Month: June 2023

MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ

A way to improve developer experience is by removing time-consuming tasks and bottlenecks from developers and from the platform team that supports them. How you introduce changes matters; creating an understanding of the “why” before performing a change can smoothen the rollout.
Jessica Andersson spoke about improving developer experience in a small organization at NDC Oslo 2023.
Andersson explained that developer experience includes all the things that a software developer does in their work for developing and maintaining software, such as writing the code, testing, building, deploying, monitoring, and maintaining:
I often think of this from a product perspective where a development team is responsible for the product life cycle. A good developer experience allows a developer to focus on the things that make your product stand out against the competition and deliver customer value.
Their strategy for increasing developer experience has been to remove time-consuming tasks and bottlenecks. They started out by unblocking developers. If a developer has to wait for someone outside their team in order to make progress, then they are not able to act as an autonomous team and take full ownership of their product life cycle, Andersson said.
Next, they looked at removing time-consuming tasks from the platform team. In order to be able to continue delivering a better developer experience to their developers they needed to make sure that the platform team wasn’t stuck in an endless upgrade and migration loop.
After having freed up time from the platform team, they shifted the focus to removing time-consuming tasks from the developers leading to an overall better developer experience.
Andersson mentioned that how you introduce changes matters and it’s easier to apply changes if you have created an understanding of the “why” before you do so. They introduced a quite different workflow for developers that they believed would be a great improvement, but met some resistance in adoption before the developers understood why and how it was an improvement:
In the long run, it turned into a very appreciated way of working, but the rollout could have gone smoother if we spent more effort on introducing the change before performing it.
You need to build the confidence with developers that you will deliver value to them, Andersson said. Having a good relationship with your developers is key to understanding their problems and how you can improve their daily lives, she concluded.
InfoQ interviewed Jessica Andersson about improving the developer experience.
InfoQ: What challenges did you face improving developer experience while being on a small team?
Jessica Andersson: We couldn’t do everything, and we couldn’t do it all at once. We aimed to take on one thing, streamline it and do it well, and once it was “just working” we could move on to the next thing.
We also had to be mindful of the dependencies we brought on and the tools we started using, everything needs to be kept up-to-date and there’s a real risk of ending up in a state of constant updates with no room for new improvements.
InfoQ: Can you give an example of how you improved your developer experience?
Andersson: For unblocking developers we had the context of using DNS for service discovery. DNS was handled manually and there were just two people who had access to Cloudflare, of which I was one. This meant that every time a developer wanted to deploy a new service or update or remove an existing one, they had to come to me and ask for help.
This was not ideal for how we wanted to work so we started looking into how we could handle this differently in the Kubernetes environment we were using for container runtime. We looked at the ExternalDNS project which allows for managing DNS records through Kubernetes resources.
For us it was really simple to get up and running and fairly easy to migrate the existing, manually-created DNS records to be tracked by ExternalDNS as well. Onboarding developers to the new process was quick and we saw clear benefits within weeks of switching over!
InfoQ: What benefits can a golden path or paved road provide for developers?
Andersson: It allows developers to reuse a golden path for known problems, for instance using the same monitoring solution for different applications. Another benefit is keeping the cognitive load lower; by applying the same way of doing things to different applications, it becomes easier to maintain many applications.
InfoQ: What’s your advice to small teams or organizations that want to improve developer experience?
Andersson: My strongest advice is to assess your own organization and context before deciding on what to do. Figure out where you can make an impact on developer experience, pick one thing and improve it! Avoid copying what others have done unless it also makes sense in your context.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Apple has introduced a new open source package, the Swift OpenAPI Generator, aimed at generating the code required to handle client/server communication through an HTTP API based on its OpenAPI document.
Swift OpenAPI Generator generates type-safe representations of each operation’s input and output as well as the required network calls to deal with sending requests and processing responses on the client side and server-side stubs to delegate request processing to handlers.
Both the client and the server code are based on a generated APIProtocol type that contains one method for each OpenAPI operation. For example, for a simple GreetingService supporting HTTP GET requests at the /greet endpoint, the APIProtocol would contain a getGreeting method. Along with the protocol definition, a Client type implementing it is also generated for use on the client side. Server-side, the package generates a registerHandlers method belonging to the APIProtocol to register one handler for each operation in the protocol.
The generated code does not cover authentication, logging, or retrying. This kind of logic is usually too strictly associated with the business logic to allow for a general abstraction. Anyway, developers can implement those features in a middleware that conforms to the ClientMiddleware or ServerMiddleware protocols to be reusable in other projects based on Swift OpenAPI Generator.
The code Swift OpenAPI Generator generates is not tied to a specific HTTP framework but relies on a generic ClientTransport or ServerTransport type, which any compatible HTTP framework should implement to be usable with the generator. Currently, the Swift OpenAPI Generator can be used with a few existing transport frameworks, including URLSession from iOS own Foundation framework, HTTPClient from AsyncHTTPClient, Vapor, and Hummingbird.
All protocols and types used in the Swift OpenAPI Generator are defined in its companion project Swift OpenAPI Runtime, which is relied upon by generated client and server code.
The generator can be run in two ways: either as a Swift Package Manager plugin, integrated in the build process, or manually through a CLI. In the first case, the plugin is controlled by a YAML configuration file named openapi-generator-config.yaml that must exist in the target source directory along with the OpenAPI document in JSON or YAML format. Using this configuration file, you can specify whether to generate only the client code, the server code, or both in the same target. The CLI supports the same kind of configurability through command line options, as shown in the example below:
swift run swift-openapi-generator
--mode types --mode client
--output-directory path/to/desired/output-dir
path/to/openapi.yaml
The Swift OpenAPI Generator is yet in its early stages and while it supports most of the commonly used features of OpenAPI, Apple says, it still lacks a number of desired features that are in the works.
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

Day One of the 9th annual QCon New York conference was held on June 13th, 2023 at the New York Marriott at the Brooklyn Bridge in Brooklyn, New York. This three-day event is organized by C4Media, a software media company focused on unbiased content and information in the enterprise development community and creators of InfoQ and QCon. It included a keynote address by Radia Perlman and presentations from these four tracks:
There was also one sponsored solutions track.
Dio Synodinos, president of C4Media, Pia von Beren, Project Manager & Diversity Lead at C4Media, and Danny Latimer, Content Product Manager at C4Media, kicked off the day one activities by welcoming the attendees and providing detailed conference information. The aforementioned track leads for Day One introduced themselves and described the presentations in their respective tracks.
Keynote Address
Radia Perlman, Pioneer of Network Design, Inventor of the Spanning Tree Protocol and Fellow at Dell Technologies, presented a keynote entitled, The Many Facets of “Identity”. Based on the history of practicing authentication methods, Perlman provided a very insightful look at how the phrase “the identity problem” may not be as well-understood. She maintained that “most people think they know the definition of ‘identity’…kind of.” Perlman went on to describe the many dimensions of “identity” including: human and DNS naming; how to prove ownership of a human or DNS name; and what a browser needs to know to properly authenticate a website. The theory of DNS is “beautiful,” as she described, but in reality, a browser search generally returns an obscure URL string. Because of this, Perlman once fell victim to a scam while trying to return her driver’s license. She then discussed how it is difficult for humans to properly follow password rules, questioned the feasibility of security questions, and recommended that people should use identity providers. Perlman characterized the Public Key Infrastructure (PKI) as “still crazy after all these years” and discussed how a certificate authority, a device that signs a message saying “This name has this public key,” should be associated with the registry from which DNS name is returned. She then described the problem with X.509 certificates such that Internet protocols use DNS names, not X.500 names. “If being able to receive at a specific IP address is secure, we don’t need any of this fancy crypto stuff,” Perlman said. She then compared the top-down and bottom-up models with DNS hierarchical namespaces in which each node in the namespace represents a certificate authority. Perlman recommended the bottom-up model, created by Charlie Kaufman circa 1988, because organizations wouldn’t have to pay for certifications. Also, there is still a monopoly at the root level and root can impersonate everyone in the top-down model. In summary, Perlman said that nothing is quite right today because names are meaningless strings and obtaining a certification certificate is messy and insecure. In conclusion, Perlman suggested to always start with the question, “What problem am I solving?” and to compare various approaches. In a humorous moment early in her presentation, she remarked, “I hate computers” when she had difficulty manipulating her presentation slides. Perlman is the author of the books, Network Security: Private Communication in a Public World and Interconnections: Bridges, Routers, Switches, and Internetworking Protocols.
Highlighted Presentations
Laying the Foundations for a Kappa Architecture – The Yellow Brick Road by Sherin Thomas, Staff Software Engineer at Chime. Thomas introduced the Kappa Architecture as an alternative to the Lambda Architecture, both deployment models for data processing that combine a traditional batch pipeline with a fast real-time stream pipeline for data access. She questioned why the Lambda Architecture is still popular based on the underlying assumption of Lambda: “that stream processors cannot provide consistency is no longer true thanks to modern stream processors like Flink.” The Kappa Architecture has its roots from this 2014 blog post by Kafka Co-Creator Jay Kreps, Co-Founder and CEO at Confluent. Thomas characterized the Kappa Architecture as a streaming first, single path solution that can handle real-time processing as well as reprocessing and backfills. She demonstrated how developers can build a multi-purpose data platform that can support a range of applications on the latency and consistency spectrum using principles from a Kappa architecture. Thomas discussed the Beam Model, how to write to both streams and data lakes and how to convert a data lake to a stream. She concluded by maintaining that the Kappa Architecture is great, but it is not a silver bullet. The same is true for the Lambda Architecture due to the dual code path making it more difficult to manage. A backward compatible, cost effective, versatile and easy to manage data platform could be a combination of the Kappa and Lambda architectures.
Sigstore: Secure and Scalable Infrastructure for Signing and Verifying Software by Billy Lynch, Staff Software Engineer at Chainguard, and Zack Newman, Research Scientist at Chainguard. To address the rise of security attacks across every stage of the development lifecycle, Lynch and Newman introduced Sigstore, an open-source project that aims to provide a transparent and secure way to sign and verify software artifacts. Software signing can minimize the compromise of account credentials and package repositories, and checks that a software package is signed by the “owner.” However, it doesn’t prevent attacks such as normal vulnerabilities and build system compromises. Challenges with traditional software signing include: key management, rotation, compromise detection, revocation and identity. Software signing is currently widely supported in open-source software, but not widely used. By default, tools don’t check signatures due to usability issues and key management. Sigstore frees developers from key management and relies on existing account security practices such as two-factor authentication. With Sigstore, users authenticate via OAuth (OIDC) and an ephemeral X.509 code signing certificate is issued to bind to the identity of the user. Lynch and Newman provided overviews and demonstrations of Sigstore to include sub-projects: Sigstore Cosign, signing for containers; Sigstore Gitsign, Git commit signing; Sigstore Fulcio, users authentication via OAuth; Sigstore Rekor, an append-only transparency log such that the certificate is valid if the signature is valid; Sigstore Policy Controller, a Kubernetes-based admission controller; and Sigstore Public Good Operations, a special interest group comprised of a group of volunteer engineers from various companies collaborating to operate and maintain the Sigstore Public Good instance. Inspired by RFC 9162, Certificate Transparency Version 2.0, the Sigstore team provides a cryptographically tamper-proof public log of everything they do. The Sigstore team concluded by stating: there is no single or one-size fits all solution; software signing is not a silver bullet, but is a useful defense; software signing is critical for any DevSecOps; and developers should start verifying signatures including your own software. When asked by InfoQ about security concerns with X.509, as discussed in Perlman’s keynote address, Newman stated that certificates are very complex and acknowledged that vulnerabilities can still make their way into certificates. However, Sigstore is satisfied with the mature libraries available to process X.509 certifications. Newman also stated that an alternative would be to scrap the current practice and start from scratch. However, that approach could introduce even more vulnerabilities.
Build Features Faster With WebAssembly Components by Bailey Hayes, Director at Cosmonic. Hayes kicked off her presentation by defining WebAssembly (Wasm) Modules as: a compilation target supported by many languages; only one .wasm file required for an entire application; and built from one target language. She then introduced the WebAssembly System Interface (WASI), a modular system interface for WebAssembly, that Hayes claims should really be known as the WebAssembly Standard Interfaces because it’s difficult to deploy modules in POSIX. She then described how Wasm modules interact with the WASI via the WebAssembly Runtime and the many ways that a Wasm module can be executed, namely: plugin tools such as Extism and Atmo, FaaS providers, Docker and Kubernetes. This was followed by a demo of a Wasm application. Hayes then introduced the WebAssembly Component Model, a proposed extension of the WebAssembly specification that supports high-level types within Wasm such as strings, records and variants. After describing the building blocks of Wasm components with the WASI, she described the process of how to build a component followed by a live demo of an application, written in Go and Rust, that was built and converted to a component.
Virtual Threads for Lightweight Concurrency and Other JVM Enhancements by Ron Pressler, Technical Lead OpenJDK’s Project Loom at Oracle. Pressler provided a comprehensive background on the emergence of virtual threads that included many mathematical theories. A comparison of parallelism vs. concurrency defined performance measures in latency (time duration) and throughput (task/time unit), respectively. For any stable system with long-term averages, he introduced Little’s Law as L = λW, such that:
- L = average number of items in a system
- λ = average arrival rate = exit rate = throughput
- W = average wait time in a system for an item (duration inside)
A comparison of threads vs. async/await in terms of scheduling/interleaving points, implementation and recursion/virtual calls defined the languages that support these attributes, namely: JavaScript, Kotlin and C++/Rust, respectively. After introducing asynchronous programming, syntactic coroutines (async/await) and the impact of context switching with servers, Pressler tied everything together by discussing threads and virtual threads in the Java programming language. Virtual threads is a relatively new feature that was initially introduced in JDK 19 as a preview. After a second preview in JDK 20, virtual threads will be a final feature in JDK 21, scheduled to be released in September 2023. He concluded by defining the phrase “misleading familiarity” as “there is so much to learn, but there is so much to unlearn.”
Summary
In summary, day one featured a total of 28 presentations with topics such as: architectures, engineering, language platforms and software supply chains.
MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ

OpenAI has introduced updates to the API, including a capability called function calling, which allows developers to describe functions to GPT-4 and GPT-3.5 and have the models create code to execute those functions.
According to OpenAI, function calling facilitates the development of chatbots capable of leveraging external tools, transforming natural language into database queries, and extracting structured data from text. These models have undergone fine-tuning to not only identify instances where a function should be invoked but also provide JSON responses that align with the function signature.
AI models can intelligently interface with external tools and APIs thanks to the crucial role played by function calling. Developers can access a large selection of functionality and services by specifying functions to these models. By using external tools to respond to queries, search databases, or extract structured data from unstructured text, this connection enables AI models to accomplish tasks that are beyond their natural capacities. As a result of function calling, AI models become more versatile and effective instruments for tackling complex challenges in the real world.
With the introduction of gpt-4-0613 and gpt-3.5-turbo-0613, developers now have the ability to describe functions to these models. As a result, the models can intelligently generate JSON objects that contain the necessary arguments to call those functions. This exciting development offers a more dependable means of connecting GPT’s capabilities with external tools and APIs, opening up new possibilities for seamless integration.
These models have developed the capability to recognize situations where a function should be activated based on the user’s input through careful fine-tuning. Additionally, they have been taught to provide JSON answers that match the particular function signature. Developers can now more reliably and consistently get structured data from the model by using function calling.
In addition to function calling, OpenAI is introducing an enhanced variant of GPT-3.5-turbo that offers a significantly expanded context window. The context window, measured in tokens or units of raw text, represents the amount of text considered by the model prior to generating further text. This expansion allows the model to access and incorporate a larger body of information, enabling it to make more informed and contextually relevant responses.
Function calls in AI development allow models to utilize tools designed by developers, enabling them to extend their capabilities and integrate customized functionalities. This collaborative approach bridges the gap between AI models and developer-designed tools, fostering versatility, adaptability, and innovation in AI systems.
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
At the recent annual Build conference, Microsoft introduced the preview of Microsoft Azure API Center – a new Azure service and a part of the Azure API Management platform that enables tracking APIs in a centralized location for discovery, reuse, and governance.
With API Center, users can access a central hub to discover, track, and manage all APIs within their organization, fostering company-wide API standards and promoting reuse. In addition, it facilitates collaboration between API program managers, developers who discover and consume APIs to accelerate or enable application development, API developers who create and publish APIs, and other stakeholders involved in API programs.
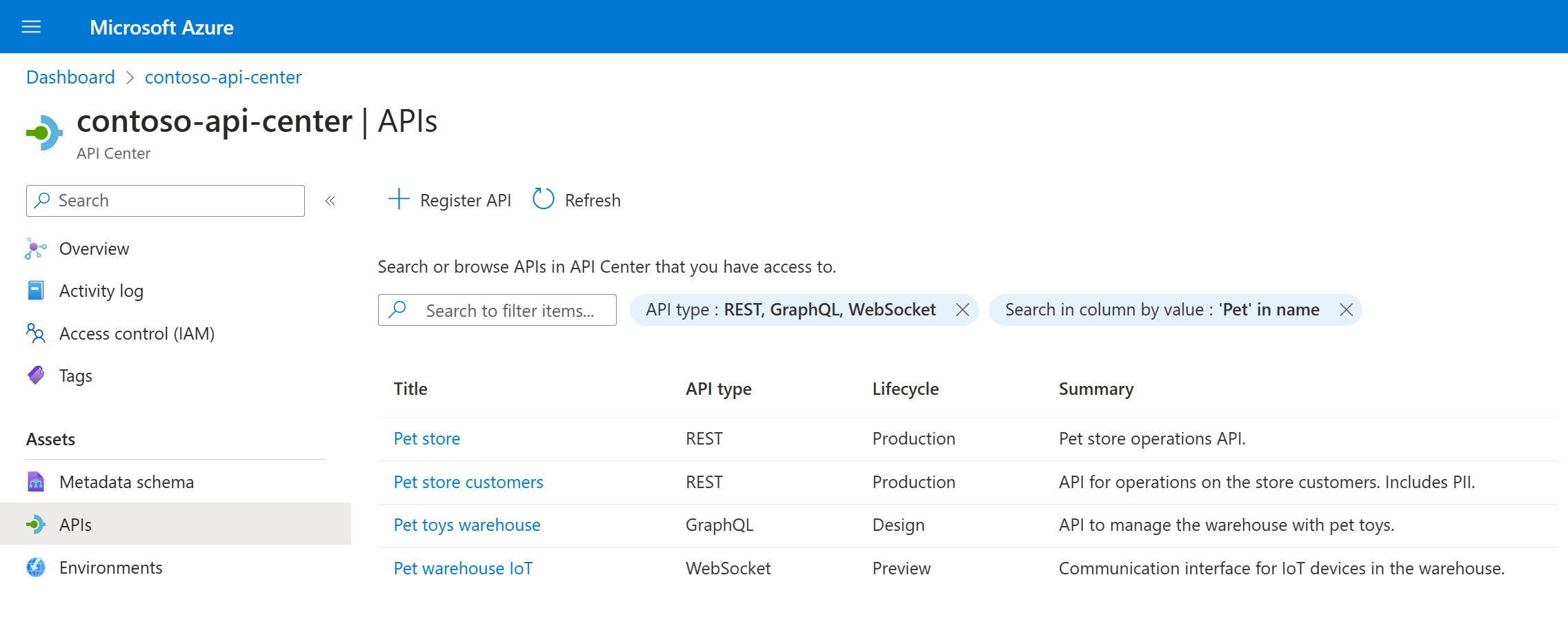
Source: https://github.com/Azure/api-center-preview
The key capabilities of API Center include:
- API inventory management centralized the collection of all APIs within an organization. These APIs can vary in type (such as REST, GraphQL, gRPC), lifecycle stage (development, production, deprecated), and deployment location (Azure cloud, on-premises data centers, other clouds).
- Real-world API representation provides detailed information about APIs, including their versions, specifications, deployments, and the environments in which they are deployed.
- Metadata properties enhance governance and discoverability by organizing and enriching cataloged APIs, environments, and deployments with unified built-in and custom metadata throughout the entire asset portfolio.
- Workspaces, allowing management of administrative access to APIs and other assets with role-based access control.
Regarding the API Inventory management, Fernando Mejia, a senior program manager, said during a Microsoft Build session on APIs:
With API Center, you can bring your APIs from Apigee, such as AWS API Gateway or MuleSoft API Management. The idea is to have a single inventory for all of your APIs.
Mike Budzynski, a senior product manager at Azure API Management at Microsoft, explained to InfoQ the release roadmap of the API Center feature:
API Center is currently in preview for evaluation by Azure customers. At first, we are limiting access by invitation only. We plan to open it up for broader adoption in the fall.
In addition, in a tech community blog post, Budzynski wrote:
During the preview, API Center is available free of charge. Future releases will add developer experiences, improving API discovery and reusability, and integrations simplifying API inventory onboarding.
Microsoft currently allows a limited set of customers to access API Center through a request form.
MMS • Anton Skornyakov
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- We all carry some developmental trauma that makes it difficult for us to collaborate with others – a crucial part of work in agile software development.
- Leading in a trauma-informed way is not practicing unsolicited psychotherapy, and it is not justifying destructive behaviors without addressing them.
- Being more trauma-informed in your leadership can help everyone act more maturely and cognitively available, especially in emotionally challenging situations.
- In trauma-informed working environments, people pay more attention to their physical and emotional state.
- They also rely more on the power of intention, set goals in a less manipulative manner, and are able to be empathetic without taking ownership of others’ problems.
In recent decades, scientific and clinical understanding of how the human nervous system develops and works has increased tremendously. Its implications are so profound they radiate far beyond the field of psychology. Topics such as trauma-informed law, volleyball coaching, legal counseling, education, and social activism have arisen.
It is time to consider how it affects working in an agile tech environment.
Defining “trauma-informed” work
Working in a trauma-informed manner means professionally conducting whatever you set out to do while taking into account different forms of trauma that humans you work with are affected by.
It is not practicing unsolicited psychotherapy, and it is not justifying destructive behaviors without addressing them.
This means different things when you do trauma-informed legal counseling, volleyball coaching, or agile coaching.
An everyday example for an agile coach would be to notice the shallow rapid breathing of participants at the start of a meeting and to invite them to briefly take three long breaths and for 20 seconds to reflect on what they each want to accomplish in this meeting and summarize that in one sentence.
Traumatic patterns make collaboration difficult
Let’s look at a typical example of a team member moving from individual responsibility for tasks to sharing in team responsibility for done increments. The reactions triggered by such a change vary strongly depending on the person affected. They could just be happy and enthusiastic about new opportunities. However, they could also experience spiraling self-doubt, become subliminally aggressive, perfectionistic and distrustful, withdraw themselves from most interactions, or become avoidant.
Any of the above reactions may be adequate for a short period in a particular situation. However, if they become a pattern that doesn’t resolve itself, it harms everyone involved. Such patterns typically originate from traumatic experiences we’ve had.
When such a pattern is triggered, our attention gets stuck within. We may think and overthink whether we are allowed to speak up and, if so, what words we can use. We may search for tricky ways to stop the change or to completely disconnect ourselves from what is changing around us.
Whatever the pattern is, once it is triggered, we pay less attention to what is actually happening – the reality, but are more preoccupied with ourselves. Dealing with these internal patterns can take up a large portion of our cognitive and emotional resources. We act less like mature adults. This makes finding a common way forward for us, our co-workers, and our leaders much harder.
Traumatic patterns used to serve us as kids but are harming us in adult life
There are different forms of trauma. Here I am not focusing on shock trauma, which typically arises from one or few particularly terrible situations. The patterns I describe usually originate from different forms of developmental trauma. These emerge when our environment systematically does not meet our basic needs as a child.
When this happens, we can’t do anything about it as children and adapt by changing what we think is normal in the world and us. We end up denying ourselves some part of being human. Paradoxically, this helps us a lot, as it dissolves a consistently hurtful dissonance.
Later, when we are confronted with this need in our adult life, we react from the altered idea of ourselves and the world. However, since what we are denying ourselves is an inevitable part of being human, we end up in an unending struggle. When we are in such an inner struggle, our capacity for using our conscious thinking and being empathic is strongly impaired.
Typical Examples from Tech Organizations
Since we are all, to some extent, affected by developmental trauma, you can find countless examples of its effects, small or large, in any organization. And as developmental trauma originates from relationships with other humans, its triggers are always somehow linked to individuals and interactions with them. Just think of colleagues with typical emotional patterns in interactions with you or notice your patterns in interactions with particular colleagues.
One pattern I’ve often observed with some software developers I worked with, and I am also familiar with myself, is perfectionism. The idea of delivering a result that is not perfect and imagining being made aware of a mistake I made is sometimes unbearable. And most of the time, it’s unconscious. I just always try to make something as perfect as I can imagine. This can make collaborating with other people very hard, they may not meet my standards for perfection, or I may fear being at the mercy of their high standards that I can’t fulfill.
Another such pattern is self-doubt, which manifests in the inability to express one’s wishes or opinions. In this pattern, the pain of others potentially seeing our statement as inappropriate or useless is so strong that we don’t even invest time into thinking about our own position. Again, this typically is unconscious, and it’s just how we are used to behaving. Overlooking a critical position can cause significant long-term damage to organizations. And almost always, another person in our place and with our knowledge would express similar concerns and wishes.
A trauma-informed approach to leading people in agile organizations
First of all, I would like to emphasize that we are still at the very beginning of professionalizing our work with respect to developmental trauma, and I would love to see many more discussions and contributions on these subjects.
I want to share how I changed my practice as an agile coach and trainer after completing basic training to become a trauma-informed (NARM®-informed professional). These insights come from understanding how professionals deal with trauma and how to deal with it without justifying destructive behavior or beating people over the head with their patterns.
Higher attention to physical and emotional states
Software is, by definition, very abstract. For this reason, we naturally tend to be in our heads and thoughts most of the time while at work. However, a more trauma-informed approach requires us to pay more attention to our physical state and not just to our brain and cognition. Our body and its sensations are giving us many signs, vital not just to our well-being but also to our productivity and ability to cognitively understand each other and adapt to changes. Paradoxically, in the end, paying more attention to our physical and emotional state gives us more cognitive resources to do our work.
Noticing our bodily sensations at the moment, like breath or muscle tension in a particular area, can be a first step to getting out of a traumatic pattern. And a generally higher level of body awareness can help us fall less into such patterns in the first place. Simplified – our body awareness anchors us in the here and now, making it easier for us to recognize past patterns as inadequate for the current situation.
One format that helps with this and is known to many agile practitioners is the Check-In in the style of the Core Protocols. I use it consequently when training and or conducting workshops and combine it with a preceding silent twenty seconds for checking in with ourselves on how we are physically feeling. It allows everyone to become aware of potentially problematic or otherwise relevant issues before we start. After such a Check-In, most groups can easily deal with any problems that might have seriously impeded the meeting if left unsaid. People are naturally quite good at dealing with emotional or otherwise complicated human things, provided they are allowed to show themselves.
The power and importance of intention
My second significant learning is that we need a deep respect for the person’s intention and an understanding of the power that can be liberated by following one’s intention.
For me, as a coach, this means when interacting with an organization, clarifying my client’s intention is a major and continuous part of my work. And it means supporting them in following their intention is more important than following my expert opinion. I should be honest and share my thoughts; however, it’s my clients journey which I am curiously supporting. I know this way, change will happen faster. It will be more durable and sustainable than if the client blindly followed my advice to adopt this or that practice.
In fact, clients who choose to blindly follow a potentially very respected consultant often reenact traumatic experiences from their child’s past. It is a different thing when organizational leaders are driven by their own intentions and are uncovering their paths faster and with more security due to an expert supporting them on their journey.
For the leadership in organizations that rightfully have their own goals and strategies, understanding the power of intention means leading with more invitations and relying more on volunteering. Instead of assigning work, they try to clarify what work and what projects need to be accomplished and allow people to choose for themselves. Even if something is not a person’s core discipline, they may decide to learn something new and be more productive in their assignment than a bored expert. This way of leading people requires more clarity on boundaries and responsibility than assigning work packages to individuals.
For all of us, respecting our own intentions and being aware of their power means looking for the parts of work that spark our curiosity or feel like fun to do and following them as often as we can.
I use this insight every time I deliver training. At the end of a typical two-day workshop, my participants will have an exhaustive list of things they want to try, look into, change, or think about. From my experience with thousands of participants, having such a long list of twenty items or more isn’t going to lead to any meaningful result. Most of the time, it’s just overwhelming, and people end up not doing any of the items on their lists. So at the end of each training, I invite my participant to take 5 minutes and scan through all their takeaways and learnings to identify 2 or 3 that spark joy when they think of applying them. Not only has this produced a tremendous amount of positive feedback, participants regularly report how relieving and empowering these 5 minutes are to them.
Set goals as changes of state, not changes in behavior
My third trauma-informed insight is that I became aware of an essential nuance when it comes to setting goals, a key discipline when it comes to leading agile organizations.
Often when we set a goal, we define it as a behavior change. Instead, a trauma-therapeutic practitioner will explore the state change the client believes this would bring.
For example, if someone says, “I want my developers to hit the deadline on our team.”
I might ask: “If your developers do start hitting the deadlines, how do you hope this will impact your leadership?”
The outcome of such a goal-setting conversation, the state someone wants their leadership or themselves to be in, is often a much more durable goal, and it’s typically more connected to the actual need of the person setting the goal. On the other hand, focusing on behavioral changes often leads to manipulation that doesn’t achieve what we really want.
The above example applies to an internal situation. However, looking for a change in the state of our customers is also a different conversation than looking into the behavioral change we want them to exhibit. Here the change in state is also a more stable, long-term goal.
Leadership topics benefiting from trauma-informed approaches
I believe that in organizational leadership, there is a lot more to learn from trauma-informed approaches, to count a few:
- Get a deeper understanding of the stance of responsibility in oneself and your co-workers and how to get there. In NARM®, this is called agency.
- Understand the difference between authentic empathy that supports someone in need and unmanaged empathy that overwhelms and disrupts relationships.
- Get a new relieving perspective on our own and others’ difficult behaviors.
Becoming trauma-informed in your daily work
I believe that you can only guide people to where you’ve been yourself. Familiarize yourself with the topic and start reflecting on your own patterns. You’ll automatically become aware of many moments that trauma plays a role in your work and will be able to find new ways to deal with it.
My journey started with listening to the “Transforming Trauma” podcast. If you like to read books, I’d recommend “The Body Keeps the Score” by Bessel van der Kolk or “When the Body Says No: The Cost of Hidden Stress” by Gabor Mate. However, the moment I truly started to reflect and apply trauma-informed practices was during the NARM®-basic training I completed last year. There is something very unique about it since it’s the first module of education for psychotherapists. Still, it is on purpose open to all other helping professionals, anyone working with humans. I’d recommend completing such a course to anyone serious about becoming trauma-informed.
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
Paypal recently open-sourced JunoDB, a distributed key-value store built on RocksDB. Daily, JunoDB, PayPal’s highly available and security-focused database, processes 350 billion requests.
PayPal’s wide variety of applications relies heavily on JunoDB, a distributed key-value store. JunoDB is used for virtually every critical backend service at PayPal, including authentication, risk assessment, and transaction settlement. Data may be cached and accessed quickly from apps using JunoDB, reducing the strain on backend services and relational databases. JunoDB, however, is not an ordinary NoSQL database. It was developed to meet PayPal’s specific requirements. Thus, it can simultaneously manage many concurrent users and connections without slowing down. Originally built in single-threaded C++, it has been rewritten in Golang to take advantage of parallel processing and many cores.
The JunoDB architecture is a dependable and extensible system that prioritizes ease of use, scalability, security, and flexibility. Proxy-based design simplifies development by abstracting away complex logic and setup from applications and allowing for linear horizontal connection scaling. When expanding or contracting clusters, JunoDB uses consistent hashing to split data and reduce the amount of data that must be moved. JunoDB uses a quorum-based protocol and a two-phase commit to guarantee data consistency and ensure there is never any downtime for the database.
Protecting information both in transit and at rest is a high priority. Hence TLS support and payload encryption are implemented. Finally, JunoDB’s flexibility and ability to adapt over time are guaranteed by its pluggable storage engine design, which makes it simple to switch to new storage technologies as they become available.
The core of JunoDB is made up of three interdependent parts:
- The JunoDB proxy allows application data to be easily stored, retrieved, and updated, thanks to the JunoDB client library’s provided API. With support for languages including Java, Golang, C++, Node, and Python, the JunoDB thin client library can be easily integrated with programs built in various languages.
- Client queries and replication traffic from remote sites are processed by proxy instances of JunoDB that are controlled by a load balancer. Each proxy establishes a connection to all JunoDB storage server instances, and routes request to a set of storage server instances according to the shard mapping stored in ETCD.
- JunoDB uses RocksDB to store data in memory or persistent storage upon receiving an operation request from a proxy.
JunoDB maintains high levels of accessibility and system responsiveness while supporting many client connections. It also manages data expansion and maintains high read/write throughput even as data volume and access rates rise. To achieve six 9s of system availability, JunoDB uses a mix of solutions, including data replication inside and outside data centers and failover mechanisms.
JunoDB provides exceptional performance at scale, managing even the most intensive workloads with response times in the millisecond range and without disrupting the user experience. In addition, JunoDB offers a high throughput and low latencies, enabling applications to scale linearly without compromising performance.
Users can get the source code for JunoDB, released under the Apache 2 license, on GitHub. PayPal produced server configuration and client development tutorial videos to aid developers’ database use. The team plans to include a Golang client and a JunoDB operator for Kubernetes in the future.
Check Out The Reference Article. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
MMS • Andrew Hoblitzell
Article originally posted on InfoQ. Visit InfoQ

Nvidia’s new NeMo Guardrails package for large language models (LLMs) helps developers prevent LLM risks like harmful or offensive content and access to sensitive data. This innovation is crucial for developers as it offers multiple features to control the behavior of these models, thereby ensuring their safer deployment. Specifically, NeMo Guardrails helps mitigate the risks of LLMs generating harmful or offensive content thereby providing an essential layer of protection in an increasingly AI-driven landscape.
NeMo Guardrails helps developers to mitigate the risks associated with LLMs by providing a number of features to control the behavior of these models. The package is built on Colang, a modeling language and runtime developed by Nvidia for conversational AI. “If you have a customer service chatbot, designed to talk about your products, you probably don’t want it to answer questions about our competitors,” said Jonathan Cohen, Nvidia vice president of applied research. “You want to monitor the conversation. And if that happens, you steer the conversation back to the topics you prefer”.
NeMo Guardrails currently supports three broad categories: Topical, Safety, and Security. Topical guardrails ensure that conversations stay focused on a particular topic. Safety guardrails ensure that interactions with an LLM do not result in misinformation, toxic responses, or inappropriate content. They also enforce policies to deliver appropriate responses and prevent hacking of the AI systems. Security guardrails prevent an LLM from executing malicious code or calls to an external application in a way that poses security.
Guardrails features a sandbox environment, allowing developers the freedom to experiment with AI models without jeopardizing production systems, thus reducing the risk of generating harmful or offensive content. Additionally, a risk dashboard is provided, which consistently tracks and scrutinizes the use of AI models, assisting developers in identifying and mitigating potential risks before they lead to major issues. Moreover, it supplies a clear set of policies and guidelines designed to direct the usage of AI within organizations.
Reception has generally been positive about NeMo-Guardrails, but some have expressed caution around the limitations. There are certain limitations and constraints developers need to be aware of when using this LLM package. Karl Freund of Cambrian-AI Research writes “guardrails could be circumvented or otherwise compromised by malicious actors, who could exploit weaknesses in the system to generate harmful or misleading information”. Jailbreaks, hallucinations, and other issues also remain active research areas which no current system has implemented fullproof protection against.
Other tools also exist for safety when working with large language models. For example, Language Model Query Language (LMQL) is designed to make natural language prompting and is built on top of Python. Microsoft’s Guidance framework can also be used for addressing issues with LLMs not guaranteeing that output follows a specific data format.
Nvidia advises that Guardrails works best as a second line of defense, suggesting that companies developing and deploying chatbots should still train the model on a set of safeguards with multiple layers.
MMS • Chris Klug
Article originally posted on InfoQ. Visit InfoQ

Key Takeaways
- Project Orleans has been completely overhauled in the latest version, making it easy to work with. It has also been re-written to fit in with the new IHost abstraction that was introduced in .NET Core.
- The actor model is wonderful for the scenarios where it makes sense. It makes development a lot easier for scenarios where you can break down your solution into small stateful entities.
- The code that developers need to write can be kept highly focused on solving the business needs, instead of on the clustering, networking and scaling, as this is all managed by Project Orleans under the hood, abstracted away.
- Project Orleans makes heavy use of code generators. By simply implementing marker interfaces, the source generators will automatically add code to your classes during the build. This keeps your code simple and clean.
- Getting started with Project Orleans is just a matter of adding references to a couple of NuGet packages, and adding a few lines of code to the startup of your application. After that, you can start creating Grains, by simply adding a new interface and implementation.
In this article, we will take a look at Project Orleans, which is an actor model framework from Microsoft. It has been around for a long time, but the new version, version 7, makes it a lot easier to get started with, as it builds on top of the .NET IHost abstraction. This allows us to add it to pretty much any .NET application in a simple way. On top of that it abstracts away most of the complicated parts, allowing us to focus on the important stuff, the problems we need to solve.
Project Orleans
Project Orleans is a framework designed and built by Microsoft to enable developers to build solutions using the actor-model, which is a way of building applications that enables developers to architect and build certain types of solutions in a much easier way than it would be to do it using for example an n-tier architecture.
Instead of building a monolith, or a services-based architecture where the services are statically provisioned, it allows you to decompose your application into lots of small, stateful services that can be provisioned dynamically when you need them. On top of that, they are spread out across a cluster more or less automatically.
This type of architecture lends itself extremely well to certain types of solutions, for example IoT devices, online gaming or auctions. Basically, any solution that would benefit from an interactive, stateful “thing” that manages the current state and functionality, like a digital representation of an IoT device, a player in an online game, or an auction. Each of these scenarios become a lot easier to build when they are backed by an in-memory representation that can be called, compared to trying to manage it using an n-tier application and some state store.
Initially, Orleans was created to run Halo. And using the actor-model to back a game like that makes it possible to do things like modelling each player as its own tiny service, or actor, that handles that specific gamer’s inputs. Or model each game session as its own actor. And to do it in a distributed way that has few limitations when it needs to scale.
However, since the initial creation, and use in Halo, it has been used to run a lot of different services, both at Microsoft and in the public, enabling many large, highly scalable solutions to be built by decomposing them into thousands of small, stateful services. Unfortunately, it is hard to know what systems are using Orleans, as not all companies are open about their tech stack for different reasons. But looking around on the internet, you can find some examples. For example, Microsoft uses it to run several Xbox services (Halo, Gears of War for example), Skype, Azure IoT Hub and Digital Twins. And Honeywell uses it to build an IoT solution. But it is definitely used in a lot more places, to run some really cool services, even if it might not be as easy as you would have hoped to see where it is used.
As you can see, it has been around for a long time, but has recently been revamped to fit better into the new .NET core world.
The actor pattern
The actor pattern is basically a way to model your application as a bunch of small services, called actors, where each actor represents a “thing”. So, for example, you could have an actor per player in an online game. Or maybe an actor for each of your IoT devices. But the general idea is that an actor is a named, singleton service with state. With that as a baseline, you can then build pretty much whatever you want.
It might be worth noting that using an actor-model approach is definitely not the right thing for all solutions. I would even say that most solutions do not benefit very much from it, or might even become more complex if it is used. But when it fits, it allows the solution to be built in a much less complex way, as it allows for stateful actors to be created.
Having to manage state in stateless services, like we normally do, can become a bit complicated. You constantly need to retrieve the state that you want to work with for each request, then manipulate it in whatever way you want, and finally persist it again. This can be both slow and tedious, and potentially put a lot of strain on the data store. So, we often try to speed this up, and take some of the load of the backing store using a cache. Which in turn adds even more complexity. With Project Orleans, your state, and functionality, is already instantiated and ready in memory in a lot of cases. And when it isn’t, it handles the instantiation for you. This removes a lot of the tedious, repetitive work that is needed for the data store communication, as well as removes the need for a cache, as it is already in memory.
So, if you have any form of entity that works as a form of state machine for example, it becomes a lot easier to work with, as the entity is already set up in the correct state when you need it. On top of that, the single threaded nature of actors allows you to ignore the problems of multi-threading. Instead, you can focus on solving your business problems.
Imagine an online auction system that allows users to place bids and read existing bids. Without Orleans, you would probably handle this by having an Auction service that allows customers to perform these tasks by reading and writing data to several tables in a datastore, potentially supported by some form of cache to speed things up as well. However, in a high-load scenario, managing multiple bids coming in at once can get very complicated. More precisely, it requires you to figure out how to handle the locks in the database correctly to make sure that only the right bids are accepted based on several business rules. But you also need to make sure that the locks don’t cause performance issues for the reads. And so on …
By creating an Auction-actor for each auction item instead, all of this can be kept in memory. This makes it possible to easily query and update the bids without having to query a data store for each call. And because the data is in-memory, verifying whether a bid is valid or not is simply a matter of comparing it to the existing list of bids, and making a decision based on that. And since it is single-threaded by default, you don’t have to handle any complex threading. All bids will be handled sequentially. The performance will also be very good, as everything is in-memory, and there is no need to wait for data to be retrieved.
Sure, bids that are made probably need to be persisted in a database as well. But maybe you can get away with persisting them using an asynchronous approach to improve throughput. Or maybe you would still have to slow down the bidding process by writing it to the database straight away. Either way, it is up to you to make that decision, instead of being forced in either direction because of the architecture that was chosen.
Challenges we might face when using the actor pattern
First of all, you have to have a scenario that works well with the pattern. And that is definitely not all scenarios. But other than that, some of the challenges include things like figuring out what actors make the most sense, and how they can work together to create the solution.
Once that is in place, things like versioning of them can definitely cause some problems if you haven’t read up properly on how you should be doing that. Because Orleans is a distributed system, when you start rolling out updates, you need to make sure that the new versions of actors are backwards compatible, as there might be communication going on in the cluster using both the old and the new version at the same time. On top of that, depending on the chosen persistence, you might also have to make sure that the state is backwards compatible as well.
In general, it is not a huge problem. But it is something that you need to consider. Having that said, you often need to consider these things anyway, if you are building any form of service based solution.
Actor-based development with Project Orleans
It is actually quite simple to build actor based systems with Project Orleans. The first step is to define the actors, or Grains as they are called in Orleans. This is a two-part process. The first part is to define the API we need to interact with the actor, which is done using a plain old .NET interface.
There are a couple of requirements for the interface though. First of all, it needs to extend one of a handful of interfaces that comes with Orleans. Which one depends on what type of key you want to use. The choices you have are IGrainWithStringKey, IGrainWithGuidKey, IGrainWithIntegerKey, or a compound version of them.
All the methods on the interface also need to be async, as the calls might be going across the network. It could look something like this:
public interface IHelloGrain : IGrainWithStringKey
{
Task SayHello(User user);
}
Any parameters being sent to, or from the interface, also need to be marked with a custom serialisation attribute called GenerateSerializer, and a serialisation helper attribute called Id. Orleans uses a separate serialisation solution, so the Serializable attribute doesn’t work unfortunately. So, it could end up looking something like this:
[GenerateSerializer]
public class User
{
[Id(0)] public int Id { get; set; }
[Id(1)] public string FirstName { get; set; }
[Id(2)] public string LastName { get; set; }
}
The second part is to create the grain implementation. This is done by creating a C# class, that inherits from Grain, and implements the defined interface.
Because of Orleans being a little bit magi – more on that later on – we only need to implement our own custom parts. So, implementing the IHelloGrain could look something like this:
public class HelloGrain : Grain, IHelloGrain
{
public async Task SayHello(User user)
{
return Task.FromResult($“Hello {user.FirstName} {user.LastName}!”);
}
}
It is a good idea to put the grains in a separate class library if you are going to have a separate client, as both the server and client part of the system need to be able to access them. However, if you are only using it behind something else, for example a web API, and there is no external client talking to the Orleans cluster, it isn’t strictly necessary.
A thing to note here is that you should not expose your cluster to the rest of the world. There is no security built into the cluster communication, so the recommended approach is to keep the Orleans cluster “hidden” behind something like a web API.
Once the grains are defined and implemented, it is time to create the server part of the solution, the Silos.
Luckily, we don’t have to do very much at all to set these up. They are built on top of the IHost interface that has been introduced in .NET. And because of that, we just need to call a simple extension method to get our silo registered. That will also take care of registering all the grain types by using reflection. In its simplest form, it ends up looking like this:
var host = Host.CreateDefaultBuilder()
.UseOrleans((ctx, silo) => {
silo.UseLocalhostClustering();
})
.Build();
This call will also register a service called IGrainFactory, that allows us to access the grains inside the cluster. So, when we want to talk to a grain, we just write something like this:
var grain = grainFactory.GetGrain(id);
var response = await grain.SayHello(myUser);
And the really cool thing is that we don’t need to manually create the grain. If a grain of the requested type with the requested ID doesn’t exist, it will automatically be created for us. And if it isn’t used in a while, the garbage collector will remove it for us to free up memory. However, if you request the same grain again, after it has been garbage collected, or potentially because a silo has been killed, a new instance is created and returned to us automatically. And if we have enabled persistence, it will also have its state restored by the time it is returned.
How Project Orleans makes it easier for us to use the actor pattern
Project Orleans removes a lot of the ceremony when it comes to actor-based development. For example, setting up the cluster has been made extremely easy by using something called a clustering provider. On top of that, it uses code generation, and other .NET features, to make the network aspect of the whole thing a lot simpler. It also hides the messaging part that is normally a part of doing actor development, and simply provides us with asynchronous interfaces instead. That way, we don’t have to create and use messages to communicate with the actors.
For example, setting up the server part, the silo, is actually as simple as running something like this:
var host = Host.CreateDefaultBuilder(args)
.UseOrleans(builder =>
{
builder.UseAzureStorageClustering(options => options.ConfigureTableServiceClient(connectionString));
})
.Build();
As you can see, there is not a lot that we need to configure. It is all handled by conventions and smart design. This is something that can be seen with the code-generation as well.
When you want to interact with a grain, you just ask for an instance of the interface that defines the grain, and supply the ID of the grain you want to work with. Orleans will then return a proxy class for you that allows you to talk to it without having to manage any of the network stuff for example, like this:
var grain = grainFactory.GetGrain(id);
var response = await grain.SayHello(myUser);
A lot of these simplifications are made possible using some really nice code generation that kicks into action as soon as you reference the Orleans NuGet packages.
Where can readers go when they want to learn more about project Orleans and the actor model?
The easiest way to get more information about building solutions with Project Orleans is to simply go to the official docs of Project Orleans and have a look. Just remember that when you are looking for information about Orleans, you need to make sure that you are looking at documentation that is for version 7+. The older version looked a bit different, so any documentation for that would be kind of useless unfortunately.
Where to go from here?
With Project Orleans being as easy as it is to get started with, it makes for a good candidate to play around with if you have some time left over and want to try something new, or if you think it might fit your problem. There are also a lot of samples on GitHub from the people behind the project if you feel like you need some inspiration. Sometimes it can be a bit hard to figure out what you can do with a new technology, and how to do it. And looking through some of the samples gives you a nice view into what the authors of the project think it should be used for. I must admit, some of the samples are a bit, well, let’s call it contrived, and made up mostly to show off some parts of the functionality. But they might still provide you with some inspiration of how you can use it to solve your problem.
For me, I ended up rebuilding an auction system in a few hours just to prove to my client how much easier their system would be to manage using an actor based model. They are still to implement it in production, but due to the simplicity of working with Project Orleans, it was easy to create a proof of concept in just a few hours. And I really recommend doing that if you have a scenario where you think it might work. Just remember to set a timer, because it is very easy to get carried away and just add one more feature.
In tech, it is rare to find something as complicated as clustering being packaged into something that is as simple to work with as Project Orleans. Often the goal is to make it simple and easy to use, but as developers we tend to expose every single config knob we can find to the developer. Project Orleans has stayed away from this, and provides a nice experience that actually felt fun to work with.
MMS • Robert Krzaczynski
Article originally posted on InfoQ. Visit InfoQ
Microsoft has introduced the C# Dev Kit, a new extension to Visual Studio Code, offering an enhanced C# development environment for Linux, macOS and Windows. This kit, combined with the C# extension, uses an open-source Language Server Protocol (LSP) host to provide an efficient and configurable environment. The source repository for the extension is currently being migrated and will be available later this week.
The C# Dev Kit brings familiar concepts from Visual Studio to make VS Code programming in C# more productive and reliable. It includes a collection of VS Code extensions that work together to provide a comprehensive C# editing environment that includes artificial intelligence-based programming, solution management and integrated testing. The C# extension provides language services, while the C# Dev Kit extension builds on the Visual Studio foundation for solution management, templates and debugging testing. Moreover, the optional IntelliCode for C# Dev Kit extension provides the editor with programming capabilities based on artificial intelligence.
Source: https://devblogs.microsoft.com/visualstudio/announcing-csharp-dev-kit-for-visual-studio-code/
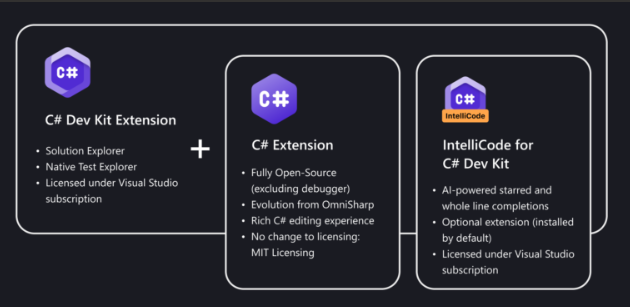
This tool streamlines project management in C# programming by adding a Solution Explorer view that integrates with the VS Code workspace. It allows developers to effortlessly add projects and files to their solutions using templates. The extension simplifies the organisation of tests for XUnit, NUnit, MSTest and bUnit, displaying them in the Test Explorer panel. The C# Dev Kit, based on the open source C# extension with LSP (Language Server Protocol) host, provides exceptional performance and integrates with Roslyn and Razor for advanced features such as IntelliSense, navigation and code formatting.
In addition, the IntelliCode for C# Dev Kit extension, which is installed automatically, provides AI-assisted support beyond the basic IntelliSense technology. It offers advanced IntelliCode features such as whole-line completion and starred suggestions, prioritising frequently used options in the IntelliSense completion list based on the personal codebase. With the C# Dev Kit, users can experience increased performance and reliability not only when programming, but also when managing solutions, debugging and testing.
By installing the C# Dev Kit extension, users of the VS Code C# extension (supported by OmniSharp) can upgrade to the latest pre-release version compatible with the C# Dev Kit, as explained in the documentation.
The following question was raised under this post on Microsoft’s website:
Does this enable creating solutions from scratch as well, or does it still require an initial dotnet new console and open folder? It is been a while since I last checked VS Code out, but that has been bugging me every time to create a new solution.
Tim Hueuer, a principal product manager at Microsoft, answered:
If you have no folder open (blank workspace) you’ll see the ability to create a project from there. I can’t paste a picture here in the comments but there is a button on a workspace with no folder open that says “Create .NET Project” that will launch the template picker with additional questions of where to create it.
Additionally, Leslie Richardson, a product manager at Microsoft, added that further information about the solution explorer experience in VS Code can be found here.
Overall, the tool gets positive feedback from the community. Users see a significant improvement in using Visual Studio Code to code in C#.