Month: August 2024

MMS • RSS

On Thursday, Google announced a whole series of database and data analytics improvements to its cloud data architecture.
In this article, we’ll focus on the substantial improvements to Spanner and Bigtable (two of Google’s cloud database offerings). These announcements substantially increase interoperability and open the door to additional AI implementations through the use of new features Google is showcasing.
Also: Cost of data breach climbs 10%, but AI helping to limit some damage
Spanner is Google’s global cloud database. It excels in providing worldwide consistency (which is way harder to implement than it may seem) due to a plethora of time-related issues that Google has solved. It’s also scalable, meaning the database can grow big and span countries and regions. It’s multi-modal, meaning it supports media data and not just text. It’s also all managed through SQL (Structured Query Language) queries.
Bigtable is also hugely scalable (hence the “big” in Bigtable). Its focus is very wide columns that can be added on the fly and don’t need to be uniformly defined across all rows. It also has very low latency and high throughput. Until now, it’s been characterized as a NoSQL database, a term used to describe non-relational databases that allow for flexible schemas and data organization.
<!–>
Both of these tools provide support for giant enterprise databases. Spanner is generally a better choice for applications using a globally distributed database that requires robust and immediate consistency and complex transactions. Bigtable is better if high throughput is important. Bigtable has a form of consistency, but propagation delays mean that data will not immediately, but eventually, be consistent.
Bigtable announcements
Bigtable is primarily queried through API calls. One of the biggest and most game-changing features announced today is SQL queries for Bigtable.
This is huge from a programming skills point of view. In a 2023 Stack Overflow survey of programming language use, SQL ranked fourth, with 48.66% of programmers using it. There was no mention of Bigtable in the Stack Overflow survey, so I turned to LinkedIn for some perspective. A quick search of jobs containing “SQL” resulted in 400,000+ results. Meanwhile, a search for “Bigtable” resulted in 1,561 results, less than 1% of the SQL number.
Also: Google upgrades Search to combat deepfakes and demote sites posting them
So, while any number of folks who know SQL could have learned how to make Bigtable API calls, SQL means that the learning curve has been flattened to nearly zero. Almost one out of every two developers can now use the new SQL interface to Bigtable to write queries whenever they need to.
One note, though: this Bigtable upgrade doesn’t support all of SQL. Google has, however, implemented more than 100 functions and promises more to come.
Also on the Bigtable table is the introduction of distributed counters. Counters are features like sum, average, and other related math functions. Google is introducing the ability to get these data aggregations in real-time with a very high level of throughput and across multiple nodes in a Bigtable cluster, which lets them perform analysis and aggregation functions concurrently across sources.
This lets you do things like calculate daily engagement, find max and minimum values from sensor readings, and so on. With Bigtable, you can deploy these on very large-scale projects that need rapid, real-time insights and that can’t support bottlenecks normally coming from aggregating per node and then aggregating the nodes. It’s big numbers, fast.
Spanner announcements
Google has a number of big Spanner announcements that all move the database tool towards providing support for AI projects. The big one is the introduction of Spanner Graph, which adds graph database capabilities to the global distributed database functionality at the core of Spanner.
Don’t confuse “graph database” with “graphics.” The term means the nodes and connections of the database can be illustrated as a graph. If you’ve ever heard the term “social graph” in reference to Facebook, you know what a graph database is. Think of the nodes as entities, like people, places, items, etc., and the connections (also called edges) as the relationships between the entities.
Facebook’s social graph of you, for example, contains all the people you have relationships with, and then all the people they have relationships with, and so on and so on.
Spanner can now natively store and manage this type of data, which is big news for AI implementations. This gives AI implementations a global, highly consistent, region-free way to represent vast relationship information. This is powerful for traversal (finding a path or exploring a network), pattern matching (identifying groups that match a certain pattern), centrality analysis (determining which nodes are more important than the other nodes), and community detection (finding clusters of nodes that comprise a cluster of some sort, like a neighborhood).
Also: OpenAI rolls out highly anticipated advanced Voice Mode, but there’s a catch
Along with the graph data representation, Spanner now supports GQL (Graph Query Language), an industry-standard language for performing powerful queries in graphs. It also works with SQL, which means that developers can use both SQL and GQL within the same query. This can be a big deal for applications that need to sift through row-and-column data and discern relationships in the same query.
Google is also introducing two new search modalities to Spanner: full-text and vector. Full-text is something most folks are familiar with – the ability to search within text like articles and documents for a given pattern.
Vector search turns words (or even entire documents) into numbers that are mathematical representations of the data. These are called “vectors,” and they essentially capture the intent, meaning, or essence of the original text. Queries are also turned into vectors (numerical representations), so when an application performs a lookup, it looks for other vectors that are mathematically close to each other – essentially computing similarity.
Vectors can be very powerful because matches no longer need to be exact. For example, an application querying “detective fiction” would know to search for “mystery novels,” “home insurance” would also work for “property coverage,” and “table lamps” would also work for “desk lighting.”
You can see how that sort of similarity matching would be beneficial for AI analysis. In Spanner’s case, those similarity matches could work on data that’s stored in different continents or server racks.
Opening up data for deeper insights
According to Google’s Data and AI Trends Report 2024, 52% of the non-technical users surveyed are already using generative AI to provide data insights. Almost two-thirds of the respondents believe that AI will cause a “democratization of access to insights,” essentially allowing non-programmers to ask new questions about their data without requiring a programmer to build it into code. 84% believe that generative AI will provide those insights faster.
I agree. I’m a technical user, but when I fed ChatGPT some raw data from my server, and the result was some powerfully helpful business analytics in minutes, without needing to write a line of code, I realized AI was a game-changer for my business.
Also: The moment I realized ChatGPT Plus was a game-changer for my business
Here’s the problem. According to the survey, 66% of respondents report that at least half of their data is dark. What that means is that the data is there, somewhere, but not accessible for analysis.
Some of that has to do with data governance issues, some has to do with the data format or a lack thereof, some of it has to do with the fact that the data can’t be represented in rows and columns, and some of it has to do with a myriad of other issues.
Essentially, even though AI systems may “democratize” access to data insights, that’s only possible if the AI systems can get at the data.
That brings us to the relevance of today’s Google announcements. These features all increase the access to data, whether because of a new query mechanism, due to the ability of programmers to use existing skills like SQL, the ability of large databases to represent data relationships in new ways, or the ability of search queries to find similar data. They all open up what may have been previously dark data to analysis and insights.
You can follow my day-to-day project updates on social media. Be sure to subscribe to my weekly update newsletter, and follow me on Twitter/X at @DavidGewirtz, on Facebook at Facebook.com/DavidGewirtz, on Instagram at Instagram.com/DavidGewirtz, and on YouTube at YouTube.com/DavidGewirtzTV.
–>
MMS • RSS
Tidal Investments LLC boosted its holdings in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 222.6% during the first quarter, according to the company in its most recent filing with the Securities and Exchange Commission. The fund owned 7,523 shares of the company’s stock after buying an additional 5,191 shares during the period. Tidal Investments LLC’s holdings in MongoDB were worth $2,698,000 at the end of the most recent reporting period.
Other hedge funds have also recently added to or reduced their stakes in the company. Transcendent Capital Group LLC acquired a new position in shares of MongoDB in the 4th quarter valued at about $25,000. Blue Trust Inc. lifted its stake in shares of MongoDB by 937.5% in the 4th quarter. Blue Trust Inc. now owns 83 shares of the company’s stock valued at $34,000 after purchasing an additional 75 shares in the last quarter. YHB Investment Advisors Inc. acquired a new position in shares of MongoDB in the 1st quarter valued at about $41,000. Sunbelt Securities Inc. lifted its stake in shares of MongoDB by 155.1% in the 1st quarter. Sunbelt Securities Inc. now owns 125 shares of the company’s stock valued at $45,000 after purchasing an additional 76 shares in the last quarter. Finally, GAMMA Investing LLC acquired a new position in shares of MongoDB in the 4th quarter valued at about $50,000. 89.29% of the stock is owned by institutional investors and hedge funds.
Wall Street Analysts Forecast Growth
Several research firms have recently weighed in on MDB. JMP Securities reduced their price objective on MongoDB from $440.00 to $380.00 and set a “market outperform” rating on the stock in a research note on Friday, May 31st. Piper Sandler dropped their target price on MongoDB from $350.00 to $300.00 and set an “overweight” rating on the stock in a report on Friday, July 12th. Truist Financial dropped their target price on MongoDB from $475.00 to $300.00 and set a “buy” rating on the stock in a report on Friday, May 31st. Scotiabank dropped their target price on MongoDB from $385.00 to $250.00 and set a “sector perform” rating on the stock in a report on Monday, June 3rd. Finally, Canaccord Genuity Group dropped their target price on MongoDB from $435.00 to $325.00 and set a “buy” rating on the stock in a report on Friday, May 31st. One investment analyst has rated the stock with a sell rating, five have issued a hold rating, nineteen have given a buy rating and one has issued a strong buy rating to the stock. Based on data from MarketBeat.com, the stock currently has an average rating of “Moderate Buy” and an average price target of $355.74.
Get Our Latest Research Report on MongoDB
MongoDB Stock Performance
NASDAQ:MDB traded down $13.03 during midday trading on Thursday, reaching $239.33. 1,842,062 shares of the company traded hands, compared to its average volume of 1,526,907. MongoDB, Inc. has a twelve month low of $214.74 and a twelve month high of $509.62. The firm has a market capitalization of $17.55 billion, a price-to-earnings ratio of -84.16 and a beta of 1.13. The company has a debt-to-equity ratio of 0.90, a current ratio of 4.93 and a quick ratio of 4.93. The company has a fifty day moving average price of $254.36 and a 200 day moving average price of $343.00.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings data on Thursday, May 30th. The company reported ($0.80) earnings per share (EPS) for the quarter, meeting analysts’ consensus estimates of ($0.80). MongoDB had a negative return on equity of 14.88% and a negative net margin of 11.50%. The business had revenue of $450.56 million during the quarter, compared to analyst estimates of $438.44 million. On average, analysts expect that MongoDB, Inc. will post -2.67 EPS for the current fiscal year.
Insiders Place Their Bets
In other MongoDB news, Director Dwight A. Merriman sold 6,000 shares of the business’s stock in a transaction on Friday, May 3rd. The stock was sold at an average price of $374.95, for a total transaction of $2,249,700.00. Following the completion of the transaction, the director now owns 1,148,784 shares in the company, valued at approximately $430,736,560.80. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which is available at this hyperlink. In other news, Director Dwight A. Merriman sold 6,000 shares of the company’s stock in a transaction on Friday, May 3rd. The stock was sold at an average price of $374.95, for a total value of $2,249,700.00. Following the completion of the sale, the director now owns 1,148,784 shares in the company, valued at $430,736,560.80. The sale was disclosed in a legal filing with the SEC, which is available at this link. Also, CFO Michael Lawrence Gordon sold 5,000 shares of the company’s stock in a transaction on Tuesday, July 9th. The shares were sold at an average price of $252.23, for a total value of $1,261,150.00. Following the completion of the sale, the chief financial officer now owns 81,942 shares of the company’s stock, valued at approximately $20,668,230.66. The disclosure for this sale can be found here. In the last quarter, insiders sold 34,179 shares of company stock worth $9,156,689. 3.60% of the stock is owned by company insiders.
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

With average gains of 150% since the start of 2023, now is the time to give these stocks a look and pump up your 2024 portfolio.
MMS • RSS
MongoDB has announced an AI Applications Program. The company describes MongoDB AI Applications Program (MAAP) as including reference architectures and an end-to-end technology stack that includes integrations with leading technology providers, professional services, and a unified support system.
MongoDB is a NoSQL document database that stores its documents in a JSON-like format with schema. MongoDB Atlas is the fully managed global cloud version of the software that can be run on AWS, Azure, or Google Cloud.

The new program, MAAP, puts together resources including ways to integrate MongoDB apps with other technology providers, professional services, and a unified support system. The aim is to make it easier to manage the multi-modal data structures required to power AI applications.
The initial links with other technology providers covers a variety of areas, including cloud infrastructure, foundation models (FM), generative AI framework and model hosting, and consultancies. The list includes Accenture, AWS, Google Cloud, and Microsoft Azure, as well as gen AI companies Anthropic, Cohere, and LangChain. Other companies on the list include Anyscale, Credal.ai, Fireworks.ai, gravity9, LlamaIndex, Nomic, PeerIslands, Pureinsights, and Together AI. MongoDB says this group of organizations will enable customers to build differentiated, production-ready AI applications.
MongoDB says that when a company signs up for MAAP, they will initially work with MongoDB Professional Services to get a good understanding of what products and technologies are in use and what business problems the company wants to solve. MongoDB Professional Services will then work with its partners to develop strategic roadmaps including the architecture, and once the initial results are validated, will optimize fully built applications for production.
In practical terms, the program makes use of composable architectures – pre-designed architectures designed to serve as accelerated frameworks for fully customizable gen AI applications. It also comes with customizable implementation patterns The architectures are extendable and can be used for projects including retrieval-augmented generation (RAG) or advanced AI capabilities like Agentic AI and advanced RAG technique integrations.
MAAP also comes with a dedicated MAAP GitHub library featuring integration code, demos, and a gen AI application prototype, as well as integration and development best practices.
Links to the technology stack are available now on the MongoDB website.
More Information
Related Articles
MongoDB 7 Adds Queryable Encryption
MongoDB 6 Adds Encrypted Query Support
MongoDB 5 Adds Live Resharding
MongoDB Atlas Adds MultiCloud Cluster Support
MongoDB Improves Query Language
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.


Comments
or email your comment to: comments@i-programmer.info
MMS • RSS

Olofson explained that this is why Spanner might not “really be in a position to challenge” specialty graph databases, such as Neo4j, OrientDB, TigerGraph, and Aerospike Graph, supporting pure graph deployments in terms of performance.
Multi-model databases vs specialty databases
Google’s move to add graph processing capabilities to Spanner is consistent with the trend of DBMS firms, who want to be seen as providing strategic database support in helping enterprises consolidate their database needs, add multi-model capabilities or capabilities that are offered by specialty databases, Olofson said.
One such example is the addition of vector capabilities by cloud database providers, such as Oracle, AWS, Microsoft, Google, and MongoDB. Previously, vector capabilities were just offered by specialty databases, such as Pinecone, Weaviate, and Milvus.
Increasing Productivity by Becoming a Dual-Purpose Stream Aligned and Platform Software Team
MMS • Ben Linders

To manage their increased workload effectively and maintain quality and efficiency, a software team decided to become dual-purpose: stream-aligned and platform. They rewrote their main application to be API-first and implemented micro releases with their customer-facing products, to provide value to their end users quickly and maintain a steady flow of accomplishments for the team. Marion Løken spoke about the changes that her software team went through at NDC Oslo.
The mobility market is under significant pressure due to economic downturns and environmental concerns; people buy fewer cars and change less often, Løken said. Schibsted marketplaces across several countries merged:
My team transitioned from selling insights to 1,000 car dealers in Norway to delivering insights to 600,000 monthly users -both private and professional buyers and sellers- and expanding to 1.5 million users in the Nordics, with new revenue streams through third-party integrations.
They used the jobs to be done (JTBD) framework to develop more specialized products for car dealers and evolve into a platform team:
We went from a generic JTBD like “help me sell my product” to more specific ones like “help me sell or buy a car,” “help me sell my car to a professional,” or “help me evaluate a car pool for compliance with financial regulations”. JBTD helps you reframe your team role effectively.
Løken explained that decision support is crucial throughout the user journey, from understanding the market, setting the sale price and choosing where to advertise, to optimizing the marketing budget. Those user journeys are owned by different teams with different products, however, the insights should be calculated and presented in a recognizable way to the end users:
Numbers and statistics can be challenging to interpret, and adding unnecessary complexity by changing the visualization can create doubt and confusion for users.
They transformed into a dual-purpose team: a stream-aligned team, serving their own users, and a platform team, supporting other internal teams:
We are only a small team with four developers; our deep understanding of what our end users want enables us to save other teams time and effort by building solutions that benefit both us and them.
They rewrote their main application to be API-first and used a component library, simplifying their architecture. The API-first shift allowed them to consolidate their services into a single API with access control, eliminating task duplication and significantly improving efficiency. The component library for the front-end also aids their setup, enabling them to reuse the same design across products and user journeys, Løken mentioned.
They leveraged generative AI to enhance productivity and get inspiration for improving the software architecture:
When creating a new invoicing system, we utilized ChatGPT to generate mermaid diagrams that could be directly integrated into GitHub, ensuring clarity in our system design and adherence to SOLID principles.
Software engineers use AI tools like Copilot for coding tasks, which enhances their efficiency, Løken said.
InfoQ interviewed Marion Løken about the changes in her team.
InfoQ: What was your approach for setting up teams to provide decision support products?
Marion Løken: To enhance the cohesion of our decision support products, we identified the need to work smarter and integrate our data products centrally. Delivering data products directly to the end users was not enough; we also needed to provide these products to our internal teams to ensure a seamless experience for our end users.
Additionally, we receive feedback on their products that helps us improve our products across the board. However, we are still too small to fully focus on customizing for the needs of our internal users, the teams we support.
InfoQ: How did you benefit from generative AI tools?
Løken: There’s a definite opportunity to accomplish tasks faster with generative AI when you have a clear understanding of what you want to achieve, what the solution should look like, and the best practices you want to adhere to. With the help of AI, we managed to deliver what the organization needed more effectively.
InfoQ: How do you do micro releases and what benefits does that bring?
Løken: Big bang releases are a thing of the past, and micro releases help boost team morale. Smaller milestones give everyone a sense of progress and achievement.
For example, we planned to deliver five key insight cards in a rotating display. Instead of waiting until all the insights were ready, we decided to go live as soon as one was complete and inform our customers that more were on the way.
As the team manager, I used these opportunities to celebrate with small gestures, like buying treats or sharing “breaking news” in the company channel. These frequent celebrations helped maintain high spirits and reinforced the incredible job the team was doing. I’m glad we didn’t wait for everything to be finished to recognize our progress.
MMS • RSS

Bloomberg’s NoSQL Infrastructure team offers Apache Cassandra as a hosted service. We have visibility across the organization as we’re providing a pathway for scalable data storage. We support a wide array of critical and highly-visible applications such as archival data stores, ultra low-latency market data caches and trade event stores. We manage thousands of Cassandra nodes storing petabytes of data and billions of requests per day.
We focus on fostering Cassandra adoption by improving its usability within Bloomberg. The team has developed automation workflows for managing the lifecycle of clusters, keyspace deployment and schema management. We’ve implemented client libraries for service discovery that we are looking to enhance with custom load balancing and retry policies. We also provide solutions engineering for application teams, helping them with data modeling and architecture. Currently, we are focused on improving our core automation and monitoring of Cassandra, developing a feature-rich self service console for managing Cassandra databases, and developing a proxy service to simplify data access to Cassandra. Underpinning all of this is an eye towards open source, adopting wherever possible industry standard solutions used by the open source community and contributing back patches.
We’ll trust you to:
– Help application teams looking to use Cassandra with workload characterization, performance tuning and failure analysis.
– Improve the operability of the solution developing infrastructure such as cluster auto-healing, containerization, and automated upgrades.
– Improve the usability of the solution by building tooling such as our proxy service that does workload management for multi-tenant deployments and our database copy system.
– Identify feature gaps in the technologies and work with the open source community to co-design and co-develop features and bug fixes.
You’ll need to have:
– 4+ years of programming experience with an object-oriented programming language (Python, Go, Java, C++, or JavaScript).
– A degree in Computer Science, Engineering or similar field of study or equivalent work experience.
– Experience with modern development methodologies and tools (Jira, Jenkins, Git, etc).
– Experience with object-oriented design.
– Solid understanding of data structures and algorithms.
– Strong problem solving and communication skills.
We’d love to see:
– Upstream, accepted contributions to open source projects.
– A strong understanding of distributed systems.
– Production experience with NoSQL databases or other distributed storage technologies in a platform/infrastructure software engineering role.
If you’d like to know more about the work we do, check out Bloomberg’s Github: https://github.com/bloomberg , our talk at Datastax Accelerate: https://www.youtube.com/watch?v=RjypMRrit9U , and a recent talk we gave on improving the snapshot subsystem in Cassandra: https://www.youtube.com/watch?v=P-aAeUH5drY&t=1428 .
Interviewing with us:
We believe interviewing is a two way street. It’s a way for us to get to know you and your skills, and also a way for you to learn more about the team, our technical challenges, and what you’d be working on. The content of each interview round will be tailored to the role and your background, but the general framework can be found here: https://www.bloomberg.com/careers/technology/engineering/software-engineering-experienced-hire
We want to ensure you can put your best foot forward throughout the process, so if you have any questions or need any accommodations to be successful, please let us know!
We have a lot of opportunities to choose from in Engineering, and it is important to us that your skills and experience aligns best with the team you are interviewing with. To help ensure you are placed on the right team, your application will be considered for all of our current vacancies in Engineering at the first stage of the interview process.
Bloomberg is an equal opportunity employer, and we value diversity at our company. We do not discriminate on the basis of age, ancestry, color, gender identity or expression, genetic predisposition or carrier status, marital status, national or ethnic origin, race, religion or belief, sex, sexual orientation, sexual and other reproductive health decisions, parental or caring status, physical or mental disability, pregnancy or parental leave, protected veteran status, status as a victim of domestic violence, or any other classification protected by applicable law.
Bloomberg is a disability inclusive employer. Please let us know if you require any reasonable adjustments to be made for the recruitment process. If you would prefer to discuss this confidentially, please email amer_recruit@bloomberg.net
Job ID 111764
<!–>
MMS • Steef-Jan Wiggers
Google Cloud has introduced a significant update to its fully-managed distributed SQL database service, Spanner, which now offers a dual-region configuration option. The company aims with this enhancement to assist enterprises in complying with data residency norms across countries with limited cloud support while ensuring high availability.
Before this update, enterprises operating in countries with only two Google Cloud regions were constrained using regional Spanner configurations. Multi-region configurations required three regions, often resulting in one region being outside the country, thereby conflicting with data residency requirements. The new dual-region configuration alleviates this issue by allowing enterprises to maintain data residency compliance and high availability even with just two cloud regions within a country.
Nitin Sagar, senior product manager at Google, detailed the operational mechanics of the dual-region configuration in a blog post. He explained that during a zonal outage affecting one of the replicas, Spanner can maintain availability as at least two replicas in each region would still be functional. However, the databases will lose availability if an entire region faces an outage. In such cases, the setup can switch to single-region mode, comprising three replicas in one region, to recover availability.
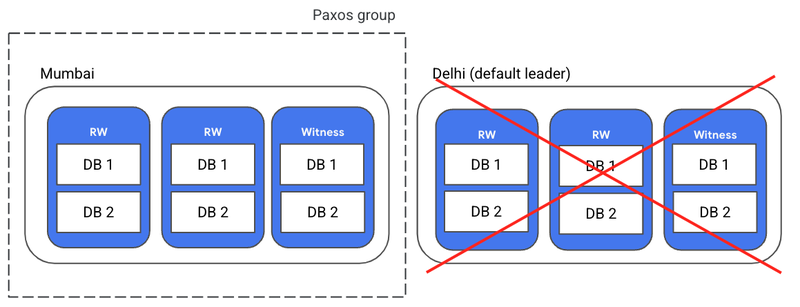
(Source: Google blog post)
The documentation states with multi-region configurations:
There are trade-offs, though, because in a multi-region configuration, the quorum (read-write) replicas are spread across more than one region. You might notice additional network latency when these replicas communicate with each other to form a write quorum. Reads don’t require a quorum. The result is that your application achieves faster reads in more places at the cost of a small increase in write latency.
The company suggests designing a schema to prevent hotspots and performance issues. To avoid single-region dependency and optimize performance in multi-region configurations, critical compute resources should be distributed across at least two regions. Additionally, keep high-priority total CPU utilization under 45% in each region to improve performance.
Google Cloud is not the only one offering such capabilities. Other cloud providers like Microsoft, AWS, and Oracle, also provide multi-region setups for their database-as-a-service (DBaaS) offerings, such as Azure SQL, Cosmos DB, Amazon Aurora, Amazon DynamoDB, and Oracle NoSQL database. Furthermore, other database vendors like Cockroach Labs and DataStax offer similar multi-region capabilities.
When it comes to multi-region traffic requirements and a Cloud DBaaS solution, a respondent on a recent Reddit thread wrote:
You’ll either need to keep things local to each region as it makes sense or move the architecture to an eventually consistent model using the various tools and techniques available for that.
Lastly, Google Cloud’s new dual-region configurations are now available in Australia, Germany, India, and Japan.
MMS • RSS

NEW ORLEANS, July 31, 2024 (GLOBE NEWSWIRE) — ClaimsFiler, a FREE shareholder information service, reminds investors that they have until September 9, 2024 to file lead plaintiff applications in a securities class action lawsuit against MongoDB, Inc. (NasdaqGM: MDB). This action is pending in the United States District Court for the Southern District of New York.