Month: July 2023

MMS • Abby Bangser Helen Beal Matt Campbell Steef-Jan Wiggers
Subscribe on:
Transcript
Introduction
Daniel Bryant: Hello, and welcome to the InfoQ Podcast. I’m your host Daniel Bryant, and today we have members of the editorial staff and friends of InfoQ discussing the current trends within the cloud and DevOps space. We’ll cover topics ranging from AI and low-code, no-code, the changing face of Serverless, the impact of shift left and security and sustainability within the cloud. I’ll start by letting everyone introduce themselves.
Helen Beal: Hi, I’m Helen Beal. I am chief ambassador at DevOps Institute. Now part of the PeopleCert family, also chair of the Value Stream Management Consortium and co-chair of the Value Stream Management Interoperability Technical Committee at Open OASIS and a strategic advisor on Ways of Working. Lovely to be here.
Daniel Bryant: Thank you very much then. Abby, over to you.
Abby Bangser: Hi, yes, I’m Abby Bangser. I’m based in London as a principal engineer at Syntasso working on platform engineering solutions. I’ve also worked with the InfoQ group before, including just recently at QCon London with the debugging production track. Glad to be here.
Daniel Bryant: Fantastic. Matt, over to you.
Matt Campbell: Thank you. Matt Campbell, I’m based in Canada, lead editor for the DevOps queue for InfoQ and then also VP of Cloud Platform for education company called D2L, where we do a lot of platform engineering stuff.
Daniel Bryant: Fantastic. And finally, last one or least Steef-Jan, over to you.
Steef-Jan Wiggers: Yes, Steef-Jan Wiggers. So I’m based in the Netherlands. I’m a lead cloud editor at InfoQ for the last couple of years. My work as an integration Azure architect for i8c in the Netherlands. And Yes, I’m happy to be here.
Is the cloud domain moving from revolution to evolution? And is DevOps dead? [01:25]
Daniel Bryant: Fantastic. Thank you so much for taking time out of your busy days to join us. We’ll launch straight in, try not to be too controversial on the first question, right? But I want to set the high-level piece. Now, two things with the cloud and DevOps space, I’m hearing cloud innovation is slowing down. Our colleague InfoQ Renato did a fantastic piece covering Amazon reinvent and even he said that it’s more evolution rather than revolution. Also, we’ve been seeing here is DevOps dead. We had some interesting conversations around that. So I love to get everyone’s thoughts in terms of what do you see the big picture with cloud and DevOps? How are things moving? Where do you think things are going?
Helen Beal: I think it’s probably true. The innovation has slowed a little bit around clouds. I mean it’s gone really, really fast for a long time and now a lot of people are trying to adopt it. I think we’ve got over things like lift and shift and learned a lot about not doing things like that, but there’s still a lot of work for people to move workloads and re-architect workloads and things like that and adopt the things that have been invented for them.
As for DevOps, definitely not dead, don’t be ridiculous. However, I would say that it has some problems sort of 13 years into its journey. It’s reached some stagnancy, maybe dormancy in some organizations they’re struggling to really get it to the next level. That’s personally one of the reasons I’m particularly interested in Value Stream management is I see that as an option to help people unlock the flow and the value realization parts of it, but definitely not dead. Absolutely in the mainstream, lots of organizations still working on getting it right in their organization. So I’m going to ask Abby to respond and let me know how much of what I’ve said she agrees with.
Abby Bangser: Yes, I think that whole, just to go for the easy one first, I agree on the cloud space. I think there’s been a lot of evolution towards the original goal of cloud computing, which is access to the resources that you need on demand and with easy scalability. And we can see that now moving across more and more types of resources and becoming more ubiquitous, which is looking like evolution even though in those spaces it’s revolutionary. I think that there’s the DevOps conversation’s really interesting ’cause as you say, the again, intention of DevOps, just like the intention of cloud I think is still alive and well.
The intention of giving people access and autonomy in their teams to create business value without blockers is still something that we are all striving for and working hard towards. I think the concept of trying to say it is a developer person and an operations person sitting together on a team was never quite the intention, but was the attempted implementation, which we’re now seeing cracks in after years of trying to do it. And I think that’s showing rise to some of the other changes we’re going to be talking a bit about in platforms, internal platforms, and other things. So absolutely.
Daniel Bryant: Matt, you’re nodding along there a few times.
Matt Campbell: Yes, I would agree. I think one of my favorite topics of late is the sort of cognitive pressure that people are put under. And I think Abby, you were hitting on that and Helen as well, where there’s just in the approach to try to localize the development to try to make sure we could deliver business value faster. We also overloaded teams and even with all the cloud innovation that’s happening, every time something new comes out, you have to figure out how that’s going to fit in your worldview. How I’m going to integrate that into what I’m doing. Does it add value to what I’m doing? And I think we’re seeing everyone has a lot on their plate. The tech landscape changes very quickly. Businesses want to evolve and adapt quickly as well. So I think it’s all somewhat interconnected with the slowdown in that we’re now in a phase where we’re trying to figure out how do we sustainably leverage all of the cool stuff that we’ve invented and created and all these ways of interacting with each other and move it to a place where we can innovate comfortably going forward.
Daniel Bryant: Love it. Steef-Jan, so you’re nodding along there too.
Steef-Jan Wiggers: Well, I did see a massive adoption of the cloud predominantly because of COVID. Yes, I agree that a lot of that gives a burden on development and even I have to deal a lot in the cloud, and this is in some evolution with regards that also concurs with DevOps is where the automated setup environments. So recently some of the cloud providers like Azure have this automated way, not just setting up a dev box but also complete environments. So I see some evolution in that area as well that we start lifting and shifting that type of way so that you have a completely development test, automated development street basically setting that up that we say, “Yes, we try to get the dev and ops sitting together.”
Because I usually still see a little bit of a wall between them and it comes around to identity and access management, that kind of stuff. You still need access to certain resources, or you need to access certain tiers and then you don’t get them because someone on the DevOps side, “Well, I haven’t got the time for it yet.” So some of that stuff is not yet automated. So I still see a little bit of a gap there too, just from personal experience. I still feel that dev and ops, there’s always this little boundary between them, and has to do with predominantly identity and access management.
Daniel Bryant: That’s very interesting, Steef-Jan. I definitely think the whole DevOps, I like everyone sort of riff on that. Joking in a presentation I did a few years ago, said it’s like should really be BizDevQaOps at least, right? There’s a whole bunch of things that should be in there, but you know what developers are like, well engineers, I should say architects, we just like that snappy title. So I think that was a great call out, which I’m sure we’ll dive into many times throughout the podcast.
What is the current impact of AI and LLMs on the domains of cloud and DevOps? [06:19]
I did like their focus on revolution. And Matt, you mentioned about sort of cognitive overload, those kinds of things popularized by Team Topologies, which I think we’ll cover as well. But on that notion, we can’t get away from the impact AI and LLMs in particular had over the last six months and definitely since the last trend report we did. I’d love to get folks thoughts on what value does AI add to someone who’s going to be listening to the podcast either as an engineer, an architect, a technical leader. What do you think the immediate impact is of these kind of large language models and where do you think it’s going?
Helen Beal: Well, I can start again if you like. I mean yesterday, funny enough, I was doing a similar one of these about observability, but we ended up talking about AI quite a lot and initially in the context of AIOps, which of course isn’t so much about the large language models but more about algorithms and machine learning and absolutely what Matt said about cognitive pressure, cognitive load limits, and humans is a big problem when we are dealing with lots and lots of data coming out of lots and lots of monitoring systems and creating huge amounts of alert noise. So AIOps has a very strong use case there in this instant management, which is where we started having the conversation. But we of course got onto ChatGPT and the generative AI as well. And one of the particularly interesting use cases I found, or I heard from the team yesterday was around, again, instant management, but this time ticketing.
So developers probably remember things like the rubber duck. You’d have a rubber duck on your desk and you’d have to talk to it if you had a problem before you were allowed to bother somebody else with your problem because, generally, you’d find if you had a conversation, you’d come to a solution and they’re doing a similar thing at the insurance company that was on this talk yesterday and they’re actually using it in their ticketing system. So instead of raising a ticket, it’s encouraging you to chat with the AI and then once you get to a point it’s like, “Actually, no, we are going to have to raise a ticket for this thing.” And I think there was a few other ones, of course, the developer kind of Copilot things are getting code snippets and I think there’s just a huge opportunity here for some leapfrogging.
I see it in some of my daily work. So for example, recently, we had a problem where we were writing a new course, and the guy that was writing it was running out of time and we needed some instructor notes writing, and usually in the past that would’ve meant I’d Google the topic, spend 15 minutes digesting the information and then regurgitate something into an instructor note, but I could leapfrog sort of 15 minutes of work by asking ChatGPT the question and then validating the information and shuffling it around into taking the right bits out and the bits I didn’t want out as well. But another slightly off-topic, but interesting ChatGPT story. I was doing some work on a novel that I’m writing this morning and a scene I’m particularly writing, it’s set on a celebrity cooking show and somebody’s about to sabotage the cooking competition.
First of all, I did it in Sudowrite actually, which is a large language program for writers, and it came out with all sorts of suggestions about fiddling with utensils and ingredients. And then I stuck it in Bard and Bard said, I’m a large language model thing and I can’t help you. And then I stuck it in ChatGPT and ChatGPT said basically, I’m morally not allowed to help you with that. You’re trying to sabotage somebody. So I thought that was great though, seeing the ethics going on in the large-scale open tools was fun. Anyway, probably a little off-topic, apologies for that.
Daniel Bryant: Who would’ve thought cooking in the InfoQ Cloud DevOps podcast? Fantastic. Anyone else got any thoughts on that?
Steef-Jan Wiggers: Well, Yes, I do. From more than Microsoft side, I see a huge push through open AI initiatives. Like Helen mentioned, Copilot, so many of the Azure and even Microsoft Cloud products or services now have a Copilot. So you see it in their tooling like Visual Studio, Visual Code, you see it at Microsoft and Dynamics side that they have Copilots, A lot of the services Microsoft, even something recent, the Microsoft Fabric, which is a complete SaaS data lake or lakehouse solution they have is completely infused with AI. So Yes, you definitely see a big push in an investment on the Microsoft side.
Abby Bangser: Yes, I think to your question of what would listeners care about in this space, I think the big thing is just to start getting involved and exploring what is possible and not possible because it’s very easy to poke fun at the prompts that show up on social media of look at how silly this AI is. The robots are definitely not coming for us because it’s true. There are things that you do need to validate. Helen talked about getting information back and then validating it before going off and posting that to a project or to a course. But at the same time having an idea of what can be done for you, even if it’s not yet in the language models today, and where you will be able to add value is I think a really big piece of what we’re trying to figure out right now.
And we’re also just trying to figure out what that evolution will look like. And I think that prompting, there’s that joke about being a prompt engineer instead of being a software engineer. I think it’s a joke today to many people, but actually, that ability to be creative and to think critically about the problem in order to generate useful suggestions that’s effective in a meeting that’s going to be even more effective when you start applying things like a large language model to it. So I think these are all the things that are coming down the pipe at us because of this new technology.
Daniel Bryant: Fantastic. Matt, any thoughts on that one?
Matt Campbell: Well, it sounds like DevOps is going to get replaced by DevPromptOps then.
Daniel Bryant: Yes, love it.
Matt Campbell: Is what you’re saying there. So Yes, I love the idea of leveraging tools like this to make our lives easier. I think that’s always been the dream of technology is that we would have flying cars and be able to not have to work as much. And in some cases, kind of circling back to the first question, a lot of the innovation I think has actually maybe made us work harder in order to achieve some of our outcomes. And I love the idea going back like Helen you were talking about with AIOps and using that for monitoring and especially with distributed systems, as you get observability in there, it’s really hard to try to trace down where something’s actually broken. And having a system be able to do the first stab at that and report back, maybe look over here and remove that something recent at work, somebody wanted to learn how to use Antlere to help process a large amount of data that we had and used ChatGPT to kind of help construct some of the initial scripts as a way to guide their learning in that.
So using it to help prompt you and fill in gaps and give you a jumpstart. I think that as an initial jump-off point is pretty awesome usage of it. I’d love to see more developments in that area.
How do AI-based and ChatGPT-like products impact the low-code and no-code domains? [12:12]
Daniel Bryant: Yes, no, I love all the great sort of comments about the validation, the ethics involved. Sure. And I think we’re all saying the Copilot, the pair programmer, the summarization is super useful. And I was kind of wondering, I was doing a lot of work back in the low-code space a while ago and what do you think the impact of say AI is on low-code? Is it disrupting it, right? The whole low-code, no-code space, or is it going to augment it in that the tools to make things simpler were already there and now they’re perhaps going to get even better. So I’d love to get people’s thoughts on where do you think these low-code, no-code tools are available in the cloud. Where do you think they’re going to go with the impact of AI?
Helen Beal: Funny enough, that came up in the conversation yesterday as well when we were doing takeaways in the same chat from the insurance company that I was talking about when I asked him for his vision of the future, that’s exactly what he wanted. And as a head of DevOps in the technical team, what he actually wanted is his business teams to be able to use AI so that they could drive particularly things like self-healing and remediation around their core business systems. So people are definitely looking for that connection. I haven’t seen anybody having it yet, but something that definitely I’ve seen people have appetite for. Has anybody seen it in action in the real world yet?
Daniel Bryant: So listeners to the podcast, there’s a business opportunity there, right?
Helen Beal: A huge business opportunity. And I found it really interesting because traditionally when I’ve been a consultant, when we’ve had conversations about businesspeople doing stuff with systems, people have started shouting about shadow IT and it being very undesirable to have these businesspeople having their hands in the systems to that extent. So I found it quite interesting that we seem to be turning a corner because AI is actually supporting the businesspeople giving them an amount of knowledge that is probably safe. The small amount of knowledge can be dangerous. It feels like actually AI is lifting us out of that space where we can be trusted. And perhaps in the point that I made in response was it would be great to stop having this division between product management and software engineering. The business as people call it in technology and actually having us collaborate as single value streams would be fabulous.
Abby Bangser: I think it’s really interesting with that point about how dangerous is it to have someone who doesn’t particularly know about code to use these low-code platforms. I think that’s been the biggest debate on their uptake. And I’ve been hearing a lot of increased conversation about ClickOps, which used to be talked about in the sense of clicking around a browser to be able to solve your problem. But today’s products and leaders in that space are talking about how you enable people to click around and do things if that is the right interface for them, but you result in code or something that is version controlled, is declarative in nature, and can be understood and evolved.
And I think that the exciting bit about the LLMs and the AI side of things is that we’re getting better and better code generation. We’re seeing that with Copilot, with Codeium, with lots and lots of other tools. Can we get even better code generation, code generation people can actually use that, don’t want to click around the UI can actually read, can actually evolve, can actually meet standards of our organization’s code. But from that no-code, low-code spot, I think that will be an interesting evolution.
Steef-Jan Wiggers: Yes, I think so too. If you can prompt or talk and then have it out visualized through low-code. I’ve worked a lot with low-code platforms at least in the Microsoft space with logic apps that it can be out generated and then you have your business process right in front of you. You could do clicking it around, that’s correct. But usually, it’s left up to us instead of left up to them. But if you can just have it generated and then your business process right in your face it runs and there’s always kind of a code-behind stuff that is generated for you. So that can definitely work.
The interesting thing though would be in the end of the day, the governance regards to accessing certain part of data. It’s always been the case with low-code. Even if you look at the low-code platforms on the Microsoft side and the cloud side, which is I feel called power automate and that kind of stuff. And then it’s easy for them to use even businesspeople and they call them citizen developers, but in the end of the day it’s also about the data and the governance that they are using at least access to data and then sometimes it gets a bit weary that they get too much power or too much access to certain data.
Matt Campbell: I think that’s the sort of merger between the low-code and platform engineering and that we want to provide a safe platform that complies with our governance needs but also empowers the users of it to be able to get their job done. And I do see even with some of the low-code systems being challenging for end users to use, so getting some of the prompt engineering and ChatGPT stuff into that I think could be helpful in almost telling it what you want, and it kind of helping to build a skeleton for you to flesh out. My guess is we’re going to see a lot more evolution in this area as we look to try to drive more business value quickly and then also see this start to Steef-Jan’s point there, improve in the layer of governance and the platform engineering kind of DevOpsy layer of that so that those platform teams can take care of that part for the users of the low-code without them needing to worry about that or worry about crossing any boundaries you don’t want to be crossing.
How will Platform Engineering evolve? [16:59]
Daniel Bryant: Fantastic summary everyone. And I’ve heard several times sort of implicitly we’ve mentioned about platforms. Now, most of us here have been building platforms for 10, 20 years, but platform engineering has become a thing du jour. People have really locked onto that with good reason like DevOps, many of us are doing DevOps before it became a thing, but giving us a label does help build a community and drive the principles of that space forward. So I’d love to get folks thoughts around platform engineering. Particularly, I was thinking of things like Kubernetes and Service Mesh, all the rage for the last five years. Are they getting pushed down to everyone’s points about hiding some of that complexity, right? Reducing some of that cognitive load. And Abby you pointed out in our sort of a chat before their podcast started around Team Topologies going through a new evolution as well and that everyone, I seem to be chatting to you too is adopting some form of Team Topologies and that platform as a service, not as in paths, but more as in offering a platform as a service is seemingly everywhere at the moment.
Abby Bangser: Yes, I think it’s really interesting to see something like Team Topologies in the early majority and something like self-service platforms in the late majority. When I look at what I see around the industry and around the people that I work with. And I think that one of the big things is what does self-service actually mean in these organizations and what application of Team Topologies is being applied, how much of it is in theory agreed and how much of it’s really driving how you organize your teams and how you organize also their interaction models, not just how you organize their teams but how they interact.
And so I think what I’m seeing is with self-service, a lot of teams are saying they have self-service. I, a couple of years ago was saying I had a self-service platform and the way that people would self-serve from that is they would make a pull request into a repo with some code because they would have to have learned how to use a Terraform modular or how to have extended a YAML values file or something else which was not core to their business value delivery and still required some level of a ticketing system.
It’s different than a ServiceNow or Jira or something else. It is a pull request in GitHub, GitLab and other repository types. But it’s still a ticketing system that relies on a human. And I think today we’re talking a lot more about what is an API, what is something where we can actually separate the concerns of the consumers being the application developers or other members around the organization and the producers being the platform team. And I think that’s where that revolution right now is happening with people because of Team Topologies conversations.
Helen Beal: I’m particularly interested in its application within Value Stream Management as well when we look at the streamline team as being what I would call the kind of core team that’s doing the work that’s going to make the difference to the ultimate customer. And then we’ve got the supporting type teams like the platform teams that help the streamline teams do that work. My particular favorite pattern for the platform team isn’t in the cloud actually it’s in the DevOps space. So it’s historically when we’ve seen adoption of DevOps and specifically CI/CD pipelines, we’ve seen the mushroom up in little development teams all through an enterprise and there becomes a critical mass where people are starting saying, “Well, we’ve got all these different tools we standardize, then there’s absolute uproar because people will get very emotionally attached to their tools quite understandably.” But then you get a whole other group of people in an organization that are desperate for the DevOps tool chains and don’t have the skills and the knowledge.
So actually, having a platform engineering team or a platform team that provide a DevOps tool chain as a service solves a few problems. It makes the whole technology stack much more available to the people that haven’t yet got there. And then kind of enables the conversation around standardization, which is much easier to have if you talk about the kind of architectural configuration of a tool chain rather than the specific flavors of tools within it. And then that central team can talk about what they’ve got skills to support and what might be exceptions that people will need to support themselves if they want to continue using them.
Abby Bangser: I think I just quickly add to that ’cause I think it’s a really good description, how much the change in the perception of the platform engineers on the platform team as a service team to the rest of the organization rather than as the keeper of the complex bottom layer information is what’s really driving all this change instead of being like, “You will use our tools ’cause we told you, you will.” Even if you really attach to the things that you used to use, they are no longer compliant and they’re no longer cost-efficient or sustainable. The engineering teams don’t care about those things. They want to use the things they want to use, and they want to go to production quickly. And today, platform engineering teams are learning about what developer relations looks like and marketing and what does it look like to actually engage with customers and get feedback and have a roadmap that meets their needs, and the business constraints of the platform engineering team is managing and working under.
Matt Campbell: Those are all fantastic points. And Daniel you kind of mentioned like platform engineering is not a new thing as many things in our industry, it’s an old thing that maybe some of us forgot about and then now we’re remembering, and it feels like a new thing. But there are new parts to it I think that maybe we’re bringing up, and Abby you kind of just commented on those where we’re as opposed to treating platform engineering as a thing we build that people must use, we’re trying to find ways to build things that delight our end users and actually drive value and make them want to use it because of the value that it’s adding.
And I think in that regard, Daniel, to your initial question, we are seeing sort of the technologies pushed down a little bit and Helen to your point, that API layer, that interface layer being added to simplify the interaction to help drive better business value and to make it easier for teams to get in there and not have to learn all the intricacies and all the fun stuff that YAML brings to the table as you mentioned, Abby. So Yes, it’s a really exciting time and a really interesting evolution that we’re seeing there. I really love the platform as a product framing that we have this time around.
Daniel Bryant: Yes, love it, Matt. Just to double down on that, when I was at KubeCon, Kubernetes conference, right? I was chatting to folks and the overwhelming anecdotal data that people were pushing Kubernetes down the stack at KubeCon. I find this kind of bizarre, right? My engineers just want to go into some interface and define something or call some API, Abby’s point. And I was like, “Wow, this is KubeCon, right? And it’s really interesting seeing the evolution of trends at a conference where it’s really like about the technology I’ll give you, right? And now it’s pushing more towards the platforms.” I saw a lot of push towards observability, which we’ve covered a few times as well, but not just observability in terms of say SLI service level indicators, but also things around KPIs like key performance indicators. And a big one of that was financial folks are now, particularly in this non-zero interest rate phenomenon we’re going through now folks are really concerned about how much my spending on this platform, no more spinning up some huge database poking around, shutting it down, whatever. You got to justify that cost.
Is FinOps moving to the early majority of adoption? [23:20]
And I think Steef-Jan, you mentioned sort of offline around FinOps going into the early majority. I’d love to get your take on that because I think I’m hearing more about FinOps. I initially learned it from Simon Wardley, fantastic blogs out there, but now I’m seeing it very much go more into the mainstream as you’re pitching Steef-Jan. So I’d love to get your thoughts on that.
Steef-Jan Wiggers: Yes, that’s correct. There’s more companies joining the FinOps Foundation which provides the support and processes around FinOps. I do see a lot of tools popping up that can support your FinOps and give you look into what you’re actually spending, but I feel that it’s also about important about the process and what are you spending versus what value are you getting out of it versus just looking at tools because Yes, the tools give you an idea, “Okay, I’m spending, but it’s the spending what you do just justify it or not.” And that’s what I think is great about FinOps Foundation coming in and more and more companies like Microsoft and I think other companies, cloud companies as well, just adopting it and are part of that journey as well. There’s even ways of getting to know the processes. I think you can even do certifications. In my line of work, I see it more and more the discussion.
We have this running, but are we actually using it? We’re not using it, we just get rid of it or we just turn it down. So even I see that back in our discussion as well, why we have things running? And even on the personal side, I’ve got an MVP subscription which allows me to basically burn money, but then I’m even, I’m starting to get them where ID demos, I’m not using them, you know what, I’m just shutting them down. Although the credits are free, but it doesn’t make sense. So even I’m studying in more aware because FinOps also has to do with sustainability, which I learned during our latest QCon in London from Holly Cummins with this light trade shop making us aware that we have stuff running that costs money. And I think it’s even like 21 billion a year or two ago they were figured out all the cloud costs combined. It’s insane. So it makes us aware that we should only spend when we should spend like a flick of a switch with energy.
Helen Beal: I think it’s related to some of the sustainability and GreenOps things as well. So with the AIOps space, we’ve been having quite a lot of conversations about data and the fact that it seems like you might need to have a lot of data and therefore a lot of storage in order to get the information that you want. But making the differentiation between data at rest and data at motion is quite important in that context. Additionally, the AI steps in, again, obviously that’s part of AIOps, but another way that AI can help us in your classic big data scenarios, increasingly it can identify where you’ve got data that’s not being used where there’s no APIs or anything that is calling. It’s not being used as an asset by any of your applications. So increasingly AI is becoming like a data housekeeper where it can tidy up and save us space. And that’s good from a planetary perspective as well as a personal kind of or a company financial perspective.
Are architects and developers being overloaded with security concerns when building cloud-based applications or adopting DevOps practices? [25:55]
Daniel Bryant: So changing gears at InfoQ, we’ve definitely seen a lot of attention being put on security now with the software supply chains, SBOMs, lots of great technology going on in that space as well. When I go to conferences, I’m hearing anecdotal information from developers that they’re getting a bit overwhelmed with this whole shift left. Some folks are even jumping, it’s more of a dump left as in they’re just dumping all the responsibilities left. Do you know what I mean? Rather than actually thinking about how can developers think more about security? I need the tools, I need the mental models. So I’d love to hear folks’ thoughts on, are you seeing folks in the wild caring more about this? Are they implementing more of the solutions and what’s the impact on developers and architects?
Steef-Jan Wiggers: Yes, I see a lot of them in my line of work. So security becomes more important. You write about the shift left, at least developers are giving the burden of making things more secure when it comes to cloud platforms. They have to deal with the operational side of things too, with identity and access management, but also their, let’s say functions or whatever they’re running like code, accessing what type of system, what type of security model is in place predominantly or most commonly or ALF. And Yes, that’s kind of what you need to do. You need to go to the identity provider to get the token and then access the service or even some of the platform have something like menace identity. So then the cloud platform takes away that and then you have to be aware of that and then it comes back to giving the menace identity access to whether it’s also key vaults and that kind of stuff. So it all migrates into that developer that needs to be aware of all these nitty-gritty details. So it’s definitely can be overwhelming if you’re less say security aware.
Abby Bangser: It’s definitely important. And I’m seeing more of a push towards it by leadership, which is usually the thing that pushes security onto the developers, right? Because developers and not every developer, but many that are there, their first instinct is not to go straight to the SBOMs, right? If they’re being pushed for new features, that’s what they’re focusing on. But when the company has raised that the risk there for security is important enough, they will take on that responsibility and do that work. I think the interesting thing about securities, it’s going through a similar evolution and growth pattern that a lot of technologies go through, which is the first solutions are made by experts and they often need to be used by experts. And eventually, those start to get smoothed to out and become easier to be used by other people in the industry more. And I think that’s maybe the phase that we’re getting into now with the security tooling is people are realizing that some of the early days security tooling isn’t quite user-friendly and the current tooling is trying to evolve into more user-friendly ways of working.
Matt Campbell: Yes, I would agree that there’s definitely a lot of research into SBOM specifically about questionable implementations and value of them and are they actually delivering on what they say they’re going to be delivering. And then I think to your point, Abby, there’s new frameworks coming out like salsa that as just a product developer might be too in-depth for me to actually be able to get into and understand how do I actually do anything with this? And I think the gap that we need to look to fill is circling back to Team Topologies, is treating security as an enablement function and finding ways to have that team build platforms that can help with some of these things, but then also enable through education to make sure the teams understand the important parts of the things that they need to do as they’re working through the code.
I would agree it definitely feels a lot like a dump left at this point with just all these things going on and the big push from leadership, even from the government level to help shore up the supply chain is leading to a lot of… To your point Abby, like expert-driven implementations, which don’t necessarily translate well to ground-level trying to get it into your code.
Is WebAssembly a final realisation of “write once, run anywhere” in the cloud? [29:22]
Daniel Bryant: Now I know we’re mainly focused on high-level techniques and approaches in our trend report, but I did want to dive a little bit deeper for a moment on a couple of cloud technologies. I think these are having an outsized impact and the first one is WebAssembly, Wasm, and the second one is eBPF, which we’re seeing a whole bunch too. Now I’ve just got back from a fantastic event in New York, QCon New York, and there was a really good presentation by Bailey Hayes from Cosmonic on WebAssembly components. I’ve also been reading a whole bunch from Matt Butcher and the Fermyon team about what they’re doing with WebAssembly too. I’m really seeing this promise of the right once run anywhere, which I appreciate is a bit ironic coming from a Java developer. I’ve worked in Java for 20-plus years, and this is one of the platform’s original promises, but I think this is the next evolution of that promise if you like.
Now, both Bailey and Matt and others have been talking about building this case for reusability and interoperability. So the idea with WebAssembly components that Bailey was talking about is you could build libraries effectively in say go and then call them from a rust application and any language that can compile down to Wasm, this kind of promise stands, which I thought was really easy for that true vision of the component model within the cloud. I also thought it was super interesting. You can build your application for multiple platform targets. Now, given the rise of ARM based CPUs across all the cloud hyperscalers and the performance and the price points, this is really quite attractive. I know Jessica Kerr has talked to InfoQ multiple times about the performance increases and some of the cost savings as well that the Honeycomb team saw when they migrated some workloads to the AWS Graviton processes from Intel processors.
So very interesting thinking points there. I’m also seeing Wasm adopted a lot in the format as the cloud platform extension format. For example, I grew up writing Lua code to extend NGINX and OpenResty, and now we’re increasingly seeing Wasm take that space. They’re being used to extend cloud-native proxies like Envoy and the API gateways and service meshes that this technology powers. In regard to eBPF, I’m definitely seeing this more as a platform component developer’s use case. So maybe we as application engineers won’t be using it quite so much. But I’m seeing the implementation of the CNCF’s contain network interface such as cilium, I shouted to my friend Liz Rice and the Isovalent folks doing a lot of great content on this and also seeing a lot in the security space on this. Project Falco or the Falco project and the Sysdig folks are embracing eBPF for security use cases, really nice general-purpose security use cases. And Matt, have you got any thoughts on this too?
Matt Campbell: Yes, no, definitely. We’re seeing a lot of really interesting usages of this technology within observability and then also circling back with security as well because it’s allowing you to get closer to the kernel, closer to what’s actually happening on your systems within your containers. So you’re getting quicker in some ways, more accurate, in some ways safer, less likely to be potentially tampered with in the event of something malicious going on data about how your system’s operating. So that’s been the major push that I’ve seen usage of this. I’ll admit this is not an area that I’m super well versed in, so I’m not going to make any predictions about where it’s going to go, but I think those current usages have definitely been really interesting.
How widely adopted is OpenTelemetry for collecting metrics and event-based observability data? [32:21]
Daniel Bryant: Fantastic, Matt. Fantastic. Should we move on to OpenTelemetry? I saw a couple of folks highlighted OpenTelemetry, and again, we’ve mentioned observability several times in the podcast, and I keep hearing OpenTelemetry all the things because it is great work. I’m lucky enough to work with you, other folks in that space. I’d love to hear folks’ thoughts on where you’re seeing the adoption and what do you think the future is on this space?
Helen Beal: So for me, it’s gone really rapidly in my AIOps world from a, “This is coming soon to, this is what you should be using de facto standard, everyone. It works really well, really, really fast.” Like faster I think than I’ve seen anything else be adopted. Abby’s nodding, she agrees to me.
Abby Bangser: Yes, I just think it’s something that took a long time to get to version one in a lot of languages, but once it got there, it had been being built by so many amazing people around the industry and was cross-vendor to begin with. There was many vendors that were actively putting their engineering time into building this the right way that I think it became quite easy to call it the de facto and it’s so core to your applications, it needs to be that cross-language friendly in order to be used across your platform. So absolutely.
Steef-Jan Wiggers: Yes, I’ve seen it too. Like Helen said, I agree. I see a rapid adoption too because Yes, last year I’ve never heard of it, but now I have, and it’s even Microsoft, even our bracing it and putting it into Azure monitor and stuff. And last QCon London, there was a great presentation on OpenTelemetry. I came about people like Honeycomb IO that have adopted it, so it’s cross-vendor. So there’s a lot of adoption there too. And it’s something similar… I wish happened in the IoT space, getting something standardized. So if it’s around eventing, right? Event driven architect, you’ve got something like cloud events, pretty rapid adoption. You see some services and left and right in cloud and even in Opensource world where they have tooling around event driven architecture with cloud events, and then you have symbol and with OpenTelemetry, right? You got this standardized that they agreed upon and then it becomes vendor-agnostic and that’s super.
So you create telemetry and then you export it and then you can use X amount of tools that all have their own little thing that can do with the telemetry. That’s what I’ve learned from people during QCon. Some of the vendors are supporting it. Yes, we have our own little thing where we do something with memory consumption and execution and that kind of stuff. Yes, it’s pretty interesting. So Yes, even I am excited.
Daniel Bryant: That’s high praise, Steef-Jan. High praise.
Abby Bangser: And I think the vendor-agnostic bit, you can think of it as, “Oh, it’s no vendor lock in. We get away from vendor.” But as you say, what it gives is actually a requirement now that the vendors optimize and provide something that’s more interesting, it’s no longer that they’re competing at getting to the baseline. I can collect your metrics, your events, your traces, and visualize them. Now they have to be doing the next level of interesting thing for them to gain customers and gain market share. That’s the really big power in my mind around something like this. OpenTelemetry or other open standards is the movement of the industry that happens once standards come about.
Daniel Bryant: One more technology thing I’d love to quickly look at is Serverless. Last year we said Serverless as a baseline and we see Serverless popping up all over the place. Steef-Jan, I was reading one of your news items, I think it was recently about Serverless for migrations, things like that. I don’t hear the word Serverless that much anymore, but is it because it’s becoming just part of the normal choices? We push the technology away, but we are embracing the actual core products that use it. So Yes. What’s thoughts on adoption levels of Serverless?
Steef-Jan Wiggers: Well, I think Serverless becomes just managed. We have a managed service for you. And then usually a lot of these services have something like outer scale in it and you have units that you need to pay for. So there’s the micro billing stuff. So it’s what you consume and it’s all migrated into what we call a managed service. Sometimes you see popup, Yes, we have a tier in our product that now is called Serverless something, Serverless database or Serverless, any type of resources when it’s AWS, Google or Microsoft, a lot of their services now also have some Serverless component in that too, which means the outer scale, which means the micro billing, which means all the infrastructures abstracted away, which you don’t see. So making it easier for the end user basically. And sometimes dropping even a name Serverless.
Daniel Bryant: Nicely said.
Matt Campbell: Yes, that move from sort of Serverless as an architectural choice of say building on Lambdas versus building on virtual machines to Steef-Jan’s point versus moving to managed services. So I think that’s the transition we’re maybe seeing here. I think Serverless became that kind of proverbial hammer and then everything became a nail where we’ve seen a few cases recently, some very overblown in the news of companies moving from Serverless back to monolithic applications. But the move towards managed services really does fit the mold with the platform engineering approach. Trying to reduce cognitive overload, shifting who is working on what to other people. For most of our businesses, our customers are not buying us because we built the best Serverless architecture. They’re buying us because we built the best product. So having somebody who’s an expert in running those managed services, run them for you is just good business sense in a lot of ways. So I think that might be the shift that we’re seeing here.
Abby Bangser: Absolutely, and I think one of the things we might be seeing is the impact of the value Serverless actually coming out in other ways at this stage. And again, moving on from the architectural decision and saying, “What does Serverless give us?” It gives us scaling to zero. It gives us the ability to cost per request. And so we talked about FinOps already. Your ability to understand where to cut costs has to be dependent on what is your cost of customer acquisition? What is your cost of customer support and of a request. That’s where Serverless really shined and now people know that’s possible and they’re asking for that. Now, does it have to be done through a service architecture? Absolutely not. But it’s something that now the organization is asking from their engineering team and that’s coming out in other architectures as well.
How is the focus on sustainability and green computing impacting cloud and DevOps?
[37:58]
Daniel Bryant: So we’ve talked about the changes of pricing several times there, and I’d like to sort of wrap this together in terms of Steef-Jan, you’ve touched on it earlier on, of pricing relating to the impact and sustainability, things like that being sort of charged maybe on how much you are consuming or polluting, arguably these kind of things, right? I’d love to get people’s thoughts on the adoption level of thinking about prices in architectures and choosing managed services as Matt said there, and where you think that’s going in the future.
Helen Beal: I’m interested to hear the others’ view on how much of this falls into the SRE camp and into the SLXs because I can’t be bothered to say them all, but it feels to me like this is the natural kind of node of the technology team to figure this stuff out. What do other people think?
Steef-Jan Wiggers: Yes, I agree. It’s my day-to-day. If you start thinking about architecture and then thinking about the services, how you want to componentize, how you want to create the architecture, and then it comes boils down to, okay, what type of isolation do, or do we not need security in the end? Then you’re coming into the price ranges of what type of products. If it’s completely what I’ve recently learned, like a term called air gap. So the environment needs to be air gap. That means, okay, then we end up in the highest skew of almost all our services, networking, firewalls, everything.
And that comes with a quieter cost. You’re talking about TCOs that come into over 10, 20, maybe 30,000 a month. And do you really need that? Is that really a requirement? If you’re a big enterprise presumably, but if you’re a small, medium, small business, I’m not so sure. And there’s other ways to secure things. And even some of the cloud vendors also providing some of the services are touching the middle ground. So not high-end or low-end with the enterprise feature, but just in the middle they could be secured just enough.
What are our predictions for the future of the cloud and DevOps spaces?
Daniel Bryant: I’d like to take a moment now for some final thoughts from each of you and it can be a reflection on where we’ve come from. Maybe looking forward to the future, something you are excited about, maybe something for the listeners you’d like them to take away. So should we go around the room? Shall I start? Matt, I’ll start with you if that’s all right.
Matt Campbell: Yes, of course. I, excellent conversation. Some really, really cool things that are covered off here. For me, the thing that I’m most excited to see and is feeling like I’m harping on the same thing, but anything that we can do in the industry to help reduce how much things we need to think about while we’re working so that teams can focus in on their area and have the biggest impact, I think that’s going to start to drive more innovation. We start to get happier people. People are excited to come to work, they’re focused on a thing. They’re not trying to juggle 10 different things and now figure out what is an SBOM, why are they throwing more acronyms at me?
So those kind of innovations, mergers of AIOps and ChatGPT and to platform engineering and even the sustainability and FinOps stuff like trying to find ways to reduce costs and reduce the amount of things that we’re working with, I think are all good shifts in that direction. So I guess if there’s a kind of a call to action, it’s try to build things that move us in that direction, I think that’s a healthy way for our industry to go.
Daniel Bryant: Love it. Abby, do you want to go next?
Abby Bangser: Sure. I think anytime we have these kinds of conversations about trends, it’s hard not to talk about the fact that a different word for that might be hype cycles. And I think there’s a lot of things that can feel like hype cycles, but the power behind what creates that hype is that there is a nugget of opportunity there. And I think what ends up happening is it’s easy to dismiss the nuance and the opportunity to the fact that there is marketing jargon and hype around it that maybe is overselling something or is particularly overselling the application of it. Not just what it can do, but also how widely applicable it can be.
And I think what’s been really interesting about the trends on this call that I’ve really enjoyed is that a lot of them are not new. We talked about from the first get-go how we’ve been building platforms for decades across the team here. And I think at the same time we are doing new things, we are learning from our experiences, and we are actively seeing evolution to create more value for our users, for our industry. And I think that’s really exciting right now.
Daniel Bryant: Fantastic stuff. Helen, do you want to go next?
Helen Beal: I’m going to be quite quick and just say that I think I’m going to go and have a chat with Bard about ClickOps ’cause that sounds very interesting.
Daniel Bryant: Fantastic. Steef-Jan, over to you.
Steef-Jan Wiggers: Yes, really happy about all the developments that happen in the cloud, the sustainability, the FinOps, but also seeing Opensource being adopted everywhere. I really enthusiastic about the OpenTelemetry. I’m interested seeing that cloud events. I see that adoption overall of what’s happens in that Opensource helps us also standardize and maybe even make our lives a little bit better than have to juggle around with all kinds of standards and things you need to do. I hope that the AI-infused services, like the Copilots and stuff and ChatGPT can make us more productive and try to help us do our jobs better. So I’m excited about that too. So Yes, I said that’s just a lot of things going on. Even enjoy talking to the other guys. We even learned a lot of things today, so that’s also cool.
Daniel Bryant: Amazing. I’ll say thank you so much all of you for taking time out to join me today. We’ll wrap it up there. Thanks a lot.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS
![]() Arizona State Retirement System grew its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 3.6% during the first quarter, according to its most recent Form 13F filing with the SEC. The firm owned 19,975 shares of the company’s stock after purchasing an additional 695 shares during the period. Arizona State Retirement System’s holdings in MongoDB were worth $4,657,000 at the end of the most recent reporting period.
Arizona State Retirement System grew its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 3.6% during the first quarter, according to its most recent Form 13F filing with the SEC. The firm owned 19,975 shares of the company’s stock after purchasing an additional 695 shares during the period. Arizona State Retirement System’s holdings in MongoDB were worth $4,657,000 at the end of the most recent reporting period.
A number of other large investors also recently modified their holdings of MDB. Vanguard Group Inc. grew its holdings in MongoDB by 2.1% during the first quarter. Vanguard Group Inc. now owns 5,970,224 shares of the company’s stock worth $2,648,332,000 after acquiring an additional 121,201 shares during the period. Franklin Resources Inc. grew its holdings in MongoDB by 6.4% during the fourth quarter. Franklin Resources Inc. now owns 1,962,574 shares of the company’s stock worth $386,313,000 after acquiring an additional 118,055 shares during the period. State Street Corp grew its holdings in MongoDB by 1.8% during the third quarter. State Street Corp now owns 1,349,260 shares of the company’s stock worth $267,909,000 after acquiring an additional 23,846 shares during the period. 1832 Asset Management L.P. grew its holdings in MongoDB by 3,283,771.0% during the fourth quarter. 1832 Asset Management L.P. now owns 1,018,000 shares of the company’s stock worth $200,383,000 after acquiring an additional 1,017,969 shares during the period. Finally, Geode Capital Management LLC grew its holdings in MongoDB by 4.5% during the fourth quarter. Geode Capital Management LLC now owns 931,748 shares of the company’s stock worth $183,193,000 after acquiring an additional 39,741 shares during the period. 89.22% of the stock is owned by institutional investors and hedge funds.
MongoDB Price Performance
Shares of MongoDB stock opened at $398.68 on Monday. The company has a current ratio of 4.19, a quick ratio of 4.19 and a debt-to-equity ratio of 1.44. MongoDB, Inc. has a 52-week low of $135.15 and a 52-week high of $418.70. The stock has a 50-day simple moving average of $346.49 and a 200-day simple moving average of $260.43.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings results on Thursday, June 1st. The company reported $0.56 earnings per share (EPS) for the quarter, beating the consensus estimate of $0.18 by $0.38. The business had revenue of $368.28 million during the quarter, compared to analyst estimates of $347.77 million. MongoDB had a negative return on equity of 43.25% and a negative net margin of 23.58%. The firm’s revenue was up 29.0% on a year-over-year basis. During the same period in the previous year, the company earned ($1.15) EPS. On average, research analysts anticipate that MongoDB, Inc. will post -2.8 EPS for the current fiscal year.
Wall Street Analyst Weigh In
MDB has been the topic of a number of research analyst reports. William Blair reaffirmed an “outperform” rating on shares of MongoDB in a report on Friday, June 2nd. Piper Sandler lifted their price target on MongoDB from $270.00 to $400.00 in a research note on Friday, June 2nd. VNET Group reissued a “maintains” rating on shares of MongoDB in a research note on Monday, June 26th. Mizuho lifted their price target on MongoDB from $220.00 to $240.00 in a research note on Friday, June 23rd. Finally, Stifel Nicolaus lifted their price target on MongoDB from $375.00 to $420.00 in a research note on Friday, June 23rd. One equities research analyst has rated the stock with a sell rating, three have issued a hold rating and twenty have given a buy rating to the company’s stock. Based on data from MarketBeat, the stock has an average rating of “Moderate Buy” and a consensus price target of $366.59.
Insider Buying and Selling
In related news, Director Dwight A. Merriman sold 606 shares of the business’s stock in a transaction that occurred on Monday, July 10th. The stock was sold at an average price of $382.41, for a total value of $231,740.46. Following the completion of the sale, the director now directly owns 1,214,159 shares in the company, valued at approximately $464,306,543.19. The transaction was disclosed in a filing with the SEC, which can be accessed through the SEC website. In related news, Director Dwight A. Merriman sold 606 shares of the business’s stock in a transaction that occurred on Monday, July 10th. The stock was sold at an average price of $382.41, for a total value of $231,740.46. Following the completion of the sale, the director now directly owns 1,214,159 shares in the company, valued at approximately $464,306,543.19. The transaction was disclosed in a filing with the SEC, which can be accessed through the SEC website. Also, CAO Thomas Bull sold 516 shares of the business’s stock in a transaction that occurred on Monday, July 3rd. The stock was sold at an average price of $406.78, for a total value of $209,898.48. Following the completion of the sale, the chief accounting officer now owns 17,190 shares of the company’s stock, valued at $6,992,548.20. The disclosure for this sale can be found here. In the last ninety days, insiders sold 117,427 shares of company stock worth $41,364,961. 4.80% of the stock is currently owned by insiders.
MongoDB Company Profile
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Which stocks are likely to thrive in today’s challenging market? Click the link below and we’ll send you MarketBeat’s list of ten stocks that will drive in any economic environment.
MMS • RSS

NoSQL Market
NoSQL Market Report 2023 expand at a CAGR of 31.08% during the forecast period, reaching USD 38144.35 million by 2030
PUNE, MAHARASHTRA, INDIA, July 17, 2023/EINPresswire.com/ — The Global “NoSQL Market” Research Report provides a comprehensive study of market dynamics, allowing organizations to make informed decisions and plan growth strategies. The research assesses the market performance of manufacturers across various geographies, as well as their company profiles, growth factors, market development possibilities, and threats. It provides a detailed review of the current and anticipated market environment, assisting organizations in gaining insight into future market trends and achieving their goals. With expert insights and research, the report is a useful resource for firms looking to understand the NoSQL Market and stay ahead of the competition. Analysts and specialists in the industry provide significant insights into the future picture, allowing firms to make educated decisions.
Get a sample PDF of the report at – https://www.marketresearchguru.com/enquiry/request-sample/22376195?utm_source=EIN_Ram
The global NoSQL market size was valued at USD 7520.13 million in 2022 and is expected to expand at a CAGR of 31.08% during the forecast period, reaching USD 38144.35 million by 2028.
Additionally, this report investigates into the top industry segments by type, applications, and regions, highlighting important aspects such as market size, share, trends, and key drivers with the aid of SWOT and PESTLE analysis. In addition, this research report provides insights into pricing strategies, business statistics, supply chain, and technological advancements over the forecast period, giving businesses a deeper understanding of the industry’s complexities and opportunities.
Here is the List of Top Key Players of NoSQL Market Report Are:
-Microsoft Corporation
-Neo Technology
-MarkLogic Corporation
-Aerospike
-DataStax
-Google LLC
-Amazon Web Services
-PostgreSQL
-Couchbase
-Objectivity
-MongoDB
Get a sample PDF of the report at – https://www.marketresearchguru.com/enquiry/request-sample/22376195?utm_source=EIN_Ram
Market Dynamics: –
-Drivers: (Developing regions and growing markets)
-Limitations: (Regional, Key Player facing Issues, Future Barriers for growth)
-Opportunities: (Regional, Growth Rate, Competitive, Consumption)
The report provides key statistics on the market status of the NoSQL Market manufacturers and is a valuable source of guidance and direction for companies and individuals interested in the NoSQL.
What are the factors driving the growth of the NoSQL Market?
Growing demand for below applications around the world has had a direct impact on the growth of the NoSQL
-Retail
-Gaming
-IT
-Others
What are the types of NoSQL available in the Market?
Based on Product Types the Market is categorized into Below types that held the largest NoSQL market share In 2023.
-Key-Value Store
-Document Databases
-Column Based Stores
-Graph Database
Regional Outlook:
Regional analysis is another highly comprehensive part of the research and analysis study of the global NoSQL market presented in the report. This section sheds light on the sales growth of different regional and country-level NoSQL markets. it provides detailed and accurate country-wise volume analysis and region-wise market size analysis of the global NoSQL market.
-North America (United States, Canada and Mexico)
-Europe (Germany, UK, France, Italy, Russia and Turkey etc.)
-Asia-Pacific (China, Japan, Korea, India, Australia, Indonesia, Thailand, Philippines, Malaysia and Vietnam)
-South America (Brazil, Argentina, Columbia etc.)
-Middle East and Africa (Saudi Arabia, UAE, Egypt, Nigeria and South Africa)
To Understand How Covid-19 Impact Is Covered in This Report – https://marketresearchguru.com/enquiry/request-covid19/22376195?utm_source=EIN_Ram
NoSQL Report Also Covers Offer for New Project Includes:
Market Entry Strategies
Countermeasures of Economic Impact
Marketing Channels
Feasibility Studies of New Project Investment
Research Conclusions of the NoSQL Industry
Following Key Questions Covered:
What are the key drivers of growth in the NoSQL market, and how do they vary across regions and segments?
How are advancements in technology and innovation affecting the NoSQL market, and what new opportunities and challenges are emerging as a result?
Which market players are currently leading the pack in terms of market share and product innovation, and what strategies are they employing to maintain their positions?
What regulatory and policy changes are on the horizon that could impact the NoSQL market, and how are market players adapting to these changes?
What are the emerging trends and market disruptors that are likely to shape the NoSQL market in the years to come, and what can businesses do to stay ahead of the curve?
How are consumer preferences and behaviors evolving with regard to NoSQL, and what implications do these trends have for market players?
Inquire or Share Your Questions If Any Before the Purchasing This Report – https://www.marketresearchguru.com/enquiry/pre-order-enquiry/22376195?utm_source=EIN_Ram
Here are some key aspects of the industry that could be relevant:
– Market size and growth: The size of the NoSQL market and its projected growth rate can provide valuable insights into the industry’s potential.
– Competition: The level of competition in the market can have a significant impact on the pricing and profitability of companies operating in the industry.
– Technology: Technology plays a critical role in the NoSQL industry, as search algorithms and consumer behavior continue to evolve rapidly.
– Consumer behavior: Understanding consumer behavior, including search habits and NoSQL preferences, can help companies optimize their marketing strategies and drive sales.
– Regulatory environment: The NoSQL industry is subject to various regulatory requirements, including data protection and privacy laws, which can impact the way companies operate in the market.
– Economic factors: Economic factors such as GDP, inflation, and consumer spending can affect the growth and profitability of the NoSQL industry.
– Emerging trends: Keeping up with emerging trends, such as voice search and artificial intelligence, can help companies stay ahead of the curve in the NoSQL industry.
Purchase this Report (Price 3250 USD for a Single-User License) – https://marketresearchguru.com/purchase/22376195?utm_source=EIN_Ram
Contact Us:
Market Research Guru
Phone: US +14242530807
UK +44 20 3239 8187
Email: sales@marketresearchguru.com
Web: https://www.marketresearchguru.com
Sambit kumar
Market Research Guru
email us here
Visit us on social media:
LinkedIn
![]()
MMS • Steef-Jan Wiggers
Microsoft recently announced the general availability (GA) of Microsoft Dev Box, a service providing developers access to preconfigured and centrally managed dev boxes.
The company first announced Microsoft Dev Box last year at their build conference as a solution for hybrid developer teams to have a central place to create code-ready developer machines. Similar to the recent GA release of Azure Deployment Environments, which allows development teams to create segregated instances centrally within Azure for deploying and managing applications in different stages, such as development, testing, and production.
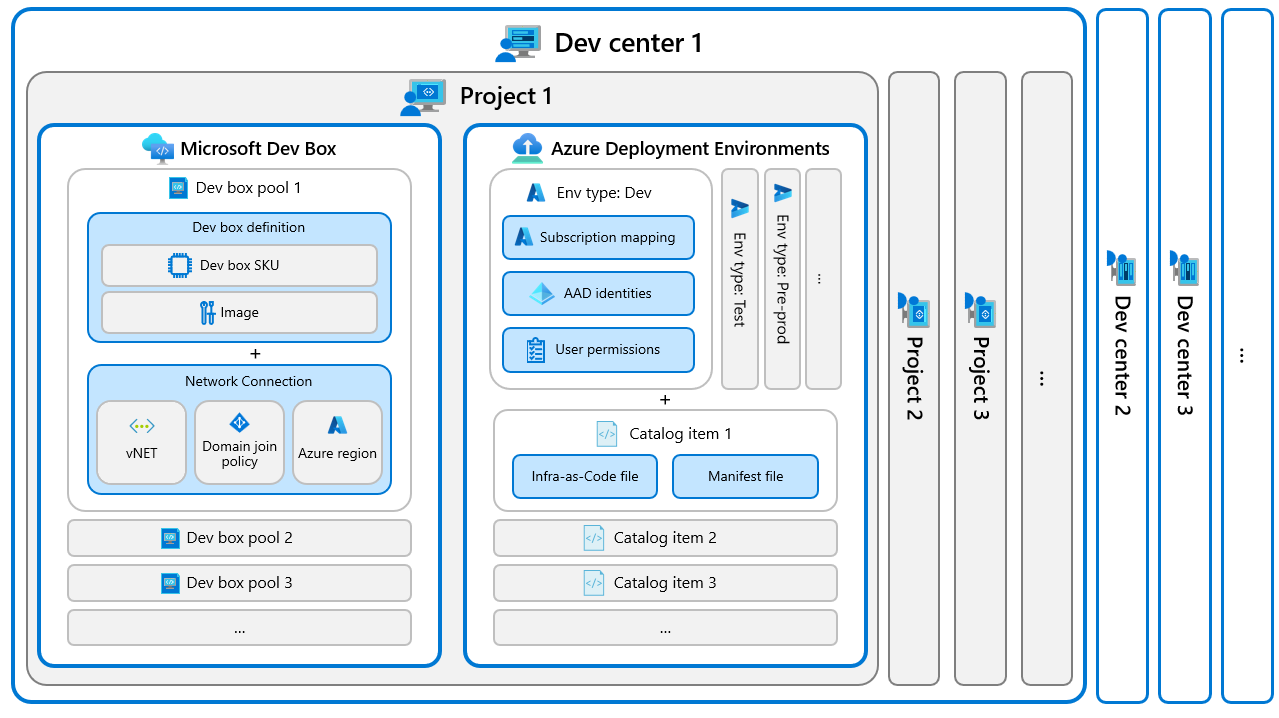
Diagram of Dev Box and Deployment Environments (Source: Microsoft Documentation Dev Box)
With the GA release, developers can benefit from the latest features that optimize performance and better Visual Studio experience. The Microsoft Dev Box starts with Visual Studio 17.7, and when spun up, it provides auto-sign in and unified settings. Additionally, developers can look forward to built-in support and integrations for Dev Drive, which is, according to the company coming soon to boost disk performance and accelerate development workloads.
Furthermore, the GA announcement of Microsoft Dev Box stated that “instead of having to shut down dev boxes every time, developers can now hibernate their dev box and pick up later where they left off. This feature is available today in public preview.” And the support of configuration-as-code YAML files that developers and dev leads can use to customize their Dev Box images further is currently in preview, according to a Microsoft Developer blog post.
The service offers three distinct roles to cater to various organizational needs. Firstly, an organization’s infrastructure admins are responsible for handling security policies, network configurations, and the management of dev boxes through Microsoft’s Endpoint management solution. The second role is dedicated to Dev team leads who can create customized pools of dev boxes for specific projects and tasks.
Lastly, the service supports developers with self-service access to on-demand dev boxes from enabled pools, ensuring flexibility and convenience. Additionally, the Azure Compute Gallery is a scalable platform for sharing base images and managing image versions within the Dev Box ecosystem, simplifying the creation of tailored workstations for teams and developers. Furthermore, there is a GitHub repo with custom images available.
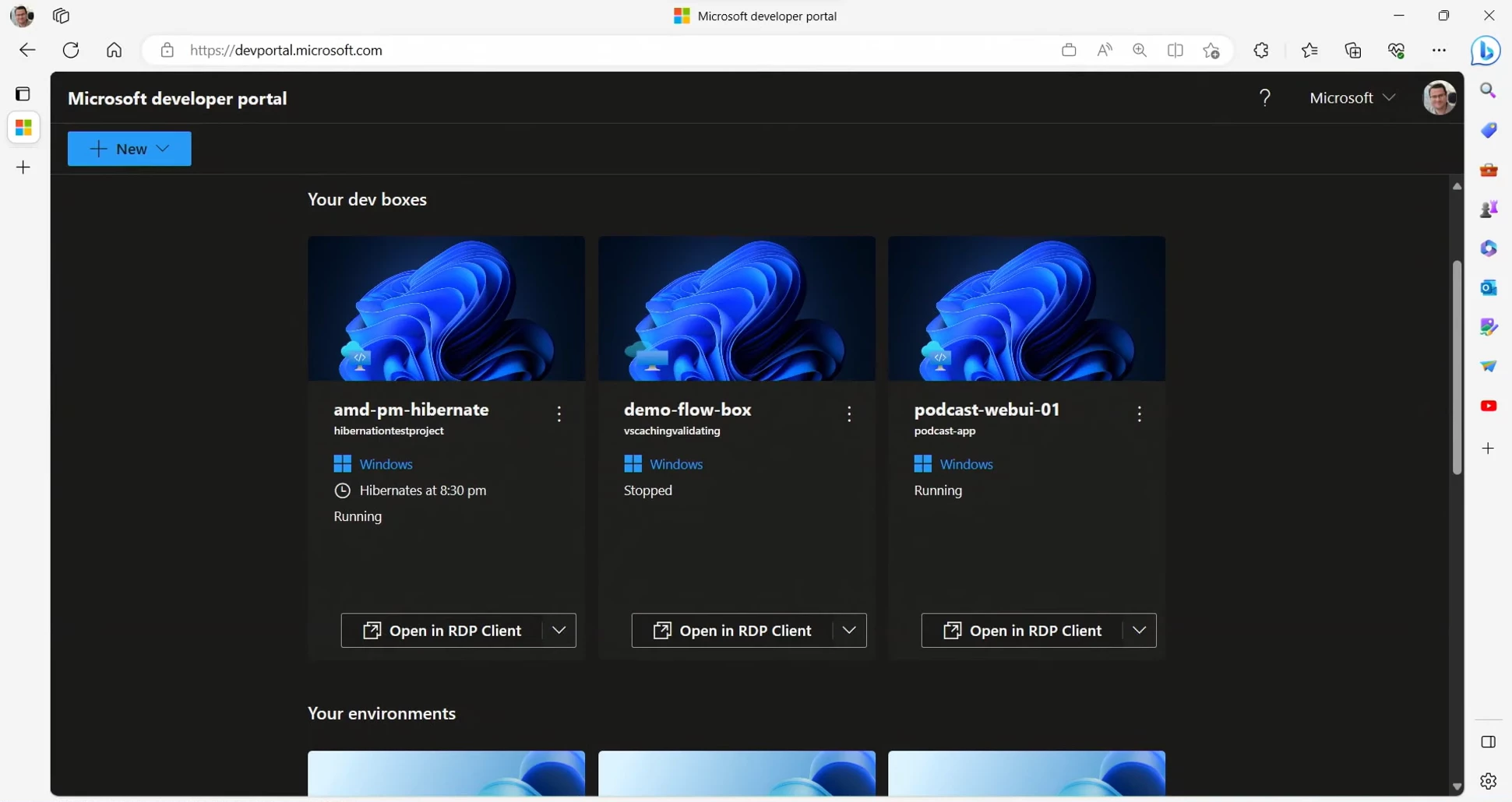
Screenshot of the Developer Portal (Source: Microsoft Blog)
When asked by InfoQ about the general availability of Microsoft Dev Box, here is what Anthony Cangialosi, Principal Group Product Manager, Microsoft Dev Box had to say:
Microsoft Dev Box builds on years of learning and innovation, which started with GitHub Codespaces, by delivering ready-to-code workstations so developers can focus on writing the code only they can write. The service is optimized around projects to match how developers work with enterprise security and control to scale to projects of any size.
In addition, Amanda Silver, a CVP of the Developer Division at Microsoft, tweeted:
It’s ready! #MicrosoftDevBox GAs today! Over 10K MSFT devs use DevBox as project-specific, ready-to-code, workstations. Excited to see more devs power up with cloud-based DevBoxes for optimized DevEx so they can focus on code that only they can write.
Pricing of the dev boxes depends on usage and size, as it is available from 8 vCPUs with 32 GB of RAM and 256 GB of storage up to 32 vCPU with 128 GB of RAM with 2048 GB of storage; for more details, see the pricing page.
MMS • Almir Vuk

Microsoft has released the third preview of Visual Studio 2022 version 17.7. Preview 3 brings a range of improvements and features aimed at enhancing developer productivity and helping maintain clean code. Preview 3 is focused on a new tool called #include cleanup for C++ developers. The latest version is available for download, and developers have the opportunity to explore and utilise its advancements in the preview version.
Preview 3 brings the changes and improvements to a couple of areas like C++, Productivity, .NET and Cloud development, Microsoft 365 development and Teams toolkit and SQL Server Data Tools.
As the biggest news, the latest update introduces an exciting addition called the “Include Cleanup” feature. This valuable tool offers developers suggestions to add direct includes when detecting indirect includes, as well as identifies any redundant includes that can be safely removed. Worth noting is that this feature comes disabled by default, ensuring developers have control over its usage. To harness its benefits, users can easily enable it by navigating to Tools > Options > Text Editor > C/C++ > IntelliSense and selecting the option to “Enable #include cleanup.
In the original blog post about #include tool, Mryam Girmay, Program Manager, C++, states the following:
… a feature that improves the quality of your code by generating suggestions to remove unused headers and add direct headers. Our suggested workflow is to first go through the direct include suggestions to add direct headers where indirect headers are used, followed by removing the unused includes.
About C++ and Preview 3, also introduces an expansion of Address Sanitizer support, now offering the continue_on_error mode. This runtime feature enables real-time detection and reporting of hidden memory safety errors with zero false positives. Developers can integrate it into their workflow by setting ASAN_OPTIONS=continue_on_error=1 for stdout or ASAN_OPTIONS=continue_on_error=2 for stderr. This update enhances application reliability and provides a more secure codebase.
Regarding developer productivity. In the Solution Explorer, a new Collapse All Descendents command has been added to the context menu, enabling users to collapse selected nodes and their descendent nodes. This can also be achieved through the Ctrl+Left arrow keys shortcut.
Moreover, the Extension Manager has been updated to simplify the process of discovering and managing extensions from the Visual Studio Marketplace, facilitating easier updates for existing extensions. Developers can access the modern Extension Manager by enabling the Extension Manager UI Refresh preview feature under Tools > Options > Environment > Preview Features.
Furthermore, the latest version brings noteworthy improvements to the HTTP Editor. Among them is the addition of a new Response View, featuring support for JSON highlighting. Now, developers can easily examine the raw response, headers of the request, and the request as it was sent to the web server. Also, the green play button for sending requests has been replaced by code lens actions, simplifying the development process.
Likewise, developers can now leverage Connected Services support for Microsoft Power Platform. As reported on the release post: You can create a custom connector to your Power Platform environment and create a dev tunnel to locally test and debug your Web API project.
Other changes are related to Microsoft 365 development, the Teams Toolkit now offers simplified Teams Tab app templates. This version also includes bug fixes and UI improvements, enhancing the user experience. Also, in SQL Server Data Tools, the latest update resolves a publishing issue when using Azure Interactive Dir to an Azure Debugger. Additionally, the Target Platform’s nomenclature for SQL Serverless has been changed to Azure Synapse Analytics Serverless SQL Pool.
Microsoft and the development team encourage users to provide feedback and share their suggestions for new features and improvements, emphasizing their commitment to constantly enhancing the Visual Studio experience. Lastly, developers interested in learning more about this and other releases of Visual Studio can visit very detailed release notes about other updates, changes, and new features around the Visual Studio 2022 IDE.
Java News Roundup: Micronaut 4.0, Payara Platform, Spring Web Flow 3.0, JetBrains AI Assistant
MMS • Michael Redlich

This week’s Java roundup for July 10th, 2023 features news from JDK 22, JDK 21, Spring Web Flow 3.0, Micronaut 4.0, Payara Platform, point and milestone releases of: Spring projects, Open Liberty, Helidon, Hibernate Reactive, Tomcat, Micrometer Metrics and Tracing, Piranha, Project Reactor, JHipster, JHipster Lite, Yupiik Fusion, Maven and Gradle; and AI Assistant in JetBrains IDEs.
JDK 21
Build 31 of the JDK 21 early-access builds was also made available this past week featuring updates from Build 30 that include fixes to various issues. Further details on this build may be found in the release notes.
JDK 22
Build 6 of the JDK 22 early-access builds was also made available this past week featuring updates from Build 5 that include fixes to various issues. More details on this build may be found in the release notes.
For JDK 22 and JDK 21, developers are encouraged to report bugs via the Java Bug Database.
Spring Framework
The release of Spring Web Flow 3.0.0 features: compatibility with Spring Framework 6 and Jakarta EE; and the removal of Apache Tiles, a project which has been retired and, therefore, has not migrated to Jakarta EE. The Spring Web Flow Samples have been updated accordingly and the booking-mvc example now uses Thymeleaf Layouts instead of Apache Tiles.
The second milestone release of Spring Framework 6.1 ships with bug fixes, improvements in documentation, dependency upgrades and numerous new features such as: an HTTP interface client infrastructure and adapter for the RestTemplate class; a new RestClient interface; and support for multiple instances of the TaskScheduler interface with the @Scheduled annotation. Further details on this release may be found in the release notes.
Versions 6.0.11, 5.3.29 and 5.2.25.RELEASE of Spring Framework have been released featuring bug fixes, improvements in documentation, dependency upgrades and new features such as: a simplification of the isDepedendent() method defined in the DefaultSingletonBeanRegistry class; add the missing @Nullable annotations in the ContentDisposition.Builder interface; and an extension of supported types in the nullSafeConciseToString() method defined in the ObjectUtils method. Versions 6.0.11 and 5.3.29 will be consumed in the upcoming releases of Spring Boot 3.1.2 and 2.7.14, respectively. Considered an out-of-cycle release, version 5.2.25.RELEASE will not ship with a Spring Boot version as Spring Boot 2.3.x has reached end-of-life. More details on these releases may be found in the release notes for version 6.0.11, version 5.3.29 and version 5.2.25.RELEASE.
The first milestone release of Spring Data 2023.1.0, codenamed Vaughn, delivers: compatibility with JDK 21; support for Kotlin value classes; the use of virtual threads through the Executor interface; and an exploration for optimizations using Coordinated Restore at Checkpoint (CRaC). Further details on this release may be found in the release notes.
Versions 2023.0.2, 2022.0.8, and 2021.2.14, service releases of Spring Data, ship with bug fixes and respective dependency upgrades to sub-projects such as: Spring Data MongoDB 4.1.2, 4.0.8 and 3.4.14; Spring Data Elasticsearch 5.1.2, 5.0.8, and 4.4.14; and Spring Data Neo4j 7.1.2, 7.0.8 and 6.3.14.
Versions 2.2.0-M1, 2.1.1, 2.0.5 and 1.5.5, service releases of Spring HATEOAS deliver bug fixes, dependency upgrades and a fix for CVE-2023-34036, Forwarded Header Exploit with Spring HATEOAS on WebFlux, a vulnerability in which hypermedia-based responses produced by Spring HATEOAS might be exposed to malicious forwarded headers if they are not behind a trusted proxy. More details on these releases may be found in the release notes for version 2.2.0-M1, version 2.1.1, version 2.0.5 and version 1.5.5.
The release of Spring Initializr 0.20.0 with new features and improvements such as: support for Spring Boot 3.x and JDK 17; improved code generation in which method bodies can now define arbitrary statements using the CodeBlock class; nested annotations; support for Gradle 8.x; and improved build and raw text test assertions. Further details on this release may be found in the release notes.
Micronaut
After five milestones and one release candidate, the Micronaut Foundation has released Micronaut Framework 4.0.0 featuring baselines to JDK 17, Groovy 4.0, Kotlin 1.8, Gradle 8.x.
There is also support for GraalVM 23, virtual threads, HTTP/3 and io_uring. This new version also introduces: an expression language that allows developers to place expressions in annotations; and a new Java HTTP Client, a lighter implementation of the Micronaut HTTP Client as an alternative to the existing Netty-based implementation. More details on this release may be found in the release notes. InfoQ will follow up with a more detailed news story.
Payara
Payara has released their July 2023 edition of the Payara Platform that includes Community Edition 6.2023.7, Enterprise Edition 6.4.0 and Enterprise Edition 5.53.0 featuring bug fixes and component upgrades that includes Hazelcast 5.3.1 for adding socket options for a per-socket keep-alive configuration. However, this is not yet supported on the Windows OS as acknowledged by Hazelcast. There was also an improvement with the reduction of duplication between the POMs and BOMs such as the removal of: an unused POM file; an outdated temporary Jakarta staging repository; and jdk8 profiles. Further details on these versions may be found in the release notes for Community Edition 6.2023.7, Enterprise Edition 6.4.0 and Enterprise Edition 5.53.0.
Open Liberty
IBM has released version 23.0.0.7-beta of Open Liberty with a test implementation of version 1.0.0-beta2 of the Jakarta Data specification as an experiment with proposed specification features so developers can try out these features and provide feedback to influence the specification as it is being developed. Jakarta Data 1.0.0 has passed its plan review and will most-likely be included in Jakarta EE 11, scheduled for a GA release in the first quarter of 2024.
Helidon
Oracle has provided Helidon 2.6.2, a second point release, featuring dependency upgrades and notable fixes such as: an intermittent failure in the CipherSuiteTest class; avoid reflecting back user data coming from exception messages; and the response from the WebServer component should not be chunked if there is no entity. More details on this release may be found in the release notes.
Hibernate
The release of Hibernate Reactive 2.0.3.Final delivers a new getFactory() method to the Mutiny.Session and Stage.Session interfaces that return instances of the Mutiny.SessionFactory and Stage.SessionFactory interfaces, respectively, that created those sessions. Further details on this release may be found in the release notes.
Apache Software Foundation
The Apache Software Foundation has released versions 11.0.0-M9, 10.1.11, 9.0.78 and 8.5.91 of Apache Tomcat this past week. All four versions provide bug fixes and introduce new classes: ContextNamingInfoListener, a listener which creates context naming information environment entries; and PropertiesRoleMappingListener, a listener which populates the context’s role mapping from a properties file. Version 11.0.0-M9 updates the implementations of the Jakarta Expression Language and Jakarta WebSocket specifications to align with the latest changes planned for Jakarta EE 11. More details on these releases may be found in the release notes for version 11.0.0-M9, version 10.1.11, version 9.0.78 and version 8.5.91.
Micrometer
Versions 1.12.0-M1, 1.11.2, 1.10.9 and 1.9.13 of Micrometer Metrics have been released featuring dependency upgrades and notable bug fixes such as: Micrometer Wavefront integration Proxy validation error with the default uri implementation; the removal of unnecessary ThreadLocal overhead for disabled log levels in the LogbackMetrics class; and a NullPointerException from the setValue() method defined in the ObservationThreadLocalAccessor class when there is no current scope. New features in version 1.12.0-M1 are: a configurable base time unit for registering Micrometer observations via the ObservationThreadLocalAccessor class; and improved instances of the Apache HttpAsyncClient interface instrumented with the MicrometerHttpClientInterceptor class to prevent meter I/O errors. Further details on these releases may be found in the release notes for version 1.12.0-M1, version 1.11.2, version 1.10.9 and version 1.9.13.
Similarly, versions 1.2.0-M1, 1.1.3 and 1.0.8 of Micrometer Tracing have been released featuring bug fixes, dependency upgrades and these new features: the addition of Java Microbenchmark Harness (JMH) benchmarks for basic tracing operations; and a new getDuration() method added to the FinishedSpan interface. More details on these releases may be found in the release notes for version 1.2.0-M1, version 1.1.3 and version 1.0.8.
Piranha
The release of Piranha 23.7.0 delivers notable changes such as: a migration from JBoss Jandex to SmallRye Jandex; a new FeatureManager interface to complement the existing Feature interface; and a new CracFeature class that enables Project CRaC. Further details on this release may be found in their documentation and issue tracker.
Project Reactor
The first milestone release of Project Reactor 2023.0.0 provides a dependency upgrade to reactor-core 3.6.0-M1. There was also a realignment to version 2023.0.0-M1 with the reactor-netty 1.1.9, reactor-kafka 1.3.19, reactor-pool 1.0.1, reactor-addons 3.5.1 and reactor-kotlin-extensions 1.2.2 artifacts that remain unchanged. More details on this release may be found in the changelog.
Similarly, Project Reactor 2022.0.9, the ninth maintenance release provides dependency upgrades to reactor-core 3.5.8, reactor-netty 1.1.9, reactor-kafka 1.3.19 and reactor-pool 1.0.1. There was also a realignment to version 2022.0.9 with the reactor-addons 3.5.1 and reactor-kotlin-extensions 1.2.2 artifacts that remain unchanged. Further details on this release may be found in the changelog.
JHipster
The second beta release of JHipster 8.0.0 delivers bug fixes and notable changes such as: a removal of the unused import of the HttpServletRequest interface; a removal of the parameter with the spring-boot-maven-plugin as it was unknown to the plugin and had issued a warning; and an improvement in the Heroku sub-generator. More details on this release may be found in the release notes.
Versions 0.38.0 and 0.37.0 of JHipster Lite have been released featuring many dependency upgrades and these new features: an upgrade to Prettier for Svelte 3 components; and support for dark mode. Further details on these releases may be found in the release notes for version 0.37.0 and version 0.37.0.
Yupiik
The release of Yupiik Fusion 1.0.5 provides: support for a contextless database; a more precise error message when the JSON module is not seen or ignored; and improvements to the generated resources.json and native-image.properties files to include Fusion JSON metadata. More details on this release may be found in the release notes.
Maven
The seventh alpha release of Maven 4.0.0 ships with notable changes such as: support for JDK 20; a migration of the internal StringUtils class to the StringUtils class offered by Apache Commons Lang; and a migration of the FileUtils class offered by Plexus-Utils to the FileUtils class offered by Apache Commons IO.
Gradle
Gradle 8.2.1, a patch release, delivers fixes on notable Gradle 8.2 issues such as: a StackOverflowError exception in building applications with Gradle 8.2 and Quarkus 2.16.7; a broken Micronaut JacocoReportAggregationPlugin; and an incorrect value of false set to the --no-feature flag when it should be set to true.
JetBrains
JetBrains has introduced a new AI Assistant in all of their IntelliJ-based IDEs. Powered by the JetBrains AI service providers (only OpenAI at this time), the service transparently connects developers to “different large language models (LLMs) and enables specific AI-powered features inside many JetBrains products.” It is important to note that: a .NET Tools version is still under development; free to use during the EAP cycle; licensing and pricing model will come at a later date; and access may currently be limited by a waitlist. Further details on the AI Assistant in the .NET environment may be found in this detailed InfoQ news story.
MMS • RSS
![]() Raymond James & Associates grew its stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 75.4% in the 1st quarter, according to its most recent disclosure with the Securities and Exchange Commission (SEC). The institutional investor owned 12,030 shares of the company’s stock after acquiring an additional 5,173 shares during the quarter. Raymond James & Associates’ holdings in MongoDB were worth $2,804,000 as of its most recent SEC filing.
Raymond James & Associates grew its stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 75.4% in the 1st quarter, according to its most recent disclosure with the Securities and Exchange Commission (SEC). The institutional investor owned 12,030 shares of the company’s stock after acquiring an additional 5,173 shares during the quarter. Raymond James & Associates’ holdings in MongoDB were worth $2,804,000 as of its most recent SEC filing.
Several other large investors also recently bought and sold shares of the business. Cherry Creek Investment Advisors Inc. increased its holdings in MongoDB by 1.5% in the 4th quarter. Cherry Creek Investment Advisors Inc. now owns 3,283 shares of the company’s stock worth $646,000 after buying an additional 50 shares in the last quarter. Allworth Financial LP grew its stake in shares of MongoDB by 12.9% during the 4th quarter. Allworth Financial LP now owns 508 shares of the company’s stock valued at $100,000 after purchasing an additional 58 shares during the period. Cetera Advisor Networks LLC grew its stake in shares of MongoDB by 7.4% during the 2nd quarter. Cetera Advisor Networks LLC now owns 860 shares of the company’s stock valued at $223,000 after purchasing an additional 59 shares during the period. First Republic Investment Management Inc. grew its stake in shares of MongoDB by 1.0% during the 4th quarter. First Republic Investment Management Inc. now owns 6,406 shares of the company’s stock valued at $1,261,000 after purchasing an additional 61 shares during the period. Finally, Janney Montgomery Scott LLC grew its stake in shares of MongoDB by 4.5% during the 4th quarter. Janney Montgomery Scott LLC now owns 1,512 shares of the company’s stock valued at $298,000 after purchasing an additional 65 shares during the period. 89.22% of the stock is currently owned by institutional investors.
Insider Activity
In other news, CTO Mark Porter sold 2,734 shares of the business’s stock in a transaction that occurred on Monday, July 3rd. The stock was sold at an average price of $412.33, for a total transaction of $1,127,310.22. Following the transaction, the chief technology officer now owns 35,056 shares of the company’s stock, valued at approximately $14,454,640.48. The transaction was disclosed in a filing with the SEC, which is accessible through the SEC website. In other MongoDB news, CTO Mark Porter sold 2,734 shares of the company’s stock in a transaction on Monday, July 3rd. The stock was sold at an average price of $412.33, for a total value of $1,127,310.22. Following the transaction, the chief technology officer now owns 35,056 shares of the company’s stock, valued at approximately $14,454,640.48. The sale was disclosed in a filing with the Securities & Exchange Commission, which is accessible through this hyperlink. Also, CRO Cedric Pech sold 360 shares of the company’s stock in a transaction on Monday, July 3rd. The shares were sold at an average price of $406.79, for a total value of $146,444.40. Following the completion of the transaction, the executive now directly owns 37,156 shares in the company, valued at approximately $15,114,689.24. The disclosure for this sale can be found here. In the last 90 days, insiders have sold 117,427 shares of company stock valued at $41,364,961. 4.80% of the stock is currently owned by insiders.
Wall Street Analyst Weigh In
A number of equities research analysts have issued reports on the company. The Goldman Sachs Group boosted their price target on MongoDB from $420.00 to $440.00 in a research note on Friday, June 23rd. Needham & Company LLC boosted their price target on MongoDB from $250.00 to $430.00 in a research note on Friday, June 2nd. Barclays boosted their price target on MongoDB from $374.00 to $421.00 in a research note on Monday, June 26th. Morgan Stanley boosted their price target on MongoDB from $270.00 to $440.00 in a research note on Friday, June 23rd. Finally, Guggenheim cut MongoDB from a “neutral” rating to a “sell” rating and lifted their price objective for the company from $205.00 to $210.00 in a research report on Thursday, May 25th. They noted that the move was a valuation call. One research analyst has rated the stock with a sell rating, three have assigned a hold rating and twenty have issued a buy rating to the company. According to MarketBeat.com, the company presently has a consensus rating of “Moderate Buy” and an average price target of $366.59.
MongoDB Stock Down 2.1 %
Shares of MDB opened at $398.68 on Friday. The stock has a market capitalization of $28.14 billion, a price-to-earnings ratio of -85.37 and a beta of 1.13. The company has a debt-to-equity ratio of 1.44, a current ratio of 4.19 and a quick ratio of 4.19. The business’s 50 day simple moving average is $346.49 and its 200-day simple moving average is $259.93. MongoDB, Inc. has a 1 year low of $135.15 and a 1 year high of $418.70.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Thursday, June 1st. The company reported $0.56 earnings per share for the quarter, beating the consensus estimate of $0.18 by $0.38. The firm had revenue of $368.28 million for the quarter, compared to the consensus estimate of $347.77 million. MongoDB had a negative return on equity of 43.25% and a negative net margin of 23.58%. The company’s revenue for the quarter was up 29.0% compared to the same quarter last year. During the same quarter in the previous year, the company posted ($1.15) EPS. As a group, equities analysts expect that MongoDB, Inc. will post -2.8 earnings per share for the current fiscal year.
MongoDB Company Profile
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Click the link below and we’ll send you MarketBeat’s list of seven stocks and why their long-term outlooks are very promising.
MMS • RSS
![]() Parallel Advisors LLC raised its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 13.4% in the first quarter, according to the company in its most recent 13F filing with the SEC. The institutional investor owned 1,338 shares of the company’s stock after purchasing an additional 158 shares during the quarter. Parallel Advisors LLC’s holdings in MongoDB were worth $312,000 as of its most recent SEC filing.
Parallel Advisors LLC raised its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 13.4% in the first quarter, according to the company in its most recent 13F filing with the SEC. The institutional investor owned 1,338 shares of the company’s stock after purchasing an additional 158 shares during the quarter. Parallel Advisors LLC’s holdings in MongoDB were worth $312,000 as of its most recent SEC filing.
A number of other institutional investors and hedge funds have also recently added to or reduced their stakes in MDB. Bessemer Group Inc. purchased a new stake in shares of MongoDB in the fourth quarter valued at $29,000. BI Asset Management Fondsmaeglerselskab A S purchased a new stake in shares of MongoDB in the fourth quarter valued at $30,000. Lindbrook Capital LLC lifted its holdings in shares of MongoDB by 350.0% in the fourth quarter. Lindbrook Capital LLC now owns 171 shares of the company’s stock valued at $34,000 after purchasing an additional 133 shares in the last quarter. Y.D. More Investments Ltd purchased a new stake in shares of MongoDB in the fourth quarter valued at $36,000. Finally, CI Investments Inc. lifted its holdings in shares of MongoDB by 126.8% in the fourth quarter. CI Investments Inc. now owns 186 shares of the company’s stock valued at $37,000 after purchasing an additional 104 shares in the last quarter. 89.22% of the stock is owned by institutional investors.
Wall Street Analysts Forecast Growth
MDB has been the subject of several recent research reports. Stifel Nicolaus increased their price objective on MongoDB from $375.00 to $420.00 in a report on Friday, June 23rd. 58.com reiterated a “maintains” rating on shares of MongoDB in a report on Monday, June 26th. Needham & Company LLC increased their price objective on MongoDB from $250.00 to $430.00 in a report on Friday, June 2nd. Robert W. Baird increased their price objective on MongoDB from $390.00 to $430.00 in a report on Friday, June 23rd. Finally, Tigress Financial increased their price objective on MongoDB from $365.00 to $490.00 in a report on Wednesday, June 28th. One equities research analyst has rated the stock with a sell rating, three have issued a hold rating and twenty have given a buy rating to the company. Based on data from MarketBeat, MongoDB has a consensus rating of “Moderate Buy” and a consensus price target of $366.59.
MongoDB Stock Performance
Shares of NASDAQ:MDB opened at $398.68 on Friday. The company’s 50 day moving average price is $346.49 and its two-hundred day moving average price is $259.93. MongoDB, Inc. has a 12-month low of $135.15 and a 12-month high of $418.70. The firm has a market cap of $28.14 billion, a PE ratio of -85.37 and a beta of 1.13. The company has a quick ratio of 4.19, a current ratio of 4.19 and a debt-to-equity ratio of 1.44.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings results on Thursday, June 1st. The company reported $0.56 earnings per share for the quarter, topping analysts’ consensus estimates of $0.18 by $0.38. MongoDB had a negative net margin of 23.58% and a negative return on equity of 43.25%. The company had revenue of $368.28 million during the quarter, compared to the consensus estimate of $347.77 million. During the same quarter in the prior year, the firm posted ($1.15) EPS. The firm’s quarterly revenue was up 29.0% on a year-over-year basis. Equities research analysts predict that MongoDB, Inc. will post -2.8 earnings per share for the current year.
Insider Transactions at MongoDB
In other news, CRO Cedric Pech sold 15,534 shares of the company’s stock in a transaction that occurred on Tuesday, May 9th. The shares were sold at an average price of $250.00, for a total transaction of $3,883,500.00. Following the completion of the sale, the executive now owns 37,516 shares of the company’s stock, valued at approximately $9,379,000. The sale was disclosed in a legal filing with the SEC, which is accessible through this hyperlink. In related news, CEO Dev Ittycheria sold 50,000 shares of the stock in a transaction that occurred on Wednesday, July 5th. The shares were sold at an average price of $407.07, for a total value of $20,353,500.00. Following the completion of the transaction, the chief executive officer now owns 218,085 shares of the company’s stock, valued at approximately $88,775,860.95. The sale was disclosed in a legal filing with the SEC, which is available through the SEC website. Also, CRO Cedric Pech sold 15,534 shares of the stock in a transaction that occurred on Tuesday, May 9th. The shares were sold at an average price of $250.00, for a total transaction of $3,883,500.00. Following the completion of the transaction, the executive now directly owns 37,516 shares of the company’s stock, valued at approximately $9,379,000. The disclosure for this sale can be found here. In the last 90 days, insiders sold 117,427 shares of company stock valued at $41,364,961. Company insiders own 4.80% of the company’s stock.
MongoDB Company Profile
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
![]() Raymond James & Associates grew its stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 75.4% in the 1st quarter, according to its most recent disclosure with the Securities and Exchange Commission (SEC). The institutional investor owned 12,030 shares of the company’s stock after acquiring an additional 5,173 shares during the quarter. Raymond James & Associates’ holdings in MongoDB were worth $2,804,000 as of its most recent SEC filing.
Raymond James & Associates grew its stake in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 75.4% in the 1st quarter, according to its most recent disclosure with the Securities and Exchange Commission (SEC). The institutional investor owned 12,030 shares of the company’s stock after acquiring an additional 5,173 shares during the quarter. Raymond James & Associates’ holdings in MongoDB were worth $2,804,000 as of its most recent SEC filing.
Several other large investors also recently bought and sold shares of the business. Cherry Creek Investment Advisors Inc. increased its holdings in MongoDB by 1.5% in the 4th quarter. Cherry Creek Investment Advisors Inc. now owns 3,283 shares of the company’s stock worth $646,000 after buying an additional 50 shares in the last quarter. Allworth Financial LP grew its stake in shares of MongoDB by 12.9% during the 4th quarter. Allworth Financial LP now owns 508 shares of the company’s stock valued at $100,000 after purchasing an additional 58 shares during the period. Cetera Advisor Networks LLC grew its stake in shares of MongoDB by 7.4% during the 2nd quarter. Cetera Advisor Networks LLC now owns 860 shares of the company’s stock valued at $223,000 after purchasing an additional 59 shares during the period. First Republic Investment Management Inc. grew its stake in shares of MongoDB by 1.0% during the 4th quarter. First Republic Investment Management Inc. now owns 6,406 shares of the company’s stock valued at $1,261,000 after purchasing an additional 61 shares during the period. Finally, Janney Montgomery Scott LLC grew its stake in shares of MongoDB by 4.5% during the 4th quarter. Janney Montgomery Scott LLC now owns 1,512 shares of the company’s stock valued at $298,000 after purchasing an additional 65 shares during the period. 89.22% of the stock is currently owned by institutional investors.
Insider Activity
In other news, CTO Mark Porter sold 2,734 shares of the business’s stock in a transaction that occurred on Monday, July 3rd. The stock was sold at an average price of $412.33, for a total transaction of $1,127,310.22. Following the transaction, the chief technology officer now owns 35,056 shares of the company’s stock, valued at approximately $14,454,640.48. The transaction was disclosed in a filing with the SEC, which is accessible through the SEC website. In other MongoDB news, CTO Mark Porter sold 2,734 shares of the company’s stock in a transaction on Monday, July 3rd. The stock was sold at an average price of $412.33, for a total value of $1,127,310.22. Following the transaction, the chief technology officer now owns 35,056 shares of the company’s stock, valued at approximately $14,454,640.48. The sale was disclosed in a filing with the Securities & Exchange Commission, which is accessible through this hyperlink. Also, CRO Cedric Pech sold 360 shares of the company’s stock in a transaction on Monday, July 3rd. The shares were sold at an average price of $406.79, for a total value of $146,444.40. Following the completion of the transaction, the executive now directly owns 37,156 shares in the company, valued at approximately $15,114,689.24. The disclosure for this sale can be found here. In the last 90 days, insiders have sold 117,427 shares of company stock valued at $41,364,961. 4.80% of the stock is currently owned by insiders.
Wall Street Analyst Weigh In
A number of equities research analysts have issued reports on the company. The Goldman Sachs Group boosted their price target on MongoDB from $420.00 to $440.00 in a research note on Friday, June 23rd. Needham & Company LLC boosted their price target on MongoDB from $250.00 to $430.00 in a research note on Friday, June 2nd. Barclays boosted their price target on MongoDB from $374.00 to $421.00 in a research note on Monday, June 26th. Morgan Stanley boosted their price target on MongoDB from $270.00 to $440.00 in a research note on Friday, June 23rd. Finally, Guggenheim cut MongoDB from a “neutral” rating to a “sell” rating and lifted their price objective for the company from $205.00 to $210.00 in a research report on Thursday, May 25th. They noted that the move was a valuation call. One research analyst has rated the stock with a sell rating, three have assigned a hold rating and twenty have issued a buy rating to the company. According to MarketBeat.com, the company presently has a consensus rating of “Moderate Buy” and an average price target of $366.59.
MongoDB Stock Down 2.1 %
Shares of MDB opened at $398.68 on Friday. The stock has a market capitalization of $28.14 billion, a price-to-earnings ratio of -85.37 and a beta of 1.13. The company has a debt-to-equity ratio of 1.44, a current ratio of 4.19 and a quick ratio of 4.19. The business’s 50 day simple moving average is $346.49 and its 200-day simple moving average is $259.93. MongoDB, Inc. has a 1 year low of $135.15 and a 1 year high of $418.70.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Thursday, June 1st. The company reported $0.56 earnings per share for the quarter, beating the consensus estimate of $0.18 by $0.38. The firm had revenue of $368.28 million for the quarter, compared to the consensus estimate of $347.77 million. MongoDB had a negative return on equity of 43.25% and a negative net margin of 23.58%. The company’s revenue for the quarter was up 29.0% compared to the same quarter last year. During the same quarter in the previous year, the company posted ($1.15) EPS. As a group, equities analysts expect that MongoDB, Inc. will post -2.8 earnings per share for the current fiscal year.
MongoDB Company Profile
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • Renato Losio

Google Cloud recently announced the Cloud SQL Enterprise Plus edition for MySQL and PostgreSQL of the managed database service. The new edition provides performance optimizations for read and write operations, improved machine types and configurations, and an integrated SSD–backed data cache option.
According to the cloud provider, the Cloud SQL Enterprise Plus edition for MySQL delivers up to 3x higher read throughput and up to a 2x improvement in write latency compared to the existing Cloud SQL. Furthermore, the new option reduces downtime for maintenance operations and provides 35 days of log retention for compliance requirements. Andi Gutmans, VP of Engineering at Google Cloud Databases, highlights the advantages of the new configurable data cache:
Data cache leverages flash memory as a way to transparently extend caches based on DRAM, lowering read latency, improving throughput, and scaling to larger data sets. Additionally, software optimizations deliver up to a 2x reduction in transaction commit latency and up to a 2x improvement in write throughput, making Cloud SQL the best destination for your most demanding MySQL workloads.
The data cache is available only for the MySQL engine. Cloud SQL Enterprise Plus offers a 99.99% availability SLA inclusive of maintenance, with a reduce planned downtime of fewer than 10 seconds.
Cloud SQL supports up to 96 CPUs and 624 GB of memory for the Enterprise edition and up to 128 CPUs and 864 GB of memory for the new Enterprise Plus edition, with pricing varying according to the region. The new edition costs on average 30% more than the existing one but Gutmans comments:
The cost difference depends on your workload as you may not need to provision the same size instance with Enterprise Plus. So suggest understanding the cost difference to benchmark on a representative workload.
As part of the announcement, the cloud provider renamed the existing version of Cloud SQL to Cloud SQL Enterprise. While user abhigm highlights on Reddit the lack of an inbuilt proxy or connection pooler, user OnTheGoTrades comments:
Cool. Too bad you can’t simply upgrade to Enterprise Plus with just a few clicks. Looks like you have to completely migrate from Enterprise to Enterprise Plus.
Currently, migrating an existing database to a Cloud SQL Enterprise Plus edition requires the use of the Database Migration Service, while an in-place upgrade option is expected to be available in the future. The new edition is accessible in a subset of regions, including Iowa, South Carolina, Belgium, Taiwan, and Singapore.
Cloud SQL is not the only option to run a PostgreSQL database on Google Cloud, with AlloyDB for PostgreSQL another managed option for enterprises.
The cloud provider expects to release a version of Cloud SQL Enterprise Plus for SQL Server at a later stage.