Month: June 2023

MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

Couchbase has introduced a slew of new features that analysts say could help make life easier for developers when using its NoSQL database.
The document-oriented database, which uses the JSON format and is open source, licensed under Apache 2.0, counts airline ticketing system Amadeus, European supermarket giant Carrefour, and Cisco among its user base.
In a effort to get closer to developers in their native habitat, the vendor has integrated its Capella database-as-a-service within the popular Netlify developer platform, and offered a new Visual Studio Code (VS Code) extension.
The aim is to make it easier for developers and development teams to build so-called modern applications — read internet scale or web-native — on Capella.
Rachel Stephens, a senior analyst at RedMonk, told us developers didn’t want to spend time operating and integrating separate elements of the application stack. “Capella’s new developer platform integrations aims to address this widespread issue, minimizing the developer experience gap and allowing teams to focus on what they do best — writing code and solving problems,” she said.
The combination of an IDE extension (VS Code) together with the Netlify app platform and Capella database service had the “potential to streamline how applications are written, delivered and run,” she said.
Couchbase has also introduced a new time series array function in its support for JSON designed to address a broader set of use cases, including IoT and finance applications.
The vendor said that to use Capella in Netlify, developers would need to create a netlify.toml file and .env file, an approach familiar to developers already using Netlify. Another optional tool that can help developers using Netlify is Ottoman.js (ottomanjs.com), a JavaScript ODM that can let developers define document structure, build more maintainable code and map documents to application objects, Couchbase said.
In doing so, developers could potentially reduce complicated mappings from a relational database to objects in code. It would also allow developers to work SQL++, a similar language to the ubiquitous SQL in relational databases.
Lara Greden, IDC research director, said it was a positive move in terms of enhancing the developer experience.
“Developer adoption is fundamentally about reducing the friction for a developer to make use of DBaaS’s capabilities. Direct integration with application platforms and IDEs takes away the friction. Direct, native integrations are increasingly a critical part of any cloud service vendor’s strategy to be a strong contender in the cloud ecosystem,” she said.
In 2021, Couchbase 7.0 introduced schema-like features in the NoSQL database, in a move the vendor said would provide the flexibility and scale of NoSQL database with the semantics and structure of relational systems.
The move liberated the developer from the DBA, but it meant running queries on a pure document database that has no indexes, which was “very inefficient,” according to one analyst.
Couchbase’s latest update came on the back of a string of other database news over the last week which included:
- Distributed relational database Cockroach has introduced its database-as-a-service on Azure as well as multi-region capabilities for its consumption-based, auto-scaling offering, CockroachDB serverless.
- Yugabyte, which offers a PostgreSQL compatible front-end with a distributed relational database underneath, has introduced its 2.18 iteration, promising to ease the deployment of multi-region Kubernetes environments “at scale”, as well as simplify the management of the DBaaS.
- DataStax, the company which offers commercial products built around the open-source wide-column Cassandra database, has formed a partnership with AI startup ThirdAI in a bid to help users build large language models and other forms of generative AI technologies. ®
Windows Dev Drive – Storage Volume Customized for Developers with Improved Performance
MMS • Giorgi Dalakishvili
Article originally posted on InfoQ. Visit InfoQ

Microsoft released Dev Drive at the Build 2023 developer conference, a custom storage volume geared for developers. Built on top of Microsoft’s proprietary ReFS (Resilient File System), Dev Drive is optimized for heavy I/O operations and has improved performance and security capabilities.
Dev Drive includes file-system optimizations and Microsoft claims up to 30% improvement in build times as well as improved security using the new performance mode in Microsoft Defender for Antivirus. In Microsoft Defender performance mode, real-time protection runs asynchronously, balancing security and performance. The balance is reached by delaying security scans until after the file operation has been completed instead of running security scans synchronously while the file operation is being executed. This performance mode is more secure than a folder or process exclusion that disables security scans altogether.
Dev Drive also speeds up other disc-bound operations such as cloning Git repositories, restoring packages, and copying files. Dev Drive is designed for storing source code, package caches and build artifacts but it is not intended for developer tools or installing apps.
Another optimization that Dev Drive implements is copy-on-write (CoW) linking, also known as block cloning. The article on Engineering@Microsoft describes how it works:
Copy-on-write (CoW) linking, also known as block cloning in the Windows API documentation, avoids fully copying a file by creating a metadata reference to the original data on-disk. CoW links are like hardlinks but are safe to write to, as the filesystem lazily copies the original data into the link as needed when opened for append or random-access write. With a CoW link you save disk space and time since the link consists of a small amount of metadata and they write fast.
Dev Drive is currently in public preview and is available to Windows Insiders running the Dev Channel of Windows 11. It requires at least 50GB in free space and a minimum of 8GB of RAM though Microsoft recommends 16GB. Users can create a Dev Drive volume as a new virtual hard disk, or it can use unallocated space.
Those developers who already tried the Dev Drive report getting faster builds, with one user seeing about 40% off npm build and about 20% speedier .NET build. Another user got 25% speed up even though Dev Drive was running on a three-times slower disk.
Dev Drive should appear in the main Windows release channel later this year. It will also be available in Azure Pipelines and GitHub Actions for faster CI builds in the cloud. In addition to the original release blog post, Microsoft has published a detailed page that describes how to set up Dev Drive, what limitations it has as well as frequently asked questions.
MMS • Rebecca Parsons
Article originally posted on InfoQ. Visit InfoQ

Subscribe on:
Transcript
Intro
Thomas Betts: Hello and welcome to the InfoQ podcast. I’m Thomas Betts, and today I’m joined by Rebecca Parsons. Dr. Parsons is ThoughtWorks’ CTO. She has more years of experience than she’d like to admit in technology and large scale software development. She’s co-author of the book, Building Evolutionary Architectures, the second edition of which was published late last year. A major premise underlying evolutionary architecture is that not only will things change, but we cannot predict how they will change. While that premise makes predicting anything problematic at best, today, we want to discuss some ways that the principles and practices of evolutionary architecture have evolved since the first edition of the book about six years ago, and what changes we might see in the near future, say the next two to five years. Rebecca, welcome to the InfoQ Podcast.
Rebecca Parsons: Thanks for having me, Thomas.
What is Evolutionary Architecture? [01:28]
Thomas Betts: So at QCon London, you gave several presentations. The one I’m most interested in today is discussing how you think evolutionary architecture will evolve. Now, before we can talk about how it will evolve, the first question I have to ask is, what is evolutionary architecture?
Rebecca Parsons: Evolutionary architecture is really a way of thinking about architecture that allows us to take into account change when we don’t know where that change might be coming from. So often people see architecture as this rock, this foundation that can’t be changed, but realistically that just doesn’t work anymore with the rate of change. And so our definition for evolutionary architecture is it’s a guided approach, and guided means that we actually specify what constitutes good for our architecture, and we use that definition to guide our architectural decisions. And it’s multidimensional because obviously we’ve got all kinds of -ilities out there that we have to worry about. And architects’ most favorite and least favorite word is trade off, because you can’t maximize everything or optimize for everything, but it’s also incremental. And so some people will say, well, why don’t you just call it agile architecture? But there’s really more to it.
This key notion of evolutionary is very closely tied to our notion of fitness functions and how we say these are the characteristics that matter the most for this particular system. Because unlike good code and bad code, where bad code is bad code, whether it’s retail or financial services or healthcare, but a good architecture in one setting is actually a bad architecture in another setting because they’re going to have different kinds of constraints. And so we really wanted to emphasize this notion of fitness functions and we are going to make sure that our architecture continues to reflect what we see as the critical characteristics.
Thomas Betts: And are those static or are those fitness functions, those characteristics, are they able to evolve over time, and is that part of the evolutionary approach?
Rebecca Parsons: Yes, they definitely need to evolve over time because business requirements change, consumer expectations change, and the fundamental technological changes might make something possible that wasn’t possible before or undesirable in a way that it wasn’t before. And so if you don’t evolve your fitness functions, if you’re not continuing to reexamine this, not on a daily basis, but probably on a quarterly or a biannual basis on what’s going on in the ecosystem, how are things changing and how does that potentially change your definition of what constitutes good for that particular system?
Thomas Betts: I like the idea of what is good today might not be what’s good tomorrow. It’s easy to see this system versus that system. You have two different characteristics, but the fact that your requirements, you said the business requirements, the user expectations, the load, whatever it is you might design for one thing today and having to find out when that changes and continually looking at those design decisions you made. And were they right? And they were right at the time based on those requirements we had, but those requirements have changed.
Rebecca Parsons: Exactly. And the other thing it allows you to do is take into account things that you’ve learned about your domain that maybe you didn’t know before. I mean, that’s one of the things I like about some of the early descriptions of technical debt is you can have inadvertent technical debt, not because you made a mistake, but because of things that you’ve learned about the domain. We’d all like to be able to reimplement every system we’ve implemented after we’ve learned all of the things that we eventually learned about it in. That’s much the same way with our architectural characteristics as well.
Architect and develop for evolvability [05:18]
Thomas Betts: And so, one of the core principles of evolutionary architecture is to architect and develop for that evolvability. How did you define evolvability when you wrote the book and has that definition had to change over the last few years?
Rebecca Parsons: The definition really hasn’t had to change because it’s really more a change in the tools that we have available to us to a system’s evolvability. And at its core, a system is only evolvable if you can easily understand it and you can safely change it.
Now notice I didn’t say that it was easy to change, and that’s where people sometimes got hung up because they want this to be about making it easy to make whatever change is necessary, but we can’t do that because we don’t know what kind of change it’s going to be. But what we can do is make it as easy as possible to understand how the system is currently working, what I have to do to make the change that I want to make as a result of whatever these change conditions are, and that I can do that as safely as possible.
And so the safety factor comes in with things like the disciplines around continuous delivery, making sure that your deployments are as risk-free as possible, making sure you’ve got a comprehensive testing safety net so that you’re able to interrogate, did this change, do for me what I expected to do? Did it do anything that I wasn’t expecting it to do?
But those are really the two characteristics of evolvability and when you look at that next layer down of architecting and developing for evolvability, it’s getting at one of those two things.
Architecting for testability [06:57]
Thomas Betts: You had a lot that you covered there, and I think we’ll break it up and come back to some of the things. I wanted to start with the idea that the system isn’t easy to change. And in some ways making changes in software is easy, like changing hardware is difficult, but changing software, it’s meant to be easy to change. The challenge is making changes safely, like you said, that you need to be able to know that what you change isn’t going to affect and break something else, or you’re changing in a way that you know what the expected behavior is now going to be. And you mentioned testability and just having a good testing safety net. What do you have to do to make sure that you are, I guess, architecting for that testability?
Rebecca Parsons: Well, one of the interesting things that we have noticed over the years is that if you think about how testable something is, whether it be a method or a component or a system, you tend to end up with the kinds of architectures and designs that make it easy to move things around and easy to change things.
One of the examples that we often use is the whole dumb pipes and smart endpoints. Many of these middleware vendors, they want you to put all kinds of business logic on those pipes. And it’s actually quite difficult to test. It’s much easier. We’ve got all this tooling and all this methodology and understanding of how to test code and code sits in those endpoints. And so if you do that, you keep the business logic off the pipe and if you keep the business logic off the pipe, then you can move the pipe. If you’ve got logic there, that pipe is now tied to those endpoints, so you can’t move it without doing a whole lot more work.
And another example which gets back not just to testability but also architecting for evolvability is if you’ve got a test name, do this and this and this and this and possibly this, and then as a result, maybe one of these things will happen, that’s probably not a good scope for whatever the thing is. You don’t have a clear notion of what you want that thing to do. If it takes that many words to describe what the test does, you don’t have a clear enough concept yet of what it is that you want that software to do. And getting back to the ability to safely change. If you don’t have a clear concept of what it’s supposed to do, how are you supposed to really be able to wrap your head around how you might want to change that thing in the future?
Thomas Betts: I like the here’s the test and the test says, do this one thing I can say, and somebody reads the test and they know what’s supposed to happen. When you get to that this and this and this and maybe something else, the person reading that next week, six months from now, a year from now and saying, well, I need to make sure that this still works. That’s hard to know what it does. I think people are going to be more likely to say, I don’t understand this test, I’ll just remove it, than to figure out what it does. And that’s really dangerous.
Rebecca Parsons: Exactly.
Postel’s Law and unexpected use cases [09:42]
Thomas Betts: I think you also mentioned in your talk that one of the things that hadn’t changed so much over the years and is probably going to stick around is Postel’s Law. That you want to be liberal in what you accept and conservative in what you send out. Does that kind of tie into that idea of dumb pipes and smart endpoints?
Rebecca Parsons: It ties in a little bit, but fundamentally, as soon as you put something out over whatever channel, if you’ve lost control of who can see that, I mean if that endpoint is locked down and they have to come to you and beg your permission to be able to access that, okay, you still have control. But in general though, we don’t know who’s going to make use of that. And so as soon as you put something out there, you are coupled, but you’re coupled to things that you don’t necessarily understand.
I remember one client we had many years ago, they did absolutely the right thing about buying an off-the-shelf product. They changed all their business processes to align with what the product wanted them to do, and they thought, great, now we can upgrade. We got this covered. And then the next major version came out and they realized, unbeknownst to them there were 87 different reports that were mission-critical, that were directly accessing their database. And so now before they could do their upgrade, they had to change all of those other 87 things and figure out how do we get that to work? And they didn’t even know it, but the database was out there. Okay, well, it’s a whole lot easier to just connect to the database than actually having to go talk to those people, so I’ll just connect to the database. And they had done everything except they forgot the fact that they had lost control over that access.
Thomas Betts: And then it goes back to that first point of you know things will change, but it’s very difficult to predict how they’re going to change. You can’t predict how people are going to use your system once you put something out there.
Rebecca Parsons: Exactly.
Thomas Betts: And so you’ve now got those dependencies that you didn’t plan for.
Rebecca Parsons: Yep. It’s like us technologists are problem solvers. So we see the problem, this is our solution to the problem and this is what people are going to do with it. Part of how things go so horribly wrong with technology is when people see something and it’s like, “Ooh, I can make this do that.” Well, you never expected anybody to do that with your product, but it does it. And we’re actually very bad at predicting those kinds of things, and that’s why we have to be able to adapt as people are using our technology in different ways.
Thomas Betts: There’s a great XKCD comic about the can you please put the feature back in because it was warming up my CPU and I was keeping my coffee warm or something like that.
Rebecca Parsons: Yeah.
Thomas Betts: We fixed this bug. Oh, I needed that bug. And that’s the classic case of we fixed the problem and it turns out that bug was a feature for somebody.
Rebecca Parsons: Exactly.
Testing fitness functions [12:26]
Thomas Betts: We’re talking about testability, but also those fitness functions. Is there tooling that we can use that helps us figure out, how do I know that I’ve satisfied my fitness functions? How do I test my system to say it is still meeting my architectural requirements as I had them defined?
Rebecca Parsons: Well, a lot of that depends on the type of fitness function. And one of the things that we lay out in the book are the different categories. Some are static, and so you just put that particular fitness function into your build and it would run like any other thing. Some of them are dynamic, and so they might be more monitoring based. Some are very specific to a particular -ility, so you might run a cyclomatic complexity test. But you might also have something that is simultaneously looking at response time and cache staleness and trying to find a balance for that. Probably the most general of the fitness functions is the Simian Army. There’s a whole load of things that are running in production, keeping an eye on different things and reporting or just kicking the thing out of production if it doesn’t satisfy it.
So some of these will be breaking, some of these will be maybe trends that you’re watching. Some of these might just be alerts to an operation staff. So it really depends on what the -ility is that you’re looking at and what kinds of things are possible.
But what we try to remind people of is everybody has used a fitness function at some time or another. If you’ve run a linter, if you’ve run a performance test, if you’ve monitored the utilization of the CPU in production, those are all fitness functions. The value is by unifying everything under this name, we can talk about the meta characteristics of fitness functions, and then you get into the individual details depending on what it is that you’re trying to measure
Thomas Betts: Yeah, I think the challenge people usually have with the -ilities is some of them are very qualitative. I want the system to be fast. I want it to respond, and turning those into quantitative values. And then once you have some quantitative metric you can measure against, great. How do we test that the system is still meeting that? Are we hitting our SLOs and SLAs? Are we having too many alerts go through? There are things you can measure, but it does take a lot of effort to think about that and figure out how can I say this is important enough to make sure that we’re still testing for it on a regular basis.
Rebecca Parsons: Yes. My personal favorite is maintainability. You can’t write a fitness function for that, but you can write something that says that this respects the layering of the architecture that we’ve agreed to, and there’s quite good tooling in many of the mainstream languages that will allow you to do that. You can put in things around cyclolmatic complexity.
There re all kinds of different ways that you can quantify those things, but it does take work, and it’s a whole lot easier for me as the enterprise architect to say, you need to write this system maintainability Thomas, and then you can come to me and, okay, I’ve given you a maintainable system. No, you haven’t. Come back and give me another one.
The onus should be on the person who is stating the requirement to say what the requirement actually means. And we don’t always do that. And that’s why we say the single most important feature of a fitness function is that you and I will never disagree on whether or not it passes.
It has to be that well-defined. And if it’s that well-defined, then you, as the developer, know what it is that I am asking you to do, and you can work until you’ve satisfied that particular requirement as opposed to having to try to, okay, I’m up to ESP303 now, so I’m sure I’ll be able to figure out what the guy wants this time.
But that is something people struggle with. And one of the things that we tried to address in the second edition was we added many more examples of fitness functions to make that idea more concrete, and we crowdsourced a lot of them from people within our network, people within the company, and all of the examples in there are concrete examples that different people have used on projects to start to answer that question, how do I go from this thing that I want to achieve to a fitness function that tells me whether or not I’m achieving it?
Thomas Betts: I think one of the other quotes from your track at QCon was that every software problem is fundamentally a communications problem. And when two people read a sentence and disagree about that sentence, that’s the communication problem. And so as long as those two people can absolutely agree and you can bring over a third person and they can also agree on it, that’s the big solution. That’s amazing.
Rebecca Parsons: Exactly.
Thomas Betts: But that’s not easy to do.
Rebecca Parsons: Nope.
Thomas Betts: None of this stuff is for free. You have to work on all these things and there are benefits when you can get that agreement.
Rebecca Parsons: Yes.
The evolution of data [17:03]
Thomas Betts: So one thing that we’ve seen evolve a lot over the past decade is how we handle data. I started this software stuff years ago, and you only stored your data in one giant database. You wanted to add new functions, you added more data to the same database. Now we have lots of microservices and each microservice owns their own data and has their own data store behind it. So we went from one database to dozens or hundreds. Was that something that was addressed in the evolution architecture book or is that something that you’re now addressing and seeing differently as a problem you have to solve separately?
Rebecca Parsons: No, it’s definitely a big part of it and a big contributor to that. And in fact, you can think of our chapter as a symbolic link to a book called Refactoring Databases, Evolutionary Database Design. And we keep telling Pramod Sadalage, one of the co-authors that they ought to reissue the book, but just flip the title and subtitle to, Evolutionary Database Design, Refactoring Databases. Because regardless of the kind of data store that you have, as soon as something goes into production with data, if you want to change the way that data is structured, you have to migrate it, and migration is hard. Anybody who’s done it knows that it might sound simple on paper, but it never goes the way you want it to go. And so this technique is what allows you to, again, more readily and safely do even large scale database changes by taking the refactoring approach.
And I’m using refactoring in the precise term as opposed to the, oh, I need to refactor my whole system because I’m swimming in technical death. For relational databases, in that book, they identified what are the atomic changes you have to make? And for each one of those big changes you want to make, it’s actually a composition of lots of atomic changes. If you break it down to those individual data refactorings and couple that with what changes you need to make to the access logic in the code, and then what’s the migration code? You can start to individually uncover those little landmines from August and September of 1984 when this field meant something completely different. And those are the reasons. The kinds of things that cause data migrations to go wrong is you’ve got all of this data and it doesn’t age well, and there’s all kinds of spots from history that cause it to change.
And the nice thing about that is as well, that the basic notion in refactoring databases applies regardless. If it’s a document database or a graph database, the individual refactorings are very different if you want to migrate a graph database from a relational database. But one of the things I think has been such a strong enabler of many of the architectural innovations that we’re seeing now is the fact that we have broken that notion that if you persist data, it must be in the relational database. And the DBAs are the gatekeepers of access to that. We’ve really been able to rethink our relationship with data as a fundamental part of the system, and I think that’s been an incredibly powerful innovation within our enterprise technology landscape.
Thomas Betts: The way you described a series of little atomic steps, that fits well with the idea of evolution, not revolution. Don’t just make one big change and hope you can jump all the way over the chasm. How do we make lots of little steps? Because when you look at it, databases are good at doing lots of little things. They do lots of little things. They just give you that nice abstraction, but sometimes you have to go down to what are the little refactorings, and I’ve been there when you have this copy of the data is in version one, and this copy is in version two, and this one’s in version three, and now I want to go to version four. If I had been updating one to two and then two to three the whole way. But if I can’t replay those steps, I don’t know how to make the jump from one to four.
Rebecca Parsons: Exactly.
Platform engineering [20:55]
Thomas Betts: Like you said, there’s a whole other book on databases. We’ll be sure to have a link to that. But I want to talk about platform engineering. How has platform engineering and a good engineering platform that helps us with continuous delivery and having all that tooling around knowing what our system looks like, how has that helped? And was that something that we didn’t have much when you wrote the first book?
Rebecca Parsons: Well, first we need to disambiguate terms a little bit because I think the story changes depending on what your definition of platform is.
We can take out of scope for this discussion, the platform businesses, Uber and Airbnb and such is the platform business model. That might be the ultimate goal of building a platform, but that’s not what we’re talking about here.
When we think about, in particular, the lower level developer platforms, maybe you’ve got capabilities like auditing or logging or single sign-on and things of that nature. And you can actually think of even the continuous delivery pipelines as part of that platform that reduces the friction for the person who is trying to deliver business logic. And some of these things were obviously around. Cloud clearly existed. Many of the SaaS platforms clearly existed in 2017. We understood about continuous delivery and such, but people didn’t necessarily think of platforms in a way that would support some of these fundamental changes.
When I first started talking about evolutionary architecture, which was long before the book came out, people would come up afterwards and whisper, “Don’t think you’re being professionally irresponsible to advocate for evolutionary architecture.” And so even during that time, you wanted your developer platform kind of locked down and then people would build things on top of it.
What I think is actually more interesting from an evolutionary architecture perspective is when we go up to that next level of platform, which is where we’re delivering fundamental business capabilities, that we then want developers to be able to hook together in different ways to create new products, new services for the users. And that’s where some of the architecting for evolvability comes in. Do you understand what this part of the system is trying to achieve? Are you constructing these capabilities from the perspective of the business that you are in?
Because when you think about how someone is going to come to you as a technologist and say, I want you to change this business process to do this. In their head, they’re not imagining an SAP system or this and that and the other microservice. They’re thinking about customers or they’re thinking about products or they’re thinking about roots. They’re thinking about the concepts that go into what this business does to make money. And so if you have those business capabilities in that platform structured around the kinds of things that people are going to imagine they’re going to want to move around, it’s going to be a whole lot easier to move them around. Because the blocks that you have available to you are the same blocks that I have in my head that I’m trying to metaphorically move around.
I do think that as we’ve refined our thinking around these business capability platforms, they are moving much more towards this notion of being able to evolve the system to do new things with the same kind of fundamental building blocks that we have. So I think we have to separate out the two different kinds of platforms in thinking about that.
Thomas Betts: Gotcha. That’s a very useful separation. I know thinking about extensibility is saying that we’ve always had extensibility like, oh, I’m going to add an API and people will consume the API. But now we’ve got low-code and no-code solutions, and the extensibility that needed a developer to be on the other side of it has been replaced by any business user’s going to fire up a little webpage and boom, they’re solving a new business problem because you gave them composable small units that they can put together in that new way. So it might not even be that you’re building something in your architecture, but you’re allowing that overall system to expand. That’s where you’re saying the business capability platform allows that kind of synthesis.
Rebecca Parsons: Yes. But those things are even useful outside of the context of a low-code no-code platform, because it might actually be a pretty complicated workflow that you’re trying to put together here with different kinds of exception handling, but you still are using those fundamental building blocks and are able to reuse them.
Microservices not required – a monolith can be evolvable [25:22]
Thomas Betts: So does that get to the idea of… It sounds like a microservices architecture is the panacea for this, but do you have to have microservices to be able to do evolutionary architecture? Could I do this with a monolith?
Rebecca Parsons: Yes. You can’t do it with a big bottle of mud, but a well-structured monolith, although you don’t have the individual deployment. We talk about the notion of a quantum, and that’s a deployable unit, and microservices of course are a much smaller deployable unit. But if you have a well-structured monolith and you are respecting all of the boundaries, many of the things that you want to be able to do, you can do for an evolutionary architecture, you will be able to move things around. Just because they live in the same monolith, it doesn’t mean they’re coupled.
Now the problem is it takes a lot more discipline. I remember hearing a talk by Chad Fowler, and he said at one point he decreed that no two microservices could share any part of the technology stack, because he didn’t want people to, oh, here, I can just reach over there and use that instead of doing it, which I think is an extreme. I think he was just trying to really make a point, but it’s a whole lot harder to do that in a microservices architecture than it is in a monolith, and it can be so tempting.
But if you have good discipline and you’ve got the right kind of separation there, a well-structured monolith can support an evolutionary approach to architecture. The structure of the monolith does matter. If it’s a layered monolith where you’ve got your data layer in your logical layer in your presentation layer, that gives you a certain level of evolvability, but it doesn’t necessarily always help you that much because most business changes are going to affect all of the layers. But if you’re structuring up more around these domain-driven design level, bounded context, if that’s your unit of organization within the monolith, you’re going to have the same level of flexibility in terms of the creation of new functionality as you would in the microservices. You just have a different deployment strategy.
Conway’s Law and the importance of shared understanding [27:33]
Thomas Betts: That comment about not having two microservices be able to reach in and touch the technology that you have to go through the interface makes me think of Conway’s Law and that those team structures, the teams can only talk to each other through their services as opposed to, oh, I’m just going to pop on Slack and ask somebody to make this change for me. How does Conway’s Law fit into evolutionary architecture?
Rebecca Parsons: It always comes down to the people. And we like to talk about the Inverse Conway Maneuver, where if you want your system to look a particular way, reorganize your team, and that’s what will happen. But the important thing really is to make sure that the boundaries between those teams are drawn in a logical way. Because again, going back to that “this and that and the other, and possibly this” test name, if you and I don’t understand what’s in your remit versus what’s in mine, we’re not going to have a clean barrier between the component that you write and the component that I write. And so Conway’s Law helps us understand how we align people to the right objectives, but it does very clearly have implications for the architecture, because it’s the people who are going to create those components. And if the communication is not there, and if the shared understanding isn’t there, then the code isn’t going to work.
Predicting the future of evolvable architecture [28:55]
Thomas Betts: I think we’re going to wrap up. I said that we were going to talk a little bit about the future. We talked about the evolution of edition one to edition two of your book. So evolutionary architecture has obviously evolved some. How do you see it going to evolve in the future? Pull out your crystal ball and let us know what’s going to happen.
Rebecca Parsons: Well, the first thing I will say is when Camilla first asked me if I would do the talk, I was thinking to myself, “I can’t do this. I can’t predict the future.” That’s the whole premise of the book. Is you can’t predict how it will change. But she said 2025, and that’s not that far away.
I do think we’re going to continue to get a more sophisticated understanding of just how we can use fitness functions to express some of these more difficult architectural characteristics. I do think we are going to see significant advances from the perspective of observability, and with this increased interest in testing and production and rollback and all of that. I think we’re going to see evolution not just in our thinking about the fitness functions, but how we can actually implement them and take action as a result of it. I do think we’re going to see more productivity from AI-based tools in things like our testing strategies.
We’re also doing some preliminary experiments, emphasis on the word preliminary at the moment, to help us with legacy modernization by using some of these AI tools to start to parse out what are the actual data flows through some of these old legacy systems. So I think some of the advances that we’re getting in generative AI and AI more broadly are going to help us in dealing with some of these legacy systems.
And then I think we’re going to continue to see evolution even the way we think about architectures. From my perspective, continuous delivery has been a great enabler, but the combination of continuous delivery and open source has been a great enabler for things like the microservices architectures and some of the other innovations we’re seeing in architecture, because it has allowed us to de-risk deployments.
And I think we’re going to continue as we see more hybrid hardware software systems with sensors, IOTs, actuators, smart homes, smart cities, smart factories, I think we’re going to see innovation in, okay, well, how do we keep those systems up to date? How do we keep our level of understanding of that system at the appropriate level, and how do we do diagnostics as those estates get larger and larger?
Thomas Betts: Well, I think that’s a great place to end. Looking ahead of the future, maybe in a few years, we’ll have the chat bot come on and tell us what the next five years will look like.
Rebecca, thanks again for joining me today.
Rebecca Parsons: Thanks Thomas. It’s been a pleasure.
Thomas Betts: And listeners, we hope you’ll join us again soon for another episode of the InfoQ Podcast.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Google and Bazel consulting firm Aspect announced version 1.0 of Bazel plugin rules_oci. Aimed to simplify secure container image creation using Bazel with special emphasis on Distroless images, the new plugin obsoletes rules_docker and improves it on a number of counts.
Both rules_oci and rules_docker, the latter now in maintenance mode, can automate the process of securely creating container images. Bazel, says Google engineer Appu Goundan, is ideal for this task thanks to it using integrity hashes to cache dependencies along with the “Trust on first use” principle, which will consider any change in the integrity hash associated to a dependency as a sign of tampering.
While rules_oci can be used to create any kind of container image, Google is specifically aiming it to the creation of distroless images as a way to improve supply-chain security:
[Distroless images] restrict what’s in your runtime container to precisely what’s necessary for your app, which is a best practice employed by Google and other tech companies that have used containers in production for many years. Using minimal base images reduces the burden of managing risks associated with security vulnerabilities, licensing, and governance issues in the supply chain for building applications.
One of the reasons why rules_oci has been introduced is its support for creating container images for multiple runtimes and formats, as specified by the Open Container Initiate, especially podman. On the contrary, rules_docker, as its name implies, is tied to creating Docker images specifically. rules_oci also benefits from a simplified architecture, thanks to the fact that it can leverage tools such as Crane, Skopeo, and Zot for container manipulation tasks like managing a local registry.
Additionally, rules_oci strives to be language-independent, while rules_oci includes specific rule sets for each supported language to deal in most cases with the peculiarities each language ecosystem has about dependency management. This will make the new plugin easier to maintain and use it with new languages, says Goundan. Google is providing, in any case, language-specific examples to help create container images using rules_oci for a number of languages, including C/C++, Go, Java, etc.
There are other rules_oci features, explains Goundan, which are especially relevant to supply-chain security. In particular, rules_oci uses Bazel to fetch layers from remote registries, which also uses code signing to enable authorship verification.
Having reached 1.0 means rules_oci provides a stronger stability guarantee, following the semver standard, and the promise that future releases won’t include breaking API changes. Aspect also provided a migration guide to make it easier to replace rules_docker with rules_oci.
Google Cloud Expands Cloud Interconnect Portfolio and Enhances Networking Capabilities
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Recently Google Cloud announced a significant expansion of its Cloud Interconnect portfolio by unveiling Cross-Cloud Interconnect. The new offering enables organizations to connect any public cloud with Google Cloud securely and efficiently, allowing seamless application deployment across multiple clouds and simplified SaaS networking in a multicloud environment.
Connecting and securing distributed environments have posed challenges for cloud infrastructure teams. Configurations often involve complex setups, dedicated hardware, and time-consuming operational processes. With the Cross-Cloud Interconnect offering, Google aims to simplify these processes by minimizing hardware requirements, reducing overhead, and providing a secure, high-performance network for connecting any public cloud like Microsoft Azure, AWS, and Alibaba with Google Cloud.
The offering is available in 10 Gbps or 100 Gbps options and does not require new hardware. In addition, it has the same features as Cloud Interconnect and is backed with an SLA (99.99%). According to the company, customers with multicloud environments can leverage Cross-Cloud Interconnect to enable the following:
- Private and secure connectivity across clouds.
- Line-rate performance and high reliability with 99.99% SLA.
- Lower TCO without the complexity and cost of managing infrastructure.
- Run Applications on multicloud.
- Migrate workloads from one cloud to another.
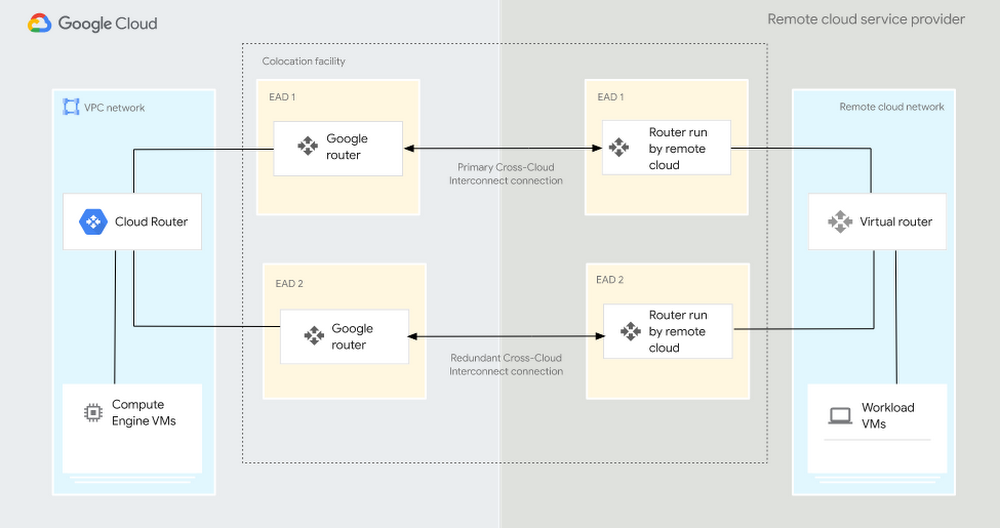
Source: https://cloud.google.com/blog/products/networking/announcing-google-cloud-cross-cloud-interconnect
Alongside the introduction of Cross-Cloud Interconnect, Google Cloud enhanced its Private Service Connect offering. Private Service Connect enables the creation of private and secure connections from virtual private clouds (VPCs) to Google Cloud, partner services, or custom services, simplifying network configuration for published services and SaaS applications. The recent enhancements include support for Cross-Cloud Interconnect, automated service connection policies, and expanded access for on-premises and multi-cloud clients.
In addition to these advancements, Google Cloud has strengthened its Cloud Interconnect capabilities with new encryption options, improved performance, and enhanced network resiliency. Features like MACsec for Cloud Interconnect provide point-to-point line-rate L2 encryption, ensuring secure communications between customers and Google Cloud, and HA VPN over Interconnect provides IPSec encryption to protect communications between a customer’s on-prem VPN gateway and the HA VPN gateway in Google Cloud.
In addition, bidirectional forwarding detection expedites the detection of link failures, enabling prompt traffic rerouting in case of path outages, and 9K MTU support (in preview) allows large packet sizes to deliver higher throughput over Interconnect offerings. Moreover, BGP enhancements (in preview) include support for custom-learned routes and increased prefix scale, further optimizing networking operations.
Several cloud providers offer similar services to Google Cloud Interconnect. For example, Azure ExpressRoute provides a private and dedicated connection between an organization’s on-premises infrastructure and Azure cloud services. It offers secure and reliable connectivity with high bandwidth and low latency options. Furthermore, it allows connectivity with other clouds. Another example is AWS Direct Connect, which enables organizations to establish a dedicated network connection between their on-premises data centers and AWS, bypassing the public internet.
Java News Roundup: JEPs for JDK 21, Hibernate Reactive 2.0, Payara Named CVE Numbering Authority
MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for May 29th, 2023 features news from OpenJDK, JDK 21, GlassFish 7.0.5, Payara, Open Liberty 23.0.0.5, IBM Semeru Runtimes, Micronaut 4.0-M6, Quarkus 3.1, Hibernate ORM 6.2.4, Hibernate Reactive 2.0, Hibernate Search 6.2.Beta1, Camel Quarkus 3.0-M2, Camel 3.14.8, Tomcat Native 2.0.4 and 1.2.37, Ktor 2.3.1, Multik 0.2.2, JobRunr 6.2.1, JDKMon 17.0.63 and Gradle 8.2-RC1.
OpenJDK
JEP 452, Key Encapsulation Mechanism API, has been promoted from Proposed to Target to Targeted for JDK 21. This feature JEP type proposes to: satisfy implementations of standard Key Encapsulation Mechanism (KEM) algorithms; satisfy use cases of KEM by higher level security protocols; and allow service providers to plug-in Java or native implementations of KEM algorithms. This JEP was recently updated to include a major change that eliminates the DerivedKeyParameterSpec class in favor of placing fields in the argument list of the encapsulate(int from, int to, String algorithm) method. InfoQ will follow up with a more detailed news story.
JEP 451, Prepare to Disallow the Dynamic Loading of Agents, has been promoted from Proposed to Target to Targeted for JDK 21. Originally known as Disallow the Dynamic Loading of Agents by Default, and following the approach of JEP Draft 8305968, Integrity and Strong Encapsulation, this JEP has evolved from its original intent to disallow the dynamic loading of agents into a running JVM by default to issue warnings when agents are dynamically loaded into a running JVM. Goals of this JEP include: reassess the balance between serviceability and integrity; and ensure that a majority of tools, which do not need to dynamically load agents, are unaffected.
JEP 453, Structured Concurrency (Preview), has been promoted from Candidate to Proposed to Target for JDK 21. Formerly a incubating API, this initial preview incorporates enhancements in response to feedback from the previous two rounds of incubation: JEP 428, Structured Concurrency (Incubator), delivered in JDK 19; and JEP 437, Structured Concurrency (Second Incubator), delivered in JDK 20. The only significant change features the fork() method, defined in the StructuredTaskScope class, returns an instance of TaskHandle rather than a Future since the get() method in the TaskHandle interface was restructured to behave the same as the resultNow() method in the Future interface. The review is expected to conclude on June 6, 2023.
JEP 446, Scoped Values (Preview), has been promoted from Candidate to Proposed to Target for JDK 21. Formerly known as Extent-Local Variables (Incubator), this JEP is now a preview feature following JEP 429, Scoped Values (Incubator), delivered in JDK 20. This JEP proposes to enable sharing of immutable data within and across threads. This is preferred to thread-local variables, especially when using large numbers of virtual threads. The review is expected to conclude on June 6, 2023.
JDK 21
Build 25 of the JDK 21 early-access builds was also made available this past week featuring updates from Build 24 that include fixes to various issues. Further details on this build may be found in the release notes.
For JDK 21, developers are encouraged to report bugs via the Java Bug Database.
Eclipse GlassFish
GlassFish 7.0.5, the fifth maintenance release, delivers a new feature that asynchronously updates the instance status in the Admin Console. Notable bug fixes include: deployment-time recursive bytecode preprocessing in the WebappClassLoader class; the JMX server accepting an arbitrary object as credentials; and a validation error upon deploying an application to a cluster. More details on this release may be found in the release notes.
Payara Platform
Payara has been authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA). Payara is now allowed to publish authoritative cybersecurity vulnerability information about its products via the CVE Program.
Discussing how Payara can better support their customers, Fabio Turizo, service manager and senior engineer at Payara, stated:
Becoming a CVE Numbering Authority creates an extra level of dependability for those using our products and continues our commitment in adhering to and maintaining the best possible security standards. A key benefit is peace of mind when developing your mission critical Jakarta EE applications. As a CVE Numbering Authority, we ensure that when problems do occur, they can be quickly identified and a solution found, with ease of communication and total transparency.
The CVE Program is sponsored by the Cybersecurity and Infrastructure Security Agency of the U.S. Department of Homeland Security. Payara joins organizations such as The Apache Software Foundation, VMware, Oracle and IBM as defined in the CNA list of partners.
Open Liberty
IBM has released Open Liberty 23.0.0.5 featuring updates to 44 of the Open Liberty Guides that now support MicroProfile 6 and Jakarta EE 10. These include: Consuming a RESTful Web Service; Accessing and Persisting Data in Microservices using Java Persistence API (JPA); and Deploying a Microservice to Kubernetes using Open Liberty Operator. There were also notable bug fixes such as: a memory Leak found in the SchemaRegistry class within the MicroProfile Open API specification; and an EntryNotFoundException when defining a non-identifier type property for the input/output mapping of federated registries.
IBM has also released versions 19.0.2, 17.0.7, 11.0.19 and 8.0.372 of their Semeru Runtime, Open Edition, as part of their quarterly update. Further details on this release may be found in the release notes.
Micronaut
On the road to version 4.0, the Micronaut Foundation has provided the sixth milestone release of Micronaut 4.0.0 that delivers bug fixes, dependencies upgrades and new features and improvements such as: new interfaces, PropagatedContext and MutablePropagationContext, for HTTP filters; improved selection in the MessageBodyHandler interface; and the ability to make the NettyClientSslBuilder class pluggable. More details on this release may be found in the release notes.
Quarkus
The release of Quarkus 3.1.0.Final provides changes: a new API to programmatically create Reactive REST Clients as an alternative to using a properties file; the ability to customize RESTEasy Reactive response headers and status code for more flexibility in streaming responses; a reactive variant of the Security Jakarta Persistence extension, quarkus-security-jpa-reactive, based on Hibernate Reactive; and the OIDC ID token audience is now verified by default. There were also dependency upgrades to Kotlin 1.8.21 and Oracle JDBC driver 23.2.0.0. Further details on this release may be found in the release notes.
Hibernate
The Hibernate team has provided GA, point and beta releases of Hibernate Reactive, Hibernate ORM and Hibernate Search, respectively.
The release of Hibernate Reactive 2.0.0.Final delivers dependency upgrades and bug fixes such as: the ClassCastException when more than one field is lazy and bytecode enhancement is enabled; pagination not working for some queries with Microsoft SQL Server; and lambda expressions causing a NoSuchMethodError exception on application startup. This new version is compatible with Hibernate ORM 6.2.4.Final and Vert.x SQL client 4.4. More details on this release may be found in the list of issues.
The release of Hibernate ORM 6.2.4.Final ships with bug fixes and notable changes: resolutions to the JDK type pollution issue (JDK-8180450); and remove support for JPA static metamodel generation in the Hibernate Gradle plugin.
The first beta release of Hibernate Search 6.2.0 includes: many bug fixes and improvements; dependency upgrades; compatibility with Elasticsearch 8.8 and OpenSearch 2.7; an upgrade of the -orm6 artifacts to Hibernate ORM 6.2.4.Final; and a new feature, Highlighting in the Search API, a projection that returns fragments from full-text fields of matched documents that caused a query match. The specific terms that caused the match are highlighted with a pair of opening and closing tags such that developers can quickly identify search information on a results page.
Apache Software Foundation
The Apache Software Foundation has provided point and milestone releases of Apache Camel, Apache Camel Quarkus and Apache Tomcat Native Library, an optional component for use with Apache Tomcat that allows Tomcat to use OpenSSL as a replacement for Java Secure Socket Extension (JSSE) to support TLS connections.
The release of Apache Camel 3.14.8 features dependency upgrades and notable bug fixes such as: suppressed exceptions in the RedeliveryErrorHandler class cause a memory leak and logging issue; an application does not recover due to waiting threads when the thread pool from the NettyProducer class is exhausted; and the onFailure() callback method defined in the OnCompletionProcessor class is executed more than once. Further details on this release may be found in the release notes.
Apache Tomcat Native 2.0.4 has been released with dependency upgrades to Apache Portable Runtime (APR) 1.7.4 and OpenSSL 3.0.9. More details on this release may be found in the changelog.
Similarly, Apache Tomcat Native 1.2.37 has also been released with dependency upgrades to APR 1.7.4 and OpenSSL 1.1.1u. Further details on this release may be found in the changelog.
The second milestone release of Camel Quarkus 3.0.0 features numerous resolved issues such as: intermittent failures in JDBC native tests and the MyBatisConsumerTest class; a JDBC resource leak from the CamelJdbcTest class; and support for Groovy causes a failure with continuous integration. This version aligns with Quarkus 3.1.0.Final and Camel 4.0.0-M3. More details on this release may be found in the release notes.
JetBrains
JetBrains has provided point releases for Ktor, an asynchronous framework for creating microservices and web applications, and Multik, a multidimensional array library for Kotlin.
The release of Ktor 2.3.1 delivers notable bug fixes such as: Ktor Client under Javascript unable to stream responses from a server; requests to a non-existing route causing the server to lock up after responding with HTTP 404 (a potential DoS); and YAML configuration unable to read variables from itself. Further details on this release may be found in the release notes.
The release of Multik 0.2.2 provides new features that include: extended support for all JVM platforms in the multik-default module; functionality to create an array from lists of different sizes; a stub for singular value decomposition; and support for the npy and npz formats for JVM in the multik-core module. There were also dependency upgrades to Kotlin 1.8.21 and OpenBLAS 0.3.23.
JobRunr
JobRunr 6.2.1 has been released with bug fixes to resolve compatibility issues with: Quarkus 3.0 when using JSONB; and Java Records not working with the JacksonJsonMapper class.
JDKMon
Version 17.0.63 of JDKMon, a tool that monitors and updates installed JDKs, has been made available this past week. Created by Gerrit Grunwald, principal engineer at Azul, this new version provides an enhancement related to loading common vulnerabilities and exposures.
Gradle
The first release candidate of Gradle 8.2 features improvements such as: new reference documentation for the Kotlin DSL; clean and actionable error reporting for the console output; and dependency verification that mitigates security risks with compromised dependencies. More details on this release may be found in the release notes.
MMS • Renato Losio
Article originally posted on InfoQ. Visit InfoQ

Cloudflare recently announced a revamp of its serverless relational database D1. Built on top of SQLite, D1 has a new architecture that provides better read and write performances and support for JSON functions.
Announced in alpha a year ago and designed to integrate with Workers, the serverless relational database went through different iterations, with the latest announcement primarily focusing on a new architecture and its performance benefits. Matt Silverlock, director of product at Cloudflare, and Glen Maddern, systems engineer at Cloudflare, write:
If you’ve used D1 in its alpha state to date: forget everything you know. D1 is now substantially faster: up to 20x faster on the well-known Northwind Traders Demo, which we’ve just migrated to use our new storage backend. Our new architecture also increases write performance: a simple benchmark inserting 1,000 rows (each row about 200 bytes wide) is approximately 6.8x faster than the previous version of D1.
With the current open alpha release, Cloudflare introduces a new console interface to issue queries directly from the dashboard, support for JSON function, and Location Hints, an option to determine where the leader database is located globally. Cloudflare confirmed as well that it is currently working on Time Travel, a point-in-time-recovery option that allows restoring a D1 database to any minute within the last 30 days or to a specific transaction.
# Using a precise Unix timestamp (in UTC):
$ wrangler d1 time-travel my-database --before-timestamp=1683570504
# Alternatively, restore prior to a specific transaction ID:
$ wrangler d1 time-travel my-database --before-tx-id=01H0FM2XHKACETEFQK2P5T6BWD
Source: https://blog.cloudflare.com/d1-turning-it-up-to-11/
According to the roadmap, Cloudflare plans to offer soon, databases up to 1GB, metrics and observability using GraphQL API, and automatic read replication. Silverlock and Maddern add:
We’re also exploring features that can surface larger changes to your database state, including making it easier to identify schema changes, the number of tables, large deltas in data stored, and even specific queries (via transaction IDs).
Commenting on the Developer Week announcements, Jeremy Daly, author of the weekly serverless newsletter Off-by-none, writes:
I’m not sure AWS is quaking in their boots just yet, but obviously, Cloudflare is making some pretty serious moves to compete with some of their core services.
Cloudflare revealed the expected prices even if billing will not be enabled until later this year, with D1 at the moment free to use and a free tier expected in the future. With a relatively simple billing model, Cloudflare will charge three components: the number of writes (as 1KB units), the number of reads (as 4KB units), and storage. Global read replication will not incur additional costs and the authors challenge alternative serverless databases:
We wanted to ensure D1 took the best parts of serverless pricing — scale-to-zero and pay-for-what-you-use — so that you’re not trying to figure out how many CPUs and/or how much memory you need for your workload.
Following the announcement, Cloudflare updated its documentation, added example projects, and opened a #d1 Discord channel.
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ

Any time we talk to someone or to a group when there are high stakes and/or high emotions, difficult conversations can happen. If we ignore difficult conversations they typically don’t resolve themselves, in fact, they often get worse. Handling difficult conversations involves thinking about the logistics, having the proper mindset, and preparing yourselves.
Andrew Murphy gave a talk about tackling difficult conversations at NDC Oslo 2023.
Murphy mentioned that many of our day-to-day conversations are difficult conversations, like performance reviews, interviews (on both sides), or persuading people to use the framework/platform/tool we prefer or built:
When the impact of having (or not having) the conversation is high, the chances are it’s a difficult conversation.
We often get worried about what other people will think of us, or our actions, Murphy said. We fear we will hurt, upset, or anger the other people involved. This makes it troublesome to separate what is truly in the best interests of the people involved, and what is just us shying away from it, he said.
Murphy presented a three-step model for tackling difficult conversations:
- Logistics: How can you, logistically, make sure the conversation is productive and effective?
- Mindset: This usually comes down to the courage to have the difficult conversation itself! Impostor syndrome is real, don’t let it stop you from achieving your goals
- Preparation: What data/observations can you gather to help? How can you plan how the conversation will go? How could it go wrong?
We should ask ourselves why having this difficult conversation is important, Murphy suggested. What do you hope to achieve from it? How does it help you, the other person, and everyone around you? This should help you gain the courage and confidence to follow through with it.
Murphy mentioned that often people have two modes when it comes to difficult conversations: neutral and turbo. They flip between the two, delaying until they have no choice but to go full throttle into it. By taking a step back and thinking about the situation as logically, and objectively, as you can you can prepare yourself for dealing with it, Murphy explained:
If you find yourself cycling and getting angry or frustrated when thinking about the situation, then it’s really important to do this.
When the conversation goes wrong, Murphy suggested staying true to the reason you are having it. Reminding yourself what’s at stake, and for whom, means you can always come back to a place of compassion for the particular situation and person, he concluded.
InfoQ interviewed Andrew Murphy about difficult conversations.
InfoQ: Why do we need to have difficult conversations?
Andrew Murphy: Because we want the world to be a better place. Because we want the people we work with to be happy, effective and productive in what they are doing. When we don’t have difficult conversations the situation doesn’t get better, in fact, it may even get worse!
How many times have you thought to yourself “I don’t want to talk to them about that”? I know I’ve thought about it a lot. But rarely the problem disappears all by itself. Most often, we need to tackle it head on and deal with it before it gets worse.
InfoQ: How can we handle the logistics of conversations?
Murphy: Think about the “who, what, where and when” of the difficult conversation:
- Who should be involved? As few people as possible to make sure it happens. Difficult Conversations aren’t a forum for airing grievances to the public
- What should the outcome be? Getting it straight in your own mind what are you going to talk about and why is that an issue.
- Where should we discuss it? Probably not in the middle of standup
- When should it happen? As soon as possible, usually!
These allow you to plan for it and ensure you have everyone you need, when you need them, in and environment that is productive and not threatening.
InfoQ: How can we prepare ourselves emotionally for difficult conversations?
Murphy: If the reason you need to have a difficult conversation with someone is that they’ve hurt you then, unless your emotional resilience is excellent, taking a breath will help put you in the right mindset for approaching it. Barelling forward in turbo mode is sure to lead to exactly what you don’t want – and unproductive conversation.
InfoQ: What’s your advice when we’re uncomfortable about a difficult conversation?
Murphy: Don’t worry about making yourself feel comfortable when you are preparing for a difficult conversation. It’s perfectly fine to feel uncomfortable! These are high stakes and highly emotional situations.
If you’re totally comfortable with them then you might have lost perspective or empathy for those around you. Do try to be confident going into it, though.
MMS • Renato Losio
Article originally posted on InfoQ. Visit InfoQ

In the next few days, AWS will start retiring the AWS documentation currently available on GitHub. After reviewing the results of the project and considering the overhead of manually keeping the internal documentation in sync, the cloud provider recently decided to retire most of its public repositories.
Created to increase openness and collaboration, the open-source documentation never gained popularity with the AWS community, with developers lamenting that pull requests were often ignored. Jeff Barr, vice president and chief evangelist at AWS, explains the change:
The primary source for most of the AWS documentation is on internal systems that we had to manually sync with the GitHub repos. Despite the best efforts of our documentation team, keeping the public repos in sync with our internal ones has proven to be very difficult and time-consuming, with several manual steps and some parallel editing (…) the overhead was very high and actually consumed precious time that could have been put to use in ways that more directly improved the quality of the documentation.
Not every repository will be retired, with the ones containing code samples, sample apps, CloudFormation templates, configuration files, and other supplementary resources remaining as primary sources.
AWS made initially available the documentation on GitHub five years ago, inviting interested developers to contribute changes and improvements in the form of pull requests. Barr wrote at the time:
You can fix bugs, improve code samples (or submit new ones) (…). You can also look at the commit history in order to learn more about new features and service launches and to track improvements to the documents.
While some developers will miss the ability to perform a diff to keep track of changes and highlight the reduced options to report issues, others appreciate that AWS finally acknowledges the suboptimal situation. In a popular Reddit thread, some users question if the solution should have been instead to make GitHub the main repository, while others suggest better automation. Corey Quinn, chief cloud economist at The Duckbill Group, comments:
Good on AWS for both recognizing when something isn’t working as they’d planned and reversing course, and also for not presenting documentation errors as customers’ responsibility to fix.
Ben Kehoe, cloud expert and AWS Serverless Hero, tweets:
I think this is the right decision. I’d love to have properly open and collaborative AWS docs, but in the absence of that, owning up to it is better than the status quo we had.
AWS was not the only cloud provider offering open-source documentation, with Microsoft Azure documentation available on GitHub.
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

Sundry Photography/iStock Editorial via Getty Images
MongoDB (NASDAQ:MDB) was 27% higher at midday Friday, making its biggest move in years after a beat-and-raise in its first-quarter earnings, spurred in large part by solid gains in managed databases and strong customer additions.
The results were strong enough that peer companies rose in sympathy Friday: Datadog (DDOG) +4.7%; Cloudflare (NET) +2.2%; Snowflake (SNOW) +6%.
Revenues rose 29% to more than $368M and earnings per share of $0.56 easily topped expectations for $0.19. And the company now forecasts much better than expected financials for the current quarter and full year, seeing second-quarter revenue at $388M-$392M (vs. $361M) and EPS of $0.43-$0.46 (vs. $0.14).
And along with the beat-and-raise, it’s almost a given that MongoDB highlighted its positioning in the burgeoning field of artificial intelligence.
The update led Goldman Sachs to reiterate its Buy rating and raise its price target to $420 from $280, implying another 13% upside on top of Friday’s sharp gains.
“With an expected boost to developer productivity from tools such as GitHub Copilot, we anticipate MongoDB will be a direct beneficiary of accelerating app development/deployment,” analyst Kash Rangan said. “Sitting at the intersection of rising cloud adoption, the shift to NoSQL and now the emergence of Generative AI, we reiterate our view that MongoDB is poised to scale to $6B-$8B in revenue longer-term,” Rangan said.
Morgan Stanley was positive as well. “Aside from the potential AI tailwinds, we were particularly encouraged by the strength in the core business with customer acquisition and improved consumption behavior leading to growing conviction in our call that new workload growth will start to outweigh cloud headwinds later this year and into 2024,” analyst Keith Weiss said.
The report “pulls forward profitability by 12 months,” Seeking Alpha analyst and investing group leader Michael Wiggins de Oliveira said. While the cloud-based Atlas platform is still growing fast, “for me, the best insight into the appeal of its platform lies in its customer adoption curve,” pointing to Atlas customers up 23% year-over-year.
For more detail, dig into Seeking Alpha’s transcript of MongoDB’s earnings call.