Month: January 2023

MMS • RSS

Enterprises are creating huge amounts of data and it is being generated, stored, accessed, and analyzed everywhere – in core datacenters, in the cloud distributed among various providers, at the edge, in databases from multiple vendors, in disparate formats, and for new workloads like artificial intelligence. In this fast-evolving space, a database vendor that is aiming for a broad reach is going to have to adapt quickly.
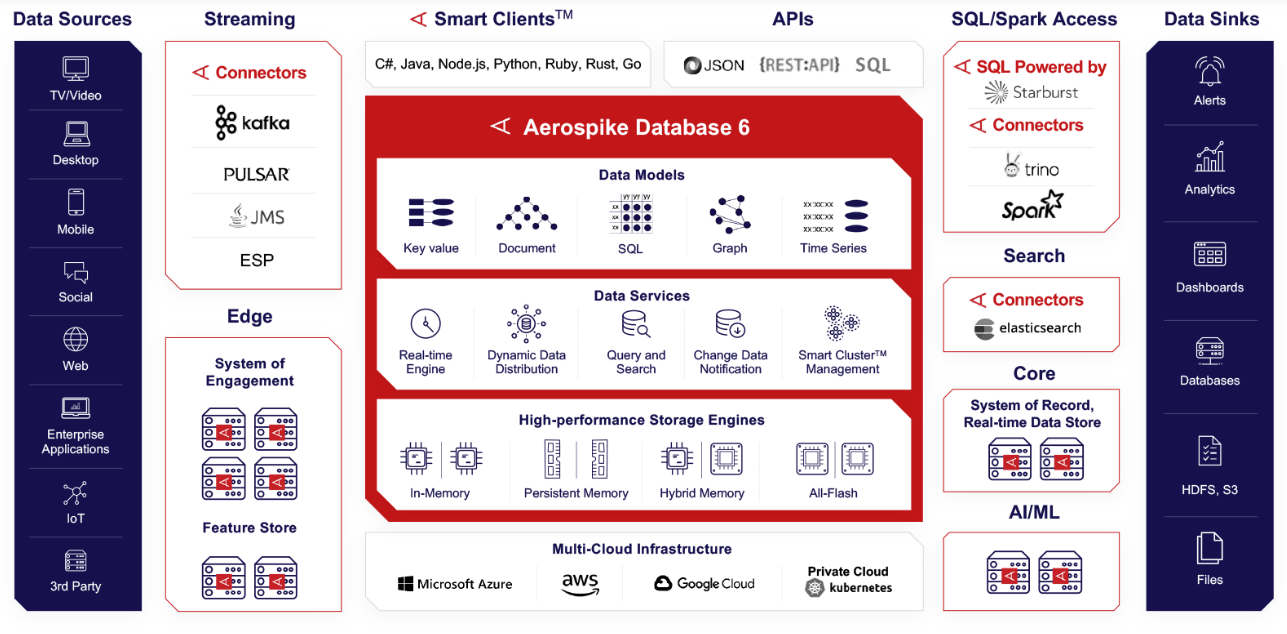
Aerospike is one of those vendors who has been constantly adapting. The company – going on 14 years, after starting off in 2009 as Citrusleaf before taking its current name in 2012 – offers its eponymous database that is the foundation of its Aerospike Real-Time Data Platform. The platform lets organizations to instantly sprint through billions of transactions, power real-time application at sub-millisecond speeds, climb to petabyte scale, and do so while reducing the server footprint by as much as 80 percent.
As we’ve mentioned in previous coverage, the goal is low latency for high throughput jobs.
At the same time, the company understands that if it wants as many transactions as possible to run through its flash-based NoSQL platform and to pull into its gravity as many organizations as possible, it needs to be able to reach into and support as many data sources as possible.
“We have supported strong consistency, which is a little rare in the SQL database,” Lenley Hensarling, Aerospike’s chief product officer, tells The Next Platform. “We find that some people actually move back to an Oracle or DB2 and this is one of the reasons that PostgreSQL has kept growing. But in the NoSQL world, we have strong consistency. We have the ability to do that for up to 12 billion transactions a day and we have some people doing more than that. But all of that data gets captured by Aerospike. As that has happened, more and more customers have said, ‘We need to make use of this data and provide this data wherever it can be used.’”
Over the years, Aerospike has moved down multiple avenues to ensure its platform is covering those bases, including through its growing portfolio of connectors, used to integrate the Aerospike Database with open-source frameworks, including Spark, Kafka, Pulsar, and Trino. The company this month unveiled Connect for Elasticsearch, an open-source search and analytics tool that will let data scientists, developers, and others to rapidly run full-text searches of the real-time data in the vendor’s database.
“We built a connector for that,” Hensarling says. “We could have built textual search into our database, but one of the things we pride ourselves on is the efficiency in handling transactions, both read and write, and being able to handle that massive ingestion. We’re very cognizant that it’s a distributed application and it can connect to other distributed applications or infrastructure like Elasticsearch.”
The Elasticsearch connector dovetails with the change data notification and change data capture abilities that first appeared in Aerospike Database 5 and has continued on in Database 6, which was released last spring.
<>
The Aerospike technology is “key to streaming data,” he says. “It’s key to being able to push data off to where it can be used best. It’s also, in this case, used to update the indices in Elastic and to put the data in Elastic to use that textual, very flexible, fuzzy search capability. We push only those fields that are necessary to do that over into Elastic. We accompany that with the digest, which is essentially the address in our database. That’s one hop back to the actual record in Aerospike. If you want to do a textual search for all the things – and sometimes companies do it not just for what’s in Aerospike, but what might be in other databases, too – and they get back those results from Elastic. But for our data, they can go directly back using that digest to the actual record. And it’s incredibly fast to do that. … We have a number of customers who said, ‘We’re using Elasticsearch. We want to make your data accessible through Elasticsearch.’ That’s what we’ve done.”
Database 6 introduced highly parallel secondary indexes, giving such queries the same speed and efficiency found in primary indexes, and also supports SQL through the Spark and Trino integrations.
The Elasticsearch Connector followed on other moves over the past year to cast a wide net over what the real-time platform and database can do and support. In Database 6, the company included support for JSON document models regardless of scale and enhanced support for Java programming models, including JSONPath for storing and searching datasets and workloads. Aerospike for four or five years has support document and object-style records, but JSON helped the company continue to push into the mainstream, according to Hensarling.
Also last year, the vendor partnered with Trino-based Starburst to launch Aerospike SQL Powered by Starburst, an integrated distributed SQL analytics engine in Aerospike Database 6 based on Starburst Enterprise and leveraging Trino. The revamped secondary indexes in Database 6 gave Aerospike better search capabilities, which Hensarling told The Next Platform the company “can support through a push down from the Starburst worker and the connector that’s in that Starburst worker. That model allows us to do a lot of search and analytic capability through Starburst and make that open up our data to our customers, to new constituencies, like data engineers, compliance people, audit people.”
All these steps – from Elasticsearch and Starburst to the other connectors and more features in Database 6 – let Aerospike extend its reach into more datasets and data sources that enterprises are using and to better compete with the likes of other NoSQL databases like CouchDB and MongoDB.
“People talk about a data pipeline,” he says. “There’s not a data pipeline in any companies. There are literally hundreds or thousands of data pipelines for different users, and we can distribute the right data to the right places in some definition of real time. The global data mesh winds up being in sync, in real time to some extent. That’s our picture of the world and how we sit in that. More and more companies are starting to see that they’re being overrun with data, but we can’t just say we’re only going to take certain things. We have to handle it all and all at the same time, by some definition. It might be milliseconds. For some it might be seconds, for others it might be you go off and do machine learning training for hours someplace else.”
The vendor is seeing some momentum behind its efforts. Aerospike last February said 2021 saw worldwide sales double and that its roster of customers – which already included PayPal, Wayfair, and Yahoo – added others like Critero in France, India-based Dream11, and Riskified in Israel. The first half of 2022 continued the trends, according to the company.
One number that stood out in 2021 was the 450 percent jump in year-over-year recurring revenue for Aerospike’s Cloud Managed Service. Hensarling says that, like other tech vendors, the company’s cloud services got a boost from the COVID-19 pandemic, when enterprises had to rapidly accelerate their cloud efforts. He describes the managed services as the “high-end production workload thing.”
The company this year is taking a deeper step into the cloud with its Database 6-based Aerospike Cloud database-as-a-service running on Amazon Web Services (AWS). Aerospike in November announced early availability and Hensarling says it will be in trials with early customers into the early part of the second quarter, with general availability later in the quarter. Customers were telling the vendor that more of their projects were starting in the cloud.
“That’s what’s driving this, being able to have an idea, go implement it, not have to think about buying cycles for hardware or availability, operations staff in your company and things like that,” he says. “That is something that we see as really critical to growth going forward.”
Aerospike this year will expand its capabilities among other data models, including graph databases. Enterprises are using more models as they triangulate to get more answers from the data. There is the push for “multi-modal database capabilities from one vendor,” Hensarling says. “That’s driven some of our investments. For 30 years, we converged on relational databases and that was the answer. Then all of a sudden we said, ‘No, there are other things. There are reasons to be more elastic and more scalable.’ So NoSQL started happening. But there’s also these new capabilities like graph databases to get different kinds of answers. But people don’t want to deal with five, six, seven different vendors.”
Similarly, they don’t want to be beholden to a single cloud provider, which means companies like Aerospike – which also supports Microsoft Azure, Google Cloud, and Kubernetes-based private clouds – will have to continue to be cloud-agnostic and expand to meet customer demands, he says.
MMS • Kai Waehner

Transcript
Waehner: This is Kai Waehner from Confluent. I will talk about resilient real-time data streaming across the edge and hybrid cloud. In this talk, you will see several real world deployments and very different architectures. I will cover all the pros and cons so that you would understand the tradeoffs to build a resilient architecture.
Outline
I will talk a little bit about why you need resilient enterprise architectures and what the requirements are. Then cover how real-time data streaming will help with that. After that, I cover several different architectures, and use real world examples across different industries. I talk about automotive, banking, retail, and the public sector. The main goal is to show you a broad spectrum of architectures I’ve seen in a real world so that you can learn how you architect your own architecture to solve problems.
Resilient Enterprise Architectures
Let’s begin with the definition of a resilient enterprise architecture, and why we want to do that. Here’s an interesting example from Disney. Disney and their theme parks, Disney World in the U.S., had a problem. There was an AWS Cloud outage. What’s the problem with the theme parks, you might wonder? The theme parks are still there, but the problem is that Disney uses a mobile app to collect all the customer data and provide a good customer experience. If the cloud is not available anymore, then you cannot use the theme park, you cannot do rides, you cannot order in the restaurants anymore. I think this is a great example why resilient architectures are super important, and why they can look very differently depending on the use case. That’s what I will cover, show you edge, hybrid, and cloud-first architectures with all their pros and cons. In this case, maybe a little bit of edge computing and resiliency might help to make the customers happy in the theme parks.
There’s very different reasons why you need resilient architectures. This is a survey, one of my former colleagues and friends Gwen Shapira did, actually the query is from 2017 but it’s still more or less up to date. The point is to show there’s very different reasons why people build resilient architectures. One DC might get nuked, yes, and disaster recovery is a key use case. Sometimes it’s also about latency and distance or implications of the cost regarding where you replicate your data. Sometimes it also is legal reasons. There’s many reasons why resilient architectures are required. If we talk about that, there’s two terms we need to understand. It doesn’t matter what technology you use, like we today talk about real-time streaming with Kafka. In general, you need to solve the problem of the RPO and the RTO. The RPO is the Recovery Point Objective. This defines how much data you will lose in case of a downtime or a disaster. On the other side, the RTO, the Recovery Time Objective means, what’s the actual recovery period before we are online, again, and your systems work again? Both of these terms are very important. You always need to ask yourself, what do I need? Initially, many people say, of course, I need zero downtime and zero data loss. This is very often hard to architect, as we have seen in the Disney example before, and what I will show you in many different examples. Keep that in mind, always ask yourself, what downtime or data loss is ok for me? Based on that, you can architect what you need.
In the end, zero RPO requires synchronous replication. This means even if one node is down, if you’re replicated synchronously, it guarantees that you have zero data loss. On the other side, if you need zero downtime, then you need a seamless failover. It’s pretty easy definitions, but it’s super hard to architect that. That’s what I will cover. That also shows you why real-time data is so important here, because if you have replication in a batch process from one node to another, or from one cloud region to another, that takes longer. Instead, if you replicate data in real-time, even in case of disaster, you lose much less data with that.
Real-Time Data Streaming with the Apache Kafka Ecosystem
With that, this directly brings me to real-time data streaming. In the end, it’s pretty easy. Real-time data beats slow data. Think about that in your business for your use cases. Many of the people in this audience are not business people, but architects or developers. Nevertheless, think about what you’re implementing. Or when you talk to your business colleagues, ask yourself and your colleagues, if you want to get this data and process it, is it better now or later? Maybe later could be in a few minutes, hours, or days. In almost all use cases, it’s better to process data continuously in real-time. This can be to increase the customer experience, to reduce the cost, or to reduce the risk. There’s many options why you would do that. Here’s just a few examples. The point is, real-time data almost always beats slow data. That’s important for the use cases. Then also, of course, for the resiliency behind the architectures, as we discussed regarding downtime and data loss, which directly impacts how your customer experience is or how high the risk is for your business.
When we talk about processing data in real-time, then Apache Kafka is the de facto standard for that. There’s many vendors behind it. I’ve worked for Confluent, but there’s many other vendors. Also even companies that don’t use Kafka, but another framework, they at least use the Kafka protocol very often, because it became a standard. While this presentation is about success stories and architectures around Apache Kafka, obviously, the same can be applied to other technologies, like when you use a cloud native service from a cloud provider, like AWS Kinesis, and so on, or maybe you’re trying to use Apache Pulsar or whatever else you want to try. The key point, however, is that Kafka is not just a messaging platform, or ingestion layer, like many people think. Yes, it’s real-time messaging at any scale, but in addition to that, a key component is the storage. You store all the events in your infrastructure, within the event streaming platform. With this, you achieve true decoupling between the producers and consumers. You handle the backpressure automatically, because often consumers cannot handle the load from the producer side. You can also replay existing data.
If you think about these characteristics of the storage for the decoupling and backpressure handling, that’s a key component you can leverage for building a resilient architecture. That’s what we will see in this talk about different approaches, no matter if you’re at the edge, in the cloud, or in a hybrid architecture. In addition to that, Kafka is also about data integration with Kafka Connect, and data processing, in real-time, continuously, with tools like Kafka Streams, or KSQL. That in the end is what Kafka is. It’s not just a messaging system. This is super important when we talk about use cases in general, but then also about how to build resilient architectures, because messaging alone doesn’t help. It’s about the combination of messaging and storage, and integration, and processing of data.
Kafka is a commit log. This means it’s append only from the producer side. Then consumers consume it whenever they need or can, in real-time, in milliseconds, in near real-time, in seconds, or maybe in batch, or in an interactive way with a request. It’s very flexible, and you can also replay the data. That’s the strength of the storage behind the streaming log. With that, Kafka is a resilient system by nature. While you can deploy a single broker of Kafka, and that’s sometimes done at the edge, but in most cases you’ll deploy Kafka as a distributed system, and with that, you get the resiliency out of the box. Kafka is built for failure. This means a broker can go down, the network can go down, a disk can break. This doesn’t matter because if you configure Kafka correctly, you can still guarantee zero downtime and zero data loss. With that, that’s the reason why Kafka is not just used for analytics use cases, but also for mission critical workloads. Without going into more detail, keep in mind, Kafka is a highly available system. It provides other features like rolling upgrades and backwards compatibility between server and client so that you can continuously run your business. That’s what I understand under a resilient system. You don’t have downtime from maintenance, or if an issue occurs with the hardware.
Here’s an example for a Kafka architecture. In this case, I’m showing a few Confluent components, obviously working for Confluent. Even if you use open source Kafka or maybe another vendor, you glue together the right components from the Kafka ecosystem. In this case, the central data hub is the platform, these are the clusters. Then you also use Kafka Connect for data integration, like to a database or an IoT interface, and then you consume all this data. However, the messaging part is not really what adds the business value, the business value is to continuously process the data. That’s what stream processing does. In this case, we’re using Kafka native technologies like KSQL and Kafka Streams. Obviously, you could also use something like Apache Flink, or any other stream processing engine for that. Then of course, there’s also data sink, so Kafka Connect can also be used to ingest data into a data lake or database, if you don’t need or don’t want to process data only in real-time. This is then the overall architecture, which has different components that work together to build an integration layer, and to build business logic on top of that.
Global Event Streaming
With that then, if we once again think a little bit about bigger deployments, you can deploy it in very different flavors. Here’s just a few examples of that, like replication between different regions, or even continents. This is also part of the Kafka ecosystem. You build one infrastructure to have a highly scalable and reliable infrastructure. That even replicates data across regions or continents, or between on-prem and the cloud, or between multi-cloud. You can do this with open source Kafka using MirrorMaker 2.0, or with some more advanced tools like at Confluent, we have cluster linking that directly connects clusters together on the Kafka protocol as a commercial offering, no matter what you choose for the replications. The point is, you can deploy Kafka very differently depending on the SLAs. This is what we discussed in the beginning about the RPO and RTO. Ideally, you have zero downtime, and no data loss, like in the orange cluster, but you stretch one cluster across regions. That’s too hard to deploy for every use case, so sometimes you have aggregation clusters, where some downtime might be ok, especially in analytics use cases, like in yellow. With that, keep in mind, you can deploy Kafka and its ecosystem in very different architectures. It has always pros and cons and different complexity. That’s what you should be aware of when you think about how to architect a resilient architecture across edge, hybrid, and multi-cloud.
Here’s one example for that. This is now a use case from the shipping industry. Here now you see what’s happening in the real world. You have very different environments and infrastructures. Let’s get started on the top right. Here you see the cloud. In this case now, ideally you have a serverless offering, because in the cloud, in best case, you don’t have to worry about infrastructure. It has elastic scaling, and you have consumption based pricing for that. For example, with Confluent Cloud in my case, again. Here you have all your real-time workloads and integrate with other systems. In some cases, however, you still have data on-prem. On the bottom right, you’ll see where a Kafka cluster is running in the data center, connecting to traditional databases, old ERP systems, the mainframe, or whatever you need there. This also replicates data to the cloud and the other way back. Once again, as I said in the beginning, real-time data beats slow data. It’s not just true for business, but also for these kinds of resiliency and replication scenarios. Because if you replicate data in real-time, in case of disaster, you’re still not falling behind much and don’t lose much data, because it’s replicated to the cloud in real-time. Then on the other side, on the left side, we have edge use cases where you deploy a small version of Kafka, either as a single node like in the drone, or still as a mission critical cluster with three brokers on a ship, for edge analytics, disconnected from the cloud, or from the data center. This example is just to make clear, there’s many different options how to deploy Kafka in such a real world scenario. It always has tradeoffs. That’s what I will cover in the next sections.
Cloud-First and Serverless Industrial IoT in Automotive
Intentionally, I chose examples across different industries, so that you see how that is deployed. Also, this is now very different kinds of architectures with different requirements and setups. Therefore, the resiliency is also very different depending on where you deploy Kafka and why you deploy it there. Let me get started with the first example. This is now about cloud-first and serverless. This is where everybody’s going. Ideally, everything is in the cloud, and you don’t have to manage it, you just use it. That’s true, if it’s possible. Here is an example where this is possible. This might surprise some people. This is why I chose this use case. Actually, it is a use case where BMW is running event streaming in the cloud as a serverless offering on Azure. However, they are actually directly connecting to their smart factories at the edge. In this case, BMW’s goal is to not worry about hardware or infrastructure if you don’t need to, so they deploy in the cloud first, what’s possible. In this case, they leverage event streaming to consume all the data from the smart factories, machines, PLCs, sensors, robots, all the data is flowing into the cloud in real-time via a direct connection to the Azure Cloud. Then the data is processed in real-time at scale. A key reason why BMW chose this architecture is that they get the data into the cloud once. Then they provide it as a data hub with Kafka to every business unit and application that needs access to it, tap into the data. With Kafka, and because it’s also, as I discussed, a storage system, it doesn’t matter what technology consumes the data. It doesn’t matter what communication paradigms consumes the data. It’s very flexible. You can connect to that from your real-time consumer, Kafka native maybe. You can consume from it from your data lake, more near real-time or batch. You can connect to it via a web service and REST API from a mobile app. This is the architecture that BMW chose here. This is very interesting, cloud only, but still connecting to data at the edge. The cloud infrastructure is resilient. Because it also has a direct connection to the edge, this works well from an SLA perspective for BMW.
Let me go a little bit deeper into the stream processing part, because that’s also crucial when you want to build resilient architectures for resilient applications. When we talk about data streaming, then we get sensor data in all the time. Then we can build applications around that. An application can be anything, like in this case, we’re doing condition monitoring on temperature spikes. In this case, we’re using Java code with Kafka Streams. Here, you see every single event is processed by itself. That’s pretty straightforward. This scales for millions of events per second. This can run everywhere where a Kafka cluster is. In this case, if we deploy that in a use case like BMW, this is running in the cloud, and typically, next to the serverless environment for low latency. There can also be advanced use cases where you do stateful processing. In this case, you do not just process each event by itself, but different events, and correlate them for whatever the use case is. In this case, we are creating a sliding window and continuously monitor the last seconds or minutes, or in this case, hour, to detect a spike in this case of a temperature for continuous anomaly detection. As you can see here, you’re very flexible with use cases and deploy them. Still, it’s a resilient application, because it’s based on Kafka, with all the characteristics Kafka has. That’s also true for the application, not just for the server side. This code, in this case, it’s KSQL now, automatically handles failover. It handles latency issues. It handles disconnectivity, outages of hardware, because it’s all built into the Kafka protocol to solve these problems.
Then you can even do more advanced use cases, like in this case, we’ve built a user defined function to embed a TensorFlow model. In this case, we are doing real-time scoring of analytic models applied against every single event, or against a stateful aggregation of events, depending on your business logic. The point here is that you can build very resilient real-time applications with that. In the same way, this is also true for the replication you do between different Kafka clusters, because it’s also using the Kafka protocol. It is super interesting if you want to replicate data and process it even across different data centers.
Multi-Region Infrastructure for Core Banking
This was an example where we see everything in the cloud. However, reality is, sometimes resiliency needs even more than that. Sometimes you need multi-region deployments. This means even in case of disaster, a cloud goes down or a data center goes down, you need business continuity. This is in the end where we have an RTO of zero, where we have no downtime, and an RTO and RPO of zero, no data loss. Here’s an example from JPMorgan. This is financial services. This is typically in most critical deployments with compliance and a lot of legal constraints so that you need to guarantee that you don’t lose data even in case of disaster. In this case, JPMorgan deploys a separate independent Kafka cluster to two different data centers. Then they replicate the data between the data centers using real-time replication. They also handle the switchover, so if one data center is down, they also switch the producers and the consumers to the other data center. This is obviously a very complex approach, so you need to get that right, including the testing and all these things. As you can see the link here, JPMorgan Chase talked about it in 45 minutes, just about this implementation. It’s super interesting to learn how the end users deploy such an environment.
However, having said that, this example is still not 100% resilient. This is the use case where we replicate data between two Kafka clusters asynchronously. In this case, it’s done with Confluent Replicator, but the same would be true with Mirrormaker if you use open source. The case is, if there is disaster, you still lose a little bit of data, because you’re replicating data asynchronously between the data centers. It’s still good enough for most use cases, because it’s super hard to do synchronous replication between data centers, especially if they are far away from each other, because then you have latency problems and inconsistency. Always understand the tradeoffs between your requirements and how hard it is to implement them.
I want to show you another example, however. Here now, we’re really stretching a single Kafka cluster across regions. With this solution then, you have synchronous replication. With that, you can really guarantee zero data loss even in case a complete data center goes down. This is a feature of Confluent platform. This is not available in open source. This shows how you can then implement your own solution or buy something where you can then solve the problems that are even harder to do. In this case, how this works is that, as discussed, you need synchronous replication between data centers, to guarantee zero data loss. However, because you get latency issues and inconsistencies, then, what we did here, we provide the option so that you can decide which topics are replicated synchronously between the brokers within a single stretch Kafka cluster. As you see in the picture on the left side, the transactional workloads, that’s what we replicate in a synchronous way, zero data loss even in case of disaster. For the not so relevant data, we replicate it asynchronously within the single Kafka cluster. In this case, here is data loss in case of disaster. Now you can decide per business case what you replicate synchronously, so you still have the performance guarantees, but still also can keep your SLAs for the critical datasets. This is now a really resilient data center. We battled tested this before the GA across the U.S., with U.S.-West, Central, and East. This is really across hundreds of miles, so not just next to each other. This is super powerful, but therefore much harder to implement, and to deploy. That’s the tradeoff of this.
On the other side, here’s another great open source example. This is Robinhood. Their mission is to democratize finance for all. What I really like about their use cases using Kafka is that they’re using it for everything. They’re using it for analytical use cases, and also for mission critical use cases. In their screenshots from their presentation, you see that they’re doing stock trading, clearing, crypto trading, messaging and push notifications. All these critical applications are running in real-time across the Kafka cluster between the different applications. This is one more point to mention again, so still too many people in my opinion think about Kafka just for data ingestion into a data lake and for analytical workloads. Kafka is ready to process transactional data in mission critical scenarios without data loss.
Another example of that is Thought Machine. This is just one more of the examples to building transactional use cases. This is a core banking platform and a cloud native way for transactional workloads. It’s running on top of Kafka, and provides the ecosystem to build core banking functionalities. Here, you see the true decoupling between the different consumers’ microservices, and not all of them need to be real-time in milliseconds, you could also easily connect a batch consumer. Or you can also easily connect Python clients so that your data scientist can use his Jupyter Notebook and replay historical data from the Kafka cluster. There are many options here. This is my key point, you can use it for analytics, but also for transactional data, and resilient use cases like core banking.
Even more interestingly, Kafka has a transaction API. That’s also what many people don’t know. The transaction API actually is intentionally called Exactly-Once Semantics. Because in distributed systems, transactions work very differently than in your traditional Oracle or IBM MQ integration where you do a two-phase commit protocol. Two-phase commit doesn’t scale, so it doesn’t work in distributed systems. You need to have another solution. I have no idea how this works under the hood. This is what the smart engineers of the Kafka community built years ago. The point is, as you see in the left side, you have a transaction API to solve the business problem to guarantee that each message that is produced once from a producer is durable and consumed exactly once from each consumer, and that’s what you need in a transaction business case. Just be aware that this exists. This has not much performance impact. This is optional, but you can use it if you have transactional workloads. If you want to have resiliency end-to-end, then you should use it, it’s much easier than removing duplicates by yourself.
Hybrid Cloud for Customer Experiences in Retail
After we talked a lot about transactional workloads, including multi-region stretch clusters, there is more resilient requirements. Now let’s talk about hybrid cloud architectures. I actually choose one of the most interesting examples, I think. This is Royal Caribbean, so cruise ships for tourists. As you can imagine, each ship has some IT data. Here, it’s a little bit more than that. They are running mission critical Kafka clusters on each ship, for doing point of sale integration, recommendations and notifications to customers, edge analytics, reservation, loyalty platform. All these things you need to do in such a business. They are running this on each ship, because each ship has very bad internet connection, and it’s very expensive. They need to have a resilient architecture at the edge for real-time data. Then, when one of the ships comes back to the harbor, then you have very good internet connection for a few hours, then you can replicate all the data into the cloud. You can do this for every ship after every tour, and in the cloud. Then you can integrate with your data lake for doing analytics. You can integrate with your CRM and loyalty platform for synchronizing the data. Then the ship goes on the next tour. This is a very exciting use case for hybrid architectures.
Here is how this looks like in more general. You have one bigger Kafka cluster. This is maybe running in the cloud, like here, or maybe in your data center, where you connect to your traditional IT systems like a CRM system, or a third party payment provider. Then also, you see in the bottom, we also integrate with the small local Kafka clusters, they are required for the resilient edge computing in the retail store or on the ship. They also communicate with the central big Kafka cluster, all of that in real-time in a reliable way, using the Kafka protocol. If you go deeper into this edge, like in this case, the retail store, or in the example from before from the ship, here, now you can do all the edge computing, whatever that is. For example, you can integrate with the point of sale and with the payment. Even if you’re disconnected from the cloud, you can do payments and sell things. Because if this doesn’t work, then your business is down. This happens in reality. All of this happens at the edge. Then if there’s good internet connectivity, of course, you’re replicated back to the cloud.
We have customers, especially now in retail in malls, where during the day, the Wi-Fi is very bad, so they can’t replicate much. During the night, when there is no customers, then they replicate all the data from the day into the cloud. This is a very common cloud infrastructure or hybrid infrastructure. Kafka is so good here, because it’s not just a messaging system, it’s also a storage system. With this storage, you truly decouple the things, so you can still do the point of sale, but you cannot push it to the cloud where your central system is. You keep it in the Kafka log, and automatically when there is Kafka connection to the cloud, then it starts replicating. It’s all built into the framework. This is how you build resilient architectures easily by leveraging the tools for that and not building that by yourself because it’s super hard.
With that, we see how omnichannel works much better also with Kafka. Again, it’s super important to understand that Kafka is a storage system that truly decouples things and stores things for later replay. Like in this case, we had a newsletter first, 90 and 60 days ago. Then, 10 and 8 days ago, we used our Car Configurator. We configured a car and changed it. Then at day zero, we’re going into the dealership, and here the salesperson already knows all historical and real-time information about me. He knows real-time because it’s a location with service with my app, I’m walking into the store. In that moment, the data about me is replayed from the Kafka log historical data. In some cases, even better, it’s advanced analytics, where the salesperson even gets a recommendation from the AI engine in the backend, recommending a specific discount because of your loyalty and because of your history, and so on. This is the power of building omnichannel, because it’s not just a messaging system, but it’s a resilient architecture within one platform where you do messaging in real-time, but also storage for replayability, and data integration and data processing for correlation at the right context at the right time.
Disconnected Edge for Safety and Security in the Public Sector
Let me go even deeper into the edge. This is about safety critical, and cybersecurity, and these kinds of use cases. There’s many examples. The first one here is, if you think about a train system. The train is on the rails all the time. Here, you also can do data processing at the edge, like in a retail store. This has a resilient architecture, because the IT is small, but it’s running on computers in the train. With that, also, it’s very efficient while it’s resilient. You don’t need to connect to the cloud all the time when you want to understand, what is the estimated time of arrival? You get this information once pushed from the cloud into the train, and each customer on the train can consume the data from a local broker. The same is when you, for example, consume any other data or when you want to do a seat reservation in the restaurant on the train. This train is completely decoupled from another train, so it can be local edge processing. Once again, because it’s not just messaging, but a complete platform around data processing and integration, you can connect all these other systems, no matter if they’re real-time, or a file based legacy integration, like in a train you often have a Windows Server running. That’s totally flexible how you do that.
Then this is also more about safety and about criticality for cyber-attacks. Here’s an example, where we have Devon Energy, in the oil and gas business. Here, on the left side, you see these small yellow boxes at the edge. This is one of our hardware partners where we have deployed Confluent platform to do edge computing in real-time. As you see in the picture, they’re collecting data, but they’re also processing the data. Because in these resilient architectures, not everything should go to the cloud, it should be processed at the edge. It’s much more cost efficient. Also, the internet connection is not perfect. You do most of the critical workloads at the edge, while you still replicate some of the aggregated data into the cloud from each edge site. This is a super powerful example about these hybrid architectures, where the edge is often disconnected and only connects from time to time. Or sometimes you really run workloads only at the edge and don’t connect them at all to the internet for cybersecurity reasons. That’s then more an air-gapped environment. That’s what we also see a lot these days.
With that, my last example is also about defense. Really critical and super interesting. That’s something where we need a resilient streaming architecture even closer to the edge. You see the command post at the top, this is where a mission critical Kafka cluster is running for doing compute and analytics around this area in the military, for the command post. Each soldier actually also has installed a very small computer, which also is running a Kafka broker, not a cluster here, it’s just a single broker, it’s good enough. This is collecting sensor data, when the soldier is moving around. Like he’s making pictures, he’s collecting other data, whatever. Even if he’s outside of the internet wide area, he can continue collecting data, because it’s stored on the Kafka broker. Then when he’s going back into the Wide Area Network, the Kafka automatically starts replicating the data into the command post. From there, you can do the analytics in the command post for this region. You can also replicate information back to Confluent Cloud in this case, where we collect data from all the different command posts to make more central decisions. With this example, I think it has shown you very well how you can design very different architectures, all of them resilient, depending on the requirements you have, on the infrastructure you have, and the SLAs you have.
Why Confluent?
Why do people work with us? Many people are using Kafka, and it’s totally fine. It’s a great open source tool. The point is, it’s more like a car engine. You should ask yourself, do you want to build your own car, or do you want to get a real car, a complete car that is safe and secure, that provides the operations, the monitoring, the connectivity, all these things. Then, that’s why people use Confluent platform, the self-managed solution. Or if you’re in the cloud, and you’re even more lucky, because there we’re providing the self-driving car level 5, which is the only truly fully managed offering of Kafka and its ecosystem in the cloud. In this case, across all clouds, including AWS, Azure, Google, and Alibaba in China. This is our business model. That’s why people come to us.
Questions and Answers
Watt: One of the things I found really interesting was the edge use cases that you have. I wanted to find out, like when you have the edge cases where you’ve got limited hardware, so you want to try and preserve the data. There’s a possibility that the edge clusters or servers won’t actually be able to connect to the cloud for quite some time. Are there any strategies for ensuring that you don’t lose data by virtue of the fact that you just run out of storage on the actual edge cluster?
Waehner: Obviously, at the edge, you typically have limited hardware. It will of course depend on the setup you have. Like in a small drone, you’re very limited. Last week, I had a call with a customer who was working with wind turbines. They actually expect that they are sometimes offline for a complete week. That really means high volumes of data. Depending on this setup, of course, you need to keep storage because without storage, you cannot keep it in a case of disaster, like disconnectivity. Therefore, of course, you have to plan depending on the use case. The other strategy, however, is then, if you really get disconnected longer than you expect, maybe not just a week in this case, but then really a month, because this is really complex to fix, sometimes in such an environment.
Then the other strategy is a little bit of workaround because even if you store data at the edge, in this case, there are still different kinds of value in data. In that case, you can embed a very simple rules engine by saying, for example, if you’re disconnected longer than a week, then only store data, which is XYZ, but not ABC. Or the other option is instead of then storing all the data, in this case now we pre-process the data at the edge and only store the aggregations of the data, or filter it out in the beginning already. Because reality is in these high volume datasets, like in a car today, you produce a few terabytes per day, and in a wind turbine even more, and in these cases, anyway, most of the data is not really relevant. There is definitely workarounds. This again, like I discussed in the beginning, always depends on the SLAs you define, how much data can you lose? If a disaster strikes, whatever that is, what do you do then? You also need to plan for that. These are some of the workarounds for that kind of disaster then.
Watt: That’s really interesting, actually, because I think sometimes people will think, I just have to have a simple strategy, like first-in, first-out, and I just lose all the last things. Actually, if you have that computing power at the edge, you can actually decide based on the context, so whether it’s a week or a month, maybe you discard different data and only send up.
How good is the transactional feature of Kafka? Have you used it in any of your clients in production?
Waehner: People are always surprised when they see this feature, actually. I’ve worked for Confluent now for five years. Five years ago, this feature was released. Shortly after I started, exactly once a month, things were introduced into Kafka, including that transaction API. The API is more powerful than most people think. You can even send events to more than a single Kafka topic. You open your [inaudible 00:38:28], you say, send messages to topic one, to topic two, to topic three. Either you send all of them end-to-end, or none of them. It’s transactional behavior, including rollback. It’s really important to understand that how this is implemented is very different from a transactional workload, from a traditional system like an IBM MQ connecting to a mainframe, or to an Oracle database. That is typically implemented with two-phase commit transactions, a very complex protocol that doesn’t scale well. In Kafka, it works very differently. For example, now you use idempotent producers, a very good design pattern in distributed architectures. End-to-end, as an end user, you don’t have to worry, it works. It’s battle tested. Many customers are using it, and so you really don’t have to worry about that. Many customers have this in production, and this is super battle tested in the last years.
Watt: We’ve got some clients as well actually, that take advantage of this. As you say, it’s been around for a little while. It has certain constraints, which you need to be aware of, but it certainly is a good feature.
Waehner: In general, data streaming is a different paradigm. If you’re in an Oracle database, you typically do one transaction, and that’s what you think about. If you talk about data streaming, you typically have come data in, then you correlate it with other data, then you do the business transaction, and you do more data. The real added value of the transactional feature is not really just about the last consumer but it’s about the end-to-end pipeline with different Kafka applications. If you use transactional behavior within this end-to-end pipeline where you have different Kafka applications in the middle, then with transactional behavior, you don’t have to check for duplicates in each of these locations, and so on. Again, because the performance impact is very low, it’s really something like only 10%. This is a huge win if you build real stream processing applications. You really also not just have to think differently about how the transactions work under the hood, but also that a good stream processing application uses very different design patterns than a normal web server and database API application.
Watt: Another question is asking about eventual consistency and real-time, and what the challenges are that you see from that perspective.
Waehner: That’s another great point because of eventual consistency. That’s, in the end, the drawback you have in such a distributed system. It depends a little bit on the application you build. The general rule of thumb is that also, you simply build applications differently. In the end, it’s ok if you do receive sometimes a message not after 5 milliseconds, but sometimes if you have a spike of p99, and it’s 100 millisecond, because if you have built the application in the right way, this is totally ok for most applications. If you really need something else, there is other patterns like that. I actually wrote a blog post on my blog about comparing the JMS API for message queues compared to Kafka. One key difference is that a JMS API, out of the box, provides a request-reply pattern. That’s something what you also can do in Kafka, but it’s done very differently. Here again, there’s examples for that. Also, if you check my blog, there’s a link to the Spring Framework, which uses the Spring JMS template that even can implement synchronous request-reply patterns with Kafka.
The key point here to understand is, don’t think about your understanding from MQ, or ESPs, or traditional transactions and try to re-implement it with Kafka, but really take a look at a design pattern on the market, like from Martin Fowler, and so on for distributed systems. There you learn, if you do it differently, you build applications in another way, but that’s how this is expected then. Then you can build the same business logic, like in the example I brought up about Robinhood. Robinhood is building the most critical transactional behavior for trading applications. That’s all running via Kafka APIs. You can do it, but you need to get it right. Therefore, the last hint for that, the earlier you get it right in the beginning, the better. I’ve seen too many customers that tried it for a year by themselves, and then they asked for review. We told them, this doesn’t look good. The recommendation is really that in the early stages, ask an expert to review the architecture, because stream processing is a different pattern than request-reply, and then transactional behavior. You really need to do it the right way from the beginning. As we all know, in software development, the later you change something or have to change it, the more costly it is.
Watt: Are there cases actually where Kafka is not the right answer? Nothing is perfect. It’s not the answer to everything. What cases is this not really applicable?
Waehner: There’s plenty of cases. It’s a great point because many people use it wrongly or try to use it wrongly. A short list of things. Don’t use it as a proxy to thousands or hundreds of thousands of clients. That’s where REST proxy is good, or MQTT is good, or similar things are good. Kafka is not for embedded systems. Safety critical applications are C, C++, or Rust. Deterministic real-time, that’s not Kafka. That’s even faster than Kafka. Also, Kafka is not, for example, an API management layer. That’s big if I use something like MuleSoft, or Apigee, or Kong these days, the streaming engines get in the direction. Today, if you want to use API management for monetization, and so on, that’s not Kafka. There is a list of things it does not do very well. It’s not built for that. I have another blog post, which is really called, “When Not to Use Apache Kafka.” It goes through this list in much more detail, because it’s super important at the beginning of your project to also understand when not to use it and how to combine it with others. It’s not competing with MQTT. It’s not competing with a REST proxy. Understand when to use the right tools here and how to combine them.
See more presentations with transcripts
MMS • Rob Zuber
Subscribe on:
Transcript
Shane Hastie: Hey, folks, QCon London is just around the corner. We’ll be back in person in London from March 27 to 29. Join senior software leaders at early adopter companies as they share how they’ve implemented emerging trends and best practices. You’ll learn from their experiences, practical techniques, and pitfalls to avoid, so you get assurance you’re adopting the right patterns and practices. Learn more at qconlondon.com. We hope to see you there.
Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today, I’m sitting down with Rob Zuber. Rob is the CTO of CircleCI, and has been there for about eight years, I believe, Rob.
Rob Zuber: Yeah, that’s right. A little over.
Shane Hastie: Well, first of all, thank you very much for taking the time to talk to us today.
Rob Zuber: Thanks for having me. I’m excited.
Shane Hastie: And let’s start with who’s Rob.
Introductions [00:57]
Rob Zuber: So as you said, CTO of CircleCI. I’ve been with the company quite a while now, joined through an acquisition, but it was a very different company at the time, small company acquiring small company sort of thing. And so prior to that was also doing some CI and CD related activities. Specifically around mobile, was the CTO of three of us. We didn’t even really have titles. It’s kind of silly at that point, but many startups before that, so have been, I guess both a practitioner from a software development perspective, a leader. And then now as you know, we’re specifically in the space of CI/CD, trying to help organizations be great at software delivery.
I have this really fun position of thinking about how we do it, but also thinking about how everyone else does it and looking at, oh, well that’s interesting. I’d be interested to learn more from this customer. Or going and meeting customers and sharing with them and understanding their problems and talking to them about how we do things. So for me, it’s having worked in many different spaces, from telco to consumer marketplaces to embedded devices. Selling to me, I guess is the best way to think about building a product for me as the customer, both as a leader and an engineer, it’s just been a really, really fun ride. I’ve always enjoyed software and it’s so fun to just be at the core of it.
Shane Hastie: So what does it mean to be great at delivering software?
What does it mean to be great at delivering software? [02:09]
Rob Zuber: Oh, wow. At the highest level, I think being great at delivering software comes down to a couple things. And this is not necessarily what we would put in our stats or the DORA metrics or whatever, but feeling like you have confidence that you can put something out in front of your customers and you can learn from it successfully. And I don’t mean feeling like everything you build is going to be perfect and it’s going to be what customers want. Because I think that’s never true. What’s true is that you’ll get to what they want if you feel really comfortable moving quickly, trying things and putting things in front of your customers in a way that doesn’t throw off their day, but gives you real feedback about what it is they’re trying to do. Whether the thing that you’ve done most recently is helping them and really kind of steer towards and adapt towards the real customer problem.
I’ll say customers, but I’m a customer of many different platforms that this is so that I’m including myself in this. We’re sort of notoriously bad at expressing what it is that we actually, the problem we want to solve. We sort of say, “Oh, it would be really cool if you had this, or it’d be really cool if you had this,” but we don’t understand what it is we’re talking about 50% of the time.
I think designers are on the receiving end of this more than anybody. Everybody’s a designer, but the best they can come up with is, “I’ll know it when I see it.” And so feeling like you can really move quickly so you have all the confidence in terms of the quality of your software and knowing what you’re building and that you’re building it correctly, but you being able to use that to really adapt and learn and solve customer problems. If you’re not solving customer problems that are real and are important and are a pain point, and ideally doing that faster than your competition, then there’s areas where you could be better, I guess is the best way I would say.
Shane Hastie: Within CircleCI, how do you enable your teams to do this?
Building a culture of safety and learning [03:50]
Rob Zuber: One of the things that I called out in there is having the confidence that you could do that. And a lot of that stems from tooling. Unsurprisingly, we use our own tooling, we think about the customer problem, try to orient ourselves around the customer problem. That’s all important. But that confidence piece is also in how you behave. Building that model that says, that mental model that says we are trying to learn. What we’re trying to do here is we’re trying to learn, we want to put things out. Those things are going to be small. There’s not an expectation that we’re going to be perfect and know everything in advance, but rather we are learning by testing. We’re starting with a hypothesis, we’re validating that hypothesis and we’re building on top of it. And so I have my own podcast and on that, we spent the last season of it talking about learning from failure.
And I think that’s a really, really important part of this is, A, how you frame failure in the first place. There’s a big difference between, we thought we were going to be perfect and it didn’t work out versus, we’re trying an experiment, we have a hypothesis, and we know going in that we’re trying to learn. It creates a safe space to learn and move quickly. And then how you react when you actually did expect something to go well. And that might be maybe it was an operational issue or something else like that. And creating the space where the response to something going poorly, let’s say, is great. What can we learn from this? How can we be better next time? Versus how could an individual have done this thing? Sadly, this comes up probably in all engineering organizations, but you’ll see the difference. The issues come up everywhere.
The difference between you should have known better and how on Earth does the system allow you to be in a place where this could happen? Those are very, very different questions. And my belief at this point is, if you allow humans to do things in systems manually as just as an example, you’ve set yourself up to have a problem. And it’s certainly not the person who did the manual thing and finally made the mistake that everyone knew was coming sort of thing. So A, it’s that overall cultural picture. And then as you start to identify those things, you say, “Okay, cool. How do we fix the system? How do we create a system where it’s safe for us to experiment and to try?” The culture has to be safe and the systems have to be safe. You need to have risk mitigations basically to allow you to try things, whether it’s the product or shipping new capabilities.
Shane Hastie: How do you make sure that you do that when things go wrong?
Leaders need to model safety and curiosity, especially when things are going wrong [06:11]
Rob Zuber: It’s an excellent question. I think if you’re asking me personally, and there’s two levels to this, how do you do that personally and then how do you build that in an organization? I think the best thing that I can do as a leader is signal. My behaviors, unfortunately for me, carry more weight than other behaviors in the organization. If an individual engineer says, “Why’d you do that?” They’re peer individual engineers, like, “You don’t understand how hard this is. Whatever, I’m going to get on with my day.” When a CTO shows up and says, “Why would you do that?” That carries a lot more weight. So really, it’s hard, particularly if we’re talking about, we’ll call them the catastrophic failures. Hey, we were experimenting, we knew this. That’s easy. It’s easy to set up, it’s easy to structure. We knew that in advance. The catastrophic failures actually, we allowed this project to run for nine months and it turns out it was a complete waste of money or something happened and we were operating with the best information that we had at the time, but that information wasn’t very good.
And now we’ve got a big problem on our hands. Those are usually crisis moments. And I would say people’s guards are down. You’re not carefully crafting every word. And so it’s practice. That has to be the habit. And I will say it’s been a long time and nobody’s perfect. I would say I’m not perfect, but acknowledging and recognizing the impact. And so still speaking to the leader point of literally everything you say and do and taking that moment to stop and think, “Okay, what is the opportunity here? What is the learning opportunity? How do I help people get through?” Often it’s the crisis in the first place. How do I get through this situation? And then, how do we learn from it? And also, I mean if we’re talking about specifically those crisis moments, usually there’s crisis remediation and then sort of learning and acknowledging and separating those things, I think it’s easy.
I’ve seen this behavior before to show up in… We’re still solving the crisis and start asking questions, how could this ever have happened? And that is just not important right now. We need to get through that moment and then we need to make sure we have a long look to say, “How did we get ourselves into this situation? What is it about?” I mean, the reality in the situation… I’ve used examples, just this required human intervention and humans ultimately are going to make a mistake. It just happens, right? I don’t care how well you document something, how careful you ask someone to be. It doesn’t help. You need a system in place. So there’s that. But if you look at other more complex scenarios, what you’ll find is they’re complex. Someone else has been asking for something or creating a sense of urgency around something that maybe wasn’t as urgent or something was misinterpreted.
Backing your way through all of that is challenging. And I think again, for me, it’s about curiosity. If you’re truly curious, if you’re genuinely curious about what is it in this organization that’s leading to these types of scenarios, well, I guess that’s number one and then if you act. Right? If I say, “I’m open to your feedback, what’s going on?” And then you give me some feedback, I’m like, “No, no, that’s not it.” Are you going to give me more feedback? I doubt it. Right? That was just a waste of your time. And it was. You’re like, “No, I’m literally seeing this problem.” If I say, “Oh, tell me more about that, let’s sit down and think through it. What could we do differently? How would this turn out differently next time?” And then go, I mean you’re not always going to succeed, but go try to implement some change around that so it’s safe and the action gets taken, then that’s where you start to have people offer up ideas. Right?
And come out and say, “Actually, I was in this scenario where I made this mistake or whatever. I didn’t understand the…” I mean I’m using sort of specific examples, but it could be anything from I decided to launch this feature that it turns out wasn’t helpful and we invested money in it. We had a production issue where we, whatever, pick any example, it maps anywhere. We honestly, openly, curiously explore the issue, right? Sure, we can say this person took this action, but when the reason we’re asking, understanding that is, what did that person know? What could they have known? Why were they prevented from knowing that thing, et cetera. Then that’s an open, honest, just curious exploration versus I need names, whatever. And so all of that, I guess I’ll just stop at signaling. At a high level, if your leaders don’t behave in that way, the rest is a waste of time to talk about, honestly.
Shane Hastie: Looking back over your career, and we can start the progression from developer through to senior exec today, what would you share? What advice would you give others who are looking at the same pathway when they’re along that journey?
Advice for aspiring leaders [10:26]
Rob Zuber: The first piece of information I usually give is don’t take my advice. Mostly because my progression is not at all a progression. So maybe there’s something in there. I started out working in an electronics factory actually doing process engineering because that was related to what I had studied in school, which was not software. Built some software to kind of understand our systems. Enjoyed that. Went to work at a startup, late ’90s, it was the time and the rest is history. And then did a bunch of small startups. So I didn’t really have a clear progression, but it’s actually one of the things I talk about with a lot of people getting into the field or even considering what field they want to get into, which is that you don’t have to have a straight progression. You can bring value to yourself in terms of this expression from the book Range, “match quality”, the thing that you end up ultimately doing, being a really good match for the strengths that you bring to the table, the most likely way that’s going to happen is not by filling out some form before you apply to college.
It’s actually going and doing a bunch of things and saying, “Wow, I’m really good at this and I’m really bad at this.” And just being able to say, “I’m actually really not that good at this,” whatever. I mean, I was a head of business development in an organization for a brief stint. I have a ton of empathy for people who do business development and sales. I think that makes me a better executive, but I was absolutely garbage at that job. I was like, “Oh, we’re doing business development. I should probably write some code to get this done.” The idea of cold calling, trying to build relationships with business, it’s not my thing. So that’s fine, good to have done it because it helps me understand where my strengths are and it helps me understand what other people might do. And so I think a lot of people get on this, I need to be a developer and then a senior developer and then a staff and then this, and then that.
And then if I’m not moving forward, I’m moving backwards, but part of the non-linearity of my career is I’ve been a CTO for over half of it because I tried a bunch of things and then I went and started some companies and I was like, “Well, there’s no one else here to be the CTO, so I guess I’ll just do that.” And it wasn’t the same CTO job that I have now, but in particular, if you want the full spectrum and I guess a crucible of learning, starting a business and being responsible for other people and trying to build a product and trying to find product market fit, all of those things is a great way to get that learning. But it’s not for everybody. So there’s other ways you could get that learning, but really for me, I kind of ignored the path, not because I was brilliant, but because I didn’t really have a plan and I believe it paid off for me.
Shane Hastie: Circling around, why is the culture at CircleCI good?
What makes the Circle CI culture good? [12:54]
Rob Zuber: Well, I think there’s a few things that play into it. I mean, one, company was founded by people. So I’m not a founder of CircleCI. When I say we, there was three of us that were acquired in and one is now the CEO. So we stepped into an environment where we were fortunate to inherit some things. And the company was founded over 10 years ago, but culture lasts. And so we stepped into a group of people who were genuinely curious about a problem, cared deeply about their customers, and were building a product that people were excited about. The people that worked there were excited about, the customers were excited about. So there was a lot of connection between customer and the engineers building every day. Of course, in a 14-person company, which is how big it was, there’s always going to be that kind of connection.
Might be possible to not have it, but I mean, we did our own support calls and everything else, you’re much closer. But being able to tap into that and build on it and then make tweaks as you go, I think is a great thing to start from. We weren’t coming in and saying, “Oh, my gosh, we got to turn 180 degrees. And I think one of the things that I reflect on sometimes is, there were great goals culturally that we had to reimplement as we grew, but we appreciated the goals. So one of those is transparency. I think this was common at the time, I don’t know if this still happens, but it was an organization where every piece of information was shared with everybody. Everybody was on every email distribution list. Everything was just wide open. And we’ve never been concerned with that level of transparency other than the overhead.
If I give you A, the reams of data, you will selectively choose whether it’s emails or anything else, you’ll selectively choose which parts to look at because they’re interesting to you. And if you and I look at it, even exactly the same data, we’ll draw different conclusions. So it’s hard to keep alignment with raw data. It’s important for leaders, others in the organization to say, “Hey, I looked at this and this is the conclusion I drew.” Here’s the data if you’re interested in challenging my conclusions, but let’s come to agreement on the conclusions because that’s what’s going to drive how we behave now. So I think that openness and with that, the willingness to say, “You might have something really interesting to add here.” I’m not saying I have all the answers, please just take my answers. I want to build that context and share the context.
But again, if I just give you the raw data, you’re going to go do something totally different because we have different interpretations of what really matters. So let’s get together and align on that, but not because I’m just telling you, “Here’s the answer,” because I actually really value people around me challenging my interpretation. I don’t have all the answers. I’m open to asking the questions, and if no one has any suggestions, I’ll seed the conversation or try to ask better questions to get people to think a little bit more deeply. There’s always someone who knows more than me. And I mean I’m sort of making this about me, but I think the leadership team that we have built is reflective of… So Jim is our CEO, he and I worked together before CircleCI, but our perspective of how we want to work, and we’re always looking for people that will challenge us comfortably.
Like, “Oh, that’s interesting, but maybe you didn’t consider this. Because when I looked at it, I saw that this other way.” “Oh, okay, tell me about that.” There’s always someone who’s closer to the problem. There’s always someone who knows more or there’s someone coming in from the outside with a different set of experiences, maybe more experience in a particular area or just a, “Hey, we tried this at my other organization, have you considered that?” Right?
So I think that willingness and openness to that and then to go experiment, right? Say, “Cool, we have a lot of ideas, let’s try something. Now let’s not sit here and talk about all our ideas, but let’s try something and let’s know that we’re trying something.” Right? When everyone frames it that way. And again, we’re not perfect, but I think that this is a thing that we really strive for is let’s try and we might be wrong, we might be right, but when we try, we’ll learn something. We’ll have new information and then we can try something that we know to be closer to the ultimate goal or the ultimate answer. Whether that’s product design, whether it’s how we run our organization, could be anything. But I’ll happily sit down and have an open conversation with you about what I’m seeing. I’ll share the context from where I’m seeing it, and then let’s kind of see how your information and knowledge can combine with mine to come up with a great answer. That would be my favorite part. Call it that.
Shane Hastie: So when you’re bringing new people into the organization, what do you look for?
Bringing new people into the organization [17:06]
Rob Zuber: There’s a couple big things. What I’ve just described in terms of open, comfortable, bringing different perspectives to extend our view of a particular problem set or in a particular area, whatever that might be. This is me personally, but also belief that we would have in the organization. Not a huge fan of you’ve done this thing, this exact thing before, because the length of time for which that thing is going to be our problem is probably measured in hours or days. And we don’t measure hires in hours or days. If I need to understand how to do a very, very specific thing, I can hire a consultant for a week who’s going to tell me how to do it. And I got the knowledge that I need. I want to know how did you learn to do that thing? What were the circumstances in which you were trying to do something and you realized this was a great solution to that problem, and how did you quickly learn how to take advantage of this thing and make it work?
On the flip side, I guess this is the balance. If there is a known solution, I don’t want you to quickly learn a new thing just because that would be fun for you. I want you to be focused on the customer problem and I want to scope down what we do to solving the problems of our customers. If there’s a thing we’re doing that has been solved a million times before, let’s take one of those million and focus on the thing that we do that’s unique and valuable in what our customers pay us for.
But in solving that problem where we do have unique, interesting challenges, I want to know that you’re comfortable not just doing the thing that you did before, but seeing the customer problem, identifying with it, and then finding a path to learn as quickly as possible, get there, solve it, we’ll implement something new if we have to, and being able to see the difference. So I think that balance is really important. And then perspective, if everybody thinks the same way, if everybody comes from the same back, I mean, known issue but not solved, then you end up in this group think and you get the solution you’re going to get instead of actually seeing it from a bunch of different angles and being able to get usually a really novel and exciting new perspective.
Shane Hastie: So how do you deliberately get different perspectives, the diversity of viewpoints?
Deliberately bring in diverse perspectives and backgrounds [19:06]
Rob Zuber: I don’t have a great answer to this, but I’ll tell you what I’ve been thinking about lately. Because if I’m not going to be honest, then who’s going to be honest with me? So one of the things that I’ve been thinking about a lot lately after wrapping up a season on failure, now we’re talking about teams. We’re building up a season, is building teams. In software, and this is true in other departments. Obviously, I’m from an engineering background and in a company delivering products to engineers, but this is true in other departments for sure. But we deliver software as a team, right? We work as a team every day. Or I say, right, if you’re a solo open source developer, not true. But for most organizations you’re building teams and then teams of teams. And then we often hire, and by we, I mean in the industry, but we’re imperfect as well, as if every person is being measured individually, as if every person needs to come with a set of skills and capabilities and whatever that would cover the whole thing.
And so that makes it not only not okay to be an imbalanced… And I’m saying I’m totally imbalanced. I’ve already said I’m really good at some things and I’m absolutely garbage at other things. And then there’s spots in between. And if you know that and can say, “Hey, I’m really good at this. I have gaps over here. It would be great to have someone else on the team who’s strong over here.” And this isn’t, not getting to all of the ways that we could talk about diversity, but just, I am actually trying to build the strength of the team. And I have junior people on the team. I probably need a senior person on the team or two or whatever, however you think about the makeup of your team. But it’s great to have energy and enthusiasm and be super smart and whatever. But there’s pathways you don’t have to go down that someone can say, “Oh, yeah, I did that before. Here’s some additional context to consider. Would you still go that way or would you try something else?”
You could save a lot of time when someone has experienced something, balanced against we never try anything new because we just do whatever they say. And so I think that team unit is the thing that’s really, I’m trying to pick apart and think better about how to build for, because again, that’s how we do all of our work. And not everyone is into sports analogies, but I think it’s really easy to make them in this regard. You build a team of players with different strength. And I think about any team that I’m structuring in that way, meaning not everyone has to be able to do everything. The team needs to be able to perform with all of their responsibilities.
And that might be like, I understand databases and you understand front end or whatever the full scope of our responsibility is. And it might be I’m super extroverted and I love presenting our work to the rest of the organization. You’re really quiet, but you spot the avenues that we were about to go down that are just going to ruin us. We have very, very different perspectives, but as a team, we achieve everything that we… We save ourselves some really big problems and we make sure everyone knows what we’re working on. If we just hired extroverts, that would be a really weird challenge in software engineering, but we would have a whole bunch of people who were clamouring and then would be fighting over who got to do the presentation. It’s usually not the case, but I need someone or someone for whom that’s a goal, and that might be the way that I fill it in.
It’s like, oh, we don’t necessarily have all the skills here, but the manager is really good at that and we’re hiring someone who wants to grow into that and we see the potential in them. So let’s try to summarize this. The way we prevent ourselves from diversifying and getting a lot of different perspectives and different backgrounds and all of the other forms is we fashion one archetype and say all of our team members need to be this, but it’s solving the wrong problem. It’s the team that I want to be great and so I need some coverage in this area and some coverage in this area and some coverage in this area. And I can have people who are great at each of those things if I allow for them to be not as great in other areas because there are people who are great in those other areas. And the team as a unit is great.
Shane Hastie: Thank you very much. Some really interesting thoughts there. I’d like to end with, what’s the biggest challenge facing our industry today and what do we do about it?
Complexity is a big problem for software development [23:04]
Rob Zuber: I will say a big, because I don’t have the confidence to say that I know exactly which is the problem that everybody needs to solve, but the problem that I think about on a regular basis is complexity. I will define complexity, but why do I think about complexity? We’re on a natural evolution. When I started in software, we wrote almost every line of code that we are going to put in production. And now we’re delighted that we can move really quickly because we’re standing on the shoulders of giants. People have built entire cloud. Just the cloud, that didn’t exist when I started building out SaaS platforms or whatever we called them back then, and open source libraries. Open source was just kind of, okay, yeah, you could use that, but that seems like a sketchy idea, right? Now, this is what everybody does. So I’ve got underlying infrastructure that I don’t understand.
I’ve got a whole bunch of libraries that I don’t understand. And that’s great because I’m writing this tiny little piece of software on top of that that allows me to do amazing things. But all of that stuff needs to be understood as a system. And all of it is constantly changing. People upgrading versions of my libraries and then there’s a security patch to apply here. And then AWS or GCP or whoever is upgrading their underlying structure, and they’re swapping out disc drives that I don’t know about. All that stuff is constantly changing and we’re sometimes fooling ourselves thinking, oh, we only need to understand this little piece, but all of it can have impact on what we’re building and operating. And so I think, A, getting your head around that complexity is a hard problem. And it comes into how we design and think about systems.
And some of it is just acknowledging that we are actually building on top of all that complexity versus pretending we’re not, because it’s easy to put something out, and then doing that in a way that allows us to actually keep executing, right? Say, okay, we get it. We have control over it, unsurprisingly, this is what we think about and build for at CircleCI, but get my head around it, feel like it’s easy to become then the deer in headlights. You know what I mean? This is terrifying. I don’t even want to write code. I don’t even know how to exist in this environment. Getting that ability to deliver on top of that, because again, we did all these things. We created the cloud and libraries and frameworks and all this stuff so that we could deliver faster, so that we could focus our energy on unique customer problems.
We’re well past the days of manually optimizing table space layout on disk arrays. Thank goodness, that was not a highlight of my career, but someone’s doing it. And so being able to reason about, Oh, this is still a thing that could impact me if it wasn’t done well,” right? I’ve never met the person that did it and I don’t know how they did it, but feeling comfortable with that, getting a grasp on it so that we can reap the reward of focusing on the customer value and delivering against that customer value. And so I think we’re getting there. Certainly we’re trying to be a part of the solution to that, but we’re getting there. But it’s a hard problem and it’s not slowing down, right?
We are accelerating ourselves because we keep building more layers to build on top of, allowing us to do bigger things with less work. And then if you want to take the whole thing off the rails, add in machines building things, right? That’s next. So the complexity is going to get deeper and deeper, bigger and bigger, whatever the measure of complexity is. And so staying on top of that, feeling good about it, delivering effectively so that we as the humans who are bringing the brain power that ultimately ties all this stuff together can continue to be effective and not mired down in all that complexity.
Shane Hastie: Well, thank you very much indeed. If people want to continue the conversation, where do they find you?
Rob Zuber: LinkedIn, on Twitter at Z00B, Z-0-0-B. Terrible decision, but I’m living with it. And again, I have my own podcast The Confident Commit where I spend lots of time talking about and thinking about with people who are way smarter and have done way more interesting things than me, the overall delivery of software and how to be good at it. And a lot of the topics that we covered here that clearly I’m obsessed with.
Shane Hastie: Thank you so much.
Rob Zuber: Thank you. It was awesome to chat.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Ben Evans

Transcript
Evans: My name is Ben Evans. I’m a Senior Principal Software Engineer at Red Hat. Before joining Red Hat, I was lead architect for instrumentation at New Relic. Before that, I co-founded a Java performance company called jClarity, which was acquired by Microsoft in 2019. Before that, I spent a lot of time working with banks and financial companies, and also gaming as well. In addition to my work in my career, I’m also known for some of my work in the community. I’m a Java champion, a JavaOne Rockstar speaker. For six years, I served on the Java Community Process Executive Committee, which is the body that oversees all new Java standards. I was deeply involved with the London Java Community, which is one of the largest and most influential Java user groups in the world.
Outline
What are we going to talk about? We’re going to talk about observability. I think there’s some context that we really need to give around observability, because it’s talked about quite a lot. I think there are still a lot of people, especially in the Java world, who find that it’s confusing or a bit vague, or they’re not quite sure exactly what it is. Actually, that’s silly, because observability is really not all that conceptually difficult to understand. It does have some concepts which you might not be used to, but it doesn’t actually take that much to explain them. I want to explain a bit about what observability is. I want to explain OpenTelemetry, which is an open source project and a set of open standards, which fit into the general framework of observability. Then with those two bits of theory in hand, we can turn and look at a technology called JFR, or JDK Flight Recorder, which is a fantastic piece of engineering, and a great source of data that can be really useful for Java developers who care about observability. Then we’ll take a quick look as to where we are, take the temperature of our current status. Then we’ll talk a little bit about the future and roadmap, because I know that developers always love that.
Why Observability?
Let’s kick off by thinking about what observability is. In order to really do that, I want to start from this question of, why do we want to do it? Why is it necessary? I’ve got some interesting numbers here. The one I want to draw your attention to is the one on the left-hand side, which says roughly 63% of JVMs that are running in production currently are containerized. This number has come from our friends at New Relic who publish data. Since I put this deck together, they actually have a nice new result out which actually says that the 2022 numbers are actually a bit higher. Now they’re seeing roughly 70% of all JVM based applications being containerized. For fun, on the right-hand side here, I’m also showing you the breakdown of the Java versions. Again, these numbers are about a year out of date. In fact, if we looked at them again today, we would see that in fact, Java 11 has increased even more than that. Java 11 is now in the lead, very slightly over Java 8. I know that people are always curious about these numbers. Obviously, they’re not a perfect proxy for the Java market as a whole because it’s just New Relic’s customers, but it still represents a sample of tens of millions of JVMs. I think Gartner estimates that around about 1% of all production JVMs show up in the New Relic data. Not a perfect dataset by any means, but certainly a very interesting one.
The big takeaway that I want you to get out from here is that cloud native is increasingly our reality, 70% of applications are containerized. That number is still rising, and rising very quickly. It depends upon the market segment, of course. It depends upon the maturity that individual organizations have, but it is still a big number. It is still a serious trend that I think we need to take seriously for many reasons, but particularly because it has been such a fast growing segment. Containerization has happened really remarkably quickly. When an industry adopts a new practice as rapidly and as wholesale as they have in this case, then I think that that’s a sign that you need to take it seriously and to pay some attention to it.
Why has this happened? Because observability really helps solve a problem which it exists in other architectures, but it’s particularly apparent in cloud native, and that’s an increase in complexity. We see these with things like microservices, we see it with certain other aspects of cloud native architectures as well. Which is that because there’s just more stuff in a cloud native architecture, more services there, there’s all kinds of new technologies, that traditional APM, Application Performance Monitoring, it’s what APM stands for, those types of approaches just aren’t really as suitable for cloud native. We need to do something new and something which is more suitable.
History of APM (Application Performance Monitoring)
To put this into some context, to justify it a little bit, we can look back 15 years, we go back to 2007. I was working at Morgan Stanley, we certainly had APM software that we were deploying into our production environments. They were the first generation of those types of technologies, but they did exist 15 years ago. We did get useful information out of them. Let’s remember what the world of software development was like 15 years ago, it was a completely different world. We had release cycles that we measured in months, not in days or hours. Quite often, the applications that I was working with back in those days, we would have maybe a release every six weeks, maybe a release every couple of months. That was the cadence at which new versions of the software came out. This was before microservices. We had a service based architecture. These were large scale, quite monolithic services. Of course, we ran this all in our own data centers or rented data centers. There was no notion of an on-demand cloud in the same way that we have these days.
What this means is two things, because the architectures are stable for a period of months, a good operations team can get a handle on how the architecture behaves. They can develop intuition for how the different pieces of the architecture fit together, the things that can go wrong. If you have a sense of what can go wrong, you can make sure that you gather data at those points and see whether things are going to go wrong. You end up with a typical view of an architecture like this, this traditional 3-tier architecture. It’s still a classic data source JVM level for application services, web servers, and some clustering and load balancing technologies. Pretty standard stuff. What can break? The load balancers can break. The web servers mostly are just serving static content, aren’t doing a great deal. Yes, you could push a bad config or some bad routing to the web layer, but in practice if you do that, you’re going to find it pretty quickly. The clustering software can have some slightly odd failure modes, and so on. It’s not that complicated. There’s just not the same level of stuff that can go wrong that we see for cloud native.
Distributed System Running On OpenShift
Here’s a more modern example. I work for Red Hat, so of course, I have to show you at least one slide which has got OpenShift on it. There we have a bunch of different things. What you’ll notice here is that this is a much more complex and much more sophisticated architecture. We have some bespoke services. We’ve got an EAP service there. We’ve got Quarkus, which is Red Hat’s Kubernetes native Java deployment. We’ve even got some things which aren’t written in Java, we’ve got Node.js. We’ve also got some things which are still labeled as services, but they’re actually much more like appliances. When we have Kafka, for example, Kafka is a data transport layer. It’s moving information from place to place and sharing it between services. It’s not a lot of bespoke coding that’s going on there, instead, that is something which is more like infrastructure than a piece of bespoke code. Here, like the clear separation between the tiers, is much more blurry. We’ve got a great admixture of microservices and infrastructural components like Kafka, and so on. The data layer is still there, but it’s now augmented by a much greater complexity for services in that part of the architecture.
IoT/Cloud Example
We also have architectures which look nothing like traditional 3-tier architectures. This is a serverless example. This one really is cloud native. This one really is the thing that it will be very difficult to build with traditional IT architectures. Here we have IoT, so the internet of things. We have a bunch of sensors coming in from anywhere. Then we have some sort of server or even serverless provisioning, which produces an IoT stream job which is fed into a main datastore. Then we have other components which are watching that serverless datastore, and have some machine learning model that’s being applied over the top of it. Now, the components are actually simpler in some ways. A lot of the complexity has been hidden, and is being handled by the cloud provider themselves for us. This is where I’m much closer to a serverless type of deployment.
How Do We Understand Cloud-Native Apps?
This basically brings us to the heart of how and why cloud native applications are different. They’re much more complex. They have more services. They have more components. The topology, the way that the services interconnect with each other is far more complicated. There are more sources of change, and that change is occurring more rapidly. This has moved us a long way away from the sorts of architectures that I would have been dealing with at the early point in my career. Not only is that complexity and that more rapid change a major factor, we also must understand that there are new technologies with genuinely new behaviors of the type that we have never seen before, things like there are services which scale dynamically. There are, of course, containers. There are things like Kafka. There are function as a service, and serverless technologies. Then finally, of course, there is Kubernetes, which is a huge topic in and of its own right. That’s our world. Those are the things that we have to face. Those are the challenges. That’s why we need to do things in a different way.
User Perspective
Having said that, despite all of that additional complexity and all of that additional change in our landscape, certain questions, certain aspects, we still need answers to. We still need answers to the sorts of questions like, what is the overall health of the solution. What about root cause analysis? What about performance bottlenecks? Is this change bad? Have I introduced some regression, by changing the software and doing a rollout? Overall, what does the customer think about all of this? Key questions, they’re always true on every type of architecture you deploy, whether this is an old school 3-tier architecture, all the way through to the latest and greatest cloud native architecture. These concerns, these things that we care about are still the same. That is why observability. We have a new world of cloud native, and we require the same answers to some of the same old questions, and maybe a few new answers to a few new questions as well. Broadly, we need to adapt our notion of what it is to provide good service and to have the tools and the capabilities to do that. That’s why observability.
What Is Observability?
What is observability, exactly? There’s a lot of people that have talked about this. I think that a lot of the discussion around it is overcomplicated. I don’t think that observability is actually that difficult to understand conceptually. The way that I will explain it is like this. First of all, we instrument our systems and applications to collect the data that we need to answer those user level questions that we had, that we were just talking about a moment or two ago. You send that data outside of your production system. You send it to somewhere completely different, which is an isolated external system. The reason why, because if you don’t, if you attempt to store and analyze that data within your production system, if your system is down, you may not be able to understand or analyze the data, because you may have a dependency on the system which is causing the outage. For that reason, you send it to somewhere that’s isolated and external.
Once you have that data, you can then use things like a query language, or almost like an experimental approach of looking at the data, of digging into it and trying to see what’s going on by asking open-ended questions. That flexibility is key, because it’s that what provides you with the insights. You don’t necessarily know what you’re going to need to ask when you start trying to figure out, what is the root cause of this outage. Why are we seeing problems in the system? That flexibility, the unknown unknowns. The questions you didn’t know you need to ask. That’s very key for what makes a system an observability system rather than just a monitoring system. Ultimately, of course the foundation of this is systems control theory, which is how well can we understand the internal state of a system from outside of it. That’s a fairly theoretical underpinning. We’re interested in the practitioner approach here. We’re interested in what insights that could lead you to taking action about your entire system. Can you observe? Not just single piece, but all of it.
Complexity of Microservice Architectures
Now the complexity of microservice architecture starts to come in. It’s not just that there are larger numbers of smaller services. It’s not just that there are multiple people who care about this Dev, DevOps, and management. It’s also things like the heterogeneous tech stacks. In modern applications, you don’t build every service or every component out of the same tech stack. Then finally, again, touched on Kubernetes, service cost to scale. Quite often that’s run dynamically or automatically these days. That additional layer of complexity is added to what we have with microservices.
The Three Pillars
To help with diagnosing all of this, we have a concept of what’s called the three pillars of observability. This concept is a little tiny bit controversial. Some of the providers of observability solutions and some of the thinkers in the space, claim that this is not actually that helpful a model. My take on it is that, especially for people who are just coming to the field and who are new to observability, that this is actually a pretty good mental model. Because these are things that people may already be slightly familiar with. It can provide them with a useful onramp to get into the data and into the observability mindset. Then they can decide whether or not to discard the mental model later or not. Metrics, logs, and traces. These are very different data types. They behave differently and have different properties.
A metric is just a number that describes a particular process or an activity, the number of transactions in, let’s say, a 10-second window. That’s a metric. The CPU utilization on a particular container. That’s a metric. Notice, it’s a timestamp, and it’s a single number measured over a fixed interval of time basically. A log is an immutable record of an event that happened at a point in time. That blurs the distinction between a log and an event. A log might just be an entry in a Syslog, or an application log, good old Log4j or something like that. It might be something else as well. Then a trace. A trace is a piece of data which is used to show what was triggered by an individual user level request. Metrics, not really tied to particular requests. Traces, very much tied to a particular request, and logs, somewhere in the middle. We’ll talk more about the different aspects of data that these things have.
Isn’t This Just APM with New Marketing Terms?
If you were of a cynical mind, you might ask, isn’t this just APM with new marketing? Here’s why. Here’s five reasons why I think it’s not. Vastly reduced vendor lock-in. The open specification of the protocols on the wire, the open sourcing of at least some of the components, especially the client side components that you put into your application, those hugely help to reduce vendor lock-in. That helps keep vendors in the space competitive, and it helps keep them honest. Because if you have the ability to switch wire protocol, and maybe you only need to change a client component, then that means that you can easily migrate to another vendor should you wish to. Related to that, you will also see standardized architecture patterns and the fact that because people are now cooperating on protocols, cooperating on standards, and on the client components, we can now start to have a discourse amongst architects and amongst practitioners as to how we build this stuff out in a reliable and a sustainable way. That leads to better architecture practice, which also then feeds back into the protocols and components. Moving on from that, we also see that the client components are not the only pieces that are being developed. There is an increasing quantity and quality of backend components as well.
Open Source Approach
In this new approach, we can see that we’ve started from the point of view of instrumenting the client side, which in this case really means the applications. In fact, most of these things are going to be server components. It’s typically thought of as being client side for the observability protocols. This will mean things like Java agents and other components that we’re going to place into our code, whether that’s bespoke or the infrastructural components which we’ll also need to integrate with. From there, we’ll send the data over the wire into a separate system, which is marked here as data collection. This component too is likely to be open source, at least for the receiving part. Then we also require some data processing. The first two steps are now very heavily dominated by open source components. For data processing, that process is still ongoing. It is still possible to either use an open source component or a vendor for that part. The next step, we’re closing the loop to bring it back around to the user again is visualization. Again, there are good stories here both from vendor code and from open source solutions. The market is still developing for these final two pieces.
Observability Market Today
In terms of today’s market, and what is actually in use, there was a recent survey by the CNCF, the Cloud Native Computing Foundation. They found that Prometheus, which is a slightly older metrics technology, is probably the most widely used observability technology around today. They found that this was used by roughly 86% of all projects that they surveyed. This is of course a self-reported survey, and only the people who were actively interested and involved with observability will have responded to this. It’s important to treat this data with a suitable amount of seasoning. It’s a big number, and it may not have as much statistical validity as we might think. The project that we’re going to spend a lot of time talking about, which is OpenTelemetry, was the second most widely used project at 49%. Then some other tools as well like Fluentd and Jaeger.
What takeaways do we have from this? One of the point which is interesting is that 72% of respondents employ up to 9 different tools. There is still a lack of consolidation. Even amongst the folks who are already interested in observability, and producing and adopting it within their organizations, over one-third of them complain that their organization lacks proper strategy for this. It is still early days. We are already starting to see some signs of consolidation. The reason why we’re focusing and we’re so interested on OpenTelemetry is because the OpenTelemetry usage is rising sharply. It’s risen to 49% in just a couple of years. Prometheus has been around for a lot longer, and it seems to have mostly reached market saturation. Whereas OpenTelemetry is only still in some aspects moving out of beta, it’s not fully GA yet. Yet, it’s already being used by about half of the folks who are adopting observability as a whole. In particular, Jaeger, which was a tracing solution, have decided to end of life their client libraries. Jaeger is pivoting to be a tracing backend for its client and its data ingest libraries, to switch over completely to using OpenTelemetry. That is just one sign of how the market is already beginning to consolidate.
This is part of the process which we see where API monitoring traditionally dominated by proprietary vendors, now we’re starting to move into this inflection point where we’re moving from proprietary to open source led solutions. More of the vendors are switching to open source. When I was at New Relic, I was one of the people who led that switch of New Relic’s code base from being primarily proprietary on the instrumentation side, to being completely open source. In the course of seven months, one of the last things I did at New Relic before I left was helped oversee the open sourcing of about $600 million worth of intellectual property. The market is definitely all heading in this general direction. One of the technologies, one of the key things behind this is OpenTelemetry. Let’s take a look and let’s see what OpenTelemetry actually is.
What Is OpenTelemetry?
OpenTelemetry is a set of formats, open standards, and libraries. It is not about data ingest, backend, or providing visualizations. It is about the components which end users will fit into their applications and their infrastructure. It is designed to be very flexible, and it is very explicitly cross-platform, it is not just a Java standard. Java is just one implementation of it. There are others for all of the major languages you can think of at different levels of maturity. Java is a very mature implementation. We also see things like .NET, and Node, and Go are all fairly mature as well. Other languages, Python, Ruby, PHP, Rust, are at varying stages of that maturity lifecycle. It is possible to get OpenTelemetry to work on top of bare metal or just in VMs, but there is no getting away from the fact that it is very definitely a cloud-first technology. The CNCF have fostered this, and they are in charge of the standard.
What Are Components of OpenTelemetry?
There are really three pieces to it that you might want to look at. The two big ones are the API and the SDKs. The API is what the developers of instrumentation and of the OpenTelemetry standard itself tend to use. Because they contain the interfaces, and from there, you can do things like, you can write an event exporter, you can write attribute libraries. The actual users, the application owners, the end users, will typically configure the SDK. The SDK is an implementation of the API. It’s the default one, and it’s the one you get by default. When you download OpenTelemetry, you get the API, you also get the SDK as a default implementation of that API. That then is the basis which you have for instrumenting your application using OpenTelemetry, and that will be your starting point if you’re new to the project. There is also the plugin interfaces, which are used by a small group of folks who are interested in creating new plugins and extending the OpenTelemetry framework.
What you want to draw your attention to is that they describe these four guarantees. The API is guaranteed for three years, plugin interfaces are guaranteed for one year, and so is the SDK, basically. It’s worth noting that the different components, metrics, logs, and tracing, are at different statuses at different points in their lifecycle. Currently, the only thing which is considered in scope for support is tracing. Although the metrics piece will probably also come into support very soon when it reaches 1.0. Some organizations depending upon the way you think about support, might consider these are not particularly long timescales. It will be interesting to see what individual vendors will do in terms of whether they honor these guarantees or whether they will treat them as a minimum. In fact, support for longer than this.
Here are our components. This is really what makes up OpenTelemetry. The specification comprising the API, the SDK, data and semantic conventions. Those are cross-language and cross-platform. All implementations must have the same view, as far as possible, as to what those things mean. Each individual language then also needs not only an API and an SDK, but we need to instrument all of the libraries and frameworks and applications that we have available. That should work as far as possible, completely out of the box. That instrumentation piece is a separate component from the specification and the SDK. Finally, one other very important component of the OpenTelemetry suite is what we call the collector. The collector is a slightly problematic name, because when people think of a collector, they think of something which is going to store and process their data for them. It doesn’t do that. What it really is, is a very capable network protocol terminator. It’s able to speak a whole variety of different network formats, and it effectively acts as a switching station, or a router, or a traffic terminator. It’s all about receiving, processing, and re-exporting telemetry data in whatever format that it can find it in. Those are the primary OpenTelemetry components.
JDK Flight Recorder (JFR)
The next section is all about JFR. It is a pretty nice profiling tool. It’s been around for a long time. It was originally first in Java 7, the first release of Java from Oracle, which is now well over 10 years ago. It’s got this interesting history because Oracle didn’t invent it, they bought it when they bought BEA Systems. Long before they did the deal with Sun Microsystems, they bought BEA, and BEA had their own JVM called JRockit. JFR originally stood for JRockit Flight Recorder. When they merged it into HotSpot with Java7, it became Java Flight Recorder, and then when they open sourced it, because from Java 7 up to Java 11, JFR was a proprietary tool. It didn’t have an open source implementation. You could only use it in production if you were prepared to pay Oracle for a license. In Java 11, JDK Flight Recorder was added to OpenJDK, renamed to JDK Flight Recorder, and now everybody can use it.
It’s a very nice profiling tool. It’s extremely low overhead. Oracle claim that it gives you about a 1% impact. I think that’s probably overstating the case. It depends, of course, a great deal on what you actually collect. The more data you collect, the more you disturb the process that’s under observation. It’s almost like quantum mechanics, the more you look at something and the more you observe it, the more you disturb it and mess around with it. I’ve certainly seen on a reasonable data collection profile around about 3%. If you’re prepared to be more light touch on that, maybe you can get it down even further.
Traditionally, JFR data is displayed in a GUI console called Mission Control, or JMC. That’s fine, but it has two problems that we’re going to talk about. JFR by default generates an output file. It generates a recording file like an airplane black box, and JMC, Mission Control only allows you to load in one file at a time. Then you have the problem that, if you’re looking across an entire cluster, you need lots of GUI windows open in order to see the different telemetry data from the different machines. That’s not typically how we want to do things for observability. At first sight, if it doesn’t look like JFR, is that suitable? We’ll have to talk about how we get around that.
Using Flight Recorder
How does it work? You can start it with a command line flag. It generates this output file, and there are a couple of pre-configured profiles, they call them, which can be used to determine what data is captured. Because it generates an output file and dumps it to a disk, and because of the usage of command line flags, this can be a bit of a challenge in containers, as we’ll see. Here’s what some of the startup flags might look like. We’ve got a Java -XX:StartFlightRecorder, and then we’ve got a duration, and then a filename to dump it out to. This bottom example will allow you to start a flight recording. When the process starts, it will run for 200 seconds, and then it will dump out the file. For long running processes, this is obviously not great, because instead what’s happening is that you’ve only got the first 200 seconds of the VM. If your process is up for days, that’s actually not all that helpful.
There is a command called jcmd. Jcmd is used not just to control JFR, but it can be used to control many aspects of the Java virtual machine. If you’re on the machine’s console, you can start and stop and control JFR from the command line. Again, this is not really that useful for containers and for DevOps, because in many cases, with modern containers and modern deployments, you can’t log into the machine. How do you get into it, in order to issue the command, in order to start the recording? There are all sorts of practices you can do to mitigate this. You can set things up so that JFR is configured as a ring buffer. What that means is the buffer is constantly running and it’s recording the last however many seconds or however many megabytes of JFR information, and then you can trigger JFR to dump that buffer out as a file.
Demo – JFR Command line
Here’s one I made earlier. This application is called heapothesys. This is by our friends and colleagues at Amazon. It is a memory benchmarking tool. We don’t want to do too much. Let’s give this a duration of 30 seconds to run rather than the 3 minutes. Let’s just change the filename as well just so I don’t obliterate the last one that I have. There we go. You can see that I’ve started this up, you can see that the recording is working. In about 30 seconds we should get an output to say that we’ve finished. The HyperAlloc benchmark, which is part of a directory called heapothesys, is a very useful benchmark for playing with the memory subsystem. I use it a lot for some of my testing and some of my research into garbage collection. Ok, so here we go, we have now got a new file, there it is, hyperalloc_qcon. From the command line, there’s actually a JFR command. Here we go, jfr print. There’s loads of data, lots of things to do with GC configuration, and all kinds of things, code cache statistics, all sorts of things that we might want, lots of things to do in the module system.
Here’s lots of CPULoad events. If you look very carefully, you can see that they are about once a second. It’s providing ticks which could easily be turned into metrics for CPU utilization, and so forth, as well. You see, we’ve got lots of nice numbers here. We’ve got the jvmUser, the jvmSystem, and the total of the machine as well. We can do these types of things with the command line. What else can we do from the command line? Let’s just reset this back to 180. Now I’m just going to take all of the detail out so we’re not going to start at startup. Instead, I’m going to run that, look at Jps from here, and now I can do jcmd. We’ll just leave that running for a short amount of time. Now we can stop it. I forgot to give it a filename and to dump it. As well as the start and stop commands, I forgot to do a dump in the meantime. You actually also needed a JFR dump in there as well. That’s just a brief example of showing you how you could do some of that with the command line.
The other thing which you can do is actually programmatic. You can actually take a file, and here’s one I made earlier. Within the modern 11-plus JDK, you can see that we actually have a couple of entries, RecordedEvent and RecordingFile. This enables us to process the file. Down here, for example, on line 19, we can take in a RecordingFile, and then process it in a while loop where we take individual events, which are of this type, jdk.jfr.consumer.RecordedEvent. Then we can have some way of processing the events. I use a pattern for programmatically handling JFR events, which involves building these handlers. I have an interface called a RecordedEventHandler, which combines both the consumer and the predicate. Effectively, you test to see whether or not you will handle this event. Then if you can, then you consume it. Here’s the test event, here’s the predicate. Then the other event that we will typically also see is the consumer, so is the, accept. Then, basically, what this boils down to is something like a G1 handler. This one can handle a bunch of different events, G1HeapSummary, GCHeapSummary, and GCPhaseParallel. Then the accept event looks like this. We basically look at the incoming name, and figure out which of these it is. Then delegate to an overload of accept. That’s just some code for programmatically handling events like this and for generating CSV files from them.
JFR Event Streaming
One of the other things which has also happened with recent versions of JFR, is this move away from dealing with files. JFR files are great if what you’re doing is fundamentally performance analysis. Unfortunately, it has problems, for doing observability and for long term, always on production profiling. What we need to have is some telemetry stream of information. The first step towards this is in Java 14, which came out over two years ago now. That basically provided a mode for JFR, where you could get a callback. Instead of having to start and stop recordings and control them, you could just set up a thread, which said, every time one of these events that I’ve registered appears, please call me back, and I will respond to the event.
Example JFR Java Agent
Of course, one way that you might want to do this is with a Java agent. You could, for example, produce some very simple code like this. This is actually a complete working Java agent. We’ve got a premain method, so we will attach. Then we have a run method. I’ve cheated a little tiny bit, because there’s a StreamEventSender object which I haven’t implemented, and I’m showing you what it does. Basically, it sends up the events to anything that we would want. You might imagine that those just go over the network. Now instead of having a RecordingFile, we have a RecordingStream. Then all we need to do is to tell it which events we want to enable, so CPULoad. There’s also one called JavaMonitorEnter. This basically is an event which lets you know when you’re holding a lock for too long, so that we’ll get a JFR event triggered every time a synchronized lock is held by any thread for more than 10 milliseconds. Long held locks effectively is what you can detect with that. You set those two up with the callback of which is the onEvent lines. Then finally, you call our start. That method does not return, because now your thread has just been sent up as an event loop, and it will receive events from the JFR subsystem as things happen.
What Is Current Status of OpenTelemetry?
How can we marry up JFR with OpenTelemetry? Let’s take a quick look at what the status of OpenTelemetry actually is. Traces are 1.0. They’ve been 1.0 for I think about a year now. They allow you to track the progress of a single request. They are basically replacing older open standards, including OpenTracing, including Jaeger’s client libraries. Distributed tracing within OpenTelemetry is eating the lunch of all of those projects. It seems very clear that that is how the industry, not just in Java, is going to do tracing going forwards. Metrics is so close to hitting 1.0. In fact, it may go 1.0 as early as this week. For JVM, that means both application and runtime metrics. There is still some work to do to make the JVM metrics, the ones that are produced directly by the VM itself, that is, the ones that we’ll use JFR for, in order to get that to completely align. It’s the focus of ongoing work. Metrics is now very close as well. Logging is still in draft state. We do not expect that we will get a 1.0 log standard until late 2022 at the earliest. Anything which is not a trace or a metric is considered to be a log. There’s some debate about whether or not, as well as logs, we need events as a related or subtype of logs that we have.
Different Areas Have Different Competitors
The maturities are different in some ways. Traces, OTel is basically out in front. Prometheus, there’s already a lot of folks using Prometheus, especially for Kubernetes. However, it’s less well established elsewhere and it hasn’t really moved a lot lately. I think that is a space where OTEL and a combined approach which uses OTel traces and OTel metrics can really potentially make some headway. The logging landscape is more complicated, because there are lots of existing solutions out there. It’s not clear to me that OTel logging will make that much of an impact yet. It’s very early days for that last one. In general, OpenTelemetry is going to be declared as 1.0 as soon as traces and metrics are done. The overall standard as a whole will go 1.0 very soon.
Java and OpenTelemetry
Let’s talk about Java and OpenTelemetry. We’ve talked about some of these concepts already, but now let’s try and weave the threads together, and bring it into the realm of what a Java developer or Java DevOps person will be expected to do day-to-day. First of all, we need to talk a little tiny bit about manual versus automatic instrumentation. In Java, unlike some other languages, there are really two ways of doing things. There is manual instrumentation, where you have full control. You can write whatever you like. You could instrument whatever you like, but you have to do it all yourself, and you have a direct coupling to the observability libraries and APIs. There’s also the horrible possibility of human error here, because what happens if you don’t instrument the right things, or you think something isn’t important, and it turns out to be important? Not only do you not have the data, but you may not know that you don’t have it. Manual instrumentation can be error prone.
Alternatively, some people like automatic instrumentation, this requires you to use a Java agent, or to use a framework which automatically supports OpenTelemetry. Quarkus, for example, has automatic inbuilt OTel support. You don’t need a Java agent. You don’t need to instrument everything manually. Instead, the framework will do a lot to support you. It’s not a free lunch, you still require some config. In particular, when you’ve got a complex application, you may have to tell it certain things not to instrument just to make sure you don’t drown in too much data. The downside of automatic is there could be a startup time impact if you’re using a Java agent. There might be some performance penalties as well. You have to measure that. You have to determine for yourself which of these two routes is right for you. There’s also something which is a little bit of a hybrid approach, which you could do as well. Different applications will reach different solutions.
Within the open-telemetry GitHub org, there are three main projects that we care about within the Java world. There’s opentelemetry-java, this is the main instrumentation repo. It includes the API, and it includes the SDK. There is opentelemetry-java-instrumentation. This is the instrumentation for libraries and other components and things that you can’t directly modify. It also provides an agent which enables you to instrument your applications as well. There’s also opentelemetry-java-contrib. This is the standalone libraries, the things which are accompaniments to this. It’s also where anything which is intended for the main repos, either the main OTel Java or the Java instrumentation repo, they go into contrib first. The biggest pieces of work that are in Java contrib right now are gathering of metrics by JMX, and JFR support, which is still very much in beta, we haven’t finished it yet. We are still working on it.
This leads us to an architecture which looks a lot like this. You have applications with libraries which depend directly upon the API. Then we have an SDK, which provides us with exporters, which will send the data across the wire. For tracing, we will always require some configuration because we need to show where the traces are sent to. Typically, traces will be sampled. It is not normally possible to collect data about every single transaction and every single user request that is sent in. We need to sample, and the question is, how do we do the sampling? Do we sample everything at the same rate? Some people, notably the Honeycomb folks, very much want to sample errors more frequently. There is an argument to be made, the errors should be sampled at 100%, 200 oks, maybe not. There’s also the question about whether you should sample uniformly or whether you should use some other distribution for determining how you sample. In particular, could you do some long tail sampling, where slow requests are also sampled more heavily than the requests which complete closer to the meantime? Metrics collection is also handled by the SDK. We have a metrics provider which is usually global as an entry point. We have three things that we care about, we have counters, which only ever increase, so transaction count, something like that. We have measures which are values aggregated over time, and observers which are the most complex type, and provide effectively a callback.
Aggregation in OpenTelemetry
One of the things which we should also say about OpenTelemetry, is that OpenTelemetry is a big scale project. It is designed to scale up to very large systems. In some ways, it’s an example of a system, which is built for the big scale, but is still usable at medium and small scales. Because it’s designed for big systems, it aggregates. Aggregation happens, not particularly in your app code or under the control of the user, but in the SDKs. It’s possible to build complex architectures, which do multiple aggregations at multiple scales.
Status of OTel Metrics
Where are we with metrics? Metrics for manually instrumented code are stable. The wire format is stable. We are 100% production ready on the code. The one thing which we still might have a slight bit of variation on, and as soon as the next release drops, that won’t change, is the exact nature or meaning of the data that’s being collected from OTel metrics. If you are ready to start deploying OpenTelemetry, I would not hold back at this point on taking the OTel metrics as well.
Problems with Manual Instrumentation
There are a lot of problems with manual instrumentation. Trying to keep it up to date is difficult. You have confirmation biases that you may not know what’s important. What counts as important will probably change as the application changes over time. There’s a nasty problem with manual instrumentation, which is that you quite often only find out what is really important to your application in an outage, which goes against the whole purpose of observability. The whole purpose of observability is to not have to predict what is important, to be able to ask those questions where you didn’t know you’d need to ask them at the outset. Manual instrumentation goes against that goal. For that reason, lots of people like to use automatic instrumentation.
Java Agents
Basically, Java agents install a hook. I did show an example of this earlier on, which contains a premain method. That’s called a pre-registration hook. It runs before the main method of your Java application. It allows you to install transformer classes, which have the ability to rewrite code as it’s seen. Basically, there is an API with a very simple hook, there’s a class called instrumentation. You can add bytecode transformers and weavers, and then add them in as class transformers into instrumentation. That’s where the real work is done, so that when the premain method exits, those transformers have been registered. Those transformers will be rewritten and able to spin up new code and to insert bytecode into classes as they’re loaded. There are key libraries for doing this. In OpenTelemetry we use the one called Byte Buddy. There’s also a very popular bytecode rewriting library called ASM, which is used internally by the JDK.
The Java agent that’s provided by OpenTelemetry can attach to any Java 8 and above application. It dynamically injects bytecode to capture the traces. It supports a lot of the popular libraries and frameworks completely out of the box. It uses the OTLP exporter. OTLP is the OpenTelemetry Line Protocol. The network protocol which is really Google Protocol Buffers over gRPC, which is an HTTP/2 style of protocol.
Resources
If you want to have a look at the projects, the OpenTelemetry Java is probably the best place to start. It is a large and sophisticated project. I would very much recommend that you take some time to look through it if you’re interested in becoming a developer on it. If you just want to be a user, I would just consume a published artifact from Maven Central or from your vendor.
Conclusion
Observability is a growing trend for cloud native developers. There are still plenty of people using things like Prometheus and Jaeger today. OpenTelemetry is coming. It is quite staggering how quickly it is growing and how many new developers are onboarding to it. Java has great data sources which could be used to drive OpenTelemetry, including technology like Java agents and JFR. There are active open source work to bring these two strands together.
See more presentations with transcripts
MMS • Yury Nino Roa

Transcript
Roa: The title of my talk is observability is programmed, and it is a work, thought, ideas, and processes for automating observability as code. My name is Yury Niño. I am cloud infrastructure engineer and chaos engineer advocate in the Spanish community. I code for Google, designing and provisioning infrastructure solutions as code.
Outline
Specifically, these are the topics that I am going to cover. I am going to present a landscape of observability which includes concepts, practitioners, technologies, and a personal perception of this evolution. With this context, I am going to present why implementing observability as code is important, not only for developers or operators but also organizations. In this part, we are reviewing, what are the benefits of implementing observability as code? Finally, I am going to present a framework based on the famous maturity model.
Observability Landscape
Observability is about good practices. In order to support these practices, the Hindustan Academy have joined efforts that should be reviewed before. Let’s explore the landscape of observability before turning to the benefits for the modern software systems. Distributed systems has been growing rapidly to meet the demands of emerging applications such as business analytics, biomedical informatics, media streaming applications, and so on. This rapid growth comes with complexity. To alleviate this, observability is emerging as a key capability of modern distributed systems that use telemetry data collected during the runtime for debugging and maintaining these complex applications. These books which were the reference for this talk, they explore the properties and patterns defined for observability and enabled readers to harness new insights from the monitor telemetry data as applications grow in complexity.
What Is Observability?
The term observability was coined by Rudolf Kálmán in 1960, as a concept of control theory in which observability is defined as a measure of how well internal states of a system can be inferred from knowledge of its external outputs. Observability is being able to fully understand our system. Observability for software systems is a measure of how well you can understand and explain any state of your system. When you have adopted observability, you must be able to comparatively debug across all dimensions of the system, any state of the system, the inner workings of their components, all without shipping any new custom code, or by interrogating with external tools. For me, observability is about asking questions, providing answers, and building knowledge about our systems.
What Is Not Observability?
Observability is different from monitoring, and it is super important to understand why. Some vendors insist that observability has no special meaning whatsoever, and it’s simply another synonym for telemetry indistinguishable from monitoring, for example. Probably, you could have heard that observability is about three pillars: metrics, logs, and traces. Proponents of these definitions relegate observability to begin another generic term for understanding how software operates. Take this away please, monitoring is about collecting, processing, aggregating, and displaying real time quantitative data about our systems. While observability is defined as a measure of how well internal states of a system can be inferred from knowledge of these external outputs. I think for modern software systems, observability is not about the data types or inputs, nor is about mathematical equations. It is about how people interact with and try to understand the complex systems. Therefore, observability requires recognizing the interaction between both people and technology in order to understand how those complex systems work together.
Observability Evolution
This is a brief history of observability and its meaning in 2022. I mentioned the term observability has its roots in control theory. In 1960, Rudolf Kálmán introduced the terms in the classical paper on the general theory of the control systems. In September 2015, engineers on Twitter wrote a blog post called Observability at Twitter. It is one of the first times that observability was used in the context of IT systems. A few years later, Anthony Asta from the observability engineering team at Twitter created a blog post called, Observability at Twitter: technical overview, part I, where he presented four pillars for observability: monitoring, alerting, tracing, and log analytics. In February 2017, Peter Bourgon published a blog post called metrics, tracing, and logging. If you notice, three metrics for that. He described the three pillars, metrics, tracing, and logging as a Venn diagram.
In July 2018, Cindy Sridharan, published a definitive book of O’Reilly called, “Distributed Systems Observability,” that is a classical book for this topic. The book outlines the three pillars again, for observability, and details which tools to use and when. In the same year, Charity Majors, CEO of Honeycomb, warns that describing observability as three pillars limits the discussion. She shared a series of tweets where she boldly explains, there are no three pillars of observability, and especially with intention to reveal why. Since 2020, it has been a massification of tools, APIs, and SDKs, to instrument, generate, [inaudible 00:06:57] for data to help analyze software performance and behavior, providing finally observability. With these whole initiatives, the Cloud Native Computing Foundation decided to create a standard for instrumentation, and that are collections of observability data. In 2022, one of the best books for observability, “Observability Engineering,” was released by Charity Majors, George Miranda, and Liz Fong-Jones. This book digs into what observability actually means. It talks about the fundamental concepts, how it all works, how these systems are not technical, they are sociotechnical systems.
Regarding this massification, InfoQ included data observability in the last DevOps, and Cloud Graph. Data observability is an emerging technology that helps to better understand and troubleshoot the data intensive systems. The concept of data observability was first coined in 2019 by Barr Moses. According to her, data observability is an organization’s ability to fully understand the health of their data in their systems. It uses automated monitoring, alerting, and triaging to identify and evaluate data quality and discoverability issues. If you notice, that is closely related to observability, and observability as code, of course.
Regarding observability as code, the topic that we have here, The Radar published in 2018 by Thoughtworks included this practice in the trial category. They established that observability as code is about non-repeatable dashboard configurations, continuously test and adjust earlier to avoid earlier fatigue or missing out on important alerts. From organizational best practices, they highly recommend treating observability as a way to adopt infrastructure as a code for monitoring and alerting, products that supports configurations through version-controlled code and execution of APIs or commands via infrastructure continuous delivery, continuous deployment pipelines. Observability as code is an often forgotten aspect of infrastructure as code. They believe that it’s crucial enough to be called out.
Observability as code is part of something bigger, observability-driven development or ODD, which is a new terminology that has started being used recently that encode actually the activities required for observability. Specifically, it talks about applications, instrumentation, a stack of technologies, and visualization in order to achieve ODD, the acronym that I am going to use. Regarding observability-driven development, or ODD, the purpose of DevOps automation isn’t just speed, it is about leveraging the intrinsic motivation and creativity of developers again. For me, I think that it uses data and tooling to observe the state and behavior of a system before, during, and after development to learn more about it.
How Does Observability Code Look?
This is how observability as code looks. It has stages separated by environments, such as local, continuous integration, continuous deployment, and continuous delivery. In this illustration, developers commit observability code in a second step, Git server invokes web code, cloud build triggers, custom workers. After that, custom workers access resources in monitoring provider. They build, test, and implement artifacts. Finally, in a continuous delivery task, the dashboards, alerts, and data are delivered frequently. Is it observability as code? Monitoring is monitoring, observing is event-first testing in production. How does observability code look under this definition? Since monitoring is monthly metrics, while observability is about events, observability as code must include many actionable active checks and alerts, proactively notifying engineers of failures and warnings. Maintaining a runbook for stability and predictability in production systems. Expecting clusters and clumps of tightly coupled systems to all break at once. Observability in production must generate us artifacts as possible to determine, what is the internal, or how is the internal state of a system. It must show you any performance degradation in tests or errors during the build and release process. If code is properly instrumented, you should be able to break down by old and new build ID, and analyze them side by side. The pipeline must provide tools to validate consistent and smooth production performance with the deployments. Or to see whether your new code is having its intended impact, or whether anything looks suspicious, or drill down into specific events.
Some reasons for thinking that observability as code is a good idea includes, it allows to identify and diagnose faults, failures, and crashes. It enables the analysis of the operational performance of the system. It measures and analyzes the business performance and success of the system or its components that is really important for product owners or product stakeholders, for example. Specifically, some of the benefits of adopting observability as code practices include repeatable, replicable, reusable activities. Reducing toiling, that is a great benefit, a great advantage of this practice. Documentation and context. Documentation is important here. Auditable, or to have a strategy for audit history. Security is another great advantage here. Since observability as code allows for stricter controls over the resources. Efficient delta changes, react to external stimulus. Ownership and packaging. Disaster recovery that is a great source for providing information for your disaster recovery strategies. Speed of deployments. They are some advantages or benefits for practicing with observability as code.
Observability Maturity Model
Finally, how to start with observability as code. Spreading a culture of observability is best achieved by having a plan that measures progress and prioritize target areas of investment. In this section, I go beyond the benefits of observability and its tangible technical steps by introducing the observability maturity model, that I design it according to my experience and according to the experience of others in the literature. We will review the key capabilities an organization can measure and prioritize as a way of driving observability adoption.
Sophistication
In this sense, the first axis that we are going to review is sophistication. I have determined some criteria to define which category of the classical maturity model do your team and your organization are. Specifically, I am going to present some characteristics for locating an organization in these stages or levels: elementary, simple, sophisticated, and advanced. In an elementary level, the engineering teams are distracted for picking the wrong way for fixing something. Even people could be afraid to make changes to the code but they have decided to implement a strategy for observability as code in order to improve this situation. They are collecting metrics but they are not monitored, visualized, neither notified. As a consequence, the incident responders cannot easily diagnose issues.
The next stage is called Simple. Here, the teams have installed agents in the code for monitoring the behavior of the system using monitoring platforms, such as Datadog, New Relic, Honeycomb, Dynatrace. They have shown interest in continuous integration, and continuous deployment, continuous delivery platforms, and infrastructure as code technologies. They are determining a strategy for defining key performance indicators, KPIs, and want to monitor based on a list of services which have been mapped in SLOs. However, this process is administered manually. The releases are infrequent and require lots of human intervention. Regarding the general release process, it is possible that lots of changes are shipped at once. The releases have not to happen in a particular order. The alternatives avoid deploying at certain days or times of year.
If you are in this stage, sophisticated, you are close to reaching an observability as a complete strategy, although it is critical to mention that it’s an evolutionary strategy. Here, the teams have familiarity with provisioning tools, such as Terraform, Pulumi multi, and their API features. They have access to CI/CD platforms that supports automation workflows. They are using tagging and naming conventions that allow to classify the events in a proper way. Regarding this stage, I would like to say automation of observability workflows are essential for scaling observability as code to teams and organizations. There are many tools and services available that can support automation observability workflows. However, these workflows to be discussed and configuring according to each engineering team, they are not the outgo solutions.
As I have mentioned, finally, implement observability as code strategy is a constant drill. However, I decided to include some criteria to identify, in the top of this axis. In this stage, an automation workflow for observability as code is implemented, and it is running in production, even using strategies such as OpenTelemetry, something common in the company, but combining tracing, metrics, and logging into a single set of system components and language specific telemetry libraries. In this stage, code gets into production shortly after being written. Engineers can trigger deployment of their own code after it’s been peer reviewed, satisfying controls, and checked in.
Adoption
Now it’s time for moving to the other axis, I am talking about adoption. According to the capacity maturity model, the capability of an organization for doing anything can be classified into four stages or levels: in the shadows, investment, in adoption, and finally in cultural expectation. According to my experience, an organization is in shadows when there is low or no organizational awareness, projects are also sanctioned. In general, the organization is spending a lot of additional time of money, staffing the on-call rotation. For example, on-call response to alerts is inefficient, and alerts are ignored. As a consequence, the product teams don’t receive feedback of the features, since early adopters infrequently perform monitoring, or observability strategies. Incident responders cannot easily diagnose issues. Some team members are disproportionally pulled into emergencies. The good news are since the organizations are aware of these pain points, the teams are starting by identifying when to observe and designing in such a way to make instrumentation easy.
With the aim of overcoming these problems, the organizations have decided to adopt observability as code. In this stage, in investment, observability as code is officially sanctioned and practitioners are dedicating resources to the practice. For example, product managers want to have enough data to make good decisions about what to build next, or they want to receive customer feedback of the product features that are growing their scope. Some criteria that allows to identify that you are here include a few critical services from monitoring, alerting, and visualization. Multiple teams are interested and engaged with that strategy for observing several critical services. Code is stable. That is a fact. Fewer bugs are discovered in production, but you are dedicating resources in a year.
In this stage, adoption, observability as code is officially sanctioned, and there is a team dedicated to implement, since in the last stage, the team decided to implement observability as code. Resources are dedicated to the practice. Developers have easy access to KPIs for customer outcomes, and system utilization cost, and can visualize them side by side. For example, after code is deployed to production your team focuses on customer solutions rather than support isolated issues that can typically be fixed without triggering cascading failures, for example. The team is following practice to enforce observability as part of continuous deployment. Finally, team is adding metric collections, tracing, and context for getting better insights.
Finally, observability is about generating the necessary data, encouraging teams to ask open-ended questions, and enabling to iterate, because effective product management requires access to relevant data with this level of visibility offered by event-driven data analysis and predictable currents of releases both enabled but also observability. That is the reason for having a standardization of instrumentation with best practices like proactive monitoring and alerting in place, with a clear definition and implementation of KPIs to measure observability as code maturity. A feedback loop from the observations to a stakeholder’s team taking advantage of observability as code. In general, the team is using insights for discussing about the learnings that are shared and implemented through these initiatives.
Conclusion
Every industry is seeing new and transforming along, they are staged by legacy systems and infrastructure. For me, there is a final quote about these things, “Waiting is not an option.” Observability as code is required in your organization. According to the size of your organization, the path could be different, but it is required to automate this strategy in order to have insights of your systems, in order to know, how is the state of your system? The most important, in order to avoid toiling, in order to keep the development team happy.
See more presentations with transcripts
MMS • Daniel Dominguez

Microsoft has introduced VALL-E, a novel language model method for text-to-speech synthesis (TTS) that employs audio codec codes as intermediate representations and can replicate anyone’s voice after listening to just three seconds of audio recording.
VALL-E is a neural codec language model where the AI tokenizes speech and uses its algorithms to use those tokens to build waveforms that sound like the speaker, including keeping the speaker’s timbre and emotional tone.
According to the research paper, VALL-E can produce high-quality personalized speech with just a three-second enrolled recording of an oblique speaker acting as an acoustic stimulus. It does so without the need for additional structural engineering, pre-designed acoustic features, or fine-tuning. It supports contextual learning and prompt-based zero-shot TTS approaches.
Audio demonstrations of the AI model in action are provided by VALL-E. The “Speaker Prompt,” one of the samples, is a three-second auditory cue that VALL-E must duplicate. For comparative purposes, the “Ground Truth” is a previously recorded excerpt of the same speaker using a certain phrase (sort of like the “control” in the experiment). The “Baseline” sample represents a typical text-to-speech synthesis example, and the “VALL-E” sample represents the output of the VALL-E model.
In comparison to the most sophisticated zero-shot TTS system, VALL-E performs significantly better on LibriSpeech and VCTK, according to evaluation data. On LibriSpeech and VCTK, VALL-E even produced cutting-edge zero-shot TTS outcomes.
The field of voice synthesis has advanced significantly in recent years thanks to the development of neural networks and end-to-end modeling. Currently, vocoders and acoustic models are often utilized in cascaded text-to-speech (TTS) systems, with mel spectrograms acting as the intermediary representations. High-quality speech from a single speaker or a group of speakers can be synthesized by sophisticated TTS systems.
TTS technology has been integrated into a wide range of applications and devices, such as virtual assistants like Amazon’s Alexa and Google Assistant, navigation apps, and e-learning platforms. It’s also used in industries such as entertainment, advertising, and customer service to create more engaging and personalized experiences.
MMS • Johan Janssen

The release of the Kubernetes Java Client 17.0.0 delivers support for Kubernetes 1.25 providing the ability to dynamically retrieve information, for example for monitoring purposes, and allows changing and deleting items in the Kubernetes cluster. The Kubernetes client may be used as an alternative for the command line Kubernetes tool: kubectl [argument].
The Kubernetes Java Client can be used after adding the following Maven dependency:
io.kubernetes
client-java
17.0.0
Alternatively the following Gradle dependency may be used:
compile 'io.kubernetes:client-java:15.0.1'
The CoreV1API offers a large amount of methods, such as retrieving all pods:
ApiClient apiClient = Config.defaultClient();
Configuration.setDefaultApiClient(apiClient);
CoreV1Api api = new CoreV1Api();
V1PodList podList = api.listPodForAllNamespaces(
null, null, null, null, null, null, null, null, null, null);
for (V1Pod pod : podList.getItems()) {
System.out.println("Pod name: " + pod.getMetadata().getName());
}
The listPodForAllNamespaces() method offers many configuration options by specifying the arguments of the method:
public V1PodList listPodForAllNamespaces(
Boolean allowWatchBookmarks,
String _continue,
String fieldSelector,
String labelSelector,
Integer limit,
String pretty,
String resourceVersion,
String resourceVersionMatch,
Integer timeoutSeconds,
Boolean watch)
Apart from retrieving information, it’s also possible to change items, or even delete items such as a pod from a namespace:
Call call = deleteNamespacedPodCall(
String name,
String namespace,
String pretty,
String dryRun,
Integer gracePeriodSeconds,
Boolean orphanDependents,
String propagationPolicy,
V1DeleteOptions body,
final ApiCallback _callback)
The kubectl logs command displays logs from a running container, comparable to the following API call:
PodLogs logs = new PodLogs();
V1Pod pod = api.listNamespacedPod(
"default", "false", null, null, null, null, null, null, null, null, null)
.getItems()
.get(0);
InputStream inputStream = logs.streamNamespacedPodLog(pod);
Apart from retrieving single results, it’s also possible to watch events by setting the watch argument of a method to Boolean.TRUE. This is comparable to the kubectl get -w command. For example, to watch changes in a namespace and print them:
Watch watch =
Watch.createWatch(
client,
api.listNamespaceCall(null, null, null, null, null, 5, null, null,
null, Boolean.TRUE, null),
new TypeToken<Watch.Response>() {}.getType());
try {
for (Watch.Response reponse : watch) {
System.out.printf("Response type:" + response.type + " name: " +
response.object.getMetadata().getName());
}
} finally {
watch.close();
}
Some advanced use cases require the client-java-extended module which can be used after adding the following Maven dependency:
io.kubernetes
client-java-extended
17.0.0
Alternatively, the following Gradle dependency may be used:
implementation 'io.kubernetes:client-java-extended:17.0.0'
One of the more advanced use cases is pagination for list requests, which reduces the server side load and network traffic. For example, by retrieving five namespaces at a time, instead of all namespaces at once:
Pager pager = new Pager((Pager.PagerParams
param) -> {
try {
return api.listNamespaceCall(null, null, param.getContinueToken(),
null, null, param.getLimit(), null, null, 1, null, null);
} catch (Exception e) {
// Handle exception
}
}, client, 5, V1NamespaceList.class);
for (V1Namespace namespace : pager) {
System.out.println("Namespace name: " + namespace.getMetadata().getName());
}
More information and examples can be found in the documentation.
Guggenheim Starts Couchbase Inc (BASE) at Buy, ‘Capella-zing Beyond the Enterprise Base’
MMS • RSS

(Updated – January 26, 2023 4:18 PM EST)
Guggenheim analyst Howard Ma initiates coverage on Couchbase Inc (NASDAQ: BASE) with a Buy rating and a price target of $20.00.
The analyst comments “We are initiating coverage of Couchbase (BASE) with a Buy rating and price target of $20, about 45% above the current share price. Couchbase has created an enterprise-grade NoSQL database with a differentiated architecture designed to power modern applications that relational databases were not designed for. To date, Couchbase has been successful penetrating large enterprises, but growth has slightly lagged overall NoSQL market growth. We believe that Capella, the recently launched, fully managed, and cloud-native version of Couchbase’s database, will be the engine to accelerate growth and is a strategy that has worked for Software peers. We estimate that if Capella ramps successfully, then subscription revenue could grow 23% in FY24 and 21% in FY25 vs. consensus at 16% growth and 18% growth, respectively. Higher Capella CAGR could result in high-20s% growth in each of FY24 and FY25. At only 2.9x EV/NTM Recurring Revenue, the potential upside far outweighs limited downside, in our view.”
For an analyst ratings summary and ratings history on Couchbase Inc click here. For more ratings news on Couchbase Inc click here.
Shares of Couchbase Inc closed at $14.01 yesterday.
You May Also Be Interested In
MMS • Ben Linders

The quality practices assessment model (QPAM) can be used to classify a team’s exhibited behavior into four dimensions: Beginning, Unifying, Practicing, and Innovating. It explores social and technical quality aspects like feedback loops, culture, code quality and technical debt, and deployment pipeline.
Janet Gregory spoke about assessing quality using this model at Agile Testing Days 2022.
The quality practices assessment model has ten quality aspects, described in Helping Team Deliver With a Quality Practices Assessment Model.
The behaviour exhibited by teams for each quality aspect, falls into one of four dimensions: Beginning, Unifying, Practicing and Innovating. This does not mean that every quality aspect for a team falls into the same dimension, Gregory mentioned.
Teams in the Beginning dimension have few quality practices in place and lack structure, Gregory explained:
Low-quality code is deployed to production, defects are logged, and the invisible backlog of defects grows. Not all teams are in the same place, some will be more chaotic than others, but pretty much every team knows they want to improve.
In the Unifying dimension, the organization has adopted one or more agile methods forming cross-functional delivery teams:
The teams follow rituals like having daily standups, keeping a product backlog that they regularly refine, or time-boxing their work into iterations. They try to take smaller chunks of work that they can finish by the end of each iteration and are learning to work together as a cross-functional team.
In Practicing, team members feel good because the practices they have learned feel natural, and they consistently deliver value to their customers:
Teams have developed fast and effective feedback loops to pivot quickly when needed. The emphasis is on preventing code defects, so few are found. Those found early are fixed immediately or as high priority in the next iteration. They build quality into the product from the beginning by bringing testing activities forward early in the cycle, and use feedback from their customers to improve their product.
Innovating teams are high performing. Their cycle time is short with customer and business value delivered frequently:
The team knows their market and has high quality defined in identified aspects. They experiment where appropriate and adapt their practices. Self-learning and self-discipline are the norms, with the team consistently striving to learn and improve. Because psychological safety is high, failure is seen as a learning opportunity. The feature development is focused on flow but is thoughtful and based on value to the customer. The team understands and monitors the impact of changes using continual feedback from production usage. Quality is built-in from the start.
The hard part is consolidating all the information gathered from the different sources and to figure out discrepancies, Gregory explained:
I like to use a spreadsheet with the different quality aspects and the practices that go with them. That makes it easier for me to compare the findings with each of the dimensions.
The model is only as good as the person using it, and facilitation is a skill, Gregory mentioned. Often when teams try to self-assess, they rank themselves higher than others may see them. That doesn’t mean it’s not a good exercise for teams to try, Gregory said.
The quality practices assessment model is described in the book Assessing Agile Quality Practices with QPAM which Janet co-authored with Selena Delesie and is listed on Gregory’s publications page.
InfoQ interviewed Janet Gregory about assessing quality.
InfoQ: What tips do you have for assessment facilitators?
Janet Gregory: There are many ways to get information. I use all I can – a combination of process retrospectives, interviewing, observing meetings or workshops, and examining artifacts like user stories and tests.
In our book, we list open-ended questions for facilitators to use. A facilitator needs to listen and observe carefully to be able to extract the information – often, what is not said is as important as what is said.
We are creating a follow-up book as a guide for facilitators which will help anyone conducting the assessment – no promises when, but hopefully in the first half of 2023.
InfoQ: How can we present the results of an assessment?
Gregory: What a facilitator shares will depend on the context, but it is important that the information is anonymous.
If you are an internal facilitator, you likely will gather all your observations, and share what you found so the team can choose what to improve on.
If you are an external facilitator (like I am), you will likely share observations and provide suggestions and recommendations.
MMS • Matt Butcher Radu Matei

Key Takeaways
- While many languages support Wasm, some are faster than others.
- Some compilers natively support optimizing Wasm for efficiency and speed.
- The wasm-opt tool can optimize a Wasm binary regardless of the original language it was used to create it.
- Using a JIT-enabled runtime can improve runtime performance depending on the hardware platform you are using.
- Some Wasm runtimes can even compile applications ahead-of-time (AOT) to reach native execution speed.
- The experimental Wizer project achieves a further performance boost by pre-initializing a Wasm binary to reduce the time it takes to launch it.
- In our practice, we saw good optimization can reduce Wasm binary size by a factor of ten.
WebAssembly (often abbreviated to Wasm) is a binary executable format. Many different languages can be executed via Wasm, including Rust, C, JavaScript, Python, Ruby, and the .NET languages.
Additionally, Wasm can run on a huge range of hardware and operating systems. The specification is designed to be fast, compact, and above all secure.
In 2022, Wasm has cropped up in many different contexts. While it was originally designed for the browser, it turns out to be useful for embedded programming, plugins, cloud, and edge computing.
One thing these different use cases have in common is that performance is tremendously important. Since loading an executable quickly is part of performance, file size often has a direct impact on raw performance.
In this article, we’ll look at six ways to optimize Wasm for performance and file size.
Language Choice
Each programming language has its own nuances, and one of those is how large a runtime the language requires in order to execute. On the lightweight side, low-level system languages like C and Rust require small runtime overhead.
Other compiled languages like Swift bring a hefty runtime along for the ride. A Swift binary may be substantially larger simply because it includes a lot of built-in behavior. Java and .NET also tend to bring larger binary sizes for a similar reason.
To illustrate, let’s take a look at a “hello world” program in Rust and in Swift.
In Rust, a basic “hello world” program looks like this:
fn main() {
println!("Hello, world!");
}
Compiled with cargo build —target wasm32-wasi, this binary is 2.0M. (This is an unoptimized binary. We’ll return to this file size later.)
Here’s a similar program in Swift:
print("Hello, World!n")
Compiling this to Wasm with the Swiftwasm project using the command swiftc -target wasm32-unknown-wasi hello.swift -o hello.wasm produces a 9.1M image. That makes the Swift version over 4x larger than the equivalent Rust version.
So which language you choose will impact the file sizes of your binaries as well as the startup time (at least to some degree). This is not the final word on file sizes, though. There are ways to optimize the binary sizes further.
Using Compiler Flags to Optimize
Some compilers offer built-in compiler flags that can optimize the binaries they produce. Long-time C and C++ users are accustomed to this. And new languages like Rust and Zig also provide optimization options.
In the previous section, we looked at a simple three-line Rust program. When we compiled it with the default cargocommand, it produced a 2.0M binary. But by adding another flag, we can trim that size down: cargo build --target wasm32-wasi --release. This produces a 1.9M binary. On a small program like this, and with Rust’s svelte runtime, not much can be shaved off. On bigger projects, though, the –release flag can drastically reduce the file size. For example, compiling the Bartholomew CMS without the release flag yields an 84M binary, while using the release flag reduces it to 7M. That’s a huge savings.
Rust’s release target does more than merely reduce the file size. It can also speed up execution because it removes symbols that are used by debuggers and analysis tools. This is almost always a worthwhile feature when you are running code in production. Launching the full 84M version of Bartholomew may take up to a second to execute, but that reduces to a mere couple milliseconds when using the optimized version.
Optimizing Size with wasm-opt
In the above section, we saw how some compilers provide optimization flags. But not all of them do. Furthermore, even compilers that can produce some optimizations might not aggressively optimize.
Wasm optimization tools can perform robust analysis of a Wasm binary and further optimize the file size and even the performance characteristics of a Wasm executable. The Binaryen project provides a number of command line tools for working with Wasm, including the wasm-opt optimizer.
Before, we looked at a Swift program that was 9.1M in size. Let’s take a look at what happens when we run wasm-opt -O hello.wasm -o hello-optimized.wasm. This command will produce an optimized binary named hello-optimized.wasm. The resulting size is 4.0M, a reduction of over 50%.
The wasm-opt tool performs dozens of optimizations on a binary, ranging from removing duplicate code to re-organizing the code. Code, here, means the Wasm instructions, not the source code you edit. So running wasm-opt won’t change the source Swift code. It just rewrites the Wasm binary. While optimizing this way definitely cuts down the file size, it also improves runtime performance. On my system, the optimized “hello world” program executed twice as fast as the unoptimized one.
Indeed, wasm-opt can even further optimize the already-optimized Rust code. Running it on the 1.9M Rust binary from the previous section generates an even more compact 1.6M binary. In such a simple case performance did not improve. Both run in a tenth of a second. But larger Rust binaries likely also gain speed improvements with wasm-opt.
The Runtime Matters
Wasm is a flexible binary format. It can be executed by an interpreter such as wasm3, which will read and execute small chunks of the code in sequence. But other Wasm runtimes like Wasmtime use a technology called JIT (Just-In-Time) compiling to speed up execution.
For small programs, like our “hello world” examples, or on devices with constrained resources such as a Raspberry Pi, an interpreter is often desirable since it does the least amount of work and uses the fewest resources.
But for larger programs like the Bartholomew CMS, a JIT-style runtime will outperform an interpreter. The reason for this discrepancy is that a JIT compiler does extra work at startup and during early execution in order to optimize the in-memory representation of the program. And this optimization shows up as the code continues to run. Because the JIT process takes time, though, this can appear to be a performance penalty for small programs that only run for a moment.
How do you choose? The traditional rule of thumb is this: If you are running on a constrained device smaller than a Raspberry Pi, use an interpreter. Otherwise, favor a JIT-enabled runtime.
When it comes to runtimes, there’s one more trick.
Ahead-Of-Time (AOT) Compiling
A JIT runtime performs in-memory optimizations at startup time. But what if we could perform optimizations once, write those optimizations back out to disk, and then take advantage of those optimizations the next time the program is run? This strategy is called Ahead-Of-Time (AOT) compiling.
There’s a big drawback to AOT compiling: the optimizations done during this stage are different-in-kind than the ones we saw earlier with wasm-opt. With AOT, optimizations are machine-specific. These optimizations take into account operating system and processor architecture, which means once we perform these optimizations, our Wasm binary is no longer portable. Furthermore, each runtime has its own format for these optimizations, so a program AOT-compiled with one Wasm runtime will no longer be runnable by other Wasm runtimes.
The Wasmtime runtime can compile a Wasm module to an AOT format. For example, we can run wasmtime compile hello.wasm to compile our Swift example. This will produce a new file named hello.cwasm that can be executed by Wasmtime.
Again, for trivial programs like our “hello world” example, AOT compiling will not have a large benefit. But when working with non-trivial programs, AOT compiling will achieve higher performance numbers than either interpreter or JIT-enabled runs. Note, however, that most AOT compilers produce binaries that may be larger than their Wasm equivalent because many elements of the Wasm runtime itself are compiled into the binary to improve performance.
There is a very specific rule of thumb for knowing when to use an AOT compiler for Wasm: only use it when you know that the program will only ever be run with exactly the same configuration of Wasm runtime, operating system, and architecture. Wasm modules should be distributed in their normal Wasm form, and only AOT-compiled at or after the installation step.
Pre-Initializing a Binary
The fifth and final optimization technique is the most peculiar of the lot. Wasm is a stack-based virtual machine, and at any given time it can be stopped and even written out to disk, to be resumed later. (There are a few limitations to this, but these limitations are not important here.) This feature of Wasm has an interesting application.
Sometimes there are parts of your code that you need to run every single time on startup. This code may do banal things like setting the default value of a variable or creating an instance of a data structure. Every time the code is run, this same bit of initialization logic must be performed. And with each run, the resulting state of the program is the same. The variable is initialized to the same value, or the data structure is initialized into the same state.
What if there was a way to run that first initialization, then freeze the Wasm state and write it back out to disk? Then the next time the program is executed, it wouldn’t have to run the initialization step. That would already be done!
This is the idea behind the Wizer project. Wizer provides a way to annotate your code with initialization blocks that can then be executed once and then written out to a new post-initialization Wasm binary. Unlike AOT compiling, the resulting binary is still a plain old Wasm binary, so this technique is portable.
Wizer can be a little finicky to use. But systems like .NET can benefit greatly from Wizer.
Bringing It All Together
Based on our experience at Fermyon, optimization is important for both developer tools and Cloud runtime, but the two cases differ substantially.
On the developer side, the best practice is to use as many optimization tools as your compiler gives you. For example, we always use the —release flag when compiling our Rust code. Our open source Spin tool, which allows developers to build WebAssembly microservices and web applications using several languages, includes these optimizations in per-language templates. We have also found including wasm-opt in the local compile pass to be useful, especially with languages that have a large runtime.
During the development process, we use a JIT-enabled runtime. There is little value in AOT compiling during the development phase.
The server side is different. For example, our SaaS-based Wasm runtime platform, Fermyon Cloud, only accepts Wasm binaries, but when it deploys them to the cloud cluster, those binaries are AOT-compiled. This is possible in a reliable way because that is the moment we know exactly what the host runtime’s configuration is. If the Wasm file is deployed to an Arm64 system, it can be AOT-compiled accordingly, without the concern that it will be executed on an Intel architecture.
When it comes to Wizer, we really only use it in the case of .NET, which benefits tremendously from this optimization.
Conclusion
We’ve picked our way through six different ways of optimizing Wasm for performance and for file size. Each method has pros and cons, and many of these methods can be combined for added benefit. Employing these techniques for production Wasm environments can be beneficial.