Month: April 2023

MMS • RSS
The advancing world of cloud and automation is inciting a transitory period for many enterprises working to adapt; these changes are sparking a domino effect within enterprise tech stacks. Database capabilities are being reevaluated in their effectiveness to underpin, secure, govern, and manage hybrid and multi-cloud environments.
Experts joined DBTA’s webinar, “Database Management in the Cloud: Adapting to the Changing Landscape,” to explore database strategies and skills that will inevitably bring about successful cloud environments.
Clint Sprauve, director of product marketing at Delphix, explained that multi-cloud environments increase data complexity, and in turn, overall risk. With each cloud offering proprietary point solutions with differing functionality and APIs, data governance, automation, and compliance suffers from over-complexity.
The key to managing this complexity is adopting a multi-cloud operating model which leverages a data mesh to unify data compliance, governance, and automation across both applications and clouds. Instead of data governance, automation, and compliance suffering from an overbearing number of solutions and APIs to manage its existence in the cloud, technologies like a data control tower (DCT), continuous data automation, and continuous compliance services will ease the tension of cloud transition on your data.
Centrally governing and automating at scale is critical toward a successful data transition to cloud environments, according to Sprauve. Technologies suggested that will attain this success include:
- Data mesh that spans across multi-cloud apps and databases
- Automated compliance for data at scale in development and testing
- Toolchain integrations with API-based automation of data into toolchains
- Governed self-service equipped with a catalog, tagging, and access control
- DevOps data APIs for CI/CD which encourages fast, ephemeral, cost-effective data
Sprauve recommended Delphix’s DevOps Data Platform, an API-first data platform designed for the multi-cloud that automates data security while simultaneously deploying data to accelerate development. Its DevOps APIs provide an automated, scalable platform to meet DevOps and CI/CD data demands, operates on a zero-trust, immutable data model, all supported by green data which increases utilization while reducing costs and environmental impact, according to Sprauve.
Tim Rottach, director of product marketing at Couchbase, asserted that both application needs and database requirements have changed. Applications are expected to be developed and deployed efficiently, consistently delivering great experiences to its end users in real-time. To accommodate a massive user environment, databases are also expected to scale and perform at high quantities while maintaining a flexible, microservice architecture.
Yet a heap of challenges remain: data sprawl, disparate platforms with multiple interfaces, differing management and security systems, as well as a significant finance drain due to licenses, integration, training, operation, and support stall many enterprises’ ability to leverage the cloud and an effective data environment simultaneously.
Rottach introduced Couchbase Capella, a cloud database platform (or DBaaS, Database-as-a-Service) for modern applications which delivers fast performance, high availability, the flexibility of a NoSQL database, and affordability with elastic scaling and sharding, multidimensional scaling, and high-density storage to drive down ramping cloud costs.
The DBaaS enables enterprises to consistently deliver great mobile/IoT experiences, as it guarantees apps stay on regardless of web connectivity and speed. It’s also familiar; Couchbase Capella uses the SQL++ query language, ACID SQL transactions, and provides SDKs for over 12 languages.
Michael Agarwal, global practice leader in cloud databases, SRE, and NoSQL at Datavail, highlighted the changing role of the DBA as the overarching thesis for making or breaking a successful database/data environment for the cloud. Ultimately, as the shift from on-premises to cloud has redefined data in an enterprise, so too has the role of the DBA. Though some areas remain the same, such as ETL work, database design and development, and database deployment, others become wildly different.
Modern DBAs are now responsible for Infrastructure-as-a-Code (Terraform, Ansible, AWS CloudFormation, Azure Resource Manager Template), with particular note that emphasizes the understanding of Python/Bash scripts. In terms of database backup and recovery, as well as high availability and disaster recovery (HADR), the DBA role lightens its load; for managed and PaaS services, many offer the ability to enable an already instituted function for backup and recovery/HADR.
Compared to on-prem responsibilities, many become more simplistic in the cloud, highlighting the advantage toward an enterprise transition, according to Agarwal. Global replication, scaling, data center reliability, and virtualization all become much easier to execute in the cloud. Luckily, Agarwal explained that performance monitoring and database tuning remains relatively the same between on-prem and the cloud; though some tools might be different, the approaches to troubleshooting and remediating are similar.
Agarwal further maintained that Datavail for cloud databases combines these advantages toward database management in the cloud, and more. Advantages include:
- Experience and trust: Datavail houses over a thousand data, analytics, and development experts; is relationship focused; and has an average client relationship of over 7 years
- Cloud and data leaders: Datavail is a world leader in data with 200,000-plus databases and 200-plus PB of data under management; coordination over 200 cloud migrations and over 50 modernizations in the past two years; maintains strong partnerships with AWS, Azure, Oracle, and MongoDB
- Longevity: Datavail’s data expats average at 20 years of experience; has a low offshore turnover; and has 15 years of experience in managing and optimizing databases
To view an in-depth discussion of database management in the cloud, you can view an archived version of the webinar here.
MMS • Robert Krzaczynski

JetBrains provides access to Remote Development Beta. The tool works by locally running a thin client and connecting to the IDE backend which gives a fully functional user interface. It can be handled by JetBrains Rider or JetBrains Gateway. It is also required to have a server with working SSH. The workflow of the tool is smooth as editing is done locally and the JetBrains client synchronises changes with the backend.
JetBrains Rider 2022.2 has access to a Beta version of Remote Development. This feature was already previously introduced for other JetBrains IDEs built on the IntelliJ platform. JetBrains Remote Development can host source code, toolchain and IDE backend on any remote server that supports SSH. A thin client based on the IntelliJ platform, allows users to leverage the same Rider development workflows as locally.
Remote Development connects to an existing server via SSH. The IDE is installed as a backend service where it loads a project without displaying a user interface. A thin client runs locally and connects to this IDE backend and provides a fully functional user interface. This gives the impression that the IDE is running locally, even though all processing is done on a remote server.
To use Remote Development, it is necessary to install the latest version of JetBrains Rider – version 2022.3 or later. An alternative option is JetBrains Gateway, which has identical features but only installs a thin client. JetBrains Gateway is a solution if only remote development is planned.
Another essential is a remote server with a working SSH server. JetBrains recommends starting with a remote server with at least 2 cores, at least 4 GB of RAM and at least 5 GB of disk space, but it all depends on the solution and development workflows. For now, the remote server must be Linux, but there are plans for Mac and Windows support.
In the JetBrains Rider launch window, there is a Remote Development section on the right. It has two options: SSH and JetBrains Space. JetBrains promises more explicit providers from partners such as Google, Amazon, GitHub, GitPod and Windows Subsystem for Linux (WSL) in the future. On the next Connect to SSH screen, it is possible to select existing connections or, for the first time, create a new SSH connection by specifying the username, host, port and local private key to add to the remote server for authentication to SSH-based services such as Git.
Working with Remote Development is smooth because the editing experience is local and the JetBrains client synchronises changes with the backend. All processing takes place on the backend machine. This includes indexing of solution files or disk access. In addition, developers can also observe remote metrics using the Backend Status Details widget at the top of the Rider instance. This widget shows resource usage on the server for CPU, memory and disk.
MMS • Steef-Jan Wiggers
AWS’s Supply Chain cloud application has recently been made generally available, offering unified data, actionable insights powered by machine learning, and contextual collaboration features to reduce costs and mitigate risk.
The company introduced AWS Supply Chain during the re:Invent conference last year to abstract away complexities involving supply chain data caused by the pandemic. With the GA release, the company added several enhancements, such as access to AWS Supply Chain Insights alerts from the supply chain network map view, support for nine languages across 24 locales, the enhanced ability to connect to SAP S/4HANA instances using AWS PrivateLink or OAuth credentials, and automatic normalization of various date-time formats into the ISO-8601 standard to reduce errors caused by inconsistent date-time data.
The application connects to the customers’ existing enterprise resource planning (ERP) and supply chain management systems and provides several capabilities beneficial for users, such as:
- A data lake set up using ML models that have been pre-trained for supply chains to understand, extract, and transform data from different sources into a unified data model.
- Data is displayed in a real-time visual map that uses interactive graphical end-user interfaces.
- Actionable insights – automatically generated for potential supply chain risks (for example, overstock or stockouts) using the comprehensive data in the data lake and shown in the real-time visual map.
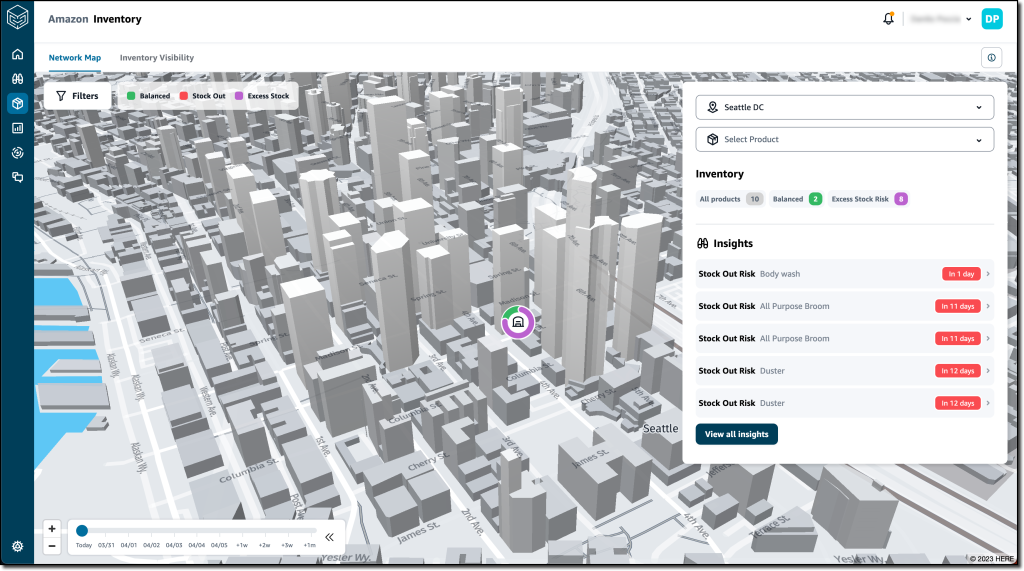
Furthermore, AWS Supply Chain can, for instance, identify a nearby logistics hub with the desired product when a store is close to depleting its stock. It can also provide multiple recommendations to resolve supply chain problems, and the suggestions are ranked to assist supply chain teams in selecting the best option.
Danilo Poccia, Chief Evangelist (EMEA) at AWS, explains in an AWS blog post:
Recommendation options are scored by the percentage of risk resolved, the distance between facilities, and the sustainability impact. Supply chain managers can also drill down to review the impact each option will have on other distribution centers across the network.
Similar solutions in the market that have comparable capabilities around supply chain and stock management are from companies such as Slimstock, Microsoft (D365 Supply Chain), Oracle (Supply Chain– and Inventory Management), and Manhattan Associates (Supply Chain Solutions and Inventory Optimization).
Currently, AWS Supply Chain is available in the following AWS Regions: US East (N. Virginia), US West (Oregon), and Europe (Frankfurt).
Lastly, AWS will charge $0.28 per hour for the first 10GB of storage and services. In addition, $0.25 per GB per month will be charged when storage data exceeds 10GB. The pricing details are available on the pricing page, and more information on the application is available on the documentation pages.
MMS • Steef-Jan Wiggers
The company LocalStack recently announced the general availability of LocalStack 2.0, an open-source tool for the local development and testing of cloud applications.
LocalStack is a fully functional local cloud environment that allows developers to develop and test their cloud applications locally without needing an actual cloud environment. In addition, it provides a local implementation of most of the popular AWS services, such as S3, Lambda, DynamoDB, and many others.
The new version is a follow-up of the company’s first version, which generally became available last year. With version 2.0, the company added several new features and improvements, such as entirely new Lambda and S3 providers, a significant reduction in LocalStack image size through the separation of LocalStack Community and Pro Docker images, a new Snapshot persistence mechanism, community cloud pods, and cloud pods launchpad.
Furthermore, version 2.0 includes enhancements for developers like improved LocalStack toolings for local cloud development, new LocalStack Developer Hub and Tutorials, and Improved LocalStack Coverage Docs Overview.

One of the improved LocalStack toolings is the docker extension enabling developers to work with LocalStack to operate their LocalStack container via Docker Desktop. The extension creates a running LocalStack instance, allowing developers to configure LocalStack easily to fit the needs of a local cloud sandbox for development, testing, and experimentation.
Ajeet Singh Raina, a Developer Advocate at Docker, and Harsh Mishra, an Open Source Engineer at LocalStack, wrote in a Docker blog post:
In upcoming iterations, the extension will be further developed to increase supported AWS APIs, integrations with LocalStack Web Application, and toolings like Cloud Pods, LocalStack’s state management, and team collaboration features.
In addition, the LocalStack team stated in a blog post:
LocalStack 2.0 delivers our strong investment across three critical areas — parity, performance, and interoperability to provide the best developer experience. With LocalStack 2.0, we have significantly optimized the internals of the platform and moved to new service implementations, images, and internal toolings to make it easy for developers to build & test their cloud applications locally!
For local development, an addition to LocalStack is AWSLocal, a thin wrapper around the aws command line. In addition, developers can look at OpenStack, Serverless, or Testcontainers as alternatives.
Maciej Walkowiak, a Freelance Architect & Developer of Java, Spring, and AWS, tweeted:
Happy to report that Spring Cloud AWS now runs all tests on @testcontainers 1.18.0 and @_localstack 2.0
Lastly, for migration to LocalStack 2.0, developers can use the migration documentation
MMS • RSS

Analyzing data in real time is an enormous challenge due to the sheer volume of data that today’s applications, systems, and devices create. A single device can emit data multiple times per second, up to every nanosecond, resulting in a relentless stream of time-stamped data.
As the world becomes more instrumented, time series databases are accelerating the pace at which organizations derive value from these devices and the data they produce. A time series data platform like InfluxDB enables enterprises to make sense of this data and effectively use it to power advanced analytics on large fleets of devices and applications in real-time.
In-memory columnar database
InfluxData’s new database engine, InfluxDB IOx, raises the bar for advanced analytics across time series data. Rebuilt as a columnar database, InfluxDB IOx delivers high-volume ingestion for data with unbounded cardinality. Optimized for the full range of time series data, InfluxDB IOx lowers both operational complexity and costs, by reducing the time needed to separate relevant signals from the noise created by these huge volumes of data.
Columnar databases store data on disk as columns rather than rows like traditional databases. This design improves performance by allowing users to execute queries quickly, at scale. As the amount of data in the database increases, the benefits of the columnar format increase compared to a row-based format. For many analytics queries, columnar databases can improve performance by orders of magnitude, making it easier for users to iterate on, and innovate with, how they use data. In many cases, a columnar database returns queries in seconds that could take minutes or hours on a standard database, resulting in greater productivity.
In the case of InfluxDB IOx, we both build on top of, and heavily contribute to, the Apache Arrow and DataFusion projects. At a high level, Apache Arrow is a language-agnostic framework used to build high-performance data analytics applications that process columnar data. It standardizes the data exchange between the database and query processing engine while creating efficiency and interoperability with a wide variety of data processing and analysis tools.
Meanwhile, DataFusion is a Rust-native, extensible SQL query engine that uses Apache Arrow as its in-memory format. This means that InfluxDB IOx fully supports SQL. As DataFusion evolves, its enhanced functionality will flow directly into InfluxDB IOx (along with other systems built on DataFusion), ultimately helping engineers develop advanced database technology quickly and efficiently.
Unlimited cardinality
Cardinality has long been a thorn in the side of the time series database. Cardinality is the number of unique time series you have, and runaway cardinality can affect database performance. However, InfluxDB IOx solved this problem, removing cardinality limits so developers can harness massive amounts of time series data without impacting performance.
Traditional data center monitoring use cases typically monitor tens to hundreds of distinct things, typically resulting in very manageable cardinality. By comparison, there are other time series use cases, such as IoT metrics, events, traces, and logs, that generate 10,000s to millions of distinct time series—think individual IoT devices, Kubernetes container IDs, tracing span IDs, and so on. To work around cardinality and other database performance problems, the traditional way to manage this data in other databases is to downsample the data at the source and then store only summarized metrics.
We designed InfluxDB IOx to quickly and cost-effectively ingest all of the high-fidelity data, and then to efficiently query it. This significantly improves monitoring, alerting, and analytics on large fleets of devices common across many industries. In other words, InfluxDB IOx helps developers write any kind of event data with infinite cardinality and parse the data on any dimension without sacrificing performance.
SQL language support
The addition of SQL support exemplifies InfluxData’s commitment to meeting developers where they are. In an extremely fragmented tech landscape, the ecosystems that support SQL are massive. Therefore, supporting SQL allows developers to utilize existing tools and knowledge when working with time series data. SQL support enables broad analytics for preventative maintenance or forecasting through integrations with business intelligence and machine learning tools. Developers can use SQL with popular tools such as Grafana, Apache SuperSet, and Jupyter notebooks to accelerate the time it takes to get valuable insights from their data. Soon, pretty much any SQL-based tool will be supported via the JDBC Flight SQL connector.
A significant evolution
InfluxDB IOx is a significant evolution of the InfluxDB platform’s core database technology and helps deliver on the goal for InfluxDB to handle event data (i.e. irregular time series) just as well as metric data (i.e. regular time series). InfluxDB IOx gives users the ability to create time series on the fly from raw, high-precision data. And building InfluxDB IOx on open source standards gives developers unprecedented choice in the tools they can use.
The most exciting thing about InfluxDB IOx is that it represents the beginning of a new chapter for the InfluxDB platform. InfluxDB will continue to evolve with new features and functionalities over the coming months and years, which will ultimately help further propel the time series data market forward.
Time series is the fastest-growing segment of databases, and organizations are finding new ways to embrace the technology to unlock value from the mountains of data they produce. These latest developments in time series technology make real-time analytics a reality. That, in turn, makes today’s smart devices even smarter.
Rick Spencer is the VP of products at InfluxData. Rick’s 25 years of experience includes pioneering work on developer usability, leading popular open source projects, and packaging, delivering, and maintaining cloud software. In his previous role as the VP of InfluxData’s platform team, Rick focused on excellence in cloud native delivery including CI/CD, high availability, scale, and multi-cloud and multi-region deployments.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.
MMS • RSS
“
The Global NoSQL Market Report is an invaluable source of understanding and insight on the current state of the industry. It provides an in-depth analysis of the key trends driving the market, including market size and growth, the competitive landscape, major players, key products, and the share of new entrants in the market. Additionally, it provides deep insights into the segmentation of the market, market dynamics and the market’s major drivers and opportunities.
This report is especially beneficial for those who want to gain an understanding of the market’s underlying trends and potential opportunities. It offers a comprehensive portrait of the global market and its major players. This report also presents a deep dive analysis of the major trends, providing key insights into the underlying forces influencing the market. Additionally, it provides analysis of the key regional markets and a comprehensive overview of the competitive landscape. Finally, the report provides detailed profiles of the major market players and their strategies for success.
Request for Sample with Complete TOC and Figures & Graphs @ https://globalmarketvision.com/sample_request/130005
Key Players Mentioned in the Global NoSQL Market Research Report:
In this section of the report, the Global NoSQL Market focuses on the major players that are operating in the market and the competitive landscape present in the market. The Global NoSQL report includes a list of initiatives taken by the companies in the past years along with the ones, which are likely to happen in the coming years. Analysts have also made a note of their expansion plans for the near future, financial analysis of these companies, and their research and development activities. This research report includes a complete dashboard view of the Global NoSQL market, which helps the readers to view in-depth knowledge about the report.
Oracle, MarkLogic, MongoDB, Couchbase, Database, Basho, Aerospike, Neo4j.
The recent report on NoSQL market provides a complete analysis of this business area focusing on the backbone of the industry: recent trends, current value, industry size, market share, output and revenue forecasts for the forecast period.
Market Segmentation:
Based on the type, the market is segmented into
Key-value Databases
Document-Oriented Databases
Column-Family Databases
Graph-Oriented Databases
Based on the application, the market is segregated into
Personal Use
Business
Other
For a better understanding of the market, analysts have segmented the Global NoSQL market based on application, type, and region. Each segment provides a clear picture of the aspects that are likely to drive it and the ones expected to restrain it. The segment-wise explanation allows the reader to get access to particular updates about the Global NoSQL market. Evolving environmental concerns, changing political scenarios, and differing approaches by the government towards regulatory reforms have also been mentioned in the Global NoSQL research report.
In this chapter of the Global NoSQL Market report, the researchers have explored the various regions that are expected to witness fruitful developments and make serious contributions to the market’s burgeoning growth. Along with general statistical information, the Global NoSQL Market report has provided data of each region with respect to its revenue, productions, and presence of major manufacturers. The major regions which are covered in the Global NoSQL Market report includes North America, Europe, Central and South America, Asia Pacific, South Asia, the Middle East and Africa, GCC countries, and others.
What to Expect in Our Report?
(1) A complete section of the Global NoSQL market report is dedicated for market dynamics, which include influence factors, market drivers, challenges, opportunities, and trends.
(2) Another broad section of the research study is reserved for regional analysis of the Global NoSQL market where important regions and countries are assessed for their growth potential, consumption, market share, and other vital factors indicating their market growth.
(3) Players can use the competitive analysis provided in the report to build new strategies or fine-tune their existing ones to rise above market challenges and increase their share of the Global NoSQL market.
(4) The report also discusses competitive situation and trends and sheds light on company expansions and merger and acquisition taking place in the Global NoSQL market. Moreover, it brings to light the market concentration rate and market shares of top three and five players.
(5) Readers are provided with findings and conclusion of the research study provided in the Global NoSQL Market report.
Key Questions Answered in the Report:
(1) What are the growth opportunities for the new entrants in the Global NoSQL industry?
(2) Who are the leading players functioning in the Global NoSQL marketplace?
(3) What are the key strategies participants are likely to adopt to increase their share in the Global NoSQL industry?
(4) What is the competitive situation in the Global NoSQL market?
(5) What are the emerging trends that may influence the Global NoSQL market growth?
(6) Which product type segment will exhibit high CAGR in future?
(7) Which application segment will grab a handsome share in the Global NoSQL industry?
(8) Which region is lucrative for the manufacturers?
Direct Purchase this Market Research Report Now @ https://globalmarketvision.com/checkout/?currency=USD&type=single_user_license&report_id=130005
If you have any special requirements, please let us know and we will offer you the report at a customized price.
About Global Market Vision
Global Market Vision consists of an ambitious team of young, experienced people who focus on the details and provide the information as per customer’s needs. Information is vital in the business world, and we specialize in disseminating it. Our experts not only have in-depth expertise, but can also create a comprehensive report to help you develop your own business.
With our reports, you can make important tactical business decisions with the certainty that they are based on accurate and well-founded information. Our experts can dispel any concerns or doubts about our accuracy and help you differentiate between reliable and less reliable reports, reducing the risk of making decisions. We can make your decision-making process more precise and increase the probability of success of your goals.
Get in Touch with Us
Sarah Ivans | Business Development
Phone: +1 617 297 8902
Email: sales@globalmarketvision.com
Global Market Vision
Website: www.globalmarketvision.com
”
MMS • Sergio De Simone

A recent paper by researchers at Zhejiang University and Microsoft Research Asia explores the use of large language models (LLMs) as a controller to manage existing AI models available in communities like Hugging Face.
The key idea behind the research is leveraging existing AI models available for different domains and connecting them using the advanced language understanding and generation capabilities shown by LLMs such as ChatGPT.
Specifically, we use ChatGPT to conduct task planning when receiving a user request, select models according to their function descriptions available in Hugging Face, execute each subtask with the selected AI model, and summarize the response according to the execution results.
According to the researchers, their approach makes it possible to solve sophisticated AI tasks in language, vision, speech, and other domains.
To establish the connection between ChatGPT and Hugging Face models, HuggingGPT uses the model descriptions from the Hugging Face library and fuses them into ChatGPT prompts.
The first stage in the process is task planning, where ChatGPT analyzes the user request and decompose it into tasks that can be solved using models from the library. The second stage consists in selecting the models that can best solve the planned tasks. The next logical step is executing the tasks and returning the results to ChatGPT. Finally, ChatGPT generates the response by integrating the prediction of all models.
For the task planning stage, HuggingGPT uses task specifications and demonstrations. A task specification includes four slots defining an ID; the task type, e.g., video, audio, etc.; dependencies, which define pre-requisite tasks; and task arguments. Demonstrations associate user requests to a sequence of task specifications. For example, the user request “In image /exp2.jpg, what is the animal and what is it doing?” is associated to a sequence of four tasks: image to text, image classification, object detection, and a final question answering task.
The six paper authors stated they used HuggingGPT for a number of experiments including both simple and complex tasks involving multiple sub-tasks.
HuggingGPT has integrated hundreds of models on Hugging Face around ChatGPT, covering 24 tasks such as text classification, object detection, semantic segmentation, image generation, question answering, text-to-speech, and text-to-video. Experimental results demonstrate the capabilities of HuggingGPT in processing multimodal information and complicated AI tasks.
According to their creators, HuggingGPT still suffers from some limitations, including efficiency and latency, mostly related to the need of interacting at least once with a large language model for each stage; context-length limitation, related to the maximum number of tokens an LLM can accept; and system stability, which can be reduced by the possibility an LLM occasionally failing to conform to instructions, as well as by the possibility that one of the models controlled by the LLM may fail.
MMS • Ben Linders

Leading in hybrid and remote environments requires that managers develop new skills like coaching, facilitation, and being able to do difficult conversations remotely. With digital tools, we can include less dominant and more reflective people to get wider reflections from different brains and personalities. This can result in more diverse and inclusive working environments.
Erica Farmer spoke about leading effectively in hybrid and remote environments at QCon London 2023.
Farmer suggested that managers should develop coaching skills to enable and foster hybrid working. A coaching approach might sound cheesy though to many managers, especially those who prefer a directive, command and control style of management. We see this a lot in more technical managers, or for those who have been “technicians” on the Friday and promoted to “people managers” on the Monday, she said.
People management and leadership is a whole different skill set and requires an ability to truly put yourself in the shoes of others (empathy), ask the right type of questions to raise self-awareness and responsibility (coach) and provide guidance and feedback when it is needed (performance management), Farmer mentioned:
Having a difficult conversation is one of the trickiest things for most managers to do (65% of managers confess to this) so being able to do this remotely or in a hybrid working environment requires these key ingredients.
Technology can enable us to include less dominant and more reflective people. Farmer mentioned that one of the many great things which has come to the changes in working practices over the last three years is the offering of new tech and ways to engage both synchronously or asynchronously.
Long gone are the days where as managers we’d rely on the extraverts in the room or on a call to come up with all the ideas, while those who are more introverted end up feeling they didn’t have the best opportunity to contribute, Farmer said. She mentioned seeing this in traditional classroom training all the time, where the trainer feels they are receiving responses from the delegates but are only really engaging about half of the class.
Farmer gave the example of digital tools such as MS Teams and Zoom, which have diverse engagement tools – reactions, polling, whiteboards, and annotation, to name a few, which are great at eliciting the non-verbal response from our more reflective team members.
Having ongoing channels post-live events also provide reflection opportunities and a place where pre and post thoughts can all be captured to provide a more thoughtful and well-rounded output, Farmer said. When done well, this drives more diverse and inclusive working practices and wider reflections from different brains and personalities.
InfoQ interviewed Erica Farmer about hybrid and remote working.
InfoQ: How can we improve the way that we digitally collaborate?
Erica Farmer: Providing flexible frameworks and ways to engage are key. Whether through technologies such as interactive whiteboards for projects, or polling opportunities for engaging team meetings, managers and leaders must embrace these skills.
We can no longer just pick up what we used to do “in-person” and just drop it online – the mindset and skill set shift is undeniable. Creativity, interaction, and facilitation are the new kids in town, and managers need to be upskilled to be able to engage their team in the right way. Again, all of this must be underpinned by trust.
InfoQ: What do you expect that the future will bring us in hybrid and remote working?
Farmer: The need for organisations to be more agile, flexible and purposeful, whilst maintaining their competitive edge, will only increase, so managers and leaders need to consider the management tool kit as part of this. Organisations need to ditch the vanilla management training and think about genuine collaborative skills to support their teams.
Deno Improves Node.js Support: Built-in Modules, package.json, Dynamic Import and Worker Compilation
MMS • Bruno Couriol

Recent releases of Deno (1.30, 1.31, and 1.32) make it easier for Node.js developers to transition to Deno projects. Deno 1.30 improves support for Node built-in modules and import maps. Deno 1.31 adds package.json support and includes the Node compatibility layer into the Deno runtime. Deno 1.32 adds deno compile support for web workers and dynamic imports.
With Deno 1.30, developers can expose Node modules with node: specifiers.
import { readFileSync } from "node:fs";
console.log(readFileSync("deno.json", { encoding: "utf8" }));
For developers using code with both Deno and Node.js, the node: scheme will work in both runtimes. Deno’s documentation helpfully advises:
Take note that importing via a bare specifier (ex.
import { readFileSync } from "fs";) is not supported. If you attempt to do so and the bare specifier matches a Node.js built-in module not found in an import map, Deno will provide a helpful error message asking if you meant to import with thenode:prefix.
The deno.json file can also now include import maps, eliminating the necessity to have two configuration files. To do so, developers specify imports and scopes keys in deno.json. Import maps are now supported in all modern browsers and allow resolving module specifiers by matching them to a location (on disk or at a remote location).
With Deno 1.31, Deno will automatically detect a package.json and use it to install and resolve dependencies. deno task will also run scripts from the scripts section of the package.json.
For instance, the following code:
$ deno run -A npm:create-vite vite-project --template vue
$ cd vite-project
$ deno task dev
will run a default Vite project in dev environment, as instructed by the template package.json installed by the create-vite scaffolding tool.
Deno 1.31 also includes the Node compatibility layer in the Deno runtime. The release note explains:
The Deno team has taken radical steps to improve the situation for users relying on npm packages – either via npm: specifiers or on the newly added package.json auto-discovery. The whole compatibility layer is now embedded in the Deno runtime itself, and V8 snapshots are used to drastically reduce the startup time. This tighter integration enables easier polyfilling of missing APIs and enhances the performance of already supported built-in Node.js modules.
Starting Deno 1.32, developers can use dynamic imports and Web Worker API with binaries created with the deno compile subcommand. The new feature makes it easier for developers to build executables for multi-threaded programs.
Deno is open-source software available under the MIT license. Contributions are encouraged via the Deno Project and should follow the Deno contribution guideline.
Meta AI Introduces the Segment Anything Model, a Game-Changing Model for Object Segmentation
MMS • Daniel Dominguez

Meta AI has introduced the Segment Anything Model (SAM), aiming to democratize image segmentation by introducing a new task, dataset, and model. The project features the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), which is the most extensive segmentation dataset to date.
Using an efficient model within a data collection loop, Meta AI researchers have constructed the largest segmentation dataset thus far, containing over 1 billion masks on 11 million licensed and privacy-respecting images.
The model has been purposefully designed and trained to be promptable, enabling zero-shot transfer to new image distributions and tasks. Following evaluation of the model’s capabilities across numerous tasks, it has been determined that its zero-shot performance is impressive, often comparable to, or surpassing, previous fully supervised outcomes.
Up until now, there have been two categories of methods available for solving segmentation problems. The first approach is interactive segmentation, which permits the segmentation of any object category but relies on human guidance to refine a mask iteratively. The second approach is automatic segmentation, which allows for the segmentation of predefined object categories (such as chairs or cats), but requires a significant amount of manually annotated objects to be trained (sometimes in the range of thousands or tens of thousands of examples of segmented cats), in addition to substantial compute resources and technical expertise to train the segmentation model. These two methods failed to provide a universal, fully automated approach to segmentation.
SAM represents a synthesis of these two approaches. It is a single model that can effectively handle both interactive and automatic segmentation tasks. The model’s promptable interface allows for versatility in its usage, making it suitable for a wide range of segmentation tasks by engineering the right prompt for the model, such as clicks, boxes, or text. Additionally, SAM is trained on a diverse and high-quality dataset of over 1 billion masks, which was collected as part of the project. This enables it to generalize well to new types of objects and images beyond what it was trained on. This ability to generalize significantly reduces the need for practitioners to collect their own segmentation data and fine-tune a model for their specific use case.
According to Meta, their goal is to facilitate further advancements in segmentation and image and video understanding by sharing their research and dataset. Their promptable segmentation model has the ability to act as a component in a larger system, allowing it to perform segmentation tasks. This composition approach enables a single model to be used in a variety of extensible ways, potentially leading to the accomplishment of tasks that were unknown at the time of model design.
With prompt engineering techniques, it is anticipated that the SAM model can be used as a powerful component in a variety of domains, including AR/VR, content creation, scientific research, and more general AI systems.