Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Minimal APIs primarily exist for writing REST API endpoints while avoiding the verbosity of using classic Web API controllers
- Minimal APIs invoke endpoints via simple method calls, such as app.MapGet and app.MapPost.
- Minimal APIs support any standard API functionality, such as authorization filters and dependency injection.
- Minimal APIs can use bespoke middleware that allows validation of the request and the capability to execute code before or after processing the request.
- Headers and query string parameters can now be auto-mapped to variables, so developers no longer need to write custom code to extract them.
- Developers can now use Minimal APIs to upload files to the server easily.
Introduction
Traditionally, ASP.NET Core applications allowed developers to build REST API endpoints using the so-called controller classes. Separate controllers would represent separate domains or entities within the application. Also, typically all endpoints assigned to the same controller would share a portion of the URL path. For example, a class called UsersController would be used to manage user data, and all of its endpoints would start with the /users URL path.
Since .NET 6, Minimal APIs on ASP.NET Core allow us to build REST API endpoints without defining controllers. Instead, we can map a specific HTTP verb to a method directly in the application startup code.
There are some major benefits to using Minimal APIs. One such benefit is that it’s way less verbose than using traditional controllers. Each endpoint requires only a few lines of code to set up. It’s easy to write and easy to read. There’s also less cognitive load associated with reading it.
Another major benefit of using Minimal APIs is that it’s faster than using traditional controllers. Because there is less code and a much more simplified bootstrapping, the methods representing the endpoints become easier to both compile and execute.
Of course, there are some disadvantages to using Minimal APIs too. Firstly, organizing REST API into separate controllers would make the code more readable and maintainable in an enterprise-grade application with a large number of endpoints. Secondly, as Minimal APIs are a relatively new technology, some features from controller-based APIs might be missing. However, since .NET 7 release, this is limited to a subset of lesser-known features that is relatively easy to find a substitute for; therefore, purely from the functionality perspective, Minimal APIs can now replace controller-based APIs in almost all scenarios.
In this article, we will cover the features that have been added to Minimal APIs with the .NET 7 release. We will examine why minimal APIs are now almost as powerful as the traditional controller-based APIs while being far less verbose.
Minimal API basics
Let’s imagine that we have an ASP.NET Core Web API project called ToDoApiApp. This is a .NET 7 project that uses a simplified Program.cs file as its entry point. The content of this file will be as follows:
using Microsoft.AspNetCore.Mvc;
using TodoApiApp;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
builder.Services.AddSingleton
();
var app = builder.Build();
app.MapGet("/todos", (
[FromServices] ITodosRepository repository) =>
{
return repository.GetTodos();
});
app.MapGet("/todos/{id}", (
[FromRoute] int id,
[FromServices] ITodosRepository repository) =>
{
return repository.GetTodo(id);
});
app.Run();
We can see two examples of Minimal API endpoints, as they are registered directly in the application startup logic. Once we have created the app variable, we call the AppGet method twice. We are associating the first call with the /todos URL path. The second call is associated with the /todos/{id} URL path.
In both cases, we have an anonymous method associated with the specified path. In the first method, we are returning the results of the GetTodos method of the repository object. In the other instance, we are passing the integer id parameter to the GetTodo method of the repository object and returning the results.
So, as we can see from the above example, Minimum API endpoints use a mapping method directly on the object that represents the application. The mapping methods are specific to an HTTP verb. In the above example, both instances use a mapping method specific to HTTP GET verb. This is why it’s called MapGet. If we were to use the POST or PUT verb, we would have used MapPost or MapPut, respectively.
Once we call this method, the first parameter is the URL path that this method maps to. We can use route parameters by wrapping them in curly brackets as in the /todos/{id} path. Then we have the method that maps to this path. We can either pass a reference to an existing method or have an anonymous method, as we do in both of the examples above.
Our methods use two types of parameters. The parameters marked with the FromRoute attribute are extracted from the URL path that the method is mapped to. The parameters marked with the FromServices attribute represent objects extracted from the dependency injection system.
In our case, we are injecting an implementation of the ITodosRepository interface in both routes. We previously mapped this interface to the TodosRepository class by calling the AddSingleton method on the Services property of the builder object. The interface and the class definitions are as follows:
namespace TodoApiApp;
public interface ITodosRepository
{
IEnumerable GetTodos();
string GetTodo(int id);
void InsertTodo(string description);
void UpdateTodo(int id, string description);
void DeleteTodo(int id);
}
internal class TodosRepository : ITodosRepository
{
private readonly Dictionary todos
= new Dictionary();
private int currentId = 1;
public IEnumerable GetTodos()
{
var results = new List();
foreach (var item in todos)
{
results.Add((item.Key,
item.Value));
}
return results;
}
public string GetTodo(int id)
{
return todos[id];
}
public void InsertTodo(
string description)
{
todos[currentId] = description;
currentId++;
}
public void UpdateTodo(
int id, string description)
{
todos[id] = description;
}
public void DeleteTodo(
int id)
{
todos.Remove(id);
}
}
Essentially, this service represents a TODO list where we can read, add, modify, and delete the items. The items are stored in the dictionary, where each item is represented as a string value while it has a unique integer identifier represented by the dictionary key. So far, we have implemented REST API endpoints for two actions: reading the whole list and reading individual items. We will now implement the remaining actions while demonstrating the Minimal APIs features added in .NET 7.
Request filters in Minimal APIs
Request filtering is a powerful feature of Minimal APIs that allows developers to apply additional processing steps to incoming requests. It can execute some code either before the request reaches the endpoint or after.
Request filtering is commonly used for request validation. This is how we will use it in our example. In our Program.cs file, we will insert the following code just before the Run method call on the app object.
app.MapPost("/todos/{description}", (
[FromRoute] string description,
[FromServices] ITodosRepository repository) =>
{
repository.InsertTodo(description);
}).AddEndpointFilter(async (context, next) =>
{
var description = (string?)context.Arguments[0];
if (string.IsNullOrWhiteSpace(description))
{
return Results.Problem("Empty TODO description not allowed!");
}
return await next(context);
});
In this example, we mapped a POST endpoint that allows us to insert an item into the TODO list. We added an endpoint filter to it by calling the AddEndpointFilter method. This is one of the ways of adding an endpoint filter. In this specific implementation, the method accepts two parameters: context and next.
The context parameter represents the context of the request. We can extract data from it and either examine or modify it. The next parameter represents the next step in the request-processing chain. We can add as many request filters as we want. The endpoint method will be executed once there are no more processing steps in the chain.
To short-circuit the request-processing chain and return the response early, we can call the static Problem method on the Results class. In our example, we are checking whether the entered TODO item is empty, and we are short-circuiting the pipeline and returning a validation error if it is. Otherwise, we pass the request to the next processing step by calling the method represented by the next delegate.
Automatic mapping of headers and query string parameters
Another useful feature of Minimal APIs is the ability to automatically map request parameters from the query string or the headers. All we need to do is create an object with the properties representing the expected parameters, pass this object as a parameter into the endpoint method, and mark it with the AsParameters attribute.
We have an example of it here. This is another endpoint mapping that we will add to the app object. This method is mapped to the PUT HTTP verb and is used for modifying the existing items in the TODO list.
app.MapPut("/todos/{id}", (
[FromRoute] int id,
[AsParameters] EditTodoRequest request,
[FromServices] ITodosRepository repository) =>
{
repository.UpdateTodo(id, request.Description);
});
We are inserting an object of the EditTodoRequest type as a collection of input parameters. The definition of this class is as follows:
internal struct EditTodoRequest
{
public string Description { get; set; }
}
Because we have a single field called Description, it will be automatically mapped to a request parameter called description. If we needed to pass additional parameters, we could create additional properties in this class, and they will be mapped accordingly.
Working with file data in Minimal APIs
Until .NET 7, Minimal APIs only accepted basic request types. But now we can perform more advanced actions, such as file processing. Uploading a file to an API endpoint is now as simple as adding an IFormFile parameter to the endpoint method.
To demonstrate how file upload works, we added the following endpoint method to the endpoint mappings in the Program.cs file. This method assumes that the file we are uploading is a text file where each line represents a new TODO item to be inserted.
app.MapPost("/todos/upload", (IFormFile file,
[FromServices] ITodosRepository repository) =>
{
using var reader = new StreamReader(file.OpenReadStream());
while (reader.Peek() >= 0)
repository.InsertTodo(reader.ReadLine() ?? string.Empty);
});
This method demonstrates that reading from the uploaded file can be as simple as calling the OpenReadStream on the IFormFile implementation. We can then check if any lines are remaining by calling the Peek method on the stream. If there are any lines, we can read the next line by calling the ReadLine method.
Conclusion
This concludes our overview of the most powerful features added to ASP.NET Core Minimal APIs with the .NET 7 release. These are not the only features that have been added. But these features are the most prominent.
With the current functionality, Minimal APIs are almost as powerful as the traditional controller-based APIs. There are still use cases when controller-based APIs would be preferable. For example, controllers are easier to organize in applications that have a large number of API endpoints. But in terms of the available functionality, there is almost nothing that controllers can do that Minimal APIs cannot.



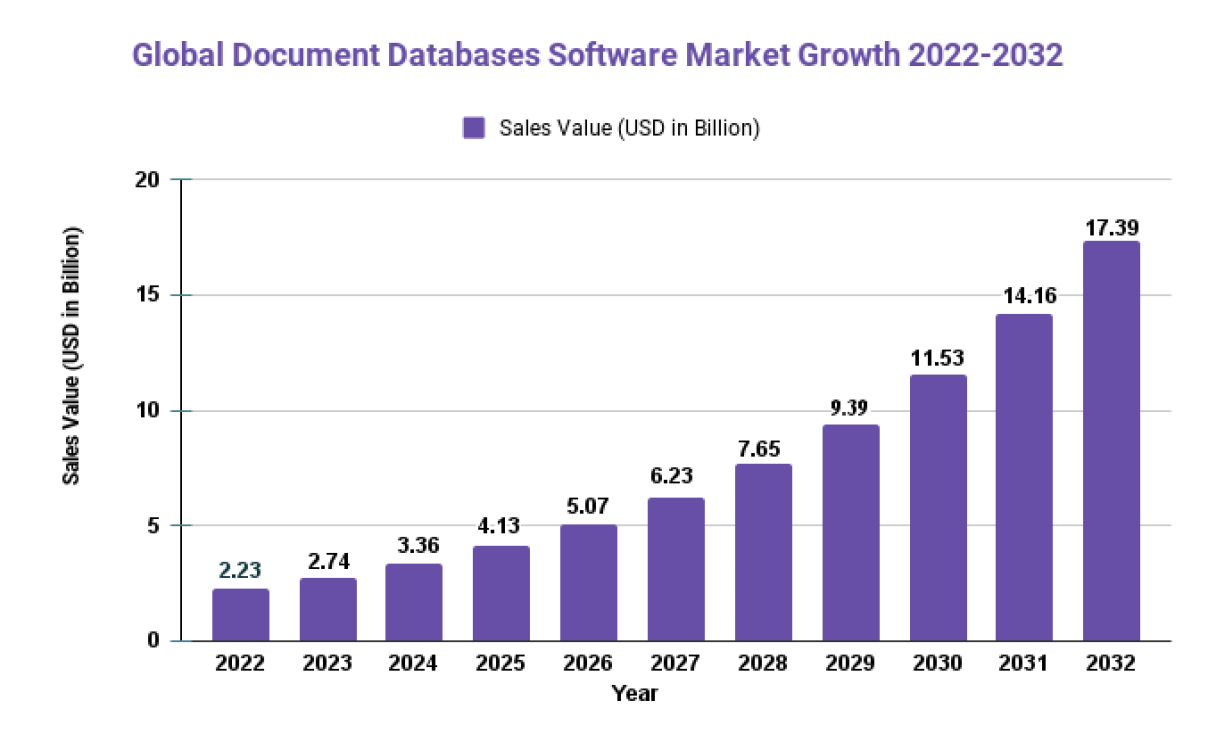
![Document Databases Software Market: Revenue 22.8% | [A Key Resource for Industry Analysis] by 2032](https://mobilemonitoringsolutions.com/wp-content/uploads/2023/03/Document-Databases-Software-Market.jpg)


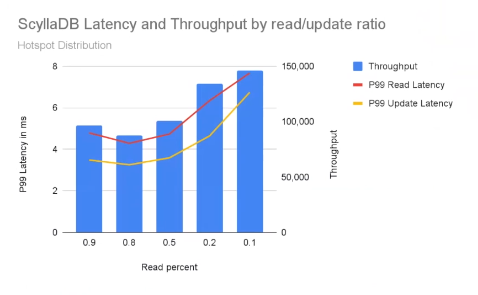
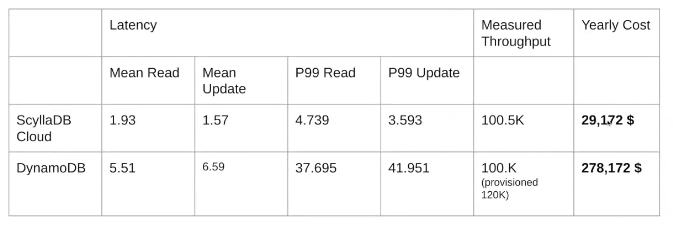
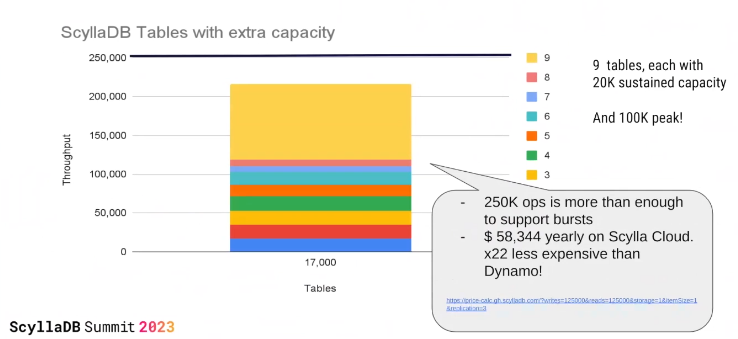
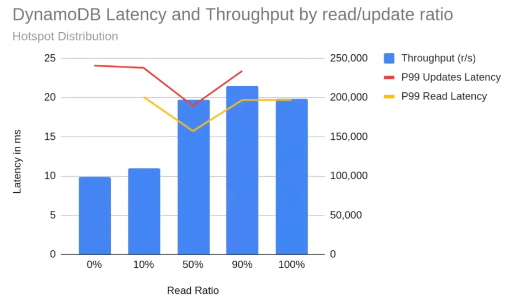 And for ScyllaDB:
And for ScyllaDB: