Month: February 2023

MMS • Steef-Jan Wiggers

Google recently announced several new updates to its Security Command Center (SCC) with a pay-as-you-go pricing model and two capabilities: deployments at the project level and self-service activation.
Security Command Center is a platform provided by Google Cloud that helps organizations manage and protect their data, applications, and infrastructure on Google Cloud. It provides a centralized, real-time security dashboard that gives organizations a comprehensive view of their security posture across their Google Cloud environment.
The platform pricing model has a flat-rate pricing model where customers pay a fixed monthly fee for unlimited usage. In addition, Google now adds another pricing model with pay-as-you-go, where customers are charged based on the number of assets they have in their Google Cloud environment and the number of security events they generate.
Next to the pricing model, Google also added the ability to enable security management features for a specific Google Cloud project providing organizations with the flexibility of applying security controls – as not every project has the same set of requirements and implementation timelines.
In a Google blog post on the updates to SSC, Anoop Kapoor, a product manager of Google Cloud, explains:
Complementing SCC’s current subscription pricing, we now offer flexible, pay-as-you-go pricing at the project level, with no spending or duration commitment. For example, when securing projects that have applications running on Google Compute Engine (GCE) but without other Google Cloud services, the cost to secure the project is based on the number of virtual cores (v-cores) consumed per hour.
In addition, Lukas Karlson, a Google Cloud Expert, tweeted:
It is now possible to purchase Google Cloud Security Command Center at the Project level, with no commitment. Only pay for what you need!
Besides project-level activation, SCC now supports self-activation by providing a full self-service implementation for individual projects.
Other Cloud Providers like Microsoft and AWS offer similar security platforms natively on their cloud offerings like SCC. For example, Microsoft’s Defender for Cloud is a security management platform that provides threat protection, security policy enforcement, and security analytics across Azure and hybrid environments. And AWS has Security Hub, a security management platform that integrates with other AWS security services.
Lastly, more details on SCC are available through the documentation landing page, and complete pricing information is on the pricing page.
MMS • Courtney Nash Matt Campbell

Key Takeaways
- Popular incident metrics such as mean time to recovery (MTTR) can be classified as “gray data” as they are high in variability but low in fidelity.
- Simplified incident metrics should be replaced, or at least augmented, with socio-technical incident data, SLOs, customer feedback, and incident reviews.
- Transitioning to new forms of reporting can be hard, but Nash recommends “putting some spinach in your fruit smoothie”. Start presenting those data along with the expected/traditional data, and use this as a way to start the conversation about the benefits of collecting and learning from them.
- The latest VOID report found no correlation between the length of an incident and the severity of that incident.
- Near-miss investigations can be a valuable source of information for improving how an organization handles incidents
The Verica Open Incident Database (VOID) is assembling publically available software-related incident reports. Their goal is to make these freely available in a single place mimicking how other industries, such as the airline industry, have done so in the past. In the past year, the number of incident reports in The VOID has grown by 400%. This has allowed the team to better confirm findings and patterns first reported on in their 2021 report.
The 2022 edition of The VOID report leveraged this influx of reports to “investigate whether there is a relationship between the reported length of the incident and the impact (or severity) of the incident.”
The 2022 report reinforced conclusions drawn in the 2021 report and presented some new findings. The report continued to reinforce the risk of simplified metrics such as incident length or MTTR. John Allspaw, principal at Adaptive Capacity Labs, LLC, calls data that underrepresents the uniqueness of incidents “shallow data”.
The report labels duration as a type of “gray data” in that it tends to be high in variability but low in fidelity. In addition, how organizations define and collect this measure can differ greatly.
The additional data in the report reinforced the notion that incident duration data is positively skewed as most incidents resolve in under two hours.
This positive skew to the data means measures like mean-time-to-resolution (MTTR) are not reliable. As Courtney Nash, Senior Research Analyst at Verica, describes:
This is the secret problem with MTTR. If you don’t have a normal distribution of your data then central tendency measures, like mean, median, and yes the mode, don’t represent your data accurately. So when you think you’re saying something about the reliability of your systems, you are using an unreliable metric.
The report makes a number of recommendations on what to replace MTTR with but it also cautions against trying to replace one simplified metric with another.
We never should have used a single averaged number to try to measure or represent the reliability of complex sociotechnical systems. No matter what your (unreliable) MTTR might seem to indicate, you’d still need to investigate your incidents to understand what is truly happening with your systems.
Recommendations include SLOs and customer feedback, sociotechnical incident data, post-incident review data, and studying near misses. The sociotechnical incident data is an approach that studies the entire system under incident including the code, infrastructure, and the humans who build and maintain them. The report highlights that common incident analysis focuses on technical data only and ignores the human aspect of incidents.
Within the report, the work of Dr. Laura Maquire, Head of Research at Jeli.io, is recommended as a source of sociotechnical data. Maquire’s concept of Costs of Coordination. Maquire recommends tracking data such as how many people and teams were involved, at what level in the organization were they, how many chat channels were opened up, and which tools were used to communicate. This data can help to showcase the “hidden costs of coordination” that can add to the cognitive demands of people responding to incidents.
The report calls out that “until you start collecting this kind of information, you won’t know how your organization actually responds to incidents (as opposed to how you may believe it does).”
However, Vanessa Huerta Granda, Solutions Engineer at Jeli.io, feels that we shouldn’t abandon shallow data metrics just yet. Huerta Granda notes that these metrics, such as MTTR or incident count, can be effective starting points for understanding complex systems. The risk is that the investigation stops at those metrics and does not delve into a deeper investigation.
One of the newer findings in the report is that there is no correlation detected between incident duration and incident severity. The report highlights that severity suffers from the same issues as duration and falls into the category of gray data. Severity can be highly subjective as many organizations use it as a way to draw more attention to an incident. The report concludes that
[C]ompanies can have long or short incidents that are very minor, existentially critical, and nearly every combination in between. Not only can duration not tell a team how reliable or effective they are, but it also doesn’t convey anything useful about the event’s impact or the effort required to deal with the incident.
InfoQ sat down with Nash to discuss the findings and learnings from the 2022 VOID Report in more detail.
InfoQ: The report highlights the challenges with simplified metrics like MTTR. However, metrics like MTTR continue to remain popular and widely used. What will it take for organizations to move past “shallow data” toward more qualitative incident analysis?
Courtney Nash: Moving away from MTTR isn’t just swapping one metric for another, it’s a mindset shift. Much the way the early DevOps movement was as much about changing culture as technology, organizations that embrace data-driven decisions and empower people to enact change when and where necessary, will be able to reckon with a metric that isn’t useful and adapt. The key is to think about the humans in your systems and capitalize on what your organization can learn from them about how those systems really function.
While MTTR isn’t useful as a metric, no one wants their incidents to go on any longer than they have to. In order to respond better, companies need to first study how they’ve responded in the past with more in-depth analysis, which will teach them about a host of previously unforeseen factors, both technical and organizational. They can collect things like the number of people involved hands-on in an incident; how many unique teams were involved; which tools people used; how many chat channels; if there were concurrent incidents.
As an organization gets better at conducting incident reviews and learning from them, they’ll start to see traction in things like the number of people attending post-incident review meetings, increased reading and sharing of post-incident reports, and using those reports in things like code reviews, code comments and commits, along with employee training and onboarding.
InfoQ: Those are all excellent measures for companies to be moving towards. However, I can see some organizations struggling with understanding how tracking, for example, the number of people involved in an incident will lead to fewer, shorter incidents. Do you have any suggestions for how teams can begin to sell these metrics internally?
Nash: It is indeed difficult to sell something new without an example of its benefits. However, if a team is already working on analyzing their incidents with an emphasis on learning from them (versus just assigning a root cause and some action items), they should be either already collecting these data along the way or able to tweak their process to start collecting them.
One option then is akin to putting some spinach in your fruit smoothie: start presenting those data along with the expected/traditional data, and use them as a way to start the conversation about the benefits of collecting and learning from them. Vanessa Heurta Granda has an excellent post with some further suggestions on how to share these kinds of “new” data alongside the traditionally expected metrics.
Another approach, albeit a less ideal one, is to use a large and/or painful incident as an impetus for change and to open the discussion about different approaches.
In a talk at the DevOps Enterprise Summit in 2022, David Leigh spoke about how his team had been conducting post-incident learning reviews on the sly, and then uses a major outage as the impetus to pitch their new approach to upper management. It turned out to be a resounding success, and now the IBM office of the CIO conducts monthly Learning From Incident meetings that have nearly 100 attendees monthly and hundreds of views of the meeting recordings and incident reports.
InfoQ: Both this year’s and last year’s reports highlight the value of near misses as a source of learning. However, the report calls out the challenges in understanding and identifying near misses. How do you recommend organizations start growing the practice of near-miss analysis?
Nash: Most of the examples of learning from near misses come from other industries, such as aviation and the military. Given the large differences in organizational goals, processes, and outcomes, I’d caution against trying to glean too much from their implementations. However, I do like this perspective from Chuck Pettinger, a process change expert focused on industrial safety: “If we are to obtain quality near misses and begin to forecast where our next incident might occur, we need to make it easy to report.” Report may be a loaded word in our industry, so instead, focus on making it easy for operators and people at the sharp end of your systems to easily note near-misses. This could be in your ticketing system, a GitHub Gist, or some other lightweight mechanism like a Slack channel.
It’s also worth emphasizing that noting a near miss doesn’t require it be investigated, lest that reduce people’s inclination to note them in the first place. As you collect these, ideally patterns will emerge that help the team(s) figure out when to dig deeper into investigating one or more of them.
Lastly, I strongly suggest being wary of formal reporting/classification systems for near misses. These risk falling into the same patterns of shallow data collection that plague more formal incident reporting (e.g. MTTR, count of severity types, total incident count, etc).
InfoQ: This year’s report sees a drastic decrease in the number of companies using Root Cause Analysis or reporting a singular root cause. The report also notes that Microsoft Azure has moved to a more positive contributing factors analysis. Are you seeing this trend in other companies? What are they replacing root cause analysis with?
Nash: Before getting to what could work, I did want to clarify that what primarily drove the decrease in RCA occurrences in the VOID was a dramatic increase in the number of incident reports in the VOID, most of which didn’t use RCA or assign formal root causes, so it was largely a volume reason.
That said, it’s currently challenging to note a trend amongst other companies given that we have only a small percentage using RCA in the VOID. We’re tracking RCA because we know from research that it tends to focus more on the humans closest to the event and rarely identifies systemic factors and improvements to those as well. It was noteworthy that the shift the Azure team made was how they both broadened and deepened their investigations and acknowledged the fact that each incident resulted from a unique combination of contributing factors that were typically not possible to predict.
This shift from root cause analysis to identifying contributing factors creates an environment that is less likely to place blame on individual humans involved, and encourages the team to consider things like gaps in knowledge, misaligned incentives or goal conflicts, and business or production pressures as incident contributors along with technical factors like bad config changes, bugs in code, or unexpected traffic surges.
InfoQ: What trends are you expecting to see in the upcoming year? Can you make any predictions on what the major finding of next year’s report will be?
Nash: Those of us in tech have long relied on Twitter to help detect/disseminate trends, and ironically Twitter itself has recently brought the notion of sociotechnical systems to the cultural mainstream.
While many (myself included) predicted early on that Twitter the product might simply fall over and stop working, what we’re seeing instead is the broader system degrading in strange and often unexpected ways. The loss of product and organizational knowledge combined with the incessant unpredictability of new product features and policy edicts have caused advertisers and users to flee the service. Now, people watching and reporting on this are focusing as much on the people as the technical systems.
This is a trend that I hope continues into 2023 and beyond – not the potential implosion of Twitter, but rather the collective realization that people with hard-earned expertise are required to keep systems up and running.
As for next year’s report, I’ll say that predicting outcomes of complex systems is notoriously difficult. However, we do plan to dig into some new areas that I expect to be very fruitful. We’ve repeatedly said that language matters – the way we talk about failures shapes how we view them, investigate them, and learn from them (or fail to). We suspect there are patterns in the data, both technical and linguistic, that might help us cluster or group different approaches to incident analysis.
We’re also curious if we can start to detect incidences of past incident fixes that led to future incidents.
Readers interested in contributing to The VOID are encouraged to share their incidents. The first step is to analyze and write up the incident. If your organization has a wealth of incident reports to submit, feel free to contact The VOID team directly for assistance.
MMS • Matt Campbell

In collaboration with companies including Google, Microsoft, and GitLab, OX Security has released a security framework for assessing and evaluating software supply chain security risks. The Open Software Supply Chain Attack Reference (OSC&R) is a MITRE-like framework covering containers, open-source software, secrets hygiene, and CI/CD posture.
OSC&R is designed to provide a common language and structure for understanding and analyzing the tactics, techniques, and procedures (TTPs) used by attackers in supply chain attacks. Hiroki Suezawa, Senior Security Engineer at GitLab, shares that:
We wanted to give the security community a single point of reference to proactively assess their own strategies for securing their software supply chains and to compare solutions.
The framework is divided into nine areas of importance defining the pipeline bill of materials (PBOM). A PBOM is similar to a software bill of materials (SBOM) but covers the pipeline and processes used to build software artifacts instead of directly assessing the artifacts themselves. On top of the areas mentioned previously, this includes reviewing source control methods, cloud security, code security, and infrastructure-as-code processes.
These areas of importance are then assessed, in a matrix format, across 12 TTPs. These TTPs include reconnaissance, initial access, persistence, privilege escalation, and credential access. For example, at the intersection of Open Source Security and Initial Access are TTPs including repojacking, typosquatting, malicious IDE extension, and vulnerable CI/CD templates. At the time of writing, only the identification of these TTPs is available on the site; a more detailed definition and description are not currently present.
As Neatsun Ziv, CEO at OX Security explains,
Trying to talk about supply chain security without a common understanding of what constitutes the software supply chain isn’t productive. Without an agreed-upon definition of the software supply chain, security strategies are often siloed.
Software Supply Chain Security has been growing as an area of concern as attacks in this area continue to increase. A report from Aqua Security found that supply chain attacks grew 300% from 2020 to 2021. Gartner predicts that 45% of organizations globally will have suffered a supply chain attack by 2025. This would be a threefold increase in the number of attacks from 2021.
Recent attacks include malicious packages on the PyPi registry, which as reported by Sergio De Simone for InfoQ “can install the Meterpreter trojan disguised as pip, delete the netstat system utility, and tamper with SSH authorized_keys file.”
These increases in attacks have been met with an increase in investment in supply chain security. Along with the new OSC&R framework, Chainguard has recently released the OpenVEX specification. The Vulnerability Exploitability eXchange (VEX) is designed to help assess and manage vulnerabilities in software. As noted by Dan Lorenc, CEO at Chainguard, “OpenVEX is complementary to SBOMs, allowing suppliers to communicate precise metadata about the vulnerability status of products directly to consumers and end users.” Other recent improvements in this area include improvements from Docker, Google, and AWS.
Reaction to the release was mixed with Nermin S., Lead Solution Strategist at Immersive Labs, wondering “BUT, [does] this industry really need more frameworks? They all add some particular value…but the amount [creates] some [friction] already.”
The authors of the OSC&R framework indicate it will continue to be updated as attacker tactics and techniques emerge and evolve.
MMS • Claudio Masolo

InfluxData releases in general availability the new version of its database engine called Influx IOx. It is now available to be used in InfluxDB Cloud.
The new engine, developed in Rust as said in an official InfluxData tweet, can handle metrics, events, and traces. Metrics are time series polled at regular intervals from the sources and are useful to understand the performances and the availability of a service. Events are state changes triggered by some conditions (i.e. deployed code, HTTP 5XX errors) and can be correlated to the metrics to have additional insights. Traces capture information to show the request propagation in a distributed system.
Influx IOx allows InfluxDB Cloud to ingest the data in real time and derive metrics on the fly. InfuxDB can now better handle the use cases of observability and distributed tracing which rely on high cardinality data. In a distributed system it is important to know how each component is working in relation to the others, as some components depend on others so errors, bottlenecks, and delays can impact the performance of the entire system.
Tracing is an observability concept used to understand how the different pieces work together. A trace provides a view of a request, operation, task, or another unit of work as it works in the distributed system. Tracing data are, by definition, high-cardinality data, and for a time series database, cardinality can become a problem for data with unbounded values such as user IDs, IP addresses, and container IDs. High cardinality can affect performances at scale due to how the database index data.
The new engine has also a new columnar structure and compression abilities, which allows InfluxDB Cloud to handle tag values of unbounded data without a drop in performance. The new format for data persistency is Apache Parquet, which allows better compression (and low cost of storage). When new data arrives, IOx writes data to columns of the table and saves it to a new Parquet file. When IOx writes data, it includes some hints in the Parquet metadata to describe the column context, these metadata are used by the query engine at query time to skip over entire Parquet files and/or not interesting portions of files. Parallelism, in-memory cache, and pushdown concepts are also used by the query engine to improve low-latency query performances.
With the utilization of Apace DataFusion, a Rust-based query engine developers can now use native SQL queries to gather information. They can still use Flux language for more advanced data processing.
At the time of writing, the new database engine is available in two AWS regions (Virginia (us-east-1) and Frankfurt (eu-central-1), but new availability zones are planned as well as the adding availability for Azure and Google Cloud.
Java News Roundup: JDK 20 RC1, Open Liberty, Micronaut, Helidon, Hibernate, Groovy, Grails
MMS • Michael Redlich

This week’s Java roundup for February 6th, 2023 features news from OpenJDK, JDK 20, JDK 21, Open Liberty 23.0.0.1 and 23.0.0.2-beta, Helidon 3.1.1, Quarkus 2.16.2 and 3.0.0.Alpha4, Micronaut 3.8.4, Hibernate ORM 6.2, 6.1.7 and 5.6.15, Grails 5.3.0, Apache Groovy 4.0.9 and 3.0.15, Apache Camel 3.20.2, Eclipse Vert.x 4.3.8, Gradle 8.0.0-RC5, Jarviz 0.2.0, Kotlin K2 compiler and Jfokus conference.
OpenJDK
Gavin Bierman, consulting member of technical staff at Oracle, has provided the third draft specification for JEP 430, String Templates (Preview). Still in Candidate status, this latest update for JEP 430 is a substantial rewrite that more fully covers how templates are tokenized and how to deal with ambiguities and text block templates.
JDK 20
As per the JDK 20 release schedule, Mark Reinhold, chief architect, Java Platform Group at Oracle, formally declared that JDK 20 has entered its first release as there are no unresolved P1 bugs in build 35.
The final set of six (6) features in JDK 20 will include:
Build 35 of the JDK 20 early-access builds was made available this past week, featuring updates from Build 34 that include fixes to various issues. More details on this build may be found in the release notes.
JDK 21
Build 9 of the JDK 21 early-access builds was also made available this past week featuring updates from Build 8 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 20 and JDK 21, developers are encouraged to report bugs via the Java Bug Database.
Open Liberty
IBM has released Open Liberty 23.0.0.1 featuring numerous bug fixes and a migration to the Eclipse Public License v2.0 (EPLv2) from EPLv1 to maintain compatibility with MicroProfile and Jakarta EE that require the EPLv2 license.
Open Liberty 23.0.0.2-beta has also been released featuring enhancements to InstantOn, first introduced in version 22.0.0.11-beta, that make it easier to create and deploy applications with Liberty InstantOn.
Helidon
The release of Helidon 3.1.1 delivers notable changes such as: add Helidon Metrics integration with Oracle Cloud Infrastructure; a new JtaConnection class that extends the ConditionallyCloseableConnection class that proxies another ordinary Connection and makes it behave as properly as possible in the presence of a global JTA transaction; and an enhancement to allow different WebSocket applications to be registered on different ports.
Quarkus
Red Hat has released Quarkus 2.16.2.Final featuring a number of bug fixes, improvements in documentation and dependency upgrades of SmallRye Config 2.13.2 and PostgreSQL 42.5.3. More details on this release may be found in the changelog.
The fourth alpha release of Quarkus 3.0.0 has also been made available to deliver significant changes such as: support for Jakarta EE 10; an Elasticsearch Java client; support for custom FlywayDB configuration, credentials and URL; allow global default cache configuration; and a new Azure Functions extension.
Micronaut
The Micronaut Foundation has released Micronaut 3.8.4 featuring bug fixes and updates to modules: Micronaut OpenAPI, Micronaut Data, Micronaut RabbitMQ, Micronaut Azure, Micronaut Micrometer and Micronaut Test. Further details on this release may be found in the release notes.
Hibernate
Three point releases of Hibernate ORM have been released this past week:
Version 6.2 provides support for table partitioning via partition key mapping using the new @PartitionKey annotation.
Version 6.1.7.Final ships with notable bug fixes such as: an EntityNotFoundException thrown when the refresh() method defined in the EntityManager interface is called for a parent entity having a child annotated with the @Where annotation; the execution of unnecessary SQL UPDATE statements when setting a property to its current value; and an IllegalArgumentException thrown when deleting an entity having an embeddable with a collection attribute annotated with the property, orphanRemoval=true.
Version 5.6.15.Final delivers notable bug fixes such as: a missing an identifier quote on a sequence query with MariaDB; an error when Hibernate tries to retrieve information about existing sequences; and execution of unnecessary SQL update statements when setting a property to its current value.
Grails
The release of Grails 5.3.0 delivers changes such as: an update Grails Profile BOM and dependabot.yml file; and groovy @generated annotation is now emitted on all generated methods and fields so that JaCoCo coverage should only consider manually generated code when calculating coverage. This release also includes numerous dependency upgrades to include: Micronaut 3.8.3, Micronaut Spring 4.3.1, Apache Tomcat 9.0.70, Apache Ant 1.10.13, Spring Framework 5.3.24 and Spring Boot 2.7.8.
Apache Software Foundation
Apache Groovy 4.0.9 has been released featuring bug fixes, dependency upgrades and an improvement in which the parameters of the overloaded findResult() and findResults() methods defined in the DefaultGroovyMethods that don’t contain an instance of the Closure class should accept an instance of Closure.IDENTITY. More details on this release may be found in the release notes.
Apache Groovy 3.0.15 has also been released featuring bug fixes and a dependency upgrade to ASM 9.4. Further details on this release may be found in the release notes.
The release of Apache Camel 3.20.2 ships with bug fixes and numerous improvements, primarily focused on the camel-jbang component, such as: the ability to run in the background; add a --watch option to the CLI to prevent restarts per call; the ability to dump logs from Camel apps; and an export to Quarkus should add resources for native compilation. More details on this release may be found in the release notes.
Eclipse Vert.x
In response to a number of reported bugs found in version 4.3.7, Eclipse Vert.x 4.3.8 has been released that addresses CVE-2023-24815, a vulnerability impacting Vert.x Web application serving static content on Windows with a wildcard route that discloses classpath resources. Further details on this release may be found in the release notes.
Gradle
The third and fourth and fifth release candidates of Gradle 8.0.0 have been made available to the Java community this past week. More details on these releases may be found in the release notes of version 8.0.0-RC5, version 8.0.0-RC4 and version 8.0.0-RC3.
Jarviz
Version 0.2.0 of Jarviz, a new JAR file analyzer utility, has been released by Andres Almiray to the Java community. This new version: adds color support to standard output; adds the windows_x86_32 and linux_x86_32 binaries; displays a module descriptor; and adds reporting capabilities. InfoQ will follow up with a more detailed introduction to Jarviz.
Kotlin
The compiler team over at Kotlin has announced that the frontend to the Kotlin compiler, codenamed K2, will be declared stable with the release of Kotlin 2.0. K2 has been available as a preview feature since Kotlin 1.7, but has been in active development for well over two years. Developers can expect a Kotlin 1.9 before the release of Kotlin 2.0. Further details on K2 may be found in this InfoQ news story.
Jfokus Conference
The Jfokus conference was held this past week at the Stockholm Waterfront Congress Centre in Stockholm, Sweden featuring many speakers from the Java community who presented talks on topics such as: cloud-native build tools; event-related software concepts and methodologies; Project Loom; GraphQL; in-memory computing; and test-driven design.
Big Data Software Market 2022-2027: Latest Updates, Industry Size, Share, Growth and …
MMS • RSS
PRESS RELEASE
Published February 13, 2023
The latest report published by IMARC Group, titled “Big Data Software Market: Global Industry Trends, Share, Size, Growth, Opportunity and Forecast 2022-2027”, offers a comprehensive analysis of the industry, which comprises insights on big data software market trends. The report also includes competitor and regional analysis, and contemporary advancements in the global market. The global big data software market reached a value of US$ 162.6 Billion in 2021. Looking forward, IMARC Group expects the market to reach US$ 314.1 Billion by 2027, exhibiting a CAGR of 11.4% during 2022-2027.
Big data software refers to the technology that is used to collect, host, and analytically process the dynamic and disparate volume of data created by humans and machines. It includes technologies, such as Hadoop, Spark, Storm, Flink, Kafka, and NoSQL databases and specialized analytic and visualization tools that help in discovering hidden patterns, unknown correlations, market trends, and consumer preferences. It provides improved decision-making, increased efficiency, enhanced customer service, innovation, and cost savings. As a result, it is used in numerous industries, including retail, healthcare, finance, and government, and is widely employed for tasks, including business intelligence, machine learning, data warehousing, and real-time analytics. It is also utilized by clinicians to uncover disease indicators and risk factors and diagnose disease and medical issues in patients.
Request to Get the Free Sample Report: https://www.imarcgroup.com/big-data-software-market/requestsample

Market Trends:
The market is primarily driven by the increasing volume of data generated by the numerous industry verticals. Moreover, the widespread integration of artificial intelligence (AI) and machine learning (ML) as cutting-edge technology with data management and analytics software, along with rapid digitalization, is augmenting the market. Furthermore, the increasing significance of data in modern enterprises backed by rising technological investments, resulting in deep assessments of current business, is creating a positive market outlook. Besides, the wide adoption of big data software by numerous industries, since it helps in protecting data by encrypting it, controlling access to it, and detecting potential threats, is further catalysing the demand across the globe. Other factors, including the emerging information technology (IT) sector and extensive research and development (R&D) activities, are projected to propel the market further.
Explore Full Report with Table of Contents: https://www.imarcgroup.com/big-data-software-market
Competitive Landscape:
The competitive landscape of the market has been studied in the report with the detailed profiles of the key players operating in the market.
- AWS
- Cloudera
- Hortonworks
- IBM
- Informatica
- Microsoft
- Oracle
- Palantir
- SAP
- SAS
- Splunk
Big Data Software Market Segmentation:
Our report has categorized the market based on region, software type, deployment type, industry and end-use.
Breakup by Software Type:
- Database
- Data Analytics and Tools
- Data Management
- Data Applications
- Core Technologies
Breakup by Deployment Type:
- On-Premise
- Cloud
Breakup by Industry:
- Banking
- Discrete Manufacturing
- Professional Services
- Process Manufacturing
- Federal/Central Government
- Others
Breakup by End-Use:
- Large Enterprises
- SMEs
Breakup by Region:
- North America (United States, Canada)
- Europe (Germany, France, United Kingdom, Italy, Spain, Others)
- Asia Pacific (China, Japan, India, Australia, Indonesia, Korea, Others)
- Latin America (Brazil, Mexico, Others)
- Middle East and Africa (United Arab Emirates, Saudi Arabia, Qatar, Iraq, Other)
Key highlights of the report:
- Market Performance (2016-2021)
- Market Outlook (2022-2027)
- Porter’s Five Forces Analysis
- Market Drivers and Success Factors
- SWOT Analysis
- Value Chain
- Comprehensive Mapping of the Competitive Landscape
Note: We are in the process of updating our reports. If you want to receive the latest research data covering the time period from 2023 to 2028, along with industry trends, market size, and competitive analysis, click on the request sample report. The team would be able to deliver the latest version of the report in a quick turnaround time.
About Us
IMARC Group is a leading market research company that offers management strategy and market research worldwide. We partner with clients in all sectors and regions to identify their highest-value opportunities, address their most critical challenges, and transform their businesses.
IMARC’s information products include major market, scientific, economic and technological developments for business leaders in pharmaceutical, industrial, and high technology organizations. Market forecasts and industry analysis for biotechnology, advanced materials, pharmaceuticals, food and beverage, travel and tourism, nanotechnology and novel processing methods are at the top of the company’s expertise.
Contact US:
IMARC Group
134 N 4th St. Brooklyn, NY 11249, USA
Email: [email protected]
Tel No:(D) +91 120 433 0800
Americas:- +1 631 791 1145 | Africa and Europe:- +44-702-409-7331 | Asia: +91-120-433-0800, +91-120-433-0800
MMS • Deepak Vohra

Key Takeaways
- PHP 8 supports array unpacking with string keys, introduces a new function to determine if an array is a list, and a stable array sort function.
- Exception handling adds support for non-capturing catches, and use of the throw statement where only an expression is usable.
- New features related to variable declarations are explicit octal notation 0o/0O for integer literals, limited $GLOBALS usage, and namespaced names as single tokens.
- New operators include an improved non-strict string to number comparison, the new null-safe operator, locale-independent float to string cast, and stricter type checks for arithmetic/bitwise operators. Support has been added to fetch properties of enums in const expressions with the ->/?-> operators.
- Some other improvements are made in traits, including validation of abstract trait methods, and support for constants in traits.
|
This article is part of the article series “PHP 8.x”. You can subscribe to receive notifications about new articles in this series via RSS. PHP continues to be one of the most widely used scripting languages on the web with 77.3% of all the websites whose server-side programming language is known using it according to w3tech. PHP 8 brings many new features and other improvements, which we shall explore in this article series. |
In this last installment of our PHP 8 article series, we are going to cover support for several new features and improvements to arrays, variables, operators, exception handling, traits, and more.
Arrays and Strings
Deprecate autovivification on false
Autovivification is the automatic creation of new arrays when undefined elements of an array are referenced, for example:
<?php
$arr['a'][1] = 'a';
var_dump($arr);
The new array $arr is created automatically even though it does not exist before it is referenced. The output is:
array(1) { ["a"]=> array(1) { [1]=> string(1) "a" } }
Autovivification allows a developer to refer to a structured variable such as an array, as well as to its subelements, without first explicitly creating the structured variable.
PHP 8.0 supports autovivification from undefined variables, null values, and false values. Autovivification from null is demonstrated by the following script:
<?php
$arr = null;
$arr[] = 1;
var_dump($arr);
The output is:
array(1) { [0]=> int(1) }
Autovivification from undefined variable is demonstrated by this script:
<?php
$arr[] = 'undefined value';
$arr['variableNotExist'][] = 1;
var_dump($arr);
The output from the script is as follows:
array(2) { [0]=> string(15) "undefined value" ["variableNotExist"]=> array(1) { [0]=> int(1) } }
PHP 8.0 even allows autovivification from false. PHP 8.0 does not however allow autovivification from from scalar values, as demonstrated by the following script:
<?php
$arr = 1;
$arr[] = 1;
var_dump($arr);
The script output is:
Uncaught Error: Cannot use a scalar value as an array
With PHP 8.1, autovivification is supported only for undefined variables and null values. Autovivification from false is deprecated in 8.1. To demonstrate, run the following script:
<?php
$arr = false;
$arr[] = 1;
The output from the script is as follows:
Deprecated: Automatic conversion of false to array is deprecated
Array unpacking with string keys
Unpacking is used in the context of an array’s elements to itemize or unpack the array elements using the unpacking operator …. Unpacking of string keys in an array is not allowed in PHP 8.0, as is unpacking of a function’s arguments. PHP 8.1 allowed unpacking a function’s arguments with the introduction of named arguments; named arguments may be used after unpacking the arguments with the condition that a named argument must not override already unpacked arguments. An example of unpacking a function’s named arguments was demonstrated in the article “PHP 8 – New Features for Functions and Methods”.
PHP 8.1 additionally allows unpacking of string keys into an array using the … operator, as demonstrated by the example:
1];
$array2 = ["two" => 2];
$array1 = ["one" => "one"];
$array2 = ["two" => "two"];
$array = ["one" => 0, "two" => 10, ...$array1, ...$array2];
var_dump($array);
$array1 and array2 get unpacked with the … operator, with the latter array’s keys overriding the former’s. The output is as follows:
array(2) { ["one"]=> string(3) "one" ["two"]=> string(3) "two" }
The array_merge() function is used when unpacking arrays behind the scenes, so unpacking the two arrays in the preceding example is the same as calling array_merge($array1, $array2).
The new feature affects only string keys, while integer keys are renumbered; original integer keys are not retained. An example of using integer keys is the following:
1];
$array2 = [2 => 2];
$array1 = [1 => "one"];
$array2 = [2 => "two"];
$array = [1 => 0, 2 => 10, ...$array1, ...$array2];
var_dump($array);
Another example of unpacking arrays with string keys is presented below, where quoted integer keys are actually used as integer keys. String keys containing integers are cast to integer types; as an example:
1];
$array2 = ["2" => 2];
$array1 = ["1" => "one"];
$array2 = ["2" => "two"];
$array = ["one" => 0, "two" => 10, ...$array1, ...$array2];
var_dump($array);
Output is as follows:
array(4) { ["one"]=> int(0) ["two"]=> int(10) [0]=> string(3) "one" [1]=> string(3) "two" }
A new function to find if an array is a list
An array type supports both string and integer keys. It may be useful to know if an array’s keys are actually numbered 0 … count($array)-1, in which case we call it a list. The new function array_is_list(array $array): bool does just that by returning a bool value true if it is a list and false if it is not. The following example demonstrates the new function:
'a', 0 => 'b', 2=>'c'];
$y = [0 => 'a', 1 => 'b', 2=>'c'];
var_export(array_is_list($x));
var_export(array_is_list($y));
The output is as follows:
false
true
Sorting of arrays made stable
In PHP 7 the array sorting operation is unstable. “Unstable” implies that the order of “equal” elements is not guaranteed in successive sorts. PHP 8.0 makes sorting stable. If multiple elements in an input array compare equal, they are always sorted adjacently. In other words, equal elements retain the order they have in the original array. Stable sorts are especially useful in sort operations involving complex data when a sort is made on a specific attribute of the data. In such cases, inconsistent output may result if sorting is unstable. The following script demonstrates a stable sort:
'c',
'c' => 'c',
'b' => 'a',
'a' => 'a',
];
asort($array);
foreach ($array as $key => $val) {
echo "array[" . $key . "] = " . $val . "n";
}
The result with a stable sort is always:
array[b] = a array[a] = a array[d] = c array[c] = c
Deprecate ${} string interpolation
Embedding variables in strings with double-quotes (“) has been allowed in various forms. PHP 8.2 deprecates two such forms of string interpolation: ${var} and ${expr}. The ${var} form has an overlapping syntax with two other forms ("$var") and ("{$var}") and is less capable than the other forms. The ${expr}, which is the equivalent to (string) ${expr}) is rarely used.
The following example allows some string interpolations while disallowing the ${var} and ${expr} forms:
<?php
$str = 'hello';
var_dump("$str");
var_dump("{$str}");
var_dump("${str}");
var_dump("${str}");
var_dump("${(str)}");
The output is as follows:
Deprecated: Using ${var} in strings is deprecated, use {$var} instead in /home/deepakvohra/php-src/scripts/php-info.php on line 8
Deprecated: Using ${var} in strings is deprecated, use {$var} instead in /home/deepakvohra/php-src/scripts/php-info.php on line 10
Deprecated: Using ${expr} (variable variables) in strings is deprecated, use {${expr}} instead in /home/deepakvohra/php-src/scripts/php-info.php on line 12
string(5) "hello" string(5) "hello" string(5) "hello" string(5) "hello"
Fatal error: Uncaught Error: Undefined constant "str"
Exception Handling
PHP 8.0 introduces non-capturing catches. Previously, each catch statement had to declare a variable for the exception being caught. As, an example the following script declares the variable $exc of type Exception in the catch statement:
<?php
function sortArray(array $arrayToSort)
{
try {
if (count($arrayToSort) === 0) {
throw new Exception("Array is empty; please provide a non-empty array");
}
}
catch (Exception $exc) {
echo $exc;
}
}
$arrayToSort = array();
The script outputs an exception message when run:
Exception: Array is empty; please provide a non-empty array
Though the $exc variable was used in the preceding example, exception variables are not always used. With non-capturing catches exception variables are made optional; they don’t have to be declared, and therefore cannot be used, as in the script:
<?php
function sortArray(array $arrayToSort)
{
try {
if (count($arrayToSort) === 0) {
throw new Exception("Array is empty; please provide a non-empty array");
}
}
catch (Exception) {
}
}
A multi-catch catch statement may also not capture the exceptions as in the example:
<?php
class Exception1 extends Exception
{
}
class Exception2 extends Exception
{
}
class A
{
public function fn1()
{
try {
throw new Exception1();
}
catch (Exception1 | Exception2) {
}
}
}
The throw expression
The throw statement could not previously be used in instances where expressions are allowed. PHP 8.0 adds support for using throw with expressions. As an example, the default case in the match expression in the following script makes use of the throw expression.
push('a');
try {
match ('set') {
'push' => $vector->push('b'),
'pop' => $vector->pop(),
default => throw new Exception()
};
}
catch (Exception $exc) {
echo $exc;
}
print_r($vector);
The output is as follows:
Exception in C:php-8.1.9-nts-Win32-vs16-x64scriptssample.php:11 Stack trace: #0 {main}DsVector Object ( [0] => a )
An example of using throw with a null-coalescing operator (??) is as follows:
<?php
$name = $_GET['name'] ?? throw new Exception("Please provide 'name' as a request parameter");
echo "Hello " . htmlspecialchars($name)."
";
Output is as follows:
Uncaught Exception: Please provide 'name' as a request parameter
As another example, throw here is used with the ternary operator (?):
<?php
try {
function fn1(bool $param1)
{
$value = $param1 ? true: throw new InvalidArgumentException();
}
fn1(true);
fn1(false);
}
catch (Exception $exc) {
echo $exc;
}
Output is as follows:
InvalidArgumentException in C:php-8.1.9-nts-Win32-vs16-x64scriptssample.php:5 Stack trace: #0 C:php-8.1.9-nts-Win32-vs16-x64scriptssample.php(9): fn1(false) #1 {main}
Variables
Explicit octal integer literal notation
A literal octal notation could produce misleading results such as 12 === 012 evaluating to false. PHP 8.1 adds support for explicit octal notation 0o/0O for integer literals, similar to the 0x/0X notation for hexadecimal and the 0b/0B notation for binary. The following script demonstrates the explicit octal notation:
<?php
var_export(0o12 === 10);
var_export(0o26 === 22);
var_export(0O12 === 10);
var_export(0O26 === 22);
var_export(012 === 0o12);
var_export(012 === 0O12);
Output is as follows:
true
true
true
true
true
true
Restrict $GLOBALS usage
The usage of the $GLOBALS variable, which provides direct access to the internal symbol table, has been restricted to disallow improper usage. As of PHP 8.1, $GLOBALS can only be modified using the $GLOBALS[$name] = $value syntax. To demonstrate, run the following script that directly accesses $GLOBALS:
<?php
$x=1;
$GLOBALS = 1;
$GLOBALS += 1;
$GLOBALS =& $x;
$x =& $GLOBALS;
unset($GLOBALS);
An error message is output:
$GLOBALS can only be modified using the $GLOBALS[$name] = $value syntax
The following use of $GLOBALS is OK:
<?php
$GLOBALS['a'] = 1;
$GLOBALS['a']--;
var_dump($GLOBALS['a']);
Output is:
int(0)
Treat namespaced names as single token
To allow reserved keywords to appear within namespaced names, PHP 8.0 treats namespaced names as a single token. This reduces the chance of introducing backward incompatibility due to new reserved words that could already have been used in a namespace name.
To demonstrate this, the following script uses reserved word fn in a namespace name. The script also makes use of the ReflectionClass to output class attributes such as whether it is a namespace, the class name, the namespace, and the class methods:
inNamespace());
var_dump($class->getName());
var_dump($class->getNamespaceName());
$methods = $class->getMethods();
var_dump($methods);
The output is as follows:
bool(true) string(18)
"dowhilefniterC" string(16)
"dowhilefniter"
array(1) { [0]=> object(ReflectionMethod)#2 (2) { ["name"]=> string(3) "fn2" ["class"]=> string(18) "dowhilefniterC" } }
Operators
PHP 8 adds quite a few new operator related features.
Non-strict string to number comparisons made more useful
Before PHP 8.0, non-strict string to number comparisons make an assumption that the string is actually a number, therefore convert the string to a number and make a number comparison. PHP 8.0 ensures that the string is a number before converting types and making a number comparison. Otherwise the number is converted to a string and a string comparison is made instead. The new feature does not apply to strict comparison operators === and !== that require both operands to be of the same type and do not perform implicit type conversion. Only the non-strict comparison operators ==, !=, >, >=, <, <= and ⇔ are affected. The following script demonstrates the new string to number comparison:
<?php
var_dump(1 == "001");
var_dump(1 == "1.0");
var_dump(1.0 == "+1.0E0");
var_dump(1 == "1 ");
var_dump(1 == " 1");
var_dump(1 == " 1 ");
var_dump("one" == "1");
var_dump("one" != "1");
The output is as follows:
bool(true) bool(true) bool(true) bool(true) bool(true) bool(true) bool(false) bool(true)
Nullsafe operator
How often have you called a method, or fetched a property on the result of an expression assuming that the result is non-null. As the result could be null, it is best to first ensure that it is not null. You could use explicit if(result!=null) comparisons but it could involve hierarchical, multiple comparisons. The following script makes use of the traditional if comparisons to make null-safe comparisons for addition of integer values:
i = 0;
}
function addA(Sum $sum,int $a):?Sum
{
$sum->i= $a+$sum->i;
return $sum;
}
function addB(Sum $sum,int $b):?Sum
{
$sum->i= $b+$sum->i;
return $sum;
}
function addC(Sum $sum,int $c):?Sum
{
$sum->i= $c+$sum->i;
return $sum;
}
function getSum(Sum $sum):int
{
return $sum->i;
}
}
$a = new Sum();
if ($a->addA($a,1) !== null) {
if ($a->addB($a,2) !== null) {
if ($a->addC($a,3) !== null) {
echo $a->getSum($a);
}
}
}
The result is 6.
The new operator ?-> could be used to link calls to make null-safe comparisons, and when the left operand to the operator evaluates to null, it stops all subsequent comparisons. The following script demonstrates linking operands to make null-safe comparisons using the new ?-> operator for the same addition.
echo $a->addA($a,1)?->addB($a,2)?->addC($a,3)?->getSum($a);
Locale-independent float to string cast
Float to string casts before PHP 8.0 are locale dependent, that is, the decimal separator varies between locales. This could lead to several inconsistencies such as interpreting strings as being malformed, or interpreting strings as numerical values. A consistent string representation for floats was much needed, and PHP 8.0 provides just that. The following script demonstrates local-independent float-to-string casts.
<?php
setlocale(LC_ALL, "de_DE");
$f = 1.23;
echo (string) $f;
echo strval($f);
The result is:
1.23
1.23
Stricter type checks for arithmetic/bitwise operators
Arithmetic/bitwise operators, which are +, -, *, /, **, %, <>, &, |, ^, ~, ++, –, must only be applied to operands that support them. An operand that is an array, resource, or non-overloaded object cannot be used with these operators. PHP 8.0 makes a strict type check and throws a TypeError if the operands are not compatible with the arithmetic/bitwise operators. To demonstrate this, the following script uses the subtraction operator (-) with arrays:
<?php
$arrayToSort = array(3, 1, 0, 2);
var_dump($arrayToSort - [1]);
Result is an error:
Uncaught TypeError: Unsupported operand types: array - array
Fetch properties of enums in const expressions with the ->/?-> operators
Enum objects aren’t allowed in constant expressions such as array keys, which wouldn’t support the use case in which you require to fetch the name and value properties of enums in constant expressions. To demonstrate, run the following script with version 8.1:
name => self::ASC->value];
}
An error message is generated:
Constant expression contains invalid operations
PHP 8.2 allows the -> ?-> operators to fetch properties of enums in constant expressions, as in the following script:
name => self::ASC->value];
}
function get()
{
static $g = Sort::ASC->value;
}
#[Attr(Sort::ASC->name)]
class SortClass
{
}
function set($s = Sort::ASC->value,)
{
}
class SortClass2
{
public string $n = Sort::ASC->name;
}
// The rhs of -> allows other constant expressions
const DESC = 'DESC';
class SortClass3
{
const C = Sort::ASC->{DESC};
}
Traits
Validation of abstract trait methods
PHP 8.0 validates abstract trait methods in the composing/using class to ensure that their signatures match. The implementing method must be compatible with the trait method, with compatibility being defined as signature compatibility:
- Arity compatibility; the number of function arguments must be the same
- Contravariant parameter type compatibility
- Covariant return type compatibility
Additionally, the static methods must be kept static. Abstract private trait methods are allowed. The following script demonstrates an accurate implementation of abstract trait methods:
hello());
}
}
class A {
use HelloTrait;
private function hello(): string {return "Hello John"; }
}
To demonstrate incompatibility, change the implemented method as follows:
private function hello(): stdClass { }
In this case, an error condition is indicated:
Declaration of A::hello(): stdClass must be compatible with HelloTrait::hello(): string
A non-static method in the trait cannot be made static in the class. To demonstrate, change the implementation as in:
private static function hello(): string { }
An error condition is indicated:
Cannot make non static method HelloTrait::hello() //static in class A
Calling a static element on a Trait is deprecated
PHP 8.1.0 deprecates calling a static element on a trait, which implies that calling a static method, or a static property, directly on a trait is deprecated. Static methods and properties should only be accessed on a class using the trait. The following script demonstrates the deprecation:
<?php
trait HelloTrait {
public static $a = 'static property in trait';
public static function hello(): string {return "Hello";}
}
class A {
use HelloTrait;
}
echo A::$a;
echo A::hello();
echo HelloTrait::$a;
echo HelloTrait::hello();
Output is as follows:
Deprecated: Accessing static trait property HelloTrait::$a is deprecated, it should only be accessed on a class using the trait
Deprecated: Calling static trait method HelloTrait::hello is deprecated, it should only be called on a class using the trait
Constants in Traits
Invariants, also called constants, are not allowed in a trait in PHP 8.1. PHP 8.2 adds support for constants in traits. The constants may be used by the trait’s methods or in the composing class. To demonstrate the usefulness of constants in traits consider the following example in which a constant called MAX_ARRAY_SIZE is declared in the composing class:
self::MAX_ARRAY_SIZE) {
throw new Exception("array size out of range");
} else {
sort($arrayToSort);
foreach ($arrayToSort as $key => $val) {
echo "$key = $val ";
}
echo "
";
}
}
}
class SortClass
{
private const MAX_ARRAY_SIZE = 10;
use SortTrait;
}
$arrayToSort = ["B", "A", "f", "C", 1, "a", "F", "B", "b", "d"];
$obj = new SortClass();
$obj->sortArray($arrayToSort);
The script runs ok to generate the following output:
0 = 1 1 = A 2 = B 3 = B 4 = C 5 = F 6 = a 7 = b 8 = d 9 = f
The following 8.2 version of the same script declares the constant MAX_ARRAY_SIZE in the trait itself.
self::MAX_ARRAY_SIZE) {
throw new Exception("array size out of range");
} else {
sort($arrayToSort);
foreach ($arrayToSort as $key => $val) {
echo "$key = $val ";
}
echo "
";
}
}
}
class SortClass
{
use SortTrait;
}
$arrayToSort = ["B", "A", "f", "C", 1, "a", "F", "B", "b", "d"];
$obj = new SortClass();
$obj->sortArray($arrayToSort);
The output is the same:
0 = 1 1 = A 2 = B 3 = B 4 = C 5 = F 6 = a 7 = b 8 = d 9 = f
As another example, the following script declares three constants in a trait and makes use of them in the trait itself:
getSortType("ASCending");
The output is:
Sort type is ASC
A trait constant cannot be accessed directly with syntax TRAIT_NAME::CONSTANT, which the following script does:
getSortType("ASCending");
An error is shown when the script is run:
Uncaught Error: Cannot access trait constant SortTrait::SORT_TYPE_1 directly
Using $this is ok, as in:
if (str_contains($sortType, $this::SORT_TYPE_1)) {
echo 'Sort type is ASC';
}
Trait constants can be declared as final for class constants. Compatibility restrictions that apply to a trait’s properties also apply to its constants.
Enumerations can use traits having constants and the constants are equivalent to defining them in the enumeration directly, as in the script:
<?php
trait SortTrait
{
private const SortType = "ASC";
}
enum Enum1: int
{
use SortTrait;
case CaseA = self::SortType;
}
Phasing out Serializable
PHP 7.4 introduced the custom serializable mechanism with two new magic methods called __serialize(): array, and __unserialize(array $data): void. The __serialize() method returns an array with all the necessary state of the object, and the __unserialize() method restores the object state from the given data array. The new custom serializable mechanism is designed to phase out the Serializable interface. PHP 8.1 generates a deprecation warning if a non-abstract class implements Serializable but does not implement __serialize() and __unserialize(). Such a class is called “only Serializable”. To demonstrate this, run the script:
<?php
class A implements Serializable {}
A deprecation message is generated:
Deprecated: A implements the Serializable interface, which is deprecated. Implement __serialize() and __unserialize() instead (or in addition, if support for old PHP versions is necessary)
Fatal error: Class A contains 2 abstract methods and must therefore be declared abstract or implement the remaining methods (Serializable::serialize, Serializable::unserialize)
Deprecate dynamic properties
A dynamic class property is one that is referred to before being declared. A dynamic property is created automatically. Dynamic properties are deprecated in PHP 8.2. The main reason for deprecating dynamic properties is to avoid the ambiguity resulting from whether a user mistyped a property name, or rather wants to create a new property. To demonstrate, run the following script that creates a dynamic property in PHP 8.2:
name = "John";
$a->firstname = "John";
A deprecation message is generated:
Deprecated: Creation of dynamic property A::$firstname is deprecated
If you still want dynamic properties implement the magic methods __get/__set, or use the new attribute #[AllowDynamicProperties]. The pre-packaged class stdClass is already marked with the #[AllowDynamicProperties] attribute.
Deprecate passing null to non-nullable arguments of built-in functions
User-defined functions don’t accept null for non-nullable arguments when coercive typing mode is set (strict_types=1). With PHP 8.1, even built-in functions won’t accept null for non-nullable arguments, generating a Deprecation notice as demonstrated by script:
<?php
$var=null;
strlen($var);
Output is:
Deprecated: strlen(): Passing null to parameter #1 ($string) of type string is deprecated
In PHP 9.0 a TypeError the deprecation notice will be replaced through an error.
In this article, we discussed new features in PHP 8 related to arrays, variables, operators, and exception handling. We also discussed some trait-, class-, and function-related features. This article concludes the PHP 8 article series.
|
This article is part of the article series “PHP 8.x”. You can subscribe to receive notifications about new articles in this series via RSS. PHP continues to be one of the most widely used scripting languages on the web with 77.3% of all the websites whose server-side programming language is known using it according to w3tech. PHP 8 brings many new features and other improvements, which we shall explore in this article series. |
MMS • Vivian Hu
Recently, the runwasiproject, with contributions from Microsoft>, Docker, and Second State officially joined containerd. This enables containerd to support a new container type: Wasm (or WebAssembly) containers. The containerd project is one of the most widely used container runtimes. It has been the default container runtime in Kubernetes since 2021. Even Docker, the original and most popular container development tool, is switching its underlying container runtime to containerd<. Since its inception, containerd has only supported one type of container: the Linux container.
Wasm containers are OCI-compliant containers that can be built, shared, and stored using standard container tools. However, inside the Wasm container, there are no Linux libraries. The container image typically contains just a compiled Wasm bytecode file, which makes the Wasm container much smaller, much faster to startup, more secure, and more portable than equivalent Linux containers. The runwasi shim for containerd unpacks and executes the Wasm file in the container using Wasmtime and WasmEdge. The example below shows how containerd’s ctr CLI pulls a Wasm image from a repository and then runs it in runwasi’s WasmEdge runtime.>
$ sudo ctr run --rm
--runtime=io.containerd.wasmedge.v1 ghcr.io/containerd/runwasi/wasi-demo-app:latest (http://ghcr.io/containerd/runwasi/wasi-demo-app:latest)
testwasm /wasi-demo-app.wasm echo 'hello'
hello
exiting
In the real world, containerd is typically embedded into other container management tools, such as Docker and Kubernetes. Docker + wasm> is built on runwasi, and it enables Docker Desktop to build, share, and run Wasm containers. The Docker command below pulls a Wasm container image for Python, and then starts a REPL for users to run Python scripts. A typical Linux container image for Python is 1GB+, while the Wasm container image for Python, developed by VMware’s Wasm Labs, is only 6.8MB. See more awesome-docker-compose example with Wasm containers.
docker run --rm
-i
--runtime=io.containerd.wasmedge.v1
--platform=wasm32/wasi
ghcr.io/vmware-labs/python-wasm:3.11.1-latest
-i
Python 3.11.1 (tags/v3.11.1:a7a450f, Jan 27 2023, 11:37:16) ... on wasi
Type "help", "copyright", "credits" or "license" for more information.
>>> print("Hello " + str.upper("WasmEdge"))
Hello WASMEDGE
With multiple container runtimes to choose from, container tools now leverage containerd to run Linux and Wasm containers side-by-side in the same network.>
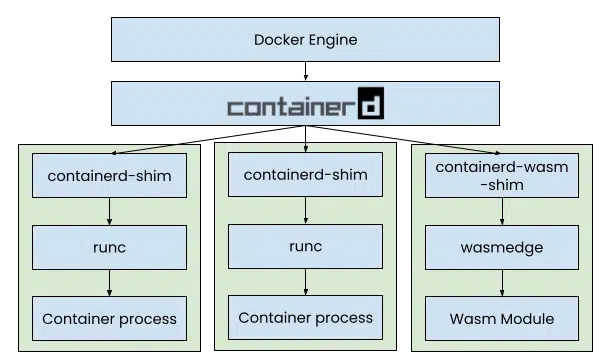
Source: Introducing the Docker+Wasm Technical Preview
Besides Docker, Kubernetes ecosystem projects, such as k3s have also started integrating runwasi into their embedded containerd runtimes. Microsoft’s Azure Kubernetes Service (AKS) uses runwasito create a Wasm node pool and then run the Wasm workload (preview).
Together with crun-based approaches, pioneered by Red Hat and WasmEdge, developers have many deployment options for Wasm containers in the cloud.
The runwasi project is originally created by Microsoft and written in Rust. Developers can participate in and contribute to the runwasi open-source project under Apache 2.0 through GitHub.
MMS • RSS

Bradley Kuhn, policy fellow at the Software Freedom Conservancy, claims a California federal court has misinterpreted version 3 of GNU Affero General Public License (AGPLv3) by allowing it to be combined with the Common Clause software license.
Kuhn, who created the Affero clause in the AGPLv1 and co-drafted v3, expects to serve as an expert witness for defendants PureThink and founder John Mark Suhy, who were sued by database biz Neo4j in November 2018, for alleged trademark and competition law violations.
PureThink at the time distributed database software called ONgDB, which was marketed as an open-source licensed version of Neo4j EE.
Neo4j EE is under a combined AGPLv3+Commons Clause license – the Commons Clause modified the APGLv3 by adding a restriction that forbids the sale of the software. However, PureThink offered a forked version of the Neo4j EE database software under the APGLv3 alone, having removed the Commons Clause from its version of the software.
So Neo4j and its Swedish subsidiary sued PureThink and others claiming that they had violated the license terms and had infringed Neo4j’s trademarks.
In May 2021, Neo4j won a partial summary judgment [PDF] when the judge overseeing the case granted the company’s request for a temporary injunction based on its trademark and unfair competition claims.
PureThink was enjoined – until the matter can be resolved – from “advertising, promoting, representing or referring to ONgDB as a free and open source drop-in replacement for Neo4j Enterprise Edition” and making false representations about ONgDB to customers.
The US Ninth Circuit Court of Appeals subsequently upheld that injunction, and the case has continued so far.
Among the remaining disputed issues to be resolved, the most important for the Free and Open Source Software (FOSS) community is whether Neo4j’s concatenation of the AGPLv3 and Commons Clause is allowed.
Kuhn, in an expert report [PDF] prepared for the case, acknowledges that the AGPLv3 language can be re-mixed and used in another license, as long as that license is not called the AGPLv3. He cites MongoDB’s modified AGPLv3 license, referred to as the Server-Side Public License, as an example of how the AGPLv3 can be altered into something that’s not a FOSS license.
But if the license is referred to as the AGPLv3, then its Further Restrictions Clause – which allows users of APGLv3 licensed software to remove added licensing terms – should apply. If the court accepts that argument, it would be a significant reversal: PureThink would be allowed to fork Neo4J EE under the AGPLv3.
A trial date has yet to be set but several possibilities in July, 2023, have been proposed. ®
MMS • Sergio De Simone

A recent report by Sonatype security researcher Ax Sharma highlights newly discovered malicious packages on the PyPI registry, including aptx, which can install the Meterpreter trojan disguised as pip, delete the netstat system utility, and tamper with SSH authorized_keys file.
Named after the popular audio codec developed by Qualcomm and used in many Bluetooth devices, aptx is not the only new threat identified on PyPI. Other malicious packages are httops and tkint3rs. What they all have in common is a strategy aiming to confuse people using purposely-crafted names. As Sharma observes, indeed, httops and tkint3rs are misspellings of https and the tkinter Python interface, respectively.
On close inspection, Sonatype engineers found out that aptx has a setup.py manifest that is able to create an ELF binary named ./pip/pip. The binary contains a Meterpreter trojan generated using Metasploit, a penetration testing tool, and allows an attacker to gain shell access to the infected machine. To make it harder for a sysadmin to track active connections, setup.py also deletes netstat.
In their January 2023 Malware Monthly, Sonatype researchers unveil details about dozen of others malicious packages found in PyPI and hundreds of new malicious packages in the npm registry.
A few of them show novel attack strategies, such as detecting whether the host where the malware is running is a virtual machine or sandbox environment. In those cases, the malware exits immediately as a way to prevent a security researchers, who will likely install the package in a VM or sandbox, from discovering it.
Another new tactic employed by recent malware is exemplified by “RAT (remote access trojan) mutants”, which use multiple-stage polymorphic payloads that change every time you run the binary to evade detection. In a number of cases, those RAT mutants combined the capabilities of remote access trojans and information stealers to access clipboard data or wallet information.
In npm case, Sonatype identified packages that while not being an immediate threat should be considered malicious. Specifically, more than 33k packages were published under the scope of “infinitebrahmanuniverse” and using the “nolb-” prefix, with the only apparent aim of creating a dependency on any other npm package. According to Sonatype, this brings the “dependency hell” problem entirely to another level. Indeed, an attacker could create a malicious package depending on some of those nolb- packages to execute a denial of service attack against a company’s download channel and consume excessive resources.
As a final note from the Malware Monthly, another trend that has been gaining force recently is that of cryptominers, that is, trojans that have no other intent than using your computational power to mine cryptocurrency and earn money.