Month: April 2023

MMS • Steef-Jan Wiggers
AWS recently announced that Lambda supports Python 3.10 as both a managed runtime and container base image, allowing developers to leverage the improvements and features of the runtime.
AWS Lambda is a serverless computing service that allows developers to run code in the cloud without managing servers, providing automatic scaling and high availability. In addition, it supports several runtimes such as Python, Node, and .NET. The service now supports Python version 3.10, which includes structural pattern matching, improved error messages, and performance enhancements.
In an AWS Compute blog post, Suresh Poopandi, a Senior Solutions Architect at AWS, mentions that structural pattern matching is one of the most significant additions to Python 3.10:
With structural pattern matching, developers can use patterns to match against data structures such as lists, tuples, and dictionaries and run code based on the match. This feature enables developers to write code that processes complex data structures more easily and can improve code readability and maintainability.
In addition, improved error messages provide developers with more information about the source of the error and suggest possible solutions, which helps identify and fix issues more quickly.
The support for Python 3.10 in Lambda comes a year and a half after the release of candidate one. After this release, support was requested for Lambda in Github base images. However, it took some time. One of the respondents in the request stated:
As a customer, it’s worrying that it’s taking AWS more than 12 months to update a system that has a fixed 12-month upgrade cycle. If AWS continues the way they have for Python 3.9 and 3.10, Lambda is going to fall further and further behind on Python versions continually.
In addition, Michael Brewer, a VP Architect Fellow Platform Engineering at Fiserv, tweeted:
Let’s hope 3.11 comes out shortly and is faster than 3.9. AWS lambda python 3.10 seems like a skip due to performance regression.
Yet the company has already published a preview Lambda container base image for Python 3.11, which is subject to change and should not be used for production workloads.
Corey Quinn, Chief Cloud Economist at DuckbillGroup, concluded in a blog post:
AWS’s major competitors all support Python 3.10 at a minimum. It’s long past time for AWS to either ship the language runtime customers are (quite reasonably!) clamoring for or else offer up better transparency than the “we’re working on it” stonewalling that we’ve gotten for over a year.
Developers can build and deploy functions using Python 3.10 using the AWS Management Console, AWS CLI, AWS SDK, AWS SAM, AWS CDK, or alternative Infrastructure as Code (IaC) choices. In addition, they can also use the Python 3.10 container base image if they prefer to build and deploy their functions using container images.
Lastly, more details on building Lambda functions with Python are available on the documentation pages.
MMS • Bruno Couriol

The Node.js team recently released Node v20 (Current release). Node v20 will be ready for full production deployments after entering the long-term support (LTS) stage in October. Key features include an experimental permission model for improved security and building Node applications into standalone executables.
Rafael Gonzaga, Node.js TSC Member explained:
With the addition of the experimental Permission Model and updates to V8, Node.js 20 is perfect for testing and assessing how Node.js will fit into your development environment. We have made excellent progress making Node.js more secure and performant over the past year,
Developers can opt in the new permission API with a --experimental-permission flag that when enabled restricts access to all available permissions. Currently, the available permissions configure access to the file system (e.g., --allow-fs-read, --allow-fs-write flags), the spawning of child processes (--allow-child-process flag), and the creation of worker threads (--allow-worker flag). For instance, --allow-fs-write=* --allow-fs-read=/tmp/ will allow FileSystemRead access to the /tmp/ folder and allow all the FileSystemWrite operations.
Permissions are process-scoped. Developers can thus not deny permissions to just a specific module. A process that has --experimental-permission will not be able to spawn a child process by default. When the --allow-child-process flag is enabled, it becomes the user’s responsibility to pass along the correct arguments to spawn the child process with the right permissions. For more information, developers can refer to this pull request and the permission model roadmap.
With Node v20, developers can build their Node applications into a standalone executable (single executable apps) for users who do not have or cannot install Node.js. Single executable app support is available on the Windows, MacOS, and Linux platforms (all distributions supported by Node.js except Alpine and all architectures supported by Node.js except s390x and ppc64). Microsoft is experimenting with single executable apps as a way to reduce vector attacks.
Additionally, the test runner that was introduced in Node v19 is now stable in v20, signaling production readiness. The V8 JavaScript/WebAssembly engine is updated to version 11.3. This makes available new JavaScript APIs, including methods that change Array and TypedArray by copy, and a resizable ArrayBuffer and a growable SharedArrayBuffer. Node v20 can also leverage V8’s support for WebAssembly tail calls (introduced in v11.2). Lastly, calls to import.meta.resolve() are now synchronous.
Node.js is open-source software available under the MIT license from the Open JS Foundation. Contributions and feedback are encouraged via the Node.js contribution guidelines and code of conduct.
MMS • RSS

Sponsored Feature Amazon’s DynamoDB is eleven years old this year. The NoSQL database continues to serve tens of thousands of customers with high-volume, low-latency data thanks to its performance-intensive key-value pair and scalable architecture. Until recently, customers wanting to take advantage of its speed and capacity had just one primary challenge: how to easily get their data into DynamoDB.
Last August, that issue was solved with the launch of a new functionality that makes it easier to import data from Amazon S3 into DynamoDB tables. The new bulk import feature was specifically designed to offer a simpler way to import data into DynamoDB at scale while minimizing cost and complexity for users since it doesn’t require writing code or managing infrastructure.
Life before bulk import
Before the bulk import feature was introduced, importing data from S3 to DynamoDB required more manual effort and complex management of throughput and retries. Customers had to write custom scripts using Amazon EMR or use AWS Glue for data integration, both involving trade-offs between cost and performance. These approaches required handling deserialization, managing throughput, and dealing with potential failures due to exceeding available write capacity units (WCUs).
DynamoDB bulk import from S3 solves all of these problems by automating the whole process for the customer, says Shahzeb Farrukh, Senior Product Manager at AWS.
“We heard from customers that they wanted an easier and quicker way to bulk load data into the DynamoDB tables. They also wanted to do this cost effectively,” he explains. “This is a fully managed one-click solution. It helps to alleviate the major pain points involved with importing data from S3.”
The bulk import system supports three file types: CSV, JSON, and an Amazon-developed data serialization language called ION, which is a superset of JSON. Customers can compress these files using GZIP or ZSTD if they wish (although the service is based on the uncompressed size).
Customers need to do very little apart from identifying their primary and sort keys. They activate the import either from the AWS Management Console or the AWS Command Line Interface (CLI), or via the AWS SDK. They select the input file and specify the final capacity mode and capacity unit settings for the new DynamoDB tables. The system then formats the data in these file formats automatically for DynamoDB, creating a new table for the import.
During the import, AWS creates log entries in its CloudWatch monitoring tool to register any errors such as invalid data or schema mismatches, which helps to identify any issues with the process. AWS recommends a test run with a small data set to see if any such errors crop up before doing the bulk import.
Under the hood
When creating the import feature, AWS understands the data sets and optimizes the distribution to create the best possible import performance. This all happens under the hood without the customer having to worry about it, says AWS.
The service creates three main benefits for customers: convenience, speed, and lower cost adds Farrukh. It eliminates the need for the customer to build a custom loader, meaning that they can put those technical skills to use elsewhere. This can shave valuable time from the setup process.
AWS manages the bandwidth capacity automatically for users, solving the table throughput capacity problem. Customers no longer need worry about the number of WCUs they’re using per second, nor do they have to write custom code to throttle table capacity or pay more for on-demand capacity. Instead, they simply run the job and pay a flat fee of $0.15 per GB of imported data, explains Farrukh.
Not only does this make pricing more predictable for customers, but it also saves them money. “We’ve purposely priced it to be simple,” he says. “It’s also priced pretty cheaply compared to the other options available today.”
AWS analyzed the cost of importing 381 Gb of data containing a hundred million records. It calculated that an import without using bulk S3 import, using on-demand capacity, would cost $500. Using provisioned capacity would cut that down to $83. Using the bulk import function slashed it to $28 while also removing the associated setup headaches.
Use cases in need of support
What potential applications could this service accommodate? Farrukh highlights three primary possibilities. The first one is migration. AWS has collaborated with clients migrating data from other databases, such as MySQL or NoSQL databases like MongoDB. Farrukh notes that the creation of new tables for imported data through the bulk import feature is particularly beneficial in this context. Bulk importing transfers historical data into a new DynamoDB table, kickstarting the process. Customers can then establish pipelines to capture any data changes in the source database during migration. This feature significantly eases the migration process, according to Farrukh.
The second application involves transferring or duplicating data between accounts. There may be multiple reasons for customers to do this, such as creating a separate function that requires access to the same data, recovering from compromised accounts, or populating a testing or development database managed by a different team with distinct data permissions. The bulk import feature works in conjunction with DynamoDB to facilitate this use case.
In November 2020, AWS introduced the ability to bulk export data from DynamoDB to S3. Before this, clients had to use the AWS Data Pipeline feature or EMR to transfer their data from the NoSQL database to S3 storage, or depend on custom solutions based on DynamoDB Streams. The bulk export feature enables clients to export data to Amazon S3 in DynamoDB JSON format or Amazon’s enhanced ION JSON-based alternative. Customers can choose to export data from any moment in the last 35 days, with granular per-second time intervals. Like the bulk import feature, the export feature does not consume WCUs or RCUs and operates independently of a customer’s DynamoDB table capacity.
Hydrate the data lake
Farrukh suggests that clients could use this data to “hydrate a data lake” for downstream analytics applications. However, it can also contribute to a database copying workflow, with the bulk import feature completing the process. Farrukh emphasizes that the exported data should be directly usable for the import process without any modifications.
The third use case that has attracted attention involves using the bulk import feature to load machine learning models into DynamoDB. This proves valuable when a model needs to be served with low latency. Farrukh envisions customers utilizing this for inference purposes, using data models to identify patterns in new data for AI-powered applications.
By adding the bulk import feature to DynamoDB, AWS enables customers to more easily introduce additional data into this high-volume, low-latency data engine. This may encourage more users to explore DynamoDB, which offers single-millisecond latency, making it suitable for internet-scale applications that can serve hundreds of thousands of users seamlessly.
As such the ability to quickly, effortlessly, and affordably populate DynamoDB with S3 data could help to drive a significant shift in adoption by delivering what for many will be a highly sought-after feature.
Sponsored by AWS.
MMS • RSS

Your job: Senior Scala Developer Amsterdam
- Would you love to work for one of the most tangible, successful, and famous online platforms of the Benelux with an amazing engineering culture, large innovation budgets, and huge ambitions?
- Do you love to work on heavily used distributed backend services used by millions per day, with direct feedback as they deploy over 200 times per day?
- Do you love to work closely with the business while enjoying an indefinite contract, a 15% bonus, and only 5 days working from the office per quarter?
Then wait no longer, this is the role you have been waiting for!
Your employer: One of the most used online platforms of the Benelux!
If you love working on very tangible, necessary products with a large utility value that impacts the lives of millions per day, you have come to the right place! This famous online tech organisation is one of the gems in Amsterdam to work for, catering to a very local European customer base. As part of one of the online powerhouse groups from Europe here you can look forward to amazing career growth, through career planning, large training budgets, lots of knowledge sharing, and exchange programs. Here when you have success in Amsterdam, this can be rolled out in all European offices adding even more impact!
Joining now means joining at an amazing time as they are currently making huge investments in their future. Upgrading their microservices architecture towards event driven, moving to AWS, and refactoring their codebase, while continuously developing innovative ways to cater to the needs of their tens of millions of end users in Europe.
Here you are well taken care of by receiving an indefinite contract from day 1, a 15% bonus, only 5 days working from the office per quarter, 4 weeks per year work from wherever, free gym membership, solid pension, 40 euro compensation for health insurance, day-care compensation and even office massages!
Your job: Senior Scala Developer Amsterdam
As Senior Scala Developer Amsterdam you will join one of the many multidisciplinary development teams, also consisting out of business to keep the feedback loop as short and efficient as possible. You will get to bite down on key challenges of scale as moving to an event driven architecture, moving to AWS, refactoring, and continuously developing new features for the millions of end users.The stack: Scala, AWS, Cassandra, Elastic Stack, Kafka, CI/CD fully automated
Growth perspective
Here you can grow any way you want: choose the technical route and become a tech lead or domain architect, choose the managerial route and move to the development manager, development director, and even CTO. With the chance to move between offices and countries!
What is required?
- A minimum of 5 years of professional development experience with a JVM language
- Experience designing and building backend services of scale (1k e/s or more)
- Proactive and communicative nature
- A strong product/ TDD mindset
- Experience with Scala, AWS, Elastic Stack, NoSQL, Kafka, or working in multidisciplinary teams is a plus!
What is offered?
- Between € 75.000 and € 85.000 gross per year based on experience and added value
- + 10% yearend bonus (has always been paid out in the last 10 years!)
- Only 5 days working from the office per quarter!
- Indefinite contract!
- 26 holidays
- € 40 net compensation for health insurance
- Life and disability insurance
- Free gym membership
- Pension
- Flexible working hours
- Training budget + personal development plan
- 1/6 of childcare paid for
- Office massages
Free snacks and drinks at the office
Would you like to join this amazing online platform to work within a solid engineering culture on systems that offer a very direct impact on the lives of millions of consumers all through Europe?
Be sure to send your CV to Roy Schaper via [email protected] or via applying on the form below.
MMS • Sergio De Simone

Android IoT apps enable running internet of things (IoT) apps in cars powered by Android Auto and Android Automotive. This will open up the possibility of controlling IoT devices like home security, lights, doors, and more, directly from within a car.
Cars using Android Auto will allow their drivers to download IoT apps from the Google Play store. IoT apps can be developed using the Android for Cars App Library, which provides a set of classes specifically designed for car apps. Additionally, the library includes app templates aimed to make it easier for developers to meet Google’s requirements in terms of driver distraction and compatibility with the variety of car screen factors and input modalities that can be found in cars.
To support IoT apps, the Android for Cars App Library adds a new IOT category to be used in the app manifest file. In addition to IOT, the library also supports the NAVIGATIONcategory, for turn-by-turn navigation apps, and the POI (point of interest) category, for apps helping to find points of interest such as parking spots, charging stations, and gas stations. An app may belong to more than one category.
The three main abstractions provided by the Android for Cars App Library are Screen, CarAppService, and Session. A Screen object is responsible to present the user the app UI and can coexist with other Screen objects in a stack. A CarAppService is an interface that the app must implement to be discovered by the host system. It also provides Session instances for each connection to serve as an entry point to display information on the car screen by controlling whether the app is hidden or not, paused, stopped, etc.
While developing an Android for Cars IoT app is not dissimilar from creating a navigation or POI app, Google provides specific guidelines developers should comply with for IoT apps.
In particular, they define new criteria as to what kind of distractions are allowed. So, while it is ok if an IoT app notifies the driver about an event taking place in their home, all tasks related to app setup or configuration, as well as fine-grained device control are not allowed. Likewise, IoT apps must support simple, one-touch features to control on and off features, such as turning lights on and oof, opening and closing a door, etc.
MMS • Ben Linders

Engineers working in the tech industry have the means to have a social impact through their network, skills, and experience. Companies can create an impact by making their business practices socially-minded. Inclusive training considers the circumstances and backgrounds of individuals, offering services with minimum entry barriers to ensure broad participation, including ethnicity, gender, neurodiversity, and socio-economic background.
Germán Bencci spoke about socially responsible companies at QCon London 2023.
Bencci mentioned that, in most cases, social impact is not what companies think they could be doing. Companies think about a small charity donation, one volunteering day, a talk at a school. There is nothing wrong with that, Bencci said, but companies could be creating much more impact by concentrating on making their business practices socially-minded:
I’m thinking about their recruitment practices, their diversity stats, their equipment and services, and their profit pledges, creating the closest alignment between impact and the business.
To have a social impact, Bencci suggested that engineers and their companies should create the best product they can, be as profitable as they can, but consider carefully the means by which the product is being created and how they can create a tight link between business success and impact:
As an engineer, you have at least three resources available: skills, experience, and network. You can make use of the first to create products with social impact, through hiring, mentorship, and usage of ethical services. The network can be used to encourage businesses to pledge a percentage of the profit to social impact work.
Engineers can influence and advise their companies on how they can make a difference through the work they do, through their recruitment practices, hiring targets, and diversity stats, Bencci mentioned. They can also volunteer in organisations like CodeYourFuture that create the optimal space for people to share their skills and experience with others with fewer opportunities, he explained:
It’s about trying to find the biggest impact with the resources you have available, but concentrating on seeing yourself as a resource.
Bencci argued that people want education and jobs. They want to have the lives that professionals have. They want a job, a social status, work colleagues, work at a company, have a salary, provide to for their families, and become a role model to their children. People want to be given an opportunity to become a working professional.
Inclusive training means that you consider a wide range of circumstances and backgrounds of individuals, Bencci said. It’s the time and money that people have available and what services can be offered to minimise the entry barriers. It is also about targeting and tracking different aspects of participants to ensure broad participation, including ethnicity, gender, neurodiversity, and socio-economic background.
Bencci gave the example of CodeYourFuture, which measures key stats for the people that join the training, to ensure that they have a fair representation across gender (40% are female), age (average age is 35 and 20% of the trainees are over 40), ethnicity (over 70% are non-European/white origin) socio-economic background (78% are living below the poverty line) and neurodiversity (approximately 30% of the trainees are neurodiverse).
InfoQ interviewed Germán Bencci about making social impact.
InfoQ: What social impact can for-profit companies have?
Germán Bencci: An example is the recruitment platform Cord, which in the past years donated up to 1% for social causes like CodeYourFuture, while making the most of that initiative to market their own services to their clients.
When they had a person being hired through their platform, they would send a message telling people that their fees had helped other folks of disadvantaged backgrounds be trained and join the tech sector
InfoQ: What impact does inclusive tech training have?
Bencci: It’s the difference between remaining unemployed or working on very low-income jobs and starting a career full of opportunities and financial rewards. It offers people independence, pride, and confidence. It creates a fundamental shift in their lives, their families, and the people around them. People start believing that a new life is possible.
InfoQ: What can companies do to increase their social impact?
Bencci: Companies that care about social impact should concentrate on creating values and a culture that makes social impact one of their company goals, while keeping their product, profitability, and growth as a priority.
A great social impact company will:
- Measure team diversity across a number of variables,
- Create diverse hiring practices,
- Create an intentional team sourcing strategy,
- Give new talent growth opportunities,
- Revise spending in areas like marketing to identify ethical spending,
- Secure a sustainable percentage of profitability to fund social impact practices, including within the organisation.
There is a lot to be done. Companies don’t have to look too far to make an impact.
MMS • Steef-Jan Wiggers
Microsoft recently announced two new offerings in the Premium v3 (Pv3) service tier and expansion in the Isolated v2 tier of Azure App Service.
Azure App Service is an HTTP-based service hosting web applications, REST APIs, and mobile backends written in languages such as .NET, .NET Core, Java, Ruby, Node.js, PHP, and Python. In addition, it offers auto-scaling and high availability, support for both Windows and Linux, and enables automated deployments from GitHub, Azure DevOps, or any Git repo.
The App Service now offers a Pv3 service tier to provide enterprises with an additional new series of memory-optimized P*mv3 plans, designated as P1mv3, P2mv3, P3mv3, and so forth. These plans offer the flexibility to increase memory configuration without incurring additional core costs. In addition, these plans range from two virtual cores with 16 GB RAM in P1mv3 (compared to two cores, 8 GB RAM in P1v3) to 32 virtual cores with 256 GB RAM in P5mv3.
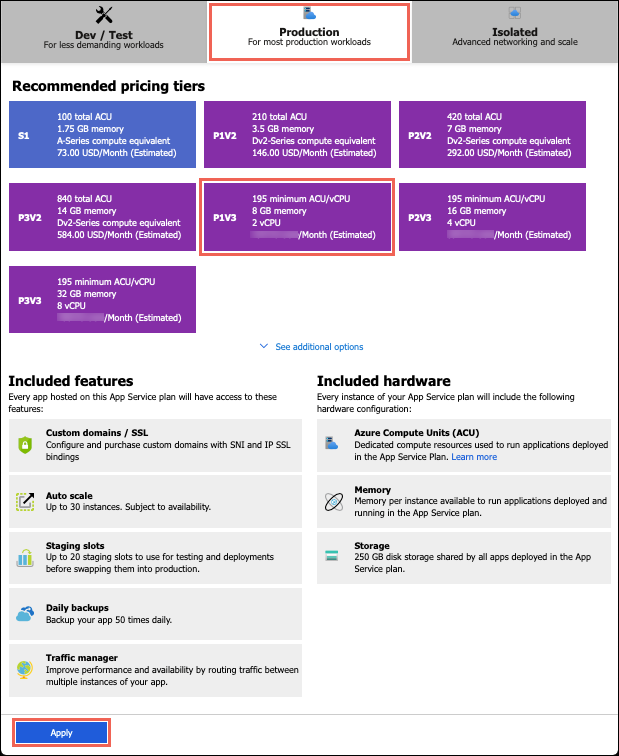
Source: https://learn.microsoft.com/en-us/azure/app-service/app-service-configure-premium-tier
Besides the memory-optimized plans, the premium also includes a cost-effective P0v3 plan, which according to the company, delivers significantly higher performance at a similar monthly cost compared to the Standard plan or Premium v2 (Pv2) plan. Furthermore, the company states that the P0v3 plan allows customers to use Azure savings plans and reserved instance (RI) pricing—only available on the Premium v3 tier—for up to 55 percent more savings than the pay-as-you-go plan.
Also, the cost management documentation of Azure App Service mentions:
In fact, Premium V3 (the highest non-Isolated tier) is the most cost effective way to serve your app at scale. To add to the savings, you can get deep discounts on Premium V3 reservations.
In addition to premium plans, Microsoft offers enterprises with stringent security and compliance requirements the App Service Environment (ASE), which grants them precise control over incoming and outgoing traffic of their applications’ networks. Unlike the shared, multi-tenant service, the App Service Environment exclusively hosts applications from a single customer and is powered by the Isolated v2 (Iv2) plans.
The lv2 plans are now expanded with three new Isolated v2 plans – the I4v2, I5v2, and I6v2, which offer compute options ranging from 16 virtual cores with 64 GB memory to as many as 64 virtual cores with 256 GB memory.
Pricing and availability details of Azure App Service are available on the pricing page. Additionally, Microsoft states in the documentation regarding Premium V3 that availability will extend continually to more Azure regions.
NoSQL Databases Software Market : Industry Analysis, Size, Share, Growth, Trends, and Forecasts
MMS • RSS

A market study Global examines the performance of the NoSQL Databases Software 2023. It encloses an in-depth analysis of the NoSQL Databases Software state and the competitive landscape globally. The Global NoSQL Databases Software can be obtained through the market details such as growth drivers, latest developments, NoSQL Databases Software business strategies, regional study, and future market status. The report also covers information including NoSQL Databases Software industry latest opportunities and challenges along with the historical and NoSQL Databases Software future trends. It focuses on the NoSQL Databases Software dynamics that is constantly changing due to the technological advancements and socio-economic status.
Pivotal players studied in the NoSQL Databases Software report:
MongoDB, Amazon, ArangoDB, Azure Cosmos DB, Couchbase, MarkLogic, RethinkDB, CouchDB, SQL-RD, OrientDB, RavenDB, Redis
Get free copy of the NoSQL Databases Software report 2023: https://www.mraccuracyreports.com/report-sample/204170
Recent market study NoSQL Databases Software analyses the crucial factors of the NoSQL Databases Software based on present industry situations, market demands, business strategies adopted by NoSQL Databases Software players and their growth scenario. This report isolates the NoSQL Databases Software based on the key players, Type, Application and Regions. First of all, NoSQL Databases Software report will offer deep knowledge of company profile, its basic products and specification, generated revenue, production cost, whom to contact. The report covers forecast and analysis of NoSQL Databases Software on global and regional level.
COVID-19 Impact Analysis:
In this report, the pre- and post-COVID impact on the market growth and development is well depicted for better understanding of the NoSQL Databases Software based on the financial and industrial analysis. The COVID epidemic has affected a number of NoSQL Databases Software is no challenge. However, the dominating players of the Global NoSQL Databases Software are adamant to adopt new strategies and look for new funding resources to overcome the rising obstacles in the market growth.
Access full Report Description, TOC, Table of Figure, Chart, etc. @ https://www.mraccuracyreports.com/reportdetails/reportview/204170
Product types uploaded in the NoSQL Databases Software are:
Key applications of this report are:
Large Enterprises, SMEs
| Report Attributes | Report Details |
|---|---|
| Report Name | NoSQL Databases Software Market Size Report |
| Market Size in 2020 | USD xx Billion |
| Market Forecast in 2028 | USD xx Billion |
| Compound Annual Growth Rate | CAGR of xx% |
| Number of Pages | 188 |
| Forecast Units | Value (USD Billion), and Volume (Units) |
| Key Companies Covered | MongoDB, Amazon, ArangoDB, Azure Cosmos DB, Couchbase, MarkLogic, RethinkDB, CouchDB, SQL-RD, OrientDB, RavenDB, Redis |
| Segments Covered | By Type,By end-user, And By Region |
| Regions Covered | North America, Europe, Asia Pacific (APAC), Latin America, Middle East and Africa (MEA) |
| Countries Covered | North America: U.S and Canada Europe: Germany, Italy, Russia, U.K, Spain, France, Rest of Europe APAC: China, Australia, Japan, India, South Korea, South East Asia, Rest of Asia Pacific Latin America: Brazil, Argentina, Chile The Middle East And Africa: South Africa, GCC, Rest of MEA |
| Base Year | 2021 |
| Historical Year | 2016 to 2020 |
| Forecast Year | 2022 – 2030 |
| Customization Scope | Avail customized purchase options to meet your exact research needs.https://www.mraccuracyreports.com/report-sample/204170 |
Geographic region of the NoSQL Databases Software includes:
North America NoSQL Databases Software(United States, North American country and Mexico),
Europe Market(Germany, NoSQL Databases Software France Market, UK, Russia and Italy),
Asia-Pacific market (China, NoSQL Databases Software Japan and Korea market, Asian nation and Southeast Asia),
South America NoSQL Databases Software Regions inludes(Brazil, Argentina, Republic of Colombia etc.),
NoSQL Databases Software Africa (Saudi Arabian Peninsula, UAE, Egypt, Nigeria and South Africa)
The NoSQL Databases Software report provides the past, present and future NoSQL Databases Software industry Size, trends and the forecast information related to the expected NoSQL Databases Software sales revenue, growth, NoSQL Databases Software demand and supply scenario. Furthermore, the opportunities and the threats to the development of NoSQL Databases Software forecast period from 2023 to 2029.
Please click here today to buy full report @ https://www.mraccuracyreports.com/checkout/204170
Further, the NoSQL Databases Software report gives information on the company profile, market share and contact details along with value chain analysis of NoSQL Databases Software industry, NoSQL Databases Software industry rules and methodologies, circumstances driving the growth of the NoSQL Databases Software and compulsion blocking the growth. NoSQL Databases Software development scope and various business strategies are also mentioned in this report.
MMS • Eitan Suez

Transcript
Suez: The title of my talk is Istio as a platform for running microservices. In the abstract for this talk, you might have noticed that I raise the following question that you see here on your screen, which is, for those organizations, for those of you who are working, either in the process of transitioning to microservices or have already transitioned to microservices, how do you deal with or address problems relating to service discovery and load balancing, and other concerns having to do with application resilience, keeping a secure system, making it observable, and dealing with issues relating to traffic management. Those are typically the types of issues that we come across in the context of transitioning to a microservice architecture.
Outline
Our agenda will be to begin by understanding the nature of the problem. It’ll be a little bit of a journey, to try to understand the transition from monolith to microservice, understand the difficulties, and then explore how these difficulties are addressed, how they’ve been, perhaps, historically addressed. Then we transition to looking at Istio, an open source project, and understanding how it functions, its design and its architecture, in order to critically evaluate how astute it is as a foundation for running microservices or distributed applications in general.
Background
My name is Eitan Suez. I work at a company called Tetrate. A relatively young company in the enterprise service mesh space. My role is with technical education and training. I’ve had the privilege in this role to spend time with this technology, with Istio and other related technologies, Envoy and so on, and really connect the dots. That’s what inspired this talk.
From Monoliths to Microservice
I would like to begin by exploring the transition from monoliths to microservices. Specifically, what are the pressures or the forces that actually drive us in this direction? The assumption is that we’re moving from an application that’s running fine, that’s been running fine for a long time where business has derived a great deal of value from. As our application becomes more important and more vital to the success of the business, things change, the application itself becomes more complex. We hire more developers, our team becomes larger, we might encounter contention with continuous integration.
Certain characteristics of our system become vital and more important than they were before, specifically high availability, uptime. The lack of availability could cost the business a lot of money. What we discover is a monolithic architecture perhaps doesn’t lend itself as well, to those new criteria or more important criteria. We have issues with deployment coupling, the idea that there may be multiple features that are coupled together, you cannot release one independently of others. Teams have less control with respect to releasing and monitoring their systems. There’s a central team that’s in charge of releases. Releases happen less often than desired. Those lead to more risk, the risk of something going down, a risk of our system not being as available. We’re pressured to move in a direction to solve these problems. That’s essentially breaking our application up into a microservice architecture.
Monolith
What I’d like to do is go through a very simple illustration to try to better understand the differences in these environments by going through a very simple or fictitious or maybe a common scenario that we typically interact with in the course of working with a system. Imagine an incoming request. The system is designed in such a way that the handler function inside our monolithic application is receiving this incoming request and perhaps a lot of the business logic is delegated to a particular service. We have a call to a service, and that service might have a number of delegates or it enlists the help of other services to get specific sub-tasks done. We may be calling some service that may be turning around and itself make maybe a call over the network to an external service and subsequently calling another service. That’s a typical flow. What we can say about the environment in which this logic execute is that with a monolith, all this happens inside of a process. This is a very well-known very comfortable environment. This is the type of environment that you typically expect to be running your business logic in. The other thing that we can say is, these actors inside of this logic may be Spring Beans, if this were a Spring application. They may be just plain objects, or they could just be pure functions. Then the main point here that I want to make is the way in which these functions or actors communicate with one another is by making function calls. Function calls are a very simple, well understood, very fast type of thing that we don’t really give much thought to, in the context of a monolith.
Distributed Application
Enter a distributed application. This is not necessarily so, of course, because we have different concerns. Let’s just assume that the flow is more or less laid out in a similar fashion. An incoming request comes in and is handled by an ingress controller, which routes the request to a particular service, which handles that request, and again, enlists the help of a couple of other services, same exact business logic. Even though the picture is the same, I think I flipped some of the colors here, just to make it look a little bit different, but it’s exactly the same picture, is an implied understanding that each of these boxes is now an independent deployable. Each may be running and deployed independently on different VMs, maybe in our data center on-prem, or they could be running in the cloud. They could be running in Kubernetes. If so, then maybe each one is deployed using a Kubernetes deployment, and so we’ve got pods, essentially, which represent our workloads. These, what used to be function calls are now network calls away.
Before we begin to investigate how this new environment affects and creates a new set of problems, let’s pause for a minute, and think of the benefits of what we’ve gained in the process of transitioning maybe by using the Strangler pattern, and other mechanisms to transition from our monolith to extract logic out into separate deployables that can be run as a distributed application. If we think of all of the pressures that we’ve had, we may get to a point where we now have smaller teams that each work on smaller code bases and separate code bases. That means it allows us to parallelize workstreams better. Our velocity comes back up. We eliminate the contention we used to have with continuous integration. We have more flexibility, we can become a polyglot. We have the freedom to choose different tools and languages for different tasks. We can eliminate the deployment coupling, eliminate risks, increase high availability. We can deploy each of these services independently of one another. In general, we’ve moved to perhaps a better place. That’s the good part of the story.
Fallacies of Distributed Computing
Of course, this is a warning that is almost 30 years old in a publication from Sun Microsystems by Peter Deutsch and others, James Gosling, the fallacies of distributed computing. You move to a distributed computing environment, and we typically make the mistake of overlooking the fact that a network call is not a function call. The network is not always reliable, those calls may sometimes fail. Latency is not zero, it’s orders of magnitude more than a typical function call. We have to be very mindful of that, otherwise, we’re going to run into a variety of problems. I’d like to call out a couple more here. One is topology is very dynamic these days, when we autoscale services in environments and maybe deploy things or have failover, multiple data centers or what have you. The network is secure is another fallacy. Things to be mindful, and these lessons typically if we heed them, will serve us well.
The Problems
Let us then move on and speak about the very specific problems that you typically encounter in the course of running a distributed system. As I go through each concern one by one, what I want you to do is to vet the concern, not only with respect to distributed applications, but ask yourself, why is this not a problem with a monolith? Or, how is this problem solved in the context of a monolith as well? The first and perhaps most evident, most fundamental problem is the problem of service discovery. You’ve got multiple services deployed in some environment, service A may need to collaborate with service B and C, it needs to know where instances of service B and C are located. There’s a need for a service registry. It’s interesting to think about in the monolith scenario, typically objects have references to other objects. Maybe we have a dependency injection framework that does all this for us, so we take that for granted. That’s built in. We have to rebuild similar capabilities in our new environment. That’s essentially what we’ve been busy doing over the last decade or so, or maybe longer. We’re now running at cloud scale. We may have 100 instances of service B, or 100 replicas. We scale out horizontally, and that gives us a great deal of flexibility, but with that flexibility, also the added burden of clients needing to load balance requests to those target workloads. What typically starts to happen is we add logic or library dependency, I like to call this maybe a barnacle of code that becomes encrusted in service A, that is necessary. It’s not related at all to the business logic, but it is necessary in order to function in this environment in which we basically know that we need to load balance requests to services that we rely on.
What happens when we have failures? What if one of these endpoints is not healthy? That’s basically the fallacy that we were talking about, about the network not always being reliable, so some requests will fail and so now we need to build in perhaps, retry mechanisms, a little bit more code inside our clients to deal with that possibility. Again, in the monolith, we did not have that problem, because we were not using the network as a mechanism for messaging because everything was, of course, in process. The matter of resilience. There are multiple concerns here. Here I depict the prototypical situation or scenario that was made popular by the Hystrix project, the idea of a cascading failure that when you have latency in the network, that latency could tie up resources, it could tie up connections in the connection pool. What happens when a service is slow? It may actually have downstream impacts, and may bring the caller down in a cascading failure scenario, especially in the face of lots of downstream requests coming into the service. There are other situations. The lesson that we’ve learned is this idea of failing fast, of having timeouts can really go a long way to resolving some of these issues that manifest themselves in the context of distributed systems.
The next problem is one that, again, is absent in the monolith, the idea that when we break two pieces of logic, and they’re now separated, and one calls the other over the network. There’s the matter of identity. What I talk about here is not the identity of the end user, but rather the identity of the workload. How does service B know that service A is calling it? How can it trust that it’s really service A? There’s a new concern here that pertains to security, which is a very important one, and increasingly being mandated by regulation as well. On top of authentication is authorization. If we have the identity of the caller, the calling service, are they allowed to call us? Do we embed those rules? Do we inject those configuration rules into every single service and add yet another layer, another dependency in our application to deal with this particular scenario? That’s the matter here. Observability. Again, back in the monolith, we begin to appreciate a lot of the tooling and a lot of the design of things, the way that they allow us to diagnose issues. For example, the very simple call stack, a stack trace goes a long way to helping us understand and reason about what’s actually happening inside the thread, the chain of calls, from object to object or function to function. Whereas, do we have something similar in the distributed world to see the chain of calls from service to service. That’s essentially what distributed traces help us do in the microservices world.
Traffic management becomes a very important thing to support high availability, to support failover. Think about the ability to govern how traffic is routed, again in a manner that’s orthogonal to the applications themselves. This supports zero downtime deployments, canary deployments, maybe rolling back after we’ve deployed a new version. There are other scenarios besides. The ability to really control and having the flexibility to control how we route a request from service A to service B, which particular subsets of a service we want to target, can help us a great deal. Here’s the situation. The idea here is maybe we want to favor service A making calls to local instances of service B in the same availability zone, but be able to fail over to another AZ or another region in a situation where the local instance is not available. That’s a potpourri of so many different concerns that are new problems that we need to tackle. Some of them already, to some extent, have solutions. That’s what we turn our attention to next.
Netflix OSS and Spring Cloud
The problems that I just described are not new, they’re typically encountered by every organization in the context of their transition to distributed services. A case in point is the story of Netflix, and the codification of a lot of their solutions, their open source solutions by the Spring engineering team. You can almost see almost a one-to-one mapping between the problems I just described and these particular solutions. Netflix in the course of moving to the public cloud and going to a microservice architecture had to develop, or they maybe didn’t have to, but chose to develop their own service registry in the form of Eureka. The Ribbon is an implementation of the client-side load balancer. Hystrix was designed to really help them with dealing with resiliency matters. Zuul was their dynamic frontend edge gateway that allowed them to really be able to dynamically control routing. Then, the other solutions in their respective spaces. They deal with observability, or exposing metrics and making your applications more observable and more visible.
If you go and visit the Spring Cloud project landing page, you come across this illustration, which I like very much, because it gives you a sense, not at a detailed level, but of how these things are arranged. We see in this picture, a variety of microservices that are running that supposedly can find each other because of that box up at the top the service registry, they register with the service registry, become discoverable. The API gateway in front is able to control routing to particular services. Maybe these microservices also are designed to emit distributed tracing and other information to a collector, a telemetry collector, so that we have more visibility into the functioning of our system. What’s implied in this picture is the fact that the way in which we enable our microservices is by adopting dependencies. Through third party dependencies, we essentially have a microservice that has extra capabilities that we didn’t have to write ourselves to be able to, for example, serve as a client to the service registry API. We don’t have to code those ourselves, which is terrific. It’s implied that these things happen in process.
Desired Traits and Design Objectives
Let’s try to imagine or envision, and in the process, create a list of desired traits, and maybe even design objectives for a system that can solve many of the problems that we’ve just described. The first one, it sounds like maybe a tall order, this idea of maybe turning the tables and rather than make an application adapt to an environment by adding dependencies in process, could we create a platform whereby the application as-is, without any changes, can just begin to function as a member of a larger distributed application? Wouldn’t it be nice if we could also bake in to that infrastructure all of these ancillary concerns I was mentioning earlier, retries, timeouts could be configured outside of the context of applications. The basic theme here is, let’s not disturb our applications. Can we actually, somehow deal with these matters in an external fashion? The realization that the workload identity problem which is intertwined with a secure environment for running distributed applications, is one that must be addressed and recognized and solved. Finally, a very general statement here with respect to separation of concerns. That is to say that if we are going to have a chance at having systems that are responsive, that we can very quickly be able to modify how they behave with respect to security policy, network policy, routing policy or other orthogonal cross-cutting concerns, that we should be able to apply them without having to rebuild, redeploy, or restart, or even reconfigure an application. That is that they’re truly orthogonal concerns that somehow can be applied without disturbing all of these running applications.
Istio
It’s high time that we discuss Istio. I want to give you an overview of the architecture of Istio. After which we can discuss how Istio solves the problems that we just described. The first thing that we should say about Istio is that it is a project that was created after the advent of Kubernetes. It leverages Kubernetes and extends it, in fact. Let’s go together through this exercise of understanding the architecture of Istio. Imagine the smallest possible building block of a distributed application, which is two services trying to call one another. We mentioned that this is going to happen in the context of a Kubernetes cluster. That’s not exactly true in that Istio supports workloads running both on and off clusters. They can be running on VMs. If these services are going to run in Kubernetes, they’re going to be deployed as Kubernetes deployments, so we’re going to end up with pods. Perhaps the first problem we tackle is the problem of service discovery. We’ve got to have somewhere to collect a registry. Istio’s main deployment is called istiod. We draw a box, maybe another pod that’s running in our Kubernetes cluster called istiod. The way this works is as a service is deployed, or as a pod is deployed to your Kubernetes cluster, the idea is that Istio can be notified of the event and update its registry, and thus build up a list of all of the services and their endpoints. That list obviously needs to be communicated to the pods. Here we have a conundrum because the desire is for the applications to not be aware of the platform, but the other way around.
The way Istio solves this problem is by introducing the Envoy sidecar. The idea is the sidecar is the landing spot where we’re going to send our copy of our registry. Those Envoys are going to do our bidding, unbeknownst to our applications. What is Envoy? Envoy has a very interesting story in that it came out of Lyft. It’s an open source project. The lead developer of this project is Matt Klein, who still today is at Lyft. The website is envoyproxy.io. It’s, you could say, a modern proxy in that it’s remotely programmable. You can configure it to essentially dictate its behavior. The way that it works is through an API known as discovery services. It can be controlled remotely via REST, or via more commonly gRPC. That’s exactly what istiod does, it has connections to all of these Envoys and it can push configuration to those Envoy’s at any time. It’s perfectly suited for this particular task. Another advantage, again, is that you do not have to restart those Envoys as you reconfigure them. They’re dynamically configurable, you can say. These sidecars are injected automatically, as a developer deploys their workloads, their manifests do not need to be modified. There’s one more important point that must be made here in terms of how this actually works. These Envoys cannot serve a useful purpose unless those pods are reconfigured in such a way that they can intercept traffic going in and out of each of our applications. That’s why I personally like to depict Envoy as a ring around each of these containers to make that more explicit, the fact that when service A calls service B, it’s going to have to go through that Envoy, and vice versa.
Where do we go next? Let’s talk about two particular flows. The first one I like to call the control plane flow. The second one we’ll see afterwards is a data plane flow. The idea that, ok, we’ve set the stage. We have a proxy, it’s intercepting requests to and from services. It doesn’t yet know what to do. It doesn’t know the state of the world. Who does? It’s istiod. Istiod as services are deployed to your Kubernetes cluster or to the mesh in general, which can be expanded to encompass multiple clusters or additional VMs, or whatever you may have. The event notifications allow Istio to essentially keep up to date, its state of the world, in what I depict here as a registry. Then Istio does the obvious next thing, which is to translate that information to an Envoy configuration, a configuration Envoy understands, and it distributes them in real time to all of these Envoys. Now we finally have all the pieces of the puzzle in place. These Envoys are armed with the information they need to know how to route requests according to that configuration. It’s important to mention that this works out of the box. You have a cluster, you deploy your workloads, assuming Istio is deployed as well, of course. Where service A is deployed, and calls service B, unbeknownst to it, that request is intercepted by the proxy. The proxy then has configuration, it’s already been armed with that configuration by Istio, but Istio is not in the path of this request. It’s strictly concerned with the control plane flow that we just went through. That proxy is able to load balance requests just like Ribbon used to. It’s able to retry requests that fail. Dealing with issues with a network is a concern that is no longer one that our application proper has to be concerned about. It’s been pushed down to the platform. On the receiving side, the other proxy receives the request and forwards it to service B. The response follows the reverse path.
We can go even further. What I just described functions out of the box, you don’t need to configure your services in any special way. That’s the beauty of Istio. If you so wish to influence the behavior of these proxies, you can. This is what exactly this picture is depicting, the idea that Istio provides a list of a handful of custom resource definitions. This one is called the destination rule, which allows us to custom configure, in this case, the exact load balancing algorithm we wish Envoy to use as it makes calls to a particular service, or this could have been configured globally for the entire mesh. The idea is you apply this custom resource to your Kubernetes cluster. Istio takes that information and updates the Envoy configuration which it distributes then to all of the proxies so that they now behave according to the specification, a cross-cutting concern.
Let’s look at another scenario. This one is called a VirtualService, which allows us to manipulate traffic. Here we define supposedly somewhere, subsets, the fact that there’s a service by the name of reviews. There are two subsets, one which happens to be version two, the second one, which is version three, in this case. What we specify is that we want 50% of traffic to be sent to one subset and the rest to the other. Again, you apply this Kubernetes resource to your Kubernetes cluster. Istio will take that information, generate an updated Envoy configuration, and distribute it to all of the Envoys that need to know about it. The reason that I repeat this pattern is to impress upon you this particular pattern that Istio implements, knowingly or unknowingly is beside the point. The idea that it injects or pushes configuration, not to the service, but to its delegate, so you could think about the service, so that it can then resolve requests to other services and do other tasks besides. That pattern is a very familiar one in the monolith world, it’s called dependency injection. Just like Spring does dependency injection within the monolith to give one service references to other services so it doesn’t have to look them up. The same thing happens in a distributed application with respect to the different actors in our distributed system that need to communicate with one another.
Resilience
Let us then proceed and talk about other facets of Istio that address other problems. Resilience. Let’s talk about resilience. This is just a simple example of another way of adding a bit of configuration to govern how many times we want to retry a particular call to a particular service. In this case, we’re saying we want three retry attempts, and we can even specify a per try timeout, and also, the type of error that should trigger a retry. We could be selective there. Retries can be incorporated again, or communicated to the platform without disturbing our applications. Here’s an example of specifying a timeout. The idea is that when I call out to a particular service, if it doesn’t respond within, typically, a good value should be in the order of tens or hundreds of milliseconds, then we can fail fast, and just terminate that call. Because, obviously, this particular service we’re calling or the instance of this service is having some issues, and we’re going to fail fast.
This is an example of a circuit breaker implementation in Istio. There are two things going on here, one is a configuration of a connection pool. The basic idea here is to limit the amount of pressure on a particular service by specifying a maximum number of requests, in aggregate, that service and all of its backing endpoints are supporting. If we exceed that maximum, we can have those Envoys just return 503s. Outlier detection is a little more sophisticated, it’s the idea that we can identify an offending pod, for example. If it throws in this case, more than seven 500 type errors or in an interval of 5 minutes, that we’re going to eject it and no longer give it any traffic for a duration that we specify, which in this case, is that base ejection time. That’s resilience.
Security
We have a bunch of knobs that allow us to configure, and get our timeouts and retries and circuit breaker configuration to tune in such a way that our system is working perfectly well. The next step is, let’s talk about addressing the problem of security. With respect to security, Istio leverages a framework known as spiffe, which stands for secure production identity framework for everyone. The basic idea is to give every service its own unique identity, a cryptographic identity based on an x.509 certificate. The basic idea is to embed in a particular field, the SAN field, a subject alternative name, a URI that follows a particular pattern that can help identify every single service in the mesh. I’ve got this illustration that I’ve taken straight out of these two documentations that illustrates the process by which that identity is imprinted on every workload. The theme here, again, is to not put that burden on the shoulders of developers. It’s automated. As every new pod is deployed, there is an Istio agent, that essentially creates a Certificate Signing Request, sends it to Istio which delegates it to a certificate authority. Signs the certificate, issues it. The Istio agent keeps it in memory for the Envoy proxy to fetch and be able to use as it upgrades connections to other services to use mutual TLS. That’s the security story. It happens transparently. You get it out of the box without any configuration whatsoever.
If we then revisit the same flow that we saw earlier, we can add on the fact that this is actually taking place. It can be configured, of course, but the basic idea is that that Istio proxy has a certificate, and it establishes a mutual TLS connection with the service that it’s calling. That certificate is communicated in both directions. Here, I depict only one but it’s happening mutually, of course. The certificate is verified and the identity of the caller extracted from that spiffe URI. The next step is that now that identity is known that we solve workload authentication in the service mesh, we can then overlay on top of it a higher-level concept, which is authorization policy. The receiving Istio proxy can look up its authorization policy from its local configuration, determine that this call is either allowed or denied, and then choose to whether pass on the request to the service or deny it. In this case, you see Envoy acting as a policy enforcement point.
Let’s look at an example authorization policy. These are actually quite flexible and versatile. This one is called the name of the resource, the kind is AuthorizationPolicy. The basic idea here on line 10, is we target a database pod, which is receiving database connections from a variety of services, but it will only allow callers that match a particular identity. The source principle here is using a spiffe URI that identifies the book application. In this case, we’re saying the book application is the only service that can talk to the book application database, which makes perfect sense. There we see Envoy serving the role of the Security Enforcer, so we apply this Kubernetes resource to our cluster. Again, the Envoy configuration has an extra filter in its filter chain, which tells it to actually check that that rule is satisfied.
Observability
Next up, observability. Observability is another very important facet of the equation that can help you reduce mean time to detection, improve mean time to recovery, and so on. Let’s talk about it for a minute. Specifically, what value does Istio bring to the table here? If we go back to this picture of two services communicating with one another. With respect to observability, the main idea here is that we have three separate and complementary pieces of information, or subsystems that bring something to the table. The first one is logs. The fact that we stream and aggregate logs, and that really does not concern Istio to a very great degree. You can configure your Envoys to also send logs to the same location that your services receive logs. The other piece is distributed tracing. Collecting of distributed traces, configuring distributed tracing, the Envoys can actually add trace IDs and these B-Tree trace headers to initiating requests. The thing to be mindful of is that there’s no way that they can ensure that every service will propagate those headers. That’s something that you have to be mindful that your development teams must propagate those trace headers.
The third piece is metrics. This is where because Envoy is in the path of all of these requests, it can collect and it does collect metrics with respect to requests that are happening between services, the volume of requests, whether they succeed or failed, all kinds of requests, metadata, and latencies as well. It exposes them itself on a particular scrape endpoint that you see there on the screen, for Prometheus to collect, and for Grafana to report upon. Istio indeed provides standard dashboards, pre-built Grafana dashboards that you can use to monitor your entire mesh. In my mind, the biggest value there is uniformity. The fact that, first of all, your teams don’t have to each fend for themselves and build their own monitoring solutions. The fact that it’s uniform, the names of the metrics, the dashboards are all the same. It gives you the uniformity that makes it very easy for your entire IT staff to become familiar with and monitor the entire mesh in the same uniform way.
There’s another tool worth talking about. Kiali is a bespoke, observability console for Istio that leverages all this information to give you these compelling visualizations and other ability to monitor and also control your mesh from a single visual dashboard. Here’s a screenshot, perhaps not a very useful one, of a service running in a mesh running locally on my machine, where you see the basic rate metrics, request volumes, success rate, and latencies durations. Here’s a screenshot from Kiali showing a visualization of an incoming request all the way from the ingress gateway on the left to database on the right, traversing a variety of microservices. That gives you a sense of the observability story with respect to Istio.
Observations and Summary
Going back to this picture, I had mentioned how vis-à-vis security, these sidecars play the role of policy enforcement points. At some point it dawned on me that it’s more general than that. More generally, these sidecars are what we call a join point, in the parlance of Aspect Oriented Programming. That’s when it dawned on me that really Istio is an AOP framework for distributed applications. One could make the case that AOP has had perhaps limited success in the realm of monoliths because it involved having to weave all of these concerns into your codebase, literally. What we see in the context of distributed application is Istio is able to weave all of these concerns through the Envoy sidecars, so when we explode the monolith into a distributed application where these services are really independent of one another, and we can put the sidecars in the path of requests between the services. It’s the perfect join point at which to apply all of these concerns, whether they be security concerns, or traffic management concerns, or network policy concerns, and the list goes on.
Let’s summarize by going back to my opening question, now you know how Istio essentially solves or addresses the problems relating to service discovery, resilience, security, observability, and traffic management. My advice is that you want a platform that is application aware and not the other way around, the dependency injection. You want all of these concerns to be baked into the infrastructure and not coupled to your applications. You want a platform that’s inherently secure with the notion of workload identities built in. Finally, and most generally, you want a clear separation of concerns, where all of these different concerns can be tuned and modified, without having to disturb the applications running in your mesh. That creates for a very highly available environment in which to run your systems.
Questions and Answers
Reisz: I don’t know that I’ve ever heard the phrase Istio is an AOP framework for distributed systems, but I think I like it. Whenever I record one of these talks, particularly ahead of time, there’s always something I wish I had added, or something I wish I had put in there, is there anything that comes to mind as it was playing or did you get everything out?
Suez: In my opinion, I got everything I wanted to say. I’m really fascinated by the questions and the comments about alternative architectures supporting event-based models. That’s really triggering a lot of interesting conversations. That was my idea, is to essentially provoke and to put out statements out there that help us connect the dots sometimes. Sometimes we study a new technology, but the pattern sometimes is familiar. It’s a lot of fun to be able to dive into technology deep enough to see those connections.
Reisz: There’s a lot of overlap, particularly when we talk north-south between load balancers, API gateway, service mesh. Where do you draw the line?
Suez: In my opinion, I think it might have started at the ingress level, load balancers, and ingress, because everybody needed that. As we break our applications, we see the same needs crop up even internally within the mesh. I think that’s where I see Istio satisfy a lot of that, and fill that gap. It’s an interesting fact that there are plenty of ingress gateways that are based on Envoy. That speaks to the fact that Envoy is a pretty good building block for supporting these scenarios.
Reisz: Would you agree that it’s at the setup where you choose to enforce it, whether it’s at the front or between?
Suez: That’s something that a lot of folks in the service mesh ecosystem try to impress is this idea, the term for it is zero trust architectures. The idea that, can we have a perimeter that we secure within which our services are safe and don’t have to worry about issues of security. Increasingly, that’s not the case, for many reasons. We’re no longer in a data center exclusively. We have code running in the cloud. We have hybrid clouds, and so being able to draw this line around all of your workloads is increasingly difficult. Maybe it’s a fallacy. The idea there is let’s just assume that we can’t trust anything, and just give me your certificate. Let’s just make everything mutual TLS, and now, it solves problems. It goes beyond just even a single Kubernetes cluster. It doesn’t matter how wide your footprint is, you’re going to be able to make more intelligent decisions that pertain to security. I like to interject how this naturally then brings the conversation to a higher level, which is the authorization policy and the kinds of things you can do there.
Reisz: Istio is amazing. It can do, like you said, cross-cutting concerns for a distributed system, but it introduces a sidecar. In the most common implementation, it introduces a sidecar. How do you talk to people when they say, yes, but you’re doubling the number of containers? What is your response to that? How do you have to think about it.
Suez: Indeed, you are. That’s a very apropos topic of conversation today, specifically with Istio has been in the news with respect to trying to refine and optimize that implementation. They’ve got an early implementation of this sidecarless option. It’s a refinement of the implementation. My personal beef is to really let one’s experiences in production speak for themselves, that is, if you apply Istio to a problem, and it solves those problems, and really alters what you’re able to do as a consequence, you’ve benefited more than it’s cost you to adopt it. I look to practitioners to vet whether that implementation has problems. There’s a company in the UK called Auto Trader, and one of its architects, his name is Karl Stoney, he is a very outspoken tech individual. I think he was at Thoughtworks, before he was at Auto Trader, and they went through a journey of adopting Istio with really amazing success. I’m not sure how many situations are really, in a sense, bitten by the presence of extra sidecars.
Now, obviously, it’s clear that you’re doubling number of containers within each pod, and so it’s going to have some extra cost in terms of operationalizing your cloud costs and so on. I think it’s myopic to really jump to the conclusion that it’s not going to work. I think the segregation of the concerns to me trumps the extra cost. Specifically, when we talk about eliminating duplication of effort, you have teams that create their own separate implementations of some cross-cutting concern for their services, but they’re only one piece of the puzzle, you got a dozen teams that are doing that, so that cost is probably orders of magnitude greater than the cost of the sidecar.
Reisz: Like I said, there’s no free lunch. Things do definitely have a cost. You gain a lot of capability, but you got to pay at some point. In some cases, some of these things are being addressed. In some cases, you’re paying with a small performance penalty to be able to do it. However, there’s lots of interesting things out there that are happening that are better at paying down some of that cost.
Suez: One takeaway that I’m going to just throw out there is how interesting it is. Sometimes when you go a little out of your comfort zone if you’re a developer type and you look at something that’s more about platform type solution, the extent to which those things are really intertwined and connected, and it’s not really something that you should consider outside your domain of expertise. Rather embrace it, and you’ll be surprised to find out to what degree it may even solve some problems that you maybe originally did envision they would help you solve.
Reisz: The service mesh is an amazing space and we’re lucky to be all involved with it.
See more presentations with transcripts
MMS • Darshan Shivashankar

Key Takeaways
- A common side effect of digital transformation is addressing the problem of API maturity
- With widespread API acceptance, you begin to get API sprawl. API sprawl results when you have an unplanned and unmanaged proliferation of APIs to address day-to-day business issues.
- Managing APIs at scale requires top-down oversight.
- When considering the lifecycles and maturity of APIs, there are two phases: API maturity and API program maturity.
- The ideal API program improvement cycle consists of five stages: Assess and Explore, Design and Recommend, Build and Implement, Test and Monitor, and Operate the New API Program.
Digital transformation can impact every aspect of an organization when it’s done correctly. Unfortunately, a common side effect of digital transformation is addressing the problem of API maturity. APIs tend to become the bridges that drive business growth, but with widespread API acceptance, you can begin to get API sprawl. API sprawl results when you have an unplanned and unmanaged proliferation of APIs to address day-to-day business issues. API sprawl describes the exponentially large number of APIs being created and the physical spread of the distributed infrastructure locations where the APIs are deployed.
Companies are seeing their APIs spread out across the globe at an unprecedented rate. This API sprawl presents a unique challenge for organizations wishing to maintain consistency in quality and experience among distributed infrastructure locations.
Managing APIs at scale requires oversight. It also requires a pragmatic approach that should start with an API program initiative that unifies APIs based on logical groupings. The program should package APIs as a product or service to drive adoption and facilitate management for their entire lifecycle. The challenge is that creating a viable program to manage API maturity is a slow process.
This article will offer a framework for building a mature API initiative. The framework uses a four-level API program maturity model that results in the evolution of a holistic API-driven business.
What is an API Maturity Model?
When considering the lifecycles and maturity of APIs, there are two phases: API maturity and API program maturity.
API maturity is specific to design and development and follows a process consistent with software development maturity. API maturity ensures that the APIs conform to recognized API specifications, such as REST. When discussing API maturity, you are talking about a set of APIs created for a specific application or purpose.
API program maturity takes priority when considering APIs on a companywide scale, i.e., the myriad of APIs a company amasses over time to meet various business objectives. With API program maturity, bundling APIs as unified services is necessary. An API program maturity model offers a benchmark to streamline APIs to promote business innovation.
The API Program Maturity Model
API program maturity assesses the non-functional metrics of APIs from the perspective of technology and business. The technical API metrics include performance, security, experience, and scalability. The business API metrics relate to improvements in processes and productivity that indirectly affect time and costs.
Like all well-thought-out business processes, API programs should start small and grow gradually. API programs must be structured to follow a continuous improvement cycle. Metrics should improve as the API program moves through a series of transitions from lower to higher maturity levels.
Before starting your journey through the API maturity model, you must start by perceiving APIs as tools. You will then progress through the model, perceiving APIs as components, models, and ecosystems as you reach higher maturity levels. Each level is viewed based on the APIs enabling everyday business processes.
The Four Levels of API Program Maturity
When you consider API program maturity as part of a holistic approach to corporate digital transformation, API programs can be characterized by four maturity levels:
Level 1: “The API Dark Age” – APIs as Tools for Data Acquisition
Historically, APIs have been built to facilitate data acquisition. The early APIs from Salesforce and Amazon are prime examples. Those types of APIs were designed to standardize data sharing across multiple business applications.
The first level of API program maturity is creating a standardized data access interface for data acquisition that offers a single source of truth. These types of APIs are categorized into different business functions. For example, you have separate APIs to access financials, sales, employee, and customer data.
Your organization achieves API Program Maturity Level 1 when you have established best practices for API design and architecture. Some examples of best practices include:
- Designing APIs with ease of integration and reusability in mind
- Creating a consistent interface across all APIs
- Incorporating versioning in the design to support multiple clients simultaneously
- Ensuring scalability of the APIs to accommodate changing user needs
However, these APIs are relatively simple and don’t require advanced programmable capabilities. Level 1 is also defined by a relatively immature, hand-cranked approach to API deployment. Manual deployment of individual APIs does not support closely-knit API lifecycle management. The technical focus is on building better APIs as standalone tools.
Level 2: “The API Renaissance” – APIs as Components for Process Integration
When reviewing the history of API development, APIs started to see a renaissance in the 2000s when they started to be leveraged as connectors to integrate different systems. Single sign-on (SSO) is a prime example. SSO is widely used as an API integration tool to authenticate users for secure access to multiple applications and third-party services.
When your organization reaches API Program Maturity Level 2, your API program will use a component-based approach. The component-based approach involves breaking down an application into its separate components. This means that each component can be developed and tested independently from the other parts of the application and then integrated to form a complete application. This approach reduces complexity, simplifies maintenance, and improves scalability.
APIs will be bundled as components that integrate different business and domain-specific processes. These API bundles streamline operations and workflows and connect multiple departments. They may even extend to integrate workflows and interactions with external partners.
Your organization takes its first steps toward utilizing APIs for business when you reach Level 2. By approaching APIs as components, Level 2 maturity gives you a catalog of APIs that are standardized and reusable. Level 2 also advances API development and lifecycle management by improving development cycles, focusing on standardization and streamlined automation through CI/CD (continuous integration/continuous delivery) pipelines.
Level 3: “The Age of API Enlightenment” – APIs as Platforms for a Unified Experience
APIs are treated as components during the API renaissance to simplify integration and reusability. Level 3 is the API Enlightenment Age and extends development further to make APIs more user-friendly and valuable.
When you reach Level 3, APIs are no longer considered components or discrete tools that improve business workflows. The focus is now on building API suites that drive better workflows by creating a connected experience. Recall that API components enable API providers to break down applications while designing and building. API suites refer to how API providers group their functionality so that API consumers can integrate with them for a better experience.
For example, a logistics company relies on a fleet of trucks and delivery vans for business continuity. It will use an API suite to monitor and manage all aspects of its fleet. At Level 3, you expect a well-conceived API suite that incorporates multiple APIs to handle everything from monitoring individual trucks to mapping routes and providing analytics for fleet performance.
At Level 3, APIs are pivotal in defining the user experience (UX). The API suite becomes the backbone of user-facing applications. In our truck fleet example, the front-end software the company uses for fleet management relies on APIs to drive the end-user experience, so the API suite becomes the backend platform that provides the interface for the entire software package.
When you reach Level 3, the API program now plays an essential role since the API suite is elevated to a mission-critical service. At this stage, API consumers become heavily invested, and API reliability and maturity are highly important. Any API program operating at Level 3 attains a degree of technical maturity, including:
- Deployment: You use the batched deployment of the API suite, and it’s closely coupled with API lifecycle stages and version control.
- Performance: APIs support a cloud-native environment for better scalability and elastic workloads to handle data traffic.
- Security: Multi-layered security is enabled to ensure strict authentication and authorization procedures.
- Automation: The CI/CD pipeline is fully automated, including rigorous API testing.
- Experience: A self-service API portal is also in place for speedier developer onboarding.
Level 4: “The Age of API Liberalization” – APIs as Ecosystems for Business Transformation
When your organization reaches API program maturity Level 4, you will have fully externalized APIs as products. This final stage of API evolution is driven more by business needs than technology. You may already have a well-oiled technology stack at this level and are driving API adoption among internal and partner stakeholders because APIs generate a lot of business value. The next logical progression is to externalize this value by monetizing it.
With Level 4, you are adopting a new approach, API-as-a-Product. At this level, APIs may be offered to customers using an as-as-service (AAS) subscription model. Depending on the nature of your company’s business, API-as-a-Product can be provided as a standalone or complementary service. Either way, the APIs are tightly integrated into your product, marketing, and sales organizations, so everyone can collaborate to boost this newfound revenue stream.
At the Level 4 program maturity level, the API program becomes the business growth engine. Some indicators that you have achieved Level 4 include:
API Governance:
You have a dedicated API product management group. This group ensures that all APIs are developed based on a predefined set of rules. It also defines API lifecycle progression policies and ensures APIs adhere to architectural and security compliances.
API Observability:
Your team goes beyond standard monitoring of APIs, capturing the internal state of API business logic to gather actionable intelligence data about performance.
API Ecosystem:
You have also built an API community for developers and consumers to exchange views and seek support. API advocacy forums further augment your API ecosystem to bolster the adoption of APIs.
The API Program Improvement Cycle
No API program is ever perfect. Any API governance framework must have a provision for periodic audits to determine the current maturity level of any API program.
Regardless of the API maturity level, adopting a DevOps approach to improve API maturity using small sprints continuously is necessary. Applying a DevOps approach also requires building an organizational-wide consensus to adopt a more agile and faster improvement cycle with small increments.
The ideal API program improvement cycle consists of five stages:
-
Assess and Explore:
The first stage is to assess the current state of the API program at both a technology and business level and explore possibilities to improve it. However, technological maturity precedes business maturity and should be the core focus of maturity Levels 1 and 2 above.
It also is essential to set small goals as sub-levels when exploring areas to improve rather than trying to leapfrog from one level to the next. You can define these sub-levels internally to improve one specific aspect of the API program, such as deployment automation, security, or scalability.
-
Design and Recommend:
This second stage is the most crucial decision point in the improvement cycle. You collate the technical specifications and business objectives from different stakeholders at this stage. Then you can recommend changes in the underlying API management tech stack that should be part of the current improvement cycle.
-
Build and Implement:
Stage three is the implementation stage of the improvement cycle. This stage encompasses development and configuration enhancements based on the proposed recommendations.
-
Test and Monitor:
In stage four, the rubber meets the road, and you test-drive the API ride. This stage is when you monitor vital performance and improvement metrics to gauge the overall effectiveness of the API improvement cycle. This stage also tends to be prolonged since you must transition back and forth with stage three until the metrics show measurable improvement.
-
Operate New API Program:
Once the test and monitor stage is complete and you see real improvement, the final stage is production deployment, where you productionize the new API program and get it up and running.
Level Up Your API Program Maturity Today
The different levels of API program maturity presented here should provide a clear pathway with logical milestones to help your organization transition from a low to a high level of API implementation. However, there is a more significant challenge you will need to tackle.
Your API program symbolizes the organizational-wide ethos of adopting additional APIs. It’s an ideal vision that positions API evolution as one of the primary engines driving business growth. However, for any API program to succeed, it must be established as a horizontal function that cuts across departments and teams.
In most enterprises, each department needs more clarity and visibility into other departments. This is one of the reasons why it takes a lot of work to enforce governance and standardization. This also increases the chance of creating duplicate APIs due to a lack of visibility.
API team silos can present several challenges, such as a lack of communication, understanding, and visibility. When teams are siloed from each other, creating an integrated strategy for API development can be challenging. Additionally, each team may have different priorities, leading to delays and errors throughout the process. Furthermore, when teams are siloed from each other, there may be limited opportunities for collaboration and knowledge sharing, which could otherwise improve the quality of the API being developed.
A horizontal API program function cuts across this interdepartmental siloing and helps to ensure consistent governance and standardization of APIs.
Here are a few overarching rules you can apply to counter any challenges to the continuous improvement cycles:
Outside-in Consensus Building:
An outside-in approach requires analyzing business workflows to devise the right digital experiences around them. Rather than adopting an inside-out approach (“build it, and they will come”), an outside-in approach is much more effective at capturing the expectations of the various stakeholders.
Top-down Cultural Shift:
Finding the best way to drive a companywide cultural shift is a highly debatable topic. Since horizontal alignment is required for a successful API program, adopting a top-down rather than bottoms-up approach has less likelihood of creating unfettered API sprawl.
The top-down approach to API development offers several advantages, including improved time-to-market, shorter development cycles, and easier maintenance. It also allows for a greater degree of clarity when it comes to the architecture of the API. This makes it easier for developers to know what they have to work with and where their responsibilities lie in the overall project. Additionally, a top-down approach can reduce the effort needed to ensure the APIs are secure, reliable, and well-documented.
Strategic Point of View:
The initial levels of API program maturity consider APIs as another part of the technical toolkit. Remember that this is a short-term, tactical perspective. As your API program continues to evolve, it is essential to continuously strive towards building a strategic vision. That way, the API program starts delivering value that can be measured in business-level KPIs.
Working your way to the highest API program maturity level will take time and effort while simultaneously managing stakeholder expectations. However, developing a mature API program will unlock new opportunities for accelerated business innovation, leading to growth.