Month: December 2023

MMS • RSS

The US Department of Justice has shut down what it claims to be one of the most prolific ransomware operations on the planet.
The Justice Department said that its Southern Florida District Office was leading the charge against operators of the ransomware family that is said to have compromised thousands of victims.
Police used a purpose-built decryption tool to help victims of the malware recover their data without the need to pay the attackers ransom demands and provide cash for cybercrime operations.
“In disrupting the BlackCat ransomware group, the Justice Department has once again hacked the hackers,” said deputy attorney general Lisa Monaco.
“With a decryption tool provided by the FBI to hundreds of ransomware victims worldwide, businesses and schools were able to reopen, and health care and emergency services were able to come back online.”
Like most modern ransomware operations, Blackcat operates under a service model; the ransomware authors sell off a license to third-party hackers who then do the dirty work of infiltrating networks and running the ransomware code.
“Before encrypting the victim system, the affiliate will exfiltrate or steal sensitive data,” the DOJ said.
“The affiliate then seeks a ransom in exchange for decrypting the victim’s system and not publishing the stolen data. Blackcat actors attempt to target the most sensitive data in a victim’s system to increase the pressure to pay.”
Officials with the DOJ passed credit on to law enforcement in the UK, Spain, Germany, Austria, Australia, and Europol.
According to officials, the crackdown on the Blackcat group (aka ALPHV and Noberus) has lead to some 500 companies being able to regain access to systems that had been locked by ransomware.
“The FBI developed a decryption tool that allowed FBI field offices across the country and law enforcement partners around the world to offer over 500 affected victims the capability to restore their systems,” the DOJ said.
“To date, the FBI has worked with dozens of victims in the United States and internationally to implement this solution, saving multiple victims from ransom demands totaling approximately $68m.”
MMS • RSS

MongoDB database hit by cyberattack exposing customer data (Source – Shutterstock).
- MongoDB database breach exposes customer data – Atlas service remains secure.
- MongoDB responds to security breach, acknolwedges customer data accessed.
- MongoDB incident highlights tech industry’s cybersecurity challenges.
MongoDB, a database software company, recently issued a warning about a breach in its corporate systems, leading to the exposure of customer data. This cybersecurity incident marks a significant event for the company, known for its extensive reach in the database software market and its substantial revenue of US$1.2 billion this year.
MongoDB database breach: unveiling the incident
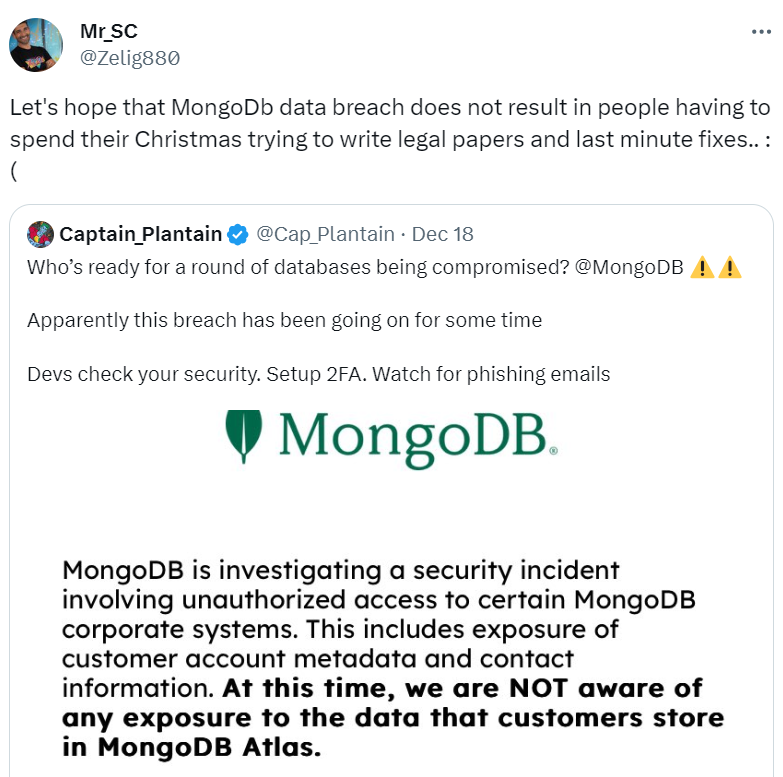
The breach was first detected on the evening of December 13, 2023 (US Eastern Standard Time), when MongoDB identified suspicious activity within its corporate systems. The company promptly initiated its incident response process. However, it is believed that the unauthorized access had been ongoing for some time before its discovery.
In a notice posted on December 16 on its alert page, MongoDB confirmed the security incident involved unauthorized access, resulting in the exposure of customer account metadata and contact information. Despite this, MongoDB assured customers there was no evidence of exposure to the data stored in MongoDB Atlas, its flagship database service.
As a precaution, MongoDB recommends customers remain alert to potential social engineering and phishing attacks. The company advises activating phishing-resistant multi-factor authentication (MFA) and the regular rotation of MongoDB Atlas passwords. MongoDB emphasizes that it has not found any security vulnerabilities in its products as a result of this incident.
Importantly, MongoDB says that access to MongoDB Atlas clusters is authenticated through a system separate from the compromised corporate systems. As of December 17, no evidence suggests any unauthorized access to MongoDB Atlas clusters or compromise of the Atlas cluster authentication system.
The breach resulted in unauthorized access to some corporate systems containing customer names, phone numbers, email addresses, and other account metadata. Notably, system logs for one customer were accessed, and MongoDB has notified the affected customer. There is no indication that other customers’ system logs have been accessed.
MongoDB database vulnerability leads to customer data leak. (Source – X).
Reflecting on past incidents
Coincidentally, MongoDB experienced its security incident around the same time as a previous event in 2020. On December 16, 2020, MongoDB issued an alert on its website saying it was diligently investigating a security breach involving unauthorized access to its corporate systems, which included the exposure of customer account metadata and contact details.
The company noticed suspicious activities on December 13 and promptly initiated its incident response process. MongoDB suspected this unauthorized access might have occurred for a while before its detection.
On December 17, MongoDB updated customers, saying that it had found no evidence of unauthorized access to Atlas customer data, referring to its Database-as-a-Service offering. The company assured users that no security vulnerabilities in MongoDB products had been identified due to the incident. They emphasized that access to MongoDB Atlas clusters is secured through a system separate from the compromised corporate systems and that there was no evidence of a breach in the Atlas cluster authentication system.
But MongoDB did discover unauthorized access to certain corporate systems containing customer names, phone numbers, email addresses, and other account metadata, including the system logs of one customer. The company informed the affected customer and stated that there was no indication that the system logs of other customers had been accessed.
This incident for MongoDB came amid several high-profile data breaches reported throughout that year. For instance, Samsung disclosed in November 2020 that a significant breach that had occurred over a year-long period, from July 1, 2019, to June 30, 2020. This breach led to unauthorized access to customer data from its UK store, although it was only discovered on November 13.
Samsung confirmed that no financial data or customer passwords were impacted while contact information was obtained. It reported the incident to the Information Commissioner’s Office and contacted the affected customers as part of their resolution steps.
Ongoing investigation and updates
MongoDB continues to investigate the breach and will provide updates on the MongoDB Alerts web page, which is used for communicating about outages and other incidents. The company remains committed to transparency and the security of its systems and customer data.
[embedded content]
This incident serves as a reminder of the ever-present cyberthreats facing technology companies. It underscores the importance of robust security measures and constant vigilance in an increasingly interconnected digital world. Customers of MongoDB and similar services are urged to follow the recommended security practices and stay informed about the latest updates regarding this breach.
MMS • RSS

MERN stack development has gained popularity as a comprehensive framework for full-stack development. Many developers aspire to become full-stack developers due to the freedom it offers in crafting end-to-end applications and the broader skill set it provides compared to other roles.
As you delve into mastering MERN stack development and showcasing your skills, creating complete projects becomes crucial. But before diving into project ideas, it’s essential to touch upon the basics of full-stack development.
What exactly is the MERN Stack?
The MERN Stack, a JavaScript-based framework, enables the swift and straightforward deployment of full-stack web applications. Comprising MongoDB, Express, React, and Node.js, this stack was designed to expedite and enhance the development process.
These four robust technologies collectively offer a comprehensive architecture for crafting open-source projects, such as online applications.
How does the MERN Stack operate?
Utilizing solely JavaScript and JSON, the MERN architecture empowers developers to swiftly construct a three-tier structure—comprising the frontend, backend, and database—facilitating seamless development.
With MERN, you can handle an entire project mainly using JavaScript and JSON. So, a developer just needs to be really good at one programming language and understand JSON files.
In MERN stack, developers create URLs like “application/users/create”. These URLs let people create, see, and change data that’s stored and retrieved from the MongoDB database. These URLs play different roles, and when someone makes an HTTP request, it gets things going.
M for MongoDB: In MERN, the “M” stands for MongoDB, the database used in a MERN app. MongoDB stores data for the back-end of applications. It organizes data as Objects within Collections within Documents.
E for Express JS: Express is a framework that manages the structure and functions of the back end. It sits on top of Node.js, speeding up web app development.
R for React: React is a tool for creating user interfaces on single-page web apps.
N for Node.js: Node.js is a tool used to run JavaScript on the backend. It’s open source and functions across various platforms, using V8 engines to process JavaScript code outside of web browsers.
MERN Stack Projects Ideas for Beginners
Full-stack developers have diverse backgrounds and different levels of expertise. You might know a lot about designing the front end but still be learning about the back end. There are many platforms where you can show off your skills in MERN stack development.
Being a full-stack developer involves tackling various challenges. A full-stack developer needs to be skilled in many programming languages and technologies. So, when you propose complete and advanced MERN stack projects, you’ll outline the main goals, but it’s up to you to figure out how to achieve them.
These MERN stack project ideas can jazz up your portfolio. These projects are particularly beneficial for budding web developers, helping lay a solid groundwork. While individuals with basic front-end and back-end knowledge can manage these tasks, executing them proficiently requires skills and expertise. Here are some beginner-friendly MERN project ideas.
Travel Log App
This complete web service will let users share their travel adventures with a community of fellow explorers.
This app will allow users to:
- Discover other travelers’ experiences.
- Share their own expertise.
- Include various details about their encounters while traveling.
TO-DO List
Making a To-Do List is a common project using the MERN stack. You’ll build a website where users who are logged in can add or remove tasks from a database. This project covers authentication, CRUD (creating, reading, updating, deleting), databases, and more.
Media Player-App
This is a straightforward MERN stack project to try out. Create a media player app to explore features like song shuffle, playlists, media player API authentication, toolbar statistics, header setup, music search, and footer design.
Chat Messaging Application
As social networking sites with their own messaging tools became more common, standalone messaging apps became less popular. Even though it’s not directly in line with current industry needs, creating a messaging app is a great MERN stack project for learning, as it’s not too complex but still offers valuable insights.
Fitness Tracker
Here’s another easy MERN stack project idea. Many New Year’s resolutions often focus on getting healthier. Plus, with the ongoing COVID situation, the idea of “survival of the fittest” has become quite popular. Because of this demand, creating a health-related app can be valuable. It offers a chance to learn how to build something with more user interaction, enhancing skills in creating a great user interface and experience.
Advanced MERN Stack Projects Ideas
As technology evolves and the website development field progresses, staying updated with new skills, tools, and methods is crucial for developers. It’s essential to move beyond basic MERN stack projects and challenge yourself with an advanced project.
It supports developers in ongoing learning and applying new skills. Plus, if you build something valuable with significant growth potential, it could turn into an excellent startup opportunity! That’s why having advanced MERN stack project ideas is important to level up your professional journey.
6. E-Commerce Platform
An e-commerce website stands out as a top MERN stack project idea for developers at any level, whether they’re beginners or seasoned professionals. This project could cater to either a brand-new business or an existing one.
The e-commerce platform is versatile: it could buy discounted items from people, refurbish and resell them for profit, or sell brand-new products to customers.
Moreover, the website needs to showcase the available products, whether used or new, that customers can buy. It should also include a user registration feature for building profiles. This project serves as an excellent example of a MERN stack website.
7. Application for Food Delivery
This app helps restaurants connect with customers. Restaurant owners can sign up, and display their menu and prices. Customers can sign up too, browse nearby restaurants, and place orders.
Restaurants confirm takeaway orders and send them to a delivery rider. Customers who order can track the delivery rider’s location. The shopping cart and payment pages in the app need to be special and easy to use.
8. News Application
As people increasingly want the latest news due to digital advancements, this app becomes handy. It lets users easily post their news or articles directly within the app. Users can also include images to make their articles more visually engaging.
9. Weather App
Creating a weather app using ReactJS is a fantastic project that doesn’t demand extensive coding time. Initially, we can use simulated, challenging data until everything works perfectly. Building this app helps us learn how to link to external APIs and show the necessary results accurately.
Mastering this skill will be incredibly valuable when crafting other single-page apps that fetch data from external sources and exhibit the outcomes.
10. Storytelling via Data Visualization
If you’re a fan of stories, you might find this topic more engaging to work with. Tools like Tableau, FusionCharts, and Sisense come in handy for these projects. They help you present your results visually and verbally, providing stakeholders with the insights they need to act upon your findings.
Conclusion
For beginners, the MERN stack opens up numerous project options spanning the entire stack. As a MERN stack development company, we’ve compiled a list of our top MERN stack projects to kickstart your journey. Our aim is to spark inspiration for your future projects as you work towards becoming a more skilled MERN Stack developer. Consider trying one of these ideas to create your own MERN stack sample project.
MMS • RSS
In a post Sunday, MongoDB said an unauthorized actor accessed systems with customer names, phone numbers and email addresses plus one customer’s system logs.

MongoDB is investigating unauthorized access to corporate systems, which may have exposed customer account metadata and contact information.
The New York-based data platform vendor posted on Saturday about “a security incident,” saying that it actually “detected suspicious activity on Wednesday (Dec. 13th, 2023) evening US Eastern Standard Time, immediately activated our incident response process, and believe that this unauthorized access has been going on for some period of time before discovery.”
At 9 p.m. Eastern Sunday, MongoDB said that it has “found no evidence of unauthorized access to MongoDB Atlas clusters” and it has “not identified any security vulnerability in any MongoDB product as a result of this incident.”
[RELATED: 10 Major Cyberattacks And Data Breaches In 2023]
MongoDB Security Incident
CRN has reached out to MongoDB for comment.
The vendor has 1,000 worldwide channel partners and 400 in North America, according to CRN’s 2023 Channel Chiefs.
In the Sunday post, MongoDB said that an unauthorized actor accessed systems with customer names, phone numbers and email addresses plus one customer’s system logs.
“We are continuing with our investigation, and are working with relevant authorities and forensic firms,” the vendor said.
In the Saturday post, MongoDB advised users to “be vigilant for social engineering and phishing attacks, activate phishing-resistant multi-factor authentication (MFA), and regularly rotate their MongoDB Atlas passwords.”
MMS • RSS

MongoDB is still investigating a security incident in which hackers penetrated customers’ business systems. Contact information and metadata were allegedly accessed. The number of involved customers stays unclear.
During the weekend of Dec. 16 and 17, a security incident occurred at MongoDB. On Saturday, it was reported that several company systems were accessed “containing customer names, phone numbers and e-mail addresses among other metadata of customer accounts.”
Furthermore, one customer’s system logs were reportedly stolen. MongoDB says it has notified the company involved and has since ruled out the possibility that other customers’ logs were also captured. The investigation may not yet have revealed how many company systems were accessed, or the company may refuse to provide this information.
No access to MongoDB Atlas clusters
Through the investigation, MongoDB can say with certainty that the hackers could not access the MongoDB Atlas clusters. The company states that in its latest update, dated Dec. 18.
MongoDB Atlas clusters is a Database-as-a-Service and is made available through major cloud players. The service contains important corporate data from MongoDB customers, and so the investigation that has been instituted is currently focusing primarily on ruling out possible incidents in this service.
Victim of phishing
The cause of the incident appears to be a phishing attack. “At the moment, as a result of our investigation in cooperation with external experts, we are confident that we have been the victim of a phishing attack,” the company said.
It is now warning customers to be alert to such attacks themselves. This is because the captured customer data can be misused by hackers to create personalized phishing emails. Among those customers are sizable IT brands, such as Bosch and Adobe. In total, the database provider serves more than 46,400 companies.
Also read: HR topics used the most as attack method in phishing attacks
MMS • Anthony Alford

Microsoft Research announced Phi-2, a 2.7 billion-parameter Transformer-based language model. Phi-2 is trained on 1.4T tokens of synthetic data generated by GPT-3.5 and outperforms larger models on a variety of benchmarks.
Phi-2 is the latest iteration of Microsoft’s Phi suite of models, which are trained on a mixture of web-crawled and synthetic “textbook-quality” datasets. The previous Phi models contain only 1.3B parameters, but showed excellent performance on coding and reasoning tasks. Phi-2 is twice as large as previous ones and was trained for two weeks on a cluster of 96 A100 GPUs. It has performance comparable to models which are up to 25x larger, outperforming the 70B parameter Llama-2 model on reasoning, language understanding, and coding benchmarks. According to Microsoft:
With its compact size, Phi-2 is an ideal playground for researchers, including for exploration around mechanistic interpretability, safety improvements, or fine-tuning experimentation on a variety of tasks. We have made Phi-2 available in the Azure AI Studio model catalog to foster research and development on language models.
InfoQ recently covered several efforts to replicate the abilities of large language models (LLMs) in smaller models. Many of these use LLMs such as ChatGPT to generate synthetic training datasets for the smaller model. Google’s Distilling Step-by-Step method prompts a teacher LLM to automatically generate a small fine-tuning dataset that contains both an input with an output label, as well as a “rationale” for why the output label was chosen. Microsoft Research’s Orca 2 uses a synthetic training dataset and a new technique called Prompt Erasure to achieve performance equal to or better than models that contain 10x the number of parameters.
The key innovation with the Phi series of models is a synthetic dataset of “textbook-like” data. Although the researchers have not released the dataset or even very many details of its generation, previous tech reports on the Phi models include high-level descriptions. One goal for the datasets was to generate “diverse and non-repetitive” examples that cover a range of “concepts, skills, and scenarios” that vary in “level of difficulty, complexity, and style.” For Phi-1.5, the team selected 20k different topics for generated examples of language understanding problems.
Sebastien Bubeck, lead ML foundations team at Microsoft Research, posted on X about some additional work fine-tuning Phi-2:
phi-2 is really a good base for further fine-tuning: we [fine-tune] on 1M math exercises (similar to phi-1 w. CodeExercises) & test on recent French nation-wide math exam (published after phi-2 finished training). The results are encouraging! Go try your own data…
Mark Tenenholtz, the head of AI at Predelo, also posted about Phi-2, that “knowledge distillation really does work.” In a Hacker News discussion about Phi-2, one user noted that the compute cost of training the model was probably around 30k USD, or “cheaper than a car.” Another pointed out:
Note the model is trained on data generated by GPT-4. It’s probably orders of magnitude more expensive to generate the data at current API prices. The whole point of these papers is that training data quality is key. I would much prefer for these companies to release the training data than the weights.
The Phi-2 model weights are available on HuggingFace.
MMS • Henrique Andrade

Transcript
Andrade: My name is Henrique Andrade. I am a Production Engineer at Meta. We will be talking about the development environment infrastructure that we have at the company. I think the main focus of this conversation is going to be in terms of what can one expect when it comes to the environment that you’re going to be using to do your work as a new software engineer joining the company. It doesn’t really matter here how senior you are. The environment that we put in place is something that is designed to basically tackle the needs of software engineers, production engineers, irrespective of their seniority. This is basically the experience that everybody is going to be exposed to. I am going to be talking about the main tenets that make this environment reliable, so you as a developer who’s joining the company, you don’t have to worry about OS upgrades, your machine going away, maintenance that might occur. All of those things that potentially can be disruptive to you, and shouldn’t be the main point of concern. That you should be focused on doing your project work and moving the project that you are allocated to forward. There is a lot of stuff that I’m going to cover here. A very large theme is behind providing the infrastructure that is as reliable as it is. I’m here as a messenger, and as someone who has used this infrastructure for a while. Also, as the team that basically keeps it going and improves on it, and all of that. Think of me as a messenger. There is a large team that I basically have to thank here for their hard work, and their thoughtfulness, and all of the infrastructure that they helped me build over the years.
Outline
I am going to give you a little bit of an introduction. As someone who is just joining the company, what are your offers in terms of environments that you can have at your disposal to do code development at Meta? One thing that I want to emphasize here is, in having that choice, what is the role of production engineers in providing that service for the software engineering community at the company? Why are PEs part of the DevEnv team, the team that provides those environments? We are going to talk a little bit about the development environment architecture. We’re going to be talking about servers. We’re going to be talking about containers. We are going to be talking about tooling. We’re also going to be talking about the user interface where you have to interact with this environment. We’re also going to be talking about a few challenges behind supporting this development environment architecture. Then towards the second half of the talk, we’re going to be talking about designing for reliability.
As a software engineer, you really don’t want to be concerned about how reliable this environment is, you just want it to be reliable. What does make that environment reliable? Then, as part of that discussion, we’re going to be talking about how intentional we are in terms of disaster preparedness. A lot of the reliability behind this environment is because we are constantly thinking about what can go wrong, and how do we smooth the usage scenarios that one has if they are facing disasters, whether it’s a disaster exercise or a natural disaster. Then I’m going to conclude this talk with a little bit about a discussion in terms of our future challenges.
What Is It Like Developing Code at Meta?
How is it like developing code at Meta? If you’re joining, most of you know that Meta has a boot camp culture. When someone is joining the company, they are not going to go directly to their team to start working. They will go through this boot camping exercise that will basically introduce you to some of the core technologies that we have, how you do things at the company, and all that you need in order to be productive when you actually join your team from day one. At Meta, we have a large community of internal developers. This can be software engineers. It can be production engineers, like myself. These are the main two groups that the developer environment infrastructure is designed for. We also have data engineers, we have data scientists, all of these individuals will be using the developer environment. We also have enterprise engineers and hardware engineers, where we provide some partial support for their functions as well. Enterprise engineers being the software engineers that design and implement the internal systems that support functions like HR, functions like finance, and things of that sort. We have the hardware engineers that are basically designing chips, accelerators, and all of the gear that Meta has in terms of hardware infrastructure.
In terms of the development environment organization, where I am one of the members, the main focus is in terms of scalably supporting the user community, and the fleet of servers that are in place to provide that service. The main goal that we have is to minimize the fuss, so as a new developer, you should be able to basically get to the development environment whatever you choose, fire up VS Code or your favorite editor, and be productive right away. How do we make that happen? The first thing is that we try to be very quick in terms of onboarding the developers. You get all that you need, day one, and it should be all ready to go. You’re not going to spend a week trying to configure your environment or install a piece of software that you need, all of these things should be there automatically for you. That means up to date tooling, and it should be there for you automatically. When it comes to actually coding, you want to be able to put your code changes in as easily as possible. The tooling in terms of access to source control, repositories, the tooling that is necessary for you to create pull requests, which we call Diffs at Meta, all of these things should be there right away. If you do make configuration changes to the environment that you’re working on, that should also be automatically persisted. You shouldn’t have to do anything special. More importantly, you should be insulated from environmental changes that might affect you. The environment is meant to be as stable as possible. If there’s maintenance going on, if there are changes in the source control system, all of those things should be more or less isolated from you. As a developer who just joined, you basically think that you have an environment that is all for you. There is no disruption. There is nothing. It’s ready to go more or less immediately.
Main Offerings
What are the main offerings that we have in the development environment? If you’re a software engineer joining right out of college or coming from another company, you have the same choices. You have basically two main choices. One is what we call devserver. The second choice is what we call on-demand containers. You’re going to see what the tradeoffs are and what the differences are, in terms of these two different environments. On the devserver, this is more similar to having a pet environment. It’s basically a Linux server that is located in one of the data centers, you have a choice of which data center is more suitable for your physical location. We have different flavors of that. It goes from VMs. They have different sizes. They have different amounts of memory. It can go all the way to a physical server for those who need that. Some people are doing kernel development, they are working on low-level device drivers and things like that. It might make sense for them to have a physical server. Then there are certain special flavors. If you’re doing development with GPUs, or if you have the need to access certain types of accelerators, there are certain flavors that you can pick that is more suitable for the work that you’re going to be doing.
In terms of the lifespan, when you get one of these devservers, they might be temporary, or they might be permanent. Suppose that you’re in a short-term project to improve a device driver, so you might need a physical server just for a couple weeks. You also have the choice to get something permanently because you’re going to be using that, basically, continuously throughout your career at Meta. The interesting thing about devservers is that they run the production environment, and they run in the production network. As you are testing, debugging, you’re basically inserted into the environment that will give you access to everything that powers the Facebook infrastructure. You can have certain utilities and tooling pre-installed. We will talk about provisioning, but there is a way for you to basically say, I need all of these tools pre-installed. If I get a new server, I should have all of these tools already pre-installed. You can do things like that. You have remote terminal access, so you can just SSH into the box, or you can also use VS Code and work on your laptop connected directly to that devserver behind the scenes. Every server is managed by a provisioning system, so that means that they are permanently provisioned. That means that if there are updates to external software, to internal software, all of the upkeep that is necessary is done for you automatically.
They have default access to internal resources, but you do not have direct access to the internet. There are tools and there is infrastructure to do that, but that is not necessarily available out of the box. We try to minimize that, because that introduces potential risk as well. There is the ability to install precooked features. By features we mean the infrastructure around certain software packages that might help in your development work. There is also what we call one-offs. Those are things or tools that you as a new developer, you might be using, a spell checker that you like, or an editor that you like. You can also set that up and have that installed in any devserver that you get from that point forward. Devservers can also be shared. Sometimes you’re working with a team, like you’re hired, and you’re going to be working closely with someone else in your team or in a different team, and you can definitely share the access to that devserver with that team. There is also the ability to do migration between devservers. Suppose that for one reason or another, you need to get a bigger devserver, or you need to get a devserver in a different region, you can migrate from one to the other quite easily. One thing that is important here is that devservers, many of them are virtual machines, so they are layered on top of the same virtualization infrastructure that powers Meta. There isn’t anything special about that.
The second offering that we have is called the on-demand containers. The interesting thing about containers is that they are pre-warmed and pre-configured with source control, the repositories that you might be working on, linters, but they are ephemeral. It’s an ephemeral environment for a specific platform. If you’re doing iOS development or Android development, you’re going to get all of the tooling that you need in order to do development with that particular software stack. They have multiple hardware profiles. This means memory amount, whether they have GPU access, whether they have access to certain accelerators. They’re also accessible via IDE, so via VS Code or via the CLI. It depends on how you like to work. They are focused on workflows. As I said, iOS, Android, Instagram, or mobile development, or Jupyter Notebooks, whatever you as a new developer joining the company will need.
They include web server sandbox, so these replicates the prod environment. Suppose that you’re making changes to Facebook, to the desktop Facebook services, you basically have a replica of that environment at your fingertips when you’re using an on-demand container. This is also true for devservers. The point here is that this is ephemeral. It’s up to date. It’s ready to go at a click of the mouse. You can also further configure this environment. Suppose that you have certain features, again, features here being a piece of software and a configuration associated with that and you want that delivered to your container, you can have that as well. This container infrastructure is layered on top of Meta’s Twine, which is something similar to Kubernetes. We have containers and the orchestration that goes with it. You’re able to basically deploy these things very quickly, very much like any container technology that you have out there. If you’re interested in more about this, there is a good talk that was given @Scale 2019, that goes deeper into what we have as part of Twine.
Production Engineering
Why do we have production engineering? I’m part of that team supporting development environment. I just wanted to do this plug here, because one would think that development environment is just something that you need a bunch of SWEs to come together and put all of the software stack necessary to support these two products that we have. The interesting thing about Meta is that in many groups, production engineers are an integral part of the organization, because production engineers and software engineers, they have different focus areas. Production engineers are software engineers, but they are basically interested in terms of how to operationalize a service, so integration and operations. They are usually the ones that are responsible for managing the service deployment, the interaction, troubleshooting, and think about all of those things at scale. PEs tend to have a bias towards reliability, capacity planning, and scalability. They are always focused on deployment, on running upgrades efficiently, on configuration management, and also on a day-to-day basis, performance tuning and efficiency. Many teams at Meta have PEs associated with them. Other companies have similar organizations like the SRE organization at Google, the SRE organization at Bloomberg where I used to work. It is an interesting mix in terms of running efficiently services at scale.
What do PEs do in the DevEnv team? One of the main missions that we have in DevEnv is basically the efficiency of our developer community. In companies like Meta, Google, other companies that are software intensive, the company’s productivity is predicated on how productive the people who are writing the code and maintaining the code are. DevEnv PEs focus on the same things that any other PE team at Meta usually does. In our case, we have a particular target on developer efficiency. We want to make the service awesome, meaning it should be as frictionless as possible. If you’re joining as a new software engineer, you want things to just work out of the box. You don’t want to spend one month trying to figure out how to get your laptop to build a particular piece of code. All of that is provided for you from the get-go.
The second thing is, we are obsessed about automation. We are a relatively small team, if we count the SWEs and PEs, but we have a very large community that we’re providing services for, in the order of thousands of software engineers. As you know, software engineers are very opinionated. You want to make sure that the service is always reliable, works as expected, is fast, all that good stuff. The engagement that we have between PEs and SWEs in the DevEnv environment is actually part of the reason why we can provide a reliable infrastructure for our community. The service is a white box, meaning both PEs and SWEs understand the code that is behind the scenes. We make contributions to the same code base, have code reviews shared between PEs and SWEs. There is a very good synergy between the teams. It’s a shared pool of resources to put together the services that we have in place. This even includes sharing their on-call workload between members of the different sub-teams.
Development Environment Architecture at a Glimpse
Let’s start talking about the development environment architecture. The central point of this talk is, how do we make this whole infrastructure reliable? The first thing that is important to realize is that all of the stack that we have here that is used by DevEnv, is not special cased for our specific service. We are organized from the standpoint of a software stack, the same way that any other project or product at Meta is: whether it’s an internal or external product.
At the bottomest layer here, we have the server hardware and the infrastructure for provisioning servers. You can get on-demand and devservers in any region where we have data centers. We’re basically layered on top of the same infrastructure that any other service at the company has. That means that when it comes to server monitoring and server lifecycle, we are under the same regimen as any other product. When it comes to provisioning, for example, there are ways for us to specialize the provisioning system, but those are basically plugins to the software stack that will provision a server, very much like a server that you would have for a database system, or logging system, or whatever you’re talking about in the company.
When it comes to the services that we’re using, the basic monitoring infrastructure that we have in place applies to the services that are part of the infrastructure that supplies the products that are part of DevEnv. Same thing is true for our service lifecycle. Most of the services, they are also run as Twine tasks. They are monitored, they are logged, all of that is the very same infrastructure that everybody else has access to. When it comes to the ‘servers’ that people have access to, whether it’s a virtual machine or a container, we are basically sitting on top of the virtualization infrastructure that powers the rest of the company and the same containerization infrastructure that powers the rest of the company. Then on top of that, we have the actual service, the devservers are on-demand. On top of the whole thing, we have the developer and the tools that they are going to be using. There is nothing special about the DevEnv environment when it comes to the tooling and the software stack within the company.
Designing for Reliability
Now let’s start talking about designing for reliability. If you are a software engineer working for Meta, the last thing that you want to worry about is, did I install the latest updates to my devserver? You don’t want to do any of that. You don’t want to worry about backups and that particular devserver potentially crashing, and you’re losing a day of working because of that. There are many things that we do when it comes to designing for reliability. We want to make that new developer as well as the longtime developers that we have in the company as productive as possible. The whole software stack relies on the internal infrastructure that we have. We design the service to be scalable and reliable from the outset. Why are those two things important? Scalability is important, because during many years, the company was growing at a very high pace in terms of onboarding new developers, creating more services, and things like that, and we have to have the ability to basically ramp up all of these people that were being hired at a very fast click. We also have to be reliable. The team is small. We don’t have the ability to handhold every single developer, so most of the things have to just work. Providing reliability in a company like Meta or many of our peers, it means that we have to design for an unreliable world. Switches die, servers die, what can you do in order to basically insulate people from all of the dynamic things that happen when you have a very large fleet. We basically relied on a bunch of internal services that were designed to cope with an unreliable world. DNS, all of the infrastructure that powers the internal systems, which is highly reliable and scalable. Service router, which is basically a way that allows users or clients of a service to find the servers. Again, to cope with any unreliability that might befall that particular service. We also rely on the Meta MySQL infrastructure. That means that the databases are running master-slave mode, and you have distribution of the workload, all of that good stuff.
We also rely on the provisioning infrastructure. You can basically ramp up a new devserver very quickly, if you have to. The provisioning system has all of the recipes, all of the infrastructure to basically bring a fresh server to a running state quickly. We also rely on the virtualization infrastructure. It’s very easy to turn up a new virtual machine to potentially supply the devserver environment to a new developer. We also rely on the containerization infrastructure. There is a plethora of other services that we rely on. One of them is the auto-remediation infrastructure, so many of the common failures that one might face when it comes to a particular service that you’re providing, has automatic remediations. Something goes wrong, there is a predefined set of logic that we will run in order to rectify that particular failure. The other things are more on the logical side. One of the things that is important, and it’s integral part of the culture at Meta is what we call SEV reviews. Every time that we have an outage, it can be an outage in our service or in one of the services that DevEnv uses, we have a formalized process to review what created that site event. SEV stands for Site Event. The main thing is that very much like in the aviation industry, if something goes wrong, we want to be able to learn from it and improve from it, so ensure like that doesn’t reoccur.
The other important aspect of designing for reliability is fitting in with the overall company infrastructure when it comes to disaster recovery. Meta as a company has a well-defined process for running disaster recovery exercises, and for potentially automating things that one might need to act on in the face of a natural disaster or a disaster exercise. This is another area that is very interesting. There is an external talk that discusses these in more detail. The key message here is that the development environment fits in very well with the disaster recovery strategy for the company. There are multiple strategies that we have in place in terms of the ops side of the business here. In terms of team facing strategies, we have on-calls, and we have runbooks. If something should happen to the service, we try to strive for having well-defined runbooks that the people who are on-call during that particular week can just follow on. There’s continuous coverage with good reporting, and basically workflows that dictate how you should transition from one call shift to the next. There are well documented workflows for every on-call, whether they are someone who has been doing this for a long time, or someone who had just joined a team. We try to basically spread that knowledge to the people who are holding the fort.
Then there are certain strategies that are user facing. How do we ensure that you have that perception that the environment is reliable? The main thing here is communicating. We try to have well developed communication strategies to talk to the user community. For example, if we know that there’s going to be outage of a particular service because we are running a company-wide disaster recovery, we have a strategy in place to communicate with the user community to alert them that they should be on the lookout and they should prepare for that exercise. More importantly, there are things that we do to minimize the pain when you do face a disaster or a disaster recovery exercise, so transparent user backups. Designing for an ever-changing world, so OS and software upgrades are a constant. How can we do those things without disrupting the user, and giving them a reliable environment to work on?
User-Facing and Infra-Facing Automations
Let’s talk a little bit about user-facing and infra-facing automations, because those automations are the things that are basically going to ensure that the environment is reliable. We try to do those things in such a way that we don’t disrupt the typical development workflow that a software engineer or a PE has in their day-to-day. The first thing is that common issues should be self-service. From a user standpoint, if something goes wrong, many of our tools have a mode by which they can self-diagnose and self-correct the issues that you have in place. There will be scripts, or there will be tooling for you to basically run, and those tools will basically go through a set of validations and eventually correct the situation for you. In the worst case, many of these tools also have what we call a rage mode, which allows you to basically run through all of those self-correcting steps, but also collect evidence in case it doesn’t work. The team that owns that particular product can look at well-defined logs and data to help rectify that situation.
On the team-facing side, we have tools like Drain Coordinator and Decominator. These are automated tools that suppose that you have a server that is going to undergo maintenance, there’s a bunch of choreographed steps that will take place in order to not disrupt the end user. One of the things that we might be doing is that if you have a devserver that happens to be a virtual machine, we could potentially move it to a different physical service without disrupting the end user who is the owner of that devserver. There is also something called Decominator that basically automates the process of sending a server to the shredder, if it has hit end of line, and potentially alerting the users doing all of the tasks that are necessary to basically drain that particular server and indicate to the user that they have to move on to a different environment.
Preparing for Disasters
The next thing that I wanted to talk a little bit about is that, again, if you’re a developer, you don’t want to be doing your own planning for disasters. More importantly, you don’t want to be concerned with when disaster preparedness exercises are going to be run. How do we prepare for disasters in such a way that we don’t disrupt the developer efficiency for the company as a whole, or for a particular developer individually? The first thing is capacity planning. We design our service to have spare capacity in different regions, under the assumption that if you need the extra capacity to move people around, because there is maintenance going on in that particular data center, that people can just migrate automatically from one, if they’re using a devserver that happens to be a VM, that they can be moved to a different physical service. We also design for ephemeral access. In fact, the majority of our developers, they tend to use the on-demand containers, which are ephemeral. Every time that you get a new one, you get the freshest setup possible because these are short-lived tasks. I think they live for a day and a half, and that’s it. When you get the new one, you have the latest version of the source control system, of the linters, whatever. It comes brand new to you. The other thing that is important is that we run these disaster recovery exercises. We have two kinds when it comes to the impact to the developer environment, we have storms. Storms is the term that we use internally. It comes from an actual storm, those tend to hit the East Coast of the U.S. rather frequently. They can be as disruptive as taking down a data center fully. We call these exercises storms. We also have dark storms where we can potentially wipe the contents of random devservers. This is to ensure that we have the infrastructure and people are aware of this particular aspect of their devservers.
The other part that is important here when it comes to disasters is that you have good tooling. You have to be able to drain people from particular regions. For example, if you’re not going to have access to a particular data center, you have to make sure that you don’t let anybody use that particular region, if they’re trying to get a new on-demand container that they don’t go to that region. For those who are in that region, or will be in that region during one of these exercises, you want to basically drain them out so they don’t lose anything as the exercise takes place. We also invest a lot in terms of automating runbooks. Runbooks are basically like a cooking recipe in terms of what one needs to do as you’re running these exercises, from notification to draining, all those things should be spec’d out in the runbook. We also have devserver live migration. That means that we have the ability relying on the virtualization stack to basically move one server from a physical server to a different one without disrupting the user. You don’t even have to power down your VM. We also invest on backup and migration workflows. If you do lose your dev VM, you have to have the ability to basically allocate a new one as painless as possible. Then we have some strategies in place to survive internal DNS failures. If that does occur, we have to lean to basically allowing you to get to the devserver bypassing DNS when that’s necessary. Then the last thing that I want to highlight is the ability to communicate. If you’re running one of these disaster exercises, we email folks, we open a task, which is our Jira like environment. We send a chatbot communication to indicate that if you have a devserver in the affected region, you will have to temporarily get a new one in a different location, and potentially restore your backups, so you’re up and running quickly.
Storms and Drains
Let’s talk a little bit about storms and drains. There are two types of exercises, storms and drains. Storms are those exercises where we completely disconnect the network from the data center. It simulates like a complete loss of that particular region. We also have drains, and drains is when we selectively drain a site and fail over to a different site. The network remains up. Why do we do these things? First, we want to periodically be able to test all of the infrastructure together signal for things not being resilient to the loss of a single region. Why do we do this thing periodically, because once you work out the kinks out of the system, it should remain good? That’s not the reality. The reality is that our software stack is constantly evolving. It might be that you cleared all of the design points in one exercise, but someone introduces a feature that creates a single point of failure again. That’s the reason for doing this thing frequently. The point really is that we want to be prepared for large scale power outages or network incidents, or even self-inflicted issues that might occur. We do this thing on a periodic basis, to again continue to validate that our design decisions, our architecture, everything is in place in order to provide that high efficiency environment that we want to provide. What types of signals do we collect when we run these exercises? Capacity, do we have enough of it that would enable people to migrate quickly if they have, for example, devserver? Or do we have enough on-demand containers in a particular region to accommodate the loss of a different region? We have failovers, so some of the services that we run in that data center will become unusable. Do we have the ability to fail over to a different region? Recovery, are we able to recover from those failures? Do we have all of the process orchestration in place to make sure that everything will remain operational. That’s basically the reason why we run storms and drains.
Runbooks
Let’s talk a little bit about Runbooks, because this is more specific to what each group at Meta eventually has to do, including us. A runbook is basically a compilation of routine procedures and operations that an operator needs to carry out in the face of a particular situation. In this case, in the face of a disaster. The goal here is that we should be able to do these things in a repeatable fashion. Which means that we should be able to automate as much as possible. Meta actually has a runbook tool that enables you to basically list all the steps that need to be carried out. Runbooks can be nested. One runbook can invoke another runbook as a step. These steps can be an operation, a logical barrier. You’re basically waiting for a bunch of steps to be completed. It can also be another runbook. When it comes to runbook development, there is a whole environment behind it that allows you to validate, debug. You can rely on preexisting templates for things that are more or less general purpose. At runtime, when you invoke one of these runbooks, there’s tooling that will basically capture the dependencies that will allow for step orchestration, that will capture execution timeline and logs. This is all in place so you can actually do a post-mortem after you have invoked one of these runbooks.
Comms
Let’s talk a little bit about comms. When you’re running these exercises, they can be highly disruptive. One of the investments that we have made, again, so the individual user, that new software engineer who joined, so they don’t have to worry about is to have a well-defined strategy in terms of how we communicate with those users. The aim here is to maximize the efficiency of a particular developer, so you don’t lose a day if we’re running one of these exercises. The first thing is that we try to communicate ahead of time, whenever it’s possible. We try to be preemptive. Obviously, when we are running a disaster recovery exercise, the whole point is that this should look like an actual disaster. We don’t give a warning like weeks in advance, this will happen a couple of hours before the exercise takes place. Because the other thing that we want to do in terms of the culture is have the developers themselves be aware that they might potentially lose a devserver. They have to be aware of what they need to do in order to be able to survive those few hours that they might not have access to that devserver. One of the things, for example, that we want to educate the users about is that you should never be running a service on your devserver because it’s an environment that can disappear under you.
The other thing that is important here is that we want to be able to empower the user to self-correct any problems that might occur and continue to work. Why is all of these important? We don’t want any surprises. We want the developer efficiency to remain high even in the face of those potential losses. In terms of the mechanics of how we do this, is that we have the ability to run banners. As you go to a particular internal website, there will be an indication that there is a disaster recovery taking place. The Shaman banners are basically a way to broadcast information, so everybody is aware of it efficiently. The second aspect to this is the automation of alerting for developers. There are emails, tasks, and chatbot messages that go out very quickly, which will enable you to basically react to the loss of a devserver, for example.
Live Migration
One other thing that I wanted to talk about is the ability to live migrate users or virtual machines. For people who are using devservers who are virtual machines, we have the concept of a virtual data center. The reason for it being a virtual data center is because every server in that data center has a mobile IP address, which enables us to basically migrate a virtual machine from a physical server to a different physical server without interrupting the workflow. This is very useful when it comes to simplifying maintenance workflows, from time to time. There might be a hardware problem, like a fan died and you need to basically carry out that maintenance workflow on that physical server. We can easily migrate all of the devserver VMs that are on that physical host to a different one, to enable that maintenance workflow to take place. This relies on something called ILA. There’s a very good talk about it at Network@Scale 2017.
Learn From Quasi-Disasters
What is the point of running disaster exercises if we don’t learn from them? The main thing when we are running these exercises is that we want to be able to learn from it. Every time we run these exercises, we open a preemptive SEV for this. Then, after the exercise has taken place, that SEV is closed, but we collect all the information related to that event in-depth in the tool that supports the management of SEVs. Subsequently to it, we have a SEV review. Every SEV that we have at Meta, the goal, at least, is to have all the SEVs reviewed. The owner of that SEV, in the case of DevEnv that will be the person who was on-call during that exercise, will put together an incident report. There is tooling for these to ensure that we do this thing in a consistent way. This thing is reviewed by a group of senior engineers and whoever wants to join that process. As a result, we will produce a bunch of tasks to drive the process of improving whatever needs improving. There will be critical tasks, those are timely reviewed, and they might be addressing the root cause that made something not work. Then we might have medium priority tasks that will basically allow us to mitigate issues in the future. They will also allow us to remediate things or prevent things. There might even be exploratory tasks that will drive architectural changes, potentially redesigning services that have shown not to be reliable to potential disaster scenarios. The key thing here, again, is we learn from disasters, so we can provide that environment where people are always productive. They don’t have to worry about their developer environment.
The Future
The first thing that is in front of us, again, to make sure that that new software engineer or the old timers, remain as productive as possible, is to harden the infrastructure to tolerate disasters. We are currently in the process of better integrating with the reliability program maturity model. We are improving our on-calls. We are investing a lot in terms of observability, and incident management, and also in terms of crisis response. What are the things that we can do in order to better respond to potential failures that we might have in the environment? We have to remember that DevEnv resources are critical in the disasters. Oftentimes, having access to your devserver is what a PE or a SWE who is working on an actual disaster needs. The environment has to be bulletproof to enable people to work through things that might be affecting other parts of the computational infrastructure at the company. There are interdependencies. One of the key things that we have been working on is on being resilient to DNS outages. One thing that might not be clear here is that devservers are Linux servers. How do you get to a Linux server if DNS is down? We have worked a lot on infrastructure to enable that to happen. Then there is the whole thing of being able to work with degraded access to source control and continuous integration and delivery. Oftentimes, in order to fix an actual SEV, or an actual disaster, you have to ship more code. Or to undo things that have been done, how can we make those things work?
Then, there is the whole thing of improving the reliability practice. We are investing a lot in terms of architecting code reviews. This is to make sure that from the outset, as we are adding new features or subsystems, that we’re not creating potential failure points in the whole stack. Then there is the periodic reassessment of the state of our production services. How do we make sure that things don’t decay, because we’re just not paying attention? Then, focus on problem areas. What are the things that on-calls are seeing day in and day out? We are putting effort in terms of improving these as well. All of the work and all of the architecture that you saw here, is in place in order to enable software engineers, production engineers, data scientists, to work as efficiently as possible without having to worry about the environment that they are working in.
See more presentations with transcripts
MMS • Claudio Masolo

Cloudflare’s blog described its MLOps platform and best practices for running Artificial Intelligence (AI) deployment at scale. Cloudflare’s products, including WAF attack scoring, bot management, and global threat identification, rely on constantly evolving Machine Learning (ML) models. These models are pivotal in enhancing customer protection and augmenting support services. The company has achieved unparalleled scale in delivering ML across its network, underscoring the significance of robust ML training methodologies.
Cloudflare’s MLOps effort collaborates with data scientists to implement best practices. Jupyter Notebooks, deployed on Kubernetes via JupyterHub, provides scalable and collaborative environments for data exploration and model experimentation. GitOps emerges as a cornerstone in Cloudflare’s MLOps strategy, leveraging Git as a single source of truth for managing infrastructure and deployment processes. ArgoCD is employed for declarative GitOps, automating the deployment and management of applications and infrastructure.
The future roadmap includes migrating platforms, such as JupyterHub, to Kubeflow – a machine learning workflow platform on Kubernetes that recently became a CNCF incubation project. This move is facilitated by the deployKF project, offering distributed configuration management for Kubeflow components.
To help the data scientists initiate projects confidently, efficiently, and with the right tools, the Cloudflare MLops team provides model templates that serve as production-ready repositories with example models. These templates are currently internal but Cloudflare plans to open-source them. The use cases covered by these templates are:
1. Training Template: Configured for ETL processes, experiment tracking, and DAG-based orchestration.
2. Batch Inference Template: Optimized for efficient processing through scheduled models.
3. Stream Inference Template: Tailored for real-time inference using FastAPI on Kubernetes.
4. Explainability Template: Generates dashboards for model insights using tools like Streamlit and Bokeh.
Another crucial task of the MLOps platform is orchestrating ML workflows efficiently. Cloudflare embraces various orchestration tools based on team preferences and use cases:
– Apache Airflow: A standard DAG composer with extensive community support.
– Argo Workflows: Kubernetes-native orchestration for microservices-based workflows.
– Kubeflow Pipelines: Tailored for ML workflows, emphasizing collaboration and versioning.
– Temporal: Specializing in stateful workflows for event-driven applications.
Optimal performance involves understanding workloads and tailoring hardware accordingly. Cloudflare emphasizes GPU utilization for core data center workloads and edge inference, leveraging metrics from Prometheus for observability and optimization. Successful adoption at Cloudflare involves streamlining ML processes, standardizing pipelines, and introducing projects to teams lacking data science expertise.
The company vision is a future where data science plays a crucial role in businesses, this is why Cloudflare invests in its AI infrastructure and also collaborates with other companies like Meta, for example, making LLama2 globally available on its platform.
EXCLUSIVE: “Rebuilding Banks…it’s a team effort!’ – Temenos, Capgemini and MongoDB in …
MMS • RSS

‘Componentisation’, sometimes known as composable banking, has emerged as the alternative to ‘big bang transformation’. By its very nature, it demands compatible solutions, underpinned by strong vendor partnerships, such as that between Temenos, Capgemini and MongoDB
We asked Joerg Schmuecker, director of industry solutions at document database MongoDB, Mark Ashton, senior director at banking IT solutions provider Capgemini Financial Services, and Paul Carr, global head of partner ecosystems at banking-as-a-service giant Temenos, to explain the concept and implementation of ‘componentisation’ and how it shapes their partnership.
THE FINTECH MAGAZINE: What is componentisation and why are banks interested in it?
PAUL CARR: Componentisation is all about breaking down big, monolithic systems into smaller, manageable chunks that are easier to install, implement, run and upgrade. This is especially important with the regulatory requirements we’re seeing around databases, enabling us to have faster, more easy and cost-effective access to data securely, without having to change entire banking systems.
MARK ASHTON: From a business perspective, the need to access data that’s spread across their organisation in real time is one of the most significant drivers of componentisation among banks. The arrival of nimble fintechs which can access data quickly, has led larger organisations to re-evaluate how they can compete using new agile, more iterative approaches, which break complex information down into simpler elements.
For legacy-based organisations, accessing data requires so much navigation and understanding, and regulatory and compliance challenges make it hard to unlock the value within it. Looking at it from a technology perspective, to transform legacy systems you have to decompose them, extract and componentise things to provide the necessary access and reinvigorate established systems.
Then there are the architecture and the ecosystems that support all that. The challenges are causing a lot of organisations to rethink their architecture, like payment systems that don’t meet modern requirements. Componentisation is one way of changing those building blocks.
“The need to access data that’s spread across their organisation in real time is one of the most significant drivers of componentisation among banks”
In terms of potential benefits, financial institutions are becoming data owners and brokers for their customers, with onboarding a classic example. Historically, a customer might see a product like a loan advertised online, but taking one out meant having paperwork sent out for them to sign and return and getting documents reviewed.
Fintechs can tell them within 30 seconds if they might be eligible and, if they choose to complete the journey, give them an answer in less than two minutes, all driven by integrating their data with that of other organisations, including credit reference and fraud prevention agencies. Componentisation can help incumbents ensure they also have the right data at the right point of need.
JOERG SCHMUECKER: The most important thing to banks that have been around for 30 or 40 years, is their ecosystem of customer data, secured and collated over that time. Bigger, older banks, are very conservative in their approach, so asking them to go big bang and convert everything in one hit is never going to happen. Componentisation, especially with data and databases, enables them to go to the next level of banking solutions without having to build everything in-house and, where you do, being able to switch to another provider’s better implementation of the same thing.
For instance, I might have a payment system at my bank that isn’t SEPA Instant payment compliant. I need a component that I can plug into my platform to make me compliant as quickly as possible. If I have everything handcrafted, that might be very difficult but componentisation makes putting stuff into the right boxes easy, and allows you to change those boxes.
Those boxes also need to be able to share data in an easy format, you need to ship the data around. That’s where componentisation and data touch together, because shared state is the hardest part in software development. Temenos is our customer and partner, and it recently announced that MongoDB will be underpinning its Transact platform. In 2022, Temenos built its platform on Amazon Web Services and ran its high-water mark benchmark with MongoDB, with a now-obsolete database behind it. Now it can do the same on Azure, by simply changing the components underpinning its infrastructure. That’s an example of a componentisation well done.
TFM: How has the changing nature and volume of data driven the case for componentisation?
JS: We used to build systems around disk spaces; now, we are building them around use cases, enabled through better storage platforms, with better development technologies and Cloud providers that can run things in a much more scalable way. When we talk about data, most people think about hard disks spinning. These things used to be incredibly expensive, but now our phones probably have way more space on them than all the disks in the world had in the 1980s.
Because we’ve transitioned to the point where this space is free, it changes the way we handle data. We don’t care about storing redundant information anymore because it’s not expensive, whereas we used to have to save bytes through steps like only referencing years as two digits, not four. That was the situation we came from, and that’s most of the relational database management systems we are dealing with – and a lot of the mindset behind them, too.
With document databases like MongoDB and others, because you have humongous amount of data space available to you, you can aggregate and bring it together on demand, and slice and dice it as needed for the consumer. So, if I pay a hotel bill via a wire transfer in Italy and then, two days later, go to Italy and want to pay with my credit card, I don’t expect my bank to flag that as a potentially fraudulent transaction. It should know I paid the hotel and I’m very likely in Italy, so should take the view that it’s a low risk, especially if I’m only buying an ice cream for €3.50.
“We used to build systems around disk spaces, now, we are building them around use cases, enabled through better storage platforms and Cloud providers”
This is what the fintechs have been brilliant at: they have a small domain, a single bucket [of data] and therefore a great overview.
TFM: What are the first steps for organisations thinking of embarking on a componentisation journey?
PC: Banks must have realistic expectations rather than thinking ‘you’re going to transform my entire business in six months if I implement this strategy’. Going from a monolithic, 30-year-old system, to a brand new, composable, componentised solution within six months, doesn’t happen, alas.
This is one of the reasons why our deployment strategy at Temenos involves engaging with partners like Capgemini early on when we start talking to banks, because we don’t know all of our competitors’ offerings, software, etc, whereas our partners do. It’s about understanding what the bank wants to achieve. Does it want to modernise, does it have an old system and wants to keep the same as it has today but on a new platform, or is it looking to do something different?
Lots of banks are looking at banking-as-a-service – not just to satisfy their customers with financial products, but also to consider selling their banking platform to other companies. So it’s understanding where banks are today, where they want to be and how we can get them there, then making sure we’re partnering with the right companies, like Capgemini, like Mongo, to offer a solution.
TFM: How can organisations get ‘componentisation-ready’?
JS: Being clear on how becoming more data-driven can benefit their business – that’s a good starting point, because otherwise they end up with big data lakes that people just pipe information into, hoping they will be able to make sense of it afterwards. It’s easy and cheap to collect large amounts of data, but making sense of it gets expensive.
Once clear what they want to achieve, they can define their data architecture, which might mean having low-latency streaming platforms as with electronic trading platforms. Then, even if their technology is clunky and fragmented, they can use something very low latency to bind their components together.
MA: There’s a lot of hype out there, in terms of what generative AI can do. Data underpins AI and the security and guardrails around it will certainly drive some interesting conversations. I’m optimistic that it will have value as a tool and help with efficiencies. But it’s not going to be a universal panacea.
Meanwhile, the use of data platforms is becoming almost mandatory in this componentised world, with lots of federated data to manage, monitor, track and keep as the core building blocks for any modern architecture. Almost all our banking customers, unless they’re a fintech, are looking at modernising and moving away from legacy systems for their core banking platforms, opening conversations around a modern architecture that leverages technologies like Temenos, AWS and Azure.
“Componentisation is the future but how we, as vendors, align is key to its success “
It also raises questions like ‘how do we define data modelling and ownership when integrating and sharing data with third parties?’. Even with something as simple as an address, we need to ensure information we share is consistent within our own and third-party environments, for seamless integration.
TFM: Banking is a highly regulated industry and banks might be concerned that componentisation introduces risks. How can that be avoided?
PC: We work with the Securities and Exchange Commission in the US, with the General Data Protection Regulation in the UK, and multiple other regulatory requirements to create our ‘Country Model Bank’. This sits above our product, satisfying country regulations.
We would love it if a bank took our entire platform, from digital front end to core banking, financial crime and wealth management, taking care of the regulatory requirements across everything. But we know that doesn’t happen in the real world, so we need to make sure that if we’re satisfying regulatory requirements in one part of the component, other vendors who are fulfilling the others are doing the same.
If we’re going to have multiple solutions componentised into smaller chunks, we have to think about how we ensure the regulatory requirements span all of them. There are certain things you must start with for componentisation – a platform and a baseline. Whether that’s a Cloud or on-prem infrastructure, everything needs to fit across the components you’re going to use.
We need to look at the basics first, and plan, plan, plan before implementing. Regulatory requirements, data sharing and data availability requirements, etc – if you don’t have that basic foundation the rest becomes impossible to manage, upgrade, implement or deploy. Componentisation is the future but how we, as vendors, align is key to its success. It really speaks to a partnership model because no one institution can cover everything, particularly with different data reporting standards and geographies.
For me, the key is having simplicity across the platform and all working together towards the same outcome.
TFM: How can componentisation support an alternative business model for legacy institutions?
PC: All our 3,500 customers are considering how they can generate more business and opportunity than just with current accounts, loans, mortgages, etc. With increasing competition, banks must be agile in offering new services to keep their existing customers and tempt new ones in. Changing their entire banking solution to enable that is not feasible, but componentising it to be able to offer a new loan or loyalty scheme, is.
Componentisation is a real enabler for selling their services, not just to customers but to other businesses, almost becoming fintechs themselves. It’s going to be a very exciting ecosystem, with greater competition, where customers have lots of banks from which to choose the one that offers something they are particularly looking for.
BaaS and SaaS, supported by componentisation, will bring this revolutionary change to a system that’s been around for three or four hundred years.
This article was published in The Fintech Magazine Issue 30, Page 12-14
Oracle Java Platform Extension for VSCode Delivers Comprehensive Support for Java Applications
MMS • Johan Janssen

Oracle has introduced the Oracle Java Platform Extension for Visual Studio Code for building, running and debugging Java applications using JDK 11 or newer for developers who use Visual Studio Code.
The extension can be installed in Visual Studio Code via Code | Settings | Extensions or by pressing CTRL-P to launch the VS Code Quick Open, then copy the command, ext install Oracle.oracle-java, and press Enter.
Afterwards, the extension makes it possible to install a new JDK or select an existing JDK from the filesystem via View | Command Palette | Download, install and use JDK. The selected JDK will be used to run the extension, but also to build, run and debug projects.
The extension searches for a JDK in the following locations: the jdk.jdkhome and java.home properties, the JDK_HOME and JAVA_HOME environment variables, and the system path.
Profiles can be used for each Java runtime version, especially when using multiple Java versions on the same machine. Each profile has a settings.json file, which can be configured via Code | Settings | Profiles | Edit Profile, and contains configuration such as the jdk.jdkhome property.
New projects may be created via View | Command Palette | Java: New Project and existing Maven and Gradle projects can be imported.
Running or debugging an application is possible via Run main | Debug. Optionally, the launch configuration may be changed by choosing Java+… from the dropdown list and then clicking on the run icon. Various options may be configured via the Run Configuration panel of the Explorer view in order to change the environment variables, VM options, working directory and arguments for the process.
The .vscode/launch.json file specifies the default launch configurations such as the mainClass. A debugger action may be attached in the launch configuration by selecting a local process or a port.
A test can be created by clicking on a light bulb and clicking on Create Test Class. This generates tests which are either empty or failing. The Test Explorer view allows running all the tests, or specific tests.
Generating code such as a constructor, logger and toString() method is possible via the Source Action context menu . Typing /** above a method triggers the extension to create JavaDoc. Right clicking on code and then clicking on Change All Occurrences allows changing the same code in multiple places.
More details may be found in this YouTube video by Ana-Maria Mihalceanu, Senior Developer Advocate at Oracle, as she explains the various features of Oracle’s Java Platform extension for Visual Studio Code.