Month: July 2023

MMS • Jessica Kerr

Transcript
Kerr: One Tuesday morning a developer sits down at their desk, opens up their laptop. They look at some dashboards, maybe, what is this blip in the error rate? Could that possibly be related to the change I pushed yesterday? They open up their log aggregator and they type in a query, take a sip of coffee. Might as well go get another cup. That’s it. That’s the whole story. They never get back to that question. Maybe their kid walked in and distracted them. Maybe they got an email. Who knows? Their attention is gone. I’m Jessica Kerr. I’m here to talk to you about how at Honeycomb, we use serverless functions to speed up our database servers.
Overview
I’m going to talk about how serverless is useful to us at Honeycomb, not for answering web requests, but for on-demand compute. Then I’ll talk about some of the ways that it was tricky. Some of the obstacles that we overcame to get this working smoothly. Finally, how you might use serverless. Some things to watch out for, what workloads you might use this for.
What Is Lambda For?
First, I need to tell you why we use serverless at all. We use Lambda functions on AWS Lambda, to supplement our custom datastore, whose name is Retriever. Your first question there should definitely be, why do you have a custom datastore? Because the answer to let’s write our own database is no. In our case, our founders tried that. It turned out that we are really specialized. Retriever is a special purpose datastore for real-time event aggregation for interactive querying over traces, over telemetry data for observability. Why would we want to do that? Because Honeycomb’s vision of observability is highly interactive. People should be able to find out what’s going on in their software system when they need to know not just learn that something’s wrong, but be able to ask, what’s wrong? How is this different? What does normal look like? A repeated question structure, always get to new questions. The difference for us between monitoring and observability, is in monitoring, you decide upfront what you want to watch for. You maybe watch for everything that has been a problem in the past. Then when you want to graph over that, you can graph that over any period of time, and it’s really fast because you’ve stored it in a time series database. You’ve done all the aggregating already. In Honeycomb, you don’t yet know what you’re going to need to ask about production data. Dump it all into events. We’ll put it into Retriever. Then we’ll make every graph fast. Each different field that you might want to group by or aggregate over, each different aggregation you might want to do, from a simple count to a p50, or a p90, or a p99, or a heatmap over the whole distribution. Our goal is to make all of these graphs fast, so that you can get the information you need and immediately start querying it for more information.
It goes like this. Say I want to know how long our Lambda functions take to execute. What’s the average execution time? Not always the most useful metric, but we can use it today. I know I need to look in Retriever’s dataset for something in Lambda, but I don’t remember the name of the spans I’m looking for. I’ll just ask it for group by name, give me all the different names of the spans. I recognize this one, invoke. I’m looking for invoke. Next question, run this query, but show me only the invoke spans. Ok, got that back. Next query, show me the average of their durations. I can scroll down and I can see what that is. Then I get curious. This is important. I’m like, why is this so spiky? What is going on over here where it’s like, super jumpy, and the count is way higher and the average duration is bouncy? I’m like, look at this, look at that spike in the p50 of the median duration down there? Let’s see, I’ll heatmap over that. Doesn’t look like they’re particularly slower in the distribution. Let’s say, what is different about these spans compared to everything else in the graph?
Honeycomb does a statistical analysis of what’s going on. Then we can scroll down and we can see what’s different. It looks like for the spans in this box I drew they’re mostly from queries, and they have a single trace ID so they’re from this particular query. Ok, so now, next aggregation. Give me only the spans inside this trace. Now I’m seeing all the invocations in this one query, but now I want to know what query were they running that made it take so long? Instead of looking for the invocations, let’s look through this trace, but let’s find something with a query spec in it. Now I’m going to get back probably just one span, a couple spans, of Retriever client fetch. I recognize that name. That’s the one that’s going to tell me what this particular customer was trying to do. If I flip over to raw data, then I can see all of the fields that we sent in Retriever client fetch. Look, there’s the query spec right there. I’m not sure exactly what that is but it looks hard. Some queries that customers run are definitely harder than others.
Interactive Investigation of Production Behavior
The point is to get this interactive feel, this back and forth, this dialogue going with your production data, so that you can continue to ask new questions over and over. For that, it has to be really fast. If I hit run query, and then I take a sip of coffee, now I should have my answer. If I have to go get another cup, complete failure. We’ve lost that developer or that SRE. That’s not good enough. The emphasis on this is on the interactivity here. Ten seconds is a little slow. One second is great. A minute, right out.
Retriever Architecture
How do we do this? Architecture of Retriever. Customers send us events. We put them in the database. Then developers, and SREs, and product, and whoever, runs the queries from our web app. Of course, the events come into Kafka. This is not weird. Naturally, we partition them. Retriever is a distributed datastore. There’s two Retrievers to read off of each topic, so that we have redundancy there. It reads all the events, and then it writes them to local disk. Because local disk is fast, in-memory is too expensive. Anywhere else is slower. It writes all these things to local disk. That’s quick. The more of Retrievers we have, the more local disks we have. Then, when a query comes in, it comes into one Retriever. That Retriever says, ok, this dataset has data in these many other partitions, sends off inner queries to all of those Retrievers so that they can access their local disks. Then there’s a big MapReduce operation going on, it comes back to the Retriever you asked, and it responds to the UI. That’s the distributed part.
The next trick to making this really fast is that Retriever is a column store. It’s been a column store since before these were super cool, but it’s still super cool. Every field that comes in with an event goes in a separate file. That’s fine. This is how we scale with quantity of fields on the event. Because at Honeycomb, we want you to send all kinds of fields and they can have all different values. We don’t care because we’re only going to access the ones we need. When a query comes in, if we’re looking for service name equals Lambda, and name of the span is invoke, and we’re aggregating over the duration, all Retriever is going to look at is the service name, the name, and the duration columns, and the timestamp. There’s always a timestamp associated with every query. That’s the next trick is, in order to segment this data, we use timestamp. At Honeycomb, I like to say we don’t index on anything, but that’s not quite true, we index on timestamp. The data is broken into segments based on like, I think, at most 12 hours, or a million events, or a certain number of megabytes in a file. Then we’ll roll over to the next segment. Then we record like, what timestamps are the earliest and latest in each segment. That way, when a query comes in, we’re like, ok, the query has this time range, we’re going to get all the segments that overlap that time range. We’re going to look through the timestamp file to find out which events qualify. That’s how Retriever achieves dynamic aggregation of any fields across any time range at that interactive query speed.
More Data and Big Datasets
Then we have the problem of success, and we’ve got bigger customers with more data coming in, and datasets are getting bigger. The thing is, our strategy used to be, whenever we run out of space for a particular dataset, new segment starts, older segments get deleted. That was fine when the oldest segment was like a week old. The point is, your current production data is what’s most important. We got datasets that were big enough that at our maximum allocation for a dataset, we were throwing away data from like 10 minutes ago. That’s not ok. You need more than 10 minutes window into your production system. We did what everybody does when there’s too much data, we started putting it in S3. This time, instead of deleting the oldest segment, we were shipping it up to S3. Each Retriever still takes responsibility for all of the segments in its partition, it’s just that now we’re not limited in storage. We can store it up to 60 days. That’s a much better time window, than, until we run out of space, much more predictable. Then those queries are going to be slower. They’re not as fast as local disk. It’s the most recent stuff that you query the most often, and that’s what you want to be really fast. It’s also the stuff that’s the most urgent.
We’re like, ok, so each Retriever, when it needs some data that’s older, it’ll go download those files from S3, and include those in the query. It won’t be quite as fast, but it’ll be a lot more flexible, because you have more data. That’s good. Now people can run queries over 60 days’ worth of data. No, 60 days is a lot. How much longer is that going to take? When you’re reading from local disk, it’s really fast, but as soon as you hit S3, the query time grows, at least linearly with the number of segments that it has to download and query. If you query for the last few minutes, yes, you can take a sip of coffee. If you query for the last few days, you might have to take a couple sips, and 60 days, we had to change our maximum query timeout to an hour. That’s way beyond a cup of coffee. That’s like roast the beans and brew the pot. I hear you can roast beans, it doesn’t take that long, but this took too long.
That was not ok. What are we going to do? Retriever is like, I need more compute. The network wasn’t the bottleneck here. It was actually the compute because we’re doing all those reads and the aggregations, and group bys, and filters, and all that stuff in memory. At query time, compute was on limitation. We could just like spin up more Retrievers. We could get more EC2 instances. You can buy compute. Except we really don’t need it all the time. The Retriever dog doesn’t always want to play. This is like when we need the compute. This is the concurrency of how many Lambdas are we running at any one time, and it’s super spiky. Often, pretty much none. Sometimes, we need thousands. This is very different from the compute profile of EC2 because we don’t need it 30 seconds from now, after use. Even if an instance spun up that fast, which they don’t all, that’s too long. We need sudden access to compute while you’re lifting your cup. That is exactly what serverless provides. Also, Lambdas are like right next door to S3. Retriever, you get some minions. Now, when a Retriever needs to access its segments in S3, it spins up a Lambda for each eight or so segments. That Lambda reads the data from S3, decrypts it, looks at the files just that it needs to. Does the aggregations. Sends the intermediate result to Retriever, and the MapReduce operation flows upward. This is much better.
See, our query time, it still goes up with the number of segments queried. That’s not weird. It’s very sublinear. If you’re running a 60-day query, and it’s a hard one, you might get more than one sip in but you’re not going to have to go get another cup. Win. It turns out that buying compute in, used to be 100 milliseconds, now it’s 1 millisecond increments, you can do it. This is like us scaling the compute, so that the time of the query doesn’t scale with how much it’s doing. We’re throwing money at the problem, but very precisely, like only when we need to.
Lambda Scales up Our Compute
We use Lambda to scale up compute in our database. We found that it’s fast enough. Our median start time is like 50 milliseconds. My cup doesn’t get very far in that amount of time. It’s ok. We don’t see much of a difference between hot and cold startups. They tend to return within two and a half seconds, which is acceptable. They are 3 or 4 times more expensive, but we run them 100 times less, at least, than we would an EC2 instance, for the same amount of compute, so this works out. There are caveats to all of these, or at least caveats that we overcame. Watch out.
We started doing this a little over a year ago, and at AWS, this was a new use case, at the time, for serverless. Because they designed it for web apps, they designed it as like a backend on-demand. The scaling isn’t exactly what we expected. The scaling for Lambda is, it’ll go up to what is called the burst limit, which in US-East-1 is 500. In US-West-2 I think it’s 3000. It varies by region. That burst limit is like 500 Lambdas. Then they stop scaling. Then AWS was like, but if you have continuous load, then over the next minute, they will scale up, I think it might be linearly, I’ve drawn it as steps, to the concurrency limit, which is like 1000. The rest of them will get a 429 response which is throttled for retry. We hit this. Spending a minute scaling up by 500 more Lambdas is not helpful, because our usage pattern looks like this. We don’t have a minute of sustained load. That doesn’t help us at all, so we really needed our burst limit raised. We talked to AWS and they raised our burst limit. You can talk to your rep and you can get your burst limit raised into the tens of thousands now. That helps, at least your concurrency limit, both fairly. The trick is to not surprise your cloud provider. We were able to measure how many Lambdas we needed to run at a given time, or are running. In fact, we added this concurrency operator to count how many of a thing it wants, just for this purpose. Now that’s available to everyone.
Startup, we need this to be fast. People talk about cold starts, warm starts. Is that a problem for us? It hasn’t been. When you invoke a Lambda function, AWS may or may not have some already ready of these processes already started up and ready. If not, it’ll start up a new one and then invoke it. Then that one will hang out a little while waiting to see if it gets some more invocations. You only get charged for while it’s running the code. You can see the difference between these. We can make a trace, and we do. We make a trace not only of our invocations, but of that wider Lambda process, because we omit a span when it wakes up and we omit a span right before the function goes to sleep. We can see run, sleep, run, sleep, run sleep. You can actually follow what’s going on in that process, even though during those sleeps, it’s not actively doing anything. I think that’s fun.
Generally, our startup within 50 milliseconds, like you saw. This is in Go, so that helps. Here it goes. Here’s the Lambda function process, you can see that this one hung out for a while. We can count the number currently running. We can use concurrency to count the number currently sleeping, and you can see that those are wider. That’s just neat. What matters is that, when we invoke them, they start up quickly, they do their processing. They return within two-and-a-half seconds, most of the time, 90% of the time, but definitely not 100%. You can see the 30,000 millisecond to the 32nd line in the middle of this graph, there’s a cluster, that’s S3 timeout. Lambda may be right next door to S3, but S3 does not always answer its knock. The trick to this is just don’t wait that long. Start up another one with the same parameters, and I hope you get a little luckier on the timing this time and S3 does respond. Watch out because the default timeout in the Lambda SDK is like 30 seconds or longer, it’s way too long. Do not want to use the default timeout, make sure you give up before the data becomes irrelevant.
We did also find a peculiar restriction that like the functions can’t return more than 6 megabytes of data. Put the return value in S3 and respond with a link. Amazon has a limit for everything. That’s healthy. They have boundaries. They will surprise you. You will find them. Also, when you try to send the functions data, we would like to send them binary data, but they only want JSON. There’s weird stuff. JSON is not that efficient. It’s not exactly JSON, it’s whatever AWS’s Lambda JSON cop has decided is JSON. Don’t deal with it. Put the input in S3 and send a link. This is fine.
Finally, everyone knows that serverless is expensive. Per CPU second, it costs like three to four times what an EC2 instance would cost. Given that we’re running at less than a 100th of the time as much, that seems like a win. What can we do to keep that down? First of all, what really worries me about Lambda costs is that you don’t know what they’re going to be, because how many of these is your software going to invoke and suddenly spin up? What are the costs associated with that? Are you going to get surprised by a bill that’s like a quarter of your AWS bill? Sometimes. This is where observability is also really important. Because we have spans that measure that invocation time, we can multiply that duration by how much we pay per second of Lambda invocation. We can count that up by customer, because all of our spans include customer ID as a dimension. Then, we can get notified, and we do, whenever a particular customer uses more than $1,000 of Lambda in a day or an hour. Then sometimes we get the account reps to reach out and talk to that customer and be like, what are you doing? Here’s a more effective way to accomplish what you’re looking for. We throttle our API and stuff like that. Really, the best you can do is find out quickly if you’re going to get a big bill.
Also, we do a ton of optimization. We do so much optimization of our Lambda execution, really all of our major database processes to get that speed. One way that we optimize is that we’ve moved from x86 to ARM processors to the Graviton2 processors, both for our Retrievers and our ingest, most of our other servers, but also for our Lambdas. Liz Fong-Jones, who’s our field CTO now, has written several articles about the ARM processors are both faster in the sense that it’s going to take less CPU to run them. Those CPU seconds are cheaper. We get lower costs in two different ways. We can measure that. We started building our Lambda functions there in Go for both x86 and ARM. The first time we tried a 50-50 split, and we ran into some, ok, maybe this, maybe not. Initially, the ARM64 processors were about the same average, but a lot more varied in their performance, and overall slower. Take it back. They were not the same average. They were more varied in their performance and overall slower. We’re like, ok, let’s change that feature flag, and we’ll roll this back so we’re running 1% on ARM processors and 99% on x86. We did that. Yes, so now you can see our ARM percentage, you can barely see the orange line at the end after the feature flag was deployed.
Why So Slow?
Then we started investigating, why was it so slow? One was capacity. Even though we had our Lambda executions limits raised, there were only so many ARM processors available to run them. The total capacity in AWS for these is still lower than for x86 Lambdas. We had to work with AWS directly, and created a capacity plan for when we would be able to spin up more of them to ARM. The next thing we noticed was that these were running slower, because at the time, the current Golang was 1.17, and 1.17 had a particular optimization of putting parameters in registers instead of having to put them in memory for function calls that made calling functions faster on x86. Because we’re doing all these super complicated queries, and which filter are we doing, and which group by are we doing, and there’s a lot of branching in what our aggregators are doing, there were a lot of function calls. A little bit of overhead on a function call went a long way. Go 1.18 also has this optimization on ARM, so we started using 1.18 a little bit early, just for our Lambdas, and that made a difference. Now Go is 1.19, it’s fine. At the time, that was a significant discovery. We figured that out with profiling.
Also, through profiling, we noticed that the compression was taking a lot longer on ARM than on x86. It turned out that the LZ4 compression library had a native implementation on x86, but had not been released yet natively in assembly for ARM64. Liz spent a couple afternoons porting the ARM32 assembly version of the LZ4 compression library to ARM64, got that out, and brought the performance more in line. These three considerations fixed the performance problems that we saw at the time. Under the capacity ones, that’s a gradual fix over time. Since then, since a year ago, we’ve been able to bump it up to 30% ARM. Then AWS called and said, “Try. Go for it.” We bumped it up to like 99, but then there were some regressions and so we dropped it down to 50, and that was ok. Then we got those fixed, and then bumped it up to 90, or gradually worked it up to 99%. Now we’re there. We keep 1% on x86 just so we don’t break it without noticing.
The performance is good. There’s a little more variation in the purple x86 lines here, but that’s just because they’re 1%. The orange lines are ARM. Yes, the performance is the same. We figured out also through profiling and observability that on ARM, with the same CPU size as x86, it was sufficiently fast enough that we’d actually hit network limitations. We scaled back the CPU by 20%. On fewer CPUs, we’re getting the same performance. Also, those CPUs are 20% cheaper. This continued optimization is how we manage to spend money very strategically on our database CPU, so that people can get that interactive query timing, even over 60 days.
Try This at Home?
We scaled up our compute with Lambda, should you? Think about it. If you do, be sure to study your limits. Be sure to change the SDK retry parameters, don’t wait 30 seconds for it to come back. Deployment is its own thing. We stub that out for automated tests. The only real test is production, so also test in production, with good observability. Observability is also really important for knowing how much you’re spending, because you can really only find that out, again, in production from minute to minute. Always talk to your cloud provider. Don’t surprise them. Work this out with them. Talk about your capacity limits. A lot of them are adjustable, but not without warning. The question is, what should you do on serverless, and what should you not? Real-time bulk workloads. That’s what we’re doing. We’re doing a lot of work while someone is waiting in our database. It needs to be a lot of work, or don’t bother, just run it on whatever computer you’re already on. It needs to be urgent, like a human is waiting for it, or else there’s no point spending the two to four times extra on serverless, unless you just really want to look cool or something. Run just a Kubernetes job, run it on EC2, something like that, if it’s not urgent.
Once you’ve got someone waiting on a whole lot of work, then what you’re going to need to do is move the input to object storage. You’ve got to get all of the input that these functions need off of local disk, and somewhere in the cloud where they can access it. If they have to call back to retrieve or to get the data, that wouldn’t help. Then you’ve got to shard it. You’ve got to divide that up into work that can be done in parallel. It takes a lot of parallelism. The MapReduce algorithms that our Lambdas are using have this. Then you’ll want to bring that data together. You could do this in Lambda, but this also can be a bottleneck. We choose to do that outside of Lambda on our persistent Retriever instances, which are also running on ARM for added savings.
Then you’re going to have to do a lot of work. You’re spending money on the serverless compute, use it carefully. You’re going to need to tune the parameters, like how many segments per invocation. What’s the right amount of work for the right Lambda execution? How many CPUs do you need on Lambda at a time? I think memory is connected to that. Watch out for things like when you’re blocked on network, no more CPU is going to help you. You’ll need to optimize properly, and that means performance optimizing your code where it’s needed. You’ll need profiling. You definitely need observability. There’s an OpenTelemetry layer, and it will wrap around your function, and create the spans at the start and end. It’s important to use a layer for this. Your function can’t send anything after it returns nothing. As soon as it returns, it’s in sleep mode until it starts up again. The Lambda layer allows something to happen to report on the return of your function. Be sure to measure it really carefully, because that’s how you’re going to find out how much you’re spending.
In the end, technology doesn’t matter. It’s not about using the latest hotness. The architecture doesn’t matter. It’s not about how cool a distributed column store is. What matters is that this gives something valuable to the people who use Honeycomb. We spend a ton of thought, a ton of development effort, a ton of optimization, a ton of observability, we put all of our brainpower and a lot of money into our serverless functions, all to preserve that one most precious resource, developer attention.
Resources
If you want to learn more, you can find me at honeycomb.io/office-hours, or on Twitter is jessitron, or you can read our book. Liz, and George, and Charity all from Honeycomb have written about how we do this, how we do observability and how we make it fast in the “Observability Engineering” book. You can learn a lot more about Retriever in there.
Questions and Answers
Anand: I was wondering how much data we’re talking about, when we say 60 days for large clients?
Kerr: I think it’s in terabytes, but tens of terabytes, not pi terabytes.
Anand: What’s the normal workflow for your customer using the Retriever function? What’s their normal method? Let’s say you have a customer, they build a dashboard with charts, do they basically say, this chart, I want to be faster or more real time.
Kerr: We just work to make everything fast. You don’t pick custom indexes. You don’t pick which graphs to make fast. We aim to make all of them fast. Because we don’t want you to be stuck with your dashboards. Yes, you can build a dashboard. That is a functionality that Honeycomb has. It’s not what we’re optimizing for, we’re really optimizing for the interactive experience. You might start at your dashboard, but then we expect you to click on the graph, maybe change the time range, maybe compare it to last week, more likely group by a field, or several fields. Get little tables of the results as well as many lines on the graph. Then maybe click on, make a heatmap, or click on it and say, what’s different about these? We’re going to go on a series of queries to tell you that.
Anand: It’s completely done on demand, in real time as the user is doing his or her analysis. It’s not about optimizing the speed of a chart in a dashboard. It’s all about the interactive part.
Kerr: Yes. We could go look in the database, what you have in your dashboards, but your dashboard queries are not any different from a live query.
Anand: Do you also speed those up with Retriever, the canned set of charts that people have?
Kerr: Yes. If you make a dashboard that’s for a long period of time, and access it a lot, we’re probably going to notice and maybe talk to you. If you’re like updating that every 30 seconds, we’re going to cache it for you. Because those are expensive queries.
When to use Lambda functions and when not to, is whether the data is in S3. If it’s in S3, we’re going to use a Lambda. If it’s on local disk, then we’re not. That’s entirely determined by time. The time isn’t the same for every dataset, though. If you have a smaller dataset, maybe all of the data is on local disk. As it gets bigger more, a larger percentage of that data is in S3.
Anand: It’s based on the dataset size. Then, do you move the data to S3, like behind the scenes?
Kerr: Retriever does.
Anand: You get to decide how much data you hold? Do I decide if I want six months of data?
Kerr: You can negotiate that a little bit with your contract. I think we have a few exceptions where customers keep more than 60 days of data in particular datasets. At Honeycomb, we keep things pretty simple. Pretty much everybody had 60 days of data. How much of that is in local disk is like a fixed amount per dataset, roughly. Some datasets have more partitions than others, and so they’d have correspondingly more data on local disk, but it’s all invisible to the customer. You don’t know when we’re using Lambda.
Anand: Can you elaborate on what makes Lambdas hard to test?
Kerr: You can test the code inside the Lambda. You can unit test that. It’s just fine. Actually testing whether it works once it’s uploaded to AWS, like integration testing Lambdas is really hard. You can’t do that locally. You can’t do that in a test environment. You can do that in a test version that you uploaded to AWS, but that’s really slow. Honeycomb is all about test in production. Not that we only test in production, but that we also test in production and we notice when things break, and then we roll back quickly. The other thing we do is we deploy to our internal environment first. Our internal environment is not test, is not staging, it’s a completely separate environment of Honeycomb, that we’re the only customer of. There’s production Honeycomb that monitors everybody else’s stuff, all of our customers’ observability data. Then, there’s our version of Honeycomb that just receives data from production at Honeycomb. We call it dog food, because we use it to eat our own dog food. The dog food Honeycomb, we deploy to that first. Technically, there’s another one that monitors dog food, but close enough. If we broke the interface between Retriever and EC2, and then the Lambdas, or anything else about the Lambdas that we couldn’t unit test, if we broke that we’ll notice it very quickly. We even have deployment gates, that normally, deployment to production would just happen 20 minutes later. If our SLOs don’t match, if we get too many errors in dog food, we’ll automatically stop the deploy to production. We test in prod, where it’s a smaller version of prod. It’s not all of prod. It’s limited rollout.
Anand: How do you compare Lambdas to Knative?
Kerr: I’ve never tried anything in Knative. We do use Kubernetes in Honeycomb.
Anand: Are you using Kubernetes over EKS, the Elastic Kubernetes Service for the control plane.
Kerr: EKS, yes.
Anand: Does it sometimes make sense to use a platform agnostic language like Java that may help avoid issues with suboptimal libraries that are not yet ported to native CPU architecture?
Kerr: Sometimes, absolutely. It depends on your business case. We’re doing something really specialized in this custom database. In general, don’t write your own database. In general, don’t optimize your code this much, for like business software. This is like the secret sauce that makes Honeycomb special. This is what makes it possible for you to not have to decide which queries you want fast, they’re just all fast. It’s a dynamically generated schema, we don’t even know what fields you’re going to send us, just that it’s going to be fast. It’s super specialized. At the scale that we do these particular operations at, it’s expensive. That’s where a significant portion of our costs are, in AWS, and a significant chunk of that is Lambda. We are constantly optimizing to run really lean in AWS, and we watch that closely. Liz Fong-Jones is always noticing something that that could be faster and could save us tens of thousands of dollars a month, which is significant at our size.
Anand: Is your entire platform written in Go.
Kerr: Pretty much. The frontend is TypeScript.
Anand: What are your timeouts? A user types in a query in the UI, how long will they wait? Will they wait as long as it takes to get a result, but you try to be as fast as possible?
Kerr: It’ll time out after 5 minutes. If it takes that long, there’s a bug. More likely something went down. The user waits until there’s a little spinny thing. Then, all the queries will populate all at once, when the results have been aggregated and sent back. Usually, it’s like 5 seconds on a long one, and 2 seconds on a typical query.
Anand: This is the Holy Grail, like call cancellation, someone closes the window, you have to schedule the workload. Everyone wants to do it, and never gets around to it.
Kerr: It’ll finish what it’s doing, there’s no really stopping it, because it’s doing everything at once already. We will cache the results if somebody runs that exact query with that exact timespan again. Those results are actually stored in S3. This makes permalinks work. Those results are actually stored forever, so that your queries that you’ve already run that you’ve put into your incident review notes, those will always work. You just won’t be able to drill further in once the data has timed out.
Anand: What’s the time granularity of your buckets, like your timestamp?
Kerr: You can set that on the graph within a range. It’ll usually start at a second but you can make it 30 minutes, you can make it 5 milliseconds, depending on your time range. You’re not going to do 5 milliseconds for a 60-day query, no, but appropriately.
Anand: They could group by second. You support group bys where they have 1-second buckets.
Kerr: That’s just bucketing for the heatmaps. Group by is more like a SQL group by where you can group by account ID, you can group by region, any of the attributes. It’ll divide those out separately, and show you a heatmap that you can hover over.
See more presentations with transcripts
MMS • Facundo Agriel

Transcript
Agriel: I’m Facundo Agriel. I’m a software engineer at Dropbox. I’m going to be talking about Magic Pocket, which is an exabyte scale blob storage system.
Magic Pocket is used to store all of Dropbox’s customer data. We also have many internal use cases. At its core, Magic Pocket is a very large key-value store where the value can be arbitrarily sized blobs. Our system has over four-nines of availability. We operate across three geographical regions in North America. Our writes are optimized for 4-megabyte blobs. Writes are immutable. We also optimize for cold data. Our system overall manages over tens of millions of requests per second. A lot of the traffic behind the scenes comes from verifiers and background migrations. Currently deployed, we have more than 600,000 storage drives. All this also utilizes thousands of compute machines.
OSD (Object Storage Device)
Let’s talk about the most important component of the Magic Pocket, which are the object storage devices, which we call OSDs. This is an actual OSD in one of our data centers. You could see all the drives in here. Typically, per storage machine, we have about 100 disks per OSD. We utilize SMR technology. Each storage device has over 2 petabytes of capacity. Let’s talk about why we use SMR technology. SMR stands for Shingled Magnetic Recording. It’s different from the conventional Perpendicular Magnetic Recording or PMR drives that allow for random writes across the whole disk. With SMR, the tradeoffs are that you offer increased density by doing sequential writes instead of random writes. As you can see here, you’re squeezing SMR drives together, which causes the head to erase the next track when you walk over it. In this case, you can still read from it, it’s just that you can’t just randomly write in any place that you want. This is actually perfect for our cases, based on the workload patterns that I just told you about. This actually ends up working really well for us. SMR drives also have a conventional zone, outside the diameter that allows for caching of random writes if you need to. This conventional zone, it’s typically less than about 1% of the total capacity of the drive.
Architecture of Magic Pocket
Let’s talk about the architecture of Magic Pocket now. At a very high-level view of our system, we operate out of three zones. We operate out of a West Coast, Central zone, and the East Coast. The first subsection here is a pocket. A pocket is a way to represent a logical version of everything that makes up our system. We can have many different instances of Magic Pocket. Some versions of that could be a test pocket. Something in like a developer desktop, you can run an instance of Magic Pocket. We also have a stage pocket, which is before our production zone. Databases and compute are actually not shared between pockets, so they operate completely independently of each other.
Zone
Now that we have a high-level view of what a pocket is, let’s talk about the different components. Let’s get into what a zone is. Within a zone, we have the first service here, which is the frontend service, and this is the service that we expose to our clients. All of our clients interact with us through this frontend service. This is what they call it to make any requests. The types of requests that our clients typically make are a PUT request with the key and a blob, a GET request, given some key. They might make a delete call. They might scan for what hashes are available in the system. They might want to update some metadata on a specific key as well. When a GET request comes in, what we first have to consult is the hash index. The hash index is a bunch of sharded MySQL databases, and everything is sharded by this hash. A hash is basically the key for a blob. We simply just take the SHA256 of that blob. Internally, we call those blocks, which are parts of a file, pieces of a file, typically, no more than 4-megabyte chunks. The index, what you’ll find is that a hash is mapped to a cell, a bucket, and we also have a checksum as well for that specific hash. A cell is another isolation unit. This is where all of the storage devices actually live. The index table just points to a specific cell and a bucket, so another level on direction where to go to in the cell. The cells can be quite large, so they can be over 100 petabytes in size, of customer data. They do have some limitations of how much they can grow. As the system as a whole, if we are low in capacity, we just simply open up a new cell. That’s how our system is able to horizontally scale forever with some limitations, of course.
Let’s talk about what else we have in a zone. Another component that we have in the zone is the cross-zone replicator. The idea behind the cross-zone replicator is that within Magic Pocket, we do cross-zone replication. That means we store your data in multiple regions. This is done asynchronously in the background. Once a commit happens and you know where your data is, we automatically queue it up into the cross-zone replicator, so it can be moved over to the other zone somewhere else. We also have a control plane. The control plane basically manages traffic coordination within a zone, for example, if we have migrations in the background, it generates a plan in order to not impede with live traffic. We also use it to manage reinstallations of specific storage machines. For example, we might want to do a kernel upgrade or an operating system upgrade, the control plane will take care of that for us. It also manages cell state information. The cells have certain attributes, as well about maybe type of hardware that’s involved in there, and so on. That’s what it’s doing.
Cell
We talked about a hash is mapped to a cell and a bucket. Let’s get into what a cell and a bucket is. Within the cell, we have a bucket, and now we already went into the cell. The first thing we have to do if we want to fetch our blob back is that we have to consult this component called the bucket service. The bucket service knows about a few things. It knows about buckets, and volumes. Anytime you want to, let’s say, as we’re doing a fetch here, we first find the bucket. That bucket is actually mapped to a volume, and the volume is mapped to a set of OSDs. The volume can be open or closed. There’s a generation associated with it. Also, volumes are of different types. Volume could be in some replicated or erasure coded state. When we ask for a bucket, that volume will tell us which specific OSD has our blob. Let’s say we go to bucket one, map to volume 10. Then within the volume, we find this OSD here. We will simply just need to ask this OSD about our specific blob, and it’ll hand it back to us. That basically completes the way that we retrieve a blob from Magic Pocket. If you want to do a write, it’s a little bit different, but essentially the same. It’s just that the buckets are pre-created for us. Simply, the frontend service needs to figure out what buckets are open for it to write to. It will write to buckets that are open and ready to be written. In this case here, if it’s an open volume, ready to be written into, what we do is we may write to this set of OSDs, so within a volume, it will be mapped to these four. That’s where your data will be stored for that specific volume.
Let’s talk about a couple other things within the cell. Another component that’s very important, is this coordinator. The coordinator is not in the path of a request for a PUT or GET call. It actually works in the background. What it does is it’s managing all of the buckets and volumes, as well as all the storage machines themselves. It’s constantly health checking storage machines. It’s asking them what information do they know, and reconciling information from the storage machines with the bucket service in the bucket database. Other things that it does is that it will do erasure coding, it will do repairs. For example, if this storage machine goes out, you will need to move data to another machine. It’s in charge of doing that. It’ll optimize data by moving things around within the cell. Or if there’s a machine that needs to go offline, it will also take care of that too, by moving data around to some other machine. The way that it moves data around, it doesn’t actually copy data itself, it’s actually all done by this component here called the volume manager. The volume manager basically is in charge of moving data around, or when we need to move data, when to recreate the new volumes, and so on. I talked a little bit about some of the background traffic that we have. A lot of verification steps also happen within the cell, as well as outside of the cell. We’ll talk about that as well.
Buckets, Volumes, Extents
Let’s talk a little bit more about buckets and volumes, and what those are in more detail. We have the concept of these three components. We have buckets, volumes, and extents. You can think about a bucket as a logical storage unit. I mentioned if we wanted to do a write, we write into a bucket which is associated with the volume, and then finally, this other concept called an extent. The extent is just about 1 or 2 gigabytes of data found on a disk. If we want to do a write, we simply figure out what open buckets are. Assuming we found this bucket 1, we have to get the set of OSDs associated with those. Then when we do the writes, we simply make a write within the extents themselves. The extent information and volume information in the buckets are all managed by the coordinator I talked about before. If any data is missing or things like that, you can always get it from the other remaining storage machines, and the coordinator will be in charge of finding new placement for that extent that was deleted. Buckets, think about as logical storage, typically 1 to 2 gigs. Volume composed of one or more buckets, depending on the type, a set of OSDs. Type, again, whether it’s replicated or erasure coded, and whether it’s open or not. Once we close a volume, it’s never opened up again.
How to Find a Blob in Object Storage Devices
Let’s talk about how we find the actual blob in a storage machine. We have the blob, we want to fetch the blob. We know now the volume. We know that the volume is associated. These OSDs are supposed to have our blob. Simply, what we do is that we store the address of these different OSDs, and we talk directly to those OSDs. The OSDs, when they load up, they actually load all the extent information and create an in-memory index of which hashes they have to the disk offset. For example, if you had some hash of blob foo, it’ll be located in disk offset 19292. In this case, this volume is of type replicated. It’s actually not erasure coded. We have the full copy available in all the four OSDs mentioned here. This is for fetching the block. If you want to do the PUT, it’ll be of the same type, it’ll be 4x replicated, and you’ll simply do a write to every single OSD itself. We do the requests in parallel. We don’t act back until the write has been completed on all of the storage machines.
Erasure Coding
Let’s talk about the difference between a replicated volume and an erasure coded volume, and how we handle it. Obviously, 4x replication, and we have two zones that we replicate the volume to. That can be quite expensive, so overall this would be 8x replication. That’s very costly. We want to be able to lower our replication factor to make our systems more efficient. This is where erasure codes come in. When a volume is in a replicated state, surely after the volume was almost full, it will be closed, and it will be eligible to be erasure coded. Erasure codes are able to help us reduce the replication costs, with similar durability as straight-up replication. In this case, we have an erasure code, let’s say this is Reed Solomon, 6 plus 3. We have 6 OSDs, and we have 3 parities over here. We call this a volume group or grouping. You’ll have a single blob in one of the data extents. Then, if you lose any one of these OSDs, you can reconstruct it from the remaining parities and the other data extents.
Let’s go into a little bit more detail here on erasure coding. In this case, as I mentioned, you can read from other extents in parity for the reconstruction. As you can imagine, this area becomes really interesting. There’s going to be a lot of variations of erasure codes out there with many different tradeoffs around overhead. Let’s talk briefly about that. For erasure codes, they can be quite simple. You can use something like XOR, where you can reconstruct from the XOR of other things, or you can use very custom erasure codes. There’s a lot of tradeoffs, for example, if you want to do less reads, you might have higher overhead. If you want to tolerate more failures, the overhead, so your replication factor is likely to increase, if you want to tolerate multiple failures within that volume group. This is a very interesting paper by Microsoft called Erasure Coding in Windows Azure Storage by Huang and others. This came out a few years ago, but it’s super interesting. It’s something very similar that we actually do within Magic Pocket, as well.
I mentioned the example before, the example with Reed Solomon 6, 3, so 6 data extents and 3 parities. With the codes that they came up with called least reconstruction codes, they have a concept of optimizing for read cost. In Reed’s element 6, 3, the read costs, if you have any failures is going to be the full set of all the extents here. Your read penalty will be 6 here. They came up with the equivalent codes such that for one type of data failures, you can have the same read costs, but a lower storage overhead. In this example here, their storage overhead, their replication factor is roughly 1.33x, where the same replication factor with Reed Solomon is going to be 1.5. It may not seem like a big savings, but at a very large scale, this ends up being quite a lot that you end up saving. Of course, this optimizes for one failure within the group, which is typically what you will see in production. If you can repair quickly enough, you will hardly see more than one type of failure within a volume group. Those types of failures are a lot rare. They typically don’t happen that often. It’s ok to make the tradeoff here with that. Yes, just to iterate, 1.33x overhead for the same as a Reed Solomon code. A super interesting paper. You can even continue to lower your replication factor. You can see here it far outpaces Reed Solomon codes for lower overhead, but similar reconstruction read costs. Typically, for LRC 12, 2, 2, you can tolerate any three failures within the group, but you can’t actually tolerate any four failures. Only some of them can be actually reconstructed, which is simply not possible.
Can We Do Better?
Can we do better than this? Notice that we have a 2x overhead for cross-zone replication. Even though our internal zone replication factor is quite good, and ideal, we still have this multi-region replication that we do. What else can we do? A while ago, the team made some really good observations about the type of data that we have in our systems. The observation was that retrievals are for 90% of data uploaded in the last year. Even as you go here, through the graph, you can see that 80% of the retrievals happened within the first 100 days. This is quite interesting, which means that we have a bunch of data that’s essentially cold and not accessed very much. We want to actually optimize for this workload. We have a workload with low reads. We want similar latency to what we have today for the rest of Magic Pocket. The requests don’t have to be in the hot part of requests, meaning we don’t have to do live writes into the cold storage. It could happen at some point later. We want to keep the same similar durability and availability guarantees, but again lower that replication factor from 2x further down. Another thing that we can do here is we can make use of more than one of our regions.
Cold Storage System
Now I’m going to talk about our cold storage system, and how that works at a very high level. The inspiration came from Facebook’s warm blob storage system. There was a paper that was written a few years ago, and had a very interesting idea there. The idea is as follows. Let’s say you have a blob, and you split it in half. The first half is blob1, and the second half is blob2. Then you take the third parts, which is going to be the XOR of blob1 and blob2. We call those fragments. Those fragments will be individually stored in different zones, you have blob1, blob2, and blob1 XOR blob2. If you need to get the full blob, you simply need any one combination of blob1 and blob2, or blob1 XOR blob2, or blob1 and the XOR over here. You need to have any of the two regions to be available to do the fetch. If you want to do a write, you have to have all regions fully available. Again, this is fine, because the migrations are happening in the background, so we’re not doing them live.
Cold Storage Wins
Let’s talk about some of the wins that we get from our cold storage. We went from 2x replication to 1.5x replication. This is a huge amount of savings. This is nearly 25% savings from a 2x replication that we had. Another win around durability is that the fragments themselves, they’re still internally erasure coded. The migration, as I said, is done in the background. When you do a fetch from multiple zones, that actually endures a lot of overhead on the backbone bandwidth. What we do is we hedge requests, such that we send the request to the two closest zone from where the originating service is at. Then if we don’t hear a response from the 2 zones, or some period of a few 100 milliseconds, we actually fetch from the remaining zone, and that is able to save quite a lot on the backbone itself.
Release Cycle
Let’s move over to some operational discussions on Magic Pocket. The first component that I want to talk about here is how we do releases. Our release cycle is around four weeks, end-to-end, across all our zones. We first start off with a series of unit or integration tests before the changes can be committed. Unit and integration tests typically run a full version of Magic Pocket with all of our dependencies. You can run this in a developer box fully. We also have a durability stage. The durability tester itself runs a series, a longer suite of tests with full verification of all the data. We’ll do a bunch of writes, and we’ll make sure that the data is all fully covered. It’s about one week per stage here. This is to allow the verifications to happen in each individual zone. Typically, we can do all the verifications for metadata checks within one week. The release cycle is basically automated end-to-end. We have checks that we do as we push code changes forward. They’ll automatically get aborted or they will not proceed if there’s any alerts and things like that. Just for some exceptional cases do we have to take control.
Verifications
Let’s get into verifications. We have a lot of verifications that happen within our system. The first one is called the Cross-zone verifier. The idea behind this is that we have clients upstream from us that know about data, so files, and how that maps to specific hashes in our system. The Cross-zone verifier is essentially making sure that these two systems are in sync all the time. Then we have an Index verifier. The Index verifier is scanning through our index table. It’s going to ask every single storage machine if they know about this specific blob. We won’t actually fetch the blob from disk, we’ll just simply ask, do you have it based on what it recently loaded from its extents that it’s storing. Then we have the Watcher. The Watcher is a full validation of the actual blobs themselves. We do sampling here. We don’t actually do this for all of our data. We validate this after one minute, an hour, a day, and a week. Then we have a component called the Trash inspector. This is making sure that once an extent is deleted, that all the hashes in the extents have actually been deleted. It’s a last-minute verification that we do. Then we also scrub or scan through the extents information checking a checksum that’s on the extents themselves.
Operations
Let’s go to more operations. We deal with lots of migrations. We operate out of multiple data centers, so there’s migrations to move out of different data centers all the time. We have a very large fleet of storage machines that we manage. You have to know what is happening all the time. There’s lots of automated chaos going on, so we have tons of disaster recovery events that are happening to test the reliability of our system. Upgrading Magic Pocket at this scale, is just as difficult as the system itself, so just not counting Magic Pocket. Some of the operations that we do is around managing background traffic. Background traffic accounts for most of our traffic and disk IOPS. Let’s say the disk scrubber is constantly scanning through all this, and checking the checksum on the extents. We do a couple things, so traffic by service can be categorized into different traffic tiers. Live traffic is prioritized by the network. We’re ok with dropping background traffic. I talk about the control plane, but it generates plans for a lot of the background traffic based on any forecasts that we have about a data center migration that we need to do. The type of migration that we’re doing, maybe it’s for cold storage, and so on.
Around failures, couple interesting notes, 4 extents are repaired every second. The extents can be anywhere from 1 to 2 gigs in size. We have a pretty strict SLA on repairs, less than 48 hours. It’s fine if we go over this, but typically, because the 48 hours is baked into our durability model, we want to keep this as low as possible. OSDs get allocated into our system automatically based on the size of the cell, the current utilization. If there’s any free pool within the data center they’re operating in. We have lots of stories around fighting ongoing single points of failures, like SSDs of a certain variety filling all around the same time. We have to manage all those things.
Another note on migrations, we have lots of them. Two years ago, we migrated out of the SJC region. There was a ton of planning that went behind the scenes for something like this to happen. I’ll show you a quick graph of a plan for our migration out of SJC. This is the amount of essentially data that we had to migrate out of SJC over the period of time. The light red line is the trend line. The blue line is about what we were expecting. Initially, when we started the migration, it was going really badly, over here. Then over time, we got really good. Then we had this like really long tail end that we didn’t really know how to address. For these migrations that are very large, hundreds of petabytes in size, there’s a lot of planning that goes on behind the scenes. We have to give ourselves extra time to make sure that we can finish it in time.
Forecasting
Forecasting is another very important part of managing a storage system of this scale. Storage is growing constantly. Sometimes we have unexpected growth we need to account for and absorb into our system. We may have capacity crunch issues due to supply chain going bad, let’s say like COVID disruptions. We always need to have a backup plan as soon as we figure out that there’s problems up ahead, because it takes so long to actually get new capacity ordered and delivered to a data center. It’s not instantaneous. Finally, we do try and our forecasts are actually directly fed into the control plane to perform these migrations based on what our capacity teams tell us.
Conclusion
In conclusion, a couple of notes that have helped us manage Magic Pocket are, protect and verify your system. Always be verifying your system. This has a very large overhead. It’s worth having this end-to-end verification. It’s incredibly empowering for engineers to know that the system is always verifying itself for any inconsistencies. At this scale, it’s actually very much and preferred to move slow. Durability is one of the most important things that we care about within our system, so moving slowly, steadily, ok, waiting for those verifications to happen before you deploy anything. Always thinking about risk and what can happen is very important to another mindset that we have to keep in mind. Keeping things simple, very important. As we have very large-scale migrations, if you have too many optimizations, there’s too much that you have to keep in mind for a mental model, that makes things difficult when you have to plan ahead or debug issues. We always try and prepare for the worst. We always have a backup plan, especially for migrations, or if there’s any single point of failures within our system, or when we’re deploying changes, make sure that things are not a one-way door.
Questions and Answers
Does Dropbox maintain its own data center, or do you partner with hyperscalers like AWS for colocation?
We do a little bit of both actually. In North America regions, we actually lease our data centers. In other regions where it doesn’t make sense, we actually utilize, for example, S3 and AWS for compute as well. A bit of a mixer.
Anand: You leverage S3?
Agriel: Yes. For example, in some European regions, some customers there want their data actually to exist locally, in their region, for various compliance reasons. In those cases, we actually utilize S3 because we don’t have data center presence there.
Anand: Then, do you use any type of compression of the actual data before storing?
Agriel: We don’t compress the data before storing it. Once the data is actually uploaded and in our servers, that’s when we do compression and encryption. The data is encrypted and compressed at rest. There’s obviously tradeoffs with that. If you were to compress data on the clients, we have many different types of clients from desktops to mobile. It could actually be quite expensive for the user to do that.
Anand: Just curious for SMR disk, how does it cost compared to other options?
Agriel: We work very closely with different hardware vendors to basically adopt always latest hard drive technology. A few years ago, probably maybe five, six years ago now, we started utilizing SMR technology very heavily. I talked about the tradeoffs. Yes, compared to PMR, so traditional drives, SMR is a lot cheaper, given the density. I can’t talk about exactly the costs on a per gigabyte basis, but it is significantly cheaper. It works so well for us, and we save a ton of money by adopting SMR technology. We actually published some information about the read speed and IOPS performance on SMR versus PMR. In the end for us, because we have sequential reads and writes, it didn’t make too much of a difference. There’s some latency differences with SMR, but given our workloads, it’s actually pretty comparable to PMR. Because again, we don’t do these random writes, and so on, so works very well for us.
Any other disk type other than SMR you may also consider in the future?
Again, so the industry is moving to various technologies in the future. SMR is hitting capacity limits over the next few years. To give you some idea, the latest drives today with SMR are coming out this year, at about 26 terabytes per drive, which is huge. Different vendors obviously looking out three, four, or five years from now, it looks like laser-assisted technology is going to be the next big thing. Look out for HAMR, for example, technology, and so on. Those drives are expected to increase density to 40 terabytes within the next few years. That looks like that’s the next big thing that’s coming for new drive technology.
Anand: Do you have tiered storage, just less recently accessed storage, you do that behind the scenes?
Agriel: We don’t do tiered storage. What we used to have is we used to utilize SSD drives as a cache for writing on a per OSD device basis. The problem that ends up happening is that that became our limiting bottleneck for writes. We actually ended up getting rid of that recently, and we’re able to get a lot more write throughput across the fleet, in order to save on that. The other thing that I talked about is colder writes, which we utilize a cold storage tier. It’s still on SMR drive, backed by SMR. Then we have explored, for example, using SSDs more heavily, and so on. That’s actually something that we might leverage. It’s just actually incredibly hard to do caching well, at this scale, for various reasons. Productions, and verifications, inconsistencies, all that stuff is really hard once you go through the motions. That’s one of the limiting factors. For a cold storage tier, because we built it on top of existing infrastructure, it was quite straightforward to build on top of that.
Anand: You’ve seen the system evolve for a few years now. What do you have on the horizon that you’d like to see built, or you’d like to build or design into the system?
Agriel: I think, for us, there’s always a few different things. The steady state status quo that we’re looking into is continue to scale the system for continuous growth. We’re growing at double digits per year. That typically means that in three, four years, we essentially have to double the overall capacity of our system. When that happens, that has a lot of implications for our system. A lot of things that you thought would be able to continually scale, you actually run into various types of limited vertical scaling limits. That’s something that we’re actively looking into for next year. The other ones are around having more flexibility around our metadata. We use MySQL behind the scenes, sharded MySQL, but that has its own set of problems around being able to manage MySQL at that scale. If you want to easily add new columns, and so on, that’s also a huge pain. If you want to continue to scale that up, you also have to completely do a split. That’s costly. Most likely your metadata stack will change next year. That’s what we’re looking at. Then again, the last one is hardware advancements and supporting, for example, HAMR once it comes out, and being able to get ahead of the curve on that is something that we’re always continually supporting as well.
Anand: Do you have any war stories that come to your mind, parts of this system that woke you up late at night, burned you, and you guys had to jump on it and come up with maybe a short-term solution, long-term solution?
Agriel: There’s a lot of interesting stories that we’ve had to deal with over the years around memory corruption, and so on, and finding areas within our system that haven’t had proper protection. For example, corruptions are happening all the time, but because of these protections, verifications that are going on behind the scenes, we don’t really notice them. The system fails gracefully. Once in a while, we’ll get woken up in the middle of the night for some new random corruption that we didn’t know about. One of them actually happened recently. Data is fine, because it is replicated in many regions. Even if the data is corrupted, the data still continues to live in what we call trash, which is another protection mechanism where the data is deleted, but it’s self-deleted, you can still recover it. We had an all-hands-on-deck situation a few weeks ago, where this happened and it took many late nights to figure out where exactly things might be. Obviously, we don’t log everything, so being able to figure out where the problem came from, is very difficult. I think we tracked it down to one or two places now.
Anand: Trash was filling up faster than you could get rid of it, because the soft deletes were not real deletes, you were running up storage.
Agriel: We always keep data around in trash for seven days. That’s part of the problem. It’s the memory corruption. We found just a single hash, single piece of data we found that it was corrupted. I was just mentioning like being able to track that stuff down is very difficult, even though you may have many different places where we do various checks, and so on, along the way.
See more presentations with transcripts
MongoDB’s Decreased Stake by Forsta AP Fonden Reflects Investor Dynamics in the … – Best Stocks
MMS • RSS
MongoDB, Inc. (NASDAQ: MDB), a leading provider of general-purpose database platforms, recently experienced a decrease in its stake held by Forsta AP Fonden during the first quarter of this year. According to the company’s 13F filing with the Securities and Exchange Commission (SEC), Forsta AP Fonden lessened its stake by 5.1%, selling 2,300 shares and leaving it with a total of 43,200 shares in MongoDB. This reduction in ownership represents approximately 0.06% of MongoDB’s total worth, which stands at an impressive $10,071,000 as per the most recent SEC filing.
MongoDB is renowned for offering a range of innovative database solutions that cater to different customer requirements across various regions. One such popular service provided by the company is MongoDB Atlas – a hosted multi-cloud database-as-a-service solution that simplifies data management for organizations operating globally. By leveraging MongoDB Atlas, firms can securely store their data while benefiting from its ease of use and scalability.
Another notable offering from MongoDB is its Enterprise Advanced platform, tailored specifically for enterprise customers. This commercial database server gives organizations the flexibility to run their databases on-premises, in the cloud, or in a hybrid environment. With features designed to meet the complex demands of modern enterprises, MongoDB Enterprise Advanced empowers businesses to leverage their data effectively while maintaining high security standards.
Additionally, MongoDB provides developers with Community Server – a free-to-download version of its database software that includes all the essential functionality needed to kick-start their projects using MongoDB technology. This democratization approach allows developers from diverse backgrounds to experiment and innovate with this cutting-edge technology without any financial constraints.
On July 6th, MDB stock commenced trading at $409.57 on NASDAQ. With a market capitalization standing at an impressive $28.69 billion, MongoDB has firmly established itself as one of the key players in the database industry. The company has exhibited steady growth, reflected in its 12-month low of $135.15 and high of $418.70. This impressive performance, coupled with its strong financials, has garnered attention from investors seeking opportunities in the technology sector.
Analyzing MongoDB’s stock reveals a price-to-earnings (PE) ratio of -87.70 and a beta of 1.13, indicating volatility relative to the overall market. The stock’s 50-day moving average hovers around $323.50, while the 200-day moving average stands at $250.14. These trends may suggest both short-term and long-term price movements that investors can assess when making informed decisions.
In terms of liquidity, MongoDB boasts a current ratio and quick ratio of 4.19 each, demonstrating its ability to meet short-term obligations comfortably. Furthermore, the company maintains a debt-to-equity ratio of 1.44, indicating an appropriate balance between debt usage and shareholders’ equity.
The recent decrease in Forsta AP Fonden’s stake in MongoDB highlights the complexity surrounding investment decisions in the world of stocks and securities. While such adjustments may raise uncertainties among shareholders, it is crucial to evaluate them within the broader context of MongoDB’s value proposition as a database platform provider.
As organizations increasingly recognize the importance of robust data management systems, MongoDB continues to position itself at the forefront by offering innovative solutions tailored for different needs and environments. While considering market dynamics and financial indicators is essential when evaluating investments, understanding the underlying potential for innovation and growth offered by companies like MongoDB plays an equally significant role in making informed investment decisions.
As July 6th signifies another milestone in MongoDB’s journey as a publicly traded company, industry analysts anticipate continued growth based on its product offerings and market reputation. By addressing various customer requirements through platforms like MongoDB Atlas and Enterprise Advanced while providing developers with Community Server to ignite their creativity, MongoDB positions itself advantageously in the highly competitive database market.
MongoDB, Inc.
MDB
Buy
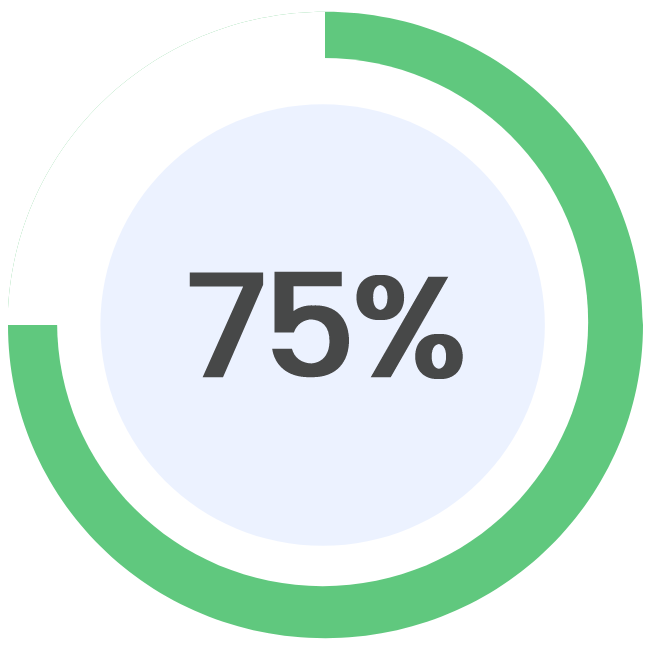
Updated on: 07/07/2023
Large Investors Show Interest in MongoDB (MDB) as Institutional Ownership Increases; Analysts Provide Mixed Ratings and Predictions
MongoDB, Inc. (NASDAQ:MDB) has attracted the attention of numerous large investors who have recently made changes to their positions in the company. Notable among these investors is the Bessemer Group Inc., which purchased a new position in MongoDB shares during the fourth quarter of the previous year, with an estimated worth of around $29,000.
Another prominent investor, BI Asset Management Fondsmaeglerselskab A S, bought a new stake in MongoDB during the same period valued at $30,000. Lindbrook Capital LLC also increased its stake in the company by a staggering 350.0% during the fourth quarter and now owns 171 shares of MongoDB stock worth $34,000 after purchasing an additional 133 shares.
Investment firm Y.D. More Investments Ltd purchased a new position in MongoDB worth $36,000. Lastly, CI Investments Inc. elevated its position in the company by 126.8%, currently owning 186 shares valued at $37,000 after acquiring an additional 104 shares within the last quarter. Altogether, institutional investors now own approximately 89.22% of MongoDB’s stock.
Over time, MDB has been subjected to various research reports that provide insights into its market performance and potential future value. Most notably, Wedbush reduced their price objective on mdb by ten dollars from $240 to $230 in a research note circulated on Thursday, March 9th.
Guggenheim further downgraded MDB’s rating from “neutral” to “sell”, increasing their price target for mdb from $205 to $210 on Thursday May 25th; this alteration came as part of an overall valuation call outlook by Guggenheim.
In contrast to these negative reviews was Robert W Baird raising mdb’s target price range from $390 to$430 on Friday June 23rd with Barclays raising it even higher from $374 to$421 on Monday June 26th; these analysts all issued a buy rating, and in general, the company has been assigned 21 buy ratings out of a total of twenty-five report is available.
Based on this data from Bloomberg.com, the stock presently has an overall consensus rating of “Moderate Buy” with a consensus price target of $366.30.
MongoDB, Inc., a leading provider of a general-purpose database platform operates its services worldwide.
Some notable products offered by MongoDB include MongoDB Atlas, which is a hosted multi-cloud database-as-a-service solution that allows clients to access their databases across various cloud platforms. The company also created MongoDB Enterprise Advanced, which is a commercial database server tailored specifically for enterprise customers to run in different environments such as the cloud, on-premise or hybrid solutions.
Additionally, the firm offers Community Server, which is a free-to-download version of their database designed to enable developers to easily access MongoDB’s functionality and begin using the platform efficiently.
Moving onto financial updates, On Thursday June 1st this year MongoDB announced its earnings results for the previous quarter ending June 1st. The company reported an impressive $0.56 earnings per share (EPS) for Q2 above expectations exceeding majority analysts’ anticipated figure of $0.18 by forty-eight cents.
Posing as minor setbacks were MDB’s negative return on equity standing at 43.25% alongside its negative net margin estimated at around -23.58%.
Regarding revenue estimates for Q2 held by analyst hopefuls balanced at approximately $347.77 million; this value was toppled by factual takings announced by mdb at approximately $368.28 million demonstrating growth trajectories within key product lines and associated operations by up to 29% compared with figures from one year earlier.
At present MDB’s stock analyst predictions peg them achieving roughly -2.8 earnings per share over this fiscal period handsomely earned combined P&L positions even under not so great expectations since this would imply turnover results of over $2.3 billion.
Recent news also highlights that one of MDB’s directors, Hope F. Cochran embarked on a transaction selling off a total of 2,174 shares during the month of June on Thursday the 15th alongside Dwight A. Merriman, who managed to sell around 2,000 shares about a month prior in early May; all actions deploying figures from precise calculations prove to yield professional profit-taking transactions at respectable prices well adhering to past and current market valuations.
To further support the argument surrounding individualistic cashing-in development, both directors had sold respective company shares for well above initial purchase rates indicating strong inherent value developed across mdb’s share price range(s).
Noteworthy is Cochran’s selling price per share accounting to around $373 inviting well-deserved applause as initial valued considerations into acquiring these particular company stakes appeared rather bearable when associated versus subsequent liquidation pricing values and overall share appreciation trends which spearheaded from mild bearish inclinations into fairly convincing bullish territories.
Considering Merriman transacting interest back in May primarily focused on obtaining a relatively steady midpoint average benchmarked generally at around $240 which later escalated towards attractive gains attracting strong interest exhibited by superb returns exhibiting price points developed
MMS • Daniel Dominguez

OpenAI announced the formation of a specialized Superalignment team with the objective of preventing the emergence of rogue Superintelligent AI. OpenAI highlighted the need to align AI systems with human values and emphasized the importance of proactive measures to prevent potential harm.
The process of creating AI systems that are in line with human ideals and objectives is known as AI alignment. It entails making sure AI systems comprehend ethical concepts, society standards, and human objectives and behave accordingly. AI alignment aims to close the gap between human needs and well-being and the goals of AI systems. AI hazards can be reduced and its potential advantages can be increased by combining it with human values.
OpenAI’s Superalignment team will concentrate on advancing the understanding and implementation of alignment, the process of ensuring AI systems act in accordance with human values and goals. By investigating robust alignment methods and developing new techniques, the team aims to create AI systems that remain beneficial and aligned throughout their development.
Our goal is to solve the core technical challenges of superintelligence alignment in four years, says OpenAI.
According to Ilya Sutsker, OpenAI’s co-founder and Chief Scientist, and Jan Leike, the Head of Alignment, the existing AI alignment techniques utilized in models like GPT-4, which powers ChatGPT, depend on reinforcement learning from human feedback. However, this approach relies on human supervision, which may not be feasible if the AI surpasses human intelligence and can outsmart its overseers. Sutsker and Leike further explained that additional assumptions, such as favorable generalization properties during deployment or the models’ inability to detect and undermine supervision during training, could also potentially break down in the future.
The field of AI safety is anticipated to emerge as a significant industry in its own regard. Governments around the world are taking steps to establish regulations that address various aspects of AI, including data privacy, algorithmic transparency, and ethical considerations. The European Union is working on a comprehensive Artificial Intelligence Act, while the United States is also taking measures to develop a Blueprint for an AI Bill of Rights. In the UK, the Foundation Model AI Taskforce has been established to investigate AI safety concerns.
MMS • Katherine Jarmul
Subscribe on:
Transcript
Shane Hastie: Good day folks. This is Shane Hastie for the InfoQ Engineering Culture Podcast. Today, I’m sitting down with Katherine Jarmul. Katherine, welcome. Thanks for taking the time to talk to us.
Katherine Jarmul: Thanks so much for inviting me, Shane. I’m excited to be here.
Introductions [00:34]
Shane Hastie: We met at QCon San Francisco last year where you gave a challenging and interesting talk on techno-solutionism. But before we get into that, possibly a better place to start is who’s Katherine?
Katherine Jarmul: Who’s Katherine? I’m currently working at Thoughtworks as a principal data scientist and recently released a book called Practical Data Privacy. I see myself kind of as a privacy activist, a privacy engineer, a machine learning engineer. I’ve been in technology for quite a long time and interested in the intersections of the political world and the technical world.
I was also a co-founder of PyLadies, the original chapter in California back in 2010, 2011-ish. So been in technology for a while, been in machine learning for the past 10 years, been in privacy in machine learning and data science for about the past five years. And we can maybe see how that progression relates to the topic of techno-solutionism.
Shane Hastie: Probably a good starting point in that conversation is what is techno-solutionism?
Defining Techno-solutionism [01:24]
Katherine Jarmul: Yes, I think I described it in the talk and I would definitely still describe it as the idea that we have a magical technology box and we take world problems or problems created by other technology boxes, and we take those problems and put it into the magical technology box. And then out comes happiness, problem solved, everything’s good.
And I think that anything that you can fit into that type of abstract narrative, I would describe as techno-solutionism. So this idea that if we just had another piece of technology, we would solve this problem.
Shane Hastie: I’m reminded of doing process models and you put a cloud in the middle and in the cloud are the letters ATAMO, which stands for And Then A Miracle Occurs and after coding, something happens. So now, we are replacing the ATAMO cloud with the, Then A Technology Occurs, and things get better. But we don’t, why not?
Katherine Jarmul: Why doesn’t technology solve our problems? I think one of the things that you have to think about when you look at the history of technology is it’s motivated mainly by either the desire to invent and create and change something, the desire to make something easier or to solve a problem or something like this, or other human desires like the desire to kill, the desire to destroy in a sense of when we look at the history of technology…
I think in my talk, I linked it back to the invention of gunpowder and the fact that when they found out gunpowder, they were actually trying to research the miracle of life. They’re trying to find a magical medicine that would solve humans’ problems and they found and created gunpowder. And so that’s just kind of a nice metaphor in our minds to think, I’m not an anti-technologist, I am a technologist. I work in machine learning and privacy.
But we have this human way of anthropomorphizing technology and also of using it as kind of a reflection of the things that we see in the world. And when we do that, we essentially imprint our own biases and our own expectations and also all of our own idea of how to solve the problem into the technology. So we cannot de-link this connection between what we think the solution should be and how we build technology.
And I think that’s where a solution for one person is actually a problem for another person. And I’m a believer in the fact that there’s probably no universal moralism or universal truth, and therefore that becomes a difficult topic when you think of. I’m going to create something that works for me and then I’m going to scale it so that it works for everyone. And where does that take us? Because depending on the context, maybe the outcomes are different.
Shane Hastie: We don’t explore the unintended consequences. We don’t even consider the unintended consequences in our optimistic, hopeful… As technologists, how do we take that step back?
The need to identify and explore unintended consequences [04:56]
Katherine Jarmul: Yes, it’s a really good question. And again, I don’t think there’s one answer. I think that one of the things that we need to think about is how do we reason about the history of our fields and technology? This has been something that’s fascinated me for years. We continuously think we’re inventing new things. And when you really study the history of computers and computing, and even you go back further of the history of mathematics, the history of science, you start to see patterns and you see the repetition of these patterns throughout time.
And so I think a useful starting point for most folks can start actually engaging with the history of your field, whatever area of technology you’re in, and of the history of your industry. If you’re in a consumer-facing industry, maybe the history of consumerism and these types of things and informing yourself about what are the things that I think are the pressing problems today and did they occur before and what did people try to do to solve them and did it solve it?
Just applying this curiosity and maybe a little bit of investigative curiosity into things before, assuming I’m the first person that had this idea, I’m the first person that encountered this problem and I’m going to be the first person to solve it, which of course sounds extra naive, but I also feel like I’ve definitely been there.
I’ve definitely been in that moment where I find out a problem and I’m like, I’m going to help solve this. And I think it’s a really enticing, appetizing storyline that we get told a lot by technologists themselves, by the, it’s zeitgeist of the era of Silicon Valley, and we’re going to apply innovation and do things differently.
And I think that it’s good to have hopeful energy. I’m a Californian, I’m very optimistic. In teams, I’m often the cheerleader. I have that energy, it’s in the culture. But I think we can also use curiosity, humility, and also taking a step back and looking at experimentations past to try to better figure out how we might quell our own maybe over expectation of our contributions and our abilities and the ability also for technology in general to address a problem.
Shane Hastie: But we don’t teach aspiring technologists any of this thinking.
Widening our perspectives through engaging across multiple disciplines [07:40]
Katherine Jarmul: I know. It’s really interesting. So one of the things I talked about in the talk that I think that you and I also chatted a bit about is like, why don’t we have multidisciplinary teams? Why don’t we have teams where there’s a historian on the team, where there’s an ethicist or a philosopher, where there’s community group involvement, so communities that are involved in combating the problems in an “analog” way?
And I think that my background is a great example of a lot of folks that I meet that have worked in kind of the ethics and technology space in that I am not from a one discipline background. I went to school on a scholarship to study computer science because I was really good at math and I loved math, but I went to school during AI winter and I really hated Java.
We mainly did Java and I had a really bad time, so I switched my major and I switched it to political science and economics because I could still study statistics and statistical reasoning, which I really enjoyed, but I didn’t have to do annoying java applets, which I really did not like.
And so I think that there’s these folks that I meet along the way who kind of have careers similar to mine or who have ended up in the space of ethics and data or ethics and computing. I think a lot of these folks ended up kind of tangentially studying other disciplines and then going back to technology or they started in tech and they went a little bit elsewhere and then they came back.
And I think it would behoove us kind of just as an educational system to give people this multidisciplinary approach from the beginning, maybe even in grade school, to think and reason about technology ethics. At the end of the day, it’s a skill that you have to think about and learn. It’s not like magically one day you’re going to have studied all of this and you can also learn it yourself. It’s not by any means something that you need to do in a university context.
Shane Hastie: Bringing in that curiosity. One of the things that we joked about a little bit before we started recording was what are we hearing in the echo chamber and how do we know what the echo chamber is? So if I’m actually wanting to find out, how do I break out of my own echo chamber?
Breaking out of our own echo chamber [10:14]
Katherine Jarmul: It’s very difficult. We have algorithmic mixed systems now that want you to stay in your chamber or go into neighboring chambers. And I think it’s hard. I don’t know what your experience has been like, but I think especially during the Corona times and so forth when people weren’t traveling, it was very difficult to figure out how to connect with people in different geographies and with different disciplines. Obviously, some of that is starting to fall away.
So conferences are starting again. We got to see each other at a conference and have chats. I think that’s one way, but I think another way is to specifically ask yourself if you were to go outside of your psychological comfort zone, and I don’t want to put anybody in harm’s way, so obviously if you’re feeling up for it, what is just at the edge of your reach that you kind of feel afraid about learning about or that you feel this tension or resistance to exploring?
And I think that sometimes those little bits of tension where you’re curious, but you kind of also always find an excuse not to do it that maybe those are pathways for people to break out of where they’re stuck and to find new ways. And most of that thinking is related by the way to lots of thinking around human psychology and communication and community.
So these are not my ideas, these are just ideas that are already out there. And I don’t know, I would be very curious how you get out of your filter bubble.
Shane Hastie: Personally, I try hard to meet people that I wouldn’t normally bump into.
Katherine Jarmul: How, just put yourself in a new environment?
Shane Hastie: I’ll go into a new environment and try and show up with curiosity.
Katherine Jarmul: Awesome.
Shane Hastie: I don’t always do it well.
Katherine Jarmul: I think that’s like part of it, is having to learn that sometimes they will be uncomfortable or it is not going to go the way you want it to go, right?
Shane Hastie: Right. I had a wonderful experience. My day job, I teach generally IT and business-related topics, and I had an opportunity to teach a group of people who were teaching nursing and plumbing and healthcare and hairdressing.
Katherine Jarmul: Awesome.
Shane Hastie: And it was a completely different group. They had a little bit in common in that they were all vocational training educators where I’m a professional training educator. So the education side of it was in common, but their audience, their topics, the challenges that the 18, 19, 20-year-olds that they’re teaching to start their careers versus maybe working with people who are mid-career, it was an enlightening three days.
Katherine Jarmul: Yes, I mean sometimes, it’s just… I have a few activist groups that I work with where folks are from very different walks of life and backgrounds, and I feel like sometimes I crave those conversations. I noticed when I haven’t attended recently and I’ve just been in kind of my tech bubble or normal life bubble of friends, and it can just be really refreshing to get out of the same topics over and over again.
Shane Hastie: The swinging back around on topics, Practical Data Privacy, the name of your new book. Tell us a bit about that.
Practical Data Privacy [13:51]
Katherine Jarmul: I wrote the book with the idea that it was a book that I wish that I had when I first got interested in privacy. And I first got interested in privacy by thinking about ethical machine learning. So how do we do machine learning in a more ethical way, in a more inclusive way, and how do we deal with the stereotypes and biases, societal biases that show up when we train large scale models, which is of pressing topic today.
But I referenced during the talk as part of looking at my own techno-solutionism, I thought to myself, I can’t myself do anything in a technology sense to fix societal biases that show up in these models. And for the researchers that are working in this space, I greatly admire their work. And I think that when I evaluated, do I feel like I could contribute here in a meaningful way and do I feel like the contributions would actually help the industry in any meaningful way and therefore bring purpose to my work?
The answer I came up with at last was no. And of course, that could be a difficult moment, but the hope for me was at that time I was also getting interested in privacy. And I saw privacy as greatly related to thinking through the ethical considerations of data use because of concept of consent, should we use this data? Are we allowed to use this data? Should we ask people if we can use their data? This was very appealing to me.
And then the further I got into privacy, the more interesting it got because there’s a lot of very cool math. And so the combination ended up being like, okay, this is a field I feel like I can contribute to. It has two things I love, math and maybe helping society in some ways, not with… Technology is not going to fix everything, but being a positive contribution to the world that I can make as a technologist.
And when I first got into the field, it was primarily academics and it was primarily PhDs who had been studying, let’s say, cryptography or differential privacy or other of these highly technical concepts for many years. And even though I pride myself on my ability to read research, it was a rough start there in some of the things to wrap my mind around some of these concepts and to really start from basically being somebody that knew how machine learning worked to get into somebody that knows how these privacy technologies work.
And so when O’Reilly gave me a call and asked would I be willing to write a book on privacy technology, I said absolutely yes. And I said, I’d be really excited to aim it towards people like me, people that know math and data science, people that have been in the field, people that have noticed maybe there’s privacy concerns they’d like to address and have heard these words but haven’t yet had a proper introduction to the theory behind them and then also how to implement them in real life, so in practical systems.
And so each chapter has a little bit, we start with a little theory and we learned some of the core concepts. And then we have some code and Jupyter notebooks that go along with the book to say, okay, here’s some open source libraries that you can take. Here’s how you can use them. Here’s how you can apply them in your technology context, whether that’s data engineering, data science, or machine learning or some other area of the programming world.
Shane Hastie: Can we dig into one of say your favorite? What is your favorite of those privacy technologies and how would I use it?
Practical application of data privacy – federated data analysis [17:32]
Katherine Jarmul: Yes. One of the ones I’m most excited about potentially shifting the way that we do things is thinking through federated or distributed data analysis, or federated or distributed learning. And the idea of this is that… There’s already systems that do this, but the idea of this is that the data actually remains always at the hands of the user, and we don’t actually collect data and store it centrally. Instead, we can either ship machine learning to personal devices, we can give machine learning away. So GPT4All is an example of this to allow people to train their own models, to allow people to guide their own experience with machine learning.
And we can also run federated queries. Let’s say we need to do data analysis on some sort of device usage or something like this. We could also run those. And a lot of times when we implement these in production systems and we want them to have high privacy guarantees, we might also add some of the other technologies. We might add differential privacy, which gives us essentially a certain element of data anonymization, or we might add encrypted computation, which can also help do distributed compute, by the way, by allowing us to operate on encrypted data and process encrypted data without ever decrypting it. So, doing the actual mathematics on the encrypted data and only when we have an aggregate result do we decrypt, for example.
And all of these can run in distributed senses, which would significantly enhance the average secrecy and privacy for people’s data, and would be, as we both probably recognize a fundamental shift that I’m not sure will happen in my career, but I would like for it to happen. I think that would be really great, and we’ll see how the winds go.
One of the cool things was the Google memo recently that got leaked of we don’t have a moat and neither does OpenAI, specifically referenced the idea of people training their open source models for their own personal use. And so maybe if Google’s afraid of it, maybe it will become real.
Shane Hastie: What about the team social aspects of data privacy? So, building cross-functional teams, dealing with privacy advocates, dealing with legal and so forth, how do I as a technologist communicate?
The need for and challenges in multidisciplinary teams for data privacy [20:05]
Katherine Jarmul: Yes. And I think we’re dealing with, again, this multidisciplinary action directly happening inside an organization is when we talk about privacy problems, we usually have at least three major stakeholder groups who all speak different languages. We have legal involvement or privacy advocates that also have some sort of legal or regulatory understanding. We have information security or cybersecurity or whatever you call it at your org, which has their own language and their own idea of what does privacy mean and what does security mean.
And then we have the actual technologists implementing whatever needs to be implemented. And we have our own jargon, which sometimes those other teams share and understand, but sometimes not depending on how we’ve specialized. So particularly when we look at specialization like something like machine learning, it could become quite difficult for a legal representative to reason about privacy leakage in a machine learning system because they didn’t study machine learning. And they may or may not know how models may or may not save outlier information or other private information as they’re trained.
And so when we look at these fields, and if you wanted to ever enter the field of privacy engineering, you’re kind of the bridge between these conversations and you kind of operate as a spoke to allow these groups to share their concerns, to identify risks, and to assess those risks, evaluate whether they’re going to be mitigated or whether they’re just going to be documented and accepted and to move forward. And I think that that’s why the field of privacy engineering is growing is when we see things like, I’m not sure if you saw the Meta fine that got announced this week of a 1.3 billion euros, that Meta was fined for transferring a bunch of personal data from the EU into the US and storing it on US infrastructure.
These things actually affect everybody. It’s not just a specialty field. It’s real regulation and real locations that’s happening. And thinking through privacy in your architecture, in your design, in your software is an increasingly expensive if you don’t do it and increasingly, I think, important for folks to address. I also think outside of thinking through just the regulatory aspects, I think there’s exciting aspects for being able to tell your users, we do data differently, we collect things differently, and we can definitely start to see that there’s starting to be marketing pushes around. Specifically, we offer something that’s more private than our competitors.
And I think that that’s because for better or worse, I maybe am somewhat cynical. I don’t necessarily think it’s all from the hearts of the CEOs around the world. I think some of it is maybe that there’s actual consumer demand for privacy. And I think that people get creeped out when they find out that things are tracking them and they don’t expect it. And I think that maybe privacy by design is finally hitting its era nearly 30 years after it was written, that is finally hitting the same thing of what people want and maybe what we should think about implementing as technologists.
Shane Hastie: Because these are things that can’t, well can, but that’s very, very difficult and expensive to retrofit afterwards. They’ve got to be right in the core of the systems you’re designing and building.
Privacy needs to be at the core of architecture and design, refactoring for privacy is doable but very hard [23:42]
Katherine Jarmul : Absolutely. I mean, I think that there’s ways to approach it in a more, this would be your specialty, iterative and agile point of view. So, don’t just rip out the core of your system and say, “Oh, we’re going to refactor for privacy. We’ll see you in two years,” but figure out, okay, this is why the risk assessments are really helpful, especially multidisciplinary, get the group together. And where is everybody’s biggest fear that they’re not talking about having a security breach or having a privacy breach or having some other bad publicity and start to prioritize those and see is there a small chunk of this that we can actually take on and redesign with privacy in mind?
Or even having a dream session, how would our architecture look like if we did privacy by design? And maybe there’s something right there that you can say, “Oh, we’ve been thinking about replacing the system for a while. Let’s start here.” And I think that there’s ways to implement small chunks of privacy, and I would never want to tell somebody, “Oh, you have to re-implement everything.” I think that’s unrealistic and punitive when the norm has been to not build things private by design. I think you should congratulate yourself and be excited at every small step towards something better than what you’re currently doing.
Shane Hastie: Katherine, some really interesting and somewhat challenging topics here. If people want to continue the conversation, where do they find you?
Katherine Jarmul: Yes, so obviously you can check out the book, Practical Data Privacy. It should be arriving shortly in physical form, hopefully, in bookstore around you or via your favorite book retailer. But I also run a newsletter called Probably Private, and I must say it is super nerdy. So I just want to give a warning there. It’s called Probably Private. It’s at probablyprivate.com, and it’s specifically around this intersection between probability, math, statistics, machine learning, and privacy, with of course, a little bit of political opinions thrown in now and then.
Shane Hastie: Wonderful. Well, thanks so much for talking to us today.
Katherine Jarmul: Thank you, Shane.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS

MongoDB, Inc. is a developer data platform company. Its developer data platform is an integrated set of databases and related services that allow development teams to address the growing variety of modern application requirements. Its core offerings are MongoDB Atlas and MongoDB Enterprise Advanced. MongoDB Atlas is its managed multi-cloud database-as-a-service offering that includes an integrated set of database and related services. MongoDB Atlas provides customers with a managed offering that includes automated provisioning and healing, comprehensive system monitoring, managed backup and restore, default security and other features. MongoDB Enterprise Advanced is its self-managed commercial offering for enterprise customers that can run in the cloud, on-premises or in a hybrid environment. It provides professional services to its customers, including consulting and training. It has over 40,800 customers spanning a range of industries in more than 100 countries around the world.
MMS • RSS

Altoros, a consultancy focusing on research and development for Global 2000 organizations, announced the results of its latest performance benchmark report, commissioned by cloud database platform company Couchbase. The study provides a comparative analysis of the performance of four NoSQL cloud databases: Couchbase CapellaTM, Amazon DynamoDB, MongoDB Atlas, and Redis Enterprise Cloud. The benchmark compares the throughput and latency of these popular databases across four business scenarios and four different cluster configurations.
“As in previous years, Couchbase Capella proved it does very well in an update-heavy and other data-intensive use cases, especially as the need for large scale increases,” said Ivan Shyrma, Data Engineer at Altoros. “The database surpassed Amazon DynamoDB, MongoDB Atlas, and Redis Enterprise Cloud in performance, speed, functionality, and TCO across most workloads and cluster sizes.”
For evaluation consistency, the YCSB (Yahoo! Cloud Serving Benchmark) was used as the default tool. It is an open-source standardized framework used for evaluating the performance of cloud-based database systems, comprising a variety of workload tests.
Workload descriptions:
-
The second workload creates a scenario where the database system primarily performs read operations, providing insights into the system’s performance and scalability specifically for read-intensive workloads.
-
The third workload represents a pagination-type query. The database system is evaluated on its ability to efficiently fetch a subset of data from a larger dataset, typically through a combination of read and seek operations.
In the report, Altoros establishes the performance of the database based on the speed at which it handles fundamental operations. These operations are carried out by a workload executor, which drives multiple client threads. Each thread sequentially executes a series of operations by utilizing a database interface layer responsible for loading the database and executing the workload.
To maintain control over the load imposed on the database, the threads regulate the rate at which they generate requests. Additionally, the threads measure the latency and throughput of their operations and communicate these metrics to the statistics module.
“The query engine of Couchbase Capella supports aggregation, filtering, and other operations on large data sets,” continued Shyrma. “As clusters and data sets grow in size, Couchbase Capella ensures a high level of scalability across these operations. Capella was good overall and showed that it is capable of performing any type of query with good performance.”
MMS • RSS

MongoDB, Inc. is a developer data platform company. Its developer data platform is an integrated set of databases and related services that allow development teams to address the growing variety of modern application requirements. Its core offerings are MongoDB Atlas and MongoDB Enterprise Advanced. MongoDB Atlas is its managed multi-cloud database-as-a-service offering that includes an integrated set of database and related services. MongoDB Atlas provides customers with a managed offering that includes automated provisioning and healing, comprehensive system monitoring, managed backup and restore, default security and other features. MongoDB Enterprise Advanced is its self-managed commercial offering for enterprise customers that can run in the cloud, on-premises or in a hybrid environment. It provides professional services to its customers, including consulting and training. It has over 40,800 customers spanning a range of industries in more than 100 countries around the world.
MMS • RSS
MongoDB, Inc. is a developer data platform company. Its developer data platform is an integrated set of databases and related services that allow development teams to address the growing variety of modern application requirements. Its core offerings are MongoDB Atlas and MongoDB Enterprise Advanced. MongoDB Atlas is its managed multi-cloud database-as-a-service offering that includes an integrated set of database and related services. MongoDB Atlas provides customers with a managed offering that includes automated provisioning and healing, comprehensive system monitoring, managed backup and restore, default security and other features. MongoDB Enterprise Advanced is its self-managed commercial offering for enterprise customers that can run in the cloud, on-premises or in a hybrid environment. It provides professional services to its customers, including consulting and training. It has over 40,800 customers spanning a range of industries in more than 100 countries around the world.
MMS • RSS
A whale with a lot of money to spend has taken a noticeably bearish stance on MongoDB.
Looking at options history for MongoDB MDB we detected 17 strange trades.
If we consider the specifics of each trade, it is accurate to state that 35% of the investors opened trades with bullish expectations and 64% with bearish.
From the overall spotted trades, 11 are puts, for a total amount of $1,009,197 and 6, calls, for a total amount of $527,225.
What’s The Price Target?
Taking into account the Volume and Open Interest on these contracts, it appears that whales have been targeting a price range from $270.0 to $520.0 for MongoDB over the last 3 months.
Volume & Open Interest Development
In terms of liquidity and interest, the mean open interest for MongoDB options trades today is 293.33 with a total volume of 584.00.
In the following chart, we are able to follow the development of volume and open interest of call and put options for MongoDB’s big money trades within a strike price range of $270.0 to $520.0 over the last 30 days.
MongoDB Option Volume And Open Interest Over Last 30 Days
Biggest Options Spotted:
| Symbol | PUT/CALL | Trade Type | Sentiment | Exp. Date | Strike Price | Total Trade Price | Open Interest | Volume |
|---|---|---|---|---|---|---|---|---|
| MDB | PUT | TRADE | BEARISH | 01/17/25 | $270.00 | $292.8K | 31 | 0 |
| MDB | CALL | TRADE | NEUTRAL | 01/17/25 | $520.00 | $170.3K | 117 | 21 |
| MDB | CALL | TRADE | NEUTRAL | 01/17/25 | $520.00 | $154.0K | 117 | 24 |
| MDB | PUT | TRADE | BULLISH | 01/17/25 | $310.00 | $129.5K | 428 | 0 |
| MDB | PUT | SWEEP | BEARISH | 01/19/24 | $350.00 | $113.7K | 584 | 0 |
Where Is MongoDB Standing Right Now?
- With a volume of 1,278,867, the price of MDB is down -2.47% at $399.45.
- RSI indicators hint that the underlying stock may be approaching overbought.
- Next earnings are expected to be released in 55 days.
What The Experts Say On MongoDB:
- Capital One downgraded its action to Equal-Weight with a price target of $396
- RBC Capital has decided to maintain their Outperform rating on MongoDB, which currently sits at a price target of $445.
- Piper Sandler downgraded its action to Overweight with a price target of $400
- Barclays has decided to maintain their Overweight rating on MongoDB, which currently sits at a price target of $421.
- Wedbush downgraded its action to Outperform with a price target of $410
Options are a riskier asset compared to just trading the stock, but they have higher profit potential. Serious options traders manage this risk by educating themselves daily, scaling in and out of trades, following more than one indicator, and following the markets closely.
If you want to stay updated on the latest options trades for MongoDB, Benzinga Pro gives you real-time options trades alerts.