Month: August 2023

MMS • RSS

Through this partnership, CloudMile’s customers will have access to MongoDB Atlas—a cloud-native developer data platform—on Google Cloud
KUALA LUMPUR, MALAYSIA, August 15, 2023: CloudMile, a leading AI and cloud technology company based in Asia that focuses on digital transformation and growth for its corporate clients, has announced a strategic partnership with MongoDB, providing CloudMile’s corporate clients with MongoDB Atlas. Through this partnership, CloudMile’s customers will have access to MongoDB Atlas—a cloud-native developer data platform—on Google Cloud to provide developers with the flexibility and scalability required to quickly and easily build enterprise-grade applications.
CloudMile’s corporate clients can now leverage MongoDB Atlas to accelerate their product development, build scalable and secure applications, and gain detailed insights into their data. MongoDB’s fully managed developer data platform works hand-in-hand with Google Cloud’s open data cloud to provide unmatched speed, scale, and security.
Strategic Partnership Empowers Customers
Businesses today face many challenges when it comes to data management, including data silos and slow query times. The partnership between CloudMile and MongoDB tackles these challenges, providing customers with a modern, intuitive, and unified developer data platform that provides detailed insights into customers, products, and operations.
Together with Google Cloud BigQuery, MongoDB Atlas allows customers to enrich operational data and enhance end-customer experiences. MongoDB Atlas handles real-time operational applications with thousands of concurrent sessions and millisecond response times. Its curated subsets of data are then replicated to BigQuery for aggregation, complex analytics, and the application of machine learning.
Accelerating Mobile Gaming Development Efficiency
The current mobile gaming market in Asia is experiencing a 3–5% compound annual growth rate (CAGR). To better leverage the power of data and address this growth opportunity, CloudMile and MongoDB’s partnership has already helped a leading gaming company in Taiwan greatly reduce maintenance and operation costs, allowing them to focus on product development. Alongside Google Cloud services delivered by CloudMile, MongoDB Atlas is easy to deploy, fulfilling the needs of scalability with performance and high availability. MongoDB Atlas streamlines data synchronisation via ACID Transaction, saving game developers time by using a unified platform through a single API, while also offering comprehensive security and data protection features to ensure business continuity and resilience during data storage and transmission. The flexible document data model, transaction function, and Google Cloud’s built-in security provide gamers with a controlled environment and allow them to enjoy games without downtime.
Fulfilling Digital Transformation With Optimised Solutions
“Through CloudMile, enterprises in Malaysia can seamlessly deploy partner products alongside our own. For example, they can release a new deployment of MongoDB Atlas alongside BigQuery to share transactional data and run complex, real-time analytics over petabyte-scale datasets. CloudMile, MongoDB, and Google Cloud are fundamentally committed to breaking down data silos and ensuring that our customers can securely harness the power of data from any source, in any location, and on any platform. We look forward to deepening our collaboration to help businesses of all sizes succeed at every step of their data-driven digital transformation journeys,” said Patrick Wee, Country Manager, Malaysia, Google Cloud.
Commenting on the announcement, Lester Leong, Country Manager of CloudMile Malaysia, said, “We are excited to announce this strategic partnership with MongoDB. MongoDB is well known for its horizontal scaling and load-balancing capabilities, which have given application developers exceptional flexibility and scalability. The collaboration will drive further growth and create new opportunities.”
“The partnership between CloudMile and MongoDB brings together the power of AI, our developer data platform, and cloud technology to empower customers to gain detailed insights into their data, accelerate their product development, and enhance end-customer experiences,” said Simon Eid, Senior Vice President of APAC, MongoDB. “We are committed to driving growth and success together in the region.”
The strategic partnership is expected to create significant synergies and opportunities for both companies, driving further growth and success in solving industry challenges, building credibility, and establishing trust amongst their joint customers.
Do Follow: CIO News LinkedIn Account | CIO News Facebook | CIO News Youtube | CIO News Twitter
About us:
CIO News, a proprietary of Mercadeo, produces award-winning content and resources for IT leaders across any industry through print articles and recorded video interviews on topics in the technology sector such as Digital Transformation, Artificial Intelligence (AI), Machine Learning (ML), Cloud, Robotics, Cyber-security, Data, Analytics, SOC, SASE, among other technology topics
MMS • Almir Vuk

The latest release of .NET 8 Preview 7 brings significant additions and changes to ASP.NET Core. The most notable enhancements for this release of ASP.NET Core are related to the Blazor alongside the updates regarding the Native AOT, Identity, new SPA Visual Studio templates, Antiforgery middleware additions and many more.
Regarding the Blazor, the endpoints are now required to use antiforgery protection by default. As reported, from this version, the EditForm component will now add the antiforgery token automatically. Also, the developers can disable this but it is not recommended. In terms of form creation, developers can now build standard HTML forms in server-side rendering mode without relying on EditForm.
Blazor introduces a range of other notable enhancements, including the Auto interactive render mode that combines Server and WebAssembly render modes seamlessly. This mode optimizes rendering by utilizing WebAssembly if the .NET runtime loads swiftly, within 100ms. Additionally, registering root-level cascading values extends their availability throughout the component hierarchy.
Moreover, interactive components can now be added, removed, and parameterized with enhanced navigation, enhanced form handling, and a streaming rendering. Also, the Virtualize component introduces the EmptyContent property, offering a concise content definition for scenarios where items are absent or the ItemsProvider yields zero TotalItemCount.
Regarding the APIs, a new middleware has been added for validating antiforgery tokens, a key defence against cross-site request forgery attacks. This middleware activates when antiforgery services are registered via the AddAntiforgery method. Placing the antiforgery middleware after authentication and authorization middleware is vital to prevent unauthorized form data access. Also, Minimal API handling form data will now require antiforgery token validation.
Concerning Native AOT, from this Preview 7 developers can benefit from the updated Request Delegate Generator, to support new C# 12 interceptors, and compiler features to support the interception of minimal API calls of Map action methods. The original blog post shares the results of changes in the startup time, so it is highly recommended to explore it. Also, there is a new WebApplication.CreateEmptyBuilder factory method which will result in smaller apps that only contain necessary features.
As reported in the original release blog post:
Publishing this code with native AOT using .NET 8 Preview 7 on a linux-x64 machine results in a self-contained, native executable of about 8.5 MB.
This Preview also introduces a notable breaking change affecting web projects compiled with trimming enabled using PublishTrimmed=true. Previously, projects defaulted to partial TrimMode. However, starting from this release, all projects targeting .NET 8 or above will now use TrimMode=full by default.
Furthermore, new Visual Studio templates have been introduced. These templates contain Angular, React, and Vue, utilizing the new JavaScript project system (.esproj) while seamlessly integrating with ASP.NET Core backend projects.
Finally, the comments section of the original release blog post has been active with responses regarding the framework changes and enhancements. The blog post has sparked considerable engagement, with users posing numerous questions and engaging in discussions with the development team. For an insight into the various viewpoints, it is strongly advised that users look into the comment section and participate in the ongoing discussions.
MMS • RSS

Prisma is a popular data-mapping layer (ORM) for server-side JavaScript and TypeScript. Its core purpose is to simplify and automate how data moves between storage and application code. Prisma supports a wide range of datastores and provides a powerful yet flexible abstraction layer for data persistence. Get a feel for Prisma and some of its core features with this code-first tour.
An ORM layer for JavaScript
Object-relational mapping (ORM) was pioneered by the Hibernate framework in Java. The original goal of object-relational mapping was to overcome the so-called impedance mismatch between Java classes and RDBMS tables. From that idea grew the more broadly ambitious notion of a general-purpose persistence layer for applications. Prisma is a modern JavaScript-based evolution of the Java ORM layer.
Prisma supports a range of SQL databases and has expanded to include the NoSQL datastore, MongoDB. Regardless of the type of datastore, the overarching goal remains: to give applications a standardized framework for handling data persistence.
The domain model
We’ll use a simple domain model to look at several kinds of relationships in a data model: many-to-one, one-to-many, and many-to-many. (We’ll skip one-to-one, which is very similar to many-to-one.)
Prisma uses a model definition (a schema) that acts as the hinge between the application and the datastore. One approach when building an application, which we’ll take here, is to start with this definition and then build the code from it. Prisma automatically applies the schema to the datastore.
The Prisma model definition format is not hard to understand, and you can use a graphical tool, PrismaBuilder, to make one. Our model will support a collaborative idea-development application, so we’ll have User, Idea, and Tag models. A User can have many Ideas (one-to-many) and an Idea has one User, the owner (many-to-one). Ideas and Tags form a many-to-many relationship. Listing 1 shows the model definition.
Listing 1. Model definition in Prisma
datasource db {
provider = "sqlite"
url = "file:./dev.db"
}
generator client {
provider = "prisma-client-js"
}
model User {
id Int @id @default(autoincrement())
name String
email String @unique
ideas Idea[]
}
model Idea {
id Int @id @default(autoincrement())
name String
description String
owner User @relation(fields: [ownerId], references: [id])
ownerId Int
tags Tag[]
}
model Tag {
id Int @id @default(autoincrement())
name String @unique
ideas Idea[]
}
Listing 1 includes a datasource definition (a simple SQLite database that Prisma includes for development purposes) and a client definition with “generator client” set to prisma-client-js. The latter means Prisma will produce a JavaScript client the application can use for interacting with the mapping created by the definition.
As for the model definition, notice that each model has an id field, and we are using the Prisma @default(autoincrement()) annotation to get an automatically incremented integer ID.
To create the relationship from User to Idea, we reference the Idea type with array brackets: Idea[]. This says: give me a collection of Ideas for the User. On the other side of the relationship, you give Idea a single User with: owner User @relation(fields: [ownerId], references: [id]).
Besides the relationships and the key ID fields, the field definitions are straightforward; String for Strings, and so on.
Create the project
We’ll use a simple project to work with Prisma’s capabilities. The first step is to create a new Node.js project and add dependencies to it. After that, we can add the definition from Listing 1 and use it to handle data persistence with Prisma’s built-in SQLite database.
To start our application, we’ll create a new directory, init an npm project, and install the dependencies, as shown in Listing 2.
Listing 2. Create the application
mkdir iw-prisma
cd iw-prisma
npm init -y
npm install express @prisma/client body-parser
mkdir prisma
touch prisma/schema.prisma
Now, create a file at prisma/schema.prisma and add the definition from Listing 1. Next, tell Prisma to make SQLite ready with a schema, as shown in Listing 3.
Listing 3. Set up the database
npx prisma migrate dev --name init
npx prisma migrate deploy
Listing 3 tells Prisma to “migrate” the database, which means applying schema changes from the Prisma definition to the database itself. The dev flag tells Prisma to use the development profile, while --name gives an arbitrary name for the change. The deploy flag tells prisma to apply the changes.
Use the data
Now, let’s allow for creating users with a RESTful endpoint in Express.js. You can see the code for our server in Listing 4, which goes inside the iniw-prisma/server.js file. Listing 4 is vanilla Express code, but we can do a lot of work against the database with minimal effort thanks to Prisma.
Listing 4. Express code
const express = require('express');
const bodyParser = require('body-parser');
const { PrismaClient } = require('@prisma/client');
const prisma = new PrismaClient();
const app = express();
app.use(bodyParser.json());
const port = 3000;
app.listen(port, () => {
console.log(`Server is listening on port ${port}`);
});
// Fetch all users
app.get('/users', async (req, res) => {
const users = await prisma.user.findMany();
res.json(users);
});
// Create a new user
app.post('/users', async (req, res) => {
const { name, email } = req.body;
const newUser = await prisma.user.create({ data: { name, email } });
res.status(201).json(newUser);
});
Currently, there are just two endpoints, /users GET for getting a list of all the users, and /user POST for adding them. You can see how easily we can use the Prisma client to handle these use cases, by calling prisma.user.findMany() and prisma.user.create(), respectively.
The findMany() method without any arguments will return all the rows in the database. The create() method accepts an object with a data field holding the values for the new row (in this case, the name and email—remember that Prisma will auto-create a unique ID for us).
Now we can run the server with: node server.js.
Testing with CURL
Let’s test out our endpoints with CURL, as shown in Listing 5.
Listing 5. Try out the endpoints with CURL
$ curl http://localhost:3000/users
[]
$ curl -X POST -H "Content-Type: application/json" -d '{"name":"George Harrison","email":"george.harrison@example.com"}' http://localhost:3000/users
{"id":2,"name":"John Doe","email":"john.doe@example.com"}{"id":3,"name":"John Lennon","email":"john.lennon@example.com"}{"id":4,"name":"George Harrison","email":"george.harrison@example.com"}
$ curl http://localhost:3000/users
[{"id":2,"name":"John Doe","email":"john.doe@example.com"},{"id":3,"name":"John Lennon","email":"john.lennon@example.com"},{"id":4,"name":"George Harrison","email":"george.harrison@example.com"}]
Listing 5 shows us getting all users and finding an empty set, followed by adding users, then getting the populated set.
Next, let’s add an endpoint that lets us create ideas and use them in relation to users, as in Listing 6.
Listing 6. User ideas POST endpoint
app.post('/users/:userId/ideas', async (req, res) => {
const { userId } = req.params;
const { name, description } = req.body;
try {
const user = await prisma.user.findUnique({ where: { id: parseInt(userId) } });
if (!user) {
return res.status(404).json({ error: 'User not found' });
}
const idea = await prisma.idea.create({
data: {
name,
description,
owner: { connect: { id: user.id } },
},
});
res.json(idea);
} catch (error) {
console.error('Error adding idea:', error);
res.status(500).json({ error: 'An error occurred while adding the idea' });
}
});
app.get('/userideas/:id', async (req, res) => {
const { id } = req.params;
const user = await prisma.user.findUnique({
where: { id: parseInt(id) },
include: {
ideas: true,
},
});
if (!user) {
return res.status(404).json({ message: 'User not found' });
}
res.json(user);
});
In Listing 6, we have two endpoints. The first allows for adding an idea using a POST at /users/:userId/ideas. The first thing it needs to do is recover the user by ID, using prisma.user.findUnique(). This method is used for finding a single entity in the database, based on the passed-in criteria. In our case, we want the user with the ID from the request, so we use: { where: { id: parseInt(userId) } }.
Once we have the user, we use prisma.idea.create to create a new idea. This works just like when we created the user, but we now have a relationship field. Prisma lets us create the association between the new idea and user with: owner: { connect: { id: user.id } }.
The second endpoint is a GET at /userideas/:id. The purpose of this endpoint is to take the user ID and return the user including their ideas. This gives us a look at the where clause in use with the findUnique call, as well as the include modifier. The modifier is used here to tell Prisma to include the associated ideas. Without this, the ideas would not be included, because Prisma by default uses a lazy loading fetch strategy for associations.
To test the new endpoints, we can use the CURL commands shown in Listing 7.
Listing 7. CURL for testing endpoints
$ curl -X POST -H "Content-Type: application/json" -d '{"name":"New Idea", "description":"Idea description"}' http://localhost:3000/users/3/ideas
$ curl http://localhost:3000/userideas/3
{"id":3,"name":"John Lennon","email":"john.lennon@example.com","ideas":[{"id":1,"name":"New Idea","description":"Idea description","ownerId":3},{"id":2,"name":"New Idea","description":"Idea description","ownerId":3}]}
We are able to add ideas and recover users with them.
Many-to-many with tags
Now let’s add endpoints for handling tags within the many-to-many relationship. In Listing 8, we handle tag creation and associate a tag and an idea.
Listing 8. Adding and displaying tags
// create a tag
app.post('/tags', async (req, res) => {
const { name } = req.body;
try {
const tag = await prisma.tag.create({
data: {
name,
},
});
res.json(tag);
} catch (error) {
console.error('Error adding tag:', error);
res.status(500).json({ error: 'An error occurred while adding the tag' });
}
});
// Associate a tag with an idea
app.post('/ideas/:ideaId/tags/:tagId', async (req, res) => {
const { ideaId, tagId } = req.params;
try {
const idea = await prisma.idea.findUnique({ where: { id: parseInt(ideaId) } });
if (!idea) {
return res.status(404).json({ error: 'Idea not found' });
}
const tag = await prisma.tag.findUnique({ where: { id: parseInt(tagId) } });
if (!tag) {
return res.status(404).json({ error: 'Tag not found' });
}
const updatedIdea = await prisma.idea.update({
where: { id: parseInt(ideaId) },
data: {
tags: {
connect: { id: tag.id },
},
},
});
res.json(updatedIdea);
} catch (error) {
console.error('Error associating tag with idea:', error);
res.status(500).json({ error: 'An error occurred while associating the tag with the idea' });
}
});
We’ve added two endpoints. The POST endpoint, used for adding a tag, is familiar from the previous examples. In Listing 8, we’ve also added the POST endpoint for associating an idea with a tag.
To associate an idea and a tag, we utilize the many-to-many mapping from the model definition. We grab the Idea and Tag by ID and use the connect field to set them on one another. Now, the Idea has the Tag ID in its set of tags and vice versa. The many-to-many association allows up to two one-to-many relationships, with each entity pointing to the other. In the datastore, this requires creating a “lookup table” (or cross-reference table), but Prisma handles that for us. We only need to interact with the entities themselves.
The last step for our many-to-many feature is to allow finding Ideas by Tag and finding the Tags on an Idea. You can see this part of the model in Listing 9. (Note that I have removed some error handling for brevity.)
Page 2
Listing 9. Finding tags by idea and ideas by tags
// Display ideas with a given tag
app.get('/ideas/tag/:tagId', async (req, res) => {
const { tagId } = req.params;
try {
const tag = await prisma.tag.findUnique({
where: {
id: parseInt(tagId)
}
});
const ideas = await prisma.idea.findMany({
where: {
tags: {
some: {
id: tag.id
}
}
}
});
res.json(ideas);
} catch (error) {
console.error('Error retrieving ideas with tag:', error);
res.status(500).json({
error: 'An error occurred while retrieving the ideas with the tag'
});
}
});
// tags on an idea:
app.get('/ideatags/:ideaId', async (req, res) => {
const { ideaId } = req.params;
try {
const idea = await prisma.idea.findUnique({
where: {
id: parseInt(ideaId)
}
});
const tags = await prisma.tag.findMany({
where: {
ideas: {
some: {
id: idea.id
}
}
}
});
res.json(tags);
} catch (error) {
console.error('Error retrieving tags for idea:', error);
res.status(500).json({
error: 'An error occurred while retrieving the tags for the idea'
});
}
});
Here, we have two endpoints: /ideas/tag/:tagId and /ideatags/:ideaId. They work very similarly to find ideas for a given tag ID and tags on a given idea ID. Essentially, the querying works just like it would in a one-to-many relationship, and Prisma deals with walking the lookup table. For example, for finding tags on an idea, we use the tag.findMany method with a where clause looking for ideas with the relevant ID, as shown in Listing 10.
Listing 10. Testing the tag-idea many-to-many relationship
$ curl -X POST -H "Content-Type: application/json" -d '{"name":"Funny Stuff"}' http://localhost:3000/tags
$ curl -X POST http://localhost:3000/ideas/1/tags/2
{"idea":{"id":1,"name":"New Idea","description":"Idea description","ownerId":3},"tag":{"id":2,"name":"Funny Stuff"}}
$ curl localhost:3000/ideas/tag/2
[{"id":1,"name":"New Idea","description":"Idea description","ownerId":3}]
$ curl localhost:3000/ideatags/1
[{"id":1,"name":"New Tag"},{"id":2,"name":"Funny Stuff"}]
Conclusion
Although we have hit on some CRUD and relationship basics here, Prisma is capable of much more. It gives you cascading operations like cascading delete, fetching strategies that allow you to fine-tune how objects are returned from the database, transactions, a query and filter API, and more. Prisma also allows you to migrate your database schema in accord with the model. Moreover, it keeps your application database-agnostic by abstracting all database client work in the framework.
Prisma puts a lot of convenience and power at your fingertips for the cost of defining and maintaining the model definition. It’s easy to see why this ORM tool for JavaScript is a popular choice for developers.
Next read this:
Article: Becoming More Assertive: How to Express Yourself, Give Feedback, and Set Boundaries
MMS • Marta Firlej

Key Takeaways
- Assertiveness is a communication style. It is being able to express your feelings, thoughts, beliefs, and opinions in an open manner that doesn’t violate the rights of others.
- The “Bill of Assertive Rights” can guide you in making decisions and show you that it is okay to change your mind, make mistakes, or simply not know the answer.
- No one is perfect in assertive communication, but as with every skill, we can improve by practicing it.
- To communicate more assertively, you need to know communication techniques and understand how and when to use them. For example, signal flexibility by providing options that would work for you or get in touch with your personal needs and values and communicate them.
- Understanding the side effects of being unassertive will help you motivate yourself to work on the skills of assertive people. Asking for help or expressing feelings may help you in your everyday professional communication.
Do you know that feeling when you are brave enough to say “NO” and then you don’t feel comfortable about it? I know that feeling very well.
During my professional career, there have been multiple times that people around me have struggled with setting boundaries. After those experiences, I have decided to learn more about communication skills, and I want to share with you what I have mastered.
In this article, we will build a proper understanding of what an assertiveness skill is, and learn how to identify communication skills we need to work on to be more assertive. You will get information about the characteristics and skills of assertive people. In addition, I will share my personal experience when I struggle with my assertiveness skill and when I practice it. Ultimately, I hope you will be equipped to make some small changes within everyday communication.
Why have I decided to learn more about assertiveness?
In a previous company I worked for, I noticed that many of my coworkers struggled to communicate their boundaries; they were not brave enough, or they lacked the knowledge of how to be assertive. I was even more surprised when I was kind but assertive with my superiors; they simply did not know how to react.
Of course, it was not happening with everyone, but it was still noticeable. My assertive communication and reaction to it in my workplace was a new situation for many of us. I tried to mentor many of my direct colleagues about assertiveness skills, and after I decided to leave that organization, I conducted a session about assertiveness. It was very impactful for some attendees and for me as well.
After that session, I realized how essential and life-changing such sharing can be. And that maybe I should share my skills and knowledge more often.
Defining assertiveness
I have been searching for a good definition, and it was not an easy task! Every source of knowledge seems to create its own definition. If I were to pick one, I would choose the definition I found on the Center of Clinical Interventions site, which is part of the Government of Western Australia:
“Assertiveness is a communication style. It is being able to express your feelings, thoughts, beliefs, and opinions in an open manner that doesn’t violate the rights of others.”
It resonates with my experience that assertiveness is not just one but multiple sets of skills. As an assertive person, you must be able to communicate your beliefs and feelings but do so without violating others. Numerous times during my career as a Test Lead or Quality Manager, I kept receiving feedback that I was either too emotional or too “aggressive” in expressing myself.
While working on that feedback with its authors, we concluded that people I worked with were simply not used to communicating assertively in a straightforward way.
Skills that assertive people have
Have you ever thought about how many skills you should have to be assertive?
Here you can find a list of skills that assertive people have based on materials from the Center of Clinical Interventions under the Government of Western Australia:
- Saying “No”
- Giving compliments
- Expressing your opinion
- Asking for help
- Expressing anger
- Expressing affection
- Stating your right and needs
- Giving criticism
- Being criticized
- Starting and keeping a conversation going
Looking at the above list, I was surprised at the length and the versatility of skills needed to gain and practice assertiveness. I was lucky that in my childhood, my parents, teachers, and colleagues taught me how to say “no” and express my opinions or thoughts without worries.
I’m actively using those skills in everyday life – for example, I refuse to drink coffee as I am not a huge coffee fan. The reality is that I dislike the taste, and I often need to use my assertiveness arsenal when someone is offering me a coffee or coffee-themed dessert. I found it interesting how many of the skills from the list above I need to use to be assertive and avoid being a part of the “coffee cult.” My co-workers and friends ask me to taste new kinds of coffee, often arguing that “it doesn’t taste like coffee” or “maybe you will change your mind.” Thankfully since childhood, I practiced avoiding foods that I don’t like, and later I refused smoking cigarettes and drinking alcohol.
Sometimes I struggle with some parts of assertiveness skills, and sometimes I will try these coffee-themed desserts or drinks just to confirm that I do not like them. Below I will share with you some ways to communicate more assertively that I use often. I know I still need to learn a lot about how to take care of my emotions, especially when someone tries to push my boundaries and I become angry. The effects of being unassertive not only manifest situations where we agree to things we do not like, but can also cause other effects mentioned below.
The effects of people being unassertive
The clinical study I mentioned showed what skills assertive people should have and presented what adverse effects can meet you when being unassertive:
- The main effect of not being assertive is that it can lead to low self-esteem.
- If we never express ourselves openly and conceal our thoughts and feelings, that can make us feel tense, stressed, anxious, or resentful.
- It can also lead to unhealthy and uncomfortable relationships.
- We can feel as if the people closest to us would not really know us.
Do you remember situations at work when someone asked you to take on extra responsibilities or support your team for longer hours, but you already had plans, or were simply tired? If you didn’t speak up before becoming more educated in assertive communication, you probably felt uncomfortable, even more tired, and angry.
As an example of lacking assertiveness, I can recall a situation when I asked off from work to go to my grand-grand-mother’s funeral. Despite my kind request, my boss asked me to stay and support the team. I stayed at work, and for years I felt bad because I made a wrong decision regarding an important situation in my personal life, and I didn’t communicate it properly to my boss and the team I worked with.
What’s more, I discussed it later with my boss, and we both agreed it was the wrong decision. I didn’t communicate that I felt uncomfortable and I missed an important moment in my life. From that day on, I created a list of my life values, and till today, they are navigating me in communicating my decisions – that helps me to be assertive.
I faced another situation during the pandemic. We had all been working too much, feeling stressed and exhausted. Did we communicate properly? I don’t think so. Later, with huge support from our HR Business Partner, my team organized a session on how to deal with stress and recognize when we are burning out. It was an eye-opening session for many of my team members and a great start for the conversation about setting boundaries. We learned that we were stressed and we shared with each other how to recognize this feeling via online tools in a new virtual reality.
What language do we use or behavior we have when we feel stressed? The trainer shared with us some tips on reducing stress or what to do when it stays with us for too long. We could not decrease stress related to the environment or work, but we changed everyday communication and supported each other a lot more. Each of us recognized what values are the most important, and making decisions became a lot easier.
I need to mention here that when people are joining a new team, organization, or environment, there is a tendency to be less assertive; we want everyone to accept us, like us, and recognize us as professionals. It is a trap that may lead us to all the mentioned negative effects. That’s why I have a printed copy of the “Bill of Assertive Rights” next to my screen at my workplace. Let’s read below what it actually is.
The Bill of Assertive Rights
I found the “Bill of Assertive Rights” when I was reading the book When I Say No, I Feel Guilty: How to Cope – Using the Skills of Systematic Assertive Therapy by Manuel J. Smith. It is an old book, and I am surprised I found it so late in my life. I strongly recommend you read it.
I believe the “Bill of Assertive Rights” is one of the things we all should print and have in front of our eyes, especially during business meetings. As I’ve mentioned, I have it at my workplace, and I read it when I feel that something is expected from me, when someone shares their feedback with me, or when I need to change decisions I’ve made. In Polish, we say “Tylko głupi nie zmienia zdania,” which translates to “Only a fool doesn’t change his/her mind,” and sometimes it may be the proper thing to do as an assertive person!
“The Bill of Assertive Rights” by Manuel J. Smith:
- You have the right to judge your own behavior, thoughts, and emotions, and to take the responsibility for their initiation and consequences upon yourself.
- You have the right to offer no reasons or excuses for justifying your behavior.
- You have the right to judge if you are responsible for finding solutions to other people’s problems.
- You have the right to change your mind.
- You have the right to make mistakes – and be responsible for them.
- You have the right to say, “I don’t know.”
- You have the right to be independent of the goodwill of others before coping with them.
- You have the right to be illogical in making decisions.
- You have the right to say, “I don’t understand.”
- You have the right to say, “I don’t care.”
Now I want to propose one exercise for you – please remind yourself of the last situation you felt uncomfortable with your decision. Then look at the list above. Are your thoughts looking different after looking at the list? For me, often – yes.
I must mention here how shocked I was to see that the book was not translated into Polish even though it was published in 1975. In the Polish language, we have a lot of books on how to avoid manipulation, but only a few on how to communicate assertively. Hopefully, in your languages, there are more translated books like that!
We know now what assertiveness is, which skills we should have, what unassertive effects can cause, and the list of rights we have, but how should we use it in practice?
Practicing assertiveness
I believe each of us needs to find our own way to communicate more assertively with respect to others. We need to consider a variety of factors – for example, gender, cultural background, the organization we are in, and our environment.
Looking at myself compared to others within my environment, I tend to express and fight for my beliefs and opinions stronger than others – so I am currently learning to be more mindful of their opinions, thoughts, or beliefs.
It is not easy for others to express themselves and present their point of view to me or to change my mind. Despite that, I found out that I have a lot of empathy, and I often put others’ needs in front of my own, so this is another thing I have to tackle with assertiveness.
There are so many things that I need to remember when I communicate with others not to cross their or my borders. Despite being perceived as an assertive person, I still have much to learn.
Some time ago, I found a few tips on communicating more assertively. I believe the points below are valuable and useful. Let’s take a look:
- Get in touch with your own needs and values.
- Be confident if your ask is reasonable, and prepare arguments WHY you need it.
- See the other person’s point of view.
- Signal flexibility by providing options that work for you.
- Keep your delivery calm and firm.
- Make yourself the scapegoat.
- Use the broken record technique.
I would like to highlight that some tips above may not work for everyone and not on every occasion. For example – “Make yourself the scapegoat.” – will depend on the situation, your relationships, and your environment. You can’t be a scapegoat all the time, and you can’t be responsible for others’ mistakes.
Let’s get back to the topic of personal life values. Personal values-based decision-making was a key to feeling good with all things I agree to in my professional and private life.
How to do it?
You can, for example, play in your head with the scenario “What would happen if__.” For example, would you quit your current job if your family member got sick and required your full attention? What should you do?
How do I make the decisions?
During my professional career, I’ve learned not to agree on anything until I take time to think about it and prepare a list of questions to set expectations and possible timelines properly.
It was something that changed a lot in my life as I am one of those people who always tries to deliver even if I am left alone with too challenging a task. Before I learned to tackle such situations and make proper decisions, it often made me feel stressed, uncomfortable, or exhausted.
What helped me a lot was learning how to ask for help or changes within deadlines or scope. Every day, I practice preparing arguments for “why” something has to be changed and what options I see.
It saved me many times, and I strongly advise you to say NO and at least provide 2-3 options about what you can do instead. If you take your time to think things through, it’ll be easy to communicate assertively, and you will be happy with your decisions.
As you see, it is a challenging task to be assertive. It requires many skills, communication techniques, and effort, but it may benefit you in achieving your goals and preserving good relationships.
Learning more about being assertive
I’m not an expert or educated psychologist but a dedicated practitioner willing to share my experience with you. I wanted to share what helped me and the people I worked with to be happier and deliver on time.
Below you will find some materials I found helpful during my research. You will likely find a lot more after reading my article and googling a bit.
And my final recommendation to you is to look at children’s books, which may help you to understand emotions and communicate more effectively and calmly.
Other resources which I recommend:
I hope to leave you with some inspiration, an understanding of how to be more assertive, and knowledge about what to work on. Good luck, you can make it!
Homework for you – exercise your communication skills and assertiveness
Your task is to look at the communication skills listed below and analyze how comfortable you feel in communicating with people that you meet the most:
- Your partner
- Your parents
- Your child
- Your best friends
- Other friends
- Strangers
- Your boss
- Work colleague
The results will show you which communication skills you should address in your future personal development.
List of skills:
- Saying “no”
- Giving compliments
- Expressing your opinion
- Asking for help
- Expressing anger
- Expressing affection
- Stating your right and needs
- Giving criticism
- Being criticized
- Starting and keeping a conversation going
The listed skills come from a study about assertiveness made by the Centre for Clinical Interventions – Government of West Australia: What is Assertiveness?
Presentation: Speed of Apache Pinot at the Cost of Cloud Object Storage with Tiered Storage
MMS • Neha Pawar

Transcript
Neha Pawar: My name is Neha Pawar. I’m here to tell you about how we added tiered storage for Apache Pinot, enabling the speed of Apache Pinot at the cost of Cloud Object Storage. I’m going to start off by spending some time explaining why we did this. We’ll talk about the different kinds of analytics databases, the kinds of data and use cases that they can handle. We’ll dive deep into some internals of Apache Pinot. Then we will discuss why it was crucial for us to decrease the cost of Pinot while keeping the speed of Pinot. Finally, we’ll talk in depth about how we implemented this.
All Data Is Not Equal
Let’s begin by talking about time, and the value of data. Events are the most valuable when they have just happened. They tell us more about what is true in the world at the moment. The value of an event tends to decline over time, because the world changes and that one event tells us less and less about what is true as time goes on. It’s also the case that the recent real-time data tends to be queried more than the historical data. For instance, with recent data, you would build real-time analytics, anomaly detection, user facing analytics.
These are often served directly to the end users of your company, for example, profile view analytics, or article analytics, or restaurant analytics for owners, feed analytics. Now imagine, if you’re building such applications, they will typically come with a concurrency of millions of users have to serve about thousands of queries per second, and the SLAs will be stringent in just a few milliseconds. This puts pressure on those queries to be faster. It also justifies more investment in the infrastructure to support those queries.
Since recent events are more valuable, we can in effect, spend more to query them. Historical data is queried less often than real-time data. For instance, with historical data, you would typically build metrics, reporting, dashboards, use it for ad hoc analysis. You may also use it for user facing analytics. In general, your query volume will be much lower and less concurrent than the recent data. What we know for sure about historical data that it is large, and it keeps getting bigger all the time. None of this means that latency somehow becomes unimportant. We will always want our database to be fast. It’s just that with historical data, the cost becomes the dominating factor. To summarize, recent data is more valuable and extremely latency sensitive. Historical data is large, and tends to be cost sensitive.
What Analytics Infra Should I Choose?
Given you have two such kinds of data that you have to handle, and manage the use cases that come with it, if you are tasked with choosing an analytics infrastructure for your organizations, the considerations on top of your mind are going to be cost, performance, and flexibility. You need systems which will be able to service the different kinds of workloads, while maintaining query and freshness SLAs needed by these use cases. The other aspect is cost. You’ll need a solution where the cost of service is reasonable and the business value extracted justifies this cost. Lastly, you want a solution that is easy to operate, to configure, and also one that will fulfill a lot of your requirements together.
Now let’s apply this to two categories of analytics databases that exist today. Firstly, the real-time analytics or the OLAP databases. For serving real-time data and user facing analytics, you will typically pick a system like Apache Pinot. There’s also some other open source as well as proprietary systems, which can help serve real-time data, such as ClickHouse and Druid. Let’s dig a little deeper into what Apache Pinot is. Apache Pinot is a distributed OLAP datastore that can provide ultra-low latency even at extremely high throughput.
It can ingest data from batch sources such as Hadoop, S3, Azure. It can also ingest directly from streaming sources such as Kafka, Kinesis, and so on. Most importantly, it can make this data available for querying in real-time. At the heart of the system is a columnar store, along with a variety of smart indexing and pre-aggregation techniques for low latency. These optimizations make Pinot a great fit for user facing real-time analytics, and even for applications like anomaly detection, dashboarding, and ad hoc data exploration.
Pinot was originally built at LinkedIn, and it powers a wide variety of applications there. If you’ve ever been on linkedin.com website, there’s a high chance you’ve already interacted with Pinot. Pinot powers LinkedIn’s iconic, who viewed my profile application, and many other such applications, such as feed analytics, employee analytics, talent insights, and so on. Across all of LinkedIn, there’s over 80 user facing products backed by Pinot and they’re serving queries at 250,000 queries per second, while maintaining strict milliseconds and sub-seconds latency SLAs.
Another great example is Uber Eats Restaurant Manager. This is an application created by Uber to provide restaurant owners with their orders data. On this dashboard, you can see sales metrics, missed orders, inaccurate orders in a real-time fashion, along with other things such as top selling menu items, menu item feedback, and so on. As you can imagine, to load this dashboard, we need to execute multiple complex OLAP queries, all executing concurrently. Multiply this with all the restaurant owners across the globe. This leads to several thousands of queries per second for the underlying database.
Another great example of the adoption of Pinot for user facing real-time analytics is at Stripe. There, Pinot is ingesting hundreds of megabytes per second from Kafka, and petabytes of data from S3, and solving queries at 200k queries per second, while maintaining sub-second p99 latency. It’s being used to service a variety of use cases, some of them being for financial analysts, we have ledger analytics. Then there’s user facing dashboards built for merchants. There’s also internal dashboards for engineers and data scientists.
Apache Pinot Community
The Apache open-source community is very active. We have over 3000 members now, almost 3500. We’ve seen adoption from a wide variety of companies in different sectors such as retail, finance, social media, advertising, logistics, and they’re all together pushing the boundaries of Pinot in speed, and scale, and features. These are the numbers from one of the largest Pinot clusters today, where we have a million plus events per second, serving queries at 250k queries per second, while maintaining strict milliseconds query latency.
Apache Pinot Architecture
To set some more context for the rest of the talk, let’s take a brief look at Pinot’s high-level architecture. The first component is the Pinot servers. This is the component that hosts the data and serve queries of the data that they host. Data in Pinot is stored in the form of segments. Segment is a portion of the data which is packed with metadata and dictionaries, indexes in a columnar fashion. Then we have the brokers.
Brokers are the component that gets queries from the clients. They scatter them to the servers. The servers execute these queries for the portion of data that they host. They send the results back to the brokers. Then the brokers do a final merge and return the results back to the client. Finally, we have the controllers that control all the interactions and state of the cluster with the help of Zookeeper as a persistent metadata store, and Helix for state management.
Why is it that Pinot is able to support such real-time low latency milliseconds level queries? One of the main reasons is because they have tightly coupled storage and compute architecture. The compute nodes used typically have a disk or SSD attached to store the data. The disk and SSD could be on local storage, or it could be remote attached like an EBS volume. The reason that they are so fast is because for both of these, the access method is POSIX APIs.
The data is right there, so you can use techniques like m-mapping. As a result, accessing this data is really fast. It can be microseconds if you’re using instant storage and milliseconds if you’re using a remote attached, say, an EBS volume. One thing to note here, though, is that the storage that we attach in such a model tends to be only available to the single instance to which it is attached. Then, let’s assume that this storage has a cost factor of a dollar. What’s the problem, then?
Let’s see what happens when the data volume starts increasing by a lot. Say you started with just one compute node, which has 2 terabytes of storage. Assume that the monthly cost is $200 for compute, $200 for storage, so $400 in total. Let’s say that your data volume grows 5x. To accommodate that, you can’t just add only storage, there are limits on how much storage a single instance can be given. Plus, if you’re using instant storage, it often just comes pre-configured, and you don’t have much control on scaling that storage up or down for that instance. As a result, you have to provision the compute along with it. Cost will be $1,000 for storage and $1000 for compute.
If your data grows 100x, again, that’s an increase in both storage and compute. More often than not, you won’t need all the compute that you’re forcibly adding just to support the storage, as the increasing data volume doesn’t necessarily translate to a proportional increase in query workload. You will end up paying for all this extra compute which could remain underutilized. Plus, this type of storage tends to be very expensive compared to some other storage options available, such as cloud object stores. That’s because the storage comes with a very high-performance characteristic.
To summarize, in tightly coupled systems, you will have amazing latencies, but as your data volume grows, you will end up with a really high cost to serve. We have lost out on the cost aspect of our triangle of considerations.
Data Warehouses, Data Lakes, Lake Houses
Let’s look at modern data warehouses, Query Federation technologies like Spark, Presto, and Trino. These saw the problem of combining storage and compute, so they went with a decoupled architecture, wherein they put storage into a cloud object store such as Amazon S3. This is basically the cheapest way you will ever store data. This is going to be as much as one-fifth of the cost of disk or SSD storage.
On the flip side, what were POSIX file system API calls which completed in microseconds, now became network calls, which can take thousands or maybe 10,000 times longer to complete. Naturally, we cannot use this for real-time data. We cannot use this to serve use cases like real-time analytics and user facing analytics. With decoupled systems, we traded off a lot of latency to save on cost, and now we are looking not so good on the performance aspect of our triangle. We have real-time systems that are fast and expensive, and then batch systems that are slow and cheap. What we ideally want is one system that can do both, but without infrastructure that actually supports this, data teams end up adding both systems into their data ecosystem.
They will keep the recent data in the real-time system and set an aggressive retention period so that the costs stay manageable. As the data times out of the real-time database, they’ll migrate it to a storage decoupled system to manage the historical archive. With this, we’re doing everything twice. We’re maintaining two systems, often duplicating data processing logic. With that, we’ve lost on the flexibility aspect of our triangle.
Could we somehow have a true best of both worlds, where we’ll get the speed of a tightly coupled real-time analytics system. We’ll be able to use cost effective storage like a traditionally decoupled analytic system. At the same time, have flexibility and simplicity of being able to use just one system and configure it in many ways. With this motivation in mind, we at StarTree set out to build tiered storage for Apache Beam. With tiered storage, your Pinot cluster is now not limited to just use disk or SSD storage. We are no longer strictly tightly coupled.
You can have multiple tiers of storage with support for using a cloud object storage such as S3 as one of the storage tiers. You can configure exactly which portion of your data you want to keep locally, and which is offloaded to the cloud tier storage. One popular way to split data across local versus cloud is by data age. You could configure in your table, something like, I want data less than 30 days to be on disk, and the rest of it, I want it to go on to S3. Users can then query this entire table across the local and remote data like any other Pinot dataset. With this decoupling, you can now store as much data as you want in Pinot, without worrying about the cost. This is super flexible and configurable.
The threshold is dynamic, and can be changed at any point in time, and Pinot will automatically reflect the changes. You can still operate Pinot in fully tightly coupled mode, if you want, or in completely decoupled mode. Or go for a hybrid approach, where some nodes are still dedicated for local data, some nodes for remote data, and so on. To summarize, we saw that with tiered storage in Pinot, we have the flexibility of using a single system for your real-time data, as well as historical data without worrying about the cost spiraling out of control.
Keep the Speed of Pinot
We didn’t talk much about the third aspect yet, which is performance. Now that we’re using cloud object storage, will the query latencies take a hit and enter the range of other decoupled systems? In the next few sections, we’re going to go over in great detail how we approached the performance aspect for queries accessing data on the cloud storage. Until tiered storage, Pinot has been assuming that segments stay on the local disk. It memory mapped the segments to access the data quickly. To make things work with remote segments on S3, we extended the query engine to make it agnostic to the segment location.
Under the hood, we plugged in our own buffer implementation, so that during query execution, we can read data from remote store instead of local as needed. Making the queries work is just part of the story. We want to get the best of two worlds using Pinot. From the table, you can see that the latency to access segments on cloud object storage is a lot higher, so hence, we began our pursuit to ensure we can keep the performance of Pinot in an acceptable range, so that people can keep using Pinot for their real-time user facing analytics use cases that they have been used to.
We began thinking about a few questions. Firstly, what is the data that should be read? We certainly don’t need to read all of the segments that are available for any query. We may not even need to read all of the data inside a given segment. What exactly should we be reading? Second question was, when and how to read the data during the query execution? Should we wait until the query has been executed and we’re actually processing a segment, or should we do some caching? Should we do some prefetching? What smartness can we apply there? In the following slides, I’ll try to answer these questions by explaining some of the design choices we made along the way.
Lazy Loading
The first idea that we explored was lazy loading. This is a popular technique used by some other systems to solve tiered storage. In lazy loading, all of the data segments would be on the remote store to begin with, and each server will have to have some attached storage. When the first query comes in, it will check if the local instance storage has the segments that it needs. If it does not find the segments on there, those will be downloaded from the remote store during the query execution. Your first query will be slow, of course, because it has to download a lot of segments.
The hope is that the next query will need the same segments or most of the segments that you already have, and hence reuse what’s already downloaded, making the second query execute very fast. Here, for what to fetch, we have done the entire segment. For when to fetch, we have done during the query execution. In typical OLAP workloads, your data will rarely ever be reusable across queries.
OLAP workloads come with arbitrary slice and dice point lookups across multiple time ranges and multiple user attributes. Which means that more often than not, you won’t be able to reuse the downloaded segment for the next query, which means we have to remove them to make space for the segments needed by the new query, because instance storage is going to be limited. This will cause a lot of churn and downloads. Plus, in this approach, you are fetching the whole segment.
Most of the times, your query will not need all of the columns in the segment, so you will end up fetching a lot of excessive data, which is going to be wasteful. Also, using lazy loading, the p99 or p99.9 of the query latency would be very bad, since there will always be some query that needs to download the remote segments. Because of this, lazy loading method was considered as a strict no-go for OLAP bias where consistent low latency is important. Instead of using lazy loading, or similar ideas, like caching segments on local disks, we started to think about how to solve the worst case. That is when the query has to read data from remote segments. Our hope was that by solving this, we can potentially guarantee consistent and predictable, low latency for all queries.
Pinot Segment Format
Then, to answer the question of what should we fetch, given that we know we don’t want to fetch the whole segment? We decided to take a deeper look at the Pinot segment format, to see if we could use the columnar nature of this database to our advantage. Here’s an example of a Pinot segment file. Let’s say we have columns like browser, region, country, and then some metric columns like impression, cost, and then our timestamp as well.
In Pinot, the segments are packed in a columnar fashion. One after the other, you’re going to see all these columns lined up in this segment file called columns.psf. For each column as well, you will see specific, relevant data buffers. For example, you could have forward indexes, you could have dictionaries, and then some specialized indexes like inverted index, range index, and so on.
This segment format allowed us to be a lot more selective and specific when deciding what we wanted to read from the Pinot segment. We decided we would do a selective columnar fetch, so bringing back this diagram where we have a server and we have some segments in a cloud object store. If you get a query like select sum of impressions, and a filter on the region column, we are only interested in the region and impressions. That’s all we’ll fetch.
Further, we also know from the query plan, that region is only needed to evaluate a filter, so we probably just need a dictionary and inverted index for that. Once we have the matching rows or impressions, we only need the dictionary and forward index. All other columns can be skipped. We used a range GET API, which is an API provided by S3, to just pull out these portions of the segment that we need: the specific index buffers, region dictionary, region inverted index, impressions for word index, impressions dictionary.
This worked pretty well for us. We were happy at that point with, this is the what to read part. Now that we know what data to read, next, we began thinking about when to read the data. We already saw earlier, that when a Pinot broker gets a query, it scatters the request to the servers, and then each server executes the query. Now in this figure, we are going to see what happens within a Pinot server when it gets a query. First, the server makes a segment execution plan as part of the planning phase. This is where it decides, which are the segments that it needs to process.
Then those segments are processed by multiple threads in parallel. One of the ideas that we explored was to fetch the data from S3, just as we’re about to execute this segment. In each of these segment executions, just before we would fetch the data from S3, and only then proceed to executing the query on that segment.
We quickly realized that this is not a great strategy. To demonstrate that, here’s a quick example. Let’s say you have 40 segments, and parallelism at our disposal on this particular server is 8. That means we would be processing these 40 segments in batches of 8, and that would mean that we are going to do 5 rounds to process all of them. Let’s assume that the latency to download data from S3 is 200 milliseconds.
For each batch, we are going to need 200 milliseconds, because as soon as the segment batch begins to get processed, we will first make a round trip to S3 to get that data from that segment. This is quickly going to add up. For each batch, we will need 200 milliseconds, so your total query time is going to be 1000 milliseconds overhead right there. One thing that we observed was that if you check the CPU utilization during this time, most of the time the threads are waiting for the data to become available, and the CPU cores would just stay idle.
Could we somehow decide the segments needed by the query a lot earlier, and then prefetch them so that we can pipeline the IO and data processing as much as possible? That’s exactly what we did. During the planning phase itself, we know on the server which segments are going to be needed by this query. In the planning phase itself, we began prefetching all of them. Then, just before the segment execution, the thread would wait for that data to be available, and the prefetch was already kick started. In the best-case scenario, we’re already going to have that data prefetched and ready to go.
Let’s come back to our example of the 40 segments with the 8 parallelism. In this case, instead of fetching when each batch is about to be executed, we would have launched the prefetch for all the batches in the planning phase itself. That means that maybe the first batch still has to wait 200 milliseconds for the data to be available. While that is being fetched, the data for all the batches is being fetched. For the future batches, you don’t have to spend any time waiting, and this would potentially reduce the query latency down to a single round trip of S3. That’s just 200 milliseconds overhead.
Benchmark vs. Presto
Taking these two techniques, so far, which is selective columnar fetch and prefetching during data planning with pipelining the fetch and execution, we did a simple benchmark. The benchmark was conducted in a small setup with about 200 gigabytes of data, one Pinot server. The queries were mostly aggregation queries with filters, GROUP BY and ORDER BY. We also included a baseline number with the same data on Presto to reference this with a decoupled architecture. Let’s see the numbers. Overall, Pinot with tiered storage was 5 times to 20 times faster than Presto.
What Makes Pinot Fast?
How is it that Pinot is able to achieve such blazing fast query latencies compared to other decoupled systems like Presto, even when we change the underlying design to be decoupled storage and compute? Let’s take a look at some of the core optimizations used in Pinot which help with that. Bringing back the relevant components of the architecture, we have broker, let’s say we have 3 servers, and say that each server has 4 segments. That means we have total 12 segments in this cluster.
When a query is received by the broker, it finds the servers to scatter the query to. In each server, it finds the segments it should process. Within each segment, we process certain number of documents based on the filters, then we aggregate the results on the servers. A final aggregation is done on the broker. At each of these points, we have optimizations to reduce the amount of work done. Firstly, broker side pruning is done to reduce the number of servers that we fan out to. Brokers ensure that they select the smallest subset of servers needed for a query and optimize it further using techniques like smart segment assignment strategies, partitioning, and so on.
Once the query reaches the server, more pruning is done to reduce the number of segments that it has to process on each server. Then within each segment, we scan the segment to get the documents that we need. To reduce the amount of work done and the document scan, we apply filter optimizations like indexes. Finally, we have a bunch of aggregation optimizations to calculate fast aggregations.
Let’s talk more about the pruning techniques available in Pinot, and how we’re able to use them even when segments have been moved to the tier. We have pruning based on min/max value columns, or partition-based pruning using partition info. Both of these metadata are cached locally, even if the segment is on a remote cloud object store. Using that, we are quickly able to eliminate segments where we won’t find the matching data. Another popular technique used in Pinot is Bloom filter-based pruning. These are built per segment.
We can read it to know if a value is absent from a given segment. This one is a lot more effective than the min/max based or partition-based pruning. These techniques really help us a lot because they help us really narrow down the scope of the segments that we need to process. It helps us reduce the amount of data that we are fetching and processing from S3.
Let’s take a look at the filter optimizations available in Pinot. All of these are available for use, even if the segment moves to the remote tier. We have inverted indexes where for every unique value, we keep a bitmap of matching doc IDs. We also have classic techniques like sorted index, where the column in question is sorted within the segment, so we can simply keep start and end document ID for the value. We also have range index, which helps us with range predicates such as timestamp greater than, less than, in between.
This query pattern is quite commonly found in user facing dashboards and in real-time anomaly detection. Then we have a JSON index, which is a very powerful index structure. If your data is in semi-structured form, like complex objects, nested JSON. You don’t need to invest in preprocessing your data into structured content, you can ingest it as-is, and Pinot will index every field inside your complex JSON, allowing you to query it extremely fast. Then we have the text index for free text search and RegEx b like queries, which helps with log analytics.
Then, geospatial index, so if you’re storing geo coordinates, it lets you compute geospatial queries, which can be very useful in applications like orders near you, looking for things that are 10 miles from a given location, and so on. We also have aggregation optimizations such as theta sketches, and HyperLogLog for approximate aggregations. All of these techniques we can continue using, even if the segment is moved on to a cloud object store. This is one of the major reasons why the query latency for Pinot is so much faster than traditionally decoupled storage and compute systems.
Benchmark vs. Tightly-Coupled Pinot
While these techniques did help us get better performance than traditionally decoupled systems, when compared to tightly coupled Pinot, which is our true baseline, we could see a clear slowdown. This showed that the two techniques that we implemented in our first version are not enough, they are not effective enough to hide all the data access latency from S3. To learn more from our first version, we stress tested it with a much larger workload.
We put 10 terabytes of data into a Pinot cluster with 2 servers that had a network bandwidth on each server of 1.25 gigabytes per second. Our first finding from the stress test was that the network was saturated very easily and very often. The reason is that, although we tried to reduce the amount of data to read with segment pruning and columnar fetch, we still read a lot of data unnecessarily for those columns, because we fetch the full column in the segment.
Especially, if you have high selectivity filters where you’re probably going to need just a few portions from the whole column, this entire columnar fetch is going to be wasteful. Then, this also puts pressure on the resources that we reserve for prefetching all this data. Also, once the network is saturated, all we can do from the system’s perspective, is what the instance network bandwidth will allow us. No amount of further parallelism could help us here. On the other hand, we noticed that when network was not saturated, we could have been doing a lot more work in parallel and reducing the sequential round trips we made to S3. Our two main takeaways were, reduce the amount of unnecessary data read, and increase the parallelism even more.
One of the techniques we added for reading less was an advanced configuration to define how to split the data across local versus remote. It doesn’t just have to be by data age, you can be super granular and say, I want this specific column to be local, or the specific index of this column to be local, and everything else on cloud storage. With this, you can pin lightweight data structures such as Bloom filters locally onto the instance storage, which is usually a very small fraction of the total storage, and it helps you do fast and effective pruning. Or you can also pin any other index structures that you know we’ll be using often.
Another technique we implemented is, instead of doing a whole columnar fetch all the time, we decided that we will just read relevant chunks of the data from the column. For example, bringing back our example from a few slides ago, in this query, when we are applying the region filter, after reading the inverted index, we know that we only need these few documents from the whole impressions column. Maybe we don’t need to fetch the full forward index, all we can do is just read small blocks of data during the post filter execution.
With that, our execution plan becomes, during prefetch, only fetch the region.inv_idx. Or the data that we need to read from the impressions column, we will read that on-demand, and only we will read few blocks. We tested out these optimizations on the 10-terabyte data setup. We took three queries of varying selectivity. Then we ran these queries with the old design that had only columnar fetch and prefetching and pipelining, and also with the new design where we have more granular block level fetches instead of full columnar fetch. We saw some amazing reduction in data size compared to our phase one. This data size reduction directly impacted and improved the query latency.
StarTree Index
One index that we did not talk about when we walked through the indexes in Pinot is the StarTree index. Unlike other indexes in Pinot, which are columnar, StarTree is a segment level index. It allows us to maintain pre-aggregated values for certain dimension combinations. You can choose exactly which dimensions you want to pre-aggregate, and also how many values you want to pre-aggregate at each level. For example, assume our data has columns, name, environment ID, type, and a metric column value along with a timestamp column.
We decided that we want to create a StarTree index, and only materialize the name and environment ID, and we only want to store the aggregation of sum of value. Also, that we will not keep more than 10 records unaggregated at any stage. This is how our StarTree will look. We will have a root node, which will split into all the values for the name column. In each name column, we will have again a split-up for all the values of environment ID. Finally, at every leaf node, we will store the aggregation value, sum of value.
Effectively, StarTree lets you choose between pre-aggregating everything, and doing everything on the fly. A query like this where we have a filter on name and environment ID and we are looking for sum of value, this is going to be super-fast because it’s going to be a single lookup. We didn’t even have to pre-aggregate everything for this, nor did we have to compute anything on the fly.
How did we effectively use this in tiered storage, because you can imagine that this index must be pretty big in size compared to other indexes like inverted or Bloom filter, so pinning it locally won’t work as that would be space inefficient. Prefetching it on the fly will hurt our query latency a lot. This is where all the techniques that we talked about previously came together. We pinned only the tree structure locally, which is very small, and lightweight.
As for the data at each node and aggregations, we continue to keep them in S3. When we got a query that could use this index, it quickly traversed the locally pinned tree, pointing us to the exact location of the result in the tree, which we could then get with a few very quick lookups on S3. Then we took this for a spin with some very expensive queries, and we saw a dramatic reduction in latency because the amount of data fetched had reduced.
More Parallelism – Post Filter
So far, we discussed techniques on how to reduce the amount of data read. Let’s talk about one optimization we are currently playing with to increase the parallelism. Bringing back this example where we knew from the inverted index that we’ll only need certain rows, and then we only fetch those blocks during the post filter evaluation phase. We build sparse indexes which help us get this information about which exact chunks we would need from this forward index in the planning phase itself.
Knowing this in the planning phase helps because now we’re able to identify and begin prefetching these chunks. In the planning phase, while the filter is getting evaluated, these chunks are getting prefetched in parallel so that the post filter phase is going to be much faster.
Takeaways
We saw a lot of techniques that we used in order to build tiered storage, such that we could keep the speed of Pinot, while reducing the cost. I’d like to summarize some of the key takeaways with tiered storage in Apache Pinot:
- We have unlocked flexibility and simplicity of using a single system for real-time as well as historical data.
- We’re able to use cheap cloud object storage directly in the query path instead of using disk or SSD, so we don’t have to worry about the cost spiraling out of control as our data volume increases.
- We’re able to get better performance than traditionally decoupled systems, because we’re effectively using our indexes, prefetching optimizations, pruning techniques, and so on.
- We also keep pushing the boundaries of the performance with newer optimizations to get closer to the latencies that we saw in tightly-coupled Pinot.
See more presentations with transcripts
MMS • RSS

TEMPO.CO, Jakarta – Beberapa orang, mungkin termasuk Anda kurang familiar jika mendengar nama dedaunan yang satu ini. Daun balakacida yang memiliki nama lain kirinyuh ini, sebenarnya masuk pada salah satu jenis tumbuhan pengganggu dari famili asteraceae. Umumnya balakacida banyak dijumpai di dataran dengan ketinggian sekitar 100 sampai 2800 mdpl, namun di Indonesia sendiri, balakacida justru dapat tumbuh di dataran rendah bahkan kurang dari 500 mdpl.
Apa itu Tanaman Balakacida ?
Tanaman balakacida merupakan gulma yang berbentuk serat berkayu yang dapat berkembang dengan cepat sehingga terkadang sulit dikendalikan pertumbuhannya. Ujung daun tumbuhan balakacida berbentuk runcing dimana kedua tepi daun di kanan kiri ibu tulang daun sedikit menuju keatas dan membentuk sudut lancip. Sementara itu, bentuk pangkal daun balakacida berbentuk ramping atau rata. Tepi daunnya adalah toreh dengan bentuk bergerigi dimana bentuk sinus dan angulusnya sama-sama lancip.
Batang tanaman balakacida berbentuk bulat dan tegak lurus dengan arah tumbuh batang. Pada permukaan batangnya, terdapat rambu dan permukaan berbulu seperti rambut. Tumbuhan tahunan ini, memiliki percabangan pada batang dengan menggunakan cara percabangan monopodial, dimana batang pokok tampak lebih jelas karena berukuran lebih besar dan panjang daripada cabang-cabangnya. Bentuk percabangan pada tumbuhan ini adalah tegak, dimana sudut antara batang dan cabang amat kecil, sehingga arah tubuh cabang lainnya pada pangkal sedikit serong keatas, namun selanjutnya hampir sejajar dengan batang pohonnya.
Apa Manfaat Tanaman balakacida?
Tumbuhan ini memiliki beragam manfaat bagi kesehatan manusia. Berikut beberapa manfaat dari tumbuhan balakacida bagi kesehatan.
Obat luka tanpa menimbulkan bengkak
Khasiat utama dari tanaman balakacida adalah untuk mengobati luka jaringan lunak, luka bakar, dan infeksi kulit. Daun dari tumbuhan ini dapat berkhasiat sebagai antelmintik, antimalaria, analgesik, antispasmodik, antipiretik, diuretik, antihipertensi, antibakteri, antijamur, anti inflamasi, insektisida, antioksidan, infeksi saluran kemih, serta juga mampu berperan dalam pembekuan darah. Secara tradisional, daun balakacida juga digunakan secara turun-temurun sebagai obat penyembuhan luka, obat kumur untuk sakit tenggorokan, obat batuk, obat demam, obat sakit kepala, dan anti diare.
Bahan insektisida nabati untuk mengendalikan beberapa jenis mikroorganisme
Menariknya lagi, tumbuhan ini juga dapat berfungsi sebagai bahan insektisida nabati untuk mengendalikan beberapa jenis mikroorganisme karena mengandung Pryrrolizidine alkaloids yang bersifat racun pada serangga.
Daun balakacida untuk mencegah kanker serviks
Seperti dilansir dari laman Steemit.com, daun balakacida dapat digunakan untuk mencegah penyakit kanker serviks. Kanker serviks merupakan salah satu penyakit yang paling banyak diderita oleh wanita. Untuk melakukan pencegahan ini, Anda bisa meminum teh daun balakacida secara rutin.
Obat Vertigo
Vertigo merupakan salah satu penyakit yang tidak bisa disepelekan, penyakit ini tidak hanya dapat mengakibatkan Anda masuk rumah sakit, tetapi juga berpotensi menyebabkan kematian. Kabar baiknya, daun balakacida dapat Anda gunakan untuk mengobati penyakit ini. Anda bisa meminum rebusan daun balkacida ketika vertigo Anda kumat.
Obat Maag
Balakacida tidak hanya mampu mencegah penyakit maag kambuh, tetapi tumbuhan ini juga dipercaya dapat mengobati penyakit maag secara keseluruhan jika Anda mengonsumsinya secara berkala.
Pilihan Editor: Ini Sebab Putri Malu Menutup saat Dipegang
<!–  –>
–>
–>
MMS • RSS
MongoDB Queryable Encryption enables organizations to meet the strictest data-privacy requirements by providing first-of-its-kind, end-to-end data encryption
CHICAGO, Aug. 15, 2023 /PRNewswire/ — MongoDB, Inc. (NASDAQ: MDB), today at its developer conference MongoDB.local Chicago, announced the general availability of MongoDB Queryable Encryption, a first-of-its-kind technology that helps organizations protect sensitive data when it is queried and in-use on MongoDB. MongoDB Queryable Encryption significantly reduces the risk of data exposure for organizations and improves developer productivity by providing built-in encryption capabilities for highly sensitive application workflows—such as searching employee records, processing financial transactions, or analyzing medical records—with no cryptography expertise required. To get started with MongoDB Queryable Encryption, visit mongodb.com/products/capabilities/security/encryption.
![]()
“Protecting data is critical for every organization, especially as the volume of data being generated grows and the sophistication of modern applications is only increasing. Organizations also face the challenge of meeting a growing number of data privacy and customer data protection requirements,” said Sahir Azam, Chief Product Officer at MongoDB. “Now, with MongoDB Queryable Encryption, customers can protect their data with state-of-the-art encryption and reduce operational risk—all while providing an easy-to-use capability developers can quickly build into applications to power experiences their end-users expect.”
Data protection is the top priority among organizations across industries today as they face a growing number of regulations and compliance requirements to protect personally identifiable information (PII), personal health information (PHI), and other sensitive data. A common data protection capability organizations use to protect data is encryption, where sensitive information is made unreadable by cryptographic algorithms using an encryption key—and only made readable again using a decryption key customers securely manage. Data can be protected through encryption in-transit when traveling over networks, at-rest when stored, and in-use when it is being processed. However, working with encrypted data in-use poses significant challenges because it needs to be decrypted before it can be processed or analyzed. Organizations that work with highly sensitive data want to improve their security posture and meet compliance requirements by encrypting their data throughout its full lifecycle—including while it is being queried. Until now, the only way to keep information encrypted during the entire lifecycle was to employ highly specialized teams with extensive expertise in cryptography.
With the general availability of MongoDB Queryable Encryption, customers can now secure sensitive workloads for use cases in highly regulated or data sensitive industries like financial services, health care, government, and critical infrastructure services by encrypting data while it is being processed and in-use. Customers can quickly get started protecting data in-use by selecting the fields in MongoDB databases that contain sensitive data that need to be encrypted while in-use. For example, an authorized application end-user at a financial services company may need to query records using a customer’s savings account number. When configured with MongoDB Queryable Encryption, the content of the query and the data in the savings account field will remain encrypted when traveling over the network, while it is stored in the database, and while the query processes the data to retrieve relevant information. After data is retrieved, it becomes visible only to an authorized application end user with a customer-controlled decryption key to help prevent inadvertent data exposure or exfiltration by malicious actors. With MongoDB Queryable Encryption, developers can now easily implement first-of-its-kind encryption technology to ensure their applications are operating with the highest levels of data protection and that sensitive information is never exposed while it is being processed—significantly reducing the risk of data exposure.
The MongoDB Cryptography Research Group developed the underlying encryption technology behind MongoDB Queryable Encryption, which is open source. Organizations can freely examine the cryptographic techniques and code behind the technology to help meet security and compliance requirements. MongoDB Queryable Encryption can be used with AWS Key Management Service, Microsoft Azure Key Vault, Google Cloud Key Management Service, and other services compliant with the key management interoperability protocol (KMIP) to manage cryptographic keys. The general availability of MongoDB Queryable Encryption includes support for equality queries, with additional query types (e.g., range, prefix, suffix, and substring) generally available in upcoming releases.
Since the release of MongoDB Queryable Encryption in preview last year, MongoDB has worked in partnership with customers including leading financial institutions and Fortune 500 companies in the healthcare, insurance, and automotive manufacturing industries to fine-tune the service for general availability.
Renault Group is at the forefront of a mobility that is reinventing itself. Strengthened by its alliance with Nissan and Mitsubishi Motors, and its unique expertise in electrification, Renault Group comprises four complementary brands—Renault, Dacia, Alpine, and Mobilize—offering sustainable and innovative mobility solutions to its customers. “MongoDB Queryable Encryption is significant for ensuring data protection and security compliance,” said Xin Wang, Solutions Architect at Renault. “Our teams are eager for the architecture pattern validation of Queryable Encryption and are excited about its future evolution, particularly regarding performance optimization and batch operator support. We look forward to seeing how Queryable Encryption will help meet security and compliance requirements.”
About MongoDB
Headquartered in New York, MongoDB’s mission is to empower innovators to create, transform, and disrupt industries by unleashing the power of software and data. Built by developers, for developers, our developer data platform is a database with an integrated set of related services that allow development teams to address the growing requirements for today’s wide variety of modern applications, all in a unified and consistent user experience. MongoDB has tens of thousands of customers in over 100 countries. The MongoDB database platform has been downloaded hundreds of millions of times since 2007, and there have been millions of builders trained through MongoDB University courses. To learn more, visit mongodb.com.
Forward-looking Statements
This press release includes certain “forward-looking statements” within the meaning of Section 27A of the Securities Act of 1933, as amended, or the Securities Act, and Section 21E of the Securities Exchange Act of 1934, as amended, including statements concerning MongoDB’s technology and offerings. These forward-looking statements include, but are not limited to, plans, objectives, expectations and intentions and other statements contained in this press release that are not historical facts and statements identified by words such as “anticipate,” “believe,” “continue,” “could,” “estimate,” “expect,” “intend,” “may,” “plan,” “project,” “will,” “would” or the negative or plural of these words or similar expressions or variations. These forward-looking statements reflect our current views about our plans, intentions, expectations, strategies and prospects, which are based on the information currently available to us and on assumptions we have made. Although we believe that our plans, intentions, expectations, strategies and prospects as reflected in or suggested by those forward-looking statements are reasonable, we can give no assurance that the plans, intentions, expectations or strategies will be attained or achieved. Furthermore, actual results may differ materially from those described in the forward-looking statements and are subject to a variety of assumptions, uncertainties, risks and factors that are beyond our control including, without limitation: the impact the COVID-19 pandemic may have on our business and on our customers and our potential customers; the effects of the ongoing military conflict between Russia and Ukraine on our business and future operating results; economic downturns and/or the effects of rising interest rates, inflation and volatility in the global economy and financial markets on our business and future operating results; our potential failure to meet publicly announced guidance or other expectations about our business and future operating results; our limited operating history; our history of losses; failure of our platform to satisfy customer demands; the effects of increased competition; our investments in new products and our ability to introduce new features, services or enhancements; our ability to effectively expand our sales and marketing organization; our ability to continue to build and maintain credibility with the developer community; our ability to add new customers or increase sales to our existing customers; our ability to maintain, protect, enforce and enhance our intellectual property; the growth and expansion of the market for database products and our ability to penetrate that market; our ability to integrate acquired businesses and technologies successfully or achieve the expected benefits of such acquisitions; our ability to maintain the security of our software and adequately address privacy concerns; our ability to manage our growth effectively and successfully recruit and retain additional highly-qualified personnel; and the price volatility of our common stock. These and other risks and uncertainties are more fully described in our filings with the Securities and Exchange Commission (“SEC”), including under the caption “Risk Factors” in our Quarterly Report on Form 10-Q for the quarter ended April 30, 2023, filed with the SEC on June 2, 2023 and other filings and reports that we may file from time to time with the SEC. Except as required by law, we undertake no duty or obligation to update any forward-looking statements contained in this release as a result of new information, future events, changes in expectations or otherwise.
Media Relations
MongoDB
press@mongodb.com
![]() View original content to download multimedia:https://www.prnewswire.com/news-releases/mongodb-announces-general-availability-of-end-to-end-data-encryption-technology-301901162.html
View original content to download multimedia:https://www.prnewswire.com/news-releases/mongodb-announces-general-availability-of-end-to-end-data-encryption-technology-301901162.html
SOURCE MongoDB, Inc.

MMS • RSS

(Gorodenkoff/Shutterstock)
Redis today unleashed a torrent of new functionality in the database, including vector search, native triggers, and a built-in change data capture capability, among others. The features reflect priorities that new CEO Rowan Trollope has brought to the growing NoSQL database vendor after joining the company in February.
Trollope arrived at Redis with some notches in his belt as a tech CEO, including four years as CEO of Five9 (FIVN), a video conferencing company that he took public and which is valued in the billions. But before accepting the Redis job, Trollope, who has 30 years of experience as a developer, took the database out for a spin.
After downloading the open source software, he used it to rearchitect the data store of an existing app. He liked what he saw, calling it “remarkable.” He also saw an opportunity for refinement in some places.
“My experience as a developer with databases was they were painful,” Trollope says. “I just want something that’s going to work, that’s going to be easy, that’s going to be seamless.”
The previous app that Trollope rearchitected was using Firebase, a mobile database that he termed “very complex.” That complexity was lacking in his Redis tryout.
“The core Redis OSS…is really, really phenomenal in terms of how easy it is to use, how delightful the API is, how straightforward it is,” Trollope tells Datanami. “There’s a handful of companies that get it really right. Stripe is a good example. The API is just a real beautiful thing, and I found that in Redis.”

Rowan Trollope joined Redis as its CEO in February 2023
Trollope was clearly intrigued by what he saw in Redis, characterizing it as a super-fast database with an elegant API. App users today demand quick loading times and rapid responses, and so he saw a tremendous growth potential for Redis, which had over 10,000 paying customers already, and many times that number using the open source product.
“That’s a big part of what I found appealing here is that, devs in general want to build apps that are faster and faster and faster,” he says. “There’s sort of like this perennial quest to make the fastest experience possible for their users, and rightly so–that’s what users want.”
Ofer Bengal, who had been Redis’ CEO since the company was founded back in 2011, decided it was time to hand the reins over to another CEO to finally get Redis over the hump: completing the long-awaited IPO. Trollope had that IPO experience, but the perspective of a developer to boot. However, Trollope realized it was not all rainbows and sunshine in Redis-land. Yes, the core technology was solid, but when you venture outside of the well-trod lanes, things get a little dicey.
“My experience with the technology out of the gate left me wanting a little bit at the edges of the experience,” he says. “…[W]hile the core was built by Salvatore [Sanfillippo] and by the Redis company, the edge of the experience–the SDKs and the integration and even the documentation–those were all built by the community. So as I visited upon this experience, it was far less than ideal.”
For example, the Redis company had no opinion, and gave customers no direction, on which software development kits to use. Instead, the default approach was to “read a bunch of random threads” on Stack Overflow.

Redis 7.2 features a new data integration capability based on Debezium CDC
“You’re kind of left to figure it out on your own as a developer and that’s not the kind of experience that you need if you’re going scale a technology like this so even greater heights,” Trollope says.
So for 7.2, Redis made a concerted effort to assemble the best SDKs for a variety of languages. This release features Jedis for Java, node-redis for NodeJS, redis-py for Python, NRedisStack for .Net, and Go-Redis for Go. In some cases, the company acquired the libraries, while in others, it brought the maintainers onboard as Redis employees. In either case, the idea is that new developers will have an easier time figuring out how to get productive.
Redis gets its speed from being an in-memory data store. But not everyone wants to put evefrything in DRAM, which is expensive. The company previously offered the capability to push some data into Flash solid state drives (SSDs).
With 7.2, the company rewrote Redis for Flash. The new version, dubbed Auto Tiering, will automatically move less frequently used data to SSDs, while offering twice the throughput of the previous version. Customers can save up to 70% of the costs they would incur if they kept all their data in DRAM, which will tamp down the temptation to look for other databases, Trollope says.
“That’s going to be a theme for us moving forward,” he says. “I heard it from a bunch of customers. They said, if you could give us a way to make certain workloads more cost effective, even if that means they’re little slower, we’re game… The more complexity you add to your application, the worse off you are. If you can do it with fewer tools and fewer platforms, that’s a good thing.”![]()
Moving data into and out of Redis gets easier with version 7.2 thanks to a new feature called Redis Data Integration. Trollope likened RDI to a CDC-type of functionality that will enable customers to move data to and from Redis Enterprise and Oracle, Postgres, MySQL, and Cassandra in real time. The offering, which utilizes open source CDC from Debezium or other CDC technologies, supports a couple of use cases, including read-through cache and write behind, Trollope says.
Redis–which dropped “Labs” from its name back in 2021–has come a long way from being just a high-speed cache, and part of that is supporting higher order functions like triggers and functions. However, the database previously required engineers to know a language like C++ or Lua to use this capability. With 7.2, Redis is lowering the bar to tap into triggers and functions by allowing engineers to use JavaScript and Typescript to build them.
“So you can very easily extend Redis now and you don’t have to be a C++ programmer or learn a new language like Lua,” Trollope says. “You can very easily extend the platform and build capabilites using JavaScript.”
Last but certainly not least is the new vector search capability. Redis had been investing in building out its vector search capabilities for years before Trollope joined the Mountain View, California company. But the timing with the release of ChatGPT last fall spurred the company to get vector similarity search out the door.
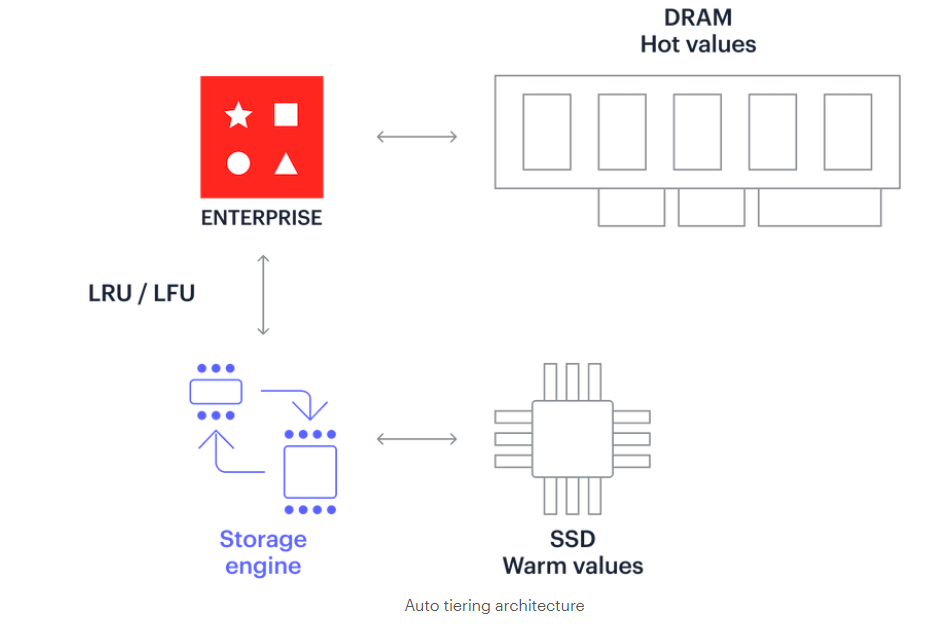
Redis Auto Tiering makes better use of Flash SSDs
Redis users can now use the database to store vector embeddings that they created by running their documents or images through an LLM managed by OpenAI, Microsoft, Google, or other provider. Storing these vector embeddings in Redis enables users to deliver a better, more customized experience to their customers via the search function on a website, chatbot interaction, or other AI use cases.
“What we found is that just a tremendous number of use cases [for vector search],” Trollope says. Chatbots are one popular use case, as is real-time face detection, he says.
As if adding vector similarity search wasn’t enough, Redis has also now made the search functionality multi-threaded. Going multi-threaded with the search capability is important, Trollope says, because search inherently relies on a scale-up architecture, rather than a scale-out architecture.
“The way that you scale search, actually–you can’t scale it horizontally,” he says. “You have to scale it vertically, because it’s a log scaling problem, not a linear scale, so therefore, having the ability to scale vertically is really important.”
Despite the large number of new gizmos to play with in 7.2, there is lots more on the way from Redis. “There’s more coming, absolutely,” the new CEO says. “There’s tons of needs from customers.”
There’s also an IPO in Redis’ future, but we’ll have to see when the market is ready for that.
Related Items:
Why Redis Needs Enterprise Developers
Redis Labs Gains VC Funding, New Enterprise Customers
Redis Labs Emerges to Push Hosted NoSQL Business
Tower Research Capital LLC TRC Increases Holdings in MongoDB, Demonstrating … – Best Stocks
MMS • RSS
Tower Research Capital LLC TRC, a prominent institutional investor, has significantly increased its holdings in MongoDB, Inc. (NASDAQ:MDB) during the first quarter of this year, according to the latest 13F filing with the Securities & Exchange Commission (SEC). The company acquired an additional 3,320 shares of MongoDB, bringing its total ownership to 6,173 shares. As of the end of the quarter, these holdings were valued at an impressive $1,439,000.
The move by Tower Research Capital LLC TRC indicates a growing confidence in MongoDB’s potential and its ability to generate substantial returns. MongoDB is a leading database platform that offers exceptional performance for handling modern applications’ complex data requirements.
In June this year, MongoDB released its earnings results for the quarter ended March 31st, revealing remarkable success. The company reported earnings per share (EPS) of $0.56 for the quarter, surpassing analysts’ consensus estimates by a staggering $0.38 per share. This positive outcome demonstrates MongoDB’s strong financial performance and reflects the successful execution of its business strategy.
Despite some skepticism surrounding the company’s negative net margin of 23.58% and negative return on equity of 43.25%, MongoDB has managed to achieve remarkable revenue growth. In the first quarter alone, it generated $368.28 million in revenue compared to analysts’ consensus estimate of $347.77 million—a significant increase of 29% year-over-year.
These impressive figures indicate that despite certain profitability concerns in previous periods, MongoDB is making significant improvements. Its ability to exceed expectations provides promising signs for future profitability and growth prospects.
Market experts are optimistic about the future outlook for MongoDB as well. They predict that for the current fiscal year, MongoDB will post earnings per share (EPS) of -2.8 on average—a notable improvement from last year’s ($1.15) loss per share.
This increased investment from Tower Research Capital LLC TRC demonstrates a high level of confidence in MongoDB’s future. Tower Research Capital LLC TRC recognizes the company’s potential and appreciates its ability to deliver valuable solutions that meet modern application requirements. As an institutional investor, their decision to augment their holdings signifies the belief in MongoDB’s long-term success and the opportunity to generate substantial returns.
Overall, with its robust database platform, notable financial performance, and positive market outlook, MongoDB is poised to continue its ascent as a key player in the industry. The increased investment by Tower Research Capital LLC TRC serves as a testament to the company’s steady growth trajectory. Investors and market analysts will undoubtedly monitor MongoDB’s progress with great interest, as it navigates through promising opportunities and expands its reach in the dynamic landscape of modern data management.
MongoDB, Inc.
MDB
Buy
Updated on: 15/08/2023
MongoDB: Hedge Fund Activity and Research Report Analysis
MongoDB: A Closer Look at Hedge Fund Activity and Recent Research Reports
August 15, 2023
In the ever-changing world of investing, hedge fund activity plays a crucial role in shaping market trends and investor sentiment. MongoDB, Inc. (MDB), a leading provider of modern, general-purpose databases, has recently seen changes in its positions by several hedge funds. These movements shed light on the investment strategies employed by these institutions.
Cherry Creek Investment Advisors Inc. increased its position in MongoDB by 1.5% during the fourth quarter of last year. The firm now owns 3,283 shares of the company’s stock, valued at $646,000 after acquiring an additional 50 shares. Similarly, CWM LLC increased its position in MongoDB by 2.4% during the first quarter, adding 52 shares to its holdings which are now valued at $521,000.
Cetera Advisor Networks LLC also boosted its stake in shares of MongoDB by 7.4% during the second quarter. The firm now owns 860 shares of the company’s stock worth $223,000 after purchasing an additional 59 shares. First Republic Investment Management Inc., on the other hand, saw its stake increase by 1.0% during the fourth quarter with the acquisition of an additional 61 shares valued at $1,261,000.
Lastly, Janney Montgomery Scott LLC increased its stake in MongoDB by 4.5% during the fourth quarter with an addition of 65 shares now valued at $298,000.
These moves reflect institutional investors’ confidence in MDB’s growth prospects and may signal potential opportunities for individual investors to consider as well.
Turning our attention to recent research reports on MDB, analysts have been avidly tracking and evaluating this technology company’s performance. Barclays raised their target price on MDB from $374 to $421 in a research note released on June 26th. The research firm 58.com also reissued their “maintains” rating on the stock in another June 26th research note.
Royal Bank of Canada joined the conversation by raising its price objective on MDB from $400 to $445. Tigress Financial was even more optimistic, lifting their price objective from $365 to $490 in another research note issued on June 28th. Finally, William Blair reaffirmed an “outperform” rating for MongoDB in a research note released on June 2nd.
This diverse range of ratings and price targets portrays the volatility and complexity surrounding the assessment of MongoDB’s current and future performance. However, data from Bloomberg.com indicates that MDB currently holds a consensus rating of “Moderate Buy,” with an average target price of $378.09 among analysts.
In other news related to MongoDB, Director Dwight A. Merriman made significant transactions involving company shares. On June 1st, he sold 3,000 shares at an average price of $285.34, amounting to a total transaction value of $856,020. Following this sale, Merriman holds approximately 1.22 million shares valued at $348,101,674.36.
Insiders have continued to offload company stock over the past three months as well, with a total of 102,220 shares sold at a value of $38,763,571. As it stands now, insiders own around 4.80% of MDB’s outstanding stock.
MDB opened at $364.41 on Tuesday and boasts a market capitalization of $25.72 billion with a negative price-to-earnings ratio (-78.03) and a beta coefficient of 1.13 indicating moderate volatility compared to the market as a whole.
The one-year low for MDB stands at $135.15 while its highest point in the same period reached an impressive high of $439 per share.
Taking into account the company’s fifty-day and 200-day simple moving averages, MDB currently stands at $394.12 and $291.06, respectively. The current ratio of 4.19 indicates a healthy liquidity position for the company.
These figures paint a picture of MongoDB as an intriguing player in the technology sector, showcasing both potential for growth and volatility. Investors and analysts alike should closely monitor developments surrounding this stock, as it may present exciting investment opportunities in the future.
In conclusion, MongoDB has seen hedge funds make adjustments to their positions while various research reports have offered differing opinions on its performance. As this data unfolds, investors can glean insights into MongoDB’s trajectory by analyzing these various factors affecting market sentiment and the overall investment landscape.
Disclaimer: This article is for informational purposes only and should not be seen as financial advice.
MMS • RSS
MongoDB has taken its “queryable encryption” (QE) capabilities to general availability (GA) – allowing users to query fully encrypted data.
MongoDB queryable encryption is a set of client-side libraries and server-side code that let applications encrypt sensitive fields in documents, so they remain encrypted while the server processes them. (Clever.)
The company has kept the underlying encryption technology open source with Go, Node/Javascript, Python and other libraries published under Apache 2.0 licences “so developers can freely examine our cryptographic techniques and code” per Kenn White, Security Principal, MongoDB.
White noted to The Stack today that “this transparency also helps our customers meet security and compliance requirements.”
MongoDB queryable encryption: An example?
The New York-based company gave the example of an “authorized application end-user at a financial services company [who] may need to query records using a customer’s savings account number.
“When configured with MongoDB Queryable Encryption, the content of the query and the data in the savings account field will remain encrypted when traveling over the network, while it is stored in the database, and while the query processes the data to retrieve relevant information.
“After data is retrieved, it becomes visible only to an authorized application end user with a customer-controlled decryption key to help prevent inadvertent data exposure or exfiltration by malicious actors.”
MongoDB said its QE design goals included protection against insider threats as well as the risk of stolen credentials, misconfigurations, phishing or system errors: “QE needs to protect the database against an adversary that accesses the database through legitimate means and, in particular, using commands that are authorized for its role” a technical whitepaper published today (August 15, 2023) emphasises.
See also: The world’s first fully specified, end-to-end encryption standard just landed. That’s big
GA comes 14 months after a preview release explored by a range of blue chip customers including Renault, and the company says it has been focused on improving user experience and latency over the past year.
Queryable Encryption can be used with AWS, Azure, and GCP key management services as well as other services compliant with the key management interoperability protocol (KMIP).
Another goal has been making it easier for developers to create queryable encrypted apps without needing cryptographic expertise.
MongoDB queryable encryption: Get your math on…

The queryable encryption capabilities build on the pioneering work of Brown University cryptographer Seny Kamara and Tarik Moataz.
The two co-founded Aroki Systems, a queryable encryption database company bought by MongoDB in 2021 – and backed by a strong MongoDB team have refined the capabilities to improve usability.
Kenn White, Security Principal, MongoDB, told The Stack that the company had been “focused on performance and optimising for typical operational workload patterns, as we talked with customers during the beta/preview phase, and it paid off – we managed to make 5-100X improvements in latency and throughput over the initial release.”
He added: “Our early adopters were curious about the levels at which data can be encrypted. Understanding that the needs for encryption may vary, we quickly made sure that flexibility was in-built to Queryable Encryption. Users can selectively encrypt individual fields within a document, a subdocument, or the entire document. Each field is secured with its own key and is decrypted seamlessly on the client.”
QE clients were designed to be stateless so that they can be used by short-lived and lightweight clients (e.g., running in containers).
White noted to The Stack in an emailed comment that “one thing that may be surprising to hear is that only a portion of the team’s work was dedicated to cryptography per se – a major amount of our engineering went into the developer experience: reducing installation and setup friction, carefully evaluating default settings and eliminating unnecessary choices in lieu of opinionated safe & performant defaults.
“This technology is integrated into virtually every major programming language, so making simple tutorials & best practices in all our developer docs was top of mind, be they C#.NET, Python, Java, Go or any of the dozen+ frameworks we support,” he added.
“Our in-house Cryptography Research Group spent hundreds of hours working side by side with the core Engineering and Product Security teams during the design and development phases…
“We’ve briefed and assisted front-line developers working on introducing Queryable Encryption into applications spanning capital markets, investment and retail banking, health insurers, retail card payments, and consumer electronics. We learned so much about how real customers struggle to shore up their defensive posture and countless interesting use cases, most of which we’re obligated to not share. It’s early days, but by every indication there is strong interest in nearly every vertical, and we’re thrilled to see this technology reach GA,” he concluded.
nb. The Stack typically aims to break down some of the technology world’s innovations into digestible language as well as explaining how it might be deployed but with structured encryption, as with homomorphic encryption, our reach exceeds our grasp; whilst the deployability of the technology may have had some of the complexity stripped out of it, its fundamental machinery is understandably formidably complex. We can, however, point more educated readers to this interesting technical whitepaper and this somewhat more esoteric paper by Seny Kamara and Tarik Moataz published this month. Happy reading.