Month: December 2022

MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for November 28th, 2022 features news from OpenJDK, JDK 20, JavaFX 20, Spring Integration 6.0, Spring Vault 3.0, Spring Cloud 2022.0.0-RC3, AWS introduces Lambda SnapStart, Quarkus 2.14.2, 2.13.5 and 2.15.0.CR1, Apache Camel 3.18.4 and progress on JHipster upgrade to Spring Boot 3.0.
OpenJDK
JEP 432, Record Patterns (Second Preview), was promoted from Proposed to Target to Targeted status for JDK 20. This JEP updates since JEP 405, Record Patterns (Preview), to include: added support for inference of type arguments of generic record patterns; added support for record patterns to appear in the header of an enhanced for statement; and remove support for named record patterns.
JEP 433, Pattern Matching for switch (Fourth Preview), was promoted from Proposed to Target to Targeted status for JDK 20. This JEP updates since JEP 427, Pattern Matching for switch (Third Preview), to include: a simplified grammar for switch labels; and inference of type arguments for generic type patterns and record patterns is now supported in switch expressions and statements along with the other constructs that support patterns.
JEP 434, Foreign Function & Memory API (Second Preview), was promoted from Proposed to Target to Targeted status for JDK 20. This JEP, under the auspices of Project Panama, evolves: JEP 424, Foreign Function & Memory API (Preview), delivered in JDK 19; JEP 419, Foreign Function & Memory API (Second Incubator), delivered in JDK 18; and JEP 412, Foreign Function & Memory API (Incubator), delivered in JDK 17. It proposes to incorporate refinements based on feedback and to provide a second preview in JDK 20. Updates include: the MemorySegment and MemoryAddress interfaces are now unified, i.e., memory addresses are modeled by zero-length memory segments; and the sealed MemoryLayout interface has been enhanced to facilitate usage with JEP 427, Pattern Matching for switch (Third Preview).
JEP 429, Scoped Values (Incubator), was promoted from Candidate to Proposed to Target for JDK 20. This incubating JEP, formerly known as Extent-Local Variables (Incubator) and under the auspices of Project Loom, proposes to enable sharing of immutable data within and across threads. This is preferred to thread-local variables, especially when using large numbers of virtual threads.
JEP 436, Virtual Threads (Second Preview), was promoted from Candidate to Proposed to Target for JDK 20. This JEP, under the auspices of Project Loom, proposes a second preview from JEP 425, Virtual Threads (Preview), delivered in JDK 19, to allow time for additional feedback and experience for this feature to progress. It is important to note that no changes are within this preview except for a small number of APIs from JEP 425 that were made permanent in JDK 19 and, therefore, not proposed in this second preview.
JEP 437, Structured Concurrency (Second Incubator), was promoted from Candidate to Proposed to Target for JDK 20. This JEP, also under the auspices of Project Loom, proposes to reincubate this feature from JEP 428, Structured Concurrency (Incubator), delivered in JDK 19, to allow time for additional feedback and experience. The only change is an updated StructuredTaskScope class to support the inheritance of scoped values by threads created in a task scope. This streamlines the sharing of immutable data across threads.
The reviews for these three JEPs conclude on December 6, 2022.
JDK 20
Build 26 of the JDK 20 early-access builds was also made available this past week, featuring updates from Build 25 that include fixes to various issues. More details on this build may be found in the release notes.
For JDK 20, developers are encouraged to report bugs via the Java Bug Database.
JavaFX 20
Build 10 of the JavaFX 20 early-access builds was made available to the Java community. Designed to work with the JDK 20 early-access builds, JavaFX application developers may build and test their applications with JavaFX 20 on JDK 20.
Spring Framework
Spring Integration 6.0 has been released featuring: a JDK 17 and Jakarta EE 9 baseline; support for native images with GraalVM and Spring AOT engine; observability instrumentation with Micrometer and Micrometer Tracing; and support for Jakarta EE 10. Further details on this release may be found in the what’s new page.
Spring Vault 3.0 has been released featuring: a JDK 17 baseline; support for additional HTTP Clients, including the reactive JDK HTTP Client; and support for Vault Repositories using versioned Key/Value secrets engines. More details on this release may be found in the release notes.
The third release candidate of Spring Cloud 2022.0.0, codenamed Kilburn, has been made available to the Java community. This version provides updates to the RC3 versions of Spring Cloud sub-projects such as: Spring Cloud OpenFeign 4.0.0, Spring Cloud Commons 4.0.0, Spring Cloud Function 4.0.0 and Spring Cloud Starter Build 2022.0.0. There are, however, breaking changes with the removal of sub-projects: Spring Cloud CLI, Spring Cloud for Cloud Foundry and Spring Cloud Sleuth. Spring Cloud 2022.0.0-RC3 requires Spring Boot 3.0.0. Further details on this release may be found in the release notes.
Amazon Web Services
At the recent re:Invent conference, Amazon Web Services (AWS) introduced a new feature for their AWS Lambda project, Lambda SnapStart, designed to reduce the cold start for Java functions and to accelerate lambda functions. Support for Lambda SnapStart has already been implemented by Quarkus and Micronaut. More details may be found in this InfoQ news story and AWS blog post.
Quarkus
Red Hat has released versions 2.14.2 and 2.13.5 of Quarkus that primarily provide a fix for CVE-2022-4116, a vulnerability in the Dev UI Config Editor that is vulnerable to drive-by localhost attacks leading to remote code execution. This release also hardens handling of Cross-Origin Resource Sharing (CORS) to include changing 200 OK to 403 FORBIDDEN when a CORS request is rejected because of an invalid origin. Further details on these releases may be found in the release notes for version 2.14.2 and version 2.13.5.
On the road to Quarkus 2.15.0, the first release candidate was also made available that delivers new features such as: integration with Quarkus CRaC/Firecracker; a migration of the gRPC extension to the new Vert.x gRPC implementation; support for filtering by named queries in REST Data using the Panache extension; and dependency upgrades to GraalVM 22.3.0, Mandrel 2.13 and SmallRye GraphQL 1.9.0.
Apache Camel
Apache Camel 3.18.4 has been released featuring 27 bug fixes, improvements and dependency upgrades to Spring Boot 2.7.6 and HyperSQL DB 2.7.1. More details on this release may be found in the release notes.
JHipster
Over at JHipster, work has begun to upgrade the platform to Spring Boot 3.0. Matt Raible, developer advocate at Okta, Java Champion and member of the JHipster development team, provided an update on issues the team has encountered so far, namely: BlockHound needs a new entry for WebFlux; Health Check doesn’t work in Elasticsearch 8+; and MongoDB and WebFlux deadlocks with JUnit and MongoDB driver 4.2+. Further details on these issues may be found in this GitHub pull request.
MMS • Bruno Couriol
Article originally posted on InfoQ. Visit InfoQ

Brian Leroux, CTO at Begin, recently introduced Enhance, a new HTML framework, at QCon San Francisco. Enhance heavily lies on web standards and progressive enhancement for future-proof web applications. Enhance provides file-based routing, reusable Custom Elements, a customizable utility CSS system, and mapped API data routes that get deployed to isolated, single-purpose cloud functions.
Brian opened his QCon talk with a quote from Amazon founder Jeff Bezos:
I very frequently get the question: “What’s going to change in the next 10 years?” And that is a very interesting question; it’s a very common one. I almost never get the question: “What’s not going to change in the next 10 years?” And I submit to you that that second question is actually the more important of the two – because you can build a business strategy around the things that are stable in time.
The quote echoes a concern shared by Geertjan Wielenga at FOSDEM’20:
Large vendors are adopting JavaScript […] to create real, serious applications. […] But in the enterprise space, it is not about what is cool and what is new, it is about what is stable and reliable […] and maintainable in a few years’ time.
Building upon the stability premise, Leroux asks:
Imagine if we could write code that just worked, and ran forever. Imagine not chasing npm updates. Imagine not hunting the forums for an elusive combination of configuration values to fix a broken build.
Good news: we can. HTML, it turns out, is a pretty good choice for web development. Specifically rendering custom elements, styling them with modern CSS, and treating the element upgrade as a progressive enhancement step with JavaScript.
Enhance claims to be a new way to build web apps with web standards with no custom dialects to learn, no build steps to configure, and minimal friction.
In his talk, Leroux observed that the popular JavaScript frameworks tend to ship with transpilers or compilers that turn higher-level abstractions (e.g., JSX, template files) into lower-level web standards. This creates a few issues. Firstly, in some cases, the distance between the higher-level dialects and the transpiled code makes it difficult to reconcile one with the other, even in the context of additional tooling (e.g, source maps). Additionally, as a given framework evolves and application code scales up, dependency management and breaking changes within the framework ecosystem become a costly maintainability concern. Furthermore, framework abstractions are not compatible with one another, which restricts technical options and reusability.
Breaking changes have been a recurrent pain point in the JavaScript ecosystem. Leroux detailed:
Angular 1 to Angular 2 famously broke everybody. React 18 introduces some new semantics that can break you. TypeScript 4.8 completely changes how TypeScript transpiles down to Node modules. That’s very breaking. And that’s unfortunate because none of that is necessary.
Leroux contrasted breaking changes with the additive changes that took place in browsers: from HTTP 1 to HTTP 2, XMLHttpRequest to Fetch, , WOFF 1.0 to WOFF 2.0. Additive changes are opt-in and do not invalidate existing code.
Leroux then explained that Enhance is built on web standards and progressive enhancement in the front-end, and cloud functions on the back-end:
Can our front-end be pure standards-based HTML, CSS, and JS? Can we just progressively enhance it? The answer is yes. We never really packaged this up but now we have. We want you to take these legos and play with them. The answer is Enhance. […] The premises are really simple: start with HTML pages, use generally available web standards, and progressively enhance working HTML if you need to. Because the baseline is built with cloud functions, this thing is going to scale up and down to whatever demand that you need. [Deployments are completely deterministic as Enhance] uses Infrastructure as Code.
Leroux then followed with a concrete demo of the Enhance framework. Notable features include file-based routing, reusable Custom Elements, a customizable utility CSS system, and mapped API data routes that get deployed to isolated, single-purpose cloud functions. For more information, developers may access the online documentation.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Apple released a set of optimizations to Core ML to enable running the Stable Diffusion text-to-image model on Apple Silicon-powered devices running the latest iOS or macOS versions, respectively iOS 16.2 and macOS 13.1.
Core ML Stable Diffusion, as Apple named it, is comprised of a Python command line tool, python_coreml_stable_diffusion, which is used to convert Stable Diffusion PyTorch models to Core ML, and a Swift package developers can use in their apps to easily enable image generation capabilities.
Once you have converted the version of Stable Diffusion you would like to use to the Core ML format using the CLI, generating an image in a Swift app from a given prompt is as easy as:
import StableDiffusion
...
let pipeline = try StableDiffusionPipeline(resourcesAt: resourceURL)
let image = try pipeline.generateImages(prompt: prompt, seed: seed).first
With its Core ML Stable Diffusion toolkit, Apple is bringing attention to the benefits to both users and developers of deploying an inference model on-device versus a server-based approach:
First, the privacy of the end user is protected because any data the user provided as input to the model stays on the user’s device. Second, after initial download, users don’t require an internet connection to use the model. Finally, locally deploying this model enables developers to reduce or eliminate their server-related costs.
The key factor enabling on-device deployment is speed, Apple says. For this reason they developed an approach to optimize the Stable Diffusion model, made of 4 different neural networks including about 1.275 billion parameters, to run efficiently on its Apple Neural Engine available on Apple Silicon.
While Apple hasn’t yet provided any perfomance data about the improvements brought by Core ML Stable Diffusion, they found that the popular Hugging Face DistilBERT model worked out of the box with 10x speed improvement and 14x reduced memory consumption. It must be noted here that Stable Diffusion is significantly more complex than Hugging Face DistilBERT, which in Apple’s view makes the case for on-device inference optimizations even more compelling in order to take advantage of the models of growing complexity that the community is generating.
According to Apple, Stability Diffusion has enabled the creation of “unprecedented visual content with as little as a text prompt” and raised lots of interest from the community of artists, developers and hobbyists. Besides that, Apple sees a growing effort to use Stable Diffusion for image editing, in-painting, out-painting, super-resolution, style transfer and other conceivable applications.
Based on a latent diffusion model developed by the CompVis group at LMU Munich, Stability Diffusion has been released by a collaboration of Stability AI, CompVis LMU, and Runway with support from EleutherAI and LAION. Its code and model weights have been released publicly and you can easily try it out the at HuggingFace or using DreamStudio AI.
MMS • Shaaf Syed
Article originally posted on InfoQ. Visit InfoQ

OmniFish, the Estonia-based Jakarta EE consulting company, launched support for Jakarta EE in September 2022 . The support includes JakartaEE 10, GlassFish 7, and Piranha Cloud and its components like Mojarra, a compatible implementation of the Jakarta Faces specification. OmniFish recently also joined the Jakarta EE Working Group as a participant member. InfoQ spoke to Arjan Tijms, David Matějček, and Ondro Mihályi about OmniFish.
InfoQ: What was the inspiration to start this new company?
Arjan Tijms: I have been involved with Java EE and Jakarta EE since 2000. With the release of OmniFaces in 2012 and contributions to Mojarra and JSF (Java Server Faces), I became more involved with specification work and APIs, which culminated in becoming the project lead of several Jakarta EE specifications and Eclipse projects. We set up OmnIFish to support this work directly and give customers access to the people who work on many Jakarta EE and Eclipse projects.
David Matějček: Jakarta EE is much more open and happy to accept any help from the community. I can now directly work on Eclipse GlassFish as a committer after 15 years of working with GlassFish and trying to work around the bugs I found. Now I would like to work on GlassFish to improve it for others that use it.
Ondro Mihályi: I strongly envision bringing innovations to the Java industry with Jakarta EE and GlassFish. I was pleased that we shared a similar vision with Arjan and David. We founded OmniFish to be able to pursue it.
InfoQ: Are there any particular Jakarta EE specifications that OmniFish will contribute?
Arjan Tijms: Yes, as I’m personally the project lead of the Jakarta Faces and Jakarta Security specifications, those will be the first and foremost ones on my list. With Piranha Cloud, we have implemented a Servlet container from scratch, so we are naturally also interested in the Servlet spec.
David Matějček: We are already committers on several specifications, but I would instead do some fixes and maintenance on whichever project requires that. Somebody has to do that when most developers just love creating new stuff!
Ondro Mihályi: We certainly plan to contribute to the new Jakarta Config specification. It has a huge potential to become a foundation for many Jakarta EE specifications in the future and make configuration in Jakarta EE easy for users. Besides that, we envision a few improvements for Jakarta Security and Jakarta RESTful Web Services.
InfoQ: What are the long-term goals for OmniFish?
Ondro Mihályi: First and foremost, we focus on making our customers successful with the Jakarta EE technology and the Jakarta EE products that we support. We would like to become a trusted and reliable partner, helping companies keep their software fast, reliable, testable, maintainable, and up-to-date. We choose the products we develop and support to provide reliable and flexible options. We aim to match the needs of Jakarta EE users as they evolve and match modern trends, be it microservices, cloud deployments, or serverless solutions.
Ultimately, we would like to establish ourselves as a leading player in the Jakarta EE ecosystem itself; both are furthering the platform and helping customers get the most out of it. We see enormous potential in the cloud, especially in the serverless area. We would like to build products that are widely used and popular for cloud deployments while being ideal also for traditional deployments. Jakarta EE is a perfect foundation for that, as it provides a standard API and allows us to innovate the runtimes under the hood.
InfoQ: What’s on the horizon for OmniFish?
Ondro Mihályi: The release of Eclipse GlassFish 7 is an important milestone in the short term. We fixed many bugs in it over the last two years and will continue improving it, together with its components such as Mojarra, Soteria, Jersey, and many others.
Further out is getting our new Jakarta EE runtime Piranha Cloud production ready. Piranha Cloud shares many components with GlassFish, but is itself a completely new development. It’s fully built up from the ground for embedded, modular and programmatic usage, with short start-up times ideal for cloud and serverless deployments. With GlassFish as a traditional application server, Piranha Cloud as our lightweight runtime, and the Jakarta EE APIs and shared components binding them, we aim to provide a coherent solution for running any backend Java applications.
GlassFish 7 is part of the growing compatible products that support Jakarta EE 10, including Payara Server, WildFly, and more. More details on Jakarta EE 10 release are in this InfoQ news story.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
At the recent re:Invent, AWS announced an update to its FaaS offering AWS Lambda with the Lambda SnapStart feature that reduces the cold start for Java Functions.
AWS Lambda functions run inside a secure and isolated execution environment, and the lifecycle of each environment consists of three main phases: Init, Invoke, and Shutdown. The first phase, Init, bootstraps the runtime for the function and runs the function’s static code.
For some languages like Java, runtimes in conjunction with frameworks such as Spring Boot, Quarkus, or Micronaut, the first phase Init can, according to the company, sometimes take as long as ten seconds (this includes dependency injection, compilation of the code for the function, and classpath component scanning). In addition, the static code might download some machine learning models, pre-compute some reference data, or establish network connections to other AWS services.
With Lambda SnapStart enabled for a function, publishing a new version of the function will trigger an optimization process. Jeff Barr, a chief evangelist at AWS, explains in the company’s news blog post:
The process launches your function and runs it through the entire Init phase. Then it takes an immutable, encrypted snapshot of the memory and disk state and caches it for reuse. When the function is subsequently invoked, the state is retrieved from the cache in chunks on an as-needed basis and used to populate the execution environment. This optimization makes invocation time faster and more predictable since creating a fresh execution environment no longer requires a dedicated Init phase.
Note that cached snapshots are deleted after 14 days of inactivity. In addition, AJ Stuyvenberg, a lead software engineer at Datadog, explains in a dev.to blog post:
This snapshot capability is powered by MicroVM Snapshot technology inside FireCracker, the underlying MicroVM framework used by Lambda as well as AWS Fargate. In practice, this means function handler code can start running with sub-second latency (up to 10x faster).
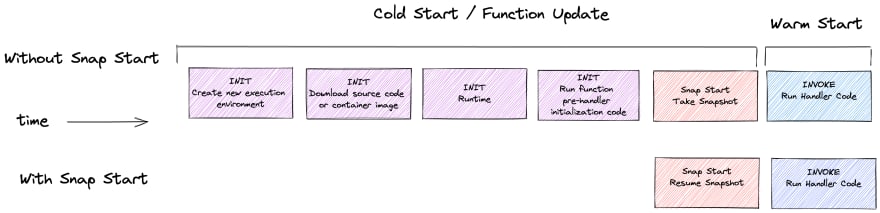
Source: https://dev.to/aws-builders/introducing-lambda-snapstart-46no
AWS states that Lambda SnapStart is ideal for synchronous APIs, interactive microservices, or data processing applications.
Developers can activate Lambda SnapStart for new or existing Java-based Lambda functions running on Amazon Corretto 11 using the AWS Lambda API, AWS Management Console, AWS Command Line Interface (AWS CLI), AWS Cloud Formation, AWS Serverless Application Model (AWS SAM), AWS SDK, and AWS Cloud Development Kit (AWS CDK).
Regarding the support for Java, a respondent on a Reddit thread wrote:
This is a very cool new feature that sounds like it virtually eliminates cold starts.
A pity this is only Java, although I have hope this will come to the rest of the runtimes in due course. The implementation doesn’t sound like it’s really specific to the JVM.
The JVM is a good place to start, though, as it seems to be the place where cold starts hurt the most in Lambda.
Currently, Lambda SnapStart is available in the US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Singapore, Sydney, Tokyo), and Europe (Frankfurt, Ireland, Stockholm) regions.
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ
Retrospective facilitators can develop their facilitation skills by self-study and training, and by doing retrospectives. Better facilitation can lead to higher effectiveness of change and impact the progress of an organization.
Reiner Kühn spoke about agile retrospectives at Agile Testing Days 2022.
Kühn mentioned that everybody attending retrospectives should have a basic understanding of this. They should know about the structure of a typical retrospective, and for instance why it makes sense to imagine being a superhero or a time traveler. Attendees should also have an idea about the influence that they can have on changes, Kühn said.
The facilitators need to know a lot more about retrospectives, Kühn explained:
They should know about human factors in the retrospective, preparing, facilitating, dealing with critical situations, decision-making, clustering work results and sometimes, not joking, how to write on sticky notes.
Facilitators can develop their retrospective facilitation skills by reading books, blogs, and websites. Kühn suggested starting a community of retrospective facilitator practitioners to exchange, coach each other and visit or assist in other teams’ retrospectives:
I must not pray for improvement without self improvement.
Kühn is running a retrospective facilitator education program in his organization. It is a one-day basic training followed by four half-day sessions within one year. Between the sessions, program participants have to do retrospectives.
The basic training builds upon what participants already learned or experienced while doing retrospectives. We set a baseline for what retrospectives are, what a facilitator is and which behavior is needed. We learn how to prepare, facilitate and post-process retrospectives. We talk about the human side of retrospectives: personalities, group dynamics, conflicts, attacks, and communication. We also touch some aspects of change management and methods for decision-finding and making.
In the four half-day sessions, we always look back on the past retrospectives the participants facilitated. And we dig deeper into elements from the basic training and practice them.
In the last five years, they have trained more than 100 facilitators in the basic training, and over 30 passed the entire program. Kühn mentioned:
This requires time. But I have seen that skilled retrospective facilitators have a significant impact on the effectiveness of change and the progress of an organization.
InfoQ interviewed Reiner Kühn about doing agile retrospectives.
InfoQ: What makes it so important to do retrospectives?
Reiner Kühn: Today, a large part of our work is knowledge work. We need to collaborate and communicate to create our products or services. And we need to improve continuously to survive in a faster changing world. Retrospectives provide space for inspection and adaptation.
InfoQ: At what levels can we do retrospectives? How do retrospectives look at these different levels?
Kühn: Retrospectives at the team level are fine. But that is not enough for an organization to improve. We need them at hierarchical levels as well as wherever people work together: in projects, in communities, etc.
Doing retrospectives on the management level is more challenging. Often we have egomaniacs, power-driven people participating. They need to learn that this is a trustful and open space for improvement. And that retrospectives aim for change, but management aims for stability.
InfoQ: What can we learn from moderating retrospectives outside our own team?
Kühn: We learn diversity. Every team is different. As a facilitator, I need to adapt to different people, problems, and environments. I also can try out exercises my own team would not be fine with. And depending on the maturity of my and other teams, we can benefit from what was learned here or there.
MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ

At AWS re:Invent, Amazon Web Services announced Amazon DataZone, a new data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on-premises, and third-party sources.
With Amazon DataZone, administrators and data stewards who oversee an organization’s data assets can manage and govern access to data using fine-grained controls to ensure it is accessed with the right level of privileges and in the right context.
Amazon DataZone makes it easy for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate with data to derive insights. All the data in DataZone is governed by access and use policies that the organization can define, and data lineage is also tracked.
By defining their data taxonomy, configuring governance policies, and connecting to a variety of AWS services like Amazon S3 and Amazon Redshift, partner solutions, and on-premises systems, data producers can set up their own business data catalog using the Amazon DataZone web portal. By utilizing machine learning to gather and recommend metadata such as origin and data type for each dataset and by training on a customer’s taxonomy and preferences to improve over time, Amazon DataZone eliminates the labor-intensive tasks associated with maintaining a catalog.
After the catalog is created, data users can search for and find data assets, look up metadata for context, and request access to datasets using the Amazon DataZone web interface. When a data consumer is prepared to begin data analysis, they create an Amazon DataZone Data Project. This shared area in the web portal enables users to access a variety of datasets, share access with coworkers, and work together on analysis.
As a result of the integration between Amazon DataZone and AWS analytics services like Amazon Redshift, Amazon Athena, and Amazon QuickSight, data users can access these services as part of their data project without having to keep track of separate login information. Their data is also automatically accessible in these services.
According to Swami Sivasubramanian, vice president of Databases, Analytics, and Machine Learning at AWS, good governance is the foundation that makes data accessible to the entire organization, but it is difficult to strike the right balance between making data discoverable and maintaining control. Amazon DataZone sets data free across the organization, so every employee can help drive new insights to maximize its value.