Month: August 2023

MMS • RSS
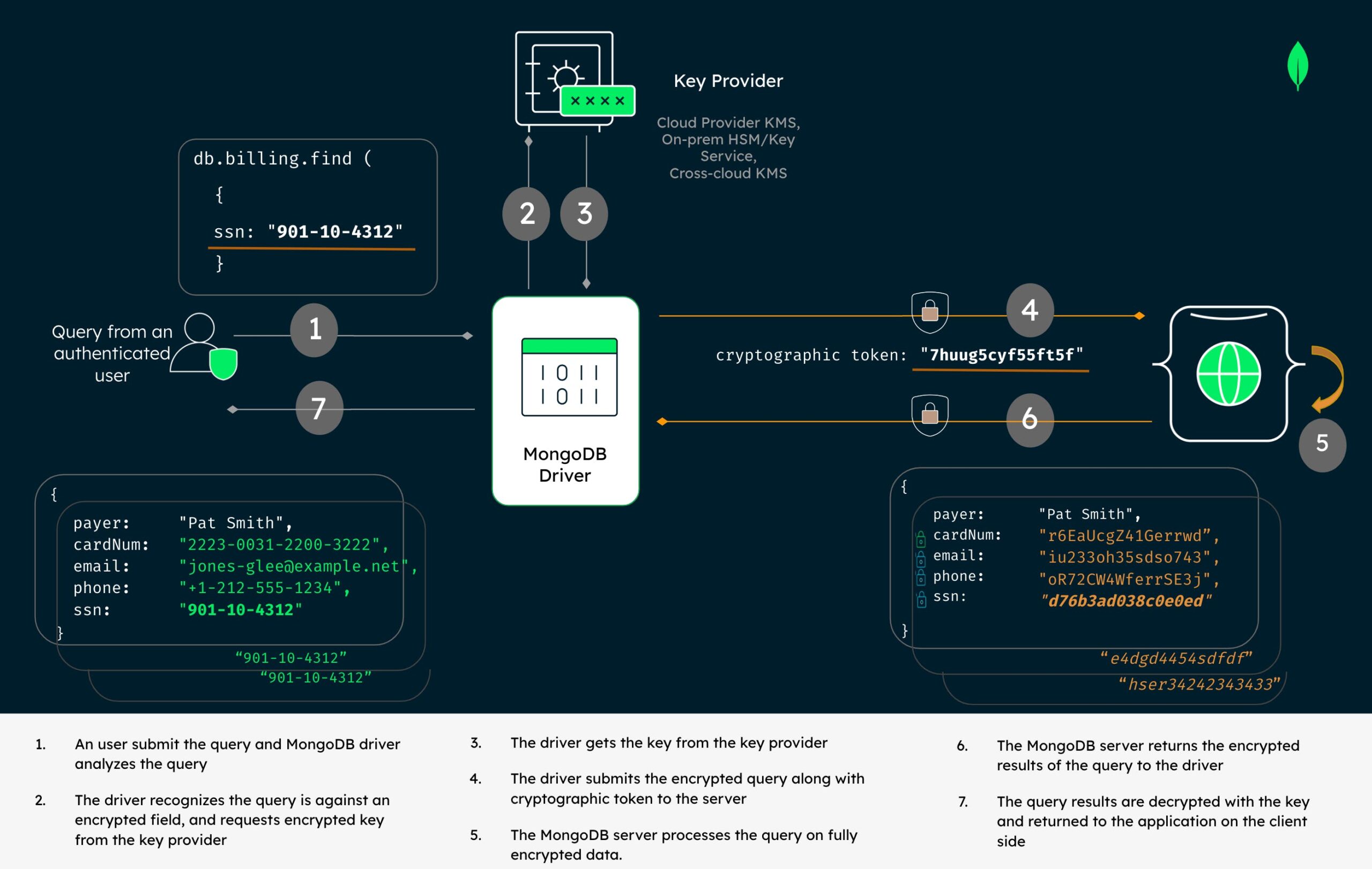
MongoDB has made its end-to-end data encryption technology available for organisations that need to meet the most stringent data privacy requirements. The Queryable Encryption system from the database tech platform is designed to make building in data privacy easier for developers with no cryptography expertise.

Announced at the company’s developer conference, MongoDB.local Chicago, Queryable Encryption is specifically designed for sensitive application workflows, adding built-in encryption capabilities. Uses could be processing employee records, processing financial transactions or even analysing medical records. Automaker Renault is the first MongoDB customer to use the system.
“Protecting data is critical for every organisation, especially as the volume of data being generated grows and the sophistication of modern applications is only increasing,” explained Sahir Azam, chief product officer for MongoDB. “Organisations also face the challenge of meeting a growing number of data privacy and customer data protection requirements.”
Businesses are facing a growing number of regulations and compliance requirements around data, particularly where it is considered high risk. This has made data protection a top priority, with encryption one of the most common approaches. There is a need to protect data at each stage of the process, including in-transit, in-situ and when in use.
The data has to be decrypted before it can be processed or analysed and this creates a risk point for companies working on particularly sensitive information. Organisations need to encrypt the data throughout its full lifecycle and previously this required a specialist team with expertise in cryptography. MongoDB says its new service makes this process easier.
MongoDB promises full process encryption
MongoDB says Queryable Encryption lets customers secure sensitive workloads by encrypting data while it is being processed and in-use. They select the fields in a database that include the sensitive data and encrypt it even during processing.
It gives the example of requesting a customer saving’s account number. The system ensures the savings data remain encrypted when travelling over the network, when stored in the database and when a query is processing the data to retrieve relevant information. Only an authorised application will be able to see the unencrypted information once it has been retrieved and processed by the system. The encryption is easily implementable by a developer working with MongoDB.
It was developed by the MongoDB Cryptography research group and it has been made available open source. Organisations can see the techniques and code behind the technology to help meet security and compliance requirements.
Content from our partners



It has been enabled for MongoDB installations using AWS Key Management Service, Microsoft Azure Key Vault, Google Cloud Key Management Service, and other services compliant with the key management interoperability protocol (KMIP).
Renault Group is one of the first companies to use MongoDB Queryable Encryption. Xin Wang, solutions architect at Renault said it was significant for ensuring data protection and security compliance. “Our teams are eager for the architecture pattern validation of Queryable Encryption and are excited about its future evolution, particularly regarding performance optimization and batch operator support. We look forward to seeing how Queryable Encryption will help meet security and compliance requirements.”
MMS • RSS
MongoDB Queryable Encryption helps organizations protect sensitive data when it is queried and in-use on MongoDB. It reduces the risk of data exposure for organizations and improves developer productivity by providing built-in encryption capabilities for sensitive application workflows—such as searching employee records, processing financial transactions, or analyzing medical records—with no cryptography expertise required.

“Protecting data is critical for every organization, especially as the volume of data being generated grows and the sophistication of modern applications is only increasing. Organizations also face the challenge of meeting a growing number of data privacy and customer data protection requirements,” said Sahir Azam, Chief Product Officer at MongoDB. “Now, with MongoDB Queryable Encryption, customers can protect their data with state-of-the-art encryption and reduce operational risk—all while providing an easy-to-use capability developers can quickly build into applications to power experiences their end-users expect.”
Data protection is the top priority among organizations across industries today as they face a growing number of regulations and compliance requirements to protect personally identifiable information (PII), personal health information (PHI), and other sensitive data. A common data protection capability organizations use to protect data is encryption, where sensitive information is made unreadable by cryptographic algorithms using an encryption key—and only made readable again using a decryption key customers securely manage. Data can be protected through encryption in-transit when traveling over networks, at-rest when stored, and in-use when it is being processed.
However, working with encrypted data in-use poses significant challenges because it needs to be decrypted before it can be processed or analyzed. Organizations that work with highly sensitive data want to improve their security posture and meet compliance requirements by encrypting their data throughout its full lifecycle—including while it is being queried. Until now, the only way to keep information encrypted during the entire lifecycle was to employ highly specialized teams with extensive expertise in cryptography.
With the general availability of MongoDB Queryable Encryption, customers can now secure sensitive workloads for use cases in highly regulated or data sensitive industries like financial services, health care, government, and critical infrastructure services by encrypting data while it is being processed and in-use. Customers can quickly get started protecting data in-use by selecting the fields in MongoDB databases that contain sensitive data that need to be encrypted while in-use.
For example, an authorized application end-user at a financial services company may need to query records using a customer’s savings account number. When configured with MongoDB Queryable Encryption, the content of the query and the data in the savings account field will remain encrypted when traveling over the network, while it is stored in the database, and while the query processes the data to retrieve relevant information. After data is retrieved, it becomes visible only to an authorized application end user with a customer-controlled decryption key to help prevent inadvertent data exposure or exfiltration by malicious actors.
With MongoDB Queryable Encryption, developers can now easily implement first-of-its-kind encryption technology to ensure their applications are operating with the highest levels of data protection and that sensitive information is never exposed while it is being processed—significantly reducing the risk of data exposure.
The MongoDB Cryptography Research Group developed the underlying encryption technology behind MongoDB Queryable Encryption, which is open source. Organizations can freely examine the cryptographic techniques and code behind the technology to help meet security and compliance requirements.
MongoDB Queryable Encryption can be used with AWS Key Management Service, Microsoft Azure Key Vault, Google Cloud Key Management Service, and other services compliant with the key management interoperability protocol (KMIP) to manage cryptographic keys. The general availability of MongoDB Queryable Encryption includes support for equality queries, with additional query types (e.g., range, prefix, suffix, and substring) generally available in upcoming releases.
MongoDB rolls out queryable encryption to secure sensitive data workflows | CSO Online
MMS • RSS

Developer data platform MongoDB has announced the general availability of queryable encryption, an end-to-end data encryption technology for securing sensitive application workflows. It is designed to reduce the risk of data exposure for organizations and helps businesses protect sensitive information when it is queried/in-use on MongoDB.
MongoDB’s queryable encryption can be used with AWS Key Management Service, Microsoft Azure Key Vault, Google Cloud Key Management Service, and other services compliant with the key management interoperability protocol (KMIP) to manage cryptographic keys, the company said.
General availability includes support for equality queries, with additional query types (e.g., range, prefix, suffix, and substring) available in upcoming releases, the firm added. MongoDB first introduced a preview version of queryable encryption at MongoDB World last year.
Queryable encryption provides the capability to reduce the attack surface for confidential data in several use cases. Data remains encrypted at insert, storage, and query, with both queries and their responses encrypted over the wire and randomized for resistance to frequency analysis. However, there is a cost to space and time requirements for queries involving encrypted fields.
Users select fields to encrypt based on data sensitivity
With the general availability of queryable encryption, customers can secure sensitive workloads for use cases in highly regulated or data-sensitive industries such as financial services, health care, government, and critical infrastructure by encrypting data while it is being processed and in use, MongoDB said in a press release. Users can select the fields in MongoDB databases that contain sensitive data that need to be encrypted.
For example, an authorized application end-user at a financial services company may need to query records using a customer’s savings account number. When configured with MongoDB queryable encryption, the content of the query and the data in the savings account field will remain encrypted when traveling over the network, while it is stored in the database, and while the query processes the data to retrieve relevant information, according to the firm.
MMS • RSS
CHICAGO, Aug. 15, 2023 — MongoDB, Inc., today at its developer conference MongoDB.local Chicago, announced the general availability of MongoDB Queryable Encryption, a first-of-its-kind technology that helps organizations protect sensitive data when it is queried and in-use on MongoDB.
![]() MongoDB Queryable Encryption significantly reduces the risk of data exposure for organizations and improves developer productivity by providing built-in encryption capabilities for highly sensitive application workflows—such as searching employee records, processing financial transactions, or analyzing medical records—with no cryptography expertise required. To get started with MongoDB Queryable Encryption, visit this link.
MongoDB Queryable Encryption significantly reduces the risk of data exposure for organizations and improves developer productivity by providing built-in encryption capabilities for highly sensitive application workflows—such as searching employee records, processing financial transactions, or analyzing medical records—with no cryptography expertise required. To get started with MongoDB Queryable Encryption, visit this link.
“Protecting data is critical for every organization, especially as the volume of data being generated grows and the sophistication of modern applications is only increasing. Organizations also face the challenge of meeting a growing number of data privacy and customer data protection requirements,” said Sahir Azam, Chief Product Officer at MongoDB. “Now, with MongoDB Queryable Encryption, customers can protect their data with state-of-the-art encryption and reduce operational risk—all while providing an easy-to-use capability developers can quickly build into applications to power experiences their end-users expect.”
Data protection is the top priority among organizations across industries today as they face a growing number of regulations and compliance requirements to protect personally identifiable information (PII), personal health information (PHI), and other sensitive data. A common data protection capability organizations use to protect data is encryption, where sensitive information is made unreadable by cryptographic algorithms using an encryption key—and only made readable again using a decryption key customers securely manage. Data can be protected through encryption in-transit when traveling over networks, at-rest when stored, and in-use when it is being processed. However, working with encrypted data in-use poses significant challenges because it needs to be decrypted before it can be processed or analyzed. Organizations that work with highly sensitive data want to improve their security posture and meet compliance requirements by encrypting their data throughout its full lifecycle—including while it is being queried. Until now, the only way to keep information encrypted during the entire lifecycle was to employ highly specialized teams with extensive expertise in cryptography.
With the general availability of MongoDB Queryable Encryption, customers can now secure sensitive workloads for use cases in highly regulated or data sensitive industries like financial services, health care, government, and critical infrastructure services by encrypting data while it is being processed and in-use. Customers can quickly get started protecting data in-use by selecting the fields in MongoDB databases that contain sensitive data that need to be encrypted while in-use. For example, an authorized application end-user at a financial services company may need to query records using a customer’s savings account number. When configured with MongoDB Queryable Encryption, the content of the query and the data in the savings account field will remain encrypted when traveling over the network, while it is stored in the database, and while the query processes the data to retrieve relevant information. After data is retrieved, it becomes visible only to an authorized application end user with a customer-controlled decryption key to help prevent inadvertent data exposure or exfiltration by malicious actors. With MongoDB Queryable Encryption, developers can now easily implement first-of-its-kind encryption technology to ensure their applications are operating with the highest levels of data protection and that sensitive information is never exposed while it is being processed—significantly reducing the risk of data exposure.
The MongoDB Cryptography Research Group developed the underlying encryption technology behind MongoDB Queryable Encryption, which is open source. Organizations can freely examine the cryptographic techniques and code behind the technology to help meet security and compliance requirements. MongoDB Queryable Encryption can be used with AWS Key Management Service, Microsoft Azure Key Vault, Google Cloud Key Management Service, and other services compliant with the key management interoperability protocol (KMIP) to manage cryptographic keys. The general availability of MongoDB Queryable Encryption includes support for equality queries, with additional query types (e.g., range, prefix, suffix, and substring) generally available in upcoming releases.
Since the release of MongoDB Queryable Encryption in preview last year, MongoDB has worked in partnership with customers including leading financial institutions and Fortune 500 companies in the healthcare, insurance, and automotive manufacturing industries to fine-tune the service for general availability.
Renault Group is at the forefront of a mobility that is reinventing itself. Strengthened by its alliance with Nissan and Mitsubishi Motors, and its unique expertise in electrification, Renault Group comprises four complementary brands—Renault, Dacia, Alpine, and Mobilize—offering sustainable and innovative mobility solutions to its customers. “MongoDB Queryable Encryption is significant for ensuring data protection and security compliance,” said Xin Wang, Solutions Architect at Renault. “Our teams are eager for the architecture pattern validation of Queryable Encryption and are excited about its future evolution, particularly regarding performance optimization and batch operator support. We look forward to seeing how Queryable Encryption will help meet security and compliance requirements.”
About MongoDB
Headquartered in New York, MongoDB’s mission is to empower innovators to create, transform, and disrupt industries by unleashing the power of software and data. Built by developers, for developers, our developer data platform is a database with an integrated set of related services that allow development teams to address the growing requirements for today’s wide variety of modern applications, all in a unified and consistent user experience. MongoDB has tens of thousands of customers in over 100 countries. The MongoDB database platform has been downloaded hundreds of millions of times since 2007, and there have been millions of builders trained through MongoDB University courses. To learn more, visit mongodb.com.
Source: MongoDB
MongoDB unveils data encryption tech for developers to boosting data privacy and compliance
MMS • RSS
MongoDB today announced at its developer conference MongoDB.local Chicago the general availability of Queryable Encryption, which it says is a first-of-its-kind technology that helps organizations protect sensitive data when it is queried and in-use on MongoDB.
As data volumes skyrocket, so do the intricacies of modern applications. Coupled with growing regulatory demands, companies face a challenging task of managing sensitive information. Enter MongoDB Queryable Encryption: a tool that not only bolsters data protection, but also ensures a seamless developer experience, according to the company — no Ph.D. in cryptography needed.
“Protecting data is critical for every organization, especially as the volume of data being generated grows and the sophistication of modern applications is only increasing. Organizations also face the challenge of meeting a growing number of data privacy and customer data protection requirements,” said Sahir Azam, chief product officer at MongoDB. “Now, with MongoDB Queryable Encryption, customers can protect their data with state-of-the-art encryption and reduce operational risk — all while providing an easy-to-use capability developers can quickly build into applications to power experiences their end-users expect.”
Breaking down the encryption game
Historically, encryption has been the cornerstone of data protection. Whether it’s in-transit across networks, at-rest in storage or in-use during processing, data encryption ensures sensitive information remains in the right hands. The roadblocks? Processing and analyzing encrypted data, which requires decryption.
The big takeaway from MongoDB’s Queryable Encryption is in its ability to keep data encrypted across its entire lifecycle — even during query processing. Picture this: A financial analyst needs to pull up a customer’s savings account details. With Queryable Encryption in play, the entire process, from querying to retrieval, keeps the data encrypted.
Only with a customer-controlled decryption key can the information be viewed, substantially mitigating the risk of unwanted exposure. The Holy Grail in encryption has been smart, high performance, secure access and retrieval of data unhackable. Now, says MongoDB, it’s here with Queryable Encryption.
Open source with a secure global vision
The encryption technology has its roots in the MongoDB Cryptography Research Group and, notably, is open source. This move allows developers and businesses worldwide to dive deep into the cryptographic methods and code that power this state-of-the-art technology — further enhancing trust and compliance.
Moreover, MongoDB’s encryption is designed to integrate with key management services across major cloud providers such as Amazon Web Services, Microsoft Azure, and Google Cloud, offering businesses flexibility in managing cryptographic keys.
MongoDB’s innovation hasn’t gone unnoticed. Renault Group, a big name in the auto industry, stands out as an enthusiastic early adopter. “MongoDB’s Queryable Encryption is pivotal for our data protection and compliance,” noted Xin Wang, a solutions architect at Renault. “As we look toward the future, we’re keen on delving deeper into this technology, especially as it pertains to performance optimization.”
For developers, grappling with data protection protocols can be a maze of complexities. MongoDB hopes to change that with its newly launched MongoDB Queryable Encryption.
Azam emphasizes the tool’s easy integration into application development, potentially reducing the steep learning curve often associated with encryption.
Developer-centric look at MongoDB’s encryption
At the heart of application development lies the crucial aspect of data management and searching data securely or encrypted. Traditional encryption processes, while effective, often introduce added layers of complexity during the data querying phase. MongoDB’s offering, on the other hand, promises consistent encryption, even during querying. This could prove a game-changer for sensitive workloads.
For a developer, this means less juggling. Imagine building a banking application: With Queryable Encryption, both the data retrieval and processing steps are encrypted, reducing the steps and potential pitfalls for developers. The promise? More secure applications, built more efficiently.
Open source: a collaborative playground for developers
The open-source nature of MongoDB’s encryption, birthed from its Cryptography Research Group, means a developer can dive deep into it, understand, tweak and even contribute to it. It’s an avenue for collective growth, though MongoDB will need to ensure the platform remains secure amid this transparency.
Additionally, its compatibility with major services such as AWS, Azure and Google Cloud suggests an ease of integration, making a developer’s life potentially less fragmented.
Game-changer for developers
While larger industry names like Renault Group have shown interest, it’s the developer community that will be the litmus test.
MongoDB’s Queryable Encryption appears poised to offer developers a more streamlined approach to data security. Though it’s early days, the signs point to a potentially indispensable tool in a developer’s workflows. As with all tech, its true value will be determined by how well developers can integrate it into their daily grind.
Kenn White, a security principal at MongoDB, talked about the story behind the technology’s development that really captured attention. MongoDB’s journey from concept to reality, and the obstacles faced along the way, shed light on the immense complexities of modern encryption.
The road to queryable encryption
According to White, MongoDB faced a myriad of challenges in the creation of their new encryption technology. Encryption is intricate, where the smallest leaks or vulnerabilities can have huge ramifications. Issues such as buffer overflows had to be navigated meticulously because they might let attackers undermine security. MongoDB says it worked with crypto pros and experts to lock down all aspects of hacking encryption.
The company took an external collaborative approach, partnering with Brown University’s Encrypted Systems Lab. The project gained valuable insights from academia. But theoretical knowledge wasn’t enough.
MongoDB recognized the gap between academia and real-world application and acquired the encryption team and encrypted search was on the road to real-world scenarios like server-side cache, coherency and state. Although MongoDB wouldn’t reveal the exact acquisition date, the strategic investment symbolizes their significant foray into advanced security for MongoDB and its high end customers and now for developers.
Performance: a crucial ingredient
Ensuring performance isn’t compromised is vital. While the initial tests for IoT streaming and heavy inserts revealed performance concerns, MongoDB dedicated five months to enhancing this. Performance is incredible and only getting better, says White. “In real-time, the delay amounted to just milliseconds — a benchmark many developers will appreciate, especially for sensitive operations like credit card transactions,” he said.
White identifies the win for developers. “Recognizing that developers aren’t cryptography experts, their goal is to simplify the process — from auto-generating keys to ensuring compatibility with cloud providers’ transition to ‘bearer tokens,’” he said.
MongoDB’s vision: beyond encryption
The release of Queryable Encryption isn’t just about adding a feature. It’s a step toward MongoDB’s vision of broader, distributed security across cloud platforms, countering both external and internal threats. As the digital landscape transforms, MongoDB seems poised to make encryption not just more robust but more user-friendly for developers everywhere.
If developers can get encryption that’s easy to use, that should make programming secure apps easier.
Images: MongoDB
Your vote of support is important to us and it helps us keep the content FREE.
One-click below supports our mission to provide free, deep and relevant content.
Join our community on YouTube
Join the community that includes more than 15,000 #CubeAlumni experts, including Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger and many more luminaries and experts.
THANK YOU
MMS • RSS

The research report “Public Cloud Non-Relational DatabasesandNoSQL Database market Insights” is currently available on Orbisresearch.com.
This intelligence report provides a comprehensive overview of and in the global market, as well as detailed information with segmentation. This paper provides a complete analysis of the current Public Cloud Non-Relational DatabasesandNoSQL Database Market in terms of demand and supply, as well as price patterns currently and over the next several years. Global important firms are profiled, including revenue, market share, profit margin, significant product portfolio, and SWOT analysis. This study looks at the supply chain from an industrial standpoint, including process chart introduction, main raw material and cost analysis upstream, and distributor and downstream buyer analysis. This study analyses market drivers and inhibitors in the context of global and regional market size and projection, important product development trends, and typical downstream segment situations.
Request a pdf sample report : https://www.orbisresearch.com/contacts/request-sample/6635563
The paper goes on to analyze the response of global Public Cloud Non-Relational DatabasesandNoSQL Database market dynamics to the severe implications of the COVID-19 breakout. The study examines the impact of an unprepared environment and substantial delays in economic activity caused by the worldwide deployment of continuous lockdowns. The unanticipated drop in market demand, along with stalled production capacity, completely decimated the global Public Cloud Non-Relational DatabasesandNoSQL Database market. The study report also captures the substantial changes caused by the epidemic in the business models of the global Public Cloud Non-Relational DatabasesandNoSQL Database sector. It also covers the challenges caused by the severe government measures adopted by governments in order to combat the disastrous effects of the epidemic.
Key Players in the Public Cloud Non-Relational DatabasesandNoSQL Database market report:
IBM
MongoDB Inc
AWS(Amazon Web Services)
Apache Software Foundation
Neo Technologies (Pty) Ltd
InterSystems
Oracle Corporation
Teradata
DataStax
Software AG
Furthermore, the global Public Cloud Non-Relational DatabasesandNoSQL Database market research provides definitive information via a detailed examination of the business’s competitive environment. It effectively integrates very crucial industry data demonstrating the primary contributions of the top market players in developing the commercial presence of the global Public Cloud Non-Relational DatabasesandNoSQL Database market. The research also looks at each competitor’s demand-to-supply ratio, comparing the biggest to lowest capacity. The investigation involves a detailed examination of the specific growth.
The study report includes profiles of leading companies in the Public Cloud Non-Relational DatabasesandNoSQL Database Market:
The researchers analyzed the market’s top competitors and the tactics they use to overcome the strong rivalry in this portion of the report. This section also contains business biographies and market share estimates for the big corporations. Furthermore, the professionals have conducted a thorough assessment of each participant. They also gave accurate manufacturer sales, revenue, price, market share, and ranking data for the years 2023-2031. This research will assist important players, stakeholders, and other participants keep updated about current and forthcoming advancements in the business, allowing them to make better-educated choices.
Do Inquiry before Accessing Report at: https://www.orbisresearch.com/contacts/enquiry-before-buying/6635563
Public Cloud Non-Relational DatabasesandNoSQL Database Market Segmentation:
Public Cloud Non-Relational DatabasesandNoSQL Database Market by Types:
Key Value Storage Database
Column Storage Database
Document Database
Graph DatabasePublic Cloud Non-Relational DatabasesandNoSQL Database Market by Applications:
Automatic Software Patching
Automatic Backup
Monitoring And Indicators
Automatic Host Deployment
This investigation looked at the two key segments: Type and Application. This study looked at the sector’s profitability and growth potential.
Reasons to Buy This Report:
• To acquire a thorough insight into the Public Cloud Non-Relational DatabasesandNoSQL Database Market
• To acquire research-based business choices and give weight to presentations and marketing tactics
• It provides a pinpoint investigation of changing rivalry elements and keeps you ahead of competitors.
• It aids in making informed company choices by having complete market information and doing in-depth research on market segments.
Buy the report at https://www.orbisresearch.com/contact/purchase-single-user/6635563
We also give insights into strategic and growth assessments, as well as the data necessary to meet business objectives and make crucial revenue choices. Our 250 Analysts and Subject Matter Experts (SME) provide a high degree of experience in data collection and governance, acquiring and analysing data on over 25,000 higher-impact and specialty areas utilizing industrial processes. Our observers are trained to employ modern information collection tools, improved research processes, abilities, and years of experience to offer meaningful and genuine research. We have a comprehensive and trustworthy understanding of all sorts of research requirements as consultants to various Fortune 2000 businesses.
About Us:
Orbis Research (orbisresearch.com) is a single point aid for all your market research requirements. We have a vast database of reports from leading publishers and authors across the globe. We specialize in delivering customized reports as per the requirements of our clients. We have complete information about our publishers and hence are sure about the accuracy of the industries and verticals of their specialization. This helps our clients to map their needs and we produce the perfect required market research study for our clients.
Contact Us:
Hector Costello
Senior Manager – Client Engagements
4144N Central Expressway,
Suite 600, Dallas,
Texas – 75204, U.S.A.
Phone No.: USA: +1 (972)-591-8191 | IND: +91 895 659 5155
Email ID: sales@orbisresearch.com
MMS • Chip Huyen

Transcript
Chip Huyen: Recently, my credit card was stolen. I only found out when the bank texted me, it looks like you’re trying to spend $300 at a Safeway in San Jose, is that you? It wasn’t me. I responded no, and the bank locked my credit card, preventing further transaction with this credit card. If the transaction had gone through, I would have disputed the transaction, and the bank would have refunded me $300 causing the bank a net loss.
However, the bank was able to prevent this loss because the bank was doing real-time machine learning. They predict whether a transaction is fraudulent or not before the transaction goes through. We say that the bank is doing real-time machine learning. Credit card fraudulent transactions prevention is a classic use case of real-time machine learning. Previously, we wouldn’t think that there are many use cases for real-time machine learning. However, earlier this year, Databricks CEO did a very interesting interview when he said that there has been explosions of machine learning use cases that don’t make sense if they aren’t in real-time. More people are doing machine learning in production and most cases have to be streamed. This is a pretty incredible statement from the company that created Spark.
Here are just some of the use cases that I think could benefit a lot from real-time machine learning. Of course, there is fraudulent detection and prevention. There are also account takeover prevention. Say, when a hacker takes over an account, whether it’s a bank account or a social media account, they usually follow some predetermined steps. They might change locations. They might change the email, change the password. If it’s a bank account, they might start draining the money, sending the money to different places. Or if it’s a social media account they might use that account to send a lot of messages to scam other people. If we are able to detect those account takeover early, then we can prevent a lot of damages down the line.
Also, there’s a use case of personalizations. Say a website may have a lot of new users or users who don’t log in enough for the site to have enough historical data to make recommendation for them. It’s going to be a lot more powerful to be able to recommend those users items while they’re still on the site, rather than recommend them items like next day after they already left the site, because they might never come back to see the recommendations. There are a lot of use cases like that for real-time machine learning, and we’re going to go over one of them.
Background & Outline
My name is Chip. I’m a co-founder of Claypot AI, a startup that helps companies do real-time machine learning. I co-founded this company with Xu, who used to be on the Real-Time Data Platform team at Netflix. We have written a lot about the topic. We’re going to go over four main topics. The first is latency and staleness. The second, we’ll talk about real-time machine learning architecture and different types of features used for real-time machine learning. Then, we’re going to talk about a huge challenge of real-time machine learning, which is the train-predict inconsistency. Last, we’re going to talk about how to truly unify stream and batch computation.
Latency vs. Staleness
The first topic is latency and staleness. We have talked a lot about how latency matters. Users just don’t want to wait, no matter how good the machine learning models are. If they take just like milliseconds to launch to make a prediction, the users might not wait and might go do something else. However, I don’t think that we have talked enough about staleness. We’re going to go over an example to see what staleness means.
Let’s go back to the credit card fraudulent preventions example, and let’s say that we are using a very simple feature to detect whether a transaction is fraudulent or not, which is like, given a transaction with credit card x, we want you to count the number of transactions this credit card x has made in the last hour. These are pretty realistic features, because when a thief takes charge of a credit card, they might want to use that credit card for a lot of transactions to maximize profit. If a credit card has not been used a lot over the last two years, and suddenly over the last hour it’s been used for a lot of transactions, then that might be a sign of fraud. Latency is usually defined as the time from the prediction to request is initiated, until the operation is received.
Say, we have a fraudulent transaction like that at different timestamps like that. For transaction 4, when the transaction 4 is initiated, we want to start to predict whether this transaction is fraud or not. The time from that request to the predictions, may be 100 milliseconds. Let’s say for this prediction, we want to use a feature that was computed at 10:45. At 10:45, the number of transactions this credit card has seen is only two. By the time it’s used, then we can see that this value is stale, and the stale is caused by the delay from the time this feature was computed until the time it was used. Staleness is caused by delay, and the higher the delay, the more likely the features will be stale.
Staleness has quite an effect on the model performance. This is a very interesting post from LinkedIn, when they showed that for the job recommender model, if the feature is stale by an hour instead of by a minute, that the model performance is going to degrade by 3.5%, which is a non-trivial amount. Of course, like the other use cases, we can see very clearly that feature staleness can cause a huge drop in performance.
However, staleness tolerance is very much feature dependent and also model dependent. Say, if you have features like the number of transactions over the last two years, then the feature staleness by a day is probably not a big deal. However, if you want to compute the number of transactions over the last hour, then staleness by 10 minutes is quite significant.
Real-Time ML Architecture
We have talked about latency and staleness. We’ve gone over how latency and staleness might look like for different types of features used in real-time machine learning. First, the classic type of features that you might want to use for the online prediction model is batch features. These features are generated in batch processes. You might have something like Airflow scheduled for once a day, or once an hour to compute this feature from a data warehouse.
Then these features are made available in a key-value store like Redis or DynamoDB, for low latency access by the prediction service. These kinds of computations can help with latency, because at prediction time, we don’t have to wait for this feature to be computed anymore, we just need to fetch the previously pre-computed features. However, these types of features may have very high levels of staleness, because we have to first wait for the data to arrive at the data warehouse and then to wait for the job to be kicked off. The staleness can be hours, or even days. To overcome staleness, a lot of companies are moving towards real-time features. What real-time features means is that you might have a database like Postgres, or Bigtable, at prediction time, you might write a SQL query to extract features from this database.
This type of feature has very low staleness because it just computes this value, as soon as the prediction request arrives, so very low staleness. However, it has high latency, because the feature computation time now contributes directly to the prediction latency.
There are also other challenges with real-time features. First, because it contributes directly to the prediction latency, it’s hard for companies who want to use complex SQL queries because then the computation time will just be too long and users just don’t want to wait. Second, because this computation is done on demand, it might be very hard to scale the service when you might have an unpredictable amount of traffic. Also, it’s very much dependent on the service availability.
Another point that is a little bit more subtle is that it’s very hard to architect these real-time computation features to be stateful. Globally, what does stateful computation mean? Say we want to compute the number of transactions a credit card has made until a certain point in time, so say if you do compute this feature at 10:30 a.m., then we go for like from beginning of time to 10:30 a.m. Now, if you want to go compute the same value, at 10:33 a.m. Stateless computation means that we again have to go through only transactions from beginning of time up until 10:33, which means that the computations from beginning of time to 10:30 a.m. is repeated and redundant. Stateful computation means that you can just continue counting from the last time the feature was computed, which was 10:30 a.m.
In theory, we can probably add some state checking, state management to that so that we can make the computation stateful. First of all, it might keep a count of the transaction for each credit card. Whenever we see a new transaction by a new credit card, we just increment that count by one. However, this makes the assumption that all the transactions are in order. Every transaction that is seen after always happens after this point in time. I know it’s a little bit convoluted.
Say, if you have a transaction that was originally started at 10:30 a.m. Then there’s some parameters, and there’s some delay in the system and the transaction is only processed at 10:45 a.m., which means the transaction is delayed and arrives late. That means that if when we receive the late arrival features, we have to go back and update on the previous count. It can be quite tricky to have it like that. Streaming computation engines like Flink actually deal with that really well. If you use a stream computation engine, we also call that near real-time computation engines, we can actually avoid this out-of-order challenge.
We talk about how batch features may have low latency, high staleness, and real-time features may have high staleness and low latency. Near real-time features can achieve the pretty sweet spot when it can be both low latency and low staleness. What that means is that like, instead of using a database to record transactions, you might use a real-time transport like Kafka and Kinesis. Instead of computing these features at prediction time, we might pre-compute them.
The difference compared to batch features is that instead of computing these features off a data warehouse, you compute them when they are still in real-time transport. Instead of computing them like once a day or once an hour, you might compute them once every minute, or once every 10 minutes, or you can even trigger the computation based on an event. Say, if you see an event, a new transaction by credit card x, you just increment, you can update the count for credit card x. Similar to batch features, you might want to store the pre-computed near real-time features in a key-value store, so that it can be accessed by a prediction service or prediction time. You just fetch the latest value of the features from the key-value store.
You might say, ok, so real-time features have low latency and low staleness, then what is the catch? The catch I’ve heard is that people complain that it can be very difficult to set up and maintain near real-time pipeline. However, I do believe that as technology progress, it’s going to get easier. I do hope that as we build our modules, building near real-time pipeline will be just as easy as building out a batch pipeline.
Train-Predict Inconsistency
The next topic is a very big challenge that people talk about a lot for real-time machine learning, the train-predict inconsistency. Say, during training, data scientists might create features in Python using batch processing engines like Pandas, Dask, Spark to compute the features of data warehouse for training. However, prediction times of models may want to compute this feature through the stream processing in near real-time transport. That means it now has a discrepancy, so you have one model, but two different pipelines. This discrepancy can cause a lot of headaches.
We’ve seen a lot of models that do really well during training and evaluations, they just don’t do well when it comes to production. Currently, a lot of companies follow what we call the development-first machine learning workflows. In this workflow, data scientists create a model with batch features, and they train and evaluate this model offline. At production, data engineers or machine learning engineers will translate these features to the online pipeline. The bottleneck here is the translation process.
We have talked to quite a few companies when this process can take weeks, even months. One company in particular told me that like it takes them a quarter for data scientists to add a new streaming feature. This process is so painful that data scientists can just resort to using batch features instead. They might have found out that like a streaming feature can be really useful as a model, but they just don’t want to wait. Why waste an entire quarter working on a streaming feature when they can work on 10 different batch features, even though these batch features may not be optimal, might be like worst performer, but you get to develop more features. We hope that as the process of adding streaming features becomes easier, then data scientists will be more inclined to use them.
Another approach that companies use for prediction is the log-and-wait. In this approach, data scientists create new online features. Then, data engineers deploy these features to incoming data, and the data logs the computed values. They just wait to have enough computed values to train the models with those. This is a pretty good workaround, because it’s pretty easy to implement. Anybody who has to wait for it, you just need to wait without having to do anything. Also, the challenge is that you have to wait for it. If you want three weeks of trained data, you have to wait three weeks. Say, if you collect the data and then you realize it’s not exactly the features you want and you want to change it a little bit, they have to repeat the process again, which can be painful.
An approach that we have found to be very promising is backfilling. In this process, data scientists also create new online features. Instead of deploying these features to log-and-wait for the values, you backfill these features on historical data to generate training data. I say historical data here to encompass all the data that has been generated, whether that data is already in data warehouse or it’s still in a real-time transport like Kafka or Kinesis. We did backfilling to look like this, so data scientists can write feature definitions in Python or SQL.
I know that Python is an official language for data scientists, but we’ve seen more people ok with SQL. Then, in production, to make predictions, you might use a stream processing engine like Flink or Spark streaming to compute the features and to generate training data. To train the models with these features, you use a backfilling process. Even though this may be the other way around, you create features to train a model with that feature first before deploying that feature to production.
Backfilling can be quite tricky. Backfilling is not a new process for batch data. Backfilling typically only means that like retrospectively process historical data with new logic. New logic in this case is a new feature. However, backfilling can be quite challenging when you have data in both batch and stream sources. Also, if you care about the time semantics. Time semantics means that you might have a feature compute over a time window, like over the last hour, over the last day.
The time semantics cause the backfilling process to have to care about the point in time correctness. Say, if the transaction happened at 10:30 a.m., yesterday, then you want to count the number of transactions that happened exactly until 10:30 a.m., because you don’t want to count that feature past that point, because that could be leakage from the future data. To be able to backfill, then we need to be able to reconstruct the data at different points in the past. Some companies, if you don’t have a data platform set up properly, it could be impossible. Say, you might do product recommendations, so one feature you use is the price of this product to make predictions, and the price of the product can change over time.
If the platform overwrites the old price with the new price. In place, so you have a product table that has the column for the price, and then whenever the price for the product changes, if you overwrite that price directly, it might be impossible for you to figure out what was the price of a product in the past. We have talked to several companies when they say they want to do this wonderful new real-time machine learning stuff, but then they realize the first thing they have to do is to update their data platform so that it can handle time semantics.
Another is that if you have features that combine data from multiple sources. Say you want to count the number of transactions over the last three days. You might use Kinesis. Kinesis has a limit on the data retention, so Kinesis only allows you to retain stored data for seven days, and then the same data is made available in the data warehouse after some delay, say after a day.
You might have the data at time T. Right now, if the time is T, then you have data from T minus 7 days to now in the stream, and all the data up to T minus 1 day in the data warehouse. Then, how can you construct these features to combine data from both sources? There’s a backfilling challenge, because now we have new features, and you want to compute this new feature over historical data.
Historical data contains the data in both stream and data warehouse. One approach is stateless backfilling. In this case, your batch pipeline and the stream pipeline share no state at all. You might need to construct two features, one to count the number of transactions over the last day, which is like to count the transaction in stream. It’s a near real-time feature. Another feature is to count the number of transactions over the last 30 days in the data warehouse, which makes it a batch feature. It can work. However, it’s up to users to maintain the consistency between these two features to make sure that the count match.
Another approach which is a lot harder to do is stateful backfilling, when the batch pipeline and the stream pipeline share state. In this approach, users say, give me the count on the transactions over the last 3 days. Then the infrastructure may think, yes, over the last 3 days, then we have to go into the data warehouse. It will just count the transactions in the data warehouse, when you run out of transaction, and then you cut over and continue counting from the stream. It’s pretty cool, however, it’s pretty challenging to do.
There are certain technologies to help with that, like Apache Iceberg, created by Netflix. Also, Flink is working on something that’s going to be a hybrid source to have you connect on data from both stream and batch sources. However, it’s still work in progress. I’m very excited to see more progress in this area.
Unify Stream + Batch Computation
The last topic is to unify stream and batch computations. This is a very interesting topic. It’s more of a thought experiment than an actual solution that I see right now. A lot of companies have talked about unifying stream and batch. However, what I think they actually mean is to make stream API look like batch API. Say, like Spark and Spark streaming. What they do is that they make the stream API look very similar to the traditional Spark API. As data scientists, you will still have to care about whether a feature or transformation is stream or batch, whether it’s applied to data in stream or whether the transformation is applied to data in a data warehouse. I’ve been thinking about it like as a data scientist, I actually don’t care about where data is, so, say, if we want to count the number of transactions. All I care about is the transactions.
I don’t care about whether those transactions occur in stream, or are they currently in Snowflake. I just want you to write the transformations, and I want my infrastructure, my tooling to figure out for me, you want to transition over the last six months, so I want to compute off Snowflake for you. If you want to compute your transaction over the last hour, then I can compute it off the stream for you. That is my dream. I wish I could have something like this, what I think of as a more data scientist friendly API.
You can start to define the transformation near the transaction count, and it can just compute that on the transaction data itself. This data transaction can be across multiple sources. It can define arbitrary window size. You don’t have to worry about like, whether this window size is going to stretch out across different sources.
Key Takeaways
The first takeaway is that latency matters, so does feature freshness. We talk a lot about latency but not enough on feature freshness or staleness. Also, we talk about different types of features used in real-time machine learning. Not all those features require streaming, however, streaming can help a lot with balancing out the latency and staleness, and can also help a lot at scale. Also, we talk about the train-predict inconsistency and backfilling can be very helpful to ensure the train-predict consistency. The last point is more futuristic, is I really hope that we can have an abstraction so that data scientists can work with data directly without having to worry about whether data is in stream or batch. What I think of as a truly unifying stream and batch API.
Impact on Model Performance, When Offline and Online Data is Combined
You’re asking about, if we combine offline and online data, then the time to access offline data might be unpredictable. This is for the backfilling, is when we have a new logic that has to look back in time, and recompute that on data that already exists. In production, we are not going to go back, we just keep on continuing computing in real-time for incoming data.
Q&A
Hien Luu: With this kind of thing, would this drastically impact the model performance?
Huyen: I don’t think it will. We mentioned that crossing data boundaries only happens when you do backfilling. It’s for when you want to maybe create data for training, then, yes, this might take a little while. That’s true for a lot of data processing. In production, when you serve data, you keep on computing on incoming data only, then it shouldn’t affect it.
Emerging and New Use Cases
Luu: Are there any emerging new use cases that you are not aware of since you started on this journey, that is interesting to share?
Huyen: There have been a lot of interesting use cases. There are classical use cases that we talk about, like detection of fraud, or a recommender system search. We see a lot recently is account takeover, and especially over COVID is what we call claim takeover, is when the government started giving out a lot of unemployment benefits. It’s possible if somebody takes over the identity or the bank account, then they can use that to claim the benefit and then disappear. We actually see quite a bit of that.
Another use case is we’ve seen more dynamic pricing. I think it’s for a lot of use cases especially where we see pricing change very frequently [inaudible 00:29:01]. Then we saw more, first of all like when people view things selling on Amazon. Like Amazon is selling something for 5 bucks, you might have a lot of merchants selling the same product. Amazon only shows like certain merchant, and as a merchant of that product you might want to be able to show your offering there comparing other merchants. It’s very important for you to be able to set up price dynamically so that you can win a slot in the Buy Box [inaudible 00:29:34] to see that product.
Of course, a lot of that also for Uber, Lyft ride sharing. For any product that you want to determine the price at the time of query, at the time of sale instead of like predetermine the price before. When thinking about pricing, it’s not just the intrinsic price, but also the discount or promotions, you might want to give each visitor to encourage them to buy.
Because for a lot of sellers, they still prefer to make a sale at a discount than not to make a sale at all, and being able to dynamically determine that price is very important. Also, we see a lot of use cases in crypto as well. If we have prices being dynamically changed, then of course, it can be another use case, when you try to predict when’s the best time to buy something. One example is from Ethereum, you have a gas fee, and the gas fee can change quite fast. When the gas fee is high, then transactions cost a lot of money, so you want to predict when is the best optimal time to do so. We’ve seen a lot more use cases.
Successful Use Cases, with Real-Time ML
Luu: There’s a lot of interesting use cases that leverages this real-time information to make predictions and such. It takes a bit of work to set this up successfully and run it end-to-end. Have you seen any companies out there that are successful at doing this?
Huyen: I think DoorDash has been doing that pretty well. I read a post recently by Instacart on their journey from batch machine learning to real-time machine learning. They divide it into two phases. The first phase is when they move their prediction service, like you have where you do batch predictions, and they have to build an online prediction service to be able to scale, or a service to serve requests in real-time. That’s what you see a lot of companies do initially.
After that, they want to move from batch feature computations to online feature computations. For online feature computations, you can have both on demand, like real-time feature computation, but also near real-time feature computation. That’s the second phase of moving feature computation from batch to real-time to online that we see that companies have a lot of trouble with. The reason is that for a prediction service, we can do that without touching much on the user experience. It can still train a model and it can still deploy, and it’s mostly infrastructure scaling. For feature engineering, we would need to be able to create an interface for data scientists to be able to sell the features.
A lot of frameworks to compute things in near real-time in online environments like JVM like Java, Scala. It’s pretty hard for a data scientist to be able to use Scala or a Java interface directly. You also touched on data sources as well. If there’s no good way for data scientists to be able to explore and discover what data sources are available, what existing features that have been computed, then it’s very hard for them to quickly create features. We see that quite challenging. Of course, there’s a question of cost. We talk to a lot of companies who do real-time machine learning, and their infra cost is quite high, and a lot of it is in feature computations.
How about you, what have you seen? You have done quite a lot of work with both LinkedIn and DoorDash.
Luu: Certainly, what you have discussed is a reflection of the experience that I’ve seen at LinkedIn and DoorDash. It does require that massive infrastructure to make it very simple for data scientists to do all this. I think once you have it in place, you can unlock a lot of use cases that they will love to start experimenting with. It’s kind of a flywheel. Initially, it takes a lot of friction. Once it’s available, it will unlock people’s imagination in terms of how they want to use these real-time features for all kinds of use cases that they may have not thought of before. This area is challenging because of that. My sense is, the benefits long-term wise will be tremendous, if and when this infrastructure is available.
Cost and Benefit Tradeoff, from Migrating to Real-Time
Huyen: I think we do talk to some companies, and they see a lot of companies getting a huge return from investing in infrastructure to move to real-time. How do they know that their company will also benefit from it because the upfront investment is not something that everyone can afford?
Luu: I think it’s all about taking baby steps. It also depends on where the company is building their product. If they have a lot of low hanging fruits, then they can start with batch, get that done and make sure that it’s solid and working. Once you got to a point that you start to think about from the customer experience, if such real-time features are available, what additional capability or experience can the company unlock or provide? Then it would be an easy conversation to invest.
Huyen: Some companies we talk to have successfully made the transition. They actually mentioned that the operational cost is really lower after they made the transitions, because now they only have one unified system to maintain instead of having separate pipelines: batch, streaming.
Luu: Different companies are on a slightly different journey in what phase they are at in terms of incorporating ML into their company, and the expertise that is needed as well. Hopefully, this will become easier as time goes on with technologies from your company, or other similar companies to make it easier.
Huyen: We see a lot of work in the space and not just from our company. A few days ago, we were looking at Facebook, and they have a lot of like, building things built in-house to unify their stream and batch to be able to compute things in real-time with Pandas’ interface. Also, a lot of other companies as well. I do expect in the next couple of years, the landscape is going to be very different.
See more presentations with transcripts
MMS • Anthony Alford

The recent Ai4 2023 conference featured a talk by Hussein Mehanna of Cruise titled “How Autonomous Vehicles Will Inform And Improve AI Model Testing.” Some key takeaways are that systems should handle the “long tail,” developers should measure model output quality, and developers should push their systems to fail.
Mehanna, Senior VP and Head of AI/ML at Cruise, began with the problem statement that while generative AI has great potential, its output is often unreliable; for example, language models are subject to hallucination. However, he believes that his company’s experience with deploying autonomous vehicles offers several lessons which can help improve the reliability of generative AI. Mehanna began by recounting some metrics about Cruise’s business—their cars have driven autonomously more than 3 million miles—then played a short video showing autonomous vehicles encountering and safely navigating several unexpected situations, such as pedestrians or cyclists darting in front of the vehicles.
Mehanna then shared several use cases of generative AI at Cruise. The company generates synthetic images to use as training data for their autonomous driving models; they generate both single frame scenes for their perception models as well as “adversarial” scenarios testing the autonomous behavior of the vehicle. In the latter instance, Mehanna gave the example of a pedestrian darting in front of the vehicle: with generative AI, Cruise can create a variation of that scenario where the pedestrian trips and falls. Mehnna also said that the vehicle software uses an equivalent of a language model to predict the motion of other vehicles.
He then delved into lessons for making generative AI more reliable. The first lesson is to handle the long tail; that is, to have an explicit strategy for when the model encounters very rare cases. He said that there is a misconception that human intelligence is more robust than AI because it has a better understanding of the world. Instead, he suggested that when encountered with an unexpected situation when driving, humans change their behavior, becoming more cautious. The key, then, is to know when the AI model encounters epistemic uncertainty; that is, to “know when they don’t know.”
The second lesson is to measure the quality of the model’s output. Mehanna admitted this is “much easier said than done,” but recommended against using simple aggregates. He gave the example of Cruise measuring their vehicles’ performance around pedestrians. On average, the performance is excellent; however, when measured by cohorts, that is, by age group of pedestrians, performance in the presence of pedestrian children is not good. He noted that it may take multiple iterations to find good quality measures. He also suggested that in many cases, so-called bias in AI models is actually a measurement problem of looking at aggregates instead of cohorts.
Finally, Mehanna encouraged developers to “push your system to the limits” and observe that quality metric in a lot of very different use cases. He mentioned that Cruise generates synthetic data for adversarial testing of their models. In these scenarios, they have control over all the objects and their behavior; they can, for example, add a pedestrian or make a human-driven car stop suddenly.
Mehanna concluded by saying, “You need to build a system of trust so that you can deploy generative AI—or any AI system—safely. And I believe we can learn a lot from autonomous vehicles.”
New Google Cloud H3 Virtual Machine Series for High-Performance Computing Workloads in Preview
MMS • Steef-Jan Wiggers
Recently Google launched a new H3 Virtual Machine (VM) Series designed for High-Performance Computing (HPC) workloads. The series of VMs are available in public preview for Compute Engine and Google Kubernetes Engine (GKE) users and offers 88 cores (Simultaneous multithreading disabled) and 352 GB of memory.
H3 VMs are powered by the 4th generation Intel Xeon Scalable processors (code-named Sapphire Rapids), DDR5 memory, and Google’s custom Intel Infrastructure Processing Engine (IPU) – providing 200 Gbps network bandwidth for standard networking. In addition, it is only available in a predefined machine type (h3-standard-88) with no support for GPUs or local SSD, egress limited to 1Gb, and the persistent disk performance capped at 15,000 IOPS and 240 MB/s throughput.
The H3 machine series is part of Google Clouds compute optimized machine family, and the company claims the machines offer up to 3x improvement in per-node performance, improved scalability for multi-node workloads, and up to 2x better price performance, compared to the prior generation C2 instances (based on Intel Cascade Lake).
In weather forecasting (WRFv3) tests, H3 enables up to three times faster time-to-results at 50% lower costs than C2.
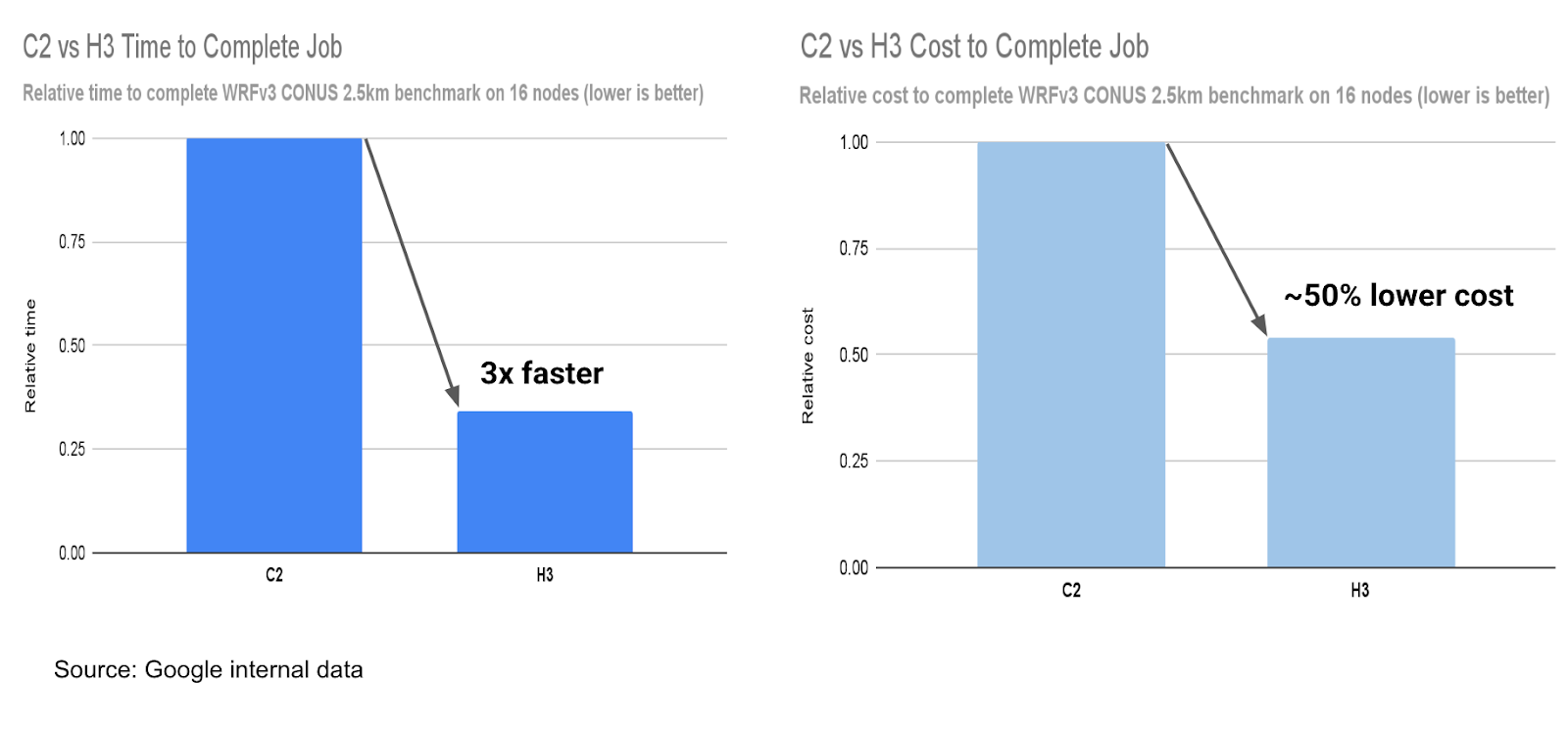
Overview of test results C2 vs. H3 performance and cost (Source: Google Cloud Blog)
The compute-optimized VMs like H3 and its other family members C2 and C2D are suitable for HPC workloads and workloads like high-performance web servers, game servers, and Artificial Intelligence (AI) and Machine Learning (ML) workloads.
Matthew Shaxted, President of Parallel Works, said in the Google Cloud blog post:
With the new H3 machine series, we’ve noticed a greater than 2.5 times performance increase when run on multiple nodes, along with a significant overall job cost savings of ~50-70%. This makes H3’s cost/performance level a necessity for leaders in the numerical weather prediction industry.
Alongside Google, Azure, and AWS offer a selection of instance types for HPC- and similar compute-optimized workloads. For instance, Microsoft introduced HBv4-series and HX-series VMs last year, and AWS recently launched Amazon EC2 P5 Instances.
Regarding the Intel Xeon Sapphire Rapids, Google released C3 Virtual Machines in late 2022 as general-purpose optimized virtual machines showing that investments with these CPUs span multiple machine-type families in the Google Cloud.
Lastly, H3 VMs are available in the US-central1 (Iowa) and Europe-west4 (Netherlands) regions. Yet the pricing of the H3 machines currently needs to be made available on the pricing page.
MMS • Daniel Bryant

HashiCorp, the maker of widespread open source infrastructure as code (IaC) tooling such as Terraform and Vault, announced last week that it is changing its source code license from Mozilla Public License v2.0 (MPL 2.0) to the Business Source License v1.1 (BSL 1.1) on all future releases of HashiCorp products. HashiCorp APIs, SDKs, and almost all other libraries will remain MPL 2.0. The initial community reaction has primarily been negative.
BSL 1.1 (often acronymized, perhaps more correctly, to BUSL 1.1) is a source-available license that allows “copying, modification, redistribution, non-commercial use, and commercial use under specific conditions”. Armon Dadgar, co-founder and CTO of HashiCorp, stated in the announcement blog post that other vendors have made similar changes in licensing:
With this change we are following a path similar to other companies in recent years. These companies include Couchbase, Cockroach Labs, Sentry, and MariaDB, which developed this license in 2013. Companies including Confluent, MongoDB, Elastic, Redis Labs, and others have also adopted alternative licenses that include restrictions on commercial usage. In all these cases, the license enables the commercial sponsor to have more control around commercialization.
Dadgar continued by stating the current goal is to “minimize the impact to our community, partners, and customers”. The HashiCorp team will continue to publish source code and updates for their products to their GitHub repository and distribution channels.
The primary friction points within the community related to this licensing change revolve around the “commercial use under specific conditions” clause and production usage of future BSL-licenced HashiCorp products. The announcement blog post makes clear the intention of the license change for “competitive services”:
End users can continue to copy, modify, and redistribute the code for all non-commercial and commercial use, except where providing a competitive offering to HashiCorp […] Vendors who provide competitive services built on our community products will no longer be able to incorporate future releases, bug fixes, or security patches contributed to our products.
Discussion of the license change announcement on HackerNews included responses from many vendors building on top of HashiCorp’s OSS products or providing competing solutions. There were several calls to create an open source fork of Terraform, although others quickly pointed out that it was too early to implement this. Similar discussions could also be seen on Twitter/X.
Alexis Richardson, CEO of Weaveworks, noted on Twitter that most of the community discussion is focused on Terraform and its integration into the broader ecosystem rather than the other HashiCorp products and their influence:
There wouldn’t be half as much shouting if [HashiCorp] had switched vault to BSL but left Terraform as open source
Why?
Terraform has become a standard, distributed and remixed by 1000s of tools. Now they’re all interwoven with BSL and no one knows what that really means
A related GitHub issue has been opened on the Cloud Native Computing Foundation (CNCF) repository, “Investigate MPL -> BUSL Changes/Impact”. The CNCF hosts many widely adopted and influential projects within the domain of cloud native software delivery platforms and tooling, including Kubernetes. Benjamin Elder, a Kubernetes maintainer, noted that while “[K]ubernetes core doesn’t depend on any [HashiCorp] libraries, plenty of subprojects do”.
Reacting to the news, several people on Twitter/X and Hacker News cautioned of the adoption of open source software when a single vendor is acting as maintainer and steward of the community. Hacker News user, alexandre_m, commented:
If a project on GitHub only has maintainers from the corporate side, you can be certain that they will ultimately drive the product for their own interest solely.
We should always pay close attention to the governance model of projects we depend on or that we wish to contribute to.
Adam Jacob, CEO of the System Initiative, discussed the untapped potential of the community and business motivations for making such a license change:
If HashiCorp had developed their open source community into a diverse and broad one, they would have been the lingua franca of the cloud. But since they failed to do that, the only rational move is to extract as much money as possible from what remains.
Others, including Chris Aniszczyk, CTO at the CNCF, highlighted that donating open source projects to vendor-neutral foundations can hedge against issues related to a single vendor project:
Corporate open source that is controlled by a single vendor and not in a neutrally owned open source foundation is part of the problem here… this wouldn’t [have] been an issue if the projects were in [the Apache Software Foundation] ASF or @CloudNativeFdn
Several organizations have issued statements responding to the HashiCorp licensing changes, including Weaveworks, Pulumi, Spacelift, Gruntwork, env0, and Upbound.
HashiCorp has published a licensing FAQ for readers interested in learning more.