Month: October 2024

MMS • RSS

According to the Zhītōng Finance APP, Piper Sandler believes that Adobe (ADBE.US), MongoDB (MDB.US), and Salesforce (CRM.US) are the most worthwhile investment stocks in cloud software.
Piper Sandler analysts led by Brent Bracelin stated: “We recommend large-cap growth investors to take on more risk and increase their position in ‘MAC’.” MAC refers to Adobe, MongoDB, and Salesforce.
Bracelin added: “These are stocks that have underperformed market expectations, with average prices still 26% below their 52-week highs, despite having healthy product and profit catalysts, as well as favorable risk-return profiles.”
After hitting a low point in the second quarter, MongoDB may accelerate its growth in the future. MongoDB’s stock price has already fallen by 29% this year. Piper Sandler believes that as a high-quality database franchise operator, the stock is expected to recover the 29% decline over the next few quarters and reach $335.
Adobe’s situation is similar, and with the benefit of its latest artificial intelligence products, the stock is expected to recover this year.
Piper Sandler pointed out: “The new innovation product cycle is underestimated, which may help revitalize growth.”
Salesforce’s stock price has risen by 9% this year, but has fallen by nearly 5% in the past six months.
Bracelin noted: “We believe Salesforce will rise by 11% to $325, and in a bullish scenario, it could rise by 39% to $405.”
Piper Sandler rates Adobe as “overweight” with a target price of $635; rates Salesforce as “overweight” with a target price of $325; rates MongoDB as “overweight” with a target price of $335
MMS • RSS
SG Americas Securities LLC decreased its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 44.2% during the 3rd quarter, according to its most recent filing with the Securities and Exchange Commission (SEC). The fund owned 2,501 shares of the company’s stock after selling 1,985 shares during the quarter. SG Americas Securities LLC’s holdings in MongoDB were worth $676,000 as of its most recent SEC filing.
Several other hedge funds and other institutional investors have also bought and sold shares of the company. Transcendent Capital Group LLC bought a new position in shares of MongoDB in the fourth quarter valued at $25,000. MFA Wealth Advisors LLC bought a new position in shares of MongoDB in the second quarter valued at $25,000. Sunbelt Securities Inc. boosted its position in MongoDB by 155.1% during the first quarter. Sunbelt Securities Inc. now owns 125 shares of the company’s stock worth $45,000 after purchasing an additional 76 shares during the period. J.Safra Asset Management Corp boosted its position in MongoDB by 682.4% during the second quarter. J.Safra Asset Management Corp now owns 133 shares of the company’s stock worth $33,000 after purchasing an additional 116 shares during the period. Finally, Quarry LP boosted its position in MongoDB by 2,580.0% during the second quarter. Quarry LP now owns 134 shares of the company’s stock worth $33,000 after purchasing an additional 129 shares during the period. Institutional investors own 89.29% of the company’s stock.
Insider Buying and Selling
In other news, CRO Cedric Pech sold 302 shares of MongoDB stock in a transaction on Wednesday, October 2nd. The stock was sold at an average price of $256.25, for a total value of $77,387.50. Following the completion of the transaction, the executive now directly owns 33,440 shares in the company, valued at approximately $8,569,000. The trade was a 0.00 % decrease in their ownership of the stock. The sale was disclosed in a document filed with the Securities & Exchange Commission, which can be accessed through the SEC website. In related news, CRO Cedric Pech sold 302 shares of the business’s stock in a transaction dated Wednesday, October 2nd. The stock was sold at an average price of $256.25, for a total transaction of $77,387.50. Following the completion of the transaction, the executive now directly owns 33,440 shares in the company, valued at $8,569,000. The trade was a 0.00 % decrease in their ownership of the stock. The transaction was disclosed in a filing with the Securities & Exchange Commission, which is available through this hyperlink. Also, Director Dwight A. Merriman sold 3,000 shares of the company’s stock in a transaction dated Tuesday, September 3rd. The stock was sold at an average price of $290.79, for a total value of $872,370.00. Following the completion of the transaction, the director now owns 1,135,006 shares of the company’s stock, valued at $330,048,394.74. The trade was a 0.00 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Over the last three months, insiders have sold 15,896 shares of company stock worth $4,187,260. 3.60% of the stock is owned by company insiders.
MongoDB Stock Down 0.4 %
Shares of MongoDB stock traded down $1.12 on Monday, hitting $291.74. The company had a trading volume of 55,119 shares, compared to its average volume of 1,448,723. MongoDB, Inc. has a 1 year low of $212.74 and a 1 year high of $509.62. The company has a debt-to-equity ratio of 0.84, a quick ratio of 5.03 and a current ratio of 5.03. The stock has a 50 day moving average of $265.14 and a 200-day moving average of $287.15. The stock has a market capitalization of $21.40 billion, a price-to-earnings ratio of -104.22 and a beta of 1.15.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its earnings results on Thursday, August 29th. The company reported $0.70 earnings per share for the quarter, beating analysts’ consensus estimates of $0.49 by $0.21. The company had revenue of $478.11 million for the quarter, compared to analyst estimates of $465.03 million. MongoDB had a negative return on equity of 15.06% and a negative net margin of 12.08%. The company’s revenue for the quarter was up 12.8% on a year-over-year basis. During the same quarter last year, the company earned ($0.63) earnings per share. As a group, sell-side analysts forecast that MongoDB, Inc. will post -2.44 earnings per share for the current year.
Wall Street Analysts Forecast Growth
A number of equities analysts have commented on MDB shares. Tigress Financial reduced their price objective on shares of MongoDB from $500.00 to $400.00 and set a “buy” rating for the company in a research report on Thursday, July 11th. Wells Fargo & Company boosted their price target on MongoDB from $300.00 to $350.00 and gave the company an “overweight” rating in a research note on Friday, August 30th. UBS Group boosted their price target on MongoDB from $250.00 to $275.00 and gave the company a “neutral” rating in a research note on Friday, August 30th. Scotiabank boosted their target price on MongoDB from $250.00 to $295.00 and gave the stock a “sector perform” rating in a research note on Friday, August 30th. Finally, Needham & Company LLC boosted their target price on MongoDB from $290.00 to $335.00 and gave the stock a “buy” rating in a research note on Friday, August 30th. One equities research analyst has rated the stock with a sell rating, five have assigned a hold rating and twenty have issued a buy rating to the stock. According to MarketBeat, the stock has a consensus rating of “Moderate Buy” and a consensus price target of $337.96.
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Which stocks are likely to thrive in today’s challenging market? Click the link below and we’ll send you MarketBeat’s list of ten stocks that will drive in any economic environment.
MMS • Robert Krzaczynski

OpenAI launched the public beta of the Realtime API, offering developers the ability to create low-latency, multimodal voice interactions within their applications. Additionally, audio input/output is now available in the Chat Completions API, expanding options for voice-driven applications. Early feedback highlights limited voice options and response cutoffs, similar to ChatGPT’s Advanced Voice Mode.
The Realtime API enables real-time, natural speech-to-speech interactions using six preset voices, combining speech recognition and synthesis into a single API call. This simplifies the development of fluid conversational applications by streamlining what previously required multiple models.
OpenAI has also extended the capabilities of its Chat Completions API by adding support for audio input and output. This feature is geared towards use cases that do not require the low-latency performance of the Realtime API, allowing developers to send either text or audio inputs and receive responses in text, audio, or both.
In the past, creating voice assistant experiences required using multiple models for different tasks, such as automatic speech recognition, text inference, and text-to-speech. This often resulted in delays and lost nuance. The Realtime API addresses these issues by streamlining the entire process into a single API call, offering faster and more natural conversational capabilities.
The Realtime API is powered by a persistent WebSocket connection, allowing for continuous message exchange with GPT-4o. It also supports function calling, enabling voice assistants to perform tasks such as placing orders or retrieving relevant user data to provide more personalized responses.
Additionally, the community observed that although the API is accessible through the Playground, the available voice options are currently limited to alloy, echo, and shimmer. During testing, users noticed that the responses were subject to the same limitations as ChatGPT’s Advanced Voice Mode. Despite attempts to use detailed system messages, the responses were still cut off, hinting at the involvement of a separate model managing the flow of conversations.
The Realtime API is available in public beta for all paid developers. Audio in the Chat Completions API will be released in the coming weeks. Pricing for the Realtime API includes both text and audio tokens, with audio input priced at approximately $0.06 per minute and audio output at $0.24 per minute.
There have been concerns about how this pricing could impact long-duration interactions. Some developers pointed out that due to the way the model processes conversations, where every response involves revisiting prior exchanges, costs can accumulate quickly. This has led to thoughts about value, especially for extended conversations, given that large language models do not retain short-term memory and must reprocess prior content.
Developers can begin exploring the Realtime API by checking the official documentation and the reference client.
Java News Roundup: JDK 24, Tomcat 11.0, Cassandra 5.0, EclipseStore 2.0, Payara Platform, Ktor 3.0
MMS • Michael Redlich

This week’s Java roundup for October 7th, 2024, features news highlighting: JEP 489, Vector API (Ninth Incubator), and JEP 484, Class-File API, targeted for JDK 24; the release of Apache projects, Tomcat 11.0.0 and Cassandra 5.0.0; the release of EclipseStore 2.0.0; the October 2024 Payara Platform release; and the release of Ktor 3.0.0.
OpenJDK
After its review had concluded, JEP 489, Vector API (Ninth Incubator), has been promoted from Proposed to Target to Targeted for JDK 24. This JEP incorporates enhancements in response to feedback from the previous eight rounds of incubation, namely: JEP 469, Vector API (Eighth Incubator), delivered in JDK 23; JEP 460, Vector API (Seventh Incubator), delivered in JDK 22; JEP 448, Vector API (Sixth Incubator), delivered in JDK 21; JEP 438, Vector API (Fifth Incubator), delivered in JDK 20; JEP 426, Vector API (Fourth Incubator), delivered in JDK 19; JEP 417, Vector API (Third Incubator), delivered in JDK 18; JEP 414, Vector API (Second Incubator), delivered in JDK 17; and JEP 338, Vector API (Incubator), delivered as an incubator module in JDK 16. Originally slated to be a re-incubation by reusing the original Incubator status, it was decided to keep enumerating. The Vector API will continue to incubate until the necessary features of Project Valhalla become available as preview features. At that time, the Vector API team will adapt the Vector API and its implementation to use them, and will promote the Vector API from Incubation to Preview.
After its review had concluded, JEP 484, Class-File API, has been promoted from Proposed to Target to Targeted for JDK 24. This JEP proposes to finalize this feature in JDK 24 after two rounds of preview, namely: JEP 466, Class-File API (Second Preview), delivered in JDK 23; and JEP 457, Class-File API (Preview), delivered in JDK 22. This feature provides an API for parsing, generating, and transforming Java class files. This will initially serve as an internal replacement for ASM, the Java bytecode manipulation and analysis framework, in the JDK with plans to have it opened as a public API. Goetz has characterized ASM as “an old codebase with plenty of legacy baggage” and provided background information on how this feature will evolve and ultimately replace ASM.
JEP 490, ZGC: Remove the Non-Generational Mode, was promoted from its JEP Draft 8335850 to Candidate status. This JEP proposes to remove the non-generational mode of the Z Garbage Collector (ZGC). The generational mode is now the default as per JEP 474, ZGC: Generational Mode by Default, delivered in JDK 23. By removing the non-generational mode of ZGC, it eliminates the need to maintain two modes and improves development time of new features for the generational mode.
JDK 24
Build 19 of the JDK 24 early-access builds was made available this past week featuring updates from Build 18 that include fixes for various issues. Further details on this release may be found in the release notes.
With less than two months before Rampdown Phase One, four JEPs are currently targeted for JDK 24:
For JDK 24, developers are encouraged to report bugs via the Java Bug Database.
Project Loom
Build 24-loom+8-78 of the Project Loom early-access builds was made available to the Java community this past week and is based on Build 18 of the JDK 24 early-access builds. This build improves the implementation of Java monitors (synchronized methods) for enhanced interoperability with virtual threads.
Jakarta EE
In his weekly Hashtag Jakarta EE blog, Ivar Grimstad, Jakarta EE developer advocate at the Eclipse Foundation, provided an update on the upcoming release of Jakarta EE 11, writing:
The refactoring of the Jakarta EE TCK continues. It looks like we will be able to release Jakarta EE 11 Core Profile pretty soon with Open Liberty as a ratifying implementation. For the Platform and Web Profile, we will have to wait a little longer. It still looks like it will be possible to release in time for JakartaOne Livestream on December 3, 2024.
The road to Jakarta EE 11 included four milestone releases with the potential for release candidates as necessary before the GA release in 4Q2024.
Spring Framework
The second milestone release of Spring Cloud 2024.0.0, codenamed Moorgate, features bug fixes and notable updates to sub-projects: Spring Cloud Kubernetes 3.2.0-M2; Spring Cloud Function 4.2.0-M2; Spring Cloud OpenFeign 4.2.0-M2; Spring Cloud Stream 4.2.0-M2; and Spring Cloud Gateway 4.2.0-M2. This release provides compatibility with Spring Boot 3.4.0-M3. More details on this release may be found in the release notes.
The third milestone release of Spring AI 1.0.0 provides new features such as: improvements to their Spring Advisors API; a new ToolContext class that replaces using Map for function callbacks; and support for additional observability models that include: Azure OpenAI, Google Vertex AI, and MiniMax AI.
The second milestone release of Spring Batch 5.2.0 provides new features such as: support for MongoDB as an implementation of the JobRepository interface; a new CompositeItemReader class to complement the existing CompositeItemWriter and CompositeItemProcessor classes. Further details on this release may be found in the release notes.
Following-up from the recent plan to release Spring Framework 7.0 and Spring Boot 4.0 in November 2025, the Spring Cloud Data Flow (SCDF) team has prepared its own plan to release version 3.0 in November 2025. The intent to align the SCDF projects (such as: SCDF server components, Composed Task Runner, and SCDF UI) with Spring Framework 7.0 and Spring Boot 4.0.
Payara
Payara has released their October 2024 edition of the Payara Platform that includes Community Edition 6.2024.10 and Enterprise Edition 6.19.0 and Enterprise Edition 5.68.0. Along with bug fixes and dependency upgrades, all three releases primarily address CVE-2024-8215, a cross-site scripting vulnerability that allows an attacker to remotely execute code via the Payara Management REST interface. These releases also feature an integration of the EclipseLink interruption enhancements to the WriteLockManager class to improve performance in database operations. More details on these releases may be found in the release notes for Community Edition 6.2024.10 and Enterprise Edition 6.19.0 and Enterprise Edition 5.68.0.
Open Liberty
IBM has released version 24.0.0.10 of Open Liberty featuring: support for JDK 23; and new versionless features that support the MicroProfile Context Propagation, MicroProfile GraphQL, MicroProfile Reactive Messaging and MicroProfile Reactive Streams Operators specifications.
Micronaut
The Micronaut Foundation has released version 4.6.3 of the Micronaut Framework featuring Micronaut Core 4.6.6 and updates to modules: Micronaut Security, Micronaut Test Resources, Micronaut MQTT, Micronaut Data, Micronaut gRPC, Micronaut Oracle Cloud and Micronaut Security. Further details on this release may be found in the release notes.
EclipseStore
The release of EclipseStore 2.0.0 delivers bug fixes and new features such as: a new BinaryHandlerSetFromMap class for the inner private static class, SetFromMap, defined in the Java Collections class, for improved data handling; and enhancements to the Storer interface that include a new UsageMarkable interface to prevent references of the Lazy interface from being cleared despite having unstored changes. More details on this release may be found in the release notes.
Apache Software Foundation
After 26 milestone releases, Apache Tomcat 11.0.0 has been released featuring: support for virtual threads; the addition of compatibility methods from JEP 454, Foreign Function & Memory API, that support OpenSSL, LibreSSL and BoringSSL, which all require a minimal version of JDK 22; and easy integration with Let’s Encrypt and an improved process to renew TLS certificates via automatic reloading of updated TLS keys and certificates with zero downtime. October 7, 2024, marks the 25th anniversary of the first commit to the Apache Tomcat source code repository since Sun Microsystems donated Tomcat to the Apache Software Foundation. Further details on this release may be found in the release notes.
Apache Tomcat 9.0.96 has also been released featuring bug fixes and notable changes such as: improved WebDAV support via a minor refactoring of the WebdavServlet class; and improved stability of the Tomcat Native Library upon destroying instances of the SSLContext interface during garbage collection. More details on this release may be found in the release notes.
OpenXava
The release of OpenXava 7.4.1 provides bug fixes, improvements in documentation, dependency upgrades and new features such as: new Maven archetypes, openxava-invoicing-archetype and openxava-invoicing-archetype-spanish, in English and Spanish, respectively; and a simple view layout with the property, flowLayout=true, that may now be applied up to 15 plain properties instead of eight. Further details on this release may be found in the release notes.
JHipster
The release of JHipster Lite 1.20.0 ships with bug fixes, improvements in documentation, dependency upgrades and new features/enhancements such as: an improved generated style using Tikui, a library for building static components; and support for JWT and OAuth2 authentication using Vue.js. More details on this release may be found in the release notes.
JetBrains Ktor
The release of JetBrains Ktor 3.0.0, the asynchronous framework for creating microservices and web applications, provides bug fixes and improvements such as: a migration to the kotlinx-io library to standardize I/O functionality across Kotlin libraries and improve performance; support for server-side events; and support for WebAssembly in Ktor Client. Further details on this release may be found in the release notes. InfoQ will follow up with a more detailed news story.
Podcast: The Ongoing Challenges of DevSecOps Transformation and Improving Developer Experience
MMS • Adam Kentosh
Transcript
Shane Hastie: Good day, folks. This is Shane Hastie for the InfoQ Engineering Culture Podcast. Today I’m sitting down with Adam Kentosh. Adam is a field CTO of digital AI and, Adam, a good starting point is who is Adam?
Introductions [01:03]
Adam Kentosh: Thanks for having me, Shane. Really, really appreciate the opportunity to be here. And just in regards to who I am. I’m a technologist at heart. I’ve spent over 20 some odd years, or close to 20 some odd years in technology, really cut my teeth on Hadoop, large scale Hadoop clusters, managing those with automation and purpose built for custom search algorithms. From there, went into the consulting business and had an opportunity to work with some Fortune 20 companies around the area, especially as they were transitioning from things like VM based architectures into cloud, containerization, Kubernetes, et cetera. From there, I went into HashiCorp. I was able to join HashiCorp very early on and got to experience just the really exciting growth that happened at that organization.
And now I’m at Digital.ai as a field CTO, and I’m helping to bridge the gap between the field teams and the product and marketing teams, making sure that I’m taking back anything that I’ve learned in the field to the product teams for potential enhancements or improvements, and then also back to the marketing team as we’re thinking about how we can have messaging that resonates with our customers.
Shane Hastie: We’re talking about shift lift and DevSecOps and so forth. Isn’t this an old, tired topic that’s dealt with already?
DevOps is a well understood approach, but still not implemented in most organisations [02:27]
Adam Kentosh: It does feel that way. We’ve been talking about this, I think, for quite a while. Even back in 2009 when I was still fairly young, I was doing work and we had conversations around Agile and what does DevOps mean to us? And at a point in time in my career, DevOps was essentially me sitting next to a developer as an operations person. Certainly not probably what we would think DevOps is, but just the fact that they moved us into the same room, they thought, “Yes, we’ve done it”. So I think we have seen obviously good evolution here. Just one interesting thing that I find fascinating though is I was reading the state of DevOps report in 2023 and they mentioned that 80% of companies are still in mid-transformation. And I just find that really interesting. I mean, I think we started talking about this 2009, 2010 timeframe, and a lot of companies really kicked off those initiatives between probably 2010 and 2012.
We’re now 10 to 12 years in on DevOps transformation and we’re still talking about it. So I think that just begs the question, why are we still talking about it? And for me, that’s a very complex, I’d say, question and complex problem. I think we’ve seen DevOps transformation happen at the team level, but I think that sort of enterprise-wide transformation is still very elusive to a lot of customers. And I’d probably pin the reason on technology changes and disruption. If we think about what’s happened over the last 10 to 12 years, not only did DevOps come around, but we also had really the just maturity of cloud. And then we’ve also had mobile devices become the number one way for customers to interact with applications these days. And so in that situation, I think that we offered up some autonomy to teams and we said, “Hey, go pick your tools. Figure out how to take advantage of cloud. Go pick your tools, figure out how to create a mobile application”.
And with that, we gave them what we would consider a DevOps team, and we paired dev teams with operations teams and we said, “Go forth and conquer on the technology that you choose”. And I think that was great for a time. It really did help people pivot. It helped people accelerate and have kind of speed to market and get better velocity. However, as you think about trying to scale that across the organization, well now you’re very challenged. It works for maybe five to 10, 20 teams. But when you start talking about hundreds of teams, we have to figure out where we standardize, right? Do we standardize at the tooling level? Are there processes that we can standardize around? Is there team makeup or structure that we can standardize around? So I think we’ve just had a compounding problem that was getting worse simply by, I’d say, the introduction of new technologies over time.
Shane Hastie: How much standardization is enough? As a developer who was given this freedom, now you’re taking it away. How do I come to terms with that?
The balance of standardisation vs team autonomy [05:35]
Adam Kentosh: I see two options, and I’ve seen this in practice at a lot of organizations and done it personally at a few. But number one, you don’t. And you build a interface layer on top of that and you’ve got something that basically integrates with all of these different technologies. Because really when we start thinking about standardization, it’s not so much that we necessarily care about what tool they’re using, it’s that we care about the metrics that we can view of that. How are my teams performing? Are they delivering at the rate that we would anticipate? Are they having more or less bugs than other teams? So I think the thing that really matters for me is sort of the metrics that can be driven out of that platform and then being able to level teams up, “Well, if we have a bit of an underperforming team, how do we take them from a two to maybe a five?”, for instance.
And I think DORA has done a great job of setting a framework and a context for us to have a level up type methodology. And so we’ve got four or five metrics. We can take a look at how that performance is across all our organization, and then we can focus in on specific areas. So I think the first approach is you don’t bother with standardization and you just care about the metrics and you figure out a way to gather those metrics and then help your teams perform better. I think the second approach is probably what we’re seeing materialize, is something like platform engineering where, “Hey, let’s create developer-oriented tooling. Let’s create standard interfaces and APIs that can be leveraged so that we can obviously make things either more productive or we can reduce just some toil from a developer standpoint”.
I feel like either one of those are viable options in many cases, though certainly I think as a business there’s probably more viability in getting some level of tool standardization. They still have to operate as a business, they have contracts that they have to worry about. There’s a lot of negotiation and renewals and things that happen to enable those contracts. So from their perspective, if we can get it down to a reasonable amount of pool set that does get the job done, I think there’s probably usefulness in that.
Shane Hastie: So finding that quite difficult balance. The other thing that certainly you and I mentioned in our conversation earlier, but also I’ve seen a lot is as we have done the shift lift, we are seeing more and more cognitive load on developers today.
The impact of cognitive load on developers [08:04]
Adam Kentosh: Definitely. It’s very interesting. There’s been a couple of reports that have come out. GitLab has published a report just around global DevSecOps and GitHub has done a lot around developer experience and what that means today. And in both cases, the numbers were somewhere between a quarter to 32% of developers time is spent actually writing code and time is spent elsewhere now in terms of maybe improving existing code or doing administrative tasks or meetings or testing or securing your application. So I think as we think about shift left, what we’re really doing is we’re putting a lot of strain and stress on a developer community and we’re asking them not only to write code, but understand how to test that code and then understand how to secure that code and then understand how to go release it and also maintain the operations of that code over time.
So for me, it puts a lot of pressure on the development teams, and I think that’s why developer experience is becoming so important these days. I’ve heard a ton of just conversations around developer experience. We work with customers that now have titles for the VP of developer experience and their initiatives is to go make sure that their developer community is productive, that they have good impact and that they’re satisfied. So I think a lot of the reason that we’re seeing developer experience sort of come around today is simply because we are putting a lot of strain and stress and pressure on the team as we continue to progress through these shift left motions.
Shane Hastie: How do we reduce that but still get the benefit?
Adam Kentosh: That is a very good question. I’d say ways that I’ve seen it be reduced and probably the most effective means of reducing it, is truly having more of a product centric approach. So we’ve seen two things, I’d say, happen over the last few years. Number one, we asked the developer to do everything, and that obviously breeds challenges. Number two, we continue to have isolated silos for testing and for security. And that again, causes challenges. Maybe we see a reduction in velocity because now I have a handoff between development to testing and then there’s a handoff between testing and security. So depending on which way you go, you’re having issues no matter what.
And I truly feel that we probably need more of a product-oriented approach, meaning that the product teams have to have these capabilities on the team themselves. We still need testing, we still need security, we still need development, but I don’t think one person needs to do all of those things. And if we can get them closer working together, more collaborative, I think we’re going to be in a much better situation.
And if you look at some of those surveys that I mentioned, it was really interesting because a lot of what the developers were asking for was better collaboration. And I think this would breed not only better collaboration, but probably a more productive product team.
Shane Hastie: But haven’t we known that collaborative cross-functional teams are the way to do things, since 2001 at least?
Adam Kentosh: We have definitely known that. I would totally agree with you there. I still feel the challenge is the organizational structure is matching the team structure, and so we’re seeing a dedicated testing organization or we’re seeing a dedicated security organization, and now we run into the people process aspect of our challenge where people don’t want to maybe give up control of the teams that they’re working with. And so the idea of blending teams means that we have organizational changes that must take place, and that, I think, is probably what’s restricting or limiting, I think, this type of approach. Inevitably we get in a situation where, like I said earlier, we either fully shift left and we have developers owning more of that delivery or we just continue to deal with our silos because it’s almost easier than trying to reorganize a large enterprise.
Shane Hastie: What are the small nudges we can make that move us to a better developer experience?
Small nudges for better developer experience [12:22]
Adam Kentosh: The best thing that I’ve seen work for nudges is really still the idea of trials, targeted use cases, where we can actually take a product-centric approach to a team and let them go be successful. And if they can be successful and we can validate that their numbers are what we would anticipate, that they’ve got great cycle time, that their bugs in code are not there or they’re infrequent, I think that gives us justification then to say, “You know what? This is a working model. This is an opportunity to work together better, and it’s a way that we can improve our overall performance as an organization”.
So for me, it’s always in doing. I think, in getting out there and actually trying out new models and then making sure that it’s a model that can scale. So come up with some best practices and actually be able to take that back to the organization and show real results and real numbers behind it. I feel like that’s probably the best way that I think we can continue to nudge, otherwise you’re in a position where you’re trying to nudge at an executive level, and that can be maybe far more challenging.
Shane Hastie: We’ve known this. As an industry, we’ve figured this out. We’ve seen organizations that have done this well, and yet 80% are still mid-transformation. We’re still facing a lot of the same problems that all of our methodology changes and everything that we’ve tried to do over the last couple of decades. Why don’t we learn?
Finding the optimum delivery frequency [13:58]
Adam Kentosh: Well, first off, I’m racking my brain to say, “Have I seen an organization that’s done it well?” And I suppose that the flagship examples are maybe your FAANG or MAANG companies, I guess now, but to me they’re operating at a different level and they also seem to be producing a lot of this content around some of the more progressive types of development approaches. So if I think about that, and I’m getting off-topic a little bit, but we’ll get back around to it, but I think about that, they’re pushing and asking for continuous delivery. Let’s just be able to deliver on a continuous basis, small incremental chunks. And I think for the vast majority of organizations that I work with in terms of financial services, insurance companies, even some level of gaming, definitely airline, I mean, those companies don’t necessarily care about delivery frequency.
They’re purposefully pumping the brakes on delivery because they want to make sure that they’re compliant, they want to make sure that they’re secure, and they want to make sure that they’re not introducing a poor customer experience with the next release that’s going out the door.
So in reality, I’d say there are companies I suppose, that do it well, but there are other companies that just maybe don’t need to do some of this. And so being pragmatic about what is useful and what will resonate with your organization, and truly at the end of the day, what outcomes you care about. If you care about new features and keeping pace, then certainly maybe continuous delivery makes sense for you. But if you care about stability, well, maybe it doesn’t. Maybe there’s the better way. And I’m not advocating that people go back to a completely waterfall style of delivery and that we take six months to get a release out the door. That’s certainly not, I think the case here, but I think technology has enabled us to take a more, let’s call it reasonable approach to delivery, and then also still be able to get better quality, more secure applications that can go out the door.
So I know that was sort of a little bit of a segue or a long way away from what your question was, but just something I was thinking about as you mentioned that. Now back to what you were asking, “Why don’t we learn?” I think that the challenge is from a developer standpoint, and you’ll see this too, if you talk to any developer, one of the things that they really enjoy is just the opportunity to learn new things. And so when you go to a developer and you say, “Hey, we want you to take on testing”. “Well, hey, that’s interesting. I’ll go learn that new thing for a little while”. Or, “We want you to take on release pipelines”. “Oh, interesting. I’ll go take on that new thing for a little while”. So I don’t think they’re shy about saying, “No”, or I guess they’re happy to say, “Yes”, rather and say, “Yes, I want to go learn new things”.
So for me, I’m not going to pin it all on the developers. It’s certainly not all their fault, but we’re asking them to do the more, we’re giving them an opportunity to learn new things. That means professional development, it means new skills. That’s something that they’re always after, so they’re just going to go do it and they’re going to solve a problem. And I find that true for most engineers. I talk to my wife and she always wants to just kind of talk at me, but I always want to solve the problem that she’s talking about. And so it’s hard for me to stop trying to solve a problem, and sometimes I have to recognize I just need to listen. But I think that’s just an engineering mindset. You’re always looking to solve a problem. So maybe we run into a situation where the problem’s been identified and nobody’s doing anything about it and they just go fix it.
So why don’t we learn? I think that’s probably the biggest reason from an individual standpoint. From an organizational standpoint, to me, this could be controversial, but I just feel that maybe organizational structure has not evolved the way that we need it to evolve to support IT. And I know IT is supposed to support the business, and we’re supposed to ultimately support the outcomes for our customers. And I definitely recognize that. But internally to the CIO on down who owns testing security and other things, maybe there has to be an evolution there that helps support better collaboration and maybe a more product oriented or product focused approach.
Shane Hastie: One of the things that struck me when you were talking about the contrast is those companies that are held up as doing this well, they have a product mindset and they were built from the ground up with the product mindset. So are we asking our “traditional” organizations, these banks, insurance companies, airlines and so forth to fundamentally shift their business model?
The challenge for non-product focused organisations [18:50]
Adam Kentosh: It sort of feels that way. Now, you can say that those companies are obviously wildly successful, so maybe it makes sense for them to try to shift their business model. But to your point, when you’re not built that way from the ground up, there is organizational structure, of course, organizational politics that are going to come into play, there is certainly a level of skill from a just perspective of people that are working there that you have to take into consideration. And so with that, I think that we might be asking companies to act in an unnatural way. And so if we’re asking them to act in an unnatural way, I think that’s where you get… And we’ve seen people get into the situation, as I’ve mentioned, where shift left is now the term, and DevSecOps is definitely still a term in trying to get everybody to work together in a meaningful way without actually maybe changing who they report to or putting them on the same team, truly together.
So the way that they’re trying to evolve is maybe not necessarily conducive to the way that some of these organizations just grew up from the ground up.
Shane Hastie: Adam, there’s a lot we’ve delved into here. What have I not asked you that you would like to get on the table?
Software engineering intelligence [20:07]
Adam Kentosh: I’d probably say, what is the role of something like platform engineering or DevSecOps and how important is Velocity truly to companies and organizations? And I think Velocity has ruled for the last 10, 15 years. Everything was about getting code out the door faster. And in reality, I think taking a deliberate approach to software development is probably more meaningful. And let’s focus not so much on Velocity, but let’s continue to focus on the outcomes that we want to deliver for our customers. And again, that kind of goes back to, what is my end goal? Is it a stable customer environment or is it a stable application environment for my customers to operate into? And if so, well then let’s just be maybe thoughtful about how we deliver software. And then from a platform engineering standpoint, I think there’s value in the idea of platform engineering, but I actually think there’s probably almost more value. I shouldn’t say more. There’s equal value in the idea of something like a software engineering intelligence platform.
And Gartner coined this term back in March, and it’s kind of interesting as we start to think about it. But if you look at software development, you’ve got to plan what you’re going to build. You’ve got to code it, you’ve got to test and secure it, you’ve got to operate that. And historically we’ve purchased solutions inside of each one of those areas, and we have engineering processes inside of each one of those areas that have to happen. And that all generates data into its own database. And that’s great for business intelligence. It gets us some information from an agility standpoint or an Agile standpoint. We can look at things like cycle time and figure out how our teams are doing.
However, when I want to ask real questions as a business leader, when I want to understand how teams are performing across the organization, when I want to understand what changes are coming down the line that are really risky or when I want to understand what teams have the biggest impact to cycle time across the organization holistically, I can’t answer those questions with that type of approach.
So for me, I think the next evolution that we really need to see, and it’s going to set up AI initiatives inside of an organization, which is why this is also important, is the idea of unifying all of that data into a meaningful data lake and then putting engineering processes in place so that we can link the data together. And what I mean by that is if I’m doing a release and I’m not opening up a ServiceNow ticket or some type of tracking for that, well now I can’t tie an incident back to a specific release. But if I could, that would be very helpful. And if I can tie a release back to specific stories or features that are actually getting into that release, well that’s also very helpful. I still talk to customers every day that spend hours on change advisory board reviews, and they spend hours on tier one resolution calls that they have to jump on, and they’ve got 80 developers on there. So if it’s a situation where we can reduce some of that, that breeds value to an organization, certainly.
So I think the important thing is being able to measure where we’re at today and being able to unify that data to answer meaningful questions about my organization, then that sets us up for truly applying artificial intelligence and machine learning on top of that data set to help make recommendations. And that’s really where I think people want to get to over the next two years as we talk about AI and ML.
Shane Hastie: A lot of good stuff here. If people want to continue the conversation, where do they find you?
Adam Kentosh: So you can find me on LinkedIn. You can definitely reach out to me as well. I’m happy to have a conversation and talk anytime. I love chatting about this stuff. I’m also very happy to be disagreed with. So if you disagree with what I’m saying, I’d love to hear a counter perspective. I’m fortunate, I get to talk to probably 50 to a hundred customers every year, if not more. And a lot of those are in that large enterprise space. So hearing other perspectives outside of that is extremely valuable for me and helps me understand what are other companies doing, how are they doing it well? And so Yes, LinkedIn is definitely the place to go.
Shane Hastie: Adam, thanks so much. Been a real pleasure to talk with you.
Adam Kentosh: Thanks, Shane. Appreciate the time today.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
NVIDIA Unveils NVLM 1.0: Open-Source Multimodal LLM with Improved Text and Vision Capabilities
MMS • Robert Krzaczynski
NVIDIA unveiled NVLM 1.0, an open-source multimodal large language model (LLM) that performs on both vision-language and text-only tasks. NVLM 1.0 shows improvements in text-based tasks after multimodal training, standing out among current models. The model weights are now available on Hugging Face, with the training code set to be released shortly.
NVLM 1.0 has been evaluated against proprietary and open-access multimodal models and performs well on both vision-language and text-only tasks. In particular, the NVLM-1.0-D 72B model shows an average 4.3-point improvement in accuracy on math and coding tasks after multimodal training. This contrasts with models like InternVL2-Llama3-76B, which lose performance in text-only tasks following multimodal training. The text improvements seen in NVLM suggest that its architecture manages multimodal data effectively without undermining its original language abilities.
Source: https://nvlm-project.github.io/
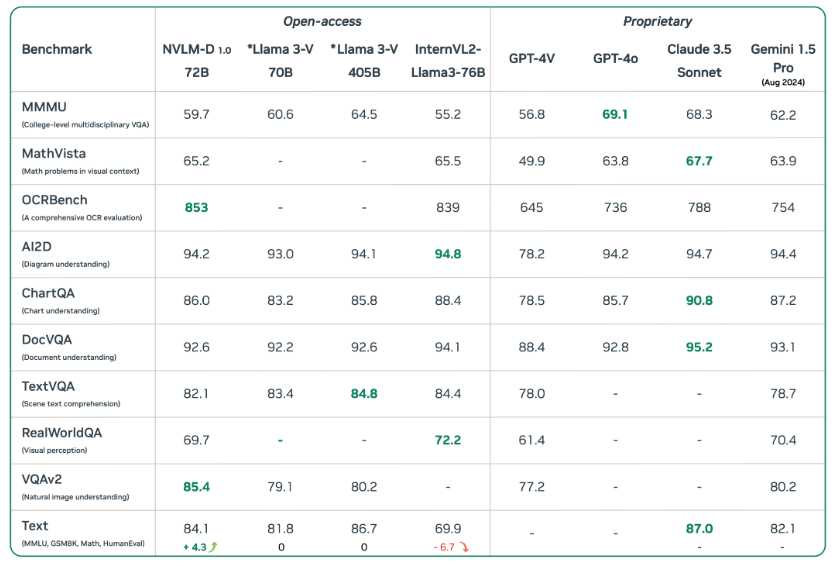
The NVLM-1.0-D 72B model is not just about text. It handles a wide range of multimodal tasks. These include object localization, reasoning, OCR (optical character recognition), and even coding tasks based on visual inputs. The model can interpret complex scenarios, such as understanding visual humor or answering location-sensitive questions in images. Its ability to perform mathematical reasoning based on handwritten pseudocode, as well as its handling of other multimodal inputs, highlights the breadth of tasks it can manage.
User Imjustmisunderstood reflected on NVLM’s potential for deeper understanding:
Extending tokenization to more ‘senses’ exponentially increases dimensionality. I would be fascinated to see whether the latent space recognizes the common temporal dimension in different modalities.
This touches on the broader implications of working with multimodal data, suggesting that models like NVLM could offer new ways of connecting different types of information.
Overall, NVLM 1.0 got very positive feedback from the community. For example, Luênya dos Santos, shared the following thoughts:
NVIDIA’s NVLM-D-72B is a huge leap in AI innovation. NVIDIA’s decision to open-source the model is a game-changer, giving smaller teams access to cutting-edge technology and pushing the boundaries of AI development! Really exciting news.
John McDonald added:
By making the model weights publicly available and promising to release the training code, Nvidia breaks from the trend of keeping advanced AI systems closed.
NVLM 1.0 is available for the AI community as an open-source AI model, with model weights accessible through Hugging Face. The training code will be released soon, allowing for further exploration of the model’s capabilities.
MMS • Karsten Silz

Java applications passed the 1 Billion Row Challenge (1BRC) from January 2024 in 1.5 seconds. 1BRC creator Gunnar Morling, software engineer at Decodable, detailed how the participants optimized Java at the InfoQ Dev Summit Munich 2024. General optimizations applicable to all Java applications cut the runtime from 290 seconds to 20 seconds using parallel loading/processing and optimized parsing. Getting to 1.5 seconds required niche optimizations that most Java applications should forego, except for possibly GraalVM Native Image compilation.
Each of the 1 billion rows has the name of a weather station and a single temperature ranging from -99.9°C to +99.9°C. Participants created that data file with a generator application, which was part of the challenge code. The application had to read that entire file and calculate the minimum, maximum, and average temperatures of the 400 hundred weather stations as quickly as possible. Using external libraries or caching was forbidden.
1BRC measured the official results on a 2019 AMD server processor with 128 GB RAM. The applications only used eight threads. The data file was on a RAM disk. Applications had about 113 GB RAM available, but most used much less. Each submission was tested five times, with the slowest and fastest runs discarded for consistency.
Morling wrote the baseline implementation, which took 290 seconds:
Collector
collector = Collector.of(MeasurementAggregator:: new,
(a, m) →> {
a.min = Math.min(a.min, m. value) ;
a.max = Math.max(a.max, m. value);
a.sum += m.value;
A.count++;
},
(aggl, agg2) -> {
var res = new MeasurementAggregator();
res.min = Math.min(aggl.min, agg2.min);
res.max = Math.max(aggl.max, agg2.max);
res.sum = aggl.sum + agg2.sum;
res.count = agg1.count + agg2.count;
return res;
},
agg -> {
return new ResultRow(agg.min,
round(agg.sum) / agg.count, agg.max);
});
Map measurements
= new TreeMap(Files.Lines(Paths.get(FILE))
.map(l -> new Measurement(l.split(";")))
.collect(groupingBy(m →> m.station(), collector)));
System.out.println(measurements);
The 1BRC is similar to back-end processing that Java often does. That’s why its general optimizations are applicable to many Java applications.
Parallel processing meant adding a single parallel()call before the map()statement in the fourth line from the bottom. This automatically distributed the following stream operations across the eight CPU cores, cutting the runtime to 71 seconds, a 4x improvement.
Parallel loading replaces Files.Lines(Paths.get(FILE)), which turns the file into a Stream sequentially. Instead, eight threads load chunks of the file into custom memory areas with the help of JEP 442, Foreign Function & Memory API (Third Preview), delivered in Java 21. Note that the Foreign Function & Memory API was finalized with JEP 454, delivered in Java 22.
The final step of the general optimizations was changing the line reading from a string to individual bytes. Together with the parallelization, this achieved the 14.5x improvement from 290 seconds to 20 seconds.
The first step of the niche optimizations is “Single Instruction, Multiple Data (SIMD) Within a Register” (SWAR) for parsing the data. In SIMD, a processor applies the same command to multiple pieces of data, which is faster than processing it sequentially. SWAR is faster than SIMD because accessing data in CPU registers is much faster than getting it from main memory.
Custom map implementations for storing the weather station data provided another performance boost. Because there were only 400 stations, custom hash functions also saved time. Other techniques included using the Unsafe class, superscalar execution, perfect value hashing, the “spawn trick” (as characterized by Morling), and using multiple parsing loops.
Mechanical sympathy helped: the applications picked a file chunk size so that all chunks for the eight threads fit into the processor cache. And branchless programming ensured that the processor branch predictor had to discard less code.
The last two optimizations targeted how the JVM works. Its JIT compiler profiles the interpreted Java bytecode and compiles often-used methods into machine code. Additionally, the JVM creates a class list at startup and initializes the JDK. All that slows down application startup and delays reaching the top speed. The GraalVM Ahead-Of-Time (AOT) compiler Native Image moves compilation and as much initialization work as possible to build time. That produces a native executable which starts at top speed. GraalVM Native Image ships alongside new Java versions.
Using GraalVM Native Image comes at the price of some possibly showstopping constraints that do not affect most Java applications and a more expensive troubleshooting process. Many application frameworks, such as Helidon, Micronaut, Quarkus, and Spring Boot, support GraalVM Native Image. Some libraries, especially older ones, do not, which may be a showstopper. These constraints were not a factor in the 1BRC, as no external libraries were used.
Finally, the JVM garbage collector frees up unused memory. But it also uses CPU time and memory. That is why applications that did not need garbage collection used the “no-op” Epsilon garbage collector.
The niche optimizations provided a further 13x improvement down to 1.5 seconds. The fastest application with a JIT compiler took 2.367 seconds, the fastest with GraalVM Native Image finished in 1.535 seconds.
Co-author of the 1BRC winner and GraalVM founder and project lead Thomas Wuerthinger published his 10 steps of 1BRC optimizations. His baseline solution takes just 125 seconds, compared to Morling’s 290 seconds, probably because it runs on a newer 2022 Intel desktop processor. Unsurprisingly, his first step is using GraalVM Native Image. After just two steps, his solution is already down to 5.7 seconds.
Morling was positively surprised by the community that quickly formed around 1BRC. They contributed a new server, a test suite, and scripts for configuring the server environment and running the applications. Morling has not thought of a new challenge.
MMS • Sergio De Simone

Linux 6.12 will officially include support for real-time processing in its mainline thanks to a PR that enables PREEMPT_RT on all supported architectures. While aimed at applications requiring deterministic time guarantees, like avionics, robotics, automotive, and communications, it could bring improvements to user experience on the desktop, too.
In development since 2005, PREEMPT_RT is a set of patches for Linux implementing both hard and soft real-time computing capabilities. It makes the Linux kernel fully preemptible and able to respond to external events in deterministic time and with low-latency on the x86, x86_64, RISC-V, and ARM64 architectures.
While PREEMPT_RT could already be used on its own to patch a Linux kernel, its introduction in the mainline means it is now just a matter of enabling the CONFIG_PREEMPT* options at compile time to build a real-time Linux kernel. But, most importantly, integrating PREEMPT_RT into the mainline has also meant polishing a number of things to make it play nicely under most circumstances.
One significant bit of work concerned the printk function, which is critical for kernel development and was not entirely ready for real-time. Developed by Linus Torvalds, this function ensures developers know exactly where a crash occurred. Its old implementation, though, introduced a delay, which has now been removed, breaking the goal of low latency.
Previous to PREEMPT_RT being part of the kernel, the easiest way to run real-time Linux was using Ubuntu Pro, available for free for personal and small-scale commercial use but at a premium for more than five machines.
It is important to stress that being real-time has nothing to do with performance but all with predictable (i.e. deterministic) task preemption, which is key for applications that depend on actions happening within a maximum time after an external event. The plain-vanilla Linux kernel is optimized instead to guarantee maximum hardware utilization and fair time allocation to all processes, but it can also be configured, for example, to minimize energy consumption or to adapt to specific tasks’ requirements (aka, utilization clamping).
According to Hacker News user femto, running real-time Linux can bring interrupt latency for each CPU core down to single-digit milliseconds from double-digit milliseconds. This requires, though, that you also run the scheduler with a real-time policy (SCHED_FIFO or SCHED_RR) to prevent hardware events like trackpad touches from coming in the way of real-time tasks such as playing audio or 3D gaming.
Others also mention that using a real-time kernel seems to improve UX by avoiding the occasional freezes of Gnome and makes it possible to synthesize more musical instruments while running Chrome and games. The Mixxx audio player also suggests to enable real-time scheduling (among other things) to reduce audio latency and avoid audible glitches.
The final release of Linux 6.12 is expected in mid or end of November 2024, while release candidate 2 is currently available for testing.