Month: September 2022

MMS • Johan Janssen
Article originally posted on InfoQ. Visit InfoQ

Akka, a toolkit for writing concurrent distributed applications based on the actor model, was created thirteen years ago by Jonas Bonér, founder and CEO at Lightbend. The company has recently announced a new Akka license model that has changed from the open-source Apache 2.0 to the source-available Business Source License (BSL) 1.1.
This means the Akka codebase is only free to use for development and on non-production systems. The BSL 1.1 license allows projects to choose another license after a specific period of time that will replace the BSL 1.1 license. Lightbend chose to revert the BSL 1.1 license back to an Apache 2.0 license after three years. Several other open source projects, such as Couchbase, Sentry and MariaBD, have moved to the BSL 1.1 license over the past several years.
The new license affects all companies with a revenue above 25 million dollars who wish to use the latest version of Akka. Current versions may still be used freely, but only critical security updates and patches are released for version 2.6.x under the current Apache 2.0 license until September 2023. Open source projects may contact Lightbend for an Additional Use Grant, which was already granted to the Play Framework.
Lightbend published the prices for production systems per core per year starting at 1,995 USD for the Standard package and 2,995 USD for the Enterprise package. These are standard prices and volume discounts might be applied.
Lightbend still encourages community members to contribute to Akka, which is permitted by the new license.
Bonér gave the following explanation for the new license:
We have decided to change Akka’s license to ensure a healthy balance between all parties, shared responsibility, and, by extension, contribute to Akka’s future development.
In the blog, Bonér details that open source software is created more-and-more by companies instead of individuals, and the companies using open source are more reluctant to pay for the software as they run it themselves. The new license model should spread the maintenance effort and cost as large companies will have to pay Lightbend to use Akka. Lightbend will then use that money to further maintain and evolve Akka.
The license change was heavily discussed by users of the Akka toolkit on social media platforms such as on Twitter, where the different options were discussed. Some of the comments included: companies might pay the license fee or remove Akka from their projects. It was even suggested that one company will buy Lightbend and revert the license back to an open source alternative. Some users debated whether or not an open source community fork will be created in the future.
More information about the licensing change can be found in the Akka License FAQ.
MMS • Nsikan Essien
Article originally posted on InfoQ. Visit InfoQ
AWS recently launched support for histories of AWS Glue Crawlers, which allows the interrogation of Crawler executions and associated schema changes for the last 12 months.
AWS Glue is a serverless data-integration service. The service is a suite of AWS integrations built around two major components: its data-cataloging functionality, Glue Data Catalog (based on Apache Hive Metastore), and its extract-transform-load (ETL) pipeline capability, Glue ETL (based on Apache Spark). A Glue Data Catalog, for which the Crawler history feature displays changes, represents a metadata store in the Glue ecosystem. The catalog houses table definitions, which describe the schema of data that exists in a location outside of Glue, such as AWS Simple Storage Service (S3) or Relational Database Service (RDS). The catalog can then be used by Glue ETL as a reference to sources or targets of data for its pipelines, as well as by other AWS analytics services such as AWS Athena. Table definitions can be added manually or created using Crawlers.
Crawlers are jobs that create or update table definitions in a Glue Catalog on their completion. They can be run ad hoc or to a schedule and interrogate the target data source by classifying and grouping the scanned data. Crawlers use built-in classifiers for inferring the data’s schema and format but can be enhanced with user-defined custom classifiers for more complex use cases.
On execution of a Crawler, the history feature shows contextual information such as the duration of the run, the associated computing costs, and the changes effected in the metadata store.
Given that AWS Glue is an amalgamation of synergistic tools, its components are often compared to other solutions rather than the entire offering. The Glue Catalog is often compared to the Apache Hive Metastore, while Glue ETL offers functionality that can be found with AWS’s Elastic MapReduce service. Yoni Augarten of lakeFS, in a comparison of Glue Catalog and Hive Metastore, recommended Hive for larger organizations heavily invested in the Hadoop ecosystem and Glue Catalog for smaller teams with more straightforward requirements.
The Crawler history feature can be used via the AWS console, programmatically via the ListCrawls Web API, or via any of the official AWS SDKs.
MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ

Amazon is introducing the Visual Conversation Builder for Amazon Lex, a drag and drop interface to visualize and build conversation flows in a no-code environment. The Visual Conversation Builder greatly simplifies bot design.
Amazon Lex is a fully managed artificial intelligence service with advanced natural language models to design, build, test, and deploy conversational interfaces in applications. Amazon Lex provides high-quality speech recognition and language understanding capabilities. The visual builder, allows to build and manage complex conversations with dynamic paths. By adding conditions directly to Lex bot, and managing the conversation path dynamically based on user input and business knowledge, all within a no-code environment.
According to Amazon, no machine learning expertise is necessary to use Amazon Lex. Developers can declaratively specify the conversation flow and Amazon Lex will take care of the speech recognition and natural language understanding functionality. Developers provide some sample utterances in plain English and the different parameters that they would like to collect from their user with the corresponding prompts. The language model gets built automatically.
To create a bot, you will first define the actions performed by the bot. These actions are the intents that need to be fulfilled by the bot. For each intent, you will add sample utterances and slots. Utterances are phrases that invoke the intent. Slots are input data required to fulfill the intent. Lastly, you will provide the business logic necessary to execute the action. An Amazon Lex bot can be created both via Console and REST APIs.
Chatbots are majorly incorporated into messaging applications, websites, mobile applications and other digital devices for interacting as digital assistants through text or text-to-speech functionalities. They offer various benefits, such as improved efficiency of business operations, customer engagement, branding and advertisement, data privacy and compliance, payment processing and automatic lead generation and qualification. Other visual chatbot builder alternatives are IBM Watson Chatbot Builder, Microsoft Bot Framework, Meta Bots for Workplace, among others.
As buying journeys grow more complex, removing friction from the digital experience is essential. Chatbots enhance the buyer and customer experience by providing a channel for site visitors to interact with brands 24/7 without the need for human intervention.
Java News Roundup: Helidon Níma, Spring Framework, MicroProfile, MicroStream, Kotlin, Piranha
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for September 12th, 2022 features news from JDK 19, JDK 20, updates to Spring Framework, Spring Cloud and Spring Tools, introducing Helidon Níma, MicroProfile Reactive specifications, Quarkus 2.12.2, MicroStream 7.1.0, Project Reactor 2022.0.0-M6, Hibernate Search 6.1.7, JHipster Lite 0.15.1, Piranha Cloud 22.9.0, Kotlin 1.7.20-RC and Apache Tika 1.28.5.
JDK 19
JDK 19 remains in its release candidate phase with the anticipated GA release on September 20, 2022. The release notes include links to documents such as the complete API specification and an annotated API specification comparing the differences between JDK 18 (Build 36) and JDK 19 (Build 36). More details on JDK 19 and predictions on JDK 20 may be found in this InfoQ news story.
JDK 20
Build 15 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 14 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 19 and JDK 20, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
Versions 6.0.0-M6 and 5.3.23 of Spring Framework have been made available to the Java community. Both releases offer new features, bug fixes and dependency upgrades. A new feature in version 5.3.23 introduces the isSynthesizedAnnotation() method defined in the AnnotationUtils class that will allow developers to migrate away from the deprecated SynthesizedAnnotation interface. Version 6.0.0-M6 defines seven new deprecations and will remove two previously-defined deprecations including the SynthesizedAnnotation interface. Further details on these releases may be found in the release notes for versions 5.3.23 and 6.0.0-M6.
Spring Cloud Dataflow 2.9.6 has been released featuring an updated PostgreSQL driver version 42.2.26 to address CVE-2022-31197, PostgreSQL JDBC Driver SQL Injection in ResultSet.refreshRow() with Malicious Column Names, a vulnerability in which the implementation of the refreshRow() method in the ResultSet class is not properly escaping column names such that a malicious column name that contains a statement terminator, such as a semi-colon, could lead to SQL injection. More details on this release may be found in the release notes.
Version 1.1.0 of Spring Cloud Sleuth OpenTelemetry, an experimental extension to Spring Cloud Sleuth, has been released featuring dependency upgrades to Spring Cloud 2021.0.4 and OpenTelemetry 1.18.0. More details on this release may be found in the release notes.
Spring Tools 4.16.0 has been released featuring: support for Eclipse 2022-09; a new experimental distribution build for Linux on ARM; and an updated M2Eclipse (m2e) 2.0.5. Further details on this release may be found in the change log.
Helidon
Oracle has introduced Helidon Níma, a microservices framework based on virtual threads, that offers a low-overhead, highly concurrent server while maintaining a blocking thread model. Under the auspices of Project Helidon, this new framework is available with the first alpha release of Helidon 4.0.0, but the Java community will have to wait until the end of 2023 for the formal GA release. More details on Helidon Níma may be found in this InfoQ news story.
MicroProfile
On the road to MicroProfile 6.0, scheduled to be released in October 2022, the Reactive Streams Operators 3.0 and Reactive Messaging 3.0 specifications have been made available to the Java community that feature alignment with Jakarta EE 9.1.
Quarkus
Red Hat has released Quarkus 2.12.2.Final featuring dependency upgrades to: SnakeYAML 1.3.2, Hibernate Validator 6.2.5.Final, and JBoss Threads 3.4.3.Final. Further details on this release may be found in the change log.
MicroStream
MicroStream has released version 7.1.0 of their Java object-graph persistence framework featuring: integration with Spring Boot; improvements to their CDI and MicroProfile Config runtime integrations; and improvements to their data channel garbage collection. There was also an open-sourcing all of their connectors to now include: Oracle and SAP HANA Database; Cloud storage (AWS S3, Azure Storage, Google Firestore, Oracle Object Storage); and others (Hazelcast, Kafka, Redis, DynamoDB, Oracle Coherence). More details on this release may be found in the release notes.
Project Reactor
On the road to Project Reactor 2022.0.0, the sixth milestone release, was made available featuring dependency upgrades to the reactor-core 3.5.0-M6 and reactor-netty 1.1.0-M6 artifacts. There was also a realignment to milestone 6 with the reactor-pool 1.0.0-M6, reactor-addons 3.5.0-M6, and reactor-kotlin-extensions 1.2.0-M6 artifacts that remain unchanged.
Hibernate
Hibernate Search 6.1.7.Final has been released that ships with a dependency upgrade to Hibernate ORM 5.6.11.Final; an alignment with Hibernate ORM dependencies in all artifacts that also include the -orm6 artifacts; and bug fixes related to Java modules.
JHipster Lite
Versions 0.15.0 and 0.15.1 of JHipster Lite, a starter project for JHipster, were released featuring numerous enhancements, bug fixes, dependency upgrades and refactoring. Further details on this release may be found in the release notes for versions 0.15.0 and 0.15.1.
Piranha
Piranha 22.9.0 has been released. Dubbed the “Core Profile just landed” edition for September 2022, this new release includes: support for the Jakarta EE Core Profile with a Piranha Core Profile landing zone; and initial support for the Jakarta Transactions and Jakarta Persistence specifications. More details on this release may be found in their documentation and issue tracker.
Kotlin
JetBrains has released Kotlin 1.7.20-RC featuring: support for several new plugins; a preview of the ..< operator for open-ended ranges; enabling the Kotlin/Native memory manager by default; and the addition of inline classes with a generic underlying type, an experimental feature.
Apache Software Foundation
Apache Tika 1.28.5 was released featuring: security fixes; a fix to avoid an infinite loop in bookmark extraction from PDFs; and dependency upgrades. Further details in this release may be found in the changelog. The 1.x release train will reach end-of-life on September 30, 2022.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Announced at WWDC 2022, Swift 5.7 is now officially available. It includes major improvements to the compiler internals, and many syntax and standard library additions, including String regex, concurrency updates, and more.
While not immediately visible to the programmer, the improvements to Swift’s generics implementation and to automatic reference counting aim to contribute to program performance and correctness. Speaking of generics, work has focused on reimplementing the type checker:
The new implementation fixes many long-standing bugs, mostly related to the handling of complex same-type requirements, such as same-type requirements on a collection’s
SubSequenceassociated type, and code making use of theCaseIterableprotocol which defines the requirementSelf.Element == Self.
Generics also get a number of improvements at the syntax level. In particular, you can now specify an associated type in a protocol declaration, for example:
protocol Contestant {
associatedtype Habitat: Territory
var home: Habitat { get set }
}
struct SeaHabitat : Territory {
...
}
struct ConcreteContestant : Contestant {
var home: SeaHabitat
...
}
The Habitat associated type is the primary type for the protocol, i.e., the one that is most commonly specified at the call site. This also opens the possibility of using opaque types with protocols and generics, for example in an object constructor that hides the concrete type of Contestant that is returned:
func currentContestant() -> some Contestant {
ConcreteContestant(home: SeaHabitat(...))
}
This extension applies to existing protocols, too, allowing you to use Sequence to represent and kind of sequence of strings irrespective of their actual implementation, be it an Array, a Dictionary, and so on.
As mentioned, Swift 5.7 also improves automatic reference counting, making it more predictable and robust to compiler optimizations thanks to new rules to shorten variable lifetimes. In particular, programmers will not need to use withExtendedLifetime() anymore, when evaluating a closure whose correctness depends on a given variable, to prevent the compiler from optimizing it away before the closure returns.
Support for concurrency has matured in Swift 5.7 with better actor isolation, which aims to reduce the chance of data race and makes possible a new strict concurrency checker in Xcode. Additionally, Swift 5.7 also introduces the Async Algorithms package to provide ready-made solutions for a number of AsyncSequence use cases.
One improvement to the language syntax which will be greatly appreciated by all Swift developers, is the new shorthand for optional unwrapping in conditionals, which allows to more succinctly write:
var startDate: Date?
if let startDate {
let newDate = startDate.addTime(...)
}
As a final mention, Swift 5.7 also bring a number of refinements to Windows support, including a more robust installer, improved support for static libraries, streamlined SDK layout, and the new Swift for Visual Studio Code extension.
Swift 5.7 includes many additional features and extensions than what can be covered here, so make sure you read the official announcement for the full detail.
MMS • Missy Lawrence
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Transcript
Shane Hastie: Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture Podcast. Today, I have the privilege of sitting down with Missy Lawrence. Missy is in sweltering Dallas, Texas, today. And among other things is the host of a Women in Digital podcast, the Digital Dish. She leads ISGs operating model capability for Americas and is talking a lot about the human side of digital. Missy, welcome. Thanks for taking the time to talk to us today.
Introductions [00:37]
Missy Lawrence: Thank you for having me. I’m a huge fan, Shane, and I’ve just been following InfoQ. As soon as I read, I think just the intro of the book, I said, “Oh, we are kindred spirits.”
Shane Hastie: Thank you so much. So for the benefit of our audience please tell us a little bit about you and your background.
Missy Lawrence: I’ve about 20 years of experience in what I like to call the intersection of human capital optimization and the people within technology and the people in digital. So the company that I work for currently focuses on research and advisory for technology, digital transformations and strategies, and ultimately what’s the best outcomes from a labor arbitrage perspective and a digital arbitrage perspective.
Prior to that, my focus was always on supporting, from maybe like the HR business partner role, the CIO, or the chief product officer, or the chief technology officer. So for the past 10 years, my focus has always been on the people who are building apps for, it could be the hospitality industry, or I’ve worked with every major US healthcare company, Aetna, Humana, all of the United Health groups. So the insurance providers, the actual caregivers, biometric screenings and how digital has changed and shifted the way non-digital companies show up. That has been my passion. And how do we actually enable and empower the people that are in digital to provide the best value ultimately to consumers and customers.
Prior to that, the first 10 years of my career was spent in pure HR. I worked for the United States Department of Labor. I was focused in the Employment and Training Administration. So my focus has always really been on people and how do we ensure that people can do their best work, that they are able, qualified, willing and available where the work is. And the work has always been in technology, at least for my generation as a professional. It’s been driving change through new applications, new software, new hardware, right?
I wasn’t born digital, but in that generation that is very digitally savvy, those are my people and I just totally geek out and nerd out around all things technology. It’s a passion for me. I don’t even think of my work as work. It’s truly looking at behavior management, behavior dynamics and how humans interact. And I apply this very scientific, brain-based leadership, neuroscience approach to how technologists and technology companies or the IT department of a company can actually optimize their human capital using brain-based leadership.
Shane Hastie: So let’s delve a little bit into that one. What are the characteristics of brain-based leadership?
Brain-based leadership [03:31]
Missy Lawrence: Man, I mean, we could talk about this for hours. As simplistically as I can say it, as simplistically as I can, you want to think about constantly reducing the functions of the amygdala. The amygdala is the oldest part of our brain. It’s our natural knee-jerk reactions. Every human that works in technology is going to need to keep that amygdala in check. We do that by employing our executive functions. That’s our prefrontal cortex.
And you’re like, “Missy, what the heck does this have to do with technology? What the heck does this have to do with a product mindset or product line delivery?” Well, I’ll tell you. If you think about someone who’s been in IT, in development or engineering for the past 30 years, they’ve gotten to where they are and they’re successful because of the habits that they have. They’re basically on cognitive autopilot. This is how you do the thing.
Well, now that we’re talking Metaverse, now that we’re talking Web3, now that we’re talking about banks and the banking and financial services institution wanting their interactions to be more like an Amazon experience, technologists have to build and deliver in a different way. They have to work with their, I would say colleagues across the aisle. It’s not a requirements document anymore. I hope not. We do still have some Fortune 100 companies we see who are following the BRDs and play and build and run and throwing it over the fence to the black box of IT, and having that relationship manager, that business requirements analyst go back and forth. But what you’re really trying to get at is breaking down a highly monolithic infrastructure and architecture, getting into microservices, DevOps, DevSecOps.
The digital product mindset shift
That’s a whole change. That is identity crisis because you’re telling someone who’s gotten successful doing and building and developing the way they always have that you need to work in a new way. And they’re like, “Okay, I’m going to go learn this new language. I’m going to learn some new skills. Be a full stack developer.” Well, you actually have to learn how to work with people who don’t speak like you or think you or have the same motivations as you, right? And so you’re sitting hand-in-hand, room-to-room and lock step, and you have the same values, the same goals, the same experiences as “the business,” as I’m doing air quotes right now, whether it’s sales or marketing or whomever your internal clients are, your external clients, it’s a different mindset shift to work in the new way.
I call this basically the product mindset. In order to do that, you have to tap into different functions and you have to create new neural pathways. And the most frustrating thing that I see in digital transformations that fail or where the ROI is not there… And this is whether it’s, I don’t know, huge clients like the IMF, huge banking institutions, the Associations of Medical Colleges.
There’s been so many instances where we just didn’t get the exact outcomes that we wanted because of the people, because we didn’t have the speed of trust. We didn’t employ the psychologically safe environment. People started freaking out because that amygdala was freaking out. So their brain, their oldest part of their brain was like, “I don’t like this. What’s happening? This is a change. Who moved my cheese?” All those things you’ve probably heard of and read of before. How do you actually teach technologists to master their executive functions. I’m doing this with my hand where the thumb is like the amygdala and it’s moving around and it’s like, “Ah!,” and you get your PFC to kind of cover that up and master your executive functions and control that.
Learning to manage the emotional response to change
How do you teach that? It’s a structured methodology. There’s a science and there’s an approach and many other industries, or I’ll say departments might do this more innately, like sales people. They might naturally know how to flow in and out of this and how to have what we call conversational intelligence and emotional intelligence. Not necessarily my geeks and my people. So what I’ve learned in supporting them over the years is how to coach them and teach them emotional intelligence, conversational intelligence, and ultimately behavior management that gets them the outcomes that they want, gets the CIOs the results that they want or that chief digital officer the results that they want.
Shane Hastie: Let’s delve into the first, almost buzz word that you brought up there, psychological safety. We hear a lot about it, but-
Missy Lawrence: Do you?
Shane Hastie: Yeah, but it’s almost become a hackneyed phrase because so many organizations I see talk that, “We’re safe. It’s great.” But you’ve talked to the people on the ground and no it’s not.
This needs real psychological safety [08:04]
Missy Lawrence: It’s the watermelon effect. If you’re looking at, from a project mindset and if you’re a provider onshore, offshore outsourcing, you’re looking at SLAs and how are we doing? How are as the development organization? It says we’re green but you actually talk to the people and the ethos is different. It’s super red. That inside being the watermelon effect.
As you look at projects and trying to move away from a project mentality, it’s kind of like the Martin Fowler sense of products over projects. I want to liken it to going all the way back to the Agile Summit. I think it’s the fourth bullet in the manifesto of people over process. Psychological safety is not like a silver bullet. It’s not one way of being. It’s not a look in a field that fits for InfoQ, that’s different than ISG, or what works for Zappos versus Spotify’s model with the tribes and guilds and squads.
It is literally about figuring out what that way is that you do things around here. And that’s how I simplify it. Your culture and the level of psychological safety, in layman’s terms, is just the ease to innovate, to try, to experiment, to fail in a safe space, to learn and to continuously move forward. I know you like that word continuous. And so that is ultimately what we’re trying to get at is how do you create a corporate culture and then on the ground, what is the climate of the actual team topologies, right? And that’s a whole ‘nother amazing book. But how do you actually think about the climate and how we develop?
And that’s what we’re getting at when we talk about psychological safety. If you go out to modernagile.org, there’s a cheat sheet. Scroll all the way to the bottom. And there’s a cheat sheet on psychological safety, lo and behold. And it talks about things around shame and guilt and a failure culture versus a blame culture. You’ll hear from Harvard Business professionals and one of my favorite authors, Amy Edmondson, who literally wrote the book and coined the phrase psychological safety, on creating a fearless organization where you’re not scared you’re going to get called to the carpet. There is not perfectionism.
And that’s typically what you see when you get process, process, process over the actual what are we delivering in the product? Are we just following a process for the sake of a process because you don’t want your hand slapped or your head bitten off, right? You’ll see this in organizations that are very, maybe document heavy, more bureaucratic organizations, highly regulated, high compliance organizations, a lot of healthcare insurance, banking, financial institutions, because they need to be, right? There’s a lot of risk. There’s a lot of PHI maybe.
So, you have to have certain levels of compliance and risk and security and data integrity built in, but in terms of how you develop and in terms of how you actually deliver value to a consumer, you need to have a psychologically safe environment to be able to do that. And that ultimately is empowerment. There are assessments that we can do. There’s culture debt dashboards. We talk about tech debt a lot. There’s a culture debt dashboard that I’ve partnered with a colleague to generate to be able to give you, here’s your dashboard of where you need to actually close and reduce your culture debt to actually see the outcomes that you want.
So there’s an approach, like I said, and a structured methodology that you can apply to close that psychological safety gap so it’s less nebulous and abstract. What are we talking about? Their dynamics, is it communication? Is it decision making pushed down to the lowest level? Is it rewards and recognition? Is it innovation and hackathons? Is it learning and shared experiences? Do you have communities of practices? There are very specific elements to fostering psychological safety and that’s what the human side of digital is all about.
Shane Hastie: Coming back to some of the points you made about the digital transformations that failed or that we didn’t achieve the outcomes we were hoping for. You made an interesting statement about they didn’t have the speed of trust.
Improving the speed of trust [12:09]
Missy Lawrence: Oh, yes. So when I think about reducing cycle time, even something as specific as MTTR, mean time to recover, how quickly you can get in a war room, how quickly you can solve problems. This is what the engineering culture is all about. It is how are we solving a problem? What is the problem that we are actually trying to ultimately address and getting to the root cause as quickly as possible?
You cannot do that and you can’t get to outcomes and business value without speed, and you can’t have speed without trust. And what I mean by that is when you have a more check-in culture or a command and control culture or a hierarchical culture on a spectrum of hierarchy, like let’s say it’s all the way here on the left and then anarchy, somewhere over here on the right, there are other things that you can do in between there that will allow for better flow. And that’s what I mean from the speed of trust.
Hierarchy says, “You don’t make this decision because I don’t trust you to make this decision. And why I don’t trust you is maybe because I’m holding the information and the insights and the intel and the data that you might need to make that decision too close to the vest or at too high of a level. And so you don’t even have the information you need to make that decision so it’s fair that I don’t trust you.” Or you could have just effed up before in the past and I don’t trust that you’re going to get this right? Whether that’s a team, an individual, a department, this whole IT, we’re going to have our own island IT because we don’t trust you.
So the speed that you need, you’re never going to get if you have to have checkers, if you have to have approvals, if you have to send this up to your manager and you’ve got 13 levels of hierarchy and bureaucracy and approvals versus maybe there’s something on the end of the spectrum that’s just before anarchy, that’s more like a holacracy. That could be an option. Or maybe just to the left of that, a sociocracy, where I trust that whomever is in this project, I’m making a circle with my hands. This is kind of like the whole holacracy, it’s a circle. You’re in this circle.
If you’re in this circle, you own everything. The risks, the failures and the success. You make all the decisions, all the budget and the ROI of that. The revenue recognition, the marketing, everything. You own this value that you’re bringing to market. And if you’re not in that circle, you have no say so. I don’t care if you are the CEO or you’re even on the board. You have allocated and said, “I trust you to make these decisions and to run with this.” That’s my definition of a product team. And so you have the right information, you have the right skills, knowledge skills and abilities. You have the right metrics, you know the value, you have the voice of the customer, you’re doing consumer journey and customer mapping. You’re going to develop what you need for that consumer and you’re going to bring value and then there’s going to be all kinds of exponential benefits that come back into the organization, because I have trust. I have speed.
If you don’t have that, you’re just going to have to make decisions, you’re going to have to wait, you’re going to have to get approvals, you’re going to have some bottlenecks, you’re going to have to have a consensus culture. We’ve seen that, where you’ve got to have 12 people in the room because I don’t trust that this person knows to bring me in to make this decision or that they know enough about my role or my work to make the best decision. So if you don’t have trust built in to the DNA of the organization or the fabric of that team, you’re just not going to get the speed that you want and then so you’re over budget. You’re over schedule. You’ve paid consultants over $8 million and you still don’t have the actual outcomes that you want.
That’s a real story that I read recently on bringing in consultants. And again, I work for a consultancy, so I’m not knocking it at all. But bringing in consultants to do process work when at the end of the day, it’s a behavior and a cultural challenge, not a process, not a strategy. It’s truly about the people.
Shane Hastie: But people are hard.
The skills needed for working well with people are not “soft” – these are hard skills that need deliberate learning and practice [16:03]
Missy Lawrence: People are so hard. And you know what, Shane, this is what drives me crazy when we say soft skills. These are not the soft skills. And I get it, they’re non-technical, so I say we have technical skills and we have human skills. Actually there are three reports last year of the state of DevOps, the state of Agile, and the state of its skills around DevOps or learning. I’ll send it to you. All three of them talked about the number one to number five challenges. Within each of those top five, one to three was always something around people and culture and psychological safety.
Just mind blowing, in the past two to three years. And I don’t know if that’s kind of a fall out of the COVID zeitgeist that’s made us focus on the fact that it’s not about having the best building or the best strategy or the best process or the best campus, it truly is people. People are hard and these are hard skills. But they are skills. They’re muscles that can be flexed. They’re skills that can be learned. You can be trained. You just have to want to and at least have a leadership imperative that says, “We need you to develop these people skills.”
Shane Hastie: Thinking of the people in these IT departments, in these digital areas, the people who are at the moment cutting code and designing the microservices architectures and so forth, our audience. What we see is we take often the best technologist and because they’re good at their job, they’re promoted into a leadership role.
Missy Lawrence: Level two, level three. Uh-huh.
Shane Hastie: And they stumble because they don’t have these human skills. How do we in our organizations support these people to build those skills?
Missy Lawrence: Our newer CIOs and chief digital officers, even like CSOs are aware of this and what we’re calling this is the contemporary CIO’s organization and their leadership team. So it’s the modern technologist and the modern leadership team, where there are playbooks that you use. There are cohorts. So they have to have their own level of psychological safety, because it’s a bit of a, what we call from a neuro-leadership perspective, Dr. David Rock of the NeuroLeadership Institute has a model called the SCARF model, and you have to acknowledge in the SCARF model… It’s an acronym. The S is for status, the C is for certainty, the A is autonomy, the R is relatedness and the F is fairness.
For leaders who have gotten to where they are, because they are the top of their class, think of it as like a dojo master. Right? They’re going to train up the next level down. They’ve moved from a level one to a level two to a level three. And now they’re responsible. They are functional domain competency leaders. And they can train all day long on how to do this functional domain competency.
You’re now asking them to get a broad skill this way. So you’re taking what we call an “i,” think of it as a lowercase “i” with a dot at the top, and you’re converting that into a capital “I” and then you’re converting it into a “T.” So they start learning these broader skills around collaboration and working across business lines. How to develop other people, how to teach conversational intelligence.
Resources and tools for building people skills
There are many different organizations and frameworks and methodologies out there. My favorite is Dr. Judith Glaser, the late great Dr. Judith Glaser, who wrote a book called Conversational Intelligence. It’s your CIQ. This is how you think through what is my status, what level of autonomy do I need? So I’m going to apply some of the things from Dr. David Rock’s model, Your Brain at Work, or Quiet Leadership, either of those two books from Dr. David Rock, and embed them with this really good, juicy mix up of a lot of different things.
We’ve created a playbook right in the human side of digital that takes maybe four or five, six different books and distils it down into micro learnings so that you can do a type indicator or a trait-based personalities test to say, “What kind of leader is Shane? What are his strengths? Where are some of his shadows and gaps that he may not know? Where does his status get in the way? Where does his level of needing to build relatedness get in the way or his inability to build relatedness get in the way?”
So you’re going to do a little bit of a self-assessment. You’re going to understand where your gaps are, and just like anything else, you’re just going to close that gap. That overly simplifies it because the work is still there. But what you need is a psychologically safe space where you feel comfortable amongst peers, like a round table. You’re not going to do this with people that you’re training at level one and level two. You’re going to want to sit with the other brilliant minds and people who’ve gotten to where you are and that’s how you actually hold yourself accountable. You need this mini cohort.
So we’ve organized these types of sessions where we kind of call it like a Coach of Coaches program. We just take you through a series of walking you through materials and helping you to practice them and teaching you how to coach other people and also how to look for where you kind of get into your own way. Because you don’t really want to do anything that’s anathema to what you ultimately want, but we don’t know what we don’t know until you know it.
And so I think there’s myriad ways that you can get more self-actualized in your leadership style as a technologist, agnostic of what you do in technology or in digital or in IT. But as soon as you are aware that this is a skill set you want to develop, there’s things out there that you can self teach or that people can coach you through.
Shane Hastie: Coming back to… Yeah, these are things we can learn.
Missy Lawrence: Yes. Yes.
Shane Hastie: I want to cycle back around to the concept of cultural debt. What are some of the things that we would look for as an organization? What are the factors that would be on that dashboard?
Identifying cultural debt in a team or organization [21:51]
Missy Lawrence: Wasted data sprawl in terms of PowerPoint presentations. Or have you seen the meme of this one Excel that requires 20 square foot within a network operating center. It’s doing process work for the sake of “This is the way we’ve always done it.” Or we’re creating materials and slideware to replace conversations and dialogue because I need to make sure that I have CYA hovering myself to the nth degree.
I’m not talking about things that you need for our traceability or SOX compliance. I’m just talking about, I want to go have a conversation with Shane. I don’t feel comfortable enough to just have that conversation or that he trusts that I know what I’m talking about. So I need to pull 10, 15 people together to work on a deck, to have 40 slides for a 30-minute conversation. That’s one kind of like a… Just a trigger, one example of a cultural behavior that says I probably don’t have the trust built in that I need because I’ve got a performance orientation versus it’s okay to not have it all fully baked and we will figure this out or I trust that you’ll figure it out, and if not, then I’m here to give you the guidance that you need without being called to the carpet or any adverse effects on you as a person.
There are other things around empowerment. When I say communications, it’s not a communication plan. Right? It’s not OCM, or Organizational Change Management. It’s not something that Shane outsources, like Shane might have a huge, multi-layered 40 different work streams, five, six different projects within this program that he’s trying to bring to life for a client. And there’s going to be a communication schedule and a cadence that says, “Here are the stakeholders.” This is not that. That’s great. You need to have that. You need OCM and you need to kind of project manage how you’re going to educate people and make them aware. And then how super users are going to adopt.
What I’m talking about is, Shane, can you communicate? And that’s different. So when I say communication, that is, are you having the appropriate level one-to-one conversations or two-to-three small group conversations with the people who are actually influencers? Are you doing vision casting and visioneering? Are you holding people accountable? Are you holding up the mirror for people? These are skills that you can learn to move from a level one to a level two to a level three in your levels of conversational intelligence, the same way you would as a site reliability engineer in your skills that way. So that’s another component that’s huge.
When I think about some of the other elements in that dashboard, decision making and where and how and who gets to make that decision. That is critical. Decision making should be pushed to the lowest level of the people who are closest to the work. And that might sound like we’re preaching to the choir with this audience, but it’s harder to actually pinpoint than you might think. And so it requires you to take a step back and constantly keep your head on the pivot and scanning the horizon and say, “Do I need to make this decision or can you make this decision? And is it okay if you make the wrong decision? Or if it’s not okay that you make the wrong decision, then I do need to give you direction. But in the future you make that decision because you’re closest to the work.”
That’s another key one. Recognition. How often do you recognize the individual? How often do you recognize the group? Which ways do you recognize them? It doesn’t necessarily always need to be a spot bonus. Be nice. I’ll take it. But there needs to be some sort of built-in, two-way dialogue that says, “Here’s how I need to feel recognized and I need to know, Shane, that you know what is of value to me and why I show up to work every day.”
People don’t leave companies. They leave teams, they leave bosses, they leave people. Right? In the face of the great resignation, everyone should be looking at their culture debt. Unplanned attrition is another huge key performance indicator around your level of culture debt. Why are people leaving? People aren’t necessarily leaving the workforce and retiring. Some people are, but people are leaving because they’ve sat at home and realized what was important to them. And so making sure that you don’t have a values gap and you can recognize and reward people based on their values. Why they’re showing up to work, why are they doing this? Are they learning something right now that they want to actually take to their dream job later?
How do you actually leverage this as a win-win and facilitate and usher and send them off, but have succession planning. So all of this human capital life cycle management and human capital optimization, that’s I think the critical indicator around your culture debt. Are you doing these types of things to bring the best out of people?
Shane Hastie: Missy, one of the things that you’ve said in the public forum is that digital demands diversity. And you represent the smallest element of the information technology community.
Missy Lawrence: I do.
Shane Hastie: A woman of color. We don’t have enough diversity at all.
Missy Lawrence: I’m working on it.
Shane Hastie: So how do we bring more diversity into our organizations?
Uniqueness awareness to help bring more diversity into tech[28:54]
Missy Lawrence: This is what… I won’t say keeps me up at night because I have a great pineal gland as I play with my little brain that I’m squishing. Yeah, I don’t have that circadian rhythm issue. My neo class nucleus is pretty good.
But I think that women in STEM in general, that’s one level of diversity that there’s been a lot of progress around in the past decade, and definitely in the past 20 years. I’m used to being the only woman in the room. I’m used to being the only minority in the room. I’m used to being the youngest person in the room. And that’s changing.
I think in general it just requires everyone to… I don’t want to even use the word “allyship.” It just requires everyone to have what I call uniqueness awareness. It’s not diversity awareness anymore, like diversity equity and inclusion is table stakes. Most people have a program. They’ve got something. They’ve probably set up some network resource groups. Fine. Check a box.
What it really is about is understanding who is Missy? What makes Missy tick? What are her skills? Who is Shane? What makes him tick? What are his skills? Can he bring his authentic self to work or does he need to fit in? So there’s a difference in… Brené Brown. If you’re not familiar with Brené Brown, who has taken her Shane research… I’m in Texas. She’s out of the University of Texas Austin. Go Longhorns. She actually has taken that approach into corporate America with her books and her works around Dare to Lead.
And so if you think about her concepts, it’s about belonging versus fitting in. And belonging says you could see me as a blob. I don’t see Shane as a Caucasian male in New Zealand. I see Shane as a combination of his brain, his heart, his mind, his interests, his efforts. And there is just kind of this blob of skill sets that comes to work. Missy is a different blob and a makeup of skill sets that comes to work. Those blobs… And I’m sorry I don’t have a better word. These blobs need to be able to do their best work.
And having that diversity of thought, interests, skills, that’s actually how you get the ROI out of your human capital and how you optimize it. So it’s less about getting a woman, getting a minority, getting multi-generations in a room. It truly is about differences of thought because I mean, I’ve definitely been there where I’ve had to be one of the guys. I’m much more androgynous. I’m like six feet tall. I played sports. I get the analogies. I can hang with dudes for the most part. And I’m just a huge nerd. Comic books, DC Comics. I kind of geek out about the things that scientists and mathematicians geek out about. So it hasn’t been a problem for me, in all fairness, in my career.
It’s a challenge when I hear women who have so much that they can contribute to technology into digital transformation, and anything right now that you have an interest in is going to be digital. There’s going to be an app or a website about it. If you’re basket weaving, there’s going to be an app on how to best weave those baskets. You know what I mean? There’s going to be some sort of technological software or hardware device that’s going to enable whatever your passion and your interest is. And I think that’s where we need to go as an industry is just talking about those things.
Inclusion and accessibility
Gosh, I mean, we could talk for days about inclusion and accessibility even more so when we think about UX and UI and development and design thinking. I had an article in Information Week on unconscious bias in artificial intelligence and how do you actually get developers to do the right amount of testing and have diversity in their testing, so when you’re doing things like artificial intelligence, I don’t show up as a cat because you’re not testing enough Black or Asian people. This is like a real thing. And we laugh about the Chihuahua versus the muffin or hot dog not hot dog and all these different things that are funny, that are memes in AI. But it’s less funny when it’s a natural language progression and someone is stressed out.
This is a real story. There’s been a death’s in a family and they need a flight. They need to get home. They’re calling. The wait times are ridiculous. And an airline says, “Do you want to book a reservation?” But the person who’s on the other side is saying, “I just want to book a flight. A reservation for what? I want to plan a trip.” So literally understanding cultural nuances and language and colloquialisms and verbiage, that’s where the companies, the providers, the engineers, the developers who are winning the deals and who are making a huge impact for clients and ultimately for customers are taking the extra step.
And so it’s not just enough to say we’ve got a chat bot. Right? It’s enough to say that this chat bot understands the customer and the consumer and where they are and can speak to them in a way that’s going to get them that speed of trust to the outcomes that they need very quickly. So there’s multiple layers and levels around what I call digital demanding diversity. And that article is out there, but it truly is starting with in an organization, the executive level, the leadership level. If you look around, if you look at your board, if you look at your website and you look at About Us, is it a bunch of white men or Indian men? How do you change that? Because that is truly going to change what filters down into the company, your net promoter score, your brand, the talent that you can attract. And the way I talk about that, or the value of that ROI of diversity is your culture coin.
So think if you have a quarter or a dime, or I don’t know any other coin phrases in other currencies. But you have the piece, like a metal coin, and on one side is your internal company culture, and the other side, heads or tails, is your external brand. That coin can only be as strong as both of those sides are. And so you might have a strong, amazing brand. We’ve heard all the horror stories about amazing companies that people love, but on the inside, the employees are disgruntled. Right?
So all of that is still a part of diversity and the diversity in digital. How do you ensure consumer engagement is also the same as customer engagement and experience? It just all has to come together. Again, back to the human side of digital. You can’t separate the need for diversity of thought and equity throughout the leadership all the way down to the interns and then inclusion of thought and of different experiences because the world is so flat right now. It’s going to keep getting flatter and flatter.
Shane Hastie: Thank you very much. Some really interesting and valuable content there. If people want to continue the conversation, where do they find you?
Missy Lawrence: Well, there is the ISG Digital Dish Podcast, where we definitely talk about all things Women in Digital. But you can email me, hit me up on Twitter, on Instagram. I am @TransformMaven, M-A-V-E-N. So Transform and then Maven, two Ms. It’s on Instagram, it’s Twitter. And missy@ transformmaven.com.
Shane Hastie: Missy, thank you so much.
Missy Lawrence: Thank you. My pleasure.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Renato Losio
Article originally posted on InfoQ. Visit InfoQ

AWS recently introduced IAM Identity Center APIs to create users and groups at scale. Administrators can use these new APIs to manage identities programmatically and gain visibility into users in the Identity Center directory.
Previously known as AWS SSO, IAM Identity Center supports the direct creation and management of users and groups and can be connected to existing sources and providers such as Microsoft Active Directory, Okta Universal Directory, or Azure AD. For audit and reconciliation purposes, the cloud provider introduced new Identity Center directory APIs to retrieve users and their group memberships. Sharanya Ramakrishnan, senior tech product manager at AWS, Bala KP, senior solutions architect at AWS, and Siva Rajamani, enterprise solutions architect at AWS, write:
As your enterprise grows, you may want to automate your administrative tasks to reduce manual effort, save time, and scale efficiently. If you’re a cloud administrator or IT administrator who manages which employees in your organization need access to AWS as part of their job role, or what AWS resources they need so they can develop applications, now you can set up automated workflows that manage this for you.
The ability to manage users and groups at scale has been a long term request from the community. Rowan Udell, principal solutions architect at Stax, tweets on the importance of a centralized service:
Always use AWS SSO/Identity Center. Always. If you have IAM users, get rid of them. If you’re following a guide that says “Create an Administration user”, don’t. Friends don’t let friends use IAM users. All roles. All the time.
Built on the per-account functionalities of AWS IAM and the multi-account features of AWS Organizations, the managed service removes the effort of federating and managing permissions separately for each AWS account. Ramakrishnan, KP, and Rajamani add:
If you use IAM Identity Center with a supported identity provider (IdP) or Microsoft Active Directory (AD), you may want to check if the right users and groups have synced into IAM Identity Center. You can do this manually, but now you can use the new APIs to make the process easier by setting up automated checks that query this information from IAM Identity Center and notify you only when you need to intervene.
IAM Identity Center can manage workforce sign-in and access to all accounts in an AWS Organization, with the possibility to delegate the administration to a member account. In a popular Reddit thread, user matheuscbjr highlights one of the use cases of the new APIs:
I had a demand to generate reports and automations based on users and groups in the old AWS SSO, at that time this was not possible and for that I had to get this information directly from AD via LDAP.
Other users argue instead that IAM Identity Center is not yet SCIM compliant and that it is easier to push users and groups from other identity and access management services.
IAM Identity Center is a free AWS service. The cloud provider updated the IAM Identity Center User Guide and the Identity Store API Reference Guide to provide more information about the new APIs.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Recently Google added a new integration in Cloud Code with its Compute Engine service (GCE) to make it easier for developers to manage their frequently used virtual machines in the IDE, view details about them, connect to them over SSH, upload application files, and view their logs.
Cloud Code is a set of IDE plugins for well-known Integrated Development Environment (IDE) like VS Code and JetBrains IntelliJ that make it easier to develop applications that use Google Cloud services. With the new integration to Compute Engine, developers have a way of exploring Virtual Machines (VM) in their GCP project and viewing details needed to effectively work with the VM from the IDE.
Developers can install Cloud Code for VS Code or Cloud Code for IntelliJ. Once installed, the developer can find Compute Engine in the activity bar in case of VSCode or a list of IDE tools in case of IntelliJ.
Richard Seroter, a director of outbound marketing at Google, tweeted:
If you’re a developer who added the @googlecloud Code extension to your JetBrains IDE or VS Code, you can now manage your VMs without leaving your editor.
In the IDE, developers can navigate to Cloud Code’s new Compute Engine explorer, select a VM and view the details such as machine type, boot image, and IP address. In addition, they can right-click on a VM for a quick link to the Google Cloud Console, where they can take additional action.
Other actions developers can perform in the IDE are:
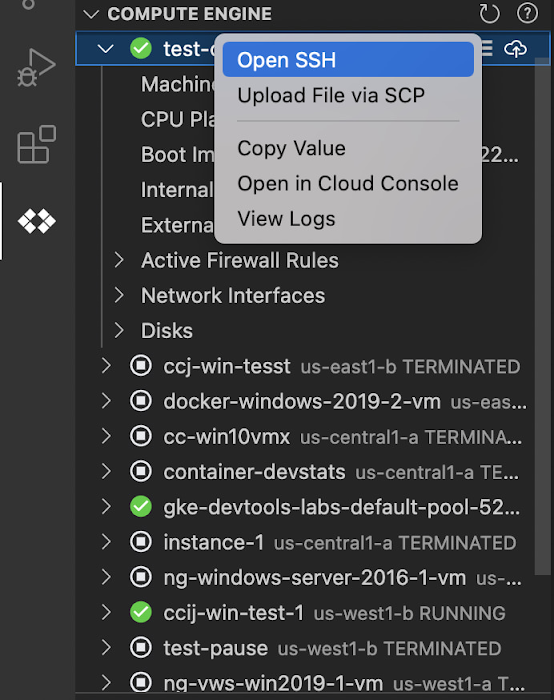
- Establish a Secure Shell (SSH) connection from the IDEs terminal into a selected VM and run a troubleshooting diagnostic in case of connectivity issues.
- Upload Code files into VM instance through “Upload File via Secure Copy (SCP).” Once uploaded, Cloud Code provides the option to open a new SSH connection to access the files and work with them on a remote VM instance.
- Inspect the VM instance logs through the logs viewer in the IDE. The same accounts for when the VM logs are collected in Cloud Logging.
Note that VS Code, for instance, also has a plugin in preview on GitHub for Azure Virtual machines. The plugin allows developers to view, create, delete, start, and stop Azure Virtual Machines. In addition, developers can add an SSH key to existing Azure Virtual Machines.
Lastly, more details are available on the Compute Engine documentation for Visual Studio Code and JetBrains IDEs.
MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ
Amazon is announcing a new built-in TensorFlow algorithm for image classification in Amazon Sagemaker. The supervised learning algorithm supports transfer learning for many pre-trained models available in TensorFlow Hub. It takes an image as input and outputs probability for each of the class labels. These pre-trained models can be fine-tuned using transfer learning even when a large number of training images are not available. It is available through the SageMaker Built-in algorithms as well as through SageMaker JumpStart UI inside SageMaker Studio.
Transfer learning is a term used in machine learning to describe the capacity to use the training data from one model to create another model. A classification layer is added to the TensorFlow hub model once it has been pre-trained, depending on the amount of class labels in your training data. The dense layer, fully linked, 2-norm regularizer, initialized with random weights, and dropout layer make up the classification layer. The dropout rate of the dropout layer and the L2 regularization factor for the dense layer are hyper-parameters used in the model training. The network can then either be fine-tuned using the fresh training data, with the pre-trained model included, or just the top classification layer.
The Amazon SageMaker TensorFlow image classification algorithm is a supervised learning algorithm that supports transfer learning with many pretrained models from the TensorFlow Hub. The image classification algorithm takes an image as input and outputs a probability for each provided class label. Training datasets must consist of images in .jpg, .jpeg, or .png format.
Image classification can be run in two modes: full training and transfer learning. In full training mode, the network is initialized with random weights and trained on user data from scratch. In transfer learning mode, the network is initialized with pre-trained weights and just the top fully connected layer is initialized with random weights. Then, the whole network is fine-tuned with new data. In this mode, training can be achieved even with a smaller dataset. This is because the network is already trained and therefore can be used in cases without sufficient training data.
Deep learning has revolutionized the image classification domain and has achieved great performance. Various deep learning networks such as ResNet, DenseNet, inception, and so on, have been developed to be highly accurate for image classification. At the same time, there have been efforts to collect labeled image data that are essential for training these networks. ImageNet is one such large dataset that has more than 11 million images with about 11,000 categories. Once a network is trained with ImageNet data, it can then be used to generalize with other datasets as well, by simple re-adjustment or fine-tuning. In this transfer learning approach, a network is initialized with weights, which can be later fine-tuned for an image classification task in a different dataset.
MMS • Justin Cormack
Article originally posted on InfoQ. Visit InfoQ

Transcript
Schuster: To continue the language discussion from before. We talked about ahead-of-time compilation and just-in-time compilation. Another dimension of this is what about garbage collection versus everything else, reference counting or manual memory management. Do you see that having an impact on cloud native languages?
Cormack: Yes, it’s an interesting one, because I think really, until Rust came along, everyone was in the basic view that garbage collection was the right thing to do. It was so much easier, solved all the problems, the performance issues were over. There’s a huge amount of engineering gone into garbage collection over the years, because it makes it so much easier for the user. It’s a research topic, and as an engineering topic. Java did a huge amount of work and a lot of other languages did a lot of work on making garbage collection fast. It’s quite a well understood problem in many ways. For most applications, it’s not really an issue. Then Rust came along, and just said, we’re not going to do it like that at all. We’re not going to do garbage collection, we’re going to be different, and came up with, there’s linear types piece, and some escapes from it, like going back to reference counting. I suppose, actually, the Apple ecosystem was the other big holdout, because Swift and Objective-C, we’ll just do reference counting, it’s good enough for everyone. It’s much simpler and more predictable performance than garbage collection, and it matters on the phone. We’re going to introduce that everywhere else as well. That was the other holdout.
Linear types originally came from work on trying to compile Haskell more efficiently and functional programming languages. It was always one of the things that was going to make functional programming much more efficient, because you could tell not about garbage collection, but about reusing the same memory location for a new thing. Because in principle, in functional programming, you declare a new variable for everything because you don’t mutate and splay. The naive implementation is to use a different memory location for each time you change something, which generally is not very efficient. The linearity thing then was all about, can I guarantee that if this thing is only used once, I can use the same memory location because you can’t have a reference to its previous state so I know I can update it. It was really about update in place linearity. It didn’t grow as a miracle in compiling functional languages that was kind of hoped, I think when they wrote the original papers. There’s some really fun papers on linearity. There’s one guy who wrote just totally bonkers papers on it, which are just incredibly funny. I’ll have to dig it out because it was just like, these papers are fun, in the early 2000s, late ’90s.
It didn’t create quite the revolution there, but Rust approached it, took the same thing and tried to solve that problem, like if we know that something is only used once, again, we don’t have to put it on the heap, we can just update in place, keep control. Then, if there’s only one thing that writes to it, then we can have read only copies temporarily, and so on. That was pretty radical as a break from the path that programming languages had been taking. I think it was very radical in terms of people thinking about how to write programs with it initially. It took time before it could even recognize all the cases where there was linearity, and so on. The later implementations were more forgiving, but it does make you think about allocation differently. It’s mental cognitive overhead having to think about allocation at all, in a sense, but also in a sense, if you care about performance, you’ve actually always thought about allocation. If you go to the high performance Java talks that we have at QCon, it’s like don’t allocate. The first rule is hot loop, never do any allocation at all. If there’s no allocation, there’s no garbage collection, so it’s not a problem. It’s always really been the case that people have thought about allocation for things where performance matters. For throw away code or things that are not performance critical, then it’s so convenient.
Zig
The other approach that Zig took more recently has been interesting too, because it came along after Rust, as a related niche. It’s obviously much less well known than Rust. It’s a niche that’s more as a replacement to C than for cases where you would definitely have to use C now. It’s very much designed around interoperability in C. They had a different model where rather than enforcing linearity, you have to specifically pass around an allocator to every type thing that could allocate, which makes it even more visible. You know of a function that allocates memory, because you have to pass it an allocator, but you can do things like do arena allocation where you pass an area of memory, this function allocates in that and afterwards, you clean it all out by releasing the whole arena. Which is actually similar to garbage collection type strategies that a lot of people use anyway. That’s where the arena term came from was garbage collect. That’s a different approach again.
Schuster: The Zig reference counter, do you have to manually free stuff?
Cormack: You have to manually free in Zig, but you can deallocate the whole allocator and create a whole arena. You can do a halfway stage where you can lose track of stuff, because you allocate a gig of memory, everything allocating to this. If it’s failed to free it, doesn’t matter because you’re going to free up the whole thing, for example. You don’t have to keep track of things as effectively, but you have to understand and create that strategy yourself. Normally, the default would be to have a C like thing where you have to free things and it’ll leak if you don’t, which is bad, but it lets you create these strategies yourself by making the allocator first class.
Zig also does other things with like have failing allocators, which most languages don’t work well in the presence of running out of memory, but in Zig, because you passed an allocator, everything you pass an allocator can fail. The allocator has a fail exit case, so everything has to catch failed allocation error. You can also do hard memory bound code effectively, which has actually been really difficult. Code that adapts to the amount of memory that’s available has been something that’s really hard to do. Linux does not encourage that either by just normally having lax allocation anyway and overcommit, as you turn it off. There’s a lot of cases where you’re in a runtime, you really want to know if anything’s failing, rather than just the standard crash, when I run out of memory, being able to catch that.
For the right kind of low level coding, it’s really important. Most code actually isn’t as resilient to running out of memory as it should be. That’s often something you can use to cause denial of service attacks by passing gigantic parameters to things and watching them crash because they run out of memory and things like that. Or if they don’t have backpressure, you can just accumulate memory and not fail correctly and feedback the backpressure and things like that. I think for resilience, explicitness in memory allocation is important as well. I think there’s been a new era since Rust of experimentations in different models, which is really valuable to find out what works, what doesn’t work. What kinds of cases does it matter? What kinds of things can we build if we do something different? How easy is it to learn how to do something like linear types, which was an academic construct for Haskell? Actually, it came from math before that.
Languages That Emulate the Rust Approach
Schuster: It’s definitely a big change from Rust, because I never thought we would have another manually memory managed language or a language that doesn’t use garbage collection, but here it is. Languages that also use the Rust approach, so you mentioned Zig.
Cormack: Zig doesn’t use the Rust approach.
Schuster: Not GC, yes.
Cormack: Yes, it doesn’t have GC. Other than Swift, those are the only three I can think of, that are doing that. I think it takes time to learn how these things work, and I think we might well see more.
C++ and Reference Counting
Schuster: I was wondering, every time I tried to poke fun at C++ developers for having a manually managed system, they always tell me, no, in modern C++, everything’s reference counted, smart pointers.
Cormack: Yes. It’s not enforced. It is used mainly as a reference counted language. C++ has been very adaptable from that point of view. If you see it as a way of adding new idioms and an evolving language without really removing everything, then, yes, you can definitely argue it’s in the reference counted piece. I don’t know if they’ll go as far as linearity and things as well. Some people will call reference counting garbage collection. It’s just a very simple form of garbage collection that doesn’t work well with cycles, but is incredibly efficient to implement. Reference counting is very old. I think the original garbage collection implementations in the ’60s were reference counting, because it’s so simple. You can argue that that’s more a continuation of GC. Even Rust has support for reference counting for all the use cases that linearity doesn’t work.
Schuster: It’s interesting with Rust, you get the type system to help you to make sure that you have the cheap reference counting operations if you don’t share it across thread boundaries, for instance, which is exciting. I find that you can use reference counting, but you don’t pay the atomic operation overhead.
Cormack: Yes.
Performance, Scalability, Cache Locality, and Dealing with Cycles
Schuster: We can talk more about languages, but we have here performance, scalability, cache locality, dealing with cycles. Yes.
Cormack: I do find it just interesting there are these tradeoffs that come back. It’s always been the case that the systems programmers, particularly the C programmers just said that garbage collection would never work for x use case. For many x use cases, that’s not been true. There are some use cases in kernel. Even then with unikernels, we have OCaml and things using garbage collection in the kernel. It’s more niche when you go down to that. As I said, for people who’re doing performance, they understand how the deallocations/allocations are taking place, regardless of what the runtime does, and they’re still doing the same things. Implicitly, you can do these things by hand, and not allocate and know that things are going to be allocated on the stack in your language and all the rest of it. Tracing and decompiling and seeing what’s going on in the runtime, and you can always build something equivalent by just not using these features.
Memory Overhead Cost of GC versus Reference Counting
Schuster: The one question I always have, and I haven’t found any good research on this, maybe that’s out there is, what is the memory overhead cost of GC versus reference counting? The answer isn’t that simple, because more than reference counting is becoming a bit lazy as well, so you don’t immediately deallocate stuff. There might still be some overhead.
Cormack: The worst case for garbage collection is, theoretically, twice as much on a really poor implementation of copying, but that’s not how it works. It’s invariably less than that, but it does depend a lot on your workload. Most GC has arenas for things that last for different amounts of time, most of the stuff is deallocated very quickly after it’s allocated. It doesn’t hang around for very long, it’s quite efficiently removed. It’s almost like stuck lifetime, and then you get a little bit longer, maybe it crosses a function boundary, and then gets deallocated. Then you’ve got stuff that lasts the lifetime of your program probably, and often stays, but maybe it changes slowly or something. It is very application dependent. There is a bunch of research on memory usage. I suspect, the memory usage has probably gone down since the research was done, the GCs have just continued to get more efficient in terms of things like that. It’s probably worth, and your application might be different. Few people rewrite things and after compare as well.
Schuster: That’s the problem. Yes.
The Cognitive Load of Memory Management
Cognitive load of memory management, doing it by hand, try to debug why it’s not working right or quickly, and frontload the cognitive load [inaudible 00:19:31].
Cormack: I think it’s like the real backlash we’ve seen against dynamic typing for the last few years. We are going to, ahead-of-time, let’s put things in the type system, let’s have more of those guarantees upfront period, again. From having a, let’s do things at runtime period, that was the dynamic language boom, the JIT compiler boom, and now we’ve gone back to the ahead-of-time old world in a sense, how things used to be because predictability is important. Predictability is a really interesting thing. If you want predictable latency rather than the lowest latency and so on, if you want to make sure that your largest latency is low, then doing things ahead of time and not doing GC just removes those tail latencies for when things can go wrong. For those types of applications, it makes a lot of sense. The developer cognitive load and debug load is interesting. I think, as you said, that one of the interesting things about linear types was it went into the type system, not somewhere else. You could use familiar tools, to some extent. It still behaved differently, and extending the type system does aid cognitive load. That’s what a lot of people say about things like Idris that tries to do a lot more in the type system. It does become very different. It’s definitely that ahead of time. Once you’ve got it right, you know it’s done, kind of thing, rather than having to then profile it and see if it worked.
Extended Berkeley Packet Filter (eBPF)
Schuster: Can we switch gears from languages a bit lower level? A few years ago at QCon London, you gave a talk called eBPF is the Amazon Lambda of the kernel. Did that work out?
Cormack: It’s interesting. I think there’s a lot going on. I think, actually, that community is still just growing and expanding. There’s actually been a lot of new things. There was an eBPF foundation set up in the Linux Foundation, Microsoft is implementing it for Windows. There’s big things. Linux stuff takes a long time, because a lot of people use quite old Linux kernels like Red Hat LTS and things. It’s only recently that the pieces of eBPF other than the profiling pieces have become really widely available. It’s still not the easiest ecosystem to program, because it’s low level and weird, and most people are programming in C still. It’s still on the growing stage. I’m seeing a lot more people interested in adopting it. A lot of companies doing things with it. It’s got really strong niches around things like networking. The first thing that happened with it was the performance stuff that was done mainly at Netflix, originally, then a lot of networking, because it turned out that manipulating packets was a really good use case. For now, things like security, it’s growing, making more complex security decisions about whether something should be allowed, which needs more context. Yes, it’s getting there. It’s still growing, taking time, expanding the tooling and so on, on that adoption curve.
eBPF in the Future
Schuster: What are the things that are being added in the future or that might expand it even more? What can we expect nowadays with eBPF, what things are stable?
Cormack: The handling of kernel interfaces is getting much easier. There was a whole revision of how the compiler works to make it easier to not have to compile a separate eBPF binary for every kernel version you wanted to run in, and to link it up at load time. That just made it annoying to just distribute code except in source code. I think that’ll make it remove a lot of barriers, because it was just annoying to just distribute binaries to people that would work. That’s probably the biggest piece is that ease of use piece on distribution.
eBPF vs. Sidecars
Schuster: I don’t know if you have an opinion on this. There was a discussion recently that was pitching eBPF versus sidecars, from an efficiency point of view, capability point of view. Is there anything to say there?
Cormack: I think that a lot of people are now using a combination, basically, eBPF if you can, because it’s much faster, and running stuff in the sidecar if you can, because it’s difficult. You haven’t written the code yet, or it’s a more complicated thing, or the kinds of manipulations that you want to do are more complicated. The other things with the networking side that hasn’t quite taken off yet is the use of in kernel, TLS, which was going to make it easier. Because if the kernel does the encryption, then it means that the eBPF code can access the data before it’s encrypted, so it can inspect more to make processing decisions before the encryption happens potentially. There’s a whole lot of optimizations you can do. If two connections are actually on the same host, you just loop them back through localhost, don’t bother to encrypt and decrypt, or don’t packetize them, and don’t run TCP over a local connection and things like that as well, which make for a lot of efficiency.
The sidecar model is simpler. The idea that you can take some bit of code and then control how it handles the outside world completely, in some code that you don’t have to deploy at the same time with that code is really powerful. I think there’s a lot more we could do there. With Docker Desktop, we manipulate a lot of the network traffic that’s coming out of containers before it reaches the host, because we’re doing it across a VM boundary, so we get that opportunity. If you could do it for a local process to effectively containerize it without it realizing, route its traffic differently, make security decisions locally, all those things as a control wrapper around some application you want to run, it’s an extension of the container model, in that sense.
Sidecars were always pitched originally as being a replacement for dynamically linked libraries. They’re dynamically linked bits of program that manipulate the outputs, which are generally like network streams and so on. If you can do this even more generally, like you can take all of the state that the application deals with, with Linux, and manipulate all of that and control all of that and monitor all of that, then that’s a really powerful way of thinking about containerization in that sense, and virtualizing, and just modifying how things work.
One of the things that Cilium does is it intercepts DNS requests using eBPF for access control. If you’re only supposed to access domains@google.com, it intercepts the DNS request, looks at the response, if you’re asking for a google.com address, and it comes back with an IP address that lets you call towards that IP address. If you ask for qconconferences.com DNS lookup, it’ll just come back, and it won’t return you the IP address, so your application can’t actually do anything. Then it configures the allowed and not allowed routes that it’s going to let you have based on those DNS requests. That model of getting more semantics around how the operating system can control you, and making it totally transparent without you having to have a DNS library or work out which DNS server that it’s even talking to, you know that an application you have control of can only resolve names through DNS. The hard coded IPs, you can just block them anyway, because it hasn’t done a DNS request. It’s a really interesting way of adding that semantic control around what things can do.
Things like access control and enforcing TLS are some of the things that sidecars were initially asked to do, because getting application developers to build in all their authorization access control framework that your organization wants is really hard, and linking to a shared library didn’t work once people started using multiple different languages. We don’t have that common linkage yet. Although, again, WebAssembly is looking at common library type things that could be multi-language, but we’re not really quite there yet.
The Security of eBPF Code
Schuster: I saw there was some concerns about the security of eBPF code or injecting its code that’s essentially running in the kernel. What’s the current thinking about that?
Cormack: I know we talked about sandboxing before. It needs to run in a sandbox. How good is the sandbox? The security issues in eBPF have been around changes that have been made to extend it when the model hasn’t been. The changes in the model generally have caused issues. Linux decided not to formally verify eBPF, but I think it’s an interesting research target. Most of the issues have been found so far, quite quickly. It wasn’t introduced as a best practice way that we have of designing sandboxes. It was a little bit more ad hoc and there’s been a number of issues. Particularly as the allowed constructor got more complicated, because initially it was really simple, and it was based on the original BPF for networking, but more features were added. Those features turned out to have security issues. It’s good to plan how you’re going to implement sandboxes because they will break and they do cause issues, and it’s just good to get those right.
Interesting Projects in the CNCF
Schuster: Justin you’re involved with the CNCF.
Cormack: Yes.
Schuster: Are there any projects that you find particularly interesting there that people should look into them?
Cormack: We have a lot of projects now. The thing we’ve done really over the last year or so is to really open up the sandbox to enormous number of experiments and projects that may or may not make it. I’ve lost track. I think there are 40 odd projects in the incubating and graduated kind of mature projects, and there are a lot of sandbox projects. There’s a core of projects connected directly to enhancing Kubernetes, and extending it in different ways. There’s a lot of interesting ones there. We’ve got things like Dapper that just came in recently, which is what Microsoft’s using for their new container runtime on Azure. It’s been open sourced, but it’s now a CNCF project. We’ve got things like Crossplane, which lets you run services as if they were native Kubernetes objects. I think it’s really interesting.
In the sandbox, we’ve got all sorts of things. We’ve got Wasm runtimes, confidential computing, key management encryption, lots of projects in Rust. We’ve got Wasm for Kubernetes from Microsoft. We’ve got all sorts of things. It’s a big experiment in things that may or may not work out, and we’re giving them the space to explore. We’ve given people visibility of these are things that people want to collaborate across companies, across their organizations, and they want to share them with other people. They don’t want to own the whole direction of the project, they want to make it open. We’re seeing projects go in quite early stages to there sometimes. We usually require that they’ve been around for a little bit, but if people are already starting to work together, and seeing multiple people coming in, then that’s a good point at which we allow projects in. It’s really a lot of fun things, a lot of experiments.
I think there’s a huge number of projects around different aspects of edge computing, and that’s where a lot of the Wasm things fall in, and that kind of thing. No one knows quite what the shape of that stuff is going to look like. There’s a lot of different approaches. We have several different projects extending Kubernetes to the edge in different architectures, in different ways. That’s great, because we don’t know what the shape of things is going to look like. We have people that are really excited about WebAssembly and the kinds of applications people might build with that. I think we’re still exploring the shape of what that will look like, and doing it in the open. We’re the big community of people who can really drive projects to success.
Was The Unikernel Killed by Docker and Containers?
Schuster: Did Docker and containers kill the unikernel, or is the unikernel still around?
Cormack: There’s a bunch of people still working on unikernels. They don’t go away because the ideas are really exciting and they’re much easier to implement than they used to be. I think the commercial models around unikernels have been really difficult, how to get mass adoption rather than niche adoption. It’s hard. What are you going to offer developers that’s radically different? I think that some of the things are related to pieces around WebAssembly and lightweight applications at the edge that people are starting to get interested in again. I think a lot of the ideas will come back again over the next few years as people explore those areas in more detail. Because smaller, lightweight and customized and specialized applications for single purposes for smaller, less resource hungry areas is an area that people are really interested in again now. We start building things that are big again, and we’ve got these reasons for thinking about small again. That’s where the interest still comes up a lot, still talk to people about things. People are still working on it, but it’s more hidden.
Schuster: It’s definitely exciting, maybe long-term.
See more presentations with transcripts