel: How 72% Revenue Mix = Compound Advantages
The Numbers: Atlas (cloud) revenue grew 26% YoY and now represents 72% of total revenue.
The Flywheel Effect:
- Higher growth rates (26% vs 22% overall)
- Better unit economics (cloud margins typically superior)
- Customer stickiness (cloud platforms = higher switching costs)
- Expansion revenue (consumption-based model drives natural growth)
Why Most Companies Fail Here: They don’t get to 70%+ mix fast enough. MongoDB’s lesson: go ALL IN on your highest-growth, highest-margin product segment.
The SaaStr Takeaway: If you have a clear cloud/platform winner, accelerate the transition aggressively. 70%+ mix is where the magic happens.
3. The “Profitable Growth” Transition: From -40% to +16% Operating Margins
The Numbers: 16% non-GAAP operating margin in Q1 2026, up from negative margins just a few years ago.
How They Did It (The MongoDB Method):
- Disciplined hiring during the 2022-2023 downturn
- Revenue scale (easier to leverage fixed costs at $2B+ revenue)
- Product mix shift (Atlas has better unit economics)
- AI automation (reducing operational overhead)
The Critical Insight: MongoDB didn’t sacrifice growth for profitability. They achieved BOTH by:
- Maintaining 20%+ growth rates
- Improving operational efficiency
- Focusing on high-margin products
The SaaStr Takeaway: The best SaaS companies don’t choose between growth and profitability. They engineer business models that deliver both.
4. Customer Acquisition at Scale: 2,600 Net Adds = Highest in 6 Years
The Numbers: 2,600 net new customers in Q1 2026, bringing total to 57,100+.
What’s Remarkable: This is their HIGHEST net customer additions in 6 years, despite being at massive scale. Most companies see customer acquisition slow down dramatically as they get bigger.
MongoDB’s Customer Acquisition Secrets:
- Self-serve motion for mid-market (efficient acquisition)
- Enterprise sales for large deals (higher ACVs)
- Developer-first approach (product-led growth at its finest)
- AI use case expansion (new buying centers)
The Pattern: Great SaaS companies don’t just rely on expansion revenue. They keep growing their customer base aggressively.
The SaaStr Takeaway: If you’re seeing customer acquisition slow down, you’re either: (a) not expanding your TAM enough, or (b) not building efficient enough acquisition motions.
5. The $800M Share Buyback Signal: Ultimate Confidence Indicator
The Numbers: MongoDB announced an additional $800M share repurchase authorization, bringing total to $1B.
Why This Matters: Share buybacks at high-growth SaaS companies send a powerful signal:
- Cash generation confidence ($105.9M free cash flow in Q1)
- Limited M&A pipeline (organic growth is working)
- Stock undervaluation belief (management thinks shares are cheap)
- Capital allocation maturity (beyond just “growth at all costs”)
The Broader Trend: We’re seeing more SaaS companies return cash to shareholders as they mature. This isn’t a sign of slowing growth – it’s a sign of capital allocation sophistication.
The SaaStr Takeaway: When you’re generating serious cash flow, thoughtful capital allocation becomes a competitive advantage.
The Bottom Line: MongoDB’s Playbook for $2B+ SaaS Success
MongoDB is showing us what “mature SaaS excellence” looks like:
- Growth: Still growing 20%+ at $2B+ scale
- Profitability: 16% operating margins and improving
- Efficiency: Record customer acquisition with strong unit economics
- Cash Generation: $105.9M free cash flow in one quarter
- Capital Allocation: Returning cash while investing in growth
The Meta-Lesson: The best SaaS companies don’t “grow up” and become boring. They become MORE impressive as they scale.
5 More Quick-Hit Learnings:
- Self-Serve Channel Explosion: Record 2,600 net customer adds (highest in 6+ years) driven by self-serve acquiring mid-market efficiently – May Petri’s promotion to CMO reflects this success
- Voyage AI Integration Speed: Released Voyage 3.5 embeddings just 4 months post-acquisition, reducing storage costs 80%+ and outperforming competitors – fast M&A integration execution
- Enterprise Penetration Strategy: 75% of Fortune 100 and 50% of Fortune 500 already customers – focus shifting to “expand in those accounts” vs new logo acquisition at top end
- Competitive Moat Widening: Dev’s take on Snowflake/Databricks buying Postgres companies: “Why does the world need a 15th or 16th Postgres derivative?” – MongoDB = Postgres + Elastic + Pinecone + Cohere in one platform
- Developer Productivity Focus: Atlas instances 80% provisioned via code (matching Neon’s stat), plus new docs in Mandarin/Portuguese/Korean/Japanese – global developer experience investment paying off
Source: MongoDB Q1 2026 Financial Results
MMS • RSS
New York State Common Retirement Fund grew its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 20.4% in the 1st quarter, according to the company in its most recent Form 13F filing with the Securities & Exchange Commission. The fund owned 113,134 shares of the company’s stock after purchasing an additional 19,174 shares during the period. New York State Common Retirement Fund owned about 0.14% of MongoDB worth $19,844,000 at the end of the most recent reporting period.
Other institutional investors have also recently modified their holdings of the company. Norges Bank bought a new position in MongoDB during the fourth quarter valued at approximately $189,584,000. Marshall Wace LLP bought a new position in shares of MongoDB during the 4th quarter valued at $110,356,000. D1 Capital Partners L.P. purchased a new position in MongoDB in the 4th quarter worth $76,129,000. Franklin Resources Inc. lifted its stake in MongoDB by 9.7% in the fourth quarter. Franklin Resources Inc. now owns 2,054,888 shares of the company’s stock worth $478,398,000 after purchasing an additional 181,962 shares during the last quarter. Finally, Pictet Asset Management Holding SA boosted its position in MongoDB by 69.1% during the fourth quarter. Pictet Asset Management Holding SA now owns 356,964 shares of the company’s stock valued at $83,105,000 after buying an additional 145,854 shares during the period. 89.29% of the stock is currently owned by institutional investors.
Insider Activity
In related news, Director Hope F. Cochran sold 1,174 shares of MongoDB stock in a transaction on Tuesday, June 17th. The stock was sold at an average price of $201.08, for a total value of $236,067.92. Following the completion of the sale, the director owned 21,096 shares of the company’s stock, valued at $4,241,983.68. The trade was a 5.27% decrease in their ownership of the stock. The sale was disclosed in a legal filing with the SEC, which is available at this link. Also, Director Dwight A. Merriman sold 820 shares of the stock in a transaction dated Wednesday, June 25th. The shares were sold at an average price of $210.84, for a total value of $172,888.80. Following the completion of the transaction, the director directly owned 1,106,186 shares in the company, valued at approximately $233,228,256.24. This represents a 0.07% decrease in their position. The disclosure for this sale can be found here. Insiders have sold a total of 32,746 shares of company stock valued at $7,500,196 in the last 90 days. 3.10% of the stock is currently owned by insiders.
MongoDB Stock Performance
Shares of NASDAQ:MDB traded up $0.98 during trading on Wednesday, reaching $209.64. 1,597,285 shares of the stock traded hands, compared to its average volume of 1,978,344. MongoDB, Inc. has a 52-week low of $140.78 and a 52-week high of $370.00. The stock has a market cap of $17.13 billion, a P/E ratio of -183.89 and a beta of 1.41. The stock has a 50-day moving average of $200.37 and a two-hundred day moving average of $213.39.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share for the quarter, topping the consensus estimate of $0.65 by $0.35. The firm had revenue of $549.01 million during the quarter, compared to analysts’ expectations of $527.49 million. MongoDB had a negative return on equity of 3.16% and a negative net margin of 4.09%. The company’s revenue was up 21.8% on a year-over-year basis. During the same quarter in the previous year, the business earned $0.51 earnings per share. Sell-side analysts expect that MongoDB, Inc. will post -1.78 earnings per share for the current year.
Wall Street Analyst Weigh In
Several equities research analysts recently weighed in on MDB shares. Piper Sandler increased their target price on MongoDB from $200.00 to $275.00 and gave the company an “overweight” rating in a report on Thursday, June 5th. Wolfe Research initiated coverage on MongoDB in a research report on Wednesday, July 9th. They issued an “outperform” rating and a $280.00 price objective for the company. Cantor Fitzgerald raised their target price on shares of MongoDB from $252.00 to $271.00 and gave the stock an “overweight” rating in a report on Thursday, June 5th. Morgan Stanley decreased their target price on shares of MongoDB from $315.00 to $235.00 and set an “overweight” rating on the stock in a research note on Wednesday, April 16th. Finally, Macquarie reissued a “neutral” rating and set a $230.00 price target (up previously from $215.00) on shares of MongoDB in a research report on Friday, June 6th. Eight analysts have rated the stock with a hold rating, twenty-six have assigned a buy rating and one has given a strong buy rating to the stock. According to MarketBeat, the stock presently has a consensus rating of “Moderate Buy” and a consensus price target of $282.39.
View Our Latest Stock Report on MDB
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Discover the 10 Best High-Yield Dividend Stocks for 2025 and secure reliable income in uncertain markets. Download the report now to identify top dividend payers and avoid common yield traps.
MMS • RSS
![]() Envestnet Asset Management Inc. lifted its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 44.6% during the 1st quarter, according to the company in its most recent filing with the SEC. The fund owned 127,425 shares of the company’s stock after purchasing an additional 39,311 shares during the period. Envestnet Asset Management Inc. owned about 0.16% of MongoDB worth $22,350,000 as of its most recent filing with the SEC.
Envestnet Asset Management Inc. lifted its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 44.6% during the 1st quarter, according to the company in its most recent filing with the SEC. The fund owned 127,425 shares of the company’s stock after purchasing an additional 39,311 shares during the period. Envestnet Asset Management Inc. owned about 0.16% of MongoDB worth $22,350,000 as of its most recent filing with the SEC.
Several other institutional investors and hedge funds also recently made changes to their positions in the business. Norges Bank bought a new position in shares of MongoDB during the 4th quarter valued at about $189,584,000. Marshall Wace LLP bought a new position in shares of MongoDB during the fourth quarter valued at approximately $110,356,000. D1 Capital Partners L.P. acquired a new stake in MongoDB in the fourth quarter valued at approximately $76,129,000. Franklin Resources Inc. raised its holdings in shares of MongoDB by 9.7% in the fourth quarter. Franklin Resources Inc. now owns 2,054,888 shares of the company’s stock worth $478,398,000 after buying an additional 181,962 shares during the last quarter. Finally, Pictet Asset Management Holding SA raised its holdings in shares of MongoDB by 69.1% during the fourth quarter. Pictet Asset Management Holding SA now owns 356,964 shares of the company’s stock worth $83,105,000 after purchasing an additional 145,854 shares during the last quarter. Institutional investors own 89.29% of the company’s stock.
MongoDB Trading Up 3.5%
Shares of MongoDB stock opened at $208.66 on Wednesday. The company has a market capitalization of $17.05 billion, a PE ratio of -183.04 and a beta of 1.41. MongoDB, Inc. has a 12 month low of $140.78 and a 12 month high of $370.00. The stock’s fifty day simple moving average is $200.37 and its 200 day simple moving average is $213.39.
<!—->
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings results on Wednesday, June 4th. The company reported $1.00 earnings per share (EPS) for the quarter, beating the consensus estimate of $0.65 by $0.35. MongoDB had a negative return on equity of 3.16% and a negative net margin of 4.09%. The firm had revenue of $549.01 million for the quarter, compared to the consensus estimate of $527.49 million. During the same quarter last year, the business posted $0.51 EPS. The company’s revenue for the quarter was up 21.8% on a year-over-year basis. Analysts predict that MongoDB, Inc. will post -1.78 EPS for the current fiscal year.
Analyst Upgrades and Downgrades
A number of research firms recently weighed in on MDB. Guggenheim boosted their price target on shares of MongoDB from $235.00 to $260.00 and gave the stock a “buy” rating in a research report on Thursday, June 5th. Piper Sandler boosted their target price on shares of MongoDB from $200.00 to $275.00 and gave the company an “overweight” rating in a report on Thursday, June 5th. Cantor Fitzgerald boosted their target price on shares of MongoDB from $252.00 to $271.00 and gave the company an “overweight” rating in a report on Thursday, June 5th. Morgan Stanley decreased their target price on shares of MongoDB from $315.00 to $235.00 and set an “overweight” rating on the stock in a report on Wednesday, April 16th. Finally, Bank of America boosted their target price on shares of MongoDB from $215.00 to $275.00 and gave the company a “buy” rating in a report on Thursday, June 5th. Eight analysts have rated the stock with a hold rating, twenty-six have issued a buy rating and one has issued a strong buy rating to the company’s stock. According to MarketBeat, the stock has an average rating of “Moderate Buy” and a consensus price target of $282.39.
Read Our Latest Stock Analysis on MongoDB
Insider Buying and Selling
In other news, Director Dwight A. Merriman sold 2,000 shares of the business’s stock in a transaction that occurred on Thursday, June 5th. The stock was sold at an average price of $234.00, for a total transaction of $468,000.00. Following the completion of the sale, the director owned 1,107,006 shares in the company, valued at $259,039,404. The trade was a 0.18% decrease in their ownership of the stock. The sale was disclosed in a legal filing with the SEC, which is available at this hyperlink. Also, CEO Dev Ittycheria sold 25,005 shares of the business’s stock in a transaction that occurred on Thursday, June 5th. The stock was sold at an average price of $234.00, for a total value of $5,851,170.00. Following the sale, the chief executive officer owned 256,974 shares of the company’s stock, valued at approximately $60,131,916. This represents a 8.87% decrease in their position. The disclosure for this sale can be found here. Over the last 90 days, insiders sold 32,746 shares of company stock worth $7,500,196. Company insiders own 3.10% of the company’s stock.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
Envestnet Asset Management Inc. grew its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 44.6% in the first quarter, according to its most recent filing with the Securities and Exchange Commission (SEC). The fund owned 127,425 shares of the company’s stock after buying an additional 39,311 shares during the period. Envestnet Asset Management Inc. owned 0.16% of MongoDB worth $22,350,000 as of its most recent filing with the Securities and Exchange Commission (SEC).
A number of other institutional investors also recently bought and sold shares of the business. Penserra Capital Management LLC increased its position in shares of MongoDB by 47.5% during the first quarter. Penserra Capital Management LLC now owns 69,890 shares of the company’s stock worth $12,257,000 after purchasing an additional 22,496 shares in the last quarter. Cloud Capital Management LLC acquired a new stake in shares of MongoDB during the first quarter worth about $25,000. Harel Insurance Investments & Financial Services Ltd. increased its position in shares of MongoDB by 6,108.2% during the first quarter. Harel Insurance Investments & Financial Services Ltd. now owns 3,042 shares of the company’s stock worth $534,000 after purchasing an additional 2,993 shares in the last quarter. IFM Investors Pty Ltd increased its position in shares of MongoDB by 8.3% during the first quarter. IFM Investors Pty Ltd now owns 14,325 shares of the company’s stock worth $2,513,000 after purchasing an additional 1,098 shares in the last quarter. Finally, GF Fund Management CO. LTD. increased its position in shares of MongoDB by 1.9% during the first quarter. GF Fund Management CO. LTD. now owns 14,261 shares of the company’s stock worth $2,501,000 after purchasing an additional 261 shares in the last quarter. 89.29% of the stock is owned by hedge funds and other institutional investors.
Insider Transactions at MongoDB
In other news, Director Hope F. Cochran sold 1,174 shares of the company’s stock in a transaction on Tuesday, June 17th. The stock was sold at an average price of $201.08, for a total transaction of $236,067.92. Following the completion of the sale, the director directly owned 21,096 shares in the company, valued at $4,241,983.68. This represents a 5.27% decrease in their position. The transaction was disclosed in a filing with the SEC, which is available at this link. Also, Director Dwight A. Merriman sold 820 shares of the company’s stock in a transaction on Wednesday, June 25th. The stock was sold at an average price of $210.84, for a total value of $172,888.80. Following the sale, the director owned 1,106,186 shares of the company’s stock, valued at approximately $233,228,256.24. The trade was a 0.07% decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders sold a total of 32,746 shares of company stock worth $7,500,196 in the last ninety days. Insiders own 3.10% of the company’s stock.
Analyst Upgrades and Downgrades
Several brokerages recently issued reports on MDB. Scotiabank boosted their price target on MongoDB from $160.00 to $230.00 and gave the company a “sector perform” rating in a research report on Thursday, June 5th. Macquarie reaffirmed a “neutral” rating and issued a $230.00 price objective (up previously from $215.00) on shares of MongoDB in a report on Friday, June 6th. Bank of America boosted their price target on MongoDB from $215.00 to $275.00 and gave the stock a “buy” rating in a research note on Thursday, June 5th. Rosenblatt Securities decreased their price target on MongoDB from $305.00 to $290.00 and set a “buy” rating on the stock in a research note on Thursday, June 5th. Finally, Loop Capital lowered MongoDB from a “buy” rating to a “hold” rating and decreased their price target for the stock from $350.00 to $190.00 in a research note on Tuesday, May 20th. Eight investment analysts have rated the stock with a hold rating, twenty-six have given a buy rating and one has given a strong buy rating to the company. According to MarketBeat.com, MongoDB currently has a consensus rating of “Moderate Buy” and an average target price of $282.39.
Get Our Latest Analysis on MDB
MongoDB Trading Up 0.5%
Shares of MongoDB stock traded up $0.98 during trading hours on Wednesday, reaching $209.64. 1,597,285 shares of the company’s stock were exchanged, compared to its average volume of 1,978,344. MongoDB, Inc. has a 52-week low of $140.78 and a 52-week high of $370.00. The firm has a market capitalization of $17.13 billion, a price-to-earnings ratio of -183.89 and a beta of 1.41. The company has a fifty day moving average of $200.37 and a 200-day moving average of $213.39.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings data on Wednesday, June 4th. The company reported $1.00 EPS for the quarter, topping analysts’ consensus estimates of $0.65 by $0.35. The business had revenue of $549.01 million during the quarter, compared to the consensus estimate of $527.49 million. MongoDB had a negative return on equity of 3.16% and a negative net margin of 4.09%. The business’s revenue for the quarter was up 21.8% on a year-over-year basis. During the same period in the prior year, the firm posted $0.51 EPS. On average, equities research analysts anticipate that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Looking to profit from the electric vehicle mega-trend? Enter your email address and we’ll send you our list of which EV stocks show the most long-term potential.
MMS • RSS

MongoDB MDB and Oracle ORCL are two leading names in the database market, but they’re built on very different foundations. MongoDB is a developer-first, cloud-native NoSQL platform optimized for flexibility and speed, while Oracle is a long-established enterprise provider known for its robust relational databases and expanding multicloud presence.
As AI adoption and cloud migrations reshape data infrastructure, the key question for investors is: Which company is better positioned to capture the next wave of growth? Let’s break down the fundamentals and financials for both MDB and ORCL to see which stock deserves a spot in your portfolio.
The Case for MDB Stock
MongoDB has been consistently gaining from the growing demand for AI-powered applications. Its flexible document model is a strong fit for handling fast-changing, unstructured data commonly used in AI. The company further strengthened its AI capabilities by acquiring Voyage AI. The latest release, Voyage 3.5, has helped improve embedding accuracy and cut storage costs by more than 80%.
The platform brings together real-time data, search and retrieval into one system, allowing developers to avoid complicated integrations. MongoDB’s tools are already in use at companies like LG Uplus, where they support thousands of agents with quicker and more accurate responses, boosting their standing in the AI space.
MongoDB has also been growing its partner ecosystem. It recently added backup integrations with Rubrik and Cohesity, improving data protection for enterprise customers, especially those using hybrid cloud setups. These partnerships highlight MongoDB’s focus on enterprise-grade reliability, adding to the momentum around the platform’s broader adoption.
In the quarter, MongoDB generated $549 million in revenues, growing 22% year over year. Atlas revenues increased 26% year over year and represented 72% of total revenues. Non-GAAP operating income was $87 million, with net income of $86 million and free cash flow of $106 million.
The Zacks Consensus Estimate for fiscal second-quarter earnings is pinned at 64 cents per share, which has remained steady over the past 30 days. The estimate indicates a year-over-year decline of 8.57%.
MongoDB, Inc. Price and Consensus
MongoDB, Inc. price-consensus-chart | MongoDB, Inc. Quote
The Case for ORCL Stock
Oracle has been expanding its cloud database business through offerings like Autonomous Database and Oracle Database 23AI. These products allow customers to run databases not only on Oracle Cloud Infrastructure but also across Azure, AWS and Google Cloud through its multicloud partnerships.
The company has focused on AI-readiness by integrating vector search into its database stack. Oracle stated that Oracle 23AI enables customer data to be accessed by large language models while preserving privacy and security. As AI adoption grows, Oracle believes its database will become increasingly central to enterprise infrastructure.
In the fourth quarter of fiscal 2025, Oracle reported that cloud database services grew 31% year over year, with Autonomous Database consumption revenues up 47%. Cloud database services were reported to have an annualized revenue run rate of $2.6 billion.
However, Oracle’s database business is under pressure as cloud migration accelerates and legacy revenue streams weaken. In fiscal 2025, database license support grew just 7%. A large portion of revenues remains tied to on-premise deployments, making Oracle vulnerable as customers shift to cloud-native alternatives. Its $21.2 billion in capital spending led to negative free cash flow of $400 million. Additionally, operating across multiple clouds adds complexity and increases reliance on rival platforms.
The Zacks Consensus Estimate for fiscal first-quarter earnings is pinned at $1.47 per share, which has remained steady over the past 30 days. The estimate indicates year-over-year growth of 5.76%.
Oracle Corporation Price and Consensus
Oracle Corporation price-consensus-chart | Oracle Corporation Quote
Valuation and Price Performance of MDB and ORCL
Valuation-wise, MDB shares are trading relatively cheaper than ORCL, although both have a Value Score of F.
In terms of forward 12-month Price/Sales, MDB shares are trading at 6.76X, below ORCL’s 9.46X.
Price/Sales (F12M)
Year to date, ORCL shares have gained 38.9%, while MDB shares have lost 11.2%. For MDB, the year-to-date plunge indicates that there is more upside left in the stock, whereas for ORCL, much of the demand and growth have already been priced in.
MDB and ORCL Stock Performance
Conclusion
MongoDB has been steadily expanding its cloud-native database platform with AI-ready features and growing enterprise adoption. While Oracle shows solid momentum in multicloud deployments, much of its growth is offset by legacy drag and capital-heavy expansion. MDB’s valuation is more attractive, and its recent underperformance leaves more room for upside. With faster product innovation, developer-led traction and improving free cash flow, MongoDB stands out as a better long-term investment in the database market.
MDB, with a Zacks Rank #2 (Buy), currently offers a better investment opportunity than ORCL, which has a Zacks Rank #3 (Hold). You can see the complete list of today’s Zacks #1 Rank (Strong Buy) stocks here.
This article originally published on Zacks Investment Research (zacks.com).
Zacks Investment Research