Month: August 2023
Java News Roundup: Liberica JDK Performance Edition, GraalVM JDK 21 Builds, Open Liberty, Quarkus

MMS • Michael Redlich
Article originally posted on InfoQ. Visit InfoQ

This week’s Java roundup for July 31st, 2023 features news from OpenJDK, JDK 22, JDK 21, GlassFish 7.0.7, GraalVM JDK 21 Developer Builds, Liberica JDK Performance Edition, JNoSQL 1.0.1, Spring Tools 4.19.1, Open Liberty 23.0.0.8-beta and 23.0.0.7, Micronaut 4.0.3, Quarkus 3.2.3 and 2.16.9, Apache Camel 4.0.0-RC2, JHipster Lite 0.40, Ktor 2.3.3, Maven 3.9.4 and Gradle 8.3-RC3.
OpenJDK
David Delabassee, director of Java developer relations at Oracle, has announced a change in annotation processing. The OpenJDK team is considering disabling default implicit annotation processing in a future release of OpenJDK. This is due to implicit annotation proceeding when there are no annotation processing configuration options. As of JDK 21 Build 29 and JDK 22 Build 4, the javac utility will print a note (as shown below) if implicit annotation processing is being used.
Annotation processing is enabled because one or more processors were
found on the class path. A future release of javac may disable
annotation processing unless at least one processor is specified by
name (-processor), or a search path is specified (--processor-path,
--processor-module-path), or annotation processing is enabled
explicitly (-proc:only, -proc:full).
Use -Xlint:-options to suppress this message.
Use -proc:none to disable annotation processing.
JDK 21
Build 34 of the JDK 21 early-access builds was also made available this past week featuring updates from Build 33 that include fixes to various issues. Further details on this build may be found in the release notes.
JDK 22
Build 9 of the JDK 22 early-access builds was also made available this past week featuring updates from Build 8 that include fixes to various issues. More details on this build may be found in the release notes.
For JDK 22 and JDK 21, developers are encouraged to report bugs via the Java Bug Database.
GlassFish
GlassFish 7.0.7, the seventh maintenance release, delivers refactoring and maintenance, component upgrades and notable bug fixes such as: creation of a new Admin Object Resource in the Admin Console; generation of Web Services Description Language (WSDL) for use with JDK 21; and a remote EJB access issue in the glassfish-naming package by updating the osgi.bundle files. More details on this release may be found in the release notes.
GraalVM
The GraalVM JDK 21 Developer Builds for GraalVM 23.1.0 Community Edition have been made available to the Java community. These builds include the JVM and developer tools for generating native images from Java applications. More details on this release may be found in the release notes.
BellSoft
BellSoft has introduced the Liberica JDK Performance Edition that delivers the performance of JDK 17 to enterprise workloads running on JDK 11 without the need to worry about migration to newer versions of the JDK. BellSoft claims that companies will “notice the instant performance boost up to 10–15% with little to no code adjustments.” Enhancements include: improved garbage collection using Shenandoah, ZGC and G1GC; and several runtime improvements. More details on the Liberica JDK Performance Edition may be found in the user’s guide.
JNoSQL
The release of JNoSQL 1.0.1 delivers notable fixes such as: logic in the getConstructors() method defined in the Reflections class to detect constructors with parameters annotated with @Id or @Column; lazy loading metadata in the EntityMetadata interface; and a redesign of the ParameterMedataData interface to not throw a NullPointException when it’s implementation with a JDK Parameter class that does not use the of the @Id or @Column annotations. More details on this release may be found in the release notes.
Spring Framework
Spring Tools 4.19.1 has been released featuring early-access builds for Eclipse 2023-09 IDE milestones and notable bug fixes such as: experimental validation support for Spring Modulith; Spring Boot language server interfering with the automatic project synchronization of Eclipse Gradle Buildship; and no classpath update after source code has been saved. More details on this release may be found in the release notes.
Open Liberty
IBM has released version 23.0.0.8-beta of Open Liberty that ships with: support for running a Spring Boot 3.0 application on Open Liberty; and a continued early preview support of Jakarta Data, a new specification that will officially be included in the upcoming release of Jakarta EE 11.
Similarly, Open Liberty 23.0.0.7 has been released featuring API and SPI Javadocs now available in the reference section of the Open Liberty documentation and notable changes such as: add missing public methods in the GlobalOpenTelemetry class; fix concurrency errors when using same JWT access token for inbound propagation; and a dependency upgrades to Apache MyFaces 4.0.1.
Micronaut
Micronaut 4.0.3, the third maintenance release, delivers a patch update to the Micronaut Core project and updates to modules: Micronaut Maven Plugin, Micronaut Data, Micronaut Multitenancy, Micronaut GCP, Micronaut RabbitMQ, and Micronaut Security.
The release of Micronaut Core 4.1.0 provides new features and improvements such as: support for Kotlin default parameters; replacement of the HttpStreamsHandler and HandlerPublisher for the client in favor of directly handling the incoming instances of the HttpRequest and HttpContent interfaces and transformed to the required types; a new builder() method in the BeanIntrospector interface to deal with all the different cases of instantiation.
Quarkus
Red Hat has released version 3.2.3.Final of Quarkus featuring notable changes such as: support for user methods with the @Transactional annotation in REST Data with the Panache ORM; the addition of a clear error message when Reactive REST Client used outside of Quarkus; and properly resolve use of the @TestProfile annotation with nested tests in base classes. More details on this release may be found in the changelog.
Similarly, Quarkus 2.16.9.Final has also been released providing notable changes such as: prevention of a ContextNotActiveException with an invalid configuration validation if the RESTEasy Reactive module is present; a fix for addressing CVE-2023-1428 and CVE-2023-32731, two gRPC Protocol Buffers-related CVEs; and a dependency upgrade to gRPC 1.53.0. More details on this release may be found in the changelog.
Apache Software Foundation
The second release candidate of Apache Camel 4.0.0 delivers bug fixes, dependency upgrades and new features such as: support for Kubernetes in Camel JBang; a new standalone Web Console available for all Camel applications; and limit the auto-conversion of all body types when stream caching is enabled due to issues when the body type is not a stream. More details on this release may be found in the release notes.
JHipster
Version 0.40.0 of JHipster Lite has been released featuring bug fixes, dependency upgrades and new features such as: add the AddDirectJavaDependency record for use in the Gradle dependency; change the logger in the CorsFilterConfiguration class to static; and an implementation of keyboard navigation for the Landscape screen. More details on this release may be found in the release notes.
JetBrains
JetBrains has released Ktor 2.3.3 that ships with notable changes such as: support for YAML configuration; a fix for Kotlin’s IllegalArgumentException upon using the UTF-8 charset after migrating from Xcode 14 to XCode 15; and a fix for a DataFormatException when WebSocket compression is enabled by default. More details on this release may be found in the what’s new page.
Maven
The release of Maven 3.9.4 features dependency upgrades and a fix for an endless loop in the getMessage() method defined in the DefaultExceptionHandler class.
Gradle
The third release candidate of Gradle 8.3 delivers continued improvements such as: support for JDK 20; faster Java compilation using worker processes to run the Java compiler as a compiler daemon; the ability to experiment with the Kotlin K2 compiler; and improved output from the CodeNarc plugin. Further details on this release may be found in the release notes.
MMS • Rafiq Gemmail
Article originally posted on InfoQ. Visit InfoQ

Sumeet Moghe, author of The Async-First Playbook and a transformation specialist at Thoughtworks, recently wrote an article titled Patterns to Build Trust and Cohesion on Distributed Teams; this follows the provocatively titled What if I Don’t Want a BFF at Work? Rather than leaders having an overfocus on fostering personal friendships in distributed teams, Moghe’s articles discussed the value that comes from investing in the creation of highly effective professional relationships. Moghe discussed building remote teams with high trust and cohesion, through the use of professional collaboration, intentional remote interactions, and transparency with “clear roles, clear measurement, and clear expectations.”.
Moghe wrote that “some leaders complain about how remote teams have fewer lasting friendships,” and responded to this by arguing that “trust and cohesion are far more important” factors to focus on than friendships. While acknowledging that “you’re likely to give your work a harder crack when you’re in it with your friends,” he wrote that bonds can also be developed through professional trust in one’s colleagues. Specifically, that they are “skillful and capable”, “share their knowledge” and can be depended upon. Writing about Martin Fowler’s input on this, Moghe wrote:
Martin Fowler once told me that relationship building for professionals often works better by working together than with artificial team-building activities. I agree. No amount of team parties, trust falls and games can substitute for collaborative work. Teams that follow extreme programming often pair with each other. There are many benefits to this, but I’ve also found this to be an excellent tool to build relationships.
Moghe recommends relationship building through collaborative techniques such as pair programming. Moghe wrote that pair programming is an “excellent tool to build relationships,” and explained:
When you pair with someone on a task, there are many things you learn. For one, you learn about the level of skill someone brings to work. You also expose yourself to the other person’s perspective on solving certain problems. You teach each other while being in the flow of work. Few activities build more trust than this kind of deep, problem-solving activity.
Laurie Barth, a senior software engineer at Netflix and member of TC39 Educator’s committee, recently published an article in LeadDev titled Being an Effective Remote Employee in which she wrote that personal connections and friendships are essential to effective working relationships. Barth wrote that such friendships were important to understanding “personality types and communication styles” of one’s team. She discussed the importance of remote staff intentionally organising social interactions and over-communicating. Barth wrote that in the workplace “natural connections” are born of shared-interactions over lunches, at the “water-cooler” or even “walking between meetings”. Highlighting areas for intentional communication, she wrote:
…personal relationships are most often born out of unstructured time. This could take the form of sending a DM to a colleague to catch up and see how they’re doing, or inviting them to an ad-hoc video chat to talk about a work item and how their weekend was. Find opportunities to develop personal relationships wherever you can.
Barth wrote that “personal connections and friendships are an essential part of any work environment.” Pointing out the disadvantages of remote staff, she described how the dynamic of “impromptu interactions” with people outside of one’s team is something that excludes “those who join each meeting via video.” To address this, Barth wrote about the importance of remote staff being self-aware as not to go “radio silent” whilst focusing on a task. Contrasting this with a physical office where individuals can constantly see and learn from one another, she wrote that while quiet focus “may feel productive, it misses opportunities for collaboration and knowledge sharing.” She advised remote staff to include visibility and communication as part of their ways of working:
…make sure you’re openly communicating risks with colleagues when and where you can. Are you blocked on something? Tell the relevant stakeholders and whoever has the potential to unblock you. Worried about the relative prioritization of tasks? Start asking questions so you can determine a path forward. Working on something in a silo? Document, knowledge share, and make sure people know what it is and what they will eventually have to help maintain.
Discussing the importance of transparency in the creation of a high-trust environment, Moghe wrote that “anything that anyone knows, everyone must know.” He points out that this is “a fundamental premise for high-performing teams.”
Moghe also wrote that “high-performing distributed teams leave nothing to chance,” and highlighted that “everything is intentional.” He explained that “if building relationships is important, then that must be intentional too.” Moghe recommends that teams stop carrying the “baggage” of physical-office patterns and focus on outcomes required in a remote environment. He recommends five “low cost” areas to start focusing on:
- Creating a “culture of one-on-one meetings” for “knowing each other well and supporting each other”
- Create a “rockstars channel” on Slack or IM to share “praise and recognition”
- Creating a “Cafe Channel” and arranging recurring coffee meetings for “general chit-chat”
- Organising “local chapter lunches and dinners” to allow teams to bond “over food”
- Organising virtual team events to enable teams to bond “over fun activities”
Moghe wrote that it’s important for organisations to make a financial investment in cultivating remote team cohesion, as it is “easy to talk about building team relationships.” He argued that organisations should “recognise that the costs they save on office space, shouldn’t just go back to the bottom line.” He wrote that a portion of cost savings should be redirected “into helping teams function cohesively,” and said:
You’ll notice that most remote-native companies organise regular retreats, at the team and company level. That’s an example of putting your money where your mouth is.
MMS • Sherwin Wu Atty Eleti
Article originally posted on InfoQ. Visit InfoQ

Transcript
Computers – A Bicycle for the Mind
Atty Eleti: I want to take us back in time to 1973, 50 years ago. In 1973, Scientific American published a very interesting article, in which they compared the movement of various animals. They set out to compare the locomotive efficiency. In other words, how many calories an animal burns to get from point A to point B, in relation to their body mass and things like that? What they did is they compared various animals, birds, insects, and of course us humans, and ranked them from most efficient to least efficient. What they found was the condor was the most efficient in terms of locomotive efficiency.
A condor is a beautiful bird, native to California and some parts of South America, and it can fly sometimes hundreds of miles without ever flapping its wings. It has really good gliding power. Humans on the other hand, humans walk, came in rather unimpressively at about one-third down the list, which is not such a great showing for us. The beauty of the Scientific American article is that, in addition to all the species, they added one more item to the list, and that was man on a bicycle. Man on a bicycle blew the competition away, almost two times as efficient in locomotion as the condor.
I love this story, because it is such a simple realization, that with a little bit of tooling, a little bit of mechanical help, we can really augment our abilities by quite a lot. Some of you might have heard this story before. You might be thinking, where have I seen this? This story was often told by Steve Jobs in the early days of Apple. Him and the Apple team used the story as inspirations with the early Macintosh. Steve compared the story and said, humans are tool builders.
We make tools like the bicycle to augment our abilities to get things done. Just as the bicycle is a tool for motorability, for moving, computers are a tool for our mind. They augment our abilities, and creativity, imagination, and productivity. In fact, Steve had this amazing phrase that he used to describe personal computers. He said, computers were a bicycle for the mind. Ten years after this article was published, in 1983, Apple released the Macintosh, and unleashed the personal computing revolution. Of course, we’re here now, many years later, still using Macs every day.
2023 – AI and Language Models
That was 1973. We’re here in 2023, 50 years later, computing has changed a lot. If the folks at Scientific American ran the study, again, I bet they would add one more species to the list. A species that for most of us has really only been around in the public imagination for six months or so. I’m talking of course about AI, or language models in specific.
Ever since ChatGPT launched in November last year, AI and language models have captured the public imagination around the world. More excitingly, they’ve captured the imagination of developers around the world. We’ve seen an amazing number of people integrate AI into their applications, build net-new products using language models, and come up with entirely new ways of interacting with computers. Natural language interaction is finally possible and high quality. There are limitations and there are problems. For any of you who’ve used ChatGPT, you know that its training data was fixed in September 2021, so it’s unaware of current events.
For the most part, language models like ChatGPT operate from memory from their training, so they’re not connected to current events, or all the APIs out there, your own apps and websites that you use every day. Or if you work at a company, it’s not connected to your company’s database and your company’s internal knowledge base and things like that. That makes the use of language models limited. You can write a poem. You could write an essay. You can get a great joke out of it. You might search for some things. How do you connect language models to the external world? How do you augment the AI’s abilities to perform actions on your behalf, to do more than its innate abilities offer it?
Overview
If computers are a bicycle for the mind, what is a bicycle for the AI mind? That’s the question we’re going to explore, a bicycle for the AI mind. We’re going to talk about GPT, the flagship set of language models that OpenAI develops, and how to integrate them with tools or external APIs and functions to power net-new applications. My name is Atty. I’m an engineer at OpenAI. I’m joined by Sherwin. Together, we’re on the API team at OpenAI, building the OpenAI API and various other developer products.
We’re going to talk about three things. First, we’re going to talk about language models and their limitations. We’ll do a quick introduction to how they work, what they are. Develop an intuition for them. Then also learn about where they fall short. Second, we’re going to talk about a brand-new feature that we announced, called function calling with GPT. Function calling is how you plug OpenAI’s GPT models to the external world and let it perform actions. Finally, we’ll walk through three quick demos of how you might take the OpenAI models and the GPT function calling feature, integrate it into your companies, your products, and your side projects as well.
LLMs and Their Limitations
Sherwin Wu: I wanted to start by just giving a very high-level overview of LLMs: what they do, what they are, how they work. Then also talk about some of the limitations that they have right out of the box. For those of you who’ve been following this space for a while, this is probably information that you all know, but I just want to make sure that we’re all on the same page before diving into the nitty-gritty.
Very high-level, GPT models, including ChatGPT, GPT-4, gpt-3.5-turbo, they’re all what we call autoregressive language models. What this means is that they are these giant AI models, they’ve been trained on a giant corpus of data, including the internet, Wikipedia, public GitHub code, other licensed material. They’re called autoregressive because all they’re doing is they’re synthesizing all this information. They take in a prompt, or what we might call context. They look at the prompts. Then they basically just decide, given this prompt, given this input, what should the next word be? It’s really just predicting the next word.
For example, if an input given a GPT is, the largest city in the United States is, the answer is New York City. It would think about it one word at a time, and it would say New, York, and then City. Similarly, in a more conversational context, if you ask it what the distance between the Earth and the Sun is. GPT has learned this somehow from the internet, it’ll output 94 million miles. It’s thinking about it one word at a time, based off of the input.
Under the hood, what it’s really doing is each time it’s outputting words, it’s looking at a bunch of candidate words and assigning probabilities to them. For example, in the original example of, the largest city in the United States is, it might have a bunch of candidates, so New for like York, or New Jersey, or something, Los for Los Angeles, and then some other possible examples. You can see that it’s really thinking that New York City is probably the right answer, because New is assigned a probability of 95%. In this case, it generally picks the most likely outcome, so it picks New, and then it moves on. After this word comes out, you now know that New is the first word, so it’s constrained a little bit more on what the next word is.
You can see now it’s thinking New York with much higher likelihood, but it’s also considering New Brunswick, New Mexico, New Delhi as well. Then once the second word has been done, this is basically a layup for the model. It basically knows that it’s New York City with almost 100% probability. It’s still considering some other options with very low residual probability, so County, New York Metro, New York Times, but with that, it chooses City and concludes its answer.
For the more astute LLM folks, it’s technically an oversimplification. You’re not really predicting words, you’re predicting tokens, like fragments of words, which are actually a more efficient way of representing the English language, mostly because fragments of words are repeated in a bunch of different words instead of the word itself. The concept is still the same. The LLM is taking in that context, and it’s probabilistically outputting a bunch of different tokens in a row. That’s it. That’s really what these language models are. With this, the crazy thing that I think surprised a lot of us is that you can get really far with just predicting the next word.
This is a graph from our GPT-4 blog post that we released in March of this year, which shows the performance of our most capable model, GPT-4, on various professional exams. This is literally just GPT-4 predicting the next word, based off of questions. You can see that it’s actually performing at human or even past human performance on a lot of different exams. The y-axis is percentile amongst test takers. It’s basically at like 80th percentile, sometimes even 90th, or even 100th percentile on a bunch of different exams such as AP exams, the GREs, LSAT, USA Bio Olympiad as well.
At this point, a lot of these tests I can’t even do, and so GPT-4 is well above my own ability, and this is just from predicting the next word. This is really cool. You can build a lot of cool things with this. Anyone who has been playing around with LLMs for a while, you will realize that you very quickly start running into some limitations here. The biggest one, of course, is the out of the box LLM or GPT is really an AI that’s in a box. It has no access to the outside world. It doesn’t know any additional information. It’s just there with its own memory. It feels like when you’re taking a test in school and it’s just you and the test and you’re coming up with things out of memory.
Imagine how much better you do on the test if it were open node, if you could use your phone or something like that. GPT today is really just in its own box. Because of this, as engineers, we want to use GPT and integrate it into our systems. Limiting GPT and not allowing it to talk to our internal systems is very limiting for what you might want to do. Additionally, even if it does have access to these tools, because the language model is probabilistic, it’s sometimes very hard to guarantee the way that the model interacts with external tools. If you have an API or something that you want to work with, the current model isn’t guaranteed to always match the input of what an API might want, and that ends up being a problem.
For example, if I were building an application and I was to give this input to GPT, basically said, below is the text of a screenplay, extract some information from it and structure it in this JSON format. I’m really just giving it a screenplay and asking it to infer a genre and a sub-genre, as well as some characters from it, and age range. What I really want is I want it to output something like this. It’s like exactly like the JSON output.
Maybe this is a screenplay about like Harry Potter romance or something. It knows that it’s romance, teen romance, it sees Ron and Hermione, and outputs it exactly in this JSON format. This is fantastic, because I can just take this output, and now I can use this and throw this into an API. Then I’m like in my code, and it all works. The problem is it does this maybe like 80%, 70% of the time.
The rest of the time, it will actually try and be extra helpful and do something like this where it says, “Sure, I can do that for you. Below is the information you asked for in a JSON format.” Which is super helpful kind of, but if you’re trying to plug this into an API, it actually won’t work because there’s all this random text in front and your API won’t know how to parse it. This is obviously very disappointing. This is not what you actually want. What we really wanted to do is we wanted to help break GPT out of the box, or give GPT basically a bicycle or another set of tools to really augment its ability, and have that work very seamlessly.
Function Calling with GPT
This brings me to the next part, which is going over what we call function calling the GPT, which is a new change to our API that we launched that makes function calling work a lot better with our GPT models in a very first-class way. To illustrate an example of this, if you asked GPT a question like this, what’s the weather like in Brooklyn today? If you ask a normal GPT this, it’ll basically say something like, as an AI model trained by OpenAI, I’m unable to provide real-time information, which is true, because it can’t actually access anything. It’s in a box. How does it know what the weather is like right now.
This obviously really limits its capabilities, and it’s not desirable. What we did was we updated our GPT-4 and our gpt-3.5-turbo models or flagship models. We took a lot of tool use and function calling data, fine-tuned our models on those, and made it really good at choosing whether or not to use tools. The end result is a new set of models that we released that can now intelligently use tools and call functions for you. In this particular example, when we were asking the model, what’s the weather like in Brooklyn today? What I can now do is parse in this input, but also tell it about a set of functions, or in this case, one function that it has access to that it should try and call out to if it needs help. In this case, we’ll give it a function that’s called get_current_weather.
It takes in a string with the location, and then it knows that it can use this. In this case, in the new world, when you parse in this input, GPT will express its intent to call this get_current_weather function. You will then call this function yourself in your own system however you want. Let’s say you get an output here that says 22 Celsius and Sunny. You can parse that back to GPT, it’ll synthesize this information and return to the user saying the weather in Brooklyn is currently sunny, with a temperature of 22 degrees Celsius.
To unpack this a little bit, what’s really happening is GPT is knowing about a set of functions, and it will intelligently on its own, express its own intent to call one of these functions. Then you execute the call and then parse it back to GPT. This is how you end up connecting it to the outside world. To walk through this a little bit more, what’s really happening at a high level, it’s still just like a back and forth, so your user asks a question, a bunch of things happen. Then you’re responding to your user. What actually happens behind the scenes with your app is you’re going through this three-step process where you’re calling out to OpenAI, then you’re using your own function, and then you’re calling out to OpenAI, or GPT again.
The first step, obviously the user asks a question, in this case, it is, what’s the weather like in Brooklyn today? Then the next step is, in your application, you call a model, you call OpenAPI, and you tell it about the set of functions that it has access to, as well as the user input, very concretely. This is an example API request that actually works today, anyone with API access can try this. This is an example curl that uses our function calling ability. You can see that it’s just normal curl to our chat completions endpoint, which is a new API endpoint that we released, that powers our GPT-4 and GPT-3.5 models. You’re curling this API. You’re parsing in a model.
In this case, you’re parsing in a gpt-3.5-turbo-0613, which stands for June 13th, which is the model that we released. This is the model that’s capable of doing function calling. You’re also parsing in a set of messages. For those of you who might not be familiar with our chat completions format, you can parse into our model, basically a list of messages. That’s the conversation history.
In this case, there’s only one message, there’s no history, really. It’s just a user asking what’s the weather like in Brooklyn today. You can imagine, as the conversation gets longer, this might be like a 5 to 10 message list. You’re parsing the messages, and the model will be able to see the history and react to that. Then, the net-new thing here is functions.
This is a new parameter you can parse in now, and what you’re parsing in here is you’re listing the set of functions that this model should be aware of, that it should have access to. In this case, we only have one function, it’s the get_current_weather function. You’re putting a natural language description here as well. You’re saying this function gets the current weather in a particular location. You’re also putting in the function signature. You’re saying it has two arguments. It has a location, which is a string, which is just city and state, and it’s in this format, so San Francisco, California. It also has a unit parameter as well, which is Celsius, or Fahrenheit.
Below the fold here, there’s also another argument in here that says the only property that is required is the location. You technically only need to parse in location, you don’t need a unit here. You parse this request over to GPT, and GPT will then respond. In the old world, GPT would probably just respond with text. It’ll say, I can’t do this, because I don’t have access. In this case, what our API responds with, is an intent to call the weather function.
What’s really happening here is GPT is intuiting on its own, that in order to figure out the current weather, I’m not able to do it on my own, but I have access to this get_current_weather function, so I’m going to choose to call it, and so I’m going to express an intent to call it. Additionally, what GPT did here, if you haven’t really noticed, is it’s constructing the argument here. You can see it’s telling you, it wants to call get_current_weather, and it wants to call it with the argument location, Brooklyn, New York.
What it did is it saw the function signature, created a request for it. Then also figured out that Brooklyn is in New York, and then structured the string in this way. It figured all of this out. With this, GPT has expressed an intent to call a function now. The next step is now it’s on you to figure out how you actually want to call this function. You have the return from the function call, get_current_weather with this particular argument. You can then execute it on your own. It could be local, running on your own web server. It can be another API in your systems. It could be an external API, you can call the weather.com API.
Then let’s say in this case, we call something, maybe an internal API, and it returns with this output that you saw, so 22 degrees Celsius and Sunny. Given that output from the model, you start your third step in this process, which is then calling the model, calling GPT with the output of the function, and then seeing what GPT wants to do. In this case, I was talking about the messages. This time, the second request you’re sending to the OpenAI API, you’re going to add a couple messages here. Originally, there’s just one message which was the, what’s the weather like in Brooklyn? Now you’re adding two new messages that represent what happened with the function call.
The first one is basically a rehash of the intent, so you’re basically saying the assistant or GPT wanted to call the get_current_weather function with this argument of Brooklyn, New York. Then you’re also adding a third message, which basically says the result of the function call that you had, so this is the result of get_current_weather. Then you’re inlining the data that is output here, which is the temperature 22, unit Celsius, and description Sunny, and you parse that all to GPT. At this point, then GPT takes in that and put it and decides what it wants to do.
At this point, the model is now smart enough to realize, “I’ll call this function. Here’s the output. I actually have all the info I need to actually fulfill the request.” It’ll now respond finally with text, and it’ll say the weather in Brooklyn is currently sunny, with a temperature of 22 degrees Celsius. At that point you finally have your final output from GPT. Then that’s when you respond to the user.
Putting this all together, you end up getting the experience that you’d ideally like to have here, which is the user asks, what’s the weather like in Brooklyn today? Your server thinks a little bit, GPT expresses the intent, you do this whole three-step process, calling out to your function. Then ultimately, what the user sees is, the weather in Brooklyn is currently sunny, with a temperature of 22 degrees Celsius. Success.
Demo 1 – Converting Natural Language into Queries
Eleti: We just went through a couple of introductory topics. First, we learned about how language models work, some of their limitations, in that they don’t have all the training data, they’re not connected to the external world, that their structured output is not always parseable. Sherwin also just walked us through the new feature, function calling and how the API works, and how you parse functions to the API and get output back, and get GPT to summarize the responses in a user facing way. Let’s walk through a few demos about how you can combine all of this and apply it to your products and your applications.
Let’s start small. The first example we’ll walk through is something that converts natural language into queries. The example we’re going to do is, imagine you’re building a data analytics app or a business intelligence tool, like Tableau or Looker. Some of you may be good at SQL, I certainly am not. Most often, I just want to ask the database, who are those top users, and just have the response back. That’s finally possible today. We’re going to use GPT, we’re going to give it one function called SQL query, all it takes is one parameter, query a string.
It’s supposed to be a valid SQL string against our database. Let’s see how that works. First, we’re going to give the model a system message describing what it’s supposed to do. We say your SQL GPT, and can convert natural language queries into SQL. Of course, the model needs access to a database schema. In this case, we have two tables, users and orders. Users have a name, email, and birthday. Orders have a user ID, purchase amount, and purchase date. Now we can start querying the database with some natural language.
Let’s ask this question, get me the names of the top 10 users by amount spent over the last week. A fairly normal business question, certainly not something I could write SQL for in a jiffy, but GPT can. Let’s run it. We can see that it’s calling the SQL query function. It has one parameter, query, and it created a nice SQL query. It’s selecting the name and the sum of amount. It’s joining on orders. It’s getting the last one week of orders, ordering it by the total spent, and limiting it to 10. Seems correct and appropriate. Let’s run it against our database. We got some results back.
Of course, this is in a JSON format, and so not user renderable. Let’s send this back to GPT to see what it says. GPT summarized the information and said, these are the top 10 users by amount spent. This is what they spent over the last week, so Global Enterprises, Vantage Partners. This is an amazing user readable answer.
We’re going to say a quick thank you to GPT for helping us out. It says thanks, and GPT says, you’re welcome. That’s a quick way to see how totally natural language, completely natural language queries were converted into structured output into a valid SQL statement that we ran against our database, got data back, summarized it back into natural language. You can certainly build data analytics apps off of this.
You can build other internal tools. Honeycomb recently built a very similar tool for the Honeycomb query language. That’s one example of using GPT and functions to convert natural language into queries.
Demo 2 – Calling External APIs and Multiple Functions
Let’s do a second demo. This one is about calling external APIs and multiple functions together. Let’s amp up the complexity level. Let’s say we’re here at a conference in New York and we want to find dinner reservations for tonight. We’re going to call GPT with two functions. The first one is, get_current_location. That runs locally on device, let’s say on your phone or on your browser, and gets the Lat and Long of where you are. The second function here is Yelp search, which uses Yelp’s API, so the popular restaurant review application, and you parse in the Lat, Long, and query.
Let’s run through a demo. The system message in this case is fairly simple. All it says is your personal assistant who is helpful at fulfilling tasks for the user, sort of puts GPT into the almost mental mode of being a helpful assistant. I say, I’m at a conference and want to grab dinner nearby, what are some options? My company is expensing this so we can go really fancy. Let’s run that with GPT and see how it can do it.
Of course, GPT doesn’t know where we are, so it says get_current_location, and we’re going to call the local API to get our Lat and Long. We’ve done that. That’s Brooklyn, New York, somewhere here, I think. We’ll give that back to GPT and see what it says. It has the information it needs, now it wants to call Yelp, and it says Lat, Long, and query, and it says fine dining. That’s good. That’s what I want. Let’s call Yelp and get some data back.
We got a bunch of restaurants from Yelp’s API. I want it in a nice summary, of course, so let’s run it again. Says, here are some fancy dining options near your location, La Vara, Henry’s End, Colonie, Estuary. It says, please check the opening hours and enjoy your meal. Sounds delicious. Thank you GPT, yet again, for helping organize dinner tonight.
That’s an example of using GPT and functions to call external APIs, in this case, the Yelp API, as well as to coordinate multiple functions together. It’s capable with its reasoning ability to parse user intent and do multi-step actions, one after another, in order to achieve the end goal.
Demo 3 – Combining Advanced Reasoning with Daily Tasks
A third demo, let’s ramp it up a little bit more. We talked about how GPT-4 can pass the SAT and the GRE. If it can, it must be smarter than just calling the Yelp API or writing some SQL. Let’s put it to the test. We’re all engineers, we have many things to do every day. One of the tasks that we have to do is pull request review. We have to review our coworker’s code. It would be awesome if GPT could help me out a little bit and make my workload a little bit lower. We’re going to do a demo of GPT that does pull request review, sort of build your own engineer.
We only need one function, submit_comments. It takes some code and returns a list of comments that it wants to review, so line, numbers, and comments. You can imagine we can then send this out to the GitHub API or the GitLab API, and post a bunch of comments. Of course, you can add more functions and make it even more powerful down the line. Let’s see how that works.
In this case, the prompt is a little bit long. Let’s scroll up and see. We’re saying, GPT, you record, review bot, you look at diffs and generate code review comments on the changes, leave all code review comments with corresponding line numbers. We’re also playing around with personality here. We’re saying 0 out of 10 on toxicity, we don’t want that.
For fun, let’s try 8 out of 10 on snark. We’ve all known a couple of engineers who display these personalities. Then 2 out of 10 on niceness. Let’s just start there. Then below here is some code that we want reviewed. It’s an API method in a SaaS application that changes permissions for a user. Let’s run it. Let’s see what GPT has to say about the code. Say, give me three review comments. We can see it called the submit_comments function, and it outputted perfectly valid JSON. Let’s see what it says. It says, are we playing hide and seek now, what happened when role is not in the body? You add a little twist there, you’re directly accessing the first item.
Casually committing to the DB session, are we? It’s a little bit rude. We don’t want that. Let’s fix this. I’m going to exit out of this right now and go and change our prompt a little bit. To do, exit. Behind the scenes, what I’m doing is going back to the prompt and just changing those numbers. Taking toxicity, and then the next one, snark, we’re taking it back to 0. We don’t want that. Let’s be polite.
We’re going to make politeness 10 out 10. Let’s do, give me three review comments again. It’s once again calling the function with perfectly valid JSON. It says, it’s nice to see you retrieving the role value. It says, your error messages are neat, nicely descriptive. I appreciate you committing to your database changes, good work. I would love somebody to review my code like this. Thank you GPT, and I will exit. That’s a quick third demo.
At its core, it’s still doing the same thing. It’s calling one function, given some prompt, responding to it. What we’re seeing at play is GPT’s reasoning ability. GPT knows code. It’s seen thousands and millions of lines of code and can give you good reviews. If you peel back some of this personality stuff, it’s pointing out typos, it’s pointing out potential error cases and edge cases. We’re combining here the advanced reasoning with daily tasks. It’s certainly very good at coding. It’s certainly very good at exams, but its intelligence applies quite broadly. It’s really up to the creativity of developers to take this and apply to as difficult tasks as possible and run the loops on that.
Summary
That’s a quick wrap up of our content. We covered three things. First, we talked about LLMs and their limitations. We learned about how LLMs work, they’re token predicting machines. We learned about their limitations. They’re stuck in time. They don’t always output structured output, and so on. Second, we learned about this new feature, function calling with GPT, which is an update to our API and to our models. It allows the model to want to express intent about when it wants to call a function, and to construct valid arguments for you to then go call that function on your end. Then, finally, we walked through some demos. At some point, I’m going to go productionize that PR thing.
Let me bring it back to where we started. We talked about this famous Steve Jobs quote, about computers being a bicycle for the mind. It’s certainly been true for me. It’s certainly been true for all of you. We’re in the computing industry, computers have changed our lives. Computers have augmented our innate abilities, and given us more productivity, more imagination, more creativity. The AI and language models in ChatGPT is a baby. It’s only been around for a few months. It’s up to us to augment the AI’s mind and give it new abilities beyond its inner reasoning abilities, connect it to tools, connect it to APIs, and make really exciting applications out of this feature.
The original quote is quite inspiring to me. We can never do justice to a Steve Jobs quote. “I remember reading an article when I was about 12 years old, I think it might have been in Scientific American, where they measured the efficiency of locomotion for all these species on planet Earth, how many kilocalories did they expend to get from point A to point B. The condor won, came in at the top of the list, surpassed everything else. Humans came in about a third of the way down the list, which was not such a great showing for the crown of creation.
Somebody there had the imagination to test the efficiency of a human riding a bicycle. A human riding a bicycle blew away the condor, all the way up on the top of the list. It made a really big impression on me, that we humans are tool builders, and that we can fashion tools that amplify these inherent abilities that we have to spectacular magnitudes. For me, a computer has always been a bicycle of the mind, something that takes us far beyond our inherent abilities. I think we’re just at the early stages of this tool, very early stages. We’ve come only a very short distance, and it’s still in its formation but already we’ve seen enormous changes. I think that’s nothing compared to what’s coming in the next 100 years.”
As much as that applied to computers 50 years ago, I think the same applies to AI today. Technology is in its infancy, so we’re very excited to see where it goes.
Q&A
Strategies for Coping with Errors and Failures
Participant 1: How should we cope with errors and failures, and what strategies might you suggest? Taking your example, where you built a SQL query, what if the question that I ask results in ChatGPT giving a syntactically correct SQL query, but semantically, it’s completely off. I then report back to my users something that’s incorrect. It’s hard to tell the user, fault here, but do you have any strategies you can suggest for coping with that?
Eleti: I think the first thing is, as a society and as users of these language models, we have to learn its limitations, almost build antibodies around its limitations. There is a little bit about just knowing that the outputs might be inaccurate. I think a second part is like opening the box. We’ve integrated function calling in production with ChatGPT. We’ve launched a product called plugins, which basically does this, it allows ChatGPT to talk to the internet. One thing we do is all the requests and all the responses are visible to the end user if they so choose to see them. That helps with the information part. I personally say I think also SQL is a very broad open surface area. I think limiting it down to well-known APIs that only will perform safe actions in your backend is a good way. You can always get good error messages and things like that. Those would be my off-the-cuff tips.
LLMs and LangChain
Participant 2: Has anybody tried to do some LangChain, and will it work with LangChain?
Eleti: Yes, actually, LangChain, Harrison and the team launched an integration an hour after our launch, so it works.
Data Leaking
Participant 2: This still exposes the leakage problem. The SQL example is a good example. If somebody reads this, and they do an SQL query against a financial database, and they feed it into the gpt-3.5-turbo, basically, you’re leaking data.
There’s these problems where if you’re using a text-davinci-003 or different models, some of that data from the query is turning into the model itself. That example seems to me would be extremely dangerous.
Wu: There’s actually a misconception that I think we haven’t cleared up very well recently, which is, up until I think March or February of this year, in our terms of service for the API, we said, we reserve the right for ourselves to train on the input data for the API. I think that’s probably what you’re talking about, which is like you’re parsing in some SQL queries, and that will actually find its way somehow back into the model as it returns. Actually, as of right now, we no longer do that. In our terms of service, we actually do not train on your data in the API. I think we haven’t made this super clear and so people are very paranoid about this. As of right now, it doesn’t. You should look it up in our terms of service. We don’t train on it. That being said, that thing parsed in is not like enterprise-grade. We’re not isolating it specific to your user. We’re just not training it on our own data. That type of feature around data isolation at the enterprise layer is obviously coming soon. That specific layer of security is not there yet.
Eleti: We do not train on API data.
Parallelization of Function Calling
Participant 3: The demos that you showed were a little bit slow. I’m wondering, do you guys support parallelization of function calling? Like right now are you even sequential, you get this function signature back, and you got to call it, but let’s say ChatGPT said, three functions should be called simultaneously, does that work?
Eleti: The API literally does not support multiple function invocation. There’s no output where it says, call these three functions. You can hack it. The way you do it is you just define one function, which is call multiple, and you provide a signature where the model calls multiple functions, and it totally works. At the end of the day, still we’re using the model’s reasoning ability to output some text.
Context Preloading for Models
Participant 4: In the SQL example you gave, you gave it some table to have access to. Is there a way for us to just preload all of the contexts for any subsequent call by anybody?
Wu: There are a couple potential solutions. We have a feature called a system message that you can parse in, which basically sets the overall conversation context for a model. That’s just really upended in the context. We’ve been increasing the context window to something like 16,000 tokens at this point. You can increasingly squeeze more things into the system message. The model is trained to be extra attentive to the system message to guide how it reacts. In this example, Atty had two table schemas in the system message. You could foreseeably add a lot more all the way up to fill up the whole context.
Participant 4: That would be how I would preload?
Wu: Yes, that’s the simplest. There are a couple other methods as well. You can hook it up to an external data source, a DB or something. Fine-tuning is another option as well. There are other things too.
Reliable Function Calling with GPT
Participant 5: A take around with integrating to GPT, into a different software. I had some problem with Enums, which are in use with me, would sometimes come in German or French when I asked it for doing some jobs in English, and in French or German. Is this also going to happen with this function API.
Eleti: Yes, unfortunately. The model is prone to hallucination, in the normal situation, as well as in this situation. What we’ve done is basically fine-tuned the model so it’s seen maybe a few 100,000 examples of how to call functions reliably. It’s much better at it than any other prompting you might do yourself. It still makes up parameters, it might output invalid JSON, it might output other languages. To prevent that, we’re going to do more fine tuning. We have a couple of low-level inference level techniques to improve this as well that we’re exploring. Then on your end, you can do prompt engineering, and just please remind the model, do not output German, and it will try its best.
Wu: It’d be really interesting to see if it’s gotten better at this, especially if you have a function signature and you’re explicitly listing out the 5 different English Enums. The newer models are probably better, but it won’t be perfect. I’m not 100 sure, we don’t have Evals for like cross-English, French Enums, unfortunately. It’s probably a good one to think about, but we’d be curious to see if it got better with this.
GPT’s Ability to Figure Out Intent
Participant 6: I have a question about the API’s ability to figure out the intent. Is there similar temperature parameters for the function call so that if I parse in two functions with similar intent, would GPT be deterministic for each function to call, or is there any randomness of picking which function to call, if I asked it multiple times.
Eleti: There is still randomness. At the end of the day, under the hood, it’s still outputting token by token, choosing which function it wants to call. Lowering the temperature increases determinism, but it does not guarantee it. That said, there is a parameter in the API called function call, where if you know which function you want it to call, you can actually just specify it upfront, and it will definitely call that function.
Function Call Entitlement
Participant 7: Do you guys have entitlements for the function calls, if we wanted to limit certain users from certain function calls or like which tables you could access in those SQL queries. Are people still needing to implement their own?
Eleti: All of that will happen on your servers, because you have the full context of who has access to what. All that this API provides is the ability for GPT to choose which function to call and what parameters to use. Then we expect that you should treat GPT’s output as any other client, so untrusted client output that you would validate on your end with permissions and stuff.
Chain of Thought Prompting, and Constraint Sampling
Participant 8: I was just wondering if you could perhaps elaborate on what’s going on under the hood here. Is this chain of thought prompting under the hood? Is this effectively an API layer on top of those techniques?
Eleti: Chain of thought prompting is a way to ask the model when given a task, first, tell me what you’re going to do, and then go do it. If you say, what’s the weather like in Brooklyn? It might say, I have been asked a weather request, I’m going to call the weather API. Then it goes and does that. That’s a prompt engineering technique. This is a fine-tune. With the launch of plugins, we’ve collected both internal and external data of maybe a few 100,000 examples of user questions and function calls. This is all fine-tuned into the model. That’s where it’s coming from.
There’s a third technique that we can use, which is called constraint sampling, where the token sampling level, you make sure that the next token that is being predicted is one of a valued set. In a JSON example, after a comma it has to be a new line or something like that. We might be getting that wrong, but you get the idea of, you have grammar that you want to assign [inaudible 00:45:02]. We don’t have that yet. It’s an area that we’re exploring. This is the long journey from prompting to fine-tuning to more low-level stuff. This is the journey to getting GPT to output reliably structured data.
Vector Database Compatibility
Participant 9: Will this work with a vector database? The idea is I want to constrain the information based on what I fed into the vector database, but it still works with the function logic?
Eleti: Yes, works exactly as it used to.
Is Function Calling Publicly Available?
Participant 10: Are we able to use it today? Is it open to the public right now?
Wu: This is publicly available today with a caveat. It’s available on the gpt-3.5-turbo model. Anyone here can actually access function calling with gpt-3.5-turbo because that’s generally available. It’s also available on GPT-4 on the API, but unfortunately that is still behind a waitlist. If you are off that waitlist and you have access to GPT-4 API, you will actually be able to do this with GPT-4. It’s way better at it. It is a little slower. If you’re still on the waitlist or you don’t have access to GPT-4 API, you can try this out today on gpt-3.5-turbo.
See more presentations with transcripts
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Google Cloud has recently introduced service account key expiry to address security challenges associated with long-lived service account keys. With this capability, the company states that “customers can now configure an Organization Policy at the organization, folder, and project level to limit the usable duration of new service account keys” – and thus reduce risks related to leaked and compromised keys.
Earlier, when creating a service account key, Google Cloud didn’t let users specify an expiry date. The key stayed valid until they either deleted the key or deleted the entire service account. Now, with the ability to set the key expiry, it is helpful for specific scenarios, such as non-production environments or using 3rd party tools that can only authenticate with service account keys. However, changing the default configuration to include key expiry may lead to unintended outages for developers accustomed to long-lived keys.
Yet, for more advanced organizations that have service account keys disabled already using Organization Policy, the service account key expiry can also act as an exception process to allow using keys for a limited time without changing their organization’s security policy.
Organizations’ cloud administrators can go to the organization policy page and find the constraint with the ID “constraints/iam.serviceAccountKeyExpiryHours”. Subsequently, through editing, they can configure a custom allow policy for a duration ranging from 8 to 2160 hours (90 days) with policy enforcement set to “Replace.”
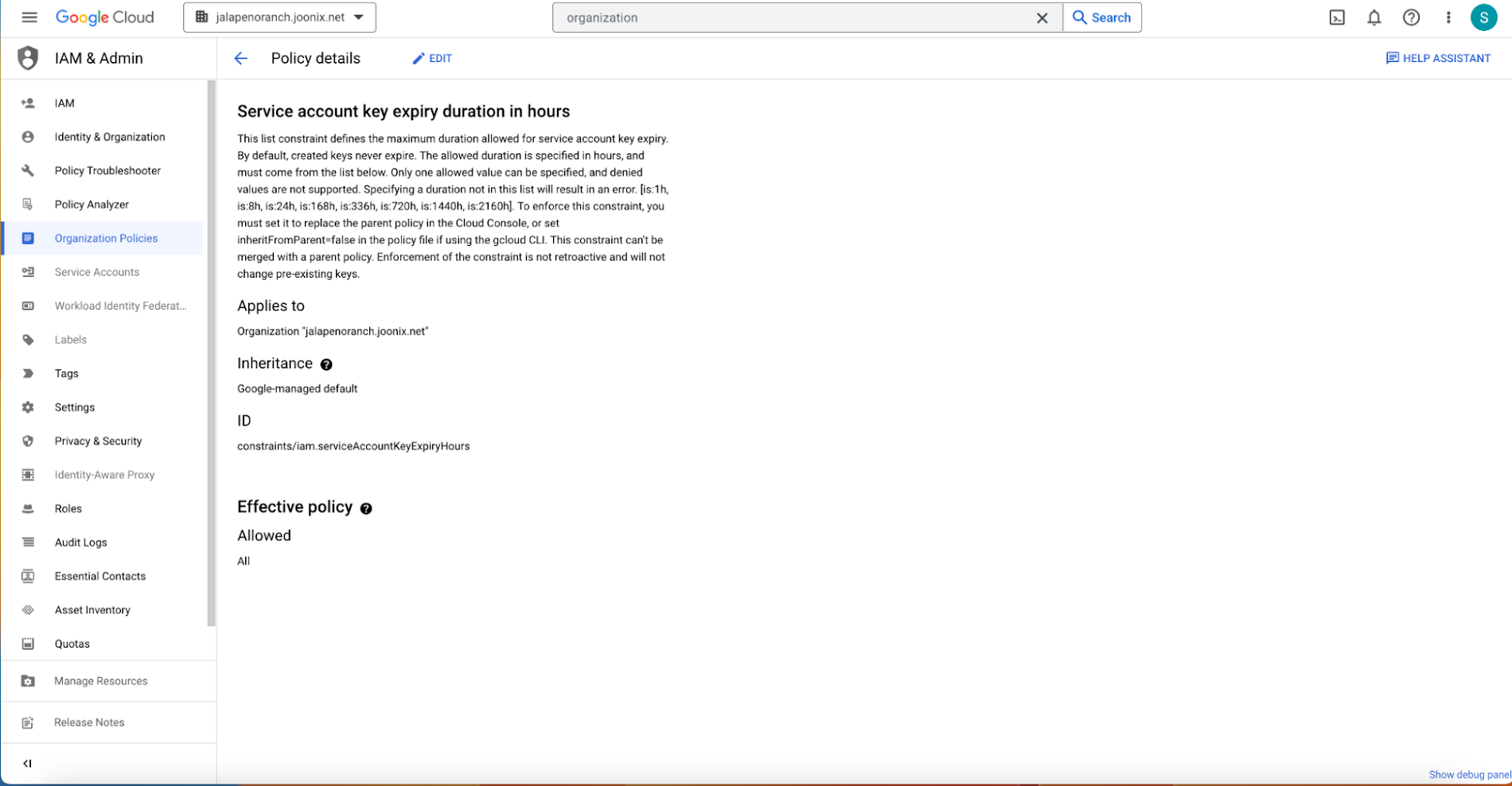
Screenshot of the organization policy page to set the expiry of the service account (Source: Google Cloud blog)
Alternatively, configuring the key expiry of the service account is to leverage the practice of key rotation – a process of replacing existing keys with new keys and then invalidating the replaced keys, a recommended way for production workloads. In a Google blog post, the authors wrote:
If you want to set up a key rotation for your service account keys in your organization, we recommend you monitor keys using cloud asset inventory instead of using key expiry to avoid potential outages. This will allow you to send warning notifications to developers when a key is about to expire, and it is time to rotate the key.
In addition, in an earlier LinkedIn post, Lukasz Boduch, a Google cloud architect at SoftServe, commented:
So, what if you Prod GCE or any other SA key expire? Also, if I remember correctly, Google has never recommended this feature for Prod, at least when this was pre-ga 🙂
And:
Btw also, in the past, you could export a key with an expiring date, did you know? All you needed is a certificate with an expiration date, so this “new” feature is not that cool and new after all.
Johannes Passing, a staff solutions architect at Google Cloud, wrote in a blog post in early 2021:
Things look different when you upload a service account key: uploading a service account key works by creating a self-signed X.509 certificate and then uploading that certificate in PEM format. X.509 certificates have an expiry date, and you can use that to limit the validity of a service account key.
Other Cloud Providers offer similar accounts like the service account in Google. For instance, in Microsoft Azure, the equivalent of a service account is called a “Service Principal.” Like service accounts in Google Cloud, a service principal is also used to authenticate applications, scripts, or services to access resources within Azure. This account also has an expiry date that can be set during creation (the default is one year); however, here, key rotation is regularly recognized as a practice to improve security posture and reduce the risk of compromise.
Lastly, more details on service accounts in Google are available in the documentation.
The 10 Best AI Databases For Machine Learning And Artificial Intelligence – Dataconomy
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
Artificial intelligence is no longer fiction and the role of AI databases has emerged as a cornerstone in driving innovation and progress. An AI database is not merely a repository of information but a dynamic and specialized system meticulously crafted to cater to the intricate demands of AI and ML applications. With the capacity to store, organize, and retrieve data efficiently, AI databases provide the scaffolding upon which groundbreaking AI models are built, refined, and deployed.
As the complexity of AI and ML workflows deepens, the reliance on large volumes of data, intricate data structures, and sophisticated analysis techniques becomes more pronounced. Herein lies the crux of the AI database’s significance: it is tailored to meet the intricate requirements that underpin the success of AI and ML endeavors. No longer confined to traditional databases, AI databases are optimized to accommodate a spectrum of data types, each uniquely contributing to the overarching goals of AI—learning, understanding, and predictive analysis.
But which AI database tools can you rely on for your artificial journey into today’s technology? Let’s take the first step of a successful AI initiative together.

What is an AI database?
An AI database is a specialized type of database designed to support the storage, management, and efficient retrieval of data used in artificial intelligence (AI) and machine learning (ML) applications. These databases are engineered to accommodate the unique requirements of AI and ML workflows, which often involve large volumes of data, complex data structures, and sophisticated querying and analysis.
AI databases are optimized to handle various types of data, including structured, semi-structured, and unstructured data, that are essential for training and deploying AI models. The types of data mentioned in the context of AI databases refer to different formats in which information is stored and organized. These formats play a significant role in how data is processed, analyzed, and used to develop AI models.
Structured data is organized in a highly organized and predefined manner. It follows a clear data model, where each data entry has specific fields and attributes with well-defined data types.
Examples of structured data include data stored in traditional relational databases, spreadsheets, and tables. In structured data, the relationships between data points are explicitly defined, making it easy to query and analyze using standardized methods. For AI applications, structured data can include numerical values, categorical labels, dates, and other well-defined information.
Semi-structured data is more flexible than structured data but still has some level of organization. Unlike structured data, semi-structured data doesn’t adhere to a strict schema, meaning that different entries can have different sets of attributes. However, there is usually some consistency in the way the data is organized.
Semi-structured data is often represented using formats like JSON (JavaScript Object Notation), XML (eXtensible Markup Language), or key-value pairs. This type of data is common in web data, sensor data, and data obtained from APIs. In AI, semi-structured data might include text with associated metadata or data with varying levels of structure.
Unstructured data lacks a predefined structure or format. It is typically more complex and challenging to process than structured or semi-structured data. Unstructured data includes text, images, audio, video, and other data types that don’t neatly fit into rows and columns.
In AI applications, unstructured data can be vital for tasks such as natural language processing, image recognition, and sentiment analysis. Analyzing unstructured data often involves using techniques like machine learning to extract meaningful patterns and insights from the raw information.

What makes AI databases different from traditional databases?
They provide the foundation for data preprocessing, feature extraction, model training, and inference.
Several key features set AI databases apart from traditional databases:
- Scalability: AI databases are designed to scale horizontally and vertically, enabling them to handle the substantial amounts of data required for training complex models. They often leverage distributed computing techniques to manage and process data efficiently
- Data diversity: AI databases can handle a wide variety of data types, including text, images, audio, video, and sensor data. This versatility is crucial for training models that require multi-modal data sources
- Complex queries: AI databases support advanced querying capabilities to enable complex analytical tasks. This may involve querying based on patterns, relationships, and statistical analysis required for ML model development
- Parallel processing: Given the computational demands of AI and ML tasks, AI databases are optimized for parallel processing and optimized query execution
- Integration with ML frameworks: Some AI databases offer integration with popular machine learning frameworks, allowing seamless data extraction and transformation for model training
- Feature engineering: AI databases often provide tools for data preprocessing and feature engineering, which are crucial steps in preparing data for ML tasks
- Real-time data ingestion: Many AI applications require real-time or near-real-time data processing. AI databases are equipped to handle streaming data sources and provide mechanisms for timely ingestion and analysis
- Metadata management: Managing metadata related to data sources, transformations, and lineage is crucial for ensuring data quality and model reproducibility
- Security and privacy: AI databases need to ensure robust security mechanisms, particularly as AI applications often involve sensitive data. Features like access controls, encryption, and anonymization may be implemented
What are the top 10 AI databases in 2023?
The selection of a suitable AI database is a crucial consideration that can significantly impact the success of projects.
The diverse options of available databases offer a range of options, each tailored to meet specific requirements and preferences.
Redis
Redis stands out as an open-source, in-memory data structure that has gained recognition for its versatility and robust feature set. It boasts the ability to support various data types, ranging from simple strings to more complex data structures, enabling developers to work with diverse data formats efficiently.
Furthermore, Redis encompasses a rich spectrum of functionalities, including support for transactions, scripting capabilities, and data replication, which enhances data durability and availability.

PostgreSQL
As an open-source object-relational AI database system, PostgreSQL has earned its reputation for its unwavering commitment to data integrity and advanced indexing mechanisms. Its support for various data types makes it a versatile choice, accommodating a wide array of data structures.
With a strong emphasis on ACID compliance (Atomicity, Consistency, Isolation, Durability), PostgreSQL is well-equipped to handle complex data workloads with the utmost security and reliability.

MySQL
MySQL, a renowned open-source relational AI database management system, has maintained its popularity for its strong security measures, scalability, and compatibility. It seamlessly accommodates structured and semi-structured data, making it adaptable to a diverse range of applications.
MySQL’s reliability and performance have made it a favored choice in various industries, and its open-source nature ensures a thriving community and continuous development.

Apache Cassandra
Apache Cassandra has emerged as a highly scalable NoSQL database, favored by major platforms like Instagram and Netflix. Its automatic sharding and decentralized architecture empower it to manage vast amounts of data efficiently.
This makes it particularly suitable for applications requiring high levels of scalability and fault tolerance, as it effortlessly accommodates the demands of modern data-driven initiatives.

Couchbase
Couchbase is an open-source distributed engagement database that offers a potent combination of high availability and sub-millisecond latencies. Beyond its performance merits, Couchbase also integrates Big Data and SQL functionalities, positioning it as a multifaceted solution for complex AI and ML tasks.
This blend of features makes it an attractive option for applications requiring real-time data access and analytical capabilities.

Elasticsearch
Elasticsearch, built on the foundation of Apache Lucene, introduces a distributed search and analytics engine that facilitates the extraction of real-time data insights. Its capabilities prove invaluable in applications demanding rapid data retrieval and analytics, enabling informed decision-making.
With its real-time querying prowess, Elasticsearch contributes significantly to enhancing AI and ML workflows.

Google Cloud Bigtable
Google Cloud Bigtable distinguishes itself as a distributed NoSQL AI database offering robust scalability, low latency, and data consistency. These features make it particularly adept at handling high-speed data access requirements.
However, it’s worth noting that while Google Cloud Bigtable excels in performance, its pricing complexity may require careful consideration during implementation.
See how Google Cloud Bigtable works in the video by Google Cloud Tech below.
MongoDB
MongoDB‘s prominence lies in its flexible, document-oriented approach to data management. This attribute, coupled with its scalability capabilities, makes it an attractive choice for handling unstructured data.
Developers seeking to manage complex data structures and accommodate the dynamic nature of AI and ML projects find MongoDB’s features well-aligned with their needs.

Amazon Aurora
Amazon Aurora, a high-performance relational database, offers compatibility with MySQL and PostgreSQL. Its ability to scale seamlessly and robust security features and automatic backup mechanisms position it as a compelling option for AI and ML applications.
Organizations leveraging Amazon Aurora benefit from its efficient handling of complex data workloads.

Chorus.ai
Chorus.ai takes a specialized approach by targeting client-facing and sales teams. It provides an AI assistant designed to enhance note-taking processes. As businesses strive to streamline interactions and gather insights from customer engagements, Chorus.ai’s AI assistant plays a pivotal role in capturing vital information and fostering efficient communication.

How to choose the right AI database for your needs
The key to selecting the right AI database lies in aligning the database’s features and capabilities with the specific requirements of the project at hand. By carefully evaluating factors such as scalability, security, data consistency, and support for different data types and structures, developers can make accurate decisions that contribute to the success of their AI and ML endeavors.
To choose the right AI database, start by clearly defining your project’s requirements. Consider factors such as the volume of data you’ll be dealing with, the complexity of your data structures, the need for real-time processing, and the types of AI and ML tasks you’ll be performing.
Once you have decided your requirements for the selection of an AI database, evaluate the types of data you’ll be working with—structured, semi-structured, or unstructured. Ensure that the AI database you choose can efficiently handle the variety of data your project requires.
Don’t forget to consider the scalability needs of your project. If you expect your data to grow significantly over time, opt for a database that offers horizontal scaling capabilities to accommodate the increased load.
Assess the performance metrics of the AI database. For real-time applications or high-speed data processing, choose a database that offers low latency and high throughput.
Once you have done that, review the querying and analytical capabilities of the database. Depending on your project’s requirements, you may need advanced querying features to extract insights from your data.
If you’re planning to use specific machine learning frameworks, consider databases that offer integration with those frameworks. This can streamline the process of data extraction and transformation for model training.

Data security is also paramount, especially if your project involves sensitive information. Ensure the AI database you are going to choose offers robust security features, including access controls, encryption, and compliance with relevant regulations.
Evaluate the user-friendliness of the database. An intuitive interface and user-friendly management tools can simplify data administration and reduce the learning curve.
Make sure that you also consider the size and activity of the user community surrounding the database. A strong community often indicates ongoing development, support, and a wealth of resources for troubleshooting.
Also, look for case studies and examples of how the AI database has been successfully used in projects similar to yours. This can provide insights into the database’s effectiveness in real-world scenarios.
By carefully considering these factors and conducting thorough research, you can identify the AI database that best aligns with your project’s needs and goals. Remember that selecting the right database is a crucial step in building a solid foundation for successful AI and ML endeavors.
Featured image credit: Kerem Gülen/Midjourney.
Graph Database Market Size to Grow at a CAGR of 23.40% in the Forecast Period of 2023-2028
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
PRESS RELEASE
Published August 7, 2023

The ‘Global Graph Database Market Report and Forecast 2023-2028’ by Expert Market Research gives an extensive outlook of the global graph database market share, assessing the market on the basis of its segments like components, deployment models, types of databases, analyses, applications, organization sizes, industry verticals, and major regions.
The key highlights of the report include:
Market Overview (2018-2028)
- Historical Market Size (2022): About USD 1.69 Billion
- Forecast CAGR (2023-2028): 23.40%
- Forecast Market Size (2028): Nearly USD 6.01 Billion
The adoption of graph database tools and services is growing as many legacy database providers are attempting to incorporate graph database solutions into their primary relational database infrastructures.
The graph database market growth can be attributed to the surging amount of data in several sectors and the growing adoption of innovative data processing solutions. In addition, growing digitalization and the rising deployment of advanced technologies by businesses are favoring the market.
Get a Free Sample Report with Table of Contents: https://www.expertmarketresearch.com/reports/graph-database-market/requestsample
Graph databases are well-suited to handle complex relationships and connections between data, which makes them an ideal tool for machine learning and artificial intelligence applications. As these technologies continue to grow in popularity, the integration of graph databases with machine learning and artificial intelligence tools is expected to increase in the forecast period.
There is a surging utilisation of graph database solutions among healthcare institutions to enhance the quality of treatment, provide better patient outcomes, and improve their operational efficiency. Moreover, businesses are increasingly adopting cloud-based solutions and surging their reliance on connected data, which is a crucial graph database market trend.
Industry Definition and Major Segments
A graph database (GDB) is a database that represents and stores data using graph topologies. The capacity to represent complex, interconnected data with enhanced flexibility and scalability is a key advantage of graph databases over conventional relational databases, which store data in tables with preset relationships between them.
Read the Full Report with the Table of Contents: https://www.expertmarketresearch.com/reports/graph-database-market
The major components of the graph database are:
- Software
- Services
On the basis of the deployment model, the market bifurcations include:
- On-Premises
- Cloud
Based on the type of database, the market is divided into:
- Relational (SQL)
- Non-Relational (NoSQL)
By analysis, the market is segmented into:
- Path Analysis
- Connectivity Analysis
- Community Analysis
- Centrality Analysis
The various applications of the product are:
- Fraud Detection and Risk Management
- Master Data Management
- Customer Analytics
- Identity and Access Management
- Recommendation Engine
- Privacy and Risk Compliance
- Others
Based on organisation size, the market is divided into:
- Large Enterprises
- Small and Medium Enterprises
The various industry verticals considered in the market report are:
- BFSI
- Retail and E-commerce
- IT and Telecom
- Identity and Access Management
- Healthcare and Life Science
- Government and Public Sector
- Media and Entertainment
- Manufacturing
- Transportation and Logistics
- Others
The major regional markets for graph database include:
- North America
- Europe
- Asia Pacific
- Latin America
- Middle East and Africa
Market Trends
The adoption of graph database solutions and services is anticipated to significantly surge amid the growing focus to integrate real-time big data mining in various operations, the increasing adoption of tools and services based on artificial intelligence (AI) for graph databases, and the rising demand for solutions that can handle low-latency queries.
North America is anticipated to account for a significant share of the graph database market in the forecast period. This can be primarily attributed to technological advancements, the establishment of various fintech start-ups, and advancements in information technology within the region.
One key driver of the market is the increasing number of partnerships between industry players and different technology companies. Another factor contributing to the expansion of the market in North America is the early adoption of innovative graph database tools in this region.
Key Market Players
The major players in the graph database market report include Oracle Corporation, IBM Corporation, Amazon Web Services, Inc., DataStax, Inc., Stardog Union, Inc., and Neo4j, Inc., among others. The report covers the market shares, capacities, plant turnarounds, expansions, investments and mergers and acquisitions, among other latest developments of these market players.
The report studies the latest updates in the market, along with their impact across the market. It also analyses the market demand, together with its price and demand indicators. The report also tracks the market based on SWOT and Porter’s Five Forces Models.
Also Read:
https://www.expertmarketresearch.com/reports/oleochemicals-market
https://www.expertmarketresearch.com/reports/reverse-osmosis-membrane-market
https://www.expertmarketresearch.com/reports/yeast-market
https://www.expertmarketresearch.com/reports/furniture-market
https://www.expertmarketresearch.com/reports/crude-oil-market
About Us:
Expert Market Research (EMR) is leading market research company with clients across the globe. Through comprehensive data collection and skilful analysis and interpretation of data, the company offers its clients extensive, latest and actionable market intelligence which enables them to make informed and intelligent decisions and strengthen their position in the market. The clientele ranges from Fortune 1000 companies to small and medium scale enterprises.
EMR customises syndicated reports according to clients’ requirements and expectations. The company is active across over 15 prominent industry domains, including food and beverages, chemicals and materials, technology and media, consumer goods, packaging, agriculture, and pharmaceuticals, among others.
Over 3000 EMR consultants and more than 100 analysts work very hard to ensure that clients get only the most updated, relevant, accurate and actionable industry intelligence so that they may formulate informed, effective and intelligent business strategies and ensure their leadership in the market.
Media Contact:
Company Name: Claight Corporation
Contact Person:- Adam Lee, Business Consultant
Email: [email protected]
Toll Free Number: US +1-415-325-5166 | UK +44-702-402-5790
Address: 30 North Gould Street, Sheridan, WY 82801, USA
Website: www.expertmarketresearch.com
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Someone with a lot of money to spend has taken a bearish stance on MongoDB MDB.
And retail traders should know.
We noticed this today when the big position showed up on publicly available options history that we track here at Benzinga.
Whether this is an institution or just a wealthy individual, we don’t know. But when something this big happens with MDB, it often means somebody knows something is about to happen.
So how do we know what this whale just did?
Today, Benzinga‘s options scanner spotted 19 uncommon options trades for MongoDB.
This isn’t normal.
The overall sentiment of these big-money traders is split between 42% bullish and 57%, bearish.
Out of all of the special options we uncovered, 10 are puts, for a total amount of $673,265, and 9 are calls, for a total amount of $658,043.
What’s The Price Target?
Taking into account the Volume and Open Interest on these contracts, it appears that whales have been targeting a price range from $310.0 to $620.0 for MongoDB over the last 3 months.
Volume & Open Interest Development
Looking at the volume and open interest is a powerful move while trading options. This data can help you track the liquidity and interest for MongoDB’s options for a given strike price. Below, we can observe the evolution of the volume and open interest of calls and puts, respectively, for all of MongoDB’s whale trades within a strike price range from $310.0 to $620.0 in the last 30 days.
MongoDB Option Volume And Open Interest Over Last 30 Days
Biggest Options Spotted:
| Symbol | PUT/CALL | Trade Type | Sentiment | Exp. Date | Strike Price | Total Trade Price | Open Interest | Volume |
|---|---|---|---|---|---|---|---|---|
| MDB | CALL | TRADE | BULLISH | 01/17/25 | $520.00 | $307.7K | 156 | 40 |
| MDB | PUT | TRADE | BULLISH | 01/17/25 | $390.00 | $223.9K | 245 | 28 |
| MDB | PUT | SWEEP | BULLISH | 09/15/23 | $400.00 | $109.0K | 167 | 29 |
| MDB | PUT | TRADE | NEUTRAL | 01/17/25 | $370.00 | $100.3K | 213 | 12 |
| MDB | CALL | SWEEP | BULLISH | 09/01/23 | $430.00 | $75.0K | 10 | 57 |
Where Is MongoDB Standing Right Now?
- With a volume of 493,347, the price of MDB is down -2.49% at $391.57.
- RSI indicators hint that the underlying stock is currently neutral between overbought and oversold.
- Next earnings are expected to be released in 23 days.
What The Experts Say On MongoDB:
- JMP Securities has decided to maintain their Outperform rating on MongoDB, which currently sits at a price target of $425.
- Keybanc has decided to maintain their Overweight rating on MongoDB, which currently sits at a price target of $462.
Options are a riskier asset compared to just trading the stock, but they have higher profit potential. Serious options traders manage this risk by educating themselves daily, scaling in and out of trades, following more than one indicator, and following the markets closely.
If you want to stay updated on the latest options trades for MongoDB, Benzinga Pro gives you real-time options trades alerts.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
![]() Robeco Institutional Asset Management B.V. lessened its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 7.0% during the 1st quarter, according to its most recent 13F filing with the SEC. The institutional investor owned 1,367 shares of the company’s stock after selling 103 shares during the period. Robeco Institutional Asset Management B.V.’s holdings in MongoDB were worth $319,000 at the end of the most recent reporting period.
Robeco Institutional Asset Management B.V. lessened its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 7.0% during the 1st quarter, according to its most recent 13F filing with the SEC. The institutional investor owned 1,367 shares of the company’s stock after selling 103 shares during the period. Robeco Institutional Asset Management B.V.’s holdings in MongoDB were worth $319,000 at the end of the most recent reporting period.
Other institutional investors and hedge funds have also recently added to or reduced their stakes in the company. abrdn plc grew its position in shares of MongoDB by 79.7% during the first quarter. abrdn plc now owns 12,019 shares of the company’s stock worth $2,802,000 after acquiring an additional 5,331 shares during the last quarter. Skandinaviska Enskilda Banken AB publ boosted its stake in shares of MongoDB by 2.5% during the fourth quarter. Skandinaviska Enskilda Banken AB publ now owns 11,467 shares of the company’s stock worth $2,256,000 after buying an additional 277 shares during the period. Clarius Group LLC grew its holdings in shares of MongoDB by 7.7% during the first quarter. Clarius Group LLC now owns 1,362 shares of the company’s stock worth $318,000 after buying an additional 97 shares during the last quarter. Moody Lynn & Lieberson LLC purchased a new stake in MongoDB during the 1st quarter valued at approximately $7,433,000. Finally, Daiwa Securities Group Inc. lifted its position in MongoDB by 3.5% during the 1st quarter. Daiwa Securities Group Inc. now owns 5,461 shares of the company’s stock worth $1,273,000 after acquiring an additional 186 shares during the period. 89.22% of the stock is owned by institutional investors and hedge funds.
Analyst Ratings Changes
Several equities research analysts recently weighed in on MDB shares. Robert W. Baird increased their price target on MongoDB from $390.00 to $430.00 in a report on Friday, June 23rd. Guggenheim lowered shares of MongoDB from a “neutral” rating to a “sell” rating and boosted their price target for the stock from $205.00 to $210.00 in a research note on Thursday, May 25th. They noted that the move was a valuation call. Capital One Financial assumed coverage on shares of MongoDB in a research report on Monday, June 26th. They issued an “equal weight” rating and a $396.00 price objective for the company. Sanford C. Bernstein increased their target price on MongoDB from $257.00 to $424.00 in a research note on Monday, June 5th. Finally, Mizuho raised their price objective on shares of MongoDB from $220.00 to $240.00 in a research note on Friday, June 23rd. One analyst has rated the stock with a sell rating, three have given a hold rating and twenty have given a buy rating to the company. According to data from MarketBeat, the stock presently has a consensus rating of “Moderate Buy” and an average price target of $378.09.
MongoDB Stock Performance
MDB opened at $401.57 on Monday. The firm’s 50 day moving average is $388.53 and its 200-day moving average is $283.95. The company has a current ratio of 4.19, a quick ratio of 4.19 and a debt-to-equity ratio of 1.44. MongoDB, Inc. has a 52-week low of $135.15 and a 52-week high of $439.00.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings results on Thursday, June 1st. The company reported $0.56 earnings per share (EPS) for the quarter, topping analysts’ consensus estimates of $0.18 by $0.38. The business had revenue of $368.28 million during the quarter, compared to analyst estimates of $347.77 million. MongoDB had a negative net margin of 23.58% and a negative return on equity of 43.25%. The business’s revenue was up 29.0% compared to the same quarter last year. During the same quarter in the previous year, the firm earned ($1.15) earnings per share. On average, equities research analysts predict that MongoDB, Inc. will post -2.8 earnings per share for the current year.
Insiders Place Their Bets
In other news, CTO Mark Porter sold 2,673 shares of the company’s stock in a transaction dated Tuesday, May 9th. The shares were sold at an average price of $250.00, for a total transaction of $668,250.00. Following the completion of the transaction, the chief technology officer now owns 40,336 shares in the company, valued at $10,084,000. The transaction was disclosed in a legal filing with the Securities & Exchange Commission, which can be accessed through this hyperlink. In related news, CTO Mark Porter sold 2,673 shares of MongoDB stock in a transaction dated Tuesday, May 9th. The shares were sold at an average price of $250.00, for a total transaction of $668,250.00. Following the sale, the chief technology officer now directly owns 40,336 shares in the company, valued at $10,084,000. The sale was disclosed in a document filed with the SEC, which is available through the SEC website. Also, CEO Dev Ittycheria sold 50,000 shares of the stock in a transaction dated Wednesday, July 5th. The shares were sold at an average price of $407.07, for a total transaction of $20,353,500.00. Following the completion of the transaction, the chief executive officer now owns 218,085 shares of the company’s stock, valued at approximately $88,775,860.95. The disclosure for this sale can be found here. Over the last three months, insiders have sold 114,427 shares of company stock valued at $40,824,961. Company insiders own 4.80% of the company’s stock.
About MongoDB
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

Introduction: Conceding the Power of MERN Stack Development
The MERN stack has become a powerhouse in the field of contemporary web development, providing a seamless and effective way to create web applications that are powerful and feature-rich. The MERN stack, which consists of MongoDB, Express.js, React, and Node.js, enables developers to easily build scalable and dynamic apps. In this article, we will examine the main advantages clients can get from MERN stack development company and examine how it has transformed the field of web development.
It is important to be on top of trends in order to deliver top-notch user experiences and sustain competitiveness in the dynamic and ever evolving world of web development. A collection of contemporary technologies, the MERN Stack is proving to be a game-changer by making it possible for programmers to create dependable and scalable web apps that satisfy the different needs of both businesses and customers.Nonetheless, because of its strong architecture, seamless integration of MongoDB, Express.js, React, and Node.js, and full-stack JavaScript techniques, the MERN stack has become immensely popular among developers and businesses worldwide. In this blog, we’ll delve deeper into the key benefits of MERN stack development, looking at how this system enables real-time data handling, transmogrifying user interface design, and expedites the development process.
Driving Innovation and Elevating User Experience through MERN Stack Mastery
Let’s take an indepth look at the potent elements that make up this gilt-edge technological stack before going into the plethora of advantages of MERN stack development company. The seamless integration of MongoDB, Express.js, React, and Node.js provides developers with an unmatched toolkit for building strong and dynamic web apps. By merging these potent elements seamlessly, the MERN stack transforms into an enormous weapon in the global arena of web development, empowering programmers to build innovative applications that change user experiences and propel companies to new heights and helps in reaching heights. Now, let’s examine the ample advantages that MERN stack offers by revolutionizing how we approach building web applications.
- Modular Components and Quick Development
The use of modular components is one of the primary characteristics of the MERN stack. React.js on the front end allows developers to build dynamic user interfaces with reusable components. The development process is sped up and maintainability and scalability are improved by this modularity. Likewise, Node.js and Express.js provide seamless interaction with backend APIs, allowing for a smooth data flow between the client and the server and significantly reducing the time and effort needed for development.
- Development of JavaScript in its entirety
The MERN stack was built entirely on top of JavaScript, allowing programmers to use a single programming language throughout the entire process. The full-stack JavaScript solution speeds up development because developers or programmers do not need to switch between multiple languages to create frontend and backend applications. Moreover, they can design whole online applications using their existing JavaScript skills, developers do not need to learn additional languages.
- MongoDB Real-Time Data Handling
For managing real-time data, the MERN stack makes use of MongoDB, a NoSQL database that offers awe-inspiring agility and adaptability. It is simple to maintain and query data in real-time applications since MongoDB is a document-oriented database and saves data in a BSON format that is comparable to JSON. Because of the features of MongoDB, developers using the MERN stack may quickly build real-time chat apps, social networking platforms, and collaborative tools.
- Rich user Interfaces and Interactive Using React
React, a front-end JAVA Script package is the backbone of the MERN stack, praised for its exceptional efficiency and reusability. React enables developers to build dynamic, responsive user interfaces that provide users with an uninterrupted surfing experience. Quick modifications are possible because of React’s virtual DOM, which reduces the number of times a page needs to be reloaded and boosts the overall efficiency of the online application.
Culminating the key points
MERN stack development has transfigured the world of web development by offering a comprehensive and successful framework for building avant-grade online applications. Because of its customizable components, full-stack JavaScript strategy, real-time data processing with MongoDB, and rich user interfaces with React, the MERN stack is a fantastic choice for developers looking to build scalable and high-performance web apps.
The MERN stack’s smooth integration of MongoDB, Express.js, React, and Node.js allows programmers to use their creativity to easily construct cutting-edge online apps. The MERN stack puts forward the flexibility and resources needed to turn ideas into reality, whether the user is a startup seeking to create a minimal viable product (MVP) or an existing business looking to completely revamp its online presence.
The MERN stack shines as a light of innovation in a frantic and cutthroat digital environment, giving developers the resources and tools they need to build cutting-edge online apps that have a lasting impression on users. Make use of the MERN stack’s capabilities from the best software product development company as you set out to build web apps that raise the bar for quality in the digital sphere.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

”
Throughout the period of forecasting, it is anticipated that the global Cloud Data Platform market will grow at a projected CAGR of X.X%. The market is anticipated to reach USD XX billion in value by 2031, propelled by increased demand for sophisticated security solutions and the expanding use of cloud-based services across a range of sectors. Furthermore, it is projected that the development of artificial intelligence and machine learning technologies in the cybersecurity sector would open up an attractive potential for market participants. The adoption of strict governmental guidelines and compliance requirements is also anticipated to increase demand for cybersecurity solutions.
Request a sample report @ https://www.orbisresearch.com/contacts/request-sample/6866741
A complete analysis of the market as a whole, taking into consideration market size, rate of development, movements, and drivers, is provided in the report on the worldwide market for Cloud Data Platform. The key market participants, their competitive environment, and their growth strategies are also covered. The study also provides insights into different market segments based on product type, application, and location. In conclusion, this research is a useful tool for anyone trying to grasp the dynamics of the Cloud Data Platform industry and make wise business decisions. A competitive landscape detailing the major companies in the market and their tactics for holding onto their positions is also included in the report’s thorough study. With this knowledge, readers can better comprehend the competitive situation of the market and develop their own plans in line with it.
Key Players in the Cloud Data Platform market:
Amazon Web Services
Google
Oracle
Microsoft
Nutanix
Cloudera
Snowflake
Databricks
ACTIAN
Acceldata
Deloitte
MongoDB
Sisense
Collibra
Tableau
Qualtrics
Datameer
HPE GreenLake
Tietoevry
Record Evolution
IBM
Clickhouse
Rockset
Materialise
Lakehouses
Informatica
Redshift
BiqQuery
Azure Synapse Analytics
Cloud Data Platform market Segmentation by Type:
Data Warehouse
Data Integration
Data Lakes
Others
Cloud Data Platform market Segmentation by Application:
Banking
Telcos
Life Sciences
Government
Others
Direct Purchase the report @ https://www.orbisresearch.com/contact/purchase-single-user/6866741
This worldwide Cloud Data Platform market study is a good investment for investors since it offers a thorough analysis of the current market trends, development drivers, challenges, and opportunities. Investors are able to make well-informed investment decisions based on data-driven analysis thanks to the report’s insights into the competitive landscape and key players operating in the market. The research also discusses different market sectors and offers projections for each segment’s growth trajectory, which can aid investors in spotting profitable investment opportunities.
Due to the rising demand for services related to digital marketing and search engine optimization (SEO), the global Cloud Data Platform market has experienced a tremendous expansion in recent years. The market is anticipated to maintain its upward trend in the upcoming years, supported by the expanding popularity of e-commerce and online advertising, as well as the increasing usage of smartphones and internet connectivity. But the market also has to contend with issues like fierce rivalry among firms and worries about the security and privacy of personal information. Despite these difficulties, the worldwide Cloud Data Platform market is anticipated to expand further as a result of the rising popularity of cloud-based services and the introduction of cutting-edge innovations like artificial intelligence and machine learning. The demand for Cloud Data Platform solutions is anticipated to increase across a range of sectors, including healthcare, finance, and retail.
Do You Have Any Query Or Specific Requirement? Ask to Our Industry Expert @ https://www.orbisresearch.com/contacts/enquiry-before-buying/6866741
Primary and secondary research techniques were combined to produce the worldwide Cloud Data Platform market study. While secondary research involved examining data from several sources such as company websites, governmental publications, and industry reports, primary research involved conducting interviews with important players and industry experts. In order to provide a thorough understanding of the market landscape and identify important trends and potential prospects, complex analytical tools including SWOT analysis, Porter’s Five Forces analysis, and trend analysis were also used.
The study on the worldwide Cloud Data Platform market provides a thorough analysis of the market’s current trends, growth factors, difficulties, and prospects for the major players involved. To assist decision-makers and provide them with a competitive edge in the market, it offers insights into the competitive landscape, market segmentation, and geographical analysis.
For a complete picture of the market, the research also provides in-depth profiles of top businesses, together with information on their product portfolios, financials, and most recent advancements. Investors, business owners, and other stakeholders may find the report’s in-depth research and thorough information helpful in identifying growth prospects and developing successful strategies. Additionally, the research emphasizes COVID-19’s effects on the market and provides information on the post-pandemic environment.
About Us
Orbis Research (orbisresearch.com) is a single point aid for all your market research requirements. We have a vast database of reports from leading publishers and authors across the globe. We specialize in delivering customized reports as per the requirements of our clients. We have complete information about our publishers and hence are sure about the accuracy of the industries and verticals of their specialization. This helps our clients to map their needs and we produce the perfect required market research study for our clients.
Contact Us:
Hector Costello
Senior Manager – Client Engagements
4144N Central Expressway,
Suite 600, Dallas,
Texas – 75204, U.S.A.
Phone No.: USA: +1 (972)-362-8199 | IND: +91 895 659 5155
Email ID: sales@orbisresearch.com
“
Article originally posted on mongodb google news. Visit mongodb google news