Month: September 2022

MMS • Bruno Couriol
Article originally posted on InfoQ. Visit InfoQ
The Preact JavaScript framework recently released Signals, a new set of reactive primitives for managing application state. Like other frameworks (e.g., Svelte, VueJS), the React-compatible framework lets developers associate parts of the user interface with state variables independently of the UI’s component tree. Alleged benefits of the extra 1.6KB: fast re-renders that are independent of the shape of the UI component tree and excellent developer ergonomics.
The Preact team explains the rationale behind the new API as follows:
Over the past years, we’ve worked on a wide spectrum of apps and teams, ranging from small startups to monoliths with hundreds of developers committing at the same time. […] We noticed recurring problems with the way application state is managed.
[…] Much of the pain of state management in JavaScript is reacting to changes for a given value, because values are not directly observable. […] Even the best solutions still require manual integration into the framework. As a result, we’ve seen hesitance from developers in adopting these solutions, instead preferring to build using framework-provided state primitives.
We built Signals to be a compelling solution that combines optimal performance and developer ergonomics with seamless framework integration.
Most popular JavaScript frameworks have adopted a component-based model that allows building a user interface as an assembly of parts, some of which are intended to be reused and contributed by open-source enthusiasts and other commercial third parties. In the early years of React, many developers credited component reusability and ergonomics (JSX, simplicity of conceptual model) for its fast adoption.
In large-enough applications, some pieces of state are often required by unrelated components of the user interface component tree. A common solution is to lift a given piece of state above all components that depend on it. That solution and the corresponding API (often called Context API) however may result in unnecessary rendering computations. The number of components which must be synchronized with a piece of context state may be fairly small when compared with the size of the component tree to which the context state is passed. A change in context state will however trigger the recomputation of the whole component tree:
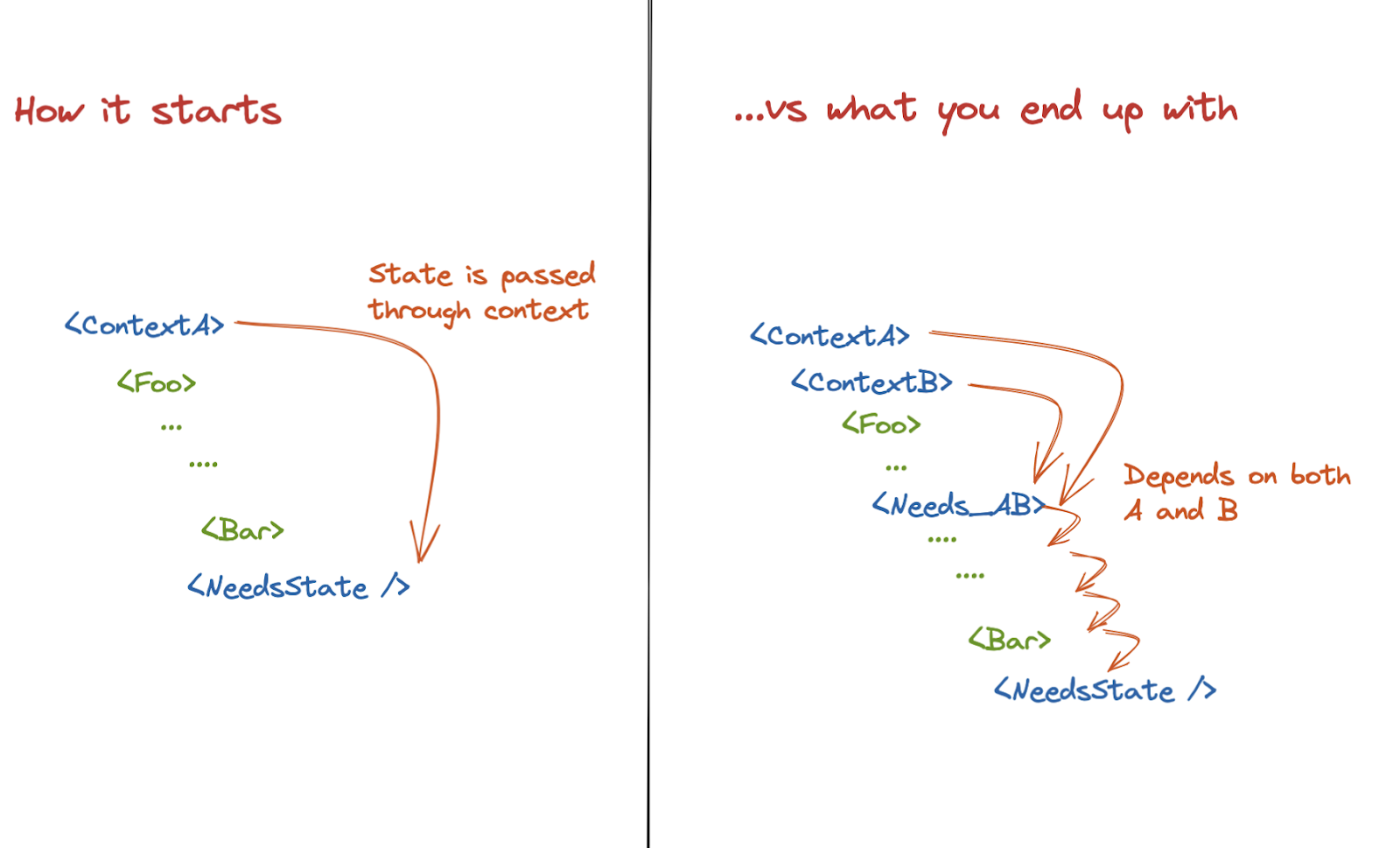
(Source: Preact’s blog)
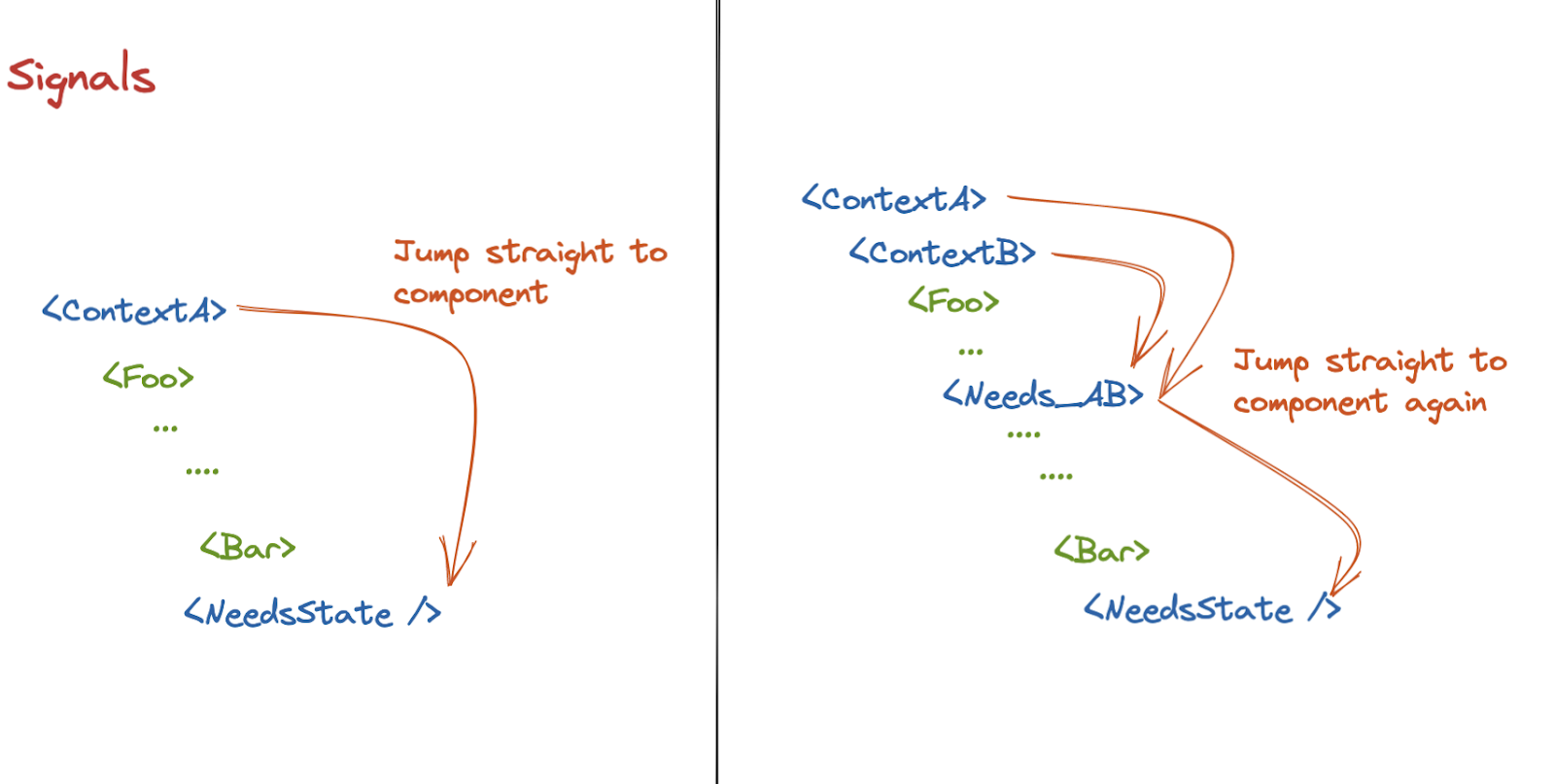
In some cases (e.g., very large component trees, expensive component renders), the unnecessary computations may lead to performance issues. Preact’s Signals API seeks to eliminate any over-rendering:
Beyond framework integration, the Preact team also claims excellent developer ergonomics. The blog article provides the following implementation of a todo list application (cf. code playground):
import { render } from "preact";
import { signal, computed } from "@preact/signals";
const todos = signal([
{ text: "Write my first post", completed: true },
{ text: "Buy new groceries", completed: false },
{ text: "Walk the dog", completed: false },
]);
const completedCount = computed(() => {
return todos.value.filter(todo => todo.completed).length;
});
const newItem = signal("");
function addTodo() {
todos.value = [...todos.value, { text: newItem.value, completed: false }];
newItem.value = "";
}
function removeTodo(index) {
todos.value.splice(index, 1)
todos.value = [...todos.value];
}
function TodoList() {
const onInput = event => (newItem.value = event.target.value);
return (
<>
<input type="text" value={newItem.value} onInput={onInput} />
<button onClick={addTodo}>Add</button>
<ul>
{todos.value.map((todo, index) => {
return (
<li>
<input
type="checkbox"
checked={todo.completed}
onInput={() => {
todo.completed = !todo.completed
todos.value = [...todos.value];
}}
/>
{todo.completed ? <s>{todo.text}</s> : todo.text}{' '}
<button onClick={() => removeTodo(index)}>❌</button>
</li>
);
})}
</ul>
<p>Completed count: {completedCount.value}</p>
</>
);
}
render(<TodoList />, document.getElementById("app"));
While the provided example does not showcase how reactive primitives eliminate over-rendering, it nonetheless showcases the key new primitives. The signal primitive declares reactive pieces of state. The computed primitive declares a reactive piece of state as computed from other reactive pieces of state. The value of the reactive pieces of state may be accessed with .value.
Developers debated on reddit the importance of performance in today’s web applications and compared ergonomics with that of React, other frameworks’ reactivity primitives (e.g., Vue 3, Solid), and other libraries (e.g., Redux, mobX, jotai, recoil).
Others worried that with this new API Preact was straying farther away from React. One developer said:
Hooks and Classes are the supported and encouraged architecture to utilize and Preact’s Signals move intentionally away from that, further defining them as a unique framework, NOT a “React add-on”.
Another developer on reddit mentioned the need for guidance and additional examples:
The problem here is that you’re going to get a lot of confusion around how to performantly utilize signals and so people are going to use them wrong all the time, unfortunately.
Preact self-describes as the “fast 3kB alternative to React with the same modern API”. Preact is an open-source project under the MIT license. Contributions are welcome and should follow the contribution guidelines and code of conduct.
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ
Working in outdated ways causes people to quit their work. Pim de Morree suggests structuring organizations into networks of autonomous teams and creating meaningful work through a clear purpose and direction. According to him, we can work better, be more successful, and have more fun at the same time.
Joost Minnaar and Pim de Morree from Corporate Rebels will speak about unleashing the workplace revolution at Better Ways 2022. This conference will be held in Athens on September 23, 2022.
According to de Morree, the way we currently work is outdated. This is caused by using an outdated idea of how work should be done:
100+ years ago we created structures to manage work in a certain way. That worked really well, but times have changed. However, our way of working has remained largely the same.
While the world is changing at a much faster pace, most organizations continue to rely on bureaucracy, top-down control and predictability. And that’s not working.
As a result, a huge amount of people are disengaged, burned out, or bored out of their mind at work, de Morree argued. It’s not that surprising that people are quitting in droves.
De Morree suggests structuring organizations into networks of teams where teams have skin in the game. Split the organization up into small teams (mostly 10-15 people) that are highly autonomous:
Think of giving teams the power to make decisions around strategy, business models, reward distribution, hiring, firing, and so on. Power to the people, to the teams I should say.
This is not an easy thing to do. But, according to de Morree, if done well it has a huge impact on motivation and success.
Pioneering organizations are changing their way of working. Many are focusing on networks of teams, transparency, distributed decision-making, and supportive leadership, de Morree claimed. They focus on creating meaningful work through a clear purpose and direction. They reduce hierarchy and unleash autonomy. They provide freedom and responsibility while allowing people to work on things they love to do.
The benefits that de Morree has seen include increased engagement, productivity, innovation and reduced sickness, mistakes, and attrition.
InfoQ interviewed Pim de Morree about exploring better ways to work.
InfoQ: What is keeping organizations from changing the way they work?
Pim De Morree: It´s a lack of understanding of how things can be done differently. It’s hard to reimagine things when you’re very much used to doing things a certain way. 99.9% of our education system, our institutions and our businesses are organized in traditional ways and therefore it’s hard to envision a different reality.
However, there are pioneers who are showing that things can look very different. In a very good way.
InfoQ: How can organizations foster freedom and trust, and what benefits can this bring?
De Morree: First of all, it’s important to understand that with freedom comes responsibility. It doesn’t make sense to just give employees freedom. To unleash true motivation, it’s important to also provide lots of responsibility.
Create clarity around the purpose of the organization, the goals of each and every team, the guiding principles to take into account, and the constraints that people have to deal with. If you set the framework properly, it’s much more interesting for teams to self-organize within that framework.
InfoQ: What can be done to establish a culture of radical transparency?
De Morree: As the term suggests, radical transparency is about opening up all kinds of information. Think of creating transparency around the company financials, important documents, team financials, salary levels, and so on. The more information people have about the company, the more they are able to make great decisions. Otherwise, they might have authority to make decisions, but no information to do so properly.
MMS • Kate Wardin James Stanier Miriam Goldberg James McNeil
Article originally posted on InfoQ. Visit InfoQ

Transcript
Verma: We are here for a panel discussion on remote and hybrid teams.
We’re mostly tech people here and we should just recognize that this is such a privilege for us to be remote. Although like, last couple years, we’ve felt like we’re forced into this remote work, but we should recognize that there are other people who were bound by their duty and motivated by their compassion to continuing being in-person, and definitely thankful for all of that.
Background, and Perks of Working Remote vs. In-Person
I’m Vishal. I’m an engineering manager at Netflix. I have some remote working experience. As we introduce everybody, I wanted to hear a little bit about your background, especially in the context of remote and hybrid teams. Why don’t you, as you introduce yourself, tell us a perk that you miss from working in-person, or a perk that you enjoy because of being remote now that we are in this world.
McNeil: I’m James McNeil. I’m an SRE at Netlify. I’ve been there for a bit over a year now. That role has been fully remote. Netlify is a fully remote company. Before that, though, I was at Pivotal and I was working on a hybrid team. Two of my teams were in different countries in different time zones, and because Pivotal was the place where you pair that also involved fully remote pairing, which was a very interesting experience. There’s one thing that I absolutely do not miss is commuting. I don’t think people should have to commute ever. It makes no sense to me. There’s a lot of very interesting stuff about how cities were developed, and why commute. It’s not a natural state of being. I do miss free breakfasts for those of us who had them.
Stanier: I’m James. I’m Director of Engineering at Shopify. I’ve been at Shopify for not long, two months. Prior to that I was a seed engineer at a startup. Then over the course of 10 years, we grew it and exited. Remote for a couple of years now. I previously didn’t think remote working was for me, but the pandemic changed all that. The perk now is that we’ve relocated to be near all of our family, which is the best possible thing that could have happened to us. I agree with James, I do miss snacks and free food and that kind of thing, but being close to family is a bit better. That’s all good.
Wardin: Kate Wardin. I’m an engineering manager at Netflix. I am in Minneapolis. What I love about working remote is of course taking care of my house plants during the day. That has been a wonderful new hobby for me. Also, of course being closer to family, getting to have lunch with my daughter and my husband, and take my dog on a walk when it’s not brutally cold, is wonderful. I’ve been working remote since March of 2020, as a lot of us have. For those of you who have visited Minneapolis, I worked downtown and we had skyways, and so you would go on one on one walks through the skyways. You could walk the equivalent of miles all inside so you don’t have to put on your jacket, go to a good bunch of different restaurants and stuff. I really miss the skyway walks. That was so fun and just a great way to support local businesses too. I miss that and I miss seeing people of course, but I’m happy to be home.
Verma: That’s so sweet, the walks. I can almost picture people walking or myself walking. It’s such a wonderful experience.
Goldberg: I’m Miriam. I’m an engineering manager at Netflix. I manage our Federated GraphQL team. I’ve been at Netflix for about seven months, and I am fully remote out of Philadelphia. I started working remotely in 2018. When I was working at Braintree, I had started in-person, and then moved back to Philly, went remote, switched into management. It was a lot of changes. What I really miss, honestly, is having a beer with my co-workers after work. I miss that a lot. I also love that I get to be in my hometown, just like you Kate. I love Philly. I love that I can be here again and work in an industry that I love. It’s a great perk.
Verma: Again, now, imagining glasses clink with co-workers or friends. That’s obviously one thing I miss. You’re right, so many good things, so many things we miss also. I miss an espresso machine so much. I’ve considered buying it, obviously, but I think it works better when you have it at a company.
Interesting Developments around the Concept of Location
The big thing I want to start with is, the concept of location used to be so important. There’s been so much written about it. We know that people have migrated countries over centuries to be in the same place at the same time. I was recently reading about Leonardo da Vinci, how he moved to Florence and he did a lot of his important work there. We all know about Silicon Valley, people migrating there. The bigger question I have for all of you, is that location used to be so important, and now we’re saying that it’s not anymore. We’re at least saying that. What are some interesting developments you are seeing towards the concept of either location ceasing to be important anymore, news from around the world?
Stanier: This one’s interesting to me, because part of going remote and relocating was that I now live in a very rural remote part of the UK. This is where my family grew up. This is where her family are from. I think the really positive thing is that when she was 18, and she was leaving home, she had to go to London six hours, seven hours away in order to have a chance at a career. I think, obviously, the whole mentorship and seniority thing in our industry, remote is hard and that’s another conversation topic. I think now at least the possibility that anyone can grow up anywhere and have the same possibility of a career is incredible. The next generation of engineers could be out here in the west of Cumbria, for all I know, it used to be the universities, the cities. I think that’s a really exciting prospect.
Verma: How about you, Kate, why don’t you add your lens on how are you seeing the industry evolve, and do you think this is for real, like these changes for you?
Wardin: First, James, I love what you said. I think this change does make a career in tech a lot more accessible to people who might not have had an opportunity to get into it before. Also, for folks who might need to do something a little bit more like part time or that freelance opportunities first, there are so many more opportunities to network and make connections if you don’t live in these major hubs. In fact, I know a lot of organizations are strategically and intentionally looking at outside of those core cities that were traditionally where people would source a lot of that technology talent. I think that’s wonderful in so many different ways.
I think this is a change for good. I think there’s too many people in the industry who are like, now I’ve moved and I’m loving it, and I’m not going back. A lot of people are going to be picky on where they’re choosing to work. I think that it is here to stay, at least for a lot of organizations, just because of the talent that we can reach and the opportunities that we can provide to people who wouldn’t have had those before. I think there’s a lot of positives.
I’ll speak to a negative. I even think about Minneapolis, and just how some of those small businesses are struggling, if their proximity was servicing folks who commuted downtown, like parking ramps, restaurants, bars. We have to figure out ways to make sure that we’re still keeping them in business, too, and so I think getting creative about that. Of course, we know the success stories, and unfortunately, some of the downfalls of that. There’s pros and cons.
Verma: Excellent point about empathy with people who might be seeing the negatives of that. Definitely not as much talked about. Actually, while I take that context, what you said to Miriam and James McNeil. James McNeil and Miriam, you’ve been doing remote before the pandemic. Going back to the bigger question of remote like, I want to ask the same thing, what are you seeing from your point of view? Is this thing real? How different is it from before when you were doing remote?
McNeil: It’s real. I can speak for myself. I work for a company that doesn’t even actually have a registered entity in the UK, and I wouldn’t have that opportunity unless they were open to remote work. In fact, not dissimilar to James, I’ve within the past week moved to a much smaller city on the west side of the country, because my partner is from Wales, which is just across the border. I think that freedom and openness to different geographies, and to people working in different places so long as they are able to work is definitely here to stay. From our perspective, I’ve seen, and just looking at the makeup of our company, we’ve definitely hired much more internationally since the pandemic. I think we were a remote company but once we took the brakes off and went fully all in, suddenly, we’re like, we can hire people from all over the world. There’s so much talent out there that doesn’t want to go to Silicon Valley or can’t. One of the two. I think that companies that are open to that and that realize that are profiting from that.
I think one thing, though, is that, it’s going to be very important to realize that location is not setting. We’ve I think in all of our talks talked about, it’s a privilege to be able to work from home, both like financially and with having the right employer who will let you do that. I could totally see myself working from a co-working space in Bristol, and I’m sure at points in my life, I will have to, just because of not having the space where I’m living. I haven’t done it personally. We definitely offer a stipend if not pay entirely for our colleagues’ co-working spaces. I think that model, sort of a WeWork plus where there are places where you can go that have the right space, but also the right security setup from an IT perspective and from an infrastructure perspective, and people’s employers, for them to feel comfortable working there. Because it’s not necessarily about working from home, it’s about working where suits you.
Goldberg: Building on what you were saying, James, about co-working spaces. When I first went remote, I worked out of a co-working space that happens to be two blocks from my house. I had no commute. It was fantastic. The co-working space shut down for COVID. They’ve since reopened, but I’ve chosen to continue to work from home. I think it depends on the co-working space. When I transitioned into management I began talking more over the course of the day, and shortly before COVID I was getting a couple of stinky looks every now and then. That I was making too much noise in this space, and maybe I should hire a private office within the co-working space and spend more time in phone booths. At that point, I was like, I make a lot of noise. I talk a lot, so I should just work from home. I think that co-working spaces are great. It was nice to have a community of people even if they were not my direct colleagues.
I think opening up these opportunities around the world and in areas where the tech industry isn’t super well established is very exciting. I lived in San Francisco for 10 years working in tech there. Moving back to Philly, I just remember my first week back here, I went to a coffee shop. I was shocked that there were people over the age of 50, drinking coffee and talking about things that were not tech. It hadn’t even occurred to me that that would be unusual, but living in the mission of San Francisco, that’s what it was. You go to a coffee shop, and everyone’s just talking about their startup. I’m hopeful that that may have some effects on diversifying the industry, getting people to think outside of industry bubbles, and get a little bit more creative and make things that are relevant to people outside of that.
Verma: The co-working space story or angle is so interesting. Normally, we would see co-working spaces in particular cities. I wonder if the trend is going to now take co-working spaces to pretty much everywhere, especially the more scenic places maybe, like where people would want to live. If anybody has any co-working space trends they want to share, I know it’s still COVID, probably maybe not taking off as much.
Wardin: The athletic club is big here, and so you’re seeing the co-working spaces like attached to a gym so you can go to a workout class, and then have your co-working space. They just opened a new one downtown Minneapolis, and then there’s one right by my house, so having it in proximity to a workout facility.
Verma: That’s such a good idea. I did not think about that. Now I’m thinking what other things you can add on to a location to make it even better for people. James Stanier, do you have any observations?
Stanier: Interestingly, just related to this, there’s a startup called Patch. Patch.work is their website. They’re now wanting to open up co-working spaces everywhere, and you register your interest, and then they try and acquire a coffee shop or a building in your location. I think they’ve launched, I saw on Twitter the other day, but the whole idea is it’s, work near home becomes a thing. I live in a very rural place, there’s not really a coffee shop here I can work from, but if there was, I would totally be there. In the same way like in the UK, the pub is like your other room in your house and you go to the pub quite a lot to hang out. Again, it’s like another extension of the home in your community, which I think is great. It drives revenue into these communities as well, that may not necessarily have had lots of people there.
Verma: Definitely the business models will evolve with where the demand goes. This is definitely a new area where all those businesses Kate was talking about are suffering, will find newer avenues. People do want to be out there and do things, and be part of the community.
Goldberg: Yes, about co-working spaces, and the move to remote. I think in the run-up to my going remote, one of the biggest gripes of the office that I worked in was that it was an open office plan. We were in a shop that pair programed full time, which was wonderful. I love pairing and I love collaborating, but there were times when it was really hard to do work because there was so much crosstalk. It was really noisy, people are walking through. I think that there are a lot of things about the office environment that are broken, particularly for ICs and people who are doing work that requires deep thought and consideration and focus that in some cases is solved by working from home.
I think that there’s an interesting impedance mismatch because the people who are making the decisions about whether you can work from home are upper management and leadership who don’t do that work. You get into the burden of space planning and making a space that is really productive for software engineers. Sometimes working from home is better. Even with my team now, we have the option to work out of the office at Netflix, and my team has settled on going in once a week to collaborate and see each other in person and build those connections. When they need to sit down and knock out some code, unanimously, they agreed that they prefer to do it from home.
Learnings and Adjustments from Pre-Pandemic Remote Work to Now
Verma: Some of you have experienced this before the pandemic started. The question is around, what adjustments did you make when you moved from pre-pandemic remote work to now, or what are some learnings that you’ve applied there?
McNeil: I think pre-pandemic, I wasn’t working fully remotely. It was, I think, two days a week or something like that. In a sense, I didn’t really take it seriously. I was working. It was like an attachment to my work week, where it was like something we’re trying out. In a way, it was for the benefit of my colleagues who were working remotely, because that’s an important muscle to flex essentially, and to understand where some of the rough edges of remote work are. I hadn’t properly set up a desk. I had a place where I worked with a screen, but it wasn’t my office. I think also, and to what Miriam was saying about offices, this is, I think, a point that we don’t quite have with co-working spaces yet, or home offices, if we don’t have the space, was that my partner and myself were in the same room. We both talk a lot for work, but in very different ways. When I’m talking something very bad is happening and I’m on a call with someone. She’s running conferences and talking to colleagues, let’s say in more of a business setting. Once the pandemic started, she left the room, and we just figured out, given the space that we had, where her office was and where my office was.
I think that what we don’t have from co-working spaces yet, because a lot of them are coffee shops and modified spaces, are places for people to either work quietly, or talk without it being those sort of cubicles that started popping up in offices, because everything was open plan, and you closed the last door, and you’re hermetically sealed away. I think that there’s probably something in the design of these co-working spaces or offices, where we could probably get away from the giant open plan with the huge table. That’s what I’ve noticed. You need a room of one’s own, to quote Virginia Woolf.
Verma: The infrastructure basically getting in your way, like whether you’re in a rural place where you’re not able to have a good internet connection, or a co-working space that haven’t quite caught up to the need for us to be talking all the time. I wonder if the technology will come in and step in and solve these problems. I almost remember seeing a tweet sometimes like if somebody could invent an AI based mic that just filters out everybody else, like just turns on itself when needed and only listens to you, that will be like a billion dollar company. It seems like a lot of things need to happen here and a lot of opportunity coming in terms of what we could do in the future.
Team Building and Personalization
I know that many of you are leaders, you hire people, you’re managers, or directors. I want to touch the aspect of the team building. I want to hear from both you as an employee and a manager. One of my theories is that as we are going into this new world, people are going to have more freedom to personalize the kind of teams they are in. They’ll affect the culture of the team much more than they were able to. James McNeil touched on some teams having international people, other teams might be more localized, so I feel like people have a lot more freedom. As you are building your team, if you’re a manager, let’s talk about like, how are you personalizing your team to be good at the job they do?
Wardin: The last question you asked is, how do you personalize the experience being on the team so that they’re good at what they are expected to do, being remote? I lead a dev productivity team. One thing that they noticed pretty quickly after not being co-located, is that a lot of those, like forums where they would receive some of the more organic feedback from the developers that we support, even just like walking by cubes, and you’re hearing someone complain about the time it takes to deploy, or build something. They’ll be like, how can we help? Where you just be a fly on the wall in some discussions. We’ve had to be really intentional being remote. This quarter, we’re trying this experiment of having developer productivity champions. Each team that we support has a dedicated champion, so they attend their demos, their retrospective, so that they can pick up on some of those things that they are missing from not being in the office. That’s one thing.
Also, surveys, but a lot of people have survey fatigue. We’re trying to find other creative ways to get feedback, so that we can understand like, how do we drive our priorities and know that we’re working on the right things. I know that that’s a pretty unique use case being a dev productivity team, as opposed to a product team. Those have so far worked for us. Also, just ways to personalize knowing that we have folks from all over the world potentially in our teams. I mentioned the photo the weekend thread. I love to say, show me something fun you did this weekend. In Slack, just post a picture that helps people get to know each other, and that trust, that bonding is going to make us a better team. We’ll do an icebreaker question. Maybe you say, tell me something cool about your hometown. Just ways to again, humanize our colleagues, get to know each other, build that camaraderie and that trust so that we can be as best effective as possible.
Intentional Things in Personalizing Teams for Remote and Hybrid Work
Verma: I want to hear also from James Stanier, since you are building a team in Europe, how are you going about it? What are some intentional things you are doing in personalizing your team for remote and hybrid work?
Stanier: The interesting thing for us is like, there’s not many Shopify engineers in Europe, in our area of the company. We’re pretty much like rolling the road out in front of us as we are going. I’m new, my leads are new. I’m hiring leads, they’re hiring their teams. We’re all in it together. One is being very open about the uncertainty and not really knowing the answers to anything goes a long way. One thing that we’re trying to do is every week, try and meet with three to five people from different parts of the organization, have a coffee, or have a chat with some of the other principal engineers, with other directors and the VPs, just talk. Because I think if you do that every single day, every single week, you start to build up a network graph in your brain of like, how does this company do things? Who does what? Then that’s great for your team as well. We could say, “We’re doing this new technical thing. Last week, I spoke to one of the other principal engineers, he spends 30% of his week mentoring people. He’s probably got some time to pair with you, just go and have a chat.” You have to be much more intentional and proactive, as Kate was saying, with your connections. You have to think of the office metaphor of corridors of unintentional bumping into people, a fly on the wall, and then convert those metaphors into intentional actions in the asynchronous and internet based world for sure.
Culture Personalization as a Remote or Hybrid Worker
Verma: That’s insightful. We’re already seeing a contrast. Kate, your team is keying on certain factors. James Stanier is talking about certain other factors, because the journey his team is in, maybe social connections are much more important right now. That speaks to how during a journey of a team, like different knobs will become more important, and we cannot personalize even during the lifetime of a team, different elements. Let’s talk to James McNeil. You talk in an SRE specific environment. You’ve already done things to make sure things work well. What are some other things you would do to personalize the culture of your org or your team as a remote worker or a hybrid worker?
McNeil: I think one thing that’s going to be interesting from an organizational perspective to look back on the past couple years, is that, we, I imagine are going to see a different interpretation of Conway’s Law. Because there’s so much more fluidity to the org structure and there are no hallways, or water coolers. Teams aren’t geolocated, and that’s going to probably break down some of the barriers that you got around, your systems reflect your organizational structure. It also creates other ones, to some of the points that some of the others have made. Some of the stuff that we do as parts of onboarding, would be essentially trying to reach out to as many people who are adjacent to the work that you’re doing. This is something that the engineering manager will put together, essentially a package for every new joiner, of these are the people on the team. This is roughly the people we work with. This is the SRE that’s associated with that team. Then, it’s essentially up to that new joiner to contact them, to put in some time in their calendar, and to get those introductions going. Because one thing that we don’t have is a lot of that informal conversation unless you make that happen.
There’s a really interesting book by a woman named Marie Le Conte, about the way that the UK Parliament works, called, “Haven’t You Heard?” Her thesis is that all of UK politics is based on gossip. Actually like being in the halls of power and seeing people in, I think there was like 10 pubs or something like that, has a big influence on the way that things work. I think that, in a colloquial sense, encouraging gossip, encouraging people to talk amongst themselves and not just get either the messages from on high or their track of work, is very important in an organization that’s fully remote. Because that organic transfer of knowledge is sometimes where some of the best ideas come from, sometimes where some of the thorniest problems get solved, because people address things in different ways. I don’t know if I’ve given too many solutions, but ways of encouraging people to just have informal chats I think are incredibly important.
Verma: I think, more solutions, the better. Right now we’re all trying to figure things out and there are so many different situations. Maybe Miriam you can add your perspective, like you worked in payments industry also. I was wondering, does this work for everybody, like every industry or like some industry, just like not, like just inimical to this thing.
Goldberg: When I went remote, we were hybrid. At Braintree, our two largest offices were in San Francisco and Chicago. Then we had a smattering of independently remote people mostly around North America. We made it work. I think it worked pretty well, because we were already broken up across offices. We had good VC. We were used to working across time zones, and making sure that we were including people who weren’t in the room on decisions. I think of a lot of the stuff that James McNeil has been saying because in payments, SRE in offices is pretty intense. That stuff is always remote, because you can’t just plan to be paged when you’re in the office. It always seems to happen at 3:00 in the morning. Yes, we did it.
I think that one thing that we haven’t been able to do since COVID, when I moved to Philadelphia, I worked really closely, for instance, with the Docs team, because I was on APIs. We worked a lot with our Docs team to document our public APIs. They were mostly based in Chicago. Some of that was very creative, open ended, like how are these things going to work together, and we flew to Chicago before COVID. I could hop on a plane at 6 a.m., and be home by 10 p.m. the same day. I would do that every couple of months if I needed to, or spend the night, or whatever. That obviously hasn’t really been an option for most people in the last couple of years. It certainly is not an option if you’re talking about cross country or transatlantic travel. I am excited to start peppering our remote work with some more in-person travel as things loosen up a bit. It’s definitely valuable. I just don’t think you need to over-index on it.
Sustainability of Remote/Hybrid Work
Verma: Since we have all taken on this, I want to talk about sustainability of this thing. We’ve taken on remote and hybrid work, we want to make it last. Obviously, so far what I’ve heard, I’m not hearing that there’s a definite point in future where we’re going to switch. Seems like we’re leaning more into this. I want to talk about sustainability. What are the things people should be doing, companies should be doing, teams and managers should be doing to make it last?
Stanier: There’s a lot to unpack in this particular area. I think a lot of it comes from managers and leadership trying to set the tone for how you make this a marathon and not a sprint. It’s so easy when you’re working remotely to check all of your messages all evening, maybe even wake up in the middle of the night and reflexively check them on your phone. You have to be much more attentive to how you spend your time and your attention. I think it’s making sure people don’t work too long hours, and the leaders of the company being very vocal about that. There’s this concept of leaving loudly, which came out of this thing, like the Australian branch of Pepsi or something. It was a program they had in their leadership where anyone who’s like C level, VP level, you leave at the end of the day, reasonable time, and you tell everyone what you’re doing. It is like, “3:30, I’m off to pick up the kids. I’m out. See you.” You embed the culture that, no, it’s not right to be checking all your emails all night, because that makes you better or you’re not missing out. You have to really prioritize that thing. At Shopify, we’ve already had the email saying, basically, we’re closed over Christmas, unless you have critical work. That’s the expectation. It really sets the tone. I think there’s a lot to unpack in this area with regards to burnout, and mental health, and FOMO, and all these kinds of things, especially if you’re in a different time zone.
Verma: Such a great point about being explicit, and leading by example, or setting the tone so others can be comfortable doing it. I want to maybe touch a little bit, of how company culture plays a role here. Maybe Miriam and Kate, since you are at Netflix, I want to talk about, like Netflix gives people a lot of freedom in terms of how they want to take time off. We don’t even have an official calendar. How are you navigating this, making it sustainable for your teams, this concept of remote work?
Goldberg: As a manager, I am always telling people to take time off. Like, you have a tickle in your throat, go home and sleep. Your kids are a lot today, go hang out with them. I have never had a manager who has really hovered over me and expected me to put in hours, and I certainly don’t want to do that to anyone else. It feels inhumane and counterproductive. I don’t know if this is true, I have a theory, just from observation and my own experience, that going remote at a company that you worked at in-person for, sets you up to have a harder time setting boundaries. If you join a company fully remote, it’s easier to set those boundaries. I think possibly some of it is just the social bonding that happens when you work in-office with people and perhaps with the company. Maybe a little bit of emotional transference that you have in those situations where you really do feel like duty bound to show up all the time for work, that maybe you don’t build those bonds. I think maybe that’s much healthier with your employee.
Going back to, I think James McNeil you mentioned the HashiCorp guy, was like you’re not going to make friends. I really like my co-workers at Netflix a lot. I enjoy working here. It is different than companies where I started in-person, and that’s ok. I think the people who I manage now all started in-person at Netflix, actually, with one exception, we’re very bonded to the work, and bonded to each other, and bonded to our mission. Just reminding them that there’s a whole world outside of work for themselves and their families and their lives, and just go do that. Go pay attention to it and nurture it.
Wardin: James Stanier, mirroring what you said, like leaving loudly. I wrote that and I love that. I think it is up to the leader to lead by example. To Miriam’s point, there is life outside of work. I’m going to take care of X, Y and Z priority, and making that ok, and actually encourage to do that. Miriam, you described so beautifully. That is exactly how it is. Of course, I was at Target before this, and I just felt this obligation. From being in the office together 40 hours a week, every single day, I felt this obligation to show up, and all the time be there. Whereas when I joined Netflix, I was like, there’s not this expectation. I’m getting my work done, and then I’m done.
An additional thought to make this sustainable, is to make sure that we have an equitable experience for folks who are remote, as equitable as the folks who are maybe going back on site. James McNeil, you spoke to, things get done, those water cooler chats. The fact that we do have to simulate those in-person interactions, those people are literally getting those interactions in-person, how do we make sure that it is equitable for folks online? Even as simple as, if you’re in a meeting room with three people in the room, and then two people online, please just turn your cameras on on your laptop so that you’re not like an ant and I can’t even see your expressions. Things like that can make a huge difference if you are intentional, or do just like call out if the experience isn’t equitable, being remote if there are folks in-person.
See more presentations with transcripts
MMS • Bryan Stallings
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Certain bad habits and collaboration anti-patterns that have been a part of in-office work for a long time are exacerbated by the dynamics of working remotely or hybrid.
- The impact of not addressing these habits is deteriorating team morale, lack of trust and connection required to do meaningful collaboration, and more silos between roles.
- Learn specific strategies for recognizing and addressing four such habits, including optimizing for in-office employees, over-reliance on desk-side chats, and backchannel gossip.
- Leaders can utilize better facilitation skills and best practices to help eliminate bad habits and improve the way their team collaborates.
- By addressing the bad habits carried over from in-person work, leaders can help remote and hybrid teams experience stronger psychological safety and inclusion, creating more engaged and innovative teams.
If you’re a leader, you’ve likely spent significant time thinking about how work—the way we communicate, share information, hold meetings, ship code, make decisions, and resolve conflict—has changed as a result of increasing remote and hybrid work.
You’ve had to learn how to deal with entirely new etiquette questions as a result of remote work, from how to deal with a constant barrage of “pings” from your corporate chat app, to whether or not it’s considered rude to have your camera off during Zoom calls. And you’ve had to adjust to all of these on the fly.
But what about all the bad work habits we should have tackled a long time ago?
It’s time to clean up our collaboration habits
Certain bad habits that were already important to address when in-office work was the standard are now exacerbated by hybrid and remote work. Instead of continuing to tolerate and accept them as the status quo, perhaps now is an opportunity instead to finally check them off your to-do list.
Why is it so important to address these patterns now, rather than later?
- Bad habits kill collaboration: The accumulated grime of bad work habits can hold your team back from feeling safe, comfortable, and valued at work—all essential components of being able to collaborate and be creative as a team. The good news? You’re holding the power washer and just need to turn it on. Set an example as a leader that you are committed to continually changing for the better—and that you want a culture where it’s okay to have hard conversations about things that need to change.
- Employees are asking for change: In a recent study on the ways companies and teams collaborate, 80% of surveyed knowledge workers said that virtual meetings are an essential part of their jobs—yet 67% of people still prefer in-person meetings. There is a clear opportunity (and need) for virtual meetings to improve, and creating better collaborative experiences for attendees is a huge piece of the puzzle.
- The stakes are incredibly high: As businesses face both recession and widespread resignation, any cultural habits that don’t serve collaboration and innovation are ultimately going to be detrimental to your bottom line. The impact of not addressing these habits is deteriorating team morale, increased burnout, and a growing lack of trust and connection required to collaborate in meaningful ways.
Four bad collaboration habits you can tackle today
So, what are the habits we need to address to improve collaboration in today’s hybrid world?
Here are four, along with recommended solutions, that I’ve observed during two decades of Agile coaching, professional facilitation, and management consulting.
Bad habit #1: Disorganized flow of information
It used to be relatively easy to pop over to a colleague’s desk to touch base on a task, quickly troubleshoot an issue, or follow up on an earlier conversation. And because of close physical proximity, it was also much easier to include other relevant parties.
This kind of impromptu collaboration is invaluable for fast-moving teams, but it’s been hard to find an effective replacement within a remote team without contributing to meeting overload. Any off-the-cuff chat between two remote employees tends to require finding spare time on a calendar. And if any part of that chat becomes relevant to someone not in the meeting, it’s not easy to pull them in because they may be in a different meeting.
All of this contributes to a very disjointed flow of information for remote teams. To combat it, teams often try to focus on cutting down on meetings in the name of communicating the most important information in larger group meetings. But this in turn can hamper teams from moving quickly by bottlenecking important information until “everyone is in the same room.”
For teams to be able to collaborate effectively, they need the right information at the right moment—and they shouldn’t have to twiddle their thumbs or schedule three separate meetings to get it.
Solution: Invest in better documentation and asynchronous coordination
If people are constantly having to schedule follow-up meetings to catch up on missed details, learn technical engineering processes, or understand the structure of a marketing program, it presents an opportunity to improve your documentation—and save yourself and others from having to schedule another meeting down the road.
If that sounds overwhelming, it doesn’t have to be! Documentation doesn’t need to be as formal as in the past. Instead of feeling like you have to invest a lot of time and energy creating documentation, you can use the approach of building an innovation repository.
With better documentation, instead of imposing on someone to find a time on their calendar to have a chat to resolve a problem, the onus can be on you to review the documentation and then follow up asynchronously with any gaps or additional questions you might have.
Bad habit #2: “One size fits all” collaboration
From the same study, a majority of the respondents felt that virtual meetings—especially those attended by both remote and in-person workers—are dominated by the loudest and most active voices. And we could see this during in-person meetings, too.
For example, many teams default to holding “brainstorming sessions” the same way each time: You have a loose topic you want to discuss, so you open it up to free-wheeling discussion for 30 or 60 minutes. The person who scheduled the meeting might be taking notes, or they might not. The team converges around the ideas of the people who spoke up first or most confidently (especially if they are in a leadership position), deferring to their vocal command of the room.
Yikes! For teams to collaborate effectively, we need to learn to not associate extroversion with engagement (or good business sense) and realize that there is more than one way to collaborate and participate as a teammate.
Solution: Make space for all voices to contribute
One effective way to avoid one-size-fits-all collaboration is to accommodate for common collaboration styles:
- Expressive: Some team members like to see ideas sketched out with drawings, graphics, and sticky notes, and are likely to express themselves with GIFs and emojis. Expressive collaborators may have trouble engaging in hybrid meetings dominated by text-heavy documents and rely more on unstructured discussion to feel their most creative.
- Relational: These collaborators gravitate toward technology that enables direct, human-to-human teamwork and connection. Fast-paced virtual meetings can feel draining to relational collaborators, so more intimate activities like team exercises or breakout sessions can help them surface their best ideas.
- Introspective: These naturally-introverted collaborators like to collect their thoughts before offering a suggestion, and gravitate toward more deliberate approaches to collaboration. They may be frustrated with virtual meetings that appear aimless or poorly facilitated, and they prefer to have a clear agenda and formalized processes for documenting follow-up.
Not everyone fits cleanly into one of these three categories, but the principle at hand is the same: You need to be open to different collaboration styles and check in regularly to make sure you’re not skewing these interactions toward one style over the others.
Bad habit #3: Optimizing meetings for in-office employees
Once when my siblings and I visited my parents, I noticed an interesting phenomenon. After a family dinner, we migrated toward the living room to chat and play games, but half an hour later, we paused and asked, “Wait, where’s mom?” Only then we realized she was cleaning up in the kitchen alone. Even though we were adults who knew better, we were unintentionally behaving like our once-teenager selves!
A similar thing often happens with hybrid teams: remote team members often get unintentionally left behind from social experiences that in-office employees are enjoying together.
This can happen in a variety of ways, especially with how teams approach collaboration. For example:
- Those physically present in a meeting overlook the need to adapt the conversation to equitably include those joining remotely. A meeting paced to in-office participants might move on from topics before someone who is remote has a chance to unmute and chime-in.
- Remote employees may miss the camaraderie-building chat that happens before and after meetings, such as discussion around where everyone is going for lunch, what they did that weekend, or a funny inside joke.
- In-office employees have the benefit of physical proximity to interpret body language, while remote employees may miss out on those more subtle cues or reactions.
When these things happen, “in groups” and “out groups” unintentionally form, making it hard to collaborate as an aligned, unified team.
Solution: Thoughtful facilitation and inclusion
Good facilitation helps create equal footing for all participants in collaborative meetings and can prevent remote employees from feeling like second-class citizens. To improve collaboration, facilitators might:
- Take responsibility to record the meeting for those who were unable to attend or may want to listen to the discussion again.
- Host a shared whiteboard or simple document for collaborative note-taking where participants may offer input and questions without coming off mute.
- Monitor the pacing of the meeting, making sure to pause when necessary, ask someone to repeat a comment that remote employees may not have caught, or seek engagement from someone that has yet to participate.
- Provide context and “room resets” to those joining late, or those who missed a pre-meeting chat, so that no one feels excluded.
It may not seem like a big deal, but going above and beyond in these ways is an important aspect of helping people feel like part of a whole—and that feeling helps them feel safe enough to contribute their best ideas.
Bad habit #4: Backchannel chat and gossip
Bias is at the core of much of the gossip that happens in offices. We make assumptions on the barest of information because we’re separated and only see faces across screens. When we’re all busy and exhausted, it becomes easy to turn a misunderstanding between coworkers into full-blown contempt for that person, quickly undermining the morale and connection of distributed teams.
And because it’s so easy to Slack someone a sarcastic comment during a company all-hands, or send that eye-roll emoji during a team meeting, we can easily pull people into our negativity, which isn’t fair to them or the person we’re creating gossip about.
Solution: Create a psychologically-safe culture that addresses conflict
It doesn’t matter whether it’s someone reheating fish in the office microwave or you feel a team member dropped the ball on a project– any conflict has the potential to derail a team’s interconnectivity and their ability to collaborate effectively.
The way to cut through that is to resist venting to our work friend. We need to address things head on! One easy place for this to happen is during retrospectives and post-mortems. With facilitation and a solid agenda in place, everyone on the team can air their frustrations and bring narratives into the light instead of keeping them in Slack DMs.
By treating each other courteously, and acknowledging that conflict is a natural part of working together, we can move past those issues and create stronger teams as a result.
Enacting change to improve collaboration
As a leader, it’s within your power to enact change. Making changes to cultural habits and patterns that have long plagued organizations is not a waste of time; it not only improves your team’s collaboration dynamics, but has an impact on your bottom line, as better collaboration means faster innovation.
By helping your teams have psychological safety, comfortability, and confidence that they can share their ideas and be treated as an equal on a team, you also give them permission to move quickly, trust their ideas, execute with autonomy, and grow your business.
MMS • Renato Losio
Article originally posted on InfoQ. Visit InfoQ

AWS recently announced that Event Ruler, the component managing the routing rules of Amazon EventBridge, is now open source. The project is a new option for developers in need to match lots of patterns, policies, or expressions against any amount of events in near real-time.
Written in Java, Event Ruler offers APIs for declaring pattern-matching rules, presenting data records (events) and finding out at scale which rules match each event, allowing developers to build applications that can match any number of rules against events at several hundred thousand events per second.
Events and rules are JSON objects, but rules additionally can be expressed through an inbuilt query language that helps describe custom matching patterns. For example, a JSON event of an image:
{
"Image" : {
"Width" : 800,
"Height" : 600,
"Title" : "View from 15th Floor",
"Thumbnail" : {
"Url" : "http://www.example.com/image/481989943",
"Height" : 125,
"Width" : 100
},
"Animated" : false,
"IDs" : [116, 943, 234, 38793]
}
}
can be filtered by a JSON rule that filters for static images only:
{
"Image": {
"Animated" : [ false ]
}
}
Source: https://aws.amazon.com/blogs/opensource/open-sourcing-event-ruler/
Rishi Baldawa, principal software engineer at AWS,,explains:
This offers a novel solution for anyone in need to match lots of patterns, policies, or expressions against any amount of events without compromising on speed. Whether the events are in single digits or several hundred thousand, you can route, filter, or compare them in near real-time against any traffic. This speed is mostly independent of the number of rules or the patterns you define within these rules.
Event Ruler is in production in multiple Amazon services, including Amazon EventBridge, the serverless event bus service that helps developers and architects to connect applications with data from a variety of sources. The new open source project includes features that are not yet available on the AWS managed service. Nick Smit, principal product manager for Amazon EventBridge at AWS, tweets:
You’ll notice it has some features such as $or, suffix match, and Equals-ignore-case, which are not yet in EventBridge. We plan to include those in future. Excited to see the new ideas the community will bring!
Talking about use cases for the new project in a “Hello, Ruler” article, Tim Bray, formerly VP and distinguished engineer at AWS and one of the developer behind Event Ruler, writes:
The software is widely used inside AWS. Will it be useful outside the cloud-infrastructure world? My bet is yes, because more and more apps use loosely-coupled event-driven interconnections. For example, I think there are probably a lot of Kafka applications where the consumers could be made more efficient by the application of this sort of high-performance declarative filtering. Yes, I know there are already predicates, but still.
A year after announcing OpenSearch, there are different new AWS open source projects and initiatives, mostly covered in the AWS Open Source Blog and the AWS open source newsletter, with many believing that AWS is improving its open source reputation. Bray adds:
AWS has benefited hugely from the use of open-source. So it is nice to see them giving something back, something built from scratch, something that does not particularly advantage AWS.
Event Ruler is available on GitHub under the Apache 2.0 license.
MMS • Suhail Patel
Article originally posted on InfoQ. Visit InfoQ

Transcript
Patel: I want to talk about curating the best set of tooling to build effective and delightful developer experiences. Here’s a connected call graph of every one of our microservices. Each edge represents a service calling another service via the network. We rely heavily on standardization and automated tooling to help build, test, deploy, and monitor, and iterate on each of these services. I want to showcase some of the tools that we’ve built to help us ship these services consistently and reliably to production.
Background Info
I’m Suhail. I’m one of the staff engineers from the platform group at Monzo. I work on the underlying platform powering the bank. We think of all of the complexities of scaling our infrastructure and building the right set of tools, so engineers in other teams can focus on building all the features that customers desire. For all those who haven’t heard about Monzo, we are a fully licensed and regulated UK bank. We have no physical branches. You manage all of your money and finances via our app. At Monzo, our goal is to make money work for everyone. We deal with the complexity to make money management easy for all of you. As I’m sure many will attest, banking is a complex industry, we undertake the complexity in our systems to give you a better experience as a customer. We also have this really nice and striking coral debit cards, which you might have seen around. They glow under UV light.
Monzo Chat
When I joined Monzo in mid-2018, one of the initiatives that was kicking off internally was Monzo chat. We have quite a lot of support folks to be a human point of contact for customer queries for things like replacing a card, reporting a transaction, and much more. We provided functionality within the Monzo app to initiate a chat conversation, similar to what you have in any messaging app. Behind the scenes, the live chat functionality was previously powered by Intercom, which is a software as a service support tool. It was really powerful and feature rich and was integrated deeply into the Monzo experience. Each support person had access to a custom internal browser extension, which gave extra Monzo specific superpowers as a sidebar within Intercom. You can see it on the right there showing the transaction history for this test user directly and seamlessly integrated into the Intercom interface. With the Monzo chat project, we were writing our own in-house chat system and custom support tooling. Originally, I was skeptical. There’s plenty of vendors out there that provided this functionality really well with a ton of customizability. It felt like a form of undifferentiated heavy lifting, a side quest that didn’t really advance our core mission of providing the best set of banking functionality to our customers.
Initially, the Monzo chat project invested heavily in providing a base level experience wrapped around a custom UI and backend. Messages could be sent back and forth. The support folks could do all of the base level actions they were able to do with Intercom, and the all useful sidebar was integrated right into the experience. A couple years in and on the same foundations, Monzo chat and the UI you see above, which we now call BizOps, has allowed us to do some really innovative things like experiment and integrate machine learning to understand the customer conversation and suggest a few actions to our customer operations staff, which they can pick and choose. Having control of each component in the viewport allows us to provide contextual actions for our customer operations folks. What was previously just a chat product has become much more interactive. If a customer writes in to say that they’ve lost their card, we can provide a one click action button to order a new card instantly and reassure the customer. We had this really nice UI within the BizOps Hub, and the amazing engineers that worked on it spent a bunch of time early on writing modularity into the system.
Each of the modules is called a weblet, and a weblet forms a task to be conducted within BizOps. The benefit of this modular architecture is that weblets can be developed and deployed independently. Teams aren’t blocked on each other, and a team can be responsible for the software lifecycle of their own weblets. This means that a UI and logic components can be customized, stitched together, and hooked up to a backend system. We’ve adopted the BizOps Hub for all sorts of internal back office tasks, and even things like peer reviewing certain engineering actions and monitoring security vulnerabilities. What was a strategic bet for more efficient customer operations tool has naturally become a centralized company hub for task oriented automation. In my mind, it’s one of the coolest products that I’ve worked with, and a key force multiplier for us as a company.
Monzo Tooling
You’re going to see this as a theme. We spent a lot of time building and operating our own tools from scratch, and leveraging open source tools with the deep integrations to help them fit into the Monzo ecosystem. Many of these tools are built with modularity in mind. We have a wide range of tools that we have built and provide to our engineers, things like service query, which analyzes a backend service and extracts information on the various usages of that particular service. Or this droid command that Android engineers have built to help with easier testing and debugging of our Android app during development.
Monzo Command Line Interface
One of the most ubiquitous tools across Monzo is our Monzo command line interface, or the PAN CLI as it’s known internally. The Monzo CLI allows engineers to call our backend services, manage service configuration, schedule operations, and interact with some of our infrastructure, and much more. For example, I can type a find command with a user ID, and get all the information relating to that particular user from our various internal APIs. I don’t need to go look up what those APIs are, or how they’re called, or what parameters are needed. Here, I’ve used the same find command, but with a merchant ID, and I automatically get information about the merchant. The CLI has all of that knowledge baked in on what IDs are handled by which internal API sources. Engineers add new internal API sources all of the time, and they are integrated automatically with the PAN CLI.
These tools don’t just function in isolation, behind the scenes, a lot of machinery kicks in. On our backend, we explicitly authenticate and authorize all of our requests to make sure that only data you are allowed to access for the scope of your work is accessible. We log all of these actions for auditing purposes. Sensitive actions don’t just automatically run, they will create a task for review in our BizOps Hub. If you were inclined, you could construct these requests done by the CLI tool by hand. You can find the correct endpoint for the service, get an authentication token, construct the right card request. To this day, I still need to look up the right card syntax, parse the output, and rinse and repeat. Imagine doing that in the heat of the moment when you’re debugging a complex incident.
Using the CLI tooling, we have various modules to expose bits of functionality that might constitute a chain of requests. For example, configuration management for our backend microservices is all handled via the PAN CLI. Engineers can set configuration keys and request peer review for sensitive or critical bits of configuration. I see many power users proud of their command line history of adaptable shell commands, however, write a small tool and everyone can contribute and everyone benefits. We have many engineering adjacent folks using the PAN CLI internally because of its ease of use.
Writing Interactive Command Line
Writing one of these interactive command line tools doesn’t need to be complicated. Here’s a little mini QCon London 2022 CLI tool that I’ve written. I wanted to see all of the amazing speaker tracks at QCon on offer. I’m using the built in command package within Python 3, which provides a framework for line oriented command interpreters. This gives a fully functioning interactive interpreter in under 10 lines of code. The framework is doing all of the heavy lifting, adding more commands is a matter of adding another do underscore function. It’s really neat. Let’s add two more commands to get the list of speakers and the entire schedule for the conference. I’ve hidden away some of the code to deal with HTML parsing of the QCon web page, but we can have a fully functional interactive command line interpreter in tens of lines of code. We have the entire speaker list and schedule accessible easily right from the command line. A sense of competition for the QCon mobile app. If you’re interested in the full code for this, you can find it at this link, https://bit.ly/37LLybz. Frameworks like these exist for most programming languages. Some might be built in like the command library for Python 3.
The Shipper CLI
Let’s move on to another one of our CLI tools. This is a tool that we call shipper. We deploy hundreds of times per day, every day. Shipper helps orchestrate the build and deployment step, providing a CLI to get code from the engineer’s fingertips into production. Engineers will typically develop their change and get it peer reviewed by the owning team for that particular service or system. Once that code is approved and all the various checks pass, they can merge that code into the mainline and use shipper to get it safely into production. Behind the scenes, shipper is orchestrating quite a lot of things. It runs a bunch of security pre-checks, making sure that the engineer has followed all of the process that they need to and all the CI checks have passed. It then brings the service code from GitHub into a clean build environment. It builds the relevant container images, pushes them to a private container registry, and sets up all the relevant Kubernetes manifests. Then kicks off a rolling deployment and monitors that deployment to completion. All of this gives confidence to the engineers that the system is guiding them through a rollout of their change. We abstract away all of the infrastructure complexity of dealing with coordinating deployments, dealing with things like Docker and writing Kubernetes YAML, behind a nice looking CLI tool. We can in the future change how we do things behind the scenes, as long as we maintain the same user experience.
We see the abstraction of infrastructure as a marker for success. Engineers can focus on building the product, knowing that the tooling is taking care of the rest. If you’re building CLI tools, consider writing them in a language like Go or Rust, which gives you a Binary Artifact. Being able to ship a binary and not have to worry about Python or Ruby versioning and dependencies, especially for non-engineering folks means there’s one less barrier to entry for adoption. There’s a large ecosystem for CLI tools in both languages. We use Go for all of our services, so naturally, we write our tools in Go too.
Monzo’s Big Bet on Microservices
Monzo has betted heavily on microservices, we have over 2000 microservices running in production. Many of these microservices are small and context bound to a specific function. This allows us to be flexible in scaling our services within our platform, but also within our organization as we grow teams and add more engineers. These services are responsible for the entire operation of the bank. Everything from connecting to payment networks, moving money, maintaining a ledger, fighting fraud and financial crime, and providing world class customer support. We provide all of the APIs to make money management easier, and much more. We integrate with loads of payment providers and facilitators to provide our banking experience, everything from MasterCard, and the Faster Payments scheme, to Apple and Google Pay. The list keeps growing as we expand. We’ve been at the forefront of initiatives like open banking. We’re expanding to the U.S., which means integrations with U.S. payment networks. Each of these integrations is unique and comes with its own set of complexities and scaling challenges. Each one needs to be reliable and scalable based on the usage that we see.
We have such a wide variety of services, you need a way to centralize information about what services exist, what functionality they implement, what team owns them, how critical they are, service dependencies, and even having the ability to cluster services within business specific systems. We’re quite fortunate. Early on, we standardized on having a single repository for all of our services. Even so, we were missing a layer of structured metadata encoding all of this information. We had CODEOWNERS defined within GitHub, system and criticality information as part of a service level README, and dependencies tracked via our metric system.
The Backstage Platform
Eighteen months ago, we started looking into Backstage. Backstage is a platform for building developer portals, open sourced by the folks at Spotify. In a nutshell, think of it as building a catalog of all the software you have, and having an interface to surface that catalog. This can include things like libraries, scripts, ML models, and more. For us to build this catalog, each of our microservices and libraries was seeded with a descriptor file. This is a YAML file that lives alongside the service code, which outlines the type of service, the service tier, system and owner information, and much more. This gave us an opportunity to define a canonical source of information for all this metadata that was previously spread across various files and systems. To stop this data from getting out of sync, we have a CI check that checks whether all data sources agree, failing if corrections are needed. This means we can rely on this data being accurate.
We have a component in our platform that slaps up all the descriptor files and populates the Backstage portal with our software catalog. From there, we know all the components that exist. It’s like a form of service discovery but for humans. We’ve spent quite a lot of time customizing Backstage to provide key information that’s relevant for our engineers. For example, we showcase the deployment history, service dependencies, documentation, and provide useful links to dashboards and escalation points. We use popular Backstage plugins like TechDocs to get our service level documentation into Backstage. This means all the README files are automatically available and rendered from markdown in a centralized location, which is super useful as an engineer.
One of the features I find the coolest is the excellent score. This is a custom feature that we’ve developed to help grade each of our services amongst some baseline criteria. We want to nudge engineers in setting up alerts and dashboards where appropriate. We provide nudges and useful information on how to achieve that. It’s really satisfying to be able to take a piece of software from a needs improvement score to excellent with clear and actionable steps. In these excellent scores, we want to encourage engineers to have great observability of their services. Within a microservice itself at Monzo, engineers focus on filling in the business logic for their service. Engineers are not rewriting core abstractions like marshaling of data or HTTP servers, or metrics for every single new service that they add. They can rely on a well-defined and tested set of libraries and tooling. All of these shared core layers provide batteries included metrics, logging, and tracing by default.
Observability
Every single Go service using our libraries gets a wealth of metrics and alarms built for free. Engineers can go to a common fully templated dashboard from the minute their new service is deployed, and see information about how long requests are taking, how many database queries are being done, and much more. This also feeds into our alerts. We have automated alerts for all services based on common metrics. Alerts are automatically routed to the right team, which owns that service, thanks to our software catalog feeding into the alerting system. That means we have good visibility and accurate ownership across our entire service graph. Currently, we’re rolling out a project to bring automated rollbacks to our deployment system. We can use these service level metrics being ingested into Prometheus to give us an indicator of a service potentially misbehaving at a new revision, and trigger an automated rollback if the error rate spikes. We do this by having gradual rollout tooling, deploying a single replica at a new version of a service, and directing a portion of traffic to that new version, and comparing against our stable version. Then, as we continue to roll out the new version of the service gradually, constantly checking our metrics until we’re at 100% rollout. We’re only using RPC based metrics right now, but we can potentially add other service specific indicators in the future.
Similarly, we’ve spent a lot of time on our backend to unify our RPC layer, which every service uses to communicate with each other. This means things like trace IDs are automatically propagated. From there, we can use technologies like OpenTracing and OpenTelemetry, and open source tools like Jaeger to provide rich traces of each service level hop. Our logs are also automatically indexed by trace ID into our centralized logging system, allowing engineers to filter request specific logging, which is super useful across service boundaries. This is important insight for us because a lot of services get involved in critical flows. Take for example, a customer using their card to pay for something. Quite a few distinct services get involved in real time whenever you make a transaction to contribute to the decision on whether a payment should be accepted. We can use tracing information to determine exactly what those services and RPCs were, how long they contributed to the overall decision time, how many database queries were involved, and much more info. This tracing information is coming back full circle back into the development loop. We use tracing information to collect all of the services and code paths involved for important critical processes within the company.
When engineers propose a change to a service, we indicate via an automated comment on their pull request if their code is part of an important path. This indicator gives a useful nudge at development time to consider algorithm complexity and scalability of a change. It’s one less bit of information for engineers to mentally retain, especially since this call graph is constantly evolving over time as we continue to add new features and capabilities.
Code Generation
Code generation is another key area we’re focusing on. RPCs can be specified in proto files with the protocol buffers language to define the request method, request path, and all the parameters associated with an RPC. We’ve written generators on top of the protocol buffers compiler to generate the RPC code that embeds within our service HTTP libraries. The definition can include validation checks, which are autogenerated beyond the standard data type inferences you get from protobuf. What this means in the end is each service is usually 500 to 1000 lines of actual business logic, the size that is really understandable for a group of engineers during review.
Earlier on, I talked about the approval system for our Monzo CLI. Many RPCs are sensitive and shouldn’t be run without oversight, especially in production, some should be completely forbidden. We encode this information in our service definitions, so these are explicit and also go through peer review. Our authorization systems on the backend check these service definitions each time before a command is executed, verifying and logging each authorized request or generating a review if a request needs secondary approval. We use option fields to add an authorization specific option within the RPC definition. Engineers can specify whether an RPC should require a secondary person to approve. By default, we run with RPC as being completely blacklisted from being called by engineers. This option provides a nice and frictionless way to open up an RPC whilst retaining review, oversight, and security.
We’re using the protocol buffers language to generate more than just RPC code. We also generate queue handling code for example. Within the service proto file, engineers can specify an event payload definition, as well as all of the validation criteria. Behind the scenes, we have a protobuf compiler plugin, which generates Kafka consumer and producer logic, handling the marshaling and unmarshaling of the payload, and interacting with our Kafka transport libraries to produce and consume from a topic. Engineers can work with strongly typed objects and autogenerated function signatures, and don’t need to worry about the underlying transport. For infrastructure teams, any bug fixes, new features, and performance improvements can be applied with ease.
One of my colleagues taught me a really cool feature of Git a couple of weeks back. When working with generated code, sometimes rebasing your Git branch can cause a merge conflict if someone else has also modified the same generated files. Git has functionality to call a script in the event of a merge conflict to try and resolve the conflict automatically. This is called a git merge driver, and can be specified in the .git extensions directory. Our script runs the protobuf generator on the already rebased proto file, which usually merges cleanly itself. The result is the correct generated code with all of the changes that you expect. It is small things like these that are paper cut into day to day development process. By eliminating this small source of toil, I never need to think about rebase conflicts for generated protobuf code. The behavior is well defined and understood and exactly what I expect. Most important of all, it’s automatic.
Static Analysis
At Monzo, the vast majority of microservices are written in Go, and follow a consistent folder and file structure and pattern. We have a service generator that generates all of the boilerplate code in a single command. Being able to assume a consistent structure allows us to write tools that can detect logic bugs, and even rewrite code on the fly. One of my favorite tools is a tool called Semgrep. Semgrep is an open source tool to write static analysis. It’s like grep, but understands a wide variety of programming languages. Say for example, you want to find all of the print statements that an engineer might have left behind for debugging. You can write a simple rule without having to go anywhere near the abstract syntax tree format of your programming language.
Static analysis is a powerful method to bring a code base towards a particular convention. Introducing a new rule stops further additions of something you want to maybe deprecate or move away from. You can then track and focus on removing existing usages, then make the rule 100% enforce. If you find a particular code bug being the contributor to an outage, consider adding that as a static analysis rule. It’s a great form of documentation and education, as well as automatically catching that same bug in other components on the fly. When writing these tools make them as informative as possible to make fixing issues a delight. Taking some time to write a code modification tool significantly lowers the work needed and can be a real driver for large scale refactoring across the codebase. Making these checks fast will encourage engineers to pitch in too. Many engineers at Monzo run these checks as pre-push hooks, because they get really fast feedback within a couple of seconds. If a check isn’t mandatory, but provides a warning anyway, engineers may take that extra few minutes fixing an issue as part of their normal day to day work.
Combining static analysis with continuous integration allows for automation to catch bugs, freeing up engineers to focus more energy on reviewing the core business logic during pull requests. Even though we have over 2000 microservices in a single repository, we can run all of our unit tests and static analysis checks in under 10 minutes. For many changes, it’s significantly faster thanks to test caching in Go and some tooling that we’ve developed internally to analyze our services and determine which services should be tested. It’s something that we actively measure and track. Slow build means you ship less often.
Summary
I’ve spoken quite a bit about the wide variety of tooling that we have. Much of this didn’t exist on day one. Some of the work that we’ve done, such as automated rollbacks, and critical path analysis using traces are improvements that we’ve rolled out really recently. This investment is ongoing, and it’s proportional to the size and scale of our organization. A lot of baseline infrastructure I’ve mentioned like Semgrep, and Prometheus, and Jaeger is all open source, so you can build on the shoulders of others. Tools like our CLI and shipper, were internally pet projects before they got adopted widely, and broadened to become more flexible.
The tools you decide to build should be focused on automating the practices of your organization. For us, internal tools like shipper allow us to fully automate what would be a complex change management process in a highly regulated banking environment. We don’t have a 20 step release procedure that humans have to follow, because all of that is encoded into the tool, and that’s what allows us to go fast. By standardizing on a small set of technology choices, and continuously improving these tools and abstractions, we enable engineers to focus on the business problem at hand, rather than on the underlying infrastructure. It’s this consistency in how we write software that makes the investment in tooling compound. You may not be able to get onto a single programming language or even a single repository, but implementing concepts like developer portals, static analysis, metrics, and tracing can be universal improvements for your organization.
Organizational Buy-in
There’s always something on fire or a product feature that needed to be released yesterday. Time spent on tooling may not be actively visible. One trick I found is to treat improvements in tooling as product releases, build excitement and energy, encourage people to try the new things and even contribute if they find bugs or issues. Do things that product managers do. Invest in developer research and data insights to help justify the investment. Keep the developer experience at the forefront and make your tools delightful.
Excel Spreadsheet as an Application Catalog
Someone did talk about having an Excel spreadsheet as an application catalog. When you’re starting off pretty small, or if you’ve got like a fixed set of services maybe that you can count on, on two hands. That is a really easy way to get started. Some amount of documentation is better than no documentation. Finding out by surprise that a particular service exists or a service dependency, finding that out by surprise during an incident is never nice. Even having that written down is always a good first step. We found Backstage to be really good when you get into the tens to hundreds stage of microservices. We’re nearing the 1000-plus mark, with the number of services that we have. We’ve found Backstage to be really good at that as well. It’s a fairly scalable and extensible platform. It’s built much more than for cataloging services, so we know people who are using it for machine learning models and things like that. That is the vision that Spotify, who originally open sourced it had to promote, and we really want to explore that a little bit further.
Questions and Answers
Synodinos: Also, regarding the shared functionality, are you sharing it as a library, as a service? Who is the owner of it?
Patel: I think it’s a mixture of both. There’s a component that gets embedded within the service binary itself. For example, we might embed a client library, and that might be at different levels of functionality. That client library might just be a thin API stub, defined in protobuf, and going over an RPC boundary, or that could be a bit more complex. For example, if you’re connecting to a Kafka cluster, or something like that, we might embed a full Kafka library connecting directly into that cluster. I think it’s a bit of a mixed functionality. What we have is each of our libraries and those services that are backing them are owned by a particular team. It depends on the team managing that level of infrastructure. For example, our Cassandra libraries, or our database libraries, is handled by a team that manages that set of infrastructure, like a group of folks who are managing the stateful layer, as we like to call it internally. Whereas we have a team that is focused on observability and deployment tooling, that is managing libraries associated with that. They also own the services that are backing that as well. In some cases, they’re owning the infrastructure as well.
Synodinos: You guys are structured in the Spotify model: tribes, squads?
Patel: Yes. It’s quite a similar model, where we have squads that are managing a centralized set of infrastructure, so that everyone can benefit and we don’t have different teams reinventing the wheel.
Synodinos: How do you balance eager development of helpful access tools with privacy concerns in the domain of banking? How much of this is done by policy versus by tooling enforcement?
Patel: It’s a really good concern. It depends on having a very strict layer when it comes to accessing data. A lot of stuff is being ferried internally and tokenized from the moment that it comes in. We have a secure definition within the systems that are holding customer level data, or banking level data, or transaction level data on the fact that this needs to be with some particular authorization policies and things like that. We scope the number of people who have access to it. Where it becomes interesting is that there’s a whole category of data that doesn’t need to fall under like strict rules. For example, if you want to figure out how many transactions were there yesterday in the McDonald’s, that point is just aggregated data, for example, and anyone can look at that within the company. There’s a balance between being internally transparent and having access to data to do a better job, versus making sure that you respect customer privacy. The two don’t need to be at odds. You can encode both things in tooling. For example, being able to tag a particular request or a particular set of fields as being sensitive means the tooling can enforce the fact that not everyone should have access to this. Whereas being able to say, ok, this is aggregated data or this is data that decodes nothing that is private, makes it easy for everyone to have access and gain visibility, and make better decisions. The two don’t need to be at odds.
Synodinos: Did you have to customize Backstage at all to fit it in with your processes?
Patel: Yes we did. There was an aspect of Backstage where we didn’t have a very strong definition, this was almost like a forcing function for us, so the whole idea of a service catalog. All of the metadata was spread across multiple different systems. We have dashboards in our monitoring system, we have the mapping between services to like what team owns them in CODEOWNERS, and we had a different system for looking up how a team could be contacted, and how they could be alerted if a particular thing was going wrong. We had a few integrations in the backend to map all of that together, but it wasn’t in one central place. The fact that we wanted to make this visible all in Backstage, meant it was a forcing function to create a metadata catalog, one system sort of row them all, as they say, like a way to be able to aggregate all of this data.
Also, the most important part was having a way to make sure that it’s consistent across all these different systems. For example, sometimes the data is going to be stored in a variety of different systems. We’ve got configuration for our alerting system. You’ve got some configuration in PagerDuty, for example, for paging people. You’ve got configuration within GitHub CODEOWNERS for enforcement at a code level. You want to make sure that when you have like a catalog that is aggregating all of this data, all the different sources agree that the catalog is correct. All the different sources and sinks of data are also correct, because if there is a disagreement, you’re going to end up with inconsistency. The moment you end up with inconsistency, rectifying that becomes infinitely harder.
It can actually lead to bad outcomes. For example, like a page being routed to a team that doesn’t exist, which might mean it might fall through the cracks, or we might have a significant delay in addressing that page, because it’s been escalated to a team that doesn’t know how to handle that system right from the get-go. That delayed reaction time can lead to bad consequences. Having that enforced from the get-go was something that we strongly invested in. Once we had the software catalog building this system that could slap that into Backstage was relatively easy, because we actually built the catalog itself to model the attributes that Backstage promotes, around having components and services. We added a few things like tiers, and also the excellent score. Those are the ways that we added Backstage plugins and things like that. The customizability of Backstage is quite a nice selling point. You’ve got a very nice plugin system, you can write plugins in Node.js. Yes, it’s fairly easy to get up and running.
Synodinos: Staying on the topic of Backstage or probably more generally about tooling, you’re making a big investment in various tools. How do you deal with deprecated tooling? What if Backstage were to stop active development, would you lock in the final version, maintain it internally, migrate your data to the next new tool?
Patel: I think it depends on the tool of choice. One of the conscious decisions that we make as part of our strategy is to invest in tools that are open source, so if we do want to make further modifications, then we can. Again, that has to be a conscious choice. We do look for active signs, like for example tools being actively maintained by an organization or like a rich community, and actually getting involved in that community. With tools like Backstage, it is part of the CNCF, which means a lot of different members getting involved. A lot of folks have gotten invested into the Backstage tooling, and so there’s now been spinoff companies who are like giving you a hosted version of Backstage. There is a rich ecosystem, that’s something that we actively look out for. When you make an investment in a tool, you do make a conscious decision to have to maintain it or lock it in. I don’t even think it’s a question of if, it’s a matter of when. When the tool has served its purpose or the folks move on, or there is a better way of going about it, you have to make a conscious choice to support or move on.
One benefit for us is we don’t lock in the data. The data within Backstage is quite ephemeral. It’s not the destination for any concrete amount of data. Most of the sources of data come from systems that we built internally or, for example, things that we’ve demonstrated, like the software catalog, so reintegrating those into a different system for visibility becomes a little bit easier. Being locked into a particular scheme of a particular tool is where it gets a little bit complicated because now you got to have a way to mutate or transform your data into a different tool, which might not support all of the same functionality.
Synodinos: It sounds like your teams are structured so that product teams don’t need to own the entire DevOps process, but instead rely on many separate teams to cover all capabilities. Is this correct? If so, have you found issues with team dependencies slowing you down?
Patel: The structure that Chris is assuming is correct. We have a centralized team that manages the state of infrastructure. There’s a phrase here which might actually be quite poignant, which is, it’s like, slow down to speed up. Yes, there are cases where, for example, a team could have moved faster if they had full control of the infrastructure, or if they could make their own infrastructure choices. By building on centralized tooling, there’s a lot of things that are abstracted away from them. Let me give a particular example. If every team rolled their own infrastructure, that means that team has to continue to maintain and take that infrastructure through audits, and make sure that it’s fully security conscious and everything like that. It’s a lot of additional overhead that they’d have to take on as part of responsibility. This responsibility they’ve been able to amortize because we have a centralized team, and that means we have a centralized group of people who are doing the risk assessments and speaking with the regulator, and staying on top of all the various things that we need to do.
For example, when we have a CVE come in, we can have a team that does patching on one set of infrastructure that everyone is aware of. We have a defined contract on how we would roll that infrastructure. When, for example, Log4j happened, the Log4j vulnerability within Java, we were able to enumerate all of our Java applications that we have running within our platform. Stuff that we run and stuff that is hosted by third parties, and have a centralized team be dedicated to incident response and patching of their systems, because there was a deep understanding and a deep contract within one centralized platform. That expedited our patching process. That applies for many other different types of vulnerabilities as well. There are aspects where teams could move potentially faster, but having a centralized platform means that the whole organization moves faster as a result, which is something that we are prioritizing for. We’re not prioritizing local team efficiency, rather, organizational efficiency.
Synodinos: How do you choose the prebuilt tooling you add to the Monzo ecosystem? Do you have a test protocol of the tool choice before it is generalized to all teams?
Patel: Yes and no. We’re not too rigid about what tools we choose. We encourage folks to experiment, because the tooling system is forever changing, there’s always new tools coming on board, new systems being developed. You’ve got to have some amount of freedom to be able to experiment. I think where we strike the balance is, we provide a rich staging environment, which is apart from the data representative of production. For example, we have the same infrastructure components. We have the same tools being used. We have the same software being deployed. It’s just at a smaller scale and not with production data, which provides a rich sandbox to experiment.
Once the experimentation has yielded results, and folks are happy with the results, and they want to spread out further. By the point that is actually becoming production ready, or we want to make a conscious significant investment in that particular set of tooling or even an infrastructure choice or even a particular design. That’s the point where we step back and take something through either an architectural review if it’s going to be a large sweeping change, or write a proposal. There’s a rich history of proposals written down, which are like decision logs almost or architectural decision records, which document why we’ve chosen a particular tool, what alternatives we may have looked at. There could be conscious reasons why we’ve chosen a particular tool over another. For example, we may pick a tool with one of the vendors that we have already onboarded, like a particular tool that is provided by AWS, because it fits nicely within our hosted ecosystem, rather than there might be a more optimal tool provided by Microsoft, which we may not choose because we’re not on Azure at the moment. Everything is a conscious, balanced decision.
All the choices we make, folks need to maintain. Something that we actively look out for when we are reviewing these decision logs, like, is that something that we can feasibly maintain for the long run? What is the reversibility cost? For example, if we wanted to change the tool, or change the architecture in the future, is it going to require significant investment, both from a technological point of view but also from a human point of view? If we’re encoding, for example, a particular practice with all of our engineers, getting engineers to move on to a new thing might be quite a substantial leap forward. If we define good interfaces and abstract the thing that is backing it away, we could change the backing implementation really easily, and potentially under the covers. Yes, they can have a much easier experience.
Synodinos: Christopher has shared with us that you have been open sourcing some of your libraries, and you demoed a bunch of tools, the PAN CLI, the shipper CLI. What type of open source contribution does Monzo have?
Patel: We have open sourced a lot of our RPC based tooling, and also the things that we use for logging and some of our libraries around Cassandra, and stuff like that, as well. Yes, definitely check out our open source repos at github.com/monzo, if you’re interested there. We also have quite a lot of blog posts about how we do things internally. Again, there’s some stuff that we can’t open source, unfortunately, because it’s embedded quite deeply into how we write the services and systems. Those things can’t be disentangled with the rest of our platform, but we document them really heavily and we put them out in the open. We do have a blog if you want to see some of our architectural designs.
See more presentations with transcripts
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

While JavaScript runtimes use garbage collection to manage memory, this does not rule out the possibility of leaking memory. To detect all possible cases where memory is leaked, Facebook created and open-sourced MemLab, a tool able to run predefined, automatable test scenarios and analyze heapshot diffs.
In a nutshell, MemLab finds memory leaks by running a headless browser through predefined test scenarios and diffing and analyzing the JavaScript heap snapshots.
Based on the diff results, MemLab builds a list of potential memory leaks and for each of them generates a retainer traces, i.e. an object reference chain from the garbage collector roots. By inspecting the retainer traces, you can visualize which references should have been set to null for proper collection. Additionally, to reduce the amount of information that needs to be analyzed, MemLab is able to cluster leaked objects based on the similarity of their retainer traces and show them for each cluster instead of for each potential leak.
There are a number of cases where JavaScript may leak memory. For example, say Facebook engineers Liang Gong and Glenn Conner, when you log an object to Chrome console, Chrome will take a hidden reference to it that will prevent it from being collected. Other cases where you can have leaks or unbound memory growth are related to the accidental use of global variables, to forgotten timers or callbacks, and to out-of-DOM references, says auth0 engineer Sebastian Peyrott.
While Chrome Developer Tools provides the essential means to inspect memory behaviour of JavaScript code, including the timeline view and the profiles view, this is not straightforward and cannot be automated. Instead, MemLab can be easily integrated in a CI/CD pipeline, say Gong and Conner.
For in-browser memory leak detection, the only input MemLab requires from developers is a test scenario file that defines how to interact with the webpage by overriding three callbacks with the Puppeteer API and CSS selectors. MemLab automatically diffs the JavaScript heap, refines memory leaks, and aggregates results.
MemLab is also able to generate a graph-view of the JavaScript head, where each heap object is represented as a node, while references are represented through edges. Besides providing general information such as the total retained size of a given set of components, the graph can also be accessed programmatically for self-memory checking. Developers can also use a CLI and a API to explore possibilities of memory optimization of their apps.
Facebook has been using MemLab for a few years, which allowed them to reduce OOM crashes on Facebook.com by 50 percent in the first half of 2021. They also used the heap graph view and the heap analysis API to further improve memory behaviour of React Fibers and to improve Relay memory interning.
MemLab is open source and can be installed running npm i -g memlab.
MMS • Susanne Kaiser
Article originally posted on InfoQ. Visit InfoQ

Transcript
Kaiser: Thanks a lot for joining me in this talk about architecture for flow with Wardley Mapping, domain-driven design, and team topologies. Most initiatives that try to change or to optimize a system are usually directed at improving parts taken separately. They tend to focus on local optimization of the separate parts of the system. From a system thinking lens, local optimization of separate parts will not improve the performance of the whole. Dr. Russell Ackoff, one of the pioneers of the system thinking movement stated that a system is more than the sum of its parts. It’s a product of their interactions. The way parts fit together determines the performance of a system, not on how they perform taken separately. He also claimed, if the systemic nature of an organization is ignored, the effort of improving and changing that system are doomed to failure.
Challenges of Building Systems
When building systems in general, we are facing the challenge between building the right thing and building the thing right. Building the right thing addresses effectiveness and addresses questions such as, how aligned is our solution to our user needs? Are we creating value for our customers? Have we understood the problem and do we share a common understanding? Building the thing right, on the other hand, focuses on efficiency, for example, efficiency of engineering practices. It’s not only crucial to generate value, but also being able to deliver that value, and about how fast can we deliver changes and how fast and easy can we make a change effective and adapt to new circumstances? The one does not go without the other, but as Dr. Russell Ackoff pointed out, doing the wrong thing right is not nearly as good as doing the right thing wrong.
Three Perspectives to Build Adaptive Systems
By considering the whole and having effectiveness and efficiency in mind, to build the right thing right, we need a holistic perspective to build adaptive systems. One approach that I would like to share with you is combining the perspectives of business strategy with Wardley Mapping, software design and architecture with domain-driven design, and team organization with team topologies in order to design, build, and evolve adaptive socio-technical systems that are optimized for fast flow of change.
Evolving a Legacy System
Let’s put these three perspectives together by evolving a legacy system. We are using a fictitious example of an online school for junior students based on a legacy system built, run, and supported by functional silo teams. The first step to evolve our system is starting with a team and analyzing their current situation in regards to their team cognitive load and encounter delivery bottlenecks. Due to handover, the functional silo teams reported high communication and coordination effort between teams when implementing and releasing changes. Dealing with a monolithic big ball of mud with a messy model and no clear boundaries leads to high cognitive load and tight change coupling. It takes a high amount of effort to understand a piece of code. In addition, the teams reported about no clear ownership boundaries they are facing in general with delivery bottlenecks and impeding their software delivery performance. Due to on-premises infrastructure, the operational activities consist of configuration, backup and recovery mechanisms, maintenance, including upgrades and security updates, scaling, monitoring, and so on. The infrastructure team faced very high operational efforts. As a reminder from system thinking, if you plan to optimize only separate parts, it does not improve the performance of the whole.
Visualizing the Landscape with a Wardley Map
Improving the performance of the whole requires to tackle the situation from a broader perspective and also understand the environment and organization it’s operating and competing in. This brings us to a Wardley Map representing the context specific landscape of an organization. A Wardley Map is part of Wardley Mapping. Wardley Mapping is a strategic framework invented by Simon Wardley, and it helps to design and evolve effective business strategies based on situational awareness and movement following a strategy cycle. The strategy cycle is representation of change and how we need to react to the change according to Simon Wardley.
It starts with a purpose, the why of our business, in our case, providing high quality education for junior students everywhere and help teachers to engage with their students online. The next section of our strategy cycle is the landscape an organization is operating and competing in, which is visualized with a Wardley Map. Let’s create a Wardley Map of our online school example. A Wardley Map is in general composed of a y axis and an x axis, and the y axis represents the value chain. To derive a value chain, it starts with identifying your users first, and your users can be customers, shareholders, staff, business partners, internal users, and so on. We are going to focus on the teachers and the junior students as the users of the online school.
Next is identifying the user needs, and the user needs are addressing the problems the users would like to get solved. They are the subject area for which we build a product. The users and the user needs, they represent the anchor of the map that all subsequent components relate to. The teachers would like to create course content for the students, they would like to plan a class supporting the students during their studies, and also evaluating their progress. The students have the user needs of studying courses, requesting and receiving help during their studies, and receiving evaluation feedback. Both teachers and students, they need to sign up and sign in as well. Next, we are identifying the components that fulfill the user needs either directly or indirectly by facilitating other components in that value chain, and determining the dependencies and the positions in the value chain. At the top, we have components that are most visible to the users, so where the users are touching the system. At the bottom, it gets more invisible to the user. The value to the user and the visibility, they are closely correlated. The more visible a component is, the more value it provides to the user.
The component that the teachers and students are interacting directly with is the online school component. It’s located at the top of the value chain. At this point, we are dealing with a monolithic big ball of mud as one single component that we are going to decompose later into modular components when we talk about the second perspectives of domain-driven design. The online school component, this depends on infrastructure components such as data storage, search engine, message broker, SMTP server, and compute platform running on top of a virtual machine component. They are less visible to the users and placed further down the value chain. Each component of this value chain is going to be plotted along an evolution axis going from left to right. At the left, we have Genesis with brand new things. Then custom built. Then product and rental such as off-the-shelf products, or open source software solutions. Then things on the right like commodity and utility. For determining the stage of evolution per component, let’s look at a couple of climatic patterns that are influencing our landscape.
That’s where we come to the next section of our strategy cycle, the climate. Climatic patterns describe external forces that are impacting our landscape over which we have no control. However, understanding climatic patterns is important when anticipating change, according to Simon Wardley. Understanding climatic patterns gives us an idea where the landscape can change and where to invest in the future. One pattern is that the landscape is never static but very dynamic. Everything evolves from left to right through the forces of supply and demand competition. For example, cloud hosted services are reflecting this climatic pattern. What was decades ago non-existent, evolved through Genesis, custom built, and became product and rental, and now commodity and utility. As the components evolve, their characteristic change from an unchartered domain, undefined market, uncertain, unpredictable, constantly changing, poorly understood chaotic domain, and while it evolves and becomes more stable and mature. While we are then facing an industrialized, mature, known, commonly understood, ordered market on the right.
We can use these characteristics to determine its stage of evolution per component. The online school component is reflecting a volatile component that is changing frequently, and that is providing competitive advantage. It shall go into the custom built evolution stage. The more stable, mature, widespread infrastructure components on the other hand can go in product and rental or commodity and utility evolution stage.
Applying Doctrinal Principles
For each evolution stage, we can apply appropriate methods, that’s where we come to the Wardley Doctrine, the next section of the strategy cycle. Doctrine describes universal principles that each industry can apply, regardless of their context. Applying doctrinal principles enables an organization to be able to respond to changes quickly and to be able to absorb changes gracefully. One of the doctrinal principle is using appropriate methods per evolution stage. It means to build components in Genesis, and custom built in-house, preferably using Agile methods. Or using or buying off-the-shelf products, or using open source software for components in product and rental evolution stage with preferably lean methods. Or outsourcing components and commodity to utility suppliers, or using preferably Six Sigma methods.
Coming back to our online school, we are going to develop the online school component in-house. For the infrastructure components such as search engine, data storage, message broker, and so on, we are using open source solutions at the current state. The virtual machine component is provided by a server hosting provider as an off-the-shelf product. With a Wardley Map at hand, we are already applying doctrinal principles. One of the doctrinal principles is that we know who our users are. We know their user needs and we can focus on them as another doctrinal principle. We know the details in terms of what is necessary to fulfill the user needs and generating value by solving the user needs. It also depicts what to build in-house and where to use off-the-shelf products, or open source software, and where to outsource to utility suppliers. We can share and discuss this map with others to challenge assumptions as another doctrinal principle in order to create a better map and a better understanding, and using a common language to be able to communicate effectively. We are going to use this map as a foundation for future discussions while evolving our legacy system.
Optimizing for Flow of Change from Team Perspective
Let’s go back to the team perspective. To optimize for flow of change, from a team perspective, we need to avoid functional silos with handover. Instead, we need to aim for autonomous cross-functional teams that are designing, developing, testing, deploying, and operating the systems they are responsible for. We need to avoid handover so that work is never handed off to another team. We need to use small long-lived teams as the norm. The teams need to own the system or subsystem they are responsible for so they need to have end-to-end responsibility to achieve fast flow. We need to reduce the team’s cognitive load. If the team’s cognitive load is largely exceeded, it becomes a delivery bottleneck leading to delays, quality issues, and so on. While the communication within a team is highly desired, we have to restrict a high communication bandwidth between the teams to enable fast flow.
Four Team Types of Team Topologies
That’s where team topologies can help us with, with their well-defined team types and their well-defined interaction modes. We have the autonomous, cross-functional, stream-aligned teams that are aligned to a continuous stream of work, focusing on fast flow of changes. To be able to focus on a fast flow of changes and to be able to produce a steady flow of feature deliveries, they need the help from the other teams. For example, they need support from the platform teams that are responsible for platforms that usually abstract away infrastructure and networking or cross-cutting capabilities. They provide internal self-service services and tools for using that platform that then the stream-aligned teams can easily consume. Or they need the help from the enabling team that help the stream-aligned teams to acquire missing capabilities. Or the complicated subsystem teams as an optional team type that are supporting the stream-aligned teams on particularly complicated subsystems that require very specialized knowledge. They all aim for increasing the autonomy and reducing the team cognitive load of the stream-aligned teams to enable fast flow of change.
Three Interaction Modes
To arrange the teams into the team types, it’s not enough to become effective. How these teams are interacting with each other and when to change and evolve team interaction is also very relevant for high effectiveness. With the interaction mode of collaborations, teams are working very closely together, aiming for a common goal. This interaction mode is suitable for rapid discovery and innovation, for example, when exploring new technologies. X-as-a-Service suits well when one team needs to use a code library or a component, an API or a platform that can be effectively provided by another team as a service, in a workspace where predictable delivery is needed. Facilitating, this is the interaction mode that comes into play when one team would benefit from active help of another team. This interaction mode is typical for enabling teams. The combination of this well-defined team types and this well-defined interaction modes promotes organizational effectiveness. While we are applying team topologies, it also helps automatically to apply Wardley’s Doctrinal principles.
Architecture for Flow
Let’s come back to our previously created Wardley Map of the online school. Optimizing for fast flow of change requires to know where are the most important changes in a system [inaudible 00:16:41] the streams of changes? The type of streams can differ in every organization, ranging from task, role, activity, geography, and customer segment oriented stream types. In the current online school example, we are focusing on activity streams represented by the user needs of a Wardley Map, and the user needs of creating course content, planning classes, evaluating students, and so on, they are good candidates for activity oriented streams of changes. They need to be focused on when optimizing for fast flow. Let’s address next the problem domain. The user and the user needs of our Wardley Map are representing the anchor of the map, but are also representing the problem domain in the domain-driven design context. Understanding the problem domain and partitioning it into smaller parts, the subdomain could be then the next step. That’s where I would like to bring in then the next perspective of software architecture and design with domain-driven design.
Domain-Driven Design (DDD)
Domain-driven design is about designing software based on domain models, first proposed by Eric Evans. It comes with a core statement, in order to build better software, we have to align its software design with the business domain with the business needs and the business strategy. While applying domain-driven design, it also helps to apply doctrinal principles of Wardley Mapping.
DDD and Wardley Map
Domain-driven design comes with patterns and practices of strategic and tactical design. In the problem space, strategic design, we’re analyzing the problem domain and distilling the problem domain into smaller parts, the subdomains. Not all subdomains are equal, some are more valuable to the business than others. We have different types of subdomains such as core, supporting, and generic. The core domain that is the center part of our problem domain providing competitive advantage, and it should be hard for competitors to copy or imitate. It’s supposed to be complex, and it tends to change often. That’s where we have to strategically invest most and innovate on. That’s the subdomain we need to build in-house and supposed to go into Genesis or custom built evolution stage.
The supporting subdomain helps to support the core domain. It does not provide any competitive advantage. It’s quite simple. They do not change often. If possible, we should look out for buying off-the-shelf products or using open source software that goes then in the product rental evolution stage. If this is not possible, and if we have to custom build the supporting subdomain, we should not invest heavily in that part of the system. The generic subdomain, these are subdomains that many business systems have, for example, authentication or payment, so they aren’t core, they provide no competitive advantage, but businesses cannot work without them. They are generally complex but already solved by someone else. Buying off-the-shelf products, or using open source software or outsourcing to commodity suppliers should be applied for the generic subdomains. There is no need for innovation here. In general, these different subdomain tabs can help us to prioritize the development effort that we should invest most in the core domain providing competitive advantage.
In regards to our online school, the user needs of creating course content, planning a class, learning support, and studying courses, they fall into the result of the core domain. They provide competitive advantage, leading to a high level of differentiation. They embody complexity, and they tend to change often and are not widespread in every other business system. It is the core domain that we will want to strategically invest in most, and that’s where we will have the most opportunity for innovation. On the other hand, the evaluation of student progress and learning does not necessarily provide a competitive advantage, but it supports the teachers experience and is necessary for the organization to succeed. It tends to be less complex and change less frequently, so we should not invest too much in that subdomain since it does not provide competitive advantage.
The user needs of signing up and signing in, they embody user needs of a generic subdomain, and many business system needs the subdomain of registration and authentication. They are widespread, standard, and expected with a high level of ubiquity and a high level of stability. They are not core, do not provide competitive advantage, but without registration and without authentication, the online school solution would not work securely. They are generally complex, but already solved by someone else. There exists several solutions on the market already, so there is no need for innovation and strategic investment here.
Bounded Contexts
Next, we can switch to the solution space of strategic design. That’s where we are going to decompose our monolithic big ball of mud into smaller modular components, designing then the bounded context. A subdomain, in the ideal case, can contain one or in some cases also more than one bounded context. A bounded context defines where a single domain model can be applied and forms a unit of purpose, mastering, and autonomy, and a domain model itself that represents the domain logic and business rules that are relevant to that area of the system. A bounded context can provide different types of boundaries. It can form linguistic and semantic boundaries so that the languages’ terms of the domain model are only consistent in silos of its bounded context. It also serves as an ownership boundary. A bounded context should be owned by one team only. However, a single team can own multiple bounded contexts. A bounded context serves also as a physical boundary and can then be implemented as separate solutions. Not all bounded contexts need to share the same architectural and business logic implementation patterns, so they can differ from context to context.
In this example, we might have derived several bounded contexts with the appropriate methods, so content creation, class management, course studies, and learning support, they fulfill the core domain related user needs. They are strategically important and require most development effort. They go into the custom built evolution stage and are going to be built in-house. Student evaluation notification handling belongs to the supporting subdomains. There might exist solutions on the market already, but the team decided that a higher level of specialization is needed to build them in-house. However, the development investment should not be too high since they do not provide competitive advantage. The Identity and Access Management bounded context belongs to a generic subdomain. There exists several solutions on the market already, and it should go either into product and rental or commodity and utility evolution stage.
Next is finding suitable team boundaries. As I said earlier, the bounded contexts serve as well-defined ownership boundaries forming a unit of purpose, mastery, and autonomy. Bounded contexts are indicating what teams to split the system into smaller parts. On the other hand, they also work as suitable team boundaries for the stream-aligned teams. To optimize cognitive load, we have to limit the number and size and complexities of software system a single team has to work with. This brings us to the evolution stages of Wardley Map. According to the characteristics of the evolution stages, the further left bounded context or a component in general is located on the Wardley Map, the higher the level of uncertainty is, which requires then practices that are focusing on exploration and discovery.
Bounded context in Genesis or components in Genesis tend to change far more frequently than components in commodity. For components residing in commodity, we can draw on best practices solutions providing a clear path to action. Each evolution stage addresses different practices for their related paths to action, ranging from best, good, emerging, and novel practices. The more unclear the path to action is, the higher the level of cognitive load is. That means that a single team could take ownership of more or larger bounded context and components that are residing in commodity than residing in Genesis. Another aspect to optimize for team cognitive load is to establish clear responsibility boundaries. For clear responsibility boundaries, we need to assign each bounded context to a single team and not sharing bounded context across teams, because that would then diffuse the ownership of teams. However, one team can own several bounded contexts.
Architecture for Flow
The next step is identifying services that are needed to support a reliable flow of changes. That brings the focus on the infrastructure and platform related components of our Wardley Map located in product and rental, and commodity and utility evolution stage. In order to be able to focus on a fast flow of change, the stream-aligned teams are relying on a platform team providing an easily consumable platform as a service. This platform shall reflect thinnest viable platform that is just big enough to fulfill the user needs of its consumers and shall not become bigger than needed. The thinnest viable platform could start with documentation, standards, best practices, templates, and can evolve later into a digital platform with self-service APIs and tools. We also need to mind the dependencies and communication bandwidth between teams. Are there tightly coupled or blocking dependencies, or a high amount of ongoing communication and coordination efforts between teams? They need to be eliminated. Identifying capability gaps and helping teams to acquire missing capability is then the responsibility of the enabling teams.
The previous consideration might result in this illustrated team constellation. In general, most teams in an organization shall be cross-functional, autonomous, stream-aligned teams. In our example, the four core domain related bounded contexts residing in the custom built evolution stage, they are going to be split among three stream-aligned teams. The supporting and the generic subdomain related bounded context of this example are going to be handled then by another stream-aligned team. The infrastructure components then will be taken care of by one or more platform teams.
Before we are going into the transition and implementation phase, we need to mind potential efficiency gaps. We want to avoid building or evolving the system based on inefficiencies, because inefficiency would also impede the fast flow of change. If the evolution stage of the components we are using in our organization internally differ from the ones that are available in the market, that might indicate an efficiency gap. For example, if we’re using custom built components, but the components in the market are available as commodity, we are lagging behind and encounter potential inefficiencies. The bigger the gap, the less efficient that organization might be. We need to close this efficiency gap. One approach to close the efficiency gap could be done by migrating components from on-premises infrastructure to the cloud. That’s what we are going to address.
Implementing flow Optimization
At this moment, we have not transitioned anything yet, but we did prior architectural and design considerations. Now the question arise, how do we transition and implement flow optimization? To close the previously mentioned efficiency gap, we want to migrate the components from on-premises infrastructure to cloud hosted services. The cloud migration could start with a team first approach. The cloud migration is going to be supported through dynamic reteaming and evolution of team topologies. Since we are addressing infrastructure components, we are starting the transition with forming the platform team first from members of the previous backend and the previous infrastructure team. This new platform team is working on the site with the freedom to learn and explore and discover and assess cloud migration strategies.
This new platform team can then determine a migration plan and its new target platform. In the example of the online school, we are starting with the replatforming cloud strategy. With replatforming, we are modifying the underlying infrastructure by replacing on-premises infrastructure components with cloud managed services, while we keep the applications architecture the same. With replatforming, we are offloading the management of the infrastructure components to the cloud provider and reducing then the operational efforts on our side and also improve performance scalability and elasticity of the infrastructure itself, and we are going to close efficiency gaps. Once the on-premises infrastructure is fully migrated to the cloud environments through replatforming, the remaining infrastructure team and the previous platform team can merge into a joint platform team. Even though the resulting team is becoming bigger, it makes sense in some cases to merge teams, when we want to bring collective intelligence together, and when the joined teams leads to a higher flexibility and to higher fluidity than having separate teams. For example, in our case, the merged team is able to share their previously gained cloud knowledge from replatforming then with the new team members, for example, by pair programming. The merged platform team can split later then in smaller teams if this is applicable.
So far, we have replatformed our infrastructure components, but we also want to modernize our monolithic big ball of mud, and eliminate its related bottlenecks. That brings us to the next level of cloud migration by refactoring the applications architecture. Refactoring typically involves breaking down the application into smaller components. In the example of the online school, we want to break the monolithic big ball of mud part by incrementally decomposing it into our previously designed bounded contexts. To start the refactoring journey, we are forming first stream-aligned teams from members of the previous frontend and backend teams.
The refactoring journey is supported by an evolution of team topologies interaction mode. At the beginning, the stream-aligned teams, they can closely collaborate with the platform team to jointly discover and assess potential cloud options for the future bounded context that the new stream-aligned team is responsible for. The stream-aligned team might decide to refactor their bounded context using serverless technologies. As soon as potential options were discovered and knowledge was shared, the interaction can go then into limited collaboration and limited facilitation mode, so going from daily to occasional on-demand interaction. At a later stage, this can then evolve to X-as-a-Service once the serverless ecosystem is more established in the organization, where then the platform team provides best practices, standards, tools, APIs, to easily consume the cloud services.
In the meantime, the remaining frontend and backend teams can merge into a preliminary joined team, which takes care of the remaining monoliths, as long as it’s existing, and as one team with no handover involved. From there, they will then incrementally split into their separate stream-aligned teams. These new formed stream-aligned teams, they receive active help from the previous stream-aligned and platform team during their cloud journey. The cloud platform team can suggest possible cloud options that are applicable for their bounded contexts. They can coach them how to use a new build pipeline and a serverless ecosystem. They can also point to the platform as a service it has established before and incorporate their feedback, why they are using it. The previous stream-aligned team can share their knowledge with the new stream-aligned teams. For example, coaching them about best practices or how to implement serverless functions using hexagonal architecture, for example, so that at the end, we have refactored our monolithic big ball of mud into modular components based on serverless technologies.
What to Adopt and What to Leave Behind
At this stage, we have transformed our functional silo teams with handover into well-defined team types and interaction modes, and could restrict the formerly high communication and coordination bandwidth between teams. We could decompose our monolithic big ball of mud with a messy model and fuzzy boundaries into a system with clear bounded contexts and domain models. With bounded context, we can establish well-defined ownership boundaries. We moved from tight change coupling to a loosely coupled system and optimized the team cognitive load, so that we could eliminate delivery bottlenecks and improve the software delivery performance. In addition, we could reduce the high operational efforts by migrating on-premise infrastructure components to cloud hosted services, and close then the related efficiency gap.
Key Takeaways
At the end, the combination of Wardley Mapping, domain-driven design, and team topologies that helps to understand the environment an organization is operating and competing in. It also helps to understand the climatic patterns that are impacting the landscape. Also helps to apply doctrinal principles that enables an organization to be able to respond to changes quickly. The combination helps us to gain domain knowledge and discovering the core, and providing competitive advantage. It helps us to know what components to build in-house, where to buy or use off-the-shelf products or open source software, or where to outsource to utility suppliers. It helps us to decompose the problem domain into modular components. It helps to align the teams and evolving their interaction to the system we build and the strategy we plan.
With this combination, we are able to identify potential efficiency gaps and trying to eliminate them, close these efficiency gaps. It helps us to eliminate bottlenecks and increase the software delivery performance so that we are then able to respond to changes quickly and absorb changes gracefully. The combination of Wardley Mapping, domain-driven design, and team topologies, that’s providing a powerful, holistic toolset to design and to build and evolve adaptive socio-technical systems that are optimized for fast flow of change with a focus on improving the performance of the system as a whole.
Questions and Answers
Skelton: What feels like a good way to start with this approach? Can you provide some advice for people who are, let’s say they’ve seen the talk, they can see the value of Wardley Mapping, domain-driven design, and team topologies together. What feels like a sensible approach to start at, let’s say, an organization that has 1000 people, relatively small, and maybe like 600 engineers in total, that kind of size? Maybe they’re doing something, they’ve got some online service or something like that, where will be a good place to start to use these techniques? Then, how would you go about doing it?
Kaiser: It can start differently. For example, what I like to start with is addressing the current state where you’re at right now. What are your current challenges that you’re dealing with. You can start with analyzing, with asking your teams as you’re also suggesting in your team topology book, where you address the team situation in regards to the team cognitive load, and communication and coordination efforts between teams. You can survey style, for example, that you ask every team regarding the challenge that they’re facing. Another aspect that you can bring in is to create a Wardley Map of your current situation, the Wardley Map that is representing the environment an organization is operating and competing in.
Every team itself can create their own Wardley Map, but they also can share their method in discovery with others. It is greatest value to the communication that you have between, because that is, for example, your view of your landscape that your organization is competing in, but sharing it with others, and communicate with others and also see blind spot that they have not seen before. It’s really a great tool to know where you are. What is your current landscape where you’re operating and competing in? What are your challenges of your teams regards to communication and coordination effort? Also, what is necessary? You could follow, for example, also, when you create this Wardley Map, the value chain. You can also identify, what is necessary? What components do you have to touch, and what teams are responsible for these specific components? Which teams need to communicate and coordinate to make this change effective? We can use this Wardley Map’s foundation to identify bottlenecks.
Skelton: It feels like a really key aspect to empower the teams, to give them these tools, like being able to use Wardley Mapping, think about things in terms of bounded context from DDD, and obviously use the ideas from team topologies, about team interactions and limiting cognitive load and so on. To empower these teams to use these techniques as part of their toolkit, so that they can have much more informed conversations, much better conversations and share that with other teams. Say, “From our perspective, it looks like this. What does it look like from your perspective?” We’re not trying to find a single perfect map or view, we’re looking for multiple perspectives to give us additional insights effectively, because no one group is going to have all of the knowledge and the awareness.
Kaiser: No, then it’s going to be not only one map. If you have a larger organization, then, for example, if they have platform teams that are providing the platform, they have a totally different Wardley Map than those that are end-to-end responsibility, or close to the customers, the stream-aligned team. They have different users, with their different user needs, and the platform team can create their own Wardley Map, where you as the stream-aligned teams are then the internal users, and you have then the user needs of designing and deploying and building your application. Where you then also need help, support from enabling teams regards to application security, testing, the software design, and so on.
There could be also from the enabling team a different Wardley Map as well, where you then can focus on your specific users of the Wardley Map and you can put them then together there. For example, the Wardley Map for the platform team. Platform as a service, for example, could be an aggregated component in the Wardley Map of the stream-aligned team. It also helps you to gather, for example, if you have multiple platform teams, if you lay them on top, then you can also identify whether you are using duplicated components, for example, for CRM systems. Then you can also see, it visualizes also duplications that you can reduce it then to one component, for example, if that makes sense, in your context.
Skelton: It feels like these things are definitely heading in the direction of, we’re not looking to create a perfect machine. We’re looking to have an ecosystem in those different perspectives. We’re not going to be able to design this thing with just one perspective. That feels like an important industry trend.
See more presentations with transcripts
MMS • Anthony Alford
Article originally posted on InfoQ. Visit InfoQ

Researchers at MIT have developed an AI model that can solve problems used in university-level mathematics courses. The system uses the OpenAI Codex engine to generate programs that output the problem solution, including graphs and plots, achieving an accuracy of 81% on the MATH benchmark dataset as well as on real problems from MIT courses.
The team described their work in a paper published in the Proceedings of the National Academy of Sciences (PNAS). The researchers found that for approximately 70% of problems, simply adding prompts to the problem description then feeding the combined text into Codex would generate a program that produced the correct answer. A “few-shot” learning scheme where similar problems were fed to the model for context could solve an additional 10% of problems. The model is also able to generate mathematics problems which human evaluators judged to be on-par with problems created by humans. According to the MIT team:
The success of this work confirms that programs serve as a good representation and computation environment for solving math problems. Since our approach requires no additional training, it is easily scalable. This work addresses significant pedagogical challenges, bringing substantial benefits to higher education like curriculum design and analysis tools and automatic content generation.
Large pre-trained language models such as GPT-3 and Google’s PaLM have shown some “zero-shot” capabilities in mathematics, particularly around arithmetic and question-answering. Until recently, however, according to Berkeley’s Dan Hendrycks, these models usually achieve only about a 5% accuracy on problem-solving benchmarks. Earlier this year, InfoQ covered Google’s Minerva, which uses a mathematics-specific dataset to fine-tune a generic PaLM language model. Minerva can generate answers that include text as well as LaTeX markup for equations, and achieved an average score of 50.3% on the MATH benchmark.
Instead of using a language model to directly generate a solution, the MIT researchers chose to use OpenAI’s Codex model to generate computer programs which can output a solution, which can include numeric values, equations, and even graphs. For most problems, simply pre-pending the string “write a program” and placing the problem text within Pythonic triple-quotes is sufficient to prompt Codex to generate the correct program.
For cases where simple prompting does not work, the researchers developed a few-shot learning workflow. First, an embedding is calculated for all problems in the dataset. Then, of the solved problems, the top five most similar to the unsolved one are used, along with their solution code, as example inputs to the model. This method can bring the overall accuracy to 81%.
The model can also generate new problem questions. Several questions from the dataset are concatenated as a numbered list, which is used as a prompt to Codex, which responds with a generated question as the next item in the list. To evaluate the quality of the generated problems, the researchers surveyed students who had taken the relevant mathematics courses at MIT. The students ranked the generated problems as “similar in difficulty” to human-created ones, although they ranked the human-created problems as “slightly more appropriate” for the MIT courses.
The MIT code as well as a dataset of problems and resulting answers are available on GitHub.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ

Microsoft recently announced that it would implement significant revisions and upgrades to its outsourcing and hosting terms to benefit partners and customers globally starting from the 1st of October.
The company is making the changes based on customer feedback and preventing an antitrust investigation from the European Union. According to a Microsoft Partner blog post, the changes have three primary goals:
- Ease migration to the partner cloud by expanding use rights to allow customers to run their software, including Windows 11, on hosters’ multitenant servers and more easily license virtual machines for Windows Server.
- Provide more opportunities for partners to work with more customers, sell the necessary solutions, and run them where they prefer.
- Enable partners to build hosted desktop and server solutions to help directly fulfill customers’ hosting needs.
In an EU policy blog post, the company stated:
We are committed to competing fairly and in partnership with the diverse group of European cloud providers, and we strongly believe in the importance of an open and competitive cloud economy in Europe.
However, in 2019, Microsoft imposed outsourcing restrictions, causing customers to pay more to run Microsoft software in non-Microsoft cloud environments. These restrictions impacted customers using AWS and Google Cloud as dedicated hosts for running Windows Server and clients. Hence, some European partners and customers complained to European antitrust authorities.
Regarding the complaints, president Brad Smith said in May this year that a new team will address them:
A European Cloud Provider support team will help European Cloud Providers achieve its goals, provide licensing and product roadmap support, and continue to support their growth around cloud solutions. This new team will also work to create a tighter feedback loop, enabling European Cloud Providers to share ongoing feedback in real-time and ensure that Microsoft is better connected and supporting their needs.
With the upcoming changes, customers will have additional choices to deploy their solutions with more flexibility. For instance, the new Flexible Virtualization provides customers with Software Assurance or subscription licenses, the benefit that they can leverage licensed software for developing and running solutions on any cloud environment (except Google, AWS, and Alibaba). It also includes a new Windows Server core licensing option, allowing customers to choose to license Windows Server on a virtual core basis.
In response to the changes Marcus Jadotte, vice president, Government Affairs & Policy Google Cloud, tweeted:
The promise of the cloud is flexible, elastic computing without contractual lock-ins. Customers should be able to move freely across platforms and choose the technology that works best for them, rather than what works best for Microsoft.
Lastly, Microsoft has also announced improvements for the Cloud Solution Provider (CSP) program. Partners will now be able to sell Remote Desktop Services (RDS), Windows Server, SQL Server, and other products on a one-year or three-year subscription basis.