Transcript
Pressler: My name is Ron. I’m an architect at Oracle’s Java Platform Group. That’s the team that specifies Java and develops OpenJDK. In the last several years, I’ve led an OpenJDK project called Project Loom, which has contributed some features to the JDK, and today, I’ll primarily be talking about one of them, virtual threads. Later on, I’ll mention a couple of others. Virtual threads are threads that are represented by the same 27-year-old java.lang.Thread class. They’re implemented in the JDK in user mode, rather than by the OS. You can have millions of them running in the same process. I like to talk about why we added the feature, and why we did it differently from some other languages.
Java Design Choices
First, to understand some of our design choices. Let’s talk a bit about Java’s general philosophy and the market environment in which it operates. Java has been the world’s most popular server-side programming platform for many years. No other platform language with the possible exception of C and JavaScript has been this popular for this long. Java has an ecosystem that is both very large and quite deep, and by deep, I mean that third and fourth level library dependencies are a common thing in the Java world. James Gosling said that he designed Java as a wolf in sheep’s clothing, a very innovative runtime that to this day offers state of the art compilation, garbage collection, and low overhead observability that together make an attractive combination of productivity, performance, and tooling. All that is wrapped in a very conservative language. Why? Because this strategy has worked well for us. Java’s users seem to like it, and there are many of them. We also place a high premium on backwards compatibility, because companies trust Java with their most important programs and we want to give them a good value for their investment. Given Java’s longevity and good prospects for the future, we try to think long-term. Many times, we’d rather wait and think whether a feature that could be attractive right now, might suffer loss in the future.
Whenever we do add user facing features, we always start with a problem. The problem in front of us when designing virtual threads was that of concurrency, in particular, concurrency in servers, which are Java’s bread and butter. First, a little bit about differences between concurrency and parallelism. If parallelism is the problem of accelerating a task, that is reducing its latency by internally splitting it down into multiple subtasks, and then employing multiple processing resources to cooperate on completing each of those subtasks and say, the one big task. Concurrency is the problem of scheduling many largely independent tasks that arrive at the application from the outside onto some set of resources. With concurrency, we’re mostly interested in throughput, or how many of these tasks, or normally they are requests, we can complete per time unit.
Little’s Law
Like I said, we’re mostly interested in servers, and there’s a very useful equation describing the behavior of servers called Little’s Law. It is actually more complex than it may first appear because it is independent of any statistical distribution of the request, and that’s why it’s interesting and it’s also more useful than it may appear. Last year I gave an entire talk just about Little’s Law at a conference devoted to performance. Little’s theorem says this, if some server-like system, so a system that requests arrive from the outside, they’re processed in it, and then they’re dispatched and leave. If such a system is stable, which means that the requests coming in don’t pile up in an ever-growing queue, waiting to get in, then the average rate of requests times the average duration that every request spends inside our system, for some arbitrary definition of inside, that product is equal to the average number of requests that will be inside the system concurrently. That’s L. Because the system is stable, the average rate at which requests arrive is equal to the average rate at which they’re handled, namely, our throughput. Lambda is our throughput.
Also, the duration that each request spends in the system depends on what the system does, and how it does it, and can be thought of as a constant for the particular system. Of course, we optimize it as much as we can. Then we still reach some number W, that is characteristic of our system. Some of you might be wondering, what if that duration W depends on the load? For that, you will need to watch that other talk. Now we can think of the maximum throughput as a function of the system’s capacity, that’s the maximum, that’s the L bar, that’s the maximum number of requests that the system can handle, or can contain within it at any given time. This is very important to repeat. We see that the throughput, or the maximal throughput of the system, is a function, given that W is a constant for the system, it’s a function of the number of requests that it can process at any given time. The number of requests that the system can contain within it, that is the primary thing that determines its throughput.
Actually, an incoming request often translates to more than one concurrent server operation. Because there’s a common pattern in servers called fanout, where every incoming request splits into multiple concurrent outgoing requests to microservices or databases. We can see how the number of concurrent operations can be quite large. It’s the number of incoming requests plus all the outgoing requests. Of course, handling every request requires a mix of both I/O and processing. The question is, what is the concurrent request capacity of a server? Depending on the ratio of processing to I/O, the capacity of the server, at least as far as the hardware goes, can be around 10,000 concurrent requests per CPU call. If you have 30 calls, then your server can support about 300,000 requests within it at any one time. It can be lower than that, but it can also be higher.
Thread-per-Request – Thread Capacity
This finally brings us to the problem. Java was one of the first languages to have threads as part of a standard library and language. The thread is the Java platform’s unit of software concurrency. The easiest approach in Java and many other languages like it, is to represent the domain units of concurrency, namely the request either incoming or outgoing, or the transaction, with the software unit of concurrency in a thread, so do one to one. That is the traditional style of writing servers, and it’s called thread-per-request. In that style, a request is mapped to a thread for its entire duration for at least one thread, because then you can split into outgoing requests in a fanout. That means that to make the best use of the hardware, we need to be able to support 10,000 threads times the number of CPU cores. Java has never specified that a Java thread must be represented by an OS thread. For a short while in the ’90s it wasn’t. Ever since all operating systems started supporting threads many years ago, the main Java implementation that nowadays is called OpenJDK has used an OS thread to represent each of its threads. The problem is that most OSes simply can’t support so many active threads.
Asynchronous Programming
What do Java programmers do? It’s not just in Java, it’s in other languages, but I’m talking primarily about Java. To get the scalability we need, going by Little’s Law, we need a great many concurrent requests, but we can’t have that many threads. Instead of representing every domain into a unit of concurrency request, with an expensive thread, and it’s expensive because we can’t have many of them, we the Java programmers started representing them as asynchronous tasks. These tasks share a small thread pool. They hold onto a thread only when they’re doing processing. Where they need to wait for I/O rather than blocking, and hanging on to the thread while waiting for the I/O to complete, they return the thread to the pool to be reused by other tasks. When the I/O operation completes, the next processing stage is triggered and submitted to the pool and so on. The small number of threads that the OS can support is no longer an issue because we can have a lot of asynchronous tasks and we get excellent scalability and good hardware utilization. This asynchronous style that’s not thread-per-request, comes at a very high cost. First, composing the different processing stages of the asynchronous task, say, you want to initiate some outgoing request, then you have to wait for it, then you get it’s resolved, then you need to process it, so composing these multiple stages requires a monadic DSL. We can no longer use the languages built in composition of loops and exceptions, because those constructs are tied to a thread. The coding style is very different unless convenient.
Second, all I/O APIs need to be separated into two disjoint worlds that perform the same operation. In one world, the asynchronous world, blocks and hangs onto a thread while it’s waiting for I/O. In the other world, the asynchronous world, we don’t block but we switch to processing some other task. This means that if your application wants to move from the synchronous world to the asynchronous world, to get better scaling, much of it needs to be rewritten. Lastly, and no less important, we must remember that software is more than just code. It’s also about observing the program as it runs. Observability has always been very important in Java. We need to do it for debugging, profiling, troubleshooting. When we use a debugger, we step through the execution of a thread, not an asynchronous pipeline. Profilers gather samples and organize them by threads. When we get an exception, we get a back trace, and it gives us the context in the form of a particular thread’s stack. We lose all that with the asynchronous style of programming.
Syntactic Coroutines
What did other programming languages do about this? Some of them, I think, pioneered by C#, introduced something called syntactic coroutines in the form of async/await. These addressed the language composition problem, so you can use loops and exceptions, but they still require two separate API worlds that do the same things but they are syntactically incompatible. You can use one of them in one context, another in another context, even though they do the same thing. As for observability, the software unit of concurrency is now either a thread in the blocking world, or this async/await thing, this coroutine in the coroutine world. All tools need to learn about this new construct. Some of them have done that, some of them haven’t. Why did other languages choose async/await despite these downsides over implementing lightweight threads in user mode, as Erlang did, and Go did, and Java has now ended up doing as well? There are different reasons, both conceptually and technically, threads and syntactic coroutines are very similar. This is how a thread state is managed. Subroutines are state machines, and they’re connected to each other and make up one big state machine in the form of a tree. Async/await is pretty much the same thing. Yet, there are still some differences both in how the construct is exposed to users and how it is implemented in a language.
Thread vs. Async/Await
First, there’s a subtle semantic difference between threads and async/await. They have a different default regarding scheduling points. Those are the points in the code where the scheduler is allowed to suspend a process, a linear composition of something, so either thread or a coroutine from running in a processor. We do schedule it and schedule another to interleave them. Those are the scheduling points. For threads, it doesn’t have to, but the scheduler is allowed to interleave another thread anywhere, except where explicitly forbidden with a critical section expressed as a lock. With async/await, it’s the opposite. The interleaving happens nowhere, except where explicitly allowed. In some languages, you need to write await, in some languages it’s implied but it’s still statically known. Personally, I think that the former, the thread style is a better default because the correctness of concurrent code depends on assumptions around atomicity, when we can have interleavings. The first option allows code to say, this block must be atomic, regardless of what other subroutines that I call do. The latter is the opposite. If you change a code unit from a subroutine to an async coroutine to allow it to block and interleave, will affect assumptions made up the call stack, and you have to go up the call stack and change everywhere. You can’t do it blindly. You have to make sure whether or not there are implied assumptions about atomicity there. The assumptions are implied. Regardless of your personal preference, many languages like Java already have threads. Their scheduling points can already happen anywhere. Adding yet another construct with different rules would only complicate matters. Some languages don’t have threads, or rather, they just have one thread. By default, they don’t have interleaving anywhere at all. For example, JavaScript has just one thread. All existing code in JavaScript was written under the assumption that scheduling points happen nowhere. When JavaScript added a built-in convenient syntactic construct for concurrency, they naturally preferred a model where atomicity is a default, because otherwise, it would have broken too much existing code. This is why async/await makes sense in JavaScript rather than threads.
The second difference is in the implementation. If we want to implement threads in user mode, it requires reifying the state of the thread, so that picture I showed, the state of each subroutine. We need to represent the state of each subroutine. To do it efficiently requires integrating with the low-level representation of ordinary subroutines, the stack frames of the ordinary subroutines, and that requires access to the compiler’s backend. That is a very low-level implementation detail. On the other hand, async/await is a completely separate construct, and all that’s required to implement it efficiently is control over the compiler’s frontend. The frontend can choose to compile one of those units, not to a single subroutine, but to something else. Sometimes it’s maybe several subroutines, and sometimes it’s the opposite. One of them is how Kotlin does it. The other one is how Rust does it. Maybe you compile multiple async/await coroutines into a single subroutine, or sometimes you compile a single async/await into multiple subroutines. Some languages simply don’t have control over the backend, they don’t have access to that low-level representation. They simply have no choice. To get an efficient implementation, they must use async/await despite any shortcomings it may have. For example, Kotlin. Kotlin is a language that compiles to Java bytecode, and also other platforms. It’s just a compiler frontend. It has no control over the design of the Java Virtual Machine. It cannot expose or change the required internals. It also compiles to Android and to JavaScript to other backends that it has no control over, which is why async/await made sense for Kotlin. This is also somewhat of an issue for Rust, because Rust runs on top of LLVM, and WebAssembly. The situation there is a little bit different because they do have some impact in how those are designed.
Another difference has to do with managing the stack’s memory. If we have a thread stack, we have to keep it in memory, somehow. Ordinary subroutines can recurse, or they can do dynamic dispatch. That means that we don’t know statically at compile time how big of a stack we need. That means that thread stacks can either be very large, that’s how OS threads work, they’re just very large. That’s the reason why we don’t want OS threads to begin with. Or, they need to be dynamically resizable to be efficient, which means some kind of dynamic memory allocation. In some languages, usually, low-level languages like C and C++, or Rust, or Zig, memory allocations are very carefully controlled, and they’re also relatively expensive. Having a separate syntactic construct that could forbid recursion and dynamic dispatch may suit them better. That’s what they’ve done. If you’re in one of those, you can’t have recursion or dynamic dispatch.
Context-Switching
There’s another reason that’s sometimes cited as supporting the preference of low-level languages for syntactic coroutines, and that is the cost of context switches. I think that deserves a few more words. There are other reasons for coroutines besides concurrency. For example, suppose we’re writing a game engine, and we need to update many game entities every frame. From an algorithmic point of view, it’s more of a parallelism problem than concurrency, because we want to do it to reduce the latency of the entire processing things. The entities don’t come from the outside. Syntactically, we might choose to represent each of those entities as a sequential process. Another example is generators, shown here in Python. It’s a way to write iterators in an imperative way, by representing the iterator as a process that yields one value at a time to the consumer. We have an ordinary loop. The yield means I have another value that’s ready. When we yield, we deschedule the producer and schedule the consumer. This also isn’t quite our definition of concurrency, at least not the one I used. We don’t have many independent tasks competing over resources. We have exactly two, and they’re performing a very particular dance. Still, we could use the same syntactic constructs we use for concurrency. While, in practice, we normally make direct use of coroutines, and the consumer in this case is also the scheduler. The consumer says, now I want the producer to produce another value. We can think of them as two processes, a consumer and producer composed in parallel communicating over an unbuffered channel.
To understand the total impact of context switching on the generator use case, we mostly care about the latency of the total traversal over the data. We care about latency and not quite throughput. Just again a quick computation. If we take the processing time by both the consumer and producer to be zero, because they do some very trivial computation, then the context switch between them however much it costs will be 100% of the total time. Its impact is 100%. It is very worthwhile to reduce these. How fast can we make it? We notice that because we only have two processes, both of their states in memory can fit in the lowest level CPU cache. Switching from one to the other can be as quick as just changing a pointer in a register. A good optimizer compiler can optimize the two processes, because they’re both known at compile time, and inline them into a single subroutine and making the scheduling just a simple jump. Their cost could be reduced to essentially zero as well. Having an entire mechanism of resizable stacks here is not very helpful.
When it comes to serving transactions in servers, now the situation is completely different. First of all, we’re dealing with many processes. There aren’t any particularly great compiler optimizations available. We call them megamorphic call sites. The scheduler doesn’t know which of the thread it’s going to call statically, so we can’t inline them, we have to do dynamic dispatch. Their states can’t all fit in the CPU cache. Even the most efficient hypothetical computation of just changing a pointer will take us about 60 nanoseconds because we’ll have at least one cache miss. Because we have external events and I/O involved in servers, the impact of even an expensive context switch is actually not so high. A very expensive context switch of around 1 microsecond, will only affect the throughput of a system where the I/O latency is even very low, let’s say 20 microseconds for I/O. That’s very good. Even then, the impact is only 5%. Reducing the cost of the context switch from huge, humongous to zero, would give us 5% throughput benefit on extremely efficient I/O systems. We can’t reduce it to zero, because like I said, we have at least one cache miss. On the one hand, the room for optimization is not large. On the other hand, the effect of optimization is low. In practice, we’re talking less than 3% difference between the most efficient hypothetical implementation of coroutines, and even a mediocre implementation of threads. Because that limited C++ coroutine model has some significant downsides, because you can’t do recursion, the question then becomes, which of those use cases is more important to you, because you will need to sacrifice one or the other, so you need to choose.
For Java, the job is simple. We already have threads. We control the backend. Memory allocations are very efficient. They’re just pointer bumps. Scaling servers is more important to us than writing efficient iterators. It’s not just that the language and its basic composition error handling constructs are tied to threads, the runtime features such as thread-local storage, and perhaps most important to all the observability tools, they’re all already designed around threads. The entire stack of the platform, from the language through the standard library, all the way to the Java Virtual Machine, it’s all organized around threads. Unlike in JavaScript, or Python, or C#, or C++, but like, Go and Erlang, we’ve opted for lightweight user mode threads. Ultimately with that, we’ve chosen to represent them as the existing java.lang.Thread class. We call them virtual threads to evoke an association with virtual memory, that is an abstraction of a plentiful resource that is implemented by selectively mapping it onto some restricted physical resource.
Continuations
The way we’ve done it is as follows. More of the Java platform is being written in Java, and the VM itself is rather small. It’s about a quarter of the JDK. We split the implementation of virtual threads into two, a VM part and a standard library part. It’s easy to do because threads are actually the combination of two different constructs. The first is sometimes called the coroutines, just to not confuse, I call them delimited continuations. That is the part that’s implemented in the Java Virtual Machine. A delimited continuation is basically a task that can suspend itself and later be resumed. Suspending the task means capturing its stack. The stack in memory is now represented by new kinds of Java objects, but it’s stored in a regular Java heap together with all the other Java objects. In fact, the interaction with the garbage collector proved an interesting technical challenge that I will talk about this summer at the JVM language Summit. For various reasons, we’ve decided not to expose continuations as a public API. This class I showed does exist in the JDK, but you can’t use it externally unless you open it up. If they were exposed, this is how they would have worked. That’s the body of the continuation up there. Prints before, then it yields, and then prints after. Its external API is basically a runnable. You call it run, and rather than it running to completion, it will run until the point that we call yield. Calling yield will cause run to return. When we call run again, instead of starting afresh, it will continue from the yield point and print after. Calling yield causes one to return, and calling run causes yield to return.
Thread = Continuation + Scheduler
Threads are just delimited continuations attached to a scheduler. The scheduler parlance is implemented in the Java standard libraries. In fact, in the future, we will allow users to plug in their own schedulers. The way it works is that when a thread blocks, so in this code, we have an example of a low-level detail of how the locks in java.util.concurrent.locks package, they’re implemented, and when they need to block they call a method called park. What it does there, simply at runtime, when you look at the current thread, both the OS threads, which we now call the all threads, we now call them platform threads. Virtual threads are represented by the same thread class. If it’s a platform thread, so an OS thread, we call the OS, and we ask the OS to block our thread, that’s the unsafe part. If it is a virtual thread, we simply yield the current continuation. When that happens, our current task just returns. In fact, the scheduler doesn’t even need to know that it’s running continuations, it’s just running tasks, it just calls run. As far as the scheduler is concerned, that task is just completed. Now, when another thread, say the thread that already had the lock now wants to release it, it needs to wake up and unblock one of the threads waiting to acquire the lock. It calls unpark on that thread. All we do is if that thread is virtual, we take its continuation and submit it to the thread scheduler as a new task to run. When the scheduler just runs it as if it were an ordinary task, it will call run again. Rather than continue from the beginning, it will continue in that yield in the left-hand side and park would return. It’s as if park just waited and then returned. Of course, there’s more machinery to manage thread identity. In this way, code in the JDK works transparently for both virtual threads and for these platform threads. All the same construct, the same classes just work. In fact, old code that’s already compiled will also work.
Replacing the Foundations
We’ve done similar changes to all areas in the JDK that block. A lot of it went into the legacy I/O packages, very old ones that used to be written in C. Our implementation of continuations can suspend native code because it can have pointers into the stack, so we can’t move the stack in memory. We reimplemented those packages in Java on top of the new I/O packages. We got rid of even more native code in the process. A very large portion of the work actually went into the tooling interfaces, that supports debuggers and profilers. Their APIs didn’t change so that existing tools will be able to work. We expose virtual threads as if they were platform threads. They’re just Java threads. Of course, tools, they will have some challenges because if they want to visualize threads, for example, they might need to visualize a million threads. We’ve raised the house, replaced the foundation, then gently put it back down with very minimal disruption. Like I said, even existing libraries that were compiled 10 years ago can just work with virtual threads. Of course, there are caveats but, for the most part, this works.
Current Challenges with Java Threads
As expected, the throughput offered by virtual threads is exactly as predicted by Little’s Law. We have servers that create more than 3 million new threads per second. That’s fine. This is intentionally left blank. As is often the case, most of the challenge, it’s still ongoing, but it wasn’t technical, but rather social, and I’d say pedagogical. We thought that adding a major new concurrency feature was this very rare opportunity to introduce a brand-new core concurrency API to Java, and we also knew that the good old thread API had accumulated quite a bit of cruft over the years. We tried several approaches, but in the end, we found that most of the thread API is never used directly. Its cruft isn’t much of a hindrance to users. Some small part of it, especially the method that changed the current thread are used a lot, pretty much everywhere. We also realized that implementing the existing thread API, so turning it into an abstraction with two different implementations won’t add any runtime overhead. I also found that when talking about Java’s new user mode threads back when this feature was in development, and back when we still called them fibers, every time I talked about them at conferences, I kept repeating myself and explaining that fibers are just like threads. After trying a few early access releases of the JDK with a fiber API, and then a thread API, we decided to go with the thread API.
Now we’re faced with the opposite challenge, that of something I call misleading familiarity. All the old APIs just work. Technically, there’s very little that users need to learn, but there is much to unlearn. Because the high cost of OS threads was taken for granted for so many years, it’s hard for programmers to tell the difference between designs that are good in themselves, or those that have just become a habit due to the high cost of threads. For example, threads used to always be pooled, and virtual threads make pooling completely unnecessary and even counterproductive. You must never pool virtual threads, so you’re working against muscle memory here. Also, because thread pools have become so ubiquitous, they’re used for other things, such as limiting concurrency. Say, you have some resource, let’s say a database, and you want to say, I only want to make up to 20 concurrent requests to that database, or microservice. The way people used to do it is to use a thread pool of size 20, just because that was a very familiar construct to them.
The obvious thing to do is to use a semaphore. It is a construct that is designed specifically for the purpose of limited concurrency, rather than the thread pool, because a thread pool was not designed for limiting concurrency. A thread pool, like any pool, is designed for the purpose of pooling some expensive objects. It’s very hard for people to see that the two of them are actually thrusting to the same operation in memory. They think of a thread pool as a queue of waiting task and then some n, let’s say 20 of them making progress because they obtained a thread pool. If you have a semaphore initialized to 20, and every single one of your tasks is a virtual thread, 20 of them will obtain the semaphore and continue running, and the others will just block and wait. How do you wait? It becomes a queue. It’s the same queue. It’s just that every task now is represented by a thread. It’s hard for people to see that. We try and tell people that virtual threads are not fast threads but rather scalable threads. That replacing some n number of platform threads with n virtual threads will yield little benefit, like we saw in Little’s Law. Instead, they should represent each task as a virtual thread.
It’s hard to get people to make the switch from thinking about threads as some resource that requires managing, to think of them as business objects. I saw a question on social media, how many virtual threads should an application have? That’s a question that shows people still think of threads as a resource. They wouldn’t ask, how many strings should be used when storing a list of usernames? As many as there are usernames. The answer regarding virtual threads is similar. The number of virtual threads will always be exactly as many as there are concurrent tasks for the server to do. Those are our current challenges, because Java will probably be very popular for at least another two decades. There’s plenty of time to learn, or rather, unlearn.
Garbage Collection
I’d like to briefly talk about two other significant areas of the platform that have seen some major innovation, the past few years. First, garbage collection. There has been a significant reduction in memory footprints over the past releases of the G1 garbage collector, and that’s a default collector since Java 8. The most notable change has been the introduction of a new garbage collector called ZGC. It is a low latency garbage collector that was added a couple years ago in JDK 15. This is a logarithmic scale graph. As you can see on the right, ZGC offers way sub-millisecond pause times, like worst case for heaps up to 16 terabytes. The way it does it is that ZGC is completely concurrent, both marking and compacting, all the phases of the collection are done concurrently with the application and nothing is done inside stop the world pauses. Not only that, gone are the days of GC tuning. I think many people would find that they need to change their consultancy services. ZGC requires only setting the maximal heap size, and optionally the initial heap size. Here, you can see the p99 and p99.9 latencies of an Oracle Cloud Service. I think it’s easy to see where they switch to ZGC. Modern Java applications will not see pauses for more than 100 microseconds. This is the latency for the service, not the GC. They have other things. That level of jitter is something experienced by C programs as well. The only case where you won’t see it is if you have a real-time OS. If you’re not running with a real-time kernel, you will see that level of jitter even if you write your application in C. ZGC had some tradeoffs, it was nongenerational. It meant that the GC had a relatively high CPU usage. You had to pay for it, not in latency or throughput. It had a bit of impact on throughput, but you had to dedicate some of the CPU for it. Also, applications with very high allocation rates would sometimes see throttling. In JDK 21, which is to be released this September, we’ll have a generational ZGC that can cope with a much higher allocation rate, and has a lower CPU usage, and it still doesn’t require any tuning. The sufficiently good GC that I think was promised to us 50 years ago is here. Java users already use it. Still, we have some ideas for more specialized GCs in the future.
JDK Flight Recorder
The other capability I want to talk about is called JFR, or JDK Flight Recorder. You can think of it as eBPF, only easy to use, and prepacked with lots of events emitted by the JDK itself. JFR writes events into thread-local in memory buffers that are then copied to a recording file on disk. They could then be analyzed offline or consumed online, either on the same machine or remotely. It is essentially a high-performance structured logger, but because the overhead is so low, compared to some popular Java loggers, it’s used for in-production, continuous profiling, and/or monitoring. Events can have associated stack traces. Having big stack traces can add to the overhead. That overhead with big stack trace is going to be reduced by a factor of 10 this year.
There are over 150 built-in events produced by all layers, pre-built, when you get into JDK, it’s already in there, all layers of the JDK, and the number is growing. Of course, libraries and applications can easily add their own. There’s a new feature in JDK 21 which is called JFR views, which are queries, like SQL queries over this time-series database. You can get views for a running program or from a recording file. JFR is the future of Java observability. It is one of my personal favorite features in Java. Even though I didn’t go into details of JIT compilers, I think that with these state-of-the-art GCs, and low overhead profiling, you can see why the combination of performance and observability makes Java so popular for important server-side software these days.
The Effect of Optimization
When you talked about compared to the best hypothetical? No, I said between the mediocre implementation and the best hypothetical one, the difference is like 3%. Virtual threads are not a mediocre implementation, but let’s say it’s 1%. You wouldn’t notice it in an IAM application.
Questions and Answers
Participant 1: Do you also agree that Loom is going to kill reactive programming? Brian Goetz made the assessment.
Pressler: Will virtual threads kill reactive programming? We’ll wait and see. Those who like reactive programming can continue using it.
Participant 2: [inaudible 00:46:57]
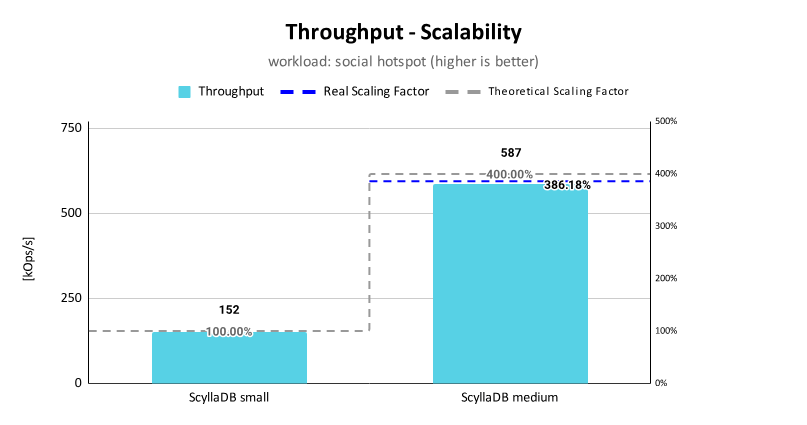
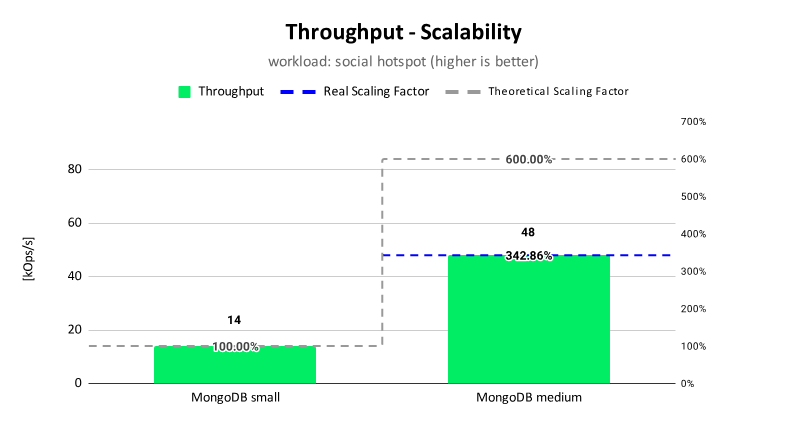
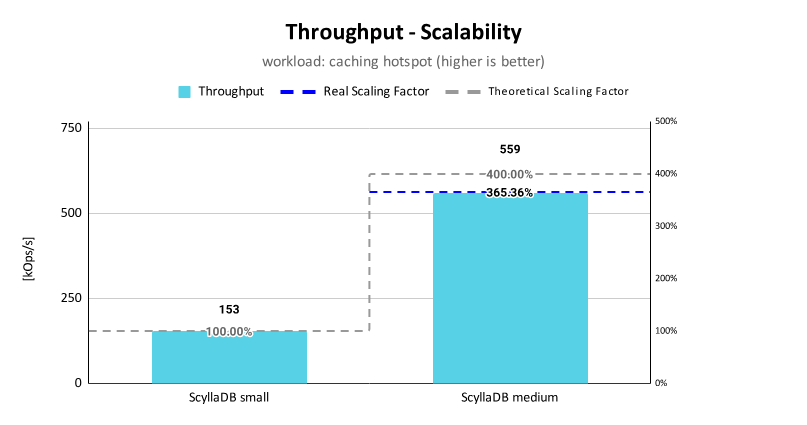
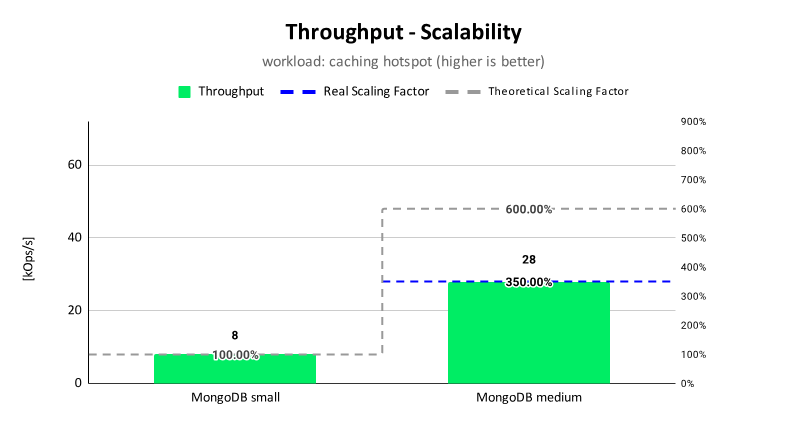
Pressler: Most libraries just work with virtual threads because virtual threads are threads. Web server containers or web server frameworks have started to adopt. In fact, I think by now all of them have, so Tomcat, Spring. There is only one that has been built or rewritten from the ground up around virtual threads, so it has better performance, for the moment it’s called Helidon. Their scaling is as good as the hardware allows. It reaches the hypothetical limit that’s predicted by Little’s Law.
See more presentations with transcripts