Month: July 2022

MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Space, JetBrains’s take on containerized, remote development environments, is now available on-premises as a beta for all organizations that prefer to have full control over their tools instead of relying on third-party Cloud services.
Since Space On-Premises will be deployed inside of the user’s network, the focus is more on its containerized nature rather than on it providing a remote development experience. In other words, Space On-Premises aims to keep the promise of commoditizing development environments and making it easier to spin up full-fledged environments in short time both for first-time or casual contributors as well across machines for regular contributors.
With this introduction, JetBrains is tackling one of the most usual form of criticism to remote development environments such as JetBrains Space Cloud or GitHub Codespaces, in particular the loss of privacy and ownership on some parts of developers’ work. Being on-premises means the user keeps full control of the deployment, although this will have a cost for the operation of the system.
Space On-Premises supports most of the features provided by Space Cloud, including Git hosting, code reviews and issues support, package management, team collaboration, and so on. It has some limitations, though, when it comes to features that require hosting on JetBrains. Specifically, it can only use external workers for automation tasks, at the moment.
Most importantly, the beta release does not support development environments yet, although this feature will be available in the public release, says JetBrains. This is especially relevant for any developers or organizations that want to try out the product in its current beta, since the ability of managing and instantiating ready-to-use development enviroments is one of the most appealing features in this kind of products.
Space On-Premises comes in two fashions, with support for Docker Compose or Kubernetes. The Docker Compose version is most indicated, says JetBrains, for quick trial runs or for smaller organizations. The benefit of Docker Compose lies with the simplicity of its configuration and management, which is bases on a YAML file that describes the available services. The Kubernetes version is, instead, more flexible and supports larger organization that need their installations to scale.
While current Space users have no facilities to migrate from Space Cloud to Space On-Premises, this is something JetBrains is currently working on and that will become available at some point in future.
JetBrains is planning to run the beta for 3-6 months, during which the produce is available through a free license. At the end of this period, Space On-Premises will remain free for organizations of up to 10 users and offer specific plans for larger organizations and enterprises.
MMS • Omar Sanseviero
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Roland Meertens: Welcome to the InfoQ podcast. My name is Roland Meertens and today I am interviewing Omar Sanseviero. He is a machine learning engineer at Hugging Face, and he works on the intersection of open source and product. He gave a talk at QCon London, and I am actually speaking to him in person at the venue of the QCon London Conference. In this interview, I will talk with him about Hugging Face and the work he’s doing there. But, we will also touch on some societal topics such as the impact deep learning models have on carbon emissions and what it means to democratize good machine learning. As I said before, Omar presented at QCon London, and he’s also presenting at QCon Plus. If you registered for any of these conferences, you can view his video there. We will also release his presentation on the InfoQ website. Keep an eye on that. Now, on to the interview itself.
Welcome, Omar, to QCon London. How are you enjoying the conference so far?
Omar Sanseviero: Hey, it’s going great. I’m engaging it quite a bit. The talks have been great.It has been an amazing experience.
Roland Meertens: You gave a talk yesterday. Can you talk a bit about who you are? What your talk was about?
Omar Sanseviero: Sure, of course. I’m Omar. I’m a ML Engineer at Hugging Face, which is a open source startup that is trying to democratize good machine learning. The talk yesterday was about open machine learning, which is about how we can do machine learning in a way that everyone can use these models. That research that is being done is something that is accessible to everyone, and that is very transparent. It’s about transparently communicating what these models do, how they work, what could be the impacts of these models. Yeah, we talked quite a bit about this, about good practices, about finding models created by the community about collaboration. It was a fun experience.
Roland Meertens: What kind of models are there right now on Hugging Face? I think you guys are mostly specialized in transformers, or do you have all kinds of different models?
Omar Sanseviero: That’s a great question. How we began a couple of years ago, maybe for a bit of context, we have a platform called the Hub. The Hub allows anyone to upload any ML model or data set or demos. By now we have over 30,000 models. And, the growth has been a bit while. About a year ago, we have 6,000 models on the Hub.
Roland Meertens: 6,000 models? That’s already big.
Omar Sanseviero: One year it has multiplied times five. It’s quite exciting. Originally, what we had a couple of years ago, three years ago, we launched a open source library in Python called Transformers, which allows anyone to load a transformer model from the Hub, which is the central platform, with a single line of code. And then, they were able to use these models. That’s how we began and Transformers have their origins, their roots, in NLP. They come from the Natural Language Processing domain. But, they have expanded quite a bit to other domains.
Now, they are being used in computer vision, in audio, or speech, and also in reinforcement learning time series.So it has expanded quite a bit. Most of the models on the Hub right now, maybe about 20,000. Two thirds are transformer models. But, now we’re also supporting other open source libraries in the ecosystem. So you have your Scikit-learn, TensorFlow, PyTorch, SpaCy, or really any other machine learning library. You can just upload your model to the hub and use it as a central platform with which you can collaborate with the community.
Roland Meertens: If I download a model from Hugging Face, does this then work with all these different backends? Or, do you have specific models for specific machine learning libraries?
Omar Sanseviero: I’m a Machine Learning Engineer working in the intersection of Open Source and Product at Hugging Face.
Previously, I was a Software Engineer at Google working in ML models and infrastructure that power multiple features in Google Assistant. I was also a 20% Product Manager in the TensorFlow Graphics team.
I have expertise in education with over 6 years of experience. I’m passionate toward education-related projects, and I’ve worked closely with different online communities helping people enter the world of Machine LearningWe have different models for different libraries. What we have in the platform is that we have tags, so you can easily discover and filter models depending on your use cases or interests. There are some libraries that have interoperability. For example, there’s a library called sentence transformers or adapter transformers. These are two other libraries. They are able to load models that are for transformers. But, for example, Scikit-learn, of course, they cannot simply load that transformer model. But, in the case of certain libraries, you can. But, what is really important to us is that people can easily find the best model for their use cases. We are working in good search experience, so people can find between these 30,000 models, which are the best models for their use cases.
Roland Meertens: What are popular models on there right now?
Omar Sanseviero: That’s an excellent question. I think that what is quite powerful about transformers is that you can easily pick a model from the Hub, and then do something called fine tuning or transfer learning. And then, you can just modify this model for your own use case. Modify is probably a bit of a oversimplification. But, you can really pick a model from the Hub and just with a bit of pure data, you can modify or fine tune, or just turn a bit more this model for your own specific use case.
What many people do is they go and pick a very classic model such as BERT. BERT is a very common language model, that then they can just do something like desk classification. But, there are many, many popular models. In the audio domain, there’s a model called Wave2Vec2. This is from Facebook. This is being used quite a bit for audio. You can see it the same way as BERT. It’s very common, pretrained model in NLP. Wave2Vec2 is a very common pretrained model for audio.
Roland Meertens: So, you get the right features or you get at least a nicely calibrated feature space, once you enter an audio file on this case.
Omar Sanseviero: Yeah, exactly. What Wave2Vec2 do in this case is that once you pass an audio file, it will map this to a embedding or a hidden states that then you can use for your end task. You can use Wave2Vec to do automatic speech recognition, which is you pass an audio file and then you get the transcription of that face. You can see it as speech to text. But, there is also work to do TTS, which is text to speech. You generate synthetic audio. But, there are many, many other applications. For example, audio classification. You pass an audio, and then you might classify which is the language being spoken here, or which is the speaker speaking here, things like this.
Roland Meertens: Also, I think I saw speaker verification being used, where you have two vectors where you can compare length and spaces to see if it’s a similar person, or the same person actually in this case.
Omar Sanseviero: Exactly. Something that is very fun about all of this is that since we’re mapping to these feature spaces, which are dnr, just vectors or arrays of numbers, you can then start to compare vectors of different modalities. You can start to compare images or the embedding of an image with the embedding of a text or a paragraph or a document or an audio file. And then, you can start to get a gross modality search. You can start to have a search systems in which you might pass an image and you might get retrieved all of the text relevant to this image or the other way around. You search funny cats, and then you will get funny cat images.
Roland Meertens: I really liked it about the CLIP model from Open AI, that you can easily build natural language image search system, where you can just align the bendings of your text to the embedding space of the images. That’s really great. But, yeah, you say what you’re working on, this is open source ecosystem. How is this work? Are many people publishing models or are many people collaborating to make models better?
Omar Sanseviero: There are many, many, many efforts going on. I’ve been working at Hugging Face for about a year right now. And, we have many efforts. In the team, we really don’t train models from scratch. We do have a science team and we are turning some models and doing some open science work. We do have research that is trying to push the state of the art with a very big effort called big science. We can talk a bit more about that. But, from the open source team, what we are doing is we are building collaborations with the open source ecosystem. This goes in many, many ways. One is that as soon as there is new research related to transformers, we are adding these new architectures to the transformers library, so people can easily train these models and use them.
Because, what happens very often is that researchers share GitHub repository. If they do, the code might not be super clean or might not follow good practices, or it’s not intended for production. And, that’s totally okay. That’s how academia research works. But, once you want to start using these models in a real world setting, you really need to have good practices. We have collaborations with many open source libraries, as we were talking before. We have collaborations with about 15 or 20 different open source teams from other companies, or just from volunteers that are working external to Hugging Face.
That is quite exciting. And then, there are people that are just training models and pushing the state of the art. For example, there is a very cool group called Somos NLP, which is focusing NLP for Spanish. This a group of volunteers that they just like to push the wonders of the state of the art in NLP in Spanish. They are training very interesting models, organizing events, creating content in Spanish. It has been quite exciting. From the Hugging Face side, we try to support them in whatever they need. Sorry, a few examples.
Roland Meertens: It’s basically really the state of the art models. The best of the best published by the big companies. But then, replicated in a more reproducible way by volunteers and other people.
Omar Sanseviero: In the team, we do have people that are implementing these models in the transformers library. It’s not that it’s done just by people outside us. But, yeah. We are trying to replicate these model implementations in a good standardized way with common interfaces that we work with similar models for the same task. If you want to use a model for text classification and you want to try different architectures, you can very, very, very easily change from one model to the other. Even if they are different models, you can do that. That’s quite powerful.
Roland Meertens: How does it work in terms of the data? Do you also host the data sets or do people download their own data sets or are all the data sets by OpenAI, for example, public?
Omar Sanseviero: Yeah, that’s a great question. Many of the data sets for these very, very famous large models, such as GPT 3, neither the model, neither data sets are public. The papers, for example, do explain quite a bit about how this data was gathered. There is information about it, but the data was not published itself. Most of the time, this is data script from the web. They go through Reddit it, for example. It’s just for many, many websites. It’s not just Reddit.
But, they go to many websites, Wikipedia, Reddit, and other platforms and they scrape data from the web and they use this to train these models that will then gain a statistical understanding of the language. From the Hugging Face side, what we do is that we have something called data sets. This is a big branch in the two. We have a open source library in Python called data sets and what it allows is to load data sets with a single line of code. With a single line of code, like load from Hub. You can load the dataset with the speed you want. It’s quite nice because you can work with huge data sets of many terabytes. You can easily do filtering or mapping or do any operations you want to do about it.
And then, what we have is the Data Sets Hub. Data Sets hub is in the Hub. It’s a platform that allows people to share their data sets. What most people do is that they just share a script to load data from other sources. What usually happens is that people might have their dataset stored in Google Cloud or Amazon services. And then, they will have a script on the Hub, in the Hugging Face Hub, that will load this data set and do the splitting, for example, or any post processing that is required. They also do the documentation for their data set on the Hub.
But, some people also share their data sets directly on the hub. That means if their dataset are CSV files or JSONs or whatever, they will upload those files to the Hub and they can also use that if they want. So, you can store the data set on the Hub. What is very nice is that, on the Hub, you have a data set preview thing, which allows you to explore and take the dataset directly on the browser. Without having to run any code or download the dataset, you can just explore a bit, this dataset, directly in the web browser.
Roland Meertens: I think the other thing you mentioned in your talk were these model cards, where if you have a model that you have some basic information about how it’s trained, what it’s trained on, what the model does, can maybe tell a bit about that.
Omar Sanseviero: Yeah, sure. The concept will sound quite obvious for anyone that has done a lot of software development. You document your code. You should also document your models. But, in practice, almost nobody was doing this. This is a concept, a model cards that was going by Google, Mitchell specifically, and her research group three years ago in 2019. The idea here is that you can have an artifact that will document your model. Of course, how you document that model is completely different as how you document your software. But, usually you have things such as what this model is. What is it supposed to do? How it was trained. Which data was used to train this model. How it was evaluated. Maybe a snippet of code to run this model. Showing how to run inference, because if you don’t do that, people want be able to use your model.
And then, you might have things such as limitations and biases. Most if not all models have some biases and we can talk a bit more about this in a second. It’s very important to document that this model might not work for certain minority group, for example. If not, what can happen is that a company or anyone can go and pick this model and try to use this model for this use case, without knowing that there were these limitations and that will just lead to many different issues.
Roland Meertens: How much do people know what the limitations of a model are? Because, I personally, when I try something, I frequently discover the weirdest things not working, which you don’t really expect. Do people really also explore what the model captures in the latent space?
Omar Sanseviero: This is something that some people are doing, but not all people. What we’re trying to do, we have a research group completely focused on this, is create tools to allow people to easily explore and really dive into the model and how it works, both model and data sets. We are trying to create those to enable researchers, but also practitioners, to really explore how their model works.
There are many explainability libraries that try to show, for example, the tension mechanism and how the model is working and which words are important ones for the model. But, in practice, this is not super actionable, let’s say. We’re trying to create tools that give actionable feedback that will help people to easily know what is going on here. But, what people do is they give or they provide high level description of which bias system model might have. This is something that does exist already.
Roland Meertens: Yeah. What do you mean in terms of biases? Like specific things? That it’s good at recognizing specific things, which it’s better at recognizing?
Omar Sanseviero: This is quite depending on the use case. But, let me give you an example with GPT. GPT is are a very famous model that predicts which is the next word. If you say, I don’t know, “Today’s a very X day,” for example. Today will be a very, and you put X, it might say, I don’t know, sunny or nice day, something like that. It will predict which is the next word. For example, if you say this man is working as a… Then next word that the model will predict might be architect, doctor, something like that. For example, with woman, it will say something like, “This woman is working as a…” And, one of the predictions might be prostitute, for example.
How is this happening? Well, the model was trained with lots of data script from the web. What is quite powerful about these huge transformer models is that you don’t require any label data. That means that you don’t need to spend a lot of money labeling data. You can just grab as much data as you want. You can pass it to the model and the model will, in an unsupervised way, learn the patterns in the data. And then, as we were talking before, people sometimes just go grab this model and then they do fine tuning or transfer learning to train a new model. What is interesting is that these biases are also learned with the transfer learning. This fine tuned model will also have the biases from this source or general model. Even if you didn’t have any data that would be concerning in the fine tuning stage, if this first model had biases, this fine tune model will also have biases. This a very clear example of what biases would mean here.
Roland Meertens: I guess that in this case, if you mostly download the Reddit data, for example, that’s not a very accurate representation of the world. I mean, maybe even in worst cases, it’s not an accurate representation of what you actually try to predict.
Omar Sanseviero: We have an effort called Big Science. Big science started as an effort that Hugging Face proposed with the French government. The French government is giving us a couple millions of compute power from their supercomputer in Paris. The idea here is to train a very, very, very, very large language model, but in a fully transparent, open science and open source way. This is something that Hugging Face is pushing, but it’s not an effort from Hugging Face. Right now, it’s a collaboration between 700 researchers from different universities. So, anyone that is a researcher in academia or industry can just join the effort. It’s quite interesting because what we’re trying to do is put all the questions up front. Which biases this model might have? How are we collecting this data? We had a lot, a lot, a lot of work.
This effort started March of last year. We just started to train the model last month, like three weeks ago. We spent eight, nine months just exploring the data, defining which data sets we want to have, which languages we want to work with, cleaning all of this data, making sure that there are no biases exploring this data. It was quite interesting and it was an effort between many people from different backgrounds. For us, that’s quite important. When you want to train these very large powerful models, if you just go and get all data from the web, you will have many issues. It’s very hard to get or find these issues if you really don’t work with this data.
Roland Meertens: Are there any practical things you can do as a machine learning practitioner when setting up a data set? Are there specific tips and tricks to try to prevent these biases? Or, is it just something you have to keep in mind when deploying your model that they are there?
Omar Sanseviero: I think you need to do both. The second thing you mentioned about just keeping in mind, making sure, is something that you will always need to do in machine learning. It’s very, very easy for your model to have biases. Especially when your models are impacting humans’ lives, you need to be especially careful about how you’re using this model. Because, of course, if your model is just doing something very silly or not having a huge impact or something that is in a feature that won’t have direct impact in a human life, maybe that’s okay. But, when you’re impacting, I don’t know, something related to healthcare, something related to loans, then you need to be extremely careful. But then, in terms of if you’re bringing a model and you want to be careful about this, you need to be very careful and really dive into your data before going and training a model.
And, it can be quite easy, really. You can just go and see how it fits your data. Many people train models without really spending one hour just looking at their data. Even unrelated to biases, this is a good practice in machine learning in general. Because, for example, if you have different ways in which people are doing spaces or around optimization method of your data, you might end up with terrible results just because you didn’t really look into your data. Once you have your model trained, there are many things you can do. For example, what you can do is, maybe I will go a bit too deep on this, but you can do things such as looking at data in which the model prediction and the label diverge quite a bit.
So, if your model is predicting zero point 99, but the label was zero, that means that the model is terribly wrong or the label is wrong. That’s an easy way to just get some data that might be interesting to look at. If you’re using a threshold, wondering, you might want to look data near the threshold, because those are samples in which the model might be struggling a bit. You should probably go because there might be an issue with the model or an issue with the data.
And then, you can do other things. For example, you can look at data based on how much loss it causes. Once you train the model, you can pass a lot of data and see which was the change of the loss based on each of these samples. The ones with the largest loss, those are the ones making a biggest change in the model. You probably want to take a look at those samples as well. Maybe those are too practical, but yeah. Those are nice ways and it helps, not just for biases, but it helps to find interesting data in your data set.
Roland Meertens: I think at least it will probably give you a hint on what extra data to collect and how to do it. Another thing I sometimes read is that if you know where your bias might be coming from, just giving it as an explicit feature into your model. If you know that maybe people from certain areas are actively being biased on school results, just adding the area as a feature might actually teach the model that this feature’s unreliable, that you have a different representation for these people.
Omar Sanseviero: I think in terms of biases there are many things that you can do. But, I don’t think there is a single solution for every problem. Right now we are talking a bit about text data. But, once we talk about image data, for example, then it gets complicated as well. Or, if you’re talking about tabular data, so tables for example, it happens a lot that you have some columns or some features that are strongly correlated with some, I don’t know, with gender for example, or some race. Even if you’re not feeding the model… Woman’s level, woman are zero. I don’t know. Something. But, you might have a feature that is strongly correlated. I think really exploring your radar is extremely important if you want to avoid biases, which if you are deploying models in production, is something that you should do to be responsible.
Roland Meertens: Oh, indeed. The other thing I think you mentioned in your talk were the carbon emissions. If you’re training massive models, carbon emissions can be quite large. Your computer power can be quite large. Can you say anything about that?
Omar Sanseviero: Sure. I think this is linked as well to the model cards. When you share models and you published the model card, which is documenting how this model works, you should also document which are the ecological implications of your model. Right now what we have on the Hub is that in the model card, you can specify in the metadata, which is some information, some metadata about the model, you can specify which are the CO2 emissions. At least to the transformers, we have added callbacks and functions that allow people to very easily track the CO2 emissions while the model is being trained.
Now, maybe to take a step back and talk a bit about what this ecological impact mean, or why are we talking about CO2 emissions now. These models are very, very, very large. They are really huge. We were talking about hundreds of billions of parameters for some of these cases. There are models that are just two or 3 billion parameters or some millions. But, training these models can have a bit of impact. Right now some of the largest models might have the impact maybe of a flight, an intercontinental flight, or maybe the lifespan of a car in the US, for example. But, this is for very large models.
These very large models is not something that everyone is training. Most people are training very small models that really don’t have as much ecological impact. But, it’s very important to document this. There is something called the loss of scaling, which shows that as you grow the model, the better the performance will be. The trend that has been happening already for the last four years is that people are just going with larger and larger and larger models. Just two days ago, today is Wednesday, so on Monday, Google released a model with 500 billion parameters, I think. And, of course, if we keep seeing this trend, and I think we’ll keep seeing this trend, the models will just consume more CO2 just to train them. And then, when you put them in production, they will also consume more compared to a Scikit-learn model with a… I don’t know. Which is super small.
Roland Meertens: Like GPT3 models. You can’t run on your laptop. You can’t even run them on a single machine. You really have to have a data center and have an API to interact with them.
Omar Sanseviero: Yeah, exactly. Exactly. Even if some of these models are open source, as you’re saying, you need to have many GPUs just to load the model. Yeah. It’s very important to document them. There were some other talks yesterday about this. It’s quite interesting. I would suggest you to look at that talk. But, I think something important is that this doesn’t mean that we should not train these models. But, we should make sure that we are training models that are solving relevant issues and that we are being careful about reducing work that already exists. This concept of fine tuning or using pre-trained models really saves, not only in money, but also in ecological impact. You can just go fine tune a model, and it’ll just take you a couple of minutes or hours in a GPU and that’s it. But, if you want to train one of these large models, it will take a lot of money, hundreds of thousands of dollars and many GPUs.
I think it’s quite important to try to leverage the existing work. If you train models, even if they are small, starting to document the CO2 emissions is, I think, a good practice that we’ll start to see more and more. Because, models are becoming larger. When we are comparing our benchmarking models, also measuring not just the accuracy or the precision or just a single number, but also look at metrics such as how fast this model is, if it can be deployed or what’s the CO2 emission to train this model, are things that are important to compare between different models. If you have a model that is extremely small and have 2% less in precision, which can happen when you do distillation, maybe you can take that hit. Maybe that 2% less precision is completely okay if that means that it will be saving in CO2 emissions, and a lot of money in compute as well.
Roland Meertens: Yeah, yeah. That’s indeed a good point. The last thing maybe you mentioned in your talk was a version control for deep learning models. Would that be a solution that you always start already with existing features and only have to train tiny bits?
Omar Sanseviero: Having version control is a good practice. What I was talking at my talk, it was comparing how we do software to how we do machine learning. When you’re working in a software project, you won’t just go and release your large software related project, or your, I don’t know, open source library. You will work and iterate on it and do an iterative approach with it. We try to do the same with these models. For example, a model you might train for 100 epochs or 100 iterations. So, instead of just pushing the last model, you might want to save every 10 epochs, for example. This is a good practice because maybe your last model was not the best one, but a previous one. So, having this is a nice way to be able to just go to different versions and really compare the different versions.
What some people have been doing already for many, many years is that they might have some call back. For example, in Keras, I think many people do this and you just save the best model. But then, we’re going again to this work in which you just look at one or two numbers. You just look at the best model with precision. But, there are really many numbers that you should look at when you want to push a model to production. So, having version control is important. If you are turning a model for a few weeks, for example, you might want to just keep pushing models to pick up and then you might want to keep updating the metrics. At one point, you might be able to compare all these metrics across time. That’s quite useful. And then, if your model just breaks, you can also just go back to a previous version.
Roland Meertens: For example, if you would normally train your model for a hundred epochs and you update your data set, you want to continue trading on the 50th epoch. So, your latent features are already relatively well, but then still have enough space to learn, right?
Omar Sanseviero: Yeah, yeah, exactly.
Roland Meertens: Do you also see that’s something on Hugging Face where people keep building on top of existing models to keep building more advanced models? Or, is this something which is relatively new?
Omar Sanseviero: It is happening. This is happening. I would not say it’s happening that much, but I’m seeing this more and more. I think this trend will just keep going up.
Roland Meertens: Yeah. And then, maybe last thing, once you talked a bit about democratizing good machine learning, can you say something about what you mean with that?
Omar Sanseviero: Sure. Yeah. Really I think this is a very complex topic and we could talk a few hours about this. But, something important to keep in mind with machine learning is that, as a software engineer, it’s very easy to see machine learning as, okay, we’re solving this problem and that’s it. But, at the end, we are impacting humans’ lives. It’s very important to always keep that in mind. When you are doing machine learning, there are many aspects to this. For example, from the research perspective, when you are doing machine learning research and you are proposing or publishing these huge models that nobody can train except these large institutions, then you’re making science or research not accessible to everyone. If you want other researchers to be able to evaluate your model, you cannot do that.
When we are talking about these huge models, people that are working in low digital resource languages, for example, if there are not that many data sets in Spanish, people won’t be able to go and train any model. These are problems that you always need to keep in mind. And, not just that. You need to involve people that are being impacted by them. Something that I talk quite a bit in my talk, was about demos. Building demos that people can just interact and play with the models. Something we are seeing is that people are creating demos for their models. And then, they are sharing those demos with people that will be impacted by the systems. This helps because most likely in a software related team, you will have a group of… If you are a team of 10 people, nine of those will be men, or eight of those statistically speaking. Most of them will be white men.
And then, you will have a set of people that will have a very narrow view of the world. When you do these kind of demos and you start them with people from different context, different backgrounds, even if they are not ML engineers, you can start to get interesting perspective. Couple of weeks ago, someone released a image captioning model and it was working extremely well with white people. But, with black people, it was labeled such as, I think, it was gorilla. And, it was similar to what happened with Google in like five years ago. It’s very important to really make sure that people from different contexts play with these models, just because of this. Involving people that will be impacted, or any stakeholder, is extremely important. That’s a huge part of good machine learning, democratizing good machine learning.
We try to involve people both from the, okay, we have a model, so let’s validate it and let’s see how it works with different groups. That’s something that we do. We try to do these open science efforts to really enable people to do things. And then, we are doing many different things to enable people from underrepresented groups to be able to use machine learning. We had a very fun effort with Yandex in July of last year. It was published at NeurIPS this year. The idea was to do distributed computing.
These people didn’t have GPUs. What we wanted to do was train a very large model for their local language. What we did instead was you could see it as distributed computing. Each of these persons provided a bit of their compute power from their own computer. And then, we had 40 or 50 people just with their computer open all the time. At the end, we had an open source model owned by them and it was published in a paper and it was also owned by them. It’s in an organization in HuggingFace that they own.
Everyone collaborated on this. Even if they were not writing any code or anything, they were just running some cells of code. They were contributing to this larger model. This is an interesting effort because this could enable people from languages or from universities or communities that really don’t have access to GPUs or any fancy compute power. This could enable them to train these larger models. This was a state of the art. So, this was quite interesting.
Roland Meertens: I think especially the underlying data can be so important. Because, for GPT 3, you can see the underlying language distribution. You can also, when you’re playing around with the model, it works perfectly for English. And then, once you get into more obscure languages like Swedish Dutch, the amount of content on the internet in that language is maybe a bit lower, but also harder to find. There’s not that many Dutch speaking subreddits. Everything is influenced, but it’s good to try to involve those people. I think you mentioned those Spanish people, who know exactly where the Spanish language resources are.
Omar Sanseviero: Exactly. Yeah, exactly. Even then, Spanish is quite interesting because Spanish, I think it’s the second most spoken language. It has 500 million speakers. Or, I think it’s much more than that probably. But, it’s interesting because the Spanish from Spain will be completely different than the Spanish from Argentina or Spanish from Mexico. You need to involve people not from Spain, but also people from different countries in Latin America to be able to get a very distributed, very fair data set distribution. So, you get data from these different sources, from these different Spanish variations.
If you just train Spanish models from Spanish from Spain, then it will be a biased model. Because, it will be just focusing the Spanish from Spain. That’s a key topic as well. Really involving the people to get these data sets. So, if you just speak English or you just live in a English speaking country, and then you want to train a large model for Italian without involving anyone that speaks Italian, you probably cannot do that. You will get some numbers that will show you that the model is doing great. But, if you don’t have any idea of how this model is really working, that’s not great.
Roland Meertens: Also just getting a feeling for what are relevant resources. Every time I’m learning a new language, you are trying to figure out where is the content, where is good quality content. As a non-native speaker, you have no clue about all the cultural aspects or the social aspects of a new country. Involving a lot of people is so important.
Omar Sanseviero: For example, with Big Science, which is this effort with 700 researchers I was talking about, we are targeting seven languages, I think. I’m not that involved in the project. But, between those languages, I think there was French, German, and Italian. Something that they did was a data set catalog. Even before creating any data set, they just explored many, many, many potential sources of data.
New places, they then analyze a bit the licensing or data quality and if there were tools to access this data from the publisher of this data. This was a distributed effort, because of course for each of these language, there was a group of native speakers and people that were living in those countries that were exploring which are the best sources for this data. And then, we collected it and then we did all the next relevant parts. But, as you were saying, really finding the right sources for these languages needs to involve people from these languages.
Roland Meertens: So, if there’s people listening who want to get involved in this, is there any way to get started?
Omar Sanseviero: You mean to Big Science?
Roland Meertens: Yeah. Or, any other projects which you can recommend people to check out, help democratizing our systems?
Omar Sanseviero: From the Big Science effort, you can just search Big Science. For that project in particular, you need to be a researcher. You need to be either at a company or at a university. But, really, there are many, many ways in which you can contribute. As a first step, I always recommend just go to the Hub and see which are the data sets available. Because, there are 3000 data sets. See which are the models available. And, many, many times, if you are already doing machine learning, you can potentially already open source your work.
Of course, it really varies of what you are doing within the machine learning ecosystem. But, there are many things that you can do to contribute back to the community. Everything we do is open source. If you’re interested in data sales or in transformers, you can go to these libraries and contribute with a new model architecture or a new data set, if that’s something you would like. I think there are many potential venues in which you can contribute to the ecosystem.
Roland Meertens: Sounds good. Thank you very much for this talk. Enjoy Qcon London. Have a good day.
Omar Sanseviero: Thank you. Thank you for invitation.
Roland Meertens: That was the interview with Omar. Thanks again, Omar, for participating. I hope you enjoyed listening to this in-person interview recorded at QCon London and thank you very much for listening to the InfoQ podcast.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Anthony Alford
Article originally posted on InfoQ. Visit InfoQ

Researchers at Google Brain recently trained Language-Image Mixture of Experts (LIMoE), a 5.6B parameter image-text AI model. In zero-shot learning experiments on ImageNet, LIMoE outperforms CLIP and performs comparably to state-of-the-art models while using fewer compute resources.
The model and several experiments were described in a paper published on arXiv. LIMoE combines a sparse mixture-of-experts (MoE) scheme with the Transformer architecture, which allows for increasing the number of model parameters while maintaining low computational requirements during inference. Unlike CLIP and other “two-tower” image-text models that use separate encoder networks for images and text, LIMoE has a single encoder for both modalities which has the potential for better scalability and generality. According to the Google Brain team:
Multimodal models that handle many tasks are a promising route forward, and there are two key ingredients for success: scale, and the ability to avoid interference between distinct tasks and modalities while taking advantage of synergies. Sparse conditional computation is an excellent way of doing both. It enables performant and efficient generalist models that also have the capacity and flexibility for the specialization necessary to excel at individual tasks, as demonstrated by LIMoE’s solid performance with less compute.
The development of LIMoE is part of Google’s Pathways strategy for developing next-generation AI models. One tenet of this effort is the use of sparse neural network models, wherein only a few of pathways through the network are activated. This means that using the model for inference requires a fraction of the compute resources—and thus the energy—used by a dense model of comparable size. InfoQ recently reported on Google’s PaLM language model, also developed as part of the Pathways project. In 2021, InfoQ reported on Google’s Switch Transformer, a sparse MoE language model that pre-dated the official Pathways announcement but is designed using some of its principles.
LIMoE is based on the Transformer architecture, in which the sequence of input tokens is processed by a series of identical blocks which contain several neural networks layers, including an attention layer and a simple feed-forward layer. In LIMoE, the feed-forward layer is replaced by an expert layer which contains parallel feed-forward layers called experts, and a router that determines which experts handle a given token.
The Brain team found several challenges in training this model. One challenge, common to all MoE models, is to make sure that the model does not collapse; that is, that the router does not always choose the same expert. Another challenge, specific to multi-modal data, is “modality unbalance”; for example, the dataset may contain much more text than image data. In this case, model collapse can occur for the smaller modality. To remedy these challenges, the team introduced two new training losses: local entropy, which “encourages concentrated router weights,” and global entropy, which results in “diverse expert usage.”
Lead author Basil Mustafa posted a Twitter thread about the work and answered user questions. When one user asked him to elaborate on how the network was “finicky” to train, Mustafa replied:
LIMoE setup is stable in that, given good [hyper-parameters], it’s [very] reliably reproducible & good. However [in my opinion] still a bit sensitive to these [hyper-parameters]; sometimes [the] recipe fails and needs trial and error tuning.
Google has not released the LIMoE model code, but Mustafa suggested the code would be available on GitHub along with a sparse MoE model for vision within “a few months.”
MMS • Rhian Lewis
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Open-source software brings its own challenges for testers, particularly in the world of Web3, whether this is integrating with libraries and systems that are outside the control of the test team, or attempting to replicate in a staging environment complex and energy-intensive networks such as public blockchains
- Open-source testing in the form of bug bounties can help broaden the scope of your testing and provide specialist support
- Bounty programs are not a replacement for professional testing; they are a tool in the test team’s armoury. They can add specialist skills and geographically localized expertise that would be difficult to find on your team
- Bounty programs are most likely to be successful when testers are involved in defining scope, triaging bugs and working with the community
- They are also a useful tool for upskilling and developing skills such as mob testing and security testing
Open-source software has changed the way we work, as testers and developers. We are more likely to use open-source libraries and packages than ever before, which means bugs can be introduced via dependencies our teams cannot control.
And now we are entering a world of open-source testing, too. Increasingly, open-source projects (and many closed-source ones) are creating bug bounty programs and asking people outside the organization to become involved in the quality and security process.
The growing importance of the Web3 ecosystem based on blockchains shows how important community test programs are, with recent examples of bugs being discovered by open-source testers who have saved projects tens of millions of dollars.
Some within the testing community see this trend as a threat. However, it is actually an opportunity. Bug bounties and open-source test contributions are a great tool for test teams, and there is every reason for testers to embrace this new trend rather than to fear it.
Challenges of testing open source software
There are two main challenges: one around decision-making, and another around integrations. Regarding decision-making, the process can really vary according to the project. For example, if you are talking about something like Rails, then there is an accountable group of people who agree on a timetable for releases and so on. However, within the decentralized ecosystem, these decisions may be taken by the community. For example, the DeFi protocol Compound found itself in a situation last year where in order to agree to have a particular bug fixed, token-holders had to vote to approve the proposal.
So you may not have the same top-down hierarchy as in a company producing proprietary software, where a particular manager or group of managers are in charge of releases.
When it comes to integrations, these often cause problems for testers, even if their product is not itself open-source. Developers include packages or modules that are written and maintained by volunteers outside the company, where there is no SLA in force and no process for claiming compensation if your application breaks because an open-source third party library has not been updated, or if your build script pulls in a later version of a package that is not compatible with the application under test. Packages that facilitate connection to a database or an API are particularly vulnerable points.
Bug-bounty programs and their purpose
Bug bounty programs are a way of crowd-sourcing testing. The author James Surowiecki popularised the idea in his book The Wisdom of Crowds that the more people who have their eyes on a particular problem, the more likely they are to find the right solution. In the case of very complex systems with multiple dependencies and integrations, where a single small loophole can cause the loss of millions of dollars, it becomes increasingly unlikely that a single tester or test team will have the specialist knowledge and predictive ability to identify every potential issue. So financially incentivising the wider community to search for bugs is becoming increasingly popular.
You can financially incentivise bug searches by publishing the terms and conditions, along with the reward table, on your own website. But more commonly, platforms like HackerOne, BugCrowd and ImmuneFi handle the process for you and provide a one-stop shop for testers and security researchers who are keen to show their prowess as well as earning rewards.
For commercial software, the decision to run a program and mandate particular rewards is one that is made centrally. The process is different for open source, particularly within the Web3 ecosystem. In this case, the foundation or DAO that runs the protocol will vote on a certain proportion of the treasury being released to fund a bug bounty.
Typical examples are Compound’s bug bounty and the one I helped set up for Boson Protocol Boson Protocol.
The Compound bug bounty program on ImmuneFi is a good example because it clearly lays out the rewards available (up to $50,000) according to the severity of the vulnerability and is also very clearly scoped to include only one particular pull request. ImmuneFi takes care of any payouts or disputes.
In contrast, the Boson Protocol program targets all the smart contracts – with a similar bounty of $50,000 – but excludes all associated websites and non-smart contract assets. In this instance, the bounty program is offered directly rather than via an intermediary.
Advantages and disadvantages of open-source bug-bounty programs
The advantage of open-sourcing testing, even on closed-source projects, is that it widens the bug-catching net and allows a much larger number of people to contribute to the security of a system, rather than depending on a project’s formally employed test team to cover all bases. A popular open-source project is usually maintained by a core development team which may include testers, but like most closed-source projects, they may not have the extremely specialist skills that are sometimes needed now and again in the software development lifecycle. Many companies will already hire specialist services, for example, to do penetration testing. You can think of a bug bounty as a kind of ongoing penetration test, where you only pay for the time and expertise of the specialist if they find a vulnerability.
But more than anything, and no matter what your project is, crowd-sourcing testing leads to a variety of different approaches, ways of thinking and skill sets that it would be impossible to find in a single person or team. A successful product or application will have tens of thousands – perhaps millions – of users, all of whom will use it in different ways and take different routes through it using different hardware. Having access to a bigger pool of skills and opinions is a valuable resource when channelled correctly.
The disadvantages mainly lie in the extra time and effort in marketing your bounty program to those with the relevant skills. And if you are not careful to define the scope of the bounty in advance, your company, foundation or project may end up paying out for bugs that you as a tester have already found.
Testing the Web3 ecosystem
Blockchain technology – or Web3 as it is sometimes known – is a very challenging area for testers for many reasons. I will highlight two of the main ones.
Firstly, it is very difficult to replicate the conditions of a production environment in Staging; as in a Production situation, you literally have thousands of validators and thousands of users, who may interact with the system in ways you have not thought of. This is impossible to replicate. If you look at the Bitcoin blockchain, for example, it would cost literally millions of dollars in electricity alone to run an entirely accurate simulation of the live network.
Secondly, Web3 systems are designed to be what we call composable, which means that they all fit together like Lego bricks. To give a simple example of this, the ERC20 token standard devised for the Ethereum blockchain can be transferred into any wallet, as can the ERC721 NFT token standard. This means that a developer can write a smart contract that creates a derivative on a decentralized exchange and then use that derivative to generate income on a completely separate savings protocol, and then use the generated income as collateral on yet another protocol. This interdependency can multiply risk many times over, especially if one key component goes wrong.
The fact that there are literally tens of millions of dollars sitting in these open-source protocols is also a risk: it acts as a honeypot. Sometimes, if you look at existing bug bounty programs, the rewards on offer can look absurdly high, but if a successful bounty hunter can find a bug before it is exploited, the cost-benefit ratio starts to make sense.
For example, the layer 2 network Polygon recently paid out $2 million to whitehat hacker Gerhard Wagner for finding an exploit. This sounds like an incredible sum, but when you think that $850 million in funds were at risk if the bug hadn’t been detected, it makes more sense (source: Polygon Double-Spend Bugfix Review — $2m Bounty ).
Simply looking at a bounty platform such as ImmuneFi gives a hint of the rewards that are currently on offer: $2.5 million for the highest category of vulnerability in The Graph Protocol, for example – and $5 million for ChainLink.
Community-focused test programs
I feel passionately that testers should be involved in defining the scope of successful bounty programs and deciding how they should run. The main thing is to either take charge of the program yourself as a team or to work very closely with the people in your organisation who set it up. You also need to agree who will triage the tickets and how bounty hunters will interact with your team. It is crucial that testers help define the scope of any program so that rewards are not offered for unimportant issues, and that particular areas can be excluded where the test team prefers to retain responsibility for bug reports. It makes more sense to ring-fence bug bounties for areas where there are likely to be edge cases, or where a particular type of expertise is needed.
For example, the Compound bug bounty program I mentioned above specifically mentions that the program is targeted at patches that were made to the protocol’s Comptroller implementation, which deals with risk management and price oracles. This is specialist financial knowledge and it makes sense to draw on a wider pool of people to find someone with these skills.
Further advantages of bug bounty programs for testers
Testers can also involve themselves in open-source software and bug bounties outside their organisation to strengthen their testing skills – and maybe even make some extra cash.
It can be a great way for a test team to practise their mob testing skills and work together on finding bugs. The best known platforms are HackerOne and BugCrowd, so go there and see if there is anything that looks interesting. It’s always a great idea to get out of your comfort zone and test something you haven’t necessarily tested before.
And if you want to target your efforts on Web3 technologies specifically, head to ImmuneFi and check out the programs there.
How radical openness improves testing
One interesting new concept that is gaining currency is radical openness – and there are definitely scenarios that apply to testing. This is a concept popularised by the 2013 book Radical Openness: Four Unexpected Principles for Success by Anthony D Williams and Don Tapscott, which argues that transparency brings benefits to all stakeholders in business environments.
In a recent excellent post by Andrew Knight on opening tests like opening source, he highlights the benefits of open-source testing:
Transparency with users builds trust. If users can see that things are tested and working, then they will gain confidence in the quality of the product. If they could peer into the living documentation, then they could learn how to use the product even better. On the flip side, transparency holds development teams accountable to keeping quality high, both in the product and in the testing.
He is not talking about bounty programs, but the principles are the same. It comes back to the wisdom of crowds. The more people who are involved in scrutinizing software and how it is used, the more likely it is that it will be fit for purpose.
Microsoft Announces the General Availability of Its Gateway Load Balancer in All Regions
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
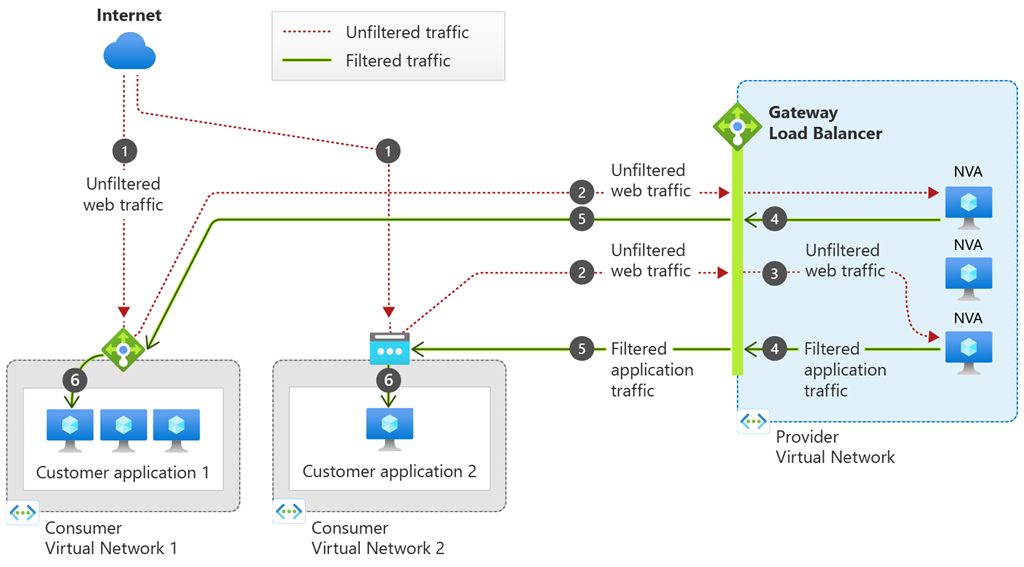
Gateway Load Balancer is a fully-managed service enabling enterprises to deploy, scale, and enhance the availability of third-party network virtual appliances (NVAs) in Azure. Microsoft recently announced the general availability of Gateway Load Balancer in all public regions, Azure China cloud regions, and Azure Government cloud regions.
Earlier, the company released the public preview release of Gateway Load Balancer (GWLB), a new Azure Load Balancer SKU targeted for transparent NVA insertion supported by a growing list of NVA providers. According to the company’s blog post by program manager Annie Fang, GWLB offers the following benefits for NVA scenarios: source IP preservation, flow symmetry, lightweight NVA management at scale, and auto-scaling with Azure Virtual Machines Scale Sets (VMSS). Furthermore, she explains in the post:
With GWLB, bump-in-the-wire service chaining becomes easy to add on to new or existing architectures in Azure. This means customers can easily “chain” a new GWLB resource to both Standard Public Load Balancers and individual virtual machines with Standard Public IPs, covering scenarios involving both highly available, zonally resilient deployments and simpler workloads.
Source: https://azure.microsoft.com/en-us/blog/gateway-load-balancer-now-generally-available-in-all-regions/
In an earlier tech community article, Anavi Nahar, senior project manager of Azure Networking at Microsoft, further describes the concept of service chaining:
Once chained to a Standard Public Load Balancer frontend or IP configuration on a virtual machine, no additional configuration is needed to ensure traffic to and from the application endpoint is sent to the Gateway LB. Traffic flows from the consumer virtual network to the provider virtual network and then returns to the consumer virtual network. Gateway Load Balancer exchanges application traffic with the appliance in its backend pool using VXLAN encapsulation.
GWLB uses Virtual Extensible LAN (VXLAN) as an encapsulation protocol, which enables traffic packets to be encapsulated and decapsulated with VXLAN headers as they traverse the appropriate data path, all while retaining their original source IP and flow symmetry and avoiding the need for Source Network Address Translation (SNAT) or other complex configurations such as user-defined routes (UDRs).
The VXLAN tunnel interfaces are configured as part of the GWLB’s back-end pool, allowing the NVAs to differentiate between “untrusted” and “trusted” traffic. These tunnel interfaces can be either internal or external, and each backend pool can have up to two. Typically, the external interface is used for “untrusted” traffic—traffic that originates on the internet and is directed to the appliance. On the other hand, the internal interface is used for “trusted” traffic—traffic from customers’ appliances to their applications.
Microsoft is not the only public cloud provider offering a Gateway Load balancer. Microsoft’s competitor in the public cloud space, AWS, also provides a Gateway Load balancer generally available since the end of November 2020.
Lastly, more details are available on the documentation pages and guidance through the quick start tutorials.
AWS Announces General Availability of its Cloud WAN for Centralized Workload Management
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Recently AWS announced the general availability (GA) of its Cloud WAN solution allowing enterprises to set up and manage a complete WAN environment from a single cloud-based console.
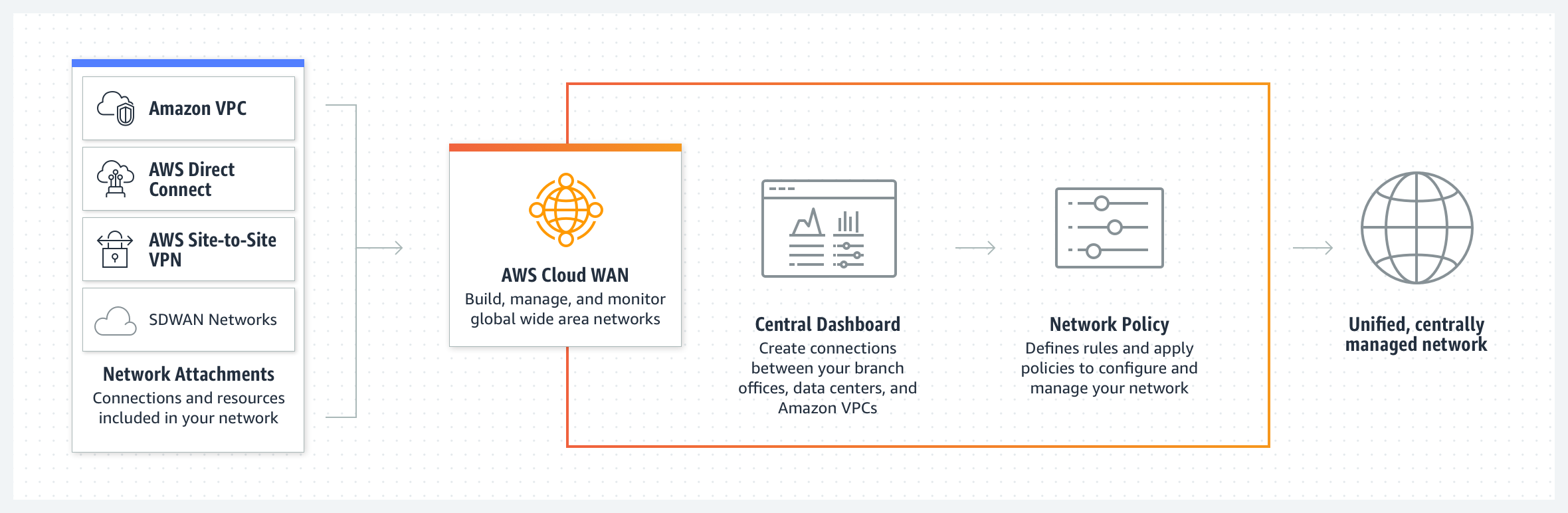
AWS Cloud WAN, which has been in preview since last year, is a cloud-based managed WAN service that will enable enterprises to bring together their entire network of on-premises data centers, branch offices, and cloud infrastructure in one global network.
With the solution, enterprises no longer have to set up various overarching networks to bring all their network environments together – which often leads to a great network complexity of different networks, each of which has a specific task, such as connectivity, security, and monitoring. They can now build, manage, and monitor a so-called “unified global network” more quickly and efficiently by connecting to various AWS cloud environments and regions, as well as Local Zones and AWS Outposts environments located in customers’ on-premises data centers.
Furthermore, the solution also integrates with various third-party SD-WAN environments such as the SD-WAN solutions and services from HPE Aruba, Aviatrix, Checkpoint, Cisco Meraki, Cisco, Prosimo, and VMware.
Source: https://aws.amazon.com/cloud-wan/
In an AWS news blog post on the GA of AWS Cloud WAN, Sébastien Stormacq, a principal developer advocate at Amazon Web Services, explains:
With Cloud WAN, networking teams connect to AWS through their choice of local network providers, then use a central dashboard and network policies to create a unified network that connects their locations and network types. This eliminates the need to configure and manage different networks individually, even when they are based on different technologies. Cloud WAN generates a complete view of your on-premises and AWS networks to help you visualize the health, security, and performance of your entire network.
The central console allows administrators to use the service to assign policies and monitor the health status of the global cloud-based WAN environment. Furthermore, they can also automate configuration and security tasks via the console, for example, by routing network traffic from offices through a dedicated firewall before it reaches cloud-based resources in an AWS region.
David Brown, vice president of Amazon EC2 at AWS, said in a press release on the GA of AWS Cloud WAN:
As the edge of the cloud continues to be pushed outward, and more customers move their applications to AWS to become more agile, reduce complexity, and save money, they need an easier way to evolve their networks to support a modern, distributed model that allows them to reach their customers and end users globally with high performance. With AWS Cloud WAN, enterprises can simplify their operations and leave the time-consuming task of managing complex webs of networks behind.
The cost of AWS Cloud WAN is based on usage. Four factors determine what customers pay: the number of Core Network Edges (CNEs) deployed, the number of connections to these CNEs, the number of Transit Gateways peered with the CNEs, and the data handling of traffic. More details are available on the pricing page.
Lastly, the AWS Cloud WAN service is available in AWS regions across the US, Asia Pacific, Europe, Canada, Cape Town, Africa, and Bahrain in the Middle East.
Java News Roundup: Microsoft Joins MicroProfile and Jakarta EE, GlassFish, Payara, Micronaut
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for July 11th, 2022, features news from JDK 19, JDK 20, Microsoft joins MicroProfile and Jakarta EE working groups, Jakarta EE 10 update, Spring updates, Payara Enterprise 5.41.0, GlassFish 7.0-M7, Micronaut 3.5.3, Hibernate Search 6.2.Alpha1, Native Build Tools 0.9.13, Project Reactor 2022.0.0-M4, Piranha 22.7.0, PrimeFaces updates, JobRunr 5.1.5 and Tomcat Native 2.0.1.
JDK 19
Build 31 of the JDK 19 early-access builds was made available this past week, featuring updates from Build 30 that include fixes to various issues. More details may be found in the release notes.
JDK 20
Build 6 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 5 that include fixes to various issues. Release notes are not yet available.
For JDK 19 and JDK 20, developers are encouraged to report bugs via the Java Bug Database.
Microsoft Joins MicroProfile and Jakarta EE Working Groups
Microsoft has joined the Jakarta EE Working Group as an Enterprise member and the MicroProfile Working Group as a Corporate member. Julia Liuson, President Developer Division at Microsoft, describing the goal of Microsoft joining these working groups, writing:
Our goal is to help advance these technologies to deliver better outcomes for our Java customers and the broader community. We’re committed to the health and well-being of the vibrant Java ecosystem, including Spring (Spring utilizes several key Jakarta EE technologies). Joining the Jakarta EE and MicroProfile groups complements our participation in the Java Community Process (JCP) to help advance Java SE.
InfoQ will follow up with a more detailed news story.
The Road to Jakarta EE 10
On the road to Jakarta EE 10, Ivar Grimstad, Jakarta EE developer advocate at the Eclipse Foundation, announced in his Hashtag Jakarta EE weekly blog that the release of Jakarta EE 10 is “imminent” as three remaining Technology Compatibility Kit (TCK) issues still need to be resolved:
- CDI Language Model TCK failure in GlassFish
- Jakarta Concurrency 3.0 TCK contains remote Jakarta Enterprise Beans
- Jakarta RESTful Web Services 3.1 TCK contains tests for Jakarta XML Binding 4.0
Grimstad also stated that the Eclipse GlassFish project team is working on a fix and pull requests to resolve these items with a small possibility that the all three Jakarta EE profiles – Platform, Web and Core – could be ready for release review ballots soon. The Jakarta EE Platform profile has passed the TCK and a Compatibility Certification Request has been filed for GlassFish 7.0.
Spring Framework
Versions 2022.0.0-M5, 2021.2.2 and 2021.1.6 of Spring Data have been released featuring bug fixes and corresponding upgrades to all (or most) of the Spring Data subprojects. Spring Data 2022.0.0-M5 includes a dependency upgrade to Hibernate 6.0 and the 2021.x releases may be consumed by the upcoming releases of Spring Boot.
Spring Framework 6.0.0-M5 and 5.3.22 have been made available to the Java community:
Spring Native 0.12.1 has been released featuring: adding a hint for Sleuth in the R2dbcTransactionManager class and publishing the Jakarta EE 10 TCK results. There were also dependency upgrades to Spring Boot 2.7.1 and Native Build Tools 0.9.13. Further details on this release may be found in the release notes.
Payara
Payara has released the July 2022 edition of their Payara Platform as an enterprise-only release. Payara Platform Enterprise 5.41.0 edition delivers two bug fixes, two component upgrades and improvements that include: the Upgrade Tool that fixes an issue with the osgi.properties file; Payara Micro shutdown using Ctrl+C; and updated Docker images that include Azul Platform Core for Distribution. It was also announced that Payara Platform 4 will enter the extended support phase as of August 2022. More details on this release may be found in the release notes.
Eclipse GlassFish
On the road to GlassFish 7.0.0, the seventh milestone release was made available by the Eclipse Foundation to deliver changes such as: adding a concurrency API JAR to the default JSP Servlet configuration; a JDK 17 profile for the MicroProfile dependency; integrating OmniConcurrent RC3; and adding a TCK runner for Jakarta Bean Validation specification. Further details on this release may be found in the release notes.
Micronaut
The Micronaut Foundation has released Micronaut Framework 3.5.3 featuring a fix for a runnable JAR that affected applications built with Grail 5.2.0 and Micronaut. More details on this release may be found in the release notes.
Hibernate
On the road to Hibernate Search 6.2.0, the first alpha release has been made available featuring a new standalone POJO mapper that allows developers to map arbitrary objects to an index, even if those objects are not Hibernate ORM entities. Custom integrations are now possible with NoSQL datastores.
GraalVM Native Build Tools
On the road to version 1.0, Oracle Labs has released version 0.9.13 of Native Build Tools, a GraalVM project consisting of plugins for interoperability with GraalVM Native Image. This latest release provides: a reversal in a change in the NativeImagePlugin that removed publicly accessible constants, such as NATIVE_TEST_EXTENSION, that broke external plugins. Further details on this release may be found in the changelog.
Project Reactor
On the road to Project Reactor 2022.0.0, the fourth milestone release was made available featuring dependency upgrades to the reactor-core 3.5.0-M4 and reactor-netty 1.1.0-M4 artifacts and a realignment to milestone 4 with the reactor-pool 1.0.0-M4, reactor-addons 3.5.0-M4, and reactor-kotlin-extensions 1.2.0-M4 artifacts.
Piranha
Piranha 22.7.0 has been released. Dubbed the “Welcome Servlet 6/EE 10” edition for July 2022, this release includes: an initial HTTP server implementation using virtual threads; support for Jakarta Servlet 6.0; and an initial implementation of the Servlet TCK. More details on this release may be found in their documentation and issue tracker.
PrimeFaces
PrimeFaces, a provider of open-source UI component libraries, has made available point releases of PrimeFaces 8.0.19, 10.0.14 And 11.0.6. Notable fixes in this release include: a required second click to close the DataPicker panel; a JavaScript error upon invoking an AJAX request; a broken @RequestScoped annotation model; and filterBy and sortBy operations failing when performing a column ordering change.
JobRunr
Ronald Dehuysser, founder and primary developer of JobRunr, a utility to perform background processing in Java, has released version 5.1.5 that ships with notable bug fixes to resolve: ElasticSearch not supporting more than 10 recurring jobs; and Spring auto configuration prematurely initializing some Spring beans that resulted in missing functionality of other components.
Apache Tomcat Native
The Apache Software Foundation has released version 2.0.1 of Apache Tomcat Native, an optional Apache Tomcat component that allows Tomcat to use OpenSSL as a replacement for Java Secure Socket Extension (JSSE) to support TLS connections. New features include: the JNI API has been reduced to only support Tomcat’s OpenSSL-based TLS implementation; the minimum supported versions upgraded to OpenSSL 3.0.x, Apache APR 1.7.x, Java 11, Windows 7 and Windows Server 2008 R2; and the Windows binaries built with OpenSSL 3.0.5. The APR/native connector is no longer supported in this branch. Further details on this release may be found in the changelog.
MMS • Kelsey Hightower
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Transcript
Shane Hastie: Good day folks. This is Shane Hastie with the InfoQ Engineering Culture Podcast. Today, I have the privilege of sitting down across the miles with Kelsey Hightower. Kelsey is a principal engineer with Google Cloud and will be doing one of the keynotes at the upcoming Agile 2022 Conference. Kelsey, welcome. Thanks so much for taking the time to talk to us today.
Kelsey Hightower: Yeah, thanks for having me.
Shane Hastie: Probably a good starting point is who’s Kelsey? Do you want to give us a bit of your background and experience?
Introductions [00:32]
Kelsey Hightower: Yeah, I’m this self-proclaimed minimalist. I try to be very intentional about everything that I own, about everything that I do. Not only question everything, but try to figure out why. If I go back to like my humble beginnings, I think as a self-taught engineer, which is someone who has learned from teachers they’ve never met, one of those people who decided to get into tech around 1999, year 2000, right out of high school. I decided college wasn’t for me and I took that certification path: A+ certification, Network+ certification, and just found my way into tech and been honing my craft ever since.
Shane Hastie: What does it mean for an engineer to hone the craft?
Fundamentals of software engineering [01:09]
Kelsey Hightower: Honestly, I think it’s really understanding your tools well, their pros, their cons, all tools have limitations, and I think the fundamentals. Like the fundamentals of software, I think sometimes we get caught up in various frameworks, whether they’re web frameworks or mobile frameworks, but the fundamental is we are basically trying to manipulate data to allow people to interact with the world. Right? If you’re buying something you put in your shipping information, maybe a payment info, and we try to give you this experience so you can explore our catalog, and ideally that thing should be in stock and then we ship it to the right address. So I think the fundamentals of writing software is applying the right algorithms over the right set of data and making sure people have a great experience with the real world. So for me, I don’t put software ahead of the experience, it’s just a tool to get us to the experience.
Kelsey Hightower: That’s where a lot of my fundamentals arrive. So if I’m going to learn about networking, I’m going to go back 30, 40 years and try to review what the discussion was when people thought about connecting the world. I’m going to go figure out who is Vincent Cerf. I’m going to go figure out why was the internet necessary? What were the naysayers saying? How did it turn out? What were the pros and cons? So I kind of look at everything through that lens. There’s a lot you can learn from history and I think as a fundamentalist, you can always find the right tool to get you the best experience that you’re after.
Shane Hastie: Ooh, some opportunities for some deep conversations of that one; self-taught engineer versus the university pathways. One of the challenges that we’ve seen in the industry that we look at is there’s not enough people. We’ve got a massive, massive shortage in technology skillsets and in roles. How do we bring more people on board?
Tackling the skills shortage – hire your customers [02:48]
Kelsey Hightower: Yeah, I have to say, I’ve been an executive for a while and one thing I used to tell other executives, a lot of tech companies are afraid to hire their customers. We kind of believe that the person necessary to build these experiences, these products and services have to be these classically trained engineers. So maybe you’re looking for people with a computer science degree or someone who can sort a red, black tree in the best sorting time ever. Honestly, that’s not the type of experience that we’re putting out. We have the benefit of standard libraries where someone has already figured out the best way to sort of list. These things are necessary, but they’re not necessary for every developer to go down into the weeds of. What we need a lot more now are people who understand real-life, real-life interactions, and we need those people to help craft these experiences.
Just from my own personal experience and the people around me, I’ve seen people go from being a flight attendant to being a software developer because they’re learning the frameworks. Maybe they can’t tell you the differences between the various algorithms that are out there, but they know how to build an experience because they have experienced themselves interacting with sites, they have lived experiences. And so I think the classical, maybe the computer science degree, what you learned in school is a fantastic journey for a lot of people, but that doesn’t guarantee that you can actually go out and build the very best experience possible because it takes experience in order to reflect it in the outcomes. I think the way we close this gap is we have to understand the experience comes first, and so you’re better off making sure that if you’re going to be building… You know, sticking with the airline analogy, if you’re going to be building tools for people to buy tickets, you want someone who’s flown before.
So who better than a flight attendant or someone that used to work behind the Delta ticketing counter, to be able to say, “Wait a minute, if we’re going to build software to make it fast for people to get their tickets and their reservations together, here’s what I need for my workflow.” That’s usually the magical piece between an okay experience and a fantastic experience is that real world workflow. And I think I’ve seen more of that happening where there’s companies like The Home Depot who have programs that take people out of their stores into a training facility that then go on to work in the IT department, improving the experience, not just for customers, but for their fellow colleagues that are still working in those stores. So I think we’re starting to understand what it takes to build software for other human beings.
Shane Hastie: The title of your keynote is Engineering with Empathy. I heard some empathy in that conversation, but I’d really like to go deeper on that one.
Engineering with empathy [05:19]
Kelsey Hightower: up skills as a software engineer and all I was worried about at that point in my career was just acquiring more skills in order to increase my pay, right? Like that was what most people were doing at that time. I remember working at that financial institution and maybe it’s like the second month in, and apparently we were having lots of outages. Every month or so there’s two outages where the payment system is down. On this particular outage, one of our payment systems, this is the EBT card. So for people on food assistance in the US, they don’t have a visa or a MasterCard, this is government assistance, and to give them dignity, it comes on the same type of plastic card that other forms of payment come on.
So this system is down, the CTO walks in a room and he lets everyone know, because there wasn’t a sense of urgency. People were just mucking around, check the logs, restart this, restart that. Now time is going on and he reminded us this system that we’re working on, on the other end of all of these nauseous alerts turning red on our projected screen, there’s a woman or someone with their family checking out at the grocery line with their children, basket full of groceries,aAnd unlike our other customers, they don’t have another form of payment. So every time that they swipe that card, they’re going to get a decline and they’re going to have to go home empty handed.
So he asked that if we could just take this a little bit more serious, if we can figure out a way to prevent these type of outages from happening over and over again, because there are people who really count on this system being up. And that was kind of my first experience of really realizing what I was actually doing. I wasn’t just a Linux system administrator, I was someone who was responsible for keeping this payment network going so that people can buy their groceries.
Shane Hastie: That deep story there of starting to think about who is the person at the end of the product we are building. Sometimes I jokingly use the term, the victims of our product, as opposed to the users. User as a horrible, horrible term. The only other domain where we talk about users is drug addiction. These are our clients, these are our customers, our phase on the art clients, the people whose lives we change. How many engineers get it and how do we help them get it?
Rethink the interview process [07:39]
Kelsey Hightower: You know, I think just the way we measure results. Think about the interview process. We don’t ask people to tell stories in interview processes, we ask them to get on the whiteboard, and maybe write some code. Can you remember rise the right flag to find the right log statement that you’re looking for? We ask a lot of this low level technical trivia as if the machine is the most important part of this equation. I do believe that it’s still important. You can’t be a technologist without tech skills, this is a given, but hardly do you ever see someone really try to figure out where do you stand as a human being? I know how to evaluate a senior engineer, but do you know how to evaluate a senior human being? There are traits to becoming a great human being, to just have this connection of when is it like to make a tough decision? What goes into that calculus? Right?
Well, like when you’re designing an on call program, having people with insomnia get off of work, go home and then sleep with one eye open because they don’t know when the pager going to ring, you develop a culture that it’s okay if the pager goes off at 1:00 AM every night, because the same system keeps falling over and no one treats it as an important thing to fix because they know someone’s on call. That is not a good way to treat a fellow human being. That’s no way to treat yourself, let alone anyone else, but hardly do we ever talk about that as a standard course of defining what a great engineer is. I think a great engineer is also going to be working on their other skills that make them a better human being as well.
Shane Hastie: Great engineers work in great environments. What is a great engineering culture look like and feel like?
Building great culture is fluid and changing [09:12]
Kelsey Hightower: You know, different parts of my career I needed different things. When I first started my career, great engineering culture was you let me use the tools I needed to get my job done. If I prefer to work on a Linux machine, then you made sure I had the right tools in order for me to execute well. You know, these days after 20 years of being in this business, I want clarity. I want to understand what is the business actually trying to do here? Because when things are very vague, no one knows why they’re working on what they’re working on. We have no idea if this project successor fail is going to impact the business, and if so, by how much. And so it’s that lack of clarity, so there’s a huge disconnect between what the executive teams think. You know, you listen to your company’s earning calls and you’re like, I” didn’t know that’s what we were doing.”
Then you try to map your everyday work. You’re trying to map your output to that vision and the more blurry it is, the more confusing it is. I don’t think people understand what they’re working on and it’s hard to bring you a very best to a job, it’s hard to bring you a very best to a problem when you’re not clear if you’re even working on the right thing. And I think this is how people tend to get burned out. It’s always weird, right? I think we’ve all been there. You can put in countless nights and as long as the thing that you build and you complete is used and people seem happy and it feels like you’re making progress, you almost feel energized to keep going even though it’s unhealthy.
You can take the same situation, put in all of that work and then the thing you produce people say, “Yeah, we don’t really need it.” That makes you feel tired, burnout, and you just don’t want to go through that again so you become apprehensive to the next task because you don’t want to go through that feeling again. So to me, the best environment has been one with a lot of clarity. The reason why I leave with the clarity is because once you have clarity, then I think individuals know what they can bring to the table, right? And say, “If that’s the problem, maybe I need a new set of skills because I don’t have the skills necessary to solve that problem.” Instead of pretending, instead of guessing, I can kind of raise my hand and say, “look, I don’t have skills in that area. I think I know how to go acquire them.” Maybe it’s a bit of training, maybe I can do some self study on my own and look, we’re in a connected world in year 2022. You can just reach out on social media, go to a meetup and ask questions and start to close that knowledge gap for yourself in pretty short order.
Shane Hastie: As a leader of technical people; is it model, is it inspire my teams to have that learning mindset? And even what is teamwork?
Leaders must model the behaviours they want in their teams [<a href="javascript:void(0);" onclick="seekTo(11,3611:36<]
Kelsey Hightower: The last time I was a director of engineering that I took over a team that was kind of in an unhealthy state, and I was always patient. The first act was moving out of my office with the window onto the floor in the same cubicles with everyone else. And then it was what are we doing as a team? And how can I help? I remember one of the problems we had at this particular company, we used to screen scrape amazon.com for pricing information on their products and services, because our core product helped you manage your inventory and gave you a recommendation on how to price that inventory to move on third party marketplaces. It turns out scraping is not an official API. Amazon can just change a header or div and your whole tooling falls apart and then your tool stops working. The team needs to run around in circles, trying to put out the fire, trying to figure out what the scraper needs to be adjusted so we can get pricing information again.
One day I was like, “How long have you all been doing this?” And they were like, “Look, Kelsey, our product people assume that information’s going to be there.” And so what I asked the team to do is commission a study. How many customers rely on that particular feature? Is there another way to get that data? If so, we need to wind down this scraping and alleviate these emergencies and fires because they’re reoccurring and this isn’t healthy. I promised them and I went to the CEO, “We have to change this.” I went to the product team, “We have to change this.” And it went from “we have to change this” to “we are going to change this” and “we changed it,” and the team just saw that we can do whatever we want to do, but I need you to bring your very best self.
Know your people and what inspires them [<a href="javascript:void(0);" onclick="seekTo(13,1013:10]
Kelsey Hightower: To do that, I had to just study how individuals was working. And I remember there were two people, one person working in a Unix-Linux team writing Java, and one person working on Windows on C#. Neither of them liked their respective areas. One person just wanted to go back on the Unix side to writing in C# and working on Windows, the other person wanted to go from working on Windows back to the Linux world. I was like, “This is too easy. Starting tomorrow, you all just swap and there you go.” And their managers are like, “Kelsey, why are we doing this?”
It’s like right now, you’re dealing with people that are working at half speed, unmotivated, and they’re wishing to be somewhere else. We’re going to erase that line and let’s just see what happens. And of course, as soon as they move their desks, they’re like I am where I’m supposed to be and now they’re focused on being the very best version of themselves. So I think as any leader, individual humans need individual things and you have to understand them as a whole person, and then you try to make small adjustments to let them be the best version of themselves. I think that’s always worked for me.
Shane Hastie: We don’t teach leaders how to do this.
Kelsey Hightower: Which is unfortunate because a lot of times we… And sometimes it’s the right move, but often it’s a mistake. We take the best engineer on the team and we try to make them the leader. That best engineer may have never worked on their human skills, right? They may be so used to just working solo, “Give me the problem, I’ll solve it by myself.” And that is not necessarily the best outcome for a team because they may not understand what’s required for someone who doesn’t have as much skill as them. They may have the wrong level of expectations, they may not understand value in others because they may only value the traits that they have and so they tend to hire for people that are just like them. And so you come up with these kind of monotone teams, and then you just kind of get this singular culture.
No one’s really thinking outside of the box, you almost like this one person; you know, hive mind over everything else. And so that’s not necessarily the best thing that you want for a leader and sometimes to those people, you have to explain to them. A 10X engineer is not someone who just working 10X better than everyone else. I think a 10X engineer is the type of person who can come in and make 10 other people better than they were before, and that’s usually the ultimate challenge for someone who could just say, “Give me the problem, I’ll do it myself.” And if I say, “Well, what if you couldn’t do that this time? What if you had to give the problem to another group of people and you had to help them along the way until they did the problem themselves, all in hopes of next month, next week, the next day, they would be better versions of themselves?” And I think that’s a challenge that is a good sign of leadership and the potential to grow into that role.
Shane Hastie: At higher levels in the organization, how do we create this culture that is a learning environment where it’s safe and easy to do this?
Changing the incentives to enable a learning culture [15:56]
Kelsey Hightower: Now the truth is it won’t be safe nor easy and I think that’s the hard part of it. When you are spending time on these human things and your team, your role definition, doesn’t know how to even evaluate, then it’s going to be hard at promotion time because you may say, “Hey, look, I’ve leveled up these five other people, but I didn’t do a bunch of things myself.” You may be penalized and so I think it’s a bit challenging if the organization doesn’t realize how valuable it is to have someone like that. So I think what we have to do is, we have to change the conversation around what we expect from a leader, like what does leadership look like? I mean, you literally have to sit down and say, “Hey, maybe, we got this all wrong.”
When a leader shows up, how do we know how to recognize it if we’re probably bad leaders ourselves? So you kind of have this kind of self-fulfilling prophecy around we want better leaders, but we’re the ones judging them, and maybe you don’t have the right rubric that you’re applying to that leadership. So I think what we have to do is for each team, each team may be different, is to really reward those situations and narratives where someone says, “I started to think and I recruited co-founders who now own the thing, and the thing is now better than when I was doing it by myself.” And that goes back to the saying, “Some people have ideas and some ideas have people.” And we need to do a better job of recognizing when something becomes bigger than just one person and then reward that person for having the courage to hand it off and let the whole team take part in this execution.
Shane Hastie: These are big shifts for many organizations. I’m thinking of our audience who are technical influences, many of them first time leaders, very often that’s highly skilled technologists thrown into a people leadership role. What advice have you got for them to really make the shift for themselves?
Advice for new leaders [17:46]
Kelsey Hightower: You know, I think it’s hard because I have a certain style and my style is really to understand the person, I mean, really understand the person and it’s awkward. I remember giving an underpaid engineer a raise. This woman came from the support organization and learned how to write code. I think she was making half of what everyone was making, but she was definitely in the top three of our engineers. As a people manager, I got to go look at all of the salaries proactively. I don’t need to wait until this person threatens to quit. I don’t need to wait until this person finds out from someone else at lunch how much they make versus what they make. I have to proactively be looking and thinking about these things. I remember identifying that and said, “This isn’t right.” Then you go to HR and say, “Listen, instead of hiring someone new, I have to make things right by this person, because right now, things are not right by this person.” That’s literally part of my job.
Then when you sit down with this person and they’re wondering if they’re in trouble, you go into the office, you close the door for privacy and you sit there and tell them, “You’ve been doing a fantastic job and here’s how, in detail, that there’s a problem though.” They don’t know what you’re going to say, “And you’re underpaid. You’re dramatically underpaid. I want to fix that today.” You slide them a piece of paper and you look at their eyes just widen at the fact that their salary has literally doubled between the time they came in, had a coffee and you asked them to jump into this meeting. All kind of things start swirling in their head about, “Maybe I’m better than I thought I was.”
They just go back to their desks, smile cannot be hidden from their colleagues and they start hacking away. And I think there’s this sense of I belong on this team and they understand my value and that’s part of the deal. But it’s these small nuanced things: that awkward silence when you have to tell people good news, that awkward silence when you have to tell people bad news. All of that is part of leadership and as long as that person knows, “I am literally trying to make you better. You’re great at some things, you need to improve in some other areas, but no one is perfect. But if I find an opportunity to make the things you’re good at great, my job, and I promise this to you, is that I’m going to invest heavily in making sure we don’t miss that opportunity. And the things you’re bad at, I’m just going to let you know you’re aware of them and then you can decide how much help you want improving them, so they don’t wash out the things that you’re good at.”
And I think that is what’s required. So there’s a level of patience. You might as well throw the word scale out of the conversation because you can’t scale human interaction when you’re in charge of individual people. This is why it’s hard to manage a hundred people with one person. You can’t do it. This is why I think you need help as you kind of go down the stack, making sure that your people have real leadership and not just management.
Shane Hastie: Moving back to early in our conversation, you were talking about how in your growth path you have looked back. So you mentioned if you wanted to understand communications, you were looking at the history of the internet. What are the things that are happening today that people like you are going to be looking at in 20 years time and saying, “What was going on then?”
Reflecting on society today and how it will be looked back on in the future [21:01]
Kelsey Hightower: For me is just where I am in my career. I’m the type of person that’s probably fortunate enough to be facing early retirement. The question I asked myself, is this the society we actually wanted? This process of buy and sell and trade, buy, sell, trade, honestly, is that what the whole universe was formed for? To buy, sell, and trade things? I don’t know. I think the fact that we’re just collective species of people that have a shared fate, regardless if we acknowledge it or not, we have to trust each other. You trust the pilot to land the plane safely. You trust a person preparing your food to prepare it safely. So we already have a web of trust amongst us, we’re just not intentional about it.
I think as a society when you look back and say the fundamentals of life is that everything around you has the opportunity to help or hurt. Then as humans with the conscious, with the ability to understand and to remember, we get to make that choice every day, you can help a hurt. You can either say hello with a smile, or you can look at them crazy as I don’t want you to talk to me, you get to decide, and it’s not super easy, but I think we have to be very intentional about the world that we create. So when I look around, whether it’s technology, whether it’s just giving someone some encouragement, or being there to talk to someone, these are the decisions that I think are more important than the 24 hour news cycle. Everyone has to have something to say about everything, but where do we think? When do we take a pause to think? And that’s the part where I look back and say, fundamentally, you need time to process information.
Even for the people that are super technical listening to this, even machines need time to process the information, right? They will even context switch so instead of receiving the data, they will process it and then they’ll get back to the thread to receive more data. Well, humans also need time to process. That means when you have an interaction you ask yourself, “Was that the best interaction possible? Was I my very best person during that interaction? What can I learn from the interaction for the next time?” And so you have to process this stuff, you really need to think, need to think critically and it’s okay to then share once you’ve had a bit of time to think and then make corrections as necessary. So to me, when I look back over, at least my time on earth is there has to be more than buying, selling, and trading things. And that’s what I wish people would kind of get back to and just say, “What is your role in this overall web of life?”
Shane Hastie: Deep thinking there. Kelsey, thank you very much. If people want to continue the conversation, where do they find you?
Kelsey Hightower: Well, I spend most of my time on Twitter. My DMs are open. I make plenty of time for one-on-ones where I can learn things from you and I can share things that I’ve had time to critically think about. If you’re going to be at Agile 22, I’ll be there for a couple days and I’ll be walking around the floor. But catch me on Twitter, DMs are open.
Shane Hastie: Thanks so much.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Molly Junck
Article originally posted on InfoQ. Visit InfoQ

Transcript
Junck: Halloween was just a few days ago, so I’m going to start today’s presentation with a scary story. Let’s imagine you work for a company that operates on the public cloud, and runs one of the largest cloud workloads in the world, spanning hundreds of services. Your company’s top priority is availability and user experience. Much further down that list is cloud efficiency. Part of your job is to keep those cloud costs under control. The company culture allows for any engineer to spin up as many machines as they want at any moment. That’s the situation that my team and I find ourselves in at Pinterest every day, and sometimes it can be a daunting or a scary task. The purpose of my talk is going to be to share some of the strategies that we’ve used to successfully scale in the cloud that may hopefully be useful for your companies as well.
Background
My name is Molly Junck. I’m a Technical Program Manager of the Infrastructure Governance Program. I work here at Pinterest, where I’ve been for the last year and a half since April 2020. Before Pinterest, I worked at Adobe on security and release engineering projects. What I’ll refer to in this talk as my team, are the other contributors to the Infrastructure Governance Program, which is a cross-functional group from finance, engineering, and data science and analytics. I may refer to infrastructure governance as infragov, but this is the same thing.
A little bit about Pinterest. First and foremost is our mission. Our mission is to bring everyone the inspiration to create a life they love. The company was founded in 2010, and we’ve now surpassed over 2500 employees. We also operate one of the world’s largest cloud workloads, which makes it a really exciting place to work. At our current scale, we’re serving almost half a billion users every month across the globe. We have over 300 billion Pins saved. In the U.S. alone, we reach 41% of internet users every month. Our cloud provider is Amazon Web Services, and we’re a cloud native company. You may hear me refer to AWS technologies such as EC2 instances for compute, or S3 for file storage. Many of the strategies that I’ll be discussing apply regardless of what cloud provider your company uses.
Challenges of Scaling
One of the challenges that organizations face as they grow is that they face a different class of risks when it comes to controlling cloud costs. Unlike smaller companies, where generally you probably have smaller staff and can operate a little more nimbly, larger companies become like slow moving ships that require significant planning and coordination for any major change. Architecture complexity often increases as well with scale, making predictions a lot harder when you’re spinning hundreds of services versus maybe dozens of services. Sometimes, unexpected challenges that companies also see is that the typical principles of infinite cloud scalability that anybody can spin up as much as they want at any time on-demand, can break down when you’re operating at scale. If we were to suddenly change the characteristics of our EC2 fleet in a major way without letting AWS know, it’s possible they may not have that volume of capacity just sitting around waiting, and we may run into shortages. Larger companies may also have other factors to consider, such as moving from single region to multi-region, which poses its own challenges.
Outline
In my talk, I’d like to cover three key strategies that we’ve used for managing our cloud resources. First of all, the foundation will be providing good data. Second, providing guidelines and strategies for how those cloud resources are used. Third, is not to micromanage your way to cloud efficiency, but using incentives instead to achieve your organization spend goals.
1. Provide Good Data to Make Good Decisions
The first key strategy that I’d like to go over is providing good data to employees so that they can make good decisions. At Pinterest, we aim to make data-driven decisions whenever possible, and data-driven decisions that take cloud costs into account. Cloud costs require a trustworthy, timely data source. Providing this data source has been one of the core focuses of the Infrastructure Governance Program.
Pinterest’s Infra Cost and Usage Data
At Pinterest, we provide our employees with this data in a set of tables that we call the BI Infrastructure Governance Data Mart. This data allows our employees to answer questions such as how much a given service costs, or whether their service’s use is in line with the targets for that service. This also powers internal dashboards sent to leadership about how much each organization is using or spending in terms of infrastructure. Two organizations within Pinterest have also embedded this data into experiment dashboards so that teams can factor changes to infra costs when deciding whether to launch an experiment, for example, if it significantly increases or significantly decreases their infrastructure cost.
The data source that we use is comprised of both internal and external sources. The major external source is the AWS cost and usage report, or CUR report, which is a detailed line by line billing item of all of the resources that we use. Internal sources include things like multi-tenant platform records. For example, our internal Hadoop platform for offline data processing, our configuration management database, or the CMDB that contains all of our internal EC2 usage records, and organizational data such as LDAP, or service ownership information. We also use custom blended cloud resource rates, which factor in details like custom pricing, and the typical ratio of reserved instances versus on-demand that we achieve for that given instance type. At Pinterest, we found that constructing our own internal data source was the best way to accomplish providing visibility for employees. This is by no means the only way that other companies have to accomplish this. For example, we’ve seen other companies address this via AWS tags or metadata from higher order services.
2. Provide Guidelines and Strategies for How Cloud Resources Are Used
The second key strategy that I’d like to go over is to provide centralized guidelines for how those cloud resources are used within your company, so that you can simplify your company’s architecture needs. At Pinterest, the Infrastructure Governance Program provides oversight for the entire cloud footprint. While we don’t mandate that every team follow these guidelines strictly, encouraging teams to align on these standards has been really critical for us.
Define Your Capacity Management Strategy
The backbone of your company’s strategy as it relates to compute especially needs to be a sound capacity management strategy. To help inform your compute capacity strategy, it’s important that if you’ve got a central team managing this, that they’re decently connected to the technical needs of the services that are most important to your business. The other critical angle here is that it’s not a one-time exercise that you create a strategy and then move on, you need to be revisiting this on a periodic basis so that it is current based on the technical needs of your services at any given time. This requires good bidirectional feedback with service teams about where they’re planning on going with their architecture and technical needs.
With the detailed knowledge of the services technical needs, simplify your architecture by standardizing. For example, here at Pinterest, we aim to simplify our compute fleet by suggesting that most workloads standardize on one of three to four top EC2 instance types out of the dozens that AWS provides. Even if an individual given workload would be more efficient on some instance type, centralizing on just a few that we use across our entire fleet gives our finance team the ability to make large purchases, because our total capacity numbers end up remaining a little steadier, even though the capacity needs of the workloads underneath them may significantly vary. This also gives us more flexibility from an availability standpoint, because we rely on large pools that can be transferable between services. This doesn’t mean that our entire fleet runs only on these three to four instance types, but we strive for only specialized workloads to run on specialized instance types.
Furthermore, it’s important to determine governance mechanisms to ensure that your company’s growth is in line with your company goals. Choose a strategy that works with your company’s culture. Here at Pinterest, we have a capacity request process, which allows for organizational leaders to approve requested capacity that meets certain thresholds to ensure they know what’s changing within their organization, and that they have an opportunity to push back if that’s not in line with the growth that they’re expecting. Engineers can also bypass governance controls here at Pinterest if needed, because, for example, if there were an incident, they may need to respond and spin up instances. It is part of our company culture that we tend not to put in controls that prevent people from making changes that they see fit in.
Beyond controls within your organization, strong bidirectional communication with your cloud service provider can be really important, especially when operating at scale. One of my favorite quotes about the cloud is from an engineer on my team that works on our cost and usage data, Elsa Birch, who likes to say, the cloud is like sweatpants, it’s elastic until it’s not. We’ve run into some challenging scaling problems that don’t really apply when you’re a smaller company. It’s important that we treat AWS like a partner in our major architecture decisions, which both helps them plan for the capacity needs that we will have, and also allows us to predict challenges before we face them.
One major example of a capacity challenge that we had was back in 2019, so two years ago, at that point, we had successfully standardized most of our fleet on just a few instance types. The company decided to make a big push that you’re to upgrade from a slightly older generation to a slightly newer generation, which had better performance metrics across the board. We worked in close communication with our account team at Amazon, and migrated teams throughout the years, the instance pools were ready for it. Going into the end of the year, we thought that we were in a good shape with our instance pools, however we hadn’t fully anticipated the organic growth those services would see over the holiday period. At Pinterest, October through December is a really critical time for the company because we see a major traffic bump, when a lot of people come to Pinterest to find Halloween costumes or come up with recipe ideas for Thanksgiving, or to complete their holiday shopping.
We ended up seeing major spikes in especially the instance types that autoscale heavily, and we ran into shortages of this newer generation, which forced us to define fallback procedures to go to other instance types or older generations. As a result of this incident, we maintain fallback procedures today for any services which autoscale heavily, and we communicate any changes in capacity that we’re expecting much more closely with Amazon to avoid future shortages.
3. Don’t Micromanage, Incentivize Optimization and Efficiency
The third, and what I’d say is the most important key strategy is that managing cloud resources and spend is a journey, not a well-defined path. When our finance team sets targets for our infrastructure spend, that’s based on the needs of the business and the industry, we don’t have a clear map of exactly how we’re going to achieve those spend goals. Pinterest’s core function isn’t optimizing our workloads. We need the vast majority of our engineers to be focused on new features that bring more inspiration to the world. However, building more efficient systems and reducing the costs of current workloads, creates the financial headroom for us to make big bets and try new things. At Pinterest, we’ve found that a small investment of staffing focused on efficiency, often 5% or less, can yield major returns.
Lean on Subject Matter Experts to Achieve Cloud Spend Goals
Today at Pinterest, we’ve built the organizational support for infrastructure goals through the nomination of what we call spend captains. Spend captains are representatives from each major organization within the company that are responsible for serving as infragov’s point of contact for cloud spend for their organization. Spend captains are responsible for partnering with infragov to define organizational level budgets, are responsible for keeping their organization’s budgets in line with their targets, and promoting optimization opportunities to create that headroom for their organization to grow. They’re often relatively senior folks within their organization so that they can have the appropriate level of influence on their roadmap. We would not be able to achieve our spend goals without the partnership from spend captains. They’re really critical to our success. We also rely on engineering teams to crowdsource ideas for efficiency projects. While the infragov group aims to have a baseline understanding of our cloud needs, we’re not subject matter experts for each of our services, or each of the AWS technologies, and we rely on engineers to share what efficiency opportunities may exist within their domain. Then we rely on the spend captains to help understand the ROI of each of those, and to support building in the engineering time to make that efficiency work happen.
Then, finally, we lean on organization leaders to celebrate and incentivize efficiency projects. For example, one way at Pinterest that we incentivize efficiency work is something that our head of engineering, Jeremy King, often does. We often have AMA sessions with engineering leadership, and he often kicks those off highlighting major efficiency wins from teams that have saved some number of millions of dollars by focusing on a change to our data transfer or something like that. Creating visibility for this work demonstrates to other engineers in the company that this is really important to our success, and helps to incentivize future engineers to prioritize efficiency projects.
Recap
To recap the three strategies that we covered. We anchor on Pinterest, providing trustworthy cost and usage data, so that engineers can make good decisions. Providing centralized guidelines to simplify our architecture, and to lean on subject matter experts, so that we’re not micromanaging how we achieve our cloud spend goals.
Questions and Answers
Watson: What optimizations have been most effective at Pinterest, in your mind? I know they’re all over the place but what do you think have been the most efficient optimizations?
Junck: As an organization, you need to balance optimizations by impact and complexity and difficulty, and ideally try and prioritize the ones that are highest impact and lowest complexity. You need to attack them from a multi-pronged angle. You need to have a multifaceted strategy, and from our side, some of the efficiency projects that have had the most impact. One example is an AWS technology called S3 Intelligent-Tiering, which is just a setting that you can have to have AWS automatically change the tier. That’s been very high impact and low effort. It’s something that is like turning a dial, and then suddenly you see a lot of savings come in. We also have financial efficiencies. Something that our finance team is adjusting the levers of, like reserved instances or savings plans so that we can make some commitments about the capacity that we are sure is going to stay around at a reduced price.
We also have a group that tracks regressions. For example, our data transfer savings, we’ve found that if we don’t have a close eye on those that we need to just check in on about a monthly basis to make sure that we don’t have any projects that have suddenly changed a setting and have unexpected cost. Then there’s also efficiency projects that are a little harder and require more complexity, for example, rightsizing instances where you have to really go in and understand the service, potentially perform load tests and make sure that you’ve got the right instance type for the workload that’s running on it.
Watson: Does Pinterest have autoscalers, and what are the key metrics on how resources get scaled up or down depending on traffic?
Junck: We definitely do have autoscaling. There’s no single autoscaling policy across Pinterest. There are hundreds of services, and some of them that respond to traffic autoscale heavily in response to demand, whereas others that are, for example, stateful systems tend not to autoscale. There’s no single answer about how we autoscale as a company.
Watson: Have you considered including carbon cost alongside financial cost so we can be carbon efficient?
Junck: That’s something that we are striving to do. That’s something that Pinterest cares about is our carbon footprint, but we’re not there yet.
Watson: How do you manage scenarios where developers forget to tag EC2 instance properly, resulting in infrastructure estate you don’t have insights into, in terms of what actually happened.
Junck: One of the interesting things about what we do at Pinterest is I know a lot of companies use EC2 tagging to track their infrastructure. We actually don’t have a unified tagging strategy across the company, so we use our own ownership tool that we internally call Nimbus. We map along with the CMDB, and then the Nimbus project, who owns what. We still run into the same problem that you’re talking about, about some instances not getting tagged appropriately. Right now we’re more reactive than proactive, but because we do have this really high quality cost and usage data, hopefully somebody notices when something changes, and suddenly they’re charged a lot more. That’s that distributed accountability that helps us keep on track with our spend.
Watson: Why do you focus on EC2 so much? Are no managed services used, and if they are used, are they shared by more than one team, and how is this calculated?
Junck: Pinterest as a company is about 10 or 11 years old. That was pretty close to the beginning of AWS. I think AWS started in 2008 or 2009, or something like that, just when companies were starting to get on the public cloud. We’re one of the few companies that is born on the cloud, cloud native. We ended up just building our own PaaS, and use a lot of just the raw AWS resources like EC2 and S3. We’ve got our own monitoring solutions, our own logging solutions, and less of those managed services.
Watson: Then, EKS’s use, how do you track spend there?
Junck: I think this does get to a different point about like, what about all these other services? I’m talking a lot about EC2 and S3, and we have this very granular solution for all of our EC2 spend, but we do have some minor other solution or minor other services that we use that aren’t a big chunk of our spend. That’s something right now that just finance and the Infrastructure Governance Program keeps an eye on, and then reacts if they get to that size, where it would actually become problematic or something that we should be tracking all the more. We don’t actually use EKS, we run our own Kubernetes.
Watson: We do have some services that are large enough we do track them, like I think hosted Elasticsearch or something like that.
Junck: We track it but we don’t have the granular cost attribution yet.
Watson: Do you manage web application versions when deploying them on the cloud?
Junck: That’s probably out of the scope of my team, or what I can answer. We’ve got a team that focus on web app.
Watson: When we’re looking at attribution cost, do you tag instance usage by the version of the app running on that instance in, say, the Data Mart?
Junck: I don’t think we do. The things that we’re more focused on are like ownership and then service. That data allows us to do a whole bunch of things with it. Knowing who owns what has benefits, not just for cost and usage where my domain cares a lot, but also security and instance upgrades, and things like that.
Watson: How do you control capacity inside Kubernetes? Is it only about tracking EC2 consumption?
Junck: Where we are in our journey with cost attribution, is we built this Data Mart about a year and change ago, and so far our primary focus has been on EC2. This is something where there’s a lot of benefits from having this granular data, and we’re wanting to break it down more. We have a group of engineers that are working on expanding that to have also cost attribution for S3, and Kubernetes is pretty high on that list as well. Where we are today is that we have detailed attribution for Kubernetes as a whole, which is a big chunk of change that we then have to use other controls. For example, when our Kubernetes team needs to grow and they know what use case is causing that growth, we evaluate that on a case by case basis, and make sure that we have the funds to do that. It’s something that we want to go towards having that same cost attribution and breakdown across all major platforms.
Watson: Ingress and egress costs make a significant portion of cloud costs, if we’re running services which involve lots of data transfer, how do you track the network usage at Pinterest?
Junck: That’s similar where actually the data transfer cost is something that we want to build detailed cost attribution for right now where it is in our spend trajectory, we’ve got that group that meets monthly to evaluate our data transport cost. That’s our strategy in general. If we don’t have the ability to have detailed granular cost attribution, we need some other controls in place to make sure that spend doesn’t go out of control, and so far, that’s worked well for us.
Watson: Maybe like data transfer, some of these are very hard to decompose, because they’re shared by tenants. Imagine a datastore where many people are looking at the same tables, and that team wants to charge back the cost to their users. That’s obviously challenging. What’s your guidelines for where you draw the cut line? Is there some size maybe at which something needs to be where you invest in multi-tenant cost attribution, and we just have to hold the line of like, we’re going to do this, but not do that. I’m sure everybody wants to charge back everything, even if their service is like this big.
Junck: If I can have a team of 30 engineers, we’d attribute all of the things and be able to have very granular data. There’s two things. There’s some things that the services can do to get ready for this. Because, thankfully, Pinterest has been on a growth trajectory, and so the size of each service continues to grow. The more services can have good logging data about who uses what, that’s helpful for them to be able to attribute cost and track their growth before they actually have the cost attribution, is just to focus on who’s using what.
Then, from my team that’s working on expanding the cost attribution to other systems, we’re looking at the ROI. We would ideally like to get a lot more multi-tenant platform systems in there, but we have to evaluate like, which systems have the most of benefit from cost attribution. Things that we think about when evaluating systems are like, how many business drivers are associated with the users on the platform? If it’s just user growth, then hopefully their system is relatively predictable, but if it’s five different factors, they’re going to have a really hard time predicting how much they’re going to need in the future and getting an accurate budget estimation. Other factors that we think about are how many users are on the platform. If they’re dealing with 5 different tenants versus 500, they’re going to have different levels of challenge of managing within their spend.
Watson: How do you track horizontal consumptions, such as, one team owns a service that’s used by other users, how can you forecast future costs? The question comes back like at Pinterest. Of course, every company goes through a budgeting process, and I want to know how much they want to spend. How do you look at forecasting if it’s challenging, by each service team?
Junck: We definitely do have some challenging situations. For example, I know Kubernetes was brought up earlier, and we don’t have cost attribution for Kubernetes yet, but that’s not even the worst of it. There’s other multi-tenant platforms that are now building on top of Kubernetes, so we’ve got like a platform inception, and so estimating the cost for that can be really difficult. This is where it’s a journey. We don’t necessarily know how we’re going to get there. We create budgets around now, actually, that are the best guess that we have for what we think that we’re going to need next year. That’s a combination of the service team’s best guess of their usage trajectory, as well as the top-down, like how much finance wants to spend. Then throughout the year, we need to respond to new information and manage within those funds, or if something really comes up, of course, argue for additional funds.
Watson: Can business drivers be a factor in that? I know it’s tough, because teams sometimes want to think they can estimate their cost, but it’s challenging. Do you have future plans about how you tie growth drivers to capacity? I know that’s a really hard problem.
Junck: Where we’re trying to go is to become more predictable with our business drivers so that every service understands how they grow with some business driver. Then, ideally, we’d have really accurate projections of our business drivers, but things come up, like global pandemics, or who knows what that can throw a wrench into your plans. That’s where we need to be nimble and respond to new information as it comes up.
Watson: Do you use any machine learning to pick up patterns and mapping those to costs?
Junck: One of the things that we have found is that machine learning isn’t a good fit for the number of services that we have, at the hundreds of services levels. It’s still something that works better with human models, but anomaly detection is something that we definitely want to use more of where it’s like, if suddenly there’s a big spike in spend, or a big drop, we want to understand why and be able to respond to that, and make sure that’s on purpose.
Watson: On a scale of 1 to 10, how far away are you from migrating away from AWS and have your own data centers?
One to 10, I would say we’re closer to 1 or 0. We do a lot of analysis around what it costs to run across multiple cloud vendors. We also do analysis of our capabilities as an engineering team. Imagine if you don’t run any data centers today. I think I was talking to another company that has 40 or 80 network engineers to run their data centers, we don’t have engineers. If you think about cost analysis, it would probably be a similar inversion of the question to, say Facebook, like when are you moving to the cloud? I know they’re using more of cloud. When you start on one, it’s actually very expensive to go the other direction. If you do a cost model of what it takes to build the equivalent of Amazon S3 in terms of redundancy and geolocation, that’s a very big number. Right now, we’re relatively low on the scale. You probably saw in the news, we just re-signed our contract with Amazon. It’s worked out really great for us from an innovation perspective. Through some independent third party analysis, oftentimes people who start on-prem or cloud and they get very large, someone called ingress, egress cost, running in a hybrid config for even a few years and shipping across petabytes of data can just wipe out any savings you’d like to expect.
See more presentations with transcripts
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

The latest beta of Android 13 is a final update that allows developers to make sure their apps are ready for the new Android release when it becomes available in a few weeks, says Google.
Android 13 includes a number of behaviour changes that will affect all apps running on it, regardless of their declared targetSdkVersion. Those include the possibility for a user to stop a foreground service using the Foreground Services Task Manager, which will terminate the entire app. Additionally, a new runtime notification permission is available in Android 13 aimed to increase user control on the delivery of notifications. If an app does not get permission from its users to display notifications, all notification channels will be blocked.
Another new feature aimed to improve privacy is the boolean flag EXTRA_IS_SENSITIVE that can be set for the ClipData’s ClipDescription to prevent any sensitive content such as passwords or credit card information from being displayed in clipboard previews.
A number of other changes only affect apps using given features of the SDK. For example, an app that sends an intent to another app will have that intent blocked unless it matches the <intent-filter> element in the receiving app. Likewise, apps working with media content will take into account the the granular media permissions that are replacing the old READ_EXTERNAL_STORAGE and WRITE_EXTERNAL_STORAGE permissions.
Android 13 also introduces many new features, like support for Bluetooth LE Audio, MIDI 2.0, a new photo picker, better multilanguage support, new copy and paste UI, and an improved Job scheduler that attempts to anticipate the next time an app is launched to prefetch required jobs ahead of time.
As a final note, Android 13 includes and extends support for tablets and large-screen devices introduced in Android 12 and 12L, including optimizations for system interface, improved multitasking through the new taskbar and multi-window mode, new compatibility modes, and more.
Developers interested in testing their apps running on Android 13 beta can enroll their Pixel devices and get the update over-the-air, or get the update from any partners for additional devices.