Month: October 2022

MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
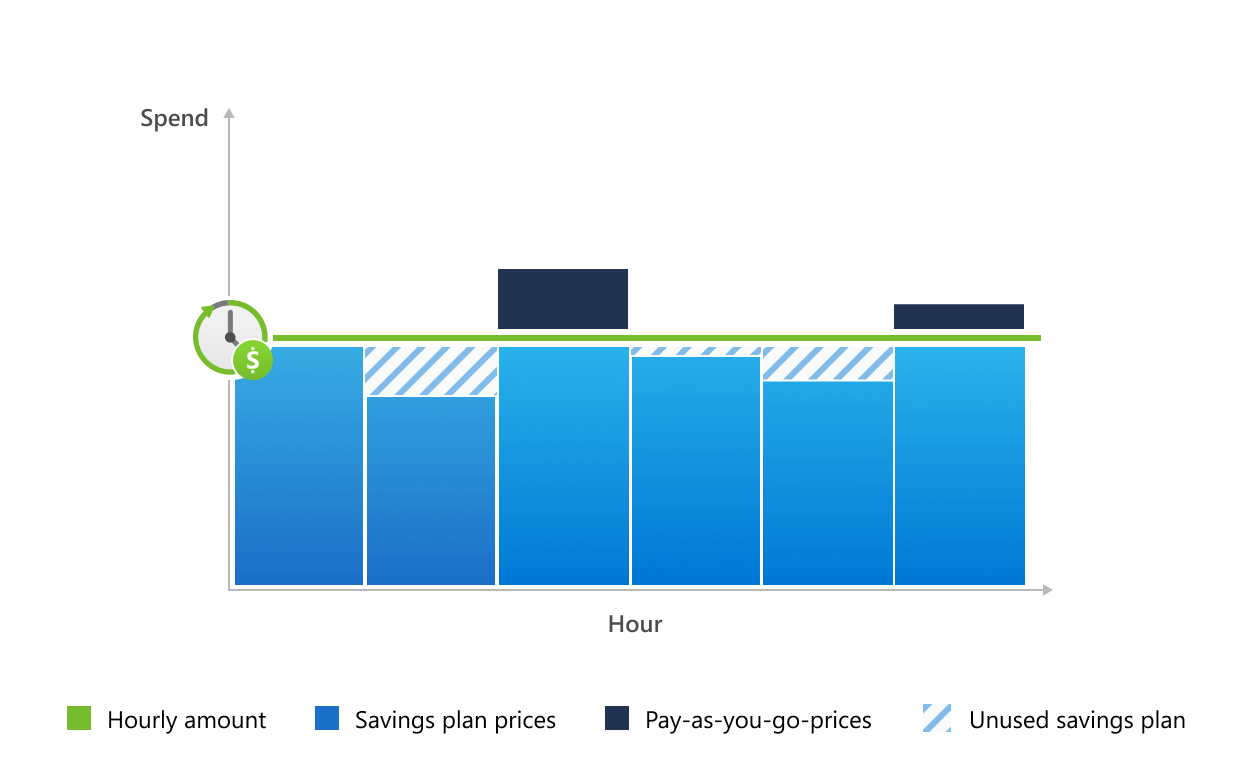
Microsoft recently announced Azure Savings Plans for Compute, providing customers with an easy and flexible way to save significantly on compute services compared to pay-as-you-go prices by committing to spend a fixed hourly amount for one or three years.
With the new pricing offer, customers can, according to the company, save up to 65% on compute costs, compared to pay-as-you-go pricing, in addition to existing offers in the market, including Azure Hybrid Benefit and Reservations. By selecting services such as Virtual Machines (VMs) and container instances, customers are covered by the plan at reduced prices. However, when the usage exceeds the hourly commitment during the plan’s duration, customers will be billed at their regular pay-as-you-go prices.
Through the Cost Management + Billing section of the Azure Portal and in Azure Advisor, customers can have insights into their historical compute usage and receive recommendations. In a Tech Community blog post, Kyle Ikeda, a senior product marketing manager at Microsoft, explains:
Using these recommendations, customers can buy a 1-year savings plan and commit to $5 USD of spend per hour. Once purchased, Azure automatically applies the savings plan to compute usage globally on an hourly basis, helping customers achieve optimized savings. The plan works by providing customers with access to lower prices on select compute services up to customer’s $5 hourly commitment, regardless of region, instance series, and operating system.
The hourly commitment is at a fixed price; any usage below or at the price level is billed as per the savings plan. Usage above in the hour is billed separately at pay-as-you-go prices.
Source: https://azure.microsoft.com/en-us/pricing/offers/savings-plan-compute/#how-it-works
Microsoft offers reservations similar to saving plans; however, they provide less flexibility, according to John Savill, a principal technical architect at Microsoft. In a YouTube video, he states:
If I go and create my Azure saving plan for compute, if that was the Azure reservation this very small square (one particular VM), what’s covered now in this new savings plan is everything, every region, every computer service included (predominantly premium SKU’s).
Therefore, it might confuse customers as Wesley Miller, a research analyst – Microsoft Identity, Security, and Management at Directions on Microsoft, tweeted:
Sigh. It’s like reservations. But it’s not. But it is. But it’s not.
In addition, he tweeted:
Okay… Azure savings plan for compute looks kind of interesting.
But be careful how much cash you leave on the table for Microsoft upfront. There’s not much benefit to that.
More details on Azure Savings plans are available on the documentation landing page and FAQs.
MMS • Ronnie Payne
Article originally posted on Database Journal – Daily Database Management & Administration News and Tutorials. Visit Database Journal – Daily Database Management & Administration News and Tutorials

Database administrators – or those that handle the administrative tasks associated with running a database system, rely on a database programming language to issue queries to retrieve and manipulate data from their respective database. Database programmers, data analysts, data modelers, and anyone who needs to access the information stored in a relational database management system (RDBMS) use some form of what is known as SQL – or Structured Query Language. In this database development tutorial, we discuss what SQL is, its benefits, and disadvantages.
Before we begin learning about SQL, a quick question: do you prefer to learn in a classroom or online course setting? If so, we have a tutorial highlighting the Best Online Courses to Learn SQL that can help you get started down the right path.
Overview of Structure Query Language
Structured Query Language (SQL) is a programming language used to issue commands to a database system for purposes of database management, adding information, manipulating data, or for the retrieval of data from a table. SQL, in particular, is the standard language used by database administrators and database programmers to interact with relational database management systems, which include:
-
- MySQL
- Oracle
- IBM DB2
- Microsoft Access
- MS SQL Server
- MongoDB
- MariaDB
- SQLite
- PostgreSQL
It should be noted that many of the above RDBMS have their own version or flavor of SQL that are proprietary to each database environment. That being said, they do share much of the same syntax and statements that standard SQL does, including statements like:
- SELECT
- INSERT
- UPDATE
- CREATE
- DELETE
- DROP
- WHERE
What Is SQL Used For?
SQL is a powerful database programming language and a standard of both the American National Standards Institute (ANSI) and the International Organization for Standardization. Primarily, the language is used to manipulate the data in a relational database in some fashion, which can include, but is not limited to, the following:
- You can use SQL to execute queries against a database or tables within a database
- You can use SQL to retrieve information from a database or tables within a database
- You can use SQL to manipulate information in a database. This can include adding records, updating records, and deleting records from a table.
- You can use SQL to manipulate database structures in general; a database admin or database programmer can create new databases, create new tables, edit existing table structures (such as adding new columns), form relationships, create stored procedures, and create views and reports.
- You can use SQL to manage database users, set permissions, perform security related tasks, and backup/restore information stored in a database or its tables
Read: How to Use the SQL SELECT Statement
What is a Relational Database Management Systems? (RDBMS)
A relational database system – also known as a RDBMS – is a database system that is based on relationships between data points in a table structure, which is made up of columns, rows, and individual cells. Rows run horizontal in a relational database, while columns run vertically. Each row consist of one or more cells, dependent upon how many columns exist. For example, consider a database table that contains the names of customers and their phone numbers. In such a database, each row would contain a cell for first name, last name, and phone number. Each of these cells would be related to one another, because they are within the same row. Each of these data points, further, would correspond to a column, which would represent each data point type.
Any data point or cell under the First Name column would be equated to a person’s first name. Likewise, any cell under the Last Name column would be considered a person’s last name, and so forth.
In addition, tables within a relational database system can also be related and the data within individual tables can be related to one another. Building upon our table of names and phone numbers, we might also have a table full of social security numbers. A database administrator could then create a relationship between the First Name, Last Name, and Social Security data so that the information would be related and considered part of the same row (essentially, if not in reality), without the data having to reside within the same table.
The reason for this separation of data into separate tables can be plentiful. Sometimes data is kept in table for security and data integrity reasons; other times, new data points might be added after a table structure has been created, and it becomes easier to store the new information in a separate table.
What are the Benefits of SQL?
There are many benefits of using SQL for database administrators and database programmers. These include the following:
- Data queries are processed faster. Information can be retrieved from tables rapidly and operations performed on data are also carried out quickly. These include deletions, insertions, and any other sort of data manipulation, updates, or changes.
- SQL is a simply language and has a simple syntax. While SQL does have a large number of statements, the language is not as complex or large as regular programming languages. This makes it easy to use, learn, understand, and reference.
- SQL is highly portable, meaning it works on many different types of operating systems, architectures, coding environments, server environments, embedded systems (such as those use in the Internet of Things or IoT), and so forth.
- The database programming language is extremely popular, and, as such, support is simple to find for SQL statements, functions, queries, and syntax.
What are the Downsides of SQL?
SQL is not a perfect language by any means, but it ranks above other database languages. Still, it does have its disadvantages, which include:
-
- Lack of control is one disadvantage of SQL; the nature of securing a database system means that SQL is limited in the elements of a database that it can control, meaning database administrators can be limited in what actions they can perform on a database dependent upon security settings, configuration, and proprietary database settings.
- Some versions of SQL can be expensive or, in the case of free versions, can be costly in terms of support and maintenance.
- Some beginning database administrators, database programmers, and data analysts may find certain SQL interfaces to be confusing at first glance; in addition, the different flavors of SQL can be confusing as well, as they each have their own unique statements (regardless of the fact that the main SQL statements are all the same). This can lead to a slight learning curve, especially to those that are new to relational databases management systems or databases in general.
Read more SQL tutorials and database development tips.
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for October 17th, 2022 features news from OpenJDK, JDK 19, JDK 20, JavaFX 20, Generational ZGC Build 20, Oracle Labs, Liberica JDK and Native Image Kit, Spring milestone, point and release candidates, EclipseLink 4.0, Quarkus 2.13.3, Micronaut 3.7.2, Hibernate Reactive 1.1.9, JHipster Lite 0.20, Apache Commons CVE, Groovy 4.0.6 and 2.5.29 and the return of JavaOne.
OpenJDK
JEP 432, Record Patterns (Second Preview), was promoted from its Draft 8294078 to Candidate status this past week. This JEP updates since JEP 405, Record Patterns (Preview), to include: added support for inference of type arguments of generic record patterns; added support for record patterns to appear in the header of an enhanced for statement; and remove support for named record patterns.
Similarly, JEP 433, Pattern Matching for switch (Fourth Preview), was promoted from its Draft 8294285 to Candidate status. This JEP updates since JEP 427, Pattern Matching for switch (Third Preview), to include: a simplified grammar for switch labels; and inference of type arguments for generic type patterns and record patterns is now supported in switch expressions and statements along with the other constructs that support patterns.
JDK 19
JDK 19.0.1, the first maintenance release of JDK 19, along with security updates for JDK 17.0.5, JDK 11.0.17 and JDK 8u351 were made available as part of Oracle’s Releases Critical Patch Update for October 2022.
JDK 20
Build 20 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 19 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 20, developers are encouraged to report bugs via the Java Bug Database.
JavaFX 20
Build 4 of the JavaFX 20 early-access builds was made available to the Java community and was designed to work with the JDK 20 early-access builds. JavaFX application developers may build and test their applications with JavaFX 20 on JDK 20.
Generational ZGC
Build 20-genzgc+1-14 of the Generational ZGC early-access builds was also made available to the Java community and is based on an incomplete version of JDK 20.
Oracle Labs
Oracle Labs has announced that they will be contributing GraalVM Community Edition source code to OpenJDK. This means: ongoing GraalVM design and development will move to the OpenJDK community; moving forward, GraalVM will use the same development methodology and processes as used for Java; and GraalVM will align with the Oracle Java release and licensing models. InfoQ will follow up with a more detailed news story.
On the road to version 1.0, Oracle Labs has released versions 0.9.15 and 0.9.16 of Native Build Tools, a GraalVM project consisting of plugins for interoperability with GraalVM Native Image. This latest release provides improvements such as: modify tests to verify that the --exclude-config command-line argument behaves as intended; fix functional tests for MacOS users; and improve the toolchain selection diagnostics. Further details on this release may be found in the changelog.
Oracle Labs has also provided a community roadmap for features in upcoming GraalVM releases planned for October 2022 and January 2023 along with features planned beyond that timeframe.
BellSoft
Also concurrent with Oracle’s Critical Patch Update (CPU) for October 2022, BellSoft has released CPU patches for versions 17.0.4.1, 11.0.16.1.1 and 8u351 of Liberica JDK, their downstream distribution of OpenJDK. In addition, Patch Set Update (PSU) versions 19.0.1, 17.0.5, 11.0.17 and 8u352, containing CPU and non-critical fixes, have also been released.
Spring Framework
On the road to Spring Framework 6.0.0, the second release candidate was made available that delivers 28 bug fixes, improvements in documentations and dependency upgrades that include: Apache Derby 10.16, GraalVM 22.3.0 and Jackson 2.14.0-RC2. More details on this release may be found in the release notes.
On the road to Spring Boot 3.0.0, the first release candidate was made available that delivers 135 bug fixes, improvements in documentations and dependency upgrades such as: Spring Framework 6.0.0-RC2, Spring GraphQL 1.0.0-RC1, Spring Security 6.0.0-RC1, Spring Web Services 4.0.0-RC1, Netty 4.1.84.Final, Micrometer 1.10.0-RC1 and Log4j2 2.19.0. Further details on this release may be found in the release notes.
Spring Framework 6.0 and Spring Boot 3.0 are scheduled for GA releases in November 2022. Developers can learn more about what to expect in this InfoQ news story.
Spring Boot 2.7.5 has been released featuring bug fixes and dependency upgrades such as: Spring Data 2021.2.5, Spring Security 5.7.4, Spring Data 2021.2.5, Hibernate 5.6.12.Final and Reactor 2020.0.24. More details on this release may be found in the release notes.
Spring Boot 2.6.13 has been released that ships with 27 bug fixes, improvements in documentation and dependency upgrades such as: Spring Data 2021.1.9, Spring Security 5.6.8, Tomcat 9.0.68, Reactor 2020.0.24 and Jetty Reactive HTTPClient 1.1.13. Further details on this release may be found in the release notes.
Versions 2022.0.0-RC1, 2021.2.5, and 2021.1.8 of Spring Data were released this past week featuring many corresponding dependency upgrades for all three versions. The release candidate delivers a revised module structure that includes eliminating Spring Data for Apache Geode and the point releases may be consumed with Spring Boot 2.7.5 and 2.6.13, respectively.
The Reactor Netty team has published CVE-2022-31684, Reactor Netty HTTP Server May Log Request Headers, a vulnerability in which logged headers may reveal valid access tokens to those with access to server logs. This may affect only invalid HTTP requests where the WARN level is enabled. Reactor Netty 1.0.24 provided the fix for this CVE.
One week after the eighth milestone release of Spring Batch 5.0, the first release candidate has been made available featuring: improvement in the execution context meta-data to add the version of Spring Batch; and the removal of GemFire support. More details on this release may be found in the release notes.
On the road to Spring Web Services 4.0.0, the first release candidate has been made available that ships with dependency upgrades that include: Spring Framework 6.0.0-RC1, Spring Security 6.0.0-RC1, log4j2 2.19.0, slf4j 2.0.3 and Ehcache 2.10.9.2. This is the last planned release candidate that supports Spring Boot 3.0.
Versions 6.0.0-RC1 and 5.8.0-RC1 of Spring Security have been released that delivers: smarter access to the HttpSession interface; simplify configuration for the RequestMatcher interface; and XML support for the shouldFilterAllDispatcherTypes property. These release candidates also bring breaking changes. Further details on this release may be found in the release notes for version 6.0.0-RC1 and version 5.8.0.
Similarly, versions 5.7.4 and 5.6.8 of Spring Security have been released featuring bug fixes and dependency upgrades such as: Spring Framework 5.3.23, Reactor Netty 1.0.24, Jackson Databind 2.13.4.1 and Eclipse Jetty 9.4.49. Further details on this release may be found in the release notes for version 5.7.4 and version 5.6.8.
The first release candidate of Spring for GraphQL 1.1.0 has been made available featuring observability support based on metrics and distributed tracing with Micrometer. There will be no new features after this release candidate as the team will focus on bug fixes and improvements in documentation until the anticipated GA release in November 2022. Spring GraphQL 1.1.0-RC1 will also be included in Spring Boot 3.0.0-RC1. More details on this release may be found in the release notes.
As monolith- and modular-based applications development has regained popularity, Spring has introduced a new experimental project, Spring Modulith, that supports developers in “expressing these logical application modules in code and in building well-structured, domain-aligned Spring Boot applications.” InfoQ will follow up with a more detailed news story.
Andy Wilkinson, staff engineer at VMware, has announced that the Spring Initializr team will be changing their default build tool from Maven to Gradle. Wilkinson, on behalf of the team, is of the opinion that Gradle is a better build system, writing:
This is particularly true for Spring Boot 3.0-based applications where the developer experience with AOT processing is quite a bit better with Gradle. We’d like to nudge the community towards using Gradle while ensuring that Maven’s only a click away for those that prefer it.
Developers who still prefer to use Maven can easily do so via https://start.spring.io/#!type=maven-project. InfoQ will follow up with a more detailed news story.
EclipseLink
Version 4.0.0 of EclipseLink, a compatible implementation of the Jakarta Persistence specification, has been released that delivers many updates such as: *Visitor classes and interfaces have been added to the EclipseLink-ASM project; clone the appropriate fields from the clone() method in the OneToManyMapping class that fixes a ConcurrentModificationException being thrown in a multithreaded environment; and update Oracle dependencies to version 21c. More details on this release may be found in the release notes.
Quarkus
Red Hat has released Quarkus 2.13.3.Final that addresses CVE-2022-42003, a denial of service vulnerability in Jackson Databind. Developers are encouraged to upgrade to versions 2.14.0-RC1, 2.13.4.1 and 2.12.17.1. There were also dependency upgrades to the SmallRye Reactive Messaging 3.21.0, Kotlin Serialization 1.4.1 and Jackson Databind 2.13.4. Further details on this release may be found in the changelog.
Micronaut
The Micronaut Foundation has released Micronaut Framework 3.7.2 featuring bug fixes and dependency upgrades to Micronaut Data 3.8.1, JUnit 5.9.1, jackson-databind 2.13.4.2, managed-testcontainers 1.17.5, managed-swagger 2.2.3 and micronaut-gradle-plugins 5.3.15. More details on this release may be found in the release notes.
Hibernate
Hibernate Reactive 1.1.9.Final has been released featuring a performance enhancement in which type caches are avoided on checks for the ReactiveConnectionSupplier interface. Further details on this release may be found in the list of issues.
JHipster
Versions 0.20.0 and 0.19.0 of JHipster Lite were released this past week that ship with: support for Neo4j; a dependency upgrade to Angular 14.2.7; and refactoring that removes deprecations and Mustache, the logic-less template utility.
Apache Software Foundation
The Apache Software Foundation has published CVE-2022-42889, Arbitrary Code Execution in Apache Commons Text, a vulnerability that allows remote code execution when applied to untrusted input due to unsecure interpolation defaults. Developers are encouraged to upgrade to Apache Commons Text 1.10.0.
Apache Groovy 4.0.6 has been released that delivers 14 bug fixes, improvements and dependency upgrades to Jackson Databind 2.13.4, JUnit 5.9.1, ASM 9.4, Spock 2.3, junit-platform 1.9.1 and japicmp 0.4.1 More details on this release may be found in the changelog.
Similarly, Apache Groovy 2.5.19 has been released that delivers 72 bug fixes, improvements and a dependency upgrade to Spock 1.3. Further details on this release may be found in the changelog.
JavaOne
After a five year hiatus, JavaOne returned to Las Vegas, Nevada this past week at the Caesars Forum and Venetian Convention and Expo Center that featured many speakers from the Java community who presented and facilitated many session types such as Birds of a Feather, hands-on labs, lightning talks, tutorials and deep dives.
One of the many highlights was the Inside Java | JavaOne 2022 Technical Keynote. Facilitated by Chad Arimura, vice president, Java developer relations at Oracle, this keynote featured a number of special guests from Microsoft and Oracle.
- Julia Liuson, president of developer division and GitHub at Microsoft, and Mark Heckler, principal Cloud developer advocate at Microsoft, presented ongoing Java development with Microsoft Azure.
- Gavin Bierman, consulting member of technical staff at Oracle, discussed Project Amber and demonstrated how to use Record Patterns and Pattern Matching in switch.
- Mikael Vidstedt, senior director, Java Virtual Machine, at Oracle, discussed ZGC.
- Sean Mullan, consulting member of technical staff at Oracle, discussed Java security technologies.
- Ron Pressler, consulting member of technical staff at Oracle, and Tomas Langer, architect at Oracle, discussed Project Loom and demonstrated how to use virtual threads in both blocking and reactive environments. Langer also introduced Helidon Níma, a new microservices framework based on virtual threads, that offers a low-overhead, highly concurrent server while maintaining a blocking thread model.
- Denys Makogon, Java developer advocate at Oracle, presenting virtually from Ukraine, presented on how Project Loom and ZGC improved the team’s telemetry ingestion engine for the Oracle Red Bull Racing F1 simulator.
The last JavaOne took place in 2017 before it was changed to CodeOne in 2018 and 2019. There were no conferences in 2020 and 2021 due to the pandemic.
MMS • Marco Valtas
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Introduction [00:01]
Thomas Betts: Hi, everyone. Before we get to today’s episode with Marco Valtas, I wanted to let you know that Marco will be speaking at our upcoming software development conferences, QCon San Francisco and QCon Plus. Both QCon conferences focus on the people that develop and work with future technologies. You’ll learn practical inspiration from over 60 software leaders deep in the trenches, creating software, scaling architectures, and fine tuning their technical leadership to help you adopt the right patterns and practices. Marco will be there speaking about green tech and I’ll be there hosting the modern APIs track.
QCon San Francisco is in-person from October 24th to the 26th, and QCon Plus is online and runs from November 29th through to December 9th. Early bird pricing is currently available for both events, and you can learn more at qconsf.com and qconplus.com. We hope to see you there.
Hello, and welcome to another episode of The InfoQ Podcast. I’m Thomas Betts. And today, I’m joined by Marco Valtas. Marco is the Technical Lead for cleantech and sustainability at ThoughtWorks North America. He’s been with ThoughtWorks for about 12 years, and he’s here today to talk about green software. Marco, welcome to The InfoQ Podcast.
Marco Valtas: Thank you. Thank you for having me.
The Principles of Green Software Engineering [01:07]
Thomas Betts: I want to start off our discussion with the principles of green software engineering. Our listeners can go find these at principles.green is the website. There are eight listed. I don’t think we need to go into all of them, but can you give a high level overview of why the principles were created and discuss some of the major issues they cover?
Marco Valtas: The principles were published around 2019 by the Green Software Foundation. They are very broad on purpose. And the need for the principles is basically that, how can we frame … Well, that’s how principles work. Principles help us to make decisions. When you are facing a decision, you can rely on a principle to guide you. Well, what is the trade-off that am doing? That’s basically what we have on the Green Software Principles.
They are generic in a sense. Like, be carbon efficient, be electricity efficient, measure your carbon intensity or be aware of your carbon intensity. I think the challenge that it posed to all development is like, okay, when I’m doing my software development decision, what trade-offs I’m making in terms of those principles. Am I making a trade-off of using a certain technology or doing something a certain way that will incur more carbon emissions or electricity consumption and so on and so forth?
Thomas Betts: Who are these principles for? Are they just for engineers writing the code? Are they CTOs and CEOs making big monetary decisions? Operations coming in and saying, “We need to run bigger or smaller servers”?
Marco Valtas: I think they are a target for folks that are making decisions on the application level. You can think about the operations and the software development itself. But operations, usually you are going to look on energy profile, like the data center that you are using, what region you are using. So operations can make big calls about what hardware you’re using.
Those are also in the principles, but the principles are also to help you to make a decision, at a very low-level. Like, what is the size of assets that you are using on your website? How much data you’re trafficking through the network, how often you’re doing that. If those apply to an operations decision, that will work. If those principles apply to a development decision, they will work. And that can be said for a CTO position. If you’re making a decision that will have an impact on any of those carbon emissions, electricity consumption, that can help you to make a decision.
Thomas Betts: I know one of the topics on our InfoQ Trends Report this year, and I think last year was the first time we put design for sustainability for one of the architecture trends that people are watching. And it’s something that people have been thinking about for a few years now, but I think you said these came out in 2019.
That’s about the same time where it says these are how you think about those decisions, and the idea of the trade-offs you’re saying architects are always concerned with. It’s like, well, the answer is, it depends. What does it depend on?
Varying carbon impact across data center regions [04:03]
Thomas Betts: Can you go into some of the details? When you say about a data center choice, what difference does that make based on which data center you use and where it’s located?
Marco Valtas: For data centers, you can think about cloud usually, not considering your own data center, but each data center is located in a geographic region. And that geographic region have a grid that provides energy, provides electricity to that data center. If that data center is located in a region where there’s way more fossil fuel energy being generated than solar or wind, that region, that data center has a carbon intensity profile of a larger carbon intensity. If you run your workloads on that region, usually you are going to count more carbon intensity.
But if you run the same workload in another data center, let’s say that you change from one cloud region to another cloud region that is on the energy grid, that region has way more solar than fossil, you are using way more renewable energy. So it lowers down the intensity of your workload. Considering where your data center is, is one of the factors, especially if you look on how the grids are distributed.
Thomas Betts: Is that information that’s easily accessible? I think there’s a general consensus. I live in the United States. The Eastern regions are very coal oriented, and so it’s very fossil fuel. But if you move more into the US Central regions for Azure or AWS, whoever, you get a little bit more of renewables. But is that something that I can go onto a website and say, “I’m running this in US-EAST-1, compare it to US-CENTRAL and tell me what the carbon offset is”? That doesn’t seem like a number I see on any of the dashboards I go to.
Marco Valtas: You won’t see it on any of the dashboards. We at Thoughtworks, we created one cloud carbon footprint tool, which actually helps you to look on the footprint by region. But the data, unfortunately, the data is not easily accessible from the cloud providers. We can go over a tangent around how cloud providers are actually handling this information, but the way that we do on our tool and most of other tools that are there, in the case of the United States, you can use the EPA Report on regions from the United States.
If you go to Europe, there will be the agents of Europe, and there’s other regions where you can get from another public databases, where they have reports around, what is the carbon intensity per watt hour in that region? You plug that and you make the assumption that that data center, it’s on that carbon intensity level. It gets complicated or complex if you consider that maybe the data center is not using that grid’s power. Maybe the data center has solar in itself, so it’s offsetting a little bit. It’s using a little bit of a renewable.
But that starts to be really hard because you don’t know, and the providers will make that information easily accessible. So you go for estimates.
Cost has a limited correlation to carbon impact [07:01]
Thomas Betts: All the data center usage, the number that people are usually familiar with is, what’s my monthly bill? Because that’s the number they get. And there’s correlations. Well, if I’m spending more money, I’m probably using more resources. But all of these have a fudge factor built in. That is not a direct correlation.
And now we’re going to an even more indirect correlation if I’m using more electricity here and it’s in a region that has a higher carbon footprint than I have a higher carbon footprint. But I’m in an 87 and I could be at a 43, whatever those numbers would be.
Marco Valtas: Cost is interesting. Cost is a fair assumption if you have nothing more to rely on. Especially on cloud resources, because you pay by the resource. If you’re using more space on the hard drives, you’re going to pay for more. If you’re using a lot of computing, you are paying more. If you’re using less, you’re going to pay less. It’s the easier assumption that, well, if I cut my costs, I will cut my emissions. But as you said, there’s a correlation, but there’s a limit to that correlation. You actually find that limit quite quickly, just moving regions.
Recently, I recorded a talk on XConf which will be published later this month, and I plotted against the cost of running some resources on AWS and how much carbon intensity on those resources. That correlation of cost and emission is not a straight line at all. If you move from the United States to Europe, you can cut your emissions considerably if you look just on the intensity of those regions. But you are going to raise your cost. That actually breaks the argument like, oh, cost? If I cut my cost, I cut my emissions. No, it doesn’t work like that.
If you have only cost, sure, use that. But don’t aim for that. Try to get the real carbon emission factor that you have on your application. That’s where our cost stands.
Taking a pragmatic approach to optimizing applications [08:57]
Thomas Betts: How do I go about looking at my code and saying, “Well, I want it to be more performant”? Anyone who’s been around for a while has run into processes that this is taking an hour. And if I change it a little bit, I can get it to run in a minute, because it’s just inefficient code. Well, there’s those kinds of optimizations, but then there’s all of the different scenarios. Like, how are my users using this system?
Am I sending too much data over the wire and they’re making too many requests? How far away are they from my data center? There’s just so many factors that go into this. You said it’s a holistic view, but how do you take the holistic view? And then, do you have to look at every data point and say, okay, we can optimize it here, and we can optimize it there, and we can optimize it here?
Marco Valtas: This is what makes this such a rich field to be in, and why I really enjoy being part of it. There are so many things that you can think of, so many actions that you can take. But in order to be pragmatic about it, you should think as an optimization loop, as you have an optimization loop in your performances of your application. You try to find, what is the lowest, what is my bottleneck? What is the thing that is more responsible for my emissions overall?
Let’s say that I have a very, very inefficient application that takes too long to answer. It sorts the data four times before delivering back to the user, and that is obviously my computing side of things are the worst culprit on my emission. So let’s tackle that. And then you can drill down over and over and over again, till you can make calls about what kind of data structure I’m using. Am I using a linked list? I’m using an array list. I’m using what kind of loop. I’m using streams.
Those are decisions that will affect your CPU utilization, which translates to your energy utilization that you can profile and make some calls. But again, it gets complicated. It gets very distributed. The amount of savings depends, so you need to go for the low-hanging fruit first.
But yeah, measuring? There is some proposals from the Green Software Foundations, like the Carbon-Aware SDK and the Software Carbon Intensity Score, which you can get some variables and do a calculation, try to measure your application as a whole. Like, what is my score?
The good thing about those scores is not just being able to see a number, but also compare that number with your decisions. If I change something on my application, does this, relative to the previous state, it gets better or it gets worse? Am I doing things that are improving my intensity or not? And of course, there’s counterintuitive things.
There’s one concept which is called the static power draw from servers. Imagine that you have a server running at 10%. It consumes in energy to be just on. And the counterintuitive idea here is that if you run your server at a 90% of utilization, that won’t be the same as increasing your 80% in energy consumption, because you have a baseline just to keep the server up. Memory also needs to be powered, but it doesn’t draw more power if it’s busy or not. Sometimes you need to make decisions of using a server more than spreading across servers. Those are trade-offs that you need to take.
Thomas Betts: That’s one of those ideas that people have about moving from an on-premise data center to the cloud, that you used to have to provision a server for your maximum possible capacity. Usually, that’s over provisioned most of your time, because you’re waiting for the Black Friday event. And then these servers are sitting idle. The cloud gives you those capabilities, but you still have to design for them.
And that goes back to, I think, some of these trade-offs. We need to design our system so that it scales differently. And assuming the run at 50 to 90% is a good thing as opposed to, oh my gosh, my server’s under heavy load and that seems bad, you said it’s kind of counterintuitive. How do we get people to start thinking that way about their software designs?
Marco Valtas: That’s true. Moving to the cloud gave us the ability of, use just the things that we are actually using and not having the servers idle. I don’t think we got there, in the sense that there was a blog post saying that it calculated around $26 billion wasted in cloud resources in 2021, with servers that are up and not doing anything or are offering resources. We can do better on our optimization of the use of the cloud.
Cloud is excellent too, because you can power off and provision as you like, other than on-prems. Bringing that to the table and how can you design your systems to think about that, it starts with measuring how complex an application can be. It’s kind of unbounded. The way that you’re going to design your application to make best use of the carbon resource is going to go through hops. And you should measure how much energy, how much resources are you using?
Some things are given in a sense like, well, if I use more compute, probably I’m doing more emissions. But then there’s more complex decisions. Like, should I use an event-based architecture? How microservice versus a monolith will behave. I don’t have answers for that. At my company, we are researching and trying to run experiments and get to some other information around, well, how much microservice architecture actually impacts on your carbon emissions?
And then the big trade-off is the last, I don’t know, 20 years on software development, we optimize to be ready for deployment, to minimize uncertainty on our releases. And be fast in delivering our values. That’s what continuous delivery is all about. But then you have to ask your question, how much of those practices, or what practices are you using that will turn out to be less carbon efficient? I can think about an example.
There are several clients that I work with that have hundreds of CI servers, and they will run hundreds of pipelines because developers will be pushing code throughout the day. And the pipeline will run and run the test, and run sometimes the performance test and everything. And the builder will stop right in the gate of being deployed and never be deployed. There’s a trade-off to be made here of readiness and carbon emissions.
Should you run the pipeline, every push of code? Does that make sense for your project, for your company? How can you balance all this readiness and quality that we develop throughout the years with the reality that our resources are not endless? They are not infinite. I think one of the impressions that we got from cloud was yeah, we can do everything. We can run with any amount of CPU, any amount of space.
I couldn’t tell you how many data scientists were happy of going to cloud, because now they can run jobs of machine learning that are huge. But now, we have to go back to the question, is this good for the planet? Is this consumption of resources unbounded something that we need to do, or we should?
Carbon considerations for AI/ML [16:42]
Thomas Betts: You touched on one thing that I did want to get to, which is, I’ve heard various reports and you can find different numbers online of how much machine learning and AI models cost just to generate the model. And it’s the idea that once I generate the model, then I can use it. And the using it is fairly efficient. But I think some of the reports are millions of dollars, or the same energy to heat 100 homes for a year to build GTP-3 and other very complex models. They run and they get calculated and then we use them, but you don’t see how much went into their creation.
Do we just take it for granted that those things have been done and someone’s going to run them, and we’ll all just absorb the costs of those being created? And does it trickle down to the people who say, “Oh, I can just run a new model on my workload”? Like you said, the data scientist who just wants to rerun it and say, “Oh, that wasn’t good. I’m going to run it again tomorrow.” Because it doesn’t make a difference. It runs really quickly because the cloud scales up automatically. Uses whatever resources I need, and I don’t have to worry about it.
Marco Valtas: One of the finer principles is, everybody has a part on sustainability, and I think that still holds true independently. What are you doing? We can get into philosophy about technology and see, are you responsible for the technology that you’re producing? And how is the ethics behind that? I don’t want to dig into that, but also we don’t want to cut the value that we’re trying to achieve.
Of course, GTP-3 and other models that are useful and important for another parts might be a case where, well, we’re going to generate this amount of emissions, but then we can leverage that model to be way more efficient in other human endeavors. But can you abstain yourself of the responsibility based on the theoretical value they’re generating? I don’t think so.
I think it’s a call every time, not knowing your emissions. In time, this is going to turn to be something that everybody needs to at least have some idea. As we do our recycling today, 10 years ago, we never worried about doing recycle. Nowadays, we look on the packages. We see, well, even separating your trash, you go like, why this vendor design this package this way that is impossible to recycle? Because this is glued in that, right?
We have that incorporated to our daily lives. And I think in the future, that will be incorporated to design decisions on software development, too.
Performance measurements and estimates [19:12]
Thomas Betts: I wanted to go back a little bit when you talked about measurements, because I think this is one of those key things. You said there are scores available and I hope we can provide some links to that in our show notes. People do performance tests, like you said. Either part of their daily build or on a regular basis, or just I’m watching this code and I know I can make it better. I’m going to instrument it. There are obviously lots of different scales.
This is one of those same things, but it’s still not a direct measurement, that I can’t say my code has saved this carbon. I can change my algorithm here and get the carbon score. I can get the number of milliseconds that it took to run something. Again, is that a good analogy, that if I can get my code to be more efficient, then I can say, well, I’m doing it because it saves some carbon?
Marco Valtas: If it is something that you are targeting at that point, yes. About how accurate is the measurement? That’s hard. The way that we set up our software development tooling, it doesn’t take that in consideration. So you’re going to have rough estimates. And it can say, well, I’m optimizing for carbon, instead of I’m optimizing for memory or something else. That’s definitely something you can do.
When we use the word performance though, it has a broad meaning. Sometimes we can talk about performance like, well, I want my code to run faster, or I want my code to handle more requests per second because I have this amount of users that are arriving at my end point. Does not necessarily means that if we’re making more performance in those dimensions, you are also making more performance on the carbon dimension.
What it boils down to is that carbon intensity will become, at least the way that you can incorporate nowadays, it’s like a cross-functional requirement or a nonfunctional requirement. It’s something that you are aware of. You might not always optimize for it because sometimes it doesn’t make business sense, or your application will not run if you don’t use certain technologies, but it’s something that you are aware of.
And you are aware during the lifetime of your software, if you’re doing certain changes, how that carbon intensity is varying. There’s a good argument like, oh, well, my carbon intensity is rising, but the amount of users I’m handling is increasing too, because I’m a business and I’m increasing my market. It’s not a fixed point. It’s something that you keep an eye on it and you try to do the best that you can for that dimension.
Corporate carbon-neutral goals [21:38]
Thomas Betts: And then this is getting a little bit away from the software, but I know there are a lot of companies that have carbon-neutral emissions. And usually that just focuses on our buildings get electricity from green sources, which got a lot easier when a lot of places closed their offices and sent everybody home, and they stop measuring individuals in their houses. Because I don’t think I have full green energy at my house for my internet.
But I don’t think a lot of companies when they talk about their carbon-neutral goals, as a company are looking at their software usage and their cloud data center usage as part of that equation. Or are they? In the same way that companies will buy carbon offsets to say, “Well, we can’t reduce our emissions, so we’re going to do something else, like plant trees to cancel out our usage,” is there something like that you can do for software?
Marco Valtas: Offsetting something that you can do as a company, not as software, you can definitely buy offsets to offset the software emission, but that’s more a corporation decision. In terms of software development itself, we just want to look on how my software is performing in terms of intensity. In general, we use the philosophy that reducing is better than offsetting. Offsetting is the last resort that you have, before when you get into a wall where are you trying to reduce.
Two philosophies of green software engineering [22:53]
Thomas Betts: The last part of the Green Software Principles, there’s eight principles and then there’s two philosophies. The first is, everyone has a part to play in the climate solution, and then sustainability is enough all by itself to justify our work.
Can you talk to both of those points? I think you mentioned the first one already, that everyone has a part to play. Let’s go to the second one then. Why is sustainability enough? And how do we make that be motivation for people working on software?
Marco Valtas: If you are following up on climate in general, it might resonate with you that we are in an urgent situation. The climate change is something that needs action and needs action now. The amount of changes that we can make to reduce emissions so that we reduce how much hotter will get Earth and how that impacts on environment in general, it’s enough to justify the work. That’s what is behind it. It’s putting the idea that this is enough of a worthy goal to do what we need to do.
Of course, cases can get very complex, especially on large corporations in, what is your part? But sustainability is just enough because it’s urgent in a sense. This is where sometimes organizations might have a conflict. Because there’s the sustainable business or making a profit or making whatever your business grow, and there’s sometimes sustainability, which is not exactly in the same alignment. Sometimes it will cost you more to emit less.
That’s an organization, that’s a corporation decision. That’s environmental governance of the corporation itself. What is behind this principle is basically that idea where focusing on sustainability is enough of a goal. We don’t think that other goals need to be conveyed in order to justify this work.
Thomas Betts: Well, it’s definitely given me a lot to think about, this whole conversation. I’m going to go and reread the principles. We’ll post a link in the show notes. I’m sure our listeners will have questions. If you want to join the discussion, I invite you to go to the episode page on infoq.com and leave a comment. Marco, where can people go if they want to know more about you?
Marco Valtas: You can Google my name, Marco Valtas. It’s easy. If you want to talk with me, I’m not in social networks. I gave up on those several years ago. You can hit me on marco.valtas@thoughtworks.com if you really want to ask a question directly to me.
Thomas Betts: Marco, thank you again for joining me today.
Marco Valtas: Thank you, Thomas.
Thomas Betts: Listeners, thank you for listening and subscribing to the show. I hope you’ll join us again soon for another episode of The InfoQ Podcast.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ

Meta AI has developed AITemplate (AIT), a unified open-source system with separate acceleration back ends for both AMD and NVIDIA GPU hardware technology. AITemplate (AIT) is a two part Python framework for AI models that transforms them into much faster C++ code. It has a front end that optimizes models through graph transformations and optimizations.
When it comes to providing computational capacity for the use of AI models, GPUs are very important, especially for large-scale pretrained models. The selection of high-performance GPU inference solutions by AI practitioners is currently limited due to their platform-specific nature. Maintaining the code that makes up these solutions is difficult due to dependencies in complicated runtime environments.
Meta AI used AITemplate (AIT) to improve performance up to 12x on NVIDIA GPUs and 4x on AMD GPUs compared with eager mode within PyTorch. The AITemplate (AIT) system consists of a front-end layer that performs various graph transformations and a back-end layer producing C++ kernel templates for the GPU target. The company stated that the vision behind the framework is to support high-speed while maintaining simplicity.
Additionally, AITemplate (AIT) offers Tensor Core (NVIDIA GPU) and Matrix Core (AMD GPU) performance that is almost identical to hardware native on popular AI models like transformers, convolutional neural networks, and diffusers. The A100 and MI200 GPU systems from NVIDIA and AMD, which are both often utilized in data centers for research institutions, IT firms, and cloud computing service providers, among others, currently have AITemplate (AIT) enabled.
AITemplate (AIT) includes advanced transformer block optimizations and enhanced kernel fusion, which is an optimization technique that combines multiple kernels into a single kernel to operate them more effectively. AIT also restricts the time it spends visiting outside libraries.
Meta AI aims to provide methods that can address environmental issues by reducing carbon emissions in addition to expanding the range of platforms that are available for AI. Studies have shown that the use of GPUs can affect carbon emissions. GPU execution is accelerated by AITemplate (AIT), which can reduce emissions even more.
Meta also plans to extend AITemplate (AIT) to additional hardware systems, such as Apple M-series GPUs, as well as CPUs from other technology providers.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Feature flags are a useful tool to conduct A/B experiments and to roll out changes in a controlled way. To make sure that their use does not end up disappointing users when a change causes a crash or degrades the user experience, Lyft created Safe Mode, specifically aimed to prevent crash loops on launch.
When a crash on launch was introduced by turning on a feature flag or changing other remote configurations, we usually had to ship a hotfix to get users out of infinite crash loops since we had no way of pushing configuration updates to the app when it was crashing so early in its lifecycle.
Key to Safe Mode implementation is Bugsnag, a platform aimed to monitor app stability that provides specific support to manage feature flags and A/B experiments. In particular, Bugsnag allows developers to declare a list of used feature flags, which is sent over along with a crash report. Bugsnag is also able to identify crashed on launch by providing an API to mark launch-time events.
Lyft starts Bugsnag very early in the app lifecycle, right in its main function, and configures it so it considers an app launch to be completed when applicationDidFinishLaunching returns on iOS and once the main screen is displayed on Android.
Safe Mode is also started in main, right after Bugsnag is initialized, and it queries the latter to see if the previous session crashed before the app fully launched. In this case, it logs a safe_mode_engaged analytic event and enters a shadow state where it first detects which feature flags were consumed in the previous session and then locks their configurations to local default values.
This effectively puts the potentially problematic features/codepaths into their default “safe” state and allows the user to use the app as they normally would (albeit with some functionality disabled).
Once an app has launched successfully after a crash, it refreshes its feature flags to give them another chance on the next launch. If the crashing feature has not been fixed before that moment, the app will crash and engage safe mode again.
A Grafana dashboard is fed with all crash-related events so engineers can easily detect a spike and take action quickly. Additionally, Lyft engineers also made sure that Safe Mode would not be itself the cause of instability. So, before rolling it out, they set up a specific feature flag that intentionally triggered a crash on launch to test the whole approach in internal, alpha versions of the app.
According to Lyft, Safe Mode has proved effective in reducing pain points with feature flags. They plan to extend it to include handling app hangs, which usually do not cause an app crash and are trickier to detect; to be more effective in determining which specific feature flag caused a crash and avoid disabling all of them; and to automatically disable feature flags that provoked too many crashes.
Lessons Learned: Emotion Library Maintainer Explains Why Company No Longer Uses Runtime CSS-in-JS
MMS • Bruno Couriol
Article originally posted on InfoQ. Visit InfoQ

Sam Magura, staff software engineer at Spot and active maintainer of the CSS-in-JS Emotion library, recently detailed why Spot abandoned the runtime CSS-in-JS library Emotion in favor of Sass modules: Runtime overhead, payload overhead, and server rendering issues contributed to a lesser user experience.
In his blog article, Magura first recalled the benefits of runtime CSS-in-JS.
Today’s web applications are often implemented as a set of collaborating components. When using runtime CSS-in-JS libraries, developers define the style of components together with the component markup and logic. It becomes harder to modify or delete the code for a component without correctly modifying or deleting the component style. This solves problems found in large applications littered with obsolete style rules that went undetected. Such applications are heavier to download and execute, negatively affecting user experience.
Scoping CSS rules strictly to the relevant component also makes it harder, if not impossible, to unwillingly impact the style of other components. In the absence of component scoping, the cascade and specificity rules of CSS may lead to style definitions that bleed to unrelated components.
Lastly, using a Turing-complete language such as JavaScript gives developers complete freedom in expressing the relationship between component style and component logic. This comes in handy when the component style is not static and should be dynamically updated in response to user actions or changes in the application environment.
Magura however concludes that, based on his study on Spot’s codebase, the benefits of CSS-in-JS outweigh the disadvantages:
So, that’s the reason we are breaking up with CSS-in-JS: the runtime performance cost is simply too high.
CSS-in-JS may negatively impact user experience with its runtime and payload overhead.
On the one hand, computing and updating styles dynamically at render time may lead to slower rendering. Magura compared the rendering time of a component of Spot’s codebase implemented with the runtime CSS-in-JS library Emotion to that from an implementation with Sass modules (compiled to plain CSS files at build time). The comparison revealed that, with Emotion, rendering time almost doubles (27.7 ms vs. 54 ms). Developers may refer to the blog article to review the experiment’s data, flame graph analysis, and more.
On the other hand, adding the CSS-in-JS library to the application code adds to the code bundle downloaded by the browser, possibly slowing down application startup. Emotion is around 8 KB (min. zipped), while styled-components, a popular alternative CSS-in-JS library, is 12 KB.
Interestingly, the dynamic insertion of CSS style rules performed by runtime CSS-in-JS libraries may not always play well with other parts of the ecosystem.
Regarding React 18, Sebastian Markage provided the following warning in a GitHub issue to developers using React’s concurrent rendering capabilities:
This is an upgrade guide for CSS libraries that generate new rules on the fly and insert them with
tags into the document. This would be most CSS-in-JS libraries designed specifically for React today – like styled-components, styled-jsx, react-native-web.NOTE: Make sure you read the section “When to Insert
on The Client”. If you currently inject style rules “during render”, it could make your library VERY slow in concurrent rendering.
Runtime CSS-in-JS may also affect server-side rendering optimizations. In an article on server streaming, Misko Hevery (creator of the Qwik framework), Taylor Hunt, and Ryan Carniato explained the following:
For example, CSS-in-JS (such as
emotion) is a very popular approach. But if that approach means all components need to fully render before thetags can be output, then that breaks streaming, as the framework is forced to buffer the whole response.
Magura mentioned that a fair number of issues logged in Emotion’s GitHub project relate to server-side rendering (e.g., React 18’s streaming, rules insertion order). The reported issues may generate significant accidental complexity (i.e., the complexity linked to the solution rather than originating in the problem). They may also result in a negative developer experience.
While Magura reminds the reader that he restricted his experiment to the Emotion CSS-in-JS library and the Spot codebase, he anticipates that most of the reasoning may identically apply to other runtime CSS-in-JS libraries and other codebases.
Tomas Pustelnik provided a year ago another data point that goes in the same direction, though following a different methodology. In his blog article Real-world CSS vs. CSS-in-JS performance comparison, Pustelnik concludes:
That’s it. As you can see runtime CSS-in-JS can have a noticeable impact on your webpage. Mainly for low-end devices and regions with a slower internet connection or more expensive data. So maybe we should think better about what and how we use our tooling. Great developer experience shouldn’t come at the expense of the user experience.
I believe we (developers) should think more about the impact of the tools we choose for our projects. The next time I will start a new project, I will not use runtime CSS-in-JS anymore. I will either use good old CSS or use some build-time CSS-in-JS alternative to get my styles out of JS bundles.
Popular build-time CSS-in-JS libraries include Linaria, Astroturf, and vanilla-extract. Facebook introduced last year stylex, its own build-time CSS-in-JS library. Developers can also use CSS modules and the related ecosystem (PostCSS modules, Sass modules).
CSS-in-JS refers to a pattern where CSS rules are produced through JavaScript instead of defined in external CSS files. Two sub-patterns coexist. Runtime CSS-in-JS libraries, such as Emotion or Styled-components, dynamically modify styles at runtime, for instance by injecting style tags into the document. Zero-runtime CSS-in-JS is a pattern that promotes extracting all the CSS at build time.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ

At the latest Cloud Next’22 conference, Google announced two new infrastructure platform offerings with the Compute Engine C3 machine series optimized for high-performance computing and next-generation block storage called Hyperdisk optimized for data-intensive workloads such as Hadoop and DBMS.
The new C3 machine series, currently in private preview, is the first to include Google’s custom Intel Infrastructure Processing Unit (IPU) and the Intel Sapphire Rapids CPU (also known as 4th Gen Xeon Scalable processor). The IPU is an ASIC (application-specific integrated circuit), a programmable network device that accelerates system-level infrastructure resources by securely accelerating those functions.
The company claims the C3 instance delivers a 20% performance gain over the previous C2 instance, made possible by combining CPUs and an IPU to provide more efficient use of processing resources. At the Cloud Next’22 event Thomas Kurian, CEO of Google Cloud, said in the keynote:
The instances are virtual machines that can take on workloads that require a heavy dose of storage and networking, with the Sapphire Rapids CPU offloading computing to the IPU.
In an Intel press release, Nick McKeown, Intel senior vice president, Intel Fellow, and general manager of Network and Edge Group, said:
We are pleased to have codesigned the first ASIC infrastructure processing unit with Google Cloud, which has now launched in the new C3 machine series. A first of its kind in any public cloud, C3 VMs will run workloads on 4th Gen Intel Xeon Scalable processors while they free up programmable packet processing to the IPUs securely at line rates of 200 gigabits per second.
In addition, Google states in a blog post that introducing system-on-a-chip architecture in C3 VMs can enable better security, isolation, and performance.
The C3 machines work well together with the next-generation block storage solution Hyperdisk, announced in a preview earlier by the company. The architecture behind Hyperdisk decouples compute instance sizing from storage performance to deliver 80% higher IOPS per vCPU. Nirav Mehta, Sr. director of product management, Cloud Infrastructure Solutions, explains in a blog post:
Compared with the previous generation C2, C3 VMs with Hyperdisk deliver 4x higher throughput and 10x higher IOPS. Now, you don’t have to choose expensive, larger compute instances just to get the storage performance you need for data workloads such as Hadoop and Microsoft SQL Server.
Customers can reach out to a Google sales representative or account manager to access C3 Virtual Machines of Hyperdisk previews.
MMS • Matt Campbell
Article originally posted on InfoQ. Visit InfoQ

HashiCorp released version 0.13 of the CDK for Terraform (CDKTF) with significant improvements to performance. The release introduces a major restructuring of the language by introducing namespaces. The namespace improvement dramatically enhances the performance of synthesizing infrastructure. This release builds upon the 0.12 release which saw CDKTF move into general availability.
The CDK allows for writing Terraform configurations in a number of programming languages including C#, Python, TypeScript, Go, and Java. It includes support for all existing Terraform providers and modules. The CDKTF application code synthesizes into JSON output that can be deployed with Terraform directly.
Version 0.13 introduces the concept of namespaces into each class in the generated provider bindings. These namespaces are automatically derived from the Terraform resource or data source it originates from. Previously, each provider’s exports were a flat list of components. This resulted in large packages that the various language compilers struggled with processing. Users of CDKTF indicated that synthesizing could be very slow and, for Python users, could cause the IDE to crash.
The namespaces change produces a number of small packages, which is faster for the compilers to process. This has led to some significant improvements in processing time according to Nara Kasbergen Kwon, Engineering Manager at Hashicorp. Kwon shares that recent benchmarking tests show:
- a 96.8% reduction in cdktf synth time when using Go with the Azure provider
- an 83% reduction in cdktf synth time when using Java with the Google Cloud provider
- a 36.8% reduction in cdktf synth time when using C# with the AWS provider
- a 61.5% reduction in cdktf synth time when using TypeScript with the Kubernetes provider
The introduction of namespaces is a breaking change, however, the 0.13 release is backward compatible with provider bindings generated by version 0.12. This allows for the mixing of namespaced and non-namespaced providers as needed. Note that providers generated by version 0.13 will be namespaced. This backward compatibility will be removed in version 0.14 and only namespaced providers will be supported.
The AWS provider was previously namespaced but in a way that was distinct from the new namespacing method. As such, how it is imported has changed to align with the new namespacing model. Previously the AWS provider could be imported in Go as follows:
import (
// ... other imports
"github.com/cdktf/cdktf-provider-aws-go/aws"
)
func NewMyStack(/* ... */) cdktf.TerraformStack {
stack := cdktf.NewTerraformStack(/* ... */)
aws.NewAwsProvider(/* ... */)
aws.NewCloudfrontDistribution(/* ... */)
aws.NewAcmCertificate(/* ... */)
}
With the new namespacing model, it will now need to be imported as follows:
import (
// ... other imports
"github.com/cdktf/cdktf-provider-aws-go/aws/cloudfrontdistribution"
"github.com/cdktf/cdktf-provider-aws-go/aws/provider"
"github.com/cdktf/cdktf-provider-aws-go/aws/acmcertificate"
)
func NewMyStack(/* ... */) cdktf.TerraformStack {
stack := cdktf.NewTerraformStack(/* ... */)
provider.NewAwsProvider(/* ... */)
cloudfrontdistribution.NewCloudfrontDistribution(/* ... */)
acmcertificate.NewAcmCertificate(/* ... */)
}
According to Kwon, the upcoming 0.14 release is scheduled for a mid-November 2022 release. Kwon shares that the release “will focus primarily on quality-of-life improvements that make it easier to use pre-built providers.” The team found that pre-built providers supply a better developer experience than locally generating them using cdktf get.
More information about the contents of the release can be found in the blog post and upgrade guide. Hashicorp hosts community office hours and has a discussion forum for questions. The CDK for Terraform Learn Guide is recommended for users new to the CDK.
MMS • Renato Losio
Article originally posted on InfoQ. Visit InfoQ

Amazon recently announced that AWS Lambda supports content filtering options for Amazon MSK, Self-Managed Kafka, Amazon MQ for Apache ActiveMQ, and Amazon MQ for RabbitMQ as event sources. The new options extend the filtering to data store and broker services and reduce traffic to Lambda functions, simplifying application logic and reducing costs.
Event filtering limits function invocations for microservices that only use a subset of events available, removing the need for the target Lambda function or downstream applications to perform filtering. Jeremy Daly, author of the weekly serverless newsletter Off-by-none, writes:
Filtering was already available for SQS, DynamoDB, and Kinesis, so this seems to round out currently supported event source mappings for Lambda. Other event triggers work differently (generally attached to the publishing service), but it’ll be interesting to see if they make a move to consolidate the underlying semantics to make everything an event source mapping.
For Kafka, the serverless platform commits offsets for matched and unmatched messages after successfully invoking the function. For Amazon MQ, it acknowledges matched messages after successfully invoking the function and unmatched messages when filtering them. While for Amazon MQ sources the message field is data, for Kafka sources, both managed and not, there are two message fields, key and value.
Both Kafka and Amazon MQ messages must be UTF-8 encoded strings, either plain strings or in JSON format. For filter rules, Lambda supports the same syntax as EventBridge.
{
"data": {
"Temperature": [ {"numeric": [ ">", 50, "<=", 60 ] } ]
}
}
Source: https://docs.aws.amazon.com/lambda/latest/dg/invocation-eventfiltering.html
When a function is triggered by an event source that supports filtering, developers can define up to five filter criteria when creating or updating the event source mappings. The filters are combined using OR logic: only an event matching at least one of the filtering criteria will trigger a Lambda function. Randall Hunt, VP cloud at Caylent, highlights the pricing benefits:
“There is no additional cost for using this feature beyond the standard price for AWS Lambda.” A huge potential price drop with no code changes, just some config changes.
Julian Wood, senior serverless developer advocate at AWS, agrees:
This is a huge additional feature. Lambda running event/stream pollers for you is just a massive productivity and simplicity boost, serverless consumers FTW! And a simple cost reducer. Don’t invoke needlessly!
According to the documentation, it can take up to 15 minutes to apply the filtering rules to events after a filter criteria is attached to a Kafka or Amazon MQ event source mapping.