Month: October 2022

MMS • Chip Huyen
Article originally posted on InfoQ. Visit InfoQ

Transcript
Huyen: My name is Chip. I’m here to talk about a topic that I’m extremely excited about, at least excited enough to start a company on it, which is streaming-first infrastructure for real-time machine learning.
I come from a writing background. I have actually published a few very non-technical books. Then I went to college and fell in love with engineering, especially machine learning and AI, and have been very fortunate to have had a chance to work with some really great organizations including Netflix, NVIDIA, and Snorkel AI. Currently, I’m the co-founder of a stealth startup.
Two Levels of Real-Time ML
Because my talk is on real-time machine learning, if you talk to software engineers, they will probably tell you that there’s no such thing as real time, no matter how fast the processing is, there’s always some delay. It can be very small, like milliseconds, but it is still delay. Real time encompass like near real time. There will be two levels of real-time machine learning that I want to cover. The first is online predictions, is when the model can receive a request and make predictions as soon as the request arrives. Another level is online learning, but then if you enter online learning onto Google, you will get a bunch of information on online courses like Coursera, Udemy. People are using the term continual learning instead. Continual learning is when the machine learning models are capable of continually adapting to change in distributions in production.
First about online predictions. Online predictions is usually pretty straightforward to deploy. If you have developed a wonderful machine learning model like object detections, the easiest way to deploy is probably to export it into some format in ONNX. Then upload it to a platform like AWS, and then get back an online prediction endpoint. If you send data to that prediction endpoint, you can get predictions onto this data. Online predictions is when the models wait to receive the request, and then generate predictions on a further request. The problem with online predictions is latencies. We know that latency is extremely important. There have been many research done to show that like, no matter how good the service is, or the models are, if it takes us like milliseconds too long to return results, people want to click on something else. The problem with machine learning is that in the last decade, models are getting bigger. Usually bigger models give better accuracy, but it generally also means that bigger models means that it takes longer for these models to produce predictions, and users don’t want to wait.
Online Prediction: Solution
How do you make online prediction work? You actually need two components. The first is you need a model that is capable of returning fast inference. There have been so much work done around this. One solution is model compression, so using quantization and distillation. You also can do like inference optimizations, like what TensorRT is doing. Or you can also build more powerful hardware, because more powerful hardware allow models to do computation faster. This is not the focus of my talk.
Real-Time Pipeline: Ride-sharing Example
My talk is going to focus on real-time pipeline. What does that mean? A pipeline that can process data, inputs the data into the model, and generate predictions and return predictions in real time to users. To illustrate real-time pipeline, imagine you’re building a fraud detection model for a ride-sharing service like Uber or Lyft. To detect whether a transaction is fraudulent, you want information about that transaction specifically. You also want to know about the user’s recent transaction, to see [inaudible 00:04:18] recently. You also want to look into that credit card recent transactions, because what happens is that when a credit card is stolen, the thief wants to make the most out of that credit card by using that actually for multiple transactions or at the same time to maximize profit. You also want to look into recent in-app fraud, because there might be a trend regarding the locations and maybe this fraud, this specific transaction is related to those other fraudulent transactions in the locations. A lot of those are recent information, and the question is, how do you quickly assess these recent features? Because you don’t want to put them into your permanent storage and have to go into the permanent storage to get them out because it might take too long and the users are impatient.
Real-Time Transport: Event-driven
The idea is just like what if we leveraged some in-memory storage, so real memory storage. Like when we have an incoming event like a user booked a trip, picks a location, cancels trip, contacts driver. Then you put all the information into interim storage, and then you keep it there for as long as those events are useful for real-time purposes. Maybe after seven days, you can either discard those events or move them to permanent storage or S3. This in-memory storage is generally what is called real-time transport. Real-time transport doesn’t have to be confined to in-memory storage. It can also be real-time transport if it can leverage more permanent storage efficiently. Real-time transport tools, you probably know like Kafka, Kinesis, or Pulsar. Because this is very much event-based, so this kind of processing is called event-driven processing.
Stream Processing: Event-Driven
First, I want to differentiate between static data and streaming data. Static data is the data that has already been generated before. You can access through a file format like CSV or Parquet. Streaming data is the data that you can access through [inaudible 00:06:30] real-time transport like Kafka, Kinesis. Static data because it has already been generated, you know exactly how many examples are there, so static data is bounded. We input a CSV file into the processing code when a job is done, like when it goes through every sample of static data, you know that the job is done. We’re assuming that it’s like continually being generated, so it’s unbounded. You will never know when the job is finished. Certainly, that allows you to assess static features, like features that don’t change very often, something like age, gender, or when the account was created. Whereas streaming data allow us to access information that is very recent which means it can change very quickly. For example like users locations in the last 10 minutes, or what have I been reading in the last few minutes. For static data you can’t leverage, so traditionally for things like static data, you need to process them using a batch processing in MapReduce, Spark. Whereas people think to process streaming data you want some stream processing tool like Flink, Samza, Spark Streaming.
One Model, Two Pipelines
There’s a problem with like separation of batch processing and stream processing, is that now we have two different pipelines for the model. First of all, during training, you have a lot of static data, and you use batch processing to generate those features. During inference, now you have to deal with, if we do like online predictions, you want to work with streaming data, so you have to use stream processing to extract features through the stream processing process. Now you have a mismatch. It’s actually one of the very common source for errors that I see in production, so like when a change in one pipeline fails to replicate in another pipeline. I personally have encountered that a few times. One time we had models that performed really well during development.
Then when we deployed the models, like really poorly, the performance was poor, and we had to look into it, so we get the same piece of data, and we’d run it through the predictions function in training pipeline, and then the prediction function in the inference pipeline, we actually got different results. We realized there’s mismatch between our two pipelines.
Stream and Batch Processing
There’s been a lot of work done in unifying the batch and stream processing. One very interesting approach is to leverage streaming-first infrastructure to unify both of them. The reason is that, especially folks at Flink have been pushing for, is like batch is a special case of streaming, because bounded dataset is actually a special case of unbounded data streaming, because if your systems can deal with unbounded data stream, you can make it work with bounded dataset, but then if your system can only deal with bounded dataset, it’s very hard to make it work with unbounded data stream. People have been using things like Flink, or a streaming-first approach to unify both stream and batch processing.
Request-Driven to Event-Driven Architecture
We talk about event-driven processing, I want to talk about a related concept, which is event-driven architecture, as opposed to request-driven architecture. I want to talk about it in terms of microservices. In the last decade, the rise of microservices is very tightly coupled with the rise of the REST API. REST API is request driven. What that means is that you usually have a concept of client and server. The client is like send a request, like a POST and GET request to the read server and get back a response. This is synchronous. The server has to listen for the request to register. If the server is down, the client will keep resending new requests until it gets a response, or until it times out.
Things look pretty great. Then problems arise when you have a lot of microservices, is the inter-service communications, because different services will have to send requests to each other and get information to each other. Here in the example we have three microservices, and we see too many arrows like information back and forth. If we have hundreds or thousands of microservices, it can be extremely complex and slow. Yes, so complex inter-service communication.
Another problem is how to map data transformation through the entire system. We have talked about how difficult it is to understand machine models in production. If you want like how management change data, you have to ping data management to get that information. You actually don’t have the full view of the data flow through the system, so it can be very hard for monitoring and observability. Instead of having request-driven communications, what if we want to do it like in an event-driven architecture. What that means is that instead of services communicating directly with each other, you want a central location, like a stream. Whenever a service wants to publish something, it pushes that information onto the stream. Whenever other services keep on listening in. If they find out that like this much is relevant to them, then they can take it and they can produce some result, and then it sends it back to the stream and then the other services keep on listening. It’s possible for all services to publish to the same stream, and all services can also subscribe to the stream to get the information they need. You can write the stream into different topics, so that it’s easier to find the information relevant to that service. This is event-driven. First, it reduces the need for inter-service communications. Another is that like, because all the data transformation is now in the stream, you can just query the stream and understand how a piece of data is transformed by different services through the entire system. It’s really a nice property for monitoring.
Model’s Performance Degrades in Production
We talk about online predictions. The next step we want to talk about is continual learning. It’s no secret that model performance degrades in production. There are many different reasons, but one key reason is data distribution shifts. Things change in the real world. The changes can be sudden, first of all, COVID. I saw recently that Zillow actually closed their house flipping because they failed to forecast house prices, because all the change with COVID made their models extremely confused, and they lost a bunch of money and they closed the service. Yes, sudden changes like COVID. It can be cyclic or seasonal, for example, ride sharing demand is probably different on the weekend and on the weekday, or during rainy seasons and dry seasons. It can also be gradual, just because things change over time, like emojis, the way people talk slowly change over time.
From Monitoring to Continual Learning
Monitoring is a huge segment of the market. Monitoring helps you detect changing data distributions, but it’s a very shallow solution, because you detect the changes then what? What you really want is continual learning. You want to continue to adapt models to changing data distributions. When people hear continual learning, they think about the case where you have to update the models with every incoming sample. It’s actually very few companies that do require that, for several reasons, like one is catastrophic forgetting. Another is that it can get unnecessarily expensive. A lot of hardware backends today are built to process a lot of data at the same time, so you just use that to process one sample at a time, it can be very wasteful. What people usually do is that they update models with micro-batches, so they wait to collect maybe like 500 or 1000 samples, and then make an update with a micro-batch.
Learning Schedule != Evaluating Schedule
Also like the difference between a learning schedule and evaluating schedule. You make an update with the model, but you don’t deploy the update because I worry if that update is really bad and is going to mess up our service. You don’t want to deploy the update until we have evaluated that update. You actually won’t update a model if you create a replica of that model, and then update that replica, which now becomes a candidate model and you only want to use it to deploy that candidate model after it has been evaluated. I can talk at length about how to do evaluations, but you have to do like offline evaluations. First of all, you need to use some static data test set to ensure that the model isn’t doing something crazy. You also need to do online evaluations, because the whole point of continual learning is to adapt a model to change in distributions, so it doesn’t make sense to test this on a stationary test set. The only way to be sure that the model is going to work is to do online evaluations. There are a lot of ways for you to do it safely, through A/B testing, canary analysis, and bandits. I’m especially excited about bandits because it allows you to test multiple models, so you frame it the same way you would frame the multi-armed bandit problem. You treat X model as an arm, so if you have multiple current models, and each of them is an arm and you don’t know the real work for each model until you push an arm. The same frame as a multi-armed bandit.
Iteration Cycle
For this continual learning, the iteration cycles can be done in order of minutes. Here’s an example of Weibo. Iteration cycle is around 10 minutes now. You can see similar examples with the Alibaba Singles’ Day, TikTok, and Shein. A lot of Chinese companies, and I’m always blown away by the speed, and then when I talk to American companies, and they don’t even talk in order of minutes, they talk in order of days. There’s a recent study by Algorithmia, and they found it’s like 64% of companies take a month or so, or longer.
I think about it as like, there’s no reason why you shouldn’t make a difference between batch learning paradigm and the continual learning paradigm. Those are lessons I learned from machine learning computing. Before, people tell us like, that’s crazy, you can spread the workload onto machines, but you can’t spread the workload to 1000 machines. That’s what people thought before. Then as you got a lot of infrastructure work done in cloud, to make it extremely easy for you to like spread the whole logic to a machine or 1000 machines. I think the same thing is happening in machine learning. If you can update the model every month, there’s no reason why you can’t update the model every 5 minutes. It’s just like the duration is just a knob to turn. I do think just like with infrastructure wasn’t being built for what we are doing right now, it’s going to make it extremely easy for a company to just update the model whenever they want.
Continual Learning: Use Cases
There are a lot of great use cases for continual learning. Of course, it allows a model to adapt to rare events very quickly. Of course, like Black Friday. Black Friday happens only once a year in the U.S., so there’s no way you can have enough historical information to predict accurately what the user is going to do on this Black Friday. For the best performance you would have to continually train the model to the data from the same days so that you boost performance. Actually, that is one of the use cases that Alibaba is using continual learning for, so they acquired Ververica the company that maintains Flink for $100 million, to adapt Flink to a machine learning use case. They use this for Singles’ Day, which is like a shopping holiday similar to Black Friday in the U.S.
It also helps you overcome continuous cold start. Continuous cold start is when you have new users or users get new device or you have a lot of users who are locked in, or like users who were locked in so you don’t have enough historic confirmations to make predictions for them. If you can update the model with in-sessions or during sessions, then you can actually overcome the continuous cold start problem. Because with in-sessions, you can learn what users want, even though we don’t have historical data, and you can make relevant predictions for them in-sessions. It can be extremely powerful. Imagine you have a new customer, users coming into the search service and if that user doesn’t find anything relevant to them, they’re going to leave, but if they find things relevant to them, because you can recommend it to them, then they might stay. Just an example, like TikTok is so addictive because they are able to use continual learning to adapt users’ preference with in-session.
What Is Continual Learning Good For?
Continual learning is especially good for tasks with natural labels, for example on recommendation systems. Like you show users the recommendations, and if they click on it, it is good predictions, and if after a certain period of time and no clicks then it’s a bad prediction. It is one short feedback loop, in order of like minutes. For online content like short video, TikTok videos, a Reddit post or tweet, then they recommend from the time, the recommender just show for this time they have click on is pretty fast, but not all recommendation systems have short feedback loops. For example if you work for Stitch Fix, and you want to recommend items that users might want, you would have to wait for the items to be shipped and users to try them on before you know, so it can take weeks.
Quantify the Value of Data Freshness
Continual learning sounds great, but is this right for you? First, you need to understand, you have to quantify the value of data freshness. People keep saying that fresh data is better, but how much better. One thing you can do is you can try to measure how much a model performance changes, if you switch from retraining monthly to weekly to daily or even hourly. Back in 2014, Facebook did this study, and they found if they’re going from training weekly to daily, they were able to increase their click-through rate by 1%, which is significant enough for them to change the pipeline to daily. You also want to know, how would retention rate change if you can do in-session adaptations, for the case like new users coming in, like if you can show the relevant information to them, and how much more they’re going to stay? You also want to understand the value of model iteration and data iteration. Model iteration is when you can make significant change to a model architecture, and data iteration like if you train the same model on newer data. In theory, you can do both. In practice, the more it’s going to run on one, means the less resource you have to spend on others. I’ve seen a lot of companies they found out, it was like data iteration actually gives them much higher return than model iteration.
Quantify the Value of Fast Iteration
You also want to quantify the value of fast iterations, like if you can run experiments very quickly and get feedback from the experiment quickly, then how many more experiments can you run. The more experiments you can run means that you can find experiments that works better for you and give you better return.
Quantify Cloud Bill Savings
One problem that a lot of people are worried about is the cloud cost. You’ve got training cost money, and the more often you train the model, you just think the more expensive it’s going to be. It’s actually not the case, it’s very interesting about continual learning. In batch learning, when it takes longer for you to retrain the model, you have to retrain the model from scratch. Whereas in continual learning, actually, you just train the model more frequently, so you don’t have to retrain the model from scratch, but you can continue training the model on only fresh data. It actually means that it requires less data and less compute. Here’s a really great study from Grubhub, when they switched from monthly training to daily training, gives them 45 times cost savings on training compute cost. At the same time, 25% increase in the metrics they use in purchase through rate.
Barriers to Streaming-first Infrastructure
Streaming-first infrastructure sounds really great. You can use that for online prediction. You can use it for continual learning. It’s not really that easy. A lot of companies haven’t switched to streaming-first infrastructure yet, one reason is that they don’t see the benefits of streaming, maybe because their systems are not at a scale where inter-service communication has become a problem. Another thing is they don’t see the benefit of streaming-first infrastructure because they have never tried that before. Because they’ve never tried that before they don’t see the benefits, so the chicken and egg problem, because they need to see the benefit to try it out, to deploy it. Because you need to deploy it first, to see the benefit. Also, there’s a high initial investment in infrastructure. When we talk about streaming-first infrastructure, a lot of companies they’re like, you need a specialized knowledge about it. It may have been true in the past, but right now the good news is that there are so many tools being built to make it extremely easy for companies to switch to streaming-first infrastructure. For example, Snowflake now has streaming. Confluent is a $16 billion company. You have services like Materialize that’s raised $60 million on top of previously $40 million, so $100 million to help companies adapt their infrastructure to streaming-first, easily.
Bet on the Future
I think it’s important to make a bet in the future, because for some companies, you can make a lot of internal updates, but then it may be cheaper to make one big jump to streaming. Maybe it’s cheaper to make that big jump instead of doing 1000 incremental updates. Other companies are now moving to streaming-first because their metric increase has plateaued, and they know that for big metric wins they will need to try out new technology, and that’s why the investment in streaming. We are building a platform to make it easier for companies to do machine learning, leveraging streaming-first infrastructure.
Questions and Answers
Lazzeri: How does reproducibility change with continual learning?
Huyen: I think that you understand that maybe we just look at, where does the difficulty in reproducibility come from? I think one of the big reasons for making it so hard to reproduce a model in production is a separation of retraining and serving. ML production has different steps, you develop a model, and then you deploy it, and that causes a lot of problems. I see for example, like somebody used the wrong binaries, it can be you used an older version of a model instead of the current version, or like, there’s some changes in the featurization of code and the training, and so they actually now use different features. One thing about continual learning is that you can design infrastructure, so that the training and serving actually use very similar infrastructure, for example, in terms of features. One trick you can do is that when you make predictions on some requests, you extract features from that request to make predictions, and then use those same extracted features to train the next generation of the model. Now we can guarantee that the features you do in training and serving are the same, so it helps with reproducibility. Also a thing like controlling, you need to be able to track the lineage of the models, because you have a model and then you want to train the next iteration of it. You have to have some model store. You could check how different models are evolving, and you know like what models inherited from what model? I think that’s going to definitely help with reproducibility.
Lazzeri: There is another question about model training and performance. If the model is constantly training, isn’t there a risk that the model starts performing worse. Does this require more monitoring?
Huyen: This is one thing that I work a lot on actually. When you train the model, the model can learn very quickly. It can fail very quickly. I’m not sure if you guys remember the example of the Microsoft chatbot, Tay. Tay was supposed to learn from users’ feedback interactions, and within 24 hours, it became extremely racist and sexist, just because it got a lot of trolls. When you put the models for continual learning online, it’s more susceptible to like attacks, more susceptible for like people to inject bad data or maliciously making the model to learn really bad things. Evaluation is extremely important in continual learning. When you think about it, updating the model is like anyone can write a function to make the model update with the number of data. The hard part is like how to ensure the performance of this model is going to be ok. The static test set is not going to be like current. You’re going to have to have some systems you test the model in production. The test in production is not a new concept. There have been a lot of really good engineering practices to retest the model performance online. First of all, like canary analysis. You can start by deploying into 1% of the users, 2% of the users, and only when it’s doing good that you can roll it out to more. A/B testing, we can have bandits. Of course, yes, so definitely a lot of model evaluation is going to be huge. I think companies with good evaluation techniques will definitely have a competitive edge.
Lazzeri: Can you tell us more how the short iteration cycles in minutes are achieved? Is this just a factor of the huge amount of traffic that the listed companies have?
Huyen: There are two different things, one is about whether you need faster iteration cycles, like if you don’t have a lot of traffic, if the model doesn’t change as much. If the model doesn’t change every five minutes, then there’s no point in changing the model every five minutes. First is, whether you need short iteration cycles. The second is if you have a lot of traffic, then how do you achieve the short iteration cycles. At this point it’s an infrastructure problem. You need to set infrastructure in a way that allows you to access fresh data. If the machine learning engineers can access new data after a day, after a week, then he doesn’t know where he can update the model every five minutes. You need some sort of infrastructure to allow you to access fresh data very quickly. Then you need some very efficient processing scheme, so you can process all the fresh data quickly, and indirectly, so process data into the model. A lot of streaming infrastructure allows that to happen, so that is a purely infrastructure problem.
Lazzeri: I do have another question on the cloud cost aspect. I really appreciated you talking about these, because I think that there should be more transparency and visibility for the customers in the industry to get total visibility into what is the cloud cost. You’re saying that, for that company, going from monthly to daily training saved them actually a lot of cost. From an architectural point of view, do you think that this is the same independently from the type of provider that you’re using? Have you also seen other companies going through a similar experience?
Huyen: I think it can be independent from the provider. I think it’s just like, if the question is, how much compute power do you need to retrain? Previously, if you trained the model from scratch on data from the last three months, then you need to use maybe a lot more epochs, or you just use a lot more data, so you just need to use more compute. Whereas if you just use data from the last day, then you can do it very quickly. The thing about software is not really scale. Sometimes 100 times scale is not 100 times more expensive, but like a lot more times expensive. When you can reduce the scale of the training compute requirement, then you can actually reduce your training cost. It’s not perfect. It’s not true for every case. I would really love to see more research on this. I would really love to see the research on how the retraining frequency affects the training data requirement, because I haven’t seen any research around that area.
Lazzeri: I haven’t either, so that’s why when I saw your slide I was like, this is such an important topic that we should investigate more. I agree with you, I would also love to see more research in the industry around that.
Huyen: I think this mostly has been anecdotal from the industry.
See more presentations with transcripts
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ

Performance testing starts by setting a baseline and defining the metrics to track together with the development team. Nikolay Avramov advises executing performance tests and comparing the results frequently during development to spot degrading performance as soon as possible.
Avramov, an automation lead at Automate The Planet, spoke about performance testing at QA Challenge Accepted 2022
One of the common approaches that Avramov is seeing is to develop a product, do functional testing on it, pass it through user acceptance, and then check if it works “fine” under the expected loads. By starting to test at the end of the development process, we are missing out on opportunities to get more information we could use, Avramov stated.
According to Avramov, having a trend of results over time is crucial for performance testing:
Performance testing should be planned before and executed during development. Knowing the types of performance tests that need to be developed, the team should identify metrics to track over the course of the project and define a baseline for their system. Over the course of development there is always a way to measure the product.
During a project, bottlenecks could be chained together and become harder and harder to fix. And even if we do, this could introduce regression issues all over the system, Avramov mentioned.
Each application has its limits and specifics, Avramov said. According to him, the first goal for performance testing is to define what those limits are, and what the “idle” performance is, looking from the client’s standpoint:
The question is, what are we trying to improve?
- If it’s the load time of a home page, there is a set of metrics and tests that we can start running and track its results.
- If it’s the number of concurrent users it could withstand, then we need to configure a set of load tests to perform and analyse the results after each change.
- If it’s a business scenario that takes too much time, the problem-solving might require profiling a database query, or a series of web requests.
Finding performance bottlenecks is always related to teamwork across multiple roles, departments, and system components, Avramov said. No one has all the answers in one place, so part of the job is to connect all these people and channel their knowledge and energy to solve the problem.
Performance testing is an iterative process where constant improvements need to be made – on the software side and the tests themselves, Avramov concluded.
InfoQ interviewed Nikolay Avramov about performance testing.
InfoQ: How would you define performance testing?
Nikolay Avramov: Performance Testing is about asserting the system works efficiently and meets the expectations in terms of reliability, speed, responsiveness, and ability to withstand peak loads.
This type of testing can be done on multiple layers of the system to uncover different problems with the setup, configuration, client-side code and bottlenecks when exposed to higher loads.
Performance testing is not only about the server response time of our managed system. It’s also about the experience of the user while working with the software. Client-side performance tests can uncover issues with third-party systems or integrations that can harm the overall look and feel of the system.
InfoQ: How are performance testing and load testing related?
Avramov: Load testing is actually Performance Testing under simulated load. The goal is to capture performance metrics, while the system is near or over its expected load levels.
Load testing has its own sub-types like Spike, Soak, and Endurance testing. We can reconfigure parameters of the load applied to the system to simulate different real-world scenarios.
We can do performance testing even without applying load. This would be capturing the performance metrics from the server and from the web requests execution.
InfoQ: What’s your advice to teams that want to improve the way that they are doing performance testing?
Avramov: There are many types of performance testing that can be performed, and they all could be beneficial if we know how to use them and what to expect. So my advice is to educate yourself on the purpose of each of these, sit together with the team and decide what is applicable in your case. The implementation comes next – it can be done in many different ways, but the most important work is done within the team.
Most of the teams that have performance tests focus only on load testing. My advice is to think about the users. Each point of your graph could be a potential customer we would lose because of lousy performance. Do not forget about the client-side performance during load testing.
MMS • Chris McLellan Jeff Jockisch Stephen Bailey Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Recent rulings by several European courts have set important precedents for restricting personal data transmission from the EU to the US.
- At the heart of the problem lies a fundamental mismatch between EU and US privacy regulations.
- It is likely that any new privacy frameworks will be challenged in courts. Yet, the newly proposed Trans-Atlantic Data Privacy Framework brings on an attempt to solve the underlying issues and may include an independent Data Protection Review Court.
- If the new framework did not pass European Courts’ scrutiny, a completely different approach to data privacy could be required, such as treating user data as a currency or similarly to copyright.
Recent rulings by several European courts have set important precedents for restricting personal data transmission from the EU to the US. As a consequence, the US and EU have started working on a new agreement, known as Trans-Atlantic Data Privacy Framework, which should replace the current Privacy Shield.
At the heart of the problem lies a fundamental mismatch between EU and US privacy regulations. While EU citizens have their privacy protected by GDPR, the US lack federated privacy laws, which fueled the proliferation of state-level laws that do not provide a specific basis for enforcement.
Given the Court of Justice of the European Union’s (CJEU) stance regarding US surveillance law, it is not clear how GDPR can be made compatible with transatlantic data transmission. Thus it is likely that any new privacy frameworks will be challenged in courts. Yet, the newly proposed Trans-Atlantic Data Privacy Framework brings an attempt to solve the underlying issues and may include an independent Data Protection Review Court as a mechanism to solve disputes that could provide an effective solution.
If the new framework did not pass European Courts’ scrutiny, it is possible that a completely different approach to data privacy will be required in future to ensure data transmission and collaboration while granting privacy rights, such as treating user data as a currency or similarly to copyright.
In this virtual panel, three knowledgeable experts in the field of data privacy discuss where the existing agreements fall short, whether a new privacy agreement could improve transatlantic data sharing while granting privacy rights for EU citizens and stronger oversight of US intelligence, and more.
The panelists who have answered our questions are:
Chris McLellan, director of operations at the non-profit, Data Collaboration Alliance, which is dedicated to helping organizations get full control of their information for global collaborative intelligence.
Jeff Jockisch, leader of the Data Privacy Group at Node Zero and Data Privacy Researcher at PrivacyPlan.
Stephen Bailey, associate director & global privacy lead at NCC Group, one of the largest security consultancies in the world.
InfoQ: Could you briefly describe the current status of data privacy across the world?
Jockish: Data privacy has become a consumer rights issue worldwide because of 1) identity theft and 2) surveillance advertising. This lack of privacy can also cause problems with fundamental freedoms, as the same data easily flows to governments and politicians, and they often have agendas.
Much of the world is responding with new and stronger data privacy legislation, but the tenor and enforcement of these laws are not uniform.
Bailey: This can be described in one word: Varied. The number of countries with legislation to protect people’s personal data has grown significantly over recent years and there are now 130+ of them, many looking a lot like the European Union’s GDPR. The fact there are so many that are versions of GDPR does give some respite to global organizations looking to create policies and procedures that will work pretty much anywhere. Add into that mix the range of enforcement approaches taken by regulators and it makes for an interesting area of compliance for organizations.
Some laws are adding in new complexities for organizations that operate globally to get to grips with, the most obvious one being the demand for data localization, which often come with different classifications of data subject to those localization rules.
McLellan: The concept of data privacy–that consumers’ confidential information should be protected–is surely universal, but there are multiple and conflicting approaches to achieving it. For example, there’s no question that Europe has set the highest bar with the adoption of GDPR, and changed the conversation on what consumers can expect, and what the private and public sectors alike should do to comply with the regulation. However, that doesn’t mean that bringing American regulations into closer alignment with the sweeping EU legislation would necessarily solve privacy issues for US citizens. This is a deeply complicated issue that needs to respect cultural norms (even between US states), technology capabilities, government policies, and a host of other factors. However, certainly in the US, we’re seeing progress: California’s CCPA legislation has been followed by other states enacting their own data privacy laws, and within the next few years, we could see nearly all US states with their own legislation in place.
InfoQ: Why are agreements like Privacy Shield and the new Trans-Atlantic Data Privacy Framework important and necessary?
McLellan: For its part, the US government has been seeking to strengthen data privacy rights. For example, the Dept. of Commerce recently announced the Global Cross-Border Privacy Rules Forum, which features primarily Asian signatories. However, the biggest and most significant data flow is between the US and the EU, and this has been an area of heightened concern since 2015, when the principles known as ‘Safe Harbor’ were first declared invalid by EU courts. Its successor, known as Privacy Shield, was also struck down by the Court of Justice of the European Union in 2020 (in a decision known widely as ‘Schrems II’). The current draft agreement, known as the ‘Trans-Atlantic Data Privacy Framework’ reestablishes this important legal mechanism to regulate transfers of EU personal data to the United States.
The reason such regulations are so important is that most modern applications operate as part of a “data supply chain” in which information is routinely exchanged between application databases that typically span multiple regulatory jurisdictions. These ‘data flows’ routinely include personal and sensitive information such as search, location, and transaction data and so setting a baseline of rules between nations to govern who can access and utilize such data is vital to establishing data privacy rights for citizens and organizations. That said, regulations can only go so far, and they do not address the root causes that make data so difficult to control.
Bailey: The statement released jointly by the European Commission and the United States government declaring they’ve agreed on a Trans-Atlantic Data Privacy Framework, at least in principle, will raise the hopes of many organizations struggling to stay one step ahead of data protection regulators’ enforcement actions across the European Union. But it’s important to keep in mind that this is just a statement of intent and the detail has yet to be worked out, some of which could require legislative change.
Agreements like this are vital for organizations that are working across international boundaries as they provide certainty and, often, a reduced burden when they share personal data of their own people or the clients/customers/members that they serve. That certainty extends to individuals, who can take some comfort in the fact that the sharing of their data is being done under a recognized framework that is there to protect them.
Jockish: Efficient global business can’t happen without data flow – and virtually all large companies and online businesses have vendors and subsystems that cross borders. When different countries have different data privacy laws, things can get tricky.
In the case of Privacy Shield and the Trans-Atlantic Data Privacy Framework (TADPF), fundamental differences exist in how Europe and the US view data privacy, particularly over government surveillance of foreigners.
InfoQ: How did Privacy Shield fall short of properly protecting EU citizens data privacy?
Bailey: There were two main issues that pulled the privacy rug out from under Privacy Shield in the Schrems II case—the access that US public authorities have for national security purposes to personal data transferred from the EU, and the lack of any meaningful redress for those individuals whose data has been accessed.
Jockish: In the eyes of the European Court of Justice, Privacy Shield did not protect European citizens from unauthorized US government access to personal data via Foreign Intelligence Surveillance Act 702 requests. Specifically, there were no measures for European citizens to challenge FISA requests for access, either before or after the event, because FISA Court proceedings are secret. The third parties who provide data to the government are under a gag order.
InfoQ: In what respects does the new Trans-Atlantic Data Privacy Framework improve on Privacy Shield?
Jockish: Details of the agreement are still vague. What is concrete is the creation of an independent Data Protection Review Court. The Review Court would be part of a multi-layer redress process designed to give Europeans an independent mechanism outside of the FISA Court and PCLOB, which have different and perhaps conflicting motivations.
If the Review Board is genuinely independent and has enough power to stand up to law enforcement overreach, it could be meaningful for more than just Europeans.
Bailey: The joint statement mentions the issues present in Privacy Shield, but whether or not they will be addressed adequately remains to be seen. There seems to be commitment on the part of the US to address the two main issues. The joint statement references the US putting in place ‘new safeguards’ to ensure that intelligence activities are ‘necessary and proportionate’, the definition and practical application of which will be one of the things that privacy campaigners will be looking at closely when the detailed text is drafted and made available.
InfoQ: Is the Trans-Atlantic Data Privacy Framework a robust solution? Does it address all the concerns related to data privacy in the context of collaboration between the US and the EU?
Bailey: EU to US transfers of personal data currently require the exporter to adopt an approach that provides for appropriate safeguards to a standard that is of “essential equivalence”. One option for this is the use of EU standard contractual clauses (SCCs), plus supplementary measures, for which the European Data Protection Board adopted a set of recommendations, but this approach has not stood up to scrutiny in a number of recent investigations undertaken by supervisory authorities in the EU. The privacy campaigners that brought recent cases have many other similar ones in process so will be watching with great interest.
At the root of the problem is the fundamental disconnect between the EU and US with respect to privacy. The absence of federated privacy laws in the US and the proliferation of laws at the state level that are still either breach oriented or lacking in providing a specific basis for enforcement creates issues that will make it highly likely that this new framework will once again be successfully challenged.
The Trans-Atlantic Data Privacy Framework makes no mention of the Court of Justice of the European Union (CJEU), the judicial arm of the European Union that invalidated the adequacy decision for the EU-US Privacy Shield. It’s possible that’s because this is the early stages, but they will no doubt be asked to rule on whatever the new Trans-Atlantic Data Privacy Framework turns out to be.
There is no doubt that an agreement will be reached on transfers of personal data between the EU and US, but there is doubt around whether it will stand up to the scrutiny of the courts when it’s inevitably brought before them.
InfoQ: If we look at how things worked out with Privacy Shield, as well as with its predecessor, Safe Harbor, do we see a pattern at work? Shall we expect another negative ruling at some point?
Bailey: There is some learning to be had, and to push forward with the same approach and expect a different outcome has already been summed up rather nicely and attributed by some to Albert Einstein. In my view, there will be greater scrutiny, certainly by those on the outside if they are able to see how the framework develops, of how it compares with the previous attempts.
Jockish: There is little doubt that someone challenges TADPF. I would wager a large amount that Max Schrems outlines a legal strategy to overturn TADPF before the ink is dry.
But I’m not in the camp of privacy activists that believe data transfer deals between Europe and the US are doomed to fail. While there are fundamental differences in how we think about data rights, we can solve this issue of government surveillance and citizen redress.
McLellan: The bottom line is that nearly all data management technologies are basically band-aids that address a structural problem which is that data is currently managed within silos which are then integrated through the unrestricted exchange of copies. These copies do not simply stay within a walled garden – they end up in all sorts of 3rd party IT ecosystems. But whether application data stays at home or gets transferred abroad, the result is that data stakeholders (including citizens, partner organizations, and indeed the app developers themselves) have little or no control over how their data is accessed and used. The fact is that many of the outcomes associated with the GDPR; things like access control, data custodianship, data portability, and the right to be forgotten – all of these are next to impossible to enforce in a digital ecosystem defined by silos and unrestricted data copies. So yes, until we fundamentally re-address how we build and connect applications, it is inevitable that we will continually see challenges (and fines) aimed at the organizations who fail to build applications with technologies and frameworks that support control and collaboration, rather than copies and chaos.
InfoQ: How does the proposal for a Data Protection Review Court fit into this picture?
Jockish: The Foreign Intelligence Surveillance Court (FISC) has civilian review via the Privacy and Civil Liberties Oversight Board (PCLOB). This mechanism has two mandates, neither of which concerns the rights of foreign citizens. PCLOB was somewhat less effective for a period before Feb 2022 since it lacked a chairman.
The conception of a Data Protection Review Court may sound like bureaucracy to some. Still, it could be the additional layer of protection European citizens need with the right power and implementation.
Will the framework address the concerns of the Court of Justice of the European Union regarding US surveillance law? The details of the Review Court’s formation and operation will matter greatly. How will it work? Will its operations be secret? At what point in the process will it be invoked? What power will the board have over the FISA Court?
Bailey: The Data Protection Review Court could address the lack of an analog to a Supervisory Authority which serves as an independent monitoring authority for GDPR in the EU. But without lawmaking to accompany the framework, any enforcement actions will be subject to question. The existence of the Data Protection Review Court, as it appears to be outside of the US justice system, could also lead to challenges from a variety of perspectives in the US legal system. Establishing the court, if successful, might provide the basis for enforcement, but absent a framework similar to GDPR, will not support proactive compliance.
InfoQ: What are your predictions about the future of data privacy, in the EU, the US, and the rest of the world?
McLellan: We’re all addicted to apps, and this is unlikely to change any time soon. Generally speaking (and with some notable exceptions within social media) this is a healthy addiction, as apps provide our business and personal lives with a great deal of convenience, efficiency, and entertainment.
However, the way apps currently manage data is at complete odds with the global movement for increased data privacy and data protection. In today’s globalized digital ecosystem, data respects no borders – it is copied (invisible and at scale) wherever it is needed in order to run the applications on which we depend.
As such, any regulation attempting to regulate such chaos is ultimately doomed to fail, because just as societies around the globe have learned with things of great value like currency and intellectual property, it is impossible to protect things that can be legally copied without restriction.
The bottom line is that if we want to get serious about data privacy, we need to start to build apps differently.
We need to accelerate the use of new frameworks like Zero-Copy Integration and encourage developers to adopt new technologies like Dataware and blockchain, all of which minimize data and reduce copies so that the data can be meaningfully controlled by its rightful owner. What’s incredibly encouraging is that building new apps via collaboration between data owners is actually far, far faster and more cost-effective than building them with data silos and copies.
This incredible efficiency will be the unstoppable force that helps to accelerate the shift away from data chaos and towards control.
Jockish: How data rights and data ownership evolve will determine the winners and losers in our future economy. We are now witnessing a fight to own the future by owning data.
Without better data privacy and the ownership of our personal data, I believe we tip further and further into a world of haves and have-nots with no middle class.
Bailey: “Essential equivalence” will always be a challenge to achieve and maintain until such time as the US passes effective data privacy legislation. As far as trans-atlantic data transfers go, few organizations will be putting their transfer impact assessment tools away any time soon.
I predict that there will be more of the same: Data protection and privacy laws appearing in countries that do not currently have them, and existing laws being tweaked or overhauled to align, no matter how loosely, to the EU GDPR and its variants. In this future, companies will continue to struggle with the many moving parts that make up an international transfer of an individual’s personal data.
InfoQ: What is the Zero-Copy Integration framework?
McLellan: Zero-Copy Integration is a national standard being developed by the CIO Strategy Council of Canada, an accredited agency of the Standards Council of Canada. It is currently in the final public review stage and expected to become an official standard in coming months. What makes this a pioneering approach is that it defines a framework for the development of new applications that is vastly more efficient, controlled, and collaborative than current approaches.
Zero-Copy Integration proposes to decouple data from applications in order to eliminate the database silos and copy-based data integration that erode the ability to meaningfully control data and to undertake a collaboration-based approach to data-centric development projects. Supporting it are a host of new technologies, including operational Data Fabrics, Dataware, blockchain, and Active Metadata.
For innovators, the elimination of database silos and copy-based integration not only maximized IT delivery capacity and accelerates the app development process, but enables application data to be protected and governed more like money, with its own innate access controls that can be universally enforced (comparable in principle to the holograms and special patterns used on physical currency).
The outcome of the adoption of Zero-Copy Integration for end users, partners, and other application stakeholders in application data is meaningful control over data access, custodianship, portability, and deletion.
MMS • Matt Campbell
Article originally posted on InfoQ. Visit InfoQ

HashiCorp released a number of new features for Terraform including continuous validation and no-code provisioning. Both features are currently in beta for Terraform Cloud Business users. Additional releases include native Open Policy Agent (OPA) support and Azure provider automation.
The new continuous validation feature builds upon the previously released drift detection. With continuous validation, it is possible to define preconditions and postconditions that are checked approximately every 24 hours. Whereas drift detection determines whether the real-world infrastructure matches the Terraform state file, continuous validation validates that these custom conditions continue to pass after Terraform provisions the infrastructure.
For example, drift detection can be used to detect if a user has manually modified a resource configuration such that it differs from what is listed in the state file. Continuous validation can be used to assess whether an API gateway certificate is valid or cause a run to fail if a newer AMI version is available. The following example shows a postcondition that validates the EC2 instance has an encrypted root volume:
data "aws_ebs_volume" "example" {
filter {
name = "volume-id"
values = [aws_instance.example.root_block_device.volume_id]
}
lifecycle {
postcondition {
condition = self.encrypted
error_message = "The server's root volume is not encrypted."
}
}
}
Continuous validation can be enforced against all eligible workspaces within organization settings. However, enforcing at the organization-level will override workspace-level settings. Health assessments may run concurrently across multiple workspaces but do not affect the concurrency limit. As noted above, health assessments will run about every 24 hours. If a Terraform run is triggered during a health assessment, the assessment will be canceled and will be run again in 24 hours.
The new no-code provisioning workflow simplifies the process of consuming Terraform modules. The introduction of the private registry streamlined publishing validated and approved modules for consumption by others within the organization. However, consumers of these modules still need to add the module to their repository, create a workspace, and provision the resources.
The new workflow enables module publishers to instead create no-code ready modules that consumers can deploy directly into workspaces. A user needs to select the module, input the required variables, and then deploy the resources directly into their workspace. The new workflow removes the need for module consumers to understand or write HCL.
Terraform Cloud has added, in beta, native support for Open Policy Agent (OPA). OPA, based on the Rego policy language, is an open-source policy management and enforcement engine. The new OPA support works alongside Sentinel, HashiCorp’s policy as code framework.
The Azure Provider Automation tool, known as Pandora, is a suite of tools which transform the Azure API Definitions into a Go SDK and Terraform resources. At the time of release only Resource Manager Services are supported, but the team has plans to add support for Microsoft Graph and possibly the Data Plane. This tool automatically generates recently introduced Azure Resource Manager Services shortening the time for them to be available within the Terraform Azure provider.
More information about these, and other releases from the recent HashiConf Global conference can be found at the HashiCorp blog.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

At Google Next ’22, GitLab launched GitLab Cloud Seed, a new open-source solution integrated in GitLab One DevOps platform that aims to simplify Google Cloud account management, deployment to Google Cloud Run, and Google SQL database provisioning.
Cloud Seed is a new capability within GitLab that simplifies the developer experience for procuring and consuming cloud services. Cloud Seed allows GitLab and Google Cloud customers to migrate to the cloud using a single platform, consolidating their tech stack without slowing down their cloud adoption process.
GitLab Cloud Seed program lead Ari Rang explained at Google Could Next ’22 how teams from GitLab and Google worked together to provide what he defined “best-in-class experiences to simplify, automate, and accelerate cloud resource provisioning, deployment automation, and configuration”.
Using Cloud Seed, devops engineers can generate Google Cloud Service accounts, deploy their applications to Cloud Run, Google’s fully managed platform for containerized applications, and provision SQL databases directly from the GitLab web interface.
Cloud Seed is able to generate service accounts, keys, and deployment permissions as well as make that information available in GitLab CI variables, optionally using secret managers to enhance security.
Deployments to Cloud Run can be automated and support deployment previews, which allow to deploy a PR without affecting the production service to preview the change and ensure it works as expected before merging. Furthermore, it is possible to control the deployment destination based on commit, branch, and tag.
Cloud Seed supports all major SQL databases, including PostgreSQL, MySQL, and SQL Server, and makes it possible to create instances, databases, and users as well as define a background worker to carry through all database setup.
Cloud Seed is available to both paid and free users as part of GitLab One DevOps platform, GitLab’s centralized toolchain that aims to tie all parts of the software development lifecycle into a single, integrated application. As mentioned, GitLab Cloud Seed is open source and currently in preview for early testers.
MMS • Adrien Joly
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- To avoid git conflicts or a long code freeze period, develop a migration script.
- Add a CI job to check that the build and tests still work after the migration.
- Use Node’s conditional exports, so internal dependencies are resolved according to the environment: TS files during development, JS files at runtime.
- Extract common TypeScript, ESLint and Prettier configuration as packages, then extend them.
- Setup Turborepo in order to orchestrate dev workflows and optimize build time.
Splitting monoliths into services creates complexity in maintaining multiple repositories (one per service) with separate (yet interdependent) build processes and versioning history. Monorepos have become a popular solution to reduce that complexity.
Despite what monorepo tool makers sometimes suggest, setting up a monorepo in an existing codebase, especially in a monolithic one, is not easy. And more importantly, migrating to a monorepo can be very disruptive for the developers of that codebase. For instance, it requires moving most files into subdirectories, which causes conflicts with other changes currently being made by the team.
Let’s discuss ways to smoothly turn a monolithic Node.js codebase into a Monorepo, while minimizing disruptions and risks.
Introducing: a monolithic codebase
Let’s consider a repository that contains two Node.js API servers: `api-server` and `back-for-front-server`. They are written in TypeScript and transpiled into JavaScript for their execution in production. These servers share a common set of development tools (for checking, testing, building and deploying servers) and npm dependencies. They are also bundled together using a common Dockerfile, and the API server to run is selected by specifying a different entrypoint.
File structure – before migrating:
├─ .github
│ └─ workflows
│ └─ ci.yml
├─ .yarn
│ └─ ...
├─ node_modules
│ └─ ...
├─ scripts
│ ├─ e2e-tests
│ │ └─ e2e-test-setup.sh
│ └─ ...
├─ src
│ ├─ api-server
│ │ └─ ...
│ ├─ back-for-front-server
│ │ └─ ...
│ └─ common-utils
│ └─ ...
├─ .dockerignore
├─ .eslintrc.js
├─ .prettierrc.js
├─ .yarnrc.yml
├─ docker-compose.yml
├─ Dockerfile
├─ package.json
├─ README.md
├─ tsconfig.json
└─ yarn.lock
(Simplified) Dockerfile – before migrating:
FROM node:16.16-alpine
WORKDIR /backend
COPY . .
COPY .yarnrc.yml .
COPY .yarn/releases/ .yarn/releases/
RUN yarn install
RUN yarn build
RUN chown node /backend
USER node
CMD exec node dist/api-server/start.js
Having several servers maintained together in a shared repository presents several advantages:
- the configuration of development tools (typescript, eslint, prettier…) and the deployment process are shared, so maintenance is reduced and the practices of all contributing teams remain aligned.
- it’s easy for developers to reuse modules across servers, e.g. logging module, database client, wrappers to external APIs…
- versioning is simple because there is just one shared range of versions used by all servers, i.e. any update on any server results in a new version of the Docker image, which includes all servers.
- it’s also easy to write end-to-end tests that cover more than one server, and include them in the repository, because everything is in the same place.
Unfortunately, the source code of these servers is monolithic. What we mean is that there is no separation between the code of each server. Code that was written for one of them (e.g. SQL adapters), ends up being imported by other servers too. Hence it’s complicated to prevent a change on the code of server A from also impacting server B. Which can result in unexpected regressions, and code that becomes more and more coupled over time, making it more fragile and harder to maintain.
The « monorepo » structure is an interesting compromise: sharing a repository while splitting the codebase into packages. This separation makes the interfaces more explicit, and therefore allows to make conscious choices about dependencies between packages. It also enables several workflow optimisations, e.g. building and running tests only on packages that changed.
Migrating a monolithic codebase into a monorepo quickly gets difficult and iterative if the codebase is large, integrated with a lot of tooling (e.g. linting, transpilation, bundling, automated testing, continuous integration, docker-based deployments…). Also, because of the structural changes necessary in the repository, migrating will cause conflicts with any git branches that are worked on during the migration. Let’s overview the necessary steps to turn our codebase into a monorepo, while keeping disruptions to a minimum.
Overview of changes to make
Migrating our codebase to a monorepo consists of the following steps:
- File structure: initially, we have to create a unique package that contains our whole source code, so all files will be moved.
- Configuration of Node.js’ module resolution: we will use Yarn Workspaces to allow packages to import one another.
- Configuration of the Node.js project and dependencies:
package.json(including npm/yarn scripts) will be split: the main one at the root directory, plus one per package. - Configuration of development tools:
tsconfig.json, .eslintrc.js, .prettierrc.jsandjest.config.jswill also be split into two: a “base” one, and one that will extend it, for each package. - Configuration of our continuous integration workflow:
.github/workflows/ci.ymlwill need several adjustments, e.g. to make sure that steps are run for each package, and that metrics (e.g. test coverage) are consolidated across packages. - Configuration of our building and deployment process: Dockerfile can be optimized to only include the files and dependencies required by the server being built.
- Configuration of cross-package scripts: use of Turborepo to orchestrate the execution of npm scripts that impact several packages. (e.g. build, test, lint…)
File structure – after migrating:
├─ .github
│ └─ workflows
│ └─ ci.yml
├─ .yarn
│ └─ ...
├─ node_modules
│ └─ ...
├─ packages
│ └─ common-utils
│ └─ src
│ └─ ...
├─ servers
│ └─ monolith
│ ├─ src
│ │ ├─ api-server
│ │ │ └─ ...
│ │ └─ back-for-front-server
│ │ └─ ...
│ ├─ scripts
│ │ ├─ e2e-tests
│ │ │ └─ e2e-test-setup.sh
│ │ └─ ...
│ ├─ .eslintrc.js
│ ├─ .prettierrc.js
│ ├─ package.json
│ └─ tsconfig.json
├─ .dockerignore
├─ .yarnrc.yml
├─ docker-compose.yml
├─ Dockerfile
├─ package.json
├─ README.md
├─ turbo.json
└─ yarn.lock
The flexibility of Node.js and its ecosystem of tools makes it complicated to share a one-size-fits-all recipe, so keep in mind that a lot of fine-tuning iterations will be required to keep the developer experience at least as good as it was before migrating.
Planning for low team disruption
Fortunately, despite the fact that fine-tuning iterations may take several weeks to get right, the most disruptive step is the first one: changing the file structure.
If your team uses git branches to work concurrently on the source code, that step will cause these branches to conflict, making them very complicated to resolve and merge to the repository’s main branch.
So our recommendation is threefold, especially if the entire team needs convincing and/or reassuring about migrating to a monorepo:
- Plan a (short) code freeze in advance: define a date and time when all branches must have been merged, in order to run the migration while preventing conflicts. Plan it ahead so developers can accommodate. But don’t pick the date until you have a working migration plan.
- Write the most critical parts of the migration plan as a bash script, so you can make sure that development tools work before and after migrating, including on the continuous integration pipeline. This should reassure the skeptics, and give more flexibility on the actual date and time of the code freeze.
- With the help of your team, list all the tools, commands and workflows (including features of your IDE such as code navigation, linting and autocompletion) that they need to do their everyday work properly. This list of requirements (or acceptance criteria) will help us check our progress on migrating the developer experience over to the monorepo setup. It will help us make sure that we don’t forget to migrate anything important.
Here’s the list of requirements we decided to comply with:
yarn installstill installs dependencies- all automated tests still run and pass
yarn lintstill finds coding style violations, if anyeslinterrors (if any) are still reported in our IDEprettierstill reformats files when saving in our IDE- our IDE still finds broken imports and/or violations, if any, of TypeScript rules expressed in
tsconfig.jsonfiles - our IDE still suggests the right module to import, when using an symbol exposed by an internal package, given it was declared as a dependency
- the resulting Docker image still starts and works as expected, when deployed
- the resulting Docker image still has the same size (approximately)
- the whole CI workflow passes, and does not take more time to run
- our 3rd-party code analysis integrations (sonarcloud) still work as expected
Here’s an example of migration script:
# This script turns the repository into a monorepo,
# using Yarn Workspaces and Turborepo
set -e -o pipefail # stop in case of error, including for piped commands
NEW_MONOLITH_DIR="servers/monolith" # path of our first workspace: "monolith"
# Clean up temporary directories, i.e. the ones that are not stored in git
rm -rf ${NEW_MONOLITH_DIR} dist
# Create the target directory
mkdir -p ${NEW_MONOLITH_DIR}
# Move files and directories from root to the ${NEW_MONOLITH_DIR} directory,
# ... except the ones tied to Yarn and to Docker (for now)
mv -f
.eslintrc.js
.prettierrc.js
README.md
package.json
src
scripts
tsconfig.json
${NEW_MONOLITH_DIR}
# Copy new files to root level
cp -a migration-files/. . # includes turbo.json, package.json, Dockerfile,
# and servers/monolith/tsconfig.json
# Update paths
sed -i.bak 's,docker-compose.yml,../../docker-compose.yml,g'
${NEW_MONOLITH_DIR}/scripts/e2e-tests/e2e-test-setup.sh
find . -name "*.bak" -type f -delete # delete .bak files created by sed
unset CI # to let yarn modify the yarn.lock file, when script is run on CI
yarn add --dev turbo # installs Turborepo
rm -rf migration-files/
echo "✅ You can now delete this script"
We add a job to our continuous integration workflow (GitHub Actions), to check that our requirements (e.g. tests and other usual yarn scripts) are still working after applying the migration:
jobs:
monorepo-migration:
timeout-minutes: 15
name: Test Monorepo migration
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- run: ./migrate-to-monorepo.sh
env:
YARN_ENABLE_IMMUTABLE_INSTALLS: "false" # let yarn.lock change
- run: yarn lint
- run: yarn test:unit
- run: docker build --tag "backend"
- run: yarn test:e2e
Turn the monolith’s source code into a first package
Let’s see how our single package.json looks life, before migrating:
{
"name": "backend",
"version": "0.0.0",
"private": true,
"scripts": {
/* all npm/yarn scripts ... */
},
"dependencies": {
/* all runtime dependencies ... */
},
"devDependencies": {
/* all development dependencies ... */
}
}
And an excerpt of the tsconfig.json file used to configure TypeScript, still before migrating:
{
"compilerOptions": {
"target": "es2020",
"module": "commonjs",
"lib": ["es2020"],
"moduleResolution": "node",
"esModuleInterop": true,
/* ... and several rules to make TypeScript more strict */
},
"include": ["src/**/*.ts"],
"exclude": ["node_modules", "dist", "migration-files"]
}
When splitting a monolith into packages, we have to:
- tell our package manager (yarn, in our case) that our codebase contains multiple packages;
- and to be more explicit about where these packages can be found.
To allow packages to be imported as dependencies of other packages (a.k.a. workspaces), we recommend using Yarn 3 or another package manager that supports workspaces.
So we added "packageManager": "yarn@3.2.0" to package.json, and created a .yarnrc.yml file next to it:
nodeLinker: node-modules
yarnPath: .yarn/releases/yarn-3.2.0.cjs
As suggested in Yarn’s migration path:
- we commit the
.yarn/releases/yarn-3.2.0.cjsfile; - and we stick to using
node_modulesdirectories, at least for now.
After moving the monolith codebase (including package.json and tsconfig.json) to servers/monolith/, we create a new package.json file at the root project directory, which workspaces property lists where workspaces can be found:
{
"name": "@myorg/backend",
"version": "0.0.0",
"private": true,
"packageManager": "yarn@3.2.0",
"workspaces": [
"servers/*"
]
}
From now on, each workspace must have its own package.json file, to specify its package name and dependencies.
So far, the only workspace we have is “monolith”. We make it clear that it’s now a Yarn workspace by prefixing its name with our organization’s scope, in servers/monolith/package.json:
{
"name": "@myorg/monolith",
/* ... */
}
After running yarn install and fixing a few paths:
yarn buildand other npm scripts (when run fromservers/monolith/) should still work;- the Dockerfile should still produce a working build;
- all CI checks should still pass.
Extracting a first package: common-utils
So far, we have a monorepo that defines only one “monolith” workspace. Its presence in the servers directory conveys that its modules are not meant to be imported by other workspaces.
Let’s define a package that can be imported by those servers. To better convey this difference, we introduce a packages directory, next to the servers directory. The common-utils directory (from servers/monolith/common-utils) is a good first candidate to be extracted into a package, because its modules are used by several servers from the “monolith” workspace. When we reach the point where each server is defined in its own workspace, the common-utils package will be declared as a dependency of both servers.
For now, we move the common-utils directory from servers/monolith/, to our new packages/ directory.
To turn it into a package, we create the packages/common-utils/package.json file, with its required dependencies and build script(s):
{
"name": "@myorg/common-utils",
"version": "0.0.0",
"private": true,
"scripts": {
"build": "swc src --out-dir dist --config module.type=commonjs --config env.targets.node=16",
/* other scripts ... */
},
"dependencies": {
/* dependencies of common-utils ... */
},
}
Note: we use swc to transpile TypeScript into JavaScript, but it should work similarly with tsc. Also, we made sure that its configuration (using command-line arguments) is aligned to the one from servers/monolith/package.json.
Let’s make sure that the package builds as expected:
$ cd packages/common-utils/
$ yarn
$ yarn build
$ ls dist/ # should contain the .js build of all the files from src/
Then, we update the root package.json file to declare that all subdirectories of packages/ (including common-utils) are also workspaces:
{
"name": "@myorg/backend",
"version": "0.0.0",
"private": true,
"packageManager": "yarn@3.2.0",
"workspaces": [
"packages/*",
"servers/*"
],
/* ... */
}
And add common-utils as a dependency of our monolith server package:
$ yarn workspace @myorg/monolith add @myorg/common-utils
You may notice that Yarn created node_modules/@myorg/common-utils as a symbolic link to packages/common-utils/, where its source code is held.
After doing that, we must fix all broken imports to common-utils. A low-diff way to achieve that is to re-introduce a common-utils directory in servers/monolith/, with a file that export functions from our new @myorg/common-utils package:
export { hasOwnProperty } from "@myorg/common-utils/src/index"
Let’s not forget to update the servers’ Dockerfile, so the packages are built and included in the image:
# Build from project root, with:
# $ docker build -t backend -f servers/monolith/Dockerfile .
FROM node:16.16-alpine
WORKDIR /backend
COPY . .
COPY .yarnrc.yml .
COPY .yarn/releases/ .yarn/releases/
RUN yarn install
WORKDIR /backend/packages/common-utils
RUN yarn build
WORKDIR /backend/servers/monolith
RUN yarn build
WORKDIR /backend
RUN chown node /backend
USER node
CMD exec node servers/monolith/dist/api-server/start.js
This Dockerfile must be built from the root directory, so it can access the yarn environment and files that are there.
Note: you can strip development dependencies from the Docker image by replacing yarn install by yarn workspaces focus --production in the Dockerfile, thanks to the plugin-workspace-tools plugin, as explained in Orchestrating and dockerizing a monorepo with Yarn 3 and Turborepo | by Ismayil Khayredinov | Jun, 2022 | Medium.
At this point, we have successfully extracted an importable package from our monolith, but:
- the production build fails to run, because of
Cannot find moduleerrors; - and the import path to
common-utilsis more verbose than necessary.
Fix module resolution for development and production
The way we import functions from @myorg/types-helpers is problematic because Node.js looks from modules in the src/ subdirectory, even though they were transpiled into the dist/ subdirectory.
We would rather import functions in a way that is agnostic to the subdirectory:
import { hasOwnProperty } from "@myorg/common-utils"
If we specify "main": "src/index.ts" in the package.json file of that package, the path would still break when running the transpiled build.
Let’s use Node’s Conditional Exports to the rescue, so the package’s entrypoint adapts to the runtime context:
{
"name": "@myorg/common-utils",
"main": "src/index.ts",
+ "exports": {
+ ".": {
+ "transpiled": "./dist/index.js",
+ "default": "./src/index.ts"
+ }
+ },
/* ... */
}
In a nutshell, we add an exports entry that associates two entrypoints to the package’s root directory:
- the
defaultcondition specifies./src/index.tsas the package’s entrypoint; - the
transpiledcondition specifies./dist/index.jsas the package’s entrypoint.
As specified in Node’s documentation, the default condition should always come last in that list. The transpiled condition is custom, so you can give it the name you want.
For this package to work in a transpiled runtime context, we change the corresponding node commands to specify the custom condition. For instance, in our Dockerfile:
- CMD exec node servers/monolith/dist/api-server/start.js
+ CMD exec node --conditions=transpiled servers/monolith/dist/api-server/start.js
Make sure that development workflows work as before
At this point, we have a monorepo made of two workspaces that can import modules from one another, build and run.
But it still requires us to update our Dockerfile everytime a workspace is added, because the yarn build command must be run manually for each workspace.
That’s where a monorepo orchestrator like Turborepo comes in handy: we can ask it to build packages recursively, based on declared dependencies.
After adding Turborepo as a development dependency of the monorepo (command: $ yarn add turbo --dev), we can define a build pipeline in turbo.json:
{
"pipeline": {
"build": {
"dependsOn": ["^build"]
}
}
}
This pipeline definition means that, for any package, $ yarn turbo build will start by building the packages it depends on, recursively.
This allows us to simplify our Dockerfile:
# Build from project root, with:
# $ docker build -t backend -f servers/monolith/Dockerfile .
FROM node:16.16-alpine
WORKDIR /backend
COPY . .
COPY .yarnrc.yml .
COPY .yarn/releases/ .yarn/releases/
RUN yarn install
RUN yarn turbo build # builds packages recursively
RUN chown node /backend
USER node
CMD exec node --conditions=transpiled servers/monolith/dist/api-server/start.js
Note: it’s possible to optimize the build time and size by using Docker stages and turbo prune, but the resulting yarn.lock file was not compatible with Yarn 3, when this article was being written. (see this pull request for recent progress on this issue)
Thanks to Turborepo, we can also run unit tests of all our packages, in one command: yarn turbo test:unit, after defining a pipeline for it, like we did for build.
That said, most developer workflows rely on dependencies and configuration files that were moved to servers/monolith/, so most of them don’t work anymore.
We could leave these dependencies and files at the root level, so they are shared across all packages. Or worse: duplicate them in every package. There is a better way.
Extract and extend common configuration as packages
Now that our most critical build and development workflows work, let’s make our test runner, linter and formatter work consistently across packages, while leaving room for customization.
One way to achieve that is to create packages that hold base configuration, and let other packages extend them.
Similarly to what we did for common-tools, let’s create the following packages:
├─ packages
│ ├─ config-eslint
│ │ ├─ .eslintrc.js
│ │ └─ package.json
│ ├─ config-jest
│ │ ├─ jest.config.js
│ │ └─ package.json
│ ├─ config-prettier
│ │ ├─ .prettierrc.js
│ │ └─ package.json
│ └─ config-typescript
│ ├─ package.json
│ └─ tsconfig.json
├─ ...
Then, in each package that contains source code, we add those as dependencies, and create configuration files that extend them:
packages/*/.eslintrc.js:
module.exports = {
extends: ["@myorg/config-eslint/.eslintrc"],
/* ... */
}
packages/*/jest.config.js:
module.exports = {
...require("@myorg/config-jest/jest.config"),
/* ... */
}
packages/*/.prettierrc.js:
module.exports = {
...require("@myorg/config-prettier/.prettierrc.js"),
/* ... */
}
packages/*/tsconfig.json:
{
"extends": "@myorg/config-typescript/tsconfig.json",
"compilerOptions": {
"baseUrl": ".",
"outDir": "dist",
"rootDir": "."
},
"include": ["src/**/*.ts"],
/* ... */
}
To make it easier and quicker to set up new packages with these configuration files, feel free to use a boilerplate generator, e.g. plop.
Next step: one package per server
Now that we have checked off all the requirements listed in the “Planning for low team disruption” section, it’s a good time to actually freeze code contributions, run the migration script, then commit the changes to the source code repository.
From now on, the repository can officially be referred to as “monorepo”! All developers should be able to create their own packages, and to import them from the monolith, instead of adding new code directly into it. And the foundations are solid enough to start splitting the monolith into packages, like we did for common-tools.
We are not going to cover precise steps on how to achieve that, but here are some recommendations on how to prepare for that splitting:
- start by extracting small utility packages, e.g. type libraries, logging, error reporting, API wrappers, etc…
- then, extract other parts of the code that are meant to be shared across all servers;
- finally, duplicate the parts that are not meant to be shared, but are still relied upon by more than one server.
The goal of these recommendations is to decouple servers from each other, progressively. Once this is done, extracting one package per server should be almost as simple as extracting common-utils.
Also, during that process, you should be able to optimize the duration of several build, development and deployment workflows, by leveraging:
Conclusion
We have turned a monolithic Node.js backend into a Monorepo while keeping team disruptions and risks to a minimum:
- to split the monolith into multiple decoupled packages that can depend on each other;
- sharing common TypeScript, ESLint, Prettier and Jest configuration across packages;
- and setting up Turborepo to optimize development and build workflows.
Using a migration script allowed us to avoid code freeze and git conflicts while preparing and testing the migration. We made sure that the migration script did not break the build and development tools by adding a CI job.
I would like to thank Renaud Chaput (Co-Founder, CTO at Notos), Vivien Nolot (Software Engineer at Choose) and Alexis Le Texier (Software Engineer at Choose) for their collaboration on this migration.
MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ

Amazon is announcing that Amazon SageMaker Clarify now supports online explainability by providing explanations for machine learning model’s individual predictions in near real-time on live endpoints.
Amazon SageMaker Clarify provides machine learning developers with greater visibility into their training data and models so they can identify and limit bias and explain predictions. Biases are disparities in the training data or model’s behavior while making predictions for various groups.
The data or algorithm used to train any model may have biases. An ML model, for instance, may perform less well when making predictions about younger and older people if it was largely trained on data from middle-aged people. By identifying and quantifying biases in a data and model, machine learning offers the chance to address prejudices.
The notions of bias and fairness are highly dependent on the application. Further, the choice of the attributes for which bias is to be measured, as well as the choice of the bias metrics, may need to be guided by social, legal, and other non-technical considerations.
ML models may consider some feature inputs more strongly than others when generating predictions. SageMaker Clarify provides scores detailing which features contributed the most to a model’s individual prediction after the model has been run on new data. These details can help determine if a particular input feature has more influence on the model predictions than expected.
To understand why models produce the predictions they do, it may also have a look at the significance of model inputs. According to Amazon, SageMaker Clarify’s new feature reduces latency for explanations from minutes to seconds.
Deepening the way machine learning systems are applied, machine learning biases can lead to illegal actions, reduced revenue or sales, and potentially poor customer service. Building consensus and achieving collaboration across key stakeholders such as product, policy, legal, engineering, and AI/ML teams, as well as end users and communities, is a prerequisite for the successful adoption of fairness-aware ML approaches in practice.
MMS • Anthony Alford
Article originally posted on InfoQ. Visit InfoQ

Researchers from New York University, University of Washington, and Johns Hopkins University have published the results of the NLP Community Metasurvey, which compiles the opinions of 480 active NLP researchers about several issues in the natural language processing AI field. The survey also includes meta-questions about the perceived opinions of other researchers.
The goal of the survey was to learn about the actual distribution of beliefs in the NLP community as well as sociological beliefs—what researchers think other researchers think. The survey was targeted at researchers who have published at least two NLP papers in the last three years. The questions cover six categories related to NLP research in particular, as well as artificial general intelligence (AGI) and social concerns; the team chose questions that are frequently discussed in the community and are subjects of public disagreement. In the results, the team found that a large majority of respondents think NLP research will have a positive impact on the future, and a narrow majority believes that recent progress in large language models (LLM) are significant steps toward AGI. According to the survey team:
By necessity, we are covering a subjectively chosen set of questions and reducing many complex issues into simplified scales, but we hope that the outcome can serve as a reference point for community discussion and for future surveys. This is not the final word in any debate, but we hope it will spark new discussions as an initial study of the range of positions people hold and ways in which the community may mis-model itself.
The survey questions covered the following categories:
- State of the Field: the role of industry and the near-term possibility of an “AI winter”
- Scale, Inductive Bias, and Adjacent Fields: whether large scale is sufficient or if linguistic expertise is needed to solve NLP problems
- AGI and Major Risks: if NLP research is making progress toward AGI and if AGI is a risk society
- Language Understanding: whether language models actually understand language
- Promising Research Programs: is NLP research on the right track?
- Ethics: if NLP has a positive impact and whether certain research areas are ethical
In addition to specifying whether they agreed with a question or not, the respondents were asked to predict what percentage of other respondents would agree with the question. The goal of collecting these meta-responses was to help researchers understand sociological beliefs, since mistaken sociological beliefs can “slow down communication and lead to wasted effort.”
Questions about the role of scaling AI models showed “striking mismatches” between what NLP researchers actually believe compared to what they think community beliefs are. Survey respondents estimated that nearly 50% of researchers would agree that scaling can solve “practically any” problem, and that less than 40% would agree that linguistic theory and expert design would be needed to solve important problems. However, in a Twitter thread highlighting some of the results, lead author Julian Michael pointed out:
Less than 20% of the field thinks that scaling up existing techniques will be enough to solve all applied NLP problems. A majority thinks that insights from linguistics or cognitive science will be an important part of future progress.
In a Hacker News discussion about the limits of current AI technology, AI writer and researcher Gwern Branwen referred to the NLP survey results and defended scaling, saying:
AGI & scaling critics are still in the majority, despite posturing as an oppressed minority…If you believe in scaling, you are still in a small minority of researchers pursuing an unpopular and widely-criticized paradigm. (That it is still producing so many incredible results and appearing so dominant despite being so disliked and small is, IMO, to its credit and one of the best arguments for why new researchers should go into scaling – it is still underrated.)
While the survey paper contains charts and summaries of the data, the survey website notes that a web-based dashboard for exploring the results is “coming soon.”
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Microsoft recently released the public preview of Azure Firewall Basic for small-medium businesses (SMBs), providing enterprise-grade security at an affordable price. The company offers the Basic SKU as it sees SMBs as particularly vulnerable to budget constraints and gaps in specialized security skills.
Azure Firewall Basic is a new SKU of Azure Firewall, a cloud-native and intelligent network firewall security service – already offering a standard and premium SKU (previewed last year and generally available later in July). The new basic SKU includes Layer 3–Layer 7 filtering and alerts on malicious traffic with built-in threat intelligence from Microsoft Threat Intelligence. Furthermore, it has tight integration with other Azure services, such as Azure Monitor, Azure Events Hub, Microsoft Sentinel, and Microsoft Defender for Cloud.
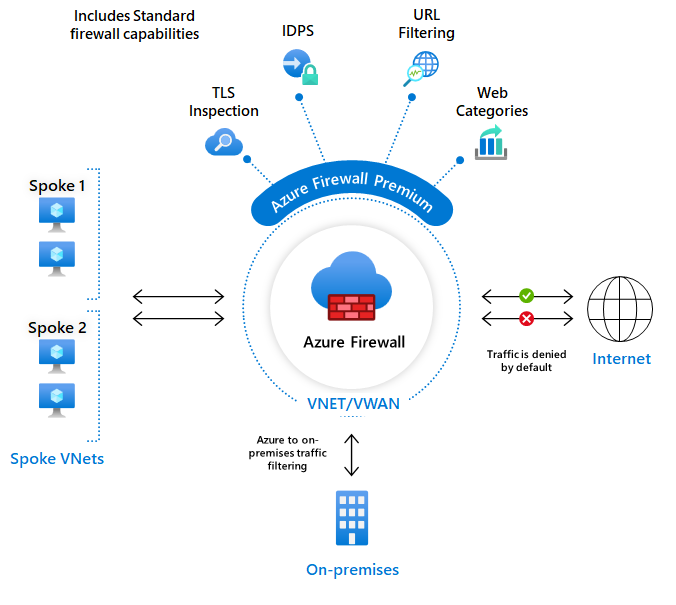
Source: https://learn.microsoft.com/en-us/azure/firewall/overview
With the basic SKU, Azure Firewall offers three SKUs for different use cases and needs of customers. Premium is suitable for organizations needing to secure highly sensitive applications (such as payment processing), with scalability needs of up to 100 Gbps. The standard SKU is for organizations requiring automatic scaling for peak traffic periods of up to 30 Gbps, and finally, basic for SMBs with throughput needs of less than 250 Mbps.
Dean Cefola explains in an Azure Academy video:
Basic is also built upon a VM Scale set, so it is highly available, but to control the cost, the SKU is limited to only two virtual machines under the hood.
Furthermore, note that the basic lacks the Premium edition’s “advanced threat protection capabilities,” which include threat-intelligence filtering, inbound and outbound TLS termination, a fully-managed intrusion detection and prevention system (IDPS), and URL filtering.
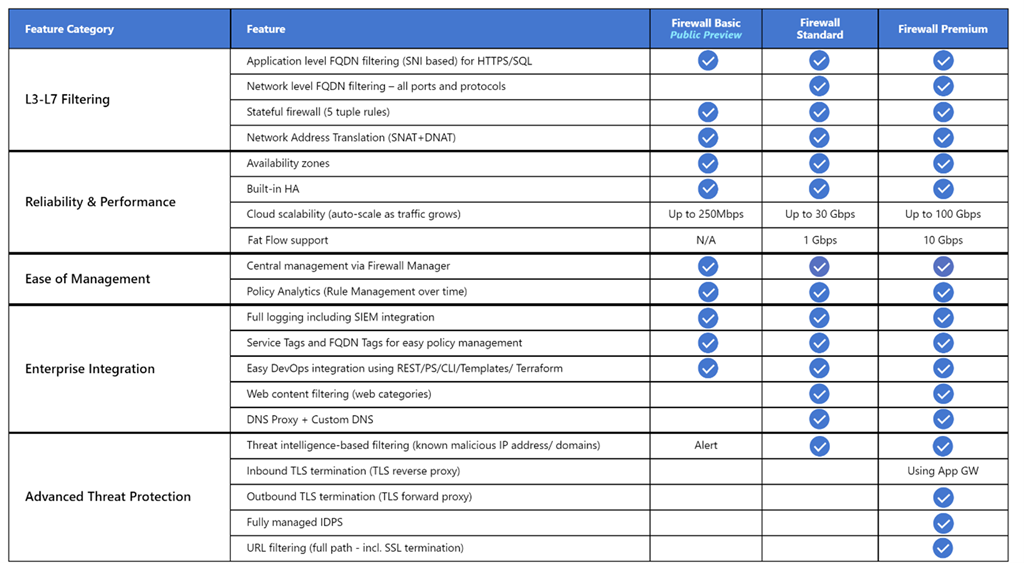
Source: https://azure.microsoft.com/en-us/blog/azure-firewall-basic-now-in-preview/
Azure MVP Aidin Finn concluded in his recent blog post on Azure Basic Firewall:
The new SKU of Azure Firewall should add new customers to this service. I also expect that larger enterprises will also be interested – not every deployment needs the full-blown Standard/Premium deployment, but some form of firewall is still required.
In addition, Alan Kilane, an Azure technical lead at MicroWarehouse, tweeted:
I’ve been waiting on the release of this new Azure Firewall Basic SKU for a while. Badly needed for the SMB space; it will be interesting to see the uptake on this.
Lastly, more details on Azure Firewall are available on the documentation landing page. Furthermore, Azure Firewall Basic pricing, like the Standard and Premium SKUs, includes both deployment and data processing charges. More details on pricing are available on the pricing page.
MMS • Flynn
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- eBPF is a tool meant to allow improved performance by (carefully) allowing some user code to run in the kernel.
- The layer 7 processing needed for service meshes is unlikely to be feasible in eBPF for the foreseeable future, which means that meshes will still need proxies.
- Compared to sidecar proxies, per-host proxies add operational complexity and reduce security.
- Typical performance complaints about sidecar proxies can be addressed by smaller, faster sidecar proxies.
- For now the sidecar model continues to make the most sense for service mesh.
Stories about eBPF have been flooding the cloud-native world for a bit, sometimes presenting it as the greatest thing since sliced bread and sometimes deriding it as a useless distraction from the real world. The reality, of course, is considerably more nuanced, so taking a closer look at what eBPF can and can’t do definitely seems warranted – technologies are just tools after all, and we should fit the tool we use to the task at hand.
One particular task that’s been coming up a lot recently is the complex layer 7 processing needed for a service mesh. Handing that off to eBPF could potentially be a huge win for service meshes, so let’s take a closer look at that possible role for eBPF.
What is eBPF, anyway?
Let’s get the name out of the way first: “eBPF” was originally the “extended Berkeley Packet Filter”, though these days it doesn’t stand for anything at all. The Berkeley packet filter goes back nearly 30 years: it’s technology that allows user applications to run certain code – very closely vetted and highly constrained code, to be sure – directly in the operating system kernel itself. BPF was limited to the network stack, but it still made some amazing things possible:
- The classic example is that it could make it dramatically easier to experiment with things like new kinds of firewalls. Instead of constantly recompiling kernel modules, just make some edits to your eBPF code and reload it.
- Likewise, it can open the door to easily develop some very powerful kinds of network analysis, including things that you really wouldn’t want to run in the kernel. For example, if you want to do classification of incoming packets using machine learning, you could grab packets of interest with BPF and hand them out to a user application running the ML model.
There are other examples: these are just two really obvious things that BPF made possible1 — and eBPF took the same concept and extended it to areas beyond just networking. But all this discussion raises the question of why exactly this kind of thing requires special attention in the first place.
The short answer is “isolation”.
Isolation
Computing – especially cloud-native computing – relies heavily on the hardware’s ability to simultaneously do multiple things for multiple entities, even when some of the entities are hostile to others. This is contended multitenancy, which we typically manage with hardware that can mediate access to memory itself. In Linux, for example, the operating system creates one memory space for itself (kernel space), and a separate space for each user program (user space collectively, although each program has its own). The operating system then uses the hardware to prevent any cross-space access2.
Maintaining this isolation between parts of the system is absolutely critical both for security and reliability — basically everything in computing security relies on it, and in fact the cloud-native world relies on it even more heavily by requiring the kernel to maintain isolation between containers, as well. As such, kernel developers have collectively spent thousands of person-years scrutinizing every interaction around this isolation and making sure that the kernel handles everything correctly. It is tricky, subtle, painstaking work that, sadly, often goes unnoticed until a bug is found, and it is a huge part of what the operating system actually does3.
Part of why this work is so tricky and subtle is that the kernel and the user programs can’t be completely isolated: user programs clearly need access to some operating system functions. Historically, this was the realm of system calls.
System Calls
System calls, or syscalls, are the original way that the operating system kernel exposed an API to user code. Glossing over a vast amount of detail, the user code packs up a request and hands it to the kernel. The kernel carefully checks to make sure that all its rules are being followed, and – if everything looks good – the kernel will execute the system call on behalf of the user, copying data between kernel space and user space as needed. The critical bits about syscalls are:
- The kernel is in control of everything. User code gets to make requests, not demands.
- The checking, copying of data, etc., take time. This makes a system call slower than running normal code, whether that’s user code or kernel code: it’s the act of crossing the boundary that slows you down. Things have gotten much faster over time, but it’s just not feasible to, say, do a syscall for every network packet on a busy system.
This is where eBPF shines: instead of doing a syscall for every network packet (or trace point, or whatever), just drop some user code directly into the kernel! Then the kernel can run it all at full speed, handing data out to user space only when it’s really necessary. (There’s been a fair amount of this kind of rethinking of the user/kernel interaction in Linux recently, often to great effect. io_uring is another example of great work in this area.)
Of course, running user code in the kernel is really dangerous, so the kernel spends an awful lot of effort on verifying what that user code is actually meant to be doing.
eBPF Verification
When a user process starts up, the kernel basically starts it running with the perspective that it’s probably OK. The kernel puts guardrails around it, and will summarily kill any user process that tries to break the rules, but – to anthropomorphize a bit – the user code is fundamentally assumed to have a right to execute.
No such courtesy can be afforded to eBPF code. In the kernel itself, the protective guardrails are basically nonexistent, and blindly running user code in the hopes that it’s safe would be throwing the gates wide open to every security exploit there is (as well as allowing bugs to crash the whole machine). Instead, eBPF code gets to run only if the kernel can decisively prove that it’s safe.
Proving that a program is safe is incredibly hard4. In order to make it even sort of tractable, the kernel dramatically constrains what eBPF programs are allowed to do. Some examples:
- eBPF programs are not allowed to block.
- They’re not allowed to have unbounded loops (in fact, they weren’t allowed to have loops at all until fairly recently).
- They’re not allowed to exceed a certain maximum size.
- The verifier must be able to evaluate all possible paths of execution.
The verifier is utterly Draconian and its decision is final: it has to be, in order to maintain the isolation guarantees that our entire cloud-native world relies on. It also has to err on the side of declaring the program unsafe: if it’s not completely certain that the program is safe, it is rejected. Unfortunately, there are eBPF programs that are safe, but that the verifier just isn’t smart enough to pass — if you’re in that position, you’ll need to either rewrite the program until the verifier is OK with it, or you’ll need to patch the verifier and build your own kernel5.
The end result is that eBPF is a very highly constrained language. This means that while things like running simple checks for every incoming network packet are easy, seemingly-straightforward things like buffering data across multiple packets are hard. Implementing HTTP/2, or terminating TLS, are simply not possible in eBPF: they’re too complex.
And all of that, finally, brings us to the question of what it would look like to apply eBPF’s networking capabilities to a service mesh.
eBPF and Service Mesh
Service meshes have to handle all of the complexity of cloud-native networking. For example, they typically must originate and terminate mTLS; retry requests that fail; transparently upgrade connections from HTTP/1 to HTTP/2; enforce access policy based on workload identity; send traffic across cluster boundaries; and much more. There’s a lot going on in the cloud-native world.
Most service meshes use the sidecar model to manage everything. The mesh attaches a proxy, running in its own container, to every application pod, and the proxy intercepts network traffic to and from the application pod, doing whatever is necessary for mesh functionality. This means that the mesh can work with any workload and requires no application changes, which is a pretty dramatic win for developers. It’s also a win for the platform side: they no longer need to rely on the app developers to implement mTLS, retries, golden metrics6, etc., as the mesh provides all this and more across the entire cluster.
On the other hand, it wasn’t very long ago that the idea of deploying all these proxies would have been utter insanity, and people still worry about the burden of running the extra containers. But Kubernetes makes deployment easy, and as long as you keep the proxy lightweight and fast enough, it works very well indeed. (“Lightweight and fast” is, of course, subjective. Many meshes use the general-purpose Envoy proxy as a sidecar; Linkerd seems to be the only one using a purpose-built lightweight proxy.)
An obvious question, then, is whether we can push functionality from the sidecars down into eBPF, and if it will help to do so. At OSI layers 3 and 4 – IP, TCP, and UDP – we already see several clear wins for eBPF. For example, eBPF can make complex, dynamic IP routing fairly simple. It can do very intelligent packet filtering, or do sophisticated monitoring, and it can do all of that quickly and inexpensively. Where meshes need to interact with functionality at these layers, eBPF seems like it could definitely help with mesh implementation.
However, things are different at OSI layer 7. eBPF’s execution environment is so constrained that protocols at the level of HTTP and mTLS are far outside its abilities, at least today. Given that eBPF is constantly evolving, perhaps some future version could manage these protocols, but it’s worth remembering that writing eBPF is very difficult, and debugging it can be even more so. Many layer 7 protocols are complex beasts that are bad enough to get right in the relatively forgiving environment of user space; it’s not clear that rewriting them for eBPF’s constrained world would be practical, even if it became possible.
What we could do, of course, would be to pair eBPF with a proxy: put the core low-level functionality in eBPF, then pair that with user space code to manage the complex bits. That way we could potentially get the win of eBPF’s performance at lower levels, while leaving the really nasty stuff in user space. This is actually what every extant “eBPF service mesh” today does, though it’s often not widely advertised.
This raises some questions about where, exactly, such a proxy should go.
Per-Host Proxies vs Sidecars
Rather than deploying a proxy at every application pod, as we do in the sidecar model, we could instead look at deploying a single proxy per host (or, in Kubernetes-speak, per Node). It adds a little bit of complexity to how you manage IP routing, but at first blush seems to offer some good economies of scale since you need fewer proxies.
However, sidecars turn out to have some significant benefits over per-host proxies. This is because sidecars get to act like part of the application, rather than standing apart from it:
- Sidecar resource usage scales proportional to application load, so if the application isn’t doing much, the sidecar’s resource usage will stay low7. When the application is taking a lot of load, all of Kubernetes’ existing mechanisms (resource requests and limits, the OOMKiller, etc.) keep working exactly as you’re used to.
- If a sidecar fails, it affects exactly one pod, and once again existing Kubernetes mechanisms for responding to the pod failing work fine.
- Sidecar operations are basically the same as application pod operations. For example, you upgrade to a new version of the sidecar with a normal Kubernetes rolling restart.
- The sidecar has exactly the same security boundary as its pod: same security context, same IP addresses, etc. For example, it needs to do mTLS only for its pod, which means that it only needs key material for that single pod. If there’s a bug in the proxy, it can leak only that single key.
All of these things go away for per-host proxies. Remember that in Kubernetes, the cluster scheduler decides which pods get scheduled onto a given node, which means that every node effectively gets a random set of pods. That means that a given proxy will be completely decoupled from the application, which is a big deal:
- It’s effectively impossible to reason about an individual proxy’s resource usage, since it will be driven by a random subset of traffic to a random subset of application pods. In turn, that means that eventually the proxy will fail for some hard-to-understand reason, and the mesh team will take the blame.
- Applications are suddenly more susceptible to the noisy neighbor problem, since traffic to every pod scheduled on a given host has to flow through a single proxy. A high-traffic pod could completely consume all the proxy resources for the node, leaving all the other pods to starve. The proxy could try to ensure fairness, but that will fail too if the high-traffic pod is also consuming all the node’s CPU.
- If a proxy fails, it affects a random subset of application pods — and that subset will be constantly changing. Likewise, trying to upgrade a proxy will affect a similarly random, constantly-changing subset of application pods. Any failure or maintenance task suddenly has unpredictable side effects.
- The proxy now has to span the security boundary of every application pod that’s been scheduled on the Node, which is far more complex than just being coupled to a single pod. For example, mTLS requires holding keys for every scheduled pod, while not mixing up which key goes with which pod. Any bug in the proxy is a much scarier affair.
Basically, the sidecar uses the container model to its advantage: the kernel and Kubernetes put in the effort to enforce isolation and fairness at the level of the container, and everything just works. The per-host proxies step outside of that model, which means that they have to solve all the problems of contended multitenancy on their own.
Per-host proxies do have advantages. First, in the sidecar world, going from one pod to another is always two passes through the proxy; in the per-host world, sometimes it’s only one pass8, which can reduce latency a bit. Also, you can end up running fewer proxies, which could save on resource consumption if your proxy has a high resource usage at idle. However, these improvements are fairly minor compared to the costs of the operational and security issues, and they’re largely things that can be mitigated by using smaller, faster, simpler proxies.
Could we also mitigate these issues by improving the proxy to better handle contended multitenancy? Maybe. There are two main problems with that approach:
- Contended multitenancy is a security concern, and security matters are best handled with smaller, simpler code that’s easier to reason about. Adding a lot of code to better handle contended multitenancy is basically diametrically opposed to security best practices.
- Even if the security issues could be addressed completely, the operational issues would remain. Any time we choose to have more complex operations, we should be asking why, and who benefits.
Overall, these sorts of proxy changes would likely be an enormous amount of work9, which raises real questions about the value of doing that work.
Bringing everything full circle, let’s look back at our original question: what would it look like to push service mesh functionality down to eBPF? We know that we need a proxy to maintain the layer 7 functionality we need, and we further know that sidecar proxies get to work within the isolation guarantees of the operating system, where per-host proxies would have to manage everything themselves. This is not a minor difference: the potential performance benefits of the per-host proxy simply don’t outweigh the extra security concerns and operational complexity, leaving us with the sidecar as the most viable option whether or not eBPF is involved.
Looking Ahead
To state the obvious, the first priority of any service mesh must be the users’ operational experience. Where we can use eBPF for greater performance and lower resource usage, great! But we need to be careful that we don’t sacrifice the user experience in the process.
Will eBPF eventually become able to take on the full scope of a service mesh? Unlikely. As discussed above, it’s very much unclear that actually implementing all the needed layer 7 processing in eBPF would be practical, even if it does become possible at some point. Likewise, there could be some other mechanism for moving these L7 capabilities into the kernel — historically, though, there’s not been a big push for this, and it’s not clear what would really make that compelling. (Remember that moving functionality into the kernel means removing the guardrails we rely on for safety in user space.)
For the foreseeable future, then, the best course forward for service meshes seems to be to actively look for places where it does make sense to lean on eBPF for performance, but to accept that there’s going to be a need for a user-space sidecar proxy, and to redouble efforts to make the proxy as small, fast, and simple as possible.
Footnotes
1. Or, at least, dramatically easier.
2. At least, not without prearrangement between the programs. That’s outside the scope of this article.
3. Much of the rest is scheduling.
4. In fact, it’s impossible in the general case. If you want to dust off your CS coursework, it starts with the halting problem.
5. One of these things is probably easier than the other. Especially if you want to get your verifier patches accepted upstream!
6. Traffic, latency, errors, and saturation.
7. Assuming, again, a sufficiently lightweight sidecar.
8. Sometimes it’s still two, though, so this is a bit of a mixed blessing.
9. There’s an interesting twitter thread about how hard it would be to do this for Envoy, for example.