Month: September 2023
Presentation: The Secret to Finding Impactful Projects to Land a Staff-Plus Engineer Role

MMS • Akhilesh Gupta

Transcript
Gupta: My name is Akhilesh Gupta. I’m an engineer at LinkedIn here in Mountain View. As an important part of my role, I mentor other engineers at LinkedIn. A very frequent question from my mentees is, how do I grow to the next level? I usually respond by saying, you need to grow your scope and impact in the organization. Which is obviously followed up by, how am I supposed to have more impact? To which I usually say, work on more impactful projects. By this point, I’ve totally annoyed them. They either say that the best projects are already taken by others in the team. Or that they feel constrained by the scope of the team they are currently working on. Or that their manager is unable to find them the right opportunities. I’m here to tell you that you can be a staff-plus engineer, even if all of these are going against you. Even if you have a manager who is far from ideal, even if your team has a tiny charter, and even if you’re not automatically chosen to lead the biggest projects in your organization.
At this point, you’re probably going, how? Let’s start with a scenario, and you will tell me if you’ve been in the scenario before. You start your new job as a senior engineer. They’ve assigned their architect, Lisa, to give you a rundown of their shiny, new tech stack. They tell you, everything is so modern in the stack. Their iOS app is on Swift. Their web app is on React. They use GraphQL because REST interfaces are so ’90s. At this point, you’re starting to feel that all your skills in Objective-C and REST API interfaces are going to be absolutely useless. Then she tells you about the backend. It was built by some legendary engineer five years ago, who is now the CTO at a stealth startup. She tells you to ignore it, because no one really knows how it works. What are your peer engineers talking about at lunch the next day? You hear your peer engineers complain about the backend. It’s written in C++, but no one in the team knows C++. The code base is 30,000 lines of code. It’s deployed once in two months. The deployment process includes manual validation of the entire app by an external contractor. No wonder none of these contractors really last for more than a few months.
Who has been in a situation like this? I bet almost every one of you at some point in your career. As you spend more time on the team, you see how the backend is making everyone’s lives miserable. There are frequent production issues. People have to be on-call all the time. Managers are complaining about wasted engineering cycles. PMs are complaining about impact to customers and the business. When you hear complaints like these, you have two choices. You can join in and make more complaints about how everything is messed up, or you can think of this as an opportunity. Raise your hand and decide to fix that problem for your team and your organization. Which choice do you think gets you closer to the staff-plus engineering role? Yes, of course, the second one. If you keep making that choice, you will keep broadening your scope of impact and ultimately land that staff-plus role. Let me tell you how. I will show you how you can recognize such problems and use them as opportunities to solve hard technical problems to grow your career.
Six Steps to a Staff-Plus Role
Let’s first talk about how you recognize such problems. What were some characteristics of this problem that I just presented? It’s super tedious and challenging. Everyone is complaining about the problem, but not many are willing to do anything about it. It’s impacting more than just your immediate team. It’s directly or indirectly having a negative impact on customers or the business. In other words, addressing the problem will not only make your peers and managers happier, but it will also matter to the business. You have now recognized a problem worth solving. Let’s go a little deeper into what you may need to do to pursue a solution to this problem. You’re all excited, and you go tell your manager that you want to work on refactoring the backend. The first question she will ask you is, why? This is probably the most important question you will answer in all your projects. What is the motivation behind your work? If you get this right, most of the battle is already won. Then, she will coach you to make a business case for solving the problem, so you can convince the leaders of the organization to work on the problem. You will answer three important questions. Why is the problem important? What are the various aspects of the problem, and the requirements from the solution? How do you plan to solve the problem? This is also when you will encounter the two most dreaded terms in the life of a senior engineer, the level of effort and the return on investment. Both are critical to making a business case for solving a problem.
The first question you should ask yourself after identifying the problem is, what are the soft skills needed to solve this problem? In this case, you may need to connect your project to business impact. Maybe it’s faster product iterations, or developer productivity, or the ability to free up maintenance and operation’s bandwidth. You may need to write a document to communicate your motivation. Get feedback from peers. Convince your peers that this is worth doing, and convince clients of the backend that a migration is worth it. You may need to gain alignment with execs. You need to present your ideas in various engineering forums in the company. You would need to align with non-engineering leaders, like product managers, who would be worried about the cost of refactoring the backend against current product priorities. These are all things that I have been most uncomfortable with in my own career as an engineer, but they keep showing up over again.
You finally convince everyone, what next? You now need to come up with a technical plan to make this happen. For this problem, you will need many technical skills: understanding the backend’s code base, creating microservices, defining better models, maybe API interfaces, and of course, a ton of refactoring and modularization. Maybe even defining a client migration plan when your refactoring is done. Doing this exercise will give you a vital understanding of whether solving this problem will help expand your skill set as an engineer. How should you evaluate whether you want to pursue a solution to this problem? You should again, ask yourself a few questions. Are you interested in solving the problem? Will it energize you to do the hard, tedious work to solve this problem? Do you believe in solving the problem enough to see it through all the eventual roadblocks? Because you will have to convince people across organization boundaries to make this happen. Are you willing to learn the technical and non-technical skills required to solve the problem? In most real-world scenarios, you will only possess maybe one or two of the skills needed to solve the problem. Maybe you have no prior experience in the other skills needed. You may need to go outside your comfort zone and embrace these skills to succeed.
What should you keep in mind while developing solutions to this problem? If you’re refactoring, are you building tools that can help make future refactoring tasks easier? If you’re having a hard time recognizing clients on the backend, are you building reusable tools to make it easier to do so and find these clients the next time? If data migration is turning out to be hard, are you building a generic data migration tool for your storage solutions? What happens when you do this? Your work starts to have an impact way beyond your organization, because there are other teams struggling with the same problems. Always ask yourself, am I building reusable tools and libraries that others can use in similar work? We now have a good framework for this. You seek and recognize impactful problems. You evaluate whether a given problem is worth solving, and build a business case for it. Then you determine the technical and non-technical skills needed to solve that problem. Of course, you ask yourself the right questions to determine whether you would be interested in solving the problem. That’s paramount. If you decide to do it, you practice the skills that are outside your comfort zone. While working on the solution, you develop generic tools that others can use when they are solving similar problems. That helps you multiply your scope of impact beyond just this immediate problem.
How Learnings Are Applied
Let’s go through a few more scenarios to see how we can apply these learnings. Let’s say you write a plan for refactoring the backend, and you want to get some feedback on your proposal. You ask the engineer John, who is sitting next to you, and they tell you that they have a weekly design review meeting. He gives you a link to sign up for it. You go up and open up the signup sheet, and you find that the next open slot is months away. You demand an explanation. John tells you that the design review is headed by His Excellency, the Distinguished Engineer, Mr. C# himself, and everybody wants in on it, so it’s not easy to find a slot. You know who I’m talking about, the uber-tech lead that everybody is afraid of. You’re obviously quite curious to know what goes on in these design review meetings, and so you decide to attend the next one, just to see Mr. C# in action. The meeting starts with a super complex 50-minute presentation. The presentation is only about the solution without any mention of the problem. Everyone pretends that they understand everything and no one except Mr. C# says anything at the meeting. The last 10 minutes of the meeting, he asks a completely unrelated question about the possible use of neural nets in the solution, and the meeting ends.
You come out of the meeting, and John complains to you how he didn’t understand anything in the design review, and hates going to these meetings. The presenters complain that they didn’t receive any useful feedback. How many of you have been in at least one design review meeting like this one? Once again, you see a significant problem. You can think of this as a huge opportunity to do something about it. Let’s apply the framework we developed before, and start with understanding the scope of this problem. This process has been used in the team forever, and it’s hard to change it. Most engineers are not happy with it, but no one is really doing something about it. It’s definitely impacting more than just your team. You find out that design reviews are generally run like this in the entire organization. Since engineers wait a long time for a slot for these design reviews, and don’t really get any helpful feedback, they end up delaying their projects, which slows down the team and of course slows down the business.
Skills Needed to Address the Problem
Let’s see what skills you need here to address this problem. The first thing you probably need is to become vulnerable and authentic, and inspire others to be the same. You may do that in your next design review meeting by asking for a clear definition of the problem being solved. The funny thing is that when you ask these questions, everyone in the room, including Mr. C# is probably thanking you for it. They’re like, finally, I understand what we’re talking about. Or you suggest that people be allowed to raise hands and ask for clarifications any time during the review. You exercise that ability to influence and inspire your peers to make better use of their time. You help engineers realize that problems may be complex, but the solutions must be simple and easy to understand. You may also take a totally new approach and propose that instead of one-way presentations, the team should pre-read a two-to-three-page design document and use the meeting time to actually discuss some of the most important areas of the design, so that engineers who are working on that project can get feedback on specific areas.
You may need the skill to convince everyone to try out your new model. Once again, you need to write a proposal, get it reviewed by maybe your peers, maybe by management, and gain more consensus to update how you do design reviews in your organization. Finally, if your revamped design review process becomes successful in your team, again, you may want to share your proposal for running efficient design reviews throughout your organization, and have a much broader impact on the entire engineering organization. At some point, you all have probably thought to yourself, I’m an engineer, do I really need to practice all these non-technical skills? Ultimately, you’re solving a real problem for yourself and your peer engineers. These skills are helping you make that happen. Each of these skills is a very valuable skill to develop and grow as a senior engineer. Some of these skills will definitely be uncomfortable, and that’s ok. This is exactly where growth occurs towards a more senior role.
Technical Example 1 (LinkedIn)
I now want to share two recent technical examples where I applied this framework that we just discussed. I hope this serves as an inspiration for you to find challenging technical problems in your own domains. At LinkedIn, I’ve been working on messaging for some time now. One of the aspects of instant messaging that makes it challenging is that users interact with each other in real time. This is not too big of an issue when users are being served by the same data center. This becomes a significant challenge when users are interacting with each other, and are routed to completely different data centers because of their geographic locations. Imagine, Alice from the U.S. sends a message to Jane in Australia, and they’re pinged to different data centers. In a naive implementation, Alice would write the message to Jane’s mailbox in our own data center in the U.S. This message would then eventually get replicated to Jane’s data center in Australia. Jane would see the message only when the replication finishes. This replication can take multiple seconds. As you can see, this naive cross-data center replication strategy doesn’t work too well for instant messaging.
Apart from LinkedIn messaging, I started noticing that other products and services across LinkedIn were running into a very similar problem when they were trying to build a live interaction with each other across multiple data centers. At this time, we were also building products like live video. We were doing events, live audio rooms. It seemed like a pretty universal problem for such experiences. This is obviously a very challenging technical problem that we have to solve. I started applying the framework that I shared with you. Many teams were complaining about a lack of a strategy to address this issue. People were resorting to brute force solutions instead of a common solution in our infra layer. The scope of the problem was clearly beyond messaging. Sure, we could have solved it only for messaging, but there was clear scope for this problem to be solved more generically. It clearly mattered to the business as we would not really have been able to ship all these important product experiences without a solution to this problem. Or maybe we would do so with expensive individual solutions at the application layer. It had all the right ingredients for a problem that needed to be addressed with a common solution for the large engineering organization.
Next, I evaluated the skills I needed to develop to solve this problem at the right level. I obviously needed many technical skills, like understanding cross-data center routing at LinkedIn, understanding cross-data center replication in our data layer, understanding atomic commit protocols on databases, and doing tradeoffs between latency and cost to serve. Apart from that, I also needed to evaluate whether we should leverage our open source solutions or build something in-house. These are all great skills to pick up for a systems engineer to grow to a staff-plus role. Even more than that, I needed many of the same soft skills that I mentioned earlier. Gathering requirements from other teams with the same problem. Building a business case for solving this problem at the right infra layer, so that all applications could leverage a single solution built within the infrastructure, connecting the work to business impact across application teams, and gaining alignment with storage infrastructure leads and executives. Of course, to do all of this, I needed to describe the problem and propose a solution with clear written technical communication.
You may wonder whether all this effort is worth it, to build a common solution instead of just solving the problem at the application layer for messaging. Such problems give you that opportunity to broaden the scope of your impact, and solve this problem not just for your team, but for similar use cases beyond your immediate team. In this case, we ended up building common remote data center write APIs, and common libraries to route traffic to objects and entities ping to a certain data center. Working with my peer engineering leaders across the company to solve this common problem, was a very important skill that I developed in my path to a staff-plus engineer.
Technical Example 2 (LinkedIn)
Let’s go through one more technical example where I encountered a problem, I recognized a pattern, and built a generic solution, which is now widely used at LinkedIn. Going back to my work on LinkedIn messaging, this diagram represents a very simple view of the messaging delivery flow. A sender sends a message. The messaging server does some preprocessing to authorize the send. Then the message is persisted in the backend. Finally, after persistence, the message is delivered to the recipient device. If the preprocessing fails, we simply return a 4xx response to the client. If the message passes that step, a payload is passed to the persist message operation, and a 202 is returned to the client. The reason for that is that the persist message operation can possibly take longer, and we don’t want the client to wait for that to complete. The challenge with this flow is that the persist operation can fail, and we can’t really expect the client to retry for these server failures. We need to make sure that the persist message operation completes reliably, once we send back the 202 Accepted to the client. It’s now the server’s responsibility to finish persisting the message that the sender sent. This is where we realized that we need a durable queue, which can queue up these persist operations, so that when we process these operations, and do it asynchronously, we reliably complete them. We also realized that this circle part of the flow is actually pretty generic. We built this generic solution for reliable processing of queued operations, where a job processor is responsible for completing these operations, and retrying any operations that fail so that we never lose any individual operation.
Going back to our team here, this needed me to learn many new technical skills. I need to build a solution with strict requirements. I needed exponential backoff with retries. I needed durability of the operations across deployments and failures. I need to evaluate various open source and in-house solutions for an asynchronous operation queue, and job processor. These were all invaluable technical skills to pick up. Even more importantly, this pattern of reliable async processing needed a generic solution for many of the problems elsewhere in the company. We needed it for async completion of large, bulk operations from end users like GDPR data export, and for operations that needed 100% reliability, like payment processing. Building this solution generically gave me an opportunity to have an impact on teams outside my organization that I would have almost never interacted with. Remember that evangelizing your solution is as important as building it. Other teams need to know that you built a generic solution that addresses their needs for them to be able to leverage it. Use the forums in your engineering organization to evangelize what you’ve built so that others can find value out of it.
What Can I Do as a Leader?
Let’s take a second to see what you can do as a leader in your company, to support your engineers looking to take this path to organically grow into a staff-plus role. First, when you hear engineers complaining about their tech stack, and their engineering processes, don’t shoot them down. Help them channel that energy towards understanding the root of their complaints, and solving the tough problems behind them. At LinkedIn, we actually encourage constructive criticism that actually leads to action, and that motivates engineers to become part of the solution and grow themselves. Second, we are living in a world of truly async communication. I want to encourage leaders to create regular forums in which engineers get to take a step back and talk about things that are going well, and things that need improvement. This will help plant those seeds in the minds of these individual engineers to start dedicating themselves to solving some of their own challenges.
Coach your engineers to sell their ideas and proposals. I’m sure an engineer at some point has come to you and said something like, I think we should use GraphQL. Ideally, the first question you would ask them is why. Why should we do this? What is your motivation behind this? This immediately helps them start reasoning about their proposal in a way that is critical to be able to convince others. They might say it’s the next best thing. It’s so much better than REST APIs. Then you ask, why is it better than REST APIs for us? This is when they pause, because you specifically asked them why it’s better for us. This forces them to think about a lot of things that they may not have considered. What is it about our company and our systems where GraphQL would have an advantage over existing REST APIs? What would the migration look like for us? What would be the level of investment needed to make that move? What do we specifically gain from this migration? Hopefully, they say, let me think about this and get back to you. At which point, you should encourage them to write down their motivation in a document, get feedback from the team, and iterate until they reach a conclusion for themselves for whether the team should be moving to GraphQL or not.
Finally, don’t hesitate to create training programs to help your engineers develop the soft skills that are needed to grow into senior roles. At LinkedIn, every few months, we dedicate an entire week to these classes that are actually run by staff-plus engineers, targeted at engineers early in their careers. The classes cover a broad range of topics, like workshops on technical communication, documentation, public speaking, understanding the business, and even presenting to executives. There is something extremely powerful about your staff-plus engineers sharing their own experiences, in how they develop these skills with junior engineers directly. We actually call it the IC Career Development Week. It is one of the most successful programs at LinkedIn. Almost all engineers at LinkedIn go and attend these workshops based on their interests and hear what their senior engineers have to say to them.
Big Takeaways
I think we covered a lot of ground. Let’s summarize the two takeaways from this presentation. First, you do not need to wait for someone to assign you a big project to grow your career. Meaningful, impactful problems are waiting to be solved all around you, as long as you’re willing to keep a keen eye for them. Engineers complain about the systems and processes all the time. These tedious, unattractive problems could be your biggest opportunities to solve hard technical issues with massive impact on your organization. Solve the problems that no one explicitly asked you to solve. Second, lose your fear. Beyond your technical skills, you must embrace the soft skills needed to solve these problems. You have to do that if you want to solve the problems at scale, even if they make you uncomfortable. Understanding the business, aligning with non-engineering leaders, presenting to executives, written communication, and even public speaking, are all skills that all engineers must constantly practice.
When you get back to work, go find your most vocal peers, the ones who never stop complaining, sit down and listen to them. Apply this framework for recognizing and solving impactful problems. There are like big technical challenges hidden behind each of these problems, except maybe some of them. If you do this, I promise you that you will discover impactful projects to organically grow into the staff-plus role at your organization.
Questions and Answers
Nardon: How many years did it take to land staff and principal position from the senior role?
Gupta: I think the place that engineers are coming from is like, is there a set timeline for when I can grow to the next level? Or, is there a specific amount of time that leaders expect somebody to spend in a particular role before they consider them for promotion to the next level? I think more engineering organizations today are not really worried about the time that you’ve spent in a particular role. They’re much more worried about how much impact you’re having on the organization. This is clear from the fact that so many of my peers at LinkedIn, and even at Uber, when I was working there, have a very broad set of timelines that they have followed in different roles in their organizations. It’s not that everybody spends the same amount of time being a senior engineer before being promoted to a staff engineer, or that they spend the same amount of time being in a staff engineering role before being promoted to a senior staff. The reason for that is that everybody has impact in a very different way. Impact itself can be achieved in a very different way. The way I would think about it is, are you having fun? Are you doing projects that get you excited? Are you having meaningful impact on your organization? When I say meaningful impact, it goes back to the same stuff that I spoke about in the presentation: it must have clear business impact. Again, everything is a business. You must make sure that the projects that you’re working on, the problems that you’re solving, have clear, meaningful business impact. As long as you’re doing that, and you’re increasing the scope in which you’re having that business impact, you will ultimately grow to the next level.
For my personal situation, I actually switched from LinkedIn to Uber when I was a staff engineer, and I spent about one-and-a-half years there as a manager, not even in an IC role. The reason I did that was because I just really wanted to get that management experience. Fabiane is a pro here, but she will tell you how it’s so important to understand how management works, apart from how ICs play a role in an organization. That experience really helped me because now I could understand how the business works, how everything needs to connect to business impact. That made me a much better IC. That helped me when I came back to an IC role and helped me grow into a senior staff role and then a principal role at LinkedIn. I have been in this for about 12-and-a-half years.
Nardon: How many such impactful projects did you need to contribute on, to get promoted?
Gupta: Lots of them, at every stage of my career. There have also been projects on which I’ve worked on, which did not result in the impact that I was hoping for. This is also very important to understand. Sometimes we only talk about the positives, only about the fact that like, this is having amazing impact, or like, this moved sessions by 3%, revenue by 5%. There are also cases where you end up putting in all that effort, and the project doesn’t succeed. One of the things that I’ve learned is like, even in those projects, you end up taking a lot of learning away. You end up recognizing, what are the things that you could have done better? What are the things that would help you not make those same mistakes in the next project. Even in projects where you realize that you haven’t achieved the impact that you were hoping for, make sure that you work with your peers, to break it apart and understand where you could have done better so that the next time you’re working on a similar project, you’re learning from it, and doing better again. Almost in each part of my career, I’ve contributed to tens or even twenties of such projects. At the same time, I’ve also failed at maybe five or six of them in each part of my career, and that has helped me a lot in learning through my mistakes.
Nardon: How did you ensure that work was noted by the upper management to get you that role? How did your leadership help in uplifting you?
Gupta: This is very important, because it’s really important to communicate what you’re doing. As an engineer, your role is not only to execute, your role is to also clearly communicate what you’re doing. Why you’re doing it. What is the impact that it is having. What were the final results? What leadership is looking for, is for you to take on the responsibility for creating that impact to the business. They want you to clearly understand what the goals of your project are, describe them, and then evaluate yourself when you’re done. When you finish doing that project, don’t just be like, I’m shipped and I’m done, and move to the next project. Get to a point where you clearly evaluate what your results were against the goals that you had set for yourself. That is what leadership is looking for. They are trying to understand whether you can really, truly, frankly, evaluate yourself against the goals that you’ve set, and against the business impact that you promised that you would have, and what you actually had.
There’s a theme in these questions, and I want to address that, which is, you’re not only growing in your organization, you actually want to grow in the industry. It’s not enough to be a senior staff engineer at LinkedIn. It’s actually more important for you to be a senior staff engineer in the software engineering industry. What I mean by that is, don’t worry too much about whether you are a certain title in your particular company. What is more important is, are you sharing your learnings broadly in the industry? That’s where conferences like these come in. Talk about your work. Write about your work. Blog about your work. The more you do that, the more you’ll be recognized as a software engineering leader, not just in your organization, but in the broader industry. That is way more important than a particular title in your company.
Nardon: What happens if what the company expects from you is not aligned with what you want for your career? Should you change jobs, change companies, or maybe try to change your expectation inside the company? Is it easier to be promoted to staff if you change companies, instead of being promoted inside your own organization. Should you change companies to be promoted, or should you try to be promoted inside your own organization? What’s your experience on that?
Gupta: I’ll first repeat the original answer that I gave you about what to do in a situation where what your skill sets are, or what your aspirations are don’t align with the current organization that you’re working on, or even the current company that you’re working for. I think you took the specific example about being a frontend engineer, and your company not creating that environment for you to grow in that role, or having a broader impact in that role. I think one important thing to realize is, again, your organization and your company is a business. The way you’re thinking about it is, am I having the business impact that is required for me to be growing in my career in that organization? If your aspirations are being technically deep in the frontend stack that you’re currently working on, make sure that the project and the work that you’re picking up is something that also connects to business impact for that organization. It is entirely possible that that isn’t the case. Maybe the organization that you’re working for, or the company that you’re working for, is simply not spending as many cycles or as many projects diving deep into the frontend stack. In that case, it is actually the right thing to do, to either broaden your scope and say that, I’m also interested in frontend iOS technologies, or Android technologies, or frontend API technologies, or even backend or near-line technologies. That’s one approach of going about it. The other is to find an organization within your company that actually values the work that excites you, and where your career aspirations lie. If not, find another company, find another organization that aligns with what your aspirations are. Because ultimately, you own your career, you own your growth. It’s your responsibility to find the right team, to find the right organization that not only aligns with the mission and vision that you have in your mind for you, but also aligns with the work that you want to do. It’s definitely something that you need to take control of.
Changing companies to grow into a new role? I wouldn’t say that that is true, de facto. As an example, I switched from LinkedIn to Uber. I did management there for about two years, but I didn’t actually grow in my role, the leveling was the same. I gained a lot of valuable experience doing that. The way to think about changing companies is, again, what I said in my previous response, which is, you would do that when it aligns with your own goals, when it aligns with your own aspirations. When you’re going and doing something and changing your role or changing your company, do it with the explicit intent of growing yourself and finding the right problems to work on, which align with the business that that particular organization is aiming for. It’s absolutely not true that you would just switch companies to grow to a staff role or a senior staff role. Because, ultimately, you would grow to that role only if you have that impact, which aligns with that business. The first order of business is to find the place where you can work on projects that align with the business goals of that organization or of that company.
Nardon: How do you find good mentors? In these roles, you have to do mentorship and coding, how do you manage time for everything? How much more time out of office hours do you have to do to keep up with everything? It’s probably one of the biggest problems in the staff-plus engineer role.
Gupta: Good mentors. I think finding a mentor is definitely an experiment. You need to go out and talk to people that you look up to. I’m sure that in everyday work in your career, you run into people where you’re like, I really like how they approach their work, or I really like how they think about their role in the organization and the contributions that they’re having to the organization. Find such people, talk to them. It’s all about this experimental phase where you understand where they’re coming from, what their goals are, do they align with your goals, and try it out. Hang out with them over coffee, or invite them to a one-on-one. See if you’re able to connect with them. See if you’re able to ask them about the problems that you are running into. That is the right way to be connected with people that you look up to, and then find that one person who you really bond with and make them your mentor. That’s probably the approach that I’ve been using.
Managing time is absolutely one of those things which is extremely hard as you grow into more senior roles. You must have heard this term over again, delegation is your friend here. The more you’re spending time mentoring and helping other engineers succeed in the project, the more you’re able to delegate work that is actually much better suited for somebody else’s growth. Think about it this way. You are working on the things that help you help other engineers. You’re taking nebulous business problems, converting them into concrete projects, and then having engineers work on them. If you do that, then you are spending your time on the most critical pieces for the business and not the stuff that other engineers could do.
See more presentations with transcripts
MMS • RSS

To ensure this doesn’t happen in the future, please enable Javascript and cookies in your browser.
Is this happening to you frequently? Please report it on our feedback forum.
If you have an ad-blocker enabled you may be blocked from proceeding. Please disable your ad-blocker and refresh.
MMS • Steef-Jan Wiggers
Google recently introduced a new future reservation feature in public preview for its Compute Engine, allowing users to request compute capacity for a future date.
Google Compute Engine is an Infrastructure as a Service Solution in the Google Cloud. It allows users to create and run virtual machines in various configurations ranging from pre-built to custom types for workloads like compute-intensive, scale-out, and ultra-high memory. Resources can be reserved on-demand and through future reservations.
With future reservations feature in place, users can request capacity via either the Google Cloud console, API, or CLI for Compute Engine and secure the capacity required for a planned and expected scale-up event.
Future reservations are basically a capacity request for the future reviewed and approved by the company. Once approved, future reservations deliver capacity by auto-creating reservations in the requester’s project, and the billing cycle starts at that reservation time.
The authors of a Google blog post on the feature explain:
You create a future reservation request by specifying the total number of VMs you expect to use for a machine type in a zone at the future start time, also indicating the end time. The chances of approval may be higher for future reservation requests that are for longer duration.
And:
After you submit your future reservation request, your request is sent to Google Cloud for review and approval. The request is reviewed to ensure the request can be fulfilled with high confidence in light of other commitments. Once approved and during the “lock period” — a period in which you can’t update or delete the request — Google Cloud will start the necessary steps required to reserve the capacity to fulfill your need.
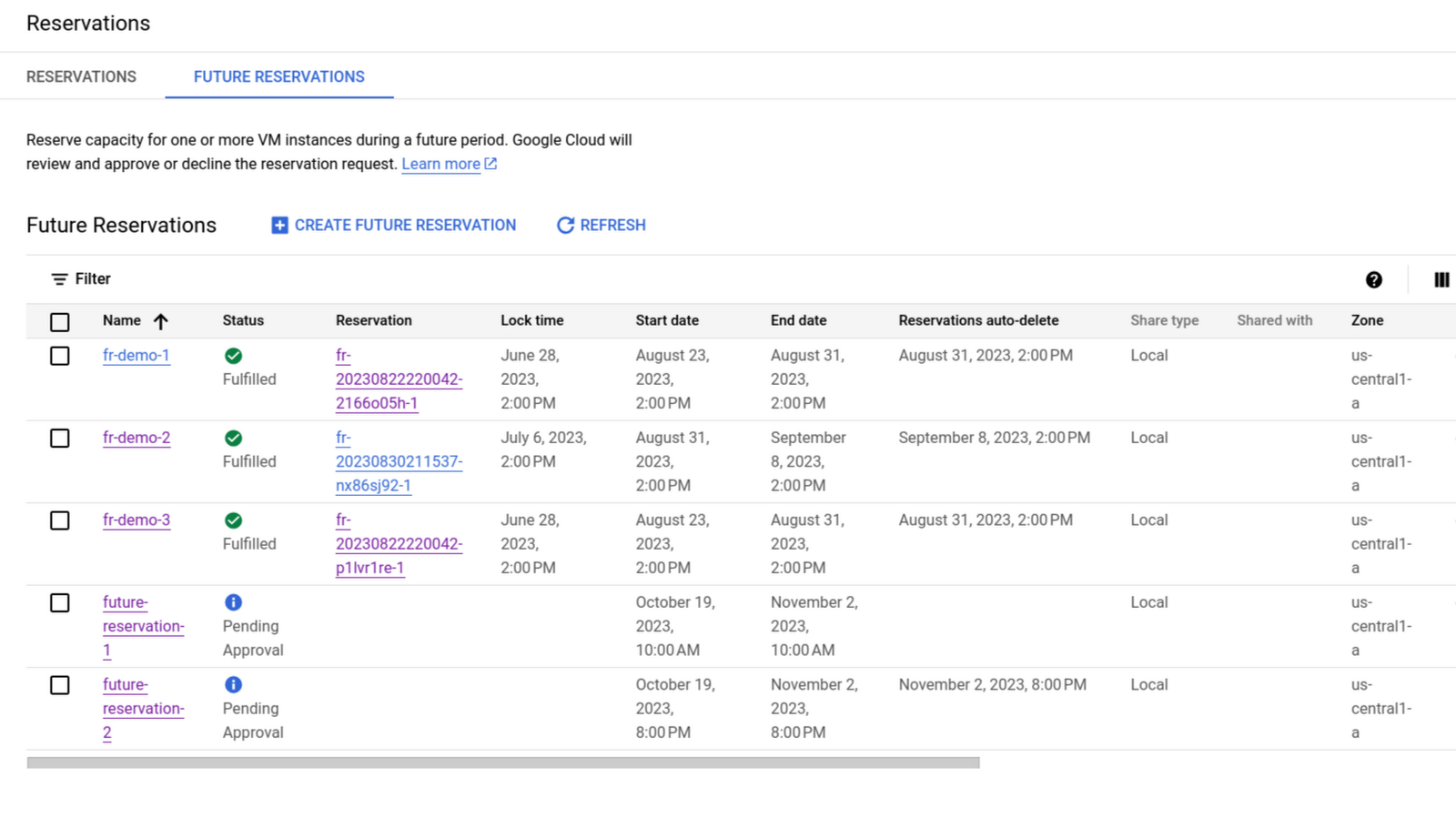
Future Reservations Screenshot (Source: Google blog post)
When Google Cloud approves a future reservation request, then on the date the user requested to have the reserved capacity available, Compute Engine subtracts any matching, existing reservations and automatically creates reservations to reach the requested capacity specified in the future reservation.
Furthermore, according to the same blog post, the feature provides users with the following benefits:
- Assurance that through a request in advance, they will have the necessary capacity available when needed. In the background, Google will prioritize resource reservations over on-demand requests.
- A self-service capability to specify what, where, and by when they need the capacity and receive a request approval from Google Cloud. The request date is maximized to one year from the date of the request.
- The ability for users to apply it on existing Google Compute Engine VMs, once approved by Google.
Google’s main competitors in the Cloud, Microsoft Azure, and AWS, offer similar features to Google Compute Engine’s Future Reservations. For instance, Microsoft Azure offers a feature called Reservations, while AWS provides its customers with On-Demand Capacity Reservations.
Lastly, reservations are billed at the same rate as their reserved resources, including the same on-demand prices and 1-minute minimum charges as unreserved, running VMs. More details on pricing are available on the pricing page.
Visual Studio 2022 17.8 Preview 2: Productivity, C++ Enhancements, and Debugging Improvements
MMS • Almir Vuk

Microsoft has released the second preview of Visual Studio 2022 version 17.8. Preview 2 brings a range of improvements and features aimed at enhancing developer productivity and code debugging as well as some additional C++ and Game Dev enhancements. The latest version is available for download, and developers have the opportunity to explore and utilise its advancements in the preview version.
Several productivity features have been introduced, aiming to enhance developer experience and simplify workflow. These additions include the ability to edit Pull Request Descriptions using Markdown, and improvements to the Summary Diff feature which was announced earlier. Also, there is an incorporation of GitHub avatars within the multi-branch graph found in the Git Repository Window. Furthermore, a notable feature, the Multi-Repo Activation Setting has been introduced, allowing users to concentrate their attention on an individual repository by concealing the multi-repository user interface.
Within the domain of C++ game development, several notable updates have been introduced. These updates include the addition of C11 Threading Support, simplifying access to the CMake Targets View within the Solution Explorer, and improvements in the Remote File Explorer, allowing users to view and edit remote files by double-clicking on them.
Additionally, developers now have the added way of converting global functions to static functions. As mentioned in the original announcement post, developers can adjust the settings for this feature by navigating to Tools > Options > Text Editor > C/C++ > IntelliSense > Make global functions static tags.
Regarding the .NET/C# development, Visual Studio now offers improved support for securely handling secrets in HTTP requests. This includes the ability to store secrets in three different secret providers, enhancing data security during development. The detailed blog post about this is also available for checking out. For JavaScript and TypeScript development, Visual Studio has added launch.json support for open folders, as reported:
When you choose to open folder on your workspace with launch.json in the .vscode directory to store your launch and debug settings, it will be recognized by Visual Studio and included in the dropdown menu for the Debug targets right next to the green button.
Additions for F# programming are new code fixes to address a common mistake made by newcomers. It automatically replaces equals (=) with a colon (:) in record field definitions, aligning with F#’s syntax conventions. Additionally, F# developers can now enjoy better autocompletion for various code elements, such as Anonymous record fields, Union case fields, Discriminated union case fields, and Enum case value expressions.
Other notable changes related to debugging and diagnostics encompass cross-platform debugging support for Enc/Hot Reload, extending to Docker and WSL environments, as well as the ability to debug Linux App Services via the Attach to Process feature, the detailed steps on how to attach are available on the announcement post.
Moreover, the improvements include the incorporation of BenchmarkDotNet IDiagnosers and .Net Counter Support for New Instruments via the Meters API. Test profiling with the VS Profiler has also been introduced to enhance the debugging and diagnostic capabilities for developers.
The comment section revealed interesting info regarding the new UI, the user asked if there is a way to use the new UI. The comment got a valuable reply from Dante Gagne, Senior Product Manager, answering the following:
At this time, the refreshed UI is only available internally. We’re working toward making it available more broadly as a preview feature, but we wanted to make sure we addressed the feedback we’ve already gotten before we start a broader roll out. We will be announcing when the new UI is available in the blog post where it goes live, so stay tuned here for more information.
Microsoft and the development team encourage users to provide feedback and share their suggestions for new features and improvements, emphasizing their commitment to constantly enhancing the Visual Studio experience.
Lastly, developers interested in learning more about this and other releases of Visual Studio can visit very detailed release notes about other updates, changes, and new features around the Visual Studio 2022 IDE.
MMS • RSS

A whale with a lot of money to spend has taken a noticeably bearish stance on MongoDB.
Looking at options history for MongoDB MDB we detected 13 strange trades.
If we consider the specifics of each trade, it is accurate to state that 23% of the investors opened trades with bullish expectations and 76% with bearish.
From the overall spotted trades, 7 are puts, for a total amount of $624,908 and 6, calls, for a total amount of $230,706.
What’s The Price Target?
Taking into account the Volume and Open Interest on these contracts, it appears that whales have been targeting a price range from $270.0 to $620.0 for MongoDB over the last 3 months.
Volume & Open Interest Development
Looking at the volume and open interest is an insightful way to conduct due diligence on a stock.
This data can help you track the liquidity and interest for MongoDB’s options for a given strike price.
Below, we can observe the evolution of the volume and open interest of calls and puts, respectively, for all of MongoDB’s whale activity within a strike price range from $270.0 to $620.0 in the last 30 days.
MongoDB Option Volume And Open Interest Over Last 30 Days
Biggest Options Spotted:
| Symbol | PUT/CALL | Trade Type | Sentiment | Exp. Date | Strike Price | Total Trade Price | Open Interest | Volume |
|---|---|---|---|---|---|---|---|---|
| MDB | PUT | TRADE | NEUTRAL | 06/21/24 | $620.00 | $314.4K | 0 | 12 |
| MDB | PUT | TRADE | NEUTRAL | 11/17/23 | $400.00 | $156.0K | 132 | 32 |
| MDB | CALL | SWEEP | BEARISH | 10/27/23 | $375.00 | $48.9K | 8 | 48 |
| MDB | CALL | SWEEP | NEUTRAL | 04/19/24 | $350.00 | $45.0K | 0 | 7 |
| MDB | CALL | SWEEP | BULLISH | 10/20/23 | $362.50 | $42.1K | 19 | 27 |
Where Is MongoDB Standing Right Now?
- With a volume of 271,537, the price of MDB is up 0.73% at $358.21.
- RSI indicators hint that the underlying stock is currently neutral between overbought and oversold.
- Next earnings are expected to be released in 76 days.
What The Experts Say On MongoDB:
- RBC Capital downgraded its action to Outperform with a price target of $445
- Morgan Stanley has decided to maintain their Overweight rating on MongoDB, which currently sits at a price target of $480.
- Argus Research has decided to maintain their Buy rating on MongoDB, which currently sits at a price target of $484.
- Piper Sandler has decided to maintain their Overweight rating on MongoDB, which currently sits at a price target of $425.
- Guggenheim has decided to maintain their Sell rating on MongoDB, which currently sits at a price target of $250.
Options are a riskier asset compared to just trading the stock, but they have higher profit potential. Serious options traders manage this risk by educating themselves daily, scaling in and out of trades, following more than one indicator, and following the markets closely.
If you want to stay updated on the latest options trades for MongoDB, Benzinga Pro gives you real-time options trades alerts.
MMS • Rebecca Parsons

Transcript
Parsons: My name is Rebecca Parsons. I’m here to talk to you about, effectively, the evolution of evolutionary architecture. This track is about architecture in 2025. I’d like to talk about how evolutionary architecture might change over the next few years. First, I want to point out a couple of things. I remember several years ago, a journalist told me that they wanted me to make a 10-year prediction for what technology would be like. This was in the year 2017, which is right around the 10-year anniversary of when the iPhone was created. If you think about all of the change that has occurred in those 10 years, the fact that this journalist wanted to question me about technology in a decade’s time, I thought it was preposterous. At least this is only two years away, but I will admit, my crystal ball is still broken. What I want to try to do during this talk is, first, I’ll give you a brief introduction to the underlying principles and definitions of evolutionary architecture to provide a little context for when I start to talk about how things might actually be different.
Key Ideas and Questions
First, the definition, what is an evolutionary architecture? Evolutionary architecture supports guided, incremental change across multiple dimensions. There are lots of important words in that definition. We’ll talk about those. The first is, why is it called evolutionary? When Neal Ford, my colleague, and I first started talking about this, I sat in on one of his early talks. He was calling it emergent architecture. Neal and I had a very robust discussion about why that was a really bad name. Because when you hear the word emergent, it just seems like, ok, I’m just doing what I can to survive, and some things are happening. I am perfectly confident, and capable, and happy with the definition of emergent design. Because regardless of the system, you and I are probably going to agree on what constitutes good code and bad code. That’s not the same thing for an architecture. That first part of the definition, guided, is what we’re trying to look at in terms of being able to say, what constitutes good for this architecture. That’s where we introduce this notion of a fitness function. A fitness function is an objective characterization on how well a particular system reflects a desired behavioral characteristic. The single most important thing about a fitness function is you and I will never disagree on what that computation results in. Something like maintainable can’t be a fitness function. Something like respects the particular naming standard, and coding standard, and has a cyclomatic complexity less than x, those we would all agree on. Those I think, arguably, do apply in the case of thinking about maintainability. It’s this fitness function mechanism that is a key part of how we specify what we want this architecture to achieve. What are the important characteristics? What are those levels that we need to support?
The second is, how do we actually operationalize this? How do we make this an incremental improvement? There are two aspects of this, how do we get the new functionality in place? Then, how do we provide the mechanism on this path to production? It’s the second one that I want to focus on here. Many times, when I’ve been on stage talking about evolutionary architecture, people will come up afterwards and whisper, don’t you think you’re being professionally irresponsible to talk about evolutionary architecture? Because, architecture, it’s the rock, it’s the foundation. How in the world can you evolve something that is so fundamental? What people are actually starting to recognize though is that they don’t really have a choice. The technology ecosystem is changing so rapidly that they have to do something about it. One of the important practices and enablers for evolutionary architecture is the level of rigor and automation that comes along with continuous delivery, and ultimately, continuous deployment. If you don’t have those kinds of mechanisms, you don’t have enough derisking in your deployment pipeline to take on some of these tasks. We need to really be conscious of what we’re actually taking on when we say, we’re going to allow you to evolve your architecture. Because although I do firmly believe we have to be able to evolve that architecture, the people weren’t wrong, you can disrupt a lot by making some of these fundamental architectural changes. There’s a reason some people say, for example, how you define architecture is the things that are hard to change. Much like the motivation behind XP, and agile more broadly, the idea behind evolutionary architecture is, let’s go ahead and try to get good at changing those things that are hard to change. Just because they’re hard to change, doesn’t mean you won’t have to change them.
Multiple Dimension Things (-ilities)
Finally, let’s think about this multiple dimension things. Here is a list from several years ago from Wikipedia of a whole bunch of -ilities. One of the things that we have to grapple with as architects is the fact that you cannot be ideal on all of those -ilities, because many of them are actually mutually exclusive. You cannot maximize something without negatively impacting something else. You can’t maximize both of them, you have to decide, what is the right balance I want between these things. Each system is different. Each organization is different. Each application and domain, they have different architectural requirements, and we should not be using the same architectural standards across every single application. That holds for evolvability as well. There may be systems because it’s a one-off, as an example, that you don’t care about evolvability. You probably don’t care about maintainability, or many of the other -ilities. It may be that you’ve got a dataset to process that is only ever going to be used once, but it’s massive. Maybe you’re going to take a lot of time to optimize the runtime performance of that thing, even though you’re going to throw it away. Not all systems need to be evolvable. If they are, and I would assert that many of the enterprise applications that exist out there need to have a certain degree of evolvability, then this is what we want to be looking at.
Principles of Evolutionary Architecture
Evolutionary architecture has some underlying principles. I’m going to first review the principles. Then for each one of these principles, I’m going to speculate, what might things look like in a few years. For these principles, the first is the last responsible moment. We want to delay decisions as long as possible, so that we have as much information as possible. You will need to trade that off between what are the decisions that you’re making, the architectural decisions, the development decisions that you’re making before you’ve made this other architectural decision? What might the consequence be for that? You determine this last responsible moment by looking at, how does this particular decision track to your fitness functions, those -ilities and those values that you’ve decided are critical for the success of your system? Because fundamentally, if a particular architectural characteristic is not terribly important, then you shouldn’t worry too much about decisions in that realm. One of my favorite examples of this is I worked early in my Thoughtworks career on a trading system. When you hear trading, everybody thinks, low latency, high throughput performance is king. This particular one they’ve never in their wildest dreams assumed they would ever have more than 100 or so transactions a day, maybe 200 a day: not an hour, not a minute, a day. What they really cared about was never losing a message. We focused our efforts on ensuring that we understood the communication hierarchy and then the synchronization points between the various systems that were actually scattered across the globe. Those were the -ilities that mattered to us, and so that’s where we focused our attention.
The second principle, architect and develop for evolvability. If you’ve decided that evolvability is a first-class citizen for you, it’s going to impact not only the way you write the code, but how you structure the code. I’ll start with develop for evolvability first. The single most important thing here is, how easy is it for you to understand the code that’s there? Readability is key. That’s where software quality metrics come in. We want to look at this and say, how easy is it for me to pick up a new piece of code and understand what it does? Because if I don’t understand what it does, then I’m not going to be able to evolve it. When we think about architecting for evolvability, this has taken into account different aspects. How do we divide up our system? Where do we draw our boundaries? This is where we think about coupling and cohesion, and all of those architectural terms. Fundamentally, the place to start is to think about dividing up your systems around the concepts that are relevant in the business. Personally, I believe one of the reasons our first attempt at service-oriented architectures failed is that we were drawing the boundaries around systems, more so than we were drawing the boundaries around concepts. Study up on your domain driven design and apply it to your architecture.
The third principle is Postel’s Law. Simply put, be generous in what you receive and be cautious in what you send. Ask the account to receive, make sure you don’t open yourself up for a security hole. The more you can adhere to that principle, the more you can make yourself impervious to all but essentially breaking changes. If all you need is a postcode, don’t validate the address. That way, if I decide I want to split the address into two lines, you don’t have to change because you’re not paying attention to any part of that message that you don’t need. Architect for testability. One of the things that we have found is that the ability to test something and how testable something is, is a pretty good indication on how well you’ve drawn your boundaries, and how well you understand where those boundaries are. If you focus on testability at all levels of the test pyramid, you’ll end up with a better design and a better architecture.
Finally, the dreaded people issue, Conway’s Law. So many people try to get around Conway’s Law, but it’s always going to win. Conway’s law effectively says that any system an organization builds is going to reflect the communication structures, I normally say communication dysfunctions of the organization that builds it. If you want a three-stage pipeline, have three groups. If you have four groups, you’re never going to get a three-stage pipeline. Those are the principles as of today. These have stayed relatively constant over the period of time. The actual principles haven’t changed much.
What Will Be Different in a Couple Years’ Time?
What do we think will be different in a couple of years’ time? My first wild speculation here is that I don’t think there’s any indication yet that there’s a principle out there that we’re missing. I’d be happy to debate it with people. I actually think the principles themselves are pretty solid. I also really don’t think there’s going to be much change from the perspective of how the principles influence our way of doing architecture. Postel’s Law, and the last responsible moment, I don’t think either one of those are going to be radically different in 2025. They’re still going to have the same impact. We’re still going to be asking the same questions. We might be dealing with different issues relative to these principles, but I don’t think the principles and our approaches are going to change fundamentally in the next couple of years.
Architect for Evolvability
For the purposes of this presentation, I want to separate out thinking about architecting and thinking about developing. First off, architecting for evolvability. I think we’re going to continue to see innovations in architecture. If you think about all of the innovations that occurred, and the adoption of innovations that really weren’t that popular, I think a lot of that has been enabled by continuous delivery. Because continuous delivery gives us that stable path to production, which allows us to do things that we simply couldn’t do before. Think about going back in time in to the late ’90s, and telling somebody that they need to deploy a microservices architecture, which meant that you had all of these different processes, and that means I need 70 Oracle licenses. It simply wasn’t practical. You couldn’t have somebody manually type in all of the stuff to deploy some of these architectures. They were just too complex. I think we’re going to continue to see innovations in that space. What they’re going to look like, I don’t know. I think we’re going to continue to see innovations in architecture.
One of the areas that I think we are going to see more activity on, broadening out from where they have application right now, is these mixed physical-digital systems. We’ve had intelligent manufacturing. We’ve had robots in factories. We’ve had intelligent warehousing. I even worked in intelligent warehousing as my first full-time job out of university, back before fire was invented, of course. We’ve had these systems for a long time, but they’re starting to permeate more fields. We have things like autonomous vehicle technology, which is a fascinating combination of machine learning systems and sensors, and radar, all combined into one. How we create these systems are going to make us think about architecture in a different way. When we think about architecture in a different way, we might end up starting to have different aspects of architecture that we have to take into account.
What does it mean to evolve a platform? I remember years ago, I was having a conversation with a colleague, shortly after Martin published the book on “Domain-Specific Languages” that I worked on with him. One of the things that he was struggling with is, what is the relationship between agile and incremental design and such with a domain-specific language? Because, aren’t you laying things out when you decide what the language is going to look like? How would you actually go about evolution? There’s similar kinds of questions to be asked about platforms. There’s a level of abstraction that’s introduced there. When we talk about what are the drivers for evolutionary architecture, a lot of it has to do with business regulations changing, and business model lifetime, and expectations of users changing. That’s very much in the outer realm. The platform is supposed to provide this enabling characteristic for building all of those rapidly changing applications. As more platforms come into being, being able to evolve the platform will be important as well. Then you have all kinds of questions around API breaking changes, and all of those kinds of things. We might want to think about what it means to evolve things in a slightly different way, when we’re talking about platforms.
Finally, what about the evolution of augmented reality, virtual reality systems, the metaverse? I think we have to step back a little bit because in many cases, what does it mean to solve a business problem in augmented reality? People talk about virtual storefronts, and try-ons, and all of that, but what about applying for a mortgage? I think we have to think a lot about, what does it mean to have these experiences, and because of the level of immersion, the way things change within that world might have a greater impact than just a traditional software change. I think we’re going to be thinking differently about, how do we architect systems, when what we’re dealing with is effectively an artificial world.
Develop for Evolvability
What about developing for evolvability? What does that look like? I have to start with AI assistants. We’ve been doing experimentation with the coding aspects of ChatGPT, we’ve got Copilot out there. I think these things are going to continue to evolve and continue to impact the way we develop things. We really haven’t talked that much about, how does this intersect with our ability to develop for evolvability? Next, what is the impact of low-code and no-code platforms on evolvability? In theory, these should be easier to develop with. That’s the whole spiel behind it. Given the fact that these platforms very much have a sweet spot, how can we distinguish between those kinds of changes that will be easy to make and those kinds of changes that will be a challenge to make? You have to understand a whole lot about how the low-code platform actually works to be able to answer a question like that.
What about fitness functions for new languages, or languages in new settings, or compliance? We’ve already started to see innovation around compliance as code and fitness functions that actually encode our compliance and regulatory expectations. I think we’re going to continue to see an increase in regulatory scrutiny, and what impact is that going to have on our fitness functions? I think we’re going to see some creativity around, what are some new kinds of fitness functions we can construct to allow us to adapt to these changing environments? Possibly better metrics that help us get a better handle on, what does it mean for code to be readable? We’ve struggled for a long time on, how do we get good code metrics? How do we deal with the fact that there’s essential complexity in all problems? It’s not like we can say, nothing’s more complex than this, because maybe the problem itself is more complex than that. Perhaps in the next couple of years, we’ll start to see a bit more innovation around that as well. That might be wishful thinking, but it would be nice.
Architect for Testability
What about testability? I’m from Thoughtworks, of course, I have to talk about testability. I think the first thing is we are going to see an increased reliance on testing in production, on more dynamic fitness functions, which are monitoring systems as they are running. I don’t know if you all caught it, but if you look back at that slide with all of the -ilities, when we pulled that, observability was not an -ility. That’s clearly something that is becoming more important as our systems and our architectures get more complex. I think we’re going to see a shift in emphasis in our testing regimens. I think we’re also going to see a broadening of the suite of fitness functions and more creativity around some of these fitness functions. We’ve already seen some remarkable examples of how people have crafted fitness functions to fit a particular problem. I think we’re going to continue to see a lot of those coming out as well. You might wonder why I put this under testability. If you’ve thought about it, many of these fitness functions mirror things that actually look like tests. If you’ve ever run a performance test to see how much throughput you’ve got, you’ve run a fitness function. Fitness functions, to me, fit squarely under the guise of how we think about testability.
I think we’re going to also see increased use of AI in testing, particularly married with more dynamic testing. We might see continued innovation in things like an artificial immune system, self-healing systems to allow a running system to detect when something’s going wrong and to guard against particular threats, and counter them. There’s a lot left to be explored here. I think we’ll see that becoming more common in a broader range of systems than it currently is. Finally, we’re going to see more innovation, I believe, in what does it mean to test a machine learning model? What does it mean to test when you’ve got reinforcement learning going on? Which is, effectively, a model being able to update itself. There’s a lot of thinking that still needs to be done around how we actually manage some of those things. We’ve made significant advances already, but there’s still a lot to be done.
Conway’s Law
Finally, Conway’s Law. I think the big thing around Conway’s Law is, how is it going to be impacted by our new remote and hybrid ways of working? Much of the research that has been done about, how do we use Conway’s Law, the inverse Conway maneuver, or the reverse Conway maneuver, ok, this is the kind of system I want so I’m going to reorganize my team here. Most of that thinking has been done in the context of primarily colocated teams. Or if they’re distributed still, within a location, you’ve got a colocated team. The dynamic is very clearly different when you have hybrid, or fully remote teams, where individuals are sitting in their own rooms like I am now, coding. That is one thing, I think, with respect to Conway’s Law that we’re going to have to reexamine. Because it’s not like we can suddenly say, there’s going to be a component of our architecture for every individual developer scattered around there. That’s just impractical. What does it mean then instead? How do we properly support teams in this hybrid or fully remote environment?
Practices of Evolutionary Architecture
Now let’s talk about practices. How do we actually do stuff? The evolutionary architecture of today has four practices that I normally try to highlight. The first is evolutionary database design. We keep telling Pramod Sadalage that he ought to put out a new version of the book, “Refactoring Databases,” and just swap the title and subtitle, and turn it into, “Evolutionary Database Design: Refactoring Databases.” DBAs, fundamentally, are one of the few roles within the software development lifecycle that I feel have a legitimate complaint about incremental design and deployment, because of data migration. This book, this approach to refactoring databases gets us around that. Neal and I often say, if you take one thing away from this talk, take away the notion that you can, in fact, more easily migrate data using this evolutionary database design approach. Contract testing, this is another way that you can allow teams to be as independent of each other as possible. Because if I understand the assumptions you’re making of me and you understand the assumptions I’m making of you, then I can change whatever I want, as long as I don’t break your test. You can change whatever you want, whenever you want, as long as you don’t break a test. That’s a very important practice to allow systems to evolve more quickly because you have that signal that says, time for a conversation. Otherwise, I can just cheerfully ignore you.
Third, choreography. This one is a little more controversial, because much like microservices, it sets a high bar in terms of complexity. There are problems that simply do not occur if you use an orchestration model with an orchestrator, as opposed to a choreography model. If evolvability is one of these critical -ilities, using a choreographed approach to the interaction of your various small C components, the different parts of your architecture, gives you much more flexibility than if you have an orchestrator. You do pay a cost in terms of complexity. That needs to be taken into account. Finally, continuous delivery. To me, this is a critical underpinning practice. Because what you don’t want to be doing is making major changes to your architecture, when you’re not sure if the configuration parameters are still what you expect them to be. You want to be able to quickly diagnose and roll back and understand what happened. That’s very difficult to do if you’ve got some poor soul there at 3:00 on a Sunday morning, trying to type in everything, just right. No matter how good your runbook is, nobody is at their best at 3:00 on a Sunday morning. They’re just not.
Practices Will Evolve but Not Radically Change
How are these practices going to be different in 2025? What kinds of things might we see? I don’t think these practices in and of themselves are going to change that much. With respect to evolutionary database design, we’re probably going to continue to see innovations in persistence frameworks, but the fundamental principles of how you approach refactoring databases, so far, at least, have morphed quite nicely across the different persistence paradigms. Even though we’re going to see innovations there, I think the fundamental practice of refactoring databases and evolutionary database design will be maintained. There might be some assistance we can get from some of these AI tools in terms of helping to develop these contracts. In my experience, some of the best enterprise architects were so good at their job, because they really understood how the different systems depended on each other and those hidden assumptions that you never really knew were there. They knew where the bodies were buried in the architecture. Sometimes those things are really hard to elicit. It may be that as we get better AI tools and code analysis tools, it will be easier to extract those relationships to construct those contract tests. Again, fundamentally, the premise of why you do contract testing remains the same.
Similarly, I think we might continue to see innovations on how can we make it easier to take advantage of choreography. There is some element of it that truly is essential complexity. As I said before, there are errors that just really can’t happen if you have an orchestrator. There might be some of the other complexity we might be able to ameliorate with some tools, potentially, with some AI support. Finally, in the realm of continuous delivery, as we continue to innovate new systems, we have to think about, what is the right automation? What are the right tools to support continuous delivery of this new thing? I think we’re going to continue to see people figuring out additional ways to provide proper telemetry to understand the business value of new features, or to provide tools that allow more readily for rollback. There are lots of different things that are truly involved in a true continuous delivery, or continuous deployment setting, which is the next stage of maturity. I think we’re going to see some innovation with respect to some of those tools.
Conclusion
Fundamentally, evolutionary architecture is going to evolve. The whole premise of evolutionary architecture is that the technology ecosystem, as well as the expectation ecosystem, and the regulatory ecosystem, and business models, all of these things will continue to evolve. Particularly as it relates to the technology ecosystem, that’s going to require our approach to evolutionary architecture to evolve. I really don’t think it’s likely to be a revolution, though, particularly since we’re talking 2025. That’s not that far away. I might be singing a different tune if all of a sudden quantum comes onto the scene, or we truly get an artificial general intelligence. My expectation is that although the pace of change is significant, within the next two years, we’re unlikely to see something that is going to cause a revolution in our approach to evolutionary architecture. There very well might be new -ilities. One of the things that I tell people about evolutionary architecture is if you’re not on a fairly regular basis scanning your list of fitness functions and the prioritization you have on the different -ilities to determine if that is still valid, I think over the next couple years, it’s quite possible. There will be new aspects, new architectural characteristics that we’ll have to say, ok, where does this slot in? As I pointed out earlier, that list that I showed you from Wikipedia from several years ago, didn’t even have observability on it. It had operability. It had some other things, but specifically did not have observability on it. I think we’re going to continue to see different -ilities arise as we have different approaches, and different perspectives on our systems, and different kinds of systems. We might have at least closer to a self-driving car within a couple of years. We might have vastly improved systems for digital twins. That will probably bring us some new -ilities. My crystal ball is still broken.
See more presentations with transcripts
MMS • Agazi Mekonnen

The Node.js team has recently released version 20.6.0, which brings improvements in environment variable configuration, module resolution, module customization, and experimental support for C++ garbage collection.
In this patch, developers gain a new feature: built-in support for `.env` files. These files, following the INI file format, offer a simplified approach to configuring environment variables. Developers can easily initialize their applications with predefined configurations using a straightforward CLI command, `node --env-file=config.env index.js`. This update streamlines the management of environment variables.
Another notable change involves the unflagged `import.meta.resolve(specifier)` function. This adjustment plays a crucial role in aligning Node.js with other server-side runtimes and browsers. The function now provides an absolute URL string for module resolution, enhancing cross-platform compatibility and simplifying module management across different environments.
Node.js 20.6.0 also introduced a new API known as `register` within the `node:module` namespace. This API simplifies module customization hooks, enabling developers to specify a file that exports these hooks and facilitates communication channels between the main application thread and the hooks thread. Developers are encouraged to transition to an approach that uses `--import` alongside `register` for efficient hook registration.
Node.js 20.6.0 enhanced the module customization load hook, allowing it to manage both ES module and CommonJS sources. This added flexibility streamlines the process of loading and customizing Node.js modules, eliminating the dependence on deprecated APIs.
Node.js C++ addons now feature experimental support for a C++ garbage collector, enhancing compatibility with V8’s memory management. This support ensures Node.js starts with a `v8::CppHeap`, allowing memory allocation using `` headers from V8. While stability may vary in minor and patch updates, the C++ garbage collector has a strong track record in Chromium, making it a promising choice for C++ addon development.
Node.js 20, released in April 2023, brought significant changes, including embracing ES2023, experimental support for the WebAssembly System Interface (WASI), and a focus on performance and stability with the V8 JavaScript engine updated to version 11.3. The release enhanced security was enhanced with the introduction of an experimental permission model, featured a stable test runner, and introduced capabilities for single executable apps, enabling the distribution of Node.js apps on systems without Node.js installed. These developments, combined with support for new operating systems, improved TypeScript compatibility, and the introduction of new developer tools and APIs solidify Node.js.
Node.js 20 is currently in its beta phase and is set to transition to long-term support (LTS) on October 24, 2023. This means that it will receive ongoing support, including security updates and bug fixes, for a minimum of three years.
MMS • RSS

|
Listen to this story |
Hallucinations have been a long-standing problem for LLMs. But they are inevitable. Researchers delved into the AI black box to search through the reasons and ultimately, find a solution, but no vain. However, when they looked outside, they found the vector databases can help in reducing the risk of hallucination.
“Pairing vector databases with LLMs allows for the incorporation of proprietary data, effectively reducing the potential range of responses generated by the database,” said Matt Asay, VP, Developer Relations in an exclusive interaction with AIM at their recently concluded Bengaluru chapter of flagship event MongoDB.local.
Hallucinations can be controlled through this method. By introducing proprietary data, developers can narrow down the pool of possible responses, significantly reducing the likelihood of hallucinations. However, it was noted that this process requires active programming efforts, and platforms like MongoDB simplify the incorporation of proprietary data into vector databases.
MongoDB’s vector search capabilities are driving generative AI by transforming diverse data types like text, images, videos, and audio files into numerical vectors, simplifying AI processing and enabling efficient relevance-based searches. MongoDB Atlas with vector search ensures precise information retrieval and personalisation, with dedicated resources for enterprise-scale search workloads.
“While generative AI is important, it’s just one aspect of a broader AI ecosystem where vectors are pivotal,” said Asay. He highlighted that Mongodb’s features, such as the need for streaming data, contribute to the development of smarter applications.
Vectors: One solution for many problems
Vectors play a pivotal role in numerically representing objects and features that were traditionally challenging to store in databases. Vectors offer a solution by enabling the numeric representation of various aspects of the world, which is vital for building effective AI applications.
To facilitate the development of AI applications, Matt explains that they are providing developers with tools to work with vectors, search indexes, metadata, operational data, and documents all in one unified platform. This consolidation of resources is presented as a key strategy to deliver a superior AI experience.
“We aim to make AI more accessible and approachable for developers, bringing together various data types, including streaming data, vectors, analytics, and more, into a unified platform. This unification is intended to lower the barrier to entry and support developers in building innovative AI applications, aligning with the increasing industry focus on AI development,” he added.
MongoDB for Low Resource Languages?
Recently, Indian IT giant Tech Mahindra introduced Project Indus – a new LLM for Indic languages starting with Hindi. While the majority of AI models like GPT primarily operate in English, support for regional languages is quite limited. To truly democratise AI in India, native language accessibility is indispensable. Project Vaani, Project Bhashini, KissanAI, Jugalbandi are all efforts in this direction. However, there remains immense language data challenges, including the scarcity of diverse and comprehensive datasets, especially in spoken language.
Discussing the potential use of MongoDB in tackling language barriers for AI models, Asay agreed that MongoDB could indeed handle the vectorization and storage of Hindi language data. However, it was also emphasised that the fundamental issue at hand was the scarcity of language-specific data. MongoDB’s role primarily lay in providing efficient querying and storage capabilities but didn’t directly address the challenge of insufficient language-specific data.
Automobiles Find their Moat in MongoDB
MongoDB plays an important role in the automotive industry by facilitating innovation and enhancing competitiveness. Through MongoDB’s, automotive manufacturers like Toyota, Volvo and Bosch Digital leverage IoT technologies, such as condition monitoring sensors, to expedite informed decision-making. This real-time access to data fosters seamless collaboration among teams, expediting the innovation process.
“Vectorisation plays a crucial role in diagnosing vehicle problems based on engine sounds. This task has always been quite challenging for traditional relational databases,” said Asay.
MongoDB’s Atlas Vector Search transforms sound into queryable data, enabling precise diagnostics. Moreover, repair manuals are similarly vectorized to offer solutions for identified problems. This innovative approach extends to startups utilising vectorization to gauge customer sentiment by processing support call transcripts. Overall, MongoDB empowers automotive manufacturers to seize significant opportunities for groundbreaking products and services, enabling them to remain at the forefront of their industry.
India As a Market
MongoDB has achieved significant popularity in India, with a rapid customer acquisition rate of about two and a half customers per day in India. Approximately 3,60,000 university registrations out of a total of 1.5 million globally are from India. The community version of MongoDB has been downloaded roughly 260 million times worldwide, with a substantial portion of these downloads originating in India. The company boasts over 2000 customers in India and is experiencing a remarkable 60% year-on-year growth.
“MongoDB’s platform has gained widespread adoption in the Indian startup ecosystem, spanning sectors like fintech, healthcare, edtech, and more. Our focus areas in India, which include startups, ISVs (Independent Software Vendors), and large enterprises, said Asay. Some prominent Indian customers include Zomato, cure.fit, Vedantu, and myBillBook. Additionally, MongoDB serves traditional and legacy companies, emphasising the advantages of its document data model, which offers flexibility for developers and scalability, setting it apart from conventional SQL databases.
Global Database As A Service Providers Market Size and Forecast | IBM, Beats, AWS, Ninox …
MMS • RSS

New Jersey, United States – Verified Market Research recently released a research report titled “Global Database As A Service Providers Market Insight, Forecast.” The report extensively discusses the Global Database As A Service Providers market, offering readers a comprehensive understanding of key trends, top strategies, and potential growth opportunities. It incorporates Porter’s Five Forces analysis, PESTEL analysis, as well as qualitative and quantitative analysis to present a complete and precise picture of the current and future market landscape. The analysts have carefully forecasted the market size, CAGR, market share, revenue, production, and other crucial factors, employing industry-best primary and secondary research tools and methodologies. This report can assist players in devising effective strategies by focusing on key segments and regions, thereby enhancing their presence in the Global Database As A Service Providers market.
The report includes an examination of ongoing and latest market trends, company market shares, market forecasts, competitive benchmarking, competitive mapping, and an in-depth analysis of key sustainability tactics and their impact on market growth and competition. To estimate quantitative aspects and segment the Global Database As A Service Providers market, a recommended combination of top-down and bottom-up approaches was used. The Global Database As A Service Providers market was studied from three key perspectives through data triangulation, ensuring accuracy in market forecasts and estimates with minimal errors. The iterative and comprehensive research methodology employed by the authors further enhances the reliability of the findings.
Database As A Service Providers Market was valued at USD 140.33 Billion in 2020 and is projected to reach USD 338.90 Billion by 2028, growing at a CAGR of 11.66% from 2021 to 2028.
Get Full PDF Sample Copy of Report: (Including Full TOC, List of Tables & Figures, Chart) @ https://www.verifiedmarketresearch.com/download-sample/?rid=160513
Leading 10 Companies in the Global Database As A Service Providers Market Research Report:
In this section of the report, the Global Database As A Service Providers Market focuses on the major players that are operating in the market and their competitive landscape present in the market. The Global Database As A Service Providers report includes a list of initiatives taken by the companies in the past years along with the ones, which are likely to happen in the coming years. Analysts have also made a note of their expansion plans for the near future, financial analysis of these companies, and their research and development activities. This research report includes a complete dashboard view of the Global Database As A Service Providers market, which helps the readers to view an in-depth knowledge about the report.
IBM, Beats, AWS, Ninox, Aiven, MongoDB Atlas, Zoho Creator, Azure, Kintone, Oracle, Google Cloud Bigtable
Global Database As A Service Providers Market Segmentation:
Database As A Service Providers Market, By Verticles
• Banking, Financial, Services, and Insurance (BFSI)
• Government and Defense
• Healthcare and Pharmaceuticals
• IT and Enterprises
• Telecommunication
• Retail
• Others (Incl. Energy, manufacturing, gaming and gambling, media and education)
Database As A Service Providers Market, By Database Type
• Structured Query Language (SQL)
• Not only Structured Query Language (NoSQL)
For a better understanding of the market, analysts have segmented the Global Database As A Service Providers market based on application, type, and regions. Each segment provides a clear picture of the aspects that are likely to drive it and the ones expected to restrain it. The segment-wise explanation allows the reader to get access to particular updates about the Global Database As A Service Providers market. Evolving environmental concerns, changing political scenarios, and differing approaches by the government towards regulatory reforms have also been mentioned in the Global Database As A Service Providers research report.
In this chapter of the Global Database As A Service Providers Market report, the researchers have explored the various regions that are expected to witness fruitful developments and make serious contributions to the market’s burgeoning growth. Along with general statistical information, the Global Database As A Service Providers Market report has provided data of each region with respect to its revenue, productions, and presence of major manufacturers. The major regions which are covered in the Global Database As A Service Providers Market report includes North America, Europe, Central and South America, Asia Pacific, South Asia, the Middle East and Africa, GCC countries, and others.
Inquire for a Discount on this Premium Report @ https://www.verifiedmarketresearch.com/ask-for-discount/?rid=160513
What to Expect in Our Report?
(1) A complete section of the Global Database As A Service Providers market report is dedicated for market dynamics, which include influence factors, market drivers, challenges, opportunities, and trends.
(2) Another broad section of the research study is reserved for regional analysis of the Global Database As A Service Providers market where important regions and countries are assessed for their growth potential, consumption, market share, and other vital factors indicating their market growth.
(3) Players can use the competitive analysis provided in the report to build new strategies or fine-tune their existing ones to rise above market challenges and increase their share of the Global Database As A Service Providers market.
(4) The report also discusses competitive situation and trends and sheds light on company expansions and merger and acquisition taking place in the Global Database As A Service Providers market. Moreover, it brings to light the market concentration rate and market shares of top three and five players.
(5) Readers are provided with findings and conclusion of the research study provided in the Global Database As A Service Providers Market report.
Key Questions Answered in the Report:
(1) What are the growth opportunities for the new entrants in the Global Database As A Service Providers industry?
(2) Who are the leading players functioning in the Global Database As A Service Providers marketplace?
(3) What are the key strategies participants are likely to adopt to increase their share in the Global Database As A Service Providers industry?
(4) What is the competitive situation in the Global Database As A Service Providers market?
(5) What are the emerging trends that may influence the Global Database As A Service Providers market growth?
(6) Which product type segment will exhibit high CAGR in future?
(7) Which application segment will grab a handsome share in the Global Database As A Service Providers industry?
(8) Which region is lucrative for the manufacturers?
For More Information or Query or Customization Before Buying, Visit @ https://www.verifiedmarketresearch.com/product/database-as-a-service-providers-market/
About Us: Verified Market Research®
Verified Market Research® is a leading Global Research and Consulting firm that has been providing advanced analytical research solutions, custom consulting and in-depth data analysis for 10+ years to individuals and companies alike that are looking for accurate, reliable and up to date research data and technical consulting. We offer insights into strategic and growth analyses, Data necessary to achieve corporate goals and help make critical revenue decisions.
Our research studies help our clients make superior data-driven decisions, understand market forecast, capitalize on future opportunities and optimize efficiency by working as their partner to deliver accurate and valuable information. The industries we cover span over a large spectrum including Technology, Chemicals, Manufacturing, Energy, Food and Beverages, Automotive, Robotics, Packaging, Construction, Mining & Gas. Etc.
We, at Verified Market Research, assist in understanding holistic market indicating factors and most current and future market trends. Our analysts, with their high expertise in data gathering and governance, utilize industry techniques to collate and examine data at all stages. They are trained to combine modern data collection techniques, superior research methodology, subject expertise and years of collective experience to produce informative and accurate research.
Having serviced over 5000+ clients, we have provided reliable market research services to more than 100 Global Fortune 500 companies such as Amazon, Dell, IBM, Shell, Exxon Mobil, General Electric, Siemens, Microsoft, Sony and Hitachi. We have co-consulted with some of the world’s leading consulting firms like McKinsey & Company, Boston Consulting Group, Bain and Company for custom research and consulting projects for businesses worldwide.
Contact us:
Mr. Edwyne Fernandes
Verified Market Research®
US: +1 (650)-781-4080
US Toll-Free: +1 (800)-782-1768
Email: sales@verifiedmarketresearch.com
Website:- https://www.verifiedmarketresearch.com/
MMS • RSS

MongoDB, Inc. is a developer data platform company. Its developer data platform is an integrated set of databases and related services that allow development teams to address the growing variety of modern application requirements. Its core offerings are MongoDB Atlas and MongoDB Enterprise Advanced. MongoDB Atlas is its managed multi-cloud database-as-a-service offering that includes an integrated set of database and related services. MongoDB Atlas provides customers with a managed offering that includes automated provisioning and healing, comprehensive system monitoring, managed backup and restore, default security and other features. MongoDB Enterprise Advanced is its self-managed commercial offering for enterprise customers that can run in the cloud, on-premises or in a hybrid environment. It provides professional services to its customers, including consulting and training. It has over 40,800 customers spanning a range of industries in more than 100 countries around the world.