Month: August 2022

MMS • Stefan Miteski
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Every company has several budgets: capital, knowledge, and risk. Each has different amounts of them and can use its specific mix to its advantage.
- The MVP stage includes only the stuff you would do in a hackathon. We care about scalability once survivability is established.
- Delaying tech decisions to the Last Responsible Moment increases team velocity in the long run, so it is not in conflict with the Build Fast and Break Things approach.
- Outsource all aspects of the tech solution which are not in a relationship with your competitive advantage. Control and build yourself everything, which is part of your competitive advantage.
- Create a tech stack direction but balance it with the team’s autonomy to make decisions outside the directive
Every company manages money, knowledge, and risk. The abundance of risk allows startups to have a different mindset and use the risk as fuel to obtain knowledge faster. A startup can set up Wizard of Oz, or a Landing Page MVP that established companies would think twice before implementing.
I was running my startup with this sentiment, and I was unhappy with my inability to make faster tech stack decisions. A few years later, working in TeamViewer and doing some gigs for Fortune 500 companies helped me learn a few tips that I want to share.
I have decided to invite an imaginary character from The Unicorn Project book – Erik, and do this in an interview format. Erik is the legendary barman who coined the Three Ways of DevOps, I hope he will help us out.
Stefan Miteski: Erik, let me dive right into the topic. When should the team switch from building an MVP “as quickly as possible” mindset towards a more scalable, maintainable, and sustainable one?
Erik: First of all, not all hypotheses need code. Use whatever is cheapest and fastest. I prefer the tech that finishes the job fastest. If this is a low code platform that I will have to re-write entirely later, it is not a problem. So this is an altogether team-knowledge-based decision. If you have a person who knows how to code in NodeJS, you use that. If you have Python, then Python it is. At this point, you should not worry about the best quality processes, CICDs, or the best agile approaches. Those are extra burdens that the startup should not care about at this stage. Do only the stuff you would do in a hackathon at the MVP stage.
So the simple answer is – that scalability and processes will become important once we have predictable revenue streams.
Miteski: What about when money is not a problem, and an already established company launches a new project?
Erik: It is more or less the same. We care about scalability once survivability is established. If the project is a testing ground, you go the MVP path. If the project is going to be there for good, think about scalability.
Miteski: OK, so glad you have put this so elegantly. I often mentor early-stage startups, and I have met a lot of startups that failed because they have spent too much effort on scalability way too early. The risk of failing as a startup by creating a product that nobody needs (35%) is far more likely than dying due to inadequate technical decisions (less than 8%).
But what about the scaleup phase? We have a predictable revenue stream. We can finally ditch that low-code spaghetti code. What technology to choose now?
Erik: Conway’s law says – any organization that designs a system will produce a design whose structure is a copy of the organization’s communication structure. So at this point, we should think about structuring the whole organization, not just the tech stack or software architecture. How many teams, how they will work together, how they will align, and what processes for testing will be there. CICD. What will be our discovery strategy? How would we achieve alignment of our marketing and development efforts? How are we going to ensure that we have a healthy culture overall? How do we acquire and integrate talent?
Every technology is built with a set of problems in mind. So for some projects, this is quite obvious. But should you develop your web app using Java or C# on the backend? It might not be so obvious. SQL or MySQL? The short answer is to let the team decide and use The principle of Emergent Architecture and The Last Responsible Moment rule. See-through both perspectives – the functional and non-functional.
The non-functional requirements:
How big is the community online? Suppose you choose C# over some exotic language. For C#, you already have comprehensive documentation and support from the likes of Jon Skeet – who has reached over 1 million points reputation on StackOverflow. The chances are far more likely to find answers online with C# than with the exotic alternative. How many available libraries are there, and how mature is their support?
How big is the total hirable market in terms of developers? What languages do graduates study at the nearby universities? Yes, you can always train people in technology, but then add the time needed into the equation and budget for higher salaries if you want to hire people into unpopular or dead languages in 5 or 10 years from now.
How long do you expect the system to last? Sometimes we forget that we as humans are developed in 9 months and have a life expectancy of roughly 70 years. So we need to have a similar approach if we build things that last. Still, it is also a matter of ongoing tech strategy, not only about the first choice we will make.
Making significant changes in the production sometimes feels like repairing a plane while flying it. That is why it is wise to postpone decisions about critical parts of the system to The Last Responsible Moment.
Miteski: So what is the Last Responsible Moment?
Erik: It is a principle that originates in the Lean philosophy. Sometimes the cost of rework is higher than the cost of slowing down. The Agile philosophy favors Empiricism – learn by doing. However, you would be taking a significant risk by deciding too early on irreversible decisions. So we are cleverly identifying them and cutting from them the parts from which we can learn and reduce the risk before making the big decision.
Miteski: Delaying things sounds like a conflicting principle with the lean startup one – speed is our main competitive advantage.
Erik: Postponing the decision does not mean we just sit and think. It means that we do a lot of architectural spikes in the surrounding of this decision and learn about the business aspects, and the user needs to make the best decision in the Last Responsible Moment. We can mock the system and build all the APIs around it.
Miteski: So, how do business aspects influence our tech-stack decision-making?
Erik: In many ways:
Where do you expect your competitive advantage to be? What technology can best support this competitive advantage?
Outsource all aspects of the tech solution which are not in a relationship with your competitive advantage. Control and build yourself every piece, which is part of the competitive advantage. We can extend this mindset to all tech and other non-essential services. Be careful, though, not to create competitors from your suppliers. After all, Microsoft and Intel were IBM’s suppliers.
So if going bare metal is not essential, it makes a lot of sense to go with a cloud provider. Which one? Well, again, it depends on the nature of the business. If it is essential for your customer how quickly the cloud provider will react during an incident, then look closely at their SLAs and the type of partnership you can build. If it is not crucial, then you can think in terms of the services that they provide. From simple things like CloudWatch to flavors of Kubernetes. What benefits would speed up your development time in the long run? And lastly, look at the pricing. Choosing a cloud partner can be like deciding on your startup co-founder. Take your time, don’t rush it, especially if you go into deep integration with their services.
Miteski: Can you tell me some traps we can fall into as the organization matures?
Erik: The first one is the Tram trap. It happens in unhealthy organizational environments where developers build silos of knowledge. I have talked to a tech giant where a single engineer wrote essential services. He held the organization hostage to receive a better salary, did not get what he wanted, and left the company in the end. They had to rewrite it as nobody was able to support it.
Silos, however, can occur naturally due to high pressure from management for fast delivery. In high-pressure environments, developers have to specialize in certain areas to be more efficient. So the de-silofication should be considered a complementary task while dealing with technical debt.
Regardless of why such silos occurred, we should know how many of them are critical. I have witnessed huge companies that should not allow five specific engineers to travel on the same tram, as the risk of survival of the company if something happens with the tram is simply too high. If this is the case in your company, then it is time for you to think about doing things differently. Spread the knowledge, and implement a proxy strategy where other engineers will start taking tasks intended for the “tram-people.” Instead, we would consult the experts only when the “proxy engineers” are stuck. This tactic slowly spreads the knowledge at the cost of short-term efficiency. We are creating long-term robustness, which will pay off as higher efficiency in the longer run. Does it make sense?
Miteski: yup, it does.
Erik: Another one is the puppy trap. Sometimes our childish naivety overwhelms us when we like a cute puppy. We decide in a rush to adopt it based on how it looks now and how we feel about it at this very moment. This puppy can grow into a big animal that will require maintenance over more than ten years. In many cases, the solutions also last over ten years. So we need to make the technological decision with this in mind. Just because an engineer drinking a beer or a manager reading an in-flight magazine got inspired by the shiny new thing, we should not dedicate the next 10-15 years to this technology. Visual FoxPro in the late 90s sounded like a great new technology, but it did not stand the test of time. The tech graveyard has many examples like this. With the pace we are getting with new front-end technologies, we can expect the tech graveyard to remain a busy place in the upcoming years.
On the other hand, it is risky to shut the organizational door to new ideas and experimentation. So if we experiment, it is easier if we have micro-services or loosely coupled systems to use a small isolated part of the system for implementing new technologies. Then we can experiment with novel technologies in production but on some completely non-essential system parts on the outskirts (which would not affect customers if we have to shut them down at some point in time). Use these to build up operational knowledge. Building just developmental knowledge is very risky. We need to experience how our tech stack behaves in a live scenario to create a holistic understanding.
Miteski: OK, we have followed the Last Responsible Moment rule and let every organization team choose what they want. A dilemma emerges when balancing the team’s autonomy – to use their “tech stack of choice” vs. the company’s unification of the tech stack?
Erik: The organizational leadership should set up a tech directive. A loose set of principles for making these decisions.
There is a significant advantage for all teams in a company to use a similar tech stack. It allows the company to negotiate better prices for licenses. The teams can reassemble faster according to new needs, making the company more adaptable. Tech challenges would be solved once, and the knowledge disseminated throughout the company.
The downside is that the wider the variety of the markets and solutions the company offers, the more significant the need for the teams to use a different tech stack is. So the rule of thumb is to create a tech stack direction but give the team autonomy to make decisions outside the directive. The team should be able to articulate the factors that led to not following the company’s direction, though.
Miteski: If we are using the Loose coupling approach (such as microservices), you would be able to allow different teams to create services/system parts in various languages. That level of flexibility can bring us certain advantages, but when should we exercise this flexibility? What would be a rule of thumb here? Engineers usually know best, but they do not always have the proper motivation when proposing a new tech stack. I have just seen the situation where some engineers created services in GO just because they wanted to learn GO as it is a novel and incredible language.
Erik: Loose coupling is always a good idea. Using various languages can enable the company to evolve slowly. What is essential is to start with a slight change. If it works well, we learn from it, and we encourage the other teams to build on top of this knowledge. Depending on the company and code size, it will take different times for the whole company tech stack to evolve towards a new concept. Maintaining a continuous evolution and having an incremental approach is less painful than cutting the cord and starting again. However, the rule of thumb is that those further language/tech explorations should be limited, planned, and executed on non-essential services/system parts. We do this exploration on a service that we can kill at any moment without a significant impact. So the evolution and the tech change waves are starting from the outskirts with the most negligible customer impact towards the inner core: slowly, the whole organization and code-base changes. We rarely start a new big wave while we have one already flowing inwards that has not yet reached all the core system parts.
Focus on what will allow you to develop at a high pace sustainably while not neglecting the operational aspect and deliver better value – sooner, safer, and happier.
Miteski: Thanks! I enjoyed this conversation. I believe every company should open it from time to time.
Erik: Thanks, and don’t forget to revisit me while re-reading The Unicorn Project.
MMS • Anthony Alford
Article originally posted on InfoQ. Visit InfoQ

Meta AI Research recently announced ESMFold, an AI model for predicting protein structure from a sequence of genes. ESMFold is built on a 15B parameter Transformer model and achieves accuracy comparable to other state-of-the-art models with an order-of-magnitude inference time speedup.
The model and several experiments were described in a paper published on bioRxiv. In contrast to other models such as AlphaFold2, which rely on external databases of sequence alignments, ESMFold uses a Transformer-based language model, ESM-2, an updated version of their Evolutionary Scale Modeling (ESM) model which learns the interactions between pairs of amino acids in a protein sequence. This allows ESMFold to predict protein structure from 6x to 60x faster than AlphaFold2. Using ESMFold, the Meta team predicted the structure of one million protein sequences in less than a day. According to the researchers:
[R]apid and accurate structure prediction with ESMFold can help to play a role in structural and functional analysis of large collections of novel sequences. Obtaining millions of predicted structures within practical timescales can help reveal new insights into the breadth and diversity of natural proteins, and enable the discovery of new protein structures and functions.
Genetic codes in DNA are “recipes” for creating protein molecules from sequences of amino acids. Although these sequences are linear, the resulting proteins are folded into complex 3D structures which are key to their biological function. Traditional experimental methods for determining protein structure require expensive specialized equipment and may take years to complete. In late 2020, DeepMind’s AlphaFold2 solved the 50-year-old Protein Structure Prediction challenge of quickly and accurately predicting protein structure from the amino acid sequence.
Besides the raw amino acid sequence, the input to AlphaFold2 includes multiple sequence alignment (MSA) information, which links several different sequences based on the assumption of having a common evolutionary ancestor; this external database creates a performance bottleneck. By contrast, ESMFold uses a learned language model representation that requires only the amino acid input sequence, which simplifies the model architecture and improves runtime performance. The language model representation is fed into a downstream component similar to AlphaFold2’s, which predicts 3D structure.
The Meta team evaluated ESMFold on CAMEO and CASP14 test datasets and compared the results to both AlphaFold2 and another model, RoseTTAFold. ESMFold’s template modeling score (TM-score) was 83 on CAMEO and 68 on CASP14, compared to 88 and 84 for AlphaFold2 and 82 and 81 for RoseTTAFold. The researchers noted that there was a high correlation between ESMFold’s TM-score and the underlying language model’s perplexity, which implies that “improving the language model is key to improving single-sequence structure prediction accuracy.”
Meta and other organizations have been researching the use of language models in genomics for several years. In 2020, InfoQ covered Google’s BigBird language model which outperformed baseline models on two genomics classification tasks. That same year, InfoQ also covered Meta’s original open-source ESM language model for computing an embedding representation for protein sequences. In 2021, InfoQ covered DeepMind’s AlphaFold2, and DeepMind recently announced the release of AlphaFold2’s predictions of structures “for nearly all catalogued proteins known to science.”
Several of the Meta team participated in a Twitter thread answering questions about the work. In response to a question about the model’s maximum input sequences length, researcher Zeming Lin replied:
Currently able to do up to 3k length proteins, though at some point it becomes computationally bound.
Meta has not yet open-sourced ESMFold, although Lin says that the model will be open-sourced in the future.
MMS • InfoQ
Article originally posted on InfoQ. Visit InfoQ
Running web-scale workloads on the cloud successfully demands using well-tested operational practices, whether the environment is cloud-native, hybrid, or considered for a move. As with any large infrastructure footprint, organizations must balance the often competing demands of various factors such as security, compliance, recoverability, availability, performance (QoS), developer productivity, the rate of innovation, infrastructure efficiency, and spending.
If leveraged effectively, cloud computing capabilities offer considerable advantages over making compromises for most of the previously identified factors. Although running large workloads, on-premise versus a public cloud, have similar underlying fundamentals, the cloud poses unique challenges which must be addressed. The shift of operations to the cloud still requires the same people and processes as on-premise data centers. However, it now focuses on a higher level of operations. No longer has server uptime is the focus, as a shift of responsibility is towards protecting client and endpoint protection, identity and access management, data governance, and cloud spend.
In this eMag, you will be introduced to the Cloud Operating Model and learn how to avoid critical pitfalls. We’ve hand-picked four full-length articles to showcase that.
We hope you enjoy this edition of the InfoQ eMag. Please share your feedback via mailto:editors@infoq.com or on Twitter.
We would love to receive your feedback via editors@infoq.com or on Twitter about this eMag. I hope you have a great time reading it!
Free download
MMS • Eric Arellano Nick Grisafi Josh Cannon
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Transcript
Shane Hastie: Good day, folks. This is Shane Hastie from the InfoQ Engineering Culture Podcast. Today I’m sitting down with Eric Arellano, Nick Grisafi and Josh Cannon, all three from the Pants Build or Pants Open Source community. Folks, welcome. Thanks for taking the time to talk to us today.
Introductions [00:24]
Eric Arellano: Absolutely. Thanks for having us, Shane. My name’s Eric Arellano. I use they/ them pronouns. I started working on the Pants build project about five years ago and have been active with a project ever since. I work on it for my day job as a software engineer, a startup called Toolchain. And I actually first got involved, I was in doing my summer internship project and ended up leading Pants Build’s Python 3 migration and fell in love with open source and the community. That was my first major time really working with open source and contributing back.
In between that, I was a middle school computer science teacher and teaching intro Python to 12 and 13 year olds and also I’ve been a volunteer crisis counselor for LGBTQ youth for two years now. So I think a lot about the human side of open source and communities and really like the focus of your podcast. I’m excited to be here today.
Shane Hastie: Nick, tell us about yourself.
Nick Grisafi: I’m Nick Grisafi. I’m a platform infrastructure engineer at Rippling. I use the Pants build system professionally and for fun. I was first introduced to Pants on a project when I first started at Rippling where we were trying to improve our testing strategies and also the tools that we wanted to introduce to the code base. We really needed a system that was flexible and allowed us to do something called incremental adoption. So we didn’t hit it all at once and Pants was the gateway into that.
One of my favorite experiences was within the first hour of using Pants. I was able to get it up from nothing to something, to show managers and people that this works. And to this day we continue to use Pants to empower developers to introduce tools and just to keep productivity as fast as possible. And yeah, I heard this podcast too is very tech oriented. So really happy to be here.
Shane Hastie: And Josh.
Joshua Cannon: I’m Josh. Howdy. I’m a build engineer at IBM’s Watson Orders. So we’re an organization designed around fully automated drive through order taking, which is really fun. And so I’m really passionate about developer experience, which is why they hired me on as a build engineer. And specifically, I got tasked with taking a look at our Bazel, which is a mono build system, a cousin to Pants, if you will. But then it was holding us back and slowing us down. And so I was tasked with either finding a way to make that better or finding a different tool that would actually lift us up and propel us forward. And so that’s how I got introduced to Pants.
Lift by one thousand breezes [02:38]
Joshua Cannon: I’m a huge advocate of developer experience and lift by a thousand breezes and so that’s something I think Pants provides the engineers, which is why I fell in love with it. But also the community on GitHub and Slack really lifts you up as well. And so that kind of propelled me through opening my first issue to fixing my first issue, to making my first feature implementation all the way through to maintainer. So kind of gone through that life cycle through Pants and it’s been really rewarding.
Shane Hastie: Josh, can we delve into that lift by a thousand breezes a little bit more?
Joshua Cannon: So it’s kind of the opposite phrase of death by a thousand paper cuts. So the way I think about it is you can try to work hard and design and do things that would give a large strong gust and that’s hard to do. Instead, what you can focus on is giving a lift by a thousand breezes, which is basically small, incremental changes that are going to add up to that strong gust. Just as how a thousand paper cuts can cause a death just as quickly as a stab wound or as something is a stab wound, a lift by a thousand breezes can lift you up as strong as the strong gust. And so I’m a really big proponent of that.
Shane Hastie: Talking about the Pants build community, what makes it special?
A welcoming open source community [03:48]
Nick Grisafi: The people, I mean, if you’re coming into open source for the first time, it’s pretty daunting to come into a channel full of what you consider experts and then ask something that you think is really stupid. But then in Pants everybody makes you feel comfortable. They look for those questions and then next thing you know, they’re improving documentation or they even push you even further like, “Hey, can you contribute to our docs? Can you find where there’s shortcomings and we’ll fix it?” And it just kind of gets you going and you could give that feedback and then quickly see them fix something. It’s pretty rewarding. So I would say, yeah, the people really drive what Pants is.
Eric Arellano: You know, Nick, you mentioned stupid questions. So we have a lot of newcomers who will come and say, “Hey, sorry, this is probably a really stupid question. Here it is.” We always respond with that, it sounds like a teacher, that we really don’t believe in stupid questions, there’s only inadequate documentation and it means that Pants isn’t intuitive enough.
We think a lot about the idea of like when your teacher would say that if you have a question, probably 10 other people have that same confusion. We view our project that same way, that if you are getting stuck on something or something’s not intuitive, we’re extremely grateful that you went out of your way to tell us that and ask for clarity because we now can then figure out, is this a documentation bug or is this a UX bug that we need to redesign something so that the next person doesn’t get us confused by this.
Shane Hastie: This is not something that open source is known for. In fact, the reputation of a lot of open source communities is directly the opposite. How do you keep out the toxicity?
Joshua Cannon: I think we’re all popping because it’s a good question.
Pay it forward to keep toxicity out [05:26]
Nick Grisafi: Pants itself is just fun. I mean, you think about Pants, you see the logo, it starts fun and then you work your way through and you meet some great people. I have never seen anything bad happen in the Pants community, just interesting things that make me want dive deeper into the system.
Eric Arellano: I think something that helps a lot also is the idea of pay it forward, that people have helped you out along your Pants journey and therefore we find that a lot of times people who in the first week they come in, they’re only asking questions and within a week they’re often jumping in and answering questions for other people, which has been amazing for the growth of the community. We’ve grown really dramatically.
So we’re a 10 year old project but we relaunched with version two in 2020. Since then, I’ve seen really dramatic growth in the community size and it would not be sustainable if it was only the core set of maintainers who are trying to do all these things like helping out new users and writing documentation. I think that that pay it forward approach has really paid dividends for us. Lots of users are helping out every day, sharing their experience with things that we as maintainers might not actually have very much direct experience, and bringing in new ideas. That’s how I got hooked was that I was an intern, felt like I had no idea what I was doing with open source, with Python and opened an issue asking what it would look like to do a Python 3 migration. People were incredibly helpful to me throughout. And here I am now that I want to pay it forward to the next generation of Pants community members.
Joshua Cannon: I think it’s part of the culture of the Pants community too. Like me personally, I think I fall into that role that Eric was describing of people helped me and so I want to help others. It’s part of the culture that got fostered. And honestly, I can’t speak for others but I try to race the other maintainers to find an answer for people just to see if I can. And again, it’s that it is rewarding, right? It’s not just altruistic. It’s quite rewarding to see and foster others.
There are some users I’ve seen now in the Slack community that have grown throughout my time, short time as a maintainer, seeing them going from, like Eric said, asking questions to answering others.
Concrete actions to welcome particiPants [07:28]
Eric Arellano: I would add for listeners a couple concrete steps that we’ve taken to create this inclusive and welcoming community. One of the big changes we did was last year, introducing a welcome channel in our Slack where we invite people, never an obligation, an invitation to share what they’re working on and how they learned about Pants and always give them a warm welcome and let them know that we love questions here and we love feedback. That has been really exciting every day to look at. Often it’s three to five new organizations joining and really creates I think a sense of community.
Other concrete things we’ve done have been getting specific about how we recognize people’s contributions. At the beginning of the project until I think a year or two ago, we like many open source projects, primarily recognized maintainers and contributors through code contributions. And we actually used to call our maintainers committers, a term from programming. And we realized that for a healthy open source project you need so much more than code, even though that is an important foundation. So we changed the name to maintainer and started recognizing all types of contributions, including a lot of new future ideas that we’ve had from users that a future request is a way of contributing to community, pointing out again where you’re confused with docs is contributing.
So we renamed committer to maintainer and then we also added a level of recognition below maintainer of contributor that you have gone out of your way to do several meaningful things to the community and we want to recognize you formally in the community.
Nick Grisafi: One experience I want to share that I totally forgot about. I don’t know how I forgot this. I joined Pants community, like what is it, over a year ago, just about over a year ago now. And the first moment I joined the channel, I got reached out to by Benji and he sent me a private message welcomed me to the channel, offering to support me if I have any questions. Was curious about our use cases and things like that and I never had that happen to me before in any open source community. So it almost had that cool factor like, “Hey, this guy runs it and he cares about me. I’m a newbie. I just joined.”
Shane Hastie: A couple of very clear pieces of concrete advice there. What else can people involved in open source communities do to be more welcoming?
Advice for other open source communities [09:46]
Eric Arellano: Another thing that’s helped us lot is we consistently invite people to our Slack community, whether it’s in a blog post or podcast like this. We are constantly inviting people because we use GitHub for all of our project tracking and for our code and everything. There is a lot of activity on GitHub but it often tends to be more focused on a specific change that someone’s trying to do, whereas Slack is a lot more that people might be running into a problem with how they deploy things with Docker and they want advice from other community members.
So we’ve had a lot of success with Slack in particular and there’s a lot of other alternatives like Discord that other communities prefer. But concretely in every blog post we do, every time we do some type of outreach, we encourage people come join our community. This is where it’s happening.
Joshua Cannon: One thing you’d see from Pants that you normally don’t see from open source projects is that really the community owns it. So there is no company that owns the project itself. There’s a nonprofit organization that I will say runs it. And so because there’s no one person owning it, it really is that community. Everyone’s ideas can be heard. Everyone’s ideas get weighed equally and I think that’s very important to fostering that sense of contribution.
Nick Grisafi: And you see that all the way through the code level too. If you’re onboarding Pants and you’re writing your first Pants plugin and you need to have some good references, the code itself really serves that purpose. You could go in. I just wrote a plug in the other day to improve our dependency and inference. Eric pointed me right to the source code with an example and that’s something I could put into our production pipeline within a day, which is pretty awesome. And the concepts are a little bit over my head. So to learn something just based on code self-explanatory is pretty amazing.
Shane Hastie: Power of the outsider. That was something that we mentioned in the conversation before we started recording. So what do we mean by that?
The power of the outsider to overcome the curse of knowledge [11:45]
Eric Arellano: The term power of the outsider I think a lot about a related idea, which is the curse of knowledge. The curse of knowledge is a cognitive bias. It’s really hard to remember what it was like before you didn’t know something. So if you think about using your phone and like how to send a text message, it’s super obvious to you and it’s really hard to think about what it would be like for someone to get a phone who’s never used if we go back 200 years, for example. You can try, but realistically you have this curse of knowledge that makes it hard for you to empathize with people and it ends up resulting in open source projects, and general in projects looking like things like writing documentation that makes a ton of sense to you as a maintainer because you wrote the thing but is super obtuse and confusing to anyone who hasn’t used the system before.
So with the power of the outsider, we as maintainers and as contributors to the project, we think about this curse of knowledge. A lot, our goal is for Pants to be extremely ergonomic and intuitive for anyone to use intuitive, meaning you can figure it out on your own. You don’t need to read our docs. We try to assume that 80% of our users will never end up reading our docs and can they figure out how to use Pants even without that? So we need help because we have this curse of knowledge. We need help that we can try our best to empathize. But realistically we need that feedback from people who have never used a build system before or have never used Pants about what they found confusing and what improvements we can make to it.
Nick Grisafi: It brings me back to our last podcast where we discussed the topic about what was it called, the bus factor, and these people who retained the curse of knowledge. And let’s say one day they randomly get hit by a bus. Where does that put you, your organization and your company? If the knowledge cannot be shared and spread and distributed, then most likely it’s only tailored to one person and that could cause failure. So it’s important to share knowledge. Share knowledge and make sure that you’re putting yourself into the shoes of other people. When you’re not around, will they understand this and be able to maintain it? It’s really important.
Shane Hastie: What’s the role of corporations? You mentioned a non-profit organization owning and guiding it, but a lot of corporations get involved with open source initiatives. What’s the role for the commercial organization for the corporation today?
The role of corporations in open source [14:13]
Eric Arellano: I think there’s a lot of opportunities for corporations to help out open source projects. It needs to be done carefully. I mean, there’s a lot of risk with it that the corporation ends up dominating. But we’d like to think that Pants has been a healthy relationship that, for example, I mentioned working for a startup where 90% of my day job is working on the Pants build project. Josh is able to do some work on Pants as well with his job and a couple of the maintainers are, whereas others are more contributing on their own free time.
So about two years ago we identified as the Pants build nonprofit organization that the majority of maintainers were coming from one company, the startup that I worked for, Toolchain, and that that was a systemic risk for the health of the open source community. The Pants build project is again going to be successful, we need outside perspectives and it can’t be dominated by anyone voice because that one voice isn’t going to represent all the different teams that we’re trying to reach.
So we made it an intentional goal among the maintainer team that we are going to invest a lot in bringing up to speed new contributors and new maintainers and growing the diversity of our maintainer base and our contributor base. And through a lot of those steps that we talked about earlier like redefining what a maintainer means, creating that welcome channel. We’ve had a lot of success that now I think the majority of the maintainers are not represented by one single organization, I think.
Joshua Cannon: Talking from two different levels as well. I can say that the corporation or a corporation’s, I’ll say, allowance of users to contribute to open source, it kind of goes back to that lift by a thousand breezes. I couldn’t do my job effectively without all of the tools I use, many of which are open source and those tools wouldn’t exist if people weren’t able to contribute to them because we all have very limited free time. And so that they did so in a corporate manner. Some corporations even own and maintain those tools. So there’s kind of that aspect of the golden rule. Do unto others as they’ve done unto you. So that’s kind of the higher level.
The lower level too is the features that you can bring from your corporate perspective to put this more concretely. I’m about to give a proposal to Pants that I think will benefit a lot of people, but for us specifically rolling it out on our own repo, we saved ourselves, I mean myself, a month’s worth of dev time and my organization a year’s worth of dev time. And so having that perspective from my real world use case that I can then reapply back to the tool is really important as well.
Nick Grisafi: One of my favorite things is that you use as Pants page, if you go there, you’ll see a bunch of different companies, some really cool companies and it just makes you think like, wow, that’s scale, they use Pants? That’s pretty amazing. So if it works for their use case, a hundred percent, can it work for our use case too. And then you find out in your use case you have something that they didn’t even think of before. You just have some pattern that wasn’t thought of and then you go into the Slack community and you bring it up and you start a discussion there. I think that’s pretty awesome.
Shane Hastie: Joshua, if I can hone in. You’ve mentioned a couple of times the importance of developer experience. What are things that our organizations are doing to improve that developer experience today?
Improving the developer experience [17:28]
Joshua Cannon: Ooh, that’s an excellent question. So I think what corporations are doing is being more intentional about it. DevOps is quite an umbrella term. It’s thrown out a lot, but you’ll see job listings now for developer experience engineers, making it a dedicated role, having somebody who can own that experience. I’ve seen kind of an upbringing at the companies I’ve been at around building a culture of that experience, helping each other out, finding the tools that work and then sharing that.
It’s not enough for me to find what works for me and now I’m successful at my job, but spreading that around. And from the corporation’s perspective, making sure that’s part of the culture. So everyone knows that they can and should do that. Because really, oh man, I’m sounding like a broken record, but that in itself is a lift by a thousand breezes.
Shane Hastie: And for those organizations that aren’t doing that deliberately yet, when they start…
Eric Arellano: So yeah, that’s actually one of the core missions and reasons why Pants exist, is that we have this hypothesis that 90% of teams don’t have the resources or perhaps the experience yet to focus on their developer experience. And they might be using a lot of custom bash scripts that they wrote and they kind of work but it doesn’t work great. It’s kind of death by thousand cuts or the analogy of the boiling frog, that a frog, which apparently this isn’t actually true, but the analogy is that a frog will be in boiling water and you increase the temperature over time and the frog won’t realize until it’s too late that the water’s already boiling. And that’s our hypothesis that that’s how developer experience is for most teams that start small. You don’t have much code and then you incrementally add more and more scripts until you get to this point where no one really understands, it’s really confusing.
Eric Arellano: The same time we know most organizations don’t really have the resources for a dedicated team of developer experience. For example, when I was working at Twitter before my current job, I was on the developer experience team and we had a team of I think it was like eight or nine people who our sole job was to help developer experience for the other engineers. Most companies don’t have that resource and that’s not realistic to expect. So part of our mission with Pants is to empower those everyday organizations that you can get rid of the custom bash scripts and have this amazing build experience without having to have a whole dedicated team trying to reproduce the wheel because you can leverage what the open source community has already done and solved.
Nick Grisafi: Touch on that point. My favorite part about Pants was deleting all those bash scripts. That just simplified things like that. It’s all controlled through a single point now, Pants. And now they’re introducing Go. So we could actually do the same thing for our Go projects, Python projects. That’s all the same interface.
Joshua Cannon: To answer Shane your question too and know your audience. On reflection, I’d say that really being intentional about developer experience is a great place to start. All of your developers are having an experience. That’s a fact. Whether they’re having a good one or not is subject to debate. And so being intentional about it.
I think in any organization of a decent size, you’ll find those people much like myself who naturally tend to gravitate towards wanting to improve the developer experience and it’s not always altruistic. I know a lot of times I started doing it because I got so frustrated. I needed to improve it for myself for my own sanity. And so finding those people and really fostering that kind of culture and that passion from those engineers will go a long way.
Getting started improving developer experience [21:00]
Nick Grisafi: To touch on that. Where do you start? Most of the time you have to acknowledge the problem and that’s getting the people at the top of the company to acknowledge that problem, to give you those resources so you can go ahead and do it. And exactly what Josh said, like finding the individuals to evangelize this and understand the frustration but have an idea for a solution and to make that a reality.
And then just wanting to help people. You have people on your team that genuinely care about this. Put them in charge and let them help people. Make sure that there’s a feedback channel that anybody in the company feels comfortable coming in and could give feedback and get feedback as quickly as possible. That feedback loop is super important so you could collect the information. It’s not a distraction. It might throw you off guard sometimes like, “Oh, this guy literally can’t do something very fundamental.” But you have to not see it as a distraction but as a point for improvement. You have to go in there, understand how they even end up in this situation, put yourself in their shoes and improve it for good. Document it and try to never let it happen again. That’s the point.
Nick Grisafi: But if you don’t have the resources at your company and the people at the top are not focused on this, then it’s almost near impossible to get it started and done. Then it just has to be community driven and organically driven, and a lot of the time people don’t have generally just time for that.
Shane Hastie: Give people the time.
Nick Grisafi: Give people the time to make things better.
Shane Hastie: Some interesting thoughts and good ideas in their folks. If people want to continue the conversation, where do they find you?
Nick Grisafi: You can find me in the Pants’ Slack community. I mean, my name is NJ Grisafi in there. I have a profile picture of hiking in San Diego. Most likely you can see me in the general channel asking something really stupid or maybe something you didn’t know about. But yeah, that’s a good place to find me.
Joshua Cannon: I think if I may, you can find us all on Slack. And I’m going to go ahead and speak for Eric and Nick here. If you don’t feel comfortable enough asking your question in general or in welcome or any of the other channels, you’re welcome to ping us directly and we’re happy to guide you along.
Shane Hastie: And we’ll include the links to the Pants’ Slack channels in the show notes. So thank you so much.
Joshua Cannon: Thank you.
Nick Grisafi: Thank you.
Eric Arellano: Thank you.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
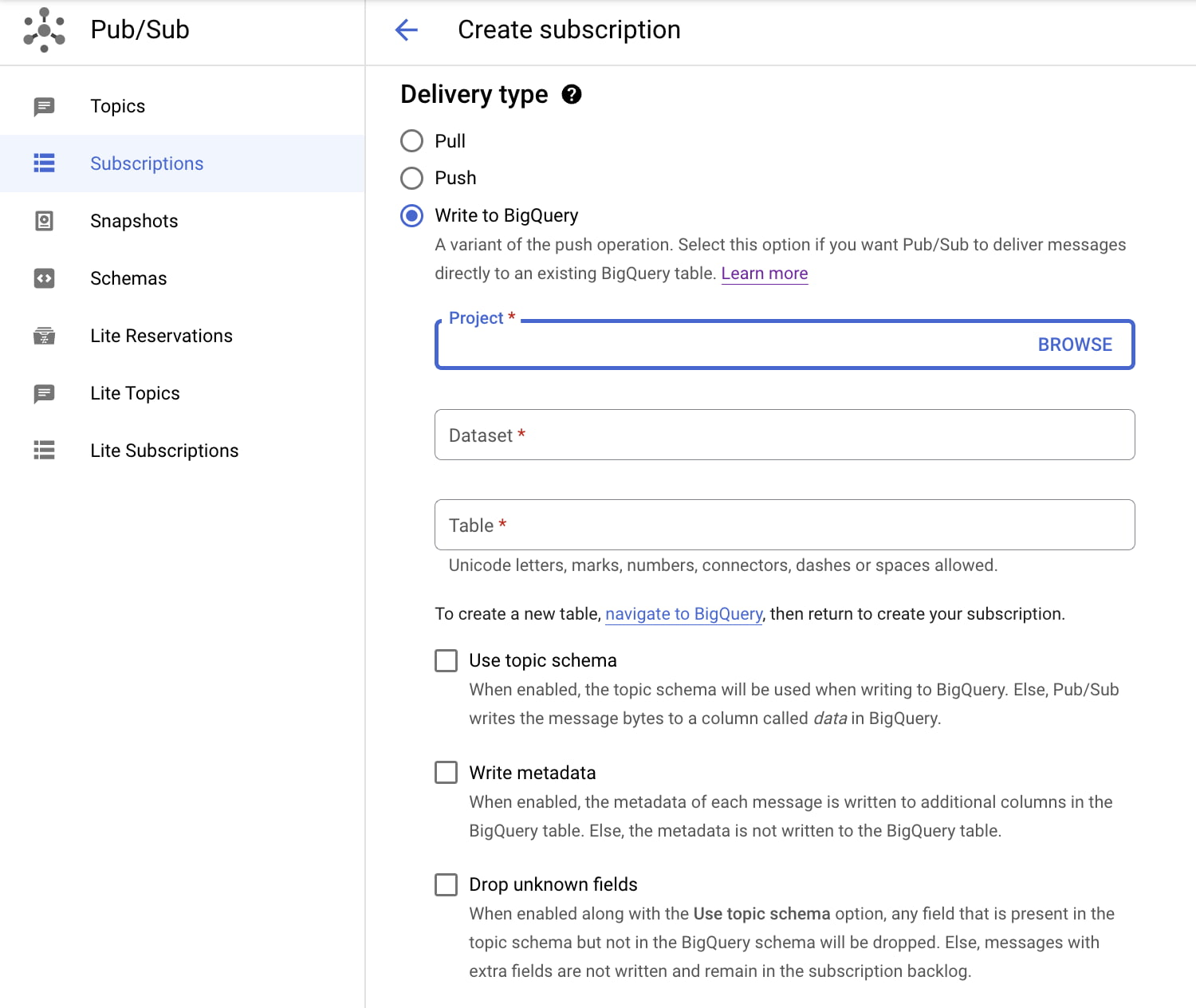
Recently Google introduced a new type of Pub/Sub subscription called a “BigQuery subscription,” allowing to write directly from Cloud Pub/Sub to BigQuery. The company claims that this new extract, load, and transform (ELT) path will be able to simplify event-driven architectures.
BigQuery is a fully-managed, serverless data warehouse service in the Google Cloud intended for customers to manage and analyze large datasets (on the order of terabytes or petabytes). And Google Pub/Sub provides messaging between applications, which can be used for streaming analytics and data integration pipelines to ingest and distribute data. For data ingestion, customers had to write or run their own pipelines from Pub/Sub into BigQuery. They can do it directly with the new Pub/Sub subscription type.
Customers can create a new BigQuery subscription linked to a Pub/Sub topic. For this subscription, they must choose an existing BigQuery table. Furthermore, the table schema must adhere to certain compatibility requirements i.e. compatibility between the schema of the Pub/Sub topic and the BigQuery table. In a blog post, Qiqi Wu, a product manager at Google, explains the benefit of the schemas:
By taking advantage of Pub/Sub topic schemas, you have the option of writing Pub/Sub messages to BigQuery tables with compatible schemas. If the schema is not enabled for your topic, messages will be written to BigQuery as bytes or strings. After the creation of the BigQuery subscription, messages will now be directly ingested into BigQuery.
Richard Seroter, director of outbound product management at Google Cloud, wrote in a personal blog post on the BigQuery Subscription:
When I searched online, I saw various ways that people have stitched together their (cloud) messaging engines with their data warehouse. But from what I can tell, what we did here is the simplest, most-integrated way to pull that off.
However, Marcin Kutan, software engineer at Allegro Group, tweeted:
It could be a #pubsub feature of the year. But without topic schema evolution the adoption will be low. Now, I have to recreate the topic and subscription on every schema change.
Note that the company recommends using Dataflow for Pub/Sub messages where sophisticated preload transformations or data processing are required before letting data into BigQuery (such as masking PII).
Lastly, the ingestion from Pub/Sub’s BigQuery subscription into BigQuery costs $50/TiB based on read (subscribe throughput) from the subscription. More details on pricing are available on the Pub/Sub pricing page.
Java News Roundup: Spring Cloud, Liberica NIK, Open Liberty, Micronaut, JHipster, Apache ShenYu
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for August 1st, 2022, features news from JDK 19, JDK 20, Spring point and milestone releases, Liberica NIK 22.2.0 and 21.3.3, Open Liberty 22.0.0.8 and 22.0.0.9-beta, Micronaut 3.6.0, WildFly 27 Alpha4, Hibernate ORM 6.1.2, Hibernate Validator 6.2.4, 7.0.5 and 8.0.0.CR2, Hibernate Search 6.1.6, JHipster 7.9.2, 7.9.1 and 7.9.0, JBang 0.96.4 and Apache ShenYu.
JDK 19
Build 34 of the JDK 19 early-access builds was made available this past week, featuring updates from Build 33 that include fixes to various issues. More details on this build may be found in the release notes.
JDK 20
Build 9 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 8 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 19 and JDK 20, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
On the road to Spring Cloud 2022.0.0, codenamed Kilburn, the fourth milestone release was made available this past week featuring updates to milestone 4 versions of Spring Cloud sub-projects such as Spring Cloud Stream, Spring Cloud Config, Spring Cloud Gateway and Spring Cloud Function. Spring Cloud 2022.0.0-M4 is compatible with Spring Boot 3.0.0-M4. More details on this release may be found in the release notes.
Spring for Apache Kafka 2.9.0 has been released featuring: a more robust non-blocking retry bootstrapping; and a new error handler mode. This version requires the kafka-clients 3.2.0 module. Further details on this release may be found in the what’s new section of the documentation.
Spring Tools 4.15.2 has been released featuring numerous fixes to the Eclipse IDE such as: improvements in the diagnostic output of Eclipse logs; a broken devtools integration with the boot dash in a Docker image; malfunctions in the pause/resume in a boot dash in a Docker image; and a “Not properly disposed SWT resource” message caused by the Spring Starter Project. More details on this release may be found in the release notes.
Liberica Native Image Kit
As part of a Critical Patch Update, BellSoft has released Liberica Native Image Kit (NIK) version 22.2.0 and an upgraded version 21.3.3. This release features enhanced support for AWS and Swing and provides security fixes for the following Common Vulnerabilities and Exposures (CVE):
- CVE-2022-21540: Vulnerability in the Oracle Java SE, Oracle GraalVM Enterprise Edition (Component: Hotspot)
- CVE-2022-21541: Vulnerability in the Oracle Java SE, Oracle GraalVM Enterprise Edition (Component: Hotspot)
- CVE-2022-21549: Vulnerability in the Oracle Java SE, Oracle GraalVM Enterprise Edition (Component: Libraries)
- CVE-2022-34169: The Apache Xalan Java XSLT Library is Vulnerable to an Integer Truncation Issue when Processing Malicious XSLT Stylesheets.
CVE-2022-21540 and CVE-2022-21541 affect JDK versions 7u343, 8u333, 11.0.15.1, 17.0.3.1, 18.0.1.1 and Oracle GraalVM Enterprise Editions 20.3.6, 21.3.2 and 22.1.0. CVE 2022-21549 affects JDK 17.0.3.1 and Oracle GraalVM Enterprise Editions 21.3.2 and 22.1.0.
Open Liberty
IBM has promoted Open Liberty 22.0.0.8 from its beta release to deliver: a fix for CVE-2022-22476, IBM WebSphere Application Server Liberty is Vulnerable to Identity Spoofing; a dependency upgrade to Apache CXF 3.4 in the jaxws-2.2 module; The stack trace separated from logged messages so that the log analysis tools can present them more clearly; and the ability for developers to enable time-based periodic rollover of all Open Liberty supported log files.
Open Liberty 22.0.0.9-beta has also been released featuring support for many of the Jakarta EE 10 specifications to include those specifications that reside in the new Jakarta EE Core Profile, namely Jakarta Contexts and Dependency Injection 4.0, Jakarta RESTful Web Services 3.1, Jakarta JSON Binding 3.0, Jakarta JSON Processing 2.1, Jakarta Annotations 2.1, Jakarta Interceptors 2.1. There is also support for the upcoming GA release of MicroProfile OpenAPI 3.1 (currently in RC2) and Password Utilities 1.1.
Micronaut
The Micronaut Foundation has released Micronaut 3.6.0 featuring: support for GraalVM 22.2, Hibernate Reactive and the OpenTelemetry specification; and a new Micronaut Test Resources project. Further details on this release may be found in the release notes.
WildFly
On the road to WildFly 27.0.0, the fourth alpha release has been made available. This release serves as a major milestone towards support for Jakarta EE 10 in WildFly that was only previously available in WildFly Preview. WildFly 27.0.0.Alpha4 supports JDK 11 and JDK 17. JDK 8 is no longer supported. Red Hat plans more alpha and beta releases over the next several weeks. More details on this release may be found in the release notes.
Hibernate
Hibernate ORM 6.1.2.Final has been released featuring bug fixes and the ability to use the @Any mapping and HQL function, type(), to access the type of a polymorphic association.
Versions 6.2.4.Final, 7.0.5.Final and 8.0.0.CR2 of Hibernate Validator have been made available as maintenance releases for the 6.2 and 7.0 release trains. Both of these versions improve testing of Java records and make sure the annotation processor is working correctly with records. The release candidate of version 8.0 will provide support for Jakarta EE 10.
Hibernate Search 6.1.6.Final has been released featuring dependency upgrades to Hibernate ORM 5.6.10.Final, Hibernate ORM 6.0.2.Final and Hibernate ORM 6.1.2.Final for the -orm6 artifacts. There were also upgrades to the latest version of Jakarta dependencies for -orm6/-jakarta artifacts.
JHipster
Versions 7.9.2 (with 7.9.1 included) and 7.9.0 of JHipster have been released featuring: dependency upgrades to Spring Boot 2.7.2, Angular 14 and React 18; support to generate custom generators using the generate-blueprint command-line argument; support for mixed use of microservice and microfrontend entities; and microfrontend support in the JHipster Domain Language (JDL). Further details on these releases may be found in the release notes for version 7.9.2 and version 7.9.0.
JBang
JBang 0.96.4 has been released featuring the removal of the --native flag that was broken and incomplete. Instead, developers should use the command, jbang export native. A deprecation warning will be issued if the old flag is used. More details on this release may be found in the release notes.
Apache Software Foundation
The Apache Software Foundation has announced that Apache ShenYu, a Java-native API gateway for service proxy, protocol conversion and API governance, has been promoted from incubation to a top-level project. InfoQ will follow up with a more detailed news story.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Announced in beta at GitHub Universe 2021, GitHub Projects is now generally available, including new features for issue grouping and pivoting, metadata customization, charting, and improved automation.
GitHub Projects provides a tabular view of issues and pull requests defined in a repository to make it easier to plan and track development progress.Issues and PRs can be easily filtered, sorted, and grouped based on a set of standard fields as well as custom fields you create to adapt the tool to your process.
Often, we find ourselves creating a spreadsheet or pulling out a notepad just to have the space to think. But then our planning is disconnected from where development happens and quickly goes stale.
As mentioned, GitHub has been extending Projects in several ways since it launched in beta last year. Specifically, Projects enables defining custom metadata fields associated to issues , including text, number, date, iteration, and single select. Additionally, issues can be organized by date using flexible date ranges to better adjust to sprints, cycles, and roadmap duration.
Completely new is the possibility of creating and customizing charts, such as bar, column, line, and stacked-area charts, which can be persisted and shared using an URL.
In this GA release, GitHub Projects also attempts to address some of the criticism it received when the beta started, specifically the impossibility of automatically add issues to a project, by extending the integration between Projects and Actions.
On the automation front, it is also worth mentioning that GitHub Projects got a new GraphQL API, dubbed V2, which also includes support for Webhooks to subscribe to events taking place in your project, such as editing an item.
GitHub says they will continue to extend Projects capabilities by focusing on improving the day-to-day scenario and adding a number of new features, including handling dependencies and relationships between issues and projects; new triggers, conditionals, and action logic to improve scriptability and automation; a new timeline layout alongside the tabular view and the classic Kanban board; and an improved mobile experience.
MMS • Justin Cormack
Article originally posted on InfoQ. Visit InfoQ

Transcript
Cormack: I’m Justin Cormack. I’m the CTO at Docker. Also, I’m a member of the technical oversight committee of the Cloud Native Computing Foundation. I also am really interested in programming languages and how they affect the way we work.
One of the things I’m talking about is, in the Cloud Native Computing Foundation, of the 42 graduated and incubating projects we have, 26 of them are written predominantly in Go. I want to explore how this happened and which new language is emerging in the cloud native space and how we got to this point where Go is so dominant. One of the things that was really important in this historically was Docker. When I started at Docker in 2015, Go was already an established language in the company.
Why Docker Adopted Go
I want to talk to Solomon Hykes, who founded Docker, about how they started off with Go, and how really early in the Go language evolution they adopted it, moving away from Python.
Hykes: We didn’t want to target the Java platform, or the Python platform, we wanted to target the Linux platform. That was one aspect. Another aspect, honestly, it was more of a personal gut feeling thing. We were Python and C developers trying to write distributed systems. A lot of what we ended up doing was writing them in Python, and then getting bitten by the typing issues of Python, so discovering problems a little bit too late at runtime when they could have been discovered earlier. Also, trying to recreate a lightweight threading system. It’s been a while, but at the time we were heavily using libraries and frameworks like gevent and Greenlets and things like that, Go had goroutines built in. That was the same thing, but better. It had the typing benefits of C. From our specific point of view of C and Python developers of distributed systems, it was just the perfect tool.
Cormack: Presumably you didn’t want to choose C for other reasons.
Hykes: No, exactly. Yes, C was not a consideration. Python was the default, because it’s what we used. Go was just better by every metric that we cared about. One factor being the fact that it compiles to a standalone binary. The other being that it was just the right programming model for us. The third, is that, because we specifically wanted to grow a large community of open source contributors, we wanted Docker to be not just a successful tool, but a successful open source project, the choice of language mattered for social reasons. For example, we wanted something that was familiar enough to enough people, that the language itself would not be a huge barrier to reading the source code and contributing to it. The nice thing about Go is it’s not radical in its syntax. If you’ve written C, you’ll be familiar with Go. If you’ve written Python, you’ll be familiar. It’s not Haskell. It’s not Lisp. It doesn’t break every possible convention compared to mainstream programming languages. That was explicitly considered a benefit, because that means it’s easier to contribute.
How Project Vitess Got Started In Go
Cormack: During this interview with Solomon. He called out that when he was looking around at the existing Go ecosystem at the time, it was, what’s now another CNCF project, Vitess, that was something that he saw that gave him confidence. Vitess was a project that was in YouTube at the time, as YouTube was growing really fast. I talked to Sugu, who was one of the founders of Vitess, about how he had got started in Go.
Sougoumarane: I can go through some of the thought process that we went through, about how we ended up choosing Go. It was not very scientific with Go. In 2010, when we were thinking of starting this project, the primary options were Python, Java, and C++. Those were the three languages that popped up for us. Python was because YouTube was written in Python. Then Python was already losing, because it’s not a systems programming language. We knew that we wanted to build an efficient proxy. Python has not the efficiency, it’s not a very efficient language. We had Java and C++. I wasn’t familiar with Java, and I think I was slightly bitter about it those days. I don’t know why, but probably based on some people I ran into. I wasn’t very excited about Java. Mike wasn’t excited about C++ because he didn’t feel like he could write something good with it.
There were a couple of reasons why we chose Go. The funny one is, it was just a passing comment, but it is still a funny comment, which is, if we use Go and if our project fails, we can blame it on that. I don’t think that’s the reason why we chose it. That was definitely one statement that was made in the conversation. Really, the reason why we chose Go is because of Rob, Russ, Ian, and Robert Griesemer. Because it was such a brand new language, we had to check out the authors, and we actually basically studied those people. We realized that their values, their thinking, their philosophy is very mature, and similar to the way we approached problems, which means that they were not too theoretical or too hacky. They had a very good pragmatic balance about how to solve problems. It was around the time where within Google there was a case where engineers were going through this phase where they had this fascination to complexity. Where anything complex is awesome, type of thing. This was one group of people that were contrarian to that. They were saying, you can be simple. I said, “I like that. I like the way you think.”
What happened at that time was, I gave Dmitry Vyukov a reproduction as to why we are stuck. The challenge I gave him was, we have eight CPUs. That’s all we have. The Go runtime today is only able to use six. If you optimize the runtime to use the other two CPUs, we will be true. That’s the challenge I gave him. He went away for, I think, two months, and came up with this work-stealing design and a prototype implementation. We tried it, it indeed start the eight CPUs. That pulled us out of trouble. He saved our project. If that had not happened, we might have moved away from Go. It was not because of Go’s design. It was just that we were getting pressured because YouTube was about to fall apart. We needed to find a solution. That solution basically restored our faith in Go. After that, we never had any struggle.
Cormack: Both Solomon and Sugu were looking for the right language for their new project, a systems language for cloud native. Both of them really also felt that community was important. We can say that for Sugu, it’s the community of the creators of Go, and the people working on making the language better. For Solomon, it was the community that he wanted to create around Docker to make the language accessible to this community.
Why Go Became a Dominant Systems and Cloud Native Language
Around this time, late 2012, Derek Collison who created the NATS project, tweeted that within two years, Go would become the dominant systems language and the language for cloud native. At the time, people were very skeptical, of course, but it actually worked out that way. In that period, Docker and Kubernetes were both released, and there was a huge explosion of usage. I talked to him about how he came to that conclusion back then.
Collison: The original NATS was written in Ruby, like Cloud Foundry was. I actually from a development perspective, and just liking working in a language once the system is set up, Ruby is still awesome to me. Deploying production systems with the Ruby VM and all the dependencies, and we had dependencies on event machine to do async stuff more efficiently and stuff, wasn’t going to work. In 2012, when we had started Apcera, we were internally huddling around, yes, NATS will be the control plane addressing discovery and telemetry system for the Apcera platform as well, called Continuum. I didn’t want to run in Ruby anymore, and we were looking at either Go, which was the newcomer. I think it was at 0.52 at the time, or Node.js, which was also a newcomer, but not as new at least from a lexicon perspective as Go. There was definitely some initial things that we chose.
Then, after being in the Go ecosystem for so long, there were some interesting observations now about why it was the right choice that weren’t necessarily the original decision makers. The original decision makers were trying to alleviate the pain that we had deploying production systems with the Ruby ecosystem. Node, even though it had npm, or the beginnings of it, at the time, it was still a virtual machine, had a package management system that had to be spun up and all wrapped around it. Go had the ability to present Quasi-Static Executables. We do full blown static executables, you had to do a little extra work. That was a huge thing, meaning our deployment could be an SCP, essentially. Goroutines and the concurrency model were interesting to us, for sure.
The other big defining factor for me, because I spent a long time at TIBCO designing a system to do this was, in TIBCO, we wrote everything in low level C. Which is still probably one of my favorite languages, even though it has a lot of challenges there, of being that close to the metal was fun. I’ve learned Rust. I’m going to learn Zig this holiday as my pet project. I probably would never program in C again, but I still liked it. At the time, it was very interesting to me within what we were trying to do, to flow from 80% to 90% use cases that would live on the stack, to transparently move themselves to the heap. That’s very hard to do in C. I spent a lot of time and effort to get that to work in C, and Go had that for free. Almost nobody cared about that. They’re like, what are you even talking about? I said, I spent so long trying to do that in C and Go has it. At 0.52, Go’s garbage collector was really primitive, very primitive mark and sweep. To me, I was like, it doesn’t matter, because I can architect to have most of the things on the stack. If they blow past the stack, they auto-promote in Go, I don’t have to do unnatural acts like we had to in the C code base at TIBCO. It was static executables, and stacks were real, were the decision points.
The concurrency was a nice to have. Again, looking back now at the ecosystem, go-funk was bigger impact than people thought, huge. Everyone does the same thing now. The tooling, Go Vet, pprof, the way the testing all was in there. The number one thing for me is that if I go away from the code base, maybe it’s because I’m old. If I come back, I immediately know what I was doing. Or even if it’s let’s say code that you wrote, I could figure out pretty quickly what your intent was with Go as a simple language versus Haskell, or Caml, or even sometimes if people went into Meta land with Ruby, and essentially we’re programming DSLs. You went back to a code after a couple months and I’m looking at it and it would take me an hour or so to figure out what I was even trying to really do. That also lends itself to bringing new people in to get up to speed very quickly with a language. I still think that’s huge.
The Adoption of Rust
Cormack: We talked a lot about how Go got started in the cloud native ecosystem. Recently, we’ve been seeing a bunch of projects in Rust as well and we’ve seen other languages. I talked to Matt Butcher about how he adopted Rust. He had started off as a Go programmer, he built Helm among other things. Recently, he started using Rust for new projects.
Butcher: Ryan Levick, who is one of Rust’s core maintainers, but he also works at Microsoft when we were starting to look into this, and he just dropped into our Slack and was like, “I heard you’re writing a Rust program Clippy style.” Basically, anybody who wanted to learn Rust, Ryan was more than happy to walk them through the basics, then point them at some resources, and then answer those first few questions about how to do the borrow checking correctly. Very rapidly, I think six or eight of us got going in the Rust ecosystem. The default started to shift. We wanted to write Krustlet in Rust, because of the way we wanted to build a Kubernetes controller. We hadn’t intended to start writing other things in Rust, it just happened out of that, that new projects started to default to being written in Rust instead of Go.
Why Krustlet Was Written in Rust
Cormack: What was it about Krustlet that made you want to write it in Rust then?
Butcher: The main one was we wanted a WebAssembly runtime, and the best WebAssembly runtimes are either written in C or C++ for the JavaScript ecosystem, or are written in Rust. The one we wanted to use was Wasmtime, which is the reference implementation of the WASI specification. That was written in Rust. We looked at, we could compile this to a library and then link it with Go. Then, once everybody else started working on Rust, and going, “I like the generics. There’s a Kubernetes library, the kube.rs crate is pretty good.” Before long, everybody wanted to write it in Rust. Ron had to write all of Krustlet in Rust. Where it started, really, because of the necessity of wanting the WebAssembly runtime, it ended with us choosing it because it felt like the right language for what we were building. Then the surprising conclusion from that was we started writing other projects in Rust because it felt like the right fit for the things we were starting to do moving forward from there.
WebAssembly and Zig
Cormack: Derek had quite similar thoughts about lighter weight languages for lighter weight processing, particularly on the edge. We talked about WebAssembly as well, and also Zig.
Collison: Most of the new ecosystems have taken a similar approach. The standard library can’t just be scalable. Even Zig, which is one of the newer lower level languages has spent quite a bit of time on their standard library, fleshing it all out.
Cormack: Even C++ has decided it needs HTTP and TLS, but it’s going to take another decade to get there.
Collison: I don’t know how long my career will keep going for, but I can say with confidence, I will never program in C or C++ again. I’m ok with that. I think there’s better alternatives now, for sure. I also think with the other prediction around edge computing, at least my opinion that it’s going to dwarf cloud computing. Cloud computing will become the mainframe very quickly. We know they exist, but who cares? Nobody ever really interacts with them, they just live in the background type stuff. Efficiency, so not necessarily performance, but efficiency. How much energy and resources are you using to do the same amount of work, is going to come back into play. I think enterprise with .NET and Java will still remain and still be driven especially within the data center or the cloud world. I think you’re going to see C, Rust, Zig, and then of course, very high speed Wasm or JavaScript engines as the looser, maybe some MicroPython, CircuitPython type stuff. TinyGo is becoming really interesting, in my opinion.
Q Programming Language
Cormack: Solomon is still a big believer and a user of Go, but it was another language that we talked about where he would like to see changes.
Hykes: I still write Go. I’m not the typical programming language early adopter. I tend to use the same tools for a long time. We were probably a strong influence in the adoption of Go, and also in the adoption of YAML in the cloud landscape, and so there’s one I feel better than in the other. YAML I think is just a source of problems. It’s not that it’s bad. It’s just that it’s used for things that it wasn’t meant to be used for. It’s just being overused. That’s the sign that there’s something missing. This new project that we’re working on, Dagger, it’s written in Go, but it’s configurable and customizable to the extreme. YAML or JSON just didn’t support the features that we wanted to express. We found this language called Q. Initially, we used HCL in our first prototype. Terraform and other HashiCorp tools use HCL. I think it’s an in-house project. It spun out as a library, so you can use it in your own tool. It has limitations, pretty severe limitations. You can tell it started its life tied to a specific tool, and not as a standalone language meant from the beginning to be used by multiple tools. Q on the other hand started out as a language. It’s Arthur [inaudible 00:21:33], is a language experts. Exactly like Go solves a specific problem, it felt like it was written perfectly for us. Q felt the same way as a replacement to YAML. I’m a huge believer in Q’s future. I think it will, or at least it should replace YAML in many cloud native configuration scenarios.
Lessons Learned from the Adoption of Languages in Cloud Native
Cormack: What have we learned about the adoption of languages in cloud native in particular? The first thing that’s clearly important, very important is community. This is the community around you as you start to think about using a new language, and the things they’ve built and the way they’re building them. Second is the community that you want to bring to your projects, and how you want them to be able to adopt the language and tools you’re building. The second one is fit for a problem domain. For cloud native, there were some requirements that a lot of people mentioned around things like static binaries that were useful to be able to distribute their code easily or let people run as easily in production that were important. Always, you knew this fit between the problem you’re working on. Moving into a new domain is actually a great opportunity to examine the fit for the tools that you’re using, the languages you’re using now and decide whether that’s a good point to make a change.
Performance was also important for the cloud native use case. It was interesting that it came up a little bit. The language performance actually grew in line with the requirements. The conversation with Sugu about YouTube, it was really interesting that Go managed to keep growing and meeting those requirements as the requirements became more difficult, and they never got to the point where they had to give up. It’s important to remember that languages can change and evolve with your users, and they grow, and the ecosystem around them grows as you start using them. Those things are really important.
Then, finally, everyone’s journey into learning new languages was different. People often thought about things, experimented maybe years before they actually adopted a language. Also, there’s a whole journey towards internalizing how to work in a new language and how to use the opportunities it presents best. That process of learning new languages is incredibly important to people. It’s really important that we all continue to learn new programming languages, experiment and see new ways we could do things, so that when we get an opportunity, like when we’re moving into a new area or experimenting with a new idea, we can think about what programming language would work best for this, and what kind of community do I want to build?
Questions and Answers
Schuster: It seems that ahead-of-time compilation, or having static binaries is one of the big selling points for languages like Go or Rust. Even Java nowadays has ahead-of-time compilation. Is that going to be essential for all future languages that come along?
Cormack: Yes, it’s interesting why it matters, and then what for? I think the comment was around serverless. Serverless, really, startup time is incredibly important, and it becomes one of the constraints because you’re there and you’ve got to do things, and you get people who work around it by trying to snapshot things after startup. Interestingly enough, Emacs even used to do that, as an editor. Emacs used to snapshot itself after startup because the startup was too slow. It does depend on what that period is, and how to work around it. Emacs no longer does, because computers were fast enough, it wasn’t an issue. It does depend exactly what those constraints are. Ahead of time has those big advantages. The user experience is worse. In theory, with the JavaScript model, you can start running the code slowly with an interpreter, and maybe it doesn’t need to be fast, and you only compile it if it’s really going to be used. Static compilation is just not worth it for those kinds of applications where most applications are so small. Even like an interpreter is fine. I think there are compromises, but I think we’re seeing a lot of spaces where ahead of time is working better.
We’ve gone back to that, because it’s how languages originally were from the ’70s. It was Java that moved away from that, but JavaScript followed there. There was a huge investment in these JIT technologies. Then we are seeing a little bit of a swing back to ahead of time. There is always the theory that JIT and profiles based on actual execution can be faster. In general, that’s mostly been true for dynamically typed languages where you can work out what the types are. I think the ahead of time thing has gone with a revival in static typing and the shift back to let’s fix these bugs at compile time, because it’s annoying to fix them at runtime as well. I think that combination of static typing and ahead of time, definitely we’ve swung back that way again, for some of those reasons.
Schuster: It’s also important for serverless, especially because there you don’t want to pay essentially for the compiler to do some work if you can do it ahead of time.
Cormack: As serverless has had billing with smaller intervals, that becomes more important, and as we want to do really lightweight things in serverless. Small code size also becomes important for those things. It’s very much the case with WebAssembly, where, again, Rust has become a popular language to compile to WebAssembly, because it compiles to a small static binary without a runtime. I remember talking to Cloudflare about the hoops they were having to go through with Go in WebAssembly, because compiling the language runtime to WebAssembly was a few megabytes of overhead. Again, they were really space constrained by how quickly they could load code into a machine. A megabyte of code is much quicker than 100 megabytes of code just to load up and how much concurrency you can get, and those types of issues as well. Those kind of constraints are related as well. I think that’s what a lot of the discussion about edge use cases, and Derek’s conversation about TinyGo, and MicroPython, and things like that, where they’re really designed for really small runtimes. That gives you advantages if you want to run them for very short periods of time, or a lot of things at once, and those kinds of things. Memory consumption is one of the big constraints for how many customers can you run at once, is take your memory consumption divide it by the size of the application. That basically gives you the amount of the things you can multiplex onto a CPU at one time. As serverless and those things started to get into those constraints, those types of constraints start to matter a lot too.
Schuster: We just heard a talk about how Shopify is using WebAssembly to allow people to extend their platform, and that also quite nice kick in by Rust for it and it can pack a lot of code into a small space, because it’s naturally isolated. It doesn’t need containers, and stuff on virtual machines to isolate the code from others. It’s also an interesting trend in what WebAssembly allows here.
Cormack: I think isolation is a technology that has always been important. It just has different shapes over time and different kinds of sizes. We started with virtual machines and containers were smaller and more convenient. We’re now looking at things like, can I isolate parts of a single application? Because I don’t trust them, or I don’t want to audit the code in them. Google has a rule that every untrusted bit of code has to have two isolation layers between that and their code, for example. Those two isolation layers could be different things in different cases, but one isolation layer could be broken, but two is much more difficult. Yes, if you’re on Shopify and you’re embedding customer code in your code, then that’s something you have to isolate, and you want isolation layers with that. Those might be the Wasm runtime and some Linux kernel process isolation. For example, you run the runtime in a separate process, or they might have a couple of other ways of doing it. The more we make our applications out of sets of code with different trust levels, the more we need isolation at lots of different scales. Everything from VMs for cloud tenants, down to containers for, “I’m running six applications at once, and I don’t want them to interfere with each other,” to, “I’m running a library that the customer provided and I have noticed it,” or, “I’m running a library that I got from npm and I don’t trust it.” Can I run that in isolation as well?
Schuster: There was some interesting work with capability based isolation inside of JavaScript Engines.
Cormack: Kate Sills did a talk a while back at QCon that was really good.
Schuster: What happened to that? It had one of those ungoogleable names that’s hard to keep up with it. It was supposed to come in one of the ECMAScripts. Something to check up on, I think.
I have not heard of this, but it occurs to me that a cloud provider could provide a JVM Platform as a Service in a serverless manner.
Cormack: I think there were some back in the day. The JVM was like the first language runtime that was designed for secure isolation. The security isolation wasn’t actually very good, in the end. It was broken a lot of times after it was initially released mainly through security issues in the standard library and so on. It was an experiment in isolation. You can see Wasm as being a more secure version of the JVM. There have been a lot of lessons learned in the last 20 years, or is it even longer, since JVM. A lot of lessons learned on how to build secure isolation for language runtimes. Wasm really is the state of the art that came out of the browser as the most attacked piece of software we ever built. There was a lot of work, particularly from the Google team around Chrome and those kinds of layers of isolation there that taught us how to do that better. I think back in the day, people did have that idea. The JVM runtime wasn’t quite designed for that, and wasn’t quite secure enough. It’s very much in the same line of forms of isolation that we’ve worked on over the years.
Schuster: The advantage that Wasm has is that it just doesn’t stuff as many features into the standard runtime, because with Java, you can import data file formats and stuff like that.
Cormack: The type system is reflected inside, which turned out to be quite complicated. Whereas Wasm has very simple linear arrays, and again, the language has to compile down the type system it wants on top of that, so it’s even simpler. WebAssembly is almost recognizably an assembly language apart from has better looping constructs, but it feels more like a machine level thing than a language level thing. That, again, makes it easier because it’s simpler.
Schuster: I found it was quite fun trying to write code in it with the text format, which is a Lispy type of thing. It’s much easier than assembly.
Cormack: Yes. It is fun. It’s not perhaps designed for that. When I was younger, I wrote PostScript, which was like that too. It was Forth based and it felt amazing to be able to program a printer.
Schuster: Did you hack the printer? Any stack overflows in there, any recursion overflows?
Cormack: Yes. You got them all the time.
See more presentations with transcripts
MMS • Jean Yang Manuel Pais Arty Starr
Article originally posted on InfoQ. Visit InfoQ

Transcript
Kerr: I’m Jessica Kerr. I work at Honeycomb.
I have invited Arty because she wrote a book called “Ideal Flow,” which is all about the development experience in the code, and how can we stay in flow? How can we reduce the number of bad surprises we get? Jean because she is CEO of Akita Software, which is very much about giving us the visibility we need into the complexity that we have, rather than trying to smooth it over and pretend we don’t have it. Manuel, because he is the co-author of “Team Topologies,” which is this most excellent book. I now have a place to point people when I want them to understand what we need to do is make it so developers have a reasonable amount of cognitive load in their team structure.
The Big, Inherent Problem in Software Development
I want to ask each of you to start out with, what do you think is the big, inherent problem in software development these days? In the real world, not the FAANGs, not the VC funded startups, but the meat of the software industry, the salt of the earth. What do we keep running up against?
Pais: To me, obviously, there’s the aspect of cognitive load that we’re discussing here. I think we’ll go more in depth in there. Essentially, teams being asked to do so many things. Like you said, Jessica, and if you’re in a FAANG, or some company that has all the resources to have the super skilled people, that’s great. That’s not the normal case.
Kerr: We talked to Phillipa from Netflix, and she talked about layers of development experience teams. What are some of these things?
Pais: In my mind, the problem I see in many teams is that they’re being asked to do all these things, usually a lot of the technical aspects that they’re being asked to do, and then not think too much about the actual business side of it, the actual customers. Just, here’s the backlog, go and execute and worry about security, worry about testing, and all these things, which are obviously, super important. I don’t see the teams empowered to actually think about, are we making progress for our customers? Are we actually helping them and therefore helping the organization as well? This is not just, the management doesn’t give them the authority. It’s not just that. I think it’s both ways. I also see many teams that shy away from taking that ownership. Sometimes, it’s easy to just hide a little bit and say, “That’s for someone else to decide. It’s not up to us.” Why isn’t it up to you? You’re the people who are closest to the customers who are on the ground, and you can see the system running. You can see what the users are doing, and is this going in the right direction or not?
Kerr: There’s so many technical decisions to worry about that they don’t get to make the really crucial decision of, what should the system do?
Pais: Exactly. A lot of focus on technical aspects, I think, not enough on the actual customers.
Kerr: Jean, what do you think?
Yang: I think for me, it is heterogeneity. Here’s what I mean by this. If we look at most software systems, I have this analogy I like to make that they’re like evolving rainforests, not plant gardens. When people talk about tech stacks, especially the influencers we see online, they’re like, just use my service mesh, or just use my new framework and all of your problems will go away. The fact of the matter is a lot of people out there, they have decades old legacy software or they had a bunch of decisions they made, and they can’t just switch everything over. For me, I came upon this view because I was working in academia on programming language design, and I was preaching, if you guys just made good choices, all of your problems would go away. Someone came up to me after one of my talks, and they said, “Jean, that’s fine. That’s like going to the doctor and the doctor saying, ‘If you had just exercised and eaten an apple a day since you were born, you wouldn’t have these problems.'”
I think a lot of people see software heterogeneity as the sum total of a series of bad choices that people made. Really, it’s like what Manuel said, it is technical meets people. People make different choices over time. People make different tools over time. The result is people contributing to a software ecosystem are going to come up with something, a multilayered heterogeneous with many different kinds of pieces. One way to think about it is, it’s like cities, like Barcelona is one of my favorite cities, it has just many layers of history all together. Do you want to be Barcelona or do you want to be like some city that got frozen in time? Everyone wants to be Barcelona, and so we should let software have the tools to do that.
Kerr: You’d rather be Barcelona than like Brasilia, which was planned and nobody likes it. The planned parts anyway.
Yang: It gets outdated. Yes, all plans have to evolve.
Kerr: We have this series of choices that were made that they weren’t bad choices, they were just choices. Now we have this heterogeneity, and that gets back to all the things that Manuel brought up, there’s just so many different things to know and think about.
Starr: Over the last decade or so, we’ve added an insane amount of complexity to the software domain, in terms of the sheer number of things you have to know to be even basically proficient, has become extremely complex. I look at all this growing complexity versus what it is we’re trying to accomplish, and it’s easy to become enamored with these new technologies. That we should do it this way because this is the new and cool hip way to do things, or idiomatic changes being made just for the sake of, let’s do something fresh and cool and different. This will be a new, neat way to do it, so let’s update the libraries to work this way instead. Then all the people that are using those libraries, they have to go and rewrite all of their API connections and stuff to make that work. Then we’re on the new cool thing. Things are moving so fast, and we build on top of a tower of dependencies. As all these things are constantly shifting, we’re always keeping up with this complexity.
If you take a step back and look at, what are some of the Grails that we chase, of the goals that we’re reaching toward, that we’re trying to optimize for. It makes me wonder if some of these things that we’re chasing, actually are counterproductive. For example, one of the Holy Grails is that we should only have to write business code, and that all of the other stuff should be part of our platform or whatever. What ends up happening in practice, though, is we manage to get rid of cyclomatic complexity through lots of dependency injection and wiring things together. We don’t have a bunch of branchy IF code, that is our code anymore, but now all that complexity has shifted to the wires and shifted to the integration space. Now when something breaks, and you’re trying to troubleshoot what’s going on, now you’ve got a million different factors of things interacting with one another. Our troubleshooting costs have exploded at an insane rate, yet, because we’re only looking at, “My code complexity went down. I don’t have lots of branchy IF things anymore, I’ve got high code coverage now because all this stuff went in the platform.” All of these metrics and things we chase as the good things we’re aiming for, show that we’re doing good. All this complexity that has exploded in other places, we don’t really have a good way to keep tabs on, so it’s become part of this invisible blind spot space where all of these costs have exploded.
Kerr: Our aesthetics, we’ve applied them to the code we’re working on right now, but as a result we’ve made a bunch of things that used to be explicit, implicit and harder to see.
Starr: Those costs are very real, though. When something breaks and you diagnose things and figure out what’s going on, they still affect us every day.
Akita Software and One-Click Observability
Kerr: Does Akita address that? Is that one of the things you are addressing?
Yang: At Akita, our dream is one-click observability, so to make it as easy as possible for people to understand how the different components of their system are talking to each other. We address some of it, but not all of it. We address cross-service, cross-API complexity. We’ve decided to take an API centric view of the world. Anything that happens across APIs, we’ll tell you about, drop us in, we’ll give you an 80% solution on day one, we like to joke. We’re not a power tool. We want to make it so that anyone can install us within a few minutes, and we’ll give you something as soon as possible. We’ll tell you this is how your APIs are talking to each other. This is what your API graph looks like. This is the data types you’re using. This is what the endpoints are structured like. This is how that’s working. I totally agree with everything Arty says. That’s a big part of the motivation. For me, the way I saw it was, we can’t solve all parts of the complexity problem, so we’ll just start with the points of communication across the network. I would love to see more tools that dug in there and did all the other parts.
Microservices and Complexity in Connections
Kerr: Because one way that complexity gets pushed out of the code you’re looking at is when you move to microservices, and each one is nice and happy and cute, but the complexity is in the connections.
Yang: Yes. I’ve had a series of conversations with people who they’ve said their org has taken on microservices, because they think it’s a technical solution to what’s actually a human problem. It doesn’t actually make any of your problems go away, it creates more problems. For us, some of our users aren’t even super microservices based, maybe they’re on a monolith. Maybe they have a handful of services. Everything calls out to a lot of stuff these days, so you are making network calls to your datastore, your data stream, your third-party services, like everything is living in this network based ecosystem.
Kerr: Even if you think you have a monolith, it’s still a distributed system.
Yang: Absolutely.
How to Solve Complexity, From the Human Side
Kerr: How do we solve this from the human side?
Pais: Unfortunately, there’s no silver bullet. Obviously, I agree with Jean, when she’s saying microservices are not the answer. They’re not the first answer. This has a lot to do with cognitive load. We’re thinking about teams, and obviously, from Team Topologies perspective, we think of the team as the unit of delivery, not the individual. When we think in particular about software architecture, we should be thinking at the team level, what is the size of this service, or this thing that makes sense for one team to handle? That they have enough capacity to build, test, operate, but also understand, what is the actual business value of this thing, of this service? Maybe this is more like macroservice, or whatever you want to call it. Looking at the architecture at the team level, I think it’s a first step. Then maybe you’re looking to microservices as the more technical implementation, and there’s a lot of good patterns to adopt.
When you do that, you also need to be mindful of how much cognitive load this is going to put on the team, if we’re now forcing them to adopt all these and take care of all these failure scenarios and all the things that make it complicated to manage and run microservices. What do you have in place in the organization to help teams address this cognitive load? Do you have maybe some enabling teams or teams that help learn the skills around microservices? Do you have proper platform services to support the microservice architecture? What do you have in place? You can’t just put it on the teams to now go to microservices. I see that with several clients where, ok, we want to move to microservice. That’s the right thing to do. Then they don’t think about, what is the support system so that the cognitive load of the teams doesn’t explode? Teams that are used to work with monolith, are used to work with different kinds of sets of constraints and problems of a monolith versus microservices.
Team Cognitive Load
Kerr: Building the team size or the software that you assign to a team, usually, traditionally, we think in terms of how much work can we assign to a single team? How much work is happening in this piece of software right now? You and your book propose that we think instead about how much is there to understand? How many of these things? How much of that heterogeneity? How many layers of choices are we putting on this team?
Pais: Exactly. The team cognitive load can be or should be a key factor in several decisions. I mentioned the architecture. Also, if we want to help this team manage their cognitive load, what is the right approach? What I see often is a very limited set of options. Like Jean was mentioning, that teams or organizations think that, if you just adopt this new framework or this new tool, it’ll make your life easier. Actually, in practice, it often increases cognitive load. The other approach is, we need someone to join the team. We need an expert in this new thing. We need to worry about, for example, we don’t know how to do CI/CD or observability very well, we need to hire someone. Actually, is that going to help address cognitive load or not really? It depends. For example, with CI/CD, maybe you don’t want to dive into the details and get to now worry about all the details of your CI/CD infrastructure and tooling. Maybe you’d like to have either a platform service or you’d like to use a third party. That’s what’s going to help minimize cognitive load, not hiring someone to take care of the CI/CD. Because then we’re taking on more cognitive load by hiring this person.
Kerr: When they bring that expertise onto the team, that’s that many more things that the team as a unit of delivery needs to maintain, and collectively understand. Especially if you hire a consultant to do it, and then let them go, and then everything.
How to Know When a Team Has a High Cognitive Load
How do you know, what are some of the signs of a team being at too high level of cognitive load, as opposed to being too busy?
Starr: I feel like I want to start with just defining what cognitive load is, because it’s a super abstract term. I feel like that would help and give me a way to answer that question of what it looks like when we’re struggling in terms of feeling overwhelmed with cognitive load. The way I think of this is, humans have a specialized capacity for focused conscious attention. Our focused conscious attention, it works like a flashlight. You can think of having a flashlight that is focused in one spot, or you can have a flashlight that is diffused. We’ve got this flashlight, and what is our flashlight doing? It’s scanning for things that are noteworthy. Then as we take note of things, so each thing is a thought that we have to hold on to in our brain while we’re trying to accomplish something. When we do this focused attention thing and try and take note of all of these things, it doesn’t happen in a vacuum. We aren’t staring at a piece of paper, we’re usually trying to solve a problem. For example, if I write some code, and then I run a test, and I’m expecting the test to return five results and it returns no results. What happened? Now I’ve got a puzzle that I’m trying to solve. I’m confused, and I’m trying to figure out why.
Then I’m going to scan the areas of code with my flashlight, and I’m going to pick up what is noteworthy as to things that might be relevant to reasons for why the code might be returning no results. Each one of those things that might be noteworthy in the code somewhere are things I’m going to try and hold on to in my intentional memory. Our cognitive load is affected by how many of these little things we have to keep in our intentional memory in order to solve a problem. If we walk away and go do something else, and we come back, all those little things aren’t in our memory anymore. These type of dynamics where task switching, for example, going and doing something else, going to lunch and coming back, affect our ability to pay attention to these things. We have to load all of these things in our brain, all of these noteworthy things to be able to solve the puzzle at large.
There’s this dynamic of us trying to absorb lots of things in our brain, and pay attention to those things and focus on that long enough such that we can solve the puzzle at hand, when there’s lots of little things that we have to pay attention to, in that sprawling because of the complexity. For example, if I just had an exception that was thrown that told me, you’re getting a NullPointerException. You know exactly where to go to solve the NullPointerException, usually, because you’ve got a line of code that you go through right there. Something like, there’s no results returned, there’s a whole bunch of different ways that that outcome can occur, that can be really tricky to end up resolving. The nature of the dynamic of how things are failing, and what observable clues that we have to diagnose those things, how much they sprawl across different systems, you can imagine all of the different sorts of things that are noteworthy that we have to pay attention to.
Things that you might see symptomatically, if a team is struggling with this, is troubleshooting times in particular, go through the roof. The number one factor I would pay attention to, is the tools I’m working on building, raise an alarm when you hit that confusion state when you start troubleshooting something. Then that gives you the ability to swarm on that and help one another if you need to, with regards to troubleshooting a problem. When those troubleshooting times skyrocket, usually there’s a problem with those cognitive load factors surpassing the team’s capabilities to do. That long, focused, conscious attention, it drains energy. It is work for the body, for your brain. Your glucose levels are dropping as your brain consumes all this energy trying to focus on these things. When troubleshooting skyrockets, and you’re spending lots of time super hyper-focused trying to solve these problems, the team gets exhausted from the stress of that.
Kerr: Exhaustion and stress, and in particular time spent troubleshooting are a really good sign that the team has too many things to think about and trace through.
Jean, what would you look for?
Yang: I really like everything Arty said. I think that’s also what I would look for in the people. I think in the technical artifacts, related to what Arty said, I would look for every time someone has to troubleshoot something, or any time someone has to figure out what’s going on, are there tools already to help with that? If people have to keep information in their own heads about, here’s my model of how the technical framework all works together. Here’s my model of how the system works together. That’s going to increase troubleshooting times, that’s going to increase the load on everybody. A lot of my goal has been, let’s take some of that and make it explicit. Let’s build tools that show your team how stuff is connected. Let’s build things so that people don’t have to put the burden on themselves of documenting their API, how their API talks to other APIs. Let’s build tools that take the things that people right now have to either talk to each other in words about or they have to reconstruct in their heads by looking at logs, by looking at traces, by looking at other kinds of things and actually doing something explicit with it, automating that process. What I would look for is, are there tools that take load off of the software teams, when it comes to modeling what’s going, when it comes to automating some of the communication about what’s going on? If there isn’t, chances are, they’re overloaded. Troubleshooting takes a long time.
Kerr: You’re looking for pieces of knowledge that are like tribal knowledge. Maybe they’re partially documented, and people talk about them word of mouth and on the whiteboard. You’re looking for that implicitly no knowledge, and then looking for tools that make that explicit without having to document it, manually?
Yang: I think that there’s this assumption that how stuff works is implicit folk knowledge. It doesn’t need to be, it just is because we don’t have things that help us map that out right now. A very simple example of something that reduces cognitive load, although this is very controversial, is types. I have many friends who will say, I can’t imagine what it’s like to work on a large JavaScript code base without TypeScript, because how do you maintain that? How do you talk to other people? This was a controversial one, but types are one example of once you make that explicit, you don’t have to talk to a human about that anymore. I also like the example of types, because once type inference got good enough, people didn’t have to sit around writing all their types all the time.
Kerr: It made it not so hard to get that explicitness.
Yang: Exactly. I think there are many other dimensions of our software systems besides the types where we could take off some of this load. Because right now, most things people think of it as, you have to ask so and so over there, if you want to know how this works. Or, let’s cross our fingers really hard and hope someone documented this, so we don’t have to dig through the code. If we can build more tooling that automatically builds the models, or automatically builds some documentation that can take a lot of load off.
Kerr: Software to investigate our software.
Manuel, what do you look for?
Pais: First, I wanted to say I really liked the flashlight description, Arty. I’m probably going to use that, if that’s ok. It’s a very visual way to think about cognitive load. Also, just wanted to add, that you have different types of cognitive load, if you go to the psychology definition. I think when you have that flashlight, and then there are different things that are playing a role, so you might have some foundational things that you need to know. If you’re working on JavaScript code base, you need to know JavaScript, how it works, how it’s a non-typed language. If you don’t have those foundations, because you don’t have the experience, or it’s something that’s new to the team or whatever, then the flashlight is going to be pointing at that. You’re going to maybe do a lot of Googling and finding out answers. That’s one type of cognitive load, which we have good techniques, like pair programming and more programming, are so important to help with that. Because then you can get, maybe it’s that tribal knowledge you were talking about, but at least have people together learning, and the people who are less experienced can learn from others. Often, there’s a very reductionist view on those techniques, as if, it’s not so productive, because you have two people working on the same task, but you’re not thinking about all the other things. If you’re actually reducing cognitive load over time, that’s actually pretty efficient. That’s one type.
Then there are other things that are distractions sometimes. To take that example where we’re running some tests, and we don’t get any results, if it’s working with a database, maybe the database was not accessible so now we will have to go and think, how do these tests run? Which database do they connect to? How do I enter the database and see if it’s running or not? Those are all distractions that are also part of the cognitive load. Now we started going off in this tangent where we’re no longer thinking about, what did we actually want to test? We’re thinking about all this other stuff. All this reduces our capacity to be thinking about actually, what did we want to do? What was the scenario we wanted to implement? What are the user personas that are going to benefit from this change we’re trying to make? What is the business context? What are the failure scenarios we need to deal with? Those three things. There’s foundational things that if you don’t have in place, like skills, that are going to take up your capacity. There’s distractions, things that you need to worry about, because you don’t have the right support, or the right practices, or what have you in place, or computers happen. That often leads to, we don’t have enough of that capacity and that focus of pointing our flashlight to the problem we’re trying to solve. At some point, we already are so far off from that.
We can ask teams, what is their experience? I wouldn’t start focusing on specific issues. Actually, a first step could be just ask the team, what can be better? Then ask the team, what is your experience to build this software? What is your experience testing? What is your experience operating, being on-call for this, troubleshooting this service? You can get a glimpse from the team and from the individuals in the team, what are the things that are difficult? What are things that are painful? One sign would be the things that they tend not to want to do very often because they’re painful. If it’s painful to deploy, then we’re probably going to want to let’s not deploy every day, because it’s so painful. Let’s do it less often.
Kerr: That’s the, if it hurts do it more thing. Because if you do it more, you’ll make it easier.
Pais: Yes, you’re forced to find ways to make this easier, so it’s not a pain. I think I heard that phrase from Jez Humble, and continuous delivery. We have an example, a forum where you can ask the team, what’s the experience like of doing these things that you need to care about for evolving your software? Then over time, you can see if it’s improving or not. If we know, cognitive load is too high to deploy, let’s say, it’s really painful. We’re going to try to do some things, maybe better tooling, maybe people following some training or what have you. Then maybe, let’s see, in three months, six months, has this pain gone down or not? Is the developer experience improving?
Kerr: This is like developer experience, in particular, whether people are having a nice time of it at work, is a big clue to your socio-technical architecture, of both your teams and your software, of, is it good? Is it getting better? Not, are they having fun playing Ping-Pong, and do they like the latest flavor of LaCroix in the fridge? Do they get into flow, and do they get to stay in flow?
How Much Open Source Adds to Cognitive Load, and When It Can Reduce It
Manuel, you used a phrase, reducing cognitive load over time. I think it’s naturally as we build software, we are inherently increasing cognitive load, because we’re always adding more things, we’re always making it do more. Working to continually reduce it is so important. How much has open source added to cognitive load? When can we use it to reduce it? Who has an opinion?
Starr: I feel like we should separate lack of familiarity from the experience of cognitive load of learning something, because there’s a different dimension of dynamic when we’re unfamiliar with something. With open source, we’ve gotten to this world where 90% of our software is made of third-party parts. We don’t build things from scratch anymore, we build on top of this mountain of things that are out there and available. We rely to a certain extent on the stability of those things, because of the eyes of the community and everyone else having to deal with the friction of upgrades and things breaking, and all that. Such that those libraries and things out there, we hope will generally be stable. That when we Google for something, the answer to the error message that’s on our screen, we should find that on Stack Overflow, hopefully.
The dynamics of how we go about doing development has significantly shifted in a couple different ways. One, of how we go about searching and finding answers and not just dependency aspect. Then, that 90% of the software that we build on top of is also things that are largely unfamiliar. We’re building on top of abstractions, and pulling all of this unfamiliar code into our code base. I think there’s inherent risk with this direction we’re headed in. I think about when the open source movement first started, and we had this very community oriented, we’re going to care for the software ourselves. We’re all going to be part of the community and build it together, and it’s going to be great, and people really did get involved. As time went on, we’ve shifted toward a mode of having an expectation that all this stuff would just be out there. As opposed to being a creator or contributor, we tend to be more a consumer of these things and relying on them existing to be someone else’s burden, but not our own.
Kerr: You can’t contribute to everything.
Starr: I’m concerned about those shifts from a safety standpoint of, what’s the consequence of us building on top of a bunch of things that we really don’t know how it works?
Kerr: We can’t know how everything works.
Starr: How does our familiarity with those things drift over time, in aggregate? As a community, are we becoming less familiar with the infrastructure that we’re all dependent on?
Yang: I think it’s not just open source, but the fact that people are buying off-the-shelf infrastructure, or people are using off-the-shelf APIs. It’s everything. Everyone’s living in a software ecosystem these days. I was talking with some Google old timers the other day, where they said, back in the day, there was one company where like, if you wanted to look at what kinds of new infrastructure was getting built? There was a small handful of companies at the cutting edge of building infrastructure pieces, and you could go there and train yourself to do it. Then you could go off and build infrastructure wherever you went next. Now, everyone buys off-the-shelf pieces for the things that they built by hand themselves, they knew how everything worked. We’re just living in a different era.
If we go back to the building analogy, it’s like, when everyone was building their own houses out of mud, you knew what mud you used, and the houses were pretty small. Now you’re getting random shipments of bricks, and all these other things from everywhere. We need to make sense of how it’s all going to fit together. I used to be very enamored with these building analogies, because there’s one guy I knew who used to give all these talks, saying, we can measure buildings, and we can talk about their structural integrity, what about code? I think code is something completely different, because the people are a part of the code. People are part of the buildings too, but it’s different. They’re not part of the structural integrity of the buildings. They are, too, but it’s still different. I do think we live in different times. I think that people are much more a part of the software processes and the code than any other analogy we can make. I don’t know what to do about that, but that’s just how it is.
Kerr: The people are part of the structural integrity of the code.
See more presentations with transcripts
MMS • Renato Losio
Article originally posted on InfoQ. Visit InfoQ

Forrest Brazeal, head of content at Google Cloud, recently argued that serverless functions are the cloud’s biggest billing risk for developers as there’s no simple way to protect against recursive calls and they can scale out almost indefinitely on all the cloud providers.
Brazeal highlights articles written by cloud developers that describe mistakes that caused “run-away” serverless functions and huge bills. Among others, Aled Sage, VP engineering at Cloudsoft, reports an example of spiralling Lambda bill on AWS, Tom Wright describes a serverless horror story on Azure, and Sudeep Chauhan, founder of Milkie Way, explains how he burnt 72K USD testing Firebase and Cloud Run on Google Cloud. Brazeal warns:
It can happen so fast. It is the flash flood of cloud disasters. This is not like forgetting about a GPU instance and incurring a few dollars per hour in linearly increasing cost. You can go to bed with a $5 monthly bill and wake up with a $50,000 bill – all before your budget alerts have a chance to fire.
Discussing the specific limitations and protections of Google Cloud, AWS and Azure, the author argues that there is no safe way to protect against the risk as none of these providers has yet mechanisms to fully protect developers. Brazeal adds:
It is straightforward to protect yourself from spending too much on continuously-priced services like VMs (…) but there is just no good way to guarantee you won’t get clobbered by a surprise bill from functions (…)
AWS has a page dedicated to the recursive anti-pattern that causes run-away Lambda functions and acknowledges:
While the potential for infinite loops exists in most programming languages, this anti-pattern has the potential to consume more resources in serverless applications.
The concurrency limit on functions might help but can give a false sense of security to developers: it protects from a recursive fork-style scenario where functions scale out indefinitely but it cannot avoid large bills in a few hours, for example using the same bucket on S3 as source as destination for a function, as Sudhir Jonathan, technical architect at Qube Cinema, reported last year. James Beswick, principal developer advocate at AWS, wrote an article on how to avoid recursive invocation with Amazon S3 and AWS Lambda and explains:
If you trigger a recursive invocation loop accidentally, you can press the “Throttle” button in the Lambda console to scale the function concurrency down to zero and break the recursion cycle.
While there are many possible optimizations to save money on Lambda, as Yan Cui, cloud consultant and AWS Serverless Hero, recently demonstrated, there is no automatic circuit breaker on AWS when things go wrong. Among the possible mitigations that cloud providers could introduce, Brazeal suggests near real-time billing, hard caps on cloud billing and better automated anomaly detection and remediation for recursive workloads.
While the author focuses on the three main providers, Corey Quinn, cloud economist at The Duckbill Group, comments in his newsletter:
Oracle Cloud does in fact have a “we are bloody serious about the free tier and will not let you run up a charge until and unless you affirmatively upgrade.” It’s one of the best things about their platform.
Last year Brazeal, then director of content and community at A Cloud Guru, highlighted the lack of sandbox accounts and hard billing limits on AWS.