Month: February 2023
Presentation: Don’t Fall Into the Platform Trap – How to Think About Web3 Architecture

MMS • Christian Felde

Transcript
Felde: I’m going to start with this slide and ask you all if you’re able to guess what we’re looking at here. This is a share price of a particular company that we are looking at over the last few years. You can tell it’s been going well, it’s been growing. Since peak, we have had a dramatic fall. The company we’re looking at here, the share price we’re looking at here is the share price of Meta, previously known as Facebook. Renamed and refocused. Since peak, since the maximum share price had dropped by 40%, which is pretty dramatic for a big, well-established company like Meta. There’s a few reasons for why this is happening. The first reason is users are leaving. The second reason is investors don’t believe Meta or Facebook are able to change enough to maintain the growth that they’ve had. Investors are doubting that they’re able to continue to grow their Web2 model. It’s not just the users and the investors, even the employees are unhappy. A lot of them have stock options and it doesn’t seem like even they are confident that they’re going to be able to recover the share price in these stock options. They’re in a pretty bad place. I’ve titled this talk, “Don’t Fall into the Platform Trap.” As we know, Facebook is a platform. The subtitle is about this, how to think about Web3 architecture. As we go through we’ll see how these things relate to each other. My name is Christian. I work at Web3 Labs.
Is this Web3?
First of all, here’s a question. You can think about this as we go through the slides and learn about Web3 architecture. Is this Web3? This is the Oculus VR headset owned by Meta. As we know, Meta have gone big on the Metaverse and the Oculus VR headset is a way to access this Metaverse VR world. Is it Web3 though? We’re going to return to this and have another think about that after going through the next few slides, because it’s difficult to answer such a question before we learn something about the Web3 architecture.
Key Points
There’s three broad main topics I would like to convey, three key points that you can keep in mind that we’re going to cover next. These three are that Web3 is a shift in information flow. It’s a change in the control structure. Finally, that Web3 is a challenge to the traditional gatekeeper models, because of what it’s introducing.
A Shift in Information Flow
Let’s start with the first one, a shift in information flow. The shift is that you now want to keep the user in the center of everything that’s happening. Let’s look at the old Web2 model, the model that we’re all familiar with and that we used to think about and develop solutions based upon. In the old world, the user isn’t in the center. In the old world, it’s the platform that sits in the center. These platforms like Facebook, they have the luxury of being gatekeepers, basically. They can choose who’s allowed to sign up to and use their platform. If you compare a popular growing platform to like the hottest club in town, if you don’t want to play by their rules, security isn’t going to let you in. If you’re a user of one of these platforms, and say you want to communicate with another user, you would send your message to the platform. It would be stored on the platform, and the other user can then come to the same platform and read the message. Data stays within the platform. If you don’t own the platform, you won’t have access to the message.
In the new world, things have changed. In the Web3 world, as I said previously, the user is put in the center of everything. There is no platform as such anymore. Instead, the user has the option to pick and choose from many different services that are made available to the user. These services are likely operated by many different entities. When the user does something with a service, we can consider them as micro-transactions, with little concern for loyalty. They might use a service only once. They might use it multiple times. It depends on what the user wants to do, at any point in time. The ability to use services in this way, we’ve had web services and those types of things for a very long time. The change here, the things that have been introduced to allow us to use services in this manner, is based on blockchains, peer-to-peer systems, and decentralized identity. In addition to technology, those types of technologies playing a role in this new structure, there’s also regulatory and law changes like GDPR that encourages this structure instead of the old one. Because in the old one, with the platform in the center, the data you collected was very much viewed as an asset, something you can run queries on big data. Platforms were created by companies like Facebook, and so on to mine all the data they managed to collect from all these different users they had. By doing that, they could take the data as an asset and create a profile, sell the data, sell advertisements, and so on, based on who you are. GDPR changes the landscape a bit and other similar rules, and changes data to become less than assets and more of liabilities. There’s both a technology play and a legal play, working together to push the Web3 architecture forward.
I said previously that one of the key points of this talk was around Web3 presenting a different type of information flow compared to Web2 model. That’s what we’re seeing here. We’re seeing on the left side, that we have a user communicating with another user, and through the platform the information flows. Without the platform in the middle, the information couldn’t reach the other end user from the first user. In the Web3 model, the user is in the center, and a user can choose to use one of these services, obtain some data from this service, and then pass it on to another service if they so choose. Many different structures we can imagine here. We can imagine that the user is using multiple services, getting data from multiple services, keeping that data with themselves. We’re combining that data before maybe using it in a third service, and so on. If you look at the history of Web1, Web2, Web3, Web2 is very much attributed with the ability to both read and write data so you can participate in these platforms. The social media platforms is a typical example here. You have your read and your write access. That was the thing about Web2. In Web3, not only do you have your read and your write access, but you also have your ownership. You own the data. You get the data and keep this with you locally.
Web2 Flow Example: Passport
I’m going to make it a little bit more concrete, because that typically helps explain these things. I’m going to use a passport as an example. We’re going to go through the Web2 way of doing a digital passport. Then we’re going to look at the Web3 way of doing it after this. Imagine you were tasked with a project to create a digital passport system, you have your Web2, your architecture hat on, your first thought would very likely be to create some passport platform where users can come and request a passport to be created for them. The passport would then be stored with the platform. Then other users can come to the platform to look up details about this particular passport. That’s what we’re looking at here. We’re looking at three different steps in the user journey of this imagined platform. Step one is user starts using the platform and sends a request to the platform saying, can you please issue me a digital passport? The platform will do whatever it needs to do to verify the identity and integrity of information provided by a user. If the platform operator, the routines, everything is good, and I was happy, a digital passport is created. This digital passport is of course stored within this passport platform. The response given back to the user isn’t the actual passport itself, but instead some sort of reference to the passport, some ID or link or something like that. Imagine then that I’m going to travel, leaving the country I’m based in going to another country and I end up at the border control. That’s me at the border control. On the other side, we have the agent too that’s going to be there to inspect my passport. When I do that, I wouldn’t share my actual passport like this, so I have my physical passport, and I’ll give the person my physical passport. In a Web2 type architecture, what I would provide to the agent over here, the user over here is the reference to the passport, to my passport. In return, they would access the platform, the same passport platform to look up the details on my passport, and then from that they could do the checks they need to do.
We can see that in this structure, both myself and the other user, the person checking our passport, both of us are required to be members of this one passport platform. We know there’s a lot of countries in the world, and it’s very unlikely that they all would be able to agree on a single platform. If someone were to create a digital passport platform, there would probably be many of them. It would require all these different checkpoints to sign up to all these different platforms, which makes it a very tough sell. You wouldn’t be able to necessarily get them all to sign up to all the different platforms that would come with this, which is maybe one of the reasons why we haven’t maybe seen a digital passport in this form because of the overheads.
Web3 Flow Example: Passport
Moving on to the Web3 example, same passport example. In a Web3 architecture, the user is in the center and the user is in control. The first step would be for me to use a passport issuing service, and the service would be operated by the country I’m based in. I will send them a request to issue me a digital passport. Much like the starting step on the previous slide, they would do all the checks that they need to do and then if they’re happy, they would issue me a passport. If this is the first step, I’m issuing the request to get a passport. The difference is that in step two, when they’ve issued the passport, this is not given to me as a digital passport, as a file, as a piece of data that represents the passport as a digital passport. I’m holding on to this. I have a copy of that data on my device, be that a phone or a laptop or something else. I have a copy of the actual data on that device. When I go traveling again, I end up at the border control, I can now, to a different service, to a passport verification service, share a copy of my actual passport. It’s not a reference or a link to a passport stored on a platform, instead, I’m actually giving them the data that represents my digital passport. This is very comparable to the physical passport. Initially, someone to issue me a physical passport, I keep it with me, I carry it around. When I go to the passport control checkpoint, I hand them my physical passport and they can look at the details and do whatever background checks they need to do. In this Web3 architecture example, in this flow, that’s very comparable, because I’m being given a piece of data which represents my passport. I can then choose to share that with someone. The operators of this service is likely not going to be the same as the operators of the issuing service, because it’s two different countries, but because they’re just two separate services that are sending some data initially and then receiving some data afterwards, they don’t have to be on the same platform. There is no platform in this picture. That’s the biggest key change here between the Web2 and the Web3 architecture.
Changing Control Structures
Moving on to the next point, then, and this is about how the control structure changes. Because we want to keep the user in the center, but we also have to ensure that the data that is being passed around is valid and that the integrity of this data remains correct. This is what we looked at previously. We have an issuing service. We have the passport that I hold on to, the digital passport. Then there’s a verification service. How do we verify that this passport is valid, because I could create my own digital passport file locally? I could hack something together, make sure it’s valid, follow some schema of some kind, and pretend that this is a legit passport. How do we ensure that it is actually a passport issued by these guys over here that the verification service can trust to be valid? In the Web3 architecture, a public-private key pair plays a key role. Through those public-private keys, we’re able to sign the passport data in this example. There’s two stamps on this. The first of these two stamps come from the issuing service. When they issue the passport data, they would sign that data with their private key. When I receive the passport in my possession, I can do something similar, I can sign the data with my private key because that validates that I’ve been involved in this process. When I share this passport data with the verification service on the right side, they can then use the public keys to verify that the data hasn’t been tampered with. That’s it been issued by those that claim it’s been issued by. There’s a challenge here. For these guys on the right, for the verification service to be able to verify the signatures and integrity of this data signed with the private keys, they need access to the public keys. Where do we store the public keys?
In a Web2 world, we would typically suggest that we somehow introduce a shared public key registry somewhere. The thing is that this then becomes another platform. The passport issuing service would upload their public key to this shared central registry platform, and I will do the same with my public key here so that when the passport data which I’m still in possession of, and then I share that with the verification service. The verification service would access this platform to download these two public keys and use that to verify the data. That’s great in itself, but it then reintroduces this platform dependency. Then everyone would need to somehow agree to use the same platform for storing these public keys, which takes us back to the original challenge of all these different platforms and the challenge of agreeing to use any one particular platform.
There are many drawbacks with such a central registry. As I said, everyone needs to agree on which one they should use. There’s also the centralization risk of vendor lock-in or whatever we want to call it with too many eggs in one basket. What happens if they change the terms and conditions and it goes down? Those questions needs to be answered. There’s also a challenge around user activity being tracked. Because we can see when someone’s trying to download a public key from the central registry, and that could indicate that the operators of the platform would be able to work out that I’m traveling, for example, and that I’ve shared my passport with the passport control in a different country, for example. Those are challenges that becomes easily solved for in the Web2 approach. There’s another thing to keep in mind here, when you store all these types of data in one central location, what you’re doing is you’re introducing a very juicy target, a place with a lot of valuable information that bold hackers would be interested in breaching and gaining access to. It’s in no way ideal to try and store all these things in a central location.
I did mention blockchain previously as a key enabler for the Web3 architecture. The Web3 approach is to not store the public keys in a central registry, but instead store the public keys in a public permissionless blockchain. A place that is tamper proof. A place that is always accessible. A place where there’s no ability to track anything, because everyone’s got a copy of all the data basically. The flow is still very much comparable to what we saw on the Web2 slides. The passport issuing service would upload their public key to this blockchain system, and so would I. I would upload my public key here. The passport verification service can then easily access this shared resource to download these public keys and run the verification or the signatures. A public permissionless blockchain is a network on those that can’t block your access, that is immutable and tamper proof. It’s always available on a pay as you go model, so you don’t need to sign up to complex agreements. You can just start using it. It doesn’t know who’s pushing data in or who’s reading it out, because if you want to know you have a copy of all the data essentially.
Taking a step back, and looking at the Web3 architecture on one slide, we can look at the picture on the right side here and summarize what this implies. The Web3 architecture consists of decentralized services. These are very likely operated by many separate entities and organizations. There’s no federated user access, or local signing in or signing up. Instead, if you want to provide a Web3 service, instead of asking potential users to sign up and register as a user with a password and so on, you let them bring their own key pair. Through their public key, you’re able to verify that they’re in possession of the private key. Through that you can give them access. It doesn’t stop you from asking them to agree to some terms and conditions of course, but you don’t ask them to create yet another profile, and to remember yet another password. The public keys are stored in a blockchain, and this is to avoid any platform or vendor lock-in risks. A public permissionless blockchain is always available to anyone. That’s why it’s a good candidate for storing these public keys and other such public data. Finally, the key thing is that data moves through the user and keeps the user in control, the user is the owner of this data when they’re holding on to it. Through that we can share in our example, a digital passport. It can be received and used in much the same way as you would use a fiscal passport. If you want to compare it to something, it’s often good to think of it like that. It’s a physical passport you hold on to, and then you can share with anyone you want to. Same way, with the Web3 architecture. You get the data. You hold on to it. You’re in control of it. Then you can choose to share with other services.
Challenge to Traditional Gatekeeper Models
Final key points of this talk is that the Web3 architecture, this way of doing it, like we saw on the previous slide, is a challenge to the traditional gatekeeper models. If you want to build Web3 architecture based services, you need to stop thinking about how you can lock people in. Just to recap on what we saw earlier in the Web2 world on the left side here, platform is in the center. A user would share information through the platform, and the information is stored as data on the platform. You can own the platform, you can’t participate. In the new world, on the right side, the user is in the center. The user can choose to use one or many services, obtain data from these services, and can then choose to share data with other services.
How can it be a challenge to the gatekeeper role or platforms in general? Can we build a blockchain platform as a way to maintain this platform thinking and platform dominance model? Instead of a shared federated central registry platform on the left, can we somehow choose to run nodes in such a way that the blockchain network isn’t really public or open, where instead it’s a tightly controlled environment where only the select few are allowed to do the operations and read data? It’s helpful to have a little bit of a background in the evolution of the thinking here of blockchain. As you probably are aware of, a blockchain network is a bunch of nodes, software running in hardware, through a shared protocol, can agree on what’s allowed to happen, and what’s allowed to take place. It’s a so-called shared ledger.
When you set up such a network, there’s a few questions you can ask yourself around the configuration of this, and also there are questions about who’s allowed to join a network and who’s allowed to execute transactions on the network. Depending on how you answer those questions, you get a different structure. In the beginning, when many thought about blockchain as some sort of decentralized or distributed database, especially in the enterprise blockchain world, the outcome of answering these questions were very much about building a private permission system. You would have a few nodes operated by your selected partners, and through shared governance, you would keep it private and permissioned. Only those you choose can connect to a node to execute transactions or read data, as a private permissioned blockchain network. These things come with a lot of overheads and they’re very complex to run, because not only do you have a software you have to manage and run, you also have the complexity of agreeing with your partners on how to operate it. That adds a lot of overhead. Also, makes it quite difficult to keep data private, because suddenly someone’s allowing someone to join, which maybe others wouldn’t agree with. Through that you’re leaking data. Over time we’ve learned to think about these things as public things, a public place to store data, so we only store data which is public.
The thinking of maintaining control is still very much there, especially if you’re trying to build a platform, which means that our public permission model is dominating the discussion. A public permissioned network is one which it’s possible to read the data, but maybe not possible to run a node or to run transactions. Again, this type of model comes with a lot of governance overhead, and cost, and complexity. Which means that as we understand more how to use options in that we want to store public data there anyway, we might as well start using what’s known as public permissionless blockchains. Those are your Ethereum type networks that are just there and are available. You don’t need to sign up to anyone’s particular network to use them. It’s easier to get going. It’s moving to the left is what this is trying to say. In the beginning, we focused on private permissions, now it’s moving to public permission, and now people are getting comfortable with the public permissionless networks as well. All of this is an argument against trying to build a blockchain platform. Instead, we should just look at these blockchains as a public utility, something for everyone to use. As we understand how to use them, just jump on and use the permissionless ones, the public permissionless ones that are available to everyone.
It doesn’t remove some of the enterprise requirements that exist. It doesn’t really make sense to talk about an enterprise blockchain system. I think it makes more sense to think about it as different layers. The point is that, an enterprise and many other use cases have requirements around privacy, for example. What’s referred to as a layer 2 solution is better suited to cater to those needs than to try and cram them into a layer 1 solution. There is a link between the layer 1 and the layer 2. It’s a bit like the internet. You use the public internet, where you add like a VPN on top to be able to communicate securely. We’re seeing something similar in the blockchain world. If you’re tasked with evaluating an enterprise blockchain, start looking into what’s known as layer 2 solutions, instead of building yet another private permissioned blockchain network.
Summary
Web3 is about services, not platforms. If you want to operate in the Web3 sphere, in the Web3 domain, think about building valuable services to users. Be prepared to give them ownership of the data returned by these services. Also, let users bring their own ID through their locally generated public-private keys. Don’t force them to sign up to yet another platform and create yet another password. Finally, blockchains, and specifically, public permissionless blockchains are the key enablers to allow this to happen securely, because that’s the place we can store these public keys that allow us to have integrity and certainty around the data that flows point to point between these different services and users.
Back to this Oculus VR headset, is this Web3? It’s just a tool to access a virtual world. If we look at how Meta is forcing us to use it, they’re forcing us to be a member of the Facebook platform, how we use it there. They use this user to sign into the Metaverse. When we’re in this virtual world, any items or digital items that we acquire in our world is locked to their platform. It’s not Web3 as it’s been executed. This is one of these classical innovator’s dilemma type challenges where a new technology or a new way of doing things enter this way, and people are struggling to think about how to use them correctly because they come with null mindset. It’s going to take a bit of time before we also get it, before these big established companies get it, and before they’re able to transition fully into such a world. It also comes with a big challenge for a platform, because if you can’t gather the data and you can’t mine the data, and you can’t sell the data, you’re not going to make as much money as you used to, maybe.
I’ve been working on Web3 strategy and Web3 implementations for a good while at Web3 Labs, where I’m head of services. We also have a book called “The Blockchain Innovator’s Handbook,” which is something we can give you to help you around how to think about these types of projects and architectures.
Questions and Answers
Couriol: You talked about Facebook as an example of Web2 platform. When you said that, I was wondering, what would the Web3 equivalent of Facebook look like? Would that be running on a public permissionless blockchain or public permissioned one, or something entirely different? I’m asking this because I was wondering, how would you go about moderating messages in a permissionless context? Because in my mind moderation is something that involves some level of centralization. I was wondering, how would that work in a decentralized way?
Felde: That’s a very interesting question, because there’s a lot of services tied to Facebook. If, for example, we’re talking about sending messages from one user to another, that there’s many ways of passing these messages around so we could imagine some service that delivers the message, and it’s a private message between two parties. Of course the benefit of that is that it’s encrypted, and there’s no Facebook in the middle who can intercept and view that private message. If we’re talking about something like the feeds, or a Twitter feed or something like that, which is essentially a public place, a forum, yes, there probably would need to be some moderators, or some algorithms in place to avoid spam and abusive behavior and those things. There is no nothing stopping someone from making a service that anyone can choose to use, where the point of the service is for me to publish a message for everyone to see. Maybe what would be different is your moderation system. If you’re publishing messages to a shared place without the traditional operator or gatekeeper in the middle, maybe you could have the public messages as just a big dataset, and then you select who you would delegate the moderation to, so to speak. Much like you have politicians and other entities and people speaking in the public domain, and you have newspapers moderating that by putting a certain angle on it. You could maybe imagine something similar in the Web3 space as well. At the end of the day, if you do want to share messages publicly then you will have to come to some place, a forum of some kind where you would publish them.
Couriol: If I summarize, you say that it could be moderation services made by someone and you would choose whether or not you want to subscribe to the services. You would have the choice whether you want to have your message moderated or not?
Felde: It’s not your choice if it’s moderated or not, that’s up to the forum operator.
Couriol: If you don’t want to use this moderation?
Felde: I think the key thing though with Web3 is that you’re in control of the data. You’re put in the center. You can choose where you want to pass the data on to, which is different than sending a message from me to you on Facebook, because then it would be at their platform. If you’re not a Facebook user, I couldn’t send you a message. If you can seamlessly connect to any service out there, and I can use a service as a intermediary for delivering a message, and that message is just an encrypted blob of data for the intermediary, it gives us freedom to choose which service to pass a message through, if that makes sense.
Couriol: Facebook ensures a good user experience by means of infrastructure and software that they developed, essentially. They do that in a way that when I post a message to a given audience, to a given group, this audience receive the message relatively immediately. It enables interactive communication. Is it possible to achieve that same level of user experience, at least, in a decentralized Web3 architecture? Who would ensure that same level of user experience?
Felde: Someone is still operating these services. If they are not doing a good job of running these services, then they wouldn’t work. Hopefully they are. If they’re interested in continuing to offer a service, they will hopefully spend the time and the resources required to make sure the services are running. There is no difference there. If Facebook is not running a good service, then it’s not going to be available. If someone else isn’t running a good service, it’s not going to be available. When I connect to a service, if it’s down and stuff, there’s nothing I can do with that. The difference is I’m in possession of my identity, for example. When I use this service, it doesn’t come with the whole platform experience as well. I don’t have to sign up to your platform to use the service.
Couriol: There was a question at the beginning about, to understand better the example of the passport that you gave. Is it analogous to the Web3 equivalent of a platform checking a service? Is that analogous to keeping my physical passport in my house rather than in a safe deposit box at a bank and only accessing it when I need to travel? I think the question probably comes from trying to understand how it would work with the public key, private key.
Felde: I think it’s a very good analogy to compare it to like a physical passport. If I want to travel, I pick up a passport and I keep it with me and I walk around with it and I give it to someone. When I’m not traveling and when I don’t need my passport I keep it at home safely stored somewhere I know where it is. Others might want to choose to store it in a safer place like in a bank vault or in a bank box. Probably not for a passport, but for some other things you might want to do that.
I think with regards to an analogy between physical and digital, I think they’re very comparable. Because if you carry something around you can share it and you can choose who to share it with. It’s the same in a Web3 architecture, you have some data that you have on your device, say your phone. When I walk up to the border control in the past, for example, I can give that passport to the machine or to the person sitting there. It doesn’t matter if it’s a digital one or a physical one, because I am in possession of both of them, basically.
I don’t know if it’s related to the public keys in any way, or the private keys. The public key is public and I want to distribute that as widely as possible. You want to store it somewhere where anyone can access it and easily find it. We want to have guarantees around the integrity of that public key. We want to make sure no one’s been able to tamper with it, and no one’s been able to replace it with another public key, for example. That’s where blockchains are very good storage locations, because they’re immutable and tamper proof, and they’re public infrastructure, they’re a utility that anyone can use. We want to store the public keys that way. We don’t want to store the data in any blockchain. That’s the last thing we want to do. We don’t want to store my passport details on a blockchain, because then it’s public. I don’t want my passport details to be public. Just like I don’t want my driver’s license details to be stored on a blockchain because I don’t want that to be public. I want to be in control of it. We don’t want to store any private data on any blockchain at all because it’s immutable or public, and it’s there forever. Only the public key is something you want to store on the blockchain.
Couriol: I understand the idea of concentrated risk of having everything stored somewhere, but is Web3 putting all of the security requirements onto individuals, there is safety from keeping my money in the bank rather than under my mattress.
Felde: I think the way you should think about it is, if I have some private data on my driver’s license, in my passport, which is, could be used to forge my identity or create a bank account somewhere, or do something really which I don’t want to. The thing is, if I take my passport and 10,000 other people take their passport and they put it in a central location, that location becomes a very attractive target. It’s worth the effort for hackers and attackers to go to that central location and try and get access to those 10,000 passports. Where if those 10,000 passports are spread across 10,000 different people, it becomes very prohibitively cost inefficient. It’s basically impractical, impossible for the hacker to obtain the same amount of information. They can’t find those 10,000 passports because they’re spread across 10,000 people. What might end up happening is if I was a rich person, if I was a high net-worth individual, I might become a target. If I’m a rich person, I could probably also afford to pay for some security measures. If I’m a less wealthy person, an average poor, I’m not an interesting target anyway, so I don’t need to spend as much effort or money on security because I’m not a juicy target. That’s what I mean by concentrating these valuable pieces of information in one central location is essentially bad practice. If you spread it out, you derisk the overall picture.
See more presentations with transcripts
MMS • Alen Genzic
Visual Studio 2022 17.5 Preview 3, released January 18th, brings the new build acceleration opt in feature to Visual Studio. Build times are improved for all SDK-style projects. Larger projects in particular will see greater improvements in build times. Build acceleration works by avoiding excess calls to MSBuild when building a dependent project.
The behavior of Visual Studio in versions prior to Preview 3 in some cases caused MSBuild to be called even if there was no code changed. When Visual Studio would need to copy the artifacts of a referenced project that was already built to an output directory, it would call MSBuild to re-build the project and copy the needed files to the output directory. Additional builds were triggered even when no compilation was required.
In this preview version, Visual Studio will avoid calling MSBuild when just a copy of the artifacts to the output directory is needed, and will instead just copy them on its own to the correct locations.
Build acceleration can be enabled by adding the AccelerateBuildsInVisualStudio property to true in a Directory.Build.props file, or alternatively, it can be enabled for a single project by adding the same key to the project file.
This feature is currently only available on Visual Studio for Windows and exclusively for SDK-style projects.
In a Reddit thread some users discussed that adding additional proprietary features to Visual Studio instead of into the .NET SDK is undesirable since it implies a vendor lock in. Reddit user Atulin expresses his concerns:
So, another thing added to proprietary VS instead of being added to the SDK? First the debugger, then the hot reload, now performance improvements also get rolled into VS?
What’s next? Algebraic data types supported only by a special VS compiler?
In Microsoft developer Drew Noakes’s Twitter thread however, he gave an explanation as to why this feature is currently only available as a Visual Studio exclusive:
VS has the advantage here as it’s a long-running process, and so has a lot of information available when you hit build. Obviously anything is possible in software, but exactly how this might work on CLI isn’t totally clear.
Adding this feature to the dotnet watch build tool is certainly a possibility, however according to Drew, it would be a significant amount of work.
The addition of this feature to Visual Studio for Mac was not ruled out, but it does not seem to be planned for now.
The latest preview version of Visual Studio can be downloaded on Microsoft’s official site. At the time of writing, the latest preview is Preview 6, released February 7th.
MMS • Diogo Carleto

After 10 years since the last release, MariaDB Server 11.0 has been released, bringing a new optimizer cost model which aims to predict more accurately the actual cost of each query execution plan, removed InnoDB change buffer, and so on.
According to MariaDB foundation, most of the optimizer problems, such as reporting performance issues about bad query plans, had been informed by the community users.
The flagship feature of MariaDB 11.0 is the new optimizer cost model, which is aimed at being able to predict more accurately the cost of each query execution plan. However, there is no guarantee that it will be better in all scenarios; some queries can be even slower. The idea is to increase the MariaDB major version as a signal.
Before MariaDB 11.0, MariaDB query optimizer used a “basic cost” of 1 for one disk access, fetching a key, fetching a row based on the rowid from the key, besides other small costs. Those costs are reasonable when finding the best index to use, but not so good for table scan, index scan or range lookup.
MariaDB 11.0 changed the basic cost for “storage engine operations” to be 1 millisecond, which means that for the most of the queries, the query cost should be close to the time the server spends in storage engine + join_cache + sorting.
The engine costs have been separated into small pieces to improve the accuracy. The disk read costs now assume by default a SSD disk with 400/second, which can be changed by modifying the OPTIMIZER_DISK_READ_COST.
All engine specific costs can be found in the information_schema.optimizer_costs. To see the default costs for an engine, the following query is available:
select * from information_schema.optimizer_costs where engine="default"G
And the results will be:
*************************** 1. row ***************************
ENGINE: default
OPTIMIZER_DISK_READ_COST: 10.240000
OPTIMIZER_INDEX_BLOCK_COPY_COST: 0.035600
OPTIMIZER_KEY_COMPARE_COST: 0.011361
OPTIMIZER_KEY_COPY_COST: 0.015685
OPTIMIZER_KEY_LOOKUP_COST: 0.435777
OPTIMIZER_KEY_NEXT_FIND_COST: 0.082347
OPTIMIZER_DISK_READ_RATIO: 0.020000
OPTIMIZER_ROW_COPY_COST: 0.060866
OPTIMIZER_ROW_LOOKUP_COST: 0.130839
OPTIMIZER_ROW_NEXT_FIND_COST: 0.045916
OPTIMIZER_ROWID_COMPARE_COST: 0.002653
OPTIMIZER_ROWID_COPY_COST: 0.002653
To change the default costs, it is only required to specify the cost as an argument, such as set global optimizer_disk_read_cost=20.
To check the default costs for InnoDB storage engine, just run
select * from information_schema.optimizer_costs where engine="innodb"G
Following the results:
*************************** 1. row ***************************
ENGINE: InnoDB
OPTIMIZER_DISK_READ_COST: 10.240000
OPTIMIZER_INDEX_BLOCK_COPY_COST: 0.035600
OPTIMIZER_KEY_COMPARE_COST: 0.011361
OPTIMIZER_KEY_COPY_COST: 0.015685
OPTIMIZER_KEY_LOOKUP_COST: 0.791120
OPTIMIZER_KEY_NEXT_FIND_COST: 0.099000
OPTIMIZER_DISK_READ_RATIO: 0.020000
OPTIMIZER_ROW_COPY_COST: 0.060870
OPTIMIZER_ROW_LOOKUP_COST: 0.765970
OPTIMIZER_ROW_NEXT_FIND_COST: 0.070130
OPTIMIZER_ROWID_COMPARE_COST: 0.002653
OPTIMIZER_ROWID_COPY_COST: 0.002653
Let’s take a look at the meaning of the different cost variables.
| Variable | Type | Description |
| OPTIMIZER_DISK_READ_COST |
Engine |
Time in microseconds to read a 4K block from a disk/SSD. The default is set for a 400MB/second SSD |
|
OPTIMIZER_INDEX_BLOCK_COPY_COST |
Engine |
Cost to lock and copy a block from the global cache to a local cache. This cost is added for every block accessed, independent of whether they are cached or not |
|
OPTIMIZER_KEY_COMPARE_COST |
Engine |
Cost to compare two keys |
|
OPTIMIZER_KEY_COPY_COST |
Engine |
Cost to copy a key from the index to a local buffer as part of searching for a key |
|
OPTIMIZER_KEY_LOOKUP_COST |
Engine |
Cost to find a key entry in the index (index read) |
|
OPTIMIZER_KEY_NEXT_FIND_COST |
Engine |
Cost to find the next key in the index (index next) |
|
OPTIMIZER_DISK_READ_RATIO |
Engine |
The ratio of BLOCK_NOT_IN_CACHE/CACHE_READS. The cost of disk usage is calculated as estimated_blocks * OPTIMIZER_DISK_READ_RATIO * OPTIMIZER_DISK_READ_COST. A value of 0 means that all blocks are always in the cache. A value of 1 means that a block is never in the cache |
|
OPTIMIZER_ROW_COPY_COST |
Engine |
Cost of copying a row to a local buffer. Should be slightly more than OPTIMIZER_KEY_COPY_COST |
|
OPTIMIZER_ROW_LOOKUP_COST |
Engine |
Cost to find a row based on the rowid (Rowid is stored in the index together with the key) |
|
OPTIMIZER_ROW_NEXT_FIND_COST |
Engine |
Cost of finding the next row |
|
OPTIMIZER_ROWID_COMPARE_COST |
Engine |
Cost of comparing two rowids |
|
OPTIMIZER_ROWID_COPY_COST |
Engine |
Cost of copying a rowid from the index |
|
OPTIMIZER_SCAN_SETUP_COST |
Session |
Cost of starting a table or index scan. This has a low value to encourage the optimizer to use index lookup, also tables with very few rows |
|
OPTIMIZER_WHERE_COST |
Session |
Cost to execute the WHERE clause for every found row. Increasing this variable will encourage the optimizer to find plans which read fewer rows |
More information of the costs and how they were calculated can be found in the Docs/optimizer_costs.txt file in theMariaDB Source distributions.
Let’s have a look at other MariaDB optimizer cost changes:
- When counting disk accesses, now it is assumed that all rows and index data are cached for the duration of the query.
- The cost of sorting (filesort) is now more accurate, allowing the optimizer to better choose between index scan and filesort for ORDER BY/GROUP BY queries.
The new optimizer changes usually matters, and probably should be able to find a better plan in the following scenarios:
- When running queries with more than two tables
- Indexes with a lot of identical values
- Ranges that cover more than 10% of a table (
WHERE key between 1 and 1000 -- Table has values 1-2000) - Complex queries when not all used columns are or can be indexed
- Queries mixing different storage engines, like using tables from both InnoDB and Memory in the same query
- When needing to use
FORCE INDEXto get a good plan - If usingANALYZE TABLE made the plans worse (or not good enough)
- Queries that have lots of derived tables (subselects)
- Using ORDER BY / GROUP BY that could be resolved via indexes
More details are available on how to upgrade between Major MariaDB versions, as well as how to upgrade from Maria DB 10.11 to 11.0.
MMS • Ben Linders

For a sustainability transformation, a business has to figure out how to measure its carbon footprint, come up with a plan to change the way it powers everything, and change the products they’re making, and even the markets that they operate in. Adrian Cockcroft spoke about sustainability in development and operations at QCon San Francisco 2022.
According to Cockcroft, “sustainability transformation” is an emerging topic, poorly understood and with immature solutions to support it:
It refers to the changes driven by our need to reduce the impact of business on the environment, including reducing greenhouse gas emissions, clean water and zero waste to landfill. The biggest of these is carbon dioxide reduction, as we need to move from extracting and burning fossil fuels to an economy based on renewable energy.
The first problem is figuring out how much greenhouse gas is being generated, Cockcroft said. There are several different gases that matter, with different impacts. The main one is carbon dioxide, but methane and CFC refrigerants are also a problem, he said. They are combined together for measurement and reporting as carbon dioxide equivalent – CO2e. The methodology published by the Green House Gas Protocol is used to calculate carbon equivalents and to get detailed guidance on what to include in scope calculations, Cockcroft mentioned.
From a developer perspective, there are three main areas of interest, Cockcroft explained. The first is that most companies start with a manual spreadsheet-based approach, but new disclosure regulations are driving the need to build some kind of data lake to report their carbon footprint, and to model their risk exposure to the impacts of climate change.
The second area Cockcroft mentioned is that sustainability is becoming a product attribute of the things companies do and build, so it’s turning up in design decisions. The third is that the efficiency of the code we write and how we deploy it affects the carbon footprint of our IT systems. Cockcroft calls this DevSusOps, adding sustainability concerns to development and operations.
Cockcroft was part of the team that published the Well Architected Pillar for Sustainability which has detailed advice on how to optimize a workload to be more sustainable. He will give a talk about the future of sustainability measurements at QCon London 2023.
InfoQ interviewed Adrian Cockcroft about measuring carbon footprint.
InfoQ: What comprises the carbon footprint of organizations?
Adrian Cockcroft: Carbon dioxide reduction reaches throughout business operations, from the fuel burned to heat buildings and power vehicles, to the fuel used to generate the electricity we consume, to the energy used by things we buy, own and sell.
InfoQ: How can we measure the carbon footprint of data processing and hosting?
Cockcroft: There are a few different ways to calculate carbon.
The economic carbon intensity of a product or a business may be reported as the grams of carbon per dollar that is spent, gCO2e/$, or metric tonnes of CO2 per million dollars mtCO2e/$M. Most companies start out by making an estimate of their carbon footprint using an Economic Input/Output (EIO) model that is based on the financial flows and uses industry average factors to relate spend to carbon. This is good enough for reporting, and to find out where most of the carbon is likely to be generated by the business. It’s not useful for optimizing carbon reduction, because if you spend more on a low carbon energy source or raw material, you will end up reporting more carbon, not less.
To get more accurate and actionable measurements, business processes need to be instrumented to calculate the carbon generated by raw material and product flows. For raw materials, carbon intensity is often reported as grams of CO2 per kilogram of the material – gCO2e/Kg. For fuels that are burned this provides a more accurate way of estimating than just basing it on the total amount spent on fuel.
The carbon intensity of fuel used to generate energy is measured as grams of CO2e per KWh. It depends how and when that electricity was generated, and changes all the time. For example, when it’s sunny or windy, there’s more solar and wind energy. The “grid mix” is usually reported by an energy supplier on an average monthly basis, however you have to wait for the bill, so an accurate report will be delayed by a month or more.
The embodied carbon from manufacturing is amortized over the lifetime of the item: gCO2e/year. For example, if you use something like a mobile phone for longer, the gCO2e that was emitted to make it is having a useful purpose for longer.
MMS • Steef-Jan Wiggers
Microsoft has officially joined the FinOps Foundation, a non-profit organization that promotes financial management in cloud technology.
The FinOps Foundation has gained significant momentum since its launch in 2019, with over 1500 members from over 600 organizations. It offers several training and certification programs, such as the FinOps Certified Practitioner and FinOps Certified Professional, geared towards helping people advance their careers and grow the community.
FinOps is a movement attempting to bring financial accountability to provide more transparency on cloud spending. It has been identified in early reporting by InfoQ as an upcoming trend in DevOps and Cloud Computing in 2021, where Cheryl Hung, VP of the ecosystem for the Cloud Native Computing Foundation (CNCF), explains FinOps as:
A group of practitioners who are trying to find the best practices and tooling to really understand and optimize where cloud is being used and how to reduce that from an organization’s point of view.
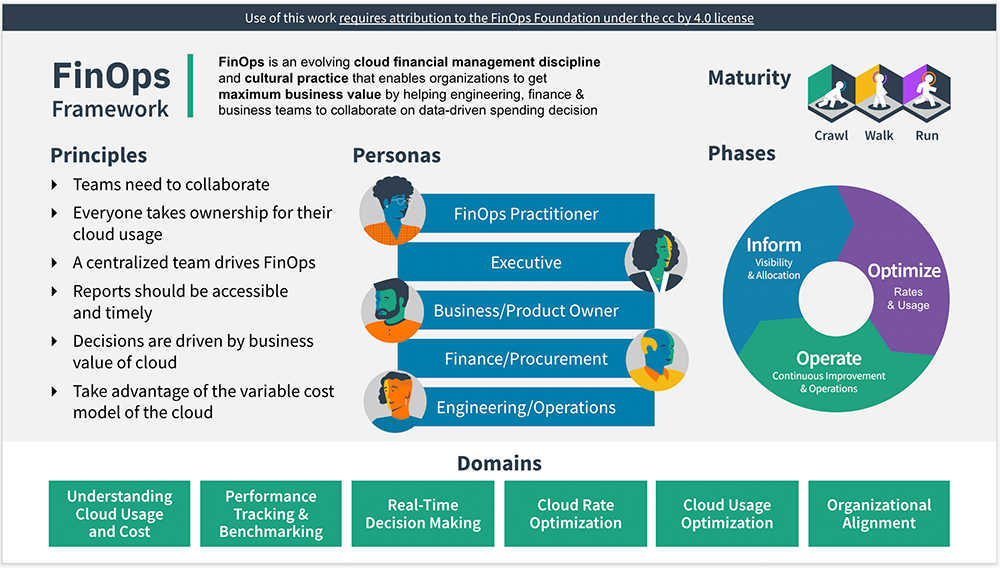
Source: https://www.finops.org/introduction/what-is-finops/
In addition, in the DevOps and Cloud InfoQ Trends Report – June 2022, where InfoQ editors and friends of InfoQ see the “cloud computing and DevOps” space concluded that FinOps practices continue to mature since awareness of cloud spending has increased, and offerings have evolved to provide better insights.
By joining the FinOps Foundation, Microsoft commits to promoting the financial management of its Azure cloud platform. The company has already been working towards this goal through its Azure Cost Management and Advisor services, which provide tools for monitoring and optimizing cloud costs. In addition, there is guidance through architecture documentation, like Microsoft Cloud Adoption Framework and Azure Well-Architected Framework.
Microsoft’s participation is expected to help further expand the organization’s reach and influence in the cloud industry. J.R. Storment, executive director of the FinOps Foundation, said in a press release, :
We welcome Microsoft as a Premier Member, as its membership will be a huge asset to the larger FinOps community and the development and maturation of best practices across industries and the world.
In addition, Amitai Rottem, a member of the FinOps Foundation Technical Advisory Council, wrote in a LinkedIn post:
The only way such a foundation can succeed with its practitioners is by having a broad set of cloud providers take an active role.
And Michael Flanakin, principal product manager, Microsoft Cost Management, stated in a Microsoft Azure blog post:
We are excited to join the FinOps Foundation and our industry partners in defining, evangelizing, and implementing best practices and specifications like the FinOps Open Cost and Usage Specification (FOCUS).
Lastly, more information and updates around FinOps and Azure cost management are available through Cost Management updates.
MMS • Steef-Jan Wiggers
AWS recently added three new Amazon CloudWatch metrics for AWS Lambda: AsyncEventsReceived, AsyncEventAge, and AsyncEventsDropped, to monitor the performance of asynchronous event processing.
Earlier, Lambda users had little visibility into processing asynchronous requests and relied on Lambda service teams to resolve processing delays that led to inefficiencies in asynchronous event processing. With the added three metrics, developers will, according to the company, have better visibility into their asynchronous invocations and can track the events sent to Lambda.
AWS describes the events as follows:
- AsyncEventsReceived – a measure of the total number of events Lambda was able to queue for processing allowing a developer to monitor this metric and alarm on the undesirable number of events sent by an event source to diagnose trigger misconfigurations or runaway functions.
- AsyncEventAge – a measure of time between Lambda successfully queuing the event and invoking the function, providing developers transparency into the event processing time of your asynchronous Lambda invocations. They can monitor the metric and alarm on different statistics for processing delays.
- AsyncEventsDropped – a measure of the total number of dropped events without successfully executing the function. The cause of the dropped events can be due to multiple reasons, such as Maximum Event Age exceeded, Maximum Retry Attempts exhausted, or function with reserved concurrency set to 0.
Developers can track events from the client using custom CloudWatch metrics or extract them from logs using Embedded Metric Format (EMF).
In an AWS Compute blog post, authors Arthi Jaganathan, Principal SA, Serverless, and Dhiraj Mahapatro, Principal SA, Serverless, explain one of the best practices on AWS Lambda in light of the new metrics:
It is best practice to alert on function errors using the error metric and use the metrics to get better insights into retry behavior, such as interval between retries. For example, if a function errors because of a downstream system being overwhelmed, you can use AsyncEventAge and Concurrency metrics. If you received an alert for a function error, you see data points for AsyncEventsDropped.
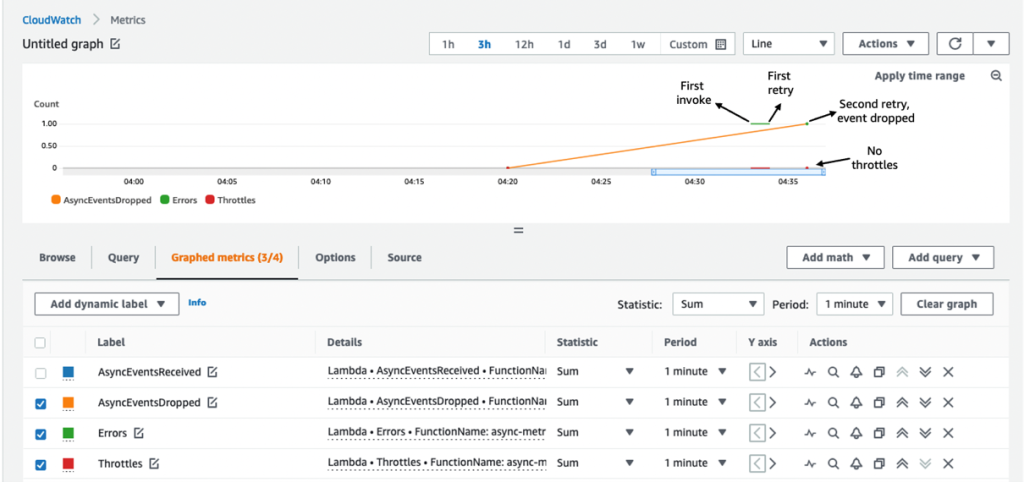
Source: https://aws.amazon.com/blogs/compute/introducing-new-asynchronous-invocation-metrics-for-aws-lambda/
Furthermore, Danilo Poccia, Chief Evangelist at AWS, tweeted:
Introducing new asynchronous invocation metrics for AWS Lambda to identify the root cause of processing issues such as throttling, concurrency limit, function errors, processing latency because of retries, and more
The metrics sent by Lambda to CloudWatch do not generate any cost; however, charges apply for CloudWatch Metric Streams and CloudWatch Alarms. Lastly, more details are available in the Lambda Developer Guide, and developers can visit GitHub to find an example with the metrics.
MMS • Edin Kapic

On February 6th 2023, Kathleen Dollard, principal program manager on .NET team at Microsoft, posted an update of the .NET language strategy. The new document is a continuation of the same ideas from the previous one, written in 2017, where C# and F# are the evolving languages, and VB.NET is a niche language.
The new strategy document is hosted on the Microsoft Learn site. It is broken down into three major .NET languages: C#, F# and VB.NET.
C# is recognised as the language with the broadest usage in the .NET community. Therefore, it will be evolved aggressively to remain a “state-of-the-art programming language”. The team states clearly that they favour the design decisions that benefit the most developers, shying away from specialised enhancements for C#. At the same time, maintaining “a high commitment to backward compatibility” will mean that the team will consider the scale and the impact of any breaking change on the whole C# ecosystem.
One of the prominent comments from C# developers on the language evolution is the continuing existence of many legacy structures, such as non-generic collections (like ArrayList from the first version of .NET) or native event support (largely obsolete in the async world of modern C#). Immo Landwerth, a program manager on the .NET framework team at Microsoft, recognises that the team already tried launching a new .NET without the legacy components in Windows 8 era and that “it has proven to be completely unworkable” and “breaking the entire ecosystem”. It is then probable to assume that those features will be kept in C# for a long time.
F# language strategy will be focused on providing “language leadership and guidance” in the first place. The language benefits from the community contributions significantly more than C#. To help keep the contribution quality high, Microsoft will support the technical decision-making and provide architectural direction.
There are two remaining strategy highlights for F#. One is to keep it interoperable with the new C#, recognising that C# and F# are often used together in real-world solutions. The other is simplifying the entry barrier for new F# developers, which may include rephrasing error messages and redesigning the language features for simplicity.
Visual Basic.NET (VB.NET) will be maintained to keep up with the new runtime and libraries’ enhancements without any new features specifically added to the language. The side-to-side co-evolution of the .NET languages was abandoned already in the first .NET strategy document in 2017, leaving VB.NET with something called a “consumption-only approach”. According to the annotated strategy document, it means that VB.NET will be able to access the new .NET runtime and API enhancements via the normal .NET cross-language interop mechanism of the common language runtime (CLR), but it won’t have any new syntax to define the new features in VB.NET code.
Replying to a developer comment on the strategy announcement blog post page, Kathleen Dollard answered that “consumption-only” means that VB.NET developers won’t be able to create Span and Memory structs but that they will be able to call methods in C# that return them.
It is also clear from the stated focus on “stable design” and “core VB scenarios” that Microsoft won’t extend either the design of VB.NET language or its workloads, largely grouped around Windows Forms applications or libraries. Furthermore, there is an explicit sentence where Microsoft “does not anticipate” supporting web front ends (meaning Blazor) or cross-platform UI frameworks (meaning MAUI).
Older .NET languages such as C++/CLI have been omitted from the strategy, although it’s stated in the comments of the announcement that those languages aren’t managed by the .NET language product team. The developers comment on social media that they are confused about what actually are the changes in the strategy.
MMS • Matt Saunders

GitLab have released further point versions of their DevOps software package, as versions 15.3 through 15.9 have emerged on a monthly cadence. Some highlights from these releases include GitLab’s first machine-learning powered feature improves merge request approvals, with other significant improvements and fixes ranging from GitOps enhancements, through improvements to IdP, to new functionality for DAST.
Merges Blocked until External Checks Pass
Many organisations use external status checks – for instance to check code and artifacts against external compliance and security tools – and it’s now possible to block merging until these checks pass.
SCIM support on self-managed GitLab
The System for Cross-domain Identity Management (SCIM) – used for automating the exchange of user identity information between identity domains – was previously available on GitLab.com, and the 15.8 release brings this functionality to self-managed instances.
Direct Transfer Project Migration
On GitLab.com it’s now possible to migrate projects directly between instances, or within the same instance, without having to manually export and import the data. This makes the process more efficient, and also ensures that user associations are not changed to the user migrating the project, thus preserving the original authors on comments on migrated projects.
Browser-Based DAST Analyzer Now Available
Moving away from a proxy-based approach, which proved extremely difficult to work with, GitLab 15.7 provides a browser-based DAST analyzer which allows in-depth DAST on web sites that make significant use of JavaScript. Moving away from a proxy-based approach, which proved extremely difficult to work with, GitLab 15.7 provides a browser-based DAST analyzer which allows in-depth DAST on web sites that make significant use of JavaScript. A new DAST API Analyzer also improves vulnerability detection significantly, and provides new functionality with scans using GraphQL, Postman and HAR files.
Google Cloud deployments with Cloud Seed
GitLab Cloud Seed allows Google Cloud customers to migrate projects simply and efficiently, with automation to leverage Google Cloud services such as Service Accounts, Cloud Run and Cloud SQL.
Tasks within Issues
It’s now possible to create tasks within issues. Previously, tasks could only be listed inside an issue in a markdown-formatted list, but this new functionality allows tasks to be assigned, labeled and managed independently.
GitOps for free, and on multiple branches
The GitOps functionality used for performing pull-based deployments is now available for free – this previously being only available in the paid tiers of the product. This allows smaller teams to get started with a GitOps deployment model with no additional cost. Furthermore, since version 15.7 it’s now possible to deploy from outside the default branch, allowing GitOps deployments to ephemeral environments
Merge Request reviews are streamlined
On reviewing a merge request, it’s now possible to quickly perform other actions such as approving the request directly from inside the comment area, using GitLab’s quick actions (such as /approve and /assign_reviewer). This reduces the labor involved in reviewing merge requests.
More flexible approval rules
GitLab allows approval rules to be set for merge requests, but these previously had to be applied across all branches. This meant that developers working on less important branches (for example, those created for a feature request) were subject to the same approval rules as for protected branches such as the master branch. This is now relaxed, with admins able to apply rules selectively to branches.
DORA metrics reporting
GitLab insights now allows querying of performance based on the well-known DORA metrics, allowing leaders to track improvements and understand trends related to the DORA metrics.
Suggested Reviewers
Using Machine Learning technology for the first time, GitLab will now recommend reviewers for a merge request based on the project’s previous contributors. This functionality is currently in beta and being rolled out gradually to customers.
Improved CI/CD integration for VS Code
GitLab Workflow provides a method for validating changes to CI/CD workflows directly within VS Code. With workflows becoming more complex, this allows admins to check in more detail that their changes will work appropriately, before pushing these changes.
More Powerful Linux Runners
Medium and Large instance sizes are now available on GitLab’s SaaS product. This allows users to choose faster servers to run their CI/CD jobs on – reducing the time taken to validate changes.
Alongside the new features listed above, there are many smaller enhancements and fixes. Commenting on the 15.7 release, @laubstein from Sao Paolo in Brazil tweeted:
This release comes with great “little” features that will improve our pipeline experience. Thanks for the gift and thanks for keep @gitlab such a great tool.
GitLab 15.8 is now available for download, and is live on GitLab.com. Release notes for 15.3, 15.4, 15.5, 15.6, 15.7 and 15.8 are also available, and GitLab 15.9 is expected on 22nd February.
Platform Engineering Challenges: Small Teams, Build Versus Buy, and Building the Wrong Thing
MMS • Matt Campbell

The team at Syntasso wrote a series of blog posts outlining twelve challenges that platform teams face. These challenges include having a small platform team support a large organization, failing to understand the needs of the platform users, and struggling with the build-vs-buy argument.
Abby Bangser, Principal Engineer at Syntasso, wrote about the challenges that a small platform team can have in trying to support a much larger organization. The platform teams that Bangser has worked on have “hovered around 5% to (at most) 10% of the headcount for the total engineering team”. This small group is expected to provide a number of services and tools to a larger organization with the goal of improving developer productivity.
Bangser shared that platform teams can quickly become bogged down in responding to tickets from their application teams. This can be corrected by introducing self-service options:
As a team we aimed to provide self-service options for anything where we were confident to define a good or best practice (see Cynefin framework for more detail).
The Cynefin framework is used to help decision-making. It offers five domains that range from clear to confusion. In the clear domain, problems tend to follow well-defined patterns and solutions can implement best practices. As problems move towards the confusion domain, it becomes harder and harder to define consistent practices and the platform team will be needed to handle the solution with a more hands-on approach.
Christopher Hedley, VP of Engineering at Syntasso, wrote about the challenges in trying to buy a ready-made platform. Hedley notes that:
Taking high-level PaaS or SaaS-like platform solutions might buy you productivity gains, but efforts to bend their opinionated workflows to match the will of your organisation often result in frustration or failure. Often you end up changing to meet the needs of the tool rather than the other way around.
Hedley stresses that the better path is a focus on building the platform as a product with close feedback loops with application teams. While off-the-shelf components can be used as building blocks for the platform, as Hedley notes “you cannot buy what only you need”.
Bangser wrote in another post in the series that another failure mode is the platform team assuming they understand the user experience and needs without doing the necessary research and collaboration. In the book Team Topologies, Matthew Skelton and Manual Pais outline that an ideal platform is built following the methodologies used to build successful consumer products. This includes techniques such as user interviews, tight feedback loops, and building a platform that delights the users to drive adoption.
Sam Newman in a recent blog post stressed the importance of making the platform be optional for adoption. Newman notes that:
When you make people use the platform, you stop caring about making it easy to use, because they don’t have a choice. You aren’t incentivised to improve the user experience to attract people to the platform, as they have to be there anyway.
Similar to Bangser, Newman also worries that platform engineering is not about empowering the application developers by building what they need. Instead, Newman wonders if “it’s about hiding the towering pile of crap we’ve assembled and now have to hide from the people we apparently got it for in the first place.”
Michael Coté agrees with Newman and Bangser that “infrastructure builders get easily distracted by building infrastructure when it’d be more helpful to pay more attention to developer usability and needs.” Cote also stresses the importance of paying “close(r) attention [to] the what developers needs, and track developer-related metrics and improvement”.
While the current hype around platform engineering is new, the recommended techniques and approaches are not. As Aaron Erickson, CEO at Orgspace, wrote in a recent piece for InfoQ, “be a good, dedicated product manager, and get closer to your customer — preferably well before you start building anything.”
For more on these platform challenges, readers are directed to the Syntasso blog.
Android 14 Brings Partial Support for OpenJDK 17, Improved Privacy and Security, and More
MMS • Sergio De Simone

Google has announced the first Android 14 beta, which provides support for over 300 OpenJDK 17 classes. Additionally, it implements a number of features aimed to keep malicious apps at bay and extends support for foldable form factors, battery usage optimization, and more.
While Android 14 aims to bring OpenJDK 17 to Android developers in its entirety, the first beta, though, only offers support for 300 classes. Google has provided no specific detail about which OpenJDK 17 classes have been added, but you can see a list of all changes in the java package in the official API diff document.
Support for OpenJDK 17 will not remain exclusive of Android 14 thanks to Google Play system updates, aka Project Mainline, which will make the latest Android Runtime (ART) available on older devices, too.
Google is also taking a step against malware and exploits by strengthening the requirements for dynamic code loading and disabling installation of apps targeting old API version.
Dynamic code loading is a mechanism often exploited by malware because it is prone to code injection or code tampering. To prevent this, Android 14 will require that for a file to be to dynamically loaded, it must be marked as read-only right after it is opened and before any content is written to disk. For an already existing file, Google recommends to delete it and recreate it following the approach just described before attempting to load it. Failing to do this will throw an exception.
Likewise, apps targeting an SDK version lower than 23 will not be installed on Android 14. This is motivated by the fact that malicious apps tend to target version 22 or older to circumvent the runtime permission model introduced in 2015 with the API level 23. Upgrading an existing device will not remove any existing app targeting older API levels, though.
Support for tablets and foldable form factor is an ongoing effort since Android 12L. In Android 14, Google is introducing a number of window size classes, to make it easier to design adaptive layouts; a sliding panel layout, to automatically switch from a side-by-side to a two-separate-panes layout depending on the display form factor; support for activity embedding, which enables splitting an application’s task window between two activities or two instances of the same activity; and other features that are all available in Jetpack Compose.
As mentioned, Android 14 beta 1 also strives to optimize battery usage by extending the Foreground Services API and the JobScheduler to make it easier for developers to use background tasks and reduce the use of foreground tasks, which are less energy efficient. Likewise, the use of exact alarms, which can significantly affect the device’s resources, now requires a specific user permission to be granted.
As a final note, Android 14 also improves customization support and introduces the Grammatical Inflection API.