Month: June 2023
Nosql Databases Software Market Dynamics, Forecast, Analysis and Supply Demand 2023-2030

MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

New Jersey, USA- This section discusses various aspects of the Nosql Databases Software Market sector, including its size, trends, and revenue forecasts. The Nosql Databases Software Market Research literature also presents sections exclusive to assessing and concluding the revenue prospects for each market sector. The Nosql Databases Software Market report concludes with a detailed assessment of this industry, highlighting the growth drivers and lucrative prospects that are likely to affect the global Nosql Databases Software Market over the forecast period.
This section discusses various aspects of this sector, including its size, trends, and revenue forecasts. The Nosql Databases Software Market is segmented by product type, end-user industry, and geography.
The Nosql Databases Software Market report provides an in-depth analysis of the current state of the industry, including its technological trends, competitive landscape, key players, and revenue forecasts for global, regional, and country levels. It also provides comprehensive coverage of major industry drivers, restraints, and their impact on market growth during the forecast period. For the purpose of research, The Report has segmented the global Nosql Databases Software Market on the basis of types, technology, and region.
Request PDF Sample Copy of Report: (Including Full TOC, List of Tables & Figures, Chart): https://www.marketresearchintellect.com/download-sample/?rid=252741
Key Competitors of the Global Nosql Databases Software Market are:
- 3M
- ATS Acoustics Putty Pads
- STI Firestop
- ROCKWOOL
- Hilti
- Nullifire
- Pyroplex
- Minerallac
- FSI Limited
- EverBuild (Firespan)
- Metacaulk
- BIOSTOP
- Remo
- Knauf Group
Major Product Types covered are:
- Elastometric Type
- Intumescent Type
The Application Coverage in the Market is:
- Electric Power
- Communication
- Others
Get a Discount On The Purchase Of This Report @ https://www.marketresearchintellect.com/ask-for-discount/?rid=252741
Regional Nosql Databases Software Market (Regional Output, Demand & Forecast by Regions):-
- North America (United States, Canada, Mexico)
- South America ( Brazil, Argentina, Ecuador, Chile)
- Asia Pacific (China, Japan, India, Korea)
- Europe (Germany, UK, France, Italy)
- Middle East Africa (Egypt, Turkey, Saudi Arabia, Iran) And More.
Major Points Covered in Table of Contents:
Nosql Databases Software Market Overview
Market Competition by Manufacturers
Production Picture of Nosql Databases Software Market and Global Nosql Databases Software Market: Classification
Overall Nosql Databases Software Market Regional Demand
Market Breakdown and Data Triangulation Approach
Business, Regional, Product Type, Sales Channel – Trends
Nosql Databases Software Market Dynamics: Restraints, Opportunities, Industry Value Chain, Porter’s Analysis, and Others
Covid-19 impact on Global Nosql Databases Software Market Demand
Market Analysis Forecast by Segments
Competitive Analysis
Market Research Findings & Conclusion The research report studies the past, present, and future performance of the global market. The report further analyzes the present competitive scenario, prevalent business models, and the likely advancements in offerings by significant players in the coming years.
Key Questions Answered by the Report
What are the top strategies that players are expected to adopt in the coming years?
What are the trends in this Nosql Databases Software Market?
How will the competitive landscape change in the future?
What are the challenges for this Nosql Databases Software Market?
What are the market opportunities and market overview of the Nosql Databases Software Market?
What are the key drivers and challenges of the global Nosql Databases Software Market?
How is the global Nosql Databases Software Market segmented by product type?
What will be the growth rate of the Global Nosql Databases Software Market 2023 for the forecast period 2023 to 2030?
What will be the market size during this estimated period?
What are the opportunities business owners can rely upon to earn more profits and stay competitive during the estimated period?
Potential and niche segments/regions exhibiting promising growth
A neutral perspective toward Global Nosql Databases Software Market performance
Access full Report Description, TOC, Table of Figures, Chart, etc. @ https://www.marketresearchintellect.com/product/global-nosql-databases-software-market-size-and-forecast/
About Us: Market Research Intellect
Market Research Intellect provides syndicated and customized research reports to clients from various industries and organizations with the aim of delivering functional expertise. We provide reports for all industries including Energy, Technology, Manufacturing and Construction, Chemicals and Materials, Food and Beverage, and more. These reports deliver an in-depth study of the market with industry analysis, the market value for regions and countries, and trends that are pertinent to the industry.
Contact Us:
Mr. Edwyne Fernandes
Market Research Intellect
New Jersey (USA)
US: +1 (650)-781-4080 US
Toll-Free: +1 (800)-782-1768
Website: -https://www.marketresearchintellect.com/
NoSQL Market 2023 Growth Opportunities and Future Outlook | IBM Corporation, Aerospike …
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

New Jersey (United States) – NoSQL Market research is an intelligence report with meticulous efforts undertaken to study the right and valuable information. The data which has been looked upon is done considering both, the existing top players and the upcoming competitors. Business strategies of the key players and the new entering market industries are studied in detail. Well explained SWOT analysis, revenue share and contact information are shared in this report analysis.
Get the PDF Sample Copy (Including FULL TOC, Graphs, and Tables) of this report @ https://www.mraccuracyreports.com/report-sample/211522
Some of the Top companies Influencing this Market include:
IBM Corporation, Aerospike Inc, MarkLogic Corporation, Hibernate, MariaDB, Oracle Database, Neo technology, MongoDB, Basho Technologies, Couchbase, PostgreSQL
Various factors are responsible for the market’s growth trajectory, which are studied at length in the report. In addition, the report lists down the restraints that are posing threat to the global NoSQL .This report is a consolidation of primary and secondary research, which provides market size, share, dynamics, and forecast for various segments and sub-segments considering the macro and micro environmental factors. It also gauges the bargaining power of suppliers and buyers, threat from new entrants and product substitutes, and the degree of competition prevailing in the market.
NoSQL Market Types:
Key-Value Store, Document Databases, Column Based Stores, Graph Database.
NoSQL Market Applications:
Retail, Online Game Development, IT, Social Network Development, Web Applications Management, Others
The report studies the key segments in the global NoSQL industry, their growth in the past few years, profiles and market sizes of individual segments, and gives a detailed overview of the profiles of various segments. The report also presents key products and various other products in the global NoSQL industry along with its market size and growth in the study period. The major demand drivers for the global NoSQL industry products and services are outlined in the report. The NoSQL report details some major success factors and risk factors of investing in certain segments.
The report provides insights on the following pointers:
Market Penetration: Comprehensive data on the product portfolios of the top players in the NoSQL market.
Product Development/Innovation: Detailed information about upcoming technologies, R&D activities, and market product debuts.
Competitive Assessment: An in-depth analysis of the market’s top companies’ market strategies, as well as their geographic and business segments.
Market Development: Information on developing markets in its entirety. This study examines the market in several geographies for various segments.
Market Diversification: Extensive data on new goods, untapped geographies, recent advancements, and investment opportunities in the NoSQL market.
Get Up to 30% Discount on the first purchase of this report @ https://www.mraccuracyreports.com/check-discount/211522
The cost analysis of the Global NoSQL Market has been performed while keeping in view manufacturing expenses, labor cost, and raw materials and their market concentration rate, suppliers, and price trend. Other factors such as Supply chain, downstream buyers, and sourcing strategy have been assessed to provide a complete and in-depth view of the market. Buyers of the report will also be exposed to a study on market positioning with factors such as target client, brand strategy, and price strategy taken into consideration.
Key questions covered in this report?
- A complete overview of different geographic distributions and common product categories in the NoSQL Market.
- When you have information on the cost of production, the cost of products, and the cost of production for future years, you can fix up the developing databases for your industry.
- Thorough break-in analysis for new enterprises seeking to enter the NoSQL Market.
- Exactly how do the most essential corporations and mid-level companies create cash within the Market?
- Conduct a thorough study on the overall state of the NoSQL Market to aid in the selection of product launches and revisions.
Table of Contents
Global NoSQL Market Research Report 2022 – 2029
Chapter 1 NoSQL Market Overview
Chapter 2 Global Economic Impact on Industry
Chapter 3 Global Market Competition by Manufacturers
Chapter 4 Global Production, Revenue (Value) by Region
Chapter 5 Global Supply (Production), Consumption, Export, Import by Regions
Chapter 6 Global Production, Revenue (Value), Price Trend by Type
Chapter 7 Global Market Analysis by Application
Chapter 8 Manufacturing Cost Analysis
Chapter 9 Industrial Chain, Sourcing Strategy and Downstream Buyers
Chapter 10 Marketing Strategy Analysis, Distributors/Traders
Chapter 11 Market Effect Factors Analysis
Chapter 12 Global NoSQL Market Forecast
Buy Exclusive Report@: https://www.mraccuracyreports.com/checkout/211522
If you have any special requirements, please let us know and we will offer you the report as you want.
MMS • Anthony Alford
Article originally posted on InfoQ. Visit InfoQ

Google DeepMind recently announced PaLM 2, a large language model (LLM) powering Bard and over 25 other product features. PaLM 2 significantly outperforms the previous version of PaLM on a wide range of benchmarks, while being smaller and cheaper to run.
Google CEO Sundar Pichai announced the model at Google I/O ’23. PaLM 2 performs well on a variety of tasks including code generation, reasoning, and multilingual processing, and it is available in four different model sizes, including a lightweight version called Gecko that is intended for use on mobile devices. When evaluated on NLP benchmarks, PaLM 2 showed performance improvements over PaLM, and achieved new state-of-the-art levels in many tasks, especially on the BIG-bench benchmark. Besides powering Bard, the new model is also a foundation for many other products, including Med-PaLM 2, a LLM fine-tuned for the medical domain, and Sec-PaLM, a model for cybersecurity. According to Google,
PaLM 2 shows us the impact of highly capable models of various sizes and speeds—and that versatile AI models reap real benefits for everyone. Yet just as we’re committed to releasing the most helpful and responsible AI tools today, we’re also working to create the best foundation models yet for Google.
In 2022, InfoQ covered the original release of Pathways Language Model (PaLM), a 540-billion-parameter large language model (LLM). PaLM achieved state-of-the-art performance on several reasoning benchmarks and also exhibited capabilities on two novel reasoning tasks: logical inference and explaining a joke.
For PaLM 2, Google implemented several changes to improve model performance. First, they studied model scaling laws to determine the optimal combination of training compute, model size, and data size. They found that, for a given compute budget, data and model size should be scaled “roughly 1:1,” whereas previous researchers had scaled model size 3x the data size.
The team improved PaLM 2’s multilingual capabilities by including more languages in the training dataset and updating the model training objective. The original dataset was “dominated” by English; the new dataset pulls from a more diverse set of languages and domains. Instead of using only a language modeling objective, PaLM 2 was trained using a “tuned mixture” of several objectives.
Google evaluated PaLM 2 on six broad classes of NLP benchmark, including: reasoning, coding, translation, question answering, classification, and natural language generation. The focus of the evaluation was to compare its performance to the original PaLM. On BIG-bench, PaLM 2 showed “large improvements,” and on classification and question answering even the smallest PaLM 2 model achieved performance “competitive” with much the larger PaLM model. On reasoning tasks, PaLM 2 was also “competitive” with GPT-4; it outperformed GPT-4 on the GSM8K mathematical reasoning benchmark.
In a Reddit discussion about the model, several users commented that although its output wasn’t as good as that from GPT-4, PaLM 2 was noticeably better. One user said:
They probably want it to be scalable so they can implement it for free/low cost with their products. Also so it can accompany search results without taking forever (I use GPT 4 all the time and love it, but it is pretty slow.)…I just used the new Bard (which is based on PaLM 2) and it’s a good amount faster than even GPT 3.5 turbo.
The PaLM 2 tech report page on Papers with Code lists the model’s performance on several NLP benchmarks.
MMS • Almir Vuk
Article originally posted on InfoQ. Visit InfoQ

Avalonia UI is an open-source and cross-platform UI framework for .NET developers, designed to facilitate the development of desktop applications that can run on Windows, macOS, Linux, iOS, Android, and WebAssembly. InfoQ interviewed Mike James, CEO of Avalonia UI, in order to understand more about this UI framework and its features.
InfoQ: How did Avalonia UI emerge within the ecosystem?
Mike James: The project has its roots in OSS, being community-led from its inception rather than being built by an established business and later shared. The core contributors established a company a few years back to provide support and development services to enterprises.
We recently announced our first foray into products with Avalonia XPF, our cross-platform WPF, which enables WPF apps to run on macOS and Linux with little to no code changes.
InfoQ: What are the key features and benefits of using Avalonia UI for developing desktop applications?
Mike: Using Skia, we enable “pixel-perfect” applications that look the same across every platform. You don’t need to learn or dig into platform-specific APIs to tweak your app’s UI or create custom controls! We’ve found that this level of customisation is essential to many of our users.
The other key benefit of Avalonia UI is that we have the broadest range of supported platforms while not compromising performance. You can develop apps for powerful desktops, low-powered embedded devices, phones, tablets, and WebAssembly.
Our API is designed to be cross-platform, and we take time to ensure that added features make sense in the context of cross-platform UI app development. While WPF and WinUI influence our APIs, we don’t simply copy them; we change things where we can improve. We’ve always regarded blindly copying Windows APIs as a flawed strategy.
InfoQ: What is the current state of Avalonia UI in the .NET User Interface landscape?
Mike: When I started exploring cross-platform UIs for .NET in 2012, the only option was Xamarin. Today the landscape is very different; we have many more options, all with their strengths and weaknesses. Our strength is our ability to provide a high-performance, consistent user experience across platforms while providing developers with a familiar, stable and proven SDK.
We’re often compared to MAUI, which interests me as we don’t view MAUI as a competitor. When I worked at Xamarin, the significant benefit was that Xamarin apps were native apps; that is, they used the native UI toolkits. In 2013, this was extremely important, but it’s no longer such a crucial component when picking a UI technology. If we look at Flutter or the growing popularity of web technologies, we see that it’s possible to deliver high-quality experiences without using native UI toolkits.
We have a ton of respect for MAUI, but we see Flutter and Qt as the main competitors going forward. That’s not to disrespect them, but we believe that technologies outside the .NET ecosystem are doing some exciting things.
In terms of our current state, we provide the most performant cross-platform UI toolkit for .NET developers. If developers prioritise performance, then it makes sense for them to use Avalonia UI. We achieve this by managing every pixel displayed within the application. We have very minimal dependencies, on Windows only using Win32 for the Window.
We previously had a version of Avalonia UI that depended on MonoMac, the precursor to Xamarin.Mac, but found its performance wasn’t acceptable, and thus created our own binding approach called MicroCOM.
On Linux, we only need X11, and iOS and Android just require NET.iOS and NET.Android. Once we have a native Window, we’re good to start pushing pixels and receiving user input events.
InfoQ: How is Avalonia UI positioned in comparison with Microsoft’s recent efforts?
Mike: We tend not to compare ourselves to MAUI, which provides respectable support for mobile but falters on other platforms. From a technical perspective, Avalonia’s approach is drastically different from that of MAUI. MAUI is less a UI toolkit and more a UI abstraction. It relies on the underlying native UI toolkit to work, while we draw the entire UI using ourselves. Most of our users are using SkiaSharp to achieve this, but our architecture makes the renderer pluggable and we’re looking at alternatives as SkiaSharp risks becoming a liability with its lack of maintenance from Microsoft.
The drawn approach yields considerable benefits, especially regarding performance, ease of development and platform support. What really illustrates this is our ability to easily support any platform. Our only requirement is the ability to push pixels and receive interaction events. To give a concrete example, you only need to look at our VNC support, which works with only ~200 LOC. It’d be impossible for MAUI to add new platforms at the speed that we can, simply due to their architecture and dependency on abstracting native UI toolkits.
Our ultimate aim is to become the first choice for every new project that requires a client app, regardless of the target platform. We deliver the best experience for desktop apps already, but we must continue improving our mobile offering to compete with Flutter. We’re going to achieve this by continuing to make investments in growing the team developing Avalonia UI.
InfoQ: What is the roadmap for future development of Avalonia UI, and what new features can we expect to see in upcoming releases?
Mike: In the short term, our roadmap focuses on releasing v11 and overhauling the documentation portal.
v11 provides vast improvements, including a new compositional renderer, accessibility, additional platform support and much more.
Past the release of v11, we’ve some plans that will help us continue to drive adoption and improve the developer experience. We’re going to improve our Visual Studio extension and investigate other renderers to remove our dependency on SkiaSharp.
Interested readers can learn more about Avalonia UI and get started using the documentation and Avalonia GitHub repository.
PostgreSQL, Oracle Database, Objectivity, Neo, MySQL, MongoLab, MongoDB, Microsoft SQL Server
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

The NoSQL market research delivers comprehensive research on the present stage of the market, covers market size with respect to assessment as sales volume, and provides a precise forecast of the market scenario over the estimated period. Also focuses on the product, application, manufacturers, suppliers, and regional segments of the market. NoSQL market report research highlights market driving factors, an overview of the market growth, industry size, and market share. Subsequently NoSQL market report depicts the constantly evolving needs of clients, vendors, and purchasers in different regions, it becomes simple to target specific market and generate large revenues in the global industry.
According to the latest research study, the demand of global NoSQL market size & share was valued at approximately USD 85.4 Billion in 2022 and is expected to reach USD 96.2 billion in 2023 and is expected to reach a value of around USD 170 Billion by 2030, at a compound annual growth rate (CAGR) of about 12%during the forecast period 2023 to 2030.”
Some of these key players include: PostgreSQL, Oracle Database, Objectivity, Neo, MySQL, MongoLab, MongoDB, Microsoft SQL Server, MarkLogic, IBM, Hypertable, DynamoDB, Couchbase, CloudDB, Cisco, Basho Technologies, Aerospike
Click here to get a Free Sample Copy of the Report: https://www.mraccuracyreports.com/report-sample/516883
Global NoSQL Market by Type:
Key-Value Store, Document Databases, Column Based Stores, Graph Database
Global NoSQL Market by Application:
Data Storage, Metadata Store, Cache Memory, Distributed Data Depository, e-Commerce, Mobile Apps, Web Applications, Data Analytics, Social Networking
|
Report Attributes |
Report Details |
|
Report Name |
NoSQL Market Size Report |
|
Market Size in 2020 |
USD 96.2 Billion |
|
Market Forecast in 2028 |
USD 170 Billion |
|
Compound Annual Growth Rate |
CAGR of 12% |
|
Number of Pages |
188 |
|
Forecast Units |
Value (USD Billion), and Volume (Units) |
|
Key Companies Covered |
PostgreSQL, Oracle Database, Objectivity, Neo, MySQL, MongoLab, MongoDB, Microsoft SQL Server, MarkLogic, IBM, Hypertable, DynamoDB, Couchbase, CloudDB, Cisco, Basho Technologies, Aerospike |
|
Segments Covered |
By Type,By end-user, And By Region |
|
Regions Covered |
North America, Europe, Asia Pacific (APAC), Latin America, Middle East and Africa (MEA) |
|
Countries Covered |
North America: U.S and Canada |
|
Base Year |
2021 |
|
Historical Year |
2016 to 2020 |
|
Forecast Year |
2022 – 2030 |
|
Customization Scope |
Avail customized purchase options to meet your exact research needs.https://www.mraccuracyreports.com/report-sample/516883 |
Regional Assessment:
Geographically, the global NoSQL market is classified into four major regions including North America (the US and Canada), Europe (UK, Germany, France, Italy, Spain, and Rest of Europe), Asia-Pacific (India, China, Japan, and Rest of Asia-Pacific), and Rest of the World (Latin America and the Middle East and Africa (MEA)).
The Research covers the following objectives:
– To study and analyze the Global NoSQL consumption by key regions/countries, product type and application, history data from 2016 to 2021, and forecast to 2028.
– To understand the structure of NoSQL market by identifying its various sub-segments.
– Focuses on the key global NoSQL manufacturers, to define, describe and analyze the sales volume, value, market share, market competition landscape, Porter’s five forces analysis, SWOT analysis and development plans in next few years.
– To analyze the NoSQL with respect to individual growth trends, future prospects, and their contribution to the total market.
– To share detailed information about the key factors influencing the growth of the market (growth potential, opportunities, drivers, industry-specific challenges and risks).
– To project the consumption of NoSQL submarkets, with respect to key regions (along with their respective key countries).
Please click here today to buy full report @ https://www.mraccuracyreports.com/checkout/516883
Strategic Points Covered in Table of Content of Global NoSQL Market:
Chapter 1: Introduction, market driving force product Objective of Study and Research Scope the NoSQL market
Chapter 2: Exclusive Summary and the basic information of the NoSQL Market.
Chapter 3: Displaying the Market Dynamics- Drivers, Trends and Challenges & Opportunities of the NoSQL
Chapter 4: Presenting the NoSQL Market Factor Analysis, Porters Five Forces, Supply/Value Chain, PESTEL analysis, Market Entropy, Patent/Trademark Analysis.
Chapter 5: Displaying the by Type, End User and Region/Country 2017-2021
Chapter 6: Evaluating the leading industrialists of the NoSQL market which consists of its Competitive Landscape, Peer Group Analysis, BCG Matrix & Company Profile
Chapter 7: To evaluate the market by segments, by countries and by Manufacturers/Company with revenue share and sales by key countries in these various regions (2022-2028)
Chapter 8 & 9: Displaying the Appendix, Methodology and Data Source
Finally, NoSQL Market is a valuable source of guidance for individuals and companies.
Key Benefits for Industry Participants & Stakeholders:
- Industry drivers, restraints, and opportunities covered in the study
- Neutral perspective on the market performance
- Recent industry trends and developments
- Competitive landscape & strategies of key players
- Potential & niche segments and regions exhibiting promising growth covered
- Historical, current, and projected market size, in terms of value
- In-depth analysis of the NoSQL Market
The report on the market presents a critical assessment of frameworks for branding decisions, market fit growth strategies, and approaches for leaders and pioneers. The study analyzes distribution channel, product portfolio, business units of top players, and goal attacking, and market expansion.
Ask Analyst for 30% Free Customized Report @ https://www.mraccuracyreports.com/check-discount/516883
Additional paid Services: –
- Client will get one free update on the purchase of Corporate User License.
- Quarterly Industry Update for 1 Year at 40% of the report cost per update.
- One dedicated research analyst allocated to the client.
- Fast Query resolution within 48 hours.
- Industry Newsletter at USD 100 per month per issue.
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

Couchbase has introduced a slew of new features that analysts say could help make life easier for developers when using its NoSQL database.
The document-oriented database, which uses the JSON format and is open source, licensed under Apache 2.0, counts airline ticketing system Amadeus, European supermarket giant Carrefour, and Cisco among its user base.
In a effort to get closer to developers in their native habitat, the vendor has integrated its Capella database-as-a-service within the popular Netlify developer platform, and offered a new Visual Studio Code (VS Code) extension.
The aim is to make it easier for developers and development teams to build so-called modern applications — read internet scale or web-native — on Capella.
Rachel Stephens, a senior analyst at RedMonk, told us developers didn’t want to spend time operating and integrating separate elements of the application stack. “Capella’s new developer platform integrations aims to address this widespread issue, minimizing the developer experience gap and allowing teams to focus on what they do best — writing code and solving problems,” she said.
The combination of an IDE extension (VS Code) together with the Netlify app platform and Capella database service had the “potential to streamline how applications are written, delivered and run,” she said.
Couchbase has also introduced a new time series array function in its support for JSON designed to address a broader set of use cases, including IoT and finance applications.
The vendor said that to use Capella in Netlify, developers would need to create a netlify.toml file and .env file, an approach familiar to developers already using Netlify. Another optional tool that can help developers using Netlify is Ottoman.js (ottomanjs.com), a JavaScript ODM that can let developers define document structure, build more maintainable code and map documents to application objects, Couchbase said.
In doing so, developers could potentially reduce complicated mappings from a relational database to objects in code. It would also allow developers to work SQL++, a similar language to the ubiquitous SQL in relational databases.
Lara Greden, IDC research director, said it was a positive move in terms of enhancing the developer experience.
“Developer adoption is fundamentally about reducing the friction for a developer to make use of DBaaS’s capabilities. Direct integration with application platforms and IDEs takes away the friction. Direct, native integrations are increasingly a critical part of any cloud service vendor’s strategy to be a strong contender in the cloud ecosystem,” she said.
In 2021, Couchbase 7.0 introduced schema-like features in the NoSQL database, in a move the vendor said would provide the flexibility and scale of NoSQL database with the semantics and structure of relational systems.
The move liberated the developer from the DBA, but it meant running queries on a pure document database that has no indexes, which was “very inefficient,” according to one analyst.
Couchbase’s latest update came on the back of a string of other database news over the last week which included:
- Distributed relational database Cockroach has introduced its database-as-a-service on Azure as well as multi-region capabilities for its consumption-based, auto-scaling offering, CockroachDB serverless.
- Yugabyte, which offers a PostgreSQL compatible front-end with a distributed relational database underneath, has introduced its 2.18 iteration, promising to ease the deployment of multi-region Kubernetes environments “at scale”, as well as simplify the management of the DBaaS.
- DataStax, the company which offers commercial products built around the open-source wide-column Cassandra database, has formed a partnership with AI startup ThirdAI in a bid to help users build large language models and other forms of generative AI technologies. ®
Windows Dev Drive – Storage Volume Customized for Developers with Improved Performance
MMS • Giorgi Dalakishvili
Article originally posted on InfoQ. Visit InfoQ

Microsoft released Dev Drive at the Build 2023 developer conference, a custom storage volume geared for developers. Built on top of Microsoft’s proprietary ReFS (Resilient File System), Dev Drive is optimized for heavy I/O operations and has improved performance and security capabilities.
Dev Drive includes file-system optimizations and Microsoft claims up to 30% improvement in build times as well as improved security using the new performance mode in Microsoft Defender for Antivirus. In Microsoft Defender performance mode, real-time protection runs asynchronously, balancing security and performance. The balance is reached by delaying security scans until after the file operation has been completed instead of running security scans synchronously while the file operation is being executed. This performance mode is more secure than a folder or process exclusion that disables security scans altogether.
Dev Drive also speeds up other disc-bound operations such as cloning Git repositories, restoring packages, and copying files. Dev Drive is designed for storing source code, package caches and build artifacts but it is not intended for developer tools or installing apps.
Another optimization that Dev Drive implements is copy-on-write (CoW) linking, also known as block cloning. The article on Engineering@Microsoft describes how it works:
Copy-on-write (CoW) linking, also known as block cloning in the Windows API documentation, avoids fully copying a file by creating a metadata reference to the original data on-disk. CoW links are like hardlinks but are safe to write to, as the filesystem lazily copies the original data into the link as needed when opened for append or random-access write. With a CoW link you save disk space and time since the link consists of a small amount of metadata and they write fast.
Dev Drive is currently in public preview and is available to Windows Insiders running the Dev Channel of Windows 11. It requires at least 50GB in free space and a minimum of 8GB of RAM though Microsoft recommends 16GB. Users can create a Dev Drive volume as a new virtual hard disk, or it can use unallocated space.
Those developers who already tried the Dev Drive report getting faster builds, with one user seeing about 40% off npm build and about 20% speedier .NET build. Another user got 25% speed up even though Dev Drive was running on a three-times slower disk.
Dev Drive should appear in the main Windows release channel later this year. It will also be available in Azure Pipelines and GitHub Actions for faster CI builds in the cloud. In addition to the original release blog post, Microsoft has published a detailed page that describes how to set up Dev Drive, what limitations it has as well as frequently asked questions.
MMS • Rebecca Parsons
Article originally posted on InfoQ. Visit InfoQ

Subscribe on:
Transcript
Intro
Thomas Betts: Hello and welcome to the InfoQ podcast. I’m Thomas Betts, and today I’m joined by Rebecca Parsons. Dr. Parsons is ThoughtWorks’ CTO. She has more years of experience than she’d like to admit in technology and large scale software development. She’s co-author of the book, Building Evolutionary Architectures, the second edition of which was published late last year. A major premise underlying evolutionary architecture is that not only will things change, but we cannot predict how they will change. While that premise makes predicting anything problematic at best, today, we want to discuss some ways that the principles and practices of evolutionary architecture have evolved since the first edition of the book about six years ago, and what changes we might see in the near future, say the next two to five years. Rebecca, welcome to the InfoQ Podcast.
Rebecca Parsons: Thanks for having me, Thomas.
What is Evolutionary Architecture? [01:28]
Thomas Betts: So at QCon London, you gave several presentations. The one I’m most interested in today is discussing how you think evolutionary architecture will evolve. Now, before we can talk about how it will evolve, the first question I have to ask is, what is evolutionary architecture?
Rebecca Parsons: Evolutionary architecture is really a way of thinking about architecture that allows us to take into account change when we don’t know where that change might be coming from. So often people see architecture as this rock, this foundation that can’t be changed, but realistically that just doesn’t work anymore with the rate of change. And so our definition for evolutionary architecture is it’s a guided approach, and guided means that we actually specify what constitutes good for our architecture, and we use that definition to guide our architectural decisions. And it’s multidimensional because obviously we’ve got all kinds of -ilities out there that we have to worry about. And architects’ most favorite and least favorite word is trade off, because you can’t maximize everything or optimize for everything, but it’s also incremental. And so some people will say, well, why don’t you just call it agile architecture? But there’s really more to it.
This key notion of evolutionary is very closely tied to our notion of fitness functions and how we say these are the characteristics that matter the most for this particular system. Because unlike good code and bad code, where bad code is bad code, whether it’s retail or financial services or healthcare, but a good architecture in one setting is actually a bad architecture in another setting because they’re going to have different kinds of constraints. And so we really wanted to emphasize this notion of fitness functions and we are going to make sure that our architecture continues to reflect what we see as the critical characteristics.
Thomas Betts: And are those static or are those fitness functions, those characteristics, are they able to evolve over time, and is that part of the evolutionary approach?
Rebecca Parsons: Yes, they definitely need to evolve over time because business requirements change, consumer expectations change, and the fundamental technological changes might make something possible that wasn’t possible before or undesirable in a way that it wasn’t before. And so if you don’t evolve your fitness functions, if you’re not continuing to reexamine this, not on a daily basis, but probably on a quarterly or a biannual basis on what’s going on in the ecosystem, how are things changing and how does that potentially change your definition of what constitutes good for that particular system?
Thomas Betts: I like the idea of what is good today might not be what’s good tomorrow. It’s easy to see this system versus that system. You have two different characteristics, but the fact that your requirements, you said the business requirements, the user expectations, the load, whatever it is you might design for one thing today and having to find out when that changes and continually looking at those design decisions you made. And were they right? And they were right at the time based on those requirements we had, but those requirements have changed.
Rebecca Parsons: Exactly. And the other thing it allows you to do is take into account things that you’ve learned about your domain that maybe you didn’t know before. I mean, that’s one of the things I like about some of the early descriptions of technical debt is you can have inadvertent technical debt, not because you made a mistake, but because of things that you’ve learned about the domain. We’d all like to be able to reimplement every system we’ve implemented after we’ve learned all of the things that we eventually learned about it in. That’s much the same way with our architectural characteristics as well.
Architect and develop for evolvability [05:18]
Thomas Betts: And so, one of the core principles of evolutionary architecture is to architect and develop for that evolvability. How did you define evolvability when you wrote the book and has that definition had to change over the last few years?
Rebecca Parsons: The definition really hasn’t had to change because it’s really more a change in the tools that we have available to us to a system’s evolvability. And at its core, a system is only evolvable if you can easily understand it and you can safely change it.
Now notice I didn’t say that it was easy to change, and that’s where people sometimes got hung up because they want this to be about making it easy to make whatever change is necessary, but we can’t do that because we don’t know what kind of change it’s going to be. But what we can do is make it as easy as possible to understand how the system is currently working, what I have to do to make the change that I want to make as a result of whatever these change conditions are, and that I can do that as safely as possible.
And so the safety factor comes in with things like the disciplines around continuous delivery, making sure that your deployments are as risk-free as possible, making sure you’ve got a comprehensive testing safety net so that you’re able to interrogate, did this change, do for me what I expected to do? Did it do anything that I wasn’t expecting it to do?
But those are really the two characteristics of evolvability and when you look at that next layer down of architecting and developing for evolvability, it’s getting at one of those two things.
Architecting for testability [06:57]
Thomas Betts: You had a lot that you covered there, and I think we’ll break it up and come back to some of the things. I wanted to start with the idea that the system isn’t easy to change. And in some ways making changes in software is easy, like changing hardware is difficult, but changing software, it’s meant to be easy to change. The challenge is making changes safely, like you said, that you need to be able to know that what you change isn’t going to affect and break something else, or you’re changing in a way that you know what the expected behavior is now going to be. And you mentioned testability and just having a good testing safety net. What do you have to do to make sure that you are, I guess, architecting for that testability?
Rebecca Parsons: Well, one of the interesting things that we have noticed over the years is that if you think about how testable something is, whether it be a method or a component or a system, you tend to end up with the kinds of architectures and designs that make it easy to move things around and easy to change things.
One of the examples that we often use is the whole dumb pipes and smart endpoints. Many of these middleware vendors, they want you to put all kinds of business logic on those pipes. And it’s actually quite difficult to test. It’s much easier. We’ve got all this tooling and all this methodology and understanding of how to test code and code sits in those endpoints. And so if you do that, you keep the business logic off the pipe and if you keep the business logic off the pipe, then you can move the pipe. If you’ve got logic there, that pipe is now tied to those endpoints, so you can’t move it without doing a whole lot more work.
And another example which gets back not just to testability but also architecting for evolvability is if you’ve got a test name, do this and this and this and this and possibly this, and then as a result, maybe one of these things will happen, that’s probably not a good scope for whatever the thing is. You don’t have a clear notion of what you want that thing to do. If it takes that many words to describe what the test does, you don’t have a clear enough concept yet of what it is that you want that software to do. And getting back to the ability to safely change. If you don’t have a clear concept of what it’s supposed to do, how are you supposed to really be able to wrap your head around how you might want to change that thing in the future?
Thomas Betts: I like the here’s the test and the test says, do this one thing I can say, and somebody reads the test and they know what’s supposed to happen. When you get to that this and this and this and maybe something else, the person reading that next week, six months from now, a year from now and saying, well, I need to make sure that this still works. That’s hard to know what it does. I think people are going to be more likely to say, I don’t understand this test, I’ll just remove it, than to figure out what it does. And that’s really dangerous.
Rebecca Parsons: Exactly.
Postel’s Law and unexpected use cases [09:42]
Thomas Betts: I think you also mentioned in your talk that one of the things that hadn’t changed so much over the years and is probably going to stick around is Postel’s Law. That you want to be liberal in what you accept and conservative in what you send out. Does that kind of tie into that idea of dumb pipes and smart endpoints?
Rebecca Parsons: It ties in a little bit, but fundamentally, as soon as you put something out over whatever channel, if you’ve lost control of who can see that, I mean if that endpoint is locked down and they have to come to you and beg your permission to be able to access that, okay, you still have control. But in general though, we don’t know who’s going to make use of that. And so as soon as you put something out there, you are coupled, but you’re coupled to things that you don’t necessarily understand.
I remember one client we had many years ago, they did absolutely the right thing about buying an off-the-shelf product. They changed all their business processes to align with what the product wanted them to do, and they thought, great, now we can upgrade. We got this covered. And then the next major version came out and they realized, unbeknownst to them there were 87 different reports that were mission-critical, that were directly accessing their database. And so now before they could do their upgrade, they had to change all of those other 87 things and figure out how do we get that to work? And they didn’t even know it, but the database was out there. Okay, well, it’s a whole lot easier to just connect to the database than actually having to go talk to those people, so I’ll just connect to the database. And they had done everything except they forgot the fact that they had lost control over that access.
Thomas Betts: And then it goes back to that first point of you know things will change, but it’s very difficult to predict how they’re going to change. You can’t predict how people are going to use your system once you put something out there.
Rebecca Parsons: Exactly.
Thomas Betts: And so you’ve now got those dependencies that you didn’t plan for.
Rebecca Parsons: Yep. It’s like us technologists are problem solvers. So we see the problem, this is our solution to the problem and this is what people are going to do with it. Part of how things go so horribly wrong with technology is when people see something and it’s like, “Ooh, I can make this do that.” Well, you never expected anybody to do that with your product, but it does it. And we’re actually very bad at predicting those kinds of things, and that’s why we have to be able to adapt as people are using our technology in different ways.
Thomas Betts: There’s a great XKCD comic about the can you please put the feature back in because it was warming up my CPU and I was keeping my coffee warm or something like that.
Rebecca Parsons: Yeah.
Thomas Betts: We fixed this bug. Oh, I needed that bug. And that’s the classic case of we fixed the problem and it turns out that bug was a feature for somebody.
Rebecca Parsons: Exactly.
Testing fitness functions [12:26]
Thomas Betts: We’re talking about testability, but also those fitness functions. Is there tooling that we can use that helps us figure out, how do I know that I’ve satisfied my fitness functions? How do I test my system to say it is still meeting my architectural requirements as I had them defined?
Rebecca Parsons: Well, a lot of that depends on the type of fitness function. And one of the things that we lay out in the book are the different categories. Some are static, and so you just put that particular fitness function into your build and it would run like any other thing. Some of them are dynamic, and so they might be more monitoring based. Some are very specific to a particular -ility, so you might run a cyclomatic complexity test. But you might also have something that is simultaneously looking at response time and cache staleness and trying to find a balance for that. Probably the most general of the fitness functions is the Simian Army. There’s a whole load of things that are running in production, keeping an eye on different things and reporting or just kicking the thing out of production if it doesn’t satisfy it.
So some of these will be breaking, some of these will be maybe trends that you’re watching. Some of these might just be alerts to an operation staff. So it really depends on what the -ility is that you’re looking at and what kinds of things are possible.
But what we try to remind people of is everybody has used a fitness function at some time or another. If you’ve run a linter, if you’ve run a performance test, if you’ve monitored the utilization of the CPU in production, those are all fitness functions. The value is by unifying everything under this name, we can talk about the meta characteristics of fitness functions, and then you get into the individual details depending on what it is that you’re trying to measure
Thomas Betts: Yeah, I think the challenge people usually have with the -ilities is some of them are very qualitative. I want the system to be fast. I want it to respond, and turning those into quantitative values. And then once you have some quantitative metric you can measure against, great. How do we test that the system is still meeting that? Are we hitting our SLOs and SLAs? Are we having too many alerts go through? There are things you can measure, but it does take a lot of effort to think about that and figure out how can I say this is important enough to make sure that we’re still testing for it on a regular basis.
Rebecca Parsons: Yes. My personal favorite is maintainability. You can’t write a fitness function for that, but you can write something that says that this respects the layering of the architecture that we’ve agreed to, and there’s quite good tooling in many of the mainstream languages that will allow you to do that. You can put in things around cyclolmatic complexity.
There re all kinds of different ways that you can quantify those things, but it does take work, and it’s a whole lot easier for me as the enterprise architect to say, you need to write this system maintainability Thomas, and then you can come to me and, okay, I’ve given you a maintainable system. No, you haven’t. Come back and give me another one.
The onus should be on the person who is stating the requirement to say what the requirement actually means. And we don’t always do that. And that’s why we say the single most important feature of a fitness function is that you and I will never disagree on whether or not it passes.
It has to be that well-defined. And if it’s that well-defined, then you, as the developer, know what it is that I am asking you to do, and you can work until you’ve satisfied that particular requirement as opposed to having to try to, okay, I’m up to ESP303 now, so I’m sure I’ll be able to figure out what the guy wants this time.
But that is something people struggle with. And one of the things that we tried to address in the second edition was we added many more examples of fitness functions to make that idea more concrete, and we crowdsourced a lot of them from people within our network, people within the company, and all of the examples in there are concrete examples that different people have used on projects to start to answer that question, how do I go from this thing that I want to achieve to a fitness function that tells me whether or not I’m achieving it?
Thomas Betts: I think one of the other quotes from your track at QCon was that every software problem is fundamentally a communications problem. And when two people read a sentence and disagree about that sentence, that’s the communication problem. And so as long as those two people can absolutely agree and you can bring over a third person and they can also agree on it, that’s the big solution. That’s amazing.
Rebecca Parsons: Exactly.
Thomas Betts: But that’s not easy to do.
Rebecca Parsons: Nope.
Thomas Betts: None of this stuff is for free. You have to work on all these things and there are benefits when you can get that agreement.
Rebecca Parsons: Yes.
The evolution of data [17:03]
Thomas Betts: So one thing that we’ve seen evolve a lot over the past decade is how we handle data. I started this software stuff years ago, and you only stored your data in one giant database. You wanted to add new functions, you added more data to the same database. Now we have lots of microservices and each microservice owns their own data and has their own data store behind it. So we went from one database to dozens or hundreds. Was that something that was addressed in the evolution architecture book or is that something that you’re now addressing and seeing differently as a problem you have to solve separately?
Rebecca Parsons: No, it’s definitely a big part of it and a big contributor to that. And in fact, you can think of our chapter as a symbolic link to a book called Refactoring Databases, Evolutionary Database Design. And we keep telling Pramod Sadalage, one of the co-authors that they ought to reissue the book, but just flip the title and subtitle to, Evolutionary Database Design, Refactoring Databases. Because regardless of the kind of data store that you have, as soon as something goes into production with data, if you want to change the way that data is structured, you have to migrate it, and migration is hard. Anybody who’s done it knows that it might sound simple on paper, but it never goes the way you want it to go. And so this technique is what allows you to, again, more readily and safely do even large scale database changes by taking the refactoring approach.
And I’m using refactoring in the precise term as opposed to the, oh, I need to refactor my whole system because I’m swimming in technical death. For relational databases, in that book, they identified what are the atomic changes you have to make? And for each one of those big changes you want to make, it’s actually a composition of lots of atomic changes. If you break it down to those individual data refactorings and couple that with what changes you need to make to the access logic in the code, and then what’s the migration code? You can start to individually uncover those little landmines from August and September of 1984 when this field meant something completely different. And those are the reasons. The kinds of things that cause data migrations to go wrong is you’ve got all of this data and it doesn’t age well, and there’s all kinds of spots from history that cause it to change.
And the nice thing about that is as well, that the basic notion in refactoring databases applies regardless. If it’s a document database or a graph database, the individual refactorings are very different if you want to migrate a graph database from a relational database. But one of the things I think has been such a strong enabler of many of the architectural innovations that we’re seeing now is the fact that we have broken that notion that if you persist data, it must be in the relational database. And the DBAs are the gatekeepers of access to that. We’ve really been able to rethink our relationship with data as a fundamental part of the system, and I think that’s been an incredibly powerful innovation within our enterprise technology landscape.
Thomas Betts: The way you described a series of little atomic steps, that fits well with the idea of evolution, not revolution. Don’t just make one big change and hope you can jump all the way over the chasm. How do we make lots of little steps? Because when you look at it, databases are good at doing lots of little things. They do lots of little things. They just give you that nice abstraction, but sometimes you have to go down to what are the little refactorings, and I’ve been there when you have this copy of the data is in version one, and this copy is in version two, and this one’s in version three, and now I want to go to version four. If I had been updating one to two and then two to three the whole way. But if I can’t replay those steps, I don’t know how to make the jump from one to four.
Rebecca Parsons: Exactly.
Platform engineering [20:55]
Thomas Betts: Like you said, there’s a whole other book on databases. We’ll be sure to have a link to that. But I want to talk about platform engineering. How has platform engineering and a good engineering platform that helps us with continuous delivery and having all that tooling around knowing what our system looks like, how has that helped? And was that something that we didn’t have much when you wrote the first book?
Rebecca Parsons: Well, first we need to disambiguate terms a little bit because I think the story changes depending on what your definition of platform is.
We can take out of scope for this discussion, the platform businesses, Uber and Airbnb and such is the platform business model. That might be the ultimate goal of building a platform, but that’s not what we’re talking about here.
When we think about, in particular, the lower level developer platforms, maybe you’ve got capabilities like auditing or logging or single sign-on and things of that nature. And you can actually think of even the continuous delivery pipelines as part of that platform that reduces the friction for the person who is trying to deliver business logic. And some of these things were obviously around. Cloud clearly existed. Many of the SaaS platforms clearly existed in 2017. We understood about continuous delivery and such, but people didn’t necessarily think of platforms in a way that would support some of these fundamental changes.
When I first started talking about evolutionary architecture, which was long before the book came out, people would come up afterwards and whisper, “Don’t think you’re being professionally irresponsible to advocate for evolutionary architecture.” And so even during that time, you wanted your developer platform kind of locked down and then people would build things on top of it.
What I think is actually more interesting from an evolutionary architecture perspective is when we go up to that next level of platform, which is where we’re delivering fundamental business capabilities, that we then want developers to be able to hook together in different ways to create new products, new services for the users. And that’s where some of the architecting for evolvability comes in. Do you understand what this part of the system is trying to achieve? Are you constructing these capabilities from the perspective of the business that you are in?
Because when you think about how someone is going to come to you as a technologist and say, I want you to change this business process to do this. In their head, they’re not imagining an SAP system or this and that and the other microservice. They’re thinking about customers or they’re thinking about products or they’re thinking about roots. They’re thinking about the concepts that go into what this business does to make money. And so if you have those business capabilities in that platform structured around the kinds of things that people are going to imagine they’re going to want to move around, it’s going to be a whole lot easier to move them around. Because the blocks that you have available to you are the same blocks that I have in my head that I’m trying to metaphorically move around.
I do think that as we’ve refined our thinking around these business capability platforms, they are moving much more towards this notion of being able to evolve the system to do new things with the same kind of fundamental building blocks that we have. So I think we have to separate out the two different kinds of platforms in thinking about that.
Thomas Betts: Gotcha. That’s a very useful separation. I know thinking about extensibility is saying that we’ve always had extensibility like, oh, I’m going to add an API and people will consume the API. But now we’ve got low-code and no-code solutions, and the extensibility that needed a developer to be on the other side of it has been replaced by any business user’s going to fire up a little webpage and boom, they’re solving a new business problem because you gave them composable small units that they can put together in that new way. So it might not even be that you’re building something in your architecture, but you’re allowing that overall system to expand. That’s where you’re saying the business capability platform allows that kind of synthesis.
Rebecca Parsons: Yes. But those things are even useful outside of the context of a low-code no-code platform, because it might actually be a pretty complicated workflow that you’re trying to put together here with different kinds of exception handling, but you still are using those fundamental building blocks and are able to reuse them.
Microservices not required – a monolith can be evolvable [25:22]
Thomas Betts: So does that get to the idea of… It sounds like a microservices architecture is the panacea for this, but do you have to have microservices to be able to do evolutionary architecture? Could I do this with a monolith?
Rebecca Parsons: Yes. You can’t do it with a big bottle of mud, but a well-structured monolith, although you don’t have the individual deployment. We talk about the notion of a quantum, and that’s a deployable unit, and microservices of course are a much smaller deployable unit. But if you have a well-structured monolith and you are respecting all of the boundaries, many of the things that you want to be able to do, you can do for an evolutionary architecture, you will be able to move things around. Just because they live in the same monolith, it doesn’t mean they’re coupled.
Now the problem is it takes a lot more discipline. I remember hearing a talk by Chad Fowler, and he said at one point he decreed that no two microservices could share any part of the technology stack, because he didn’t want people to, oh, here, I can just reach over there and use that instead of doing it, which I think is an extreme. I think he was just trying to really make a point, but it’s a whole lot harder to do that in a microservices architecture than it is in a monolith, and it can be so tempting.
But if you have good discipline and you’ve got the right kind of separation there, a well-structured monolith can support an evolutionary approach to architecture. The structure of the monolith does matter. If it’s a layered monolith where you’ve got your data layer in your logical layer in your presentation layer, that gives you a certain level of evolvability, but it doesn’t necessarily always help you that much because most business changes are going to affect all of the layers. But if you’re structuring up more around these domain-driven design level, bounded context, if that’s your unit of organization within the monolith, you’re going to have the same level of flexibility in terms of the creation of new functionality as you would in the microservices. You just have a different deployment strategy.
Conway’s Law and the importance of shared understanding [27:33]
Thomas Betts: That comment about not having two microservices be able to reach in and touch the technology that you have to go through the interface makes me think of Conway’s Law and that those team structures, the teams can only talk to each other through their services as opposed to, oh, I’m just going to pop on Slack and ask somebody to make this change for me. How does Conway’s Law fit into evolutionary architecture?
Rebecca Parsons: It always comes down to the people. And we like to talk about the Inverse Conway Maneuver, where if you want your system to look a particular way, reorganize your team, and that’s what will happen. But the important thing really is to make sure that the boundaries between those teams are drawn in a logical way. Because again, going back to that “this and that and the other, and possibly this” test name, if you and I don’t understand what’s in your remit versus what’s in mine, we’re not going to have a clean barrier between the component that you write and the component that I write. And so Conway’s Law helps us understand how we align people to the right objectives, but it does very clearly have implications for the architecture, because it’s the people who are going to create those components. And if the communication is not there, and if the shared understanding isn’t there, then the code isn’t going to work.
Predicting the future of evolvable architecture [28:55]
Thomas Betts: I think we’re going to wrap up. I said that we were going to talk a little bit about the future. We talked about the evolution of edition one to edition two of your book. So evolutionary architecture has obviously evolved some. How do you see it going to evolve in the future? Pull out your crystal ball and let us know what’s going to happen.
Rebecca Parsons: Well, the first thing I will say is when Camilla first asked me if I would do the talk, I was thinking to myself, “I can’t do this. I can’t predict the future.” That’s the whole premise of the book. Is you can’t predict how it will change. But she said 2025, and that’s not that far away.
I do think we’re going to continue to get a more sophisticated understanding of just how we can use fitness functions to express some of these more difficult architectural characteristics. I do think we are going to see significant advances from the perspective of observability, and with this increased interest in testing and production and rollback and all of that. I think we’re going to see evolution not just in our thinking about the fitness functions, but how we can actually implement them and take action as a result of it. I do think we’re going to see more productivity from AI-based tools in things like our testing strategies.
We’re also doing some preliminary experiments, emphasis on the word preliminary at the moment, to help us with legacy modernization by using some of these AI tools to start to parse out what are the actual data flows through some of these old legacy systems. So I think some of the advances that we’re getting in generative AI and AI more broadly are going to help us in dealing with some of these legacy systems.
And then I think we’re going to continue to see evolution even the way we think about architectures. From my perspective, continuous delivery has been a great enabler, but the combination of continuous delivery and open source has been a great enabler for things like the microservices architectures and some of the other innovations we’re seeing in architecture, because it has allowed us to de-risk deployments.
And I think we’re going to continue as we see more hybrid hardware software systems with sensors, IOTs, actuators, smart homes, smart cities, smart factories, I think we’re going to see innovation in, okay, well, how do we keep those systems up to date? How do we keep our level of understanding of that system at the appropriate level, and how do we do diagnostics as those estates get larger and larger?
Thomas Betts: Well, I think that’s a great place to end. Looking ahead of the future, maybe in a few years, we’ll have the chat bot come on and tell us what the next five years will look like.
Rebecca, thanks again for joining me today.
Rebecca Parsons: Thanks Thomas. It’s been a pleasure.
Thomas Betts: And listeners, we hope you’ll join us again soon for another episode of the InfoQ Podcast.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Google and Bazel consulting firm Aspect announced version 1.0 of Bazel plugin rules_oci. Aimed to simplify secure container image creation using Bazel with special emphasis on Distroless images, the new plugin obsoletes rules_docker and improves it on a number of counts.
Both rules_oci and rules_docker, the latter now in maintenance mode, can automate the process of securely creating container images. Bazel, says Google engineer Appu Goundan, is ideal for this task thanks to it using integrity hashes to cache dependencies along with the “Trust on first use” principle, which will consider any change in the integrity hash associated to a dependency as a sign of tampering.
While rules_oci can be used to create any kind of container image, Google is specifically aiming it to the creation of distroless images as a way to improve supply-chain security:
[Distroless images] restrict what’s in your runtime container to precisely what’s necessary for your app, which is a best practice employed by Google and other tech companies that have used containers in production for many years. Using minimal base images reduces the burden of managing risks associated with security vulnerabilities, licensing, and governance issues in the supply chain for building applications.
One of the reasons why rules_oci has been introduced is its support for creating container images for multiple runtimes and formats, as specified by the Open Container Initiate, especially podman. On the contrary, rules_docker, as its name implies, is tied to creating Docker images specifically. rules_oci also benefits from a simplified architecture, thanks to the fact that it can leverage tools such as Crane, Skopeo, and Zot for container manipulation tasks like managing a local registry.
Additionally, rules_oci strives to be language-independent, while rules_oci includes specific rule sets for each supported language to deal in most cases with the peculiarities each language ecosystem has about dependency management. This will make the new plugin easier to maintain and use it with new languages, says Goundan. Google is providing, in any case, language-specific examples to help create container images using rules_oci for a number of languages, including C/C++, Go, Java, etc.
There are other rules_oci features, explains Goundan, which are especially relevant to supply-chain security. In particular, rules_oci uses Bazel to fetch layers from remote registries, which also uses code signing to enable authorship verification.
Having reached 1.0 means rules_oci provides a stronger stability guarantee, following the semver standard, and the promise that future releases won’t include breaking API changes. Aspect also provided a migration guide to make it easier to replace rules_docker with rules_oci.
Google Cloud Expands Cloud Interconnect Portfolio and Enhances Networking Capabilities
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Recently Google Cloud announced a significant expansion of its Cloud Interconnect portfolio by unveiling Cross-Cloud Interconnect. The new offering enables organizations to connect any public cloud with Google Cloud securely and efficiently, allowing seamless application deployment across multiple clouds and simplified SaaS networking in a multicloud environment.
Connecting and securing distributed environments have posed challenges for cloud infrastructure teams. Configurations often involve complex setups, dedicated hardware, and time-consuming operational processes. With the Cross-Cloud Interconnect offering, Google aims to simplify these processes by minimizing hardware requirements, reducing overhead, and providing a secure, high-performance network for connecting any public cloud like Microsoft Azure, AWS, and Alibaba with Google Cloud.
The offering is available in 10 Gbps or 100 Gbps options and does not require new hardware. In addition, it has the same features as Cloud Interconnect and is backed with an SLA (99.99%). According to the company, customers with multicloud environments can leverage Cross-Cloud Interconnect to enable the following:
- Private and secure connectivity across clouds.
- Line-rate performance and high reliability with 99.99% SLA.
- Lower TCO without the complexity and cost of managing infrastructure.
- Run Applications on multicloud.
- Migrate workloads from one cloud to another.
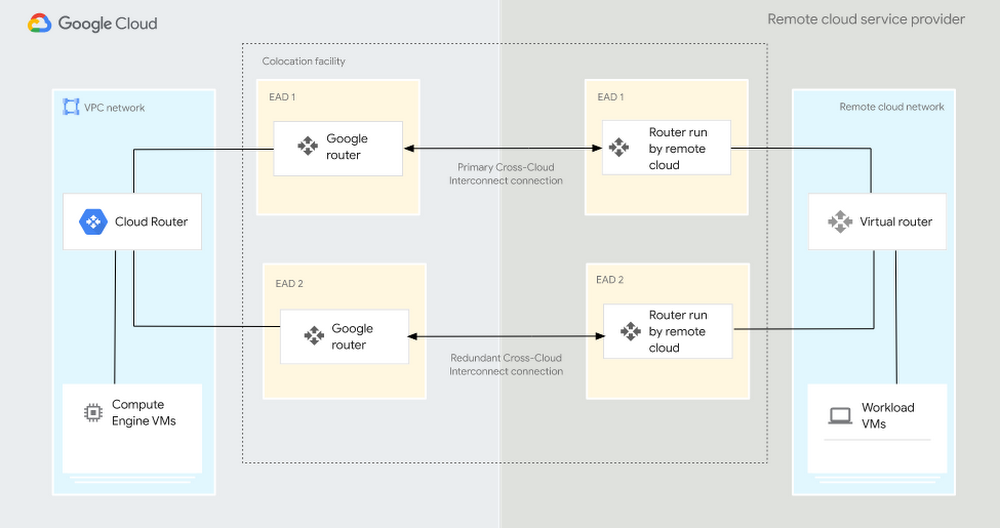
Source: https://cloud.google.com/blog/products/networking/announcing-google-cloud-cross-cloud-interconnect
Alongside the introduction of Cross-Cloud Interconnect, Google Cloud enhanced its Private Service Connect offering. Private Service Connect enables the creation of private and secure connections from virtual private clouds (VPCs) to Google Cloud, partner services, or custom services, simplifying network configuration for published services and SaaS applications. The recent enhancements include support for Cross-Cloud Interconnect, automated service connection policies, and expanded access for on-premises and multi-cloud clients.
In addition to these advancements, Google Cloud has strengthened its Cloud Interconnect capabilities with new encryption options, improved performance, and enhanced network resiliency. Features like MACsec for Cloud Interconnect provide point-to-point line-rate L2 encryption, ensuring secure communications between customers and Google Cloud, and HA VPN over Interconnect provides IPSec encryption to protect communications between a customer’s on-prem VPN gateway and the HA VPN gateway in Google Cloud.
In addition, bidirectional forwarding detection expedites the detection of link failures, enabling prompt traffic rerouting in case of path outages, and 9K MTU support (in preview) allows large packet sizes to deliver higher throughput over Interconnect offerings. Moreover, BGP enhancements (in preview) include support for custom-learned routes and increased prefix scale, further optimizing networking operations.
Several cloud providers offer similar services to Google Cloud Interconnect. For example, Azure ExpressRoute provides a private and dedicated connection between an organization’s on-premises infrastructure and Azure cloud services. It offers secure and reliable connectivity with high bandwidth and low latency options. Furthermore, it allows connectivity with other clouds. Another example is AWS Direct Connect, which enables organizations to establish a dedicated network connection between their on-premises data centers and AWS, bypassing the public internet.