Month: October 2022
Microsoft Announces the General Availability of Azure Automanage Machine Best Practices

MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
During the recent Ignite Conference, Microsoft announced the general availability (GA) of Azure Automanage Machine Best Practices for Azure Virtual Machines (VMs) and Arc-enabled servers (the company’s multi-cloud management solution). This consolidated management solution, in short, named Azure Automanage, simplifies daily server management by handling the initial setup and configuration of Azure best practice services such as Azure Monitor, Backup, Microsoft Defender, and Update Management.
The company released a public preview of Azure Automanage two years ago at Ignite 2020 as a service that implements VM management best practices for business continuity and security as defined in the Azure Cloud Adoption Framework. The GA release now supports new customization options and more operating systems, including Windows 10/11, Red Hat Enterprise Linux, Canonical Ubuntu, and SUSE Linux Enterprise Server.
Furthermore, in a Tech Community blog post, software engineer Akanksha Agrawal mentions the additional features in the GA release:
You now have the ability to apply different auditing modes for Azure Compute Security Baselines through the custom profile. For Log Analytics, Automanage supports custom workspaces and the ability to apply custom tags consistently across servers to aid with tag-based governance policies. Automanage also supports more Arc-enabled services, such as Microsoft Antimalware.
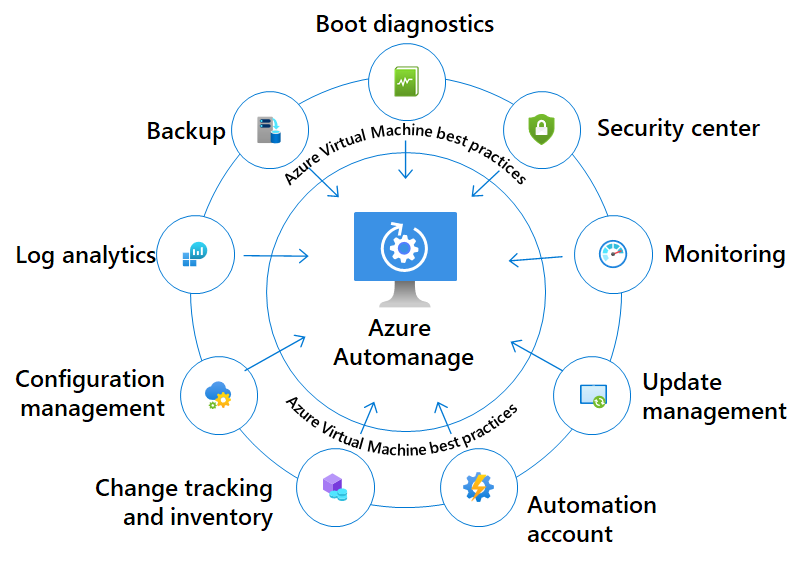
Source: https://learn.microsoft.com/en-us/azure/automanage/overview-about
With Azure Automanage, customers can onboard VMs or Arc-enabled servers by leveraging Microsoft’s best practices configured accordingly or adjusted using the available custom profile option (using Azure Policy or ARM templates). The service also automatically monitors for drift and corrects it when detected – meaning during the entire life cycle of the VMs or Arc-enabled servers, the service will continuously check if it is compliant with its configuration profile. If not, the service will correct it and pull the machines back into the desired state (DSC).
Tim Warner, a senior content developer at Microsoft, tweeted:
Automanage gives you not only DSC but Azure Policy compliance coverage.
In addition, Billy York, a consultant at Microsoft, stated in another tweet:
Pretty sure azure auto manages just deployed azure automation with update management and change tracking with it, along with the security center.
More details and guidance are available on the documentation landing page. Furthermore, Azure Automanage Machine Best Practices is free of charge – customers are billed for Azure services onboarded through the service.
MMS • Erik Costlow
Article originally posted on InfoQ. Visit InfoQ
The Quarkus team released version 2.13.0, a new release that integrates RESTEasy APIs with an integrated control against CSRF attacks, making web applications more resilient against certain types of fraud.
CSRF stands for Cross Site Request Forgery, an attack that can cause an authenticated user to submit requests into one web application while using other tabs or windows within the same browser. Oliver Moradov from BrightSec explains how CSRF attacks work using three simple examples. Attackers decide which web application they want to target, and craft custom GET requests that exchange parameters to actions within the web app using a zero-sized non-displaying image. For POST requests, the hosting web page can leverage JavaScript to create or submit forms to the web application, using a known action and parameters with the harmful form element. When performed, users who are not logged in to the target application will have their CSRF attacks silently fail while users who are logged in will perform the attacker’s custom action via their credentials.
Quarkus’ guide explains the feature in a guide for developers to enable CSRF defense. The approach of adding an application-generated token to each request matches best practice defense from OWASP. Quarkus’ automated feature creates a unique token per user that is validated on each incoming request. This token is transparent for the developer, but requires knowledge that cannot be known to any attacker who attempts to attack the web application using CSRF techniques. When present, this defense causes CSRF attacks to fail.
The CSRF defense comes alongside many other security-positive decisions by the Quarkus team that make it possible for developers to produce secure applications without requiring complex security decisions. In December 2021, Quarkus developer Max Rydahl Anderson clarified that Quarkus was unaffected by Log4Shell. By decreasing the scope of external dependencies needed to develop with Quarkus, the framework minimizes the opportunity for CVEs to appear through transitive dependencies. Anderson further clarified that some composition analyzers that attempt to locate Log4J via vile scanning could erroneously categorize Quarkus as vulnerable when it is not. Due to transitive dependencies of some integrations, applications could pull in log4j-core using a version which was allegedly vulnerable. However this was a false positive with many scanners, because the code was never actually invoked.
Another secure-by-default feature of Quarkus comes from its integration with Panache, an overlay for database access via Hibernate ORM. By modeling tables using Java objects with JPA Entity annotations and using an active record pattern rather than queries, Panache minimizes the opportunity for SQL Injection attacks. Unlike applications where SQL or HQL queries are coded, Panache favors an API through inheritance of the PanacheEntity or PanacheRepository classes that cleanly separate code and data for a higher level of security with easier development.
Developers interested in other security defenses and capabilities of the Quarkus framework can consult the dedicated Quarkus Security page. The page goes beyond standard authentication/authorization features of web applications to include development configuration and implementation guidance that can secure applications from many different vectors.
MMS • Anthony Alford
Article originally posted on InfoQ. Visit InfoQ

PyTorch, the popular deep-learning framework developed by Meta AI Research, has now become an independent top-level project of the Linux Foundation. The project will be managed by the newly-chartered PyTorch Foundation, with support from several large companies including Meta, AWS, NVIDIA, AMD, Google, and Microsoft.
PyTorch co-creator Soumith Chintala announced the move on the PyTorch blog. The move is intended to make sure business decisions about the framework are open and transparent, and take into account the needs of the many PyTorch stakeholders. The new Foundation also formalizes the technical governance of the project, defining a hierarchical maintainer organization and processes for making technical decisions. The project leaders chose the Linux Foundation as the parent organization because of its experience managing large open-source projects with a diverse community of stakeholders. According to Chintala:
PyTorch started with a small group of contributors which have grown and diversified over the years, all bringing in new ideas and innovations that would not have been possible without our community. We want to continue the open-source spirit – for the community and by the community. Thank you to our contributors, maintainers, users, supporters and new foundation members. We look forward to the next chapter of PyTorch with the PyTorch Foundation.
Chintala and his colleagues began developing PyTorch in 2016 and released version 1.0 in 2018. The framework quickly gained popularity, especially among the academic researchers; it’s currently used by approximately 80% of researchers who contribute to major machine learning conferences. InfoQ covered the initial 1.0 release as well as many of the framework’s major releases since.
The PyTorch Foundation is overseen by a governing board with members from Meta as well as from other large companies who have invested in and contributed to the project: computer chip manufacturer NVIDIA and AMD; and cloud providers Amazon Web Services (AWS), Microsoft Azure, and Google Cloud. This board will “prioritize the continued growth of PyTorch’s vibrant community.” Technical oversight will remain with the contributors and small group of core maintainers who “drive the overall project direction.”
The community reaction to the move has largely been positive, but in a Hacker News discussion, one user pointed out the lack of academic representatives on the governing board:
As an academic myself who does research on PyTorch, I wonder if there should have been more academics involved in the guidance or governance of PyTorch, especially given how much the future of machine learning may depend on choices made by such frameworks. Maybe it is unfounded, but I fear that over-optimizing for large industry uses and forgetting what it is like to run a single network training on your desktop GPU might be detrimental to PyTorch and machine learning as a whole.
Other users wondered whether the move signaled a reduction in Meta’s investment in PyTorch. Chintala addressed these concerns on Reddit, saying that “Meta is not divesting the project, if anything it’s the opposite — they’re investing more and more into PyTorch.” Yann LeCun, a Meta AI researcher and deep-learning progenitor, expressed a similar opinion on Twitter:
No. More resources from Meta, and way more resources from contributors other than Meta, now that PyTorch is a perennially open community project…It ensures that continued support is not subject to resource allocation decisions in one company. With this structure, there will be support as long as there are users who care sufficiently.
The PyTorch Foundation charter and technical governance documents can be found on the PyTorch site. PyTorch project source code is available on GitHub.
MMS • Edin Kapic
Article originally posted on InfoQ. Visit InfoQ

OpenSilver, a ‘plugin-free’ replacement for retired Silverlight browser technology, has released an update that claims to be able to reuse 99% of existing Silverlight application code and run it in a modern browser with WebAssembly and HTML5.
Silverlight was a rich internet application (RIA) technology using Microsoft XAML (extensible application markup language) for UI and supported by a custom .NET Framework runtime that ran inside the browser and provided the developers with capabilities to make desktop-like applications that were mainly targetting business scenarios. Launched in 2007, it required that the users install a browser plugin to run Silverlight applications, similar to Adobe Flash, another popular browser plugin. At its peak in 2011, Silverlight was installed in more than 60% of web users’ browsers.
However, the mainstream technology for browser applications shifted from plugins to HTML5 standards and the major browsers started blocking plugins to reduce vulnerabilities. Silverlight was eventually blocked by all major browsers except for Internet Explorer 11. Microsoft announced in May 2013 that Silverlight would reach the end of support in October 2021.
The existing Silverlight developers reacted angrily and vocally to Microsoft’s abandonment of the technology. The migration of the existing Silverlight applications was not clearly defined, as HTML5 and JS frameworks were radically different to their programming model. That made the owners of existing Silverlight applications decide to keep them running, as the rewrite would have been costly.
As early as 2014 a French company called Userware, which specialises in providing support for migrating existing XAML applications into modern web platforms, started working on CSHTML5, a solution that compiled .NET and XAML code into JavaScript and HTML5. In 2020, CSHTML5 evolved into OpenSilver (the name stands for ‘Open-source reimplementation of Silverlight’). OpenSilver compiles .NET and XAML code into HTML5 and WebAssembly and reimplements standard Silverlight controls together with some of the most popular third-party controls such as Telerik UI suite of components, allowing the developers to reuse instead of rewriting their XAML applications. OpenSilver 1.0 was released in October 2021.
One year later, in October 2022, OpenSilver 1.1 came out with new features and performance improvements. The developers claim that more than 99% of the existing Silverlight applications’ code is reusable in this release. Specifically, popular controls such as DataGrid, Silverlight toolkit library controls or the mentioned Telerik RadGridViewsilve ‘work flawlessly’ now and are ‘pixel-perfect’. The compatibility extends to some popular Silverlight libraries such as Caliburn.Micro or Microsoft Enterprise Library.
The plans for OpenSilver 2.0, slated for the first quarter of 2023, foresee adding support for VB.NET Silverlight applications. Later in the roadmap, OpenSilver developers are eyeing migrating WPF applications and supporting Visual Studio LightSwitch applications.
The reactions to OpenSilver release have been generally positive. Some developers have stated that it would solve their Silverlight migration problems while others are cautious about the alleged compatibility. Even in 2022, with only 0.02% of the browsers running Silverlight, there are still new Silverlight migration projects, apparently justifying the existence of the OpenSilver initiative.
MMS • Matt Campbell
Article originally posted on InfoQ. Visit InfoQ

HashiCorp has released a number of new features and improved core workflows for Vault, their secrets and identity management platform. The improvements include a new PKCS#11 provider, support for Redis and Amazon ElasticCache as secrets engines, improvements to the Transform secrets engine, and a better user experience for working with plugins.
Vault 1.12 has added a new PKCS#11 provider for Enterprise customers. This enables the Vault KMIP (Key Management Interoperability Protocol) secrets engine to be used via PKCS#11 calls. PKCS#11 is an open-standard C API used to access cryptographic capabilities on a device, such as a Hardware Security Module (HSM), from a local program. This addition allows Vault to be used as a Software Security Module (SSM). This includes supporting operations for key generation, encryption, decryption, and key storage operations.
The PKCS#11 library works with Vault Enterprise 1.11+ with the advanced data protection module included in the license with KMIP Secrets Engine. The provider comes in a shared C library for Linux (libvault-pkcs11.so) and MacOS (libvault-pksc11.dylib).
The provider can be configured through an HCL file and environment variables. The HCL file contains directives to map the PKCS#11 device slots to Vault instances and KMIP scopes. It is also used to configure how the library will authenticate to KMIP via a client TLS certificate. The code below shows a sample configuration of the HCL file:
slot {
server = "127.0.0.1:5696"
tls_cert_path = "cert.pem"
ca_path = "ca.pem"
scope = "my-service"
}
The slot block configures the first PKCS#11 slot to point to Vault as the server value is set to the Vault server’s IP or DNS name and port number. tls_cert_path is the location of the client TLS cert to use to authenticate to the KMIP engine. The ca_path is the location of the CA bundle to use to verify the server’s certificate and scope represents the KMIP scope to authenticate against and where the TDE master keys and associated metadata will be stored.
This release also adds support for both Redis and Amazon ElastiCache as secrets engines. The new Redis secrets engine supports the generation of both static and dynamic user roles and root credential rotation. The Amazon ElastiCache secrets engine allows for generating static credentials for existing managed roles within the service.
The Transform secrets engine lets Vault Enterprise use data transformations and tokenization to protect secrets stored in untrusted systems. This release sees an extension of the bring-your-own-key improvements introduced in Vault 1.11. With this, it is now possible to import existing keys into the Transform secrets engine.
This release also adds support for using Microsoft SQL Server as an external storage engine with tokenization in the Transform secrets engine. Finally, automation key rotation, added in Vault 1.10 for the Transit secrets engine, has been added to the Transform secrets engine in this release. It is possible to set a rotation policy during key creation to have Vault automatically rotate the keys when that period expires.
This release also introduces an upgraded plugin user experience by adding the concept of versions to plugins. The plugin catalog supports specifying a semantic version when registering an external plugin. Vault will report a version for built-in plugins when vault plugin list is executed:
$vault plugin list secret
Name Version
---- -------
ad v0.14.0+builtin
alicloud v0.13.0+builtin
aws v1.12.0+builtin.vault
More details on these and other changes included in this release can be found in the release post. An upgrade guide is available to assist in the process of upgrading existing clusters. Vault can be found either as open-source or in an enterprise edition.
MMS • Johan Janssen
Article originally posted on InfoQ. Visit InfoQ
Picnic, the “supermarket on wheels” company, has released Error Prone Support, an open source project that extends Google’s Error Prone, that contains thirty new bug checks to detect, and optionally resolve, possible mistakes during compilation of a Java project. More than fifty new Refaster rule collections are available to improve code uniformity by automatically rewriting the codebase.
Error Prone is a Java compiler plugin, open sourced by Google, which performs static analysis during compilation to detect bugs or suggest possible improvements. The plugin contains more than 500 pre-defined bug checks and allows third party and custom plugins. After detecting issues, Error Prone can display a warning or automatically change the code with a predefined solution.
One of the thirty new bug checks provided by the recently released Error Prone Support is the EmptyMethod class, a bug check which will display a warning or optionally remove the following methods:
void method() {}
static void staticMethod() {}
Whenever an empty method is necessary, the false positive may be suppressed with the following annotation:
@SuppressWarnings("EmptyMethod")
The AutowiredConstructor bug check removes the redundant @Autowired annotation whenever a class has just one constructor as in the following examples:
class Course {
@Autowired
Course() {}
}
class Student {
@Autowired
Student(String name) {}
}
The MethodReferenceUsage class detects lambda expressions and converts them to method references. For example, () -> course.method() is changed to course::method.
Writing a bug check in Error Prone involves working with abstract syntax trees (AST) and Error Prone’s APIs. This is often necessary to detect bugs, but mostly not when rewriting code. Google’s Refaster is easier to use and now part of Error Prone. Refaster rules may be used to define rewrite rules in Java with @BeforeTemplate and @AfterTemplate annotations. Error Prone Support offers more than fifty new Refaster rule collections containing more than 500 Refaster templates, such as the StringRules class, which replaces various expressions to evaluate whether a String is empty with the String.isEmpty() method:
@BeforeTemplate
boolean before(String str) {
return Refaster.anyOf(str.length() == 0, str.length() <= 0,
str.length() < 1);
}
@AfterTemplate
@AlsoNegation
boolean after(String str) {
return str.isEmpty();
}
The @AlsoNegation annotation indicates that the rule can also match the logical negation of the @BeforeTemplate bodies. For example, the code str.length() != 0 will be changed to !str.isEmpty().
The TimeRules class contains various rewrite rules for time expressions such as replacing various Zone offsets with UTC:
@BeforeTemplate
ZoneId before() {
// `ZoneId.of("Z")` is not listed, because Error Prone flags it out of the box.
return Refaster.anyOf(
ZoneId.of("GMT"),
ZoneId.of("UTC"),
ZoneId.of("+0"),
ZoneId.of("-0"),
UTC.normalized(),
ZoneId.from(UTC));
}
@AfterTemplate
ZoneOffset after() {
return UTC;
}
Or replacing the compareTo method with the more readable isBefore method:
@BeforeTemplate
boolean before(Instant a, Instant b) {
return a.compareTo(b) < 0;
}
@AfterTemplate
@AlsoNegation
boolean after(Instant a, Instant b) {
return a.isBefore(b);
}
The installation instructions for Error Prone can be used as a basis, as Error Prone Support is built on top of it. After that, the relevant Error Prone Support modules should be added to the annotationProcessorPaths, for example, with the maven-compiler-plugin:
com.google.errorprone
error_prone_core
${error-prone.version}
tech.picnic.error-prone-support
error-prone-contrib
${error-prone-support.version}
tech.picnic.error-prone-support
refaster-runner
${error-prone-support.version}
InfoQ spoke to Rick Ossendrijver, Software Engineer at Picnic and one of the creators of Error Prone Support:
InfoQ: What made you decide to create Error Prone Support instead of adding the bug checks to Error Prone?
Ossendrijver: Google Error Prone doesn’t accept many new checks and Error Prone Support contains some Picnic-opinionated checks. Releasing the bug checks separately also prevents overloading the Google maintainers of Error Prone with contributions. A separate project also allows us to release faster and more often without being dependent on the Error Prone maintainers.
InfoQ: Is the focus of Error Prone Support on code uniformity, bug detection, or both?
Ossendrijver: We definitely focus on both. We highly value code consistency (uniformity). For code uniformity we prefer refaster rules as they are easier to write then bug checks which require more in-depth Java knowledge. For bug detection one usually needs to write a bug check as a more thorough analysis is required.
InfoQ: Can you already tell us something about upcoming features?
Ossendrijver: Yes for sure, we plan a number of improvements. First of all, the existing matching algorithm is relatively slow and we made some major improvements to speed up Refaster.
Next to that, Error Prone bug checks show compilation warnings or errors as shown in the example on the website. The message provides a link to the documentation of that specific bug check. We have support for running Refaster rules “as a bug check”. That means that we also show compilation warnings or errors. Soon we will add links to the documentation website when a Refaster rule matches in the code. On top of that, we will be introducing new annotations and processing thereof, to provide better error messages when a Refaster rule flags something.
Lastly, we will introduce more bug checks and Refaster rules. Our Maven `self-check` profile applies those bug checks and Refaster rules on the codebase itself. That way we can easily increase the quality of our codebase.
Error Prone Support welcomes contributions and provides contribution guidelines.
Java News Roundup: Sequenced Collections, Spring 6.0-RC1, Apache Tomcat, Reactor 2022.0-RC1
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for October 10th, 2022 features news from OpenJDK, JDK 20, Spring Framework 6.0-RC1, Spring Batch 5.0-M8, Quarkus 2.13.2, Helidon 3.0.2 and 2.5.4, Project Reactor 2022.0-RC1, Piranha 22.10.0, JHipster Lite 0.18.0, Apache Tomcat 8.5.83 and 10.1.1 Apache James 3.7.2 and Devoxx Belgium.
OpenJDK
JEP 431, Sequenced Collections, was promoted from its Draft 8280836 to Candidate status this past week. This JEP proposes to introduce “a new family of interfaces that represent the concept of a collection whose elements are arranged in a well-defined sequence or ordering, as a structural property of the collection.” Motivation was due to a lack of a well-defined ordering and uniform set of operations within the Collections Framework.
JDK 20
Build 19 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 18 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 20, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
On the road to Spring Framework 6.0, the first release candidate was made available this past week that ships with baselines to JDK 17+ and Jakarta EE 9+ and a broader revision of the Spring infrastructure. This release candidate completes the foundation for Ahead-of-Time (AOT) transformations and corresponding AOT processing support for Spring application contexts. Other new features and refinements include: an HTTP interface client based on @HttpExchange service interfaces; support for RFC 7807 problem details; and Micrometer-based observability for HTTP clients. More details on this release may be found in the what’s new page.
Similarly, on the road to Spring Batch 5.0, the eighth milestone release features: an updated DefaultExecutionContextSerializer class to serialize/deserialize context to/from Base64; and an enhanced SystemCommandTasklet class with a new strategy interface, CommandRunner, to decouple the command execution from the tasklet execution. Further details on this release may be found in the release notes.
Quarkus
Red Hat has released Quarkus 2.13.2 that delivers fixes such as: prevent a possible null pointer exception while building a violations report; ensure all CLI commands work with Windows Powershell; and introduce a version of the @OidcClientFilter annotation to enhance RestClient Reactive to support registering providers via custom annotations. More details on this release may be found in the changelog.
Helidon
Oracle has released Helidon 3.0.2 that ships with updates to Helidon components such as WebServer, WebClient, DBClient and CORS. There were also dependency upgrades to Hibernate 6.1.4.Final, EclipseLink 3.0.3, GraphQL Java 17.4, SnakeYAML 1.32, Reactive Streams 1.0.4 and Oracle Cloud Infrastructure 2.45.0.
Similarly, in the 2.5 release train, Helidon 2.5.4 was made available to deliver updates to the Helidon components and dependency upgrades to Hibernate 5.6.11.Final, Hibernate Validator 6.2.5, EclipseLink 2.7.11, GraphQL Java 17.4, SnakeYAML 1.32, Reactive Streams 1.0.4,
Project Reactor
On the road to Project Reactor 2022.0.0, the first release candidate features dependency upgrades to the reactor-core 3.5.0-RC1, reactor-pool 1.0.0-RC1, reactor-netty 1.1.0-RC1, reactor-netty5 2.0.0-M2 and reactor-kafka 1.3.13 artifacts. There was also a realignment to RC1 with the reactor-addons 3.5.0-RC1 and reactor-kotlin-extensions 1.2.0-RC1 artifacts that remain unchanged.
Piranha
Piranha 22.10.0 has been released. Dubbed the “Stabilization is ongoing” edition for October 2022, this new release includes deprecations to: Piranha Micro, MicroExtension, StandardExtension and the old server distribution. There was also a dependency upgrade to Weld 5.1.0, the compatible implementation to the Jakarta Contexts and Dependency Injection specification. Further details on this release may be found in their documentation and issue tracker.
JHipster
JHipster Lite 0.18.0 has been released that ships with bug fixes, enhancements and dependency upgrades that include modules: consul 1.13.2, vite 3.1.8, prettier-plugin-svelte 2.8.0, docker/build-push-action 3.2.0 and vue-tsc 1.0.7.
Apache Software Foundation
Apache Tomcat 10.1.1 has been released that ships with an updated Eclipse JDT compiler 4.23 and fixes for: a refactoring regression that broke JSP includes; and unexpected timeouts that may appear as client disconnects when using HTTP/2 and NIO2. More details on this release may be found in the changelog.
Apache Tomcat 8.5.83 has also been released featuring: support for authenticating WebSocket clients with an HTTP forward proxy when establishing a connection to a WebSocket endpoint; various fixes for edge case bugs in expression language processing; and an enforcement of RFC 7230, Hypertext Transfer Protocol (HTTP/1.1): Message Syntax and Routing, such that a request with a malformed content-length header should always be rejected with a 400 response. Further details on this release may be found in the changelog.
Apache James 3.7.2 has been released that delivers bug fixes and dependency upgrades to Scala 2.13.9, slf4j 2.0.1, Netty 4.1.81.Final, Logback 1.4.0 and jsoup 1.15.3. More details on this release may be found in the release notes.
Devoxx Belgium
Devoxx Belgium 2022 was held at the Kinepolis Antwerp this past week featuring many speakers from the Java community who presented on topics such as Java, Architecture, Server-Side Java, Security and Development Practices.
MMS • Erik Costlow
Article originally posted on InfoQ. Visit InfoQ

DataDog has published their State of AWS Security report, an overview of practices based on data analysis from over 600 organizations. The report compares intersection and divergence between actual usage against industry best practices and the cause of breaches/data leaks.
The first set of analysis covers Identity and Access Management (IAM) including credential age/rotation, Multi-Factor Authentication, and key loss. Over its analysis the survey revealed challenges of managing IAM at scale across many users and systems. Key rotation and usage is a particular issue with 75% of IAM users’ keys being older than 90 days and a portion of those exceeding a year without actual usage.
The report does not cite the level of permissions associated with keys, as the AWS IAM Access Analyzer provides a capability for identifying over-permissions IAM policies. Brigid Johnson, AWS Director of Identity, explains the connection that helps align IAM policies against CloudTrail logs to identify permissions that go unused for a particular account and can be removed:
“This is how policy generation works: You ask Access Analyzer for a policy based on your role. We go and review your CloudTrail logs and identify all the activity your role used. Then we convert it into a pretty IAM policy”
DataDog’s report reveals the scope of other causes for data loss. Particularly revealing is that 15% of organizations have a publicly exposes SQS topic that would enable remove users to retrieve and/or send publish notifications, either with no credentials or with easily identifiable shared credentials. Additionally over a third of respondents had one or more publicly exposed S3 buckets. While there are valid uses for exposed S3 buckets such as web hosting, these exposed buckets are often the source of large data leaks. In January 2022, Sega exposed their S3 bucket revealing a leakage of many API keys, internal messages, and user-related data. In another S3 bucket incident from 2020, unauthorized users were able to modify Twilio’s JavaScript SDK for TaskRouter, allowing their modified code to be served to Twilio’s users.
The report revealed several positive trends where good AWS security was the default. Across the recorded users, 77% of organizations did not use root user credentials in a 30 day period (only 23% did). Beyond that scope, only 10% of organizations had an active root user key at all. AWS maintains documentation describing the root user best practices,
“We strongly recommend that you do not use the root user for your everyday tasks, even the administrative ones. Instead, adhere to the best practice of using the root user only to create your first IAM user. Then securely lock away the root user credentials and use them to perform only a few account and service management tasks.”
Developers and Architects of cloud applications can consult the AWS Well Architected Tool, a suite of tools that helps compare systems and policies against good AWS practices to product more secure and reliable applications that would put their work on the good-end of DataDog’s report.
MMS • Johan Janssen
Article originally posted on InfoQ. Visit InfoQ

ArchUnit allows developers to enforce architecture rules such as naming conventions, class access to other classes, and the prevention of cycles. The library was originally created in 2017 by Peter Gafert and version 1.0.0 was released in October.
ArchUnit works with all Java test frameworks and offers specific dependencies for JUnit. The following dependency should be used for JUnit 5:
com.tngtech.archunit
archunit-junit5
1.0.0
test
Now the ClassFileImporter can be used to import Java bytecode into Java code. For example, to import all classes in the org.example package:
JavaClasses javaClasses = new ClassFileImporter().importPackages("org.example");
Now the ArchRule class may be used to define architectural rules for the imported Java classes in a Domain Specific Language (DSL). There are various types of checks available, the first one is for package dependencies. The check specifies that no classes inside repository packages should use classes inside controller packages:
ArchRule rule = noClasses()
.that().resideInAPackage("..repository..")
.should().dependOnClassesThat().resideInAPackage("..controller..");
Two classes are used to verify the rules, a CourseController class inside a controller package and a CourseRepository class inside a repository package:
public class CourseController {
private CourseRepository courseRepository;
}
public class CourseRepository {
CourseController courseController;
}
This is not allowed by the ArchRule defined before, which can be tested automatically with JUnit:
AssertionError assertionError =
Assertions.assertThrows(AssertionError.class, () -> {
rule.check(javaClasses);
});
String expectedMessage = """
Architecture Violation [Priority: MEDIUM] -
Rule 'no classes that reside in a package
'..repository..' should depend on classes that reside in a package
'..controller..'' was violated (1 times):
Field has type
in (CourseRepository.java:0)""";
assertEquals(expectedMessage, assertionError.getMessage());
The CourseController and CourseRepository depend on each other, which often is a design flaw. The cycle check detects cycles between classes and packages:
ArchRule rule = slices()
.matching("org.example.(*)..")
.should().beFreeOfCycles();
AssertionError assertionError =
Assertions.assertThrows(AssertionError.class, () -> {
rule.check(javaClasses);
});
String expectedMessage = """
Architecture Violation [Priority: MEDIUM] - Rule 'slices matching
'org.example.(*)..' should be free of cycles' was violated (1 times):
Cycle detected: Slice controller ->s
Slice repository ->s
Slice controller
1. Dependencies of Slice controller
- Field has type
in (CourseController.java:0)
2. Dependencies of Slice repository
- Field has type
in (CourseRepository.java:0)""";
assertEquals(expectedMessage, assertionError.getMessage());
Class and Package containment checks allow the verification of naming and location conventions. For example, to verify that no interfaces are placed inside implementation packages:
noClasses()
.that().resideInAPackage("..implementation..")
.should().beInterfaces().check(classes);
Or to verify that all interfaces have a name containing “Interface”:
noClasses()
.that().areInterfaces()
.should().haveSimpleNameContaining("Interface").check(classes);
These containment checks may be combined with an annotation check. For example, to verify that all classes in the controller package with a RestController annotation have a name ending with Controller:
classes()
.that().resideInAPackage("..controller..")
.and().areAnnotatedWith(RestController.class)
.should().haveSimpleNameEndingWith("Controller");
Inheritance checks allow, for example, to verify that all classes implementing the Repository interface have a name ending with Repository:
classes().that().implement(Repository.class)
.should().haveSimpleNameEndingWith("Repository")
With the layer checks, it’s possible to define the architecture layers of an application and then define the rules between the layers:
Architectures.LayeredArchitecture rule = layeredArchitecture()
.consideringAllDependencies()
// Define layers
.layer("Controller").definedBy("..controller..")
.layer("Repository").definedBy("..Repository..")
// Add constraints
.whereLayer("Controller").mayNotBeAccessedByAnyLayer()
.whereLayer("Repository").mayOnlyBeAccessedByLayers("Controller");
AssertionError assertionError =
Assertions.assertThrows(AssertionError.class, () -> {
rule.check(javaClasses);
});
String expectedMessage = """
Architecture Violation [Priority: MEDIUM] - Rule 'Layered architecture
considering all dependencies, consisting of
layer 'Controller' ('..controller..')
layer 'Repository' ('..Repository..')
where layer 'Controller' may not be accessed by any layer
where layer 'Repository' may only be accessed by layers ['Controller']'
was violated (2 times):
Field has type
in (CourseRepository.java:0)
Layer 'Repository' is empty""";
assertEquals(expectedMessage, assertionError.getMessage());
More information can be found in the extensive user guide and official examples from ArchUnit are available on GitHub.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Created by JetBrains to enable using Kotlin to build iOS and Android apps with native UI from a single codebase, Kotlin Multiplatform Mobile has exited the experimental phase and is now available in beta.
Kotlin Multiplatform Mobile is an SDK for iOS and Android app development that allows you to maintain a shared codebase for networking, data storage, and analytics, as well as the other logic of your Android and iOS apps.
During the experimental phase JetBrains tried multiple approaches to memory management, libraries, and project configuration and refined the balance between cross-platform features, including networking, data storage, and analytics, and access to the native SDKs.
Specifically, Kotlin Multiplatform Mobile beta implements a native automatic memory manager that aims to simplify sharing objects between threads by providing lock-free concurrent programming primitives.
According to JetBrains, the beta release provides enough stability for developers to start adopting Kotlin Multiplatform Mobile. As a sign of its readiness for adoption, JetBrains highlights the growing multiplatform library ecosystem, community support, and especially a number of early adopters’ case studies, which include Autodesk, VMware, Netflix, and many more.
Furthermore, a number of popular libraries have already adopted Kotlin Multiplatform, including async event handling framework Ktor, typesafe SQL API generator SQLDelight, GraphQL client Apollo, and dependency injection framework Koin.
Kotlin Multiplatform is integrated with Android Studio, leveraging tooling and ecosystem familiar to Android developers, whereas iOS developers will surely have a somewhat less gradual learning curve. While Android Studio is the main IDE for Kotlin Multiplatform development, Xcode will still be required to build iOS apps and submit them to the App Store.
At the moment of this writing, the Kotlin Multiplatform Mobile plugin is still at an alpha stage. The Kotlin Multiplaform plugin provides a collection of directives to use in Gradle files, including new targets for the iOS, watchOS, and tvOS platforms, sourceSet, compilation, and others.
If you prefer a different approach, you can also use Kotlin Multiplatform to create cross-platform libraries() and then use them within your independent iOS and Android projects.
You can find here a curated list of Kotlin Multiplatform Mobile samples.