Month: September 2022

MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

JDK 19, the second non-LTS release since JDK 17, has reached its initial release candidate phase as declared by Mark Reinhold, chief architect, Java Platform Group at Oracle. The main-line source repository, forked to the JDK stabilization repository in early June 2022 (Rampdown Phase One), defines the feature set for JDK 19. Critical bugs, such as regressions or serious functionality issues, may be addressed, but must be approved via the Fix-Request process. As per the release schedule, JDK 19 will be formally released on September 20, 2022.
The final set of seven (7) new features, in the form of JEPs, can be separated into three categories: Core Java Library, Java Specification and Hotspot Compiler
Four (4) of these new features are categorized under the Core Java Library:
Two (2) of these new features are categorized under the Java Specification:
And finally, one (1) lone feature is categorized under the Hotspot Compiler:
We examine these new features and include where they fall under the auspices of the four major Java projects – Amber, Loom, Panama and Valhalla – designed to incubate a series of components for eventual inclusion in the JDK through a curated merge.
Project Amber
JEP 405, Record Patterns (Preview), proposes to enhance the language with record patterns to deconstruct record values. Record patterns may be used in conjunction with type patterns to “enable a powerful, declarative, and composable form of data navigation and processing.” Type patterns were recently extended for use in switch case labels via JEP 406, Pattern Matching for switch (Preview) (delivered in JDK 17), and JEP 420, Pattern Matching for switch (Second Preview) (delivered in JDK 18). More details on JEP 405 may be found in this InfoQ news story.
JEP 427, Pattern Matching for switch (Third Preview), incorporates enhancements in response to feedback from the previous two rounds of preview: JEP 406, Pattern Matching for switch (Preview) (delivered in JDK 17), and JEP 420, Pattern Matching for switch (Second Preview) (delivered in JDK 18). Changes from JEP 420 include: guarded patterns are replaced with when clauses in switch blocks; and runtime semantics of a pattern switch are more closely aligned with legacy switch semantics when the value of the selector expression is null.
Project Loom
JEP 425, Virtual Threads (Preview), introduces virtual threads, lightweight threads that dramatically reduce the effort of writing, maintaining, and observing high-throughput concurrent applications, to the Java platform. More details on JEP 425 may be found in this InfoQ news story and this JEP Café screen cast by José Paumard, Java developer advocate, Java Platform Group at Oracle.
JEP 428, Structured Concurrency (Incubator), proposes to simplify multithreaded programming by introducing a library to treat multiple tasks running in different threads as a single unit of work. This can streamline error handling and cancellation, improve reliability, and enhance observability. Further details on JEP 428 may be found in this InfoQ news story.
Project Panama
JEP 424, Foreign Function & Memory API (Preview), introduces an API for Java applications to interoperate with code and data outside of the Java runtime by efficiently invoking foreign functions and by safely accessing foreign memory that is not managed by the JVM. This JEP evolves: JEP 419, Foreign Function & Memory API (Second Incubator), delivered in JDK 18; and JEP 412, Foreign Function & Memory API (Incubator), delivered in JDK 17; to incorporate improvements based on Java community feedback.
JEP 426, Vector API (Fourth Incubator), incorporates enhancements in response to feedback from the previous three rounds of incubation: JEP 417, Vector API (Third Incubator) (delivered in JDK 18), JEP 414, Vector API (Second Incubator) (delivered in JDK 17), and JEP 338, Vector API (Incubator), delivered as an incubator module in JDK 16. JEP 426 proposes to enhance the Vector API to load and store vectors to and from a MemorySegment as defined by JEP 424, Foreign Function & Memory API (Preview).
Hotspot Compiler
JEP 422, Linux/RISC-V Port, proposes to port the JDK to Linux/RISC-V, a free and open-source RISC instruction set architecture. The template interpreter, C1 and C2 JIT compilers, and all current mainline GCs, including ZGC and Shenandoah, will be supported. The main focus of this JEP is to integrate the port into the JDK main-line repository.
JDK 20
Scheduled for a GA release in March 2023, there are no targeted JEPs for JDK 20 at this time. However, based on recently submitted JEP drafts and JEP candidates, we can surmise which JEPs have the potential to be included in JDK 20.
JEP 429, Extent-Local Variables (Incubator), under the auspices of Project Loom, proposes to enable sharing of immutable data within and across threads. This is preferred to thread-local variables, especially when using large numbers of virtual threads. More details on JEP 429 may be found in this InfoQ news story.
JEP Draft 8277163, Value Objects (Preview), a feature JEP under the auspices of Project Valhalla, proposes the creation of value objects – identity-free value classes that specify the behavior of their instances. This draft is related to JEP 401, Primitive Classes (Preview), which is still in Candidate status.
JEP 401, Primitive Classes (Preview), also under the auspices of Project Valhalla, introduces developer-declared primitive classes – special kinds of value classes as defined in the aforementioned Value Objects (Preview) JEP Draft – that define new primitive types.
JEP Draft 8273943, String Templates (Preview), a feature JEP proposes to enhance the Java programming language with string templates, which are similar to string literals but which contain embedded expressions that are incorporated into the string template at run time.
JEP Draft 8280836, Sequenced Collections, proposes to introduce “a new family of interfaces that represent the concept of a collection whose elements are arranged in a well-defined sequence or ordering, as a structural property of the collection.” This is motivated by the lack of a well-defined ordering and uniform set of operations within the Collections Framework.
JEP Draft 8284289, Improved Way of Obtaining Call Traces Asynchronously for Profiling, a feature JEP type, proposes to define an efficient API for obtaining asynchronous call traces for profiling from a signal handler with information on Java and native frames.
JEP Draft 8283227, JDK Source Structure, an informational JEP, describes the overall layout and structure of the JDK source code and related files in the JDK repository. This JEP proposes to help developers adapt to the source code structure as described in JEP 201, Modular Source Code, delivered in JDK 9.
JEP Draft 8280389, ClassFile API, proposes to provide an API for parsing, generating, and transforming Java class files. This JEP will initially serve as an internal replacement for ASM, the Java bytecode manipulation and analysis framework, in the JDK with plans to have it opened as a public API. Brian Goetz, Java language architect at Oracle, characterized ASM as “an old codebase with plenty of legacy baggage” and provided background information on how this draft will evolve and ultimately replace ASM.
JEP Draft 8278252, JDK Packaging and Installation Guidelines, an informational JEP, proposed to provide guidelines for creating JDK installers on macOS, Linux and Windows to reduce the risks of collisions among JDK installations by different JDK providers. The intent is to promote a better experience when installing update releases of the JDK by formalizing installation directory names, package names, and other elements of installers that may lead to conflicts.
We anticipate that Oracle will start targeting some of these and other JEPs for JDK 20 very soon.
MMS • Sabri Bolkar
Article originally posted on InfoQ. Visit InfoQ

A recently published study, MiCS, by AWS provides experimental evidence that the infrastructure used to carry out model training should be taken into account when designing architectures, especially for large deep neural networks trained on the public cloud. The article shows distributing the model weights unevenly between nodes decreases inter-node communication overhead on AWS V100 (p3dn.24xlarge) and A100 (p4d.24xlarge) GPU instances. As a result, the bulk of the gradient exchange happens within a node thus providing a throughput boost during training depending on the model size. The work is part of the recent effort to increase the efficiency of large-scale training workloads.
Test loss scales logarithmically with the number of network parameters and utilized data for deep neural networks. Therefore, in the last couple of years, research and industrial efforts have shifted towards developing high-capacity deep networks that can be used for many downstream tasks (e.g. by supervised tuning). To be able to satisfy the requirements of training such large networks, the scaling of training compute has also accelerated, doubling approximately every 6 months.
As large-scale deep network usage became common, parameter sharding strategies for training these models have been proposed such as ZeRO and GShard. When developing the proof-of-concept frameworks, on-prem GPU stations are generally preferred that are equipped with large-bandwidth communication primitives. In practice, however, industrial applications generally reside on the public cloud. This brings additional technical challenges due to the limitations and availability of architectural components on the cloud.
The public cloud employs software-defined reusable components which allow straightforward management of compute instances. Unlike purpose-designed GPU stations, cloud virtual machine clusters may have 12 to 24 times slower inter-node bandwidth than intra-node bandwidth between GPUs (e.g. NVIDIA NVLink and NVSwitch, AMD xGMI). This makes distributed gradient synchronization a major bottleneck for training large deep networks.
MiCS proposes to limit inter-node communication by placing model parameters to GPUs that are as close as possible. This can be done by decreasing the model partition size and by favoring intra-node GPUs. When multiple nodes are required to cover the whole parameter range, the smallest amount of nodes is preferred to divide the weights. In this way, practical communication differences are reflected at the algorithmic level. The authors also modify the gradient accumulation method to adopt the uneven weight distribution.
The results of several experiments performed in 100Gbps and 400Gbps network settings are presented in the paper. The number of GPUs and the size of the deep networks are also varied to have comparative performance results. MiCS shows consistent improvements up to 2.82 times more throughput for 100Gbps network settings and up to 2.21 times more throughput for the 400Gbps case.
Additional information about the paper can be obtained from the official Amazon Science blog post. A similar recommendation can be also seen in the official GCP blog post (3rd suggestion).
MMS • Tilde Thurium
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- There are some tips for hosting a successful hackathon at your company
- Hackathons can boost morale, foster collaboration and create a more engaged workforce
- Projects built during hackathons can have real-world impact
- Hackathons are driving digital transformation, especially within traditional, non-tech enterprises
- There is great value in bringing developers closer to business problems
We are living in a hyper-digital world. One where the companies that prioritize agility and adopt new technologies early are the companies that will not only gain competitive advantage but stay in business. For tech-native companies, this is nothing new. But for traditional, non-tech enterprises that have long resisted digital transformation for one reason or another, it’s a bigger challenge.
In the past few years, my company, Twilio, has uncovered a unique way of sparking digital innovation. It involves bringing a developer community mainstay – the hackathon – to large, traditional enterprises. We call them Enterprise Hackathons.
In these hackathons, enterprise employees and software developers come together for a day of brainstorming and building digital solutions to address real-world business problems. Participants don’t need to have deep technical expertise – anyone involved with the business challenge, regardless of team or department, is invited to take part. We aim to make these events as diverse and dynamic as possible. At the end of the day, the solutions the team develops are presented Shark Tank-style and many of them are eventually implemented within the organization.
Hackathons bring enterprise employees inside the mind of the software developers. We all know that developers are generally more productive when given a higher-level problem to solve, rather than a simple task. Hackathons lead with the problem and offer the freedom, inspiration, and creativity to find an innovative solution. We’ve seen the Enterprise Hackathon approach improve business outcomes and instill a collaborative workplace culture in which developers and non-tech employees can learn from each other.
Do it yourself: Hackathon best practices to consider
Hackathons can be effective for companies of every size, and in every industry. We’ve had success hosting hackathons within highly regulated industries like healthcare and finance, which demonstrates how legacy industries must innovate to gain a competitive edge. Where we currently see the need for urgent transformation is within traditional enterprises and hackathons are a great first step for adopting new practices that embrace innovation.
Here are a few recommendations for hosting a hackathon at your company:
- Carefully consider the goals of the hackathon before doing any planning. What business problems are you hoping to tackle? What is top of mind for leaders? What do you want participants to take away? Taking the time to lay out such criteria beforehand can be a lot of work, but it makes it easier to hit the ground running on the day of the event.
- Hackathons are no easy feat. Give yourself enough time to organize the event and set up a clear structure for the day, so that all the participants know what to expect and can prepare accordingly. You want everyone in the right mindset for creativity and collaboration, so advance preparation is key.
- Be inclusive, transparent and encourage open dialogue. Remember that anyone with a stake in the business should be invited to participate in the hackathon, technical or not. The most successful hackathons break down silos and bring together ideas from diverse teams.
- Freedom and flexibility are essential. Again, developers thrive when given a problem to solve rather than an assignment. Approach the participants with respect and provide autonomy during the event
- Even if a prototype isn’t fully developed at the end of the hackathon, offer everyone a platform to showcase what they have worked on. Encourage rehearsals to boost confidence, and give feedback afterward for continued learning.
- Stay adaptable – no two hackathons are the same. Be sure to tailor the agenda and content to the specific group of participants, but if something isn’t resonating with the group, be ready to pivot.
- Hackathons should be fun and revolve around creativity and learning – not all hackathons require tangible outcomes. Coming up with an exciting theme or fun prizes is a great way to boost enthusiasm and foster friendly competition.
- Hackathons can work both in-person and virtually. In today’s day and age, digital fatigue must be taken into account when hosting a virtual hackathon to ensure innovation and engagement. Make sure people have a few breaks in between sessions to recharge and boost creativity. Breaking into small groups is also a good way to make sure everyone stays engaged.
- In terms of structuring the event, consider a brief kickoff to set the stage and welcome the participants. This will get the attendees excited and you will have the opportunity to address any questions or concerns they may have. You can make the kickoff fun and interactive by including a demo that will inspire your builders.
- When putting teams together, we’ve found that 3-5 participants is the sweet spot in terms of team size. If you’re creating cross-functional teams, we recommend including at least one developer on every team.
- Choose a panel of judges that will review demos in a fair and objective manner. It’s common for hackathon judges to have extensive technical backgrounds. While the judges deliberate with each other, take the time to ask for feedback from hackathons participants. You’ve got a captive audience, and the event is fresh in their minds. This feedback will help you assess what worked and what didn’t so that you can make improvements to your future hackathons.
- Keep in mind that there’s always potential for unexpected issues during live events. At a recent hackathon, one team struggled to set up their development environment. While they eventually worked through the issue, the setback ate into their hacking time — making it impossible for the team to build a full demo. As a workaround, the team modified their demo ceremony presentation to include the lessons they learned and examples of what they would have built given more time. To prevent these types of issues, provide explicit logistics instructions in advance of the event and follow up with each team to ensure they complete any pre-work.
Developers are often kinesthetic learners and learn by doing. Hackathons offer an opportunity for everyone involved to step outside of the typical day-to-day work and try something new. Remember that the outcome of a hackathon isn’t just the code written, it’s what’s learned and applied in the future.
Bringing developers closer to business problems – and inspiring solutions
Hackathons are much more than a fun day of problem-solving and team bonding. They give developers a closer connection to customer problems and, as a result, can drive real, tangible business and even social impact.
For example, in a recent hackathon, an all-female developer team from a major insurance company built software that used drone footage from natural disasters to inform homeowners if their home was affected by the disaster and offer help with the next steps.
We’ve also seen humanitarian technology as front of mind for hackathon participants at Lionbridge. Lionbridge enables global organizations to communicate with their customers and workforce in more than 350 languages. At a Twilio hackathon, they started an integration of Twilio’s Flex Contact Center with Lionbridge Language Cloud. Today, this translation tool is fully productized and ready for easy deployment and use by business, government and non-profit customers across the globe. It’s easy to picture how powerful this technology will be in a relief efforts setting.
Another success story we’ve seen first hand was with the engineering org at EnlivenHealth. EnlivenHealth builds advanced patient engagement, clinical and financial solutions that are used by more than 50,000 pharmacies nationwide. During a hackathon, they built a prototype of a personalized IVR using artificial intelligence. Today their Personalized IVR experience not only saves time for providers, but also leads to higher patient satisfaction and improved patient health outcomes.
And a few months into the Covid-19 pandemic, a prestigious cancer center spent two and a half days building telemedicine prototypes. The end result? A platform that allowed cancer patients to continue to receive life saving medical care, even during lockdown.
Two years later, telemedicine services are here to stay. Now, individuals around the world benefit from the technological advancements of telehealth, as it provides convenience for doctors and patients alike, reduces costs, and improves patient outcomes.
The benefits of hosting an internal hackathon are not limited to developing a new product or solving a business problem. Hackathons are a disruption to normal work life that bring your innovation community together to help solve a problem immediately. At their best, hackathons boost team morale and foster collaboration among cross-functional teams, which can lead to lateral thinking and ground-breaking ideas. Involving developers in business problems from the start and giving them a stake in the solutions implemented creates a more engaged workforce. And building a project that moves the needle on business metrics is a career milestone for anyone, technical or not.
Unlocking developer creativity drives real business impact
Developers are essential to any company that wants to keep up in the digital era, and hackathons are one way to create space to unleash developer creativity within an enterprise. There is no one-size-fits-all approach to organizing a hackathon, but understanding your goals and staying true to your company values will not only make the event a success, but will result in tangible business impact.
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ

For low code applications there are technical things you don’t have to test, like the integration with the database and the syntax of a screen, says Jan Jaap Cannegieter. But you still have to test functionally, to check if you’re building the right thing. End-to-end testing and non-functional testing can be very important for low code applications.
Cannegieter will speak about testing low code at QA&TEST Embedded 2022. This conference will be held from October 19-21 in Bilbao, Spain.
Testing can help to address risks in low code development as Cannegieter explains:
With low code, we still have risks related to human mistakes and complex business rules. But there is an extra risk because low code platforms look misleadingly simple. It looks as if everybody can build systems. And in some situations, this is true! But when the business rules are complex, the database is big and complex, and the customer journey asks for several related functionalities, defects are easily introduced. The extra risk is that inexperienced developers introduce defects.
According to Cannegieter, technical reviews and testing of the screens, business rules, and database handling can help to address the risks of low code development. It is up to the team to use the platform in the right way and make the right functionality, and reach the desired level of performance and security.
InfoQ interviewed Jan Jaap Cannegieter about testing low code applications.
InfoQ: What are the main differences between “high code” and “low code”?
Jan Jaap Cannegieter: High code is program code as we know it, where developers type in the code using a specific syntax. Like C# or Java. This is very labor-intensive and error-prone. Besides that, there are not enough well trained and experienced developers available.
In a low code platform, you build an application by means of a user interface. For instance, building screens by dragging and dropping items and building logic using process-like flows. This sounds simple but it can be very complex and error-prone.
We’ve seen four generations of low code applications. First, there were small, simple, stand-alone applications. Then we have small apps on top of SAP, Oracle Fusion or Microsoft Dynamics. The third generation were business-critical but still small apps to offer extra functionality besides the ERP system. With these apps, you don’t have a workaround. Now we’re building big, complex, business-critical core systems that should be reliable, secure and compliant. The level of testing increases with every generation and in the fourth generation, we see that testing is only slightly different from testing high code applications.
InfoQ: What about the vendors of low code platforms, what kind of testing do they do?
Cannegieter: That differs per vendor. For the big, well-known platform vendors, the platforms work well. Some vendors also have standard building blocks available; these blocks also work well. But when you use building blocks built by others you never know what the quality is. With so many low code platforms today, there are also platforms that are not that well-tested.
InfoQ: What can we skip when testing low code applications?
Cannegieter: The technical working of the platform, integration within the platform and the standard functionality of the platform can be skipped when you are using a well-known, widely used platform.
If you select a date-field and drop it on the screen, you are making a connection to a database field. You don’t have to test the integration with the database, but I would certainly test if the date entered in the field is used correctly in the business rule.
Testing is important if you want to limit the risks when you go into production. Especially when the application is critical for the users you should test it in a professional way, or when the application is technically seen as complex. Testing is still an important part of system development, no matter whether you use high code or low code.
If you’re making simple applications only using the standard functionality of the platform, only using standard building blocks, don’t use high code, and when there is a workaround available you could test less or test with non-professional testers, like untrained users.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Microsoft recently announced the general availability (GA) of Azure Managed Grafana, a managed service that enables customers to run Grafana natively within the Azure cloud platform. With the managed service, they can connect to existing Azure Services to enhance observability and cloud management.
Azure Managed Grafana is based on the open-source Grafana observability platform and is a result of the collaboration of Microsoft and Grafana that started last year. Earlier this year, Microsoft released Azure Managed Grafana in preview, allowing customers to view their Azure monitoring data in Grafana dashboards and have new out-of-the-box Azure Monitor dashboards. With the GA release, the company added new capabilities that include the latest Grafana v9.0 features with its improved alerting experience as well as zone redundancy (in preview) and API key support.
Azure Managed Grafana has several new out-of-the-box dashboards for Azure Monitor, such as the Availability Tests Geo Map dashboard for Azure Monitor application insights, where users can view the results and responsiveness of their application availability tests based on geographic location.
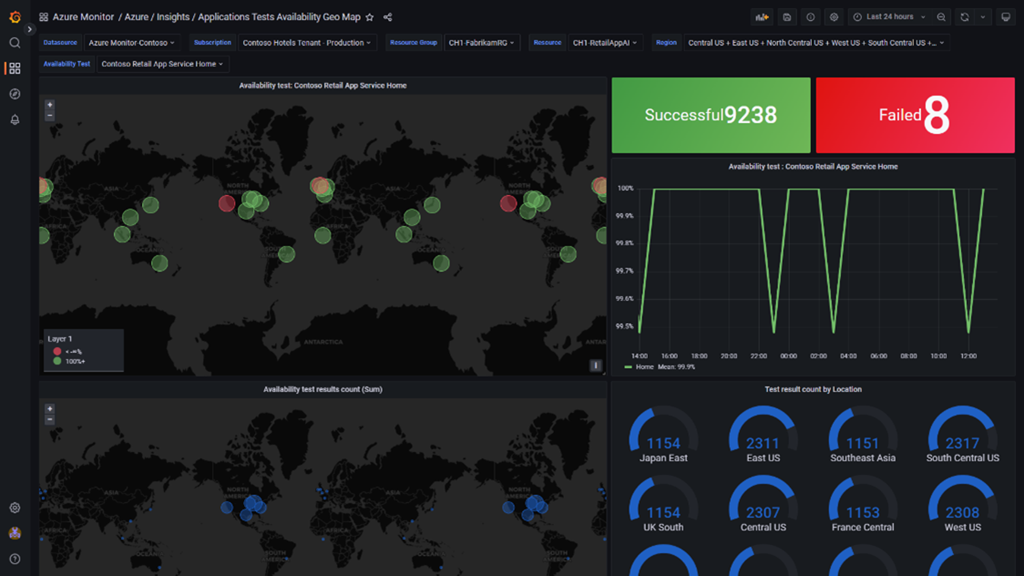
In addition, there is also a Load Balancing dashboard for Azure Monitor network insights, where users can monitor key performance metrics for all their Azure load balancing resources, including Load Balancers, Application Gateway, Front Door, and Traffic Manager.
Other new capabilities are:
- A new “pin to Grafana” feature for Azure Monitor Logs allows users to seamlessly add charts and queries from Azure Monitor Logs to Grafana dashboards
- New out-of-the-box dashboards for Azure Container Apps, such as an Aggregate View dashboard for Azure Container Apps, which depicts a geographic map of container apps, and a new App View dashboard for Azure Container Apps that monitors the performance of Azure Container Apps.
Stefano Demiliani, an Azure MVP< concluded in his blog post on Azure Managed Grafana:
I think that the most interesting Azure Managed Grafana feature is the possibility to configure multiple data sources (external storage backend that holds your telemetry data). Azure Managed Grafana supports today lots of popular data sources (Microsoft and non-Microsoft) like Azure Monitor, Azure Data Explorer, SQL Server, Azure SQL, MySQL, Google Cloud Monitoring, CloudWatch, Alert manager, Elasticsearch, Grapite, and many more.
Lastly, the documentation landing page shows more details on Azure Managed Grafana. And pricing details of the service are available on the pricing page.
MMS • Lukonde Mwila Rosemary Wang Alexander Matyushentsev Eric Goo
Article originally posted on InfoQ. Visit InfoQ

Transcript
Losio: In this session, we are going to be chatting about how to simplify and accelerate the adoption of Kubernetes.
Let’s clarify a couple of words, what we mean by simplify and accelerate Kubernetes adoption. Basically, Kubernetes deployment might suffer different operational challenges, including security, stability, governance, whatever you want, and how we’re going to address them, how we can make that simple. Today’s panel will explain how to avoid basically underperforming deployments, prevent excessive cost, and give advice on how to overcome barriers such as low skill gaps, for example.
Background, and Journey to the Cloud and to Kubernetes
My name is Renato Losio. I’m an editor here at InfoQ. I’m a cloud architect. We are joined by four industry experts, coming from very different background and experience, but all very much on Kubernetes. I would like to give each of them the opportunity to introduce themselves and share about their own journey to the cloud and to Kubernetes specifically.
Goode: My name is Eric Goode. I am a Principal Architect on D2IQ’s professional services team. I come from more of a enterprise software background. I was a developer for about 17 years. I’ve been with D2IQ about four years now. I’ve been working to help people decompose their monoliths and get them into Kubernetes.
Matyushentsev: My name is Alexander Matyushentsev. I used to be principal software engineer, and now I’m a Chief Software Architect at Akuity. I’m a co-founder of the company. I’ve been doing social engineering for like 15 years. I got into infrastructure maybe seven, six years ago. My focus from the beginning was Kubernetes. I am one of the co-creators of an open source project called Argo, which we created in a startup company called Applatix. Then me and my team, we joined a bigger company, Intuit, where we helped to drive Kubernetes adoption, and Argo adoption as well. Most recently, we started our own company where we pretty much do the same, but now we’re helping not one but many companies. I’ve been in this domain for quite a long time.
Mwila: My name is Lukonde Mwila, or you can also call me Luke. I’m a Principal Technical Evangelist at SUSE. Started off in application development years ago, and then transitioned into more of the DevOps and solution architecture space, specifically in the cloud environment. Did that for a couple of years. That’s also where I had the opportunity to lead teams that were focused on building out Kubernetes clusters and administering them, as well as running different training initiatives for the banking sector, as well as consulting firms. Then eventually moved over into developer advocacy with a specific focus on the cloud native world. Yes, just to try to simplify the process of Kubernetes adoption for a number of developers in the community, operators as well, as well as just evangelizing some of SUSE’s container management tech stack.
Wang: I actually did the reverse path. I came from a systems administration network engineering background actually, and got into private cloud. That’s how I ended up learning about cloud technologies early on. I was working with container technologies, wanted to get more into open source, and decided I should learn development. I can tell you, I’m like a development dabbler. I’m not really the best software engineer. Since then I’ve done a lot of work with Kubernetes. A lot of it is content oriented, ran into production for a while. Then I decided, I could learn a little bit more. Now I’m a developer advocate at HashiCorp. I primarily cover Consul, which is a service mesh vault, a secrets management offering, as well as how they run on Kubernetes and how you use them on Kubernetes. I also work a little bit in infrastructure as code too. End to end, I get to see everything from Kubernetes and the infrastructure supporting Kubernetes, to developers who are deploying Kubernetes.
Speeding Up the Adoption of Kubernetes
Losio: Let’s say my team has started working with Kubernetes, but you still don’t have it in production, you have it somewhere. You have some environment running it. It is like, what should be the main worry? How can I speed up the adoption, and do the final mile or whatever?
Mwila: The first time I worked with Kubernetes, I did have a good understanding of container orchestration, because of working with ECS prior to that Kubernetes project, but there were a lot of people in the team that were brand new to Kubernetes as a whole. I actually think one of the first things you have to start off with is considering the makeup of your team. What’s the level of proficiency around Kubernetes? That could definitely determine how you’re going to go to production. In our case, we ended up going with a hosted cluster, because that would essentially take away the responsibility of managing the control plane and administering that as well as the data plane. That simplified the process for us in many ways, especially the other people on the team. Then as maturity grows, you can then move in a direction where you take on some of those responsibilities if you want to move away from a hosted cluster.
I think another barrier that you need to be very careful of would be the temptation to import someone else’s solution into yours. I think everyone here on the panel would attest that there’s so many tools and add-ons in the cloud native space. If you see a lot of shiny things in someone else’s solution, and you just want to import those into your context, you’re going to run into issues, because you’ve probably got a lot of discrepancies in terms of your use cases. Work from your own problem definition, and build out from there, and pick tools to support the solutions for your problem definition as opposed to seeing what someone else is doing and trying to import that into your context.
Goode: I agree with that. I think one of the biggest hurdles that a lot of enterprise groups find is getting to production is that they try to get the whole big bang go, and they try to get the whole thing done into microservices and get it in all at once. When if you really take a look at how Kubernetes is structured and use some of the tools that are there, you can do it incrementally and get into production incrementally and bring it in little by little instead of trying to wait for everything to be perfect.
Advice on Containerization, and When to Move from Monolith to Microservices
Losio: When do you start with container, and when not to, and when should we break monolithic towards distributed architecture? If you have any concrete advice or main guidelines will be really appreciated.
Wang: I think with monoliths, as an industry, we think about monoliths being bad, but they may not be bad. You may not have a choice but to run it. In which case if your monolith is an application that it’s really difficult to decouple, you’re not planning to make an additional financial investment to necessarily replatform it, refactor it, then probably not a good idea to try to containerize it. I think the joke was someone told me I want to containerize my COBOL application. My question was like, are you planning to refactor and replatform or you just want to take it and lift and shift it into a container? What is the benefit you get from that? What is the benefit you get from repurposing or replatforming an application that is a monolith, maybe you’re not using all that often. Versus a monolith you’re using all the time, you’re making lots of changes, and you can’t make changes without affecting someone else anymore. There’s almost a cost of the time and effort to maintaining the application to a point where it’s no good as a monolith anymore. In which case, maybe you start thinking about breaking it down into a distributed architecture.
The question to containerize, when to and when not to, tends to be, it’s easier to containerize when you’re moving toward a distributed architecture, when you’re breaking down all of that code, and you’re able to replatform it and rethink the way that you’ve written it in the first place. If your application isn’t going to be used that often, and quite frankly, it’s going to be running there, what is the point?
Losio: Basically what you’re saying is the answer to this question is, even this question should come before simplify and accelerate the adoption. It should be, do I need to go that step? That’s the very first.
Goode: I think it’s more of an art form than a science, though. It’s like determining where your trouble spots are, and what can you pull out?
Losio: There’s not one single answer that fits.
Matyushentsev: I feel like I wanted to address the question as when to start using Kubernetes, and if you decide to start, what to look for. I really like to promote the idea that you have to define your goals first. Basically, I started myself playing with Kubernetes because it was a new shiny tool, and I just wanted to give it a try. Then only a few years later, I think I realized what the whole purpose of it was. In my opinion, it’s the tool that let application developers to manage infrastructure without creating tickets. It was really eye opening for me. If you have a problem in your company that your engineers could be more productive by changing YAML files, as opposed to creating tickets, then Kubernetes is a good tool, and you would have to containerize to use Kubernetes. I think it’s a good enough reason, if it improves velocity, and teams can deliver more frequently, and quicker, then maybe it is worth to consider containerizing.
The Skills Gap in Kubernetes Mastery
Losio: One topic that I see recurring over is the topic of skill gaps, and the fact that not many people know Kubernetes. It’s something that people should learn more. Companies complain that there’s not enough knowledge. My first feeling is, is that really a topic? Actually, does anyone in the development team need to know Kubernetes or care about Kubernetes? Sometimes I feel like I’m a developer, I want to build my application, and should almost abstract myself from that. I was wondering if anyone has any feeling about that.
Goode: I teach one of our CKAD preparation classes. I always get that question right at the very beginning from the developers, why do I need to know Kubernetes if all I’m going to do is check stuff into Git, and it’s going to get built by a CI/CD system? I’m never going to actually log in or see Kubernetes. The answer to that is understanding what Kubernetes brings to you, things like service discovery, and config injection, and networking, and load balancing. All these things that you get for free with Kubernetes are things that we had to code for in the past. I come from a pretty heavy Java background and we used a lot of the Netflix stack, and we were using things like Eureka, and Ribbon, and all this to accomplish things that Kubernetes gives us for free and we don’t have to put that in our code anymore. We can simplify our code. We can just bring our containers and we can run it and take advantage of those things. I think understanding as a developer how Kubernetes works and what things as a developer you can take advantage of that you don’t have to code for is very important.
Mwila: Just to piggyback off what Eric was saying, I think contextual understanding of what Kubernetes brings to the table is a big part too that plays a role for developers. On the other hand, I do think, it’s more contextual than technical. Something that I’ve been seeing happening a lot to the frustration of application developers is they’re becoming cross functional in their roles within themselves. They’re feeling like why is it that Ops is now being forced on our plate as well. I think that teams and companies just need to manage that well to make sure you develop a good workflow. Some of it might stem from a misunderstanding of what DevOps should actually be. Because application development, and that’s something that I’ve done, it’s a beast in and of itself. It’s very involving. You just need to make sure you understand what responsibilities are being put on the developer’s plate when it comes to the Kubernetes world. I think more of it should be contextual than technical. I think other operators and DevOps engineers can be involved on the technical side of things there.
Getting Hands-On with Kubernetes
Losio: Let’s say I’m a developer that knows Kubernetes there, but I want to get really into it. I want to start to get my hands dirty, and I want to play with it, and I haven’t paid much attention on the operational side. Until now, I just know the idea behind how it works, but I don’t know tools. I haven’t used it myself. What should be the very first step? How can I start that?
Wang: Your security team may not like this very much. If it’s within your organization, explore what you understand in the namespace that’s provided to you. If you’re a developer, you’re probably going to be constrained to a namespace. Understand what’s running in that namespace. Ask your Ops teams questions about, how do certificates work? How does load balancing work? Is there something special with some of the tools you’re using? The other way to get hands-on with it is start from scratch. It’s fantastic in Kubernetes where you can spin things up locally and try things out. It may not be representative of your application or your enterprise or organization situation, but it’s a good way to get hands-on and go from ground up. This is how you understand Kubernetes and networking. How you understand how it’s handling security, whether it be certain segmentation, role based access control. There are a lot of tutorials now that go at it from the hard way, and that’s the first way to just get into Kubernetes and learning all the ins and outs.
Matyushentsev: Kubernetes is meant to empower engineers. Basically, platform team has tools to put boundaries in place, and basically they protect you from shooting yourself in the foot. That’s why if you get access to Kubernetes, I think you’re free to experiment, unless you already run the application in production, you can just do whatever you want. If something is not allowed, you will get a 401 error, basically. You get way more freedom to experiment as opposed to if you have access to AWS account, for example. My advice would be to try to continue to apply something, see what happens, and play with and get your work experience.
Learning Kubernetes, for New Developers
Losio: I was wondering about that. That’s something that bothers me as someone that is familiar with Kubernetes, but I don’t use it on a daily basis. Even as you just mentioned now one cloud provider, I was thinking even if you limit yourself to one cloud provider, you want to try something. There are basically now so many ways to write Kubernetes, I’m thinking about AWS, but Google, Azure that you almost don’t know where to start, how to choose. Which one is the, not easy, but maybe a starting way for a new developer?
Mwila: I think you pretty much got about three different options in a cloud environment, four if it’s AWS’s case. You have a hosted cluster, so that takes away control plane and data plane, and then you’re responsible for the worker plane, or you can go fully serverless where you’re just focused on your application, all of that is taken away. Then you can provision a cluster yourself, just take on the compute resources in a specific cloud environment and then provision it. The fourth one, obviously, in the case of AWS is EKS Anywhere, where you can have cloud and on-prem. Just based on those different models that exist, and you’re just starting out, make your life a little bit easier and go with the fully serverless approach. Because that way you get to test out just deploying an application and what’s involved in deploying an application while you’re still learning the architecture from a theoretical perspective. Then as you start to get a better understanding of the nuts and bolts of the architecture, you can take on additional responsibilities like the control plane and data plane, and then go all the way and provision a custom cluster by yourself and break things and run into issues. Just work on the easy way, upwards. Of course, if you want to do it the other way around, no one’s stopping you.
Goode: I think it really just depends on how you learn as yourself. I know I’m a very much a learn-by-example type person. I can go out to YouTube and watch some videos and pick this stuff up, and then launch Docker Desktop, or Kind on my local laptop and just run things. Those are good options if you don’t have access to a cloud platform. A lot of people don’t. Signing up for one of the free trials with the cloud platforms is also a really good way to go. Taking a class, like there’s a lot of great online classes through different providers like Udemy, and things like that, are a great approach. Or you can take an in-person class. We offer monthly in-person classes they can sign up for, and you get me as an instructor, and you get to go through and have somebody that you can interact with and ask questions. It really just depends on how you’ve learned, picking the right approach for you, because otherwise, it’s not going to stick. You’re not going to continue with it.
A Platform Team, and a Tool’s Cognitive Load
Losio: I tried to do my container, I containerized a project and I ended up learning so many things that is good, but at the same time it is pretty not bad. The question is just to try to understand how much cognitive load is good in the name of using any tool. I think we’re back to the problem, it’s like, I need to gain something out of it. Yes, I’m not going to adopt Kubernetes, actually, it’s valid for any tool just for the sake of it, hopefully. Should I have a specific team to handle it? Any advice or any comment on it?
Wang: Despite coming from some networking experience, I wouldn’t say that I’m an expert in it. I rely on a number of better network engineers than myself. I think functionally we have to strive for good enough knowledge. We don’t know what knowledge we need to use. For example, you could be debugging something on Kubernetes and it could be legitimately a networking issue and you wouldn’t know, and you wouldn’t have the deep knowledge to do that. I think that it is advisable to have a platform team or some specialist who has a little bit more knowledge in Linux networking security, to give you advice and to help you understand that. We should all be empowering each other, just as much as a security team needs to understand how a developer is using that platform. What are the common patterns? We don’t want to be blocking people from deploying, but we do want to be secure. Each group has to learn from each other. I think that’s the most difficult part of it. Yes, it does help to have a platform team with specialization.
Matyushentsev: I feel like it’s inevitable, you would have to have a platform team. The reason is, even if you use a managed Kubernetes, it’s not 100% managed, you still have to make a set of choices to figure out how you’re going to manage load balancers. Maybe you need to provision certificates, and even lower basic things like how networking is going. Someone would have to run those projects, and that’s usually a platform team. More of these, I think, maybe taking care of big cloud providers, but we’re not there yet. I would recommend to focus just on learning what you would have to learn anyway. The whole idea is that engineers actually use Kubernetes directly, not through some abstractions that abstract Kubernetes away. Kubernetes is abstraction itself and the basic primitives of Kubernetes such as Pods, ReplicaSets, Deployments, I think we will have to understand like all of us. Even if your focus is building applications, it’s inevitable that in the future you will have to deal with these basic Kubernetes primitives and you will get a lot of advantage if you understand it.
The Role of Tools in the Adoption of Kubernetes
Losio: We keep talking about Kubernetes, and then we talk about adoption and how to accelerate adoption usually different tools, different vendors and different option come to mind. Of course, it gets more complicated, because if you have no knowledge, you don’t know. Which tool, or do tools help? How do I choose a tool? One of the benefits of Kubernetes has been to see as well almost no vendor lock-in. I can move from one provider. Will tools help or is that a risk?
Goode: I come from the software engineering side, the enterprise side. Yes, that’s one of the big questions that’s always asked on that side of the table, what’s my risk of vendor lock-in? Am I going to get locked into a tool that I can’t get rid of two years from now when something else comes along? I think the important thing is when you’re picking your distribution, when you’re picking your tools, pick stuff that’s standard open source. You’re not dependent on a particular vendor’s documentation, you can go out and ask the wider community. You can go back and open pull requests, if you want to make a change or do something different. It’s really important to stick with a distribution that sticks as close to the open as possible. Find a vendor that its tools are mostly additive on top of the open source versus putting their own container network interface in place or putting their own storage behind the scenes. That way, you don’t get locked into those kinds of things. Then when the new great thing after Kubernetes comes along, then you pick your containers up and you move to the next thing.
The Future of Kubernetes
Losio: I liked the last comment you made because actually it was one of my feelings about that as well, is like, yes, now we are all into Kubernetes after actually many years. It is like, are we still going to talk about Kubernetes in 5 years’ time, or in 10 years’ time? Or it will become some standard, or it will be entirely replaced by something else.
Matyushentsev: I don’t think Kubernetes is going away very soon. I hope at some point we stop talking about it because it became a boring topic. Then that would mean it became stable, finally. The ecosystem is not changing that rapidly. I think it will be a good thing. In regards to choosing the tools that you run on top of Kubernetes, I agree 100%, that you should choose open source. An open source tool that solves a real pain, it has a very high chance of survival, because if one company steps away, then someone else pick up and you still have a whole community around it, and it’s not going to just disappear. If you choose a very nice tool that is run by a small startup, and it’s not open source, the startup can get acquired by a company and you lose your tool. Take a look at CNCF landscape, it will be overwhelming, but you will be looking from a very good set of tools.
Losio: Do you agree as well that it’s going to be boring in a few years or do you have a different view?
Mwila: I think right now, one of the reasons why it’s being spoken about so much is obviously the excitement and the buzz. I can attest that, in my context, specifically, there’s a lot of excitement. I would argue we’re probably on the tail end compared to adoption in other parts of the world because of a skills issue. The excitement might take longer to wear out on my side of the world compared to other parts. Another thing is, I’ve seen how there’s more attention being given towards best practices now, which is a good thing. Now there’s a lot of talk around security around Kubernetes and containers. I think that that is also what’s going to have the discussion last a little longer, because it’s going to catch up with the excitement, which is what you want. Then there’ll be more talk around the best ways to implement Kubernetes, because I think right now, what’s leading the race is still let’s adopt Kubernetes, and best practices is still far behind, so you want best practices to catch up to that, if not overtake it.
The Kubernetes Adoption Curve
Losio: You’re basically saying we are still in the, not early phase, but still in the phase where it matters to run Kubernetes. The how and the best practice are still lagging a bit behind. Being this on a roundtable from InfoQ, there’s one common concept that we use is the adoption curve to see, at the moment, do you consider Kubernetes something for early adopters still, or early majority, or is that, everyone is using it? Because I have to say on a personal level if I go to a conference, I had a feeling, everyone is using Kubernetes. There’s not anyone left that is not using. Then when I dig through a specific company, you have the feeling that, maybe it’s not really the truth behind. There’s something maybe there, but we are not there yet. Do you have a feeling where we are, or what do you think?
Wang: At least in my impression I get is early majority. I think part of it is also regional as well. Depending on how you’ve developed all of your technical architecture up to this point, you may or may not choose to adopt Kubernetes. For some folks, they’ve moved off of Kubernetes already, or they’ve evaluated Kubernetes, then they’ve said, this just really doesn’t work for our particular use case. At least in my experience, it’s mostly early majority. There are some folks who are using it really proficiently, and for very advanced production workloads. For even the long tail folks who have gone even further in the Kubernetes journey, they’ve actually moved off of it, and some have just started to adopt. That’s why we categorize it there.
Goode: A vast majority of people are using Kubernetes. It seems like there’s not a huge number that are actually in production for their frontend type applications. Where I’m seeing a lot more adoption and a lot more what I would call production type applications, is in things like software factories, and AI/ML, and things like that, where you’re still using it as a development tool. You still treat those systems like a production system, your CI/CD system as your developer’s production system. That software factory and running all those things internally is a really good first step to learning Kubernetes, learning how to operate in production, and learning how to secure it, and then take that to your customer driven apps or your customer facing apps.
Losio: I was wondering, with Luke’s experience as a developer advocate as well, if you see anything different internally or externally, in terms of adoption.
Mwila: Yes, not necessarily. I think, pretty much just echoing what Rosemary and Eric have said as well. I think I implied to this earlier, in part it’s a contextual thing. In some parts of the world, I think there’s a lot of adoption. There are some great use cases, you can even find them online from CNCF events, teams that are running I think, well over 500 clusters. That’s fantastic. That’s a testament to a high level of proficiency. At the same time, you have a number of examples of teams that probably shouldn’t even have adopted Kubernetes to begin with. I would argue that it’s probably early majority, as well. Just goes back to what I said earlier as well, lots of excitement. Some people, unfortunately, are leaping before they looked. They even say, ‘everyone’ is using Kubernetes, but they actually haven’t worked from the problem definition. Does this actually solve our issue? I love using the example of, in many cases, if you have an event driven architecture, maybe you could have just used Cloud Functions to solve your problem, as opposed to going with something as robust as Kubernetes. I think time will trim things as well, in terms of the number of people who have adopted it as well.
Losio: Very interesting point as well about the pattern that might actually advise against using Kubernetes.
Matyushentsev: I think I’m a little bit more optimistic about Kubernetes. Kubernetes is not a product, it’s a platform that you can use to do anything. Then, if you are lucky enough and your use case already is implemented by some tool on top of Kubernetes, then it’s really easy to use it now. New tools get created and more use cases get unlocked. I believe in the future, we will see more tools that focuses on a particular use case. Hopefully, we will finally get a shiny CI tool that is built on top of Kubernetes, and it’s like, it will be at GitHub Actions, and Jenkins, and then finally, people will move and use Kubernetes for CI. Then, there are more examples of such use cases. I agree that ML and data processing use cases also, because basically you need an orchestrator that updates and delegates compute resources. Kubernetes can do a lot, basically. It’s a generic orchestrator that can orchestrate all kinds of things. I believe we will see more adoption, and it’s just beginning.
Common Mistakes to Avoid When Deploying Kubernetes
Losio: I like to go back a bit to the topic that Luke raised before about best practice or whatever it is. I’m thinking, if I have a running Kubernetes, if I think one or two common mistakes that people do that they should fix, action item they could do to usually simplify their deployment, improve their deployment. I know that best practices vary according to industry, according to size or whatever. In your experience, what are common mistakes or things that people should take care of?
Goode: One of the things that we see a lot, is a lot of the tools out there are very imperative. You go out, you run a command line interface, you launch your cluster, everything’s great. This leads you to the whole Snowflake server problem, like all over again. Martin Fowler has a great article out there called The Snowflake Server, where any time somebody touches a server separately, you got to remember to make that change everywhere else. There’s a newer product out there, or open source project out there called Cluster API, which is the basis for our distribution that allows you to make that more declarative. Everything’s just objects, you can store it all in GitOps. We have a customer right now that does all of their clusters through GitOps style. It’s just a check in, in Git. Flux picks it up, moves everything over. All the Cluster API objects launch, and everything goes. Then you get the whole safeguard of if things are checked into Git, if somebody makes a change, I can go in and look at that Git history. I can look at that commit history and see what changed, instead of somebody running a command line interface, or jumping on a server and making a change. One of the best practices that we’re really starting to see come out is to make these clusters themselves declarative and make them clusters as code and using GitOps to do that.
Wang: When you first start operating Kubernetes, and you’re focused quite a bit on production delivery, you omit a number of security practices. It’s hard to justify slowing down your delivery pace in order to focus on these delivery practices. For example, deploy in a secure network, if you can, in a private network, if you can. Apply role based access control, if possible. There’s a balance between the two, but identify what’s the minimum from a security perspective that you need. It’s really hard to go back and lock some of these things down after the fact, after you’ve started running in production. Sometimes you take more time and possibly incur downtime to applications running on the cluster, because you’ve gone back and you’ve locked something down, and you haven’t fully tested it end-to-end from a security perspective. There’s a number of minimum lists that you have from a Kubernetes perspective, from a cloud security perspective. We’re not saying go for industry benchmark level, like CIS level 2, which is the U.S. security benchmark. Start with a minimum list, and start earlier than later, and it will help you accelerate your adoption without necessarily compromising that much on security practices.
Losio: I was wondering if you have some advice or do you agree.
Mwila: Yes, 100%. A big one, again, just what I’m seeing is there’s a lot of attention being given to what are the security best practices around this because there is excitement to adopt it, which is great. I love trying to evangelize security best practices as much as I can to teams, and companies can accelerate that adoption process. Just recently, I was presenting to different companies, and one of the people in that room asked, “How will Kubernetes and containers strengthen our security posture?” I chuckled to myself, and I said, “It won’t.” People’s faces fell, I’m like, “It’s insecure by default.” I just went on to elaborate. I’m like, these are its strengths. I know everyone’s looking for that tool that does absolutely everything, but these are its strengths. We don’t throw the baby out with the bathwater. We just put the relevant defensive measures around it. Especially in my context, that’s something where there are companies who are really concerned and so they typically have red tape. For example, financial services sector. They’re reluctant to take on open source software, but we don’t want that to be the case. The open source ecosystem is highly innovative, just look at the tools and technologies we’re talking about right now. Sometimes what can strengthen the argument is to have good security best practices around things like that.
Security in Kubernetes
Losio: I was wondering, as everyone is mentioning security, do you see security in Kubernetes something like easier, harder? I don’t expect that is out of the box, or a magic solution that Kubernetes is going to fix everything, but is doing security in Kubernetes easier?
Matyushentsev: I think Kubernetes helps you with security simply because you get a database that has information about pretty much everything, all the infrastructure that you manage. I think security teams should be happy because they can query the database and get real time information. Plus, they have a choice to inject security measures. A simple example, you can just say, no, we do not run privileged containers ever. That’s it. You improved your security, and you can do it centrally for everyone. You have a chance to do it afterwards. Once adoption happens, you can discover that maybe you missed something in the beginning and you want to tighten that security. You don’t have to chase teams, you still have a single control plane where you can put those things in place. I do feel like Kubernetes helps with security. You get a little bit increased maybe attack surface. For example, before you would naturally separate your tenants of your cloud, and everyone runs in a separate machine. In Kubernetes, most likely they’re going to be neighbors, and we’ll be running containers on the same machine. You do have options to make even that secure.
Losio: Do you agree with Alexander, or do you see differently in terms of security in Kubernetes?
Goode: I actually agree with both Alexander and Luke on this one. It’s a matter of picking the correct tool for the job. Kubernetes is not super difficult to secure. It almost comes clear back around to what we said earlier with developer training and making sure developers understand that you don’t want to use NodePorts unless you have to. You should have a single point of ingress using an ingress controller. You should do things like don’t use host paths, because they can be inherently dangerous. You need to put Gatekeeper policies in place to make sure that people are setting their users correctly. There’s a lot of best practices that are out there. Like Luke said, it’s open by default to increase adoption, and then it’s up to you to lock everything down. Learning those best practices is a really big step towards securing it.
The First Action Item on Starting the Kubernetes Journey
Losio: I attended this roundtable. I’m a developer. I’m very happy of what I learned. I want to start tomorrow, my very first step. I want something that I can do really tomorrow, a couple of hours, or whatever, how can I help my team start this journey? What should be the very first action item? Do you have any action item that I can really do immediately until I have the enthusiasm?
Wang: I think one of the things is start looking at what interests you in the Kubernetes community. There’s a lot of use cases out there. Kubernetes supports a lot of different workstreams and working groups as well. Find one that’s really interesting to you. It could be something creative. It may not be your day to day. It might be something like Cluster API. It could be something like Open Policy Agent and Gatekeeper because you want to improve your security posture. Just look at it, examine it, and find out ways that the community is innovating on something that you’re really interested in.
Mwila: Just jump right in. If you can download, whether it’s Docker Desktop, minikube, Rancher Desktop, you name it. A lot of developers are usually tinkering, and they probably have some example application, figure out how you can get that running on Kubernetes.
See more presentations with transcripts
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Baidu, the company behind the homonymous search engine, has announced its first quantum computing processor, named Qian Shi, along with an “all-platform” integration solution aimed to simplify access to quantum hardware resources via mobile, desktop, and the Cloud.
Qian Shi, which means “the origin of all things is found in the heavens” in Chinese, provides 10 high-fidelity qubits. While this might not be the most powerful quantum hardware available, Baidu says they have completed the design of a 36-qubit superconducting quantum chip with couplers.
Most interestingly, Qian Shi comes with a complete software stack, which Baidu dubs “all-platform quantum hardware-software integration solution”, that provides a set of services for private deployment, cloud services, and hardware access. This solution, called Liang Xi, aims to be compatible with heterogeneous quantum hardware, including a 10-qubit superconducting quantum device and a trapped-ion quantum device developed by the Chinese Academy of Sciences. To complete the idea of “all platform”, Baidu says Liang Xi can be used via mobile and desktop apps, as well as the Cloud.
With Qian Shi and Liang Xi, users can now create quantum algorithms and use quantum computing power without developing their quantum hardware, control systems, or programming languages.
Baidu’s quantum software stack includes Quanlse, a cloud-based platform for quantum control, Paddle Quantum, a quantum machine learning platform, Quantum Leaf, a quantum computing platform, and others.
Quanlse supports the pulse generation and scheduling of arbitrary single-qubit and two-qubit gates. It can be used for modeling real superconducting quantum chips and for simulating noisy quantum devices. It also supports error analysis to help characterize and mitigate errors.
Quantum Leaf can be used for programming, simulating, and executing quantum computers. It provides the quantum programming environment for Quantum infrastructure as a Service (QaaS).
Paddle Quantum enables bridging Quantum Leaf with machine learning and can be used for a number of popular quantum machine learning topics, including combinatorial optimization, local operations and classical communication.
With the Qian Shi and Liang Xi announcement, Baidu is entering the arena of quantum solutions that researchers and companies can use to experiment with quantum algorithms. Other players in the same arena are IBM with its IBM Quantum, Microsoft with Azure Quantum, Google with Quantum AI, D-Wave, and others.
MMS • Anthony Alford
Article originally posted on InfoQ. Visit InfoQ

Stability AI released the pre-trained model weights for Stable Diffusion, a text-to-image AI model, to the general public. Given a text prompt, Stable Diffusion can generate photorealistic 512×512 pixel images depicting the scene described in the prompt.
The public release of the model weights follows the earlier release of code and a limited release of the model weights to the research community. With the latest release, any user can download and run Stable Diffusion on consumer-level hardware. Beside text-to-image generation, the model also supports image-to-image style transfer as well as upscaling. Along with the release, Stable AI also released a beta version of an API and web UI for the model called DreamStudio. According to Stable AI:
Stable Diffusion is a text-to-image model that will empower billions of people to create stunning art within seconds. It is a breakthrough in speed and quality meaning that it can run on consumer GPUs…This will allow both researchers and…the public to run this under a range of conditions, democratizing image generation. We look forward to the open ecosystem that will emerge around this and further models to truly explore the boundaries of latent space.
Stable Diffusion is based on an image generation technique called latent diffusion models (LDMs). Unlike other popular image synthesis methods such as generative adversarial networks (GANs) and the auto-regressive technique used by DALL-E, LDMs generate images by iteratively “de-noising” data in a latent representation space, then decoding the representation into a full image. LDM was developed by the Machine Vision and Learning research group at the Ludwig Maximilian University of Munich and described in a paper presented at the recent IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR). Earlier this year, InfoQ covered Google’s Imagen model, another diffusion-based image generation AI.
The Stable Diffusion model can support several operations. Like DALL-E, it can be given a text description of a desired image and generate a high-quality that matches that description. It can also generate a realistic-looking image from a simple sketch plus a textual description of the desired image. Meta AI recently released a model called Make-A-Scene that has similar image-to-image capabilities.
Many users of Stable Diffusion have publicly posted examples of generated images; Katherine Crowson, lead developer at Stability AI, has shared many images on Twitter. Some commenters are troubled by the impact that AI-based image synthesis will have on artists and the art world. The same week that Stable Diffusion was released, an AI-generated artwork won first prize in an art competition at the Colorado State Fair. Simon Williamson, a co-creator of the Django framework, noted that
I’ve seen an argument that AI art is ineligible for copyright protection since “it must owe its origin to a human being” – if prompt design wasn’t already enough to count, [image-to-image] presumably shifts that balance even more.
Stable AI founder Emad Mostaque answered several questions about the model on Twitter. Replying to one user who tried to estimate the compute resources and cost needed to train the model, Mostaque said:
We actually used 256 A100s for this per the model card, 150k hours in total so at market price $600k
Mostaque also linked to a Reddit post giving tips on how best to use the model to generate images.
The code for Stable Diffusion is available on GitHub. The model weights as well as a Colab notebook and a demo web UI are available on HuggingFace.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Recently Google introduced a pay-as-you-go pricing model for Apigee’s API management to provide customers with more flexibility in using the service and control costs.
With the new pay-as-you-go model, the company is providing customers with an additional pricing plan for the service, allowing them to only pay for what they use. Customers will only be charged based on the consumption of Apigee gateway nodes (API traffic based on the number of Apigee gateway nodes), API Analytics (total number of API requests analyzed per month), and networking usage (such as IP address, network egress, forwarding rules, etc.). Note that there is no startup cost, and customers can get started with Apigee through the console and choose the plan accordingly.
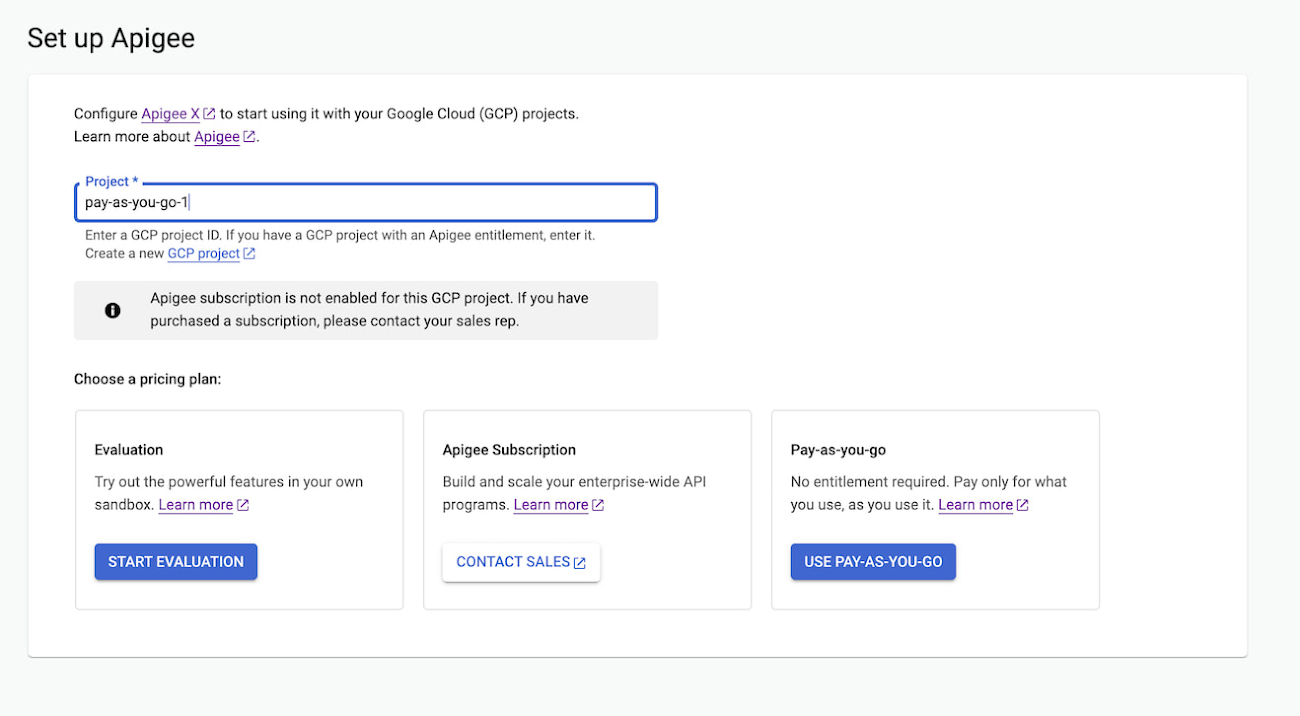
Apigee now offers three pricing models, including the pay-as-you-go. The other two are the evaluation plan, which allows customers to access Apigee’s capabilities at no cost for 60 days, and subscription plans (Standard, Enterprise, or Enterprise Plus) based on customer API needs. The pay-as-you-go is offered as a complement to the existing Subscription plans (or) the ability to evaluate it for free.
Vikas Anand, a director of product, Google Cloud, explains in a Google Cloud blog post the distinction between the paid subscription plans and pay-as-you-go:
Subscription plans are ideal for use cases with predictable workloads for a given time period, whereas Pay-as-you-go pricing is ideal if you are starting small with a high-value workload.
Google acquired Apigee in 2016, integrating the startup’s cloud-based API creation and management platform into a service available for Google Cloud Platform customers. This service has evolved to become a dominant leader in the Magic Quadrant for Full Life Cycle API Management since 2018 and still is next to MuleSoft, IBM, Axway, Kong (open source), and Microsoft.
For instance, competitive offerings like Microsoft Azure API Management also include a pay-as-you-go pricing model that is offered as a consumption tier – a lightweight and serverless version of API Management service, billed per execution.
In response to the Pay-as-you-go pricing model, Gustavo Fuchs, regional director, solutions and technology, APAC at Google, tweeted:
APIs are the key way to monetize additional business opportunities across boundaries. Apigee is a leader in this segment, and great to see we can now serve more organizations as they start their journey on API Economy!
Lastly, more details on Google Apigee API pricing models are available on the pricing page. Furthermore, customers can also use the available pricing calculator.
MMS • Ratnesh Singh Parihar
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- When selecting a cloud option, it’s important to understand that the level of abstraction that each one provides has a direct impact on the administration cost.
- Consider the company’s ability to manage the infrastructure, including day-to-day management, and how resilient the product is to future changes. Continuous customization may require deploying the product multiple times.
- Decide how much control you want over the infrastructure. High-end dedicated instances will provide maximum control versus Serverless, low-code, and no-code platforms, which offer the least amount of control.
- Determine the amount of customization, major changes, vertical shift, horizontal shift, and new business needs that may arise then select data and application services accordingly.
- Avoid any fixed cost as long as possible. Pick the cheapest and pay-as-you-go subscription and move to better possibilities later.
Gartner’s prediction of cloud adoption investment reaching $482B in 2022 is a weighty indicator of how the cloud is penetrating diverse sectors. But what is alarming is the cloud migration failure rate. At present, it is hovering in between 44% to 57% for businesses across strata, which puts start-ups, with obvious budget constraints, under a lot of pressure.
Software as a Service (SaaS) start-ups are no exception. As a solution architect, I have been designing SaaS applications for years and I have seen start-ups struggle to find the right cloud infrastructure and improve their product offering.
These experiences prompted me to write this article as a tool to help companies make a pragmatic fact and data-driven decision.
Before we jump into the cloud options, it is important to understand the level of abstraction that each one provides as it directly impacts the administration cost. A higher level of abstraction provides less control, lower performance output, and increases cost, but also involves less effort and more utilization.
If you are building a SaaS product, then you will need to purchase and procure the hardware first. Then, install the operating system on top of it, followed by the installation of runtimes like JVM, v8 and Python. After that, you will install all dependencies and finally, deploy your code.
Cloud Infrastructure Options
Every infrastructure option available today abstracts one or two of the following:
Cloud Virtual Machines (IaaS): They primarily abstract the hardware layer, you don’t need to provision anything physical but still have to build other layers. This will give you maximum control but it will take time to set-up Examples are EC2, Azure VMs, Google Cloud Platform (GCP).
Platform as a Service (PaaS): It provides another layer of abstraction over hardware and you don’t need to worry about OS/containers, upgradation, security, etc. Examples are Azure PaaS, AWS Elastic Beanstalk, and GCP PaaS.
Serverless (Function as a Service) (FaaS): This is PaaS with the abstraction of run time. You don’t need to worry about runtime in this one. Major examples are AWS Lamda, Azure Function, and Google Cloud Functions.
Low Code: Along with hardware, OS, and runtime, you also get an abstraction of dependencies management. For example, Parse. You need to put serious thought into best practices.
Kubernetes (K8)(Container Orchestration): If you invest initially in Kubernetes or use any Kubernetes as a service (EKS) when it is production-ready, you will ship your code as pods. From an abstraction perspective, it is similar to Serverless but still provides more control.
Zero Code: There are platforms and services which allow you to create applications without writing any code. However, it doesn’t mean you don’t need developers. It will deliver a fast prototype, MVPs, and initial bootstrap code. For example, Zoho or Quick Base. We are not going to cover zero code platforms.
Now let’s drill down to discuss key factors that can impact the outcome.
7 Factors Impacting the Infrastructure of a SaaS Application
Factor 1: Administration Overhead
The first consideration is the company’s ability to manage the infrastructure, including the time required, whether humans are needed for the day-to-day management, and how resilient the product is to future changes.
If the product is used primarily by enterprises and demands customization, then you may need to deploy the product multiple times, which could mean more effort and time from the infra admins. The deployment can be automated, but the automation process requires the product to be stable. ROI might not be good for an early-stage product. My recommendation in such cases would be to use managed services such as PaaS for infrastructure, managed services for the database/persistent, and FaaS—Serverless architecture for compute.
Factor 2: Time to Market (TTM)
The keys to quick TTM are fast development, testing, and release. And the key to fast development to release is to spend more time in coding and testing than in provisioning and deployments. Low-code and no-code platforms are good to start with. Serverless and FaaS are designed to solve these problems. If your system involves many components, building your own boxes will consume too much time and effort. Similarly, setting up Kubernetes will not make it faster.
PaaS still provides better options than cloud virtual machines, but you may need to build deployment pipelines(CI/CD) to speed up TTM. CI/CD pipelines are available implicitly in low code platforms. You may also want to pick tools that are cloud agnostic and allow you to migrate to other platforms later. There is significant risk with zero and low-code platforms in this regard.
Factor 3: Agility
Product agility is a key factor. You need to consider the amount of customization, major changes, vertical shift, horizontal shift, and new business needs that may arise. Imagine that you are building a multi-tenant system and there are different customization requirements for different tenants. These changes/requests will keep on coming to you. From an infrastructure perspective, you need a system where you don’t have to change them for each request/change. Being cloud agnostic is irrelevant here.
For data, Serverless data services like AWS Aurora or Azure’s Cosmos DB are great choices. If you are building a workflow or data processing, then online services like step functions are the way to go. For applications, Serverless or FaaS is a great choice. You can also build the multitenant system with Kubernetes but it is not a good starting point as you may need to maintain many versions of the application, data, and function. Serverless architecture might be the right starting option.
Factor 4: Control
It’s important to think about how much control you will get over the infrastructure. You would want more control if:
- a) There will be lots of apps, lots of databases, and lots of services.
- b) It is a system where you have to provision hardware for your customer (MongoDB Atlas).
- c) You need to isolate data or runtime or both for your tenants.
- d) It is an online service or API and your USP is to save license, hardware, and administrative cost for your customers.
You would get maximum control with a physical machine or your own rack, but these aren’t used anymore—so the next best thing to maintain a high level of control is high-end dedicated instances. Serverless, low-code, and no-code platforms offer the least amount of control.
Kubernetes will consume lots of time and effort, but from a long-term control perspective, it is a good deal and you have to be 100% cloud agnostic here. Avoid online services as much as possible and remember you are building one.
Factor 5: Cost
Cost is one of the most important factors. Early cost estimates are always difficult, but let’s start with an example:
For 10K requests per hour per day, a Serverless infrastructure will cost you much more than cloud virtual machines. But if the load is heterogeneous and for some random hours it’s 10K and for others it’s 1K, then setting up cloud virtual-machine instances might be costly since they will be underutilized for most of the time and will be of no value during their idle time.
To start with, you will try to avoid any fixed costs as long as possible. But for better utilization, you need to figure out break-even points and switch back to a lower level (low-code to Serverless or Serverless to containerized app). Avoid premature optimization and in the beginning, don’t pursue optimization or balance at all. Pick the cheapest and pay-as-you-go subscription and move to better possibilities later.
Factor 6: Migration
Migration is directly related to cloud agnostic. There are always newer, cheaper, and better cloud offerings that keep coming, so you need to migrate. Sometimes migration depends on which cloud providers your customers want to work with. Just using virtual machines doesn’t make your system cloud agnostic.
For example, if you have different components to access other components and your DevOps team has designed this access management entirely on the IAM role, then migrating from AWS to GCP could be a tough nut to crack. Similarly, if you have to build an entire computation layer on Serverless, then migrating to a virtual machine might not be straightforward.
Factor 7: Integration
If you are building an aggregator platform, then you might be collecting data from third-party APIs scrappers or doing transactions with other APIs for your customers. This is an integration space and as a startup, your primary concern is how fast, reliable, and consistent is your infra.
With integration, you might be spawning multiple spot instances or multiple Serverless instances in a short time to collect/submit data from other APIs to overcome throttling and API rate limits. Serverless is a great help here. Auto-scaled Kubernetes nodes are also good. If you are choosing a cloud virtual-machine instance, then you must spend some time and effort in automating provisioning.
With the infrastructure options available and the factors defined above, I am proposing a Decision matrix that can help you make decisions for your infrastructure.
Decision Framework
I’ve created a framework with the options, factors, and level of difficulty. The ratings that I have used here are purely subjective as it is based on my experience of working with different infrastructures for over a decade and not on benchmarks.
The table that I have created will allow you to understand how difficult it is to achieve (build and set up) a factor using a particular type of infra choice.
- Easy: You can do a simple configuration and you are done. With less effort and time, you can achieve the required factor.
- Medium: You might need to do more configuration/tuning in order to achieve a particular factor, which might not be a straightforward way.
- Hard: To achieve the factor, you may need to invest time and effort using an explicit strategy. You may require certain expertise as well.
| Factor | Cloud Virtual Machines | PaaS (GCP, Azure) | Serverless (FaaS) | Kubernetes | Low code |
| Administration | Hard | Easy | Easy | Medium | Easy |
| Fast Time to Market | Hard | Medium | Easy | Medium | Easy |
| Agility | Hard | Hard | Easy | Easy | Easy |
| Control | Easy | Hard | Hard | Easy | Hard |
| Cost | Easy | Medium | Hard | Easy | Hard |
| Migration | Easy | Hard | Hard | Medium | Hard |
| Integration | Hard | Hard | Easy | Easy | Easy |
| Utilization | Hard | Hard | Easy | Easy | Easy |
The Verdict
For SaaS start-ups, I have realized that it is better to start with Kubernetes (container orchestration) and if Kubernetes is not an option, then Cloud virtual machines should be the next infrastructural option. Kubernetes provides maximum control with minimum effort and ensures cost optimization along with future migration and integration.
You need to keep yourself away from low-code/no-code platforms, they might seem easy to start with but they are minefields for the future, they will not help you with three crucial factors: infrastructure cost, IT administration cost, and licensing cost. PaaS is somewhat acceptable, but it will also provide some blockers if it comes to operating system level upgradation.