Month: March 2023
Podcast: Becoming a Great Engineering Manager and Balancing Synchronous and Asynchronous Work

MMS • James Stainer
Subscribe on:
Transcript:
Shane Hastie: Good day folks, this is Shane Hastie for the InfoQ Engineering Culture podcast. Today I’m sitting down across about 13 time zones with James Stanier. James, welcome. Thanks for taking the time to talk to us today.
James Stanier: No, no worries. Just before we started recording, talking about time zone difference and how you are in a beautiful mid-summer weather at 9:00 PM and I’m 8:00 AM in the morning in freezing cold. So, the magic of the internet, huh?
Shane Hastie: It is indeed. We can be together remotely and I can experience my summer. You are the Director of Engineering at Shopify. You were also the track host at the recent QCon San Francisco conference, looking at what’s next in terms of remote and hybrid work. But before we delve into either of those, I’d like to just explore who’s James?
Introductions 01:04
James Stanier: That’s a very good question. I asked myself that on a regular basis. So, you’ve said my job title already. I work for Shopify. I’m Director of Engineering. I run a bunch of initiatives there in engineering. Also, I guess I could call myself an author. I’ve written a couple of books. The first one was called Become an Effective Software Engineering Manager and it’s with Pragmatic Programmers and that book’s done really well.
And it’s all about getting into leading a team for the first time and what are the tools that you need to do so. And then I wrote a follow-up to that book about a year ago now called Effective Remote Work, which is very similar template of how do you get into something for the first time and what are the tools that you need. But this time turning towards remote work as the thing that people are learning. And really both of those, I wanted to be field guides to that particular area.
It’s super practical, super hands-on. And I guess moving away from work even further, leave the work at the side, I’m a pretty normal human being. I like music, I like playing music, I like taking photos, I like being outside. I like going on hikes and runs and cycles and all those nice things.
Shane Hastie: Thank you very much. So, let’s start by maybe exploring the two books. What does it take to be an effective software engineering manager?
What it takes to be an effective software engineering manager 02:09
James Stanier: It’s a good question. And I think where I went with the book, where did it come from? That’s probably a better question to ask myself. So, I probably in about 2013, a while ago now, became a team lead for the first time, engineering manager, whatever you want to call it. The landscape for material is better now for sure. There’s other authors as well as myself that has written really good field guides. But back then there wasn’t a huge amount of really good material as to how to run teams practically in a modern way for software engineering folks.
So, when I started that and I was part of the startup at the time, I joined at the seed round and then we did a few venture rounds and we grew very, very quickly. I had the opportunity to step up and lead the team, great opportunity and I just didn’t know how to do it. And I think I found myself surrounded by lots of startuppy people who had never done it either. So, I didn’t have good mentors and I didn’t have lots of people in my network who were great managers, because I was fairly fresh out my PhD at the time. So, I just wrote a blog and I wrote every week on my blog stuff that I was learning, things that I was thinking about on that management topic.
And I wrote that blog for four years and that kind of manifested into the book. And really what the book was, to come back to your initial question as to what does it take? It really was writing every single week my thoughts and then those thoughts coalescing over a longer period of time into what I thought were really good tools for people to use. And I use the word tools very specifically there, because I think there’s a lot of advice out there for managers, programmers, authors, whatever, any kind of industry, that’s extremely prescriptive.
There’s lots of articles that say, “Here are the top five things you need to do to do this thing.” And often that’s very shallow. So, I was very careful to write the book in such a way that was super practical and hands-on, but didn’t prescribe too much. Instead it introduced techniques, tools, frameworks, and then kind of gave that to the reader to say, “Hey, go try this out. It could go this way, it could go that way, but here’s like the core of what I think the job is and here’s the scaffolding you should build it upon.” And as a follow on to that, I think that’s very much the framework I went with with effective remote work too.
It’s not, “You have to do this, because this is the way you do remote work.” Instead it was, “Here’s the toolbox. Go and learn how to become a carpenter with the tools,” rather than here’s how to do it.
Shane Hastie: What’s a piece of practical advice for a new software engineering manager, a new team lead in that space?
Practical advice for new managers 04:35
James Stanier: There’s a couple of things. So, one of them, which I think is probably the core principle, is that it’s fundamentally a different job and you have to get into that mindset very quickly in that it’s a new set of skills, your output is defined differently. And the quicker you can get into that mindset, the better that you will do. What I mean by that is when you’re leading a team, when you’re managing a team, your output is the output of the team for the first time. Whereas when you’re an individual contributor, you are very much focused on your output. So, how can you be as efficient as possible? How can you ship the most code or build the best architecture? But you’re very much judged by your own personal output in the context of the team. But when you are a manager, your output is the output of the team.
So, what that might mean is that from one week writing some code might be the most impactful thing that you could do for the team, because it may move them forward. But on another week, coaching people for most of your time and not writing any code whatsoever might be the thing that makes the output of the team the best. So, getting into that mindset early, and I guess as a follow on from that, being very mindful that most people who get into technology and become individual contributors have spent an awful lot of time practicing that thing. So, maybe they went to university, they went to college, maybe they hacked around with programming languages as a teenager growing up, they’ve had a lot of hours of practice into becoming the craftsmen. And often when people step into a management role for the first time at work, they’ve never really done any formal training whatsoever.
Taking a management role should not be a one-way door 06:06
So, they might not even know if they’re going to be good at it. And this isn’t necessarily just for the individual, but for the person who is the new manager and the contract that they have with their manager to know that, “Hey, you’ve never done this before.” Obviously that person doing that job for the first time should get some training, some support, some continual coaching, yes. But also having a safety net I think is super important to say, “Hey, can I do this for a certain period of time with a two-way gate where I can go backwards and go back to individual contributor if it doesn’t work out?” And that being a perfectly acceptable outcome.
And I think that’s something that I’ve done a lot with my reports over time who wanted to become managers, is try and give a safe environment to say, “Hey, this is totally new in terms of a job. So, if you want to try it for a bit and then go back, that’s cool. Not a problem whatsoever,” because there is no formal training.
Shane Hastie: Thank you very much. And let’s jump to the effective remote. Obviously that’s become so much a thing since COVID, but it was around before, but when we were chatting earlier you made the point, it’s a hygiene factor now. Organizations don’t have a choice. People want to work remotely or have a hybrid work environment. There’s still a lot of, I would say leaders in organizations, who are struggling with this.
The ability to work remotely work is a hygiene factor in technology organisations now 07:39
James Stanier: It’s true, it’s true. I mean one thing before I start talking about this that I have to catch myself or my own biases. I work in technology, you work in technology. So, when we talk about everybody, we usually mean everybody in technology. And I’m going to scope my answer to that to begin with, because often it can get a little bit tricky to answer, but there is a lot of inertia. Why I don’t know. Now I’m biased in my opinions towards remote work, because I work for a fully remote company and that was a choice of mine. It was a culture that I wanted. In terms of those that are struggling, I can’t answer why people may want to go back to the office. There are many reasons. Community, some people really like that home life separation in the physical space, all of that’s great.
Hybrid is hard and should be avoided 08:24
But the thing that’s hard is hybrid. And I think hybrid is way harder than being one or the other. Being in office, being remote, you are just doing one thing and you can focus on doing that one thing well. So, if you want to go all in on the office, have great offices, make sure that they’re always filled with people so that when you go into work, there’s lots of people to talk to and interact with, you get that office environment and that’s great. If you want to go fully remote, then that’s also great because you can focus all of your time, your effort and your money into making the remote experience really good. So, if you’re not paying for any offices which are very expensive, then you can probably afford to have a stipend that kits everyone’s home office out really well.
So, it works if you’re doing one or the other. But if you’re doing hybrid, it’s hard because how do you do two things well? And that’s not just in terms of allocation of time and money, i.e. how do you have amazing offices that are full of people, because it really sucks going into an office when there’s only three people in out of a potential 250. It just feels dead. It’s not the same. But how do you provide a world-class office experience and a world-class remote experience? And laid on top of that is that the environment that you’re in, whether you like it or not, and even if you are the most disciplined practitioner of asynchronous working and using all the tools that we have primarily rather than synchronous in person stuff, you just can’t fight the office when you’re in it.
It’s so easy to have conversations with people in the physical space and then forget that three quarters of the team just haven’t heard what you’ve talked about because you’ve just done it in person. So, it’s that layer of hybrid that’s super hard. And personally I am curious to see over the next say five years how it works out. Will those on the fence drift back to their preference and choose one only, or will we still be in this middle ground? It’s really tricky actually at the moment, isn’t it, with the economy and the recession and certainly the layoffs that we’ve seen in tech. Companies are trying to save money, and doing hybrid well and saving money at the same time is even harder. So, I’m curious as to what you think as well. Is hybrid something that you can see happening forever, or will people choose?
Shane Hastie: Hoisted on my own petard. My personal feeling, and I will confess a bias as well, I’ve worked remotely for the last seven years and loved it. And I find the opportunity to get together in person occasionally very valuable, but I wouldn’t particularly want the once a week. I would want this to be once a month, maybe every couple of months, and then have that together time, very, very focused on collaboration and building relationships and so forth. But going into an office to spend seven hours on Zoom calls with people who are not there just doesn’t work.
James Stanier: Yeah. And I think that’s the taste that people got during the pandemic that I think almost lifted the curtain on what was happening, so I can fully understand it. And I have been part of companies where everyone is in the office and there’s nobody else anywhere else around the world. I’ve been part of a small startup just in one building, one room, and that is a nice magical experience. But the reality is that most companies will grow, they’ll be successful and someone will be remote in some way. You’ll have another office in another location. It might even be on the same time zone. But you certainly, as you say, begin to find that each meeting that you’re having in a physical space starts to get more and more people who are on the end of a video call.
And the normalizing effect of the pandemic, which was that everyone started to experience those meetings with their own camera, their own microphone. Okay, we can’t fix time zones, that’s still a difficult thing, but when that communication playing field was completely leveled and everyone experienced what was a form of digital equality in some way, that the whole office thing seems like a bit of a strange charade after that, didn’t it? I mean I agree with you, at Shopify we do a few times a year have teams meet up very intentionally for things that are just easier to do in person. If you’re going to try and think about your next six-month roadmap and just jam loads of ideas together for a couple of days, yeah, it’s way easier to do that if you’re in the same room. But a couple of times a year is enough for me. Meet people, get the energy from that, but then bring it back and then focus on building things at home.
Shane Hastie: So, let’s talk about Shopify. You mentioned to me earlier 14,000 people fully remote. How do you build a great culture with 14,000 people in 14,000 locations?
Building a great culture with 14000 remote workers 12:41
James Stanier: That’s a good question. So, obviously I can’t take personal credit for everything they’ve done now. I joined in 2021, Shopify, so I’ve been there for a year and a quarter now. I think the first thing that comes to mind is intentionality. So, when Shopify went fully remote, it didn’t do so half-heartedly. It was very much, we are now fully remote, and that is how everyone is all the way from the CEO down to the individual contributor in every team. There is no physical center of gravity of the company anymore. Everyone is remote completely. And the money that was being spent on offices, a few of them remained open but were converted to meeting spaces. And I can always talk to that a bit more in a sec.
There was no office desk for anybody anymore. There was nowhere to go. You had to work from home and the money was reinvested into making sure that people had remote setups that work for them, being able to get super good quality standing desks, chairs, monitors, all the computer set up at home that you need. So, one was definitely intentionality. And then two was the tools. So, really shifting everything so that it was async friendly. And I think this was before Shopify went remote, but centralizing all the company documentation in a place that’s effectively an internal wiki and there’s a newsfeed where everything important flows by, making sure that all important meetings are streamed in such a way that you can play them back later async if they’re outside of your time zone, that they’re rebroadcast in different time zones for the important town halls so that different communities of people in different time zones can watch them together.
So, really just going all in I think was the main thing. And embracing it, seeing is exciting. And I think also mapping the experience of working there to the experience of the people that we are serving as well. So, it’s an eCommerce company, we have millions of merchants that use us around the world of all sizes of business and they are globally distributed and we are able to serve them. So, surely we can also work together collaboratively to build that product while not being in an office also.
Shane Hastie: Where does Conway’s law come into play?
Structure teams deliberately to take advantage of Conway’s law 14:38
James Stanier: I would say that in my experience, I guess for listeners that aren’t familiar with Conway’s law, it’s that the shape of the organization or the way the organization’s communication is structured reflects the way in which the software is organized and shipped. The classic sort of siloing thing. I think Conway’s law, in my experience, I mean one, it still happens when you’re remote but not so much from geographical clustering, more so on the way you organize your teams for sure. You see teams organized around a particular product and they focus completely building on that product and maybe they haven’t had the chance to stick their head up above where they’re working to go, “Oh, actually we could maybe reuse this piece of work over here that this other team’s doing.” So, the problems I think are the same whether you are remote or not remote.
And I think good team structure is the first thing you try and solve. And that’s not just individual teams, but also good group structures that are not necessarily siloed around building particular products, but instead have important metrics and missions that they contribute towards. That’s the way that we try to break it. So, we are very intentional with each team having KPIs that are meaningful. And the nice thing about working for an e-Commerce company is that everything that happens with our product is people running their business and using it to make money and to be successful. And that does make KPIs easier to ladder up because you can look at user adoption, you can look at the GMV, you can look at revenue of our merchants. So, we make sure that every team has a north star that they can go towards fairly autonomously in a way that doesn’t solve the problem by building things in a silo, and then structuring those groups so that everything ladders up to larger goals and encourages collaboration.
So, if you have a wider group which contains say eight or nine teams and they’re all working towards the same metrics, that naturally facilitates collaboration because you find the teams look to each other to go, “Hey, how can we all work together? Maybe if we are building this thing in this quarter, you could then fast follow in your team next quarter using what we’ve built so that it’s a multiplicative effect.” So, Conway’s law does happen, but I think you can fix it with metrics and team structure. And to address the siloing thing, I think communication is key there. So, this is something that we are still trying lots of different ways, trying to get better at. I don’t think there’s one solution to it, but how do you have teams communicate in such a way that you just naturally in your day-to-day get the sort of smell and the sight of other things that are interesting to you in your area?
The impact of removing all meetings from everyone’s calendars 16:39
And one thing we’ve been trying in the last few weeks was in the news that we had this kind of Shopify refactor thing in January where we had what was called the chaos monkey that was an automated script that went round and killed all the meetings in everyone’s calendar that were over three people. And this isn’t us saying that you should never have meetings, but I think there’s a leadership aspect of Shopify that says fight against silos, fight against wasting time, make sure you are spending your time on building things and then sharing what you’re building. And our teams over the last few weeks have been trying out, they’re not sprints, I’m not a huge fan of the word sprints, but sort of weekly heartbeats of teams where on Monday the teams really think about what they’d like to achieve in that week and then they think about how could that be demonstrated on Friday by recording a demo and sharing it more widely asynchronously.
And then that kind of bubbles up in the internal systems that we are using in order to share information. So, you sort of fight it by team structure, good metrics and then also just lots and lots of sharing. I can’t say that we’ve solved it, I’m not going to say that we’ve solved, it will always exist, but we’re fighting it.
Shane Hastie: So, asynchronous and your example there of removing all the meetings that are more than three people, pushing much more towards that asynchronous work. How do we keep relationships and bonds while still working very asynchronously?
Balancing synchronous and asynchronous work 17:54
James Stanier: I guess I’ll append onto your description of the meeting killing thing there, that we again haven’t said that you can’t ever have a meeting ever again, but I think there is great power in maybe once a year just setting fire to your calendar because it just accumulates cruft and you accumulate status meetings or group meetings that maybe once were relevant, but then you’ve just kept doing them forever because they’re just in your calendar. So, meetings are being booked back in, but we are asking people to be very, very intentional as to why they exist and also to just kill them when that importance does diminish and just kill them. The asynchronous meaning collaboration is difficult and personal bonds is difficult, is just truth. You can’t change that. And when we work asynchronously, typically the unit that is synchronous is still the team at Shopify.
So, we do, at least in my area, in the areas around me, we do structure teams so that they have a lot of time zone overlap. So, if you are on a team, your manager, your peers, usually only one to two hours difference. So, if you’re thinking about that in terms of continents, East Coast, West Coast of the US and Canada, Europe shares a fairly wide overlap in time zone. So, we still have teams so that they can be online at the same time most of the day. And that’s great, because there’s things that we do a lot of like pair programming, collaborative design, all the general facilitated group activities. It’s just way easier synchronous. But within a larger division of many teams, the boundaries between those synchronous teams is asynchronous, and that’s where it comes in as to sort of the information sharing between teams. If you are a manager, you don’t need as much overlap as your own manager or the other peer managers and your team, because you’re mostly writing to each other anyway. So, within teams is synchronous, between teams, those edges that the communication flows along are asynchronous.
Shane Hastie: How do you tackle re-teaming? How often do you reform teams? How do you move people around?
Be deliberate about reteaming 19:49
James Stanier:There’s a few things there. So, typically we find that people don’t want to move team too much themselves. And I can go onto my reasoning behind that in a second. Usually, and this isn’t actually a Shopify thing, this is now my own personal opinion. I think that reorgs are healthy because the business changes, the business needs change and you want to align teams to the business needs. So, you have to change the teams. It happens. Making sure that every team and area has clear metrics makes re-teaming way easier, because the purpose of changing the teams then is self-evident. Where I’ve optimized in the past at previous companies is the managers of teams stay fairly solid. So, if there’s some particular product, we try and keep the same manager if they want to be on it for a long period of time, but optimize so that people can self-select onto different teams if they want to over time.
Recently we went through an exercise where we sort of effectively just sent out a survey and said, “Are you happy on your current team? Would you prefer to work somewhere else?” And then we can get all that data in and then you can stack it up side by side with where is the business need for this year? And then you can take the overlap of those two and you go, “Okay, well, we need to rejig the teams a little bit, but also we have a whole bunch of people who would very willingly do something different,” which just makes the whole thing a lot easier. And I say every 18 months or so, it’s fairly healthy to re-team. And I think if you have structured your teams previously, by no means am I saying that we do things perfectly, but if you have structured teams well in the first place that they are very metrics driven rather than very siloed around particular parts of the architecture or particular products, then re-teaming is way easier.
Because I think people just naturally gravitate towards making an impact as opposed to naturally gravitating towards clinging onto their products. But I think a good mixture is every 18 months, try and do it intentionally, rip the bandaid off, be very clear in your communication, be bold, get it done. Do it in such a way that you think will last for at least 18 months, and also add in an element of self selection if you can, because I think that also has a really positive effect on people’s retention is that if you have the ability to sort of say, “Hey, I’d love to go and work in a different team,” and you can actually go and do it, is a net win for everybody.
Shane Hastie: And onboarding, this is one of the things that we hear of the horror stories about onboarding in person is tough, onboarding in remote is fraught with difficulty, or is it?
Onboarding new people in remote teams 22:13
James Stanier: It’s still challenging for sure. Onboarding is just hard full stop. Remote onboarding is challenging, but I think it has some benefits in the sense that what you really want in a good onboarding experience is some structure and some space and to make it really clear what you need to learn, and then have a really good handoff with your team at the end. I think the Shopify onboarding that I did in the program that we still run is excellent. And I’ve written about this and spoken about it before, which means I can tell you about it. And effectively when people join the company, it’s a four-week period of onboarding where we are very open and say, “Hey, this is your onboarding time.” That removes the stress of thinking that on day one you’re going to join the company and then we’re going to throw you into a team, give you a hazing with a high priority bug and then you stress out.
Instead we realize that onboarding somebody well, you only get one chance and that chance is when they join. So, take advantage of it, design a really good program, think about the funnel of the general things you need to know about the company and the mission and the values and then taper it down to their role over time. And you said remote? Well, Shopify is reasonably large now and we do fortunately have the staff that can facilitate these things, and our program is facilitated by people in our knowledge management team and they start in week one with what is quite passive learning for the new joiner, where in your cohort because everyone joins at the same time every month. So, you’ll have a cohort of people who are also new, which is quite nice because you can all be on Slack together, you can all be new together, you can sort of be protected together in a safe space.
And the first week is all about the company and the mission and the values, and you pretty much in your cohort receive information. So, you watch some videos together, you start using the product together, you start understanding what it is that we do. You start understand who are the people that use our software and what makes them successful. And then in your first week you also ship something into production, which is quite fun. You get to use our tooling and get something out there, but as the onboarding progresses, it becomes more active and it becomes more specialized. So, week one, you could have any employee whatsoever go through that week in any department.
So, you get to, if you think about sort of reuse that, that’s a really good part of your program. So, for everyone that week one funnel is super relevant. The week two funnel is also super relevant for everybody, because week two is all about understanding what the periphery of the business looks like. So, answering support tickets paired up with support agents, listening in to support calls and understanding, “Okay, so when someone has a problem and when someone has a difficulty, what actually happens and what kind of things do they have problems with?” Also in week two you build your own store, like you’re given a brief to pretend you are a merchant who is in Mexico selling beer and you have to work out how to sell it in different jurisdictions using different taxes and real life scenarios where you get to not just see the happy path through the product, but also the things that are really challenging for some people.
And you really get into a merchant’s mindset in week two. So, the end of week two, you’ve understood the company in week one, week two, you know how to use the product at a high level when you’ve started to experience like what works really well, what’s really challenging for merchants. Just in general, taxes is very challenging. And then we taper off in week three and four to more craft specific things. So, if you’re in engineering, in week three you get access to a whole bunch of learning materials around our architecture, you do group work, you look through the code, you get more hands on and you understand how everything is put together. And then week four is purposefully light, because in week four we effectively have a whole bunch of self-serve learning that you can do.
So, we know that everyone that we hire might not have coded in Ruby, or maybe hasn’t done a particular React framework before. So, we make it so that if you want, you can then spend half a day and go into a crash course in any of those things. And we have some internal materials, internal courses, so that really at the end of that fourth week you should be up to speed on what we do, our mission and values, our culture, understand what our merchants do, you understand the big box and arrow diagram of how things are put together, and you also managed to get your hands a little bit dirty in a crash course as to anything that you want to skill up on.
And then there’s that manager handoff, and that’s where you exit the formal program and your manager, and every team will be different here, will have put together here’s the welcome to our team. Then you go into the Slack channels. And that’s one thing that’s worth noting, is that we purposefully make it so that our onboarding staff don’t go into their teams Slack channels and emailing lists and rituals immediately. That’s sort of a thing that happens in the fourth week gradually. So, yes, you’ll meet your manager in the first week, you’ll have a quick one-to-one, just to say hi. But really that one-to-one is all about, “Hey, I’m here, we can talk, let me know what you need at any time, but the most important thing is that you do the onboarding and you focus your attention there and you enjoy it.”
Because it is a sort of a special fun time where the people who were in my onboarding cohort when I joined the company, I still talk to them every day. You make a really nice bond with that cohort that you go through in the first month, and that gives you some hooks into different parts of the business just by default as well, which is really nice.
Shane Hastie: It’s a really, really important topic, and that’s a great model. Thank you very much for sharing that. Reflecting back to Qcon San Francisco, you were the track host for the Hybrid and Remote: What Next track. What stood out for you from that track?
Where is hybrid and remote work heading in the future? 27:41
James Stanier: One is it’s an area where there still is a huge amount of uncertainty, not just uncertainty about what the future holds for somebody as a worker in the industry to think where is this going? But I think also a huge amount of uncertainty from leaders as to what they should be doing. Not just how they implement remote or how they implement hybrid, but just where is this going. I think we’ve all seen how quick to react humans can be to different situations and I think it’s extremely hard to predict what people are going to want in the next five years and also how to prepare. And as we said at the beginning of this conversation, it’s so much easier going fully remote or fully office-based. You can imagine in the future that in the same way that remote was niche for a particular type of worker, say 15 years ago, and there was only a tiny handful of companies that did it, but those that did attracted a certain type of person who really thrived.
You wonder whether physical office-based work may become the niche of the future where there are just some people who love working in offices and companies may design themselves in such a way that actually in-person collaboration is all they really do. That’s the most important thing. And if that’s for you, then you will find one of these companies to work for. But I think the reality is that any company succeeding means growing geographically to a point where you have to deal with different locations, different time zones, different cultures, and you begin to butt up against the challenges of remote, whether you like it or not. So, I think also the other thing that people are trying to think about at the moment is what are the core principles of remote work that still also apply to office work, to hybrid work? And that that’s partially what I got into with the book was like, yes, it was pitched as a book about doing remote work well, but I think what I did was write it in such a way that everyone is remote to each other in some way, even if you are in the same time zone, even if you’re in the same building, you might be on a different floor.
And the primary way in which we are communicating with each other is digital in terms of digital artifacts, digital communication, and all of our code is in GitHub, isn’t it? It’s all asynchronously, contributable towards and work on-able. So, what are the core tenets of doing distributed work well? I think is what is on everyone’s mind at the moment and whether or not that manifests in the future as remote, hybrid, not remote, I think we’ll see where people vote with their feet. But maybe we can use remote as an opportunity to really think about the way in which we communicate intentionally in a way that’s going to work now and into the future and just reset our habits a bit. Because I think doing remote well and using our tools well benefits you regardless of where you are working. And I think that’s what we’re trying to extract from it at the moment. What are the best practices that mean that we could be smarter and more efficient together in the future?
Shane Hastie: James, thank you very, very much for taking the time to talk to us. If people want to continue the conversation, where do they find you?
James Stanier: Twitter is probably the easiest way to contact me and it’s @jstanier as one string. And if you want to read my blog, it’s theengineeringmanager.com and that’s a many year archive of thoughts about remote, management, software, so on. So, those two places are probably the two main vectors that you can get me on. And please let me know if you have any thoughts, opinions, if you disagree with me, I’d love to talk. So, do get in touch.
Shane Hastie: Thank you so much.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Steef-Jan Wiggers
Recently, the Dapr maintainers released V1.10 of Distributed Application Runtime (Dapr), a developer framework for building cloud-native applications, making it easier to run multiple microservices on Kubernetes and interact with external state stores/databases, secret stores, pub/sub-brokers, and other cloud services and self-hosted solutions.
Microsoft introduced Dapr in October 2019 and has had several releases since its production-ready release V1.0 in February 2021. Since the V1.0 release, Dapr has been approved by Cloud Native Computing Foundation (CNCF) as an incubation project, received approximately 43 new components, and has over 2500 community contributors.
The Dapr project continued releasing new versions, with the V1.10 release introducing several new features, improvements, bug fixes, and performance enhancements such as:
- Dapr Workflow: a new alpha feature that allows developers to orchestrate complex workflows using Dapr building blocks and components. For example, a workflow can provide task chaining – chain together successive application operations where outputs of one step are passed as the input to the next step. In addition, a quickstart for workflows is available.
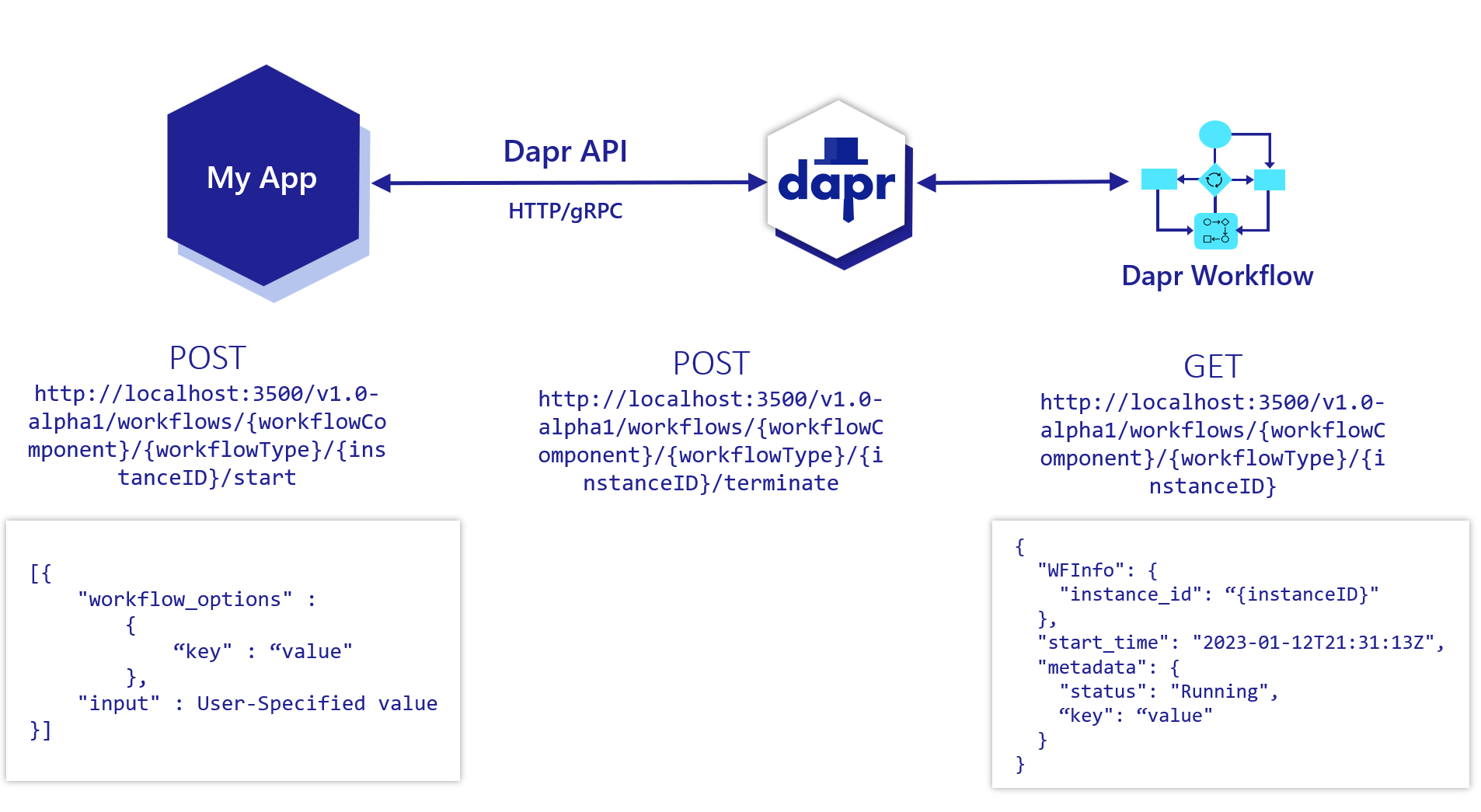
Source: https://v1-10.docs.dapr.io/developing-applications/building-blocks/workflow/workflow-overview
- Stable resiliency policies: Dapr provides a capability for defining and applying fault tolerance resiliency policies (retries/back-offs, timeouts, and circuit breakers). The resiliency policies, first introduced in the v1.7.0 release, are now stable and production ready and apply to all building block APIs, such as Pub/Sub, State Management, Bindings, and Actors.
- Multi-App Run template: a new template for the Dapr CLI that allows developers to run multiple Dapr applications with a single command, simplifying the local development and testing experience.
- Pluggable component SDK: a new SDK that allows developers to create custom components for Dapr, such as state stores, pub/sub systems, and bindings.
- Publish and subscribe to bulk messages: a new feature that enables Dapr applications to publish or subscribe to multiple messages in a single request, improving the throughput and efficiency of pub/sub scenarios.
In a stack overflow thread, a respondent, nedad, commented on the performance of the Bulk-Publish API:
It turns out that the Dapr team is already working on a Bulk-Publish API, which gives much better performance. I was able to increase it to 9000 messages/sec with a batch-size of 100.
The Dapr 1.10.0 release also includes many fixes and improvements in the core runtime and components, such as support for multiple namespaces in Kubernetes, gRPC reflection in Dapr sidecar, custom headers in HTTP bindings, Azure Key Vault with managed identities and improved logging and error handling.
Marc Duiker, a Microsoft MVP and senior developer advocate at Diagrid, told InfoQ:
Dapr is excellent when you need to build event-driven applications. It provides a standardized set of API building blocks that allow developers to focus on their business logic. With release 1.10, many components have graduated to the stable level, ready to be used in production workloads. In addition, new features and components have been added that expand the functionality of Dapr.
In addition, he added:
Dapr Workflow is a new building block allowing developers to write long-running and resilient workflows in code. Improvements to the local development experience have also been made, like Multi-App Run, which simplifies running microservice-based applications locally by starting multiple apps with just one command. Both Workflow and Multi-App Run are alpha/preview features. Wait to use them in production, but try them out, either locally or in a test environment, and give feedback to the Dapr team, so they can keep improving the project.
InfoQ also spoke to Nick Greenfield, a Dapr maintainer who was able to comment on the project roadmap decided by project maintainers and the STC (Steering Technical Committee):
Dapr will continue investing in building blocks that help developers implement and solve common distributed system challenges. Furthermore, two open proposals for introducing two new Dapr building blocks are Cryptography API and Document Store API. Additionally, the Dapr project will continue to invest in building the community and look to expand the STC, as well as project maintainers and approvers.
Lastly, the Dapr 1.10.0 release is available for download from the Dapr GitHub repository or via the Dapr CLI. Furthermore, the Dapr documentation provides detailed instructions on how to install, upgrade, and use Dapr.
MMS • Renato Losio

AWS recently introduced global condition context keys to restrict the usage of EC2 instance credentials to the instance itself. The new keys allow the creation of policies that can limit the use of role credentials to only the location from where they originated, reducing the risk of credential exfiltration.
The two new keys are aws:EC2InstanceSourceVPC, a condition key that contains the VPC ID to which an EC2 instance is deployed, and aws:EC2InstanceSourcePrivateIPv4, a condition key that contains the primary IPv4 address of the EC2 instance.
IAM roles for EC2 are used extensively on AWS, allowing applications to make API requests without managing the security credentials but the temporary credentials were at risk of credential sprawls. Sébastien Stormacq, principal developer advocate at AWS, recently explained the risk and showed how to use GuardDuty to detect EC2 credential exfiltration:
Imagine that your application running on the EC2 instance is compromised and a malicious actor managed to access the instance’s metadata service. The malicious actor would extract the credentials. These credentials have the permissions you defined in the IAM role attached to the instance. Depending on your application, attackers might have the possibility to exfiltrate data from S3 or DynamoDB, start or terminate EC2 instances, or even create new IAM users or roles.
Until now, developers had to hard-code the VPC IDs and/or IP addresses of the roles in the role policy or VPC Endpoint policy to restrict the network location where these credentials could be used. Liam Wadman, solutions architect at AWS, and Josh Levinson, senior product manager at AWS, explain:
By using the two new credential-relative condition keys with the existing network path-relative aws:SourceVPC and aws:VpcSourceIP condition keys, you can create SCPs to help ensure that credentials for EC2 instances are only used from the EC2 instances to which they were issued. By writing policies that compare the two sets of dynamic values, you can configure your environment such that requests signed with an EC2 instance credential are denied if they are used anywhere other than the EC2 instance to which they were issued.
{
"Statement": [
{
"Effect": "Deny",
"Action": "*",
"Resource": "*",
"Condition": {
"StringNotEquals": {
"aws:ec2InstanceSourceVPC": "${aws:SourceVpc}"
},
"Null": {
"ec2:SourceInstanceARN": "false"
},
"BoolIfExists": {
"aws:ViaAWSService": "false"
}
}
}
]
}
Example of a deny policy using the ec2InstanceSourceVPC key.
While many developers like the new context keys, Liz Fong-Jones, field CTO at Honeycomb.io, comments:
I’m shocked this wasn’t automatically default-on enforced before and now looking at how quickly, exactly, we can do the opt-in for this across all our IAM policies.
In the “fixing AWS temporary credential sprawl the messy way” article, Seshubabu Pasam, CTO at Ariksa, agrees:
Unless you are on top of every new announcement from AWS, this is not going to surface to common users for a while. Completely misses the mark on secure by default. Like a lot of new security-related announcements, this and other security features are completely useless even in a new account because it is not on by default.
The new condition keys are available in all AWS regions.
Global NoSQL Database Market Size Business Growth Statistics and Key Players Insights 2023-2030
MMS • RSS

New Jersey, United States – Our report on the Global NoSQL Database market provides a comprehensive overview of the industry, with detailed information on the current market trends, market size, and forecasts. It contains market-leading insight into the key drivers of the segment, and provides an in-depth examination of the most important factors influencing the performance of major companies in the space, including market entry and exit strategies, key acquisitions and divestitures, technological advancements, and regulatory changes.
Furthermore, the NoSQL Database market report provides a thorough analysis of the competitive landscape, including detailed company profiles and market share analysis. It also covers the regional and segment-specific growth prospects, comprehensive information on the latest product and service launches, extensive and insightful insights into the current and future market trends, and much more. Thanks to our reliable and comprehensive research, companies can make informed decisions about the best investments to maximize the growth potential of their portfolios in the coming years.
Get Full PDF Sample Copy of Report: (Including Full TOC, List of Tables & Figures, Chart) @ https://www.verifiedmarketresearch.com/download-sample/?rid=129411
Key Players Mentioned in the Global NoSQL Database Market Research Report:
In this section of the report, the Global NoSQL Database Market focuses on the major players that are operating in the market and the competitive landscape present in the market. The Global NoSQL Database report includes a list of initiatives taken by the companies in the past years along with the ones, which are likely to happen in the coming years. Analysts have also made a note of their expansion plans for the near future, financial analysis of these companies, and their research and development activities. This research report includes a complete dashboard view of the Global NoSQL Database market, which helps the readers to view in-depth knowledge about the report.
Objectivity Inc, Neo Technology Inc, MongoDB Inc, MarkLogic Corporation, Google LLC, Couchbase Inc, Microsoft Corporation, DataStax Inc, Amazon Web Services Inc & Aerospike Inc.
Global NoSQL Database Market Segmentation:
NoSQL Database Market, By Type
• Graph Database
• Column Based Store
• Document Database
• Key-Value Store
NoSQL Database Market, By Application
• Web Apps
• Data Analytics
• Mobile Apps
• Metadata Store
• Cache Memory
• Others
NoSQL Database Market, By Industry Vertical
• Retail
• Gaming
• IT
• Others
For a better understanding of the market, analysts have segmented the Global NoSQL Database market based on application, type, and region. Each segment provides a clear picture of the aspects that are likely to drive it and the ones expected to restrain it. The segment-wise explanation allows the reader to get access to particular updates about the Global NoSQL Database market. Evolving environmental concerns, changing political scenarios, and differing approaches by the government towards regulatory reforms have also been mentioned in the Global NoSQL Database research report.
In this chapter of the Global NoSQL Database Market report, the researchers have explored the various regions that are expected to witness fruitful developments and make serious contributions to the market’s burgeoning growth. Along with general statistical information, the Global NoSQL Database Market report has provided data of each region with respect to its revenue, productions, and presence of major manufacturers. The major regions which are covered in the Global NoSQL Database Market report includes North America, Europe, Central and South America, Asia Pacific, South Asia, the Middle East and Africa, GCC countries, and others.
Inquire for a Discount on this Premium Report @ https://www.verifiedmarketresearch.com/ask-for-discount/?rid=129411
What to Expect in Our Report?
(1) A complete section of the Global NoSQL Database market report is dedicated for market dynamics, which include influence factors, market drivers, challenges, opportunities, and trends.
(2) Another broad section of the research study is reserved for regional analysis of the Global NoSQL Database market where important regions and countries are assessed for their growth potential, consumption, market share, and other vital factors indicating their market growth.
(3) Players can use the competitive analysis provided in the report to build new strategies or fine-tune their existing ones to rise above market challenges and increase their share of the Global NoSQL Database market.
(4) The report also discusses competitive situation and trends and sheds light on company expansions and merger and acquisition taking place in the Global NoSQL Database market. Moreover, it brings to light the market concentration rate and market shares of top three and five players.
(5) Readers are provided with findings and conclusion of the research study provided in the Global NoSQL Database Market report.
Key Questions Answered in the Report:
(1) What are the growth opportunities for the new entrants in the Global NoSQL Database industry?
(2) Who are the leading players functioning in the Global NoSQL Database marketplace?
(3) What are the key strategies participants are likely to adopt to increase their share in the Global NoSQL Database industry?
(4) What is the competitive situation in the Global NoSQL Database market?
(5) What are the emerging trends that may influence the Global NoSQL Database market growth?
(6) Which product type segment will exhibit high CAGR in future?
(7) Which application segment will grab a handsome share in the Global NoSQL Database industry?
(8) Which region is lucrative for the manufacturers?
For More Information or Query or Customization Before Buying, Visit @ https://www.verifiedmarketresearch.com/product/nosql-database-market/
About Us: Verified Market Research®
Verified Market Research® is a leading Global Research and Consulting firm that has been providing advanced analytical research solutions, custom consulting and in-depth data analysis for 10+ years to individuals and companies alike that are looking for accurate, reliable and up to date research data and technical consulting. We offer insights into strategic and growth analyses, Data necessary to achieve corporate goals and help make critical revenue decisions.
Our research studies help our clients make superior data-driven decisions, understand market forecast, capitalize on future opportunities and optimize efficiency by working as their partner to deliver accurate and valuable information. The industries we cover span over a large spectrum including Technology, Chemicals, Manufacturing, Energy, Food and Beverages, Automotive, Robotics, Packaging, Construction, Mining & Gas. Etc.
We, at Verified Market Research, assist in understanding holistic market indicating factors and most current and future market trends. Our analysts, with their high expertise in data gathering and governance, utilize industry techniques to collate and examine data at all stages. They are trained to combine modern data collection techniques, superior research methodology, subject expertise and years of collective experience to produce informative and accurate research.
Having serviced over 5000+ clients, we have provided reliable market research services to more than 100 Global Fortune 500 companies such as Amazon, Dell, IBM, Shell, Exxon Mobil, General Electric, Siemens, Microsoft, Sony and Hitachi. We have co-consulted with some of the world’s leading consulting firms like McKinsey & Company, Boston Consulting Group, Bain and Company for custom research and consulting projects for businesses worldwide.
Contact us:
Mr. Edwyne Fernandes
Verified Market Research®
US: +1 (650)-781-4080
UK: +44 (753)-715-0008
APAC: +61 (488)-85-9400
US Toll-Free: +1 (800)-782-1768
Email: sales@verifiedmarketresearch.com
Website:- https://www.verifiedmarketresearch.com/
MMS • Oghenevwede Emeni

Microsoft has released the TypeScript 5.0 beta version, which aims to simplify, speed up and reduce the size of TypeScript. The beta release incorporates new decorators standards that enable users to customize classes and their members in a reusable manner.
One of the key highlights of this beta release is the incorporation of new decorators standards that enable users to customize classes and their members in a reusable manner. Daniel Rosenwasser, program manager of TypeScript, wrote in a recent post on the Microsoft blog that these experimental decorators have been incredibly useful, but they modeled an older version of the decorators proposal and always required an opt-in compiler flag called --experimentalDecorators. Rosenwasser stated that developers who have been using “--experimentalDecorators” are already aware that, in the past, any attempt to utilize decorators in TypeScript without enabling this flag would result in an error message.
Rosenwasser described the long-standing oddities around enums in TypeScript and how the beta release of TypeScript 5.0 has cleaned up some of these problems while reducing the number of concepts needed to understand the various kinds of enums one can declare.
TypeScript is an open-source programming language and a superset of JavaScript, which means it builds upon and extends the functionality of JavaScript. It was developed and is maintained by Microsoft.
The new decorators proposal in TypeScript 5.0 allows developers to write cleaner and more maintainable code with the added benefit of being able to customize classes and their members in a reusable manner. While the new decorators proposal is incompatible with --emitDecoratorMetadata and does not support parameter decoration, Microsoft anticipates that future ECMAScript proposals may be able to address these limitations.
In addition to the new decorators proposal, TypeScript 5.0 includes several improvements such as more precise type-checking for parameter decorators in constructors, const annotations, and the ability to allow the extends field to take multiple entries. It also includes a new module resolution option in TS, performance enhancements, and exhaustive switch/case completions.
TypeScript targets ECMAScript 2018, which means that Node.js users must have a minimum version of Node.js 10.
To start using the beta version, users can obtain it through NuGet or use the npm command:
npm install typescript@beta
MMS • Steef-Jan Wiggers
Microsoft recently announced the general availability release of AKS Edge Essentials, a new Azure Kubernetes Service (AKS) offering designed to simplify edge computing for developers and IT professionals.
AKS Edge Essentials is a lightweight, CNCF-conformant K8S (Kubernetes) and K3S (Lightweight Kubernetes) distribution supported and managed by Microsoft. It simplifies the process of Kubernetes setup by providing PowerShell scripts and cmdlets to set up Kubernetes and create single or multi-node Kubernetes clusters. In addition, it fully supports both Linux-based and Windows-based containers that can be easily deployed at the edge on any Windows PC class device with Windows 10 and 11 IoT Enterprise, Enterprise, and Pro.
After setting up on-premises Kubernetes using AKS Edge Essentials and creating a cluster, customers can manage their infrastructure through the Azure portal. In addition, various Azure Arc-enabled services like Azure policy, Azure monitor, and Azure ML services enable them to ensure compliance, monitor their clusters, and run cloud services on edge clusters.

Source: https://learn.microsoft.com/en-us/azure/aks/hybrid/aks-edge-overview
When customers create an AKS Edge Essentials deployment, AKS Edge Essentials creates a virtual machine for each deployed node. In addition, ASK Edge Essentials manages the virtual machines’ lifecycle, configuration, and updates. Deployments can only create one Linux VM on a given host machine, acting as both the control plane node and as a worker node based on the customers’ deployment needs. Optionally, a Windows node can be created if customers need to deploy Windows containers.
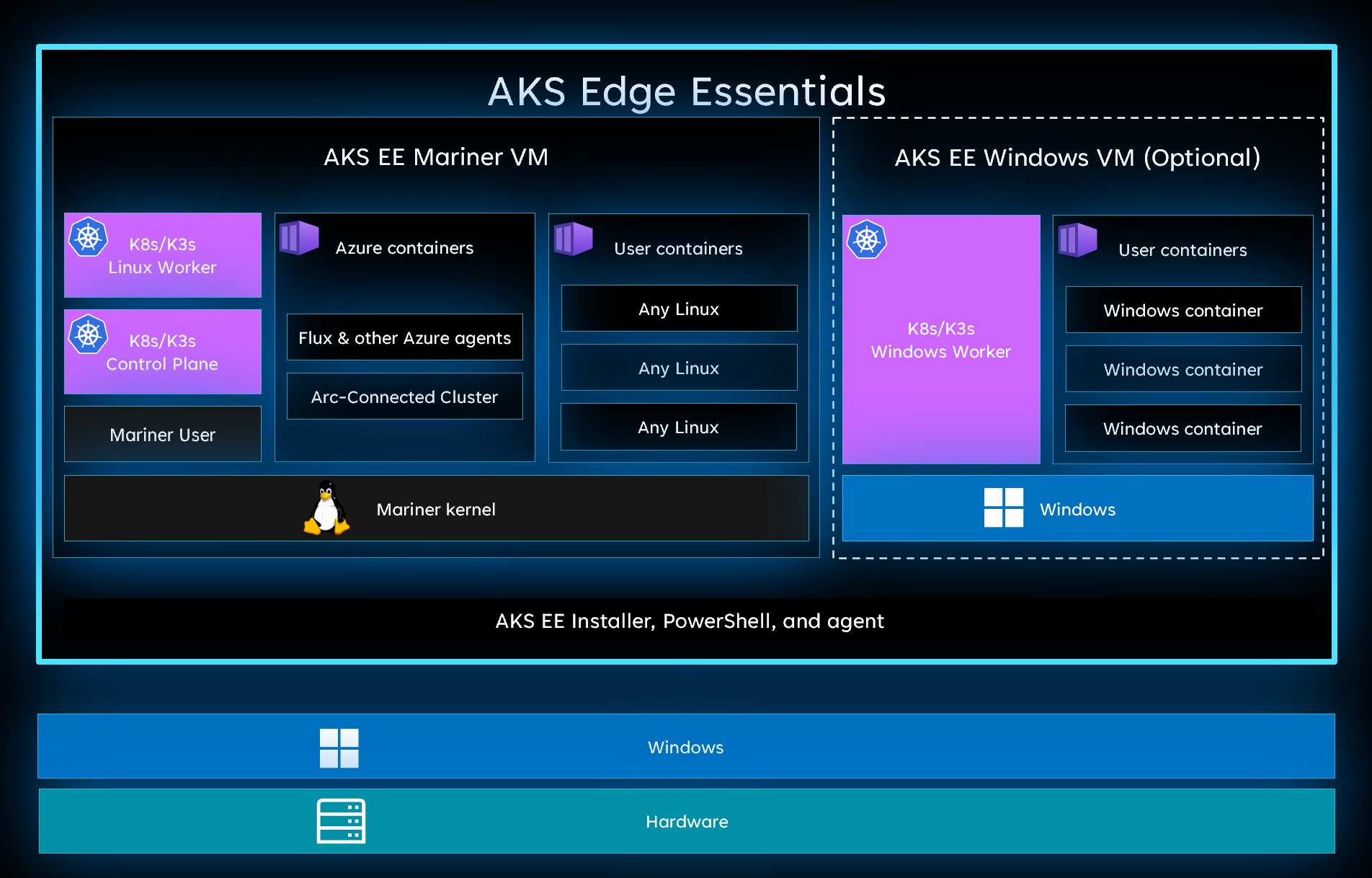
Source: https://learn.microsoft.com/en-us/azure/aks/hybrid/aks-edge-concept-clusters-nodes
With AKS Edge Essentials, Microsoft will support and manage the entire stack, from hardware drivers to cloud services and everything in between. In addition, customers can choose the 10-year Long-Term Servicing Channel (LTSC) version of the Windows IoT OS, ensuring long-term stability with critical and security fixes.
Furthermore, Microsoft has partnered with Lenovo, Scalers AI, Arrow, Anicca Data, and Tata Consultancy Services (TCS) to enable AKS Edge Essentials across more devices and develop new solutions that allow customers to get started with AKS Edge Essentials quickly.
Jason Farmer, principal program manager, Azure Edge + Platform, told InfoQ:
With this release, customers can now run a fully Microsoft-supported, simple, and managed Kubernetes distribution on Windows. Now, any workload built for Kubernetes can be run and securely maintained by Microsoft across the ecosystem of Azure-connected devices built on the Windows OS.
In addition, Kevin Viera, a cloud infrastructure engineer, tweeted:
Microsoft is making it really easy to get started with k8s with Azure Kubernetes Service Edge Essentials “AKS Edge Essentials” which is basically an on-prem Kubernetes with cloud mgmt via Azure Arc.
More service details are available on the documentation pages, including a QuickStart.
Lastly, the company will update the product with new capabilities like commercial support for multi-machine deployment, Windows containers, and additional Azure Arc-enabled services on AKS Edge Essentials clusters.
MMS • Alex Porcelli

Transcript
Porcelli: We are living in a world, almost post-pandemic. We have an unprecedented shortage of software engineers, especially the most senior ones. One very hot topic in the recent times has been the staff-plus career. In this talk, I will cover the staff-plus career, from the lens of open source, more specific, how open source engagement can accelerate and solidify your staff-plus career. Our staff-plus engineers that I know, they create their own unique path to reach that level. It’s hard to find a set of guidelines, or receipts, or steps that you follow to reach that point, and especially when you reach there, how to stay there. I don’t think we have much understanding on that. However, we as engineers, we always try to look and identify patterns across a population. Looking into the staff-plus engineers, we can have a similar approach, try to find what’s common in terms of skills, achievements, and how they do their work as staff-plus engineers. This is exactly the great work that these two particular books have done. The Staff Engineers by Will Larson. Then, Staff Engineer’s Path from Tanya Reilly. These books cover a lot of information, from skills, achievements, and daily work of staff-plus engineers. Of course, that’s not the scope of this talk.
Skills and Achievements
However, the scope of this talk is looking specifically to skills and achievement, that you can sharpen and gain through the open source engagement. I have this list of seven items, four them are skills, and three of those are achievements. The first skill that we’ll cover is the written communication. As you’ll see later, open source software is all based on communication, written communication. Open source, long ago, has been a completely async and fully remote execution. Then, we’ll tackle, manage technical quality. In open source you have exposure to a lot of source code from different perspectives, and you definitely contributed to your manage technical quality. Then we go to the last two skills. One is the leadership, that to lead you have to follow. I love this aspect of the Will Larson book. Last, the art of influence. How you influence open source communities. That’s very interesting, because in the world of open source, there is no exact hierarchy, there is no power that you do, you are just a community member. That’s very related to how staff-plus engineers have to influence their organization. Then we have here the achievements, how you can expand your network, and create visibility. Last, the staff-plus project.
Community Members: Growth
Before diving into those skills and achievements, let’s look at what’s the common growth path community members take. When you join an open source community, usually you start as a user. You’re using that software, you’re probably not sure about many things. You started to use the communication channels of that particular community to ask questions, in the beginning, probably beginner’s questions: how you set up, how you use. As you advance, you probably ask, what’s the best practice to use that? You interact and start to create relationships in that mailing list while you are evolving your knowledge about that particular software. Over time, it’s natural that you progress if you continue engaging on that community, you progress to become an expert. That’s the point that you contribute back to the community. You start to help new users, new people that start to struggle with that technology, you are able to help them. That’s a very big thing for the community, that empowers that community. That’s very welcome and it’s very common to happen for the majority of engineers engaged in open source software.
Then, you can jump to the next session, the next step of the growth is to become a contributor. Not necessarily code yet, but you can start promoting that technology. You may start blogging about that, writing articles, that will somehow help new users or experienced users to better take advantage of that software. Depending on how engaged you are, creating content for that particular piece of software in that community, you may spark the need to get more deep on the code base once you understand the internals. Why not start contributing to code? Then you open the world of possibilities. Again, that’s not mandatory, that you take this approach, there are many users that stay as experts. It’s up to you to define your path. If you are interested in the open source space, I think that’s the common path. You get into the code. You start contributing. You start contributing in a regular pace. I think you become a community member, a very engaged community member. That’s fantastic. From here, you already benefited your career at this point. If you are really into open source, if you get into it like I did, you’ll have the opportunity from here to maybe become a maintainer of a component of that open source software, and over time, to become a leader of that open source community.
Background
My name is Alex Porcelli. I’m a Senior Principal Software Engineer at Red Hat. I’m an engineer leader for Red Hat Business Automation product line. I’ve been a staff-plus engineer for the last 10-plus years. I have 25 years of experience, 15-plus years dedicated to open source. My passions are open source, business automation, leadership, and my family. Back to that growth path, and I will relate my personal path to that. I’m not looking from when I became a Red Hat employee forward, because I think that’s unfair comparison, because my daily job is to write code in the open source community. I will relate to how I got into the open source world. That’s the story.
I started as a user of a framework called ANTLR, that is a technology to help you build parsers. I’ve always been fascinated by building parsers. I built a lot of parsers in my free time in the past. I started to engage in open source ANTLR community, asking questions, how this works, why this is not working. I progressed in that community, and became an expert. In a point in time, I became well known in that community, because I was providing a lot of instructions to new members. In a point in time, another person joined the community, and started also asking questions about the grammar, the structure of grammar, what the errors that they’re facing was like. That’s why I start to exchange a lot of emails as an expert. That was the Drools team member asking questions related to the Drools language, that we have a rules engine. The Drools project has a rule language that has the parser, written in ANTLR. I got very engaged. Moving a little bit forward, I ended up being hired as a Red Hat employee to work in that particular compiler and the parser. Today, I’ve become an open source leader. I all started that in the past as a user, as a beginner. Like me there are many other people that I know in the open source community that follow a little bit of this path. I had some contribution to the ANTLR project as well. Where I am today, we’re more towards my Drools contribution.
Contributing to Open Source
This is not a talk about how to contribute to open source. There’s a lot of material out there about that. However, I think it’s important to level set. I’ll cover how to get started contributing to open source. The first important thing to do is find your community. To find that community, you take a few things into account. First, try to invest your time in something that you are already a user. It will help a lot to understand how that technology is used and the context of that technology. Try to look at something that is related to work. This will help especially if you’re looking at the staff-plus career, and have the impact in your career, something that is related to your work will benefit in the long run. If possible, look for something that’s an important piece and part of your work infrastructure. Today, it’s very common. Majority of data center infrastructure is built on top of open source. It’s not that hard to find a piece of software that your business runs on top of. After you find this community, join the communication channels, the mailing lists, the IRC, Slack, Zulip, Discord. Each community has their particular way to communicate. Join all these communication channels. Start to ask questions there, or at least observe how they interact. Because that will give you a sense, what’s the pulse of that community. In parallel, you can start having your hands dirty. It’s time to try and build it. I think it’s a very important aspect, try to build the project by yourself. Sometimes that may not be as easy as you would expect. Some configuration is going to be missing. Some projects will not have detailed configuration instructions for you. Take the opportunity to go back to the communication channel, ask the questions, iterate until you get the first build in your environment.
At this point, you have it built. You are now almost ready to focus on the code contribution. Almost ready, because before you define what you’re going to implement, I think you need to keep in mind to narrow the scope. Some open source projects are huge, complex modules. There are others that are not that big, but it’s still a complex code base. Focus on something, again, back to what you understand. If you are already a user of a particular module of that software, try to focus on that area, because it’s going to easy for you to understand the context of the code, and also understand the real use cases associated with that. Also, it will help you test and implement. Look for something small. Don’t try to shoot for the stars at the beginning. Try to avoid a little bit of snacking. Snacking in this context means that something that is low value to the product. For example, changing typos. Those changes are important, but it’s not what you’re looking to have the impact in your career. Try to look for something simple, but still provides additional value. A good starting point also is bug fixing. There’s also lots of open source projects that publish in their issue tracking a label specifically for the first time contributors. I think if there is such a list, starting there is also a great opportunity to get your first contribution.
At this point, you are almost ready to jump in the code. Almost ready because before working on something, unless you already have an issue defined, open the issue, discuss in the community. Even if there is an issue, and you have defined that you want to tackle that issue, is this the issue? Try to engage in the community and ask feedback for a proposed solution. If there’s no issue open, open the issue. Focus on the problem, and try to engage again with the community to get the feedback to build the solution together. Don’t jump directly into the solution. At this point, if you follow that, you are almost ready to start coding. You open an IDE, but before typing, take a look at the community standards. Try to follow the naming conventions, the project structure, and project format. This is important. This seems to be a silly advice, but many times external contributors follow different formats that ended up frustrating them because their code wasn’t merged. Don’t expect that maintainers or project leads will be able to do it for you. They have a busy life as everyone has, and the backlog and adding some adjustments to the code base of external contributors is not exactly on their top priority. Try to follow the community standard. Many projects have these published somewhere. Some even have predefined configuration that you can import in an IDE.
You start to code, and you get engaged, but try also to publish a draft pull request early in the development cycle. Because if you invest too much of your time on something and just try to collect the feedback, in the end, the community may nudge you to a different path. If you collect this feedback early on, instead, do this, go to that, there’s other references in other parts of the code that you can check. These will help you to be more effective, and your time also in a way that’s more effective. Once you’re done, you are ready to open your pull request. Good title, good description, and link to the original issues are a good starting point. Also, it’s mandatory to look to automated tests. These days, I don’t know any open source software that would accept external contribution without automation tests.
Engagement for Career Impact
At this point, if you follow all these instructions, it’s almost certain that you have your first contribution merged in open source. You already check-boxed that item in your bucket list. It’s a fact that you celebrate. However, it may not create the impact that you are looking for in your career. If you’re looking through the eyes that you want to land or establish your staff-plus career, you need more than that. You need engagement for that impact. What do I mean by engagement? The first thing that means is present. Try to be present on those communication channels that I mentioned. This is important, because in there, you build a relationship with other community members, not only build the relationship, but you’ll be able to support new users, communicate and discuss things through the channels. Be present. It gives you in the long run, also, visibility to that project. Another thing is, try to provide feedback, try new features, suggest new features. If those features are implemented, or you have new features available, try to provide meaningful feedback for the community. Try it in your company environment. Of course, try it in a sandbox safe environment, but bring back that input to the maintainers. They’ll always be happy to listen more of your experience with that new feature. Then, of course, you have the contribution. You can contribute also beyond the code. Promoting the technology is also a great way to contribute. Blog about it. Publish articles about that technology. This is very helpful. It keeps you engaged in that community. Share it on the communication channels, when you write something.
Of course, code contribution. Expected contribution on the code is also expected on the staff-plus perspective. You have to contribute code to grow on your path. Try to build a pace that is constant. Do a contribution every x weeks, because then you become an active member of that community. Again, you will strengthen your relationships over time, and you become a more integral part of that community. Of course, this demands your time investment on that. I think it’s majority of the things that you want to benefit in the long run. The investments on open source and engagement in open source is no different. This will pay off in the future. For that payoff, you need to invest a lot of your time. Again, if you connect it with your work, you’re probably able to manage a little bit better how you invest, instead use just personal time, you connect with the work somehow. Try to be smart on your choices. That’s the content of engagement.
Written Communication
Let’s jump on the skills, and then followed by achievements that you can get by contributing to open source. Written communication is key in open source. It’s the foundation. It’s very important. Open source software is built async and remote, way before the pandemic where a majority of the people were working remote. Writing is the best form for async communication, and a critical skill for all staff-plus engineers. There’s also the fact that the best way to get better in writing is writing. I don’t know another way to practice this particular skill than practicing. The written communication, after the pandemic, in a world that remote work is more common, became part of some interview loops of some companies to ask for engineers to write an essay that you highlight your writing skills. Sharpening this skill will further your career, for sure. This is the foundation. Why is it the foundation? Because as everything is done async and remote, all the other skills you have or the achievements that you are looking for in the open source engagement will happen through the written communication. That is a fundamental, important skill to have.
What are the writing opportunities that you see when you contribute to open source? One of them is blog posts. Others are interacting with the mailing lists, submitting feature requests, and pull requests. You have these four items. You have more, but these are basically a few items that can sharpen your writing skills. Let’s talk about the blog post. That’s the lower bar here to contribution first. It is a great way to promote technology. That’s the strongest way to contribute to open source software without coding. It’s also the best way to learn a new technology. One of the best ways I have when I want to learn something, is try to teach the same technology to someone else. This gives me a better understanding of that technology by creating my own mental models about that software. Again, practice makes improvement: write.
Here, I will talk about a friend of mine, Mauricio Salatino, also known by Salaboy. He started writing about open source software around 2008, on his personal blog, and he was a constant blogger. He still is. He blogs a lot. He still blogs a lot. He’s originally from Argentina. He started to blog in Spanish. He started to post every week or more than once a week, blog posts about open source technology. One in particular was JBPM. He was blogging a lot about JBPM. He started to share the blog posts in the open source community channels to collect feedback. That’s the point that he noticed that his audience started to increase, and the audience were more than just Spanish speakers. He could use the analysis and could notice a lot of people from other countries that don’t necessarily have and probably were using resources like Google Translate. He ended up changing his approach. He started to blog just in English. This was around 2009. He continued to blog about the technology, JBPM specifically, many times. He got involved in the community, and as naturally, it happens to engineers, wanted to get involved in the code base. He started to contribute to the JBPM project. That was fantastic for him. Not only that, that created an opportunity that later on he was hired as a Red Hat engineer to maintain and to work on JBPM. Today, Mauricio is a staff engineer at VMware working on Knative. He’s still blogging. He’s a very active open source advocate, and blogging about technologies.
Let’s go over the mailing list. We have the users’ mailing list. There are multiple ways to engage your mailing list. I will talk about the developer mailing list. The developer mailing listing, a parallel that you can do with the staff-plus daily work, is that dev mailing lists sometimes look like the architectural review lists that you may have in your company. That you go through the RFCs, being architecture reviews, architecture documents, or design documents that you have to review or write to. It’s very similar to the approach that you can take with developer mailing lists. Maybe one difference that you see is that in that mailing list, you have a little bit more diversity. Open source projects are usually in the global scale, multiple contributors from different parts of the world, what will reach you to have all this exposure to different cultures and backgrounds. Here’s one example from OpenJDK mailing list that one engineer is sending a draft of a proposal to collect feedback. Again, that’s what you’re looking for in this engagement. You want to collect feedback. You want to interact with other engineers across the globe, so you collect and improve whatever proposal for a code or whatever you’re looking for.
The next one is writing a feature request. A good feature request, in parallel with the staff-plus engineers, you may consider a feature request like a mini design document. Design document is a very common document that staff engineers need to write or review in their company. You can consider a feature request, like a mini design document. For that, a good format for a feature request will be, provide some background, some context of the feature that you are requesting. Then, go in details about the problem description. Give a good description of the problem, without much of the solution, just focus on the problem. Try to assess the impact in the user, of course. If possible, if you have this ability, try also to provide some inputs around the impact on the code base. Then, and only then you start to propose a solution. You describe your solution as best you can. Don’t forget also to provide alternatives, because these will make sure that you assess all the alternatives and you give out the context for these community members that will review this feature request. It’s not guaranteed that you’ll be able to get your feature in, but if you cover and write a very good feature request, at least it will be read and considered for future releases.
Now we have the pull request. Besides the part of the code that you keep its size small, don’t submit a pull request of 405 changes, try to be concise, focus, like don’t try to mix refactoring, new features, and bug fixing in the same. Single responsibility here is key. Also, again, back to avoid the snack, try not to engage much, and don’t do much pull requests around typos or just minor things like that. Those things are important, again, but that’s not what will bring the impact that you’re looking for, and the engagement that you are looking for, to have an impact in your career. Then, when you’re writing the description, the title, be very clear about it. Clear title, what is that pull request about? A short description, and also very important, a link to the original issue. Again, if you go back to the contribution guide, the 101 that we did, it’s important to always have an issue related, and providing the link with the pull request is always really welcome. This will be considered by community members.
If you’re starting to browse your community that you’re watching first and looking for poorly defined pull request, it’s normal, it’s expected, especially from the maintainers. This is a good example, not much clear aspect for the title and no description at all. These usually are from maintainers. If it’s not from maintainers, you don’t need to set your bar on what exists in that community, you are here looking forward to practicing your skills to get to the next level. You can raise the bar on that community. If that’s not common, you’re starting this new trend. That’s a good way to contribute to that project.
Manage Technical Quality
Let’s go to managing technical quality. When you start to work in the open source community, you are exposed to a lot of different code bases, written by different engineers around the globe. It provides you a lot of different ways to solve similar problems. You will realize different cultures will have different ways to implement certain problems. This will reach you as an engineer, so be exposed to code from people around the world. You’ll get this knowledge, and you can bring out this knowledge to your daily work at a company. Code reviews. Your code will be reviewed by people from different backgrounds and different places in the world maybe, so that feedback loop, it will be very good to understand and start to work with this diversity of backgrounds. It’s also an opportunity to collaborate and learn at industry level. Lots of open source projects have multiple vendors, have multiple companies contributing to the same code base. You’re going to be exposed to how these companies deal with that open source community, and tackle source and the quality. Open source software are not different from other software, they have technical debt, and you can learn at the scale of your open source community how to tackle the technical debt, and how this community arranges and defines the path to manage technical debt. Again, you can bring all this knowledge back to your company and make it better and reevaluate the process of the quality in your company.
To Lead, You Have to Follow
The next one is about leadership, and later, the art of influence. They are a little bit connected. I love this statement from Will Larson’s book, “Effective leaders spend more time following than leading.” That’s true, that’s also my experience. Lots of great, especially in the open source community, they are leaders, but majority of the time they are following, or following some trend, or following the market, or following the organization strategy. There is a lot of following as a leader. You starting to contribute to open source, you need to become a follower first, then maybe aspiring for a leadership position. To start in that community, you need to align your contributions to that community direction. It’s going to be very hard to get your contributions in if you are working on a different direction that the community is going. Try to understand that. By contributing and effectively engaging in multiple contributions to that community, you are able to shape the future of that community. This is a little bit related to the art of influence. Again, all this influence, all these communications, the leadership is all through the written format.
The Art of Influence
The art of influence is very interesting in open source. First, you don’t have authority. It’s an environment that there’s no authority, you are one more contributor. That’s very close to home to all staff-plus engineers, because they are still on IC track, they do not necessarily have power, they do not have direct reports they can force any change. All the influence that the staff-plus engineers have in the organization are usually without authority. You need to learn that skill. For that, one important thing is, read the room, understand the players. Again, back to the communication channels. You observe and understand the dynamics of that community. Once you understand a little bit, you will be able to get better at interacting with the key stakeholders. When you are looking for influence to get a feature in, or to influence the architecture of that, start engaging on the problem, not on the solution. Once you start exploring the problem, you will be probably building a collective solution, not your own solution to that.
I’ll give an example that happened in the product that I work with. One community member sent an email to the list asking for a specific feature. That was a good feature, it was a nice feature, but we didn’t have the time and no engineers got engaged to invest their time on that. That was ok. It was part of the backlog and life moving on. A few months later, another community member sent an email, but this time without asking for a feature. This community member was just defining the problem. Very clear, very good context, the problem, everything was really well defined in that email. Implicitly, it was the same solution, the feature that was originally asked. This time, we got an engineer engaging in that conversation, tackled the problem, implemented that feature, and quickly released a new version that this community member was able to test in their environment. The complete change of approach was based on the solution, not on the problem. That’s a very important way to influence the community.
You’ll learn also that open source community, you have multiple players around that. Not just one or two companies, you have multiple ones. I’ll give an example, the QEMU project is part of Linux virtualization. You have in that particular community several community members with different interests. One of them, for instance, is Red Hat. QEMU is part of the virtualization stack of Red Hat offering. It’s an enterprise level offering for our customers. It’s a key aspect of the virtualization stack, that has to be a very robust, very solid piece of software. In the same community, you have hobbyists that are playing with their own machines and try to simulate different environments as part of their hobby. They also contribute to the code. You also have other vendors that are providing different patches and code to that community, like drivers for different hardware and things like that. You have multiple forces acting in the same community, and you need to learn what is your place and how you influence that dynamic in that open source space.
Expand Network
Let’s start with the achievements that you can get in the open source space. The first one is, expand your network. Open source software is distributed usually across the globe. You’ll be able to build a multicultural network. It will increase your diversity exposure. I think this alone is a huge advantage. You are exposed to different cultures. You will learn how to communicate. However, if you are new to multicultural work, I recommend the Culture Map book by Erin Meyer. It will open your mind to understand how different cultures will have different ways to communicate, and how this is related to personalities and all these things. It’s a very good book. It will allow you to create a network across the industry, and what is very powerful.
Create Visibility
The next achievement is create visibility. It’s important to create visibility to reach the staff-plus and to stay there. The good thing is, creating visibility in the open source space is mostly based on contribution. You have less space for politics. I’m not saying there’s no politics in open source, I just said that it has less space. If you work hard and make a lot of contributions, your contribution will get a certain merge, your visibility will increase no matter what. That’s very positive. If your contribution is aligned with your business, your company business, even better, because it will create the opportunity to increase visibility within your company. You align both sides of the thing, the open source contributions and your daily work in terms of business. You may have access to new sponsors. Because now you’re working across the globe, you may have new opportunities in your career. That’s another thing.
I have a true story from one of my mentees, Tom Bentley, at Red Hat. Tom started to contribute to Apache Kafka. He liked the idea to work there, the challenge. The code base is super dense, complicated. He started slow, but picked over time. In parallel, Red Hat in a point in time decided to adopt Kafka as a majority in the industry these days, as part of the core parts of the strategy. Now, all of a sudden, Tom’s position became business critical, because Red Hat didn’t have much footprint in the open source Kafka contribution. He became a committer. His manager, to celebrate, sent an email to the mailing list that we have in the company to celebrate Tom’s achievement. A few emails in the list, and he got an email directly from the Red Hat CEO, Paul Cormier, congratulating Tom for the great achievement to become a committer. If this is not good visibility to get an email directly from the CEO of a huge company, I don’t know what it is. Again, it’s a great opportunity. Today, Tom became a PMC member of Apache Kafka.
Staff-Plus Project
Last, is the staff-plus project. Depending on how consistent you’ve been contributing to open source, you may create your staff-plus project beyond the boundaries of your company, because everything is on the open source. You have a potential to have an impact on the industry itself. That’s very unique. It’s a very strong staff-plus project.
Conclusion
If you combine these skills and achievements, you’ll have the impact that you’re looking for in your career. What’s more interesting, this impact is auditable. If everything was done on the open, everything’s public, you may change companies and you still create a reference to that impact that you created. If you follow this, I’m quite sure your staff-plus career will skyrocket. You didn’t come this far to only come this far. If you reach that point, you are close to becoming a leader on the open source space. There’s a lot of leadership opportunities in the open source space. You may become a mentor of other engineers. You may sponsor other engineers, give other engineers the same chance that you have to reach the staff-plus status. You’re also being the glue. I love this blog from Tanya, that covers the important aspect of being the glue. The same thing is possible and needed in the open source space, and you can play a role in there.
Questions and Answers
Nardon: Working in open source, you probably work with people from several different countries, and cultures, and companies. How do you see this staff-plus roles in different countries and companies? Do you see that there are markets that are more mature. Is everyone at the same level? How do you see this happening worldwide?
Porcelli: It’s hard to have visibility across the market. What I’m seeing more is that staff-plus is a very much recognized position, as a career ladder for engineers on the leadership side, on IC leadership track in companies. It’s not about the geos, it’s more about the companies. You have companies that are of course across geos. You’ll be able to find that structure of ladder for the staff-plus is very well structured. This goes across things. That’s how I see. I can mention a few ones that I have more close relationships, some of the engineers, like Qualcomm. At Qualcomm, they have a very clear ladder for staff-plus, Red Hat is another one. There are many others. Those companies have very a good structure. It’s less about the geo.
Nardon: As you mentioned, most of the interactions are asynchronous. In a way, this is happening to all of us right now since we’re working from home and many companies are even hiring overseas, so you have different time zones, and most of the communication happens asynchronously. Someone once told me that it’s very hard to fight with someone that’s in front of you, it’s easier to fight with someone that you’re just writing to. I wonder how this impacts the soft skills that you need to have as staff-plus engineers, because a good part of what we do is mentorship, is talking to people, and sometimes influencing people or explaining things. Doing this asynchronously, I imagine that’s going to be a lot harder and different than doing face to face. How do you see this?
Porcelli: It’s absolutely different. It’s a different world. First, I think there are multiple communities, there are multiple ways. Fight for ideas is always great, but fight on the personal level is always bad, no matter the setting. That’s one aspect. If you look to some communities that are not that great or not inclusive, I will not invest my time to join those communities. In terms of the face-to-face time, in general, it is important from time to time. I’ve been working remote for the last 15 years, 10 at Red Hat, but from time to time we get together. It’s important, especially on strategic directions or strategic thinking and planning. You can also do a lot of things async: code reviews, documents. The place that it helps a lot is when you have good writing skills. Writing becomes the foundation. Because of this foundation, if you’re able to communicate well what you’re trying to achieve, it helps the team, and this gives visibility to both sides, for upper management to understand, and also the team understanding what the group is trying to achieve. In the staff-plus role you are the glue on those two sides, like the communication to upper management, and also, communication to the team.
See more presentations with transcripts
MMS • Sergio De Simone
The Swift team has just released two new server-side packages that aim to provide developers a faster and safer implementation of X.509 certificates, including their underlying ASN.1 DER encoding/decoding mechanism.
According to the Swift team, the new packages will eventually replace the existing X.509 implementation based on BoringSSL, written in C and included in the swift-nio-ssl package. This should bring significant performance improvements for TLS-based applications as well as memory safety thanks to the use of Swift.
The Swift Certificate package makes it possible to serialize, deserialize, create, and interact with X.509 certificates, enabling the creation of certificate verifiers, authentication mechanisms, as well as to interact with certificate authorities. The package includes a default verifier and a number of built-in verifier policies.
Server-side applications make frequent use of X.509 certificates. At a minimum, most web servers will load a TLS certificate to secure their network connections. Many more complex use cases exist, from dynamically provisioning TLS certificates using ACME to validating identities using x5c. This makes a fully-featured X.509 library a powerful asset for a server-side ecosystem.
The second package announced by the Swift team provides support for ASN.1, which is a requirement in order to use X.509 certificates. It includes an implementation of the common ASN.1 currency types and of DER serialization and deserialization. ASN.1 is a very flexible format, albeit a complex one allowing for recursive references, default and optional values, and more.
In this case, too, the Swift team emphasizes the advantages of a Swift-based implementation thanks to its memory safety guarantees:
Making this parser safe is particularly valuable as a major goal of DER parsers is to parse untrusted user input. Memory safety bugs in ASN.1 parsing commonly lead to high severity issues.
X.509 lies at the foundation of public key infrastructures and certificates and is used in many internet protocols, including TLS/SSL. Typical use cases for X.509 include verifying an actor’s identity through a certification authority, signing a document to attest its authorship, and more.
ASN.1, also known as Abstract Syntax Notation One, is an abstract language used to define file formats and data structures in a language-agnostic way. An ASN.1 interface definition can be automatically translated into a number of different programming languages and use a binary format based on a set of encoding rules, such as the Basic Encoding Rules (BER), the Distinguished Encoding Rules (DER), and so on. Other popular interface definition languages used in networking applications are Protocol Buffers and Apache Thrift.
MMS • Chris Seaton

Transcript
Seaton: My name is Chris Seaton. I’m a Senior Staff Engineer at Shopify. I’m going to talk about understanding Java programs using graphs. Here’s where I’m coming from with this talk. I’ve got a PhD in programming languages, but I’ve got a personal interest in languages beyond that. One of the great things about working in programming languages is that you can have a conversation with almost anybody in the tech community. Almost anyone who uses programming languages has opinions on languages, has things they wish were better in languages, things they wish were faster in programming languages. A great thing about working in languages is you can always have a conversation with people and you can always understand what they want out of their languages. You can think about how you can provide that as someone who works on the implementation of languages, which I think is a really great thing about working in this field. I’m formerly from the Oracle Labs VM research group, part of the Graal team. Graal is a new just-in-time compiler for Java that aims to be really high performance and give many more options for how we optimize in compiler applications. I worked there for many years, but I’ve currently moved to Shopify to do compiler research on the Ruby programming language. I work on Ruby, but I work within a Java context, because I’m using Java to implement Ruby. That’s the TruffleRuby project. TruffleRuby is a Ruby interpreter working on the JVM, not to be confused with JRuby, which is another existing implementation of Ruby on the JVM. What I’m trying to do is apply Java compilation technology to make Ruby faster, to make Ruby developers happier. We use the same technology in Java, applying it to Ruby.
Outline
What’s this talk about? This talk is about understanding what your Java program really means. We can read our Java source code. We can have a model for how a Java program works in our heads. We can use, if we wanted, the Java specification to get a really deep understanding of its semantics and what it really means. I think it’s good to understand how the JIT compiler, so the just-in-time compiler understands your Java program as well. It’s got a slightly different model of the program. We can reveal that by using some internals of the compiler. We can see how the compiler understands your Java program. I think that can help us better understand what our Java programs are doing, if we’re at the level where we’re trying to look at performance in detail. We’ll be thinking in more depth than bytecode. If you’ve heard of bytecode, we’ll be starting there, but not quite as much depth as machine code. I’m aiming to keep this all accessible. We’ll be using diagrams to understand what the compiler is doing rather than using dry text representation, something like that. It should help it be accessible, even if you’re not sure what goes on beyond bytecode.
This talk is about knowing rather than guessing. I see a lot of people argue about what Java does, and the performance of Java, and what’s fast and what isn’t, and what Java can optimize and what it can’t. I often see people guessing online and trying to guess what Java does. This talk is about knowing what Java does, and how we can use some tools to really understand how it’s understanding your Java program, and how it’s optimizing them. Rather than guessing about what you’ve read online. It’s about testing rather than hoping for the best. We can use some of the techniques I’m going to talk about in this talk to test the performance of Java applications. Again, rather than simply relying on what you think it should do, we can test how it should optimize. All of that is in order to get the performance we want. We’re talking about context where we want high performance out of our Java applications, and how do we do that? How do we test it?
Graal
The first thing I’ve done is I went to graalvm.org, and I downloaded the GraalVM, which is the description of Java we’re going to use to do these experiments. Go to the download link, and you can download the community edition for free. It’s GPL licensed, so it’s easy to use. Graal means a lot of different things. Unfortunately, it can be a little bit confusing. Different people use it to mean slightly different things. Sometimes people can talk past each other. Essentially, Graal is a compiler for Java that’s written in Java. By that I mean it produces machine code from Java bytecode. I’m not talking about a compiler from Java source code to Java bytecode. It can be used as a just-in-time compiler for Java within the JVM. Replacing something that is called opto or C2 within the HotSpot JVM, so it plays that top tier compiler with a different JIT compiler.
It can also be used to ahead-of-time compile Java code to a Native Image, so a standalone executable, which runs specifically compiled from C or C++, or something like that, that has no requirements on a JVM. It can also be used to compile other languages via a framework called Truffle. This is what TruffleRuby does. It compiles Ruby code to source code via Java, using Graal as a just-in-time compiler. The reason it can do all these different things is because it’s essentially a library for compilation. You can use that library in many different ways. You can use it to build a just-in-time compiler, or you can use it to build an ahead-of-time compiler. You could do other things with it as well. It’s a library which you can use with different things. That’s why it’s one term that’s used for doing so many different types of things. That’s packaged up as something called a GraalVM. The GraalVM is a JVM with the Graal compiler, and with Truffle functionality within it. That’s what the GraalVM means. You may hear the term GraalVM compiler, that’s the same as Graal compiler.
I took GraalVM and I’ve put it on to my path. I’m going to do PATH equals GraalVM contents, home, bin, PATH, and that gives me Java on my command line path. Now I’ve got an example Java program here that has a simple class. It has a main method, which simply runs a loop, and it calls this method called test. What test does is simply adds together two parameters and returns the result. It’s kept as a static to keep it nice and simple. The way I’ve set this up is with this loop, the purpose of that is to cause this method to be just-in-time compiled. It’s an endless loop because I want the compilation to happen naturally, I don’t want to force the compilation in any unusual way. The input to the method are two random variables. I have a random source, and the random variables go into the test routine. The reason I do that is because I want the program to not be static at compilation time, so I want real dynamic data flowing through it. The just-in-time compiling can’t cleverly optimize anything away, because actually, it’s static.
Now we’ve got our javac, which is our Java compiler on our command line from GraalVM as normal. We can do javac Test.java like that. That converts our Java program to bytecode as you’d normally do. We have the source code now, which is how we normally understand the program as human beings. We can read that and we can reason about it. There’s more ways than that to understand your Java program. The first one you may be aware of is an abstract syntax tree. What it is, is a representation that javac uses to understand your program. I’m using a plugin here for IntelliJ that allows you to see how the javac compiler understands your program. You can take an example source file like the one we have here, and you can use this parse button, which gives us an option to inspect. Then we can see how the javac compiler understands our source code. We have here a class, which is our test class. It tells us what comprises that. Then after that, we have a method declaration, which is our add declaration. You can see it highlights the source code which corresponds to it, and it has private, static, has a name, has a return type. Within that it has a block which is the body, has a return statement. Then it has the binary operator. Within that, we can see it has x and y as two of those. This is the abstract syntax tree or the AST, which is the simplest representation the machine can use to understand your Java source code.
We already said we compiled to Java bytecode, so that means there’s another representation we can use to understand our Java source code. I’m going to use javap. Javap, and the command is C on test. This will disassemble our Java bytecode from the class file. Because it’s static, you need to use p to get extra members. What we have here is a representation of that, adding routine test as written as the Java bytecode. We have the AST which is how javac understands it. It produced this bytecode which is what goes into the class file. We have, it loads an integer, loads another integer, so 0 and 1 corresponds to the two parameters. It adds them as integers and then it returns an integer. That’s what it does: load them, add them, and return them out. Nice and simple Java bytecode there.
When you run this Java program at runtime within HotSpot with the just-in-time compiler enabled, it converts it to machine code. We can see the output of that machine code using some special flags. What I’m going to do here is use this set of flags here. What all these flags mean isn’t particularly important. If you look up on some blog posts, you can quickly see how to get machine code out. I’m going to simply run one of these. This tells us the machine code that the Java just-in-time compiler has produced from our Java code. It tells us it’s compiling. Test, there we go. This is the test method. This is the machine code it’s produced that actually runs on your processor. There is a add operation in here. That is the actual add, which corresponds to the add we wrote in Java, but it’s buried around some other stuff.
JITWatch
There’s quite a bit of gulf here, we talked about the AST, and then the bytecode, now we’ve jumped all the way to this low level, hard to understand machine code, which we can’t really use to understand our Java program. It’s far too dense. This is a tiny method. There’s already quite a lot going on there. In this talk, what I’m going to do is address that gulf between the Java bytecode and the Java machine code. There’s a couple of tools we can use to do this that exist already. One of them is called JITWatch. I’m running JITWatch here as an application in the background. It’s a tool. What you can do is you can use basically this flag called log compilation. I’m going to run our test program with that. It runs as before, but now it’s producing an extra file of output, which we can interrogate to understand a bit more about what the JIT has done. I’m going to open the log that we just produced, and I will analyze it. There’s our class, and it tells us there’s a method in there, which is just-in-time compiled. This tool is a bit better than the javap command line tool, and the print disassembly we used, in that now it gives us all those together. It tells us the source code, the bytecode, and the machine code output. This add operation corresponds to this add operation in the bytecode. Then we said that this was where the actual add was, and yet we can see it’s connected up, and it tells us that’s the actual add operation going together. This is a bit better. It shows us how these things link up. There’s still somewhat of a gulf here, in that how’s it getting from this bytecode to this machine code? That’s what we’re going to answer using the next tool.
Seafoam
I’m going to use some more flags now. I’m going to add something called graal.Dump. What this does is it asks the Graal JIT compiler to print out the data structures it uses to understand the compilation. The program runs as normal. After a while, I’ll cancel it. Then we get an extra directory, which is this graal_dumps, which lists all the compilations which the JIT compiler has done. I’m going to use a tool here called Seafoam, which is a command line tool for reading out these graphs. We’ve got a directory. I’m going to run the Seafoam, and I’ve got directory of these graal_dumps. I’m looking for HotSpot compilation, and these are all things HotSpot has compiled, and we’re looking for Test.test, so 172. I’m going to ask it to list all the things it compiled within when it was compiling that method. This list is hard to understand, but these are all the phases the compiler runs, but I’m going to simply jump in and get it to look at after parsing. What does the code look like after it’s been parsed? I’m going to say I want you to render this. This is what Seafoam does. This prints out a compiler graph. This is the central idea of what this talk is about.
This is a graph. It’s a data structure. It has edges or arrows, lines, and it has boxes, nodes. It’s a flowchart effectively. It tells us how the just-in-time compiler is understanding your Java program. What we have here in the center is an add operation, which is that add operation in our method, the key thing. What this graph is telling us is that there’s input flowing from the zeroth parameter, so the first parameter, and the first parameter, so the second parameter which flow into the add production as x and y. Then the add operation goes to be returned as the result. There’s also a node which says where the method starts and where it ends. They simply are connected by one straight line. There’s no control flow going on. The green arrows represent data flowing. The red arrows which we’ll see more of later, the thicker arrows, they represent the control flowing through the program. The green or the oval boxes represent data sources. The green or diamond boxes represent operations on data. The red or rectangular boxes represent some decision or some control flow being made. You can see that this adds operations that goes together.
Example: Understanding Java Programs
How can we use this to understand some Java programs? What can we use this to understand about how Java understands your Java programs? Let’s look at an example. We’ve got this add routine here. I’m going to expand it to have another parameter, so x, y, and z. What I’m going to do is I’m going to introduce the extra variable here like that, so x + y + z. Then I’m going to run the program again. I have to compile it, because I’ve modified it, and then run it as before. Now we’ve got two add operations, and you can see the result of the first add operation flows into the input to the second operation. This is x + y + z, the third parameter. Java has got local variables. What do local variables mean to how the just-in-time compiler understands it? It doesn’t make a difference to your program when you use local variables to change how your program works. I’ve seen some people argue online that using local variables is slower than just using code directly of an expression, because they think the compiler has to set a local variable somewhere. Let’s look at what that actually looks like. I’m going to modify this code now to do int a = x + y, and then do, a + z. We’ve got different Java source code now, but that achieves the same thing. Let’s look at how the compiler understands that.
I’ve compiled again, run again. We introduced a local variable, but you can’t see any difference in the resulting graph. The result of this is x + y that’s now assigned to the local variable a, but that local variable doesn’t appear in the graph. It’s like the just-in-time compiler’s forgotten about it entirely. What this edge here represents is the data flowing from the add operation from x + y into the input that adds it to z? It doesn’t matter if that value was calculated and stored in a local variable, or if it was simply part of an expression, all the compiler cares about is where the data is flowing. There is a local variable here between node 5 and 6, but the compiler doesn’t care about that. It can ignore that and just know that this is where the data comes from, this is where the data is going. We can see, we get exactly the same graph out of the program if we use local variables, or if we don’t. It doesn’t make a difference to how the just-in-time compiler optimizes it. This is what I mean by we can use this tool to understand how the just-in-time compiler understands our program, because we can change things in the program. We can see what differences that actually makes to the just-in-time compiler, and why.
So far, graphs have been pretty simple. I’m going to introduce some control flow now, so some if statements, things like that. I’ve got an example already set up, so exampleIf. Now I’ve got this method, exampleIf, and it has a condition, an x and y. If the condition is true, it sets a to be x, of y sets a to be y, and then it returns whatever one of those was. We also have something in the middle, which sets an int field to be the value we’re setting it to. The reason we do that is to put a point in the program where there’s some action taken so we can see that action more easily in the graph of why sometimes the graphs get very compact very quickly, and it’s hard to see what you’re looking for. I’ll run this program. I’ll remove the graal_dumps, I think. ExampleIf, 182. What we have now is a graph that includes control flow. Before, the only red things, the only rectangular things were start and end, but they come in now when we have a control flow, such as a loop or an if. Now what we have is the first parameter, so our condition is equal to 0, 0 meaning false. If it is equal to false, then we use x, of y’s we use y, and we can see us assigning x that field here, and then we can see the results comes from either x or y depending on which way we took the if. What this is, is a special node called a phi node that says, take which value we want based on where we control flow diverged. We can see our control flow now has a diverge in it where it can go one of either way, just like our program. We can see now that the red or the thick arrows have a meaning for control flow.
Now we can use this example to see a really interesting point about how Java optimizes your program. What I’m going to do is I’m going to change this random Boolean that says whether we want to take the first branch or second branch, and I’m going to give it a constant value. I’m going to change it from random to always being false. This condition is always false now, so we’re only ever going to use this branch. What do you think this is going to do to the way the Java just-in-time compiler understands your program? We see this pattern quite often in things like logging, for example. You may have a logging flag, which is off most of the time, or sometimes is on, sometimes is off. Does that add some overhead to the way your program is compiled? Let’s try it out. 180. We’ve no longer got any control flow in our graph, but we had control flow and now I have a source code. Where has it gone? What the compiler says is it has never seen that value be anything apart from false. It’s gone ahead and it’s just-in-time compiled your program, assuming it’s always going to be false. Because that value is coming in dynamically, it could change. What it’s done is instead of an if node, it’s now got something called a Guard node, which is saying, I want you to check that the first parameter is still false, so the first parameter equals false. Check that’s true. Then it carries on assuming it’s true. We have the StoreField, and it returns simply the first parameter. If it wasn’t true that the value is false, then it does something called deoptimizing, where it jumps out of this compiled code and goes back into the interpreter. What we can see here is that the just-in-time compiler looks and profiles what values you have flowing through your program, and uses those to change how the program is being optimized. The benefit of this is there’s less code here now, because only one of the branches are compiled. Also, it’s straight line code. This Guard is written in such a way that the process will know it’s not likely to fail. Therefore, it can go ahead and do this code afterwards while that Guard is still being checked. Here we can see the profiling going on and working in action.
Example: JIT Compiler
I’ll give you a more advanced example now of what we can see about what the just-in-time compiler is doing by using an example which looks at locks. I’m going to take an example here. I’m going to take the code which calls this. We don’t need that anymore. What we have here now is a method called exampleDoubleSynchronized, it takes an object, and an x. We did need the field still. Then it synchronizes an object once, write to field, and then it synchronizes an object again, and write to field. Why would you write code that synchronized on an object twice, back-to-back like this? You probably wouldn’t, but you may get this code after optimizations, so if you call two synchronized methods that you’re effectively doing this, if you call them back-to-back. Or if you have code that inlines other code that uses synchronized locks, you may get them back-to-back like this. You may not write this manually, but it’s the thing you may get out automatically from the compiler. The driving code used the same object for each lock, but it allocates it new each time, then it’s parsed in a random integer.
Let’s compile this. I’ll remove the graal_dumps first, 175. What we can see is what we’d expect to start with. We have straight line code. Those kinds of synchronized blocks, the objects that uses them is called the monitor of the object. We take that object in as the first parameter, and we enter the monitor of the object, and then we leave it, and in between, we write the field, and then we enter it again, write the field and leave it. We can see here that we’re locking the same object twice, which is wasteful. What I’m going to do now is look at a later phase of that same method being optimized, so I’m going to use the list thing, which gives me all the phases which are being done. I’m going to grep for lock elimination. We’ve got two phases here, before lock elimination phase and after lock elimination phase, so it is 57 and 58. I’m going to render the graph again at stage of compilation 57. What’s happened here is the program has already been optimized a bit. Some things have already been changed, and it’s also been lowered too. Some higher-level things being written as lower-level things. For example, implicitly we can’t synchronize on that object if it’s null, so a null check has been inserted and made explicit here. We still have the MonitorEnter, the write to field, the MonitorExit, the MonitorEnter, write to field, and the MonitorExit.
What I’m going to do now, though, is look at the same graph after something called a lock elimination phase has run. This is a compiler phase within Java’s just-in-time compiler, which is designed to improve our utility of locks. This is at stage 58 now. I’m looking at just after the next phase, and we can see what has gone on here. What’s happened is we now have just one MonitorEnter, we write both fields, and then one MonitorExit. We can see what’s going on here is it’s seen the two locks are next to each other, back-to-back. It has said, I must as well combine them into one single lock. I might as well lock just once, do both things inside the block, and then release the lock. This is an optimization that you may have been aware is going on, you may not be aware it was going on. Instead of debating whether Java is able to do this for our code or not, we can look at the graph and find out. We can either do this as a manual process, as I’ve done here. I said for this example code, I want to know if the two locks are synchronized or not. I wanted to know effectively, I was going to get this code out, which is what we have done. I can test that. Because we’re using command line tools, and we’re using these files that come out of the compiler, what we can do is we can also write a test to do this.
TruffleRuby
I work, in my day job at Shopify, on a system called TruffleRuby. TruffleRuby is a Ruby interpreter. It’s an interpreter for the Ruby programming language. It’s written in Java, and it runs on the JVM as a normal Java application if you want to. It doesn’t require any special functionality inherently. It uses the Truffle language implementation framework. This is a framework for implementing programming languages, produced by Oracle Labs. It can use the Graal compiler to just-in-time your interpreted language to machine code somewhat automatically. It uses a technique called partial evaluation. Instead of emitting bytecode at runtime, and compiling that as if it came from Java, what it does is it takes your Java interpreter, applies a mathematical transformation to it with your program, and produces machine code from that. It’s capable of some really extraordinary optimizations thanks to Graal. It can inline very deep. It can constant fold through lots of metaprogramming, things like that, which is essential for optimizing the Ruby programming language, which is very dynamic.
This is how we actually test TruffleRuby at Shopify. The optimizations we care about having been applied are very important to us because they’re very significant for our workloads. We have tests that those optimizations are applied properly, and what they effectively do is they automatically look at the graphs, as I’m doing here, but they do it using a program. They check that the graph looks as it expects, so here, you could query this graph. You could say, I expect to only see one MonitorEnter and one MonitorExit. The great thing about Java that people don’t always know as well, when they try to understand and guess what we do is, of course, Java is open source, the compiler is open source. You can just go and look at how they work. We can see here that this lock elimination phase has worked really well for us, and it’s done what we would expect.
If you go to Graal on GitHub, you can look at how this works. We set it to the lock elimination phase, it did what we wanted. We have a test for it. Here you go, lock elimination phase. This is the optimization which applied what we wanted. The great thing about Graal is because it’s written in Java, you can jump in, and it’s very readable. I’m not pretending that anyone can do compiler stuff, anyone can work on compilers. I think anyone can read this code who is familiar with Java and Java performance work, and can understand what’s going on here. This is a full production optimization phase here. We’re saying for every MonitorExit node in the graph, so get all the MonitorExit nodes in the graph, look at the next node. If the next node is another enter, and if the two locks are compatible, so they’re the same object, then replace the exit with the next enter. That’s what it’s done to our graph to be able to optimize it. There was an exit here and it said, replace it with the next node after the next enter, which was this right here.
Summary
The point of all this is that we can get the compiler’s representation for how it understands our programs out of the compiler. We can use that to gain a better understanding of what Java is doing with our programs ourselves. That means that you don’t have to guess at how your Java program is being optimized. You don’t have to rely on working through the spec. You don’t have to rely on hearsay that you see online about what Java might do or might not do. You can check it yourself and you can see what it’s doing. I think it’s relatively accessible via these graphs, because you’re looking at a visual representation, not having to pore through a log. You can simply see how it’s transformed your program and understand what it’s doing. Because of this, logs are files that we can get out of the compiler, we can also use them to test stuff. We can build tests by saying, does the graph look like how we expect? Has it been compiled how we expect? I think these are some more options for understanding Java and for understanding how our Java code has been optimized, checking that it’s been optimized as we expect, which makes it easier, I think, to get the performance we want out of our Java application.
Resources
A lot of the work here on how to understand these Graals come from a blog post, Understanding Basic Graal Graphs. If you look at that one, that’ll give you a way to understand all the concepts you might see in a graph. What edges you see, what nodes you see, what normal language concepts compile to. You can get Graal from graalvm.org. You can get the Ruby implementation from there as well. The tool I’m using to look at graphs is something produced by Shopify called Seafoam. I also demonstrated JITWatch, and the Java Parser which allows us to look at the Java ASTs.
Questions and Answers
Ritter: I’m a big fan of understanding more about what JIT does. It’s very interesting to see what you’re doing with the idea of the graphs and then getting the JITWatch to expand out the information.
Seaton: I think a lot of people spend their time guessing at what Java does. There’s a lot of myth and misinformation and old information there. We can just check. I see people having arguments online, “Java does this, Java does that.” Let’s just go and take a look, and you can find out for real what is working on your code. You can even write automated tests to figure out what it’s doing for real by looking at these graphs.
Ritter: Yes. Because as you say, if you put a local variable in, does it actually really get produced as a local variable? Is that like escape analysis? Because you’re not actually using that variable outside of the method, or the result outside of the method. Is it related to escape analysis, or is that just simply optimization?
Seaton: No, it happens in a different phase. What it does is it says, every value that’s produced in the program, every expression that is in the source program, is given a number. What it says is every time you refer to that expression it’s using the same number. It’s called global value numbering. If an expression has gone through a local variable, it still has the same number as if you wrote it there directly, so if you go to the compiler, it’s exactly the same thing. This is why if you write a + b twice, independently, they’re the same expression so the compiler says, I’ll give them the same number that’ll be used once. Again, people don’t use a local variable and think I’ve got a + b twice here, I’ll put in a local variable and use it. Does that make it faster? No, it doesn’t because it’s exactly the same thing. There are still readability reasons. It’s important to say that making your code readable is a separate concern, and that’s a very human thing. It’s important to understand how the compiler actually understands your code and what it actually does.
Ritter: Because I remember from my days, many years ago, doing C programming, and do you make a variable a register, and what impact that has on whether it improves the performance or not?
Seaton: Yes. It’s historic, and it doesn’t really mean anything anymore.
Ritter: Yes, because then they ended up with register-register. It’s like, what?
The other thing I really liked you explaining about was how the code can be optimized based on previous profiling. I talk a lot about that with the stuff we do, speculative optimizations, which is the same approach as what you were describing there.
Seaton: Again, these graphs allow you to see what’s happening there. One of the properties you can find on a graph, because there’s more information in the graphs than is visible, because of the tool I use, tries to show enough stuff to be reasonably useful without putting an avalanche of data. Another thing it can do is it can tell you the probabilities. You look at the graph and you can see which path is more likely to be taken than the other. You can see what if a path is never taken, or it’s always taken, or whether it is taken 25% of the time. You can use that information to understand your programming. The compiler uses that in different ways. People often think it only uses it for binary reasons. It says if a branch hasn’t been taken, then compile it, if it’s never been taken, don’t. You may wonder why does it collect more profile information than that? Why is it collecting fine-grained information? It actually has a float for the probability to call log precision. The reason for that is the register allocator, will try and keep registers here live but longer on the more common paths, or the most common paths. It’s worth gathering that more detailed information, and you can start to do something. Obviously, these are like, last 1% optimizations rather than the most important things in the world.
Ritter: That’s the thing I always find interesting, because, obviously, you’ve worked on the Graal project, so Graal has become very popular recently, because of the idea of Native Images, and ahead-of-time compilation. I get that that’s very good from the point of view of startup time, so you’re immediately running native code, so you don’t have to warm up. The JIT compilation, because you can do things like speculative optimizations more, and you can do profile guided optimizations with Graal, but you can do proper speculative optimizations, and as you said, deoptimize if need be. You can get that slightly higher level of performance through JIT compilation or optimizations.
Seaton: Again, graphs are great for seeing this. The same tool can be used for Native Image. If you want to understand how your Native Image programs are being compiled, you can dump out graphs in a similar way. If you look at the C-Frame repository, there’s commands for using Native Image as well. If we looked at some example, realistic Java code, we’ll be able to see, the Native Image graph is actually more complicated. Why is that? It’s because the JIT was able to cut this off, no, this wasn’t needed, get rid of that, and so on, and get to be simpler code. Because it’s the same tool and it works for both, you can look at them side by side and see where the Native Image attempted to do more stuff to keep it going. That’s a common misconception that Native Image will always be faster. Maybe in some cases, faster peak performance. It may actually work in the future. It may get there. Yes, you’re right, it’s a startup and a boot warm-up tool.
See more presentations with transcripts
MMS • RSS
SQL (Structured Query Language) is a language used to manage and manipulate data in relational databases. In today’s data-driven world, SQL is an essential tool for data analysts, developers, and anyone else who works with data. As AI tools and models grow in popularity, so will supporting languages like SQL that work with data. In this article, I will discuss what SQL is, its importance, relevance, and ways to learn it. I will also answer some common questions that beginners might have about SQL.
Table of contents
What is SQL and What is it Used For?
SQL is a programming language that is used to manage and manipulate relational databases. A relational database is a structured collection of data that is stored in tables, which are made up of rows and columns.
SQL allows users to interact with these tables using various commands and statements (queries). For example, a user can use SQL to select specific data from a table, update existing data, or insert new data into a table. SQL also allows users to create and modify tables, set up relationships between tables, and define constraints to ensure data integrity.
Here’s an example of an SQL query that gets a list of users that have ordered a product:
SELECT customer_name, order_date
FROM customers
JOIN orders ON customers.customer_id = orders.customer_id
JOIN order_items ON orders.order_id = order_items.order_id
JOIN products ON order_items.product_id = products.product_id
WHERE products.product_name = 'Roller Skates';This query joins four tables – customers, orders, order_items, and products – to retrieve the names of customers who have ordered Roller Skates and the dates they placed the orders.
A sample response to this query might look like:
| customer_name | order_date |
|-----------------|-------------|
| John Faith | 2023-01-01 |
| Kiara Johnson | 2023-01-05 |
| Michelle Dams | 2023-01-10 |
| Jennifer Liu | 2023-01-15 |
Is SQL still relevant in 2023?
Yes! SQL continues to be one of the most widely used programming languages, particularly in the field of data analytics and database management. In fact, SQL’s popularity has grown in the past year (TIOBE index). Not bad for a 49 year old language!
Data literacy is expected to be the most in-demand workplace skill by 2023. The need for data management and analysis is increasing as more and more businesses and organizations rely on data-driven decision-making. With the rise of AI powered tools, any language that supports the updating and retrieving of this data will remain popular.
If you work in tech, not only is know data useful for your career but it will soon become essential.
Should you learn SQL?
If you’ve come to this article and are interested in data, analytics, or working as a backend developer, I would highly recommend learning SQL. Even if your goals are not related to data, SQL can still be a valuable skill to have. Here’s a list of benefits learning SQL might bring:
- Learn in-demand skills: SQL is used by many industries, including finance, healthcare, retail, and technology, so there are many job opportunities available for those who have SQL skills. As mentioned earlier, AI, and therefore database interactions are becoming increasingly popular.
- Become better at analyzing data: If you work with data, SQL can help you extract valuable insights and information from large datasets. SQL allows you to quickly and efficiently query and manipulate data. Any developer, analyst, UX researcher, or Product person can leverage these skills.
- Improve your productivity: SQL is a powerful tool that can help you manage and organize data. With SQL, you can automate repetitive tasks and streamline your workflow, which can save you time and increase your productivity.
- Learn Transferable skills: SQL is not limited to any particular industry or job role. Once you have learned SQL, you can apply it to a wide range of tasks and projects.
- Open up career opportunities: SQL is often a prerequisite for roles in data analysis, data science, and data engineering. Learning SQL can help you take your career in new directions.
Different ways to learn SQL
There are several ways to learn SQL and each one has its place depending on your goals, learning style, time availability, and budget. Below are some popular options to consider:
- Self-learning through online resources and courses: There are a plethora of books and courses available to learn SQL. These resources range from free YouTube videos to paid online courses from reputable institutions like SitePoint, Coursera, Udemy, and Codecademy. Self-learning is a flexible option for those who prefer to learn at their own pace and have a limited budget.
- Bootcamps and intensive training programs: Bootcamps and intensive training programs are designed to provide hands-on training in a condensed time frame. These programs are typically shorter than traditional college courses and aim to teach practical skills that can be immediately applied to real-world projects. Bootcamps and intensive training programs can be expensive but provide a faster and more immersive learning experience.
- Specialized SQL certifications: For those looking to advance their career in data-driven areas, SQL certifications can be a valuable credential to have. Certifications are offered by various organizations, including Microsoft, Oracle, and the Data Warehousing Institute. These certifications validate your SQL skills and knowledge and can increase your chances of landing a higher-paying job.
- Traditional classroom-based learning: If you prefer a structured learning environment and have the time and resources, traditional classroom-based learning might be a good option. Many universities and community colleges offer SQL as part of their core computer science or business programs. This option provides a more hands-on and interactive experience, allowing you to ask questions and get feedback from an instructor.
Getting started with SQL
Here’s a suggested approach to learning SQL. Each person if different, with varying programming skill level and goals, so take this with a grain of salt.
A shameless plug: our famous Simply SQL course follows these steps and more and we believe it’s the best way for a beginner to start.
- Understand the basics: Before diving into the complex queries, you need to understand the basic concepts of SQL, such as tables, columns, rows, and relationships between tables.
- Choose a database: Select a database management system (DBMS) and become familiar with it. Some popular ones include MySQL, PostgreSQL, Microsoft SQL Server, and Oracle. They are all very similar and MySQL Community edition and PostgreSQL are free. I recommend starting with one of those two.
- Practice with simple queries: Start practicing with simple queries, such as selecting data from a single table or filtering data based on certain criteria.
- Venture into complex queries: As you gain more experience, start building on your knowledge with more complex queries, such as joins or aggregating data.
- Use resources: There are plenty of resources available to help you learn SQL, including online tutorials, books, and courses. Make use of these resources to help you gain a deeper understanding of the language.
- Practice, practice, practice: The key to mastering SQL is practice. Try to work on real-world projects or challenges to help you improve your skills.
Questions SQL Beginners might be afraid to ask
What are the prerequisites for learning SQL, and do I need to have any coding experience?
You do not necessarily need to have any coding experience however, it is helpful to have some basic understanding of data and how it is organized. Some familiarity with spreadsheets or databases can be beneficial. It is also recommended that you have a basic understanding of algebraic concepts and logic, as SQL involves working with data sets and manipulating them through logical queries.
What are some real-world applications of SQL, and which industries rely on this skill?
SQL is used in many industries, including finance, healthcare, retail, and technology. It is used for tasks such as data analysis, reporting, and management. Companies of all sizes rely on SQL to store and manage their data. Some examples of real-world applications of SQL include customer relationship management, inventory management, and fraud detection.
How long does it take to learn SQL, and how much time should I invest in practicing to become proficient?
In general, it’s best to set realistic expectations for yourself and focus on continuous learning and improvement rather than trying to master SQL in a specific timeframe.
However, since you asked – the amount of time it takes to learn SQL varies depending on the individual and the level of proficiency they wish to achieve. Learning the basics of SQL can take anywhere from a few days to a few weeks. Becoming proficient can take several months of consistent use.
It is important to keep practicing and applying what you learn in real-world scenarios to solidify your understanding of the language.
What are some popular RDBMS, and which one should I start with?
Some popular RDBMS include MySQL, Oracle, Microsoft SQL Server, and PostgreSQL. The choice of RDBMS depends on your project requirements, budget, and level of expertise. MySQL is a popular choice for web development projects, while Oracle is commonly used in enterprise-level applications.
The main differences between them are:
- Cost: Oracle and Microsoft SQL Server are commercial products that require a license, while MySQL and PostgreSQL are open-source and free to use.
- Features: Each RDBMS has its own set of features and capabilities that can make it more suitable for certain use cases.
- Popularity: While all four are widely used, some are more popular in certain industries or among certain groups of developers.
As for which one to learn first, it depends on your specific goals and needs. If you are just starting to learn SQL and want to get some hands-on experience, MySQL or PostgreSQL might be good choices since they are free and easy to set up. If you are interested in pursuing a career in a specific industry, it might be worth researching which RDBMS are commonly used in that field. Additionally, if you are already familiar with a certain RDBMS, it might make sense to continue learning and building on that knowledge.
What is an RDBMS?
An RDBMS stands for Relational Database Management System. It is a type of database management system that stores data in tables with relationships between them. RDBMS uses SQL to manage and manipulate the data stored in the tables. Examples of RDBMS include MySQL, Oracle, and Microsoft SQL Server.
What is NoSQL and what is the difference between SQL and NoSQL?
NoSQL stands for “not only SQL”. It is a type of DBMS that is used to store and manage unstructured or semi-structured data. On the other hand, SQL is used for structured data in relational databases.
One of the main differences between SQL and NoSQL is that SQL databases use a schema (a predefined structure for how data is organized), while NoSQL databases are schemaless, meaning data can be stored in a flexible and dynamic way.
SQL databases are typically better for handling complex queries and transactions, while NoSQL databases are better for handling large volumes of unstructured data, and for scalability.
If you are working with structured data and need complex querying capabilities, SQL may be the better choice. However, if you are working with unstructured data and need scalability, NoSQL may be the better option.
Summary
I hope this guide has helped you decide on whether you want to learn SQL and, if so, how to get started. It’s a popular and useful language that is expected to remain relevant for many years to come. Even if you aren’t interested in becoming a backend developer or database manager, SQL provides many benefits for career or personal productivity.