Month: October 2024
MongoDB Announces Redemption of All of Its Outstanding Convertible Senior Notes due 2026

MMS • RSS
NEW YORK, Oct. 16, 2024 /PRNewswire/ — MongoDB, Inc. (“MongoDB”) (Nasdaq: MDB), the leading, modern general purpose database platform, today announced that it issued a notice of redemption for all $1,149,972,000 aggregate principal amount outstanding of its 0.25% convertible senior notes due 2026 (the “Notes”). The redemption date will be December 16, 2024. The redemption price with respect to any redeemed note will equal 100% of the principal amount thereof, plus accrued and unpaid interest, from July 15, 2024, to, but excluding the redemption date. On the redemption date, the redemption price will become due and payable upon each note to be redeemed and interest thereon will cease to accrue on and after the redemption date.
![]()
The notes may be converted by holders at any time before 5:00 p.m. (New York City time) on December 13, 2024 (the “conversion deadline”). The conversion rate for notes converted after today and through the conversion deadline is equal to 4.9260 shares of common stock of MongoDB, par value $0.001 per share (the “Common Stock”), per $1,000 principal amount of the notes, which includes an increase to the conversion rate of 0.1911 shares of Common Stock per $1,000 principal amount of the notes as a result of the notes being called for redemption. MongoDB has elected to settle any conversions of the notes during the redemption period by delivering shares of its Common Stock, together with cash, if applicable, in lieu of delivering any fractional share of Common Stock (physical settlement).
About MongoDB
Headquartered in New York, MongoDB’s mission is to empower innovators to create, transform, and disrupt industries by unleashing the power of software and data. Built by developers, for developers, MongoDB’s developer data platform is a database with an integrated set of related services that allow development teams to address the growing requirements for today’s wide variety of modern applications, all in a unified and consistent user experience. MongoDB has tens of thousands of customers in over 100 countries. The MongoDB database platform has been downloaded hundreds of millions of times since 2007, and there have been millions of builders trained through MongoDB University courses.
Forward Looking Statements
This press release includes certain “forward-looking statements” within the meaning of Section 27A of the Securities Act of 1933, as amended, or the Securities Act, and Section 21E of the Securities Exchange Act of 1934, as amended, including statements concerning the planned redemption of the notes. These forward-looking statements include, but are not limited to, plans, objectives, expectations and intentions and other statements contained in this press release that are not historical facts and statements identified by words such as “anticipate,” “believe,” “continue,” “could,” “estimate,” “expect,” “intend,” “may,” “plan,” “project,” “will,” “would” or the negative or plural of these words or similar expressions or variations. These forward-looking statements reflect our current views about our plans, intentions, expectations, strategies and prospects, which are based on the information currently available to us and on assumptions we have made. Although we believe that our plans, intentions, expectations, strategies and prospects as reflected in or suggested by those forward-looking statements are reasonable, we can give no assurance that the plans, intentions, expectations or strategies will be attained or achieved. Furthermore, actual results may differ materially from those described in the forward-looking statements and are subject to a variety of assumptions, uncertainties, risks and factors that are beyond our control including, without limitation: risks associated with executing the redemption of the notes and events that could impact the terms of the redemption, as well as those described in MongoDB’s filings with the United States Securities and Exchange Commission (“SEC”), including under the caption “Risk Factors” in our Quarterly Report on Form 10-Q for the quarter ended July 31, 2024, filed with the SEC on August 30, 2024, and other filings and reports that we may file from time to time with the SEC. Except as required by law, we undertake no duty or obligation to update any forward-looking statements contained in this press release as a result of new information, future events, changes in expectations or otherwise.
Investor Relations
Brian Denyeau
ICR for MongoDB
646-277-1251
ir@mongodb.com
Media Relations
MongoDB
press@mongodb.com
![]() View original content to download multimedia:https://www.prnewswire.com/news-releases/mongodb-announces-redemption-of-all-of-its-outstanding-convertible-senior-notes-due-2026-302278502.html
View original content to download multimedia:https://www.prnewswire.com/news-releases/mongodb-announces-redemption-of-all-of-its-outstanding-convertible-senior-notes-due-2026-302278502.html
SOURCE MongoDB, Inc.
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) CFO Michael Lawrence Gordon sold 5,000 shares of the stock in a transaction that occurred on Monday, October 14th. The stock was sold at an average price of $290.31, for a total transaction of $1,451,550.00. Following the transaction, the chief financial officer now owns 80,307 shares in the company, valued at approximately $23,313,925.17. The trade was a 0.00 % decrease in their position. The sale was disclosed in a filing with the Securities & Exchange Commission, which is accessible through this hyperlink.
Michael Lawrence Gordon also recently made the following trade(s):
- On Wednesday, October 2nd, Michael Lawrence Gordon sold 1,884 shares of MongoDB stock. The shares were sold at an average price of $256.25, for a total value of $482,775.00.
MongoDB Price Performance
NASDAQ MDB traded down $6.27 on Wednesday, reaching $278.39. The company had a trading volume of 675,476 shares, compared to its average volume of 1,444,229. MongoDB, Inc. has a 12 month low of $212.74 and a 12 month high of $509.62. The company has a quick ratio of 5.03, a current ratio of 5.03 and a debt-to-equity ratio of 0.84. The firm’s 50 day moving average price is $267.72 and its 200 day moving average price is $286.14. The stock has a market capitalization of $20.42 billion, a PE ratio of -101.30 and a beta of 1.15.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings results on Thursday, August 29th. The company reported $0.70 earnings per share for the quarter, topping the consensus estimate of $0.49 by $0.21. MongoDB had a negative net margin of 12.08% and a negative return on equity of 15.06%. The company had revenue of $478.11 million for the quarter, compared to analysts’ expectations of $465.03 million. During the same quarter in the previous year, the business posted ($0.63) earnings per share. MongoDB’s quarterly revenue was up 12.8% on a year-over-year basis. As a group, equities analysts predict that MongoDB, Inc. will post -2.44 earnings per share for the current year.
Institutional Inflows and Outflows
Several institutional investors and hedge funds have recently added to or reduced their stakes in MDB. MFA Wealth Advisors LLC bought a new position in MongoDB during the second quarter valued at $25,000. Sunbelt Securities Inc. grew its holdings in MongoDB by 155.1% during the 1st quarter. Sunbelt Securities Inc. now owns 125 shares of the company’s stock valued at $45,000 after purchasing an additional 76 shares during the last quarter. J.Safra Asset Management Corp grew its holdings in MongoDB by 682.4% during the 2nd quarter. J.Safra Asset Management Corp now owns 133 shares of the company’s stock valued at $33,000 after purchasing an additional 116 shares during the last quarter. Quarry LP raised its position in MongoDB by 2,580.0% in the 2nd quarter. Quarry LP now owns 134 shares of the company’s stock worth $33,000 after purchasing an additional 129 shares during the period. Finally, Hantz Financial Services Inc. bought a new stake in MongoDB in the second quarter worth about $35,000. Hedge funds and other institutional investors own 89.29% of the company’s stock.
Wall Street Analysts Forecast Growth
MDB has been the subject of a number of recent analyst reports. Stifel Nicolaus upped their target price on MongoDB from $300.00 to $325.00 and gave the company a “buy” rating in a research report on Friday, August 30th. Citigroup raised their target price on shares of MongoDB from $350.00 to $400.00 and gave the company a “buy” rating in a report on Tuesday, September 3rd. Mizuho increased their price target on shares of MongoDB from $250.00 to $275.00 and gave the stock a “neutral” rating in a research report on Friday, August 30th. UBS Group boosted their price objective on shares of MongoDB from $250.00 to $275.00 and gave the company a “neutral” rating in a research report on Friday, August 30th. Finally, Bank of America lifted their price target on MongoDB from $300.00 to $350.00 and gave the company a “buy” rating in a research note on Friday, August 30th. One analyst has rated the stock with a sell rating, five have issued a hold rating and twenty have assigned a buy rating to the company. According to MarketBeat.com, MongoDB presently has a consensus rating of “Moderate Buy” and an average price target of $337.96.
Read Our Latest Report on MongoDB
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Almost everyone loves strong dividend-paying stocks, but high yields can signal danger. Discover 20 high-yield dividend stocks paying an unsustainably large percentage of their earnings. Enter your email to get this report and avoid a high-yield dividend trap.
MMS • RSS

| Reporter Name | Gordon Michael Lawrence |
| Relationship | COO and CFO |
| Type | Sell |
| Amount | $1,451,571 |
| SEC Filing | Form 4 |
Gordon Michael Lawrence, COO and CFO of MongoDB, sold 5,000 shares of Class A Common Stock on October 14, 2024, under a Rule 10b5-1 trading plan. The sales were executed at weighted average prices ranging from $287.39 to $295.26, resulting in a total sale amount of $1,451,571. Following these transactions, Lawrence directly owns 80,307 shares and indirectly owns 4,000 shares through family members.
SEC Filing: MongoDB, Inc. [ MDB ] – Form 4 – Oct. 16, 2024
MMS • RSS
While major stock market benchmarks – including the S&P 500 Index ($SPX) and the Dow Jones Industrial Average ($DOWI) – are hovering near all-time highs, many individual stocks are still trading at a discount from their own record levels. That includes software stocks, most of which have significantly lagged the broader market this year.
However, for investors willing to “lean into more risk,” here are three underperforming cloud stocks that look like solid long-term investments in October 2024, according to investment bank Piper Sandler. Let’s see why.
#1. MongoDB Stock
Valued at $20.8 billion by market cap, MongoDB (MDB) provides enterprises with a general-purpose database platform. Its commercial data server can run in the cloud, on-premise, or in a hybrid environment. MongoDB also offers the MongoDB Atlas, a multi-cloud database-as-a-service solution.
Down 51% from all-time highs, MDB stock has returned 126% to investors in the last five years.
In fiscal Q2 of 2025 (ended in July), MongoDB reported revenue of $478.1 million, an increase of 13% year over year. The Atlas platform saw sales rise by 27% to $339.7 million, accounting for 71% of the top line.
With more than $1.3 billion in cash, MongoDB is well capitalized, as the company continues to report a positive free cash flow. In the last 12 months, its free cash flow totaled $149 million, up from $115 million in fiscal 2024. Further, MongoDB increased its customer count from 45,000 to 50,700 in the last four quarters.
Piper Sandler believes that MongoDB is positioned to experience accelerated growth going forward, after hitting a trough in the second quarter. It has an “Overweight” rating on MongoDB, with the target price of $335 indicating an upside potential of over 21% from current levels.
Out of the 31 analysts covering MDB stock, 22 recommend “strong buy,” three recommend “moderate buy,” five recommend “hold,” and one recommends “strong sell,” for a “strong buy” consensus. The average target price for MDB stock is $334.07, about 21% higher than current levels.
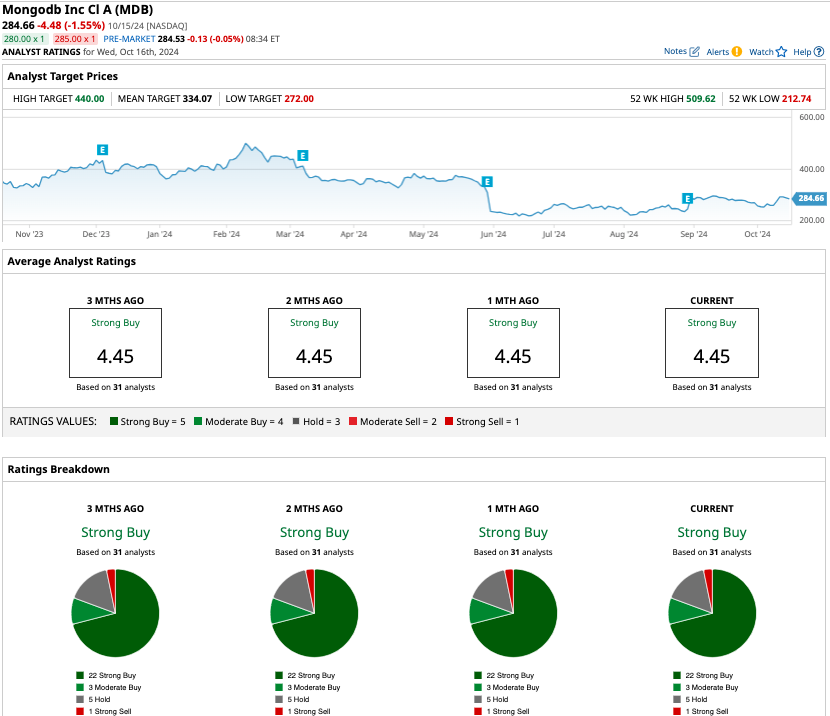
#2. Adobe Systems Stock
Valued at $224 billion by market cap, Adobe Systems (ADBE) provides digital marketing and media solutions.
Adobe’s suite of graphic design solutions is already popular among users, and it might gain further traction due to the tech giant’s generative AI model called Firefly. Today, Firefly has created over 12 billion images and will soon launch a version that can be used for video.
With gross margins of over 90% and a net margin north of 30%, Adobe is highly profitable. However, in the last 12 months, it has reported a free cash flow of $6.55 billion, down from $6.9 billion in 2023, driving the tech stock lower.
Down 27.4% from all-time highs, Piper Sandler expects ADBE stock to recover its losses in 2024 due to the software company’s AI-powered offerings. In an investor note, the firm wrote, “The new innovation product cycle is underappreciated, and could help reignite growth.”
Piper Sandler is “Overweight” on Adobe with a target price of $635, indicating an upside potential of 26.5%.
Out of the 31 analysts covering ADBE stock, 22 recommend “strong buy,” one recommends “moderate buy,” six recommend “hold,” and two recommend “strong sell.” The average target price for ADBE stock is $611, 21.7% higher than the current trading price.
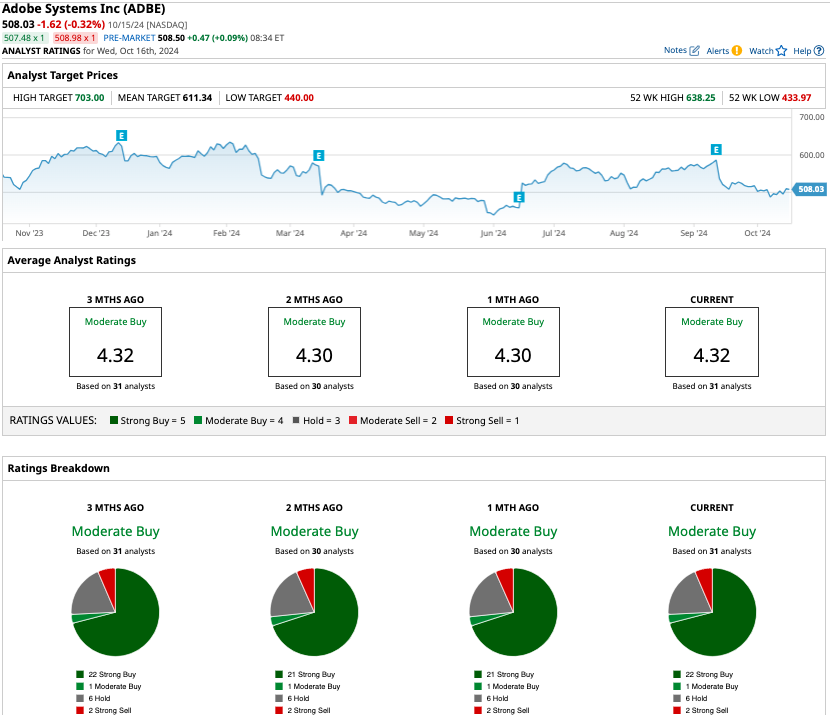
#3. Salesforce Stock
Finally we have Salesforce (CRM), one of the largest SaaS (software-as-a-service) companies globally. Salesforce stock is valued at $279.4 billion by market cap, and is down 9.5% from record levels.
Salesforce’s revenue has increased from $21.1 billion in fiscal 2021 (which ended in January) to $36.46 billion in the last 12 months. In this period, operating income has grown over 12x from $455 million to $6.95 billion, while free cash flow has widened from $4 billion to $11.46 billion.
Piper Sandler has an “Overweight” rating on CRM stock with a target price of $325, 12% higher than the current price. It also has a bull-case price target of $405, indicating an upside potential of almost 40%. Piper Sandler explained that Salesforce has outperformed the broader indices in the last three months due to consistent revenue growth and expanding margins.
Out of the 42 analysts covering CRM stock, 30 recommend “strong buy,” two recommend “moderate buy,” nine recommend “hold,” and one recommends “strong sell.” CRM is now a “strong buy” on Wall Street, up from “moderate buy” one month ago. The average target price for CRM stock is $309.82, about 6.8% higher than the current trading price.
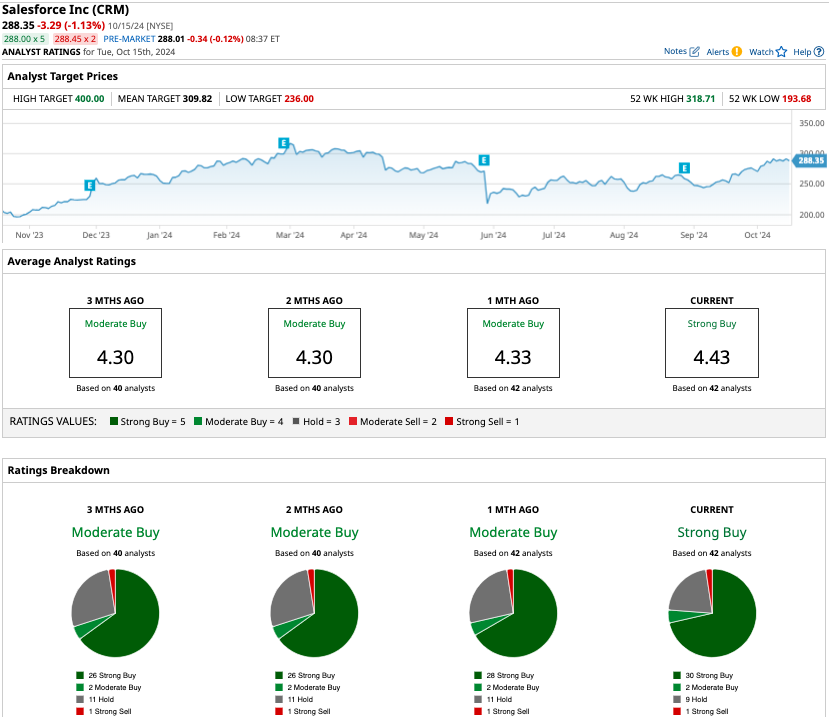
More Stock Market News from Barchart
On the date of publication, Aditya Raghunath did not have (either directly or indirectly) positions in any of the securities mentioned in this article. All information and data in this article is solely for informational purposes. For more information please view the Barchart Disclosure Policy here.
MMS • RSS

Amazon is making it easier to analyze transactional data held in its Aurora PostgreSQL and DynamoDB databases by avoiding the need for ETL routines when moving data from them into its Redshift data warehouse.
Aurora is Amazon’s relational database service built for its public cloud with full MySQL and PostgreSQL support. Aurora MySQL is a drop-in replacement for MySQL, the open-source RDBMS, and Aurora PostgreSQL is a drop-in replacement for PostgreSQL. MySQL and PostgreSQL are both open-source relational database management systems (RDBMS) for transactional data, with Amazon saying: ”They store data in tables that are interrelated to each other via common column values.”
DynamoDB is Amazon’s fully managed proprietary NoSQL database intended for use with non-relational databases. Such databases store data within one data structure, like a JSON document, instead of the tabular structure of a relational database.
Redshift is Amazon’s cloud data warehouse for data analytics. It needs feeding with transactional data if its analytic processes are going to analyze that data. Normally ETL (Extract, Transform and Load) routines are used to select datasets from a source, transform them and move them into a target data warehouse. The zero-ETL concept is to do away with such routines by having the necessary integration functions built in to the source databases.
There are existing, generally available, zero-ETL integrations for Aurora MySQL and Amazon RDS for MySQL with Redshift, which enable customers to combine data from multiple relational and non-relational databases in Redshift for analysis. Amazon RDS (Relational Database Service) is a managed SQL database service which supports Aurora, MySQL, PostgreSQL, MariaDB, Microsoft SQL Server, and Oracle database engines.

Amazon claims Zero-ETL integrations mean that IT staff do not have to build and manage ETL pipelines and operate them. AWS blogger Senior Solutions Architect Esra Kayabali says zero-ETL: “automates the replication of source data to Amazon Redshift, simultaneously updating source data for you to use in Amazon Redshift for analytics and machine learning (ML).”
You still need an ETL function but these AWS products now set up, operate, and manage the whole thing. Kayabali blogs: “To create a zero-ETL integration, you specify a source and Amazon Redshift as the target. The integration replicates data from the source to the target data warehouse, making it available in Amazon Redshift seamlessly, and monitors the pipeline’s health.”
Her blog tells readers how to “create zero-ETL integrations to replicate data from different source databases (Aurora PostgreSQL and DynamoDB) to the same Amazon Redshift cluster. You will also learn how to select multiple tables or databases from Aurora PostgreSQL source databases to replicate data to the same Amazon Redshift cluster. You will observe how zero-ETL integrations provide flexibility without the operational burden of building and managing multiple ETL pipelines.”
Amazon is here integrating its own databases with its own data warehouse. When the target data warehouse is owned and operated by one supplier and the source databases by others, partnerships with third parties are needed to get rid of the ETL pipeline development and operation burden.
Bryteflow tells us: “The zero-ETL process assumes native integration between sources and data warehouses (native integration means there is an API to directly connect the two) or data virtualization mechanisms (they provide a unified view of data from multiple sources without needing to move or copy the data). Since the process is much more simplified and the data does not need transformation, real-time querying is easily possible, reducing latency and operational costs.”
Snowflake says it has zero-ETL data sharing capabilities across clouds and regions. It is partnering with Astro so that customers can orchestrate ETL operations in Snowflake with Astro using the Snowflake provider for Airflow.
CData says itsSync offering “provides a straightforward way to continuously pipeline your Snowflake data to any Database, Data Lake, or Data Warehouse, making it easily available to Analytics, Reporting, AI, and Machine Learning.”
You can learn more in Kayabali’s post.
MMS • RSS

Large language models generally train on unstructured data such as text and media. But most enterprise data security strategies are designed around structured data (data organized in traditional databases or formal schemas).
The use of unstructured data in GenAI introduces new challenges for governance, privacy and security that these traditional approaches aren’t equipped to handle.
We spoke to Rehan Jalil, CEO of Securiti, to discuss how organizations need to rethink how they’re governing and protecting unstructured data in order to safely leverage GenAI.
BN: How does unstructured data differ from structured data?
RJ: At a high level, the difference is straightforward. Structured data is any data that lives in traditional row-column databases (i.e., relational or SQL databases, Excel documents or data warehouses) or has a predefined data model. This tends to include things like financial transactions, inventory information, and patient records.
Unstructured data is all the other data that doesn’t exist in spreadsheets and databases (often stored in non-relational or NoSQL databases or data lakes). It’s typically text-heavy and lacks the organization and properties of structured data — for example, all of the documents, emails, social media posts, web pages, and multimedia content that a company may have or own. It can also include all the regulations and policies that companies may need to adhere to, such as tax codes or insurance terms of coverage.
Today, about 90 percent of data being generated in enterprises is unstructured.
BN: How does this impact generative AI deployments?
RJ: In the past, companies really just mined their structured data to make business decisions. But GenAI is upending that. Most generative AI models work by analyzing unstructured data, such text data on the web, and provide outputs based on that data. Generative AI technologies employ this data to train models and build natural language processing capabilities. This causes a problem for organizations as the vast majority of their data management solutions were built for structured data.
The issue is that the industry has not put the same resources into developing technologies and strategies for managing unstructured data like they have for structured data. Lots of organizations struggle to even identify all the locations where their unstructured data might live — across which shared drives, cloud systems, applications, and so on. And once it is identified, unstructured data requires different, more complex management and specialized techniques in order for data teams to extract meaningful insights and patterns from it — techniques such as natural language processing, text mining, and machine learning.
BN: Why is unstructured data so challenging to manage and secure?
RJ: There are a number of factors at play. The biggest issue is simply volume and variety. There’s massive amounts of unstructured data within organizations and it comes from a diverse range of sources, such as emails, documents, social media posts, and multimedia files. This makes it difficult for teams to keep track of and enforce consistent governance and security policies across the organization.
Uncontrolled access and sharing is another hurdle. Once created, unstructured data tends to grow quickly across various systems, devices, and cloud services as people copy, modify, manipulate, and share the content. Because of this, it can be very difficult to keep track of where data came from and who should have access.
Unstructured data also tends to live across many siloes and ownership is often fuzzy. The data is frequently created and managed by different departments or individuals within an organization, leading to data silos and ambiguity around data ownership and accountability. While structured data is more likely to have known ownership within an organization due to understood security or cost implications, a company’s unstructured data is often either sequestered for legitimate reasons (e.g., upcoming commentary for an acquisition) or for less desired causes (e.g., political boundaries between divisions).
Last, unstructured data comes in a diverse number of formats. Whereas structured data has collapsed into a small set of universal standards, SQL being a principal one, unstructured content systems have a multitude of formats and legacy patterns. The tools needed to manage these formats in a unified way are unique and require a commitment from the organization to deploy and use them.
BN: What should organizations do to safely use unstructured data for GenAI?
RJ: Managing unstructured data for generative AI is possible if enterprises acquire the seven key capabilities:
- Discover, catalog, and classify unstructured data: Automatically discover, catalog, and classify files and objects on the fly, which are essential for GenAI projects.
- Preserve access entitlements of unstructured data: Maintain existing enterprise entitlements at source systems to ensure that only authorized users access relevant data via GenAI prompts.
- Trace the lineage of unstructured data: Understand data mapping and flows from source to end results, showing how the data moves from unstructured data systems to vector databases, to LLMs, and finally to endpoints.
- Curate unstructured data: Automate the labeling or tagging of files to ensure that only relevant data with associated context is fed to GenAI models, thereby providing accurate responses with citations.
- Sanitize unstructured data: Classify and redact or mask sensitive data from files that GenAI projects use.
- Focus on the quality of unstructured data: Emphasize the freshness, uniqueness, and relevance of data to prevent unintended data usage in GenAI projects.
- Secure unstructured prompts and responses with pre-configured policies: Detect, classify, and redact sensitive information on the fly, block toxic content, and enforce compliance with topic and tone guidelines.
Image credit: SergeyNivens/depositphotos.com
MMS • RSS

Others Specials
Binstellar: Your Premier Mean Stack Development Company
In the ever-evolving world of web development, having a robust technology stack is crucial for creating scalable and efficient applications. One of the most powerful stacks available today is the MEAN stack, which consists of MongoDB, Express.js, Angular, and Node.js. Partnering with a proficient mean stack development company Binstellar can significantly enhance your web application development process.
Understanding the MEAN Stack
The MEAN stack is a collection of technologies that allows developers to build dynamic web applications using JavaScript at every layer of the development process. Here’s a brief overview of each component:
1. MongoDB: A NoSQL database that stores data in a flexible, JSON-like format, making it ideal for applications with large volumes of unstructured data.
2. Express.js: A web application framework for Node.js that simplifies the development of web applications and APIs by providing a robust set of features.
3. Angular: A front-end framework maintained by Google, designed for building dynamic single-page applications (SPAs) with a rich user experience.
4. Node.js: A server-side platform built on Chrome’s JavaScript runtime, enabling developers to build scalable network applications.
By leveraging the MEAN stack, businesses can develop full-stack applications with a consistent language, reducing complexity and improving efficiency throughout the development process.
Why Choose Binstellar’s MEAN Stack Development Services?
When it comes to hiring a mean stack developer, choosing Binstellar ensures you receive top-notch services tailored to your business needs. Here are some reasons why you should consider our MEAN stack development services:
Expertise and Experience
At Binstellar, we boast a team of highly skilled MEAN stack developers with extensive experience in building robust applications. Our developers are proficient in the latest technologies and best practices, ensuring that your project is executed to the highest standards.
Customized Solutions
We understand that every business has unique requirements. Our team works closely with you to comprehend your vision and goals, allowing us to create customized solutions that align perfectly with your objectives. Whether you need a new application or want to enhance an existing one, we’ve got you covered.
Agile Development Process
Binstellar employs an agile development methodology, allowing for flexibility and adaptability throughout the project lifecycle. This approach enables us to deliver high-quality products while accommodating any changes or feedback you may have along the way.
Comprehensive Support
Our commitment to your success doesn’t end with the delivery of your project. We offer ongoing support and maintenance services to ensure your application remains up-to-date, secure, and optimized for performance. Our team is always available to address any issues or make enhancements as needed.
Cost-Effective Solutions
We believe that high-quality development services should be accessible to businesses of all sizes. Binstellar offers competitive pricing for our MEAN stack development services, ensuring you receive exceptional value without compromising on quality.
Proven Track Record
Our portfolio showcases a wide range of successful projects across various industries. We take pride in our ability to deliver solutions that not only meet but exceed our clients’ expectations. Our focus on quality and client satisfaction has earned us a strong reputation in the industry.
Conclusion
In the fast-paced digital landscape, choosing the right technology stack and development partner is crucial for your business’s success. The MEAN stack offers unparalleled advantages, and Binstellar stands out as a leading mean stack development company dedicated to delivering top-quality applications tailored to your needs. Our experienced mean stack developers are ready to bring your vision to life with innovative solutions that drive results.
If you’re looking to develop a scalable and dynamic web application, don’t hesitate to contact Binstellar today. Let us help you leverage the full potential of the MEAN stack for your business.
MMS • RSS
![]() SG Americas Securities LLC cut its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 44.2% in the 3rd quarter, according to the company in its most recent disclosure with the SEC. The fund owned 2,501 shares of the company’s stock after selling 1,985 shares during the quarter. SG Americas Securities LLC’s holdings in MongoDB were worth $676,000 as of its most recent filing with the SEC.
SG Americas Securities LLC cut its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 44.2% in the 3rd quarter, according to the company in its most recent disclosure with the SEC. The fund owned 2,501 shares of the company’s stock after selling 1,985 shares during the quarter. SG Americas Securities LLC’s holdings in MongoDB were worth $676,000 as of its most recent filing with the SEC.
Other institutional investors also recently bought and sold shares of the company. Transcendent Capital Group LLC acquired a new position in shares of MongoDB during the 4th quarter worth $25,000. MFA Wealth Advisors LLC purchased a new position in MongoDB during the 2nd quarter valued at about $25,000. Sunbelt Securities Inc. raised its position in MongoDB by 155.1% during the first quarter. Sunbelt Securities Inc. now owns 125 shares of the company’s stock worth $45,000 after acquiring an additional 76 shares during the last quarter. J.Safra Asset Management Corp lifted its holdings in shares of MongoDB by 682.4% in the second quarter. J.Safra Asset Management Corp now owns 133 shares of the company’s stock valued at $33,000 after purchasing an additional 116 shares in the last quarter. Finally, Quarry LP grew its position in shares of MongoDB by 2,580.0% in the second quarter. Quarry LP now owns 134 shares of the company’s stock valued at $33,000 after purchasing an additional 129 shares during the last quarter. 89.29% of the stock is currently owned by hedge funds and other institutional investors.
MongoDB Price Performance
Shares of NASDAQ MDB opened at $292.86 on Monday. The company has a debt-to-equity ratio of 0.84, a current ratio of 5.03 and a quick ratio of 5.03. MongoDB, Inc. has a 1-year low of $212.74 and a 1-year high of $509.62. The company has a market capitalization of $21.48 billion, a price-to-earnings ratio of -104.22 and a beta of 1.15. The business has a 50-day moving average of $265.14 and a 200-day moving average of $287.65.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Thursday, August 29th. The company reported $0.70 earnings per share (EPS) for the quarter, beating the consensus estimate of $0.49 by $0.21. MongoDB had a negative net margin of 12.08% and a negative return on equity of 15.06%. The company had revenue of $478.11 million during the quarter, compared to the consensus estimate of $465.03 million. During the same quarter last year, the company earned ($0.63) earnings per share. MongoDB’s revenue for the quarter was up 12.8% on a year-over-year basis. On average, equities analysts anticipate that MongoDB, Inc. will post -2.44 EPS for the current fiscal year.
Insider Transactions at MongoDB
In other MongoDB news, CAO Thomas Bull sold 1,000 shares of the stock in a transaction on Monday, September 9th. The shares were sold at an average price of $282.89, for a total transaction of $282,890.00. Following the transaction, the chief accounting officer now directly owns 16,222 shares in the company, valued at $4,589,041.58. This represents a 0.00 % decrease in their position. The transaction was disclosed in a legal filing with the SEC, which is available through this link. In other news, CEO Dev Ittycheria sold 3,556 shares of MongoDB stock in a transaction that occurred on Wednesday, October 2nd. The stock was sold at an average price of $256.25, for a total value of $911,225.00. Following the completion of the transaction, the chief executive officer now owns 219,875 shares in the company, valued at approximately $56,342,968.75. This trade represents a 0.00 % decrease in their position. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which can be accessed through the SEC website. Also, CAO Thomas Bull sold 1,000 shares of the company’s stock in a transaction that occurred on Monday, September 9th. The shares were sold at an average price of $282.89, for a total value of $282,890.00. Following the sale, the chief accounting officer now directly owns 16,222 shares in the company, valued at approximately $4,589,041.58. This represents a 0.00 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Over the last quarter, insiders sold 15,896 shares of company stock valued at $4,187,260. 3.60% of the stock is currently owned by corporate insiders.
Analysts Set New Price Targets
A number of equities research analysts recently issued reports on the company. Stifel Nicolaus upped their target price on MongoDB from $300.00 to $325.00 and gave the company a “buy” rating in a research note on Friday, August 30th. Piper Sandler lifted their price objective on MongoDB from $300.00 to $335.00 and gave the stock an “overweight” rating in a research report on Friday, August 30th. DA Davidson boosted their target price on shares of MongoDB from $330.00 to $340.00 and gave the company a “buy” rating in a research note on Friday. Truist Financial raised their price target on shares of MongoDB from $300.00 to $320.00 and gave the stock a “buy” rating in a research note on Friday, August 30th. Finally, Morgan Stanley boosted their price objective on shares of MongoDB from $320.00 to $340.00 and gave the company an “overweight” rating in a research report on Friday, August 30th. One analyst has rated the stock with a sell rating, five have assigned a hold rating and twenty have given a buy rating to the stock. Based on data from MarketBeat.com, the company presently has an average rating of “Moderate Buy” and an average price target of $337.96.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • Bernd Ruecker
How Did You Become An Architect? [00:46]
Michael Stiefel: Welcome to the Architects Podcast, where we discuss what it means to be an architect and how architects actually do their job. Today’s guest is Bernd Ruecker, who is the founder and chief technologist at Camunda, a company involved with process orchestration. It now has about 500 people, and your clients include banks, insurance companies, and telcos. Bernd has contributed to various open source workflow engines over the past 20 years and has written three books, and is writing a fourth. And I’ve written two books, and I know how time-consuming book writing is. It’s great to have you here on the podcast, and I’d like to start out by asking you, were you trained as an architect? How’d you become an architect? Because it’s not something you decided one morning, you woke up and said, “Today I’m going to be an architect”.
Bernd Ruecker: Yes. Thanks for having me, Michael. No, it’s probably not like that. For me, honestly, I mean, I have probably a very typical thing that I started to do things like programming with a computer super early on, when I was like 13 or 14 or whatever. And then I think one of the key moments for me was really when a friend of mine during high school basically started to start his own business. He was selling a kind of modded graphic card, it’s a very specific thing back then, but over the internet. And he had a lot of trouble because he got successful with that, and he had a lot of piles of everything, piles of hardware lying there, piles of emails lying there, piles of invoices lying there, piles of stuff lying everywhere, and basically asked me if I could help him.
And I started to, naive as I was, I basically, from the perspective I have now, I would say I started to write an ERP system for that, and that was really by accident. And I dived into that, and that was kind of coexisting with, let’s say, my interest about a kind of software architecture in a way. I tried to get books around that. I tried to understand how to structure a system, and I could try that out. And I got into Enterprise JavaBeans back then. I got into how to structure different components, how to build them that I can run them, and I wrote a system that is, really weird, still up-and-running today, to some extent.
And that taught me a lot of things about, and also taught me that I find it more interesting to understand that kind of bigger picture around that system instead of diving into one thing very, very deep, and I think that was kind of the roots of it. And I did study computer science. I did a master’s degree for software engineering, so I really focused on that in my university, as well, but I got started, I would say, even earlier than that.
Michael Stiefel: So, in other words, it was sort of an accidental discovery of necessity that got you into architecture?
Bernd Ruecker: Probably, yes. Yes.
Michael Stiefel: In other words, the mess it is and you figured out how I’m going to organize this mess that I’m in, and that led you to sort of architecture. And then you somehow, you mentioned that you were working on essentially an ERP system. Was that sort of what got you thinking about orchestration?
Bernd Ruecker: Oh yes. 100%. So I mean, part of what the system has to do is basically looking at the data address, kind of what orders do I have, what hardware do I have lying around and stuff? But at the same time, you also have to look at the processes, and that’s where we started, like the workflows, like the order fulfillment, like the returns good handling. These were basically the problems where we started, like how can we manage that process that it runs efficiently?
And also back then I started to look into that, I found it fascinating, and probably we can discuss that later on, as well, but I’m a big fan of visuals. I also was always a big fan of UML Class diagrams, for example, for structuring, and I looked into visuals for workflows. And back then that was not yet very well-developed, I would say. There were a couple of weird things happening. There was BPEL-
Michael Stiefel: I remember BPEL.
Bernd Ruecker: Okay, yes. Hopefully a lot of people forgot about that. But there was not really a good solution for these kinds of workflows, and that got me hooked into the whole question, but there should be. And even back then, there were two options I found. The one was going with super expensive enterprise software on a really complex tech stack, which was obviously not an option for that at all. And I looked at open source projects, and there were not many back then and they were super technical. But I looked into one, I got a contributor there, and I worked with that, actually, to implement the workflow within that system, basically auto-fulfillment and returns good handling. And that got me into the whole process orchestration thing, first of all, thinking about it, also in the community. Then I started giving a talk about that. That brought me into freelancing around workflow engines. And in a way that’s also the story how I co-founded a company that does process orchestration as a product. I stumbled into that, as well, if you will.
What is Process Orchestration? [05:40]
Michael Stiefel: Well, look, life, sometimes some people know where they’re going from day one and some people just stumble their way to success. But you said two things that were kind of interesting, and I want to sort of focus in on them. You mentioned process orchestration, and process orchestration is a type of distributed system, and distributed systems are becoming increasingly common in our world. We see them all over the place, but people still really do not understand when people are involved in the distributed system. And process orchestration is all about that. And why do you think people have so much trouble dealing with process orchestration?
Bernd Ruecker: It’s a very good question. To be honest-
Michael Stiefel: And you might want to define, just for our listeners who are not familiar with this, you might want to also define what process orchestration is.
Bernd Ruecker: Probably that’s a good first step. So process orchestration is basically getting order in certain steps you have to do. So you orchestrate those steps, you coordinate those steps, that’s kind of the wording behind that. And normally, then you have technology that can do that. And the way it works is you define models, like nowadays, it’s BPMN. I’m a big fan of BPMN, business process model and notation. It’s a graphical model. You define where you say, “I have those, for example, three steps I have to do in a sequence”. So I do the first step first. When that’s done, the next step is happening. And then you can run such a workflow engine or process orchestrator that can interpret those models and can run instances of that, like the orders I talked about.
And then they run through basically all those steps. And then the workflow engine makes sure that, if there are decisions on the way, there are complex patterns, like if you are waiting for too long, you should do something else or push something to a human and whatever. So that’s one thing, process orchestrators can interpret those models so you get a visual. And the second big thing is it’s also about long-running processes. So the process orchestrator can wait for things to happen, that’s very often a human, but it might also be an asynchronous answer from a system that takes longer or a response from a customer. So there are a lot of things where you might need to wait, and that’s what a process orchestrator can do. And then it’s normally like persisted and you have all the tooling around that, where you can see what’s currently happening, where are you waiting, and so on and so forth.
What Is So Difficult About Understanding Orchestration? [08:01]
Michael Stiefel: So what do people find so difficult about this?
Bernd Ruecker: That’s the question that also puzzles me for a decade now, I think. I think that there are a couple of perceptions around that. It’s a lot about perception, I think, because I started with visual models, for example. If you ask developers about visual models, very often you get a negative feeling around that. That’s true for UML Class diagrams, I never understood that. That’s also true for process models. And I make the case with UML first, because that’s probably what most people out there know, and a lot of people probably learned that in university and it’s a drawing, it’s like dead paper. Or you even had model-driven architecture quite a while back, where we tried to generate software out of these models, which never worked very well.
But I also recall when I started there was a tool, which was actually super great that where you wrote Java code and then you could just look at the code you wrote as an UML diagram, because it knows if I have a collection typed of that type, I can just make two boxes in the right arrow. So it was kind of a automatically documenting things, it was live documentation, and it worked the other way around, as well. You could add attributes there and it was adding that to the code. I found that so helpful to get an overview of what I was doing, and the same is true for these process models. They are so helpful at their executable code, so they are not a wishful thinking document, they are executable code, but they are readable by every human. And that does not actually have to be a computer scientist, it can be a business person, as well, it can be whatever. And that’s so valuable, but somehow developers are scared of these process models. That’s the first perception I see everywhere.
Michael Stiefel: I mean, some of that is sort of historical. After all, the original idea behind COBOL was that even a manager could program. I don’t know if you remember COBOL, but that was one of the first computer languages developed, and of course, that was an utter failure, from that point of view. I mean, COBOL is used all over the place from the idea that that would be obvious. I think some of the fear programmers have, and I remember from when I used some of those visual tools, is sort of the paradox of programming.
Normal engineers, or a civil engineer, can essentially spend their entire career conceptually building the same bridge over and over again. But in software, if we want to build something new, we reprogram it all from scratch, because if you want another copy of Microsoft Word, you just copy the bits and you’re done. You only undertake a programming project if there’s something new to do. But the technology that we’ve automated is based on what we knew in the past. So there’s a disconnect between what we could automate in the past, but the fact that we’re doing something new that we never did before and that the tools are not capable of doing that. And that’s the frustration I had when I used some of those visual modeling tools.
Bernd Ruecker: Yes. But I would look at it from a different lens. For me, it’s really a little bit of a different view on the same thing. I mean, you can write code in whatever, Java, Node, or C#, it’s also an abstraction. You don’t write it on whatever assembler level anymore, right? And the same is for BPMN, for example. It’s a language that’s defined exactly how it should behave, and then you express problems with that language on a different abstraction level, but it’s still general purpose. You can model whatever you want to model there. And the other thing people forget then very often is you’re not, especially if you could use good tooling, that’s probably, again, something a lot of vendors did pretty bad in the past, but if that’s flexible enough or developer-friendly enough, you can say, “There is an SPI, there is a hook where it can hook in code, if I don’t get any further with BPMN, then I simply just code it”.
But there are certain elements in BPMN which are great for expressing long-running problems, and I simply should use them because that’s what I see on a weekly basis, at least. Otherwise, people start implementing their own homegrown, bespoke workflow engines without knowing it. It’s the, “Oh, we just need that order status column in that table over there”, but we have to monitor that. We write a small schedule looking at that every day and then we do this and that, and they start to build workflow engines. I see that so often, and it always starts with, “Oh, we don’t want to have the complexity of an additional component”, but you have the complexity of that mess you wrote.
Michael Stiefel: Plus, you’re rethinking something from scratch and not getting the benefit of other people’s experience. So that raised something also interesting that makes me think about the low-code movement. So in other words, when you use a system such as this, you’re trying to minimize the amount of code that a developer has to write, which is generally a good thing.
However, when you’re trying to figure out why the system is not working, do these orchestration engines, or whatever you want to call them, get in the way of understanding what’s happening? Are they too much of a black box?
Bernd Ruecker: Let’s say the core engine itself should be a black box. I mean, even if you have the source available, you could look into that, nobody wants to do that. I mean, I recall times when I debugged into Hibernate, that’s nothing you ever want to do just because you can.
Michael Stiefel: Yes, I’ve done that. Yes.
Bernd Ruecker: So I would say overall, that it should a black box, and that’s good as it is. But it’s, again, very general purpose, so if you have a good product there, the core should work and it’s not… I mean, it’s still complex to get that right, especially at scale, for example. But what it does, from looking at it from the outside, is not that complicated. So it basically triggers certain activities, and that’s either connector, which is code, or it’s your code, so it’s normally not that big of a problem. So you still have the possibility to debug into things, for example, that you just don’t debug into the core engine, you debug into what you made out of that, basically the activities you put into the process. You have the possibility to write automated unit tests, for example. So that’s not gone because you used such an orchestrator.
Michael Stiefel: I guess what you’re sort of saying is that we write stuff on top of the operating system, and we don’t step into the operating system.
Bernd Ruecker: Yes. Yes. Yes, you’re right.
Michael Stiefel: And there are bugs in the operating system, but I guess what you’re saying is we look at them sort of as a, this system is supposed to X, it doesn’t do X. We have to call up the vendor and understand why that is the case.
Bernd Ruecker: And I mean, overall, it’s a bit like also the cloud discussion, “Oh, we can’t put that in the cloud. Is that secure?” I’m 100% sure it’s more secure than what most companies do at home.
Michael Stiefel: Yes, yes, yes. The only interesting thing about the cloud, just as a side issue, as you mentioned it, it just builds a more tempting target for someone to hack.
Bernd Ruecker: Probably, yes. Yes.
Michael Stiefel: Yes. Willie Sutton, who was a very famous bank robber, and he was asked why he robbed banks and he said, “Well, that’s where the money is”.
Bernd Ruecker: True, it makes sense. But at the same time, if you compare using a product that’s built for that-
Michael Stiefel: Obviously. Yes, yes, yes.
Bernd Ruecker: And used in a lot of organizations, it’s probably better than just code it yourself. Yes.
Michael Stiefel: Yes, yes. But again, when you’re dealing with human fear-
Orchestration vs. Event-Driven Architectures [15:44]
Bernd Ruecker: Yes. But honestly, the typical objections are not about, “Ooh, is my software still stable?” It’s very often about, “I don’t need that component”. It’s still that belief, because it’s so simple, my problem is so simple. It’s not. And probably because people are not really looking into, let’s say, the full scope of process orchestration, like on an enterprise level, that’s a different topic we should probably look into. And the one thing, and that kept me actually busy for a couple of years, discussing orchestration versus choreography, basically. The whole thing, do I want to control what’s happening, or do I want to let it evolve by pushing events around, for example?
And there was a belief for quite a while, I think it changed at that moment, but there was a belief that event-driven is so much easier to do. It’s so much more decoupled. It’s better, or probably more beautiful or modern or whatever you want to call it, architecture. And that led a lot of projects into we don’t need orchestration. Orchestration is kind of bad. They brought that together with, oh, centralized bottlenecks and whatever, and that’s 100% not true. And that’s another perception we saw there where people deliberately didn’t want to go into the orchestration route, especially out of IT, which is kind of weird.
Michael Stiefel: Yes, it is. But you’re not arguing against event-driven architectures altogether?
Bernd Ruecker: No. No. So my point is there is a place for event-driven and there is a place for orchestration. Basically, both are typically about different components or services communicating their way back to the distributed system. Because in my whatever, order fulfillment process, I need to talk to the CRM system, to the ERP system, to the stock, to the whatever, logistic system, so I need to get all those pieces together. So the question is how do those components interoperate? And with orchestration, basically I have one component that has the duty, the responsibility, of orchestrating the end-to-end process and saying, “Okay, the first thing I have to do is, for example, getting the stuff from stock or retrieving the payment”, and so on and so forth. It can control that, to some extent. With event-driven, with the choreography, you basically distribute that responsibility, saying, “There’s an event, the order just came in”, and then some component knows, okay, then I have to collect money.
And that’s an architecture question, actually, one of the core architecture questions, how do you want to distribute responsibilities amongst the components? And that’s a design choice you can make. And there are sometimes good arguments where you want to be event-driven, and there are sometimes good arguments where you want to be orchestrated. And especially if I look at these typical business processes, like order fulfillment or whatever, I want to get a new bank account, I want to get a claim settled or all these kind of business processes, then you very often, from a business perspective, you want to have somebody responsible for the end-to-end, because the customer is only happy if the parcel arrives at my door. It doesn’t look at how beautiful my events are flowing within, just if I get my stuff here or if I get my money paid out or whatever, then the customer is happy. So there is a big emphasis on the end-to-end and understanding certain KPIs (Key Performance Indicators) and bottlenecks and everything on the end-to-end level.
And because of that you want to have one owner, and because of that you should have also on the IT side probably one personal, one component being responsible for that. And if you want to help that component responsible for something, it needs to control certain aspects, like the sequence of things for example, or the SLA. What happens if the logistic provider doesn’t talk back to me within two hours? Is that okay or not? And deciding all these kind of factors, that’s an architectural decision, and that’s… To make a very long answer short, it depends on how you want to lay out the system, and in most bigger systems I see a coexistence of both event-driven and orchestration.
Michael Stiefel: Where do you see, ideally speaking, event-driven should predominate in your architecture choice?
Bernd Ruecker: Every time when the component that triggers something is not really responsible for doing it. I’ll give you one example, I like examples. I find that much easier to understand, and it’s actually one thing I discussed with Sam Newman regularly. He wrote these microservices books, and he has an example also of an account opening in his book and I have an account opening in my book, so that’s a good collision of examples. And basically, what I look at from an orchestration perspective is the whole the customer applies to the bank account, for example, is opened because that’s a responsibility of one component, one microservice, if you will, or however you want to implement that, and that should be orchestrated.
He looks at, okay, the customer needs to be put into the loyalty points bank, he needs an account there, he probably needs a whatever letter, and certain things that are not in the responsibility of that core opening process. And then events are great because then you could just push an event on the bus saying, “Hey, the customer is created”. And then it could build different components reacting to that saying, “Okay, then we do this, but if we don’t do that, nothing happens”. The bank account is still open. Your COO will not come to you basically asking you, “Why is it not on the loyalty points bank?” It’s a different responsibility, and this kind of trade-off, I think, is very important to think about.
The Real Problem Is Most Systems Are Architectural Spaghetti [21:19]
Michael Stiefel: So, if I could summarize what you said in sort of a sentence or two, and tell me what I’ve got it right about, it’s basically, from a business perspective, where the responsibility lies?
Bernd Ruecker: Yes. Interesting side note here, while this is one of the things, I think, on a conference level I discussed the most over the last years, it’s still, when I look into our customer base, it’s not the predominant problem. It might be discussed, but the predominant problem is that they have an integration spaghetti there, where systems are talking to each other in a totally uncontrolled manner and you have no way of really extracting the end-to-end business process. It’s already hard to understand it, which makes it almost impossible to adjust it, and that’s a big, big problem at the moment because there is so much change. You might want to drive customer experience, you might want to add new services, you might want to infuse AI everywhere, and they have mostly no idea how the process is currently running and they can’t touch it. And I think that’s a much bigger problem at the moment, to be honest.
The Public Does Not Understand How Fragile These Systems Are [22:26]
Michael Stiefel: Yes. Well, it’s also a big problem from the public’s point of view because they don’t understand how fragile these software systems actually are. I don’t know if you’re familiar, for example, in the United States there was this, the security vendor for some Microsoft systems had a bug, and this caused tremendous outages in the airlines and, especially Delta, took days to recover, and there’s all kinds of finger pointing going back and forth. But the public really doesn’t understand how hodgepodge or fragile these software systems are, and you seem to, when you talk about this from the IT perspective, I don’t think upper management sometimes realizes how fragile these systems are. Do you have any feeling about this one way or the other, how to explain this to people, whether upper management or the public?
Bernd Ruecker: But I think that’s, honestly, one of the, let’s say, core areas where we also look at when we talk about business processes and process orchestration, because it’s exactly that connection between business and IT. The IT side is implementing the process, okay, but the business side needs to understand the end-to-end process. And if I talk to the business, they have different language. They talk about whatever business model canvas, customer journeys, value streams, and these kind of things. We can get also the business to level where we talk about an end-to-end business process and probably business capabilities. And then we want to link that to implementation, and the process, for me, is one of the key elements to do that because that’s also what a business person understands. And then as soon as you have that running, you can even link data to that, yes.
The Architect is the Translator Between Business and IT [24:12]
Michael Stiefel: You hit on one of what I think is a key role of an architect, because the architect is the person who can talk to the business people about business and the technical people about technology. They’re sort of the interpreter of the two different worlds.
Bernd Ruecker: Yes, 100%. When you ask about architecture, what always comes to my mind first is I think there are still different levels to an architect. So I started, I would say, as a solution architect, looking at a single solution only, which is a bit different to looking on an enterprise architect or in the business architecture level. But I totally agree, especially the latter two should be able to, I like the Gregor Hohpe metaphor, actually, of the architect elevator, that you have to ride the elevator up and down, from the engine to the penthouse and you have to be able to talk to all of them.
Michael Stiefel: Which means that one of the skills of an architect is, even if because of their generalization they lose some of their technical chops, they still have to keep their intuition about what is technically right and wrong.
Bernd Ruecker: I agree, and I’ am still a big fan, I mean, I also do a lot of discussions nowadays about business value, for example, express business value, and I understand why it’s so important to do that, right? At the same time, I try to program, probably not on a daily basis anymore, but at least a weekly basis. I need to touch code very regularly to, exactly, keep that feeling what you’re talking about, so yes, 100%
Michael Stiefel: Yes, yes. Good. So you mentioned about processes in the enterprise and you wanted to get back to that. Is there anything that comes to mind when you think about that?
Bernd Ruecker: I think I touched on that briefly. So what we are currently seeing is a lot of change in organizations. That’s probably not news. AI or agentic AI, or whatever the buzzword of the day is, puts a lot of pressure, and we see organizations struggle with that. And what we also see them doing, if you look at it from an enterprise perspective, very often they try to optimize things in local areas, like in that one application or I use a, whatever, robotic process automation bot over here, I want to use that AI tool over here. But very often that’s local because that’s how the teams are siloed in that organization, very often the business teams. And then they start to do projects which, on a local level, might make sense because they have an ROI, oh, we automated that, we saved manual labor, there’s a ROI.
But zooming out, and that’s what a lot of companies miss, zooming out, looking at these end-to-end processes, it doesn’t have to be necessarily good what they are doing. Either it doesn’t have any influence on the overall end-to-end process, it can even cement certain bad behaviors, bad patterns, like making it harder to change that overall process, and it definitely not looks at improving it end-to-end. There are tons of examples. So we have seen, for example, AI to do support requests you could save if you make the overall application process much smoother, for example. And then, of course, you should invest there and not making the support better, even if that looks good on an isolated basis.
And all these kind of local optimizations, I think, are a huge problem. So we need to elevate that discussion to understand that value stream and the business process, and for me, process orchestration is kind of the key element to make that happen because it can actually look at the process and make the connection to really executable software and then orchestrate different pieces, different tasks, together. And that’s super powerful if you look at that on an enterprise level. So not so much in my local project, how can I orchestrate the process better? We have that, as well, but really look at it more holistically. And that’s what we are currently doing with quite a couple of customers, which is super interesting.
Michael Stiefel: I don’t know if you’re aware of this or not, but this is actually a broad economic phenomenon. I don’t know if you’re familiar with something called Pareto optimization, but the argument there is very much the one that you mentioned, is that if you want to optimize something and you can’t do local optimizations, you generally have to reoptimize the whole system to get an incremental optimization. And what you’re describing actually fits into a larger economic system, and you seem to say that process orchestration is a way of forcing that issue to the front.
Bernd Ruecker: Yes. And it’s a way of probably solving the riddle, at least to some extent. I mean, that’s not the only piece, but I think it’s a centerpiece. And it’s something, again, which you can make a CIO or a CEO or a COO understand because business process is not-
Michael Stiefel: A foreign language.
Bernd Ruecker: I think that’s one problem of the microservice community, for example, it’s discussed in IT, IT only. If I go to a business process, business capability level, I can talk to business, as well. And that’s a different thing because you need them. I mean, that’s actually why the business exists, so you need them, and that’s saying me as kind of an engineer by heart, you need them, of course, on board to make transformation happen.
The Technology Is Fun Trap [29:24]
Michael Stiefel: I think, in my career, I’ve had the same experience, that it’s amazing how many of the technology people think in terms only of technology and don’t understand the business reason for doing something. After all, it’s the business that’s paying, it’s the business that’s driven. I mean, yes, I’m fascinated with technology, too, but the idea is in service of a goal.
Bernd Ruecker: Yes. I totally agree. I thought about that quite a bit, as well, because for me it was kind of a transformation, a journey, I would say, personally because I was super nerdy and enthusiastic about technology for a long time.
Michael Stiefel: It’s fun. Technology is fun.
Bernd Ruecker: It is, and I loved it. I mean, we did a cross-orchestration engine that can scale on geographically-distributed data centers without adding latency, but we still have the same throughput, for example, so that’s obviously awesome and exciting.
Michael Stiefel: But you tell that to a business person and they go, “Duh”.
Bernd Ruecker: Yes, it’s like, “Duh”.
Michael Stiefel: Right.
Bernd Ruecker: On georedundancy, they might understand, but not how we did it.
Michael Stiefel: Right.
Bernd Ruecker: But I still had that progression, I would say, to understand why business value is important, and then also starting to understand how you can explain that better. Because very often it’s an indirect story you have to tell why this technology enables this, what it can do in a software application, and that will basically increase whatever customer experience, and then you can talk to them. And that’s so important, and probably, I would say, it’s a typical journey a lot of people run through, and I think it’s probably a good thing. I want to keep all those enthusiastic 20-years-old people that love technology. They are awesome, and we need them.
Architecture and Development are Two Equal Roles [31:05]
Michael Stiefel: And maybe some of them will stay that way for 40 years.
Bernd Ruecker: Yes, it’s also fine. Yes, yes, yes, true.
Michael Stiefel: I think it’s a mistake to think that everybody has to become an architect. To be a super developer is great, too.
Bernd Ruecker: It is. It is. And for me, for example, I did a very conscious decision not to go into people management. And for me, that architect, for example, is also a path you could take where you say, “I don’t want a people manage, but I want to get to a broader view”, and have kind of whatever, probably making bigger decisions, if you will.
Michael Stiefel: That must be tough running a company.
Bernd Ruecker: You have to find the right co-founder. Again, a piece of luck I had in my life.
Michael Stiefel: But also, it’s important to explain that story to the technology people, why they can’t fall in love with this piece of technology, and they have to do it maybe the old-fashioned way because that’s better for the business.
Bernd Ruecker: Yes. It’s not always easy. You probably know that there’s a blog post called Choose Boring Technology, or something like that, and that’s what it’s very often about.
How Do You Train Developers? [32:06]
Michael Stiefel: Yes. So two questions that sort of come to mind, and they’re separate questions, but I think they’re things that you’ve touched on that are important, how do you train developers? If developers have trouble understanding when to use events and choreograph and when to orchestrate and distributed systems and asynchronous systems, how do you train new developers to understand this?
Bernd Ruecker: There is, as always, nuance to that. So there are things where I just think people have to be made aware just by trying things out, and that’s, I would say, for the smaller problems, for example, mastering asynchronous communication, having probably consistency problem, like transactional problems, long-running things, those you can occasionally train by doing examples, probably let them writing things, probably review stuff, so that-
Michael Stiefel: And wonder why their system’s hanging.
Bernd Ruecker: Yes. I even personally learned the trouble of two-phase commit early on in my life in a real-life scenario. I mean, that’s something that sticks with you afterwards. So that’s okay. I would say the bit more architectural questions, the bigger, hairy ones like event-driven or orchestration, which might influence not only one communication link, but probably how you lay out the whole architecture, that’s probably not for a newbie. That’s probably something where it’s good to have some experienced people on board. We very often do coachings, but when I talk to people, it’s very often architects that already have seen something, otherwise it might be hairy.
Michael Stiefel: So sort of what you’re saying is that gradual exposure to increasingly more complex situations is basically the way people learn?
Bernd Ruecker: Yes, probably. I would say so.
The Importance of Visual Tools [33:51]
Michael Stiefel: And the other thing you talked about is sort of your love, if that’s too strong a word, but your appreciation of visual communication and visual tools.
Bernd Ruecker: Oh, I would say love is a good word.
Michael Stiefel: Okay. I think, given that people very often don’t appreciate this, and I know from the work that I’ve done with workflow and the little work that I’ve done with process orchestration, visuals are very, very important, especially with long-running processes that you can’t necessarily get in your head completely.
Bernd Ruecker: Yes. It’s even a problem that you can express very well with visuals. It’s a flow of activities, probably some different path, then there are events happening where you go somewhere else, so it’s a problem that fits well on a visual. And to be honest, I don’t get it why people are so against it. And every time, when I discuss a process with people that don’t like visuals, what they do first is take a whiteboard and draw it.
Michael Stiefel: Yes.
Bernd Ruecker: It’s like, because otherwise you can’t follow. So I personally don’t get it. And then sometimes get arguments like, “But how can I do diffing?” Yes, you can do visual diffing. I’m not sure if that’s the most important question, but you could do it. So no, I just don’t get it.
Michael Stiefel: There’s a limit to the amount of complexity the human mind can conceive of, and they’re not linear processes, necessarily, and there’s feedback. It seems almost perfect for a diagram.
Bernd Ruecker: Yes, I agree. And same thing, and probably you need different levels of abstractions, for example, you can do subprocesses or certain things that might happen you might want to handle in a different process or some things you might still want to handle in code, so you can play with that. It’s one tool in your tool belt, and if it fits, it simply should be used.
The Architect’s Questionnaire [35:39]
Michael Stiefel: Yes. So one of the things I like to do to ask all the architects that appear on the podcast is the architect’s questionnaire, which gets into the more human side of being an architect. So what’s your favorite part of being an architect?
Bernd Ruecker: I think I said that relatively in the beginning, seeing the big picture. Not going super deep in one element, but understanding the different pieces and how they are connected. Probably also how they are connected to business strategy, how they are connected to the technical implementation, so I think that’s my favorite part, I would say.
Michael Stiefel: So what is your least favorite part of being an architect?
Bernd Ruecker: To some extent, that’s probably also connected to my current role, which means I’m very often talking to a lot of companies, but always as an external. And I think that’s also true for architects in organizations, so you’re not part of the team typically. You’re very often an outsider, which I can live with, but it’s probably the one my least favorite thing of it.
Michael Stiefel: Is there anything creatively, spiritually, or emotionally about architecture or being an architect?
Bernd Ruecker: I love that question. I mean, the creativity part, I think it’s clear. I think it’s super creative. You have to very often find elegant solutions for very complex problems and make or communicate them in a way that they’re easy to understand. That’s very creative, and I love doing that. It always makes you a little bit happy if you see that this seems to be understood and works. And the spiritual or emotional element, it’s probably harder to answer, but for me it’s, again, I would say happy is kind of the thing. If you see that it’s working out, if you see that people are understanding it, if you see that whatever you draw helps people understand things or implement that, it’s just a good feeling.
Michael Stiefel: The world is a little better off incrementally. What turns you off about architecture or being an architect?
Bernd Ruecker: I would say it’s the, there is a typical perception around architects also being kind of the naysayers, the no-sayers, the governance entity, the police, if you will, which I think is not true, at least not for good architects at all, but it’s kind of the one thing very often I hear.
Michael Stiefel: Do you have any favorite technologies?
Bernd Ruecker: That’s easy. Of course, BPMN. Of course, Camunda. I contributed to a couple of other workflow engines in the past, as well. So there it’s great technology. Otherwise, I would say simply also programming. So I am a Java person, I started with Java and I like Java. I like the type languages, to be honest. I like the dependency management, I like the tooling, the ecosystems, the open source around it.
Michael Stiefel: What about architecture do you love?
Bernd Ruecker: Probably repetition. I would say breaking things down into manageable pieces, solving a complex problem. I would say that’s more or less it.
Michael Stiefel: And what about architecture do you hate?
Bernd Ruecker: Discussions. Too long discussions, too many discussions, not fruitful discussions. I know it’s part of the thing, and to some extent I like it and it makes things better, but at some point in time it’s too much.
Michael Stiefel: What profession, other than being an architect, would you like to attempt?
Bernd Ruecker: I haven’t found any so far. I mean, co-founding the company, I had a couple of roles in the past, but it always was architecture related, to be honest. I think my absolute favorite was kind of what we now call a solution engineer doing proof of concepts, like flying into the customer three days, get something to work in their environment, and leave. You don’t have to finish it, but you can draw the boxes to sketch the idea and prove that it really works, so that was always my favorite.
Michael Stiefel: Do you ever see yourself as not being an architect anymore?
Bernd Ruecker: Probably, let’s see. I mean, what I said early on, what I experienced at the moment is that I had that phase of my life that, I would say 10 years, where I was so into enthusiastic about technology. When I was at a conference I picked up something, some keyword I had to Google that, I could try it out. I was sitting in the evening in the hotel room hacking something to understand it. To some extent, that changed a little bit, probably also with family and kids and whatever, not so much time, and seeing that generation is still there doing that, probably now with AI and stuff. So I kind of foresee to probably do more mentoring than architecture actively myself, but not yet.
Michael Stiefel: And when a project is done, what do you like to hear from the clients or your team?
Bernd Ruecker: When I read the question, my first thought was, it’s not really an answer, but my first thought was, don’t make any more projects. Go into the product thinking world, that’s where you should be, actually. So a product is never done. If you do software, it should be kind of a product, it should be maintained, it should be a life cycle, it should keep doing things. So that’s one thing. But I totally get the question.
So the other thing, and that’s probably, again, because of my time in my life I’m currently, I would like to hear from them what’s the value of what we just did? What’s the story that connects it to the business value? What could we tell everybody in the company why we did what we just did, and why is this great? I think if they achieve that, for me, that would be even better than, quote unquote, just having a great technical solution.
Michael Stiefel: Well, thank you very much. I found this conversation fascinating, and I think you’ve illuminated many dark corners for people about both orchestration and how to think about architecture, so thank you very much.
Bernd Ruecker: Thanks for having me, Michael.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS

As the craze of earnings season draws to a close, here’s a look back at some of the most exciting (and some less so) results from Q2. Today, we are looking at data storage stocks, starting with Couchbase (NASDAQ:BASE).
Data is the lifeblood of the internet and software in general, and the amount of data created is accelerating. As a result, the importance of storing the data in scalable and efficient formats continues to rise, especially as its diversity and associated use cases expand from analyzing simple, structured datasets to high-scale processing of unstructured data such as images, audio, and video.
The 5 data storage stocks we track reported a strong Q2. As a group, revenues beat analysts’ consensus estimates by 2.5% while next quarter’s revenue guidance was 1.3% above.
After much suspense, the Federal Reserve cut its policy rate by 50bps (half a percent) in September 2024. This marks the central bank’s first easing of monetary policy since 2020 and the end of its most pointed inflation-busting campaign since the 1980s. Inflation had begun to run hot in 2021 post-COVID due to a confluence of factors such as supply chain disruptions, labor shortages, and stimulus spending. While CPI (inflation) readings have been supportive lately, employment measures have prompted some concern. Going forward, the markets will debate whether this rate cut (and more potential ones in 2024 and 2025) is perfect timing to support the economy or a bit too late for a macro that has already cooled too much.
Luckily, data storage stocks have performed well with share prices up 15.2% on average since the latest earnings results.
Couchbase (NASDAQ:BASE)
Formed in 2011 with the merger of Membase and CouchOne, Couchbase (NASDAQ:BASE) is a database-as-a-service platform that allows enterprises to store large volumes of semi-structured data.
Couchbase reported revenues of $51.59 million, up 19.6% year on year. This print was in line with analysts’ expectations, but overall, it was a mixed quarter for the company with full-year revenue guidance exceeding analysts’ expectations but a miss of analysts’ billings estimates.
“I’m pleased with our hard work and execution in the quarter,” said Matt Cain, Chair, President and CEO of Couchbase.
Couchbase delivered the weakest performance against analyst estimates and weakest full-year guidance update of the whole group. Unsurprisingly, the stock is down 14.4% since reporting and currently trades at $16.24.
Is now the time to buy Couchbase? Access our full analysis of the earnings results here, it’s free.
Best Q2: Commvault Systems (NASDAQ:CVLT)
Originally formed in 1988 as part of Bell Labs, Commvault (NASDAQ: CVLT) provides enterprise software used for data backup and recovery, cloud and infrastructure management, retention, and compliance.
Commvault Systems reported revenues of $224.7 million, up 13.4% year on year, outperforming analysts’ expectations by 4.2%. The business had an exceptional quarter with an impressive beat of analysts’ billings estimates and full-year revenue guidance exceeding analysts’ expectations.
Commvault Systems scored the biggest analyst estimates beat among its peers. The market seems happy with the results as the stock is up 30.7% since reporting. It currently trades at $161.12.
Is now the time to buy Commvault Systems? Access our full analysis of the earnings results here, it’s free.
Weakest Q2: Snowflake (NYSE:SNOW)
Founded in 2013 by three French engineers who spent decades working for Oracle, Snowflake (NYSE:SNOW) provides a data warehouse-as-a-service in the cloud that allows companies to store large amounts of data and analyze it in real time.
Snowflake reported revenues of $868.8 million, up 28.9% year on year, exceeding analysts’ expectations by 2.1%. Still, it was a slower quarter as it posted a miss of analysts’ billings estimates.
As expected, the stock is down 8% since the results and currently trades at $124.19.
Read our full analysis of Snowflake’s results here.
DigitalOcean (NYSE:DOCN)
Started by brothers Ben and Moisey Uretsky, DigitalOcean (NYSE: DOCN) provides a simple, low-cost platform that allows developers and small and medium-sized businesses to host applications and data in the cloud.
DigitalOcean reported revenues of $192.5 million, up 13.3% year on year. This number surpassed analysts’ expectations by 2%. Overall, it was a very strong quarter as it also recorded full-year revenue guidance exceeding analysts’ expectations and a solid beat of analysts’ ARR (annual recurring revenue) estimates.
DigitalOcean scored the highest full-year guidance raise among its peers. The stock is up 48.7% since reporting and currently trades at $43.28.
Read our full, actionable report on DigitalOcean here, it’s free.
MongoDB (NASDAQ:MDB)
Started in 2007 by the team behind Google’s ad platform, DoubleClick, MongoDB offers database-as-a-service that helps companies store large volumes of semi-structured data.
MongoDB reported revenues of $478.1 million, up 12.8% year on year. This print surpassed analysts’ expectations by 3%. Overall, it was a very strong quarter as it also recorded an impressive beat of analysts’ billings estimates and full-year revenue guidance exceeding analysts’ expectations.
MongoDB had the slowest revenue growth among its peers. The company added 52 enterprise customers paying more than $100,000 annually to reach a total of 2,189. The stock is up 19.2% since reporting and currently trades at $293.01.
Read our full, actionable report on MongoDB here, it’s free.
Join Paid Stock Investor Research
Help us make StockStory more helpful to investors like yourself. Join our paid user research session and receive a $50 Amazon gift card for your opinions. Sign up here.