Month: September 2022
Amazon Announces the Improvement of ML Models to Better Identify Sensitive Data on Amazon Macie

MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ
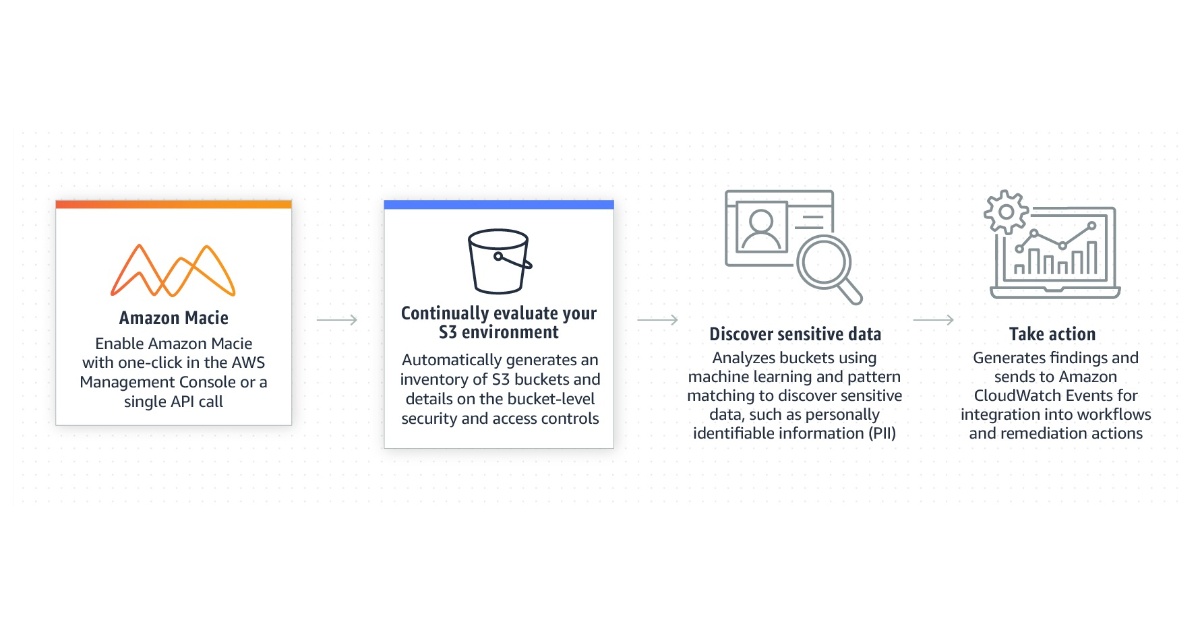
Amazon is announcing a new capability to create allow lists in Amazon Macie. Now text or text patterns not desire for Macie to report as sensitive data can be specified in allow lists. Amazon Macie is a fully managed data security and data privacy service that uses machine learning and pattern matching to discover and protect sensitive data in AWS.
According to Amazon, when evaluating JSON data in Amazon S3 buckets, Macie has improved the machine learning models used by managed data identifiers to produce more precise and useful results. Extraction of additional information from surrounding fields in JSON data and JSON Lines files improves the machine learning models’ accuracy even further. This enhancement also speeds up the processing of certain kinds of files, which will accelerate the completion of sensitive data finding tasks.
Macie applies machine learning and pattern matching techniques to selected buckets to identify and alert about sensitive data, such as names, addresses, credit card numbers, or credential materials. Identifying sensitive data in S3 can help in compliance with regulations, such as the Health Insurance Portability and Accountability Act (HIPAA) and General Data Privacy Regulation (GDPR).
Once activated, Macie automatically compiles a complete S3 inventory at the bucket level and examines each bucket to detect public access, lack of encryption, sharing, or replication with AWS accounts outside of a customer’s business. If Macie detects sensitive data or potential issues with the security or privacy, it creates detailed findings to review and remediate as necessary.
Analysis of data promises to provide enormous insights for data scientists, business managers, and artificial intelligence algorithms. Governance and security must also ensure that the data conforms to the same data protection and monitoring requirements as any other part of the enterprise.
Tools for identifying such information are useful in the event of a ransomware attack to quickly identify what information could have been compromised and help understand the scope of potential security concerns and fallout. Following security recommendations, to further secure data, workloads, and applications it’s also recommended to combine AWS Security Hub and Amazon GuardDuty with Amazon Macie. Other security tools to consider are OpenSSL, Let’s Encrypt, and Ensighten.
MMS • Edin Kapic
Article originally posted on InfoQ. Visit InfoQ
Microsoft announced the first .NET-compatible version of SynapseML, a new machine learning (ML) library for Apache Spark distributed processing platform. Version 0.1.0 of the SynapseML library adds support for .NET bindings, allowing .NET developers to write ML pipelines in their preferred language.
SynapseML, formerly known as MMLSpark (Microsoft Machine Learning for Apache Spark), is a library that integrates several ML algorithms into a coherent API for building heterogeneous machine learning solutions that will be running on top of the Apache Spark platform. For example, it allows developers to leverage other powerful libraries such as OpenCV (for computer vision), VowpalWabbit (fast reinforcement learning algorithm), or LightGBM (for decision-tree learning models). It is an ongoing initiative for Microsoft, outlined by a paper published in 2019 by Mark Hamilton, one of Microsoft’s engineers behind the SynapseML project.
SynapseML runs on Apache Spark and requires Java installation, as Spark uses the JVM to run Scala. However, it has bindings for other languages such as Python or R. The current 0.10.0 version adds bindings for .NET languages.
.NET support for SynapseML runs on top of .NET for Apache Spark library. It is contained in a set of SynapseML NuGet packages. The packages haven’t been published to the main NuGet feed, and their source has to be added manually. Once installed, SynapseML API is then available to be called from .NET applications.
The following code fragment illustrates how SynapseML API can be called from a C# application.
// Create LightGBMClassifier
var lightGBMClassifier = new LightGBMClassifier()
.SetFeaturesCol("features")
.SetRawPredictionCol("rawPrediction")
.SetObjective("binary")
.SetNumLeaves(30)
.SetNumIterations(200)
.SetLabelCol("label")
.SetLeafPredictionCol("leafPrediction")
.SetFeaturesShapCol("featuresShap");
// Fit the model
var lightGBMClassificationModel = lightGBMClassifier.Fit(trainDf);
// Apply transformation and displayresults
lightGBMClassificationModel.Transform(testDf).Show(50);
SynapseML allows developers to call other services in their pipeline. The library has support for Microsoft’s own Cognitive Services, a set of general-purpose AI services powered by models trained by Microsoft. In addition, the current release of SynapseML permits developers to leverage pre-trained OpenAI models in their solutions, such as GPT-3 for natural language understanding and generation and Codex for code generation. The use of OpenAI models currently requires access to Azure OpenAI Service.
Finally, the current version adds support for MLflow, a platform to manage the ML lifecycle. Developers can use it to load and save models and to log messages during the execution of the models.
It is conspicuous that Microsoft has renamed the SynapseML library to match the name of their existing Azure Synapse Analytics, which according to the product description is “a unified experience to ingest, explore, prepare, transform, manage, and serve data for immediate BI and machine learning needs.”
SynapseML joins the community of .NET machine-learning libraries:
- ML.NET is a .NET library for running single-machine workloads using .NET languages.
- Microsoft Cognitive Toolkit (CNTK) is a Microsoft ML library that stopped being actively developed last month. It also has a .NET API.
- Accord.NET is an ML library for .NET geared towards vision and audio processing.
- Other popular general ML libraries have .NET versions:
In the .NET community, there is confusion among developers about how all these libraries compare against each other or whether they replace one another. SynapseML project members appear to actively answer those questions on Reddit.
Extended VMware and Microsoft Collaboration with Major Updates to the Azure VMware Solution
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ

During the recent VMware Explore 2022, VMware announced it would strengthen its collaboration with Microsoft regarding the Azure VMware Solution. In addition, the solution received several new updates, including extended availability.
The intensified collaboration means customers can now purchase Azure VMware Solution as part of VMware Cloud Universal, a flexible purchasing and consumption program for executing multi-cloud and digital transformation strategies.
Furthermore, Microsoft announced several significant updates to the Azure VMWare solution. It now offers, including extended availability:
- Expansion to 24 regions Azure regions.
- Public preview of Azure NetApp Files datastores for storage-intensive workloads running on Azure VMware Solution.
- Generally availability of public IP to NSX Edge capability in 17 Azure regions. There are now three primary patterns for creating inbound and outbound internet access to resources on Azure VMware Solution private cloud.
- Public preview of Enterprise VMware Cloud Director Services, allowing customers with Azure VMware Solution deployed under their Microsoft Enterprise agreement to purchase the VMware Cloud Director Service from VMware.
- General availability of Jetstream DR, providing customers with disaster recovery protection needed for business and mission-critical applications while leveraging cost-effective cloud storage such as Azure Blob Storage.
- General availability of VMware vRealize Log Insight Cloud, a service that provides centralized log management, deep operational visibility, intelligent analytics, and improved troubleshooting and security.
- Global availability of VMware vSphere 7.0 for all cloud deployments in Azure VMware Solution.
Jeff Woolsey, a principal program manager of Azure Stack at Microsoft, tweeted:
This solution is so powerful. You can deploy VMware VMs in Azure & on-premises & use the vSphere tools you know. You can deploy Azure Arc to your virtualized servers to provide consistent governance, security & lifecycle management. Arc even extends multi-cloud to AWS, Google, etc.
Regarding the availability of Azure VM Solution as part of VMware Cloud Universal, Zia Yusuf, senior vice president, strategic ecosystem and industry solutions, VMware, said in a press release:
The availability of Azure VMware Solution through VMware Cloud Universal makes it easier for customers to adopt Azure VMware Solution as part of a multi-cloud strategy. VMware Cloud Universal customers will gain greater flexibility to adopt Azure VMware Solution at their own pace to speed cloud migration, simplify ongoing operations, modernize applications faster and achieve better economics while benefitting from a single operating model across clouds.
Lastly, more details of the Azure VMware solution are available on the documentation landing page, and the pricing details of the solution are available on the pricing page.
MMS • Karsten Silz
Article originally posted on InfoQ. Visit InfoQ

With Google’s UI framework Flutter, users can build natively-compiled applications for mobile, web, and desktop from one codebase. Google just announced the third Flutter release of 2022, version 3.3, and version 2.18 of Flutter’s language Dart. Both releases are refinements without significant new features. A new rendering engine called Impeller is available, but only in preview and only for iOS. Google also launched a new showcase app, Wonderous, built with Flutter 3.3 and using Impeller on iOS.
What’s New In Flutter 3.3
Flutter apps do not use UI elements of the underlying platform but emulate them. Flutter ships with Material UI, which works on all platforms, and an iOS UI element set. Open-source libraries offer Windows, macOS, and Linux UI element sets.
Text selection in Flutter web apps now works as expected – users can select multiple rows of text at once. Trackpad gestures work better in desktop applications. Windows apps now get their version number from the pubspec.yaml build file. And iPad apps can use Scribble with Apple Pencil for handwriting input.
Some Material 3 components improved in this release: IconButton, Chips, and AppBar. Loading images that are included in the app is faster and uses less memory with the new ui.ImmutableBuffer.fromAsset() method. And pointer compression is now disabled on iOS to make more memory available to non-Dart parts of a Flutter app (such as libraries).
The Flutter team’s go_router package simplifies routing within an app with URL-based declarations. Version 4.3 supports asynchronous code. The Flutter Visual Studio Code extension and the Flutter DevTools have also improved.
Flutter 3.3 doesn’t run on 32-bit iOS devices anymore. That excludes iPhone models 5C (from 2014) and earlier and the 2nd through 4th generation iPad (the latter launched in 2012). The upcoming Q4/2022 Flutter release won’t work on macOS 10.11 (from 2015) and 10.12 (from 2016), either.
Apple dropped Bitcode from its upcoming fall iOS and iPadOS versions. That’s why Flutter will also remove Bitcode support in a future release.
Flutter has used Skia as its graphic engine since the very beginning. Skia powers Chrome, Firefox, Android, ChromeOS, and more. In contrast, Impeller is custom-built for Flutter and “takes full advantage of modern hardware-accelerated graphics APIs such as Metal on iOS and Vulkan on Android.” That enables better animations and removes a common source of “yank” – stuttering animations and transitions.
When announcing the previous release, the Flutter team cited the existence of 500,000 Flutter apps as a success indicator. This time the Flutter team said that “every day, more than 1,000 new mobile apps using Flutter are published to the Apple and Google Play stores”. Unfortunately, both numbers lack context, such as how competing platforms perform.
What’s New In Dart 2.18
Dart is strongly typed and optimized for UI development. Starting as a “mixture of JavaScript and Java”, it now has features neither of these two languages do (such as sound null safety).
Dart introduced sound null safety in March 2021, covering both applications and libraries. That’s the same as Swift, but unlike Kotlin, which can’t guarantee null safety for libraries. All the top 250 Flutter and Dart libraries migrated to null safety, and only 2% of the top 1,000 libraries have not. More than 80% of all Flutter applications run in July 2022 used sound null safety. That’s why Dart plans to stop supporting Dart versions without null safety by mid-2023.
Dart includes a multi-platform HTTP library. It offers experimental support for two platform-specific libraries. The first one is cupertino_http for iOS and macOS. It uses Apple’s NSURLSession for features such as WiFi-only networking or VPN access. The second library is cronet_http for Android, building upon the popular Cronet library.
The Dart Foreign Function Interface (FFI) for calling native C APIs can now interact with Objective-C and Swift code on iOS and macOS. Improved type inference detects some cases of non-nullable parameters better. And asynchronous code is a little smaller and runs a little faster.
Java News Roundup: Eclipse GlassFish, Open Liberty, MicroStream, JHipster, WildFly, EclipseLink
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for August 29th, 2022, features news from OpenJDK, JDK 20, Eclipse GlassFish 7.0.0-M8, Quarkus 2.12.0, Open Liberty 22.0.0.9 and 22.0.0.10-beta, MicroStream 07.01.00-beta2, WildFly 26.1.2, JHipster 7.9.3, EclipseLink 4.0.0-RC1, Hibernate 5.6.11, JDKMon 17.0.35 and Apache Camel Quarkus 2.12.0.
OpenJDK
Joe Darcy, member of the technical staff at Oracle, Java Platform Group, has proposed to drop support for -source/-target/--release 7 command-line options from javac with the release of JDK 20. Darcy refers to JEP 182, Policy for Retiring javac -source and -target Options, that discusses the appropriate time frame to support older versions of the JDK. Feedback, so far, has been a concern for the Maven compiler plugin that still uses version 1.7 as default.
Magnus Ihse Bursie, principal member of technical staff at Oracle, has proposed to drop support for Visual Studio 2017 (VS2017) for the following reasons:
- VS2017 was moved to “Mainstream End Date” by Microsoft in April, 2022
- VS2017 does not support C11 properly, which makes the fix for JDK-8292008 non-ideal
- VS2017 does not support the new conformant preprocessor, which will likewise make JDK-8247283 only half-fixed
- VS2017 required ugly workarounds like, JDK-8286459, which should likely be reverted once support has been dropped
Feedback, so far, has been a concern for development teams that still use VS2017.
JDK 19
JDK 19 remains in its release candidate phase with the anticipated GA release on September 20, 2022. The release notes include links to documents such as the complete API specification and an annotated API specification comparing the differences between JDK 18 (Build 36) and JDK 19 (Build 36). InfoQ will follow-up with a more detailed news story.
JDK 20
Build 13 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 12 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 19 and JDK 20, developers are encouraged to report bugs via the Java Bug Database.
Eclipse GlassFish
On the road to GlassFish 7.0.0, the eighth milestone release was made available by the Eclipse Foundation to deliver integrations of: Eclipse Exousia 2.1.0 (a compatible implementation of Jakarta Authorization); Eclipse Krazo 3.0 (a compatible implementation of Jakarta MVC); Eclipse Expressly 5.0.0 (a compatible implementation of Jakarta Expression Language); Hibernate Validator 8.0.0.CR3 (a compatible implementation of Jakarta Bean Validation); and a re-integration of Jakarta MVC 2.1.
GlassFish 7.0.0-M8 compiles and runs on JDK 11 to JDK 19, contains the final Jakarta EE 10 APIs, and fully passes the Jakarta EE 10 Full TCK and the Jakarta EE 10 Web Profile TCK.
Quarkus
Red Hat has released Quarkus 2.12.0 featuring: upgrades to Kotlin 1.7, Microsoft SQL Server 11.2.0.jre11 and version 22.2 of GraalVM and Mandrel, a downstream distribution of GraalVM Community Edition; and support for SmallRye Config SecretKeys. More details on this release may be found in the release notes.
Open Liberty
IBM has promoted Open Liberty 22.0.0.9 from its beta release to deliver Password Utilities 1.1 that eliminates undesired behavior of forcefully federating stand-alone user registries via a default initialization of the Federated User Registry or Jakarta Connectors.
Open Liberty 22.0.0.10-beta has also been released featuring: support for JDK 19; a preview of MicroProfile Telemetry, a new specification to be included in MicroProfile 6.0; the ability to programmatically choose an alternative implementation of Jakarta XML Binding 4.0; and the ability to expose SPI interfaces of the Basic Extensions using Liberty Libraries (BELL) 1.0 and inject properties into those BELL services.
MicroStream
On the road to MicroStream 07.01.00, the second beta release has been made available to provide: improved CDI integration that clearly indicates what objects have changed, i.e., objects marked as dirty, and synchronously stores those changes; improved integration with Spring Boot that adds interceptor logic to store marked objects at end of a method; storing a reference to a marked implementation of the Lazy interface; and enabling the MicroStream cache.
WildFly
Red Hat has released WildFly 26.1.2.Final featuring component upgrades such as: WildFly Core 18.1.2.Final; Netty 4.1.79; Apache MyFaces 2.3.10 and 3.0.2; Hibernate ORM 5.3.28.Final; RESTEasy 4.7.7.Final; and Jackson Core and Databind 2.12.7.
According to the WildFly Release Plans for 2022, there will no longer be support for JDK 8, Jakarta EE 8 and MicroProfile 4.1 with the release of WildFly 27. Jakarta EE 10 and JDK 11 will be defined as minimal versions. More details on this release may be found in the list of issues.
JHipster
JHipster 7.9.3 has been released featuring; an dependency upgrade to Spring Boot 2.7.3; the ability for the JHipster Domain Language (JDL) to search with no value; support for Keycloak 19.0.1; and fixed issues with Microsoft SQL Server and the generate-blueprint workflow.
EclipseLink
The first release candidate of EclipseLink 4.0.0, one of the compatible implementations of the Jakarta Persistence 3.1 specification, has been made available to the Java community. Among the many changes: an improved query parameter binding; a memory leak fix in the clone() method defined in the BatchFetchPolicy class; updates to the Jakarta Persistence test framework; dependency upgrades to PostgreSQL 42.4.1 and MongoDB; and a fix for the query exception in the CriteriaBuilder interface. More details on this release may be found in the release notes.
Hibernate
Hibernate ORM 5.6.11.Final has been released featuring fixes for: an issue that caused severe performance drops in large projects; and an exception when trying to select the ID of an association annotated with the @NotFound annotation.
JDKMon
Version 17.0.35 of JDKMon, a tool that monitors and updates installed JDKs, has been made available to the Java community this past week. Created by Gerrit Grunwald, principal engineer at Azul, this new version ships with: an updated CVE scanner; a fix for the detection of Zulu Prime; and a new property to display unknown builds of OpenJDK.
Apache Camel
Maintaining alignment with Quarkus, Camel Quarkus 2.12.0, containing Camel 3.18.1 and Quarkus 2.12.0.Final, features the long-awaited and highly-requested CXF SOAP extension that is now available for both JVM and native modes. More details on this release may be found in the list of issues.
MMS • Chris Seaton
Article originally posted on InfoQ. Visit InfoQ

Transcript
Seaton: I’m Chris Seaton. I’m a senior staff engineer at Shopify, which is a Canadian e-commerce company. I work on optimizing the Ruby programming language. I do that by working on a Ruby implementation on top of Java and the JVM and Graal called TruffleRuby, which is why I’m here today. I’m the founder of TruffleRuby. I write about compilers and optimizations and data structures. I maintain the rubybib.org, which is a list of academic writing on Ruby. In this talk, when I talk about compilers, I mean the just-in-time or JIT compiler, that’s the compiler that runs as your program is running. I don’t mean javac in this context. I spend a lot of time trying to understand what the Java compiler is doing with my code, and how I can change my code to get the result I want out of the compiler. I also spend a lot of time trying to teach other people to do this.
Tools for Understanding the Compiler
There’s a few tools for understanding the compiler. You can look at the assembly code that’s produced by the compiler. You can use a tool like JITWatch to look at the logs that the compiler produces as it produces the code. The ultimate option is to reach into the compiler and actually look at the data structures it uses to understand, optimize, transform, and compile your code. All these options are quite complicated and they aren’t very accessible. I’m experimenting with some new ways to understand what the compiler is doing, including by trying to give you back pseudo Java code from the compiler after it’s finished running, or part of the way through its running. The idea is that anyone who can understand Java, which should be most Java programmers, can look at what the compiler is doing in terms of Java code, which they already understand.
At Shopify, I maintain a tool called Seafoam, to help us look at these data structures, and to do this decompilation from optimized Java back to pseudo Java. It works within the context specifically of Graal, so if you’re not a Graal user already, it may not be immediately applicable to you, but maybe it’s another good reason to experiment with adopting Graal. Using it, we can gain a bit more of an understanding of what the JIT compiler really does. I’m always amazed that people argue online about what the JIT compiler does do or doesn’t do for some given code. Let’s simply dive in and check.
What the Just-In-Time (JIT) Compiler Does
Most of the time, your Java program will start as source code in Java files on disk. You’d normally run those through the Java compiler, so javac, to produce bytecode, which is a machine readable representation of your program. Not everyone’s aware that there’s a second compiler, the just-in-time compiler. This takes your bytecode while the program is running, and convert it to machine code which can run natively on your processor. There’s also another compiler you can use, an ahead-of-time compiler that produces the same machine code, but instead of you keeping it in memory, like the JIT does, it can write it out to a file on disk, or an executable file, or a library, or something like that. That’s a bit more popular these days due to native-image, which is part of the GraalVM. It’s been an option for a long time, but it’s getting more popularity these days.
In this talk, the compiler we’re interested in, and the configuration we’re interested in is using the JIT compiler to compile bytecode to machine code at runtime. Some of the ideas apply the same for the AOT as well, but we’ll just keep it simple for this talk. We had a little arrow there for the JIT, but really, the JIT is a big thing. It’s a very important thing for the performance of your Java application, getting the performance out of your application you’d like. It does a lot of things. One of the problems with it is, it’s a bit of a black box. If you’re not sure why it’s giving you the machine code it is, why it’s optimizing in the way it is, what it’s going to do with a given program. It’s quite hard to figure it out, because it’s definitely seen as a monolith. It’s quite hard to see inside. Really, there’s lots of things going on there, there’s multiple processes. It parses the bytecode, so it re-parses it like it parsed your Java source code originally. It produces machine code. In the middle, it uses a data structure called a graph, which is what this talk is about. It’s about looking inside the JIT compiler at that data structure.
Why Would We Want To Do This?
Why would we want to do this? Just for interest for one thing, it’s interesting to see how these programs work, especially if you spend a lot of time using the Java JIT. It’d be interesting to see how it’s running and why, just for interest. You may want to understand what the JIT is doing for your program, actually, for your work. You may want to understand what it’s doing with it. You may want to figure out why it isn’t optimizing as you were expecting. If you’re trying to get a particular performance out of your program, you may want to understand why the JIT compiler is doing what it is in order to get the best out of it. Or perhaps you’re working on a language that runs on top of the JVM. For example, I work on TruffleRuby, which is a Ruby implementation, but it runs on the JVM, which is why I’m speaking in a JVM track at a conference. Or if you’re working on the Java compiler yourself, obviously, that’s a bit more niche. There are people doing that. What we can use it for is we can use it to resolve online discussions where people are guessing what the JVM and the JIT does, and we can find out for real by actually looking inside and asking the JIT what it does. Nobody is advocating that this should really be a normal part of your daily work to analyze what the Java JIT is doing as part of your workflow. Nobody is suggesting that. It can be useful sometimes.
The GraalVM Context
This talk is all in the context of the GraalVM. The GraalVM is an implementation of the JVM, plus a lot more. It runs Java. It also runs other languages, such as JavaScript, such as Python, such as Ruby, such as R, such as Wasm, and some more. It also gives you some new ways to run Java code, such as the native-image tool I mentioned earlier, which allows you to compile your Java code to machine code ahead of time. This is available from graalvm.org. If you’re not using GraalVM, then a lot of this won’t be applicable, I’m afraid. Maybe it’s another good reason to go and look at GraalVM if you haven’t done it already.
Assembly Output
Understanding what the JIT compiler does. We said that the output of the JIT compiler was machine code, so the simplest thing we can do is look at the machine code. A human readable version of machine code is called assembly code. If you use these two options, so if we unlock the DiagnosticVMOptions, and if we print assembly, then it will print out the assembly for us every time it runs the JIT. This option depends on a library called hsdis, that isn’t included with the JVM. It can be a little bit annoying to build, which is an unfortunate thing. You can’t just use these flags out of the box, unfortunately, and get actual assembling. That’s what it would look like. It gives you some comments which help you orientate yourself, but it’s pretty hard to understand what’s been done to optimize here. It’s definitely hard to understand why. This is the most basic of tools.
A better tool is something like Chris Newland’s JITWatch. If you are not for DiagnosticVMOptions, again, you can TraceClassLoading, you can LogCompilation, and the JIT will write out a log of what it’s done, and to some extent, why it’s done it. Then you can use JITWatch to open this log. It’s a graphical program, where it can run headless. It will do something to explain what’s going on. For example, in this view, it’s showing us the source code, the corresponding bytecode, and the assembly. If we zoom in, you’re still getting the same assembly output here, but now you can get a bit more information about which machine instructions correspond back to which bytecode in which line in the program. This is a better option. I’m not going to talk more about JITWatch here, it’s got loads of really useful tools. I will consider using JITWatch most of the time.
Problems with Assembly and JIT Logs
What’s the problems with assembly and these JIT logs, though? You’re only seeing the input and the output, still, not really the bit in the middle. JITWatch will show you the bytecode. Some people think it is a bit in the middle, but really, it’s the input to the JIT compiler, and then it shows you the output as well, the assembly code. You’re trying to understand what was done and why by looking at the lowest level representation. When you look at assembly, most information is gone, so it’s not useful to answer some detailed questions. Assembly code is very verbose as well, so it’s hard to work with.
Graphs
We said in the middle of the JIT compiler is this data structure, and this is a compiler graph. That’s graph as in nodes and edges, not graph as in a chart or something like that. It’s this data structure we’re going to look at. We’re actually going to reach inside the JIT, and we’re going to look at this data structure in order to understand what the compiler is doing and why.
How to Get Compiler Graphs
How can we get the compiler to give us its internal data structure? Graal’s got a simple option, so graal.Dump equals colon 1. Colon 1 is a notation you can use to specify what things you want. It’s got some complexity but colon 1 gives you what you probably want for most stuff. Here’s an interesting thing. Why is this a D system property? That’s because Graal is more or less just another Java library, so you can communicate to it using system properties like you would any other Java library or application. This then prints out the graphs when the compiler runs.
What to Do With Graphs
What can we do with these graphs? Like JITWatch, there’s a tool called the Ideal Graph Visualizer, usually shortened to IGV. This lets you load up the graphs into a viewer and analyze them. This is a tool from Oracle. It’s part of the GraalVM project. It’s being maintained by them at the moment. We can zoom in on the graph. I’ll explain what this graph means when I start to talk about the tool I’m specifically using. This is what Ideal Graph Visualizer will show you. At Shopify where I work, we use a tool which prints out the graph to an SVG file or a PDF or a PNG. That’s what we’re going to use instead. It’s just the same data structure, it just looks a bit different and it’s generated by an open source program instead. Seafoam is this work-in-progress tool for working with Graal graphs, and we can produce these images from them.
What else do we do with these graphs? How do we read them and understand them? Here’s a simple example. I’ve got an example arithmetic operator, so a method: it takes an x, it takes a y, and it returns adding together the x and the y, and they’re both integers. To read this graph, we’ve got boxes, nodes, and we’ve got edges, which are lines between them. It’s a flowchart basically. In this case, P(0) is a parameter, first parameter, P(1) is the second parameter. They are the x and y for this ADD operation. The 4 just means it’s node number 4, all the nodes are numbered. The result of that flows into returning, so we return the result of adding parameter 0 and parameter 1. Then, separately, we have a start node. What we do is we run from the start node to the return Node. Then every time we need a result, we then run whatever feeds into the result. It’s a flowchart, and it’s a data graph, and it’s a control flow graph at the same time. It’ll become a bit more clear when we look at a slightly larger example. I’ve got a website where I talk about how to look at these graphs and how to understand them a bit more.
A slightly more concrete example is an example compare operator. This compares x and y and returns true if x is less than or equal to y. We have our less than operator here. Again, we have the two parameters. We notice this is less than rather than less than or equal to. What the compiler has done is it’s using a less than rather than a less than equal to, and has swapped them around. Instead of saying this is less than equal to this, it’s saying this is less than this. The reason it’s saying that is something called canonicalization. The compiler tries to use one representation to represent as many different types of programs as possible. It uses one comparison operator if it can, so it uses less than, rather than using less than and less than equal to. That returns a condition, and then Booleans in Java are 0 or 1 under the hood. We then say if it’s true, return 0, if it’s false, return 1. Again, we have a start node and a return node.
It starts to get more clear how these edges work when we start to talk about local variables. Here we do a is x plus y, and then we do a times 2 plus a. If you notice here, we have x plus y. Then that is used twice. This represented the value of a, but it’s never stored in something called a in the graph, it simply becomes edges. Anyone who uses a simply gets connected to the expression which produces a. Also notice, we have the multiplied by 2 has been converted by the compiler into a left shift by one, which is a compiler optimization.
That red line becomes more complicated. The red line is the control flow, if we have some control flow, so we have an if. The red line diverges out so now there’s two paths to get down to the return depending on which side was taken of the if. The reason for the StoreField in here is just to make sure there’s something that has to happen, so the if sticks around, doesn’t get optimized away. That you see the if takes a condition. As I said, because the Booleans represented 0, 1 in Java, it actually compares the parameter against 0, comparing it against false.
Why This Can Be Hard
Why could this be hard? This is a useful way to look at programs. I’ve shown fairly small programs before. There’s lots of reasons why this gets really hard really quickly. It’s still a trivial Java method written out as a graph. I can’t even put it on one slide. It gets so complicated, so quickly, and it gets almost impossible to read, they get very large very quickly. Graphs are non-linear as well. This is an abstract from a graph. You can’t read this. You can’t read it from top to bottom very well. You can’t read it from left to right. It’s just an amorphous blob, we call it a sea of nodes, or a soup of nodes. If you notice, there’s things beneath the return, but obviously, they aren’t run after the return, so it can be hard to read.
They’re inherently cyclic. They’re not trees, they’re not ASTs. They’re graphs with circles. Here, this code has a loop in it. It loops from this node here, back up to this one and runs in a circle. This is a while loop or something like that. I think humans just aren’t particularly great at understanding circles and things, to try to reason about where in the program it is, and the circle is, is complicated. They can be just hard to draw. Even when they’re not large, they can be tricky to draw. This is an example of IGV, Ideal Graph Visualizer the other tool. This has lots of things crossing over each other when ideally they wouldn’t. This is part of the reason why we built Seafoam at Shopify. Laying out these graphs can be very tricky, and it gets trickier as they get more non-trivial.
What Could We Do Instead, Decompilation?
What could we do instead? This is the idea. I’m floating it at this conference and in some other venues. How about we decompile these graphs? The JIT compiler takes these graphs that it’s using to compile your Java code, and it produces machine code from them. Perhaps we could take the graphs and produce something else instead. Perhaps we can produce some pseudo Java code. Something that’s readable, like Java is. Not a graphical representation, but still allows us to understand what the compiler is doing by looking at similar things within the compiler.
Here’s a simple example. We’ve got the same arithmetic operator from before. What I’m doing now is I’m decompiling that to a pseudocode. It’s the same operations we saw before, but now things are written out like a normal program I’d understand. T1 is the parameter 0, so x. T2 is the parameter 1, so y. Then t4 is t1 plus t2, and then we return t4. This is all within something we call a block, so there’s a label like you would with gotos in C and things like that. It’s a pseudocode. It’s not really Java code. This helps understand what’s going on. Now the graph we have is much more linear, and you can read it from top to bottom and left and right, like you would do with Java code.
If we look at an example with control flow. Here we have statements such as if t6, and t6 is t1 equals t5, and the parameters are comparing and things, then goto b1, else goto b2. You can see which code is run within those. What I’m trying to do over time is restore a structured if as well, so you see if and you see curly brace for the true and then else and the curly brace for the false.
Problems That Can Be Solved With This
What problems can be solved with this? This is the so what, and the interesting bit from this whole talk. We said we’d like to understand what the JIT compiler is doing, gain more knowledge of how the JIT compiler works and what it does, and maybe resolve some queries in the workplace or online about what the JIT compiler is doing or why. We can give a couple of concrete examples here that I’ve seen people actually debate and not know how to answer without looking at what the compiler is actually doing.
Lock Elision
Lock elision, you may not be aware that if you have two synchronized blocks next to each other, and they synchronize on the same object, then, will Java release the lock between these two blocks? It’s synchronizing on one object, and then it’s synchronizing on the object again. Will it acquire and release the monitor twice, or will it acquire it once and then keep going? You may think, why would anyone write code like this in the first place? Code like this tends to end up after inlining, for example. If you have two synchronized methods, and they’re called one after the other, and they’re both synchronized, then will Java release the lock between them or will it keep hold of them? We can answer this for ourselves using Seafoam, this tool we’re talking about. What we have when the compiler starts, if we look at the graph decompiled the pseudocode before optimizations are applied, we can see a MonitorEnter, which is the start of a synchronized block, and MonitorExit which is the end of a synchronized block. We can see the StoreField inside it. Then we acquire it again, so we MonitorEnter again, we store the second field. Then we MonitorExit again. At the start of compilation, there are two separate synchronized blocks and we acquire the lock once, and we release it and acquire it again and release it.
The first thing the compiler does is it lowers it. It lowers the program. This means it replaces some high level operations with some lower level operations. The program gets a little bit more complicated before it gets simpler, but we can still see here we’ve got an enter and an exit, and an enter and an exit. It’s just there’s some more stuff about how to use the object that’s been expanded out. Then as the compiler runs, we can look at the graph, the data structures of the compiler at a slightly later point. We can see actually, it’s combined the two synchronized blocks because we can see, now there’s only one MonitorEnter and one MonitorExit, and the two field writes are actually right next to each other. We can answer this for ourselves. Yes, the Java JIT compiler, or at least Graal, I think HotSpot does as well, will keep the lock while it runs two back to back synchronized objects. We can answer that for ourselves by using decompilation and compiler graphs to look at what it’s doing and why.
Escape Analysis
Another example, say we’ve got a vector object, so it’s got symbol x and y. Let’s say we’ve written everything in quite a functional way, so it’s final, and adding produces a new vector. Then if we want to sum but only get the x component, we would do a Add and then get x. The query is, does this allocate a temporary vector object? Some people will say, yes, it will. Some people will say, no, it won’t, the JIT compiler will get rid of it. Let’s find out by asking the JIT compiler. Again, this is covered in a blog post in much more depth. Here we go. When the JIT compiler starts running before it starts optimizing, we can see it creates a new vector object. We can see it stalls into the vector, and then it loads out just x to return it. It returns t10, and t10 is loading out the x from the object it just allocated. If we let the compiler run, we let escape analysis run, which is an optimization to get rid of object allocations, we can see, all it does is it takes the two vectors in, you can see it loads x from the first one, loads x from the second one. It adds them and returns them. There we wrote a method which looks like it’s allocating objects, it looks a bit wasteful, we can see actually JIT compiler can show us that it is removing that allocation. Actually, it’s doing what you might do if you manually optimized it.
Something that Seafoam can also do if you still want to see assembly, Seafoam can also show you assembly, so it includes a tool called cfg2asm. This tool doesn’t need that annoying hsdis file, and it will give you some assembly output as well. We can see the assembly if we want to with our tool, but we can also use it to answer questions like, will the JIT compiler combine my synchronized blocks? We can use it to answer questions like, will the JIT compiler remove the allocation of this object, which I think isn’t needed?
Summary
That’s just a little jaunt through the Graal JIT compiler and the Graal graphical intermediate representation, and Seafoam and decompilation, and how I think it can be used. It can also be used for other applications, such as looking at how Ruby is compiled by TruffleRuby, or looking at how your code is compiled by ahead-of-time or AOT compilers, like native-image from the GraalVM if you were using that. It’s a prototype development tool, not a product. It’s open source and on GitHub.
Questions and Answers
Beckwith: I think maybe the audience would like a little bit of background on hsdis, because I know you spoke about it. It’s basically associated with the HotSpot disassembly and that’s why it’s HS for HotSpot. Would you like to provide how it’s different for different architectures and how it’s dependent on disassembly?
Seaton: It’s effectively a plug-in architecture. The idea is that HotSpot can dump out machine code, by default will just give you the raw bytes, which almost nobody can use to do something useful. Even someone who has experience of working with machine code. There is a plug-in architecture where you can plug in a tool to do something else with it. Normally, you just print out the actual assembly code that you’d like to see, so if you used a debugger or something like that. For complicated licensing reasons that I don’t fully understand, and I’m not a lawyer, so I will choose to try and explain, that it can’t be bundled by default. I think it is built on a library that isn’t compatible with GPL the way it’s used in HotSpot. The reason it doesn’t matter why the problem is that means that people won’t distribute it normally. You have to go and find your own. You can go and download one from a dodgy website, or there’s some reputable ones as well. Or you can try and build it yourself. It’s a bit of a awkward piece of software just to build, so building parts of JDK on their own aren’t very fun. They’re trying to improve this actually. As well as using a tool like Seafoam where the machine code gets written to a log, and then you can use that tool offline to decompile it. I think they’re trying to plug in now standard permissively licensed decompilers. The situation should get better in the future. At the moment these are really awkward little warts on trying to look at assembly.
Beckwith: It’s true. When we did the Windows on Arm port, of course, we had to have our own Hsdis for Windows on Arm, and we used the LLVM compiler to do that. Now I think we’re trying to get it out to OpenJDK so that it’s better licensing agreement and everything, so it could be a part of OpenJDK. Let’s see where we get with that.
Seaton: There’s a question about native-image. Native-image is a compiler from Java code to native machine code, in the same way that a traditional C compiler runs. You give it class files, and it produces an executable, and that’s a standalone executable that includes everything you need to run it. The great thing about Graal is it actually does this by running the same compiler as the Graal JIT compiler, just slightly reconfigured, so it doesn’t need any extra support. Then they write the machine code out to disk. You can use Seafoam and the decompiler to look at how it’s compiled that ahead-of-time code in exactly the same way, so you can see what code you’re really going to run. I think native-image also produces some other locks in the same graph file format. I think it might give you some information about which classes call methods on which other classes, things like that. I think you can use to look at that as well. If you use Truffle, which is a system for building compilers automatically, you can use it to understand what Truffle is doing and why. Lots of other data structures in compilers are graphs. It’s like a common point of communication and a common point of tools for understanding compilers, is being able to look at things in these graph representations.
Beckwith: There is another question about how this will help with finding out errors at the time of compilation.
Seaton: It’s pretty rare that there’s an error from the JIT compiler. Remember, we’re making a distinction here between the Java source code to class file compiler, that’s javac, and we’re not talking about that. We’re talking about when runtime or ahead of time it’s compiled to machine code. It’s extremely rare for the compiler to miscompile something. If it does, then, yes, Seafoam is a very good tool for using that. I think something’s gone pretty wrong if an advanced application developer is trying to debug the JIT compiler. We could expand your definition of errors to be compiled in a way you didn’t like, so if you were expecting the JIT compiler, or depending on the JIT compiler to work in a certain way. We have people who, for example, build low latency applications, and they don’t want any allocations. For example, what they could do with Seafoam is they could look at all the graphs involved in their application, and they could programmatically detect if there were things they didn’t like. You could actually use it to test that your program isn’t allocating anything. You could do that for more subtle things as well.
Something we did at Shopify once is we were trying to add a new optimization for boxing. Boxing is where you have a capital I integer. We had some things being boxed and unboxed that we didn’t think should be, and we wanted to argue to the Oracle team that they should implement a better optimization to get rid of them. Oracle said, we don’t think it’s that relevant, this probably doesn’t appear in reality. What we did was we dumped out all the graphs for running our production application, and because Seafoam is a library, as well as a command line application, we wrote a little program to use the library to query how often this pattern of boxing and unboxing appeared. We could say, it appears in this percent of graphs, and this percent of time is being done unnecessarily, and things like that. You can use it to reason about your code that has been compiled. We think about using it in tests, just to test that something is compiled in the way we like, rather than manually checking it or monitoring performance. If you want to test it in CI, you can check the graph and say, it has been powered like I wanted. That’s good, and assertive.
Beckwith: Do you find it helpful to optimize the running time of the code?
Seaton: Yes, so not all code is just-in-time compiled. If it doesn’t get just-in-time compiled, then, by definition, you’re not interested in what the JIT compiler would do with it, because it hasn’t been called enough to make it useful to do so. Something you can do is you can understand why code is being recompiled. Often, you’ll see, say you have code which goes to one of two branches, and it says if x, then do this, if y then do this. If your program starts off by just calling x, then it’ll only compile x into the generated code, and it’ll leave y as like a cutoff part that says that we’ve never seen that happen so we won’t compile that. Then you can see the second time it’s compiled, if you start using y, it’ll compile y and you can see which parts of your code have been compiled in and not. Say you write a method that has something that’s designed to handle most cases, and then something that’s designed to handle degenerate cases that you only encounter rarely. If you look at your graph, and you see the degenerate cases being used, then you think, my optimization isn’t quite working, I’d like to not compile that.
In native-image, if there are no additional optimizations or recompilations to machine code? Yes, native-image can’t optimize quite as aggressively in all cases as the JIT compiler, that’s because the JIT compiler can optimize your code as it’s actually being used. It can observe that the runtime values flowing through the program, it’s called profiling. Native-image has to be a little bit more conservative, because it doesn’t know what value is going to run through your program. A good example in a system I work with, if you have a function which adds together two numbers, and one of the numbers is always the same. Say you have a function called Add, and it’s only ever called with 1 and then another number, it will turn that into an increment operator automatically because it sees what the values actually are.
How’d you install on Windows? It’s a Ruby application, so it should work on Windows. If you’d like to try running on Windows, and it doesn’t do what you’d like, then please do open an issue and I will fix it as quickly as I can. I’m trying to do a website version of it as well, so you can just run it online. We’re looking at doing like an Electron version. It’s just a graphical application, so it’s a bit easier to use.
How would you affect the running machine code? That’s where it gets tricky. The graph can tell you what may not be ideal or may be wrong in your mind, but how you fix that is then up to you. We do a lot of deep optimization of Java stuff with my job, because we’re implementing in another language, Ruby on top of Java. We’re trying to make that fast, so it’s fast for everyone else. What we do is we look for things in the graph, we think shouldn’t be there that we don’t want to be there. If we see a method call, we think that should have been inlined, I don’t know why we’re left with that call, then we’ll go and examine why that call is still there. These graphs include a whole lot of debugging information so you can query where it came from, and why it’s still there.
Beckwith: What are the other options with respect to the graal.Dump, you said one was the one that you used, but can Seafoam support other options?
Seaton: What you can get it to do, ultimately, is you can get it to dump out the graph before and after every optimization. I don’t have any optimizations on Graal, I’m guessing I had 50 major phases. That turns out to be a lot of files very quickly. The number can set the verbosity of it. You may want to see major phases, not all of them, [inaudible 00:35:30] you get a huge amount of files on your disk. You can configure how much verbosity is. You can also get it to only print graphs for certain methods. You can just constrain what you see, so you get a low volume of stuff. It also makes your application run slower because it’s doing a lot of IO to write out these graphs, things like that.
Beckwith: Why do you use Ruby on top of the JVM? Is it for performance or is it for the tools?
Seaton: It’s mostly for performance, but also about tooling. GraalVM lets you run other languages on top of the JVM, and the JVM has absolutely world beating functionality in terms of compilers, and garbage collectors, and stuff like that. We’d like to reuse that for Ruby at Shopify. That’s what we work on. We’re reimplementing Ruby on top of the JVM. It’s similar to another project called JRuby, which is also Ruby on the JVM, but trying in a different way. It’s a polyglot thing.
Beckwith: In your experience, how often does Seafoam lead to refactoring of high level Java Ruby code versus recommending new JIT optimizations?
Seaton: It’s almost always refactoring the Java code to make it more minimal. Java’s optimizations work really well. They’re almost always good enough to do what we want. It’s just sometimes you have to phrase your things in Java in a slightly different way to persuade it to work, and maybe we can make the optimizations better. There’s complicated rules in the Java language that the JIT compiler has to meet. The JIT compiler has to always be absolutely correct for your Java code as per the spec. Sometimes, it’s just a case of slightly restructuring your code, a little bit refactoring. It’s important then to comment because it means we end up with Java code that on the face of it, you think, why it would be written like that. There’s a reason that pleases the JIT compiler. Now I say that, it doesn’t sound great, actually, maybe we should make the JIT compiler optimizations better.
See more presentations with transcripts
MMS • Aaron Rinehart
Article originally posted on InfoQ. Visit InfoQ

Transcript
Rinehart: I’m going to talk about building trust and confidence with security chaos engineering. I’m going to talk about complexity in modern software. I’m going to talk about what chaos engineering is. I’m going to talk about the application of chaos engineering to cybersecurity. Some use cases it can be applied to, for example, chaos experiment for security experiment, and the framework you can also use in applying and building your own experiments.
Background
My name is Aaron Rinehart. I am the CTO, co-founder at Verica. Before I was at Verica, I was the former chief security architect for UnitedHealth Group, like a CTO for security for the company. I also have a background in safety and reliability with NASA. Most of my career I’ve been a software engineer builder before I got into security. I’m a speaker in the space. I also wrote the security chaos engineering content for the main body of knowledge for Chaos Engineering for O’Reilly. Kelly Shortridge and I wrote the O’Reilly Report on Security Chaos Engineering. I was the first person to apply Netflix’s chaos engineering to cybersecurity. I wrote a tool called ChaoSlingr.
What Are We Doing Wrong?
The crux of the problem is that no matter all these new things we keep doing, we don’t seem to be getting much better at the problem. It seems to be the breaches and outages seem to be happening more often. We should wonder why. One of my reasons why I think that this keeps happening is, it’s because of complexity. It’s not for lack of trying. It’s that complexity is really complex adaptive systems, which is a term in applied science. Meaning that there are some characteristics that the outcomes in complex adaptive systems are nonlinear versus linear. It’s due to the acting and reacting of different components and things through the system, causing a magnification effect, and also causing them to be unpredictable for humans.
Furthermore, complex adaptive systems cannot be modeled by humans in our own brains. It’s difficult for us to conceptually keep an idea of what is happening from a system understanding perspective, as the system evolves at a rapid speed. In the end, what has happened is our systems have evolved beyond our human ability to mentally model their behavior. How can we continuously change something that we can’t really drive an adequate understanding of, especially when it comes to security? If we don’t understand what the system is doing, how do we expect the security to be much different? Security is very context dependent, so if we don’t know what it is we’re trying to secure, we can’t really deliver good security as a result.
Speed, Scale, And Complexity of Modern Software Is Challenging
What has happened is today’s evolution in modern systems engineering is that we’ve increased the speed, scale, and the complexity of which we’ve been dealing with. We’ve never ever had speed, scale, and complexity at the rates we have them today. If you look at the image on the left here, you see what a lot of folks know as the Death Star diagram. What that means is every dot is a microservice, and every line is connecting them together. Because microservices are not independent, they’re dependent upon each other. It’s very easy for microservices to sprawl from hundreds to thousands, pretty quickly.
Where Does It Come From?
Where does all this complexity come from? There’s a couple different schools of thought. There’s the accidental complexity, and there’s the essential complexity. Essential complexity comes from things like Conway’s Law, where organizations are destined to design computer systems that reflect the way they are as a business or really communicate as a business. It’s hard to change that complexity without changing the nature of the business itself. The second area where complexity comes from is something called accidental complexity. Basically, that is the way in which we build software. There are some people that believe you can actually simplify the amount of complexity by improving the rate of accidental complexity. Most people believe, really, you’re just moving the complexity around, because you will take a complex system, and you try to make it simple, you have to change it to do that. There’s inherent relationship between changing something and making it complex. What are some things we’re doing today to make it complex? Look at all these things on the screen, you see cloud computing, service mesh, CI/CD, and circuit breakers. You see all these techniques that are helping us to deliver value to market in better and faster ways. Also, they’re also increasing the amount of complexity we’re having to deal with as humans, in terms of how the software’s operating at speed and scale.
Software Has Officially Taken Over
I’m not saying these things are bad. We should also recognize that software now has officially taken over. If you look at the right, you’ll see the new OSI model, it is software. Software, it only ever increases in complexity because software is very unique in that what makes it valuable is the ability to change it. That also creates an inherent level of complexity in the nature of its construct. What we’re trying to really do with chaos engineering, is we’re trying to learn to proactively navigate the complexity, and learn out where it is, and give engineers better context, so they know where the boundaries of their systems are, so they can build better and more reliable systems.
How Did Our Legacy System Become so Stable?
For example, let’s consider a legacy system, whether you’re cloud native, or you’re a digital native company, or you’re a large enterprise that relies on mainframe. Everyone has some of them on legacy system. Legacy system, what that usually means is it is business critical. One of the characteristics of a business critical or a stable legacy system, is that it becomes known as somewhat stable. Engineers feel confident in how it works, and somewhat competent in the ability to run and operate it without having too many problems. What’s interesting is that, if you consider the question of, was the system always that way? Was that legacy system, that critical system that we rely on, that makes all the money for the company, was it always so stable, and really so competent? The answer is, no, it wasn’t. We solely learn through a series of surprise events, the difference between what we thought the system was versus what it was in reality. We learned through outages and incidents, and said, the system didn’t work exactly the way we thought it did. We discover, and we remediate the system. We continuously react and respond and fix, and improve the system over time. Through that process, we’re learning about the system, and ways to improve it, and how it operates.
Unfortunately, that’s a very painful exercise, not only for the engineers involved, but also for establishing trust and confidence with customers, because they’re also encountering your pain. You can think about chaos engineering. What it is, is it’s a proactive methodology for introducing the conditions by which you expect the system to operate, and say, computer, do you still do the things you’re supposed to do? If you think about things like retry logic, failover logic, circuit breakers, or even security controls that are supposed to prevent or detect under certain conditions, that logic almost never gets exercised until the problem itself manifests or occurs. With chaos engineering, we introduce the conditions by which that logic is supposed to fire upon to ensure that it still does do what it’s supposed to do. Because what happens is, is that we design that logic at some point, early in the system, but the system itself has evolved several times in cycles beyond that logic, and it may not work. That’s why we need to proactively make sure the system is going to do what it needs to do under the conditions we’ve designed it for. That’s what we’re doing. We’re being proactive. We’re proactively identifying some of these issues in the system before they manifest into pain.
Systems Engineering is Messy
One of the issues with why this is so prevalent is that we often forget as engineers that the process is pretty messy. In the beginning, as humans we have to simplify things, and our brains keep it all straight. In the beginning we love to think that there’s this easy plan with the time, resources. We got the Docker images, the code. We have secrets management taken care of. We’ve got different environments for staging and production. We got a plan there. We got a nice 3D diagram of what it was going to look like. In reality, a system never is this simple, this clear. It’s never as clear as this understanding that we’ve derived. We learn this because what happens after a few weeks or a few days is that there’s an outage on the payments API, and get the hard coded token. Of course, you should go back and fix that. There’s a DNS issue. It’s always DNS. There’s a DNS resolution issue, or somebody forgot to update the certificate of the site. Things that we slowly discovered, we forgot to do that. We’re human.
What happens is, over time, our system slowly drifts into this state where we no longer recognize it, because no one has actually a full complete understanding. Usually, you’re part of a team that is looking at a different lens of the system. You’re looking at the security pieces of it. You’re in the payments microservice. You’re looking at the payment microservices code and delivering that. Let’s say you’re on the reporting microservice. One team and one group of individuals typically focus on that. What I’m seeing is everybody has a different lens of what the system is, but nobody has a complete picture. What happens is over time those gaps start to surface as problems and we wonder why. In the end, what you take away from this is our systems have become more complex and messy than we remember them.
Cybersecurity is Context Dependent
What does all this have to do with security? I’m getting to it. Cybersecurity is a context dependent discipline. As an engineer, I need the flexibility and convenience to change something. That’s my job. My job is to deliver value to a customer through product, and that product is [inaudible 00:11:36] software. I need the convenience and flexibility to change something because I’m not sure what permissions and security I need just yet. My job is to deliver value to the customer. I’m constantly changing the environment, changing what I need in order to do that. I need the flexibility. Security itself is context dependent. You got to know what you’re trying to secure, in order to know what needs to be secured about it. Security by the nature of how it works is that we’re forced into a state of understanding in terms of context. Before we build the security, what’s happening is the engineers are constantly changing, and delivering value to the market via product. What’s happening is the security, we don’t know it no longer works, until it no longer works. We start to get this misalignment, or the need for recalibration. What happens is we don’t know there’s a problem that security no longer works, until it no longer works. The problem with that is, is that if we can’t detect that fast enough, an adversary can take advantage of that gap before we can actually fix it. With chaos engineering for security, what we’re doing is proactively introducing the conditions we originally designed for to ensure that they can still do the things they’re supposed to. What’s interesting is you’ll find that it’s not often that they actually do anymore. It’s just we’re changing things so fast, and we’re not recalibrating often enough.
Instrumenting Chaos Testing vs. Experimentation
Where does chaos engineering fit in terms of instrumentation? It’s a very loose definition but I’m a huge believer in instrumentation, and data, and feedback loops when it comes to engineering. Testing is verification or validation of something we know to be true or false. We know we’re looking for it before we go looking for it. In terms of security, it’s a CVE. It’s an attack pattern. It’s a signature. We know what we’re looking for, we go looking for those things. With experimentation, we’re trying to proactively identify new information that we previously did not know. A greater understanding about contexts we’re unaware of, by introducing exploratory type of experiment. That’s where chaos engineering for security fits in.
How Do We Typically Discover When Our Security Measures Fail?
How do we typically discover when security measures fail? We typically discover there’s some footstep in the sand, so some log event, some observability material. It could be a log event. It could be an alert. It could be that it can no longer phone home to get a manifest. It could be that it can’t access a certain resource because a port’s been blocked. We typically discover them through observable events. Usually, those observable events cause some security incident. The point I want to recognize here is that often security incidents are not effective measures of detection, because often we’re not actually traditionally very good at detecting nefarious actors in our systems. We have to start using good instrumentation to identify the problem before it becomes a problem. Because when there’s a security incident happening, it’s already too late. It’s not a very good learning environment for engineers to discover really the things that led up to it.
What Happens During a Security Incident?
Let’s look at what happens during a security incident. In reality, people freak out. People are worried about the blame, name, shame game. They’re worrying about, “No, I shouldn’t have pushed that code. Somebody’s going to blame me for this. I’m going to lose my job. This is all my fault.” On top of that, people are really worrying about figuring out what went wrong. Within 15 minutes, there’s some executive, or the CEO’s on the phone saying, “Get that thing back up and running, we’re losing money.” This context is too much cognitive load for any human to work under. It’s not a good way for engineers to learn. We don’t do chaos engineering. Chaos engineering is a proactive, not a reactive exercise. This is the reactive world that we typically live in today, which is chaos. We don’t do chaos engineering here. We do chaos engineering here. There is no problem. We think the world is going our way. We’re doing to proactively verify that the system is what it was supposed to be. We do that by asking it questions in a form of experiment and hypotheses. In summary on this, we don’t do chaos engineering here, we do it here. We do it here because it’s about learning, about deriving better context from an engineering perspective.
What Is Chaos Engineering?
Chaos engineering, what is it? Chaos engineering in terms of Netflix’s original definition, is this discipline of experimentation on distributed systems. We want to build confidence in the system’s ability to withstand turbulent conditions. Another definition I use is, this idea of proactively introducing failure or faults into a system to try to determine the conditions by which it will fail, before it actually fails. It’s about proactively building trust and confidence, not about creating chaos. We’re deriving order from the chaos of the day to day reactive processes in our system. Currently, there are three publications on chaos engineering. There’s the original O’Reilly Report from Netflix. There’s this book that Casey Rosenthal and Nora Jones from Netflix wrote. I wrote one chapter in there. There’s the report on Security Chaos Engineering.
Security Chaos Engineering
Security chaos engineering, there’s not a whole lot different to chaos engineering. Really, it is chaos engineering as applied to security use cases to proactively improve the way we build and deliver secure solutions. The point I want to recognize about this is chaos engineering and engineers, I’ve always believed this, is that we don’t believe in two things. We don’t believe in hope, and we don’t believe in luck. They’re not effective strategies. We believe in good instrumentation, in sensors. We believe in feedback loops that inform us, it worked or didn’t. Ok, what do we need to fix? That’s what we’re hoping that our security works the way we think it does. Is it not a very effective strategy? It works in Star Wars, but it doesn’t work in what we do. What we’re trying to do is proactively understand our system security gaps, before an adversary does.
Use Cases
Some use cases, these are not the end all be all of use cases for chaos engineering for security. These are the ones I liked. These are also documented in this O’Reilly Report. A great use case is incident response. A great place where most people start is proactively validating that security controls and measures and technologies work the way they’re supposed to, by introducing the conditions that they’re supposed to trigger upon. Another way is, because we’re being proactive, we’re introducing the signal proactively, we can actually monitor that signal. We can look at whether the technologies actually provide good observability data, because during an active incident, we’re not looking at the log data, we’re looking at the log quality. Because we’re doing this proactively, we can say, that firewall or that configuration management error didn’t give us enough context to derive the problem that we introduced. Had this been a real world problem, we would not really know where to go or what to do, we would have been scrambling for finding good context.
Because we’re proactively introducing these conditions in the system, we know when it started. It’s not a real failure. We can see how the event unfolds and how it performs, and derive better context. Prima Virani at Pinterest has a great use case in this book. You can read about how she started applying this at Pinterest. The last thing that’s important, is all chaos experiments, availability, stability, or security based have compliance value. Basically, you’re proving whether the technology or the security worked the way it was supposed to. You should keep that output in a high integrity way, by hashing it or whatever way you would like to achieve that, and overlaying it with some control framework. It could be PCI. It could be NIST. Don’t lose the good audit data that you can derive there.
Incident Response
The problem with incident response, is response. You’re always constantly responding and being reactive to an event. The problem is that security incidents are a subjective thing. At UnitedHealth Group, when I was directly over 1000 people in security, we spent a lot of money, like a billion dollars on security controls. It wasn’t proactive trying. No matter how much we prepare, how much we do, or how many things we put in place, we still don’t know what they’re trying to do. Why they’re getting in. How they’re going to get in. What they’re trying to achieve, and where it’s going to happen. We just don’t know these things. We put all these things in place, hoping that when those things happen, we’re ready. Being reactive is very hard to measure and manage how effective you are. When you’re proactively inducing the signal into the system, you can start to see, did we have enough people on call? Were the runbooks correct? Did the security technologies or the load balancer, whatever, give us the right information to understand what was happening? We could proactively improve that context and understanding. We can also measure how long it took, and where we can improve. There’s a lot of great opportunity with incident response, and sharpening that sword with chaos engineering for security.
ChaoSlingr – An Open Source Tool
One of the first tools ever written for security chaos engineering was ChaoSlingr. This tool is a deprecated tool now on GitHub. I’m no longer at UnitedHealth Group. For the tool actually, if you go to the GitHub repo, you can actually find a good framework for writing experiments. There are three major functions. There’s Slinger, Tracker, and Generator. What generator does is it identifies where you can actually run an experiment based upon AWS security tags, a tag of opt in or opt out. A lot of chaos tools have this. For example, you may not want to introduce a misconfigured port on the edge of your internet in AWS. There is Slinger. Slinger actually makes the change, in this case Port Slinger. It opens or closes a port that wasn’t already open or closed, to introduce that signal, that condition to the environment to understand how well our security response is. The last thing is Tracker. What Tracker does is it actually keeps track of what happened in terms of the events with the tool. It reports that to Slack so we can respond and understand it in real time.
Example – Misconfigured Port Injection
Back to this example of Port Slinger in context. When we released ChaoSlingr at UnitedHealth Group, we needed a good example experiment that everyone can understand whether you’re a software engineer, a network engineer, executive, or a security engineer. You need to understand what we’re trying to do and the value we’re trying to achieve. This was actually a really valuable experiment that we ran. For some odd reason, misconfigured port seemed to happen all the time. We’ve been solving port for 20 years, but it still happens. I don’t mean maliciously, on accident. Accidents occur. It could be that somebody didn’t understand flow, because network flow is not intuitive. It could be that somebody filled out a ticket wrong, and they got applied incorrectly. It could be administrative that entered incorrectly, and they entered the change wrong. Lots of different things. Our expectation at the time was that our firewalls would immediately detect and block that activity. It’d be a non-issue. We’re proactive so we started running this on all of our instances. We started finding out that, about 60% of the time it caught, and blocked it with the firewall, but we expect 100% of the time. That’s the first thing we learned. What we learned was there was a configuration drift issue between our non-commercial software and our commercial software environments. There was no incident. There was no problem. Proactively discovered, we got an issue here, and fixed it.
We were very new to AWS at the time, so we needed a way of understanding that what we’re doing is right or wrong. We figured out it wasn’t as good as we thought. The second thing we learned was as a cloud native configuration management tool, it caught it and blocked it almost every time. That was like, this thing we’re not even really paying for is performing better than the firewall. That’s the second thing we learned. The third thing we learned is that we didn’t really have a SIEM, a Security Incident Event Management tool, like essential volume tool for security. We build our own. It wasn’t because we were new to the cloud, I wasn’t confident that that was actually going to drive alerts and send those alerts to the SOC in a meaningful way. It actually happened. The log data was sent from the firewalls to the AWS environment, from a configuration management tool, and it correlated an alert. The alert went to the SOC. The SOC stands for Security Operation Center. The SOC analyst, the analyst in the operating center got the alert, they couldn’t tell which AWS it came from. As an engineer, you can say, Aaron, you can map back the IP address to figure out where it came from. Yes, you could. If this were a real world incident, that could take 15, 20, or 30 minutes. If SNAT, which hides the Source NAT address intentionally, it could be an hour.
When I was at UnitedHealth Group, it was very expensive every minute we were down. What was great is that there was no loss. There was no war room. We proactively understood that this wasn’t working the way it was supposed to. They didn’t have the right information to understand it. All we had to do is add metadata pointers to the log event. We fixed it. Nobody is worried about being fired here. Nobody was freaking out. There was no real problem. We proactively identified all these issues with the ability to fix them. That’s what’s great about this. This practice can really improve the way you build and deliver reliable systems, in a confident, trustworthy way.
Here’s the link to download the report on Security Chaos Engineering. It is verica.io/sce-book. On the right, you see my co-author, Kelly Shortridge. She is amazing. We’re really proud of what came out of this. We’re actually writing the main O’Reilly book right now on security chaos engineering.
Summary
We’re trying to proactively validate our system security by navigating complexity. That’s what security chaos engineering helps us do, and chaos engineering does in general. You can use the practice of security chaos engineering to build confidence at the things you actually built, and your security continued to work. You start off with experimenting with these misconfigured port things. We’re trying to observe and understand how well the system works. Once the experiment succeeds, and your security does what it was supposed to do, then you can continue to run it like a regression test, and continuously verify that your security works the way it does.
We got a great burst of information in the O’Reilly book. We’re trying to be proactive, versus reactive. I know it sounds simple, but you’d be surprised what you can find, and you’ll love the value you get from practicing this. Lastly, I’d like to leave you with some words from John Allspaw that really resonate with me, with what we’re trying to do. John Allspaw is one of the fathers of resilience engineering for software. It’s really about, stop looking for better answers, and asking yourself better questions.
Questions and Answers
Westelius: The first thing that comes to mind is that in the past few years, we’ve seen more investments in security with shifting left, essentially security moving closer and earlier in the SDLC to reduce investment later. From your perspective, do you see this as another step in security shifting left, or is it engineering shifting right? Is it a tool for engineers to do security experimentation, or is it something for security to drive in an organization? What does the collaboration model with engineering look like?
Rinehart: Really, the problem we’re addressing is post deployment. It’s post-deployment complexity. It’s not necessarily in the build. Doing chaos engineering, or chaos engineering for security, we’re not changing. We’re not saying you don’t do smoke tests. You don’t do unit tests. You still do all those things. You still do all your traditional scanning and fuzzing and things like that. What’s happening is the world of post-deployment is getting super complex and large in scale. We have so many different groups of humans working in that pool. We’re not all responsible for everything in that pool. We are collectively.
Let’s say you have 10 microservice applications. Microservices are dependent upon each other and they’re not independent. They depend upon functionality for the services. Immediately out of the gate, for each microservice, you got a team of humans. Rarely do you have one team doing multiple, but that could happen. Still, not every team of humans has an idea of all of the services, all the dependencies, and so we’re all delivering at maybe the same schedule, maybe different schedules. That’s all ending up in that post-deployment system of hundreds to thousands of microservices. Nobody has a good mental model of really what’s going on out there. We’re continually changing things like DevOps and even CI/CD. We’re just changing things so rapidly. It’s hard. If we don’t have a good understanding of the system itself, how is it ever possible that the security is any different? It’s moving context left by instrumenting right. What’s been interesting is that people adopting chaos engineering for security, and also reading the books are mostly software engineers, and software security folks. I found that really interesting.
Westelius: I think it is super interesting, because as we experience more security issues in general at large, how all these systems become more complex, I think automation and scale is hugely important. I think this is a huge part of it. How do you foresee this? When does it stop being chaos? You said testing versus weird science. When does chaos engineering turn into regression testing or standardization? Where does that feedback loop fit into the process? When is it experimentation? When does it turn into something else?
Rinehart: There’s the experimentation phase. Chaos engineering is not about chaos. There’s too much BS on the internet about breaking things in production. Netflix never really said that. It’s about fixing them in production. What we’re doing is proactively verifying that the system, after all those changes, all those events, all those things, still does what it’s supposed to. What we’re doing in the beginning is introducing the conditions we expected. Let’s say a security control to detect an issue, or to prevent some problem. We’re introduced to conditions that would trigger that. I started off with the Port Slinger example, which is ChaoSlingr’s main example, by opening or closing a port that wasn’t already open or closed. I sent that signal to the system to see what happened if it expected.
In the beginning, what we’re doing is we’re learning. We’re doing it slowly. We’re experimenting on the system to make sure it does what it does. I rarely have ever seen a chaos experiment succeed the first time. We’re almost always wrong about how we think the system works. That’s not just the security, that’s the system in general. Once you’ve validated that the system did exactly what it was supposed to do. It could be a cron job, let’s say you wrote some Bash, or you wrote a Python script, that’s all you really need to do. You don’t need a fancy tool to really do it. That’s all chaos engineering is, is just a bunch of Python and Lambdas. You can schedule via cron, run it from Spinnaker, or a Pipeline, periodically, and just verify that it’s still doing what it’s supposed to do. That’s automation.
Westelius: One of the questions was, how is this different from penetration testing by fuzzing inputs? Do you see, essentially, security chaos engineering as a framework in which you can do all of these different kinds of testing? What does that look like for you? Would you foresee this being a tool used by people who do penetration testing when companies don’t invest in this locally?
Rinehart: As a former penetration tester myself, I fear putting that label on it. I actually have a whole section on this because I get this question a lot, especially how is it different than purple teaming? How is it different than red teaming? What is pen testing versus purple, versus red anymore, and adversarial testing, and breach and attack simulation? Where does it fit in all these AppSec crowns? Really what we’re doing is we’re doing fault injection. We’re injecting fault conditions. They’re the conditions, you can think of it also that way. We’re being very targeted, very specific, from an engineering perspective.
We’re also trying to account for distributed systems. Distributed systems have problems magnified quickly. The example I gave was, if it’s a Node.js app, and you’re doing a Node.js Mass Assignment attack. I’m making so many changes and sending so many signals to the system, it’s difficult to sift what worked, what didn’t. That’s the goal, what we’re doing. We’re not trying to overwhelm the system. We’re not trying to break in. That’s not the goal. Don’t mishear me either. There’s value in purple teaming. There’s value in red teaming, however you see the definitions. I prescribe the definition of red teaming was supposed to evolve to purple, but it didn’t. Because red, there is a wall of confusion like Dev and Ops. Then there was blue and red. Then it was like, we got in. You guys suck. Here’s a PDF file. Purple was supposed to evolve into more of a cohesive, collaborative exercise, but it evolved into something else.
I don’t know if pen testers will use it. I’ve talked to a lot of pen testers that see value in it, and can probably do it. I’d love to see where this goes. I am seeing a lot of software engineers pick this up. I see a lot of people building programs around this that are in the red teaming, or they’re in the architecture function. A lot of chaos engineering and SRE are blurring with architecture in an interesting way, because you’re trying to validate those diagrams actually represent something in the system.
Westelius: I think to some extent, it’s almost a representation of how software and systems engineering have developed, and we have infrastructure as code now. I think that the lines between all those different responsibilities have definitely blurred.
When do you think it is worthwhile making the investment into security chaos engineering as an organization? Is there a point where you shouldn’t?
Rinehart: Here’s how I see the world. I don’t think you’re going to have a choice to the future. We’re asked to do so many things in security. It’s almost an impossible task, if you really think about it. If you’re going to spend the time and effort to launch a new commercial solution, or write a bunch of code to do a thing, to satisfy a requirement. Don’t you want to make sure it works? Don’t you want to have some feedback loop that as the engineer is building product and delivering that, that your tool is still providing the value you promised them? That we’re delivering on the value? What I’m saying is like, now, yesterday, we need to be expanding this as a field. There’s probably 20 or 30 different companies now experimenting with this. Just because these are areas I started in, doesn’t mean you can’t take it in a new direction. These feedback loops, post-deployment, it’s going to kill us in security. The complexity is what’s causing a lot of our problems, in my opinion.
See more presentations with transcripts
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ

Microsoft recently announced the general availability (GA) of virtual machines (VMs) on Azure featuring the Ampere Altra, a processor based on the Arm architecture. In addition, the Arm-based virtual machines can be included in Kubernetes clusters managed using Azure Kubernetes Service (AKS).
Earlier, the company launched the preview of the new general-purpose Dpsv5 and Dplsv5 and memory-optimized Epsv5 Azure Virtual Machine series, built on the Ampere Altra processor. These machines were designed for efficiently running scale-out, cloud-native workloads.
Paul Nash, vice president, Azure Compute Platform, explained in an Azure Virtual Machines blog post on the Ampere Altra Arm-based processors:
Azure’s Ampere Altra Arm-based virtual machines represent a cost-effective and power-efficient option that does not compromise the level of performance that customers require.
Azure Arm-based VMs support up to 64 virtual CPU cores, 8 GB of memory per core, 40 Gbps of networking bandwidth, and SSD local and attachable storage. The VMs are suitable for various workloads such as web and application servers, open-source databases, microservices, Java and .NET applications, gaming, and media servers. The Azure Arm VMs include support for preview releases of Windows 11 and Linux OS distributions, including Canonical Ubuntu, Red Hat Enterprise Linux, SUSE Enterprise Linux, CentOS, and Debian, with further support for Alma Linux and Rocky Linux coming soon.
Alexander Gallagher, vice president of Public Cloud at Canonical, said in an Ubuntu blog post:
We see companies using Arm-based architectures as a way of reducing both cost and energy consumption. It’s a huge step forward for those looking to develop with Linux on Azure. We are pleased to partner with Microsoft to offer Ubuntu images.
With the Ampere Altra VMs, Microsoft will compete with the Arm-powered VMs from Amazon Web Services and Google. AWS acquired startup Annapurna Labs in 2015 to build its own Arm-based, general-purpose server hardware lineup called Graviton – the latest available instances are the Graviton 3 instances. And Google recently released VMs based on the Arm architecture of Compute Engine called Tau T2A (also Ampere Altra Arm-based processors).
Jeff Wittich, chief product officer, states in an Ampere Computing blog post:
The Arm-based server ecosystem has rapidly matured over the last few years with open-source Cloud Native software stacks extensively tested and deployed on Ampere Altra-based servers. For example, Ampere runs over 135 popular applications across five different cloud native infrastructures to ensure that our customers have confidence in the Ampere software environment across the marketplace.
The Ampere Altra Arm-based VMs are currently available in ten Azure regions and multiple availability zones worldwide. Pricing details of Azure VMs are available on the pricing page.
Cloud Providers Target Middle East: AWS Adds Region in the United Arab Emirates, Microsoft in Qatar
MMS • Renato Losio
Article originally posted on InfoQ. Visit InfoQ

Amazon recently announced a new region in the United Arab Emirates, its second one in the Middle East. Microsoft just opened its first global datacenter region in Qatar where Google plans to open a new region too.
The official name of the new AWS region is Middle East (UAE) and the API name is me-central-1. The launch increases the AWS global infrastructure to 87 availability zones across 27 regions. AWS opened a region in Bahrain in 2019 and has since expanded its presence in the Middle East, with a region in Israel expected in the first half of 2023. Marcia Villalba, senior developer advocate at AWS, writes:
In addition to the two Regions—Bahrain and UAE—the Middle East has two AWS Direct Connect locations, allowing customers to establish private connectivity between AWS and their data centers and offices, as well as two Amazon CloudFront edge locations, one in Dubai and another in Fujairah. The UAE Region also offers low-latency connections to other AWS Regions in the area.
Applications running in the new available zones can use a subset of EC2 instances (C5, C5d, C6g, M5, M5d, M6g, M6gd, R5, R5d, R6g, I3, I3en, T3, and T4g), with latest generation m6i Intel and c7g Graviton notable misses, and the majority of the AWS managed services. Corey Quinn, chief cloud economist at The Duckbill Group, highlights some issues with the new region:
I can’t deploy LastTweetinAWS.com to the new UAE region because despite being shiny and new it doesn’t support v2 API Gateways yet. It also doesn’t support Graviton-based Lambda functions either (…) No Ubuntu, macOS, RedHat, or SUSE. Congratulations to AWS on its launch of half of a region. Even the Amazon Linux 2 AMI is on kernel 4.14 instead of 5.10 like regions that actually work. Why would you open the doors before you stock the store shelves?
AWS is not the only cloud provider expanding their datacenters in the Middle East. In collaboration with the Qatari Ministry of Communications and Information Technology, Microsoft announced the launch of its new datacenter region in Qatar. Microsoft is the first major cloud provider to open in Qatar, supporting Microsoft Azure services and Microsoft 365. Available with three zones, the new region is based in Doha and available to all customers and partners.
With more than 70 percent of country startups on the Microsoft Founders hub, Lana Khalaf, country manager at Microsoft, explains:
This data center has the largest number of cloud services since the history of Microsoft. It helps companies in major industries to accelerate their digital transformation and innovate from Qatar to the world (…) The data center will contribute to Qatar National Vision 2030 (…)
Google Cloud confirms the trend, expecting to open a region in Doha and one in Tel Aviv soon.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Google has announced a developer preview of its new Cross device SDK for Android, aimed to help developers build cross-device experiences using high-level, intuitive APIs.
This SDK abstracts away the intricacies involved with working with device discovery, authentication, and connection protocols, allowing you to focus on what matters most—building delightful user experiences and connecting these experiences across a variety of form factors and platforms.
Device discovery enables finding nearby devices and engage in peer-to-peer communication using secure authentication and end-to-end encryption for bi-directional data sharing. A controlling device can also launch the same app on a target device, which is key to task handoff, where you start a task on a device and continue it on another. According to Google, the new capabilities can be used to create multiplayer games, to carry through productivity tasks across different devices, or to enable group experience, like group food ordering.
The new Cross device SDK provides a higher-level API on top of a number of distinct lower-level APIs, including Bluetooth, Wi-Fi, and Ultra-wide band. To make things easier and more transparent for both developers and users, apps using the Cross device SDK will not need to request permissions for using the underlying services. Instead, the user will authorize their use when enabling an app to communicate with specific devices.
The following code snippet shows how you can start a device discovery session based on the standard OS-provided dialog and launch an activity on a target device:
//-- callback called when the user has completed their device selection
handleDevices = { participants -> participants.forEach {
// Use participant info
}
}
val discoveryClient = Discovery.create(this)
devicePickerLauncher = discoveryClient.registerForResult(this, handleDevices)
devicePickerLauncher.launchDevicePicker(
listOfTargetDeviceFilters(),
startComponentRequest {
action = "com.example.crossdevice.MAIN"
reason = "I want to say hello to you"
},
)
On the receiving device, you override two methods, onCreate and onNewIntent, to handle the activity creation if the user accepts the request. For example, you can create a secure connection to exchange data between the devices.
The Sessions API leverages both the discovery and secure connection APIs to provide a higher-level notion of a session that can be created on an originating device and transfer or share with another device capable of handling it.
To make it easier for developers to adopt the new SDK, Google has created a “rock, paper, scissors” app that demonstrates the use of device discovery, secure connections, and session transfer and sharing. Another good starting point for interested developers is the Google I/O ‘22 Multi-device development session.