Month: August 2023
Article: Streamlining Code with Unnamed Patterns/Variables: A Comparative Study of Java, Kotlin, and Scala

MMS • A N M Bazlur Rahman

Key Takeaways
- Java’s JEP 443: Enhances code readability by allowing the omission of unnecessary components in pattern matching and unused variables.
- Kotlin’s unused variables: Simplifies code by denoting unused parameters in functions, lambdas, or destructuring declarations.
- Scala’s unused variables: Used as a wildcard to ignore unused variables and conversions, improving code conciseness.
- Underscore as Syntactic Sugar: A common feature in many languages, including Java, Kotlin, and Scala, that simplifies code.
- Enhanced Code Readability and Maintainability: The underscore character improves code readability and maintainability.
- Future Language Evolution: Expect further enhancements and innovative uses of the underscore as languages evolve.
In the world of programming, the underscore (`_`) is a character with a wide range of uses. It’s often referred to as syntactic sugar, as it simplifies the code and makes it more concise.
This article will explore the use of underscores in three popular programming languages: Java, Kotlin, and Scala.
Java: Unnamed Patterns and Variables with JEP 443
Java, the ever-evolving language, has taken another significant step towards enhancing its code readability and maintainability with the introduction of JEP 443. This proposal, titled “Unnamed Patterns and Variables (Preview),” has been completed from the targeted status for JDK 21.
The JEP aims to enhance the language with unnamed patterns, which match a record component without stating the component’s name or type, and unnamed variables, which you can but not use.
Both of these are denoted by the underscore character, as in r instanceof _(int x, int y) and r instanceof _.
Unnamed Patterns
Unnamed patterns are designed to streamline data processing, particularly when working with record classes. They allow developers to omit the type and name of a record component in pattern matching, which can significantly improve code readability.
Consider the following code snippet:
if (r instanceof ColoredPoint(Point p, Color c)) {
// ...
}
If the Color c component is not needed in the if block, it can be laborious and unclear to include it in the pattern. With JEP 443, developers can simply omit unnecessary components, resulting in cleaner, more readable code:
if (r instanceof ColoredPoint(Point p, _)) {
// ...
}
This feature is particularly useful in nested pattern-matching scenarios where only some components of a record class are required. For example, consider a record class ColoredPoint that contains a Point and a Color. If you only need the x coordinate of the Point, you can use an unnamed pattern to omit the y and Color components:
if (r instanceof ColoredPoint(Point(int x, _), _)) {
// ...
}
Unnamed Variables
Unnamed variables are useful when a variable must be declared, but its value is not used. This is common in loops, try-with-resources statements, catch blocks, and lambda expressions.
For instance, consider the following loop:
for (Order order : orders) {
if (total < limit) total++;
}
In this case, the order variable is not used within the loop. With JEP 443, developers can replace the unused variable with an underscore, making the code more concise and clear:
for (_ : orders) {
if (total < limit) total++;
}
Unnamed variables can also be beneficial in switch statements where the same action is executed for multiple cases, and the variables are not used. For example:
switch (b) {
case Box(RedBall _), Box(BlueBall _) -> processBox(b);
case Box(GreenBall _) -> stopProcessing();
case Box(_) -> pickAnotherBox();
}
In this example, the first two cases use unnamed pattern variables because their right-hand sides do not use the box’s component. The third case uses the unnamed pattern to match a box with a null component.
Enabling the Preview Feature
Unnamed patterns and variables are a preview feature, disabled by default. To use it, developers must enable the preview feature to compile this code, as shown in the following command:
javac --release 21 --enable-preview Main.java
The same flag is also required to run the program:
java --enable-preview Main
However, one can directly run this using the source code launcher. In that case, the command line would be:
java --source 21 --enable-preview Main.java
The jshell option is also available but requires enabling the preview feature as well:
jshell --enable-preview
Kotlin: Underscore for Unused Parameters
In Kotlin, the underscore character (_) is used to denote unused parameters in a function, lambda, or destructuring declaration. This feature allows developers to omit names for such parameters, leading to cleaner and more concise code.
In Kotlin, developers can place an underscore instead of its name if the lambda parameter is unused. This is particularly useful when working with functions that require a lambda with multiple parameters but only some of the parameters are needed.
Consider the following Kotlin code snippet:
mapOf(1 to "one", 2 to "two", 3 to "three")
.forEach { (_, value) -> println("$value!") }
In this example, the forEach function requires a lambda that takes two parameters: a key and a value. However, we’re only interested in the value, so we replace the key parameter with an underscore.
Let’s consider another code snippet:
var name: String by Delegates.observable("no name") {
kProperty, oldValue, newValue -> println("$oldValue")
}
In this instance, if the kProperty and newValue parameters are not used within the lambda, including them can be laborious and unclear. With the underscore feature, developers can simply replace the unused parameters with underscores:
var name: String by Delegates.observable("no name") {
_, oldValue, _ -> println("$oldValue")
}
This feature is also useful in destructuring declarations where you want to skip some of the components:
val (w, x, y, z) = listOf(1, 2, 3, 4)
print(x + z) // 'w' and 'y' remain unused
With the underscore feature, developers can replace the unused components with underscores:
val (_, x, _, z) = listOf(1, 2, 3, 4)
print(x + z)
This feature is not unique to Kotlin. Other languages like Haskell use the underscore character as a wildcard in pattern matching. For C#, `_` in lambdas is just an idiom without special treatment in the language. The same semantic may be applied in future versions of Java.
Scala: The Versatility of Underscore
In Scala, the underscore (`_`) is a versatile character with a wide range of uses. However, this can sometimes lead to confusion and increase the learning curve for new Scala developers. In this section, we’ll explore the different and most common usages of underscores in Scala.
Pattern Matching and Wildcards
The underscore is widely used as a wildcard and in matching unknown patterns. This is perhaps the first usage of underscore that Scala developers would encounter.
Module Import
We use underscore when importing packages to indicate that all or some members of the module should be imported:
// imports all the members of the package junit. (equivalent to wildcard import in java using *)
import org.junit._
// imports all the members of junit except Before.
import org.junit.{Before => _, _}
// imports all the members of junit but renames Before to B4.
import org.junit.{Before => B4, _}
Existential Types
The underscore is also used as a wildcard to match all types in type creators such as List, Array, Seq, Option, or Vector.
// Using underscore in List
val list: List[_] = List(1, "two", true)
println(list)
// Using underscore in Array
val array: Array[_] = Array(1, "two", true)
println(array.mkString("Array(", ", ", ")"))
// Using underscore in Seq
val seq: Seq[_] = Seq(1, "two", true)
println(seq)
// Using underscore in Option
val opt: Option[_] = Some("Hello")
println(opt)
// Using underscore in Vector
val vector: Vector[_] = Vector(1, "two", true)
println(vector)
With `_`, we allowed all types of elements in the inner list.
Matching
Using the match keyword, developers can use the underscore to catch all possible cases not handled by any of the defined cases. For example, given an item price, the decision to buy or sell the item is made based on certain special prices. If the price is 130, the item is to buy, but if it’s 150, it is to sell. For any other price outside these, approval needs to be obtained:
def itemTransaction(price: Double): String = {
price match {
case 130 => "Buy"
case 150 => "Sell"
// if price is not any of 130 and 150, this case is executed
case _ => "Need approval"
}
}
println(itemTransaction(130)) // Buy
println(itemTransaction(150)) // Sell
println(itemTransaction(70)) // Need approval
println(itemTransaction(400)) // Need approval
Ignoring Things
The underscore can ignore variables and types not used anywhere in the code.
Ignored Parameter
For example, in function execution, developers can use the underscore to hide unused parameters:
val ints = (1 to 4).map(_ => "Hello")
println(ints) // Vector(Hello, Hello, Hello, Hello)
Developers can also use the underscore to access nested collections:
val books = Seq(("Moby Dick", "Melville", 1851), ("The Great Gatsby", "Fitzgerald", 1925), ("1984", "Orwell", 1949), ("Brave New World", "Huxley", 1932))
val recentBooks = books
.filter(_._3 > 1900) // filter in only books published after 1900
.filter(_._2.startsWith("F")) // filter in only books whose author's name starts with 'F'
.map(_._1)
// return only the first element of the tuple; the book title
println(recentBooks) // List(The Great Gatsby)
In this example, the underscore is used to refer to the elements of the tuples in the list. The filter function selects only the books that satisfy the given conditions, and then the map function transforms the tuples to just their first element (book title). The result is a sequence with book titles that meet the criteria.
Ignored Variable
When a developer encounters details that aren’t necessary or relevant, they can utilize the underscore to ignore them.
For example, a developer wants only the first element in a split string:
val text = "a,b"
val Array(a, _) = text.split(",")
println(a)
The same principle applies if a developer only wants to consider the second element in a construct.
val Array(_, b) = text.split(",")
println(b)
The principle can indeed be extended to more than two entries. For instance, consider the following example:
val text = "a,b,c,d,e"
val Array(a, _*) = text.split(",")
println(a)
In this example, a developer splits the text into an array of elements. However, they are only interested in the first element, ‘a‘. The underscore with an asterisk (_*) ignores the rest of the entries in the array, focusing only on the required element.
To ignore the rest of the entries after the first, we use the underscore together with `*`.
The underscore can also be used to ignore randomly:
val text = "a,b,c,d,e"
val Array(a, b, _, d, e) = text.split(",")
println(a)
println(b)
println(d)
println(e)
Variable Initialization to Its Default Value
When the initial value of a variable is not necessary, you can use the underscore as default:
var x: String = _
x = "real value"
println(x) // real value
However, this doesn’t work for local variables; local variables must be initialized.
Conversions
In several ways, you can use the underscore in conversions.
Function Reassignment (Eta expansion)
With the underscore, a method can be converted to a function. This can be useful to pass around a function as a first-class value.
def greet(prefix: String, name: String): String = s"$prefix $name"
// Eta expansion to turn greet into a function
val greeting = greet _
println(greeting("Hello", "John"))
Variable Argument Sequence
A sequence can be converted to variable arguments using `seqName: _*` (a special instance of type ascription).
def multiply(numbers: Int*): Int = {
numbers.reduce(_ * _)
}
val factors = Seq(2, 3, 4)
val product = multiply(factors: _*)
// Convert the Seq factors to varargs using factors: _*
println(product) // Should print: 24
Partially-Applied Function
By providing only a portion of the required arguments in a function and leaving the remainder to be passed later, a developer can create what’s known as a partially-applied function. The underscore substitutes for the parameters that have not yet been provided.
def sum(x: Int, y: Int): Int = x + y
val sumToTen = sum(10, _: Int)
val sumFiveAndTen = sumToTen(5)
println(sumFiveAndTen, 15)
The use of underscores in a partially-applied function can also be grouped as ignoring things. A developer can ignore entire groups of parameters in functions with multiple parameter groups, creating a special kind of partially-applied function:
def bar(x: Int, y: Int)(z: String, a: String)(b: Float, c: Float): Int = x
val foo = bar(1, 2) _
println(foo("Some string", "Another string")(3 / 5, 6 / 5), 1)
Assignment Operators (Setters overriding)
Overriding the default setter can be considered a kind of conversion using the underscore:
class User {
private var pass = ""
def password = pass
def password_=(str: String): Unit = {
require(str.nonEmpty, "Password cannot be empty")
require(str.length >= 6, "Password length must be at least 6 characters")
pass = str
}
}
val user = new User
user.password = "Secr3tC0de"
println(user.password) // should print: "Secr3tC0de"
try {
user.password = "123" // will fail because it's less than 6 characters
println("Password should be at least 6 characters")
} catch {
case _: IllegalArgumentException => println("Invalid password")
}
Higher-Kinded Type
A Higher-Kinded type is one that abstracts over some type that, in turn, abstracts over another type. In this way, Scala can generalize across type constructors. It’s quite similar to the existential type. It can be defined higher-kinded types using the underscore:
trait Wrapper[F[_]] {
def wrap[A](value: A): F[A]
}
object OptionWrapper extends Wrapper[Option] {
override def wrap[A](value: A): Option[A] = Option(value)
}
val wrappedInt = OptionWrapper.wrap(5)
println(wrappedInt)
val wrappedString = OptionWrapper.wrap("Hello")
println(wrappedString)
In the above example, Wrapper is a trait with a higher-kinded type parameter F[_]. It provides a method wrap that wraps a value into the given type. OptionWrapper is an object extending this trait for the Option type. The underscore in F[_] represents any type, making Wrapper generic across all types of Option.
These are some examples of Scala being a powerful tool that can be used in various ways to simplify and improve the readability of your code. It’s a feature that aligns well with Scala’s philosophy of being a concise and expressive language that promotes readable and maintainable code.
Conclusion
The introduction of unnamed patterns and variables in Java through JEP 443 marks a significant milestone in the language’s evolution. This feature, which allows developers to streamline their code by omitting unnecessary components and replacing unused variables, brings Java closer to the expressiveness and versatility of languages like Kotlin and Scala.
However, it’s important to note that while this is a substantial step forward, Java’s journey in this area is still incomplete. Languages like Kotlin and Scala have long embraced similar concepts, using them in various ways to enhance code readability, maintainability, and conciseness. These languages have demonstrated the power of such concepts in making code more efficient and easier to understand.
In comparison, Java’s current use of unnamed patterns and variables, although beneficial, is still somewhat limited. The potential for Java to further leverage these concepts is vast. Future updates to the language could incorporate more advanced uses of unnamed patterns and variables, drawing inspiration from how these concepts are utilized in languages like Kotlin and Scala.
Nonetheless, adopting unnamed patterns and variables in Java is a significant step towards enhancing the language’s expressiveness and readability. As Java continues to evolve and grow, we expect to see further innovative uses of these concepts, leading to more efficient and maintainable code. The journey is ongoing, and it’s an exciting time to be a part of the Java community.
Happy coding!
MMS • RSS
SINGAPORE (AP) — SINGAPORE (AP) — JOYY Inc. (YY) on Tuesday reported earnings of $155.1 million in its second quarter.
On a per-share basis, the Singapore-based company said it had profit of $2.02. Earnings, adjusted for one-time gains and costs, came to $1.29 per share.
The social media company posted revenue of $547.3 million in the period.
_____
This story was generated by Automated Insights (http://automatedinsights.com/ap) using data from Zacks Investment Research. Access a Zacks stock report on YY at https://www.zacks.com/ap/YY
MMS • Johan Janssen

The experimental Spring AI project was introduced during the SpringOne conference and allows the creation of AI applications by using common concepts of Spring. Currently the project integrates Azure OpenAI and OpenAI as AI backends. Use cases like content generation, code generation, semantic search and summarization are supported by the project.
Historically, Python was often used to provide fast access to AI algorithms written in languages such as C and C++. Generative AI, used by solutions such as OpenAI’s ChatGPT, makes it possible to access pre-trained models via HTTP. This makes it easier for languages such as Java to interact efficiently with AI algorithms.
The abbreviation ChatGPT stands for Chat Generative Pre-Trained Transformer as it uses pre-trained models. This makes it easier for developers to use AI, similar to using a database. AI no longer requires data scientists to gather data and train a model.
However, the various Java Client APIs for AI solutions such as OpenAI and Azure OpenAI differ, which makes it harder to switch between those solutions. Spring AI provides an abstraction layer on top of those client APIs inspired by the Python libraries LangChain and LlamaIndex. Those libraries are based on similar design values as Spring projects such as modularity, extensibility and integration with various data sources.
Spring AI offers several features such as integration with AI models through a common API. Prompts, optionally using templates comparable to views in Spring MVC, are used to interact with the AI model. Chaining calls to the model is supported, for more difficult questions, in order to break down the problem and solve it piece by piece. Output parsing allows converting the String output to, for example, CSV or JSON. The model might use custom data, such as a project’s FAQ, and is able to learn a specific conversation style. Evaluating the answers through testing may be used to maintain the quality of the project.
Spring AI can be used after adding the following repository, as it’s an experimental project with only snapshot releases:
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
false
When using OpenAI the following dependency may be used:
org.springframework.experimental.ai
spring-ai-openai-spring-boot-starter
0.2.0-SNAPSHOT
In order to use Azure OpenAI instead of OpenAI, the following dependency may be used:
org.springframework.experimental.ai
spring-ai-azure-openai-spring-boot-starter
0.2.0-SNAPSHOT
Alternatively, the Spring CLI might be used to create a new project. Spring CLI provides binaries for various operating systems and more information may be found in the documentation. The following command may be used to create a new project for OpenAI:
spring boot new ai
Otherwise, the following command may be used to create a new project for Azure OpenAI:
spring boot new ai-azure
The Spring CLI Getting Started guide offers more information about creating a project with Spring AI.
The API key should be provided, before the project can use OpenAI or Azure OpenAI. For OpenAI a token may be generated on the API Keys page. Then the token should be available for the spring.ai.openai.api-key property, for example, by exporting the environment variable:
export SPRING_AI_OPENAI_API_KEY=
For Azure OpenAI, the endpoint and api-key may be retrieved from the Azure OpenAI Service section. Then the tokens should be made available for the properties such as spring.ai.azure.openai.api-key, for example by exporting the environment variables:
export SPRING_AI_AZURE_OPENAI_API_KEY=
export SPRING_AI_AZURE_OPENAI_ENDPOINT=
Now the configuration may be used to ask a question to the Azure OpenAI service:
AiClient aiClient = new AzureOpenAiClient();
String response = aiClient.generate("What's the answer to the Ultimate Question of Life, the Universe, and Everything?");
Actually, the Spring Boot Starter will create the AiClient, which makes it possible to interact with an AI model in just one line of code.
Instead of creating hard coded questions, it’s also possible to use prompt templates. First a file with type .st should be created, for example your-prompt.st, which contains a sentence with a placeholder called topic:
Tell me a fun fact about {topic}
Next, the prompt template can be used when calling the AI model, for example by providing the value developers to the topic template:
@Bean
ApplicationRunner applicationRunner (@Value("classpath:/your-prompt.st)
Resource resource, AiClient aiClient) { return args -> {
var promptTemplate = new PromptTemplate(resource);
var prompt = promptTemplate.create(Map.of("topic", "developers");
var response = aiClient.generate(prompt);
System.out.println(response.getGeneration());
};
}
The project allows users to provide custom information or data to the model, for example company internal information such as FAQs, or new data which wasn’t available when the model was created. A resource may be defined for the relevant information:
@Value("classpath:/myCustomInformation.txt) Resource myCustomInformation;
Then the context may be added as a prompt template:
var prompt = "... {context}...";
Lastly, the context is filled with the provided information:
var promptTemplate = new PromptTemplate( prompt);
promptTemplate.create(Map.of("context", myCustomInformation)));
The prompt input is first verified before sending it to the AI model, to reduce the number of requests and thereby the cost.
Josh Long, Spring Developer Advocate at VMware, conducted an interview with Dr Mark Pollack, the leader of the Spring AI project, where they discussed the various possibilities and created several code examples.
More information can be found in the reference documentation and a workshop with instructions for Azure OpenAI is available. The workshop example may be converted to support OpenAI instead of Azure OpenAI by using the correct dependency.
MMS • Sirisha Pratha

MicroStream, an open-source Java native persistence framework, recently released Eclipse Store, hosted by the Eclipse Foundation.
This first release contains two core components from MicroStream, its Serializer and StorageManager restructured as Eclipse Serializer and Eclipse Store, respectively. Version 1.0.0-SNAPSHOT of Eclipse Store is available in the Maven Central snapshot repository.
In December 2022, MicroStream announced its Eclipse Foundation membership and began preparing code for the migration based on MicroStream 7.1, the latest version at that time, and as such, the minimum JDK version for the first release of Eclipse Store is JDK 8. Changes from MicroStream versions 8.0 and 8.1, which included support for Lazy collections and other significant improvements, will be available in the next release of Eclipse Store. After this migration, MicroStream will further develop only on Eclipse Store.
Notable migration changes include group, artifact, version, and package name changes to reflect the Eclipse Store project’s new home under the Eclipse Foundation (org.eclipse.*). Most of the changes for this first release stemmed from restructuring Serializer and StoreManager.
MicroStream Serializer, one of the crucial aspects of its technology, is responsible for converting object graphs into a binary representation. This custom serializer was restructured to Eclipse Serializer.
MicroStream StoreManager, one of its fundamental components responsible for providing access and managing the in-memory data store, was restructured into Eclipse Store. It provides all the necessary APIs to store and retrieve the Java objects from the database. Eclipse Store uses Eclipse Serializer when objects are persisted into the MicroStream’s embedded database.
While the above two components underwent substantial restructuring, MicroStream’s integrations with Spring Boot, Quarkus and Jakarta EE frameworks will remain open source and be available in a new MicroStream repository after being refactored to use the new Eclipse Serializer and Eclipse Store.
Eclipse Store can be used as a dependency with Maven as:
org.eclipse.store
storage-embedded
1.0.0-SNAPSHOT
All MicroStream storage targets are available within Eclipse Store.
Another noteworthy mention is that MicroStream’s Enterprise Serializer solution and MicroStream Cluster will stay closed-source.
First introduced in 2019, MicroStream was open-sourced under the Eclipse Public License (EPL) in 2021. In 2022, Micronaut and Helidon incorporated MicroStream into their codebase. MicroStream joined Eclipse Foundation in the same year. In 2023, MicroStream released MicroStream Cluster and MicroStream Cloud. MicroStream publishes a major release every 12 months.
For more information about the new features and improvements in MicroStream, developers and users can refer to their official blogs.
MMS • Karsten Silz

Spring Modulith 1.0 was promoted from its experimental status and became a fully supported Spring project. It structures Spring Boot 3 applications through modules and events using conventions and optional configuration. That module structure is now visible in IDEs like Spring Tool Suite and Visual Studio Code through actuators. The Event Publication Registry (EPR) persists event completion faster. And Integration Tests Scenarios ease testing events.
Spring Modulith modules exist because Java packages are not hierarchical. In the sample below, Java’s default visibility already hides the example.inventory.SomethingInventoryInternal class from other packages. But the example.order.internal package must be public so example.order can access it. That makes it visible to all other packages.
└─ src/main/java
├─ example
| └─ Application.java
├─ example.inventory
| ├─ InventoryManagement.java
| └─ SomethingInventoryInternal.java
├─ example.order
| └─ OrderManagement.java
└─ example.order.internal
└─ SomethingOrderInternal.java
Spring Modulith modules neither use the Java Platform Module System (JPMS) nor generate code. Instead, each direct sub-package of the main package is simply a module by default. That’s inventory and order in the example above. All public types in the package make up the module API. Crucially, Spring Modulith considers sub-packages internal to the module. That solves the problem of the public example.order.internal package described above.
Java still compiles when modules access other modules’ internal packages. But the Spring Modulith test ApplicationModules.of(Application.class).verify() will fail then. Spring Modulith uses ArchUnit to detect such violations.
Spring Modulith encourages using Spring Framework application events for communication between modules. Spring Modulith enhances these events with the EPR, guaranteeing event delivery. So even if a module receiving the event crashes or the entire application does, the registry still delivers the event when the module or application runs again.
The EPR stores events with JPA, JDBC, and MongoDB. The latter one gained automatically configured transactions in this release. An application with Spring Modulith can use modules and events together or each feature alone.
Until now, asynchronous transaction event listeners required three annotations:
@Component
class InventoryManagement {
@Async
@Transactional(propagation = Propagation.REQUIRES_NEW)
@TransactionalEventListener
void on(OrderCompleted event) { /*…*/ }
}
The new @ApplicationModuleListener shortcut in version 1.0 simplifies that:
@Component
class InventoryManagement {
@ApplicationModuleListener
void on(OrderCompleted event) { /*…*/ }
}
Testing asynchronous transactional code can be challenging. That’s where the new Integration Test Scenarios help. They can be injected into Java tests and allow to define both the start of an event-driven test and its expected results. Furthermore, these scenarios can customize execution details and define additional event tests.
jMolecules defines annotations for architectures, such as Domain-Driven Design (@ValueObject or @Repository, for example) or Hexagonal Architecture (like @Port and @Adapter). Spring Modulith 1.0 detects jMolecules annotations and generates application documentation that groups classes by their annotated role, such as “Port” or “Adapter”.
VMware announced the upcoming Spring Modulith 1.1 at Spring One in August 2023. This new version requires Spring Boot 3.2, which will be released on November 23, 2023. Version 1.1 will support additional databases for event persistence, such as Neo4J, to better align with Spring Data. And it can automatically send events to external destinations. That’s helpful when at least some of the events are of interest to other applications. Version 1.1 will support Kafka, AMQP, and potentially Redis as external event destinations.
Oliver Drotbohm, Staff 2 Engineer at VMware and the driving force behind Spring Modulith, spoke to InfoQ about Spring Modulith.
InfoQ: Spring Modulith has been out for ten months. How has the feedback been so far?
Oliver Drotbohm: The feedback at conferences and in online communities has been overwhelmingly positive. The primary aspect that made folks slightly hesitant was the fact that the project was considered experimental until its release a few days ago. We’re looking forward to how the community will adopt it with that impediment removed.
InfoQ: How do you define success for Spring Modulith? And how do you measure it?
Drotbohm: As with all Spring projects, we are monitoring the Maven Central download numbers, of course, because those are skewed in either direction. Still, the trends in the number’s development are usually a good indicator of the usage growth rate of an individual project. We also have numbers from start.spring.io. Given that Spring Modulith’s primary target is new applications, those will hopefully give us a good impression as well. Other than that, GitHub stars, definitely as well.
InfoQ: Spring Tool Suite and VS Code can read the module structure. What are your plans for also supporting IntelliJ and Eclipse?
Drotbohm: Eclipse is supported via the STS plugins. For IDEA, we’re in touch with the development team, and they’re currently looking into it.
InfoQ: Spring Modulith currently has two core abstractions – modules and events. What other abstractions do you envision in future versions – if any?
Drotbohm: The two abstractions actually serve the two fundamental activities in software architecture as described by Neil Ford and Mark Richards in “Software Architecture — The Hard Parts“: “pulling things apart,” i.e., defining an application’s functional decomposition, and “putting them back together,” by defining a programming model for the decomposed individual parts to interact eventually. The application modules concept helps to implement functional structure within a code base, including means to make sure that things that are supposed to stay apart actually do. The event-based application integration programming model we recommend allows those modules to still interact in an eventually consistent way.
We are currently primarily looking for these two parts to evolve, find out how the community will use them, and how we can react to make them even more useful. The event externalization mechanism currently scheduled for 1.1 M1 reflects that.
InfoQ: In your estimation, what percentage of Spring Modulith applications use modules, and what percentage uses events?
Drotbohm: We’ll have to see what the download numbers for the individual Spring Modulith artifacts will tell. The stats during the experimental phase show a 90/10 split for modules (including the module integration test support) versus events.
Oppenheimer Asset Management Inc. Increases Holdings in MongoDB, Inc. Showing … – Best Stocks
MMS • RSS
Oppenheimer Asset Management Inc., a leading institutional investor, has increased its holdings in MongoDB, Inc. (NASDAQ:MDB) by 33.9% during the first quarter of the year. According to its most recent filing with the Securities and Exchange Commission (SEC), Oppenheimer now owns 1,865 shares of MongoDB, worth approximately $435,000.
This significant increase in ownership highlights Oppenheimer’s confidence in the company’s potential for growth and success. MongoDB is a well-known provider of modern, cloud-based database platforms that help businesses manage their data more efficiently and effectively.
MongoDB recently announced its quarterly earnings results on June 1st. The company reported earnings per share (EPS) of $0.56 for the quarter, surpassing analysts’ consensus estimates of $0.18 by an impressive $0.38. Furthermore, MongoDB generated revenue of $368.28 million, exceeding analyst estimates of $347.77 million.
Despite a negative net margin of 23.58% and a negative return on equity of 43.25%, MongoDB demonstrated robust growth in revenue compared to the same quarter last year, with a 29% increase. In the previous year’s corresponding period, the company had reported earnings per share of ($1.15). These positive results reflect MongoDB’s ability to consistently meet and exceed expectations.
Looking ahead to the current fiscal year, research analysts anticipate that MongoDB will post earnings per share of -2.8. Although this suggests a loss for the company, it is important to consider that these projections are subject to change based on various factors such as market conditions and business strategies implemented by MongoDB.
Oppenheimer Asset Management Inc.’s increased investment in MongoDB indicates their belief in the long-term profitability and potential growth opportunities offered by this innovative tech company within an ever-evolving digital landscape.
As investors assess their portfolios and seek potential investment opportunities, it is essential to consider companies with a strong track record of financial performance, like MongoDB. Its ability to consistently deliver impressive earnings results and drive revenue growth makes it an attractive option for those looking to invest in the tech sector.
Disclaimer: Our analysis is based on publicly available information and should not be considered as financial advice. Investors are advised to conduct their own research before making any investment decisions.
MongoDB, Inc.
MDB
Buy
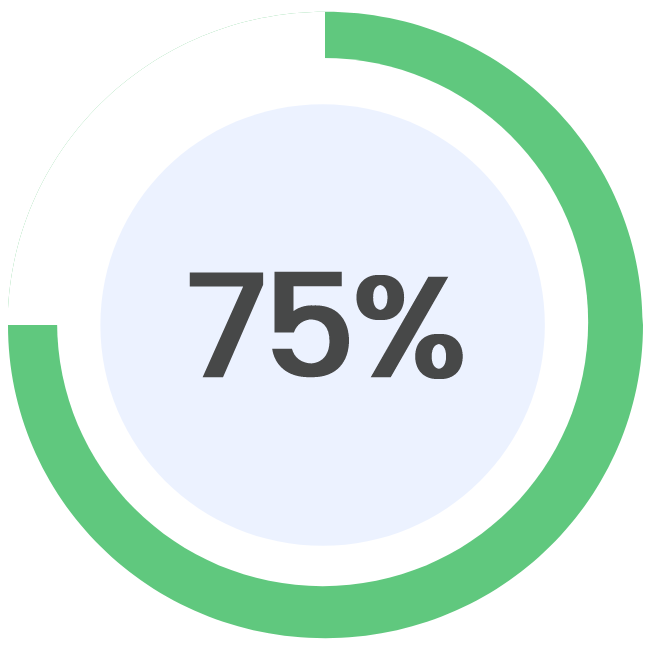
Updated on: 29/08/2023
MongoDB Attracts Significant Institutional Investor Interest and Continues to Garner Positive Ratings From Analysts
In recent months, several institutional investors have made significant changes to their positions in MongoDB, a leading data platform company. Private Advisor Group LLC, for instance, acquired a new stake in the company during the first quarter of this year, amounting to approximately $700,000. Vanguard Personalized Indexing Management LLC also increased its holdings in MongoDB by 11.2% during the same period, now owning around 6,362 shares worth $1,483,000. LPL Financial LLC and Pictet Asset Management SA followed suit with gains of 8.5% and 2.6%, respectively. LPL Financial now owns a noteworthy 22,757 shares worth $5,305,000 while Pictet Asset Management holds approximately 23,681 shares valued at $5,521,000. Keybank National Association OH ended the list of institutional investors reporting changes to their positions with a significant increase of 20.9%, currently owning 1,915 shares worth $446,000.
These revelations shed light on the fact that an overwhelming majority (88.89%) of MongoDB’s stock is owned by hedge funds and other institutional investors.
On Tuesday August 29th , NASDAQ MDB opened at $354.32 per share. Over the past fifty days leading up to this date, the firm maintained a moving average of $390.26 whereas over the course of two hundred days its average ranged from $135.15 (12-month low) to $439 (12-month high). Consequently,MongoDB boasted a quick ratio as well as current ratio of 4.19 coupled with a debt-to-equity ratio standing at 
In other news pertaining to MongoDB Inc., Cedric Pech who serves as chief revenue officer recently sold 360 shares totaling an estimated value of roughly $146k on July 3rd. Pech now directly owns 37,156 shares in the company valued at over $15 million. Director Dwight A. Merriman also sold 6,000 shares of MongoDB stock on August 4th with an average price per share of $415.06 reaching a total transaction value of $2,490,360. Merriman currently holds 1,207,159 shares valuing approximately $501 million.
In addition to these transactions, Cedric Pech sold another 360 shares on July 3rd at an average price of $406.79 amounting to a total value of $146k.
It is also worth noting that insiders have cumulatively sold 102,220 shares valued at approximately $38.8 million in the last three months alone thereby becoming owners of a mere 4.80% of the company’s stock.
Following these developments and amidst continuous growth and success,MongoDB received positive ratings from several brokerages in recent times. Tigress Financial notably increased its price target for MDB from $365 to $490 while Mizuho upped its target price from $220 to $240. William Blair continues to reaffirm an “outperform” rating on MongoDB stock and even Needham & Company LLC unanimously boosted their target price dramatically from $250 to an impressive $430. Furthermore,A Bloomberg consensus suggests that the stock has an overall moderate buy rating accompanied by an average price target of around $379 per share.
As the data platform industry evolves and expands rapidly,MongoDB strives to maintain its position as a leading provider in the market,gaining recognition and support from key institutional investors along the way.The continuous investments made by these institutions underscore their confidence in MongoDB’s future growth potential,and serve as a testament to the positive outlook surrounding the company within the financial community.
MMS • RSS

A whale with a lot of money to spend has taken a noticeably bullish stance on MongoDB.
Looking at options history for MongoDB MDB we detected 32 strange trades.
If we consider the specifics of each trade, it is accurate to state that 50% of the investors opened trades with bullish expectations and 50% with bearish.
From the overall spotted trades, 10 are puts, for a total amount of $661,603 and 22, calls, for a total amount of $1,500,345.
What’s The Price Target?
Taking into account the Volume and Open Interest on these contracts, it appears that whales have been targeting a price range from $70.0 to $590.0 for MongoDB over the last 3 months.
Volume & Open Interest Development
In terms of liquidity and interest, the mean open interest for MongoDB options trades today is 118.95 with a total volume of 912.00.
In the following chart, we are able to follow the development of volume and open interest of call and put options for MongoDB’s big money trades within a strike price range of $70.0 to $590.0 over the last 30 days.
MongoDB Option Volume And Open Interest Over Last 30 Days
Biggest Options Spotted:
| Symbol | PUT/CALL | Trade Type | Sentiment | Exp. Date | Strike Price | Total Trade Price | Open Interest | Volume |
|---|---|---|---|---|---|---|---|---|
| MDB | PUT | SWEEP | BULLISH | 09/01/23 | $370.00 | $224.5K | 53 | 38 |
| MDB | CALL | SWEEP | BEARISH | 12/19/25 | $500.00 | $195.3K | 3 | 14 |
| MDB | CALL | SWEEP | BEARISH | 12/19/25 | $500.00 | $174.9K | 3 | 43 |
| MDB | CALL | SWEEP | NEUTRAL | 12/19/25 | $520.00 | $166.3K | 1 | 17 |
| MDB | PUT | TRADE | BEARISH | 01/19/24 | $360.00 | $129.2K | 512 | 29 |
Where Is MongoDB Standing Right Now?
- With a volume of 740,162, the price of MDB is up 4.41% at $369.94.
- RSI indicators hint that the underlying stock may be approaching oversold.
- Next earnings are expected to be released in 2 days.
What The Experts Say On MongoDB:
- Citigroup has decided to maintain their Buy rating on MongoDB, which currently sits at a price target of $455.
Options are a riskier asset compared to just trading the stock, but they have higher profit potential. Serious options traders manage this risk by educating themselves daily, scaling in and out of trades, following more than one indicator, and following the markets closely.
If you want to stay updated on the latest options trades for MongoDB, Benzinga Pro gives you real-time options trades alerts.
MMS • Frederic Branczyk

Transcript
Branczyk: Meet Jane. Jane finds herself thinking about a new business idea. Jane does come up with a new business idea. Without further ado, Jane starts coding, starts writing a bunch of software, starts putting it on servers, people start using it. It feels like overnight, there’s a huge amount of success. Thousands of people start using the software, and everything just goes through the roof. All of a sudden, we see unexpected things happening in our infrastructure. Maybe we put a little bit of Prometheus alerting into place for some high-level alerting. We put all of this on Kubernetes as we do these days, and we get a high CPU alert, for example. In all of our success, we were not thinking about observability enough. Now we’re in the situation where we are maintaining a production service, but have no insight into what’s happening live. This really happens to all of us. Whether it be starting a new company, starting a new project, creating a new service within a company, companies get acquired, code bases get inherited, probably all of you can relate to this problem. A lot of you probably have even experienced one or the other version of this, where now you’re in charge of maintaining a piece of software that you don’t have the amount of visibility into that you would like, and maybe even that you need.
I’m here to tell you why you should be sprinkling some eBPF into your infrastructure, and how and why you can be confident in this. In this case, I’m deploying a profiling project called Parca, it’s open source, onto an existing Kubernetes cluster. I waited for a little bit of time for data to be generated. All of a sudden, without ever having touched any of these applications that are running on my Kubernetes cluster, I can now, down to the line number, explore code, and where CPU time in this entire infrastructure is being spent. I can look at Kubernetes components. I can look at other infrastructure. I can look at application code, everything. I didn’t do anything to my code, but I was still able to explore all of this at a very high resolution, and in a lot of detail.
Background
My name is Frederic. I am the founder of a company called Polar Signals. We’re a relatively early-stage startup. I’ve been working on observability since 2015. I’m a Prometheus maintainer. I’m a Thanos maintainer. Prometheus is an open source monitoring system modeled after internal Google systems. Thanos is essentially a distributed version of Prometheus. Both of these are Cloud Native Computing Foundation projects, CNCF. Also, for several years, I was the tech lead for all things instrumentation within the Kubernetes project. I am actually the co-creator of the project that I just showed you. As I said, everything that I just showed you is open source. As a matter of fact, everything I’ll be showing you is open source.
eBPF
Let’s talk about eBPF. I want to make sure that we all have the same foundations to talk about the more advanced things that I’m going to dive into. I’m going to start from zero. Basically, since forever, the Linux kernel, literally, the kernel itself has been actually a fantastic place to implement observability. It always executes code. It knows where memory is being allocated. It knows where network packets go, all these things. Historically, it was really difficult to actually evolve the kernel. The kernel was on a release schedule. The kernel is very picky, and rightfully so, about what is being included in the kernel. Millions of machines run the Linux kernel. They have every right to be very picky about what goes in and what does not. eBPF on a very high level allows us to load new code into the kernel, so that we can extend and evolve the kernel in a safe way, but iteratively and quickly, without having to adhere to kernel standards, or do things in a certain way.
What is an eBPF program? At the very bare minimum, an eBPF program consists of a hook. Something in the Linux kernel, it may be a syscall like we’re seeing here that we can attach our eBPF program to. Essentially, what we’re saying is, every time this syscall is being executed, first, run our eBPF program, and then continue as usual. Within this eBPF program, we can do a whole lot of things. We can record the parameters that were parsed to the syscall. We can do a bunch of introspection. It is also very limited what we can do. The first thing that I was talking about were hooks. There are a lot of predefined hooks in the Linux kernel, like I said, syscalls, kernel functions, predefined trace points where you can say, I want to execute this eBPF program when this particular trace point in the kernel is passed. Network events. There are a whole lot more. Probably there is already a hook for what you’re looking for. The reason why this ecosystem is already so rich, even though eBPF is a relatively young technology, is these things have always been there. The kernel has always had these hooks. eBPF is just making them accessible to more people than just those working directly on the kernel. Then the kernel allows you to create a bunch of custom hooks, kprobes, these are essentially that you can attach your eBPF program to any kernel function that’s being called. Uprobe, you can attach your eBPF probe to a function by a program in userspace. The applications we typically write, we can run an eBPF program. Or perf_events. This is essentially working on some overflow and saying every 100 CPU cycles, run this eBPF program. We’ll see particularly perf_events because this is the one that I happen to be most familiar with, we’ll see a lot more of that.
Communicating With Userspace, and Compiling eBPF Programs
How does an eBPF program even communicate to us normals? The way this works is, like I said, a hook, and the hook can be either something from userspace or from kernel space, which is why it’s here in the middle of everything. It runs our eBPF program which definitely runs in kernel space. It can populate something called eBPF maps. These are essentially predefined areas of memory that we also allow userspace programs to read. This is essentially the communication means. Userspace programs can also write to these eBPF maps, and eBPF programs can also read from these, so they’re bidirectional in both ways. This is essentially our entire communication mechanism with eBPF. In order to compile a piece of code to be an eBPF program, we use an off-the-shelf compiler. LLVM and clang are the standard tool chain here. GCC does have some support for this as well. For some of the more advanced features, which we’ll be looking at as well, LLVM is really the thing that you want to be looking at. Typically, if we have an AMD64 machine on Linux, this may be the target that we’re using to compile our programs to. With eBPF, we have a new target, because eBPF essentially defined its own bytecode. Maybe you’re familiar with bytecode in the Java Virtual Machine, where we pre-compile also something to Java bytecode. Then this bytecode is what the Java Virtual Machine loads, and ultimately executes. eBPF works incredibly similar to that. We take our compiler client here, and say, I want this piece of code to be BPF bytecode, once you’ve compiled it. Then we can take that binary and load it and attach it to a hook.
Ensuring It’s Safe to Load
That’s essentially all that a userspace program has to do. It needs to have some eBPF bytecode that it wants to load. We’ve already compiled this with our previous command, and now we’re handing it off to the kernel. The first thing the kernel does is, it verifies that this bytecode that you’ve just handed it will definitely terminate. If you’ve done computer science in university or something, you may be familiar with something called the halting problem, where essentially, we cannot prove that a Turing complete program will halt.
There’s theory behind this. Basically, what the kernel has done is it starts to interpret the bytecode, and makes sure that it doesn’t do anything that potentially could cause the program to be unpredictable. Essentially, it unrolls all loops. It cannot have potentially endless for loops. There are a whole set of things that this verifier restricts you from doing. Essentially, what we end up with is something where we can write arbitrary code, and load more or less arbitrary code into the kernel. The kernel ensures that whatever we’re loading is not actually going to impact the kernel enough that it would be totally devastating, or at least, it attempts to do that. Once the Kernel has verified this, it actually turns the generic bytecode using a just-in-time compiler to actually machine executable code that our hardware understands how to execute, just like any other program, essentially at that point. We have ensured that what we’re executing is definitely safe to be executed.
In the early days of eBPF, you would often find something like this. Here, we can see an eBPF program at the top that actually is attached to a perf_event. Essentially, what we’re saying is up to 100 times per second, call this eBPF program. We’ll go into later why this might make sense. I want to focus our attention on the later thing in this slide. What we used to do, using a tool chain called BCC, the BPF Compiler Collection, we essentially wrote C code, but in essence, it was just a templateable string. We would literally string replace something that we would want to configure with the actual value that we would want, throw it through clang, and then actually do the loading at runtime, like I just showed you. This was fine for a little bit while we were exploring eBPF. Over time, as we realized this is pretty solid technology, we want to continue evolving this. We realized that this is not going to be all that good in the long run. For one, if we’re doing string templating, we’re losing essentially all ability to know whether this code that we’re producing is valid at all. Maybe worse, we could have injection attacks and execute arbitrary code in the Linux kernel. A lot of really terrible things could happen, apart from this being pretty difficult to get right. Then also, and this is maybe more of an adoption/convenience hurdle, but you actually have to have a compiler locally on every machine that you want to run eBPF code on. That also means you have to have all the libraries, all the headers, all of these things available locally. This can be a huge burden on people running your software. This resulted in eBPF programs that were not very portable, and overall, pretty brittle and complex to use.
Compile Once, Run Everywhere (CO:RE)
The eBPF community came up with a very catchy acronym, compile once, run everywhere, CO:RE. Essentially, the goals were pretty simple. All of the things that were previously causing a lot of difficulties, we wanted to get rid of, so that we could truly just compile our eBPF bytecode once, and then run it everywhere. That is very easy to say, and very hard to get right. Ultimately, reiterating here, the goals were, we did not want to need a compiler on the host, we did not want to have kernel headers, or any headers for that matter, have to be on that host. We want to be able to configure our eBPF programs, at least to some degree, to the degree that we could do before ideally with string template. How do we create portable CO:RE eBPF programs? One change once this was introduced, was that we needed to start using these somewhat specific function calls if we wanted to read data from kernel struct. Part of the whole problem of needing kernel headers was that we needed the kernel headers in order to say, what is the layout of these structs when we get them in memory? How do we read the right information from memory, essentially?
Compile once, run everywhere introduced a set of functions and macros to make this easier. We’ll see how this works. At the end of the day, essentially, the way it works is that we parse some version of kernel headers. In this case, it’s actually in the format of what we call BTF, BPF Type Format. We parse that at compile time, and it essentially gets included into our BPF bytecode, the layout of the kernel that we compiled it with essentially. Then, when the BPF program is loaded, or wants to be loaded by our userspace program, we actually look at the locally available BPF Type Format and modify the bytecode so that it now matches the Linux kernel that we actually have locally. The first time I heard this, I thought this sounds completely insane, and that it could never work. I don’t know what to say, kernel developers are pretty genius. They did make all of this work. It truly just works like a charm ever since this has been implemented.
Let’s go through this one more time now with compile once, run everywhere. Again, we pre-compile our program using clang, with the target being BPF. We have our bytecode already. Our userspace program first modifies our bytecode using the locally available BPF Type Format information to relocate the struct to access the things the way that they’re actually available on our local machine. The userspace program then takes that now essentially modified bytecode and parses that to the kernel. The kernel then verifies that bytecode, and then just as before, just-in-time compiles it to be executed by the kernel locally. Now we’ve actually created portable BPF programs. In order to be able to do this, I highly recommend using at least clang version 11. With earlier versions, some of this may actually work. For some of the more advanced features, you definitely want version 11 or later. We actually use a much newer version than 11, but require an absolute minimum of 11.
Then the whole magic essentially happens in a library called libbpf. Theoretically, all these relocations, they could be reimplemented in just about any language, and could be completely custom. It turns out that a standard library has evolved for this called libbpf. There are wrappers in various languages, there’s one for Go, there’s one for Rust. I think these are the only ones that I’m aware of. I wouldn’t be surprised that there were more packages out there that would use libbpf from other languages. The really cool thing is now we can finally create BPF programs. The thing that eBPF was always promising us to do, we can actually now compile our eBPF programs, ship them side by side with our userspace program, or maybe even embed it into the binaries of our userspace program so that they can then load this locally to the kernel wherever they’re being executed.
What does our previous example look like with compile once, run everywhere, then? As we can see, we are no longer doing string replacements. We define a constant with the process ID. Previously, we were doing string replacements to template the process ID into the program and then compile it. We’ve actually already compiled this code, and we already have it as BPF bytecode. Our userspace program is only replacing the constant within the BPF bytecode with the new PID that we want to modify. Then it loads it and attaches our BPF program to some hook that we specify. Some stats, we no longer need clang on a host. This means that we’re saving up to 700 megabytes in artifact size. We do not need kernel headers locally because all of these things are either located in BPF type information, or we don’t need them at all. We’ve saved potentially up to 800 megabytes of space that we didn’t actually need or don’t need anymore. Interestingly enough, it doesn’t really stop here, because of various reasons, compile once, run everywhere programs are also more efficient. There are lots of reasons for this. Essentially, it’s better on every dimension. It’s more portable. Artifacts are smaller. It uses less memory at runtime. Feels like magic.
Language Support with eBPF
eBPF is portable. This was one of the core things that I wanted to talk about, because I think it’s important to have a good foundation of the technology that you may either be developing with, or more likely that you may be operating. I want to give you a framework of what tools are using the technologies that we should be using, and give you a framework to understand how all of these things fit into the eBPF ecosystem. Thanks to compile once, run everywhere, we’re actually able to distribute eBPF based observability tools with single commands, like the one that we’re seeing here to install it into a Kubernetes cluster, for example. Just like what I showed you at the very beginning, in that demo video. All of a sudden, we go back to the beginning where Jane started a new company. Now there are colleagues, and you’re using all of these technologies, Kubernetes, Spark, Java, C++, Python, and you need visibility into all of those.
I started with the premise that eBPF is here to save the day. I’m going to contradict myself here for a second. The thing that often comes up with eBPF, and I think this is a myth, is that with eBPF, it’s very easy to support all the languages out there. You’ll hear this a lot in the marketing speak for all the eBPF tools. There’s some truth to this. I want to make sure that I give all of you the information you need to understand to what extent this is actually true, or how you can understand whether this thing is just marketing talk, or if this is real. The brutal truth is, language support with eBPF is incredibly hard. This next section, I’m going to walk through a real-life example. The one that I’m most familiar with is profiling, because that’s what I happen to do on an everyday basis. This is where we’re going to look at how can we actually support lots of languages for profiling with eBPF. Here, I have a snippet of code that actually shows us the very concrete hook that we happen to use for profiling purposes. I want to take one more step back to talk about profiling. Profiling essentially allows us software engineers to understand where resources are being spent, down to the line number. The Linux kernel actually has a subsystem called the perf_event subsystem that allows us to create hooks to be able to measure some of this. We’re going to walk through how this works.
The first thing that we do is we create this Custom Event. Remember earlier when I was saying that you can create custom hooks to attach your eBPF programs to, so this is the very example of that. In this case, what we’re saying is, I want you to call my eBPF program at up to a frequency of 100 Hz per CPU. I want this only to happen on CPU, is what we call this. That means we’re not actually measuring anything if the CPU isn’t doing anything, but if it’s doing something at 100%, we’ll be sampling 100 samples per second. Here I have a version of our actual eBPF program with only a few lines highlighted just for the sake of being able to get it onto this slide. Let me walk you through what we’re seeing here. At the very top, what we’re seeing is just the struct definition, plain old struct. In this case, what we’re defining is the key that we’re using in order to say, have we seen this stack trace before? The combination that we’re using here is the process ID, the userspace stack ID, so the stack of the code that we tend to be working on. Then the functions that call stack within the kernel. This is essentially the unique key that identifies a counter.
We’re setting a couple of limits, because all the memory within an eBPF program essentially needs to be predetermined. We need to ensure that it’s exactly the size, and it will only execute so many instructions, and so on. These actually tend to be, relatively speaking, fairly simple programs. What we’re seeing here is, the only piece of code that I highlighted is obtaining the process ID, but it’s also only four or five lines of code. We’re starting our key. Our key starts with our process ID. Then we retrieve our stack ID from the userspace stack, and add that to our key. Then we obtain our kernel space stack. Finally, we check if we’ve seen this key before. If we’ve seen it before, we increase it. If we haven’t seen it before, we initialize it with a zero, and then increase it. Ultimately, all we’re doing here is finding out, have we seen the stack before? If yes, we count one up. It’s really that simple. Because we’re sampling it up to 100 times per second, that means that if we’re seeing the same stack trace 100 times per second, then 100% of our CPU time is being spent in this function. That’s ultimately how CPU profilers work.
How Do We Get a Stack?
The problem is, how do we as humans actually make sense of it? Because if you’ve ever tried something like this, you will have noticed that the only data that we get back from a program like the one that I’ve just shown you is, the stack is just a bunch of memory addresses. I don’t know about you, but I don’t happen to know what my memory addresses correspond to in my programs. We’ll need to make sure that these memory addresses actually make sense so that we can then translate them into something that we humans can understand. The problem is, how do we even get this stack? For this, we need to look back at how does code actually get executed on our machine. Essentially, you may be familiar with the function call stack. The way it works is that we have these two registers, the rsp register, and the rbp register. Rsp is essentially always pointing at the very top of our stack. Essentially, it’s telling us this is where we’re at right now. Rbp is something that we call the frame pointers. They essentially keep pointing down the stack, so that we understand where the two frames start and end. We essentially just need to keep going through the saved rbp addresses to figure out where all the function addresses are. If we ignore that this is some random memory in our computers, what I’ve just described to you is we’re walking a linked list. We’re just finding where a value is to find out where the next value is. We just keep going until we’re at the end.
Frame pointers are really amazing when they are there. Unfortunately, there are very evil compiler optimizations. Unfortunately, in some compilers, these are even on by default, that omit these frame pointers. Because what I’ve just described is essentially that we’re using two registers in order to keep track of where we need to go. The thing is, the machine doesn’t actually need this to execute code. We will always have to maintain where we’re at, because the machine needs to be able to place new things onto the stack, but we don’t actually, truly need rbp register. Essentially, what these compilers are saying is they would rather use this register, because with more registers they can do more things simultaneously. They rather utilize this register for performance reasons, than allow us to debug these programs very easily. That’s essentially the tradeoff that’s being made here. It turns out, most hyperscalers, Meta, Facebook, I believe Netflix, they actually have frame pointers on for everything. This works out really well when you can dictate this throughout the entire company. At least from what I’ve been told, there were discussions about this internally, as well, of course. Essentially, what it always boils down to is, it’s always better to be able to debug your programs, than squeeze out a little bit of performance. It’s really minuscule the amount of performance that you can get out of an optimization like this.
However, the problem that we’re facing is hyperscalers may be able to do this, but the rest of the world cannot. We’re at mercy for what binaries we can obtain. Unfortunately, most Linux distributions, for example, omit frame pointers. We have to find a way to walk these stacks without frame pointers. This is where something called unwind tables come into place. These are standardized, so these are pretty much always going to be there. The way these work, is that given some location on the stack, we can calculate where the frame would end. Then we can keep doing this, to figure out where we need to go next. This is an alternative way. What I want you to go away from this section with is, this is theoretically possible, but it’s an insane amount of work to get this working. Just to give you a data point, we’ve had up to three full-time senior engineers that already understand how these things work for almost a year working on this now. We’re just about there to getting this to work. This is all getting extra complicated when we have to do these pretty complex calculations in eBPF space, where we’re restricted with the programs and what these programs can do. They have to terminate and all of these things. Lots of challenges. If you are interested in the very nitty-gritty details of how this works, because these unwind tables don’t just exist, of course. There’s a whole lot of effort that you need to go through to generate the tables, make sure that they’re correct, and then ultimately using them to perform the stack walking. If you’re interested in how this works, my colleagues Vaishali and Javier just gave a really amazing talk at the Linux Plumbers Conference that was in Dublin, about exactly how this works.
Ultimately, what that means is, we are able to walk stacks and unwind stacks for anything that is essentially considered a native binary. Where compilers output a binary for us to execute: C, C++, Rust, Go, anything that compiles to a binary, essentially. Now we can support those languages. How about Java? How about Python? How about Node.js? The good news for anything that is a just-in-time compiled language, so Java, Node.js, Erlang, all of these, just like the name says, they are eventually just-in-time compiled to native code. For those kinds of languages, “all we need to do” is figure out where is that natively executable code ending up, and wiring it up with all the debug information, so that we can perform everything that I just walked you through on that code as well. More complicated, but ultimately doable. The ones where it really gets really complicated, are those that are true interpreters, truly interpreted languages like Python, I think maybe still currently Ruby, but I think Ruby is getting a just-in-time compiler. Python in particular, there’s no just-in-time compiler. The only way that we can reconstruct frames and function names and all of these things in Python is we actually have to read the memory of the Python virtual machine to reconstruct what pointers into some space in memory corresponds to in terms of our function names, or something like that. All of this is doable, but it’s incredible amounts of work to get this working.
eBPF Tooling – Pixie
It’s easy to say that eBPF allows you to have wide language support. It turns out, it’s actually incredibly hard. The really amazing and good news is there is already tooling out there that does a lot of the very heavy lifting for you. One of the ones that I wanted to talk to you about is called Pixie. Pixie is a pretty cool project. It is eBPF based. It has a bunch of features, but I picked out three or four of the ones that I think are the most amazing ones where Pixie really shines. It can automatically produce RED metrics, so rate of requests, errors, and durations. This is super cool, because it can automatically generate these for gRPC requests, for HTTP requests, all of these kinds of things. It can understand whether you’re talking to a database, and automatically analyze the queries that you’re doing against these databases. It can do request tracing, which ultimately corresponds to the RED metrics. The other ones, if you’re doing it well, you may be able to do some auto-instrumentation by dropping a library into your project and you may get something of similar quality. All of this works without ever modifying your applications. That’s the whole premise. The thing that I think is really cool is this dynamic logging support. Essentially, you write these little scripts called Pixie script, where you can insert new log lines without having to recompile code. Essentially, it works the same way as I was just talking about walking frames. It uses a couple of tracing techniques that are available in the Linux kernel to stop and inspect the stack at a certain point. If you’re reading a variable, for example, it can write out that new log line and continue function execution at that point. You don’t have to deploy a new version just to see if something may be interesting to understand in this function. Of course, with great power comes great responsibility. I thought this was mind blowing when I saw it for the first time.
eBPF Tooling – Parca
I happen to work on the Parca project, where we concern ourselves with always profiling everything in your entire infrastructure all the time. eBPF is a really crucial piece of this puzzle, because eBPF allows us to not only do all of the things that I just showed you about stack walking from within the kernel. The best prior thing that we had was we had to snapshot the entire stack, copy it into userspace, and unwind it there asynchronously. Now we’re able to actually do all of this online, so that we can not do a bunch of copies of data unnecessarily, we may be copying potentially sensitive data out of the kernel. We’re not doing any of that, because we’re walking the stack within the kernel, and the only thing we’re returning is a couple of memory addresses that ultimately just correspond to function names. eBPF allows us to capture all of this data, exactly the data we need, at super low overhead. We’ve done a couple of experiments with this, and we tend to see about something anywhere between 0.5% to 2% in overhead doing this. We find that most companies that actually start doing continuous profiling can shave off anywhere from 5% to 20% in CPU time, just because, previously, we didn’t know where this time was being spent. Because we’re always measuring it all the time throughout time now, it’s becoming painfully obvious.
eBPF Tooling – OpenTelemetry Auto-Instrumentation for Go
The last thing that I wanted to highlight is something that I think is more of an experimental one. Pixie and Parca, they’re both pretty production-ready. They’re pretty battle-tested. They’ve been around for a couple of years at this point. This one is one of the more recent ones, and I’m still pretty excited about it. Although I think I haven’t made up my mind yet whether this is crazy or crazy cool. I wanted to highlight it anyways, because I think what they’ve done is pretty ingenious. Essentially, what this project is doing is it is utilizing uprobes. Probes that are attaching to some function name within your Go process, in this case, to be able to figure out where to stop a program to patch distributed tracing context into your application. This solves one of those problems that is notoriously difficult about distributed tracing, which is, you have to instrument your entire application infrastructure to be able to make use of distributed tracing in a meaningful way. I think this is super exciting but at the same time, this essentially monkey patches your stack at runtime. That’s also super scary because it actually breaks a bunch of other things. It’s also definitely one of the more experimental things out there.
Conclusion
I hope I have shown you that eBPF is here to stay. It’s incredibly powerful to use as an instrumentation technology. While it is a lot of complicated work to make language support possible, it is possible, but most projects out there aren’t actually doing what I described to you. I think it’s healthy to go with some skepticism to projects that just claim eBPF means lots of language support. Hopefully, I’ve convinced you to sprinkle some eBPF into your infrastructure. I think eBPF is incredibly transformational. It is not magic, just like it often seems like, but it is actually a lot of work to make it useful. There is already eBPF tooling out there that is ready for you to use today.
See more presentations with transcripts
MMS • RSS
MongoDB Inc (
MDB, Financial), a leading player in the software industry, has seen a significant surge in its stock price over the past three months. With a market cap of $26.22 billion and a current price of $371.55, the company’s stock has gained 2.29% over the past week and a whopping 30.69% over the past three months. This impressive performance is further underscored by the company’s GF Value, which currently stands at $582.7, up from $540.75 three months ago. According to the GF Valuation, the stock is significantly undervalued, suggesting potential for further growth.
Company Overview
Founded in 2007, MongoDB Inc operates in the software industry, providing a document-oriented database to its customers. The company boasts nearly 33,000 paying customers and well over 1.5 million free users. MongoDB’s NoSQL database, compatible with all major programming languages, can be deployed for a variety of use cases. The company offers both licenses and subscriptions for its service. 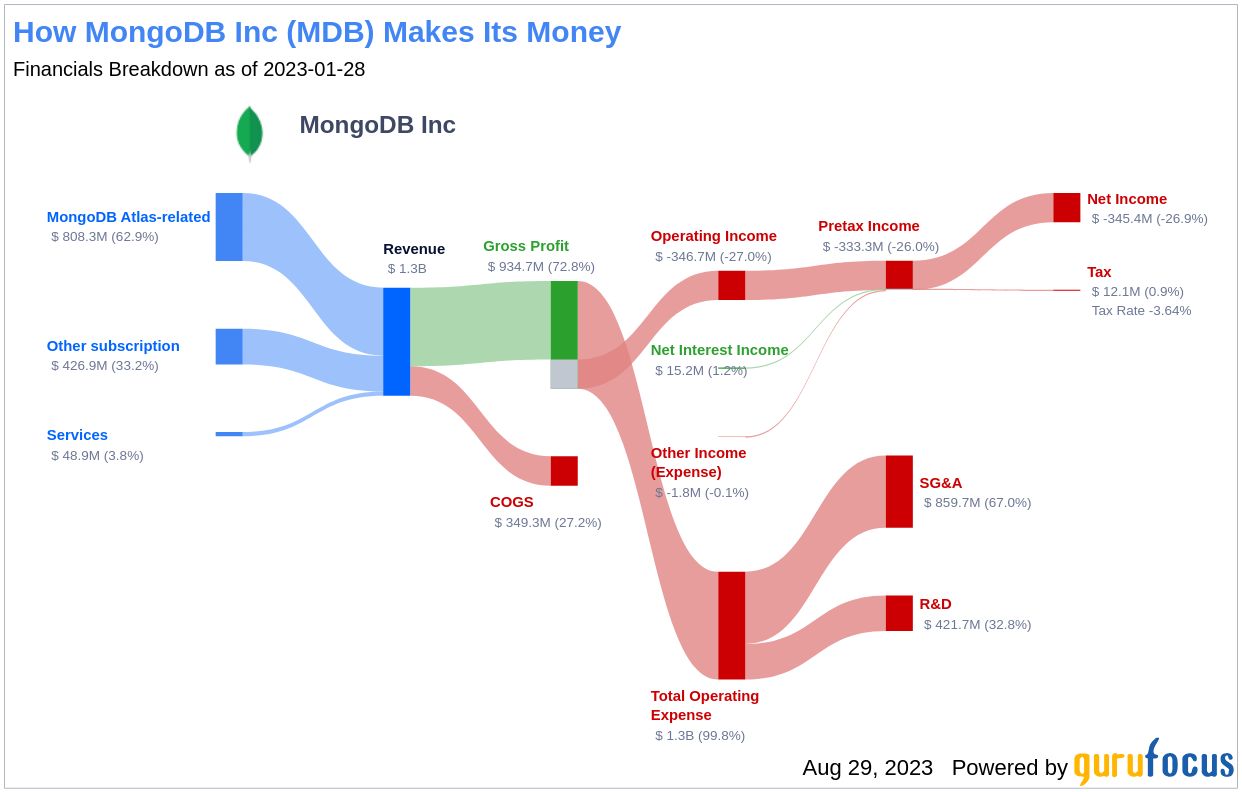
Profitability Analysis
Despite its impressive stock performance, MongoDB’s Profitability Rank stands at 3/10, indicating that its profitability is relatively low compared to other companies. As of April 30, 2023, the company’s Operating Margin was -24.82%, better than 25.02% of companies in the industry. Its ROE and ROA were -45.31% and -12.87% respectively, while its ROIC stood at -43.42%. These figures suggest that MongoDB has room for improvement in terms of profitability. 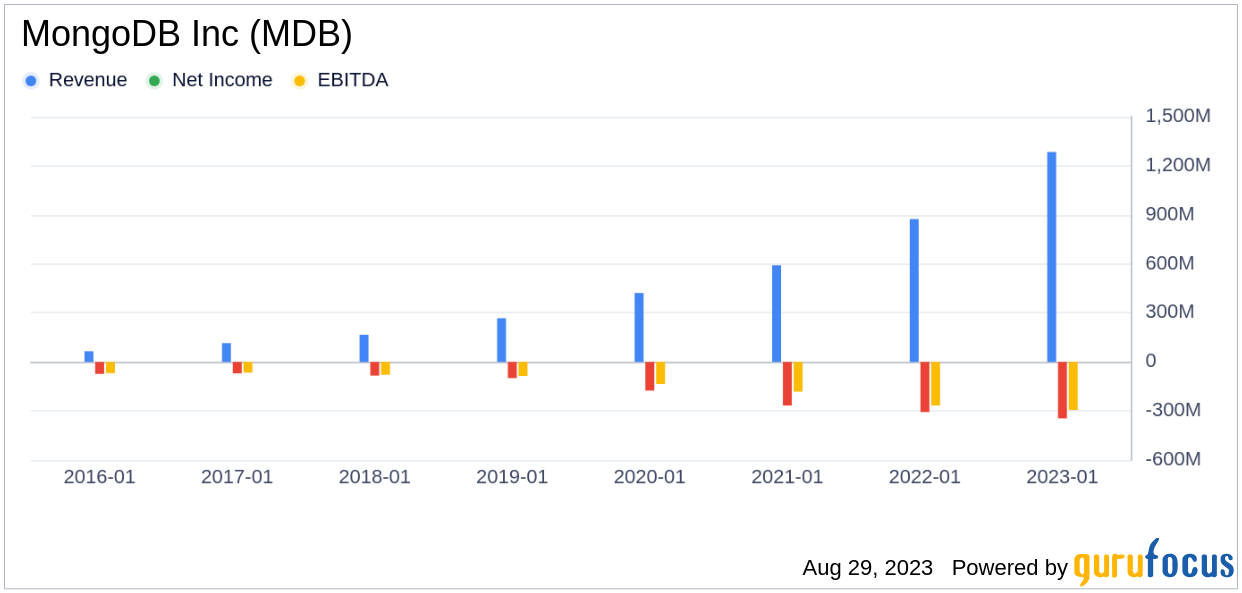
Growth Prospects
Despite its profitability challenges, MongoDB has demonstrated strong growth, with a Growth Rank of 8/10. The company’s 3-Year and 5-Year Revenue Growth Rates per share stand at 35.40% and 26.10% respectively, outperforming 88.16% and 88.89% of companies in the industry. Furthermore, MongoDB’s future total revenue growth rate is estimated at 22.52%, better than 85.2% of companies. However, its 3-Year and 5-Year EPS without NRI Growth Rates are -17.00% and -14.90% respectively, indicating some volatility in earnings. Nonetheless, the company’s future EPS without NRI growth rate is projected at a robust 75.50%, suggesting strong potential for future growth. 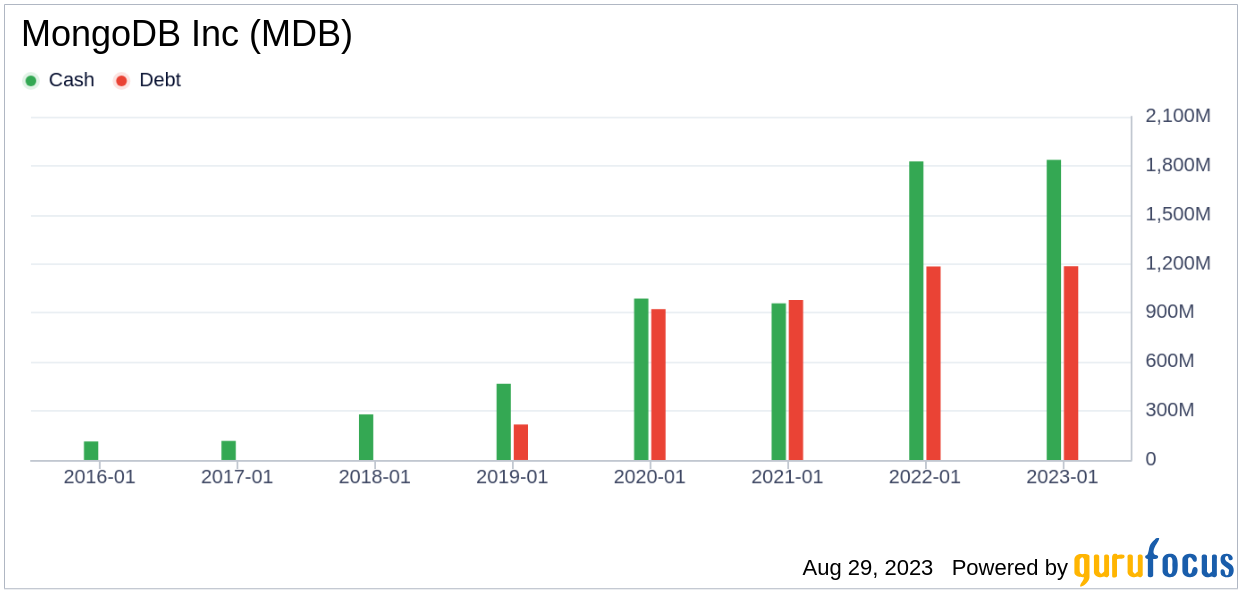
Major Stockholders
Among the top holders of MongoDB’s stock are
Jim Simons (Trades, Portfolio),
PRIMECAP Management (Trades, Portfolio), and
Paul Tudor Jones (Trades, Portfolio). Simons holds 142,600 shares, representing 0.2% of the total shares, while
PRIMECAP Management (Trades, Portfolio) and Jones hold 74,700 and 24,762 shares respectively, accounting for 0.11% and 0.04% of the total shares.
Competitive Landscape
MongoDB faces stiff competition from other software companies such as Check Point Software Technologies Ltd (
CHKP, Financial) and Akamai Technologies Inc (AKAM, Financial), both with market caps of $15.65 billion and $15.68 billion respectively. Despite this competition, MongoDB’s higher market cap and strong growth prospects position it favorably in the industry.
Conclusion
In conclusion, MongoDB Inc’s stock has shown impressive performance over the past three months, gaining 30.69%. Despite its relatively low profitability rank, the company’s strong growth prospects and undervalued stock suggest potential for further gains. However, investors should also consider the company’s competitive landscape and the performance of its major stockholders when making investment decisions.
Also check out:
MMS • Anthony Alford
Stability AI, makers of the image generation AI Stable Diffusion, recently launched Stable Chat, a web-based chat interface for their open-access language model Stable Beluga. At the time of its release, Stable Beluga was the best-performing open large language model (LLM) on the HuggingFace leaderboard.
Stable Beluga is based on the LLaMA foundation model released by Meta. The model is fine-tuned using a synthetic dataset generated by GPT-4. The largest Stable Beluga model contains 70B parameters and outperforms ChatGPT on several benchmarks, including AGIEval, which is based on several common examinations such as LSAT and SAT. To help evaluate Stable Beluga, Stability AI created the Stable Chat web interface to help users interact with the model and give feedback on its output. According the Stability AI,
As part of our efforts at Stability AI to build the world’s most trusted language models, we’ve set up a research-purpose-only website to test and improve our technology. We will continue to update new models as our research progresses rapidly. We ask that you please avoid using this site for real-world applications or commercial uses.
The Stable Beluga models were inspired by a paper published by Microsoft on Orca, a fine-tuned version of LLaMA. In the paper, Microsoft described a technique called explanation tuning. Like instruction tuning, which has been used on many open LLMs recently, including ChatGPT and Vicuna, explanation tuning uses a dataset of example inputs and desired model outputs that are generated by a teacher. In the case of ChatGPT, the teachers are actual human users of the model. In contrast, for Orca and Stable Beluga, the explanation tuning dataset is generated by prompting GPT-4 to explain why it generated the output it did (“explain like I’m five.”)
Stability AI created their own explanation tuning dataset of 600,000 examples—one-tenth the size of the Microsoft dataset. They then trained two versions of Stable Beluga: Stable Beluga 1, based on the 65B parameter original LLaMA model, and Stable Beluga 2, based on the 70B Llama 2 model. Both are released under a non-commercial license. Although the models achieved fourth and first place, respectively, on the leaderboard when they were released, the proliferation of LLaMA-based fine-tuned models has currently pushed Stable Beluga 2 out of the top ten, and Stable Beluga 1 even lower.
The models were released under a non-commercial license to encourage researchers to help iterate and improve on the technology, according to Stability AI. However, the company noted that this required resources that are “beyond the reach of everyday researchers,” and decided to create the Stable Chat website. Users can create a free login or use a Google account to access the chat. The responses from the model can be up-voted, down-voted, or flagged; this user feedback will be used to help improve the model in the future.
Stability AI founder Emad Mostaque posted about the release on Twitter/X. One user replied that the model was “too cautious in giving factual information.” Mostaque urged the user to give that feedback via the web interface.
Stability AI also recently announced that their LLMs will be used at an AI red-teaming event at DEF CON 31. This event is sponsored by the White House and features models from “Anthropic, Google, Hugging Face, Microsoft, NVIDIA, OpenAI, and Stability AI.” The goal is to help identify risks and vulnerabilities in the models.