Month: December 2022

MMS • Andres Garzon
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- The growing skills gap is contributing to staffing challenges
- The need to build a competitive team that has skills relevant to your org’s needs
- Traditional outsourcing falls short of building dream teams
- Nearshore staff augmentation—outsourcing’s modern, innovative cousin—allows orgs to scale up quickly and effectively
- What to look for in an excellent nearshoring partner
The technology industry, in many ways, makes the world go round. But with growing market challenges and global uncertainties, what does the future of tech look like, and how can tech companies weather the storm?
What We’re Facing
Projections indicate several market challenges. These include the widening skills gap, too few developers to meet current demand, and low retention. When it comes to the skills gap, it’s estimated that 87% of companies are struggling to find candidates who align with their technical needs. There’s a widening difference between the skills businesses require and the skills tech workers are trained in. This gap could lead to 2.4 million jobs being unfilled between 2018 and 2028. Meanwhile, in addition to lacking IT staff who are trained in relevant skills, there are simply too few tech workers on the market. The National Foundation for American Policy estimates that vacant tech positions currently exceed 804,000, with 326,000 representing software development roles. That’s a lot of jobs left unfilled, and understaffed companies are hurting. And perhaps worst of all, even when companies are able to find (or train up) staff who meet their needs, they often struggle to retain them. 52% of workers say they’re interested in looking for a new job, and tech is facing the highest turnover rate of any industry. Retaining top performers is a significant challenge across the board. None of these issues are ideal.
What We Want
But what future do we envision for our tech companies? What’s the dream? I think many of us would say: a well equipped team that can help our company surpass its goals and innovate new solutions for our customers. And if that’s the dream, what factors do we need to make this a reality?
First, we need an upskilled team, trained in the technical competencies that will allow us to create and upgrade our products or services. We also need a consistent team, AKA low turnover. Our team should benefit from the institutional knowledge that comes with longer staff tenure. This means that we need to keep our staff happy enough to stay onboard, but it also means that we need to be scaling our teams thoughtfully, not recklessly. We’ve seen how companies that grow too quickly can end up suffering from sudden layoffs. This impedes company success, both because of a shrunken staff and because workers on the job market will be less interested in working for companies that could let them go with little notice. And finally, to get to the point where we have a highly skilled team with low turnover, we need to streamline our hiring and onboarding processes.
So we know what we need in order to equip our companies for success, but how do we get there? How do we overcome these hurdles and thrive in the face of adversity? The answer is outsourcing, but in a newer, evolved form.
When Outsourcing Falls Short
Outsourcing is becoming more widely practiced by American companies looking to increase support for their internal teams, save money, or expedite a project. The current value of American spending on outsourcing is $62 billion. It’s estimated that about 66% of US companies outsource the labor of at least one department, and that number is expected to increase in the coming years.
The appeals of outsourcing include reducing labor costs, providing temporary support for your in-house team, or assigning an auxiliary project to external contractors so that your in-house team can focus on the bread and butter of your business.
But these benefits come with certain challenges. Outsourcing’s common setbacks are so well known they’re practically clichés.
Firstly, outsourcing firms have traditionally been located overseas, which means these staff work wildly different hours from US companies. For example, there is a 12.5 hour time difference between San Francisco and New Delhi. Such timing differences often lead to project and communication delays. If a sudden issue arises—a cyber attack, a client complaint, a software vulnerability—overseas outsourcing can’t put these fires out in a timely manner. Surprise challenges are left unaddressed for longer than they have to be, leaving your company vulnerable to hackers, poor customer experience, and lost revenue.
In addition to delays, there are usually other communication difficulties when outsourcing overseas. As a client, you will likely need to spell out exactly what you want, in the most direct language possible. It is often not a good idea to assume outsourced staff will use their own common sense and take initiative to suggest alternatives. This leaves large room for error.
And when you outsource overseas, this often means you don’t directly supervise the work being performed. Typically outsourcing firms will have you liaise with a project manager who moderates feedback between your in-house team and the outsourced staff. Having to communicate via a middleman can exacerbate project delays and contribute to miscommunication.
It’s clear that traditional outsourcing’s many setbacks make it unideal for companies looking to perform with excellence. But can we make outsourcing a viable staffing solution? Is there an option that allows for the benefits of outsourcing, without its many issues?
Nearshoring: The Modern Solution
In recent years, outsourcing has innovated. Its modern incarnation—nearshore staff augmentation—allows for all the benefits of traditional outsourcing without any of the setbacks.
But what is nearshore staff augmentation? “Nearshore” means your temporary staff are working in a compatible time zone to your in-house team. They are neither domestic nor overseas. For example, a nearshoring firm that services North American clients will likely source their staff from South America. For European clients, staff might be based out of Africa. These arrangements allow nearshore staff to work the same (or similar) hours as your in-house team. “Staff augmentation” means that these contractors are integrated into your in-house team, rather than operating as an external team overseen by an unfamiliar project manager. You directly manage the work of augmented staff the same way you would with traditional W-2 hires.
Let’s take a look at how nearshore staff augmentation (or nearshoring) can help you leverage the benefits of outsourcing with none of the pitfalls.
Accessing the Global Talent Pool
When you nearshore, you’re open to staff working remotely, which allows you to consider candidates outside your immediate geographic area. Increased remote work and a larger hiring pool mean we can more easily find candidates who perfectly align with our company’s needs. A wider net is cast during the hiring process. This gives us access to more candidates, and therefore increases our chances of finding a perfect match.
We also don’t have to worry about convincing great candidates to relocate for work. They can stay near their families, friends, and preferred school districts. Excellent, well-aligned candidates will prefer working for companies who don’t require them to upend their personal lives.
In recent decades, Latin America has enjoyed an increase in software developer talent. Some nearshore firms have chosen to leverage the LATAM tech boom for their US clients. Partnering LATAM developers with US clients gives companies access to premium tech staff, and it enables Latin American countries to retain their population of talented engineers, who can then support their loved ones and local economies. Meanwhile, countries like Rwanda and Kenya are experiencing the benefits of the Fourth Industrial Revolution, allowing their tech workers to partner with companies based out of Europe. Nearshoring helps enable global economic prosperity.
Cost Savings
Nearshoring makes this access to great talent possible at a reduced cost. While not downright cheap (like traditional outsourcing tends to be), nearshoring allows some companies to save around 33–50% on staffing costs. It’s not a scrimp-and-save option, but it is more cost effective than hiring domestically. Cutting edge companies can work with top notch talent at a reduced price.
Similar Time Zones
When you nearshore, you’re contracting staff who operate in a compatible time zone to yours, usually within three hours of your in-house team. This eliminates delays with projects and communication, because everyone is clocked in around the same time. This also means your augmented staff can respond to surprise challenges in a timely manner. They’ll be available for impromptu problem-solving sessions and can put out sudden “fires.”
Ease of Communication
There also tend to be little to no communication difficulties with nearshore staff. This does depend on which staffing firm you partner with, but excellent nearshoring companies typically vet their staff for language fluency, clear communication, initiative in asking questions, and the ability to collaborate.
Direct Management
Nearshore staff augmentation involves contractors working alongside your in-house team, collaborating to make your dream projects a reality. No middlemen complicating your feedback, and no distinct teams struggling to sync up. Nearshoring enables increased productivity and fewer issues along the way.
Screening for Soft Skills
Not all outsourcing firms are the same. If you’re going to try nearshoring, it’s important to find a firm that sweats the little things. To that end, find a firm who screens for soft skills, in addition to technical competencies. It’s no use partnering with a software developer who is well credentialed but doesn’t communicate proactively. Same goes for taking initiative with identifying problems and collaborating on solutions. Those aren’t qualities you’ll see on a candidate’s resume, so make sure your nearshore firm has ways of testing those skills.
This might look like holding extended, discussion-based interviews. A firm’s technical challenges should also involve the candidate proposing alternative solutions, communicating their thought process, and asking clarifying questions. It’s also a good sign if the firm allows you to interview candidates yourself, so that you can screen for these qualities with your own unique methods.
Protecting Retention
An ideal nearshore firm will also have a strong company culture and imbue its values in its contractors. In order to mitigate turnover, firms should encourage contractors to be personally invested in their work. Beyond compensation, it’s essential for staff to have a vested interest in their company. A firm that keeps their staff engaged and happy is primed for long-term partnerships and the innovation that comes with it.
How It’s Done
For companies considering outsourcing, nearshore staff augmentation is a great way to do it. Organizations like McGraw Hill, a digital education innovator, have been able to scale their teams swiftly and affordably by partnering with nearshore developers from Jobsity. The aerospace manufacturer Boeing chose to partner with wiring technicians from Mexico, and now 95% of Boeing’s 787 Dreamliner aircrafts are wired by Mexican nearshorers. And Groupon was able to maintain the high quality of its marketplace, LivingSocial, with the help of nearshore software engineers. Outsourcing works, and its benefits are significant—if it’s done right. Nearshore staff augmentation is the best way to do it.
If nearshore staff augmentation is sounding like a good option for your organization, prioritize firms with strong recruitment and vetting procedures, staffers located in your same time zone, and low staff turnover. These will allow you to take full advantage of the benefits of nearshoring: seamless onboarding, reduced costs, and collaborative partnerships. The future of technology depends on the talent to run it, and nearshore staff augmentation paves the way.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

The Swift language workgroup has detailed the main focus areas for the development of Swift in 2023 and further on, which include defining an ownership model for memory management, non-copyable types, a macro system, and C++ interoperability.
Ownership is an approach to memory management that has recently become popular thanks to Rust, where it holds as one of the most defining language features and at the foundations of its ability to provide memory safety guarantees.
Rust uses a third approach: memory is managed through a system of ownership with a set of rules that the compiler checks. If any of the rules are violated, the program won’t compile. None of the features of ownership will slow down your program while it’s running.
Discussions on the introduction of ownership in Swift began back in 2017 and led to the definitions of an Ownership Manifesto.
While work on ownership did not lead anywhere, the Swift language workgroup is bringing it back with the aim to provide programmers with more control on values in memory. This could include prohibiting implicit copies, enabling ownership transfers, and borrowing values without copying them. Additionally, Swift could get support for non-copyable types to restrict the lifecycle of critical values.
These controls will enable new ways to work with data in memory, combining the performance of current “unsafe” constructs with the safety of Swift’s standard library features.
Another promising area for Swift is the creation of a procedural macro system to enable the creation of advanced libraries and DSLs. Macros are a mechanism for code generation that applies a transformation to source code at the lexical, syntactical, or semantic level. A number of existing features in Swift that could be implemented as macros are the Codable protocol, string interpolation, property wrappers, and result builders. According to the Swift language team, using macros to build new features like those listed above would free up more resources for alternative work on the language and its tooling.
While work on Swift macros is still in very early stages, there are already some ideas about what they could look like in Swift. Here is an example of a possible stringify macro:
macro(contexts: [.expression, .parameter], external: "MyMacros.Stringify")
func stringify(_ value: T) -> (T, String)
C++ interoperability aims to enable calling C++ code from Swift as well as calling into Swift from C++ code. It is the feature that will probably make it first to an official Swift release given its more advanced status. The current implementation of C++ interop already supports owned value types, trivial value types, foreign reference types and iterators, and provide an answer to fundamental questions around methods, pointers, and l-value and r-value references, according to the language team.
While the three areas delineated above are the most innovative, Swift evolution will also focus on bringing forth existing features, such as concurrency and generics.
In particular, for concurrency the goal will be improving data isolation provided by Sendable and actors, whereas work on generics will bring support for variadic generics, i.e., generics that have a variadic number of placeholder types.
No schedule has been provided for the new features described here and it is not clear whether they will be available in Swift 6 or later. InfoQ will continue to report about Swift development as new information becomes available.
MMS • Nsikan Essien
Article originally posted on InfoQ. Visit InfoQ
AWS announced support for local development and testing of AWS Serverless Application Model (AWS SAM) projects defined in Hashicorp Terraform configuration files. The functionality is provided via the AWS SAM Command Line Interface (AWS SAM CLI) as of version 1.63.0 and is currently released as a public-preview feature.
AWS SAM is an open-source framework for defining serverless application infrastructure as code. It operates as an extension to AWS’ Infrastructure-as-code service, Cloudformation, by enabling AWS Lambda functions, AWS DynamoDB tables and AWS API Gateways to be described and connected together succinctly. The AWS SAM CLI is a tool that facilitates the easy creation, build and deployment of AWS SAM projects and their associated infrastructure. To build an application, the CLI applies transformations to the resources specific to SAM, e.g. AWS::Serverless::Function, and converts them into their CloudFormation equivalents according to AWS’ recommended practices.
Terraform is an open-source framework for provisioning, changing and versioning infrastructure resources on cloud environments. Although the Terraform HCL syntax is cloud-vendor neutral, the AWS resource provider allows for a declarative specification of AWS infrastructure in a similar fashion to Cloudformation.
Previously, SAM applications could only be built and run locally by the CLI if they had been defined with AWS SAM syntax templates. Executing the commands sam build && sam local invoke in a compatible project would instantiate the SAM application’s Lambda function on the user’s computer and make it available for testing and debugging. With the newly released feature, serverless applications defined using Terraform can also be executed locally using the CLI by including the flags: --hook-name terraform --beta-features.
A common pattern for serverless application development has historically been to provide Lambda function application code alongside infrastructure definitions, with the AWS SAM CLI being a simplified mechanism for packaging and releasing both types of code changes together. As Terraform became more widely used for managing infrastructure, community discussion arose, for example on r/aws or r/serverless, on the best way of managing serverless applications. The open-source and community-developed framework Serverless.tf was eventually created as,
an organic response to the accidental complexity of many existing tools used by serverless developers
with the goal of enabling infrastructure and application development using only Terraform modules.
By adding support for a SAM metadata resource within Terraform, the CLI is now able to locate and package Lambda function source code, easing some of the pain-points Serverless.tf was created to fix.
Terraform support in the AWS SAM CLI is available as of v1.63.0 and its source code can be found on GitHub.
Amazon EventBridge Pipes Support Point-to-Point Integrations between Event Producers and Consumers
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
At re:Invent, AWS introduced Amazon EventBridge Pipes, a new feature in Amazon EventBridge providing developers a more straightforward way to connect events from multiple services.
With Amazon EventBridge Pipes, the company expands the EventBridge offering beyond event buses and scheduling. The new feature allows developers to create point-to-point integrations between event producers and consumers. Werner Vogels, chief technology officer at Amazon, explained the feature during the re:Invent keynote:
So the idea is that you should no longer have to write the glue code because you can easily stitch these services together. And if you would want to actually manipulate the events before they reach the consumer, you can actually provide a lambda function or a point-to-step function or API gateway to actually run some code to manipulate the events that are flowing through your pipe. And it has built-in filtering meaning that if you only want to get a real subset of the events that need to flow to the consumer you can add that too.
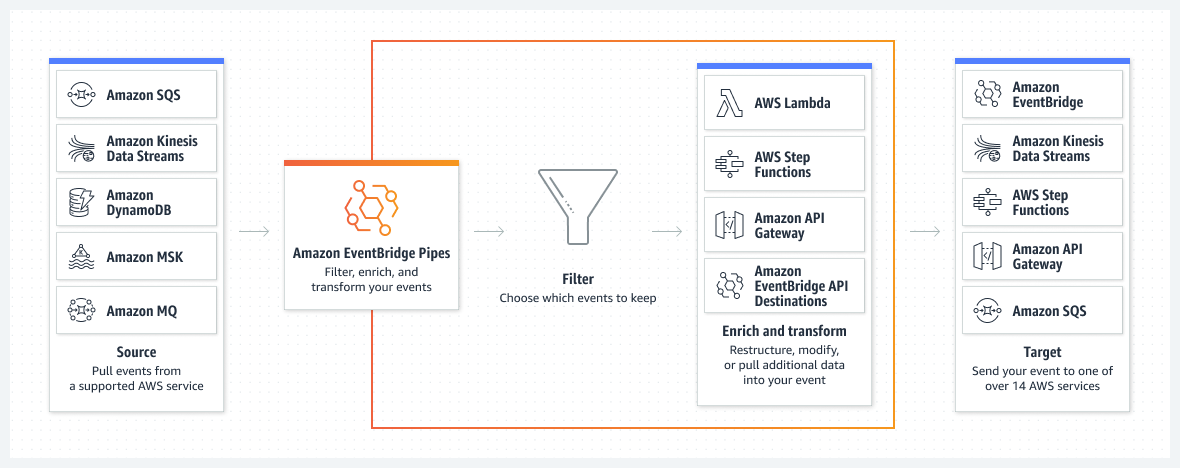
Source: https://aws.amazon.com/eventbridge/pipes/
Developers can create pipes by clicking “Pipes” in the Amazon EventBridge console or using the AWS Command Line Interface (CLI), AWS CloudFormation, and AWS Cloud Development Kit (AWS CDK). Next, they choose a source producing events like Amazon DynamoDB, Amazon Kinesis, and Amazon MQ. Then they can optionally specify an event filter to only process events that match the filter. Subsequently, they can also optionally transform and enrich events using built-in free transformations, or AWS Lambda, AWS Step Functions, Amazon API Gateway, or EventBridge API Destinations to perform more advanced transformations and enrichments. And finally, they choose a target destination such as AWS Lambda, Amazon API Gateway, and Amazon SNS.
Ian McKay, a DevOps lead at Kablamo, tweeted:
EventBridge Pipes allows for data pipelines between AWS services such as DDB, SQS, Kinesis, MSK etc., to destinations such as Lambda, Kinesis, and other 3rd parties – including field-level mapping/filter/enrichment support, suspiciously similar to the way AppFlow works.
In addition, Nik Pinski, a principal engineer at AWS, tweeted:
This is something our friends at Lambda solved quite elegantly already with the EventSourceMapping – giving an easy way to run a Function in response to an event source. But some Lambda Function code is also undifferentiated glue to downstream systems.
Amazon EventBridge Pipes are currently generally available in all AWS commercial regions except Asia Pacific (Hyderabad) and Europe (Zurich). Pricing details of the service are available on the pricing page.
MMS • W. Watson
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Cloud native standards, such as the OpenMetrics standard, are bottom up, driven by the ecosystem and competing open projects, instead of being driven by top-down standards bodies, such as traditional telecommunications RFCs or vendor-driven groups.
- There is no centralized kingmaker in the cloud native ecosystem. Ease of use, utility, and openness create traction for a standard while keeping vendor influence to a minimum.
- Implementations drive cloud native standards and specifications instead of the other way around. Developers trust standards that emerge from working code instead of promises of functionality with ambiguous semantics.
- The cloud native community strongly prefers open standards instead of proprietary ones. Open standards with open implementations have better network effects, are much more difficult to embrace, extend, and extinguish, and are therefore seen as much more legitimate than closed implementations.
- The cloud native community communicates, competes, and cooperates using interfaces and open standards. The symbiotic relationships of cloud native projects and vendors are enhanced in the plain sight of the rest of the ecosystem, with compatibility and performance being quickly judged within tight iterations.
Bottom Up Versus Top Down
What happens when an ecosystem driven from the bottom up collides with a community characterized by top-down development? The 5g broadband cellular network standard by the 3rd Generation Partnership Project (3GPP), the Network Function Virtualization (NFV) standard by the European Telecommunications Standards Institute (ETSI), and the Service Function Chain RFC (request for comments) by the Internet Engineering Task Force (IETF) are examples of the telecommunication community’s methods for creating standards. These are usually developed in a coarse-grained, top-down fashion with complementary features intertwined and specified. The cloud native community takes a bottom up approach driven by the ecosystem’s needs and demonstrated by fine-grained implementations, which then produce the specifications. An example of this would be the OpenMetrics standard that emerged from the observability and Prometheus cloud native community. This contrast in standards development has made integrating the desired cloud native forms of availability, resilience, scalability, and interoperability into telecommunications a difficult process.
One of the main reasons agile development has superseded big up-front design, also known as the waterfall method, is that within agile, the customer has a tighter feedback loop with the implementers. Implementation-driven feedback loops expose deliverables earlier to the customer, so adjustments happen quicker.
Big and expensive projects like government rewrites 1 have slowly been replaced with agile methods, but has this affected how we develop standards?
Top-Down Standards
There are two types of standard design: top down and bottom up. Historically, standards bodies are assembled with people from academia, industry, and corporate sources. The industry would then adopt the standard based on the buy-in from the major players who contributed to the standard, the marketing of the standard, and the validity of the standard itself. Control of the standard in this model flows from the top down.
Bottom-Up Standards
Software standards that emerge organically do so from code bases that get adopted by the community. The code bases that need to be interchangeable (via libraries), interoperable (via APIs), or need to communicate well (via protocols), gain an advantage from being developed, scrutinized, and adopted in the open.
Whether top down or bottom up, after considering the effectiveness of the standard, the next most important thing about a standard is where the control lies. The control of the standard in this model flows from the bottom up based on user adoption and fork threats. In the bottom-up style, the ecosystem has the last say. This is not to say that bottom-up control can’t overreach. Bottom-up control can actually be more powerful than top down, as we will discuss later.
Telecommunications protocols and standards are usually top down and are developed by standards bodies like 3GPP, ETSI, and IETF. Cloud native standards are bottom up and emerge from subcommunities such as the observability community.
Top-down and bottom-up design or control contrasts are depicted in many places. One such place is within the Agile methodology’s pull versus push methods. In the push method, the tasks are assigned, top down, from the project manager to the implementer. In the pull method, the tasks are developed and prioritized by the team, put in a queue, and then implementers select the tasks from the queue. Another fact worth noting is that design researchers believe a significant portion of user design is from the bottom up 2. Christopher Alexandre, the architect that the pattern movement in software is based on, also noted that the implementers often choose architecture (e.g., farmers building a barn) and is merely facilitated 3 by architects. These architects help best by providing a pattern language. An even stronger position on architecture is by Peter Kropotkin, who said that the great craftsmanship of the European cities 4 was not “commissioned” by a solitary effort 5 but rather developed by the guilds in competition with each other, an argument he uses as an example of the process of mutual aid.
No Kingmakers
The avoidance of picking winners and losers is reflected in the CNCF technical oversight committee (TOC)’s principles as:
No kingmakers. Similar or competitive projects are not excluded for reasons of overlap.
In an environment with no kingmaker, competing solutions and implementations are allowed regardless of the political influence of the vendor. This is because vendor favoritism kills innovation, especially within the open-source community. While in the traditional business world, creating barriers to entry is considered a good practice, in the open-source community, barriers to entry are frowned upon. Open source communities reflect the marketplace of ideas, where every idea deserves a fair shot on a level playing field.
There is a fairness component to the design of standards as well. In the book Design Justice, Sasha Costanza-Chock reveals how the credit for design is often misattributed in a top-down hierarchy 6. Attribution is an important factor in how the incentives for open-source work 7. The misattribution of attribution and attention is destructive to open-source communities 8. Since attention and attribution are both rival resources (i.e. a resource that when allocated to one person, another person is excluded), the gratuitous reassignment of such a resource disincentivizes innovation. Reassignment of a resource that was developed openly in a market setting is called playing market 9 and has been shown to have negative consequences on innovation10.
A CNCF TOC stance is that there shouldn’t be architects commissioned to develop the masterpiece standard at the head of an open-source community. The power in the community is that it isn’t centrally planned but project-centric:
We Are Project-Centric. Principle: If it can be on a modern public source code control system, then it can be a project. And we put projects front and center.
So the project developers are educators of their implementation pattern that facilitates and solves a cloud native problem.
Implementations Drive the Standard
An argument can be made that programming languages are the most reusable software11. If this is the case, programming language design is foundational to all software, and the design thereof could be illuminating.
When the programming language Ada was developed, it was commissioned in a top-down manner from the U.S. Department of Defense 12 to be an international standard. Ada is an example of the kingmaker’s decree (the DoD) coming to fruition some 11 years13 after developing a standard.14 This could be compared to another general-purpose language, C++, which came into existence later, was developed more organically, albeit commercially, and overtook Ada in popularity. Initially, C++ was more of a de facto standard 15 than a de jure standard like Ada. Interestingly, both of these languages struggled to adopt the crown of the dominant object-oriented language. C++ was object oriented earlier but wasn’t an ISO standard. Ada became the first internationally standardized language that was object oriented in 1995. Still, the C++ enjoyed so much commercial adoption by that time that the crown race was already won, even with the kingmaker decree of Ada happening five years earlier.
The 1990s brought open source implementation-based languages. One of the major differences in the adoption of these languages is that the interpreter or compiler was open source, and the implementation (usually built by the founder) was used as the standard. Other implementations were judged by how they compared with the original implementation. Based on the implementation, the de facto standard would be debated within their respective language communities with the founder of the language but with one key difference: the community now can fork the source and provide a credible threat to the benevolent dictator’s decisions.
The development of HTTP is another example of a code implementation driving a standard. The code for the Apache and Netscape web servers was passed around so that HTTP behavior could be shared between the different developers 16. The architecture of HTTP 1.0, combined with other web architecture, is arguably the world’s largest distributed application, and it wasn’t standardized until 1996.
What can we draw from the bottom up, open, and community-driven implementations? First, open-source implementations are not patent driven. Everyone must be able to use, modify, and contribute to the code for it to be community influenced and driven. Second, early adoption trumps codification. Passing around code is the primary form of communication in the early phase of successful, widely used standards.
What Is a Cloud Native Implementation: The Cloud Native Pattern of Communication
When we reason about cloud native implementation principles, de facto standards, and patterns, we should describe what a pattern actually is. To start, events, or recurring activities, are the driving factor for patterns. Events, when harnessed or facilitated, domesticate an environment for users. In this way, a pattern is a recurring series of facilitated steps. This goes for both physical and digital architecture. Multiple patterns, or ways to facilitate recurring events, can be part of an interconnecting ubiquitous pattern language 17.
An example of recurring events within the cloud native architecture is the numerous logs for the numerous nodes and containers within a deployment. A way to facilitate these logs is to treat them as event streams. Routing log data to stdout allows tools in the execution environment to capture them and acts as a best practice. This behavior is a cloud native pattern, a best practice, and accepted by the cloud native community, regardless if a standards body codifies the practice. Implementing this pattern within the projects of the cloud native community is all that is needed. Instead of a top-down decree, the cloud native pattern is a preferred form of exchange in community discourse.
Describing the cloud native community’s implementation of interfaces as a ubiquitous language is useful because natural languages are driven from the bottom up. We will return to this later.
Open, Transparent Standards Beat Closed Proprietary Ones
During the browser wars of the late ’90s spanning into the 2000s, the closed-source Internet Explorer competed with multiple open source HTML browsers such as Firefox, Safari, Chrome, and Opera (which switched to being based on Chromium in 2013). The fierce competition incentivized differentiation in the form of proprietary extensions, which repeatedly threatened to balkanize the HTML standard and browser world. Reusing open standards implemented in libraries such as the WebKit rendering engine used by Safari and Chrome proved to be a superior strategy in browser implementation. By 2020 even Microsoft’s new browser, Edge, was based on the open-source engine in Chromium.
With open implementations and standards, free use incentivizes widespread usage, creating network effects. This is probably the most pragmatic rationale for open implementations and standards.
Because of the openness, there are more people critiquing not only the design of the standard but the implementation of the standard. This creates the aura of legitimacy for the standard that emerges from the code base. The standard seems more thoroughly tested because one can see how it was implemented. Furthermore, when a standard is implemented openly, such as with an Apache, BSD, or GPL license, it is much harder to embrace, extend, and extinguish.
Apis, Interfaces, and Standards Are How the Community Communicates
Previously, we established that the bottom-up community is composed of projects that communicate with one another through a ubiquitous language of patterns. What is the nature of these patterns, and how are they implemented? The cloud native patterns, such as the reconciler pattern, are implemented as interfaces exposed from open-source libraries. The interfaces between popular upstream/producer projects and downstream/consumer projects incentivize competing producer projects to “standardize” on rough de facto agreements that become a common interface. This is to say that if multiple implementations of upstream-producing projects are encouraged, the best interface should emerge. The CNCF TOC states it this way:
No single stack. Encourage interoperability for the emergence of a variety of stacks and patterns to serve the community and adopters.
The implementation of interfaces is presented by the community at conferences. This encourages participation in the project’s development. Again, the proverb “given enough eyeballs, all bugs are shallow” by Eric S. Raymond comes to bear here.
One thing to beware of is that interfaces can still take a form of control that is either too slow to compensate for user demands or too manipulative and therefore kills competition. This is why the CNCF TOC shuns hard, codified standards developed from standard bodies:
Principle: Promote interfaces and de facto implementations over standards for real-world use. … We want markets and users to drive interop, not committees. We want to help real-world use happen faster, and foster collaboration. We do not wish to become gated on committees.
Standards documentation can still be used as a form of communication between producers or producers and consumers and can even be in the form of an RFC. Still, this documentation isn’t recognized formally outside the projects:
CNCF may develop written materials in the style of the current CNI interface document or the style of an IETF RFC, for example. These CNCF “specification” materials are not “standards.” It is [possible in the future] that an independent and recognized international standards body takes a CNCF document as “upstream” and evolves it into a standard via (e.g.) the IETF process. The CNCF is morally supportive of independent parties doing this but does not see this work as its own responsibility.
Some examples of these rough, de facto implementations are CNI (network), CSI (storage), CRI (runtime), OpenMetrics, and CLI (logging).
Finally, within the cloud native community, the reconciliation pattern is valued as a way for the infrastructure to communicate with applications hosted by that infrastructure. If the project supports the infrastructure of applications, it is exceedingly important that the interface to that project supports declarative configuration instead of imperative steps toward a correct state. This supports communication because the declarative configuration is easier to reason about. 20
What Is the Protocol for Making Protocols
Robert Chisholm identified a problem one runs into in an attempt to create a set of rules. The problem is that you need yet another set of rules for judging the validity, usefulness, and capability of those rules for producing outcomes and truth claims. This creates an infinite regress and is known as the problem of the criterion.
When reasoning about standards, we have to decide whether the top-down development of rules is more desirable than bottom up. From the standpoint of pure pragmatism, the bottom-up development wins if you desire buy-in. Some of the hardest, seemingly intractable problems have been solved by bottom-up methods. Elinor Olstrom discovered that the longest-lasting institutions (defined as a set of rules), which have been in place for 500+ years, emerge from the bottom up with no centralized planner. In the book Convention, David Lewis proposed that languages develop from the bottom up based on a game theoretical concept known as focal points, which are not decided upon by any committee 19. On the other hand, top-down rules production seems to win if control is the main criterion at first glance, but even this may not be the case.
Top-down standards development prefers a command and control, decentralized power structure reminiscent of what Melvin Conway talks about in his paper “How do committees invent.” Applied to our topic, instead of software being constructed in the fashion of the organization that develops it, here it is the standards body that prefers to develop standards that structure power in the way it was organized. DNS is a perfect example. DNS is structured in a decentralized manner 20, just like the top-down body that created it. It is decentralized in the sense that the power is structured in a hierarchy of servers, each with a reduced level of authority. In contrast, a distributed standard like TCP-IP has no centers of control 21. Conway says that given that all large organizations have sub-organizations, there will be interfaces between those sub-organizations by which they communicate. The sub-organizations are constrained by the parent organization on what responsibilities they have. These interfaces and constraints are the preferred sites of architectural choice within not just software but any artifact of the parent organization. Since the artifact of standards bodies are protocols and specifications, the constraints and interests that comprise the sub-organizations will dominate the design of how power is implemented within the protocol itself. Given this view of organizations and the desire for control, it seems that top-down design would be prone to implement standards that are closed source (with power in the hands of one implementer), and bottom up would prefer an open standard (with power being in the hands of the people capable of implementing a successful fork). It also seems that top-down standards bodies would prefer decentralized standards like DNS (if the decentralized nodes represent the interests in the standards body), even if open, over TCP-IP, which is distributed 22. Given this extension of Conway’s law, bottom-up, implementation-driven efforts have organizational structures that are the more likely of the two to produce protocols and specifications with distributed control.
For those that desire more control, the counterintuitive truth of a distributed standard is that the level of control is actually elevated because each node has full buy-in to the standard’s power structure. This is why the bottom-up emergence of a standard like OpenMetrics is so much more subversive. The legitimacy of the standard gets much more buy-in here. With a bottom-up standard, there is heightened control over both the standard and what the standard produces (often a distributed implementation). Bottom-up standards are like speed bumps. The community adopts them because they think the adoption is in their own interest, not unlike how a driver slows down when they see a speed bump in their own interest, not in the interest of the lawmaker 23.
Conclusion
We have described the rationale for the cloud native, bottom-up development of principles, best practices, and de facto standards. We have also described top-down, committee-driven standards such as those from the telecommunications industry. Is it possible for the two worlds of top-down and bottom-up standards development to meet in the middle? What happens when the stewards of protocol meet with cloud native standards? What happens is probably something like governance bodies with technical oversight committees, special interest groups, and working groups. It probably looks something like the emergence of the architecture of the web, which was implementated years before standards bodies codified the standard.
To learn more about cloud native principles, join the CNCF’s cloud native network function working group. For information on CNCF’s CNF certification program, which verifies cloud native best practices in your network function, see here.
Endnotes
1. “The IRS conceded yesterday that it had spent $4 billion developing modern computer systems that a top official said ‘do not work in the real world,’ and proposed contracting out the processing of paper tax returns filed by individuals.”
2. “In his text Democratizing Innovation, MIT management professor Eric Von Hippel both theoretically and empirically demonstrates that a significant portion of innovation is actually done by users, rather than manufacturers. Further, he finds that particular kinds of users (lead users) are the most likely to innovate and that their innovations are more likely to be attractive to a broader set of users.” Costanza-Chock, Sasha. Design Justice (Information Policy) (p. 111). MIT Press. Kindle Edition.
3. The Timeless Way of Building describes the fundamental nature of the task of making towns and buildings. It is shown there, that towns and buildings will not be able to become alive, unless they are made by all the people in society, and unless these people share a common pattern language, within which to make these buildings, and unless this common pattern language is alive itself.”, Alexander, Christopher. A Pattern Language (Center for Environmental Structure Series) (p. ix). Oxford University Press. Kindle Edition.
4. “The results of that new move which mankind made in the mediæval city were immense. At the beginning of the eleventh century the towns of Europe were small clusters of miserable huts, adorned but with low clumsy churches, the builders of which hardly knew how to make an arch; the arts, mostly consisting of some weaving and forging, were in their infancy; learning was found in but a few monasteries. Three hundred and fifty years later, the very face of Europe had been changed. The land was dotted with rich cities, surrounded by immense thick walls which were embellished by towers and gates, each of them a work of art in itself. The cathedrals, conceived in a grand style and profusely decorated, lifted their bell towers to the skies, displaying a purity of form and a boldness of imagination which we now vainly strive to attain.” Kropotkin, Peter. Mutual Aid: A Factor in Evolution (Annotated) (The Kropotkin Collection Book 2) (p. 114). Affordable Classics Limited. Kindle Edition.
5. “A cathedral or a communal house symbolized the grandeur of an organism of which every mason and stone-cutter was the builder, and a mediæval building appears — not as a solitary effort to which thousands of slaves would have contributed the share assigned them by one person’s imagination; all the city contributed to it.” Kropotkin, Peter. Mutual Aid: A Factor in Evolution (Annotated) (The Kropotkin Collection Book 2) (p. 115). Affordable Classics Limited. Kindle Edition.
6. “The typical capitalist firm is arranged in a pyramid structure so that resources (time, energy, credit, money) flow from bottom to top. This is also the case within most design firms. At the extreme, in large multinational design enterprises, armies of poorly paid underlings labor to produce work (concepts, sketches, prototypes), while the benefits (money, attribution, copyrights, and patents) flow upward into the hands of a small number of high-profile professional designers at the top.” Costanza-Chock, Sasha. Design Justice (Information Policy) (p. 113). MIT Press. Kindle Edition.
7. “When people talk about the ‘attention economy,’ they’re usually referring to the consumer’s limited attention, as when multiple apps compete for a user’s time. But a producer’s limited attention is just as important to consider.” Eghbal, Nadia. Working in Public: The Making and Maintenance of Open Source Software (p. 214). Stripe Press. Kindle Edition.
8. “The production of open source code, however, functions more like a commons—meaning that it is non-excludable and rivalrous—where attention is the rivalrous resource. Maintainers can’t stop users from bidding for their attention, but their attention can be depleted.”, Eghbal, Nadia. Working in Public: The Making and Maintenance of Open Source Software (pp. 161-162). Stripe Press. Kindle Edition.
9. “…concentration of ultimate decision-making rights and responsibilities (i.e., ownership) in the hands of a central planning board,” Strategy, economic organizations, and the knowledge economy, Nicolai J Foss, pg. 174
10. “First, because managers could always be overruled by the planning authorities, they were not likely to take a long view, notably in their investment decisions. Second, because managers were not the ultimate owners, they were not the full residual claimants of their decisions and, hence, would not make efficient decisions. …The problem arises from the fact that it is hard for the ruler to commit to a noninterference policy,” Strategy, economic organizations, and the knowledge economy, Nicolai J Foss, pg. 175
11. “Bottom-up programming means writing a program as a series of layers, each of which serves as a language for the one above. This approach tends to yield smaller, more flexible programs. It’s also the best route to that holy grail, reusability. A language is, by definition, reusable. The more of your application you can push down into a language for writing that type of application, the more of your software will be reusable.” Graham, Paul. Hackers & Painters: Big Ideas from the Computer Age (Kindle Locations 2563-2566). O’Reilly Media. Kindle Edition.
12. “The Ada standard was approved February 17, 1983. At that time, it became ANSI/MIL-STD 1815A-1983. Subsequently, it became an International Standards Organization (ISO) standard as well. Interpretations of the standard are made by an international committee that was originally under the auspices of the U.S. Department of Defense and called the Language Maintenance Committee, but now falls under the jurisdiction of ISO and is called Ada Rapporteur Group.” Weiderman, Nelson. A Comparison of ADA 83 and C++.
13. “The price of making Ada a real, rather than hollow, standard has already been paid. Since the draft standard was released in 1980, it has taken 11 years of considerable effort to institute the technology.” Weiderman, Nelson. A Comparison of ADA 83 and C++.
14. “Public Law 101-511, Section 8092 prescribes, ‘Notwithstanding any other provisions of law, after June 1, 1991, where cost effective, all Department of Defense software shall be written in the programming language Ada in the absence of special exemption by an official designated by the Secretary of Defense.’” Weiderman, Nelson. A Comparison of ADA 83 and C++.
15. “Commercial de facto standards such as C++ have the advantages of widespread visibility and acceptance. The marketplace moves rapidly to ensure that C++ can work with other software systems. C++ is ahead of Ada in this regard. Much commercial investment has been made in the infrastructure for tools and training.” Weiderman, Nelson. A Comparison of ADA 83 and C++.
16. “The early Web architecture was based on solid principles—separation of concerns, simplicity, and generality—but lacked an architectural description and rationale. The design was based on a set of informal hypertext notes 14, two early papers oriented towards the user community 12, 13, and archived discussions on the Web developer community mailing list (www-talk@info.cern.ch). In reality, however, the only true description of the early Web architecture was found within the implementations of libwww (the CERN protocol library for clients and servers), Mosaic (the NCSA browser client), and an assortment of other implementations that interoperated with them.” Fielding, Roy. (2000). Architectural Styles and the Design of Network-based Software Architectures. Pg. 90
17. “The elements of this language are entities called patterns. Each pattern describes a problem that occurs over and over again in our environment, and then describes the core of the solution to that problem, in such a way that you can use this solution a million times over, without ever doing it the same way twice.” Alexander, Christopher. A Pattern Language (Center for Environmental Structure Series) (p. x). Oxford University Press. Kindle Edition.
18. “Declarative configuration is different from imperative configuration, where you simply take a series of actions (e.g., apt-get install foo) to modify the world. Years of production experience have taught us that maintaining a written record of the system’s desired state leads to a more manageable, reliable system. Declarative configuration enables numerous advantages, including code review for configurations as well as documenting the current state of the world for distributed teams. Additionally, it is the basis for all of the self-healing behaviors in Kubernetes that keep applications running without user action.” Hightower, Kelsey; Burns, Brendan; Beda, Joe. Kubernetes: Up and Running: Dive into the Future of Infrastructure (Kindle Locations 892-896). Kindle Edition.
19. “Conventions are agreements—but did we ever agree with one another to abide by stipulated rules in our use of language? We did not. If our ancestors did, how should that concern us, who have forgotten? In any case. the conventions of language could not possibly have originated by agreement, since some of them would have been needed to provide the rudimentary language in which the first agreement was made.” David Lewis. Convention: A Philosophical Study (Kindle Locations 58-61). Kindle Edition.
20. “Because the DNS system is structured like an inverted tree, each branch of the tree holds absolute control over everything below it.” Galloway, Alexander R. Protocol (Leonardo) (Kindle Locations 540-541). MIT Press. Kindle Edition.
21. “On the one hand, TCP/IP (Transmission Control Protocol/Internet Protocol) enables the Internet to create horizontal distributions of information from one computer to another. On the other hand, the DNS (Domain Name System) vertically stratifies that horizontal logic through a set of regulatory bodies that manage Internet addresses and names. Understanding these two dynamics in the Internet means understanding the essential ambivalence in the way that power functions in control societies.” Galloway, Alexander R. Protocol (Leonardo) (Kindle Locations 189-193). MIT Press. Kindle Edition.
22. “Distributed networks are native to Deleuze’s control societies. Each point in a distributed network is neither a central hub nor a satellite node—there are neither trunks nor leaves. The network contains nothing but ‘intelligent end-point systems that are self-deterministic, allowing each end-point system to communicate with any host it chooses.’ 15 Like the rhizome, each node in a distributed network may establish direct communication with another node, without having to appeal to a hierarchical intermediary.” Galloway, Alexander R. Protocol (Leonardo) (Kindle Locations 581-585). MIT Press. Kindle Edition.
23. “With bumps, the driver wants to drive more slowly. With bumps, it becomes a virtue to drive slowly. But with police presence, driving slowly can never be more than coerced behavior. Thus, the signage appeals to the mind, while protocol always appeals to the body. The protocol is not a superego (like the police); instead, it always operates at the level of desire, at the level of ‘what we want.’” Galloway, Alexander R. Protocol (Leonardo) (Kindle Locations 4880-4884). MIT Press. Kindle Edition.
MMS • Anthony Alford
Article originally posted on InfoQ. Visit InfoQ

Microsoft Research recently open-sourced FarmVibes.AI, a suite of ML models and tools for sustainable agriculture. FarmVibes.AI includes data processing workflows for fusing multiple sets of spatiotemporal and geospatial data, such as weather data and satellite and drone imagery.
The release was announced on the Microsoft Research blog. FarmVibes.AI is part of Microsoft’s Project FarmVibes, an effort to develop technologies for sustainable agriculture. The key idea in FarmVibes.AI is fusion of multiple data sources to improve the performance of AI models. The toolkit contains utilities for downloading and preprocessing public datasets of satellite imagery, weather, and terrain elevation. It also includes models for removing cloud cover from satellite images and for generating micro-climate forecasts. According to Microsoft:
In addition to research, we are making these tools available to the broader community. Scientists, researchers, and partners can build new workflows leveraging these AI models, to estimate farming practices, the amount of emissions, and the carbon sequestered in soil.
World population growth and climate change are two of the major concerns motivating Project FarmVibes. As the population grows, farmers will need to produce more food; yet farming is not only impacted by climate change, it is also considered to be one of its causes. Project FarmVibes aims to help farmers increase their yields while reducing their use of water and chemicals. The project builds on FarmBeats, a previous research effort that was released as an Azure Marketplace product in 2019.
The core of FarmVibes.AI is a Kubernetes-based computing cluster for executing workflows. The cluster has four components: a REST API for invoking workflows and monitoring results; an orchestration module for managing workflow execution; workers for processing chunks of data through the workflow; and a cache for storing reusable intermediate results. There is also a pre-built Python client for interacting with the REST API.
The system comes with several built-in workflows for data ingestion, data processing, machine learning, and farm-related AI. The data ingestion workflows can download and process nearly 30 publicly available geospatial datasets. The data processing workflows implement several statistical and transformative operations, such as thresholding and Normalized Difference Vegetation Index (NDVI). The ML and AI workflows implement several models for identifying features on a farm, such as crops or pavement, as well as “what-if” scenarios such as water conservation and carbon sequestration.
FarmVibes.AI also includes several example Jupyter notebooks demonstrating data fusion, model training, and inference. These notebooks showcase some of Microsoft’s agriculture-related AI research, including SpaceEye and DeepMC. SpaceEye is a deep-learning computer vision model that can “recover pixels occluded by clouds in satellite images.” This can improve the performance of downstream models that use satellite imagery as input; for example, models that identify crops in satellite images. DeepMC is a model that can make short-term predictions of microclimate parameters, including temperature, humidity, wind speed, and soil moisture, which can help farmers identify optimal times for planting and harvesting.
Besides FarmVibes.AI, Project FarmVibes also includes: FarmVibes.Connect, technology for networking remote farms; FarmVibes.Edge, an IoT solution for processing data locally instead of in the cloud; and FarmVibes.Bot, a chatbot interface for communicating with farmers. Although only the FarmVibes.AI source code is currently available on GitHub, Microsoft says that the other components “will be released to GitHub soon.”
MMS • Shane Hastie
Article originally posted on InfoQ. Visit InfoQ
Dr Frederick P Brooks Jr, originator of the term architecture in computing, author of one of the first books to examine the nature of computer programming from a sociotechnical perspective, architect of the IBM 360 series of computers, university professor and person responsible for the 8-bit byte died on 17 November at his home in Chapel Hill, N.C. Dr Brooks was 91 years old.
He was a pioneer of computer architecture, highly influential through his practical work and publications including The Mythical Man Month, The Design of Design and his paper No Silver Bullet which debunked many of the myths of software engineering.
In 1999 he was awarded a Turing Award for landmark contributions to computer architecture, operating systems, and software engineering. In the award overview it is pointed out that
Brooks coined the term computer architecture to mean the structure and behavior of computer processors and associated devices, as separate from the details of any particular hardware implementation
In the No Silver Bullet article he states:
There is no single development, in either technology or management technique, which by itself promises even one order-of-magnitude improvement within a decade in productivity, in reliability, in simplicity.
Quotations from the Mythical Man Month:Essays on Software Engineering permeate software engineering today, including:
- Adding manpower to a late software project makes it later.
- The bearing of a child takes nine months, no matter how many women are assigned.
- All programmers are optimists.
On April 29, 2010 Dilbert explored the adding manpower quote.
In 2010 he was interviewed by Wired magazine. When asked about his greatest technical achievement he responded
The most important single decision I ever made was to change the IBM 360 series from a 6-bit byte to an 8-bit byte, thereby enabling the use of lowercase letters. That change propagated everywhere.
He was the founder of the Computer Science Department at the University of North Carolina at Chapel Hill, where the Computer Science building is named after him. In an obituary the University says:
Dr. Brooks has left an unmistakable mark on the computer science department and on his profession; this is physically recognized by the south portion of the department’s building complex bearing his name. He set an example of excellence in both scholarship and teaching, with a constant focus on the people of the department, treating everyone with respect and appreciation. His legacy will live on at UNC-Chapel Hill
His page on the university website lists his honours, books and publications.
The Computer History Museum has an interview of Dr Brooks by Grady Booch.
He leaves his wife of 66 years Nancy, three children, nine grandchildren and two great-grandchildren.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
At re:Invent, AWS announced the preview release of Amazon Security Lake. This managed service automatically centralizes an organization’s security data from the cloud and on-premises sources into a purpose-built data lake stored in their account.
Amazon Security Lake automates storage tiering, manages data lifespan with customizable retention, and normalizes from integrated AWS services and third-party services. The service can aggregate data from AWS’s services, such as CloudTrail or Lambda, and security tools like AWS Security Hub, GuardDuty, or the AWS Firewall Manager. In addition, it supports the new Open Cybersecurity Schema Framework (OCSF), which provides an open specification for security telemetry data and thus allows the ability to ingest data from third-party solutions like Cisco, CrowdStrike, Okta, Orca, and Palo Alto networks.
Ty Murphy, a director at Orca Security, stated in a recent Orca Security blog post:
Security Lake is one of the many solutions that now supports the Open Cybersecurity Schema Framework (OCSF), an open industry standard, making it easier to normalize and combine security data from AWS and dozens of enterprise security data sources.
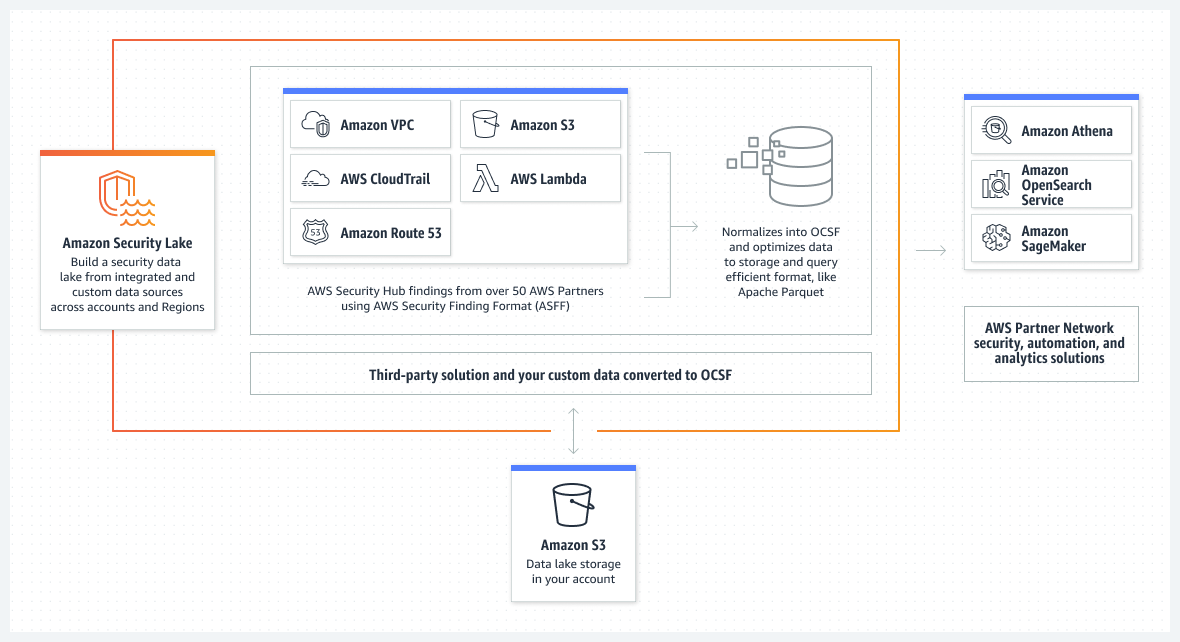
Source: https://aws.amazon.com/security-lake/
Furthermore, Security Lake automatically partitions and converts incoming data to the OCSF and query-efficient Apache parquet format, making the data broadly and immediately usable for security analytics without the need for post-processing. It also supports integrations with analytics partners such as IBM, Splunk, and Sumo Logic to address security use cases such as threat detection, investigation, and incident response.
An early adopter of Security Lake and a leading community member implementing OCSF standards, Splunk released a public preview of Splunk Add-On for Amazon Security Lake to their Splunkbase content marketplace. Paul Agbabian, chief architect at Splunk, wrote in a recent Splunk blog post:
By storing data in OCSF-compliant format, Amazon Security Lake simplifies the work it takes to ingest and analyze security data within Splunk by being a single feed to manage versus multiple services coming from AWS or other Amazon Security Lake security partners.
Holger Mueller, principal analyst and vice president at Constellation Research Inc., who attended re:Invent, told InfoQ:
Data Lakes are the winners in storing and processing information in the 2020ies. They are affordable and allow insights without having to design for them when storing data. As such, they are the perfect platform for security offerings. Data lakes can ingest and store all information and then accommodate the queries needed to get the relevant insights to trigger the right security action.
In addition, Channy Yun, a principal developer advocate for AWS, explained the benefit of Security Lake in an AWS news blog post:
By reducing the operational overhead of security data management, you can make it easier to gather more security signals from across your organization and analyze that data to improve the protection of your data, applications, and workloads.
Lastly, Amazon Security is currently available in the US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), and Europe (Ireland) regions. The pricing details of the service can be found on the pricing page.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

At its recent re:Invent 2022 conference, Amazon previewed CodeCatalyst, a service aimed to ease developer collaboration by integrating remote workspaces, project templates, issue management, continuous integration and delivery, and more.
The main motivation for CodeCatalyst, explains AWS senior developer advocate Steve Roberts, is the growing complexity that modern development has run into, causing a feeling of uneasiness for developers:
This is due to having to select and configure a wider collection of modern frameworks and libraries, tools, cloud services, continuous integration and delivery pipelines, and many other choices that all need to work together to deliver the application experience.
To solve these issues, CodeCatalysts attempts to bring a number of different tools and features together under the same umbrella. Key to CodeCatalyst is the concept of blueprints, which can be seen as project templates on steroids, used not only to create a default structure for a project, but also to set up all resources needed for software delivery and deployment, says Roberts.
Parameterized application blueprints enable you to set up shared project resources to support the application development lifecycle and team collaboration in minutes—not just initial starter code for an application.
CodeCatalyst provides a unified interface to allow you to create a project belonging to a given organization and define its access control policies, to connect to a repository with issue management and dashboards, to set up CI/CD pipelines, and to have the complete project lifecycle under control.
CodeCatalyst also includes a fully-fledged Cloud-based development environment running on-demand on AWS, currently supporting four resizable instance size options with 2, 4, 8, or 16 vCPUs. To make setting up the remote project a repeatable and effortless task, CodeCatalyst uses a devfile to define the configuration of all resources needed to code, test, and debug. This also greatly reduces the overhead required to switch from one project to another and thus enables collaboration on multiple projects at the same time, says Roberts.
Cloud-based development environments can use AWS Cloud9 as their IDE or a local IDE such as JetBrains IntelliJ IDEA Ultimate, PyCharm Pro, GoLand, and Visual Studio Code as a frontend to CodeCatalyst.
As mentioned, CodeCatalyst also include support for CI/CD pipelines, which can use on-demand AWS compute as well as interact with external services, including GitHub Actions, and others. Automatic deployment is supported for AWS services, including Amazon ECS, AWS Lambda, and Amazon EC2.
CodeCatalyst is currently available as a preview and can be tried out using a free tier.
MMS • Johan Janssen
Article originally posted on InfoQ. Visit InfoQ

Resilience4j, a lightweight fault tolerance library designed for functional programming, has released version 2.0 featuring support for Java 17 and dependency upgrades to Kotlin, Spring Boot and Micronaut. This new version also removes the dependency on Vavr in order to become a more lightweight library.
Robert Winkler, Solution Architect at Deutsche Telekom AG and creator of Resilience4j explained the removal of Vavr on Twitter, writing:
I still love Vavr, but users of Resilience4j requested to have an even more lightweight library.
Vavr, a functional library for Java, provides immutable collections and supporting functions and control structures. The latest version, 0.10.4, was released July 2021. The library, formerly called Javaslang, was first released in 2013 before rebranding to Vavr in 2017.
Resilience4j 2.0.0 succeeds version 1.7.1, released in June 2021, and is the first major release since version 1.0.0 in September 2019.
The library now requires Java 17, the latest available LTS version, which allows users to run on Java 17 and use features such as Sealed Classes. There were also dependency upgrades to Kotlin 1.7.20, Spring Boot 2.7 and Micronaut 3.7.3.
Resilience4j offers several features such as the CircuitBreaker which prevents calls to a service whenever the service isn’t responding properly on time. This prevents the service from overloading. Consider the following example in which CircuitBreaker may be implemented for a retrieveStudents() method on a SchoolService class:
Supplier decoratedSupplier = CircuitBreaker
.decorateSupplier(circuitBreaker, schoolService::retrieveStudents);
String result = Try.ofSupplier(decoratedSupplier)
.recover(throwable -> "Recovered from throwable").get();
Alternatively, the CircuitBreaker may be implemented without a decorator:
String result = circuitBreaker
.executeSupplier(schoolService::retrieveStudents);
TimeLimiter allows limiting the amount of time spent calling a service by specifying a timeout. For example, by using a CompletableFuture to create a non-blocking solution:
TimeLimiter timeLimiter = TimeLimiter.of(Duration.ofSeconds(1));
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(3);
timeLimiter.executeCompletionStage(scheduler, () -> CompletableFuture.supplyAsync(schoolService::retrieveStudents))
.toCompletableFuture();
While TimeLimiter restricts the call duration from the client, RateLimiter restricts the number of calls per second from client(s). By default, the requests are limited to 50 calls per 500 ns:
CheckedRunnable restrictedCall = RateLimiter
.decorateCheckedRunnable(rateLimiter, schoolService::retrieveStudents);
Try.run(restrictedCall)
.andThenTry(restrictedCall)
.onFailure((RequestNotPermitted throwable) -> LOG.info("Please
wait"));
RateLimiter also limits the total number of calls in a certain period and ThreadPoolBulkhead limits the number of concurrent calls:
ThreadPoolBulkheadConfig config = ThreadPoolBulkheadConfig.custom()
.maxThreadPoolSize(10)
.coreThreadPoolSize(2)
.queueCapacity(20)
.build();
ThreadPoolBulkhead bulkhead = ThreadPoolBulkhead.of("name", config);
ThreadPoolBulkhead.executeSupplier(bulkhead,
schoolService::retrieveStudents);
Retry is another feature which, by default, retries the call three times with 500ms between calls:
CheckedFunction0 retryableSupplier = Retry
.decorateCheckedSupplier(retry, schoolService::retrieveStudents);
Try result = Try.of(retryableSupplier)
.recover((throwable) -> "Recovered from throwable");
Spring Boot makes it even easier to use Resilience4j by providing annotations such as @CircuitBreaker, @RateLimiter, @Bulkhead, @Retry and @TimeLimiter. The Getting Started Guide for Spring Boot 2 describes the options in more detail.
More information about Resilience4j may be found in the User Guide.