Month: October 2024

MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Linux 6.12 will officially include support for real-time processing in its mainline thanks to a PR that enables PREEMPT_RT on all supported architectures. While aimed at applications requiring deterministic time guarantees, like avionics, robotics, automotive, and communications, it could bring improvements to user experience on the desktop, too.
In development since 2005, PREEMPT_RT is a set of patches for Linux implementing both hard and soft real-time computing capabilities. It makes the Linux kernel fully preemptible and able to respond to external events in deterministic time and with low-latency on the x86, x86_64, RISC-V, and ARM64 architectures.
While PREEMPT_RT could already be used on its own to patch a Linux kernel, its introduction in the mainline means it is now just a matter of enabling the CONFIG_PREEMPT* options at compile time to build a real-time Linux kernel. But, most importantly, integrating PREEMPT_RT into the mainline has also meant polishing a number of things to make it play nicely under most circumstances.
One significant bit of work concerned the printk function, which is critical for kernel development and was not entirely ready for real-time. Developed by Linus Torvalds, this function ensures developers know exactly where a crash occurred. Its old implementation, though, introduced a delay which has been now removed, breaking the goal of low-latency.
Previous to PREEMPT_RT being part of the kernel, the easiest way to run real-time Linux was using Ubuntu Pro, available for free for personal and small-scale commercial use but at a premium for more than five machines.
It is important to stress that being real-time has nothing to do with performance but all with predictable (i.e. deterministic) task preemption, which is key for applications that depend on actions happening within a maximum time after an external event. The plain-vanilla Linux kernel is optimized instead to guarantee maximum hardware utilization and fair time allocation to all processes, but it can also be configured for example to minimize energy consumption, or to adapt to specific tasks’ requirements (aka, utilization clamping).
According to Hacker News user femto, running real-time Linux can bring interrupt latency for each CPU core down to single digit milliseconds from double digit milliseconds. This requires, though, that you also run the scheduler with a real-time policy (SCHED_FIFO or SCHED_RR) to prevent hardware events like trackpad touches to come in the way of real-time tasks such as playing audio or 3D gaming.
Others also mention that using a real-time kernel seems to improve UX by avoiding the occasional freezes of Gnome and makes it possible to synthesize more musical instruments while running Chrome and games. The Mixxx audio player also suggests to enable real-time scheduling (among other things) to reduce audio latency and avoid audible glitches.
The final release of Linux 6.12 is expected in mid or end of November 2024, while release candidate 2 is currently available for testing.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

Piper Sandler has confirmed its Overweight rating on MongoDB shares (NASDAQ: NASDAQ:MDB), maintaining a $335.00 price target.
The firm addressed concerns about the company’s recent performance, noting a decline in growth to 13% in the last quarter from 40% in the same quarter the previous year. Despite this slowdown, the firm anticipates a potential growth rebound for MongoDB.
The investment firm highlighted the recent downturn in MongoDB’s stock value, pointing out a year-to-date drop of 33%. This decline has brought the company’s forward enterprise value to sales (EV/S) multiple for the calendar year 2026 estimate (CY26E) to 7.7 times, nearing its two-year next twelve months (NTM) low of 7.1 times. According to the firm, these figures present a compelling opportunity for large-cap growth investors to consider MongoDB as it approaches a period of renewed growth.
In other recent news, MongoDB’s strong second fiscal quarter performance has led to multiple analyst firms revising their price targets upwards. DA Davidson has increased its price target to $330 while maintaining a Buy rating, following MongoDB’s robust earnings, with a significant boost from its Atlas (NYSE:ATCO) product and enterprise agreement (EA) upside. Similarly, KeyBanc Capital Markets, Oppenheimer, and Loop Capital have raised their price targets due to the company’s impressive performance.
The company’s Q2 results showcased a 13% year-over-year revenue increase, totaling $478 million, largely driven by the success of its Atlas and Enterprise Advanced offerings. MongoDB added more than 1,500 new customers during the quarter, bringing its total customer base to over 50,700.
Looking ahead, MongoDB’s management anticipates Q3 revenue to be between $493 million to $497 million, with full fiscal year 2025 revenue projected to be between $1.92 billion to $1.93 billion. These projections are based on MongoDB’s recent performance and the analyst firms’ expectations.
To complement Piper Sandler’s analysis, recent data from InvestingPro offers additional context on MongoDB’s financial position and market performance. Despite the challenges noted in the article, MongoDB’s revenue growth remains positive, with a 22.37% increase over the last twelve months as of Q1 2023. This aligns with the firm’s expectation of potential growth acceleration.
InvestingPro Tips highlight that MongoDB holds more cash than debt on its balance sheet, indicating financial stability amidst the current growth slowdown. Additionally, 22 analysts have revised their earnings upwards for the upcoming period, suggesting a positive outlook that supports Piper Sandler’s growth rebound thesis.
The recent 8.89% price return over the last week, as reported by InvestingPro, may indicate that investors are beginning to recognize the potential value in MongoDB’s stock, as suggested in the article. However, it’s worth noting that the company is trading at a high revenue valuation multiple, which investors should consider alongside the growth prospects.
For those interested in a deeper analysis, InvestingPro offers 11 additional tips for MongoDB, providing a more comprehensive view of the company’s financial health and market position.
This article was generated with the support of AI and reviewed by an editor. For more information see our T&C.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Zahan Malkani
Article originally posted on InfoQ. Visit InfoQ

Transcript
Malkani: I’m Zahan. I’ve been an engineer at Meta for over a decade. I’m here to tell you about how we launched the Threads app last year. Let’s start by talking about the opportunity that presented itself. It was January last year, and I’d just returned to work after a couple of months on leave. I was looking for something to work on and the tech scene was buzzing about Elon’s business decision since he took Twitter private in November. We were talking about it at Meta as well. For reference, back in 2019, Mark had made the call that public conversations were not the focus, and pivoted both Facebook and Instagram to focus on private communication between friends instead. The analogies were the public town square and the living room.
Mark’s view was that communication in the living room was going to grow more over the next decade. That left Twitter as the de facto forum to debate ideas in public, a function so important, I think we all can agree, to society. Since Elon took over at Twitter, he made a number of controversial decisions, pretty lightly. Popular opinion was that it was just a matter of time before the site had an extended outage depriving millions of their favorite place online. It was increasingly obvious that there was an opportunity opening up here.
The world clearly valued a service like Twitter, and the primary value in a social network is the people in it not the product. As many people abandoned Twitter, they were looking for somewhere else to hang out. At first, we thought that maybe the differentiating feature here is the text format, so we made it easier to make text posts on our existing products. In Instagram, some double-digit percentage of posts have some form of text on them, so we figured, what if it were easy to make posts that had nothing but text in it? How would that fare? It didn’t get much usage.
Few used the format, because while Instagram and Twitter share mechanical similarities, like a directed follow graph, and a feed that’s based on interest, each product has its own culture, its own raison d’etre that’s set early in the product lifecycle. While Twitter was the public town square, Instagram was where you caught up with your friends’ lives, or where you are entertained by short-form videos. We realized that to build a competing product, we really would have to build a new product with a new set of norms.
The main concern we had starting from scratch was how long this could potentially take. We were acutely aware that we had a fleeting window of opportunity to capitalize on here, that could disappear as quickly as it appeared. People still love Twitter as a brand, though little did I know of his plans for the brand. Still, in our view, time to market was all that mattered, and we enshrined that in everything we did. Every shortcut was on the table, every bit of scope up for debate, every complication a source of concern. The ask was that we needed to be prepared to ship at very short notice.
Part 2 – The Product
Let’s focus on exactly what we wanted to build. We started by laying out the basic values of this product, we had four. First, the format here was text. Every post needed to start with text. Instagram put media front and center but not here. Two, we wanted to carry over the design language and ethos of Instagram. The simplicity, the feel of the product that so many love around the world. We felt like that was a good foundation. Three, we knew that one of the values that helped early Twitter establish itself was its openness. By this I mean that the community was free to craft their own experience with an API.
Public content was widely available on the web through embeds. People generally used these tools to share their Twitter feed all over the place. While this is a new world, with GenAI coming up, we felt like a new walled garden product just wouldn’t fly. We were paying attention to Mastodon, the fediverse, the interoperable social networks. I’ll talk more about that later. Lastly, we felt like we needed to prioritize the needs of creators. Every social network has a class of folks who produce the majority of the content that others consume. This usually follows the Zipfian exponential distribution. On text-based networks this is exaggerated, and it’s a smaller proportion of the user base who produce most of the content. It’s hard to be interesting and funny in 500 characters. We knew that keeping the needs of this community in mind was critical for long term success.
With these values in mind, we sketched out what the absolute bare minimum product was and got to work building. To give ourselves goalposts, we outlined four milestones we’d like to get to. An important objective was that we wanted to have a product ready to ship as soon as possible to give us options. Each milestone was designed to be a possible end state itself, where we could ship if needed, each one gradually layered on the next most essential bit of functionality. Milestone one was just about standing up the app. You can see how bare bones that is.
Being able to log in, to make a text post that gets associated with your account. Really just the basics. Milestone two was our essentials bucket. Giving the app its familiar look with tabs for feed, notifications, and profile. Getting the basics of integrity working, being able to block another profile, to report it. Milestone three was what we called the lean launch candidate. Here we fleshed out services that had been neglected before, like a basic people search, a full screen media viewer to view photos and videos. Starting to figure out what to do with conversations, the lifeblood of the app. How do you rank them as a unit? Copying your follow graph from IG so that you can bootstrap your profile, and the ability to mute other profiles.
That’s a long laundry list. Milestone four was where we enabled interoperability with the fediverse, and was a final ship candidate. For anyone who knows the product, you might be laughing at the ambitiousness because we are far from full fediverse interop even today. In one of my weaker moments, I promised we could have this ready within the month. This was going to be the last thing we tackled in May. We took this very seriously. As each milestone neared, we’d shifted from a building features mindset to a polish for launch mindset. This was honestly exhausting as an engineer, as the context switching between building mods is taxing.
In some ways, we shipped three products in those six months. Each time we’d call a war room, burn the midnight oil, and push through to get a complete app. Then we decide whether we were ready or not to ship. With the benefit of hindsight, I now see there was a big upside to the strategy. It served as a strong forcing function to simplify the product. If all you get is three weeks to pick what features you will add, and which will add the most incremental value, you really have to boil it down to just the basics. The actual product we shipped was something like M3.5. We never got anywhere near M4, but we did get a much-needed iteration on top of M3.
Part 3 – Shortcut
All of this would be extremely ambitious to build from scratch in five months. We started in earnest in Feb, and we were promising our leadership that we’d have it ready by the summer. We had a trick up our sleeves, and that was that we had no intention of building this from scratch. When you take a wide-angle view, broadcast sharing on Instagram is fairly straightforward. You can follow profiles, access a feed of their posts, plus some recommendations. You can respond to one another, building up communities around interests. Coincidentally, this is exactly the set of features we wanted for Threads on day one, so we did it.
We took the biggest shortcut ever and reused Instagram wholesale. For the backend, it literally just is the Instagram backend with some custom functionality for Threads. For the apps, we forked the Instagram app code base on each platform. Starting from Instagram, and that we started with a fully featured product and had to strip it down to just the functionality needed. The screen recording shows what I mean. Our first prototype added a mod to the Instagram feed that surfaced text-only posts. We reused the ranking. For the post, the inside joke is that we just reordered the layout. We put the caption on top and the media on the bottom, everything else is just the same. This drastically reduced technical scope.
We’ve now taken the intractable problem of how do you build a new text-based social network and turn it into a very specific one? How do I customize Instagram feed to display a new text post format? As engineers, you will undoubtedly note that this approach has major downsides. You’re accumulating massive tech debt using a code base for something new that it wasn’t designed to serve. There’s a whole series of paper cuts that you accumulate as a result. You also need to know said legacy code base inside and out. It’s millions of lines of code, but you need to customize just a few so that you can effectively repurpose it.
My favorite one-liner about this is that it’s harder to read someone else’s code than it is to write your own. With this, you’re losing your one chance to start over clean. This approach help us stay focused on the product and keep this experience simple. A user could onboard by just logging in with Instagram. We borrowed Instagram’s design language. Your Instagram identity bootstrapped your Threads one.
We carried the spirit throughout, surgically reusing what we could and rebuilding only where necessary. It also means that the Threads team has much to be grateful for, the existence of Threads itself owes itself to the foundation laid by Instagram infra and product teams over the years. We’d be nowhere without it. I like to think that this focus on simplicity paid off. Much of the praise we received at launch was for the sparkling simplicity of the app without it feeling like it lacked essential features.
Part 4 – The Details
Now to dive into a couple of areas with interesting implications. One technique we use to tune the experience quickly was to make iteration in the product itself very easy. We did this using server driven UI. In a traditional client-server model, the client is responsible for everything about how the data is laid out on-screen. The server is just middleware pulling data out from stores. What we did was for the core interfaces which showed a list of posts, we instead sent down a full view model, which told the client exactly how to render it. This meant that when we were experimenting on the call to action and the reply bar, or when and how we show different reply face files, we could do that with just a code change on the server, which only takes a couple of hours to roll out and takes effect on all platforms.
This let us iterate on the core Threading UI very quickly in the early days. Another big focus was making the space feel safe and welcoming for all. We’d seen public social networks before and many turn into angry spaces where people just don’t hear each other out. Of course, the jury is still out on what degree Threads can live up to this aspiration, but I think there’s a few factors that are important. First is the product culture, set from the early days by those who are the seed of your network. A lot of our early users were experienced in this and so you saw a lot of callouts like, block early and often. Don’t engage with rage bait. Don’t use quote posts to dunk on people.
Then there’s the tooling that helps people maintain control over their experience. For instance, it starts with the ability to block, of course. There’s variations on this for different circumstances, like restrict, which ensures that the other party doesn’t know you took action, and mute which hides their content from your feed.
There’s the popular hide reply functionality, which gives you some small control over the conversation that your post generates. Lastly, there’s moderation. It’s tricky to get right. There’s no doubt in my mind that robust moderation is essential. To make a space acceptable to a mainstream audience, you need to do something about the extremes of speech. There’s just too much breadth in what one can find on the open internet. I’ll go as far as to say that for a new social network today, that is the unique value you’re providing. In many ways, moderation is the product people are subscribing to. Luckily, we brought a decade of experience with this from Facebook and Instagram here. While I’m sure it needs further tuning to feel right, at least we started from a good starting point. Combined with features and culture, all these helped set healthy new norms.
The last focus I want to touch on is creating a buzz for the product before launch. An example of this is the golden ticket Easter egg, which we had made and hidden in Instagram. You might call this holographic effect overengineered, but it looked beautiful and felt playful, which sparked interest. We had little hidden entry points, specific keyword searches, hashtags, and long presses, to let people know that something was launching soon and let them sign up for a reminder. Moreover, we had a small early access launch for journalists and creators who had shown an interest. It ended up being just a day or so, but it gave them a chance to learn and see what this new platform was like. It didn’t hurt that when they shared their impressions with their audience, the curiosity grew.
Part 5 – The Launch
If you’re tired of fuzzy stories, this is when we get to the more technical part of the talk. To understand the launch, I need to give you a quick technical overview of the Threads stack. Meta in general is big into monolithic binaries and its monorepo. There’s a number of reasons for this. The upshot is that much of Instagram’s business logic lives in a Python binary called Distillery, which talks to Meta’s bigger monolith, a massive PHP binary or Hack binary called WWW. Distillery is probably the largest Django deployment in the world, something I don’t know if we’re proud of, even if we run a pretty custom version of it.
The data for our users is stored in a variety of systems. The most important ones are TAO, a write-through cache that operates on a graph data model, and UDB, so a sharded MySQL deployment that stores almost all our data. By graph data model, I mean that TAO is natively familiar with links between nodes and has optimized operations to query details of those. There’s indexing systems on top that let you annotate particular links with how you want to query them. They build in memory indexes to help. The whole model has evolved over many years of building social products as Meta, and this has served us well.
There’s also other systems involved, and I can’t do them all justice. There’s a big Haskell service that fronts a lot of the rules that go into our decision making around restrictions, like looking for inauthentic behavior in user actions. There’s a key-value store called ZippyDB that’s used to stash lots of transient data that’s written too often for MySQL to handle the load. There’s a serverless compute platform, async, which was critical, and I’ll cover it later. Then there’s a Kubernetes-like system for managing, deploying, and scaling all these services. All of these need to work in concert.
That’s the background into which you insert our little product going live in July of last year. The story is that we were planning for a mid-July launch when news started doing the rounds that Twitter planned to restrict consumption of tweets for free users. This started a significant new cycle and we saw an opportunity, so we decided to launch a week early, even though it meant forgoing some load testing and final prep work. The launch was set for July 6th, and we opened up the Easter eggs I mentioned to generate buzz, and we started our early access program. On July 5th, anyone who wasn’t an engineer was happily hanging out on the product with the celebs who had come on for early access. This was probably the closest anyone was going to get to a personal chat with Shakira. For engineers, it was an all hands on deck preparation for launch the next day, upsizing systems, sketching out the runup show, and the like. I’ve never forgiven my product manager for that.
Then in the middle of the day, our data engineer popped up in the chat and mentioned something odd. He was seeing tens of thousands of failed login attempts on our app. This was odd, because no one, certainly not tens of thousands of people should have access to the app yet. We pivoted quickly and ruled out a data issue. Then we noticed that all of these were coming from East Asian countries. Maybe you figured it out, it would take us another beat to realize that this was time zones. Specifically, we were using the App Store’s preorder feature where people can sign up to download your app once it’s available, and you specify a date. Since we said July 6th, once it was past midnight in these countries, the app became available, and they couldn’t log in because of another gate on our end.
This was an oh-shit moment. The warm fuzzy feeling of being safely ensconced in an internal only limited testing was gone. We pulled together a war room and a Zoom call with close to 100 experts from around the company and all the various systems I mentioned. Given that this was the middle of the night in those countries, it was evident that demand was going to far exceed our estimations once this all went live. We had a healthy preorder backlog built up and they were all going to get the app once the clock struck midnight in their local time.
We chose a new target launch time, specifically midnight UK time, which gave us a couple of hours to prepare. We spent that time upsizing all the systems the Threads touched. I fondly remember a particular ZippyDB cache that is essential for feed to function at all, that needed to be resharded. It had to be resharded to handle 100x the capacity it was provisioned for. That job ended minutes before Mark posted that Threads was open for signups. I don’t think I’ll ever forget the stress of those final moments.
The user growth in those first couple of days has been well covered elsewhere. Broadly, a million people downloaded our app and onboarded to try it out in the first hour from when it went live. Ten million in the first day. Seventy million in the first two days, and about 100 million in the first five days. After that, the novelty effect started to wear off and the buzziness subsided, but surviving those first five days was quite the feat. While people would later opine that it was great that Threads had a relatively smooth ride with no major visible downtime, it certainly didn’t feel that way to me.
We had a number of fires going at all times, and I didn’t sleep much that week. What kept us up was all the experts in the room, certainly not me, who had the experience of dealing with larger user bases if not facing this kind of explosive growth. We tweaked the network enough to stay afloat, and we furiously fought the fires to keep things from spiraling. To pick a couple of interesting fires. The first is that we were consuming more capacity than one should. We were serving just as relatively small pool of posts to a smallish user base.
This was most evident on our boss’s timeline. We started getting reports it was actually failing to load. The thing is that Mark had an order of magnitude more interactions with his posts than anyone else in that early network. More likes, replies, reposts, quote posts, you name it, Mark was at five digits when everyone else was at four. We finally root caused this to a particular database query that we needed to render every post, but the runtimes scaled with the number of repos. It needed an index. With a couple of tries, we nailed the problematic query, and the site got healthier.
Another fire revolved around copying the follower graph from Instagram to Threads. When someone signed up for Threads, we gave them the option to follow everyone that they already follow on Instagram, on Threads. That might sound daunting, but it’s actually a limited operation. You have a maximum number of people you can follow, in the single digit thousands. That works fine. It’s a limited operation. Our serverless compute platform soaked up the load. I think at one point, we had a backlog in the tens of millions in the job queue, but with some handholding, it worked just fine.
Again, a testament to the wonderful engineering that’s gone into these systems. The issue with graph copying was that you could also say that you wanted to follow people who hadn’t signed up for Threads yet. Maybe you can see the issue now, because handling that person signing up is an unbounded operation. When big celebrities, say former President Barack Obama signed up for Threads, they had a backlog in the millions of people who were waiting to follow them. The system that we had originally designed simply couldn’t handle that scale. We raced to redesign that system to horizontally scale and orchestrate a bunch of workers, so it could eat through these humongous queues for these sorts of accounts. We also tried to manually get through the backlog since this was a sensitive time for the product.
We didn’t want to leave potential engagement on the table. It was a hair-raising couple of days, but I loved the design of the system we finally made, and it’s worked smoothly ever since. All told, I doubt I’ll ever experience a product launch quite like that again. I learned a bunch from others about staying graceful in stressful situations. I’ll carry that wherever I go.
Part 5 – After Launch
Past the launch, we needed to quickly pivot to address features that users were asking for. It had now been nine months. In that time, we finally opened to Europe in this last December. We shipped a following feed, a feed you have full control over with content from people you follow, sorted chronologically. We got our web client out there which caters to our power users. We have a limited release of an API that allows you to read and write posts. We polished content search and started showing what conversations are trending on the network.
We also have big questions that loom over us. What should play a more important role in ranking? The follow graph that people choose, or understanding content and matching it with people’s reveal preferences? How do we cater to the needs of power users who’ve come over from Twitter who have very clear ideas about what to expect from the product, while also serving all the people who are new to a text-based public conversation app? One of the developments you might find more interesting is about the adoption of ActivityPub. This is an open protocol for interoperating between microblogging networks. The accumulation of those networks is called the fediverse. Keen-eyed listeners will note that I had promised fediverse interop on an insanely ambitious timeline pre-launch, but thankfully that wasn’t put to the test.
Today we’re approaching fediverse interop, piece by piece, and we want to build it right instead of building it quickly. The reason is that we cannot integrate it into the legacy Instagram broadcast sharing stack. It has too many integration points with the rest of Meta, and we want to make strong guarantees about how we process this important data. We essentially need to rewrite our business logic and backend stack, which is ongoing.
Takeaways
In conclusion, getting this off the ground was a unique experience for me. My biggest takeaway is the power of keeping things simple. It’s certainly not easy. The aphorism about it taking longer to write a shorter letter applies to anything creative. If you’re clear about the value you want to provide, it can guide all your hard decisions on where you want to cut scope. The other learning is that cleaner, newer code isn’t necessarily always better. All the little learnings encoded into an old battle tested code base add up. If you can help it, don’t throw it away. The compliment to this is us saying that code wins arguments.
This is to say that building a product often answers questions better than an abstract analysis. We got through a lot of thorny questions quicker with prototypes instead of slide decks. Of course, nothing can be entirely generalized, because we need to acknowledge how lucky we are for the opportunity and the reception once this product came out. None of that was guaranteed. I feel very grateful for the community that embraced the product. We have a saying that goes back to the early days of Facebook that this journey is just 1% finished. It indeed feels that way to me, especially with Threads.
Questions and Answers
Participant 1: What was the size and maturity of the engineering team put on this task?
Malkani: I think, as we started building, it was like a rolling stone. We started with maybe 5 to 10 engineers, in Jan. By the middle of it, we were up to 25, 30 engineers. By launch, we were up to maybe 30, 40 engineers on the core product team. Again, standing on the shoulders of giants. This doesn’t count all the pieces that we were able to reuse, and platform teams we could lean on for different pieces. In the end, maybe it was more like 100 engineers who contributed in some way. Of course, we got to reuse all those bits of infra and stuff. The core product team stayed under 50.
Participant 2: Can you talk a little bit about the testing? How did you ensure that it worked, and you don’t kill yourself, Instagram and everything?
Malkani: We didn’t get to test much because of the timeline. We lived on the product, of course. From the time that it was a standalone app, and we could download it on our phones, we published all the time, we shared. Instagram itself is a fairly big organization. They’re like a couple of thousand people. For at least a couple of months, a couple of thousand people were using the app. It was all internal only content, and we wiped it all before we went public.
We got a fair amount of ad hoc testing that way. We were not prepared for the scale. That’s again what a lot of this talk is about, is about handling that. Then we were able to react quickly and rely on these systems that have been built for the scale. On the backend, we do have a pretty good test-driven development culture where we write a lot of integration tests for APIs, as we make them and stuff. There’s no religiousness about it.
Participant 3: You mentioned earlier that you were onboarding tech debt with your code, one year later, what happened to that?
Malkani: We’re paying down that debt. Reusing the code base meant that you’re reusing it with all its edge case handling and all its warts. Sometimes it’s difficult to know which context you’re operating in. Are you serving an Instagram function or are you serving a Threads function? We have a big project underway to disentangle that. This is where being opportunistic was important. That opportunity was only going to last for that time. I think Ranbir mentioned like, everything in architecture is a tradeoff. Here the right tradeoff definitely was to take on that tech debt and enable launching the product sooner. Now we have this like changing the engine of the plane while it’s in flight sort of project, to rewrite it and tease things apart and stuff, but we’re doing it.
Participant 4: If I understood you correctly, you said you started out by forking the Instagram code. Are you planning on reunifying that or do you want to split it further apart?
Malkani: It’s drifting apart over time. It was a convenient starting point. With us embedding more deeply with this interoperable like ActivityPub support and things, and just leaning into more of the uniqueness of what makes Threads, Threads, and what makes Instagram, Instagram, they’re drifting apart over time and we have to tease that apart.
Participant 5: You mentioned reusing the backend of Instagram. How does it say the data model and the APIs look for Threads versus Instagram? Are you reusing the same data model with some fields, or a new API for each operation?
Malkani: They’re similar, but we’re starting to tease them apart. Instagram had a custom REST API, which is how the clients and servers spoke to each other. We started by reusing that, but we’re moving towards adopting GraphQL more. GraphQL is used by Facebook extensively. With GraphQL, you get to do a lot more granular specification of what data the client needs, and also like how you define that on the server.
Moving to that more field-oriented model, and it’s this whole inverting the data model idea. Instead of business logic living on the server, for compositing data together, the client just requests specific pieces of data. We can label those things as being either Threads only or Instagram only, and tease it apart that way. We started with Instagram, and now we’re teasing it apart.
Participant 6: One of the differentiators you mentioned was that you could iterate quickly on the UI from the mobile applications. At Uber we specify a generic card format, that the backend then was returning with text first then for the other stuff. Is there something similar in place here?
Malkani: It was a little more product specific than that. We have frameworks to do that very generic stuff. Like, specify a shadow DOM, and that’s your API. There’s server-side rendering stuff. That was not what we were doing over here. This is more like product specific. This is the post you should put here, but stuff that usually you would do on the client, whether it’s figuring out what reply CTA to use, how to render the line. Like, is there a loop here, or stuff like that? It was like a custom data model, but it did let us iterate. We had variations on how we ran the self Threads, where you reply to yourself in a chain.
How do we show that? We tried a number of ideas, and we were able to do this with our dogfooding community of a few thousand people, on the fly, quickly, thanks to this. No, we were not doing a generic server-side rendering thing. We do use that in other places for some of the onboarding things, or like the fediverse onboarding uses that sort of a server driven rendering thing, but that’s not what this was.
Participant 7: If you have to do it again, what would you do differently?
Malkani: This reusing to move quicker was what saved our bacon. I would do that. I would take a few architectural decisions differently where like, specific data models that we reused, I would choose to spend a little time detangling them. Maybe it would push us back a month or something, but it would have been worth it because untangling it now is very complicated. No, the overall ethos of like, reuse what you can, yes, I wouldn’t change that.
Participant 8: Coming back on the question relating to technical debt, how are you unfolding that? How do you address that thing on a day-to-day basis? What does that look in the team planning and backlog?
Malkani: We have pretty mature frameworks for doing data migrations on this scale, because we’ve had to split things out before in Meta. When you think of like splitting Messenger from Facebook, or splitting Marketplace out from Facebook. There are a couple of examples of this. We have frameworks, for instance, that tail all mutations that happen, so that UDB that I talked about, that’s our main datastore in MySQL. There are systems that tail those bin logs and let you do things with that, so they’re observers. I’m sure there are open source equivalents of this, like tailing a Kafka. You can write an observer that tails that and says, ok, double write this, and so now we have two versions of this particular data model, say, the user model, that we need to keep up to date.
Then we start migrating the product logic over to start reading from both of those places. Depending on whether it’s an Instagram context, or a Threads context, you now start reading from the new data model. Then you start doing the double reading and comparing consistency and stuff. There’s a number of techniques like that. Part of the problem is, it’s quite a deep data model. When you think about the post itself, the post itself can have a lot of things linked to it, and all of those things recursively need to now either be Threads data, or Instagram data. We need to go in deep and do those annotations and stuff, some of which can be done statically, some of which need to be done dynamically at runtime, because it depends on who created it. It’s complicated, but still the right tradeoff.
Participant 9: When reusing the code, you’re also potentially reusing the technical debt which was originally in that code, and then you’re ending up with multiple places using the same mistakes or problems. How do you see that?
Malkani: It’s part of the tech debt you take on. Again, it was a tradeoff. We could either take on that tech debt and build a product in six months, or we could start from scratch and probably take a year or something to have a fully-fledged product. We knew that we needed to take advantage of this window. Yes, we were ok with taking that on and paying for it later. You’re taking out a loan, and you’re saying, I’m going to pay interest later.
Participant 10: When you say that you first inherited the code from Instagram, and now you are decoupling this code, so in terms of coding and backlog and storage that are being done by the developers, do you have a certain allocation for this decoupling? For example, a certain team is working on removing the unneeded parts and just keeping what is needed in terms of code, so that in the future the code is more maintainable and easier to read and everything that is needed is there without extra stuff?
Malkani: Absolutely. We have to balance needs now. On the one hand, we need to evolve the product because we haven’t found product market fit at all. We’re a brand-new product. On the other hand, we need to make this code base more maintainable and pay down some of the tech debt and remove footguns, remove things that can catch developers unaware and lead to big outages. We need to balance that. Right now, we’re balancing that by having a separate team focus on this particular migration. At some point, it impacts all product developers and you can’t get away from that. That will temporarily slow down progress in building the product. We know that we’re going to have to pay that at some point. It’s a tricky thing of how to organizationally set this up. So far, it’s been with a separate team.
Participant 11: Are there any development decisions you’ve made in the development of Threads that have then influenced things that have gone back into the code bases and applications at Meta?
Malkani: I hope the ActivityPub stuff makes it at some point. That has not happened yet. I think that has a lot of promise. Or generally interoperating with other networks. Certainly, the lean nature of this has been lauded within Meta. The fact that we were able to do this with a small team. Meta has a playbook of building large teams around important goals. This was a counterpoint example. That organizational lesson has definitely been taken to heart. I think on the technical side, there’s a lot of interesting stuff we’re doing with ranking, that’s new to Meta.
Other networks, with their ranking, the most important thing they’re predicting, obviously with checks and balances, is how engaging is this post going to be? I’m going to go look back and find the most interesting post and then sequence it by the next most interesting post. That’s how you build up your feed. With Threads, you need to pay attention to the real-time nature of this product to a much greater degree.
Some of the luxury and slack you have in your ranking stack, from the time a post is made to the time it’s eligible for ranking and the time it starts actively getting picked up, that latency window can be much bigger for something like Instagram than it needs to be. For Threads, like from the moment you post, it needs to be eligible near real time, because this is how news breaks. If there’s an earthquake, you want to know right now. If there’s a helicopter flying overhead, you want to know why. That novelty in the ranking stack is something we’ve had to push on. It’s something Twitter does very well, for instance.
On the subject of technical debt, are we working with the Instagram teams that we inherited this from and potentially have a similar solution to?
Organizationally, Threads and Instagram team is still a subsidiary. We do work with those teams. In many cases, it was not like a straight fork as much as we’re reusing the same code. If we had a shared solution, it improves in both places. Meta has this system called better engineering, it’s almost like a 20% time thing, which is similar to what Google used to have, where we incentivize people to work on tech debt type problems in their spare time. We’re falling in into that. We’re working with these teams. The main short-term focus now is making the data models clear between these apps.
Participant 12: Thinking about the products of Meta, was there a specific reason to use the Instagram architecture rather than Facebook’s, maybe something else?
Malkani: I think it started from the fact that Instagram is a directed follow graph, as opposed to Facebook, which is bidirectional friends. That one decision has a lot of technical implications. We probably could have started from somewhere else, but I think that, plus the fact that there’s a bit of Conway’s Law. The team who was building this was familiar with the Instagram tech stack, and so it made sense to repurpose that. Our options were Facebook and Instagram, and Instagram seemed like a better fit.
Participant 13: How many people were involved initially in the project, boiled down to how many teams? How did you structure that based on the fact that you were just starting on a huge code base?
Malkani: It was small. It started out with 10-ish engineers, snowballed into maybe 50-ish by the end. The fact that we could lean on these platform teams made a lot of difference. In the end, maybe 100 engineers or so, touched something that made it into the Threads app. We kept it small deliberately. A, we wanted to stay a nimble team, and we wanted to pivot the product itself that we were making. We wanted to keep the product simple. B, we were certainly worried about leak risks and stuff.
Participant 14: You said you did some ranking stuff. I’m curious if you had issues with bots, and if you’re taking steps in the security area?
Malkani: Yes, bots are a problem. Again, very lucky that we can rely on a long history of teams fighting bots on Instagram and Facebook as well. They do show up in unique ways on Threads. We have had problems where it’s gotten out to users. Sometimes you get spammy replies and stuff like that, which we’re fighting hard. Integrity is very much like a firefighting domain. These are adversaries who continually evolve their patterns. You learn one pattern, you put in a mitigation against it, and then they shift to a different abuse pattern. It’s taxing, but it is something that we know how to do and we have teams who do this well.
Among the more interesting novel challenges we have here is, Threads to a much greater degree than Instagram or Facebook, is about linking out to the web. Facebook and Instagram can be more internally referenced, but not as much outbound links. We have a number of challenges there we have to figure out about awareness of what’s going on in the web, redirects and link crawlers, and that fun stuff. Yes, it’s hard.
See more presentations with transcripts
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ
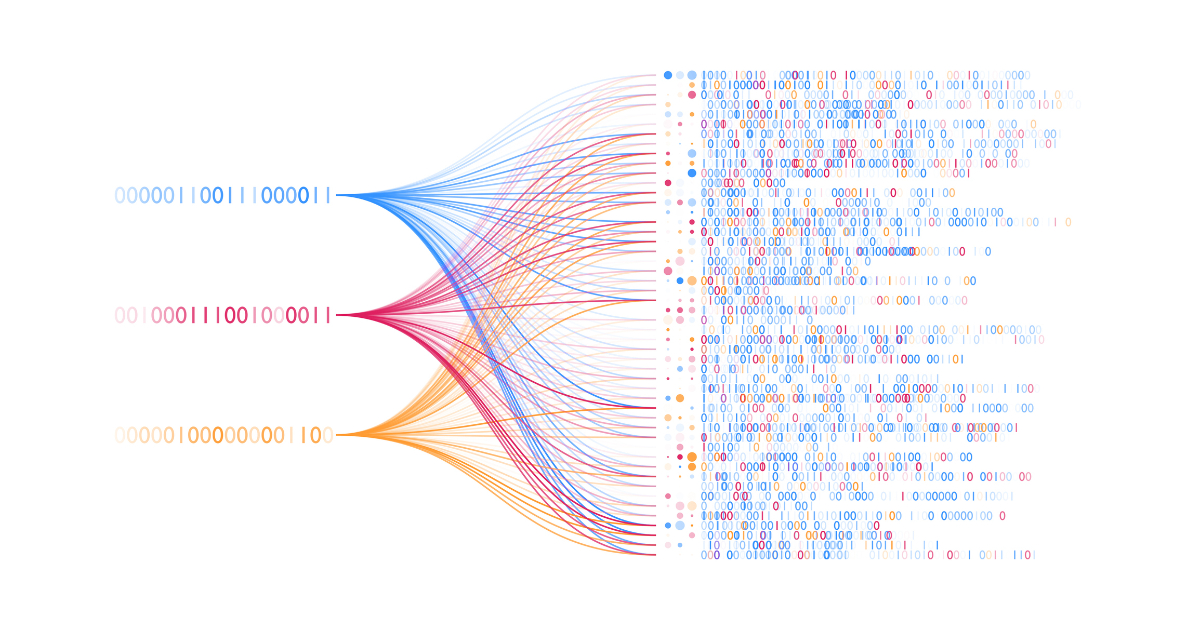
A data mesh organization: producers, consumers, and the platform. According to Matthias Patzak, the mission of the platform team is to make the lives of the producer and consumers simple, efficient and stress free. Data must be discoverable and understandable, trustworthy, and shared securely and easily across the organization.
Matthias Patzak gave a talk about data mesh platforms at FlowCon France.
In the InfoQ article How Data Mesh Platforms Connect Data Producers and Consumers, Patzak explained the concept of a data mesh:
A data mesh is an organizational paradigm shift in how companies create value from data where responsibilities go back into the hands of producers and consumers. It eliminates the specialized data organization as a proxy and bottleneck in the communication between producers and consumers.
Patzak mentioned that there are three roles in a data mesh organization: producers, consumers, and the platform. Producers are teams that generate transactional data with their applications, such as the web store or ERP system, he said. In the data mesh approach, they extend their applications so that they can easily use their transactional data for analytical use cases.
Consumers are teams that generate insights from analytical data, such as marketing, finance, or sales. They build their own business intelligence (BI) or analytics applications, Patzak said.
To ensure that this is done efficiently and in a reasonably standardized way, there is also the data platform, as Patzak explained:
It provides tools and infrastructure that make life for producers and consumers simple, efficient, and stress-free.
The data mesh platform consists of teams that support the producers and consumers. They should provide tooling and infrastructure, training and consulting, and governance and security, Patzak said.
Patzak referred to the book Data Mesh in Action by J. Majchrzak et al., which defines a data product as “an autonomous, read-optimized, standardized data unit containing at least one dataset (Domain Dataset), created for satisfying user needs”. He adapted this definition:
A “data product” is a self-contained dataset curated by a cross-functional team, designed to be valuable and usable for end users. Its purpose is to provide reliable, quality data that’s ready for analysis, facilitating better decision-making within the organization.
Patzak said that transforming data into a data product within a data mesh requires more than just raw data. It requires a quantum of data that includes metadata, code, configuration files, and infrastructure, in fact, infrastructure-as-code, he added.
Patzak mentioned that data must be discoverable and understandable, ensuring that it’s easy to find and that its content is clear to users from both a technical and organizational perspective. It should also be trustworthy, maintaining integrity and SLAs to ensure reliable use. Above all, it should be secure, allowing it to be shared securely and easily across the organization.
Simply building and providing a data product does not guarantee success or benefit, Patzak mentioned. You have to measure and prove the success of the data product. The best way to do this is with hypothesis-driven experiments in which A/B tests are used to measure whether the use of the data product delivers added value, similar to features in transactional applications, he concluded.
InfoQ interviewed Matthias Patzak about using a data mesh.
InfoQ: How can data producers and data consumers collaborate effectively?
Matthias Patzak: As written in the agile manifesto: “The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.” Producers and consumers of data should communicate, collaborate and co-create directly.
When you implement a data mesh, you can apply a lot of things that we as a community have already learned through agile, microservices, and especially DevOps, where two different parties work together successfully. Data mesh from a people and process perspective is not different.
InfoQ: How can consumers use data to generate value?
Patzak: Just like producers, consumers need to work backwards from their customers and their problems. The data product must generate very specific insights and enable human or automated decisions.
InfoQ: What can be done to make it easier to discover data products in a data mesh?
Patzak: In large organizations data catalogues are useful, comparable to a telephone book or a directory, but not to look up a specific data set and consume it straight away. Instead, the main purpose of a data catalogue is to discover the owner of the data product and provide some context about the data product. The next step is to reach out to the owner of the data product and communicate directly.
MMS • Vinod Goje
Article originally posted on InfoQ. Visit InfoQ

Hugging Face has recently released Open LLM Leaderboard v2, an upgraded version of their popular benchmarking platform for large language models.
Hugging Face created the Open LLM Leaderboard to provide a standardized evaluation setup for reference models, ensuring reproducible and comparable results.
The leaderboard serves multiple purposes for the AI community. It helps researchers and practitioners identify state-of-the-art open-source releases by providing reproducible scores that separate marketing claims from actual progress. It allows teams to evaluate their work, whether in pre-training or fine tuning, by comparing methods openly against the best existing models. Additionally, it provides a platform for earning public recognition for advancements in LLM development.
The Open LLM Leaderboard has become a widely used resource in the machine learning community since its inception a year ago. According to Hugging Face, Open LLM Leaderboard has been visited by over 2 million unique users in the past 10 months, with around 300,000 community members actively collaborating on it monthly.
Open LLM Leaderboard v2 addresses limitations in the original version and keeps pace with rapid advancements in the open-source LLM field.
InfoQ spoke to Alina Lozovskaia,one of the Leaderboard maintainers at Hugging Face, to learn more about the motivation behind this update and its implications for the AI community.
InfoQ: You’ve changed the model ranking to use normalized scores, where random performance is 0 points and max score is 100 points, before averaging. How does this normalization method impact the relative weighting of each benchmark in the final score compared to just averaging raw scores?
Alina Lozovskaia: “By normalizing each benchmark’s scores to a scale where random performance is 0 and perfect performance is 100 before averaging, the relative weighting of each benchmark in the final score is adjusted based on how much a model’s performance exceeds random chance. This method gives more weight to benchmarks where models perform close to random (harder benchmarks), highlighting small improvements over chance. Conversely, benchmarks where models already score high in raw terms contribute proportionally less after normalization. As a result, the normalized averaging ensures that each benchmark influences the final score according to how much a model’s performance surpasses mere guessing, leading to a fairer and more balanced overall ranking compared to simply averaging raw scores”.
InfoQ: Benchmark data contamination has been an issue, with some models accidentally trained on data from TruthfulQA or GSM8K. What technical approaches are you taking to mitigate this for the new benchmarks? For example, are there ways to algorithmically detect potential contamination in model outputs?
Lozovskaia: “In general, contamination detection is an active, but very recent research area: for example, the first workshop specifically on this topic occurred only this year, at ACL 2024 (it was the CONDA workshop that we sponsored). Since the field is very new, no algorithmic method is well established yet. We’re therefore exploring emerging techniques (such as analyzing the likelihood of model outputs against uncontaminated references) though no method is without strong limitations at the moment. We’re also internally testing hypotheses to detect contamination specific to our Leaderboard and hope to share progress soon. We are also very thankful to our community, as we have also benefited a lot from their vigilance (users are always very quick to flag models with suspicious performance/likely contamination)”.
InfoQ: The MuSR benchmark seems to favor models with context window sizes of 10k tokens or higher. Do you anticipate a significant shift in LLM development towards this type of task?
Lozovskaia: “There has been a recent trend towards extending the context length that LLMs can parse accurately, and improvements in this domain are going to be more and more important for a lot of business applications (extracting contents from several pages of documents, summarizing, accurately answering long discussions with users, etc). We therefore have seen, and expect to see, more and more models with this long-context capability. However, general LLM development will likely balance this with other priorities like efficiency, task versatility, and performance on shorter-context tasks. One of the advantages of open-source models is that they allow everybody to get high performance on the specific use cases they need”.
For those interested in exploring more into the world of large language models and their applications, InfoQ offers “Large Language Models for Code” presented by Loubna Ben Allal at QCon London. Additionally, our AI, ML, and Data Engineering Trends Report for 2024 provides a comprehensive overview of the latest developments in the field.
MMS • Mohit Palriwal
Article originally posted on InfoQ. Visit InfoQ

JFrog has introduced JFrog Runtime to its suite of security capabilities, adding real-time vulnerability detection to its software supply chain platform. This update is aimed at developers and DevSecOps teams working with Kubernetes clusters and cloud-native applications.
JFrog Runtime enhances the security of a Kubernetes cluster by providing real-time monitoring. This allows the team to detect and prioritize security incidents based on actual risk, ensuring that they promptly address vulnerabilities. By integrating security into the development process, JFrog Runtime helps maintain the integrity of container images and ensures compliance with regulatory requirements.
JFrog Runtime complements JFrog’s existing suite of advanced security capabilities by enhancing the security measures in place for software development and deployment. A key feature, AI/ML Model Curation, allows organizations to protect their software supply chain by detecting and blocking potentially malicious ML models from open-source repositories like Hugging Face before they enter the organization. JFrog’s scalable security platform natively proxies Hugging Face, enabling developers to access open-source AI/ML models while simultaneously providing the ability to detect and block any malicious models and enforce license compliance, ensuring a safer use of AI.
Additionally, the Secure OSS Catalog functions as a “search engine for software packages”, accessible through the JFrog UI or API. Supported by both public and proprietary JFrog data, this catalog offers users rapid insights into the security and risk metadata associated with all open-source software packages, thereby enhancing the security and reliability of software deployments.
Industry research shows that one in five applications contain runtime exposure, with 20 percent of all applications having high, critical, or apocalyptic issues during the execution stage. By automating security for fast-moving, dynamic applications like those that run in containers, JFrog Runtime addresses the visibility and insight needs of cloud-native environments.
One of the important challenges in cloud-native environments is managing the complexity of security across various stages of the development lifecycle. JFrog Runtime simplifies this by offering advanced triage and prioritization features. These features help security teams quickly identify and mitigate risks, allowing developers to focus on coding rather than security-related tasks.
The update also improves the handling of Google IDs and IAM binding for external resources. This makes it easier for teams to secure applications running in the cloud. Here, tools like Terraform play a crucial role. Terraform is an open-source infrastructure as code (IaC) tool that allows developers to define and provision data center infrastructure using a declarative configuration language. By parsing Google IDs when adding IAM binding to resources managed outside of Terraform, JFrog Runtime simplifies the process and reduces the potential for errors, making cloud security more accessible and reliable.
In addition to these enhancements, JFrog Runtime addresses the common issue of runtime exposure in applications. By automating security for dynamic, containerized applications, it ensures that vulnerabilities are detected and mitigated during the execution stage. This is particularly important for organizations that rely on fast-moving, dynamic applications where manual security checks are not feasible. The integration of JFrog Runtime into software supply-chain platforms also improves collaboration among R&D, DevOps and security teams.
At its core, the platform deploys real-time monitoring agents across a Kubernetes cluster, continuously scanning for potential threats. These agents feed data into an incident response engine, which prioritizes security incidents based on their severity and potential impact. This prioritization is powered by advanced machine-learning algorithms, ensuring that the most critical vulnerabilities are addressed first. Additionally, the compliance manager ensures that all container images and running instances adhere to regulatory and organizational policy. The platform’s centralized dashboard views security posture, enhancing collaboration and response times.
Essential Strategies for PostgreSQL Upgrade Success – Database Trends and Applications
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
<!–
 Join us free for the Data Summit Connect 2021 virtual event!
Join us free for the Data Summit Connect 2021 virtual event!
We have a limited number of free passes for our White Paper readers.
Claim yours now when you register using code WP21.
–>

Essential Strategies for PostgreSQL Upgrade Success is your guidebook for navigating a PostgreSQL upgrade with confidence and expertise. Whether you’re an experienced database administrator, developer, or IT professional tasked with overseeing deployments — or just getting started in PostgreSQL – it’s crafted to be your companion for understanding the best practices for PostgreSQL upgrades. Inside, you’ll discover…
- What to do before starting an upgrade: We provide a checklist that acts as a guide to ensure all essential measures and precautions are in place for a seamless and effective upgrade.
- How to optimize performance and minimize downtime: Discover strategies for tuning and optimizing your PostgreSQL environment and ensuring uninterrupted access to your data after an upgrade.
- Techniques for troubleshooting common challenges: Gain insights into common pitfalls and challenges during PostgreSQL upgrades and learn how to resolve them effectively.
- Ways to safeguard your data: Understand best practices for data migration, backup, and recovery, ensuring the safety and consistency of your data throughout the upgrade process.
Download PDF
Article originally posted on mongodb google news. Visit mongodb google news
Event Store Cloud’s Latest Enhancements Improve Management, Ease of Use, and Time-to-Value
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Event Store, the event-native data platform company, is announcing a series of improvements to Event Store Cloud, the company’s fully managed offering of EventStoreDB, centered on streamlining management as well as increasing ease of use and time-to-value. In addition to the enhancements, Event Store Cloud is now available on the AWS Marketplace.
Event Store Cloud delivers fully managed EventStoreDB clusters in the cloud, streamlining cluster management so that developers can focus more of their energy on innovation. Unlike more traditional databases, Event Store Cloud logs every event in sequence, forming a comprehensive lineage of data that creates rich context for downstream models, according to the company. With Event Store Cloud, users can feed real-time, business-critical data into fine-grained streams, accommodating a wide variety of use cases from analytics to microservices and AI.
“Event Store is the first event-native data platform that marries databases and streaming, providing the best of both worlds for a wide variety of use cases,” said Kirk Dunn, CEO of Event Store. “This approach captures the full content and context of the data in a guaranteed way, ensuring full fidelity of business-critical data and making it available—by streaming any or all of it—for an enterprise to run their business more effectively than ever before.”
The latest enhancements to Event Store Cloud include:
- Self-service capabilities, such as the ability to resize clusters up and down, to improve ease of operations
- Credit card sign-up and automated provisioning on AWS, Azure, and Google Cloud Platform, reducing provisioning time from days to minutes
- Access to the AWS Marketplace that enables customers to user their AWS credits for Event Store Cloud, delivering the benefits of AWS’ streamlined deployment and centralized management functionality
- Enhanced security and management including multi-factor authentication and a detailed audit log for tracking user actions
- Easier network configuration with access to public internet and AWS private links, coming soon
“We are extremely pleased with Event Store Cloud,” said Daniel Cano, application transformation architect at Holcim EMEA Digital Center. “Their fully managed service allows us to streamline our technology stack, ensuring optimal efficiency. Zero downtime is essential for our operations, as it enables uninterrupted business transactions across the system.”
To learn more about Event Store Cloud, please visit https://www.eventstore.com/.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
<!–
Join us free for the Data Summit Connect 2021 virtual event!
We have a limited number of free passes for our White Paper readers.
Claim yours now when you register using code WP21.
–>

In database management, keeping pace with the ever advancing landscape of technologies and features isn’t just a choice; it’s essential. This holds especially true for MongoDB users, as it continuously evolves to deliver enhanced performance, heightened security, and unmatched scalability. However, upgrading MongoDB isn’t a matter of just clicking a button; it demands meticulous planning, exacting execution, and an intricate understanding of how upgrades work.
Whether you’re a seasoned DBA well-versed in MongoDB or a newcomer looking to harness its potential, this ebook provides the insights, strategies, and best practices to guide you through MongoDB upgrades, ensuring they go as smoothly as possible and your databases remain optimized and secure.
Download PDF
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
By
BleepingComputer Deals
- October 9, 2024
- 02:11 PM
Did you know that tech and IT professionals are consistently one of the most in-demand employees? According to the University of Cincinnati, these professionals are so coveted that they earn, on average, double the annual wage of other occupations.
If you’d like to join the industry as a data analyst, data engineer, or software developer, you’ll need the skills to succeed. You might not want to go back to school to learn them, though. Why not learn online? This comprehensive database bundle can teach you practical experience in database technologies and management for $24.99 (reg. $199).
Learn SQL, NoSQL, GitHub, and more
SQL Server is one of the most used database systems in the world, and it’s currently the third most popular tag on Stack Overflow. This bundle hones in on SQL, offering five courses on its foundational background, applications, and more.
Students unfamiliar with SQL or who plan on starting a career that relies on Microsoft SQL Server can start with the course ‘Learn MS SQL Server from Scratch.’ Here, you’ll gain hands-on experience in creating and managing databases using MS SQL queries.
Start by learning the fundamentals of SQL and MS SQL Server before jumping into data manipulation skills and conditional logic and data conversion techniques. You’ll even gain the skills to retrieve data from various tables and perform set operations. This knowledge could benefit aspiring data analysts or software developers.
GitHub is another software that’s widely used by companies, and in recent years, it has become an invaluable necessity for those looking to join the tech and IT industries. For those interested in applying for a system administrator or DevOps engineer position, having practical Git and GitHub knowledge will be an asset.
In the ‘Complete Git & GitHub Beginner to Expert’ course, students will start with the basics of version control and how Git and GitHub help with managing and collaborating on code. From there, you’ll master core Git commands for creating projects, commits, and more, and learn to use GitHub to collaborate with other tech professionals and manage repositories through pull requests.
Open your professional opportunities in tech and IT by mastering SQL and GitHub with this bundle, now $24.99 (reg. $199) while supplies last.
Prices subject to change.
Disclosure: This is a StackCommerce deal in partnership with BleepingComputer.com. In order to participate in this deal or giveaway you are required to register an account in our StackCommerce store. To learn more about how StackCommerce handles your registration information please see the StackCommerce Privacy Policy. Furthermore, BleepingComputer.com earns a commission for every sale made through StackCommerce.