
Month: May 2023

MMS • Steef-Jan Wiggers
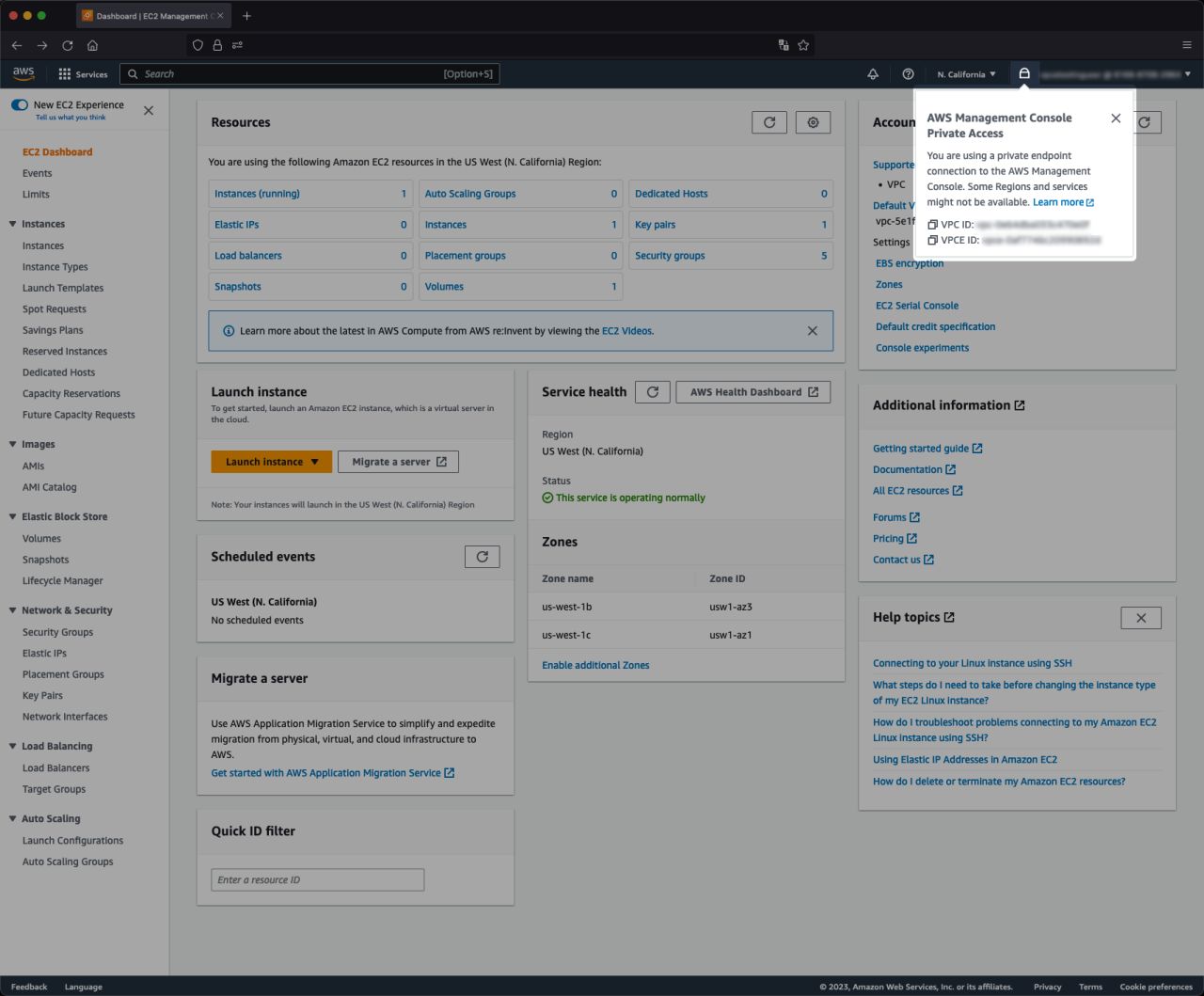
AWS recently announced the general availability (GA) of private access to the AWS management console. Private access is a new security feature that allows customers to limit access to the AWS Management Console from their Virtual Private Cloud (VPC) or connected networks to a set of trusted AWS accounts and organizations.
Under the hood, private access to the management consoles is possible using VPC Endpoints and AWS PrivateLink, which provides customers control over which networks can access their accounts and AWS Organizations and denies attempts from others.
Customers can use VPC endpoint policies for AWS Management Console Private Access to limit the set of accounts that are allowed to use the AWS Management Console from within their VPC and its connected on-premises networks.
A respondent on a Reddit thread on the Private Access feature for the AWS Management Console asked:
Is this AWS throwing up their hands to everybody who thinks IP addresses are a reasonable security measure?
With another one answering:
As a DevOps person, I would argue that having an IP allowlist is better than not having one. I don’t think it’s a matter of which is better or worse. I think, ‘porque no los dos’ because there’s a lot of dangerous stuff the console is there to protect. I’m purely responding to the notion that IP allowlists are not as good as authentication, which to me, feels like saying the luggage scanner at the airport is better/worse than the full-body scanner.
In addition, Etienne Beurex tweeted:
Very nice feature that will be very helpful for compliance audits, just wish AWS wouldn’t call “GA” features that are available in only a handful of regions.
Sébastien Stormacq, a principal developer advocate at AWS, responded:
I understand the frustration. We prefer to release early and release often to gather feedback and iterate quickly based on customer requirements. Regional expansion is a priority with the long-term goal to have feature parity between regions.
Currently, Private Access is available in the following AWS Regions: US East (Ohio), US East (N. Virginia), US West (Oregon), Europe (Ireland), and Asia Pacific (Singapore).
MMS • Vitaly Bragilevsky

Key Takeaways
- The Rust community is expanding, and the usage of Rust is on the rise.
- Rust seamlessly integrates with other programming languages in codebases, making it an excellent choice for mixed-language projects.
- Although relatively young, Rust developers possess professional experience in other programming languages.
- While the Rust ecosystem and tooling may have some drawbacks, there has been significant progress.
- Rust is widely regarded in the community as a language that delivers on its promises of memory safety and performance.
The Rust ecosystem is regularly explored in numerous developer surveys. Carefully reading these reports can yield insights into the community and the potential of the technology. For example, most Rust developers got started with the language only recently, which may be a sign that employers should review their job descriptions and stop expecting 10 years of Rust experience.
The community is growing rapidly. Adoption in the industry is slightly behind, but tech giants are already paving the way. We can also identify weak areas in the tooling, mainly in profiling and debugging support, related to the prevalence of naive techniques in these areas.
In this article, we share findings and insights about the Rust community and ecosystem and elaborate on the peculiarities and pitfalls of starting new projects with Rust or migrating to Rust from other languages.
Rustaceans
How many Rust developers (or Rustaceans, as they call themselves) are there out there? Although counting developers is not an exact science, we have some estimates. In its 23rd State of the Developer Nation report (Q3 2022), SlashData estimates the number of Rust developers to be 2.8 million, which is 1/7 the size of the JavaScript community and less than 1/4 of the C/C++ community.
The same survey reports that this number has tripled over the last two years, making it one of the fastest-growing developer communities. Is there any potential for growth left?
According to the Stack Overflow 2022 Developer Survey, 17.6% of developers who don’t use Rust want to use it, which makes Rust the most wanted language among the developer community. Given current trends and the relatively young age of the technology, the future looks bright.
The Rust community is young. According to the State of Developer Ecosystem 2022 report by JetBrains, 60% of developers who mentioned Rust as their primary language are under 30.
The 2021 State of Rust Survey by the Rust Team reports that half of the developers have less than 10 years of programming experience in any programming language.
Let’s also look at the background programming experience Rust developers have. The State of Rust Survey identifies the following large (possibly intersecting) groups of Rust developers with respect to other programming languages used:
- 41% of Rust developers consider themselves experts in dynamically typed languages (JavaScript, Python, PHP, etc.).
- 27% consider themselves experts in statically typed object-oriented languages with garbage collection (Java, C#, Go, etc.).
- 20% consider themselves experts in languages with manual memory management (C, C++, etc.).
The Stack Overflow Survey also reports significant numbers of JavaScript, TypeScript, Python, Java, and C++ developers interested in working with Rust. Interestingly, C developers are not that inclined toward Rust, although this may change given the recent changes in Linux policies about kernel development and the trend of supporting Rust in other major C-based projects (for example, curl).
According to the Rust section of the State of Developer Ecosystem 2022, only 5% of Rust developers have been using the language for more than 3 years. About half of Rust projects are purely Rust projects, while others share their codebases with JavaScript/TypeScript (22%), Python (15%), C++ (12%), Go (12%), C (11%), and other languages. A GitHub search for popular repositories with Rust as a primary language reveals that 20% of them also contain code in Python, with another 20% containing JavaScript.
Based on this data and my observations of the Rust community, I suspect that it is growing thanks to the huge number of young people with Python and JavaScript backgrounds who are moving to their first systems programming language. Such languages are much harder to learn but introduce them to a whole new experience in software development. Older languages like C and C++ are not that appealing to them, but Rust is.
Technology Domains and Industry Adoption
The Rust Team’s survey reveals that server-side (backend) projects are the primary technology domain for Rust. Cloud computing infrastructure and applications is another huge area for applying Rust, while distributed applications are also a popular choice among the Rust community.
Linux is the most targeted platform (77% vs. about 41% for Windows and 36% for macOS). WebAssembly is at 22%, while embedded systems are only targeted by 11% of Rust developers. Rust’s usage for mobile applications is mostly negligible.
CLI tools are much more popular than GUI applications for Rust projects. This can be attributed to the predominant supply of CLI libraries in the ecosystem, while GUI libraries are less common. According to the State of Developer Ecosystem 2022 survey, 46% of Rust developers use it for developing CLI tools.
There is a technology area that may not be easily visible simply from looking at the numbers, though it is extremely important for showcasing Rust applications: tooling for other programming languages. We can see that Rust is used both in the JavaScript and Python communities for developing high-performance alternatives to the current tooling available for those languages. Projects like deno (a JavaScript and TypeScript runtime) and Ruff (a Python linter) are good examples of this trend. These open-source projects show that Rust provides both high performance and pace of development while also attracting a lot of contributors. There is a long-standing tradition of developing tooling for a programming language using that language. Rust breaks from this tradition quite effectively.
Tech giants like Microsoft, Google, Amazon, and Meta endorse and support Rust. Still, the State of Developer Ecosystem 2022 survey reports that most Rust developers use Rust outside their jobs. Only 18% of respondents develop software in Rust as part of their official work. Less than half of the respondents of the Rust Team’s survey consider themselves productive in Rust. Less than half of the respondents of the same survey use Rust daily or so. These numbers suggest that others are still learning it or use it occasionally as a hobby for personal projects.
Job postings on various websites don’t allow us to conclude that there are thousands of mid-size or small companies interested in hiring Rust developers. Only 15% of the Rust Team’s survey respondents reported that their company uses Rust for a large number of projects, while another 18.5% saw it being used in a small number of projects. It seems that the main way to introduce Rust in a company is by rewriting non-critical components from other languages or starting a new non-essential project in Rust to measure its effectiveness. The Rust community is actively discussing both success stories and failures regarding the process of transitioning to Rust or launching new projects.
Starting a Rust journey requires a company to have some senior engineers with long-time Rust experience who can supervise the transition. As we’ve already highlighted, there is a shortage of such sort of developers in the community. Fortunately, this is something that is going to be fixed automatically as time goes on.
The 2021 State of Rust Survey identifies Rust’s lack of usage in the industry as the number one concern. The situation is, however, expected to change.
Language and Tooling
One big thing about Rust is that it delivers on its promises. Being memory safe allows for the elimination of certain classes of bugs. Google partially attributes the decline of critical vulnerability numbers in Android to the adoption of Rust as a memory-safe alternative to C++. Rust performance allows Amazon to be sustainable in terms of energy efficiency. Both reduced CPU usage and effective memory management are outcomes of Rust language features.
70% of developers using Rust at work strongly agree that Rust’s performance characteristics (such as speed, memory footprint, and others) influence its adoption. 64% of them value Rust security and safety features. About 80% of them agree that Rust allows them to achieve their goals and pays off the cost of adoption. 65% of developers consider Rust language and standard library documentation to be great. These numbers explain why Rust is in its seventh year as the most loved language, with 87% of developers saying they want to continue using it according to the Stack Overflow survey. Rustaceans are loyal to Rust, which says more about the language and its quality than it does about the developers themselves.
38% of Rust Team’s survey participants agree that Rust is significantly more complicated to program in than other programming languages. 62% agree that it requires significantly more effort to learn. They also worry that it is becoming even more complex. This was the second most common concern about Rust’s future among the survey participants.
All the surveys agree that Visual Studio Code powered by rust-analyzer is the most popular IDE for writing in Rust. It is used by about half of Rust developers. The share of the runner-up, JetBrains IDEs (CLion, IntelliJ IDEA, and others) powered by our IntelliJ Rust plugin, varies from 25% to 40% depending on the survey. Vim/Neovim is the third most popular option. Two-thirds of Rust developers consider their IDE experience great or good enough.
When going into the details of the development experience, the surveys reveal that the most problematic parts are debugging and profiling. 32% of the State of Developer Ecosystem 2022 survey participants mention that they miss a native debugging experience. 29% of the Rust Team’s survey respondents believe the debugging experience could be better. More than half of Rust developers use println-style debugging as their main way to debug issues with their code, and one-third of them use that approach exclusively.
The code profiling experience is even worse; more than 80% of Rust developers don’t use profiling tools at all. One reason may be that the tools currently available are very difficult to use and their findings are hard to interpret. Teaching materials focused on profiling are mostly absent. It seems developers are happy to blindly believe in Rust performance without actually checking it. This attitude could become a critical problem with the growing adoption of Rust in the industry. Profiling tools themselves and learning materials both require serious efforts to improve.
Unfortunately, the available surveys don’t go into Rust libraries. We don’t have good data on the parts missing from the library ecosystem. Being a young technology entails issues with technological completeness, though given Rust good interoperability this is never seen as a critical problem.
Conclusions
As is often the case with surveys, these results both back some interesting conclusions and undermine some prominent theories. In an example of the latter case, these results suggest that the original perception of Rust as a C/C++ killer doesn’t seem relevant today. We don’t have evidence of a massive replacement of C/C++ code in the existing codebases, nor do we expect that to happen in the future. Why? Well, because both C and C++ continue to work. C++ is evolving, and long-standing problems are being solved. It simply isn’t necessary to rewrite everything in Rust. Additionally, there is not enough workforce to do it. Nevertheless, starting a new project in C or C++ nowadays requires careful consideration. Rust might be a good choice for that project too, especially if the target platform is Linux and you care about performance and safety.
The young age of community members indicates that Rust has a bright future. It is not going anywhere, and adoption in the industry will continue to rise. As the number of experienced Rust developers grows, we’ll see more pure Rust projects emerge. Tech giants are already in the Rust boat, and we expect small and mid-sized companies to follow suit soon.
Tooling for Rust is constantly evolving, with many enthusiasts and companies around the world contributing to the tooling ecosystem.
Being productive in Rust requires a deep understanding of its concepts, especially in the areas of ownership, memory management, and approaches to concurrency. Programming efficiently in Rust requires dedicated learning and training. This is why the common practice of having developers skilled in other programming languages to switch to Rust could be more problematic than for other languages. Switching from any language requires changing a lot of habits. Don’t expect developers to master those concepts and acquire new habits quickly by themselves; instead, educate and train them beforehand.
MMS • Edin Kapic

The latest release of the .NET MAUI Community toolkit, version 5.1.0, brings two main features and several bug fixes for the last version.
One of the features is the reintroduction of the LazyView control, which is ported from the Xamarin Community Toolkit. LazyView allows the developers to delay the initialization of a MAUI view until it’s absolutely needed. To do so, LazyView control has a LoadViewAsync method. There is a HasLazyViewLoaded property that returns the status of the loading of the LazyView. The documentation and the sample application are updated to reflect the new feature.
Another significant addition is the addition of the keyboard extensions. These are a set of extension methods that support interacting with the soft keyboard on the UI controls that support text input.
There are two extension methods called ShowKeyboardAsync and HideKeyboardAsync, that show and hide the soft keyboard, respectively. One additional property, IsSoftKeyboardShowing, returns the soft keyboard visibility status. These extensions can be found under the CommunityToolkit.Maui.Core.Extensions namespace.
Gerald Versluis, the developer from Microsoft who released the 5.1.0 version of the toolkit, uploaded a video that shows how to fix the keyboard overlapping problem in .NET MAUI applications. The video has attracted a lot of comments from the developers.
The release notes for version 5.1.0 of the toolkit also mention several bug fixes regarding the FileSaver component bugs:
- The component didn’t truncate existing files on writing over them. It meant that junk data was visible at the end of the overwritten file if the newly written data was shorter than in the previously existing file.
- In the case of saving non-seekable streams, such as web download streams, the
FileSavercomponent methodSaveAsyncwould fail. - On the Apple Mac platform, the component would ignore the provided file name in the ‘Save As’ text box, using a random GUID as the filename.
- Saving a file without an extension would result in a cryptic error message:
'The parameter is incorrect'.
A minor fix has been added to the FolderPicker component. Previously, on some Android devices, the folder picker would give a ‘No application can perform this operation’ error message. The underlying bug was related to the component specifying an intent chooser for the folder picker. This code was removed from the implementation.
This version also includes updates to several dependencies, namely Newtonsoft.Json and Microsoft.Extensions.Http.Polly libraries.
In addition, developers interested in tracking the .NET MAUI Community Toolkit project’s roadmap and general progress can find detailed information on the official GitHub repository.
Presentation: The Zen of Green Software: Finding Balance in the Sustainable Growth Journey
MMS • Lisa McNally Marco Valtas
The Zen of Green Software: Finding Balance in the Sustainable Growth Journey
Summary
Lisa McNally, Marco Valtas discuss open source software tools and methodologies for balancing carbon with growth across an IT organization.
Bio
Lisa McNally is Head of Cleantech & Sustainability @Thoughtworks.
Marco Valtas is Technical Lead for Cleantech and Sustainability @Thoughtworks.
About the conference
May 16, 2023
MMS • RSS
According to a research report Cloud Database and DBaaS Market by Database Type (SQL and NoSQL), Component, Service, Deployment Model, Organization Size, Vertical (BFSI, Telecom and IT, Manufacturing, Healthcare and Life Sciences), and Region – Global Forecast to 2025
The growing demand to process low-latency queries is one of the major factors driving the growth of the market.
The global Cloud Database and Database as a Service (DBaaS) Market size is expected to grow from USD 12.0 billion in 2020 to USD 24.8 billion by 2025, at a Compound Annual Growth Rate (CAGR) of 15.7% during the forecast period, according to a new report by MarketsandMarkets™.
Browse in-depth TOC on “Cloud Database and DBaaS Market“
105 – Tables
35 – Figures
160 – Pages
Download PDF Brochure: www.marketsandmarkets.com/pdfdown…gn=paid+pr
The Banking, Financial Services and Insurance vertical segment to account for the highest market share during the forecast period
The Banking, Financial Services and Insurance (BFSI) vertical is one of the most data-centric verticals where large volumes of databases are generated at an exponential rate. Various factors are expected to contribute to the growth of the database in the financial sector.
Some of these factors include electronic transactions, Automated Teller Machines (ATMs), credit cards, call centers, and mobile-based sources. The database generated from these sources is scattered across various branches and departments across various financial institutions and needs to be interlinked together.
The linking of this database is important to derive meaningful insights and sustain in the competitive market.
The BFSI vertical demands an additional secured environment to secure its online transactions 24*7, which can be achieved by cloud database and DBaaS. Hence, the adoption of cloud database and DBaaS solution helps BFSI companies to store, manage, access, and modify data for further processes.
Cloud database and DBaaS ensure the seamless execution of transactions. These solutions further improve the accuracy and efficiency of various processes and assist in the regulatory and compliance reporting by collating data from multiple sources.
Most banks are increasingly deploying cloud database and DBaaS solutions to enhance performance and improve cost-savings.
The Not only Structured Query Language segment to grow at a higher CAGR during the forecast period
The growing amount of digital data in unstructured data format generates the need for dynamic scalable database. Structured Query Language (SQL) offers databases only in the tabular format, but Not only Structured Query Language (NoSQL) offers database and queries in various formats: column, graphical, document, and others.
Thus, the need is fulfilled by the non-relational database with its highly scalable and easy to program model. NoSQL is also known as non-relational database.
It offers great features to the clients; scalability is apparently the most important one. In addition to this, NoSQL allows users to store and retrieve unstructured data.
Today, most of the cloud database and DBaaS vendors provide NoSQL compatible cloud database services. Owing to this, dealing with huge data processing on the web has been made cost-effective.
North America to lead the cloud database and DBaaS market during the forecast period
North America is expected to account for the highest share of the cloud database and DBaaS market in 2020. The region comprises developed countries, such as the US and Canada, and is considered the most advanced region in terms of adoption of advanced technologies.
The North American region exhibits a wide presence of key industry players offering cloud database and DBaaS solutions and services, and its financial position enables the region to invest majorly in leading tools and technologies for effective business operations.
Report: www.marketsandmarkets.com/request…gn=paid+pr
Google (US), Microsoft (US), AWS (US), IBM (US), Oracle (US), Alibaba Cloud (China), SAP (Germany), MongoDB (US), EnterpriseDB (US), Redis Labs (US), Tencent (China), Rackspace (US), Teradata (US), CenturyLink (US), Neo4j (US), DataStax (US), TigerGraph (US), MariaDB (US), RDX (US), and MemSQL (US) are some of the leading companies operating in this Cloud Database and DBaaS Market.
Browse Other Reports:
Chatbot Market – Global Forecast to 2028
AI as a Service Market – Global Forecast to 2028
Healthcare Cybersecurity Market – Global Forecast to 2028
Video Conferencing Market – Global Forecast to 2027
Artificial Intelligence Market – Global Forecast to 2027
News From
 MarketsandMarkets™
MarketsandMarkets™ Category: Market Research Publishers and Retailers Profile: MarketsandMarkets™ is a blue ocean alternative in growth consulting and program management, leveraging a man-machine offering to drive supernormal growth for progressive organizations in the B2B space. We have the widest lens on emerging technologies, making us proficient in co-creating supernormal growth for clients.
The B2B economy is witnessing the emergence of $25 trillion of new revenue streams that are substituting existing revenue streams in this decade alone. We work with clients on gro …
For more information:
MMS • RSS
<!–
 Join us free for the Data Summit Connect 2021 virtual event!
Join us free for the Data Summit Connect 2021 virtual event!
We have a limited number of free passes for our White Paper readers.
Claim yours now when you register using code WP21.
–>

If you’re wondering whether data modeling is still relevant in today’s fast-paced, data-driven world, this white paper is for you. You’ll discover how data modeling can help you overcome challenges and achieve success in your database-related role. You’ll learn why it’s still an essential component of modern-day data management strategies, helping you reduce errors and increase efficiency. The paper also covers key concepts and best practices, helping you create better models that more accurately represent your data. Ultimately, this white paper is a must-read for anyone looking to understand the critical role data modeling plays in data management and governance.
Download PDF
MMS • A N M Bazlur Rahman

JEP 440, Record Patterns, has been promoted from Proposed to Target to Targeted status for JDK 21. This JEP finalizes this feature and incorporates enhancements in response to feedback from the previous two rounds of preview: JEP 432, Record Patterns (Second Preview), delivered in JDK 20; and JEP 405, Record Patterns (Preview), delivered in JDK 19. This feature enhances the language with record patterns to deconstruct record values. Record patterns may be used in conjunction with type patterns to “enable a powerful, declarative, and composable form of data navigation and processing.” Type patterns were recently extended for use in switch case labels via: JEP 420, Pattern Matching for switch (Second Preview), delivered in JDK 18, and JEP 406, Pattern Matching for switch (Preview), delivered in JDK 17. The most significant change from JEP 432 removed support for record patterns appearing in the header of an enhanced for statement.
With all these changes, Java is now on a path towards a more declarative, data-focused programming style with the introduction of nestable record patterns. This evolution comes after the successful integration of pattern matching with the instanceof operator introduced in Java 16 with JEP 394.
Consider a situation where you have a record, Point, and an enum, Color:
record Point(int x, int y) {}
enum Color { RED, GREEN, BLUE }
The new record pattern allows testing whether an object is an instance of a record, and directly deconstructing its components. For instance:
if (r instanceof Rectangle(ColoredPoint ul, ColoredPoint lr)) {
System.out.println(ul.c());
}
Even more powerful is the ability to use nested patterns, which allow further decomposition of the record value. Consider the following declaration:
record ColoredPoint(Point p, Color c) {}
record Rectangle(ColoredPoint upperLeft, ColoredPoint lowerRight) {}
If we want to extract the color from the upper-left point, we could write:
if (r instanceof Rectangle(ColoredPoint(Point p, Color c), ColoredPoint lr)) {
System.out.println(c);
}
This evolution of record patterns extends pattern matching to deconstruct instances of record classes, thus enabling more sophisticated data queries. It allows for testing if an object is an instance of a record and directly extracting the components of the object. This approach makes the code more concise and less error-prone.Consider the following example:
static void printXCoordOfUpperLeftPointWithPatterns(Rectangle r) {
if (r instanceof Rectangle(ColoredPoint(Point(var x, var y), var c),
var lr)) {
System.out.println("Upper-left corner: " + x);
}
}
In addition, the introduction of nested patterns takes this further by providing the ability to destructure nested data structures. They give developers the power to centralize error handling since either the entire pattern matches or not. This eliminates the need for checking and handling each individual subpattern matching failure.
These nested patterns also play nicely with the switch expressions introduced by JEP 441. Pattern matching for switch expressions augments the switch statement to allow the use of patterns in case labels. This leads to more expressive code and reduces the chances of bugs due to missed cases in switch statements.
For example, consider the declarations:
class A {}
class B extends A {}
sealed interface I permits C, D {}
final class C implements I {}
final class D implements I {}
record Pair(T x, T y) {}
Pair p;
With the record pattern and exhaustive switch we can do the following:
switch (p) {
case Pair(C c, I i) -> ...
case Pair(D d, C c) -> ...
case Pair(D d1, D d2) -> ...
}
However, these updates come with some risks and assumptions. As with any language change, there’s a risk of impacting the existing codebase. Additionally, these changes assume that developers are familiar with record classes and pattern matching, two features that are relatively new to Java.
Looking ahead, there are many directions in which the record patterns could be extended. These include varargs patterns for records of variable arity, unnamed patterns that match any value but do not declare pattern variables, and patterns that can apply to values of arbitrary classes rather than only record classes.
In conclusion, the introduction of record and nested patterns in Java is a significant leap forward for the language. It allows for a more declarative style of coding, which can lead to cleaner, more understandable code. While there are some risks involved, the potential benefits make this a promising feature for future versions of Java.
MMS • Sergio De Simone

The latest release of GCC, GCC 13.1, adds support for a number of new features and improvements to the C language defined in the upcoming C2x standard, including nullptr, enhanced enumerations, auto type inference, and more.
C2x is adopting a number of changes to the language that first made their appearance in C++, to make it easier for the two languages to coexist in the same codebase. Such changes include nullptr, enhanced enumerations, auto type inference, constexpr specifier, and others.
The new nullptr constant will attempt to remove one of the issues with the old NULL macro, whose definition is implementation-dependent. This leads to a number of potential shortcomings when using it with type-generic macros, with conditional expression such as (true ? 0 : NULL) (since NULL could be defined as (void*)0), with vararg functions where NULL is used as a sentinel, and in other cases.
To improve this, nullptr will have its own type nullptr_t; will not have a scalar value, so it cannot be used in arithmetic expressions; will be convertible to any pointer type; and will always convert to a boolean with false value.
Enhanced enumerations is another change to the language that tries to fix a case of under-specification of the previous standard, in this case concerning the underlying type associated to enums. In fact, while C normally uses int for enumerations, this is not always the case, which can cause portability issues. Additionally, when ints are effectively used, this rules out the possibility of using enumerations at bitfield level. The new standard thus allows developers to state the enumeration type, as in the following example:
enum a : unsigned long long {
a0 = 0xFFFFFFFFFFFFFFFFULL
// ^ not a constraint violation with a 64-bit unsigned long long
};
C2x also tries to make it away with some restrictions to variadic functions that are considered leaky or dictated by outdated assumptions concerning their requirements on the argument list. Specifically, the new standard is going to permit that a function declaration’s parameter list may just consist of an ellipsis not preceded by a named argument, e.g. int a_variadic_function(...). This change is considered safe as it does not break any existing code.
Another new C feature inspired by C++ is the use of the auto keyword to leave the definition of a variable type implicit. This is possible when the definition includes an initializer from which the variable type can be derived. It is worth noting that C auto is a much more limited feature than C++ auto, which relies on C++ template type deduction rules, and can be used less generally.
The introduction of constexpr in C2x responds to the goal of improving initialization of object with static storage duration, which require the use of constant expressions or macros evaluating to constant expressions. Thanks to this, the following definition, valid in C17:
static size_t const bignum = 0x100000000;
can be replaced by
constexpr size_t bignum = 0x100000000;
which has the added property of ensuring the constant is checked at compile time.
Other new C2x features that are supported by GCC 13 are storage-class specifiers for compound literals, typeof and typeof_unqual, the noreturn attribute, support for empty initializer braces, removal of trigraphs and unprototyped functions, the adoption of the Unicode Identifier and Pattern Syntax, and more.
C2x is the upcoming C language standard revision, expected to be approved this year, thus getting the official C23 denomination.
MMS • Olimpiu Pop

At his Devoxx UK presentation, Josh Long – Spring Developer Advocate at VMWare – coded his way through the new features coming in Spring Framework 6, and Spring Boot 3 emphasizing the benefits at the Java language level in the latest versions starting with version 17.
He starts the presentation by mentioning that he considers Spring Boot 3(released on the Thanksgiven Day in 2023) the biggest release since version 1 (released on April Fool’s Day in 2014). During his presentation, he intends to showcase the multiple features added to this version by coding a “production-grade” REST service and the corresponding client.
He uses the spring initializr pointing out that even if you can choose between gradle(both groovy or kotlin) and maven the default is now gradle with groovy. When choosing the Java version he emphasizes that the current default, Java version 17, is the minimal logical choice because 11 and 8 are non-choices as version 17 is the baseline for Spring Boot 3.
…You should choose 11 or 8 only when you want to show people what not to do
Further, he generated a project supporting JDBC, Web, GraalVM and Spring Boot Actuator. The resulting zip file he opened in InteliJ Idea. He coded a service using the old-fashioned JdbcTemplate, RowMapper and Service which returned the new entities defined as Java records. In the next step, he adds DB schema and DB data by adding the corresponding SQL files in the resources folder.
The http controller implementation follows, which is transformed into production-worthy code by the addition of validation and centralization of the error handling by writing an aspect. To be able to create a standard representation of the errors he uses the newly added support for RFC-7807: Problem Details for HTTP APIs which returns a ProblemDetais object when any exception would be handled. The behaviour can be enabled by setting spring.mvc.problemdetails.enabled=true in application.properties. Introducing the HttpRequest in the exception as well, he underlines that the HttpServletRequest has now a new home in jakarta.servlet.http package. Which, even though it seems just a small change it required a sustained effort and collaboration from the community. Spring 6 is the new baseline and everything just works having under the hood the new types.
…finally we have Jakarta EE 10 and this means that as a community we can move faster as a community
Next, he addresses observability: “I cannot tell if am winning if I don’t know when I am losing”. There are two ways to approach this:
- Metrics – statistics. How many requests do you have, how many customers are logged in etc
- Tracing – the details of an individual request to the system
In order to avoid circular dependencies and to enable tracing at any level, in Spring 6 sleuth (the project that was used for tracing in the “old world”) was removed and micrometer can do both tracing and metrics. In order to take advantage of all these, actuators should be enabled as well.
Now that the application is production ready it is time to take it to production and buildpacks.io will do that to any type of package of your application (regardless of packaging or programming language). The other necessary thing to be done is to make the application as efficient and small as possible reminding that Java is an efficient technology and that garbage collection and the JIT do a good job to keep Java efficient.
As GraalVM is an alternative that could make things even better, Spring 3 and Spring 6 provide a mechanism to generate native images for you. In his humoristic seriosity, Long mentioned that as he feels the compilation was taking too long he decided to ask for either elevator music or at least a notification, like the toasters, to alert him when the compilation is done.
As the service was done, he shifted focus to implementing a client that consume the implemented service. During the implementation, he showcased the new @GetExchange which is the client-side equivalent of @GetMapping from the server side. Initially, you could’ve found it in parts of Spring Cloud, but now it is part of the framework and it supports any implementation (HTTP, Reactive or RSocket). By providing the benefit of aggregating multiple calls to the same service, he introduced the newly added support for GraphQL.
Concluding his presentation he reiterated the fact that Spring 6 and Spring Boot 3 are a new baseline: both from the perspective of the Jakarta EE namespace but also with the newly added support for native compilation.
MMS • Rosemary Wang

Subscribe on:
Transcript
Thomas Betts: Hello and welcome to the InfoQ podcast. I’m Thomas Betts, lead editor for architecture and design at InfoQ, and an application architect at Blackbaud. Let’s say you’ve committed to the journey of running in the cloud, however you soon realize it’s not quite as simple as moving your code or writing a new application on a cloud offering. Between a diverse service catalog, greater developer autonomy, rapid provisioning, surprise billing and changing security requirements, you might find that hosting applications on the cloud does not make the most of the cloud.
Today, I’m joined by Rosemary Wang to talk about the patterns and practices that help you move from cloud-hosted to cloud-native architecture and maximize the benefit and use of the cloud. We’ll talk about the essential application and infrastructure considerations as well as cost and security concerns you need to think about when approaching a cloud-native architecture.
As the author of Infrastructure as Code, Patterns and Practices, Rosemary works to bridge the technical and cultural barriers between infrastructure, security and application development. She has a fascination for solving intractable problems as a contributor, public speaker, writer and advocate of open source infrastructure tools. When she’s not drawing on whiteboards, Rosemary debugs stacks of various infrastructure systems on her laptop while watering her house plants. Rosemary, welcome to the InfoQ podcast.
Rosemary Wang: Thank you for having me.
Cloud-Hosted vs. Cloud-Native [01:28]
Thomas Betts: So you spoke at QCon London and your talk was titled From Cloud-Hosted to Cloud-Native. Can you start us off by explaining what the difference is between those two terms and what does it mean to make the transition from cloud-hosted to cloud-native?
Rosemary Wang: Sure. So most applications that run on cloud are cloud-hosted. You host them on the cloud, and they’re able to run on any of the cloud providers, so long as you’ve configured them to do so. Whether it be interact with cloud services or databases that run there, databases on-prem, there’s a lot of variety into what goes into a cloud-hosted application and what’s important about it. But not many applications are cloud-native. And the key differentiation between an application that’s cloud-hosted and cloud-native is that whether or not that application can scale in a very dynamic environment.
And I think that there is a very broad definition to what dynamic means. But in order for an application to be truly cloud-native, it has a couple of considerations that I think are important, and some of these considerations include its adaptability because whenever you have a cloud environment, you expect it to change. You expect everything to grow. You expect it to evolve. It’s important that this application that you’re putting on the cloud is adapting to all of these changes. There’s observability or it’s observable. You need information telemetry about how that application is running because that will inform decisions about how you change that application or service for the future.
Immutability is something that’s really important for cloud-native. It’s this idea that you have to create something new to implement changes. It’s not changing in place. And the reason why implementing something completely new with the changes built in becomes important in cloud-native is that it’s the only way you keep up with changes to the environment and do it in a stable, consistent manner. So it’s a lot easier to put together new components than it is to change existing ones in place.
Elasticity is a really subtle consideration. Most of the time, we think about cloud being scalable. Can I increase all of my application instances to handle increased workload, increased traffic or increased requests from my customers? But elasticity is a lot more subtle than that. Elasticity is scaling down as well, and I think we fail to think about that sometimes from a cloud-native perspective.
And finally, changeability. We always want to take advantage of the latest offerings, the latest ecosystems, and it’s important that we have this ability to change not just our services but also their underlying systems.
Designing for Adaptability [03:56]
Thomas Betts: And I think that changeability goes back to your first point when you said adaptability was we want to be able to adapt to changes both from within our application and our needs, but also changes in the cloud-hosted and the cloud-native environment. Can you talk about any tips for accomplishing that good separation that what my app has to do and what the environment around me is doing and how do I design for better adaptability?
Rosemary Wang: We’ve depended heavily on abstraction in order to accomplish this, and I think it’s important in a cloud-native environment to adopt the right abstraction. There’s just enough abstraction for you to do something effectively and to be able to change your services without necessarily affecting the underlying dependencies. And so that’s why you see Kubernetes gaining a lot of traction in the cloud-native space. That’s partly why you see service mesh gaining a lot of traction as an abstraction. So we’re slowly pushing what we consider infrastructure functions, as well as coexisting with service functions into different layers of abstraction. And as we build on those, it becomes important that we maintain the abstraction, but it becomes a lot easier to maintain that abstraction while independently evolving the services that are running on top of the infrastructure as well.
You’ll also find a lot of abstractions in the open source space as well. That’s becoming more prevalent. Open standards are becoming the defacto way that people build these abstractions. They don’t have to maintain them themselves in an organization. Instead, what they’re doing is they’re relying on these open standards as a contract of sorts between services and then their infrastructure dependencies.
Thomas Betts: And you said something like Kubernetes. I know there’s some approaches that say, again, I want to move to a cloud-hosted. Instead of just taking my app and deploying it, I’m going to first package it up in Kubernetes and then I’m going to put it on the cloud. Does that mean I’m cloud-native because it’s in Kubernetes?
Rosemary Wang: It’s closer. I would say it’s closer. It doesn’t fulfill all the other four requirements or considerations that I outlined. Not necessarily. Just because you put something on Kubernetes, it doesn’t necessarily mean it’s elastic. I think that’s the one argument that I get the most. It’s like, “Oh yeah, I packaged it. I put it on Kubernetes.” But is it truly elastic? Are you taking advantage of the ability for those service to scale up? But are you also scaling them down dynamically? And that’s usually the place where it goes from cloud-hosted closer to cloud-native but still not perfectly what we would consider cloud-native. And I think that there’s a misnomer here where if you manage to lift and shift an application from one runtime to another, that magically means that you’re more cloud-native, and that’s not necessarily the case either.
Testing in the Cloud [06:25]
Thomas Betts: And how does it affect our plans for testing our application? So I used to run all my tests locally, but now they’re in the cloud and I might not control everything, so I’m not running my web server on my machine and getting tested there. I need to say it’s inside this container or there’s other dependencies. What do I have to consider for making those tests work properly in the cloud?
Rosemary Wang: That’s a good question, and I get a lot of interest in local testing because no one wants to spin up all of these cloud-native components. Right now, if you wanted to test interactions between microservices, now you might have to implement a service mesh locally for some reason and test all integration tests locally with a service mesh in place. It’s a lot of overhead.
And so testing now looks a little bit different. I think that we’re getting better about either mocking some of these abstractions, whether it be if you’re interfacing with a cloud provider’s API, there are some community libraries available for you to mock those APIs and you get an understanding of how those infrastructure components will return important values and important information for your services.
The other options that are interesting is that there’s more and more focus on implementing some of these open source tools locally. So you can use a Docker container and spit up a Redis cache if you really wanted to. You can similarly create a Kubernetes cluster on your own local machine and test your deployments that way. So I think we’re looking at testing the abstractions. And even if the abstractions are mocked or they’re able to be implemented locally, that is much better for us from a development standpoint. But overall, there are some abstractions that cannot be mocked, unfortunately, or cannot be run locally, and those will still have to rely on either the remote cloud instance or sometimes the on-prem instance.
Thomas Betts: And then that’s when we’re getting into the subject of doing a full end-to-end test that’s saying that my application, I did my unit tests, but I need to make sure that it will work in this cloud-native environment because I have these other dependencies. And so you have to consider that some of those now have to be tests you have to write that you didn’t have to before.
Rosemary Wang: Exactly. There’s also, I think, merit to considering the contract test. We talk about contract tests between microservices predominantly, but we don’t necessarily talk about contract testing in the form of infrastructure because it’s complicated. Infrastructure schemas are not uniform across the board. What information you need to log into a cache is going to be different than what you log into a database and many other components. How you interface with Kafka is going to be very, very different than how you interface with Amazon’s SQS service. There’s a lot of different nuances there.
But one of the things that I’ve noticed that has worked really well with services is the ability to say, okay, I know these are my contract tests, point in time for certain infrastructure. I’m going to run these contract tests and make sure that what I understand my application needs to do to interface with these components. I am able to articulate that, communicate that knowledge, and if it’s a little bit different, maybe the cloud provider’s API changes, then I’m able to accommodate for those changes very dynamically because they don’t match what I’ve done in my contract tests.
Changing Observability Needs [09:19]
Thomas Betts: I think that’s a good segue into your next capability, which was observability, and that’s about being able to understand what the system is doing, both when it’s working but also when you’re trying to troubleshoot it. And you look at the spectrum from my application was on-prem or maybe in a colo server and then it was cloud-hosted and then it’s cloud-native. When you move across that spectrum, how do our observability needs change?
Rosemary Wang: t’s very easy to start with I guess our traditional monitoring system where we would push all of the information. We would say, okay, here’s an agent that’s gathering all this information and we push it to a monitoring server somewhere. What we’re seeing in the cloud-native environments now is more of a push-pull model or a pull model. There’s some server and it’s extracting the information dynamically, but the application itself has to give this information, this telemetry freely and there of course has to be some standard in place. So that’s where Prometheus formatted metrics are now particularly of interest for folks. You’ll see OpenTelemetry, the standardization of libraries that emit traces or emit metrics. We’re starting to get a little bit more consistent in the protocols and the formats that we’re using to support a better observability in our systems.
But unfortunately, there is not one tool to rule it all. So you’re not going to get the same monitoring tool or the same observability tool that you’re using in cloud as on-prem. I think there’s just too much specialization at times as well from some of these tools. So you might be on-prem using application performance monitoring, something that’s a little bit more agent based, and then when you go to your cloud environment, you might decide to go with something like a third-party managed service, and it’s up to you to decide how you’re going to aggregate all that information. And so we’re seeing organizations building their own observability systems, particularly on the aggregation side of the house where they’re responsible for aggregating, adding metadata, the proper metadata to services and then indexing in this big pool of telemetry. They’re not necessarily depending on the different vendored monitoring systems anymore. They’re instead aggregating in one place.
Thomas Betts: Yes, I think it’s another place where people sometimes make the assumption that just like going to cloud-hosted, oh, I’m now in the cloud and I can scale and I can get all these benefits. Sometimes there’s a perception if I just add OpenTelemetry, now I’m going to have all these benefits. You still have to do some work and you have to do your own customization and find out what works for you. Right?
Rosemary Wang: Exactly. And I think we’ve also got a lot of complexity now too with all these different libraries and different protocols. Let’s say you have a cloud-hosted application and you’ve invested in distributed tracing with Zipkin. Well, Zipkin traces aren’t necessarily compatible with other instrumentation libraries, with other use trace aggregation tools, etc. So you go down this rabbit hole of trying to figure out, okay, even though it’s cloud-hosted where it’s what we think is cloud-native, there’s a lot of disparity or inconsistencies with the compatibility across all of these tools as well as the protocols that we’ve already put in place or instrumentation that we’ve put in place in these services.
I think that complexity from going from cloud-hosted to cloud-native comes really from this historical implementation of us depending on what was available at the time and now we’re responsible for re-platforming or re-factoring to something that we recognize as the open standard for a cloud-native service.
Thomas Betts: Where it used to be traditional, I owned everything that was on the server that I built and I deployed, now I’m depending on all these other services, and if I really want to get the benefit of, well, what’s happening in all of those dependencies, you might have to adapt to understand what they’re producing. Are they using the same OpenTelemetry that you should then figure out how to get that integrated? That’s that aggregation you were talking about, right?
Rosemary Wang: Yes, exactly. And I think there’s plenty of abstractions out there now. We depended on the abstraction of the monitoring agent. Now I think we’ve got different kinds of abstractions. We’ve got the code libraries or SDKs, the instrumentation you put directly into the service, and then you also now have sidecars or sidecar processes. So it’s not just in the case of containers, but also if you’re doing a virtual machine that’s on a cloud, you might consider a sidecar process that’s retrieving some of this information. So there’s a lot of patterns now, and we’re pushing a lot of these into abstractions. Service mesh also being one of those as well saying, okay, I’m going to turn on telemetry on the proxy level and not necessarily need to think about instrumentation on the application side.
Thomas Betts: Those abstraction layers can be a benefit but also a curse. You’re giving up some control and you don’t have to think about all those things. It’s the traditional buy versus build model. I don’t have to build a service mesh because I can buy one off the shelf and it can do that type of work for me, but it means I do have to understand what am I giving up and what is that abstraction boundary.
Rosemary Wang: Yes, exactly.
The Importance of Immutability [14:07]
Thomas Betts: I want to move on to immutability. And immutability I think is great because it applies to a lot of different things. I can go down to I’m doing functional programming and my data is immutable, but I can also have immutable infrastructure, which is usually what’s talked about for infrastructure as code. You want to build once and deploy many times so that it’s repeatable. Why is it important to have all those things that we cannot change when we’re saying we’re cloud-native?
Rosemary Wang: Well, part of the problem is everything changes so quickly when it comes to a cloud-native environment. I think the best example of this is actually in secrets. Oftentimes when we’re starting to think about cloud-native, we’re using a lot of different services. We’re using many different approaches to authentication, API authorization, and there’s a secret sprawl of sorts. So now you’ve got tokens everywhere. You’ve got database credentials everywhere. You’ve got certificates. Who knows where the certificates are and when they’re going to expire?
And whenever you have so many of these components floating around, and it’s very natural in the cloud-native environment to have a lot of credentials across multiple providers, multiple systems, you start to wonder, well, what are we doing with them and what happens if one of them is compromised? Do we have the ability to (a) observe that something has been compromised? So that’s where observability is important. But also (b) make the changes with least disruption to our systems, and that’s where immutability becomes really key to surviving in a cloud-native environment.
Part of this is that it’s easier to say I will completely create something net new with the changes rather than go in and change or tweak one or two different configurations and lovingly go in and identify where all of these credentials are, where all these passwords are being used, when they’ve been used, who’s using them?
And so immutability becomes really powerful because when you say, okay, I don’t need to go in and make a change in place, instead I can just create something completely new and fail over to that new instance or new secret or new server or new set of applications without necessarily removing the old one. You can still use it, still debug, you can put them in isolation, and you generally mitigate the risk of how your changes may impact the system. And so immutability is all about mitigating risk at the end of the day and mitigating the impact of a potential change failure.
And whenever we talk about immutability, it’s scary. People don’t necessarily want to think about creating something new. They think about, oh, the resources are really expensive for me, but in a true cloud-native environment, resources are not as expensive as you expect, and it’s a decision that you make from the cost of failure versus the cost of creating that resource and making sure that you’re doing your due diligence and implementing the change correctly.
Thomas Betts: Yes, I think that speaks to a lot of how you have to design to be cloud-native, that you want smaller units, and that makes the immutability easier because you think about your whole system can’t change. Well, it’s got all these different pieces that have to connect, but if you break it down, it’s easier to say, well, that isn’t going to change. And how do you adapt to having the ability to deploy each of those small pieces individually or being able to change the one immutable thing without having to change all of it?
Rosemary Wang: There’s a balance to it. There’s also a science. It’s almost like dependency injection but for cloud-native environments. And we think about dependency injection oftentimes in software where we say, okay, we’ll not only have the abstraction but we’ll also make sure that higher level resources will call lower level resources. That’s a way that we make sure we decouple those dependencies. In the case of larger systems, modularity is a science. You have to identify what groups of functions are that make the most sense, and so there is a fine line between making too many small modules in your system.
Generally, I joke like if you find yourself putting one or two resources or one or two components into a bucket and saying that’s like one part of the system that I’m always going to change, maybe you should question if there are maybe more pieces to that that you should be adding to that group. On the other hand, you shouldn’t necessarily have a hundred different resources into let’s say one group of a change. It’s a little bit harder to describe at times, but I would certainly say that the rule of immutability that I have is if it takes more than two or three lines of code to make the change, then I should probably do it immutably. And that goes for infrastructure. That also goes for application code as well. But it’s a very difficult thing.
It’s a good question. I wonder if there is a scientific graph for evaluating it.
Thomas Betts: The answer is always it depends. You have to evaluate your own situation. I think you mentioned optimizing for the provisioning that this only works if you can deploy those things quickly. If it takes half an hour to deploy or longer, you’re going to let that thing live longer and you might design it differently. But if you say, oh, I can change this and turn it off and back on again, is the joke for IT, that if that’s going to happen in seconds or a few minutes, then that’s just the easier answer.
Rosemary Wang: And there’s also the other thing where if a change has gotten so drastically wrong that recovery is just not looking very promising, in place recovery is just not looking very promising, and this happens sometimes in the case of lets say data corruption or in a system where it’s been compromised from a security standpoint, then immutability works really well. It is worth, let’s say, taking two days to stand up the new environment when you might take a week trying to restore everything in place when all has gone wrong. So there’s still a power to immutability. And I think it will depend on, as you’ve pointed out, the scenario, the day-to-day what you’re doing, what change it is, and what state that system is in, in that point in time.
Thomas Betts: And you said state, and I was just thinking that you don’t want to have a whole lot of state being managed in that service. You want to think about the service is just doing the operation and the data is stored somewhere else. It’s another big design consideration.
Rosemary Wang: It is. We don’t talk enough about data in I think cloud-native. Most of the time when we talk about cloud-native, we often mix it with the idea of statelessness. The application does not contain any of the data. It does not track any of the data. It is merely processing it, but we don’t talk about state enough, and I think that what makes cloud-native state important tends to be whether or not you’ve handled the distribution of that data correctly. It’s no longer enough for us to say, okay, we’ve got one database and we’re just going to store it somewhere. That data, oftentimes, we have to think carefully about where it’s going to be replicated to, as well as how we’re going to manage it. I think we have to be more careful at times as well about how we do disaster recovery or data recovery for cloud-native components. We oftentimes just funnel that and ignore that consideration when we talk about environments in the cloud. But I think it becomes more important to think about backup, think about recovery whenever you have those components.
Elasticity: The Hallmark of Cloud-Native [20:57]
Thomas Betts: Yes. Again, nothing is for free. Nothing happens automatically. You have to design for it and plan for it. I think we’ll move on to elasticity. You talked about this being the hallmark of cloud-native, and that’s where we’re … So go to the cloud and you can just expand and shrink to meet your demand, almost automagically. And we talk about that usually as horizontal scaling that we want these small units to just expand out and they work in parallel, but is that always the right advice? And for cloud-native, do we sometimes need to have the vertical scaling as well?
Rosemary Wang: So vertical scaling is what we traditionally thought about in terms of resource efficiency. Are we using our memory? Are we using our CPU to the greatest extent? And if not, and we need more, well, we would say, okay, we’ll need a server or we’ll need a resource with more memory, more CPU. As you pointed out with horizontal scaling, instead, we’re focused on workload density, so how many of these instances in the smallest unit of resource usage can we schedule? And most of the time, cloud-native tends to be thought in the context of horizontal scaling. How many of these containers can we schedule or how many of these small, little instances can we use to distribute this amount of data?
And the reality is that vertical scaling is actually incredibly important in cloud-native as well because not everything can be horizontally scaled and not everything should be horizontally scaled either. And it’s all dependent on the idle versus active resources you do have. Sometimes it is more efficient, especially if you have something that is running with great frequency, sometimes you don’t want necessarily horizontal scaling. It’s more efficient to allocate one resource and that resource is allocated to running a job or some process very frequently. And then other times, you might have a need for volume, very, very adjustable volume over time. So volume adjusted based on demand. That could be requests for an application. That could be how much information or how many functions you’re running or processing something at one time? So it’s a pretty nuanced assessment.
With elasticity, what I will say is that part of our problem is that we think a lot about scaling up and we don’t think necessarily about scaling down. And even whether you’re doing vertical scaling or horizontal scaling, there is a possible scale down for both scenarios, and that’s where we have to be a little bit more careful about how we optimize and where we schedule some of these workloads.
Thomas Betts: That scaling down I think was another talk at QCon about cloud zombies that we have all these instances that are running around and they either got too big and they never got smaller or we left them running. I think Holly Cummins gave that talk, talking about #lightswitchops. She just wants people to go around and start turning things off. You think, oh, it’s in the cloud, it will just automatically turn off, and nothing is as automatic as you think.
Rosemary Wang: No, it is not. One thing that I see, elasticity tends to affect cost. And the thing that people don’t realize is networking components often are probably the culprit of the zombie resource that’s just hanging out there and not really doing anything. So in the case of AWS, Elastic IPs. Data transfer, there’s surprising amount that you get charged for transfer out of your network and across regions as well. We don’t think of those as zombies per se because we’re transmitting data out. That’s got to have some use. And the reality is sometimes we don’t need to be what I call doing the traffic trombone. We don’t need to send that traffic out. Really we should be just keeping it within our network. So there’s a lot of considerations there. I like the zombie resources analogy.
Thomas Betts: That was part of the green software track or design for sustainability and just that’s another idea about going cloud-native, is you have all this power but you also have to be cognizant of how much carbon are you using? And it’s harder to measure. It’s getting better. A lot of times, we just look at the cost of the resources and think, oh, that must be how efficient it is. And your example of you’re having a lot of small things, sometimes it’d be useful to have a few larger instances running. I think a lot of examples of people went to a serverless offering because they thought it would save money and they went back to a full VM or Kubernetes or whatever because it turned out having one thing provisioned all the time was cheaper than spinning up all these little instances all the time. So you can’t just assume that, oh, we can go smaller and it’ll be cheaper or be more efficient.
Rosemary Wang: Yes, exactly. I see a lot in data processing, specifically. People will spin up a lot of functions, and the cost of the functions, unfortunately it gets quite expensive and then they end up going to a dedicated data processing tool, and that’s something that they host themselves. And over time, they’ve made this discovery that it’s no longer feasible for them to maintain the volume of functions and the frequency of functions that they’re spinning up.
Changeability Often Involves Paradigm Shifts [25:27]
Thomas Betts: Well, let’s wrap up with changeability. So this is another promise of the cloud, is the ability to be flexible and we get to try new things. That might be a new resource capability that was just offered or maybe it’s a new way of working among the teams. What are some of the pitfalls that we’re running into if we just assume that we’re going to the cloud and we get all this flexibility to do whatever we want?
Rosemary Wang: Most of the time, these latest offerings involve paradigm shifts, and they’re not paradigm shifts about the technology themselves. They’re paradigm shifts about how we work. It’s about process and about people. A good example of this is GitOps. People have been really interested in GitOps recently because it’s this promise of continuous deployment of services with a metrics-based approach. Automated deployment, you get a sense of what these metrics are. You get automated rollback. It handles the operational aspect of rollout, but it’s a paradigm shift. It’s not that easy to say I’m going to defer all decision-making automatically to a controller that’s going to assess whether or not these metrics are good or bad and then handle the rollout for me, and then I’ll trust that it will roll back. It’s a really difficult thing to change your mindset on.
And so when we talk about changeability in the context of cloud-native, it’s this idea that you may have to convince someone to take on new perspective for these latest offerings or latest technologies, and that in some ways is a more difficult prospect than some technical implementation. But what I generally say is that in the context of changeability, there’s always an intermediate step. You don’t have to take advantage of the latest offering immediately. In order to get buy-in and to really think carefully about whether or not this new offering is for you from a cultural standpoint for your organization, choose the intermediate step. And that may mean that you do something manually or you do something that is not ideal in the beginning, but then you eventually shift toward that latest approach.
So in the example of GitOps, maybe you do some kind of CI automation that allows you to do some deployment that is partially manual, partially automated, and that gets you a little bit closer to the GitOps model, a little bit more comfortable with it. I think it’s important to differentiate cloud-native changeability from cloud-hosted changeability. Cloud-hosted changeability is this idea that you’re hosting it and you may not necessarily re-platform it on the latest offering or you may not want to take advantage of all these latest technologies. With cloud-native, you do because to be honest, they’ll probably deprecate the service offering you’re using in a couple of years, so you always need to rethink about what is the latest offering that you’re going to have to move to in a couple of years’ time.
Thomas Betts: I like the idea of having those intermediate steps. You don’t have to jump to the end and assume you can get all the benefit and the overlap between the, “I want this technical feature, but I have to think about the socio-technical impacts and that for us to change our process or change our application, we have to get the people to change as well.”
Rosemary Wang: It’s something we forget about sometimes. I think it’s easy to say, okay, I’m going to quit my application, and that’s where this journey starts, saying, I’m going to put this application on the cloud. It’s easy enough to say I hosted on the cloud and therefore I’m running it. But cloud-native, it changes a lot of perspective, and I think that’s where we go wrong. We forget that we ourselves have to change to accommodate for a very dynamic environment because we’re no longer able to control the next version of Kubernetes or the next version of a monitoring tool anymore. If we’re using open standards, this will be driven by the community. This will be driven by outside forces that are not directly in our control, and we have to make sure that we can adapt to all those things.
It’s Okay If You’re Cloud-Hosted [28:57]
Thomas Betts: Any final advice for the people who are thinking about how to get either onto the cloud-hosted, onto the cloud-native or what they’re doing and how to make any little incremental changes for their process?
Rosemary Wang: It’s okay if you’re cloud-hosted. I think people are like, oh, we must be cloud-native. And the thing is it’s okay if you’re cloud-hosted. It’s working for you. You’ve got the cost optimization you’re looking for. Really, it’s already incremental progress for you. You don’t have to wait around for procurement of infrastructure, for example. Maybe that’s what the value you’re seeing right now. And it’s okay, you’re cloud-hosted.
If you do want to go to cloud-native and you want to scale the way you are offering infrastructure as well as how people are developing services because you’ve reached that point, again, take those incremental steps. You don’t have to jump immediately to a new greenfield offering and commit to changing everything. Change one or two things that are already going to improve your workflow. So think about what your workflow is today. Think about small things that might make it a little bit better, and then eventually, you’ll get to a point where you can say I’m fully cloud-native.
Thomas Betts: Well, that’s a good place to end. So I want to thank you, Rosemary Wang, for joining us on the InfoQ Podcast.
Rosemary Wang: Thank you for having me.
Thomas Betts: And we hope you’ll join us again soon for another episode.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.