Month: October 2022

MMS • Matt Butcher
Article originally posted on InfoQ. Visit InfoQ
Subscribe on:
Introduction [00:17]
Wesley Reisz: Cloud computing can be thought of as two, or as today’s guest will discuss, three different waves.
The first wave of cloud computing can be described as virtualization. Along came the VM and we no longer were running on our physical compute. We introduced virtual machines to our apps. We improved density, resiliency, operations. The second wave came along with containers and we built orchestrators like Kubernetes to help manage them. Startup times decreased. We improved isolation between teams, we improved flow, velocity. We embraced DevOps. We also really introduced the network into how our applications operated. We’ve had to adapt and think about that as we’ve been building apps, taking all of that into consideration. Many have described Serverless (or functions as a service) as a third wave of cloud compute.
Today’s guest, the CEO of Fermyon Technologies, is working on functions as a service delivered via Wasm (Web Assembly), and that will be the topic today’s podcast.
Hi, my name is Wes Reisz. I’m a technical principal with ThoughtWorks and cohost of the InfoQ podcast. In addition, I chair a software conference called QCon San Francisco. QCon is a community of senior software engineers focused on sharing practical, no marketing based solutions to real-world engineering problems. If you’ve search the web for deeply technical topics and ran across videos on InfoQ, odds are you’ve seen some of the talks I’m referring to about QCon. If you’re interested in being a part of QCon and contributing to that conversation, the next one is happening at the end of October in the Bay Area. Check us qconsf.com.
As I mentioned, today our guest is Matt Butcher. Matt is a founding member of dozens of open-source projects, including Helm, Cloud Native Application Bundles, Krustlet, Brigade, Open Application Model Glide, the PHP HTML5 parser and Query Path. He’s contributed to over 200 open source projects spanning dozens of programming languages. Today on the podcast we’re talking about distributed systems and how Web Assembly can be used to implement functions as a service. Matt, welcome to the podcast.
Matt Butcher: Thanks for having me, Wes.
What are the three waves of cloud computing? [02:11]
Wesley Reisz: In that intro, I talked about two waves of cloud compute. You talk about a third, what is the third wave of cloud compute?
Matt Butcher: Yes, and it actually, spending a little time on the first two autobiographically helps articulate why I think there’s a third. I got into cloud services really back when OpenStack got started. I had joined HP and joined the HP Cloud group right when they really committed a lot of resources into developing OpenStack, which had a full virtual machine layer and object storage and networking and all of that. I came into it as a Drupal developer, of all things. I was doing content management systems and having a great time, was running the developer CMS system for HP, and as soon as I got my first taste of the virtual machine world, I was just totally hooked because it felt magical.
In the past, up until that time, we really thought about the relationship between a piece of hardware and the operating system as being sort of like one to one. My hardware at any given time can only run one operating system. And I’m one of those people who’s been dual booting with Linux since the nineties and suddenly the game changed. And not only that, but I didn’t have to stand up a server anymore. I could essentially rent space on somebody else’s server and pay their electricity bill to run my application, right?
Wesley Reisz: Yes, it was magic.
Matt Butcher: Yes, magic is exactly the word that it felt like at that time, and I was just hooked and got really into that world and had a great time working on OpenStack. Then along came containers and things changed up for me job wise and I ended up in a different job working on containers. At the time I was trying to wrestle through this inner conflict. Are containers going to defeat virtual machines, or are virtual machines going to defeat containers? And I was, at the time, really myopically looking at these as competitive technologies where one would come out the victor and the other one would fall by the wayside of the history of computing, as we’ve seen happen so many other times with different technologies.
It took me a while, really all through my Deis days, up until Microsoft acquired Deis, and I got a view of what it looked like inside the sausage factory to realize that no, what we weren’t seeing is two competing technologies. We were really seeing two waves of computing happen. The first one was us learning how to virtualize workloads using a VM style, and then containers offered an alternative way with some different pros and some different cons. But when you looked at the Venn diagram of features and benefits and even patterns that we used, there was actually very little overlap between the two, surprisingly little overlap between the two.
I started reconceptualizing the cloud compute world as having this wavy kind of structure. So here we are at Microsoft, the team that used to be Deis, and then we joined Microsoft and we gain new developers from other parts of Microsoft and we start to interact with the functions as a service team, the IoT team, the AKS team, and all of these different groups inside of Azure and get a real look, a very, very eyeopening look for what all of this stuff looks like under the hood and what the real struggles are to run a cloud at scale. I hate using the term at scale, but that’s really what it is there. But also we’re doing open source and we’re engaged with startups and medium-sized companies and large companies, all of whom are trying to build technologies using this stuff, containers, virtual machines, object storage and stuff like that.
We start seeing where both the megacorp and the startups are having a hard time and we’re trying to solve this by using containers and using virtual machines. At some point we started to realize, “Hey, there are problems we can’t solve with either of these technologies.” We can only push the startup time to containers down to a few hundred milliseconds, and that’s if you are really packing stuff in and really careful about it. Virtual machine images are always going to be large because you’ve always got to package the kernel. We started this checklist of things and at some point it became the checklist of what is the next wave of cloud computing?
That’s where we got into Web Assembly. We start looking around and saying, “Okay, what technology candidates are there that might fill a new compute niche, where we can pack something together and distribute it onto a cloud platform and have the cloud platform executed?” serverless at the time is getting, and we should come back to serverless later cause it’s an enticing topic on its own. serverless is getting popular but wasn’t necessarily solving that problem and we wanted to address it more at an infrastructure layer and say, “Is there a third kind of cloud compute?”
And after looking around at a couple of different technologies, we landed on Web Assembly of all things, a browser technology, but what made it good for the browser, that security isolation model, small binary sizes, fast startup times, those are just core things you have to have in a web browser. People aren’t going to wait for the application to start. They’re not going to tolerate being able to root your system through the browser and so all these security and performance characteristics and multilanguage, multi-architecture characteristics were important for the browser. That list was starting to match up very closely with the list of things that we were looking for in this third wave of cloud computing.
This became our Covid project. We spent our Fridays, what would it mean to try and write a cloud compute layer with Web Assembly? And that became Krustlet, which is a Web Assembly runtime essentially for Kubernetes. We were happy with that, but we started saying, “Happy, yes, but is this the right complete solution? Probably not.” And that was about the time we thought, “Okay, it’s time to do the startup thing. Based on all the knowledge we’ve accrued about how Web Assembly works, we’re going to start without the presupposition that we need to run inside of a container ecosystem like Kubernetes and we just need to start fresh.” And that was really what got us kicking with Fermyon and what got us excited and what got us to create a company around this idea that we can create the right kind of platform that illustrates what we mean by this kind of third wave of cloud computing.
What is the ecosystem around Web Assembly in the cloud? [08:12]
Wesley Reisz: We’re talking about Web Assembly to be able to run server side code. Are we talking about a project specifically, like Krustlet’s a project, or are we talking about an idea? What is the focus?
Matt Butcher: Oh, that’s a great question because as a startup founder, my initial thing is, “Well, we’re talking about a project,” but actually I think we’re really talking more about an ecosystem. There’s several ecosystems we could choose from, the Java ecosystem or the dotnet ecosystem as illustrations of this. But I think the Docker ecosystem, it’s such a great example of an ecosystem evolving and one that’s kind of recent, so we all kind of remember it, but there were some core technologies like Docker of course, and early schedulers including Mesos and Swarm and Fleet and the key value storage systems like ETCD and Consul. So there were a whole bunch of technologies that co-evolved in order to create an ecosystem, but the core of the ecosystem was the container.
And that’s what I think we are really in probably the first year or two years of seeing that develop inside of Web Assembly, a number of different companies and individual developers and scholars in academia have all sort of said, “Hey, the Web Assembly binary looks like it might be the right foundation for this. What are the technologies we need to build around it and what’s the community structure we need to build around it?” Because standardizing is still the gotcha for almost all of our big efforts. We want things standardized enough so that we can run reliably and understand how things are going to execute and all of that while we all still want to keep enough space open that we can do our own thing and pioneer a little bit.
I think that the answer to your question is the ecosystem is the first thing for this third wave of cloud compute. We need groups like Bytecode Alliance where the focus is on working together to create the specifications like Web Assembly system interface that determines how you interface with a system clock, how you load environment variables, how you read and write files, and we need that as a foundational piece. So there’s that in a community.
There’s the conferences like Web Assembly Summit and Wasm Day at KubeCon, and we need those as areas where we can collaborate and then we need lots and lots of developers, often working for different companies, that are all trying to solve a set of problems that define the boundaries of the ecosystem. I think we are in about year one and a half to year two of really seeing that flourishing. Bytecode Alliance has been around a little longer, but only formalized about a year and a half ago. You’re seeing a whole bunch of startups like Fermyon and Suborbital and Cosmonic and Profion bubbling up, but you’re also seeing Fastly and CloudFlare buying into this Microsoft, Amazon, Google buying into this so we’re really seeing once again the same replay of a ecosystem formation that we saw in the Docker ecosystem when it was Red Hat at Google.
Wesley Reisz: I know of Fastly doing things at the Edge, being able to compile things at the Edge and be able to run Web Assembly Wasm there. I can write Wasm applications myself and deploy them, but the cloud part, how do I deploy Wasm in a Cloud Native way? How does that work today?
Matt Butcher: In this case, Cloud Native and Edge are similar. Maybe the Edge is a little more constrained in some of the things it can do and a little faster to deliver on others. But at the core of it, we need to be able to push a number of artifacts somewhere and understand how they’re going to be executed. We know, for example, we’ve got the binary, a Web Assembly binary file, and then we need some supporting file. A good example of this is fermyon.com is powered by a CMS that we wrote called Bartholomew. For Bartholomew, we need the Web Assembly binaries that serve out the different parts of the site, and it’s created with a microservice architecture. I think it’s got at this point five different binary files that execute fermyon.com.
Then we need all of the blog posts and all the files and all the images and all the CSS, some of which are dynamic and some of which are static. And somehow we have to bundle all of these up. This is a great example of where Bytecode Alliance is a great entity to have in a burgeoning ecosystem. We need to have a standard way of pushing these bundles up to a cloud. And Fastly’s Compute@Edge is very similar. We need a way to push their artifacts up to Compute@Edge with Fastly or any of these.
There’s a working group called SIG Registry that convenes under Bytecode Alliance that’s working on defining a package format and defining how we’re going to push and pull packages, essentially where you think of in the Docker world, pushing and pulling from registries and packaging things up with a Docker file and creating an image file, same kind of thinking is happening in Bytecode Alliance specific to Web Assembly. SIG Registries is a great place to get involved if that’s the kind of thing that people are interested in. You can find out about it at bytecodealliance.org. That’s one of the pieces of community building/ecosystem building that we’ve got to be engaged in.
What is the mission of Fermyon? [12:57]
Wesley Reisz: You started a company, Fermyon, and now what’s the mission of Fermyon? Is it to be able to take those artifacts and then be able to deploy them onto a cloud footprint? What is Fermyon doing?
Matt Butcher: For us, we’re really excited about the idea that we can create a cloud run time that can run in AWS, in Azure, in Google, in Digital Ocean that can execute these Web Assembly modules and that we can streamline that experience to make it frictionless. It’s really kind of a two part thing. We want to make it easy for developers to build these kinds of applications and then make it easy for developers to deploy and then manage these applications over the long term.
When you think about the development cycle, oftentimes as we build these new kinds of systems, we introduce a lot of fairly heavy tooling. Virtual machines are still hard to build for us now even a decade and some into the ecosystem. And technologies like Packer have made it easier, but it’s still kind of hard. The number one thing that Docker did amazingly well was create a format that made it easy for people to take their applications that already existed, package them up using a Docker file into a image, and we looked at that and said, “Could we make it simpler? Could we make the developer story easier than that?”
And the cool thing about Web Assembly is that all these languages are adding support into their compilers. So with Rust, you just add –target Wasm32-wasi and it compiles the binary for you. We’ve really opted for that lightweight tooling.
What is Spin? [14:22]
Spin is our developer tool, and the Spin project is basically designed to assist in what we call the inner loop of development. This is a big microsoft-y term, I think inner and outer loop of development.
Wesley Reisz: Fast compile times.
Matt Butcher: What we really mean is when you as the individual developer are focused on your development cycle and you’ve blocked out the world and you’re just wholly engaged in your code, you’re in your inner loop, you’re in flow. And so we wanted to build some tools that would help developers when they’re in that mode to be able to very quickly and rapidly build Web Assembly based applications without having to think about the deployment time so much and without having to use a lot of external tools. So Spin is really the one tool that we think is useful there, and we’ve written VS code extension to streamline that.
And then on the cloud side, you got to run it somewhere, and we built the tool we call Fermyon or the Fermyon platform, to really execute there. And that’s kind of a conglomeration of a number of open source projects with a nice dashboard on top of it that you can install into Digital Ocean or AWS or Azure or whatever you want and get it running there.
Wesley Reisz: And that runs a full Wasm binary? Earlier I talked functions as a service, does it run functions or does it run full Wasm binaries?
Matt Butcher: And this gets us back into the serverless topic, which we were talking about earlier, and serverless I think has always been a great idea. The core of this is can we make it possible so that the developer doesn’t even have to think about what a server is?
Wesley Reisz: Exactly. The plumbing.
Matt Butcher: And functions as a service to me is just about the purest form of serverless that you can get where not only do you not have to think about the hardware or the operating system, but you don’t even have to think about the web framework that you’re running in, right? You’re merely saying, “When a request comes into this endpoint, I’m going to handle it this way and I’m going to serve back this data.” Within moments of starting your code, you’re deep into the business logic and you’re not worried about, “Okay, I’m going to stand up an HTTP server, it’s got to listen on this port, here’s the SSL configuration.”
Wesley Reisz: No Daemon Sets, it’s all part of the platform.
Matt Butcher: Yes. And as a developer, that to me is like, “Oh, that’s what I want. No thousand lines of YAML config.” serverless and functions as a service were looking like very promising models to us. So as we built out Spin, we decided that at least as the first primary model that we wanted to use, we wanted to use that particular model. Spin for example, it functions more like an event listener where you say, “Okay, on an HTTP request, here’s the request object, do your thing and send back a response object.” Or, “As a Redis listener, when a message comes in on this channel, here’s the message, do your thing and then optionally send something back.” And that model really is much closer to Azure functions and Lambda and technologies like that. We picked that because developers seem to really enjoy that. Developers say they really enjoy that model. We think it’s a great compliment for Web Assembly. It really gets you thinking about writing microservices in terms of very, very small chunks of code and not in terms of HTTP servers that happen to have microservice infrastructure built in.
Wesley Reisz: Spin lets you write this inner loop, fast flow, event driven model where you can respond to the events that are going like the serverless model, and then you’re able to package that into Wasm that can then be deployed with Fermyon cloud? Is that the idea?
Matt Butcher: Yes, and when you think about writing a typical HTTP application, even going back to say Rails, Rails and Django I think really defined how we think about HTTP applications, and you have got this concept of the routing table. And in the routing table you say, “When somebody hits /foo, then that executes myFoo module. If I hit /bar that executes myBar module.” That’s really the direction that we went with the programming model where when you hit fermyon.com/index, it executes the Web Assembly module that generates the index file and serves that out. When you hit /static/file.jpeg, it loads the file server and serves it back. And I think that model really kind of resonates with pretty much all modern web application and microservice developers, but all the writing in the back end is just a function. I really like that model because it just feels like you’re getting right to the meat of what you actually care about within a moment of starting your application instead of a half hour or an hour later when you’ve written out all the scaffolding for it.
How do you handle state in cloud-based Web Assembly? [18:35]
Wesley Reisz: What about State? You mentioned Redis before having Redis listeners, how do you manage State when you’re working with Spin or with Fermyon cloud? How does that come into play?
Matt Butcher: That’s a great architectural discussion for microservices as a whole, and we really have felt strongly that what we have observed coming from Deis and Microsoft and then on into Fermyon or Google, in the case of some of the other engineers who work on Fermyon, Google into Fermyon, we’ve seen the microservice pattern be successful repeatedly. And Statelessness has been a big virtue of the microservice model as far as the binary keeping state internally, but you got to put state full information somewhere.
Wesley Reisz: At some point.
Matt Butcher: The easy one is, “Well, you can put it in files,” and WASI and Web Assembly introduced file support two years ago and that was good, but that’s not really where you want to stop. With Spin, we began experimenting with adding some additional ones like Redis support and generic key-value storage, which is coming out and released very soon. Database support is coming out really soon and those kinds of things. Spin, by the way, is open source, so you can actually go see all these PRs in flight as we work on PostgreSQL support and stuff like that.
It’s coming along and the strategy we want to use is the same strategy that you used in Docker containers and other stateless microservice architectures where State gets persisted in the right kind of data storage for whatever you’re working on, be that a caching service or a relational database or a noSQL database. We are hoping that as the Web Assembly component model and other similar standards kind of solidify, we’re going to see this kind of stuff not be a Spin specific feature, but just the way that Web Assembly as a whole works and different people using different architectures will be able to pull the same kinds of components and get the same kind of feature set.
What is the state of web assembly performance in the cloud? [20:20]
Wesley Reisz: Yes, very cool. When we were talking just before we started recording, you mentioned that you wanted to talk a little bit about performance of Web Assembly and how it’s changed. I remember I guess a year ago, maybe two years ago, I did a podcast with Linn Clark. We were talking about Fastly and running Web Assembly at the Edge, like we were talking about before, and if I remember right, I may be wrong, but if I remember right, it was like 3 ms was the overhead that was for the inline request compiled time, which I thought was impressive, but you said you’re way lower than that now. What is the request level inline performance time of Web Assembly these days?
Matt Butcher: We’re lower now. Fastly’s lower now. As an eco, we’ve learned a lot in the last couple years about how to optimize and how to pre initialize and cache things ahead of time. 3ms even a year and a half ago would’ve been a very good startup time. Then we are pushing down toward a millisecond and now we are sub one millisecond.
And so again, let’s characterize this in terms of these three waves of cloud computing, a virtual machine, which is a powerhouse. You start with the kernel and you’ve got the file system and you’ve got all the process table and everything starting up and initializing and then opening sockets and everything, that takes minutes to do. Then you get to containers. And containers on average take a dozen seconds to start up. You can push down into the low seconds range and if you get really aggressive and you’re really not doing very much, you might be able to get into the hundred milliseconds or the several hundred milliseconds range.
One of the core features that we think this third wave of cloud compute needed, and one of our criteria coming in was it’s got to be in the tens of milliseconds. That was a design goal coming out of the gate for us, and the fact that now we’re seeing that push down below the millisecond marker for being able to get from cold State VM to something executing, to that first instruction, having that under a millisecond is just phenomenal.
In many ways we’ve kind of learned lessons from the JVM and the CLR and lots and lots of other research that’s been done in this area. And in another, some of it just comes about because with both us and with Fastly and other cloud providers distinctly from the browser scenario, we can preload code, compile it ahead of time into Native and then be able to have it cached there and ready to go because we know everything we need to know about what the architecture and what the system is going to look like when that first invocation hits, and that’s why we can really start to drive times way, way down.
Occasionally you’ll see a blog post of somebody saying, “Well, Web Assembly wasn’t terribly fast when I ran it in the browser.” And then those of us on the cloud side are saying, “Well, we can just make it blazingly fast.” A lot of that difference is because the things that the run time has to be able to learn about the system at execution time in the browser, we know way ahead of time on the cloud and so we can optimize for that. I wouldn’t be surprised to see Fastly, Fermyon, other companies pushing even lower until it really does start to appear to be at Native or faster than Native speeds.
Wesley Reisz: That’s awesome. Again, I haven’t really tracked Web Assembly in the last year and a half or so, but some of the other challenges were types and I think component approach to where you could share things. How has that advanced over the last year and a half? What’s the state of that today?
Matt Butcher: Specifications often move in fits and starts, right? And W3C, by the way, the same standards body that does CSS, HTML and HTTP, this is the same standards body that works on Web Assembly. Types was one of the initial, ‘How do we share type information?” And that morphed in and out of several other models. And ultimately what’s emerged out of that is borrowing heavily from existing academic work on components. Web Assembly is now gaining a component model. What that means in practice is that when I compile a Web Assembly module, I can also build a file that says, “These are my exported functions and this is what they do and these are the types that they use.” And types here aren’t just like instant floats and strings. We can build up very elaborate struct like types where we say, “This is a shopping cart and a shopping cart has a count of items and an item looks like this.”
And the component model for Web Assembly can articulate what those look like, but it also can do a couple of other really cool things. This is where I think we’re going to see Web Assembly really break out. Developers will be able to do things in Web Assembly that they have not yet been able to do using other popular architectures, other popular paradigms. And this is that Web Assembly can articulate, “Okay, so when this module starts up, it needs to have something that looks like a key value storage. Here’s the interface that defines it. I need to be able to put a string string and I need to be able to get string and get back a string object or I need a cache where it lives for X amount of time or else I get a cache miss.” But it has no real strong feelings about, it doesn’t have any feelings at all. It’s binary, it has no real strong…
Wesley Reisz: Not yet. Give a time.
Matt Butcher: Anthropomorphizing code.
And then at startup time we can articulate, Fastly can say, “Well, we’ve got a cache-like thing and it’ll handle these requests.” And Fermyon can say, “Well we don’t, but we can load a Docker container that has those cache-like characteristics and expose a driver through that.” And suddenly applications can be sort of built up based on what’s available in the environment. Now because Web Assembly is multi-language, what this means is effectively for the most part, we’ve been writing the same tools over and over again in JavaScript and Ruby and Python and Java. If we can compile all of the same binary format and we can expose the imports and exports for each thing, then suddenly language doesn’t make so much of a difference. And so whereas in the past we’ve had to say, “Okay, here’s what you can do in JavaScript and here’s what you can do in Python,” now we can say, “Well, here’s what you can do.”
Wesley Reisz: Reuse components.
Matt Butcher: And whether the key value store is written in Rust or C or Erlang or whatever, as long as it’s compiled to Web Assembly, my JavaScript application can use it and my Python app can use it. And that’s where I think we should see a big difference in the way we can start constructing applications by aggregating binaries instead of fetching a library and building it into our application.
What’s happening in the language space when it comes to Web Assembly? [26:23]
Wesley Reisz: Yes, it’s cool. Speaking of, language support was another thing that you wanted to talk about. There’s a lot of changes, momentum and things that have been happening with languages themselves and support of Web Assembly like Switches, there’s things with Node, we talked about Blazer for a minute. What’s happening in the language space when it comes to Web Assembly?
Matt Butcher: To us, Web Assembly will not be a real viable technology until there is really good language support. On fermyon.com we actually track the status of the top 20 languages as determined by Red Monk and we watch very closely and we continually update our matrix of what the status is of Web Assembly in these languages. Rewind again back only a year or two and all the check boxes that are checked are basically C and Rust, right? Both great languages, both well-respected languages, both not usually the first languages a developer says, “Yes, this is my go-to language.” Rust is gaining popularity of course, and we love Rust, but JavaScript wasn’t on there. Python wasn’t on there, Ruby wasn’t on there. Java and C Sharp certainly weren’t on there. What we’ve seen over only a year, year and a half is just language after language first announcing support and then rapidly delivering on it.
Earlier this year, I was ecstatic when I saw in just the space of two weeks, Ruby and Python both announce that the CRuby and CPython run times were compilable to Web Assembly with WASI, which effectively meant all of a sudden Spin, which applications were kind of limited to Rust and C at the time, could suddenly do Python and Ruby applications. Go, the core project is a little bit behind on Web Assembly support, but the community picked up the slack and Tiny Go can compile Go programs into Web Assembly Plus WASI. Go came along right around, actually a little bit earlier than Python and Ruby, but now what we’re seeing, now being in the last couple of weeks, is the beginning of movement from the big enterprise languages. Microsoft has been putting a lot of work into Web Assembly in the browser over the past with the Blazer framework, which essentially ran by compiling the CLR, the run time for C Sharp in those languages into Web Assembly and then interpreting the DLLs.
But what they’ve been saying is that was just the first step, right? The better way to do it is to compile C#, F#, all the CLR supported languages directly into Web Assembly and be able to run them directly inside of a Web Assembly runtime, which means big performance boost, much smaller binary sizes and all of a sudden it’s easy to start adding support for newly emerging specifications because it doesn’t have to get routed through multiple layers of indirection.
Steve Sanderson, who’s one of the lead, I think he’s the lead PM for the dotnet framework, has been showing off a couple times since KubeCon in Valencia, now I think four or five different places has shown off where they are in supporting dotnet to Web Assembly with WASI, and it’s astounding. So often we’ve thought of languages like C# as being sort of reactive, looking around at what’s happening elsewhere and reacting, but they’re not. They are very forward thinking engineers, and David Fowler’s brilliant and the stuff they’re doing is awesome. Now they’ve earmarked Web Assembly as the future, as one of the things they really want to focus on. And I’m really excited, my understanding is the next version of dotnet will have full support for compiling to Native Web Assembly and the working drafts of Native’s out now.
Wesley Reisz: Yes, that’s awesome. You mentioned that there’s work happening with Java as well, so Java, the CLR, that’s amazing.
Matt Butcher: Yep. Kotlin too is also working on a Native implementation. I think we’ll see Java, Kotlin, the dotnet languages all coming. I think they’ll be coming by the end of the year. I’m optimistic. I have to be because I’m a startup founder and if you’re not optimistic, you won’t survive. But I think they’ll be coming by the end of the year. I think you’ll really start to see the top 20 languages, I think we’ll see probably 15 plus of them support Web Assembly by the end of the year.
Wesley Reisz: That’s awesome. Let’s come back for a second to Fermyon. We’re going to wrap up here, but I wanted you to walk through, there’s an app that you talk about, Wagi, that’s on one of your blog posts, that’s how you might go about using Spin, how you use Fermyon cloud. Could you walk through what it looks like to bootstrap an app? Talk about just what does it look like for me if I wanted to go use Fermyon cloud, what would it look like?
Matt Butcher: Spin’s the tool you’d use there? Wagi is actually just a description of how to write an application, so when you’re writing it. Think about Wagi as one of You download Spin from our GitHub repository and you type in Spin new and then the type of application you want to write and the name. Say I want to create Hello World in Rust, it’s Spin New Rust Hello World. And that commands scaffolds out, it runs the cargo commands in the background and creates your whole application environment. When you open it from there, it’s going to look like your regular old Rust application. The only thing that’s really happening behind the scenes is wiring up all the pieces for the component model and for the compiler so that you don’t have to think about that.
“spin new”, you’ve got your Hello World app created instantly. You can edit it however you’d normally edit, I use VS code. From there, you type in Spin Build, it’ll build your binary for you. And again, largely it’s invoking the Rust compiler in Rusts case or the Tiny Go compiler in Go Case or whatever. And then Spin Deploy will push it out to Fermyon. So assuming you’ve got a Fermyon instance running somewhere, you can Spin Deploy and have it pushed out there. If you’re doing your local development, you can just, instead of typing, Spin Deploy, you can type Spin Up and it’ll create you a local web server and be running your application inside there so the local development story is super easy there. In total, we say you should be able to get your first Spin application up and running in two minutes or less.
Wesley Reisz: How do you target different endpoints for when you deploy out to the cloud? Or do you not worry about it? That’s what you pay Fermyon, for example.
Matt Butcher: Yes, you’re building your routing table as you build the application. There’s a toml file in there called Spin.toml where you say, “Okay, if they hit slash then they load this module. If they hit /fu, they hit that module,” and it supports all the normal things that routing tables support. But from there, when you pushed out to the Fermyon platform, the platform will provision your SSL certificate, set up a domain name for you. The Fermyon dashboard that comes as part of that platform will allow you to set up environment variables and things like that. So as the developer, you’re really just thinking merely in terms of how you build your binary and what you want to do. And then once you deploy it, then you can log into the Fermyon dashboard and start tweaking and doing the DevOps side of what we would call the outer loop of development.
What’s next for Fermyon? [32:42]
Wesley Reisz: What’s next for Fermyon?
Matt Butcher: We are working on our software as a service because again, our goal is to make it possible for anybody to be able to run Spin applications and get them up and running in two minutes or less, even when that means deploying them out somewhere where they’ve got a public address. So while right now if you want to run Fermyon, you got to go install it in your AWS cluster, your Google Cloud cluster, whatever. As we unroll this service later on this year, it should make it possible for you to get that started just by typing Spin Deploy, and have that up and running inside of Fermyon.
Wesley Reisz: Well, very cool. Well, Matt, thank you for, thanks for the time to catch up and help us further understand what’s happening in the Wasm community and telling us about Fermyon and Fermyon cloud.
Matt Butcher: Thanks so much for having me.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Java News Roundup: Introducing OmniFish, Oracle Joins Micronaut Foundation, OpenJDK Updates
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for October 3rd, 2022 features news from OpenJDK, JDK 20, Spring milestone updates, Eclipse Tumerin 19, OmniFaces 4.0, PrimeFaces 12.0, Introducing OmniFish, Quarkus 2.13.1, Oracle joins Micronaut Foundation, Eclipse Vert.x 4.3.4, JobRunr 5.3, Apache Tomcat 9.0.68, Apache Camel 3.19, Apache Tika 2.5, ArchUnit 1.0 and conferences Devoxx Morocco and JAX London.
OpenJDK
Two JEP Drafts, 8294285, Pattern Matching for switch (Fourth Preview), and 8294078, Record Patterns (Second Preview), have been submitted by Gavin Bierman, programming language designer at Oracle. Under the auspices of Project Amber, These JEP drafts propose a fourth and second preview, respectively, of their corresponding predecessor JEPs that were delivered in JDK 19. Preview features allow for refinements based upon continued experience and feedback.
For JEP Draft 8294285, updates since JEP 427, Pattern Matching for switch (Third Preview), include: a simplified grammar for switch labels; and inference of type arguments for generic type patterns and record patterns is now supported in switch expressions and statements along with the other constructs that support patterns.
For JEP Draft 4294087, updates since JEP 405, Record Patterns (Preview), include: added support for inference of type arguments of generic record patterns; added support for record patterns to appear in the header of an enhanced for statement; and remove support for named record patterns.
JEP Draft 8294992, 64 bit object headers, was submitted by Roman Kennke, principal engineer at Amazon Web Services. Under the auspices of Project Lilliput, the JEP draft proposes to reduce the size of Java object headers from 96 or 128 bits to 64 bits. Project Lilliput, created by Kennke, marked a milestone 1 in May 2022 by achieving 64-bit headers.
JDK 20
Build 18 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 17 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 20, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
On the road to Spring Cloud 2022.0.0, codenamed Kilburn, the fifth milestone release has been made available featuring updates to version 4, milestone 5 versions of Spring Cloud sub-projects such as Spring Cloud Consul, Spring Cloud Gateway, Spring Cloud OpenFeign and Spring Cloud Commons. Spring Cloud Netflix 4.0.0-M1 features a dependency upgrade to Eureka 2.0.0 that allows Spring Cloud Netflix to be compatible with the upcoming GA releases of Spring Framework 6.0 and Spring Boot 3.0. More details on this release may be found in the release notes.
Point and milestone releases of Spring Shell have been released to the Java community. Version 2.1.2 is built on Spring Boot 2.7.4 and back ports bug fixes. Notable changes in version 3.0.0-M1 include: a dependency upgrade to Spring Boot 3.x; support for GraalVM that is mostly complete; and Spring Shell is now built with Gradle. Further details on these releases may be found in the release notes for version 2.1.2 and version 3.0.0-M1.
On the road to Spring Batch 5.0.0, the seventh milestone release features: support to use any type as a job parameter; and improved conversion of job parameters. More details on this release may be found in the release notes.
Eclipse Tumerin
The Adoptium Working Group has released Eclipse Tumerin 19, their downstream distribution of OpenJDK 19.
OmniFaces
OmniFaces has released version 4.0 of their utility library for Faces that introduces a new method, addFacesScriptResource(), defined in the Components class to allow compatibility with Jakarta Faces 3.0 and 4.0. Breaking changes include minimal dependency upgrades to JDK 11 and Jakarta EE 9 specifications, namely Faces 3.0, Expression Language 4.0, Servlet 5.0, Contexts and Dependency Injection 3.0, Enterprise Web Services 2.0 and Bean Validation 3.0. Further details on this release may be found in the what’s new document.
PrimeFaces
PrimeFaces 12.0.0 was released featuring numerous dependency upgrades to modules such as hibernate-validator 6.2.1.Final, tomcat.version 9.0.58, slf4j-api 1.7.33, mockito-core 4.2.0, hazelcast 4.2.4 and other Maven-related modules.
Introducing OmniFish
OmniFish, a new Jakarta EE consulting and support company, have introduced themselves to the Java community. Focusing on support for Jakarta EE, Eclipse GlassFish and Piranha Cloud, OmniFish has also joined the Jakarta EE Working Group as a Participant Member. Co-founders Arjan Tijms, Ondro Mihályi and David Matějček along with web engineer Bauke Scholtz, have many years of experience with GlassFish, Jakarta EE, Java application development and Java middleware production support. They are also leading members of the Eclipse GlassFish project. InfoQ will follow up with a more detailed news story.
Quarkus
Red Hat has released Quarkus 2.13.1.Final that ships with bug fixes and improvements in documentation. The SmallRye implementations of the MicroProfile OpenTracing and Metrics specifications have been deprecated due to changes in the MicroProfile specifications. More details on this release may be found in the changelog.
Micronaut
The Micronaut Foundation has announced that Oracle has joined the Micronaut Foundation as an Engineering Partner, a new program that “recognizes partner organizations that sponsor the full-time work of one or more members of the Micronaut framework core committer team, with a focus on the critical shared and common portions of the code base.” Since 2020, Oracle has been providing open source contributions to Micronaut projects such as Micronaut AOT and Micronaut Serialization.
Eclipse Vert.x
In response to a number of reported issues in version 4.3.3, Eclipse Vert.x 4.3.4 has been released featuring fixes to those bugs along with documenting deprecations and breaking changes. There is also continued support for the virtual threads incubation project. Further details on this release may be found in the release notes.
Hibernate
Hibernate ORM 6.1.4.Final has been released featuring bug fixes and an enhancement in which an unnecessary multi-table insert is no longer generated upon executing an INSERT from a SELECT statement containing an assigned identifier.
JobRunr
JobRunr 5.3.0 has been released that ships with support for Kotlin 1.7.20, Spring Boot 3.0.0-M5 and the Spring Boot Context Indexer, a utility that allows for generating a Spring component index for faster startup times. More details on this release may be found in the release notes.
Apache Software Foundation
Apache Tomcat 9.0.68 has been released with notable bug fixes such as: a refactoring regression that broke JSP includes; and unexpected timeouts that appeared upon client disconnects when using HTTP/2 and NIO2. This release also includes an enforcement of RFC 7230, Hypertext Transfer Protocol (HTTP/1.1): Message Syntax and Routing, such that a request with a malformed content-length header should always be rejected with a 400 server response. Further details on this release may be found in the changelog.
Apache Camel 3.19.0 has been released that ships with 259 bug fixes, improvements and dependency upgrades that include: gRPC 1.48.1, Spring Boot 2.7.3, JUnit 5.9.x and Artemis 2.25.x. The hadoop-common module was upgraded to version 3.3.3 to address CVE-2022-26612, a vulnerability in which a TAR entry may create unresolved symlinks that point to an external directory under the expected extraction directory. More details on this release may be found in the release notes.
Apache Tika 2.5.0 released featuring: improved extraction of PDF subset information for PDF/UA, PDF/VT and PDF/X; avoid an infinite loop in bookmark extraction from PDFs; and enable the configuration of digests through the AutoDetectParserConfig class. Further details on this release may be found in the release notes. As of September 30, 2022, the Apache Tika 1.x release train has reached its End of Life and is no longer supported.
ArchUnit
TNG Technology Consulting has released version 1.0.0 of ArchUnit, an open-source extensible library for checking the architecture of Java code by checking dependencies between packages and classes, layers and slices, and checking for cyclic dependencies. Enhancements in this release include: ignored rules defined in the archunit_ignore_patterns.txt file no longer populate an instance of the ViolationStore interface in conjunction with the FreezingArchRule class. There are breaking changes due to renaming numerous “getter” methods to remove any ambiguities. InfoQ will follow up with a more detailed news story.
JHipster
JHipster Lite 0.17.0 has been released that ships with bug fixes, enhancements and dependency upgrades that include modules: keycloak 19.0.3, mongodb 1.17.5, react-hook-form 7.37.0 and vite 3.1.6.
Conferences
Devoxx Morocco 2022 was held at the Hilton Taghazout Bay Beach Resort & Spa, Taghazout in Agadir, Morocco this past week featuring many speakers from the Java community who presented on tracks such as: Java & Programming Languages; Architecture & Security; Devops, Cloud, Containers & Infrastructure; and Data & AI.
Similarly, Jax London 2022 was held at the Business Design Centre in London, England this past week featuring many speakers from the Java community who presented sessions and workshops.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Google recently announced the preview of a new feature called Log Analytics in its Cloud Logging service, allowing companies to analyze data collected from their cloud environments.
Cloud Logging is a fully-managed real-time log management service that enables storage, search, analysis, and alerting. With the Logs Explorer feature, for instance, users can search, sort, and query logs. The added Log Analytics powered by BigQuery allows them to perform advanced analytics using SQL to query logs. For example, they can run a query to determine the average latency of the requests sent to a cloud application. In addition, there is a new user interface optimized for analyzing log data (private preview).
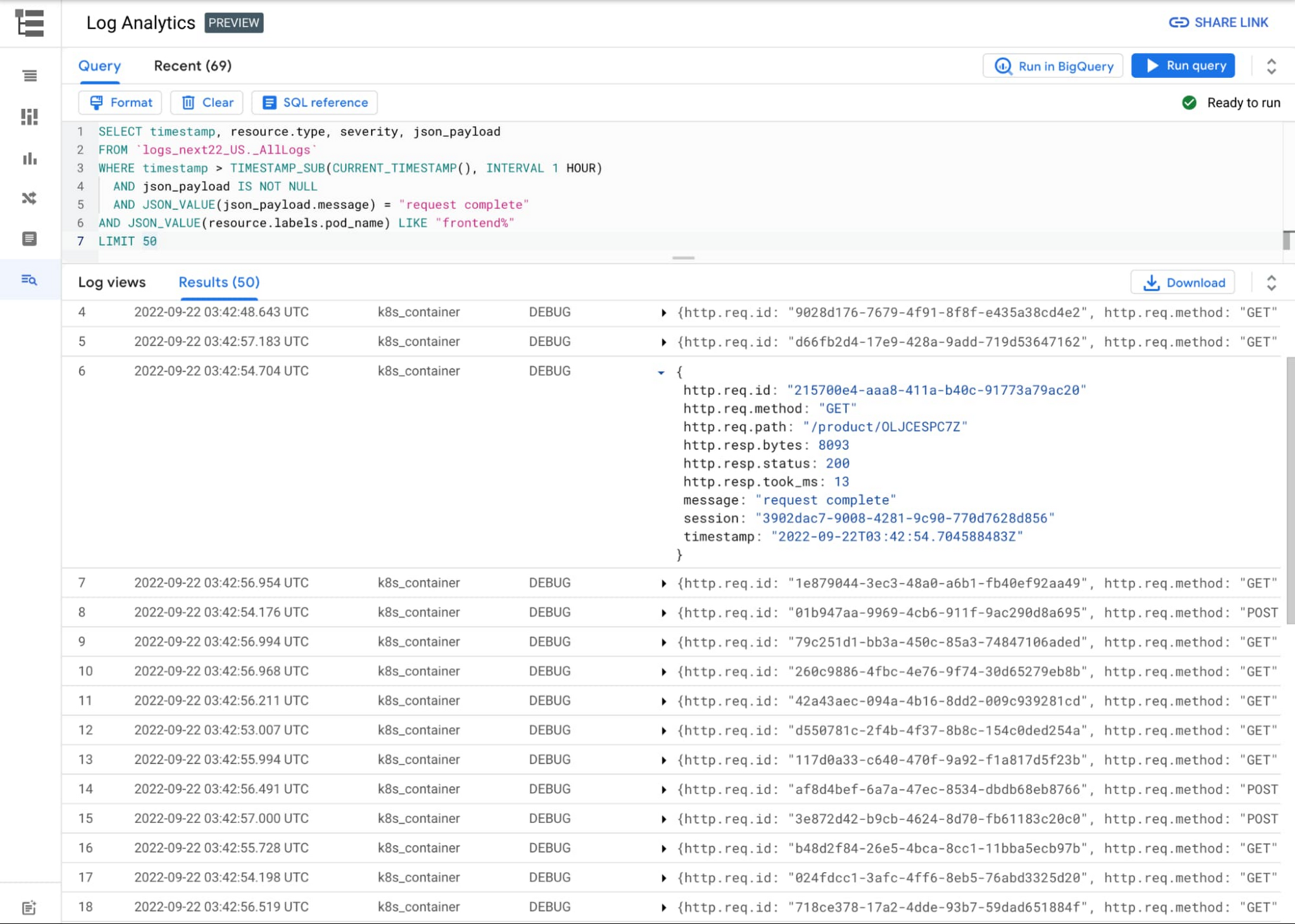
When using BigQuery, users need to analyze their logs with data stored outside of Logging. This can be accomplished by upgrading a log bucket to use Log Analytics and creating a linked dataset. Subsequently, with the linked dataset, users can join their log data with other data, such as a dataset that stores known malicious URLs or data generated from business intelligence tools like Looker and Data Studio.
Mimoune Djouallah, a business intelligence analyst at Downer, tweeted:
Google Cloud introduced Log analytics; use #bigquery to analyze your data, notice the data is not duplicated as it is using a linked dataset, Querying the data in log analytics itself is free, again using Standard SQL!!! Google Cloud analytics is another league!!!
In addition, Charles Baer, a product manager at Google Cloud, explains in a Google blog post that Log Analytics is powerful for its:
- Centralized logging: there is no need for duplicate copies since log data is collected and centrally stored in a dedicated log bucket
- Reduced cost and complexity, as data can be reused across the organization
- Ad hoc analysis: users can perform ad-hoc query-time log analysis
- Scalable platform, as it can scale for observability using the serverless BiqQuery platform.
Google’s competitor in the public cloud space, Microsoft, has a similar service in Azure also called Log Analytics (part of Azure Monitor). It is a tool in the Azure portal allowing users to edit and run log queries against data in the Azure Monitor Logs store. The queries are performed with a proprietary Kusto query language (KQL).
The pricing of Log Analytics is included in the standard Cloud Logging pricing. According to the company, queries performed through the Log Analytics user interface do not incur additional costs. Furthermore, enabling analysis in BigQuery is optional. If enabled, queries submitted against the BigQuery linked data set, including Data Studio, Looker, and via BigQuery API, incur the standard BigQuery query cost.
Lastly, users can get started using available sample queries and sign up for charting capability in Log Analytics, which is still in private preview.
Android Gradle Plugin 8.0 Improves Build Times, Requires Updating Third-Party Plugins and Libraries
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Google has announced the upcoming Android Gradle Plugin (AGP), version 8.0, reduces build times by removing the Transform APIs and replacing them through the Artifacts API and Instrumentation API. All third-party plugins and apps relying on them are required to migrate to the new APIs.
The Transform API is being removed to improve build performance. Projects that use the Transform API force AGP to use a less optimized flow for the build that can result in large regressions in build times.
The Transform APIs are a collection of APIs provided by the Android Gradle plugin to process intermediate artifacts of the build process, enabling to transform bytecode, synthesize new classes, or analyse the whole program.
A typical use of this feature is instrumenting compiled classes to add traces, custom logging, performance analysis and so on. For example, the Android Hilt plugin uses the Transform APIs to embed Dagger dependency injection into an Android app and Firebase uses it for performance monitoring. While the Transform APIs is typically used in Gradle plugins, a number of libraries also exist that use them, such as mobile database Realm. Additionally, Transform features may be helpful to create test classes.
For developers, this change means they may need to migrate their own codebases, as well as to update any dependencies using the Transforms APIs to newer versions using the replacement APIs. While a number of plugins and libraries, including the mentioned Hilt, Firebase, and Realm, have been working on adopting the new APIs, it is not unlikely that migration may cause some headache for developers. In particular, upgrading to the latest version of a plugin/library may not be just as simple as changing its version number in a configuration file, but could also require modifications to the codebase that is using it.
To make the migration as easy as possible, Google is making the new replacement APIs available in AGP 7.2 so developers can adapt their code in preparation for version 8. AGP 7.2 will output a prominent warning for each use of the Transform APIs, which will cause a failure in AGP 8. To make AGP warning provide more detail about which component is causing it, you can set android.debug.obsoleteApi=true in gradle.properties.
As mentioned, there are two distinct APIs that replace Transform: the Instrumentation API, which can be used for transforming bytecode, and the Artifacts API, which enables adding new classes to an app. Google has not provided specific information regarding the build time reduction brought by the new plugin. Anyway a few details as to how it is achieved can be inferred from Google docs.
Specifically, to make the Instrumentation API fast, AGP restricts the instrumentation code to run independently on each class with no visibility of other classes. The first benefit this provides is that libraries can be instrumented in parallel rather than at the end of compilation. It also contributes to speed up incremental builds, since a change in a class will only require that class and those that depend on it to be processed again.
Regarding the Artifacts API, the key factor bringing the performance benefit seems to be the isolation of whole-program analysis transformation into a specific API, called Artifacts.forScope. This API should be used with caution, says Google, since it has a high build-performance cost and making it a separate part means you can handle cases where this kind of whole-program analysis is not used more efficient.
MMS • Johan Janssen
Article originally posted on InfoQ. Visit InfoQ

Error Prone, a Java compiler plugin open sourced by Google, performs static analysis during compilation to detect bugs or suggest possible improvements. The plugin contains more than 500 pre-defined bug checks and allows third party and custom plugins. After detecting issues, Error Prone can display a warning or automatically change the code with a predefined solution. Error Prone supports Java 8, 11 and 17 and may be used for bug fixing or large scale refactoring.Installation and configuration instructions for Maven, Bazel, Ant or Gradle can be found in the documentation. The compiler should be configured to use Error Prone as an annotation processor, for example when creating a test project with Maven:
org.apache.maven.plugins
maven-compiler-plugin
3.10.1
17
UTF-8
-XDcompilePolicy=simple
-Xplugin:ErrorProne
com.google.errorprone
error_prone_core
2.15.0
Now an example class can be created. Consider the following method that uses equals to compare two arrays, more precisely it compares the objects and not the content of the arrays:
public boolean compare(String firstList[], String secondList[]) {
return firstList.equals(secondList);
}
Executing mvn clean verify triggers the Error Prone analysis and results in the following error message:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.10.1:
compile (default-compile) on project ErrorProne: Compilation failure
[ERROR] …/ErrorProne/src/main/java/org/example/Main.java:[5,28]
[ArrayEquals] Reference equality used to compare arrays
[ERROR] (see https://errorprone.info/bugpattern/ArrayEquals)
[ERROR] Did you mean 'return Arrays.equals(firstList, secondList);'?
The ArrayEquals bug pattern is found and Error Prone suggests to change the implementation in order to compare the content of the array instead of the objects:
return Arrays.equals(firstList, secondList);
Receiving an error helps to improve the code, but it’s also possible to let Error Prone apply the solution automatically. The -XepPatchChecks argument should contain a comma separated list of bug patterns to apply. In this case, only the ArrayEquals solution is applied to the codebase. The -XepPatchLocation argument is used to specify the location of the solution file. In this case the original file is modified:
-XDcompilePolicy=simple
-Xplugin:ErrorProne -XepPatchChecks:ArrayEquals
-XepPatchLocation:IN_PLACE
Now, after executing mvn clean verify the class file is automatically changed to:
public boolean compare(String firstList[], String secondList[]) {
return Arrays.equals(firstList, secondList);
}
The documentation provides more information about the command-line flags.
Apart from the built-in bug patterns, it’s also possible to use patterns from other organizations such as SLF4J or to create a custom plugin. The source code for the built-in rules provides various examples that may be used as the basis for a new plugin. For example, a custom Error Prone plugin can replace the older @Before JUnit annotation with the new JUnit 5 @BeforeEach annotation.
The custom Error Prone plugin should be placed in another Maven module than the example project shown earlier. Error Prone uses the service loader mechanism to load the bug checks. Normally, that requires some configuration, however Google’s AutoService project simplifies the configuration by using the @AutoService annotation. The @BugPattern annotation is used to configure the name, summary and severity of the bug. The following example returns Description.NO_MATCH if no @Before annotation is found or the SuggestedFix which replaces the @Before annotation with an @BeforeEach annotation:
@AutoService(BugChecker.class)
@BugPattern(
name = "BeforeCheck",
summary = "JUnit 4's @Before is replaced by JUnit 5's @BeforeEach",
severity = BugPattern.SeverityLevel.SUGGESTION
)
public class BeforeCheck extends BugChecker implements BugChecker.AnnotationTreeMatcher {
private static final Matcher matcher =
isType("org.junit.Before");
@Override
public Description matchAnnotation(AnnotationTree annotationTree,
VisitorState visitorState) {
if (!matcher.matches(annotationTree, visitorState)) {
return Description.NO_MATCH;
}
return describeMatch(annotationTree,
SuggestedFix.replace(annotationTree, "@BeforeEach"));
}
}
Error Prone and AutoService dependencies are required to build the custom Error Prone plugin:
com.google.errorprone
error_prone_annotations
2.15.0
com.google.errorprone
error_prone_check_api
2.15.0
com.google.auto.service
auto-service-annotations
1.0.1
The AutoService should be configured as an annotation processor:
com.google.auto.service
auto-service
1.0.1
Now the custom Error Prone plugin can be installed to the local Maven repository with the mvn install command. After executing the command, the example project should be configured to use the new custom plugin as an annotation processor:
org.example.custom.plugin
ErrorProneBeforeCheck
1.0-SNAPSHOT
The new BeforeCheck should be added to the Error Prone analysis:
-XDcompilePolicy=simple
-Xplugin:ErrorProne -XepPatchChecks:BeforeCheck
-XepPatchLocation:IN_PLACE
An example Test class may be added which contains a mix of both @Before and @BeforeEach annotations:
public class ErrorProneTest {
@Before
void before() {
}
@BeforeEach
void beforeEach() {
}
}
When running mvn verify the new custom Error Prone plugin replaces the @Before annotation with the @BeforeEach annotation:
public class ErrorProneTest {
@BeforeEach
void before() {
}
@BeforeEach
void beforeEach() {
}
}
Error Prone uses Java internals, that are nowadays hidden, which might result in errors such as:
java.lang.IllegalAccessError: class com.google.errorprone.BaseErrorProneJavaCompiler
(in unnamed module @0x1a6cf771)
cannot access class com.sun.tools.javac.api.BasicJavacTask (in module jdk.compiler)
because module jdk.compiler does not export
com.sun.tools.javac.api to unnamed module @0x1a6cf771
The solution for Maven is to expose the Java internals by creating a directory called .mvn in the root of the project containing a jvm.config file with the following content:
--add-exports jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED
--add-exports jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED
--add-exports jdk.compiler/com.sun.tools.javac.main=ALL-UNNAMED
--add-exports jdk.compiler/com.sun.tools.javac.model=ALL-UNNAMED
--add-exports jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED
--add-exports jdk.compiler/com.sun.tools.javac.processing=ALL-UNNAMED
--add-exports jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED
--add-exports jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED
--add-opens jdk.compiler/com.sun.tools.javac.code=ALL-UNNAMED
--add-opens jdk.compiler/com.sun.tools.javac.comp=ALL-UNNAMED
Alternatively the --add-exports and --add-opens configuration may be supplied to the Maven Compiler Plugin’s arguments in the pom.xml:
org.apache.maven.plugins
maven-compiler-plugin
3.10.1
--add-exports
jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED
…
More information about using Error Prone with Bazel, Ant and Gradle can be found in the installation instructions.
MMS • Max Stoiber
Article originally posted on InfoQ. Visit InfoQ

Transcript
Stoiber: My name is Max Stoiber. I am the co-founder of GraphCDN, which is the GraphQL CDN. If you are in the React community, in the ReactJS community or in the JavaScript community more generally, you might have used some of the open source projects that I helped build, like styled-components, or react-boilerplate, or micro-analytics, or a whole bunch of others. I’m really active in that scene. If you’re there, you might have used some of those projects as well.
The Story of GraphCDN (2018)
The story of GraphCDN and how we got there, started in 2018. At the time, I was the CTO of another startup called Spectrum. At Spectrum, we were building a modern take on the classic community forum. Essentially, we were trying to combine the best of what phpBB gave us 20 years ago, with the best of what Discord and Slack give us nowadays. That was essentially the idea. It was a public forum, but all of the comments on any posts were real time chat. We tried to take these two worlds that are currently very separate where communities in Slack and Discord write lots of messages, but none of them are findable, and make them public and a little bit more organized so that you could find them afterwards, on Google or elsewhere. I tried to combine those two worlds together. That actually worked out surprisingly well, which led to quite a bit of user growth. As you can imagine, with all of this user generated content, lots of people found us on Google and elsewhere, and started visiting Spectrum quite regularly. That meant we had quite a bit of growth.
Unfortunately, I had chosen a database that wasn’t very well supported. I’d chosen RethinkDB, which nowadays doesn’t even exist anymore. The company behind it shut down after a while. I’d chosen that database originally, because they advertised themselves as the real time database. Their key feature or the thing they praised externally was that you could put this changes key at the end of any database query, and it would stream real time updates to that database query to you. You could listen to changes, to practically any data changes, which felt like a fantastic fit for what we were trying to do. Because obviously, almost anything in Spectrum was real time. The post popped in in real time. The chat was real time, of course. We had direct messages, which had to be real time. This felt like a great fit for what we were trying to do. Lesson learned in hindsight, rely on the databases that everybody uses. There’s a reason everybody uses Postgres and MySQL, and now Mongo. There’s a reason those databases are as prevalent as they are is because they work.
I’m a lot wiser now, I wasn’t that wise back then. It very quickly turned out that RethinkDB, the real time nature of it didn’t scale at all. We had hundreds of thousands of users every single month, but RethinkDB couldn’t even handle 100 concurrent change listeners. As you can imagine, every person that visits the website starts many different change listeners. We’re listening to changes of the specific posts that they’re looking at. We’re listening to changes of the community that the post is posted in. We’re listening to new notifications. We had a bunch of listening as per user. Essentially, our database servers were on fire, literally on fire. Thankfully, not literally, but they were crashing quite frequently. I Googled servers on fire and found this amazing stock photo of servers on fire, which if your data center looks like this, you have some really serious problems. Ours weren’t quite as bad, but they were still pretty bad.
We had this database that didn’t scale. Essentially, we had to work around that limitation. We wanted to switch to a more well-supported database, however, that’s a lot of work. Rewriting the hundreds of database queries we’d written and optimized up to that point, migrating all that data without any downtime, that was just a whole project. We wanted to get there eventually, but we needed a solution for us crashing literally every day, right at this moment. As I was thinking about this, of course, I realized that caching, we had an ideal use case for caching because our API was really read-heavy. Of course, it’s public data, lots of people read it, but not as many people write to it. Actually, we had an ideal use case for caching. We’d originally chosen GraphQL for our API, because we had a lot of relational data. We were fetching a community, all the posts within that community, the authors of every post, the number of comments, a bunch of relational data, and GraphQL was a fantastic fit for that use case. It worked out extremely well for us, and we really enjoyed our experience of building our API with GraphQL.
The one big downside that we ran into was that there weren’t any pre-built solutions for caching GraphQL at the edge, which is what we wanted to do. We wanted to essentially run code in many data centers, all around the world. We wanted to route our users to the nearest data center and cache their data very close to them for a very fast response time, but also so that we could reduce the load on our servers. If you’ve ever used GraphQL, then you know that that is essentially what GraphQL clients do in the browser. If you’ve heard of Apollo Client, Relay, URQL, all of these GraphQL clients, what they are is essentially a fetching mechanism for GraphQL queries that very intelligently caches them in the browser for a better user experience.
How GraphQL Clients Cache
In my head, basically, the question I wanted to answer was, can’t I just run a GraphQL client at the edge? GraphQL clients do this in the browser, why can’t I just take this GraphQL client that’s running on my local browser, put it on a server somewhere, and have that same caching logic but at the edge? To answer that question, I want to dive a little bit into how GraphQL clients cache. If we look at this example of a GraphQL query which fetches a blog post by a slug, and it fetches its ID, title, and the author, and of the author it fetches the ID, name, and avatar. There is one magic trick that makes GraphQL caching really great, and that is the __typename meta field. You can add that to any GraphQL object, in your query, you can add that to any object type, and you will get back the name of the type of the response. For example, with this query, we will add type name in these two places for the post, and also for the author.
When the origin responds with the data, the response will look something like this, with the important piece being that now we have the post data, and we know that the type that was returned there was a post. The same thing for the author. We got the author data, and we also know that the author is a user. When we take this response, and we store it in our cache locally in the browser, we can now associate that cached query response with those two objects. We can target with post with the ID 5, and user with the ID 1. That’s fine. We’ve just taken this query response, we’ve put it in the cache. We key that by the query that we saw, so by the get post query. Anytime we see the same query, we return that same data. Why are these tags relevant? Why do I care that this contains the post with the ID 5 and the user with the ID 1? This is where the magic comes in. GraphQL also has something called mutations, which are essentially just actions, anything that changes data needs to be a mutation. For example, if we had a mutation that was called edit post, which edits a post. In this case, we’re editing the post with the ID 5, and changing its title. Any mutation also has to fetch whatever it changed. In this case, we’re getting back the post.
Again, we can do the same thing we did for the query and add the __typename field to the response. When that response comes back from the origin to our client, the client can look at this response and go, we just sent a mutation to the origin, that mutation has come back from the origin, and the data that was returned was the post with the ID 5. I actually have a cached query response that contains that post with the ID 5, and I can now automatically invalidate that cache query result that contains the stale data of this post. That’s amazing. This is what GraphQL clients do under the hood. They do this magic invalidation based on the __typename field and the ID field. Then they combine them to invalidate any stale data that has been changed at the origin.
There’s one slight edge case here where the magic ends, which is list invalidation. If you imagine a query that fetches a list of blog posts, in this case, just their ID and title, when we look at the response to this query, it’s an array that just contains the one blog post that we have right now, the post with the ID 5, how to edge cache GraphQL APIs. A mutation that creates a new post now poses an interesting problem, because of course, the response to this createPost mutation will look something like this. It will return an object of post with the ID 6. Of course, our cached query result for the post list doesn’t contain the post with the ID 6. That’s really annoying because that means that GraphQL clients can’t automatically invalidate lists when new items are created.
Thankfully, they found a good workaround for this, which is manual invalidation. Essentially, GraphQL clients give you different APIs to manually influence the cache, and change it depending on which things pass through it. For example, with URQL, which is the third biggest GraphQL client, this would look a little bit like this. You could tell URQL that when the createPost mutation passes through the GraphQL client, invalidate any cached query result that contains the posts query, that contains the list of posts. That way, we can automatically invalidate that, no problem. Whenever a post is created, our GraphQL client will automatically refetch the fresh data from the origin.
GraphQL clients actually go one step further, and they do something called normalized caching. If we go back to our original query of fetching a single blog post, its ID, title, and its author, then, rather than taking the entire response of the post with ID 5 and the user with the ID 1 and putting that entire thing keyed by the query into the cache. They actually take each object within the query response individually, and store that individually. Inside of URQL’s cache, this looks a little bit like this, where we essentially in the cache store, ok, the post with the ID 5, corresponds to this data, and the user with the ID 1 corresponds to this other data. Why do we care to do this? Because now, if a query comes in that, for example, fetches the user with the ID 1, then the cache can go, you’re fetching the user with the ID 1, although we haven’t seen the specific query before, we do actually have that specific data in our cache. We can just serve you that on the client without you having to go to the origin to fetch that data, again, because we’ve already fetched it. It was just deeply nested in some other query, but we’ve normalized that for you and can now give you the user data for the user with the ID 1, no problem, just like that. Which is very nice and actually makes for less network traffic and a much nicer user experience, because things will resolve much faster, since they’re already on the client and loaded. You essentially only ever fetch every object once, which is fantastic, particularly if people navigate around your app quite frequently.
The one thing that’s missing here that you might have noticed is the post.author. We have the post with the ID 5 data and the user with the ID 1 data. How do we know that the post author is the user with the ID 1? URQL stores that in a separate data structure that looks like this, which essentially just talks about the relations or the links between things. Here, we’re essentially saying, if you’re fetching the post with this specific slug, that corresponds to the post with the ID 5. If you’re fetching the post with the ID 5’s author, then that corresponds to the user with the ID 1, and then the user with the ID 1 doesn’t have any further relations or links that you can go into.
What I really want you to take away from this section is that GraphQL is actually awesome for caching. It’s actually really good for caching because of its introspectability, it tells you what data you’re returning. This introspectability combined with the strict schema where you have to return something that matches that schema means it’s actually really good for caching. That’s also a lot of the reason why so much great tooling has spun up around GraphQL. It’s gotten such wide community adoption that if one person builds tooling for it, because it’s always the same GraphQL spec that it has to follow, everybody else gets to benefit from that tooling. That’s incredibly powerful.
The Edge
To get back to my original question that I posed way back in 2018, can’t I just run a GraphQL client at the edge? Can’t I just take this logic that Apollo Client, Relay, and URQL have internally anyway, take that same code and just put it on a bunch of servers around the world at the edge so that everybody that uses Spectrum everywhere gets super-fast response times and we get to reduce the load our server has to handle massively? The key to the answer of this question lies in the last part, the edge, because as it turns out, GraphQL clients are designed with very specific constraints that differ ever so slightly from the constraints we would have to work with at the edge. One of the main ones that we have to deal with if we were to deploy caching logic to the edge is authorization. Because of course, if a GraphQL client runs in the browser, it knows that if something is in the cache, whoever’s requesting this again, can access it, because it’s the same person. If I’m using Spectrum, and I’m querying for the post with the ID 5, and the GraphQL client puts that in the cache, then the GraphQL client doesn’t have to worry about authorization. It doesn’t even have to know anything about authorization, because I am allowed to access the post with the ID 5. If I request the same post again, the client can just give that to me from the cache, and go, “Yes, of course. No problem.”
At the edge, that’s slightly differently. If we have one server sitting that a lot of users are requesting data from, some of those might be allowed to access the posts with the ID 5, but others maybe aren’t. Or maybe if more specifically, if you think about user data, maybe somebody is allowed to access their own email, but nobody else’s. We can’t just take a query and put that result in the cache, because that would mean everyone gets served the same data. If somebody creates some data that’s sensitive, that’s specific to that user, suddenly, that will be served to everyone. That will be a nightmare. That’ll be a terrible security nightmare, and a really bad experience, because we will essentially just be leaking data. Very bad idea.
At the edge, what we have to do is, rather than just making the cache key, a hash of the query, so essentially, we take the query text that we have in the variables, and we use that as a cache key. Rather than doing just that, we also have to take the authorization token into account, whether that’s sent via the authorization header, or whether that is a cookie, we have to just add that to the cache key so that if somebody else sends the same query, they don’t get the same response. It’s as simple as that. Just put the authorization token in the cache key, and everything will be fine.
Global Cache Purging
The other part that’s a little bit different, is cache purging. Because not only do we have to do automatic cache purging, and support manual invalidation for list invalidation, we also have to do it globally. If you’re running at the edge in all of these data centers globally, then you have to invalidate that data globally. If the post with the ID 5 changes and the user sends a mutation to edit that, or the server says, “This has changed, and it was manually invalidated.” Then you have to do it globally. You can’t just do it in one data center. That will be a terrible experience, because the stale data would stick around in every other data center. You have to do it globally.
Fastly Compute@Edge
As we were thinking about these problems for GraphCDN, as we were building out this GraphQL edge cache solution, we came to the conclusion that we’re going to use Fastly’s Compute@Edge Product. We are huge fans of Fastly here, and the reason we chose Fastly is because like their name suggests, they are super-fast. Fastly has about 60, and ever-increasing data centers worldwide, spread across the entire globe. Here is a crazy fact, Fastly’s invalidation logic. If you take a query response, and you put it into Fastly’s cache, and you tag it with the post with the ID 5. If you then send an API request to Fastly to invalidate any cached query result that contains the post with the ID 5, they can invalidate stale data within 150 milliseconds, globally. That is probably faster than you can blink. In the time that it takes me to do this, Fastly has already invalidated the data globally. That is absolutely mind blowing to me.
I actually looked up a while ago, I was like, how fast even is the speed of light? Surely that takes a while to go around the globe once. I looked it up, and actually light does take 133 milliseconds to get across the entire globe. How can Fastly invalidate within 150 milliseconds? That is super-fast. The answer is, of course, that they don’t have to go around the entire globe, because they’re going bidirectional, they’re going both ways at the same time. They only have to go around half the globe, which cuts the time in half. Then of course, they have a really fancy gossiping algorithm, which you can Google. They’ve written some great articles about it. I bow down in front of their engineers, because it’s absolutely genius. It is so fast that it enables our customers now to cache a lot more data. If you can invalidate stale data within 150 milliseconds globally, imagine how much more data you can cache because it will never be stale. When the data changes, send an API request, and 150 milliseconds later, everybody globally has the fresh data. Imagine how much more data you can cache if you have this super-fast invalidation. That’s the reason we use Fastly. They’re super-fast, and we’re super happy with them.
That’s essentially what GraphCDN is. We rebuilt this caching logic to run at the edge to take authorization to account and to have this global cache purging. We deploy it to Fastly’s Compute@Edge, 60 worldwide data centers to allow our customers to cache their GraphQL queries and their GraphQL responses at the edge. I wish this would have existed back in 2018 when we had our scaling problems with Spectrum. At the time, I just built a terrible in-memory caching solution that reduced the load slightly, until we eventually got acquired by GitHub. If we had had GraphCDN, we would have been able to scale so much more smoothly, we would have saved so much money, because of course running something at the edge is much cheaper than running the request through our entire infrastructure. It would have been a much better experience for all of our global user base because everybody would have had super-fast response times from their local data center.
Key Takeaway
The main thing I want you to take away is GraphQL is amazing for caching. That’s really the takeaway I want to hone in on, GraphQL, absolutely fantastic for caching. The introspectability, the strict schema, just absolutely fantastic.
Questions and Answers
Fedorov: Can you share some of the success stories and the real-world numbers from the actual APIs in production that you currently manage and help to cache? What are the real-world numbers and if you can share any specific examples and what domains those numbers are from?
Stoiber: One of our recent customers is italic.com, which is an e-commerce retailer. They pride themselves on selling really high quality stuff that is completely unbranded, so there’s no italic logo on anything. It’s all completely unbranded, and they do it in the same factories and at the same manufacturers that other big brands are working on. You can buy a Prada bag without the Prada logo for much cheaper, is the point of Italic. They’re really worried about Black Friday coming up. They had a huge traffic spike last year, and they really couldn’t scale. Their servers apparently crashed every few hours. About a month or two ago, they started thinking ahead again, Black Friday is coming up, how can we solve this problem this year round? They added GraphCDN to their stack in front of their GraphQL API. It reduced their overall server load by 61%, database load by two orders of magnitude, and page load times by over 1 second. That’s just one of the most recent ones that I know off the top of my head, who’ve been really successful with GraphCDN. We’re actually seeing a lot more e-commerce companies signing up and putting us in front of their GraphQL APIs. One of them actually said, in a customer call, “Milliseconds mean money.” For e-commerce, while they’re not latency critical, they’re very latency sensitive. The faster they can render their web pages, the faster their APIs are, the more money they will make. That’s a very strong correlation there. Then our product really helps scale but also make more money, ultimately, because we can really reduce the page load times across the globe.
Fedorov: Actually, I think it was Amazon back in 2009, if I recall correctly, who did one of the first studies and mentioned some of the impressive numbers of matching the milliseconds delay on the e-commerce site to the revenue that they would generate for shopping. Definitely not a surprise to see more e-commerce retailers jumping on board.
Stoiber: There’s a few studies like that, Walmart has done, famously some, Staples I think has done some, Nike has done some. Practically everywhere the outcome is, the faster your website is, the more money you make. I was recently talking with one of our other customers, and there’s like a spike. If you get faster from 20 seconds to 10 seconds, it’s not going to matter that much. You’re still so slow that your conversion drop-off will just be massive. If you can get from 10 or even 5 seconds down to 3 to 1 second, that’s a huge difference. We really enable our customers to get to speeds even faster than that globally, everywhere around the world, even though they usually only have their data centers in Virginia most of the time. A single data center in U.S.-East is the standard setup that we see there. That’s really exciting for us, because ultimately, they enable us, and hopefully, they make a lot more money than they would ever have to pay us off of the back of performance improvements, which is quite amazing.
Fedorov: Let’s dive a little bit more into the technical details. You mentioned that authentication is generally a challenge when you put the data from the client to the shared infrastructure, like a CDN edge. How do you generally define and what recommendations do you provide to the API authors, to categorize their APIs as authorized or generically shared? Can you generally share any more details into the internals of how it works?
Stoiber: What’s interesting about GraphQL API is that certain types of fields might be authenticated, but others really aren’t. Maybe a blog post type is publicly available if the data is the same for everyone, but then you might have a current user query that fetches the currently authenticated user. That obviously has to be specific to the authentication token that is present in the request. Essentially, we as GraphCDN, but I think every solution should do this, allows you to specify, the current user, for example, that’s an authenticated query. If that’s in the query, then please cache this entire result that you’ve just gotten from the origin, and cache it for every user separately so that we don’t share that data. Then, corollary, if only a blog post is in the query, then please cache it publicly. Please make sure that if only the blog post is in there, just cache it the same for everyone, no matter if they’re authenticated or not.
That configuration aspect of it of saying, ok, which fields and which types are specific to a user versus public, actually has interesting implications down the line, because with GraphQL, you can query for many of these fields at the same time. You can query for a blog post and the current user at the same time. Actually, a lot of what our customers end up doing right now is they manually end up sending two requests to increase their cache hit rate. Because otherwise, if you send both of these queries in the same HTTP request, then you’ll end up with a very low cache hit rate on the blog post, and unnecessarily so, because you could have almost probably 100% cache hit rate on that. Because suddenly, every cached response has to be scoped to the user because it also contains the current user. At the moment, our customers manually end up splitting these usually into two HTTP requests and sending authenticated requests separately from public requests.
However, that’s also something really interesting that we’re thinking about because we at the edge, we can look at your configuration and we can go, hold on, the current user is specific to the user, and the blog post is public. Why don’t we just split them automatically? We can just go in and say, we know that this part of the GraphQL tree is specific to the current user, this part is public. We’re just going to split them at the edge into two HTTP requests, so you don’t even have to worry about it. It’s an under the hood optimization from us to make sure that you’re getting the highest cache hit rate possible. That’s something we’re thinking about. We’ve so far been very conservative in messing with people’s GraphQL queries, because that’s where the danger lies. So far, we’ve tried to stay as dumb as possible. We just take the entire query, we cache the entire query. No magic, nothing can go wrong. It just works. Now with the feedback from our customers, we’re starting to figure out, where are the areas and what are the features that we can provide now that we have this safe way of doing things? Where can we make it slightly less safe, but maybe get you a much higher cache hit rate in return? That is definitely one of the areas that we’re very much thinking about.
Fedorov: You mentioned that you ask the users to specify, which is a public and which is a private API? How was it declared? Is it standard, or is it something that’s specific to your product, or is it something that could become like the part of the GraphQL spec?
Stoiber: There’s two different ways you can specify this, the default way is that we have the concept of rules, which is very similar to if you use Cloudflare before, they have page rules. Where, essentially, you can define rules and say, if the query contains this type of field, then set the cache configuration to that. You can create as many rules as you want. You can be like, if it contains the current user, it’s authenticated. If it contains the blog post, it’s public and cached for a year or whatever. You can set any configuration that way. That’s specific to our product.
The other way you can do it is that we respect the origin cache control header, and that’s a setting you can enable or disable as well. Particularly in a Node.js ecosystem, many GraphQL servers come with the ability to add annotations for cache control, two types and fields in your GraphQL schema. In your GraphQL schema, you can add things like the add cache control directive, and say add cache control, Max age 900. The GraphQL server then goes through the query, figures out what are all the directives that are in there in the schema for all the types and fields in that query, and computes the cache control header out of that, and sends that back through to response. We as GraphCDN, we can look at that header and we can go, you told us we should cache this for 900 seconds. We’re going to cache it for 900 seconds. We also support that as an enhancement.
Depending on your GraphQL server implementation, that doesn’t quite have the same flexibility as our rule structure, hence why we added the rule structure because we were like, some people are going to need more power than this. We also support essentially just a standard cache control header sent back from your origin depending on what the query contains or doesn’t contain.
Fedorov: Another question about the internals. You mentioned how you invalidate the data and you talked about relationships between objects. How do you invalidate the relationships? Does it work similarly, or are there any nuances?
Stoiber: What we do is we essentially walk through the entire response. We take whatever you sent back from the origin that contains the blog post, the author, maybe all of the comments and their authors, and we figure out which objects are in this response. That might be a blog post, a user that is the author, a comment, and then the author of the comment might be another user. We tag the cached response with every single one of the objects that we see in the data, and then you can essentially ping us and say, “The user with the ID 5 has changed.” We can go through and we can invalidate any cache query result that contains that specific object, that specific user. We don’t even really have to be aware of relations. Those are still defined in your GraphQL schema, and with your GraphQL queries, but we can still invalidate them, because you have to send them back through the response.
Fedorov: What observability tools are needed for the edge caching? What were your findings and learnings that you integrated into your product?
Stoiber: We realized very early on that now people are passing all the GraphQL requests through us, we can provide analytics for people. We added GraphQL analytics to our system where you can essentially see, how many requests are you getting? What is your cache hit rates per timeframe? Which queries are you seeing? Which mutations are you seeing? What are their individual performance metrics, p50, p95, p99? What are the individual cache hit rates? Then we realized, we have all this data on your queries, but we also have a lot of data on your errors. Because we’re in front of your infrastructure, we essentially see every single error that is sent back from your API, and so we added error tracking to our system. We have performance monitoring, and we have error tracking where essentially you can very finely trigger alerts very similar to what you might be used to from a Sentry, or a Datadog, or whatever. You can say, “If I see more than 50 GraphQL errors in a minute, if I have a huge spike, probably something’s going wrong. I should probably be aware of that.” We can then send you an email, it’s like message on PagerDuty, triggered incident, whatever you want. The same thing is true for GraphQL and HTTP errors. That’s the analytics we provide.
As we talk with more companies that are using GraphCDN in production, we realized very quickly that caching is pretty scary. Adding caching to your stack comes with a lot of inherent risk of maybe the data isn’t fresh anymore. How do you know what is even in the cache? How do you know that all of this stuff is fresh? That’s something we’re very much thinking about. We do solve a big problem for a lot of people, and so people are already using us. There’s a lot of risk associated with implementing caching, and thus, there’s also a lot of hesitancy with implementing caching. We’ve been thinking about ways we could get rid of that. We have plans to work on more caching insights and give you a little bit more security with your caching.
Fedorov: What are the cases when CDN edge caching might not be a good idea? You mentioned that authentication is already one headwind, but especially thinking about invalidation and that 150 milliseconds delay, which on one side sounds fast, but on the other side for a use case like transactions, that might not be that fast. Are there any more details on what’s your general thinking and guidance on this?
Stoiber: It definitely boils down to latency critical things where we’re talking about milliseconds or something, you can’t cache those at the CDN edge. That doesn’t make any sense. Then it also only makes sense for very read-heavy APIs. I have good friends that work at Sentry, the error tracking service. Obviously, they get billions of errors sent to them, but only a small percentage of them are ever looked at. For them, caching doesn’t make any sense because their data will change way more frequently than the cache hit would ever be. It would probably have a 0% cache hit rate. If you have a very write-heavy API, caching is probably not for you. On the other hand, if you have a very read-heavy API, that is latency sensitive but maybe not latency critical, I think that’s really where GraphCDN comes in, or edge caching generally comes in. This can be a very powerful tool to help you scale, but also make your stack way more performant across the globe.
See more presentations with transcripts
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ

Automation makes it possible to build a reliable continuous testing process that covers the functional and non-functional requirements of the software. Preferably this automation should be done from the beginning of product development to enable quick release and delivery of software and early feedback from the users.
Alexander Velinov spoke about continuous testing and automation at QA Challenge Accepted 2022.
We see more and more organizations trying to adopt the DevOps mindset and way of working. Velinov stated that software engineers, including the QA engineers, have to care not only about how they develop, test, and deliver their software, but also about how they maintain and improve their live products. They have to think more and more about the end user.
Velinov mentioned that a significant requirement is and has always been to deliver software solutions quickly to production, safely, and securely. That’s impacting the continuous testing, as the QAs have to adapt their processes to rely mainly on automation for quick and early feedback, he said. They also have to develop and introduce more automated validations like performance, security, and accessibility, he argued.
Automated testing in the continuous delivery process has always been the key to delivering quickly and with high confidence, Velinov said; we cannot respond to the market needs competitively if we don’t have a continuous testing process in place.
Velinov advised to start building all the repetitive and reliable processes sooner rather than later, preferably at the beginning of their product development:
It requires a great level of discipline where the team can simultaneously complete the development of both features and the required automated tests. It’s not an easy thing to do, but in the end, it will make a difference and enable the quick release process.
Of course, to deploy with confidence requires having a good and mature delivery pipeline, Velinov concluded.
InfoQ interviewed Alexander Velinov about continuous testing and automation.
InfoQ: What are the trends that are impacting continuous testing in the enterprise world?
Alexander Velinov: Nowadays we see more and more enterprises trying to solve complex issues with their products. A lot of companies are migrating to microservices, micro-frontends, and as a whole to an event-driven architecture, so that they can decouple their code, manage it in smaller chunks, and improve the maintainability, development, and delivery.
All this requires a very good level of automation, and this automation is now part of every single step in the process of development, testing, delivery, and operations.
InfoQ: What’s your view on continuous testing? What’s needed, and why?
Velinov: I’ve worked with organizations that needed months to deliver new relatively simple features for their live products. A high percentage of this time was spent on the testing process, which was taking weeks, due to a lack of proper automation testing coverage of both functional and non-functional requirements. The mature automated delivery process and pipelines were also partially or completely missing. These organizations typically were losing competitive advantage and some market share, because of this.
InfoQ: What’s your advice for building mature delivery pipelines?
Velinov: Maturity comes with time and experience. But implementing most functional and non-functional tests as part of the delivery pipelines helps you get closer.
Of course, this is not enough. I know companies that have a lot of automated jobs, but don’t have the continuous process set up. My recommendation is to identify your must-have tests and checks for each environment (try shifting to the left of course) and enforce them in your pipeline (fail your pipeline if the corresponding tests/scans are failing).
Prevent deploying to a higher environment without having a 100% pass rate of your automated test if your quality gates are not met, if you have a performance degradation, or if you have new security vulnerabilities and issues. In time, this will make your process mature and will help you release with confidence.
QCon Events 2022: Uncover Emerging Trends & Learn From Practitioners Driving Innovation in Software
MMS • Artenisa Chatziou
Article originally posted on InfoQ. Visit InfoQ

Each of us has different preferences in evolving our software development skills and knowledge. Depending on our schedules, we emphasize distinct aspects that help us understand new technologies, get answers to questions we are facing, or seek fresh perspectives to make decisions.
That’s why QCon offers two international software development conference formats, in-person QCon San Francisco (Oct 24-28) and online QCon Plus (Nov 29-Dec 9). Level up on the skills most in demand in the industry by uncovering emerging software trends to solve your complex engineering challenges. QCon is the only software development conference that creates unique experiences to help you learn directly from people like you; senior software engineers, software architects, and team leaders.
Leading software practitioners in the industry such as Tapabrata Pal, Vice President of Architecture @Fidelity, Vinod Sridharan, Principal Software Engineering Architect @Microsoft, Facundo Agriel, Software Engineer / Tech Lead @Dropbox, Aditi Gupta, Staff Security Software Engineer @Netflix, and many more are sharing their best practices at QCon San Francisco and at QCon Plus. Don’t miss the opportunity to learn something new, connect with a global community, and bring back implementable ideas to explore with your team.
Software architecture tracks not to miss
QCon San Francisco (Oct 24-28) and QCon Plus online (Nov 29-Dec 9) bring together world-class software architects from early adopter companies to share their experiences and insights on stage, and online. Some of the topics the conference will explore include:
- Operating Microservices: Patterns for Success hosted by Wes Reisz, Technical Principal @thoughtworks & Creator/Co-host of “The InfoQ Podcast”, previously Platform Architect @VMware: QCon SF & QCon Plus
- Architectures You’ve Always Wondered About hosted by Randy Shoup, consulting CTO (former eBay, Google, Stitch Fix): QCon SF & QCon Plus
- Modern APIs: Building and Evolving hosted by Thomas Betts, Laureate Application Architect @Blackbaud: QCon SF & QCon Plus
- Architecting for Change at Scale hosted by Haley Tucker, Senior Software Engineer for Productivity Engineering @Netflix: QCon SF & QCon Plus
- Green Tech hosted by Adrian Cockcroft, Former VP Amazon Sustainability Architecture @Amazon: QCon SF & QCon Plus
- Practical Security hosted by Julia Knecht, Manager, Security Platforms Engineering @Netflix: QCon SF & QCon Plus
QCon SF workshops: Learn modern software architecture practices
Sometimes you just can’t beat hands-on learning and working on practical projects with step-by-step walkthroughs, taught by software leaders. That’s why in addition to the three-day conference from Monday to Wednesday (October 24-26), QCon San Francisco has two days of workshops available on Thursday and Friday (October 27-28). You’ll get focused training from practitioners and experts who have mastered their skills and want to help you master yours. Add workshops to your QCon San Francisco ticket and select from our range of half-day, one-day, and two-day workshops to level up on in-demand skills:
Bring your team together to QCon
Build better-connected teams and foster professional collaboration by bringing your entire team together and sharing a learning experience in-person or online. Connect over new ideas to current challenges, get clarity on emerging tech decisions, and take advantage of the group discounts for QCon San Francisco or QCon Plus.
QCon San Francisco | In-person Oct 24-28, 2022
Teams as small as 3 attendees working for the same company are eligible for a group discount. For more details, email info@qconsf.com and mention the size of the group. Discounts cannot be combined or applied retroactively.
QCon Plus | Online Nov 29-Dec 9, 2022
Get tickets for your team now and save. For every 4 tickets, you register get 1 additional complimentary ticket. Order your tickets now, and add names later. Discounts cannot be combined or applied retroactively.
QCon charges a premium price point, but I can’t remember the last conference I attended (of 100s) where every single talk was interesting, and I learned something. If you’re used to being in the group that has seen and heard it all, try out this one.
Donnie Berkholz, QCon 2022 Past Attendee, DevX Leader, SVP Product @Percona
Level up your skills and learn from practitioners driving innovation and change in software at the upcoming QCon events. Attend the conference in person at QCon San Francisco (Oct 24-28) or online at QCon Plus (Nov 29-Dec 9).
MMS • Thiyagarajan Kamaraj
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- API design guidelines are important in an organization’s API standardization journey.
- Design guidelines can help organizations to achieve API standardization and governance.
- Zally helps organizations to automate their validation of style guidelines against API specifications.
- A Gradle plugin can help organizations to achieve a shift left approach for their API development process.
- Shift Left approach helps to increase efficiency in the development and testing process of API development.
There has been a growing trend among the organizations API team to better standardize their API design and development process. With an increased adoption towards micro services, software products being more and more just a bunch of micro-services and third-party APIs mashed together.So, it gets more crucial for us to get API structure in order using the de facto standard like OpenAPI (a.ka. Swagger). To achieve this consistency organizations have started to define their own guidelines for standardizing their API.
What is API standardization
API design is the creation of an effective interface that allows you to better maintain and implement the API, while enabling consumers to easily use this API.
Consistent API design means, standardizing the design, across all APIs, and the resources they expose, within an organization or team. It is a common blueprint for developers, architects and technical writers to follow, to ensure a consistent brand and experience in the API consumption. Organizations standardize design using Style Guidelines that aim to ensure consistency in the way APIs are designed and implemented. Some popular style guidelines are shared below.
I often refer to this stylebook for developing a consistent API for my side projects while following the industry best practices for API development.
Why Standardization
A clear design methodology ensures that APIs align with the business needs. With more standardized API, there’s less ambiguity, there’s more collaboration, quality is more ensured, and API adoption increases.
Having clear and consistent API design standards is the foundation for a good developer and consumer experience. They let developers and consumers understand your APIs in a fast and effective manner, reduces the learning curve, and enables them to build to a set of guidelines.
API standardization can also improve team collaboration, provide the guiding principles to reduce inaccuracies, delays, and contribute to a reduction in overall development costs. Standards are so important to the success of an API strategy that many technology companies – like Microsoft, Google, and IBM as well as industry organization like SWIFT, TMForum and IATA use and support the OpenAPI Specification (OAS) as their foundational standard for defining RESTful APIs.
Without standardization, individual developers are free to make subjective choices during design. While creativity is something to encourage it quickly can become chaos when not appropriately governed by a style guide.
Organizations cannot ensure quality within their API design and delivery process without standardization. Reinforcing design standards improves the ability to predict successful outcomes and contributes to an organization’s ability to scale their API development at speed while ensuring quality.
Journey into API standardization
It wouldn’t be possible to scale your API design and development processes successfully, or comply with regulatory and industry standards, without a formal process to reinforce standardization. Having an API design style guide provides the “guardrails” needed to let internal and external teams collaborate when building API definitions and re-using assets.
Initially, organizations start publishing their API guidelines internally as PDF or wiki for everyone to reference and processes are put in place to make sure teams are following the design guidelines.One solution to develop consistency is providing a manual review during the API development.
The API’s are specified in OpenAPI format and maintained in version control, we can follow the same review process for API definitions that we follow for other code artifact. Developers can create pull requests for their API changes and have a colleague provide feedback.This manual process can be an effective way to ensure governance and compliance with the API guideline, but like all manual processes it is subject to human error and not always timely.
Waiting for a colleague to review our API change can result in a slow turnaround that hurts developer productivity, especially when it comes to aspects of the review process that can be automated. This process is also not scalable when organization scales and more developers start to develop API. This is where shifting left with automated API reviews is helpful. It’s always better to get feedback early with the help of some automated tools or linters like we do get for our other artifacts.
What is Shift Left approach
The term “shift left” refers to a practice in software development in which teams begin testing earlier than ever before and help them to focus on quality, work on problem prevention instead of detection. The goal is to increase quality, shorten long test cycles and reduce the possibility of unpleasant surprises at the end of the development cycle—or, worse, in production.
Open API validators
When it comes to OpenAPI linters, I came across a few linters. These linters convert the API style guidelines into a set of rules and validate against the Open API specification. These linters can provide you an option for customizing the rules as per your organization style guide. One tool which caught my attention was linter called Zally which was written using Kotlin and open sourced by Zalando. OpenAPI style guide validators workflow looks like below.
- The API standard or style guidelines are expressed as a set of rules. Zalando has one such guideline here.
- API Written according to OpenAPI specification
- Linting tools such as Zally, sonarQube, Spectral that can validate that the OpenAPI specification the developer has written is complying with the specification’s rules defined in step 1.
What is Zally
Zally is a minimalistic and easy to use API-linter. Its standard configuration will check your APIs against the rules defined in Zalando’s RESTful Guidelines, but anyone can use it out-of-the-box. It’s written in a more extensible way to allow us to add our own set of rules as well. It also provides the following feature.
- enable/disable rules on the server side based on your needs
- Accepts both json and yaml format for Swagger V2 and OpenAPI V3 specification
- Write and plug your own rules
- Intuitive Web UI that shows implemented rules and result of your spec validation
- Github integration using web hooks which validates your OpenAPI on each pull request and echo back the violation in the comments
Motivation behind Zally Gradle plugin
Though Zally is written in a more extensible and customizable way, I felt that we can still improve zally current validation workflow further to reduce the developer feedback loop. Since Zally lacks the plugins like checkstyle, ktlint, spot bug etc,. Below are a few pain points I experienced when I used Zally.
- Developers need to host the Zally server either locally or in a remote system to use the CLI tool.
- Developers need to switch context for running CLI tools or some additional work needed to configure the CLI execution as part of the maven/gradle build process with prerequisite of point 1.
- Using github integration components to validate our API for each pull request increases the feedback loop time.
All these options are increasing the feedback time for the developers with some manual overhead of hosting the Zally server. So I decided to write my own gradle plugin which can be integrated in the local development environment as well as in the CI tool which helps me to validate and extract the validation result in different formats. .
Custom Zally plugin
zally-gradle-plugin is a gradle plugin which is written in kotlin and can be integrated in the build script. The plugin validates the specification against the set of rules and provides the report in both json and html format.
The project includes an example task configuration:
```
// settings.gradle.kts
pluginManagement {
repositories {
gradlePluginPortal()
mavenLocal()
}
}
// build.gradke.kts
plugins {
id("io.github.thiyagu06") version "1.0.2-dev"
}
zallyLint {
inputSpec = File("${projectDir}/docs/petstore-spec.yml")
reports {
json {
enabled = true
destination = File("${rootDir}/zally/violation.json")
}
rules {
must {
max = 10
}
}
}
}
//execute task
./gradlew clean zallyLint
```
```
Run ZallyLint task
./gradlew zallyLint
```
With this gradle plugin I’m able to get real time feedback during API development. This enables me to fix issues with the API before getting into a manual review step. The plugin can also be integrated with the CI jobs to check to validate the style guidelines. Because all development teams use the same rules, the organization can provide a more consistent API for their users. The benefits of the approach are outlined below.
The plugin provides an option to enable exporting violation reports into JSON and HTML format. This also provides an easy way to configure rules to define the max number of violations allowed in the spec for each severity level.
The json format can be parsed and exported into any database to calculate the API design compatibility score and build a dashboard to share it to the wider organization for decision making on the API standardization initiatives. The same way HTML reports can be exported to S3 bucket or google cloud storage and hosted as a website to a broader audience.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Fitbit Health Solutions and Google Cloud have recently announced the release of Device Connect for Fitbit, which will provide healthcare and life sciences enterprises with accelerated analytics and insights to help people live healthier lives.
With the solution, the companies hope to remove some barriers preventing healthcare organizations from using Fitbit data for patient monitoring, research, and population health projects. Device Connect for Fitbit includes several pre-built components that aid in making Fitbit data accessible and interoperable such as:
- A pre-built patient enrollment and consent app – enabling organizations to provide their users with permissions, transparency, and frictionless experience.
- An open-source data connector that provides automated data normalization and integration with Google Cloud BigQuery for advanced analytics.
Furthermore, from BigQuery, users can use AutoML Tables to build advanced models or custom models with Vertex AI. - A pre-built Looker interactive visualization dashboard that can be easily customized for different clinical settings and use cases to provide faster time to insights.
Fitbit metrics include activity, sleep, breathing rate, cardio fitness score (Vo2 Max), heart rate variability, weight, nutrition, SP02, and more will be accessible through Device Connect Fitbit. Similar to what Apple Watch provides with Healthcare, which allows users to share data with Apple; however, there’s no public cloud offering behind it like Device Connect for Fitbit.
Jane Sarasohn-Kahn, a health economist, advisor, at THINK-Health LLC, tweeted:
Ever-morphing #digitalhealth & #wearabletech for #health, @Google announced “Device Connect for @Fitbit (part of #Google)
“#Healthcare will be able to gain >holistic view of patients outside clinical settings.”
A la @Apple HealthKit?
In addition, the authors, Alissa Hsu Lynch, global lead, MedTech Strategy and Solutions at Google Cloud, and Amy Mcdonough, managing director at Fitbit Health Solutions, explain in a Google blog post :
With this solution, healthcare organizations will be increasingly able to gain a more holistic view of their patients outside of clinical care settings. These insights can enhance understanding of patient behaviors and trends while at home, enabling healthcare and life science organizations to better support care teams, researchers, and patients themselves.
Uses cases for Connect for Fitbit vary, such as chronic condition management; for instance, people living with diabetes can benefit from maintaining their blood glucose levels within an acceptable range, or clinical research as these depend on rich patient data.
One of the early customers of the Device Connect for Fitbit service is the Hague’s Haga Teaching Hospital in the Netherlands. The solution is to assist the organization in funding a new study on the early detection and prevention of vascular disease. Its cardiologist Ivo van der Bilt said in another Google blog post:
Digital tools and technologies like those provided by Google Cloud and Fitbit open up a world of possibilities for healthcare, and a new era of even more accessible medicine is possible.
Lastly, note that Google’s interactions with Fitbit are governed by strict legal requirements, including how Google accesses and manages Fitbit health and wellness data.