Month: July 2022

MMS • Robert Krzaczynski
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- TensorFlow is an open-source framework developed by Google scientists and engineers for numerical computing.
- TensorFlow.NET is a library that provides a .NET Standard binding for TensorFlow, allowing you to design neural networks in the .NET environment.
- Neural Networks may be applied wherever answers, not quantitative but qualitative, are required.
- Feedforward Neural Network (FNN) is one of the basic types of Neural Networks and is also called multi-layer perceptrons (MLP).
- The Feedforward Neural Network (FNN) algorithm returns Loss Function and Accuracy in each iteration
Building and creating Neural Networks is mainly associated with such languages/environments as Python, R, or Matlab. However, there have been some new possibilities in the last few years.
Among others, within .NET technology. Of course, you can work on Neural Networks from scratch in every language, but it is not a part of the scope of this article. In my first words, I was thinking about libraries that give us such opportunities. In this article, I will focus on one of these libraries called TensorFlow.NET.
Neural Networks
Let me explain the general concept of Neural Networks. We will centre on the Feedforward Neural Network (FNN), which is one of the basic types of neural networks. this type of Neural Network is also called multi-layer perceptrons (MLP).
The objective of the Feedforward Neural Network is to approximate some function f*.
Neural Networks use classifiers, which are algorithms that map the input data to a specific category.
For instance, for a classifier, y = f*(x) maps the input x to the category y. MLP determines the mapping y=f(x;α) and learns the parameter values α – exactly those that provide the best approximation of the function.
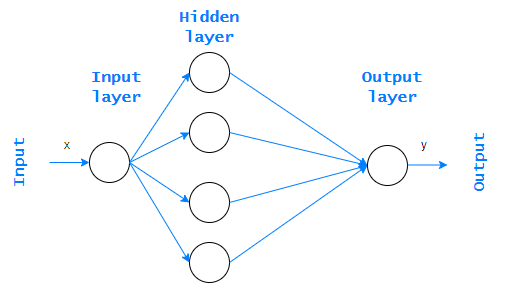
Note the graphic below. It shows an MLP perceptron, which consists of one input layer, at least one hidden layer, and an output layer.
This is called a feedforward network because information always goes in one direction. It never goes backwards. It is worth mentioning that if a neural network contains two or more hidden layers, we call it the Deep Neural Network (DNN).
The main applications of Neural Networks
Artificial Neural Networks are a fundamental part of Deep Learning. They are mathematical models of biological neural networks based on the concept of artificial neurons. In artificial neural networks, an artificial neuron is treated as a computational unit that, based on a specific activation function, calculates at the output a certain value on the basis of the sum of the weighted input data. They are scalable and comprehensive compared to other machine learning algorithms, which suit perfectly huge and complex Machine Learning tasks. Due to the specific features and unique advantages, the application area of neural networks is extensive.
We can apply them wherever not quantitative but qualitative answers are required. Quantitative data relates to any information that can be counted or measured, and to which a numerical value can be given. On the other hand, qualitative answers are descriptive in nature, expressed in language rather than numerical values. Therefore, Neural Networks include applications such as:
- price forecasting
- interpretation of biological tests
- analysis of production problems
- medical researches
- electronic circuit diagnostics
- sales forecasting
For better understanding, I will give you the following examples from real life. A certain company with business in 20 countries in the Central and Eastern European market distributes components for hydraulic and temperature control systems. The problem lies in determining the amount of stock available at each distribution point. The administrative staff has been collecting detailed data for several years by using reports on the quantity of demand and supply for a given type of product. This data shows that sometimes too much is stored, and sometimes there are shortages in supply. It was decided to use an artificial neural network to solve this problem.
In order to create the inputs of the neural network, reports from 5 years of the stores’ prosperity were used. This resulted in 206 cases prepared by office workers, of which 60% were used for the learning set, 20% for verification and the remaining 20% for testing. Each case contained certain features such as weather conditions in a particular region or locations of stores, i.e., whether they are in downtown or the suburbs.
The results were not sufficiently convincing to use the created algorithm for stock management (effectiveness within 65%), but the result was three times better and closer to the truth than “classical methods” based on basic calculations. It can be concluded that the author will make another attempt to create a system taking into account more factors in order to obtain a more reliable solution.
Artificial Neural Networks are used in various branches of science, economy, and industry. Since more and more entrepreneurs and specialists are noticing their effectiveness, the number of technologies that allow for their creation and implementation into commercial systems is also growing. There are many libraries implementing the technologies I mentioned before One of them is TensorFlow.NET, which I will introduce in a moment.
TensorFlow.NET
TensorFlow.NET is a library that provides a .NET Standard binding for TensorFlow. It allows .NET developers to design, train and implement machine learning algorithms, including neural networks. Tensorflow.NET also allows us to leverage various machine learning models and access the programming resources offered by TensorFlow.
TensorFlow
TensorFlow is an open-source framework developed by Google scientists and engineers for numerical computing. It is composed by a set of tools for designing, training and fine-tuning neural networks.TensorFlow’s flexible architecture makes it possible to deploy calculations on one or more processors (CPUs) or graphics cards (GPUs) on a personal computer, server, without re-writing code.
Keras
Keras is another open-source library for creating neural networks. It uses TensorFlow or Theano as a backend where operations are performed. Keras aims to simplify the use of these two frameworks, where algorithms are executed and results are returned to us. We will also use Keras in our example below.
Example usage of TensorFlow.NET
In this example, we will create FNN and use some terms related to Neural Networs such as layers, the loss function etc. I recommend checking out this article written by Matthew Stewart to understand all these terms.
First, you need to create a console application project (1) and download the necessary libraries from NuGet Packages (2).

(1)

(2)
At this point, you can start to implement and create the model. The first step is to create a class corresponding to your neural network. It should include the fields of the model, learning and test set. The Model class comes from TensorFlow.Keras.Engine, and NDArray is just part of NumSharp, which is the corresponding NumPy library known in the Python world.
using NumSharp;
using Tensorflow.Keras.Engine;
using Tensorflow.Keras.Layers;
using static Tensorflow.KerasApi;
namespace NeuralNetworkExample
{
public class Fnn
{
Model model;
NDArray x_train, y_train, x_test, y_test;
.....
}
}
The second step is to generate test and training sets. For this purpose, we will use the MNIST datasets from Keras. MNIST is a massive database of digits that is used to train various image processing algorithms. This dataset is loaded from the Keras library. The training images measure 28* 28 pixels and there are 60,000 of them. We need to reshape them into a single row of 784 pixels (28*28 pixels) and scale them from the 0-255 range to the 0-1 range, because we need to normalize the inputs for our neural network. As for the test images, they are almost the same, except there are 10,000 of them.
public class Fnn
{
....
public void PrepareData()
{
(x_train, y_train, x_test, y_test) = keras.datasets.mnist.load_data();
x_train = x_train.reshape(60000, 784) / 255f;
x_test = x_test.reshape(10000, 784) / 255f;
}
}
Now we can focus on the code responsible for building the model and configuring the options for the neural network. Here is where we can define the layers and their activation functions, the optimizer, the loss function, and the metrics. The general concept of neural networks is easily explained there. So the implementation of our neural network can be seen below.
public class Fnn
{
....
public void BuildModel()
{
var inputs = keras.Input(shape: 784);
var layers = new LayersApi();
var outputs = layers.Dense(64, activation: keras.activations.Relu).Apply(inputs);
outputs = layers.Dense(10).Apply(outputs);
model = keras.Model(inputs, outputs, name: "mnist_model");
model.summary();
model.compile(loss: keras.losses.SparseCategoricalCrossentropy(from_logits: true),
optimizer: keras.optimizers.Adam(),
metrics: new[] { "accuracy" });
}
}
In this example, we have the shape set up to 784 (because we have a single row of 784 pixels), an input layer with output space dimensions equal to 64, and an output layer with 10 units (you can set a different number of layers here, choose it by trial and error). The activation function is ReLU and Adam’s algorithm is applied as an optimizer. In general, that has been designed specifically for training deep neural networks. Additionally, accuracy will be our metric for checking the quality of learning. I think this is a good time to explain what accuracy and loss function mean.
Loss function in a neural network defines the difference between the expected result and the result produced by the machine learning model. From the loss function, we can derive gradients, which are used to update the weights. The average of all the losses represents the cost.
Accuracy is the number of correctly predicted classes divided by the total number of instances tested. It is used to determine how many instances have been correctly classified. The accuracy score is sought to be as high as possible. In our case, the accuracy is over 90%. Generally, the results seem very good, but our analysis is not complex. It would require more specific studies. Having completed the previous steps, you can now move on to training and testing the model:
public class Fnn
{
....
public void Train()
{
model.fit(x_train, y_train, batch_size: 10, epochs: 2);
model.evaluate(x_test, y_test);
}
}
Set the batch size value, which represents the size of a subset of the training sample, for example, to 8, and epochs to 2. Here, we also select these values in the form of an experimental process. Then proceed finally to create an instance of the Fnn class and execute the code.
class Program
{
static void Main(string[] args)
{
Fnn fnn = new Fnn();
fnn.PrepareData();
fnn.BuildModel();
fnn.Train();
}
}
Once the application has started, the training phase should begin. In the console, you should see something similar to this:

After a while, depending on how large your dataset is, it should proceed to the testing phase:

As you can see, a loss function and an accuracy are returned in each iteration. The obtained results of the mentioned parameters indicate that the neural network we created in this example works very well.
Summary
In this article, I wanted to focus on showing how a neural network can be designed. Of course, to leverage this neural network-based algorithm in TensorFlow.NET, you do not need to know the theory behind it. Nonetheless, I suppose this familiarity with the basics allows for a better understanding of the issues and the results obtained. Until a few years ago, Machine Learning was only associated with programming languages like Python or R. Thanks to libraries like the one discussed here, C# is also starting to play a significant role. I hope it will continue in this direction.
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for July 4th, 2022, features news from JDK 19, JDK 20, Spring projects updates, Open Liberty 22.0.0.7 and 22.0.0.8-beta, Quarkus 2.10.2, Hibernate ORM 5.6.10, Hibernate Reactive 1.1.7, Eclipse Foundation projects updates, Apache Software Foundation projects updates, JDKMon 17.0.31 and 17.0.29 and JetBrains product updates.
JDK 19
Build 30 of the JDK 19 early-access builds was made available this past week, featuring updates from Build 29 that include fixes to various issues. More details may be found in the release notes.
JDK 20
Build 5 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 4 that include fixes to various issues. Release notes are not yet available.
For JDK 19 and JDK 20, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
On the road to Spring Shell 2.1.0, the first release candidate was made available featuring: a rework of the theming functionality and interaction mode; full support for experimental Spring Native; and improvements to ensure interactive commands fail-fast in a non-TTY environment. More details on this release may be found in the release notes.
The first release candidate of Spring for Apache Kafka 2.9.0 was also made available that delivers: a dependency upgrade to Kafka Clients 3.2.0; a more robust non-blocking bootstrapping retry; and a new seekAfterError property for the DefaultErrorHandler class to eliminate unnecessary strain on the network when there are high error rates and large value defined in the max.poll.records property. More details on this release may be found in the What’s New section of the documentation.
Open Liberty
IBM has promoted Open Liberty 22.0.0.7 from its beta release to deliver the ability to: add the name of an application, and corresponding JSON entry, to the LogRecordContext class; and merge stack traces into a single log event.
Open Liberty 22.0.0.8-beta has also been released featuring a separation of stack traces from logged messages such that downstream log analysis tools can provide easier-to-read visualizations.
Quarkus
Red Hat has provided a second maintenance release with Quarkus 2.10.2.Final that ships with bug fixes and upgrades to JReleaser 1.1.0, Hibernate Reactive 1.1.7.Final, Keycloak 18.0.2, smallrye-common-bom 1.13.0, Testcontainers 1.17.3 and proto-google-common-protos 2.9.1. More details on this release may be found in the changelog.
Hibernate
Hibernate ORM 5.6.10.Final has been released featuring: improved memory allocation using the resolveDirtyAttributeIndexes() method as defined in the AbstractEntityPersister class; and a fix for a bug that threw an exception upon trying to delete an entity having an association annotated for a cascading delete.
Hibernate Reactive 1.1.7.Final has been released featuring notable bug fixes such as: a many-to-one lazy association using the fetch() method defined in the Mutiny interface; and a pagination issue with Microsoft SQL Server.
Eclipse Foundation
Eclipse Soteria 3.0.0, the compatible implementation to Jakarta Security 3.0, has been released featuring: a fix in the implementation of the Weld SPI; an initial implementation of OpenId Connect; and dependency upgrades to JUnit 4.13.1 and JSoup 1.14.2.
Eclipse Vert.x 4.3.2 has been released complete with bug fixes and dependency upgrades within the Vert.x modules such as: GraphQL Java 18.2, Thymeleaf 3.0.15 and jte 2.1.1 in vertx-web; JUnit 4.13.2 and gRPC 1.47.0 in vertx-grpc; and Netty 4.1.78.Final in vertx-dependencies. This release also includes a deprecation and breaking change related to the use of the jackson-databind module involved in some recent CVEs. More details on this release may be found in the release notes.
Eclipse Collections 11.1.0 has been released featuring the addition of new APIs, as requested by the Java community, and a decrease in technical debt, such as: a replacement of implementation factories and dependencies with API factories where possible; an improved overall test coverage by adding missing tests; and improved code generation logic into separate goals for sources, test-sources, and resources.
Apache Software Foundation
On the road to Apache MyFaces 4.0.0, the first release candidate was made available. Serving as the compatible implementation to Jakarta Faces Server 4.0, new features include: first class support for creating views in Java; an implementation of automatic extensionless mapping; and a new getLifecycle() method in the FacesContext class. More details on this release may be found in the release notes.
Apache Camel on Quarkus (Camel Quarkus) 2.7.2 has been released containing Camel 3.14.4, Quarkus 2.7.6.Final and a number of bug fixes. More details on this release may be found in the release notes.
Apache Camel 3.18.0 has been released featuring 117 bug fixes, improvements and dependency upgrades that include: Testcontainers 1.17.3, Vert.x 4.3.1, Camel Quarkus 2.10.0 and the Spring Boot 2.7 release train. More details on this release may be found in the release notes.
Apache Log4j 2.18.0 has been released that ships with bug fixes and new features such as: a new MutableThreadContextMapFilter class that filters based on a value defined in the Thread Context Map; a custom LMAX disruptor WaitStrategy configuration; support for adding and retrieving appenders in Log4j 1.x bridge; and support for the Jakarta Mail specification in the SMTP appender.
JDKMon
Versions 17.0.31 and 17.0.29 of JDKMon, a tool that monitors and updates installed JDKs, has been made available to the Java community this past week. Created by Gerrit Grunwald, principal engineer at Azul, these new versions ship with: a dependency upgrade to the latest version of DiscoClient which includes fix for obtaining a direct download URI of a package; and a fix for an issue related to comparing the architecture of the machine with the packages.
JetBrains
Version 2.0.3 of Ktor, the asynchronous framework for creating microservices and web applications, has been released that ships with a number of bug fixes, improvements and dependency upgrades in the core, client, server and test infrastructure sections of the framework. More details on this release may be found in the changelog.
On the road to IntelliJ IDEA 2022.2, a beta release was made available to preview new features such as: a migration from JetBrains Runtime (JBR) 11 to JBR17; improvements in remote development; support for Spring Framework 6 and Spring Boot 3; an experimental GraalVM Native Debugger for Java; and clickable URLs in JSON, YAML, and .properties string values.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

In a recent article on Swift blog, Graphing Calculator‘s creator Ron Avitzur recounted how his decision to fully rewrite his app in Swift allowed him to shrink its codebase down to 30% of its original size, improving maintainability and readability while not losing performance.
Graphing Calculator is an app that makes it possible to create function graphs in two and three dimensions. Originally created in 1985, it was bundled by Apple with the original PowerPC computers, later moved on to live as an independent product available for macOS, Windows, and iOS. After 35 years of continued development, the best way forward, says Avitzur, was a full rewrite, although this is always a major feat, requiring a lot of work.
Legacy code embodies decades of hard-learned lessons […]. While a fresh start can be aesthetically satisfying, it creates an enormous surface area for bugs. In a typical dot release, focusing testing on new features is easy. With a complete rewrite, everything is new.
Graphing Calculator used a set of different languages and stacks, including C++ and Objective C/C++, Lex and YACC, AppKit and UIKit, and OpenGL. All of this morphed into a coherent Swift codebase using SwiftUI and Metal over 18 months with a reduction of the line count from 152,000 lines to 29,000.
Less code means less to debug, less to read and understand, and that alone makes the port easier to maintain. Using SwiftUI, view controllers go away entirely: a big win for declarative programming over imperative.
Among the major benefits of the rewrite, Avitzur mentions the reduction in boilerplate code, which made the logic and the meaning of code clearer; the use of value types in collection types, which made it simpler to reason about them; the conciseness brought by type inference, enumerations, closures, and Swift concurrency.
The biggest challenge, on the other hand, was keeping the same level of performance in comparison to a codebase which had been highly optimized for over 30 years.
As Avitzur explains in a Twitter thread, the first port paid a 10x penalty in terms of performance. He could reduce it down to 2x by disabling all Swift runtime checks and using vDSP for innermost loops. One remaining issue, though, is the cost of automatic reference counting on tree traversal, since the Swift compiler has no way to specify that a given portion of the code will not change any reference counts.
Overall, says Avitzur, both Swift and SwiftUI have lived up to their promises and opened up the possibility of contribute portions of the code in form of stand-alone Swift Packages for mathematical typesetting, editing, numeric and symbolic computation, and graphing.
MMS • David Williams
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Transcript
Shane Hastie: Good day folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today, I’m sitting down with David Williams from Quali. David, welcome. Thanks for taking the time to talk to us today.
David Williams: Thanks, Shane. It’s great to be here.
Shane Hastie: Probably my first starting point for most of these conversations is who’s David?
Introductions [00:23]
David, he’s a pretty boring character, really. He’s been in the IT industry all his life, so there’s only so many parties you can go and entertain people with that subject now. But I’ve been working since I first went to school. My first jobs were working in IT operations in a number of financial companies. I started at the back end. For those of you who want to know how old I was, I remember a time when printing was a thing. And so decorating was my job, carrying tapes, separating print out, doing those sort of things. So really I got a very grassroots level of understanding about what technology was all about, and it was nowhere near as glamorous as I’ve been full to believe. So I started off, I’d say, working operations. I’ve worked my way through computer operations systems administration, network operations. So I used to be part of a NOC team, customer support.
David Williams: I did that sort of path, as low as you can get in the ladder, to arguably about a rung above. And then what happened over that period of time was I worked a lot with distributed systems, lights out computing scenarios, et cetera and it enabled me to get more involved in some of the development work that was being done, specifically to manage these new environments, specifically mesh computing, clusters, et cetera. How do you move workloads around dynamically and how does the operating system become much more aware of what it’s doing and why? Because obviously, it just sees them as workloads but needed to be smarter. So I got into development that way, really. I worked for Digital Equipment in its heyday, working on clusters and part of the team that was doing the operating system work. And so that, combined with my knowledge of how people were using the tech, being one of the people that was once an operations person, it enabled me as a developer to have a little bit of a different view on what needed to be done.
And that’s what really motivated me to excel in that area, because I wanted to make sure that a lot of the things that were being built could be built in support of making operations simpler, making the accountability of what was going on more accountable to the business, to enable the services to be a little more transparent in how IT was using them around. So that throughout my career, luckily for me, the tech industry reinvents itself in a very similar way every seven years. So I just have to wait seven years to look like one of the smart guys again. So that’s how I really got into it from the get go.
Shane Hastie: So that developer experience is what we’d call thinking about making it better for developers today. What are the key elements of this developer experience for us?
The complexity in the developer role today [02:54]
David Williams: When I was in development, the main criteria that I was really responsible for was time. It was around time and production rates. I really had no clue why I was developing the software. Obviously, I knew what application I was working on and I knew what it was, but I never really saw the results. So over the years, I wasn’t doing it for a great amount of time, to be honest with you. Because when I started looking at what needed to be done, I moved quite quickly from being a developer into being a product manager, which by the way, if you go from development to product management, it’s not exactly a smooth path. But I think it was something that enabled me to be a better product manager at the time, because then I understood the operations aspects, I was a developer and I understood what it was that made the developer tick because that’s why I did it.
It was a great job to create something and work on it and actually show the results. And I think over the years, it enabled me to look at the product differently. And I think that as a developer today, what developers do today is radically more advanced than what I was expected to do. I did not have continuous delivery. I did not really have a continuous feedback. I did not have the responsibility for testing whilst developing. So there was no combined thing. It was very segmented and siloed. And I think over the years, I’ve seen what I used to do as an art form become extremely sophisticated with a lot more requirements of it than was there. And I think for my career, I was a VP of Products at IBM Tivoli, I was a CTO at BMT software, and I worked for CA Technology prior to its acquisition by Broadcom, where I was the Senior Vice President of Product Strategy.
But in all those jobs, it enabled me to really understand the value of the development practices and how these practices can be really honed in, in support between the products and the IT operations world, as well as really more than anything else, the connection between the developer and the consumer. That was never part of my role. I had no clue who was using my product. And as an operations person, I only knew the people that were unhappy. So I think today’s developer is a much more… They tend to be highly skilled in a way that I was not because coding is part of their role. Communication, collaboration, the integration, the cloud computing aspects, everything that you have to now include from an infrastructure is significantly in greater complexity. And I’ll summarize by saying that I was also an analyst for Gartner for many years and I covered the DevOps toolchains.
And the one thing I found out there was there isn’t a thing called DevOps that you can put into a box. It’s very much based upon a culture and a type of company that you’re with. So everybody had their interpretation of their box. But one thing was very common, the complexity in all cases was significantly high and growing to the point where the way that you provision and deliver the infrastructure in support of the code you’re building, became much more of a frontline job than something that you could accept as being a piece of your role. It became a big part of your role. And that’s what really drove me towards joining Quali, because this company is dealing with something that I found as being an inhibitor to my productivity, both as a developer, but also when I was also looking up at the products, I found that trying to work out what the infrastructure was doing in support of what the code was doing was a real nightmare.
Shane Hastie: Let’s explore that when it comes, step back a little bit, you made the point about DevOps as a culture. What are the key cultural elements that need to be in place for DevOps to be effective in an organization?
The elements of DevOps culture [06:28]
David Williams: Yeah, this is a good one. When DevOps was an egg, it really was an approach that was radically different from the norm. And what I mean, obviously for people that remember it back then, it was the continuous… Had nothing to do with Agile. It was really about continuous delivery of software into the environment in small chunks, microservices coming up. It was delivering very specific pieces of code into the infrastructure, continuously, evaluating the impact of that release and then making adjustments and change in respect to the feedback that gave you. So the fail forward thing was very much an accepted behavior, what it didn’t do at the time, and it sort of glossed over it a bit, was it did remove a lot of the compliance and regulatory type of mandatory things that people would use in the more traditional ways of developing and delivering code, but it was a fledging practice.
And from that base form, it became a much, much bigger one. So really what that culturally meant was initially it was many, many small teams working in combination of a bigger outcome, whether it was stories in support of epics or whatever the response was. But I find today, it has a much bigger play because now it does have Agile as an inherent construct within the DevOps procedures, so you’ve got the ability to do teamwork and collaboration and all the things that Agile defines, but you’ve also got the continuous delivery part of that added on top, which means that at any moment in time, you’re continually putting out updates and changes and then measuring the impact. And I think today’s challenge is really the feedback loop isn’t as clear as it used to be because people are starting to use it for a serious applications delivery now.
The consumer, which used to be the primary recipient, the lamp stacks that used to be built out there have now moved into the back end type of tech. And at that point, it gets very complex. So I think that the complexity of the pipeline is something that the DevOps team needs to work on, which means that even though collaboration and people working closely together, it’s a no brainer in no matter what you’re doing, to be honest. But I think that the ability to understand and have a focused understanding of the outcome objective, no matter who you are in the DevOps pipeline, that you understand what you’re doing and why it is, and everybody that’s in that team understands their contribution, irrespective of whether they talk to each other, I think is really important, which means that technology supporting that needs to have context.
I need to understand what the people around me have done to be code. I need to know what stage it’s in. I need to understand where it came from and who do I pass it to? So all that needs to be not just the cultural thing, but the technology itself also needs to adhere to that type of practice.
Shane Hastie: One of the challenges or one of the pushbacks we often hear about is the lack of governance or the lack of transparency for governance in the DevOps space. How do we overcome that?
Governance in DevOps [09:29]
David Williams: The whole approach of the DevOps, initially, was to think about things in small increments, the bigger objective, obviously being the clarity. But the increments were to provide lots and lots of enhancements and advances. When you fragmented in that way and give the ability for the developer to make choices on how they both code and provision infrastructure, it can sometimes not necessarily lead to things being unsecure or not governed, but it means that there’s different security and different governance within a pipeline. So where the teams are working quite closely together, that may not automatically move if you’ve still got your different testing team. So if your testing is not part of your development code, which in some cases it is, some cases it isn’t, and you move from one set of infrastructure, for example, that supports the code to another one, they might be using a completely different set of tooling.
They might have different ways with which to measure the governance. They might have different guardrails, obviously, and everything needs to be accountable to change because financial organizations, in fact, most organizations today, have compliance regulations that says any changes to any production, non-production environment, in fact, in most cases, requires accountability. And so if you’re not reporting in a, say, consistent way, it makes the job of understanding what’s going on in support of compliance and governance really difficult. So it really requires governance to be a much more abstract, but end to end thing as opposed to each individual stay as its own practices. So governance today is starting to move to a point where one person needs to see the end to end pipeline and understand what exactly is going on? Who is doing what, where and how? Who has permissions and access? What are the configurations that are changing?
Shane Hastie: Sounds easy, but I suspect there’s a whole lot of… Again, coming back to the culture, we’re constraining things that for a long time, we were deliberately releasing.
Providing freedom withing governance constraints [11:27]
David Williams: This is a challenge. When I was a developer of my choice, it’s applicable today. When I heard the word abstract, it put the fear of God into me, to be honest with you. I hated the word abstract. I didn’t want anything that made my life worse. I mean, being accountable was fine. When I used to heard the word frameworks and I remember even balking at the idea of a technology that brought all my coding environment into one specific view. So today, nothing’s changed. A developer has got to be able to use the tools that they want to use and I think that the reason for that is that with the amount of skills that people have, we’re going to have to, as an industry, get used to the fact that people have different skills and different focuses and different preferences of technology.
And so to actually mandate a specific way of doing something or implementing a governance engine that inhibits my ability to innovate is counterproductive. It needs to have that balance. You need to be able to have innovation, freedom of choice, and the ability to use the technology in the way that you need to use to build the code. But you also need to be able to provide the accountability to the overall objective, so you need to have that end to end view on what you’re doing. So as you are part of a team, each team member should have responsibility for it and you need to be able to provide the business with the things that it needs to make sure that nothing goes awry and that there’s nothing been breached. So no security issues occurring, no configurations are not tracked. So how do you do that?
Transparency through tooling [12:54]
David Williams: And as I said, that’s what drove me towards Quali, because as a company, the philosophy was very much on the infrastructure. But when I spoke to the CEO of the company, we had a conversation prior to my employment here, based upon my prior employer, which was a company that was developing toolchain products to help developers and to help people release into production. And the biggest challenge that we had there was really understanding what the infrastructure was doing and the governance that was being put upon those pieces. So think about it as you being a train, but having no clue about what gauge the track is at any moment in time. And you had to put an awful lot of effort into working out what is being done underneath the hood. So what I’m saying is that there needed to be something that did that magic thing.
It enabled you with a freedom of choice, captured your freedom of choice, translated it into a way that adhered it to a set of common governance engines without inhibiting your ability to work, but also provided visibility to the business to do governance and cost control and things that you can do when you take disparate complexity, translate it and model it, and then actually provide that consistency view to the higher level organizations that enable you to prove that you are meeting all the compliance and governance rules.
Shane Hastie: Really important stuff there, but what are the challenges? How do we address this?
The challenges of complexity [14:21]
David Williams: See, the ability to address it and to really understand why the problems are occurring. Because if you talk to a lot of developers today and say, “How difficult is your life and what are the issues?”, the conversation you’ll have with a developer is completely different than the conversation you’ll have with a DevOps team lead or a business unit manager, in regards to how they see applications being delivered and coded. So at the developer level, I think the tools that are being developed today, so the infrastructure providers, for example, the application dictates what it needs. It’s no longer, I will build an infrastructure and then you will layer the applications on like you used to be able to do. Now what happens is applications and the way that they behave is actually defining where you need to put the app, the tools that are used to both create it and manage it from the Dev and the Op side.
So really what the understanding is, okay, that’s the complexity. So you’ve got infrastructure providers, the clouds, so you’ve got different clouds. And no matter what you say, they’re all different impact, serverless, classic adoption of serverless, is very proprietary in nature. You can’t just move one serverless environment from one to another. I’m sure there’ll be a time when you might be able to do that, but today it’s extremely proprietary. So you’ve got the infrastructure providers. Then you’ve got the people that are at the top layer. So you’ve got the infrastructure technology layer. And that means that on top of that, you’re going to have VMs or containers or serverless something that sits on your cloud. And that again is defined by what the application needs, in respect to portability, where it lives, whether it lives in the cloud or it’s partly an edge, wherever you want to put it.
And then of course on top of that, you’ve got all the things that you can use that enables you to instrument and code to those things. So you’ve got things like Helm charts for containers, and you’ve got a Terraform where developing the infrastructure as code pieces, or you might be using Puppet or Chef or Ansible. So you’ve got lots of tools out there, including all the other tools from the service providers themselves. So you’ve got a lot of the instrumentation. And so you’ve got that stack. So the skills you’ve got, so you’ve got the application defining what you want to do, the developer chooses how they use it in support of the application outcome. So really what you want to be able to do is have something that has a control plane view that says, okay, you can do whatever you want.
Visibility into the pipeline [16:36]
David Williams: These are the skills that you need. But if people leave, what do you do? Do you go and get all the other developers to try and debug and translate what the coding did? Wouldn’t it be cool instead to have a set of tech that you could understand what the different platform configuration tools did and how they applied, so look at it in a much more consistent form. Doesn’t stop them using what they want, but the layer basically says, “I know, I’ve discovered what you’re using. I’ve translated how it’s used, and I’m now enabling you to model it in a way that enables everybody to use it.” So the skills thing is always going to exist. The turnover of people is also very extremely, I would say, more damaging than the skills because people come and go quite freely today. It’s the way that the market is.
And then there’s the accountability. What do the tools do and why do they do it? So you really want to also deal with the governance piece that we mentioned earlier on, you also want to provide context. And I think that the thing that’s missing when you build infrastructure as code and you do all these other things is even though you know why you’re building it and you know what it does to build it, that visibility that you’re going to have a conversation with the DevOps lead and the business unit manager, wouldn’t it be cool if they could actually work out that what you did is in support of what they need. So it has the application ownership pieces, for example, a business owner. These are the things that we provide context. So as each piece of infrastructure is developed through the toolchain, it adds context and the context is consistent.
So as the environments are moved in a consistent way, you actually have context that says this was planned, this was developed, and this is what it was done for. This is how it was tested. I’m now going to leverage everything that the developer did, but now add my testing tools on top. And I’m going to move that in with the context. I’m now going to release the technology until I deploy, release it, into either further testing or production. But the point is that as things get provisioned, whether you are using different tools at different stages, or whether you are using different platforms with which to develop and then test and then release, you should have some view that says all these things are the same thing in support of the business outcome and that is all to do with context. So again, why I joined Quali was because it provides models that provide that context and I think context is very important and it’s not always mentioned.
As a coder, I used to write lots and lots of things in the code that gave people a clue on what I was doing. I used to have revision numbers. But outside of that and what I did to modify the code within a set of files, I really didn’t have anything about what the business it was supporting it. And I think today with the fragmentation that exists, you’ve got to give people clues on why infrastructure is being deployed, used, and retired, and it needs to be done in our life cycle because you don’t want dormant infrastructure sitting out there. So you’ve got to have it accountable and that’s where the governance comes in. So the one thing I didn’t mention earlier on was you’ve got to have ability to be able to work out what you’re using, why it’s being used and why is it out there absorbing capacity and compute, costing me money, and yet no one seems to be using it.
Accountability and consistency without constraining creativity and innovation [19:39]
David Williams: So you want to be out of accountability and with context in it, that at least gives you information that you can rely back to the business to say, “This is what it cost to actually develop the full life cycle of our app, in that particular stage of the development cycle.” So it sounds very complex because it is, but the way to simplify it is really to not abstract it, but consume it. So you discover it, you work out what’s going on and you create a layer of technology that can actually provide consistent costing, through consistent tagging, which you can do with the governance, consistent governance, so you’re actually measuring things in the same way, and you’re providing consistency through the applications layer. So you’re saying all these things happen in support, these applications, et cetera. So if issues occur, bugs occur, when it reports itself integrated with the service management tools, suddenly what you have there is a problem that’s reported in response to an application, to a release specific to an application, which then associates itself with a service level, which enables you to actually do report and remediation that much more efficiently.
So that’s where I think we’re really going is that the skills are always going to be fragmented and you shouldn’t inhibit people doing what they need. And I think the last thing I mentioned is you should have the infrastructure delivered in the way you want it. So you’ve got CLIs, if that’s a preferred way, APIs to call it if you want to. But for those who don’t have the skills, it’s not a developer only world if I’m an abstraction layer and I’m more of an operations person or someone that doesn’t have the deep diving code skills, I should need to see a catalog of available environments built by coding, built by the people that actually have that skill. But I should be able to, in a single click, provision an environment in support of an application requirement that doesn’t require me to be a coder.
So that means that you can actually share things. So coders can code, that captures the environment. If that environment is needed by someone that doesn’t have the skills, but it’s consistently, because it has all that information in it, I can hit a click. It goes and provisions that infrastructure and I haven’t touched code at all. So that’s how you see the skills being leveraged. And you just got to accept the fact that people will be transient going forward. They will work from company to company, project to project, and that skills will be diverse, but you’ve got to provide a layer with which that doesn’t matter.
Shane Hastie: Thank you very much. If people want to continue the conversation, where do they find you?
David Williams: They can find me in a number of places. I think the best place is I’m at Quali. It is David.W@Quali.com. I’m the only David W., which is a good thing, so you’ll find me very easily. Unlike a plane I got the other day, where I was the third David Williams on the plane, the only one not to get an upgrade. So that’s where you can find me. I’m also on LinkedIn, Dave Williams on LinkedIn can be found under Quali and all the companies that I’ve spoken to you about. So as I say, I’m pretty easy to find. And I would encourage, by the way, anybody to reach out to me, if they have any questions about what I’ve said. It’d be a great conversation.
Shane Hastie: Thanks, David. We really appreciate it.
David Williams: Thank you, Shane.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Renato Losio
Article originally posted on InfoQ. Visit InfoQ

Amazon recently announced that Aurora PostgreSQL supports PostgreSQL major version 14. The new release adds performance improvements and new capabilities, including support for SCRAM password encryption.
PostgreSQL 14 includes improvements for parallel queries, heavily-concurrent workloads, partitioned tables, logical replication, and vacuuming. The 14.3 version adds new capabilities such as the ability to close idle sessions or to cancel long-running queries if a client disconnects. Other benefits of PostgreSQL 14 include multiranges, allowing representation of non-contiguous data ranges, and stored procedures returning data using OUT parameters.
The new Aurora release adds support for SCRAM password encryption, an alternative to the default MD5 algorithm for encrypting passwords. SCRAM has been backported to previous Aurora PostgreSQL versions (10, 11, 12, 13) and AWS recommends using SCRAM rather than MD5 for any new cluster.
Aurora for PostgreSQL provides continuous backups, up to 15 read replicas, multi-region replication and the option to run in serverless mode. The general availability of the on-demand, auto-scaling configuration was announced last April and is now compatible with PostgreSQL 14.
Existing clusters can be upgraded to the PostgreSQL 14 version. Further upgrades of minor versions can be achieved without downtime as the cloud provider has recently released zero-downtime patching (ZDP), a feature to preserve client connections when the database restarts.
There were initially some concerns in the community related to the choice of version 14.3, but the cloud provider backported a few of the most recent fixes from 14.4, including the one for the CONCURRENTLY bug. To simplify the release process, the Aurora version is going forward the same as the major.minor version of the PostgreSQL community version, with a third digit in the patch location.
Murat Demirbas, principal applied scientist at AWS, recently wrote a popular article on the decoupled architecture of Amazon Aurora. The new release of the high-throughput cloud-native relational database includes new features for Babelfish for Aurora PostgreSQL version 2.1, the open source capability to run Microsoft SQL Server applications on PostgreSQL. Version 14.3 is the third major version of the managed service since the beginning of 2021: last year Aurora introduced support for PostgreSQL 12 and PostgreSQL 13, as reported by InfoQ, showing a significantly shorter release cycle than for the MySQL versions.
Amazon Aurora is not the first managed service with PostgreSQL 14 compatibility: Amazon RDS supports it and other providers have already added support too, including Flexible Server PostgreSQL on Azure and Azure’s Hyperscale (Citus).
PostgreSQL 14 is available in all regions supported by Aurora. There are no price differences among engine versions.
MMS • Jason Maude
Article originally posted on InfoQ. Visit InfoQ

Transcript
Maude: My name is Jason Maude. I am the Chief Technology Advocate at Starling Bank. What that means is I go around and talk about Starling Bank’s technology, its technology processes, practices, its architecture, and present that to the outside world. Technology advocacy is very important, and I think growing more important as technology grows more present in everyday life. It’s especially important for a bank, because as a bank, you need to have trust, the trust of your customers, the trust of the industry, the trust of the regulators. As a highly technological bank, we need to have trust in our technology. It’s my job to go round and talk about that.
What Is Starling Bank?
What is Starling Bank? Starling Bank is a fairly new bank. It was founded in 2014. It’s a bank based in the UK. At the moment it’s UK only, but we hope to be expanding beyond that. It launched to the public in 2017. Its launch was slightly unusual in the sense that there were no branches, no physical presence on the high street, no way you could walk into. It was an entirely app based bank. For the customers, the way they got a bank account was like going on to their mobile phone, their iPhone, their Android phone, downloading the Starling Bank app, and then applying for a bank account through there. Having applied for the bank account, doing all of their banking via the app. We’re entirely based in the cloud, and always have been, with a few caveats, but almost entirely based in the cloud, and have been since day one. Completely cloud native. Our technology stack is fairly simple, generally speaking, where most of our backend services are written in Java. They’re running over Postgres relational databases. There’s nothing fancy, not very many frameworks in place. They’re running in Docker containers on EC2 instances. We are just starting to migrate all of these over to a Kubernetes based infrastructure.
Starling Bank’s Tech Stack
I often get asked at these presentations, do you use such a framework, or such a way of doing things? My answer is always, “No, not really. We don’t use that framework. We don’t have many complicated frameworks, or methodologies, or tooling in place.” We have some, obviously, but we don’t have a lot of them. People are often surprised. They’re surprised that a very modern, tech savvy, cloud native company is running on such vanilla infrastructure, as well.
I’ve seen someone already asking, you started in the 2010s, why are you using Java? It’s an old language. Absolutely, why are we using Java? Why are we running on such a simple vanilla tech stack? That is going to be the main focus of my presentation, trying to answer this question, why are we focused on such a simple tech stack? Why are we focused on this very vanilla, very old school, not modern languages way of doing things? It comes down to this philosophy of rampant pragmatism. I want to talk through what rampant pragmatism is, how we apply it at Starling Bank, and use the example of how our deployment procedures have evolved over time. Why we’re only just now getting to Kubernetes to try and draw out the reasons for this.
Essential Complexity and Accidental Complexity
I’m going to start with the academic paper that inspired this philosophy of rampant pragmatism. It’s a paper that is called, “No Silver Bullet—Essence and Accident in Software Engineering.” No Silver Bullet. It’s a paper about the difference between essential complexity and accidental complexity. It tries to draw a distinction between these two in software engineering. What is the difference? Essential complexity is when you have a problem, the essential part of it is the part you’re never getting away from. It’s the part about looking at the problem and the solution, and trying to work out what the solution to the problem is. How the solution should be formed. That is the essential complexity. Then the accidental complexity is everything that surrounds that to implement that solution, to actually take that solution and put it into practice.
Let’s use an example to illustrate the difference between the two of these. We can imagine a scenario in a far-flung mythical future in which a group of people are sitting down to design a new software product. They are, as many of us do, starting by the time honored tradition of standing round a whiteboard with marker pens, drawing on the whiteboard, boxes and circles and arrows between them. Trying to define the problem space that they’re working in, and how they would like to solve it. Trying to define the architecture of the system that they are trying to design. They’ve drawn all these boxes, and arrows, and circles, and so on. Except, rather than then picking up their phones and taking a picture of it, they instead go to a magic button. This magic button lies by the side of the whiteboard, and when you press it, it takes what is drawn on whiteboard, turns it into code. Make sure that code is secure. Make sure it will work. Make sure it is optimized for the volumes you’re currently running at. Tests it, make sure there are no regressions. Integrates it into the rest of the code base, and deploys it into production. All through this magic button.
The point of this example is to illustrate that the drawing on the whiteboard, the drawing of the circles and the squares, and the lines, and arrows, and so on, that bit is the essential complexity. That bit is the bit that really truly you can never get away from, and to the problem space, is what you actually need. All of the rest of the job that we do, the creating of the code, the deploying of it, the testing of it, all of that is accidental. It’s an implementation detail. It’s an implementation detail that we can eventually try and get away from. We have tried to get away from. We know no one is sitting there trying to write machine code. No one is there tapping out 1s and 0s. We’re all writing in higher level languages, which are gradually compiled down. We’ve tried to move away from the low level implementation into something that is closer to the essential complexity, but we still have a lot of accidental complexity in our day-to-day jobs. The accidental complexity isn’t bad. It’s not a problem to have accidental complexity. Some accidental complexity such as the writing of the code is necessary. It’s required for our job to work. Some accidental complexity isn’t. It’s unnecessary. It slows us down. It’s there but it complicates matters. It makes matters more difficult and tiresome to deal with. Trying to deal with tools and processes and pieces of code that slow you down and stop you implementing your problem, your whiteboard circles, and diagrams, and squares, that is unnecessary accidental complexity.
Unnecessary Accidental Complexity and Necessary Accidental Complexity
You’ve got unnecessary accidental complexity and necessary accidental complexity, but how do you tell the difference between the two? How do you make sure that you are working with the necessary stuff only and not introducing any unnecessary stuff? What has this got to do with the cloud? The cloud and our move to the cloud as an industry has made this question more important, more pertinent. The reason it’s made it more pertinent, is because the cloud opens up a world of possibilities to us. It opens up the ability for us to go in and say, we’d like to try something out. We’d like to try a new thing. Let’s write something up, spin it up on an instance, and test it out, see if it works. If it doesn’t, we can take it down again. Gone are the days where you would have to write up a business case for buying a new server, and installing the server and all of the paraphernalia and fire safety equipment in a server room somewhere, in order to be able to try out your new thing. That squashed a lot of innovation. Nowadays, you can just spin up a new instance, brilliant, and try it out.
As a wise comic book character once said, with great power comes great responsibility. The power that you now have to create, and design, and spin up things very quickly means that you also have the responsibility to question whether that thing you’re generating is necessary accidental complexity or unnecessary accidental complexity? Is it actually helping you deploy what you need, what you drew on the whiteboard, the problem that your organization is trying to solve, or is it going to slow things down? The sad reality is that the answer for the vast majority of tooling that you have is probably both. It’s probably introducing both necessary accidental complexity and unnecessary stuff. It’s probably both helping you deploy the thing and putting blockers in your way. The question is less how can you stop introducing unnecessary complexity, but how can you limit it as much as possible?
This has been Starling Bank’s key thinking since day one. Our philosophy of rampant pragmatism is the question of how do we make sure that we don’t introduce, or introduce unnecessary accidental complexity as little as possible, to reduce it down to the minimum it can possibly be? That is the philosophy. We carefully weigh up our options every time we have something. We go, what do we need right now? What is necessary now in order to deploy this thing? Is what we’re deploying here really necessary, or could we get away with doing something simpler? As a result, our tech stack ends up being fairly simple, because every new tool, every new framework, every new way of doing things is subjected to a rigorous question of, is this going to increase the amount of unnecessary accidental complexity too much? If it is, then it is rejected, which is oftentimes why we use old languages such as Java, and so on.
Starling Bank’s Code Deploy Journey
Let’s talk through our journey through our various different ways we have deployed code into production, as an illustration of this philosophy. We start off with, what does Starling look like in the backend? What Starling looks like is reasonably simple. We have about 40 to 50, what we call self-contained systems. Whether these are microservices or not, is a question up for debate. I personally think they’re too big, but then, how big is a microservice is a question that we could spend all day discussing? I call them microliths. What they do is each one of them has a job to do that covers an area of functionality, such as processing card payments, for example, or storing a customer’s personal details perhaps, or holding details about customers’ accounts and their balances, and so on. Each one of these self-contained systems holds those details.
We had all of those individual systems and they are theoretically deployable on their own. They’re theoretically individually deployable. We could go and increase the version of one of them, and none of the others. When we started, we rarely did that. By convention, we deployed them all together. They were all on version 4, and then we all move them all up to version 5, and then 6, and so on. They were all in lockstep with one another. We were deploying as a monolith. The question becomes, if you were deploying as a monolith, why not just write a monolith? Which is an interesting question. The reason that we kept deploying them as a monolith is because it made things much simpler. It reduced the amount of accidental complexity we had to deal with. We weren’t being hamstrung by the fact that we had to deploy them all together as a monolith and keep going. It wasn’t slowing us down in the early days. Trying to deploy them individually would have meant that we had to test the boundaries between them. They each had their own APIs, which they use to contact each other. If we had deployed them individually, we would have had to put tests around these APIs to make sure that we weren’t deploying a breaking change, for example, and those tests would have hardened the API shell and made it more difficult to change and that sort of thing.
In the early days, we didn’t want that, because we were changing these services all the time, not just internally, we were also changing what concepts they were dealing with. We were splitting them apart. We were moving pieces of functionality between one service and another, and so on. We were moving all this functionality around, and as such, we decided, it’s easier for us if we just test the whole thing, test everything as a whole, rather than trying to test individual bits and pieces of it individually, and the boundaries and the contracts between.
This went on for some time, and we were nicely and safely deploying things. Then things started to get a bit difficult with that model. The thing that caused the difficulty was scale. As we increase the number of engineers, as we increase the number of services, as we increase the volume of customers, we quickly developed a problem, where the amount of code we were trying to deploy all at once was too big for us to really get a handle on. We had been deploying up to that point every day, and we noticed that cadence slowing down. We were deploying every day, then every two days. Some days it became too difficult to deploy our platform services. We were starting to slow down. We sat down and decided, what can we do about this? The answer was, it was time to stop deploying as a monolith. That was what was slowing us down, because we had to ensure the safety of every single change that took place. As those number of changes had increased, that process of trying to ensure every single change every time we deployed, the bank as a whole, mean we became too slow. If there was a problem in one section of the bank, we stop deploying everything, even if other services were perfectly fine.
We decided to split things down. We decided not to deploy everything individually, we decided to deploy things as large groups of services. For example, anything that dealt with processing payments was one group. Anything that dealt with customer details and account management was another group. Anything that dealt with customer service and chat functionality and helping customers was another group, and so on. Once again, the reason was that each of these groups were working as a team. There was a team surrounding this group of services, and they could ensure the efficacy, the workingness of these services, and deploy them as groups.
It also helped us not fall afoul of Conway’s law, the law that states that your organizational structure and your software architecture will align. I forget which way Conway says the causation arrow goes in that alignment, but the two are intimately linked. If you have three teams, but five different services, you will quickly find that you have a problem, because what the teams do and how the teams work will mean that if you have five services and three teams that parts of your software will either get neglected or will be fought over by two different teams. That can be difficult.
Surrounding your deployment procedures and methods around the teams, again, helps you stop introducing accidental complexity because they are aligned, and we decided it was easier to manage 6 teams than 50 teams, which would have been excessive. We moved into this situation where we were deploying these groups of services all together, and each group deployed all their services at once as a collection of services in a small monolith. A minilith, however we’re going to determine these terms here.
Kubernetes
That was the situation for a while. Then we started bringing in Kubernetes. Why only Kubernetes just now? What we realized we wanted to do is that as these teams had split up, and they were all responsible for their individual sections, they wanted to create more of these services to better control their functionality. Creating new services was a bit difficult, it was long and laborious spinning up a new service and creating all of the infrastructure around it. A tool like Kubernetes helps you to have a standard framework template that allows you to spin up these things without the developers having to do endless amounts of work in infrastructure, defining all of these services in any great detail.
Another key aspect of doing this is, back to our old friend, the regulator. Starling Bank is working as a fully licensed bank, so it’s in a regulated industry. Regulators are starting to worry, at least in the United Kingdom, about what they call concentration risk, that is, the risk that everyone is using AWS, and if AWS goes down, everyone goes down. In order to stop that they have tried to get people to move to a more cloud neutral solution. This is a good thing. We need to move to a situation where one cloud provider either disappearing, unlikely as that might be, in all zones, in all regions simultaneously. The way out of that is to make sure that you are running on multiple cloud providers at once.
We started on AWS and our infrastructure was very tied to it, not by design, simply by the fact that that’s how we had started and that was what was practical at the time. The philosophy of rampant pragmatism often demands that you have to go and you have to make sure that you’re doing what’s right at the time, not just trying to push yourself forward to an imagined future where you think things could be better. We decided for those reasons, and the increased speed of delivery that we hope to get under Kubernetes to start migrating onto Kubernetes, and moving in. Once again, we’re trying to keep it fairly simple, fairly vanilla. I’ve been to talks on Kubernetes, where people have rattled off huge lists of tooling, and so on. I couldn’t tell you whether they were reciting lists of Kubernetes tools or Pokémon, I have no idea. There were so many of them, it’s difficult to keep track of. Once again, there is that temptation, let’s grab all the tools, let’s bring all the tools in, without stopping and asking, is this tool going to increase our unnecessary accidental complexity, or decrease it in net sense? Which way is the dial going to move? That’s been Starling Bank’s journey.
Lessons Learned
Various lessons I draw from this on trying to work out where the difference lies between necessary and unnecessary accidental complexity, and how you can tell the difference. One simple way is just doing a cost benefit analysis. If you introduce a new tool, or a new framework, or what have you, are you going to spend more time maintaining that framework than you’re going to save by implementing that framework? It sounds like a simple idea. This is really an exhortation for everyone to stop and think, rather than becoming very excited about new tools and the possibilities that they bring. New tools, new languages, new frameworks can all be very exciting, but are you really going to get more benefit out of it than the cost to maintain it?
Another point is about onboarding time. The more tools and so on that you introduce, the more complicated frameworks and so on, the longer it takes to get someone up to speed who has just joined your organization. I’d love for there to be some standard tools or standard frameworks, but my experience tells me that there really isn’t. There’s a plethora of different things that people use. Whatever you think is standard, you’ll always be able to find somewhere that doesn’t use that and uses something else. How long does it take you to get someone up to speed? At Starling Bank, we really want our new engineers who join the company to be able to start committing code and have that code running in production within the week that they join. We really want to make sure that they can have an impact on the customer, really change what the customer is seeing very quickly. If we have lots of accidental complexity, it becomes harder to do that. Measuring, how long does it take someone to be productive? How long does it take someone to learn all the tooling? How long does it take to train a new engineer at our company, even if they are experienced as an engineer? A good measure of whether you have introduced too much accidental complexity or not.
Of course, there is the big one, which is, how long does it take you to actually fix a problem? If something goes wrong, and the customer is facing a problem, trying to scroll through the endless tools and going, is it this tool? Is it something in our CI/CD pipeline? Is it a code bug? Is it something to do with our security? Walking through all of these different things can be long enough if you’ve got loads of tools, and loads of different things, and loads of different frameworks and so on, walking through all of them to try and work out where the bug is, could take ages. The more accidental complexity you introduce through this tooling, the longer it’s going to take you to actually fix something when it goes wrong, and deploy it and get it out and working. Those are my lessons I have learned. I encourage you all to think about essential and accidental complexity, and then your necessary and unnecessary accidental complexity, and see if you can pragmatically reduce down your unnecessary accidental complexity to as low as possible.
Questions and Answers
Watson: Why would you pick that language? Is it still pertinent today?
Maude: There are a number of reasons. A lot of people go, why Java? Java is like 30 years old almost at this point. One of the answers is because it’s 30 years old at this point. It’s been around for 30 years, and it’s still around. It’s still working. That gives us the reliability aspect that we need. Also, it’s really easy to hire people who can code in Java, and the ability to have a good recruitment pipeline, an easy recruitment pipeline is a good thing. That’s a positive thing. Again, something that increases our reliability, and so on. You should be able to find out the talks I’ve done at QCon in the past about why reliability is so important to us, and how we insure it. That’s one aspect of it.
Watson: I know that at a former company I was at, one of the benefits of Java was people could use Clojure, Scala, like a lot of the base RPC language libraries could be common. I’m in a company now that has five languages and it’s unpleasant, just to be clear.
Was there a decision made early on you would deploy services as a monolith? Are these microservices tightly coupled or loosely coupled on your end?
Maude: They are reasonably loosely coupled by now, mainly because they have very distinct jobs as it were. This distinctness of job means that the coupling is as loose as we can make it, as proper as we can make it. We know whose responsibility storing a customer’s address, for example, is. If we got a new piece of personal information about the customer, we know exactly which service to store it in, and exactly what the API should look like to transfer it out. They’re relatively loosely coupled. We know under the covers that service can just constantly churn as much as it likes, because as long as it keeps fulfilling its contract, we’re happy with it. I’m happy with the level of coupling we have.
Watson: I saw Alejandro picked up on YAGNI, you aren’t going to need it, like the pragmatism. I think people connected with that. I don’t know if you have anything you want to say on that.
Maude: Absolutely. I think this is YAGNI taken to its logical conclusion. YAGNI is a bit too definitive for me. It’s like, you aren’t going to need it. That sounds like you are not. We know that you’re not going to need it. I think that’s rarely true. What is true is you don’t know that you’re going to need it yet. You have to be able to say, we don’t know, so let’s not do it, because we’re not really sure. The caveat to that is that you have to be ready if you don’t know you’re going to need it. You have to be ready when you do know that you need it to change quickly. That’s the essential thing you have to have in place in order to employ this rampant pragmatism, for example.
Watson: How are you managing networking among services, are you using service mesh? How do you look at the networking perspective of your move?
Maude: Again, no, there isn’t anything. We are very much of the philosophy that the smarts should be in the services, not in the pipes. The connection between our different systems is simply a REST API, that’s it. We send JSON payloads over the wire between the two services, and that’s it. There’s nothing smart or clever happening in the pipework. All of the smarts take place in the service. As soon as the service receives an instruction, it saves the instruction. That basically becomes a thing that must be executed, a thing that must be processed. That’s put onto queues and the queues have a lot of functionality to make sure that they do things. They do things at least once and at most once. They make sure that they retry if things go wrong. That things are picked up again if the instance disappears, and then reappears. There is a retry functionality in there. There is idempotence in there to make sure that multiple processings don’t produce like sending the same payment five times or what have you. All of that smarts is contained in the service, not in the pipework, the pipework is boring, just a payload over the wire.
Watson: How do you handle deploy and rollback with your monolith approach, if you don’t have API versioning?
Maude: This was interesting in the really early days, when we were deploying the whole thing as a monolith. We didn’t need to deploy the whole thing as a monolith. We could have deployed it as individual services, but deploying it as a monolith was easier to test. When we needed to roll back, oftentimes, if an individual service was the problem, we would check that rolling back that service would be fine. We would essentially do a manual check to see if the APIs had broken, and then roll back that individual service. We then would have a situation where one service was on version 5, and everything else was on version 6. That was possible. We could do that in an emergency scenario. The same is true nowadays. We will sometimes do that. Obviously, the preference nowadays is to roll back the entire service group. If a service group, payments processing, say, encounters a problem in one service, we’ll roll back the entire service group to an older version, if we can.
Watson: Besides the Silver Bullet paper, do you recommend some literature paper blogs on the topic?
Maude: I don’t have anything off the top of my head that I can think of.
Watson: Given you went through the process of moving from monolith to microservices, have you ever backed out of a tech decision because it unexpectedly produced too much unnecessary complexity?
Maude: We’ve certainly backed out of using suppliers because they introduce unnecessary complexity. Yes. A lot of the time, what we do is we get a supplier to do something. Then we think actually maintaining the link with the supplier is too complicated. It’s basically generating more complexity than it’s solving, we write it ourselves. We have done that on a number of occasions. If you are doing Software as a Service, please make sure that you are there to reduce the unnecessary complexity of your customers, not increase it. Because otherwise, hopefully, they will get rid of you.
Watson: You mentioned the cost benefit ratio of adopting something as a factor, and someone said, what type of timeline would you assume when you’re assessing that cost benefit ratio? Does it depend, and do you have criteria?
Maude: We’re assessing it all the time. We’re fairly open to people grumbling about tooling and saying, I don’t like this tool, and so on. Because if the grumbling gets too much, then people will start going, this tool really does need to be replaced. We don’t have a formalized, “We will review it every six months to see.” Instead, we’re constantly looking at what are the problems now? Where are the accidental complexities now? How can we increase, decrease them, and so on? That sort of investment.
Watson: How do you test contracts between these big blocks, those that are launched independently?
Maude: How we test them is we have what we call an API gateway, which is a fairly transparent layer, that traffic into and out of a group we’ll go to. We have contract tests that we write, one on either side. We have a consumer and a provider contract test on both sides of the line. The consumer in Group A and the provider in Group B, will both be tested. One to test that it generates the correct payload, the other to test that if it is given a payload, it can consume it. It’s very much not trying to test the logic of the consumption. It’s not trying to test that it processed correctly, simply that it can be consumed. That you haven’t broken the API to the extent that you can’t send that payload. Again, one of the reasons we can do that is because the pipeline is very simple. There is no complexity in the pipeline that we need to be concentrating on maintaining.
See more presentations with transcripts
MMS • Travis Nelson
Article originally posted on InfoQ. Visit InfoQ

Transcript
Nelson: We’re here to talk about authorization at Netflix scale. My name is Travis Nelson. I work as a senior software engineer at Netflix. I work for a team called AIM, which deals with the identity, authorization, and authentication of our users. We do that for the website and for streaming applications, and also for mobile games. It’s the consumer side of the house and not the corporate identity side of the house.
Here are some questions for you to think about while we’re going through this presentation. The first is, how do you authenticate and authorize 3 million requests per second? It’s a lot. We have to deal with that all the time. How do you bring design into evolution? Our system, as many systems do, evolved over time. When you have things that evolve, it can be hard to bring a good design into it that wasn’t thought of in the beginning. Our particular problem is, how do we bring in a more centralized way of thinking about authorization into our evolving product? How do we bring in complex signals, things like fraud and device signals that might be potentially ambiguous? How do we think about that? Finally, how do we build flexibility? The last thing we want to do is knock our system down to the point where it’s hard to make changes. We actually want to make changes easier to implement, make the authorization system an enablement mechanism for product changes.
Outline
Here’s what we’re going to talk about. First of all, where we were. The state of our system before we started this effort. What are our authorization needs in the consumer space? We had to think about what are the requirements? What do we actually need to do? Talk about centralizing authorization, what that means, and how to go about it. At least how we went about it. Then, how we think about things like scaling and fault tolerance, because we have such a large amount of traffic coming in all the time.
Authorization in the Netflix Streaming Product Circa 2018
Here’s where we were circa 2018. We had this authorization built in the system as the system evolved. The client will basically pass an access token into our edge router, edge router, which transformed that into what we call a Passport, which is our internal token agnostic identity, which contains all the relevant user and device information. That would go to any number of microservices. These microservices, each would potentially have their own authorization rules based on that identity. It might also call out to our identity provider to ask the current status of that user. That might mean that several different of the microservices are also calling into that same identity provider. The trouble with this, of course, is that the authorization rules, they might be different for microservice, or they might be the same, might end up with several different microservices, all having the same authorization rule. That might be replicated potentially hundreds of times in a very large system. That’s where we were.
Pros and Cons of this Approach
There are some pros and cons of doing that. First of all the pros. It’s pretty scalable. If you do that, and you put authorization rules in every one of your microservices, and these microservices are all independently scalable, you have a pretty easy way to scale your system. You just scale up all the services at once. You never really run into roadblocks with the authorization being a limit to scaling. You also have good failure domain isolation. What I mean by that is, if somebody in one of those microservices messes up one of those authorization rules, and then pushes their service live, it only affects that particular service and the other services around that are resilient to that failure. It might not be noticed or it might cause a small partial outage somewhere, but nothing catastrophic. That’s actually a good thing. We don’t want to have catastrophic failures that impact the entire system all at once.
There are some cons too. One is that the policies can be really too simple. One of the most common policies that we found was that if your membership is current, then you get the stuff. We have that check everywhere throughout the code. It’s a good thing often to check that, but that’s not really the question that people are asking. The question really should be more like, can I access this particular thing? Is this particular feature on the site or in the mobile app accessible by this member, or this user, or this device? The questions are far more nuanced than they’re actually expressed in code. Then, when you add the complexity, the complexity gets distributed. If you want to change something like that, if you want to say that, if they’re current, and they’re not in this country, or if they’re current in an anonymous device, then that ends up getting distributed among all those different services that also contain that rule. Of course, if it’s distributed, then it’s also difficult to change. Tens of services might need to do the same change, instead of potentially a single point of change. That means that you’re going to do a lot more change, you’re going to involve a lot more teams, and your timeline is going to increase because of that.
Exceptional access in that scenario is also quite difficult. Because if you have some special piece of content, or some special feature that you’re trying to enable just for a certain set of users, that can be hard to do. Because if your access controls are all that simplistic, then it’s not being replicated everywhere else. If you have something that violates that constraint, and you still want to give them a certain level of access, then you can’t do that. If you want to enable a certain privilege, and do that privilege check at various points in the system, you’d also have to distribute it. It becomes untenable at a certain point, if your rules become more complex. You can’t really do that thing anymore. Also, fraud awareness ends up being localized in that model. Because when you have complex fraud detection systems you want to make sure that you can put them at the various points where the checks for fraud are useful. If you only do that at certain points, you can easily miss other points. By putting that more in a central location and knowing when your fraud checks are being executed, then you can have a much clearer picture and have much better coverage of that signal.
Some Netflix Authz Concerns
We also had some specific Netflix Authz concerns as well. We wanted to take a step back and look at, what do we actually need for our consumer presence or consumer facing experience? One is we needed a way to model the things that a user can and can’t do. Maybe some users on some devices can access some functions like a linking function to your TV, and others cannot due to various reasons. Maybe their device is insufficient. Maybe their plan is insufficient. There’s all kinds of different reasons. We also wanted to be able to get the same answer everywhere. We wanted all the microservices to have a common point of reference to be able to get that same answer. If everyone’s looking at the same feature, they should be able to get the same answer for that. We also wanted to look at how we think about the corporate versus the consumer identity versus the partner identity. There’s different places that they intersect, and we needed to make sure that we accounted for that. We also have things like API access. We have special access for special users, where we give them some amount of privileged access that normal users don’t. We also needed to accommodate things like device, and presence, and fraud signals. We wanted to be able to basically have a way to write policies around all of this, around the user, their status, their plan, their device, their presence, fraud signals, all of it.
What are we authorizing? We’re authorizing things like the product features, the different things that you can do via the website or via a mobile app or a TV app, things like the profile gate, whether you have access to mobile games or not. Also, we want to be able to authorize the videos that you have access to play back or download. Those were also part of the equation. If you’re authorizing that, then it also becomes a discovery issue, because we want to have policies around discovery because what the user can see in terms of what they’re going to be able to interact with on their UI is directly related to what they’re authorized to use. For example, if you have a title that you have early access to that will appear in your list of movies, whereas if you don’t have access to it, it won’t appear. That’s the thing that we need to be able to express in these policies. We want to have discovery, and the playback rules to be coherent.
Approaches to Authz in the Corporate Applications Space
There are some different approaches to authorization that we looked at, and there’s obviously some pros and cons to each and some applicability here and there. The first one is role based access control. This is where you assign each user a role, and you give the role permissions. Then the client basically asks, does this user have this permission or not? Which is a fine model. It actually is really nice. We look at this extensively. We really realized that we wanted to be able to accommodate a much broader variety of signals, and create different policies that were based on many more things other than just the user and some role assignments. We ended up with something beyond that.
Next point I talk about here is attribute or policy based access control. This is where you look at all the different attributes, and then you assign permissions to the sets of attributes through policies. That’s pretty close to what we’re doing. We do have policies that look at all of those different signals. There’s another kind of access control which is based on that, which is called Risk Adaptive Access Control, or RAdAC. We’re moving in that direction, where we include the fraud and risk signals into that as well. It’s not only attribute based, but it’s also based on risk scoring, and that sort of thing. We want to make sure that we are able to create different decisions based on various kinds of attributes of the user, including things like risk based signals.
Role Based Access Control (RBAC)
RBAC is simple. We could have started with that, but the complexity we realized was a little bit beyond that. Our system looks a little bit more like this one. We have clients coming in to our Authz provider. Then we have different identity providers that we need to work with. We have our customer identity provider, sometimes those are linked to a corporate identity where the user might have additional features enabled. Then the customer might also have billing attached, so we need to sometimes look at to see if they’re current on their billing or not. We have all these different dimensions of the user that we need to think about in terms of just the user. We also have a fraud detection system that we call into, to determine if the user has engaged in suspicious behavior before, and that provides a score, we can write policies based on that. We have also customer presence. We have ways of knowing which country a user is in right now, whether they’re on a VPN potentially or not. We have all of that coming in. There’s also device identity signals. Many of our devices are fully authenticated cryptographically, some are not. We have different trusts for each of them. We know at least what the device is purporting to be and whether it’s proved to be that. We can use that also in our policies. That’s the lay of the land. We have a lot of different signals coming in. The question is really, how do you make that coherent? How do you scale it?
Enter PACS
What we did was we decided to create a central authorization service and we called it PACS, our Product Access Service. We actually have several different types of clients for it. We have the UIs. We have different kinds of offline/online tasks that call into it, and they’re actually asking different questions. The UIs are asking things like, what are the features that are enabled for this user in terms of overall features? Can they do things like look at the profile gate? Can they browse the [inaudible 00:13:37]? Can they link their mobile and TV device? We also have offline tasks. One of those is something like building [inaudible 00:13:48] offline. We have the ability to classify our content in terms of groups, and then the groups are basically entered into the calculation. Then that gives you the kinds of content the user can see. That goes into the calculation to build that.
Messaging can also ask the questions, can this user see this title or not? That might tell them whether or not they should match that title. Or potentially, we also have some fraud type messages that could go through that path as well. Then playback will ask any question, can this user play back or download especially a title? We have different kinds of APIs that actually represent that, but it doesn’t really matter. In the end, it’s different use cases and different things that we’re processing. We do that through a coherent set of policies, and the policies can be referenced between each other inside of PACS. Then PACS goes and can reach out to visit the user state from our identity provider, can also look at request attributes, things like the Passport. Then we look at various other systems like the presence, signals, and fraud signals as well to come up with our determination of whether or not we allow that access.
Failure Domain Isolation
How do we get back the failure domain isolation? Having the authorization rules in each service was a good thing in some ways, because then if somebody screws up one of the rules and pushes the code, then it’s not going to bring the whole system down. How do we achieve that same thing with a centralized authorization service? What we ended up doing, in Netflix we have different regions where we deploy basically the full stack of all our services. Here, they’re listed as region A, B, and C. Then each region will have a full stack of services. We’ve done this further. Within each region we’ve sharded the clusters by use case. We have one for online discovery in region A, that’d be one cluster. Another one for playback in region B, and so on. I haven’t listed them all here, but there’s a number of them. That way, if one of them has an issue, because we push that code or push to that policy, we tend to push them one at a time, so that we can get this isolation effect. If one of them goes bad for some reason, and that’s never happened, and never will, we could easily figure out what the problem was and roll back the process, and get back to a clean slate. We can do that really without bringing the whole system down. That’s how we were able to isolate the failures.
Scaling and Cache Consistency – Approach 1
Next, let’s talk a little bit about scaling and cache consistency. This is the first approach we did. We don’t want to have every client call PACS server for every request. If we did that, we would have very large clusters, and it would be really expensive to maintain, and there would be a certain amount of latency that would be undesirable. We have two different levels of caching that we implement. One is the request scoped cache, which is wherein if a client asks for the same result more than once, within the scope of the same overall request, then we just return the response back immediately, within that particular request. It’s all contained locally within the client. The second level of caching is a distributed cache represented here as Memcached. What we do there is we go, and the PACS clients, whenever it gets a request will first reach out to Memcached and ask for that record. If it doesn’t find it, it will go to PACS to calculate it. If PACS calculates something, then it will write it back to the Memcached. We do that to eliminate the pressure on the client. Otherwise, we could theoretically write the response from the client as well. We like to do it more from the server side.
That’s all well and good. Actually, that works pretty well. If you have a certain amount of cached entries in your distributed cache, then the odds of hitting the server become lower, and then your latencies will improve, which is all good. The problem with that, of course, is this is an authorization service and it has lots of impacts on various pieces of the infrastructure. If the underlying data changes to your decision, then you need some way to evict that cache. Our first approach at eviction was to do that asynchronously. Our identity provider would send us a stream of events, and we would process those events and go and delete the entries in our cache. What we realized was that was not going to work because the clients were asking for the answers again too quickly. We would have a quick page refresh on a change to a user data, and then we would need that to be reflected almost immediately. The latency was really too high with this approach. We ended up not doing that.
Scaling and Cache Consistency – Approach 2
What we’ve arrived at is something a little bit different, but achieves the same result. Instead of having the IDP send events due to changes for that, we actually have the IDP produce a dirty record, which is basically the account ID. Then basically just has reference to the fact that it is dirty inside of it, and we put that into Memcached directly from where the user data is stored. Put that into the cache. That way, when the PACS client is looking for records, it always does a bulk read and it always includes the key of the account for the dirty record as part of the request. Then we know that if we get that dirty record back, then we can’t use the results of the cache, we have to go back to the server. In doing that, we actually achieve the near synchronous approach that we were looking for. We also didn’t need a couple of assistants too much, because all the IDP really has to know is the fact that it needs to write this dirty record and doesn’t need to know anything about the internals of the caching structure that PACS uses. It was two reasons for that, one is we didn’t want to put too much information into the identity provider. We also wanted to have this near synchronous approach. Doing that actually achieved the ends that we needed. You can see some statistics here, we had about 4 million RPS on the client, and about 400k RPS on the server. We do get very high cache reads on this.
Dynamic Fallback (Certain Use Cases)
We also have something called dynamic fallbacks, which means that we can actually potentially produce a result directly from the client if a call to PACS fails. Our Passport, which is our token agnostic identity, actually contains some fallback data within it that we can actually use, and some very simple rules that we keep in the client. For certain use cases, ones that are not highly sensitive, we actually can authorize the use of a particular feature without going up directly to the server if the server call were to fail. That’s how we accomplish that. It’s very non-critical things, non-sensitive things. If we were to get a certain percentage of failures on the PACS server, we would still be able to move along this way. It’s how we handle the fallback.
Summary
In large scale applications, a simplistic approach to authorization might not be good enough. There’s just not enough flexibility there. You need to have a way to introduce this complexity without putting the complexity everywhere. You want things to be more risk adaptive. You want them to be more policy driven, more easily changed. It’s probably a good idea to start centralizing those things. How do you handle it? Centralizing the policies around Authz is a good idea, but you still want to handle things like the failure domain isolation. You still want to create the right surface area for failures. Distributed caching is a good idea to help with performance. If you’re going to do that, then you need to worry about cache consistency.
Questions and Answers
Westelius: How do your services interact with PACS? Is the client embedded into applications, or is it a standalone process?
Nelson: We actually use a gRPC type model, mostly. We have a lightweight client that’s generated from the proto definition. Then the lightweight client ends up getting embedded into those services. We actually ended up doing some custom filters inside of the gRPC client, so it’s not entirely generated. We had to do that because we were doing more advanced caching. It’s still a pretty lightweight client, so it really just has that simple gRPC type interface.
Westelius: Mike is asking for dynamic fallback. When the call fails open, are these rules encoded into the PACS client?
Nelson: For the dynamic fallback, we did have to also do some custom code inside of the client, inside of those gRPC filters. The rules ended up being fairly simple. We just picked a few things that we knew that could be called very commonly and things that we could use a fail open model. Really, those just check the fallback data inside of the input, and then run the rule if the gRPC call fails.
Westelius: I think that’s really interesting as well given the exposure of how you’re dealing with localized rules in the fallbacks.
Does PACS provide APIs for other services or systems to validate client permissions?
Nelson: Yes. We have a number of different APIs that we provide in PACS, so we can allow access to what we call features, we can allow access to videos. It’s not really about asking if something has a particular facet or something, it’s more about can I do this particular thing? Those are the kinds of questions that we like to answer. Can I play back this video? Can I show this cast type button on the screen on my UI? That’s the kind of question that we’re generally handling.
Westelius: I’m also a little bit curious, actually, if you’re expanding that a little bit, as we’re thinking about things like trust, for example, for today’s track, how much of these other segments that you’re thinking about some device information versus fraud information is taken into consideration, as you’re showing these different types of content?
Nelson: We have different kinds of policies that apply in different cases. Often, it’s the status of the user, whether they’re paying or not, the plan. These things are the basic attributes. Then also the plan metadata that’s associated with that, so we know how many streams they’re paying for, that sort of thing. Then, on the device side, we have whether the device was fully authenticated or not, or whether this is a completely untrusted device. Then we know from that also what kind of a device it is and what that device should be doing, so we can use that in our policies. Then the fraud is a layer on top of that, where we can also say, if all those other attributes are correct, and we think you don’t have a high fraud score, then we’re going to let you do this particular action. It’s a layering approach is how I would think about it.
Westelius: It’s also interesting given that it’s not just in terms of what the user should be able to access in terms of permissions, but also, what are they able to access and in what format are they able to access it? It’s really complex that way.
Nelson: We ended up doing that because we realized that a pure permissions based approach just on the user was just not expressive enough with what we were trying to do. Often, these device and other signals were really impacting the user experience and what they should be able to do, so we ended up with a more complex model.
Westelius: As you’re thinking about the fragments that make that identity, is there a way in which you consider that whole for when you have certain amounts of data, or are you able to make those decisions when you might not have high trust, or maybe not have parts of that dataset?
Nelson: I think that’s true. We don’t always have a full picture of what’s going on. For example, if a device was unauthenticated, then we don’t really know the device identity. In those cases, we have to account for that. We don’t really know what this device is, but what are the things that an unknown device can do? It ends up being that kind of a model.
Westelius: How do you handle internationalization, if different countries have different auth requirements? Do you handle it in a centralized form, or do we take that into consideration?
Nelson: Yes, we do. We do have rules sometimes that are based on country. It really depends. There’s a lot of different systems that have dealt with country in Netflix. We have to work in the context of those other systems as well. We have our catalog system which assigns the content windows to each title. We take advantage of that. We actually look at that. We have our plan metadata, which allows users to sign up for particular plans, and those might be different per country. Then we have the actual request that’s coming in, which is from a particular country, and it may or may not be on a VPN. We have to think about country in a very nuanced way, is what I’m saying. It’s rare that we could say, just in this country, you can only do this thing. It’s like, all these other things have to be true as well. The video might have to be available in that country, this plan might have to be available, and the user might have to be coming from that country at that point in time. It’s a complex thing. We do include country in those rules.
Westelius: Expanding on that a little bit, is it so that the resource then is defined to be available from a certain area or country? Are those rules localized to the resource or is that something that you maintain in PACS?
Nelson: We take a higher level approach in PACS. We don’t usually directly encode a particular resource, not in terms of like a video. The rule would be more like if this video is supposed to be available in this country and the user is coming from this country, then we’re going to allow it. That would be the kind of thing that we would express. There might be certain APIs that we might only open up to certain countries. It’s quite possible we would do that, and that might be encoded in a PACS policy.
Westelius: I didn’t quite understand why it’s better for the IDP to mark records as dirty rather than deleting the records. Could you elaborate on the differences a little bit?
Nelson: What we were trying to do was not build in really tight coupling between PACS and the IDP. We wanted to make sure that the contract was very simple, so that we could expand in many different ways. In the PACS we actually have many different kinds of records that we deal with as well. For every one of our different APIs, we actually have a different record type in the cache. That’s because we need to basically encode the full response in the value. If the question is different, then the value we encode in the cache has to be different. What we didn’t want to do is build in nine different record types into the IDP and have them go delete it directly. It was too much. We figured if we just had one record that it wrote, that would be a sufficient level of coupling, without being a brittle system, where if we added another one, we’d have to go and update the IDP again. Or maybe it would slow down the IDP to delete that many records. Really, it was just about coupling. I think we achieved a pretty good level of coupling with that single dirty record.
Westelius: With the PACS clients connecting directly to Memcached, how do you connect Memcached from being overwhelmed with number of connections/requests?
Nelson: We just have very large Memcached clusters. We understand what our traffic patterns are. We have very large clusters that can handle that. Then we have autoscaling built into that as well. It’s not really been a problem so far. We just are used to operating at scale, and there’s other services at Netflix that also use that same scale with Memcached.
Westelius: Are you saying that maybe this isn’t for those who can’t maintain really large Memcached clusters?
Nelson: It depends on the level of scale that you’re dealing with, I think. If you have that kind of scale, you probably have some distributed caching that can also scale up to that level as well. The other way to think about it is we also have ways of failing out of a region. If we really had stress in a particular region, the entire Netflix service will fail over to another one. That’s also a possibility.
Westelius: Have you considered JWT based access tokens so clients don’t even need to hit Memcached?
Nelson: Yes. We originally thought, ok, what if we just did all our authorization rules at the beginning and then pass down that information, say, in our Passport. The JWT I think that you’re talking about is equivalent to our Passport. They’re very similar concepts. We ended up not doing that, because there was just a lot of information that we would need to encode inside of that. We didn’t really want to pass that around. Then we didn’t want to also have too much knowledge about what things would be downstream, all the way at the gateway. We settled on this approach where we would just put in fallback data as necessary for the really critical use cases, and then pass that down. That model has worked a little better for us. You’re right, it depends on what you’re doing. If you have a simpler model and a simpler system, and less things that you need to authorize, then yes, doing that right at the edge and then passing it down is a perfectly valid model.
Westelius: Yes, very lengthy JWTs can definitely become a hassle. I know that for sure.
Do all server calls at Netflix include a Passport, including offline tasks or scheduled jobs?
Nelson: No. The Passport is really about the access tokens, and it’s our token agnostic identity that comes through. It’s not necessarily true that every call will have a Passport because we don’t always have it for the offline tasks. We have ways for those tasks to create them, but often an offline task will be something that goes through almost every user that we have and might want to do an operation on each of them. Having them call a service to create a Passport and then call PACS is a bit too much overhead. We actually have different APIs that don’t necessarily require a Passport. Those wouldn’t have the same kinds of fallbacks, either, because it’s not a thing to have a fallback if you’re just providing, say, a user ID. It’s a little bit of a different model, but we can also support that with the same policies, just the interface is a little bit different.
Westelius: How does PACS work? Cross data center?
Nelson: PACS is deployed in each region. We tend to think about things in regions, so we have a few major regions, and we make sure that everything is deployed in each of them. Then there’s availability zones within the region, but we don’t really worry about that too much. We have basically the equivalent model in each region, and each one can answer the questions exactly the same. The thing that could be a little bit different when a request gets moved from one region to another, is that there’s a slight possibility of a race condition. That’s something that we just have to deal with. The use case might be if you change the user’s data in one region, and then immediately went to another region, then it might be a slightly different thing that you’d see. In our experience, it’s not the end of the world. We don’t really bounce between regions, very often. We tend to keep the user within a given region, and it’s only if we have an evac, then we’ll move them to another one. Generally, chasing those replication delays is just not a big issue. It’s pretty fast. It’s not a case where large numbers of users are going to see problems.
Westelius: Given that you mentioned that as a resolution to the failure domain isolation when that occurs, if by mistake, I’ve released something that turns out to not be effective, what does that look like for the users or for the system?
Nelson: If we did have a massive problem, where we literally were denying everything, then when we push to a given shard, then the clients would then start seeing failure responses from that. Then we would notice within probably about 20 seconds that that region was going bad, and then core would start evacuating the region, if we didn’t catch it before then. If we caught it before, then we could roll it back. That’s what would happen.
Westelius: How do you change the rules embedded into the PACS client? How do you deploy rule sets, essentially? Do you need to redeploy every service or any of these when you make changes to these rules, essentially?
Nelson: We have a separate rule set repository that we use for our production rules. Those are what end up getting deployed. We have a separate Spinnaker pipeline that is capable of deploying those. We actually deploy the code and the rules entirely separately. It’s actually an internal rule language that we’ve developed in Netflix for other purposes, but we’ve adapted to use it in PACS, which is called Hendrix. It allows us to express very complex trees of rules that we like. Then we basically can have tests that run against those rules as well built in the high level, is this rule valid? Then we have tests that run against that with the PACS codes. We know that the rule is also valid in the PACS code. Then our pipeline basically does CI on that. Then it publishes to the regions in a specific order. That’s how we achieve that.
See more presentations with transcripts
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
At the recent Sustainability Summit, Google launched several new sustainability offerings to help public sector agencies and researchers to improve climate resilience. These offerings are Climate Insights for natural resources and Climate Insights for infrastructure.
Brent Mitchell, managing director US State & Local and Canada Public Sector, and Franco Amalfi, strategic business executive, Climate Action, Google Cloud, explain in their collaborative blog post:
With these data-driven insights, public sector agencies and researchers can improve their response time to climate disasters, make more accurate predictions, and implement disaster-response plans with greater confidence.
Climate Insights takes advantage of the scale and power of the recently updated new version of the Google Earth Engine (GEE) on Google Cloud, combining artificial intelligence (AI) and machine learning (ML) capabilities with geospatial analysis via Google BigQuery and Vertex AI. According to the company, climate researchers can access a multi-petabyte catalog of satellite imagery and geospatial datasets with planetary-scale analysis capabilities through GEE.
More specifically, the Climate Insights for natural resources relies on Google Earth Engine’s data catalog of more than 900 open datasets spanning 40 years and leverages the expertise of Climate Engine to provide departments and agencies with an efficient way to ingest, process, and deliver pre-built Earth observation insights via API into decision-making contexts. Rebecca Moore, director, Google Earth, Earth Engine & Outreach, explains in a blog post:
With one of the largest publicly available data catalogs and a global data archive that goes back 50 years and updates every 15 minutes, it’s possible to detect trends and understand correlations between human activities and environmental impact. This technology is already beginning to bring greater transparency and traceability to commodity supply chains, supporting climate resilience and allowing for more sustainable management of natural resources such as forests and water.
The other offering, Climate Insights for infrastructure, is the result of a collaboration between Google and CARTO. It is a unified solution built upon Google BigQuery, Google Earth Engine, Google Maps, and CARTO. Moreover, the solution can, for instance, provide policy-makers unified access to their agency infrastructure data, earth observation insights, weather information, and other relevant spatial datasets from the CARTO Data Observatory.
Source: https://carto.com/blog/announcing-carto-for-climate-insights/
In a Carto blog post, Matt Forrest, VP of Solutions Engineering, provided another example of benefiting from the solution:
With better access to climate insights and spatial risk models, Departments of Transportation can effectively plan for potential hazards to road networks resulting from erosion, extreme heat, flooding, fire, drought, and severe precipitation.
Lastly, the offerings are part of the overall strategy of Google to support its cloud customers by operating the cleanest cloud in the industry and helping them to decarbonize their digital applications and infrastructure. The company itself strives to operate on 24/7 carbon-free energy at all their campuses, cloud regions, and offices worldwide by 2030.
MMS • David Manda
Article originally posted on Database Journal – Daily Database Management & Administration News and Tutorials. Visit Database Journal – Daily Database Management & Administration News and Tutorials
![]()
![]()

Changes in customer behavior have caused a new focus for the structure of commercial databases. The flexibility of data storage is essential in fulfilling the demands of customer needs and predicting future business. MongoDB and MySQL are both valuable database solutions that align to this shift in commercial objectives in database management systems. The difference between the two applications is that MongoDB is an object-based system, while MySQL is a table-based system.
For its part, MongoDB is a database that features bulk data storage through a NoSQL
structure in a document format. The main feature of this software is the option to modify documents and their variables. MySQL, meanwhile, functions through a query system where data can be searched and its point of relation identified.
When deciding between MongoDB vs. MySQL, having knowledge of the language structure is important. MongoDB simplifies the data query process, but MySQL has a proven record of Structured Query Language (SQL) for defining and manipulating data. In order to understand which software is better, this database programming and administration tutorial will analyze the features of these applications to identify which one is better.
If you opt to choose MySQL as your database of choice, you should check out our article: Best Online Courses to Learn MySQL, which has a great list of database administration classes that will help you get started.
What is MongoDB?
MongoDB is a database management system that uses NoSQL queries, while providing flexibility and scalability functions. MongoDB is a non-relational database system that uses the JavaScript language to search data and modify documents into smaller sizes. Commercial companies rely on MongoDB because it is compatible with multiple storage engines.
The database management software retains a dynamic structure that favors the organization of information, making data modification faster than other database options. This process also makes data management more efficient and faster, especially when large documents need to be encoded into smaller sizes. MongoDB uses JSON and BSON languages to make data management more flexible and lighter to process when compared to MySQL.
MongoDB faces competition from 20 NoSQL database vendors. It leads the market share of other NoSQL databases with a 48.05% lead. The major competitors of MongoDB include NoSQL, with 24.41%, Amazon DynamoDB at 9.74%, and Apache Cassandra with 5.56%. The United States has the highest number of customers of MongoDB with 33.41%, followed by India with 9.95% of customers, and the United Kingdom with 5.84% of users.
MongoDB is typically used for designing specialized data sets through document compression and is able to adapt to data variations. Geospatial data format does not require technical monitoring when structures show variation, because MongoDB has resilient data structures. MongoDB also functions in multi-cloud application environments. The database system can execute cloud services based on personal configuration to support both current and future software needs. Healthcare, gaming, retail, telecommunications, and finance industries – to name but a few – rely on MongoDB for software development for database-driven applications, data management, data analytics, and solutions to server issues.
Benefits of MongoDB
Below are some of the key benefits of MongoDB:
- Scalability is a significant benefit of using MongoDB because it is easy to organize the database system laterally and scale per software requirements.
- The storage structure of MongoDB supports the addition of any file regardless of its size without disrupting the file stack.
- MongoDB can improve the performance of database systems with the configuration of indexes. Documents that use MongoDB can alternate the index field.
- MongoDB improves the performance of servers by adjusting the data load or replicating files when the system is struggling. The application also supports multiple servers and offers improved functionality over other options.
- Aggregation process is possible when using MongoDB, which means aggregation commands, aggregation pipeline, and map reduce operations are supported.
- The replication of documents in the database is quicker and more flexible when using MongoDB.
What are MongoDB’s Cons?
Below are some of what we consider to be MongoDB’s cons and negatives:
- MongoDB has a complex procedure for performing transactions that is tedious and time consuming.
- ACID (Atomic, Consistency, Isolation, and Durability) certification is absent in the system catalog, especially for data transactions. This feature is available in other relational database management systems.
- MongoDB does not operate like most relational database systems, which means it lacks support for Stored Procedures or commands. The addition of a business structure is impossible in the database system.
You can learn more about MongoDB’s latest features and updates by reading our cousin sites coverage of MongoDB’s Conference.
What is MySQL?
MySQL is a relational database system that serves client-server systems in storing data. It is a reliable system that supports the classification of data in rows and tables. MySQL operates through the master-slave approach, where replication and backup of data is possible, making it very reliable. Atomic Data Definition Language is also possible with MySQL, which provides storage engine operations and updates for the data dictionary to simplify transactions.
MySQL ranks second in the world in the database market. The relational database management system has 44.04% of the market share based on its support for web development and applications like phpBB and WordPress. MySQL is easy to customize and is open-source software.
Small, mid-sized, and large enterprises can use MySQL for data storage management because of its built-in functions. The software has a 31.39% market share in the USA and has a proven record of being scalable to major business functions, like marketing. Twitter and Facebook are popular social media websites that were developed, in part, through MySQL. Oracle is the major competitor to MySQL in the database management market.
Benefits of MySQL
Below are some of the benefits of using MySQL:
- The security protocols used in MySQL are complex enough to prevent exposure of private databases when developing web applications. Web designers can rely on security algorithms that deny exposure of information, especially for regular web users.
- MySQL can function on multiple servers and is easily accessible to most database systems. The high portability of the software makes it easier for users to complete web functions from any location.
- Since MySQL is open-source software, any web developer can use its services to store and manage data for most functions. Commercial enterprises with limited investment can use the database system to grow their business with little effort or cost.
Cons of MySQL
Some of the cons of MySQL include:
- MySQL lacks a server cache for stored procedures. This condition means the operator must repeat the data input procedure after the process concludes.
- The system catalog is susceptible to corruption when a server crash occurs. This process can cause loss of data and time spent recovering the database system.
- MySQL cannot process bulk data, which can limit the performance ability of commercial enterprises. The software is not as fast as industry standards for data processing.
- Support for MySQL is limited because it is open-source software. This condition means security updates or reports on server bugs may not be as available compared to paid subscription software. MySQL cannot support innovative web development functions especially significant to commercial companies.
Read: Top Common MySQL Queries
Database Comparison: MySQL versus MongoDB
Below, we compare the differences between MySQL and MongoDB database solutions.
User-friendliness
MongoDB is more user-friendly than MySQL. MongoDB has a predefined structure that supports the entry of different information to the database without having similar fields. However, MySQL demands the configuration of columns and tables. Also, the structure of the database cannot be changed depending on the number of columns.
In terms of structured and unstructured data, MongoDB is better than MySQL; this is because MongoDB functions as an object database system, while MySQL functions as a relational database system. The support for a database system with rapid web development is possible with MongoDB and not MySQL.
Features
MySQL uses the Structured Query Language – or SQL – while MongoDB functions through JavaScript as a query language. Some consider MongoDB is to be better than MySQL because the design of data structures is limitless.
MongoDB supports cloud-based services that are essential to online transactions and data storage management. MySQL does not support cloud-based services because its priority is data security. MongoDB is better than MySQL because of this feature gets a slight edge here if you are a cloud developer.
Software support is consistent with MongoDB because the company publishes bug reports and security updates as a part of the ongoing development of the software. Oracle develops updates and fixing problems relating to MySQL. However, the updates are not frequent on MySQL, which makes MongoDB the winner here.
Integrations
MongoDB integrates with multiple storage engines with a dynamic structure design that favors simpler configuration for data management. The software uses JSON language and MongoDB query language to change the structure of JSON and BSON documents. In contrast, MySQL uses the Structured Query Language to organize and manage databases. MySQL supports C, C++, and JavaScript languages. MongoDB is more flexible than MySQL in integrating databases because it can embed additional data in existing file stacks. From an integration perspective, these two are evenly matched.
Collaboration
MySQL makes it simpler easier to execute structured commands because it uses Structured Query Language. This condition means creating commands for data queryries is easier because of Data Definition Language and Data Manipulation Language. With MySQL, you can link several documents and data with minimal commands. In contrast, MongoDB requires several commands to execute data configurations because it uses a non-structure system. MySQL is better for collaboration because combining different files is easier in MySQL than it is in MongoDB.
Pricing
MySQL is better than MongoDB in pricing for small businesses and individuals because it is open-source software. This standard means that any web developer or business can use the software for database system management. The Enterprise Edition of MySQL costs $5000 annually for web developers and end -users.
MongoDB requires a licensing fee for its Enterprise Edition that includes additional security protocols, data monitoring, authentication, administration, and a memory storage engine. This package costs $57 per month. The open-source version of MongoDB is less advanced in functionality compared to the paid option. For this reason, MongoDB is better than MySQL..
The Verdict: MySQL or MongoDB
MongoDB is better than MySQL because it takes a shorter time into query data, which is that is important for managing databases relating to customer behavior. Although when handling structured data, MySQL is better than MongoDB,; when there is a query against unstructured data, MongoDB is preferential. In the database management market, speed and performance are significant to many businesses. MongoDB can deliver speed and performance given its fast queries of data, as well as the ability to handle both structured and unstructured data.
Real-time analytics is a benefit that comes with MongoDB and gaining quick query results is possible through object database systems like MongoDB. With MySQL, the data queries take longer, so configuration can delay after updates. However, in terms of security protocols to protect private information, MySQL is better than MongoDB because it uses a relational database system.
At the end of the day, there are many factors that might make you choose one database over another. Weigh the benefits and drawbacks of each against the needs of your particular project.
Looking for more database comparisons? Check out our article on PostgreSQL vs MySQL.