Month: August 2023

MMS • RSS

Orbisresearch.com recently posted a brand-new study titled “Global “Cloud-based Database” Market Trends and Insights”.
The Market Research Report on Cloud-based Database presents a thorough examination of the Cloud-based Database market, encompassing crucial elements like market size, factors driving growth, obstacles, company backgrounds, partnerships, significant strategic advancements, and the influence of the COVID-19 pandemic. The objective of this report is to provide valuable perspectives to industry stakeholders, investors, and decision-makers, empowering them to comprehend the market’s dynamics and make well-informed business choices.
Introduction: The Cloud-based Database market has been witnessing substantial growth in recent years, driven by factors such as technological advancements, changing consumer preferences, and increasing investments in research and development. However, the outbreak of the COVID-19 pandemic had a significant impact on the industry, altering market trends and presenting new challenges and opportunities.
Request a pdf sample report : https://www.orbisresearch.com/contacts/request-sample/6486059
Key Aspects of the Report:
1. Market Size and Growth Forecast: The report provides an in-depth analysis of the current market size and forecasts its growth trajectory for the next five years. Historical data analysis and predictive models offer a comprehensive understanding of the market’s past performance and future potential.
2. Market Drivers and Challenges: The report identifies the key drivers fueling market growth, such as rising demand, technological advancements, and favorable regulatory policies. Additionally, it highlights the challenges faced by the industry, including supply chain disruptions and regulatory uncertainties.
3. Impact of the COVID-19 Pandemic: The report evaluates the impact of the COVID-19 pandemic on the Cloud-based Database market, examining how it has affected market trends, consumer behavior, and industry dynamics. This analysis helps clients strategize for the post-pandemic era.
Key Players in the Cloud-based Database market report:
Amazon Web Services
IBM
Microsoft
Oracle
Rackspace Hosting
Salesforce
Cassandra
Couchbase
MongoDB
SAP
Teradata
Alibaba
Tencent
4. Company Profiles: The report examines prominent enterprises in the Cloud-based Database industry, offering valuable information about their corporate tactics, range of products, financial achievements, and latest advancements. The comprehensive company profiles assist clients in understanding the competitive landscape and identifying potential business partners.
5. Collaborations and Partnerships: The report highlights recent collaborations and partnerships in the Cloud-based Database market. These strategic alliances enable clients to grasp emerging trends and potential growth opportunities arising from synergies among industry players.
6. Key Strategic Developments: The report covers key strategic developments such as mergers and acquisitions, product launches, expansions, and investments. Clients can analyze these developments to gauge market trends and identify investment hotspots.
7. Market Segmentation: The Cloud-based Database market is segmented based on product types, applications, end-users, and geographical regions. This granular level of segmentation allows clients to target specific market segments and optimize their marketing strategies.
Buy the report at https://www.orbisresearch.com/contact/purchase-single-user/6486059
Cloud-based Database Market Segmentation:
Cloud-based Database Market by Types:
SQL Database
NoSQL DatabaseCloud-based Database Market by Applications:
Small and Medium Business
Large Enterprises
8. Regulatory Environment: The report examines the prevailing regulatory environment in the Cloud-based Database market, helping clients navigate compliance challenges and stay updated on potential regulatory changes.
9. Emerging Opportunities: The report identifies emerging opportunities in the Cloud-based Database market, such as untapped geographical regions, nascent product categories, and potential customer segments. Clients can leverage these opportunities to gain a competitive advantage.
10. Conclusion and Strategic Recommendations: The report concludes with a summary of key findings and strategic recommendations for businesses to succeed in the Cloud-based Database market. The suggestions provided stem from a thorough examination of market patterns, obstacles, and potential areas for expansion.
11. Customer Insights: Customer preferences, buying behavior, and needs are carefully examined to help clients tailor their products and services to meet customer demands effectively.
Do Inquiry before Accessing Report at: https://www.orbisresearch.com/contacts/enquiry-before-buying/6486059
12. Quality Control Checks: Throughout the research process, we have multiple layers of quality control checks in place. Our team of researchers and analysts meticulously review and verify the data to eliminate errors and inconsistencies.
In conclusion, the Cloud-based Database Market Research Report provides a comprehensive and detailed analysis of the Cloud-based Database market, covering all key aspects including company profiles, collaborations, key strategic developments, and the impact of the COVID-19 pandemic. Armed with these valuable insights, industry stakeholders, investors, and decision-makers can make informed decisions, seize emerging opportunities, and navigate the dynamic Cloud-based Database market successfully in the forecast period and beyond.
About Us:
Orbis Research (orbisresearch.com) is a single point aid for all your market research requirements. We have a vast database of reports from leading publishers and authors across the globe. We specialize in delivering customized reports as per the requirements of our clients. We have complete information about our publishers and hence are sure about the accuracy of the industries and verticals of their specialization. This helps our clients to map their needs and we produce the perfect required market research study for our clients.
Contact Us:
Hector Costello
Senior Manager – Client Engagements
4144N Central Expressway,
Suite 600, Dallas,
Texas – 75204, U.S.A.
Phone No.: USA: +1 (972)-591-8191 | IND: +91 895 659 5155
Email ID: sales@orbisresearch.com
MMS • RSS
Here’s a look at the most interesting products from the past week, featuring releases from Action1, MongoDB, Bitdefender, SentinelOne and Netskope.


Action1 platform update bridges the gap between vulnerability discovery and remediation
Action1 Corporation has released a new version of its solution. The updated Action1 patch management platform brings together vulnerability discovery and remediation, helping enterprises fortify their defenses against threats such as ransomware infections and security breaches.

MongoDB Queryable Encryption enables organizations to meet data-privacy requirements
MongoDB Queryable Encryption helps organizations protect sensitive data when it is queried and in-use on MongoDB. It reduces the risk of data exposure for organizations and improves developer productivity by providing built-in encryption capabilities for sensitive application workflows—such as searching employee records, processing financial transactions, or analyzing medical records—with no cryptography expertise required.

Bitdefender enhances security for iOS devices with Scam Alert
Bitdefender has launched an advanced security feature for iOS users, Scam Alert. The new technology protects users from phishing scams delivered through SMS/MMS messages and calendar invites. Layered on top of existing protection in Bitdefender Mobile Security for iOS, Scam Alert proactively identifies attacks and prevents them from reaching the mobile user – providing iPhone and iPad users complete, layered protection.

SentinelOne Singularity App for Netskope secures remote work from endpoint to cloud
Employees today want the freedom to work where and how they perform best. SentinelOne and Netskope are joining forces to help customers deliver it in a secure way. The technology partners today announced the launch of the SentinelOne Singularity App for Netskope, a joint solution that provides the comprehensive, context-rich visibility needed to detect, respond to, and mitigate threats across the ever-expanding attack surface opened by distributed work.

MMS • RSS
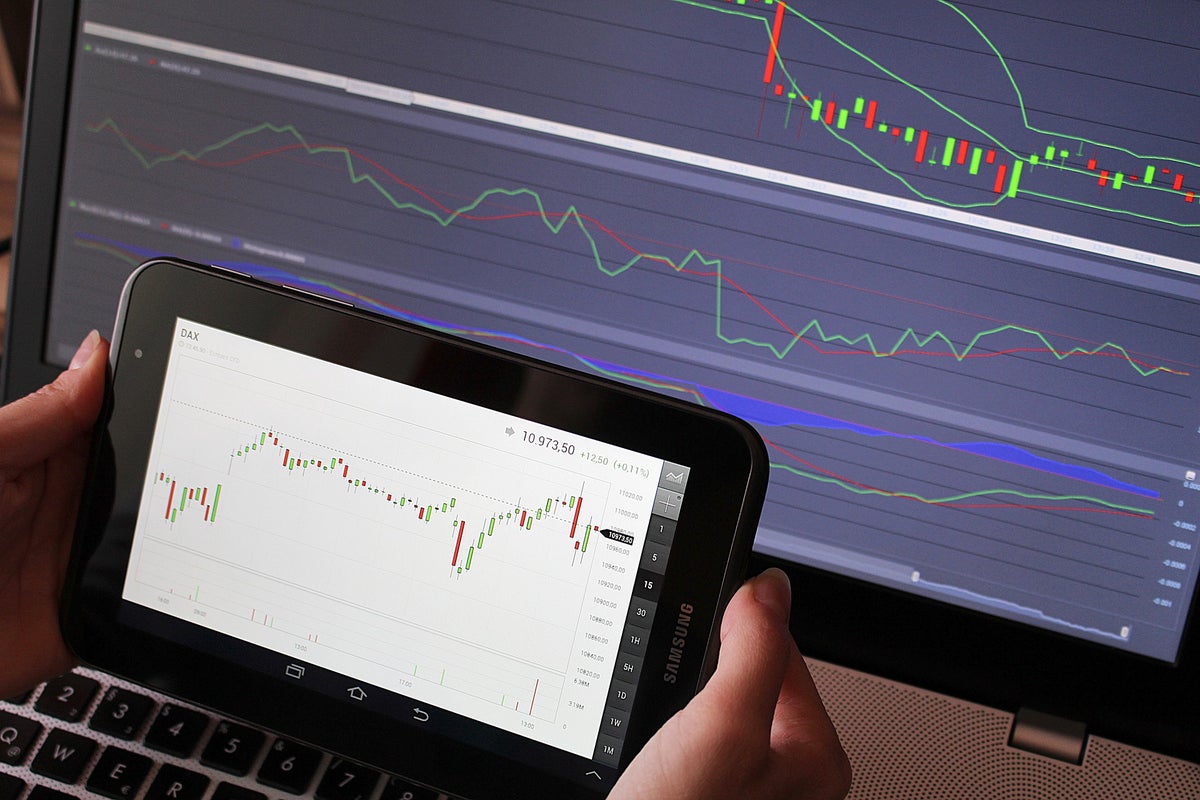
Someone with a lot of money to spend has taken a bearish stance on MongoDB MDB.
And retail traders should know.
We noticed this today when the big position showed up on publicly available options history that we track here at Benzinga.
Whether this is an institution or just a wealthy individual, we don’t know. But when something this big happens with MDB, it often means somebody knows something is about to happen.
So how do we know what this whale just did?
Today, Benzinga‘s options scanner spotted 10 uncommon options trades for MongoDB.
This isn’t normal.
The overall sentiment of these big-money traders is split between 40% bullish and 60%, bearish.
Out of all of the special options we uncovered, 7 are puts, for a total amount of $322,343, and 3 are calls, for a total amount of $110,595.
What’s The Price Target?
Taking into account the Volume and Open Interest on these contracts, it appears that whales have been targeting a price range from $360.0 to $500.0 for MongoDB over the last 3 months.
Volume & Open Interest Development
Looking at the volume and open interest is a powerful move while trading options. This data can help you track the liquidity and interest for MongoDB’s options for a given strike price. Below, we can observe the evolution of the volume and open interest of calls and puts, respectively, for all of MongoDB’s whale trades within a strike price range from $360.0 to $500.0 in the last 30 days.
MongoDB Option Volume And Open Interest Over Last 30 Days
Biggest Options Spotted:
| Symbol | PUT/CALL | Trade Type | Sentiment | Exp. Date | Strike Price | Total Trade Price | Open Interest | Volume |
|---|---|---|---|---|---|---|---|---|
| MDB | PUT | TRADE | NEUTRAL | 09/15/23 | $500.00 | $58.6K | 27 | 4 |
| MDB | PUT | TRADE | BULLISH | 01/17/25 | $360.00 | $54.2K | 150 | 26 |
| MDB | PUT | TRADE | BULLISH | 01/17/25 | $360.00 | $53.5K | 150 | 16 |
| MDB | PUT | TRADE | BULLISH | 01/17/25 | $360.00 | $45.0K | 150 | 31 |
| MDB | PUT | TRADE | NEUTRAL | 01/17/25 | $360.00 | $44.8K | 150 | 40 |
| Symbol | PUT/CALL | Trade Type | Sentiment | Exp. Date | Strike Price | Total Trade Price | Open Interest | Volume |
|---|---|---|---|---|---|---|---|---|
| MDB | PUT | TRADE | NEUTRAL | 09/15/23 | $500.00 | $58.6K | 27 | 4 |
| MDB | PUT | TRADE | BULLISH | 01/17/25 | $360.00 | $54.2K | 150 | 26 |
| MDB | PUT | TRADE | BULLISH | 01/17/25 | $360.00 | $53.5K | 150 | 16 |
| MDB | PUT | TRADE | BULLISH | 01/17/25 | $360.00 | $45.0K | 150 | 31 |
| MDB | PUT | TRADE | NEUTRAL | 01/17/25 | $360.00 | $44.8K | 150 | 40 |
Where Is MongoDB Standing Right Now?
- With a volume of 307,345, the price of MDB is down -1.21% at $354.5.
- RSI indicators hint that the underlying stock is currently neutral between overbought and oversold.
- Next earnings are expected to be released in 14 days.
What The Experts Say On MongoDB:
- JMP Securities has decided to maintain their Outperform rating on MongoDB, which currently sits at a price target of $425.
- Keybanc has decided to maintain their Overweight rating on MongoDB, which currently sits at a price target of $462.
Options are a riskier asset compared to just trading the stock, but they have higher profit potential. Serious options traders manage this risk by educating themselves daily, scaling in and out of trades, following more than one indicator, and following the markets closely.
If you want to stay updated on the latest options trades for MongoDB, Benzinga Pro gives you real-time options trades alerts.
MMS • RSS

Orbisresearch.com has just released a new study titled “Global “NoSQL Database” Market Trends and Insights.”
1. This research report provides a comprehensive analysis of the NoSQL Database market, focusing on its historical size, growth, market drivers, trends, challenges, and the impact of the COVID-19 pandemic. The report aims to offer valuable insights into the market’s performance, changes in consumer behavior, supply chain disruptions, and economic challenges faced by the industry. Additionally, it examines the impact of regulatory changes and policies on the market.
Request a pdf sample report : https://www.orbisresearch.com/contacts/request-sample/6568366
2. Geographic Coverage and Market Segments
The report encompasses the NoSQL Database market in different geographic regions, encompassing North America, Europe, Asia-Pacific, and the Rest of the Globe. It analyzes the market’s performance in each of these regions and provides insights into regional trends and growth patterns. Furthermore, the market is segmented based on product type, application, end-user industries, and distribution channels. This segmentation allows for a more in-depth analysis of specific market segments and their unique characteristics.
2.2 Time Frame and Data Sources
The research report utilizes data collected from multiple sources, including primary and secondary research. Primary research entails conducting interviews with industry professionals, important stakeholders, and decision-makers within the NoSQL Database industry. Secondary research includes data from reliable publications, company reports, and government sources. The report covers historical data from the past five years to provide a comprehensive understanding of market trends and growth patterns. Additionally, it incorporates the most recent data available up to the present year.
2.3 Research Methodologies
To ensure the accuracy and reliability of the findings, this report employs various research methodologies, including quantitative and qualitative analysis. The quantitative analysis is based on market size, revenue, and growth rates, while the qualitative analysis involves insights from industry experts and key stakeholders. The research methodologies used in this report aim to provide a holistic view of the NoSQL Database market and facilitate a deeper understanding of the market dynamics and key influencing factors.
Key Players in the NoSQL Database market report:
DynamoDB, ObjectLabs Corporation, Skyll, MarkLogic, InfiniteGraph, Oracle, MapR Technologies, he Apache Software Foundation, Basho Technologies, Aerospike
3. Market Overview
3.1 Historical Market Size and Growth
This section presents an overview of the historical performance of the NoSQL Database market, including market size and growth rates over the past five years. It analyzes historical data to identify growth patterns and market trends that have shaped the current market landscape.
3.2 Market Drivers and Trends Pre-COVID-19
In this section, the report highlights the key drivers and trends that contributed to the growth and development of the NoSQL Database market before the COVID-19 pandemic. Understanding these factors is crucial in assessing the market’s resilience and adaptability to changing conditions.
3.3 Market Challenges
This section examines the challenges faced by the NoSQL Database market before the pandemic. It identifies potential obstacles that the industry encountered in terms of regulations, technological advancements, and competitive pressures.
Do Inquiry before Accessing Report at: https://www.orbisresearch.com/contacts/enquiry-before-buying/6568366
NoSQL Database Market Segmentation:
NoSQL Database Market by Types:
Column
Document
Key-value
GraphNoSQL Database Market by Applications:
E-Commerce
Social Networking
Data Analytics
Data Storage
Others
4. COVID-19 Impact on the NoSQL Database Market
4.1 Disruptions in Supply Chains and Manufacturing
The COVID-19 pandemic caused significant disruptions in supply chains and manufacturing processes. This section evaluates the impact of the pandemic on the NoSQL Database market’s supply chain, production, and distribution networks.
4.2 Changes in Consumer Behaviour and Demand Shifts
The dynamics of the NoSQL Database market were impacted by shifts in consumer behavior and demand patterns, brought about by the pandemic. This section explores the shifts in consumer preferences and buying habits and their implications for market players.
4.3 Economic Challenges and Market Contraction
The economic fallout from the pandemic had far-reaching effects on various industries, including the NoSQL Database market. This section assesses the economic challenges faced by the market and examines its contraction during the pandemic.
4.4 Impact on Industry Regulations and Policies
Government responses to the pandemic included implementing new regulations and policies that affected the NoSQL Database market. This section examines the regulatory changes and their implications for market participants.
Buy the report at https://www.orbisresearch.com/contact/purchase-single-user/6568366
Conclusion
In conclusion, this research report provides a comprehensive analysis of the NoSQL Database market, covering its historical performance, market drivers, trends, challenges, and the impact of the COVID-19 pandemic. The objective of this report is to provide valuable information to individuals involved in the NoSQL Database market, such as industry stakeholders, policymakers, and investors, to aid them in making well-informed choices and devising successful approaches.
About Us:
Orbis Research (orbisresearch.com) is a single point aid for all your market research requirements. We have a vast database of reports from leading publishers and authors across the globe. We specialize in delivering customized reports as per the requirements of our clients. We have complete information about our publishers and hence are sure about the accuracy of the industries and verticals of their specialization. This helps our clients to map their needs and we produce the perfect required market research study for our clients.
Contact Us:
Hector Costello
Senior Manager – Client Engagements
4144N Central Expressway,
Suite 600, Dallas,
Texas – 75204, U.S.A.
Phone No.: USA: +1 (972)-591-8191 | IND: +91 895 659 5155
Email ID: sales@orbisresearch.com
MMS • Ben Linders

Risk management techniques can be used to decide which security and privacy aspects are important. You can simplify the risk impact calculations by identifying low, medium and high and critical losses, and by taking likelihoods from the industry to do likelihood calculations. This helps you to identify a few key risks, and ruthlessly ignore the rest.
Charles Weir gave a workshop on ruthless security at XP 2023.
Ruthless security is about taking ruthless decisions about which kinds of security and privacy actually matter, and which should we ignore, Weir explained. The way to evaluate risk is to break it down into manageable and understandable chunks. You identify different kinds of risk, and for each kind, you figure out the impact; it’s usually easiest to estimate impact in terms of the money lost.
There will be a range of possible losses from any given risk, and it’s impractical to try and work out exact numbers, as Weir explained:
It’s usually reasonably easy to work out, say, whether a loss is low, medium, or high, he said. What matters is that everybody agrees on what those low, medium, and high values mean.
For each kind of risk, you also figure out the likelihood: what is the chance of something happening in a given year? Weir mentioned that they identified a set of possible types of risk, and the order of magnitude likelihood of each happening in a typical company. They created risk cards, where each card identifies a type of risk in the form of a short story telling how the risk occurs, and gives a likelihood for that risk happening in a year.
You multiply the impact and likelihood to give an “expectation of loss” for each kind of risk, which you can think of as the amount of money you expect to lose annually due to that risk, Weir described.
When a team has constructed their list of risks, it becomes obvious which ones are worth worrying about, and which people can safely ignore, Weir argued. Both probabilities and impacts are expressed as orders of magnitude, so you multiply them by adding the orders of magnitude together as logarithms.
Usually, you will get only one or two key risks that have the highest order of magnitude expectation. Those are likely to be the only risks you need to worry about, and you can usually ruthlessly ignore the rest, Weir concluded.
InfoQ interviewed Charles Weir about ruthless security.
InfoQ: How would you define risk-based security?
Charles Weir: The big problem is that developers are not being given the time to act on the security problems they found, and frequently not even the time to look for them. Developers can only get the time if it is in the interest of their stakeholders.
The best and most commercially convincing way to decide about security and privacy—or anything else—is to put numbers on the decision, preferably financial numbers. And the way risk based security does that is to look at the different possible risks and see how big each one is numerically.
InfoQ: How do impact thresholds help to estimate potential losses?
Weir: The first step is for the team to agree what, in the context of the particular project being considered, would be considered low, medium, and high. The particularly important thing we have found is that these are usually orders of magnitude. Thus, the thresholds—the boundaries between them—will be in factors of 10 or so. If the lowest were €1000, the next might be €10,000 and the highest threshold €100,000.
InfoQ: How do risk cards work and what benefits can they bring?
Weir: To use risk cards, people consider each card in turn. They brainstorm their own ways in which that kind of risk may happen in their project, and assess the likelihoods based on those on the risk cards. And they also estimate the impact of each as low, medium, high or critical. And thus they can calculate a #loss expectation# for each kind of risk.
InfoQ: How do you integrate security and privacy practises into agile development?
Weir: This risk list is a document, a deliverable for the project and it is maintained in an agile way over the lifetime of the project. Typically, it might get revisited every few months, but the key risks will be assessed for each new story that developers tackle.
InfoQ: If people want to learn more about ruthless security, where can they go?
Weir: The Hipster project (Health IoT Privacy and Security Transferred to Engineering Requirements) explores how software development teams and product managers can work together to identify risks and privacy issues. It provides materials that you can download to run your own workshop.
MMS • RSS
![]() Brown Advisory Inc. grew its stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 40.8% in the 1st quarter, according to its most recent disclosure with the Securities & Exchange Commission. The firm owned 2,104 shares of the company’s stock after buying an additional 610 shares during the quarter. Brown Advisory Inc.’s holdings in MongoDB were worth $490,000 at the end of the most recent reporting period.
Brown Advisory Inc. grew its stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 40.8% in the 1st quarter, according to its most recent disclosure with the Securities & Exchange Commission. The firm owned 2,104 shares of the company’s stock after buying an additional 610 shares during the quarter. Brown Advisory Inc.’s holdings in MongoDB were worth $490,000 at the end of the most recent reporting period.
Several other institutional investors and hedge funds also recently made changes to their positions in MDB. Raymond James & Associates boosted its holdings in shares of MongoDB by 32.0% in the first quarter. Raymond James & Associates now owns 4,922 shares of the company’s stock valued at $2,183,000 after buying an additional 1,192 shares during the period. PNC Financial Services Group Inc. boosted its holdings in shares of MongoDB by 19.1% in the first quarter. PNC Financial Services Group Inc. now owns 1,282 shares of the company’s stock valued at $569,000 after buying an additional 206 shares during the period. MetLife Investment Management LLC acquired a new position in MongoDB during the first quarter worth $1,823,000. Panagora Asset Management Inc. boosted its holdings in MongoDB by 9.8% during the first quarter. Panagora Asset Management Inc. now owns 1,977 shares of the company’s stock worth $877,000 after purchasing an additional 176 shares during the last quarter. Finally, Vontobel Holding Ltd. boosted its holdings in MongoDB by 100.3% during the first quarter. Vontobel Holding Ltd. now owns 2,873 shares of the company’s stock worth $1,236,000 after purchasing an additional 1,439 shares during the last quarter. Institutional investors and hedge funds own 89.22% of the company’s stock.
MongoDB Price Performance
NASDAQ:MDB opened at $358.83 on Thursday. MongoDB, Inc. has a 52 week low of $135.15 and a 52 week high of $439.00. The firm has a market cap of $25.33 billion, a price-to-earnings ratio of -76.84 and a beta of 1.13. The firm’s 50-day simple moving average is $393.52 and its 200 day simple moving average is $292.54. The company has a debt-to-equity ratio of 1.44, a quick ratio of 4.19 and a current ratio of 4.19.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings results on Thursday, June 1st. The company reported $0.56 EPS for the quarter, topping analysts’ consensus estimates of $0.18 by $0.38. MongoDB had a negative net margin of 23.58% and a negative return on equity of 43.25%. The business had revenue of $368.28 million for the quarter, compared to analyst estimates of $347.77 million. During the same period last year, the firm earned ($1.15) earnings per share. MongoDB’s revenue for the quarter was up 29.0% compared to the same quarter last year. As a group, sell-side analysts predict that MongoDB, Inc. will post -2.8 earnings per share for the current year.
Insiders Place Their Bets
In other MongoDB news, CRO Cedric Pech sold 360 shares of the stock in a transaction dated Monday, July 3rd. The shares were sold at an average price of $406.79, for a total transaction of $146,444.40. Following the sale, the executive now directly owns 37,156 shares in the company, valued at $15,114,689.24. The sale was disclosed in a filing with the Securities & Exchange Commission, which is available at this link. In other news, Director Dwight A. Merriman sold 6,000 shares of the firm’s stock in a transaction that occurred on Friday, August 4th. The shares were sold at an average price of $415.06, for a total value of $2,490,360.00. Following the sale, the director now directly owns 1,207,159 shares in the company, valued at approximately $501,043,414.54. The transaction was disclosed in a filing with the SEC, which is available at the SEC website. Also, CRO Cedric Pech sold 360 shares of the firm’s stock in a transaction that occurred on Monday, July 3rd. The shares were sold at an average price of $406.79, for a total transaction of $146,444.40. Following the completion of the sale, the executive now owns 37,156 shares in the company, valued at $15,114,689.24. The disclosure for this sale can be found here. Insiders have sold 102,220 shares of company stock worth $38,763,571 over the last ninety days. Corporate insiders own 4.80% of the company’s stock.
Wall Street Analyst Weigh In
Several research analysts recently commented on MDB shares. Citigroup increased their target price on shares of MongoDB from $363.00 to $430.00 in a report on Friday, June 2nd. 22nd Century Group restated a “maintains” rating on shares of MongoDB in a report on Monday, June 26th. Tigress Financial increased their target price on shares of MongoDB from $365.00 to $490.00 in a report on Wednesday, June 28th. Guggenheim cut shares of MongoDB from a “neutral” rating to a “sell” rating and increased their target price for the stock from $205.00 to $210.00 in a report on Thursday, May 25th. They noted that the move was a valuation call. Finally, Sanford C. Bernstein increased their price target on shares of MongoDB from $257.00 to $424.00 in a research note on Monday, June 5th. One research analyst has rated the stock with a sell rating, three have given a hold rating and twenty have issued a buy rating to the company. According to data from MarketBeat, the stock has a consensus rating of “Moderate Buy” and an average price target of $378.09.
Check Out Our Latest Stock Analysis on MongoDB
MongoDB Profile
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • Justin Cormack

Transcript
Justin Cormack: I’m Justin Cormack. I’m the CTO at Docker. I’m also on the Cloud Native Computing Foundation Technical Oversight Committee. I’m going to be talking to you about policies and making policies programmable. It’s great to be in this track about configuration beyond YAML. We’re going to talk about a bunch of things that you can do when you have some YAML and you can go beyond just using the YAML. It’s good to be talking about this.
What Does Policy Mean?
What do we actually mean by policy? I think this is a really important question so that we’re all clear. The simplest policy is something like, who can run this program? Another policy might be, who can make this API call with these parameters? A more complex case is, who can make this database query and get back all the results and are allowed to see all the results? These are the kinds of things, it’s really about access control. Who can do things? Rather than defining what we do. It is about who can do it and who’s allowed to see the results. Who, can be a person. Effectively, it’s generally another computer program that’s calling perhaps on behalf of a person. There’s complexities around, how do we know who it is, as well, that are important.
History of Security in Computing
I’m going to start with a little bit of history. I like to ground what we’re doing in history. It helps me think about where we come from, where we’re going. We’re talking about policy and security, and authorization, authentication, those things. We have to start back in 1972, when there was the first real computer worm. A great design called CREEPER sent this scary message onto your terminal. This was back in 1972.
The first antivirus program called Reaper was created to get rid of this thing again, because it was spreading everywhere and being annoying. This was the beginning of the world where we are today where we have strong access control. There’s actually quite a big backlash against access control and security at all. One example is Richard Stallman, who famously didn’t like passwords, thought computers should be available to anyone. For a long time, he didn’t have passwords. Then everyone knew that his username was RMS and his password was also RMS. If you wanted to access lots of computers, you could just log in as RMS. This backlash was quite a common thing for a while, I think. There was a sense of openness and control. Because originally, you had to walk up to a computer to get access to it, and it was kept in a locked room. Once things got connected to the internet, people’s views on this really started changing.
Probably the biggest stake in the ground for what the future was going to look like was this so-called Orange Book. This was from 1983. The Orange Book was written by the U.S. Department of Defense. It was all about how access control should work. It was very much involved in a thing called multi-level security, which, often, lots of it comes with revivals every now and again. A lot of it has to do with classified documents. You have levels of document classification from anyone can see this, to top secret, and so on.
There’s a complicated thing where there’s people who have clearance to see the documents at different levels, and documents at different levels. Then there are processes whereby as someone who can see a document at a higher level, I can change its classification downwards with certain controls. There was all sorts of worries about things like leaking documents between levels and side channel attacks and things like that. It’s really a basis of a lot of our security.
SELinux comes from this world, as well eventually around about root. It really has influenced those things. It particularly influenced the Multics operating system, that had a lot of complexities due to this. As we know, Multics didn’t take off and I think old Unix did, which was a joke about Multics. We’ve only got one of them, not many of them. Unix really took off. It had a very simplified model of permissions, compared to Multics. It worked for a long time for most people. Eventually, I think we saw it didn’t really scale.
The Unix permission model is really quite simple. It’s like read-write access with groups, users, and everyone. When you scale to trillions of files, how do you make sure they’ve all got the right permissions and ownership? It’s just really hard. You really want to have sets of policies that you can check globally to make sure that you’ve actually set the right permissions for things. It becomes a real scalability problem and it was never going to live with the size of data that we have.
We can see if we look at the OWASP Top 10 vulnerabilities for web applications that access control related issues are really significant. They’ve been rising in significance. These problems have become harder to deal with. Attackers have found very good ways to get into systems because you can’t manage all your access control correctly. I’ve seen a lot of policy code written as imperative code. It’s very difficult to maintain and understand and change. Often, it’s a lot of conditionals. It’s very difficult to get a big picture of what these really mean.
Policy frameworks have really gravitated towards declarative configuration, not imperative, just to have an easier to understand way of thinking about things. Logic programming is often the basis of this. Logic programming is really about taking a series of statements about the world about facts, and then combining them with a set of rules or ways to infer new things about them. The classic, Mog is a cat. Cats are allowed through the cat flap, therefore, Mog is allowed through the cat flap. That kind of straightforward inference.
Open Policy Agent
Datalog is a programming language that’s often used. It’s what Open Policy Agent is based on. Datalog was built around trying to extend SQL. It’s another Turing complete language, but it’s very much an extension of SQL that also supports recursive queries, which actually is really useful for making the policy queries we want. We’re going to talk about Open Policy Agent in particular. This is a CNCF graduated project that’s pretty mature. It’s one of the most commonly used projects for policy management in the cloud native world. Let me show you how it works first. Let’s start with a demo.
We’re just going to do this demo in the Rego Playground, which is where you can try out Open Policy Agent yourself. We’re just going to write a really simple example. We’re going to make a QCon Auth package. We’re going to start with default deny, which is a good state of the world. We’re going to be authorizing HTTP requests. We’re going to allow GET requests and nothing else. Let’s try.
Let’s make an example. This is where we’re going to parse to the input to evaluate. This is just a JSON document, we can expand it later. We might have more parameters that we want to parse later, as well as the type of request, we might want to parse some parameters or inputs that we want to authorize on. We’ll just start with a really simple case now. We’re going to turn on the coverage. We’re going to parse a GET request, and this is the happy case, it should succeed. Yes, it allows true. On the coverage you can see that it parsed this bit here. It didn’t evaluate the default deny condition. If we change this to something different, like a POST. We can evaluate this again, and obviously we get false as we’d expect.
It’s a really simple, really straightforward thing, and we can just add more rules there or anything as we want. We can also publish this as something we can integrate into our application. Press the publish button and we’ll get the instructions here. It’s got install instructions if you need to install OPA.
We can run a server. I have a server, let’s just run this server here. It’s updated the server. Then I can just hop over, we can just go and see. First of all, let’s just break this apart. This is the input that we had last time. We can just go and have a look, see what the input we used was. It was just our straightforward input method equals POST. We just want to curl that into localhost 8081, which is where our server is running. We can just go, POST, put that into our server, which was here. It will tell us as we expected, the authentication was allow false. We go there, and we can just edit this and check out other stuff on the command line. GET and it’s true. It’s all very straightforward.
We can just integrate this directly into our code, just like any other way we would integrate an HTTP server. We can run the Open Policy Agent maybe in a container, or locally, or whatever, as part of our application. Then we can just do HTTP requests into this to get success or failure and integrate that into our code as we want. Very simple.
What did we learn from that demo? I think Kelsey Hightower the other day summarized it really well. Open Policy Agent is really easy to integrate into your code. That’s one of the reasons it’s popular, and any kind of code. It’s not just easy to integrate it in one place, but you can integrate it across a whole ecosystem. One of the reasons it’s easy is it takes your existing JSON or YAML, because JSON and YAML have the same data model, and you can use this as the basis for making your policy decisions.
That means that often you’ve already got suitable documents to make decisions from, such as your Kubernetes configs. As well as integrating with your existing YAML or JSON configuration files that you’ve already got, Open Policy Agent also comes with a range of integrations across the whole ecosystem, which is really powerful. Those already off-the-shelf integrations for anything from Kubernetes, to SSH, and everything in between.
Another thing is it enables you to easily share policies that you’ve created. I work at Docker, and the Build, Share, Run workflow that we created for Docker is a really powerful model for all sorts of other things. Being able to build a policy, share it, and reuse it is really important. One of the things I think that we’ll see more of is that for sharing, it really helps if you use the same data model, so that we can all share the same code. I think we’ll see more work on standardization of data models in more areas so that we can share more policy related code than we can now.
I think that’s why we’re seeing use in Kubernetes, where there’s already a standard config model for Kubernetes. You can easily write rules on that. Other areas don’t have so many standard models yet. There’s more work to do to increase standardization in other areas so that we can share our own policies. If you have a non-standard data model in your organization, you can’t use someone else’s policies because they don’t immediately apply and you have to modify them, rewrite them to work with your data model. That’s much more work. Being able to share is really convenient. It saves a lot of time, makes it consistent. It’s easy to update. Makes it easier to reuse code. That’s going to be a really important trend.
The Big Vision, Going Forward
What’s the big vision going forward? Looking forward, software is just going to eat compliance. Compliance is not going to be a thing that people do by looking at a bunch of printed out documents, or PDFs, or asking questions. It’s starting already. It’s really going to accelerate into something that’s consumed via testing policies. We’re already seeing little bits of this moving towards this in smaller areas, but this trend is really going to accelerate.
One of the screenshots there is the NIST 800-53 documents, which are still written out as manual controls that you should check. More people are working out how to think about ways of automating these controls. The other screenshot is from Drata, which is a startup that has a system for checking some sorts of controls against common frameworks like PCI compliance, and so on. These kind of frameworks for managing controls that someone just bring up and so they can be more automated testing, and this is working towards this future vision.
What We Have to Do to Get There
What do we have to do to get there? I think one of the things that sometimes people misunderstand and misestimate is the amount of work we actually have to do on observability. I think people are quite good at thinking of controls they would like to put in an organization, but they don’t necessarily always realize what’s really going on in the real world. I think we all know cases where controls are bypassed, and people have access to things that perhaps they’re not supposed to have, in theory, according to the theoretical policies. There’s often a big gap in organizations as they mature, between what people think is going on and what really happens.
I think we probably all have lots of stories about organizations where everyone has the root password, or people bypass things. There are usually systems to the common path that have good controls. Often, there are systems that bypass the common path to deal with things that haven’t been worked on yet. There’s a lot of work to do. Observability is a really key piece of like, what’s really happening in your organization? Can I see what’s happening in order to find out what controls are appropriate?
One of the things that people find where they have controls is the first thing that happens when you have a control is, someone’s going to ask you, how do I bypass the control? Bypassing controls is often reality. Sometimes it’s like, how do I bypass the control if there’s an emergency? Then sometimes it turns out, how do I bypass the control on a day-to-day basis? How do I get an exemption for the next six months for this? There’s a whole lot of nuance. I think that understanding what’s going on in your organization in a really detailed level is actually really vital to extend the scope of policy beyond the easy cases.
We mentioned before standards and reusability, I think there’s a lot more work to do there. We have standards for small areas of organizations, but we will need standard data models for everything about how people work in organizations. That’s really hard. It will take time. It will require a lot of software to be written, a lot of work to be done, and a lot of community work, and standards bodies, and tests. We’re going to talk about tests.
One way to view security controls is to view them actually as tests. I think it’s a really fruitful way of thinking about them. Once you have written your policy as code, once you’ve got this blob that you can test against, you can actually start to use it in lots of places. You don’t have to just run it in one place at the end, at the final gate to production, check all the tests have passed. One of the things that we do in the real world is we publish policies so that people know what they are, so they can plan for them in advance. In convenient times we call this shift left.
Before you travel, you know that you’re not going to be able to carry large amounts of liquid, so you prepare yourself by buying things in small little bottles, for travel, and so on. Mostly people conform to the tests upfront. Ideally, with software, the good thing about tests is you can run them everywhere. You can make sure you’re compliant, as a developer working on your desktop long before your code actually gets to production. That makes things much smoother. Rather than you having to go all the way to production and be told it’s no good, and then go back and start again. This is really a great thing about having these policies in a reusable, portable form that you can reuse everywhere.
It’s really important that you can ship updates separately. You might be going to revise your policies. You can ship through the revised versions up front, so people are not surprised by them. It’s really important to think about division of responsibility in the organization. Your developers are not necessarily the people who should be writing the policy tests. You might be shipping them in externally, using common tests that the community builds. You might have a compliance team building tests, but you can ship these to developers ahead of time. You can modify them on a different schedule, all these things.
You think about them as tests that they’ve got to pass. You can update them independently of code, which is really helpful. Division of responsibility in an organization is incredibly key to getting things done, effectively. If the developer has to go and rewrite their code every time as you want to change the policies, it makes things more difficult. Whereas if the compliance team can do that, then that lets things move faster, and gives you the domain expertise in the right place.
Another thing you can do is you can reverse the direction of testing. I think, again, like treating things just as a blocker at production time, it’s annoying, but you can reverse the flow and treat it as a promotion piece, so that you promote something to production when it meets policy automatically. This is the merge when green model that more people are using with their tests, generally. Once you have comprehensive tests, if it’s passing the tests, it must be good, so you can promote it. If you have a policy on staging and a policy on production, then once the staging policy is met, things can get automatically shipped to staging.
Once the production policy is met, which might involve, has it been tested in staging, for example? Soon as it’s passed the test in staging, perhaps it can be automatically promoted to production, perhaps behind gates and so on, still. Once you think of it just as a set of tests to pass, you can be really much more flexible in how you work with it in the same way as you do with tests. Another way to manage promotion is to use signed attestations. There’s another CNCF project called in-toto that is really about how to manage signed attestations about things.
The model here is that, basically, you go and get a pre-declaration that you passed the tests, so that you have a way that you can validate this. You have a statement from someone that you passed the test. It’s like coming along with a driving license to say that you’re allowed to drive. It’s difficult to forge. You can just show it, and people will believe that you can drive. Attestations are really a way of, again, turning around the model and saying, I’ve got the approval already up front, you don’t need to actually run the test again. This saves a lot of time and lets you move around when tests take place. That’s a really powerful way of thinking about policy.
As well as Open Policy Agent, there are a couple other frameworks that you might come across for policy. Very recently, there’s been a bunch of interest in Google’s Zanzibar project. The Zanzibar paper was published a few years ago, but a couple of open source projects have started implementing this. OpenFGA just joined the CNCF sandbox. They’re exploring this. Zanzibar is really designed to operate at a gigantic scale. It’s what Google uses internally for things like access to things like Google Docs. It’s got a real scalability record behind it. It runs a slightly simpler model perhaps than Open Policy Agent. It’s something that there’s definitely interest in in the community.
Kyverno is another CNCF sandbox project. It is very focused just on making the Kubernetes use case easier, but not covering any other use cases. It’s designed to feel more Kubernetes native.
Conclusion
There’s a huge amount going on in this space. It’s a really exciting space. It’s really early, interesting. It’s really going to change the way we work. One thing you can see is that we got these configuration documents that we made for other reasons. People may either complain about all the configuration documents YAML are generating, but actually it turns out this stuff is really useful in that you can actually process the configuration with declarative code in order to do other things with it, and draw inferences out from it and enforce policy with it.
That is actually a really useful outcome of a world in which we’ve been generating a lot of configuration documents. I think it shows us an interesting path, it’s in line with this beyond YAML track that we’re taking YAML, and going beyond just YAML’s a thing we have in terms of what can we do once we have all this YAML? However you generate your YAML, or however you generate your config documents, you can still process them through these pretty powerful declarative policy systems, which is a really exciting move.
Barriers to Adopting Policy
Carmen Andoh: What are some of the barriers to adopting policy regardless of the implementation and organizations to you?
Cormack: I think the first thing that people do is, [inaudible 00:26:33] without understanding what the impact for that is going to be. That’ll stop people actually being able to [inaudible 00:26:46]. You start off by understanding what people do and why. I think as developers we’re often in situations where people try and stop the developers doing things in different ways, and things like that. It’s a common thing. I think that just understanding what people are actually doing as a starting point is also really important.
Then, I think, trying to express the thing you want to do in policy is often difficult, because the domains are really complicated. If you look at Kubernetes policy, for example, and you want to block privilege escalation attacks, there isn’t the kind of thing that defines a privilege escalation attack in Kubernetes. If there was just a config option to turn it off, it would be easy, but it’s not like that. There’s a combination of things that are bad that you really have to understand the domain really well to work out what they are.
I think just converting a thought of what you want to do into a really good policy, is often quite difficult in the domains that we work with, which tend to be quite complex. You can make policy that’s not actually effective, or it’s just a lot of work. I think that’s why you see quite a lot of people interested in sharing and reusing other people’s policies, because all these areas, it’s like, I don’t really want to spend all my time working on that myself. The domain expertise versus the program expertise is often quite mixed. Your security department sets policies, but they’re not usually used to writing formal policies, they’re used to audits and checks rather than writing rules.
Policy Sharing and Software Reuse
Andoh: You mentioned a little bit about policy sharing, or reuse. Is this the future of policy in the way that software and code has evolved over time, where we had these standard libraries and then different libraries, and then this trajectory of software reuse. Then we get to supply chain security and other aspects of that, and we’re coming to the other end of the ease of reuse and flexibility. Do you see what is that trajectory for policy? I’m going in a second direction for this question with the reuse, which is, do you see that there’s a possibility to reuse when things are proprietary, or your company has very specific, very high niche, specific context? Can policy be shared in the same way as code? How so, how not?
Cormack: Reuse is something that has to be designed for. I think there’s always these big tradeoffs between how reusable something is versus how specific it is to your use case. If you look at any artifact reuse, there’s always some form of customization, and there’s some form of commonality of reuse, and there’s always a balance in every ecosystem about how those things work. I think that we haven’t necessarily found exactly where that is, but I think that usually there’s a bunch of things where if you look at domains, like configuration management, where it’s worth making your things more similar to other people’s things in order to reuse their stuff, because it saves you a lot of time.
There’s a convergence to, let’s all run this piece of software in the same way in this ecosystem, because running it differently is not valuable. Let’s use the same recipe. Then that extreme becomes too extreme, and you see things like, now we need to add a lot of hooks in this, so you can configure it and make overrides, and do your own piece of thing. Then that becomes a move back towards extensibility. You see they’re mirrored in all the ecosystems that share objects and share code.
Open-source code, often, is very unopinionated. It lets you do a lot of things. It’s rare to see open source projects that don’t accept more features and hooks and additional options, because that tends to be the way that they approach that tradeoff. There’s going to be a big spectrum of those things, and it will have to evolve. I think that with some kinds of sets of policies, where the policies are driven by outside people, like SOC 2, or things like that, there’s probably more of a convergence of, these are the kinds of patterns that people use because they’re trying to achieve the same outcomes.
I think we’ve seen a bunch of these in like Kubernetes admission controllers and things like that, because people are trying to do the same things, which are mostly things that just Kubernetes doesn’t give you any controls over itself. There will always be organization specific things or models. Unless they’re giving you real competitive advantage, it’s worth thinking like, should we make our organization more like other organizations? Should we reuse more that’s not differentiated? That commoditization argument always comes, like, only differentiate where you really have to.
Learning About Policy, Beyond OPA
Andoh: In your talk, you used OPA as the implementation, but you mentioned a couple others. Large organizations have lots of different constraints they have to put on various entities in their distributed systems and whatnot, and they want to codify that, they want to audit that. Beyond OPA, where would you go for various different contexts for people to learn more about policy in your opinion?
Cormack: I think understanding a little bit the things to build around is helpful. I think that understanding the types of decisions these things are optimized for is useful. I think the difference between, say, Zanzibar and OPA and Datalog, for example, as models is useful to understand. It’s still a new area. There’s not a lot of experience published with using these things at scale still. I remember talking to you about when we were talking about this track about who’s using these things at scale, who’s written about it, talked about it.
It’s still very early days for really people talking about this at scale. I think there are some examples, but they don’t tend to be public yet. It’s still relatively in the early adopter phase. I think conference talks from people with practical experience is still really valuable. You talk to people and find out their experiences, they’re still important. It still feels early to me in terms of like, there isn’t a set of standard practices and principles for implementing this yet.
There’s still a bit of experimentation, and really trying to prioritize what your organization is trying to get out of this, and what’s important for you and what’s valuable. I think there’s different things that are valuable to different people. I think even things like just separating our authentication code from normal code for normal pieces of software is actually valuable. I’ve worked with bits of software that have very complicated sets of RBAC rules that are very hard to read in imperative code, for example, and just pulling those out and turning those into a refactored library using some code that’s designed for this.
That’s one of the things, I think it’s valuable, regardless of like a big vision of how policy sits in your organization. Just thinking about, is this code doing policy? Should I think about this thing differently? The questions I was trying to ask about like, where should I run this code? Do I want to run it in multiple places? Should it be maintained differently from the rest of my code? Those questions are good things to think about, even if you’re not thinking about as a big picture of what policy might do in the long run.
Andoh: The outcome of a policy isn’t going to be the way that traditional code would be. Simply, it could be just a report that gets mailed to the higher-ups or to some regulatory person, or a team that now needs to go do remediation on that, depending on it.
Why Logic Programming Languages Have Emerged as Good Policy Languages
You mentioned various papers and research, and Datalog isn’t one of them. OPA has the language Rego, which is a Datalog derivative. This is me putting on my language nerd hat, but I’ve noticed many logic programming languages have emerged as good policy languages. Would you maybe care to talk about why that is happening, or what is the deal with that?
Cormack: I think it’s really about the declarative versus imperative thing. I think, partly it’s just a matter of readability. It’s like, I want to list the six things that mustn’t happen. Then, I just make sure these things never happen. You don’t want to say which order you check these six things in or whatever, it’s just like, this is just the list of things that don’t happen. It’s actually interesting. I think there’s a long history of using logic programming for this kind of thing about trying to understand complex sets of rules and their interactions.
Once you have a set of rules, you can actually, in principle, do other things with them, like, make sure that there is a solution to them, and things like that, and what it looks like. I think just being able to write something down in that concise form of, these things mustn’t happen, these things must happen, is actually kind of [inaudible 00:40:54], and it works as a pattern matching thing. It’s mostly to do with that kind of readability and the way of trying to solve those kinds of constrained problems that this fit. It’s interesting, though, for example, that logic programming for testing hasn’t turned up as a thing or anything like that. It’s been limited to databases, which is a weird set of things.
Andoh: I’ve started to hear the munging of policy, and the people in the BDD camps of software, this behavior driven development, because the concept is somewhat similar. I have this behavior that must happen, or these constraints that need to happen. It’s just very interesting in the policy space.
Cormack: I think logic programming is definitely an interesting thing, if you’re interested in programming languages. For a long time, it’s been a forgotten set of programming languages. Functional programming really became almost mainstream, in terms of programming language gigs, whereas logic programming didn’t in the same way, or hasn’t so far. It’s sitting around at the fringes of a lot of things that people do in an interesting way.
I think there’s some interesting things you can do. Because I think functional programming was also about more declarative things, less imperative. Logic programming historically was very much coupled with that movement towards this make programming languages more declarative. It got forgotten about in some ways. I think it was very tied to the old implementations of AI before ML and things like that.
Andoh: I’m starting to hear this idea that the future is declarative. I’m not just talking about infrastructures. This is, of course, the track that is infrastructure, or languages of infrastructure. If infrastructure includes instantiation, it is very much tied to a declarative model. The logic programming, probably, we might see a rise as policy is thrown into that mix as well.
Additional Resources on Policy Evaluation and Policy Learning Journeys
Cormack: One of the things I like about OPA is just that it’s very accessible as a thing to just try out, and it has great documentation. I think it’s a good place to start learning is just to play around with it. It’s a good introduction to thinking about the space. It’s a good, friendly project, and a good playground.
See more presentations with transcripts
MMS • Sergio De Simone

Security researcher Daniel Moghimi discovered a new side-channel vulnerability affecting Intel processors that could be exploited to steal data from other users or apps running on the same computer. Dubbed Downfall, the vulnerability has been patched by Intel and mitigated by most major OS vendors.
According to Moghimi, who is senior research scientist at Google, most computer users are affected by Downfall, either directly or indirectly, given the market share that Intel processors own of the Cloud computing market. In Downfall case, additionally, even disconnected devices, such as laptop and desktop computers, are affected.
A malicious app obtained from an app store could use the Downfall attack to steal sensitive information like passwords, encryption keys, and private data such as banking details, personal emails, and messages.
Affected CPUs are any Intel Core processor from the Skylake to the Tiger Lake generations. This spans a significant amount of years since Skylake was introduced in 2014.
Downfall is caused by a memory optimization feature in those Intel processors aimed at speeding up access to scattered data in memory using the Gather instruction. As Moghimi demonstrated, this instruction leaks the content of the internal vector register file during speculative execution, which makes the content of hardware registers unintentionally available to any software running on the same CPU. This implies an untrusted program can access data stored in those registers by other programs.
To prove Downfall, Moghimi developed two attack techniques, named Gather Data Sampling (GDS) and Gather Value Injection (GVI), and showed how you can steal 128-bit and 256-bit AES keys or arbitrary data from the Linux kernel, and even spy on printable characters. Moghimi says that GDS is highly practical and it only took two weeks for him to carry through a first successful attack.
On the good side, this vulnerability does not seem to be easily exploitable without having physical access to the target computer. Indeed, says Moghimi, there is no current evidence that a Downfall attack could be carried through in a browser.
To prevent this vulnerability from being exploited, Intel released firmware updates for all affected CPUs. The microcode updates are available on Intel public GitHub repository. Non-SGX processors may be patched at the OS level, while SGX CPUs require a more complex process.
Debian, Ubuntu, Gentoo and others have already made available microcode updates, while Redhat stated a microcode update will be made available in a coming release of their microcode package. Amazon, Google, and Microsoft have all released statements to inform their users of the possible impact of this vulnerability.
MMS • RSS
 This in-depth research of the NoSQL Databases Software Market includes a comprehensive competitive analysis with the goal of evaluating financial development and enhancing the organization’s profit potential. It promotes logical investment choices based on customer requirements. The report also projects that the market would grow overall between 2023 and 2030. Additionally, it provides precise information on consumer spending patterns and expert industry evaluations.
This in-depth research of the NoSQL Databases Software Market includes a comprehensive competitive analysis with the goal of evaluating financial development and enhancing the organization’s profit potential. It promotes logical investment choices based on customer requirements. The report also projects that the market would grow overall between 2023 and 2030. Additionally, it provides precise information on consumer spending patterns and expert industry evaluations.
The business is able to generate large earnings because to this NoSQL Databases Software Market research’s ease in helping it to grasp the preferences of distinct customers. Important new firms can use it as a detailed reference guide to learn about industry trends and business strategies that will help them grow their operations. By putting partnerships, acquisitions, and new product launches into practice, new participants will walk away with a solid understanding of how to run a profitable business. Verifiable data backs up the market growth percentages given here. Because it is so exact, the data acquired here is especially beneficial for calculating production.
GET | Sample Of The Report: https://www.marketresearchintellect.com/download-sample/?rid=252741
The study uncovers key advancements in both organic and inorganic growth strategies within the worldwide NoSQL Databases Software Market. Many enterprises are prioritizing new product launches, approvals, and other strategies for business expansion. The study also delivers profiles of noteworthy companies in the NoSQL Databases Software Market, which includes SWOT analyses and their market strategies. The research puts emphasis on leading industry participants, providing details about their business profiles, the products and services they provide, recent financial figures, and significant developments. The section on Company Usability Profiles is as follows:
- MongoDB
- Amazon
- ArangoDB
- Azure Cosmos DB
- Couchbase
- MarkLogic
- RethinkDB
- CouchDB
- SQL-RD
- OrientDB
- RavenDB
- Redis
The NoSQL Databases Software Market Statistical Research Report also includes extensive forecasts based on current Market trends and descriptive approaches. Quality, application, development, customer request, reliability, and other characteristics are constantly updated in the NoSQL Databases Software Market segments. The most critical adjustments in the item model, production technique, and refining phase are facilitated by little changes to an item.An Analysis of NoSQL Databases Software Market segmentation.
This Report Focuses On The Following Types Of Market :
- Cloud Based
- Web Based
According To this Report, The Most Commonly Used Application Of the Market Are:
- Large Enterprises
- SMEs
The paper exhibits a thorough awareness of competitor positioning, global, local, and regional trends, financial projections, and supply chain offerings in addition to information on segment classification. A thorough overview of the industry, including details on the supply chain and applications, is provided by NoSQL Databases Software industry research. A study has been conducted to analyse the NoSQL Databases Software Market’s current state and its potential for future growth.
NoSQL Databases Software Market Report Provides The Following Benefits To Stakeholders:
- Detailed qualitative information on Market s with promising growth can be found in the analysis, as well as insights on niche Market s.
- This report provides information on Market share, demand and supply ratios, supply chain analysis, and import/export details.
- There is a detailed analysis of current and emerging Market trends and opportunities in the report.
- An in-depth analysis provides an understanding of the factors that will drive or inhibit the Market ‘s growth.
- It is conducted a thorough analysis of the industry by monitoring the top competitors and the key positioning of the key products within the Market context.
- The NoSQL Databases Software Market Report offers a detailed qualitative and quantitative analysis of future estimates and current trends and assists in determining the Market potential for the present.
What questions should ask an expert? And Ask For Discount: https://www.marketresearchintellect.com/ask-for-discount/?rid=252741
What is the Purpose Of The Report?
It provides an in-depth analysis of the overall growth prospects of the global and regional Market s. Moreover, it provides an overview of the competitive landscape of the global Market . Furthermore, the report provides a dashboard overview of leading companies, including their successful Market ing strategies, Market contributions, and recent developments in both historic and current contexts.
What is the impact of NoSQL Databases Software Market forces on business?
An in-depth analysis of the NoSQL Databases Software Market is provided in the report, identifying various aspects including drivers, restraints, opportunities, and threats. This information allows stakeholders to make informed decisions prior to investing.
Our key underpinning is the 4-Quadrant which offers detailed visualization of four elements:
- Customer Experience Maps
- Insights and Tools based on data-driven research
- Actionable Results to meet all the business priorities
- Strategic Frameworks to boost the General Purpose Transistors growth journey
GET FULL INFORMATION ABOUT Click Here: NoSQL Databases Software Market Size And Forecast
Overview Of The Regional Outlook of this NoSQL Databases Software Market
The report offers information about the regions in the Market, which is further divided into sub-regions and countries. In addition to the Market share of each country and sub-region, information regarding lucrative opportunities is included in this chapter of the report. Share and Market growth rate of each region, country, and sub-region are mentioned in this chapter of the report during the estimated time period.
Geographic Segment Covered in the Report:
The NoSQL Databases Software report provides information about the market area, which is further subdivided into sub-regions and countries/regions. In addition to the market share in each country and sub-region, this chapter of this report also contains information on profit opportunities. This chapter of the report mentions the market share and growth rate of each region, country and sub-region during the estimated period.
About Us: Market Research Intellect
Market Research Intellect is a leading Global Research and Consulting firm servicing over 5000+ global clients. We provide advanced analytical research solutions while offering information-enriched research studies.
We also offer insights into strategic and growth analyses and data necessary to achieve corporate goals and critical revenue decisions.
Our 250 Analysts and SMEs offer a high level of expertise in data collection and governance using industrial techniques to collect and analyze data on more than 25,000 high-impact and niche markets. Our analysts are trained to combine modern data collection techniques, superior research methodology, expertise, and years of collective experience to produce informative and accurate research.
Our research spans a multitude of industries including Energy, Technology, Manufacturing and Construction, Chemicals and Materials, Food and Beverages, etc. Having serviced many Fortune 2000 organizations, we bring a rich and reliable experience that covers all kinds of research needs.
Contact the US:
Mr. Edwyne Fernandes
Market Research Intellect
US: +1 (650)-781-4080
US Toll-Free: +1 (800)-782-1768
MMS • RSS

Ascend.io’s CEO/founder Sean Knapp believes that the data ingestion market won’t exist within a decade, because cloud data players will provide free connectors and different ways to connect to external sources without moving data. He thinks consolidation in the data stack industry is reaching new heights as standalone capabilities are getting absorbed into the major clouds.
…
SaaS app and backup provider AvePoint reported Q2 revenue of $64.9 million, up 16 percent year on year. SaaS revenue was $38.3 million, up 39 percent year on year, and its total ARR was $236.2 million, up 26 percent. There was a loss of $7.1 million, better than the year-ago $11.1 million loss. It expects Q3 revenues to be $67.6 to $69.6 million, up 9 percent year on year at the mid-point.
…
Backblaze, which supplies cloud backup and general storage services, has hired Chris Opat as SVP for cloud operations. Backblaze has more than 500,000 customers and three billion gigabytes of data under management. Opat will oversee cloud strategy, platform engineering, and technology infrastructure, enabling Backblaze to scale capacity and improve performance and provide for the growing pool of larger-sized customers’ needs. Previously, he was SVP at StackPath, a specialized provider in edge technology and content delivery. He also spent time at CyrusOne, CompuCom, Cloudreach, and Bear Stearns/JPMorgan.
…
An IBM Research paper and presentation [PDF] proposes to decouple a file system client from its backend implementation by virtualizing it with an off-the-shelf DPU using the Linux virtio-fs/FUSE framework. The decoupling allows the offloading of the file system client execution to an ARM Linux DPU, which is managed and optimized by the cloud provider, while freeing the host CPU cycles. The proposed framework – DPFS, or DPU-powered File System Virtualization – is 4.4× more CPU efficient per I/O, delivers comparable performance to a tenant with zero-configuration or modification to their host software stack, while allowing workload-specific backend optimizations. This is currently only available with the limited technical preview program of Nvidia BlueField.
…
MongoDB has launched Queryable Encryption with which data can be kept encrypted while it’s being searched. Customers select the fields in MongoDB databases that contain sensitive data that need to be encrypted while in-use. With this the content of the query and the data in the reference field will remain encrypted when traveling over the network, while it is stored in the database, and while the query processes the data to retrieve relevant information. The MongoDB Cryptography Research Group developed the underlying encryption technology behind MongoDB Queryable Encryption and is open source.
MongoDB Queryable Encryption can be used with AWS Key Management Service, Microsoft Azure Key Vault, Google Cloud Key Management Service, and other services compliant with the key management interoperability protocol (KMIP) to manage cryptographic keys.
…
Nexsan – the StorCentric brand survivor after its Chapter 11 bankruptcy and February 2023 purchase by Serene Investment Management – has had a second good quarter after its successful Q1. It said it accelerated growth in Q2 by delivering on a backlog of orders that accumulated during restructuring after it was acquired. Nexsan had positive operational cash flow and saw growth, particularly in APAC. It had a 96 percent customer satisfaction rating in a recent independent survey.
CEO Dan Shimmerman said: “Looking ahead, we’re recruiting in many areas of the company, including key executive roles, and expanding our sales and go-to-market teams. Additionally, we’re working on roadmaps for all our product lines and expect to roll these out in the coming months.”
…
Nyriad, which supplies UltraIO storage arrays with GPU-based controllers, is partnering with RackTop to combine its BrickStor SP cyber storage product with Nyriad’s array. The intent is to safeguard data from modern cyber attacks, offering a secure enterprise file location accessible via SMB and NFS protocols and enabling secure unstructured data services. The BrickStor Security Platform continually evaluates trust at the file level, while Nyriad’s UltraIO storage system ensures data integrity at the erasure coded block level. BrickStor SP grants or denies access to data in real time without any agents, detecting and mitigating cyberattacks to minimize their impact and reduce the blast radius. Simultaneously, the UltraIO storage system verifies block data integrity and dynamically recreates any failed blocks seamlessly, ensuring uninterrupted operations. More info here.
…
Cloud file services supplier Panzura has been ranked at 2,075 on the 2023 Inc. 5000 annual list of fastest-growing private companies in America, with a 271 percent increase year on year in its ARR. Last year Panzura was ranked 1,343 with 485 percent ARR growth. This year the Inc. 5000 list also mentions OwnBackup at 944 with 625 percent revenue growth, VAST Data at 2,190 with 254 percent growth, and Komprise at 2,571 with 212 percent growth. SingleStore and OpenDrives were both on the list last year but don’t appear this year.
…
Real-time database supplier Redis has upgraded its open source and enterprise product to Redis v7.2, adding enhanced store vector embeddings and a high-performance index and query search engine. It is previewing a scalable search feature which enables a higher query throughput, including VSS and full-text search, exclusively as part of its commercial offerings. It blends sharding for seamless data expansion with efficient vertical scaling. This ensures optimal distributed processing across the cluster and improves query throughput by up to 16x compared to what was previously possible.
The latest version of the Redis Serialization Protocol (RESP3) is now supported across source-available, Redis Enterprise cloud and software products for the first time. Developers can now program, store, and execute Triggers and Functions within Redis using Javascript. With Auto Tiering, operators can keep heavily used data in memory and move less frequently needed data to SSD. Auto Tiering offers more than twice the throughput of the previous version while reducing the infrastructure costs of managing large datasets in DRAM by up to 70 percent.
The preview mode Redis Data Integration (RDI) transforms any dataset into real-time accessibility by seamlessly and incrementally bringing data from multiple sources to Redis. Customers can integrate with popular data sources such as Oracle Database, Postgres, MySQL, and Cassandra.
…
Silicon Motion is terminating its merger agreement with MaxLinear and intends to pursue substantial damages in excess of the agreement’s termination fee due to MaxLinear’s willful and material breaches of the merger agreement.
…
HA and DR supplier SIOS has signd with ACP IT Solutions GmbH Dresden top disribute its products in Germany, Switzerland, and Austria.
…
SK hynix is mass-producing its 24GB LPDDR5X DRAM, the industry’s largest capacity.

…
Decentralized storage provider Storj has a partnership with Artificial Intelligence-driven mental health tech company MoodConnect. The two intend to unveil a state-of-the-art mental health tracker designed to help individuals and corporations capture, store, and share sentiment data securely. MoodConnect empowers users to track, store and share their own emotion data from conversations and to securely possess this data for personal introspection, to share with healthcare professionals, with friends and family, or to gauge organizational sentiment within a company. It will use Storj distributed storage. MoodConnect has appointed Robert Scoble as its AI advisor.