Month: October 2022
Google AI Introduces TensorStore, a High-Performance Open-Source Library for Array Storage

MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ
Google has introduced TensorStore, an open-source C++ and Python framework intended to speed up the design for reading and writing large multidimensional arrays.
Modern computer science and machine learning applications frequently make use of multidimensional datasets that span a single wide coordinate system. Such datasets are difficult to work with because users may receive and write data at unpredictable intervals and different scales, and they frequently want to do studies utilizing many workstations working in parallel.
In order to avoid problems with data storage and manipulation, Google Research created TensorStore, a library that gives users access to an API that can handle massive datasets without the need for powerful hardware. This library supports several storage systems like Google Cloud Storage, local and network filesystems, among others.
TensorStore offers a straightforward Python API that can be used to load and manipulate huge arrays of data. Due to the fact that no actual data is read or maintained in memory until the specific slice is needed, arbitrary large underlying datasets can be loaded and edited without having to store the entire dataset in memory.
The syntax for indexing and manipulation, which is much the same as that used for NumPy operations, makes this possible. TensorStore also supports virtual views, broadcasting, alignment, and other advanced indexing features such as data type conversion, downsampling, and lazily on-the-fly generated arrays.
TensorStore also has an asynchronous API that lets a read or write operation continue in the background. At the same time, a program completes other tasks and customizable in-memory caching which decreases slower storage system interactions for frequently accessed data.
Processing and analyzing large numerical datasets requires a lot of processing power. Typically, this is done by parallelizing activities among a large number of CPU or accelerator cores dispersed across multiple devices. A core objective of TensorStore has been to enable parallel processing of individual datasets while maintaining high performance.
TensorStore application cases include PaLM, Brain Mapping and other sophisticated large-scale machine learning models.
MMS • Claudio Masolo
Article originally posted on InfoQ. Visit InfoQ

In recent years, neuroscientists have tried many types of neural networks to model the firing of neurons in the human brain. In a recent project, two researchers Whittington and Behrens found that the hippocampus, a structure of the brain critical to memory, works as a particular kind of artificial neural network called: transformer.
The fact that we know these models of the brain are equivalent to the transformer means that our models perform much better and are easier to train
This is said by Whittington who also said that transformers can greatly improve the neural network’s ability to mimic the behavior of the brain and its computations. David Ha, from Google Brain said that they are not trying to recreate the brain, but they are trying to create a mechanism that can do what the brain does.
Transformers work with the self-attention mechanism in which every input is always connected to every output. An input can be a word, a pixel, or a number in a sequence. The difference with the other neural networks is that in other networks only certain inputs are connected with other inputs. Transformers first appeared five years ago with the BERT and GPT-3, a new revolutionary way for AI to process languages.
Whittington and Behrens tweak the approach of Hopfield network, modifying the transformers in a way to encode the memories as coordinates in higher-dimensional spaces rather than linear sequences as Hopfield and Dmitry Krotov did at MIT-IB Watson AI lab. The two researchers showed also that the model is mathematically equivalent to the model of the grid cell firing patterns that neuroscientists see in fMRI scans. Beharens said transformers as another step to understanding better the brain and having an accurate model, rather than the end of the quest.
I have got to be a skeptic neuroscientist here, I don’t think transformers will end up being how we think about language in the brain, for example, even though they have the best current model of sentences.
Schrimpf, a computational neuroscientist at MIT, that analyzed 43 different neural net models to understand how well they predicted behavior of human neural activity as reported by fMRI and electrocorticography, noted that even the best-performing transformers worked well with words or small sentences and not for larger-scale languages tasks. This is why he claims:
My sense is that this architecture, this transformer, puts you in the right space to understand the structure of the brain, and can be improved with training. This is a good direction, but the field is super complex.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Meta has been developing its own Chromium-based WebView for Android for a few years and has now started rolling it out to users of its Facebook app. The new WebView, which has not been open-sourced yet, improves security, stability, and performance, says Meta.
While Android allows users to upgrade the system browser separately from the OS itself, many users update their Facebook app but not Chrome or the WebView app, says Meta.
This WebView can update in sync with Facebook app updates, and function as a drop-in replacement for the System WebView inside the Facebook app without compromising or changing the user experience in any way.
Keeping the WebView up-to-date will thus prevent potential stability and security issues caused by outdated versions. Meta says they will rebase their WebView code on the latest Chromium codebase at regular intervals, thus benefiting of any security patches to the latest Chromium. Additionally, since the Facebook app is now independent from the default OS WebView, when users decide to upgrade the latter, the OS will not need to kill the Facebook app to force it to reload its WebViews.
Most significantly, Meta says its new WebView improves performance by running its compositor, i.e., the component that decides how to display a page, on a GPU thread.
The System WebView compositor needs to account for the various ways Android allows apps to display it. Because of this, it needs to run synchronously with the Android widget layout, which means that it is unable to run in a separate GPU process.
While the new Android WebView has not been open-sourced yet, Meta says they will submit any major changes to upstream Chromium.
Meta’s announcement has raised some privacy-related concerns on Twitter and Reddit. While Meta is not the first vendor to use its own Web-engine for Android, just last month iOS developer and Fastlane creator Felix Krause warned of Meta injecting JavaScript code in the WebViews used by its Instagram and Facebook apps even when visiting external web pages. This is similar to what popular apps like TikTok, Amazon, and others all do, Krause found out. While realizing that injecting JavaScript is not a sign of any wrong-doing, Krause set up InAppBrowser.com to raise awareness of such practices.
As a last remark, the Facebook and Instagram apps both offer the possibility to visit any external link using the default browser thus letting users and organizations more concerned about their data privacy bypass the embedded WebView.
MMS • Dr Natalie Baumgartner
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- 56% of HR leaders say the C-suite doesn’t understand that the world of work has changed.
- Business leaders have to come to terms with the fact that organizations must adapt to the new world of work if they want to attract, engage, and retain top talent.
- Employees are sharply focused on having an experience of connection and belonging, but they are confident they can achieve it while working from anywhere.
- In a dispersed workforce, technology is a critical tool for building connection and belonging. Investing in the right technology at the right time is key to success in this new era of work.
- The four types of technology that can foster the culture that both employees and company leaders are seeking, include: network, recognition, wellness and feedback.
Major tech companies like Apple and Tesla have announced that they are requiring employees to return to office, creating a debate around the disconnect between leaders and employees when it comes to where work needs to take place. In fact, 56% of HR leaders have stated outright that their C-Suite has not yet come to terms with the extent to which the world of work has changed. Employees are vocalizing the value of working from home and tech workers are concerned that more companies will announce similar policies in the months to come.
Mandatory return to office policies are still in place for many organizations, even though troves of employees are self-selecting out, resulting in a migration of top talent to organizations more supportive of a flexible work approach. Remote work is not just a company perk, it’s now a requirement for many tech workers. The 2022 Culture Report on Tech-Enabled Employee Experience from Achievers Workforce Institute (AWI) found that 53% of tech workers prefer hybrid work, 39% prefer remote, and only 8% prefer working full-time on-site. Additionally, the report found that the top reason tech workers leave their job is for better flexibility. Despite the preference for remote and hybrid work though, two-thirds say company leaders still expect them in the office, at least part-time.
There are many benefits to offering remote work options. 83% of employees believe working remotely supports a healthy work-life balance. Remote employees are also equally likely to report being productive as those in the office and are also more engaged and more likely to advocate for their company. In addition, employees who are happy with their remote or hybrid work options are more likely to state that they trust their company leaders.
If employees are vocal about not wanting mandatory return to office policies and the science proves that remote employees are productive and engaged, then why is the C-suite reluctant to embrace remote and hybrid work? Especially since failing to do so means losing out on top tech talent.
The main driver stems from company leaders worrying that they won’t be able to foster a culture of connection and belonging among a dispersed workforce. This is a valid concern, considering a strong sense of belonging drives a 3x return on a wide number of business outcomes. Many leaders believe that to achieve their desired culture, employees must be in the same physical space. However, this is an outdated mindset and one that needs to shift, as the world of work has changed. Leaders must adapt and take a new approach to developing an experience of belonging in a remote/hybrid context, to avoid a workforce resigning in mass. One of the key ways to do this is through the investment in technology that fosters the connected culture that both employees and company leaders are seeking.
Tools for Connecting and Belonging
Achievers Workforce Institute found that 70% of tech workers feel it’s very important to have technology and tools that support their experience of belonging and connection at work, higher than any other industry surveyed. Below are the four main tools that companies should consider leveraging to foster connection and belonging in the workplace.
Network Tools
Remote employees don’t have the opportunity to get to know their coworkers through water cooler banter or in-person lunches, so it’s important to provide digital options to help them establish connections with their co-workers and find their new work bestie or mentor. These tools could include a Teams or Slack Channel where co-workers can share pictures of their pets or discuss their favorite TV show or a tool to schedule virtual coffee chats with colleagues around the company.
Employees at organizations with connection tools outperform the average in factors such as engagement, belonging, trust, and productivity. In fact, 71% of tech employees and 42% of employees overall, feel that connection/networking tools would increase their feelings of connection and belonging – regardless of their work setting.
Network tools are a great opportunity for employees to build connections with co-workers that they don’t usually interact with. For instance, Kellogg’s uses a tool which pairs employees at random with a colleague in another area of the business and invites them to schedule a virtual coffee chat. Kellogg’s employees responded strongly in favor of this feature – they loved being able to meet and network with a new colleague to learn about each other on a personal and professional level, and in many cases even learn how their jobs impact one another. These informal conversations have led to continued relationships and coaching, and a greater sense of connection and belonging.
One employee remarked,
“I am so happy my partner and I were paired up through Employee Connections. That first connect turned into several “catch-up” connects over subsequent weeks. Without Achievers Employee Connections, we likely would have never had the opportunity to connect and forge a working friendship.”
Recognition Tools
Recognition can be a superpower in retaining employees and boosting satisfaction. It is crucial for making employees feel seen and valued. In fact, more than half (57%) of employees say feeling recognized would reduce the likelihood that they would take a call from a headhunter.
Simply saying thank you is not enough though. Recognition provided must feel meaningful for it to be effective and for employees to feel truly appreciated. To provide meaningful recognition, tech leaders should:
- (1) highlight something specific the person being recognized did,
- (2) note what it was about this individual specifically that had an impact,
- and (3) how the person being recognized made a difference to the person giving recognition.
For example, the head of the software engineering team could say something like “thank you for catching and fixing that coding error, it ended up saving the team about X number of hours and ensured the company had a successful product launch. Your attention to detail and problem-solving skills saved the company a lot of money and time.”
Managers should also endeavor to make praise public. Employees ranked social recognition as most important (42%) before frequent low-monetary recognition and infrequent high-monetary recognition.
It can be challenging to consistently provide frequent, public meaningful recognition to employees when physically isolated from each other. Managers might not have the option to make an announcement to everyone or throw a celebration in the office. Recognition platforms can help with this to ensure team members receive meaningful, public praise.
Currently however, only 29% of employees say that their company provides access to a recognition platform. Moving toward incorporating a platform to promote recognition is a powerful investment, given that employees with a recognition platform are more likely to say they feel meaningfully recognized – leading to higher employee satisfaction and retention.
Discover is a great example of the power of using an employee recognition platform. The company rolled out a recognition platform to their entire employee population in order to better recognize employees. Discover surveyed people leaders to learn how the platform helps them drive results among their teams. They found that Achievers saves them time, allows them to recognize more frequently and broadly and allows their recognitions to be more visible across the organization. In the first three months of using the platform, they saw an 80% adoption rate and recognitions increased by 400% in the first year. As a result, engagement has been at an all time high of 87%, with 94% of employees saying that they are personally committed to helping the organization succeed.
Feedback Tools
Research from AWI reveals that organizations who collect feedback from their employees have 50% higher levels of engagement and that 88% of those employees are more likely to feel they belong.
Currently, less than half of tech employees say their company uses employee listening tools like surveys and chatbots. Tech leaders that want to boost engagement and belonging should talk to decision makers at their company about adopting listening tools to collect feedback. This way, leaders are making decisions based on data that is specific to their organization and not just based on what they think an employee might want.
Once feedback has been collected, companies need to take action and communicate how they plan to implement feedback. One of the top drivers of trust for employees is employers acting on feedback. Unfortunately, just 21% of tech employees say that their organization takes meaningful action on employee feedback. Listening to and implementing feedback is an important step that tech leaders need to take to keep engagement high, retain top talent and boost trust in leadership.
For instance, if leaders are seeing feedback in anonymous surveys that employees want more flexibility and time off, leaders can announce during an all-staff that the company is implementing new policies to support this like summer Fridays, additional PTO or recharge days and allowing employees to work wherever they want.
If executives are seeing a lot of feedback/requests for something they are not able to change at the moment, they should still acknowledge it and let employees know they are looking into other solutions to improve the workplace based on employee feedback.
Feedback proves to be one of the most powerful actions an employer can take to drive key outcomes. Those companies that do not act on feedback see incredibly low rates of engagement, belonging, commitment, and productivity. An organization struggling to increase engagement scores and other key metrics should look at how they collect, assess, and act on employee feedback.
Wellness Tools
Burnout is a real and serious issue facing the workforce, with 43% of employees stating they are somewhat or very burnt out. Burnout is a combination of exhaustion, cynicism, and lack of purpose at work. This burden results in employees feeling worn out both physically and mentally, unable to bring their best to work. It often causes employees to take long leaves of absence in an attempt to recover and is a key driver of turnover, as they seek new roles that they hope will reinvigorate their passion and drive.
Sources of burnout might include overwork, lack of necessary support or resources, or unfair treatment. Feedback tools can help find the root cause of burn out and how to mitigate them.
Implementing wellness tools are another way to address this issue and demonstrate that the company prioritizes mental health. Employees whose organizations provide wellness tools are less likely to be extremely burnt out. Currently, only 26% of tech employees say their company provides wellbeing support tools. With the potential dire consequences of extreme burnout, including low productivity, high absenteeism, and increased turnover, tech leaders should talk to their HR department about identify wellness tools to combat this issue.
Adapting to the new world of work is essential for attracting, engaging, and retaining top talent. The bottom line is that employees are no longer willing to compromise on flexibility at work, and companies with a hardline return to office policy will lose out on top tech talent. However, this shift does not mean that company culture must suffer. In order to provide employees with the flexibility to work where they want while also maintaining a strong culture of belonging and connection, tech leaders need to talk to the C-Suite and their HR departments about leveraging technology tools that have been proven to boost engagement and employee retention.
MMS • Alen Genzic
Article originally posted on InfoQ. Visit InfoQ
The release of .NET 7 RC 1 has introduced the new wasm-experimental workload and new JavaScript interop features that allow invoking of .NET code in JavaScript applications running on WebAssembly without using the Blazor UI component model.
Until this release, it was possible to use WebAssembly without the need for Blazor by leveraging the Mono WASM SDK, Uno.Wasm.Bootstrap library or the NativeAOT LLVM. Although the new workload and features are the basis for Blazor WebAssembly, with .NET 7, using .NET code inside a WebAssembly context is possible without use of specialized libraries or Blazor and leveraging only utilities from inside .NET.
To allow usage of .NET code inside JavaScript, you can use the new JSExport attribute to expose a method to JavaScript. When applied to a method in .NET, the dotnet.js runtime exposes it through the getAssemblyExports function and you can use it as follows:
import { dotnet } from './dotnet.js'
const { getAssemblyExports, getConfig, runMainAndExit } = await dotnet.create();
const configuration = getConfig();
const exports = await getAssemblyExports(configuration.mainAssemblyName);
const myValue = exports.MyClass.MyMethod(); // Call into your method from ```js
await dotnet.run(); // Run the Program Main method
To use JavaScript code inside of .NET, you can use the JSImport attribute to expose a JavaScript method to .NET. The following code snippet demonstrates how to allow .NET to import a method.
import { dotnet } from './dotnet.js'
const { setModuleImports, getConfig, runMainAndExit } = await dotnet.create();
const configuration = getConfig();
// Set module imports that can be called from .NET
setModuleImports("main.js", {
window: {
location: {
href: () => globalThis.window.location.href
}
}
});
await dotnet.run(); // Run the Program Main method
Alternatively, instead of needing to call setModuleImports, you can create a ES6 module, export the methods from there and use JSHost to load a JavaScript ES6 module directly in .NET:
await JSHost.ImportAsync("main.js", "./main.js");
And on the .NET side, this is how you can import the method, regardless of the exposure variant you use:
[JSImport("window.location.href", "main.js")]
internal static partial string GetHRef();
Pavel Šavara’s GitHub repository presents additional code samples, along with a more detailed explanation of some parts of the code in the accompanying article. A video overview of the same sample is available in the ASP.NET Community Standup recording.
With this release, the IJSUnmarshalledRuntime interface, previously used to make unmarshalled synchronous calls to JavaScript interop, becomes obsolete, and developers are encouraged to use JSImport and JSExport going forward.
Debugging the interop code is not possible from Visual Studio yet, but the application can be debugged by running the application from the command-line and attaching the Visual Studio Code or Chrome debuggers.
In the context of Blazor WebAssembly, usage of the new interop feature is recommended only in scenarios when you need to use your .NET code on the client side only, IJSRuntime is still the recommended way to do asynchronous JavaScript interop in other scenarios and is supported across all Blazor runtimes.
The .NET 7 RC 1 SDK is available for download and after installation, you can install the new WebAssembly workload and create a new WebAssembly browser application by running the following commands:
dotnet workload install wasm-tools
dotnet workload install wasm-experimental
dotnet new wasmbrowser
This release makes additional improvements for Blazor applications including Debugging Improvements, availability of WebAssembly build tools for .NET 6, and Dynamic authentication requests in Blazor WebAssembly.
Microsoft has a more comprehensive list of updates in .NET 7 RC 1 for ASP.NET Core and the official announcement for further information on what is new in .NET 7 in general.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Confluent recently released Stream Designer, a visual interface that lets developers quickly build and deploy streaming data pipelines.
The company aims to simplify data streaming pipelines with a point-and-click visual builder with Stream Designer. The company describes Stream Designer as a service accessible to developers beyond specialized Apache Kafka experts in a press release.
Stream Designer allows users to build pipelines from a unified view in Confluent Cloud and take advantage of built-in integrations with fully-managed connectors, ksqlDB, and Kafka topics. In addition, it provides integration with the users’ existing DevOps practices and allows them to switch between the graphical canvas and a complete SQL editor.
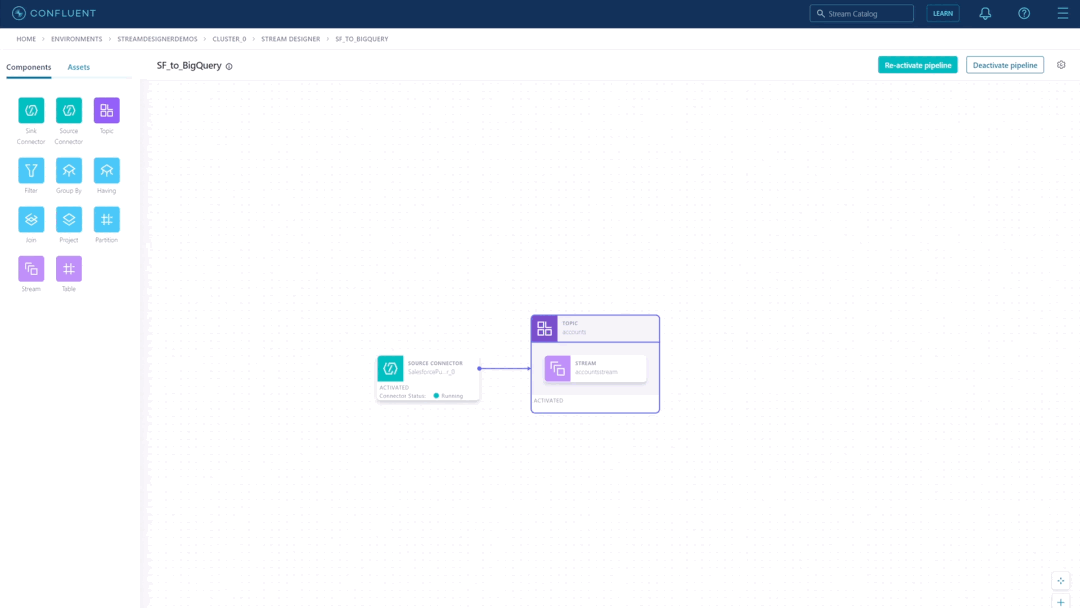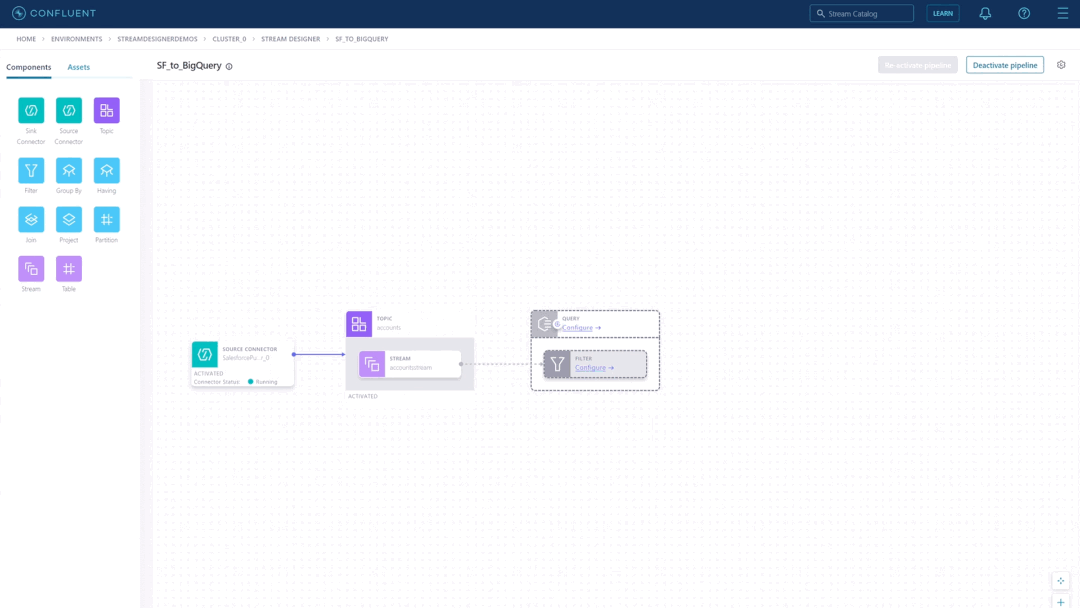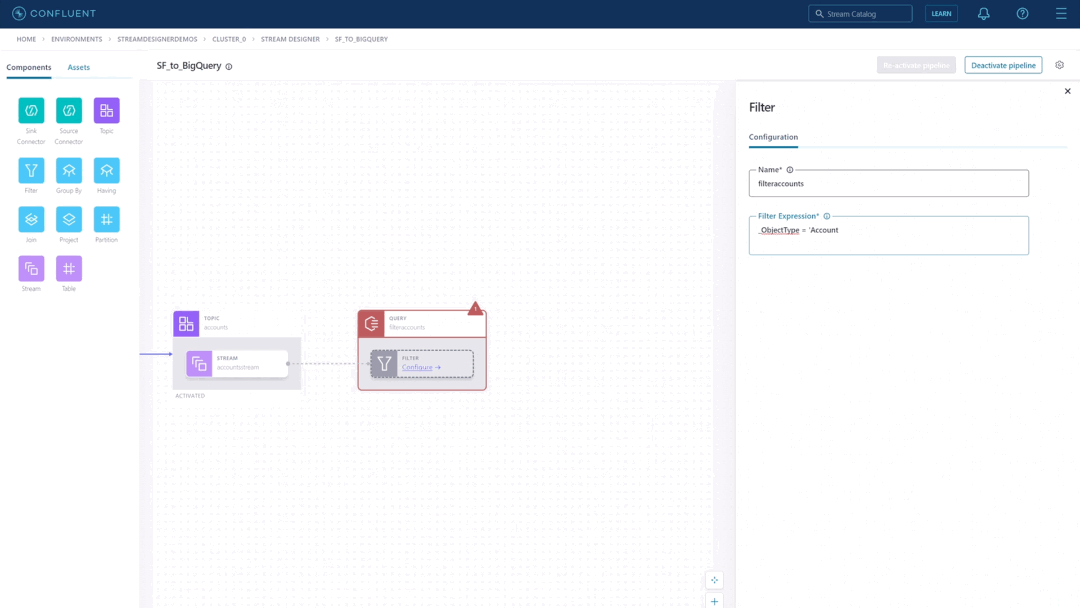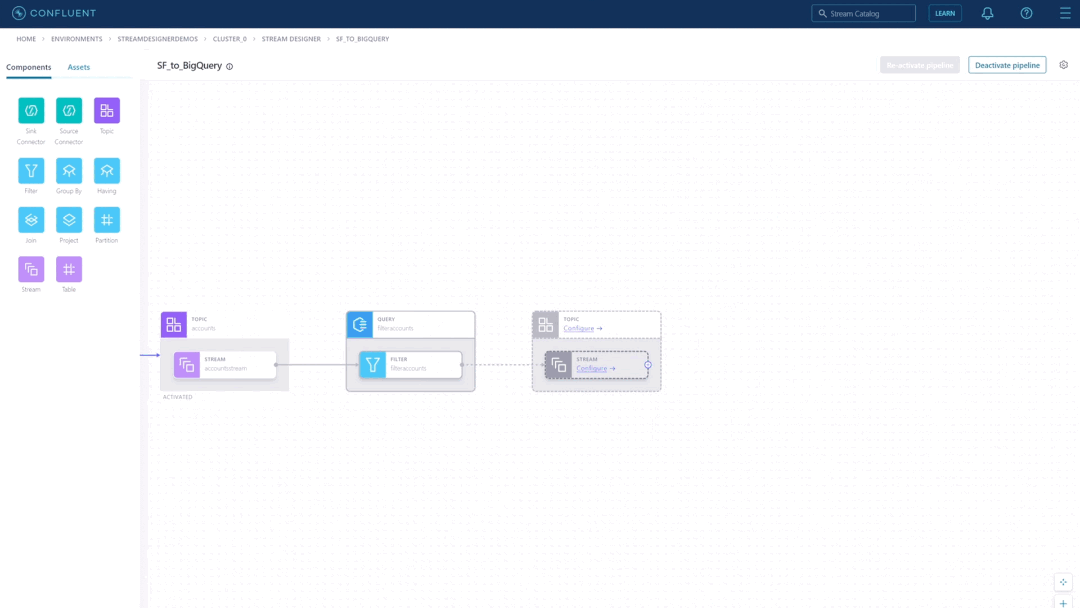
Source: https://www.confluent.io/blog/building-streaming-data-pipelines-visually/
Jay Kreps, co-founder and CEO of Confluent, said in the same press release:
We are in the middle of a major technological shift, where data streaming is making real-time the new normal, enabling new business models, better customer experiences, and more efficient operations. With Stream Designer, we want to democratize this movement toward data streaming and make real-time the default for all data flow in an organization.
To learn more about the Stream Designer, InfoQ reached out to Jon Fancey, a principal product manager who acted as product owner for the new service.
InfoQ: Where did the Stream Designer come from? Was this an internal product to become a public offering, or was this created from the start to be customer-facing?
Jon Fancy: Many companies are building data pipelines with Kafka today, and many of them face the same challenges: Kafka expertise shortages and taxing development cycles. We wanted to make data streaming accessible to organizations that cannot afford huge Kafka teams and developers with various skill sets. It was created from the start to be customer-facing.
InfoQ: What are the clear use cases for the Stream Designer?
Fancy: Stream Designer can be used to make building anything on Kafka and Confluent Cloud easier and faster. For example, it’s excellent for building, testing, and deploying streaming data pipelines for operational and analytical use cases and turning traditional ETL pipelines that serve in those areas into a real-time paradigm.
InfoQ: How do users interact with the Stream Designer? What’s the UX?
Fancy: Users can interact with Stream Designer through the browser-based visual canvas and the built-in SQL editor – whatever method works best for them. They can point and click to add pipeline components on the canvas and configure them from the right panel. Users can also drag and drop connections between components to create joins and forks. Pipeline definitions are translated to SQL under the hood and can also be extended with code. Stream Designer also allows users to import pre-built pipelines as code, such as recipes, for teams to use as templates.
InfoQ: What are comparable products in the markets? Or is it unique?
Fancy: Stream Designer is the industry’s first visual interface for building streaming pipelines natively on Kafka. There are undoubtedly other GUI-based stream processors out there, but other messaging technologies power them. Stream Designer is built on Kafka, the de facto standard for data streaming and the developer’s open platform of choice with high scalability and resiliency.
InfoQ: How does pricing now work for the Stream Designer?
Fancy: There is no extra cost for Confluent Cloud customers.
InfoQ: What is the roadmap for the future of Stream Designer?
Fancy: My philosophy with any product is that GA is just the beginning. We plan to further integrate Stream Designer with our platform and the streaming ecosystem and listen to customer feedback to guide what we iterate on next.
MMS • InfoQ
Article originally posted on InfoQ. Visit InfoQ
In this eMag on “Modern Data Architectures, Pipelines and Streams”, you’ll find up-to-date case studies and real-world data architectures from technology SME’s and leading data practitioners in the industry.
“Building & Operating High-Fidelity Data Streams” by Sid Anand highlights the importance of reliable and resilient data stream architectures. He talks about how to create high-fidelity loosely-coupled data stream solutions from the ground up with built-in capabilities such as scalability, reliability, and operability using messaging technologies like Apache Kafka.
Sharma Podila’s article on “Microservices to Async Processing Migration at Scale” emphasizes the importance of asynchronous processing and how it can improve the availability of a web service by relieving backpressure using Apache Kafka by implementing a durable queue between service layers.
“Streaming-First Infrastructure for Real-Time Machine Learning” by Chip Huyen nicely captures the benefits of streaming-first infrastructure for real-time ML scenarios like online prediction and continual learning.
And “Building End-to-End Field Level Lineage for Modern Data Systems” authored by Mei Tao, Xuanzi Han and Helena Muñoz describes the data lineage as a critical component of data pipeline root cause and impact analysis workflow, and how automating lineage creation and abstracting metadata to field-level helps with the root cause analysis efforts.
We at InfoQ hope that you find the value in the articles and other resources shared in this eMag and potentially apply the design patterns and techniques discussed, in your own data architecture projects and initiatives.
We would love to receive your feedback via editors@infoq.com or on Twitter about this eMag. I hope you have a great time reading it!
Free download
MMS • Anthony Alford
Article originally posted on InfoQ. Visit InfoQ

OpenAI recently released Whisper, a 1.6 billion parameter AI model that can transcribe and translate speech audio from 97 different languages. Whisper was trained on 680,000 hours of audio data collected from the web and shows robust zero-shot performance on a wide range of automated speech recognition (ASR) tasks.
Whisper uses an encoder-decoder Transformer architecture and processes audio in 30-second chunks. Unlike most state-of-the-art ASR models, Whisper is not fine-tuned on any benchmark dataset; instead, it is trained using “weak” supervision on a large-scale, noisy dataset of speech audio and paired transcription text collected from the internet. In zero-shot evaluations on a set of speech recognition datasets, Whisper made on average 55% fewer errors than Wav2Vec, a baseline model. According to OpenAI:
We are open-sourcing models and inference code to serve as a foundation for building useful applications and for further research on robust speech processing…We hope Whisper’s high accuracy and ease of use will allow developers to add voice interfaces to a much wider set of applications.
Training a deep-learning speech-recognition model using only supervised learning would require a large dataset containing audio data with corresponding accurate or gold standard transcripts. Acquiring such a dataset can be challenging, so researchers usually turn to transfer learning: fine-tuning models that have been pretrained on a large publicly-available dataset of audio only. For example, Meta’s XLS-R is pretrained on 436K hours of speech audio, then fine-tuned on much smaller benchmark-specific training sets.
However, the OpenAI researchers contend that this process has downsides; in particular, the fine-tuned models often do not generalize well, “which limits their usefulness and robustness.” Instead of pretraining Whisper on audio-only data, the team collected a large dataset of audio with “noisy” transcripts: 680,000 hours of audio with “a large amount of subpar transcripts” scraped from the Internet; 117,000 hours of this data was speech in 96 non-English languages. By trading quality for quantity, the resulting model achieves good zero-shot performance on a wide range of tasks, including speech transcription in several languages as well as translation and language identification.
To evaluate Whisper, the team compared its performance on a set of benchmark tasks to several baseline models, focusing on zero-shot scenarios. Although Whisper had “unremarkable” performance on the LibriSpeech benchmark for English transcription, on other datasets it outperformed baseline models that were fine-tuned on LibriSpeech “by large amounts.” On the CoVoST2 translation benchmark, Whisper set a new zero-shot state-of-the-art record, without using any of the benchmark training data. On long-form transcription, Whisper outperformed NVIDIA STT, the best open-source model, and was “very close to human-level accuracy.”
In a Hacker News discussion about Whisper, several users wryly commented on OpenAI “finally living up to their name” by open-sourcing Whisper, referring to OpenAI’s reluctance to do the same with some of their other models. Another user commented on Whisper’s performance:
The 4 examples are stunningly good (the examples have speakers with heavy accents, speaking in foreign language, speaking with dynamic background noise, etc.), this is far and away better than anything else I’ve seen. Will be super curious to see other folks trying it out and seeing if it’s as robust as it seems, including when confronted with audio speech with natural tics and uhhh’s and uhmm’s and everything in-between.
The Whisper source code and pre-trained model files are available on GitHub.
MMS • Anil Kumar Ravindra Mallapur
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Incident management frameworks help organizations manage chaos during production outages and resolve incidents faster.
- The incident management lifecycle can be divided into 7 stages: Detect, Create, Classify, Troubleshoot, Resolve, Review, and Follow Up.
- Incident management processes require a dedicated set of folks performing different roles and responsibilities including incident managers, communications leads, on-call engineers, customer escalation managers, and executives.
- Dedicated incident management tools (Alert Management, On-call Management, Project Management, Incident Tracking, and Collaboration) enable efficient resolution of incidents and reduce toil.
- It is essential to track and measure key incident metrics, such as TTD, TTR, TTM, and Availability, to continuously evaluate the progress in the organization.
In this article, we provide an opinionated generic framework for effective incident management inspired by LinkedIn’s internal process that can be tailored to fit the needs of different organizations. There are standardized ITIL processes for Incident Management, but the following framework differs from that and is customized to resolving live production outages.
Most companies offer services online, and any outages entail poor end-user experience. Repeated outages can impact the business and brand value. Frequent production outages are expected in complex distributed systems with high velocity. Organizations should embrace the reality of incidents and create an incident management process to facilitate faster resolution times.
What are Incidents?
Incidents are unplanned production outages that significantly disrupt the end-user experience and require immediate organized intervention.
Incidents can be internal or external based on the impacted users.
- Internal Incidents – Outages that impact employee productivity due to issues within tools that are used to get their job done can be termed internal incidents (e.g., deployment tooling is not functioning for an extended duration, employees cannot log into the VPN).
- External Incidents – Outages impacting the end-user experience of a company’s products/services are termed external incidents (e.g., users cannot purchase items from an e-commerce website, and users are not able to send messages in messaging software).
The above incidents can be further divided based on severity into Minor, Medium, and Major.
- Major – Severely impacts the end-user experience for many users, and there is a clear impact on business due to revenue loss or brand value.
- Medium – Incidents impact a significant part of the service but are usually localized to a specific region, unlike major incidents.
- Minor – Incidents that impact the non-critical workflow of the service for a select few percentages of the users.
Consider a hypothetical example of the severity of incidents on a social media website. The service being unavailable for most users for more than 30 minutes can be classified as a major incident. In contrast, the direct message feature not working for users in the Middle East might be a medium, and the verified badge not showing up on users’ profiles for users in Indonesia might be classified as a minor outage.
It is highly recommended to consider business goals and establish strict data-based guidelines on the incident classification to promote transparency and prevent wasting engineering bandwidth on non-critical incidents.
What is Incident Management?
Incident management is the set of actions taken in a select order to mitigate and resolve critical incidents to restore service health as quickly as possible.
Incident Management Stages
Detect
Outages are proactively detected via monitoring/alerts set up on the infrastructure or by user reports via various customer support channels.
Create
Incidents are created for the detected outages triggering the initiation of the incident management process. Ideally, an organization can rely on a ticket management system similar to Atlassian’s JIRA to log incident details.
Classify
Incidents are then classified based on the established guidelines. It is highly recommended to draft these guidelines in alignment with business needs. There are multiple terminologies used across the industry today, but we will stick to the major, medium, and minor categorization to keep it simple. The incident management process and sense of urgency remain the same for all incidents, but identifying incidents helps prioritize when multiple incidents are ongoing simultaneously.
Troubleshoot
The incident is escalated to the oncall engineers of the respective service by the person who initially reported the incident to the best of their knowledge after consulting the internal on-call runbook. Escalations continue until the root cause of the issue is identified; sometimes, an incident may involve multiple teams working together to find the problem.
Resolve
As their highest priority, the teams involved focus on identifying the steps to mitigate the ongoing incident in the shortest amount of time possible. The key is to take intelligent risks and be decisive in the following steps. Once the issue is mitigated, teams focus on resolving the root cause to prevent the recurrence of the problem. Throughout the resolution process, communication with internal and external stakeholders is essential.
Review
The incident review usually takes place after the root cause identification. The team involved during the incident and critical stakeholders get together to review the incident in detail. Their goal is to identify what went wrong, what could be improved to prevent or resolve similar issues faster in the future, and identify short/long-term action items to prevent or improve the process/stack.
Follow Up
Incident action items are reviewed regularly at the management level to ensure all the action items related to the incidents are resolved. Critical metrics around incidents, such as TTD (Time To Detect), TTM (Time to Mitigate), TTR (Time To Resolution), and SLAs (Service Level Agreement), are evaluated to determine incident management effectiveness and identify the strategic investment areas to improve the reliability of the services.
Incident Management Roles & Responsibilities
A dedicated set of folks trained to perform specific roles during the incident is essential to successfully manage production incidents with minimum chaos. Ideally, people assume one function as the responsibilities are substantial and require particular skills. Roles can be merged and customized to fit the business needs and the severity of the incidents.
Incident Manager
The Incident Manager, referred to as IM for brevity in the document, is the person in charge of the incident, responsible for leading the incident to resolution with the proper sense of urgency. During an incident, a person should be responsible for the general organization of the incident management process, including communication and decisions. This person will be empowered to make decisions and ensure incidents are handled efficiently according to strategy.
Responsibilities:
The Incident Manager is responsible for four main aspects of incident management: organization, communication, decision management, and post-incident follow-up.
- The organization of an incident is paramount to efficient resolution.
- The IM will be responsible for pulling in the correct teams and stakeholders to ensure a quick resolution.
- The IM will work with stakeholders to ensure that work items raised during investigation and remediation are assigned and tracked.
- During an incident, many decisions need to be made.
- The IM is responsible for identifying inflection points between investigation and quick resolution and ensuring that decisions are made promptly and appropriate stakeholders are engaged/aware.
- The IM is empowered to judge who owns decisions when consensus cannot be reached during troubleshooting.
- After an incident, the IM is the communications point of contact for the incident.
- As the IM was actively involved in the incidents, they are responsible for leading the post-mortem in collaboration with service owners and stakeholders.
- IM will collaborate with service owners and present the incident overview and essential action items from the post-mortem to higher management.
On-Call Engineers
During an active incident, on-call engineers from impacted services and owning services are engaged to investigate and mitigate the issues responsible for the incident.
Responsibilities:
On-call engineers from affected services are responsible for evaluating the customer impact and service impact and validating the mitigation/resolution steps before giving the all-clear signal to close the incident.
Owning on-call engineers accountable for the service causing the outage/issues are responsible for actively investigating the root cause and taking remediation steps to mitigate/resolve the incident.
Communication Lead
Effective communication between stakeholders, customers, and management is critical in quickly resolving incidents. Dissemination of information to stakeholders, management, and even executives avoids the accidental compounding of incidents, helps manage chaos, prevents duplicate/siloed efforts across the organization, and improves time to resolution.
Responsibilities:
The Communications Manager is responsible for all the written communications of the incident to various internal and external stakeholders (employee & executive updates, social media updates, and status pages)
Customer Escalation Manager
In large companies that cater to a wide variety of enterprise customers with strict SLA requirements, it is common to have dedicated Customer Escalation Managers to bridge the communication between the customers and internal incident teams.
Responsibilities:
- Stay in contact with customers, collect details about ongoing incidents and relay the information to the internal team debugging the issue.
- Distill communication updates from the Communications Manager and regularly pass customized updates to customers.
- Identify mitigation steps for customers to try and mitigate until the full resolution of the issue is put in place.
Executives
Executives responsible for the services causing the customer impact are constantly updated on the incident status and customer impact details. Executives also play a crucial role in making decisions about the incident that may impact the business, routing resources to speed up the incident resolution process.
Incident Management Tools
Many tools are required at each stage of the incident management lifecycle to mitigate issues faster. Large companies roll out custom-built tools that interoperate well with the rest of the ecosystem. In contrast, many tools are available in the market for organizations that don’t need to build custom tools, either open-sourced or commercial. This section will review a few standard categories of essential tools for the incident management process.
Alert Management
Alert management helps set up alerts and monitor anomalies in time series metrics over a certain period. It sends notifications to on-call personnel to inform them of the abnormality detected in the operational metrics. Alert management tools can be configured to escalate the reports to on-call engineers via multiple mediums; a pager/phone call for critical and messages/email for non-critical alerts.
Alert management tools should support different mediums and the ability to interop with the observability tools such as Prometheus, Datadog, New Relic, Splunk, and Chronosphere. Grafana Alert Manager is an open-sourced alert management tool; PagerDuty, OpsGenie, and Firehydrant are some of the commercial alert management tools available in the market.
On-Call Management
In a large organization with thousands of engineers and microservices, engaging the correct person in a reasonable amount of time is crucial for resolving incidents faster. On-call management tools help share on-call responsibilities across teams with on-call scheduling and escalations features and service to on-call engineers mappings to enable seamless collaboration during large-scale critical incidents.
On-call management tools should support customizations in scheduling and service ownership details. PagerDuty and Splunk Oncall are some of the most well-known commercial options, whereas LinkedIn’s OnCall tool is an open-sourced version available for organizations looking for budget options.
Collaboration Tools
It is not uncommon to have hundreds of employees engaged during critical incidents. Collaboration and communication are essential to manage chaos and effectively resolve incidents. These days, every software company has messaging or video conferencing software that engineers can readily use to hop on a bridge and collaborate. Easy and fast access to information on which groups in messaging applications to join or which bridge to participate in the video conferencing software is critical in reducing the time to resolve incidents.
A separate channel for every incident discussion is vital to enable easier collaboration. Bridge links are usually pinned to the group chat’s description for new engineers to join the meeting. A well-established process reduces the noise of logistical questions such as “where should I join” or “can someone please share the bridge link” in the group chat and keeps the communication channel clear for troubleshooting.
Incident Tracking
Incidents generate vast amounts of critical data via automated processes or manual scribing of the data for future reference. Classic note-taking applications won’t go too far due to a lack of structure. A ticketing platform that supports multiple custom fields and collaboration abilities is a good fit. An API interface to fetch historical incident data is crucial.
Atlassian’s JIRA is used by many companies for all incident tracking, but similar tools such as Notion, Airtable, and Coda work equally fine. Bugzilla is an open-sourced alternative that can help with incident tracking.
Knowledge Sharing
Knowledge-sharing tools are essential for engineers to find the correct information with ease. Runbooks, service information, post-mortem documents, and to-dos are all part of the knowledge-sharing applications. Google Docs, Wikis, and Notion are all good commercial software that helps capture and share knowledge within the organization.
Status Pages
Status pages are a medium to easily broadcast the current status of the service health to outside stakeholders. Interested parties can subscribe to the updates to know more about the incident’s progress. Status pages reduce inbound requests to customer service departments regarding the system’s health when an external incident occurs.
Incident Response Lifecycle
In the last sections, we discussed different stages, roles, and tools in incident management. This section will use the above information and detail the incident response process stages.
Detect
Issues are detected by internal monitoring systems or by user reports via customer support or social media. It is not uncommon for internal employees to see the issue first and escalate it to the centralized site operations team. Organizations should adopt reasonable observability solutions to detect problems faster so that Time To Detect (TTD) metrics are as small as possible.
In case of user escalations, a process should be implemented for employees to quickly escalate the issues to the relevant teams using the available on-call management tools. Escalation of issues marks the beginning of the incident management lifecycle.
Create
The team collects the required information about the incidents and creates an incident tracking ticket. Additional details about affected products, start time, impacted users, and other information that may help engineers troubleshoot should also be captured.
Once the ticket is created, the on-call Incident Manager needs to be engaged using the internal incident management tool. A shared channel for communications in the internal messaging service and a video bridge for easy collaboration should be started.
Analyze
The Incident Manager works with the team to identify the on-call engineers for impacted services and collaborates with them to better understand the user impact. Based on the impact, the Incident Manager classifies the incident into major, medium, or minor. Major incidents are critical and would typically be an all-hands-on-deck situation.
Troubleshoot
Once the issue is classified as a major, a preliminary incident communication is sent out to all relevant stakeholders that a major incident has been declared and noting the available information about the incident. This initial communication lacks details but should provide sufficient context for recipients to make sense of the outage. The external status page should be updated, acknowledging that an issue is in progress and the organization is working on resolving the issue.
The Incident Manager should escalate the issue and engage all relevant on-call engineers based on the best available information. The communications lead will take care of the communications, and the customer escalation manager should keep the customers updated with any new information. The incident tracking ticket should capture all necessary incident tracking data.
If more teams are required, the Incident Manager should engage the respective teams until all the people needed to resolve the incident are present.
Resolution
Teams should focus on mitigating the incidents and finding the root cause and resolution later. In this case, the teams can explore options to redirect all the traffic from the affected region to available healthy regions to try and mitigate the issue. Mitigating the incident using any temporary means can help reduce the TTM (Time to Mitigate) of the incidents and provide much-needed space for engineers to fix the root cause.
Throughout the troubleshooting process, detailed notes are maintained on things identified that may need to be fixed later, problems encountered during debugging, and process inefficiencies. Once the issue is resolved, the temporary mitigation steps are removed, and the system is brought to its healthy state.
Communications are updated with the issue identified, details on steps taken to resolve the problems, and possible next steps. Customers are then updated on the resolution.
Post-Incident Review
Once the root cause is identified, a detailed incident document is written with all the details captured during the incident. All stakeholders and the team participating in the incident management get together and conduct a blameless post-mortem. This review session aims to reflect on the incident and identify any technology or process opportunities to help mitigate issues sooner and prevent a repeat of similar incidents. The timeline of the incidents needs to be adequately reviewed to uncover any inefficiencies in the detection or incident management process. All the necessary action items are identified and assigned to the respective owners with the correct priorities. The immediate high-priority action items should be addressed as soon as possible, and the remaining lower-priority items must have a due date. A designated person can help track these action items and ensure their completion by holding teams accountable.
Metrics to Measure
As it is said in SRE circles: “what gets measured gets fixed.” The following are standard metrics that should be measured and tracked across all incidents and organizations.
Time To Detect (TTD)
Time to Detect is the time it takes to detect the outage manually or via automated alerts from its start time. Teams can adopt more comprehensive alert coverage with fresher signals to detect outages faster.
Time To Mitigate (TTM)
Time To Mitigate is the time taken to mitigate the user impact from the start of the incident. Mitigation steps are temporary solutions until the root cause of the issue is addressed. Striving for better TTM helps increase the availability of the service. Many companies rely on serving users from multiple regions in an active-active mode and redirecting traffic to healthy regions to mitigate incidents faster. Similarly, redundancy at the service or node level helps mitigate faster in some situations.
Time To Resolution (TTR)
Time to Resolution is the time taken to fully resolve the incident from the start of the incident. Time to Resolution helps better understand the organization’s ability to detect and fix root causes. As troubleshooting makes up a significant part of the resolution lifecycle, teams can adopt sophisticated observability tools to help engineers uncover root causes faster.
Key Incident Metadata
Incident metadata includes the number of incidents, root cause type, services impacted, root cause service, and detection method that helps the organization identify the TBF (Time Between Failures). The goal of the organization is to increase the Mean Time Between Failures. Analyzing this metadata helps identify the hot spots in the operational aspect of the organization.
Availability of Services
Service availability is the percentage of uptime of service over a period of time. The availability metric is used as a quantitative measure of resiliency.
Conclusion
This article discussed the incident management process and showed how it can help organizations manage chaos and resolve incidents faster. Incident management frameworks come in various flavors, but the ideas presented here are generic enough to customize and adapt in organizations of any size.
Organizations planning to introduce the incident management framework can start small by collecting the data around incidents. This data will help understand the inefficiencies in the current system or lack thereof and provide comparative data to measure the progress of the new incident management process about to be introduced. Once they have a better sense of the requirements, they can start with a basic framework that suits the organization’s size without creating additional overhead. As needed, they can introduce other steps or tools into the process.
If you are looking for additional information on improving and scaling the incident management process, the following are great places to start:
Organizations looking to improve their current incident management process must take a deliberate test, measure, tweak, and repeat the approach. The focus should be on identifying what’s broken in the current process, making incremental changes, and measuring the progress. Start small and build from there.
AWS Introduces Amazon Workspaces Core and Support for Ubuntu Desktops on Amazon Workspaces
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
AWS recently introduced a new addition to Amazon Workspaces with a fully-managed, infrastructure-only Virtual Desktop Infrastructure (VDI) offering called Amazon Workspaces Core. In addition, customers can provision Ubuntu desktops on Amazon Workspaces for their developers, engineers, or data scientists.
Amazon Workspaces Core is a VDI offering that includes a set of APIs for customers and third-party VDI software providers wanting to integrate with Amazon Workspaces’ purpose-built VDI infrastructure. It enables IT administrators to keep using their familiar VDI software solution while end users can keep using their existing VDI client software. As a result, the end-user experience is consistent.
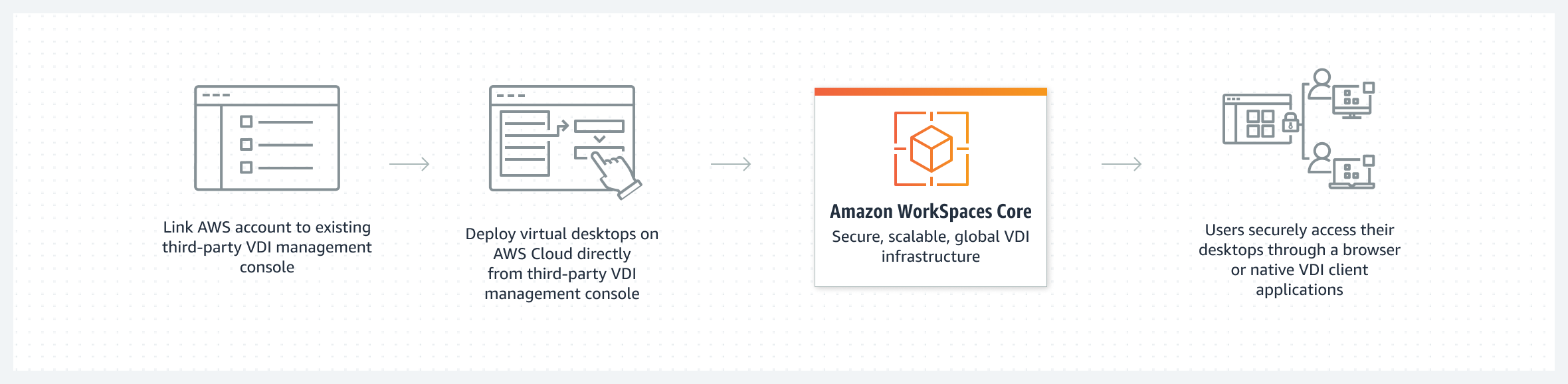
Source: https://aws.amazon.com/workspaces/core/
Muneer Mirza, general manager, End User Experiences at AWS, told InfoQ:
Flexibility and choice are the two primary tenets driving our focus to empower customers in building their own purpose-built virtual desktop infrastructure. With Amazon WorkSpaces Core, customers now have all the benefits of AWS’s reliability and security, global availability, and cost efficiency of the AWS Cloud—with the familiarity of their existing management console and client software.
In addition, Harry Labana, a managing director at Goldman Sachs, stated in a tweet:
I think this offering is a great direction for #DaaS #VDI. Separate the infrastructure from admin experience and provide greater choice plus granular cost transparency. Multi-cloud for DaaS will be important for enterprise resilience.
AWS also brings support for Ubuntu to Amazon Workspaces, where users will now have more choices for new categories of workloads, since Ubuntu is a popular operating system among professional developers, according to HackerEarth 2020 Developer Survey. In particular, developers and DevOps engineers have many scripts, tools, or libraries thoroughly tested on their Ubuntu desktops or laptops.
Sébastien Stormacq, a principal developer advocate at Amazon Web Services, explains in an AWS news blog:
Providing Ubuntu desktop on Workspaces gives developers and engineers a familiar and compatible environment allowing them to work from anywhere, with access to a wealth of open-source tools and libraries in cutting-edge fields like data science, AI/ML, cloud, and IoT. All Ubuntu WorkSpaces benefit from Ubuntu Pro, which includes support for expanded security patching for 10 years.
And Alex Gallagher, VP cloud for Canonical, said in a Canonical blog post:
Ubuntu virtual desktops on WorkSpaces enable IT organizations to quickly and easily provision high-performance Ubuntu Desktop instances, delivered as a fully managed AWS service. In the face of constant and increasing pressure to support the security and productivity needs of hybrid workers, that’s a win for IT organizations and their end users.
Amazon Workspaces is an answer to Microsoft’s VDI offering Azure Virtual Desktop and the recently released Microsoft Dev Box, a service aimed at developers providing a VDI desktop in Azure. Microsoft also provides Ubuntu images on its Azure marketplace.
Lastly, Ubuntu Workspaces are available in all AWS Regions where Workspaces are available (except a region in China: [Ningxia]). Furthermore, Workspace pricing details are available on the pricing page.